re:Invent 2024: AWSがOpenSearch Serviceのコスト削減と効率化を解説
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Maximize efficiency and reduce costs with Amazon OpenSearch Service (ANT347)
この動画では、Amazon OpenSearch Serviceを使用したログ分析と検索ワークロードのコスト削減と効率改善について詳しく解説しています。OpenSearchの基本的な説明から始まり、プロビジョニング型とServerlessの違い、Vector検索の最適化手法、そしてコスト削減のための具体的な戦略を紹介しています。特に、Trellixの事例では、UltraWarmストレージの活用やReserved Instancesの採用により35%以上のコスト削減を達成した実績が共有されています。また、Zero-ETLやOpenSearch Ingestionを活用した最新のコスト最適化パターンや、Graviton3プロセッサーへの移行によるパフォーマンス向上についても具体的に説明されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon OpenSearch Serviceによるコスト削減と効率改善:セッション概要

本日のセッションへようこそ。Welcome Receptionとの選択は難しかったと思いますが、きっと価値のある時間にしたいと思います。このセッションでは、Amazon OpenSearch Serviceを使用してログ分析と検索ワークロードのコスト削減と効率改善を実現するための強力な戦略について詳しく説明していきます。私はHajer Bouafifです。AWSでSenior Open Source Solutions Architectとして働いており、お客様の検索とログ分析におけるオープンソースワークロードの改善をサポートしています。本日は Kevin Fallisも同席しています。Kevin、自己紹介をお願いできますか?
はい、Kevin Fallisです。Amazon OpenSearch ServiceのWorldwide Sales Organizationでプリンシパルとして、お客様のAmazon OpenSearch Serviceのコスト最適化の理解を支援しています。皆さん、こんにちは。Trellixから参りましたPavanです。Senior Software Engineering Managerとして、Trellix XDR製品の運用を担当しています。Pavanさん、よろしくお願いします。ありがとう、Kevin。
OpenSearchとAmazon OpenSearch Serviceの概要

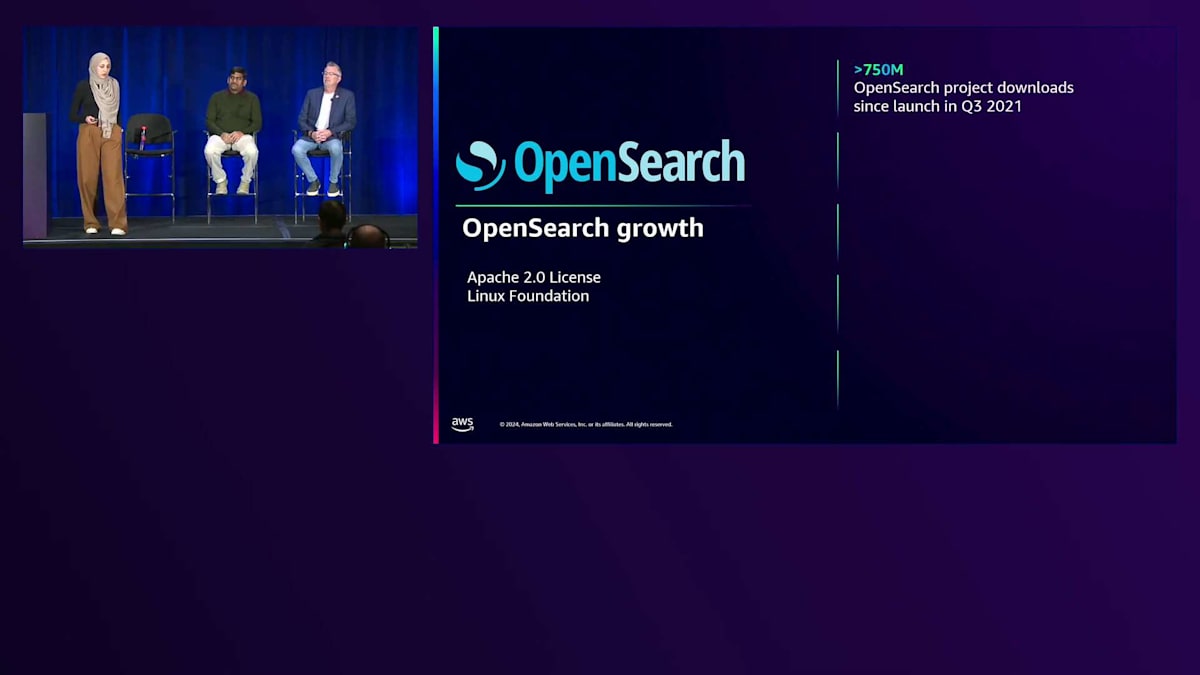
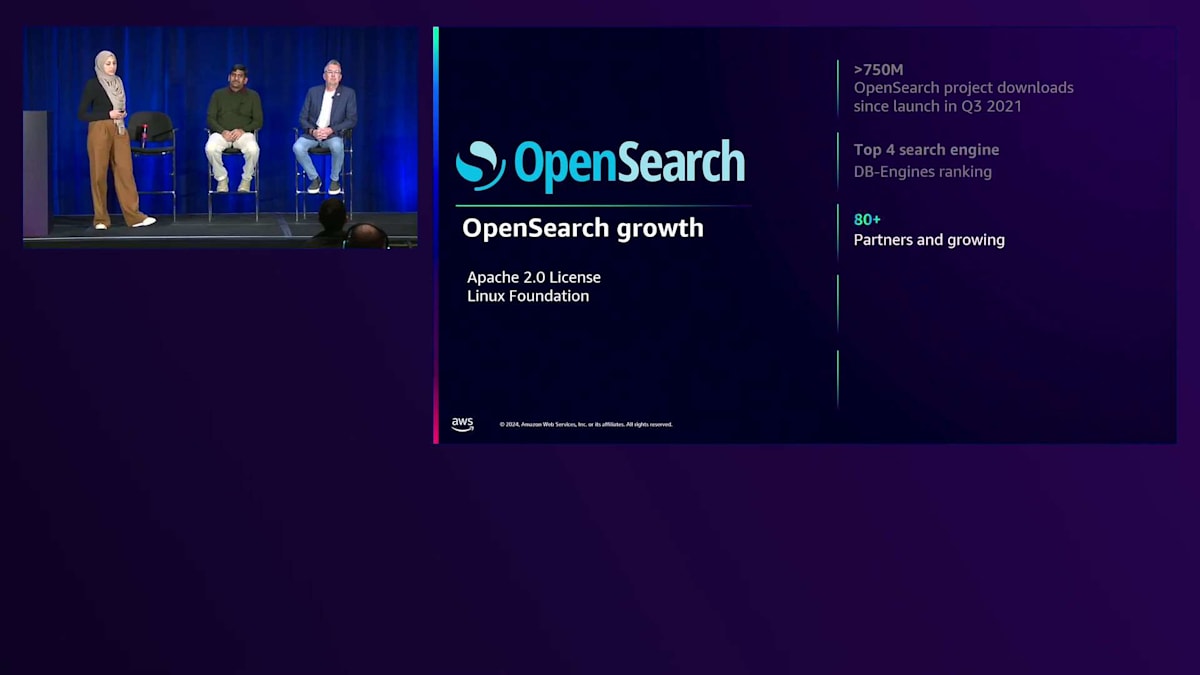
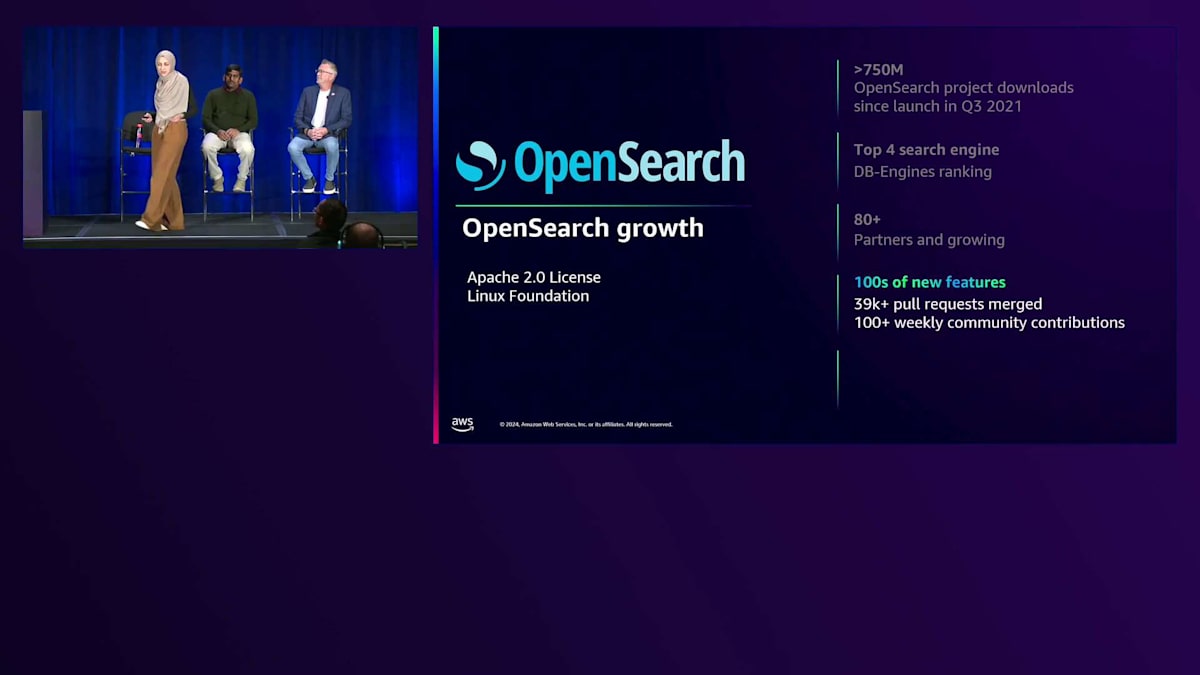
まずは、Amazon OpenSearch Serviceを支えるオープンソースプラットフォームであるOpenSearchについて説明させていただきます。OpenSearchはApache 2.0ライセンスのオープンソースプラットフォームです。最近Linux Foundationの一員となり、オープンソースコミュニティへの貢献をさらに強化しています。 OpenSearchは7億5000万回以上のダウンロード数を誇り、多くのお客様にご利用いただいています。 OpenSearchはDB-Enginesのウェブサイトで上位4位の検索エンジンにランクインしています。 80社以上のパートナーが参加し、毎週数百件の貢献があるなど、パートナー数も増加を続けています。もちろん、OpenSearchはAWS、Oracle、Azureなど、さまざまなプロバイダーにデプロイすることができます。



AWSでは、このOpenSearchオープンソースのマネージドバージョンとして、Amazon OpenSearch Serviceを提供しています。OpenSearch Serviceでは、OpenSearchオープンソースの全機能に加えて、AWSクラウドのスケーラビリティ、セキュリティ、可用性を備えています。さらにAWSは、OpenSearchのデプロイメントの第3のバージョンとしてAmazon OpenSearch Serverlessも提供しています。 OpenSearch Serverlessでは、インスタンスのプロビジョニングが不要で、シャーディングのベストプラクティスやインデックス作成のベストプラクティスなど、OpenSearchの内部構造についての知識もほとんど必要ありません。

検索やログ分析のワークロードを構築する際には、総保有コスト(TCO)全体について考える必要があります。TCOは共有責任と考えてください。AWSはスケーラビリティや可用性、さらにサービスのコンプライアンス対応やセキュリティを担当します。一方、お客様は、コンピューティング要件やストレージ要件などの重要な要素に注力する必要があります。また、ユーザーパターン、つまりデータを検索するユーザーは誰か、何人のユーザーがいるのか、検索の頻度はどのくらいか、そして実行される検索クエリの種類についても考慮する必要があります。例えば、大規模な集計を行う場合、コンピューティング要件が増加します。また、先ほど説明したself-managed、マネージドサービス、OpenSearch Serverlessなど、さまざまなデプロイメントオプションによる運用の簡便性についても考慮してください。Kevinとともにこれらの主要な要素を最適化し、コストと効率を改善するための戦略について詳しく説明していきます。
Vector検索の最適化:k-NN検索と量子化テクニック


OpenSearchは検索エンジンであり、特に検索のユースケースにおいては、テキスト検索を超えてVector検索機能を提供します。これにより、アプリケーションにおけるユーザーの意図をより深く理解することができます。これは、Retrieval Augmented Generation(RAG)のユースケースや、eコマースのウェブサイト検索、ドキュメント検索などを実現します。では特に、Vectorワークロードに焦点を当てて、このタイプのワークロードのコストを最適化する方法を見ていきましょう。 Vectorサーチについて話す際、k-nearest neighbor検索、略してk-NN検索について触れる必要があります。ここで、k-NN検索についてまだ聞いたことがない方がいるかどうか、確認させていただきたいと思います。
Vector検索の核心には、高次元の数値ベクトルでデータを表現するという概念があります。テキスト、画像、音声など、類似した特徴を持つデータは、同じVector空間内で互いに近い位置に表現されます。ユーザーのクエリVectorがある場合、k-NN検索は同じVector空間内でK個の最近傍を見つけます。


検索操作は、厳密検索または近似検索が可能です。 厳密なk-NN検索では、入力されたクエリVectorをインデックス内の全てのVectorと比較しようとします。これにより高い精度が得られますが、特に数十億のVectorのような大規模なワークロードの場合、検索レイテンシーが高くなる可能性があります。ここで近似k-NN検索の出番となります。 近似k-NNはIVF-HNSWなどのアルゴリズムを使用します。これらのアルゴリズムを使用することで、精度を若干犠牲にする代わりに、入力クエリVectorに対するK個の最近傍を素早く見つけることができます。

良好な検索速度を実現するには、k-NNインデックスまたはVectorデータがメモリにロードされていることを確認する必要があります。そのため、Vectorワークロードは主にメモリコストに影響されます。Vectorワークロードのメモリ要件、つまりメモリフットプリントを削減し、全体的なコストを下げるために、 Vector量子化技術の使用を検討してください。OpenSearchでは、Scalar量子化、Binary量子化、Product量子化を使用できます。これらの技術は圧縮手法であり、Vectorの次元を32ビットから16ビット、8ビット、さらには1ビットにまで削減します。

量子化技術以外にも、Vectorの適切な次元数を確保することを考慮してください。数千の次元がある場合、それもメモリフットプリントの要件を増加させることになります。 結果の精度や検索速度など、Vectorワークロードの効率性を測定する指標について考えることをお勧めします。また、インデックス作成速度も考慮してください。データを迅速にインデックス化して検索可能にする必要がある場合は、そのデータのインデックス作成にかかる時間を測定する必要があります。例えば、HNSW近似k-NNを使用する場合、頻繁な更新の管理や更新速度についても考慮してください。そしてもちろん、メモリ、コンピュート、ストレージの要件も測定してください。
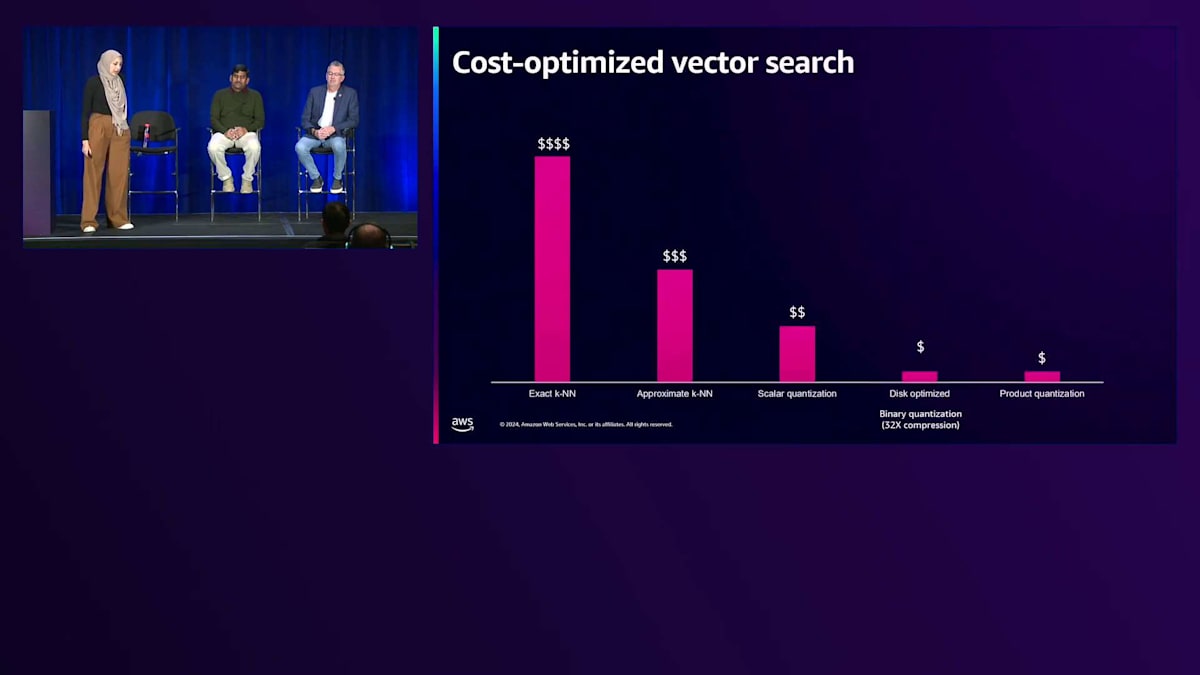
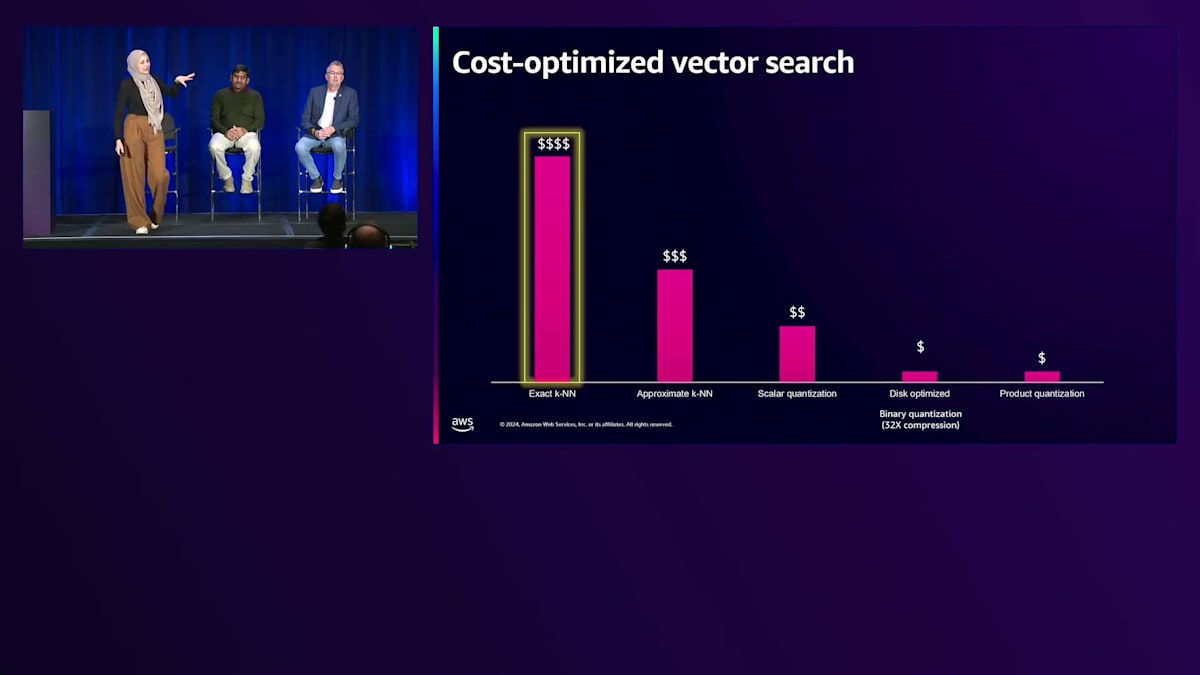
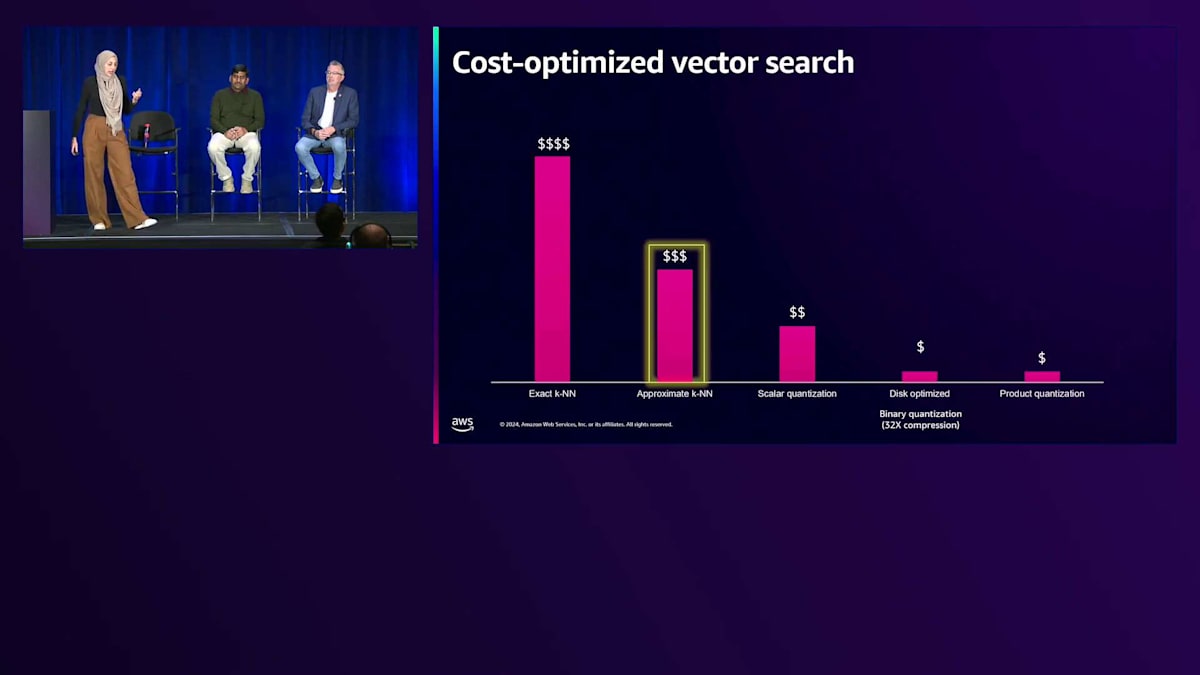
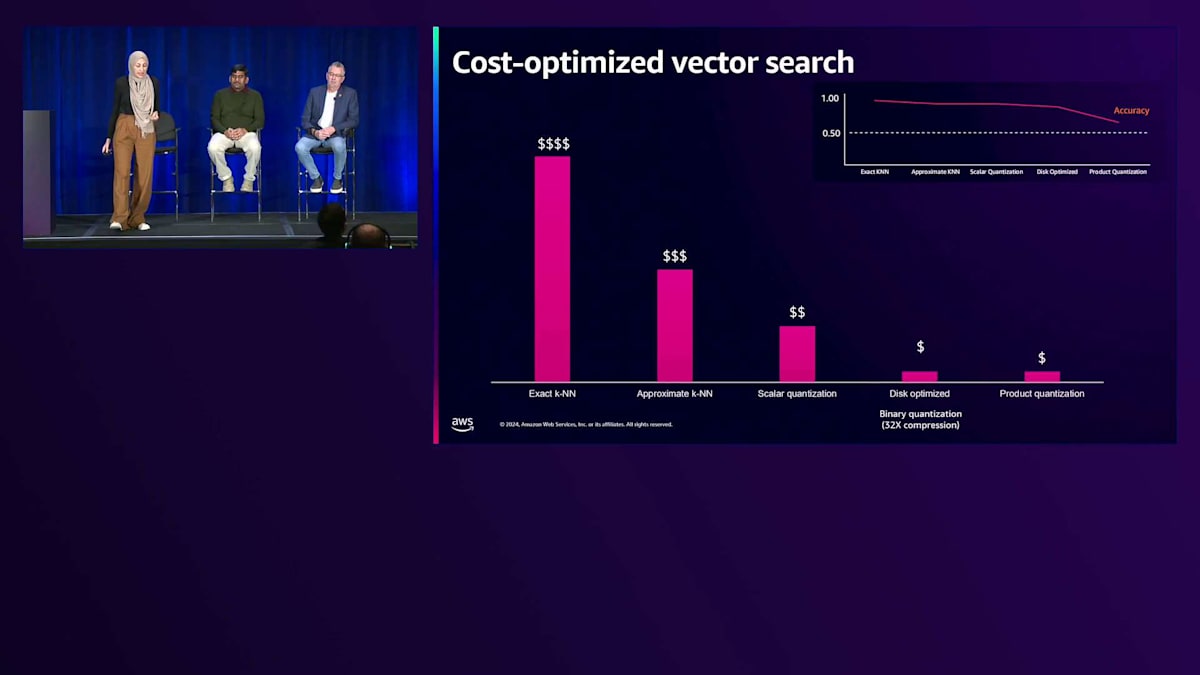
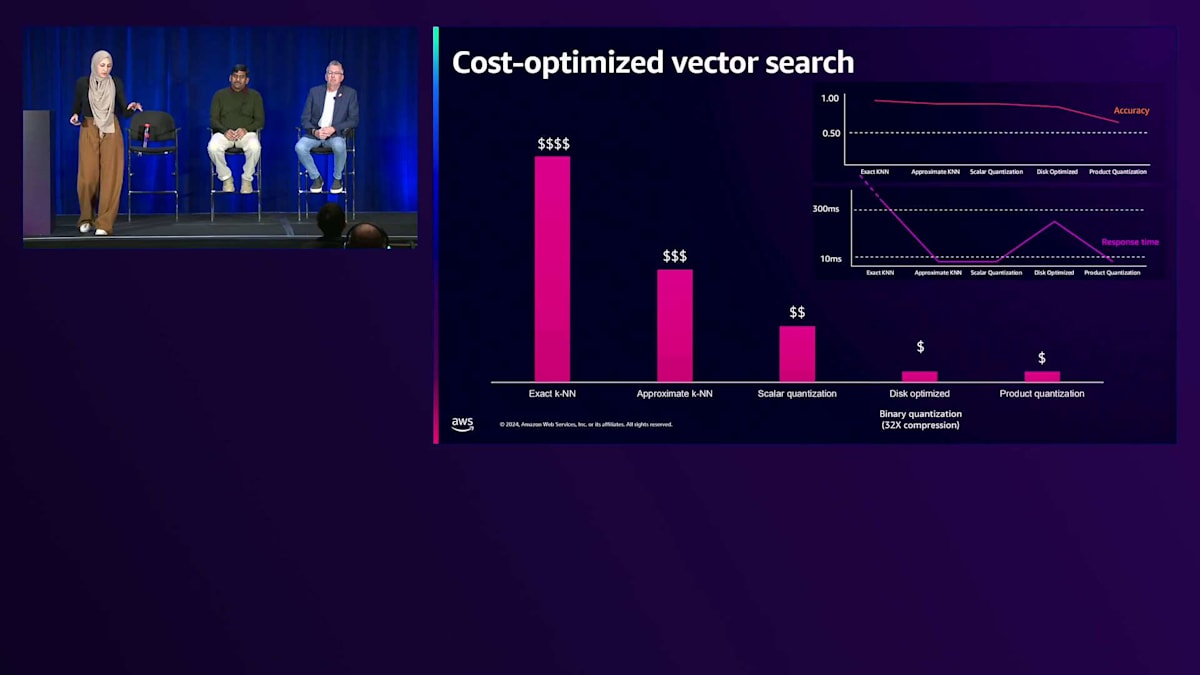
これまでご紹介した量子化に関する様々なテクニックと最適化について、Vector処理のコスト全体がどのように見えるかを、このグラフを使って説明させていただきます。特に、 厳密なk-NNの場合、データが増加または大規模化すると非常に計算負荷が高くなることは先ほど述べた通りです。 これを最適化するために、厳密なk-NNから近似k-NNに移行し、 さらに説明してきた量子化テクニックによってコストを削減することができます。ただし、これらの量子化テクニックには精度と遅延のトレードオフが伴います。精度に関しては、Scalar QuantizationとBinary Quantizationはかなり一貫した精度を提供します。一方、Product Quantizationテクニックでは精度がより変動的ですが、Product Quantizationモデルをトレーニングすることでこれを克服できます。 検索速度に関しては、厳密なk-NNは特に数十億のVectorを扱う場合に高い遅延をもたらしますが、それでも300ミリ秒以下のミリ秒単位で動作しており、RAGのユースケースや社内文書検索には十分効率的です。
Binary Quantizationを使用したディスク最適化アプローチは、ディスクベースの検索を行うため、Vectorをメモリにロードする場合と比べて遅延が大きくなります。Generativeアプリケーションの研究開発チームが様々なテクニックを試す場合は、ディスク最適化を伴うBinary Quantizationの使用を検討してください。

近似k-NNとScalar Quantizationは特に、検索速度、精度、全体的なコストの間で最適なバランスを提供します。この分析から強調したいのは、それぞれのアプローチに独自のメリットがあるため、特定のユースケースに対してどのようなメリットをもたらすかを測定する必要があるということです。
OpenSearch Serverlessの特徴と最適化

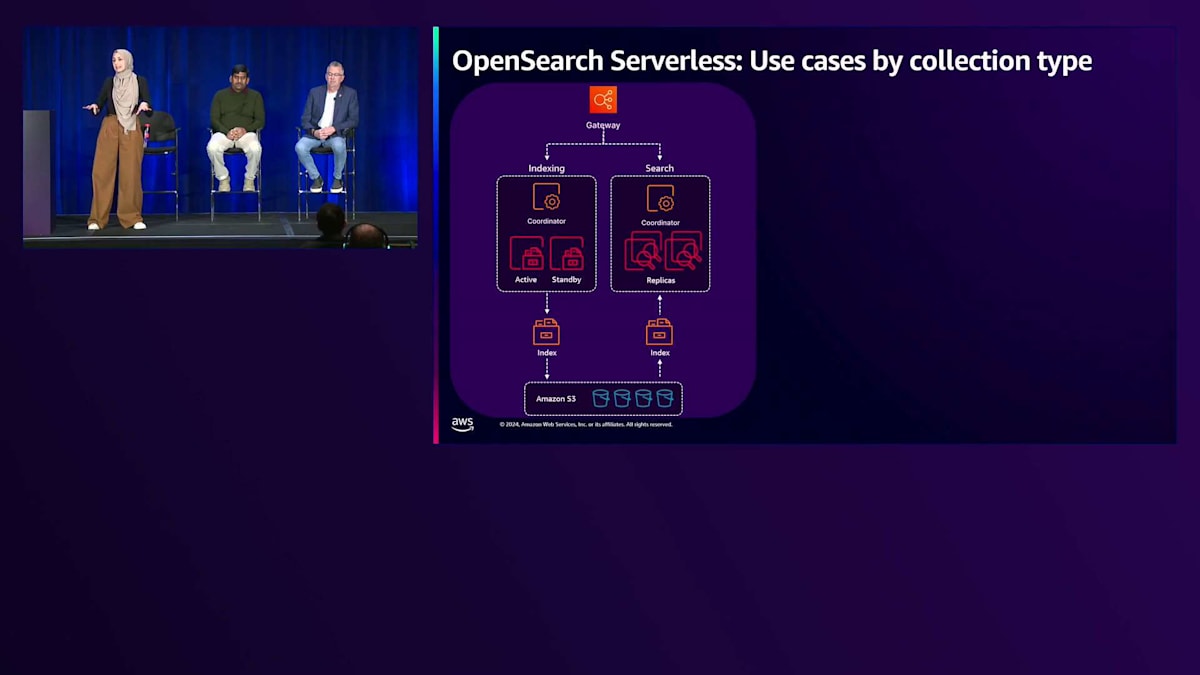
Vector処理の最適化方法を探ってきましたが、これらはAmazon OpenSearchのマネージドサービスやOpenSearch Serverlessで利用できます。 OpenSearch Serverlessのアーキテクチャは、コンピュートとストレージレイヤーを分離し、ストレージはスケーラビリティの高いAmazon S3をベースにしています。この関心の分離により、インデックス作成と検索を独立してスケールでき、 サービス内のリソース利用を最適化することができます。

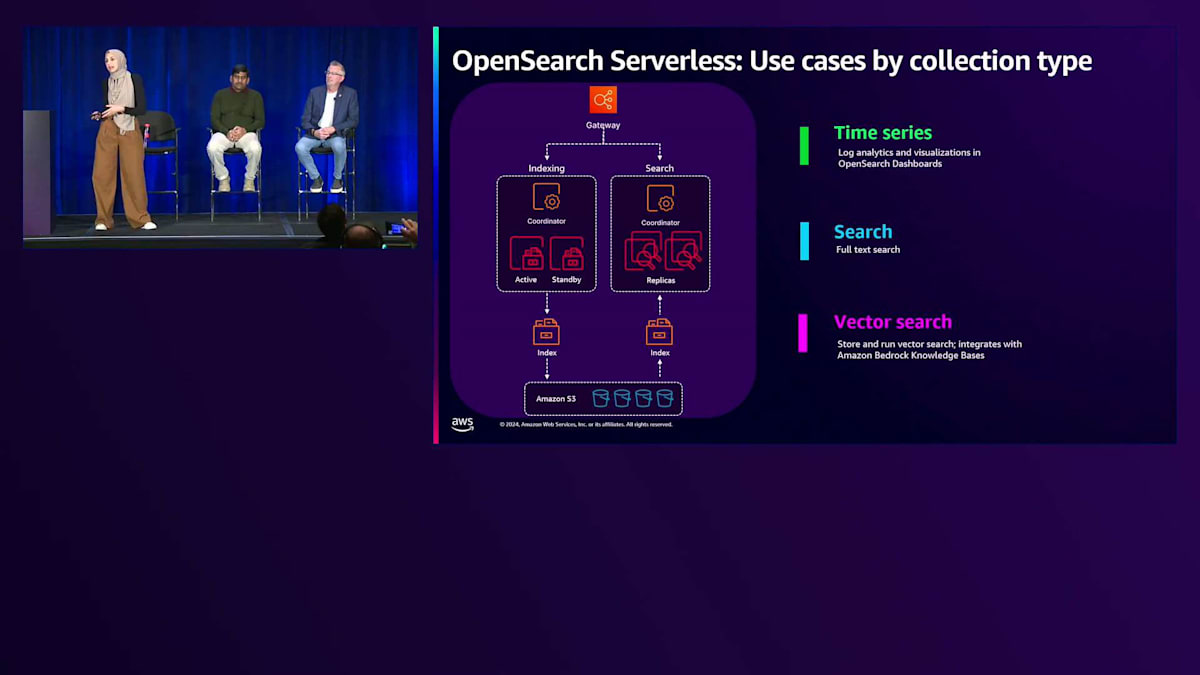
OpenSearch Serverlessは3種類のCollectionを提供しています。Time Series Collectionはログ分析に最適化され、ビルトインのストレージ階層化機能を備えており、最新のデータをOCU(コンピュートレイヤー)に、古いデータをAmazon S3に保持します。Search Collectionはテキスト検索に最適化され、ビルトインのシャードレプリカスケーリング機能があり、検索スパイク時にコンピューティングを追加する代わりに、シャード数をスケールしてそれらのスパイクに対応します。Vector Search Collectionはベクトル検索ワークロード向けに最適化されており、Amazon Bedrockでナレッジベースを使用する場合、Amazon Bedrockが自動的にOpenSearch ServerlessのVector Collectionを作成します。

これらの特殊なCollection typeを提供することで、基盤となるインフラストラクチャやシャーディング戦略、インデックス戦略がワークロードに最適化され、インフラの調整ではなくビジネスに注力する時間を確保することができます。OpenSearch Serverlessは、ワークロードのスパイクに応じて自動的にスケールアップ・ダウンし、インデックス作成と検索のために最大500 OCUまでスケールアップできます。アカウントごとの最大OCU数を設定することが重要で、さらに異なるCollection間でOCUやコンピュートユニットを共有することでコストを削減することもできます。
Amazon OpenSearch Ingestion Serviceによるデータ取り込みの効率化

検索やログのワークロードを構築する際に、お客様が直面する最も一般的な課題の1つは、データをOpenSearchに素早く取り込む方法です。ライセンスが必要なツールに依存していると、環境内の他のツールとの統合に関してソリューションの成長やアーキテクチャ設計が制限される可能性があります。データパイプラインを自己管理している場合、チームの運用負荷が増加し、インフラのスケーリングや全体的なコストの管理に時間を取られ、ビジネスの構築に集中できなくなる可能性があります。この重労働を解消するため、 AWSはAmazon OpenSearch Ingestionサービスを導入しました。これはDataPrepperを基盤とする、完全マネージド型の従量課金制データ取り込みサービスです。DataPrepperはOpenSearchの一部であるオープンソースのデータコレクターです。
このサービスは、マルチAZデプロイメントを通じて安全で信頼性の高い取り込みパイプラインを提供し、AFCA、OpenTelemetry、その他のデータベースなど、一般的なソースのほとんどと統合できます。また、Amazon OpenSearchやAmazon S3などのダウンストリームアプリケーションにデータをフィルタリング、変換、取り込むための、すぐに使える変換機能も備えています。

取り込みパイプラインの導入をサポートするため、OpenSearch Ingestion Serviceは画面に一部表示されているように、最大38のBlueprintを提供しています。これらのBlueprintはテンプレートで、取り込みパイプラインをすぐに開始できます。インデックス名を修正または変更し、ソースからの読み取りとダウンストリームサービスへのインデックス作成を可能にするIAMロールを設定するだけです。 OpenSearch Ingestion Serviceを使用することで、エンジニアリングチームはビジネスに集中する時間を取り戻すことができます。このサービスはData Prepperをベースにしているため追加料金はなく、ワークロード需要に応じて自動的にスケールします。また、DynamoDB、S3など、この後Gavinが紹介する他のサービスや、re:Inventで発表される他のサービスとの統合も加速します。
OR1インスタンスによるパフォーマンス向上とコスト削減


これまで説明してきた様々なオプションは運用を簡素化しますが、Amazon OpenSearchの管理機能を使用してさらにコストを最適化する方法もあります。 OpenSearchを実行する際、信頼性と可用性の高いソリューションを確保するために、通常、少なくとも1つのデータレプリカを持つことを推奨しています。従来は、プライマリシャードとレプリカシャードの両方にデータをインデックス付けする必要があり、クラスター上で冗長な計算が発生していました。
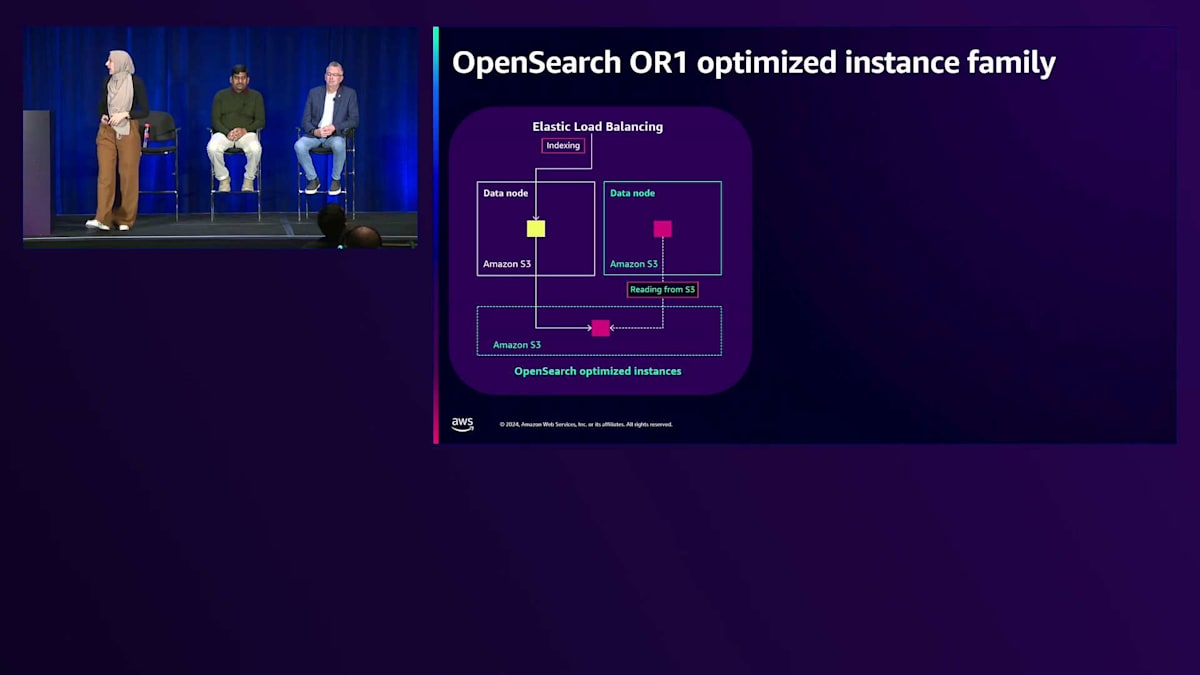
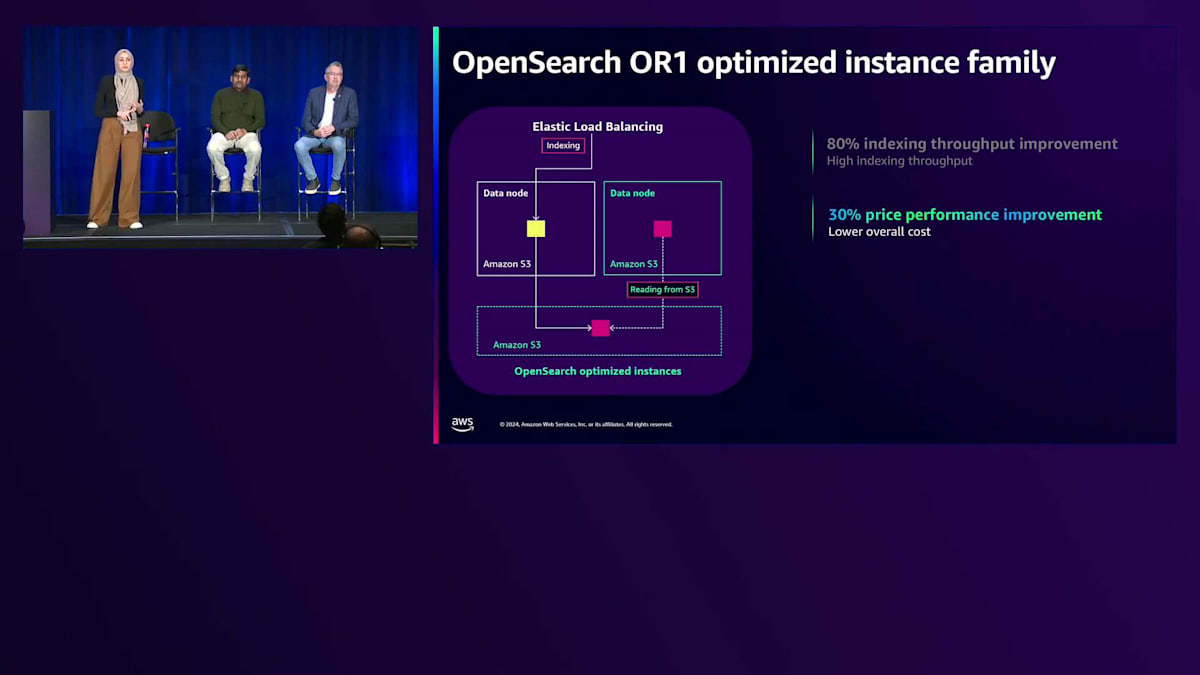
OR1インスタンスの導入により、Remote Storageを使用したセグメントレプリケーションという、より優れたレプリケーション手法が実現しました。その仕組みをご説明します:まず、プライマリシャードのみにデータをインデックス化し、新しいセグメントはAmazon S3に保存されます。そして、レプリカシャードへの再インデックス化の代わりに、2番目のデータノードがS3から新しくインデックス化されたデータを取得します。これにより、インデックス化のスループットが80%向上します。また、レプリカへの再インデックス化以外のタスクにより多くのコンピュートリソースを活用できるため、30%のコストパフォーマンス向上につながります。
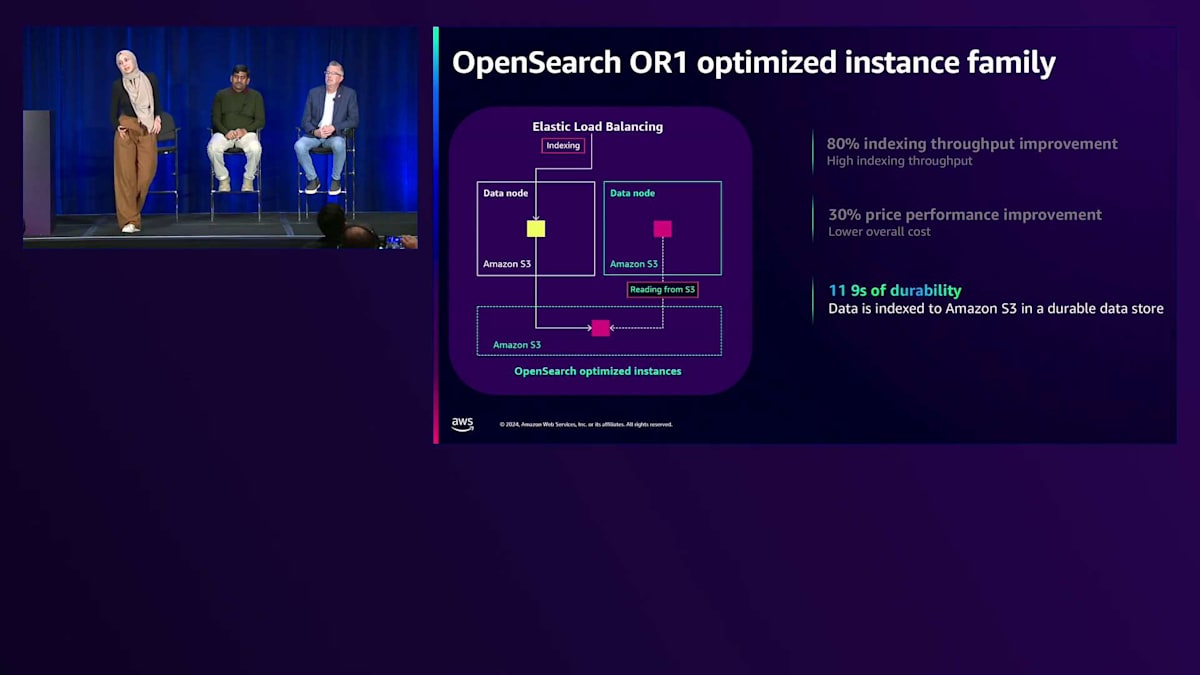
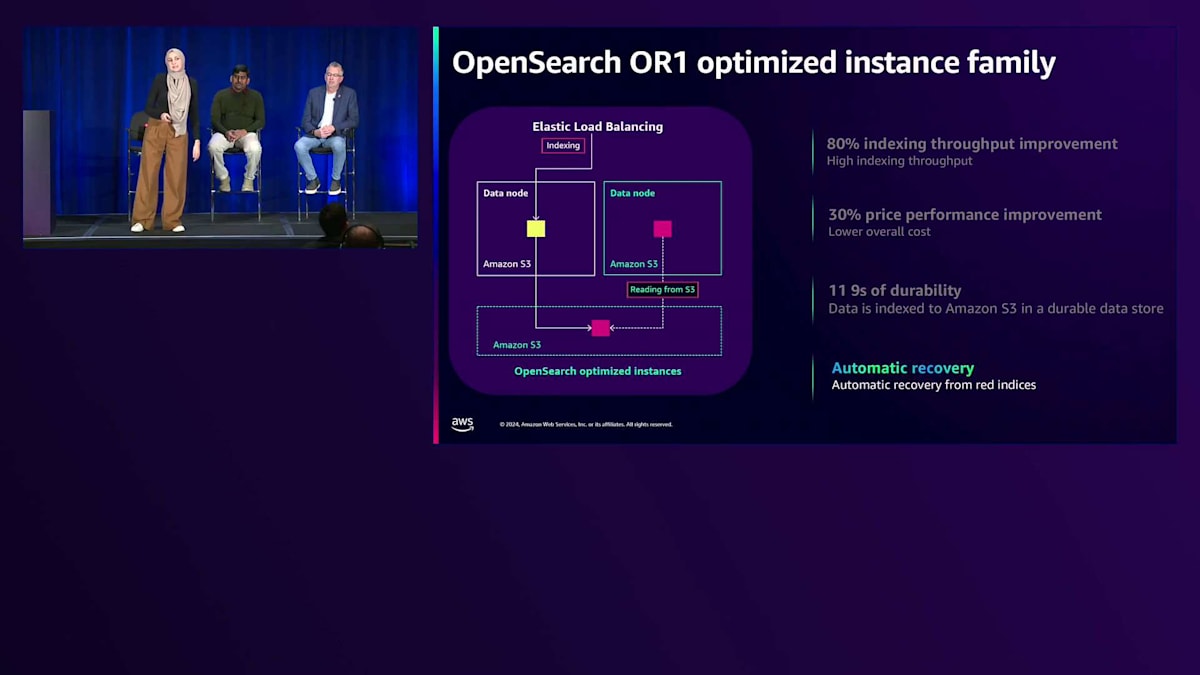
Amazon S3の11ナインの耐久性をすでに活用できるため、レプリカが不要になる可能性もあります。OR1インスタンスは、データのコピーをAmazon S3に保持し、インデックステンプレートやインデックスマッピングなどのクラスター設定も保存します。障害が発生した場合、データだけでなくクラスター設定も復旧できるため、回復力と復旧時間が向上します。
Trellixの事例:OpenSearch Serviceによる35%以上のコスト削減
ここからは、Kevinが Amazon OpenSearch Serviceのコスト最適化のアプローチとテクニック、そしてAmazon OpenSearch Ingestion Serviceを使用した効率的なデータ取り込みワークロードの構築について詳しく説明します。その前に、Trellixが OpenSearch Serviceで35%以上のコスト改善を達成した事例について、Pavanからお話を伺いましょう。はい、ありがとうございます。皆様、こんばんは。私はTrellixに所属しており、当社はサイバーセキュリティ分野で事業を展開しています。


当社は、多くのセキュリティコントロールの統合を実現したAI搭載のオープンプラットフォームを提供しています。世界のFortune 100企業の多くから信頼を得ており、ご覧の通り、トップイノベーターとして数々の成果を上げています。私たちのユースケースは、主にプラットフォームのセキュリティニーズと、そのバックエンドでOpenSearchをどのように活用しているかに関するものです。

エンドポイントセキュリティ、ネットワークセキュリティ、メールセキュリティ、データ保護、クラウド、サードパーティなど、多くのセキュリティコントロールがあり、これらはクラウド、オンプレミス、ハイブリッドなど様々な環境で運用されています。これらすべてのイベントを統合し、インテリジェンスを追加して、最大限のアラートを生成するには、ダッシュボード、ケース管理、ポリシー、脅威ハンティングなどの機能を提供するコンソールが必要です。これらの機能を提供するために、ほぼリアルタイムでイベントを検索できるバックエンドシステムが必要でした。私たちのユースケースでは、外部検知および応答製品のバックエンドとしてOpenSearchを使用しています。

これは私たちのワークロードと直面した課題についての詳細です。毎日数十億件のイベントを取り込んでいます。その理由は、ほとんどの企業が複数のセキュリティベンダーを利用しており、各セキュリティベンダーがクリティカルなイベントを生成しているからです。時には数百もの異なる製品を扱うことがあり、それぞれの製品が数百から数千のイベントを生成しています。多くの地域で何千もの顧客にサービスを提供しているため、毎日数十億件のイベントを受け取り、これを実現するために検索するデータ量はペタバイト規模になります。
私たちは多くのAWSリージョンとVPCにまたがって数千のノードを持つElasticsearchを運用していました。これに加えて、複数のリージョンにあるAzureクラスターもアップグレードする必要がありました。管理面でも運用面でも課題がありました。時にはAWSからインスタンスの廃止通知を受け取り、停止して起動し、新しいインスタンスに移行しなければならないこともありました。数千のノードを管理する必要があったため、このような問題が頻繁に発生していました。状況が手に負えなくなってきたため、解決策を探していました。

AWS Account Teamと話し合い、 OpenSearchを紹介されました。Amazon Managed OpenSearch Serviceを試してみることを提案されました。最初の印象として、私たちは運用上の課題を最適化するだけでなく、コストも削減したいと考えていました。Managed OpenSearchサービスに移行すると、当然コストは増加する可能性があるため、コストを最適化しながら運用の負担も減らしたいと考えていました。これが私たちが提示したユースケースでした。
プロダクトチームは、多くのVPCとリージョンにまたがる現在のワークロード分布を調査した後、解決策を提供してくれました。レプリカの削減、特定のインスタンスタイプの使用、複数のオプションの中からSavings Planの購入など、特定の方法でOpenSearchを試すことを提案しました。これらすべてを実装する前に、POCを実施したいと考えていました。最適化の観点から考慮した主な要因は、取り込まれるデータ量に基づくOpenSearchの課金に関連していました。顧客データなのでデータ量を減らすことはできませんが、データを圧縮してより効率的に送信する方法を見つけたいと考えていました。その解決策を提供してもらいました。また、EBSのコストを削減するために、圧縮形式でディスクに保存するデータ量を減らしたいと考えていました。
顧客の要件に基づいてできるだけレプリカを削減するために、契約内容に応じて異なるライフサイクルポリシーを提供しています。顧客によって3日、5日、7日、15日のデータ保持期間があります。しかし、検索パターンを見ると、全ての顧客が毎日毎時間、15日分や1週間分のデータを検索しているわけではありません。ほとんどの顧客は、脅威ハンティングを行っているため、数時間分のデータしか検索しません。24時間分や48時間分のデータを取得して対処したいと考えているかもしれません。通常、15日分全てを検索することはありません。

つまり、すべてのデータを高性能ノードに保存する必要はないということです。一部のデータは高性能ノードに置き、他のデータは低性能ノードに保存することで、お客様が検索する際の許容可能な遅延の範囲内で対応できます。これが一つのユースケースでした。 もう一つの提案は、OpenSearch Ingestionパイプラインを使用することでした。当時は自社で開発・管理していた既存のカスタムインデックス作成オプションを使用していました。私たちが直面していた課題は、お客様ごとのイベントサイズが毎月あるいは毎年増加していることでした。今日のために設計したシステムが、明日には対応できなくなる可能性があります。より良いコスト最適化のために、スケールアップとオートスケールダウンの両方に対応する必要がありました。
そのコードの管理には課題がありました。お客様のセキュリティデバイスからイベントを受信する際、時として大量のイベントが突発的に発生するためです。お客様側で1日分のデータを保存していても、突然データが大量に送られてくることがあります。そのため、スパイクへの対応と、日々あるいは月々増加するデータの処理が必要でした。私たちは、これらすべての要件に対応でき、かつ最適なコスト効率を実現できる、スケーラブルで堅牢なソリューションを探していました。そこでOpenSearch Ingestionパイプラインを採用しました。OpenSearchのコストの一つの要因は、取り込むデータ量に基づいています。OpenSearch Ingestionパイプラインを選択した際、データを圧縮する設定オプションがありました。この方法を採用したところ、90%以上の圧縮率を達成し、1テラバイトのデータを使用していても、すでに圧縮されているため、はるかに少ない料金で済むようになりました。

実証実験の際、 レプリカを減らしてコストを削減できると想定していましたが、それは現実的ではありませんでした。その理由は、既存のインスタンスタイプでは、データはまだEBSに存在しており、レプリカなしでデータを復旧する場合、即座には実行できないためです。バックアッププロセスを経由してデータを取得する必要があり、それには30分、40分、場合によっては1時間以上かかります。そのため、このオプションは実用的ではなく、結局レプリカを使用する必要がありました。信頼性のために複数のシャードが必要で、より高速な検索のために多数のインデックスを作成してシステムを再構築しようとしましたが、数千のお客様が複数のノードに分散している状況で、ノードあたりのシャード数の制限に直面しました。
パイプラインでは、私たちが試みていた取り込みの規模とAWSが行っていたチューニングの種類との違いにより、初期の取り込み時に多くの問題に直面しました。バックエンドエンジニアリングチームと協力し、実際のユースケースを示しながら、パフォーマンスパラメータのチューニングを試みました。彼らはいくつかのバグを修正し、最終的にうまく機能するようになりました。同時に、複数のレプリカを作成しようとしても、大きなコスト削減は見込めないことがわかりました。
ちょうど昨年同時期に、AWSがOR1インスタンスを導入し、私たちは最大の顧客となりました。OpenSearch Ingestionパイプラインに対して、すぐにこれを採用しました。先ほど見たように、バックエンドにAmazon S3があるため、それを使用して大量の負荷をかけてみました。最初に遭遇した問題はS3のスケーリングで、S3のパラメータをチューニングする必要がありました。これらのパラメータが調整された後、バックエンドチームは私たちのようなワークロードに合わせてOR1を最適化し、完璧に動作するようになりました。
インデックス作成のパフォーマンスが大幅に向上し、多くのレプリカを使用する必要がなくなりました。ノードが失われた場合でもクラスターの安定性を維持するため、1対1のレプリカ構成を採用しました。災害復旧テストを実施し、ノードの再起動を試み、クラスターの回復にかかる時間を確認しました。回復時間は7〜10分程度で、許容範囲内だったため、1対1のレプリカ構成で進めることにしました。
シャーディング戦略については、顧客データの検索パターンに基づいたアプローチを実装しました。データは6時間ごと、あるいは1日ごとにUltraWarmに移動し、場合によってはHotノードに残すこともあります。OpenSearch Ingestionパイプラインの問題をすべて解決した後、OCU(コンピュートユニット)のチューニングを行う必要がありました。各リージョンで調整を行い、すべての数値化が完了すると、システムは順調に動作し始めました。
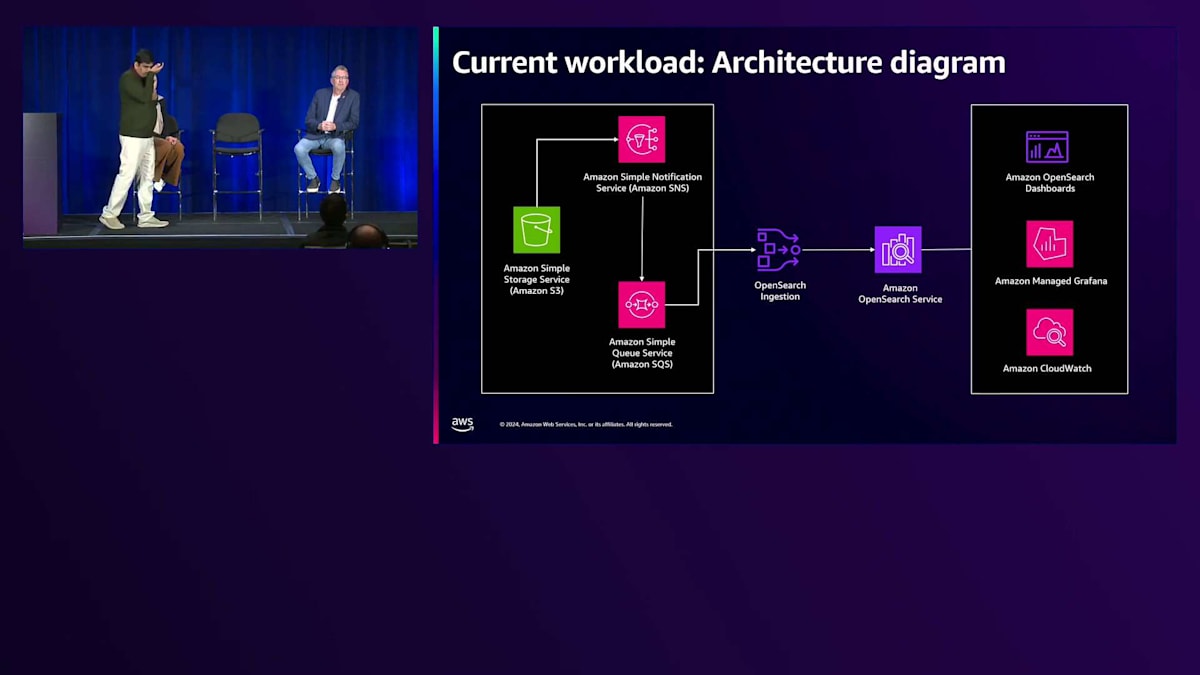
これは簡略化したアーキテクチャ図です。 図を見ると、顧客データはJSON形式でAWS S3に入ってきます。データはSQSキューに基づいてOpenSearch Ingestionで受信されます。新しいデータが挿入されると、OpenSearch Ingestionパイプラインがデータを取得し、Amazon OpenSearch Serviceにインジェストします。3つのブロックがあり、左側にデータ部分、中央にOpenSearchとAmazon OpenSearch Service、右側に監視部分があります。
OpenSearch Ingestionについては、ここでは1つだけ示していますが、最適化の過程で、リージョンごとのクラスター数を削減するよう努めました。各リージョンに多くのクラスターを作成したくなかったのですが、過去のデータには複数のパイプラインがありました。これを解決するために、複数のOpenSearch Ingestionパイプラインを1つのAmazon OpenSearch Serviceに向けることで、クラスターを1つに統合することができました。圧縮率、インジェストの場所、インジェスト失敗時の再試行回数を定義するだけの、シンプルな設定でした。
インジェストに失敗したデータについては、DLQバケットと呼ばれる場所に保存します。別のインジェストパイプラインを作成し、DLQバケットを指定して、例えば前日のデータなど、期間を指定してデータを再インジェストすることが非常に簡単にできます。これによりOpenSearch Ingestionパイプラインで大きな柔軟性が得られます。多くの再試行を設定する必要はありません。なぜなら、インジェストできなかった場合でも、いつでもそれらのデータを再試行できるからです。コスト最適化の観点からは、残念ながらSavings PlanやReserved Instanceは利用できません。
私たちはエンジニアリングチームに対して、サービスプランがないため多額の費用を支払いたくないと強く主張しています。そのため、各クラスターを細かく調整し、AWSに必要な変更を実装してもらうことで、適切な数のOCUが適切にスケールアップ・ダウンし、OpenSearchエンジンに過剰な費用をかけないようにしています。この取り組みは上手くいきました。
OpenSearchサービスの費用構造は、取り込まれるデータ量、Hotノードごとの EBS ストレージの使用量、使用するUltraWarmノードの数、そしてHotノードに使用するインスタンスタイプに基づいています。コストを削減するため、頻繁に検索されるデータをHotノードに、あまり検索されないデータをUltraWarmノードに保持しています。UltraWarmノードはレプリカを持たず、低パフォーマンスのノードです。以前は全てのデータを15日間Hotノードに保持する必要がありましたが、現在は1日分のデータのみをHotノードに保持しています。
この場合、インデックス作成と検索を同時に行う高性能なOR1インスタンスを使用できます。頻繁に検索されるデータをHotノードに、あまり検索されないデータをUltraWarmノードに保持することで、コストを削減できます。監視に関しては、AWSはAmazon CloudWatchで、クエリの遅延や取り込みパフォーマンスなど、主にシステム関連の情報について、すぐに使えるアラートと監視機能を提供しています。しかし、私たちはインデックスレベルでの監視が必要でした。ストレージやHotからUltraWarmへのロールオーバーの失敗など、その動作を理解するためです。
現在、詳細な情報が得られないため、APIを使用して独自のスクリプトを作成する必要がありました。バックエンドからすべてのデータを取得し、必要なアクションを実行するための独自のスクリプトを作成しました。これらの機能を独自のスクリプトで管理するのではなく、最初から実装してほしいとOpenSearchチームにフィードバックを送っています。また、多くのリージョンに多数のクラスターがあるため、各リージョンにログインして各クラスターを個別に監視する必要があります。これらすべてを表示する単一のダッシュボードがないため、すべての監視を1ページにまとめるために独自のManaged Grafanaを構築しました。多くの顧客にとって有用だと考えられるため、同様の機能の実装をAWSに依頼しています。

移行プロセスについては、POCが完了した後、多くのリージョンとVPCに分散された何千もの顧客データを移行する必要がありました。1、2日では完了できないため、デュアルライト方式を採用しました。リージョンを選択し、OpenSearchクラスターを作成し、顧客に必要な保持ポリシーに基づいて、既存の検索ソリューションとOpenSearchの両方に書き込むように実装しました。例えば、顧客が7日分のデータを検索する場合、両方のシステムにデータが存在することを確認するため、7日間並行して運用しました。
私たちはクラスターを安定化させ、パラメーターを調整し、すべてのライフサイクルポリシーが正常に機能していることを確認しました。そして、ある日、古い検索システムからOpenSearchへの切り替えを実施しました。このようにして、多くのVPCにまたがる多数のクラスターの移行を実現できました。時間はかかりましたが、チームにとっては大変な作業でした。チームの協力なしでは、この移行は実現できませんでした。AWSチームがバックエンドで監視を行い、常にサポートを提供してくれました。エンジニアリングチームはBlue-Greenデプロイメントに関する問題に対して、いつでもサポートできる体制を整えていました。
プロセス全体を通じて、AWSチームから多大なサポートを受けることができました。先ほど述べたように、コスト最適化のために複数のパイプラインを1つに統合しました。複数のクラスターにまたがるモニタリングは、自分たちで実装する必要がありました。

実装した改善点をまとめますと、インデックスサービスを分割し、以前は自分たちでインデックスポリシーを管理していましたが、現在はOpenSearchのIndex State Management Policyを使用することで、データをHotノードに6時間または6日間保持し、その後UltraWarmに移動させ、15日後に削除するといった保持期間を簡単に設定できるようになりました。これらのポリシーは、顧客の設定に基づいてインデックスごとに記述することができます。システムが過負荷状態になった際の障害を監視し、発生した問題に対処しています。また、OR1インスタンスを使用することで、コストを削減し、耐久性を向上させることができました。これは私たちにとって優れた選択であり、独自のモニタリングダッシュボードも構築しました。

多くの方が興味を持っているコスト削減の面について説明しますと、約35%のコスト削減を達成し、これは私たちにとって数百万ドル規模の削減となりました。コスト削減を実現できた主な理由は、UltraWarmストレージの活用と、利用可能なすべてのオプションを検討したことです。ハードウェアとインデックス戦略の最適化に加えて、毎年データ量が増加することが分かっていたため、Savings PlanとReserved Instancesを購入しました。Reserved Instancesを採用したことで、コストを大幅に削減できました。AWSには、インジェストパイプラインにもSavings Planを拡張していただけることを期待しています。これによりさらなるコスト削減が可能になるからです。

インデックス作成のパフォーマンスは大幅に向上し、以前の設定と比較して40%の改善が見られました。これにより、データを取り込んでからほぼリアルタイムで検索可能になりました。最近では、インデックス作成に関する運用上の問題は発生しておらず、これは大きな改善を示しています。
次のステップとして、UltraWarm ストレージでのクエリパフォーマンスの改善に注力しています。現在、UltraWarmで標準的なデータを検索する際に、パフォーマンスの低下が見られます。AWSチームと協力して、AIを活用した機能やVector検索を組み込むことで、お客様により多くの価値を提供できるようバックエンドの改善に取り組んでいます。また、ハードウェアを24時間稼働させる必要のない環境向けに、OpenSearch Serverlessの活用も検討しています。
プレゼンテーションをお聞きいただき、ありがとうございました。これを実現できたのは私のチームのおかげであり、心から感謝申し上げます。多くのお客様の移行を成功させることができました。本日このような機会を与えてくださった私のチーム、リーダーシップ、そしてAWSチームの皆様に深く感謝いたします。
Amazon OpenSearch Serviceのインスタンスタイプとコスト最適化戦略


Trellixの事例とそのコスト削減効果は非常に興味深いものでした。ここからは、プロビジョニング型のサービスについてお話ししていきます。先ほどHajerが説明したように、Amazon OpenSearch Serviceは運用コストの削減に貢献しますが、多くの組織では大規模なワークロードを扱っており、Serverlessで提供される一部の制限や機能がまだ利用できない状況です。プロビジョニング型のサービスとそのコスト最適化について見ていきましょう。
サービス提供に関しては、EC2インスタンスをベースにT-シャツサイズのような形で展開しており、Intel XeonプロセッサーやGravitonチップ(特にGraviton 2とGraviton 3)を含む様々な選択肢をご用意しています。

大量のログ分析ワークロードを扱う場合、通常は Rシリーズのインスタンスを使用します。Rシリーズには、Intel搭載のR5シリーズに加えて、R6およびR7シリーズ(R7 GDとR6 GDを含む)があります。これらはGraviton2およびGraviton3を採用したものであり、CPUと比較してメモリの割合が大きいため、ログやベクトル処理に特に適しています。

大規模なホットデータ量のワークロードの場合、 I シリーズインスタンスの高密度ストレージを利用することでコストを抑えることができます。これらは NVMe ベースのインスタンスです。Intel Xeon 側では、ログやベクトルワークロードに最適な NVMe SSD やインスタンスストアを備えた I3 と I4i があります。Graviton 側では、高密度ストレージと高性能 CPU を備えた I4g と、EBS バックアップボリュームを使用する I4gs があります。



M シリーズインスタンスは一般的な用途に使用されます。 お客様との作業では、R シリーズインスタンスからクラスターを水平方向にスケーリングすることを気にせずに、より多くの CPU が必要な場合、Intel、Graviton2、Graviton3 のオプションを提供する M シリーズを使用することがよくあります。C シリーズインスタンスは、高カーディナリティの集計に適しており、これらは一般的に検索ワークロードで見られます。 このサービスで長年働いてきた中で、ログ分析のユースケースはあまり見たことがありませんが、検索を行う場合には非常に優れています。
マネージド側またはプロビジョニング側で OpenSearch Service を始めたい場合は、フリーティアで提供されている T2 や T3 などの汎用低コストの T シリーズインスタンスを使用できます。これらを使用することで、API を試し、OpenSearch Service で利用可能な検索機能の使い方を効果的に理解することができます。
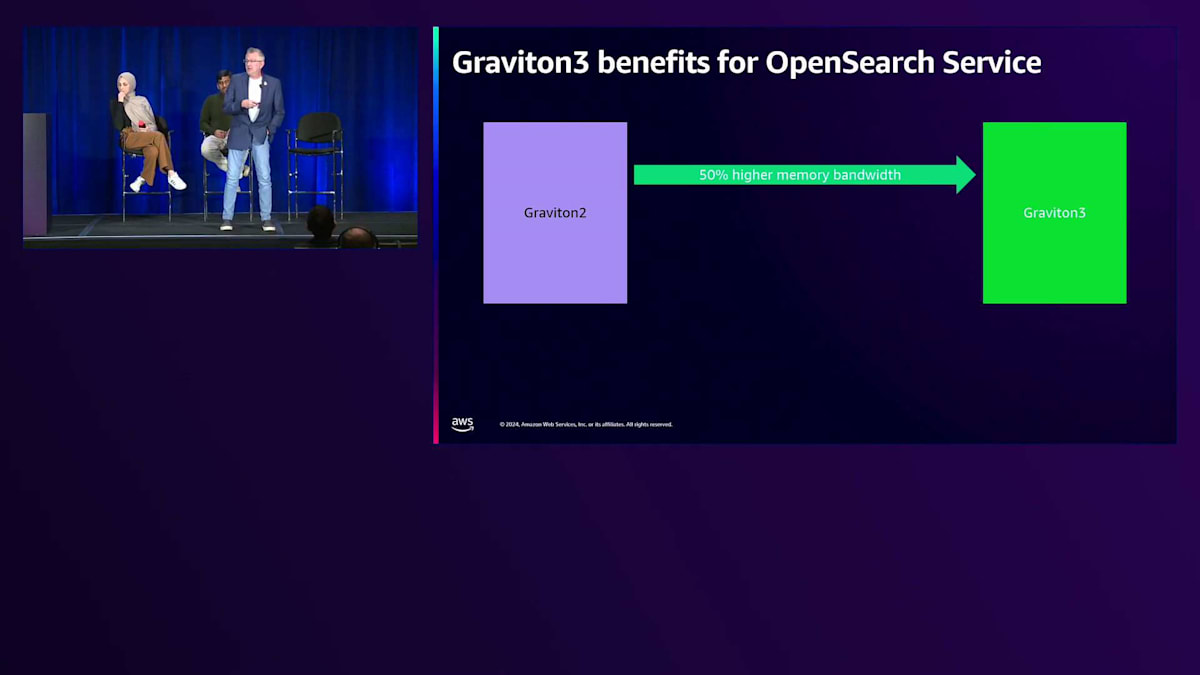
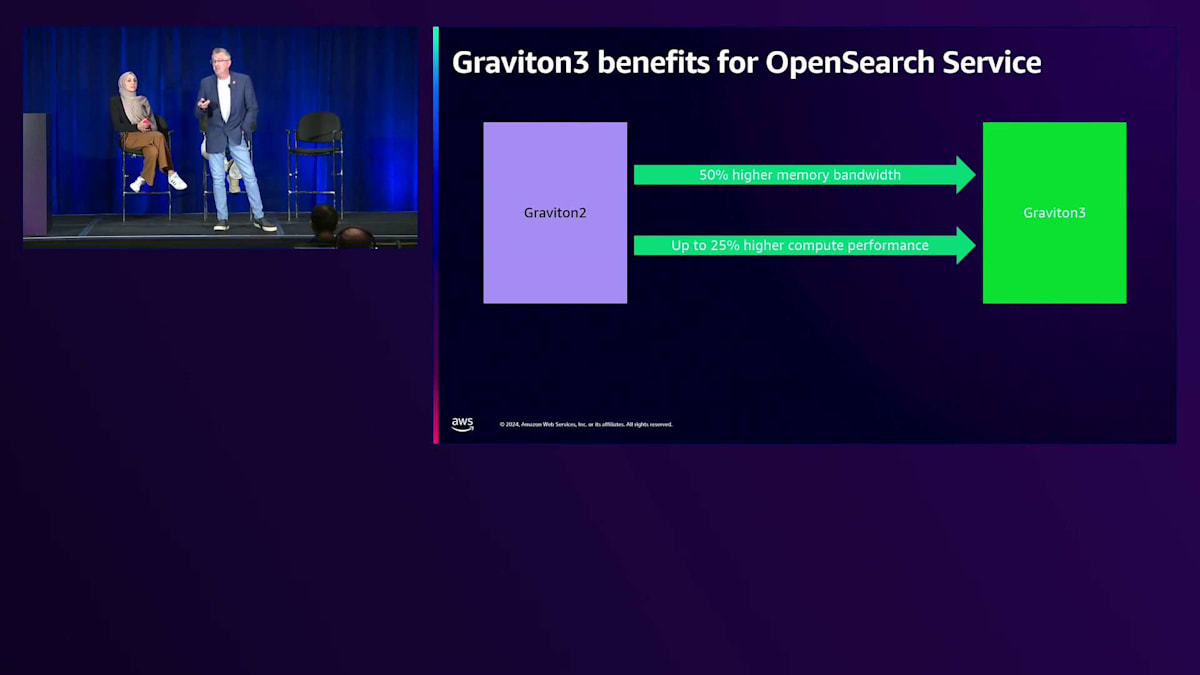
最近導入された Graviton3 プロセッサーは大幅な改善を提供します。 Graviton2 から Graviton3 に移行すると、メモリー帯域幅の利用率が50%向上し、CPU と検索操作間のレスポンスが速くなります。また、 最大25%の計算性能の向上も実現します。つまり、Graviton2 から Graviton3 にアップグレードすると、より高い CPU パフォーマンスが得られ、同じパフォーマンスレベルを維持しながらクラスターのスケールダウンが可能になる場合があります。
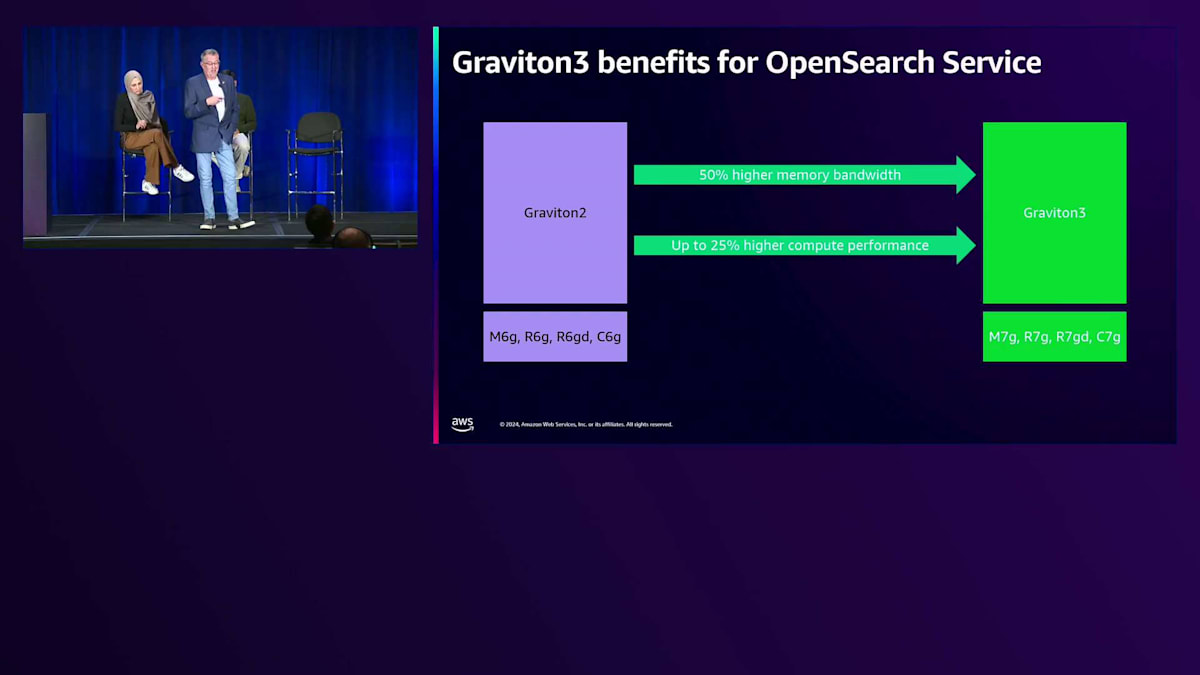
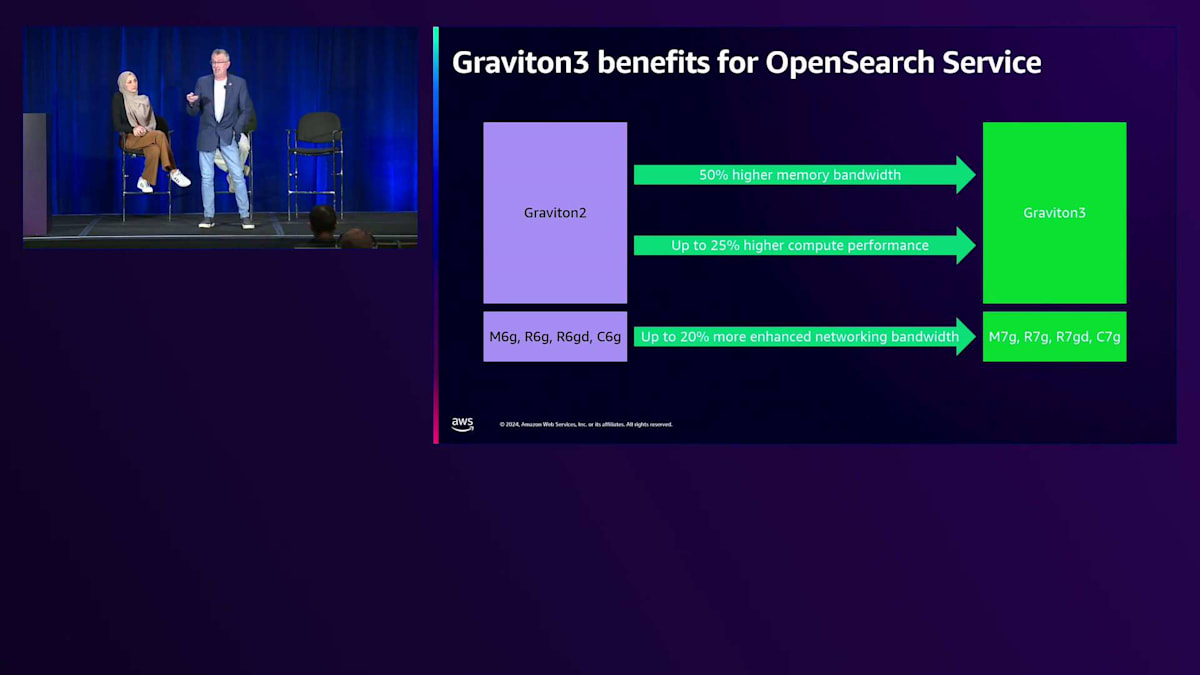
Graviton2 向けには M6、R6、 R6gd、C6 シリーズがあり、C、 M、R シリーズについては、同じインスタンスファミリーとサイズで比較可能な 7 シリーズインスタンスが利用可能です。ネットワーキング帯域幅が最大20%向上し、クラスター内のデータノード間の通信が高速化され、ネットワーク機能によってワークロードのパフォーマンスが向上する可能性があります。



Intel プロセッサについて、私たちは Intel Broadwell 上で I3、C、M5、R5 シリーズなど、さまざまなインスタンスタイプで 5 シリーズインスタンスを実行してきました。Intel Xeon Scalable では、 そのインスタンスファミリーに移行することで、30% 優れた価格性能比が期待できます。アップグレードにかかるコストは最小限ですが、テストシナリオによってはパフォーマンスの向上が大きく得られます。ストレージレイテンシーが最大 60% 低減され、 インスタンスがバックエンドストレージ(通常は GP3 ボリューム)とやり取りする際、はるかに高速になります。これにより、CPU、メモリ、ディスク間のデータ I/O 転送速度が向上し、ワークロードのパフォーマンスとレスポンスタイムが改善されます。

I3 インスタンスと Intel Xeon Scalable を搭載した I4i を比較すると、利用可能な最大インスタンスで最大 75 ギガビット/秒の ネットワークスループットを実現できます。コスト削減とパフォーマンス向上を目指してフリートを最新化する際は、これらのオプションを検討してください。お客様とコストについて話し合う際、私たちはよくクラスターのチューニングを行い、シャーディング戦略を練り、オンデマンドで実行しながらコストを削減するためのさまざまな最適化テクニックを使用します。コストを下げるためのあらゆる手法を駆使しながら、オンデマンドで運用しているのです。
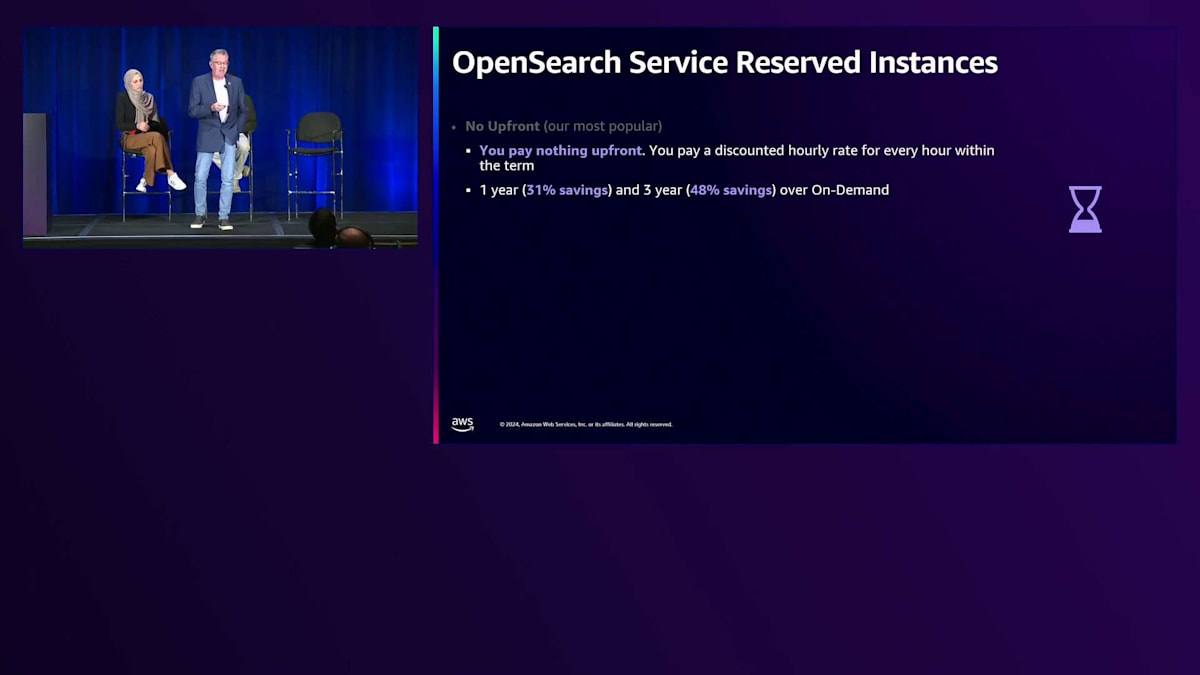
Reserved Instance について話したいと思います。多くの方が、Reserved Instance 契約を結ぶとインスタンスファミリー間を移動する柔軟性がなくなると考えています。通常、私はそういった懸念がある場合、1年間の Reserved Instance を検討します。 前払いなしオプションが最も人気があります。これは前払い金が不要で、割引された時間料金を支払うだけだからです。これらのワークロードを見渡すと、1年間の前払いなし RI で最大31%の節約、3年間では48%の節約が可能です。これは Amazon OpenSearch Service で得られる長期的な価値を考えると、かなり大きな節約となります。
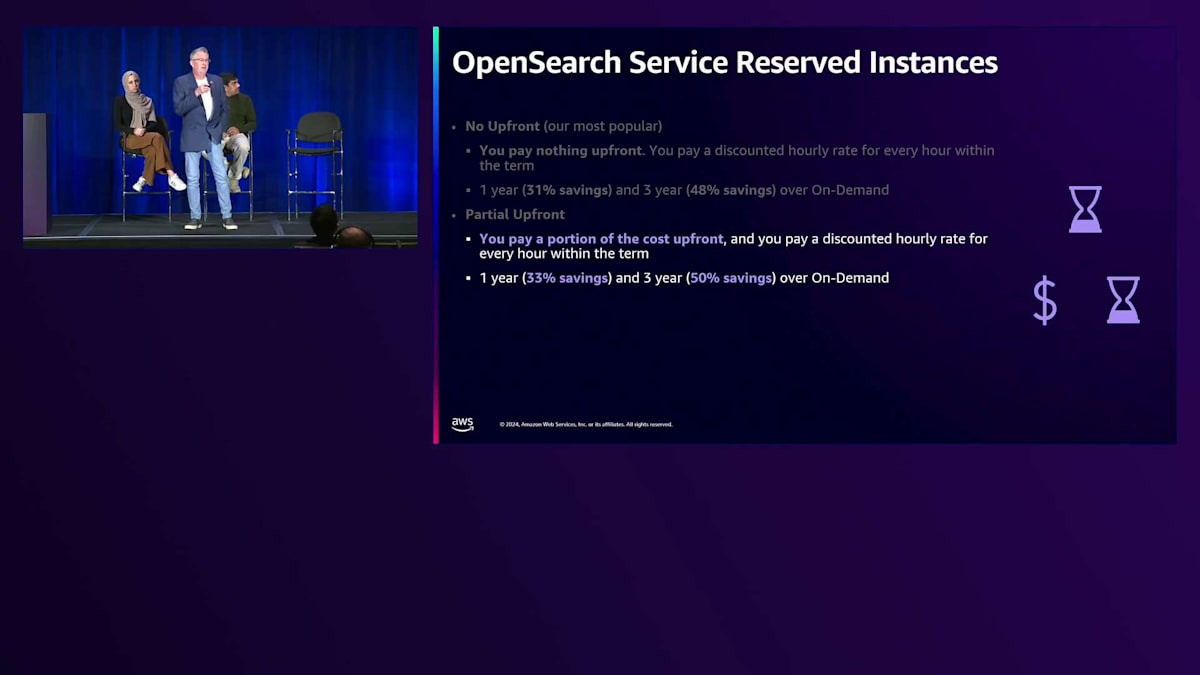

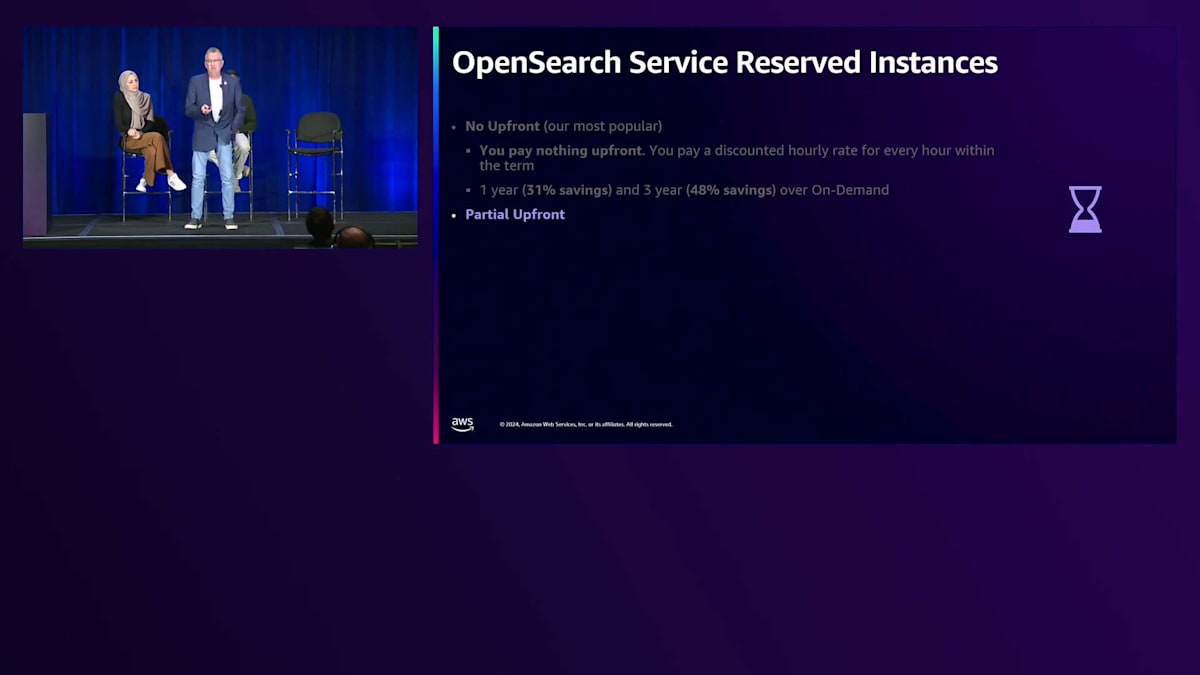
一部前払いとは、一定額を前払いし、時間料金も支払うというものです。コストの一部を前払いし、割引された時間料金を支払うことで、1年間の一部前払いで33%の節約、3年間の一部前払いではオンデマンドコストに対して約50%の節約を実現できます。 最後に、全額前払いオプションは、すべての費用を前払いで支払うものです。予算を計画的に管理したい多くの金融機関は、その年の支払いを済ませて、残りの期間は心配せずに済むことを望んでいます。この場合、1年契約で最大35%の節約、3年契約でオンデマンド比最大52%の節約を提供しています。



さて、お客様とクラスターのチューニングについて話し合う際、私たちはプロの技を紹介します。以前 AWS で一緒に働いていた同僚は、ユニークで面白いことができる方法についていつも議論していました。例えば、I3 インスタンスを使用している場合、Im4gn インスタンスにアップグレードできます。これは基本的にストレージの密度が2倍になるため、目的を達成するために必要な量が少なくて済みます。具体的なユースケースを見てみましょう:1日あたり2テラバイトの生データ、90日間のホットリテンション、 3つのアベイラビリティーゾーンにまたがる構成です。 Hajer や他のスペシャリスト SA と一緒に計算すると、適切なコストプロファイルが得られます。この場合、一貫したワークロードをオンデマンドで実行する場合、約45台の I3 インスタンス(各3,800ギガバイトのストレージ)が必要となり、このサイズのクラスターの月額オンデマンドコストは約67,000ドルとなります。



このワークロードを実行する際に、前払いなしの1年Reserved Instanceを調達した場合、月額約46,000ドルのみを支払うことになります。私のコスト最適化のテクニックを試して、同じストレージ容量でIm4gnを選択した場合、コストは基本的にデータ保管時のストレージ料金だけになります。前払いなしのReserved Instanceで、月額約27,000ドルになります。これは現状と比べて42%のコスト削減となります。エンタープライズのお客様、さらには小規模なセグメントのお客様も、担当のService SAにご相談ください。私たちがこれらの活動をサポートさせていただきます。



ストレージの階層化について説明しましょう。先ほど述べたように、私たちには様々なオプションがあります。ホットティアでは、IntelとGravitonチップの間で、最速のアクセスが可能で、データを追加するとコストは線形に増加し、OpenSearchのすべての機能を提供します。Amazon S3をバックエンドとするハイブリッドインスタンス、Amazon S3をバックエンドとするServerless、同じくAmazon S3をバックエンドとするUltraWarm、そして最近導入されたAmazon S3への直接クエリが可能なZero ETL機能を見ていくと、S3ティアにデータを保存することで大幅なコスト削減が可能になります。多少のレイテンシーは伴いますが、データとワークロードの耐久性を向上させることができます。

Zero ETLを使用すると、データは常にS3に置いておき、クエリ時に必要な場合にのみデータを取り込むことができます。コールドストレージでは、データはS3のコストでS3に保存され、必要な時にのみ取り込むことができます。3年や7年の法令遵守要件などのアーカイブ活動を考えると、Zero ETLとコールドストレージは、ウォームティアやホットティアと組み合わせることで、これらのユースケースに最適です。

Direct Queryは約4~5ヶ月前にリリースされました。素晴らしいのは、Amazon S3に保存されているデータにクエリを実行するパスが用意されていることです。S3上のデータに対してインタラクティブな分析を行い、データが保存されている場所で直接クエリを実行できます。すべてのデータをクラスターに取り込む必要はなく、バックグラウンドではSparkエンジンであるCerberusコンピュートを使用してデータをクエリします。場合によっては、後ほど説明するスキッピングインデックスや、可視化のための結果セットのみを取り込むマテリアライズドビューなどの機能を活用することで、パフォーマンスを向上させることができます。
仕組みとしては、Amazon OpenSearch Serviceでは、すべてのホットデータはホットティアに格納され、通常はアプリケーションログや迅速なレスポンスが必要なものが対象となります。VPCフローログ、WAFログ、その他の大量に取り込むとコストがかかる可能性のある発見的な分析に興味深いログについては、S3とZero ETLを使用してデータをクエリすることを検討してください。すべてのデータを取り込まなくても、データに対するダッシュボードや可視化が可能で、ホットデータとウォームティアやコールドティアのデータをうまく組み合わせることができます。
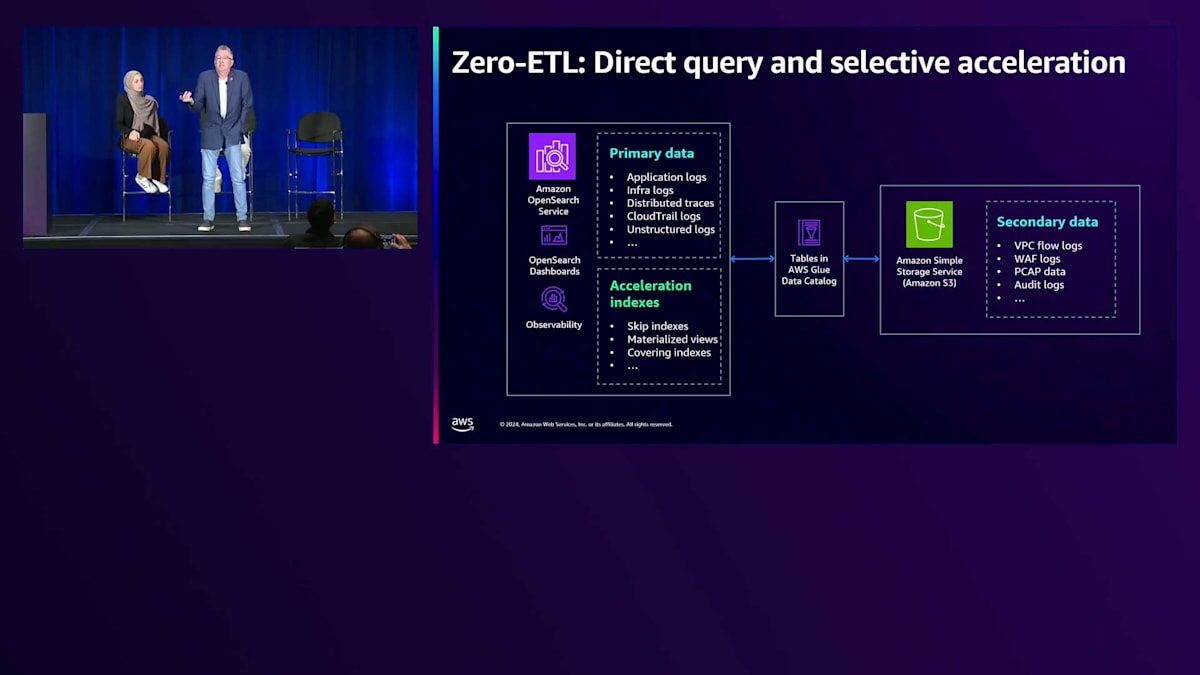
インデックスのスキップにより、特定のクエリを保存することができます。 すでに中身がないことがわかっているデータは無視できるため、S3上のオブジェクトをスキップすることができます。Materialized Viewsは、基本的に何十万、場合によっては何百万もの文書を1行または1つのドキュメントに集約したものです。Covering Indexesは、クエリを実行してS3から結果セットを取得するだけです。これらはすべて、コールドストレージ層を活用することを可能にします。
効率的なコスト最適化パターンとOpenSearchワークロードの活用ポイント

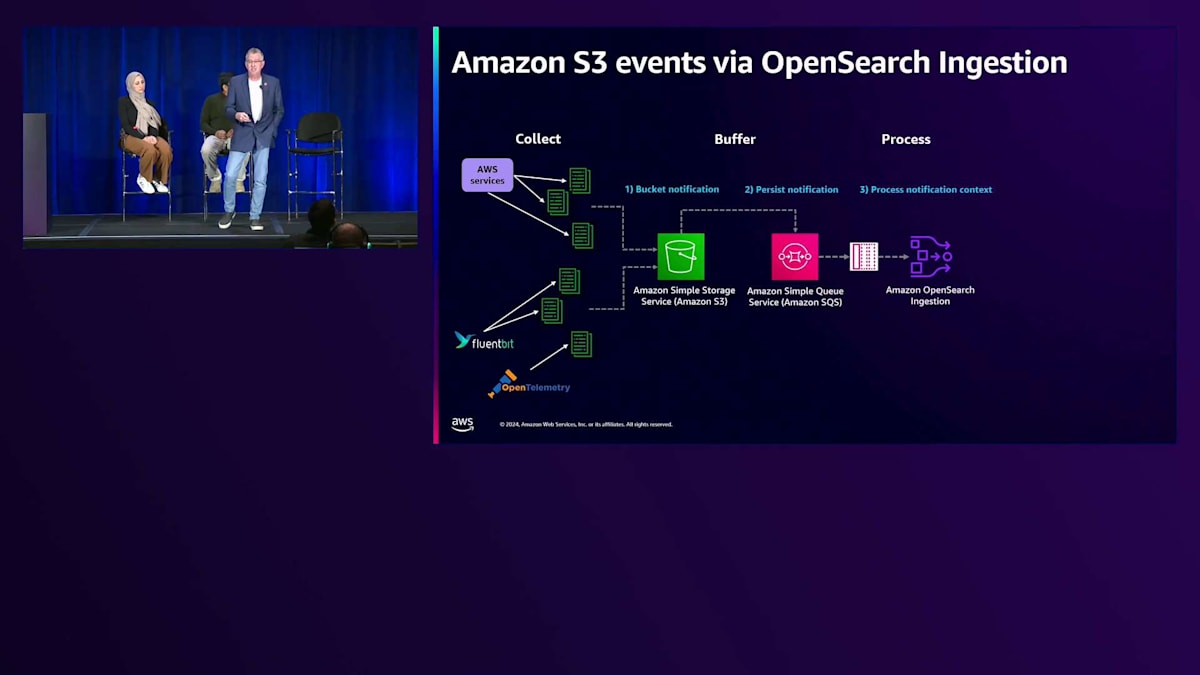
お客様と一緒に取り組んでいる効率的なコスト最適化パターンをいくつか見てみましょう。Pavanさんの会社では、そのうちの1つを活用しています。それが、Amazon S3イベントとOpenSearch Ingestionサービスを組み合わせたパターンです。S3への書き込みは、Fluent BitやOpenTelemetryエージェントなどの特定のエージェントでも行うことができます。 S3のバケット通知パターンとAmazon SQSを使用することで、OpenSearch Ingestionを使用して非常にシンプルなブループリントでデータのインデックス作成ができます。シンプルなセットアップとIAMルールを設定するだけで、データの取り込みを開始できます。これにより、すべてのログがS3に保存され、コンプライアンス要件を満たしながら、必要なデータのみをAmazon OpenSearch Serviceに取り込むという、コスト効率の良いパターンが実現できます。
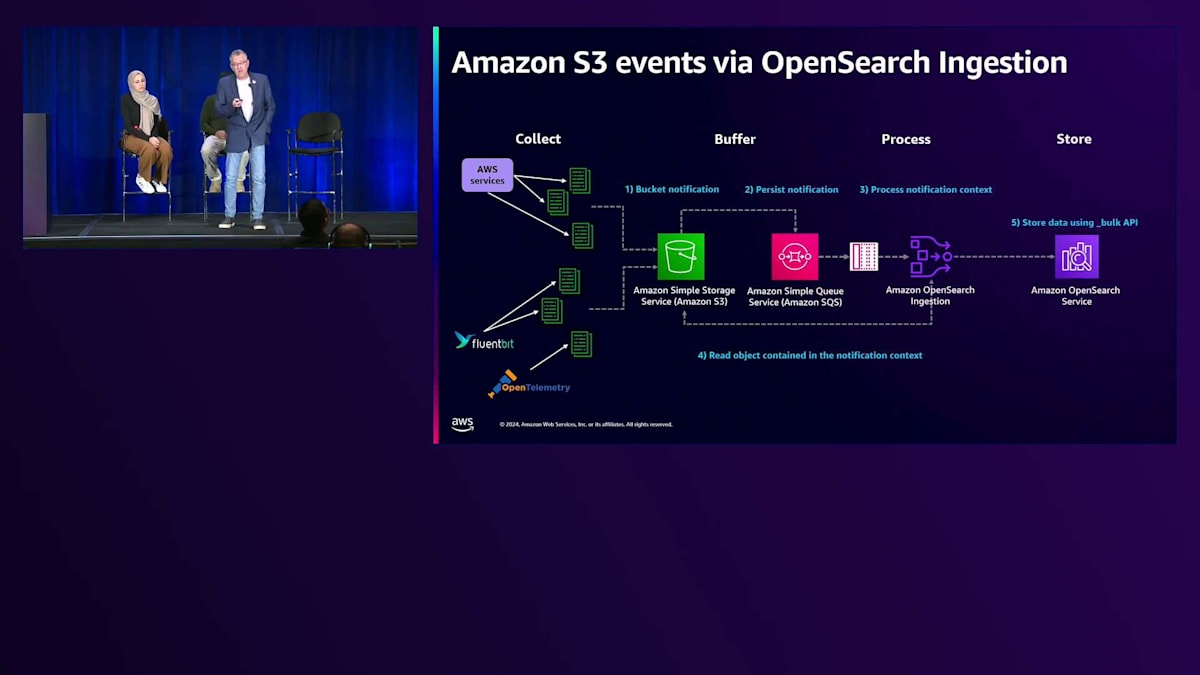
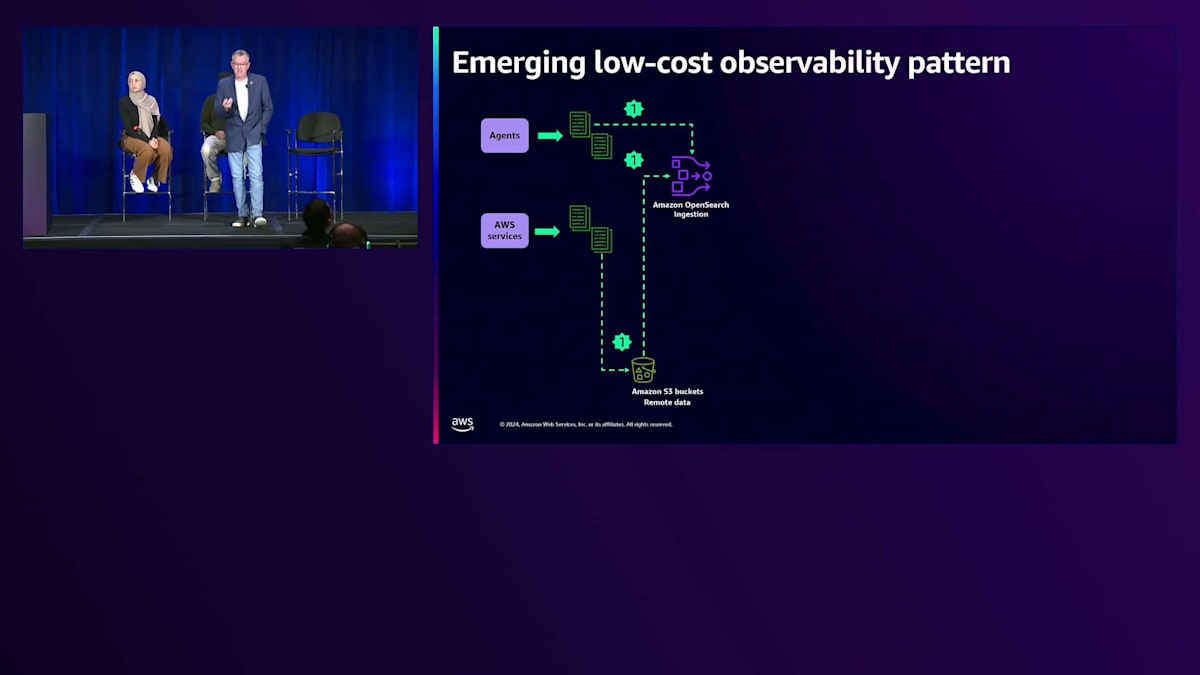
通知がトリガーとなってオブジェクトを開き、OpenSearchにインデックスを作成します。最近注目されている低コストパターンの1つが、Zero-ETLとOpenSearch Ingestionを活用する方法です。 これはどのように機能するのでしょうか?エージェントやサービスは、S3またはOpenSearch Ingestionのいずれかに書き込むことができます。OpenSearch Ingestionを使用して、任意のフォーマットで入ってくるデータをS3上のParquetに書き込むことができます。これは、より大規模なデータレイクやその他のクエリを実行したいものがある場合に最適です。あるいは、Zero-ETLのためにAmazon S3でDirect Queryを使用してS3上のデータにクエリを実行することもできます。Parquetは非常に効率的で、圧縮されており、コストが最適化されています。
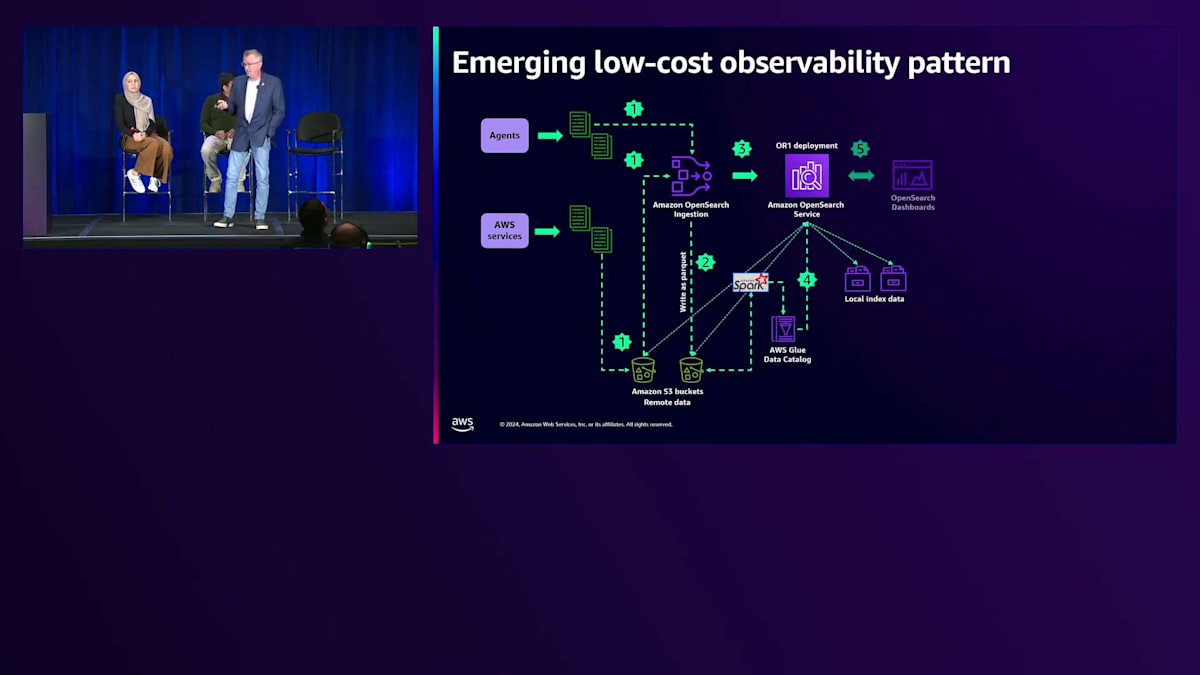
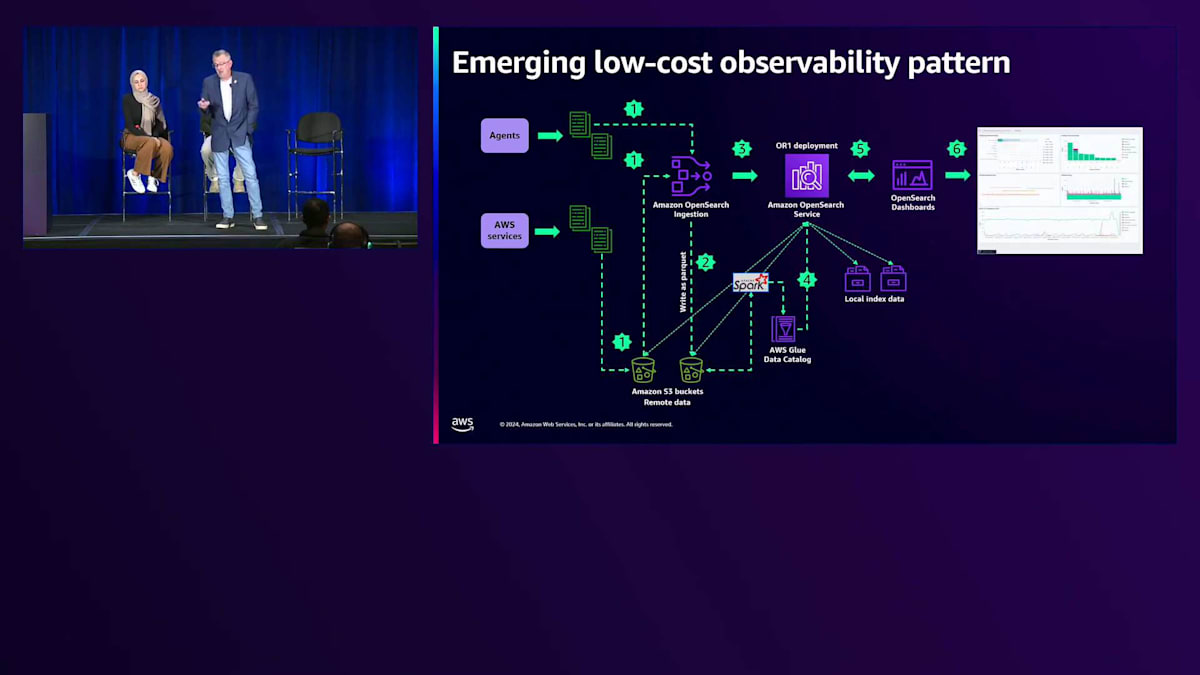
そうすると、現在ホットインデックスに取り込まれているデータ以外にはレプリカが必要なくなるため、そこで大きなコスト削減が可能になります。長期保存データやコンプライアンスのために必要なデータについては、S3に保存されているデータにクエリを実行できます。 最終的に、Amazon OpenSearch Dashboardsを通じて、S3に保存されているコールドデータとホットデータの両方に対して、 そして取り込んだかもしれないウォームデータに対してクエリを実行し、そのデータを可視化することができます。

OpenSearchワークロードを最大限に活用するためのポイントをいくつかまとめてみましょう。 まず、Serverlessを採用する余地があり、特定のワークロードに適している場合は、これを使用して運用の負担を軽減できます。また、チームが検索エンジンの構築方法や仕組みを学ぶ必要もありません。次に、Zero-ETLとUltraWarmを活用することで、データを取り込み、クエリ用にS3にバックアップする機能が得られます。Amazon S3でのZero-ETLは、もう1つのコスト削減メカニズムとして使用できます。可能な場合は、Reserved Instancesを活用することをお勧めします。
明日は別会場で11時から12時30分の間に、もう1つのコスト最適化に関するセッションがございます。最後になりましたが、本日はご参加いただき、ありがとうございました。皆様のre:Inventでの残りの時間が素晴らしいものになりますように。ご質問がございましたら、私か、Hajer、あるいは後方にいるPavanまでお声がけください。お時間を頂戴し、誠にありがとうございました。皆様とお話しできて光栄でした。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion