AWS OpenSearch Service (Elasticsearch) を導入するにあたってのメモ
※ 検索重み付けとかスコアリングの話はここでは触れない。
まずは絶対押さえておきたい OpenSearch(Elasticsearch) で使われる基本概念/用語
クラスタの中に専用マスターノード、データノードがある。AWS OpenSearch serviceはデータノードの役割も持つマスターノードは作れず、「専用」マスターノードしか作れない点は注意。
データノードが複数のインデックスを持つ。
インデックスは複数のドキュメントを持つ。
データノードはこのドキュメントをインデックスごとに数を設定できるプライマリシャードに分散して置く。("number_of_shards" : 1 の設定は各データノードにそのインデックスのシャードを1つ置くということ。つまりデータノードが3つある場合はそのインデックスのドキュメントは3つのノードに分散して配置される)
耐障害性や検索パフォーマンス向上のためにレプリカシャードを置くこともできる。これはそれぞれプライマリシャードのコピーである。また、自動的に異なるデータノードに配置されているプライマリのレプリカがそれとは異なるデータノードに配置される。
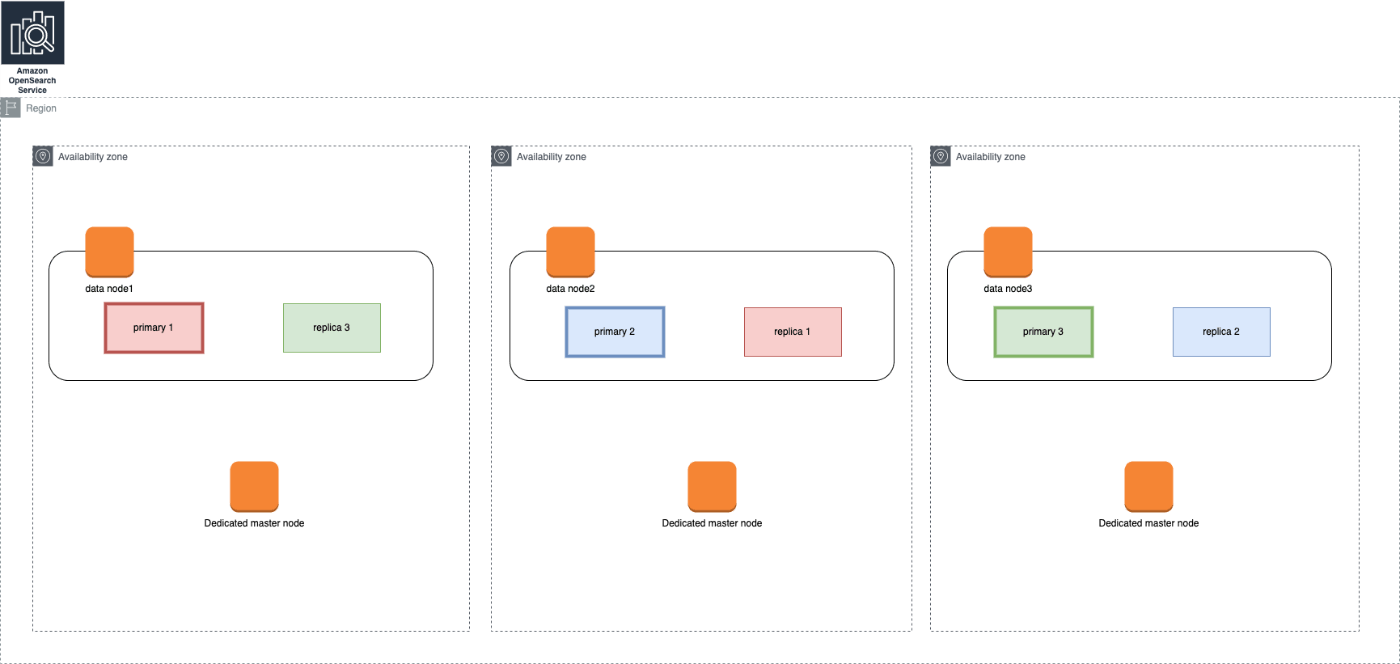
たとえば、3AZ 構成で専用マスターノードとデータノードをそれぞれ1つずつ配置し、
"settings" : {
"number_of_shards" : 1,
"number_of_replicas" : 1
}
で設定したインデックスの配置イメージを下に示す。
一応検索クエリはMySQLでいうところの limit, offset と同義な仕様のページング(size, from を使う)もサポートしているが、index.max_result_window の上限設定を上げるのをお忘れなく。だいたい OpenSearch に載せるような案件はドキュメント数が多いと思うのでここの上限に引っかかると思う。
しかし、size, from のページングだと後半の方のページになるほど遅くなるので DynamoDB や Facebook API などで導入されているような、現在の最後の要素からN件みたいなページング(OpenSearch だと scroll や search_after がこれに当たる)をできるように検討すべき。
index.refresh_interval の設定が割とデータ移行時には大事で、数時間かかるような大量のドキュメント作成処理が refresh_interval を -1 (リフレッシュしない)にすると数十分で終わった。その後 refresh_interval をデフォルトの 1s に戻すとちゃんと 1sec で全てのドキュメントが検索可能になった。
ちなむとこの設定値は、 1 とやるとこれは msec を指すので注意。1msec だとリフレッシュの頻度が多すぎてリフレッシュに多くのリソースが割かれてしまう。
他にどんな設定があるかはここを参照すると良いかも
OpenSearch のクラスタ内部は分散アーキテクチャなので、専用マスターノードが死んだ時にスプリットブレインが起こり得るのでケアできるように本番環境などでは専用マスターノードが3つにしておきたい。
また、VPC 内に構築する場合は、 EC2 や ECS からのアクセスは同じ VPC に置かれているリソースでないと IAM やSecG が通っていてもアクセスすることはできない。
これは AWS OpenSearch Searvice のしょうがない仕様なので注意。
この仕様があるので、VPC内に構築した AWS OpenSearch Service のインデックスを AWS コンソールからは確認することはできない(VPC内ではなくパブリックドメインだと可能)。
なので、内部のインデックスを確認する必要があるなら、別途確認できるシステムなり仕組みを構築する必要がある。
ドメインのサイジングの検討だったりは AWS ドキュメントが充実しているのでそちらを参照できる。
※ ちなみにそもそも本当に OpenSearch が必要になったというシチュエーションはつまり、あいまい検索が必要になったということなんだ
Discussion