PyTorchを使ってCNNで野菜の仕分け作業自動化
はじめに
こんにちは。皆さんは日本の農業人口の推移の状況についてご存知でしょうか。統計によると2020年には2000年の農業人口の約6割まで落ち込み、またその多くは65歳以上の高齢者で支えられているそうです。農業人口は減少、高齢化の一途なのです。私の祖父母も農業に携わっていることから、機械学習で仕事を少しでも自動化できないかと思ったのが執筆のモチベーションです。
この記事では、Pythonの機械学習用ライブラリであるPyTorch用いて、きゅうりの鮮度の分類を行うモデルを構築します。曲がっていたり太さが均一でないキュウリは鮮度が良くないと見なされることを利用し、画像特徴量からそれらを識別します。こちらの、TensorFlowで実装されたきゅうりの分類の記事を参考にしました。
実装の流れ
学習の流れは以下のようになります。
- データの取得
- データを訓練用、テスト用、検証用に分割する
- データローダでモデルが訓練できる形にする
- モデルの定義
- 最適化アルゴリズムの定義
- 訓練データで訓練
- テストデータで推論
- 推論結果を可視化
実装
モジュールのインポート
下記のコードでimportします。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from torchinfo import summary
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import glob
import os
import sys
import pickle
import numpy as np
きゅうりのデータの取得
まずはきゅうりのデータを取得します。
データセットはこちらからいただきました。
pickle.load()は、pickleライブラリを使って、ファイルに保存されたデータを読み込む関数です。'rb'モードでファイルを開くのは、バイナリモードで読み込むためです。そして、読み込んだデータをlabels変数に格納しています。
glob.glob()関数を使って、pathフォルダ内のdata_batch_で始まるすべてのファイル名を取得し、files_trainというリストに格納しています。os.path.join()は、パスとファイル名を適切に結合するために使用しています。
path = 'きゅうりデータセットのパス'
with open(path + '/batches.meta','rb') as f:
labels = pickle.load(f, encoding='bytes')
files_train = glob.glob(os.path.join(path, 'data_batch_*'))
data = []
きゅうりのデータの整形
このコードは、pickleファイルから画像データと関連するメタデータを読み込み、一定の前処理を行った後、必要なデータを抽出しています。
具体的には以下の手順を実行しています。
-
files_trainに対して以下の処理を繰り返しています。 -
with open(file, 'rb')as f:で、1つのpickleファイルを開きます。 -
pickle.load(f,encoding='bytes')で、pickleファイルの内容を読み込みます。読み込まれたデータには、'filenames'、'labels'、'data'というキーがあり、それぞれファイル名、ラベル、画像データが対応する値として格納します。 -
images = np.reshape(images,(len(filenames),-1))で、画像データを適切な形状に変形します。 - その後、
zip(filenames,labels,images)でファイル名、ラベル、画像データをまとめて、以下のループ処理を行います。
・画像データを[3,-1]の形状に変形し、さらにRGBの3チャンネルを分離します。
・RGB画像の最初のチャンネルのみを取り出し、[32,32,3]の形状に変形します。
・ラベルが0以外の場合のみ、(ファイル名, ラベル, 画像データ)のタプルをdataリストに追加します。
for file in files_train:
with open(file, 'rb')as f:
images = pickle.load(f,encoding='bytes')
filenames = images[b'filenames']
labels = images[b'labels']
images = images[b'data']
images = np.reshape(images,(len(filenames),-1))
for i, (f,l,imgs) in enumerate(zip(filenames,labels,images)):
imgs = np.reshape(imgs,[3,-1])
top_img = imgs[0]
top_img = np.reshape(top_img,[3,-1]).T
top_img = np.reshape(top_img,[32,32,3])
if l !=0:
data.append((f,l,top_img))
data = np.array(data,dtype='object')
取得したデータの確認
取得したデータを確認するための関数を作り、取得したデータを確認してみましょう。
#データ確認用
def show_images_w_labels(data, figsize=(20,10),columns=5):
plt.figure(figsize=figsize)
for i,ent in enumerate(data):
ax = plt.subplot(int(len(data)/columns+1),columns,i+1)
ax.imshow(ent[2])
ax.set_title(ent[1])
plt.show()
#先頭から20事例を表示
show_images_w_labels(data[:20])
正しくきゅうりの画像とラベルが取得できていることが確認できました。
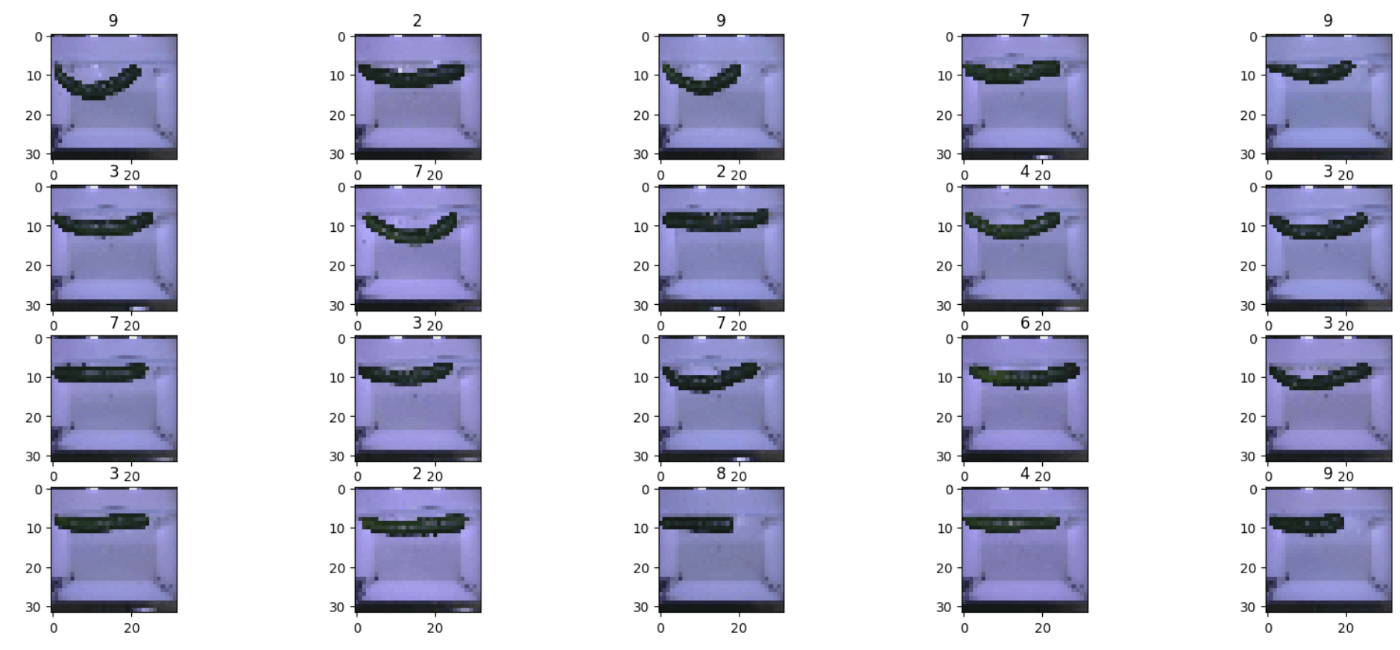
各画像に振られている数字は、その鮮度を表す指標である鮮度の等級を表しています。
GPUを使用
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
このコードは、PyTorchを使用してディープラーニングモデルを実行する際に、使用するデバイス(ハードウェア)を決定するためのものです。具体的には、以下のような処理を行います:
torch.cuda.is_available():
PyTorchがインストールされている環境で、NVIDIAのCUDA対応GPUが利用可能かどうかを確認します。
CUDA対応GPUが利用可能であれば、True を返し、利用できない場合は False を返します。
三項演算子 ('cuda' if torch.cuda.is_available() else 'cpu') を使用して、条件に基づいて文字列を選択します。
torch.cuda.is_available() が True の場合、'cuda' を選択し、False の場合は 'cpu' を選択します。
torch.device:
torch.device オブジェクトを作成し、選択されたデバイスを設定します。
これにより、以降のPyTorchの操作で、このデバイスを使用することができます。
正規化
X = np.stack(data[:, 2]).astype(np.float32) / 255.0
X = X.transpose(0, 3, 1, 2)
y = data[:, 1].astype(np.int64) # CrossEntropyLoss には int64 が必要
# データのチェック
print(f'X shape: {X.shape}, y shape: {y.shape}')
print(f'Labels: {np.unique(y)}')
X = X.transpose(0, 3, 1, 2)は、配列の軸の順番を入れ替える操作です。具体的にはデータの形状を(N, H, W, C)から(N, C, H, W)に変更しています。これは、PyTorchが処理できる配列のがこの順番だからです。
N (Number of images): 画像の総数を表します。例えば、Nが32であれば、32枚の画像が含まれています。
H (Height): 各画像の高さ(ピクセル数)を表します。
W (Width): 各画像の幅(ピクセル数)を表します。
C (Channels): 各画像のチャンネル数を表します。カラー画像の場合、通常は3(赤、緑、青の3チャンネル)です。グレースケール画像の場合は1になります。
例えば、(32, 64, 64, 3)という形状のデータは、32枚のカラー画像(各画像が64ピクセルの高さと64ピクセルの幅を持つ)を含んでいることを意味します。
転置操作によって形状を(N, H, W, C)から(N, C, H, W)に変更する理由は、ディープラーニングフレームワーク(例えばPyTorchなど)の期待する入力フォーマットに合わせるためです。PyTorchの場合、画像データは通常(N, C, H, W)の形式で提供される必要があります。
訓練データとテストデータに分ける
train_test_split関数を使用して、データセットを訓練データとテストデータに分割します。test_size=0.2はデータの20%をテストデータとして使用することを意味します。同様に、訓練データをさらに訓練データと検証データに分割します。ここでもtest_size=0.2は訓練データの20%を検証データとして使用することを意味します。
訓練データは、文字通りモデルの訓練用のデータです。
検証データは、各エポックごとにモデルが過学習を起こしていないかを確認するためのデータです。
テストデータは、モデルが訓練(学習)を終えた後に分類するデータです。
イメージとしては、訓練用データは練習問題。検証データはその日の振り返りテスト。テストデータは本番のテストみたいに想像してもらって大丈夫です。
torch.from_numpyを使用してNumPy配列をPyTorchテンソルに変換します。
to(torch.float32)を使用して、テンソルのデータ型をfloat32に変換します。これは、画像データが通常float32で処理されるためです。to(torch.int64)を使用して、ラベルのデータ型をint64に変換します。これは、CrossEntropyLossがint64のラベルを必要とするためです。to(device)を使用して、テンソルを指定したデバイス(通常はGPU)に転送します。
#訓練データとテストデータを用意
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, test_size=0.2, random_state=0)
print('Number of train, valid, test samples: ', y_train.shape[0], y_valid.shape[0], y_test.shape[0])
X_train = torch.from_numpy(X_train).to(torch.float32).to(device)
X_valid = torch.from_numpy(X_valid).to(torch.float32).to(device)
X_test = torch.from_numpy(X_test).to(torch.float32).to(device)
y_test = torch.from_numpy(y_test).to(torch.int64).to(device)
y_train = torch.from_numpy(y_train).to(torch.int64).to(device)
y_valid = torch.from_numpy(y_valid).to(torch.int64).to(device)
データローダを作成
データローダとは、データセットからどのようにデータを取り出すかを設定するクラスである。ディープラーニングではミニバッチ学習を行い、複数のデータを同時にデータセットから取り出して学習することが一般的です。
ミニバッチ学習とは、データセットをサブセットとしてバッチサイズに分け、サブセットごとに分けて学習を行いながら損失関数を最小にして最適なパラメータを見るける手法です。
まずはじめにデータセットを作成します。dataset = TensorDataset(X, y)とすることで、データセットを作成することができます。
次に作成したデータセットをデータローダに変換します。データローダは、PyTorchのtorch.utils.data.DataLoaderクラスをそのまま利用します。
バッチサイズは、32,64くらいを指定するのが一般的です。バッチサイズを大きくするほど一度に学習させるデータが増えるので学習の精度は向上しますが、メモリの乗り切らなくなることがあるため注意が必要です。
#データローダーを作成
dataset_train = TensorDataset(X_train, y_train)
dataset_valid = TensorDataset(X_valid,y_valid)
batch_size = 64
learning_rate = 0.001
loader_train = DataLoader(
dataset = dataset_train,
batch_size = batch_size,
shuffle=False
)
loader_valid = DataLoader(
dataset = dataset_valid,
batch_size = batch_size,
shuffle=False
)
ニューラルネットワークを定義
ここからはネットワークの定義に移ります。torchモジュールのnnモジュールを継承することでモデルを作成します。ここでは、画像処理用のニューラルネットワークである畳み込みニューラルネットワーク(CNN)を用いてモデルの作成を行います。具体的には、二つの畳み込み層と、一つの全結合層を持ちます。
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(3,6,kernel_size=3), #3*32*32→6*30*30
nn.BatchNorm2d(6),
nn.ReLU(),
nn.MaxPool2d(2) #6*30*30→6*15*15
)
self.layer2 = nn.Sequential(
nn.Conv2d(6,12,kernel_size=3), #6*15*15→12*13*13
nn.BatchNorm2d(12),
nn.ReLU(),
nn.MaxPool2d(2) #12*13*13→12*6*6デフォルトがfalseなので、切り捨て
)
self.fc = nn.Linear(432,10)
#順伝播の計算を記述
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = x.view(x.size(0),-1)
x = self.fc(x)
return x
ここでは、クラスCNNを定義します。このクラスはPyTorchのニューラルネットワークモジュールであるnn.Moduleから継承されるようにします。
nn.Sequentialはいくつかのレイヤーを並べて実行するためのコンテナのようなものです。
nn.Conv2dは、2次元の畳み込みレイヤー、nn.BatchNorm2dはバッチ正則化レイヤー、nn.MaxPooling2dはプーリングを行うレイヤー、nn.ReLUはReLU活性化関数、nn.Linearは全結合層です。
最後にdef forward(self,x):でコンストラクタで初期化したレイヤーの順伝播の構造を記述します。
まとめると、
- nn.Moduleを継承し、クラスを作る。
- コンストラクタでレイヤーの初期化
- forwardメソッドで順伝播の計算を定義
の流れになります。
訓練を行う関数を定義
次にCNNの訓練を行う関数を定義します。
train_loaderを引数に受け取り、model.trainでモデルを訓練モードに変更します。これは、ドロップアアウト層やバッチ正則化層が訓練ように動作するためです。
この関数は1エポック分の訓練を行う関数なので、前の損失を受け継がないように初期化します。
そしてtrain_loderからバッチを取得して訓練します。
def train(train_loader):
model.train()
running_loss = 0;
# トレーニングループ内
for inputs, labels in train_loader:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad() # 勾配のゼロリセット
outputs = model(inputs) # 順伝播
loss = criterion(outputs, labels) # 損失の計算
loss.backward() # 勾配の計算(逆伝播)
# 各パラメータの勾配はここで計算される
# 例: model.layer1[0].weight.grad などに格納される
optimizer.step() # パラメータの更新
# optimizer.step() が呼ばれると、オプティマイザーは
# 各パラメータの .grad 属性を参照して更新を行う
loss_train = running_loss / len(train_loader) #バッチの平均損失を計算
return loss_train
推論を行う関数を定義
次にモデルを評価するための関数の定義に移ります。まずはmodel.eval()でモデルを評価モードに切り替えます。評価時に勾配の計算は不要なため勾配計算を無効化する処理をするのが一般的です。評価データ全体の累積損失を保持するための変数 running_loss を初期化し計算を行います。
def test(valid_loader):
model.eval()
with torch.no_grad():
running_loss = 0
for inputs, labels in valid_loader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs) # 順伝播
loss = criterion(outputs, labels) # 損失の計算
running_loss += loss.item() #累積損失に現在のバッチの損失を加算
loss = running_loss / len(valid_loader) #バッチの平均損失を計算
return loss
訓練を実行
では実際に訓練を行なってみましょう。
loss_list,loss_list_valid = [],[] #後々描画するために、損失を保存しておきます。
num_epochs = 50
loss_valid_best = sys.float_info.max
for epoch in range(num_epochs): #エポックごとに訓練とテストを繰り返す。
loss_train = train(loader_train)
loss_valid = test(loader_valid)
print('epoch %d, loss(train): %.4f, loss(valid): %.4f' % (epoch, loss_train, loss_valid))
loss_list.append(loss_train)
loss_list_valid.append(loss_valid)
テストデータにおける誤差を評価
では評価に移ります。最終的な損失を計算してみましょう。testデータでテストしてみましょう。
model.eval()
with torch.no_grad():
y_pred = model(X_test)
loss_test = criterion(y_pred, y_test).item()
print('test loss (Cross Entropy): %.4f' % (loss_test))
学習曲線を描画
損失がどのように減少しているか可視化してみましょう。
#学習曲線を描画
plt.plot(loss_list, label='train') #線1
plt.plot(loss_list_valid, label='valid') #線2
plt.xlabel('epoch') #x軸
plt.ylabel('loss (Cross Entropy)') #y軸
plt.legend()
plt.show()
推論
ランダムな一本を分類
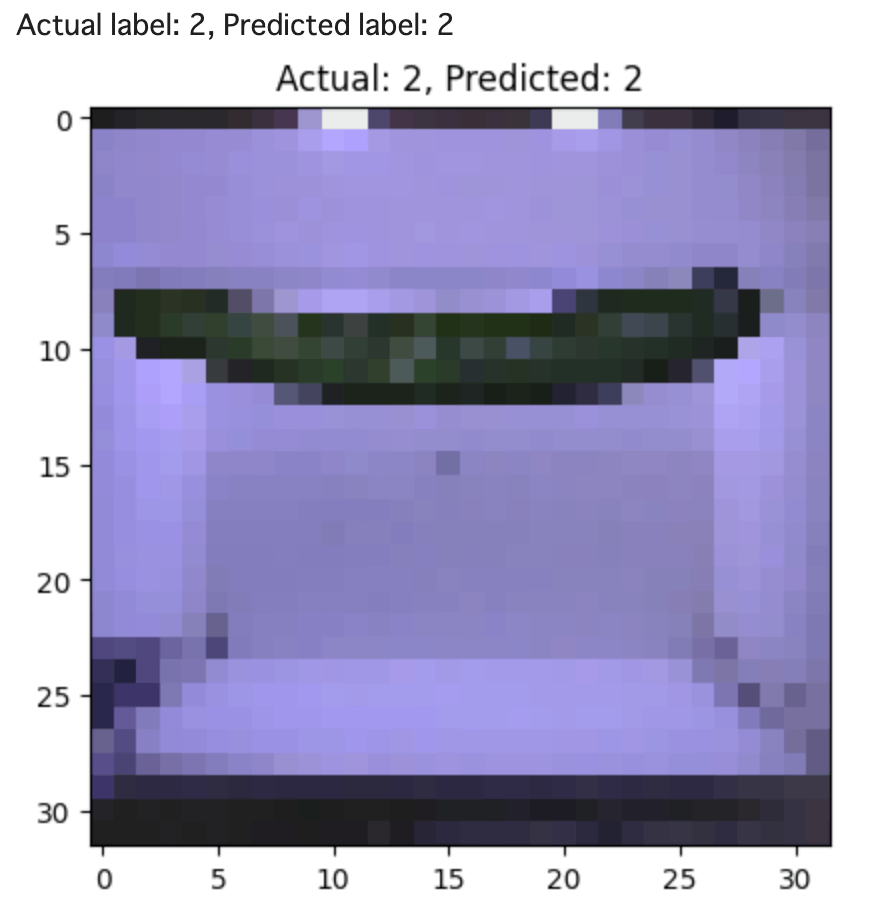
ではランダムな一本のきゅうりを推論してみましょう。実際のラベルとモデルが予測したラベルを比較してみます。
import random
# ランダムな一枚の画像を推論して結果を表示
random_index = random.randint(0, X_test.size(0) - 1)
random_image = X_test[random_index].unsqueeze(0) # バッチサイズの次元を追加
random_label = y_test[random_index].item()
model.eval()
with torch.no_grad():
random_output = model(random_image)
_, predicted_label = torch.max(random_output, 1)
predicted_label = predicted_label.item()
# 画像の表示
import matplotlib.pyplot as plt
image = random_image.cpu().numpy().squeeze().transpose(1, 2, 0) # CHW to HWC
plt.imshow(image)
plt.title(f'Actual: {random_label}, Predicted: {predicted_label}')
plt.show()
ランダムに選ばれたきゅうりの鮮度の等級を分類することができました。
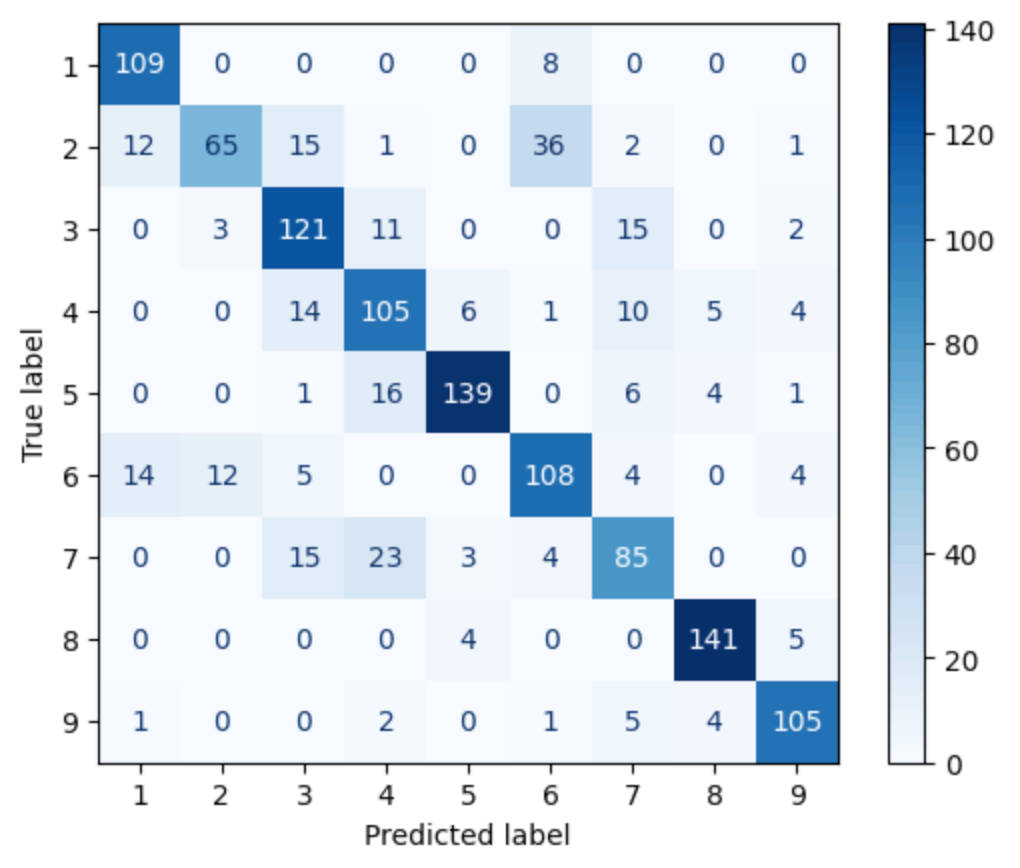
混合行列で分離結果を可視化
混合行列を用いてモデルがどのクラスをどの程度正確に予測できているかを視覚的に確認してみましょう。
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# 混合行列の生成と可視化
model.eval()
with torch.no_grad():
y_true = []
y_pred = []
for inputs, labels in loader_valid:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
y_true.extend(labels.cpu().numpy())
y_pred.extend(predicted.cpu().numpy())
# 混合行列を生成
labels = np.arange(1, 10)
conf_matrix = confusion_matrix(y_true, y_pred, labels=labels)
# 混合行列の表示
disp = ConfusionMatrixDisplay(confusion_matrix=conf_matrix, display_labels=labels)
disp.plot(cmap=plt.cm.Blues)
plt.show()
混合行列が出力されました。これにより、各クラスの予測精度や誤分類のパターンを理解することができますね。概ね良い精度で分類することができたのではないでしょうか。
おわりに
最後まで読んでいただき、ありがとうございました。畳み込みニューラルネットワーク(CNN)を用いることで、画像からきゅうりの鮮度を分類するモデルを構築することができました。この記事を通じて、農業における機械学習の可能性を感じていただけたでしょうか。なお、筆者自身は機械学習の初心者(PyTorchを使い始めて1年程度)ですので、誤りや改善点がございましたらご指摘いただけると幸いです。
Discussion