Next.js App Router on Cloudflare Workers, d1 構成を試す
個人用のちょっとしたものを作るのに Cloudflare Workers + d1 +(今回は App Router)が低コストでちょうど良さそうなのでやってみていたら結構ハマりどころ多かったのでメモっていくやつ
環境構築は cloudflare-cli からできる。ちなみにボイラープレートから作成するやつは create-cloudflare CLI で通常 C3 と読んでるらしい。
公式ドキュメント:
# デプロイやリソース作成に必要なのでCLIからログインしておく
$ pnpm dlx wrangler login
# 初期設定の諸々を作る
$ pnpm create cloudflare my-app-name --framework=next
Next.js のカスタマイズから Cloudflare の設定まで色々聞かれるので好きに設定していく
✔ Would you like to use TypeScript? … No / Yes
✔ Would you like to use ESLint? … No / Yes
✔ Would you like to use Tailwind CSS? … No / Yes
✔ Would you like to use `src/` directory? … No / Yes
✔ Would you like to use App Router? (recommended) … No / Yes
✔ Would you like to customize the default import alias (@/*)? … No / Yes
✔ What import alias would you like configured? … @/*
# next-on-pages が必要なので eslint を追加しておくのが良さそう
├ Do you want to use the next-on-pages eslint-plugin?
│ yes eslint-plugin
# ここまでできているか確認するのに一応デプロイする
├ Do you want to deploy your application?
│ no deploy via `pnpm run deploy`
Next.js の初期アプリがデプロイされたらOK
d1 のリソースを作成と接続
$ pnpm wrangler d1 create my-app-db-name
⛅️ wrangler 3.37.0 (update available 3.38.0)
-------------------------------------------------------
✅ Successfully created DB 'my-app-db-name' in region APAC
Created your database using D1's new storage backend. The new storage backend is not yet recommended for
production workloads, but backs up your data via point-in-time restore.
[[d1_databases]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "my-app-db-name"
database_id = "<your-uuid-here>"
この設定の内容を wrangler.toml に書いておく(それぞれの意味は後述)
name = "my-app-name"
compatibility_date = "2024-03-20"
compatibility_flags = ["nodejs_compat"]
# Variable bindings. These are arbitrary, plaintext strings (similar to environment variables)
# Note: Use secrets to store sensitive data.
# Docs: https://developers.cloudflare.com/pages/functions/bindings/#environment-variables
# [vars]
# MY_VARIABLE = "production_value"
# Bind the Workers AI model catalog. Run machine learning models, powered by serverless GPUs, on Cloudflare’s global network
# Docs: https://developers.cloudflare.com/pages/functions/bindings/#workers-ai
# [ai]
# binding = "AI"
# Bind a D1 database. D1 is Cloudflare’s native serverless SQL database.
# Docs: https://developers.cloudflare.com/pages/functions/bindings/#d1-databases
[[d1_databases]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "my-app-db-name"
database_id = "<your-uuid-here>"
# Bind a Durable Object. Durable objects are a scale-to-zero compute primitive based on the actor model.
# Durable Objects can live for as long as needed. Use these when you need a long-running "server", such as in realtime apps.
# Docs: https://developers.cloudflare.com/workers/runtime-apis/durable-objects
# [[durable_objects.bindings]]
# name = "MY_DURABLE_OBJECT"
# class_name = "MyDurableObject"
# script_name = 'my-durable-object'
# Bind a KV Namespace. Use KV as persistent storage for small key-value pairs.
# Docs: https://developers.cloudflare.com/pages/functions/bindings/#kv-namespaces
# KV Example:
# [[kv_namespaces]]
# binding = "MY_KV_NAMESPACE"
# id = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# Bind a Queue producer. Use this binding to schedule an arbitrary task that may be processed later by a Queue consumer.
# Docs: https://developers.cloudflare.com/pages/functions/bindings/#queue-producers
# [[queues.producers]]
# binding = "MY_QUEUE"
# queue = "my-queue"
# Bind an R2 Bucket. Use R2 to store arbitrarily large blobs of data, such as files.
# Docs: https://developers.cloudflare.com/pages/functions/bindings/#r2-buckets
# [[r2_buckets]]
# binding = "MY_BUCKET"
# bucket_name = "my-bucket"
# Bind another Worker service. Use this binding to call another Worker without network overhead.
# Docs: https://developers.cloudflare.com/pages/functions/bindings/#service-bindings
# [[services]]
# binding = "MY_SERVICE"
# service = "my-service"
worker -> d1 へのアクセスは Bindings という仕組みで実現する
公式ドキュメント:
D1 bindings allow you to query a D1 database from your Worker.
- Create your first D1 binding.
- Configure a D1 bindings via your wrangler.toml file.
- Learn more about how to query a D1 database using the client API.
d1 に実際に繋ぐ方法はチュートリアルがわかりやすい
export interface Env {
// If you set another name in wrangler.toml as the value for 'binding',
// replace "DB" with the variable name you defined.
DB: D1Database;
}
export default {
async fetch(request: Request, env: Env) {
const { pathname } = new URL(request.url);
if (pathname === "/api/beverages") {
// If you did not use `DB` as your binding name, change it here
const { results } = await env.DB.prepare(
"SELECT * FROM Customers WHERE CompanyName = ?"
)
.bind("Bs Beverages")
.all();
return Response.json(results);
}
return new Response(
"Call /api/beverages to see everyone who works at Bs Beverages"
);
},
};
とはいえ、上記のコードだと hono なり App Router の Server Actions なりから使いたいから env にアクセスできなくて困るが、普通に process.env から読める
なので
declare global {
namespace NodeJS {
interface ProcessEnv {
DB: D1Database
}
}
}
const getCustomers = async () => {
const { results } = await env.DB.prepare(
"SELECT * FROM Customers WHERE CompanyName = ?"
)
.bind("Bs Beverages")
.all()
return results
}
で良い
process.env['DB'] で文字列以外が返ってくるのがクソキモいけどこういうものらしい。
wrangler.toml の設定値について
[[d1_databases]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "my-app-db-name"
database_id = "<your-uuid-here>"
- binding は↑で使った
process.env.??のどこにバインドされるかを指定する文字列 - database_id: d1 データベースの識別子
- database_name は CLI とかで指定する名前
- wranger.toml の database_name, database_id は key-value の関係になっているらしく、例えば全然関係ないプロジェクトから
wranger d1 execute my-app-db-name --remote ...とかを叩くとこのプロジェクトの database_id で書かれている識別子につながってくれる - なんでローカルではヒューマンリーダブルな識別子としてdatabase_nameで解決し、remote に飛ばすときには対応するdatabase_idを見つけて投げるという動きっぽい。たぶん
- wranger.toml の database_name, database_id は key-value の関係になっているらしく、例えば全然関係ないプロジェクトから
また他に preview_database_id なる設定値もあり、本番以外のプレビュー環境のDBの指定もできる
$ pnpm wrangler d1 create my-app-preview-db
とかで別のDBを作って uuid を控えて
[[d1_databases]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "my-app-db-name"
database_id = "<your-uuid-here>"
preview_database_id = "<your-uuid-here>"
で設定をおけば本番・プレビュー・ローカルの向け先にそれぞれクエリを投げられるようになる
# 本番環境向けの実行: --remote
$ pnpm wrangler d1 execute my-app-db-name --remote --command "SELECT 1;"
⛅️ wrangler 3.38.0
-------------------
🌀 Mapping SQL input into an array of statements
🌀 Parsing 1 statements
🌀 Executing on remote database my-app-db-name (xxx):
🌀 To execute on your local development database, remove the --remote flag from your wrangler command.
🚣 Executed 1 commands in 0.2406ms
┌───┐
│ 1 │
├───┤
│ 1 │
└───┘
# プレビュー環境向けの実行: --remote --preview
➜ pnpm wrangler d1 execute my-app-db-name --remote --preview --command "SELECT 1;"
⛅️ wrangler 3.38.0
-------------------
🌀 Mapping SQL input into an array of statements
🌀 Parsing 1 statements
🌀 Executing on remote database my-app-db-name (xxx):
🌀 To execute on your local development database, remove the --remote flag from your wrangler command.
🚣 Executed 1 commands in 0.2272ms
┌───┐
│ 1 │
├───┤
│ 1 │
└───┘
# ローカル向けの実行: --local
$ pnpm wrangler d1 execute my-app-db-name --local --command "SELECT 1;"
⛅️ wrangler 3.38.0
-------------------
🌀 Mapping SQL input into an array of statements
🌀 Executing on local database my-app-db-name (xxx) from .wrangler/state/v3/d1:
🌀 To execute on your remote database, add a --remote flag to your wrangler command.
┌───┐
│ 1 │
├───┤
│ 1 │
└───┘
ローカルで Worker -> d1 に繋ぐ
C3 で作成された初期状態の package.json が以下
{
# ...
"scripts": {
"dev": "next dev",
"build": "next build",
"start": "next start",
"lint": "next lint",
"pages:build": "pnpm next-on-pages",
"preview": "pnpm pages:build && wrangler pages dev .vercel/output/static",
"deploy": "pnpm pages:build && wrangler pages deploy .vercel/output/static",
"build-cf-types": "wrangler types --env-interface CloudflareEnv env.d.ts"
},
# ...
}
Next.js は本来 node で動かすものなのでプレーンな状態では Worker で動かせない
じゃあどうやって動かしているのかというと
がつなぎを頑張ってくれている
仕組みがリポジトリやドキュメントにはしっかり書かれていなくて
公式のブログ記事:
日本語記事だとこの辺:
がわかりやすい
要は Vercel 用に build された成果物を cloudflare workers 用に改変・上書きしてデプロイする、という感じ。
(一応ちゃんと動いてはいたけど力技感がすごくて本当にこれで大丈夫なのか...?という気持ちにはなった)
↑を踏まえると変更を加えるたびに vercel build が必要じゃん、ホットリードできないじゃんと思いながら preview 連打してこれは厳しいな...という気持ちだったけど
next dev で良かったらしいことにあとから気づいた。
next.config.mjs を除いてみるとたしかにそれっぽい変更が追加されていた。
import { setupDevPlatform } from '@cloudflare/next-on-pages/next-dev';
// Here we use the @cloudflare/next-on-pages next-dev module to allow us to use bindings during local development
// (when running the application with `next dev`), for more information see:
// https://github.com/cloudflare/next-on-pages/blob/5712c57ea7/internal-packages/next-dev/README.md
if (process.env.NODE_ENV === 'development') {
await setupDevPlatform();
}
/** @type {import('next').NextConfig} */
const nextConfig = {};
export default nextConfig;
簡単なコードで試してみると
export default async function Page() {
const { results } = await process.env.DB.prepare("SELECT 1").all()
console.log(results)
return (
<div></div>
)
}
# ...
[ { 1: 1 } ]
ログが流れており手元で動作を確認できた。
wrangler dev の方だとログも表示が安定してなかったのでとても大きい。
本番(or Preview) で d1 に繋ぐ
公式ドキュメントの手順に従って
- ダッシュボード→ Workers & Pages → Settings → Functions に進む
- 下にスクロールしてくと D1 database bindings のセクションがある
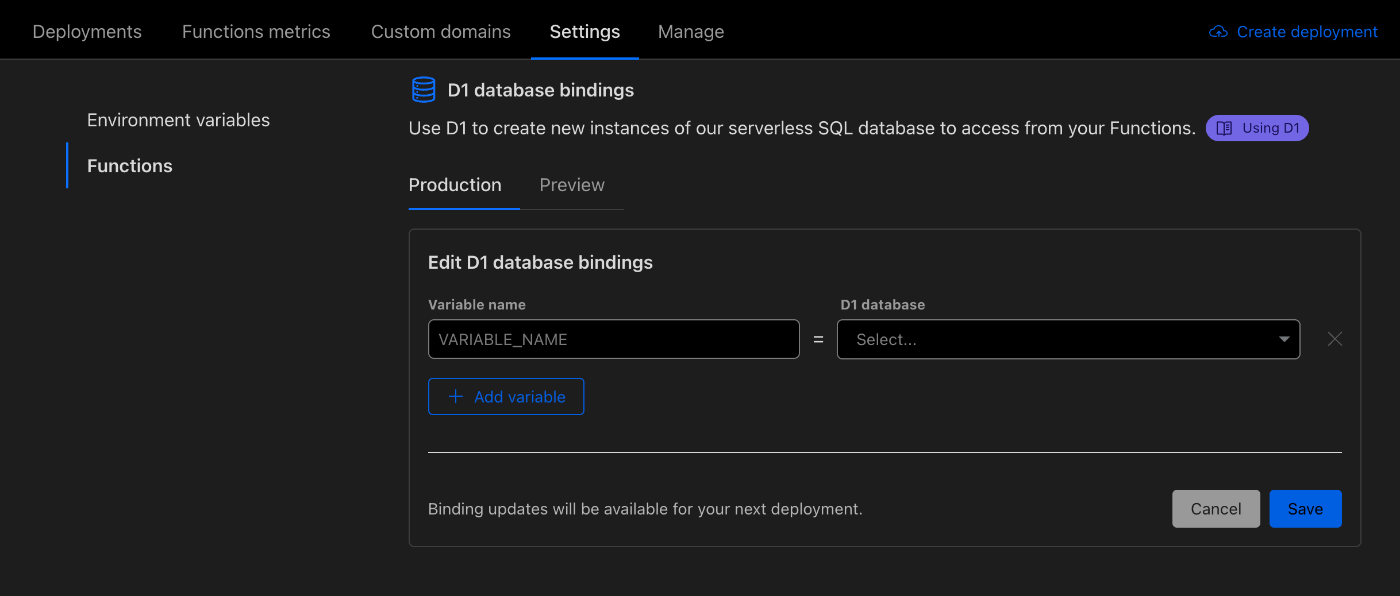
- ここに
変数名=DB名でいれる - 変数名は↑をそのまま使っているなら
DB, DB 名の方はセレクトボックスになっているので作成したDBを選ぶ
これで設定は終わり
TODO: 実際に繋いでみてないのであとで確認する
マイグレーション及び ORM あるいは クエリビルダ
事前調査
d1 でのORM事情は上記が参考になった。dizzle-orm が良さげという結論
prisma いずれ動くでしょ、というのでマイグレーション管理だけ prisma に任せようぜがこっちの記事。クエリビルダは kysely を使う
prisma のサポートは2024年3月28日現在で comming soon
Quick update: We are currently testing the D1 adapter with a selected number of users via an Early Access. If you want to participate, just go by https://pris.ly/survey/driver-adapter-d1 again and leave a response where you only select D1 as the database you are interested in an I can prioritize inviting you for this as well. Thanks!
試したいのでとりあえず申し込んではみたが、それはそれとしてまだ利用できない。
prisma のサポートが来そうなことと、drizzele も軽く触ったことはあるもののやっぱり開発者体験が prisma なんだよなの気持ちだったので後者(スキーマ及びマイグレーション管理ツールとしての prisma + kysely) を使っていく
drizzele-orm でやるなら こちらの記事で一貫したやり方が書かれていたので参考になりそう
これを軸に試していたけどまず
次に、.env に prisma の接続先を書く
DATABASE_URL="file:../.wrangler/state/v3/d1/<database_id>/db.sqlite"
これは wrangler d1 がローカルにsqlite を生成するパスで、prisma と wrangler が同じDBを見るようにする。
これが動かなくなっていた
$ pnpm wrangler d1 migrations create my-app-db-name init
# 適当なマイグレーションを書く
$ cat migrations/0001_init.sql
-- Migration number: 0001 2024-03-27T16:27:13.355Z
CREATE TABLE "User" (
"id" TEXT NOT NULL PRIMARY KEY,
"name" TEXT NOT NULL
);
$ pnpm wrangler d1 migrations apply my-app-db-name --local
⛅️ wrangler 3.38.0 (update available 3.39.0)
-------------------------------------------------------
Migrations to be applied:
┌───────────────┐
│ name │
├───────────────┤
│ 0001_init.sql │
└───────────────┘
✔ About to apply 1 migration(s)
Your database may not be available to serve requests during the migration, continue? … yes
🌀 Mapping SQL input into an array of statements
🌀 Executing on local database my-app-db-name (xxx) from .wrangler/state/v3/d1:
🌀 To execute on your remote database, add a --remote flag to your wrangler command.
┌───────────────┬────────┐
│ name │ status │
├───────────────┼────────┤
│ 0001_init.sql │ ✅ │
└───────────────┴────────┘
マイグレーションは通っているので SQLite に書き込まれているはず。
$ ls -al .wrangler/state/v3/d1
total 0
drwxr-xr-x 3 kaito staff 96 3 27 23:46 .
drwxr-xr-x 3 kaito staff 96 3 27 23:46 ..
drwxr-xr-x 11 kaito staff 352 3 28 01:27 miniflare-D1DatabaseObject
が、いない。
miniflare-D1DatabaseObject の中に複数の SQLite ファイルがあるのでこの辺を見ていってもよいが
- いずれにせよ非公開の部分をいじってる感じになる
- reate-only だけやってという形だと diff がないときに作られてしまう(空だけど)
- apply 状況を吹き飛ばしたときに削除するマイグレーションが作られちゃったり
と雑な運用がめんどそうだったので
- マイグレーション用に SQLite 立てて prisma migration はそっちに向ける
- prisma のマイグレーションファイルはいじらず wrangler 用のマイグレーションだけいじる
でやっていくことにする
追記: この後使っていて気づいたら .wrangler/state/v3/d1 以下に出現していた。どのタイミングで出てくるのかわからない...
お試し用の仮スキーマ
datasource db {
provider = "sqlite"
url = env("DATABASE_URL")
}
generator kysely {
provider = "prisma-kysely"
output = "../src/server/db"
fileName = "types.ts"
enumFileName = "enums.ts"
}
model User {
id String @id
title String @unique
// relations
posts Post[]
}
model Post {
id String @id
userId String
title String @unique
// relations
user User @relation(fields: [userId], references: [id])
}
マイグレーションのパス構造・PRAGMAを修正するスクリプト
// @ts-check
import { readFileSync, writeFileSync } from "node:fs"
import { globSync } from "glob"
const wranglerMigrationDir = "prisma/wrangler-migrations"
/** @see https://developers.cloudflare.com/d1/build-with-d1/d1-client-api/#pragma-statements */
const supportedPragmas = ["table_list", "table_info", "foreign_keys"]
const main = async () => {
// サポートされていない pragma を削除
for (const prismaMigrationFile of globSync(
`./prisma/migrations/*/migration.sql`,
{
cwd: process.cwd(),
}
)) {
const newData = readFileSync(prismaMigrationFile, "utf-8").replace(
new RegExp(`pragma\\s+(?!${supportedPragmas.join("|")})\\w+\\s*;`, "gi"),
""
)
const migrationName = prismaMigrationFile.split("/")[2] // prisma/migrations/<here>/migration.sql
const wranglerMigrationFile = `${wranglerMigrationDir}/${migrationName}.sql`
writeFileSync(wranglerMigrationFile, newData)
}
}
main().catch(console.error)
機械的な変更で対応できないものは手動対応するので gitignore の対象外に置く
[[d1_databases]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "my-app-db-name"
database_id = "xxx"
migrations_dir = "prisma/wrangler-migrations"
{
"scripts": {
"migrate:generate": "DATABASE_URL=file:./migration-db.sqlite prisma migrate dev && node ./scripts/convert_d1_migrations.mjs",
"migrate:local": "wrangler d1 migrations apply my-app-db-name --local",
"migrate:prod": "wrangler d1 migrations apply my-app-db-name --remote",
}
}
$ mkdir prisma/wrangler-migrations
$ pnpm migrate:generate
> xxx@0.1.0 migrate:generate xxx
> DATABASE_URL=file:./migration-db.sqlite prisma migrate dev && node ./scripts/convert_d1_migrations.mjs
Environment variables loaded from .env
Prisma schema loaded from prisma/schema.prisma
Datasource "db": SQLite database "migration-db.sqlite" at "file:./migration-db.sqlite"
Already in sync, no schema change or pending migration was found.
✔ Generated Kysely types (1.8.0) to ./src/server/db in 101ms
で生成できた。prisma/migrations が prisma が書き出す標準的なマイグレーションで、prisma/wrangler-migrations がパス構造・PRAGMA削除がされたマイグレーションファイル。apply に失敗したらこっちのみいじる
それぞれの環境に apply する
$ pnpm migrate:local
> xxxt@0.1.0 migrate:local xxx
> wrangler d1 migrations apply my-app-db-name --local
⛅️ wrangler 3.37.0 (update available 3.39.0)
-------------------------------------------------------
Migrations to be applied:
┌─────────────────────────┐
│ name │
├─────────────────────────┤
│ 20240327171036_init.sql │
└─────────────────────────┘
? About to apply 1 migration(s)
✔ About to apply 1 migration(s)
Your database may not be available to serve requests during the migration, continue? … yes
🌀 Mapping SQL input into an array of statements
🌀 Executing on local database my-app-db-name (xxx) from .wrangler/state/v3/d1:
🌀 To execute on your remote database, add a --remote flag to your wrangler command.
┌─────────────────────────┬────────┐
│ name │ status │
├─────────────────────────┼────────┤
│ 20240327171036_init.sql │ ✅ │
└─────────────────────────┴────────┘
$ pnpm migrate:prod
> xxx@0.1.0 migrate:prod xxx
> wrangler d1 migrations apply my-app-db-name --remote
⛅️ wrangler 3.37.0 (update available 3.39.0)
-------------------------------------------------------
Migrations to be applied:
┌─────────────────────────┐
│ name │
├─────────────────────────┤
│ 20240327171036_init.sql │
└─────────────────────────┘
✔ About to apply 1 migration(s)
Your database may not be available to serve requests during the migration, continue? … yes
🌀 Mapping SQL input into an array of statements
🌀 Parsing 5 statements
🌀 Executing on remote database my-app-db-name (xxx):
🌀 To execute on your local development database, remove the --remote flag from your wrangler command.
🚣 Executed 5 commands in 0.7628ms
┌─────────────────────────┬────────┐
│ name │ status │
├─────────────────────────┼────────┤
│ 20240327171036_init.sql │ ✅ │
└─────────────────────────┴────────┘