re:Invent 2024: Amazon SageMakerでFoundation Modelをカスタマイズ
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Customize FMs with advanced techniques using Amazon SageMaker (AIM303)
この動画では、Amazon SageMakerを使用したFoundation Modelのカスタマイズについて解説しています。SageMaker JumpStartを使用したFine-tuningの手法や、Domain Adaptation、Instruction Tuning、Visual Q&Aなどの具体的な手法を紹介しています。特に、Fine-tuningに必要なデータ量は従来考えられていたよりも少なく、数百の例で十分な場合が多いことが示されています。後半では、IntuitのDistinguished EngineerのMerrin Kurianが、QuickBooksでの取引分類において、従来型MLベースの400万個のモデルをFine-tuningされたLLMで置き換え、5-10%の精度向上を実現した事例を紹介しています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
SageMakerを用いたFoundation Modelのカスタマイズ:セッション概要

AIM 303へようこそ。今日のReinventorの皆さん、わくわくしていますか?もう一度聞きますよ - わくわくしていますか?本日、会場にお越しの皆様、そして他の会場でバーチャル参加されている皆様をお迎えできることを大変嬉しく思います。今日は、Amazon SageMakerを使用したFoundation Modelのカスタマイズについてお話しします。私はKarl Albertsenで、SageMakerとBedrock Inferenceのプロダクトマネジメントチームを率いています。一緒に登壇するのは、SageMakerのソリューションアーキテクトのMarc Karpと、IntuitのDistinguished EngineerのMerrin Kurianです。

なぜ今日ここに集まったのでしょうか?会場の多くの方々は、すでにオフザシェルフのFoundation Modelをテストし始めているのではないでしょうか。また、パフォーマンスの向上や精度の改善、あるいは本番環境でのデプロイメントを拡大する際のコストなど、その限界に挑戦し始めている方も多いのではないでしょうか。ここで重要になってくるのが、Foundation Modelのファインチューニングです。 これから60分間で、Foundation Modelのファインチューニングが適している場面、モデルの選択方法とデータの準備方法、そしてSageMakerが提供する多くのプロセスを簡素化する機能についてお話しします。その後、Marcが登壇してどのように始めるかのデモを行います。そして、Merrinが登壇し、Intuitが現在、皆さんが日常的に使用している製品で、ファインチューニングされたモデルをどのように本番環境で活用しているかについてお話しします。
Foundation Modelのファインチューニング:必要性と準備

詳細に入る前に、一般的なFoundation Modelのワークフローについて確認しておきましょう。多くの場合、オフザシェルフのモデルを選択し、特定のプロンプトライブラリやパフォーマンスベンチマークに対して評価を行います。デプロイメントをカスタマイズして実装することもあります。これは非常に反復的なプロセスです。複数のモデルファミリーやさまざまなサイズのモデルをテストし、3ヶ月ごとに新しいモデルがリリースされると、このプロセス全体をやり直す必要があります。このサイクルにファインチューニングを導入すると、少し複雑さが増しますが、多くの場合、この複雑さは管理可能で、むしろ有益なものとなります。

では、モデルのファインチューニングが必要な場面について説明し、その後、実際に始める準備が整っているかどうかについて見ていきましょう。ファインチューニングが適している場面については、冒頭で述べたように、多くの方が限界に挑戦し始めると、自然と明らかになってきます。例えば、特定のユースケースに対して堅牢性が求められるProof of Conceptの精度を向上させたい場合、これは特定のドメインや機能、ビジネスに特化したものかもしれません。オープンウェブデータで学習されたモデルだけでは十分な結果が得られない場合です。次に、有望なProof of Conceptはできているものの、本番環境で想定されるトラフィックに対してスケールアップするとコストが法外になる場合。同様の、あるいは同じ精度を維持しながら、より小さなモデルでより多くの成果を得て、本番環境でのスケーリングを経済的に行うための方法を探している場合です。三つ目は、チャットアプリケーションのような、素早いレスポンスが必要な低レイテンシーのユースケースがある場合です。
一方で、ファインチューニングを始める準備が整っているかどうかは、主に2つの点に集約されます。元のトレーニングコーパスには含まれていない、ユニークで差別化されたデータセットを持っているかどうかです。多くの方がお持ちだと思います - これは製品やサービスでの顧客とのやり取りから得られるデータかもしれません。これはモデルのファインチューニングに使用できる貴重な情報の宝庫です。また、社内プロセスやユースケースの改善を目指している場合は、ドキュメントを活用してチームのレベルアップやプロセスの簡素化を図ることができます。多くのお客様が最初に取り組んでいるのは、カスタマーサービスやサポートのユースケースです。社内ユースケースから始めることで、レスポンスの不適切な表現に関する懸念の多くが軽減されます。問題と回答の豊富なデータがあり、顧客への応答に使用される言葉遣いやトーンは、企業やビジネス全体でユースケースを拡大していく際の優れたデータセットとなることが多いのです。

Fine-tuningを行う理由とFine-tuningの準備が整ったところで、実際にどのようにFine-tuningを進めていけばよいのでしょうか?実は、これはかなり時間のかかる骨の折れる作業なのです。まず、データセットを準備し、適切なインスタンスタイプを選択して、必要な設定を行う必要があります。次に、適切なHyperparametersを選択し、それを改善するために多くの試行錯誤を重ねることになるでしょう。そして、評価スクリプトを作成し、評価指標を設定する必要があります。これらすべてが完了したら、モデルをパッケージ化してデプロイメントの準備を整える必要があります。これら全ての作業は非常に時間がかかり、正直なところ、あなたのデータや知識を活かすという点では、あまり差別化につながらない作業です。

ここでSageMakerの出番です。SageMakerは、これらの基本的な作業の多くを代行してくれるため、差別化につながる部分に注力することができます。それは、先ほど話したように、あなたのビジネスに固有のデータセットであり、お客様についての知識であり、製品についての知識です。SageMaker Suiteのツールやサービスを使い始めることで、このような本質的な部分に集中できるようになります。
SageMakerによるファインチューニングプロセスの簡素化

まず何より重要なのは、SageMakerでは何百もの事前学習済みFoundation Modelsを提供しており、その多くがFine-tuning可能だということです。これらのモデルを見つけやすいように、モデルファミリーやモデルサイズ、Fine-tuning可能なモデルなどでフィルタリングできるようにしています。SageMaker StudioのSageMaker JumpStartという製品を通じて、使いやすいUIで簡単に操作することができます。同様に、SageMaker SDKを使用してプログラムからも簡単にアクセスできます。さらに、企業内で利用可能なモデルをキュレーションする機能も追加しました。多くのお客様から、チーム内で利用できるモデルの種類をコントロールしたいというフィードバックをいただいており、特定のライセンスタイプや、検証済みの特定のモデルファミリー、個別のモデルに限定したいというニーズがありました。キュレーション機能により、チームが使用できる承認済みモデルを制限することができます。これらのモデルはすべてAWSのインフラストラクチャからデプロイされるため、機密性の高い環境や、VPCでネットワーク分離された環境にデプロイすることができ、機密データや機密環境で作業する場合に重要となります。

さて、使用したいモデルを1つまたは複数選択したので、次はデータ準備について説明しましょう。Fine-tuningのタイプによってデータの準備方法が異なるため、少し時間をかけて説明したいと思います。一般的なユースケースの1つが、Domain Adaptationと呼ばれるもので、既製の基本モデルを取り、特定の業界や機能のニーズに合わせて改良するというものです。例えば、法律事務所や金融サービス会社の場合、法律文書や法律関連の書類、あるいはこれらの企業の内部調査資料などのデータを学習させます。これは比較的単純で、文書自体を提供し、初期トレーニングプロセスの続きとして、この新しいトレーニングコーパスに基づいて次のトークンを予測することを学習するだけです。
Instruction Tuningと呼ばれる方法は少し異なります。これは、モデルに特定の質問と回答のペアを提供し、そうすることでこれらのタイプの質問にどのように応答すべきかをモデルに学習させます。これは、会社全体で使用される特定の方法で情報を要約したい場合や、一般的なテンプレートに従って新しいデータを生成したい場合に非常に役立ちます。新しい情報を提示された時にそれらのテンプレートや典型的な指示に従うように、モデルを事前に学習させることができます。3つ目はVisual Q&Aと呼ばれるものです。モデルがテキストベースだけでなくマルチモーダルに進化していく中で、Instruction Tuningと同様に質問と回答のペアを使用しますが、それに加えて画像という新しい層が加わります。これらのテクニックのためのデータセットを準備する初期段階はこのようになります。実際にデータを構成してモデルに送信する方法については、Domain Adaptationが最もシンプルで、単純なテキストファイルを使用します。一方、Instruction TuningやVisual Q&Aの場合は、質問と回答のペアにおけるモデルの役割を具体的に指定するJSONフォーマットを使用します。
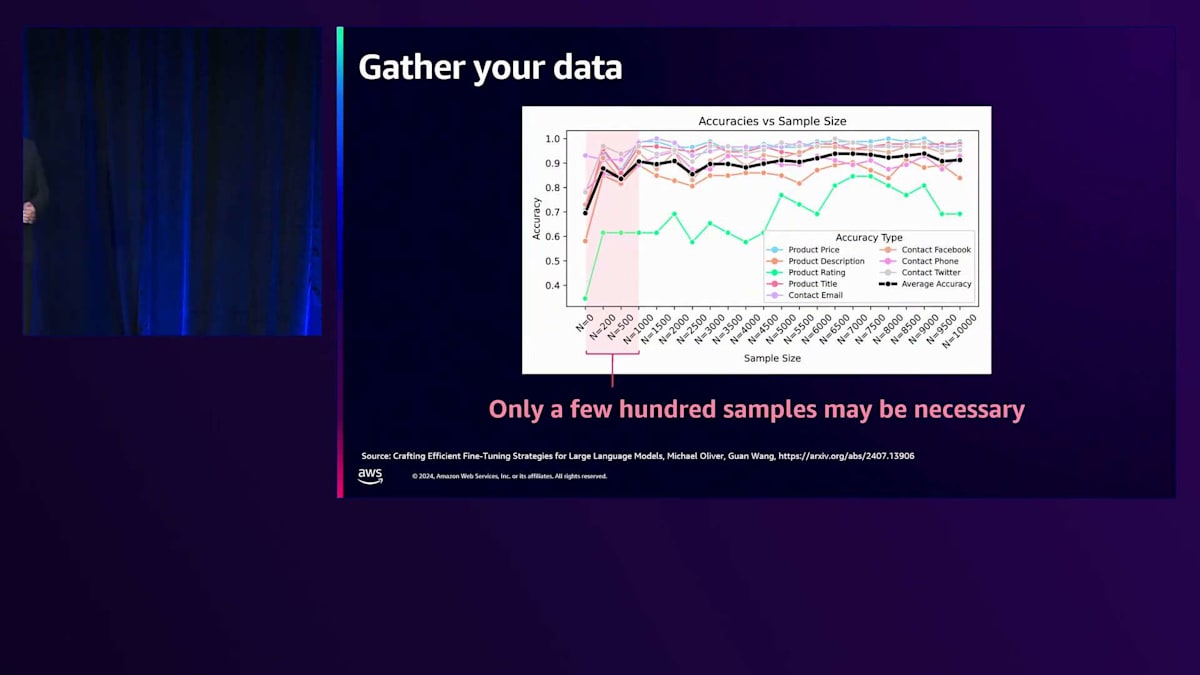
ここで、お客様からよく質問されるのが、良い応答を生成するために実際にどれくらいのFine-Tuningデータが必要かということです。多くの方は、元のモデルが学習したデータセットと同じオーダーの、数十万や数百万規模のデータが必要だと考えがちです。今夜は良いニュースをお伝えできます:実際にはそれよりもずっと少ないデータで十分な場合が多いことがわかってきています。常にそうとは限りませんが、多くの場合、数百の例、時には100個未満の例でも、Fine-Tuningされたモデルの精度を大きく向上させることができることがわかっています。これをお伝えする理由は、お持ちのデータ量に関わらず、まずはモデルのFine-Tuningを試してみることをお勧めしたいからです。比較的小規模なデータセットでも、驚くほどの効果が得られる可能性があります。
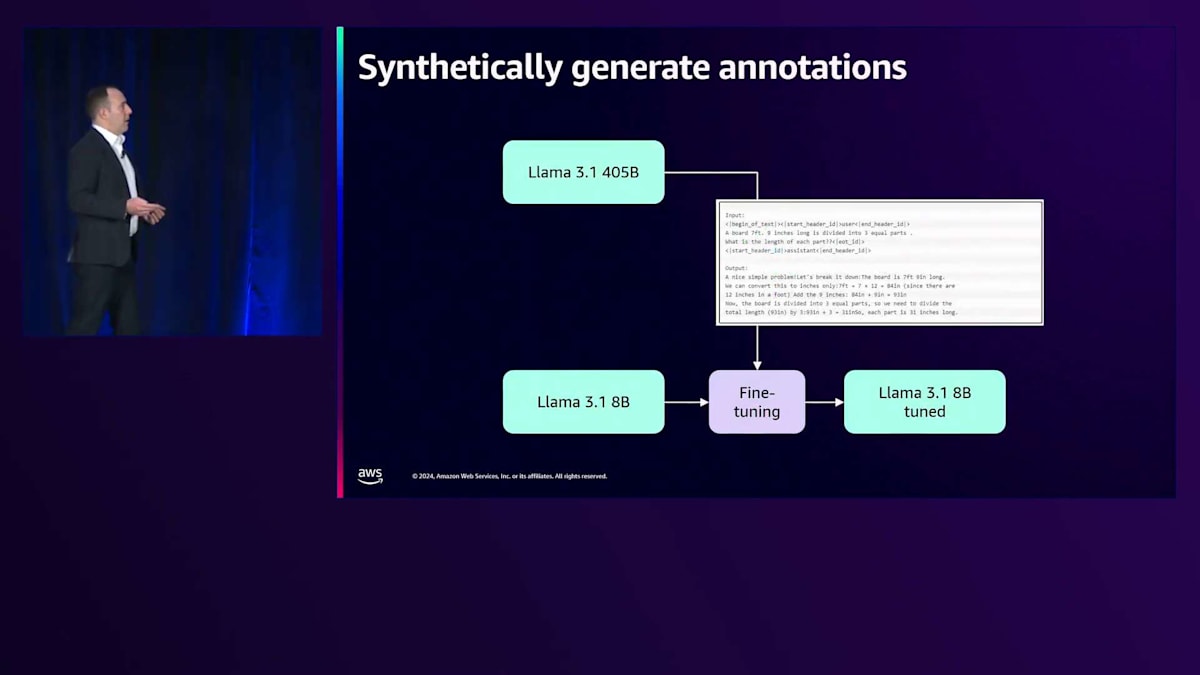
もう一つ付け加えたいのは、お客様がデータセットの作成や拡張にSynthetic Dataを使用することを、ますます試し始めているということです。数十や数百の例がない場合でも、必ずしも行き詰まるわけではありません。私たちは、お客様が大規模なモデル、この場合でいえばLLaMA 405ビリオンパラメータモデルのようなものを使用して、質問に対する非常に正確な回答を生成している印象的な例を見てきました。
その後、それらの回答が自分たちのドメインに適しているかどうかを人間のチームに確認してもらい、より小規模なモデルをInstruction Tuningするための優れた質問と回答のペアとして使用することができます。画面で共有している例では、44または5ビリオンのモデルを使用してそれらの回答のアノテーションを生成し、本番環境でよく使用される8ビリオンモデルに対して、その質問と回答のペアを使ってInstruction Tuningを行うことで、多くの場合、経済的にスケールできる正確な結果を得ることができます。
SageMaker JumpStartを使用したファインチューニングのデモ

Fine-Tuningが必要な理由を理解し、データセットの準備ができたところで、 次は実際のFine-Tuningに進みます。SageMakerには2つの方法があり、これらは互いに置き換え可能です。SageMaker JumpStartは、簡単に始められるように設計されています。シンプルなUIで、事前に用意されたFine-Tuningスクリプト、サンプルデータセット、そしてほとんどのケースでそのまま使える適切なデフォルトのハイパーパラメータが用意されています。より複雑なトレーニングジョブが必要な場合や、すべてを完全にコントロールしたい場合は、SageMaker Trainingを使用することで、必要な深さまで掘り下げることができます。

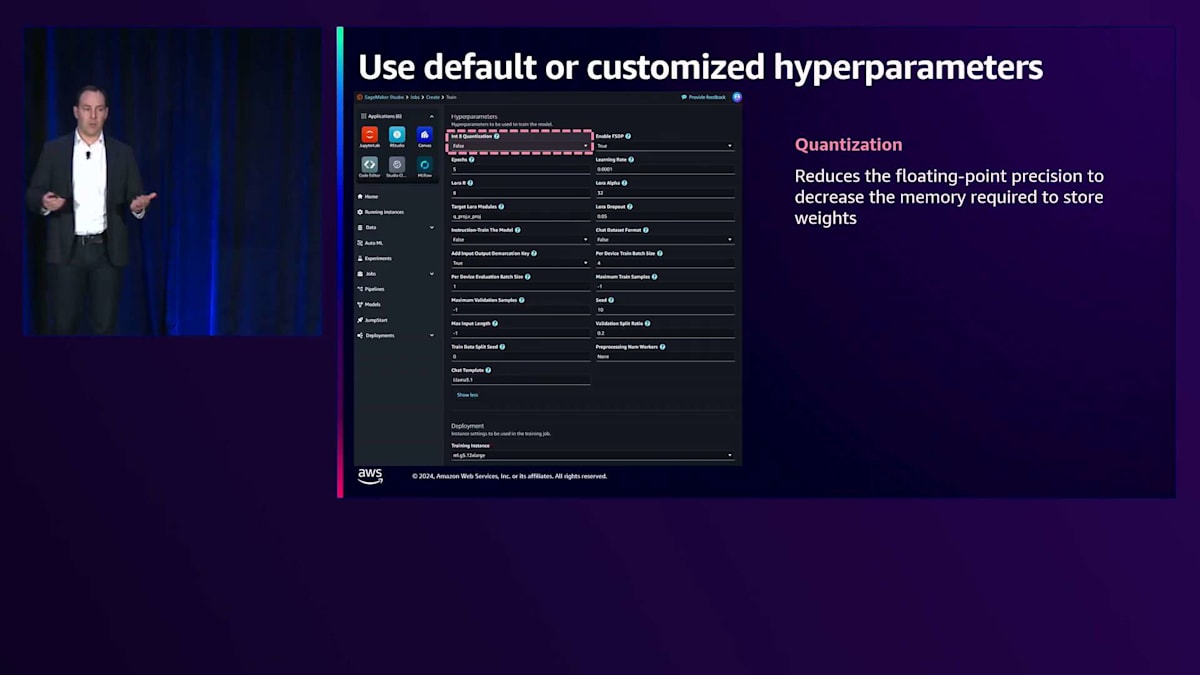
ここでお見せしているのは、SageMaker JumpStartのハイパーパラメータのスクリーンショットです。かなりの数がありますが、これは複雑で困惑するということを示すためではありません。むしろ、必要に応じていつでもオーバーライドやカスタマイズができる完全なコントロールを提供していることを示すためです。私たちが提供するFine-tuningモデルでは、これらのパラメータのそれぞれに、ほとんどの場合すぐに使える優れたデフォルト値が設定されています。 ここでは、Fine-tuningプロセスを効率的に行い、高品質な結果を生成するために特に重要な3つのパラメータについてご説明します。
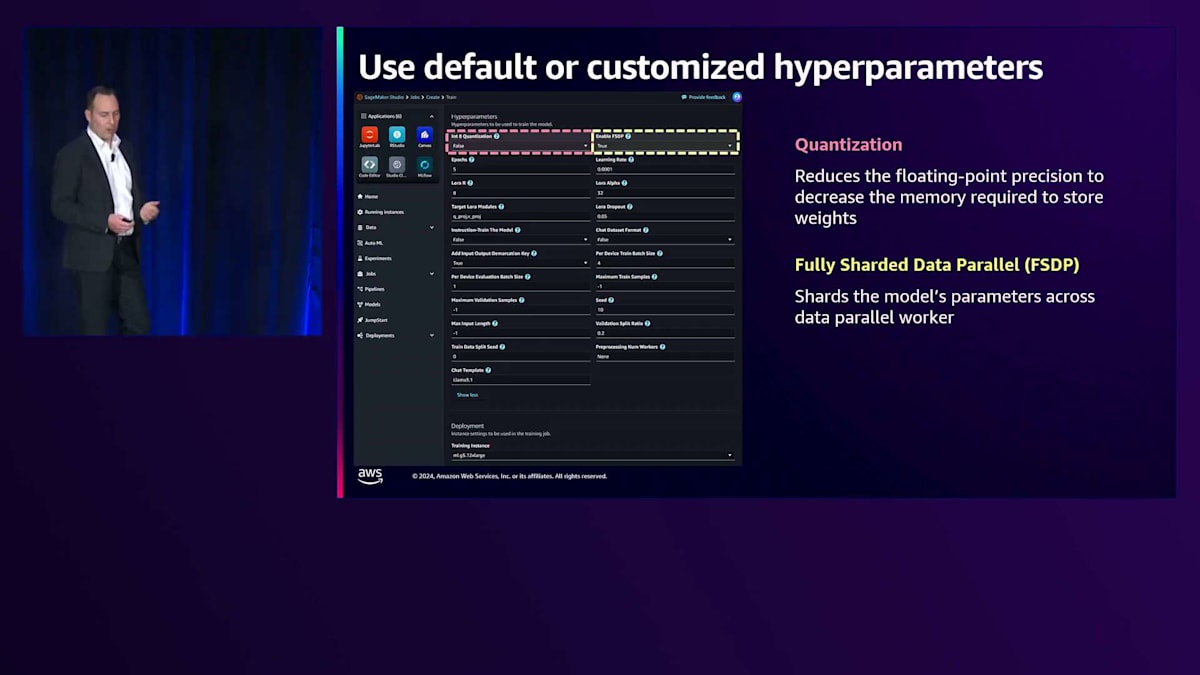
1つ目はQuantizationです。これは、モデルの浮動小数点の精度を下げるテクニックです。多くの場合、モデルの精度にはそれほど影響を与えずに、メモリ使用量を大幅に削減できることがわかっています。これにより、トレーニングプロセスを高速化できるだけでなく、推論時にも効率的なモデル実行が可能になります。 2つ目は、FSDPつまりFully Sharded Data Parallelismについてお話しします。これは、非常に大規模なモデルのFine-tuningを可能にする素晴らしいテクニックで、すぐに使用できる形で提供しています。モデルを自動的にシャーディングし、複数の並列ワーカーでの使用を可能にすることで、SageMakerが大規模モデルのFine-tuningのバックボーンとして機能することを容易にします。
最後に、この会場の多くの方がご存知かもしれませんが、Low-Rank AdaptationつまりLoRAアダプターについてです。私たちのスクリプトは、LoRA Fine-tuningをすぐに使用できる状態で提供しています。この場合、モデル自体のすべての重みをFine-tuningするのではなく、モデルのごく一部(多くの場合1%以下)だけをFine-tuningします。これにより、Fine-tuningプロセスを非常に迅速に実行でき、その後のモデルも効率的に使用できます。これらは、私たちが提供する多くのハイパーパラメータの中のほんの3つの例です。それぞれのケースで、スマートなデフォルト値を設定しているので、このページを見て何も読まずに「開始」をクリックするだけでFine-tuningジョブを開始できます。しかし、後から戻って反復的に調整したり、より深く掘り下げたりすることも、意思決定者として常に可能です。

モデルのFine-tuningが完了したら、デプロイメントの前にもう1つステップがあります。複数のモデルアーティファクトをパッケージングする必要がありますが、SageMakerではこれが自動的に行われます。Fine-tuningジョブが完了すると、そのモデルを直接エンドポイントにデプロイするオプションが提供されます。SageMakerはバックグラウンドでモデルのパッケージングとセットアップを行い、Fine-tuningされたモデルを本番ユースケースやさらなるテストのためにすぐにエンドポイントの背後にデプロイできるようにします。

今日はSageMakerについて多くお話ししましたが、これはデプロイメントに使用するインスタンスを完全にコントロールしたい場合の素晴らしいオプションです。しかし、多くのお客様が最近Amazon Bedrockを中心にワークフローを構築していることも承知しており、これについてお話しできることを大変嬉しく思います。Bedrockのカスタムモデルインポート機能を使用すると、SageMakerでFine-tuningしたモデルをBedrockにインポートし、BedrockのInvokeModelやConverse APIで使用できます。これにより、既存のBedrockワークフローに直接組み込むことが可能になります。
SageMaker StudioとPython SDKを用いたファインチューニングの実践
それでは、Markを壇上にお迎えしたいと思います。Markは私が話したことについて、そしてさらにそれ以上のことについてデモを行い、これを本当に取り組みやすいものにしてくれます。このセッションを終えた時には、皆さんが自信を持って独自のデータセットでモデルのFine-tuningを始められるようになることでしょう。ありがとう、Mark。ありがとう、Carl。それでは、具体的にSageMakerでのFine-tuningの始め方を見ていきましょう。
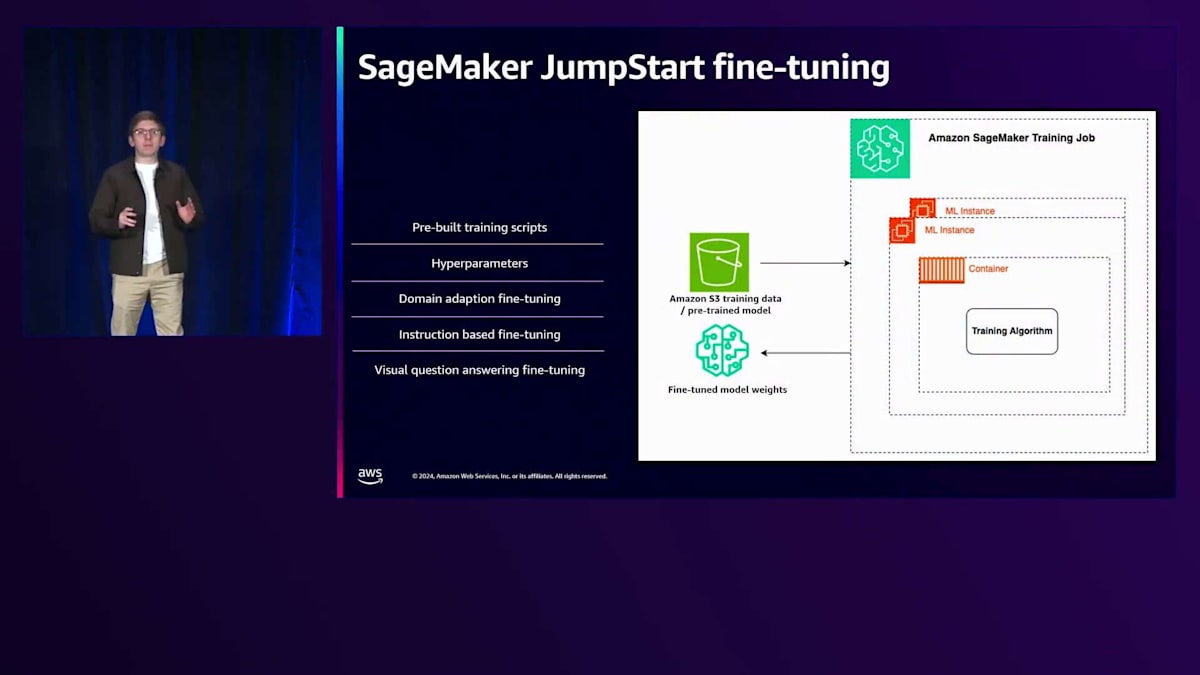
SageMaker JumpStartを使用してこのデモを行います。 SageMaker JumpStartでのFine-tuningの核となるのは、SageMaker Training Jobという概念です。Training Jobの構成要素を見ると、GPUベース、CPUベース、あるいはTrainingなどのアクセラレーターベースのインスタンスとなり得るMLインスタンスが含まれています。Foundation ModelのFine-tuningの場合、ほとんどの場合GPUかアクセラレーターベースになります。そのMLインスタンス内には、モデルのTraining ScriptやTraining Algorithmを含むコンテナがあり、モデルのトレーニングに使用するS3入力データはS3内に配置されます。事前学習済みモデルの重みもS3に配置され、トレーニングが完了すると、すべてのインスタンスは終了し、Fine-tuning後のモデルの重みもS3に送信されます。
SageMaker JumpStartは、すべてのFine-tuningスクリプトをカプセル化します。テストやチューニングのための多くのハイパーパラメータを公開し、Fine-tuningを始めるためのデフォルトのインスタンスタイプも選択してくれます。先ほど述べたように、さまざまなタイプのモデルに対して多くの事前構築されたTraining Scriptがすぐに使用できます。テスト用の多くのハイパーパラメータがあり、Domain Adaptation、Instruction-based Training、Visual Question Answeringも現在サポートされています。
デモに移って、SageMaker JumpStartでのFine-tuningが実際にどれほど簡単かを見てみましょう。このデモでは、2つのFine-tuning手法を探ります:1つはSageMaker StudioのUIを使用する方法、もう1つはSageMaker Python SDKを使用する方法です。ドキュメントの理解と質問応答のために、手書きと印刷の両方のコンテンツを含むカスタム画像から情報を抽出する必要があるシナリオを考えてみましょう。多くの組織には、Foundation Modelが以前に遭遇したことのない独自のドキュメント、フォーム、その他の画像があるかもしれません。これらのカスタム画像やドキュメントを理解する際のモデルの全体的な精度を実際に向上させるために、Fine-tuningが不可欠となるのはここです。
このために、マルチモーダルモデル、LLaMA 3.2モデルを使用します。これはテキスト理解を超えて、特定のユースケースのために画像を理解し分析する能力を持つ次世代のモデルです。この例では、組織からのカスタム画像があり、会社名とその所在地を実際に抽出したい場合を想定しています。

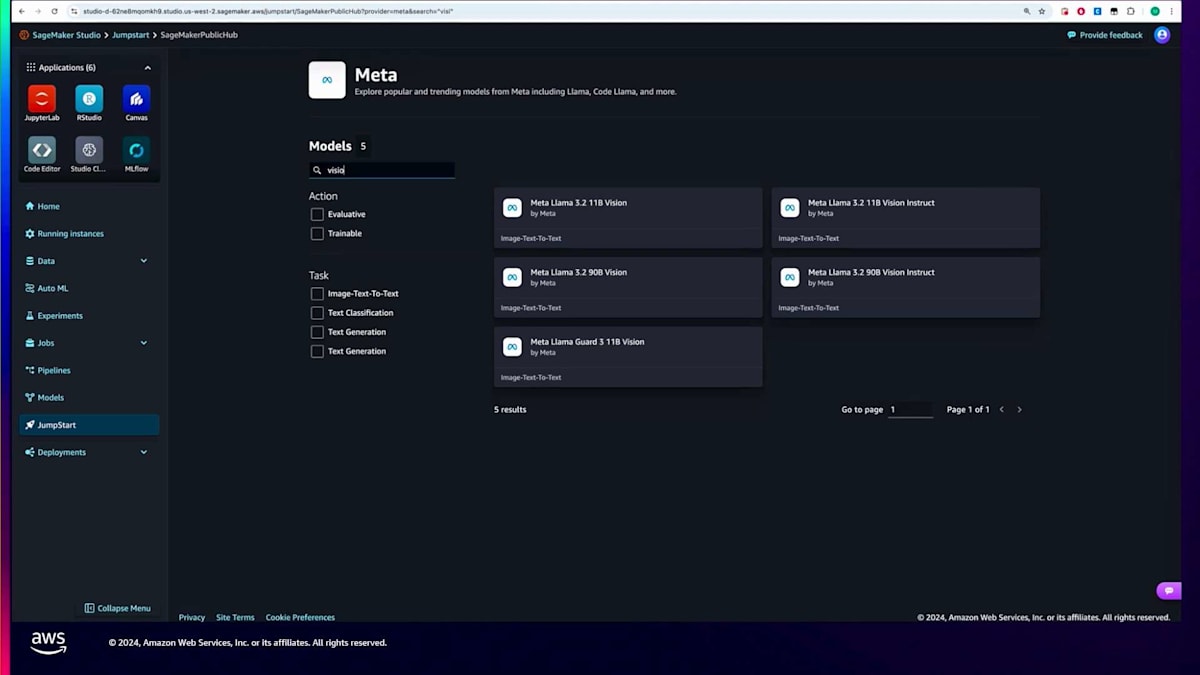
まずはSageMaker StudioのUIについて見ていきましょう。SageMaker内の左側のナビゲーションパネルには、JumpStartセクションがあります。このJumpStartセクションを選択すると、プロプライエタリとオープンウェイトの両方のモデルプロバイダーが多数表示されます。今回は、Metaファミリーのモデルを見ていきます。Metaを選択すると、利用可能なMetaのモデルが表示されます。今回はLLaMA 3.2 11 billionモデルをファインチューニングしたいので、「vision」で検索してみましょう。このモデルのさまざまなバリエーションが表示されますが、11 billionパラメーターバージョンを選択します。
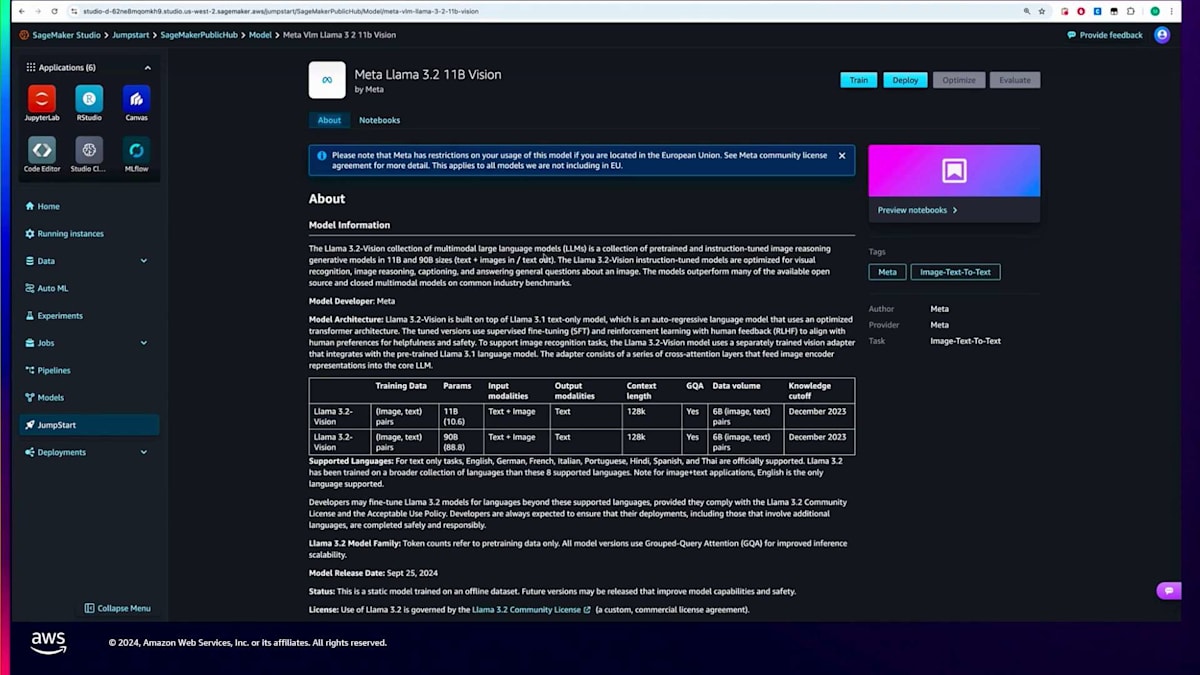

ここでは、モデルカードとモデルの詳細を確認できます。重要なのは、上部に「train」と「deploy」の2つのボタンがあることです。deployは事前学習済みモデルをデプロイしますが、trainを選択すると実際にモデルのファインチューニングができます。ここでS3の入力データを指定します。今回の場合、SageMakerが提供しているサンプルデータセットを使用できます。これは画像と正解の回答を含む3,000の例を持つDocVQAデータセットで、ビジョンモデルの評価によく使用されます。もし組織独自の画像を含むデータセットがある場合は、それを使用することもできます。その後、ハイパーパラメータを設定します。ここではLoRAなどのパラメーター効率の良いファインチューニング手法を選択できます。これにより、モデルの全パラメーターではなく、一部のパラメーターだけをファインチューニングすることができます。また、勾配チェックポイントやBF16混合精度学習などの他のハイパーパラメータも設定できます。混合精度学習を使用すると、より大きなバッチサイズでファインチューニングができ、ハードウェア要件も軽減されます。

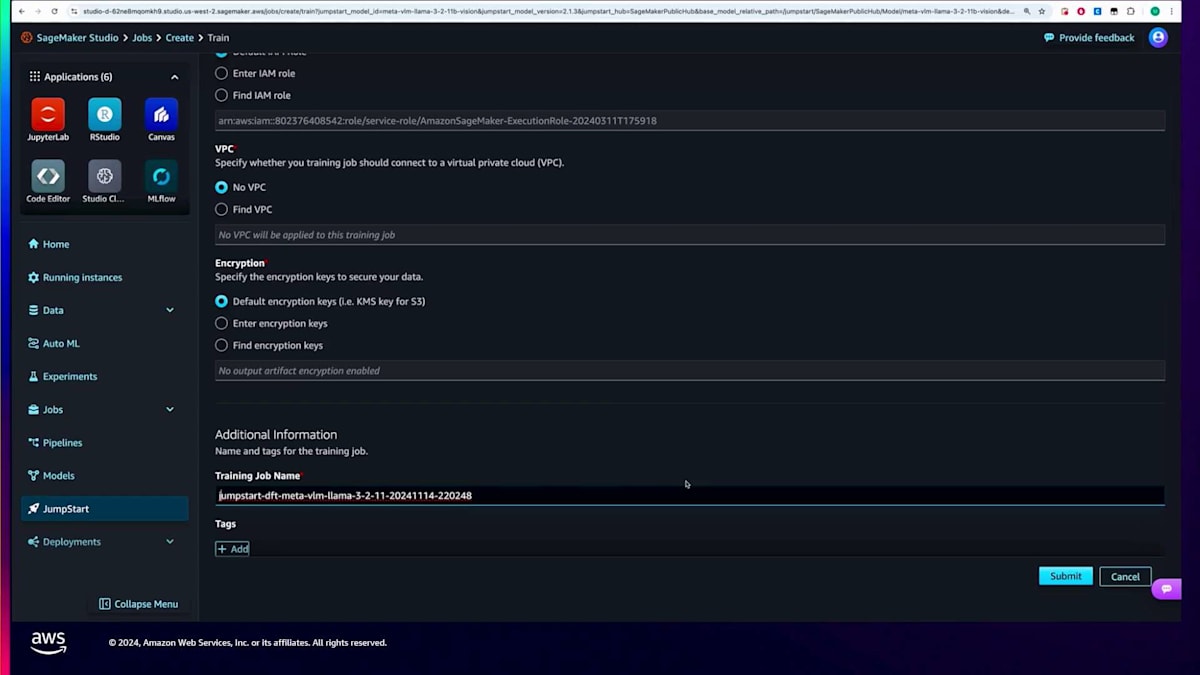
インスタンスタイプの選択時には、SageMakerが利用可能なインスタンスタイプを表示し、デフォルトを使用するか別のものを選択することができます。その後、結果として得られるモデルの重みが保存されるS3パスを設定します。また、必要に応じてIAMロール、VPC設定、暗号化などの追加設定も行うことができます。


設定が完了したら、利用規約を読んで同意した上で送信をクリックします。実際のトレーニングジョブが開始され、実行中の状態となります。しばらくすると、トレーニングジョブは完了状態となり、パフォーマンスを確認することができます。評価損失とトレーニング損失を確認でき、また入力データの場所やファインチューニングされたモデルの重みの場所など、ジョブで使用されたアーティファクトの詳細も下部で確認できます。
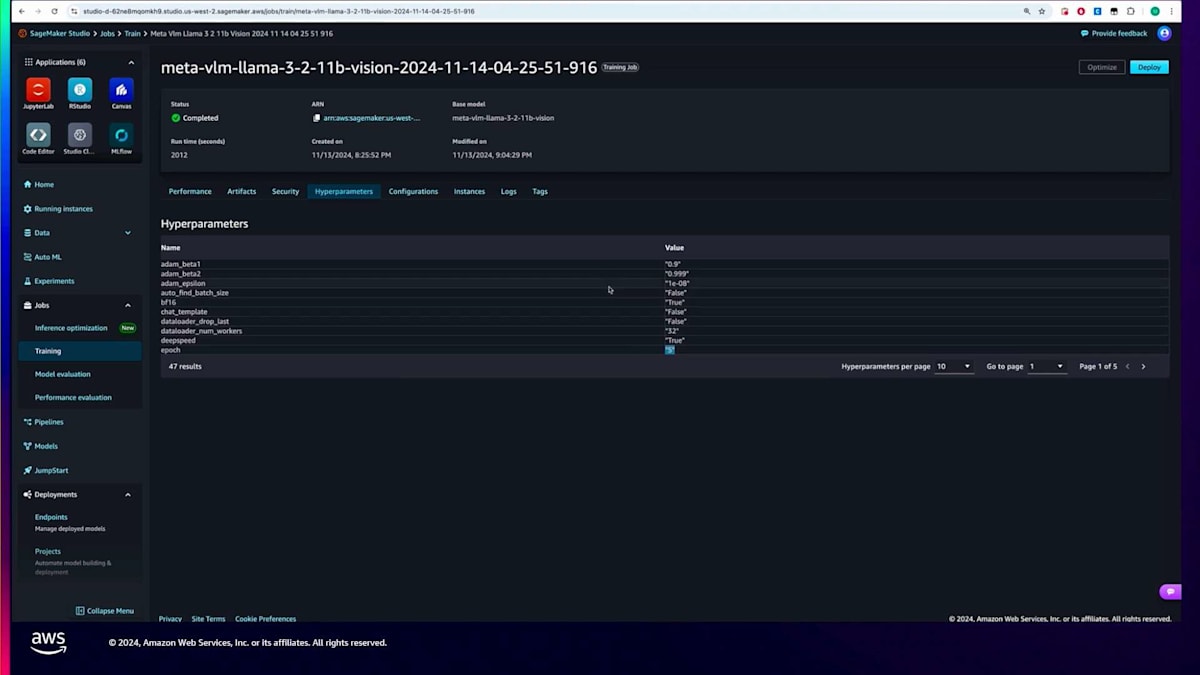
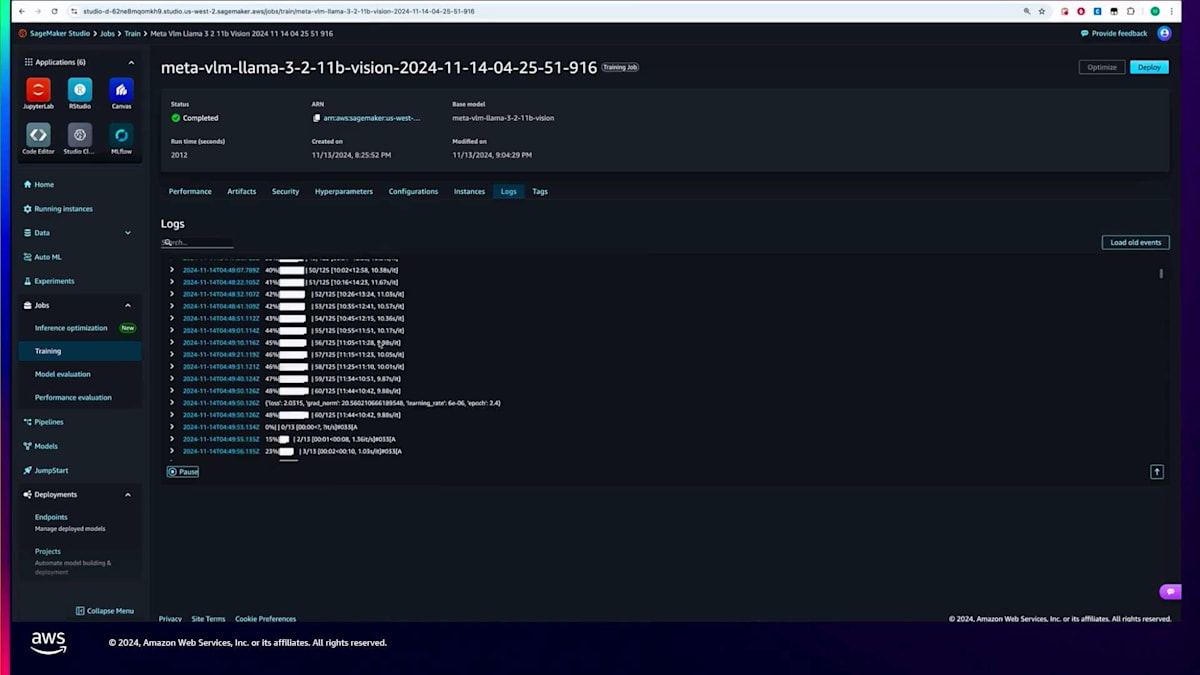

そのランのハイパーパラメータも確認できます。このジョブは4~5エポック実行されました。また、ジョブに使用された実際のインスタンスやトレーニング実行ログも確認できます。これらのログはCloudWatchで利用可能ですが、SageMaker Studioに直接取り込むこともできます。
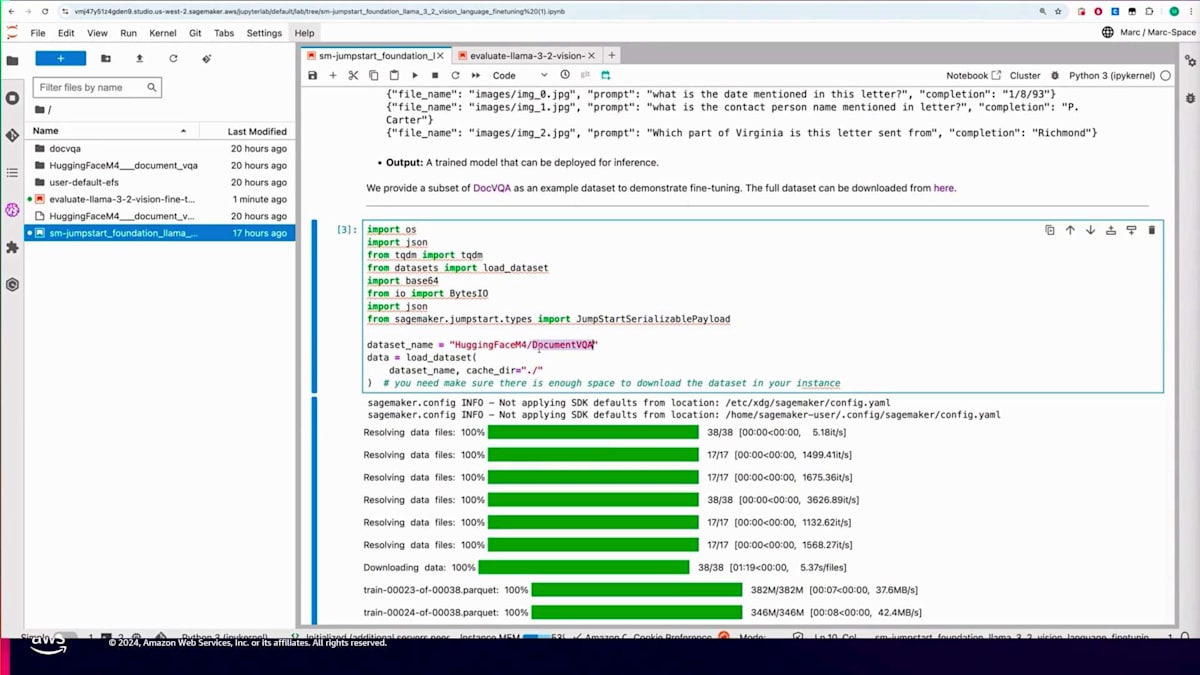

これまでStudio UIでの操作をご紹介しましたが、SageMaker Python SDKを使用してFine-tuningを行うこともできます。同じトレーニングジョブをプログラムで実行する方法をノートブックを使って説明していきましょう。ノートブックの冒頭では、110億パラメータのVisionモデルのModel IDを設定します。 その後、DocVQAデータセットをローカルにダウンロードし、先ほど説明したメタデータJSONファイルを作成します。

すぐにお見せしますが、こちらがそのためのコードです。トレーニングデータとして1000個の例と、バリデーション用に約20個の例を使用します。メタデータJSONファイルがどのようなものか見てみましょう。このファイルには、 DocVQAデータセットの実際の画像への参照が含まれており、Fine-tuningに必要なプロンプトや質問、そして正解となる回答が記載されています。画像フォルダには、メタデータJSONファイルが参照する実際の画像が格納されます。


1000個の例を使用しましたが、必要に応じて増減することも可能です。これが完了したら、 データセットとメタデータJSONファイルをS3にアップロードする必要があります。アップロード後、JumpStartによってこのモデル用に設定されたデフォルトのハイパーパラメータを確認できます。今回の場合、エポック数を5に上書きし、ハイパーパラメータを検証した後、JumpStart Estimatorを作成します。ここで、Model ID、インスタンスタイプ、ハイパーパラメータ、そして重要なポイントとして、S3上のトレーニングデータセットの場所をfitメソッドに渡します。その後、トレーニングジョブが実行され、完了します。

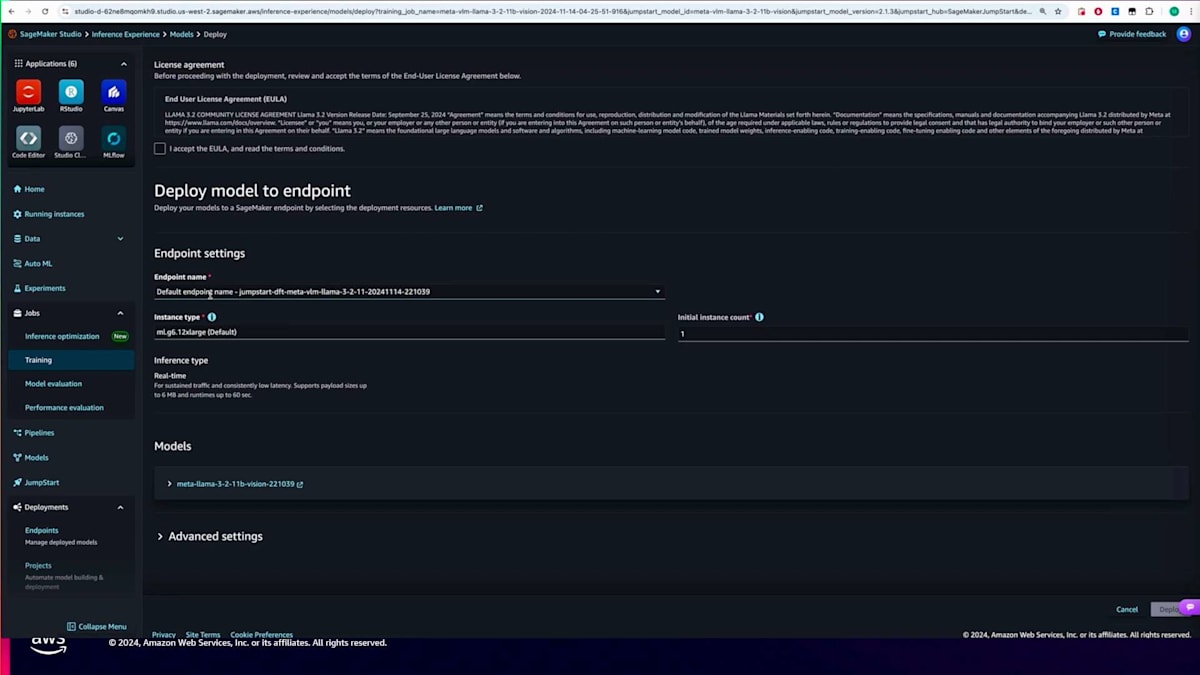

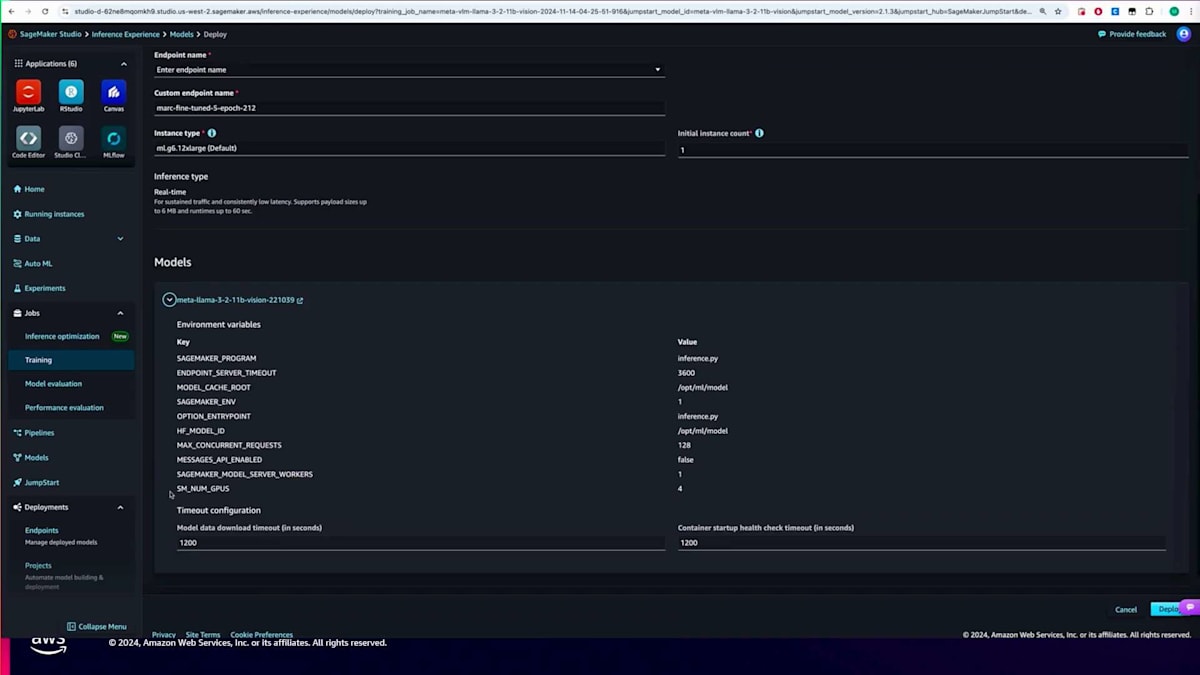
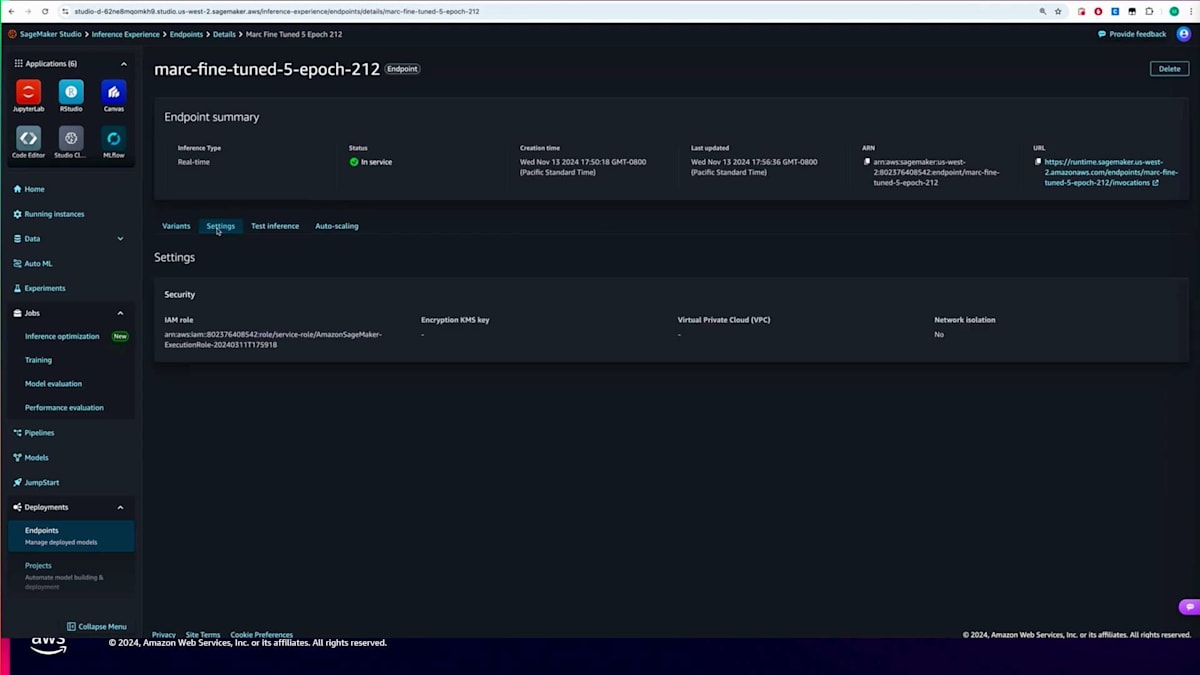
モデルのデプロイもdeployメソッドを使用してプログラムで行うことができます。ただし、今回はUI経由でデプロイしてみましょう。トレーニングジョブが完了したら、単純にデプロイをクリックします。デプロイをクリックすると、エンドポイントの設定詳細が表示されます。エンドポイント名やインスタンスタイプを設定し、利用規約に同意します。今回の場合、JumpStartが自動的にデプロイに必要な設定、コンテナ、環境変数をすべて設定してパッケージングしてくれるので、デフォルトのままデプロイをクリックするだけで大丈夫です。エンドポイントが起動して実行状態になれば、モデルを呼び出して推論を実行することができます。
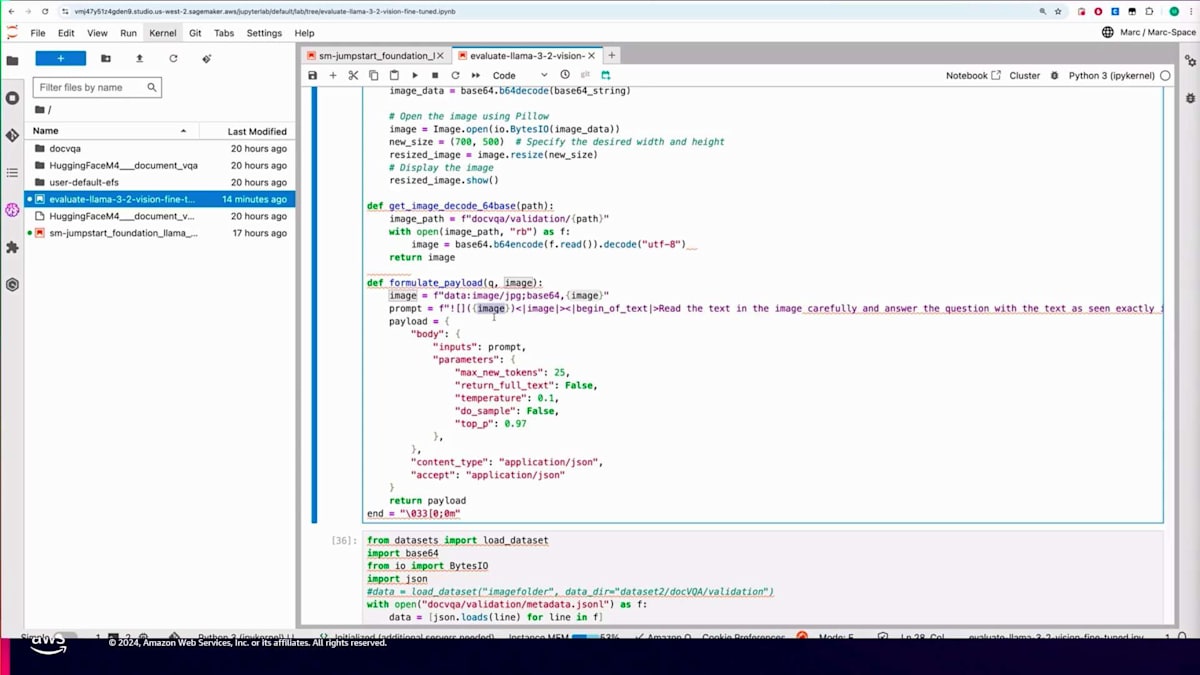
その方法を示すために、SDKを使用してプログラムで実行する方法を見てみましょう。こちらがSageMakerエンドポイントを呼び出すコードです。ここでは、バリデーションデータセットから画像をBase64エンコードされた形式で取得し、プロンプトを作成しています。
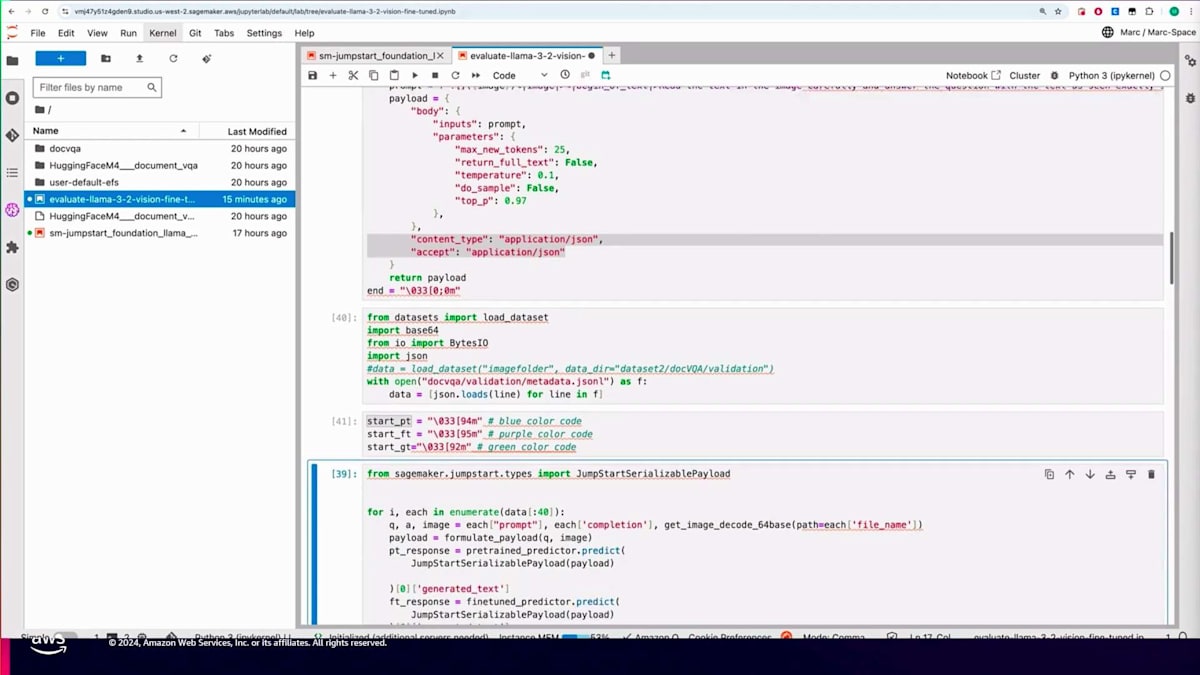
次に、モデルに対して、画像内のテキストを注意深く読み、画像に表示されている質問に正確に答えるよう指示を出します。また、簡潔な回答を促すための追加指示も含めます。その画像に対する質問を入力し、モデルから回答を得ることを想定しています。推論用のペイロードには、入出力ともにapplication/jsonを含む複数のパラメータを設定します。
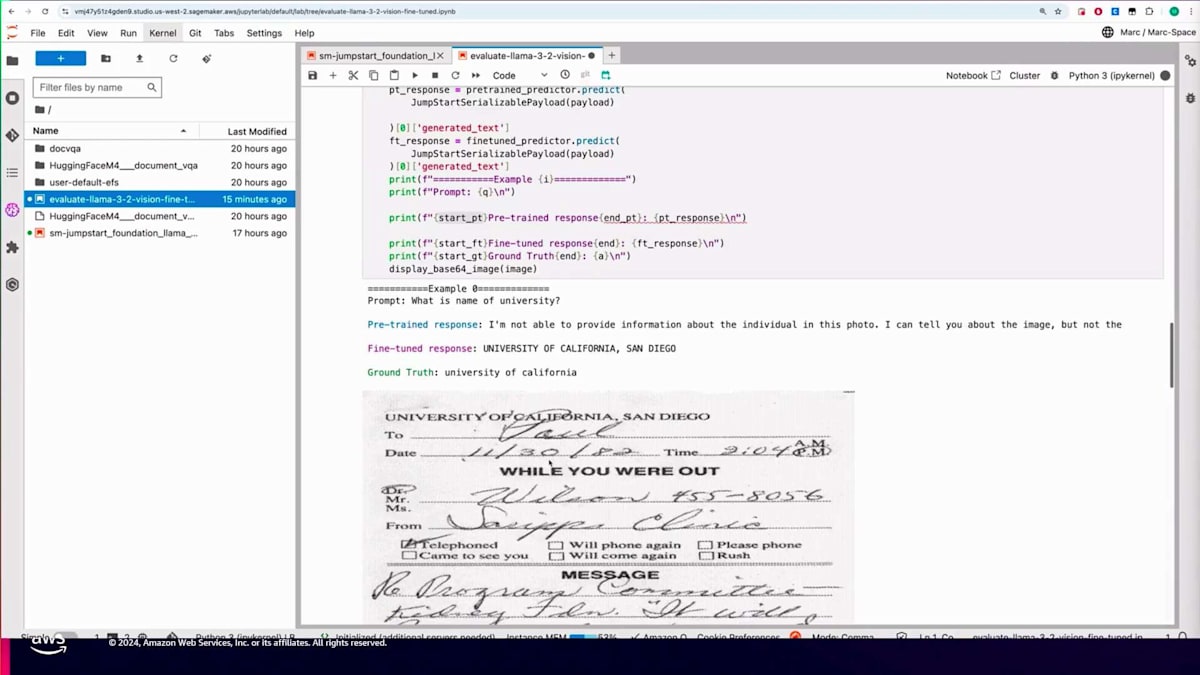
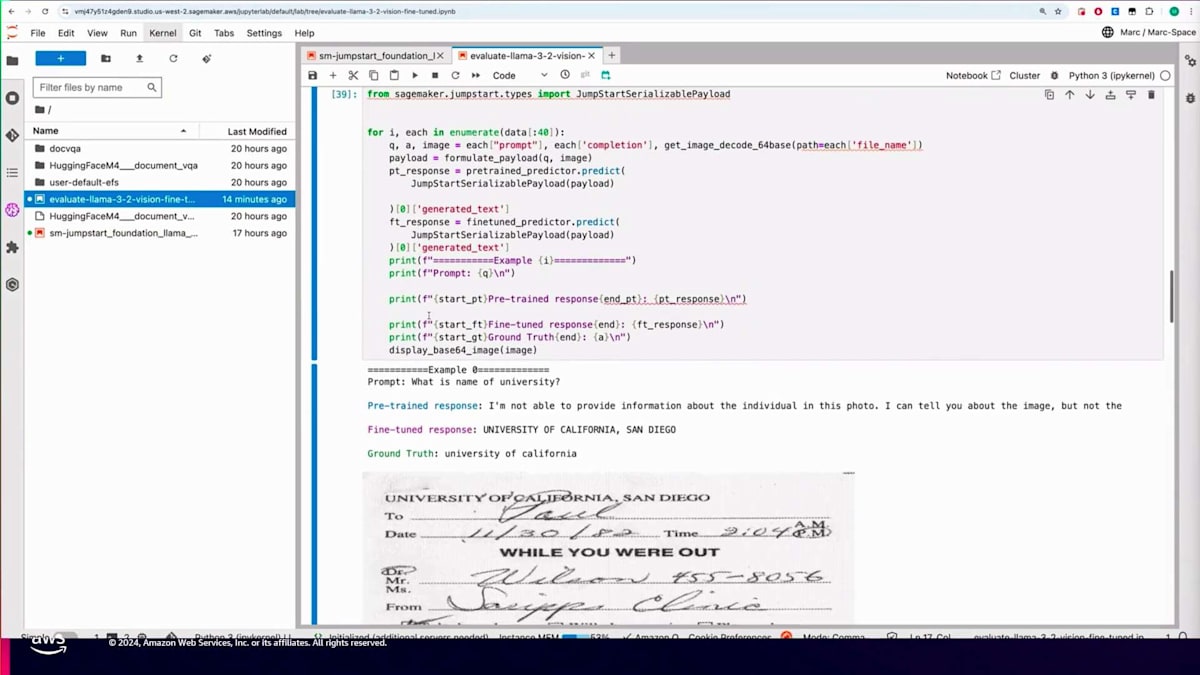
先ほど作成した検証用データセットを読み込み、predicted.predictメソッドを使用して5つほどの例を実行してみます。また、比較のために事前学習済みのモデルもデプロイしています。例えば、「大学の名前は何ですか?」という質問に対して、答えは明らかにUniversity of Californiaです。事前学習モデルはこれを特定できませんでしたが、Fine-tuningを施したモデルは正しい答えを提供できました。
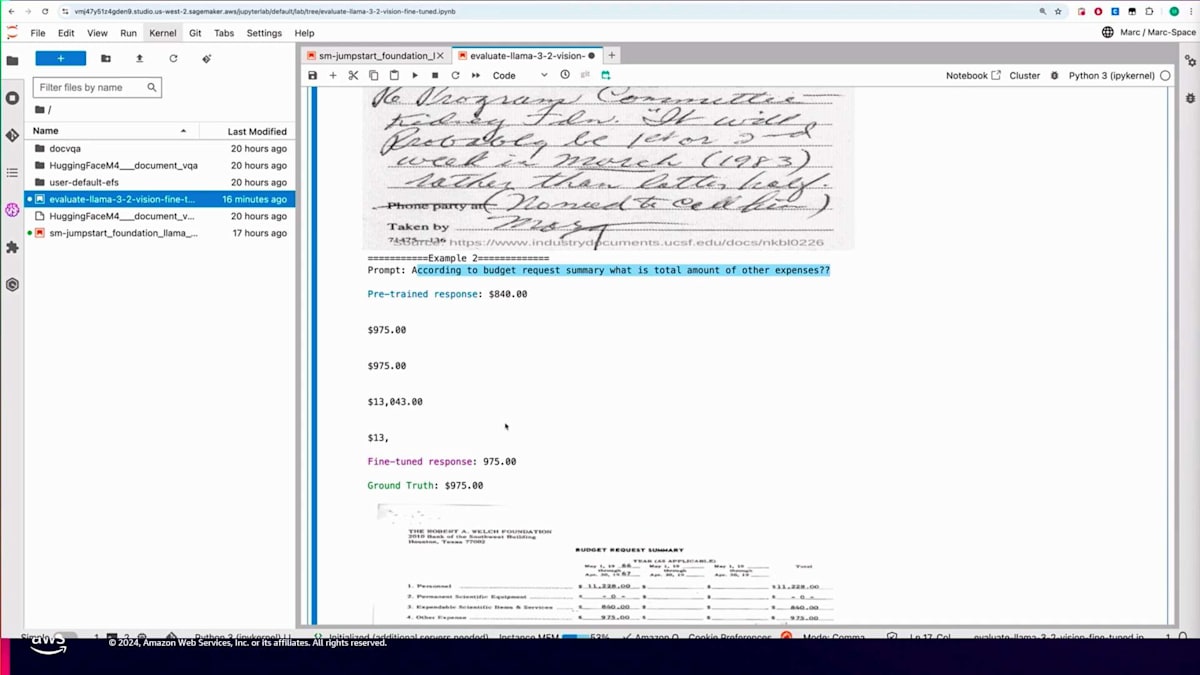
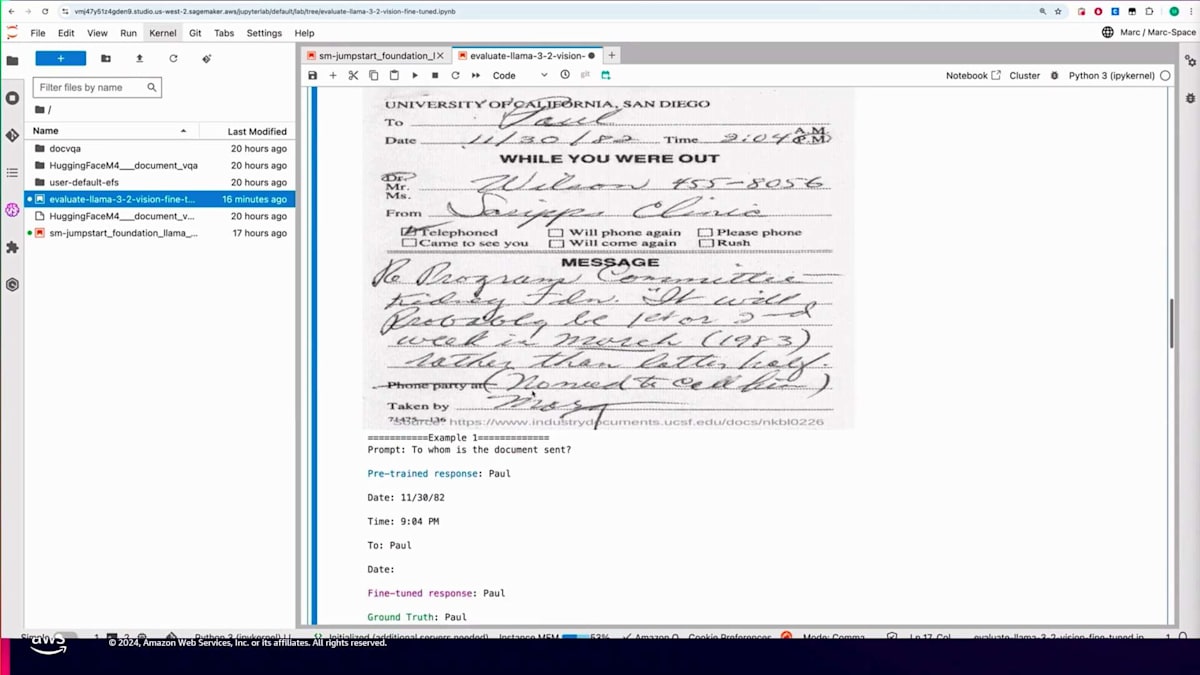
もう一つ興味深い例として、「このドキュメントは誰に送られていますか?」という質問があります。同じドキュメントを見ると、Paulであることがわかります。事前学習モデルは答えを得られましたが、不要な詳細情報も含んでいました。一方、Fine-tuningモデルは正確に特定できました。次の例は印刷された文書またはフォームに関するものです。予算申請概要によるその他の経費の合計額について尋ねたところ、答えは975ドルです。事前学習モデルは金額に言及しましたが、正確に抽出できませんでした。一方、Fine-tuningモデルは正確な金額を抽出することができました。
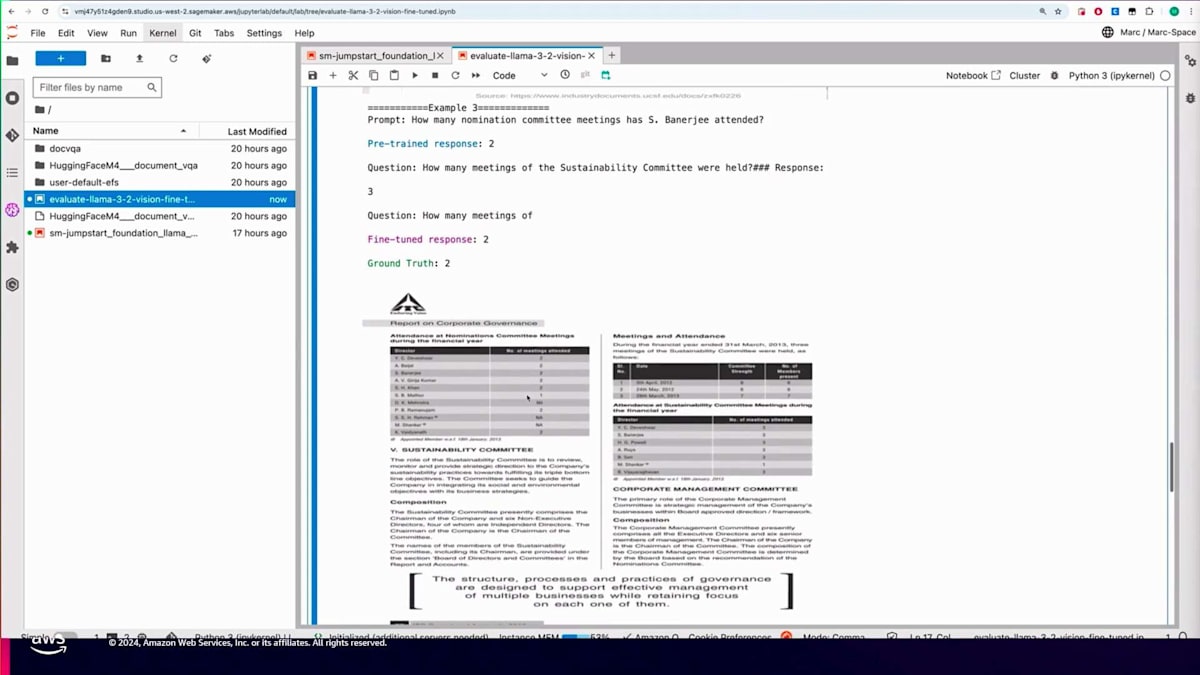

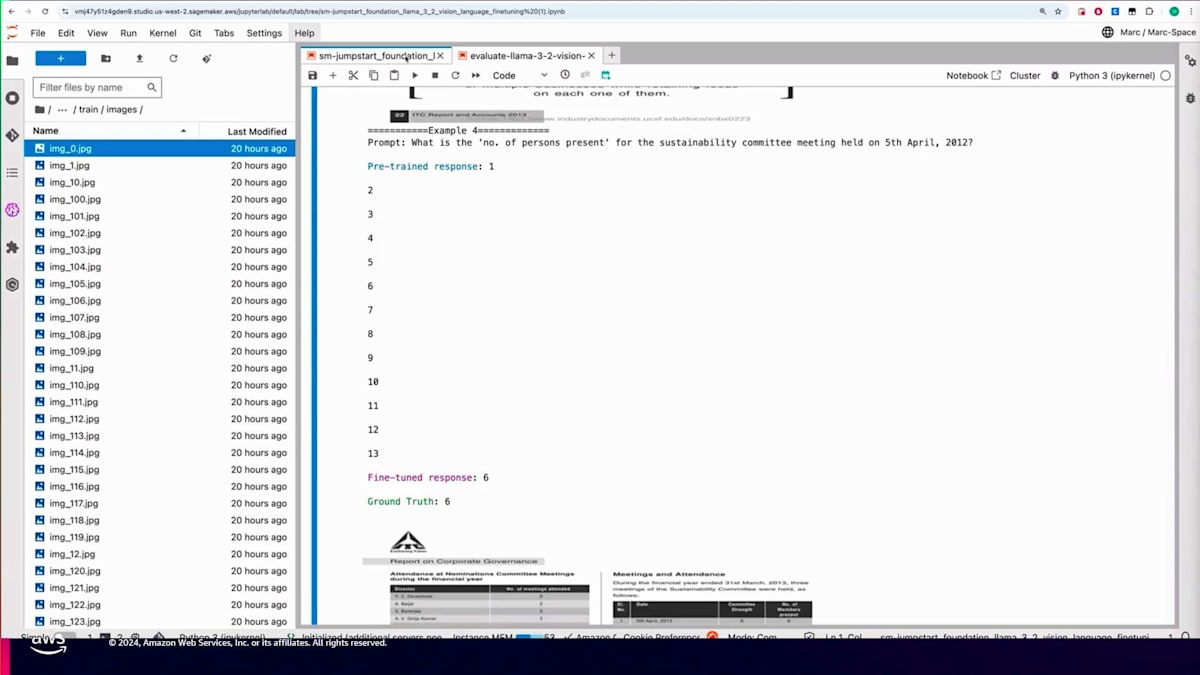
別の例を見てみましょう。「S. Banerjeeは何回のNomination Committee meetingsに出席しましたか?」という質問に対して、画像をよく見て情報を理解すると、S. Banerjeeは2回の委員会に出席したことがわかります。事前学習モデルは正しい数字を挙げましたが、その後質問を繰り返してしまいました。一方、Fine-tuningモデルは正確な回答を提供しました。最後の例として、4月5日に開催されたSustainability Committeeの出席者数について尋ねました。その日付の部分を拡大すると、答えは6人であることがわかります。事前学習モデルは不必要なカウントを始めましたが、Fine-tuningモデルは正しい結果を抽出することができました。

このように、画像やドキュメントの理解度が大幅に向上していることがわかります。独自の文書やフォームを持つ組織では、事前学習モデルがそれらの資料に特化して学習されていないことがよくあります。これは、これらのモデルのFine-tuningが不可欠である理由を示しています。以上で終わりですが、さまざまなFoundation Modelの提供に関する情報が含まれているSageMaker JumpStartの製品詳細ページなど、利用可能なリソースをぜひ探索してください。優れたサンプルリポジトリもあり、このデモで示したようにLLaMA 3.2モデルをFine-tuningしたい場合は、最近公開されたブログを参照することができます。
Intuitの紹介とQuickBooksにおける取引分類の課題

それでは、SageMakerでのFine-tuningに関するIntuitの取り組みについて、興味深い詳細をご紹介させていただきます。皆様、こんにちは。Mary Kenと申します。IntuitのDistinguished Engineerとして、Intuitの製品における従来型AIとGenerative AI両方のワークロードをサポートするAIプラットフォームを率いています。 ユースケースの詳細に入る前に、Intuitについてご紹介させていただきます。Intuitのストラテジーは、AI駆動型のエキスパートプラットフォームになることです。私たちのミッションは、世界中の繁栄を支援することです。このストラテジーの一環として、1億人の中小企業、個人消費者、中堅企業のお客様に向けて、より多くの収益を上げ、より少ない労力で時間を節約し、完全な自信を持って財務上の意思決定ができるようなプラットフォームを開発したいと考えています。
私たちは製品体験を強化するためにAI機能を活用してきました。QuickBooksやTurboTaxをご存知の方もいらっしゃるかもしれません。いくつか例をご紹介します。QuickBooksでのレシートからの自動データ抽出、QuickBooksでのキャッシュフロー予測、そしてTurboTaxへのW-2や1099からの自動データ入力などがあります。

2023年9月、私たちはIntuit Assistをローンチしました。これは、TurboTax、Credit Karma、QuickBooks、Mailchimpといった製品ポートフォリオ全体にわたる、Generative AI搭載の金融アシスタントです。 こちらが私たちのプラットフォームの概要です。データレイクには95ペタバイトのデータがあり、毎日600億件のMachine Learning予測を生成しています。消費者向けに6万の属性、中小企業向けに約58万の属性があり、これらはお客様が共有してくださったデータで、製品体験をパーソナライズすることを可能にしています。私たちはGenerative AIを積極的に取り入れ、エンジニアがIntuit Assist体験を開発できるよう、プラットフォーム上で10以上の言語モデルを提供しており、その結果、月間1,200万件のインタラクションが生まれています。
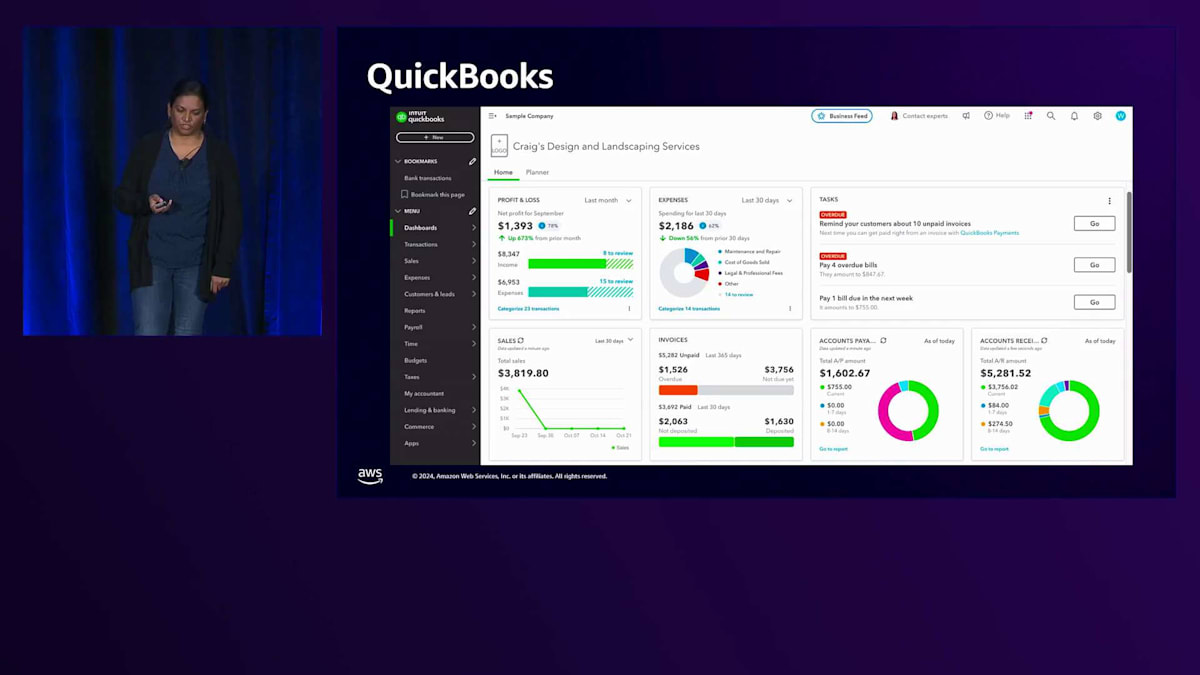
では、Fine-tuningのユースケースについてお話ししましょう。そのために、まずQuickBooksについてご紹介する必要があります。QuickBooksは北米における中小企業向けの主要な財務管理ソリューションです。世界中で700万以上の中小企業がQuickBooksを利用しています。ここに表示されているのはQuickBooks企業のホームページです。中小企業のオーナーとして、QuickBooksをセットアップし、銀行口座を接続すると、取引フィードの取り込みが始まります。取引の分類を開始すると、バックグラウンドで会計処理が行われ、QuickBooksが財務レポートを生成します。画面には、QuickBooksが分類・会計処理した取引から得られる財務状況に関するインサイトを提供するダッシュボードが表示されています。過去30日間の損益、経費、売上、そして最新の買掛金と売掛金のスナップショットを確認することができます。
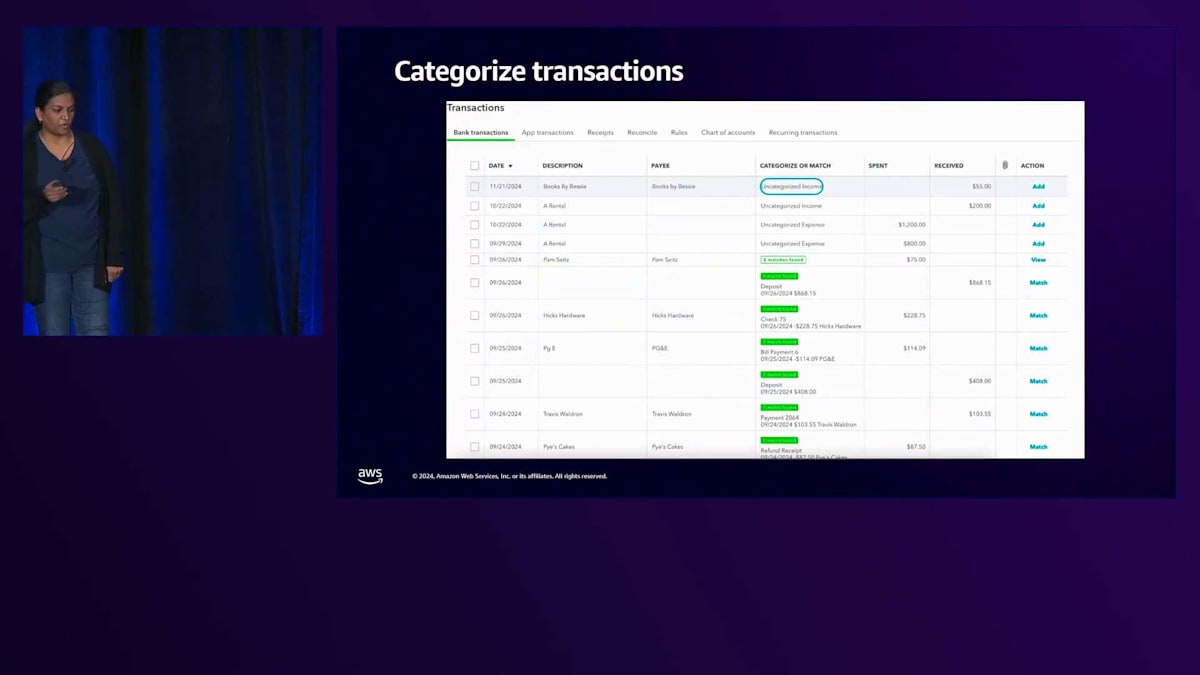
これは魔法ではありません。取引フィードの取り込みからQuickBooksによる会計処理の生成までの間には、重要なステップが1つあります。それが取引の分類です。 取引の分類とは何かをお見せしましょう。この画面には取引のリストが表示されています。上位4件に注目してみましょう。1件目は11月21日のBooks by Bessieで55ドルです。もしこれが実際にビジネスの売上取引であれば、正しく会計処理する必要があります。未分類の収入のままにはできないので、これがビジネスの収益であることを示すために「売上」に変更します。同様に、3件目と4件目の取引は9月と10月の賃貸に関する経費です。中小企業のオーナーとして、これらが実際にオフィススペースや機器のレンタルに関する経費である場合、税控除の対象となる可能性があるため、「賃貸経費」として正しく分類する必要があります。
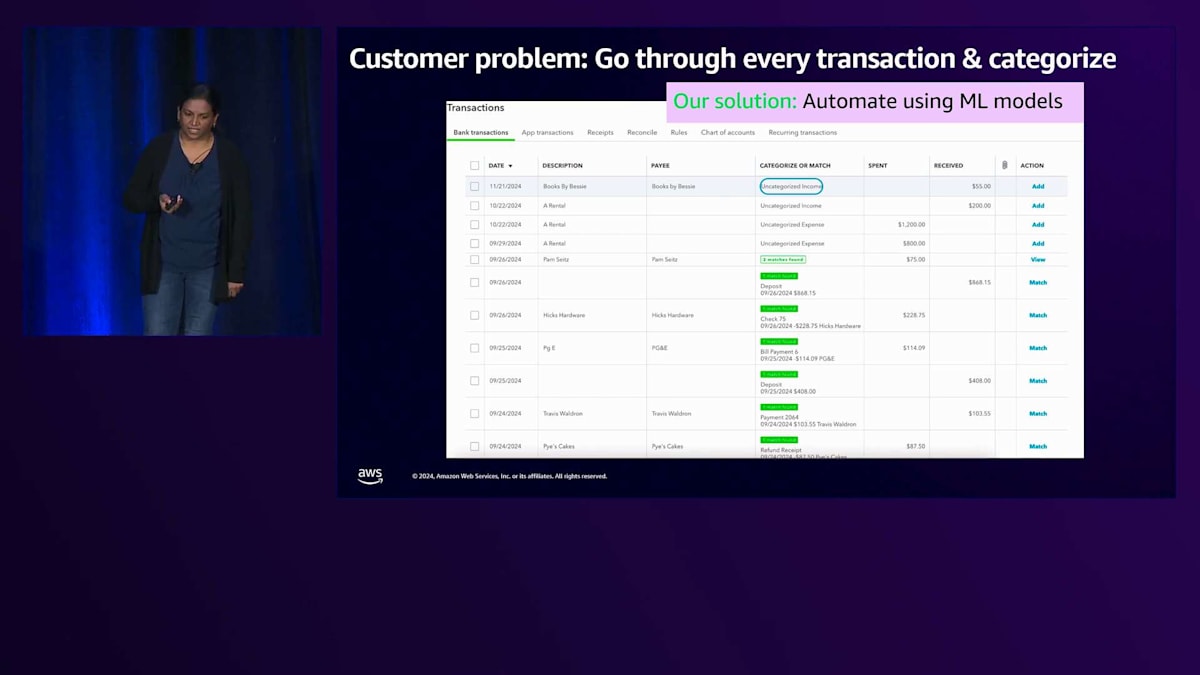
お客様が直面している問題をご説明します。すべての取引を一つ一つ確認し、手作業で分類していくのは、非常に時間のかかるプロセスです。小規模企業が成功して事業が拡大すると、毎週何百、場合によっては何千もの取引を分類する必要が出てきます。本来ビジネスに集中すべき時間を、この作業に何時間も費やすことになってしまいます。しかし、もうそんな心配は不要です。QuickBooksは、取引の分類をできるだけ簡単にするため、この分野で継続的にイノベーションを行ってきました。何年も前から、Rule-basedシステムを導入し、小規模企業のオーナーが特定の取引タイプや支払いタイプのパターンに基づいてルールを作成できるようにし、QuickBooksが自動的に分類を行えるようにしました。ただし、このルールは手動で作成する必要があり、面倒な作業です。また、取引先が多い場合は、依然として時間のかかる作業となってしまいます。現在本番環境で稼働している最新のソリューションは、従来型のMLをベースにしており、過去の取引分類の履歴に基づいてカテゴリを予測します。

まず、なぜこれが難しい問題なのか、背景を説明させていただきます。お気づきかもしれませんが、これはn-クラス分類問題です。小規模企業には、取引を割り当てる必要のあるnカテゴリが存在します。
この分類が特に難しい理由は、この要件が小規模企業特有のものであり、私たちにはサービスを提供する何百万もの小規模企業があるからです。小規模企業が会計を行う方法には大きなばらつきがあり、それぞれの企業が独自の方法でQuickBooksを使用しています。また、小規模企業は非常にダイナミックで流動的なエコシステムであり、その会計ニーズもそれを反映しています。事業の拡大や縮小、従業員の採用や解雇、新しい地域への展開に伴う給与関連費用や税控除の発生、さまざまな市や郡、州での新しい種類の売上税率の導入など、会計の方法を変更する必要が出てきます。
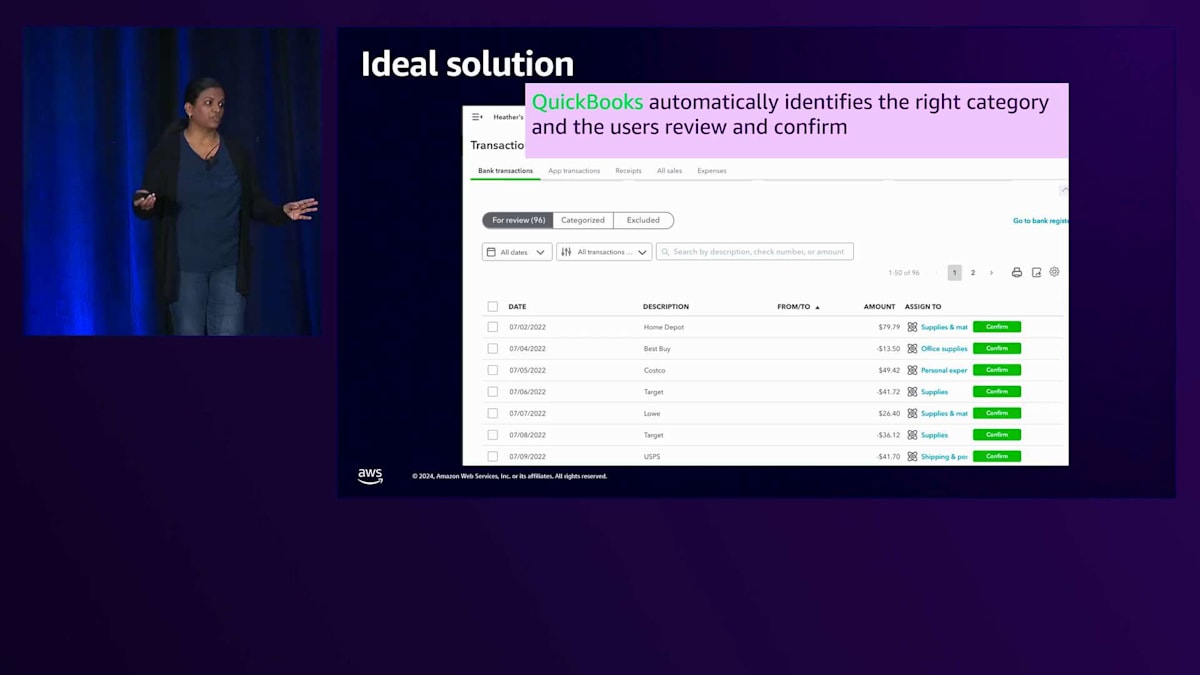
言うまでもありませんが、歯科医院の会計方法は、造園業の会計方法とは全く異なります。過去に分類された取引をGround Truthとして使用し、これらのモデルを訓練して将来の取引を予測することができると考えるかもしれません。しかし、ここでの課題は、実際にプロの会計士を雇って帳簿を整理している小規模企業のユーザーは一部に過ぎないため、ラベル付きデータの品質が問題となることです。 理想的なソリューションは、QuickBooksがお客様のビジネスの詳細を自動的に理解し、入ってくるすべての取引の意図と目的を理解して、適切なカテゴリを自動的に識別することです。ユーザーは選択された内容を確認するだけでよく、取引のリストを一つ一つ確認する代わりに、さっと目を通して確認するだけで済むようになります。
IntuitによるLLMを活用した取引分類の改善:SageMakerの活用と成果

これが私たちの現在のソリューションです。お約束通り、共有させていただきます。私たちは、従来型MLベースのPopulationモデルと多数のPersonalizedモデルを組み合わせて使用しています。顧客データのみに依存している場合、訓練に使用できるデータには限りがあるため、ソリューションの精度向上には限界がありました。モデルアーキテクチャはとてもシンプルなので、かなり前から精度は改善していません。モデルアーキテクチャが小規模なため、汎用性が低くなっています。実際、取引の分類のために小規模企業ごとに1つのPersonalizedモデルを持っており、本番環境で継続的にメンテナンスしている約400万のモデルが運用上のオーバーヘッドとなっています。先ほど述べたように、Ground Truthとなる高品質なデータの確保が大きな課題であり、これらのモデルを継続的に訓練して維持するためには、大量のデータが必要となります。

このような背景を踏まえ、Large Language Modelは、この問題領域へのアプローチに全く新しい方法を提供してくれました。LLMは非常に柔軟で汎用性が高いため、小規模なモデルアーキテクチャに合わせてデータを加工することをそれほど気にせずに、様々なデータソースを活用して問題を定式化することが格段に容易になりました。もちろん、LLMは会計や様々な業種、ビジネスタイプなど、世の中のことを広く理解しているため、そうした知識が非常に役立ちました。私たちは最初に、商用のLLMを使ってプロンプトエンジニアリングのテストを行い、様々なデータセットで検証を進めました。その結果、精度の向上が見られ、これは非常に興味深い発見でした。というのも、それまでのシステムでは精度向上の限界に達していたからです。

チームは大いに興味を持ち、Few-shotサンプル、Chain of Thoughtによる推論サンプル、業界情報、そして分類方法に関する過去のデータなど、様々なデータセットの組み合わせを試し始めました。しかし、その後、商用LLMの限界に直面し始めます。コンテキストウィンドウのサイズ、レイテンシーの増加、そしてスケールの課題に遭遇したのです。そこで私たちは、カスタマイズの選択肢がより多いOpen Weightsモデルの評価にフォーカスを移しました。私たちの目標は、数百万の小規模ビジネスのお客様向けに、取引を分類することに特化したモデルを構築することでした。これは、特定のタスクのためにFoundation Modelをファインチューニングするという、私たちにとって新しいシナリオでした。そのため、初期の課題の一つは、このアプローチの実現可能性の証拠を集めることでした。これには、さらなる投資のための戦略的方向性を示すための多くの実験が含まれていました。
このアプローチが正しいという確信が得られた後、次の課題は、毎週のように登場する様々なモデルの評価を行い、ファインチューニングするモデルを絞り込むことでした。また、多くのステークホルダーに最新情報を提供する必要があり、テストすべきアイデアも多数あったため、スピーディーに進めることが重要でした。

チームは、迅速な実験と素早い意思決定というアプローチを強化し、すべてのアイデアを体系的にテストし、有望でないものを排除し、最良のものをさらに改良することに注力しました。

ここで、Amazon SageMakerが私たちの取り組みを大きく加速させました。チームは、SageMakerが提供するボイラープレートコードとインフラストラクチャツールを積極的に活用し、初期のモデル評価を加速させました。チームがデータパイプラインを構築すると、ファインチューニングするベースモデルを選択するための実験を素早く実行できるようになりました。また、SageMakerは最新のモデルを安全に探索できるサンドボックス環境を提供してくれます。これは、顧客データを扱う際の責任あるAIとデータガバナンスの基準を満たすために重要です。Continuous Trainingの機能により、データの層を様々に組み合わせた実験を、一つの実験を別の実験の上に重ねる形で実行することができました。まとめると、私たちは数週間のうちにLoRAを使用して10以上のモデルをファインチューニングし、現在はSageMakerが提供するInferenceソリューションを使用して、数百万の顧客向けにホスティングをスケールアウトする作業を進めています。
以前お話ししたように、従来のMLベースのシステムには3つの主な課題がありました。精度が向上しない、本番環境で数百万のモデルを維持する運用の複雑さ、そして真実データの不足です。嬉しいことに、Fine-tuningを施したモデルが初期段階で良好な結果を示し、大規模な本番環境での使用が期待できる状況です。異なるユーザー層において5~10%の精度向上が確認できています。従来のMLシナリオでは、モデルの学習に数百万のサンプルが必要でしたが、LLMsでは数千のサンプルで済みます。先ほど述べたように、私たちは小規模企業ごとに400万の個別モデルを運用していますが、Fine-tuningされたモデルでこのソリューションを置き換えることで、運用の複雑さを軽減できる可能性があります。さらに、SageMakerは費用対効果の高い推論オプションを提供しているため、大規模な展開が可能です。これはIntuitで特定のタスクに対してFine-tuningされたFoundation Modelを提供する最初のユースケースの1つであり、今後の道筋を切り開くものとなっています。データパイプラインが整備されたことで、チームは新しいモデルが利用可能になった時点で評価を行うことができ、開発の速度を上げることができます。

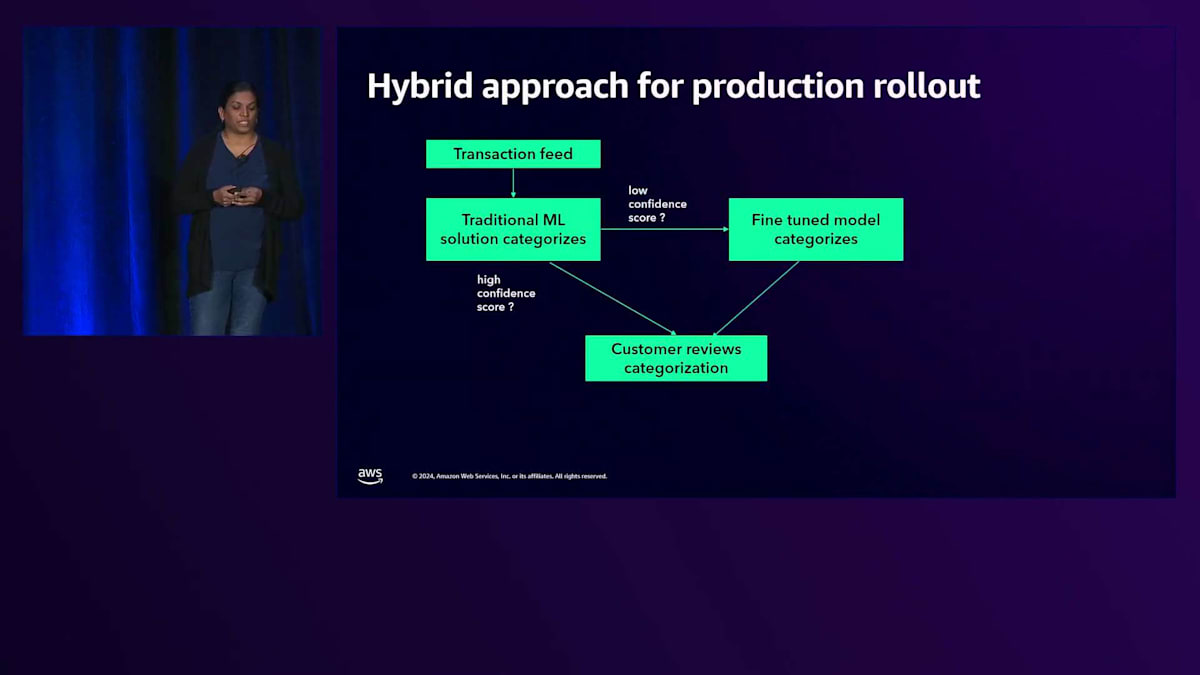
このソリューションは以下のように展開していく予定です。既存のソリューションを完全に置き換えるのではなく、Hybridアプローチを採用し、段階的な展開を行います。まず既存のソリューションでカテゴリ分類を行い、信頼度スコアを生成します。信頼度スコアが高ければ追加の処理は不要ですが、低い場合はFine-tuningされたモデルを使用してカテゴリ分類を行います。カテゴリ分類が生成されたら、お客様のレビューに送ることができます。
最後に、このユースケースから得られた学びをいくつか共有させていただきます。小規模企業ごとに会計実務が異なるため、精度の基準を満たすには数千のサンプルを含む大規模なデータセットが必要でした。一般的にFine-tuningには数百のサンプルで十分と言われていますが、この特定のケースではそうではありませんでした。また、幅広いシナリオをカバーするには実際の顧客データが必要だったため、Synthetic dataは役に立ちませんでした。Fine-tuningにより、推論に大量のコンテキストデータが必要な顧客体験に求められる精度、レイテンシー、スケールを管理することができました。私たちの経験では、適切なユースケースと適切なデータセットがあれば、Fine-tuningはLLMsを試すための費用対効果の高い方法です。この新しい分野で素早く学び、方向転換し、アイデアを洗練させて反復するため、私たちは迅速な実験を重視するアプローチを採用しました。このユースケースはIntuitにおけるタスク特化型Fine-tuningの道を切り開くものであり、今後さらに多くの展開を期待しています。以上で発表を終わります。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion