[Flutter]ひらがな・カタカナ対応の検索文字列ハイライト実装
本記事はFlutter大学 Advent Calendar 2024の20日目の記事です。
はじめに
皆さん、こんにちは!
今回は業務で実装した検索文字列に一致した部分をハイライト表示する機能の実装方法をご紹介します。この実装方法が他の開発者の方の参考になれば幸いです🙇♂️
実装したい機能について
実現したいのは以下のような機能です!
- ユーザーが入力した検索文字列に一致する部分を見つける
- その一致部分をハイライト表示して、視覚的にわかりやすくする
- ひらがな/カタカナの表記揺れにも対応する(例:「ドラヤキ」で検索したら「どらやき」もヒット)
今回実装するものはこちら
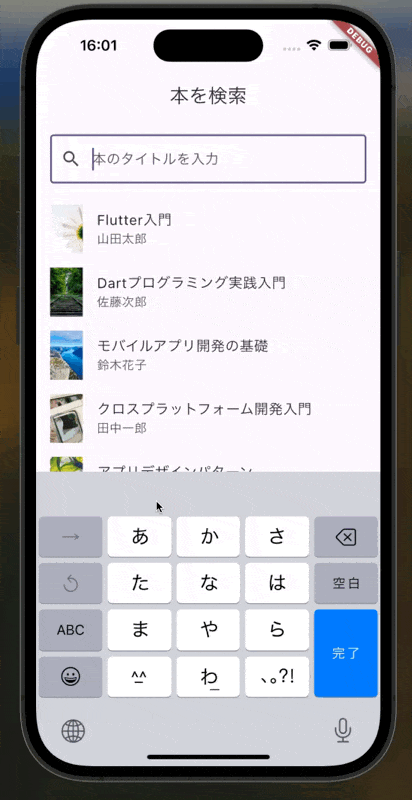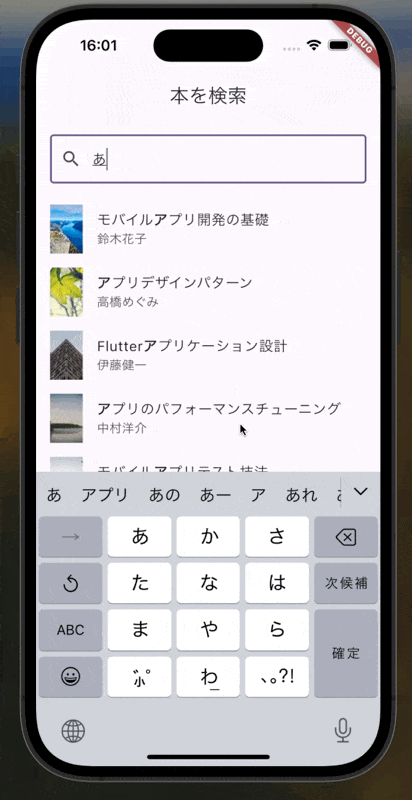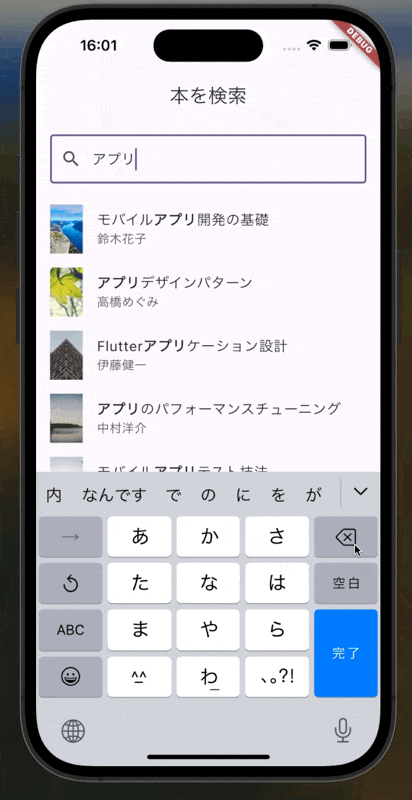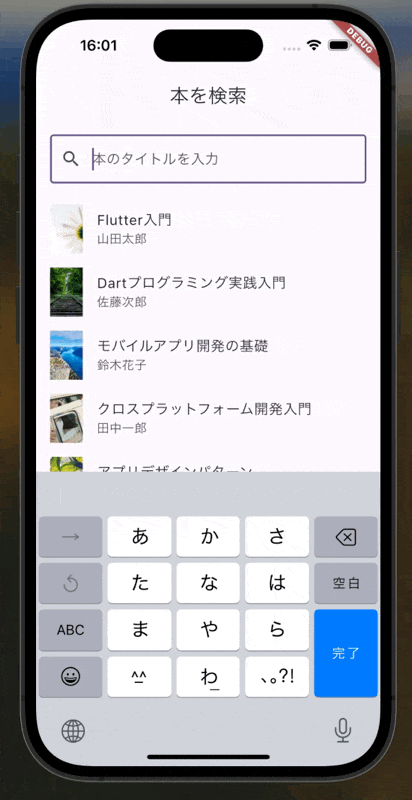
実装
1. ひらがな/カタカナの文字コード変換
まず最初に、検索で重要となる文字の変換処理を実装します。日本語特有の課題である「ひらがな/カタカナの表記揺れ」に対応するため、以下のような変換処理を実装します。
/// ひらがなをカタカナに変換する。
///
/// 処理の流れ:
///
/// 1. テキスト内のひらがなを検出する。
/// - 正規表現 r'[\u3041-\u3096]' を使用して、ひらがなの文字コード範囲(0x3041-0x3096)に
/// マッチする文字を検索する。
/// 2. 各ひらがなの文字コードを取得する。
/// - マッチした文字列の最初の文字(group(0))のUnicodeコードポイントを codeUnitAt(0) で取得する。
/// 3. 文字コードに96(0x60)を加算してカタカナの文字コードに変換する。
/// - ひらがなとカタカナの文字コードの差は96(0x60)なので、これを加算することで
/// 対応するカタカナの文字コードが得られる。
/// 4. カタカナの文字コードから文字列を生成する。
/// - String.fromCharCode() を使用して、カタカナの文字コードから実際の文字列を生成する。
/// - この処理をマッチしたすべての文字に対して行い、変換後の文字列を元の位置に置換する。
String _toKatakana(String text) {
// マッチした文字列のインデックス。
const matchedStringIndex = 0;
// マッチした文字列の最初の文字のインデックス。
const firstCharacterIndex = 0;
// カタカナとひらがなの文字コードの差分コードポイント。
const katakanaHiraganaDiff = 0x60;
// ひらがなの文字コード範囲を表す正規表現。
const hiraganaRange = r'[\u3041-\u3096]';
return text.replaceAllMapped(
RegExp(hiraganaRange),
(match) => String.fromCharCode(
match.group(matchedStringIndex)!.codeUnitAt(firstCharacterIndex) +
katakanaHiraganaDiff,
),
);
}
/// カタカナをひらがなに変換する。
///
/// 処理の流れ:
///
/// 1. テキスト内のカタカナを検出する。
/// - 正規表現 r'[\u30A1-\u30F6]' を使用して、カタカナの文字コード範囲(0x30A1-0x30F6)に
/// マッチする文字を検索する。
/// 2. 各カタカナの文字コードを取得する。
/// - マッチした文字列の最初の文字(group(0))のUnicodeコードポイントを codeUnitAt(0) で取得する。
/// 3. 文字コードから96(0x60)を減算してひらがなの文字コードに変換する。
/// - カタカナとひらがなの文字コードの差は96(0x60)なので、これを減算することで
/// 対応するひらがなの文字コードが得られる。
/// 4. ひらがなの文字コードから文字列を生成する。
/// - String.fromCharCode() を使用して、ひらがなの文字コードから実際の文字列を生成する。
/// - この処理をマッチしたすべての文字に対して行い、変換後の文字列を元の位置に置換する。
String _toHiragana(String text) {
// マッチした文字列のインデックス。
const matchedStringIndex = 0;
// マッチした文字列の最初の文字のインデックス。
const firstCharacterIndex = 0;
// カタカナとひらがなの文字コードの差分コードポイント。
const katakanaHiraganaDiff = 0x60;
// カタカナの文字コード範囲を表す正規表現。
const katakanaRange = r'[\u30A1-\u30F6]';
return text.replaceAllMapped(
RegExp(katakanaRange),
(match) => String.fromCharCode(
match.group(matchedStringIndex)!.codeUnitAt(firstCharacterIndex) -
katakanaHiraganaDiff,
),
);
}
ここでのポイントは、ひらがなとカタカナの文字コードの差が0x60(96)であることを利用している点です。この性質を使って文字の変換を行っています。
2. 検索文字列の一致判定
変換した文字列を使って、以下のように検索文字列との一致を判定します。
int? _findMatchIndex(String text, String searchText) {
// それぞれカタカナとひらがなに変換
final katakanaText = _toKatakana(text);
final katakanaSearchText = _toKatakana(searchText);
final hiraganaText = _toHiragana(text);
final hiraganaSearchText = _toHiragana(searchText);
// 元の文字列、カタカナ変換、ひらがな変換のいずれかで一致するか確認
return [
text.indexOf(searchText),
katakanaText.indexOf(katakanaSearchText),
hiraganaText.indexOf(hiraganaSearchText),
].where((index) => index != -1).firstOrNull;
}
これにより、「どらやき」で検索しても「ドラヤキ」がヒットするようになります。
3. テキストの分割処理の実装
検索文字列が見つかった場合、テキストを適切に分割する必要があります。
以下の関数を実装することで、テキストを「一致前」「一致部分」「一致後」の3つに分割します。
/// テキストを検索文字列の前後で分割する。
///
/// 例えば、以下のように使用します:
/// ```dart
/// final text = 'どらやき美味しい';
/// final result = _splitMatchedText(
/// text: text,
/// matchIndex: 4, // '美味しい'の開始位置
/// matchLength: 3, // '美味しい'の長さ
/// );
/// print(result.before); // 'どらやき'
/// print(result.match); // '美味しい'
/// print(result.after); // ''
/// ```
///
/// - [text] 分割対象の元のテキスト文字列。
/// - [matchIndex] 検索文字列が見つかった開始位置(0から始まるインデックス)。
/// - [matchLength] 検索文字列の文字数。
({String before, String match, String after}) _splitMatchedText({
required String text,
required int matchIndex,
required int matchLength,
}) {
return (
before: text.substring(0, matchIndex),
match: text.substring(matchIndex, matchIndex + matchLength),
after: text.substring(matchIndex + matchLength),
);
}
4. RichTextを使用した強調表示の実装
一致する箇所が見つかった場合、テキストを以下の3つの部分に分割し、RichTextウィジェットを使用して一致部分のみスタイルを変更します。
RichText(
text: TextSpan(
children: [
TextSpan(text: beforeMatch), // 一致前のテキスト
TextSpan(
text: match, // 一致部分のテキスト
style: const TextStyle(fontWeight: FontWeight.bold),
),
TextSpan(text: afterMatch), // 一致後のテキスト
],
),
)
実装コード
画面
import 'package:auto_route/annotations.dart';
import 'package:flutter/material.dart';
import 'package:hooks_riverpod/hooks_riverpod.dart';
import 'book_provider.dart';
/// 本の検索画面。
///
/// タイトルで本を検索することができる。
()
class SerchBookPage extends HookConsumerWidget {
/// コンストラクタ。
const SerchBookPage({super.key});
Widget build(BuildContext context, WidgetRef ref) {
// 本のリストを取得する。
final filteredBooks = ref.watch(filteredBooksProvider);
// 検索文字列を取得する。
final searchQuery = ref.watch(searchQueryProvider);
// 本の検索画面を表示する。
return Scaffold(
appBar: AppBar(
title: const Text('本を検索'),
),
body: Column(
children: [
Padding(
padding: const EdgeInsets.all(16),
child: TextField(
decoration: const InputDecoration(
hintText: '本のタイトルを入力',
prefixIcon: Icon(Icons.search),
border: OutlineInputBorder(),
),
onChanged: (value) {
// 検索文字列を更新する。
ref.read(searchQueryProvider.notifier).state = value;
},
),
),
Expanded(
child: ListView.builder(
itemCount: filteredBooks.length,
itemBuilder: (context, index) {
final book = filteredBooks[index];
return ListTile(
leading: Image.network(book.imageUrl),
title: _HighlightedBookTitle(
title: book.title,
searchQuery: searchQuery,
),
subtitle: Text(book.author),
onTap: () {
// 本の詳細画面への遷移
},
);
},
),
),
],
),
);
}
}
/// 検索文字列がタイトルに含まれている場合、その部分を太字で表示するウィジェット。
///
/// ひらがな・カタカナの違いを吸収して検索できるように、文字列の変換処理も行っている。
class _HighlightedBookTitle extends StatelessWidget {
/// 検索文字列がタイトルに含まれている場合、その部分を太字で表示するウィジェット。
///
/// ひらがな・カタカナの違いを吸収して検索できるように、文字列の変換処理も行っている。
const _HighlightedBookTitle({
required this.title,
required this.searchQuery,
});
/// タイトル。
final String title;
/// 検索文字列。
final String searchQuery;
Widget build(BuildContext context) {
// 検索文字列が空の場合は、そのままタイトルを表示する。
if (searchQuery.isEmpty) {
return Text(title);
}
// 検索文字列がタイトルに含まれているかを検索する。
final matchIndex = _findMatchIndex(title, searchQuery);
// 一致する文字列がない場合は、そのままタイトルを表示する。
if (matchIndex == null) {
return Text(title);
}
// 一致する文字列を分割する。
final parts = _splitMatchedText(
text: title,
matchIndex: matchIndex,
matchLength: searchQuery.length,
);
// 分割した文字列を太字で表示する。
return RichText(
text: TextSpan(
children: [
// 検索文字列より前の部分を表示する
TextSpan(text: parts.before),
// 検索文字列を太字で表示する
TextSpan(
text: parts.match,
style: const TextStyle(fontWeight: FontWeight.bold),
),
// 検索文字列より後の部分を表示する
TextSpan(text: parts.after),
],
),
);
}
/// 文字列内で検索文字列を探す。
int? _findMatchIndex(String text, String searchText) {
// ひらがなをカタカナに変換する。
final katakanaText = _toKatakana(text);
// 検索文字列をカタカナに変換する。
final katakanaSearchText = _toKatakana(searchText);
// カタカナをひらがなに変換する。
final hiraganaText = _toHiragana(text);
// 検索文字列をひらがなに変換する。
final hiraganaSearchText = _toHiragana(searchText);
// 検索文字列がタイトルに含まれているかを検索する。
return [
text.indexOf(searchText),
katakanaText.indexOf(katakanaSearchText),
hiraganaText.indexOf(hiraganaSearchText),
].where((index) => index != -1).firstOrNull;
}
/// ひらがなをカタカナに変換する。
///
/// 処理の流れ:
///
/// 1. テキスト内のひらがなを検出する。
/// - 正規表現 r'[\u3041-\u3096]' を使用して、ひらがなの文字コード範囲(0x3041-0x3096)に
/// マッチする文字を検索する。
/// 2. 各ひらがなの文字コードを取得する。
/// - マッチした文字列の最初の文字(group(0))のUnicodeコードポイントを codeUnitAt(0) で取得する。
/// 3. 文字コードに96(0x60)を加算してカタカナの文字コードに変換する。
/// - ひらがなとカタカナの文字コードの差は96(0x60)なので、これを加算することで
/// 対応するカタカナの文字コードが得られる。
/// 4. カタカナの文字コードから文字列を生成する。
/// - String.fromCharCode() を使用して、カタカナの文字コードから実際の文字列を生成する。
/// - この処理をマッチしたすべての文字に対して行い、変換後の文字列を元の位置に置換する。
String _toKatakana(String text) {
// マッチした文字列のインデックス
const matchedStringIndex = 0;
// マッチした文字列の最初の文字のインデックス
const firstCharacterIndex = 0;
// カタカナとひらがなの文字コードの差分コードポイント
const katakanaHiraganaDiff = 0x60;
// ひらがなの文字コード範囲を表す正規表現
const hiraganaRange = r'[\u3041-\u3096]';
return text.replaceAllMapped(
RegExp(hiraganaRange),
(match) => String.fromCharCode(
match.group(matchedStringIndex)!.codeUnitAt(firstCharacterIndex) +
katakanaHiraganaDiff,
),
);
}
/// カタカナをひらがなに変換する。
///
/// 処理の流れ:
///
/// 1. テキスト内のカタカナを検出する。
/// - 正規表現 r'[\u30A1-\u30F6]' を使用して、カタカナの文字コード範囲(0x30A1-0x30F6)に
/// マッチする文字を検索する。
/// 2. 各カタカナの文字コードを取得する。
/// - マッチした文字列の最初の文字(group(0))のUnicodeコードポイントを codeUnitAt(0) で取得する。
/// 3. 文字コードから96(0x60)を減算してひらがなの文字コードに変換する。
/// - カタカナとひらがなの文字コードの差は96(0x60)なので、これを減算することで
/// 対応するひらがなの文字コードが得られる。
/// 4. ひらがなの文字コードから文字列を生成する。
/// - String.fromCharCode() を使用して、ひらがなの文字コードから実際の文字列を生成する。
/// - この処理をマッチしたすべての文字に対して行い、変換後の文字列を元の位置に置換する。
String _toHiragana(String text) {
// マッチした文字列のインデックス
const matchedStringIndex = 0;
// マッチした文字列の最初の文字のインデックス
const firstCharacterIndex = 0;
// カタカナとひらがなの文字コードの差分コードポイント。
const katakanaHiraganaDiff = 0x60;
// カタカナの文字コード範囲を表す正規表現。
const katakanaRange = r'[\u30A1-\u30F6]';
return text.replaceAllMapped(
RegExp(katakanaRange),
(match) => String.fromCharCode(
match.group(matchedStringIndex)!.codeUnitAt(firstCharacterIndex) -
katakanaHiraganaDiff,
),
);
}
/// テキストを検索文字列の前後で分割する。
///
/// 例えば、以下のように使用します:
/// ```dart
/// final text = 'どらやき美味しい';
/// final result = _splitMatchedText(
/// text: text,
/// matchIndex: 4, // '美味しい'の開始位置
/// matchLength: 3, // '美味しい'の長さ
/// );
/// print(result.before); // 'どらやき'
/// print(result.match); // '美味しい'
/// print(result.after); // ''
/// ```
///
/// - [text] 分割対象の元のテキスト文字列。
/// - [matchIndex] 検索文字列が見つかった開始位置(0から始まるインデックス)。
/// - [matchLength] 検索文字列の文字数。
({String before, String match, String after}) _splitMatchedText({
required String text,
required int matchIndex,
required int matchLength,
}) {
// 検索文字列より前の部分を取得
// 例: 'どらやき美味しい' から 'どらやき' を取得
final before = text.substring(0, matchIndex);
// マッチした検索文字列を取得
// 例: 'どらやき美味しい' から '美味しい' を取得
final match = text.substring(matchIndex, matchIndex + matchLength);
// 検索文字列より後の部分を取得
// 例: 'どらやき美味しい' から '' を取得
final after = text.substring(matchIndex + matchLength);
return (
before: before,
match: match,
after: after,
);
}
}
エンティティ
import 'package:flutter/material.dart';
/// 本のデータクラス。
class Book {
/// 本のデータクラスのコンストラクタ。
///
/// [id] は本のID。
/// [title] は本のタイトル。
/// [author] は本の著者。
/// [imageUrl] は本の画像のURL。
/// [description] は本の説明。
const Book({
required this.id,
required this.title,
required this.author,
required this.imageUrl,
this.description,
});
/// 本のID。
final String id;
/// 本のタイトル。
final String title;
/// 本の著者。
final String author;
/// 本の画像のURL。
final String imageUrl;
/// 本の説明。
final String? description;
}
ロジック
import 'package:hooks_riverpod/hooks_riverpod.dart';
import 'book.dart';
/// 本のリストを提供する。
final booksProvider = Provider<List<Book>>((ref) {
return [
const Book(
id: '1',
title: 'Flutter入門',
author: '山田太郎',
imageUrl: 'https://picsum.photos/200/300?random=1',
),
const Book(
id: '2',
title: 'Dartプログラミング実践入門',
author: '佐藤次郎',
imageUrl: 'https://picsum.photos/200/300?random=2',
),
const Book(
id: '3',
title: 'モバイルアプリ開発の基礎',
author: '鈴木花子',
imageUrl: 'https://picsum.photos/200/300?random=3',
),
const Book(
id: '4',
title: 'クロスプラットフォーム開発入門',
author: '田中一郎',
imageUrl: 'https://picsum.photos/200/300?random=4',
),
const Book(
id: '5',
title: 'アプリデザインパターン',
author: '高橋めぐみ',
imageUrl: 'https://picsum.photos/200/300?random=5',
),
const Book(
id: '6',
title: 'Flutterアプリケーション設計',
author: '伊藤健一',
imageUrl: 'https://picsum.photos/200/300?random=6',
),
const Book(
id: '7',
title: 'モバイルUXデザイン',
author: '渡辺真理',
imageUrl: 'https://picsum.photos/200/300?random=7',
),
const Book(
id: '8',
title: 'アプリのパフォーマンスチューニング',
author: '中村洋介',
imageUrl: 'https://picsum.photos/200/300?random=8',
),
const Book(
id: '9',
title: 'Flutterウィジェット完全ガイド',
author: '小林直子',
imageUrl: 'https://picsum.photos/200/300?random=9',
),
const Book(
id: '10',
title: 'モバイルアプリテスト技法',
author: '山本博',
imageUrl: 'https://picsum.photos/200/300?random=10',
),
const Book(
id: '11',
title: 'アプリのセキュリティ対策',
author: '木村達也',
imageUrl: 'https://picsum.photos/200/300?random=11',
),
const Book(
id: '12',
title: 'FlutterとFirebase',
author: '松田優子',
imageUrl: 'https://picsum.photos/200/300?random=12',
),
const Book(
id: '13',
title: '状態管理手法入門',
author: '斎藤健一',
imageUrl: 'https://picsum.photos/200/300?random=13',
),
const Book(
id: '14',
title: 'アプリのCI/CD実践ガイド',
author: '岡田隆',
imageUrl: 'https://picsum.photos/200/300?random=14',
),
const Book(
id: '15',
title: 'クラウドサービス連携術',
author: '藤田みどり',
imageUrl: 'https://picsum.photos/200/300?random=15',
),
const Book(
id: '16',
title: 'アプリのローカライゼーション',
author: '佐々木翔',
imageUrl: 'https://picsum.photos/200/300?random=16',
),
const Book(
id: '17',
title: 'レスポンシブデザイン実践',
author: '村上さくら',
imageUrl: 'https://picsum.photos/200/300?random=17',
),
const Book(
id: '18',
title: 'アプリのアクセシビリティ',
author: '近藤大輔',
imageUrl: 'https://picsum.photos/200/300?random=18',
),
const Book(
id: '19',
title: 'デバッグ技法マスター',
author: '石川裕子',
imageUrl: 'https://picsum.photos/200/300?random=19',
),
const Book(
id: '20',
title: 'アプリ開発プロジェクト管理',
author: '西田健',
imageUrl: 'https://picsum.photos/200/300?random=20',
)
];
});
/// 検索文字列を提供する。
final searchQueryProvider = StateProvider<String>((ref) => '');
/// 検索結果を提供する。
final filteredBooksProvider = Provider<List<Book>>((ref) {
final books = ref.watch(booksProvider);
final query = ref.watch(searchQueryProvider);
if (query.isEmpty) {
return books;
}
return books.where((book) => _isMatch(book.title, query)).toList();
});
/// 検索文字列が本のタイトルに含まれているかを検索する。
///
/// 検索文字列がひらがな・カタカナの違いを吸収して検索できるように、文字列の変換処理も行っている。
bool _isMatch(String text, String searchText) {
// 検索文字列がタイトルに含まれている場合は、そのまま検索結果として返す。
if (text.contains(searchText)) {
return true;
}
// 検索文字列をカタカナに変換して検索する。
final katakanaText = _toKatakana(text);
// 検索文字列をカタカナに変換する。
final katakanaSearchText = _toKatakana(searchText);
// カタカナに変換した検索文字列がタイトルに含まれている場合は、そのまま検索結果として返す。
if (katakanaText.contains(katakanaSearchText)) {
return true;
}
// 検索文字列をひらがなに変換して検索する。
final hiraganaText = _toHiragana(text);
// 検索文字列をひらがなに変換する。
final hiraganaSearchText = _toHiragana(searchText);
// ひらがなに変換した検索文字列がタイトルに含まれている場合は、そのまま検索結果として返す。
if (hiraganaText.contains(hiraganaSearchText)) {
return true;
}
// 検索文字列がタイトルに含まれていない場合は、検索結果として返す。
return false;
}
/// ひらがなをカタカナに変換する。
///
/// 処理の流れ:
///
/// 1. テキスト内のひらがなを検出する。
/// - 正規表現 r'[\u3041-\u3096]' を使用して、ひらがなの文字コード範囲(0x3041-0x3096)に
/// マッチする文字を検索する。
/// 2. 各ひらがなの文字コードを取得する。
/// - マッチした文字列の最初の文字(group(0))のUnicodeコードポイントを codeUnitAt(0) で取得する。
/// 3. 文字コードに96(0x60)を加算してカタカナの文字コードに変換する。
/// - ひらがなとカタカナの文字コードの差は96(0x60)なので、これを加算することで
/// 対応するカタカナの文字コードが得られる。
/// 4. カタカナの文字コードから文字列を生成する。
/// - String.fromCharCode() を使用して、カタカナの文字コードから実際の文字列を生成する。
/// - この処理をマッチしたすべての文字に対して行い、変換後の文字列を元の位置に置換する。
String _toKatakana(String text) {
// マッチした文字列のインデックス
const matchedStringIndex = 0;
// マッチした文字列の最初の文字のインデックス
const firstCharacterIndex = 0;
// カタカナとひらがなの文字コードの差分コードポイント
const katakanaHiraganaDiff = 0x60;
// ひらがなの文字コード範囲を表す正規表現
const hiraganaRange = r'[\u3041-\u3096]';
return text.replaceAllMapped(
RegExp(hiraganaRange),
(match) => String.fromCharCode(
match.group(matchedStringIndex)!.codeUnitAt(firstCharacterIndex) +
katakanaHiraganaDiff,
),
);
}
/// カタカナをひらがなに変換する。
///
/// 処理の流れ:
///
/// 1. テキスト内のカタカナを検出する。
/// - 正規表現 r'[\u30A1-\u30F6]' を使用して、カタカナの文字コード範囲(0x30A1-0x30F6)に
/// マッチする文字を検索する。
/// 2. 各カタカナの文字コードを取得する。
/// - マッチした文字列の最初の文字(group(0))のUnicodeコードポイントを codeUnitAt(0) で取得する。
/// 3. 文字コードから96(0x60)を減算してひらがなの文字コードに変換する。
/// - カタカナとひらがなの文字コードの差は96(0x60)なので、これを減算することで
/// 対応するひらがなの文字コードが得られる。
/// 4. ひらがなの文字コードから文字列を生成する。
/// - String.fromCharCode() を使用して、ひらがなの文字コードから実際の文字列を生成する。
/// - この処理をマッチしたすべての文字に対して行い、変換後の文字列を元の位置に置換する。
String _toHiragana(String text) {
// マッチした文字列のインデックス
const matchedStringIndex = 0;
// マッチした文字列の最初の文字のインデックス
const firstCharacterIndex = 0;
// カタカナとひらがなの文字コードの差分コードポイント。
const katakanaHiraganaDiff = 0x60;
// カタカナの文字コード範囲を表す正規表現。
const katakanaRange = r'[\u30A1-\u30F6]';
return text.replaceAllMapped(
RegExp(katakanaRange),
(match) => String.fromCharCode(
match.group(matchedStringIndex)!.codeUnitAt(firstCharacterIndex) -
katakanaHiraganaDiff,
),
);
}
まとめ
本記事では、文字列検索とハイライト表示の実装において、文字コード変換とRichTextウィジェットを組み合わせた手法を紹介しました。ひらがな/カタカナの文字コード変換を活用することで、日本語特有の表記揺れに対応した自然な検索体験を提供することができます!
また、現在の実装を発展させる余地もあります。
例えば、大文字・小文字を区別しない英語検索に対応することで、より汎用的な検索機能を実現することができます。これはtoLowerCase()メソッドを活用し、検索対象と検索文字列を両方小文字に変換して比較することで実装可能です。さらに、アルファベットの異体字(例:é, è, ê)にも対応することで、より国際的なアプリケーションの開発も視野に入れることができます。
今後もFlutterを活用した開発において有用なテクニックやパッケージの活用法をキャッチアップし、共有していきたいと考えています。もし気づいた点や改善提案などがありましたら、ぜひコメントいただけると幸いです🙇♂️
Discussion