re:Invent 2024: SK TelecomがAWSで開発したTelClaude LLM
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - SK Telecom's TelClaude: Redefining telco CX with generative AI on AWS (TLC203)
この動画では、SK TelecomとAnthropicがAWSと協力して開発したTelco Large Language Modelについて解説しています。通信業界向けにFine-tuningされたこのモデルは、コンタクトセンターでの活用を主目的に開発され、Tel TaskとTel Instructという2つの重要なデータセットを用いて学習されました。その結果、Telco expertise scoreで38%の改善を達成し、カスタマーサービスエージェントからの満足度も90%を超える高評価を得ています。Real-time AssistやPost-callなどの具体的なユースケースが紹介され、Amazon Bedrockを通じて世界で初めてカスタムモデルを提供した事例として、スケーラビリティと信頼性の観点からAWSのインフラストラクチャーの重要性も強調されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
SK TelecomとのAI協業:コンタクトセンターのイノベーション

ご参加いただき、ありがとうございます。 本日は、SK Telecomとの協業、特にコンタクトセンターのユースケースに向けたクラウドモデルのファインチューニングについてお話しできることを大変嬉しく思います。本日のプレゼンテーションは、少し異なる形式で進めさせていただきます。Eric Davisが一緒に登壇する予定でしたが、残念ながら参加できなくなってしまいました。そこでEricが自身のパートを事前に録画してくれましたので、それを活用させていただき、私からは業界の概要やユースケース、そしてEricのプレゼンテーション内容についての導入をさせていただきます。

まず、アジェンダについてご説明させていただきます。状況や背景、そしてユースケースについてお話ししますが、今回のセッションは、Large Language Modelのファインチューニングにおけるプロセス、課題、そしてメリットに興味をお持ちの方にとって、非常に有意義な内容になると思います。私たちはこれらを「高付加価値ワークフロー」と呼んでいますが、プレゼンテーションの中で、Generative AIを活用して価値提供を飛躍的に向上させる方法についてもお話しさせていただきます。
通信業界におけるカスタマーサービスの課題と機会

まずは通信業界とコンタクトセンターについて説明させていただきます。これはSK Telecomが最初に注目したユースケースでもあります。多くの業界と同様に、通信事業者のお客様は、自分たちの都合に合わせたサービス提供を求めています。つまり、いつでも、どこでも、どんな方法でも - チャットであれ、実店舗であれ、どのような形態でもサービスを受けられることを期待しています。しかし、通信業界において、主要な接点や対話手段は依然として電話です。およそ80%の顧客接点が、お客様がコンタクトセンターに電話をかけることによって生まれています。
参考までに、北米の大手通信事業者の場合、年間約10億件の顧客接点があり、これは40億から50億分という膨大な通話時間を生み出しています。このスケールは非常に大きく、それゆえに最適化の機会も大きく、顧客体験の大幅な改善とコスト削減の可能性を秘めています。実は、この大量の通話量こそがチャンスなのです。なぜなら、通信事業者へのお客様からの問い合わせの60〜70%は、請求や契約に関連するものだからです。これらは一般的な対話パターンや意図であり、マッピングや理解、自動化が可能なものです。
お客様の期待値は以前より確実に高まっています。パーソナライズされたサービスへの期待、お客様のニーズを理解してサポートすることへの期待が高まっているのです。この期待の高まりは、Amazonのようなデジタルネイティブ企業が、Webでの顧客体験やスムーズな対話に注力してきたことが要因です。その結果、あらゆる業界でお客様の期待値が上昇しているのです。

通信業界には様々な顧客接点があり、他の業界と比べてより複雑だと言えます。店舗に直接来店されるお客様、チャットでのやり取り、電話での対応、Webサイトの利用、モバイルアプリの使用など、多岐にわたります。これらすべてを統合し、カスタマージャーニーを理解し、そのジャーニーが良いか悪いかを判断することは非常に困難です。実際、通信事業者は全般的にこれらの期待に応えられていないのが現状です。長い待ち時間や、リソース不足により店舗から離れていってしまうお客様の存在など、フィードバックからその課題が見えてきています。私たちが目指しているのは、これらすべてを統合し、どのようにしてこの体験を改善できるかを理解することです。
また、コンタクトセンターは、単なる顧客の問題に対応するコストセンターから、収益を生み出すプロフィットセンターへと変化しています。McKinseyのレポートによると、今後の増分収益の最大60%がコンタクトセンターでの対応を通じて生み出されると予測されています。これらの対応は、クロスセルやアップセルの機会として捉えられています。私たちが協業している通信事業者の中には、コンタクトセンターでのアップセル成功件数に関する指標や目標を設定し始めているところもあり、顧客体験を向上させるための新しい目標が設定されています。
Telco Large Language Model:通信特化型AIの必要性
私はSK TelecomのAI Tech Collaboration GroupのVPを務めるEric Davisです。SK Telecomに入社して6年になりますが、これまで様々な自然言語処理プロジェクトを主導してきました。最近では、AnthropicとAWSとの協業で開発したTelco Large Language Modelを担当しています。多くのチームや人々が関わる大規模な共同プロジェクトであり、通信業界に大きなイノベーションをもたらしたこの取り組みについて、今日皆様にお話しできることを大変嬉しく思います。

本日最初のトピックは、なぜこのTelco Large Language Modelを構築する必要があったのかという点です。他の企業がChatGPTにプロンプトを入力するだけで製品をリリースできたという話を聞いたことがあるかもしれません。SK Telecomでも最初はそのアプローチを試みましたが、私たちのニーズを満たすことができませんでした。 Large Language Modelは素晴らしい技術ですが、同時に「何でもできるが、どれも中途半端」という状態でした。ギリシャ詩について学びたければ、モデルにギリシャ詩を生成させることもできます。しかし、私たちのユースケースはもっと具体的でした。通信分野に特化したモデルが必要だったのです。

通信分野におけるタスクとは何か?どのようなニーズがあるのか?これらのニーズに応えるため、私たちはモデルのチューニングを行う必要がありました。まず第一に、製品やサービスの理解です。ユーザーが電話やその他の方法で問い合わせる際、製品やサービスに関する多くの質問があります。そのため、これらの製品、サービス、プランを認識し理解することが非常に重要です。ベースモデルは、そのままではこれを提供できません。第二に、製品のレコメンデーションと選択です。お客様は新しい製品について問い合わせをしますが、ベースモデルはある程度認識はできても深いレベルでの理解には至りません。私たちは、お客様と製品・サービスの両方を深く理解し、適切な製品をお客様にレコメンドできる必要があります。 第三に、意図の認識です。トラブルシューティングが必要な問題について、多くの電話やチャットメッセージを受け取ります。これらの意図を理解し、アクションを起こすことが非常に重要ですが、これもベースモデルがそのままでは対応できない機能です。これらの理由から、私たちはAnthropicと協力して、これら3つの重要なタスクに対応できるようにベースモデルのチューニングを行うことにしました。
高価値ワークフローへのGenerative AIの適用

私たちが通信事業者向けのGenerative AIの適用について考え始めた時、この1年間はPOCと実験的な取り組みが中心でした。現在は、POCから本番環境への移行を通じて、Generative AIから実際の価値を生み出そうとする動きが本格化しています。結局のところ、本番環境のワークロードを実装するまでは、Generative AIは何の価値も生み出さないのです。通信事業者との協業や対話を通じて、現在私たちが提唱しているのは、Generative AIをビジネスに適用する際には、「高価値ワークフロー」と呼ばれるものに焦点を当てるべきだということです。これらは、収益、コスト、顧客満足度の指標を持ち、最適化の余地が大きいワークフローです。これらの特定のワークフローに特化してモデルを適応させることで、Generative AIを適用した際に、ワークフローの価値が飛躍的に向上することを確認しています。

これから、これらの具体的な指標について、なぜそれらが体験を向上させ、最終的にコストプロファイルとモデルのパフォーマンスを改善するのかについてお話しします。 次のセクションでは、Ericが彼らのデータを使用したClaudeモデルのFine-tuningについて、そしてその過程で生み出された価値について説明します。現在、マネージドサービスでAnthropicモデルをFine-tuningできるのは、AWSだけです。そのため、私たちはAmazon Bedrockで構築したものを非常に誇りに思っています。
簡単に言えば、私たちやSK Telecomが行っているのは、この文脈では、コンタクトセンターに焦点を当てたラベル付きデータを使用してモデルをFine-tuningすることです。これは大まかに言えば、新しい情報でモデルの重みを更新することを意味します。SK Telecomの業界における意味論、文脈、使用される言語をモデルが理解できるように、段階的に情報を追加しているのです。さらに、これは韓国語であるという複雑さも加わります。最先端のFoundation Modelの多くは主に英語が中心です。そのため、このFine-tuningの多くは韓国語を使用することにも重点が置かれました。これらの要因を考えると、SK Telecomが達成した成果はさらに印象的なものとなります。
SK TelecomのTelco LLM:開発プロセスと特徴

では、なぜTelco LLMが必要なのかが分かったところで、Telco Large Language Modelとは何かを説明させていただきます。多くの企業がLarge Language Modelを構築していますが、主要なプレイヤーはOpenAIとAnthropicです。OpenAIはGPTで最初のモデルを作り、もう一つの主要プレイヤーがAnthropicです。 SK Telecomでは、通常、内部で開発を行ってきました。このスライドにあるように、私が以前担当していたA.X Large Language Modelという独自のモデルを持っています。しかし、会長からトップダウンで、私たちはAI企業としてナンバーワンになる必要があり、グローバル企業にもならなければならないという指示がありました。その時点から、大手テクノロジー企業とのパートナーシップやコラボレーションを大幅に増やしていきました。
このプロジェクトでは、先ほど申し上げたように、TelClaudeと呼んでいるものを構築するためにAnthropicとパートナーシップを組みました。このプロジェクトの目的は、通信ドメイン向けにこのベースモデルを適応・最適化することでした。私たちは大量のドメイン内データを使用し、Anthropicと多くのFine-tuning実験を行って、通信ドメインのエキスパートとなり、そのドメイン内でアクション(検索やAPIの呼び出しなど)を実行できるこのTelco Large Language Modelを作成しました。このモデルが完成すると、ユースケースの展開がはるかに容易になりました。ユースケースについて話す際、これらは社内で取り組む必要のあるものです。今年のSK Telecomの焦点は、社内の業務効率化とプロセスの効率化にありました。
私たちはコールセンターに焦点を当て、チャットや音声、マルチモーダルなど、さまざまな接点でお客様とつながることを重視してきました。この Telco LLM を手に入れてからは、目の前のユースケースに合わせてモデルをチューニングすることが非常に容易になりました。これにより、非常に強力なモデル、強固な基盤を得ることができ、将来に向けて良いポジションを確保することができました。ただし、これらの製品やサービスを提供した後も、関連するデータを収集し、モデルを継続的に更新しています。はっきりさせておきたいのですが、このモデルは静的なものではなく、ユーザー体験と社内オペレーションの向上のため、常に更新を続けています。

では、Telco LLM とは何か、なぜ必要なのかを理解したところで、Telco LLM の具体的な仕組みについてお話ししましょう。 繰り返しになりますが、OpenAI の GPT モデルでも Anthropic のモデルでも、どのベースモデルから始めるかは問題ではありません。Telco LLM が特別なのは、スライドに示されているこのピラミッドのような構造にあります。これはモデルだけでなく、Fine-tuning されたモデルだけでもなく、製品やサービスをより迅速かつ容易にリリースするために、スタック全体を構築していく取り組みなのです。SK Telecom では何故かピラミッドが好きで、CEOが AI ピラミッド戦略を示しました。これは製品やサービスをより迅速かつ効率的にリリースできる、すぐに使えるLLMの戦略です。このピラミッドを見ると、基盤層がベースモデルになっています。

私たちは迅速な市場投入を目指して、意図的に Anthropic とパートナーシップを結びました。そして、前のスライドで述べたように、このモデルは目の前のタスクのユースケースに対応していなかったため、モデルの Fine-tuning に多大な努力を注ぎました。ここで満足することもできましたが、さらに数歩先に進みました。これらのモデルはチャットが得意ですが、私たちは具体的なアクションを起こしたかったので、バックエンドの API を呼び出す方法や、実際に情報を取得する方法の確立に多くの時間を費やしました。そこで重要になってくるのが Tool レイヤーです。

バックエンドシステムとの連携は極めて重要でした。私たちは素晴らしいナレッジシステムを持っていますが、Telco LLM でそれを活用できなければ意味がありません。ナレッジベースシステムとの統合作業には多くの労力を費やし、関連する事実をどのように見つけ、それをエンドユーザーにどのように提示するかに注力しました。それ以外にも、複雑なクエリが多かったため、オーケストレーションも非常に重要でした。オーケストレーションは、クエリを適切なバックエンドシステムにルーティングし、それらのクエリにどのように応答するかを決定します。これは単なるパイプではなく、クエリを適切なバックエンドシステムと実際のタスクに振り分けるスマートルーターあるいはスマートオーケストレーションなのです。

最後のレイヤーは Prompt Engineering でした。ユーザーを驚かせ、喜ばせるために、トーン、スタイル、フォーマットを測定することを確実にするため、Anthropic と協力して Prompt Engineering に相当な時間を費やしました。このスライドで伝えたいポイントは、これが単なるモデルではなく、私たちが段階的に構築してきたエコシステムだということです。これは今や完成品となり、製品やサービスをより迅速かつ効率的に市場に投入することを可能にしています。これは SK Telecom 内部にとってもメリットがあり、また外部のエンドユーザーやお客様にとってもメリットのある取り組みとなっています。
Telco LLMの性能評価と開発プロセス

このモデルの利点や、ベースモデルと比較してどのように優れているのかを判断する方法について、皆さん気になっているのではないでしょうか。SK Telecomでは一歩先を行くことを心がけており、特許出願中のTelco LLM Capacity Indexを開発しました。このインデックスは、モデルのパフォーマンスを評価する際の3つの重要な側面を測定します。1つ目はパフォーマンス、つまり専門性です。このモデルがTelcoドメインをどれだけ理解し、適切なアクションを取れるかということです。これについても、特許出願中のTelco expertise scoreという指標を開発しており、Telcoドメインにおける重要タスクでのモデルのパフォーマンスを総合的に評価します。
2つ目の側面は効率性で、具体的にはスピードとコストに注目しています。これらのモデルは非常に大きく処理が遅いことで知られているため、チューニングと最適化を通じて、より速い回答提供を実現したいと考えました。コストも大きな課題です。モデルの運用コストは大幅に下がってきていますが、何百万もの問い合わせを処理する場合、すぐに非常に高額になってしまいます。私たちは入力と出力の両方を最適化し、トークン数を削減することでコストを最適化しました。3つ目の指標は開発期間です。先ほど述べたように、既製のモデルを持つ目的は、製品やサービスの市場投入までの時間を短縮することです。このモデルの導入前後で、本格的なサービスの開発にかかる時間を比較し、効率性の改善率を測定しています。

これらが、このモデルのパフォーマンス、適用方法、そしてパートナーとともにモデルをチューニングすることで達成しているコスト削減を示す3つの重要な指標です。これは4つの主要なステップからなる、非常に緊密な共同開発プロセスです。SK Telecomは言語に精通しており、当然ながらTelcoドメインにも精通しています。このプロセスでは、私たちがデータ構築を担当しています。昨年の私の宿題は、Telco LLMが実際に何を意味するのかを定義することでした。素晴らしい言語学者チームとの慎重な検討の結果、モデルのチューニングに使用する主要タスクと主要データセットを定義しました。

2つ目のステップは、ファインチューニングです。A.X LLMで行ったように社内で実施することもできましたが、より早く市場に投入するためにAnthropicと協力しました。彼らはモデリングとファインチューニングのエキスパートです。データの混合方法やウェイト付けについて私たちが意見を提供し、真の意味での協働となりました。3つ目のプロセスは、AnthropicならではのRLHF(Reinforcement Learning from Human Feedback)です。これはChatGPTを「良い」から「素晴らしい」レベルに引き上げ、人々を魅了した秘密の要素です。Anthropicがこのサービスを提供してくれたため、私たちは選好データの収集と、エンドユーザーが望む応答を実現するためのモデル最適化に多大な時間を投資しました。

ドメインと言語のエキスパートとして、私たちはこのモデルの性能の良さを評価し、改善が必要な領域を特定し、このモデルを完全に次のレベルに押し上げるために何をすべきかを判断する責任があります。
Telco LLMの実装:コンタクトセンターでの活用事例
これは非常に反復的なプロセスでした。1回のサイクルで完了とはせず、各イテレーションは約2週間続き、1年かけて約24回のイテレーションを実施しました。その結果、モデルは「まあまあ」のレベルから「素晴らしい」、そして「十分に実用可能」なレベルへと進化しました。私たちはこの成果を誇りに思っています。

ここで、SK Telecom、Anthropic、AWSの3社間のコラボレーションについてお話しします。AWSには Generative AI Innovation Centerというプログラムがあり、データサイエンティストやストラテジストがお客様と協力して、Generative AIの導入を加速させています。これには、実証実験の構築、戦略策定の支援、ユースケースやロードマップに関するガイダンスが含まれます。Generative AI Innovation Centerには、当初AnthropicのClaudeモデルのFine-tuningに特化していたModel Customizationプログラムなど、様々な機能があります。私たちはFine-tuning APIを開発し、Generative AIイノベーションチームがお客様と協力してモデルのFine-tuningを行ってきました。
これが、SK Telecomとの取り組みの一部であり、AnthropicとSK Telecomとの3社協力により、Fine-tuningとRetrieval Augmented Generationの最適化に関してこのような成果を上げることができました。Generative AI Innovation Centerは、AWS Silicon上でのFine-tuningにも対応を広げています。今週、私たちはTrainum 2を発表しましたが、現在Trainumでの取り組みを進めており、Trainum 2も加わることで、お客様のコストパフォーマンスの向上支援に重点を置いています。

これは3社間のコラボレーション、それぞれの役割、そして各社が持ち寄った能力を示しています。Anthropicは、Amazon Bedrockでホストされている最高峰のモデルの一つと考えられているClaude系モデルを提供しています。私たちはGenerative AI Innovation CenterとBedrockチームを通じて協力し、モデルをホストし、AnthropicとのコラボレーションでAPIを使用してFine-tuningを行いました。AnthropicとSK Telecomは昨年密接な関係を築き、AWSとSK Telecomを結びつけてこのソリューションを構築しました。
私たちは通信業界向けのビジネスユニットの一部として通信業界に注力しており、業界とユースケース、そして提供しようとしている価値を理解しています。これはSK Telecomのユースケース要件と合致しています。SK TelecomはデータとAIの専門知識を提供しました。SK Telecomは2020年初頭のTransformerアーキテクチャの登場以来、モデルのトレーニングとFine-tuningに深く取り組んでおり、最先端の技術を追求してきました。これは3社すべての間で素晴らしいコラボレーションとなり、優れた成果を上げることができました。

SK Telecomには深い専門知識があり、私たちには言語に関する専門知識があり、これらのモデルをどのようにベンチマークするかを知っています。このプロセスにおいて、この図の下半分は、SK Telecomがデータに関する責任を持っていることを示しています。これには、データの構築方法や高品質であることの検証、そしてベンチマークと評価基準が含まれます。一方、この象限の上半分は、この場合Anthropicであるビッグテックの責任を表しています。これはFine-tuningやRAGの実装を含むモデルのチューニング自体です。彼らはモデルやアルゴリズムの専門家なので、この作業分担は自然なものでした。
しかし、これは単にデータを投げ渡して、モデルを構築してもらうのを祈るだけということではありませんでした。私たちが入力を提供し、彼らがデータやベンチマークについて意見を提供し、また逆に、私たちがモデルのチューニング方法についての意見やフィードバックを提供するという、非常に深い協力関係でした。ここで強調したいポイントは、単にお金やデータを投げ渡して良い結果を期待するのではなく、Anthropicの開発チームと実際に協力して作業を進めたという点です。

その開発チームはどのようなものだったのでしょうか? 私たちはPrompt Engineerと一緒に仕事をする特権を得ており、現在も協力関係を継続しています。彼は、これらのAnthropicモデルのパフォーマンスを最大限に引き出すためのPromptの最適化について、本当に良いアドバイスをしてくれました。モデルのFine-tuningを手伝ってくれる人材が必要だったので、Supervised Fine-tuningとRLHFの専門知識を持つ素晴らしいResearcherにアクセスすることができました。このことは、データの使い方を知り、結果を引き出せる人材がいたということで、成功の可能性が高まりました。後で詳しく説明しますが、モデルのサービング提供も非常に重要で、Infra Engineerにもアクセスできました。彼らは、モデルを最適化し、特にGPU上で完璧に動作することを確認する責任者です。速度とコストの議論に関わるLLM容量指数を覚えているかもしれませんが、これらの側面を最適化するために、これらの人々の助けが必要でした。
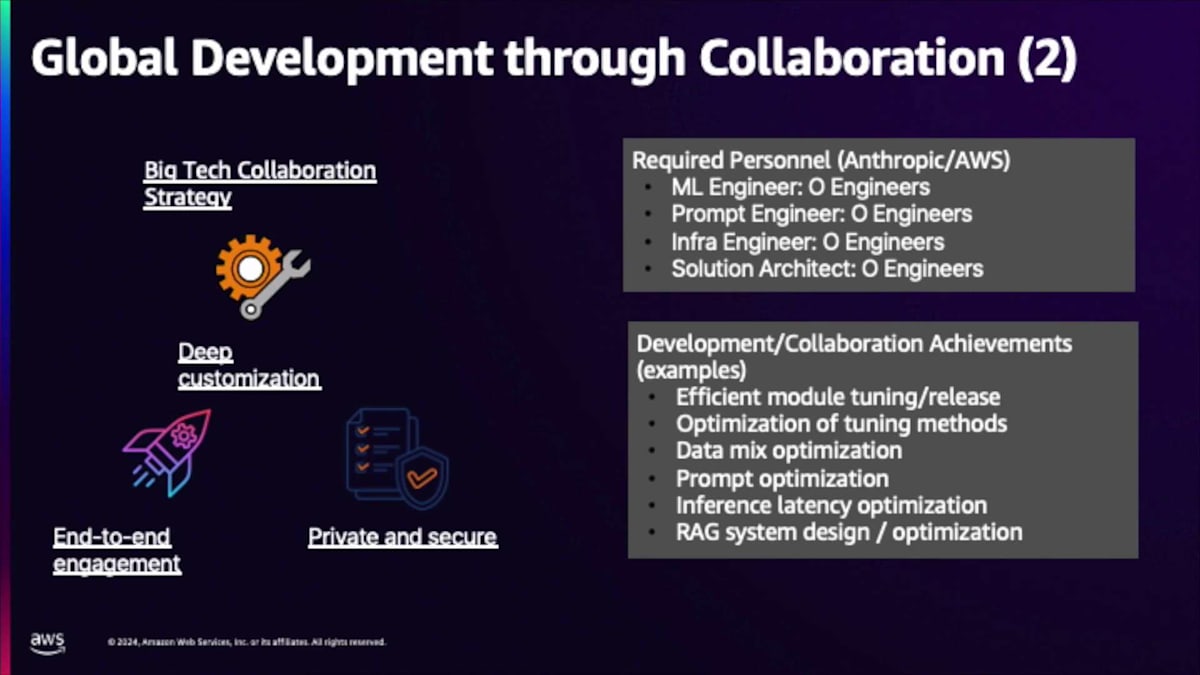
最後の側面はSolution Architectでした。多くのテンプレートがありますが、すべてに適用できる単一のテンプレートはありません。Architectは、Retrievalシステムの接続方法、バックエンドの接続方法、フローがどのようになるべきかについて提案してくれました。現場で私たちに合ったソリューションを最適化し、見つけ出すのを手伝ってくれる人がいたことは、もう一つの重要な差別化要因でした。 重要なのは、これらの様々な役割にわたって、このプロジェクトに専念するフルタイムのリソースを得られたことで、これによってプロジェクトを前進させ、確実に成功し、期限内に完了することができました。
Promptingは単純明快に見えるかもしれませんが、多くのタスクがあります。これらを順番に、タスクA、タスクB、タスクCと呼び出していくと、コストが本当に積み重なり、非常に遅くなります。私たちは、速度を改善しコストを最適化するために、多くのタスクを一度に呼び出すためのPromptを最適化する「Mega Prompt」に取り組みました。Fine-tuningは単純に見えるかもしれません - データを投入すれば、モデルができあがるというように - しかし、実際はそうではありません。私たちは、人間が小学校から中学校、高校へと学んでいくのと同じように、モデルをチューニングできるCurriculum Learningを使用しました。簡単なタスクから始めて、中程度のタスクに進み、難しいタスクで終わります。このアプローチは本当に効果があり、はるかに良い結果を得ることができました。

Solution Architectは、RAG(Retrieval Augmented Generation)の実装を支援してくれました。これはシステムの重要なコンポーネントで、AIが誤った情報を作り出したり嘘をついたりすることなく、真実を伝えることを保証するものです。彼らは、適切な知識に対して適切な回数のコールを行えるよう、システム設計の最適化を支援してくれました。 先ほど、私たちが「高付加価値ワークフロー」と呼んでいるものへのGenerative AIの応用について話しましたが、これはカスタマーケア組織の業務フローにGenerative AIを組み込んだ典型的な例です。
右側のACW(After Call Work)から見ていきましょう。これは、エージェントが通話を終えた後に行うすべての作業を指します。通常、通話後には何が起こったのか、どのような対応を行ったのか、問題は解決したのかなどを要約します。また、後の分析のために通話を分類するドロップダウンメニューなどを使って、通話の区分けを行います。これらの作業にはエージェントの時間と労力が必要で、その間は当然新しい電話に出ることができません。しかし、この過程で得られる情報は、何百万件という規模で集まると、非常に価値のある分析対象となります。
何百万件もの通話を分析し始めると、パターンが見えてきます。SK Telecomはピラミッドについて語るのが好きですが、私たちはフライホイールについて語るのが好きです。このフライホイール効果は、得られた情報を活用して、左側に示されているFirst Call Resolutionの領域にフィードバックすることで、ボットにその知見を組み込むことができます。ボットは、顧客がどのような問題で電話してきたのか、それらの問題がどのように解決されたのか、どのようなアクションが取られたのか、どのAPIが呼び出されたのかを理解できるようになります。
これは単に知識ベースにアクセスして正しい回答を得るだけの話ではありません。Ericがモデルのファインチューニングについて話していた際に触れていたように、その一部には実行すべきアクションやどのAPIを呼び出すべきかを定義することも含まれています。つまり、情報だけでなく、アクションも重要なのです。Average Handle Time(平均処理時間)に話を移すと、これは通話にかかる時間のことを広く指しており、通信会社や全てのコールセンターは、この通話時間をできるだけ短くしたいと考えています。それは顧客の質問に答え、問題を解決し、効率的かつ効果的に対応できたということを意味します。参考までに、北米の大手通信会社の場合、1通話あたり平均1秒を節約できれば、約300万ドルの削減になります。その規模でAIと自動化によって通話を10秒短縮できれば、年間3,000万ドルの削減となります。
このエージェントアシストのコールフローを最適化することで、いかに急激に結果と価値を向上させることができるかがお分かりいただけると思います。一方、このような特定のフローにおいて、ファインチューニングされていない一般的なモデルを使用した場合、多くの情報をコンテキストとして送信する必要が出てきます。これは応答に遅延を引き起こし、レスポンスを遅くします。ドメイン知識やセマンティクス、取るべきアクションを理解できないため、おそらく正確で十分な深さのある応答を得ることができず、エージェントは顧客に適切な情報を伝えることができません。時間の経過とともに、エージェントはこのワークフローでAIに依存するようになるため、AIが適切な応答を提供できない場合、エージェントは間違った情報を伝えていることに気付かない可能性があります。
通信事業者にとって非常に重要なワークフローです。FCR(First Call Resolution)については、お客様に適切な回答を提供し、適切なコンテキストを把握し、実際に人が対応する前にそれを確実に捉える必要があります。このFlywheel(好循環)について説明すると、フロントエンドのChatbotに知能を追加することで、通話の意図、取るべきアクション、そしてお客様対応に必要な情報を実際に理解できるようになります。これらはすべてCSAT(Customer Satisfaction Score)とNet Promoter Scoreに反映されます。これが20%向上すると、通信事業者にとって大きな収益につながります。つまり、お客様の満足度が高まることでChurn(解約率)が低下するということです。顧客生涯価値はChurnの関数なので、Churnが低ければ低いほど、顧客生涯価値は長くなり、それらの顧客がより多くの収益を生み出すことになります。
Telco LLMの成果と今後の展開

これらはすべて、私たちが高価値ワークフローと呼ぶものに集約され、一般的に、ドメイン固有のタスク固有の知識を適用することで、これを本当に変革することができます。この分野で広く成果が出始めています。Laura Landによる素晴らしい論文があり、31の異なるタスクにわたる10の異なるFoundation Modelについて説明しています。最終的に310の異なるモデルがあり、平均してベースモデルを34ポイント上回り、GPT-4を10ポイント上回りました。これらはFalconやMistralなどの小規模なモデルですが、これに対して最適化されています。一般的に、これらの高価値ワークフローにデータを適用することで、価値が飛躍的に向上するという考え方です。また、ここで気づいていただきたいのは、評価について話すとき、新しいモデルがリリースされ、評価が行われます - 今週もNovaモデルで他のモデルと比較しました。最終的には、これをビジネス価値に変換し、ビジネスに適用する必要があります。
ROGUEスコアは、コンタクトセンターの誰かにとってはあまり意味がありません。重要なのは、レイテンシーが低く、精度が高く、幻覚(Hallucination)がほとんどないか全くないモデルを持っていることです。9月のTM Forumイベントで、AT&Tはレイテンシーと精度がGenerative AIの重要な機能であり、これらは妥協しないと述べていました。モデルの精度が90-95%未満の場合、誤った情報を提供する可能性があるため、そのモデルに価値を見出せないと考えています。

私たちはFlywheelが好きです。Foundation Modelについて話し始めると、Transformer アーキテクチャは結局のところ予測を行っており、AIは予測を人間とビジネスにとってよりアクセスしやすいものにしました。それにより、より多くの予測を行うことができます。より多くの予測を行うということは、直感や勘に頼るのではなく、より良い決定を下せるということです。人間はその予測を検証する判断力を使って、そのプロセスのより高次な価値を持つ部分となっていることがわかります。最終的に、このフィードバックループによって、より正確になります。データを収集し、改良し、モデルの微調整と最適化を続けることで、より良い出力が得られ、それらの決定はさらに良くなります。このようなAIによる価値のFlywheelが、これらのモデルのFine-tuningのコンテキストの中で今現れてきているのを私たちは目にしています。


では、Ericに、彼らがどのようにデータを使用し、TelClaudeモデルを彼らのビジネスに適用した際にどのような結果や成果が得られたかについて説明してもらいましょう。私は「何を」そして「どのように」についても多くを話してきましたので、人々が恐らく非常に興味を持っているデータについてもう少し詳しく話しましょう。この1年間、私は通信事業者のドメインが実際に何を意味するのかについて多くの時間を費やして考えてきました。最終的に、私たちは非常に価値があると考える2つのデータセットを作成しました:Tel TaskとTel Instructと呼ばれるものです。これらのスライドを見ると、Tel Taskデータセットは濃紺で、Tel Instructはティールまたはライトブルーで示されています。

Tel taskは基本モデルの能力を向上・拡張することを目的としており、私たちは様々なユースケースで普遍的に存在するタスクに焦点を当てました。 一般的な機能としては、大量の情報を取り込んで消化しやすい形に凝縮する要約があります。私たちは文書だけでなく会話の要約にも多くの労力を費やしました。入力は通常、カスタマーサービス担当者と顧客との通話記録で、このデータセットの出力は要約です。ここでの違いは、単に重要な情報を要約するだけでなく、通常の要約と比べてより行動指向で詳細かつ具体的な内容になっているということです。
Customer intentも非常に重要です。適切なバックエンドAPIや適切な担当者にルーティングできるよう、お客様が何のために電話してきたのかを知る必要があります。私たちは、お客様が何について電話してきたのか、そして実際に何のアクションを取る必要があるのかというIntentの分析に多くの時間を費やしました。もう一つの異なる要素はTopic分析です。私たちは通話後の分析を大量に行い、なぜ人々が電話してくるのか、どのような重要な問題やトレンドがあるのかを理解します。このケースでのTopicsは、担当者と顧客との会話を入力として受け取り、その会話に基づいて最も関連性の高い5つのトピックを抽出します。通常のモデルとの違いは、一般的なトピックが得られる可能性がありますが、後でお見せするように、私たちのモデルはより具体的でアクション指向であるということです。
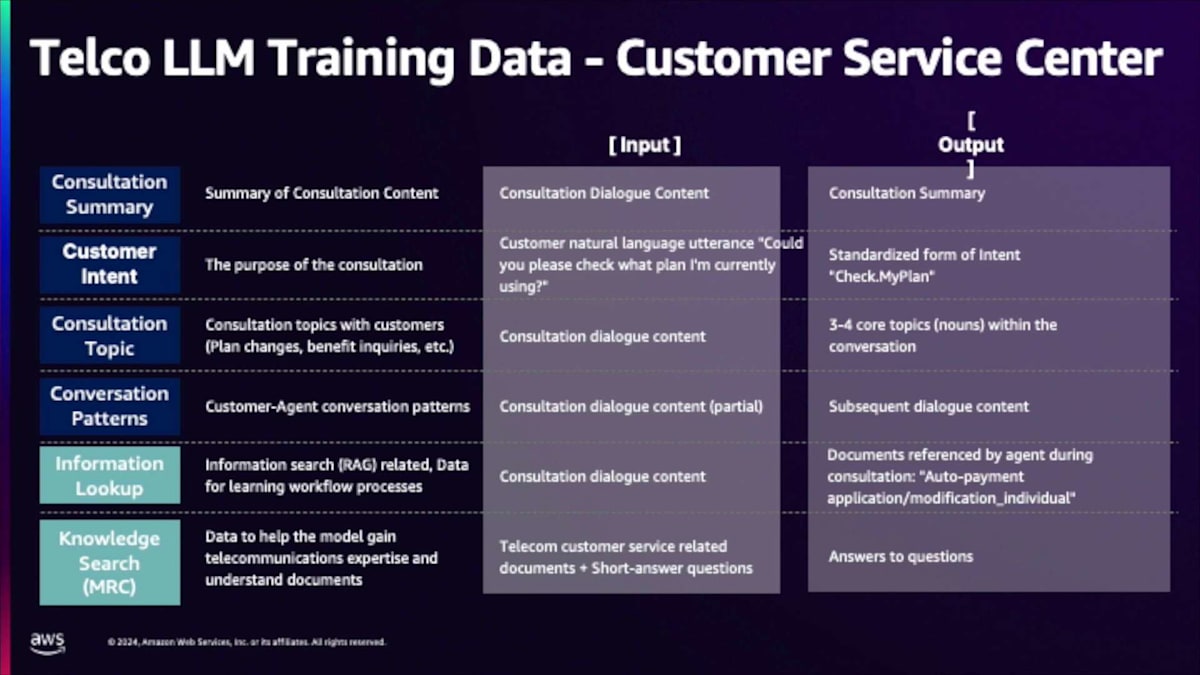
Tel instructについて詳しく説明させていただきます。 これらの機能やタスクを学習することは完全に問題ありませんが、このプロジェクトの本質は、Telcoドメインについての深い知識と専門性を持つことでした。Tel instructデータセットは、モデルにTelcoドメインについて指導・教育することを目的としています。強調したい重要なデータセットが2つあります。1つはMRC(Machine Reading Comprehension)です。文書を単に取得するだけでなく、その内容を理解することが非常に重要です。私たちは文書に焦点を当て、その主要なテーマを理解し、人々が尋ねそうな質問を予測することに多くの努力を払いました。もう1つの重要なデータセットはRetrievalに関するものです。私たちの内部アクションの多くは知識や文書の検索を伴うため、文書検索についてモデルに教えるためのデータセット構築に集中的に取り組みました。さらに重要なのは、質問に回答するために使用される生成コンテンツについて、根拠を示したり推論したりする方法を教えることです。この質問に回答する際、単に回答を生成するだけでなく、Retrievalシステムから得た情報を見て、それに基づいて実際に回答を生成するのです。
これによりHallucinationが減少し、それは非常に重要だったため、私たちはこれらの側面に多くの焦点を当てました。T taskとT instructを組み合わせることで、要約のような私たちが重視するタスクに優れ、さらにTelcoドメインの文書を理解し、必要なアクションを理解できる専門家モデルが得られます。

私たちは1年間Anthropicと協力し、 素晴らしい結果を得ました。Telco expertise scoreについて話すと、それは主にこの赤い線で示されています。Telco expertise scoreは、私たちにとって非常に重要な5つのタスクで構成されています。要約は非常に重要で、もう1つの重要なタスクはプランニングです。複雑なクエリを受け取り、それをサブタスクに分解し、それぞれのタスクに対してアクションを取ることができます。これらのタスクを組み合わせると、全体的なTGA expertise scoreが得られます。青いバーを見ると、それはベースモデルです。Anthropicとの取り組みを開始した時点ではClaude-3(sonnet)で、プロジェクトの終わりにはClaude 3.5でした。それでも、チューニングを行うことで、私たちが実際に重視するタスクにおいて、ベースモデルと比較して顕著な改善が見られることがわかります。前年比で、Telco expertise scoreにおいてベースモデルから38%という素晴らしい改善が見られ、これは大きな進歩です。使用不可能なレベルから非常に出荷可能なレベルになり、製品やサービスに適用できるようになりました。

私は自動評価が大好きですが、実際にはそれを完全には信用していません。そこで、エンドユーザーである顧客サービスエージェントに評価をお願いしました。 最高スコアは5で、これは素晴らしい革新的なものであることを意味し、最低スコアは1です。社内では、すべてのスコアが4以上であれば出荷可能、そうでなければ出荷する価値がないと判断することにしました。私たちが重視するすべてのタスク - 要約、意図理解、その他のタスク - において、スコアは4を大きく上回りました。平均は約4.5で、一部は4.6に達しています。エンドユーザーの満足度は現在90%を超えており、これは実際に出荷できるレベルに達したことを示しています。チューニングを開始する前の3点台半ばから4点台後半まで向上し、顧客満足度(ここでの顧客はカスタマーサービスエージェント)が73%も改善されました。90%という顧客満足度スコアは、Fine-tuningが非常に効果的だったことと、このプロジェクトが価値のあるものだったことを示しており、今後他の領域でも同様のアプローチを取ることは理にかなっています。

Trust and Safetyには多くの時間を費やしました。これら2つは非常に重要です。なぜなら、私たちにはブランドイメージと評判を維持する必要があるからです。このモデルが見た目は良いものの、嘘や幻覚的な応答を出力してしまうと、それは大きな問題となります。また、お客様が電話をかけてこられる際、退屈で関係のないことを話したい場合や、酔っ払って暴言を吐く場合があり、これはカスタマーサービスエージェントにとって大きな負担となっています。Trust and Safetyに関しては、主にエージェントの生活をいかに改善できるか、領域外や話題外の通話をいかに避けられるか、そして幻覚的な応答を出力しないようにする方法に焦点を当てました。
私たちは3つの異なるコンポーネントで構成される素晴らしいSafety and Trustシステムを持っています。手始めとなる簡単な部分は、暴言や領域外の内容を除去するためのキーワードマッチングやフレーズマッチングです。これは非常に更新しやすく、説明も容易な部分です。また、キーワード以外の問題を検出するのが非常に得意なモデルも持っています。皮肉や文脈の理解が必要な場合が多く、このモデルは文脈を理解し、Safety or Trustの問題かどうかをより深く理解することができます。3つ目の側面として、これらのモデルは非常に教えやすく、指示に従いやすい特徴があります。これらの問題を検出するためのプロンプティングに多くの労力を費やし、Telco LLMの力を別のドメインで活用しました。ここでの焦点は外部ではなく、主に内部 - カスタマーサービスエージェントの生活の質を向上させることにありました。

このシステムは導入され、非常に高い評価を受けています。 Telco LLM導入前の状況では、カスタマーエージェントはストレスを抱え、時間的プレッシャーに追われ、離職率も高い状況でした。正直に言って、やりがいのない仕事でした。この技術と、次のスライドでお話しする使用事例を導入した後は、右側の画像にあるような両手親指を立てたイメージの通り、仕事の満足度が大幅に向上し、ストレスが軽減され、離職の可能性も大きく減少しました。これは、Trust and SafetyやTelco LLMなどのサポートツールが整備されたためです。これは大きな変化であり、カスタマーサービスエージェントの置き換えではなく、彼らの仕事を支援することを目的としていることを明確にしておきたいと思います。

ユースケースについてお話ししましょう。モデル自体は良いのですが、ユースケースの展開こそが、このモデルを構築している本来の目的です。これをContact Center AIと呼んでいますが、お話しする2つのユースケースがあります。1つはReal-time Assist、もう1つはPost-callです。まずはPost-callについて、主にそのプロセスについてお話ししたいと思います。
このモデルが導入される前は、プロセスは完全に手作業でした。通話後、Customer Service Representativeは通話内容の文字起こし、要約、トピックの割り当てを行わなければなりませんでした。非常に手間のかかる負担の大きいプロセスでしたね。このプロセスをできる限り自動化することが目的でした。もちろん、人間によるチェックは残っています - 担当者が全て問題ないかを確認したり、必要に応じて結果を編集したりします。しかし、担当者の時間を確保するために、できる限り自動化したいと考えています。

もうひとつのユースケースは、通話中のリアルタイムアシスタンスです。Customer Service Representativeは多くの文書を検索し、それらを読んで理解し、そして回答を組み立てなければなりません。これも同様に、ミスが起きやすい手作業のプロセスでした。私たちはこれをAI Searchと呼ぶもので自動化したいと考えました。バックエンドで関連文書を検索し、それらの文書を基に、Customer Service Agentが画面で読むことができる回答を生成します。回答が気に入れば、そのまま使用できます。気に入らない場合は、参照できる文書の引用があります。このように、検索プロセスと回答生成の両方をある程度自動化します。要するに、Customer Service Representativeの仕事をより楽にして、より仕事を楽しめるようにすることが目的です。

ポストコールシステムは先月10月にローンチされ、現在はリアルタイムシステムを展開中です。例を挙げましょう:様々な理由で名前を変更したい人がいて、その方法について問い合わせの電話をかけてきます。これまでは、Customer Service Agentがこのような問い合わせを受けると、バックエンドを検索して2、3の文書を取得し、それらを読んで理解してから結果を提供していました。新しいリアルタイムアシストシステムでは、自動的に検索を行います。名前の変更方法について説明している文書1と文書2があり、モデルはこれらの文書を参照して結果をまとめ、カスタマーサービスに電話するか、オンラインで手続きするか、実店舗に行くかという方法を説明する回答を生成します。また、重要な部分がわかるようにハイライトも行います。もちろん、全ての情報には出典があるので、担当者は詳細情報を得るために文書をクリックすることができます。

ポストコールシステムの実際の出力がどのように見えるか、いくつか例をお見せしましょう。これらは説明用の例ですが、要点をよく表しています。これは、料金について問い合わせの電話をかけてきた会話です。上部の要約は一般的なLarge Language Modelによるもので、メインポイントは押さえているものの、料金や料金プラン、割引に関する具体的な言及がなく、実用的には不十分なことがわかります。下部の要約は私たちのTelco LLMによるものです。数字や割引の獲得方法について言及していることがわかります。具体的でアクションにつながる要約になっています。Customer Service Representativeがこの要約を見れば、誰がなぜ電話をかけてきて、どのようなアクションが必要なのかを正確に理解できます。

ローミングに関する問い合わせも多く受けています。お客様がローミングする際は、様々な国に行き、利用可能な様々なプランがあります。一般的な流れとしては、どこに行くのか、どのプランが必要かを確認します。ここでも、一般的なモデルと私たちのTelco LLMを比較できます。上部の一般的なモデルによる要約は非常に具体性に欠け、ローミングや一般的な用語に言及するだけです。一方、Telco LLMは実際にどの国に行くのか、どのローミングプランが必要かについて非常に具体的です。これにより、担当者は電話をかけてきた理由を素早く理解でき、分析を行う際には、人々がどこに行き、どのプランを実際に使用しているかを把握することができます。トレンド分析に本当に役立っています。

私たちは、ユースケースの拡大に関して広範な取り組みを行っています。これは主に3つの方向性があります。1つ目は、マーケティングやネットワークなど、通信事業者の領域内での展開です。多くのお客様が来店するT storeでは、チャットボットとの対話が必要になります。オンラインでの相談は重要であり、製品やサービスについて説明し、推奨を行うアシスタントの需要は非常に高いのです。ネットワーキングについても同様で、お客様は問題解決や製品・サービスに関する質問があるため、ネットワーキング用のアシスタントも現在注力している大きな社内ニーズです。社内業務に関しては、法務チームには多くの問い合わせがあり、人々がフォームをアップロードして法的な確認や文書生成について質問します。この確認プロセスをある程度自動化することで、人を置き換えるのではなく、一般的なケースではなく複雑なケースに集中できるようにすることで、業務を効率化できます。法務以外にも、PRは非常に大きな一般的なプロセスです。

これは冗談のつもりで言っているのですが、実は半分本当だと思うのですが、私たちは恐らく世界最大のPR企業の一つで、PRコンテンツを途方もない量で生成しています。PR部門は記事の作成や執筆で非常に忙しい状況です。これを100%自動化することはできませんが、大部分を自動化して人間がレビューするだけにすることはできるため、PR生成器の構築に注力しました。これにより、文書を作成し、トーン、スタイル、内容について人がレビューするだけで、PRの配信がはるかに効率的になります。

また、B2B(企業間取引)に注力するという大きな社内方針があります。金融、製造業、公共部門のパートナーとの協業を開始しました。単一のフレームワークはありませんが、Retrieval systemの最適化とこのモデルの最適化に関して広範な作業を行ってきました。このテンプレートを他の業界やセクターに適用し、他の企業に販売したいと考えています。これらが3つの主要な注力分野ですが、私たちは勝利の方程式を手に入れたと感じているため、Telco Large Language Modelの適用範囲を他のユースケースやドメインにも拡大していきたいと考えています。
AWS、Anthropic、SK Telecomの協業:成功の鍵と今後の課題
最後にまとめとして、SK TelecomがAWSとAnthropicとの協業を選んだ理由についてお話しします。これらの多くは、AWS全体で共通する機能です。この環境において、スケーラビリティと柔軟性は重要です。一貫性のある予測可能な体験を提供しながら、スケールアップとダウンができる能力が必要です。私たちは34のRegionと108のAvailability Zoneを世界中に持っており、これは確実にクラウドプロバイダーの中で最も広範なインフラストラクチャです。SK Telecomの機密性の高いデータを使用したFine-tuningに関しては、プライバシーとセキュリティが最も重要です。これはAmazon Bedrockや任意のAWSサービスに最初から組み込まれているため、SK Telecomはデータとトランザクションが環境内で安全であることを確信できます。

Amazon Bedrockはマネージドサービスであり、私たちがすべてのインフラストラクチャを管理し、すべてのツール、ガードレール、ナレッジベース、評価機能を提供します。これらすべてが、厳選されたトップモデルのリストを通じて、単一のAPIでアクセス可能です。そのため、Ericが複数のユースケースにわたって展開を図る際には、シンプルなAPIを通じてすべてのツールに簡単にアクセスできます。ここでEricにAWSを選んだ理由について話してもらいましょう。モデルのチューニングは一つの課題で、ユースケースの展開は別の課題ですが、実際に本番環境に投入しようとすると非常に複雑になります。世界最高のインフラストラクチャと多くの優秀な人材を持つAWSの専門知識に頼ることで、AWS、Anthropic、SK Telecomの協力的な取り組みによって、このモデルを本番環境に導入することができました。
先ほど申し上げたように、Anthropicはモデリングにおいては非常に優れていますが、モデルのサービング提供やスケーリングに関しては、それほど強みがないかもしれません。AWSの強みは、インフラストラクチャーとスケーリング能力にあります。私たちがAWSと協業した理由はいくつかありますが、まず第一にスケーラビリティです。Anthropicも優れていますが、ユーザー数が100万人規模になると課題が出てきます。AWSはこの分野で豊富な専門知識を持っています。一度に100万件のクエリを処理する必要はないかもしれませんが、スケールアップとダウンが自在にできることは私たちにとって非常に重要で、AWSはそれを見事に実現し、各ユースケースに合わせて最適なサイジングを提供してくれました。また、信頼性も重要です。これは本番サービスであり、ダウンタイムが発生すると大きな経済的影響があります。AWSにはSLAが設定されており、モデルの稼働時間が保証され、問題が発生した場合の応答時間も保証されています。最後に、協業体制についても強調したいと思います。AWSが単独で作業を行ったわけではありません。SK TelecomとAnthropicから多大な支援を受けました。Anthropicは誰よりも自社のモデルについて熟知しており、モデルの最適化とレイテンシーの削減に大いに貢献してくれました。これらはすべて、これらのユースケースを市場に投入し、お客様を驚かせるために必要不可欠でした。
さらに、AWSはAmazon Bedrockのサポートにおいても素晴らしく、SK Telecomは世界で初めてBedrockを通じてカスタムモデルを提供した企業だと思います。これも大きな成果だったと考えています。そして、3つの重要な教訓があります。

応答が速くなったことで、カスタマーエクスペリエンスが向上しました。お客様は応答が速くなったことで、より満足度が高まっています。韓国は「今すぐ」を重視する社会なので、正確で迅速な応答を得られることは非常に重要です。これが大きな変化をもたらしました。もう1つの改善点は、応答の統一性です。以前は、各担当者が独自のスタイルと問題へのアプローチ方法を持っていました。現在は、この技術により、応答を一貫させることでユーザーエクスペリエンスを統一できます。ユーザーAとBが同じ問題で問い合わせをしたときに異なる回答を得るのは、良くないユーザーエクスペリエンスです。この技術により、各クエリに対して同じ応答を確実に提供できるようになりました。
3つ目の改善点は、Customer Service Representativeの満足度です。この技術が導入されたことで、新入社員の研修期間が大幅に短縮されました。業務をサポートする先進的な技術があるからです。また、この技術を活用することで業務の負担も軽減され、ストレスや時間的プレッシャーを感じることなく仕事ができるようになりました。これらすべての面で大きな成果を上げることができ、この技術の導入を非常に喜ばしく思っています。

以前の自然言語処理におけるベンチマーキングは非常にシンプルでした。固有表現認識を例に取ると、精度や再現率といった指標を見ることができました。静的なデータセットで、自動化も容易でした。しかし、Large Language Modelの世界では、特に複雑なワークフローやタスクがある場合、これはより曖昧になってきています。もはや精度やF1値、再現率を見るだけでは十分ではありません。私たちはこのモデルのベンチマーキング方法に多大な努力を費やしてきました。自動化された指標を使用するなと言っているわけではありません - もちろん私たちもTelco Expertise Scoreを使用しています。ただ、それだけでは不十分だということです。
私たちは、モデルの出力を評価するために、Large Language Modelを審査員として活用することに多大な努力を注いできました。また、カスタマーサービス担当者に実際に出力を評価してもらい、フィードバックを得るという手動評価にも相当な労力を費やしてきました。これを見ていくと、右側のような複雑なワークフローのシステムになっていることがわかります。単なる入力と出力だけではなく、システムを通して実行し、出力を確認し、中間段階を確認し、それらすべてに対する評価とフィードバックを得て、モデル全体を改善していくのです。ここでの重要なポイントは、評価が非常に複雑になっているということです。もはや画一的なアプローチは通用せず、単にいくつかの指標を当てはめて最善を期待するという古いアプローチではなく、目の前のタスクに合わせて適切なベンチマーク評価を行う必要があります。

以上で私の講演を終わらせていただきます。お時間をいただき、ありがとうございました。韓国のAWSスタジオからこの講演をお届けできて、大変嬉しく思います。この講演が皆様にとって有益で、興味深く、説得力のあるものとなっていれば幸いです。それでは、これにて終了とさせていただきます。ご清聴ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion