re:Invent 2024: AWSが解説 Aurora高可用性とDR設計パターン
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Amazon Aurora HA and DR design patterns for global resilience (DAT304)
この動画では、Amazon Auroraにおける高可用性と災害対策の設計パターンについて解説しています。Single AZからMulti-AZ、Cross-Region Backupから対称的なGlobal Database構成まで、段階的な可用性向上の手法を紹介しています。特にGlobal Databaseでは、RPOが1秒未満、RTOが2分未満という高いレジリエンスを実現できる点や、Write forwardingによる読み取り耐障害性の向上、Global DB RPOによるデータ損失の上限保証など、具体的な機能と効果が説明されています。また、AWS BackupとCross-Account設定を組み合わせることで、アカウントレベルでの障害対策も実現できることが示されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon Auroraにおける高可用性と災害対策の重要性

はい、始めましょう。皆さん、DAT 304へようこそ。私はTimです。ここで質問ですが、re:Invent以外で、毎日の仕事内容が完全に予測できる方はいらっしゃいますか?毎日が全く同じで、とても退屈で、すべてが想定通りに進む。自然災害も、お客様からのエスカレーションも、メンテナンスウィンドウもない、そんな職場の方は?誰も手を挙げていないようですね。もし「はい」と答えた方がいたら、正直者じゃないと思いますよ。そんなことは決してありません - それは神話です。だからこそ、そういった事態に備える必要があるんです。レジリエントなシステムを構築しなければなりません。

今日は、Amazon Auroraにおける高可用性と災害対策のための設計パターンについてお話しします。これらを活用してデータベースシステムにレジリエンスを組み込む方法を見ていきましょう。私はTim Stoakesで、この後Grant McAlisterも加わります。私たち二人ともAWSのSenior Principal Technologistで、Auroraチームで働いています。 これには唯一の解決策というものはありません。選択肢は様々で、障害モード、パフォーマンスコスト、運用の複雑さの間でトレードオフが発生します。これらのトレードオフは、私たちが決めることではありません。AuroraやAWSの他のツールを使って、お客様自身が決定することなのです。
可用性と災害対策の基本概念

今日は、この領域における様々なパターンと、それらが適切な場合にどのように活用できるかについて説明していきます。まず、これらの柱について詳しく見ていきましょう。 可用性とは、ワークロードが利用可能な時間の割合のことです。これは通常、一定期間にわたる履歴的な指標として表現されます。例えば、年間で4ナイン、月間で4ナインといった具合です。システムに冗長性を追加することは、可用性を高める優れた方法であり、単一障害点の影響を回避することができます。

次は災害対策です。これもレジリエント戦略において考慮すべき重要な要素です。これは災害が発生した場合にワークロードを復旧するための技術と戦略です。自然災害や大規模な技術的障害に対応するための一回限りの復旧対策に焦点を当てています。ここではRecovery Time Objective(RTO)を使用して測定します - これは、障害発生から業務再開までの許容される最大時間です。また、Recovery Point Objective(RPO)もあります - これは失ってもよいデータの最大量です。通常、災害やサービス停止後の時間量として測定します。例えば、非同期ネットワークの遅延が10秒あった場合、失う可能性のある最大のデータは10秒分となり、それがRPOとなります。
Aurora Single AZパターンとStorage Fleetの仕組み

ここにいらっしゃる皆さんは、それぞれ何百通りもの方法でAuroraを使用されているので、HAとDRのニーズも千差万別でしょう。そこで、例を挙げて説明していきたいと思います。皆さんご自身の状況と重なる部分があるかもしれません。あなたがDBAだとイメージしてください。それほど難しくないかもしれませんね。あなたは、ホットな新興スタートアップのDBAとして採用されました。このスタートアップは日の出の写真を販売するウェブストアを運営しています。もしここにジョークが隠されていることに気づいた方は、後で私のところに来てステッカーをもらってください。スタートアップなので初期投資資金は限られていますが、Auroraを選んだのは、小規模からスタートでき、空の写真を売るこのユニコーン的な成長をサポートできることを知っているからです。

まず最初に、Auroraの最小構成では、3つのAvailability Zoneにまたがるデータの耐久性と、1つのAvailability Zoneでの可用性が提供されます。これをSingle AZパターンと呼んでいます。1つのDatabase Instanceが1つのAvailability Zoneに存在し、コストとパフォーマンスのバランスを取ります。このInstanceでクエリ処理が行われ、Buffer Poolが存在し、一般的なデータベース用語で説明される処理が行われます。パフォーマンスは、そのInstanceのサイズを大きくするか、自動的にスケールするSurplus Instanceを使用することで向上させることができます。

Auroraは、3つのAvailability Zoneにまたがる大きなボックスで示されているAurora Volumeにデータを保存します。これをAurora Storageと呼んでいます。これは一見、High AvailabilityやDisaster Recoveryにとってそれほど重要に見えないかもしれませんが、実際には非常に重要で、多くの機能の基盤となっています。他の機能がどのように動作するかを理解するために、もう少し詳しく見ていきましょう。



そのDatabase Instanceが何らかの理由で利用できなくなると、データベースは利用できなくなります。 しかし、これはデータの耐久性の問題では全くありません - そのStorageは依然としてデータの耐久性を保持しています。 このStorageについてもう少し詳しく見ていきましょう。下部の緑色のボックスは、1つのAWS Region内の3つのAvailability ZoneにまたがるマルチテナントのStorage Fleetです。 これは多数の特殊な目的を持つStorage Nodeで構成されています。図では6つしか描いていませんが(私の絵の才能の限界です)、実際にはたくさんのNodeがあり、データの保存、修復、ヒート管理、その他Auroraが行う多くのタスクを処理しています - これらすべてがStorage Fleet内で行われています。

小さなボックスは、マルチテナントのStorage Fleetなので、他のVolumeからのデータがすでにStorage Nodeに含まれていることを示しています。これらのAvailability Zoneは物理的に分離されているため、複数のZoneが同時に利用できなくなる可能性は非常に低いです。 Auroraは、まず必要に応じてデータを指定されたキーで暗号化し、3つのAvailability Zoneにまたがって6つのコピーを作成してStorage Nodeに書き込みます。新しい書き込みに対して、お客様が支払うのは1つのコピー分のみです。Auroraが書き込みを完了として次に進む前に、これら6つのコピーのうち4つのクォーラムが永続的なストレージに書き込まれる必要があります。


これは、Auroraが1つのAvailability Zone全体とさらに1つのNode、つまり合計3つのStorage Nodeの障害に対応できることを意味します。これは非常に印象的で、しかもすぐに使える機能です。 では、ここに実際に保存されているデータについて見ていきましょう。生のVolumeは、Protection Groups(PG)と呼ばれる10ギガバイトのチャンクに分割されています。修復やヒート管理などのStorage機能は、このPGを単位として動作します。


従来のデータベースは一般的に、実行予定の操作をログに記録してから実際の操作を書き込みます。 しかしAuroraは、特別なAuroraログフォーマットでそれらのログをAuroraストレージに書き込むだけで、ページ自体は書き込みません。ストレージがこのフォーマットを理解しているため、スペース再利用の必要性に応じて、またはエンジンに読み戻す際に、これらのログレコードをデータベースページに変換する方法を把握しています。 もしデータを読み戻す必要がなければ、この作業は簡単なのですが、もちろん読み戻しは必要です。これらのログレコードを適用して読み戻す必要があるのです。これがAuroraのパフォーマンスの秘密です。すべてのストレージノードで並列処理を行っているからですが、これは後ほど説明するHigh AvailabilityとDisaster Recoveryの機能の多くを支える基盤にもなっています。
Auroraのバックアップと復元機能

さて、Dawn Picturesは順調に成長しており、アプリケーションの頻繁かつスムーズなデプロイが行われ、データベースも成長してたくさんのログレコードを保存しています。ところがある日、アプリケーション開発者が誤って不具合のあるビルドをリリースしてしまい、白黒の写真が配信されてしまいました。しかし心配はいりません。Auroraには継続的な増分バックアップが組み込まれているからです。Auroraストレージの各Protection Group(PG)は、それらのログレコードとデータベースページを継続的にAmazon S3に書き込んでいます。この処理はヘッドノードやデータベースインスタンスではなく、ストレージが行うため、パフォーマンスへの影響はありません - すべてバックグラウンドで処理されています。

バックアップの保持期間は1日から35日の間で設定できます。最も古い復元可能な時点(保持期間で設定)から最新の復元時点の間の任意のポイントで復元を選択できます。アクティブなデータベースの場合、通常、最新の復元時点は現在時刻から約5分以内です。 アプリケーションログなどのツールを使用して時点を選択し、このLatest Restore Timeポイントへの復元をAuroraに依頼できます。新しいボリュームとインスタンスを作成し、適切な時点を選択できたかどうかを確認するため、アプリケーションでテストを実行することができます。この間、元のインスタンスやボリュームには一切変更を加えません。

確認が取れたら、必要に応じてプライマリデータベースとしてオンラインに戻すことができます。では、復元を実行する際に具体的に何が行われているのか、もう少し詳しく見ていきましょう。


復元を実行する際の詳細なプロセスを見てみましょう。これまでのデータベースページとログレコードがすべてAmazon S3に保存されていることを思い出してください。 すべてがそこに保存されているのです。下部のコンソールスクリーンショットに示されているように、Amazon RDSコンソールを通じてPoint-in-Time Restore(PITR)を使用して復元ポイントを指定します。これによってLRTポイントがいつなのかが分かり、その中から適切なポイントを見つけることができます。ここでは、time sevenが必要なポイントだと判断できます。


その後、その時点より前のすべてのページの最新コピーを復元します。これは先ほど見た全てのStorage Nodeで並列に実行されます。そして、その時点から今回の場合は時点7までの全てのログレコードを取得し、ページに適用します。この時点でそれらの命令を再実行するのです。これによって、データベースページはデータベースエンジンの観点からクラッシュ整合性のある状態となります。その後、データベースエンジンが通常のリカバリを実行しますが、これは通常数秒程度の時間しか扱わないため非常に高速です。通常のデータベースエンジンの場合、最後のチェックポイントから数時間かかる可能性があるのとは対照的です。最後の小さなステップの実行方法はMySQLやPostgreSQLとは少し異なりますが、下層のAuroraの仕組みは全て同じです。


優秀なDBAであれば、このような出来事から学び、開発者と話し合って、異なるアプローチが必要だと判断するでしょう。異なるテスト方法が必要です。本番環境でのテストは明らかに良くない結果になってしまいました。本番に近いデータと本番に近いワークロードやパフォーマンスでテストしたいところです。全てを複製するのは多大な労力とコストがかかるため、代わりにAura Cloneを使用します。ここでは、本番インスタンスと、ログレコードとページを含む本番のStorageボリュームがある設定を見ていきます。



次に、下部に新しいCloneを作成します。見た目が異なることがお分かりいただけると思います - 中が空洞になっているように表現しています。下部には実際のログレコードやページは存在せず、新しいインスタンスと、ボリュームへの一連のポインタだけが存在します。Clone volumeから読み取る際、まだ変更されていない場合は、リダイレクトされたポインタを辿って元のボリュームから読み取ります。Storageがこれを処理するため、別途の間接参照は不要で、パフォーマンスへの影響もありません。ログレコードに書き込みたい場合、この間接参照を解除し、Clone volume内に新しいコピーを書き込み、その後直接読み戻すことができます。元のボリュームに書き込む場合も、同様のプロセスが逆方向で発生します。まず古いコピーをClone volumeにコピーしてClone用のコピーを保持し、間接参照ポインタを解除して、新しいデータを本番のStorageに書き込みます。


どちらかのボリュームを拡張しても全く問題ありません - それぞれのボリューム内の新しい領域に書き込むことができます。ここで重要なのは、データの変更分に対してのみ課金されるということです。下部には数個のボックスだけが埋まっているので、それらの少数のボックスのStorage容量と、サイズを変更可能な2つ目のCloneインスタンスに対してのみ課金されます。これがCloneの魔法です。

Dawn Pictures Startupでは、CTOがAmazonのCTOであるDr. Werner Vogelsの言葉に強く共感します。Tシャツでも見かけたことがあるかもしれません - "Everything fails all the time"(すべては常に故障する)というものです。これは真実です。CTOに対して、これまで話してきた3つのAZの耐久性については満足していますが、可用性についてはさらなる改善が必要だと提案できます。Auroraは1つのRegion内で99.99%(4ナイン)のSLAを提供しており、私たちもそれを目指したいと考えています。計算すると、これは年間約52分のダウンタイムに相当します。
Multi-AZ構成とRead Replicaによる可用性向上

これを実現するには、複数のAvailability Zoneを利用する必要があります。2つのゾーンがありますので、同じリージョン内に2つ目のインスタンスを作成しました。可用性を確保するため、同じAurora volumeを使用しています - データの複製や同期は行っていません。すべてのデータは同じAuroraストレージに保存されています。スタンバイを立ち上げると - ご覧のように、db.r8g.16xlインスタンスを2つ用意しています。同じサイズである必要はありませんが、ここでは、プライマリでフェイルオーバーイベントが発生した場合に、スタンバイが同じ負荷を処理できるように、同じサイズを選択しています。 ここではRPO(Recovery Point Objective)について議論する必要はありません。共有ストレージが1つだけなので、これはRPOゼロと呼ばれるものです。フェイルオーバー中またはその前に、プライマリは新しいトランザクションでスタンバイを最新の状態に保ちます。通常、フェイルオーバーには約30秒かかりますが、それは許容できる範囲で、その後すぐに運用を再開できます。

さらに成長すると、より多くのトランザクションスループットが必要になるかもしれません。すでにかなり大きなインスタンスを使用していますが - これは最大のRDSではなく、もう少し大きくすることはできますが、追加の読み取りスループットが必要です。以前フェイルオーバーのスタンバイターゲットとして追加した2つ目のインスタンスを、他に何もせずにReplicaとして使用することができます。要求すれば、読み取り専用のクエリを処理することができます。Writerは通常数ミリ秒以内に新しいトランザクションでReplicaを最新の状態に保つので、読み取り専用トランザクションには若干の遅延が発生しますが、それ以外は完全にハンズオフで運用できます。


アプリケーションをReplicaに向け、 読み取り専用の問い合わせを実行するように設定します。ここでは、両方のインスタンスが処理可能な最大負荷の約70%で動作していることがわかります。 しかし、これには問題があります。プライマリに障害が発生した場合、負荷が一定のままだとすると、1つのインスタンスに対して140%の負荷がかかることになります。Amazon Auroraは優れた性能を持っていますが、100%を超えることはできないので、ここでオーバーロードの問題が発生します。Read Replicaは役立ちましたが、別の問題を引き起こしてしまいました。


では、これにどう対処すればよいでしょうか?このパターンを単純に複製し続けることができます。Replicaを追加し続けることができます - ここでは3つありますが、さらに増やすことができ、サイズを変えることもできます。先ほどの70%という数字に注目すると、フェイルオーバーが発生した場合、 100%を超えることはないので、オーバーロードの問題は発生しません。この場合、3つのAvailability Zoneに配置しているので、実際にはAvailability Zone 1と2が使用できなくなっても、まだサービスを継続できます。Availability Zone 3はまだ稼働しているからです。



ただし、この場合は再びオーバーロードの問題が発生するので、パフォーマンスは低下しますが、システムは稼働し続けます。負荷が増え続けると、これでも十分ではなくなる可能性があります - さらにパフォーマンスの余裕が必要かもしれません。 リージョン内で最大15個のReplicaを追加し続けることができます。サイズを変えることもできますし、サイズ調整が自動的に行われるServerlessを使用することもできます。 元の16xlインスタンスが2つあり、さらに8xlインスタンスなど、より小さなインスタンスも追加しました。これはReplica用のトラフィックに適しています。

先ほど説明したように、小規模なインスタンスへのフェイルオーバーは避けたいところです。そこでAmazon Auroraでは、フェイルオーバーティアという考え方を使って、フェイルオーバー時にインスタンスを選択する順序を指定します。ティア0のような小さい番号のものが、大きい番号のものより優先的に選択されます。複数の選択肢がある場合は、元のWriterのサイズに合うものが選ばれるため、オーバーロードの問題を回避できます。

これらのReplicaを追加しても、アプリケーションがそれらと通信できる必要があります。その時々で適切なReplicaを知る必要があるのです。 書き込み操作の場合は、Writerに送信する必要がありますが、フェイルオーバーが発生すると変更されるため、アプリケーションはどれがWriterなのかを把握している必要があります。Amazon Auroraではエンドポイントという概念を提供しており、WriterエンドポイントまたはClusterエンドポイント、そしてReaderエンドポイントがあります。WriterエンドポイントはDNSを通じて現在のWriterを指し、ReaderエンドポイントはラウンドロビンDNSを使用して読み取り可能なすべてのReplicaを指します。アプリケーションにIPアドレスをハードコードする代わりに、DNS名を使用すれば、DNSが自動的に処理してくれます。


これにより、フェイルオーバーの発生時やReplicaの追加時、Auto Scalingの起動時にアプリケーションがトポロジーの変更を検出するまでの時間が短縮され、可用性が向上します。カスタムエンドポイントを設定して、任意のエンドポイントをグループ化することもできます。例えば、フロントエンドトラフィックを処理するものとバックエンドトラフィックを処理するものを指定できます。 このように、フリートは急速に成長しています。 PHPを実行するEC2インスタンスのプールであるフロントエンドアプリケーションフリートと、バックエンドでJavaを実行するサーバーのプールがあります。これらのサーバーはそれぞれAuroraのエンドポイントに接続を確立しています。ここでは書き込み側についてのみ説明しますが、読み取り側でも同じことが起こります。スライドが複雑になりすぎるので省略していますが。
これは回復性に関する課題をもたらします。なぜなら、これらの接続はすべて処理能力を使用するからです。ソケットスロットを使用し、常に再接続を行い、認証と認可を実行し、TLSなどを処理します。アイドル状態でもリソースを消費します。そのため、この接続管理をコントロールする必要があります。

私たちのツールボックスには、接続の制限とプーリングという2つのテクニックがあります。 接続を制限することで、オーバーサブスクリプションの問題を回避できますが、パフォーマンスが制限される可能性があります。プーリングを使用すると、接続を再利用することでパフォーマンスを回復できます。JVM用のJDBCなど、多くのドライバーパッケージには、すでに一定レベルのプーリング機能が組み込まれています。ただし、課題の1つは、Amazon Auroraのようなクラスター化されたシステムで何が起こっているのかを認識できないことです。シングルノードデータベースしか認識できないのです。

これを自分で対処しようとすると、それぞれの接続に対して、フェイルオーバーが発生した時の特別なロジックを実装する必要があります。Writerからエラーが返ってきた時、特定のエラーを認識して、適切な再接続やトランザクションのやり直しなどの対応が必要になります。また、DNSの変更が世界中に伝播するまでに通常30秒程度かかるため、即時性の問題にも対処しなければなりません。これらの課題に対応するため、AWS Advanced JDBC Wrapperドライバーを提供しています。


このWrapperは、データベースクラスターのトポロジー内で何が起きているかを把握しています。ノードの存在、役割、そして変更が発生した時の状況を、DNSよりもはるかに早く認識できます。これはAWS独自の秘密の仕組みではなく、誰でも利用できるオープンソースのソリューションです。 このプラグインの設定によっては、フェイルオーバーを最大66%速く、約6秒以内、あるいはそれ以上早く処理することができます。最近、さらに高速な新しいフェイルオーバープラグインを発表しました。以前からこれを使用していた方は、新しいバージョンではより高速になっています。また、ここで説明した機能はPythonやNode.jsでも利用可能で、MySQL ODBC Driverも提供しています。


次に、Amazon RDS Proxyを実装できます。これにより、先ほど説明したPHPのフロントエンドのような、よりステートレスなフリートでの制御が向上します。コンソールで数回クリックするだけでAmazon RDS Proxyを設定でき、複雑な設定は必要ありません - Proxyを有効にするだけです。アプリケーション側では、クラスター用のReaderエンドポイントとWriterエンドポイントの代わりに、Proxyエンドポイントと通信するように設定するだけです。Proxyは自身のレベルでReaderとWriterのエンドポイントを提供します。Proxyを使用すれば、この複雑な設定は不要になります。 すべてをProxyレイヤーに移行し、Proxyの背後でプール化された接続を管理します。


前回はWriterについて説明しましたので、今回はReader側に焦点を当てましょう。 アプリケーションは前面で多くの接続を作成しており、異なる色で何が起きているかを示しています。黄色のトランザクションは、このバックエンド接続プールを通じて実行されています。青いトランザクションは、最大制限が1だったため、キューに入れられて待機していました。その後、青いトランザクションが実行され、Pinningを引き起こしました。 Pinningとは、内部状態が変更されたため、このプール化された接続が後続のセッションで使用できなくなる状態を指します。これは、ロック関数、プリペアドステートメント、ストアドプロシージャなどが原因で発生する可能性があります。Pinningが気になる場合や可視性が必要な場合は、CloudWatchメトリクスでPinningの発生状況を監視できます。可能な限りアプリケーションでこれらの操作を避けることで、Pinningを最小限に抑えることをお勧めします。
グローバルレジリエンスへの進化:Cross-Region Backup


フェイルオーバー時、セッションがPinningされていなければ、フロントエンドのアプリケーション接続は切断されません。ここでは紫色のセッションが実行されており、黄色と紫色のセッションは切断を経験していません。しかし、青いセッションはPinningされていたため切断されました。 夜明けの写真を販売するビジネスは大成功を収め - 誰が予想したでしょうか?スタートアップは大きな投資を獲得し、グローバル展開の時期を迎えました。DBAにとってこれは大きな課題です。Dr. Werner Vogelsの「すべては常に失敗する」という言葉を思い出し、万が一のAWSリージョン全体の障害が発生した場合でもデータの耐久性を確保する必要があると判断しました。
では、Grantにその説明をしてもらいましょう。こちらがGrant McAlisterです。Global Resilienceについてお話しします。ありがとうございます、Tim。
ビジネスが成長し拡大するにつれて、考慮しなければならない要素の1つがGlobal Resilienceです。私たちのRegionは非常に堅牢で可用性が高いのですが、Hurricane Sandyが東海岸に接近した際、多くの人々がUS East 1データセンターを心配していました。結果的には問題ありませんでしたが、このような事態はより深刻になる可能性があり、ビジネスを守るために真剣に考える必要があります。私たちのビジネスが大きくなるにつれて、リーダーシップからもこの点について考えるよう求められています。



最初に検討する方法はCross-Region Backupです。 Timが説明したのと同じようなセットアップをRegion A(プライマリーRegion)に示していますが、Region Bで保護対策を講じたいと考えています。 最も簡単な方法は、create-db-cluster-snapshotコマンドを実行してデータベースのバックアップを取得することです。これはサービスの一部としてAmazon S3に保存されます。 その後、copy-db-cluster-snapshotコマンドを使用してスナップショットを2番目のRegionにコピーすることができます。



これは実質的にはAsynchronous Replicationです。1時間ごとに実行する場合、それがラグとなります。10分ごとや1日ごとなど、異なるタイミングを選択することもできます。さて、バックアップが完了しました。 ここで、Region Aに写真の販売が入ってきたとしましょう。しかしRegion Aで問題が発生したとします。 ここが課題です - バックアップはその写真が入る前に取得されていたため、その写真データは含まれていません。

このソリューションでのRPO、つまり失う可能性のあるデータ量は、おそらく10分から70分の範囲になります。 この範囲になる理由は、非常に運が良ければ問題が発生する直前にスナップショットを取得できていますが、私のように運が悪い場合、スナップショットは59分前に取得され、さらにコピー時間が加わるため、1時間以上のデータを失う可能性があるということです。そのため、これを黄色で表示しています - この方法は機能しますが、1時間ごとのバックアップの場合、かなり大きなRPOとなります。


朗報なのは、私たちは実際に2番目のRegionにデータベースのコピーを持っているので、すべてのデータを失ったわけではないということです。このDB Clusterをリストアして、DB Instanceを作成することができます。これで一応動作します - 少しデータは失われますが、システムは復旧します。RTOは約60分になります。これは、リストアを実行し、Instanceを作成し、アプリケーションを再起動する必要があるためです。これが黄色でマークされているのは、ビジネスの立ち上げ時には問題ないかもしれませんが、成長するにつれて十分ではなくなる可能性があるためです。
Aurora Global Databaseによる高度な災害対策


Timも言っていたように、障害は発生するものなので、もう一つの種類の障害についてお話ししたいと思います。私たちがよく考えるのはRegion全体がダウンするケースですが、実はそれが最悪のケースというわけではありません。最悪のケースは、ネットワークパーティションです。つまり、Regionの外からそのRegionにアクセスしようとしても見えない状態のことです。Region BからRegion Aが見えませんが、Region A内部では全てが正常に動作し続けています。画像を送信するプロセスは依然として実行され、配信サービスに画像のコピーを送信します。つまり、Region Aでの画像販売データを失うだけでなく、そのネットワークパーティション時間中は出荷も見逃してしまうため、システムは利用できない状態となります。


これは非常に複雑に見えますが、AWS Backupというサービスがあり、Amazon Auroraと統合されてこの全体のオーケストレーションをシンプルにしてくれます。ビジネスとして次のステップは、RPOとRTOの両方を削減することを真剣に考えることです。Amazon Auroraのグローバルデータベース機能を見ていきましょう。まずはストレージのみのオファリングから始めます。これは、作業を行う別のRegion、Region Bを持つことを意味します。create-global-clusterコマンドは、Clusterを作成する前に実行することも、元のRegionのClusterを参照して既存のClusterを追加することもできます。その後、2番目のRegionでcreate-db-clusterを実行するだけです。


これで、そのRegionにストレージを持つことができます。これはAuroraの特別な機能の1つであるストレージレプリケーションです。2番目のRegionにInstanceは必要ありません。私たちがバックグラウンドで行うのは、レプリケーションサーバーとエージェントをセットアップし、



現在のシステムからサーバーへ、そしてエージェントを経由してストレージへとレプリケーションを開始することです。このプロセスは非同期ですが、重要な違いは、レプリケーションのラグが通常、秒、分、時間単位ではなく、ミリ秒単位だということです。データが入力されると、数ミリ秒以内に両方のRegionに存在することになります。数ミリ秒と言いましたが、Regionによっては数百ミリ秒程度になる可能性があります。RPOは通常、1秒未満にネットワークパーティション時間を加えた値となります。




Aurora Global Databaseのもう1つの大きな利点は、各リージョンでローカルバックアップを取得できることです。これにより、稼働中のシステムを保護するだけでなく、誰かがテーブルを削除してしまうような事態に対しても、独立したコピーを維持することで保護することができます。もしRegion Aで問題が発生した場合、 2番目のリージョンでデータベースインスタンスを起動し、Global Clusterのフェイルオーバーを実行することが可能です。ここで重要なのは、--allow-data-lossパラメータです。 これは非同期レプリケーションであり、Region AとRegion Bは必ずしも同期しているわけではなく、数ミリ秒の差が生じる可能性があるためです。このデータの差異を認識した上で、Read-Writeノードを確立し、 アプリケーションを起動して運用を再開します。

この構成では、RTOは約15分程度となり、スクリプティングの内容によってはさらに短縮することも可能です。この時間には、インスタンスとアプリケーションの起動時間が含まれています。レジリエンスを実装する際、 目的地となるリージョンを慎重に検討する必要があります。世界中に多数のリージョンがありますが、この例では、ソースをUS West 2(Oregon)に置き、デスティネーションをAP Southeast 1と2つのUS Eastリージョンに設定しています。AP Southeastへのレイテンシーは、US西海岸からかなり離れているため約170-200ミリ秒で、時には250ミリ秒までスパイクすることがあります。

より近いUS Eastリージョンを選択した場合、レイテンシーは60-70ミリ秒程度になります。East 1とEast 2は地理的にほぼ同じ場所にあるため、同様のレイテンシーを示すことがわかります。最も離れた2つのリージョンを選択すると最大のレイテンシーとなりますが、より近いリージョンを選択するとレイテンシーは減少する一方で、レジリエンスのカバー範囲も減少します。これは設計における基本的なトレードオフとなります。



ビジネスにおける次のステップは、対称的な構成の実装です。 Region Bには、Region Aのセットアップと全く同じコピーを作成します。同じデータベースインスタンスをRead-Onlyモードで実行し、レプリケーションを確立して、ローカルのRead-Onlyノードと同じように最新の状態を維持します。アプリケーションもそこで実行できます。フェイルオーバー時 や障害時には、新しいインスタンスを作成する必要なく、単にフェイルオーバーコマンドを実行するだけです。 これにより、RTOは2分未満に大幅に改善され、毎年このタイミングの最適化を続けています。


ネットワークパーティションのシナリオを再度見てみましょう。この構成では、ネットワークパーティション時に、 フェイルオーバーによって一時的に2つのRead-Writeノードが存在することになりますが、まだそのリージョンは分離されていません。リージョンの分離が解決されると、そのノードをRead-Onlyに変換します。ただし、この非同期ワークフローでは、この期間中にトランザクションが発生する可能性があり、これは重要な考慮事項です。フェイルオーバーを完了して運用を再開した後は、 Region Bのみで運用しているため、もはやレジリエントな状態ではありません。

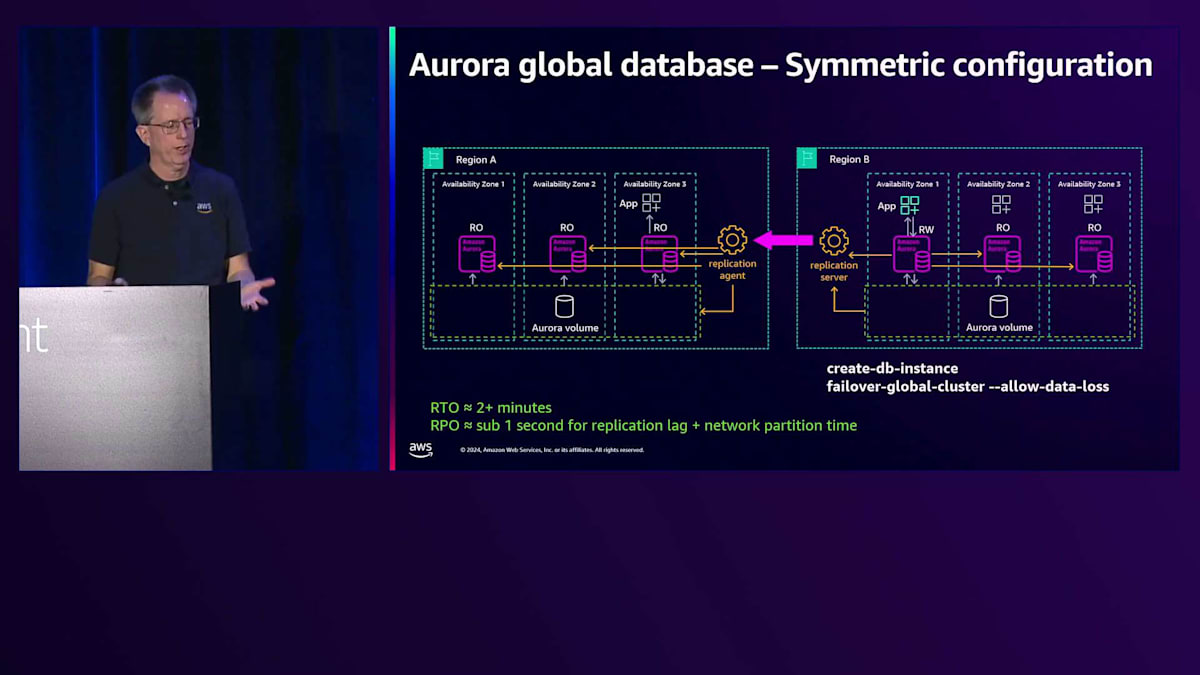
レジリエンスを回復するためには、Region Aを再確立する必要があります。まず、自動サービスの一環として、Region Aクラスターのバックアップを取ります。これは、Region Bに複製されていないデータが含まれている可能性があるためです。このバックアップにより、データの違いを復元して分析することができます。次に、反対方向にレプリケーションサーバーとエージェントを設定します。 Region AのデータはRegion Bとは異なり、おそらく先行している状態なので、レプリケーションを再開してレジリエントな設定を復元する前に、同期を行う必要があります。

この復元プロセス全体は、リージョンが正常な状態に戻ると自動的に実行されます。その状態になると直ちに、必要な手順を開始します。スイッチオーバーは、あるリージョンから別のリージョンに移行するもう一つの方法です。これはデータ損失のない方法で、通常はRegion AからBへの移行に使用されます。例えばSandyのような嵐の場合、スイッチオーバーを使って事前に移行することができます。また、DRセットアップをテストする良い方法でもあり、切り替えて想定通りに動作するかを確認できます。



コマンドは「switchover-global-cluster」です。ここでの設定ではデータ損失が発生しないことに注目してください。まず、新しいトランザクションの受け付けを停止するため、Read-Writeノードを即座にRead-Onlyに変更します。その後、レプリケーションを待ち、すべてのデータが同期されていることを確認します。そしてRegion Bを昇格させます。Region AがRead-Only、Region BがRead-Writeとなり、基本的にリージョンを切り替えたことになります。ただし、Region Aをグローバルクラスターの一部として戻す必要があるため、まだレジリエントな状態ではありません。これらのリージョンは一致しているため、同期を行う必要はなく、レプリケーションエージェントとサーバーを設定してレプリケーションを開始するだけで済みます。また、スイッチオーバー時間もかなり改善されました。


レジリエンスに関するもう一つの重要な点は、アプリケーションが実際にアクティブなデータベースとの通信先を特定できることです。このグローバルな性質において、各データベースは異なるエンドポイントを持っています。これは、AWSのDNSサービスであるAmazon Route 53によって提供されるRegion Aクラスターの CNAMEです。 Region Bは異なるものを持っており、サブドメインが一方でRegion A、もう一方でRegion Bとなっていることがわかります。名前は異なっていても構いませんが、必ず異なるものになります。以前はグローバルエンドポイントがなかったため、フェイルオーバーやスイッチオーバー時にアプリケーション側でこの切り替えを設定する必要がありました。


現在は、クラスターに対して「describe-global-cluster」を実行すると、この新しいエンドポイントが表示されます。私たちは、これがグローバルであることを確実に認識してもらうため、名前に「global」を2回入れました。これは異なるサブドメインの一部ですが、命名規則の一部としても追加しました。重要なポイントは、現在Region Aがプライマリリージョンであるため、そのグローバル名の解決を要求すると、Region AのCNAMEを指すということです。


Switchoverやフェイルオーバーを実行する場合、Region Aを読み取り専用にして、Region Bを昇格させます。その時点で、名前解決は異なる方法で行われ、Region BのCNAMEに解決されます。このシステムの利点は、Amazon Route 53のコントロールプレーンを使用する必要がないことです。これらのヘルスレポーターが存在し、非常に高可用性であるため、どのような状況でも確実に機能します。これにより、アプリケーションのグローバルな観点での耐障害性が簡素化され、アプリケーション開発者が設定を正しく行うことがより容易になります。
グローバルデータベースの高度な機能と考慮事項



アプリケーションとデータベースの耐障害性を向上させるもう一つの領域は、読み取り耐障害性です。対称的な構成では、アプリケーションの一部を読み取り専用で動作するように変更します。例えば、商品画像の一覧表示などは、書き込みの必要がなく、表示するだけで十分です。これを両方のリージョンで実行することで、お客様により近い場所でサービスを提供できるため、レイテンシーが改善されます。障害が発生した場合でも、これらの読み取り専用ノードは稼働を継続できるため、フェイルオーバーやスイッチオーバーの実行中も運用を継続できます。これにより、スイッチオーバーやフェイルオーバー時の数分間のダウンタイムが発生する読み書き両用の構成と比べて、より高い可用性を実現できます。



この構成では、Write forwardingも利用できます。読み取り専用アプリケーションの課題は、時々小さな書き込みコードが必要になることで、そのようなコードをアプリケーションから切り離すのは困難です。Write forwardingがない場合、Region Aのアプリケーションに書き込みリクエストを送信するためにVPNトンネルが必要となり、複雑で脆弱な構成になってしまいます。代わりに、Global write forwardingを有効にできます。これにより、そのクラスターに書き込めるように見せかけ、書き込みをRegion A にフォワーディングします。

これはマルチライターシステムではなく、シングルライターシステムのままです。単にバックワードにフォワーディングを行い、プロセスを簡素化しているだけです。一貫性の観点から、アプリケーションが書き込んだものを読み取るためには、それらが複製されて戻ってくるのを待つ必要があります。ここで、Aurora Global Databaseの一貫性についてもう少し詳しく説明しましょう。


Write forwardingの機能には、セッション読み取り可視性に関する耐障害性のための重要な設定がいくつかあります。ここではPostgreSQLの設定を示していますが、MySQLにも同様の設定があります。デフォルトはセッションレベルで、これは「自分の書き込みを読む」という意味です。更新を実行すると、それがフォワーディングされ、戻ってくるのを待つ必要があります。US EastとUS West間のかなり広い範囲で、約195ミリ秒かかります。


Selectは自分が書き込んだデータを確実に読み取るために、書き込みの伝播を待つ必要があり、これは国をまたぐレプリケーション時間のため76ミリ秒かかります。 良いニュースは、自分の書き込みを読み取れているので、アプリケーションで不整合なデータを見ることはありません。次のSelectは、変更を加えていないため、ローカルで読み取れて1ミリ秒で済みます。 これは上手く機能しますが、最初のSelectがかなりの時間を要することを認識しておく必要があります。



もしこの速度に満足できない場合は、Eventual Consistencyを選択することもできますが、これには独自の課題があります。 Eventual Consistencyでは、Updateは依然として195ミリ秒かかり、Selectは1ミリ秒で済みます。 ただし、以前の書き込みが見えないため、アプリケーション開発者にとって問題となる可能性があります。もう1つの選択肢はGlobal Read Visibilityで、これは慎重な検討が必要なため赤で表示しています。

Global Read Visibilityは完全なグローバルな読み取り一貫性を提供します。Updateに195ミリ秒かかった後にSelectを実行すると、伝播を待つ必要があります。時刻tにおいて、自分の書き込みだけでなく、プライマリで発生するすべての操作が伝播されるのを待つ必要があります。これには205ミリ秒かかりますが、すべての書き込みが見えるため、アプリケーション設計がしやすくなります。ただし、すべての書き込みが見えるようになるまで待つ必要があるため、すべてのSelectに205ミリ秒かかります。 この可視性は有益ですが、レジリエンシーの観点からは、レプリケーションのラグに依存することになります。


マルチリージョンのグローバルデータベースも実行できます。Region AとRegion Bを対称的な構成で見ると、最大5つのデスティネーションを持つことができます。ここに示すRegion C はストレージのみで、デスティネーションが同一である必要がないことを示しています。コストとRTOの要件に応じて設定できます。2つの対称的なデスティネーションで対称的にすることもできます。Aurora PostgreSQLでは、 Global DB RPOという興味深い機能があります。


Global DB RPO設定により、少なくとも1つのデスティネーションが指定したRPO時間(秒単位)以内に収まることが保証されます。20秒に設定すると、1つのリージョンが20 秒以内のレプリケーションラグに収まらない限り、Region Aでコミットを受け付けません。例えば、Region Bへ200ミリ秒、 Region Cへ100ミリ秒でコミットする場合、RPO制限内なのでコミットできます。Region Cのラグが60秒になっても、Region Bが200ミリ秒を維持していれば、問題ありません。


しかし、ネットワークパーティションが発生した場合、Region Bのラグが21秒に達して20秒の閾値を超えると、コミットがブロックされ始めます。これにより、Region Bにフェイルオーバーする際に、データ損失が最大20秒に抑えられることが保証されます。この機能は20秒以上の値に設定することも可能で、金融取引や契約など、データ損失の上限を保証する必要がある場合に特に有用です。広く使用されているわけではありませんが、金融機関にとっては重要な機能です。
もう一つの重要な領域は、Cross-Account設定です。これは厳密にはグローバルな機能ではありませんが、ローカルとグローバルの両方のシナリオに適用できます。Global Databaseの例を使って説明しましょう。標準的なセットアップでは、すべての設定がAccount Aという1つのアカウントで行われます。Account Aにとってはこれで問題ありません。

ただし、Account Aに何か問題が発生した場合はどうでしょうか。怖い話はしたくありませんが、実際に起こり得ることです。そこで私たちができるのは、Account Bをセットアップし、AWS Backupを使って各リージョンでスナップショットを取得し、それをAccount Bのアカウントにコピーすることです。これにより、Account Aで何か問題が発生しても保護されます。これは非同期なので、同じRPOの考慮事項が適用されます - スナップショットの頻度によって、失う可能性のあるデータ量が決まります。ただし、これはAWS Backupで非常に簡単にセットアップできる強力な機能です。
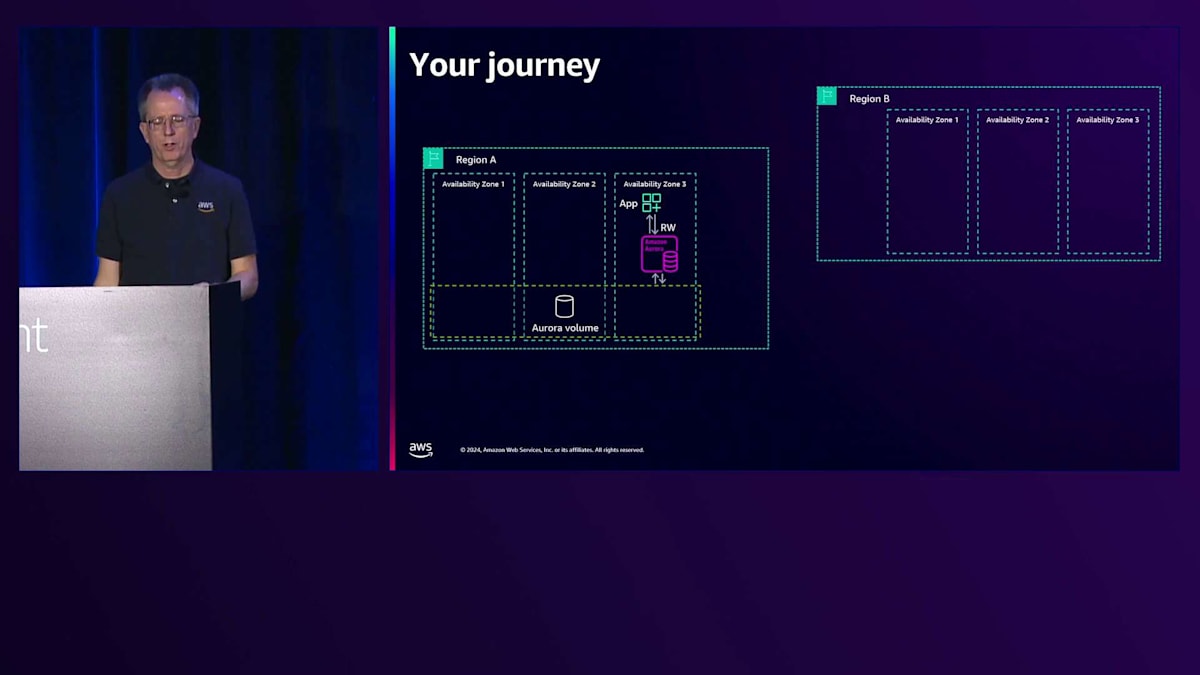



では、私たちの会社としての成長の過程を振り返ってみましょう。最初は単一のAvailability Zoneに単一のインスタンスがあるだけでした。その後、異なるAvailability Zoneに複数のデータベースインスタンスを追加し、Multi-AZで最大限の可用性を確保しました。さらにRegion BにStorage-onlyのGlobal Databaseを追加し、対称的な構成にすることでRTOの時間を短縮しました。最後に、これらすべてのリージョンにバックアップを追加し、非常に良好なRTOとRPOの値を達成することができました。

以上で発表を終わります。今週は他にも関連するセッションがあります。すでに終了したものもありますが、ビデオで視聴することができます。ご清聴ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion