re:Invent 2024: AWSのELBによる高可用性トラフィック分散の最適化
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Optimizing ELB traffic distribution for high availability (NET401)
この動画では、AWSのElastic Load Balancingにおける高可用性の実現方法について、Head of Customer SuccessのJon ZobristとSolutions ArchitectのEnrico Liguoriが詳しく解説しています。Load Balancerの各種ルーティング機能やDNSの仕組み、Application Load BalancerとNetwork Load Balancerそれぞれの特徴的な動作について具体的に説明されています。特に、Round Robin、Least Outstanding Request、Weighted Randomという3つのルーティングアルゴリズムの違いや、新機能のLCU Capacity Reservationによるスケーリング制御など、実践的な内容が豊富に含まれています。また、AWS Global AcceleratorやApplication Recovery Controller Zonal Shiftなど、高可用性を実現するための周辺サービスとの連携についても深く掘り下げられています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
高可用性とELBトラフィック最適化:セッション概要


高可用性を実現するためのELBトラフィックの最適化についてのセッションへようこそ。私はElastic Load BalancingのHead of Customer SuccessのJon Zobristです。そして本日は、Solutions ArchitectのEnrico Liguoriも同席しています。 今日は、インターネット配信アプリケーションにおける高可用性へのさまざまなアプローチについて説明し、Load Balancerのルーティング機能について掘り下げ、さらに最近リリースした新機能であるApplication Load BalancerとClassic Load Balancer向けのLCU容量予約についてご紹介します。

このセッションを通じて、AWSにおける高可用性についての理解を深め、Load Balancerやその他のシステムを適切に設定して、正常で十分なスケールを持つエンドポイントへのトラフィックルーティングを確保する方法を学んでいただけます。また、DNSについて学び、Application Load Balancerの高度なルーティング機能を探求し、Load Balancer容量予約について理解を深めていただけます。 プレゼンテーションでは、内部の詳細、新機能のリリース、そしてQRコードによるドキュメントへのリンクを示すために、さまざまなアイコンを使用しています。これらの情報を記録する時間を設けており、また録画は後ほどYouTubeで視聴可能になります。
インターネット配信アプリケーションの基本構造
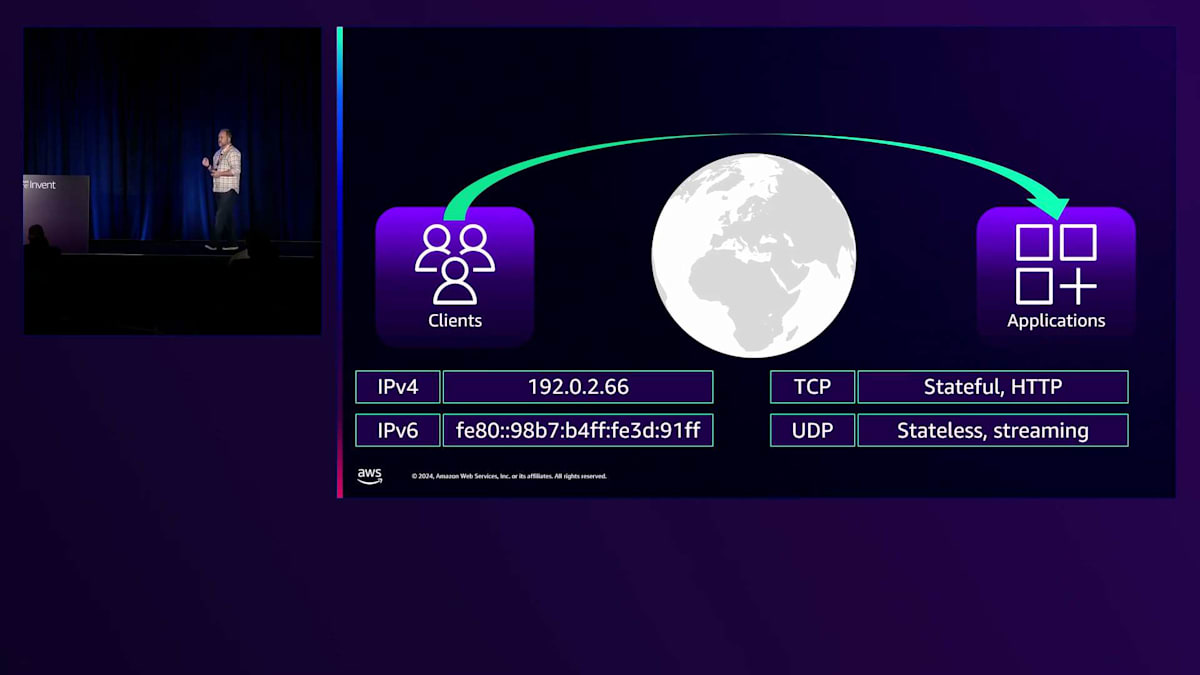
私たちがここにいるのは、パブリックインターネットであれプライベートネットワークであれ、皆さんがインターネットを介してアプリケーションを提供しているからです。現在では、一般的にIPネットワーキングが使用されています。現在使用されているプロトコルバージョンはIPv4とIPv6の2つです。Load Balancerや各種AWSシステムの利点の1つは、フロントエンドでメリットを得るために、スタック全体をIPv6にアップグレードする必要がないことです。また、TCPやUDPに加えて、HTTPリクエストトラフィックについても説明し、これらのプロトコルに対して各Load Balancerがどのようにルーティングを行うかを見ていきます。
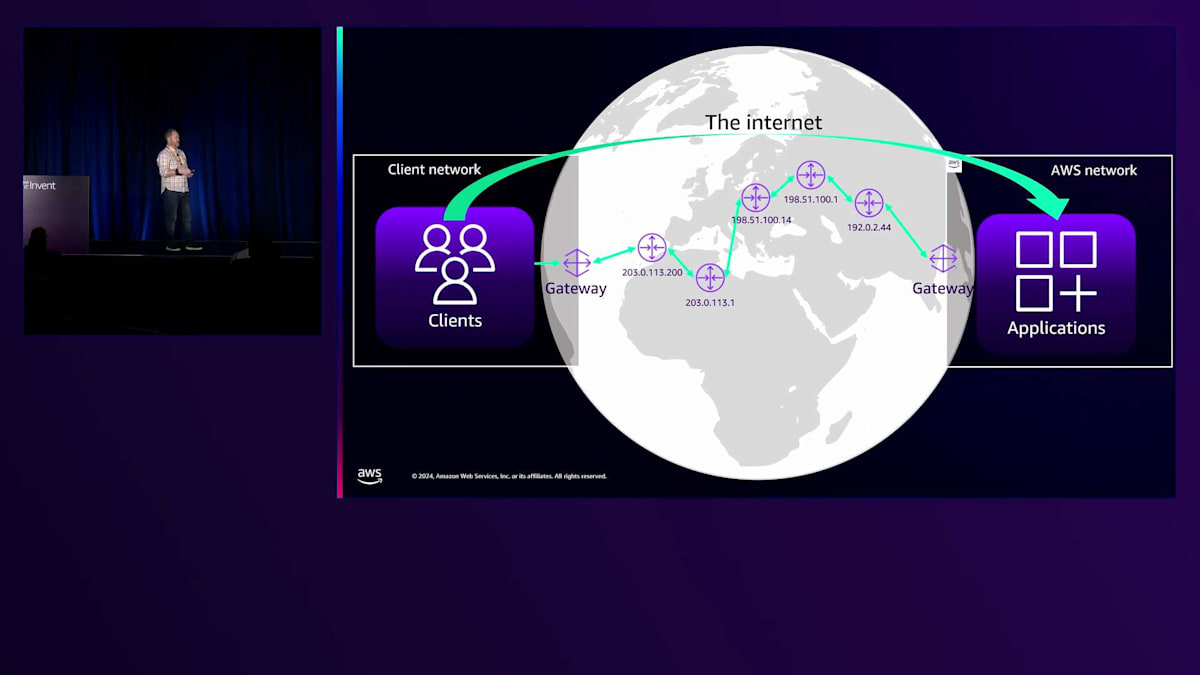
クライアントがサービスに接続する基本的な仕組みを見てみましょう。クライアントにはIPv4ゲートウェイとプライベートネットワークがあります。ゲートウェイはパブリックIPへのNATを実行し、インターネットへの接続を可能にします。AWSのアプリケーションの場合、トラフィックは最終的にイングレスゲートウェイに到達し、そこで逆方向のネットワークアドレス変換が行われ、プライベートネットワークにトラフィックが転送されます。
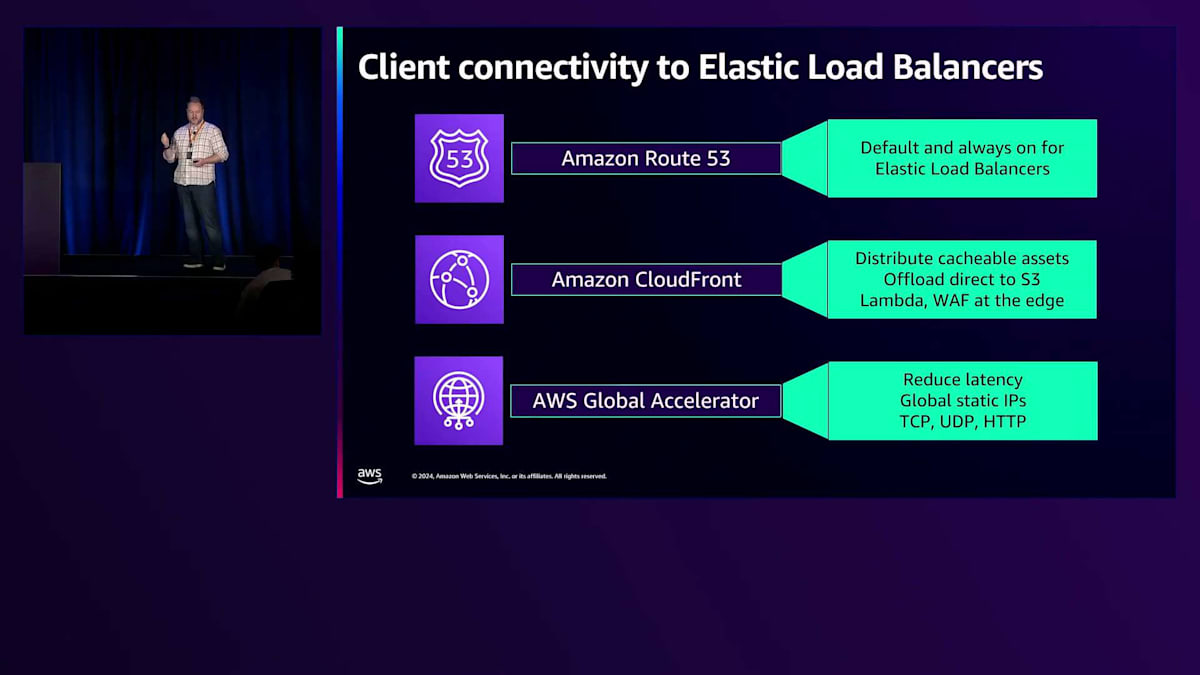
すべてのElastic Load Balancerには、ヘルスチェックとDNSを備えたRoute 53が組み込まれています。Load Balancerを作成すると、CNAMEやRoute 53エイリアスとして使用できる一意のホスト名が生成され、クライアントがLoad Balancerに接続できるようになります。これをヘルスチェックと適切なスケーリングに使用しています。Load BalancerのDNSには、検出されたトラフィックレベルに適切にスケールされ、ヘルスチェックに合格したIPが表示されます。CloudFrontとGlobal Acceleratorは、Load Balancerの前段に配置する優れたサービスで、追加機能を備えた同様の可用性オプションを提供します。
AWS Global AcceleratorとELBの高可用性機能

私のプレゼンテーションのパートでは、AWS Global Acceleratorに焦点を当てていきます。 その主な利点は、クライアントをできるだけ早くAWSのバックボーンに接続できることです。製品ページには、実際の違いを示す素晴らしいデモが用意されています。すべてのリージョンにルーティングできるプライベート容量を持つ、多数のEdge Locationのいずれかにアクセスできることが利点です。シンプルなシングルゾーンまたはシングルリージョンのセットアップでは、クライアントは最寄りのEdge Locationに接続し、そこからAWSバックボーンを経由してアプリケーションをホストする最寄りのリージョンまで移動します。
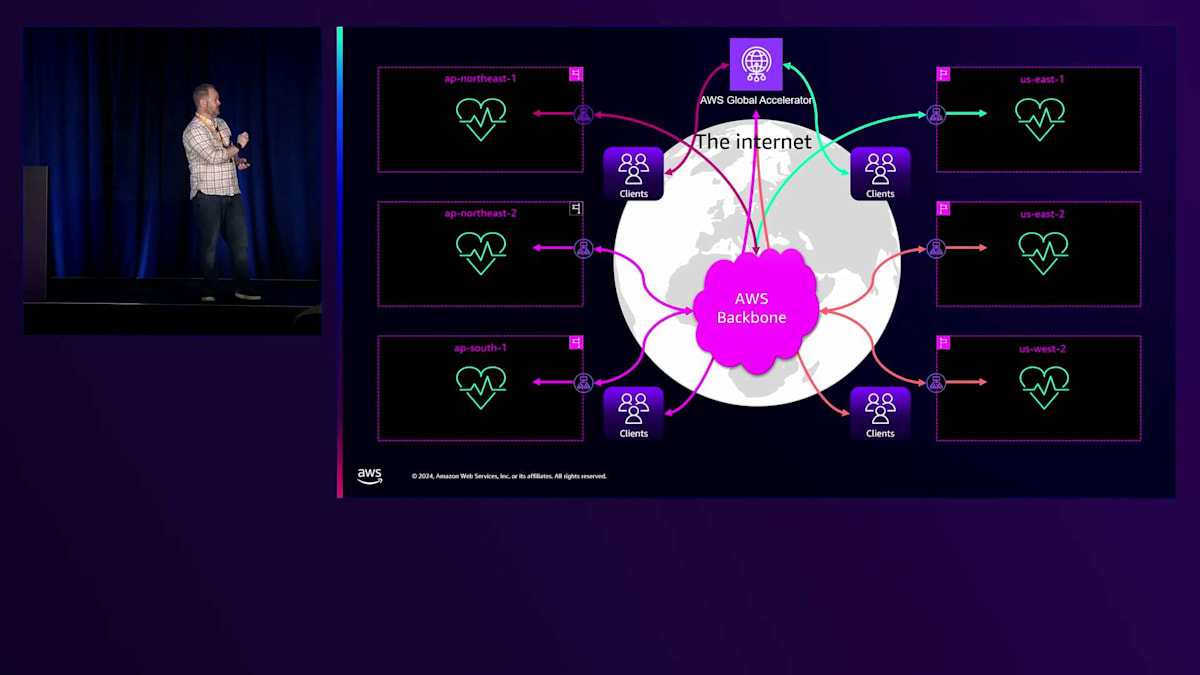
これを複数のリージョンで同時に実装することができます。各リージョンのヘルスチェックは複数のレベルで動作し、Route 53が不健全なIPをDNSから除外するのと同様に、AWS Global Acceleratorは健全なIPにのみトラフィックを転送します。ここでいうトラフィックとは、TCPやUDPの場合は新しいTCP接続、HTTPトラフィックの場合は新しいHTTPリクエストを指します。

単一のリージョンを見てみると、ALB FQDNがあり、通常はゾーンごとに1つのIPアドレスが表示されますが、ALBは成長要件に応じてゾーンごとに複数のIPにスケールできます。各IPは、Route 53によって個別にヘルスチェックされます。

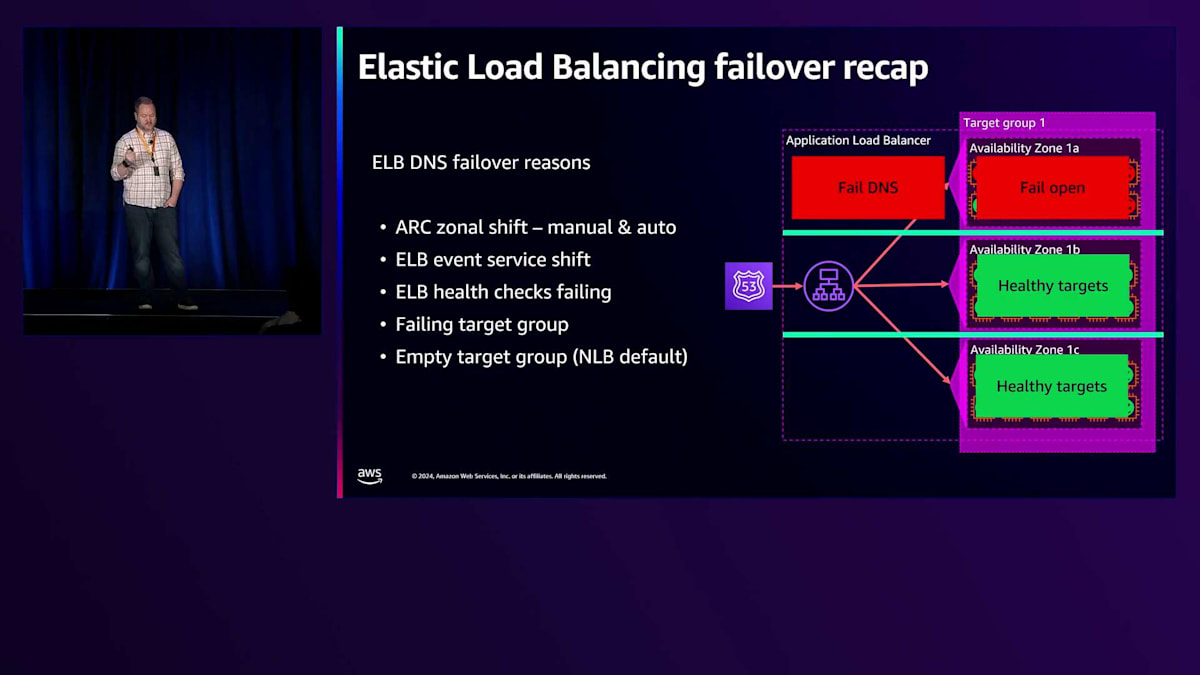
これらのヘルスチェックは、AWS Global Acceleratorのルーティングにとって重要で、IPが不健全になるとDNSから除外される可能性があります。多くの人が混乱している点の1つで、私たちが明確にしたいのは、IPやゾーンがいつ除外されるかということです。Load Balancerを見て、これらの異なるIPがすべてあるとき、どれが健全なのか、あるいはそのうちの1つが不健全になった場合に何を期待すべきなのかを知るにはどうすればよいのでしょうか? これらが、Load Balancer IPがゾーンから除外される様々な理由です。
Network Load Balancerは、Application Load Balancerとは少し異なります。というのも、Availability Zoneごとに1つのIPを持ち、そのIPはLoad Balancerの存続期間中は変更されないからです。パブリックLoad Balancerを使用する場合は、事前に割り当てたパブリックElastic IPを使用することをお勧めします。これは保持できるからです。Elastic IPなしでインターナルNLBを割り当てる場合、私たちはお客様の範囲から1つを使用します。個々のゾーンがある場合、Network Load Balancerゾーンは、その1つのIPを除外することで完全に除外できます。Application Load Balancerでは、そのゾーンに多くのノードがある可能性があるため、ゾーンの一部が健全で、一部が不健全である可能性があります。
各Load Balancerに設定されているTarget Groupは、ヘルスチェックで失敗する可能性があります。デフォルトでは、全てのTargetが100%不健全な状態になった場合にのみ失敗と判定されます。AWSはデフォルト設定を変更することを好まないため、この機能を導入した際もそのままにしています。ユースケースに応じて適切な設定を検討し、構成することをお勧めしています。設定可能な項目は2つあります。1つ目は「Target Groupsのフェイルオープン」で、これは全てのTargetを健全な状態として扱うというものです。より重要なのは「DNSの失敗」の設定で、これらの設定を適切に組み合わせることで、Route 53のヘルスチェックを実質的に無効化することができます。
AWS Application Recovery Controller Zonal Shiftは、全てのLoad Balancerと統合されています。特定のゾーンを不健全と宣言してそこからフェイルアウトすることができ、最近では特定の指標が不健全な状態を示した場合に自動的にゾーンからフェイルアウトできるAutoshiftも導入されました。Elastic Load Balancingでは、重大な問題が発生した場合、そのゾーンから全てのLoad Balancerをフェイルアウトさせることがありますが、影響を最小限に抑えるよう努めています。ベストプラクティスとしては、Load Balancerに設定された全てのゾーンを実際に使用することです。使用していないゾーンがある場合は、Load Balancerの設定から除外すべきです。
Target Groupsに関して1つ例外があります。特にNLBの空のTarget Groupsについてです。Application Load Balancerではクロスゾーンロードバランシングがデフォルトでオンになっているため、空のTarget Groupはそれほどリスクとは考えていません。しかし、Network Load Balancerではクロスゾーンがデフォルトでオフのため、空のTarget Groupはデフォルトで不健全とみなされます。これは無効化できますが、一部のゾーンに空のTarget Groupsがあり、クロスゾーンがオフの場合、DNSに含まれないゾーンが発生する可能性があります。健全なゾーンがDNSから除外されるようなことが起きた場合、フェイルオープンとなり、不健全なゾーンにトラフィックが送られる可能性があります。したがって、ゾーンには適切にTargetを配置し、AWS Application Recovery Controllerを使用し、アプリケーションのメトリクスに基づいてトラフィックをシフトする準備が整ったらAutoshiftを設定することをお勧めします。
グローバルアプリケーションにおけるELBの動作と障害対策
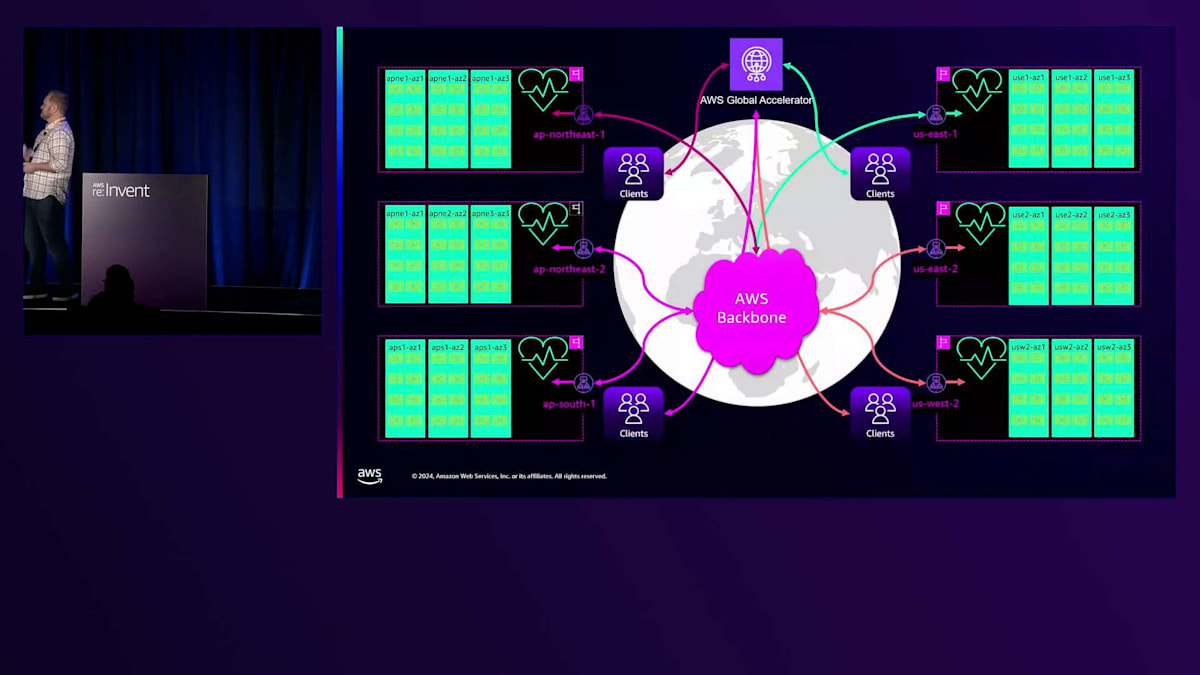
グローバルアプリケーションに話を戻し、Targetの観点から見てみましょう。これらは世界の6つのリージョンの複数のゾーンに分散配置されたアプリケーションサーバーです。
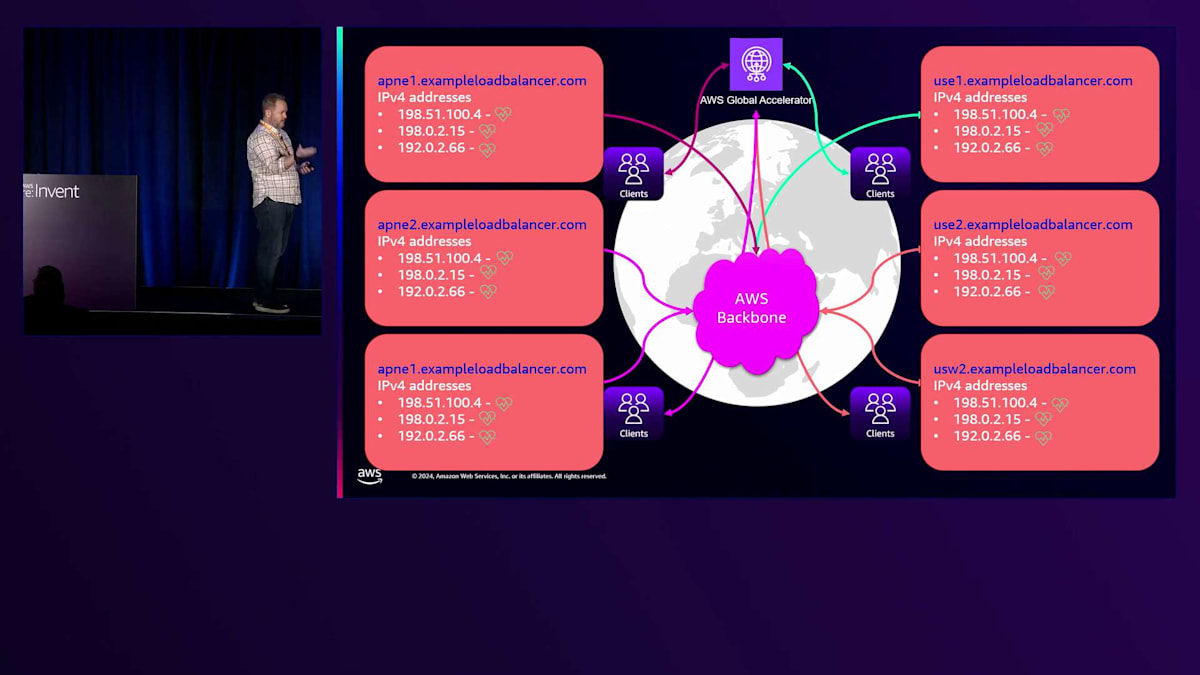
AWS Global Acceleratorを使用して、各リージョンへの地理的な近接性に基づいてトラフィックを振り分けています。詳しく見ると、各リージョンのElastic Load Balancingには、ゾーンごとに少なくとも1つのIPが割り当てられていることがわかります。 これらのIPは全て、先ほど説明したようにAmazon Route 53によってヘルスチェックされており、ヘルスチェックが失敗した場合は、そのゾーンから除外されます。

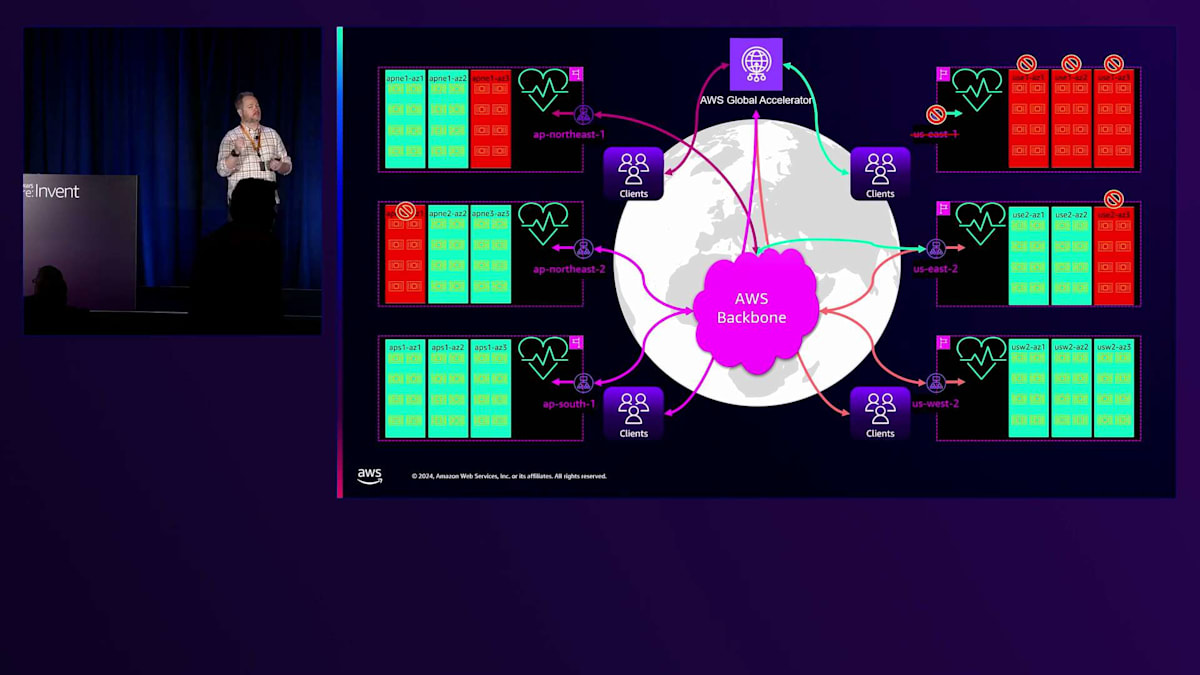
ある1つのリージョンに注目してみましょう。これらのIPはそれぞれ、1つのゾーン内のマシンに関連付けられています。何らかの理由で1つが異常になると、DNSから削除されます。グローバルな視点で見ると、複数のゾーン障害、さらにはリージョン障害をアクティブにルーティングして回避できるグローバルアプリケーションを構築できることがわかります。AWS Global Acceleratorを通してトラフィックを送信すると、異常のあるゾーンを回避し、正常なゾーンにのみ転送されます。
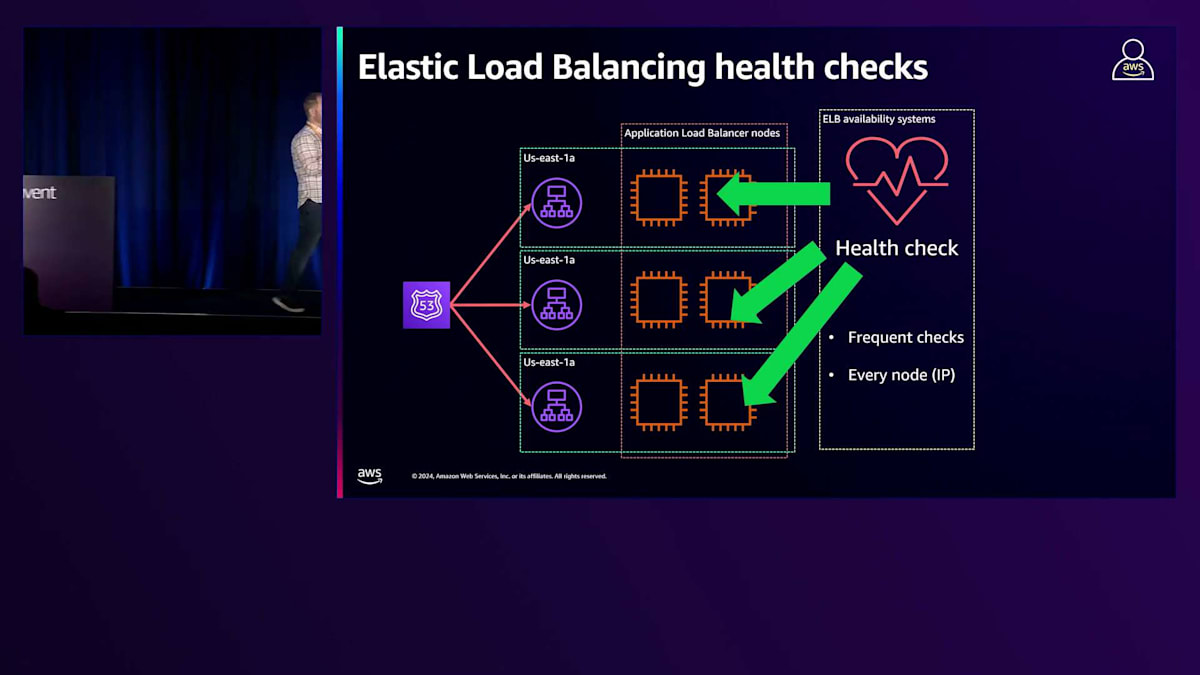
もう1つの側面として、Route 53が実行しているのと同じヘルスチェックをノード自体に対して実行しています。ノードの健全性をチェックするためにPingを送信すると、Route 53も全く同じことを行っています。Route 53の対応はDNSから削除することで、私たちの対応は置き換えることです。障害を検出してDNSから削除しますが、これは通常、約30秒でトリガーされ、DNSのTTLが60秒であるRoute 53ほど速くはありません。つまり、約90秒でIPはDNSから完全に削除され、クライアントはエラーが発生した場合に再接続し、その後ノードを置き換えます。
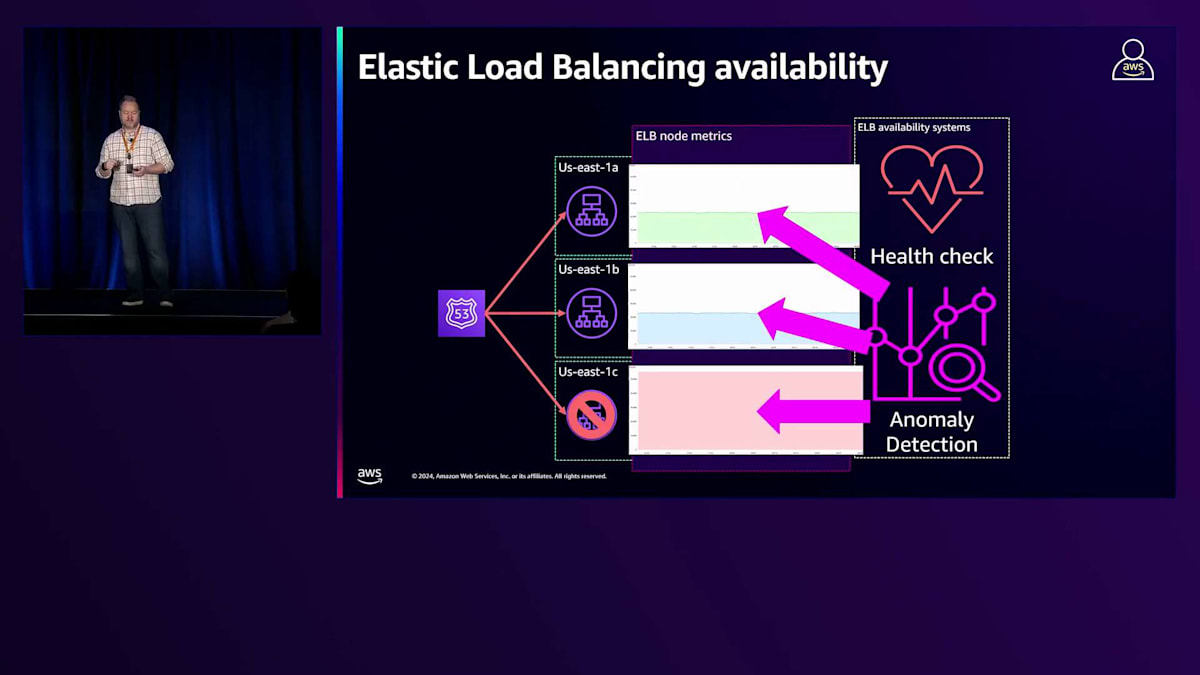
同様の障害が発生した場合、ピア間でノードのパフォーマンスを検査する別のシステムがあります。Load Balancer内のすべてのノードを評価して、異常な指標を特定します。ELB 5XXエラーの増加や異常なホスト数の増加など、問題を示す指標がある場合、そのIPをDNSから段階的に削除し、新しいノードを追加して置き換えます。その後、良い置き換えだったかどうかを確認します。この異常検知は、5分、15分、4時間の時間枠で継続的にすべてのLoad Balancerで実行され、ヘルスチェックをトリガーするほど深刻ではないグレー障害を検出します。これはTarget Groupではなく、AWS側で発生します。
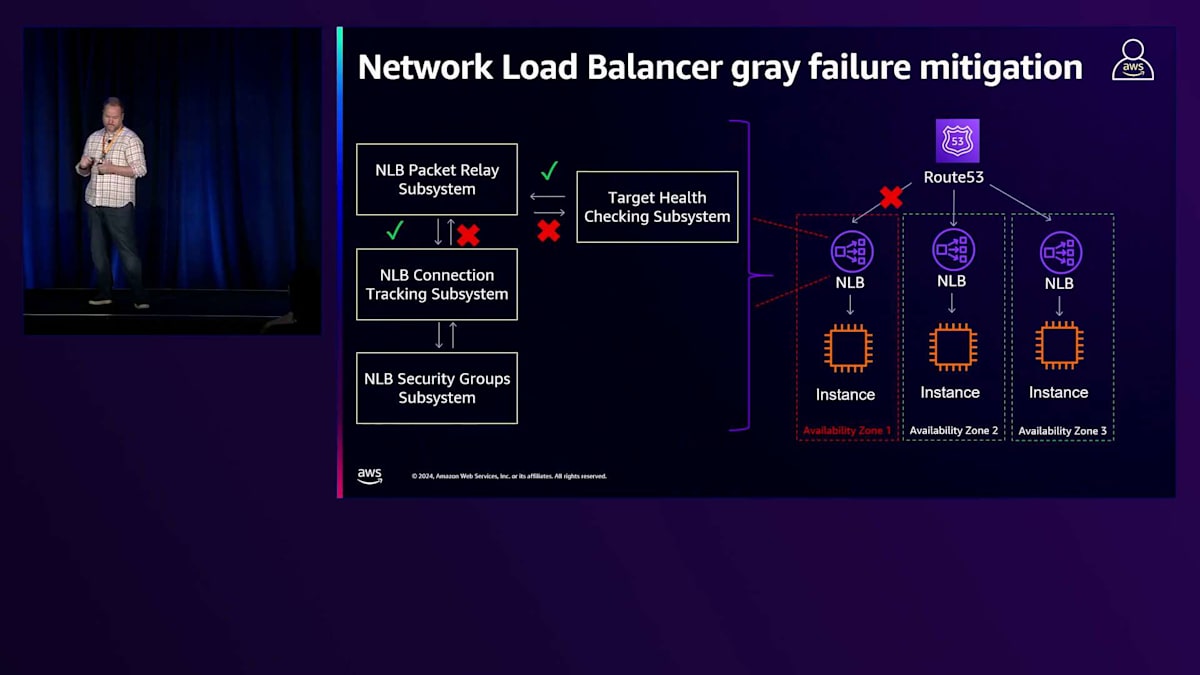
Network Load Balancerでは、Application Load Balancerと同様のシステムを持っています。NLBでは、ヘルスチェックパケットにタグを付けています。基盤となるAWS Hyperplaneを使用しており、これによってEC2のソフトウェア定義ネットワーキングと統合するENIが提供されます。これにより、入力トラフィックをサポートリソース間で分散し、ターゲットにルーティングできます。Hyperplaneとの統合により、進行中のトラフィックに影響を与えることなく、これらのコンポーネントを変更できます。すべてのヘルスチェックは、このENIを通じてターゲットまで同じパスをたどります。

このパスでパケットドロップを検出すると、グレー障害としてそのLoad Balancerを予防的にそのゾーンからシフトできます。時々、あるゾーンのIPがDNSから削除されるのに気付くことがありますが、ホストに問題が見られない場合は、この予防的なシフトプロセスが原因かもしれません。昨年、Application Recovery Controllerのゾーナルシフトとの統合について説明しました。今年は、クロスゾーン機能とゾーナルシフトをサポートするように変更を加えました。以前は、ゾーナルシフトを機能させるためにクロスゾーンを無効にする必要がありました。現在は、クロスゾーンが有効な場合でも、シフトアウト時にゾーン全体のトラフィックを移動させています。

先ほど少し触れましたが、Application Recovery Controllerが今年リリースした新機能であるAuto Shiftについてお話しします。 この機能により、アラームが発生した際にZone Failoverをトリガーするように設定できるようになり、他のFailover要因と組み合わせて使用することができます。 まとめますと、私たちは論理的にFailoverを行うZoneを持っています。これらはEC2のBlast Radiusであり、Zone間で完全な分離を維持しています。これには地震、洪水、電力網といった自然災害への配慮も含まれています。これらすべてのZoneで分離を保ち、制御できない要因を含む複数のZonal Failoverのトリガーを用意しています。ここで一旦休憩を取り、Enricoに引き継ぎたいと思います。
Application Load Balancerのトラフィック分散メカニズム

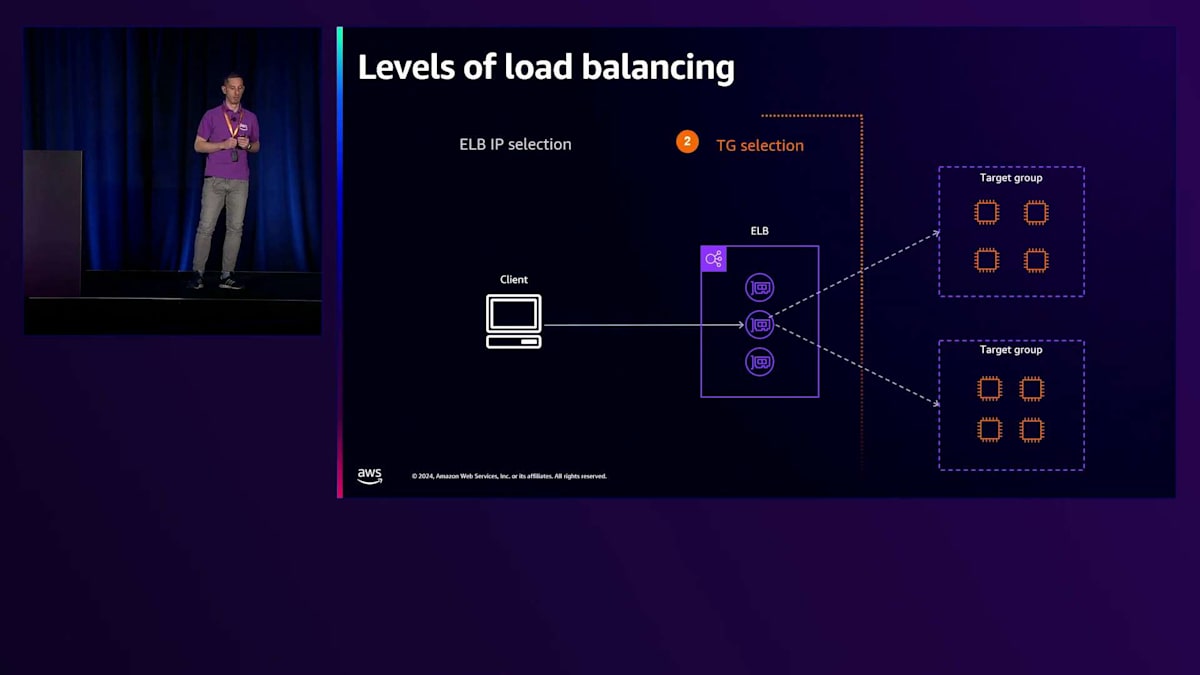
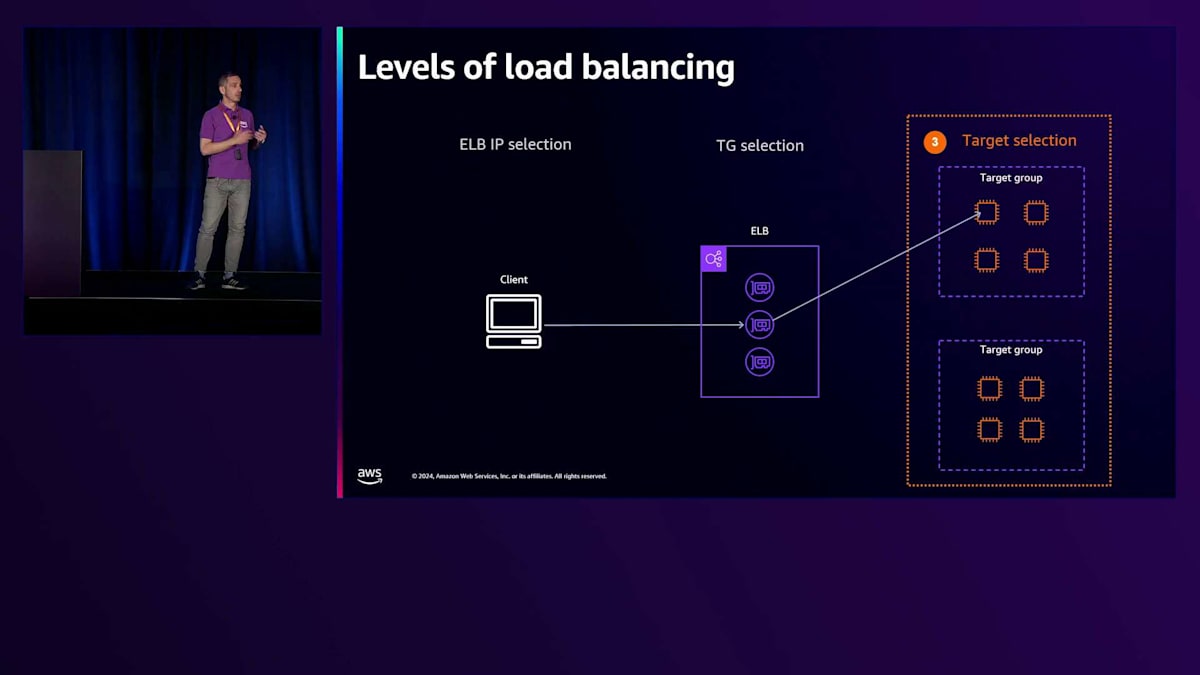
Application Load Balancer(ALB)におけるターゲットへのトラフィック分散は、実際には異なるレベルで行われる複数の判断の結果です。最初の判断レベルは、クライアントがLoad Balancerにトラフィックを送信する際に選択するELB IPに関するものです。このトラフィックが到着すると、ELBによってトラフィックを処理するTarget Groupが選択されます。第3段階は、選択されたTarget Group内での実際のターゲット選択に関するものです。それでは、ELB IPの選択から始めて、これらの各段階を見ていきましょう。
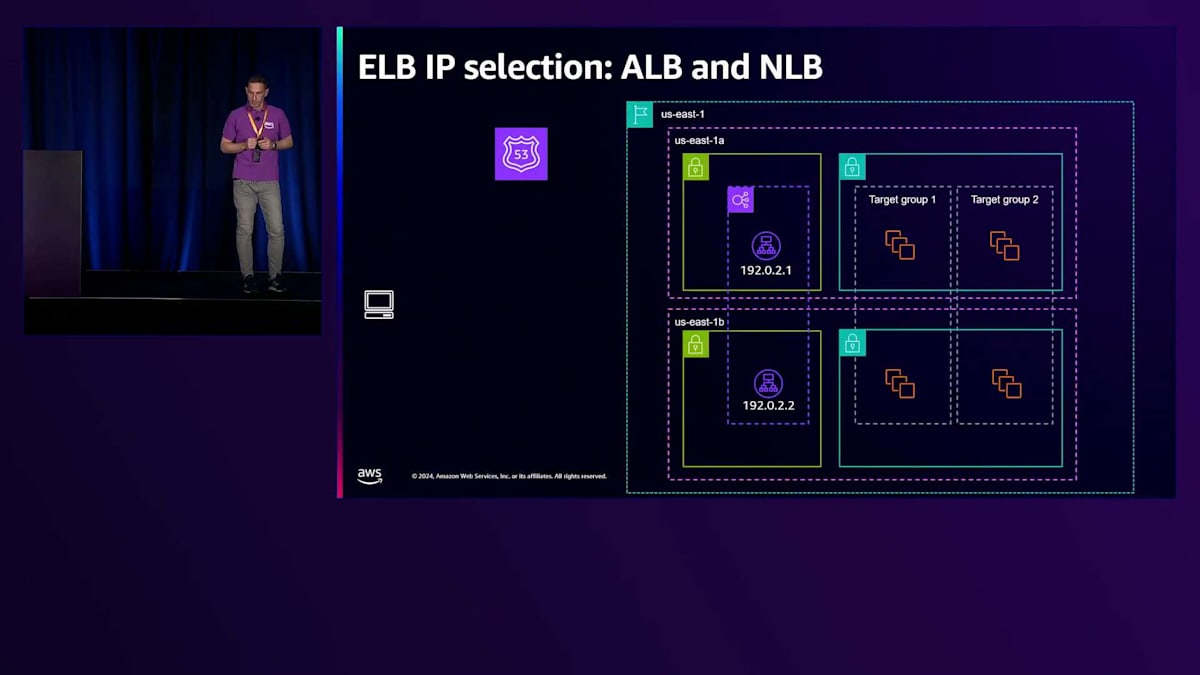
トラフィックの送信に使用されるELB IPの選択は、クライアントによって行われ、DNSに依存しています。お客様がLoad Balancerを作成すると、ELB DNS名が生成されてLoad Balancerに割り当てられます。このDNS名はALBに割り当てられたIPアドレスを返し、IPの数は使用する製品によって異なります。Network Load Balancerの場合、各Availability Zoneに1つのIPが割り当てられ、Application Load Balancerの場合は常に最低2つのIPが割り当てられ、製品の種類に関係なく最大100個のIPまで増やすことができます。
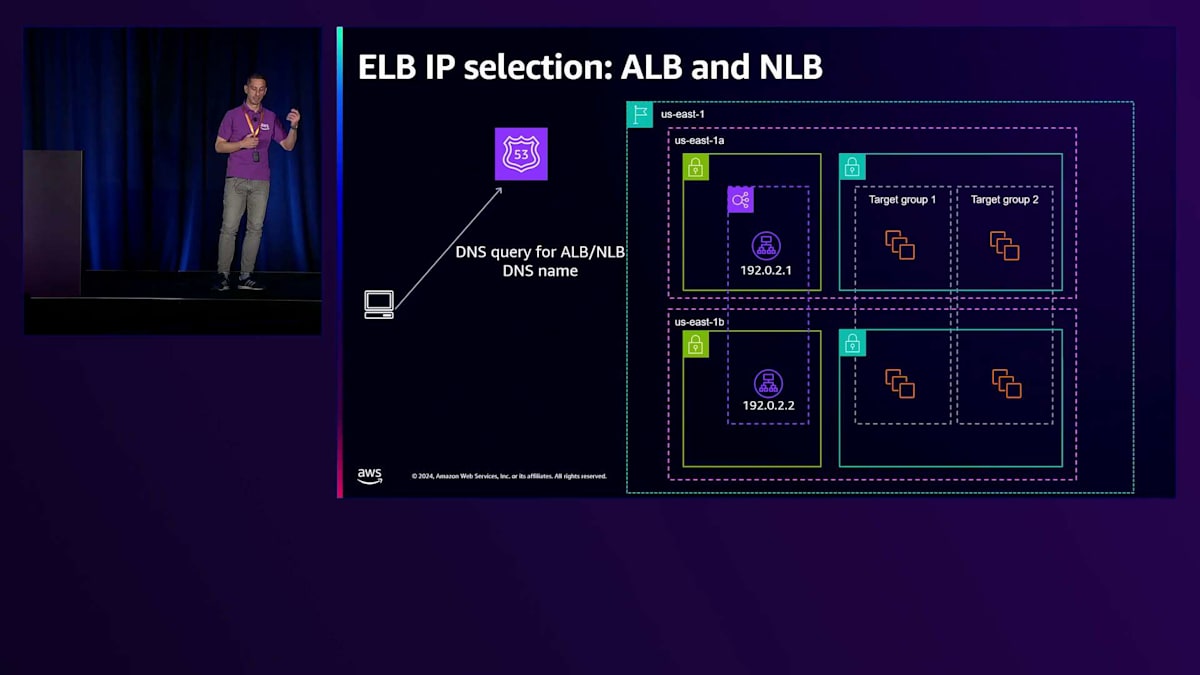
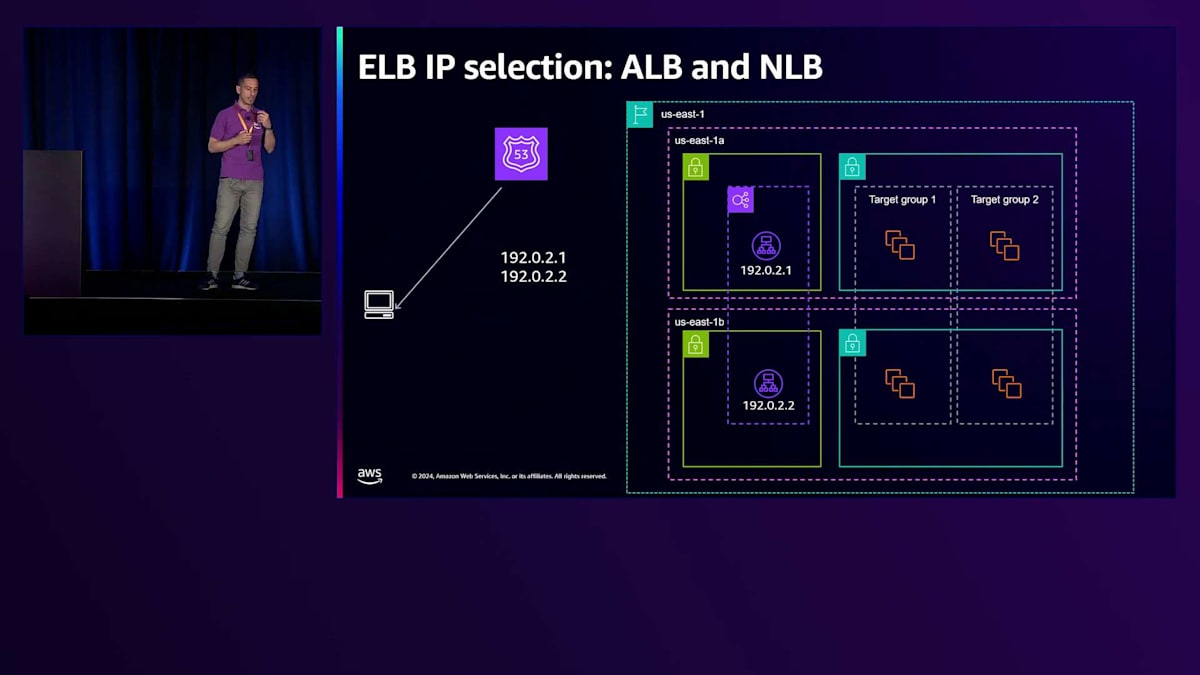
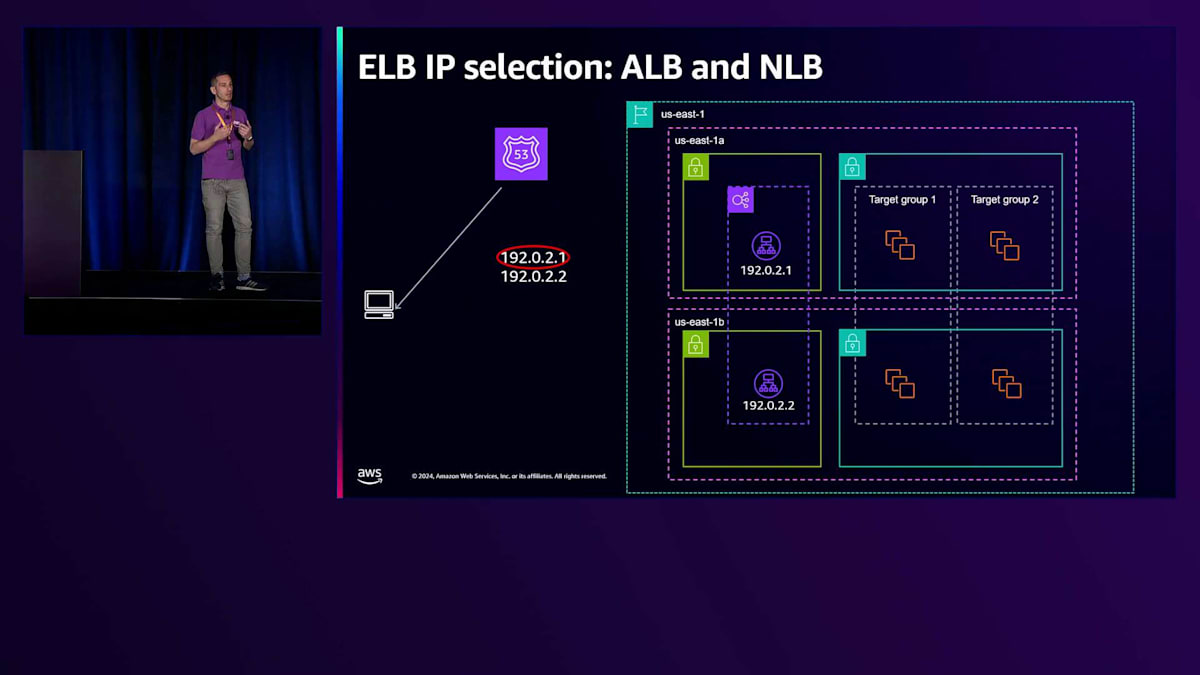
ELBにアクセスする正しい方法は、このDNS名を通じて行うことです。クライアント内で最初に行われるのがDNS解決です。クライアントがRoute 53にDNSクエリを送信し、先ほどJohnが説明したように、Route 53はLoad Balancerに割り当てられた正常なIPアドレスの最新リストを管理するAWSサービスで、これらのIPは検出されたワークロードに対して十分なスケールを持つと判断されたものです。Route 53がクライアントにリストを返すと、クライアントはリストから1つのIP(通常は最初のIP)を選択します。これが、同じDNS名に対するDNSクエリを複数のクライアントに返す際に、常に異なる順序で返そうとする理由でもあります。これは、利用可能なすべてのIPにわたってより均等な選択に影響を与えるために行われています。
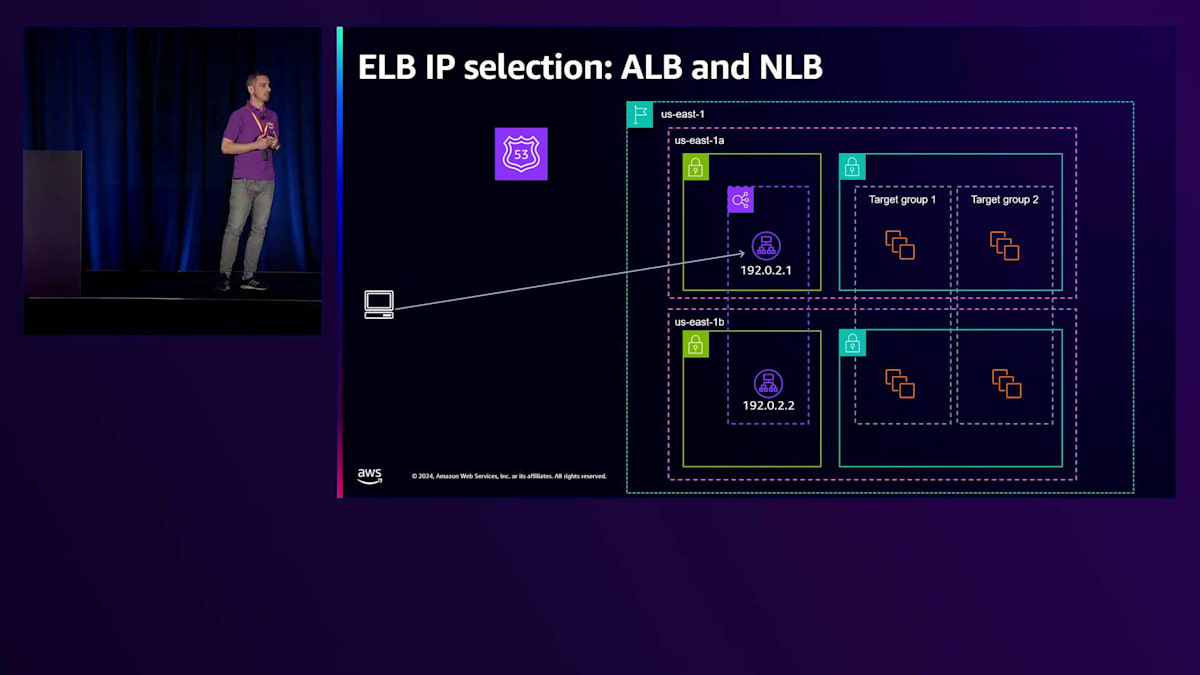

最終的には、トラフィックの送信に使用するIPについてはクライアントの判断に委ねられます。このため、お客様がELBにトラフィックを送信する際には、クライアントがDNSを解決し、DNS エントリに関連付けられたTTL(Time To Live)を尊重するように設定することが非常に重要です。これはApplication Load Balancerでは特に重要です。なぜなら、IPアドレスは時間とともに動的に変化するためですが、Network Load Balancerでも同様に重要です。先ほどJohnが説明したように、ELBコントロールプレーンがDNS名からIPを削除するイベントが発生する可能性があるためです。
お客様がクライアントを設定する際は、常にフォールトトレランスと可用性の側面を考慮する必要があります。これは、TCP接続が予期せず切断された場合にDNSを更新するようクライアントを設定し、再接続時に最新のリストを取得できるようにすることを意味します。多数のクライアントが同時に再接続する場合、特定のIPに過負荷をかけないよう、指数バックオフとジッターを使用する必要があります。また、特定のIPで問題が発生している場合は、リスト内の別のIPを試すことをお勧めします。ALBのコントロールプレーンは、IPが不健全な状態を検出して自動的に置き換える作業を行いますが、このプロセスには通常約30秒かかるため、リスト内の他のIPを試すことで回復プロセスを迅速化できます。
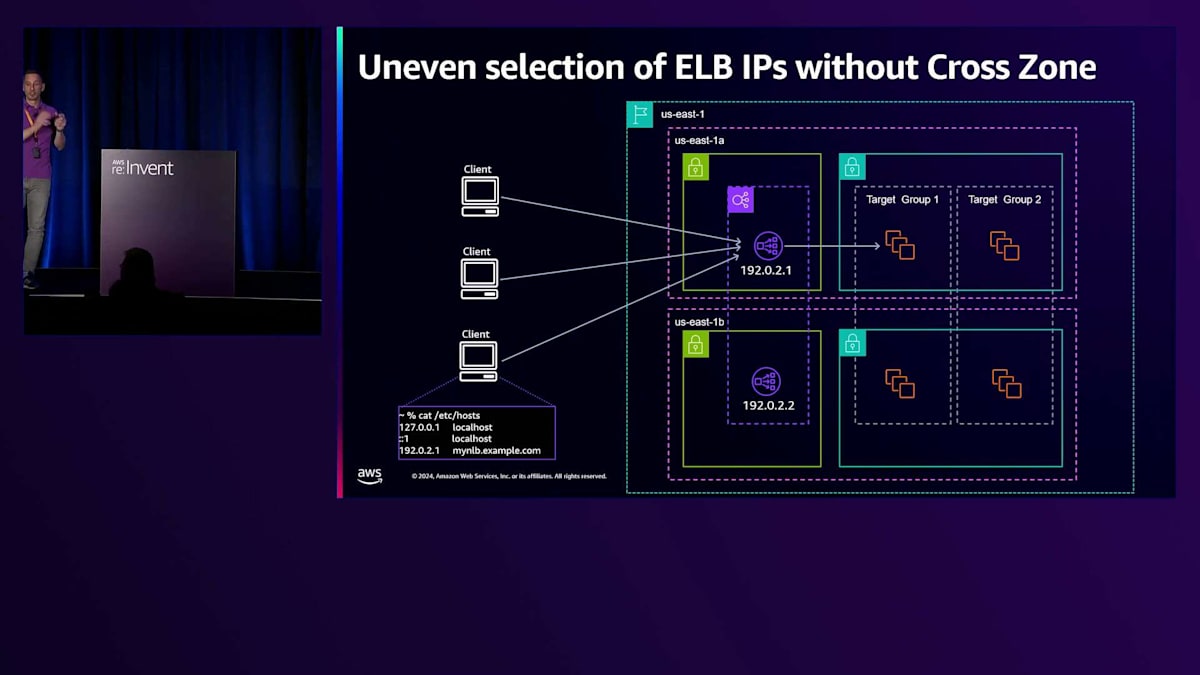

クライアントによるIPの選択は、ALBによって生成されるトラフィック分散に直接的な影響を与える可能性があります。これは特に、Cross-Zone Load Balancingが無効になっている場合に顕著です。Cross-Zoneは、ALBがトラフィックを受信したIPとは異なるAvailability Zoneにあるターゲットにトラフィックを送信できるようにする設定です。Cross-Zoneがオフの場合、ALBはトラフィックを受信したALB IPと同じAvailability Zone内のターゲットのみを選択します。クライアントがバランスの取れた方法ですべての利用可能なIPを選択せず、かつCross-Zoneがオフの場合、このスライドに示すような不均一な分散が生じます。ここでは、いくつかのターゲットが受信したリクエスト数を示すグラフを見ています。ご覧の通り、

私は各Availability Zoneに2つずつ、合計4つのターゲットを持つTarget Groupでテストを実施しました。基本的に2つのターゲットのみがトラフィックを受信していました。これは、私のクライアントが1つのElastic Load Balancerにのみトラフィックを送信し、Cross-Zoneが無効になっていたためです。お客様がこのような不均一な分散を検出した場合は、Cross-Zone設定を有効にすることを検討すべきです。これにより、Elastic Load Balancerはトラフィックを受信するターゲットを選択する際に、Target Group内のすべてのターゲットを考慮することができます。ただし、これによってApplication Load Balancerに適用される料金が増加する可能性があることにも注意が必要です。Network Load Balancerの場合、リクエストがAvailability Zoneの境界を越える際にはインターAvailability Zone料金が適用されますが、Application Load Balancerではこのトラフィックは無料です。
Network Load BalancerとGateway Load Balancerのルーティングアルゴリズム
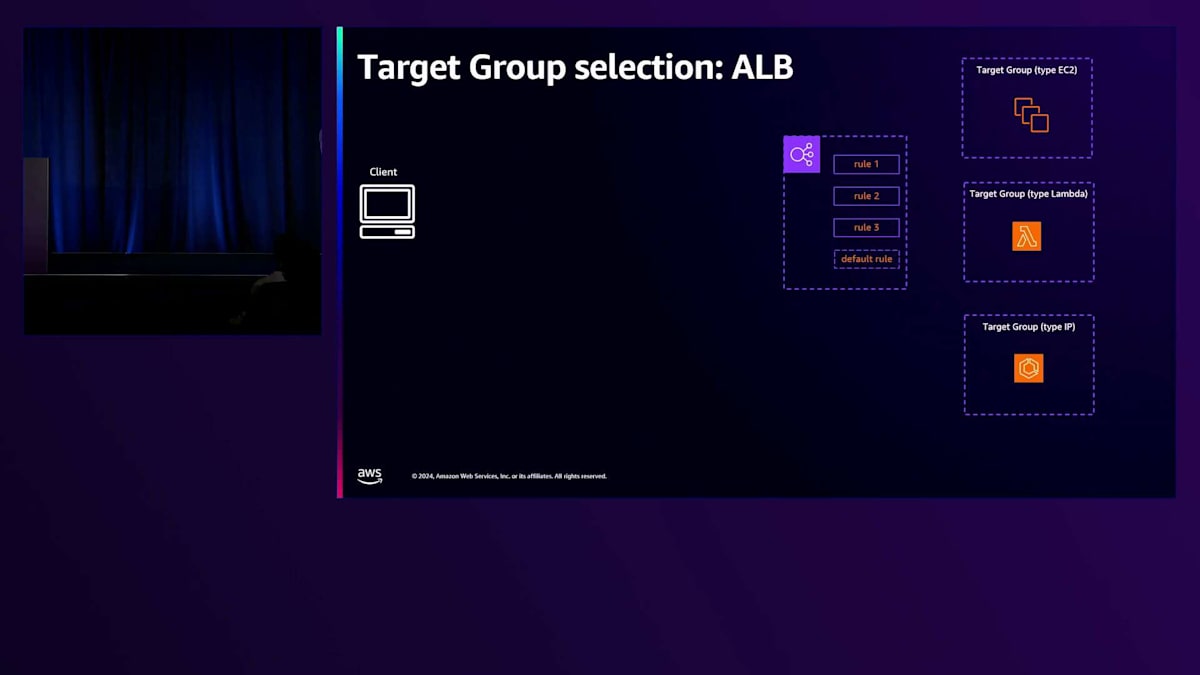

次に、Target Groupの選択に関する第二のレベルの判断に移りましょう。Network Load BalancerとGateway Load Balancerでは、トラフィックを受信するリスナーに基づいてTarget Groupの選択が固定されているため、ここではApplication Load Balancerにのみ焦点を当てます。これは、お客様が単一のリスナーの背後に設定できるTarget Groupが1つだけだからです。Application Load Balancerでは、お客様は同じリスナールールの背後に、同じリスナーの背後に複数のTarget Groupを設定し、これらのリスナールールを活用することができます。つまり、複数のルールが関連付けられているElastic Load BalancerリスナーにHTTPリクエストが到着すると、これらのルールはルールに関連付けられた優先順位に従って順番に評価されます。特定のルールとマッチが決定されると、そのルールに関連付けられたTarget Groupが選択されます。いずれのルールにもマッチしない場合は、デフォルトケースを処理する最終的なデフォルトルールが常に存在します。
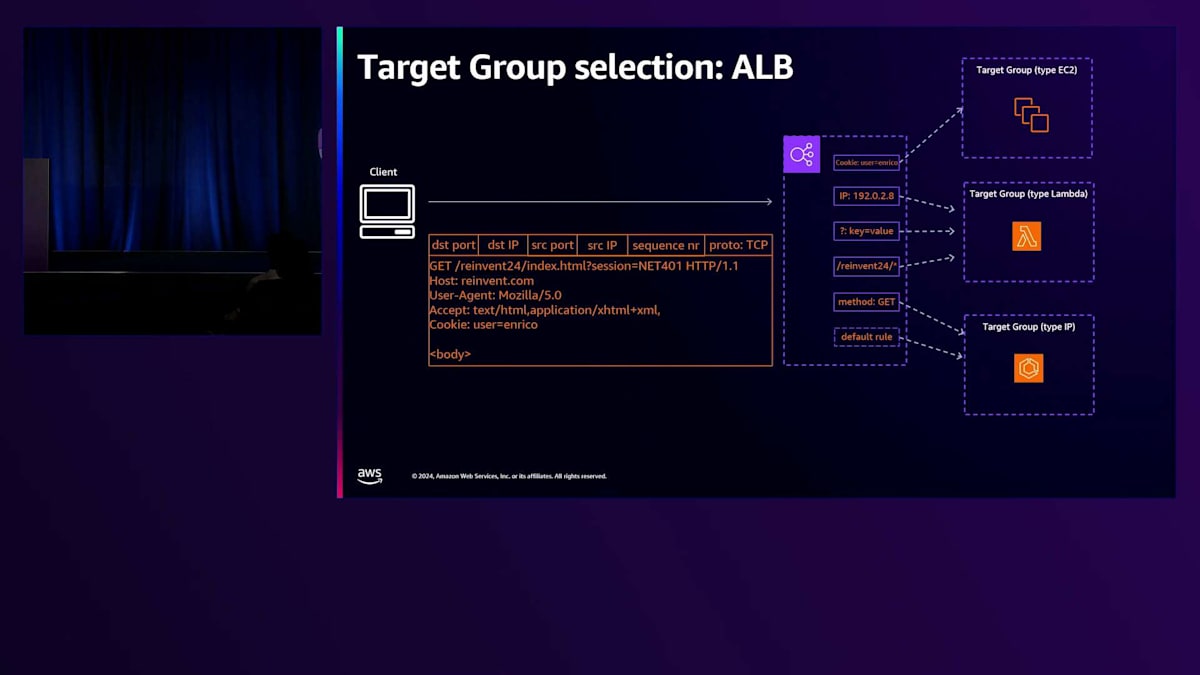
ルールには、Elastic Load Balancerが評価する条件が技術的に関連付けられています。これらの条件は、クライアントリクエストに含まれるさまざまなパラメータに基づくことができます。これには、リクエストに含まれるパス、HTTPメソッド、そしてより一般的には、Cookieやクエリパラメータ、Elastic Load Balancerにリクエストを送信するために使用されたクライアントのIPアドレスを含む、あらゆる種類のHTTPヘッダーが含まれます。このような豊富なオプションにより、Elastic Load Balancerは大きな柔軟性を持っています。実際、Elastic Load Balancerはアーキテクチャを簡素化するように設計されており、Load Balancerの背後にあるアプリケーションで使用される特定の技術に関係なく、直接ターゲットにトラフィックを負荷分散することを目的としています。
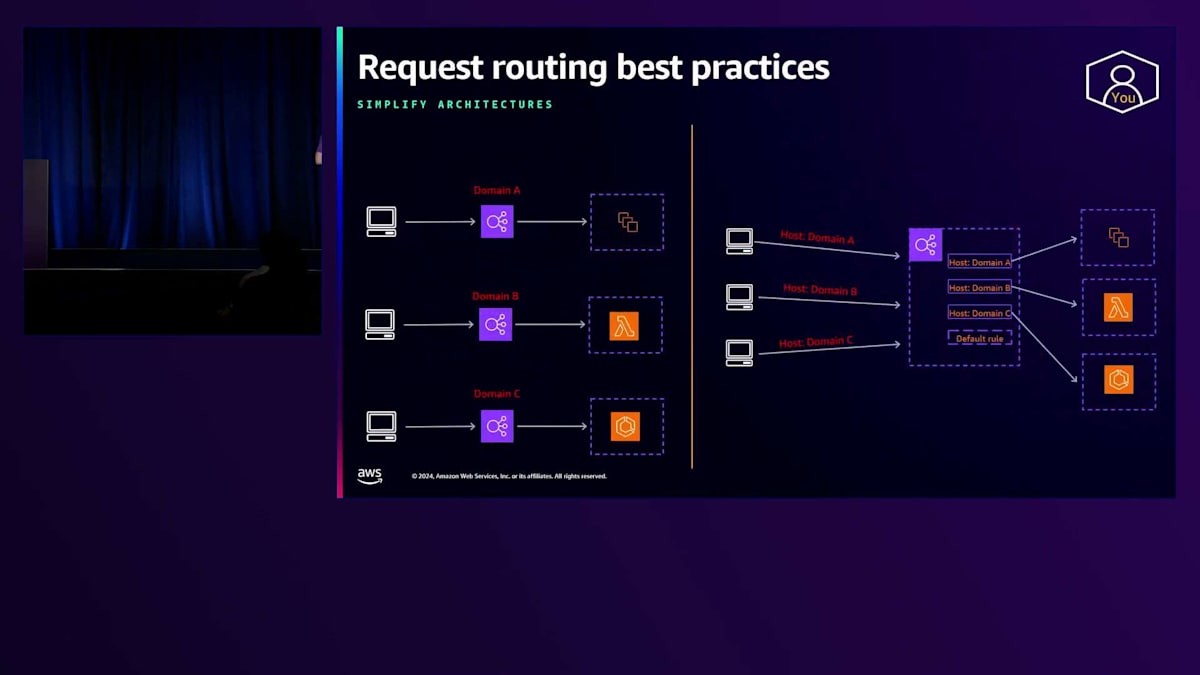


このようなアーキテクチャを簡素化する方法の1つとして、複数のドメインへのトラフィックを処理するために複数のロードバランサーを設定しているお客様の場合、ホストヘッダーベースのルールを使用して、それらの複数のバランサーを1つのElastic Load Balancerに集約することを検討できます。クライアントリクエストのホストヘッダーには、クライアントがアクセスしようとしているドメインが含まれています。お客様がロードバランサーでTLSオフロードを行っている場合、 同じリスナーに複数の証明書を設定でき、Application Load Balancerは適切なリクエストに対して適切な証明書を提示します。 これはServer Name Indication(SNI)のサポートにより可能となります。SNIは、クライアントリクエスト、特にTLSハンドシェイクに含まれる情報で、クライアントがアクセスしようとしているホスト名が含まれています。この情報をチェックすることで、ロードバランサーはクライアントに適切な証明書を提示し、HTTPSが必要な場合でも、1つのバランサーで複数のドメインへのトラフィックを処理することができます。
これにより、管理が必要なロードバランサーが1つだけになるため運用の負担が軽減され、コスト最適化にも役立ちます。ただし、この決定を行う際は、ロードバランサーが提供しているすべてのドメインに影響を与えるため、影響範囲と影響度に注意する必要があります。このタイプのアーキテクチャで得られるメリットと影響範囲のバランスを常に考慮する必要があります。
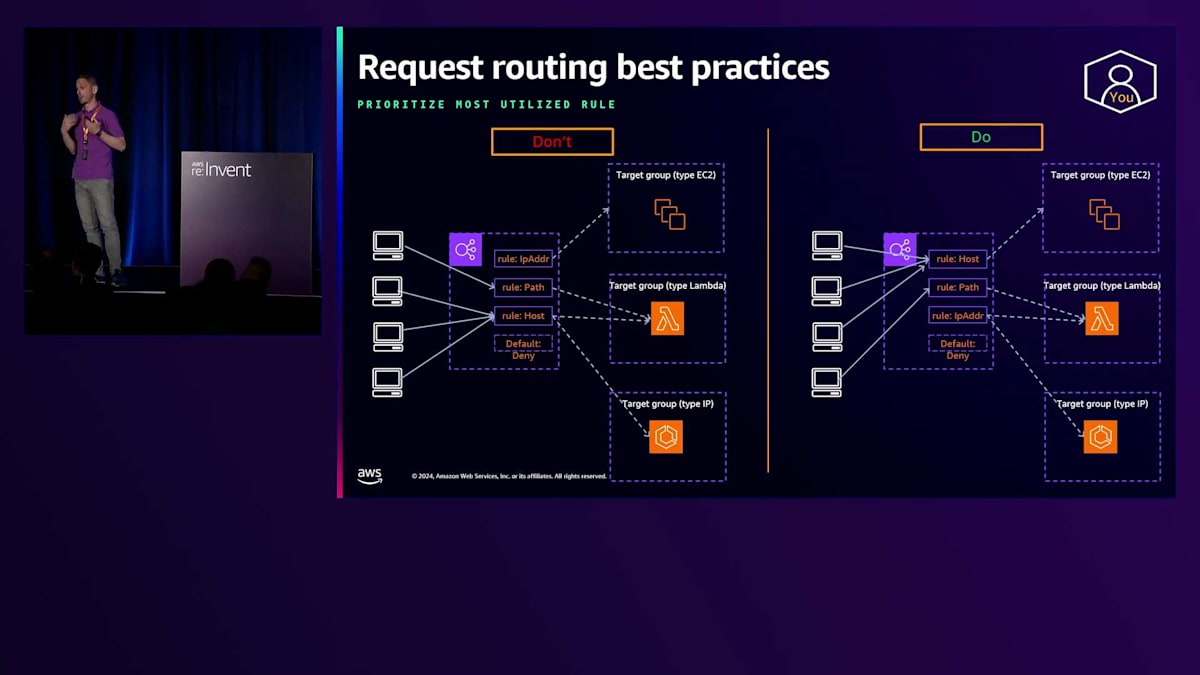
2つ目のベストプラクティスは、 リスナー上のルールの順序に関するものです。最も利用頻度の高いルールを常に優先順位付けすべきです。これにより、Load Balancerはリスナーで受信した各リクエストに対して実行する評価の数を最小限に抑えることができます。Load Balancerは評価の数に基づいて容量をスケールできますが、これらの評価には依然として計算コストがかかります。これらの評価による遅延を最小限に抑えたいお客様は、最も利用されると予想されるルールを優先することを検討すべきです。
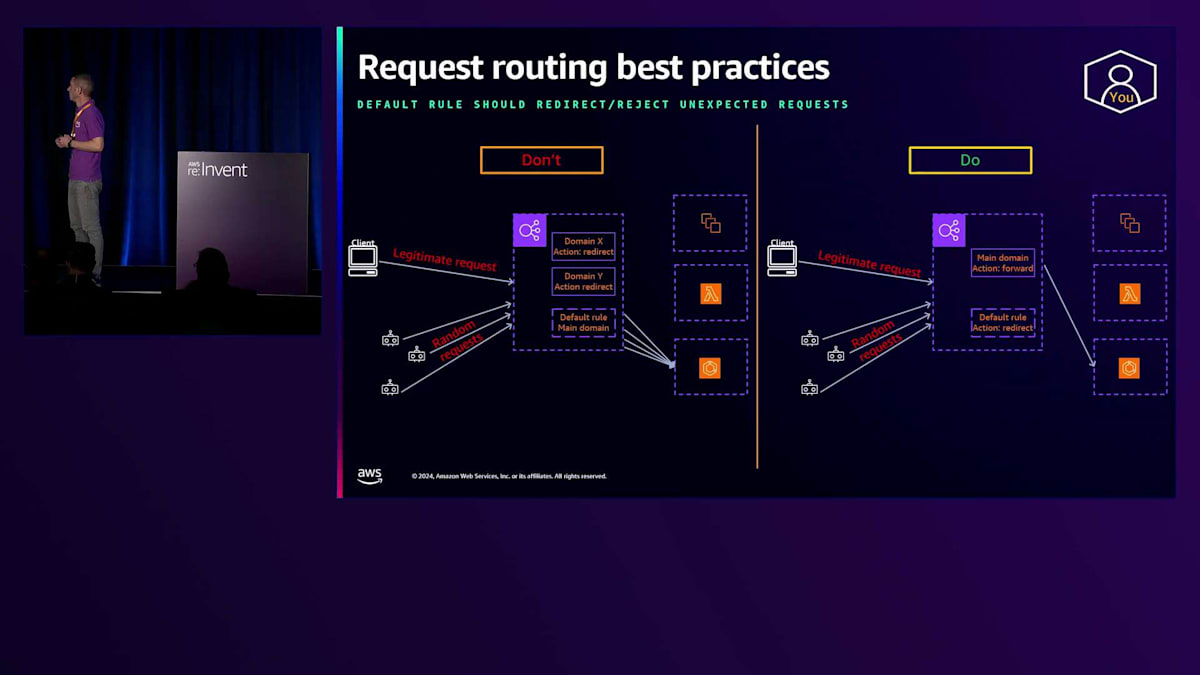
次に共有したいベストプラクティスは、特にインターネット向けロードバランサーに関するものです。ロードバランサーをインターネットに公開する場合、どのようなリクエストを受け取るかを正確に予測することはできません。正当なリクエストと共に、ボットや侵入者からのランダムなリクエストも一定数受け取ることになります。デフォルトルールを通じてこれらのランダムなリクエストをリダイレクトおよび拒否することをお勧めします。これにより、Elastic Load Balancingは、それらのランダムなリクエストをターゲットに転送することなく、応答を生成する責任を負うことになります。ELBがこれらのランダムなリクエストを大量に受信した場合、ELBのスケーリングシステムがスケールアップしてこの増加したトラフィックを吸収することで、ロードバランサーの背後にあるターゲットは保護されます。

リクエストルーティングに関する最後の言及は、 Weighted Target Group機能についてです。この機能により、お客様は同じリスナールールの背後に複数のTarget Groupを関連付け、一方のTarget Groupに対して別のTarget Groupよりも多くのトラフィックを振り分けたいパーセンテージを設定できます。これはBlue-Greenデプロイメントで非常に役立ちます。アプリケーションの新バージョンをロールアウトする際、お客様はWeighted Target Group機能を活用して、実際のクライアントリクエストで新バージョンをテストできます。また、Target Groupレベルでスティッキネスをオンにすることもでき、これにより単一のクライアントは一貫して同じTarget Group、つまり同じバージョンのアプリケーションにルーティングされます。



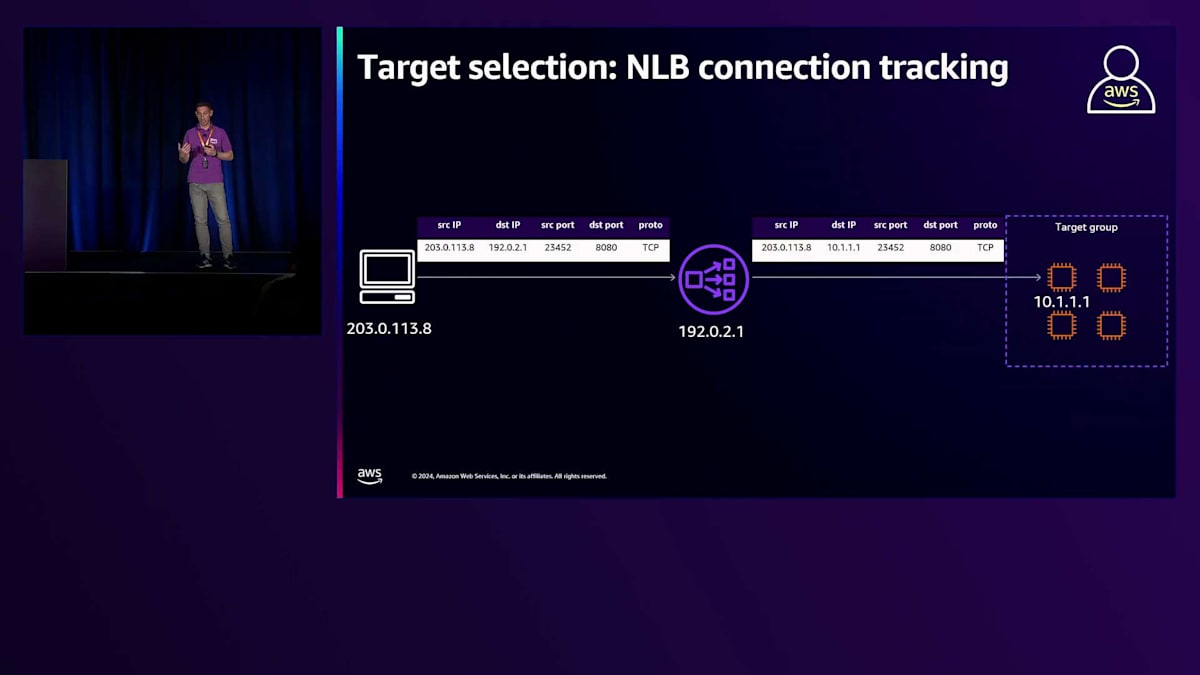
それでは最後のステージである、ターゲットグループ内のターゲット選択に移りましょう。各ELB製品には独自のルーティングアルゴリズムがあるため、それぞれ個別に説明していきます。まずはNetwork Load Balancerから始めましょう。 NLBは、レイヤー4のバランシングを提供するAWSのマネージドサービスです。レイヤー4のバランサーとして、レイヤー3とレイヤー4の情報を組み合わせてターゲット選択を実行することができます。NLBをTCPリスナーで使用する場合、 ターゲット選択は新しい接続が確立されたときに実行されます。トラフィックがNetwork Load Balancerに到達すると、TCPとIP情報からフローハッシュが抽出され、これがNetwork Load Balancerがターゲットを選択してトラフィックを転送する際のアルゴリズムの入力パラメータとなります。この選択を実行する際、Network Load Balancerは分散データベースにフローハッシュと選択されたターゲットの関連付けを記録します。

戻りトラフィックについては、ターゲットから生成されてクライアントに送信されるトラフィックも Network Load Balancerを経由します。新しい接続が確立されNLBによってターゲットが選択されると、トラフィックはターゲットに転送されます。AWSハイパープレーン(NLBがトラフィックを操作し、クライアントとターゲット間でトラフィックを双方向に送信できるようにする基盤技術)に実装された接続追跡システムと、EC2ソフトウェアとの統合により、戻りトラフィックは必ずNetwork Load Balancerに戻されます。
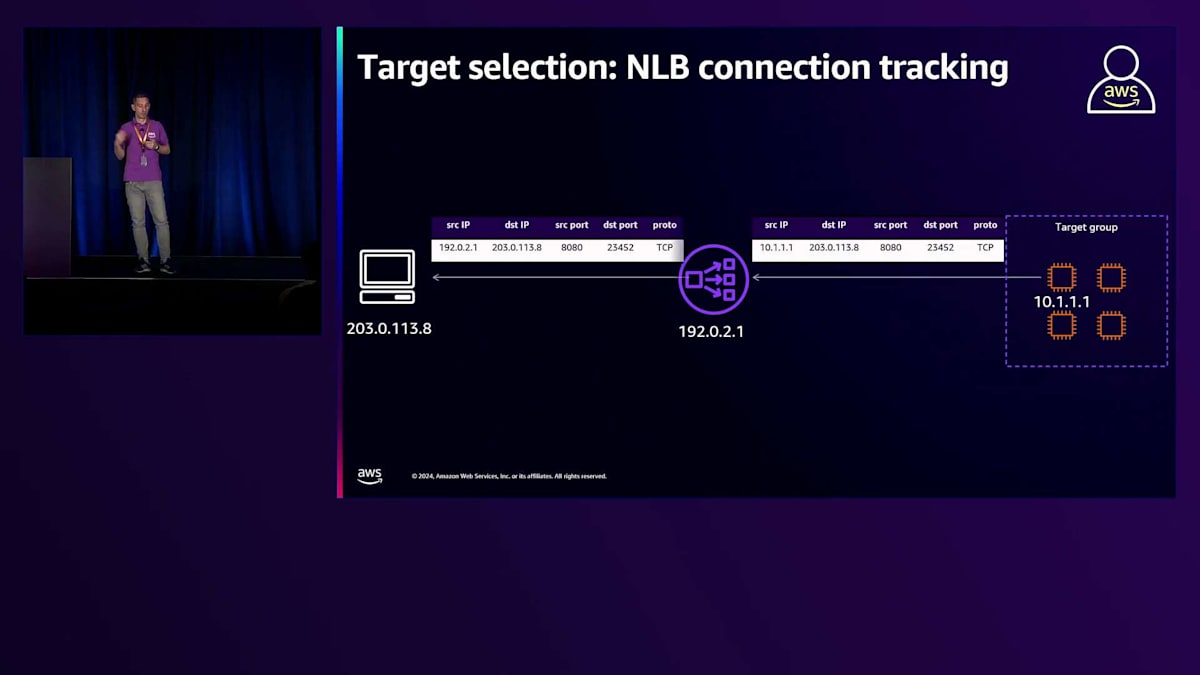
これは特に、Network Load BalancerでクライアントIPの保持機能が有効になっている場合、一見すると自明ではありません。 実際、この場合、ターゲットからクライアントに送信されるトラフィックの宛先IPには、接続を開いた実際のクライアントIPが含まれます。このIPはNetwork Load Balancerに割り当てられたIPではないため、AWSのソフトウェア定義ネットワークに実装された特別な追跡システムが必要となります。このシステムにより、トラフィックは強制的にNetwork Load Balancerに戻され、そこでトラフィックの送信元IPが自身のIPに書き換えられてからクライアントに送り返されます。



この分散データベースは複数の理由で重要です。第一の理由は、既存の接続に対するトラフィックを受信するたびにフローアルゴリズムを再計算する必要がないということです。 既存の接続に対するデータが到着すると、Network Load Balancerは分散データベース内で、この接続を識別する6タプルと 選択されたターゲットとの関連付けを検索します。レコードが見つかれば、最初に選択されたのと同じターゲットを選択します。つまり、Network Load Balancerは接続確立時に一度だけターゲット選択を実行し、その後は同じ接続内でトラフィックがやり取りされる限り、最初に選択されたターゲットに一貫してトラフィックをルーティングします。





第二の理由は、先ほど述べたように、トラフィックを操作する物理ホストから独立して ハイパープレーンで接続状態を維持することで、Network Load Balancerはそれらの物理ホストの1つを 顧客トラフィックに影響を与えることなく置き換えることができるということです。すべてのオープン接続にはアイドルタイムアウトがあり、デフォルトでは 350秒に設定されています。接続がこのタイムアウト時間以上アイドル状態になると、Network Load Balancerはその接続の レコードを分散データベースから削除します。これは、同じ接続に対してトラフィックが到着しても、Network Load Balancerは分散データベース内にレコードを見つけることができず、クライアントにTCPリセットを返すことを意味します。

Network Load Balancerをリリースして以来、お客様から最も多くいただいていたリクエストの1つが、アイドルタイムアウトをカスタマイズする機能でした。最近、TCPリスナーに対してこの新機能をリリースしました。これにより、お客様はアイドルタイムアウトの値を60秒から6000秒の範囲で設定できるようになりました。この機能についてより詳しく知りたい方は、このスライドのQRコードからアクセスしてください。
Application Load Balancerのルーティングアルゴリズムと異常検出
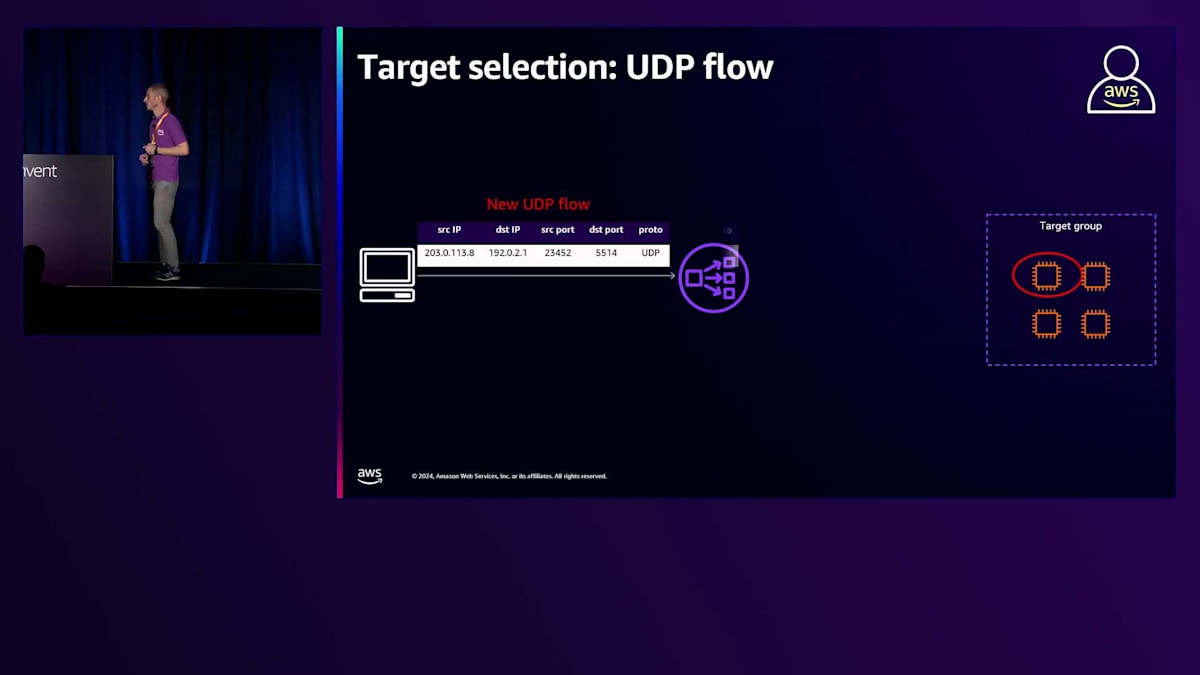


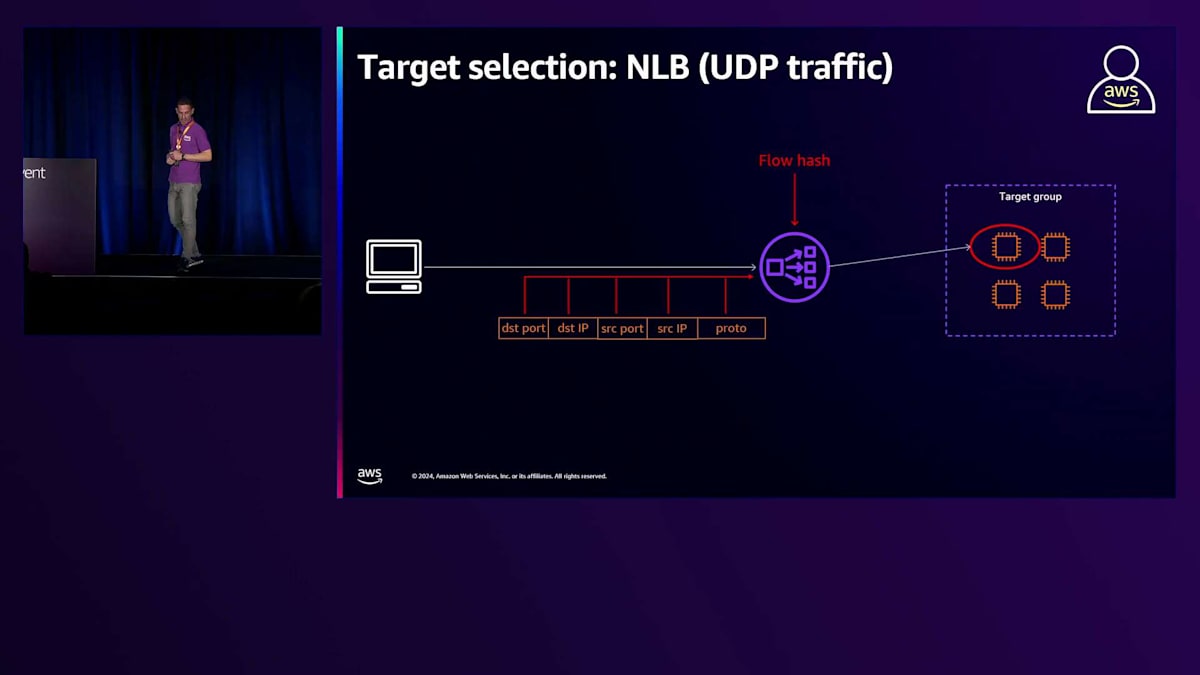
Network Load Balancerをリスナーと共に使用する場合、ターゲット選択には同じFlow hashアルゴリズムが使用されます。ただし、Flow hashの計算には5つの要素が使用されます:プロトコル、送信元IPアドレス、送信先IPアドレス、送信元ポート、送信先ポートです。TCPリスナーと比べて欠けているパラメータはシーケンス番号です。これは、UDPにはコネクションやシーケンス番号の概念がないためです。しかし、Network Load Balancerは、UDPフローという概念を適用しています。つまり、新しいフローのトラフィックが到着すると、Network Load Balancerはターゲットを選択し、そのトラフィックをルーティングします。そのターゲットが30秒以内に応答すると、Network Load Balancerは、このUDPフローを識別する5つの要素と選択されたターゲットとの関連付けを分散データベースで追跡します。これは、UDPトラフィックの場合、Network Load Balancerは一度ターゲットを選択し、その後、同じUDPフローに属するトラフィックを一貫して同じターゲットにルーティングすることを意味します。

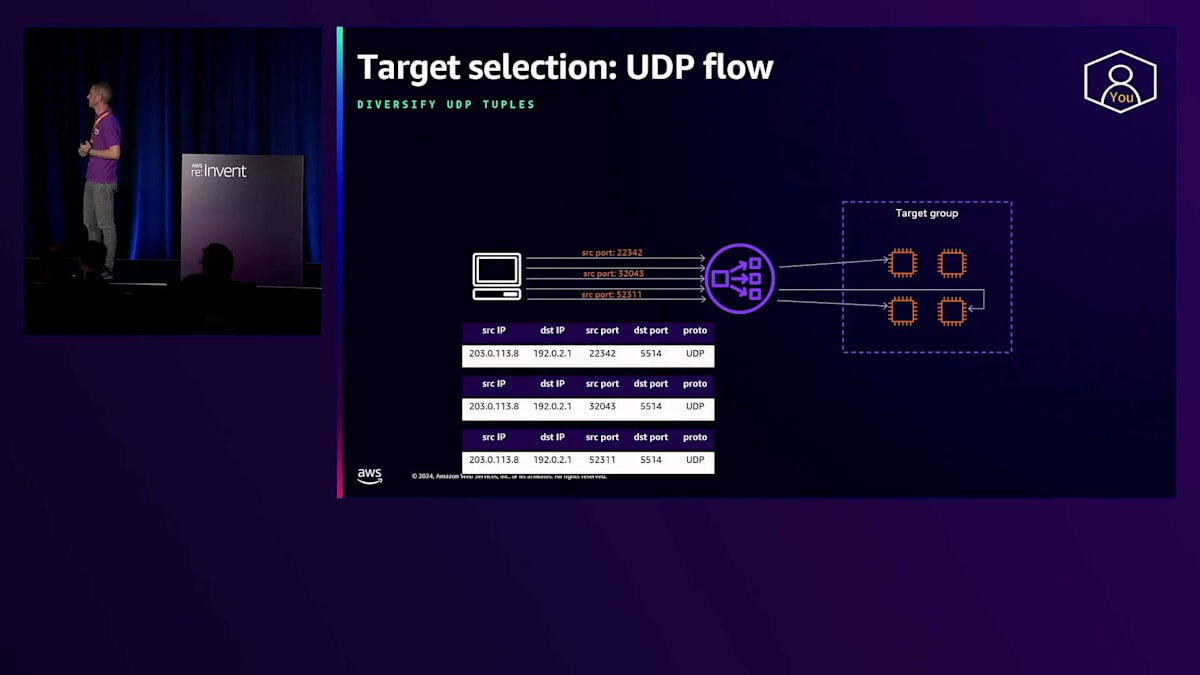
これは重要な概念です。なぜなら、時々、複数のUDPフローに対して同じ送信元ポートを使用するようにクライアントを設定しているお客様を見かけるからです。これが発生すると、Network Load Balancerに到着するすべてのトラフィックが同じ5つの要素を含むことになり、Network Load Balancerは1つのターゲットだけを選択してすべてのトラフィックを処理することになります。したがって、クライアントが送信元ポートを分散するように設定することが重要です。
複数のフローに対して送信元ポートを分散させることで、Load Balancerはターゲットグループ内の正常なターゲット全体にトラフィックを均等に分散させることができます。
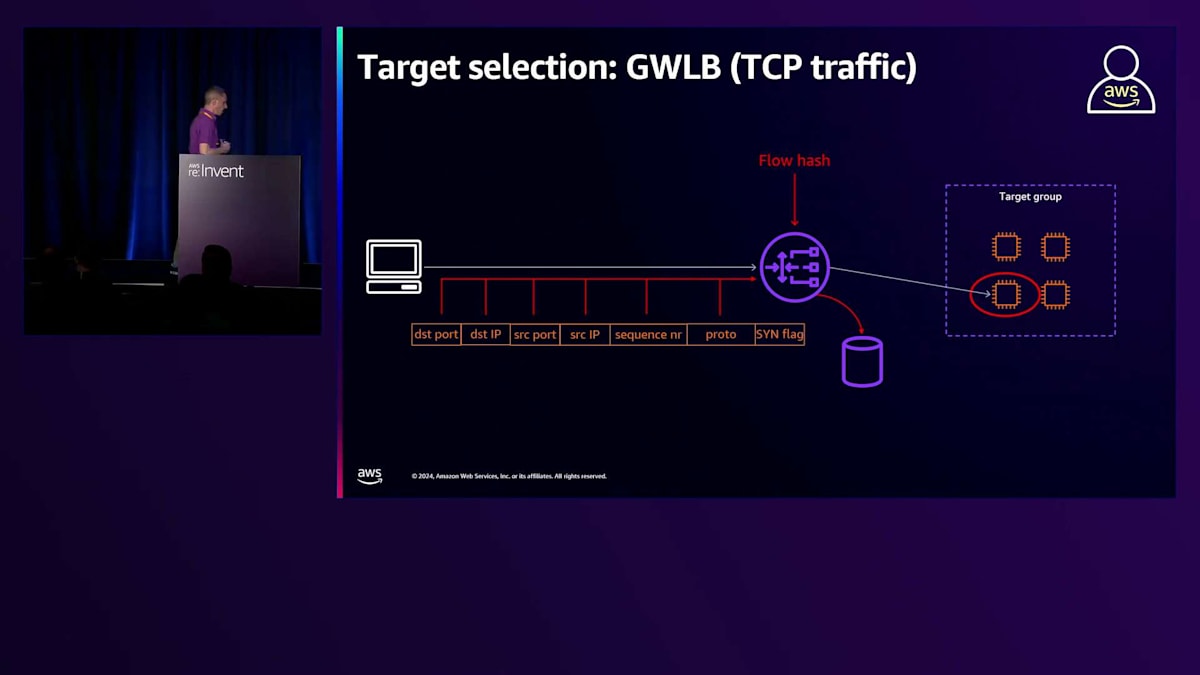
次に、TCPトラフィックで使用される場合のGateway Load Balancer(GWLB)について説明しましょう。ターゲットの選択には同じFlowアルゴリズムが使用され、Flowの計算には同じ6つの要素が使用されます。TCPコネクションとターゲットの関連付けは、サーバーからクライアントへの戻りトラフィックにも拡張されます。Gateway Load Balancerは、クライアントとサーバーの間に位置するリソースで、両方向のトラフィックがLoad Balancerを通過します。GWLBの背後には通常、トラフィックに対してステートフルなルールを適用するように設定されたファイアウォールアプライアンスがあるため、Gateway Load Balancerがターゲット選択に関して一貫した決定を行うことが重要です。GWLBは、TCPコネクションと各方向のトラフィックに選択されたターゲットとの間のStickinessをネイティブに提供します。

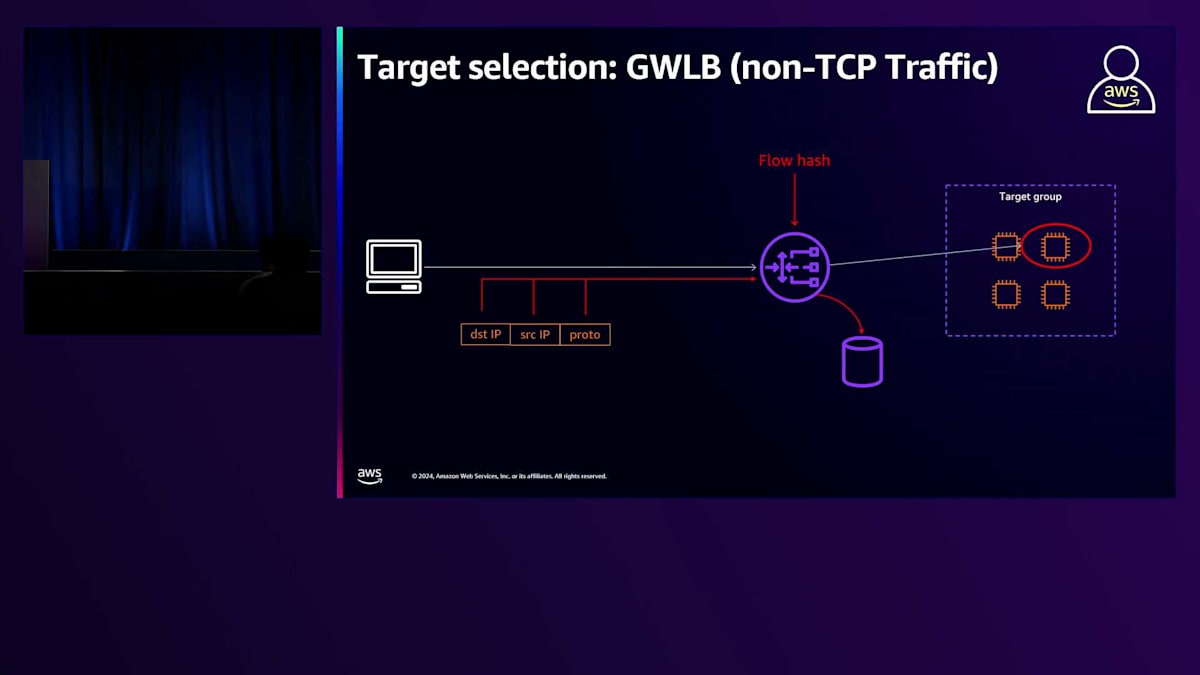
非TCPトラフィックでLoad Balancerを使用する場合、フローの計算には送信元IP、宛先IP、プロトコルの3つの要素のみが使用されます。

次に、Application Load Balancer(ALB)について説明していきましょう。まずはターゲット選択のタイミングについて明確にしていきます。ALBは受信した個々のHTTPリクエストごとにターゲット選択を実行することができます。これは、同一クライアントが同じTCP接続を再利用して複数のHTTPリクエストを送信する場合でも同様で、これらのリクエストは利用可能で正常なターゲット全体に個別に分散されます。ALBがターゲットとの接続を確立すると、その接続を維持しようとします。これにより、ALBは常に使用可能な接続プールを維持でき、HTTPリクエストをターゲットに配信するたびにTCP接続を再確立する必要がなくなります。左側に示すように、この例でNetwork Load Balancer(NLB)を使用した場合、NLBは接続をルーティングするため、すべてのHTTPリクエストを同じターゲットにルーティングしますが、ALBはHTTPリクエストをルーティングすることができます。

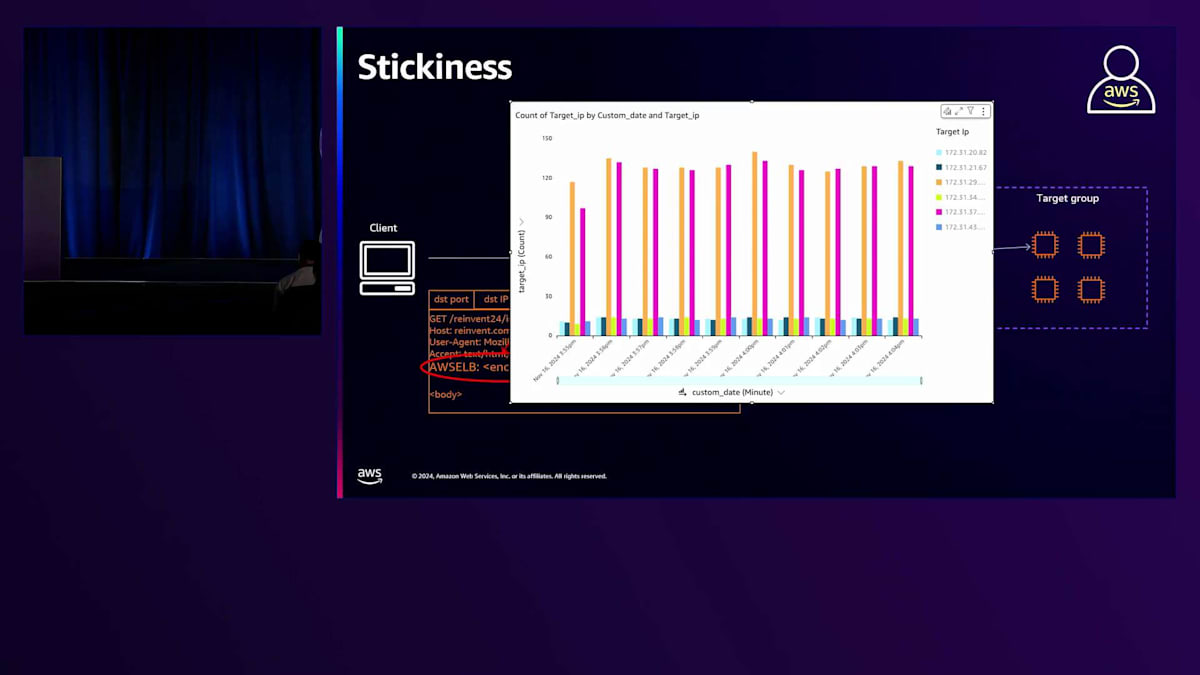
先ほど説明したHTTPリクエストごとのターゲット選択機能は、ALBでセッションスティッキネスが有効になっていない場合に限り有効です。スティッキネスとは、同じクライアントセッションに属するトラフィックを繰り返し同じターゲットにルーティングするLoad Balancerの機能です。スティッキネスが有効なALBに新しいリクエストが到着した場合、そのリクエストが新しいセッションであれば、ALBはターゲット選択を実行します。 リクエストが既存のセッションのものである場合、つまりAWS ELBクッキーが含まれている場合、Load Balancerはこのクッキーの中を確認して最初に選択されたターゲットを特定し、ルーティングアルゴリズムを適用する代わりにそのターゲットを使用します。

少数のクライアントが既存のクライアントセッションを使用してLoad Balancerにリクエストの大部分を送信する場合、結果として分散が不均衡になります。この例では、わずか2つのクライアントセッションがリクエストの大部分を送信するという極端なケースを示していますが、スティッキネスは本質的にALBによる不均衡な分散を生み出すことに注意が必要です。お客様はこの機能を慎重に、必要な場合にのみ使用し、可能であればこの依存関係を解消すべきです。
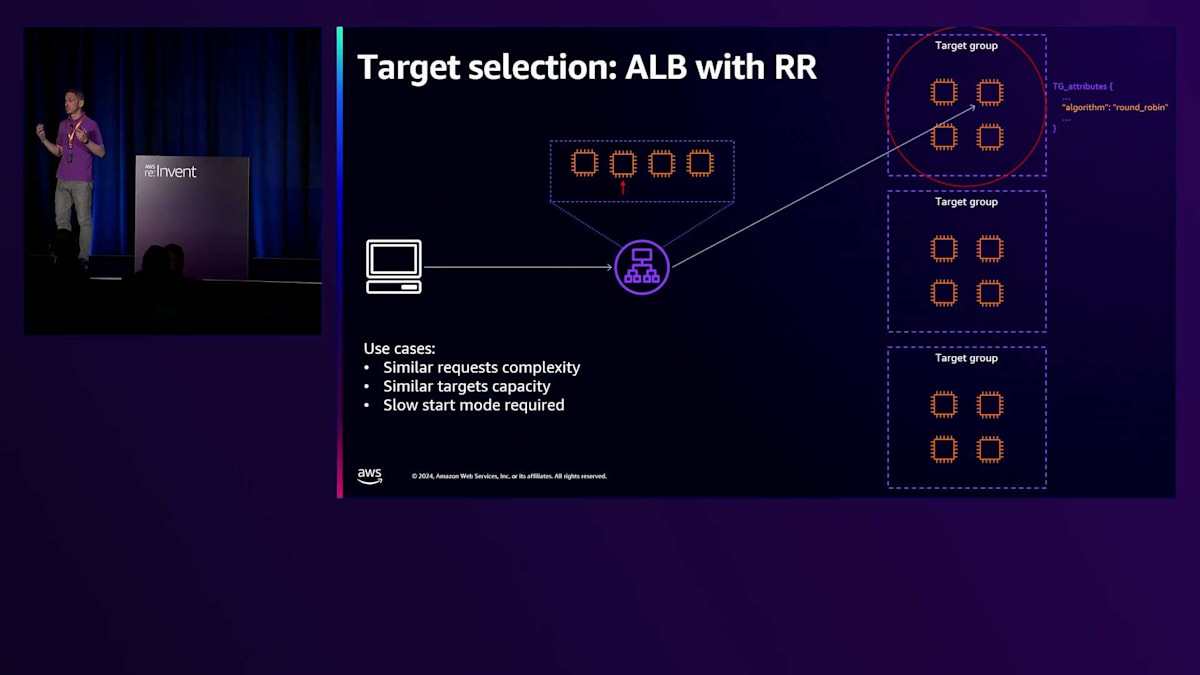
最後に、ALBで利用可能なルーティングアルゴリズムについて説明しましょう。3つのルーティングアルゴリズムがあり、これはTarget Groupに関連付けられた属性です。お客様が特定のルーティングアルゴリズムを設定しない場合、デフォルトでRound Robinが選択されます。Round Robinでは、ALBノードはトラフィックを受信できる正常なターゲットのリストを維持し、ターゲットを選択する際には順番に選択していきます。

Elastic Load Balancing (ELB) は、Application Load Balancer (ALB) で利用できるルーティングアルゴリズムの中では比較的シンプルな選択肢です。しかし、ターゲットごとのリクエスト数という観点では、非常にバランスの取れた分散を実現できます。このアルゴリズムは、リクエストの複雑さが似通っていて処理時間がほぼ同じ場合や、ターゲットグループ内のターゲットの処理能力が同程度である場合に適しています。ただし、Round Robinを使用する場合、ALBはターゲット選択時に特別なロジックを実行することはありません。

例えば、ターゲットグループ内の特定のターゲットがどれだけビジーであるかという点については考慮されません。この概念は、ルーティングアルゴリズムの2番目の選択肢であるLeast Outstanding Requestで実装されています。 Least Outstanding Requestでは、ノードは各ターゲットが処理中のin-flightリクエスト数を含むテーブルを保持します。ここでいうin-flightリクエストとは、ターゲットに転送されたものの、まだターゲットから応答が返されていないリクエストのことです。このルーティングアルゴリズムを使用するALBは、その時点で最も少ないin-flightリクエストを処理しているターゲットを選択し、これによって負荷の少ないターゲットを優先的に使用することができます。

トラフィック分散の観点から見ると、Least Outstanding Requestは、ターゲットグループ内に異なるサイズのEC2インスタンスが混在している場合に非常に適した選択となります。この場合、Least Outstanding Requestは処理能力の高いターゲットを優先的に使用することができます。処理能力が高いということは、リクエストをより速く処理できることを意味し、そのため各時点で、より高い処理能力を持つターゲットは未処理のリクエスト数も少なくなることが予想されます。このグラフは、ターゲットグループ内の4つのターゲットそれぞれが受け取ったリクエスト数を示しており、Least Outstanding Requestがこれらのターゲットをどのように優先的に使用するかを表しています。
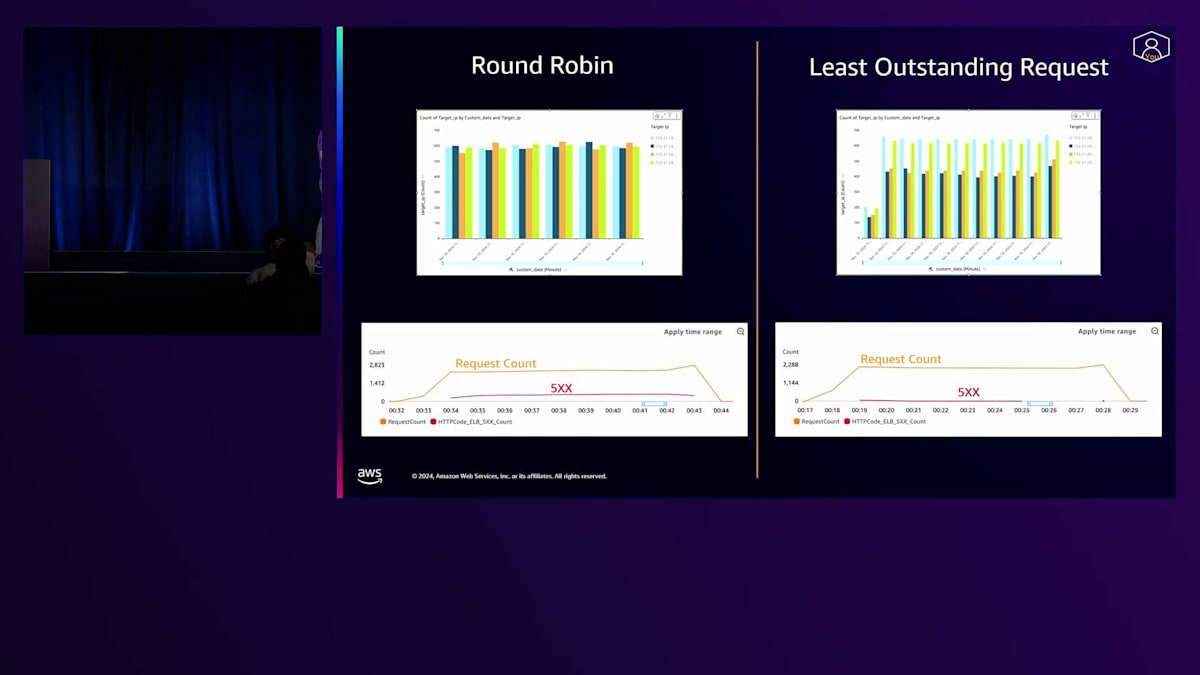
このルーティングアルゴリズムの利点として、特に異なるサイズのEC2インスタンスが設定されている場合に、サービスの可用性が向上することが挙げられます。ここでは、Round RobinとLeast Outstanding Requestを使用したロードテストを比較しています。Round Robinでは、処理能力の低いターゲットが容易にオーバーワークしてしまい、Least Outstanding Requestでは見られなかった586のエラーが発生しました。これは、ALBがリクエストを処理する能力の高いターゲットを優先的にルーティングしていたためです。

ルーティングアルゴリズムの最後の選択肢は、Weighted Randomです。Weighted Randomでは、ALBノードはターゲットグループからランダムにターゲットを選択します。Weighted Randomを使用するお客様は、Anomaly Detection Systemに基づく異常緩和機能を有効にすることができます。 Anomaly Detection Systemは、使用するルーティングアルゴリズムに関係なく、ELBで常に有効になっている機能です。ALBノードは、ターゲットから返される応答を常時監視し、TCPやHTTPエラーを示すTCPメトリクスを監視します。この監視の目的は、エラーを返し始めているターゲットを特定することであり、そのような状況が確認されると、ALBはそれらのターゲットを異常としてマークします。これはAWSコンソールや、CloudWatchのAnomaly Host Countメトリクスで確認することができます。

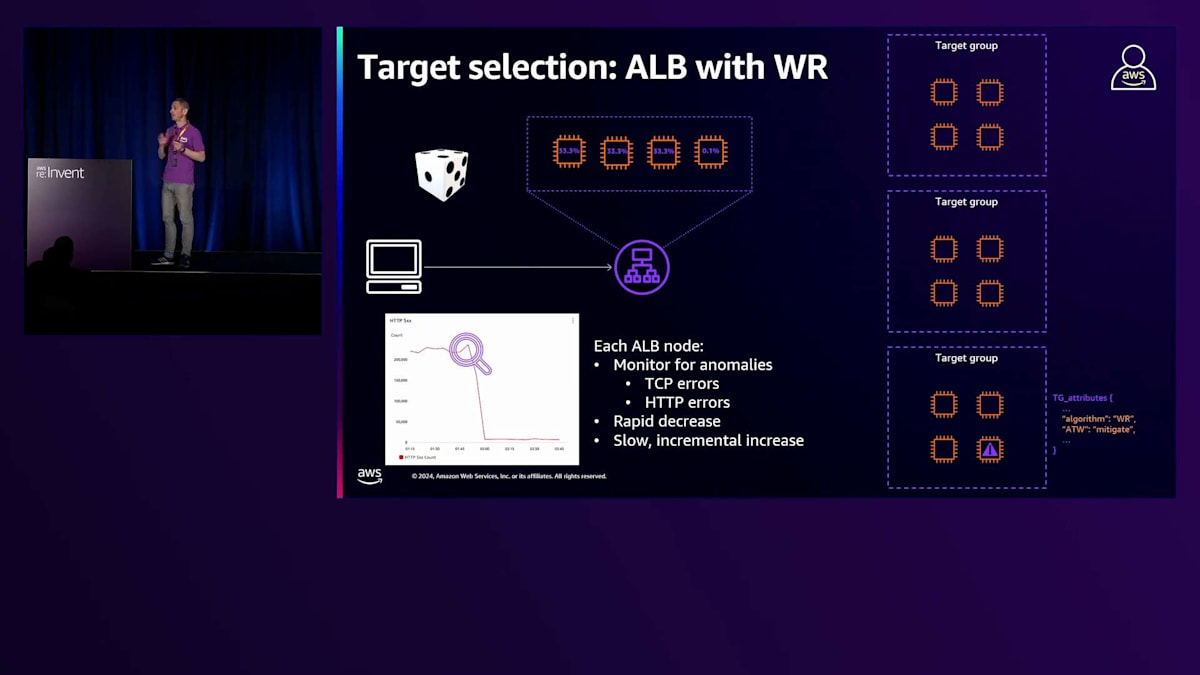
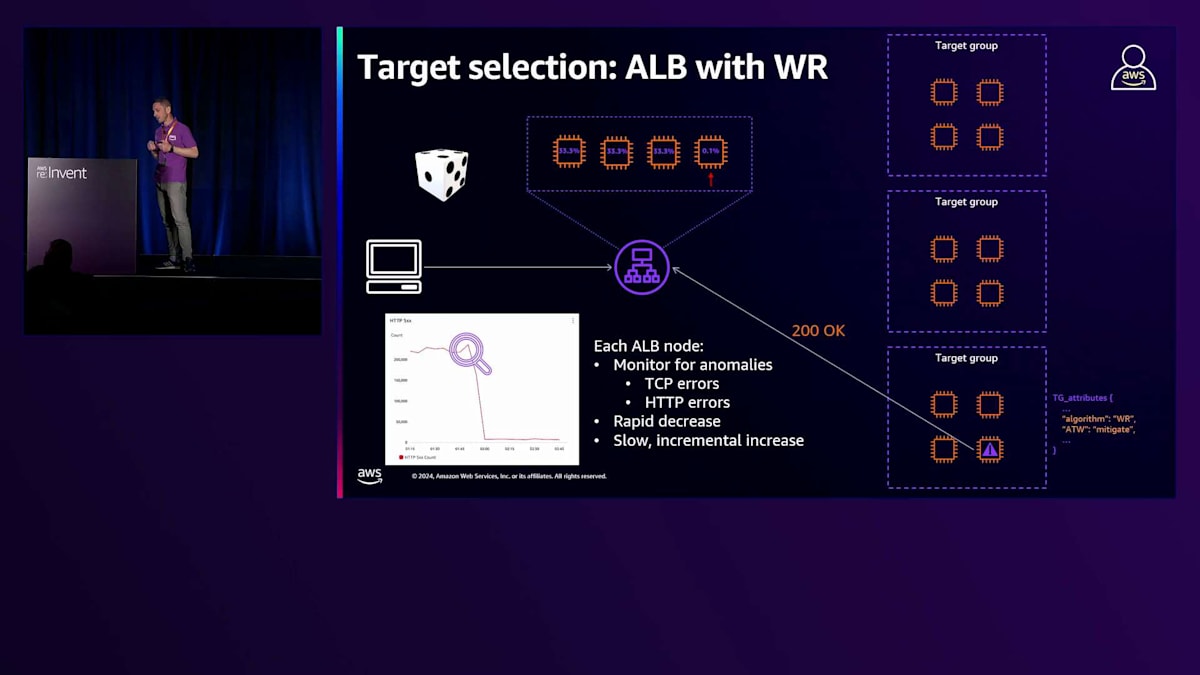
これらの2つの情報源を見て、お客様はAnomaly Mitigationシステムを有効にするかどうかを判断できます。 Anomaly Mitigationシステムにより、ALBは検出された異常に対して対策を講じることができます。実際、あるターゲットが異常と判断された場合、ALBは素早くそのターゲットからトラフィックを切り離し、正常と判断された他のターゲットを優先して選択します。ただし、異常のあるターゲットに対しても一部のトラフィックは引き続き転送されます。これは、それらのターゲットの健全性を確認し続けるためです。異常のあるターゲットが正常なレスポンスを返し始めた場合、ELBは徐々にトラフィックを増やし、最終的に完全な配分に戻します。このAnomaly Mitigation機能は、ヘルスチェックシステムの代替として考えるべきではありません。ヘルスチェックシステムは引き続き機能し、存在しています。その主な機能は、ターゲットを異常と判断してトラフィックの送信を停止することです。ただし、ターゲットがエラーを返し始めてから異常と判断されるまでには時間がかかります。Anomaly Mitigation機能を使用することで、ロードバランサーはこのような状況により迅速に対応できるようになります。
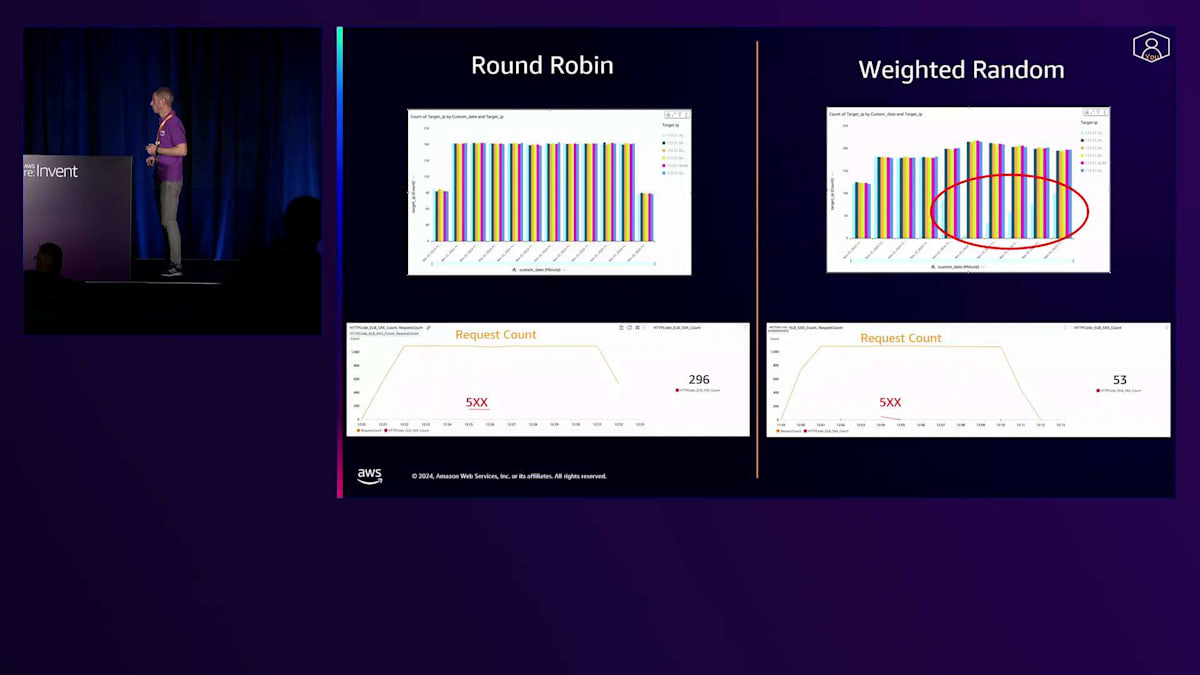
この概念は、Round RobinとWeighted Randomを比較したロードテストを見るとより分かりやすくなります。私は意図的に1つのターゲットで特定のサービスを停止して、サービス不能な状態にしました。Round Robinでは、ヘルスチェックシステムによってまだ異常とは判断されていないターゲットに通常通りリクエストがルーティングされ、そのターゲットは5XXエラーを返していました。一方、Weighted Randomを使用すると、ロードバランサーが素早く他の正常なターゲットにトラフィックを振り向けることができたため、これらのエラーは減少しました。その後、ターゲットのサービスを再起動すると、ロードバランサーが異常のあったターゲットに対して徐々にトラフィックを増やしていく様子が分かります。これにより5XXエラーが減少し、サービスの可用性が向上しました。Jonは昨年のセッションでWeighted Randomについて詳しく説明していますので、QRコードをスキャンして昨年のJonのセッションをご覧ください。
ELBの新機能:Load Balancer Capacity Unit予約

これが最後のスライドです。このセッションでは、いくつかのベストプラクティスを共有しました。スライドのQRコードからGitHub上のELBベストプラクティスのページにアクセスすることをお勧めします。そこでは、本日説明したベストプラクティスと、Well-Architectedフレームワークの柱に沿って分類された拡張版のベストプラクティスをご覧いただけます。それでは、最近リリースされた素晴らしい機能について説明するJonにバトンを渡したいと思います。


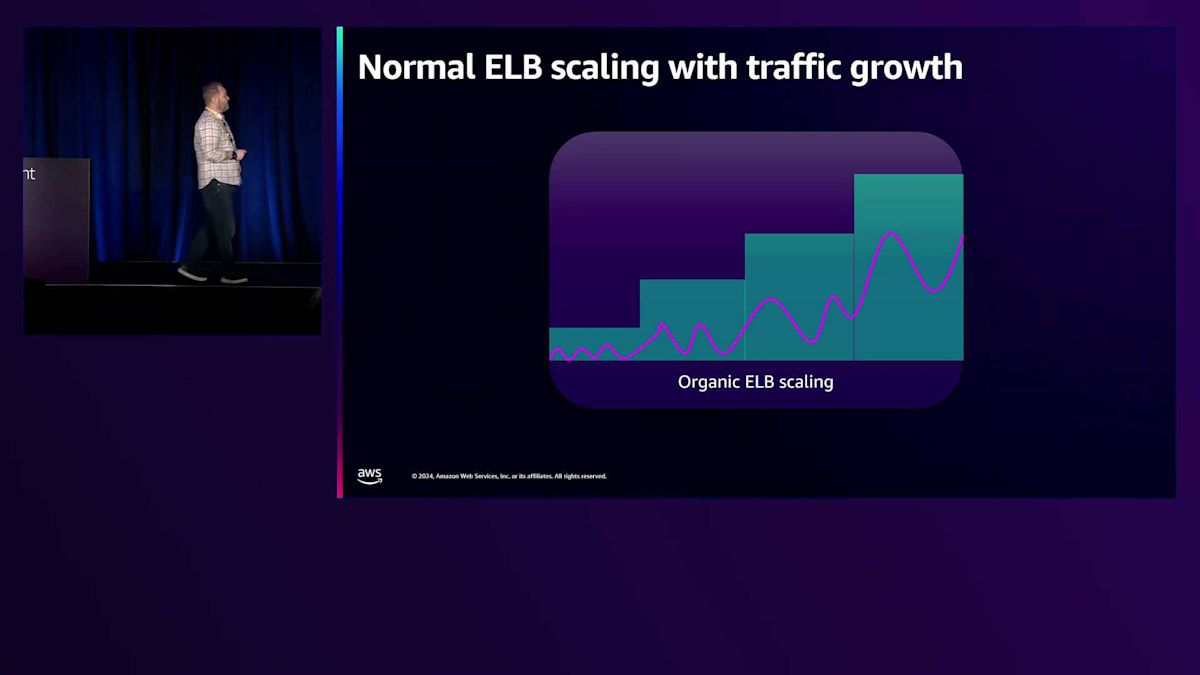
ありがとう、Enrico。ELBのプリウォームを経験したことがある方はいらっしゃいますか?はい、ありがとうございます。この機能は約1週間前にリリースしたばかりの新機能です。Load Balancer Capacity Unit予約と呼んでいます。具体的な内容に入る前に、ELBのスケーリングについて知っておくべきことをお話ししましょう。ELBは検出されたトラフィックレベルに応じて、何も設定しなくても自動的にスケールします。大規模なワークロードを移行したり拡大したりする場合、通常はこれらの設定は必要ありません。私たちは、いつでも1つのゾーンが故障しても、スケーリングすることなく十分な容量を確保できるよう、冗長なゾーンで過剰にプロビジョニングしています。スケーリングをトリガーする際は、迅速なスケールアップのために最小のしきい値で積極的に行い、一方でスケールダウンは慎重に行います。一般的なワークロードの場合、頻繁なスケールアップとスケールダウンの影響を受けないよう、スケールダウンには制限を設けています。帯域幅、CPU、接続数など、ロードバランサーが受け取るほぼすべての次元でスケーリングを行います。繰り返しになりますが、CPUの場合、平均で35%程度という非常に低いしきい値を設定しています。これは、オーバースケーリングを促進したいからです。昨年のセッションでは、スケーリングに関する取り組みについてより詳しく説明しました。これらはApplication Load BalancerとNetwork Load Balancerの両方に適用されます。

Capacity Reservationは、現在Application Load BalancerとNetwork Load Balancerの両方で利用可能で、将来的にはGateway Load Balancerでも利用できるようになります。これはELBのスケールアップ能力を変更するものではなく、スケールダウンの制限のみを設定し、キャパシティの下限を引き上げるようなものと考えることができます。何も設定していない場合、
下限は設定されておらず、慎重にほぼゼロまでスケールダウンします。トラフィックの送信を開始すると、積極的にスケールアップを試みます。重要なポイントとして、これは更なるスケーリングを制限するものではありません。通常、設定には数分かかりますが、APIは即座に反応します。APIコールを行うと、すぐにキャパシティの設定を開始します。その後、Describe関数を使用してプロビジョニングが完了したかどうかを確認できます。この機能はApplication Load BalancerとNetwork Load Balancerで利用可能です。
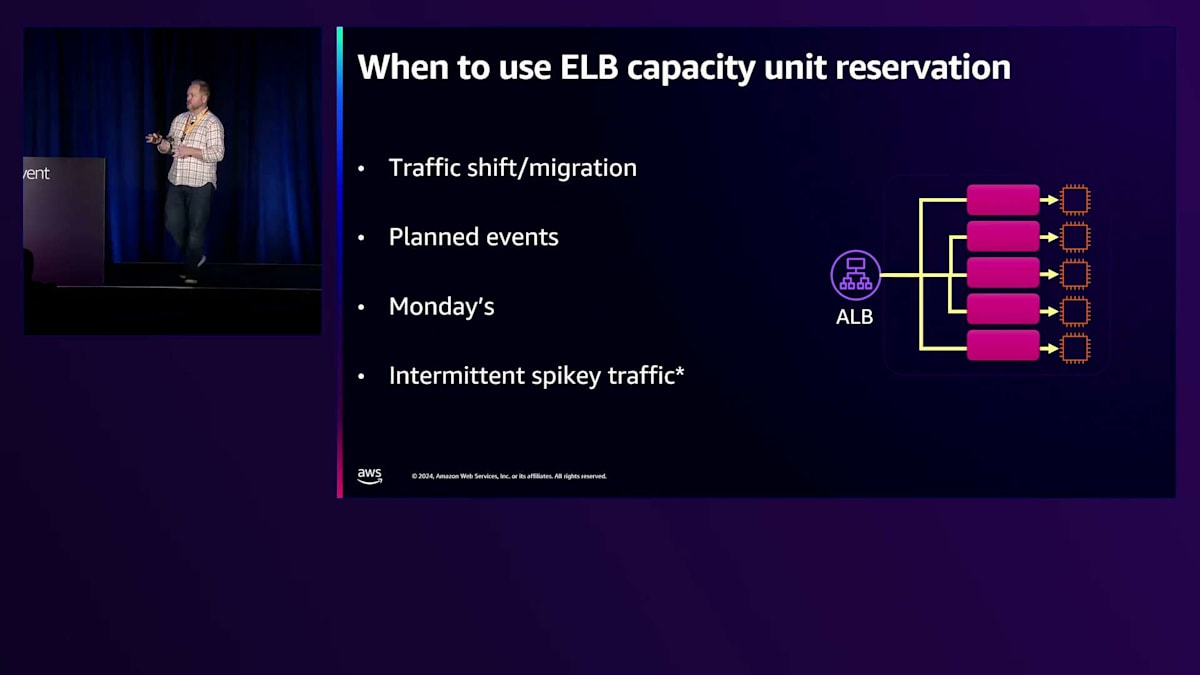
トラフィックの移行は重要なユースケースです。あるLoad Balancerから別のLoad Balancerへ、または異なるプロダクトからLoad Balancerへ移行するお客様がいます。AWSで情報を持っていて、メトリクスを確認できる場合は、これを活用できます。特にELBからELBへの移行は、私たちがリリースしたメトリクスのおかげで最も簡単です。 また、計画的なイベントにも役立ちます。大規模なセールが予定されている場合や、特定の時間にサイトへのトラフィックが急増することが分かっている場合、イベントの1〜2時間前にこれを設定し、スケールアップさせて、すべてが正常であることを確認してからイベントを実施することができます。
月曜日に関して、これは12時間単位でスケールインするという事実に基づいています。Load Balancerにトラフィックを送信してスケールアップした場合、スケールインは行われません。これはApplication Load Balancerの場合です。Network Load Balancerはより動的ですが、ALBでは12時間以内のスケールインは行いません。トラフィックが急増した後、すべてのトラフィックを取り除いても、各スケーリング層に対して少なくとも12時間かかり、それが数十層になる可能性があります。数日から数週間かかる可能性があります。週末に2回以上、トラフィックが十分に低下してスケールダウンする人もいます。
毎日同じ時間に市場が開き、すべてのクライアントが市場に合わせてあなたのプロダクトを使用するためにサイトにアクセスするような場合、金曜日の市場終了時からスケールダウンが十分に進んでいる可能性があり、この機能の恩恵を受けることができます。断続的なスパイクトラフィックについては、これは難しい問題です。このようなケースがある場合は、AWSサポートに連絡してユースケースについてフィードバックを得ることをお勧めします。なぜなら、この機能は基本的に指定されたキャパシティを常時確保するものだからです。断続的なスパイクトラフィックがある場合は、昨年ALBについて話したシャーディングなど、他の戦略を検討することをお勧めします。

私たちは段階的にスケールアップし、その後スケールアウトを行います。ご存知の通り、私たちはシングルテナントのEC2インスタンスをプロビジョニングしています。ELBを起動すると、そのためのインスタンスが作成され、それらのインスタンスにIPが割り当てられ、そのIPがDNSに登録されます。Route 53がヘルスチェックを行い、健全な場合にそれらを返すため、Route 53またはDNSには常に健全で適切にスケールされたノードが存在することになります。スケーリングを行う際には、既存のノードに対しても慎重に対応します。DNSからノードを削除する場合、5分間接続がゼロになるまでシャットダウンせず、クライアントがDNSを更新しない場合は数日間維持されます。
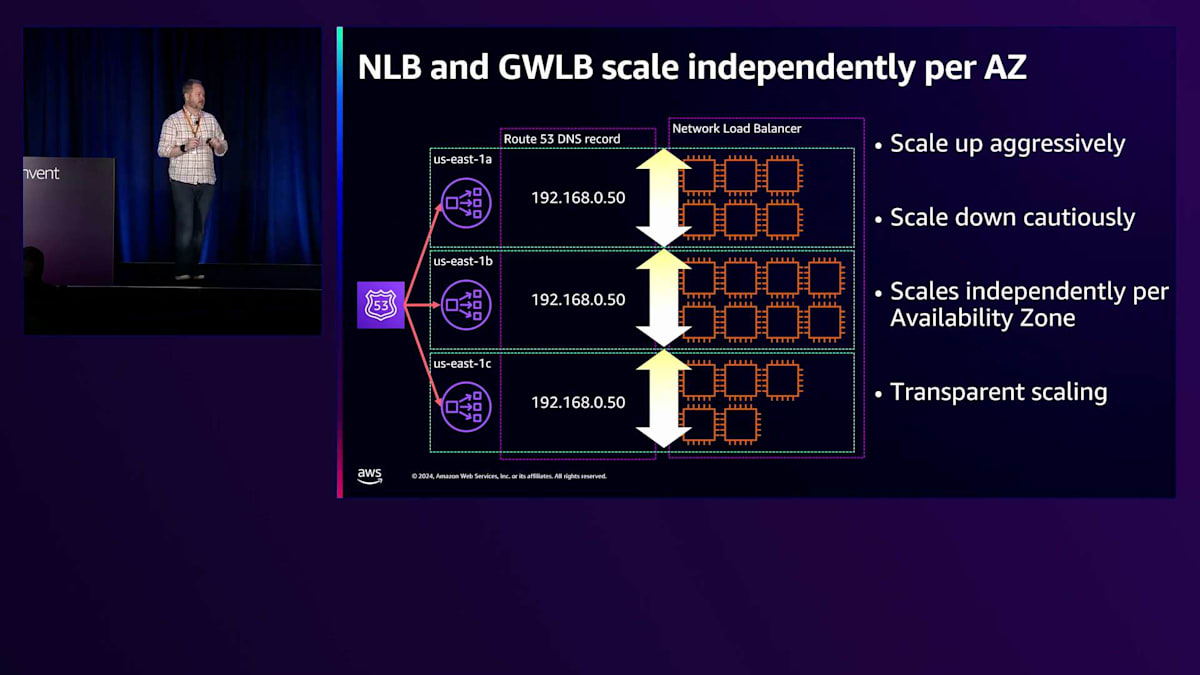
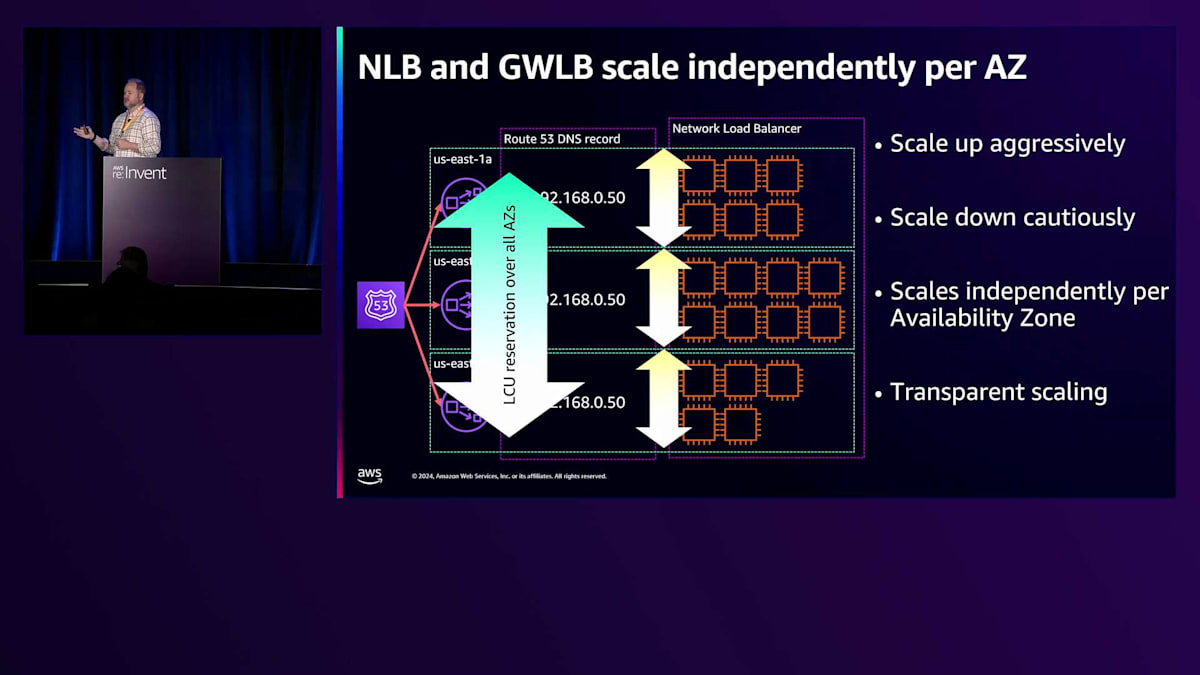
Network Load Balancerのスケーリング方式は少し異なります。NLBのオーガニックスケーリングはゾーン単位で行われ、あるゾーンのキャパシティや使用率が他のゾーンのスケーリングに影響を与えることはありません。3つのゾーンにNLBがあり、そのうちの1つが他より多くのトラフィックを受けている場合、そのゾーンは他のゾーンよりもはるかに大きなサイズにオーガニックスケーリングされる可能性があります。 NLBでLCUリザベーションを設定すると、実際にはそれがすべてのゾーンに分割されます。これは、実際に使用していないゾーンをNLBに設定しないようにする理由の一つです。この機能では、プロビジョニングしている内容を確認し、できるだけ多くのキャパシティを提供しますが、それはすべてのゾーンに分散されることになります。

イベントの計画を立てる際、ALBで導入したメトリクスがPeakLCUsです。PeakLCUsは、このワークロードに必要なLCUの数をALBが推測するために使用するメトリクスです。この場合の「I」は実際にはELBスケーリングシステムを指します。スケーリングシステムはトラフィックのあらゆる側面を監視し、それをLCUキャパシティにマッピングしようとします。1分間の合計は1時間の請求に関連しており、1時間で1000 LCUを使用する場合、1分間の合計は約1000程度になるでしょう。必要な量が分からない場合は、負荷テストが最適な方法です。
AWSに移行する場合は、必要と考えるキャパシティまたはその一部に対して負荷テストを実施し、Peak LCUに基づいて全体の値を算出します。これは1時間メトリクスからも取得できます。1分メトリクスは数週間しか保持されませんが、1時間メトリクスは1年半以上保持されます。1時間メトリクスは1分メトリクスの組み合わせであり、1時間メトリクスの最大値を取ることで、その時間における単一ノードのP100または最大値として信頼できます。
その最大値にサンプル数を掛けることができます。サンプル数はノードの数を示し、最大値はそれらのノードの中で最もコストの高いものを表します。この情報を使用して、年間セールなどの過去のイベントを1年半前まで遡って分析できます。コンソールも同じ計算方式に更新されており、現在の期間を表示している場合でも、1時間メトリクスからこれらの値を確認できます。
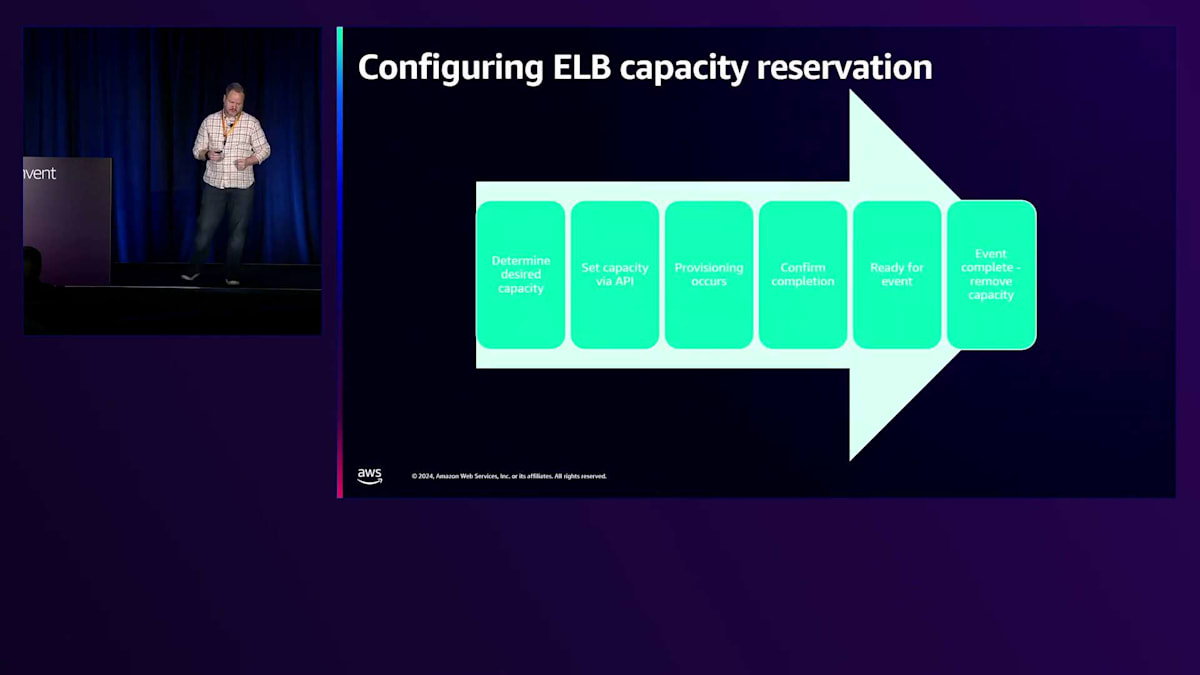
予約を行った際の動作を詳しく見ていきましょう。まず必要なキャパシティを決定し、APIに要求を伝えると、私たちがそれをプロビジョニングし、すべてが正常であることを確認します。これでイベントの準備が整います。イベントが終了するか、トラフィックがピークに達したと判断したら、プロビジョニングを安全に解除できます。プロビジョニングを解除すると、過去42時間の実際の使用量を確認し、最も高いポイントを選んでそのレベルまでスケールします。その後、ALBとNLBでは12時間以上の間隔で慎重にスケールダウンする有機的なスケーリングに戻ります。
LCU Capacity Reservationの活用シナリオと効果
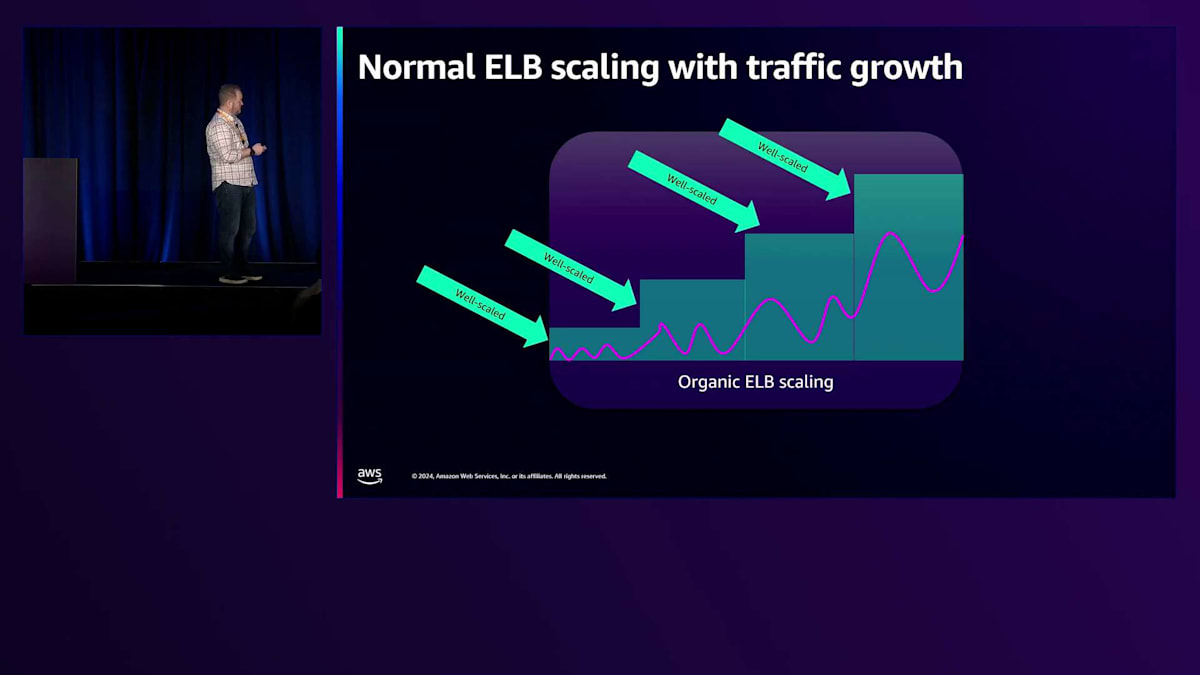
トラフィックのパターンを具体的に見てみましょう。緑色の部分はELBが使用しているキャパシティを表し、紫色の部分は日々の周期的なワークロードでよく見られる正弦波パターンを示しています。これらのピークは昼夜のサイクルと考えることができます。成長期にある場合は、5分ごとに倍増するため、より急速な上昇となる可能性があります。有機的に成長する場合、トリガーに応じて追加のキャパシティをプロビジョニングしています。35%でトリガーする場合、トラフィックが継続的に増加した際に備えてキャパシティを確保します。これが有機的なスケーリングの仕組みです。

これは適切にスケールされた例で、私たちが日常的に目にするパターンです。これがプロビジョニングの一般的なケースです。もう一つの一般的なケースは正弦波パターンです。12時間のスケールダウン遅延があるため、通常は1日から次の日の間でスケールダウンすることはありません。トラフィックが1日の遅い時間に終わり、翌日の早い時間に始まる場合、前日と同じスケールを維持することになるでしょう。1レベルだけスケールダウンする場合でも、各レベルは1つ上のレベルをサポートできるため、月曜日の問題は発生しません。
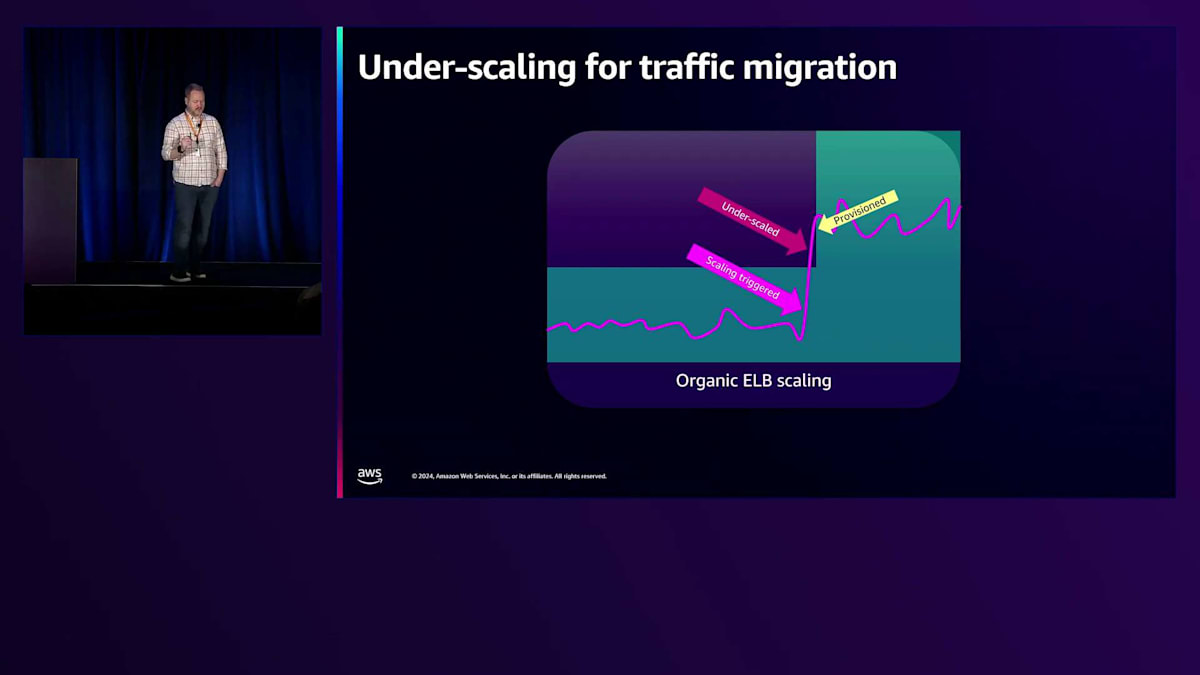
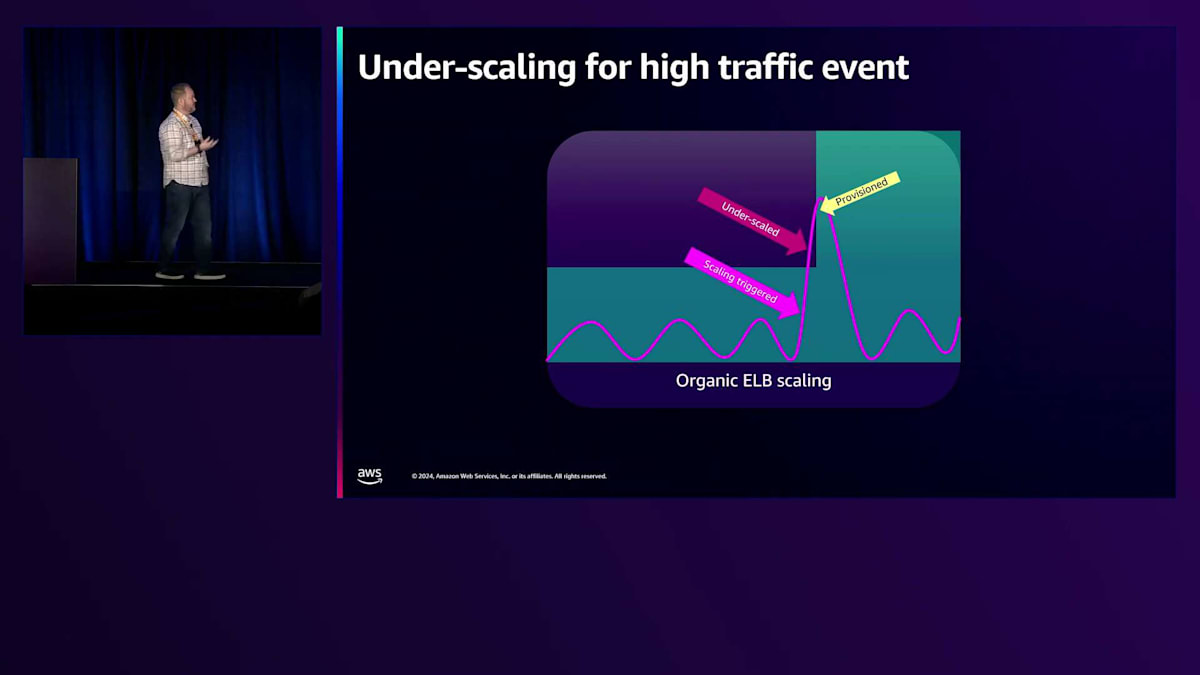
プロビジョニングするキャパシティは、急速なスケールアップに対応できる量を確保し、さらに冗長性を維持するために追加のキャパシティを確保します。スケーリング自体は、将来の成長や障害に備えたキャパシティの補充と考えることができます。最初の悪いケースであるアンダースケーリングを見てみましょう。この場合、トラフィックが何らかの場所からALBまたはNLBに移行しています。スパイクが上限を超えているのが分かります。現在のキャパシティの35-45%を超えたときにスケーリングを検知しますが、プロビジョニングには数分かかります。そのため、実際のトラフィックスパイクに対応するには遅すぎる可能性があります。
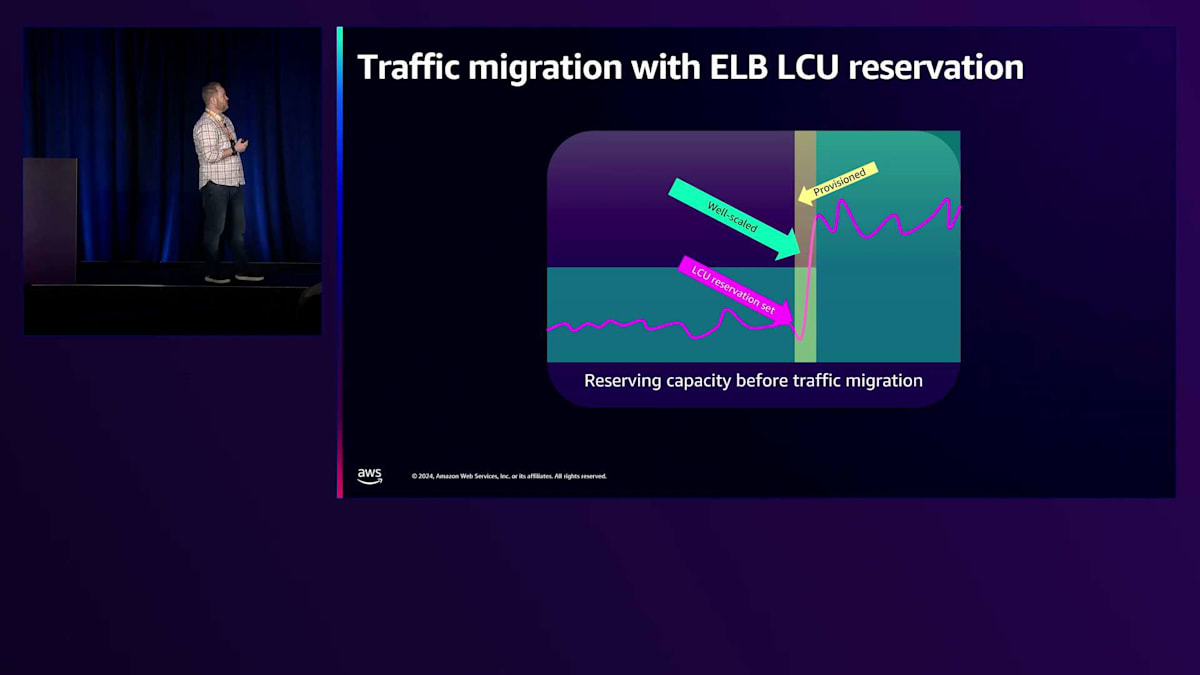

そのために、新機能のLCU Capacity Reservationがあります。これを使えば、トラフィックのプロビジョニングを1時間前または数分前に確実に行うことができます。トラフィックが到着したら、ピークに達した時点ですぐに解除でき、スムーズに移行できます。トラフィックの到来が予測できる期間があり、その間予約を行い、その後解除するという非常にシンプルな流れです。イベントの場合も同様ですが、通常はイベント後にトラフィックが減少します。ここでも同じように、事前にプロビジョニングを行い、イベントを開始し、その後解除することができます。私たちは急激なスケールダウンを行わないため安全です。


これは月曜日の例です。週末にいくつかのスケールダウンがあり、月曜日になってキャパシティが不足していたため、スケールアップしましたが、追いつくまでに数分かかりました。マーケットの開始1時間前にプロビジョニングすることで、この状況に先手を打つことができます。このLoad Balancerを見ると、LCUメトリクスの数値がここに表示されます。ピークLCUはこれらの1つになり、開始前のこのタイミングでそれを設定すれば、実際に同じキャパシティを得ることができます。なぜなら、プロビジョニングを指示した際、さらなるスケーリングが必要になった場合に備えて、私たちはこの余分なキャパシティを追加しているからです。
まとめましょう。この新機能により、Application Load BalancerやNetwork Load Balancerの最小キャパシティを引き上げることができます。プロビジョニングは即座に開始され、通常数分で完了し、さらなるスケーリングを妨げることはありません。ALBとNLBで利用可能なこの機能を、ぜひ今日からお試しください。質問がございましたら、会場でお待ちしております。ご参加いただき、ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion