re:Invent 2024: AWSのマルチテナントSaaSにおけるLLM活用アーキテクチャ
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Generative AI meets multi-tenancy: Inside a working solution (SAS407)
この動画では、LLMを活用したマルチテナントSaaSアーキテクチャの構築方法について詳しく解説しています。RAGとFine-tuningという2つの主要なアプローチの特徴と使い分け、Basic TierとPremium Tierそれぞれにおけるテナント分離の実装方法、Amazon BedrockやOpenSearch Serverlessなどを活用したアーキテクチャパターンが示されています。特に、テナントごとのコスト計算方法や、CloudWatch LogsとAthenaを使用したメトリクス収集・集計の具体的な実装、API GatewayとLambda Authorizerを組み合わせたNoisy Neighbor問題への対処など、実践的な課題解決方法が豊富に盛り込まれています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
マルチテナントSaaSアーキテクチャの課題と本セッションの概要

本セッションでは、様々なマルチテナントアーキテクチャの構築方法についてご説明します。堅牢なマルチテナントアーキテクチャを実現するため、SaaSアーキテクチャにおける様々な課題の解決方法をご案内します。これは400レベルのセッションで、アーキテクチャの課題について説明する際にはコードの詳細にまで踏み込んでいきます。具体的なコード例を示しながら、堅牢なアーキテクチャを作るための特定の課題の解決方法を説明します。セッションの最後には、今日お話しする概念をカバーする新しいワークショップのGitHubリポジトリと、コードの大部分を含むリポジトリのリンクをご提供します。
私はAWS FactoryチームのシニアソリューションアーキテクトのUjwal Bukkaです。私のチームは、様々なISVや企業のSaaSへの移行をサポートし、そのプロセスを加速するためのビジネスおよび技術的なガイダンスを提供しています。本日は、カナダのトロントを拠点とするPrincipal Solutions ArchitectのMehran Najafiと一緒に発表させていただきます。
LLMを組み込んだマルチテナントソリューションの複雑さ
LLMを組み込んだソリューションの構築は、1つの顧客にサービスを提供する場合でも複雑になり得ます。高価になる可能性のあるハードウェアアクセラレーターでホストするか、トークンごとに課金される複雑で高額になる可能性のあるSaaSソリューションを使用するかの選択に直面します。顧客にサービスを提供するためにモデルをFine-tuningし、それをホストする必要があるかもしれません。機密性の高い顧客データを扱う必要があります。エージェントのようなワークフローを使用する場合、APIや他のデータベース、サードパーティへのアクセスが必要な複雑なエージェントを扱うことになります。
数千のテナントへのスケーリングは、さらに多くの課題をもたらします。各ドメインやユーザータイプに対応するためにFine-tuningされた複数のLLMを扱う必要があります。ある顧客が誤って、あるいは意図的に他の顧客のデータにアクセスしないよう保証する必要があります。一部のユースケースではコストが指数関数的に高くなり、特定のユースケースが経済的に実現不可能になる可能性があります。また、多数のエージェントも扱う必要があります。このトークでは、これらの多くのアーキテクチャ上の課題を検討し、AWSのマネージドソリューションがどのようにマルチテナントLLMベースのソリューションのスケーリングを支援し、お客様が自社のソリューションに特有の領域に集中できるようにし、複雑な部分をAWSに任せられるかを見ていきます。
RAGとFine-tuningによるGenerative AIアーキテクチャの構築



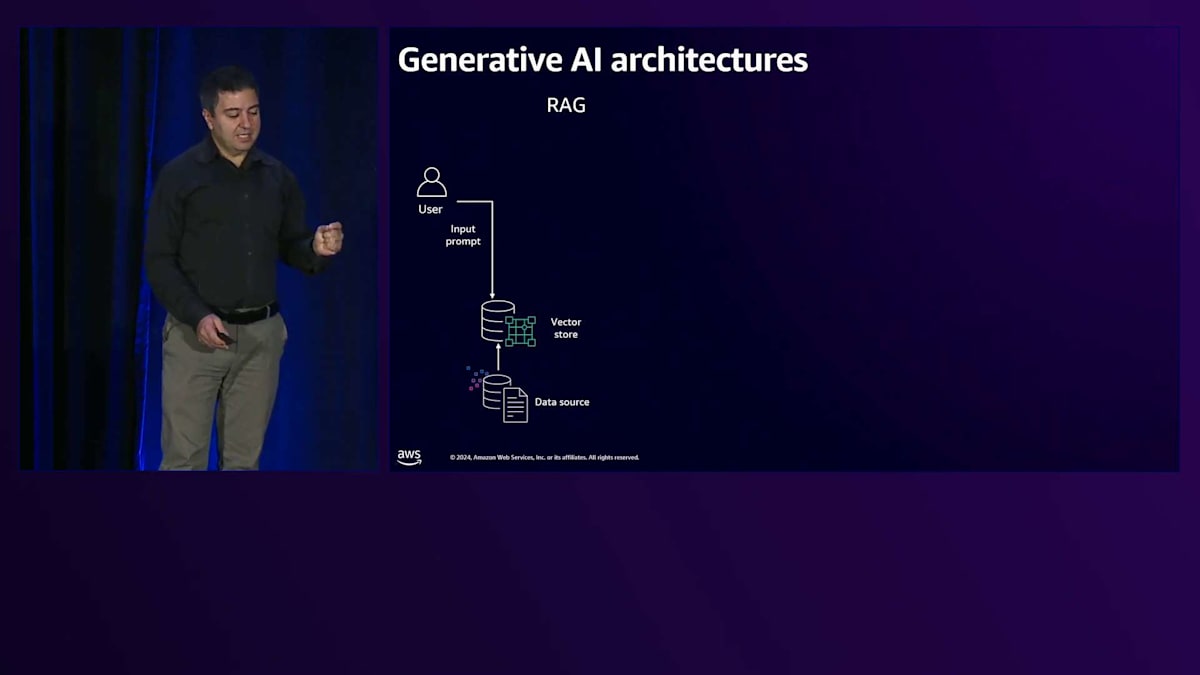
LLMベースのソリューションを構築するための2つの一般的なGenerative AIアーキテクチャを見てみましょう。 1つ目は非常に一般的なRAGを通じた構築方法で、もう1つはFine-tuningを通じた方法です。 RAGでは、カスタマイズやFine-tuningを行わない汎用的なLLMを活用します。すでに大量のデータで学習済みのLLMを使用します。 RAG(Retrieval Augmented Generation)を通じて、顧客のリクエストにより特化したものにします。顧客データは埋め込まれてベクトル化され、そのナレッジはVector Store内に保存されます。 ユーザーリクエストが来ると、Vector Storeに送られ、類似性検索機能を使用してそのユーザーのプロンプトやクエリに関連するナレッジを取得します。

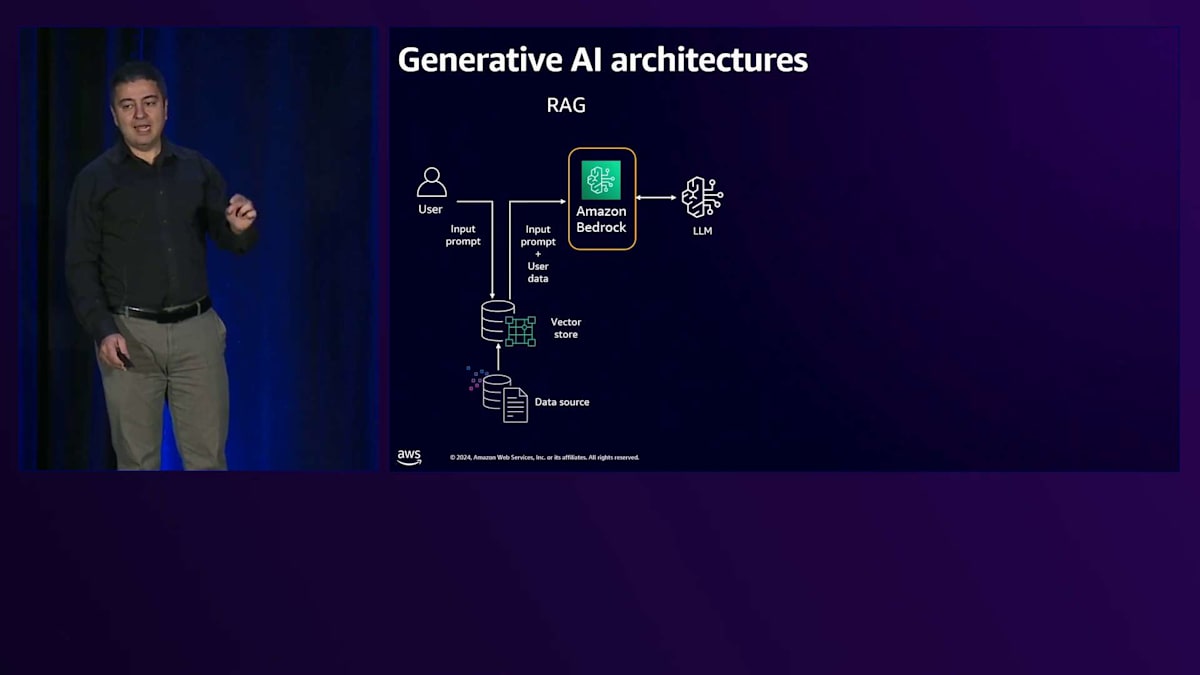
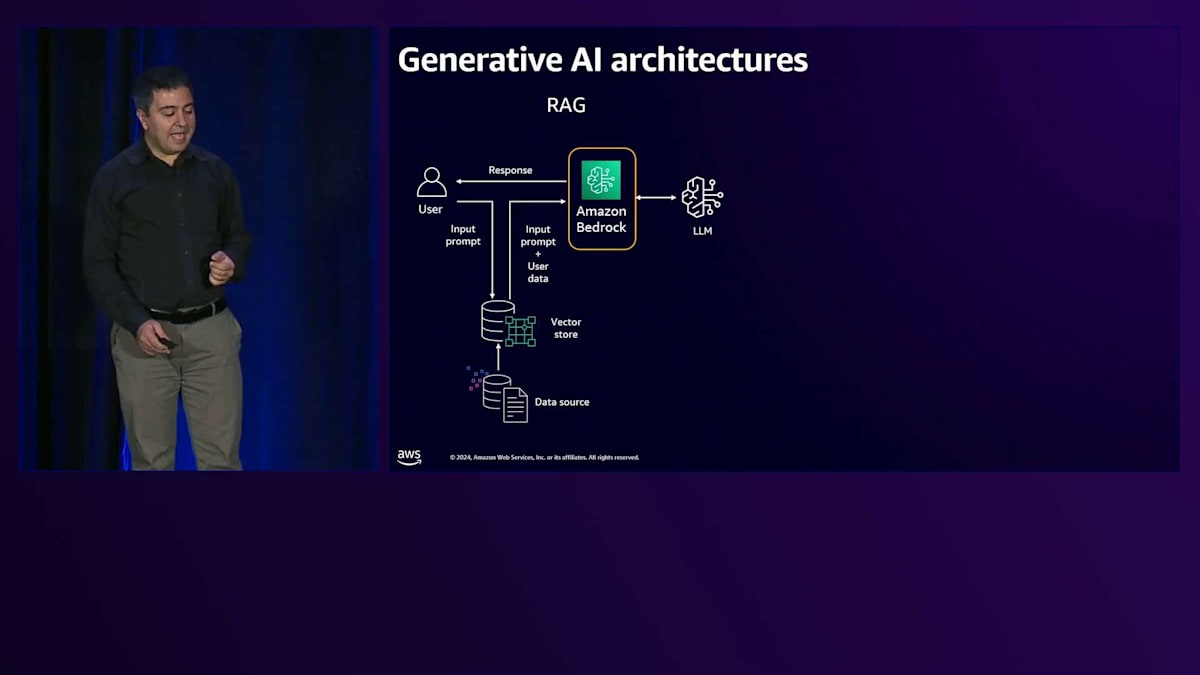
Amazon Bedrockは、さまざまなLLMオプションにアクセスするためのAWSのソリューションです。 Bedrockは関連する知識とともにリクエストをLLMに送信します。 これはAmazon Titanのようなアマゾン独自のものや、Anthropic Claude、Meta Llama 2、Cohereなどのパートナー企業のものが含まれ、生成された応答がユーザーに返されます。もうひとつのパターンはFine
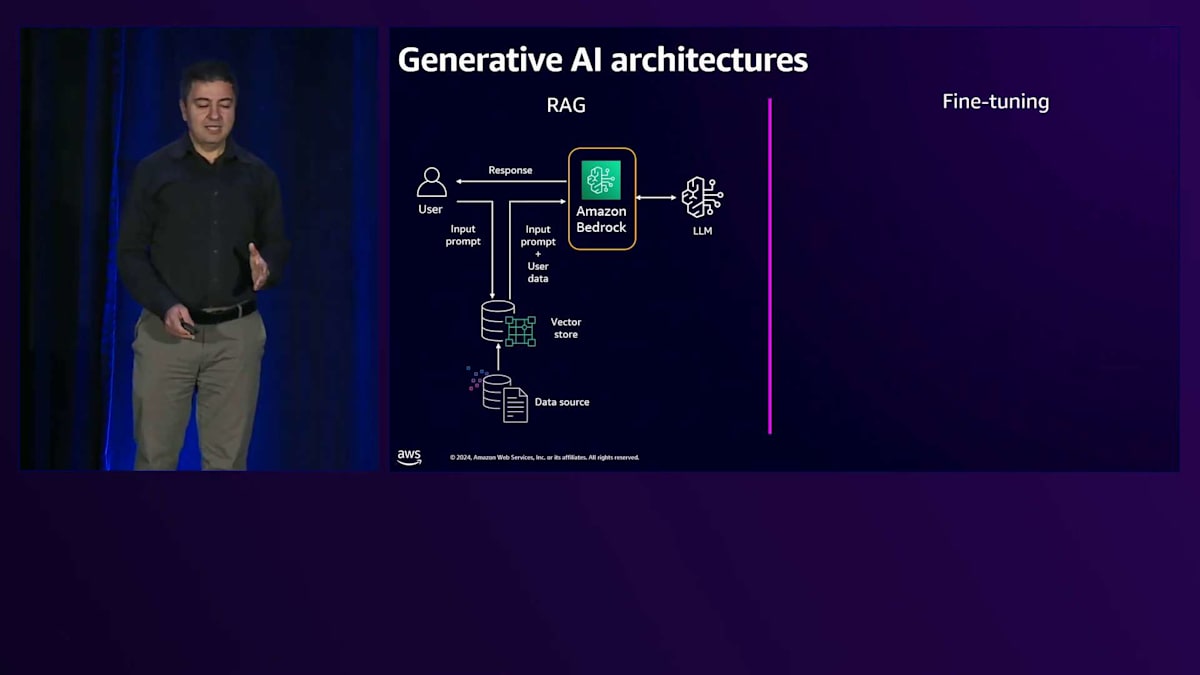
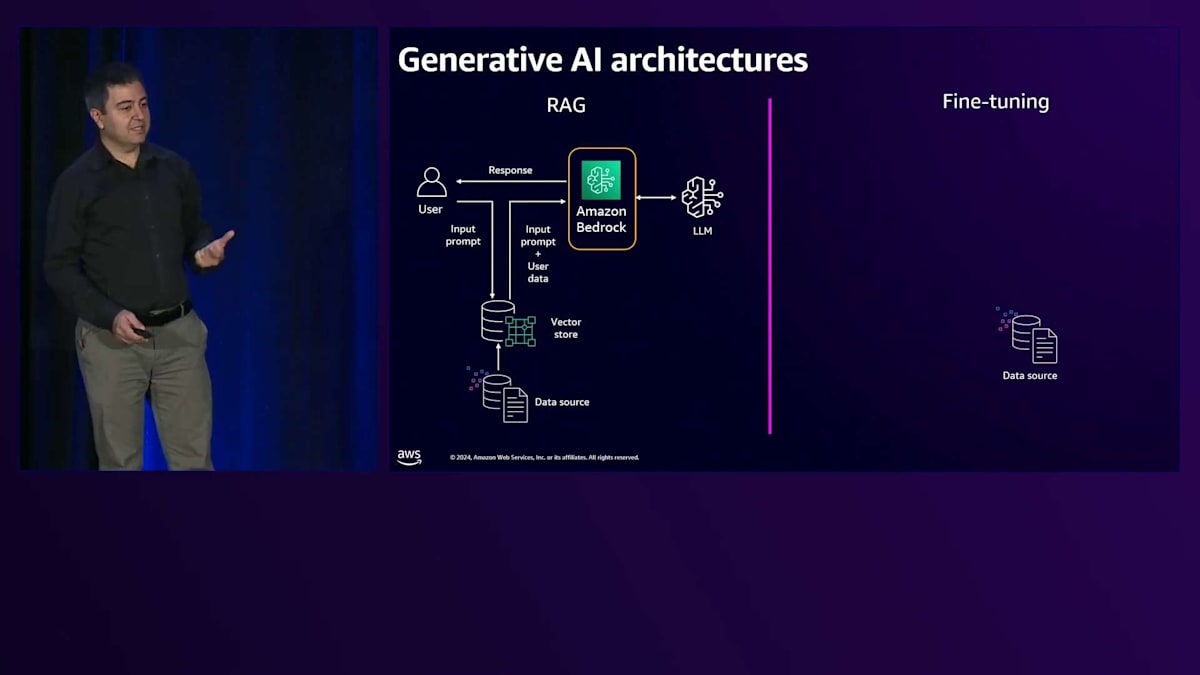
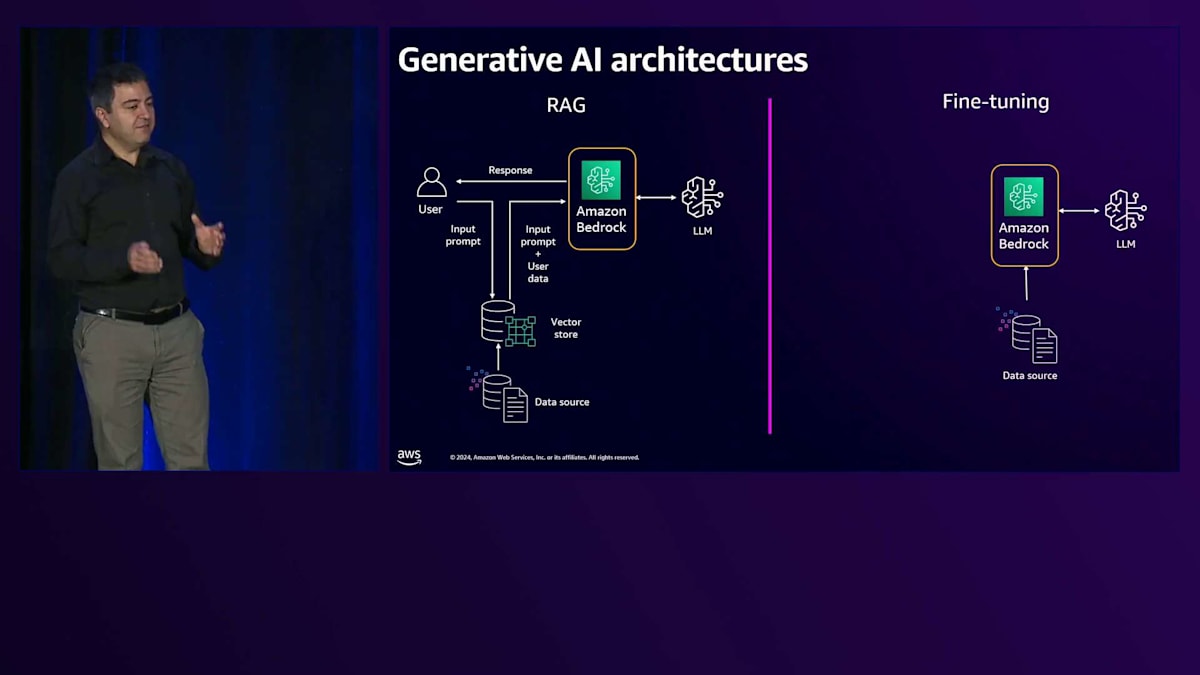
tuningです。この目的は、プロンプトの長さが増加してしまう可能性があるため、コンテキストや関連知識を毎回送信しないようにすることです。 その代わりに、ユーザーのトレーニングデータを使用してモデルをFine-tuningします。トレーニングジョブとFine-tuningを通じてLLMをカスタマイズし、 その知識をモデルに組み込みます。Fine-tuningされたモデルができあがると、ユーザーからリクエストが来た時に、 すでにその背景知識を持っているため、応答を生成してユーザーに送信することができます。
考慮すべき重要なポイントがいくつかあります。多くのユースケースでは、RAGやFine-tuningを使用しますが、それぞれに長所と短所があります。RAGの場合、Fine-tuningの必要がなく、汎用的な共有モデルを使用できるため、LLMにとってはよりシンプルです。Fine-tuningの場合は、そのプロセスを経る必要があり、カスタマイズされFine-tuningされた独自のLLMができた時には、それをホストし、バックグラウンドで動作するアクセラレーターやハードウェアのコストを支払う必要があります。しかし、ユーザープロンプトがLLMに送信される度にコンテキストを含める必要がないため、プロンプトの長さを節約できます。
場合によっては、これら2つのアプローチを組み合わせて使用します。汎用的なLLMの代わりにFine-tuningされたモデルを使用するRAGアーキテクチャを構築することができます。これは、静的なデータを使用してモデルをFine-tuningし、毎分、毎晩、あるいは毎週Fine-tuningしたくない動的な部分についてはRAGを使用すると考えることができます。このセッションの目的は、AWSのマネージドサービスを使用することで、この複雑さの多くを抽象化し、マルチテナントソリューションをより簡単に構築できることを理解していただくことです。
Amazon Bedrockを活用したマルチテナントRAGとFine-tuningの実装
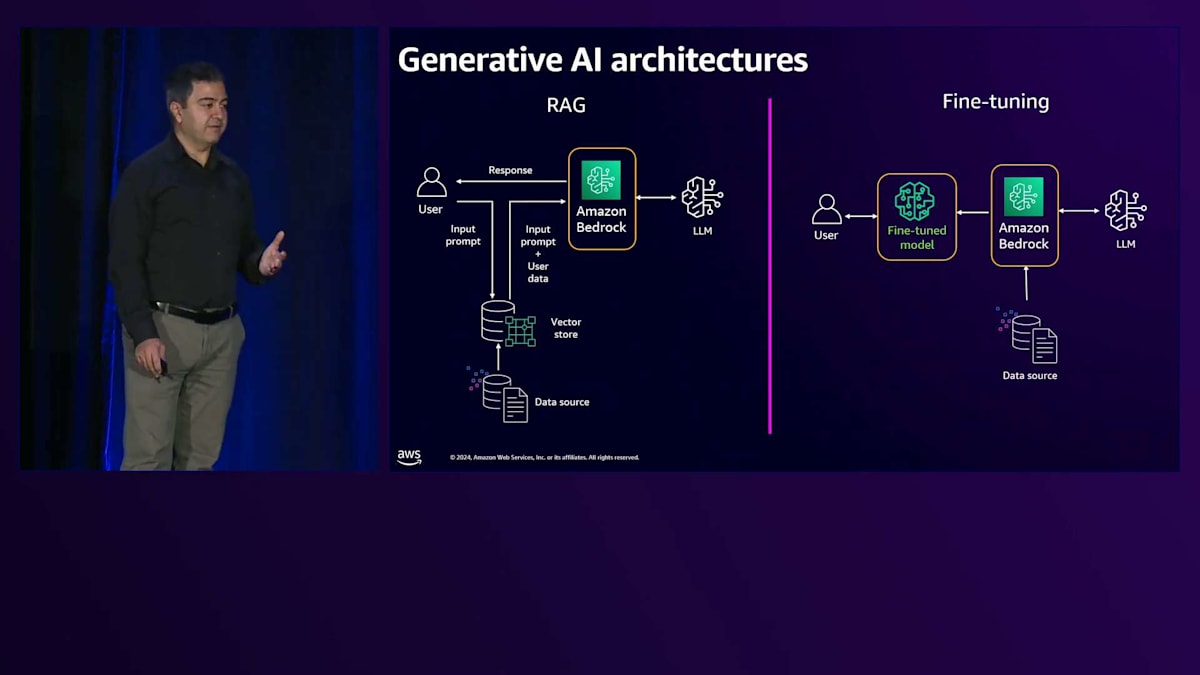
RAGについては、Amazon Bedrockには、マネージド型RAGソリューションであるAmazon Bedrock Knowledge Baseという機能があります。これを使用すると、ユーザーデータが保存されているAmazon S3などのデータストアとBedrock Knowledge Baseを接続できます。そして、OpenSearch ServerlessなどのVector storeに接続し、使用するLLMを設定することができます。Amazon Bedrock Knowledge Baseはすべてを管理してくれます - データの埋め込み、Vector storeへの格納、検索、そしてBedrockへの送信を行います。Fine-tuningについては、Amazon Bedrockにはカスタマイズモデル機能があり、データが保存されている場所を指定し、カスタマイズしたいLLMを定義するだけで済みます。

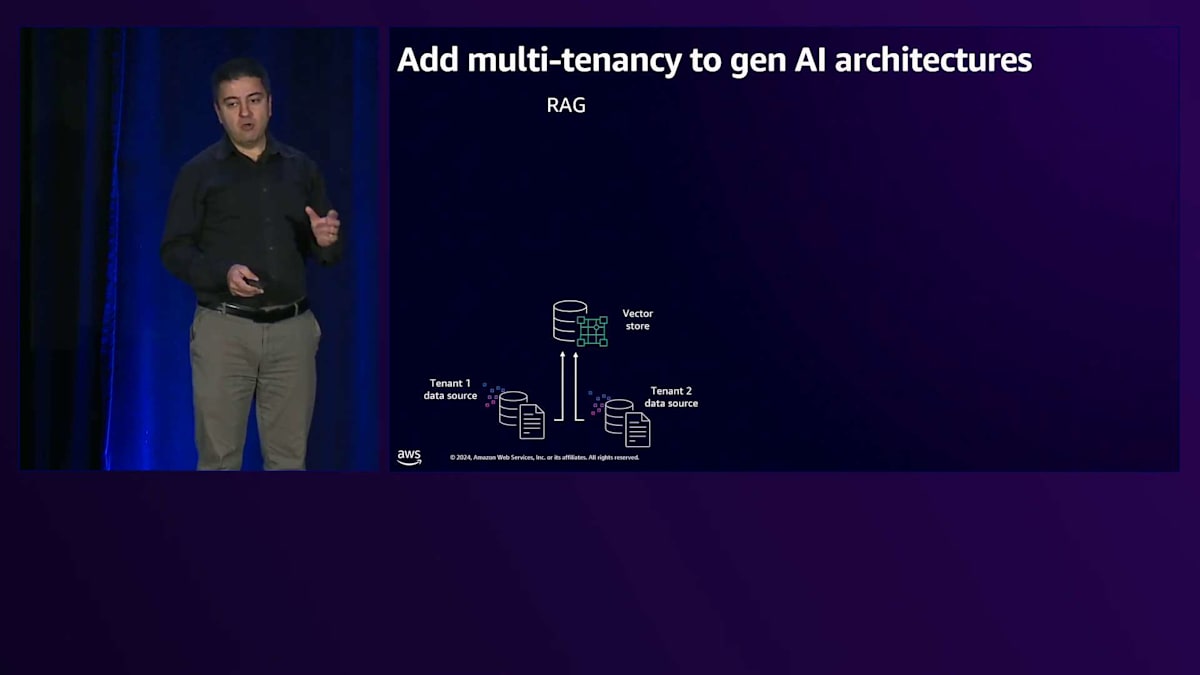
では、1人のユーザーについて説明した内容を見て、Multi-tenancyの側面がどこに現れるのか確認してみましょう。私たちには1人のユーザーだけでなく、複数のテナントがいます。ここでは2つのテナントを示していますが、実際には何千もの可能性があります。2つのテナントがある場合、各テナントは独自のデータストアを持ちます。これらをVector storeに格納する必要があります。ここでの最初の課題は、すべてのテナントに1つのVector storeを使用するか、複数のインスタンスで分離するかを決めることです。いずれの方法でも、各テナントのナレッジが他のテナントのナレッジと混ざらないよう、確実に分離する必要があります。
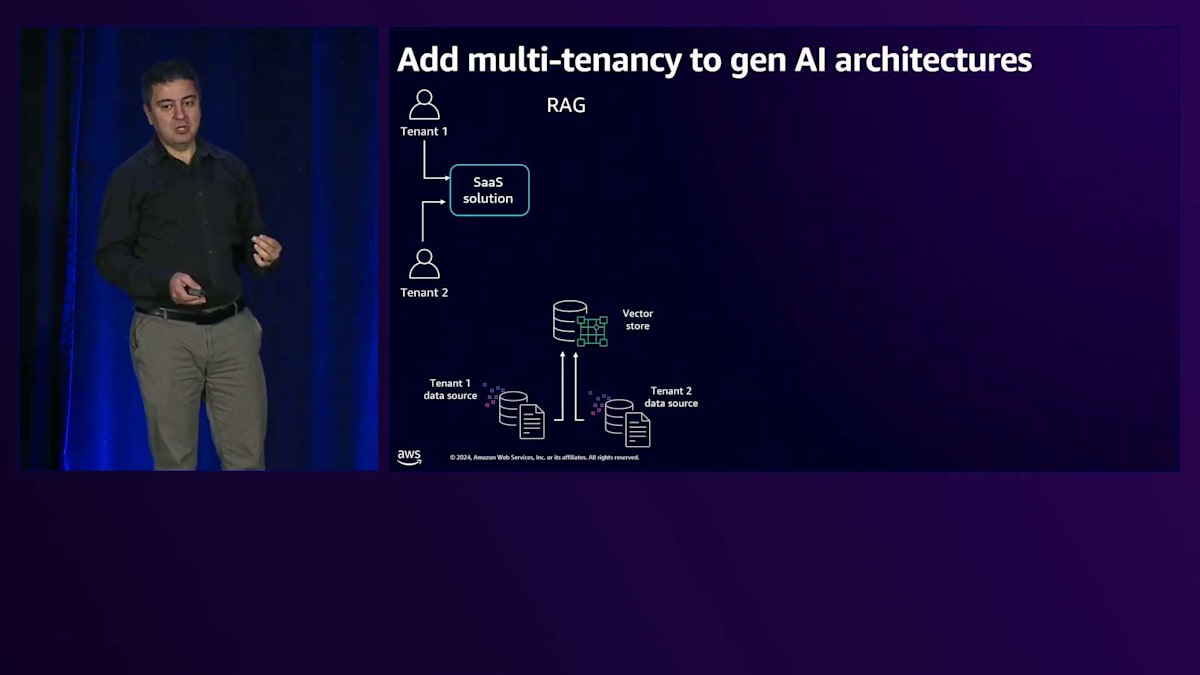
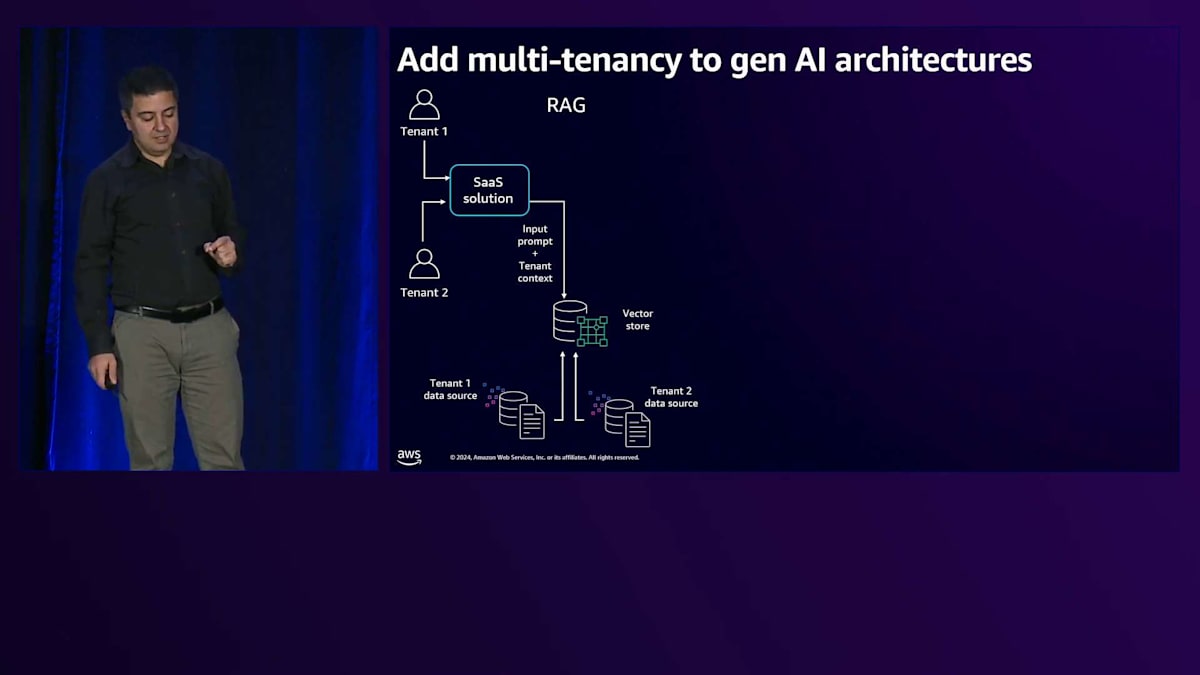
次に、これらをSaaSソリューションのフレームワークに組み込む必要があります。SaaSは単に1つの顧客にサービスを提供するだけではありません。テナントのオンボーディング、各テナント専用のリソースのプロビジョニング、課金・監視・制御のためのテナント管理など、数多くのタスクがあります。ここでは、LLMをサポートするSaaSソリューションを検討し、ユーザーがそのSaaSソリューションを通じてプロンプトを送信すると、Multi-tenantのナレッジが組み込まれたVector storeに送られます。テナントのコンテキストに基づいて、関連するナレッジが抽出され、Bedrockに送信されます。
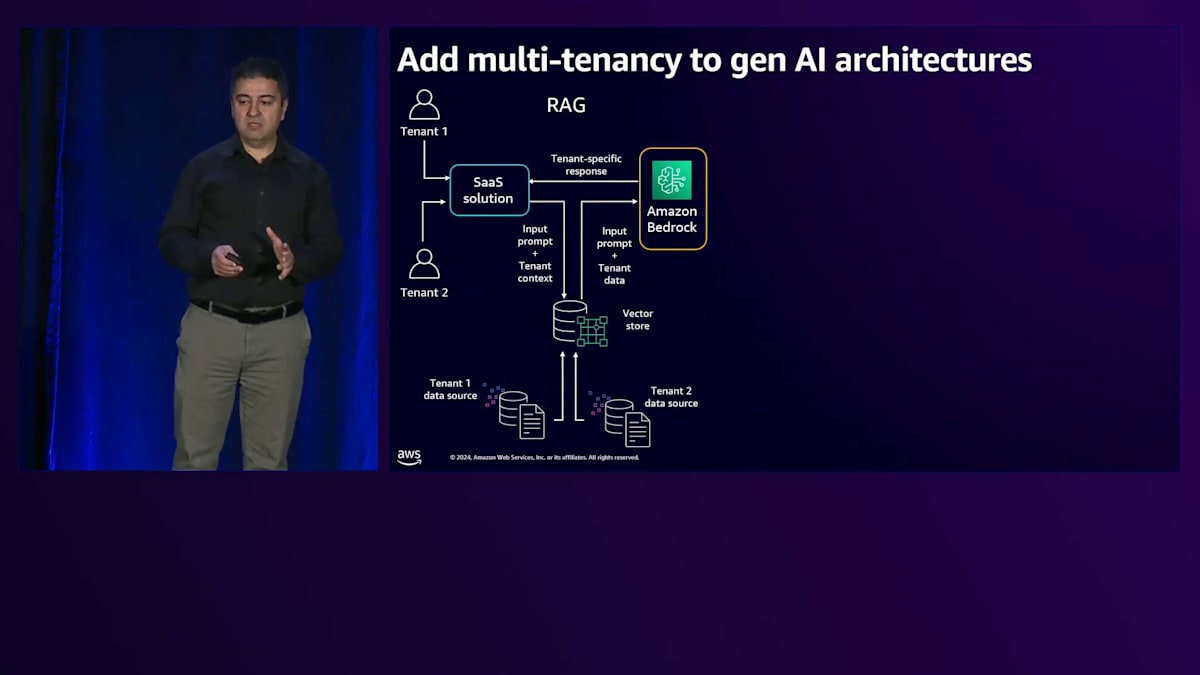
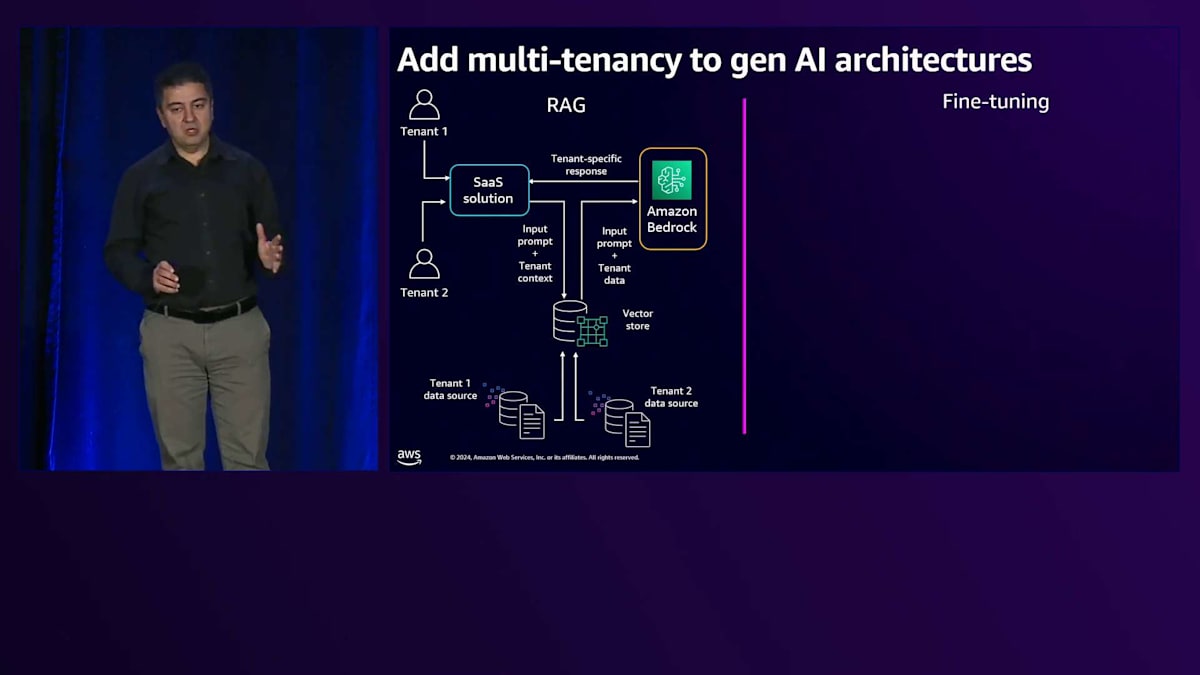
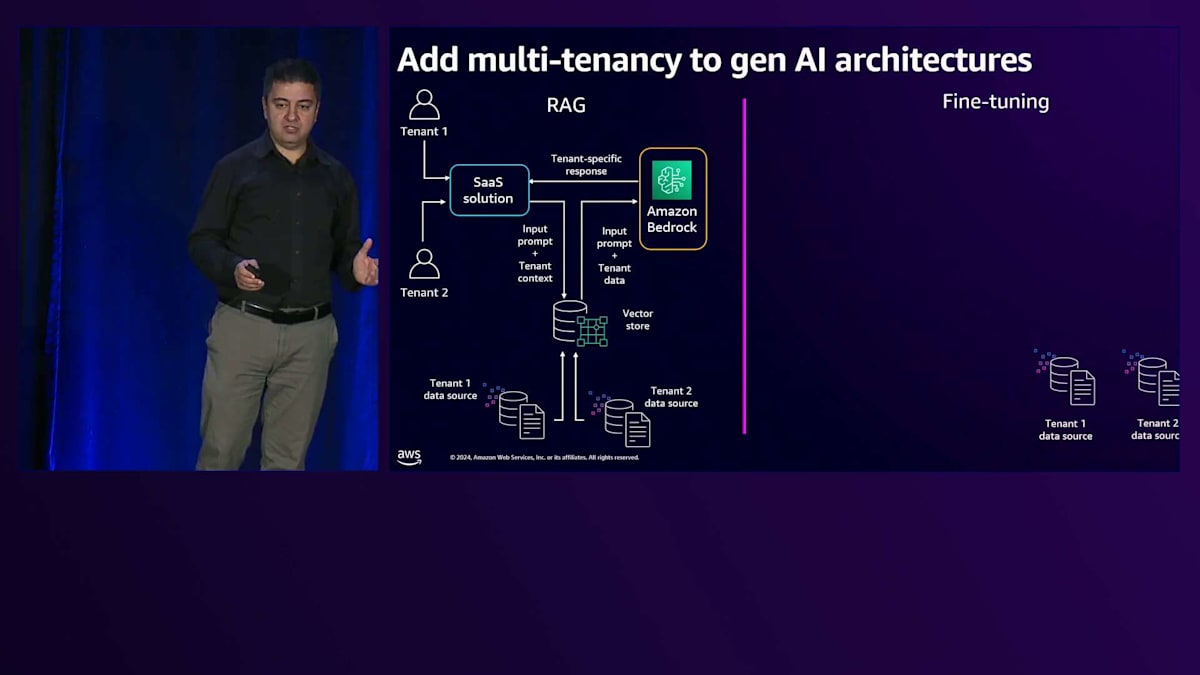
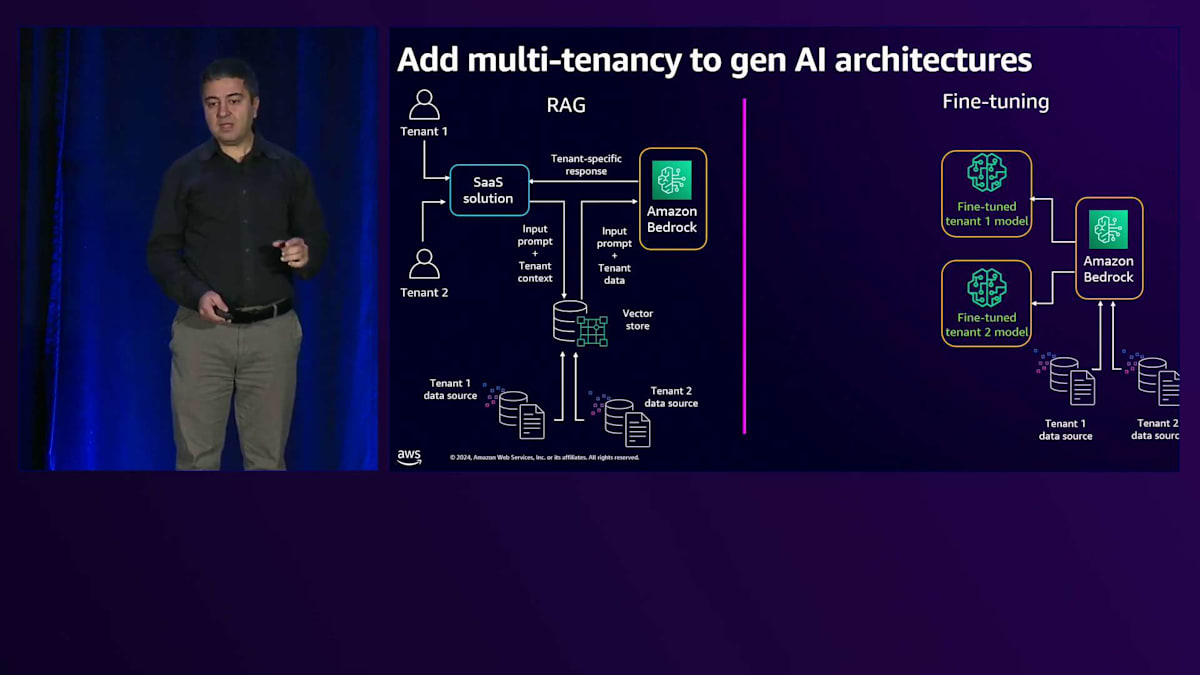
Bedrockの背後にあるLLMは、Fine-tuningやカスタマイズの必要がないため、同じ汎用の共有LLMを使用してテナントにサービスを提供できます。これはMulti-tenancyを持つRAGの実装についてでしたが、Fine-tuningの場合は、1人のユーザーではなく多数のテナントがあり、各テナントが独自のデータストアを持っています。Amazon Bedrockのカスタマイズ機能を使用して、それぞれのテナントのためにFine-tuningされたモデルを作成します。各モデルはProvisioned throughputモデルでホストでき、他のテナントやユーザーがそのテナントのモデルにアクセスできないようにすることができます。これらのLLMは各テナント専用です。テナントからリクエストがソリューションを通じて送られると、そのテナント専用のFine-tuningされたモデルに送信されます。
SaaSにおけるマルチテナンシーの課題とBasic/Premiumティアの設計
これがMulti-tenancyのコンテキストにおけるRAGとFine-tuningの概要です。ここからは、SaaSとMulti-tenancyの課題それぞれについて、より深く掘り下げて解決方法を見ていきましょう。SaaSを考えるとき、いくつかの分離パターンをご存じかもしれません。その1つがPoolと呼ばれるもので、共有リソースを活用します。同じサービスを使用しながら、複数のテナントに対して使用します。もう一方の極端な例がSiloで、各テナントに専用のリソースを割り当てます。このトークでは、これら2つの極端な例を見ていきますが、皆さん自身のユースケースやアプリケーションでは、共有サービスとして適しているものと、専用サービスとして適しているものに基づいて、その中間的なアプローチを検討することができます。
おそらくすべてのSaaSプロバイダーが最初に答えなければならない質問は、Generative AIに関してどのようなユーザーエクスペリエンスを提供したいかということです。これは新しい技術なので、多くの顧客は、より高額な有料サービスに移行する前にまずサービスを試してみたいと考えています。異なるタイプのユーザーをサポートするために、階層化された戦略を持つことは良い考えです。ここで重要なのは、基本層において最も経済的に実現可能なアーキテクチャを採用することです。なぜなら、高額になって損失を出したくないからです。そのため、できるだけ低コストに抑える必要があります。より多くのPoolつまり共有サービスを使用し、可能な限り多くの共有サービスを活用したいと考えています。しかし同時に、テナントの分離とスケーリングの側面も考慮する必要があります。
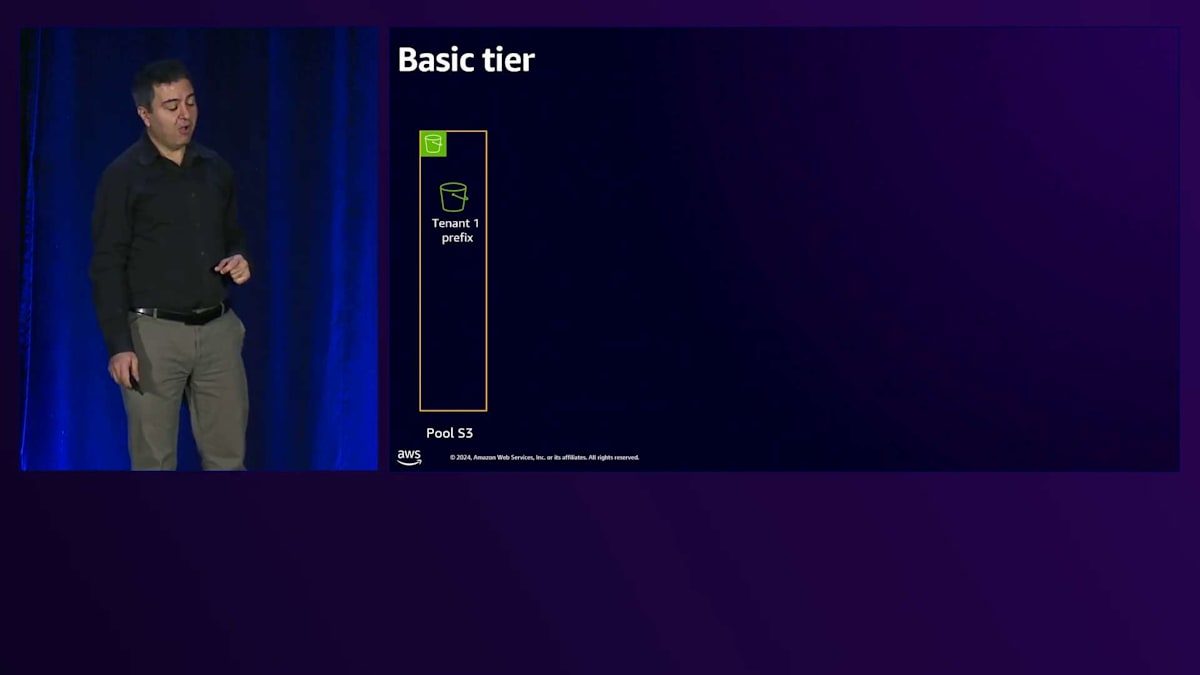
Basic tierについて、先ほど申し上げたように、ここでの目標は可能な限り多くのShared serviceを使用することです。そしてRAGを採用しています。なぜRAGを使用するのでしょうか?それは、ソリューションの中で最も複雑で高価な部分であるLLMを活用したいからです。Fine-tuningは避けたいと考えています。なぜなら、あるテナント用にFine-tuningを行うと、他のテナントがそれを使用できなくなり、トークンごとの課金ではなく時間単位での課金が必要になってしまうからです。そのため、Basic tierではまずRAGを使用します。テナントデータを保存するためのStorageがあり、1つのBucketを使用していますが、そのBucket内で各テナントに専用のPrefixを割り当てています。

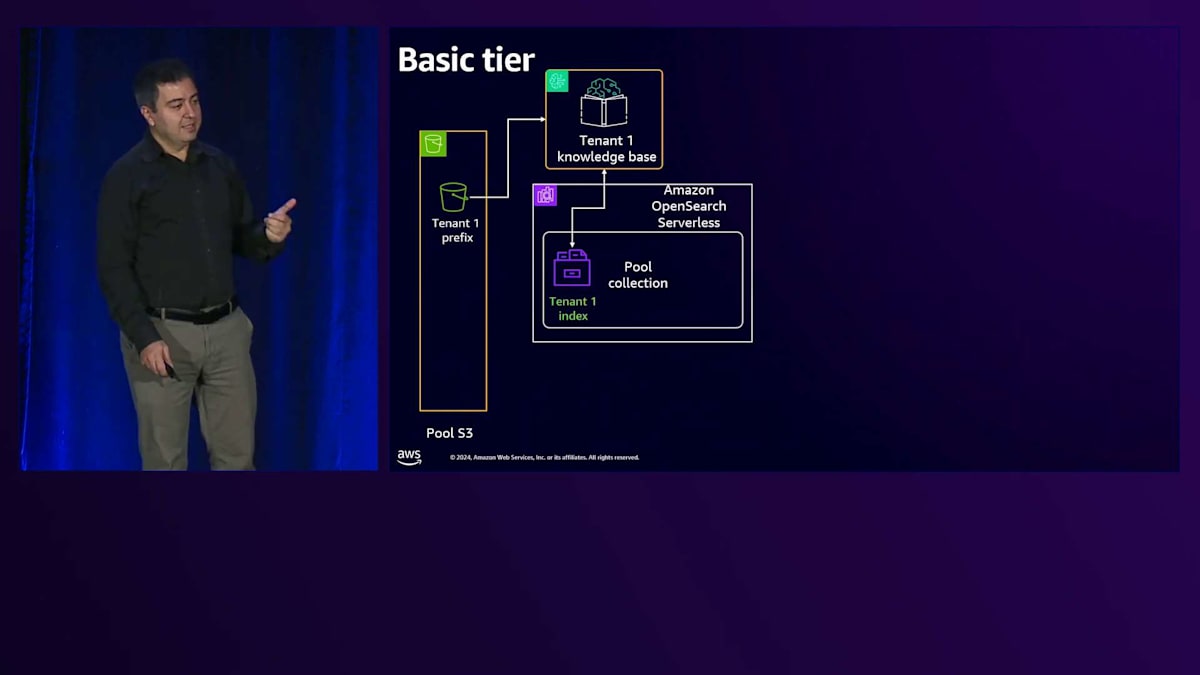
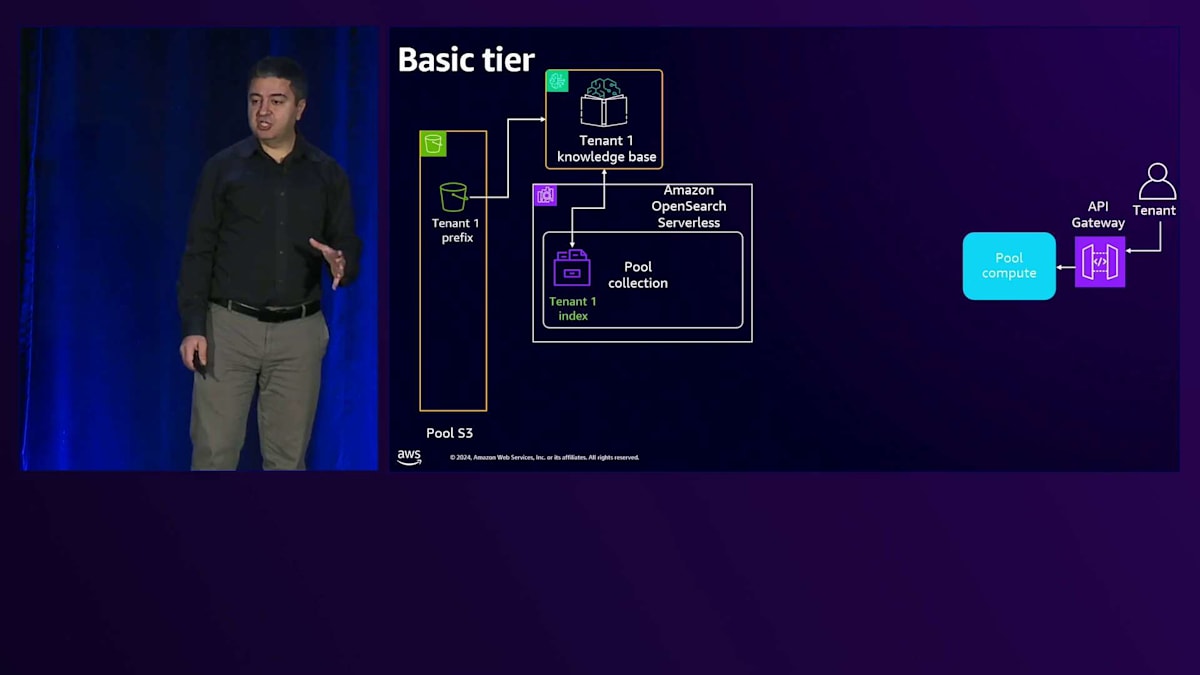
次に、Amazon Bedrock Knowledge Baseを使用しています。Amazon Bedrock Knowledge Baseは抽象化レイヤーであり、それ自体にコストは発生せず、使用するリソースやサービスに応じてコストが発生します。これをAmazon S3というStorageに接続し、データが注入されると、Knowledge BaseはBedrockを使用してそのデータの埋め込みとベクトル化を行い、Vector storeに保存します。Vector storeにはAmazon OpenSearch Serverlessを使用しており、同じCollectionを使用しながら、Collection内でテナント固有のIndexを使用することができます。1つのCollection内に多数のIndexを持つことができ、各Indexがそれぞれのテナントを表現します。テナントごとに異なるCollectionを用意する必要はありません。テナントからリクエストが来ると、共有のAPI Gatewayを通過し、その後、LLMを呼び出すロジックを持つPool computeに到達します。これはLambda関数やEC2、Amazon EKS、またはECSである可能性があります。
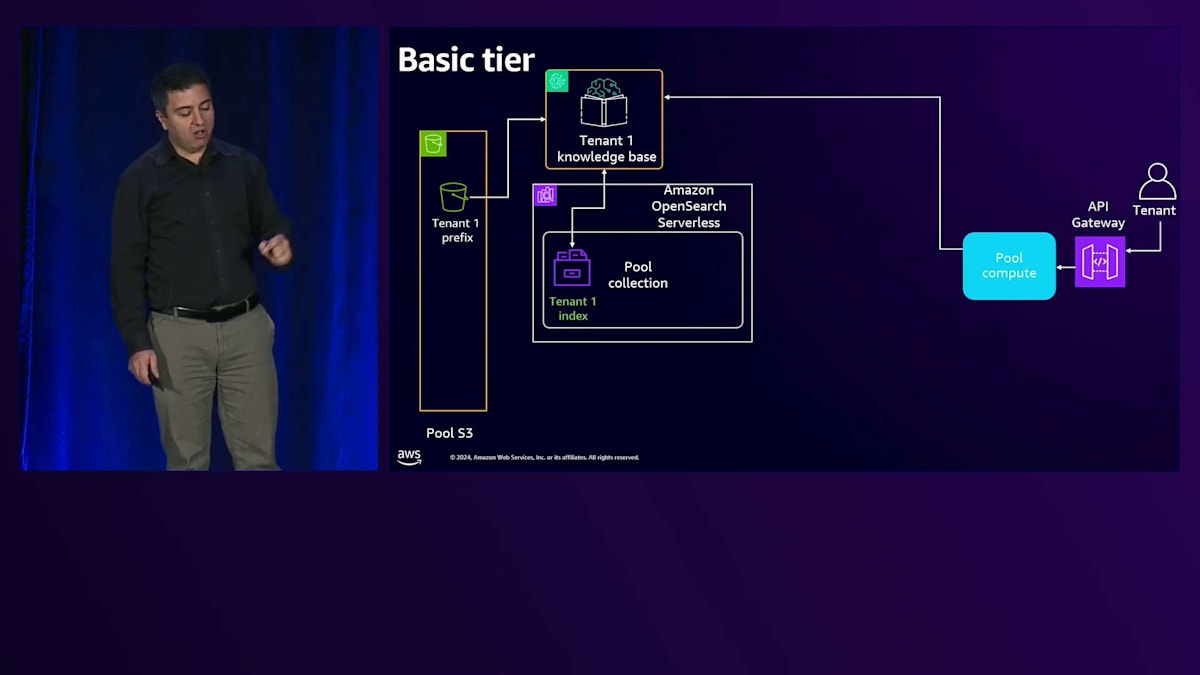
最初のステップは、そのPromptに関連する知識をテナント1のKnowledge Baseから取得することです。Knowledge BaseはOpenSearch Serverlessを通じて関連する知識を見つけ、そのリクエストは共有のAmazon Bedrockに送信されます。
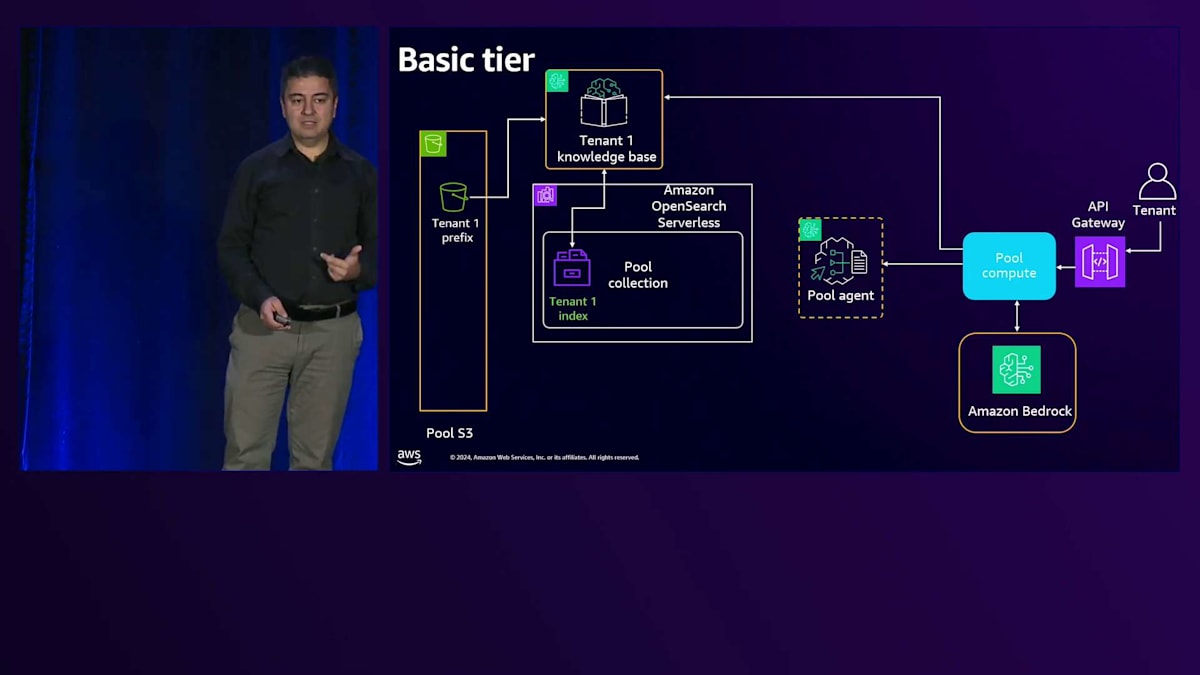
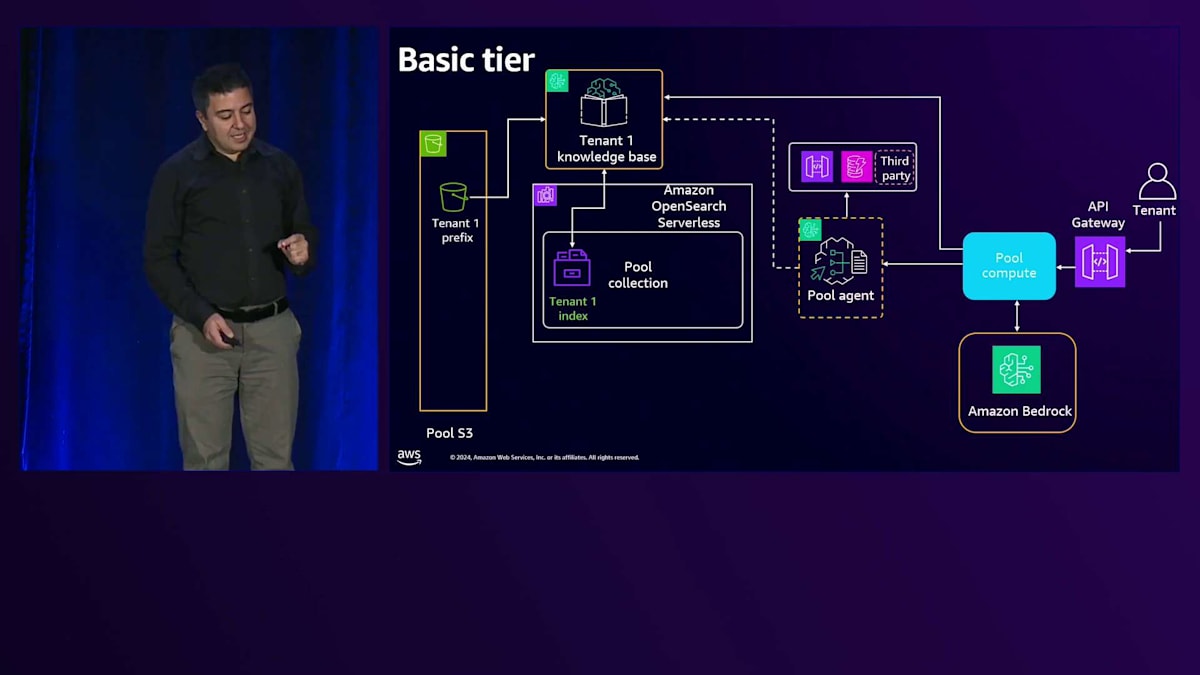
これがAgenticワークフローの場合、単なる質問応答ではありません。APIコールやデータベースからのデータ取得など、特定のタスクを実行する必要があります。共有のAgentを使用しており、Amazon Bedrock Agentはコンテキストを持つマルチテナンシーをサポートできます。どのAPI Gatewayやどのアクショングループを呼び出すか、またはどのデータベースにアクセスするかを判断します。1つのAgentと複数のKnowledge Baseがあり、各テナントに1つのKnowledge Baseが割り当てられている状況では、後ほどPremiumで見るように、AgentとKnowledge Baseは1対1の関係になります。ここでAgentはコンテキストを確認し、テナントIDを判断して、そのテナント専用のKnowledge Baseにアクセスする必要があります。
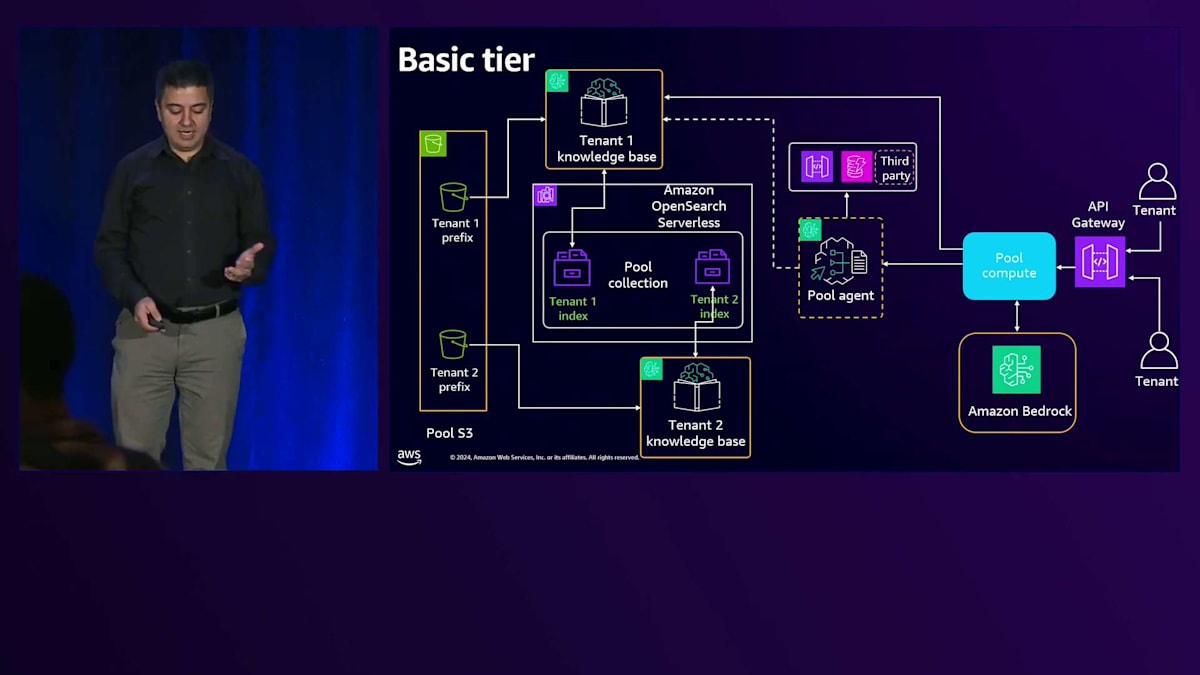
テナント2の場合、Amazon S3内に専用のPrefixがあり、それが独自のKnowledge Baseに接続されています。OpenSearch Serverless内に専用のIndexを持っています。テナント2からリクエストが来ると、Amazon Bedrockを経由してテナント2のKnowledge Baseに到達し、そのテナントにサービスを提供します。次にPremium tierを見てみましょう。これは既に料金を支払っているお客様向けのものなので、最高のユーザー体験と最低のレイテンシー、そして最大限の分離を提供したいと考えています。パターン内の各サービスに専用のサービスを用意するSiloパターンを検討しています。
テナント分離とデータパーティショニングの実装手法
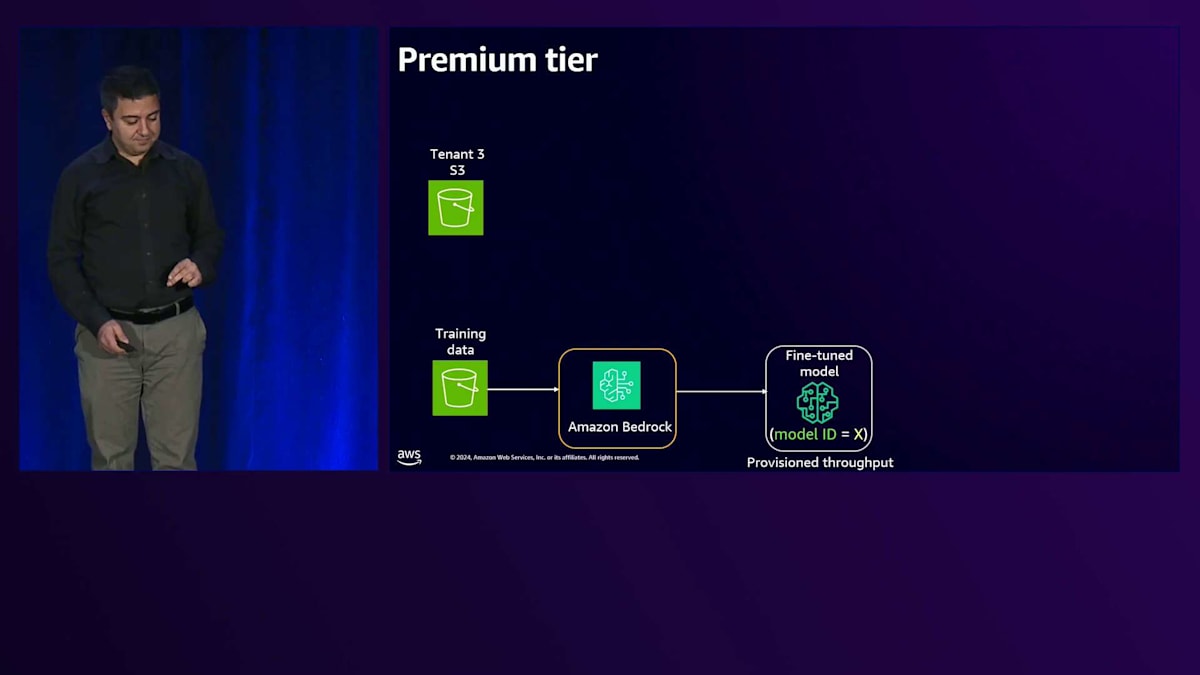

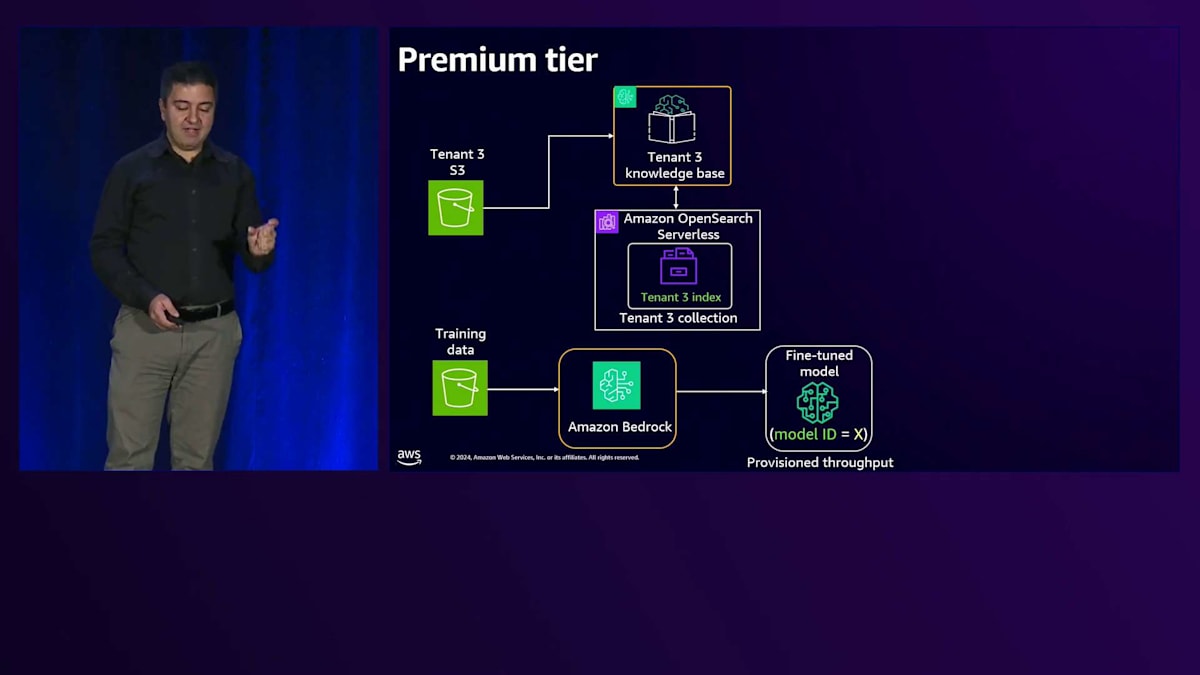
私たちはRAGとFine-tuningを組み合わせて使用しています。まず、トレーニングデータを使用して、Amazon Bedrockのカスタマイズモデルを用いてモデルをFine-tuningします。このテナント用にFine-tuningされたモデルができあがります。次に、ソリューションの右側の部分では、ナレッジベースに投入するデータがあります。これはより動的な性質を持つデータです。各テナントには専用のOpenSearch Serverlessコレクションがあり、その中にインデックスを持っています。
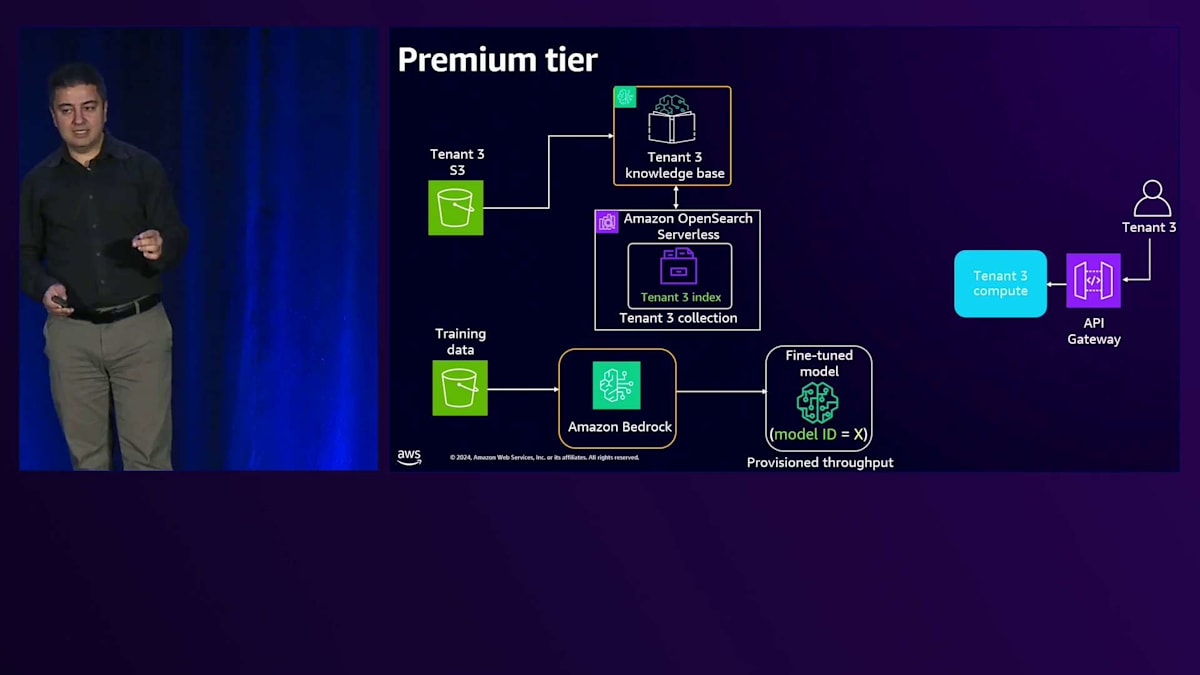
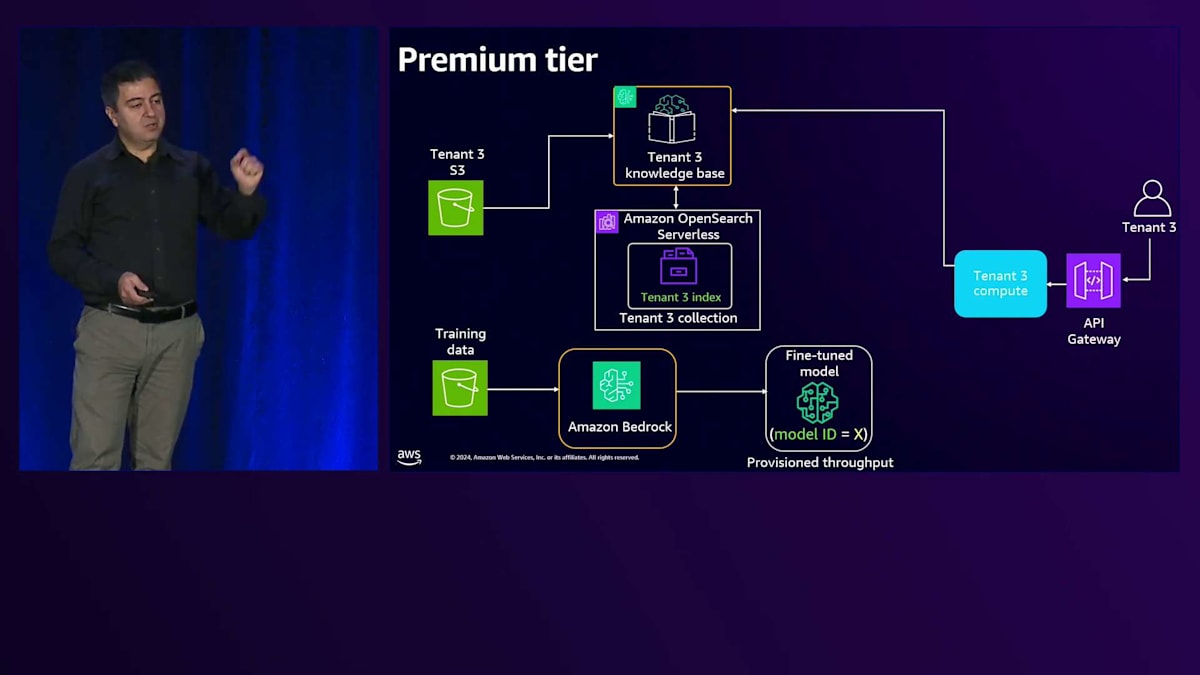
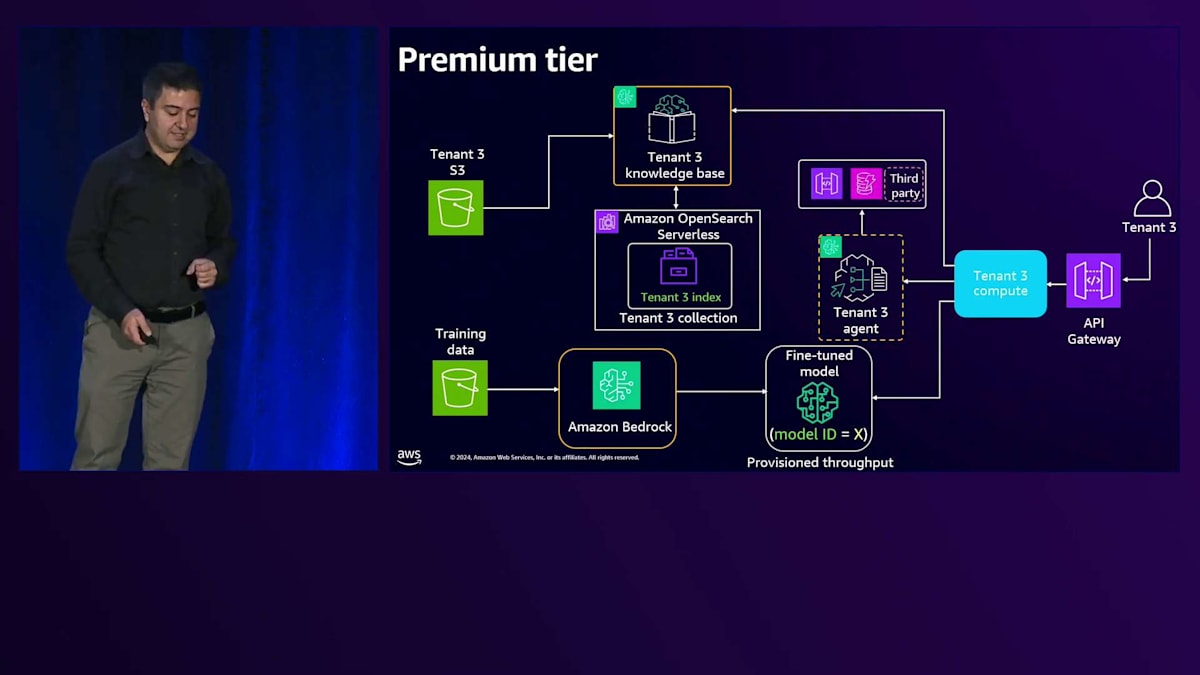
リクエストが来ると、専用のAPI Gatewayと、専用のLambdaや専用のEC2といった専用のコンピュートリソースを使用します。これについては、Gitリポジトリに実際に動作するコードを含むワークショップがあります。リクエストは専用のナレッジベースに送られ、データを取得するリクエストは共有リソースから専用リソースへと送られ、BasicとPremiumの両方のティアをサポートします。エージェントワークフローについては、このPremiumティア用に専用のエージェントがあり、これが専用のアクショングループに接続され、そこからAPIやデータベース、あるいはエージェントが必要とする他のサードパーティリソースにアクセスします。
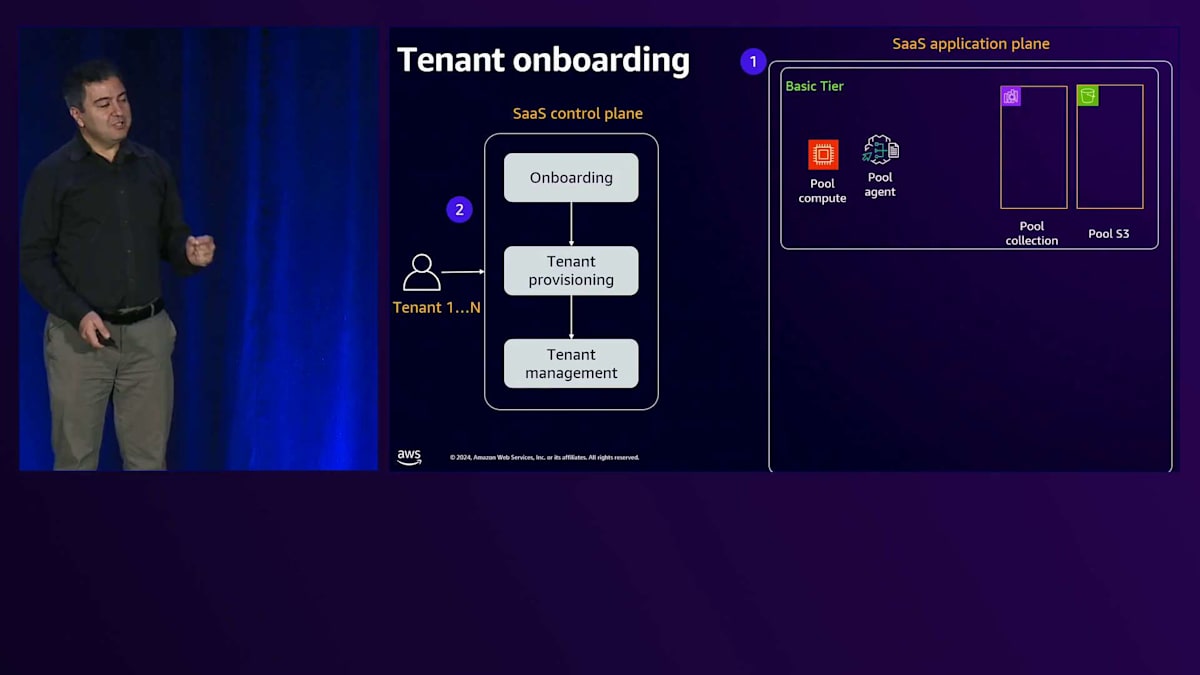
次の課題はSaaSソリューションの構築です。コンポーネント1は、テナントのオンボーディングの問題を解決するSaaSコントロールプレーンです。テナント情報、支払いデータ、そして参加を希望するティア(BasicまたはPremium)の情報が必要です。テナント管理については、ユーザーがサービスをどのように使用しているかを示すメトリクス、ログ、そしてソリューション内でのテナントのアクティビティを監視するのに役立つすべてのデータを収集したいと考えています。テナントプロビジョニングについては、テナントがオンボードされる際にプロビジョニングが必要なリソースがあり、これはBasicティアとPremiumティアで異なります。Basicティアでは、主に共有サービスを使用しています。つまり、テナントがシステムにオンボードされる前から、これらのサービスは存在しているということです。ここでは、空のプール用S3専用バケットと、インデックスのないプール用OpenSearch Serverlessコレクション、そしてすでにセットアップされているエージェントがあります。

新しいBasicティアのテナントがオンボードされる際には、そのテナント用のプレフィックスを作成し、OpenSearch内にインデックスを作成し、そしてナレッジベースを作成する必要があります。これらのサービスのほとんどがすでに存在しているため、比較的迅速に処理できます。
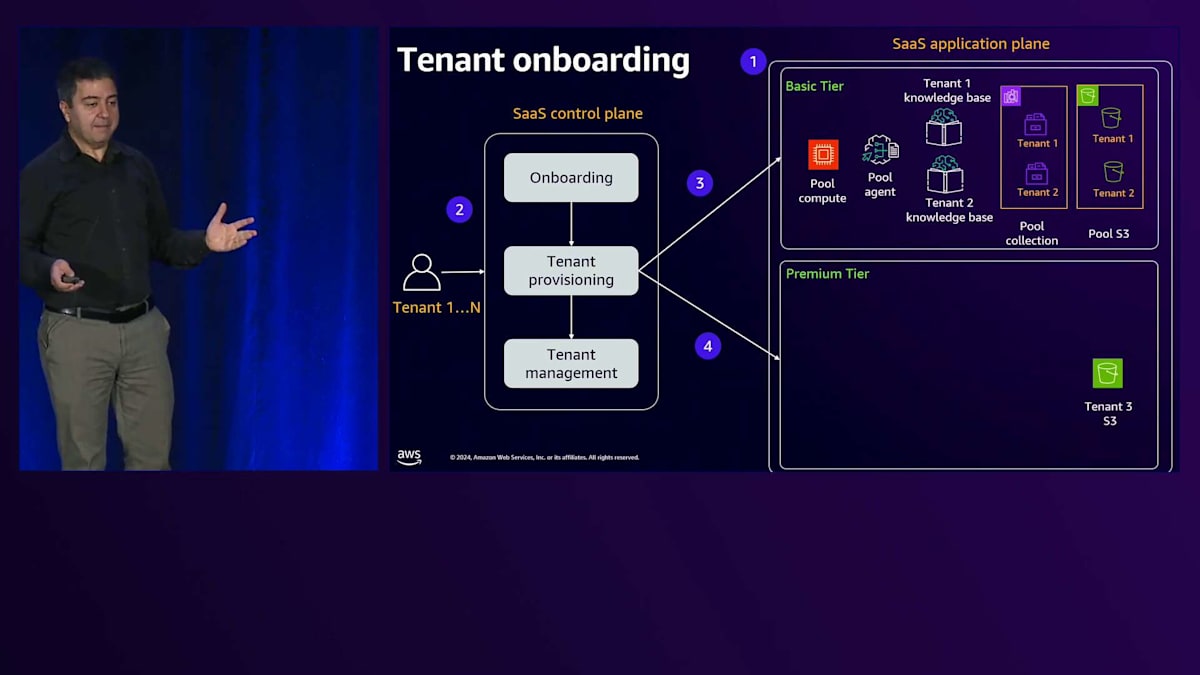
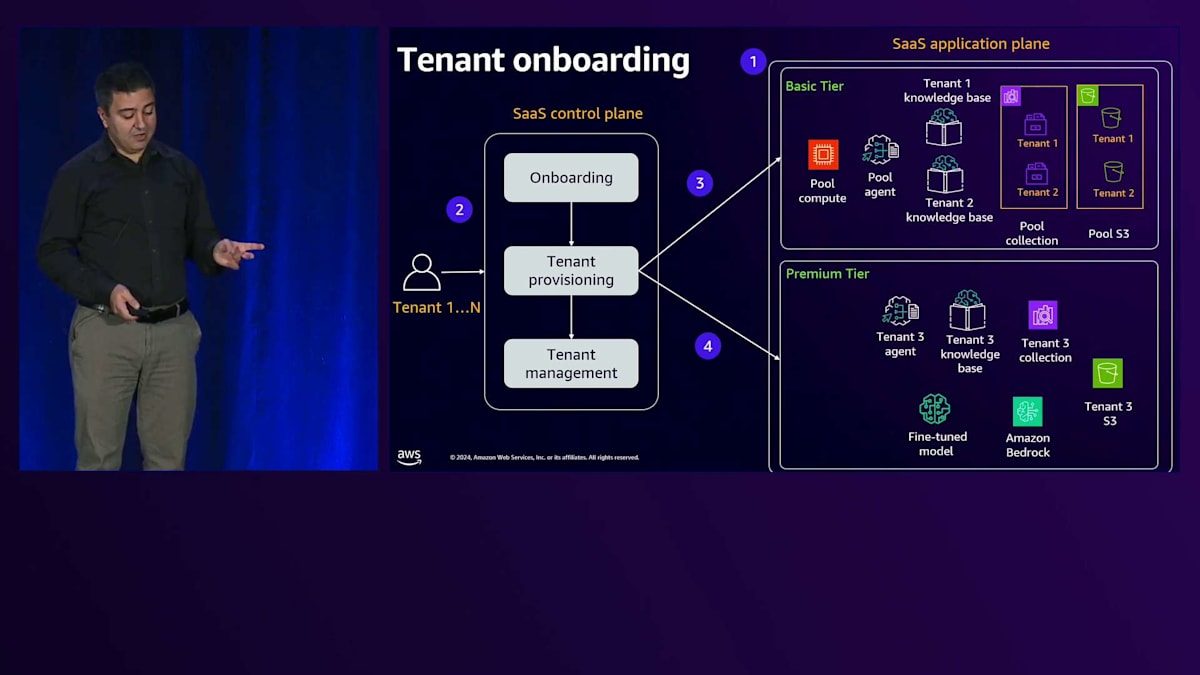
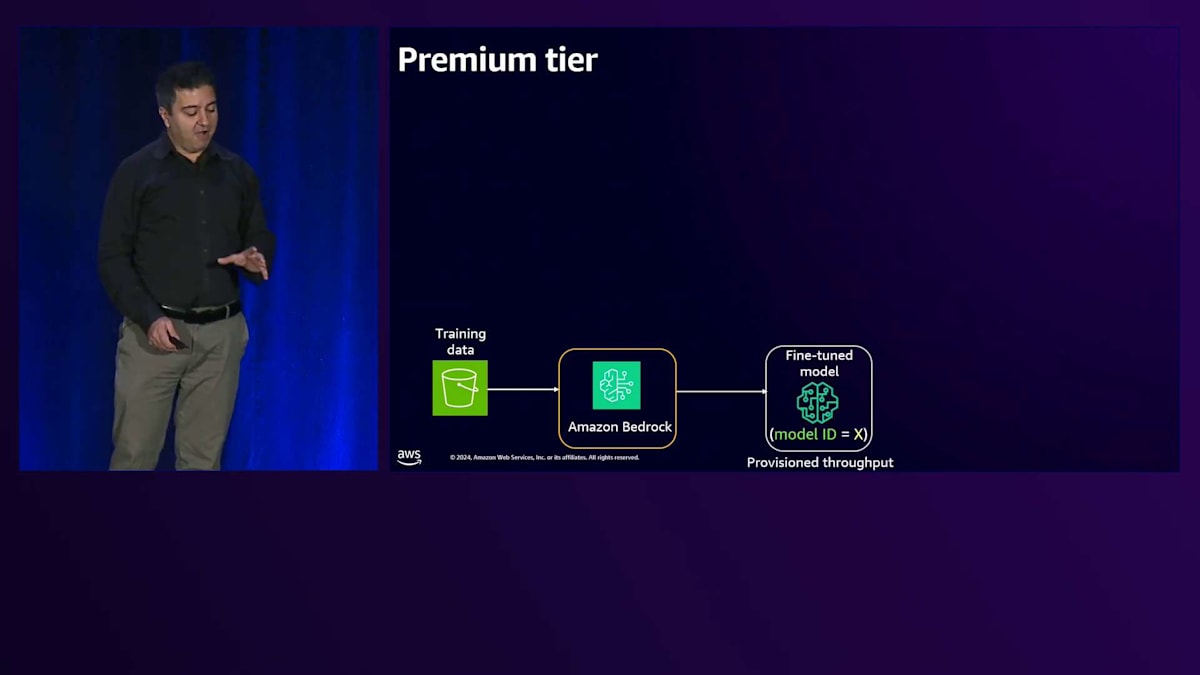
Premiumティアの場合、空のリソースから始めます。Premiumテナントがオンボードされると、専用のS3、専用のFine-tuneモデル、専用のナレッジベース、そして専用のOpenSearch Serverlessコレクションを作成します。
次に検討すべき課題はData Partitioningです。SaaSではテナントデータや顧客データを大量に扱うため、Data Partitioningは非常に重要です。可能な限り分離を徹底する必要があります。あるテナントが他のテナントのデータにアクセスすることは許されません。後ほど、この分離をどのように実現するかについて見ていきますが、まず最初のステップとして、効率的に分離を適用できるよう、データを論理的かつ物理的に分割する必要があります。
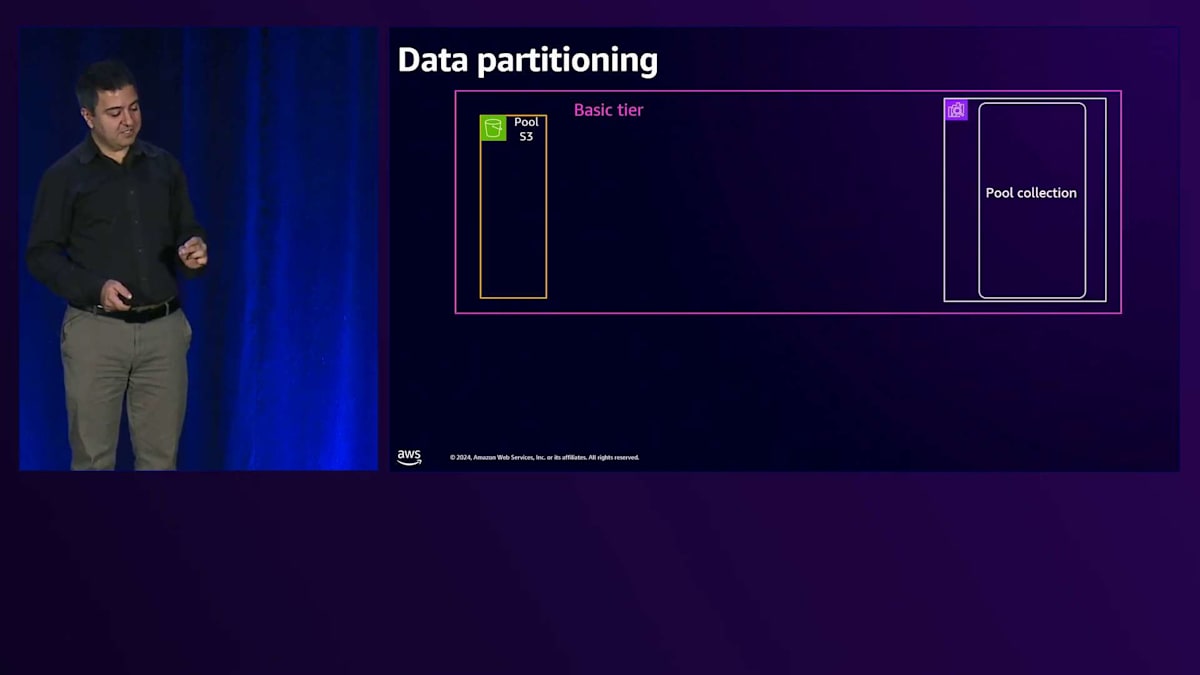
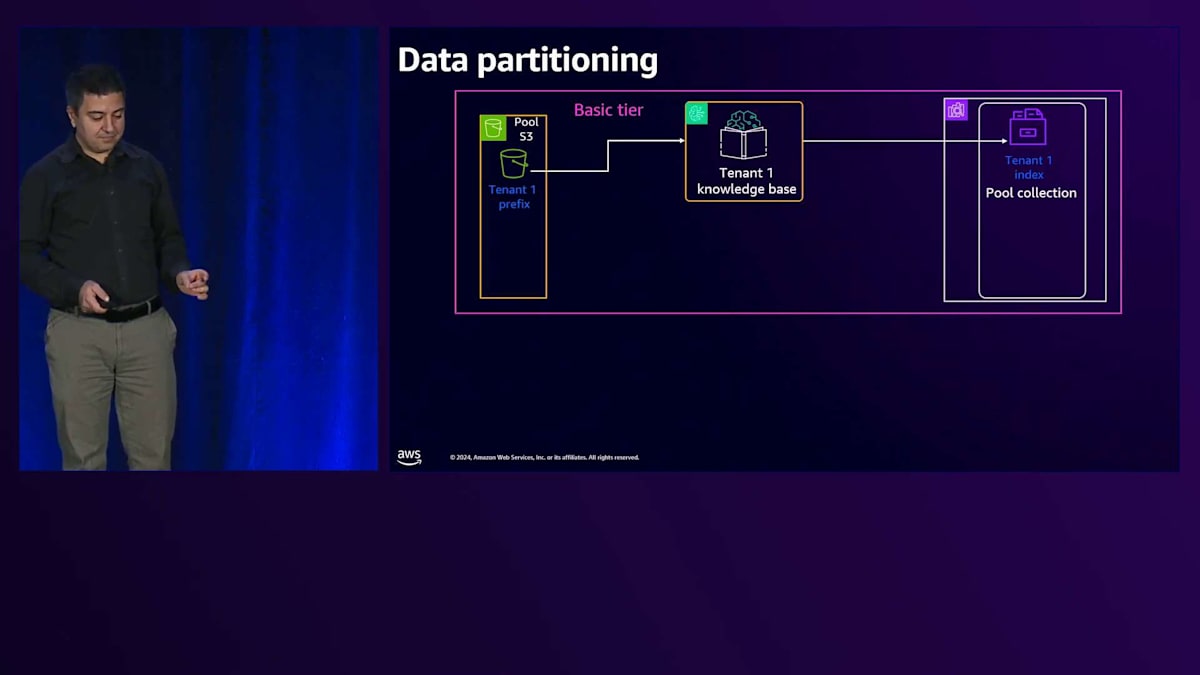
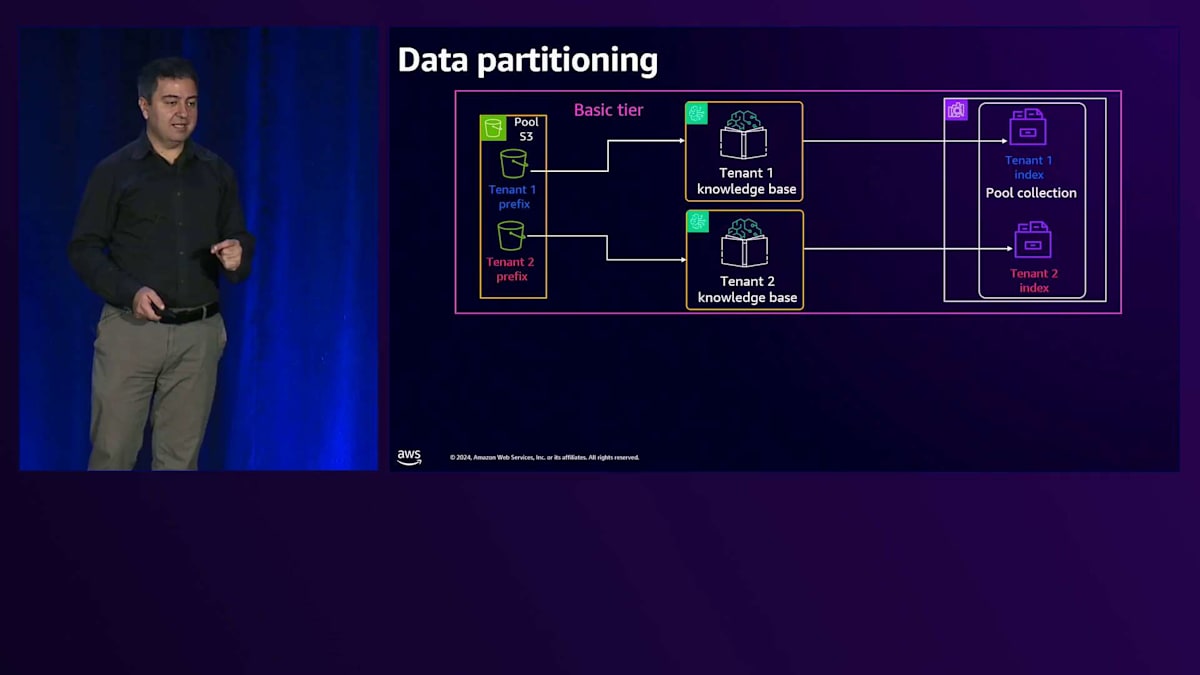
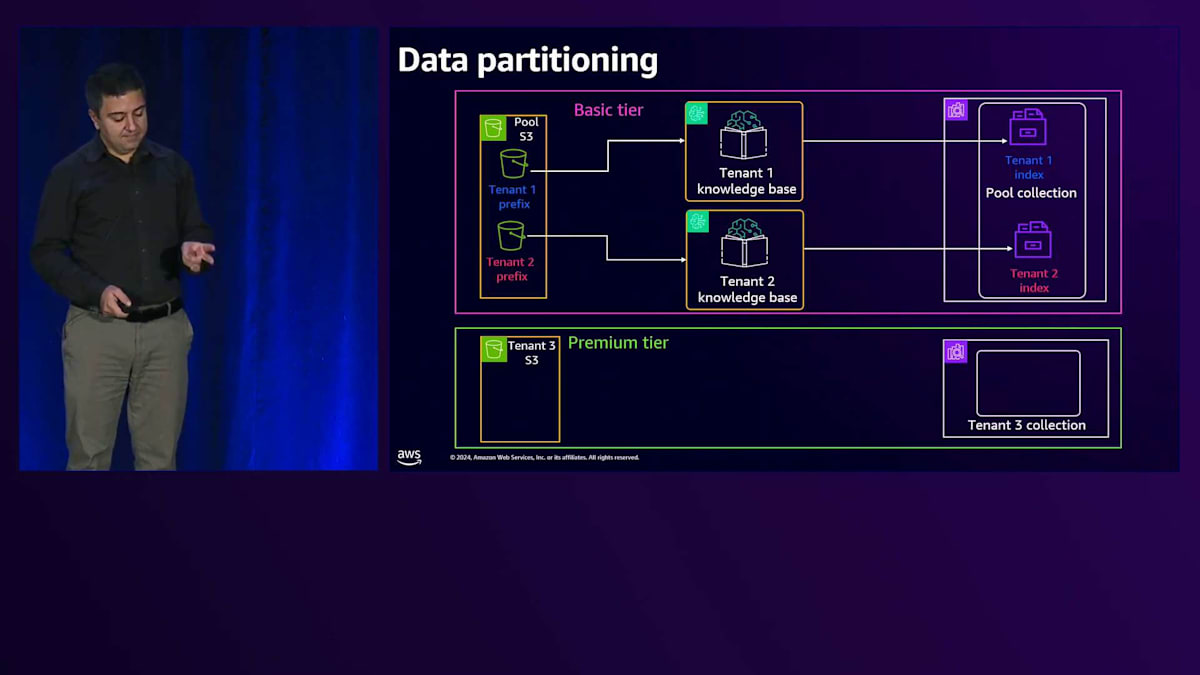
共有サービスを使用する基本プランでは、共有サービス内で分離を行います。S3では、各テナント専用のプレフィックスを設定します。Vector Store用のOpenSearch Servicesでは、専用のインデックスを用意します。Knowledge Baseは抽象化されているため、プールに入れる必要がないというのは良いニュースです。各テナントは専用のKnowledge Baseを持ちます。プレミアムプランの場合はもっとシンプルで、専用のバケット、専用のOpenSearch Serverlessクラスター、そしてこのタイプのテナント専用のKnowledge Baseという形で、リソースが専有化されています。
次は、テナント分離について説明します。テナント分離とは、特定のテナントがテナント固有のリソースにのみアクセスできるようにすることです。基本プランとプレミアムプランの両方について見ていき、どこで実装が必要か、そしてその実装の詳細について掘り下げていきます。基本プランのアーキテクチャでは、Knowledge Baseでテナント分離を実装する必要があります。各テナント用にKnowledge Baseを作成し、このKnowledge Baseがテナント固有のプレフィックスからのみデータを取得し、共有プールコレクション内のテナント固有のインデックスとの間でデータをやり取りすることを保証する必要があります。
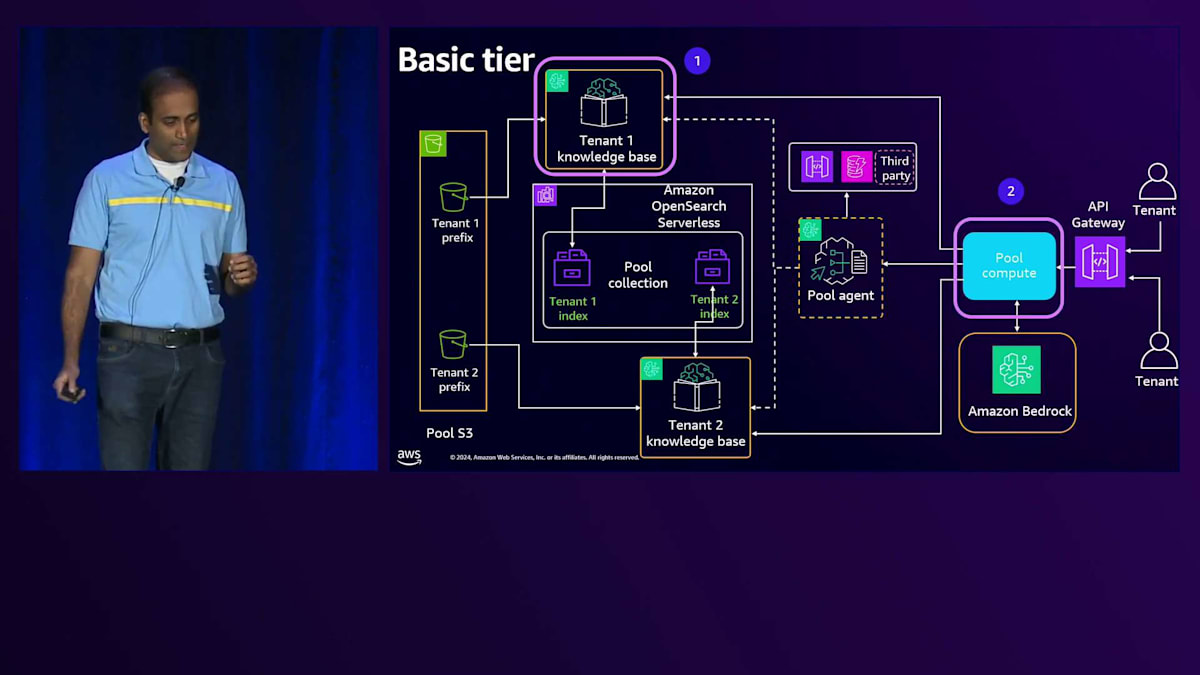
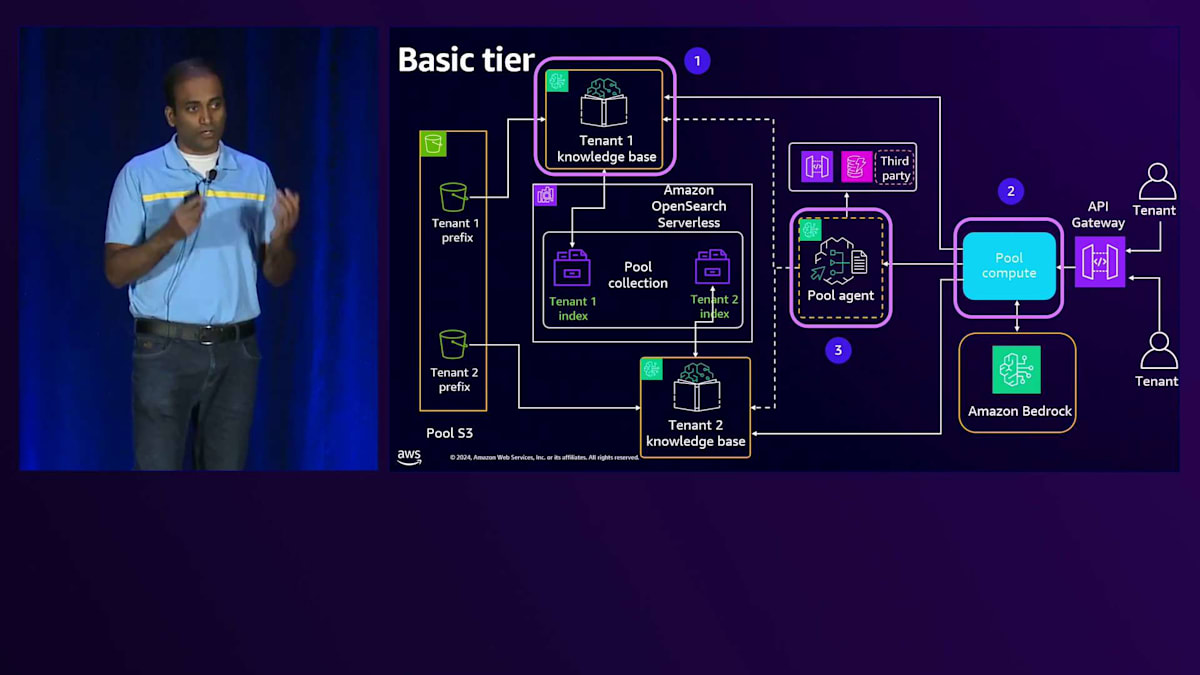
プールコンピュートは複数のテナント間で共有されているため、このコンピュート内のサービスも複数のテナント間で共有されています。そのスコープに実行ロールを直接付与することはできません。代わりに、実行時に特定のテナント用のスコープ認証情報を生成し、それを使用してテナント固有のリソースにアクセスするよう、これらのサービスを拡張する必要があります。プールエージェントも複数のテナント間で共有されているため、実行時に生成される特定のテナント用のスコープ認証情報を使用するよう、このプールエージェントを拡張する必要があります。
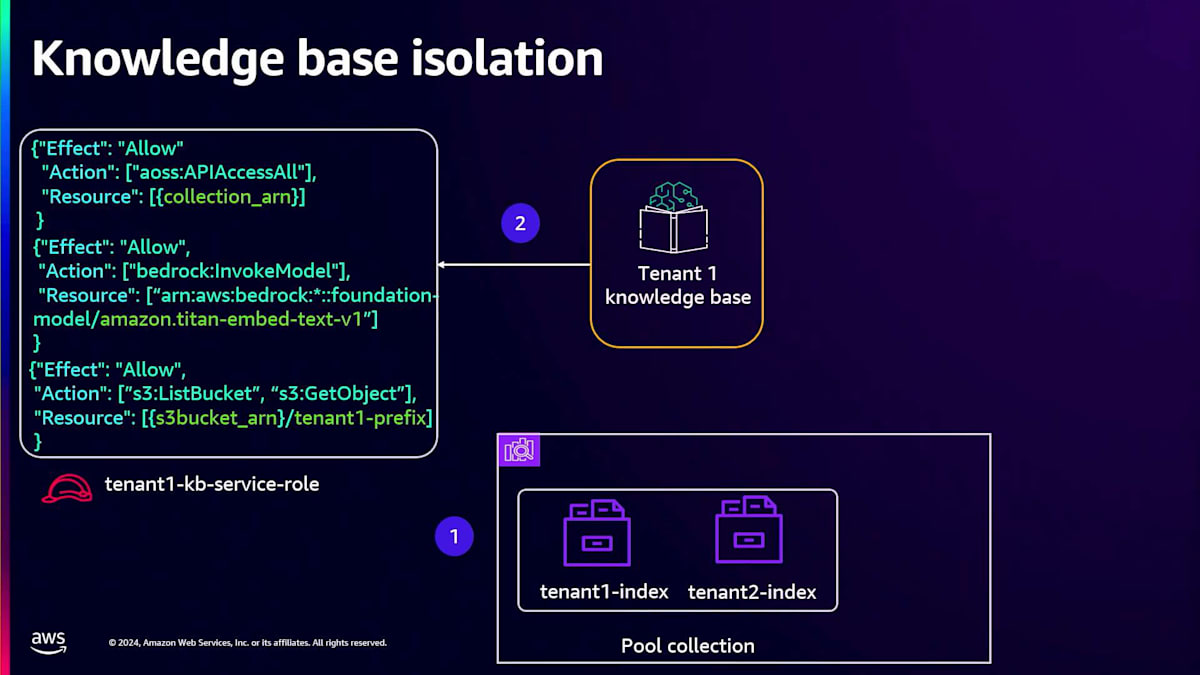
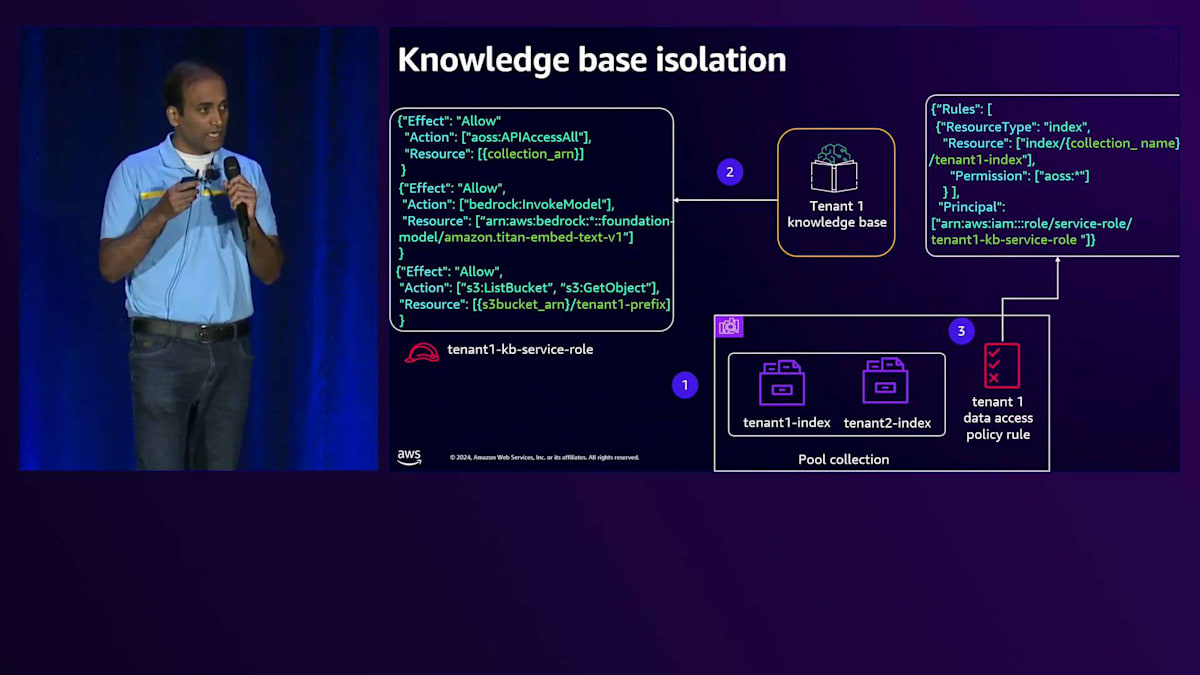
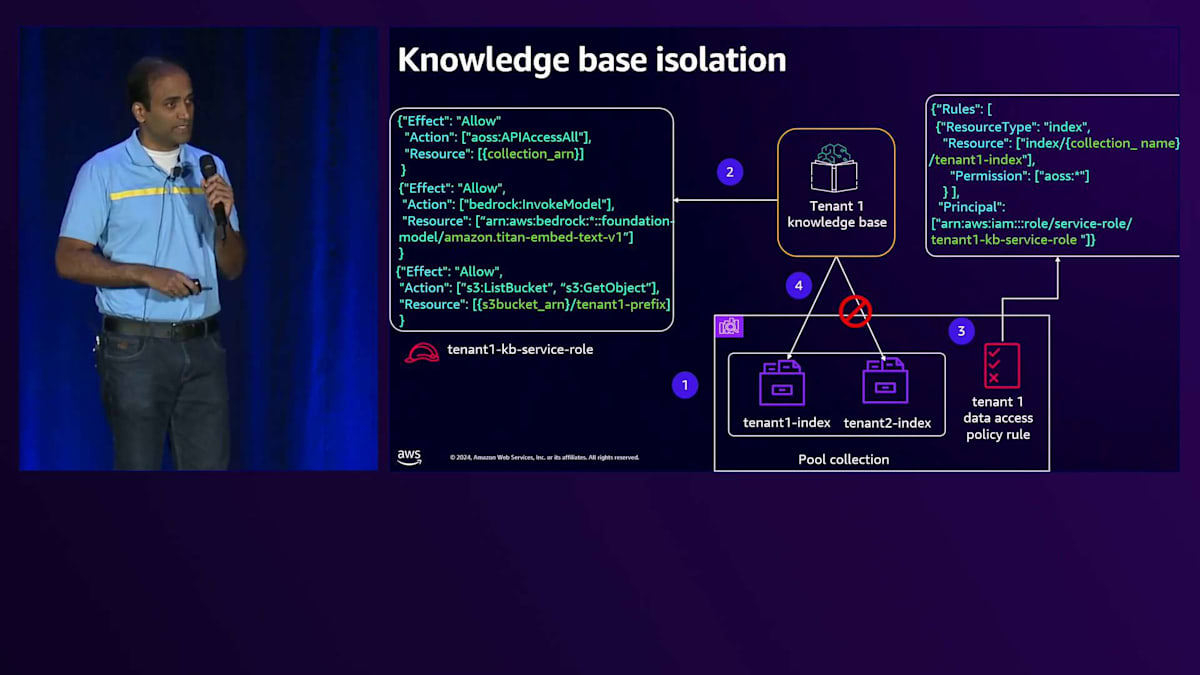
Knowledge Baseがテナント固有のインデックスとの間でのみデータをやり取りできるようにする必要があります。これは、OpenSearch Serverlessコレクションで定義されたデータアクセスポリシーを活用することで実現されます。このポリシーには、Knowledge Baseのサービスロールがプリンシパルとして含まれています。権限を見てみると、このKnowledge Baseはテナント固有のインデックスとの間でのみデータをやり取りする権限を持っていることがわかります。これがKnowledge Baseのテナント分離を実現する方法です。プールコンピュートに話を移すと、先ほど述べたように、このプールコンピュートが特定のテナント用のスコープ認証情報をリアルタイムで生成し、それを使用してテナント固有のリソースとやり取りすることを確実にする必要があります。
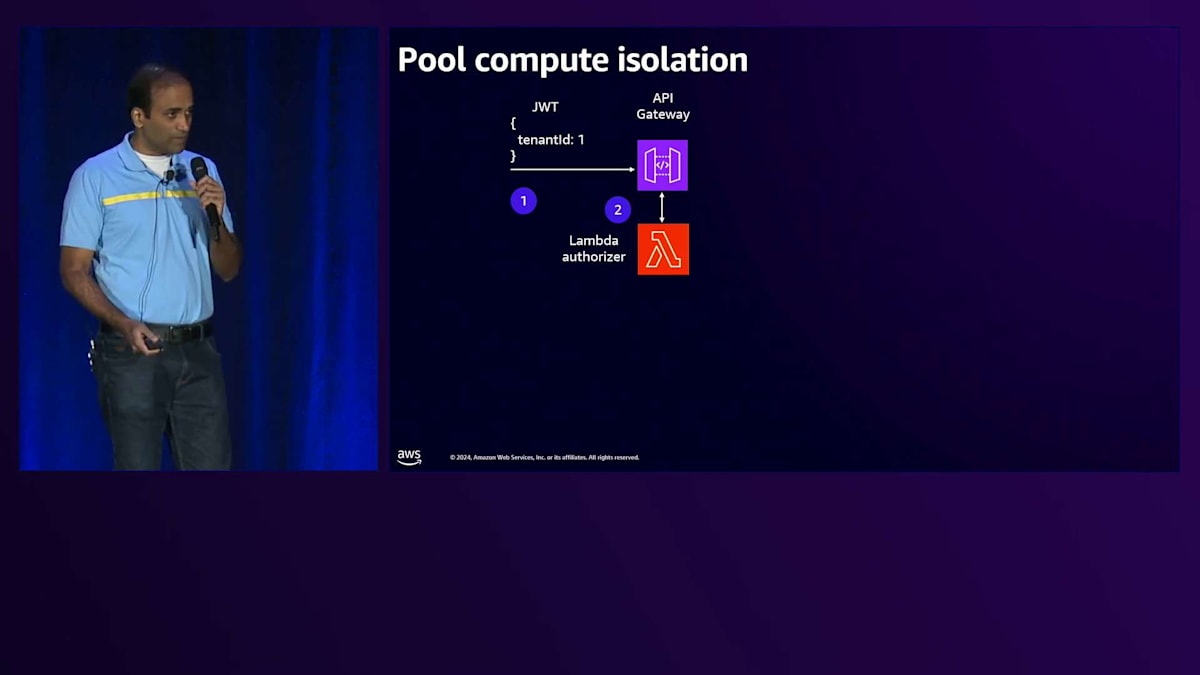
それでは、具体的な実装方法について見ていきましょう。 ABACロールを定義する際、プレースホルダーを配置します。Lambda authorizerは、JWTトークンからTenant IDを取得し、Control PlaneにアクセスしてそのTenantの Knowledge Base IDを取得します。Tenantのオンボーディング時には、Tenant Management Serviceと呼ばれるサービスが、オンボーディングプロセス中に生成されるTenant固有のメタデータを取得します。この場合、Tenant oneのオンボーディング時に、そのTenantのKnowledge Base IDを取得します。
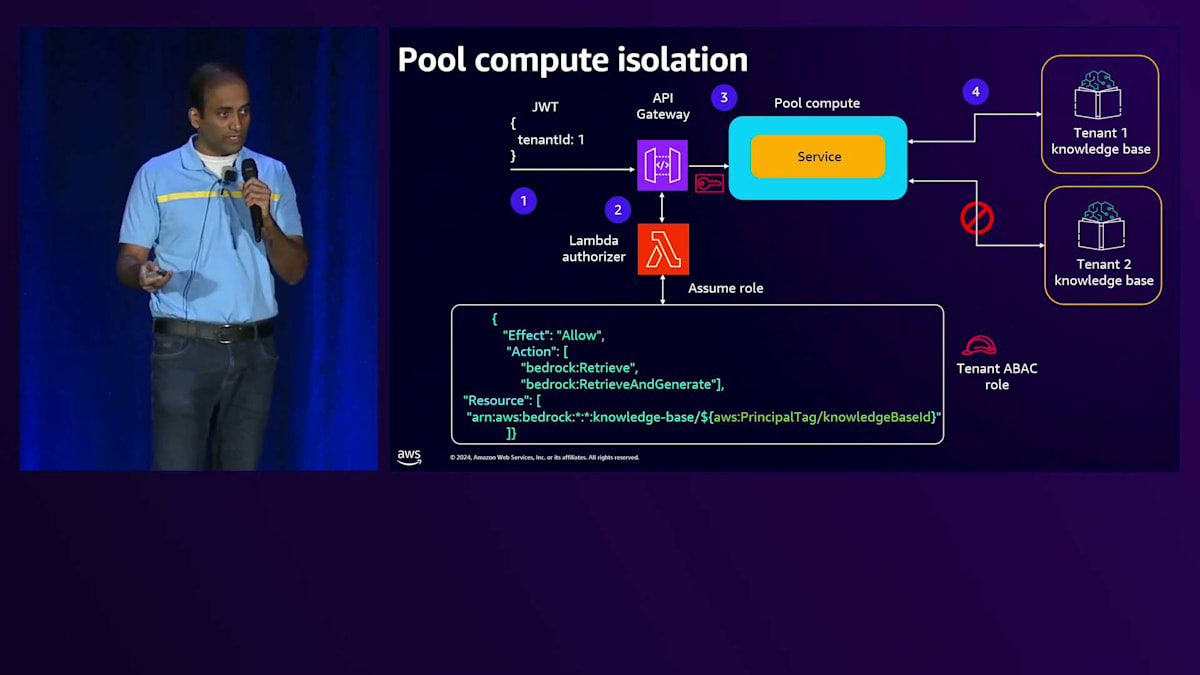
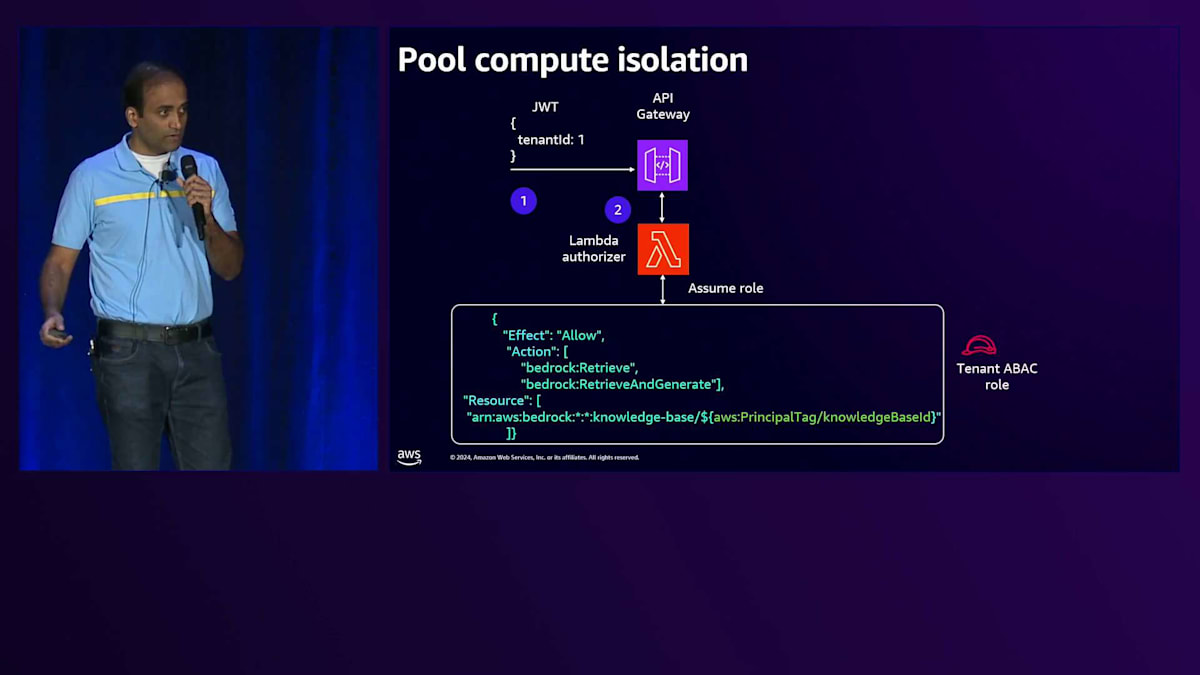
Lambda authorizerに話を戻すと、トークンからTenant IDを取得し、Control PlaneからKnowledge Base IDを取得した後、このKnowledge Base IDとABACロールを使用してSecurity Token Serviceと通信します。これら2つのパラメータを含むAPIコールを行い、そのTenant固有のリソースにのみアクセスできるScope Credentialsを取得します。 これらのCredentialsはバックエンドサービスに渡され、サービスはそのCredentialsを使用してTenant固有のリソースにアクセスします。


では、Lambda authorizerのコードとサービスコードをより詳しく見ていきましょう。Lambda authorizerコードでは、まずJWTトークンを検証してTenant IDを取得します。Tenant IDを使用して、Control PlaneにAPIコールを行い、Knowledge Base IDを取得します。この情報を取得したら、 Assume Roleメソッドを呼び出します。このAssume Roleメソッド定義の中で、Security Token ServiceにAPIコールを行い、引き受けたいロールと置き換えたい追加パラメータ(この場合はKnowledge Base ID)を渡します。このメソッド呼び出しのレスポンスとして、そのTenant固有のScope Credentialsが返されます。

Lambda authorizerに戻ると、 API Gatewayがこのリクエストを認可できるように、成功または失敗のレスポンスをパッケージ化する必要があります。このレスポンスの一部として、これらのScope Credentialsを追加し、API Gatewayに返します。API Gatewayはリクエストを認可し、レスポンスをバックエンドサービスに渡します。バックエンドサービスコードでは、まず入力イベントからそのTenant固有のScope Credentialsを取得します。これらのScope Credentialsを使用して、Tenant固有のリソース(この場合はKnowledge Base)にのみアクセスできるBedrockクライアントを作成します。

このBedrockクライアントを使用して、Knowledge Base Retrieverと呼ばれるKnowledge Baseとやり取りするためのコンストラクトを作成します。このコンストラクトの作成時に、前のステップで作成したTenant固有のScope Credentialsを使用したBedrockクライアントを使用していることがわかります。そして、 入力プロンプトとKnowledge Base Retrieverを渡してLLMを呼び出すことで、これらすべてを組み合わせます。入力プロンプトはKnowledge Base Retrieverに送られてTenant固有のデータを取得し、その入力プロンプトとTenant固有のデータが組み合わされてBedrockで処理され、最終的なTenant固有のレスポンスが得られます。

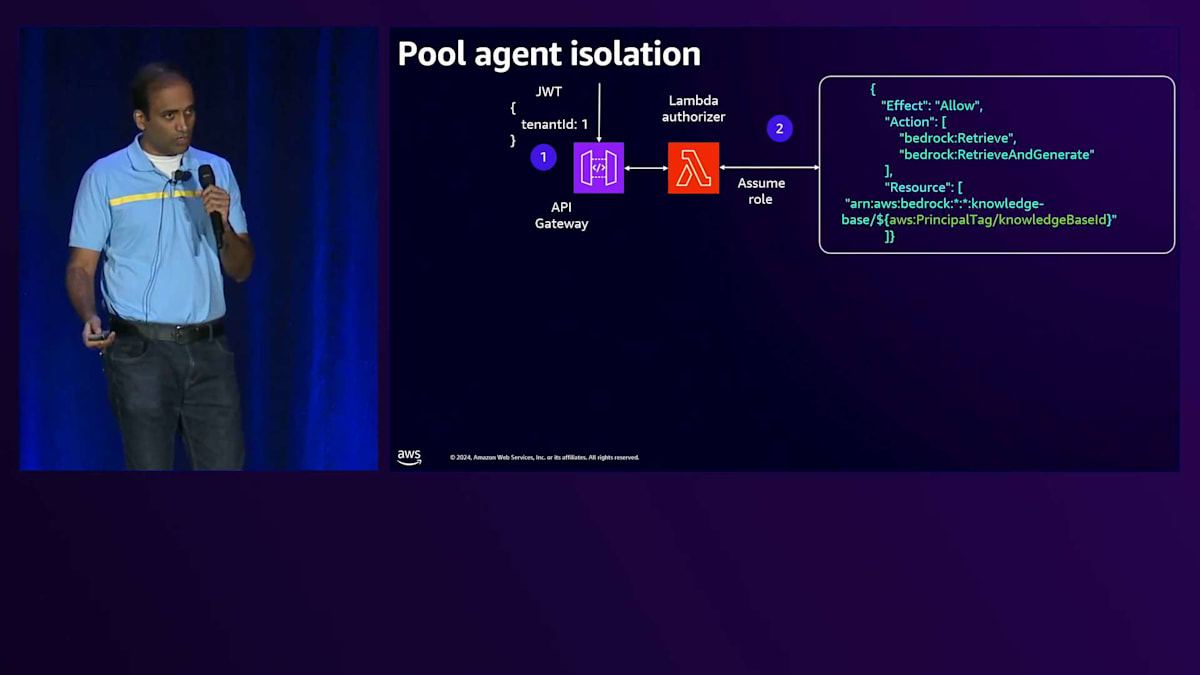
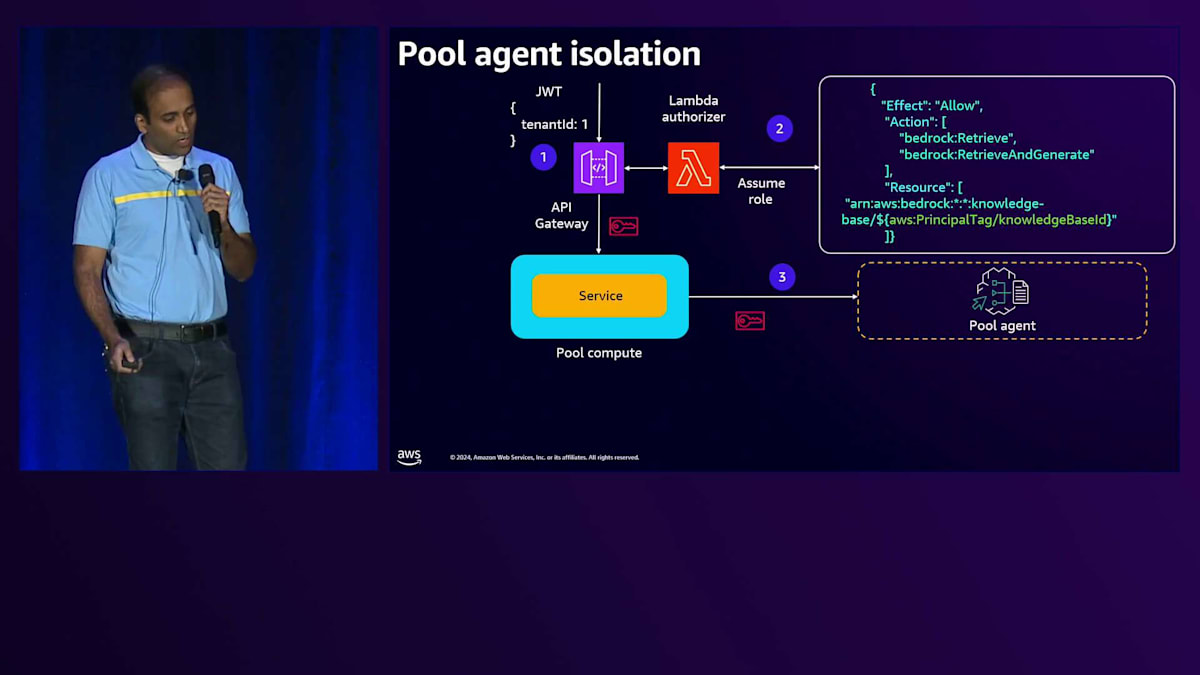
次にPool Agentについて説明しますが、こちらも同様のアプローチで分離を実装しています。例として、Tenant One がAPI Gatewayにリクエストを送信するケースを考えてみましょう。API Gatewayには、トークンを検証してIAM ロールを取得する同じLambda Authorizerがあります。Lambda AuthorizerはJWTトークンからTenant IDを取得し、Control PlaneにアクセスしてナレッジベースIDを取得し、そしてこのナレッジベースIDとロールをSecurity Token Serviceに渡してスコープ付きの認証情報を取得します。このスコープ付き認証情報はバックエンドサービスに渡され、このバックエンドサービスがAgentを呼び出す際に、Agentにこのスコープ付き認証情報を渡すことになります。
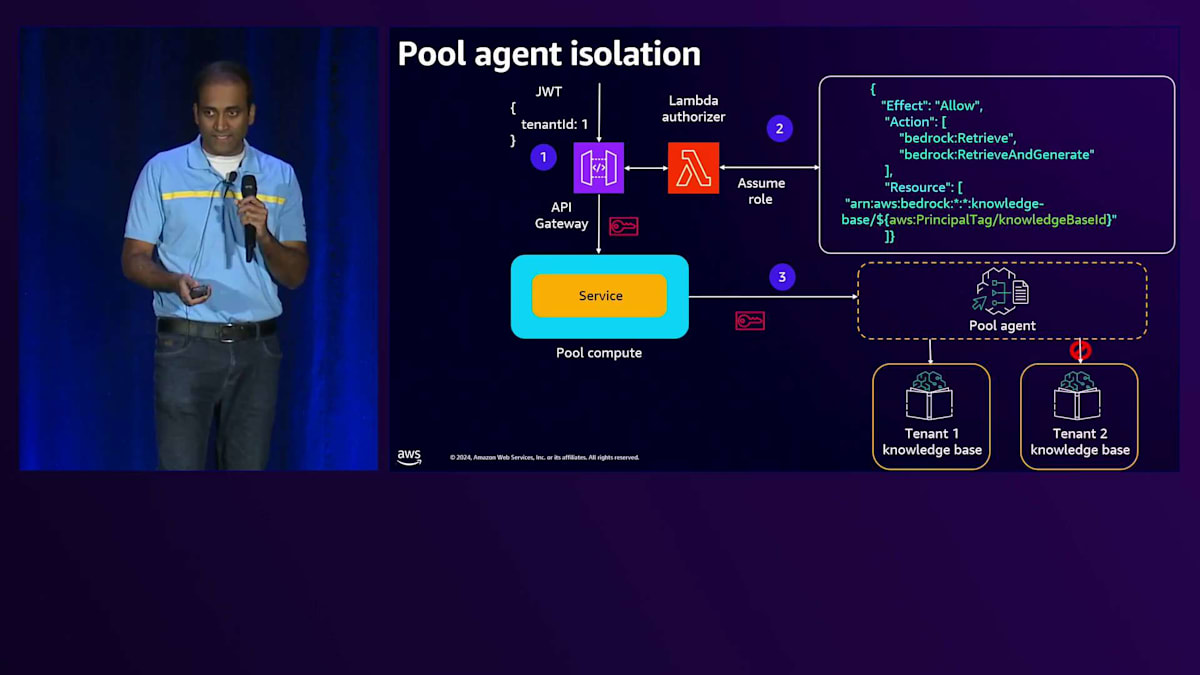
Agentは、特定のTenantに固有のこの認証情報を使用して、Tenant固有のリソースとやり取りを行います。この例ではTenant固有のリソースとしてナレッジベースを示していますが、S3バケットやテーブルなど、他のTenant固有のリソースにもこの概念を適用できます。そのS3バケットやテーブルへのアクセス権をIAMロールに追加することになります。

サービスコードとAgentコードを見て、これらがどのように連携しているか詳しく見ていきましょう。サービスコードでは、まず最初にTenant固有のスコープ付き認証情報を取得します。Tenant固有のスコープ付き認証情報を取得したら、Agentを呼び出すための呼び出しを実行します。属性を通じてスコープ付き認証情報を渡します。スコープ付き認証情報と、セッション属性を通じて渡したい追加のメタデータを渡していることがわかります。

この時点でAgentが起動し、Agentコードが実行されます。最初の部分を見ると、特定のTenantに固有のセッション属性からスコープ付き認証情報を取得しています。必要な追加メタデータも取得していることがわかります。スコープ付き認証情報を取得したら、これらの認証情報を使用してBedrockクライアントを作成します。これにより、Tenant固有のリソースへのアクセスのみが許可されます。AgentコードはそのBedrockクライアントを使用して他のメソッドを呼び出し、Pool Agentに対してTenant固有のリソース分離を提供します。
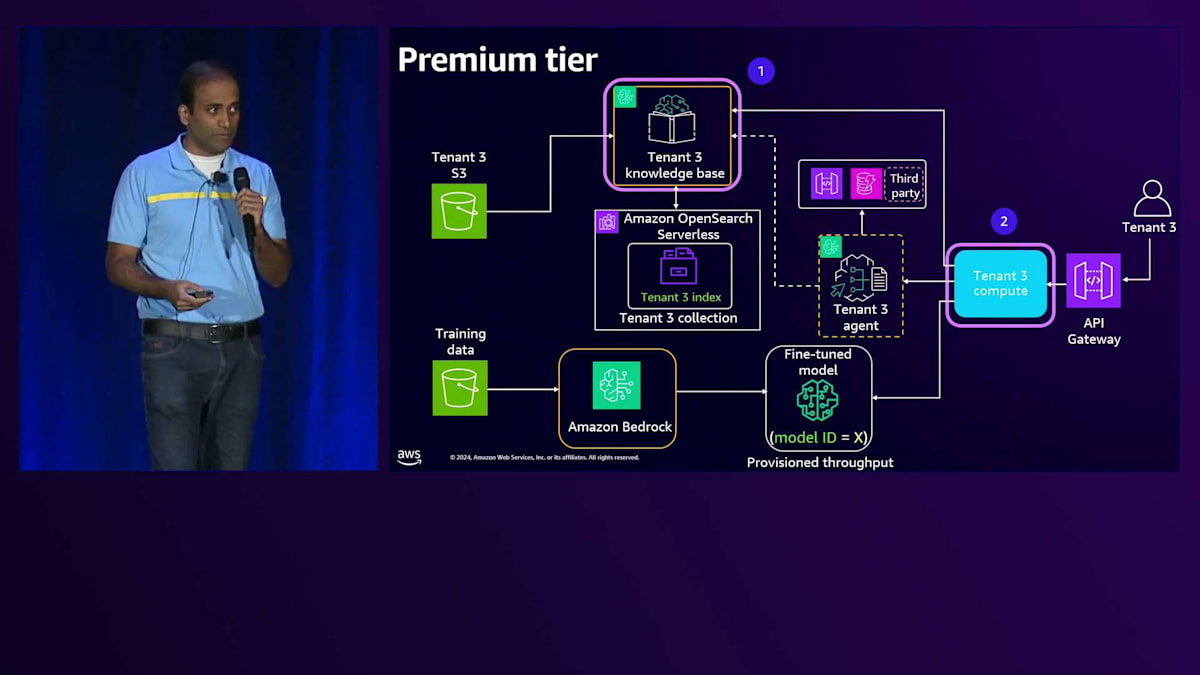
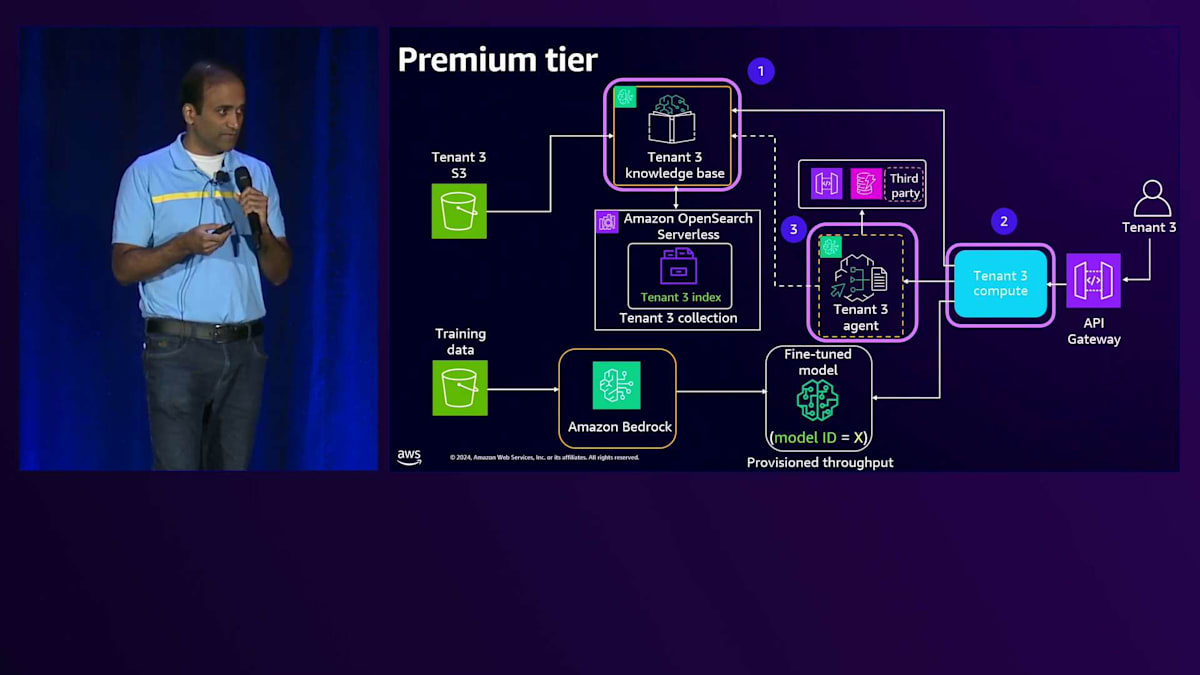
Premium Tierのアーキテクチャに移ると、Tenant分離を実施する必要がある領域は、ナレッジベースとSilo Computeになります。特定のTenant専用のコンピュートを作成するため、分離アプローチは単純明快です。専用コンピュートでは、Tenant固有のリソースへのアクセスのみを許可する実行ロールを直接このコンピュートにアタッチできるためです。同様に、特定のTenant専用のAgentがあり、これに実行ロールをアタッチすることで、Tenant固有のリソースへのアクセスを提供できます。

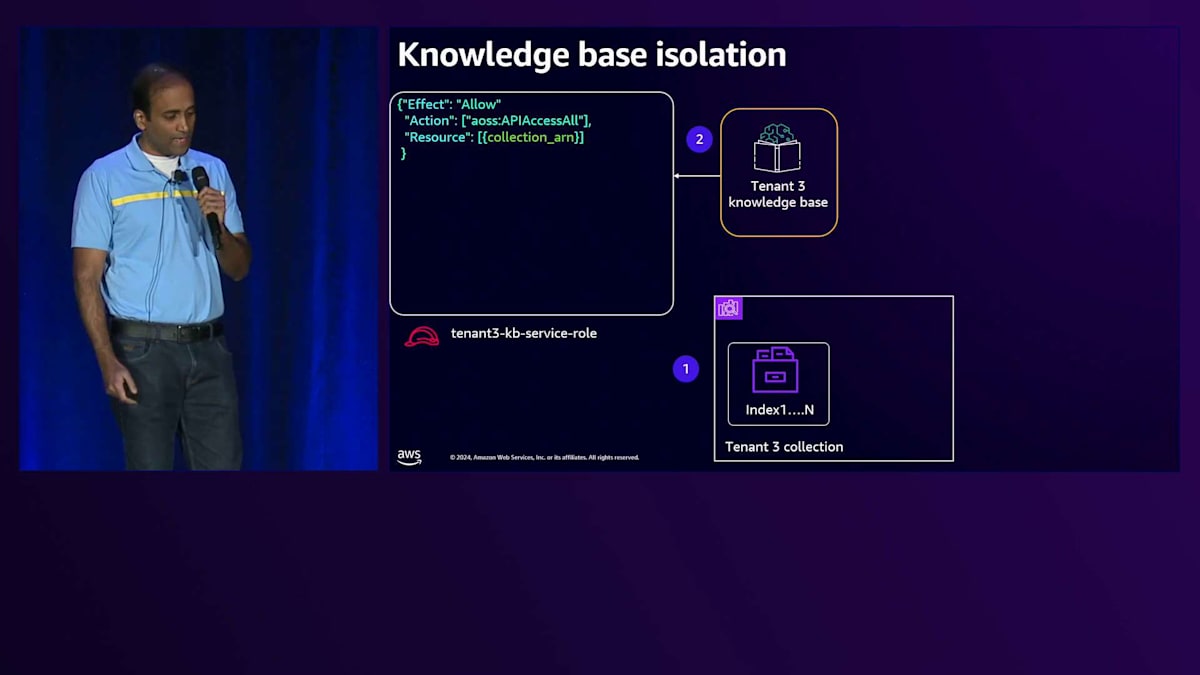
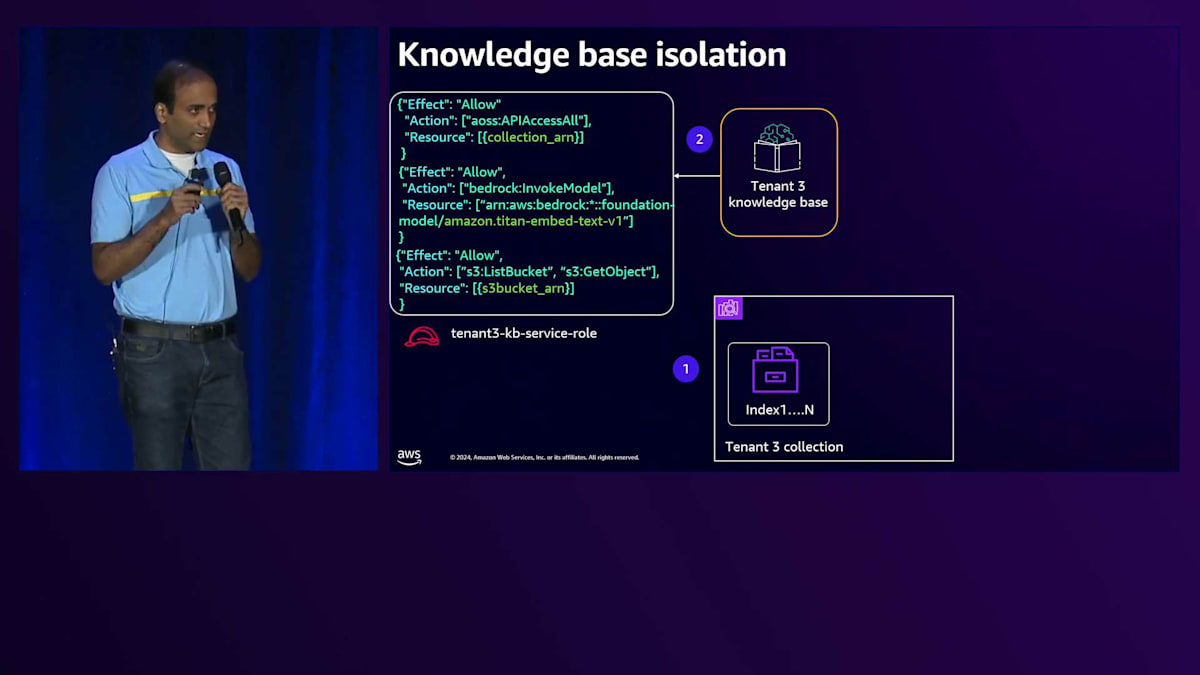
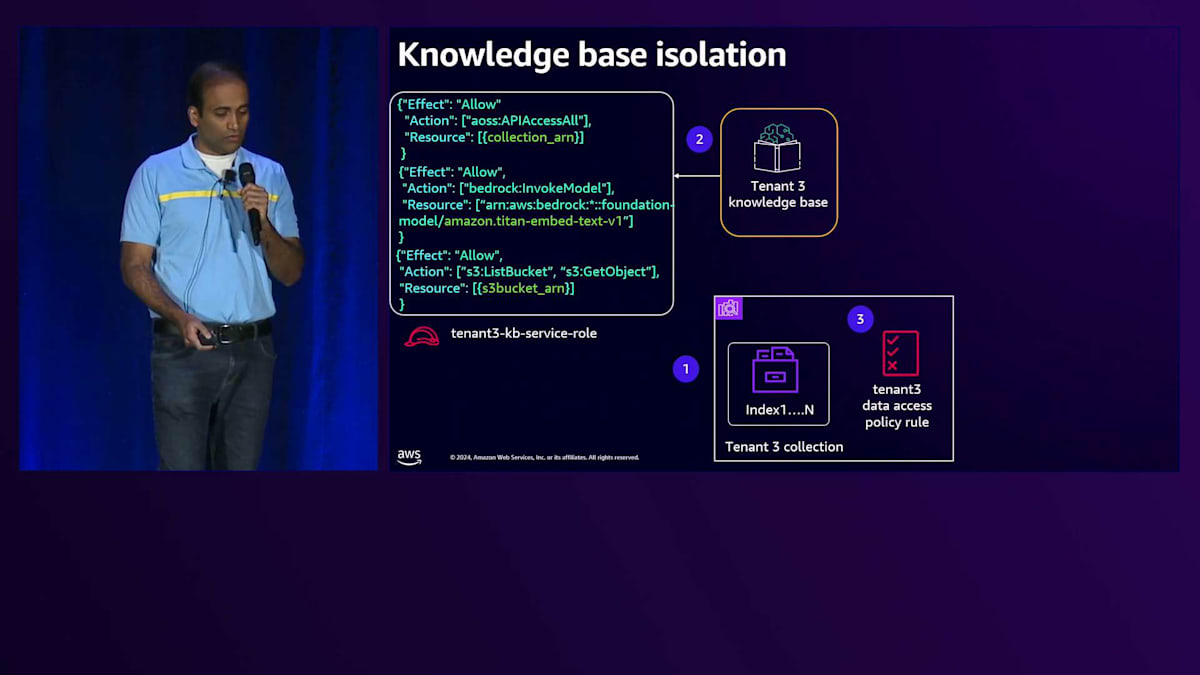
これら3つのコンポーネントを見ながら、テナント分離を実現する方法について説明していきましょう。Premium tierのKnowledge baseでは、OpenSearch構成内に専用のCollectionを作成します。Knowledge baseには、Collectionへのアクセスを提供するService roleを付与します。次に、このKnowledge baseが専用のS3 bucketとのみやり取りするようにモデルを設定します。専用のS3 bucketなので、直接アクセスを許可します。OpenSearch Collectionレベルでは、Data access policyを使用します。
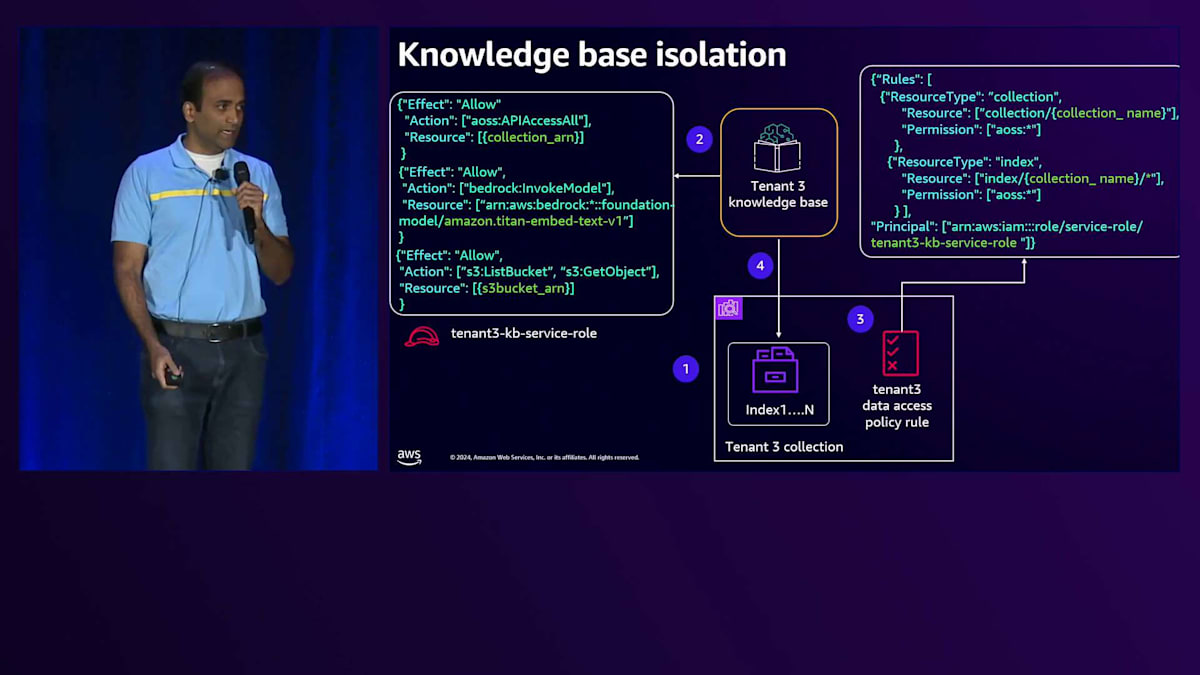

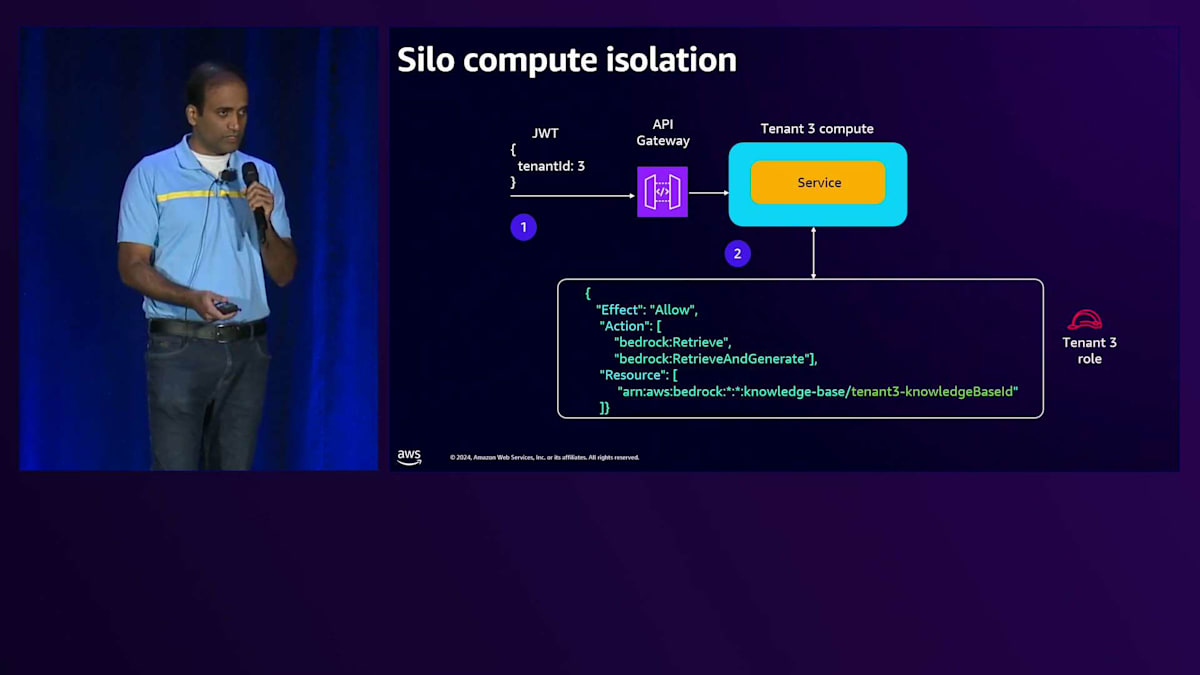
Data access policyを見ると、まずPrincipleを定義します。そして一連のPermissionsで、このKnowledge baseが専用のCollectionとのみやり取りできるようにします。これがPremium tierのKnowledge baseにおけるテナント分離の実現方法です。Silo computeについて、Tenant 3がAPI Gatewayとやり取りする例を見てみましょう。リクエストは専用のComputeに送られ、そこには専用のServiceがあります。専用のServiceなので、Execution roleを付与でき、この実行roleを見ると、特定のテナントに対する権限が設定されています。この場合、これらのPermissionsを使ってテナントにアクセスを提供しています。
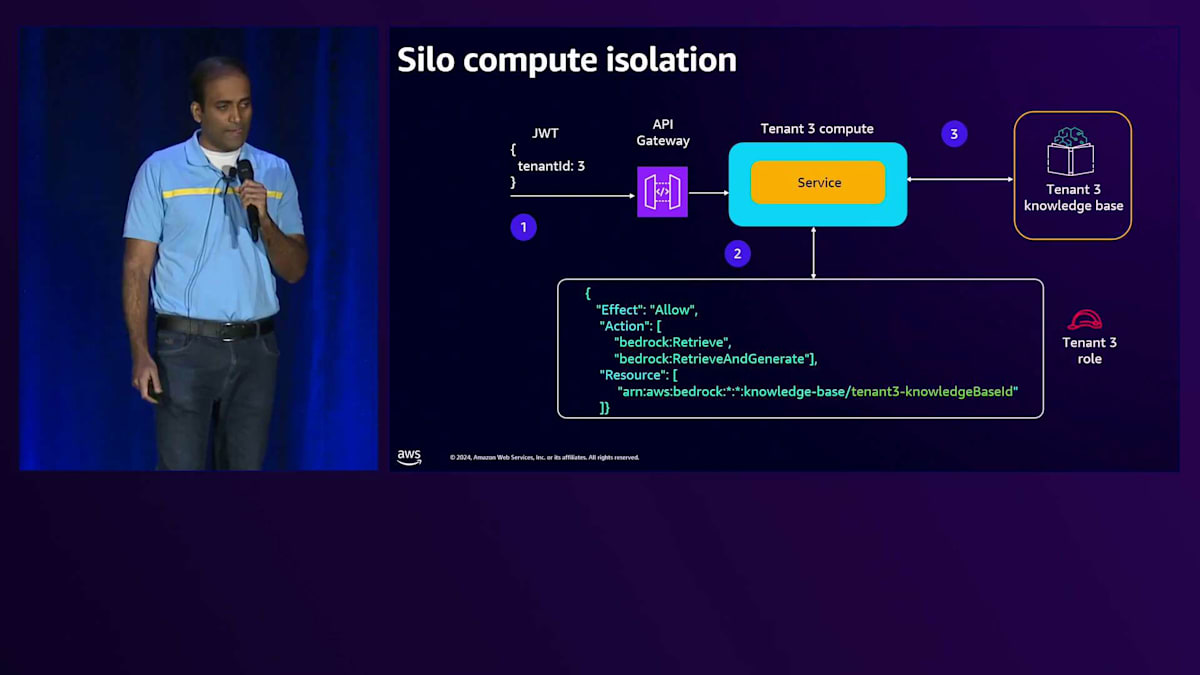

このServiceはKnowledge baseとやり取りを行い、Serviceのコードを見ると、専用のServiceなのでEnvironment variablesを通じてKnowledge base IDを直接注入できることがわかります。次にBedrock clientを作成します。Serviceは直接Execution roleに紐付けられているため、このBedrock clientを作成すると、そのExecution roleから権限を取得します。このBedrock clientを使って Knowledge base retrieverを作成し、すべてを組み合わせて、入力プロンプトとKnowledge base retrieverを渡してLLMを呼び出します。

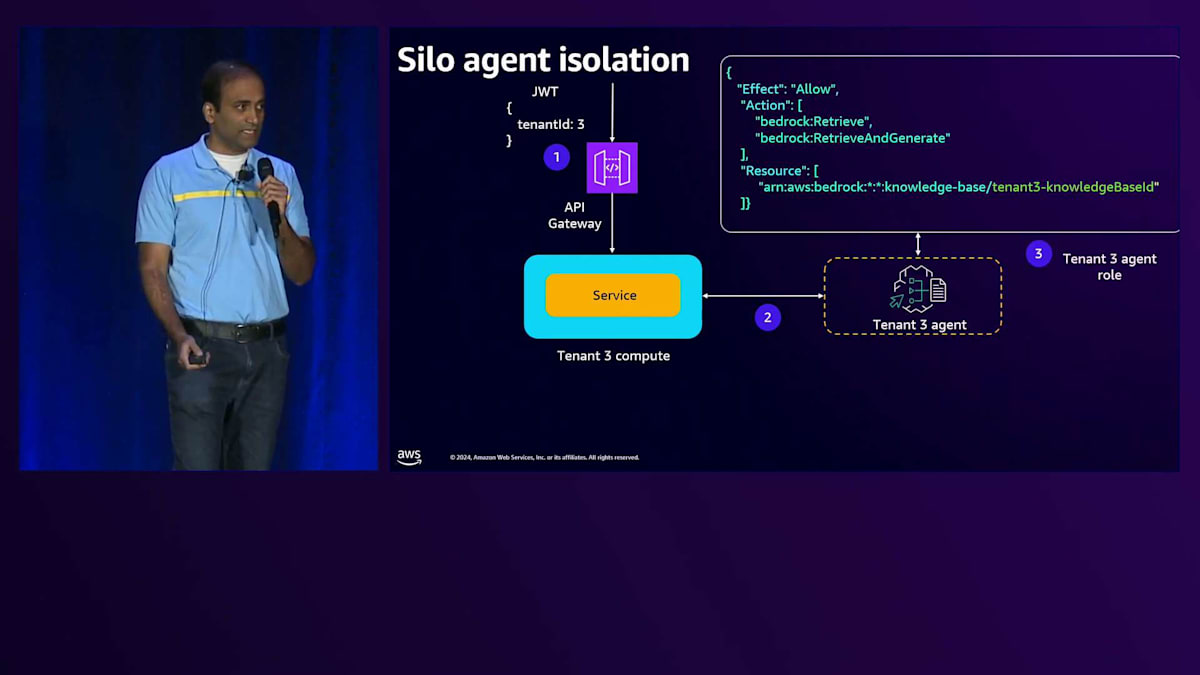
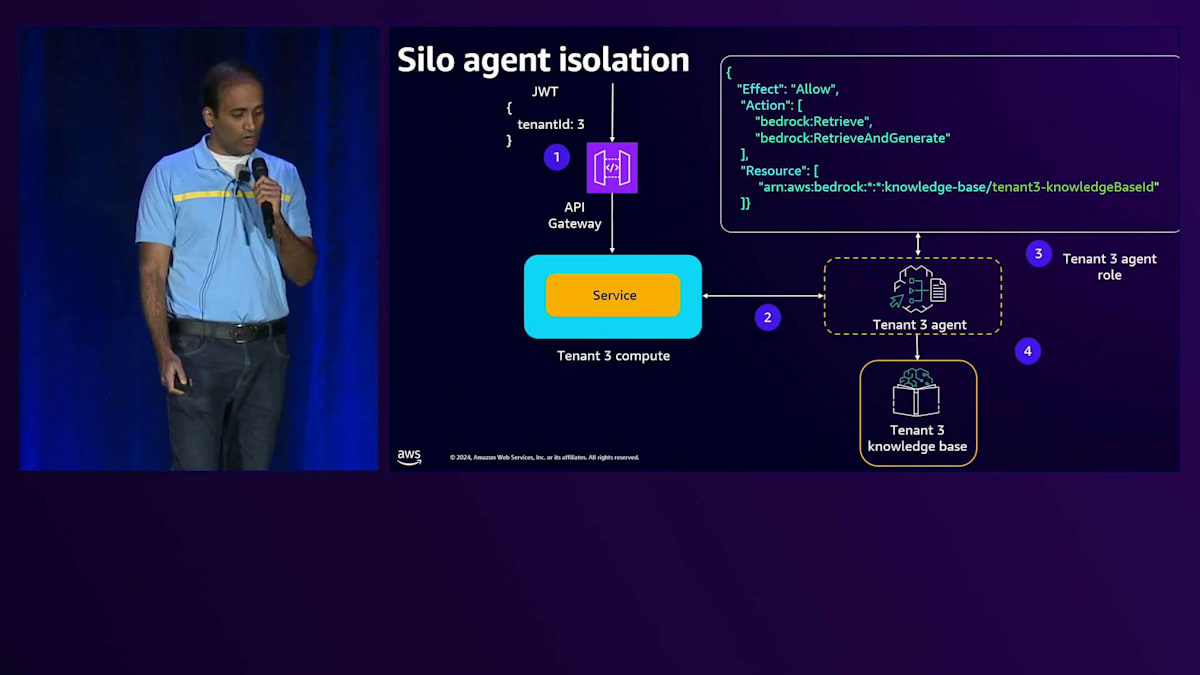

Silo agentについて、Tenant 3がAPI Gatewayとやり取りする場合を考えてみましょう。リクエストはServiceに送られ、ServiceがAgentを呼び出します。同様に、Agentには、テナント固有のリソースへの権限を付与するAgent execution roleを直接付与します。これがAgentがテナント固有のリソースとやり取りする方法です。このAgentのコードを見ると、とてもシンプルです。ServiceコードがAgentを呼び出し、Agentのコードを見ると、付与されたExecution roleからすべての権限を取得していることがわかります。
テナントごとのコスト計算とメトリクス収集の方法
次に取り上げる課題は、これらのアーキテクチャでテナントごとのコストを計算する方法です。テナントごとのコストを計算するには、まず理解しておくべきことがいくつかあります。テナントごとのコスト計算を考える際には、特にテナントのコンテキストを含めてメトリクスを収集する必要があります。
アーキテクチャのうち、テナントのリソース消費を測定したい部分については、テナント別にメトリクスを収集・集計して、各テナントの消費割合を把握する必要があります。消費割合が分かれば、サービスの総コストにその割合を掛けることで、テナントごとのコストを算出できます。
メトリクスを収集する際は、AWSの請求額に最も影響を与える部分を特定することをお勧めします。この場合、Large Language Modelとのやり取りに関連するコストが最も大きな割合を占めることになります。Basic TierとPremium Tierを見ると、LLMと連携するアーキテクチャのさまざまなコンポーネントが確認できます。LLMの課金は、Large Language Modelとのやり取りで生成される入力トークンと出力トークンの数に基づいて行われます。




Basic TierとPremium Tierにおいて、Large Language Modelと連携する各コンポーネントについてまとめてみましょう。まず、Computeは主にテナント固有のレスポンスを取得するためにLLMと連携します。 Knowledge Baseは主にエンベディングを生成するためにLLMと連携します。また、すでに見てきたように、Agentはタスクを割り当てられ、それを実行するためにLLMと連携します。

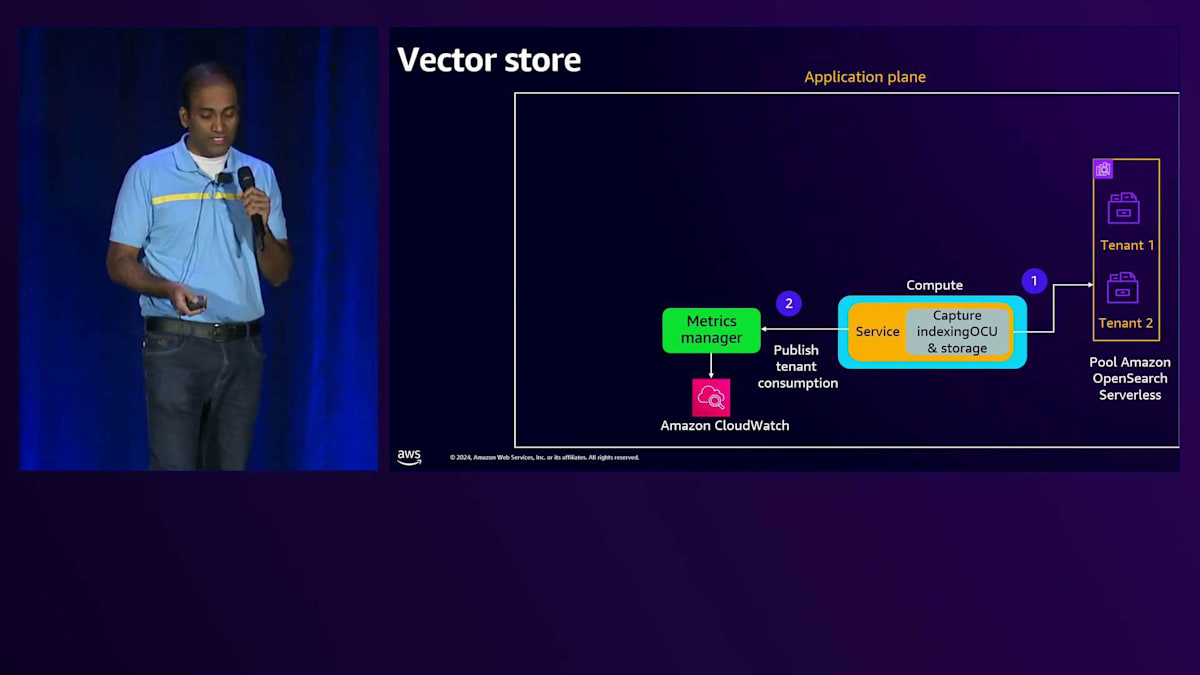
これらのメトリクスを収集すると、テナント間の消費割合が分かります。例えば、これは仮の数字ですが、テナント間の消費割合が分かれば、それをサービスコスト(この場合はAmazon Bedrockのコスト)に掛けることで、テナントごとのコストを算出できます。メトリクス収集について説明するもう一つの領域はストレージです。特にBasic Tierについては、複数のテナントで共有されるCollectionをテナントごとにインデックス化して使用していることを確認しました。


Basic TierとPremium Tierからこれらのコンポーネントを除外すると、残りのコンポーネントは主にPremium Tierの専用リソースとなります。これらは専用リソースなので、テナントIDでタグ付けすることで、異なるアプローチでコストを計算できます。AWS Billing and Cost Managementサービスから提供される AWS Cost and Usage Reportを使用して、タグに基づいてこれらの専用コンポーネントのコストをテナントIDごとに集計することができます。
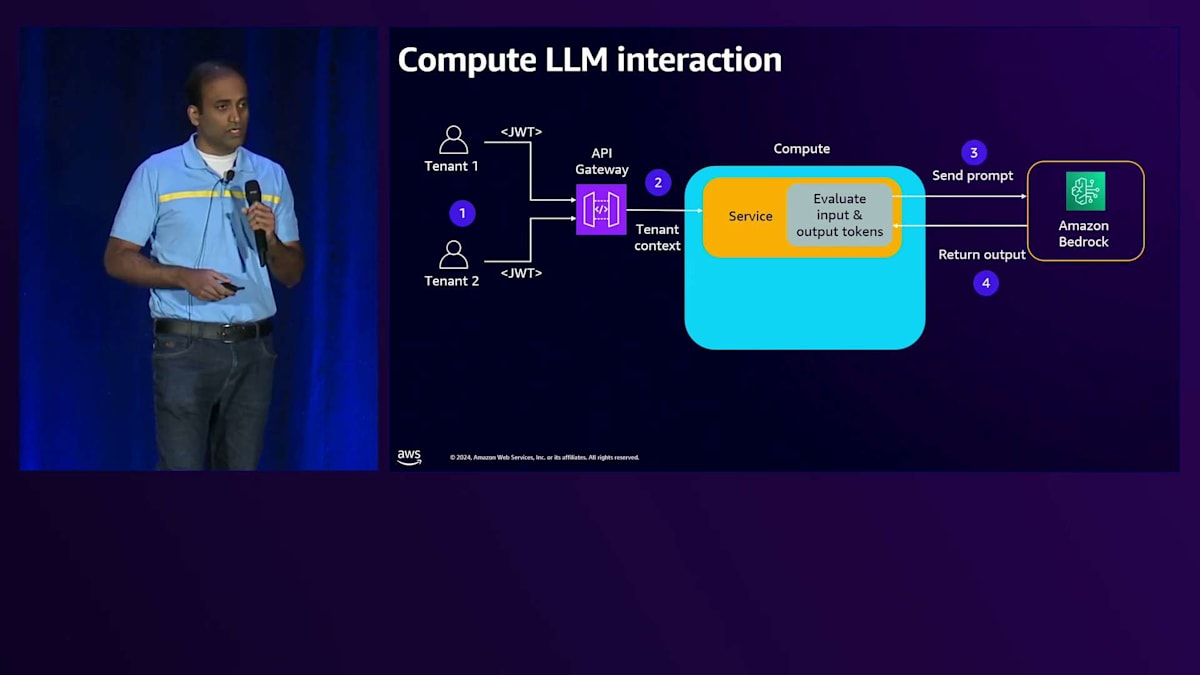
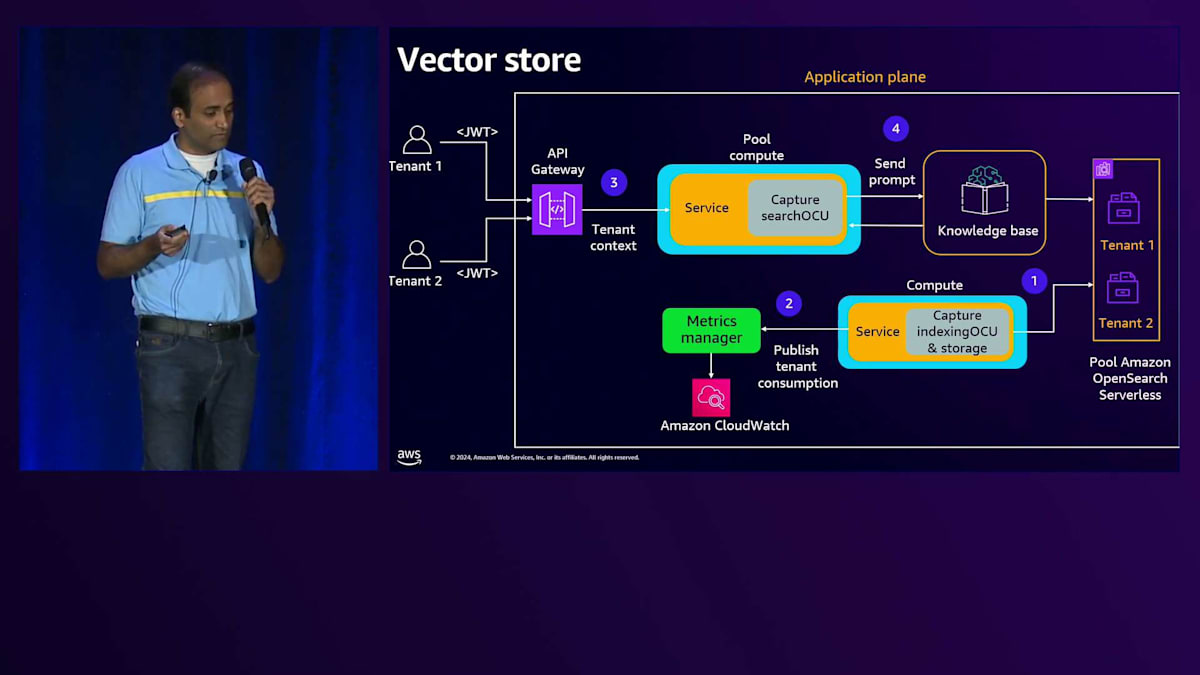
それでは、Large Language Modelとやり取りする各コンポーネントを見ていき、メトリクスの収集方法について理解していきましょう。まず、コンピュートの部分からですが、複数のテナントがAPI Gatewayとやり取りし、リクエストはバックエンドサービスに送られ、このサービスはAPIを使ってAmazon Bedrockとやり取りして応答を受け取ります。会話APIを使用する場合、応答にはその特定のやり取りで生成された入力トークン数と出力トークン数が含まれます。
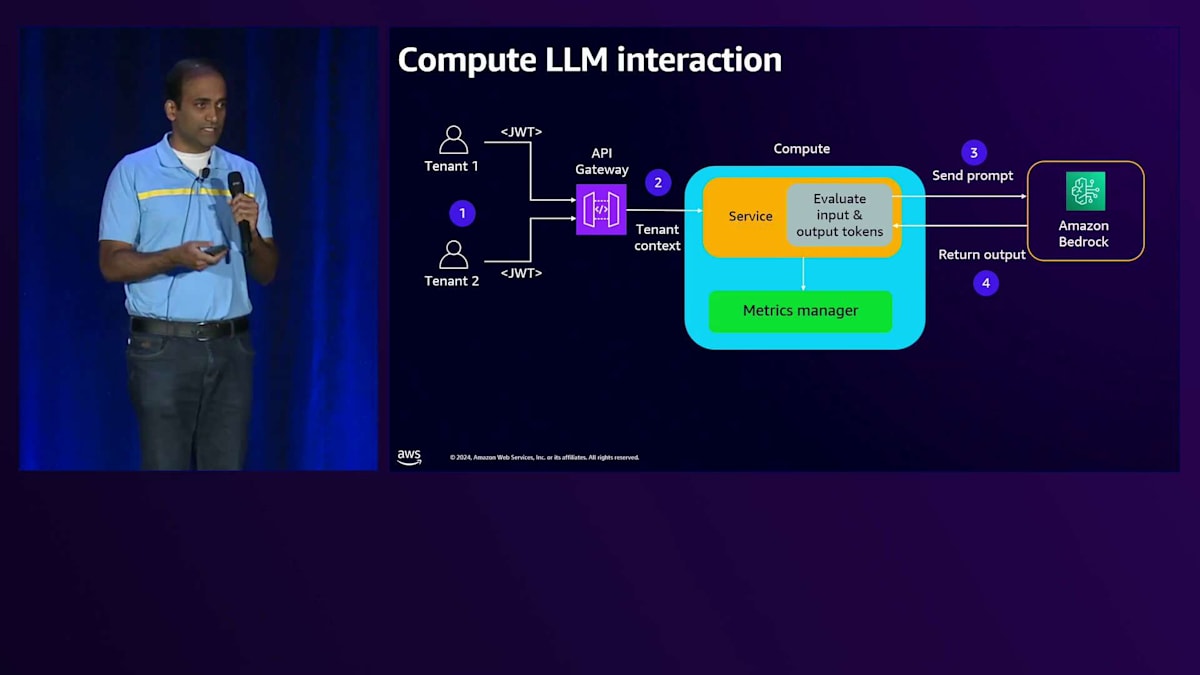


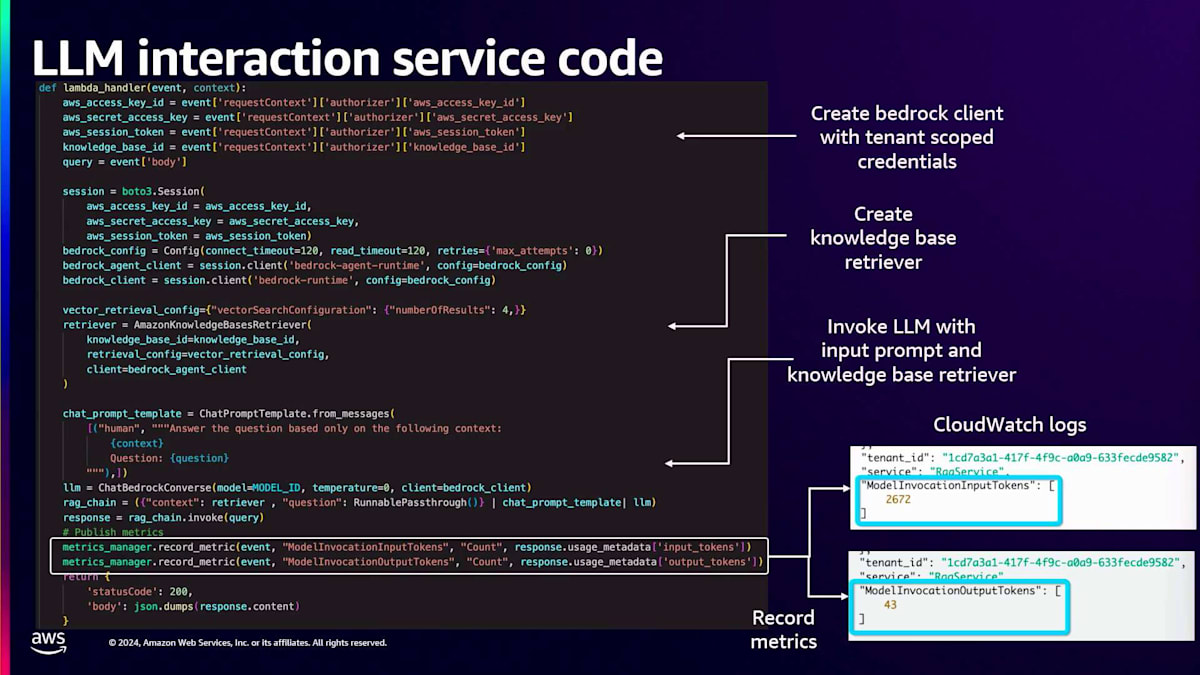
このサービスはメトリクスマネージャーライブラリを使用できます。これは基本的に、テナントのコンテキストと出力レスポンスを受け取るコードです。テナントのコンテキストからテナントIDを取得し、レスポンスから入力トークン数と出力トークン数を取得して、それらをAmazon CloudWatch Logsに発行します。サービスコードでは、まずスコープ付きの認証情報を取得してAmazon Bedrockクライアントを作成し、そのクライアントでKnowledge Baseリトリーバーを作成し、LLMを呼び出します。ここで会話APIを使用してLLMを呼び出します。レスポンスに基づいて、メトリクスマネージャーライブラリを使用し、テナントコンテキストを取得するための入力イベントと、レスポンスから生成された入力トークン数と出力トークン数をパラメータとして渡します。そして、このやり取りで生成されたテナントIDと入力トークン数、出力トークン数の情報をCloudWatch Logsに記録します。

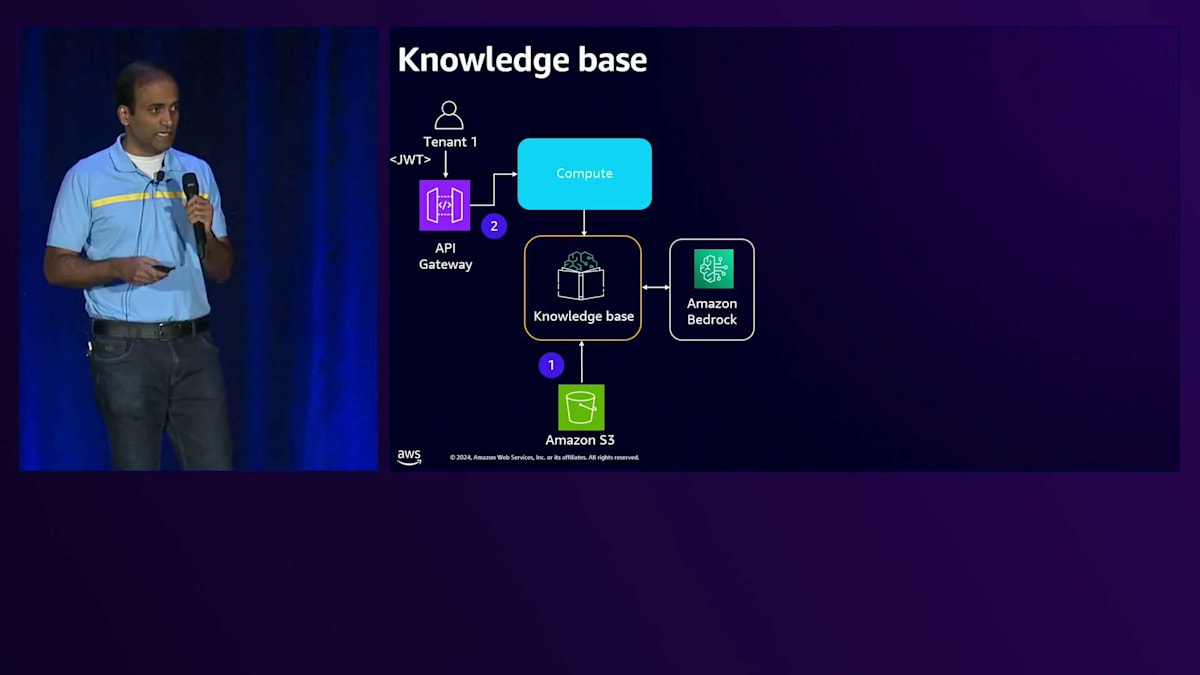
次にKnowledge Baseについて見ていきましょう。Large Language Modelとやり取りする異なる領域を理解することが重要です。まず、Knowledge Baseにデータをロードする際、Amazon Bedrockと連携して埋め込みを生成します。Knowledge BaseがLarge Language Modelとやり取りするもう1つのユースケースは、特定のテナントのリクエストが来た時に、コンピュートがKnowledge Baseとやり取りしてテナント固有のデータを取得する場合です。
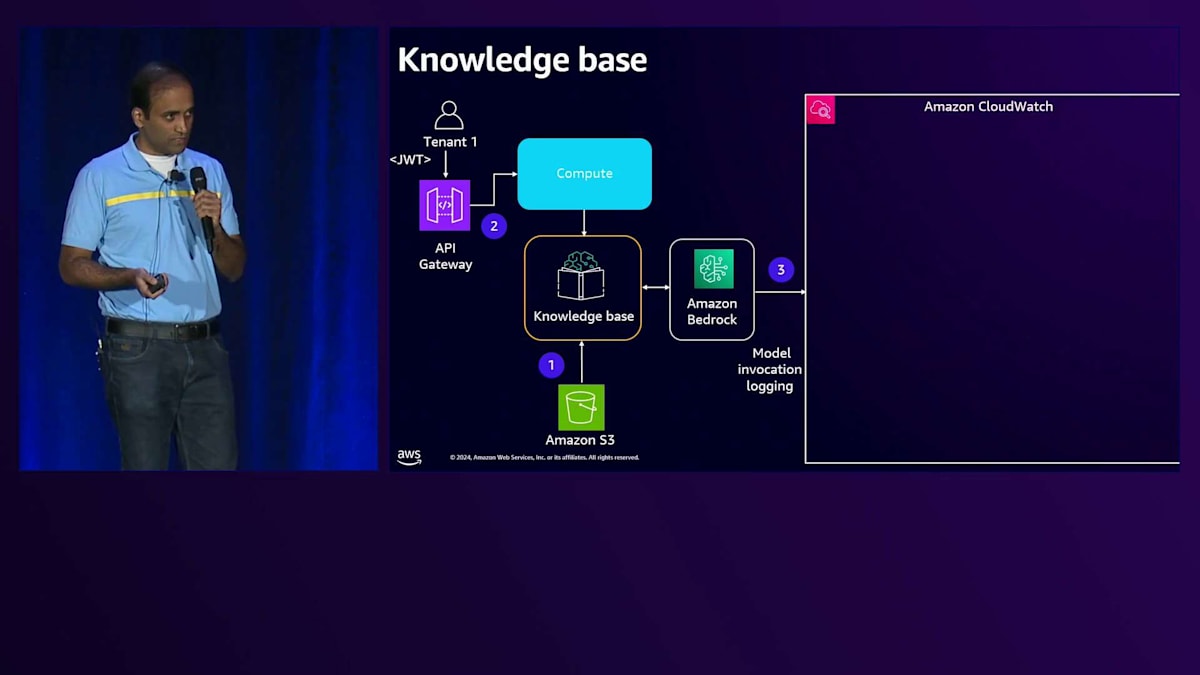
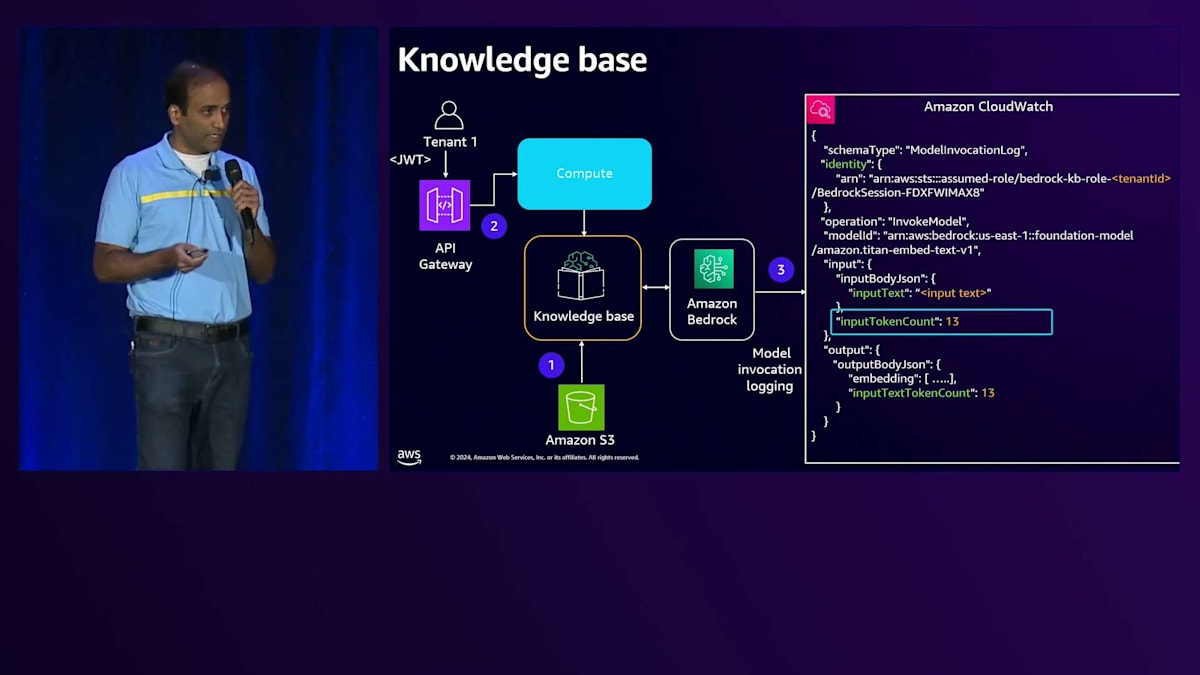
ここでの課題は、Knowledge BaseとAmazon Bedrockとのやり取りが標準で提供されているため、メトリクスを収集するためのカスタムコードを挿入する方法がないことです。これらのBedrock レベルでの課題に対して、ロギングを有効にすることができます。ロギングを有効にすると、Bedrockはログメッセージを生成し、そのログメッセージの中で、その特定のやり取りで消費された入力トークン数を取得できます。Knowledge Baseは埋め込みモデルを扱うため、入力トークンのみを扱い、出力トークンはありません。
入力トークン数が取得できるのは良いのですが、課題はテナントコンテキストをどのように関連付けるかです。解決策の1つは、Knowledge Baseを定義する際に、テナントIDを含むサービスロールを定義するという規則を採用することです。このメッセージを見ると、ここでハイライトされている別の属性があり、サービスロールにテナントIDを付加するという規則を使用しています。このため、メトリクスを集計する際に、このメッセージを解析してそのIDからテナントIDを取得し、入力トークンと組み合わせることができます。

次にAgentについて説明しましょう。複数のTenantがサービスとやり取りをしていると仮定すると、サービスはAgentを呼び出してタスクを割り当てます。AgentはLarge Language Modelとやり取りしながらタスクを完了させます。Agentがタスクを実行する方法としては、タスクが割り当てられると、それを分解して3つのステージ(前処理ステージ、オーケストレーションステージ、後処理ステージ)で実行します。各ステージでは、特定のペイロードフォーマットを使用してLarge Language Modelとやり取りを行います。
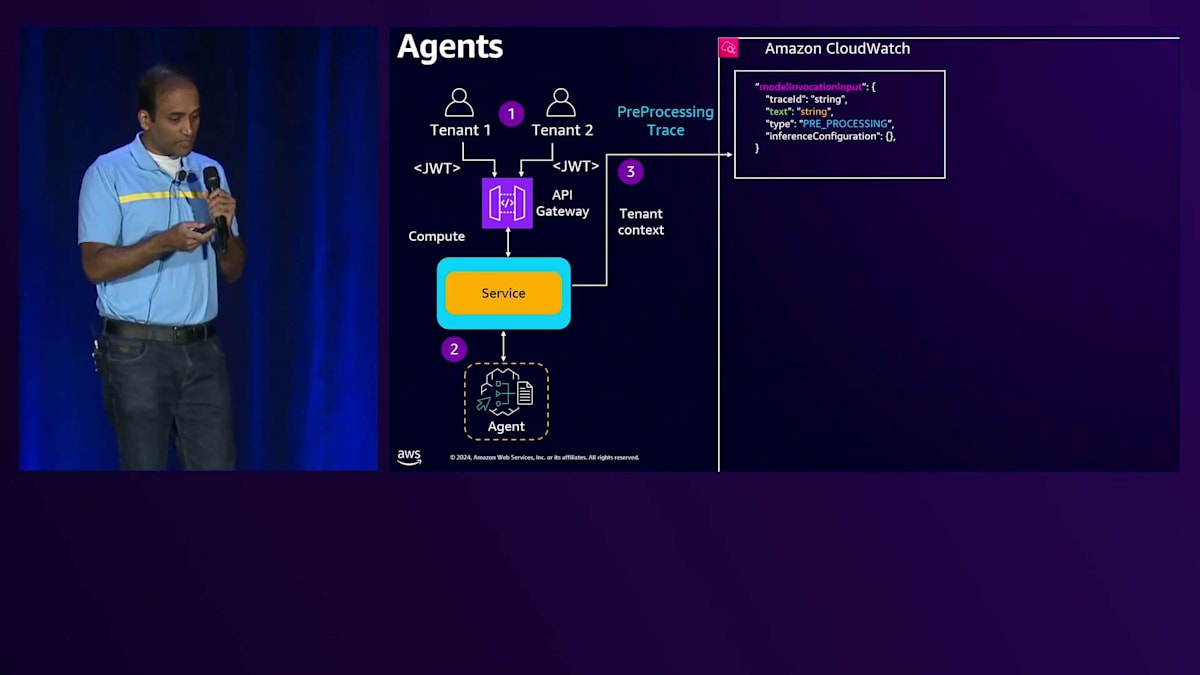
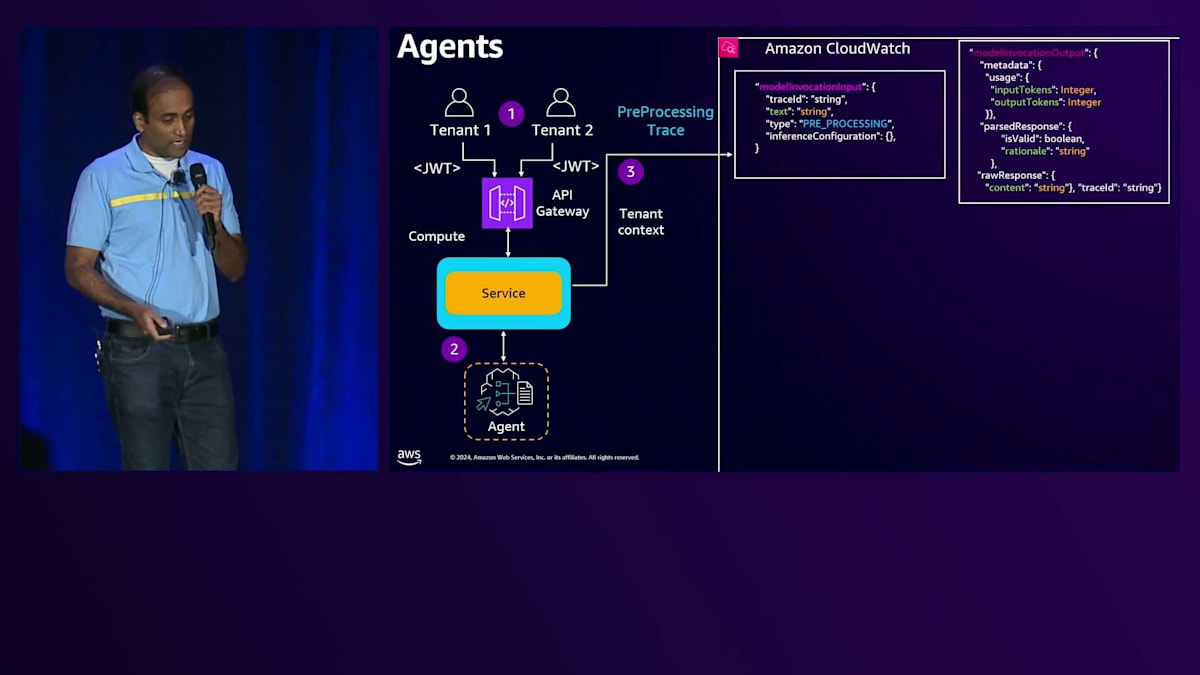
これらのペイロードを見ると、入力トークン数と出力トークン数を解析することができます。サービスはAgentとLarge Language Modelとのやり取りを追跡する必要があります。サービスがAgentを呼び出す際にトレーシングを有効にすると、Agentはトレーシングメッセージをサービスに送り返し続け、そこから入力トークン数と出力トークン数を解析できます。このように、サービスは前処理ステージで生成されたトレーシングを確認できます。Agentの入力フォーマットはこのような形式で、Large Language Modelに送信され、応答はこのようなモデル出力になります。
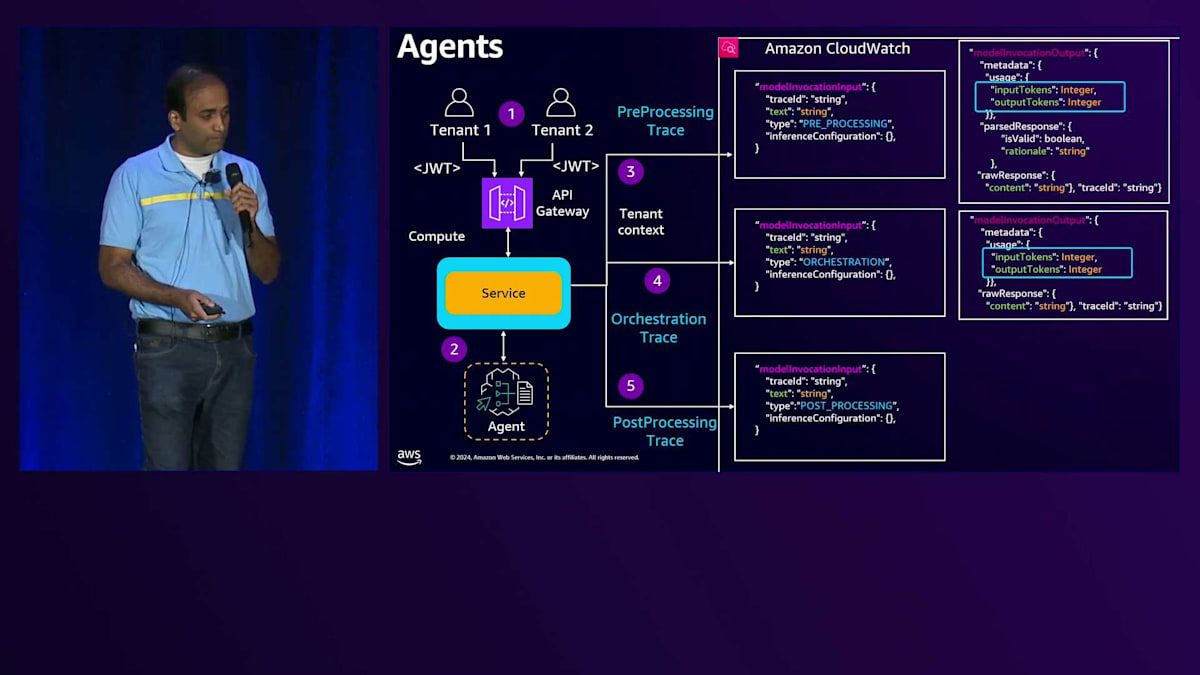
これらの応答を見ると、入力トークン数と出力トークン数が含まれていることがわかります。オーケストレーションステージを見ても、同様のフォーマットで、モデル出力に入力と出力が含まれています。同じように、後処理ステージを見ても、入力と出力を含むモデル出力メッセージがあることがわかります。サービスはこれらのモデル出力メッセージを解析して、入力トークン数と出力トークン数を取得できます。さらに、サービスからTenant IDを取得するためのTenantコンテキストを取得し、これらを組み合わせてCloudWatchにログを記録できます。

では、これをどのように実装するのか、サービスコードを見てみましょう。サービスコードでは、基本的にAgentを呼び出しています。Agentを呼び出す際に、トレーシングを有効にしているのがわかります。トレーシングを有効にしているため、Agentはトレースメッセージを送り返し続けます。メッセージのストリームをリッスンし、それらのストリームを確認することができます。Metrics Managerを使用して、モデル出力メッセージからこれらのメッセージを解析します。また、入力イベントからTenantコンテキストを取得し、これらを組み合わせてCloudWatchログに記録します。
次にVector Storeに移りましょう。特に、コレクションが複数のTenantで共有されるBasic Tierでのストレージメトリクスの取得方法について説明します。Application Planeがあり、その中に複数のTenantで共有されるPool Collectionがあり、各Tenantに対してインデックスを作成すると仮定しましょう。

メトリクスの収集方法を理解する前に、Amazon OpenSearch Serverlessの課金方法について理解する必要があります。課金は3つの方法で行われます。1つ目はストレージコストで、これはCollectionに保存されているデータ量に基づきます。2つ目はインデックスコストで、特定のインデックスとのやり取りで消費される計算ユニットの量です。3つ目は検索・クエリコストで、データの検索やクエリ実行時に消費される計算量です。

これらのテナントインデックスそれぞれについて、ストレージコスト、インデックスコスト、検索・クエリコストを取得する必要があります。ストレージコストについては、これらのインデックスに保存されているデータ量を直接取得できるので、比較的簡単です。しかし、インデックスコストと検索・クエリコストについては、それらのコストに近い指標を選ぶアプローチを考える必要があるため、より複雑で興味深い課題となります。例えば、インデックスコストについては、これらのインデックスのデータ量を指標として使用することができます。 これを実装するには、OpenSearch Collectionにアクセスしてこれらのインデックスに保存されているデータ量を取得し、その情報をCloudWatchにログとして記録するスタンドアロンサービスを構築することができます。
ここでの課題は、このスタンドアロンサービスが独立しており、テナントコンテキストを取得するためのJWTトークンにアクセスできない可能性があるため、テナントコンテキストの取得が難しいことです。この問題に対しては、OpenSearch Collectionを定義する際に、インデックスの命名にテナントIDを使用するという規則を設けることができます。これにより、スタンドアロンサービスはインデックス名からテナントIDを取得し、保存されているデータ量と共にCloudWatchログに記録することができます。 ストレージコストとインデックスコストの対応が済んだところで、次は複数のテナントがKnowledge Baseを通じてコンピュートと対話する際に発生する検索・クエリコストを考える必要があります。

検索・クエリコストについては、これらのコストを適切に表す指標を特定する必要があります。一つのアプローチとして、特定のクエリの実行時間を計測し、それを指標として使用する方法があります。クエリの実行時間を計測する小さなライブラリを作成し、 テナントコンテキストと共にその情報をMetrics Managerに渡してメトリクスを公開することができます。
ここまで説明してきたのは、OpenSearch Collectionに関する特定のテナントのストレージコストを計算・収集するための細かいアプローチです。ただし、要件に応じて、より粗いアプローチを採用することもできます。その場合は、近似値を使用して1つの指標を選び、それを基にテナント間でコストを按分します。例えば、これらのインデックスに保存されているデータ量を単一の指標として使用し、テナント間でコストを配分することができます。 アーキテクチャのこの段階では、テナントコンテキストを含むすべてのメトリクスがCloudWatchログに記録されている状態となります。




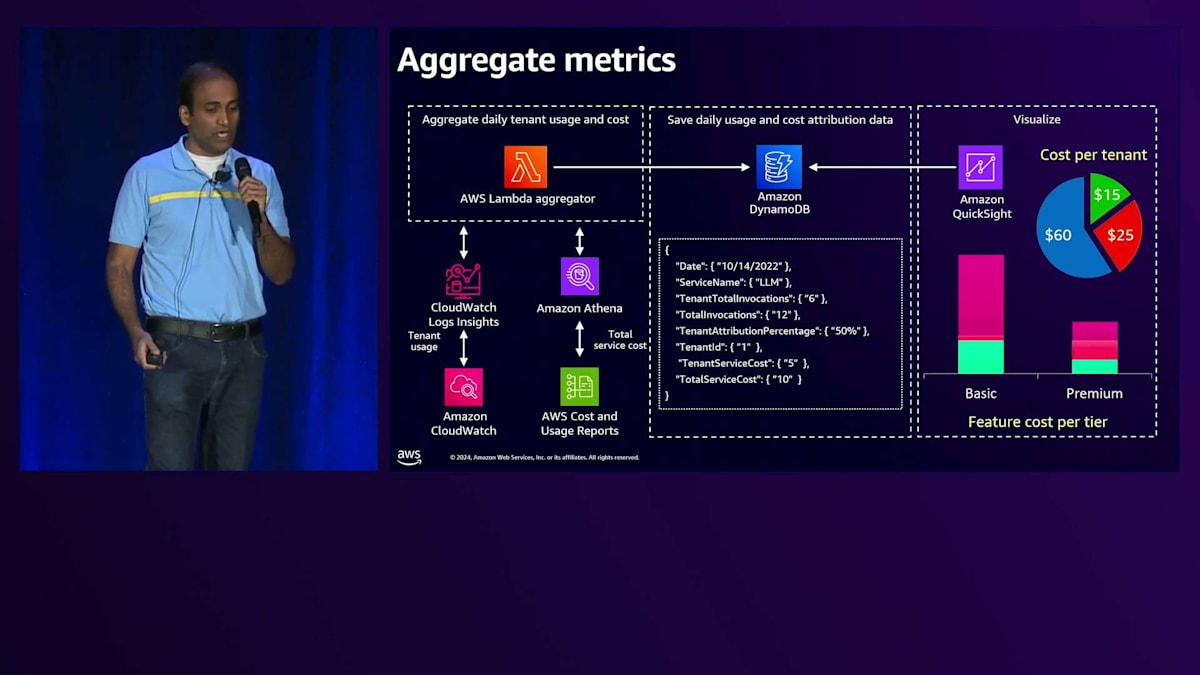
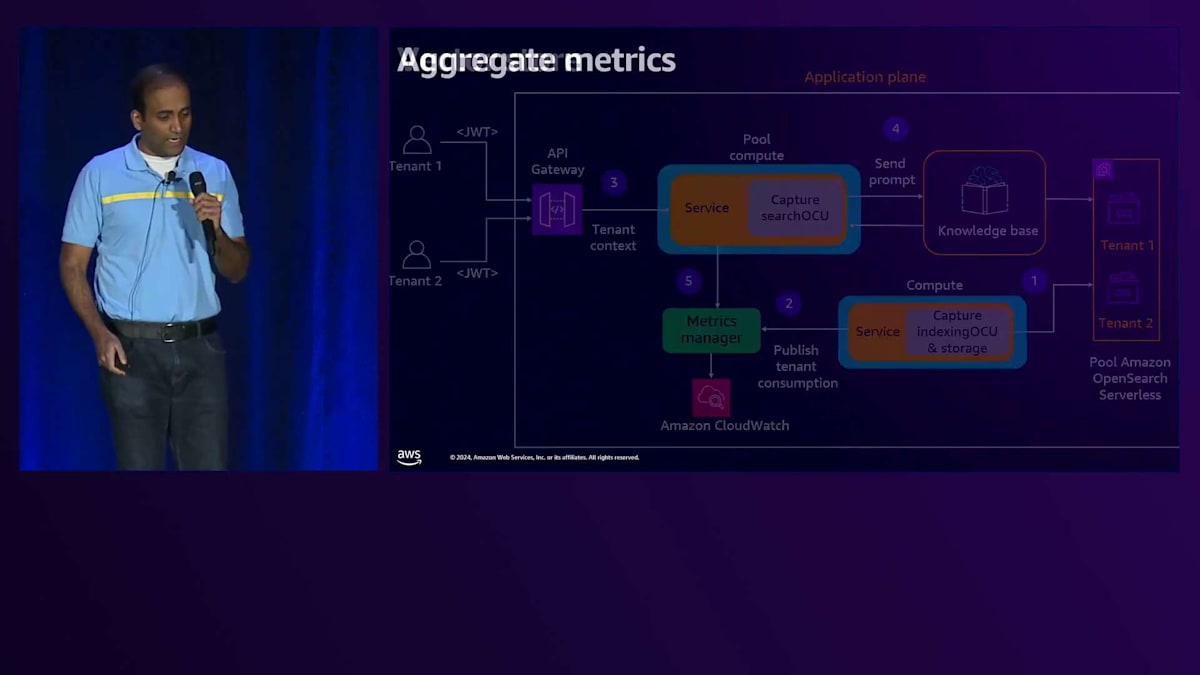
次にメトリクスの集計が必要です。 コンポーネントの詳細に入る前に、メトリクスの集計方法の全体像についてお話しします。まず、CloudWatch Insightsクエリを使用してCloudWatch logsと連携するLambda関数を作成し、 テナント全体での消費率を集計します。具体的には、各テナントに対して生成された入力トークンと出力トークンをすべて集計します。 これが完了したら、Cost and Usage Reportsと連携するサービスを使用して、総サービスコストを取得します。この総サービスコストに消費率を掛けることで、 テナントごとのコストを算出し、その情報をDynamoDBテーブルに保存します。この保存された情報を使って、 データを様々な方法で可視化・分析することができます。

このLambda集計関数のコードを見て、このロジックの実装方法を理解しましょう。最初に必要なのはメトリクスのクエリです。 このコードでは、CloudWatch Insightsクエリを使用して、テナントコンテキスト、特にテナントIDを含むCloudWatch logsから入力トークン数と出力トークン数を取得しています。次のクエリでは、全テナントの入力・出力トークンの合計を取得します。これらの値を除算することで、テナント間の消費率、つまり入力トークンと出力トークンのテナント帰属率を計算します。


次のステップはサービスコストの取得です。先ほど述べたように、コストと使用状況データにアクセスするためにAthenaを使用できます。 サービスコストを取得するには、クエリを実行する必要があります。このAthenaクエリを実行すると、 特定のモデルを使用する際の入力トークンと出力トークンのサービスコストを結果から解析できます。サービスコストと消費率の両方を取得したら、コスト配分を計算する必要があります。


コスト配分を計算するには、テナントの使用率に総サービスコストを掛けるだけです。この方法で、各テナントの入力トークンと出力トークンに対する課金額を計算します。これらの値を合算して、このサービス(この場合はAmazon Bedrock)の総コストを決定します。 総サービスコストを計算したら、その情報をデータベースに保存します。
Noisy Neighbor問題の緩和策:APIレベルでのスロットリング実装
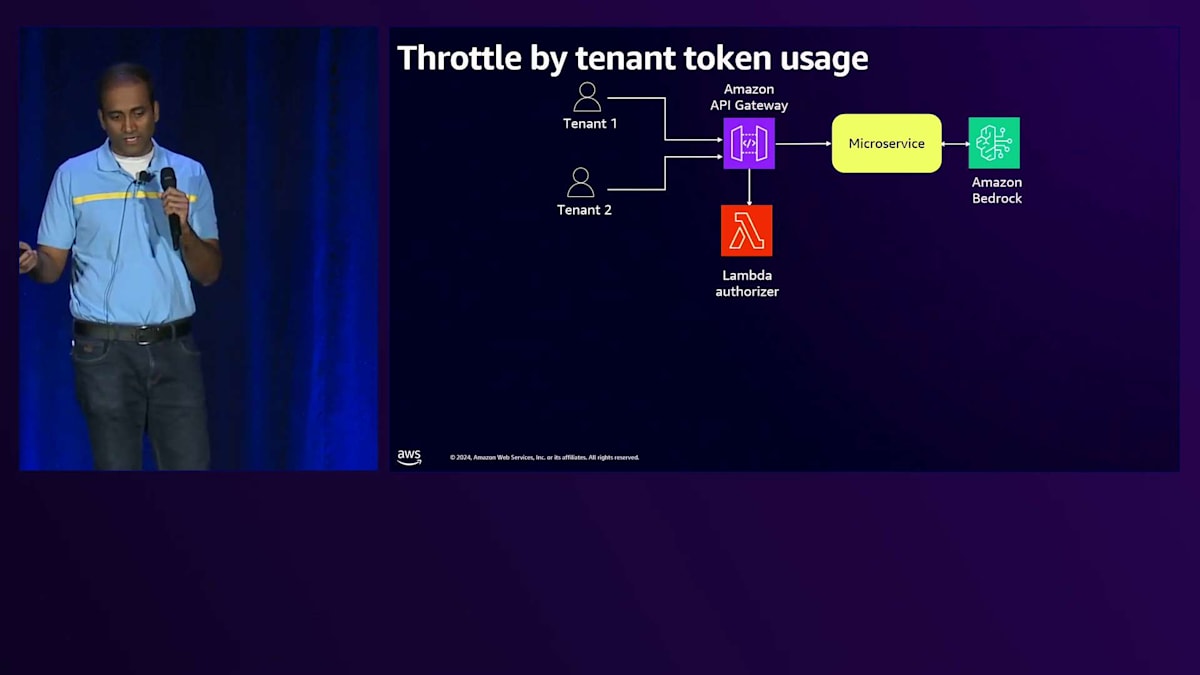
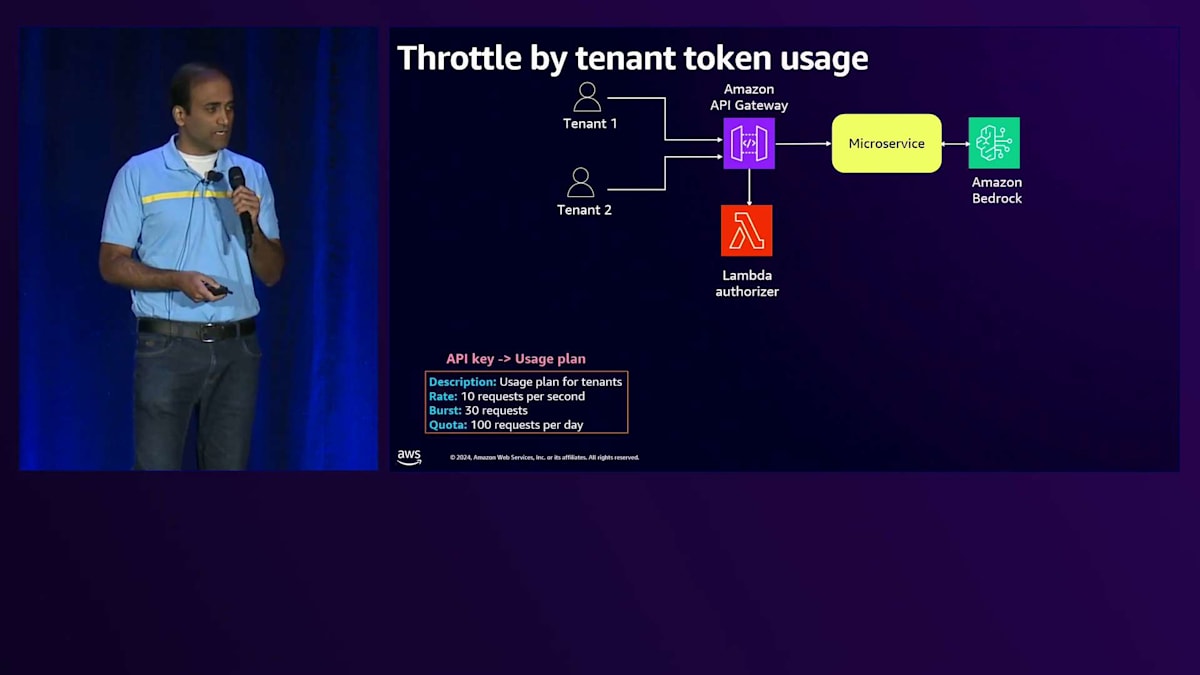
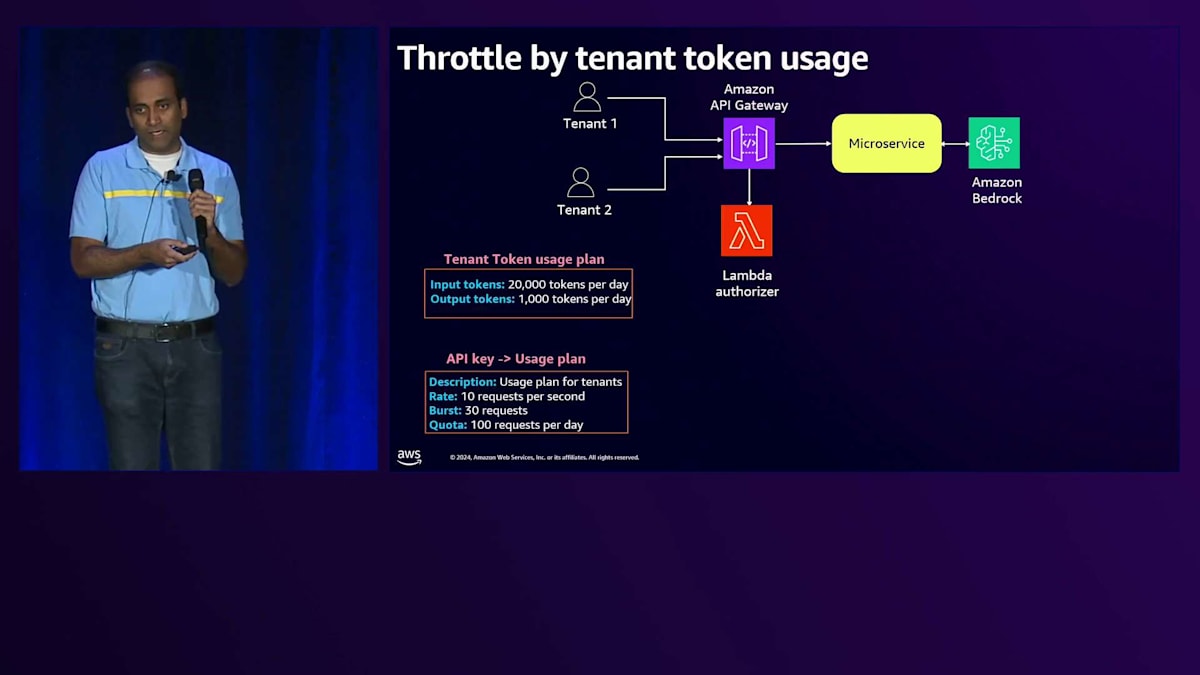
本日お話しする最後のアーキテクチャの課題は、Noisy Neighbor問題です。Noisy Neighbor状態を緩和する一つの方法は、APIレベルでテナントに対するスロットリングを実装することです。テナントのトークン使用量に基づいてスロットリングを実装する方法をお見せしましょう。BasicティアとPremiumティアを見ると、共通のアーキテクチャコンポーネントがあります。 API Gatewayがリクエストの認可にLambda Authorizerを使用し、それらをマイクロサービスに渡して、そこからAmazon Bedrockと連携します。 API Gatewayには、リクエストのスロットリングのためにUsage Planを有効にする機能があることはご存知かもしれません。 さらに、テナントのトークン使用量プランを導入することができます。ここでは仮の数字を使用していますが、BasicティアとPremiumティアで異なるUsage Planを設定することができます。
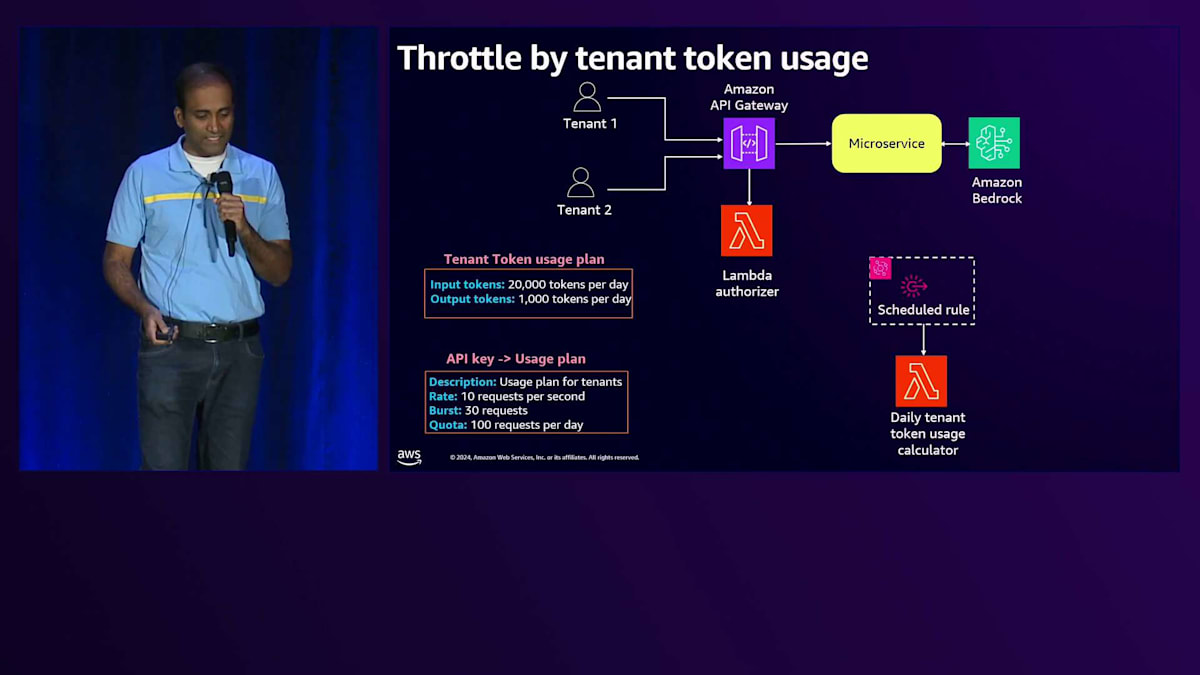
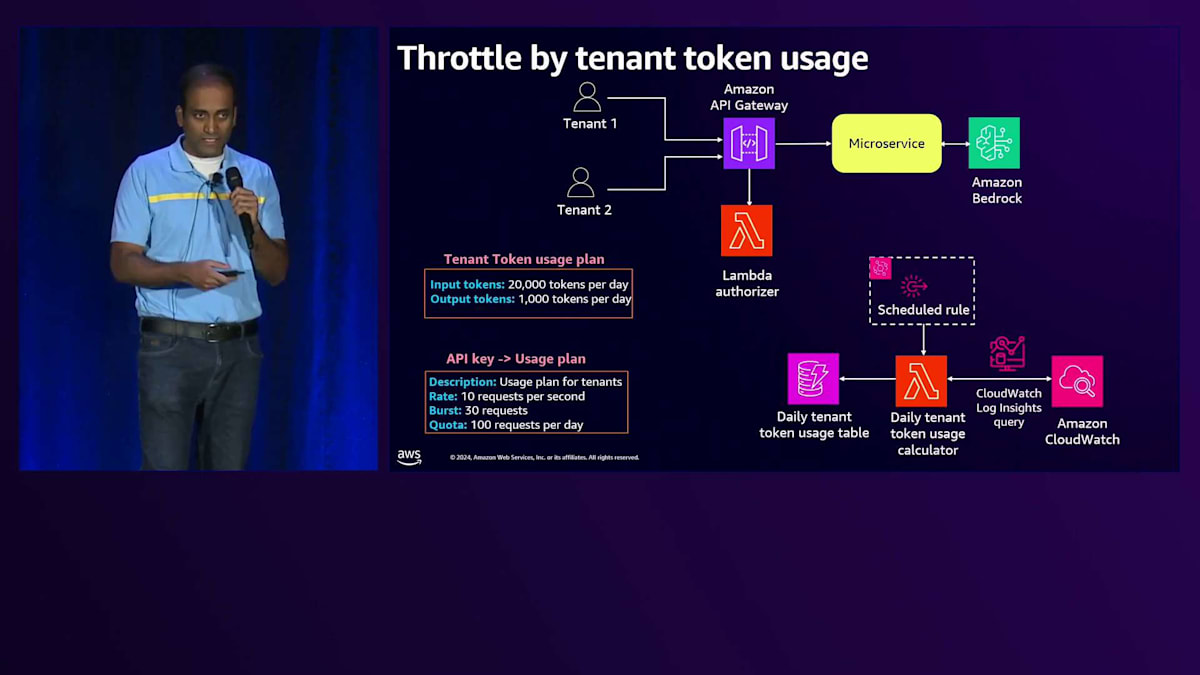
テナントのオンボーディング時には、このToken使用プランを割り当て、その情報はControl PlaneのTenant管理サービスによって記録されます。各テナントのInput TokenとOutput Tokenの数をリアルタイムで集計できるアーキテクチャが必要です。 そのために、CloudWatchログをクエリしてテナント全体のTokenの数を集計し、そのデータをDynamoDBテーブルにプッシュするシンプルなLambda関数を構築できます。この情報をどの程度リアルタイムに必要とするかに応じて、より堅牢なToken消費追跡アーキテクチャを構築することも可能です。
リクエストがAPI Gatewayに到達すると、Lambda Authorizerが呼び出され、テナントのコンテキストまたはテナントIDを使用してControl Planeにアクセスし、そのテナントに割り当てられた使用プランを取得します。その後、テナント使用量テーブルをリアルタイムで確認して現在の使用量を取得し、両方の値を比較してリクエストの許可・不許可を判断します。APIレベルでキャッシングを有効にすることもでき、その場合このロジックは全てのリクエストで実行されるわけではありませんが、要件に応じてこれらの設定を調整できます。
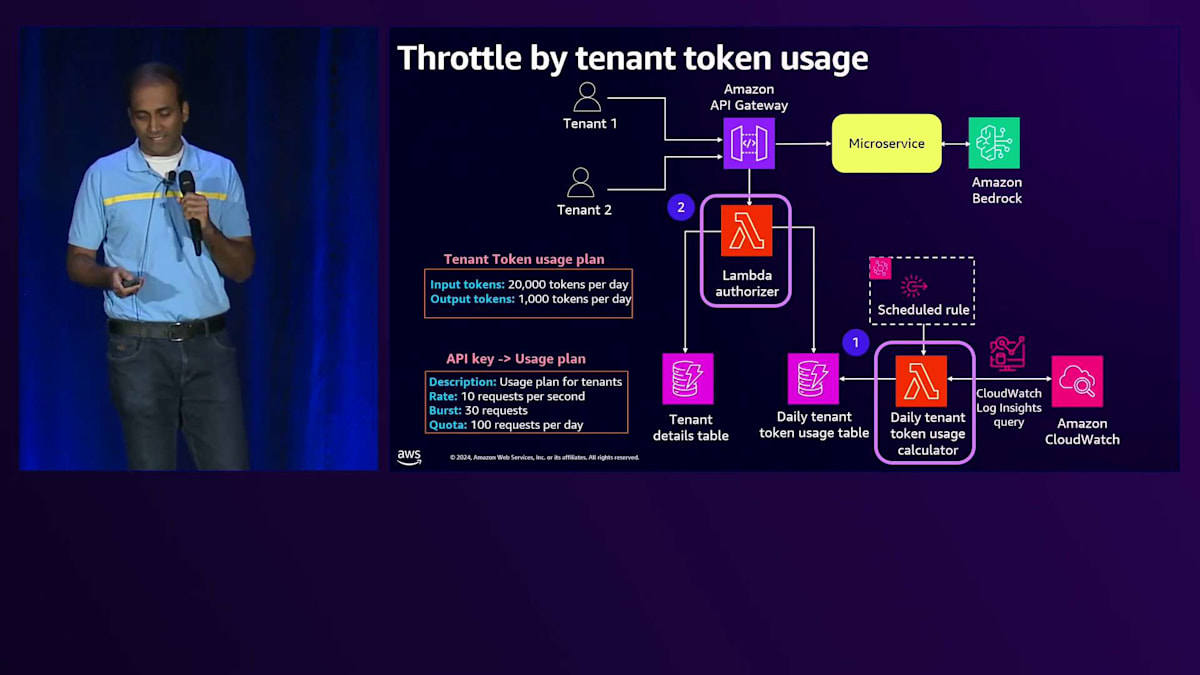

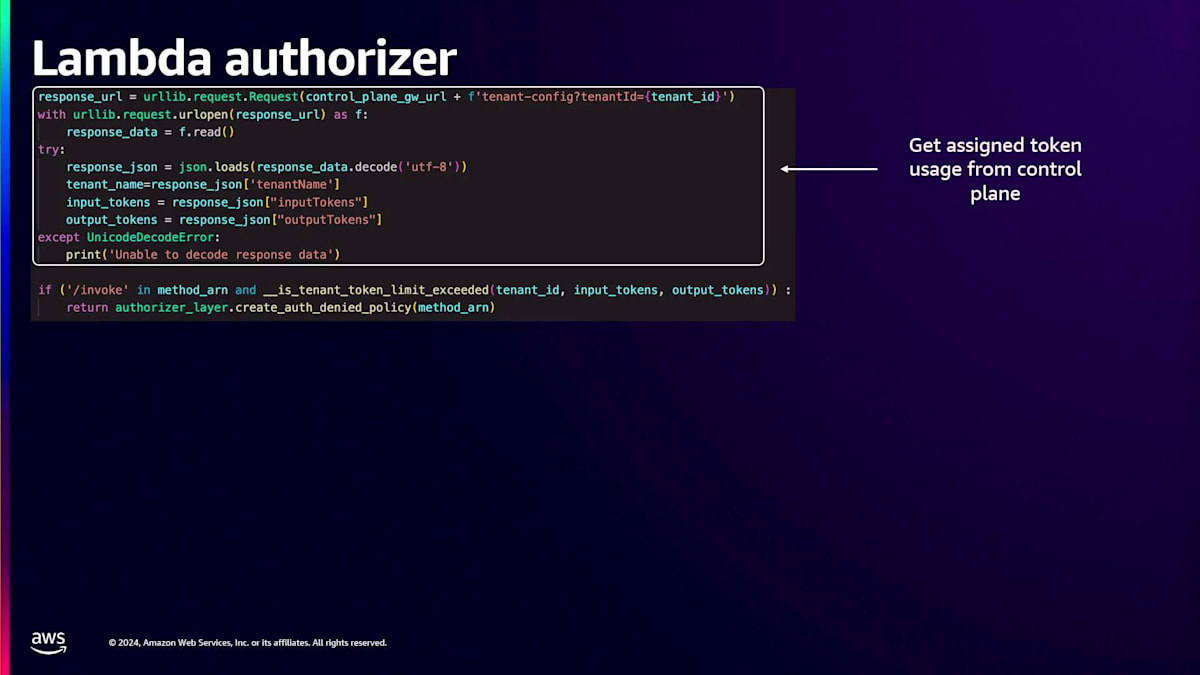
テナント使用量計算機能とLambda Authorizerのコードをより詳しく見てみましょう。 テナントToken使用量計算機能では、まずCloudWatchログクエリを使用してテナントごとの使用量を集計し、その情報をDynamoDBテーブルに保存します。Lambda Authorizerでは、テナントIDを使用してControl Planeを呼び出し、そのテナントに割り当てられたToken使用量を取得します。その後、テナントToken使用量テーブルをクエリして現在の使用量を取得し、割り当てられたToken数と比較して、リクエストの許可・不許可を判断するメソッドを呼び出します。
セッションのまとめと今後の展望


このセッションの重要なポイントをまとめると、BasicティアとPremiumティアのアーキテクチャを紹介しました。 アーキテクチャを構築する際には、AWSのサービスクォータと制限を考慮する必要があります。 アーキテクチャの構築にあたっては、堅牢なソリューションを作るためのさまざまな課題の解決方法を示してきました。自身のアーキテクチャ開発においても、これらの考慮事項を念頭に置き、ティア戦略を活用してテナントベースのエクスペリエンスを提供する方法など、要件に特化したアーキテクチャ上の課題に取り組むべきです。


説明してきたように、異なるテナントに異なるエクスペリエンスを提供するために、BasicティアとPremiumティアを定義しています。テナント分離とデータパーティショニングを実装する際、基本的な概念は同じですが、実装方法は異なる場合があります。例えば、今回はOpenSearch Collectionを使用して分離を実装する方法を示しましたが、実際には異なるVector Storeや異なるツールを使用して実装することもあります。コアとなる概念は同じですが、実装アプローチは異なる可能性があります。

テナント分離を実装する際は、可能な限り IAM を活用すべきです。メトリクスを収集する際は、必ずテナントのコンテキストと共に収集するようにしてください。これにより、後でテナント間でメトリクスを集計することができます。セッションでデモンストレーションしたように、各テナントの入力トークン数と出力トークン数をテナントコンテキストと共に収集し、それを使用してテナントごとのコストを算出しました。また、同じメトリクスを使用して、API レベルでテナントのトークン使用量に基づくスロットリング制御を実現しました。



これは先ほど言及した GitHub のリンクで、このコードのほとんどを見つけることができます。水曜日の朝にこのワークショップを実施する予定です。SAS405 にご興味がある方は、ぜひこのワークショップにご参加ください。こちらは私のチームメイトが発表する追加セッションです。興味を持たれたものがありましたら、ぜひご参加ください。様々なワークショップや Builder Session についての情報を提供しています。

最後に、お立ち寄りいただき、私たちのトークを最後まで辛抱強く聞いていただき、ありがとうございました。皆様のご参加を心より感謝いたします。アンケートへのご協力もよろしくお願いいたします。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion