re:Invent 2024: JPMorganChaseの大規模リアルタイム不正検知システム
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - JPMorganChase: Real-time fraud screening at massive scale (FSI315)
この動画では、JPMorganChaseが1日10兆ドルを超える決済取引を保護する不正検知エンジンの構築について解説しています。AWS上に構築された同システムは、毎秒数千件の取引を処理し、Machine Learningモデル、異常検知、例外リストを活用して不正を検知します。Amazon EKS、DynamoDB、AWS Load Balancer Controllerなどを活用し、高いスループットと低レイテンシーを実現。また、マルチリージョン展開やAnti-affinityの活用による高い可用性の確保、Feature Registry、Detection Engine、ML Scoring APIなどの重要コンポーネントの実装方法、そしてコスト最適化のアプローチまで、大規模な不正検知システムの具体的な設計と実装の詳細が語られています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
JPMorganChaseの大規模不正検知ソリューション:概要と課題

みなさん、ようこそ。自動化された再現可能な方法で、グローバルに利用可能で回復力があり、スケーラブルなプラットフォームを構築する必要がある場合、それはビジネスに価値をもたらすでしょうか?もしそうであれば、まさに適切な場所にいらっしゃいました。FSI 315「JPMorganChaseの決済における大規模なリアルタイム不正検知ソリューション」へようこそ。私はAWSのPrincipal Solutions ArchitectのBernie Herdanです。本日は、Karthik DevarapalliとJimit Raithathaと共に、1日あたり10兆ドルを超える決済取引を保護しながら、毎秒数千件の取引を処理できるクラウドネイティブな不正検知エンジンの構築についてお話しします。この1時間で、AWSサービス上に不正検知エンジンを構築するために必要な要素、グローバル展開に伴う影響、そして途中で得られた教訓についてご紹介します。

それでは、Karthikにアジェンダについてご説明いただき、JPMorganChaseのリアルタイム不正決済スクリーニングの旅を始めたいと思います。本日は、不正対策にAWSをどのように活用しているかについての知見を共有させていただきます。セッションのアジェンダをご紹介します。まず、決済における脅威の状況と最新の不正統計について見ていき、業界で注目されている傾向とJPMorganChaseがどのように問題に対処しているかをご説明します。次に、AWS上での不正検知プラットフォームの構築方法について見ていきます。現在提供できているサービス、AWSを使用したモダナイゼーションプロセスにおけるコスト最適化の取り組み、そして最後に重要なポイントについてお話しします。
決済における脅威の状況と不正検知プラットフォームの設計

決済における脅威の状況は、テクノロジーの進歩とサイバー攻撃の手法が巧妙化するにつれて、絶えず進化しています。私たちが通常注目している不正傾向の主要な側面には、フィッシングとソーシャルエンジニアリングがあります。サイバー犯罪者は、フィッシングメール、偽のウェブサイト、またはソーシャルエンジニアリングの手法を使用して、個人や企業からクレジットカード情報やログイン情報などの機密情報を騙し取ることができます。また、悪意のある者の口座に送金させるように個人や企業を騙すこともできます。
eコマースの成長に伴い、非対面取引での不正も増加しています。このような状況では、悪意のある者やサイバー犯罪者が盗んだ情報を使用してオンライン購入を行うことができ、また、eコマースサイトで購入を目的としたカードテスト攻撃を仕掛けるために、クレジットカード情報の一部を使用することもできます。この種の不正は、物理的なカードが取引に関与していないため、検出が困難です。
犯罪者が誰かのコンピュータにマルウェアをインストールすることに成功すると、そのマルウェアはデバイス上の機密情報にアクセスできるようになります。マルウェアは中間者として機能し、コンピュータから送信される決済情報を傍受したり、コンピュータから発信されるペイロードを変更したりすることができます。その他の傾向としては、アカウントの乗っ取りや、POSデバイスやモバイル端末の脆弱性を悪用した不正な決済などが見られます。

最近の不正統計を見てみましょう。2023年には組織の80%が支払い詐欺を経験しています。これは2022年と比較して大きな増加で、Commercial Card詐欺は前年比10%増、ACH Credit詐欺とVirtual Card詐欺はともに前年比6%増加し、71%の企業がメールによる詐欺の被害に遭っています。年々、不正事案は増加傾向にあることから、組織は不正対策のためのセキュリティ対策を本気で講じる必要があります。おそらくこれは、企業が前年比での減少を報告したい指標の一つでしょう。

JPMorganのTrust and Safety Solutionsは、取引やお支払いのライフサイクル全体を通じてクライアントを保護します。不正を防止するためのソリューションをクライアントに提供しており、口座、事業書類などの検証を行うValidation Servicesも用意しています。
Account Confidence Scoreサービスは、クライアントやマーチャントの支払いライフサイクルに統合でき、口座のリスクスコアを提供することで、支払い前により多くの情報に基づいた判断を可能にします。これにより、不正な口座への取引を回避し、支払いの遅延を防ぐことができます。Payment Control Centerは、クライアントが利用できるユーザーインターフェースベースのアプリケーションで、ビジネスの支払いパターンや行動パターンに基づいてルールを作成したり、ルールのしきい値を変更したりすることができます。

今回のセッションでは、リアルタイムの不正監視プラットフォームであるFraud Intelligenceプラットフォームについて見ていきます。これは、Machine Learningモデルのスコア、異常検知、例外リストを活用した社内ルールに基づいて、不正の防止や検知を行います。この不正検知プラットフォームを構築する際に考慮した主な要件を見ていきましょう。まず、プラットフォームへのリアルタイムな支払いデータの取り込みが必要です。世界中の複数のアプリケーションを通じて様々な種類の支払いが処理されているため、不正を検証するための共通のパターンや接続方法が必要となります。




支払いデータを分析して不正を検知するためのサービス群が必要で、そこではMachine Learningスコア、チェック、異常検知、例外処理を使用します。システムは、休暇シーズンや連休、支払い活動が多い時期に特に、高い取引量を処理できるよう自動でスケールする必要があります。支払い活動は世界中で24時間行われているため、アプリケーションは低レイテンシー、高可用性、そして回復力を備えている必要があります。不正検知の分野で重要な側面の一つは、オフライン分析用のデータを保持することです。これにより、新しい不正傾向を事前に特定し、既知の不正パターンを調査して対策を決定することができます。最後に、アクティブな不正を軽減、修正、または抑制するための機能を迅速に提供することに注力する必要があります。システムには、新しいルールの導入や既存のルールの更新によって不正に対処できるインターフェースが必要です。
AWSを活用した不正検知エンジンの構築と最適化

これらの不正検知に関するビジネス要件と技術要件に基づいて、私たちは不正検知プラットフォームのコンポーネント図を作成しました。 私たちは様々な要件を特定し、それぞれの責任を持つコンポーネントを設計しました。リクエストの取り込みとリクエストの優先順位付けを行うコンポーネントがあり、これらはリクエストデータの検証とクリーンアップを担当します。Embedding Signalsコンポーネントとベンダーエンリッチメントコンポーネントは、効果的な不正検知のために、ベンダーデータや銀行の参照データを用いて支払いデータを強化します。Feature Storeはデータ変換と集計の計算に使用されます。Detection Serviceは重要なコンポーネントで、ルールの作成アプリケーションと、支払いデータに基づく不正検知のためのルールエンジンを含んでいます。Inference Serviceでは、データサイエンティストがモデルの開発、トレーニング、テスト、検証、デプロイを行い、APIを通じてモデルスコアを提供します。最後に、Action Handlerが支払いルールのヒット結果に基づいて、どのようなアクションを取るかを決定します。

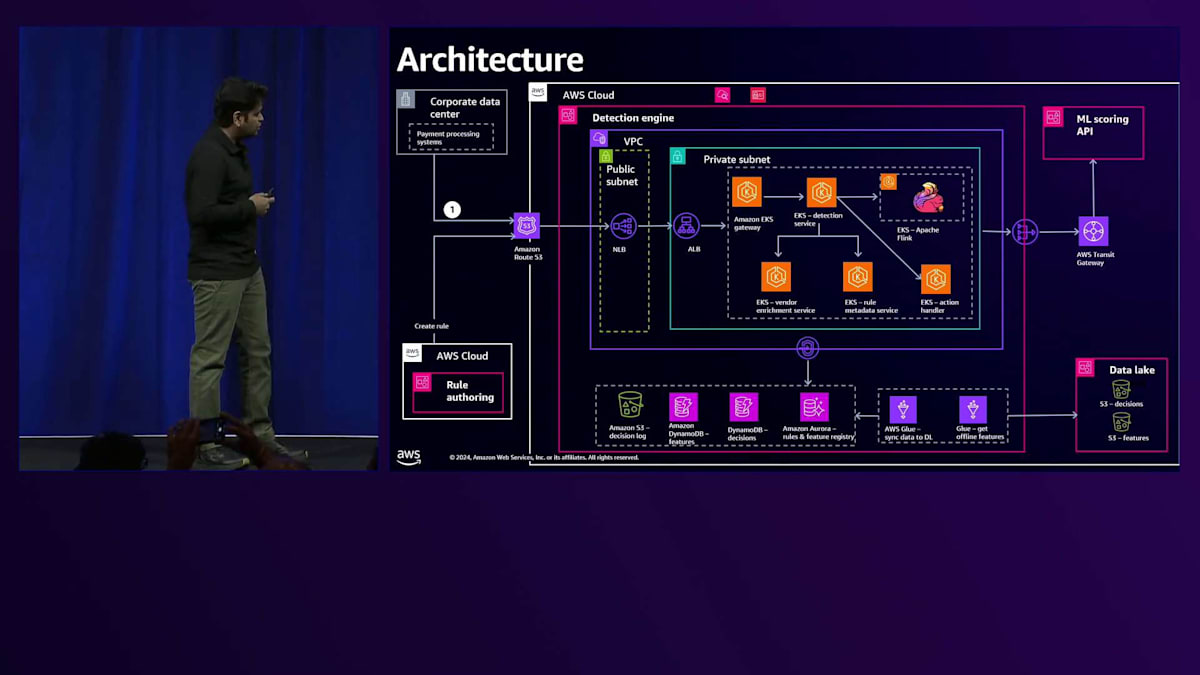

大量のデータを適切に処理し、低レイテンシーで処理することが重要なため、タスクを複数のコンポーネントに分割しました。それでは、不正検知プラットフォームのアーキテクチャをより詳しく見ていきましょう。 まず最初のステップとして、支払い処理システムが不正検知プラットフォームに対して、支払いの分析や評価のリクエストを行います。 リクエストは私たちの支払いシステムから送信され、AWS内のDetection Engineで受け取られます。Detection Engineには、 包括的な不正検知機能を提供するマイクロサービス群が含まれています。
Detection Engine内には、Gatewayマイクロサービスがあり、リクエストを受け付け、検証し、必要に応じてデータをクリーンアップしてから、Detection Serviceに転送します。Detection Serviceはプラットフォームの中核となるコンポーネントで、支払いデータに対してルールを実行します。ルールを実行する前に、初期データ、集計された特徴量、ベンダーデータなどの他のデータセットを取得します。さらに、支払いタイプに基づいて実行する必要のある特定のルールを特定します。これは、支払いタイプによって異なるルールが必要となる場合があるためです。
これらの追加データセットと支払いデータが揃ったら、ML Scoring APIを呼び出してモデルスコアを取得します。ML Scoring APIは、すべての支払い情報、特徴量データ、その他の強化されたデータセットを処理してスコアを提供します。スコアを受け取った後、ルールを実行するために必要なすべてのデータが揃います。サービスは特定されたルールをこれらのデータセットで実行し、ルールの実行が完了すると、Action Handlerが結果に基づいて適切なアクションを実行します。
Detection Engine内のマイクロサービスは、異なるデータストアを使用します。ルールのメタデータ、Feature Registry、アプリケーション設定の保存にはAmazon Auroraを使用します。エンリッチメントデータ、特徴量データ、例外リストの検索にはAmazon DynamoDBを使用します。Amazon S3は監査ログとして機能し、システムが受け取ったすべてのトランザクションが日次ベースで継続的に保存されます。
ML Scoring APIは、データサイエンティストによってデプロイされたMLモデルに基づいてスコアを提供する重要なコンポーネントです。外部のお客様が利用できるRule Authoringシステムは、支払いデータセットと利用可能なFeatureに基づいて、必要な情報を提供しながらルールの作成をサポートします。ユーザーはFeatureを定義し、新しいルールを作成したり、既存のルールを更新したりすることができます。このRule Authoring UIが重要な理由は、ルール変更のデプロイに必要な時間を最小限に抑え、長期化するプロセスを避けたいからです。
次に、システムが受け取るすべての支払いデータと履歴データを含むData Lakeについてご説明します。Detection EngineとData Lakeの間のやり取りは、AWS Glueジョブを通じて行われます。これらのGlueジョブは、Detection Engineからデータを取得し、日次データを実際のストアとプラットフォーム上のData Lakeに同期させます。

私たちのプラットフォームには、バッチFeature集計機能も備わっています。Data Lakeで実行されるバッチFeature集計は、日末に集計されたFeatureとしてDynamoDBにコピーされ、より高速な検索を可能にします。Featureは不正検知において非常に重要で、集計Featureまたはデータ送信のいずれかの形を取ることができます。それでは、Feature Engineeringにどのようにアプローチしたのかを見ていきましょう。
簡単なルールを例に、Featureとは何かを説明させていただきます。あるアカウントからの取引回数が過去1ヶ月間で1000回を超えた場合に今後の支払いを停止するというルールがあるとすると、この取引回数が私たちが言う集計Featureになります。Featureは昨日末まで、先月まで、または過去3日間までの履歴データに基づくことができます - これらをオフラインFeatureまたはバッチFeatureと呼んでいます。また、最後の1分または1秒前までを計算するリアルタイムFeatureもあります。

Feature Engineeringの実装における最初のステップは、Feature Registryです。Feature Registryは、Amazon EKS上にデプロイされたサービスで、任意のアカウントから引き落とされる取引回数などのFeatureを定義するためのインターフェースを提供します。ルールで使用されるすべてのFeatureは、このFeature Registryを使用して定義されます。先ほど申し上げたように、オフラインFeatureとリアルタイムFeatureの両方があります。 両方のFeature Engineは、Feature Registryから定義を取得し、バッチFeatureはAWS Glueジョブを使用してData Lakeで計算され、リアルタイムFeatureはApache Flinkを使用して計算されます。
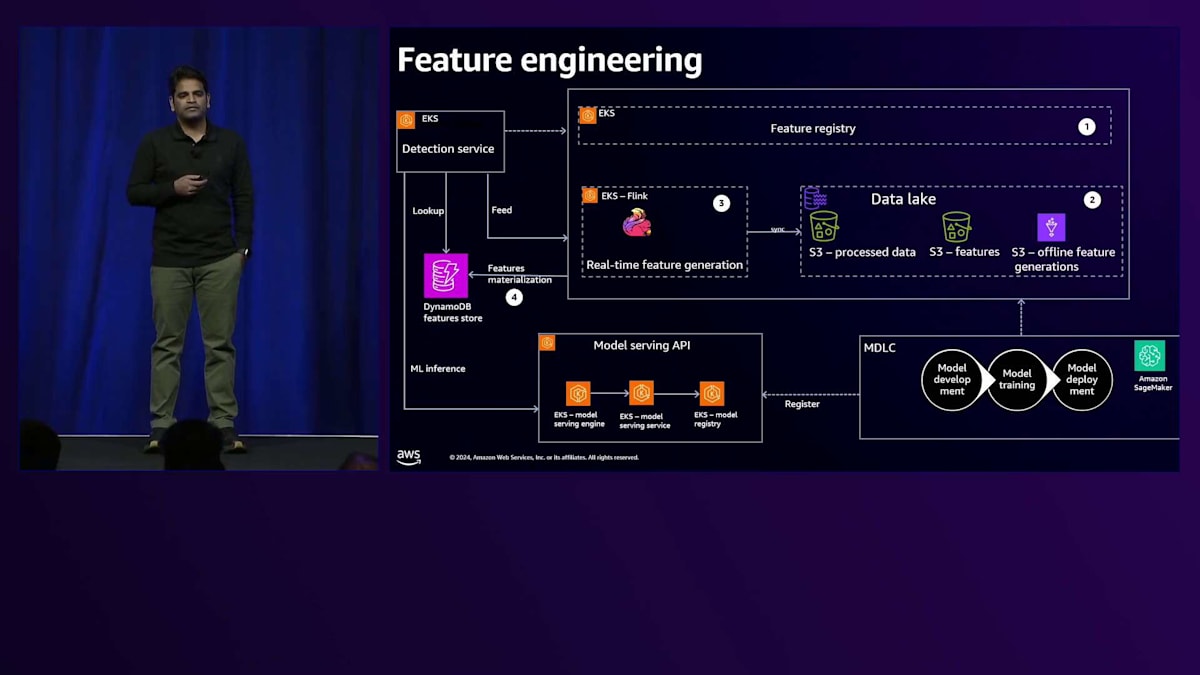
これらの機能を利用・作成するユーザーには、いくつかの異なるグループがあります。まず、エンジニア、Product Operations、Fraud Analystが不正検知ルールを作成する際に機能を定義します。2つ目のユースケースは、Model Development Life Cycle(MDLC)に関連します。 Data Scientistは、モデルのトレーニング、テスト、検証、デプロイのために機能を定義します。Data ScientistとFraud Analystの両方が、Feature Registryでこれらの機能を定義できます。
Feature Registryに登録されたすべての機能は、Feature Engine Servicesによって計算され、DynamoDBに具現化されます。この具現化のステップは非常に重要です。なぜなら、これらの機能は大量の履歴データに基づいて計算されるため、インラインでの計算は避けたいからです。私たちは低レイテンシーでスケーラブルなシステムを必要としており、これらの機能をオフラインで計算してDynamoDBに具現化することで、スケーラビリティとルール評価のための低レイテンシーな参照の両方を実現できます。

不正を検知するためにルールを実行するDetection Serviceは、DynamoDBから必要なすべての機能を参照し、決済情報と実行が必要なルールに基づいて、どの機能を取得するかを理解します。すべての機能が揃ったら、 Detection ServiceはModel Serving APIにMLインファレンスのコールを行い、モデルスコアを取得します。MDLCは機能を定義するプロセスであり、他のコンポーネントはルールに必要なものです。Detection Serviceはその後、DynamoDBからデータを参照し、最終的にルール実行で使用します。Model Serving APIは、Data Scientistがモデルを準備してデプロイする準備が整った際に、MDLCの一部としてモデルを登録する場所です。ここに登録されたモデルが実行され、そのスコアがDetection Serviceに書き出されてルールの実行に使用されます。
高スループットと低レイテンシーを実現するAWSインフラの設定

ここで、このプラットフォームで高いスループットを実現するために役立つAWSインフラのセットアップと設定について、Jimmyに説明してもらいましょう。ありがとう、Clark。皆さん、こんにちは。私はJPMorganChaseでインフラ側のLead Software Engineerを務めているJimmyです。本題に入る前に、このセッションの後半では、Amazon EKSとKubernetesについて頻繁に言及することをお伝えしておきたいと思います。これは、このプラットフォームが要求する非常に高いスループットと非常に低いレイテンシーを考慮して、EKSを私たちのプラットフォームとして選択したためです。

1日に数千万のリクエスト、秒間300-400リクエストを処理することを想定したプラットフォームを設計する際には、プラットフォームに導入するすべてのインフラコンポーネントとネットワーク層を慎重に分析することが非常に重要になります。追加する層ごとに処理時間が数ミリ秒増加し、また各層には障害の閾値があります。 それでは、レイヤー数とレイテンシーを削減するために、どのような改善を行ったのかを見ていきましょう。

私たちが最初に行った改善は、AWS Load Balancerのレベルでした。標準的なAmazon EKSの実装では、Application Load Balancerがあり、EKSクラスター内で実行されている基盤サービスがあり、その間にLoad Balancerから基盤となるEKS Podへトラフィックをルーティングするリバースプロキシ層があります。私たちはその代わりに、AWS Load Balancer Controllerを活用することを選択しました。これはオープンソースのプラグインで、EKS PodをApplication Load Balancerのターゲットグループに直接リンクすることができ、それによってリバースプロキシ層を完全に排除することができました。

次に、私たちは全体的にVPC Endpointを積極的に活用しています。VPC Endpointは、すべてのAWSサービスへの直接リンクをサブネットに提供し、非常に高いパフォーマンス上の利点をもたらすことで知られています。負荷テスト中のクロスリージョンシナリオの1つでは、DynamoDB VPC Endpointを導入した後、DynamoDBのクロスリージョンクエリで86%のパフォーマンス向上を観察することができました。

次の設計上の決定は、大規模なデータ検索が必要な操作にDynamoDBテーブルを選択することでした。ご存知の通り、DynamoDBテーブルはすべてスタンドアロンのテーブルで、各テーブルのスケーリングパラメータを個別に設定することができます。大規模なデータ検索を行う操作に関連するテーブルには、より多くの読み取りおよび書き込みキャパシティユニットを追加しました。その結果、どのような量のデータでも数ミリ秒以内にデータベースから検索することが可能になりました。

次に、私たちが目指す大規模なスケールを実現するために行ったAuto Scalingの調整について見ていきましょう。同期トラフィックを処理するEKS Podは、Pod全体の平均CPUとメモリ使用率に基づいてスケールアップし、非同期トラフィックを処理するPodは、トラフィックを受信するSQSキューに到着する未処理メッセージの数に基づいてスケールアップします。
このスケーリングプロセスを最適化するために行った調整は、早めにスケールすること、つまり「反応するのではなく行動する」というアプローチです。EKS Podは起動してから、トラフィックを実際に処理し始めるまでに数秒から1分程度かかる場合があります。そこで、同期トラフィックを処理するPodのスケールアップをCPU使用率50%、メモリ使用率50%の時点で開始します。これによる最大の利点は、トラフィックのスパイクが発生した際に、新しいPodが起動している間も、既存の実行中のPodが一貫して増加したトラフィックを処理できることです。

それでは、Resiliencyについてお話ししましょう。決済取引ビジネスは24時間365日稼働しています。消費者や企業が絶え間なく決済取引を行っているためです。 詐欺師や悪意のある人々も世界中に散らばっているため、同じく24時間365日活動しています。そのため、これらの決済を処理し不正をスクリーニングするプラットフォームも24時間365日オンラインである必要があります。24時間365日オンラインのプラットフォームを構築するには、あらゆる種類の障害から回復できるよう、複数層のResiliencyをプラットフォームに組み込む必要があります。これから3つのスライドで、このプラットフォームに組み込まれた3つのレベルのResiliencyについて見ていきましょう。
第一のレベルは、基盤となるサービスのResiliencyです。基盤サービスは24時間365日、着信要求に応答できる必要があります。これからご紹介する設定と構成により、基盤サービスでほぼゼロのダウンタイムを実現することができます。最初の設定は、Application Load Balancerの構成です。Application Load Balancerには、InstanceタイプとIPタイプという2つのTarget Groupモードが用意されています。適切なモードを選択することが非常に重要です。これから両方のTarget Groupモードの動作を説明し、どちらが適切なモードかを結論付けていきましょう。
InstanceタイプモードでTarget Groupを作成すると、AWS Load Balancer Controllerは、EKSクラスター内のインスタンスを直接Target Groupに登録します。Load BalancerとTarget Groupはノードを認識しますが、ノード上で実行されているPodは認識しません。このアプローチには欠点があります。サービスをデプロイすると、利用可能なリソースが見つかった場所にPodがデプロイされるためです。例えば、最小6個のPodを持つサービスを起動した場合、EKSが1つのノードに4個のPodを起動するのに十分なリソースを見つけると、1つのノードに4個のPod、残りの2個のPodは別のノードに配置されます。Target Groupは2つのノードしか認識しないため、2つのノード間で均等にトラフィックを分散します。これにより、1つのサーバーで実行されている2つのPodは高負荷時にオーバーロードして停止する可能性がある一方、もう1つのサーバーで実行されている4つのPodは軽い負荷で動作するという状況が発生します。

Instanceタイプのターゲットグループは適切なTarget Groupタイプではありません - IPタイプが適切なTarget Groupです。6個のPodを持つサービスがあり、IPタイプのTarget Groupを作成すると、AWS Load Balancer Controllerは6個すべてのPodを直接Target Groupに登録します。これにより、Target Groupは6個すべてのPodを認識し、すべてのPod間でトラフィックを均等に分散します。次の設定は、Namespace レベルのアノテーションで、Pod Readiness Gateと呼ばれるものです。このアノテーションをアプリケーションPodのNamespaceに追加することで、Target Groupに登録されたPodは、実際にトラフィックを受け入れる準備ができた時点で初めてHealthyとマークされるべきであることを、NamespaceとTarget Groupに通知します。
Podがトラフィックを受け入れる準備ができているかどうかを制御するのは何でしょうか?コンテナ化されたサービスの標準的な実装には、コンテナで有効にできるReadiness Health Endpointと呼ばれるものがあります。Readiness Health Endpointを有効にすると、成功レスポンスを返す前に、Readiness Endpointの一部として必要な検証を実行することができます。サービスにReadiness Endpointを追加し、このアノテーションをNamespaceに追加すると、これらの2つの設定により、Readiness Endpointが設定可能な回数の成功レスポンスを返した時点で初めて、PodがTarget Group下でHealthyとマークされるようになります。

3番目の設定は、Podが終了する際に関係してきます。Podが終了する理由はさまざまです。例えば、一時的にトラフィックが急増した後に収まり、もはやトラフィックがない場合、Podはスケールダウンして終了します。また、既存のサービスの新バージョンをデプロイする場合、すべてのPodが終了し、新しいPodに置き換えられます。負荷テストで観察したところ、デフォルトの実装では、終了中のPodは32秒後に強制終了されることがわかりました。大量のトラフィックがある状況では、Load Balancerがドレイン中のPodへのトラフィック送信を停止するのに、この30秒では実際には不十分でした。
私たちが気付いたのは、PodがTerminating状態に移行してLoad Balancerでドレイン状態とマークされた後、Load Balancerが実際にそのPodへのトラフィック送信を停止するまでに90秒から2分かかるということでした。つまり、Terminating状態に移行した後、Podは2分以上生存している必要があります。これを実現するには、Podのライフサイクルに「preStop sleep hook」と呼ばれるものを追加します。これはAmazon EKSのデプロイメント定義に記述します。このsleep hookは、設定可能な分数だけsleepコマンドを実行するものです。ここでは5分(300秒)に設定しています。Podが終了状態に入ると、実際に強制終了される前に5分間sleepコマンドを実行します。
これはブロッキング操作ではないことに注意してください。sleep hookは、アプリケーショントラフィックを処理するスレッドとは別のスレッドで実行されます。その結果、sleep hookが実行されている間もPodはトラフィックの処理を継続できます。これらの設定を組み合わせることで、基盤となるサービスの回復力が高まり、ほぼゼロのダウンタイムを実現できます。これらの設定はすべて言語に依存しません。Load BalancerレベルとAmazon EKSデプロイメント定義での設定だからです。そのため、コンテナ化されたサービスの基盤となるコードベースが何であれ、これらの設定を活用できます。
マルチリージョン展開とコスト最適化戦略

次に、Amazon EKSクラスターが実行されているAvailability Zoneの1つで障害が発生した場合に、アプリケーションを回復力のあるものにする方法を見ていきましょう。3つのAvailability Zoneでアマゾン EKSクラスターを起動したとします。標準的なAmazon EKSの実装では、そのアルゴリズムは多数のPodを単一のAvailability Zoneにまとめて配置し、残りのAvailability Zoneには少数のPodのみを実行させる傾向があることがわかります。つまり、3つのAvailability Zoneがあり、例えば40個のPodがある場合、約30個のPodが単一のAvailability Zoneのノードにデプロイされ、他の2つのAvailability Zoneのノードには4、5個の実行中のPodしかないという状況になります。このようなPodの単一Availability Zoneへの集中を避けるために、Amazon EKSデプロイメント定義にanti-affinityと呼ばれるものを追加します。

Amazon EKSデプロイメント定義のanti-affinityは、Podを互いに反発させます。私がPodで、デプロイメント設定でZone Aレベルでこの設定を行っている場合、同じサービスの新しいPodが同じゾーンで起動しようとすると、私はすでにここで実行中なので、そのPodに別のゾーンを見つける必要があることを通知します。

このような設定をさらに一歩進めたのが、Topology Spread Constraintsです。これは基本的にAnti-Affinityと同じことをサーバーレベルで実現します。あるPodがサーバー上で実行されている場合、同じサービスの別のPodが同じノードで起動しようとすると、Topology Spread Constraintsによってそのポッドは別の場所に配置されます。私がすでにこのサーバーで実行されているので、あなたはこのサーバーで実行すべきではありません。なぜなら、このホストがダウンした場合、私たち両方が影響を受け、障害シナリオが発生してしまうからです。これら2つの設定を組み合わせることで、Amazon EKSクラスター内の利用可能なすべてのAvailability Zoneにわたって、Podを均等に分散させることができます。

AWS サービスが地域全体で障害に見舞われた場合に備えて、アプリケーションをどのように耐障害性のあるものにしたのかを見てみましょう。AWSサービスが地域全体で障害に見舞われることは非常にまれですが、JPMorganChaseはシステム上重要な金融機関であるため、そのようなシナリオにも備える必要があります。 特定の地域におけるAWSサービスの影響から保護するために、マルチリージョン展開を実装しています。2つのリージョンで100%同一のプラットフォームを実行し、それらの間でクリーンな分離を維持しています。2つのリージョンで実行されているサービス間に相互依存関係はないため、影響が出た場合にはそのリージョンからクリーンに退避し、次のリージョンで処理を再開することができます。次のリージョンで処理を再開できるのは、レプリケーションを通じて、同じ基盤データが両方のリージョンから参照可能だからです。ご覧のように、両リージョンのAmazon S3バケットは双方向にレプリケートされ、2つのリージョンにまたがるグローバルデータベースを活用し、さらに2つのリージョンにレプリケートされるAmazon DynamoDBのグローバルテーブルも使用しています。

レジリエンシーに関連するもう一つの設計上の決定は分離です。 具体的には、異なる決済パターンの物理的および論理的な分離です。異なる決済パターンをそれぞれ独自のAWSアカウントに分離しています。例えば、クレジットカード決済やリアルタイム決済は同期的な決済であり、特定の季節に取引量が増加するため、より迅速なスケーリングが必要です。これらの決済は、ACH決済やその他のバッチ型決済が展開される別のAWSアカウントとは異なる、独自のAWSアカウントに分離されています。これにより得られる最大の利点は、異なる取引パターンを独立してスケールできることです。異なるトラフィックパターン間で完全に分離されたアカウントを持つことで、それぞれを異なる方法でスケールし、独立して展開し、問題が発生した場合の影響を軽減することができます。

さらに、サービスを独自のNamespaceとNode Groupに論理的に分離することで、もう一歩進んでいます。 連携が必要なサービスは同じNamespaceに配置され、その他のサービスセットは異なるNamespaceに分離されています。
論理的な分離にも同じ原則が適用されます。これらのサービスセットを異なる方法でスケールし、個別に展開し、将来問題が発生した場合の影響範囲を縮小することができます。

コスト最適化についてお話ししたいと思います。 コスト最適化は初日から取り組むべき活動です。プラットフォームを構築してから、後からコストを削減しようとするのは非常に困難なプロセスです。特に大量のトラフィックが発生している場合はなおさらです。私たちは、すべての設計判断においてコスト分析のための余地を確保しています。私たちが従っている4つの主要な柱があります。1つ目はオンデマンド利用です。開発者は必要なときに環境を起動できるべきですが、環境は24時間365日常時稼働している必要はありません。
私たちは、Lambda関数とワークフローを使用して、毎晩特定の時間にAWSアカウントにアクセスし、すべての環境をシャットダウンします。基本的に、EC2インスタンスを使用しているものはすべて翌日にはシャットダウンされます。これらの環境は自動的には起動されず、開発者は使用したいときに自由に起動できます。すべての環境を常時使用しているわけではないため、これは大きな利点となっています。例えば、負荷テストを実行する必要があるパフォーマンス環境を考えてみましょう。数日間負荷テストを行い、その後何週間も使用されないかもしれません。このため、誰かが起動した場合に備えて毎日環境をシャットダウンしていますが、翌日に自動で起動することはありません。
2つ目の柱は、コストを非機能要件として扱うことです。前述のように、すべての設計に関する議論にはコストに関する議論も含まれます。3つ目の柱は、環境内の低使用率を削減するための観測可能なメトリクスを持っていることです。サーバーやデータベースのCPUやメモリ使用率の傾向を示すアラートを設定しています。使用率の低いインスタンスがある場合は、スケールダウンしたり、インスタンスのサイズを縮小したり、使用していないデータベースのサイズを縮小したりします。4つ目は、Cost Championを設置したことです。Cost Championとは、観測可能な低使用率を常に改善し、常にコストを削減するための新しいアイデアやアプローチを提案する個人またはチームのことです。このCost Championのアイデアは、KarthikがかつてAWS re:Inventのセッションで学んだものです。
プラットフォームの主な利点と今後の展望


では、今日議論したことの要約をKarthikにお願いしましょう。私たちは1日に数千万件のトランザクションをサポートできるシステムを設計しました。 特に決済活動は24時間体制で行われているため、24時間365日デプロイが可能です。いつでも不正を防止できるシステムが必要なので、24時間365日のデプロイが可能であることは重要な機能です。また、市場投入までの時間も短縮できます。 具体的なユースケースとして、規制要件やデータ主権要件に基づいて、特定のリージョンでアプリケーションを実行する必要がある場合について説明できます。AWSリージョンをグローバルインスタンスやグローバルストアに追加するのは簡単です。例えば、US EastやUS Westでアプリケーションを実行していて、APACリージョンでリージョンを有効にしたい場合、簡単にアプリケーションのブループリントをそこで実行できます。
同様に、プロビジョニングプロセスは非常に重要です。必要に応じてサービスを提供し、スケールダウンすることもできるからです。Fail-fastアプローチのような概念実証を実行したい場合、それを簡単に行うことができ、その後前に進むことができます。


主なポイントをご紹介しますと、インフラではなくビジネスに注力できるようになり、安定性とメンテナンスが向上しました。不正を防止できるような機能やデータセットをクライアントに提供することに、より多くの時間を費やせるようになりました。例えば、Eコマースサイトでクレジットカードのテスト攻撃が発生した際に対処できる、クレジットカード不正テストソリューションを加盟店に提供できるようになりました。また、AWS環境で、Commercial Cash不正検知機能の提供も開始しています。

すぐに利用可能なデータサービスを活用することで、実際のビジネス機能やビジネス機能の提供における生産性が向上しました。強固な基盤は極めて重要なスケールを実現します。これは非常に重要で、AWSでは、特定の設計を試す際に、テストを行い、成功しなければ早期に失敗を確認できることを学びました。決済は24時間365日続くため、現在だけでなく、より高いボリュームや予期せぬボリュームにも対応できる将来を見据えたシステムに必要な、強固な基盤を確立することができました。

コスト最適化とセキュリティは、初日から取り組むべき活動です。これらのデジタル機能でクライアントをサポートする一方で、コストは非常に重要な要素です。AWSの導入やモダナイゼーションの過程を通じて、コスト最適化を行うことは非常に重要です。そしてもちろん、セキュリティも同様です。これら2つの側面は、設計段階から初日の活動としてライフサイクルに組み込まれています。セッションは以上です。ここからは質疑応答に移らせていただきます。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion