re:Invent 2024 - Monday Night Live with Peter DeSantis


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Monday Night Live with Peter DeSantis
この動画では、AWSが誇る革新的なハードウェアインフラの詳細に迫ります。Senior VP of AWS Utility Computing の Peter DeSantis がカスタムシリコン開発の歴史からGraviton4の進化、そしてNitro Systemによるセキュリティ革新について解説します。さらに、AI時代の新たな挑戦として、最もパワフルなAIサーバーTrainium2の開発秘話や、数千台のサーバーを10マイクロ秒未満のレイテンシーで接続する10p10uネットワークの実現方法、そしてAnthropicとの協力で実現する数百エクサフロップス規模のProject Rainierで、次世代Claudeの学習基盤としてTrainium2を数十万個規模で展開する壮大な計画など、AWSのインフラストラクチャにおける技術的ブレークスルーを包括的に紹介しています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
re:Invent 2024の開幕:クラウドコンピューティングの革新

re:Invent 2024へようこそ。 Monday Night Live、あるいは私が「Keynote Eve」と呼んでいるこのセッションにお越しいただき、ありがとうございます。素晴らしいバンドの演奏もあり、ビールも用意していますが、一点お詫びがあります。IPAを用意できていなかったことが判明しました。IPA好きの皆様には申し訳ありませんが、来年は必ず改善いたします。これは私の責任です。

今夜は技術革新について深く掘り下げていきます。良き Keynote Eve らしく、プレゼントを一つ開封できるかもしれません。まあ、一つくらいかな、といったところです。しかし、まずは最も重要なことから始めましょう。それは Monday Night Live でいつもお話ししている「どのように」という部分です。この「どのように」が重要なのは、 クラウドコンピューティングの最も重要な特性を実現する方法だからです。これらは単なる機能のローンチではありません。 これらはサービスに組み込んで設計する必要がある要素であり、まさにそれが私たちのやり方なのです。これらは私たちの構築方法の具現化なのです。
AIアシスタントを活用したプレゼンテーション準備

今夜は、なぜ Amazon Web Services がこれらの機能を提供することに特に長けているのかについて、私の考えを説明できたらと思います。 このキーノートのこの部分を準備する際、AI アシスタントを使ってみることにしました。私のチームや Amazon 全体のチームが、コードの作成やクリエイティブの制作にAIアシスタントを活用している様子に触発されたのです。これは良い実験の機会だと思いました。そこで、このプレゼンテーションをどのように始め、どのように視覚化したいかをAIアシスタントに伝えました。

いくつかのアイデアが出てきました。最初のアイデアは氷山でした。 表面下にあるものについて話したかったのですが、氷山のアナロジーはあまり気に入りませんでした。氷山の場合、小さな一角しか見えませんが、下にあるのは氷だけです。2番目のアナロジーの方がずっと良かったです。それは宇宙飛行で、AIアシスタントは、私たちが短い打ち上げの瞬間しか目にしないものの、舞台裏では大勢のエンジニア、オペレーター、デザイナーが関わっているという説明を提案してきました。それはより適切でしたが、 まだ私が求めているものにぴったりとはきませんでした。

そこでAIアシスタントとさらにやり取りを重ねた結果、木について話すことに決めました。 木は、私たちが毎年議論する大きな差別化された技術投資を表しています。例えば、AWS のお客様に最高のパフォーマンスと最も低コストなインフラストラクチャオプションを提供する、カスタムシリコンへの長期的な投資などです。また、セキュアなサーバーレスコンピューティングを可能にする AWS カスタムハイパーバイザーへの投資や、差別化されたデータベース機能とパフォーマンスを提供するためのデータベーステクノロジーへの深い投資も含まれます。
AWSの特徴:細部へのこだわりと長期的視野

今夜は木についてお話しする前に、まず根っこについてお話ししたいと思います。根っことは、木を支え、養分を与える地中の重要な構造のことです。まずは主根から見ていきましょう。すべての木に主根があるわけではありませんが、主根を持つ木は地中深くの水分を独自に取り込むことができ、厳しい環境下でも生き残ることができます。AWSとAmazonの最も特徴的な点の1つは、リーダーたちが細部に多くの時間を費やすことです。細部にこだわることが重要なのは、細部を把握することで顧客やサービスの実態を理解でき、素早い意思決定が可能になり、問題が発生する前に修正や予防ができるからです。
他の組織でもこういったことは行われていますが、多くの場合、情報が組織の多くの層を経由して上に伝わっていく必要があります。そしてそれは決して十分な速さではありません。上司に何か良くないことを報告するのがどれほど気が重いことか考えてみてください。誰もが好んでやることではありませんし、通常は十分なスピードで行われません。細部にこだわりたいと言うのは簡単ですが、難しいのは、そのために必要な仕組みを作ることです。

私たちはまさにそれを実践し、規模を拡大しながらも細部へのこだわりを維持しています。その良い例が、毎週水曜日に開催しているAWS全体のオペレーションミーティングです。このミーティングでは、すべてのチームが集まって問題について議論し、学びを共有し、お互いから学び合います。これは私を含むリーダーたちが細部を把握し続けるための重要な仕組みです。細部を把握することは、他の面でも役立っています。その1つが、必要な長期的な難しい決断を下しやすくなることです。

良い例が、カスタムシリコンへの投資を始めるという決断でした。今では当然の決断に見えますが、12年前は全く明確ではありませんでした。細部を把握していたからこそ、Nitroのようなものがなければ、AWSに必要なパフォーマンスとセキュリティを実現できないことがわかっていました。私たちはAnnapurnaチームと協力することを決め、これは結果的に私たちのビジネスにおける最も重要な技術的な推進力の1つとなりました。課題への深い理解がなければ、簡単に待つという選択をしていたかもしれません。しかし幸運なことに、私たちは待ちませんでした。その決断のおかげで、AWSの物語は全く異なるものとなりました。
AWSの強み:スタック全体にわたるイノベーション

主根の例えは素晴らしいのですが、最も巨大な木々を支えているのは深い根ではありません。代わりに、木々は水平な根の構造に依存しています。この水平な根の構造の魅力的な例が、Amazonの熱帯雨林に見られる板根システムです。この地上に出ている根のシステムは、不安定な土壌で成長する世界最大級の木々を支えています。板根は木の根元から数百フィートにも広がり、近くの木々と絡み合って、これらの熱帯雨林の巨人たちを支える基盤を作り出しています。
これは、AWSのもうひとつのユニークな特徴につながります。それは、スタック全体にわたってイノベーションを生み出す能力です。データセンターの電力から、ネットワーキング、チップ、ハイパーバイザー、データベースの内部構造、そして高レベルのソフトウェアに至るまで、これほど多くの重要なコンポーネントに深く投資している企業は、ほとんど、あるいは全くないと言えるでしょう。今週、私たちはこの幅広いイノベーションが、お客様にとってどのようにユニークで差別化された機能を生み出すことができるのかをご紹介します。

しかし、これらの板根システムは、樹木が相互につながっている驚くべき方法のひとつに過ぎません。おそらく最も驚くべき、そして予想外なのは「Wood Wide Web」でしょう。私たちはよく、キノコを地面から生えてくる菌類だと考えがちですが、実はキノコは地下で成長する菌類の実なのです。それは樹木の根に生息する巨大な生命体です。樹木はこの菌類と共生関係にあり、これを使って互いにコミュニケーションを取り、情報やリソースを共有しています。これにより、森は個々の木よりもはるかに強くなるのです。

これは、私が考えるAWSの最も重要でユニークな点、つまり私たちのすべての活動を支える文化につながります。私が若いエンジニアとして1998年にAWSというかAmazonに入社した時、会社の進化のこんなに早い段階で、リーダーシップが文化の構築にこれほど注力していることに驚きました。上級リーダーたちは、今日のような規模の会社に成長できるようなメカニズムを構築するために時間を費やしました。私たちはリーダーシッププリンシプルを文書化し、採用したい人材に対する高い基準を維持するためのBar Raiserプログラムを構築しました。先ほどお見せした週次オペレーションミーティングのようなメカニズムを構築し、規模が拡大しても善意だけに頼らないようにしました。

振り返ってみると、これらの投資の緊急性について、私がいかに間違っていたかが簡単に分かります。文化というものは、あるかないかのどちらかです。そして、もしないのなら、それを手に入れるのは至難の業です。私たちの文化はユニークで、セキュリティ、運用性能、コスト、そしてイノベーションへの揺るぎない焦点を維持しながら、規模を拡大することを可能にしています。そして、イノベーションの規模拡大という精神に則り、今夜は新しいことを試してみようと思います。今夜お話しするいくつかのイノベーションについて、これらのイノベーションを推進しているAWSの他のリーダーたちから直接お話を聞いていただくのは、興味深いのではないかと思います。
AWS Computeの進化:Dave Brownによる解説

AWS ComputeとNetworkingの VP であり、長年のリーダーである Dave Brown をステージにお迎えしましょう。


Peter、ありがとうございます。本日はこのような機会をいただき、光栄です。私のAWSでの旅は、約18年前に 南アフリカのケープタウンで14人の小さなチームの一員として始まりました。私たちは、後にEC2(Elastic Compute Cloud)となるものを開発していました。 私たちの使命は野心的なもので、最終的にクラウドを支えることになる基盤的なオーケストレーション層を設計することでした。当時の私たちには これが、コンピューティングにおけるさらに大きな変革の始まりに過ぎないということは分かっていませんでした。それ以来、私たちは インフラストラクチャのあらゆる側面を再発明し、お客様に最高の回復力、パフォーマンス、効率性を提供することに取り組んできました。


その journey の重要な部分を占めているのが、私たちのカスタムシリコン開発です。2018年にGravitonを初めて発表した時、 最速のチップを作ることが目的ではありませんでした。むしろ、市場にシグナルを送り、開発者に実際のハードウェアで実験してもらい、データセンターにおけるArmを中心とした業界のコラボレーションを活性化することが目的でした。その後、私たちはさらに野心的な目標を設定しました。 完全にゼロから設計された、私たちの最初の目的特化型プロセッサーの開発です。Graviton2では、当時お客様が注目し、その限界に挑戦していたスケールアウトワークロードに特に焦点を当てました。Webサーバーやコンテナ化されたマイクロサービス、キャッシュフリート、分散データ分析などです。これこそが、Armが真にデータセンターに到達した瞬間でした。


Graviton3では、全体的な性能向上を実現しながら、私たちの領域を拡大しました。 私たちは、extraordinary な計算能力を必要とする特殊なワークロードに焦点を絞り、その結果は劇的なものでした。機械学習の推論から科学的モデリング、ビデオトランスコーディング、暗号化処理まで、多くの計算集約型ワークロードで性能を2倍以上に向上させました。 今日、Graviton4は、クラウドでのプロセッサー開発に関する私たちのすべての知見の集大成を表しています。 これは私たちの最もパワフルなチップであり、マルチソケットのサポートと、初代の3倍のVCPU数を備え、大規模データベースや複雑な分析など、最も要求の厳しいエンタープライズワークロードにとってゲームチェンジャーとなっています。
Gravitonプロセッサーの革新

Gravitonの各世代で、お客様は単に最新のインスタンスタイプに切り替えるだけで、すぐに性能向上を実感できています。ここで、実際のワークロードに対して Gravitonの性能をどのように最適化してきたかを見てみましょう。最新のCPUは、命令をフェッチしてデコードするフロントエンドと、それらを実行するバックエンドを持つ、洗練された組み立てパイプラインのようなものです。性能を評価する際、私たちは異なるワークロードがCPUのマイクロアーキテクチャにどのように負荷をかけるかを検討します。

ワークロードは、分岐の数や分岐ターゲット、命令などの要因に影響されるフロントエンドストールに敏感なのか、それともL1、L2、L3キャッシュやインストラクションウィンドウサイズの影響を受けるバックエンドストールによるパフォーマンスに敏感なのか。従来、プロセッサーのアーキテクチャをストレステストするためにマイクロベンチマークが使用されてきました。 例えばこのベンチマークを見てください。これはL3キャッシュを激しく叩き、大量のバックエンドストールを引き起こしています。エンジニアリング的に言えば、 これはCPUパイプラインがL3キャッシュから追い出されたデータを待って、手持ち無沙汰になっているような状態です。長年、業界はこのようなベンチマークの最適化に執着してきました。しかし、これはまるでマラソンのトレーニングを100メートル走で行うようなものです。確かに両方とも走っているのですが、根本的に異なる課題に向けてトレーニングしているのです。実際のワークロードは、このような整然としたベンチマークとは全く異なる振る舞いをします。それらは複雑で予測不可能であり、正直なところ、はるかに興味深いものです。このマイクロベンチマークを お客様が毎日実行しているCassandra、Ruby、Nginxのような実際のアプリケーションと比較してみましょう。

マイクロベンチマークがバックエンドのストールに焦点を当てていた一方で、実際のワークロードではさまざまな要因がボトルネックとなっています。分岐予測の失敗がより頻繁に発生し、L1キャッシュやL2キャッシュからの命令ミス、そしてTLBミスも発生します。マイクロベンチマークとは異なり、フロントエンドが主なストールの原因となり、マイクロベンチマークで観察されたバックエンドのストールよりも、フロントエンドのストールが多くなっています。


AWSでは、実際のワークロードのパフォーマンスを最優先しています。プロセッサの設計において、私たちの目標はベンチマークで優位に立つことではなく、お客様の実際のアプリケーションで優れた性能を発揮することです。これらは実際のワークロードに徹底的に焦点を当てた結果です。Graviton3では、従来のベンチマークでGraviton2と比較して30%の性能向上を示しました。しかしそれだけではありません。Nginxをテストしたところ、標準的なベンチマークではほとんど考慮されていなかった分岐予測ミスを劇的に削減したことで、驚異の60%のパフォーマンス向上を達成しました。Graviton4でも同様のパターンが見られています。マイクロベンチマークでは25%の向上を示唆していますが、実際のMySQLワークロードでは40%のパフォーマンス向上を達成しています。これは大規模なデータベースを運用するお客様にとって大きな意味を持ちます。


これこそが、お客様がGraviton4を愛する理由です。これらは単なるスライド上の数字ではありません。実際のお客様が、自社のお客様に恩恵をもたらす実際の改善を体験しているのです。AWSでは、Gravitonの利点について語るだけでなく、自社のサービスを移行することで、その効果を直接体験しています。Aurora、DynamoDB、Redshiftなどのサービスは、Graviton上で実行することで大きな恩恵を受けています。世界最大級のショッピングイベントであるAmazon Prime Dayでは、25万以上のGraviton CPUが運用を支えました。私たちは重要なマイルストーンに到達しました:過去2年間で、データセンターの新規CPU容量の50%以上がAWS Gravitonによるものでした。これは、他のすべてのプロセッサタイプを合わせた数よりも多いGravitonプロセッサが導入されたことを意味します。
AWS Nitro Systemの開発


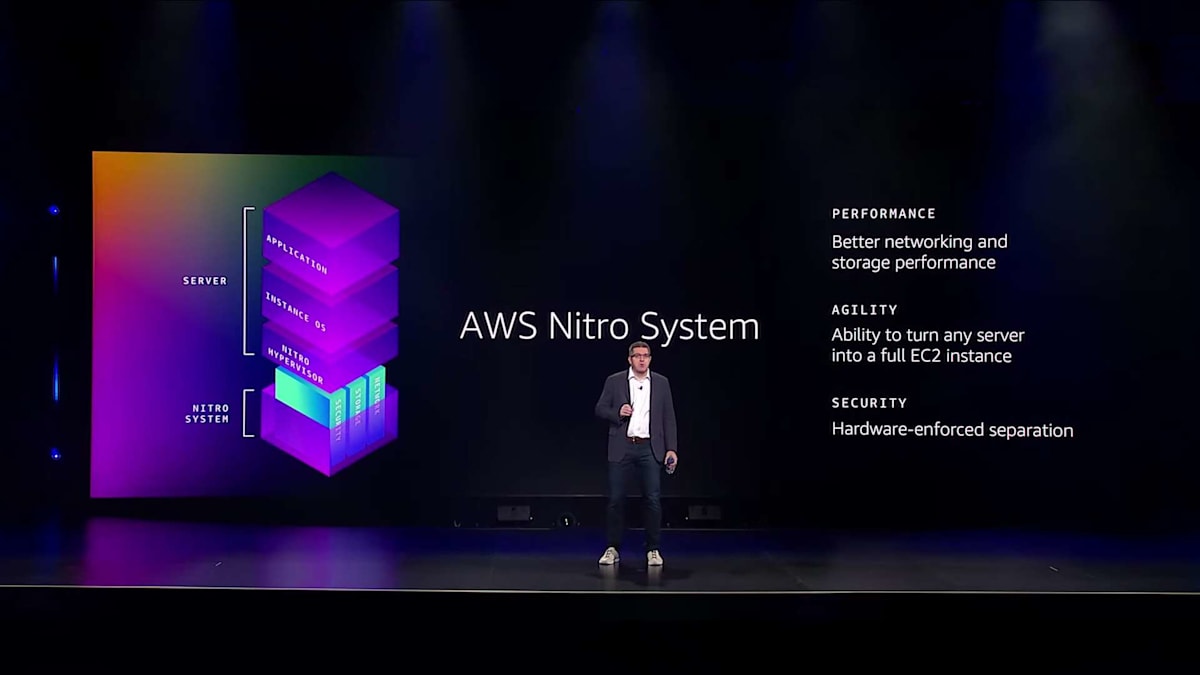
しかし、Gravitonは私たちがシリコンレベルでイノベーションを起こした最初の分野ではありません。早い段階から、世界クラスのパフォーマンスとセキュリティを増加するEC2インスタンスに提供するためには、スタック全体にわたってイノベーションを起こす必要があることを認識していました。これがAWS Nitro Systemの開発につながり、サーバーアーキテクチャを完全に再考し、クラウドの構築方法とセキュリティ確保の方法を根本的に変革しました。Nitroにより、他のクラウドプロバイダーが今でも直面している従来の仮想化オーバーヘッドを排除しました。Nitroのアーキテクチャにより、クラウドでApple Macを実行する場合でも、ベアメタルEC2インスタンス上で基盤となるハードウェアに直接アクセスを提供する場合でも、事実上どのようなコンピュータでもEC2インスタンスに変換できる俊敏性を手に入れました。
この旅の始まりとなった分野に焦点を当ててみましょう:セキュリティです。AWS Nitro Systemは、セキュリティを向上させただけでなく、ハードウェアのサプライチェーン整合性に対する私たちのアプローチを革新しました。クラウドにおけるセキュリティには、絶対的な確実性が求められます。AWSでは、すべてのハードウェアが期待通りの方法で期待通りのソフトウェアを実行していることを確認する必要があります。これは、フリート全体でソフトウェアとファームウェアを更新するだけにとどまりません。私たちは暗号による証明、つまりアテステーションと呼ばれるものを必要としています。これにより、すべてのシステムで何が実行されているかを把握できます。私たちの規模では、グローバルインフラストラクチャ全体で何百万ものコンポーネントの整合性をリアルタイムで証明することは、非常に大きな課題となっています。
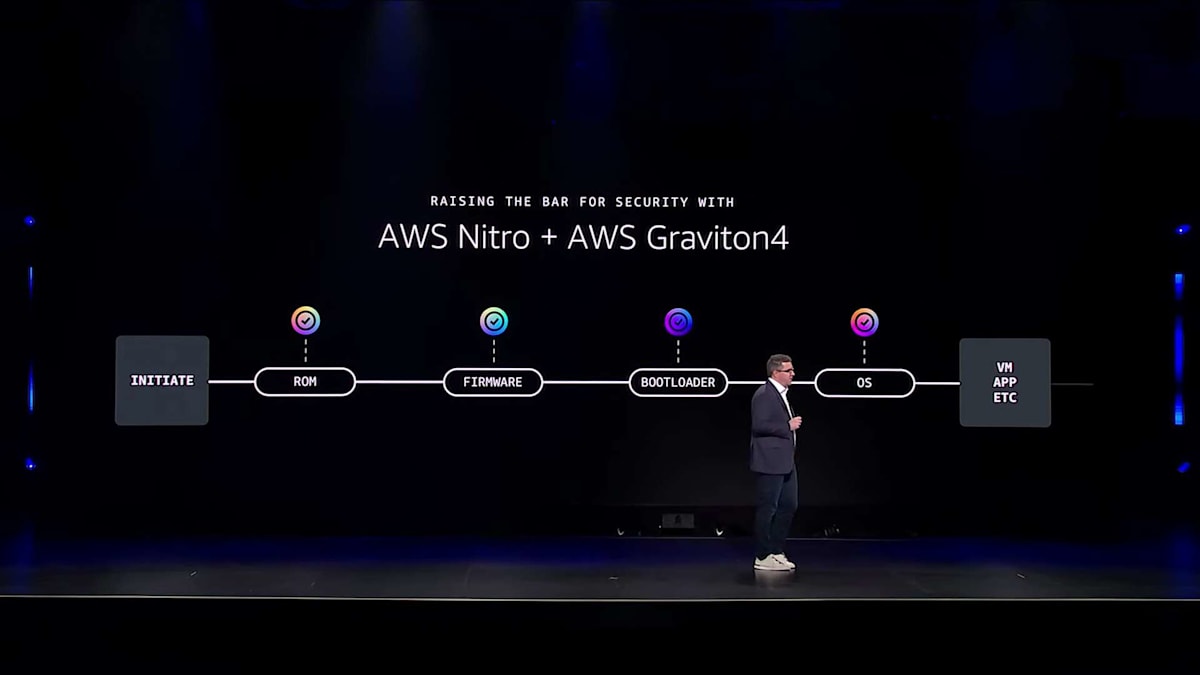
ブートシーケンスを一連の緻密な手順として見ていきましょう。まず、ROM(Read-Only Memory)からスタートし、チップの基本的な部分が起動します。そこからプロセッサは次のファームウェア層を読み込み、次にブートローダーへと進み、そこからオペレーティングシステムへ、最終的にはアプリケーションへと受け渡されていきます。ここで重要なのは、これらの各ステップが潜在的な脆弱性を持っているという点です。
さらに根本的な問題として、このチェーン全体が信頼の起点(root of trust)に依存しています。そこで本当の課題となるのは、最初のリンクをどのように検証するかということです。その答えを見つけるために、私たちは製造現場にまで立ち返る必要があります。
製品が辿る道のりは、初期製造から組み立て、輸送ルートを経て、データセンターへ、そして最終的な設置まで、非常に長いものです。各ステップにおいて、何も侵害されていないという確信を持つ必要があります。これは脆弱性を事後に発見することではなく、部品の製造時点から実際の顧客ワークロードの実行まで、途切れることのない管理と検証の連鎖を作り出すことなのです。
AWS Nitro SystemとGravitonの協調


Graviton4ベースのワークロードの起動プロセスについて詳しく見ていきましょう。私たちのハードウェアセキュリティと信頼の起点は、Nitroチップそのものの中にあります。各Nitroチップの製造時に、固有のシークレットが生成され、チップ内に保存されます。これは、チップ固有の指紋のようなもので、シリコンから外部に出ることはありません。このシークレットが公開鍵と秘密鍵のペアの基礎となります。秘密鍵はチップ内に永続的にロックされたまま、公開鍵は安全な製造記録の一部となります。

ここから私たちの管理の連鎖が始まります。Nitroチップ内の秘密鍵が、検証付き起動プロセスのアンカーとなります。起動の各段階で、新しい秘密鍵を生成して署名し、前の秘密鍵は破棄します。これはセキュアなバトンの受け渡しのようなものです。各受け渡しは完璧でなければならず、そうでなければレースは停止します。この署名の連鎖により、チップの製造品質からファームウェアのバージョン、そしてその識別情報まで、すべてを検証することができます。


システムは、この完全な認証プロセスを通過するまで、AWS の他のリソースへのアクセスが制限されます。 認証に失敗した場合は、直ちに隔離され、調査が行われます。Graviton では、セキュリティの境界をさらに押し広げました。Nitro の安全な基盤の上に、認証を Graviton4 プロセッサー自体にまで拡張したのです。これにより、重要なシステムコンポーネント間で信頼の連鎖が生まれます。
2つの Graviton4 プロセッサーが連携する必要がある場合、まず暗号化によってお互いの身元を確認し、暗号化された通信を確立します。同様に、Graviton4 と Nitro の間でも、ホストの ID と秘密鍵に紐づいた鍵交換が行われます。 これが意味することを考えてみてください。CPU間通信から PCIe トラフィックまで、システム内のあらゆる重要な接続が、製造時から始まるハードウェアベースのセキュリティによって保護されているのです。

Nitro と Graviton4 が協調して動作することで、継続的な認証システムを実現しました。これは単なるセキュリティの段階的な改善ではありません。Nitro のハードウェアベースのセキュリティ と Graviton4 の強化された機能を組み合わせることで、これまでで最も安全なコンピューティング環境の1つを生み出しました。お客様にとって、これは製造時から運用の1秒1秒まで、暗号で検証されたハードウェア上でワークロードが実行されることを意味します。従来のサーバーやデータセンターでは実現不可能なレベルのセキュリティです。
では、Nitro でどのような課題を解決できるのでしょうか?それを理解するために、ストレージの動向を見てみましょう。 ハードドライブの容量の進化は止まることを知りません。ドライブメーカーは数年ごとに、プラッターにより多くのデータを格納する新しい方法を見出してきました。 AWS の草創期である2006年頃を振り返ると、当時使用していたドライブの容量は数百ギガバイト単位でした。今日では、20テラバイト以上のドライブを導入しています。
AWSの分散ストレージ:典型的な設計

同時に、設計や製造プロセス、材料における革新により、ストレージの1テラバイトあたりのコストは過去数十年で劇的に低下しています。 ストレージシステムを常に最も効率的に運用するために、次世代のドライブサイズや新しいストレージ技術に常に対応できる準備を整えておく必要があります。

それでは、このような複雑さをより深く理解するために、典型的なストレージシステムの設計を詳しく見ていきましょう。 S3やEBSのようなストレージサービスは、3つの重要なコンポーネントで構成されています。まず、フロントエンドフリートがあります。これはAPIトラフィックや認証リクエストを処理し、顧客インターフェースを管理するWebサーバーです。その背後にあるのが、インデックスまたはマッピングサービスと呼ばれるものです。
これは言わば、システムの頭脳のようなものです。すべてのデータとその保存場所を正確に追跡します。お客様がデータを読み取りたい場合、このサービスが正確なデータの場所を教えてくれます。そして最後に、ストレージメディアレイヤーがあります。ここが実際のデータが保存される場所です。

そのストレージサーバーをより詳しく見てみましょう。従来、私たちのストレージサーバーは、ヘッドノードアーキテクチャと呼ばれる方式で構築されてきました。ヘッドノード自体は、基本的に標準的なコンピュートサーバーです。CPUやメモリ、ネットワーク機能を備え、データの耐久性やドライブの健全性監視、すべてのIO操作の調整など、ストレージの重要な機能を管理する専用ソフトウェアを実行しています。 このヘッドノードに接続されているのが、私たちが親しみを込めてJBOD(Just a Bunch of Disks)と呼んでいるものです。その名の通り、ハードドライブを詰め込んだシャーシで、すべてのドライブがSATAやPCIe接続を通じてヘッドノードに直接配線されています。

ただし、この設計には一つ課題があります。コンピューティングとストレージの比率が設計時に固定されてしまうのです。これらのサーバーを構築して展開すると、CPU、メモリ、ストレージ容量の特定の比率に縛られてしまいます。 ドライブ容量は年々劇的に増加していますが、この固定比率がより一層効果的な管理を難しくしています。 その結果として、私たちはドライブサイズと搭載数の両方を増やすことで、ストレージシステムの容量を拡大する道を歩んできました。最初は1台のサーバーに12台か24台程度という比較的控えめな構成からスタートしました。そしてドライブ技術が進歩し、より大きなドライブプールの管理が上手くなるにつれて、1台あたり36台、そして72台とその数を増やし続け、密度と管理のしやすさのバランスポイントを探り続けてきました。

そして私たちはBargeを作り出しました。Bargeは、私たちの最も野心的なストレージ密度エンジニアリングプロジェクトで、1台のホストに288台のハードドライブを搭載した巨大なストレージサーバーでした。この数字を考えてみてください。288台のドライブです。今日の20テラバイトドライブを使えば、1台のサーバーで約6ペタバイトの生ストレージ容量になります。これは、AWSの初期の頃のデータセンター全体の容量を上回るものです。これは、ストレージ密度の可能性の限界に挑戦する試みでした。そして、印象的なエンジニアリングの成果でありながらも、密度の限界について重要な教訓を私たちに与えてくれました。
分散ストレージの利点と未来への準備

Bargeから学んだ最初の教訓は、物理的な制約についてでした。これは文字通り重い制約でした。Bargeラック1台の重量は4,500ポンド、つまり2トン以上もありました。これにより、データセンターでは大きな課題が生まれました。床の補強が必要になり、設置場所を慎重に計画し、これらを移動させるだけでも特殊な機器が必要でした。288台の回転するドライブを一緒に詰め込むと、重量が増すだけでなく、私が「振動オーケストラ」と呼ぶものが生まれます。通常、ドライブを一緒に収納することは大きな問題ではありませんが、7,200 RPMで回転する288台ものドライブがあると、振動の影響が大きくなり、ドライブのパフォーマンスと信頼性に実際に影響を及ぼすようになります。

そして、ソフトウェアの複雑さの問題もありました。単一のホストから288台のドライブを管理することは、私たちのソフトウェアシステムを限界まで追い込みました。対処が必要な様々な障害モード、データ配置アルゴリズムの複雑さ、そしてこれほど大規模なドライブ群全体で一貫したパフォーマンスを維持することの難しさを考えてみてください。しかし、おそらく最も重要な教訓は、障害の影響範囲についてでした。Bargeサーバーに障害が発生した時(そしてサーバーは必ず障害を起こします)、その影響は甚大でした。突然、6ペタバイトものストレージが利用できなくなる可能性に直面します。冗長性があっても、そのような大量のデータの復旧には、かなりの時間とネットワーク帯域幅が必要です。そこで、私たちはBargeに別れを告げる必要があることを悟りました。


これらの教訓を踏まえ、私たちは一歩下がって考え直す必要がありました。お客様に高いパフォーマンスを提供しながら、運用の複雑さを減らし、ストレージインフラストラクチャの俊敏性を高めるにはどうすればよいのでしょうか?そこで、私たちはストレージサービスに着目しました。S3やEBS、EFSといったストレージサービスは、すべて標準的なストレージサーバーアーキテクチャ上に構築されていましたが、それぞれに固有の要件がありました。あるサービスはより多くのメモリを必要とし、あるサービスはより少ない計算能力で済みました。しかし、ストレージ層自体の機能は同一でした。では、コンピュートとストレージの密結合が私たちの制約となっていたのでしょうか?

コンピュートとストレージを分離するという分離(disaggregation)の概念が、とても魅力的に見え始めました。サービスが必要とする直接アクセスとパフォーマンスを維持しながら、コンピュートとストレージを独立してスケールできる方法を見つけることができれば、両方の利点を得られるかもしれません。そしてここで、私たちは既に持っていたツールキットの中のNitroの活用を考え始めました。

ドライブをヘッドノードに接続する代わりに、JBODエンクロージャに直接Nitroカードを組み込むことでストレージを分離しています。これらのNitroカードは、ドライブに独自の知能とネットワーク接続性を与えるものだと考えてください。各ドライブは、セキュアに仮想化された、分離されたネットワークエンドポイントとなります。このアプローチの素晴らしい点は、ドライブやストレージサービスが必要とする低レベルの直接アクセスを維持しながら、以前の物理的な制約から完全に解放されることです。そして、Nitroがネットワークの複雑さ、暗号化、セキュリティのすべてを処理します。Nitroは高性能と低レイテンシーを念頭に設計されているため、ネットワーク経由でアクセスする場合でも、ドライブ本来のパフォーマンスをすべて提供することができます。

これが私たちのデータセンターでの実際の様子です。一見すると標準的なJBODシャーシのように見えるかもしれませんが、重要な違いがいくつかあります。 先ほどお話したNitroカードが、ドライブと一緒に組み込まれているのです。このデザインの素晴らしさは、その単純さにあります。ラック内部を覗くと、従来型のストレージサーバーというよりも、ネットワークスイッチに近い外観をしています。これにより保守作業も簡単になりました。私たちの分散ストレージアーキテクチャのおかげで、 故障したドライブは数回のAPI呼び出しだけで、すぐにサービスから切り離して別の正常なドライブと交換できます。ホットスワップ可能なドライブコンテナにより、データセンターの技術者はサービスの可用性に影響を与えることなく、簡単にこれらのユニットを保守できます。

ドライブの故障は既に心配の種ではなくなりましたが、ヘッドノードについてはどうでしょうか?ここで話はさらに面白くなります。従来のアーキテクチャでは、ヘッドノードの故障は重大な事象でした。サーバーを修理または交換できるまで、 数十から数百のドライブへのアクセスが失われてしまいます。1台のサーバー故障が288台のドライブに影響を与えたBargeの例を覚えていますか?分散ストレージでは、ヘッドノードの故障はほとんど些細な問題となります。ドライブはネットワーク上で個別にアドレス指定されているため、新しいEC2インスタンスを起動して、すべてのドライブを再接続するだけでよいのです。これは標準的なEC2インスタンスのリカバリと同じプロセスで、通常数分で完了します。データ移動も複雑な再構築プロセスも必要なく、再接続して運用を再開するだけです。
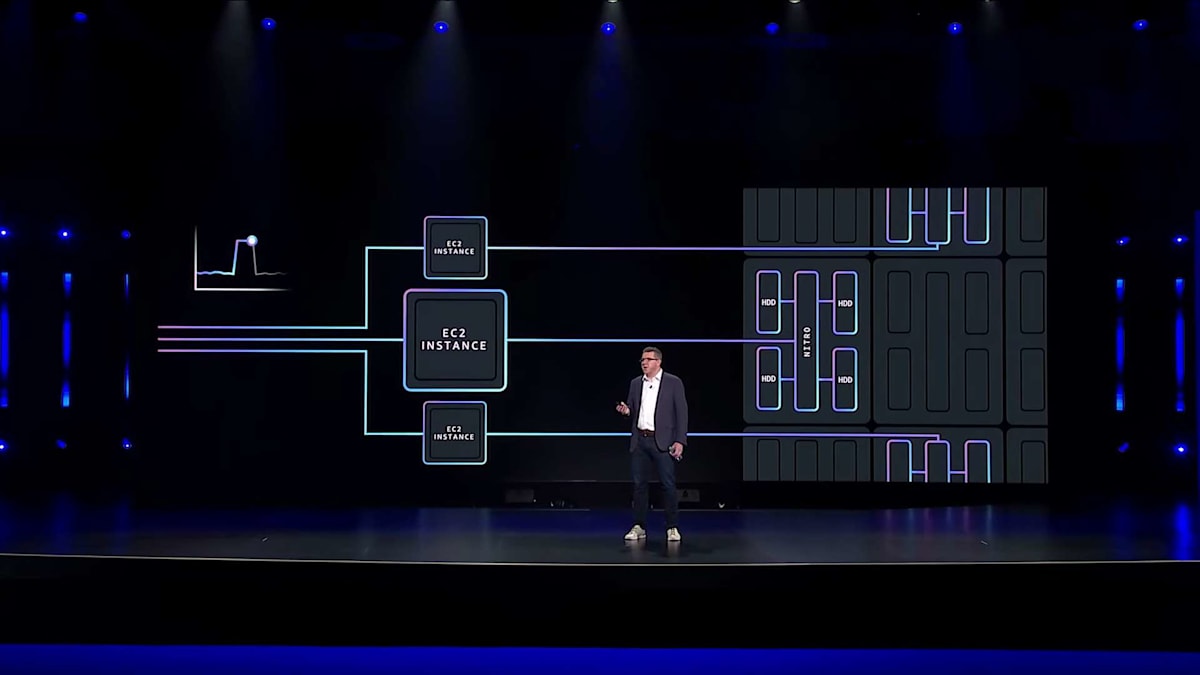
これらの故障シナリオは重要な点を浮き彫りにしています。私たちは障害の影響範囲を劇的に縮小しながら、 実際にリカバリ速度も向上させることができました。これは、コンピュートとストレージを切り離すことで可能になる、ほんの始まりに過ぎません。分散ストレージのもう一つの強力な利点は、コンピュートとストレージを独立してスケールできることです。Amazon S3では、新しいストレージ容量を導入する際、 新しいドライブにデータを展開してリバランスする際に、通常は高負荷のコンピュート処理が発生します。今では、この初期段階だけコンピュートリソースを一時的にスケールアップ・アウトし、通常運用時には縮小することができます。この柔軟性により、より効率的な運用が可能になり、最終的にお客様により良い価値を提供できます。

分散ストレージにより、長年ストレージアーキテクチャを制約してきた固定比率から解放されました。コンピュートとストレージを分離することで、 高いパフォーマンスを維持しながら、各コンポーネントを独立してスケールできるようになりました。クラウド環境で期待される通り、障害の影響範囲を大幅に縮小しました。障害を局所化でき、リカバリが高速化され、サービスの回復力が以前にも増して向上しました。俊敏性の向上により、 実際の運用面でも大きな恩恵を受けています。各サービスは、ハードウェアの制約ではなく、実際のニーズに基づいてコンピュートリソースを適切なサイズに調整できます。保守が簡単になり、キャパシティプランニングがより柔軟になり、 イノベーションのスピードも上がりました。

おそらく最も重要なのは、このアーキテクチャが私たちの未来への準備を整えてくれることです。ドライブ容量が継続的に増大する中、分散ストレージは私たちのインフラストラクチャを適応・進化させる柔軟性を提供してくれます。ストレージ密度の課題を解決するための解決策として始まったものが、より根本的なものに発展しました - お客様により効率的で信頼性の高いストレージサービスを構築するための新しいプリミティブとなったのです。では、Peterにバトンを渡したいと思います。 はい、素晴らしい発表でした。
AIワークロードの特性とスケーリングの課題

Dave が AWS Compute における革新的な取り組みについて素晴らしい概要を説明してくれました。ここからは、まったく異なる種類のワークロード、人工知能についてお話ししたいと思います。実際には、AI モデルのトレーニングと AI 推論という2つのワークロードがあります。AI ワークロードの興味深い点の1つは、私たちのチームが全く新しい方法で革新を起こすチャンスを与えてくれることです。今夜は、最高性能のチップを開発し、革新的な技術で相互接続するなど、そういった革新的な取り組みをいくつか見ていきます。また、この10年間で培ってきた革新的技術を、この新しい領域にどのように適用し、AWS の高性能、信頼性、低コストを AI ワークロードにもたらしているかについても見ていきます。

私たちはよく、Web サービス、ビッグデータアプリケーション、分散システムなどのスケールアウトワークロードについて話をします。スケールアウトワークロードは、システムにリソースを追加すると非常に効率よく動作し、私たちはこれらのワークロードに最適化されたインフラを作るために多大な投資を行ってきました。Dave が先ほど、そういった革新的な取り組みのいくつかについて説明してくれました。しかし、AI ワークロードはスケールアウトワークロードではありません。スケールアップワークロードなのです。その理由を説明させていただきます。


AI の能力が飛躍的に向上している要因の1つは、モデルが大きくなっている、それも非常に大きくなっているということです。2022年に私がこの話をした時は、数十億のパラメータを持つモデルに興奮していました。昨年は、数千億のパラメータに興奮していました。そして近い将来、最先端のモデルは数兆のパラメータを持つようになるでしょう。なぜこのような成長が見られるのでしょうか?2020年、研究者たちは画期的な論文「Scaling Laws」を発表しました。この論文では、パラメータ数、データセットサイズ、計算量といった要素をスケールアップすることで、モデルの能力が向上するという仮説を立てました。それ以来、より大きく、より計算集約的なモデルを構築する動きが加速し、実際にこれらのモデルはより高性能になっています。皆さんも日常生活でその進化を実感されているのではないでしょうか。

これらのグラフをよく見ると、非常に興味深いことに気づきます。これらは対数-対数グラフで、x軸とy軸の両方が対数目盛りになっています。対数-対数グラフにおける直線は誤解を招く可能性があります。計算量のグラフを詳しく見てみましょう。私たちは通常、xを1単位増やすとyも1単位増える、という線形の関係に慣れています。しかし対数-対数グラフでは、直線は「xを4倍にするとyが2倍になる」といった乗数的な関係を表します。これらのスケーリンググラフで見られる関係は驚くべきものです。y軸で示される損失を半分にするためには、100万倍もの計算量が必要になります。このy軸の測定値で50%改善されたモデルは、実際には他の多くのベンチマークでは桁違いに賢くなっているのです。この計算量とモデルの損失との関係が、業界が AI インフラの改善に数百億ドルもの投資を行っている理由を説明しています。

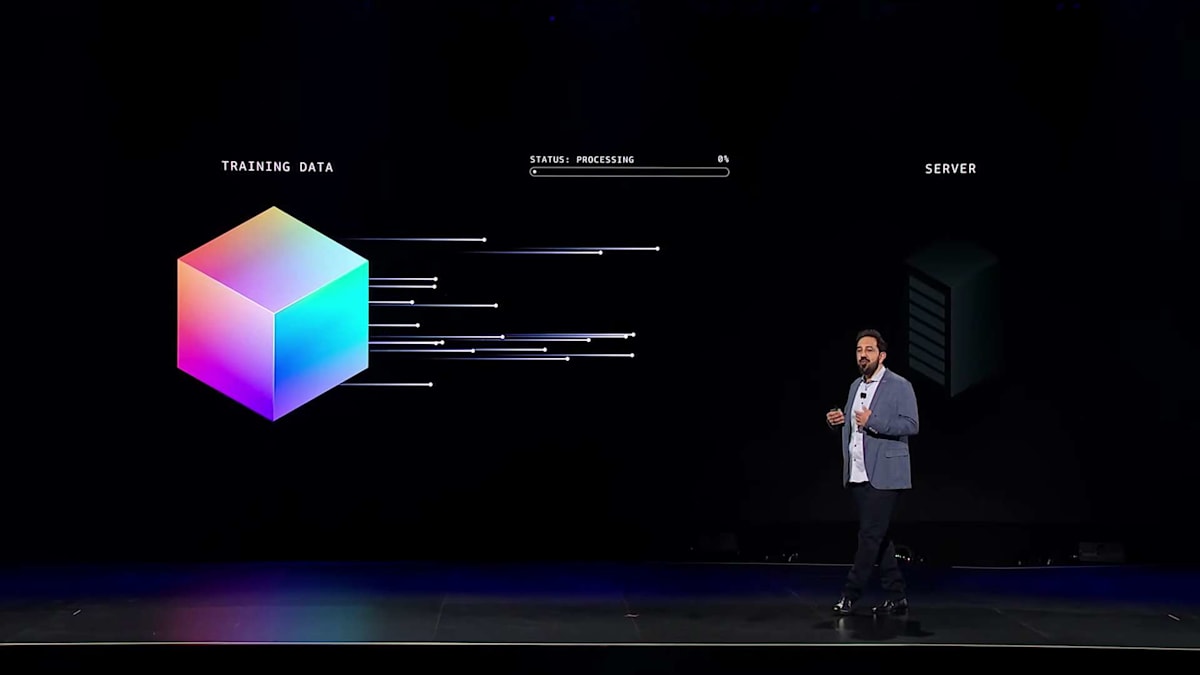
より良い AI インフラが何を意味するのか理解するために、大規模 AI モデルがどのようにトレーニングされるのかを見てみましょう。最新の生成 AI アプリケーションの核心は、予測エンジンです。単語の一部であるトークンで入力を与えると、次のトークンを1つずつ順番に予測していきます。次のトークンを予測するというこの基本的な能力から、推論や問題解決といった驚くべき特性が生まれてくるのです。このような予測モデルを構築するために、トレーニングデータ全体での予測誤差を最小化するモデルの重みを見つけるまで、数兆のトークンのデータでモデルをトレーニングします。これだけ膨大なトークンでトレーニングを行うプロセスには、莫大な計算量が必要となります。

最大規模のモデルを単一のサーバーで学習させようとすると、最も性能の高いサーバーでさえ、何世紀、あるいは何千年もかかってしまいます。そのため当然、並列化が必要になります。まず最初に考えられるのが、学習データの分割です。一見シンプルに思えます - 1台のサーバーで1000年かかる処理を1000台のサーバーで実行すれば、1年で済むはずです。これは、ワークロードがスケールアウト型であれば確かにその通りなのですが、実際にはそう単純ではありません。今説明した、データを分割するというアプローチは、データ並列処理と呼ばれています。人生の多くの良いものと同じように、データ並列処理にも注意すべき重要な点がいくつかあります。
データ並列処理における重要な考慮事項は次の通りです。単純な分割統治アプローチを取ると、複数の独立したモデルを構築し、最後にそれらを組み合わせようとすることになりますが、それは上手くいきません。代わりに、データ並列処理を採用する場合、すべてのサーバーが継続的にモデルの重みを共有して組み合わせる必要があります。これにより、大規模なサーバークラスターが1つの共有モデルを構築できるようになります。

ここで重要になってくるのが、グローバルバッチサイズです。グローバルバッチサイズとは、すべてのサーバーの結果を組み合わせる必要が出る前に処理できる最大のデータセットのことです。このグローバルバッチサイズは、全体の学習データのごく一部に過ぎません。データ並列処理の仕組みはこうです:グローバルバッチサイズを超えない大きさのデータの塊を取り、それを均等に分割し、すべてのサーバーに配布します。各サーバーが割り当てられたデータで学習を行い、完了したら、クラスター内の他のすべてのサーバーと結果を組み合わせます。全サーバーの結果が組み合わされたら、次のバッチのデータに進むことができます。

実際には、このグローバルバッチサイズの制限により、学習クラスターは最大でも数千台のサーバーまでしかスケールアウトできません。それ以上増やすと、各サーバーが処理するデータ量が少なすぎて、データの処理よりも結果の調整に多くの時間を費やすことになってしまいます。サーバーを追加しても速度は向上せず、コストが増えるだけです。データ並列処理とその限界について理解することは、AIインフラストラクチャの2つの基本的な柱を浮き彫りにします。まず、グローバルバッチサイズによるスケールアウトの制限があるため、より大きなモデルを構築するには、より強力なサーバーを構築する必要があります。これがインフラストラクチャの課題におけるスケールアップの部分です。

次に、AIモデルの構築におけるスケールアウトの制限があるにもかかわらず、これらの大規模クラスターを構築することには依然として大きな価値があります。それを上手く実現するには、効率的なデータセンター、高速なスケーリング、優れたネットワーキングなど、長年かけて構築してきたスケールアウトツールを活用する必要があります。まずはスケールアップの課題から見ていきましょう。最も強力なサーバーを構築するということは、可能な限り小さなスペースに、大量の計算能力と高速メモリを詰め込んだ一貫性のある計算システムを作ることを意味します。
Trainium2:最もパワフルなのAIサーバーの構築

スペースが重要な理由は、これらすべてのコンピューティングとメモリを近接させることで、大量の高帯域・低レイテンシーの接続を使用してすべてを配線できるからです。レイテンシーの利点は直感的にわかりますが、近接性によってスループットも向上します。コンポーネントを近づけることで、データ伝送に使用する配線を短くでき、より多くの配線を詰め込むことができます。また、データ交換のためのレイテンシーを下げ、より効率的なプロトコルを使用することも可能になります。

昨年、私たちは次世代のTrainiumチップであるAWS Trainium2を発表しました。今夜は、このTrainium2を使って、これまでで最もパワフルなAIサーバーをどのように構築しているかについてご説明します。まずはシステムの最小単位であるTrainium2チップから始めて、最大規模のAIサーバーを構築する際に直面するエンジニアリング上の制約についてお話ししましょう。チップは優れた製造技術によってシリコンウェハー上で製造され、これらのプロセスは絶え間なく改善されています。システム上で最大限のコンピューティングとメモリを実現するには、最先端のパッケージング技術や製造技術を用いて、可能な限り大きなチップを作ることが良い出発点となります。


ここで最初のエンジニアリング上の制約に遭遇します。チップ製造プロセスには、シリコンウェハーのエッチングに使用されるレンズに起因する、チップサイズの上限があります。これはレチクルと呼ばれ、チップの最大サイズを約800平方ミリメートル、つまり1.25平方インチに制限します。私が手に持っているものは1.25平方インチよりもずっと大きく見えるかもしれませんが、これはチップではなくパッケージなのです。私たちの多くは、コンピューターチップというと、マザーボードの中央にある、ヒートシンクの下にあるものを思い浮かべますが、実はそれはパッケージであり、その中にチップが入っているのです。

数年前まで、パッケージはかなりシンプルなものでした。基本的に、単一のチップを収納し、マザーボードに接続するための方法に過ぎませんでした。パッケージによって、シリコンチップの非常に小さな世界から、マザーボード上で全てを接続する比較的大きな配線へと移行することができました。

しかし今日では、パッケージははるかに高度になっています。最新のパッケージングは、インターポーザーと呼ばれる特殊なデバイスを使用して、複数のチップを1つのパッケージ内で接続する技術と考えることができます。インターポーザーは実際には小さなチップで、通常のPCBベースのマザーボードと比べて約10倍の帯域幅でチップを相互接続できる、小型のマザーボードのような役割を果たします。私たちは直近の数世代のGravitonプロセッサーでこの高度なパッケージング技術を使用してきました。ここに示すGraviton3とGraviton4では、両方のパッケージに複数のチップ、つまりチップレットが内蔵されているのがわかります。Graviton4のパッケージには実際に7つのチップレットが搭載されています。中央の大きなチップがコンピューティングコアで、周囲の小さなチップがメモリやその他のシステムバスへのアクセスを可能にしています。コンピューティングコアを分離することで、Graviton4プロセッサーのコア数を50%増加させることができ、しかもコスト効率よく実現することができました。

このアプローチはGravitonにおいて非常に有効でしたが、優れたAIサーバーを構築する上では当たり前のことと言えます。こちらが私が手に持っていたTrainium2パッケージです。ご覧の通り、パッケージの中央に2つのTrainiumチップが並んで配置されています。各Trainium2チップの両側には、それぞれ2つの別のチップが配置されています。これらのチップはHBM(High-Bandwidth Memory)モジュールです。HBMは、メモリチップを積層した特殊なモジュールです。メモリチップは消費電力が少なく発熱も抑えられるため、同じ面積により多くのメモリを詰め込むことができるのです。
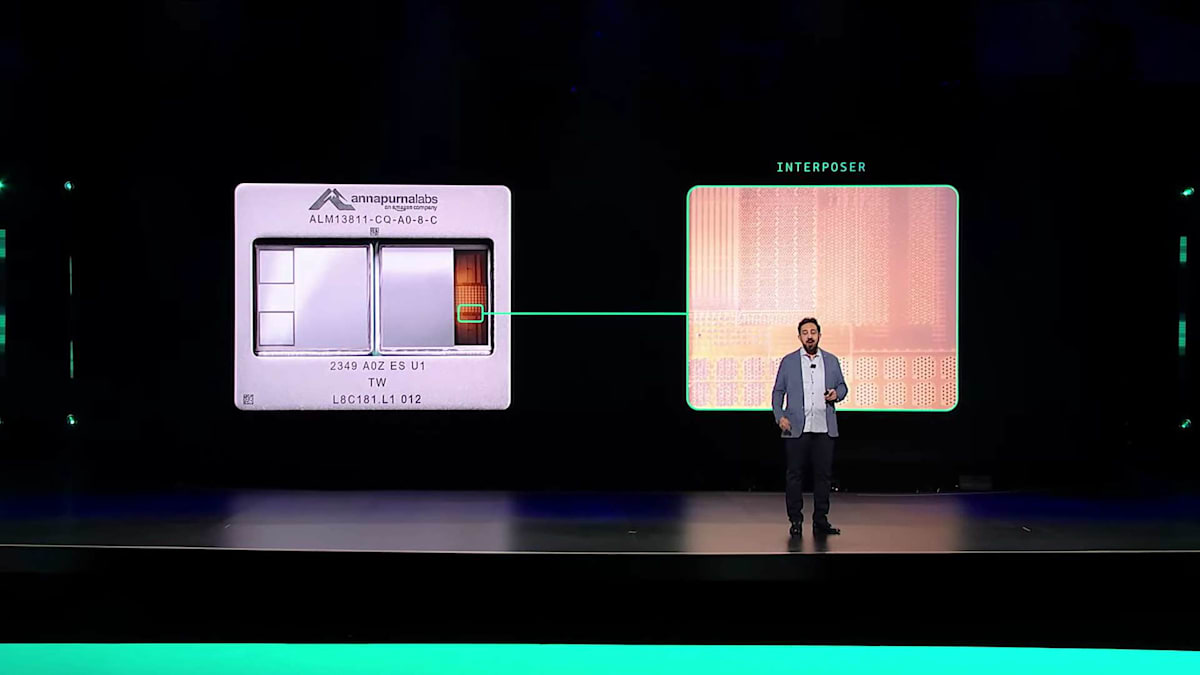
このパッケージには大量の計算用メモリが搭載されていますが、なぜパッケージをさらに大きくできないのか疑問に思われるかもしれません。ここで2つ目の制約に直面します。現在、パッケージサイズは最大チップサイズの約3倍までに制限されています。これは、ご覧のように2つのチップとHBMを考慮した場合のサイズにほぼ相当します。この図では、下にあるインターポーザーをご覧いただけるよう、HBMをいくつか取り除いています。チップとインターポーザーを接続する極小のバンプが見えますが、これをもっとよく見える角度からお見せしましょう。

これは、Annapurnaチームが私のために作成してくれた非常に興味深い画像です。紫色の線に沿って慎重にスライスし、断面を作成した後、顕微鏡でその側面を拡大したものです。左上にTrainium2の演算チップが見え、その横にHBMモジュールがあります。特に興味深いのは、HBMモジュールの層が実際に見えることです。そして両方とも薄い連続したウェハーの上に載っています。これがチップ同士を相互接続するインターポーザーです。チップとインターコネクターを接続する極小の接続部が見えます。チップとインターポーザー上部との間の電気的接続は信じられないほど小さく、それぞれが約100ミクロンで、見たことのある中で最も細かい塩の粒よりも小さいのです。チップを接続状態に保つには、これらの接続部すべてが所定の位置に留まっている必要があります。そのため、パッケージのサイズには制限があるのです。すべての接続を維持できるよう、パッケージは十分な安定性を保つ必要があるからです。
Trainium2の電力管理と製造プロセスの革新

しかし、このような微細な寸法に惑わされてはいけません。これらのチップには大量の電力が流れ、熱も発生するからです。Trainiumチップ1つで、人間が何百万年もかかる計算を1秒で処理できるほどの性能があります。この処理を行うには、チップに大量の電力を供給する必要があります。低電圧で大量の電力を供給するには、太い配線が必要になります。もちろん「太い」は相対的な表現ですが、パッケージの底部にある配線をご覧ください。チップの専門家はこれらをPowerViaと呼んでいます。太い配線が必要な理由は、電圧降下を避けるためです。半導体は、微細な電荷の有無を利用して情報の保存や処理を行います。そのため、チップが電圧降下やサグを経験すると、通常は電力供給システムが調整されるまで待機する必要があります。チップに待機時間が生じることは望ましくありません。
チップには低電圧の電力が必要ですが、より高い電圧で電力を供給する方が効率的です。そのため、データセンターでは実際に複数の電圧で電力を供給し、チップに近づくにつれて段階的に電圧を下げていきます。最後の電圧降下は、電力がパッケージに入る直前に行われます。


Trainium1のマザーボードを見ると、この一般的な実装方法がよくわかります。 最終的な電圧降下は、パッケージにできるだけ近い位置に配置された電圧レギュレータによって行われています。ここでボード上のそれらの位置を強調表示しています。Trainium2では、電圧降下を抑えて最適化するために、開発チームはこれらの電圧レギュレータをさらにチップに近づけることに取り組みました。Trainium2のボードを見ると、ボードの表面にはそれらの電圧レギュレータが見当たりません。代わりに、電圧レギュレータはパッケージの周辺部の下に配置されています。これは電圧レギュレータが熱を発生させるため、革新的なエンジニアリングが必要な、かなり難しい取り組みでした。

電圧レギュレータをチップにより近づけることで、より短い配線を使用することができ、短い配線は電圧降下の低減につながります。これはTrainium1の様子ですが、 負荷が増加したときの応答を見ることができます。これは大量の計算を開始したときに起こる現象です。 負荷が急増すると電圧が大きく低下することがわかります。この現象は一時的なものですが、この電圧低下によってチップは最適な状態で計算を行えなくなります。このような極端な変動はチップにとって負担となり、寿命を縮める可能性があります。一方、Trainium2で同じ負荷をかけた場合を見てみましょう。配線が短くなったことで、顕著な電圧降下が見られず、その結果チップの性能抑制も起こらず、より良いパフォーマンスを発揮できています。

さて、チップの話はここまでにして、サーバーを見てみましょう。これは2台のTrainium2サーバーを搭載したラックで、上下にそれぞれ1台ずつあります。かなり大きなサーバーですね。各Trainium2サーバーは8つのアクセラレータトレイで構成されており、 各トレイには専用のNitroカードを備えた2枚のTrainium2アクセラレータボードが含まれています。NVIDIAベースのシステムのGPUと同様に、Trainiumサーバーは、AIモデルの構築に必要な計算や演算を行うために設計されたアクセラレータです。ただし、オペレーティングシステムやプログラムを実行するために必要な通常の命令はサポートしていません - そのためにはヘッドノードが必要です。

これが実際、私たちのサーバーの技術的な限界となっています。 サーバーに搭載できるTrainiumアクセラレータの数は、ヘッドノードがそれらのノードを効率的に管理してデータを供給できる能力によって制限されています。これ以上アクセラレータを追加しても、追加のパフォーマンスは得られず、単にコストが増加するだけです。これは私たちの目指すところではありません。最後に、すべてのアクセラレータとヘッドノードをネットワークに接続するためのスイッチが必要です。
では、Trainium2サーバーはどれほどのパワーを持っているのでしょうか?Trainium2サーバーは、20ペタフロップスの計算能力を提供するAWSの最も強力なAIサーバーです。これはTrainium1の7倍、現在の最大のAIサーバーと比べても25%多い性能です。また、Trainium2サーバーは1.5テラバイトの高速HBMメモリを搭載しており、これは現在の最大のAIサーバーの2.5倍です。これはスケールアップサーバーですが、最も強力なAIサーバーを持っているということは、それを迅速にお客様の手元に届けられる場合にのみ意味があります。

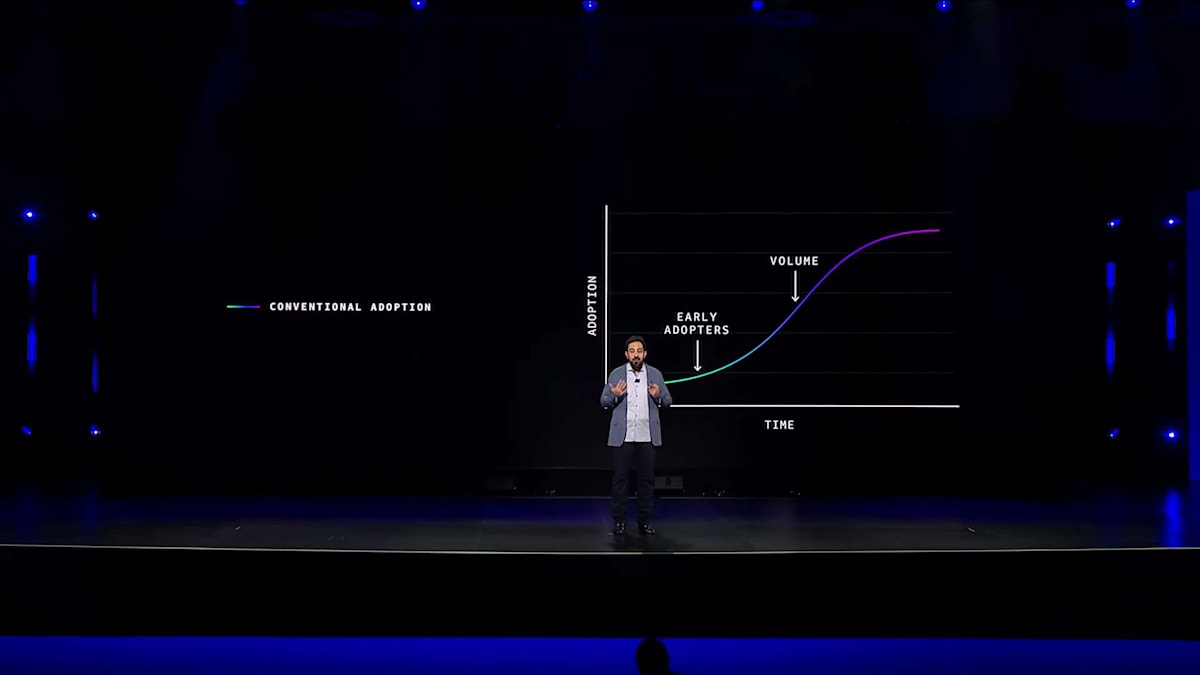
数年前まで、新しいチップやサーバーが登場すると、このような採用曲線を描くのが一般的でした。新しいサーバーの登場から数ヶ月の間は、一部のアーリーアダプターが採用を始めます。通常は最大規模のデータベースや、最も要求の厳しいワークロードを扱うユーザーです。これらのアーリーアダプターが新しいワークロードをハードウェアに移行している間に、初期の製造上の課題を解決することができました。しかし、AIの世界ではそうはいきません。より優れたモデルを構築するために強力なサーバーが必要とされるため、お客様は最高のAIインフラストラクチャーを求めており、しかもそれを初日から使いたいと考えているのです。
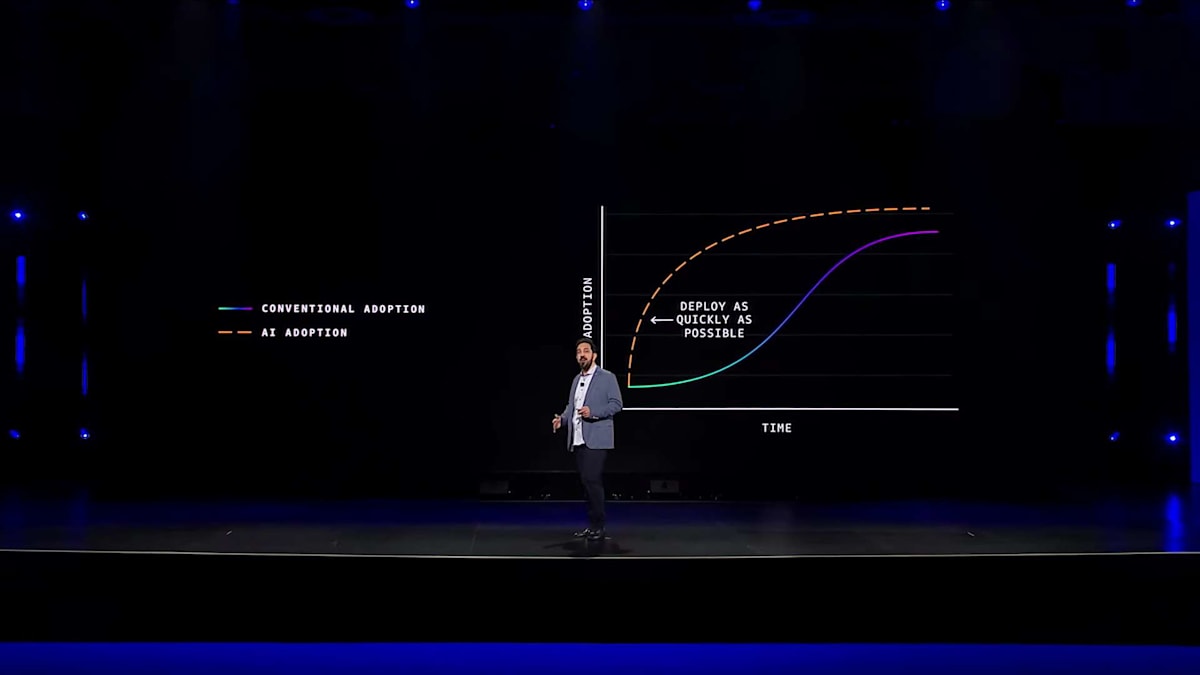

私たちは、このかつてない需要の急増を予測して、この分野でも革新を行いました。先ほどご覧いただいたTrainium2のトレイをもう一度見てみましょう。ここで興味深いのは、目に見えないものです。つまり、大量のケーブルが見当たらないということです。なぜなら、開発チームはケーブルの本数を減らすことに力を注いだからです。ケーブルの代わりに、これらのコンポーネントはすべて下部のマザーボード上の配線トレースで接続されています。なぜそうしたのでしょうか?それは、ケーブル接続が一つあるごとに、

製造時の不具合が発生する可能性があり、それが製造速度を低下させるからです。実際、Trainium2サーバーの最も優れた特徴の一つは、自動製造・組立に特化して設計されていることです。この高度な自動化により、初日から迅速なスケールアップが可能になります。つまりTrainium2は、最も強力なAIサーバーであるだけでなく、これまでに私たちが開発したどのAIサーバーよりも素早くスケールアップできるように特別に設計されているのです。
Trainiumのシストリックアレイアーキテクチャ

しかし、それだけではありません。強力なAIサーバーとは、単に生の計算能力とメモリを小さなスペースに詰め込んだだけのものではないのです。それは、AIワークロードを最適化するための専用ツールなのです。そしてここで、Trainium2のアーキテクチャが重要な役割を果たします。Trainiumについて最初に理解しておくべきことは、従来のCPUやGPUとは全く異なるアーキテクチャを採用しているということです。それは「シストリックアレイ」と呼ばれるものです。

簡単にその違いを説明させていただきましょう。ここでは、命令を実行する標準的なCPUコアをいくつか図示しています。CPUにはさまざまな種類がありますが、すべてのCPUに共通する特徴がいくつかあります。まず、各CPUコアは完全に独立したプロセッサーです。そのため、現代のCPUで複数のプロセスを同時に実行できるのです。もう一つ注目すべき点は、すべてのCPUコアが少量の作業を実行した後、データの読み書きのためにメモリにアクセスするということです。これによってCPUは非常に汎用性が高くなりますが、同時にパフォーマンスは最終的にメモリ帯域幅によって制限されることになります。最後に、近年CPUのコア数は大幅に増加していますが、現在最大規模のCPUでも、せいぜい数百コア程度にとどまっています。

GPUは全く異なる存在です。現代のGPUには数百から数千のコンピューティングコアが搭載されており、これらは並列処理ユニットとして構成されています。GPUでは、複数のコアが同じ処理を異なるデータに対して実行することで、同じスペースにより多くのコアを詰め込むことができます。つまり、各GPUコアは完全に独立しているわけではなく、他のコアと結びついているのですが、そのおかげでCPUの完全独立型コアと比べて少ないトランジスタで各GPUコアを構築できるのです。このGPUアーキテクチャにより、グラフィックスをはじめとする多くのワークロード、特にAIの処理が大幅に高速化されました。
GPUは間違いなく革新的なハードウェアアーキテクチャですが、私たちは異なるアプローチを選択しました。シストリックアレイアーキテクチャは、長い相互接続された計算パイプラインを作成できる独特のハードウェアアーキテクチャです。CPUやGPUでは、各計算命令がメモリを読み込み、処理を行い、そしてメモリに書き戻す必要があります。シストリックアレイでは、ある処理ユニットから次の処理ユニットへと直接結果を受け渡すことで、計算ステップ間のメモリアクセスを回避できます。これによりメモリ帯域幅の負荷を軽減し、計算リソースを最適化することができます。

Trainiumでは、AIワークロード向けにシストリックアレイを設計しました。先ほど図示したような処理ユニットの直線的な連鎖ではなく、このようなレイアウトになっています。私たちのレイアウトは、AIコードの基盤となる一般的な行列やテンソル演算に対応するように特別に設計されています。このアーキテクチャにより、Trainiumは従来のハードウェアアーキテクチャと比べて優位性を持ち、AIサーバーで利用可能なメモリと帯域幅を最適に活用できます。これにより、Trainium2サーバーに搭載された計算能力とメモリを最大限に活用することができるのです。

Trainiumで私たちが行ったもう一つの決定は、アプリケーションのパフォーマンスを最適化できるよう、ハードウェアへの直接アクセスを提供することでした。Neuron Kernel Interface(NKI)は、基盤となるTrainiumハードウェアを最大限に活用できるコードの開発とデプロイを可能にする新しい言語で、AIアプリケーションをより費用対効果の高い方法で構築する新しい手法を実験することができます。先月、私たちはBuild on Trainiumプログラムを発表し、研究者にTrainiumハードウェアへのアクセスを提供して新技術の開発を支援することを発表しました。UC Berkeley、Carnegie Mellon、UT Austin、Oxfordなどの大学の研究者たちは、Trainiumとその革新的なハードウェア機能を使用してAIの新しい研究を行うことに大きな期待を寄せています。そして私たちは、明日の最も要求の厳しいAIワークロードを支えるハードウェアのイノベーションに向けて、これらの研究機関とのパートナーシップを楽しみにしています。
NeuronLinkとAmazon Bedrockの新機能

さて、AIワークロード向けに最適化された革新的なハードウェアアーキテクチャを備えた最強のAIサーバーを構築し、かつてないスピードで展開する準備が整いました。


しかし、最新のフロンティアモデルを支える最も要求の厳しいAIワークロードについてはどうでしょうか?これらのワークロードにとって、いくら性能が高くても十分ということはありません。そこで登場するのがNeuronLinkです。 NeuronLinkは、私たちが独自に開発したTrainium向けの相互接続技術です。NeuronLinkを使用すると、複数のTrainium2サーバーを1つの論理サーバーとして結合でき、それらのサーバー間を1マイクロ秒という低レイテンシーで、毎秒2テラバイトの帯域幅で接続できます。従来の高速ネットワークプロトコルとは異なり、NeuronLinkサーバーは互いのメモリに直接アクセスすることができ、これにより特別なもの、私たちが「ウルトラサーバー」と呼ぶものを作り出すことができます。

実は私はずっと、ステージにハードウェアを持ち込みたいと思っていたのですが、毎年それは却下されてきました。画面を遮ってしまうからです - 申し訳ありませんが、確かに画面は見えにくくなってしまいます。でも今年は、ウルトラサーバーとは何かをお見せするために、実際にステージ上にウルトラサーバーを持ち込みました。これが1台のウルトラサーバーです。64個のTrainium2チップが協調して動作し、現在のEC2 AIサーバーの5倍の計算能力と10倍のメモリを提供します。これこそが、1兆パラメータのAIモデルを構築しようとする際に必要となるサーバーなのです。かなりすごいでしょう?きっと会場の中には、1兆パラメータのAIモデルの構築を考えている方が少なくとも1人はいらっしゃると思いますが、それ以外の方々にとっても興味深い話があります。

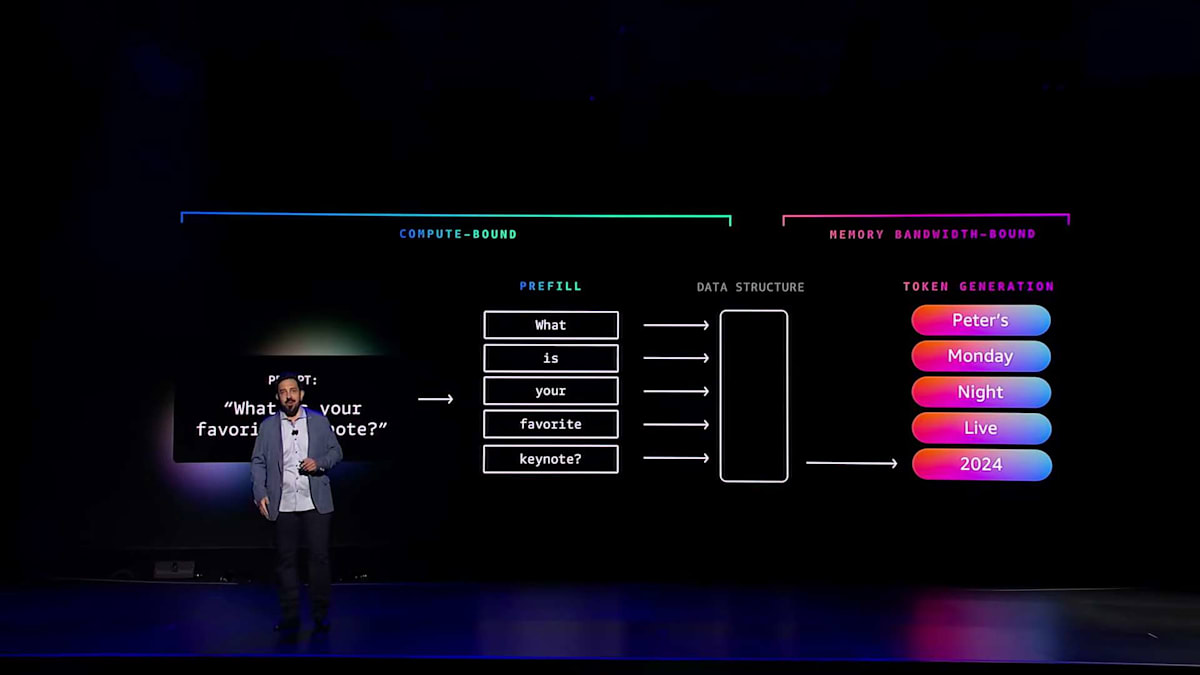
では、誰もが頻繁に行っているAI推論について見ていきましょう。大規模モデルの推論は、それ自体が非常に興味深く、要求の厳しいワークロードですが、実際にはこれは2つのワークロードから成り立っています。1つ目のワークロードは入力エンコーディングで、プロンプトやその他のモデル入力をトークン生成の準備のために処理します。このプロセスはプリフィルと呼ばれ、入力を次のプロセスに渡すデータ構造に変換するために、大量の計算リソースを必要とします。プリフィルが完了すると、計算されたデータ構造は2つ目の推論ワークロードに渡され、そこでトークン生成が行われます。
トークン生成の興味深い特徴の1つは、モデルが各トークンを1つずつ順番に生成することです。これによりAIインフラストラクチャーに対して全く異なる要求が生まれます。トークンが生成されるたびに、モデル全体をメモリから読み出す必要がありますが、使用される計算量はわずかです。このため、トークン生成はメモリバスに大きな負荷をかけますが、計算負荷は小さく、プリフィルワークロードとはほぼ正反対の特性を持っています。
では、これらのワークロードの違いは、皆さんやAIインフラストラクチャーにとって何を意味するのでしょうか?しばらく前まで、チャットボットのような多くのワークロードは、主にプリフィルのパフォーマンスを重視していました。なぜなら、プリフィルの実行中、ユーザーは通常画面を見つめたり、くるくる回る待機アイコンを見つめたりして待っているからです。一方、トークンの生成が始まれば、人間が読める速度より速く生成できれば十分でした。それほど速い速度は必要ありませんでした。しかし最近では、モデルはエージェント型のワークフローで使用されることが増えています。ここでは、ワークフローの次のステップに進むために、レスポンス全体が生成されるのを待つ必要があります。

現在、お客様が重視しているのは、高速なプリフィルと非常に高速なトークン生成です。そしてここで、AI推論インフラに対する需要で興味深い現象が起きています。高速な推論への要求により、AI推論ワークロードもまた、最も強力なAIサーバーを必要とするようになってきているのです。素晴らしいことに、先ほど説明した2つの異なるワークロードは相互補完的です。プリフィルはより多くの計算能力を必要とし、トークン生成はより多くのメモリ帯域を必要とします。そのため、同じ強力なAIサーバー上でこれらを実行することで、優れたパフォーマンスと効率性を実現できます。

そこで私たちは、Trainium2の利点をAWSのお客様に推論用としてどのように提供できるか考えました。本日、Amazon Bedrockの新しいレイテンシー最適化オプションを発表できることを大変嬉しく思います。これにより、最新のAIハードウェアやその他のソフトウェア最適化にアクセスして、様々な主要モデルで最高の推論パフォーマンスを得ることができます。レイテンシー最適化推論は、選択されたモデルに対して、すぐにプレビューとして利用可能です。そのモデルの1つが、広く普及しているLlamaです。そして、レイテンシー最適化版のLlama 405Bと、より小規模なLlama 70Bモデルが利用可能になったことを発表できて大変嬉しく思います。
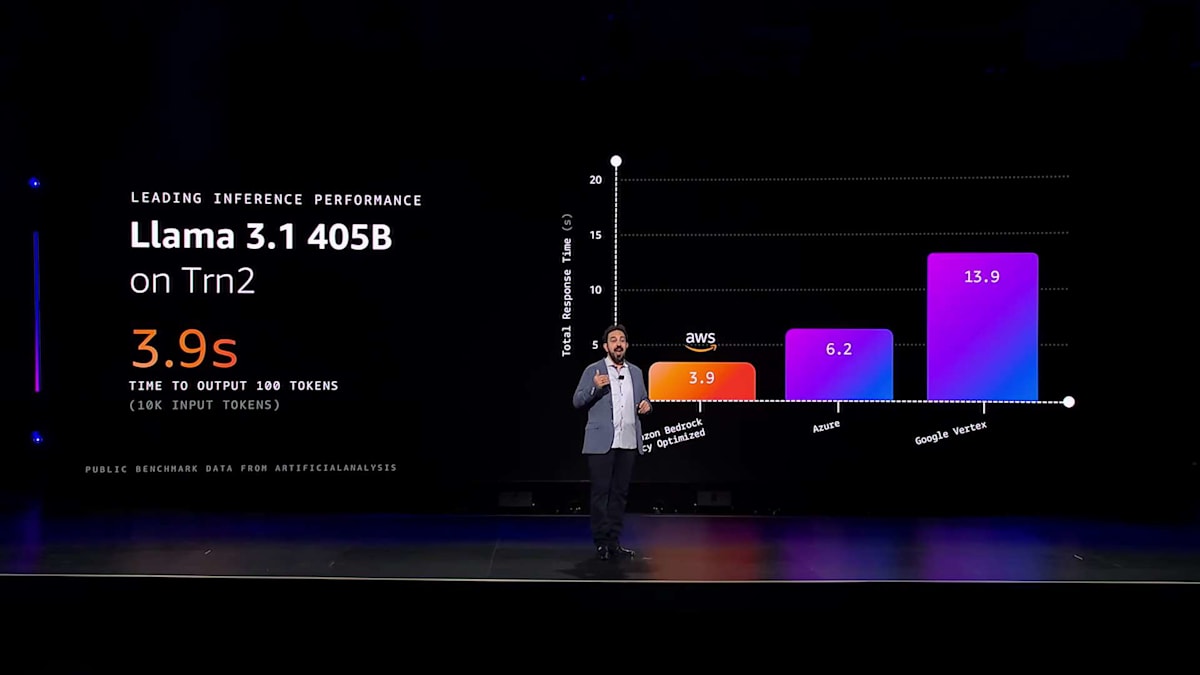
これらのモデルは現在、どのプロバイダーと比べてもAWS上で最高のパフォーマンスを提供しています。こちらが最大かつ最も人気のあるLlamaモデル、Llama 405Bのパフォーマンスです。プリフィルワークフローとトークン生成ワークフローの両方を含む、リクエストの処理から応答生成までの合計時間を示しています。数値が低いほど良好です。ご覧の通り、Amazon Bedrockのレイテンシー最適化版は、他の提供サービスと比べて大幅に低い値を示しています。


Anthropicとのパートナーシップにより、新しく非常に人気の高いClaude 3.5モデルのレイテンシー最適化版を発表できることを嬉しく思います。リクエストによっては、レイテンシー最適化されたHaiku 3.5は標準のHaiku 3.5と比べて60%高速に動作し、どこよりも速いHaiku 3.5の推論を提供します。そして、Llamaと同様に、Haiku 3.5もこのパフォーマンスを達成するためにTrainium2を活用しています。先ほど言及したScaling Law論文の共著者の一人を壇上にお招きできることを大変嬉しく思います。Anthropicの共同創業者でありChief Compute OfficerのTom Brownをお迎えし、TrainiumとAWSを使ってどのようにイノベーションを起こしているかについてお話しいただきます。
AnthropicとAWSの協力:Claude 3.5の高速化

ありがとうございます、Peter。Anthropicでは、信頼できるAIの構築に取り組んでいます。世界中の何百万もの人々が、日々の業務でClaudeを利用しています。Claudeはコードを書き、文書を編集し、ツールを使用してタスクを完了します。正直に申し上げますと、これから私が話す基調講演の半分はClaudeが書いたものです。そして、AWSとのパートナーシップのおかげで、大小を問わずあらゆる企業が、すでに信頼している安全なクラウド上でClaudeを利用できるようになりました。
それでは、私たちのコラボレーションがどのように機能しているのか、より詳しく掘り下げていきたいと思います。まず、Peterが先ほど触れたClaude 3.5 Haikuについてお話ししましょう。これは最新かつ最速のモデルの1つです。小規模なモデルながら、驚くべきことに、時には15倍もコストが低い中で最上位モデルのOpusに匹敵する性能を発揮します。Peterが説明したように、私たちは協力してTrainium2上でHaikuをさらに高速に実行できる低レイテンシー最適化モードを開発しました。つまり、本日からHaikuを60%高速に実行できるようになり、しかもお客様側での変更は一切不要です。APIのスイッチを切り替えるだけで、リクエストが新しいTrainium2サーバーに転送されます。

この高速性は、インタラクティブな操作において特に重要です。プログラマーの方なら、キーストローク間の短い時間でサジェストを補完する必要があるコード補完機能を想像してみてください。60%の高速化は、この場面で大きな違いを生み出します。補完候補が表示されるか、まったく表示されないかの分かれ目となりうるのです。では、どのようにしてこれほどの高速化を実現したのでしょうか?まず、このハードウェアをご覧ください。まさに化け物です。そして、Peterが説明したように、搭載された各チップには驚異的なスペックが備わっています。Systolic Arrayには1ペタフロップ以上の計算能力があり、豊富なメモリ帯域幅と高速なインターコネクトを備えています。
素晴らしいスペックを持っていますが、エンジニアなら誰でも知っているように、スペックだけでは不十分です。最高のパフォーマンスを引き出すには、常にSystolic Arrayに十分なデータを供給し続ける必要があります。つまり、メモリやインターコネクト、その他のソースからの入力待ちでブロックされることがないように、処理を適切にスケジューリングしなければなりません。これはまるでテトリスのようなもので、より密にパックすればするほど、モデルのコストは下がり、速度は上がります。では、このテトリスのような課題をどのように解決したのでしょうか?実は、Anthropicのパフォーマンスエンジニアリングチームは、この課題に取り組むためにAmazonとAnnapurnaと1年以上にわたって緊密に協力してきました。

コンパイラは多くのことをこなせますが、完璧ではありません。そして、私たちの規模では、完璧を目指す価値があります。Anthropicにとって1つのパフォーマンス最適化は、100万人の新規顧客にサービスを提供できるだけの計算能力を解放する可能性があります。そのため、プログラムの最も重要な部分をPythonからCに移行するように、NKIのような低レベルまで降りて、可能な限りハードウェアに近いレベルでカーネルを書く価値があるのです。そして、Trainiumの設計は、このような低レベルのコーディングに最適であることがわかりました。あまり知られていないかもしれませんが、他のAIチップでは、カーネル内でどの命令が実行されているのかを知る方法が実際にはありません。

これでは推測に頼らざるを得ません。目隠しをしてテトリスをプレイするようなものです。Trainiumは、システム内のあらゆる場所で実行される全ての命令のタイミングを記録できる初めてのチップです。これは、私たちAnthropicで開発した実際の低レベルTrainiumカーネルの例です。Systolic Arrayがいつ実行され、いつブロックされ、そしてなぜブロックされて何を待っていたのかを正確に確認することができます。目隠しを外すことで、低レベルカーネルの作成がより速く、より簡単に、そしてより楽しくなります。

さて、エキサイティングなお知らせをさせていただきます。これまでは推論に焦点を当ててきましたが、Trainiumという名前には理由があります。次世代のClaudeが、数十万個のTrainium2チップを搭載した新しいAmazonクラスター「Project Rainier」で学習されることを、大変嬉しく思いながらお伝えします。 これは数百エクサフロップスの密度の高い演算能力を意味し、これまで使用してきたどのクラスターと比べても5倍以上の性能です。Project Rainierがお客様にもたらす影響は非常に大きいものです。 今年初め、AnthropicはClaudeシリーズで最も高度なモデルとなるClaude 3 Opusをリリースしました。その4ヶ月後には、Opusを上回る性能を持ちながら、コストは5分の1で済むClaude 3.5 Sonnetを提供しました。最近では、3.5 Haikuと、人間のようにコンピュータと対話できる機能を備えた改良版3.5 Sonnetもリリースしています。

Project Rainierは、私たちの開発をさらに加速させ、研究と次世代スケーリングの両方を推進します。 この進歩により、お客様はより低コストで、より高速に、より高度な知能を手に入れることができ、より重要なプロジェクトを任せられるスマートなエージェントを利用できるようになります。 Trainium2とProject Rainierにより、私たちは単に高速なAIだけでなく、スケーラブルで信頼性の高いAIを実現していきます。
10p10uネットワーク:AIに最適化された高性能ネットワーク

先ほど、最高のAIインフラを構築するには、最も強力なサーバーを作る必要があると申し上げました。これがスケールアップの要素です。 しかし、これは方程式の半分に過ぎません。最大規模のモデルを学習させるには、Project Rainierのような最大規模のクラスターも構築する必要があります。ここで重要になるのがスケールアウトの話です。AWSは高性能なスケールアウトインフラの革新において豊富な経験を持っています。このスケールアウト革新の代表例が、弾力性のあるAI最適化ネットワークの開発です。優れたAIネットワークは、優れたクラウドネットワークと多くの特徴を共有していますが、 すべての面で劇的に強化されています。これをラスベガスのファイトに例えると、比較にならないほどの差があります。

クラウドネットワークはお客様の妨げにならないよう十分な容量が必要ですが、AIネットワークはそれをはるかに上回る要求があります。各Trainium2ウルトラサーバーは 約13テラビットのネットワーク帯域幅を提供し、学習時には全てのサーバーが同時に相互通信する必要があります。これにはサーバーの速度低下を防ぐための巨大なネットワークが必要です。クラウドネットワークは急速な拡張が求められ、 世界中のデータセンターに毎日数千台のサーバーを追加しています。しかし、AIはさらに急速に拡大しています。AIインフラに数十億ドルを投資する場合、即座の導入が極めて重要になります。
クラウドネットワークには信頼性が求められ、最も洗練されたオンプレミスネットワークよりもはるかに優れた可用性を提供する必要があります。私たちのグローバルデータセンターネットワークは 99.999%の可用性を実現しています。しかし、AIワークロードはさらに要求が厳しく、ネットワークの短時間の障害でさえ、クラスター全体の学習プロセスを遅延させ、アイドル容量と学習時間の延長につながる可能性があります。では、クラウドネットワークの革新を基に、より優れたAIネットワークをどのように構築するのでしょうか?最新世代のAIネットワークファブリックについてご説明させていただきます。

これを私たちは10p10uネットワークと呼んでいます。このネットワークファブリックは、Ultra Server 2クラスターを支えており、TrainiumとNVIDIAベースのクラスター両方に使用しています。10p10uと呼ぶのは、数千台のサーバーに対して数十ペタバイトのネットワーク容量を、10マイクロ秒未満のレイテンシーで提供できるからです。10p10uネットワークは大規模な並列処理が可能で、密に相互接続されており、柔軟性があります。数台のラックから始めて、複数のデータセンターキャンパスにまたがるクラスターまで、自在にスケールできます。

ここでご覧いただいているのは、10p10uのたった1つのラックです。 お気づきかもしれませんが、スイッチが美しい緑色をしています。 実は緑は私の好きな色なんです。British racing greenが特に好きなんですが、これもなかなかいい色です。データセンターで緑色のスイッチを見たのは初めてでした。この緑色は「グリーナリー」と呼ばれ、2017年のPantone Color of the Yearだったんです。実はサプライヤーの1社が余った塗料を持っていて、とてもお得な価格で提供してくれたんです。この話は私たちの設計哲学をよく表しています:お客様にとって重要なものにはお金をかけ、塗料のような重要でないものではコストを抑えるということです。

もう1つお気づきかもしれないのは、このラックには非常に多くのネットワークケーブルが接続されているということです。緑色ではない部分がネットワークパッチパネルです。このような高密度のネットワークファブリックを構築するには、非常に正確なパターンでスイッチを相互接続する必要があり、それを可能にするのがこのパッチパネルです。このパッチパネルは長年にわたって私たちに貢献してきましたが、ご覧の通り、10p10uネットワークではケーブルの複雑さが大幅に増加したため、かなり煩雑になってきています。 先ほど説明したように、設置作業のスピードも上がっているため、チームにとってイノベーションを起こす絶好の機会となりました。

そのイノベーションの1つが、独自のトランクコネクターの開発です。これは16本の光ファイバーケーブルを1つの頑丈なコネクターにまとめた、いわばスーパーケーブルと考えることができます。画期的なのは、この複雑な組み立て作業がデータセンターの現場ではなく、工場で行われるということです。これにより設置プロセスが大幅に効率化され、接続ミスのリスクもほぼゼロになります。 一見控えめな改善に思えるかもしれませんが、その影響は絶大でした。トランクコネクターを使用することで、AIラックの設置時間が54%短縮されただけでなく、見た目もずっとすっきりしました。あの緑色のスイッチが本当に映えるようになりました。

チームのイノベーションはそれだけではありません。 もう1つの素晴らしいイノベーションが、Firefly Optic Plugと呼ばれるものです。この独創的な低コストデバイスは小型の信号反射装置として機能し、ラックがデータセンターに到着する前にネットワーク接続を包括的にテストして検証することができます。つまり、サーバーが到着してからケーブル配線のデバッグに時間を費やす必要がないのです。AIクラスターの世界では、時間が文字通りお金なのです。Firefly Plugには保護シールとしての二次的な役割もあり、光学接続部への埃の侵入を防ぎます。些細なことに聞こえるかもしれませんが、ほんの小さな埃の粒子でも、接続の完全性を大きく損ない、ネットワークのパフォーマンスに問題を引き起こす可能性があるのです。

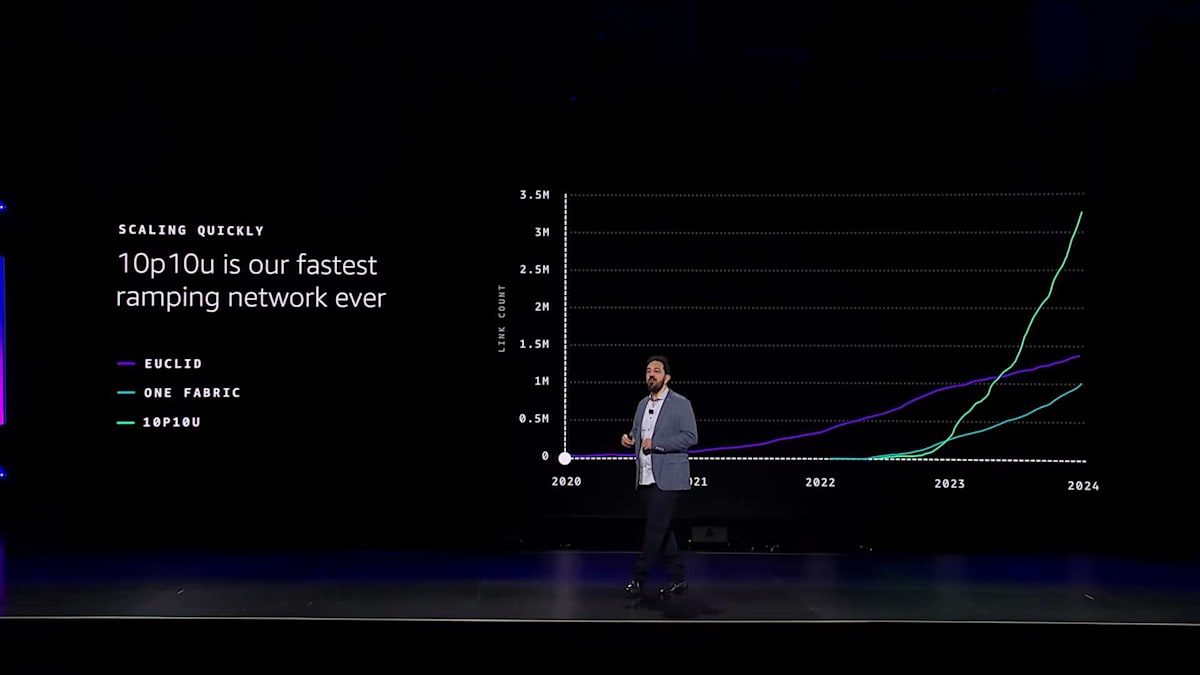
エレガントな解決策によって、2つの重要な課題を解決することができました。まさに一石二鳥というわけです。このような革新により、10p10uネットワークは、これまでで最も急速に拡大したネットワークとなりました。 このチャートは、私たちが異なるネットワークファブリックにインストールしたリンク数を示しています。10p10uネットワークの成長カーブは、私たちにとっても前例のないものでした。 過去12ヶ月間で300万以上のリンクを設置しましたが、これはTrainium2の展開を始める前の数字です。

そして最後の課題は、ネットワークの信頼性向上です。AIネットワークにおける最大の障害要因は光リンクです。 光リンクとは、私たちが見てきたすべてのケーブルで光信号の送受信を行う小型レーザーモジュールのことです。AWSは長年にわたり、独自の光学機器の設計と運用を行ってきました。その運用の厳格さと大規模なスケールにより、故障率を着実に低下させることができました。 このスケールによる進歩は印象的ですが、どれだけ故障率を下げても、完全になくすことはできません。

故障を完全になくすことができないのであれば、その影響をいかに軽減できるかを考える必要があります。すべてのネットワークには、パケットの経路を指示するためのデータを使用するスイッチがあります。 これは基本的にネットワークの地図のようなものです。AIネットワークでは、この地図は数十万のパスを考慮する必要があり、光リンクが故障するたびに地図を更新しなければなりません。


では、それをどうすれば迅速かつ確実に行えるのでしょうか?シンプルなアプローチは、地図を中央で管理することです。 ネットワークを最適化する単一の頭脳というのは魅力的に聞こえますが、問題があります。ネットワークが巨大になると、中央制御がボトルネックになります。障害の検出が難しく、スイッチの更新が非常に遅くなり、中央コントローラーが単一障害点となってしまいます。そのため、大規模なネットワークは通常、分散型を採用します。 BGPやOSPFなどのプロトコルを使用して、スイッチ同士が健全性の更新情報を共有し、協力してネットワークマップを作成します。このアプローチは堅牢ですが、完璧ではありません。大規模なネットワークでは、リンクが故障した際に、ネットワークスイッチが協力して新しい最適なマップを見つけるまでに相当な時間がかかることがあります。そして、AIネットワークでは、それは作業ができない時間となってしまいます。


このように2つの最適とは言えない選択肢に直面した時、新しい道を切り開く必要があります。10p10uネットワークでは、まったく新しいネットワークルーティングプロトコルを構築することにしました。 これをScalable Intent-Driven Routing(SIDR)と呼んでいます。そうです、ネットワーキングに詳しい方々には、これが言葉遊びに聞こえるかもしれません。SIDRは両方の利点を兼ね備えています。SIDRを簡単に説明すると、中央プランナーがネットワークを構造化し、それをすべてのスイッチにプッシュダウンすることで、障害を検知した際に各スイッチが迅速に自律的な判断を下せるようにするというものです。つまり、SIDRは中央計画の制御と最適化を、分散型の速度と回復力と組み合わせたものなのです。 その結果、SIDRは最大規模の10p10uネットワークでも、1秒未満で障害に対応できます。これは、他のネットワークファブリックで使用している代替アプローチと比べて10倍速いのです。他のネットワークがまだルートを再計算している間に、10p10uネットワークは既に作業を再開しているのです。
AWSのイノベーション:スタック全体にわたる差別化


さて、今夜は多岐にわたるトピックについてお話ししてきました。NitronやGraviton、ストレージに関する私たちの投資における中核的なイノベーションから、Trainium2を搭載した私たちの最大かつ最強のAIサーバーの構築方法、そして長年のクラウドスケールアウトにおけるイノベーションがAIにどのように活かされているかまで。皆様には、私たちがスタック全体にわたってイノベーションを進め、お客様のために真に差別化されたソリューションを生み出していることをご理解いただけたのではないかと思います。それでは、これで本日の講演を終わらせていただきます。ご清聴ありがとうございました。re:Inventをお楽しみください。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion