Time domain 音声分離の始まりを追う(TasNet)
はじめに
音声分離において,Time-FrequencyでSTFTを使って周波数領域で音声分離することが多かったのですが,2018年頃から,フーリエ変換をしないで,時間領域で特徴量に変換して,音声にマスクすることで,音声分離をする手法が増えて来ました.
その中でも特にConv-TasNetはブレイクスルーとなった重要な手法です.
そこで,Conv-TasNetでも紹介されたTasNetについて軽く読んだので,まとめておきます.
Abstract
本論文ではAudio Separation Network(TasNet)を提案します.これは,encoder-decoderで音声を分離する,時間領域で直接シグナルを推定するモデルです.
このモデルは,今までのような音声分解ステップを削除して,分離問題をエンコーダからの出力の特徴量に落とし込み,マスク推定してデコーダで合成される.
これは周波数領域で学習する手法よりも精度と計算量に大幅な改善があった.
introduction
-
STFTを用いた手法は以下の点で問題である.
- フーリエ変換が音声分離に最適な信号の変換であるかどうか不明
- STFTは信号を複素数領域に変換するが,振幅と位相の両方を扱う必要がある.
-
今までは,位相の情報は,応急処置として,noisy音声から持ってきてdecodeに用いることが多かった.
-
最近真相学習の精度がどんどん良くなってきたので,本論文ではTime-domain Audio Separation Network(TasNet)を提案した.
Model description
2.1 Problem formulation
考え方は非常に簡単です.
まずx(t)を入力音声s_i(x)をi個に分離された音声とすると,以下のように表せます.
例えば,ノイズと綺麗な音声だとi=2となります
まず,長さLのK個のフレームに分割します.ここで,フレームの重なりはないように分割します
また、

式の簡素化のために、kは以降で省略します。
convolution のカーネルを
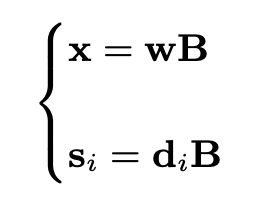
ここで、convolution後の混合音声の特徴ベクトル

その理由として、
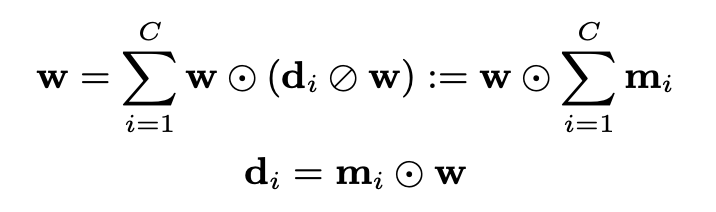
Network design
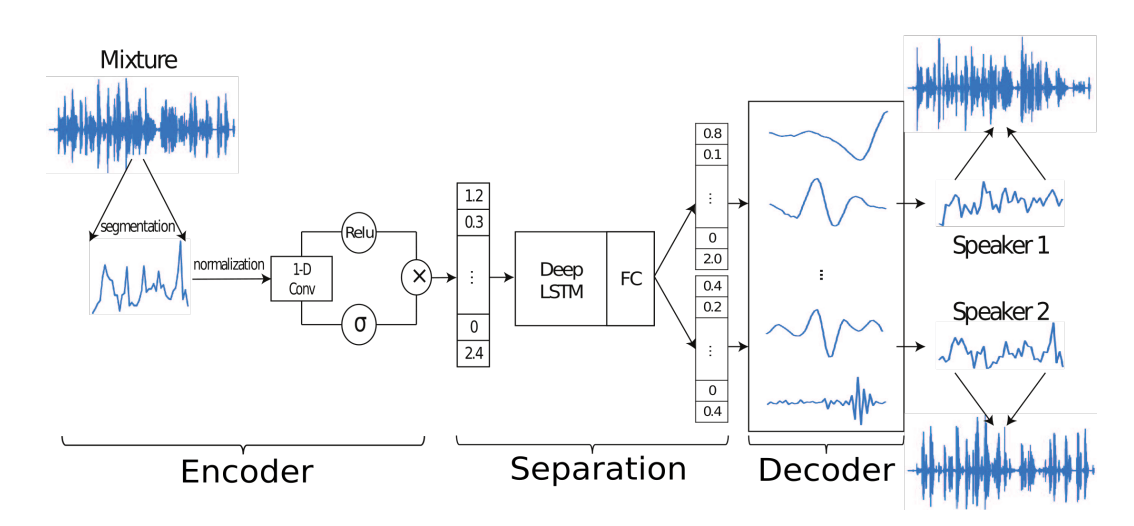
以下にネットワークの図を示します。
Networkは、混合音声特徴量を推測するencoder、分離モジュール、音声を再構成するdecoderの3つに分かれています。
中の1-D convolutionによって、混合波形の非負のオートエンコーダが構築されます。
2.2.1 Encoder for mixture weight calculation
まず、Encoderの機構として、Convolutionのカーネルを

なぜこのようにしたのかは、こちらに影響されたらしく、ReLUやSigmoidを単体で使うより性能が上がったらしいです。
これは他でも使えそうですね。
2.2.2 Separation network
マスクを推定するモジュールとしてLSTMとFC層を使っています。
LSTMの入力は混合音声特徴量のwで、出力はマスクmです。
また、学習を高速化させるために、Layer Normalizationをしています。
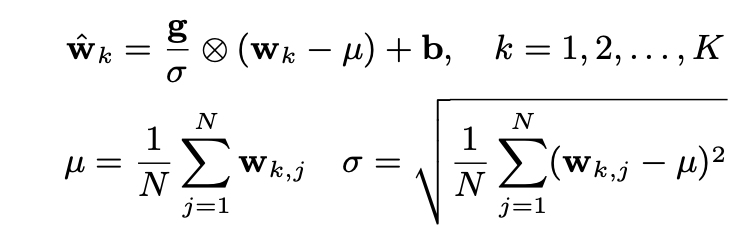
また、2層目のLSTMには、スキップ結合(おそらくresidual connection)
2.2.3 Decoder for waveform reconstruction
最後に、推測したマスクと混合音声特徴量を要素ごとに乗算して強調音声の特徴量
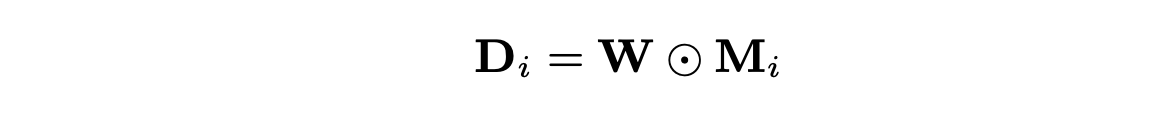
最終的に分離された音声の
また、
2.4 Training objective
学習は、SDRを直接SDRの代わりにSI-SNRを最大化することを目標として学習していきます。

これを用いてPermutation Invariant Training(PIT)でlossを算出するようだ。(まだあんまり分かっていない...)
[追記]PITについて 2022/07/04
Permutation問題について少し理解したので、記述しておく。
Speech EnhancementやSpeech Dializationなど、音声を分離するタスクのなかで、分離された音声がどちらの正解ラベルの推論値であるかを知る必要がある。(これが Permutation問題)
そこで、それを解決するために、推論値と正解ラベルを交差検証的にLossを計算して、より小さかったほうを正解ラベルとあっている方にするというのが、PITなどのPermutationを解決する手法である。
他にも色々あるので、調べてほしい。
Experiments
Dataset
データセットは、WSJ0(Wall Street Journal)のデータから2話者の音声を重畳したWSJ0-2mixを用いる。
Network configration
細かいところは論文を読んでみてほしい。
ここで、特筆することは、LSTMとBLSTMを使っていることだ。しかし、BLSTMは未来の情報も利用していることから、リアルタイムの処理には使えない。
result

Causalとは、現在と過去の値のみを考慮して推測するということである。BLSTMは未来の情報が過去にリークしちゃっているので、現実的には使えない。
LSTM、BLSTMともに、Conv-TasNetは非常に良い性能が出ていることが考察される。

また、最小レイテンシー(ms)も、TasNetを用いたときのほうが大幅に上回っている。
まとめ
最後の結果から見ると、Time Domainで音声分離する方法は非常に有効で、また、計算時間も大幅に改善されていることが分かった。
現在では、より精度のよく、早い、Conv-TasNetがあり、そちらはSEのブレイクスルーとなるなど、Time Domainで音声分離やSEする手法が盛んである。
これからも様々な手法を追っていきたい。
参考資料
Discussion