re:Invent 2024: AWSによるAurora 10周年の革新技術と進化


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Deep dive into Amazon Aurora and its innovations (DAT405)
この動画では、Amazon Auroraの10周年を記念して、その革新的な技術と進化について詳しく解説しています。クラウドネイティブに設計されたAuroraのアーキテクチャ、特にストレージシステムの特徴的な設計や、Local Write Forwarding、Global Database、Zero-ETLなどの重要な機能について説明しています。また、IO-optimized StorageやTiered Cacheなどの最新の性能改善機能、200万TPSを超えるスケーリングが可能なLimitless Database、そして新たに発表されたAurora DSQLについても言及しています。特に、PostgreSQL 17での新機能Durable Queueによる最大6.4倍のレイテンシー改善や、Tiered Cacheによるベクトル処理時間の9分の1への短縮など、具体的な性能向上の数値も示されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon Auroraの概要と特徴

みなさん、こんにちは。0.405へようこそ。本日は、Amazon Auroraとそのイノベーションについて詳しくお話ししていきます。Amazon Auroraは10周年を迎えましたが、約13年前にこのプロジェクトを提案し、構築に携わってから、実に素晴らしい道のりでした。今日は、この技術と、皆様のデータベースのニーズにどのように役立つかについて掘り下げていきたいと思います。

Amazon Auroraは、クラウドネイティブに特化して設計されたデータベースです。MySQLとPostgreSQLの両方と完全な互換性がありますが、同時にではなく、それぞれ個別の互換性となります。MySQLとPostgreSQLの分野で皆様がよく知っているオープンソースソフトウェアを補完する、多くのエンタープライズレベルの機能を組み込んでいます。優れたパフォーマンス、スケーラビリティ、可用性、耐久性、セキュリティを備え、RDSファミリーの他のサービスと同様に完全マネージド型となっています。
Aurora独自のストレージアーキテクチャと高可用性


それでは、Auroraのアーキテクチャと、その特徴的な部分について詳しく見ていきましょう。まず最初にストレージについてです。3つのAvailability Zoneを持つ1つのリージョンを見てみると、クラスターを作成すると、このストレージボリュームが得られます。図の黄色いボックスは、ストレージサーバーを表しています。ここでは9つしか示していませんが、実際のリージョンでは数千から数万のストレージサーバーが存在する可能性があります。 これができると、データベースインスタンスを持つことができ、最初のインスタンスは通常アプリケーションが接続する読み書き用のデータベースインスタンスとなります。
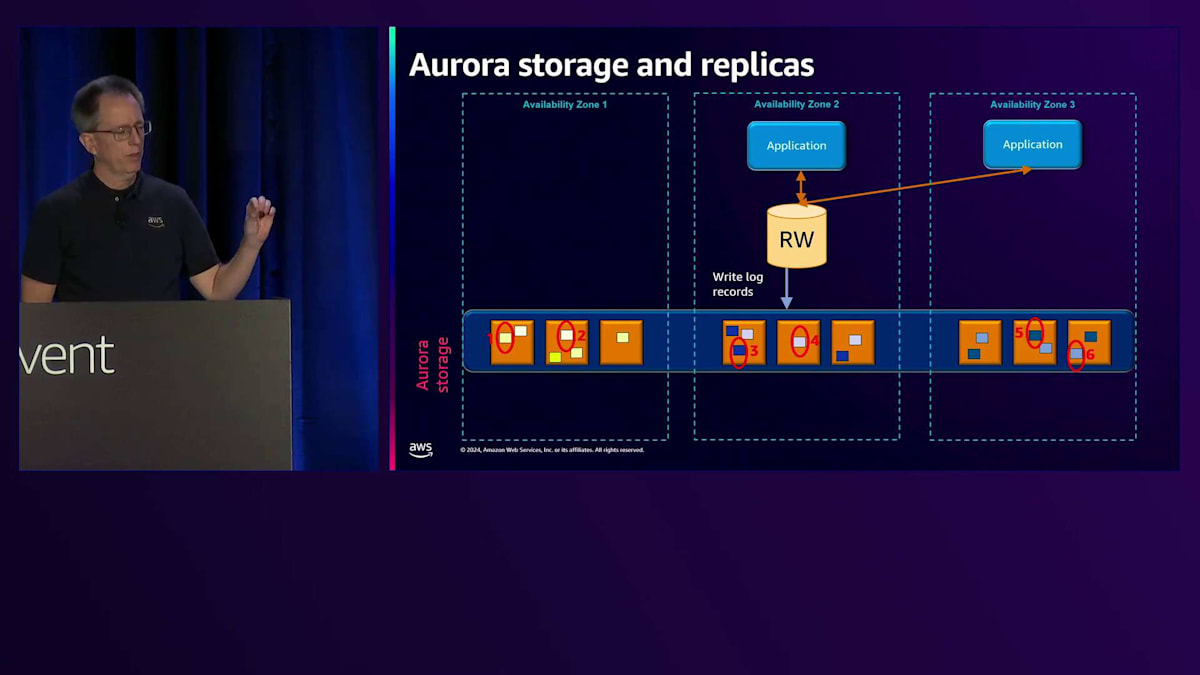
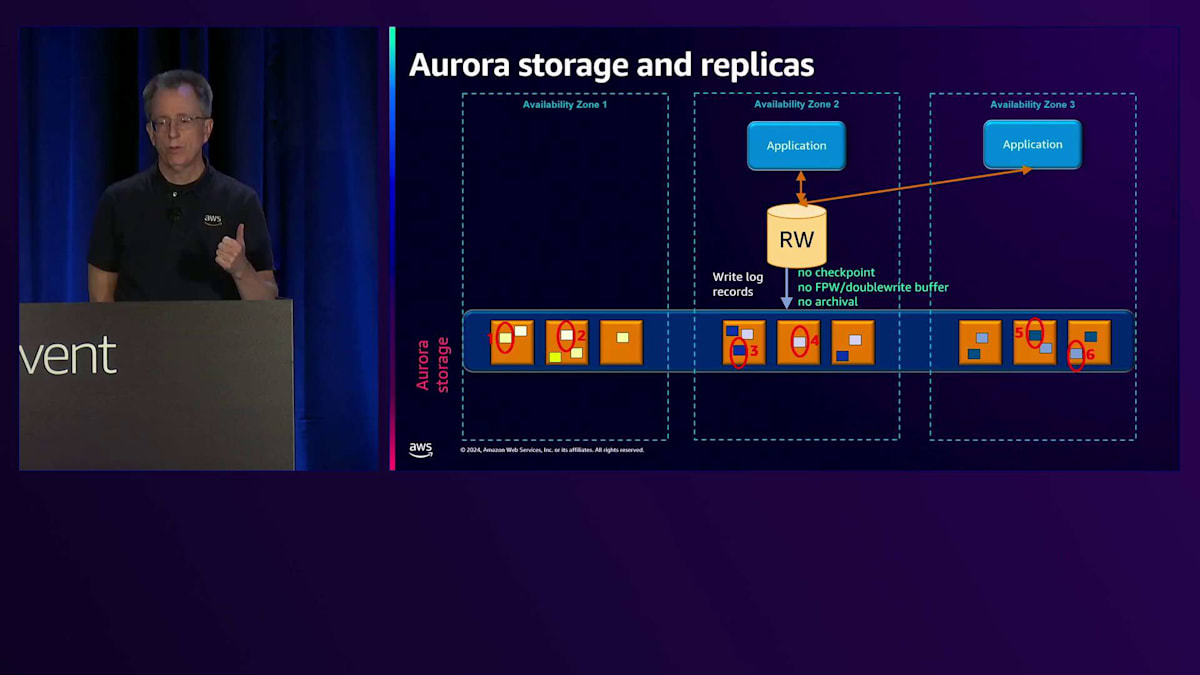
通常のデータベースと比べて最初の大きな違いは、ログレコードのみを書き込むという点です。図では6つの書き込みを示していますが、それぞれが異なるチャンクまたはセグメント(各10ギガバイト)に書き込まれ、各Availability Zoneに2つずつ分散されています。これらの6つのうち4つが完了すると、ログ書き込みを確認し、お客様にコミットメッセージを返します。 もう1つの違いは、チェックポイントを行わない点です。PostgreSQLのフルページ書き込みやMySQLのダブルライトバッファも使用せず、読み書きノードでバックアップを行わないため、ログのアーカイブも必要ありません。
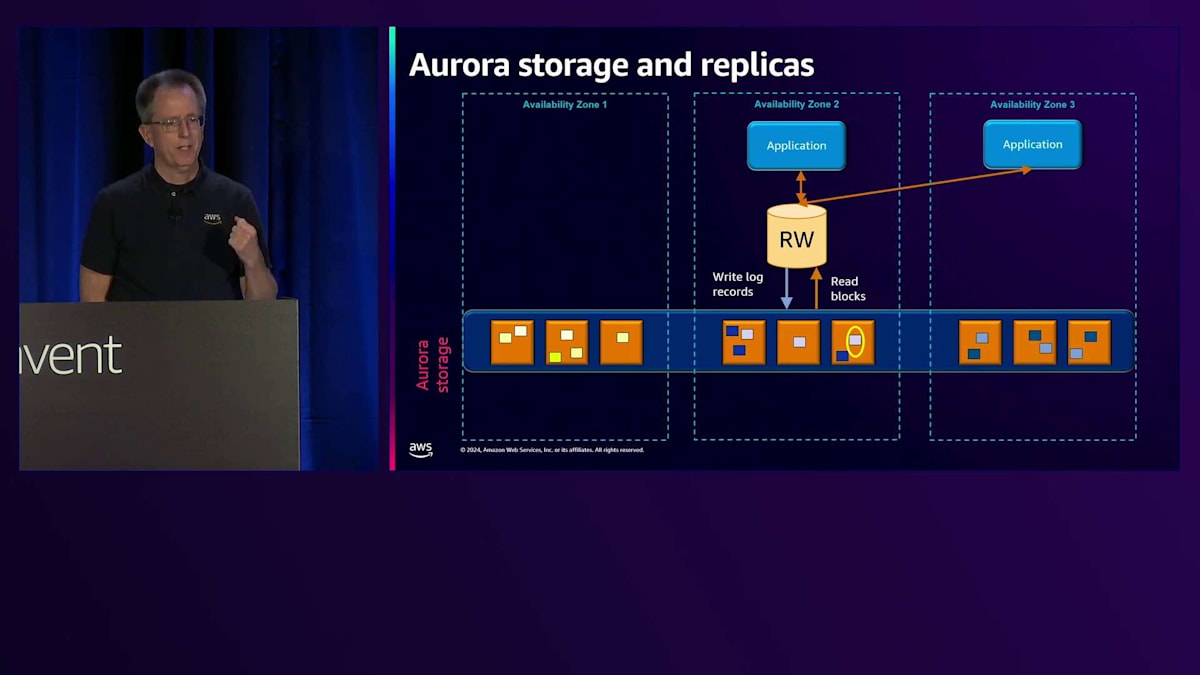
これにより、作業が少なくなり、効率性が向上し、特に書き込みに関してより優れたスケーラビリティが実現します。ブロックの読み取りについては後ほど説明しますが、データベースにとって理解しやすい仕組みとなっています。というのも、その部分は変更する必要がなかったからです。通常、各Availability Zoneにコピーがあるため、最も近いところから読み取りを行い、最速のパフォーマンスを実現します。シーケンス番号から最新のコピーを持っていることが分かるため、クォーラム読み取りは必要ありません。
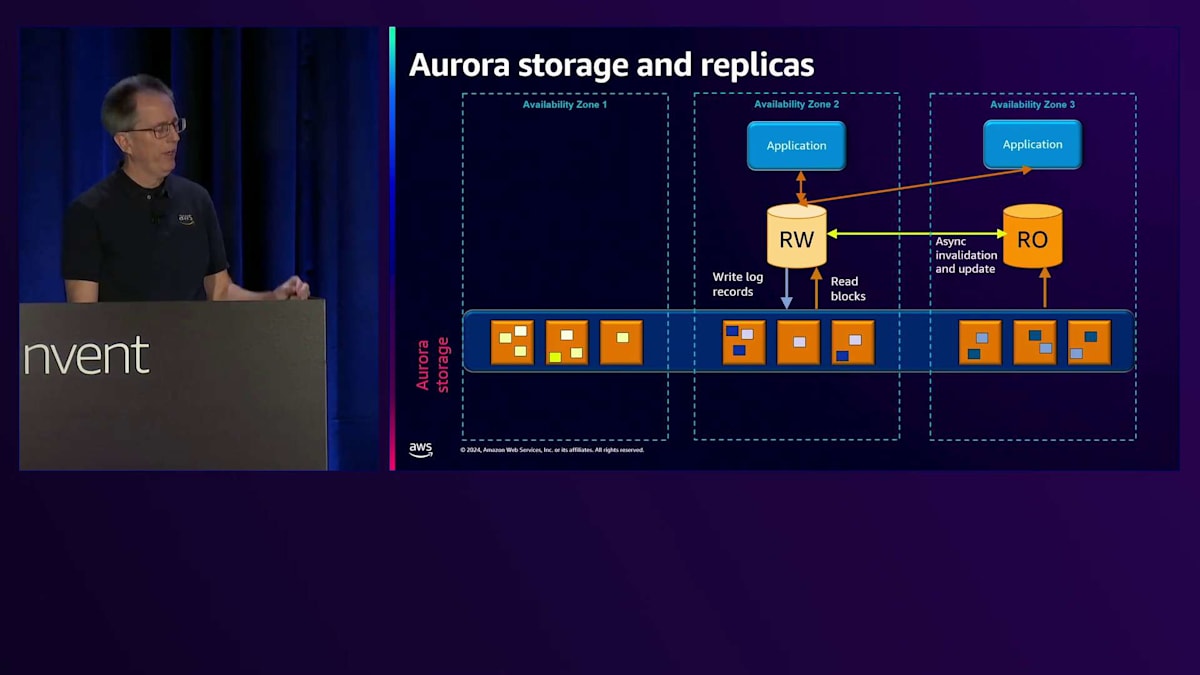
問題が発生した場合、書き込みの失敗に対して修復を実行できます。同じAvailability Zoneまたは別のAvailability Zone内の別のチャンクから、失敗した書き込みを修復します。ストレージサーバー全体が故障した場合は、別のコピーからそのチャンクを複製して新しいストレージサーバーに配置します。これは自動的に行われます。 Auroraのもう一つの大きな違いは、PostgreSQLやMySQLのRead Replicaでは通常、EBSに別のボリュームを用意してデータベースを起動する必要がありますが、ここではクラスター化されたストレージを使用して、それに接続するだけで済みます。メモリの同期を保つために、Read-WriteノードからRead-Onlyノードに対して、通常約30ミリ秒のラグで非同期的に無効化または更新メッセージを送信します。
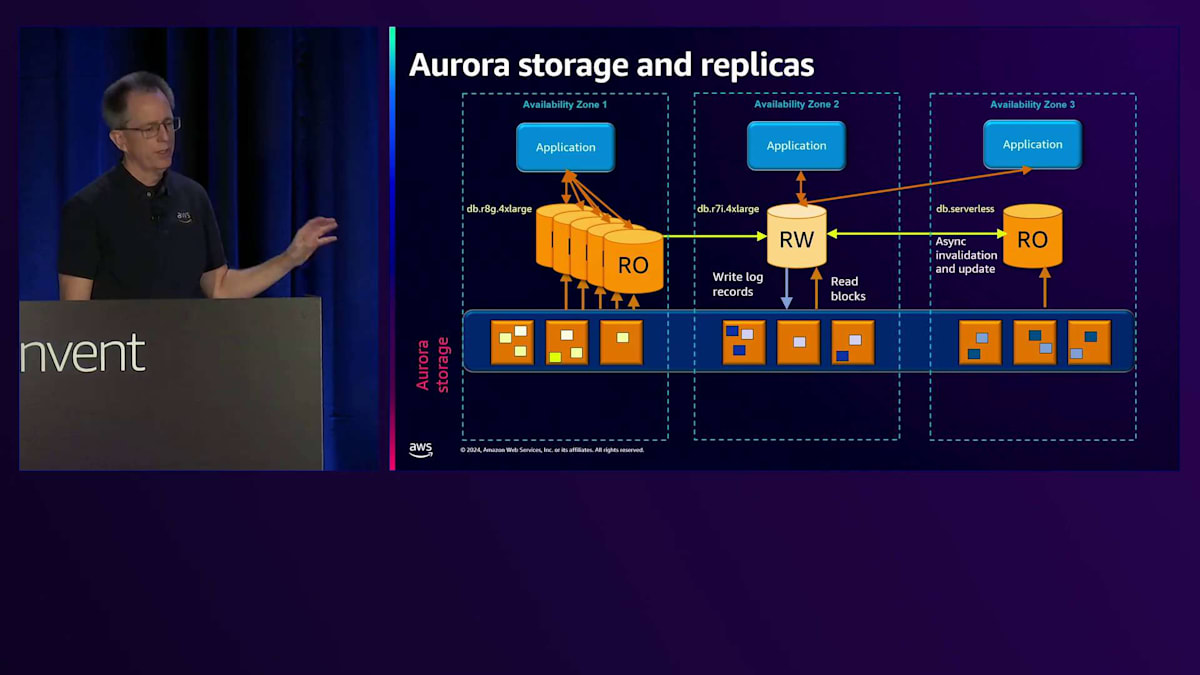
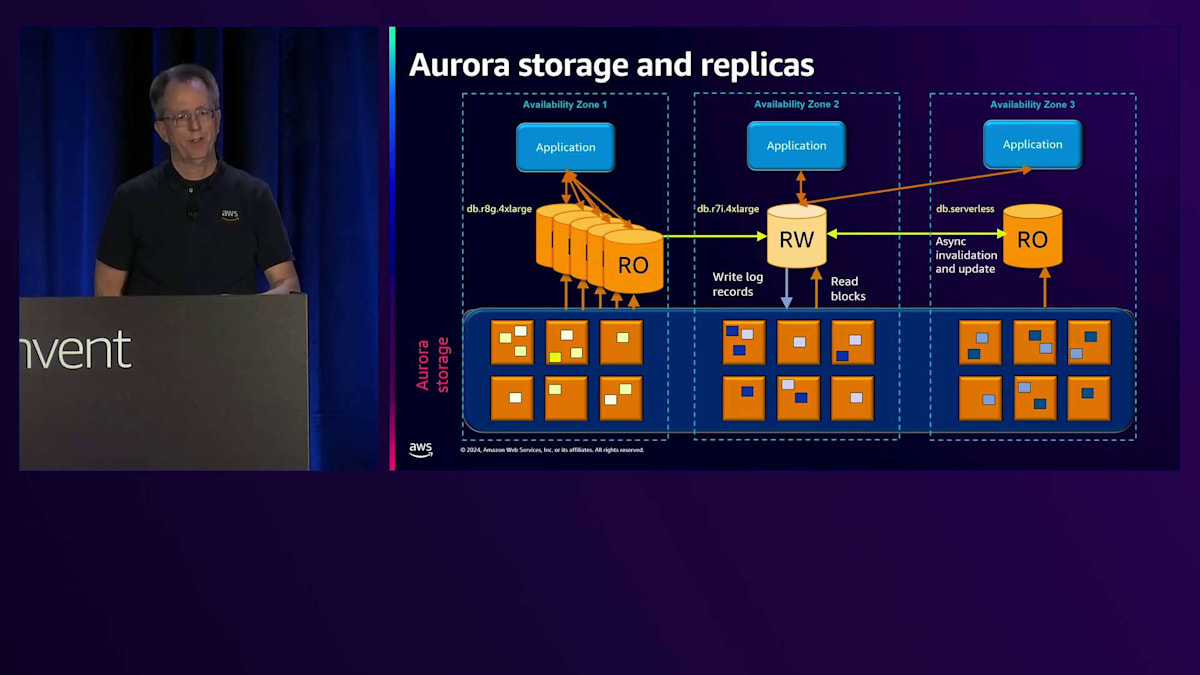
最大15個のRead-Onlyノードを持つことができ、AZ全体でそれらを自由に組み合わせることができます。異なるタイプを選択できます - 片側にGraviton、中央にIntel、反対側にServerlessを示しています。 1つのタイプとサイズだけを選ぶ必要はなく、様々な組み合わせを選択できます。ストレージは必要に応じて拡大縮小し、使用した分だけ支払えばよいのです。これは、事前に容量を割り当てる必要がある一般的なファイルシステムベースのデータベースとは根本的に異なります。



障害が発生した場合、別のAZにあるRead-Onlyノードの1つにフェイルオーバーします。 アプリケーションは新しいWriterの場所を知る必要があります。通常は、そのデータベースのCNAMEを参照してRoute 53経由で解決しますが、その更新の伝播には時間がかかります。 そこで、MySQLとPostgreSQLの両方に対応したJDBC、Node.js、Pythonのラッパー、そしてMySQLのODBCラッパーを作成しました。これらのラッパーはWriterの場所を把握しているため、DNS伝播を待つ必要がなく、より迅速なフェイルオーバーと短い停止時間を実現できます。 これらの機能により、私たちは様々な方法でイノベーションを起こすことができます。
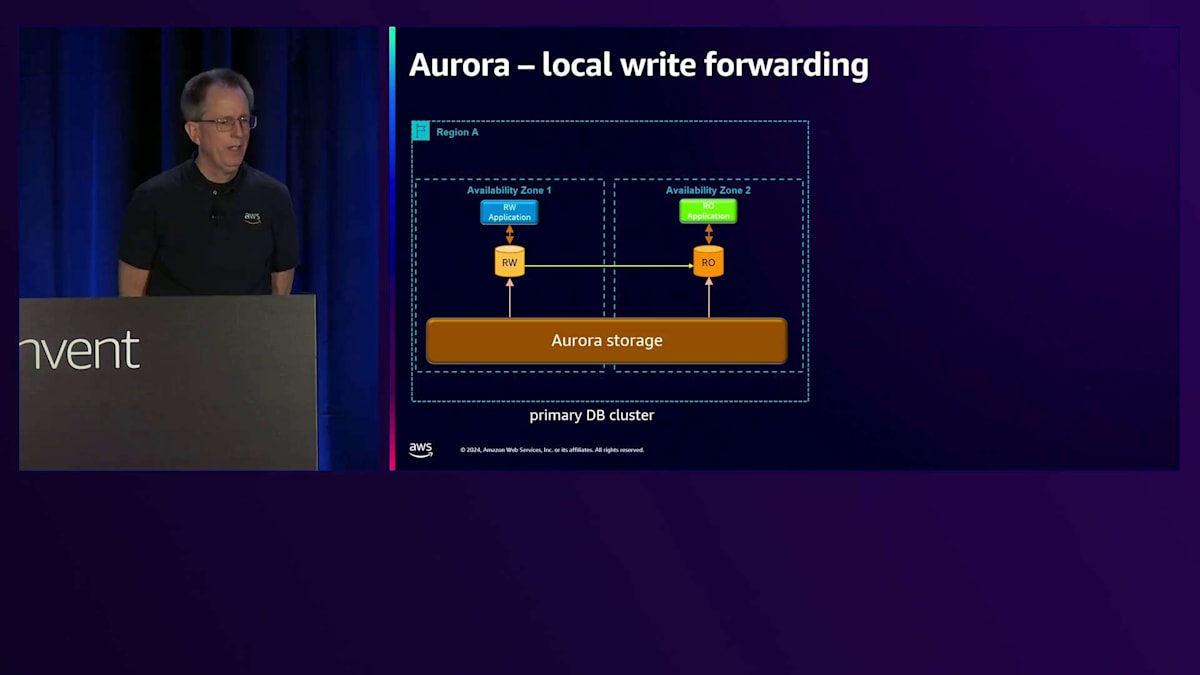
Local Write Forwardingと可視性モードの詳細
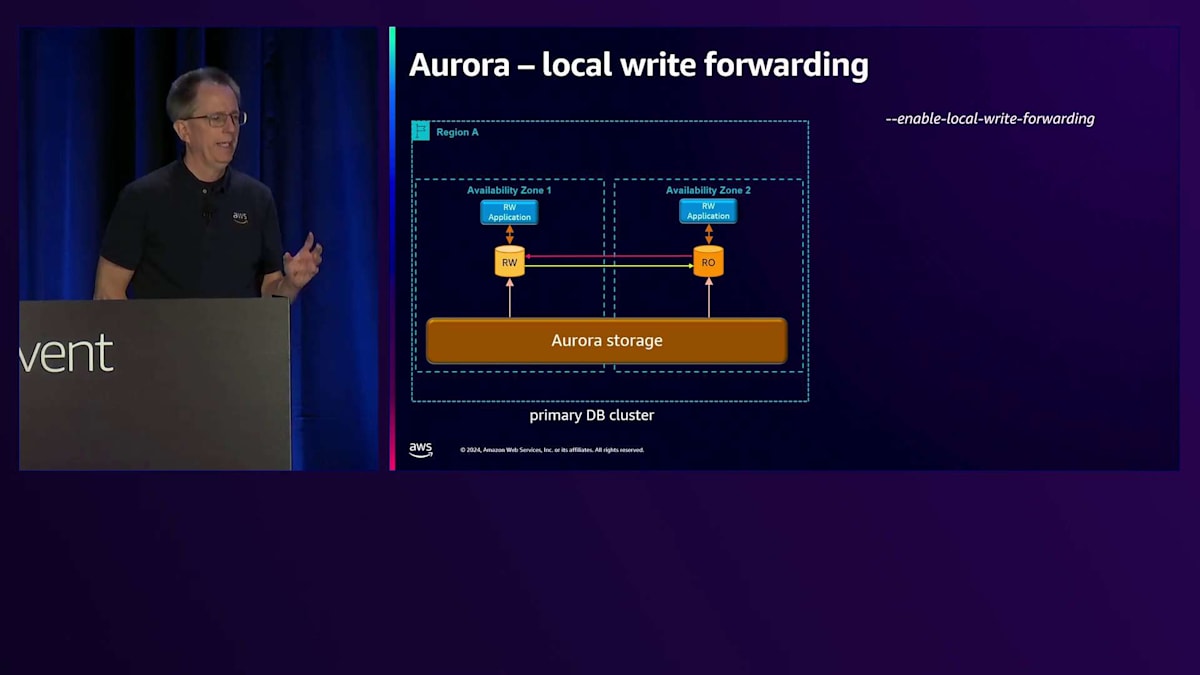
そのイノベーションの1つが、Local Write Forwardingです。このリージョンの簡単なバージョンを示していますが、ここではRead-Writeアプリケーションと、Read-Onlyアプリケーションが実行されています。ある時点でスケールアップしたいと考えますが、すべてを再コーディングしたくはありません。そのアプリケーションをRead-Onlyにするのは課題です。なぜなら、Read-Writeにしたい場合でも、それはRead-Onlyノードなので書き込みができないからです。しかし、MySQLとPostgreSQLの両方で利用可能になったLocal Write Forwardingを有効にすることができます。PostgreSQLバージョンをリリースしたばかりで、今ではそのインスタンスに書き込むことができ、その書き込みはRead-Writeノードに転送されます。
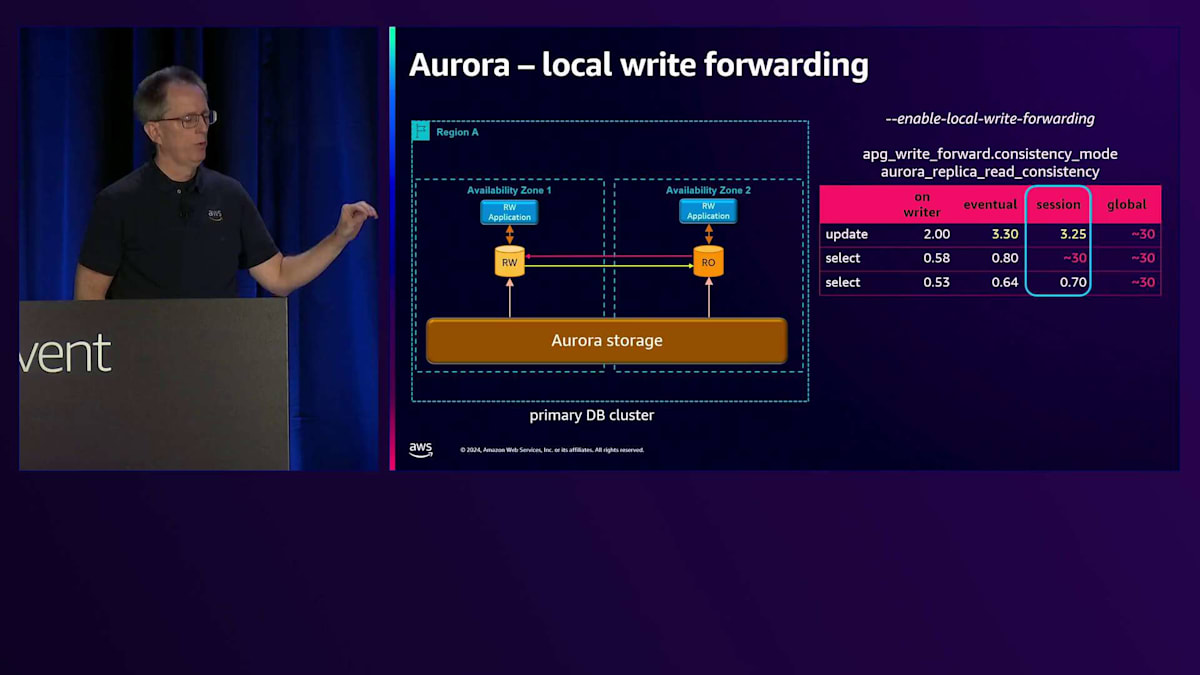
ここで重要なのは、Write Forwardingの可視性です。異なる設定があるので、更新を実行し、その後に2回のSelect文を実行するテストを行いました。Writerでの時間を見ると、 更新に2ミリ秒、Selectに約0.5ミリ秒かかっています。デフォルトの可視性モードはSessionです。更新を実行すると、Availability Zone間で転送する必要があるため、Writerよりもやや長い約3ミリ秒かかります。最初のSelectは30ミリ秒かかりました。これは、自分の書き込みを読み取りたいため、書き込みが戻ってきて複製されるのを待つ必要があるからです。これがSessionレベルの可視性が提供するもので、自分の書き込みを読むことができます。次のSelectは非常に高速です。変更を加えていないため、最新の状態であることがわかっているからです。
より興味深いモードとして、パフォーマンス重視の「シートベルトなし」モードとも言える、結果整合性モードがあります。更新速度は変わりませんが、最初のSelect操作は通常の速度であることに気づくでしょう。これは、書き込みの結果をすぐには確認できない - つまり、それを待たないためです。書き込んだ内容をすぐに読み取る必要がない場合は問題ありませんが、必要な場合はデータの整合性の面で好ましくないかもしれません。一部のユースケースで興味深いもう一つのオプションが、グローバル整合性です。このモードでは、すべての操作時間が同じになります。なぜなら、ステートメントを実行するたびに、その時点以降に変更されたすべてのデータが自分のところにレプリケーションされるのを待つからです。広範な使用はお勧めしませんが、絶対に正しい答えが必要な場合に役立ちます。これらのモードはセッション単位で設定可能で、セッション中に切り替えることができます。
Global Databaseとグローバルエンドポイントの機能
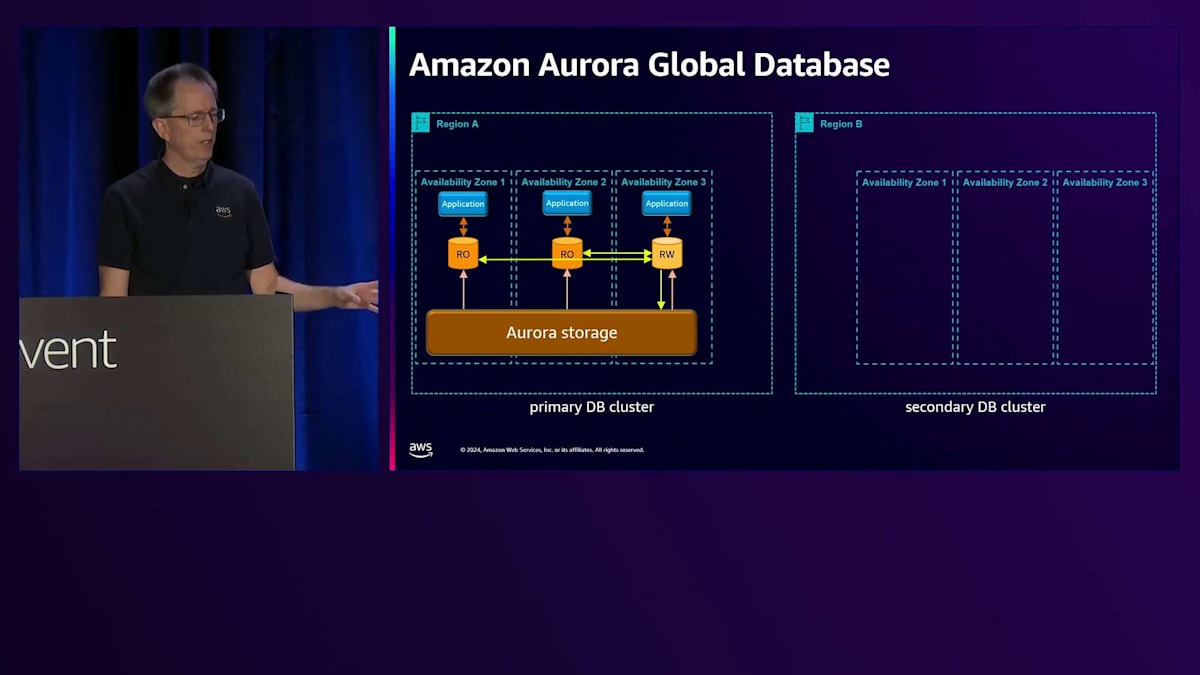
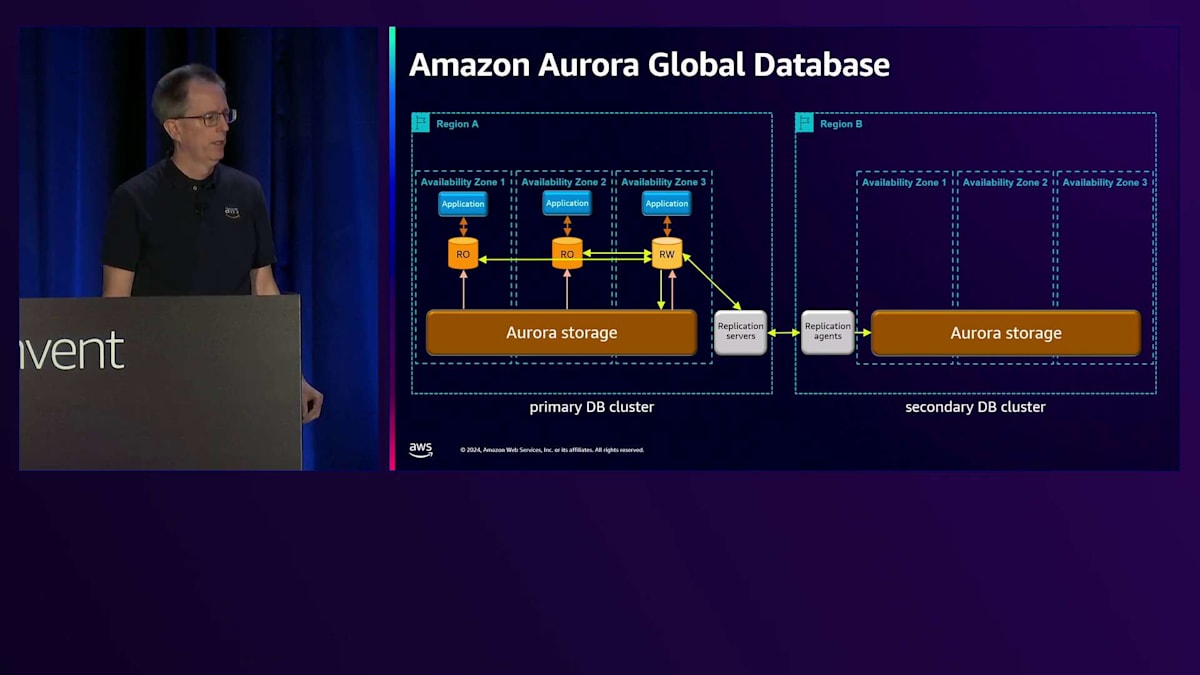

さて、このストレージシステムには、Global Databaseという強力な機能があります。 Region Aで、何らかの災害対策が必要な場合、セカンダリのデータベースクラスターを作成できます。そのRegionにストレージボリュームを設定すると、 裏側でReplication Agentがデータのレプリケーションを処理してくれます - これらのコンポーネントを管理する必要はありません。これはストレージベースのレプリケーションなので、インスタンスは必要ありません。書き込みを行うと、データが流れていきます。先ほど言及した10ギガバイトのチャンクを覚えていますか? 利点は、単一のストリームによるボトルネックを避け、並列でレプリケーションできることで、高い書き込みワークロードを処理できます。
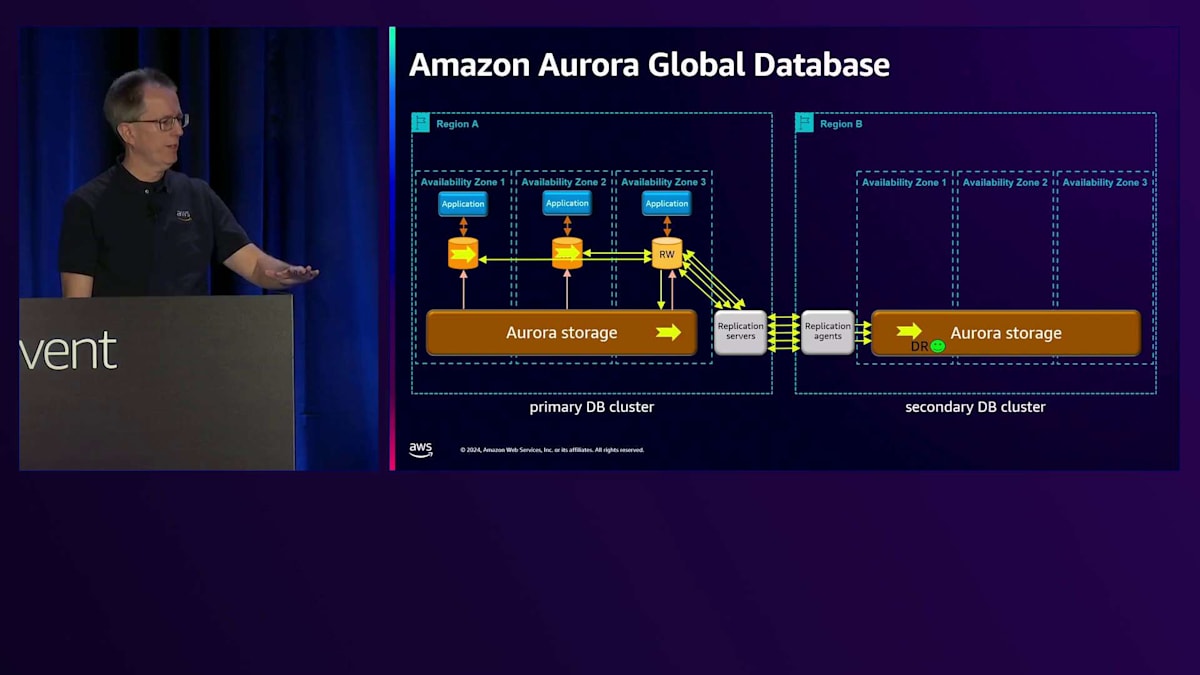
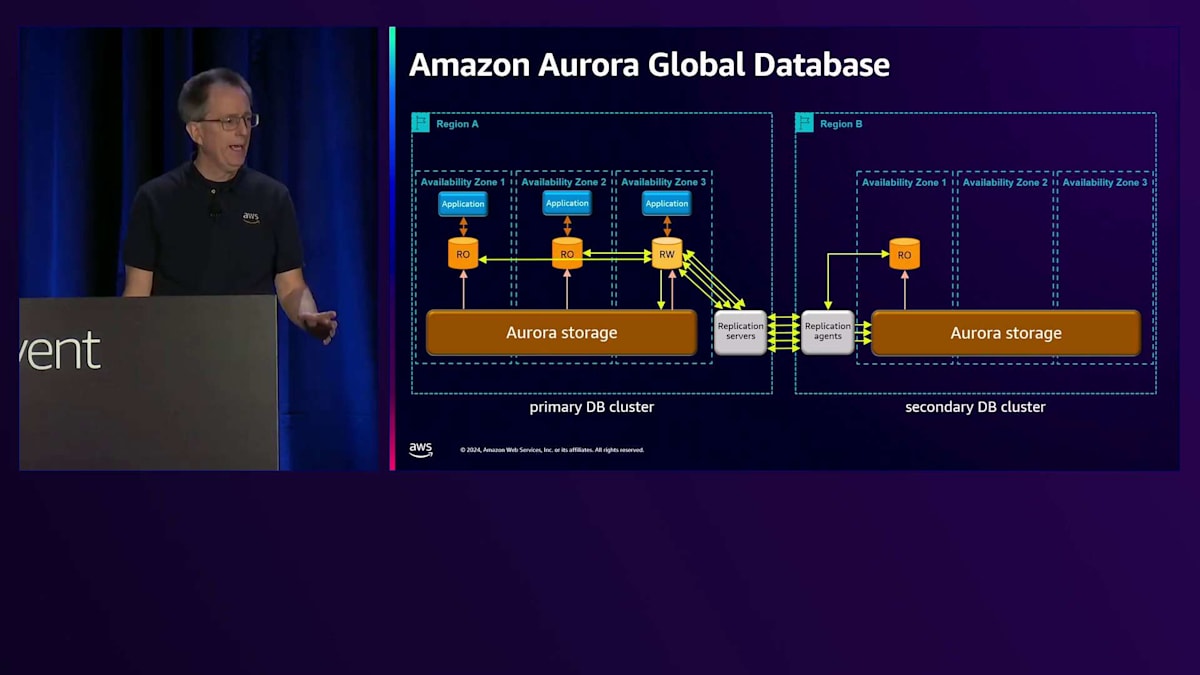
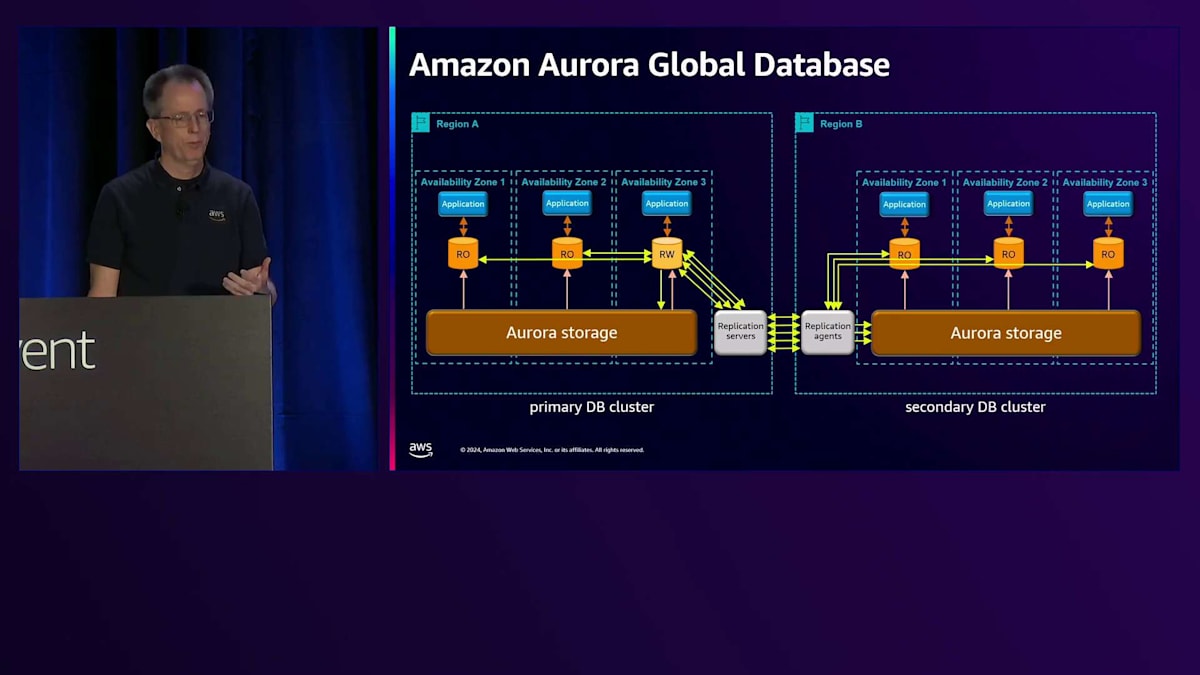
書き込みが入ってくると、通常の場所に加えてReplication Serverにレプリケーションされ、そこからAgentを経由してストレージに到達します。 この時点で、災害対策機能が整います。スピンアップには時間がかかるかもしれませんが - これについては別の講演で話しますが - これが基本的なセットアップです。 Read-onlyノードを1つまたは複数追加でき、Replication AgentはRegionと同じようにこれらのRead-onlyノードを更新するので、読み取り用に使用できます。 複数のノードを持つことができ、アプリケーションはRead-only操作を実行できます。先ほど説明した書き込み転送もここで機能し、ストレージは直接自己修復できるので、ネットワークの問題を心配する必要はありません。

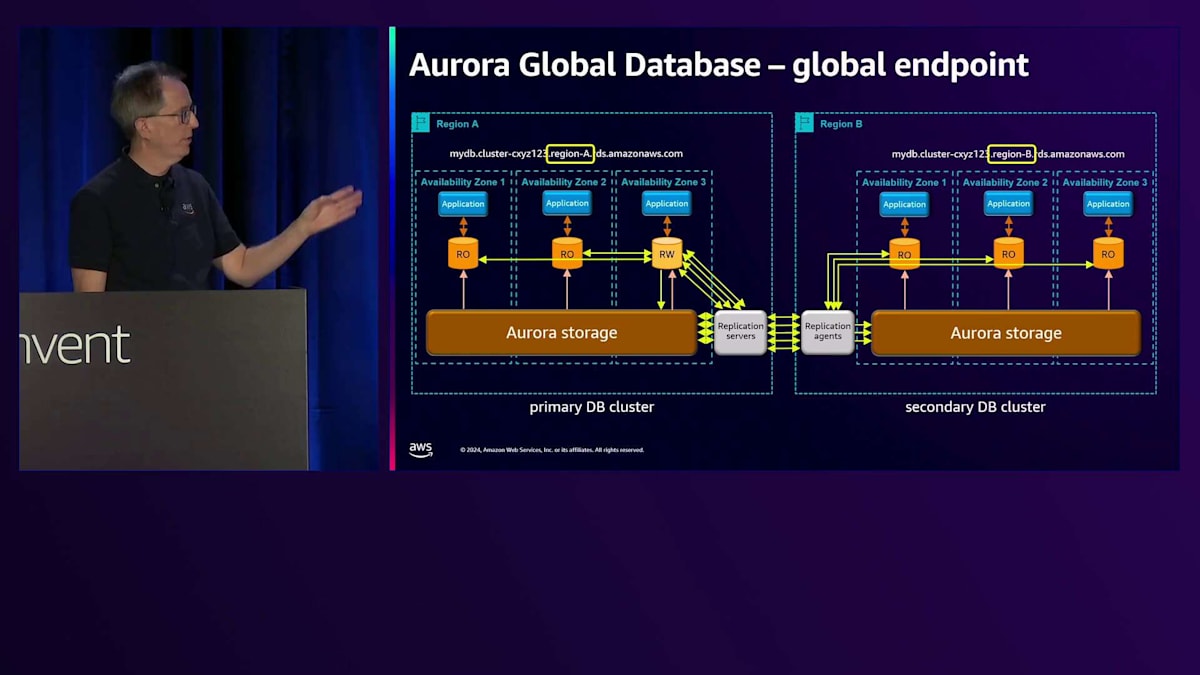
このセットアップは効果的ですが、アプリケーションがどのRegionがプライマリかを知る必要があるため、時として課題となります。最近、Global Databaseのための グローバルエンドポイントを導入しました。各Regionには、クラスター用のCNAMEがあり、それによって解決されます。 それらは異なっており、実際にはサブドメインは本物のRegion名になります。
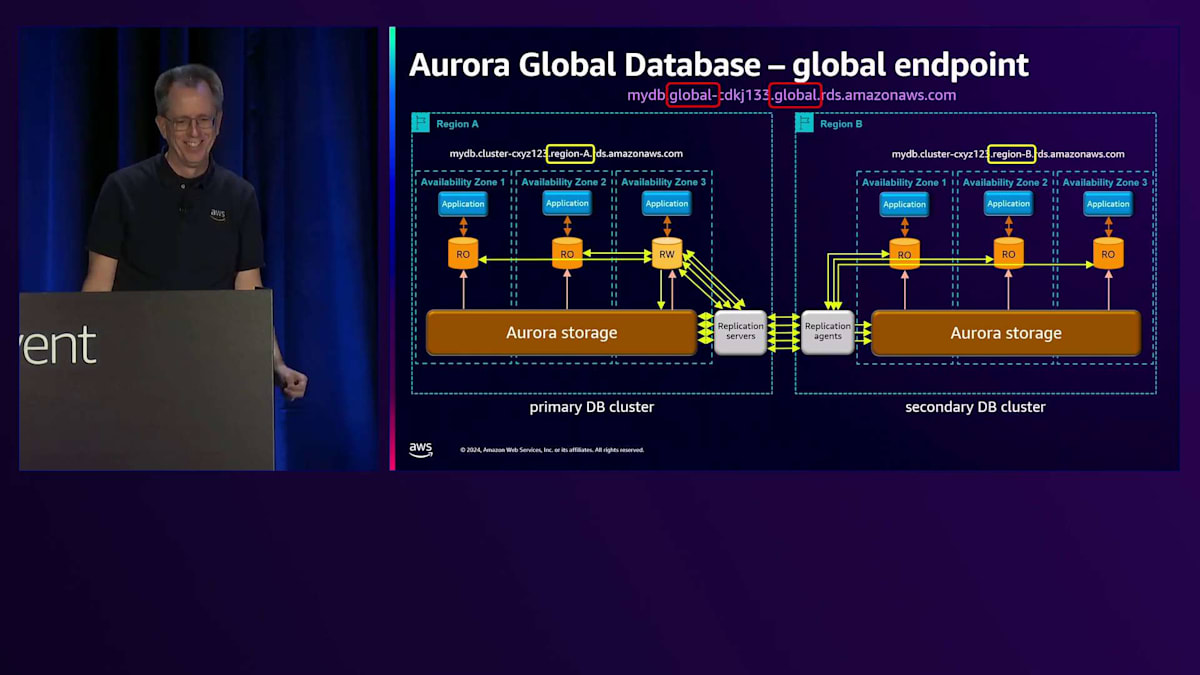
ただし、この例ではシンプルにRegion AとRegion Bとラベル付けされています。つまり、あるRegionから別のRegionに切り替えたい場合、アプリケーションに変更を加える必要があり、これは緊急時に問題となります。そこで、このグローバルエンドポイントを導入しました。そして本当にグローバルであることを確実にするため、名前を2回入れました。 これを見たとき、私は本当に気に入りました。部分的には名前にそれが必要だからですが、異なるサブドメインにも必要だからです。
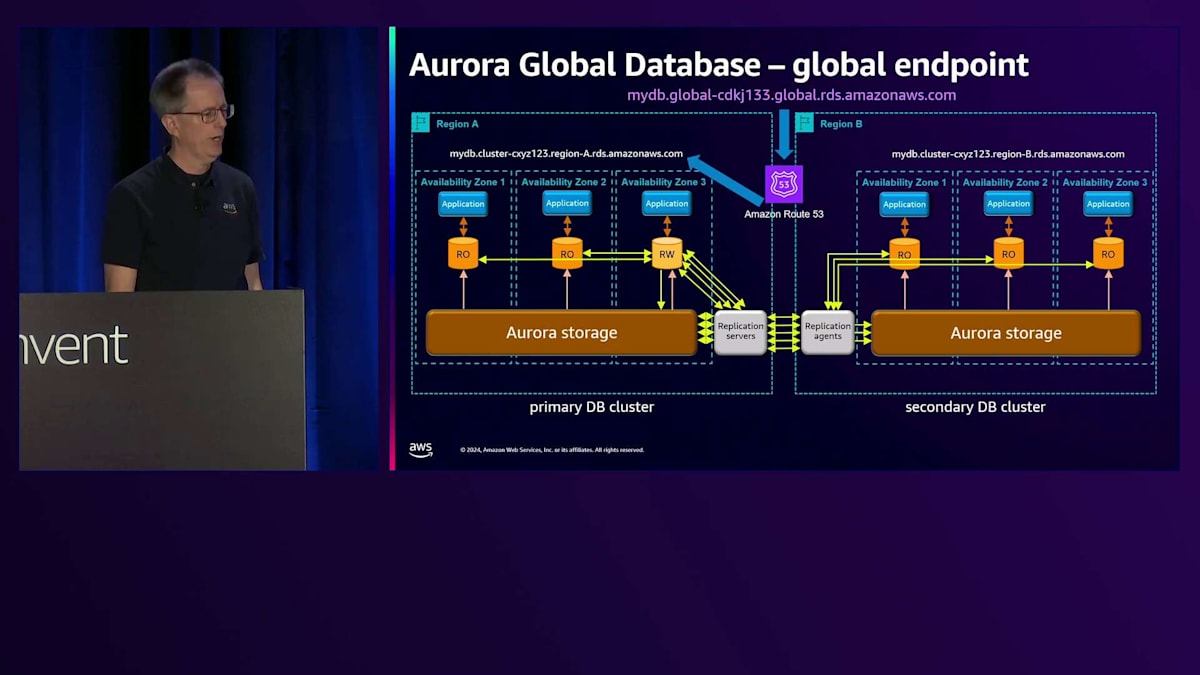
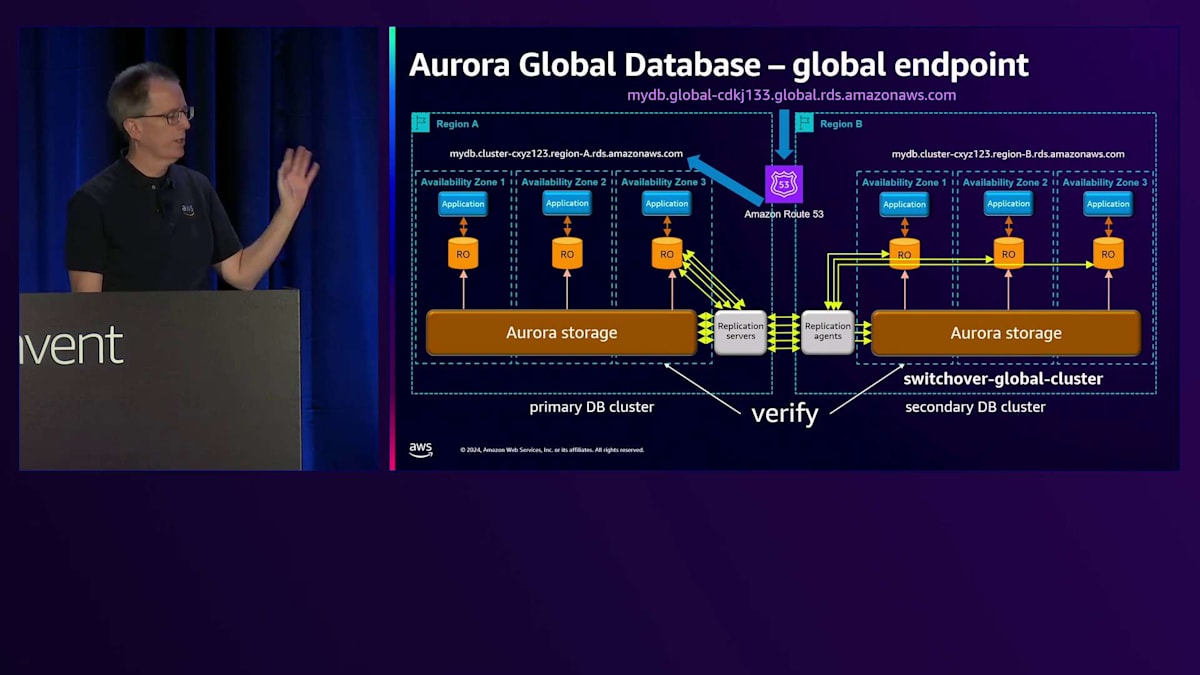
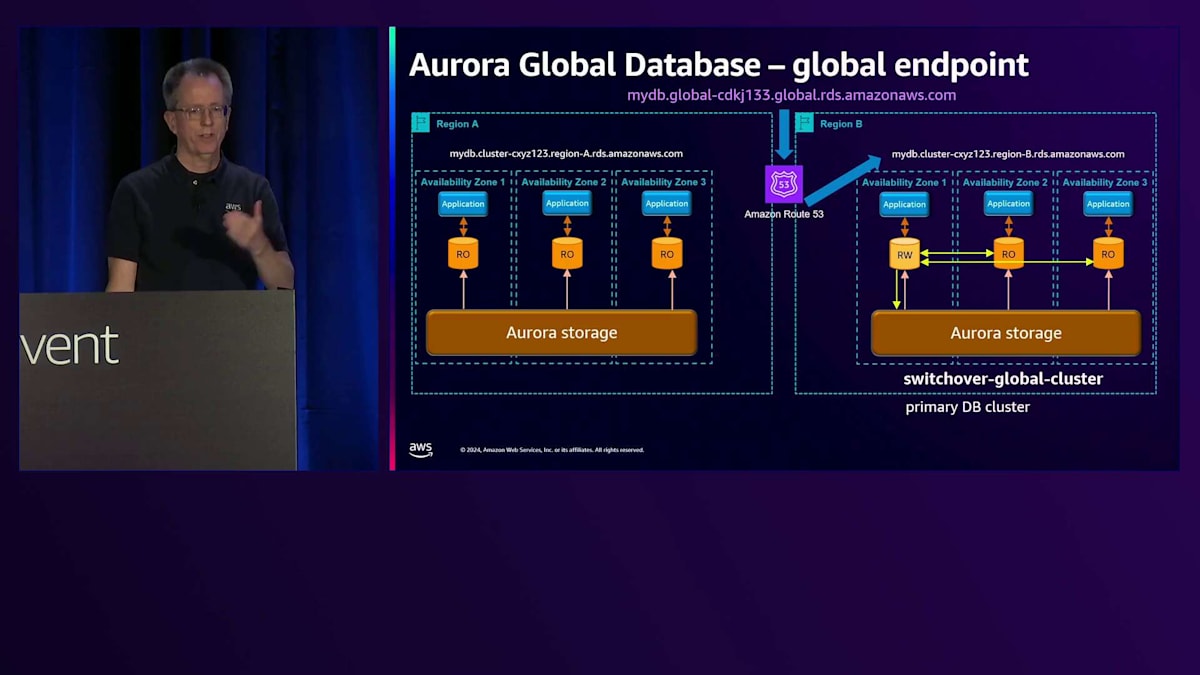
Amazon Route 53による名前解決の仕組みについてご説明します。現在、Region Aがプライマリーとなっているため、その名前の解決を行うと、Region Aの CNAME を指すことになります。あるリージョンから別のリージョンへの切り替えを行う場合、まず通常のスイッチオーバーの手順として、すべてが正常であることを確認します。 その後、Region Bでread-writeノードが稼働していることを確認してから切り替えを行います。すると、同じ名前解決を行った場合 、今度はRegion Bを指すようになります。特別な操作は必要なく、これは非常に優れた技術で実現されています。Route 53のコントロールプレーンを使用する必要がないため、この切り替えは非常に高可用性を備えています。
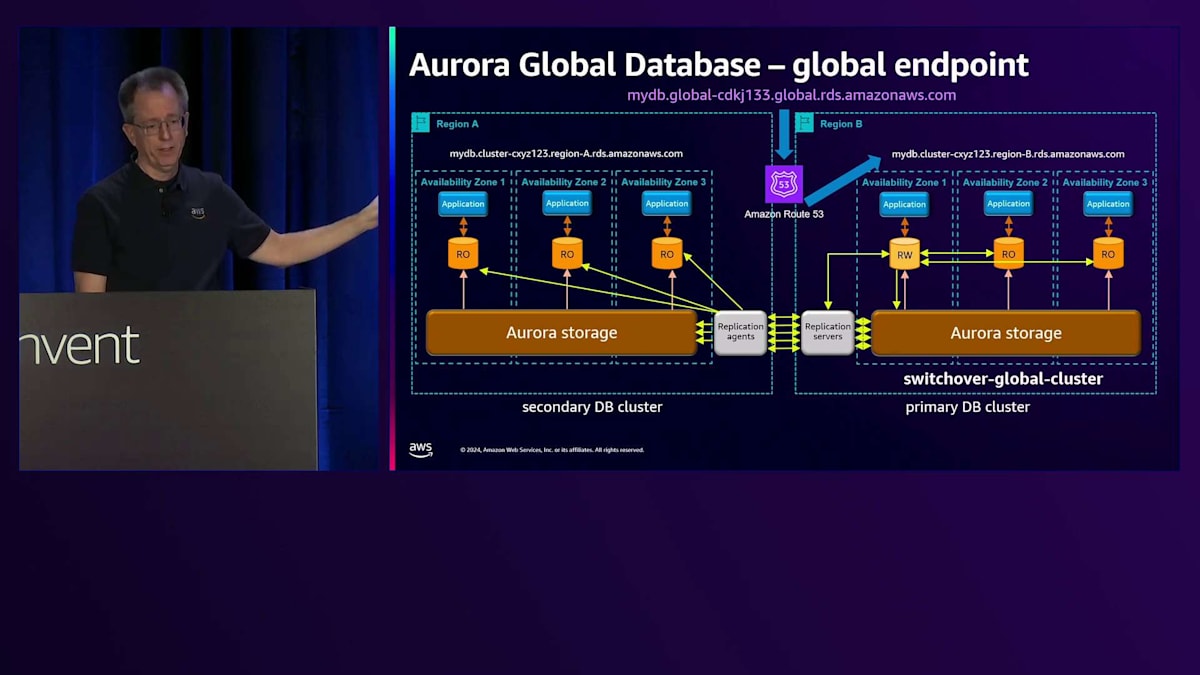
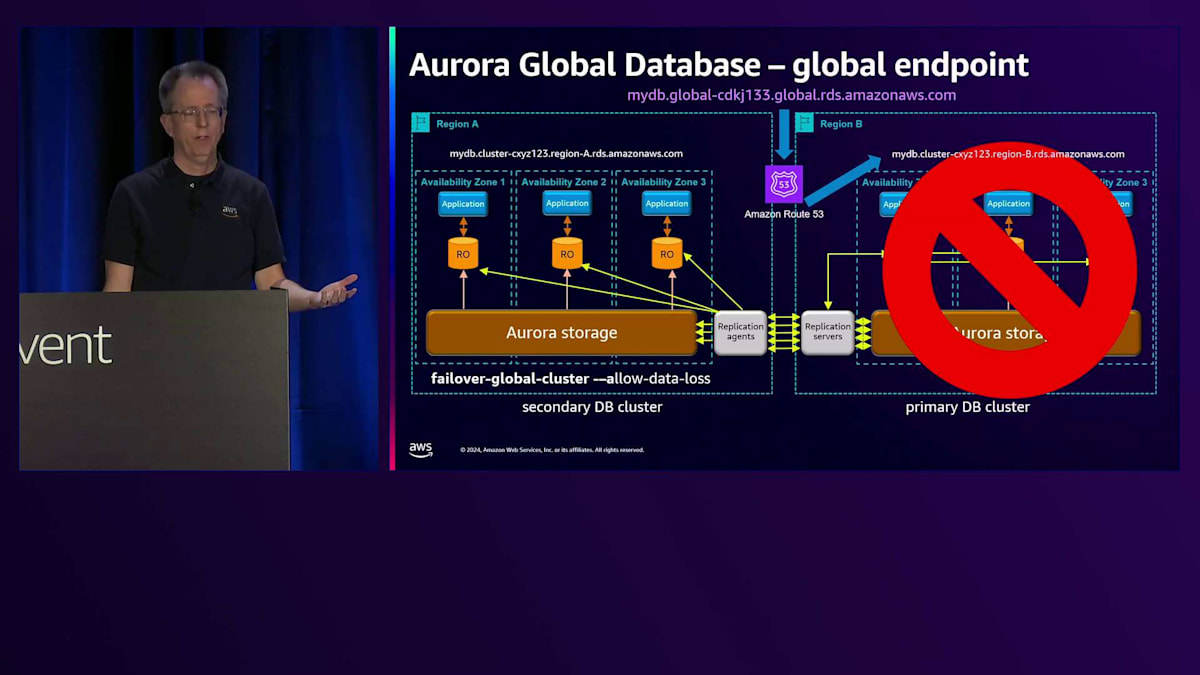
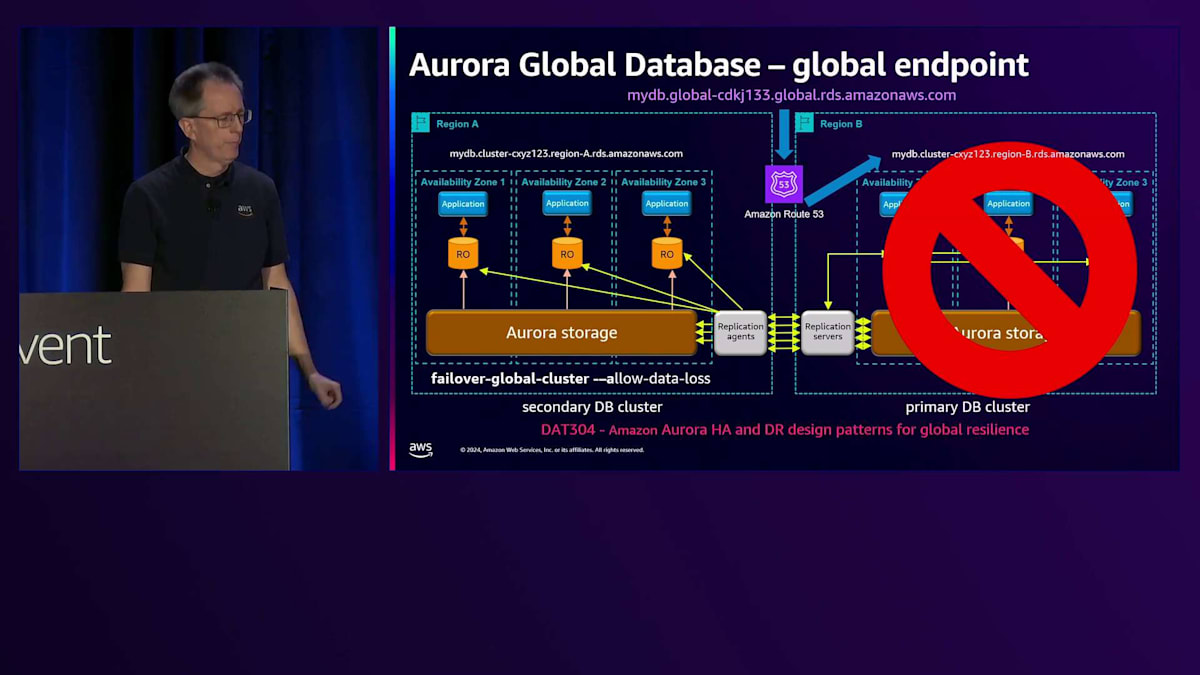
これで問題ありませんが、次はRegion A の設定を元に戻す必要があります。これはスイッチオーバーの最後に自動的に行われます。通常のレプリケーションは正常に動作しているものの、Region Bで問題が発生した場合 、必要に応じてフェイルオーバーを実行できます。その場合は、failover-global-clusterコマンドに--allow-data-lossオプションを付けて実行します。緊急時にはRegion Bが利用できないため同期が取れていない状態となり、データに差異が生じる可能性があることをご理解いただく必要があります。このように、切り替えとフェイルオーバーには2つの異なるコマンドがあります。以前の名称が紛らわしかったため、途中で変更を行いました。 これは月曜日に同僚と行った別の講演、DAT304「Aurora HAとDRの設計パターン:グローバルレジリエンスのために」についてです。近々YouTubeで公開される予定です。
Auroraストレージの内部構造と最新の改善点

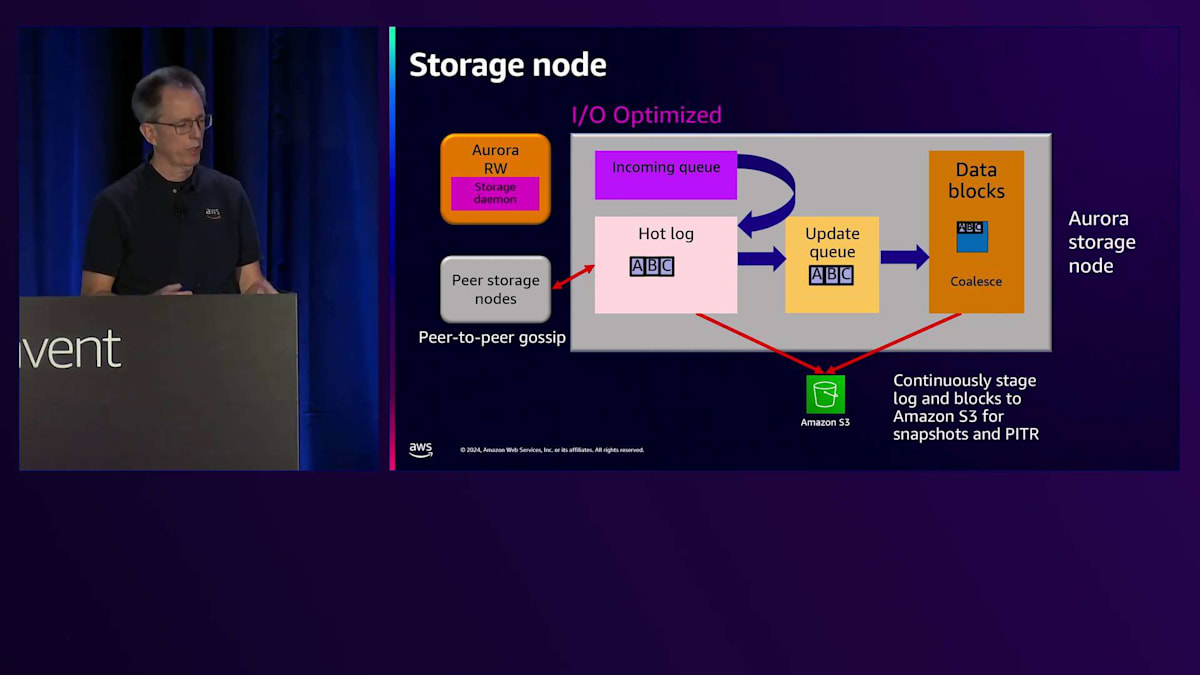
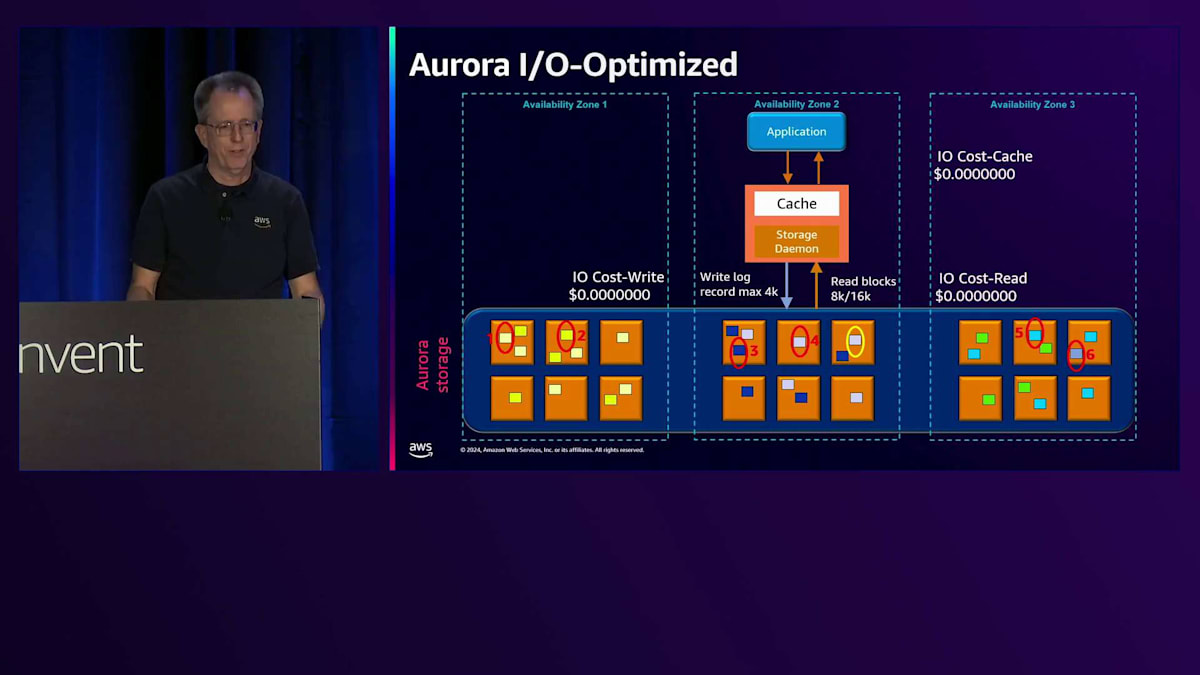
では、Auroraストレージの内部構造について詳しく見ていきましょう。ここに示しているのは、さまざまなコンポーネントを持つAuroraストレージノードです。 順を追って説明していきます。先ほど示したようにread-writeインスタンスがありますが、前回の図には含まれていなかったStorage Daemonについても説明します。このデーモンはホスト上で動作し、エンジンからストレージへの通信を担当します。書き込みが発生すると、Storage Daemonを通じてincoming queueに送られます。このincoming queueはメモリ上にあるため、この時点では確認応答を返すことができません。hot logに移動するのを待つ必要があり、ディスク上のhot logに書き込まれた後で、初めてStorage Daemonを経由してエンジンに確認応答を返し、コミットが完了します。

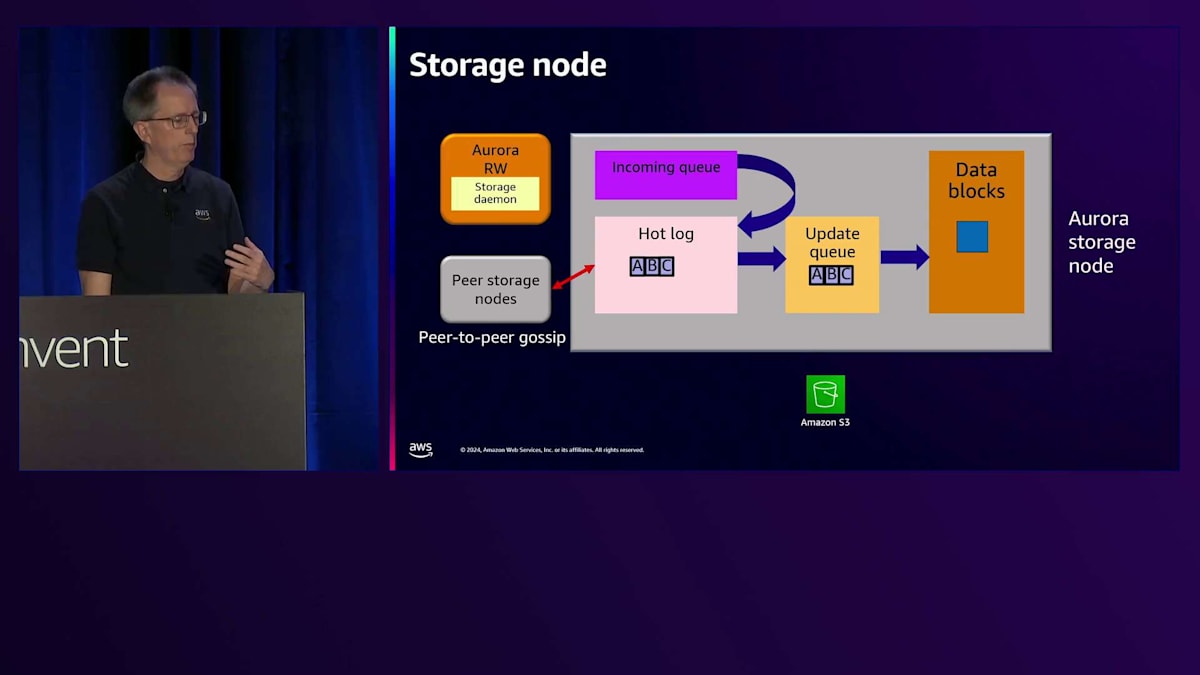

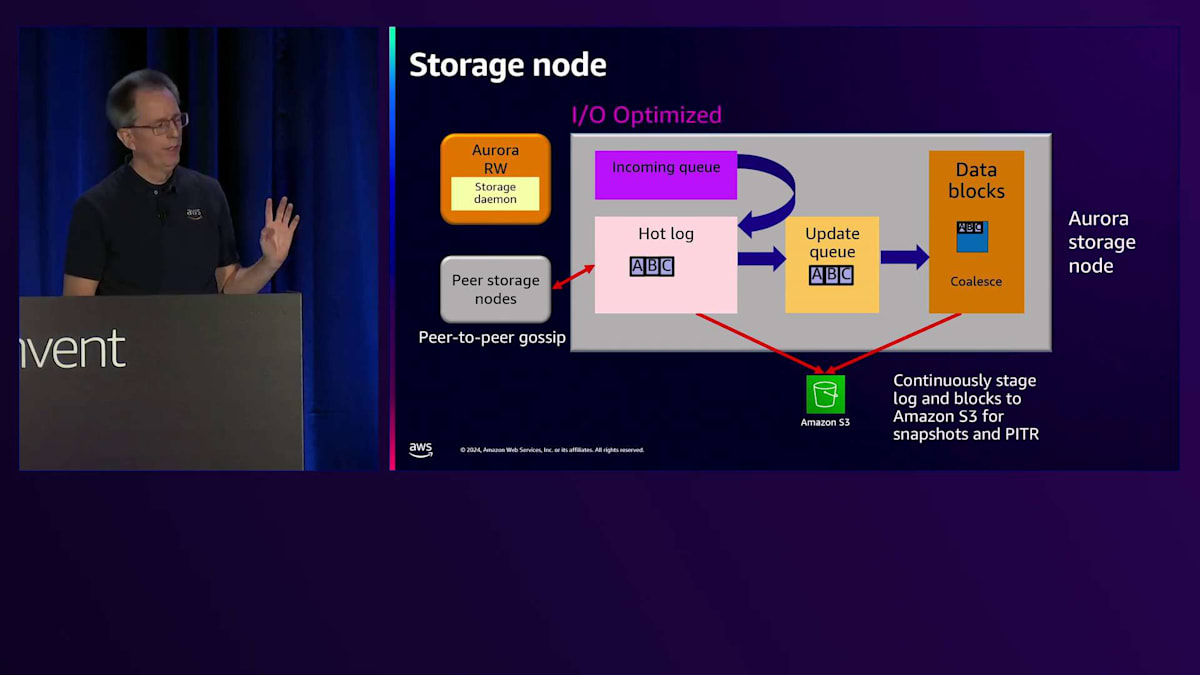
次の書き込みが発生すると、incoming queueに入り、hot logに移動します。確認応答が返されますが 、この時点でBが欠落していることに気付きます。ここでリペア機能が働き、ピアノードが欠落したBの変更を送信できます。シーケンスが完全な状態になったら、update queueに入れて データブロックにマージします。これがログからブロックへの変換を行う統合プロセスです。読み取りを行う際は、単にブロックを読み戻すだけです。 これらのログとデータブロックは、スナップショットとPoint-in-Time Recoveryの両方のために、ストレージから Amazon S3に継続的にバックアップされます。
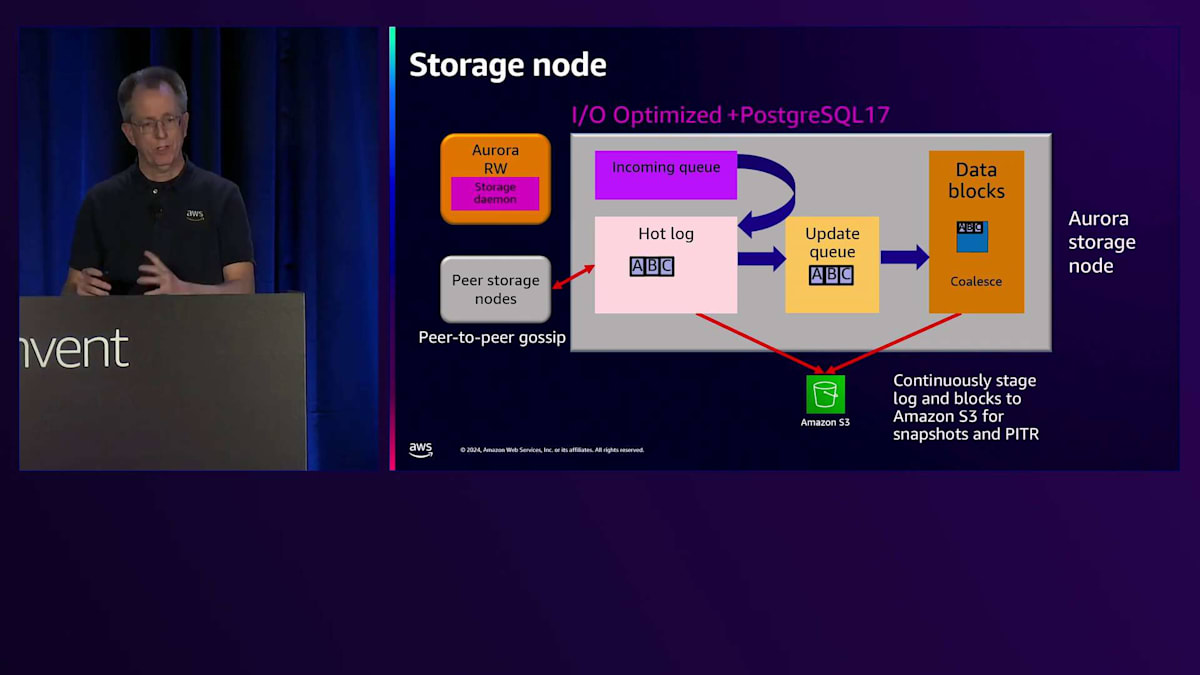
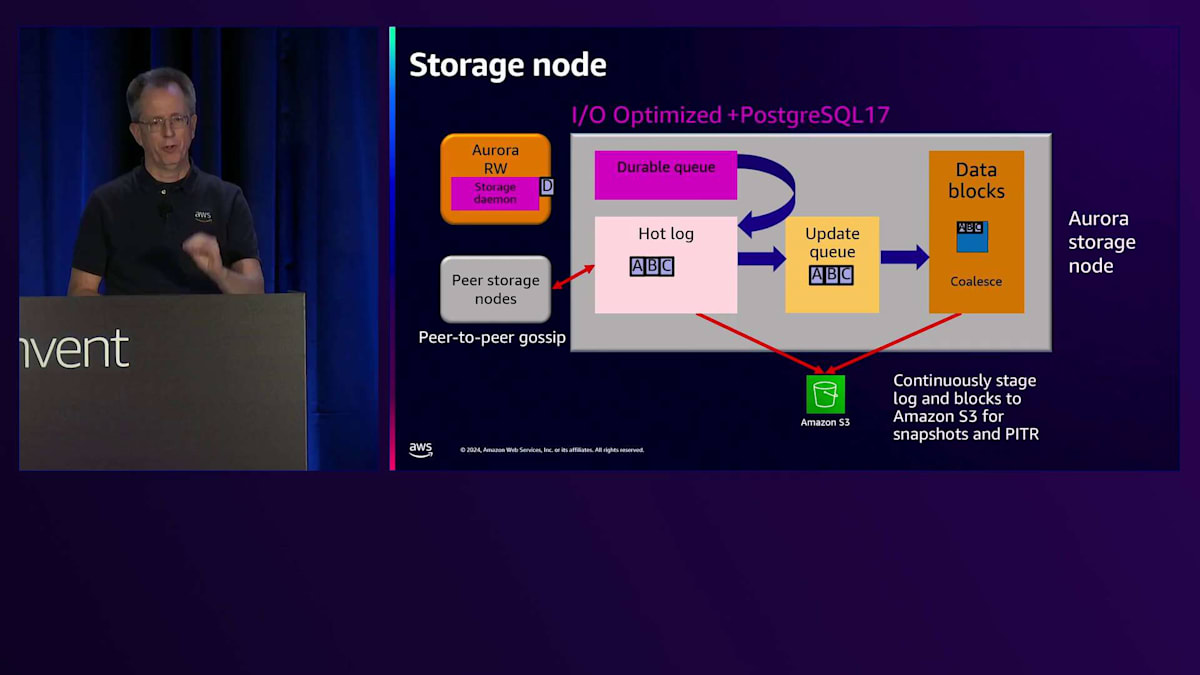
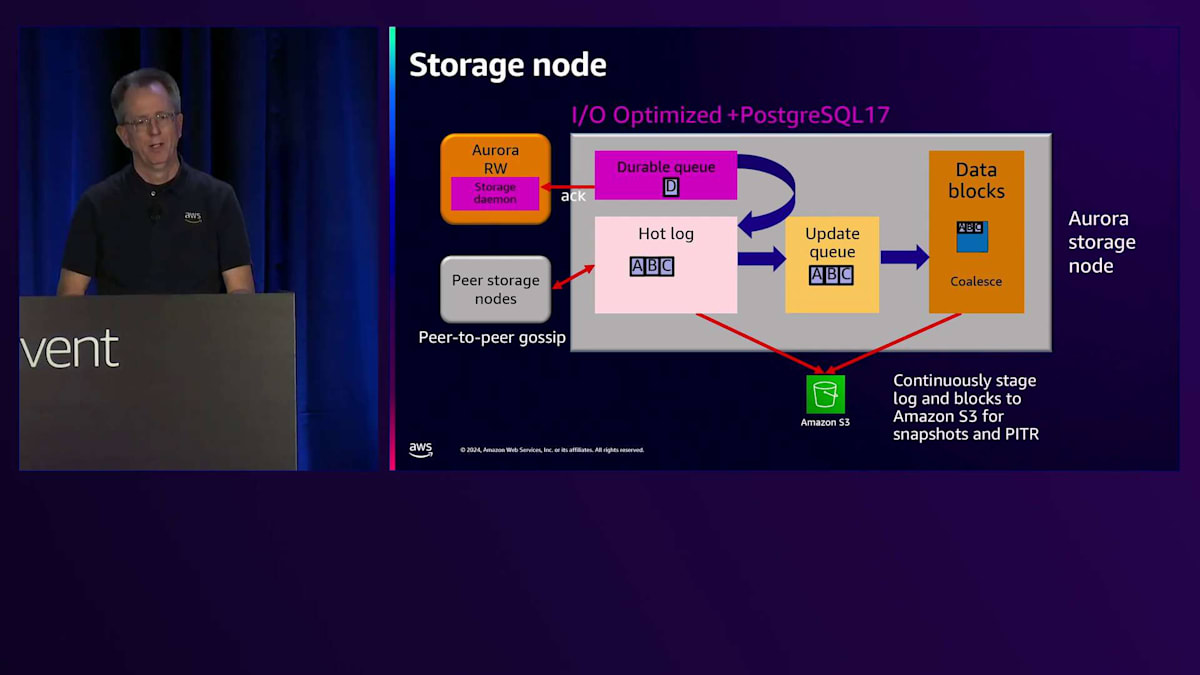
現在、新しいI/Oタイプに関連していくつかの変更を加えています。その一環として、I/O Optimized StorageのSKUで性能改善を実施しています。最初の改善点は、Storage Daemonの動作方法とバッチ処理に関する変更でした。これにより、レイテンシーの改善とCPU使用率の低下が実現されました。 これらはすべて望ましい改善点ですが、この最適化は大量のI/Oを処理する場合にのみ効果を発揮するため、Standard I/Oとの違いが依然として存在します。最近のPostgreSQL 17(現在プレビュー中)では、さらに大きな変更を加えています。具体的には、従来のincoming queueを durable queueに置き換えました。これにより、書き込みが発生した際、durable queueに到達した時点で即座に確認応答を返すことが可能になりました。想像できる通り、必要な処理が減ることで レイテンシーが低下し、ジッターも減少します。この素晴らしい改善は現在プレビュー中で、来年リリース予定です。
PostgreSQLとMySQLの最新アップデートとServerless v2の進化


この1年間のPostgreSQLのアップデートについてお話ししましょう。今年1月にPostgreSQL 16のサポートを追加し、先日r7iとr8gインスタンスファミリーのサポートを開始しました。また、Query Plan Managementをレプリカ上でも実行できるようになり、レプリカでも安定したプランを使用できるようになりました。Logical Replicationのパフォーマンスとキャッシングについても多くの改善を行いました。Generative AI向けにpgvectorを新しいバージョンに更新し、新しいPostgreSQL拡張機能もいくつかサポートしました。そして先ほど申し上げた通り、PostgreSQL 17がプレビュー版として利用可能になっています。プレビュー版が利用できるということは、本番環境での提供も間近だということを意味します。
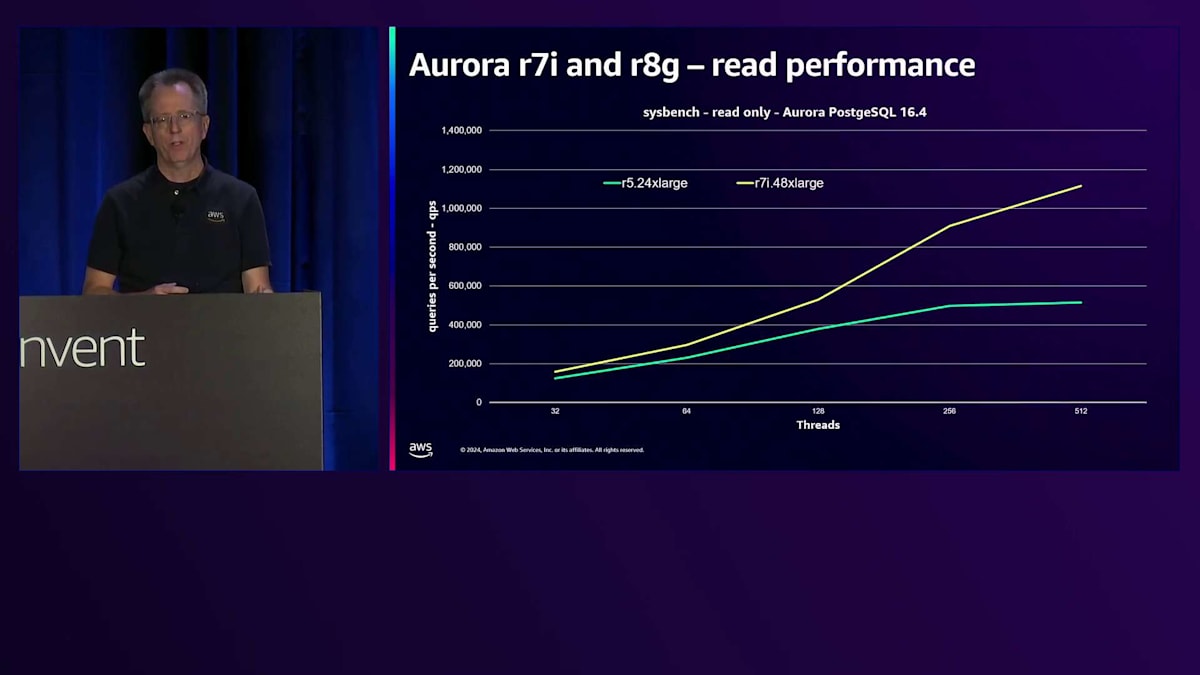
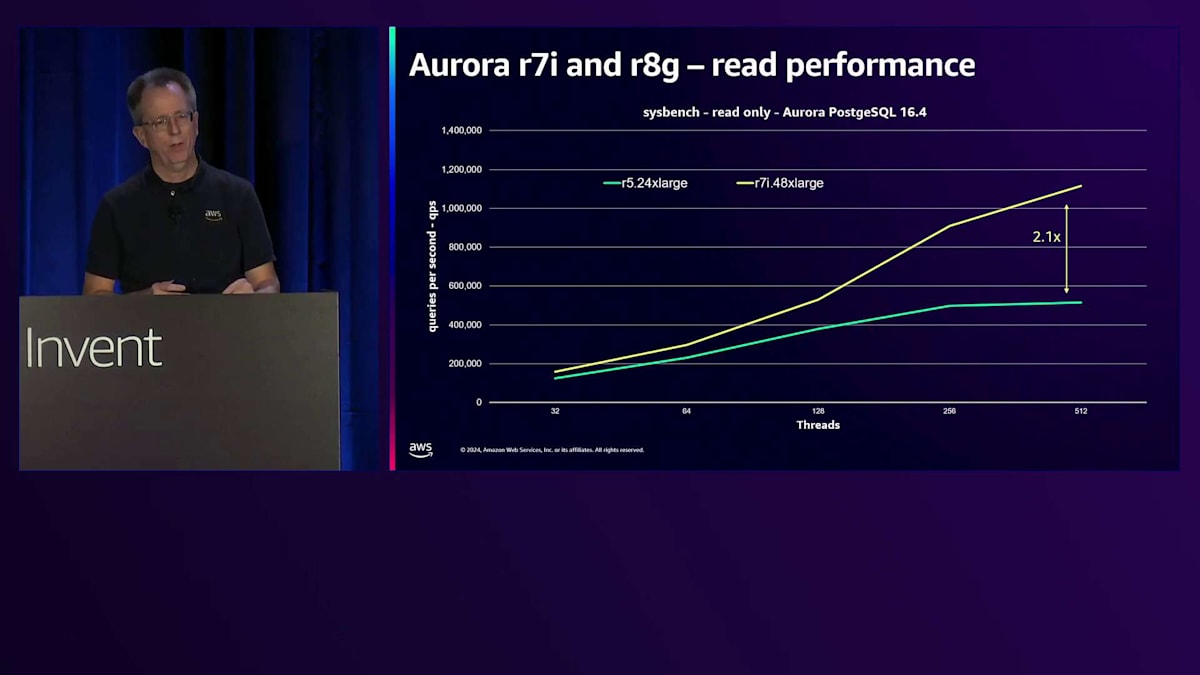
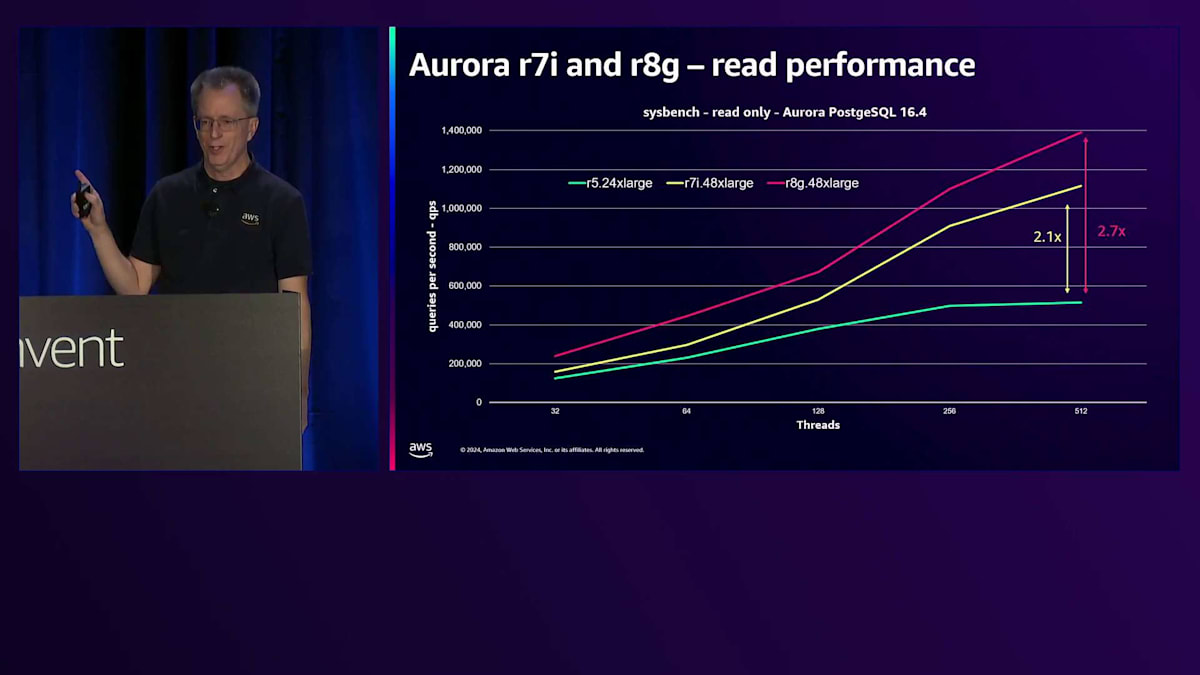
新しいr7iとr8gインスタンスで実現した世代間の性能向上について見てみましょう。これはsysbenchのread-onlyワークロードで、キャッシュされたデータの読み取りのみを行うため、CPUのベンチマークとして考えています。縦軸は1秒あたりのクエリ数で、数値が高いほど良い性能を示しています。青緑色の線は数年前の最上位インスタンスだったr5.24xlargeを表しています。現在は、メモリが2倍のr7i.48xlargeを提供しています。読み取り性能は2倍のスケーラビリティを実現しています。リレーショナルデータベースのスケーラビリティは限界に達したと言う人もいますが、実際にはより大きなインスタンスでより高いスケールを実現し続けています。さらに素晴らしいことに、r8g.48xlarge Gravitonインスタンスが利用可能になり、以前と比べて2.7倍、つまりほぼ3倍の性能を実現しています。



MySQLの面でも大きな進展がありました。現在8.0.39互換の3.0.8まで対応しています。MySQLも先ほど触れたr7iとr8gをサポートしています。切り替えを高速化する高度なMySQL ODBCドライバーを実装し、S3への並列エクスポートや、以前お話しした拡張バイナリログも実装しました。Aurora Serverlessは、インスタンスの運用をより簡単にする管理性の面で、私たちが未来だと考えているソリューションです。Serverlessについて話す際は、v2を指しています。v1は徐々に廃止していく予定ですが、その過程がゆっくりとしている理由についても説明させていただきます。



Serverless v2では、数秒以内にその場でスケーリングが可能です。CPUとメモリを1秒単位で追加でき、課金も1秒単位で行われ、スケールアップやダウン時の影響もありません。個々のLambda関数がAmazon Auroraインスタンスに接続する場合、多くのRAMやメモリは必要ありません。しかし、Lambda関数が増えるにつれて、より多くのメモリとCPUを使用します。大規模なレポーティングジョブが実行される場合、大量のリソースを使用しますが、その後は再び縮小します。これは1日を通して、あるいは週単位で、まさにワークロードに応じて真にスケールする仕組みです。



このスケーラビリティの重要なポイントの1つは、CPUのスケーリングはそれほど難しくないものの、メモリの移動は非常に複雑だということです。チームはバッファプールのリサイジングに関して素晴らしい仕事をしました。バッファプールを監視し、読み取りが発生すると、どのデータがホットになっているか、アクセス頻度を追跡します。より多くのブロックを取り込む必要がある場合、自動的にバッファプールを拡張してより多くのブロックを収容できます。しばらくデータにアクセスしない場合、それらのページを追い出してメモリを縮小し、結果としてフットプリントとコストを削減します。これは私たちのサービスの中で最も印象的な機能の1つです。
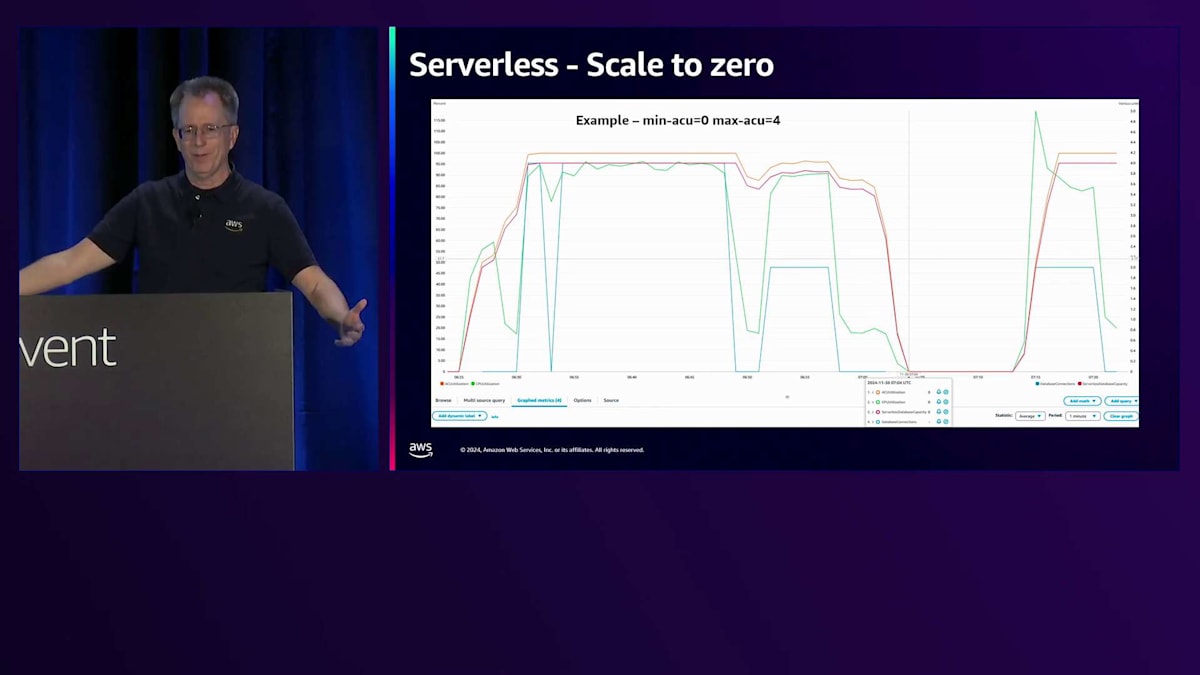
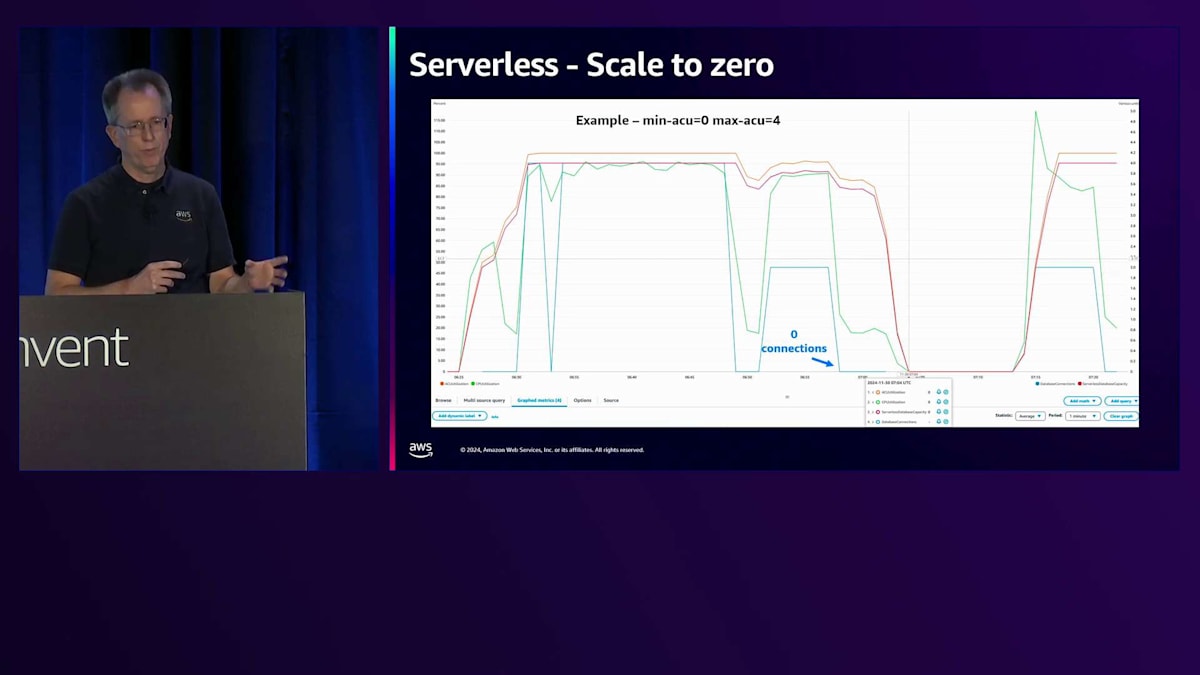
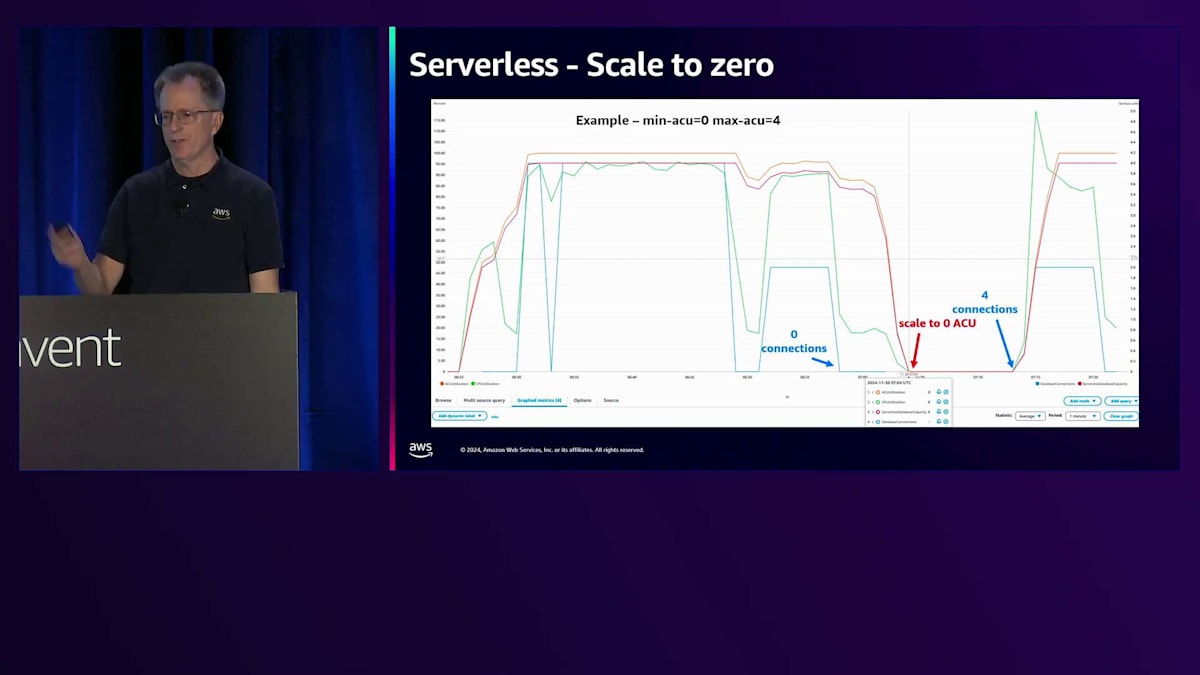
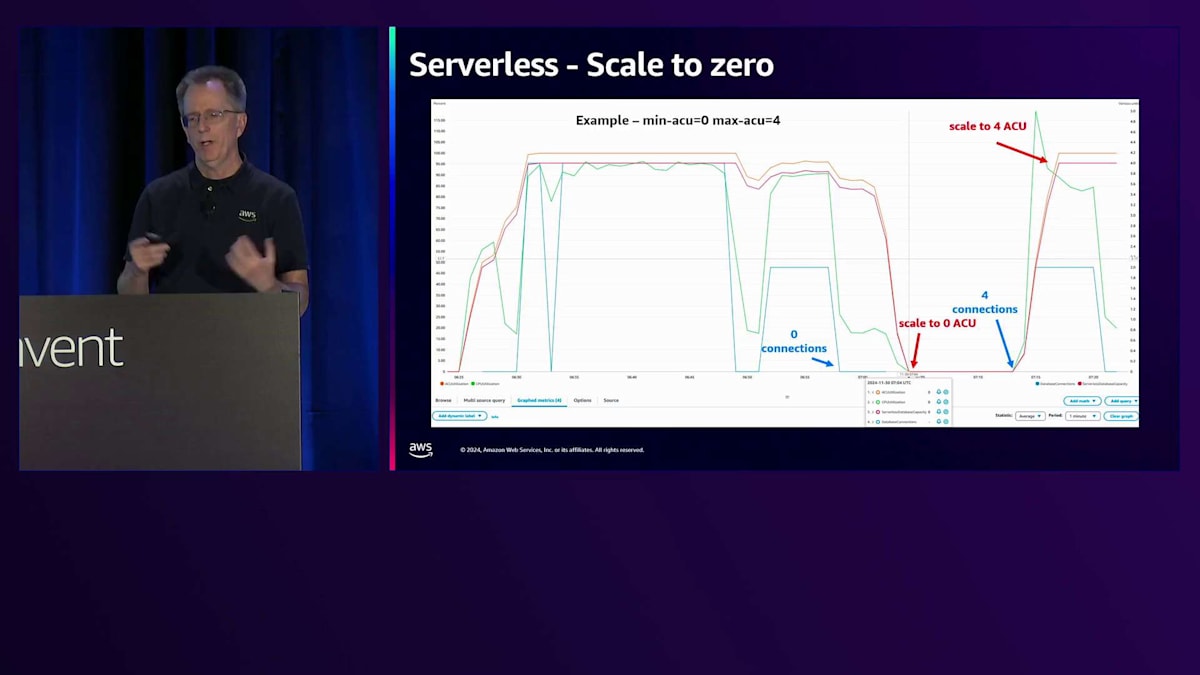

Serverless v2において、v1と比較して欠けていた機能の1つがスケールtoゼロでした。現在、Serverless v2でスケールtoゼロが実現しています。これを実証するために、青い線が接続数を表すワークロードを実行していました。接続数がゼロになりベンチマークの実行を停止すると、スケールtoゼロの最小タイムアウトである5分に設定されているため、約5分後にACUがゼロになり、インスタンスが実質的に停止状態になります。数分後、ベンチマークを再開すると、スケールアップが始まります。スケールアップ時は0.5 ACUから開始するため、4 ACUに到達するまでに数分かかりましたが、これはテスト目的では通常問題ありません。接続数が一時的にゼロになったことに気付くと思いますが、5分間の完全な停止には至りませんでした。このタイムアウトは設定可能です。スケールtoゼロするとキャッシュが失われるため、10分や20分に設定したい場合もあるでしょう。アクティブに作業している場合は長めのタイムアウトが望ましいかもしれませんが、コストが主な関心事であれば5分に設定することをお勧めします。
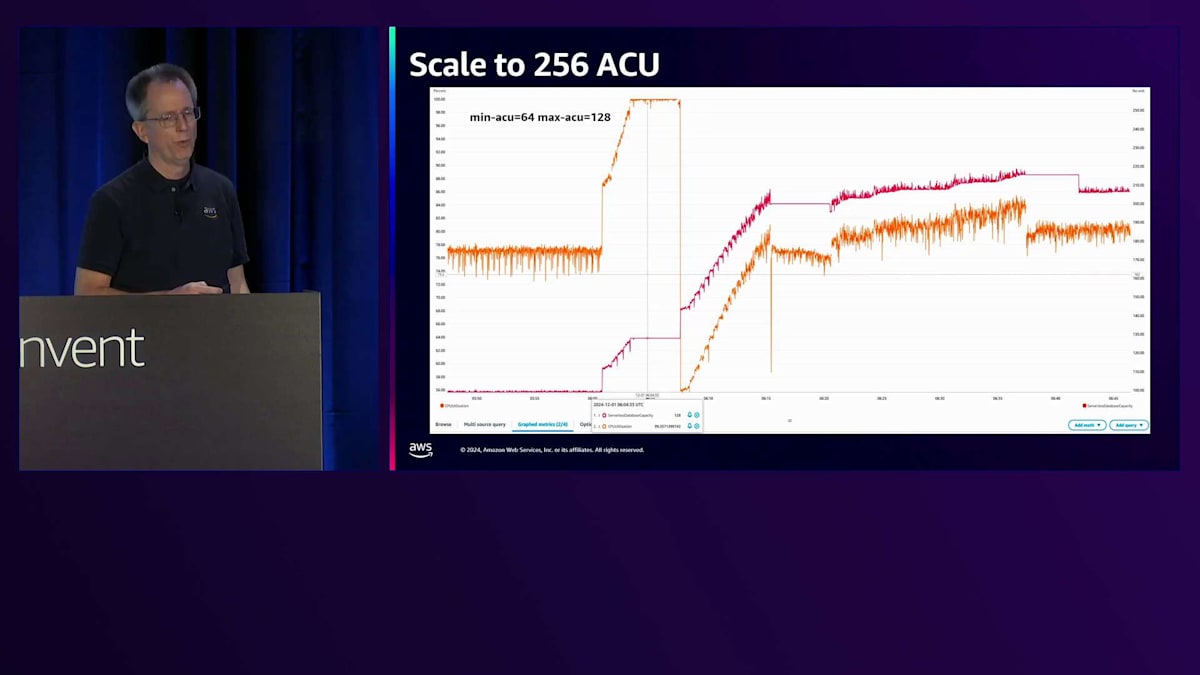
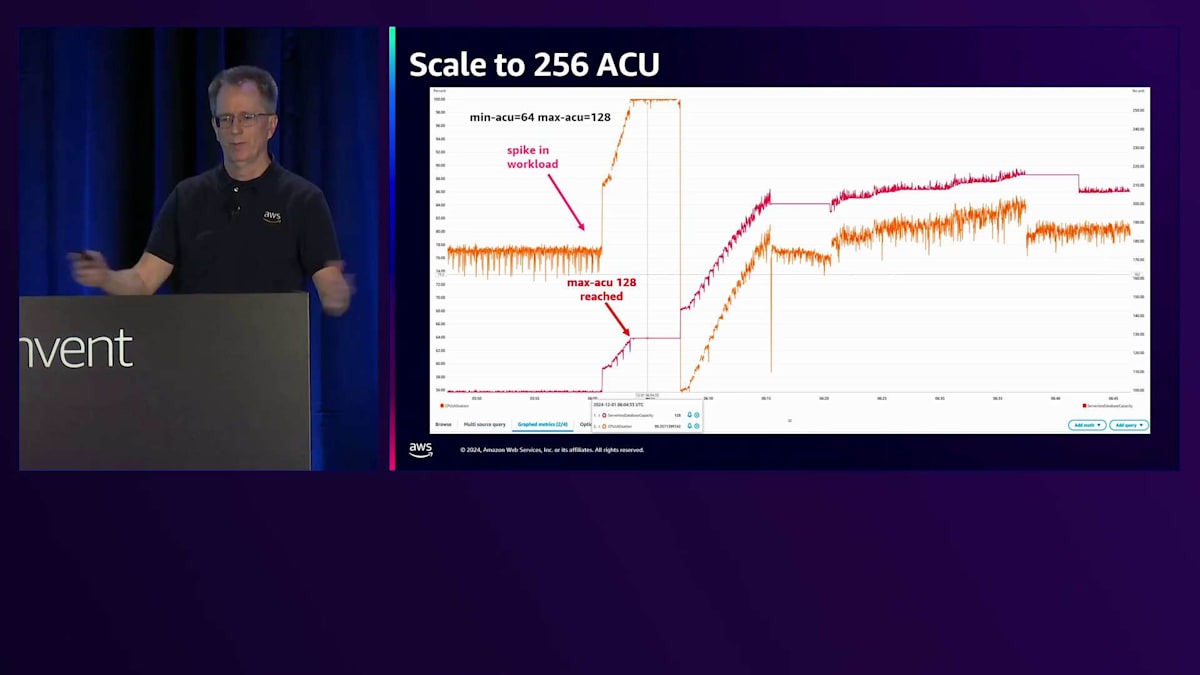
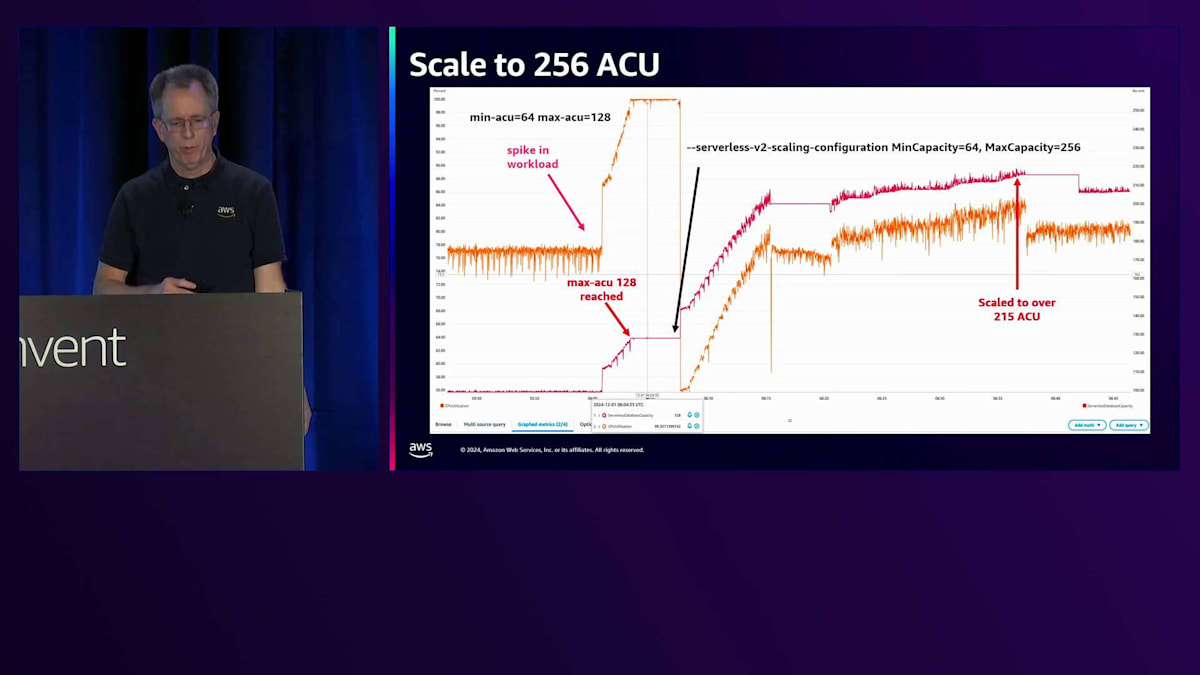
もう1つ必要だった改善点は、より大きなスケールへの対応です。現在は256 ACUまでスケール可能で、メモリとCPUが2倍になりました。この設定例では、最小64 ACU、最大128 ACUで、オレンジの線がCPU使用率を示しています。ここでCPU使用率が70%から100%にスパイクし、128 ACUに到達していることがパフォーマンスの問題を示しています。そこで、最大値を256に設定するコマンドを実行すると、スケールアップが開始されます。このケースでは、ワークロードによって約215 ACUまで上昇しました。これには数分かかりましたが、現在ではオンラインで実行可能です。



これは大きな問題ではなく、その機能は利用可能です。最後に残っていた機能はData APIのサポートでした。AuroraにアクセスするLambdaは一見シンプルに見えますが、データベースと通信するためにはLambdaにドライバーをロードする必要があります。これは少し面倒でした。また、多くのLambdaが同時に起動するとデータベースに過負荷がかかる可能性があるため、接続の管理も必要でした。そのため、負荷などすべてを管理する必要がありました。現在は、HTTPエンドポイントを有効にするだけで、Data APIを利用してHTTP接続を行うことができます。そして、データベースへの接続プーリングを私たちが管理します。設定で微調整することもできますが、一般的にはかなり簡単になりました。これで、V1とV2を区別していた最後の機能が揃い、単に「Serverless」と呼べるようになったと思います。
Optimized ReadsとTiered Cacheによるパフォーマンス向上



管理性についても多くの取り組みを行っており、ここでパッチ適用と言っているのは、マイナーバージョンのアップグレードのことです。私たちは「ゼロダウンタイムパッチ適用」という機能を導入しました。「ゼロ」という言葉は難しい目標ですが、この機能の意図は実際のダウンタイムをなくすことであり、多少の影響はあるかもしれません。PostgreSQLデータベースに接続されたアプリケーションがあり、バージョン16.3を実行しているとします。16.4にアップグレードしたい場合、まずポーズポイントを探します。約1秒間、新しいトランザクションの受け入れを一時停止し、実行中のトランザクションの完了を待ちます。完了しないトランザクションは強制終了されますが、1秒未満の短いトランザクションであれば(そうであることが望ましいのですが)、問題にはなりません。
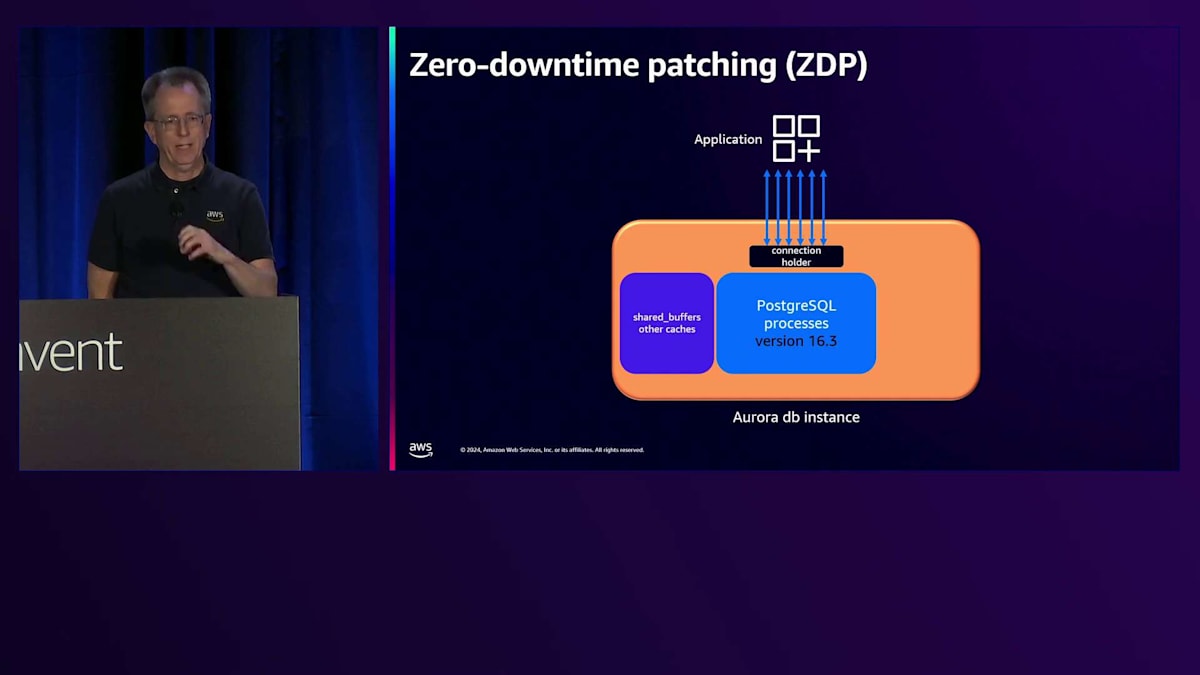
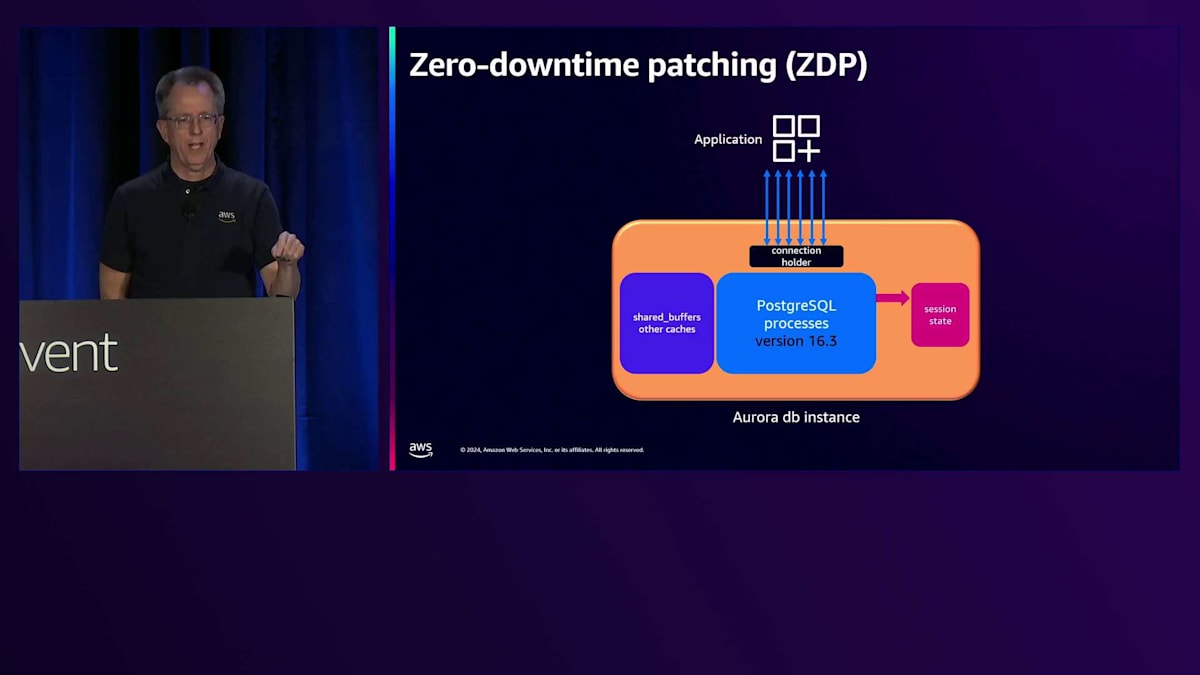
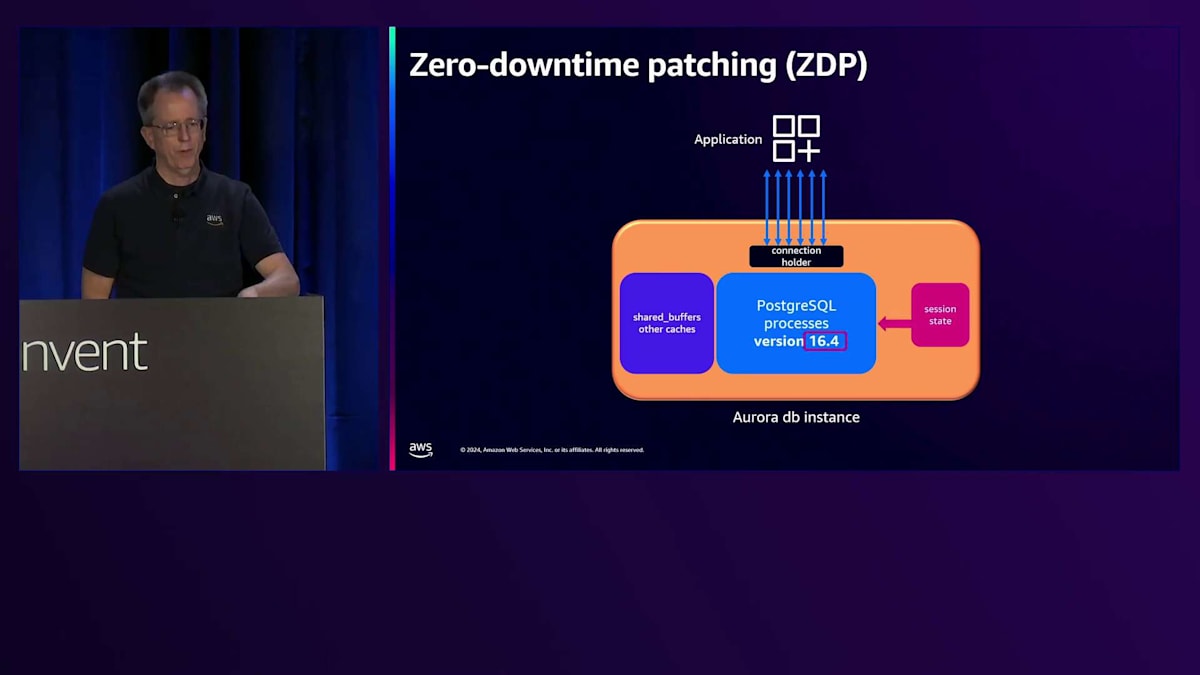
そのポーズポイントの後、基本的にインスタンス内で、それらの接続を「Connection Holder」と私が呼んでいる別のプロセスに引き渡します(実際にはこの名前ではありません)。その時点で、インスタンスからセッション状態を取り出し、インスタンスを停止して16.4で新しいインスタンスを起動します。その後、セッション情報を再度読み込み、接続を戻して完了です。これにはどのくらい時間がかかると思いますか?以前はかなり時間がかかっていましたが、現在ではずっと短くなっています。これは私が実行しているベンチマークで、今回はdb.r6i.4xlargeでSysbenchのread-writeを使用しています。かなり大きなインスタンスで、約35,000 QPSを処理しています。
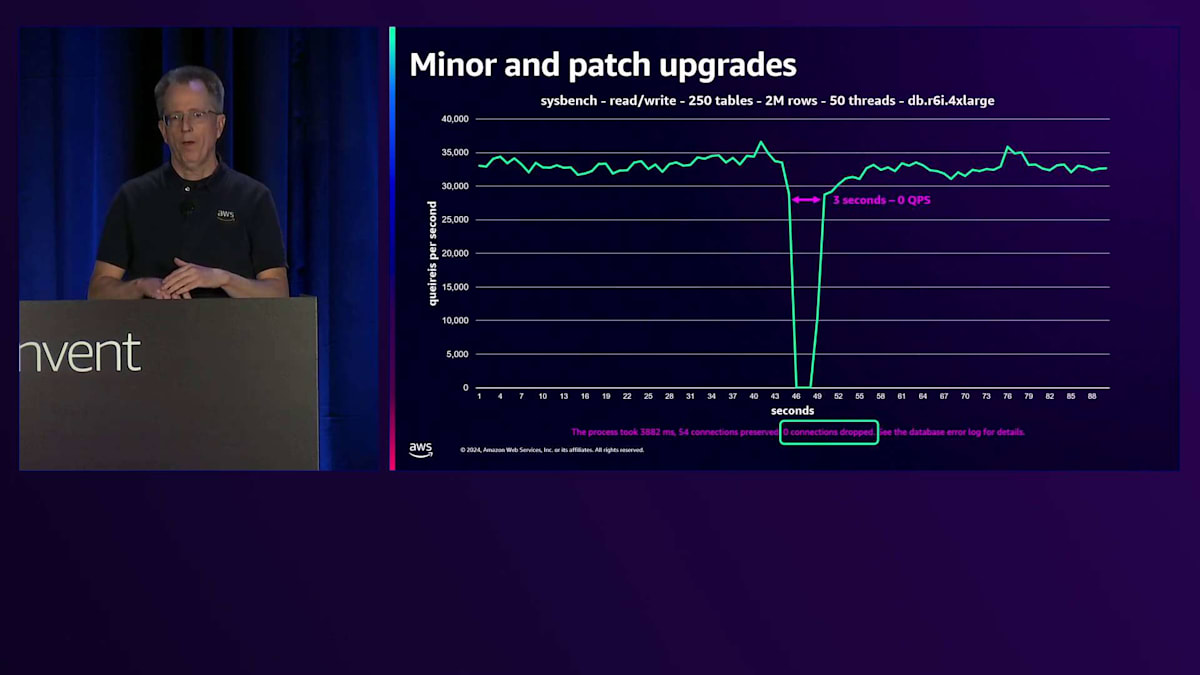
そのパッチを適用すると、QPSがゼロになる時間はわずか3秒です。このマイナーアップグレードは3秒で完了します。ここで注目すべき点は、トランザクションサイズが小さいため、接続が一切切断されなかったことです。3秒後に気付くのは、レイテンシーのスパイクだけで、これは1つの処理に3.5秒かかったと報告されますが、その後は通常の状態に戻ります。下部に表示されるこの情報は、イベントストリームに記録され、接続数や処理時間を正確に把握できます。これはワークロードによって多少変動しますが、私たちはこの時間を短縮するよう努めており、来年は1秒を目指しています。

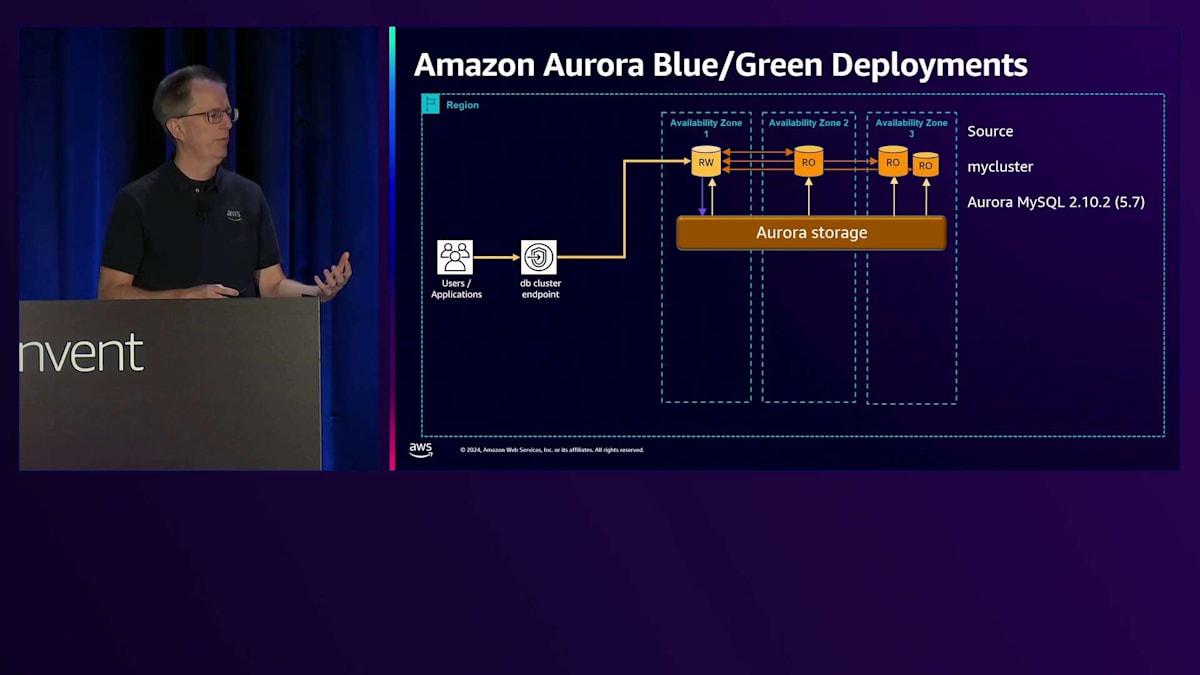
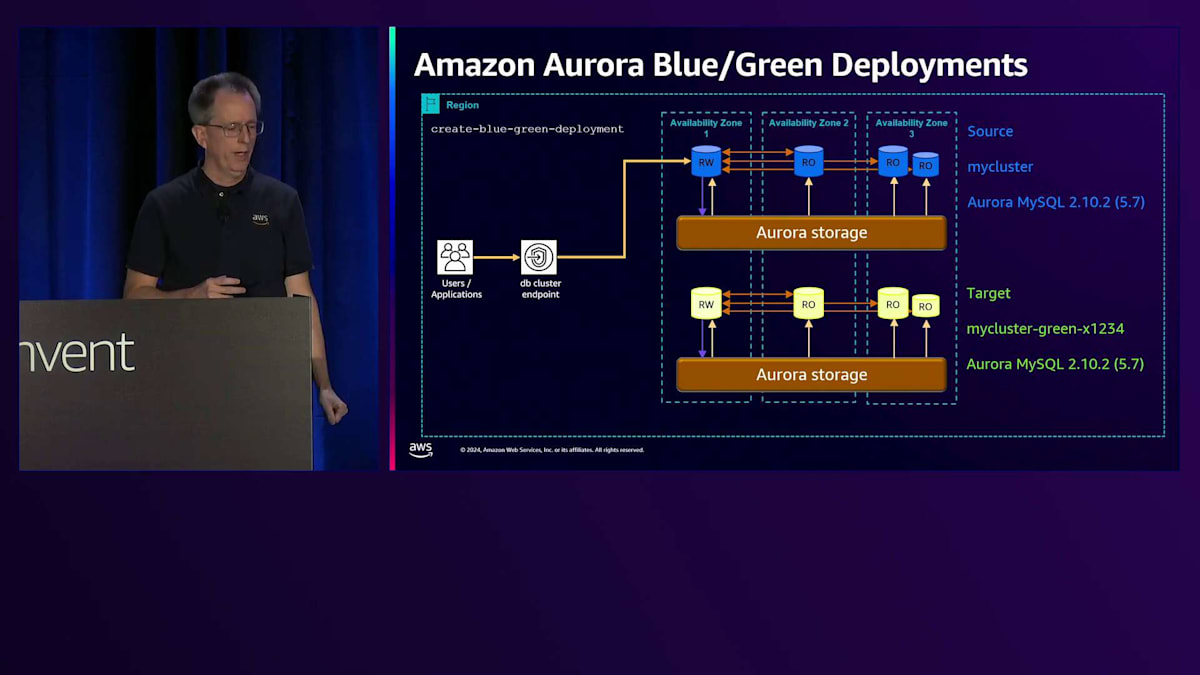
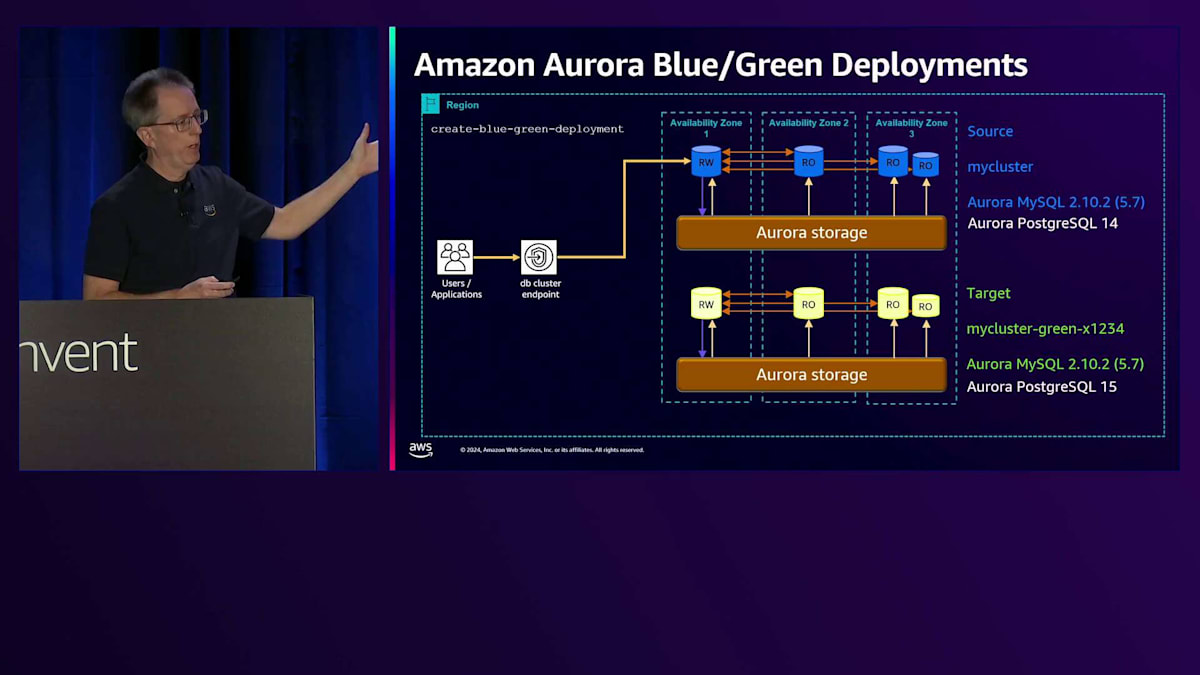
アップグレードの管理性に関するもう一つの分野は、Blue/Green Deploymentsです。データベースのBlue/Green Deploymentsとは何でしょうか?例えば、Aurora MySQL でバージョン5.7から8.0にアップグレードする場合、長時間のダウンタイムが必要になります。これをより迅速に行うために、Blue/Green Deploymentを使用できます。まず、create-blue-green-deploymentというコマンドを実行します。これにより、基本的にGreenバージョンが作成され、元のバージョンがBlueになります。ターゲットにはMySQLクラスター名の後ろにgreen-数字が付いているのが分かります。これで区別が付きます。これはAurora PostgreSQLでも実行できます。MySQLだけでなく、両方のデータベースをサポートしています。
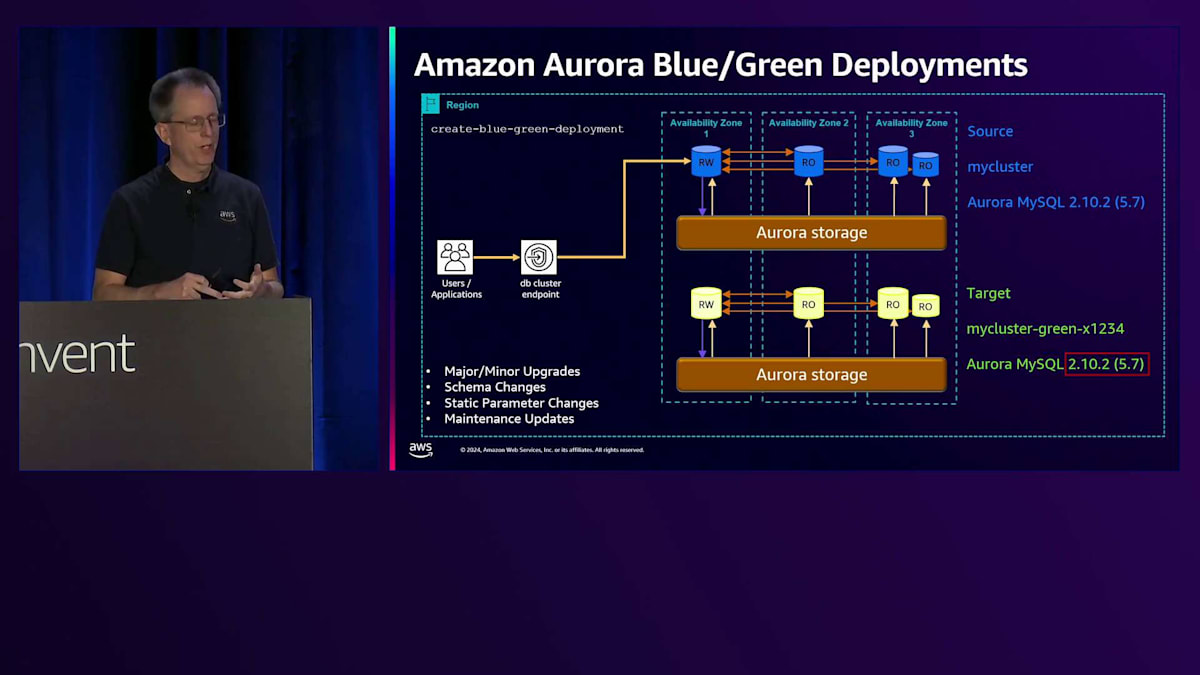
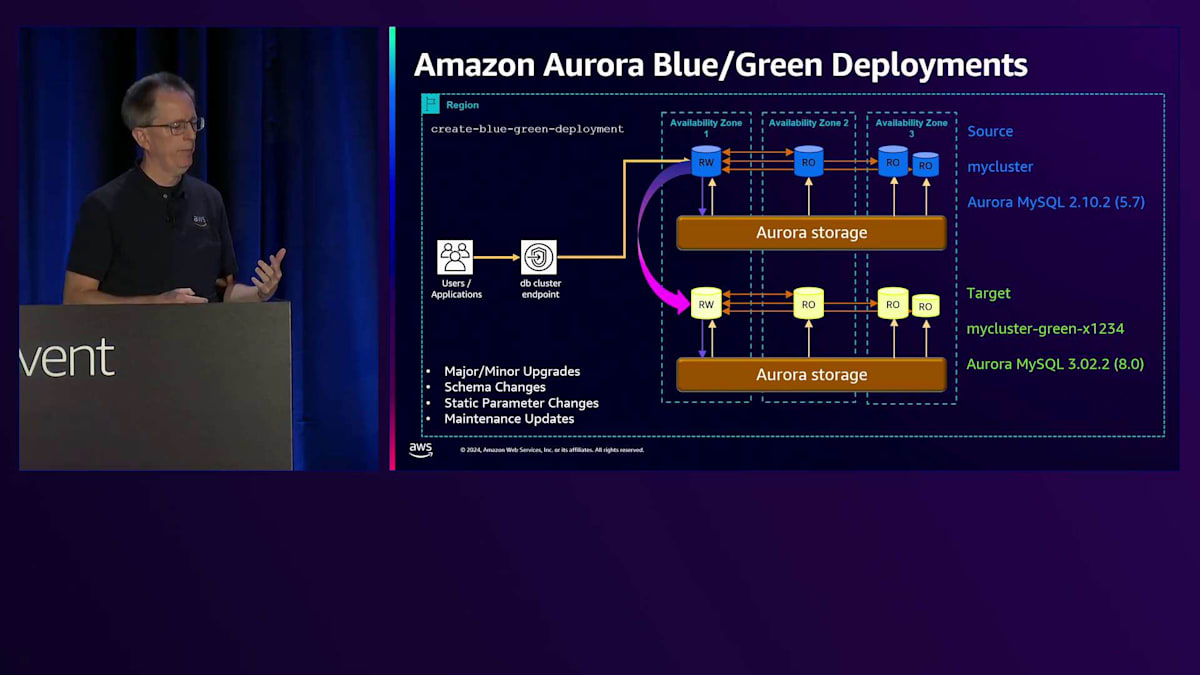
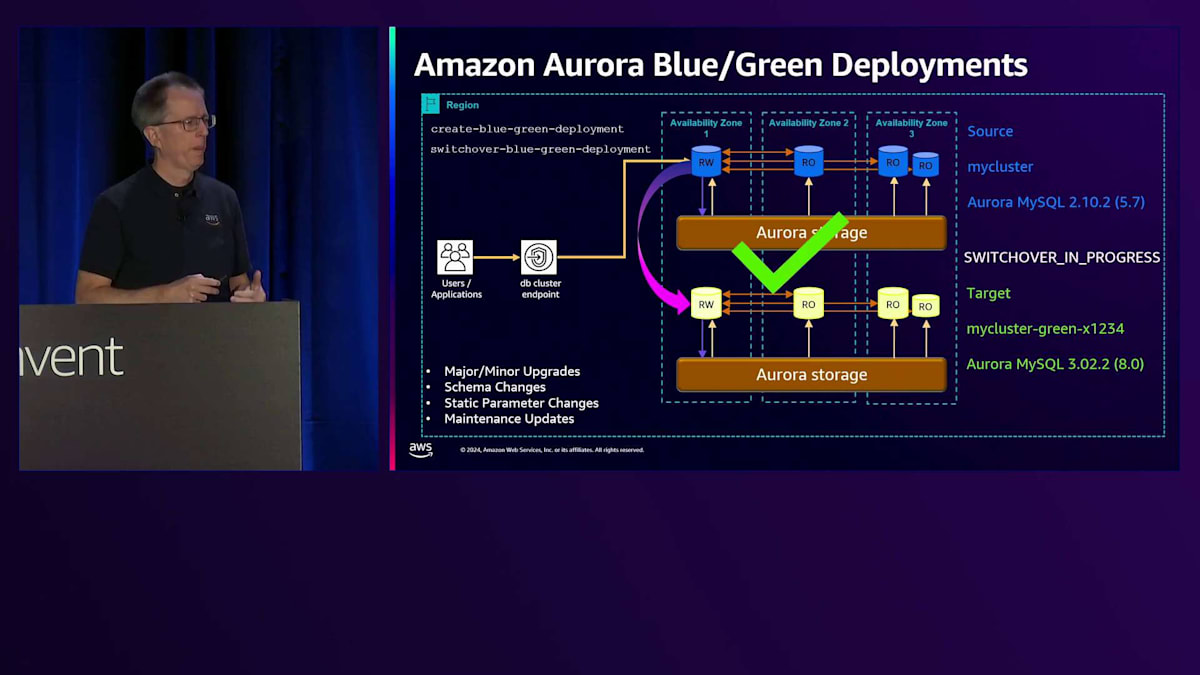
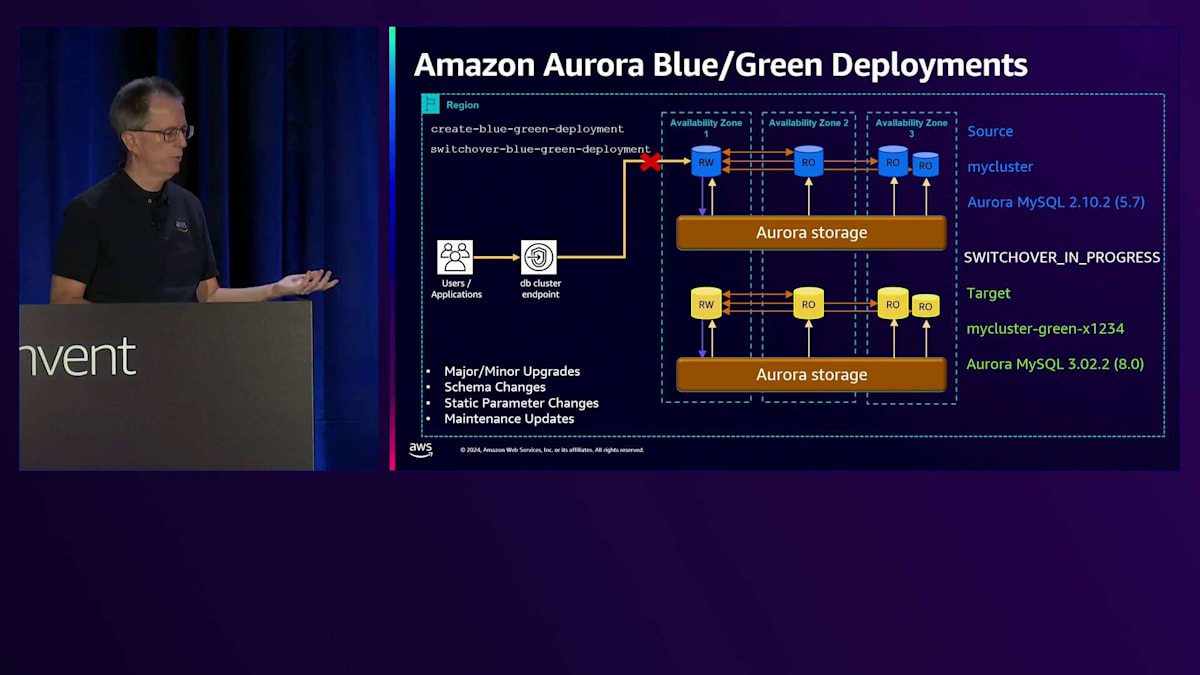
開始時のバージョンは同じであることに注目してください。最初の時点では両方が同一です。しかし、コマンドの一部として、マイナーバージョンやメジャーバージョンのアップグレードを指定することができ、それを自動的に実行します。スキーマの変更やパラメータの変更、その他の手動変更を行う場合でも、これを使用できます。その場合は、変更内容を指定する必要はありません。まず、Green側のデータベースを3.0にアップグレードします。次に、これらを同期させる必要があります。そこでレプリケーションを開始し、両者が近い状態になったら、スイッチオーバーコマンドを実行できる状態になります。スイッチオーバーコマンドを実行すると、「switchover in progress」と表示され、同期が確認され、すべての書き込みが停止されます。最後のレプリケーショントラフィックが完了するのを待ち、その後実際にスイッチオーバーが行われ、「switchover complete」と表示されます。この時点で、新しいクラスターに移行完了です。
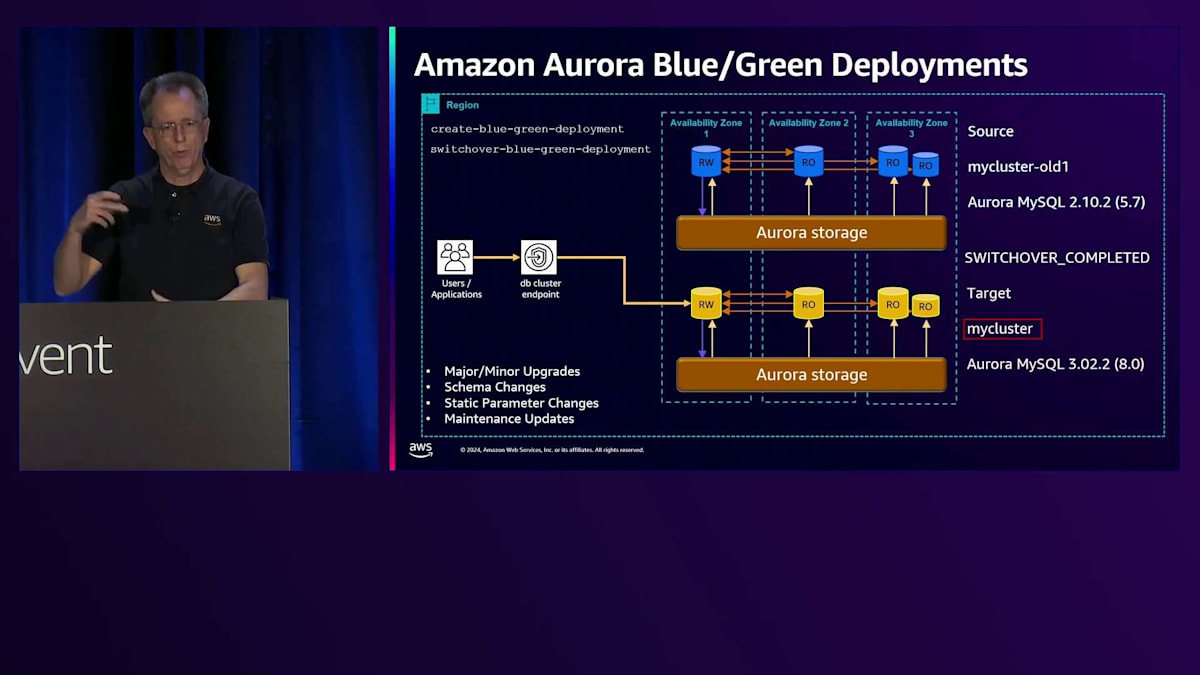
新しいクラスターに移行すると、ARNがすべて変更されていることに気付くでしょう。ただし、自動化の設定は手動での名前変更や修正を必要とせず、そのまま継続して機能します。これらのステップは手動でも実行可能ですが、このプロセスによって多くの操作が自動化され、より簡単に実行できるようになっています。

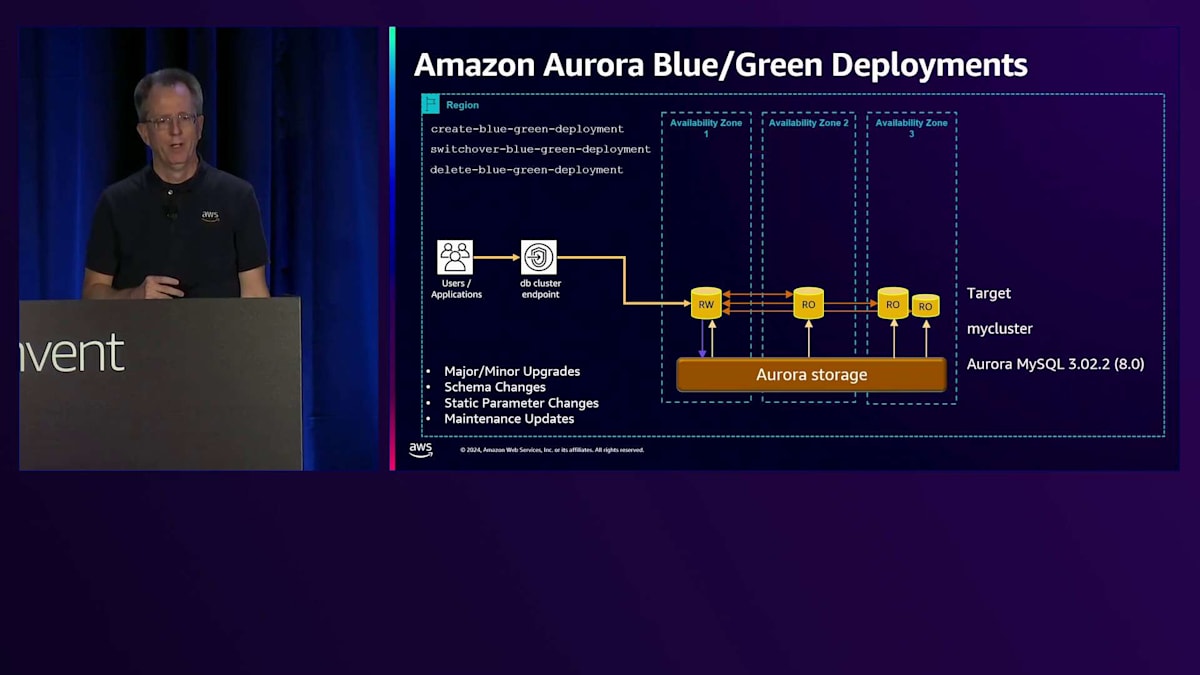
完了後、Blue/Green Deploymentを削除できます。この操作ではクラスターは削除されず、2つの環境の関連付けが解除されるだけです。これは、バージョンアップグレード中にプランの変更が発生する可能性があるため、お客様による検証が必要な場合に便利です。すべてが正常に動作していることを確認したら、元のクラスターを削除して通常の設定に戻ることができます。
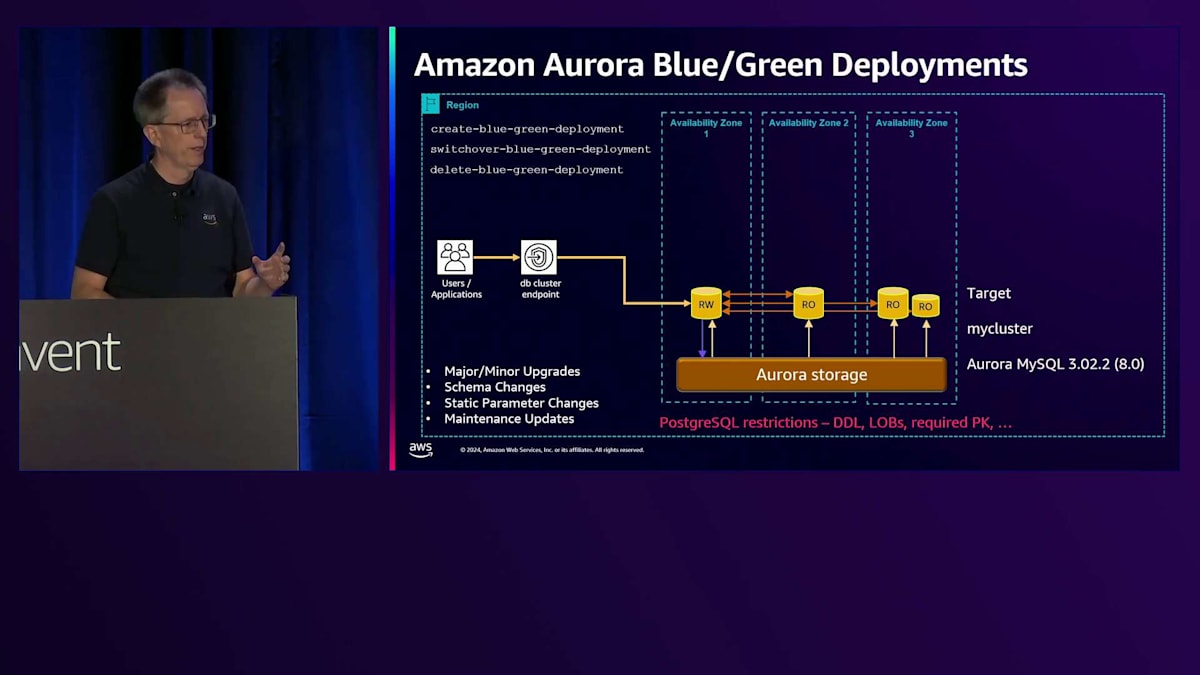
私たちは、Blue/Green対応機能を継続的に拡充しています。現時点で動作しない機能がある場合は、ぜひフィードバックをお寄せください。PostgreSQLには論理レプリケーションの要件による制約がいくつかあります。DDL操作がプロセス中に実行できない、LOBが使用できない、主キーが必須であるなどの制約です。ただし、ユースケースに適している場合は非常に有益な機能となります。



管理性の改善におけるもう一つの分野は、Zero-ETLです。 Zero-ETLは、AuroraからAmazon Redshiftへのデータ移動を可能にします。DMSやその他の手法を使用する代わりに、単純にZero-ETL統合を追加するだけです。これにより、特定のテーブルを選択してデータをAmazon Redshiftクラスターにレプリケーションする管理されたレプリケーションチャネルが設定されます。稼働後のレイテンシーはわずか5〜10秒で、Amazon Redshiftを通じてOLTPシステムデータをリアルタイムでダッシュボード分析することができます。

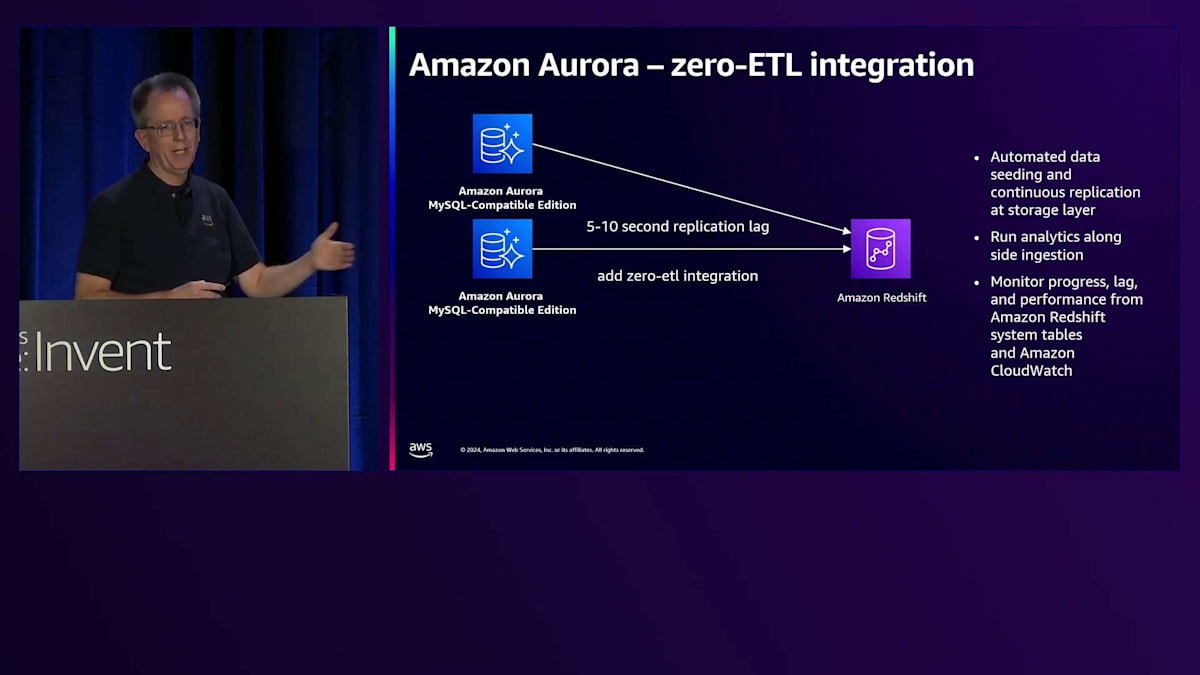
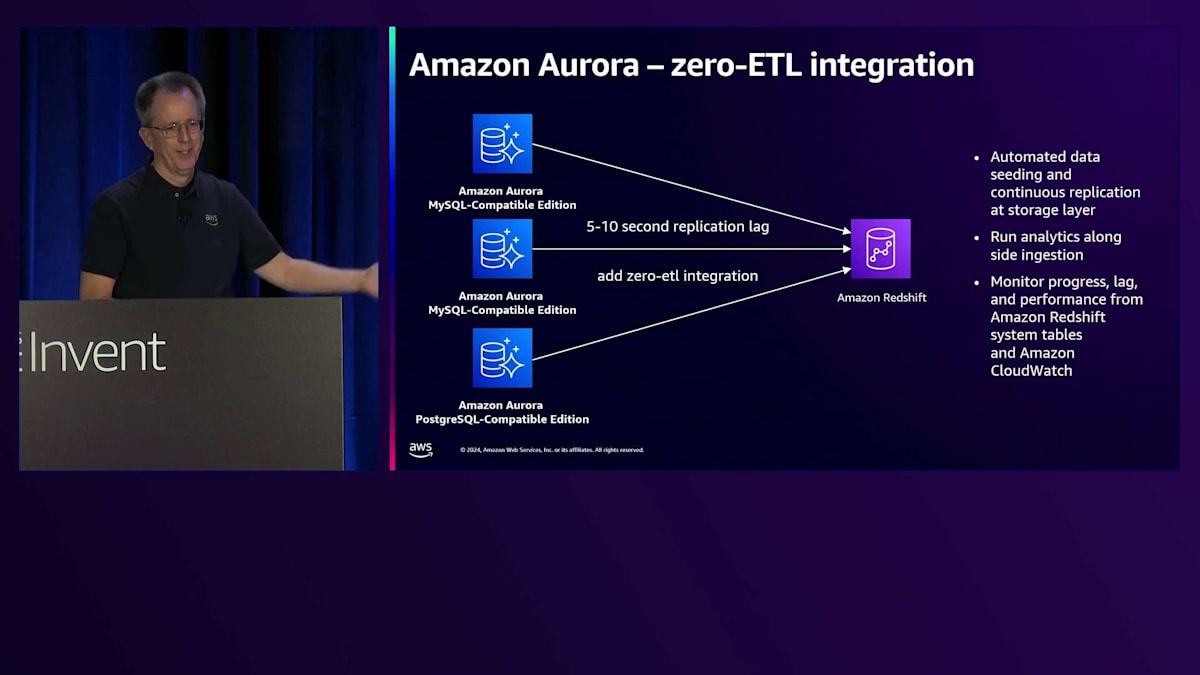
このプロセスは完全に自動化されており、初期シーディング、レプリケーション、モニタリングをすべて処理します。データの取り込み中でも分析を実行でき、モニタリング用にAuroraとAmazon Redshiftの標準的なAmazon CloudWatchメトリクスにすべてアクセスできます。特に強力な機能の一つは、複数のデータベースを1つのAmazon Redshiftクラスターに統合できることです。例えば、MySQLデータベースを組み合わせ、さらにPostgreSQLデータベースも含めることができます。Amazon Redshift内で異なるエンジンソースからのデータを照会できるこの機能は素晴らしく、ここでお話ししている以上に、Zero-ETLを中心とした広範なエコシステムを構築しています。

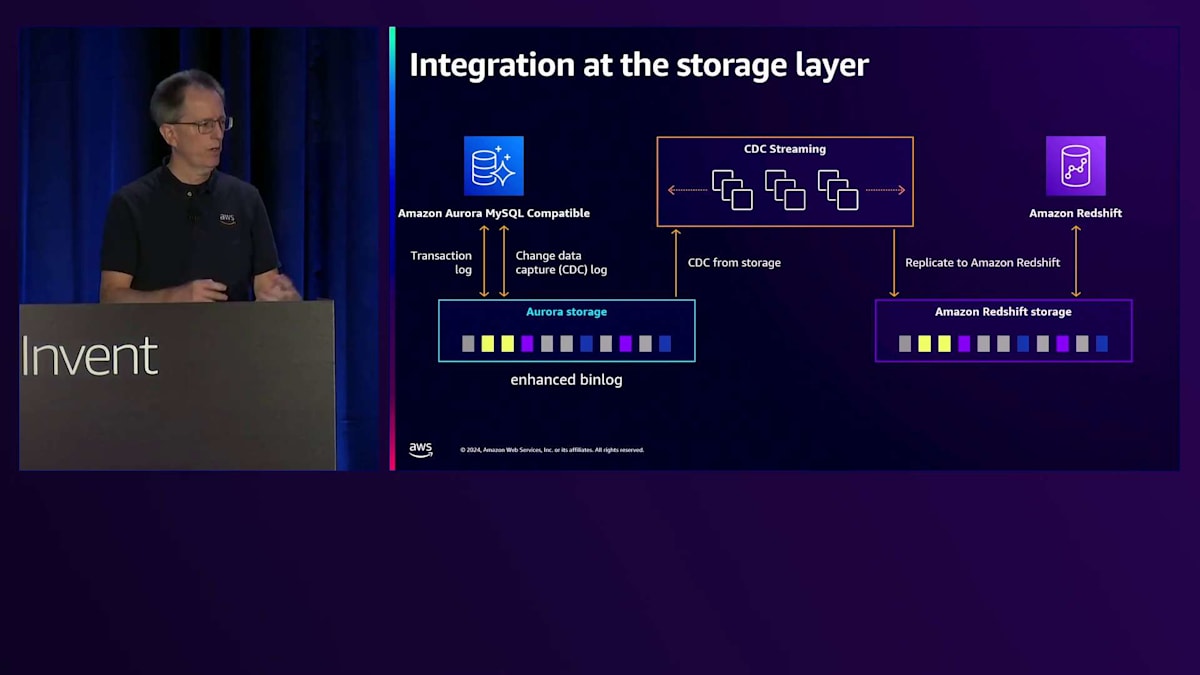
Auroraのストレージレイヤーにより、より効率的な操作が可能になります。MySQLでは、ストレージレイヤーでのパラレルダイレクトエクスポートを使用して、Amazon Redshiftへの初期データロードを高速化しています。その後、ストレージから直接CDCストリーミングのための拡張バイナリログを利用します。これにより、Zero-ETLは主要なOLTPシステムに大きな影響を与えることなく、Amazon Redshiftでの堅牢な分析機能を提供できます。Zero-ETLについての詳細は、セッション331で詳しく解説しています。


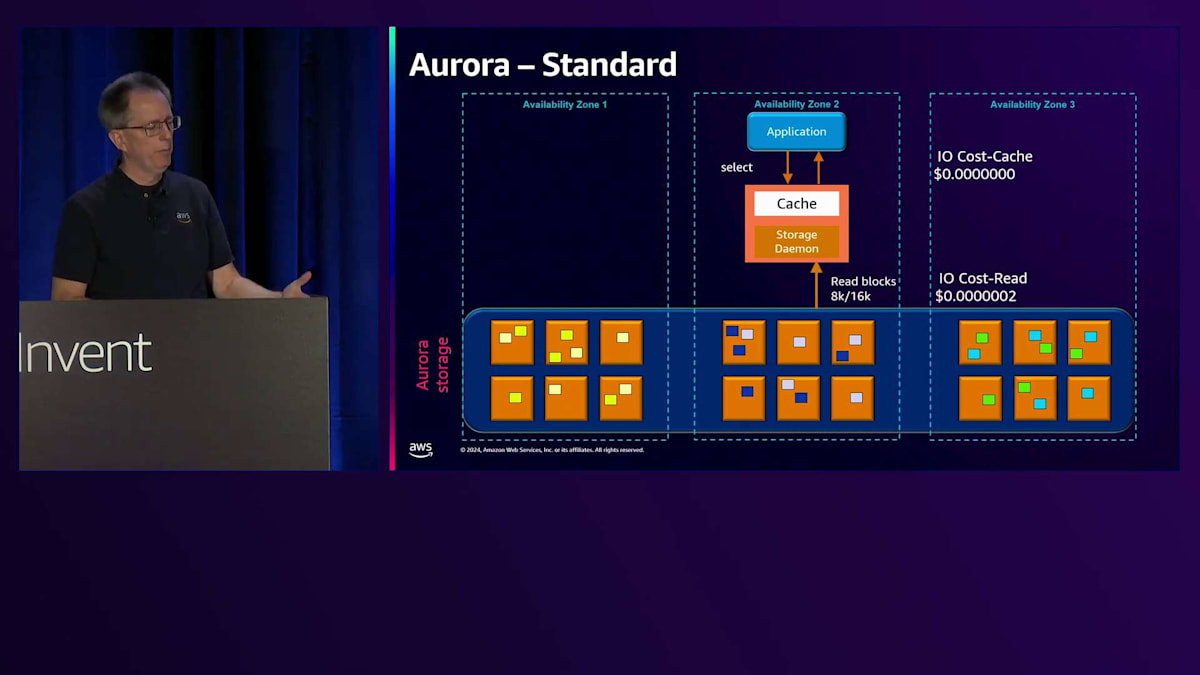

新しいストレージタイプについてお話しします。まず、オリジナルのストレージオプションである標準タイプから始めましょう。より予測可能な価格設定が必要だと考えた理由を説明したいと思います。アプリケーションがSelect操作を実行してキャッシュにヒットした場合、メモリからの読み取りなのでIO費用は発生しません。しかし、MySQLかPostgreSQLかによって8Kまたは16Kのブロックを読み取る場合、1ペニーの一部の費用が発生します。同様に、ログに最大4Kを書き込む場合も同じ価格がかかります。


6つのコピーが保持されていても、論理的な操作としては1回分のコストしかかかりません。ただし、1Kのような小さな量を書き込む場合でも、同じコストがかかります。混乱の原因となっていたのは、4Kの記録を1回書き込む代わりに1Kの記録を4回書き込むと、4倍のコストがかかることでした。 これは、特に大量の書き込み操作を行うワークロードでは、コストが大きく変動する可能性があることを意味していました。この問題に対処するため、私たちはIO-optimizedを導入しました。これは、すべてのワークロードで予測可能な価格設定を提供し、 IO負荷の高い操作のコストパフォーマンスを改善することを目的としています。
IO-optimizedストレージオプションとその効果

IO-optimizedは、ConsoleやCLIで簡単に選択できるオプションで、クラスターレベルで利用可能です。 これはストレージに関連する設定であるため、インスタンスレベルではなく、クラスターレベルの設定であることに注意が必要です。ストレージタイプの切り替えは月1回可能で、必要に応じてテストや調整ができます。このオプションは、特にIOコストが総請求額の25%を超える場合に価値があり、実際に導入したお客様から好評をいただいています。例えば、今日お話したお客様は、IO使用量が多かったためAuroraの請求額を70%削減することができました。
このオプションで最大40%のコスト削減を達成したお客様もいます。すべてのインスタンスタイプで利用可能で、Reserved Instancesを使用する場合は追加の割引も受けられます。また、すべての新バージョンでも利用可能です。


価格設定の詳細を見てみましょう。 標準オプションには、Reserved Instancesオプション付きの通常のOn-demandコンピュートが含まれており、ストレージとI/Oは従量課金制です。IO-optimizedでは、コンピュートとストレージに追加料金がかかりますが、I/Oの料金は一切かかりません。一見大幅な増額に見えるかもしれませんが、I/Oコストが高額な場合、そのコスト関係はI/Oコストに大きく左右されます。 先ほどの例に戻りますが、すべてのI/Oコストがゼロになるため、詳しい説明は不要です - もはやI/Oの料金を支払う必要がないのです。
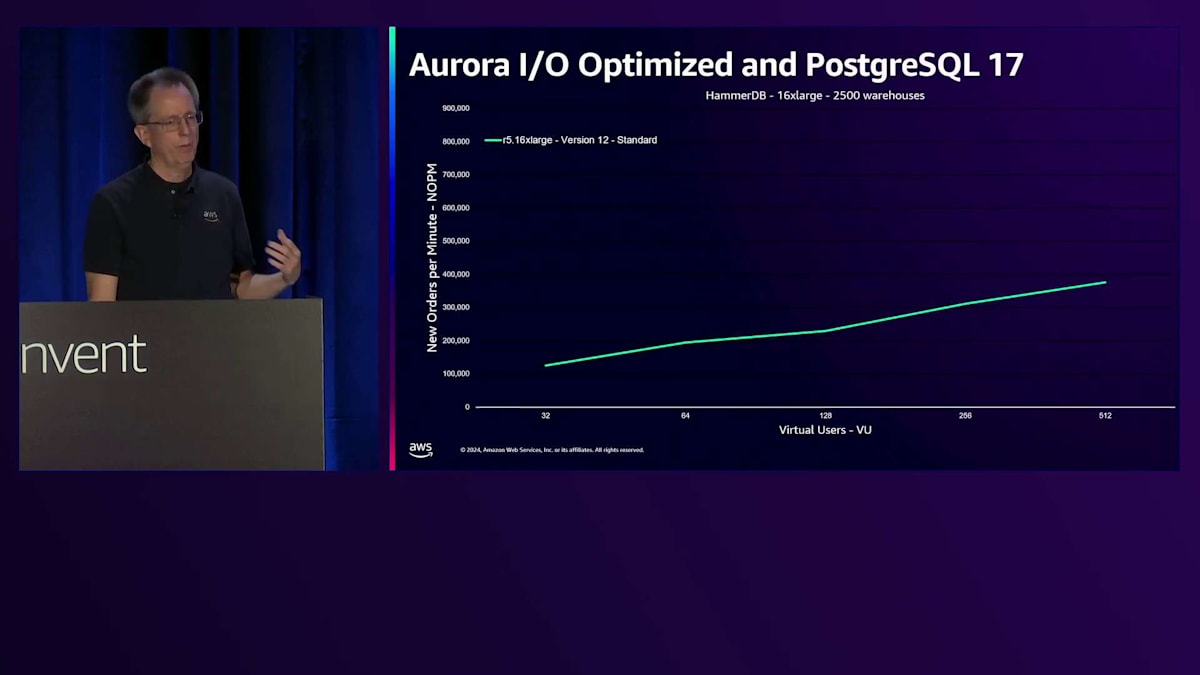
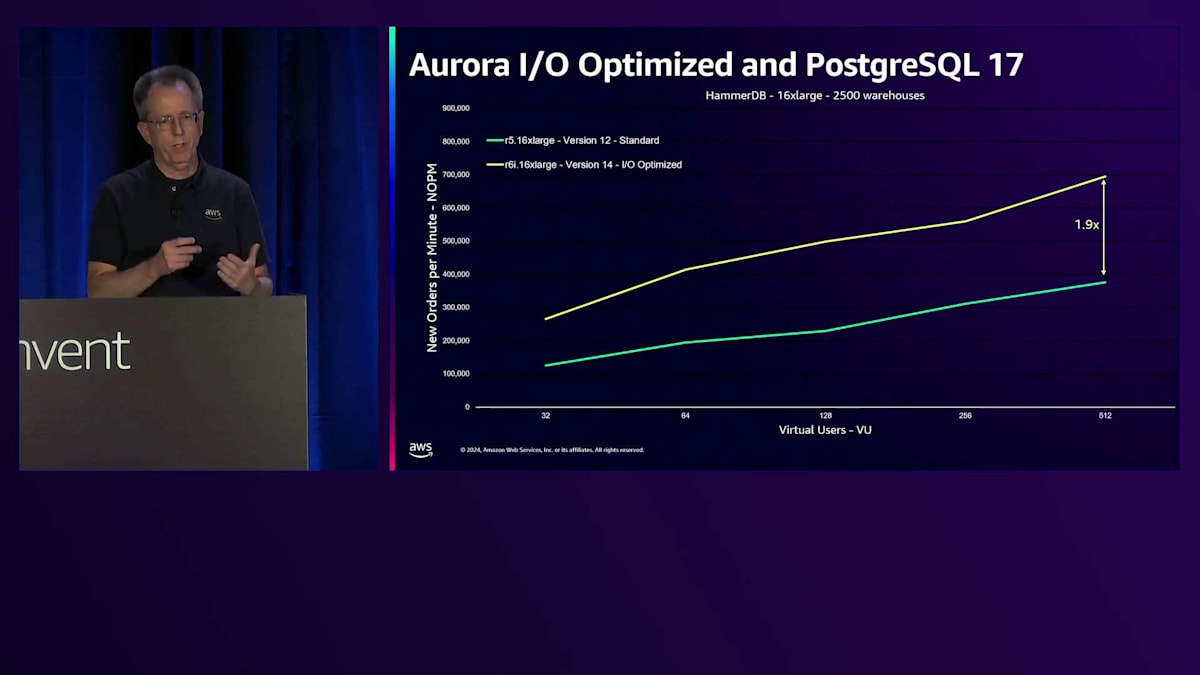
私たちは、IO負荷の高いお客様向けにパフォーマンスを改善する仕組みを本当に必要としていました。 それがIO-optimizedで実現してきたことです。PostgreSQL 17とDurable Queueに関する最新の変更は、このパフォーマンスの向上を示しています。このHammerDBベンチマークでは、縦軸に新規注文数/分を示しており、数値が高いほど良好です。これらはすべて16 xlargeインスタンスですが、世代による違いがあります。最初の緑色のバーは、標準I/O設定でPostgreSQL version 12を実行しているR5です。 PostgreSQL version 14を搭載したR6iに移行すると、わずかなパフォーマンス向上が見られますが、大きな違いはありません。しかし、IO-optimizedを使用すると、このベンチマークでスループットが1.9倍に向上しました。
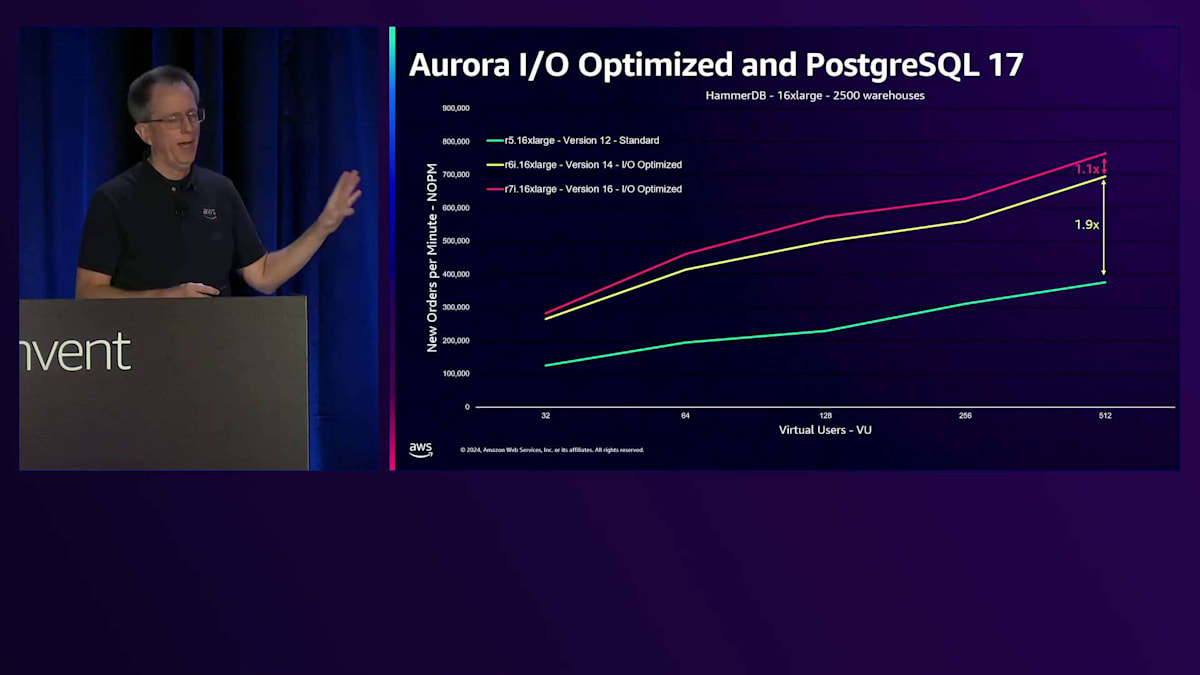
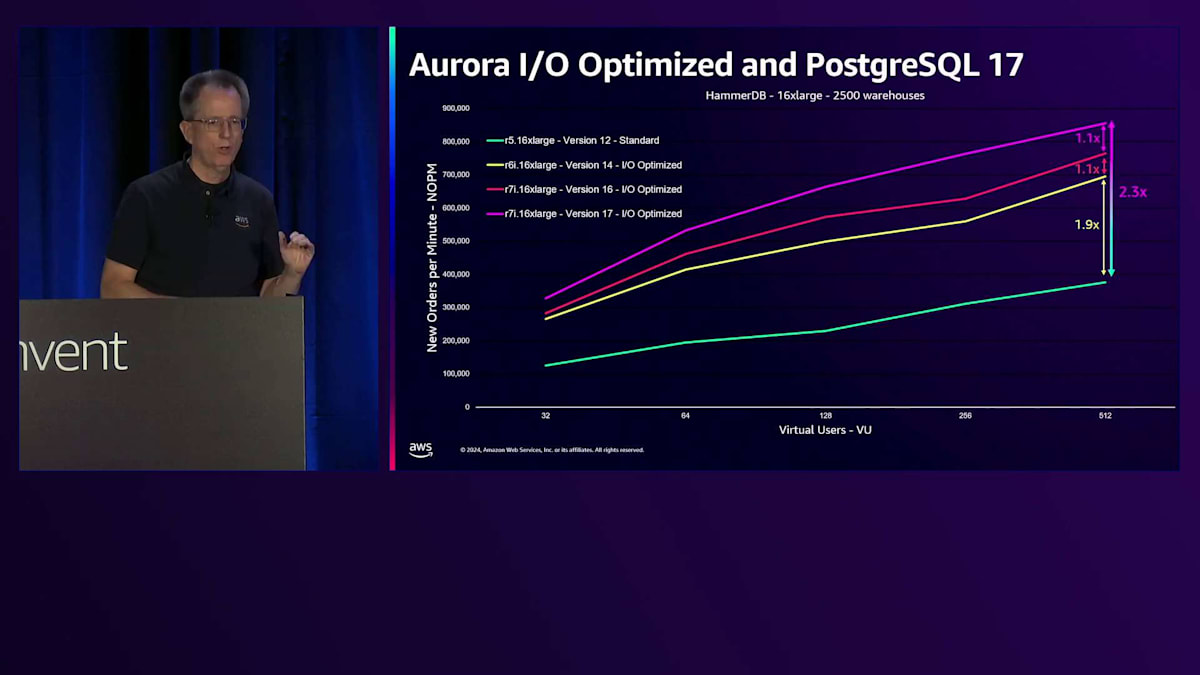
PostgreSQL version 16を搭載した最新のIntelバージョンであるR7iに移行すると、 I/O Optimizedにより10%のパフォーマンス向上が得られ、さらにDurable Queueに関する改良により、さらに10%の向上が実現します。数年前と比較すると、スループットのスケーリングが2.3倍も改善されたことになります。これは書き込みの多いワークロードにとって素晴らしい進歩です。
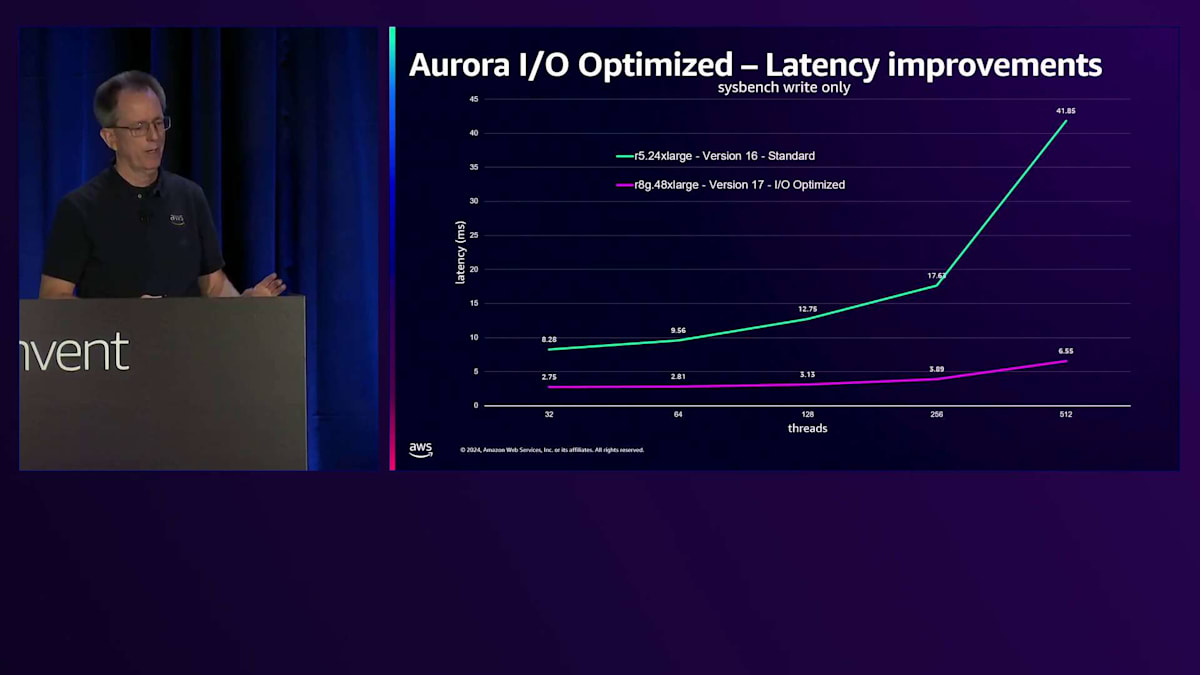
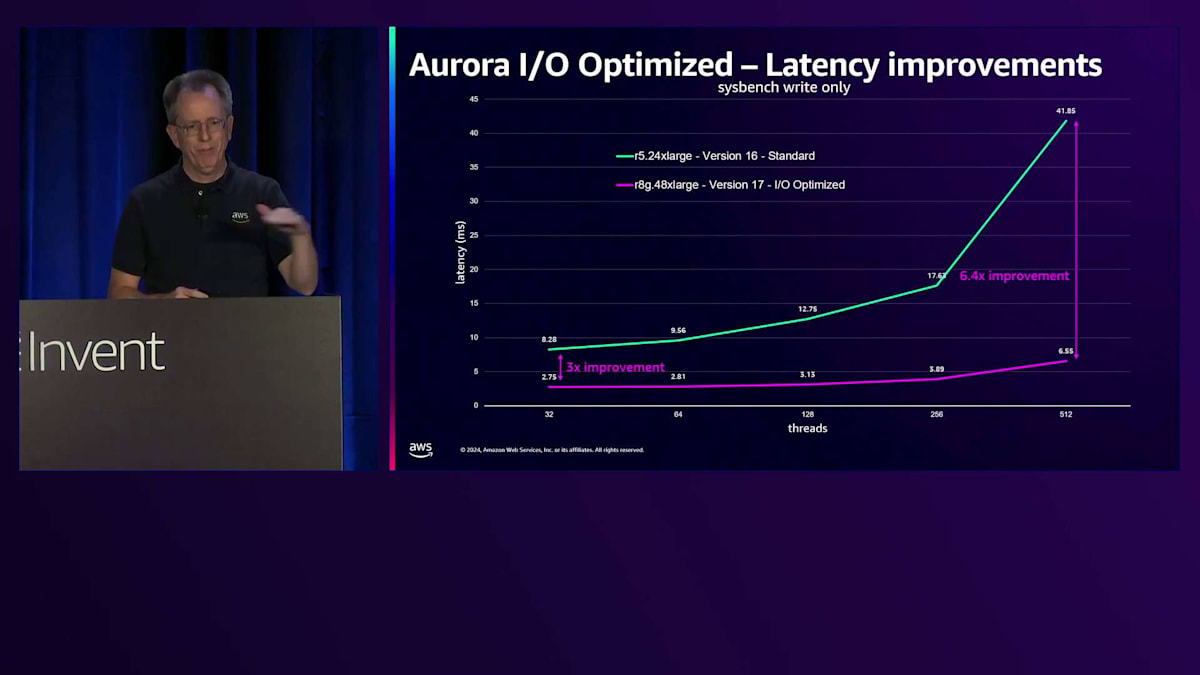
レイテンシーの改善はさらに印象的です。これは書き込み専用のパフォーマンスを示しており、縦軸は書き込みレイテンシーを表しています(低いほど良い)。緑の線はStandard I/OのR5.24XLを表しています。現在、PostgreSQL version 17を搭載し、I/O Optimizedと新しいDurable Queueを実装した48XLがあります。 その結果、低負荷時で3倍、スケールアップ時で6.4倍のレイテンシー改善が見られます。下部の曲線が非常にフラットになっていることがわかります。以前からスループットのスケーリングは優れていましたが、レイテンシーを犠牲にする必要がありました。今ではそのようなトレードオフは不要で、低レイテンシーを維持したままスケールできます。
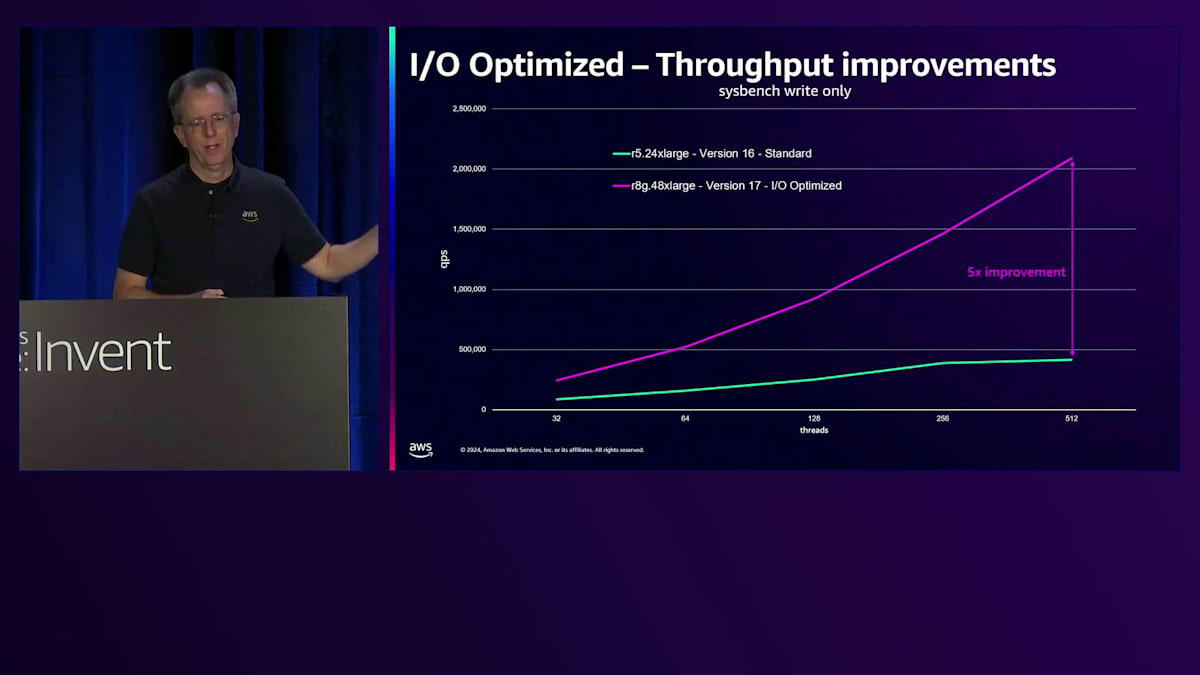


この改善により、書き込み専用のワークロードでは、以前の世代と比べて最大5倍のスループット向上が実現しています。 読み取りについても改善を進めており、Optimized Readsという新機能を導入しました。 その一つの側面は、一時オブジェクトやスピル操作に関するものです。例えば、RAMの容量を超えるソート処理を実行する際に、ディスクにスピルする必要がある場合です。従来では、これはメモリの2倍のストレージを持つAmazon EBSに書き込まれていました。

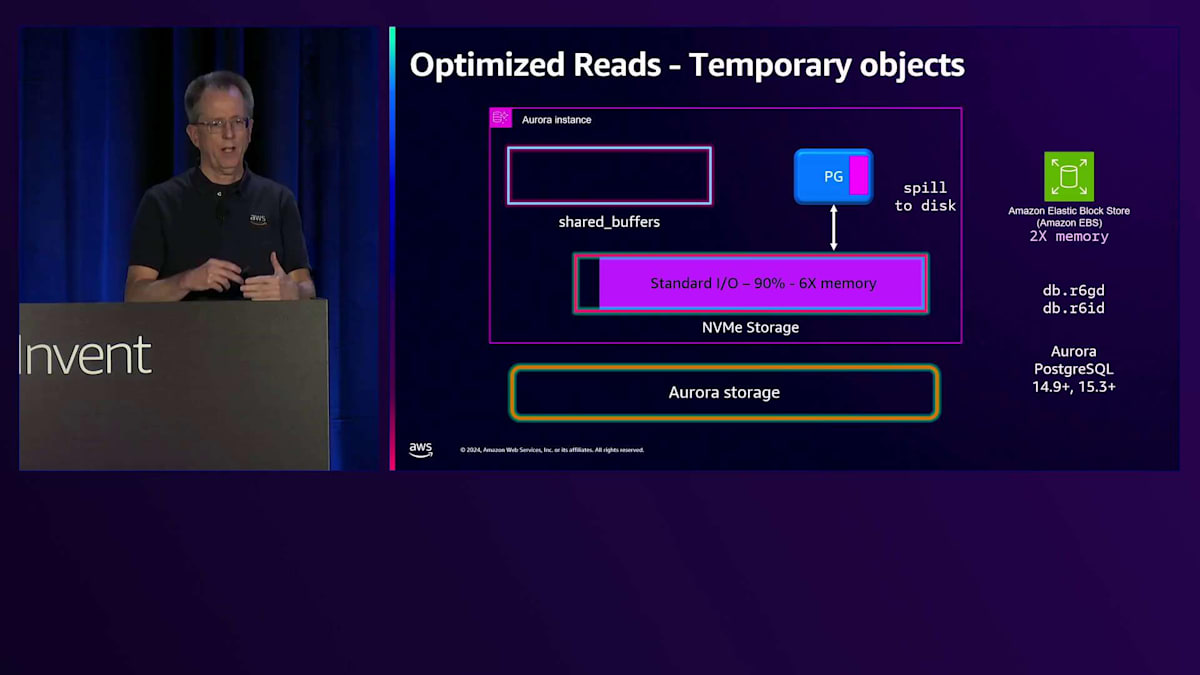
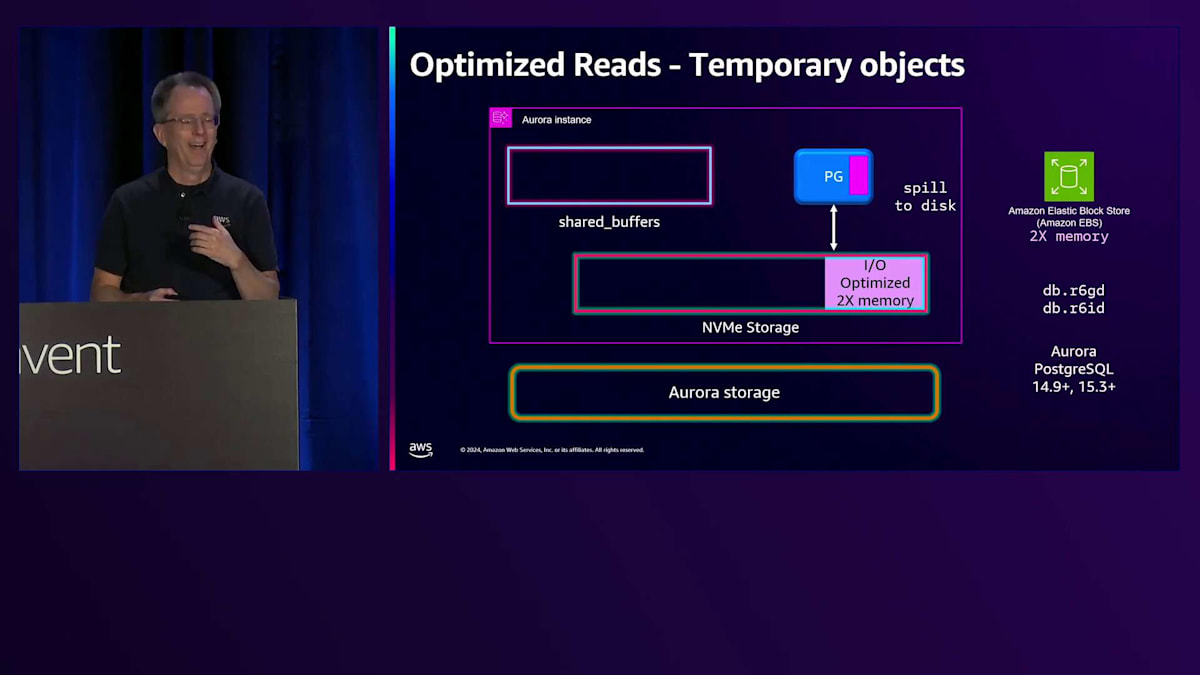
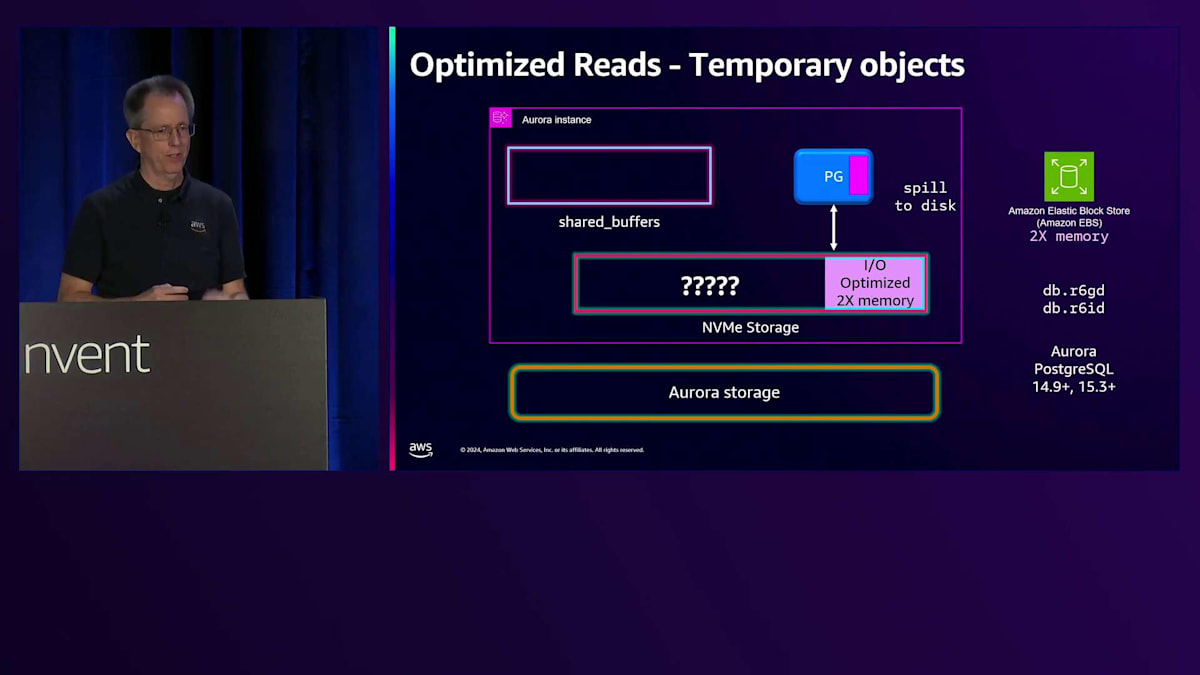

新しいインスタンスタイプとしてR6GDとR6IDを導入し、これらにはシステム上にNVMeストレージが搭載されています。 Standard I/Oでは、スピル用にメモリの6倍のNVMe容量を割り当て、より多くのソート領域と高速化を実現しています。 I/O Optimizedでは、一時ストレージ用にメモリサイズの2倍のNVMe容量を割り当てています。 これにより、残りのスペースをどのように使用しているのかという興味深い疑問が生まれます。そこで実装しているのがTiered Cacheです。PostgreSQLでは、ブロックを読み取る際、それがメモリ上のShared Buffersにある場合は高速に取得できます。しかし、Shared Buffersにない場合は、ストレージからの取得が必要になります。


このストレージからの取得には時間がかかり、アプリケーションによっては許容できる場合もあれば、特に大量の読み取りを行う場合には、システムの速度低下を招く可能性があります。

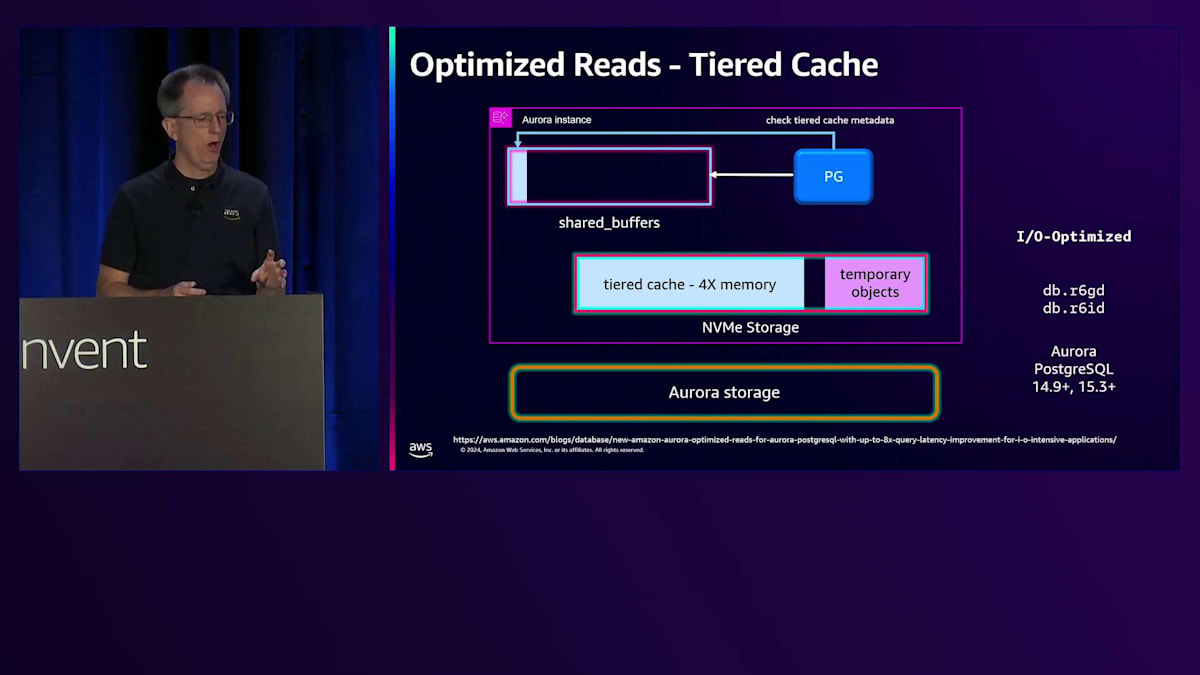
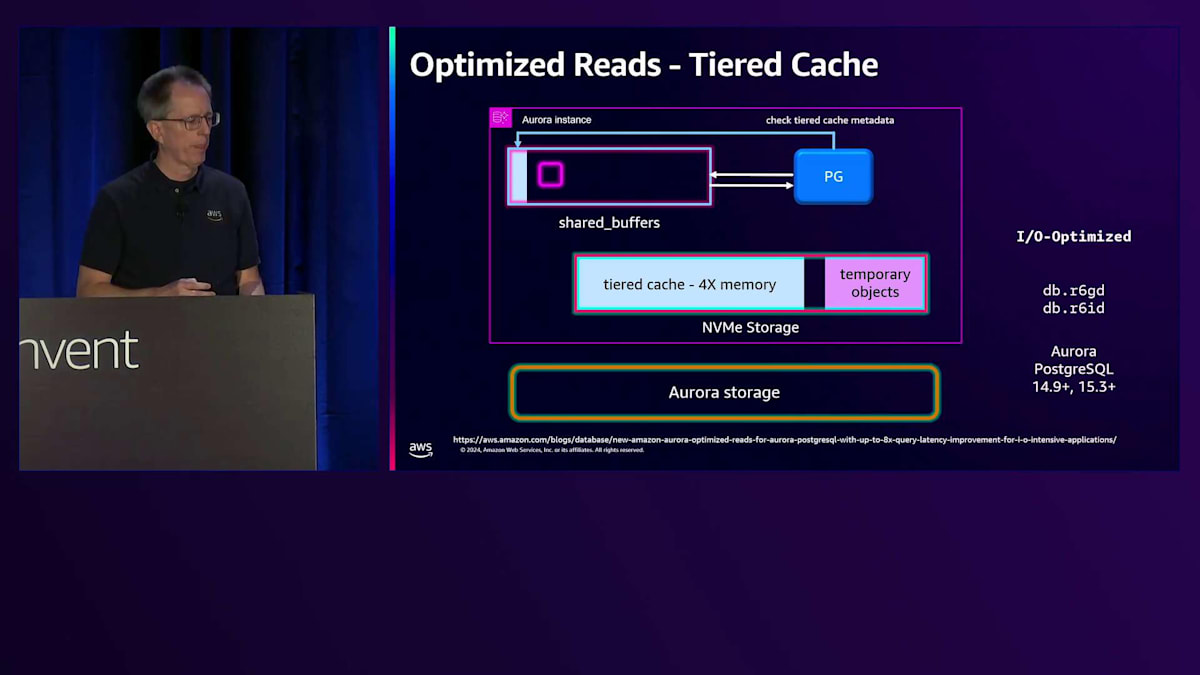
現在、NVMeをCacheとして使用することで、一時オブジェクト用のスペースが4倍のメモリを確保できています。Shared BuffersのRAMの一部をメタデータ用に使用します。読み取りを行う際は同様の仕組みで動作しますが、メタデータをチェックしてTiered Cache内にデータがあるかどうかを確認します。もしなければ、Storageから読み取ってメモリに配置します。ここで注意すべき点は、Cacheを経由して読み取りを行わない点です。システムの読み取り特性はまったく変更されません。


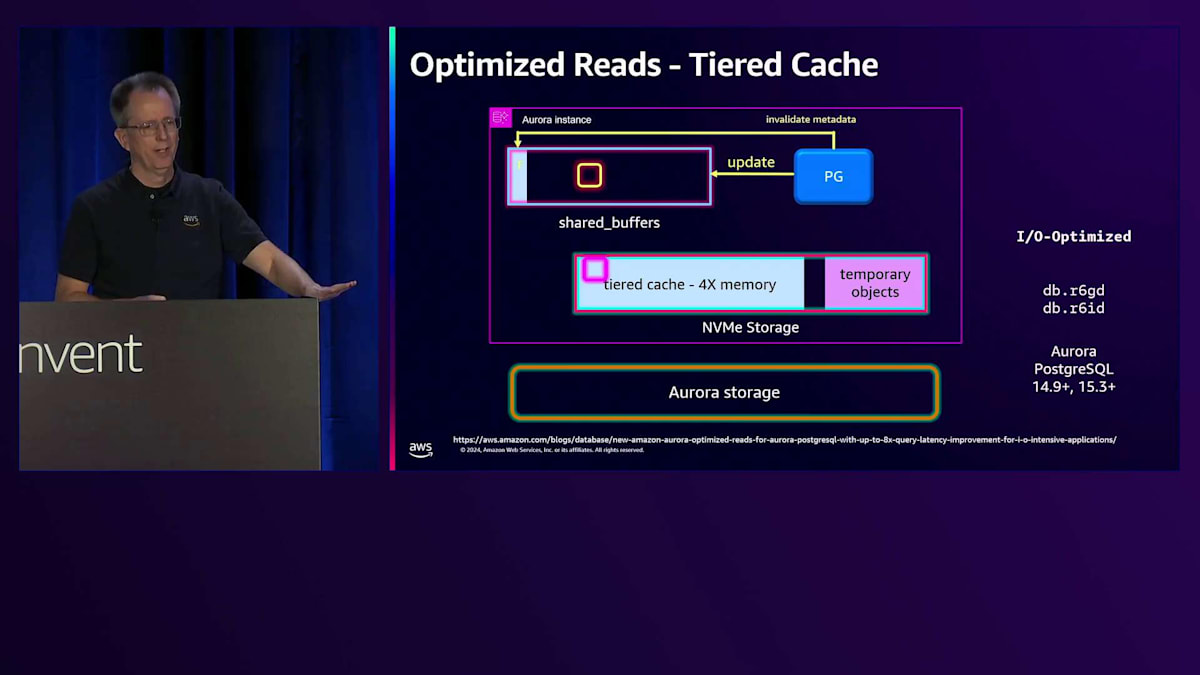
そのブロックが不要になると、システムから徐々に削除されていきます。コールドになると、メタデータ内のTier Cacheにそのブロックが存在することを示す「1」が表示されます。次の読み取り要求があった際、システムはそのブロックの存在を確認し、Cacheから素早く取得します。この時点で、メモリとCache両方にデータが存在することになりますが、これは問題ありません。多くのシステムが直面する問題は更新処理のコストです。しかし、私たちのシステムではブロックのCheckpointが不要なため、更新が発生した場合はメタデータを無効化するだけです。Cache自体を更新する必要もなく、単にそのデータを参照しないようにします。次回Evictされる際に、新しいコピーを取得します。




このシステムは非常にうまく機能し、優れたパフォーマンス特性を持っています。現在はランダムなEvictionを採用しており、Working Set SizeがTiered Cacheに収まる場合に最も効果を発揮します。他のEviction戦略についても検討していますが、まだ実装には至っていません。データの熱さを考える際は、Working Set Sizeを考慮する必要があります。例えば、複数年分の注文データが800ギガバイトあるテーブルの場合、頻繁に使用されるのは直近の数年分のみでしょう。そのため、このInventoryテーブルのWorking Set Sizeは80から100ギガバイト程度かもしれません。空港コードごとに、各ロケーションで異なる熱さレベルが存在し、あるロケーションは他より活性が高いかもしれません。どの程度の熱さがあり、それがTiered Cacheに収まるかどうかを理解する必要があります。
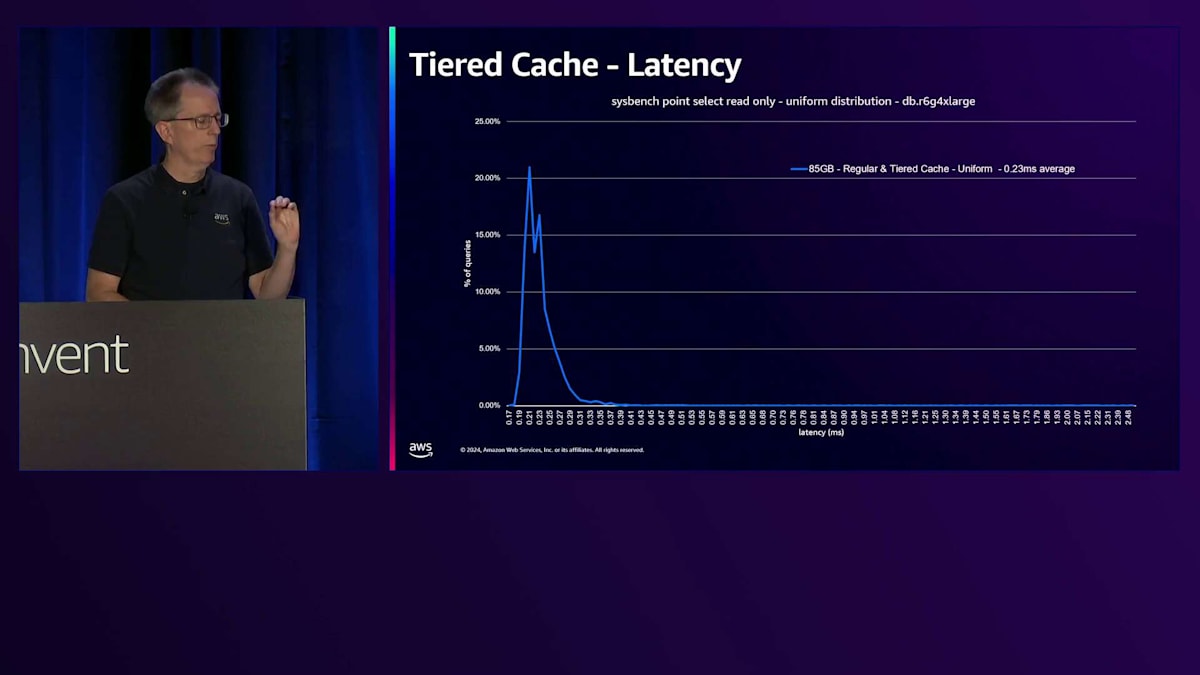
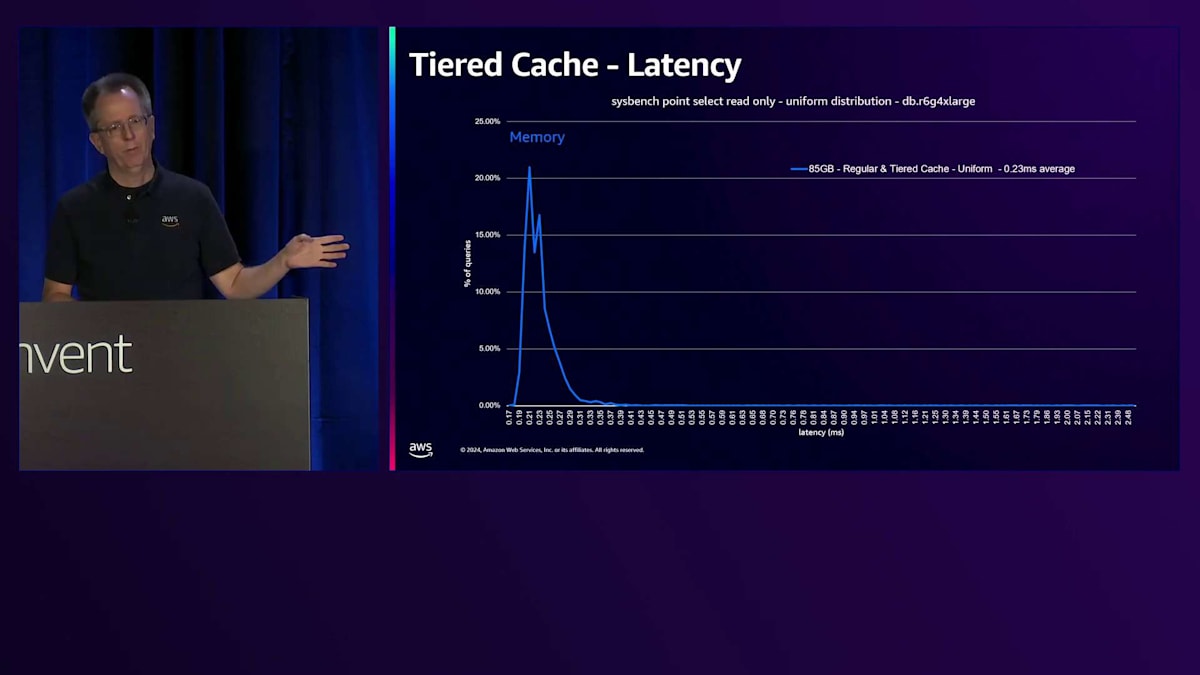
ベンチマークを実行した際の様子を見てみましょう。これはSysbenchのポイントセレクト読み取り専用で、一様分布を使用したものです。これは一般的なシナリオではありませんが、時間とともにすべてのブロックにアクセスすることになります。4 Extra Largeで、ワークロードは最初85ギガバイトで、これが青い線で示されています。縦軸は各レイテンシーで発生するブロック数を表しています。最初の青い線はメモリのパフォーマンスを表しており、この時点では通常のCacheでもTiered Cacheでも、すべてのデータがメモリから取得され、平均0.23ミリ秒という優れたレイテンシーを示しています。
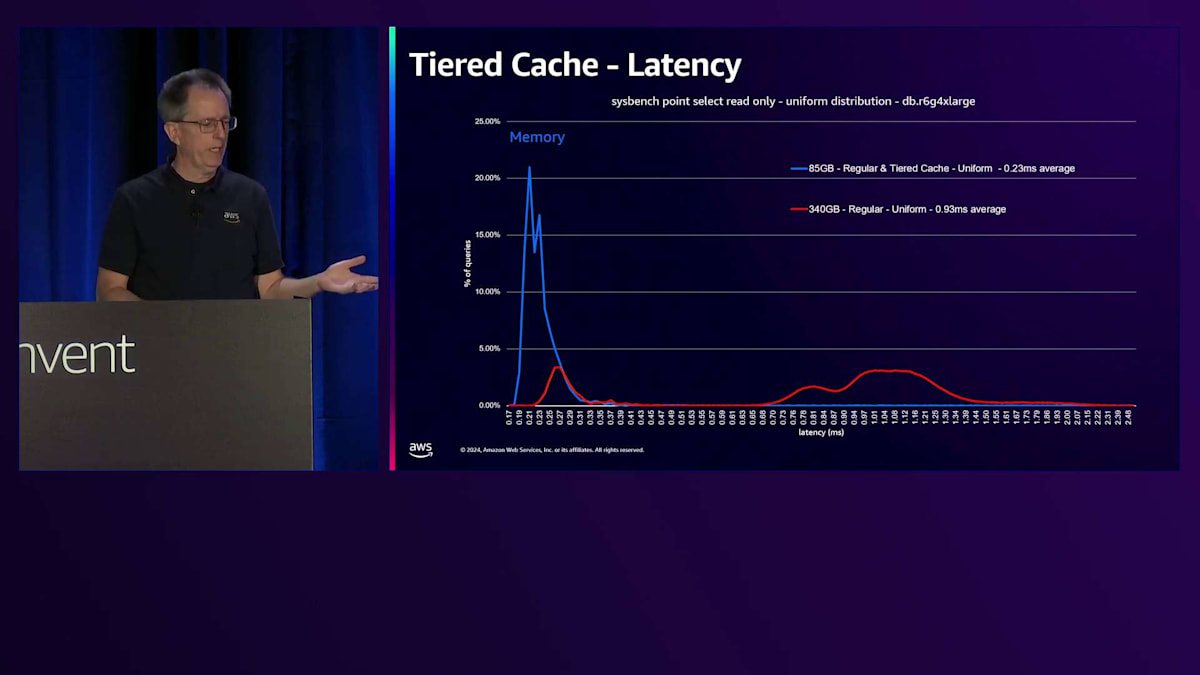
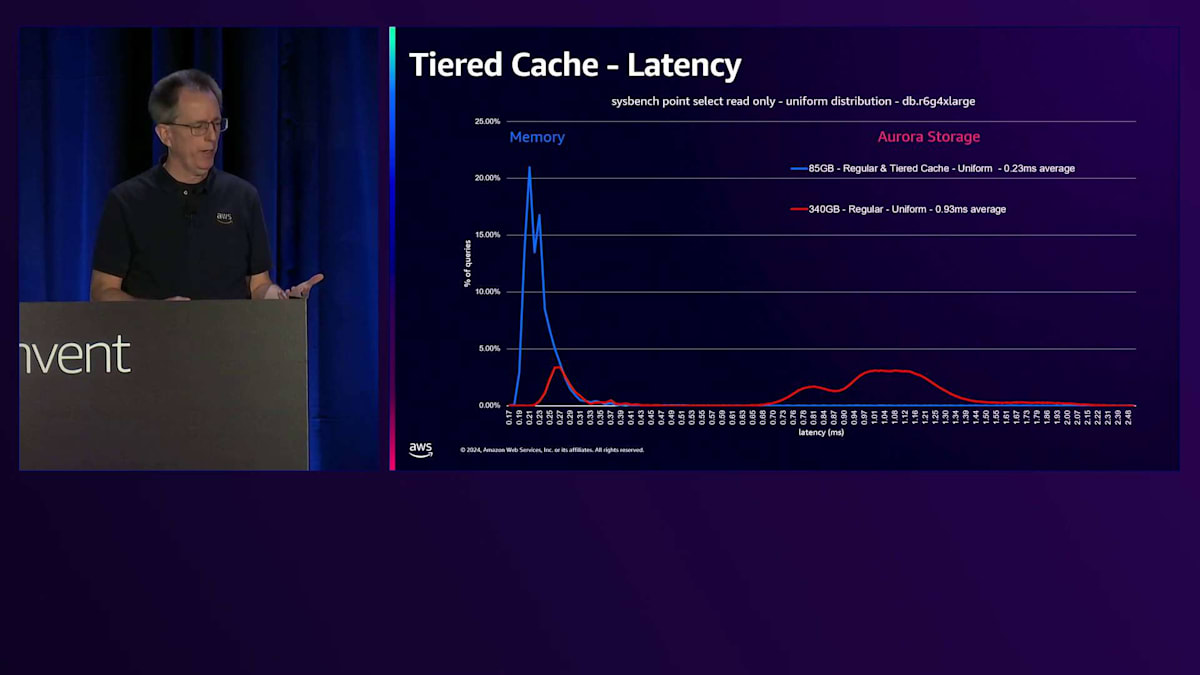
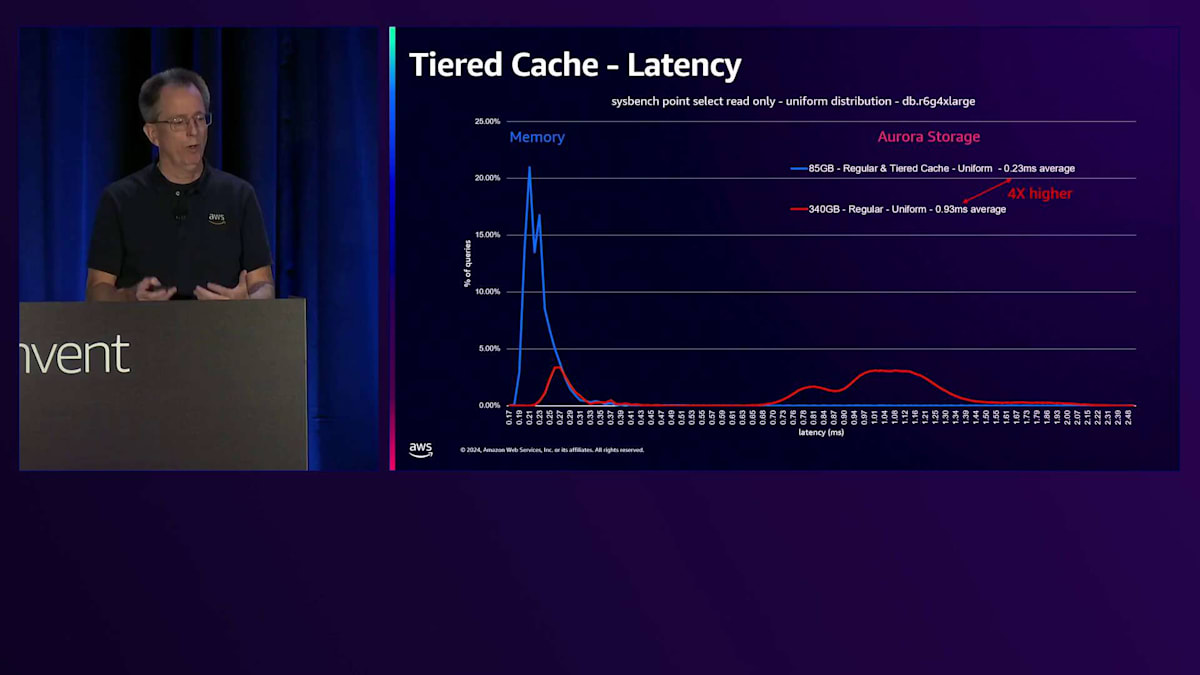
Working Setのサイズを4倍の340ギガバイトに増やし、すべてのデータにアクセスし続けると、一部のデータがStorageから取得されるため、下端のレイテンシーが増加します。レイテンシーは実際にかなり増加し、4倍高くなります。これはアプリケーションによっては許容できる場合もありますが、そうでない場合もあります。一般的な解決策はより多くのRAMを搭載した大きなマシンを購入することですが、これは私たちにとっては良いことかもしれませんが、通常は顧客にそのような出費を避けていただくことを目指しています。
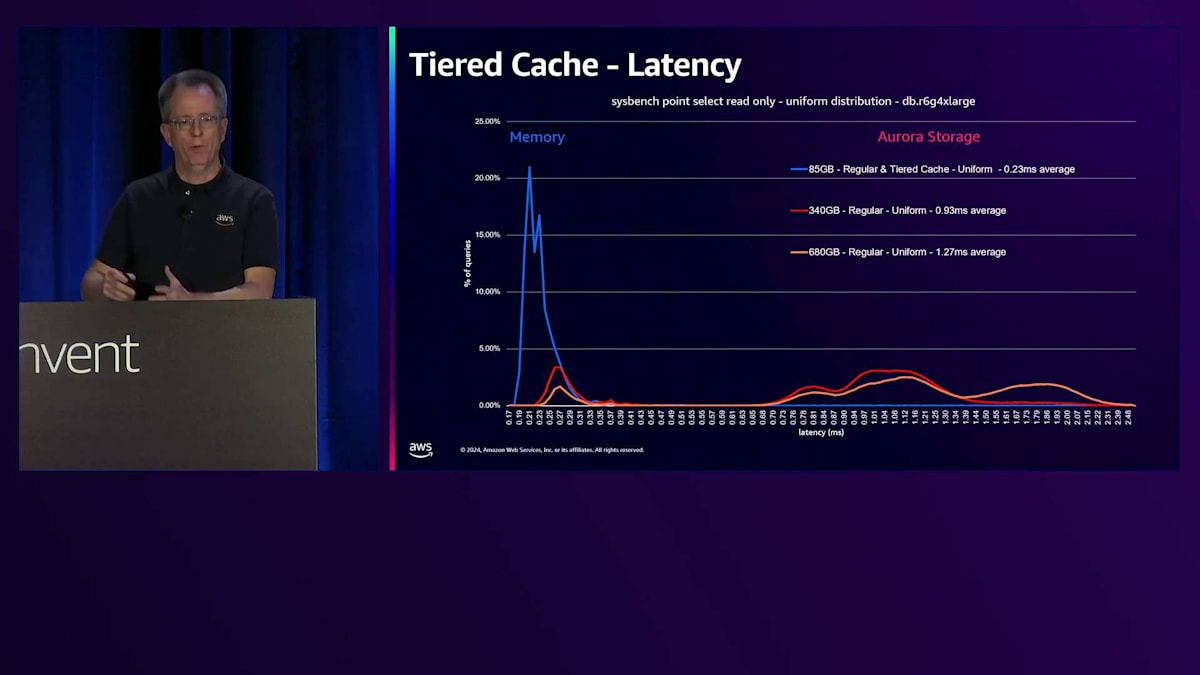
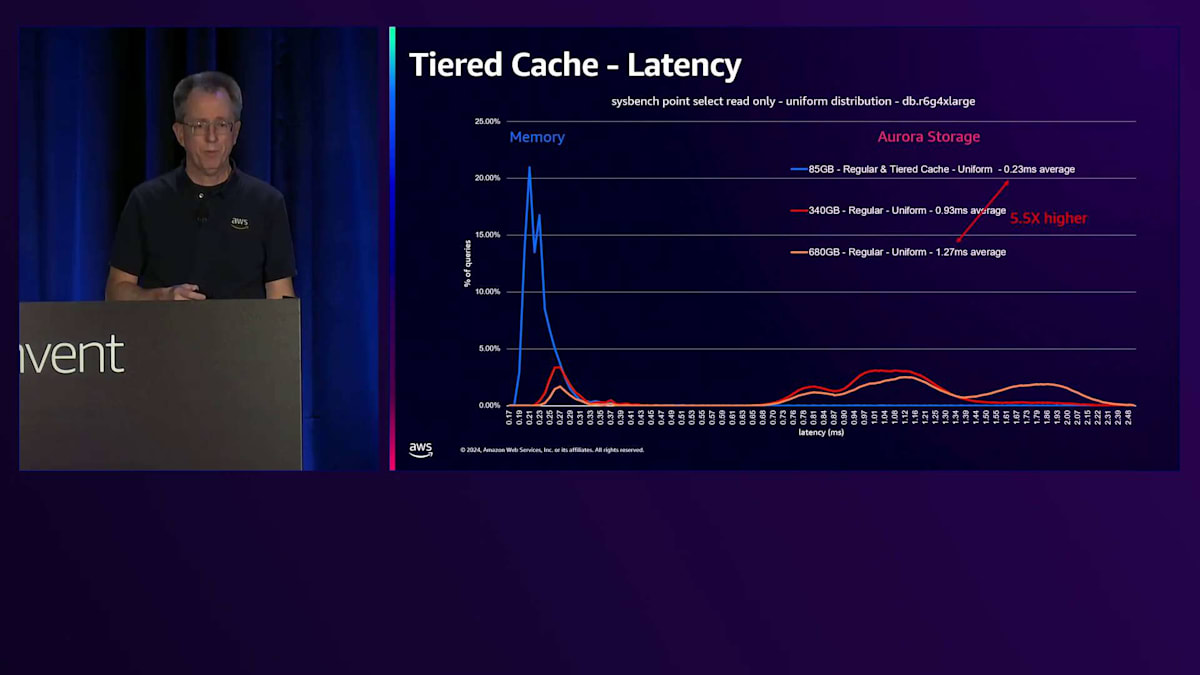
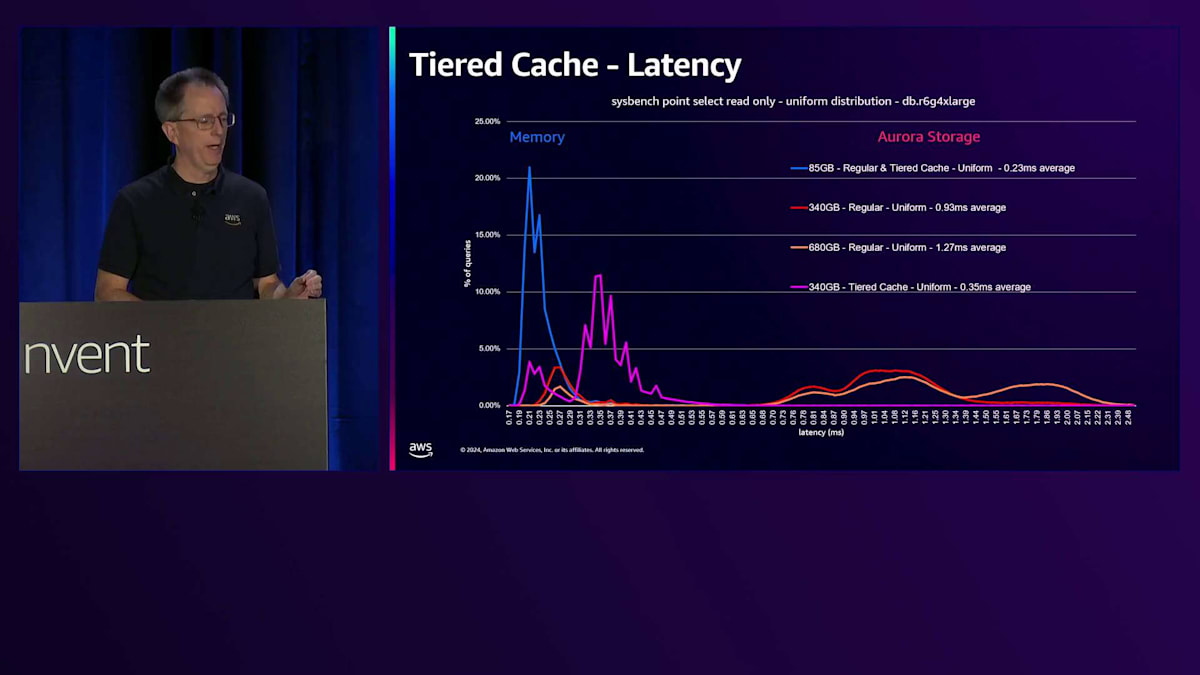
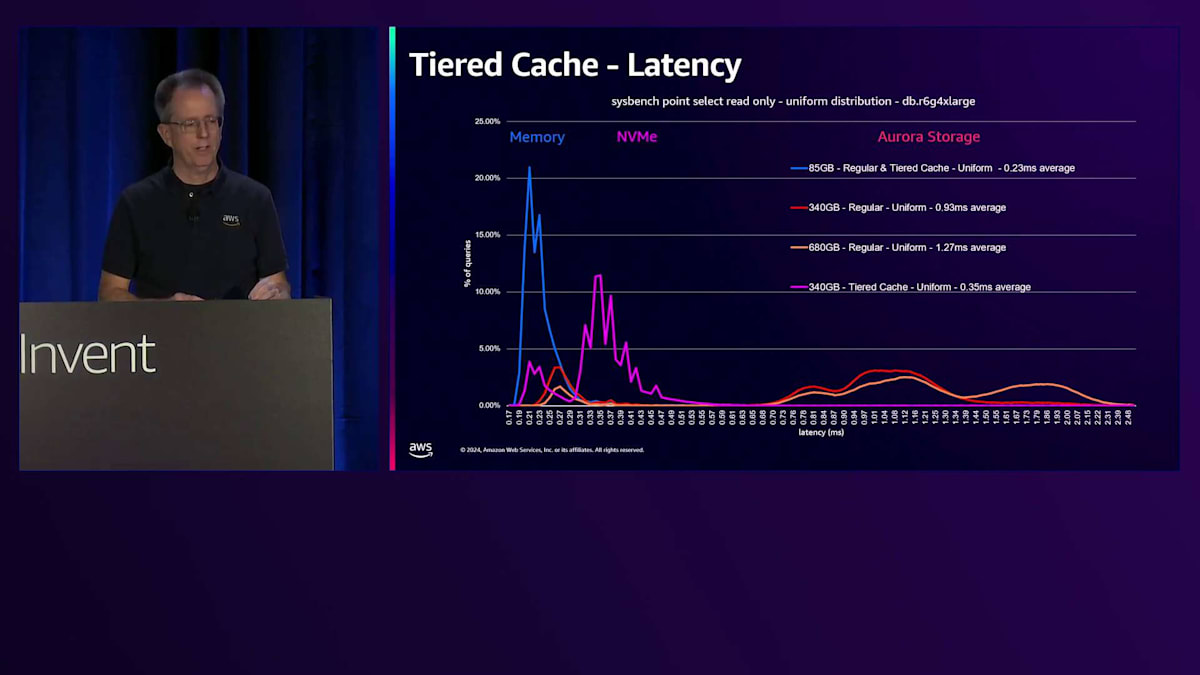
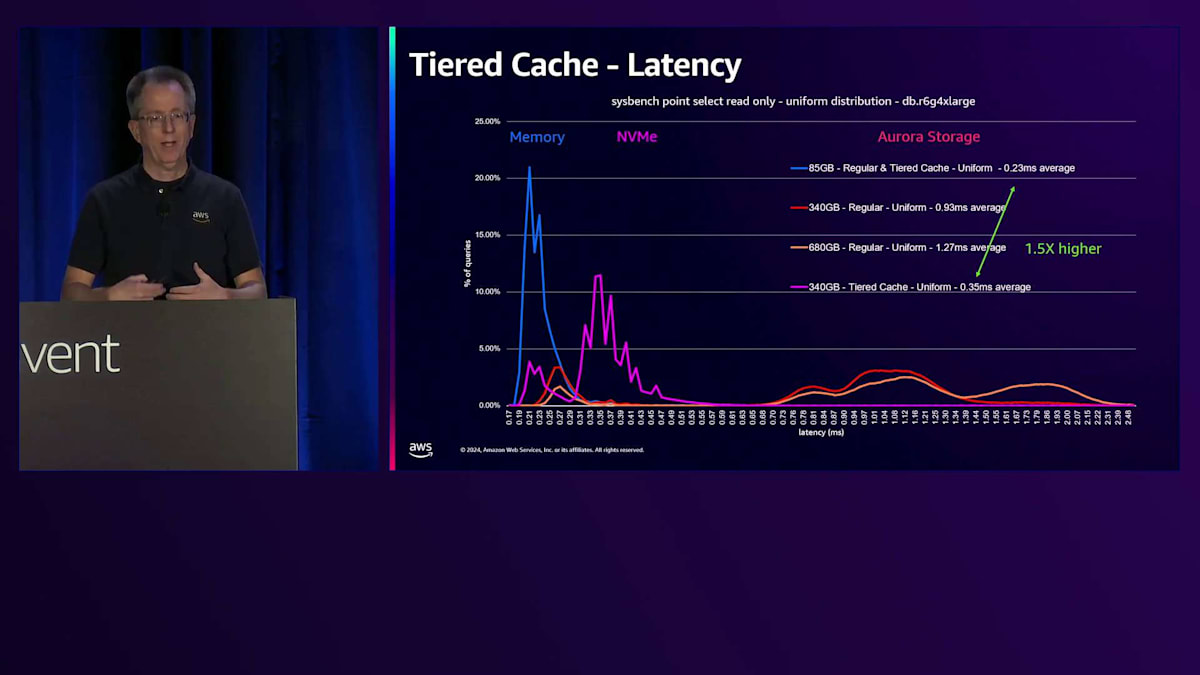
さらにデータ量を増やすと、同じようなパターンが見られますが、RAMに収まりきらないデータが出てきます。RAMに収まる部分は、ストレージ上のデータが増えるにつれて小さくなっています。ここでは5.5倍のレイテンシーの上昇が見られ、これはアプリケーションにとって無視できない影響となるでしょう。Tiered Cacheを追加すると、このピンクの線を見ていただくと、NVMeを表す2番目のスパイクが確認できます。データの一部はメモリーから、そして相当な部分がキャッシュから取得されています。340ギガバイトのデータは、このインスタンスサイズではTiered Cacheに収まるため、ストレージからのデータ取得は発生しません。レイテンシーの上昇は約1.5倍とわずかで、多くのアプリケーションにとって、ベースインスタンスクラスと比べてわずかなコスト増で4倍のデータ量を扱えることは十分許容できる範囲でしょう。
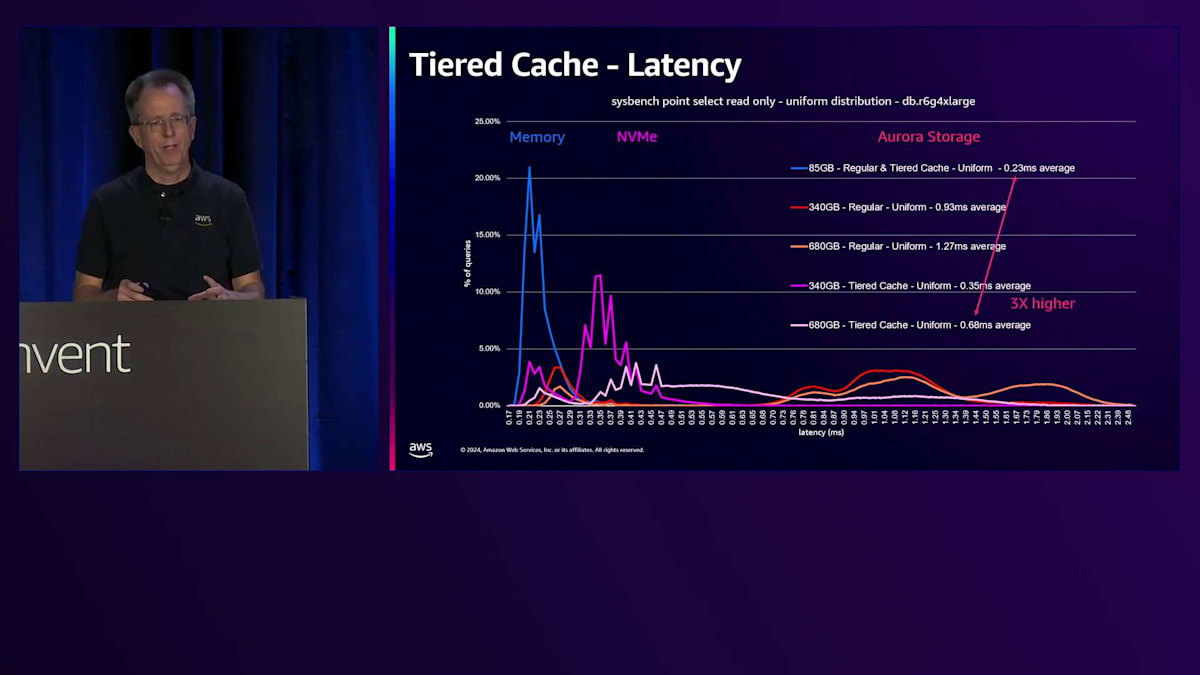
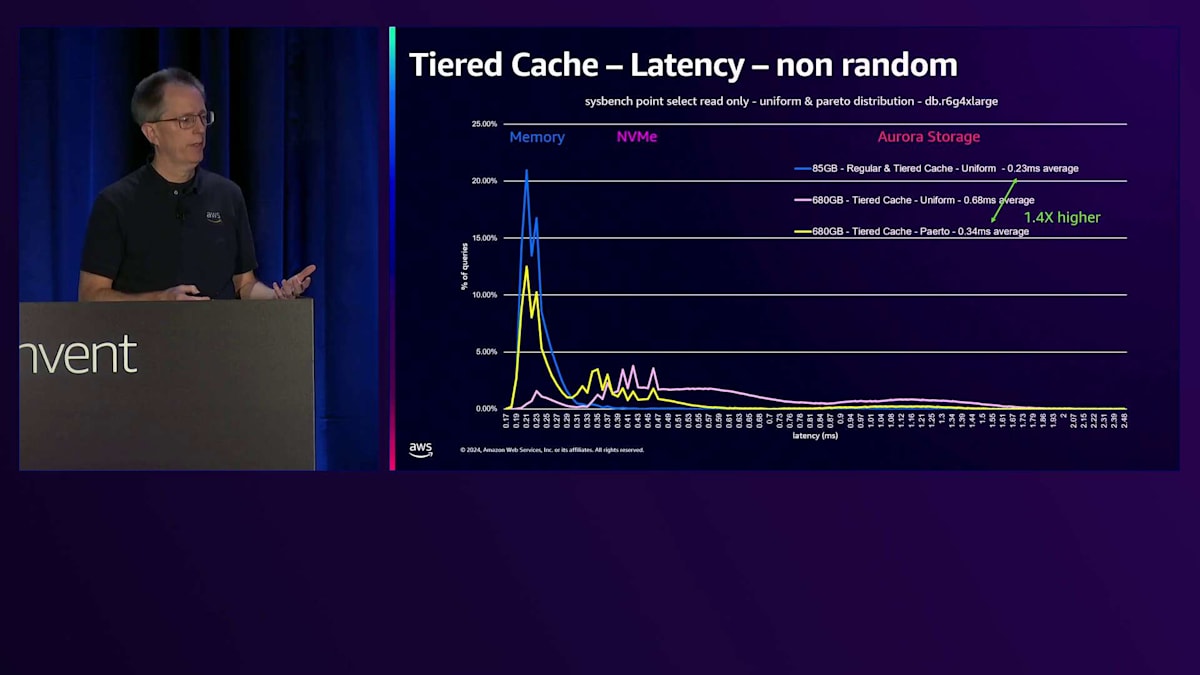
さらにサイズを2倍にすると、ワーキングセットサイズがTiered Cacheの容量を超えるため、パフォーマンスが低下し、約3倍のレイテンシーとなります。しかし、これは一様分布の場合であり、実際のユースケースではテーブル内のすべてのデータを読み取ることは珍しいです。Paretoディストリビューションを使用してSysbenchを実行し、一部のブロックのみにアクセスする場合、Tiered Cacheからはるかに良いパフォーマンスが得られます。約680ギガバイトという非常に大きなデータベースでも、ほとんどすべてのデータがShared BuffersまたはTiered Cacheから取得され、ストレージからのランダムアクセスは極めて少なくなります。
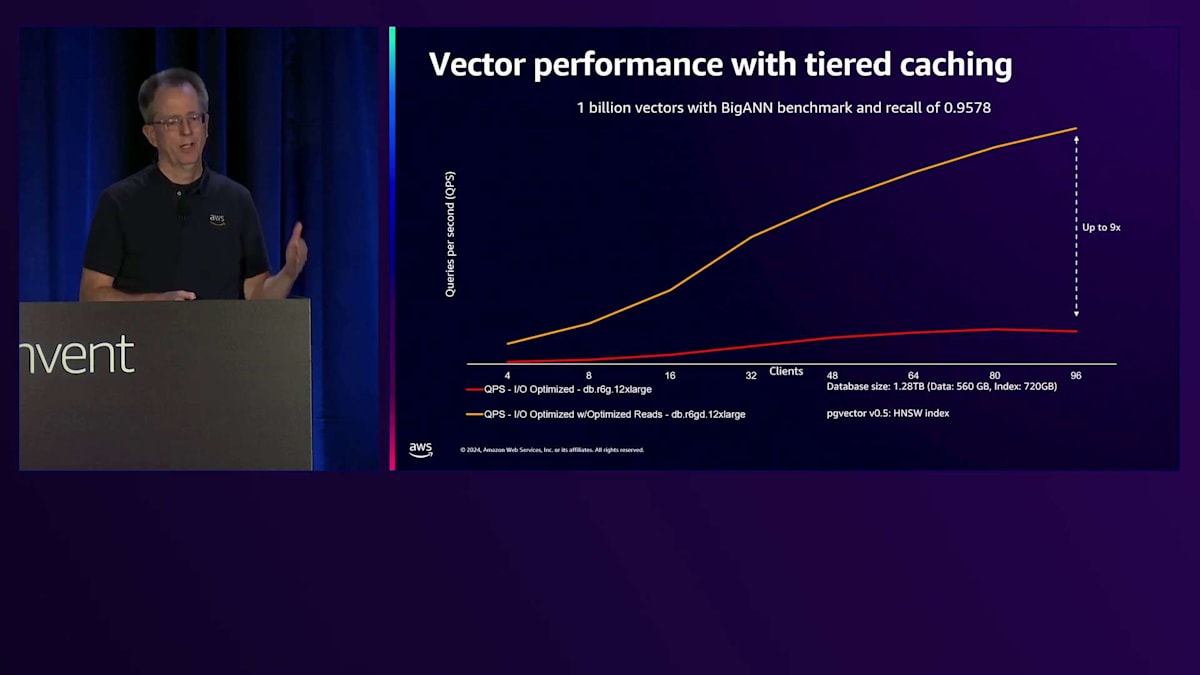
これによるレイテンシーの上昇は1.4倍程度に抑えられます。実際のユースケースとして、PgvectorのテストをTiered Cacheで実行してみました。その結果、この機能を有効にすることで、ベクトル処理にかかる時間が最大9分の1に短縮されました。より大きなマシンを購入したり、長時間待機したりする必要がなくなるため、非常に効果的です。読み取り処理が多い場合は、ぜひ試してみる価値のある機能です。
Aurora Limitless DatabaseとAurora DSQLの紹介


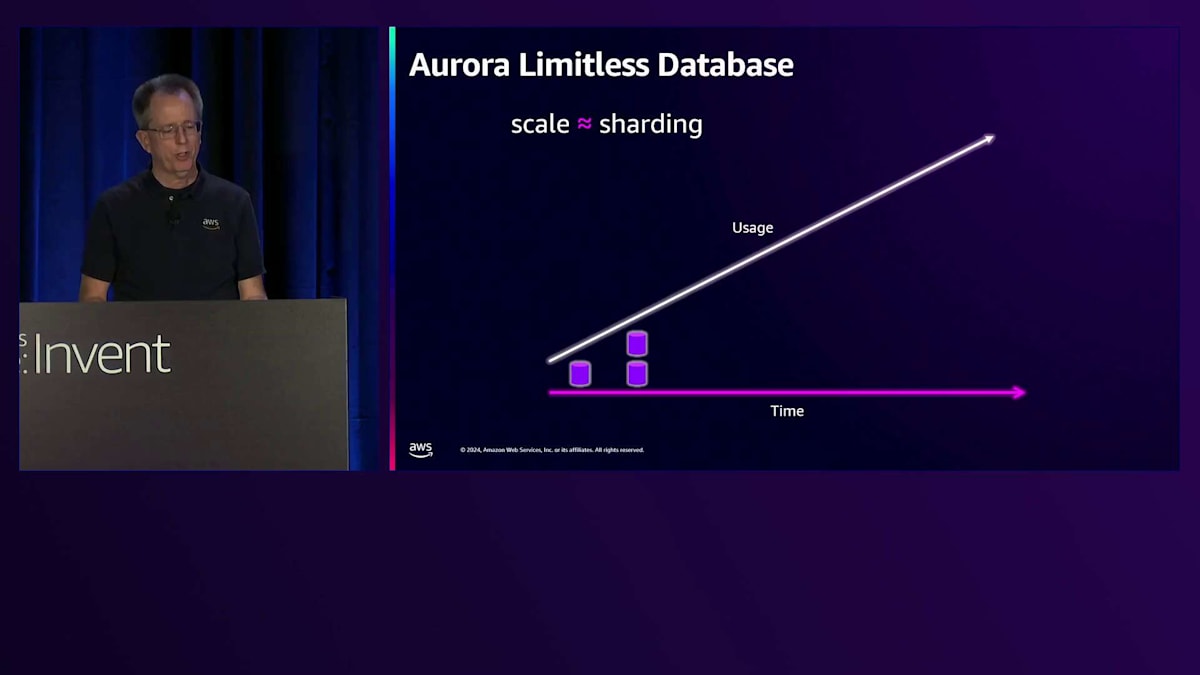

さて、昨年のre:Inventで発表し、今年のre:Inventの直前にGAとなったもう一つの機能が、Aurora Limitless Databaseです。Limitless Databaseとは何でしょうか?多くの方がご存知の通り、スケールアウトにはシャーディングが必要です。1つのデータベースから始めて、使用量の増加に伴い、シャーディングを行って複数のシャードに分割していきます。しかし、シャードが多くなると管理が大変になります。私にとって、真のスケーラビリティとはマネージドシャーディングを意味し、それこそがLimitless Databaseで実現しようとしていることです。シャーディングを簡単にすることが目標です。





シャーディングの課題の一つは、最初にシャーディングを行い、4つが適切だと考えて実装しても、しばらくは問題なく動作するものの、データにホットスポットが発生したり、特定の大規模顧客が多くのスペースを使用したりすると問題が発生することです。そうなると再度シャーディングが必要になります。データが成長し続ける場合、これは継続的な課題となります。もう一つの課題は一貫性です。シャーディングでは、カラムを追加する場合、4つのデータベースすべてに追加する必要があり、アプリケーションがタイミングの問題や1つでも追加し忘れた場合の影響に対応できるようにする必要があります。4つなら管理可能かもしれませんが、100個あったらどうでしょうか。未処理の注文を照会する場合、それらのクエリは微妙に異なるタイミングで実行されます。バックアップを実行しようとしても、すべてが微妙に異なるタイミングで実行されます。そのため、誰かが深夜0時時点のリストアを要求しても、深夜0時に近い時点のデータしか提供できません。




Limitless Databaseでは、通常のAuroraクラスター内でこれらの問題を解決しようとしています。 プレビュー以降、アーキテクチャに変更を加えました。クラスター内の通常のインスタンスを削除し、現在はLimitlessシャードグループのみとなっています。このグループの一部として、複数のコンポーネントを持つ分散トランザクションルーターレイヤーがあり、そこに接続することになります。 通常のクラスターのCNAMEと同様に、このルーターレイヤーを指すCNAMEがあります。ここですべてのルーティングとトランザクションを処理します。 そして、すべてのデータを保存するデータアクセスシャードレイヤーがあります。 これは少し古い数字ですが、200万TPSを超えるスケーリングが可能です。


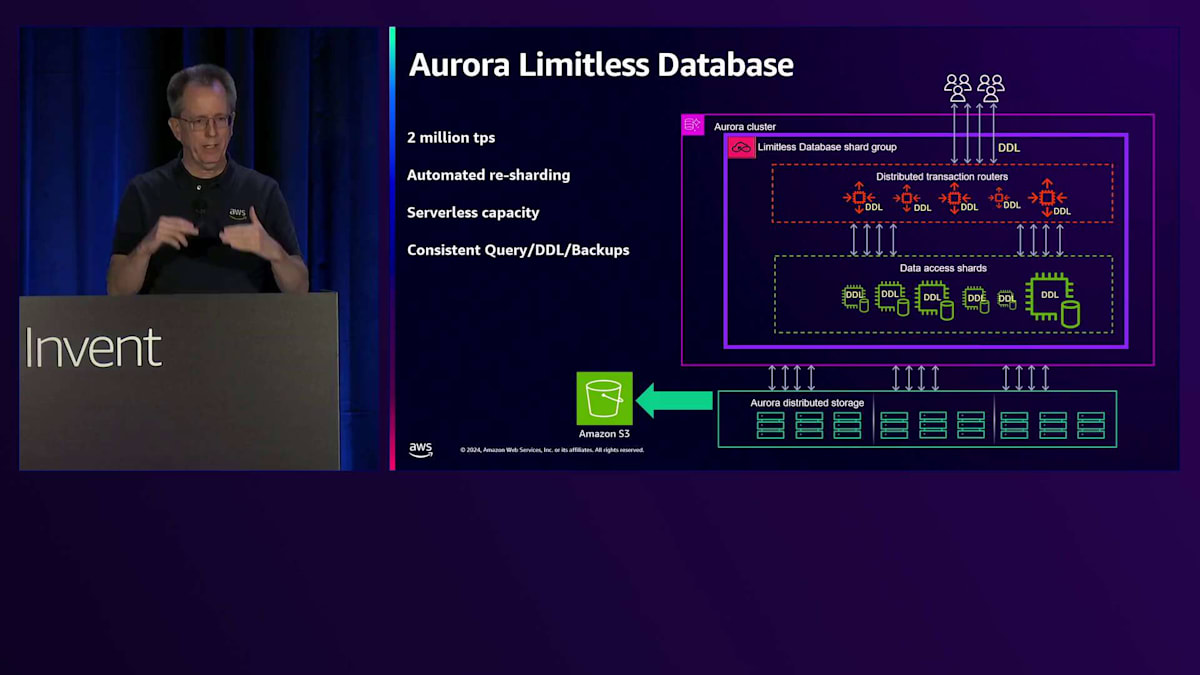
自動リシャーディングを提供しており、ホットシャードがある場合は自動的にリシャーディングを行うことができます。また、分割をリクエストすることで手動で行うこともできます。 Serverlessで見られるテクノロジーを活用したServerlessキャパシティを備えています。これらのシャードは日中に拡大縮小しますが、256 ACUを超えない限りリシャーディングする必要はありません。また、一貫性のあるクエリ、DDL、バックアップも提供しています。 DDLを実行すると、すべてのルーターとすべてのシャードに同時に分散トランザクションとして適用されます。これにより、アプリケーションのデプロイメントの観点から不整合の心配がなくなります。すべてのバックアップは一貫性があり、深夜にバックアップをリクエストして復元した場合、分散トランザクションはバックアップ時点の状態とまったく同じになります。





これは時計を使用して実現しています。他の機能でもご覧になったかもしれませんが、現在はより精密な時計を持ち、同期に使用できます。トランザクションを開始してpgbenchテーブルから値を選択すると、そのステートメントが到着した時点でルーターがT100という時間を割り当てます。そして、スナップショットテクノロジーを使用して、シャード上でT100の時点で実行し、過去の可視性を利用して正しい答えである704を取得します。トランザクション2では、同じテーブルの異なるBIDから選択していますが、これは更新用なので、通常のセマンティクスでロックを行います。これはルーターで103を取得するため、そのスナップショットで実行されます。ここでは1という答えを得ます。その後、そのバランスを1から1001に更新してコミットします。

この時点で、シャードと通信する必要があります。コミットポイントをT110に設定し、それが永続化されるのを待ち、その時間が経過するのを待つ必要があります。これは通常、コミットされるまでのわずかな遅延です。


ここで、別のトランザクションが同じBIDに対してそのクエリを実行する場合、125という時間を取得することになります。これは110の後なので、答えは正しく1001となり、1ではありません。しかし、トランザクション1では、まだコミットしておらず、トランザクションを終了していないことに注目してください。そのため、まだ元のトランザクションスコープ内にいます。このselectを実行すると、T100で実行されるため、読み取りの可視性は過去に戻るべきなので、正しい答えである1が得られます。この時計はこれらのクエリだけでなく、バックアップの方法などにも使用され、それによって一貫性を確保しています。これは多くの問題を解決する素晴らしいシステムで、420での私の同僚による講演でAurora Limitlessについてより詳しく知ることができます。

おそらく皆さんの多くは、今朝発表したAuroraファミリーの新メンバー、Aurora DSQL についてのアナウンスをご存知ないかもしれません。そのため、私の講演は彼の後に設定されているのです。どの家族にも共通点があるように、Auroraファミリーにも共通点がありますが、もちろん違いもあります。これについて1時間話す時間はありませんし、別のセッションでも取り上げられますが、Aurora PostgreSQLとAurora DSQLの比較について簡単にご紹介したいと思います。

左側にAurora PostgreSQL(長いので以降APGと呼びます)、右側にDSQLを示しています。最初に気づくのは、DSQLの場合、完全なPostgreSQLの互換性ではなく、PostgreSQL互換となっている点です。これは、同じクエリを実行すれば同じ結果が得られ、PostgreSQLの方言コマンドも使えますが、必ずしもすべての機能があるわけではないということを意味します。


両者とも、Auroraファミリーの共通点として、コンピュートとストレージが分離された分散データベースです。 Aurora PostgreSQLはログとブロックを一緒に保存しますが、DSQLは別々のログストアを持っています。アプリケーションから読み書き操作が 来ると、APGの場合はServerlessインスタンスやProvisionedインスタンス、あるいは任意のサイズのコンテナがそこにあります。一方、DSQLでは、接続が来たときにFirecrackerコンテナが起動します。これは接続前には存在しないという意味で、真のServerlessと言えます。


両者とも、ログをリージョン全体の ログストレージに書き込むため、リージョン全体でHAが確保されています。これは共通のパターンですので、レイテンシーは同程度でしょう。ただし、DSQLは分散型のため、若干高くなる可能性があります。Aurora PostgreSQLの特徴の一つは、 シングルライターであることです。別のAZから別の接続が来た場合でも、ライターノードは1つしかないため、そのRead-Writeノードにアクセスする必要があります。明示的および暗黙的なロックが可能で、Select for Updateや単純なUpdateを実行できます。

DSQLはこれとは異なります。DSQLは真のマルチライターシステムで、どこからでも書き込みが可能です。 同じAZでもAZ3でも可能です。ただし、Optimistic Concurrency Controlを使用しており、コミット時に最初の操作が成功し、他は失敗します。行のロックはできず、これは現在のPreviewでは10,000行、5分という制限のあるトランザクションサイズにも影響します。このように特性は異なりますが、真のマルチライターであり、1つのインスタンスのスケールに制限されないという点でスケーリングも異なります。

これまで説明してきたように、APGにはRead-onlyノードがあり、それらすべてにShared Buffersが存在します。


Aurora PostgreSQLとDSQLについてお話ししましょう。 両者にはキャッシュがあります。Shared Buffersが存在するため、キャッシュを同期させるために非同期の検証を行う必要があります。 Read-onlyノードから読み取りを行う場合、可能であればキャッシュからデータを読み取り、そうでない場合はストレージにアクセスします。

DSQLでは、これが根本的に異なります。キャッシュは存在せず、Availability Zone内にブロックを持つBlock Storeがあります。読み取りを行う際は、毎回ストレージから直接読み取ります。 この利点は、すべてがストレージにあるため、ノード間でキャッシュの整合性を取る必要がないことです。ストレージからの読み取りには時間がかかる可能性があるため、チームは読み取りのPush-down最適化を実装しました。従来のデータベースのような多数の往復が発生しないため、NVMEストレージでも非常に優れた読み取りパフォーマンスを実現しています。



Aurora PostgreSQLのRead-onlyでは非同期処理を行うため、Write Forwardingを有効にして整合性を要求しない限り、最終的な整合性のある読み取りとなります。DSQLでは、ストレージから読み取るため、すべてが整合的です。DSQLで接続数を増やすと、接続ごとにこれらのコンテナが増えていきます。 先ほど説明したServerlessでは、5分間インスタンスを使用しないと、そのインスタンスは消えて後で復活することができます。 DSQLでは、接続が終了するとすぐにそれらは消滅するため、使用しているワークロードに対してのみ課金されます。 もちろん、これはPreview段階なので、皆様からのフィードバックをお待ちしています。ここでお話ししている内容は、お客様からのフィードバックによって変更される可能性があることをご考慮ください。



これらのシステムは、どちらもグローバルなプレゼンスを持っているという点で似ています。 どちらも、ほとんどのビジネスがグローバルである現状をサポートできます。Aurora PostgreSQLは両方のロケーションに通常のボリュームを持ち、書き込みを行う際には、ストレージとすべてのノードに対して非同期で行います。これはActive-Passiveシステムなので、 それらの間でフェイルオーバーを行う必要があります。これは、Writerが1つしかないため、リージョン内のAuroraと同じです。 非同期であるため、クロスリージョンの書き込みのコストを払うことなく、リージョンレベルのコミットレイテンシーを実現できます。

一方、DSQLでは両方のロケーションにストレージがあり、真の意味でのマルチライター機能を実現しています。どちらのリージョンでも、複数のAvailability Zoneで書き込みが可能で、これは真のアクティブ-アクティブ構成です。Mattのプレゼンテーションで説明した最適化により、すべての書き込みや更新で毎回ラウンドトリップを行うのではなく、コミット時にのみ行います。リージョン間のコミットレイテンシーは、リージョン間の距離によって異なります。例えば、US WestからUS East間では100ミリ秒未満で、2つのEastリージョン間ではさらに高速です。これにより、リージョン間でRPOをゼロにしたいシステムを構築することができます。

これで概要の説明は以上です。より詳しい情報については、DSQLのタイトルで更新されたディープダイブセッション424をご確認ください。ご清聴ありがとうございました。セッションのアンケートへのご協力をお願いいたします。皆様からのフィードバックを心よりお待ちしております。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion