🕌
Pythonで建築構造最適化の評価


概要
建築構造設計の中でも、超高層物件(評定物件)を対象とする。制振ダンパーの最適配置問題を解く。解析ソフトにはSNAP Ver.8を使う。メインプログラムにはPythonを使い、最適化アルゴリズムにはGAを用いる。①PythonでSNAPへの入力テキストファイルを作成→②SNAPで解析→③SNAPの解析結果をPythonで読取り→④GA→①・・・のような流れで最適化を行う。
フォルダ構成
src
├─GA.py :: メインファイル。GAによる最適化計算を行う。
├─macro_inputpy.py :: [make_input2.xlsm]の特定タブからinput.s8iの作成
├─△make_input.xlsm :: input.s8iというcsvファイルの記載内容を作成
├─△input.s8i :: SNAP入力テキストファイル
├─△command.bat :: SNAP実行用のバッチファイル
├─macro_result.py :: [make_result.xlsm]のマクロ実行&pythonへのデータ取得を行う。
├─△make_result.xlsm :: 結果のまとめを行う。
├─resultGA.csv :: 各解析後に結果を保存する。
| パレート解のグラフ作成、多次元解析チャート作成に使う。
└─plot_multi.ipynb :: 最適化評価のためのグラフ化を行う。
△はアップロードしていない。
最適化の実行
GA.py メイン
import numpy as np
import matplotlib.pyplot as plt
from deap import base, creator, tools, algorithms
import subprocess
import macro_inputpy as mi
import macro_result as mr
import csv
import os
batch_file_path = r".\command.bat" # 実行するバッチファイルのパスを指定
excel_file_path_I = "./make_input2.xlsm" # Excelファイルのパスを指定
input_maker = mi.make_input(excel_file_path_I)
excel_file_path_R = "./make_result.xlsm" # Excelファイルのパスを指定
result_maker = mr.make_result(excel_file_path_R)
# 総評価回数 = 初期集団の評価回数+(各世代の評価回数×世代数)
# 初期集団の評価回数
Gcounter = 1
big_num = 100
population_n = big_num # 初期集団のサイズ
lambda_ = big_num # 各世代の評価回数
mu = lambda_
ngen = 40 # 世代数
GNum = population_n + (lambda_*ngen) # 総評価回数
def run_batch_file():
global Gcounter
try:
result = subprocess.run(batch_file_path, check=False, capture_output=True, text=True, shell=True)
# 実行結果を確認する
if result.returncode != 0:
print("バッチファイルが正常に終了しませんでしたが無視できるエラー")
else:
print("バッチファイルは正常に終了しました。")
except subprocess.CalledProcessError as e:
print(f"エラーコード {e.returncode} でバッチファイルが終了しました。")
print(f"エラーメッセージ: {e.stderr}")
print(f"計算回数 {Gcounter} /{GNum}")
Gcounter += 1
# 目的関数
def evaluate(N_damper):
input_maker.change_N_damper(N_damper) # エクセルへのダンパー数書き込み
input_maker.make_csv_with_xlwings("inputs8i", "input.s8i") # s8iファイル作成
run_batch_file()
result_maker.do_macro()
Ci, R = result_maker.get_CiR()
min_R = min(R)
# 結果をCSVに保存
save_result_to_csv(N_damper, Ci, min_R, R)
return Ci, min_R
def save_result_to_csv(N_damper, Ci, min_R, R):
file_exists = os.path.isfile('resultsGA.csv')
with open('resultsGA.csv', 'a', newline='') as csvfile:
fieldnames = ['N_damper', 'Ci', 'min_R', 'R']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
if not file_exists:
writer.writeheader() # CSVファイルが存在しない場合はヘッダーを書き込む
writer.writerow({
'N_damper': N_damper,
'Ci': Ci,
'min_R': min_R,
'R': R
})
# 最適化の定義
creator.create("FitnessMulti", base.Fitness, weights=(-1.0, 1.0)) # Ciを最小化、Rを最大化
creator.create("Individual", list, fitness=creator.FitnessMulti)
toolbox = base.Toolbox()
toolbox.register("attr_bool", np.random.randint, 2)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_bool, 15)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
# 目的関数の登録
toolbox.register("evaluate", evaluate)
def feasible(individual):
_, min_R = evaluate(individual)
return min_R >= 200
def distance(individual):
_, min_R = evaluate(individual)
return abs(min_R - 200)
# デコレーションを適用
toolbox.decorate("evaluate", tools.DeltaPenalty(feasible, 100.0, distance))
toolbox.register("mate", tools.cxTwoPoint)
toolbox.register("mutate", tools.mutFlipBit, indpb=0.05)
toolbox.register("select", tools.selNSGA2)
def main():
# CSVファイルを初期化
if os.path.exists('resultsGA.csv'):
os.remove('resultsGA.csv')
population = toolbox.population(n=population_n)
#ngen = ngen
cxpb = 0.5
mutpb = 0.2
#algorithms.eaMuPlusLambda(population, toolbox, mu=300, lambda_=300, cxpb=cxpb, mutpb=mutpb, ngen=ngen,
algorithms.eaMuPlusLambda(population, toolbox, mu=mu, lambda_=lambda_, cxpb=cxpb, mutpb=mutpb, ngen=ngen,
stats=None, halloffame=None, verbose=False)
if __name__ == "__main__":
main()
エクセルとマクロの操作
macro_inputpy.py [make_input2.xlsm]の操作
import pandas as pd
import os
"""
240519 make_imput.xlsm に記載の内容よりs8iを作成
"""
import xlwings as xw
import os
class make_input:
def __init__(self, excel_file_path):
self.excel_file_path = excel_file_path
self.app = xw.App(visible=True)
self.book = self.app.books.open(excel_file_path)
def make_csv_with_xlwings(self, sheet_name, output_file_name):
sheet = self.book.sheets[sheet_name]
rng = sheet.used_range
values = rng.value
excel_file_dir = os.path.dirname(self.excel_file_path) # excel_file_path を self.excel_file_path に変更
csv_file_path = os.path.join(excel_file_dir, output_file_name)
with open(csv_file_path, 'w', newline='', encoding='cp932') as file:
for row in values:
if not isinstance(row, list):
row = [row]
line = ','.join('' if v is None else str(v) for v in row)
file.write(line + "\n")
print(f"CSVファイルが保存されました: {csv_file_path}")
def read_range_to_list(self, sheet_name, cell_range):
sheet = self.book.sheets[sheet_name]
range_values = sheet.range(cell_range).value
result_list = [0 if v is None else int(v) for v in range_values]
return result_list
def get_N_damper(self): # N_danmper ダンパー台数を取得する。
sheet_name = "damper" # シート名を指定
cell_range = "D4:D18" # 読み込む範囲を指定
data_list = self.read_range_to_list(sheet_name, cell_range)
print(data_list)
return data_list
def change_N_damper(self, data_list): # chenge → change に修正
sheet_name = "damper" # シート名を指定
cell_range = "D4:D18" # 読み込む範囲を指定
sheet = self.book.sheets[sheet_name]
# セルの範囲を取得
cells = sheet.range(cell_range)
for i in range(len(data_list)):
cells[i].value = data_list[i]
self.book.save() # 保存後に再度データを読み込む必要はない
def __del__(self): # クラスのデストラクタを追加して Excel ファイルを閉じる
self.book.close()
self.app.quit()
if __name__ == "__main__":
excel_file_path = "./make_input2.xlsm" # Excelファイルのパスを指定
input_maker = make_input(excel_file_path)
input_maker.make_csv_with_xlwings("inputs8i", "input.s8i")
N_damper = input_maker.get_N_damper() # N_damper
#input_maker.change_N_damper([10] * 0) # N_damper → 目的関数ノード(O_Nd) → damper
macto_result.py [make_result.xlsm]の操作
import pandas as pd
import os
import xlwings as xw
class make_result:
def __init__(self, excel_file_path):
self.excel_file_path = excel_file_path
self.app = xw.App(visible=True)
self.book = self.app.books.open(excel_file_path)
def read_range_to_list(self, sheet_name, cell_range):
sheet = self.book.sheets[sheet_name]
range_values = sheet.range(cell_range).value
if isinstance(range_values, list):
result_list = [0 if v is None else float(v) for v in range_values]
else:
result_list = float(range_values)
return result_list
def get_CiR(self): # N_danmper ダンパー台数を取得する。
sheet_name = "result" # シート名を指定
cell_range1 = "G24" # 読み込む範囲を指定
cell_range2 = "N3:N28" # 読み込む範囲を指定
data_Ci = self.read_range_to_list(sheet_name, cell_range1)
data_R = self.read_range_to_list(sheet_name, cell_range2)
return data_Ci, data_R
def do_macro(self):
self.book.macro('read_csv')()
self.book.save()
def __del__(self): # クラスのデストラクタを追加して Excel ファイルを閉じる
self.book.close()
self.app.quit()
if __name__ == "__main__":
excel_file_path = "./make_result.xlsm" # Excelファイルのパスを指定
result_maker = make_result(excel_file_path)
result_maker.do_macro()
最適化の評価
plot_multi.ipynb パレート曲面
import matplotlib.pyplot as plt
from matplotlib.ticker import FuncFormatter
import csv
# 組合せ数2^15 = 32,768コ
csv_file = "resultsGA2.csv"
data = []
with open(csv_file, newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
data.append(row)
# 必要に応じてデータを整形
N_dampers = [eval(row['N_damper']) for row in data]
N_damper_sum = [sum(li) for li in N_dampers]
Cis = [float(row['Ci']) for row in data]
min_Rs = [float(row['min_R']) for row in data]
lastx = len(Cis) - 100
print(N_dampers)
print(Cis)
print(min_Rs)
# 縦軸の目盛りフォーマッタを定義
def y_format_func(value, tick_number):
return f"1/{value:.0f}"
plt.scatter(Cis, min_Rs)
plt.scatter(Cis[lastx:], min_Rs[lastx:])
plt.scatter(Cis[:100], min_Rs[:100])
plt.xlabel('Ci')
plt.ylabel('MAX(R)')
plt.title('Pareto Front')
plt.gca().invert_yaxis() # 縦軸を反転
plt.gca().yaxis.set_major_formatter(FuncFormatter(y_format_func)) # 縦軸の目盛りをカスタマイズ
plt.show()
plt.scatter(N_damper_sum, min_Rs)
plt.scatter(N_damper_sum[lastx:], min_Rs[lastx:])
plt.xlabel('damper total number')
plt.ylabel('MAX(R)')
plt.title('Pareto Front')
plt.gca().invert_yaxis() # 縦軸を反転
plt.gca().yaxis.set_major_formatter(FuncFormatter(y_format_func)) # 縦軸の目盛りをカスタマイズ
plt.show()
plt.scatter(N_damper_sum, Cis)
plt.scatter(N_damper_sum[lastx:], Cis[lastx:])
plt.xlabel('damper total number')
plt.ylabel('Ci')
plt.title('Pareto Front')
plt.show()
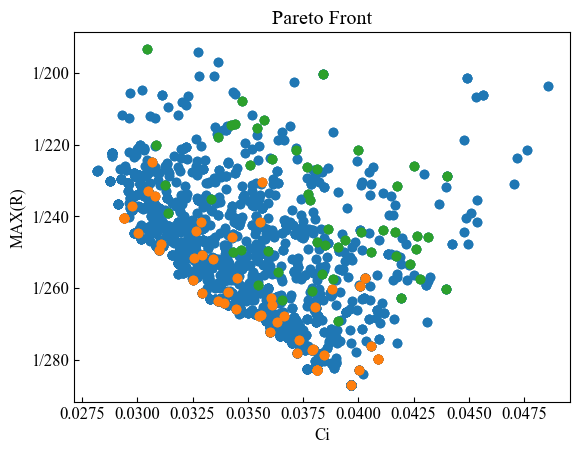
※青:全プロット,オレンジ:最後の100点,緑:最初の100点
plot_multi.ipynb 多次元解析チャート
# 必要に応じてデータを整形
import pandas as pd
import csv
csv_file = "resultsGA2.csv"
data = []
with open(csv_file, newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
data.append(row)
N_dampers = [eval(row['N_damper']) for row in data]
N_damper_sum = [sum(li) for li in N_dampers]
Cis = [float(row['Ci']) for row in data]
min_Rs = [float(row['min_R']) for row in data]
df_N_dampers = pd.DataFrame(N_dampers, columns=[f"D{i+1}" for i in range(len(N_dampers[0]))])
df_N_dampers["Dsum"] = N_damper_sum
df_N_dampers['Ci'] = Cis
df_N_dampers['min_R'] = min_Rs
df0 = df_N_dampers
df0
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
def Multidimensiona_analysis_chart(df):
# プロットに必要な設定
n_col = len(df.columns) # 列数
n_row = len(df) # 行数
maxs = np.zeros(n_col) # 正規化用最大値配列の初期化
mins = np.zeros(n_col) # 正規化用最小値配列の初期化
col = df.columns # 列名取得
cm = plt.get_cmap('jet', n_row) # jetのカラーマップを行数分の階調で用意
best = df.iloc[n_row - 1] # 最適解(正規化前)を抽出
# 各列を最大値と最小値で正規化
for i in range(n_col):
maxs[i] = df.iloc[:, i].max()
mins[i] = df.iloc[:, i].min()
df.iloc[:, i] = (df.iloc[:, i] - mins[i]) / (maxs[i] - mins[i])
best_norm = df.iloc[n_row - 1] # 最適解(正規化後)を抽出
# グラフ描画事前設定-------------------------------------------------------------------------
# フォントの種類とサイズを設定する。
font_mysize = 12
plt.rcParams['font.size'] = font_mysize
plt.rcParams['font.family'] = 'Times New Roman'
# 目盛を内側にする。
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
# figureを定義する。
fig = plt.figure(figsize=(10, 5))
# グラフの上下左右に目盛線を付ける。
ax1 = fig.add_subplot(111)
ax1.yaxis.set_ticks_position('both')
ax1.xaxis.set_ticks_position('both')
# 軸のラベルを設定する。
ax1.set_ylabel('Normalized value')
# -------------------------------------------------------------------------------------------
# データプロット
for j in range(n_row):
# プロットの最後(最高スコア)だけ赤太ラインにする
if j == n_row - 1:
ax1.plot(col, df.iloc[j], label=str(j), color='red', lw=8)
# 他のデータは昇順ソートされているので、カラーマップの階調を順番に当てはめる
else:
ax1.plot(col, df.iloc[j], label=str(j), color=cm(j))
# 実際の値をプロット上に描画
for k in range(n_col):
ax1.text(k, 1.0, str(round(maxs[k], 2)), fontsize=font_mysize, horizontalalignment='center')
ax1.text(k, 0.0, str(round(mins[k], 2)), fontsize=font_mysize, horizontalalignment='center')
ax1.text(k, best_norm[k], str(round(best[k], 2)),
fontsize=font_mysize,
color='white',
backgroundcolor='red',
horizontalalignment='center')
# グラフを表示する。
fig.tight_layout()
plt.show()
plt.close()
df = df0.sort_values('min_R', ascending=True) # Score列で昇順ソート(高スコア値を最後にする)
#df = df[df['min_R'] >= 250]
Multidimensiona_analysis_chart(df)
df = df0.sort_values('Ci', ascending=False) # Score列で昇順ソート(高スコア値を最後にする)
Multidimensiona_analysis_chart(df)
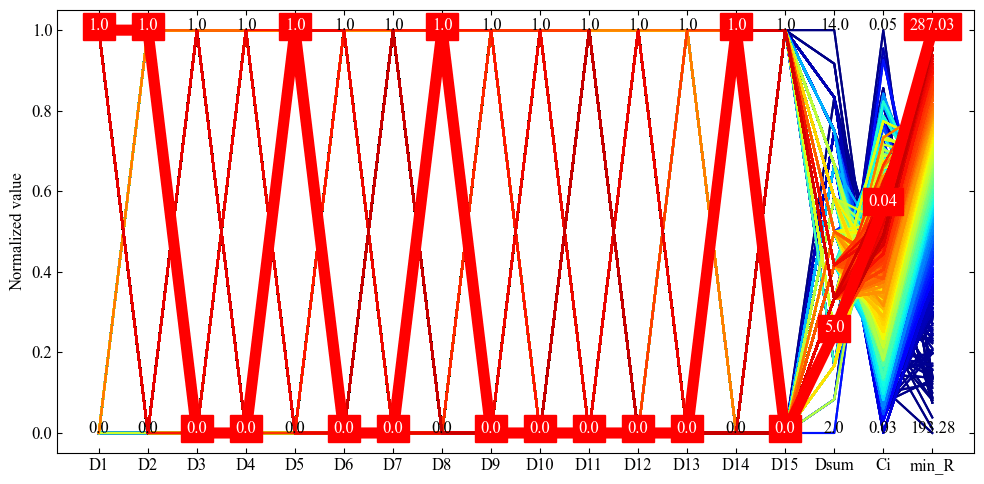
Discussion