re:Invent 2024: AWSのCloud Resilienceチームが語る多層的な耐障害性
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Mastering resilience at every layer of the cake (ARC327)
この動画では、AWSのCloud Resilienceサービスのgo-to-marketをリードするShlomi Ezraが、高度なResilienceの特性と実装について解説しています。Zonal、Regional、Global Servicesの違いや、Static Stabilityの概念、AWS Fault Injection ServiceによるChaos Testingの実践方法など、具体的な実装パターンを詳しく説明しています。また、VanguardのChristopher Volosが品質を向上させながらデプロイ速度を5倍に向上させた事例や、UnitedのJenny Zhouが開発した自動フェイルオーバーソリューション「Rapid Recovery」により復旧時間を80%短縮した事例など、実践的な取り組みも紹介されています。AWS Resilience Lifecycle Frameworkに基づく体系的なアプローチと、具体的なツールやサービスの活用方法が示されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Cloud Resilienceの概要と重要性

みなさん、おはようございます。お越しいただき、ありがとうございます。声が大きすぎる場合は、このようにお知らせください。本日は私、Shlomi Ezraが担当させていただきます。Cloud Resilienceサービスのgo-to-marketをリードしております。本日のセッションには、VanguardのChristopherさんとUnitedのJennyさんにもご参加いただいております。


本日は、高度なResilienceの特性、機能、パターンについてご紹介させていただきます。考慮すべき依存関係や検討事項についてお話しし、皆様に実践可能な有益な知見をお持ち帰りいただければと思います。できるだけ具体的な状況に即してご説明していきます。いつものように、ケーススタディやお客様の事例を交えながら、AWSの社内での取り組みと外部のお客様の事例の両方をご紹介します。本日は素晴らしいお客様にステージに来ていただいており、ご自身の体験をお話しいただきます。また、プレゼンテーションを通じてデモやケーススタディもご覧いただきます。

本題に入る前に、まず整理させていただきたいと思います。本日のフォーカスは、特定のサービスではなく、Resilienceという概念そのものです。Chaos TestingやResilience Testing、Disaster Recoveryなど、Cloud Resilienceの提供内容の一部を含むトピックについてお話しします。目的は、他のお客様やAWSサービスがどのようにResilienceカルチャーを構築しているかの例をご紹介することです。


Cloud Resilienceとは、インフラストラクチャ、依存サービス、設定ミス、一時的なサービス障害、負荷スパイクなど、あらゆる障害に対して、アプリケーションが耐性を持ち、回復する能力を指します。 プレゼンテーションの導入として、ケーキを例に説明させていただきます。まず底辺にあるのがプラットフォームです。ここではクラウドビルダーが私たちのクラウドを使用し、EC2を作成し、オブジェクトを作成し、AWSコンソールやCLIを使用します。次の層は、インフラストラクチャ、オペレーティングシステム、データベースです。そして最上層が、これら全ての本来の目的であるアプリケーションの実行層です。これらの異なる層は、異なるユーザーによって使用されます。アプリケーションは上層のユーザーによって使用され、底辺では、この基盤全体を構築するビルダーがいます。最終的に、企業の目的は、アプリケーションをResilientな方法で実行することであり、そのためには、長持ちするケーキを作るように、考慮すべき多くの依存関係があるのです。
AWSのサービス構造とResilience戦略


これは上級セッションですので、Availability ZonesとRegionsの概念はご存知かと思います。現在、AWSは世界中に34のRegionと108のAvailability Zonesを展開しています。ここで、私たちのサービスがどのように構築されているかを詳しく見ていきましょう。 最初のタイプはZonalサービスです。これらのサービスは各Zoneに構築されています - Amazon EC2やAmazon EBSを思い浮かべてください。これらはZonalなデータプレーンを持ち、コントロールプレーンは場合によってはZonal、場合によってはRegionalです。Zonalサービスの利点は、Zone単位でプロビジョニングされ、各Zoneで独立して障害が発生するということです。この特性により、お客様はより耐障害性の高いアーキテクチャを構築することができます。



アクセスプレーンについて見てみましょう。例えばEC2では、データプレーンがあります。これはネットワークを通じてリソースに接続する部分です。コントロールプレーンは、インスタンスの起動や停止、新しいリソースのデプロイを行う際に使用するAPIです。 これがZonal Servicesと呼ばれる基本的な構成要素の一つです。また、Regional Servicesも構築しています。Regional ServicesはZonal Servicesを使用して構築されており、後ほどAmazon DynamoDBを例に詳しく説明します。Regional Servicesのポイントは、AWSが高い回復力を備えた形で構築しているため、お客様自身で構築する必要がないということです。 Regional Servicesのアクセスプレーンについて考えると、両方のサービスに対して統一されたAWS APIというアプローチを取っています。そして3つ目のグループがGlobal Servicesです。

RegionalとZonalのサービスに加えて、コントロールプレーンとデータプレーンが各リージョンで独立して存在しないAWSサービスが少数存在します。これらのサービスもコントロールプレーンとデータプレーンを分離するパターンは維持していますが、異なる点は、コントロールプレーンが単一のリージョンでホストされ、データプレーンがグローバルに分散されているということです。

スライドの太字で示されている重要なポイントの一つは、復旧計画において分割可能なGlobal Servicesへの依存は推奨しないということです。これは統計的に見て、コントロールプレーンはデータプレーンよりも信頼性が低いためです。障害が発生した場合、復旧パスでコントロールプレーンに依存したくないはずです。AWS Identity and Access ManagementやOrganizationsなどのサービスがこのカテゴリーに該当します。

アプリケーションの設計を考える際にこの分野をさらに探求したい場合、 AWS Fault Isolation Boundariesの利用を強くお勧めします。これはZonal、Regional、Global Servicesの違いについて詳しく説明しています。私が説明した情報はすべてウェブサイトで確認できます。
Static StabilityとAWS Fault Injection Serviceの活用

次に注目したい領域はStatic Stabilityです。 これは最も重要な回復力の特性の一つです。AWSではStatic Stabilityを、変更を加えることなく同じ作業パターンを維持できる状態と定義しています。これは、Availability Zoneの損失が発生した場合でも運用を継続できるシステムを構築する際に非常に有用なパターンです。この状況については多く議論されており、デモでその様子をお見せする予定です。
このコンセプトは、コントロールプレーンがデータプレーンよりも統計的に障害が発生しやすいという事実を考慮しています。3つのAvailability Zoneにまたがるアプリケーションを考えた場合、6つのインスタンスを稼働させる必要があるなら、合計で9つのインスタンス(50%増)をデプロイすることで、1つのAvailability Zoneが故障しても、追加リソースをプロビジョニングするためにコントロールプレーンに依存する必要がなくなります。確かにコストは少し高くなりますが、これが目標を達成する方法なのです。

この例として、AWS Lambdaがどのように静的安定性を実現しているかという公開事例を紹介したいと思います。 ご覧のように、チームは3つのAvailability Zoneにわたってインスタンスをデプロイしています。Lambdaはリージョナルサービスですが、ゾーンサービスで構成されています。Lambdaには80以上のサービスがあり、その多くがAmazonに依存しています。Lambdaチームは3つのAvailability Zone構成を構築しており、1つのAvailability Zoneが異常と判断されても、他のAvailability Zoneが負荷を処理でき、パフォーマンスが低下することはありません。LambdaチームはAmazon CloudWatchと共に、いずれかのAvailability Zoneで性能低下が発生していないかを識別し、そのAvailability Zoneからトラフィックを素早く退避させて正常なゾーンに移行するためのヘルスチェックの仕組みを構築しました。

お客様からは、このような機能が欲しいという声をいただいていました。 2023年に私たちはこの記事を公開し、Amazon Application Recovery Controller Zonal Autoshiftというサービスを発表しました。このサービスは、お客様が何も操作することなくトラフィックをシフトすることを可能にします。Application Load BalancerとAuto Scalingをサポートしており、基本的にLambdaチームが同じ構成要素を使って構築したものと同様に、AWSがお客様に代わってトラフィックをシフトすることを可能にします。また、Zonal Shift Observerを使用することで、AWSがAvailability Zoneの性能低下を検知した際に通知を受け、自動的な移行ではなく手動でトラフィックをシフトすることもできます。これは、移行を自動制御したくないステートレスアプリケーションのケースにより適しています。このように、お客様のアプリケーションのより制御された復旧を実現することができます。


さらに詳しく知りたい方は、こちらのリンクをご覧ください。 Availability Zoneを使用した静的安定性についてより詳しく学ぶことができます。皆さんはこのスライドをご存知かと思いますが、「すべてのものは常に故障する」というものです。 そしてレジリエンスについて考える時、これが共有責任モデルであることを強調したいと思います。AWSはクラウドのレジリエンスに責任を持ちます。


スライドは後ほど共有させていただきますが、もう少しお待ちください。 AWSがクラウドのレジリエンスに責任を持つ一方で、お客様はその上に構築するものに対して責任を持ちます。私たちは、お客様がレジリエントなアプリケーションを構築しやすくするためのプロセスとツールを開発しています。 また、レジリエンスと呼ばれるものについて、Continuous ResilienceとFoundational Resilienceという2つの区別をしたいと思います。Foundational Resilienceは、より耐障害性の高いアプリケーションを構築するために私たちのサービスに組み込まれているすべての機能を包含します。RDSのマルチAZやマルチリージョンを考えてみてください。昨日発表したばかりのElastic MemoryDBマルチリージョンなど、多くの機能を開発しています。Continuous Resilienceは、目標達成状況を監視するのに役立つ、組織の人材、プロセス、システムの動きを指します。レジリエンスの状態を監視するための目的特化型レジリエンスサービスを考えてみてください。



私たちは、より多くのツールやサービスの構築に多大な投資を行っています。後ほどこのプレゼンテーションで、AWS Resilience Hub、AWS Fault Injection Service、Disaster Recovery Backup、そして先ほど触れたAmazon Application Recovery ControllerやAWS Solutions Libraryなど、皆様の作業を容易にするためのいくつかのサービスについてご紹介させていただきます。 ここで、お客様との対話を通じて見えてきたトレンドについて共有させていただきたいと思います。 まず第一に、Resilienceテストへの需要が高まっています。GameDaysや臨時のテストから、継続的な実験、あるいはCanaryリリースにおけるCI/CDへのテスト組み込みまで、あらゆる規模のお客様でこの傾向が見られます。
なぜこのような状況が起きているのか、お考えになるかもしれません。これは業界によって異なります。金融サービスやヘルスケアなどの規制産業で事業を展開されているお客様は、米国やヨーロッパのコンプライアンス要件に従う必要があります。Doraからの要件などもあり、Resilienceを実証することが求められています。お客様は、システムの障害が発生した場合にアプリケーションがどのように対応するかを実証する必要があります。多くのお客様は、四半期ごとや年に一度の臨時テストやGameDaysから始め、時にはDisaster Recoveryテストと密接に関連付けて実施されています。AWSは、ガイダンスと実装のためのツールの両面で、多くのソリューションを提供しています。




私たちは、ほとんどのお客様が先ほど説明したMulti-AZを使用して、安定的にリージョン内でワークロードを実行できると考えています。ただし、極めて高いResilienceが要求される場合、お客様は複数のリージョンにアプリケーションをデプロイする必要があります。これは、顧客への近接性を高めてレイテンシーを削減するため、データレジデンシーやデータ主権の要件に対応するため、あるいは可用性を向上させるためです。この分野に関心を示している業界は金融サービス、 主にビジネス継続性とデータ規制へのコンプライアンスのため、そしてヘルスケアおよびライフサイエンス分野です。 健康記録を処理するお客様からの要件も見られます。 また、顧客に優れたストリーミング体験を提供し、復旧時間を限定したいと考えているメディアやエンターテインメント企業からもこのような要望が寄せられています。Multi-regionは、これらの高度な要件を達成するための手段となっています。



また、自動車産業や航空産業における コネクテッドビークルの分野でも、グローバルな規模での展開とローカルデータ要件への対応を目指す動きが見られます。第三のトレンドは、おそらく最も一般的なものですが、 より多くのお客様がResilience文化プログラムの構築に投資していることです。お客様から「AWS、あなたたちはこのような大規模な運用を行っていますが、どのようにしてResilience文化を構築しているのですか」という質問をいただきます。2023年中、私たちは社内チームとお客様の両方からデータを収集する作業を行いました。 1000社以上のお客様にResilience文化の構築方法についてアンケートを実施し、AWS Resilience Lifecycle Frameworkを公開しました。これから10分ほどかけて、これらの各段階について説明させていただきます。これは、各アプリケーションにResilience Lifecycleを組み込むための提案されたメンタルモデルです。AWSは、ほぼすべてのステップでソリューションを提供しており、これから順にご説明していきます。
AWS Resilience Lifecycle Frameworkの詳細

最初のステップは、しばしば見過ごされがちな目標設定です。目標の設定は、技術チームだけの仕事ではありません。私たちは、これらの決定の一部が極めて重要であり、顧客の期待、契約上の義務、収益の流れを理解することなしに、単独で判断することはできないと確信しています。単に技術チームに「解決策を見つけて、非常にResilienceの高いアプリケーションを作れ」と指示しても、彼らはそのアプリケーションにどの程度投資できるのかを理解するためのツールを持っていません。目標設定は、プロダクトチームやビジネスチームと技術チームの共同の取り組みなのです。
目標が明確になってはじめて、その目標を達成するために監視すべき具体的な指標を定義することができます。それらはRPO、SLAなどと呼ばれ、チームが適切なアーキテクチャを構築するための指標となります。これはアプリケーションごとのフレームワークで、目標を設定し、ビジネスの目的、投資可能な金額、そのアプリケーションのダウンタイムコストを理解する必要があります。意図的な判断でない限り、アプリケーションが会社にもたらす収益の5倍もの費用がかかるインフラへの投資は避けるべきです。また、レジリエンスを高めることはサステナビリティにも影響を与えるため、これも考慮すべき側面です。


この段階では、ガイダンス以外に私たちが直接関与することは少ないのですが、設計と実装のフェーズで目標を検討します。 ここでは、サービスからガイダンスまで、多くのオファリングを提供しています。Well-Architected Frameworkはアーキテクチャのガイダンスを提供し、私たちはお客様にレジリエンスをパイプラインの早い段階で考慮することを推奨しています。Pearson Educationのようなお客様は、GitLabのパイプラインでFault Resilience Testingを使用し、障害分離境界、依存関係、復旧パス、バックアップと災害復旧ツールについて理解を深めています。



次のステップは、Well-Architected Frameworkのレジリエンシーピラーで、信頼性とレジリエンスの側面について詳しく説明します。 私たちが強調する原則の1つは、障害から自動的に回復できるようにアプリケーションを構築することです。 もう1つの原則は、復旧手順をテストすることです。お客様は、劣化を予測していても、1年間復旧計画を実行していないために、フェイルオーバーを実施しないケースをよく目にします。頻繁なテストは、お客様の経験から共有できる重要な推奨事項の1つです。



その他の原則には、ワークロードの可用性を高めるための水平スケーリングや、キャパシティの推測をやめることが含まれます。ある程度のオーバープロビジョニングは必要かもしれませんが、 AWSのAuto Scalingを使用することは大きな利点です。可能な限り自動化を活用することが、このセクションの最後の原則です。レジリエンシーピラーの最新のアップデートをぜひご確認ください。 サイクルの次のステップは評価とテストで、パフォーマンステストの実施やトレーシングの設定に多くの投資を行い、障害を理解し予測します。


特に、過去2年間で活発に取り組んできたFault InjectionとGameDaysに焦点を当てたいと思います。 Fault Injection Serviceは、テストを始めるのに役立つ事前構築されたサービスです。コーディングなしで実際のシナリオを構築でき、制御された実験を確実に行うための事前構築されたセーフガードを備えています。 昨年のre:Inventでは、シナリオライブラリのコンセプトを発表し、実際の事象をテストするために複数のアクションを組み合わせた事前構築されたテストを導入しました。


最も一般的に使用されるシナリオの1つが、Availability Zone(AZ)の電源障害です。ライブラリでは、必要なシナリオを選択し、複数アカウントでテストするか単一アカウントでテストするかを選ぶだけです。 実行可能な事前構築された実験が用意されており、すぐにデモをご覧いただきます。 これにより、複数アプリケーションにまたがるシナリオのテストが可能になります。これは最も一般的なユースケースであり、お客様が求める回復性を実現するための要件のほとんどを満たすと考えています。


2つのAvailability Zoneにまたがるアプリケーションについて考えると、 EC2、RDS、コンテナ、その他のサービスでサポートしているアクションの完全なリストをテストしたいと思うでしょう。この実験を実行すると、AZ障害の一般的な症状をすべてシミュレートします。 セカンダリAZが負荷を処理できるかどうかを確認できます。これは、先ほど説明したStatic Stabilityをテストする優れた方法です。


それでは、 デモをご覧いただきましょう。先ほどのケーキの例え話を思い出してください - 私たちは上層のアプリケーションが期待通りに動作するかをテストしたいのです。 これは、ペット養子縁組に関する実際の顧客体験の例です。ペット養子縁組UI、ペット検索UI、養子縁組支払いAPI、そしてデータベースがあります。4つのビルディングブロックだけのシンプルな構成ですが、その下には多くのコンポーネントが含まれる可能性があります。
Vanguardにおけるレジリエンシー実践例



APIはEC2とEKSで構築され、 検索機能はEC2とECS、支払いはFargate ECSとEC2、そしてデータベースはAPI GatewayとLambdaで構成されています。先ほど説明したAWS Fault Injection Serviceには、 シナリオライブラリが組み込まれており、1つのAZが故障した場合にアプリケーションの継続的なジャーニーがどのように反応するかをテストできます。 なお、「Bootstrap your chaos engineering journey with AWS FIS」というブログ記事があり、この実験を自分で実行する方法が紹介されています。



それでは、このシナリオの構築方法を見ていきましょう。コンソールからAWS Resilience Hubに移動し、 Resilience Testingに進みます。非常にシンプルで、シナリオライブラリに移動してAvailability Power Interruptionを選択するだけです。 この段階では、 すべてデフォルト設定を使用できます。説明と名前があり、シングルアカウントかマルチアカウントかを選択できます。一度に最大40アカウントまでこの実験を実行できます。


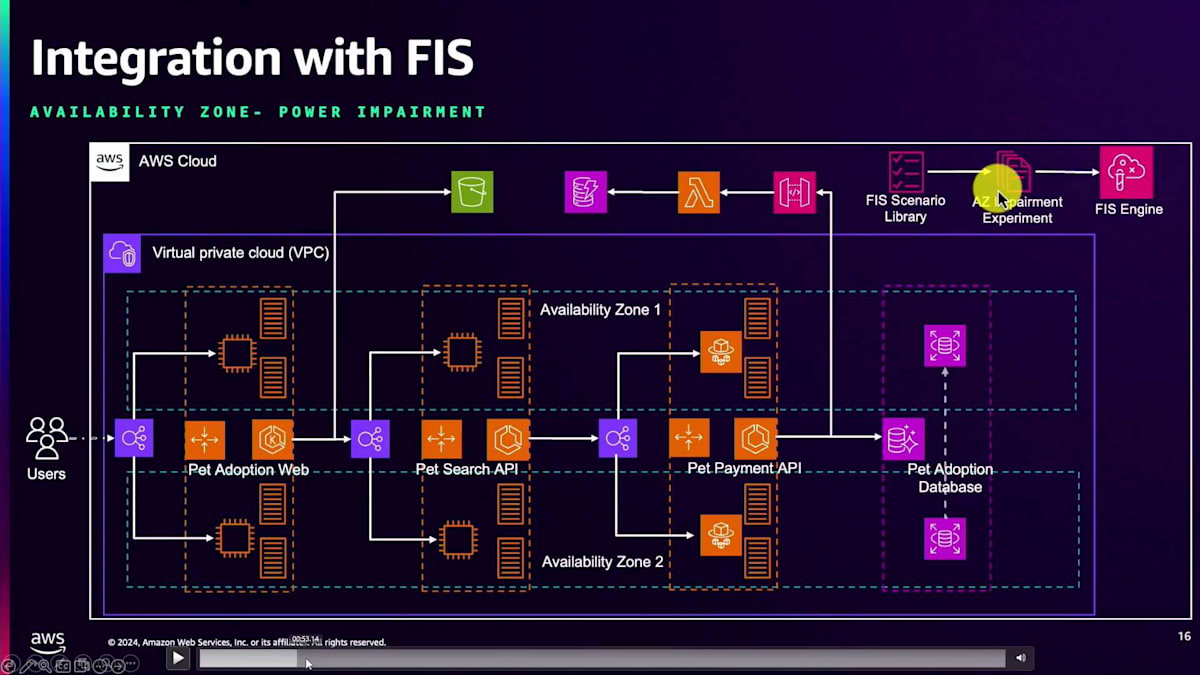



それでは Navigation に戻って、 このシナリオを見ていきましょう。本日は、お客様の間で最も一般的なシナリオである Availability Power Interruption のデモを行います。また、Cross-Region Connectivity Testing についても後ほど説明します。 まず実験を作成するために名前を入力し、デフォルトの説明文のままで Next をクリックします。この例では単一のアカウントを使用します。


シナリオでは、すべてのアクションとターゲットタイプが事前に選択されているのがわかります。 ここでは、実験に影響を与える AZ などの共有パラメータを定義する必要があります。AZ を選択し、Advanced Parameters では外部の Carpenter をスケーリングに使用するかどうかを設定できます。今回は使用しないのでブランクのままにしておきます。ただし、お客様が Carpenter をスケーリングに使用している場合は、そのロールをここに含めて同様に障害を発生させることができます。 また、リソースタグの Key と Value などの Advanced Parameters も設定します。先ほど申し上げたように、AWS FIS の重要な要素の1つは、非常に限定された実験を提供することです。これにより、特定のリソースのみをターゲットにすることが確実になります。

次のステップでは、障害の継続時間に重点を置いた Advanced Parameters に移ります。デフォルト値は2分です。 これを20分から10分に短縮します。これが障害の継続時間とリカバリー時間になります。私たちはこれもコントロールできます。そしてこれを保存します。


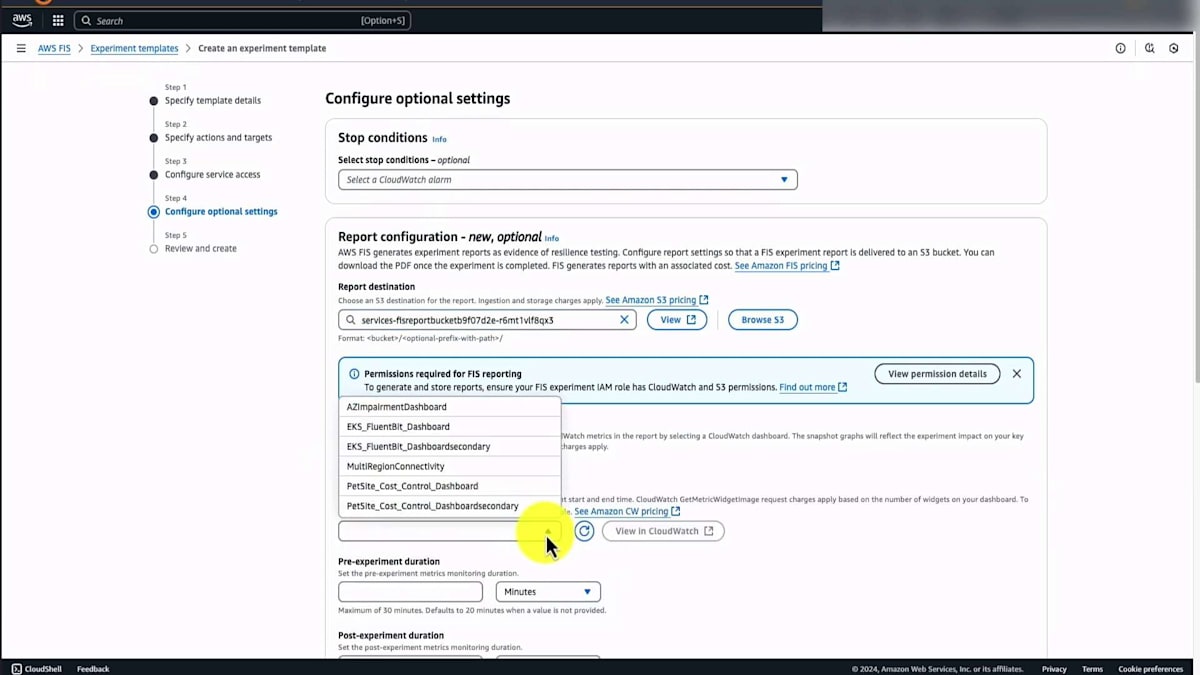
次のページに進みます。 リソースが特定されない場合は、実験を失敗させることもできます。今回は Skip のままにしておきます。 実験には事前定義されたロールを使用します。ここが実験の出力を保存する場所です。 現在は CloudWatch Dashboard の作成を許可しており、実験の前後20分間のデータを取得して、アプリケーションが安定状態にあった時と、実験完了後に安定状態に戻った時の様子を示すことができます。つまり、実験の前後における CloudWatch Dashboard のデータをすべて記録することができます。




CloudWatch Logs を送信する Log Group を選択し、AC ID を使用してその実験のタグを設定します。 これで実験の準備が整いましたので、実験テンプレートを保存します。次のステップは、実行されるアクションを確認して実験を開始することです。ターゲットを見てみると、EC2、ECS、EKS が均等に分散されているのがわかります。 AZ 1A には Reader と Writer があり、1B には Reader があります。データベースへの接続は安定しています。


それでは、実験の一部としてダッシュボードをキャプチャできる新機能について確認していきましょう。実験を開始し、CloudWatchダッシュボードでどのように表示されるか見ていきます。処理が進行中であることと、影響を受けるターゲットがAction Summaryに表示されているのが分かります。また、実験における全イベントのタイムラインについても、より詳細な情報を確認することができます。

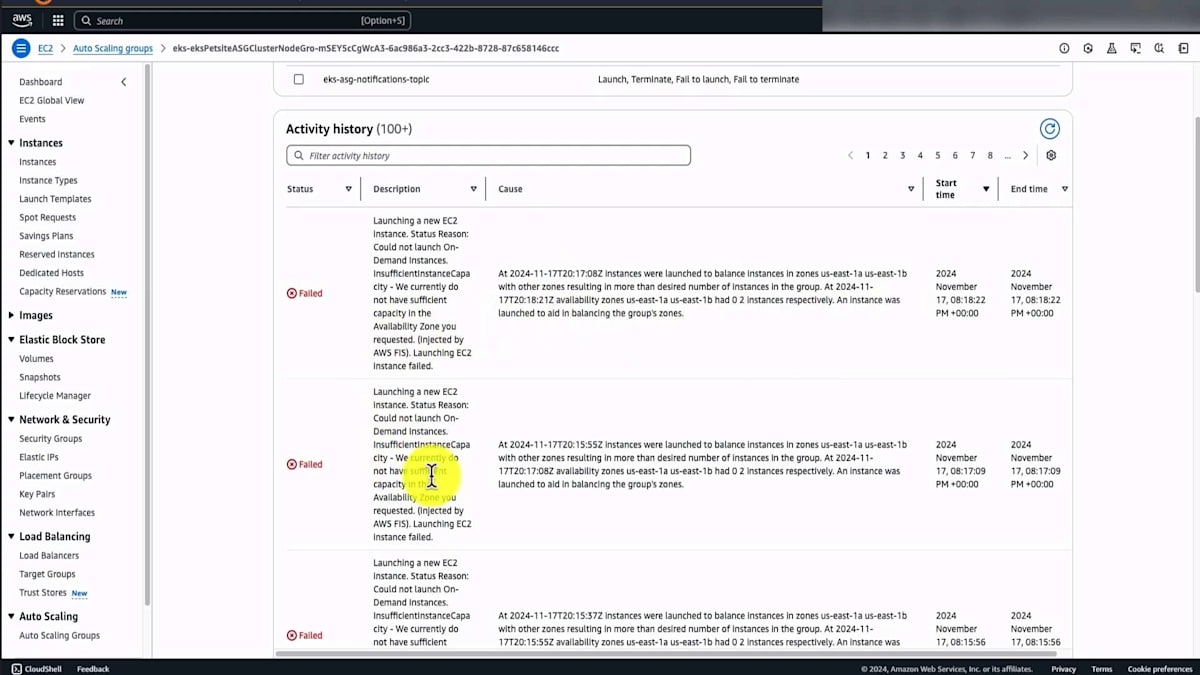

CloudWatchダッシュボードを確認してみましょう。EKSを含むすべてのゾーンサービスが影響を受けることが予想されます。左側でその様子が確認できます。データベースが2番目のAZにフェイルオーバーしたことも確認できます。Auto Scaling Groupでは、一部のリソースが失敗していることが分かります。新しいリソースのプロビジョニングを試みていますが失敗し、その後、正常なAZでのプロビジョニングを試みることになります。実験の続きを見ていきましょう。ユーザーがアプリケーションにアクセスできない期間があることが分かります。そして今、正常な状態に戻りつつあり、EC2とEKSが2つのAZ間でバランスを取り戻し、通常の状態に復帰しています。

実験が完了しました。ログを確認すると、ユーザートラフィックがALBを通過し、別のAZにシフトして、その後元に戻ったことが分かります。アプリケーションにアクセスできない短い時間がありましたが、このケースではアプリケーションは正常な状態に戻ることができ、AZ間でバランスを取ることができました。これは、アプリケーションが単一のAZの障害という混乱を乗り越えられることを実証する方法です。また、RDSについても、接続が別のAZにシフトし、現在は正常な状態に戻っていることが確認できます。




以上がPower Interruptionのデモでした。次のデモは行いませんが、マルチリージョンデプロイメントを選択するお客様がいることを認識しています。この分野についてのガイダンスやホワイトペーパーを提供しています。また、セカンダリリージョンがプライマリに依存せずに独立して機能できることをテストするために、クロスリージョン接続シナリオも構築しています。時間の都合上、手短に説明しますが、このシナリオは主にDynamoDB Global Tables、S3クロスリージョンレプリケーション、クロスリージョンネットワーキングの障害をシミュレートすることに焦点を当てています。基本的に、セカンダリリージョンがプライマリへの接続なしで独立して機能できるかどうかを確認することができます。アクションには、ネットワーキング、DynamoDB Global Tables、クロスリージョンレプリケーション、S3が含まれます。これにより、独立して運用できることをテストすることができます。


これらの概念をさらに探求したい場合は、ぜひ実施することをお勧めするワークショップがあります:Resilience HubとAWS Fault Injection Serviceの使い方がここで学べます。アプリケーションのテストについて多くお話ししましたが、ここでVanguardでの実践についてChrisにお話しいただけることを大変嬉しく思います。Chris、お願いします。
United AirlinesのRapid Recoveryソリューション

おはようございます。私は Christopher Volos と申します。Vanguard の Resiliency Architecture and Testing 部門を率いております。 本題に入る前に、Vanguard について簡単にご紹介させていただきます。私たちは世界最大級の投資会社の一つで、約10兆ドルのクライアント資産を運用し、世界中の5,000万人のクライアントにサービスを提供しています。クライアントの方々は人生の貯蓄を私たちに託してくださっており、これは Vanguard が非常に重く受け止めている責任です。そのため、システムの健全性と信頼性は常に最優先事項ですが、課題も抱えています。品質を犠牲にすることなく、迅速に行動する必要があります。テクノロジーの環境は絶えず進化しており、分散アーキテクチャでは依存関係や障害モードの管理において、ソフトウェア開発時に考慮すべき複雑さが生じています。

これらの課題に対応するため、私たちはソフトウェア開発ライフサイクルにレジリエンシーを組み込む必要がありました。そこで、エンジニアリングチームがオンデマンドでパフォーマンステストを実行できるレジリエンシーテストスイートを構築しました。これにより、アプリケーションの限界点を見つけ出し、本番環境で想定されるさまざまなトラフィックパターンをシミュレートすることが可能になりました。緩やかで着実なトラフィックの増加から、突発的なトラフィックの急増まで、さまざまなパターンに対応できます。障害は必ず発生するものですから、システムがそれらの障害にどう反応し、どのように回復するかを理解する必要があります。そこで、エンジニアリングチームには、単独でも、あるいはパフォーマンステスト中でも、オンデマンドで Chaos テストを実行できる環境を提供しています。これには、レイテンシーの注入から、メモリーや CPU 使用率の高負荷、さらには AWS を使用した地域停止のシミュレーションまで、さまざまなテストが含まれます。
分散アーキテクチャの世界では、Service Virtualization が非常に重要な概念となっています。これにより、チームはダウンストリームの依存関係をモック化することで、よりローカライズされたコンポーネントレベルのレジリエンシーテストを実行できます。本質的に、これは大規模なエンドツーエンドのジャーニーテストに向けた準備として、より頻繁にレジリエンシーテストを実行するための敷居を下げることになります。私たちが構築するアプリケーションの多くは、完全なエンドツーエンドのジャーニーテストが複数のチームや数十のコンポーネントにまたがることがあります。そのため、個々のコンポーネントでもより頻繁にテストを実行できるようにしたいと考えています。最も重要なのは、実行される全てのテストにおいて、開発者が構築している製品のレジリエンシーをさらに高めるために何ができるかを理解できるよう、実用的な洞察を継続的に反復していることです。


レジリエンシーへの取り組みを開始して以来、レガシーシステムと比較して5倍のデプロイ速度を実現しながら、回復時間を約60%削減し、可用性と顧客満足度を向上させることができました。つまり、品質を損なうことなく、むしろ品質を向上させながら、より迅速に進められるようになったのです。 まとめますと、Vanguard で私たちが継続的に注力している3つの重要な成功要因は、エンジニアリングチームにレジリエンシーテストを実行するための適切なツールを提供すること、これらのツールをセルフサービス化して使いやすくすること、そしてテスト結果を実用的で解釈しやすいものにすることです。

ありがとうございます。Chris、ありがとうございました。あなたとチームの皆さんと一緒に仕事ができて大変光栄でした。これは皆さんにとって参考になる素晴らしい例だと思います。開発者がテストを実行しやすくするツールを構築することが重要なポイントです。この点を特に強調しておきたいと思います。 レジリエンスライフサイクルの次のステップは運用です。つまり、設計と実装のフェーズで、適切なレベルでお客様にサービスを提供できるようにアプリケーションを設計し、テストを行った後、アプリケーションのオペレーターとして、問題を予測できるようにする必要があります。これには、シンセティックトラフィックの導入(ご存じない方のために CloudWatch Synthetics をご紹介しますが、パートナーソリューションも使用可能です)や、通常の運用からの逸脱を理解するための CloudWatch アラームなどのアラームの設定が含まれます。
これにより、期待される状態からの逸脱がないかを理解することができます。システムを本番環境に投入する前に、Operational Readiness Reviewを設定してください。私たちの社内のOperational Readiness Reviewをウェブサイトで公開していますので、参考にしていただけます。アプリケーションの負荷テストを実施して、アプリケーションがどのように、どこで障害が発生するかを理解し、復旧時間をコントロールできるようにしましょう。

このサイクルの最後のステップについて、ここで役立つサービスが複数あります。このサイクルは反復的なプロセスで、どの段階からでも開始できることを強調しておきたいと思います。目標設定から始めると説明しましたが、既存のワークロードに対して、Respondとlearn段階で改善を試みるケースもあるでしょう。ここでいう自動化とは、より迅速かつ体系的に復旧するために構築するもので、エスカレーションパスを通じて行われます。PagerDutyやSlackを使用したイベントのエスカレーション方法、そしてもちろんイベント管理プロセスやRunbookについても考慮する必要があります。


Correction of Error (COE)について、AWSでの実践方法をもう少し詳しくお話ししたいと思います。私たちは、失敗とその教訓を共有することを積極的に推奨しています。運用上の失敗からどのように学んでいるかを、お客様にも理解していただけるよう、COEプロセスを公開しています。予期せぬ事態が発生した際は、根本原因を突き止め、同僚と共有することで、同様のケースを回避できるようにします。実際に、私たちには共有のためのプロセスがあります。毎週水曜日に全エンジニアリングチームが集まる運用会議があり、ルーレットを用意しています。各チームが過去1週間のCOEを持ち寄り、全員と共有します。そしてルーレットを回して、選ばれたチームが非威圧的な方法で自分たちのストーリーを共有します。これはAWSの文化的要素として私が特に気に入っている点で、皆さんと共有したいと思いました。
このCOEは公開されており、来年チームで取り組めることを考える際の、文化に加えるべき新しい要素の一つになるかもしれません。自動復旧については、役立つ主要なサービスをいくつかご紹介したいと思います。Auto Scalingから、自動フェイルオーバーを支援するAmazon RDSなどのサービスに組み込まれた機能、Application Recovery Controllerについても説明しましたが、もちろんAmazon S3も自動復旧の手段の一つです。


自動テストと復旧について説明してきましたが、ここでUnitedの Jenny Zhouさんをご紹介し、彼らが構築した印象的なサービスとアーキテクチャについてお話しいただきたいと思います。ではJennyさん、お願いします。皆様、おはようございます。本日は、United Airlinesのレジリエンスに関する取り組みをご紹介できることを光栄に思います。Unitedをご存じない方のために説明しますと、利用可能座席マイル数で世界最大の航空会社です。Unitedには10万人以上の従業員がおり、2023年だけでも1億6000万人以上のお客様にサービスを提供し、世界中の約350の目的地に就航しています。2021年には、United Nextプログラムを立ち上げました。この戦略的イニシアチブは、800機以上の燃料効率の良い航空機を追加し、グローバルネットワークを拡大することを目指しており、この急速な成長を支えるためにレジリエンスと信頼性がより一層重要になっています。

Unitedは現在、500以上のアプリケーションをAWS上で運用しています。私たちの最優先事項の1つは、ビジネス継続性の確保です。本日は、アプリケーション全体のディザスタリカバリを効率化・迅速化するために実装した包括的なソリューションについてご紹介させていただきます。 これまでの経緯を簡単にご説明します。当初はオンプレミスで、年に1回、一部のアプリケーションに限定したDRテストしか行えず、個々のアプリケーションのフェイルオーバー機能もありませんでした。AWSへの移行により、すべてのアプリケーションに対してDRソリューションを構築・テストできるようになりました。この文化的な転換は、すべてのアプリケーションにとって大きな課題でした。
最初の段階では、経営陣の強力なサポートのもと、全社的なDR戦略を必須とし、設計ガイダンスとDRテストの実施手順書を提供しました。この時点では、まだ手動フェイルオーバーに依存しており、1つのアプリケーションのフェイルオーバーに30分から数時間を要していました。人の介入がボトルネックとなりエラーの原因となっていたため、非効率的でした。これが、私たちの自動フェイルオーバーソリューション「Rapid Recovery」の開発につながりました。私たちの目標は、プロセス中の人的介入を必要とせず、アプリケーションが自律的にディザスタリカバリを展開・実行できる、事前構築された完全自動化ソリューションを提供することでした。

フェイルオーバーは、外部の監視ツールに格納された事前定義されたリカバリワークフローから開始されます。権限を持つアプリケーションオーナーは、ターゲットリージョンとアプリケーションのフェイルオーバー層(サービス層、データベース層、または両方)を指定してフェイルオーバーを開始できます。また、ワークフローを事前定義されたアラートと関連付けることで、完全自動化されたトリガーを設定することも可能です。このソリューションにより、Chaos Testingとのシームレスな統合が実現しました。ワークフローが実行されると、フェイルオーバーイベントはセントラルEventBridgeに送信され、その後ターゲットアプリケーションアカウントに伝播されます。この中央制御層により、統合を一元化し、外部監視ツールの変更時の影響を最小限に抑えることができました。プロセス全体を通じて、イベントを使用して異なるアカウント間の状態を同期し、実行された各ステップに関する通知が送信され、フェイルオーバーの進捗を追跡・監視するための事前構築されたダッシュボードが提供されます。

データベースのフェイルオーバーが要求された場合、フェイルオーバーイベントはDBAの認識とサポートを備えた別の中央アカウントにルーティングされます。事前にデプロイされたStep Functionがデータベースの管理されたフェイルオーバーを開始します。ライターインスタンスがターゲットリージョンに正常に切り替わった後、対応するデータベースのRoute 53エンドポイントが変更され、アプリケーションからのシームレスな接続が確保されます。この完全自動化されたデータベースフェイルオーバーのステップは、通常4〜6分で完了します。

サービス層のフェイルオーバーには、AWS Application Recovery Controllerのルーティング制御スイッチを切り替えるだけの簡単な方法を採用しました。アプリケーショントラフィックはミリ秒単位でターゲットリージョンにリダイレクトされます。また、ビジネスポートフォリオ内の複数のアプリケーション間でルーティング制御クラスターを共有することでコストを最適化しています。各アプリケーションには専用のコントロールパネルがあり、対応するアプリケーションフェイルオーバー層に複数のルーティング制御セットを設定できます。このソリューションは、アプリケーションの要件に基づいて追加のフェイルオーバーステップを追加することで、容易に拡張やカスタマイズが可能です。

現在、Rapid Recoveryソリューションは100以上のアプリケーションアカウントで実装されており、重要なアプリケーションには必須となっています。簡単なオンボーディングを実現するため、標準的なデプロイメントスターターキットの一部としてもこのアプリケーションを組み込んでいます。また、このソリューションは確立された運用モデルによって完全にサポートされています。
この運用モデルには、専任のPlatform Engineeringチームとサポートチームが含まれています。画面に表示されているApplication Reliability Dashboardを実装し、アプリケーション品質の全体像を把握できるコントロールタワービューを提供しています。これによりDRコンプライアンスを可視化し、アプリケーションチームやリーダーがギャップを特定して改善アクションを取ることができます。

このソリューションによる成果とビジネス上のメリットをご紹介します。過去1年間で、私たちのアプリケーションは1,600回以上のRapid Recoveryを実施し、その中には400回以上の自動データベースフェイルオーバーが含まれています。このソリューションにより、アプリケーションの復旧ダウンタイムが大幅に削減され、RTOを最大80%短縮することができました。また、システム全体の年初来のダウンタイムを20%削減することにも貢献しています。

Continuous Resilienceに向けて、私たちは準備状況の検証と信頼性向上のため、DRテストの頻度を年1回から四半期ごとに増やすことを計画しています。さらなるテストシナリオを追加することで、Rapid Recoveryの採用拡大とChaos Testingの充実を続けていきます。また、大規模な障害をシミュレートするため、クロスアプリケーションのGameDaysの導入も計画しています。最後に、AIを活用した予測分析により、事前に障害を特定し、予防措置を講じる機会も模索しています。
まとめと今後の展望
以上で私のプレゼンテーションを終わりますが、同じトピックについてAWSのブログを近々公開予定であることをお伝えしておきたいと思います。ご興味のある方は、メールでご連絡いただければ、公開後にリンクをお送りさせていただきます。ありがとうございます、Jenny。先ほど申し上げたように、極めて高い回復力要件を持つお客様がいらっしゃいますが、Jennyは、Unitedでそうした要件にどのように対応しているかを共有してくれました。

最後のステップである「対応と学習」について締めくくりたいと思います。Resilience Lifecycleについてぜひ検討していただき、私たちが提案したこの概念的なResilience Lifecycleで見落としている点があれば、ぜひフィードバックをお寄せください。これで本日のプレゼンテーションは終了となります。朝早くからご参加いただき、ありがとうございました。セッションの評価にお時間を割いていただければ大変ありがたく存じます。予定より少し早く終わりましたので、ご質問のある方は個別に承らせていただきます。Cloud Resilienceについてさらに詳しく知りたい方は、AWSアーキテクチャブログの「Know Before You Go for Cloud Resilience」やre:Invent参加者ガイドをご覧ください。

改めまして、お時間をいただき、ありがとうございました。共同発表者のChristopher A VokolosとJenny Zhouにも感謝申し上げます。本日は皆様とご一緒できて大変光栄でした。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion