Google Cloud で生成 AI アプリを評価するアーキテクチャパターン
用語について
オンライン評価とオフライン評価
評価はそのタイミング、やり方によってオンライン評価とオフライン評価に分けられます。
オンライン評価とは、システムやモデルが実際の運用中にリアルタイムで評価される手法です。
オフライン評価は、事前に用意されたデータセットを使用し、システムやモデルの性能をテスト環境で評価する方法です。
生成 AI アプリケーションの場合には、オンライン評価は実際のユーザが生成 AI を利用した際の入出力に対して評価を行います。
特徴としては、模範解答を用意することができないため生成 AI による評価(LLM as a Judge)をします。
オフライン評価ではあらかじめ作成しておいた入力(と模範解答)を用いて評価します。
手法としては模範解答なしでの LLM as a Judge をすることもできますし、模範解答ありでの LLM as a Judge や従来の評価手法を用いた評価もできます。
このように手法の柔軟性はオフライン評価の方がありますが、評価に用いる入力が実際のユーザの入力から乖離してしまう可能性は常にあります。
構成要素の選定
評価を実行するサービス
評価の実行は多くの場合で Cloud Run functions(旧 Cloud Functions)が最適です。
評価は通常、以下のようなイベント駆動での実行になります。
- オンライン評価:ユーザが生成 AI 機能を利用したタイミング
- オフライン評価:モデルやプロンプト、アプリケーションの実装を変更したタイミング
そのため評価を行うサービスとしてはイベント駆動型のサービスである Cloud Run functions がファーストチョイスです。
その他の候補としては、
- Cloud Run ジョブ
- GKE
があります。
Cloud Run ジョブでは Cloud Scheduler からスケジュール実行することになります。[1]
オンライン評価の場合はバッチ処理的に複数件の評価を行うことになりますが、Cloud Run functions で 1 件ずつ評価する方がシンプルです。
オフライン評価では、変更のたびに評価するのではなく日次などで十分な場合は Cloud Run ジョブでも実現できます。
しかし同じことは Cloud Run functions でも実現できる[2]ため、トリガーを柔軟に変えられる Cloud Run functions の方が良いです。
GKE については、アプリケーションを GKE クラスタ上にデプロイしており、イベント駆動処理を扱う仕組みを既に構築している場合には、既存の仕組みに乗っけてしまうのも良いでしょう。
そうでない場合は評価のために仕組みから作るのは不適当です。
以上をふまえて本記事では、多くの場合に適当な Cloud Run functions を採用するとして進めていきます。
評価の実装
評価結果の送信先とも関係があるため、評価の実装についても簡単に触れておきます。
Google Cloud では先月末(2024/8/30)に生成 AI の評価を行う Generative AI Evaluation Service が GA になりました。[3]
Generative AI Evaluation Service には以下の特徴があります。[4]
- Vertex AI SDK for Python を利用して評価を行う
- 評価の指標として、事前定義されたテンプレートでの評価とユーザ定義のメトリクスでの評価の両方が可能
- オンライン評価/オフライン評価両方で利用可能
- 結果は Vertex AI Experiments に送信される
アプリケーションの生成 AI 機能で Vertex AI を利用している場合は候補になります。
その他の候補としては LangSmith, Ragas などがあります。
評価用プロンプトの配置
Generative AI Evaluation Service で独自のメトリクスを定義する場合など、評価用のプロンプトが必要になる場合があります。
プロンプトの管理については
- プロンプトを利用するコードと同じリポジトリで管理する
- コードとは別のツールで管理する
の 2 つの方法があります。
「コードとは別のツールで管理する」方法ではツールにもよりますが、画面上でプロンプトの編集を行えるものが多く、アプリケーションエンジニアでなくても編集できるというメリットがあります。
Google Cloud でのプロンプト管理には Vertex AI Studio を用いるのが最適です。[5]
評価のトリガー
Cloud Run functions は以下のようなトリガーをサポートしています。[6]
- HTTP
- Pub/Sub
- Cloud Storage
- Firestore
オンライン評価の場合は、まずアプリケーションで生成 AI 機能が実行されたあと、通常の機能と同様に入出力結果をログに出力するかと思います。
ログ監視のために Cloud Logging を利用している場合は、Cloud Logging から Pub/Sub にログをシンクすることができる[7]ため、アプリ → Cloud Logging → Pub/Sub → Cloud Run functions となります。
またログシンクではフィルタ機能によってサンプリングも可能です。[8]
Cloud Logging を利用していない場合はアプリケーションから直接 HTTP トリガーします。
オフライン評価では、評価用のデータをどこで生成するかから考えてみましょう。
普通、アプリケーションのソースコードは GitHub や GitLab などの VCS で管理し、GitHub Actions や GitLab CI/CD などの CI/CD パイプラインでテストを実行しているかと思います。
CI/CD パイプラインでは生成 AI 機能を動作させる準備が既にできていることになるので、テストなどと同じようにそこで評価用データの生成も実行してしまうのが素直です。
トリガーについてですが、CI/CD パイプラインとして Cloud Build を利用している場合は、cloud-buildsという Pub/Sub トピックに自動でパブリッシュされる[9]ため、それを利用すれば良いです。
Cloud Build を利用していない場合はそれぞれの CI/CD パイプラインから直接 HTTP トリガーします。
評価結果の送信先
評価結果の送信先には以下のような候補があります。
- Vertex AI Experiments
- Cloud Monitoring
- Big Query
Generative AI Evaluation Service を利用して評価する場合、結果は Vertex AI Experiments に送信されます。[10]
アプリケーションの他のメトリクスと同じ画面で見たり、評価結果を分析したり、ということがなければ Vertex AI Experiments でも良いです。
その他のメトリクスと同じように監視をしたい場合には、スコアをメトリクスとして Cloud Monitoring に送信します。
また評価結果を分析したい場合は Big Query に送信します。
送信先に関しては実際の運用次第で上記から条件にあったものを選ぶことになります。
評価のアーキテクチャパターン
オンライン評価(監視に Google Cloud を使っている場合)

アプリケーションは Cloud Run で動いていることにしていますが、必要に応じて GKE や App Engine などに置き換えてください。
監視に Google Cloud を使っているため、生成 AI 機能の入出力を Cloud Logging に送信します。
ログを Pub/Sub にシンクし、Pub/Sub トリガーで評価用の Cloud Run functions を起動します。
評価用プロンプトは Vertex AI Studio から取得し、評価を行います。
評価結果は監視目的で Cloud Monitoring に、分析目的で BigQuery に送信します。
オンライン評価(監視 SaaS を使っている場合)

アプリケーションは Cloud Run で動いていることにしていますが、必要に応じて GKE や App Engine などに置き換えてください。
監視に SaaS を使っている場合、Cloud Run functions はアプリケーションから HTTP トリガーで起動します。
評価用プロンプトは Vertex AI Studio から取得し、評価を行います。
評価結果は監視目的で Cloud Monitoring に、分析目的で BigQuery に送信します。
オフライン評価(CI/CD パイプラインに Cloud Build を使っている場合)

モデル、プロンプト、生成 AI 機能の実装などに変更が加えられたタイミングで Cloud Build を起動し、パイプラインの中で結果を生成します。
ビルド終了時のcloud-buildsトピックへの自動パブリッシュをトリガーに、評価用の Cloud Run functions を起動します。
評価用プロンプトは Vertex AI Studio から取得し、評価を行います。
評価結果は監視目的で Cloud Monitoring に、分析目的で BigQuery に送信します。
オフライン評価(CI/CD パイプラインに Cloud Build を使っていない場合)
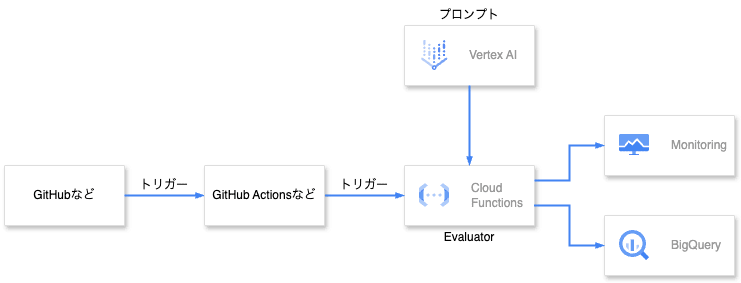
モデル、プロンプト、生成 AI 機能の実装などに変更が加えられたタイミングで CI/CD パイプライン を起動し、パイプラインの中で結果を生成します。
CI/CD パイプラインに Cloud Build を使っていない場合、Cloud Run functions はパイプラインから HTTP トリガーで起動します。
評価用プロンプトは Vertex AI Studio から取得し、評価を行います。
評価結果は監視目的で Cloud Monitoring に、分析目的で BigQuery に送信します。
Discussion