Treasure2024 参加体験記
はじめに
こんにちは、きむです。
初めての投稿になりますが、今回は、株式会社CARTA HOLDINGSが開催しているサマーインターン「Treasure2024」に参加してきたので、自分の学びのアウトプットベースで体験記を書いていきたいと思います。
拙い文章ではあるかと思いますが、温かい目で見ていただけると嬉しいです!
Treasureってなにやるの?
2024年度のTreasureは3週間で、前半の1週間はエンジニアの方による講義パート(DBモデリング/バックエンド/フロントエンド)、後半の2週間でプロダクトマネジメント講義とハッカソン形式のチーム開発を行うという流れでした。
今年のTreasureの技術スタックは、フロントエンドがReact + TypeScript、バックエンドはHono(TypeScript)でした。昨年度まではバックエンドはGoが採用されていたそうですが、今年からTypeScriptに変更した理由について、「フロントエンドとバックエンドの言語を統一することで、学習コストを減らし、CARTAのフルサイクル開発を色濃く体験してほしいから」とのことでした。
講義パート
導入講義(day1)
初日の導入講義では、Treasureでの心得や開発するうえで意識すること、技術選定理由などについて講義していただきました。
この講義の中で特に、「問題と人を関連付けない」というお話が印象に残っています。
何か問題が起きた時に、その原因を人に求めるのをやめましょう。
誰かがトリガーを引いた問題であってもそれが起き得る環境に課題を求め、
同じことを繰り返さないために仕組みを改善することがエンジニアリングです。
むしろ皆を代表して潜在的な問題を明らかにした人を称えるぐらいでいい。
すごく素敵な考え方だなと感じました。このアプローチはエンジニアリングに限らず、日常生活にも活かしていきたいです。
DBモデリング講義(day2)
2日目はDBモデリング講義でした。外部講師として和田卓人(@t_wada)さんに来ていただいて、RDBMSの立ち位置の遷移からERDの書き方のポイントまで幅広く教えていただきました。以下個人的学びだった部分を記載していきます。
1.データと情報の違い
データと情報は同じような意味で使われがちですが、違うニュアンスを持っているんだそう。
データ:意思を持たない事実の積み重ねのこと
情報:人間の意思決定に使うために加工されたもの、データに文脈を付与したもの
DBモデリングにおいて重要なのは、事実を失わないように「データ」を保持すること。なぜなら、適切にデータが格納されていれば、あとから欲しい「情報」を獲得することができるから。
2.リレーションとリレーションシップの違い
ER図におけるリレーションとリレーションシップは意味合いが異なる。
リレーション:テーブルのこと、日本語で関係
リレーションシップ:箱と箱をつなぐ線のこと、日本語で関連
3.論理設計と物理設計
論理設計:理想のスキーマ定義のこと(理想とは、データを漏らさずに格納することができる状態)
物理設計:論理設計からパフォーマンスなどの現実問題を考えて行うスキーマ定義のこと
モデリングは、初めに論理設計を行い、そのあとに物理設計を行うとよい。イメージとしては、一度山頂に上ってから(理想の追求)、物理設計を行うと、作るアプリケーションの解像度が上がる。
物理設計を行うときのポイントは、そこは頑張りどころなのかということ。解決するべき課題から遠いところは単純化する。
バックエンド講義(day3)
3日目のバックエンド講義は、ブログアプリケーションのAPIを実装してみよう!ということで実際に手を動かしながらHonoの使い方を学んでいきました。具体的には、記事の検索機能、コメント機能、記事の削除&編集機能などです。
講義で使用されるアプリケーションでは、レイヤードアーキテクチャが採用されていました。インターフェイス→usecase→repositoryのような形で、役割ごとにレイヤーに分けて、上位層が下位層に依存するような設計になっていました。
この講義の前までは、レイヤードアーキテクチャ聞いたことあるけどなんぞや?という感じでした。講義を経て基本的にusecase層では記述量を少なくして、repository層でロジックを書いていく点など、なんとなくMVCのcontrollerとmodelに似ているな~と感じました。
フロントエンド講義(day4)
4日目のフロントエンド講義でも引き続きブログアプリケーションを使って、フロントエンド実装を行っていきました。ツールの話になってしまいますが、TanStack Queryという存在を初めて知りました。普段はデータをフェッチするときには脳死でaxiosを使用していました。TanStack Queryを使うと、
- データのフェッチと同時に、キャッシュを保存できるため、パフォーマンスの向上が見込める
- 効率的に非同期状態を管理できる(isPending, isErrorなど)
のが嬉しいポイントです。また、同様のライブラリにSWRというのもあるみたいです。ふむふむ
プロダクトマネジメント講義(day5)
5日目のプロダクトマネジメント講義では、「2011年にタイムスリップ!LINEを再発明せよ」というテーマでDesign Docを埋めていくワークショップを行いました。Design Docとは、アプリケーションの要件定義を行うフレームワークのようなもので、取り組みのゴール/何を作るのか/作る背景/ユーザーストーリー/MVP/あえて実装しないと決めたこと/検討した代替案/マイルストーン(MVPの優先度)といった項目があります。
Design Docを埋めると、作りたいアプリケーションのイメージが明確になるなと感じたので、今後も使っていきたいです。
開発パート
チームについて
ここからは開発パートに入ります。自分たちのチームは、同期4人と、現役エンジニアの方が2人、人事のサポーターの方が1人というチーム構成でした。1つのチームに3人ものサポーターの方が専属でついてくれていたため、わからないことがあればいつでも聞けるような環境でした!
そしてチーム名はずばり、「ザキムダイモンズ」。チームメンバーの名前をGPTに投げたところこのチーム名が出てきて、あまりのインパクトにこの名前から離れられなくなってしまいました笑このチームは結成当初から心理的安全性がとても高く、お互いに気を遣いあえる最高のチームでした!!(余談ですが、結成2日目の終わりのチームごとの振り返りを発表する時間で、チームメンバーのM君がみんなの前で「このチーム大好きです」と告白をしてくれたことが忘れられません。)
どんなアプリケーションを作ったか
自分たちのチームは、「engineer.find(getExperience)」というサービスを開発しました!以下サービス名はエンファイと称します(諸説あり) ↑発表スライド
エンファイとは、エンジニア学生向け経験閲覧プラットフォームです。すごく簡単に説明すると、他人の「サポーターズさんに記載しているようなプロフィール+インターンと本選考の合否」を閲覧できるサービスになります。エンジニア就活生が自分が行きたい企業に受かるために、その企業に合格する人との差を知る、というのがこのプロダクトのコンセプトです。
以下、エンファイの画面遷移について簡単に説明していきます。

このページでは企業一覧が表示されていて、自分が興味のある企業を選択することができます。
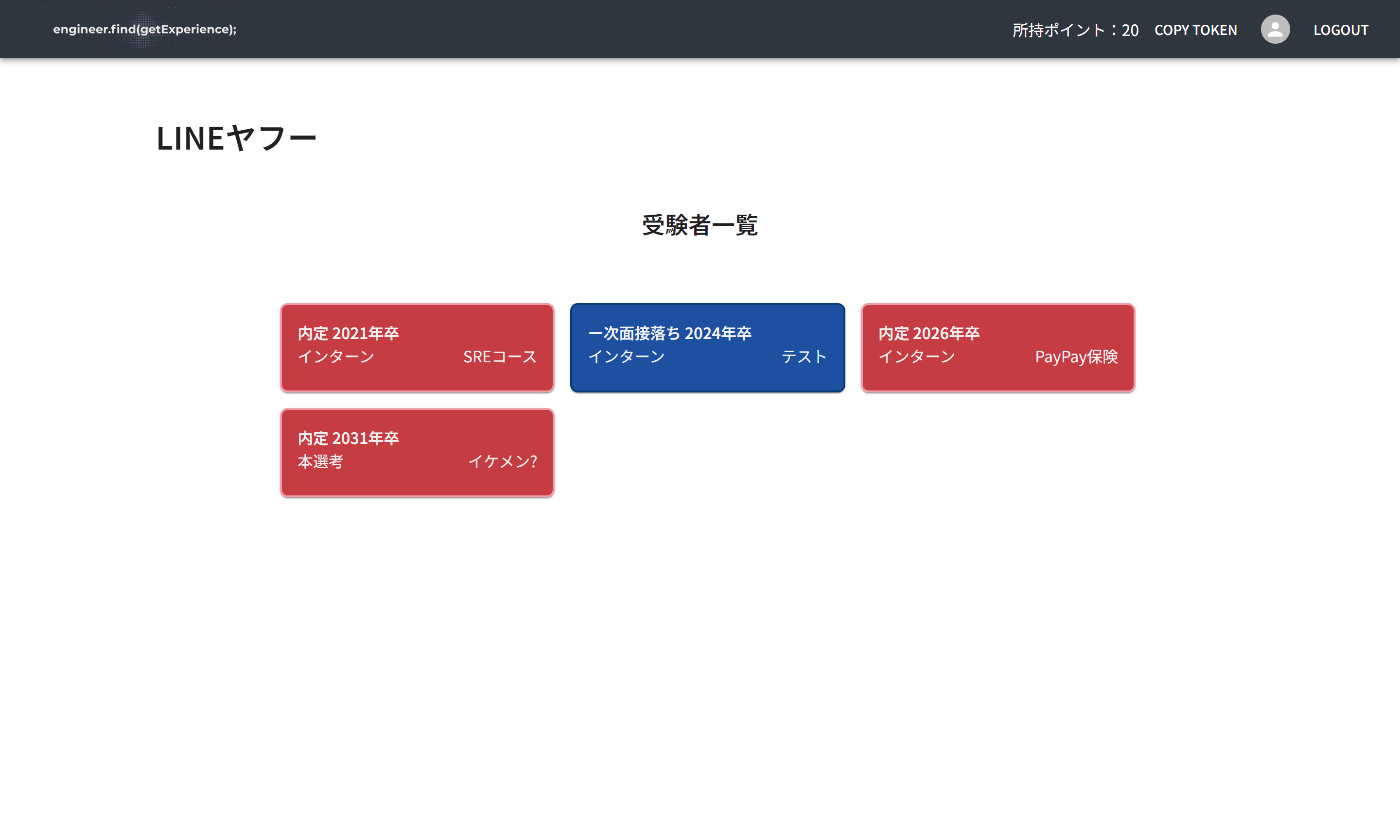
行きたい企業を選択すると、その企業に受けた人の合否が表示されます。他人のプロフィールを閲覧するには1ポイントが必要です。ただし、一度閲覧した人のプロフィールは何度でも見れるようになります。

プロフィール画面はこのようになっています。

最後に、この画面は合否入力、制作物追加を行う画面です。合否を1つ追加するor制作物を1つ追加することで3ポイントが付与されます。ポイント制にすることで、入力するという面倒くさい作業に対してインセンティブを与えようと考えました。
結果として、最優秀賞は獲得することはできませんでしたが、アイデア賞を受賞することができました!
アイデア賞を受賞することができた理由として、
- Design Docsを最後まで諦めずに詰めていたチームだった
- 今すぐに運用できるイメージが一番沸いた
- MVPからずれずに作り切れた
というフィードバックを講師の方からいただけました!
工夫したこと
個人として工夫した点と、チームとして工夫した点の2つを書きたいと思います。
- チームとして工夫した点
DB設計にはかなりこだわりました。最終的に2回の仕様変更を行ったので、それぞれ設計の時に何を考えていたのかを書こうと思います。

↑ version1

↑ version2

↑ version3
version1で考えたこと、version2を採用した理由
version1では、①Pointテーブルをどうするか②SelectionResultテーブル(選考結果テーブル)に、本選考とインターンシップ選考の二つのテーブルを紐づけるかの二つが論点でした。
①Pointテーブルをどうするか
最初にPointという概念をどのように表現するかで、Userテーブルにpointというカラムを持たせ、都度UPDATEを行うorイベントエンティティとして捉え、別テーブルに切り分けるという2つのアイデアがありました。ここに関しては、ユーザーのポイントの履歴を詳細に追跡できるようになり、ポイント獲得や消費のタイミングを「データとして」蓄積できることから、、別テーブルに切り分ける設計を選択しました。
ただ別テーブルに切り分けて、レコード数が増えてきたときにクエリのパフォーマンスが低下するという問題が発生してしまうと考えました。ポイントの履歴が増えるにつれて、全てのポイントを集計してユーザーの現在のポイントを取得するクエリを発行しなければならないからです。
そこで、total_pointというカラムを作ることで、Userのポイント遷移を追跡できるかつPointテーブルのレコードの中で最新のものを取得すれば、Userの現在のポイントを取得することができることからこのような設計にしました。
②SelectionResultテーブルをどうするか
論理設計の段階では、SelectionResultテーブル(選考結果テーブル)は拡張性の観点から、本選考用とインターンシップ選考用の二つのテーブルに分けたほうがいいと考えました。具体的には、今後インターンシップが長期と短期で分かれる可能性や、本選考とインターンシップ選考では、記述する内容が変更するといった可能性があったためです。
しかしチームの中で議論した結果、今回のMVPの段階で上記のような可能性が低いことから頑張りどころではないと判断し、テーブルを一つにまとめるという設計にしました。
version2→3への変更理由
version2から3への変更点としては、Experienceテーブル(制作物のデータを保管する)のカラムを増やしたということです。これはモデリングの話とはあまり関係がありませんが、アプリケーションの仕様変更に合わせて、カラムを追加することになりました。
もともとのExperienceテーブルには、contentというカラムしかなく、ここに自由記述で入力してもらおうと考えていました。しかし、中間レビューを講師の方にいただいたときに、「これで本当に学生が知りたい情報を掲示することができるのか」というフィードバックをいただき、次の日は一度開発をストップし、本当に必要な項目は何なのか半日かけて洗い出し、変更を行いました。
もう一つ、最終日のフィードバックタイムに「ExperienceテーブルのNOT NULL制約をゆるくしてもよかったんじゃないか」というご意見をいただきました。自分たちはあらかじめカラムに対してNOT NULL制約をつけるものを決定し、それを基にフロント側でも同様のバリデーションをかけていました。しかし、DB上での制約をゆるくし、フロント側でのみバリデーションをかけることで、柔軟に必須項目か否かを変更することができると聞き、なるほど!と思いました。
- 個人として工夫した点
export const createExperienceAlternative = async (
db: knex.Knex,
user: User,
development_reason: string,
app_feature: string,
start_date: string,
end_date: string | undefined,
tech_thought: string,
app_thought: string,
head_count: number,
responsible_part: string,
github_repository_url: string | undefined,
deploy_url: string | undefined,
opportunity: string,
company_name: string | undefined,
hard_skill_learned: string,
soft_skill_learned: string,
app_technologies: { name: string; reason: string }[]
): Promise<number> => {
// 別々のテーブルに挿入するため、トランザクションを利用
return await db.transaction(async (trx) => {
// experiencesテーブルに挿入
const res = await trx
.insert({
user_id: user.id,
development_reason,
app_feature,
start_date,
end_date,
tech_thought,
app_thought,
headcount: head_count,
responsible_part,
github_repository_url,
deploy_url,
opportunity,
company_name,
hard_skill_learned,
soft_skill_learned,
})
.into('experiences')
.returning('id')
assert(res.length === 1, '作成した経験のidが返される')
const experienceId = res[0].id
assert(typeof experienceId === 'number', '経験が作成されて返されるidはnumber型である')
// app_technologiesテーブルに挿入
for (const app_technology of app_technologies) {
await trx('app_technologies').insert({
experience_id: experienceId,
name: app_technology.name,
reason: app_technology.reason,
})
}
// point_transitionsテーブルに挿入
const userPointData = await getPointByUserId(db, user.id)
const currentPoint = userPointData.totalPoint
await trx('point_transitions').insert({
user_id: user.id,
total_point: currentPoint + 3,
})
return experienceId
})
}
このファイルは、自分が実装した、制作物について入力した値をデータベースに挿入するロジック部分です(app_technologiesテーブルは使用技術と選定理由を保存するテーブル)。トランザクションを使用することで、複数のテーブルに対して一連のデータ挿入をアトミックに行い、途中でエラーが発生してもデータの整合性を保つことができると考えました。 概念としてトランザクション処理は知っていたのですが、実装するのは初めてだったので、意外と簡単に書けるんだな~と感じました。
ただこのように振り返ってみてみると、この関数だけでも「関数名と実際に行っている処理が一致していないため、ほかの関数に切り出す」であったり、「引数が多すぎるのでオブジェクトとして引数を渡すようにする」などリファクタリングの余地があるなと感じます。
学んだこと
今回の開発パートで学んだことを3つ挙げたいと思います。
- そプデカにならないようにする
そプデカとは、「そのプルリクエストでかすぎませんか」の略です。普段の開発であまりプルリクエストの大きさについて意識することはなかったのですが、自分がレビューする側になってみてfile changesが多いとレビュアーの負担になるんだなと感じました(自分もそういうプルリクエストを出していました...)
素早くマージできるようなPRを出すことで、余計なコンフリクト解消をせずに済み、結果開発速度向上につながると感じたので、「PRは肥大化させない」と「今ここにいない誰かが3年後に読んでも伝わるように書く」を意識していきたいです。
また、チームメンバーでloomを使って動画で挙動を説明している子がいて、分かりやすかったので自分も使っていきたいです。
- レビューの話
実は自分、開発パートの途中でコロナに感染してしまい、最後の1週間はリモートから参加していました。オンラインでコミュニケーションをとることになり、もともと自分で立てていた目標を達成することが難しそうでした。そこで「チームメンバーのコードレビューを積極的に行う」という裏目標を立てました。
最初は自分がコードレビューしていいのかな?と不安な気持ちもありましたが、サポーターの方から「レビューは自分よりできる人がやるんじゃなく、わからないことや疑問に思ったことを聞く場でもある」というアドバイスをいただいたことで、積極的に行うことができました。
コードのレビューを行うことで、「こんな書き方があるのか」や「こういう実装方法があるのか」を知れたのが個人的によかったです!
また、自分がレビューを行う中でこんな細かいところ指摘するべきなのかな...みたいなシーンがあったのですが、メンバーからラベルを付けるとよいというアドバイスをいただきました。ありがとう!
- 作るアプリケーションのスコープの話
もともと自分たちのチームは、「学生だけのクローズドな空間で、面接内容やコーディング試験内容、書いたESの内容を共有するアプリケーション」を作ろうと考えていました。ところがPM講師の方からのレビューの時間で、スコープが広すぎるからもっと絞ってもいいというアドバイスを受けて、エンファイのような構想へと変わりました。
もともとのアプリを構想する段階では、スコープが広いという感覚があまりなく、「もっと対象とするものを絞らないとだめなのかな、切り捨てたくないな...」と思っていたのですが、いざ画面の設計などを行ってみるとやりたいことが明確でやりやすいなと感じました。現役のPMの方と、自分の感覚のずれみたいなものを感じられて、とても勉強になりました。
アプリケーションの改善点
- いいね機能の実装
- ユーザーに初めからポイントを持たせる
- 入力コストを下げるために、サポーターズさんとDBを同期させてもらう(あくまでアイデア)
- パスを直接たたくと、他人のプロフィールが見えてしまうバグの修正
などがあると考えています。特に、受験者一覧画面では、その人のプロフィールがどれだけ充実しているのかがわからないにも関わらずポイントを消費しないといけない仕様になってしまっているため、いいね機能を実装することで解消できると思っています。
終わりに
長くなってしまいましたが、ここまでお読みいただきありがとうございます。
Treasure始まる前まではついていけるかな...と不安だったのですが、TAの方々や、サポーターの方々、優しいTreasure生のおかげで走り切ることができました。
最後に、運営の方々、講師の方々、サポーターの方々、Traesure生のみんな、そしてザキムタイモンズのみんな、短い間だったけどありがとうございました!またどこかでお会いしたときはお話ししましょう!!
Discussion