re:Invent 2024: AWSのデータストリーミング最新機能 - MSK Express Brokers他
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - What’s new: Data streaming on AWS (ANT327)
この動画では、AWSのストリーミングサービスの最新情報について、パフォーマンス、コスト、可用性、使いやすさの4つの観点から解説しています。特に注目すべきは、Amazon MSKの新機能であるExpress Brokersで、Apache Kafkaと比較して3倍のスループットと20倍速いスケーリングを実現しました。また、Verizonの事例では、自己管理型KafkaからAmazon MSKへの移行により、1日10億件のトランザクションを処理する環境で、データ損失を5-10テラバイトから0.01%未満に削減できた具体的な成果が示されています。Amazon Data FirehoseやManaged Service for Apache Flinkなど、他のストリーミングサービスの新機能についても、実用的なユースケースとともに紹介されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
AWSのData Streamingセッション:概要と進行

こちらはAnalytics 327、AWSのData Streamingの最新情報についてのセッションです。私はAshish Palekarと申します。AWSでManaged KafkaとManaged Serviceを担当しており、お客様とお話しして、どのようなことを実現したいのかを理解し、適切な品質基準で最適な製品や機能を提供できるよう努めています。本日は皆様とお話しできることを大変嬉しく思います。後ほど、MSKチームのPrincipal Software EngineerであるAnusha Dasarakothapalliが登壇します。そして、VerizonのAssociate DirectorであるVidyasagar Kammaにもお話しいただく予定です。

セッションの進め方についてご説明します。まず、ポートフォリオについて簡単にお話しし、Streamingで重要と考えている点について説明します。これにより、私たちが何をどのように機能をリリースしているのかについての考え方をご理解いただけると思います。次に、重要と考える観点からStreamingポートフォリオ全体での主要なリリース内容についてお話しし、その後、Streamingをご利用のお客様からお話を伺います。本日は盛りだくさんの内容となっていますので、セッションの最後に質疑応答の時間を設けています。
Streamingデータ技術の重要性とAWSのポートフォリオ

皆様がこのStreamingセッションにお越しいただいた理由は、Streamingデータ技術が現在、組織に大きな価値をもたらすからだと思います。これは、お客様が4つの異なるモデルに着目されているからです。リアルタイムですべてのデータを活用したい、最適化とコスト削減を実現したい、より迅速な洞察とより良い分析で意思決定を改善したい、そしてシステムを最新の状態に保ち同期を取りたい、というものです。これらはすべて、お客様がStreamingデータ技術を活用される重要な理由となっています。

時間とともにデータの価値が低下していく中で、これらのニーズに対応するため、AWS内には一連の技術が用意されています。私たちはこれを取り込み、保存、処理、そして技術の接続という観点で考えています。取り込みと保存については、Amazon Kinesis Data Streams(KDS)とAmazon Managed Streaming for Apache Kafka(Amazon MSK)があります。ストリーム処理については、Amazon Managed Service for Apache Flink(MSF)があります。エンドツーエンドのStreamingやソースとデスティネーションの接続には、Amazon Data FirehoseとAmazon MSK Connectがあります。

これらのStreamingサービスは、幅広いお客様にご利用いただいています。重要な点や構築すべき機能についてご意見をいただき、フィードバックを提供していただき、全般的にサービスの方向性を形作るのを助けていただいている、これらのお客様をはじめとする多くのお客様に、心から感謝申し上げます。お客様のご協力なしには、ここまで来ることはできませんでした。
Mercado Libreの事例とストリーミングサービスの4つの利用パターン

ここで、実際のお客様の事例として Mercado Libre をご紹介したいと思います。ご存知ない方のために説明しますと、Mercado Libre は南米最大級のEコマース企業の一つです。彼らが直面していた課題は、1分間に3,000万件の受信メッセージと5,000万件の送信メッセージを管理することでした。また、支払い、商品、配送に関する17,000のデータベースを処理し、それらが1秒以内に目的地に到達することを保証する必要がありました。この課題を解決するため、彼らは社内プラットフォームである Fury に Amazon Kinesis Data Streams を統合しました。Fury により、データを取り込み、その周りにシステムを構築し、複製し、開発者が容易に統合できる統一されたインターフェースを提供することが可能になりました。これにより、決済、商品管理、配送、認証、不正検知、機械学習、分析など、あらゆるワークフローをリアルタイムで処理できるようになりました。その結果、SLAの稼働時間を6ナインにまで向上させ、リージョン間で一貫性のある信頼性の高いデータレプリケーションを顧客に提供することができました。

Mercado Libre の事例は、私たちが顧客に見られるパターンの一つを示しています。 実際、お客様がストリーミングサービスを利用する方法は4つあります。1つ目は、リアルタイム分析です。これは、リアルタイムで入ってくるデータを処理して結果を得るために使用されています。2つ目は、リアルタイムデータ変換で、入力データをフォーマット変換したり、エンリッチメントしたりします。3つ目は、データレイクへの取り込みで、より広範なデータレイクにデータを取り込んで活用します。そして最後に、イベント駆動アーキテクチャでの活用です。

この12-18ヶ月の間、 ストリーミングワークロードがビジネスにとってますますミッションクリティカルになってきていることに気付き始めています。これは先ほどの Mercado Libre の例とも一致しており、この後 Saga が説明するように、ワークフローが時間とともに進化し変化していく中で重要な意味を持っています。

ストリーミングにおいて、ミッションクリティカルとは何か、お客様にとって重要なものは何かを考えると、4つの要素が挙げられます。1つ目はパフォーマンスです。特に、スケーリング単位あたりのパフォーマンスと、全体的なユニット数が重要で、当然ながら高いパフォーマンスが求められます。2つ目はコストです。ソリューション全体のコストを考える必要があり、言うまでもなく低いほど良いです。3つ目は回復力です。可用性がどの程度か、そして回復力のあるアプリケーションをどれだけ簡単に構築できるかということです。そして最後は使いやすさです。価値実現までの時間、統合のしやすさ、運用のしやすさが、お客様にとって非常に重要です。


このセッションでは、これらすべてについて説明します。Anusha が可用性と使いやすさに焦点を当て、私が最初の2つを担当します。 その理由は、パフォーマンスとコストが密接に関連しているからです。コストを一定に保ちながらパフォーマンスを向上させることも、パフォーマンスを一定に保ちながらコストを改善することも可能です。
Amazon MSKのExpress Brokersがもたらす革新

まずはパフォーマンスとコストについてお話しします。つい最近、Kinesis Client Library KCL 3.0をリリースしました。これは新しいコンシューマーライブラリです。KCL 3.0以前は、データを処理する際にEC2インスタンスの使用率にばらつきがあり、高負荷のインスタンスと低負荷のインスタンスが混在する状況でした。つまり、処理の分散が適切に行われていなかったのです。その結果、クライアント側ではピーク時に合わせてインスタンスをプロビジョニングする必要がありました。KCL 3.0では、これらのインスタンス間でワークロードがより均等に分散されるようになり、情報処理に必要なCPU数を削減できるようになりました。私たちの分析では、これによって計算コストを削減でき、お客様によっては最大30パーセントのコスト削減が可能となっています。さらに、Java 2.xのサポートにより、パフォーマンスも向上しています。


Apache Flinkをご利用のお客様向けに、最近重要な変更を行いました。これまでは1時間単位の課金を行っていたため、15分の使用でも1時間分の料金が発生していました。今後は15分の使用に対して15分の料金のみが発生します。10分を最小単位として、1秒単位の課金に移行しました。料金自体は変更ありません。同じ時間単位の料金を1秒単位で適用するだけです。1時間の境界にとらわれないジョブを実行しているApache Flinkユーザーにとっては、請求額の直接的な削減につながります。



パフォーマンスとコストについて話している中で、時にはこれら4つの特性すべてに同時に影響を与えるような機能をリリースする機会があります。それがAmazon MSKのExpress Brokersです。11月にリリースしたこの機能については、お客様にとって何ができるのかとても期待しています。では、Express Brokersの誕生秘話についてお話ししましょう。私たちはKafkaを愛しています。

このサービスチームでは、Amazon MSKとして5年以上にわたってKafkaを運用してきました。大規模、中規模、小規模など、さまざまな規模のワークロードを運用し、幅広いワークロードに対応してきました。私たちは常に、AWSでKafkaをより良く動作させる方法を模索してきました。チームは、より良い方法や異なるアプローチを見つけるためにさまざまな試みを重ねてきました。


最初のステップは、外部パートナーと協力して開発したティアードストレージでした。2022年10月にリリースしたティアードストレージでは、ローカルとリモートの両方のストレージを作成することができました。リモートストレージはブローカー間で共有され、特定の特性を実現するのに役立ちました。具体的には、データ保持のコストを最大60%削減することができました。お客様は従量制の無制限ストレージとストレージの弾力性を手に入れることができ、ティアードストレージの可能性に大変期待しています。

同様に重要なのは、Tiered Storageが実現できないことを理解することです。 Tiered Storageでは、ストレージ管理のオーバーヘッドという課題は解決できません。これはどういう意味でしょうか?ローカルストレージのプロビジョニングは依然として必要で、適切な容量があるか、ローカルストレージが不足した場合どうするか、また時間とともにそれがどう変化するかを考慮しなければなりません。また、Kafkaにおけるリソースのカップリング(特に重要な課題で、この後Anilが詳しく説明します)も解決できません。Kafkaでリバランシングが発生した際に、プロデューサーやコンシューマー側にどのような影響があるか、これが私たちが言うリソースカップリングです。さらに、コンピュートの弾力性、つまりノードを素早く追加・削除してアーキテクチャを変更する能力も提供できません。


これらは、チームが検討してきた観察結果です。また、皆様からも「Tiered Storageの機能は素晴らしいが、さらに機能を追加できないか」というフィードバックをいただきました。そこで私たちは考えました。ストレージ管理のオーバーヘッドを完全に排除できないだろうか? Kafkaのリソースを分離し、コンピュートの弾力性を最適化し、これまでの経験を活かしてKafkaのベストプラクティスをデフォルトで実装できないだろうか? これらの4つの要素を組み合わせたものが、まさにAmazon MSKのExpress Brokersなのです。


では、具体的にどのような成果が得られるのでしょうか?お客様にとって、これは実際どのような意味を持つのでしょうか?まず第一に、Apache Kafkaブローカーと比較して最大3倍のスループットを実現します。 昨年Gravitonで発表したM7gの例を見てみましょう。現行のStandard Brokerは、全体的に安定したスループットを示しています。安定したスループットとは何を意味するのでしょうか?確かに、これ以上のスループットを達成できると主張されるお客様もいらっしゃいます。しかし、これらのブローカーでスループットを超過させる場合の問題は、障害が発生したり、ワークロードが急増したり、予期せぬリバランシングが発生したりした際に、突然対応に追われることになるのです。

Express Brokersでは、全体的に性能が向上し、特に8xlarge以上のインスタンスでより大きな改善が見られます。8xlarge以上で何が起こるかに注目してください。Standard Brokersでは、他の要因による制限のため、ほぼ横ばいになってしまいます。一方、Express Brokersでは、インフラストラクチャの持つ本来の性能を最大限に引き出すことができます。このスループットが3倍になることで、お客様はブローカーの数を削減でき、コストを削減しながらワークロードのパフォーマンスを向上させることができます。

Express Brokersは、Apache Kafkaと比較して最大20倍速いスケーリングを実現し、Tiered Storageと同様に、実質無制限の従量課金制ストレージを提供します。この特長は維持されています。

可用性の観点から見ると、標準的なApache Kafkaブローカーと比較して90%速い復旧が可能です。ベストプラクティスをデフォルトで実装しているため、中央ITチームとしてKafkaサービスを顧客に提供する場合、これらのベストプラクティスをアプリケーション全体に適用できます。そして、リソースの分離により、障害対応が改善されています。

使いやすさについてはどうでしょうか? ストレージを完全に管理しているため、保持期間を選択するだけで、ストレージインフラストラクチャは完全に管理されます。次の特徴は私の個人的なお気に入りなのですが、パッチ適用のためのメンテナンスウィンドウが不要で、これによってKafkaの使用体験が根本的に変わります。Express brokerはエラスティシティと高速な復旧を実現するため、ワークロードの変更に応じて簡単にサイジングと調整が可能です。これらが私たちが注目している4つの特徴です。



次に自然と浮かぶ疑問は、「Express Brokerはどんな時に使うべきか?」ということでしょう。 私たちは大きく2つの観点で考えています:Kafkaのより多くのコントロールを求めるお客様と、より多くのKafkaの自動化を求めるお客様です。 左側には、Amazon MSKの標準ブローカーがあります。これは、既存のKafkaセットアップからの移行を行う場合や、Kafkaの細かな制御が必要な場合、そしてKafkaとは何か、どのように動作するか、選択肢とトレードオフについて深い知識をお持ちの場合に適しています。


より多くのKafka自動化については、Amazon MSK Serverlessがあります。こちらはブローカー固有ではなく、Kafkaを迅速にデプロイし、スケールアップ・ダウンできます。Kafkaの管理は不要で、パーティションの再バランシングも行います。これは、Kafkaの細かなニュアンスを知る必要がない、あるいは知りたくないワークロードに適しています。 Express brokerはその中間に位置します。これはパフォーマンスとエラスティシティを重視するワークロードに適しています。標準ブローカーよりは制御が少なく、Serverlessよりは少し多い制御が必要な場合に最適です。本質的に、これは大規模なKafkaサービスの運用のためのものです。


大規模なKafkaサービス、つまり複数のクラスターや単一の大規模クラスターを検討している場合、Express brokerをお勧めします。 時にはワークロードについてより詳しい知識をお持ちの場合もありますが、特別な要件がない限り、KafkaワークロードにはExpress brokerが良い出発点となります。
料金設定とリージョンの提供状況についてご説明します。us-east-1では、標準的なブローカー料金と、ストレージ料金が発生します。このストレージ料金は興味深い点があります。標準ブローカーでは、接続されたブローカーごとにストレージ料金が発生しますが、このケースでは、ストレージは私たちが管理するため、基盤となる機能を管理した上で、一律の料金をご請求します。また、ワークロードの変化により適切に対応するため、データイン料金も設定しています。現在8つのリージョンで利用可能で、チームは引き続き急ピッチでロールアウトを進めています。
ストリーミングサービスの可用性と使いやすさの向上

これがパフォーマンスとコストの観点からの説明でした。では、これらすべての新機能が可用性と使いやすさの面で何を意味するのか、Anushaに説明してもらいましょう。ありがとうございます、Ashish。私はAmazon MSKのPrincipal Software EngineerのAnushaです。お客様にとって重要な点について、引き続きお話しさせていただきます。可用性についてお話ししましょう。Apache KafkaやAmazon Kinesisのようなストリーミングサービスは、ビジネスにおけるデータ処理の基盤であり、リアルタイム分析からインスタント通知まで、あらゆるものを支えています。これらのサービスは、超低レイテンシーで大量のデータを処理できるアプリケーションを実現し、リアルタイムインサイトを可能にします。

私たちは、お客様にこのような体験を提供するため、3つの重要な柱を継続的に革新しています。高可用性ストリーミングサービスのこれらの柱を、大きく分けると、影響の検出と回避、リアルタイムの応答性、そして冗長システムとなります。それぞれについて詳しく見ていきましょう。最初の重要な柱は、影響の検出と回避です。私はAWSでソフトウェアエンジニアとして10年近く働いていますが、影響を回避するシステムの構築は、ソフトウェアを本番環境にデプロイしてお客様のシステムに届くずっと前から始まっています。これは私たちにとって、設計段階に深く根ざしているのです。機能を設計するたびに、どんなに可能性が低くても、あらゆる障害シナリオを考え、お客様への影響が出る前にシステムが検出して軽減できるようにしています。

Amazon MSKサービスでの最近のローンチで、これをどのように実装したかをご紹介します。今年初め、MSKでクラスターから複数のブローカーを削除できる機能をリリースしました。これはMSK Expressブローカーで特に価値があります。なぜなら、Expressが提供する20倍速いスケーリングを活用して、ピーク時と低負荷時にクラスターをスケールアップ・ダウンしてコストを最適化できるからです。しかし、この機能を提供する前に解決すべき重要な課題がありました。例を使って説明させていただきます。6つのブローカー(ブローカー1から6)を持つクラスターを考えてみましょう。多くのKafkaユーザーがご存知の通り、ブートストラップブローカー文字列は、KafkaクライアントがKafkaクラスターのトポロジーを発見するための方法です。データの生産や消費には関係ありませんが、アプリケーションを開始する上で重要です。

ブローカー削除機能を使用して、クラスターから3つのブローカー(1、2、3)を削除したいとします。しかし、これらが設定のブートストラップブローカーでもあることを忘れていたとしましょう。これにより、アプリケーションがクラスターとブートストラップできなくなってしまいます。お客様としては、この障害シナリオを避けるために、クラスターからブローカーを削除する前にクライアントを更新しておく必要があります。しかし、企業規模で数百のクライアントがある場合、すべてのクライアントの更新を確実に行うことは事実上不可能で、障害はほぼ避けられません。私たちはこの機能を構築する際にこれを考慮し、削除されたブローカーをクラスター内のライブブローカーにシームレスにマッピングすることで、可用性を損なうことなくコストを最適化できるようにしました。


2番目の柱であるリアルタイムレスポンスについて説明しましょう。ストリーミングサービスでは、トラフィックやピークイベント時の急激なデータ量の変動に直面することがよくあります。システムがリソースのスケールアップやロードの分散によって素早く対応できない場合、データの遅延や損失を経験することになります。この分野における2つの重要な機能をご紹介したいと思います。まず1つ目は、Kinesis on-demandストリームが現在、秒間10ギガバイトの書き込みスループットと秒間20ギガバイトの読み取りスループットをサポートできるようになったことです。これは昨年同時期と比べて5倍以上のスループットであり、非常に大きな進歩です。これにより、Kinesis on-demandストリームの運用のシンプルさとPay-as-you-goの料金モデルを活用しながら、さらに高いスループットのワークロードを扱えるようになりました。


次に、Amazon MSKがどのようにリアルタイムレスポンスを実現しているかを見ていきましょう。先ほどAshishが紹介したExpress brokerは、20倍速いスケールアップが可能です。では、Kafkaのブローカーベースのセットアップにおいて、これは具体的に何を意味するのでしょうか?現在のインスタンスやブローカーのセットアップでピークやトラフィックイベントに対応するためにスケールアップする場合、まず新しいブローカーを追加します。しかし、それだけでは終わりません。新しく入ってくるトラフィックを処理できるように、これらのブローカーを準備する必要があります。つまり、古いブローカーから新しいブローカーへトピックパーティションを再配分する必要があるのです。したがって、Kafkaにおけるスケーリングの速度とは、トラフィックが増加し続ける中で、新しいブローカーを追加した後にパーティションをどれだけ速く再配分できるかということを意味します。


私は、標準的なApache Kafkaブローカーと比較して、Express brokerが実際にどのようなパフォーマンスを示すのかテストしてみたいと考えました。3つのブローカー、1つのトピック、2000パーティション、各ブローカーに4テラバイトのデータという一般的なケースのセットアップを用意しました。実験では、3つのブローカーを追加してインスタンス数を2倍にし、パーティションの半分(1000個)を再配分することにしました。その間、このクラスターに対して秒間90メガバイトのトラフィックを継続的に生成し、さらなる負荷をかけ続けました。このプロセスにどのくらいの時間がかかると思いますか?

このクラスターに負荷をかけた時の標準的なApache Kafkaブローカーのパフォーマンスをご覧ください。最初の赤い線は3つの新しいブローカーへの1000パーティションの再配分を開始した時点で、2番目の赤い線が完了した時点です。最初の赤い線の前では、3つのブローカーが6つのブローカーと同様の集計スループットを消費していました。赤い線の後、1000パーティションを3つのブローカーに再配分するのに約175分(3時間)かかりました。さらに問題なのは、この3時間の間、プロデューサーのスループットが実際に低下してしまったことです。3時間が経過するまで新しい3つのブローカーを活用できず、さらにそれらのブローカーを追加する前に得られていたスループットまで失ってしまいました。

では、同じシナリオでのExpress brokerのパフォーマンスを見てみましょう。はるかに良好な結果が出ています - ブローカーは古い3つのブローカーから新しいブローカーへ1000パーティションを再配分するのにわずか10分しかかかりませんでした。標準的なブローカーのセットアップとは異なり、新しい3つのブローカーを最初から活用することができました。このように、Express brokerは3倍のスループットを提供するだけでなく、20倍速い再配分を実現し、アプリケーションへの影響を最小限に抑えながら予期せぬピークに対応できるように設計されています。

それでは3番目の柱である冗長システムについてお話ししましょう。冗長性の本質は、プライマリシステムが故障した際にバックアップシステムが引き継げる状態を維持することです。AWSでは全般的に、そしてストリーミングにおいても、これを複数の方法で実現しています。データとストリームを複数のAvailability Zone間でレプリケーションすることで、1つのゾーンで障害や影響が発生しても、アプリケーションは他のゾーンに流れることで継続的に機能します。さらに、Cross-Region Replicationのような機能を使用して地理的な境界を複数のリージョンに拡張することで、リージョン全体が停止や影響を受けた場合でも、ストリーミングアプリケーションは継続して動作します。

Amazon MSKの最近のローンチについて、そしてこの機能のローンチ時に解決する必要があった興味深い課題についてお話ししたいと思います。今年初め、Amazon MSKでSame Topic Name Replicationのサポートを開始しました。この機能により、クラスター間でトピックをレプリケーションする際に、元のKafkaトピック名を保持できるようになりました。これは冗長性の利点を得ながらKafkaの設定を統一できるため、お客様にとって非常に重要でした。しかし、2つのクラスター間で同じトピックをレプリケーションする際に解決すべき課題がありました。

例えば、クラスターAに重要なトピックがあり、それをレプリケーションすることにしたとします。クラスターBを立ち上げ、AからBへのレプリケーションを有効にします。ここで、会社の別の部署の同僚が、クラスターBに重要なトピックがあることに気付きます。その同僚は、これが既にレプリケーションされていることを知らずに、クラスターBからクラスターAへのレプリケーションを有効にしてしまいます。ここで何が起きたかお分かりでしょうか - 私たち2人は実質的に無限ループを作ってしまい、同じメッセージがクラスターAとB間を行き来することになります。これによりデータの重複が発生し、特にスループットの高いトピックの場合、両方のクラスターでリソースが枯渇することによってレイテンシーが増加してしまいます。この機能を構築する際、複数のクラスター間で同じトピックをレプリケーションした場合でも、無限ループが発生しないように設計しました。

3つの異なる側面での改善に焦点を当てたこれらのローンチを通じて、私たちはお客様に高可用性のストリーミングサービスを提供し続けています。ストリーミングにおいて、お客様にとってもう1つ重要な機能は使いやすさです。データストリーミングにおける使いやすさとは、よく整備された機械のようなものです。つまり、設定を常に調整し続ける必要はなく、単純に動作してほしいということです。使いやすさというと、すぐに美しいUIやファンシーなインターフェースを思い浮かべるかもしれませんが、AWSでは、今日ご紹介したExpress BrokersやKinesisのような基本的なアーキテクチャの変更が、お客様にとっての使いやすさとして表れることが多いと考えています。


可用性と同様に、この体験を提供するために重要な属性についてお話ししたいと思います。大まかに言って、ここでもニーズに合わせた選択肢、ソースとシンク、そして新バージョンへの迅速な移行が重要です。選択肢について話しましょう。AWSでストリーミングアプリケーションをセットアップする際、お客様はストリーミングの導入段階において様々な状況にあります。初めてのストリーミングアプリケーションかもしれませんし、オープンソースへの親和性からKafkaやFlinkを検討されているかもしれません。
信頼性とベストプラクティスを最初から組み込んで、運用上のオーバーヘッドを気にする必要がないようにしたいと考えているかもしれません。また、単にデータを取り込むだけでなく、目的地に到達する前にデータの処理、集計、変換も行いたいと考えているかもしれません。ストリーミングの導入においてどの段階にいても、私たちは幅広い機能を持つサービスポートフォリオを用意しており、お客様のニーズに応じた対応が可能です。
ソースとシンクについてお話ししましょう。コアとなるストリーミングプラットフォームで幅広いソースとシンクをサポートすることで、データベース、IoTデバイス、分析ツールなど、実質的にあらゆるものと接続できます。この柔軟性により、データが生成される場所から必要とされる場所まで、シームレスにデータを流すことができます。これらの統合の多様性は重要です。なぜなら、企業はデータシステムを統合し、サイロを解消し、所有するすべてのチャネルでリアルタイムのインサイトを得ることができるからです。

新しい機能のローンチについてお話しする前に、最近お客様が構築しているユースケースやパターンをいくつかご紹介したいと思います。最初のパターンは、複数のアプリケーションやサービスからデータを統合されたデータレイクにストリーミングまたはバッチで送信するというものです。このパイプラインでよく見られるソースはデータベースです。これはAurora、RDS、あるいは自己管理型のデータベースかもしれません。お客様は、このデータベースの変更を捕捉し、データレイクに取り込んで、AI/MLアプリケーションやイベント駆動型アーキテクチャに供給したいと考えています。

もう一つよく見られるパターンは、お客様がApache Icebergテーブルの形式でデータを保存するというものです。Apache Icebergは、ビッグデータ分析向けの高性能なオープンソーステーブルフォーマットです。この設定での使いやすさとは、複雑なETLパイプラインのセットアップのオーバーヘッドを避けたいということです。私たちは、お客様がリアルタイム分析を簡単に実現できるようにするにはどうすればよいか考え、まさにそれを実現しました。先月、Amazon Data Firehoseで、データベースの変更をAmazon S3上のApache Icebergテーブルにレプリケートする機能をローンチしました。キャパシティを管理したり、クラスターを微調整したりする必要はありません。Amazon Data Firehoseはスキーマのレプリケーションも処理し、ソースのスキーマが進化するにつれて、それらの変更をIcebergの宛先のスキーマにレプリケートします。

NoSQLデータベースで同様のことを行いたいお客様向けに、マネージドFlinkサービスにDynamoDBストリームコネクターもローンチしました。これを使用して、DynamoDBテーブルのアイテムレベルの変更を変換および分析できます。このコネクターはAWSからFlinkオープンソースコミュニティにも提供されました。
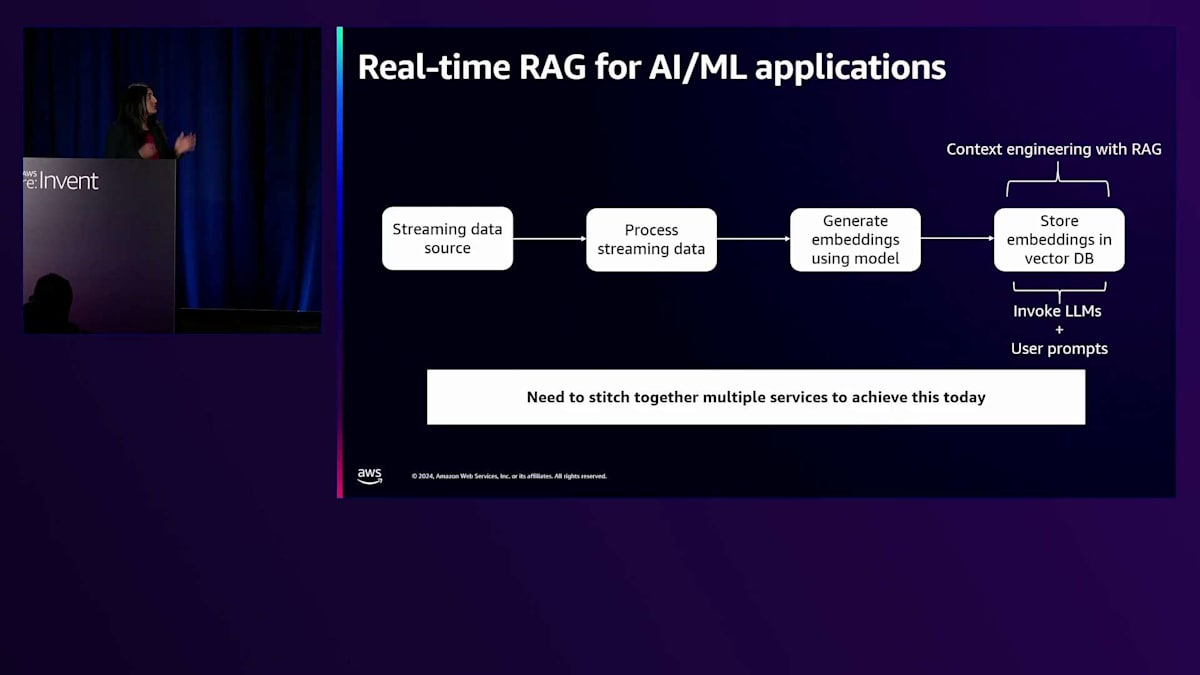
よく見かけるもう1つのユースケースについてお話ししましょう。それは、リアルタイムRAG(Retrieval Augmented Generation)をAI向けに構築するお客様のケースです。RAGは、大規模言語モデルの能力と最新のデータソースを組み合わせることで、AIをさらに進化させ、レスポンスがただ賢いだけでなく、正確で文脈に即したものとなることを保証します。これをリアルタイムで実現するパイプラインを構築するには、まずストリーミングデータソース(KafkaストリームやKinesisストリームなど)を選択し、前処理を行い、チャンキングやフィルタリング用のライブラリを選び、Amazon Bedrockなどのソースから埋め込みモデルを使用してデータをベクトル化し、最後にベクトルデータベースに埋め込みを保存します。この時点で、RAGでコンテキストエンジニアリングを行うためにLLMやユーザープロンプトを呼び出すことができます。これは多くのステップがあり、現在のリアルタイムRAGを実現するには複数のサービスを組み合わせる必要があります。

ここでも私たちは、RAGを使用してリアルタイムインサイトを始めたいと考えているお客様にとって、これをいかに簡単にできるかを考えました。先月、Amazon MSKで新機能をリリースし、Amazon Bedrockからお好みのモデルを活用し、Amazon OpenSearchを出力先として使用する、このパイプラインを自動的にセットアップする方法を提供しました。これを当社のマネージドFlinkサービスのブループリントとしてリリースしたので、クリック1つでベクトル埋め込みの配信を開始できます。

また、このコードをオープンソース化し、様々なユースケースに応じて修正できるようにしました。ストリーミングサービスの使いやすさに関する3つ目の特性について話しましょう。それは、スケールでストリーミングアプリケーションをオープンソースサービス上で実行する際の、新バージョンへの移行の俊敏性です。最新の状態を保つことは贅沢ではなく、ほぼ必須となっています。これこそがマネージドオープンソースサービスが重要となる部分です。手動メンテナンスの手間なしに新バージョンにアップグレードできる俊敏性を提供し、最小限のダウンタイムで最新の機能、パフォーマンスの改善、セキュリティアップデートにアクセスできます。この俊敏性により、企業は複雑さに悩まされることなく、より速くイノベーションを起こし、競争力を維持し、オープンソースの力を活用できます。


この分野でも私たちはいくつかの新機能をリリースしています。最新のApache Flinkバージョン1.18、1.19、1.20のサポートを最近開始しました。また、インフラ全体を再構築することなくFlinkアプリケーションをアップグレードできるインプレースアップグレードもリリースしました。さらに、新バージョンで問題が発生した場合に、以前の正常なバージョンに安全に戻れるシステムロールバックと自動ロールバックという異なるタイプのロールバック機能もリリースしています。また、今年Amazon MSKでKRaftモードのサポートも開始しました。ご存知の方も多いと思いますが、Apache Kafkaはメタデータ管理層としてZooKeeperから離れ、Kafka on Raft(KRaft)に移行しています。これはAmazon MSKのバージョン3.7から利用可能で、クライアント側の変更を一切必要とせずに開始できます。

このトークを通じて、お客様にとって最も重要な主要分野と、私たちがそれらを継続的に革新してお届けする方法について見てきました。しかし、これは実際にはどのように機能するのでしょうか?それを聞くために、オンプレミスのApache Kafka管理のオーバーヘッドをAmazon MSKに移行することで変革を遂げたお客様をステージにお招きできることを大変嬉しく思います。VerizonのアソシエイトディレクターであるVideyasagar氏をお迎えし、彼らのストーリーを共有していただきましょう。
VerizonによるAmazon MSK導入事例

こんにちは、Verizonのvidyasagarです。 Verizonは、何百万人ものお客様の生活、仕事、娯楽をいかにパワフルに、そして充実したものにできるか、モビリティ、信頼性の高いネットワーク接続、セキュリティに関するお客様のニーズにお応えしています。ニューヨーク市に本社を置き、世界中の国々とFortune 500のほぼすべての企業にサービスを提供し、2023年の売上高は1,340億ドルに達しています。私たちの世界クラスのチームは、お客様の現在のニーズに応え、明日のニーズに備えるため、絶え間なくイノベーションを続けています。

私たちのストリーミングプラットフォームには、いくつかの課題となるユースケースがあります。Amazon EKSプラットフォームにデプロイされた複数のマイクロサービスがログを生成し、Fluent Bitに送信しています。Fluent Bitはログを解析してフィルタリングした後、Apache Kafkaに送信します。Kafkaでは60のノードと5つのZooKeeperノードを使用しています。Kafka Connectを使用して、Apache Kafkaからメッセージを取得し、Amazon OpenSearchに送信しています。これらのログのサイズは11KBから5MBの範囲です。ライフサイクル管理を使用して、コスト削減のためにデータノードからUltraWarmノードにログを移動し、30日後にノードからログを削除しています。これが私たちの全体的なインフラストラクチャ設計で、1日10億件のトランザクションレコード、120テラバイトのデータ、つまり月間3.5ペタバイトを処理しています。Black FridayやiPhoneの発売などの大規模イベントに基づいてスケールアップとダウンができる必要があり、信頼性の高いリアルタイムデータ処理を確保しています。
リアルタイムデータを分析や意思決定に使用しているため、信頼性の高いリアルタイムデータ処理は不可欠です。私たちの可観測性プラットフォームのスケーラビリティと安定性は極めて重要です。主要なデータソースの1つがAmazon OpenSearchであり、ログデータに基づいてスケールアップとダウンの判断を行っています。障害発生時には、コスト最適化とともに自動修復と自動スケーリングを実装しています。コストを最小限に抑え、人的介入を減らしながら、データ損失のないコスト最適化を実現したいと考えています。

2番目のユースケースは、データベースから下流のデータベース(SQLとNoSQLの両方を含む)に数百のテーブルを複製することです。Amazon EKSプラットフォーム上に2つのインスタンスでデプロイされたオープンソースのApache Kafkaを使用しており、コンシューマーポッドがメッセージを消費して、データベースやNoSQLデータベースなどの下流システムに送信しています。このアーキテクチャを使用して、分析目的のリアルタイムデータ処理機能で1日約30億件のトランザクションを処理する必要があります。このシステムは、コスト最適化を維持しながらデータ損失なく運用する必要があります。

しかし、私たちはいくつかの課題に直面しています。最初の問題は、メンテナンス時間が長いことです。60ノードのクラスターで再水和パッチアップグレードを実行する際、1つのノードをローテーションから外し、Amazon EC2インスタンスを作成し、EBSボリュームをスイングし、Kafkaを起動し、データを同期し、パーティションリーダーを再選出する必要があります。このプロセスは1ノードあたり8〜10分かかり、60〜70ノード全体で完了するまでに8〜10時間かかります。大規模イベント時にノードの追加や削除には2〜3時間かかり、予期せぬイベントによってデータ損失が発生します。各パーティションについて、コンテナあたり30MBのログデータを保持しています。
Amazon EC2インスタンス間で2〜3のノードやネットワークの問題が発生した際、データ保持量が30MBしかないため、データ損失が発生していました。In-sync replicasが1つになると、最小レプリケーション係数を2に維持しているにもかかわらず、クライアントがメッセージを投稿できなくなります。その結果、3〜6時間分のデータが失われてしまいます。また、Observabilityプラットフォームが不安定なため、データ不足によって重要なシグナルを見逃し、多くの障害が発生していました。既存のインフラでは効果的なオンデマンドのスケールインとスケールアウトができないため、大規模イベント時にシステムをスケールできない状況でした。

これらの課題に対処するため、AWSチームと協力して、2つのインスタンスで稼働していた自己管理型Kafkaを Amazon MSKに置き換えました。
自己管理型KafkaとKafkaサービスが同じ2つのインスタンス上で稼働していたため、リソースを共有して相互に干渉するシンドロームが発生していました。さらに、Kafka ConnectがEC2インスタンス上で稼働していたため、スケーラビリティに欠けていました。パーティションの追加や削除時に、自動的にスレッドの追加や削除が行われていませんでした。そのため、スケーラビリティを実現するためにApache Kafka ConnectをAmazon EKSプラットフォームに移行しました。これにより、障害に備えたクラスター設計が可能になりました。Amazon MSKは自動障害回復機能を備え、マルチAZ設計となっています。

これらの変更により、目標を達成することができました。Amazon MSKへの移行とKafka Connectのプラットフォームへの移行により、アップグレード、Kafkaアップグレードの自動化、スケーリング、メンテナンスの課題がすべて解決されました。2つ目のユースケースでは、自己管理型KafkaをAmazon MSKに置き換え、ConsumerポッドをAmazon EKSプラットフォームに移行することができました。また、パーティション数に基づいてConsumerポッドをスケールする機能も実装しました。Kafkaに新しいパーティションを追加するたびに、パーティション数に応じてConsumerポッドをスケールアップまたはスケールダウンできるようになりました。

その結果、ダウンタイムなしで容易にスケールインとスケールアウトが可能になり、スケーラビリティとキャパシティが大幅に向上しました。以前経験していたネットワークやIOPSのパフォーマンスの問題も解決されました。可用性とデータ損失に関しては、以前は5〜10テラバイト程度でしたが、Amazon MSKに移行後は0.01%未満にまで削減されました。信頼性とメンテナンス面では、インプレースアップグレードやセキュリティパッチの適用も問題なく実施できるようになりました。先週の金曜日には、クラスターの1つが80%の容量に達した際、1つのコマンドで2〜3分以内にEBSボリュームを増やすことができました。以前はこれにかなりの時間を要していました。
セッションのまとめと今後の展望

セキュリティに関しては、以前はSSL認証のみを使用していましたが、Amazon MSKに移行後はSCRAMとSSL認証の両方を実装することができるようになりました。 このセッションでは多くのローンチについてお話ししましたが、もちろん今年私たちが皆様のために実施したすべてをカバーすることはできませんでした。このスライドはしばらく表示したままにしておきますので、セッション後にすべてのローンチ内容を確認できるよう、写真を撮っていただければと思います。いつものことながら、私たちのお客様であり続けていただき、AWSのイノベーションの原動力となる貴重なフィードバックを提供していただき、ありがとうございます。それでは、よい一日を、そしてre:Inventの残りの日程もお楽しみください。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion