Mattermost 投稿数順に集計して通知
やりたいこと
ノウハウチャンネルにたくさん投稿してくれる人を称えたい。
なので、投稿してくれた数を集計するスクリプトを作ろうと思いました。
こだわりたいポイント
・期間を指定したい(週刊MVP的な考え方)
・多い人が上にくるように、上位●人的な指定をしたい
本当はRe:dashとか使ってみたいけど導入するのはちょっとハードル高いな、、と思ったので地道に集計する方法をとっています。
実行結果
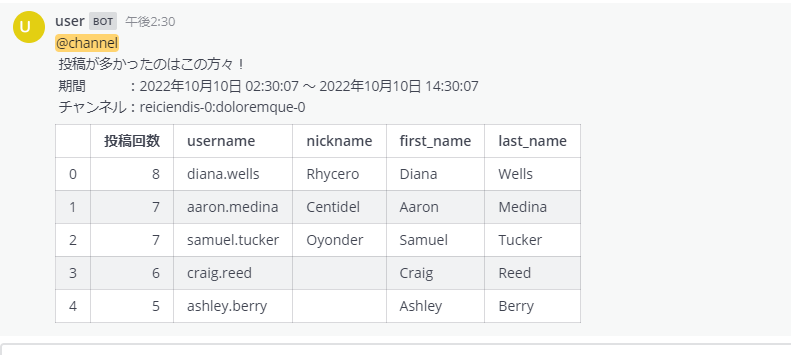
こんな感じに表示されるようにしました。
コード説明
とりあえず一気にコピペする用。細かい説明はここでは割愛しますが、環境依存パラメータ(HOSTNAME,PORT,PASSWORD等)があるので各自の利用環境に合わせてカスタマイズする必要があります。
全コード
def getLinuxCommand(LINUX_COMMAND):
import paramiko
print(LINUX_COMMAND)
with paramiko.SSHClient() as client:
HOSTNAME = '127.0.0.1'
PORT = '20022'
USERNAME = 'bitnami'
KEY_FILENAME = 'C:\\ssh\\wsl_ubuntu'
PASSWORD = 'bitnami'
# SSH接続
client = paramiko.SSHClient()
client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 1. パスワード認証認証方式
client.connect(hostname=HOSTNAME, port=PORT, username=USERNAME, password=PASSWORD)
# 2. 公開鍵認証方式
#client.connect(hostname=HOSTNAME, port=22, username=USERNAME, key_filename=KEY_FILENAME)
# コマンド実行
channel = client.get_transport().open_session(timeout=10)
# exec_commandで標準エラー出力が約2MiB(1,900,000Byte)未満の場合は雑に書いても動作しますが
# 出力が多いと失敗するらしいので受取サイズに注意しながら処理
# https://qiita.com/fukasawah/items/7ae2ab0057c565607d88
try:
channel.exec_command(LINUX_COMMAND)
RECV_SIZE = 1024 * 32
stdout = b''
stderr = b''
while not channel.closed or channel.recv_ready() or channel.recv_stderr_ready():
stdout += channel.recv(RECV_SIZE)
stderr += channel.recv_stderr(RECV_SIZE)
# 終了コードを受け取る
code = channel.recv_exit_status()
finally:
# ssh接続断 ガーベージコレクションの削除
channel.close()
del client, stderr
return stdout
def countUserPosts(posts,users,start_date="",end_date="",fn="test.csv",headers=5):
import pandas as pd
import json
import datetime
# 名前が重複する列名はあらかじめリネームしておく
# print("---- ユーザ情報のデータフレーム ----")
df_users = pd.json_normalize(json.loads(users)).rename(columns= \
{'id':'user_id', \
'create_at':'user_create_at', \
'update_at':'user_update_at', \
'delete_at':'user_delete_at'})
# print(df_users)
# print("---- 投稿情報のデータフレーム ----")
df_posts = pd.json_normalize(json.loads(posts)).rename(columns= \
{'id':'post_id', \
'create_at':'post_create_at', \
'update_at':'post_update_at', \
'delete_at':'post_delete_at'})
# print(df_posts)
# 開始時刻と終了時刻でフィルタリング
joken = (df_posts.post_create_at >= start_date) & (df_posts.post_create_at < end_date)
df_posts_datefilterd = df_posts[joken]
# print(df_posts_datefilterd)
# 集計
df_posts_groupby = df_posts_datefilterd.groupby('user_id').count()
print(df_posts_groupby)
# user_id 毎に結合し、post_idの降順にソートする
df_user_posts = pd.merge(df_users,df_posts_groupby,how='left',on='user_id').sort_values(by='post_id',ascending=False).reset_index()
print(df_user_posts)
# 集計して出力する
# print("---- 集計表(降順ソート) ----")
df_user_posts.to_csv("df_user_posts.csv", sep=",")
# print(df_user_posts.columns)
df_results = df_user_posts[['post_id','username','nickname','first_name','last_name']].rename(columns={'post_id':'投稿回数'})
# headers で指定された数を出力
# print(df_results.head(headers))
# 結果保存
df_results.to_csv(fn)
# マークダウンに変換して返す
# pip install tabulate しておかないとここでエラーになる
return df_results.head(headers).to_markdown()
def postResults(comment):
import slackweb
import pandas
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# incoming webhook
mattermost = slackweb.Slack(url="https://localhost:20443/hooks/pg6xu6q3ztds9k1cdaxfpjas7c")
mattermost.notify(text=comment,username="投稿数カウントボット",channel="town-square")
def main():
# 一日分だとテスト用データは全部出てしまうので12時間前まで。
# 実際に使うときは集会時間に合わせてチューニング
import datetime
end_date = datetime.datetime.now()
#start_date = end_date + datetime.timedelta(days=-1)
start_date = end_date + datetime.timedelta(hours=-12)
# MattermostのDB上はミリ秒で値が入っているので1000倍する
end_date_timestamp = end_date.timestamp()*1000
start_date_timestamp = start_date.timestamp()*1000
# チャンネル名
channels="reiciendis-0:doloremque-0"
# 一度に取得する投稿数
# 周回範囲でこれくらいだろ、という数を指定する。小さいと周回範囲分を取り切れないことがあるので大きめに。
posts_cnum = 500
print("---- mmctlコマンドでユーザー情報を取得 ----")
LINUX_COMMAND = "sudo -u mattermost mmctl --local user list --json"
users = getLinuxCommand(LINUX_COMMAND)
print("---- mmctlコマンドで投稿内容を取得 ----")
LINUX_COMMAND = 'sudo -u mattermost mmctl --local post list ' + channels + ' --json -n ' + str(posts_cnum)
posts = getLinuxCommand(LINUX_COMMAND)
print("---- 集計 ----")
fn = channels.replace(":","_") + "_" + str(start_date.strftime('%Y%m%d%H%M%S')) + "-" + str(end_date.strftime('%Y%m%d%H%M%S')) + ".csv"
df_count = countUserPosts(posts,users,start_date_timestamp,end_date_timestamp,fn,5)
# 内向きWebhookを使って投稿
# コメントには改行2個入れておかないとテーブルがうまく表示されない
comment = "@channel \n 投稿が多かったのはこの方々!" + \
"\n 期間 :" + start_date.strftime('%Y年%m月%d日 %H:%M:%S') + " ~ " + end_date.strftime('%Y年%m月%d日 %H:%M:%S') + \
"\n チャンネル:" + channels + \
"\n\n" + df_count
postResults(comment)
if __name__ == "__main__":
main()
全体構成
ざっくり流れはこんな感じです。
- mmctlコマンドでユーザー情報を取得(利用関数:getLinuxCommand)
- mmctlコマンドで投稿内容を取得(利用関数:getLinuxCommand)
- pandasで集計(利用関数:countUserPosts)
- 内向きWebhookを使って投稿(利用関数:postResults)
使う前に・・tabulateが必要なので入れます。
pandasのDataFrameをMarkdownにするために、tabulateが必要になります。
コマンド実行例
pip install tabulate
ローカル環境に持っていきたいぞ、という方は以下のリンクの「Download files」から取得してください。
関数説明
getLinuxCommand
Linuxコマンドを発行した結果を取得するための関数。主にmmctlの結果を取得するのに利用。
流用時にはHOSTNAME,PORT,USERNAME,PASSWORDを自分の環境に合わせる必要あり。
Qiitaのこちらの記事を参考にさせていただきました。ほぼ丸パクリなのでここでは説明は割愛します。
countUserPosts
Pandasを使ってユーザ別に投稿数を集計するための関数。
列名変えたり、左外部結合使ったり、ソートしたりとpandasの勉強になりました。
戻り値はMattermostに投稿できるようにMarkdown形式にしています。
ちょっとだけやっていることを解説。
引数
def countUserPosts(posts,users,start_date="",end_date="",fn="test.csv",headers=5):
引数の説明は以下の通りです。
| 引数 | 説明 | 初期値 |
|---|---|---|
| posts | 投稿情報。mmctlで取得したjsonデータを入れています。 | 無し |
| users | ユーザ情報。mmctlで取得したjsonデータを入れています。 | 無し |
| start_data | 集計期間(自)。 | "" |
| end_date | 集計期間(至)。 | "" |
| fn | 保存ファイル名。headersで名前が出なかった人の順位確認用。(将来的に推移とかを調べたいときに使うイメージ) | test.csv |
| headers | 表示する行数。トップ5だけ出すイメージです | 5 |
jsonデータの受け取り
pandasを使って、json形式のユーザ情報を投稿情報を受け取ります。
ユーザ情報と投稿情報では列名がかぶっているので、列名を変えてあとで扱いやすくしています。(変えないとuser_create_x、user_create_yみたいになってどっちがどっちかわかりづらくなる)
import pandas as pd
import json
import datetime
# 名前が重複する列名はあらかじめリネームしておく
# print("---- ユーザ情報のデータフレーム ----")
df_users = pd.json_normalize(json.loads(users)).rename(columns= \
{'id':'user_id', \
'create_at':'user_create_at', \
'update_at':'user_update_at', \
'delete_at':'user_delete_at'})
# print(df_users)
# print("---- 投稿情報のデータフレーム ----")
df_posts = pd.json_normalize(json.loads(posts)).rename(columns= \
{'id':'post_id', \
'create_at':'post_create_at', \
'update_at':'post_update_at', \
'delete_at':'post_delete_at'})
# print(df_posts)
フィルタリング
開始時刻と終了時刻でフィルタリングしています。
main関数のほうで実装している *1000 がここで効いてきます。
# 開始時刻と終了時刻でフィルタリング
joken = (df_posts.post_create_at >= start_date) & (df_posts.post_create_at < end_date)
df_posts_datefilterd = df_posts[joken]
# print(df_posts_datefilterd)
集計
pandasのgroupbyを使って投稿情報をもとにユーザ別投稿数を集計します。
その後、ユーザ情報テーブルと結合させて、ユーザ名等を引き出せるようにします。
# 集計
df_posts_groupby = df_posts_datefilterd.groupby('user_id').count()
print(df_posts_groupby)
# user_id 毎に結合し、post_idの降順にソートする
df_user_posts = pd.merge(df_users,df_posts_groupby,how='left',on='user_id').sort_values(by='post_id',ascending=False).reset_index()
print(df_user_posts)
DB加工と保存
投稿数を意味するpost_idがそのまま出力されても意味が分かりづらいので、投稿回数に名前を変えて出力します。
また、usernameだけだと直感的にわかりづらい、nicknameだと設定していない人がいる、ということでfirst_name,last_nameも出すようにしました。(ここも日本語にしたほうがよかったかな?わかるからまあいいや、と思いましたが)
後述のMattermostに投稿するデータではトップ5だけを選出するようになっているので、ここでファイルに保存しています。
# 集計して出力する
# print("---- 集計表(降順ソート) ----")
df_user_posts.to_csv("df_user_posts.csv", sep=",")
# print(df_user_posts.columns)
df_results = df_user_posts[['post_id','username','nickname','first_name','last_name']].rename(columns={'post_id':'投稿回数'})
# headers で指定された数を出力
# print(df_results.head(headers))
# 結果保存
df_results.to_csv(fn)
戻り
最終的にMattermostに投稿したいので、markdownに変換して返します。
# マークダウンに変換して返す
# pip install tabulate しておかないとここでエラーになる
return df_results.head(headers).to_markdown()
postResults
内向きWebhookを使ってMattermostに投稿するための関数。
今回は投稿するテキストをmainのほうで作っているので、本当にただ投げるだけのものになっています。流用時にはWebhookのアドレスを書き換えないといけないので注意。
こちらも説明は割愛します。
最後に
mmctlで結果を引き出した後は、pandas等を使っていろいろ集計するだけでしたがやってみると結構知らないことが多くて時間がかかりました。
全チャンネルを通して最も投稿が多いのは●●さん、みたいなことも機能拡張したらできそうだけど今日のところはおしまい。
7.3で本体の集計機能もパワーアップしたみたいだけど、今後さらにパワーアップしていったらこの辺のものをわざわざ実装しなくてよくなるのかなぁ。。
Discussion