🗻
rinna-3.6bをmlc-llmを使ってMacで動かす
rinna/japanese-gpt-neox-3.6b-instruction-ppoをMac単体(Metalを使ってApple Silicon)で動かす手順をまとめました.
こんな感じで動きます↓
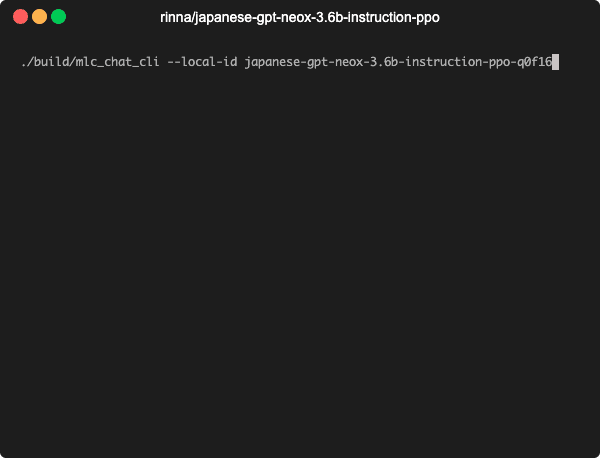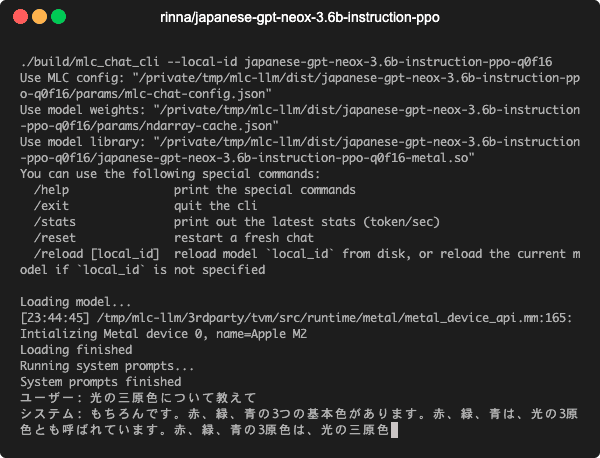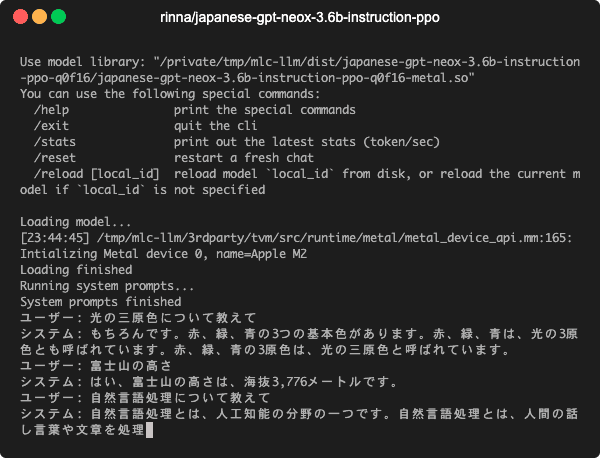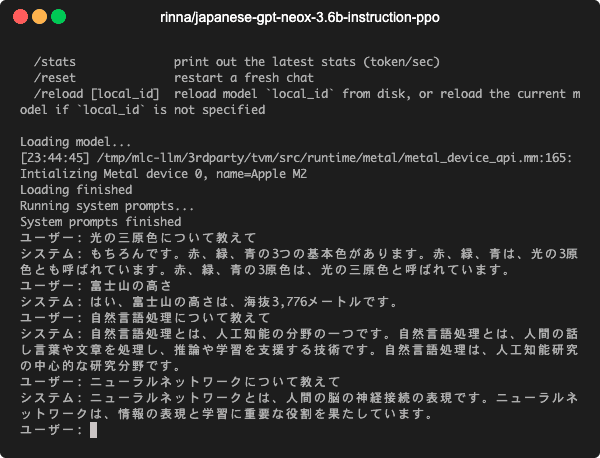
mlc-llmはLLaMAやVicunaなどの言語モデルを色々な環境で実行するための仕組みですが,RedPajamaもサポートされています.同じgpt-neoxベースであるrinnaのモデルも手を加えることで動作させることができました.
前提
- Apple SiliconのMac
- homebrew導入済み
準備
必要なツール類の導入
brew install python cmake rust git git-lfs
mlc-llmのclone
git clone --recursive https://github.com/mlc-ai/mlc-llm.git
cd mlc-llm
python設定
python3 -m venv myenv
source ./myenv/bin/activate
pip install torch transformers sentencepiece protobuf==3.20.3
pip install -I mlc_ai_nightly -f https://mlc.ai/wheels
mlc-llmのコードの修正
japanese-gpt-neox-から始まるモデルに対する設定を追加.
./mlc_llm/relax_model/gpt_neox.py
@@ -606,6 +606,9 @@ def get_model(
ffn_out_dtype = "float16"
elif model.lower().startswith("redpajama-"):
stop_tokens = [0]
+ elif model.startswith("japanese-gpt-neox-"):
+ stop_tokens = [3, 0]
+ ffn_out_dtype = "float16"
else:
raise ValueError(f"Unsupported model {model}")
モデルの設定に加えて,cpuでmodelをloadできるようにmap_locationも指定.
./mlc_llm/utils.py
@@ -69,6 +69,7 @@ def argparse_postproc_common(args: argparse.Namespace) -> None:
"dolly-": ("dolly", "gpt_neox"),
"stablelm-": ("stablelm", "gpt_neox"),
"redpajama-": ("redpajama_chat", "gpt_neox"),
+ "japanese-gpt-neox-": ("rinna", "gpt_neox"),
"moss-": ("moss", "moss"),
"open-llama-": ("LM", "llama"),
"rwkv-": ("rwkv", "rwkv"),
@@ -208,7 +209,7 @@ def transform_params(
torch_pname = f_convert_pname_fwd(pname)
assert torch_pname in pname2binname
torch_params = torch.load(
- os.path.join(model_path, pname2binname[torch_pname])
+ os.path.join(model_path, pname2binname[torch_pname]), map_location=torch.device('cpu')
)
torch_param_names = list(torch_params.keys())
rinna用の設定を追加.(とりあえず動作しているが正しくpromptが組めているかは確認していない)
./cpp/conv_templates.cc
@@ -95,6 +95,25 @@ Conversation RedPajamaChat() {
return conv;
}
+Conversation Rinna() {
+ Conversation conv;
+ conv.name = "rinna";
+ conv.system = "";
+ conv.roles = {"ユーザー", "システム"};
+ conv.messages = {};
+ conv.separator_style = SeparatorStyle::kSepRoleMsg;
+ conv.offset = 0;
+ conv.seps = {"<NL>"};
+ conv.role_msg_sep = ": ";
+ conv.role_empty_sep = ":";
+ conv.stop_str = "ユーザー";
+ // TODO(mlc-team): add eos to mlc-chat-config
+ // and remove eos from stop token setting.
+ conv.stop_tokens = {3, 0};
+ conv.add_bos = false;
+ return conv;
+}
+
Conversation RWKV() {
Conversation conv;
conv.name = "rwkv";
@@ -285,6 +304,7 @@ Conversation Conversation::FromTemplate(const std::string& name) {
{"vicuna_v1.1", VicunaV11},
{"conv_one_shot", ConvOneShot},
{"redpajama_chat", RedPajamaChat},
+ {"rinna", Rinna},
{"rwkv", RWKV},
{"gorilla", Gorilla},
{"dolly", Dolly},
モデルのconvert
downloadしてconvertする.
python build.py --quantization q0f16 --hf-path=rinna/japanese-gpt-neox-3.6b-instruction-ppo
cliのcompile
prepを実行して,
./scripts/prep_deps.sh
mkdir build
下記の内容でcmakeの設定をして,
% python cmake/gen_cmake_config.py
Use CUDA? (y/n): n
Use Vulkan? (y/n): n
Use Metal (Apple M1/M2 GPU) ? (y/n): y
set(CMAKE_BUILD_TYPE RelWithDebInfo)
set(USE_CUDA OFF)
set(USE_VULKAN OFF)
set(USE_METAL ON)
Writing configuration to config.cmake...
makeする.
cp config.cmake build
cd build
cmake ..
make
tokenizer.jsonの配置
元のディレクトリに戻って,tokenizer.jsonを生成し,所定の場所にコピー.
cd ..
python3 -c "import transformers; tokenizer=transformers.AutoTokenizer.from_pretrained('rinna/japanese-gpt-neox-3.6b-instruction-ppo'); tokenizer.save_pretrained('tokenizer', legacy_format=False)"
cp tokenizer/tokenizer.json dist/japanese-gpt-neox-3.6b-instruction-ppo-q0f16/params/
cliの実行
./build/mlc_chat_cli --local-id japanese-gpt-neox-3.6b-instruction-ppo-q0f16
以上の手順で上のgifのように動作するかと思います.
further work
-
Conversation Rinna(){}の確認: modelの期待に沿ったpromptが生成されているか - 量子化オプション: 変えて速度や出力の質の違いを見る
- iOSやWebGPUでの実行: mlc-llmとしては対応しているので動くはず
Discussion