re:Invent 2023: PinterestのDeep Learning AMIとPyTorchによる大規模モデル学習
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Large model training on AWS Deep Learning AMIs & PyTorch, ft. Pinterest -AIM326
この動画では、Pinterestが大規模モデルのトレーニングにAWSのDeep Learning AMIとPyTorchをどのように活用しているかを詳しく解説しています。UltraClusterやAWS Batchを駆使した分散トレーニングの実装方法や、PyTorchの最新バージョンへの迅速なアップグレード戦略など、Pinterestならではの工夫が満載です。特に、グラフニューラルネットワークの活用やS3からのデータストリーミング手法は、業界をリードする先進的な取り組みとして注目に値します。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
AWSとPinterestによる大規模モデルトレーニングセッションの概要

みなさん、こんにちは。 AIM326「AWSのDeep Learning AMIとPyTorchを使用した大規模モデルのトレーニング」セッションへようこそ。Pinterestの事例を紹介します。私はAWSのシニアプロダクトマネージャーのArindam Paulです。一緒に登壇するのは、PinterestのMLプラットフォームのエンジニアリングマネージャーであるKarthik Anantha Padmanabhanと、Karthikや私と密接に協力しているプリンシパルソリューションアーキテクトのZlatan Dzinicです。始める前に、簡単にお聞きしたいのですが、PyTorchを使ってモデルトレーニングの直接的な経験がある方は手を挙げていただけますか?ありがとうございます。
本日は盛りだくさんの内容をご用意しています。まず私から、大規模モデルのトレーニングの課題と、それらが私たちにもたらす利点について簡単にお話しします。その後、Karthikに引き継ぎ、Pinterestにおける大規模モデルトレーニングについて、このトークの主要な内容をお話しします。具体的には、Pinterestにおける大規模モデルトレーニングの目標、ビジネスへの影響、採用しているアーキテクチャ、そしてこれまでの結果と影響について説明します。その後、Zlatanが、Pinterestのために実装したソリューションアーキテクチャについて説明します。最後に重要なポイントをまとめ、質疑応答の時間を設けます。私からKarthik、そしてZlatanへと、徐々に技術的な内容が深まっていくことにお気づきかもしれません。私たちの服装からもそれが伺えるでしょう。
大規模モデルトレーニングの課題と利点
大規模モデルは今や至る所に存在しています。SNSを利用している方や、ニュースをチェックしている方なら、どこでも目にすることでしょう。映画、テキスト、書籍の執筆、音楽の生成、コードの生成、要約、チャットボット、スマートな検索など、様々なタスクでかなり優れた性能を発揮しています。私たちのデジタルな存在、そして恐らく物理的な存在までもが、これらの大規模モデルによって形を変え始めています。私たちは、言葉足らずかもしれませんが、革命の入り口に立っているのです。皆様のような顧客が、この技術の最前線を常に押し広げ、より興味深い使用事例を次々と解決していることからも、それが見て取れます。

しかし、大規模モデルのトレーニングには独自の課題もあります。まず第一に、大規模モデルには大量の計算リソースとストレージが必要です。規模が大きくなれば、特有の問題が生じます。例えば、ご存じの通り、業界全体に影響を与えている最大の問題は、特にGPUなどの計算リソースの不足です。Amazonでは、TrainiumとInferentiaを開発し、トレーニングとホスティングの両方を行うシリコンに投資しています。しかし、現在の業界では、これらのチップが深刻に不足しています。では、どうすればよいのでしょうか?どのように対処すればよいのでしょうか?
一つの方法は、手持ちのチップの効率を上げることです。つまり、1時間のGPU使用時間すべてがモデルトレーニングに貢献するようにすることです。計算リソースに加えて、データの問題もあります。大規模モデルのトレーニングにはペタバイト規模のデータが必要です。そのデータをどのようにホストするのか?データのコストはどうするのか?データにどのようなアクセス制限を設けるのか?これらはすべて、モデルをトレーニングする人が対処しなければならない問題です。
トレーニング実行中には、安定性の問題も発生する可能性があります。GPUでOOMエラーやその他のエラーが発生することがあります。そのため、トレーニング実行を適時に回復させ、モデルが妥当な時間内に収束するようにする必要があります。定期的な健全性チェックと、GPUの障害に対してトレーニング実行が頑健であることを確認することが重要な課題です。この大規模なインフラ(計算、メモリ、ストレージ)を調整してモデルトレーニングを可能にし、適切な時間内に適切な精度で収束することを保証するのは難しい課題です。Pinterestがどのようにこれを解決しているかを、数分後にご覧いただきます。数分後に、Karthikに引き継ぎます。
AWS Deep Learning AMIとContainerの特徴と利点

その前に、Pinterestからより詳しく説明される2つの特定のAWSテクノロジーについて簡単に説明したいと思います。これらは使用されている多くのテクノロジーのうちの2つに過ぎません。より詳細な情報をお求めの方のために、最後のスライドにリリースノートのQRコードをご用意していますので、写真を撮る必要はありません。
私たちのテクノロジーの最初の要素は、AWS Deep Learning AMI(DLAMI)とAWS Deep Learning Container(DLC)です。AMIはEC2インスタンス上で動作するAmazon Machine Imageです。DLAMIの特徴は、ディープラーニングワークロード向けに特別にキュレーション、テスト、セキュリティ対策、最適化されていることです。これらのAMIを作成する際には、ディープラーニング機能がすぐに使えるようにするために多くの作業を行っています。AMI上でモデルをトレーニングする場合、AWS のインフラ、コンピューティング、ネットワーキングに対してテストされ最適化されたAMI上で実行されることが保証されています。
ディープラーニング用のAMIは様々なものがあります。最もシンプルなのはベースAMIで、Amazon LinuxとUbuntuをサポートする2種類があります。ベースAMIには、最新のNVIDIAドライバーと、ネットワーキング用の最新のEFAスタック、NCCLの最高のパフォーマンスを得るためのOFI NCCLがパッケージされています。これらはGPU向けに最適化されており、フレームワークをインストールしたり、独自のコンテナを実行したりするためのキュレーションされたライブラリセットが事前にテストされています。
次のAMIセットは、フレームワークAMIとフレームワークコンテナ、つまりDLCです。これらにはベースAMIと、その上にPyTorchまたはTensorFlowのディストリビューションが含まれています。PyTorch AMIとTensorFlow AMI、そしてPyTorch DLCとTensorFlow DLCがあります。また、PyTorchとTensorFlowが共存するマルチフレームワークAMIもあります。
お客様からよく寄せられる質問の1つは、これらのAMIやDLCの作成の難しさについてです。作成自体はそれほど難しくないかもしれませんが、本当の課題は、年に何度もリリースされる新しいバージョンのフレームワークに対応し、パッチを当て、セキュリティを確保し、最新の状態を維持するための継続的なコストにあります。私たちがそのすべての作業を行いますので、当社のDLAMIを選択すれば、常に動作が保証され、すべてのセキュリティパッチが適用された状態であることが保証されます。
この分野での3つ目のオファリングは比較的新しいものです。昨年、私たちはAWS PyTorchのConda distributionを作成しました。これは特に、PyTorchの様々なバージョンとCUDAやNVIDIAドライバーの異なるバージョンを組み合わせて、最高のパフォーマンスと機能性を確保したいと考える機械学習チームにとって魅力的です。私たちがすべてのテストを行い、お客様が自由に組み合わせて使用できるようにしています。機械学習の科学者の方々は、私たちのPyTorch-Conda distributionをご利用いただけます。

これらのディープラーニングツールを使用することの利点は大きいです。まず、追加費用はかかりません。EC2の使用料金のみをお支払いいただきます。これらのツールは、お客様がより効果的かつ効率的に仕事を行えるよう準備されており、本質的にはTotal Cost of Ownershipの削減を支援します。また、これらのツールはカスタマイズ可能で、サービスガイドに従うことで簡単にパッケージを修正できます。
セキュリティも重要な利点の1つです。私たちのAMIとコンテナは、セキュリティ脆弱性に対してNIST CVDを使用して毎日スキャンされ、新しい脆弱性が発見されてから数日以内にパッチが適用されます。これにより、エンタープライズサポートのオーバーヘッドが削減されます。なぜなら、これらはAWSによってテストされ、バージョン管理され、オープンソースリリースの最新のメジャーおよびマイナーバージョンに常に更新されているからです。つまり、ML Opsチームはもはや環境をゼロから開発する必要がなくなります。
金融サービス、メディア・エンターテインメント、自動車など、様々な業界の何千ものAWSのお客様が、AWS DLAMIとDeep Learning Containersを使用することで、MLインフラストラクチャのTCOを削減し、市場投入までの時間を短縮しています。
皆さまの業務をより効果的かつ効率的に行えるよう、AWS Deep Learning AMI(DLAMI)とDeep Learning Container(DLC)を活用することで、ディープラーニングスタックの維持にかかる総所有コストを削減できます。これらの製品は、いわばブループリントのようなものです。DLAMIやDLCをそのままの形で完全に使用できなくても、それらを基に自社用にカスタマイズすることができます。多くのお客様がこれを行っており、ビジネスニーズに合わせてエンジニアリングやカスタマイズができるブループリントとして活用しています。最後のスライドには、これらの製品の詳細な説明が掲載されたウェブサイトへ誘導するQRコードがあります。
セキュリティは最優先事項です。私たちは、NIST CVDデータベースに対して日々スキャンを行い、重大な脆弱性を定期的にパッチ適用することで、これらの製品の安全性確保に細心の注意を払っています。要するに、Amazonで分散トレーニングジョブを実行する際の総所有コストを可能な限り低く抑えたいと考えています。これらの製品は2~3年前から提供されており、あらゆる業種や用途で数千のお客様にご利用いただいています。
AWS Batchの概要と機械学習ワークロードへの適用
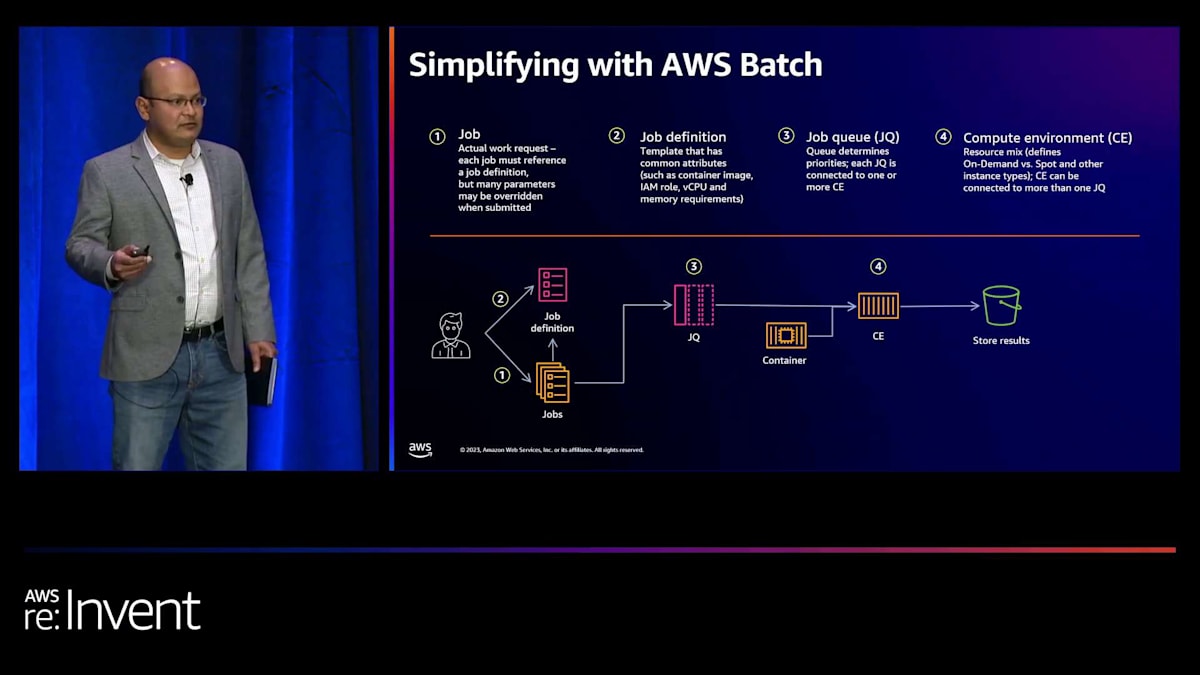
次にお話ししたい技術は、AWS Batchです。ご存じない方のために説明しますと、Batchは、従来からHPC(ハイパフォーマンスコンピューティング)コミュニティで非常に人気のあったバッチコンピューティングを実行するためのAWSのマネージドサービスです。Pinterestでは、ZlatanさんとKarthikさんがモデルトレーニングにBatchを活用するユニークな方法を実装しており、後ほどその話を伺います。
Batchをご存じない方のために簡単に説明しますと、作業の単位はジョブと呼ばれます。ユーザーは特定のパラメータでジョブを定義し、キューイングサービスにキューイングします。その後、実際の計算環境にスピンオフされ、ジョブが実行され、結果が返されます。これはBatchの概要説明で、詳細はオンラインでご確認いただけます。重要なポイントは、Batchが素晴らしい機能を提供しており、機械学習に関していくつかの非常に興味深いユースケースがあるということです。ここでの抽象化により、データサイエンティストや機械学習の実務者は、インフラストラクチャや低レベルの詳細をすべて理解する必要なく、作業を行うことができます。
BatchとDLAMIを組み合わせることで、機械学習ワークロードの実行に強力な組み合わせが生まれます。それでは、PinterestについてKarthikさんにバトンタッチし、同社の目標や課題、そしてAmazonでの機械学習と分散トレーニングの実施方法についてお話しいただきます。ありがとうございました。
Pinterestのコンテンツ構造とMLの重要性

こんばんは、ここにいられて光栄です。私はKarthikと申します。PinterestのML training infrastructureチームのEngineering Managerを務めています。本日は、PinterestでPyTorch、DLAMI、そしてその他のAWSサービスを使用して大規模モデルをトレーニングするためのインフラストラクチャをどのように構築したかについてお話しします。まず、ここでのトレーニングインフラストラクチャの仕組みについて簡単に概要を説明し、その後、AWSと協力して構築した基盤インフラストラクチャコンポーネントに関する2つのケーススタディを紹介します。これらは、MLエンジニアやMLプラットフォームエンジニアが大規模モデルをトレーニングする際に役立っています。

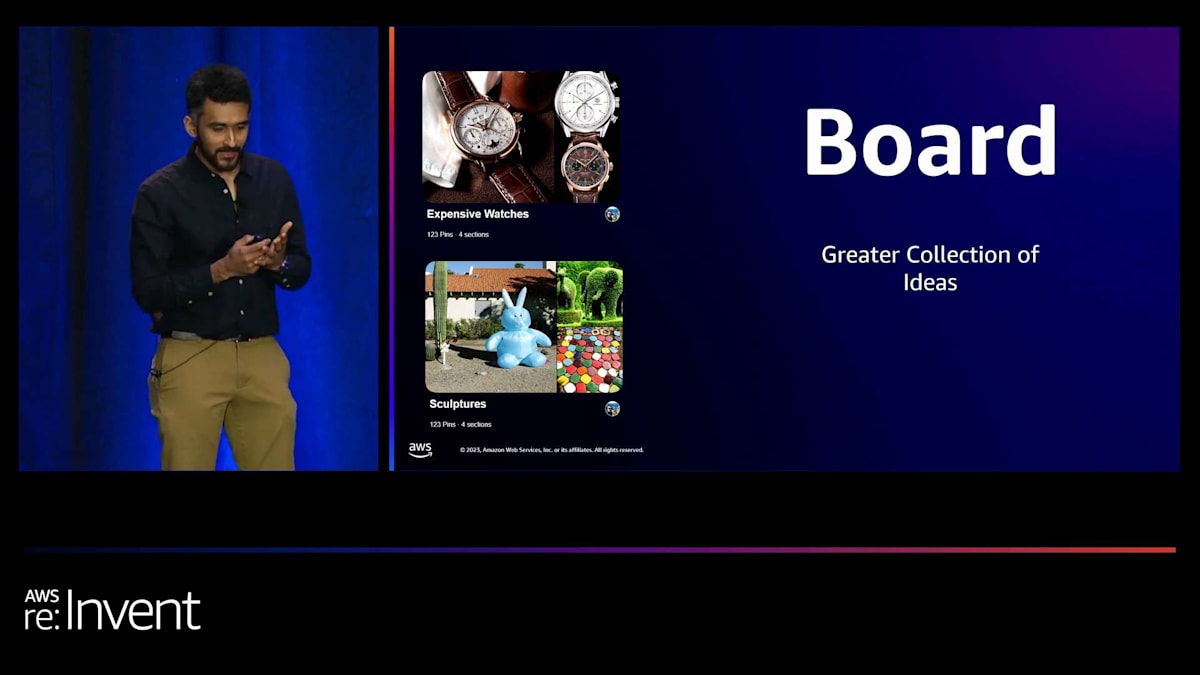
Pinterestの使命は、誰もが自分の愛する人生を創造するためのインスピレーションを得られるようにすることです。これは私たちのコンテンツを通じて実現され、すべてはピンから始まります。ピンは、画像、説明文、タイトルで構成されています。画像の代わりに動画を使用することもできます。ユーザーはピンをボードと呼ばれるコレクションに整理できます。例えば、私には手が届かない高級時計のためのボードがあります。

ウェブサイト全体で、人々はピンをボードにキュレーションしてきました。ボードの素晴らしい点は、ユーザーの非常に繊細な好みや理解を表現していることです。このピンを例に取ってみましょう。ユーザー1は自分のウェディングボードにこれを追加しているので、おそらく結婚式の衣装に時計をどう合わせるかを考えているのでしょう。ユーザー2も高級時計に興味があります。ユーザー3はこの時計の茶色のストラップに興味を持っています。ここで素晴らしいのは、各ユーザーがそのピンに対して異なる視点をもたらしていることです。
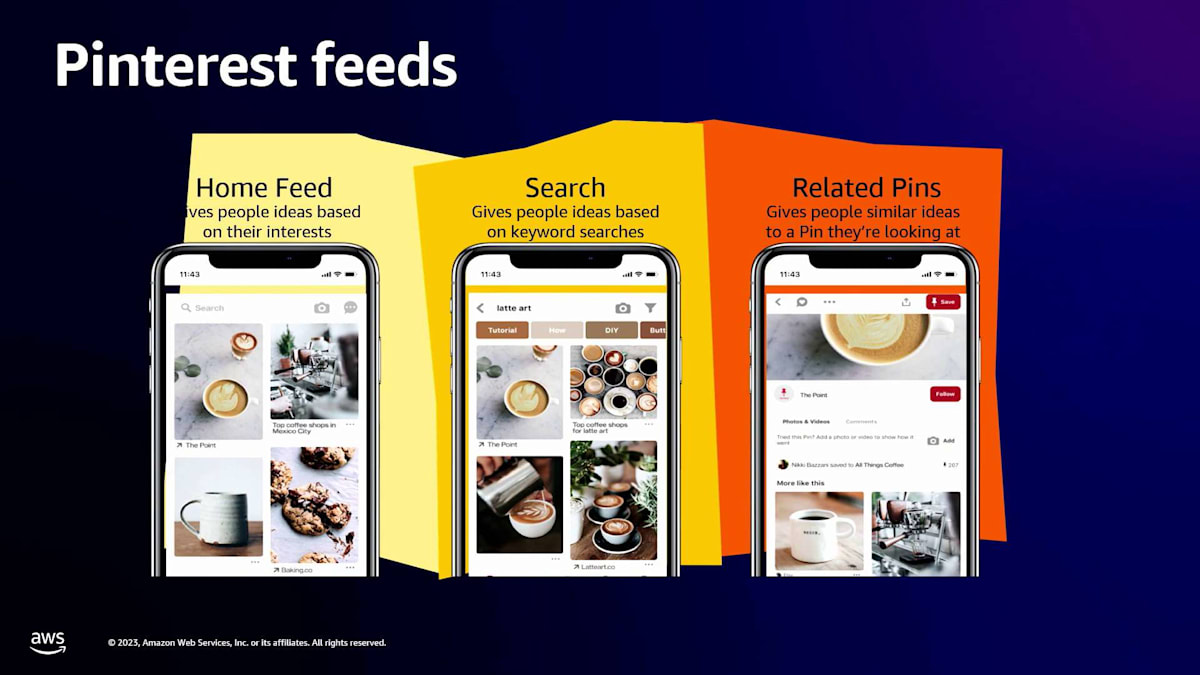
ユーザーはこのピンに他のピンを関連付けており、これが私たちのPinterestフィードの構築に役立っています。クエリレスな体験のためのHome Feedがあります。Pinterestに初めてアクセスすると、あなたの興味に基づいたピンのフィードが表示されます。次に、入力がテキストであるSearchがあり、関連するピンを表示します。そしてRelated Pinsでは、クエリ自体がピンであり、そのピンに類似したアイデアを見つけることができます。


素晴らしいのは、ユーザーが大規模にPinterestをキュレーションしアクセスしていることです。私たちが運営している規模のおかげで、人々がものをどのように整理し説明するかについて、大規模にキュレーションされたデータセットを持っています。想像できるように、MLは私たちの行うすべてのことの中心にあります。ここでスナップショットとして、Home Feed、Search、Related Pins、そして私たちが配信する広告はすべて推薦問題です。表示される各ピンについて、私たちはそのピン自体を理解できます。表示しても安全なピンかどうか?特定のピン内の画像を理解することもできます。これらはすべて機械学習によって支えられていますが、大まかに言えば、ML問題は2つに分類できます。
PinterestのMLモデルとトレーニングインフラストラクチャの概要

まず、レコメンデーションモデルについてお話しします。先ほど申し上げたように、これは私たちのフィードエコシステム全体を指します。レコメンデーションモデルは、私たちのGPUフットプリントの大部分を占めています。これらは埋め込み層を持つTransformerベースのディープニューラルネットワークです。レコメンデーションモデルの推論の特徴は、フィードの1 QPSが通常、何千ものアイテムのスコアリングに変換されることです。毎秒数億回の推論が行われています。もう一つのユースケースはコンテンツ理解です。ここでは、コーパス全体で学習されたモデルがあります。例えば、あるpinが安全かどうかをどのように判断するかといったものです。
コンテンツ理解の推論特性はユースケースによって異なりますが、すべてのpinが安全かどうかスコアリングされるバッチ推論ワークロードの場合もあります。時には、リアルタイムでこれを行う必要もあるかもしれません。モデルトレーニングに関しては、レコメンデーションのユースケースでは通常7〜30日分のトレーニングデータで学習され、後ほど説明する重要なデータ前処理も必要です。コンテンツ理解のユースケースでは、モデルサイズがより大きくなり、それらのモデルのトレーニングをどのように最適化できるかについても話し合います。

これらすべてを支えているのは、もちろんデータ、コンピューティング、そして優秀なMLエンジニアたちです。ここでMLトレーニングインフラストラクチャが重要になります。私たちは、MLエンジニアがこれらのデータに簡単にアクセスできるようにし、コンピューティングリソースへのアクセスを提供して、これらのモデルを本番環境に導入できるようにしています。MLエンジニアの作業速度を最適化し、効率的に迅速に動けるようにしています。興味深いのは、MLエンジニアの数が果たす役割です。5人のエンジニアで企業のMLをサポートするのと、200人のエンジニアでサポートするのとでは大きく異なります。例えば、MLエンジニアが毎日1時間を運用に費やしているとすると、200人のエンジニアではその時間が倍増し、そこで無駄にされる時間の量が見えてきます。

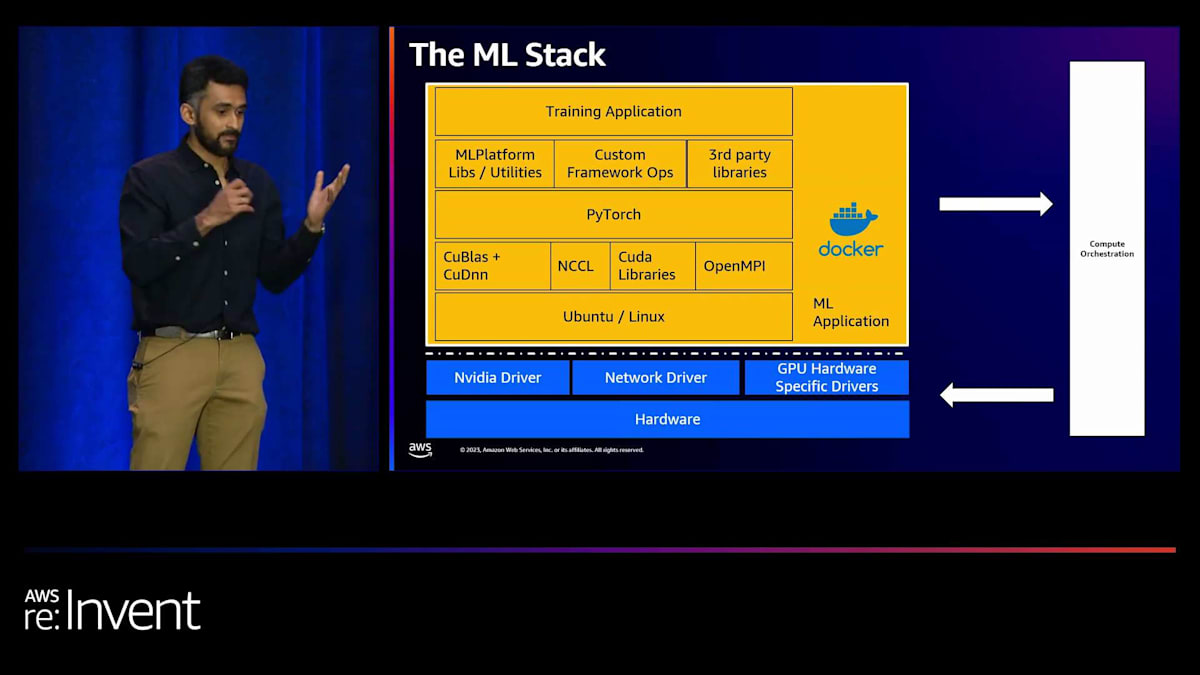
MLトレーニングインフラストラクチャの3つの主要な柱を特定しました。 それは、MLアプリケーション開発、コンピュート・オーケストレーション、そしてトレーニングハードウェアです。これらについて簡単に説明します。これらはそれぞれ、エンジニアがどれだけ速く動けるか、そしてどれだけ効率的にモデルを構築できるかに大きな影響を与えます。これら3つの柱の関係は、 私たちが「MLスタック」と呼ぶもので示すことができます。黄色で示されているのがトレーニングアプリケーション自体です。Pinterestでは、トレーニングアプリケーションをDockerコンテナとしてパッケージ化しています。
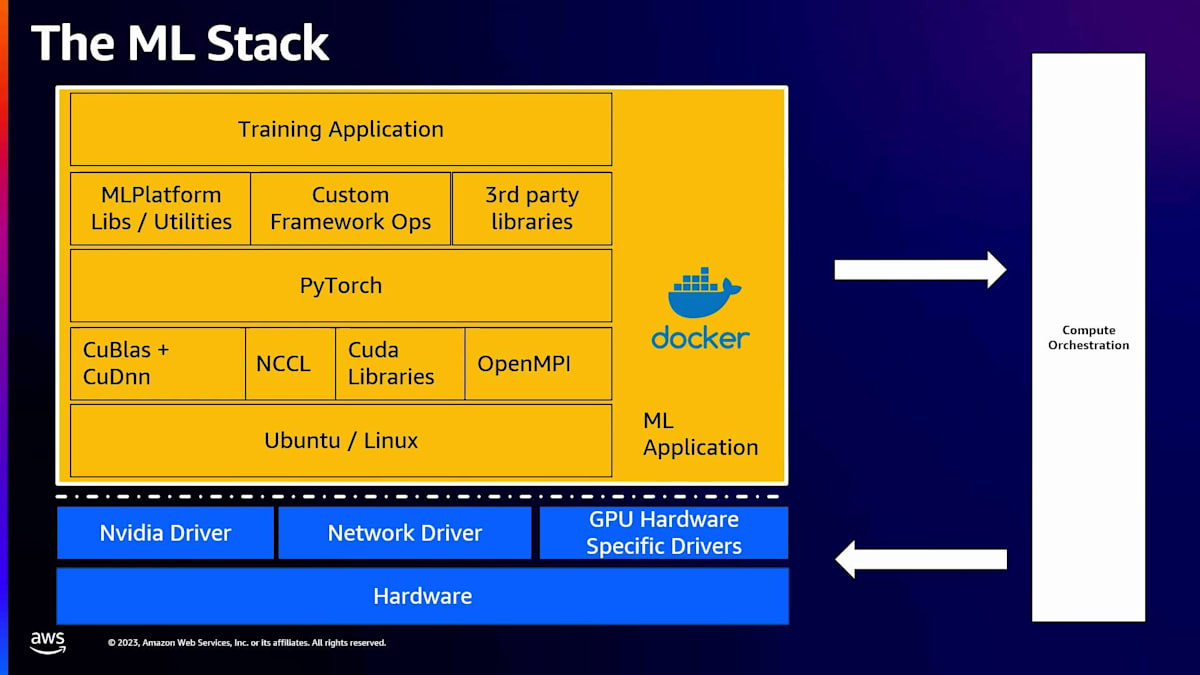
Dockerの本当に素晴らしい点は、完全な再現性を提供することです。3ヶ月前にトレーニングされたモデルがあれば、使用されたDockerイメージがわかり、そこにはUbuntuのバージョン、CUDAライブラリ、PyTorchのバージョンなど、すべてが組み込まれています。コンピュート・オーケストレーションの役割は、このDockerイメージを特定のハードウェアにターゲティングすることです。モデルによって、このモデルを実行したいGPUは大きく異なる可能性があり、それがコンピュート・オーケストレーションの役割です。効率性にも大きな役割を果たします。最後に、ハードウェア自体が実際のモデルトレーニングが実行される場所です。
レコメンデーションモデルのトレーニングにおける課題と解決策
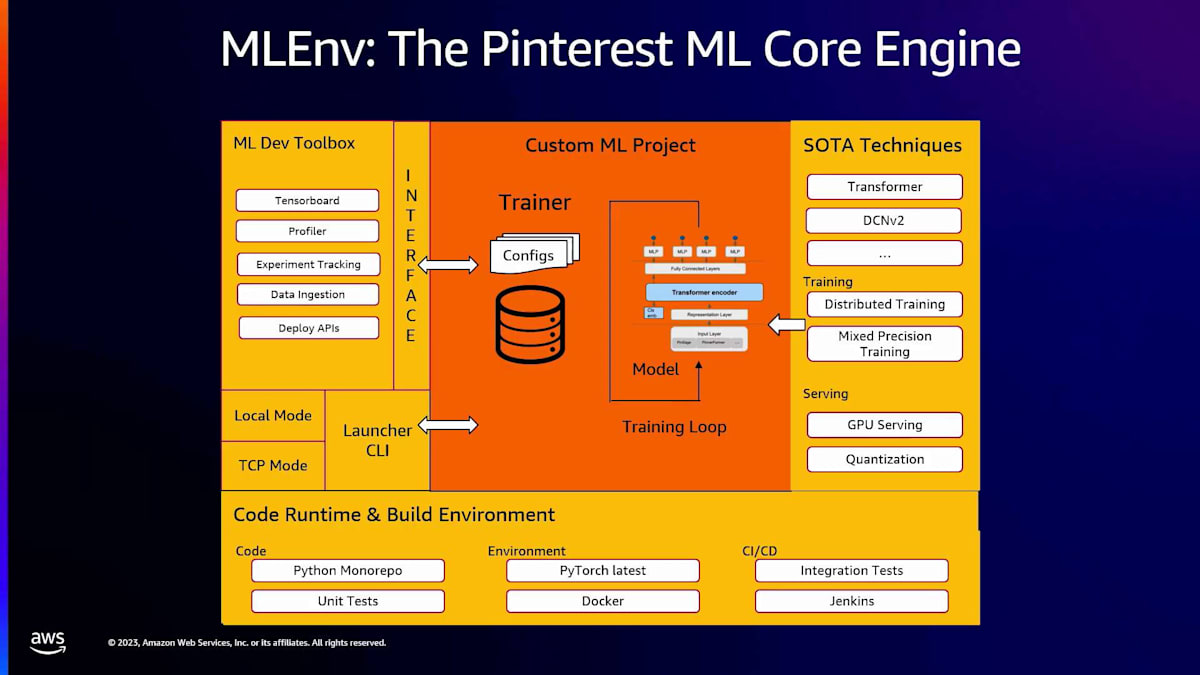
私たちが気づいたのは、AIのハードウェアが急速に進化する中で、最新のハードウェアを採用できることが重要になってきており、その分野で本当に素早く動きたいということです。Pinterestでの機械学習アプリケーション開発は、内部でMLEnvと呼んでいるSDKを通じて行っています。これはPyTorch LightningやHugging Face Accelerateによく似たものだと考えてください。機械学習エンジニアの責任は、単にPyTorchモジュールを書くことだけです。オプションでトレーニングループを書くこともできます。それ以外のすべてはこのSDKが処理します。
では、「それ以外のすべて」とは何でしょうか?これは、データエコシステムとの統合方法に関するもので、静的なデータをPyTorchが理解できるテンソルに変換できます。データ読み込みの効率性に関するメトリクスも提供しています。そして、トレーニング中は、MLflowのような実験追跡ツールとの自動統合も行われます。また、ローカル開発インスタンスでのトレーニングから、マシンクラスターへの移行も、簡単なフラグ設定で行えるようにしています。モデルのトレーニングが完了したら、サービングクラスターが取り込めるよう適切なフォーマットになっていることを確認し、正しいメタデータを持っていることを確認します。ここでは量子化を可能にする最適化も行っています。
機械学習エンジニアがこれらのモデルを開発する方法は、Pythonモノレポを使用することです。これの良い点は、最先端の技術を構築しようとする応用研究コミュニティがいることです。彼らが技術を利用可能にしてテストすると、誰もが使えるようになります。通常、最先端の技術を製品化する方法は、1つのユースケースで利用可能になったら、最適化を確実に行います。そして、うまく機能すれば、他のユースケースへの適用も比較的容易になります。
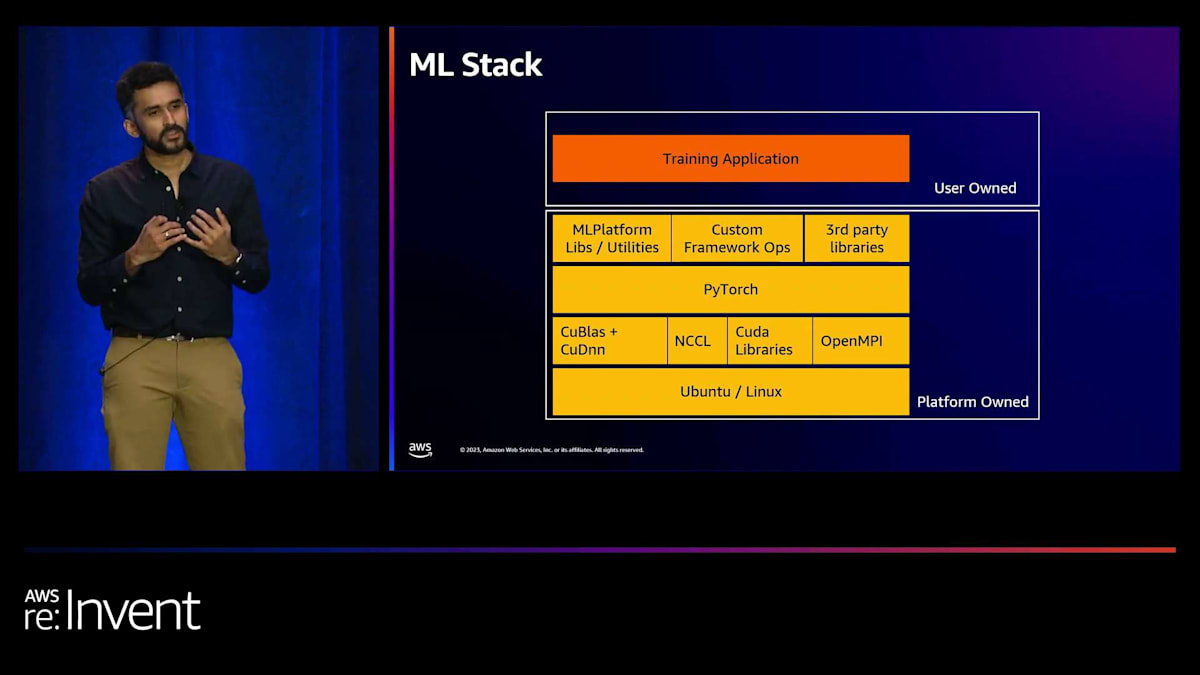
モノレポを持つことで、ML学習アプリケーションのCI/CDインフラストラクチャも構築できました。例えば、PyTorchをアップグレードする際、完全な統合テストスイートを実行し、MLトレーナーが壊れないことを確認できます。つまり、MLスタックにとっては、ユーザーが所有しているのはトレーニングアプリケーションだけで、それ以下のすべてはプラットフォームが所有しているということです。その結果として、プラットフォームはPyTorchのバージョン、Ubuntuのバージョン、CUDAのバージョンを完全に所有しています。そのため、私たちは迅速に動く必要があります。そうすることで、最先端のモデルをトレーニングしたい機械学習エンジニアが、適切なPyTorchバージョンを持っていることを確認できます。

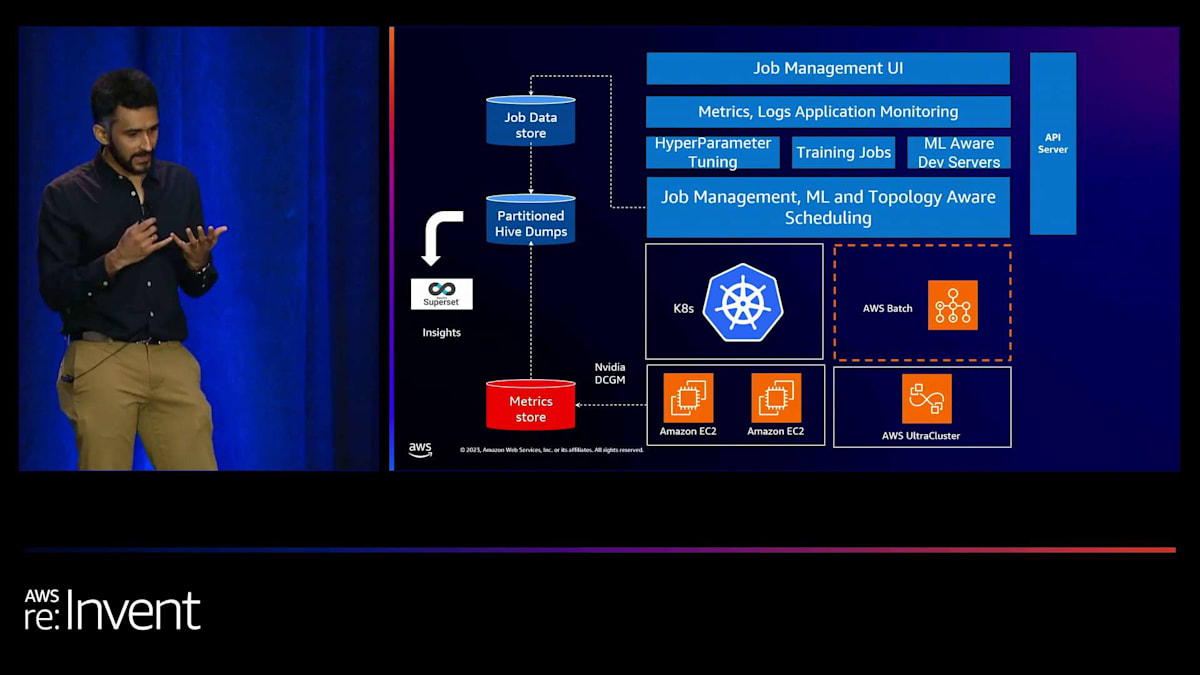
また、PyTorchの最新リリースを追跡する安定版と、ナイトリービルドも用意することを検討しています。そうすれば、PyTorchにコミットが入った場合でも、それを取り込むことができます。はい、これがML学習アプリケーションについてです。次はML計算オーケストレーションです。先ほど言ったように、トレーニングアプリケーションがDockerを使用して構築されたら、それを何らかのハードウェアにターゲットにしたいと考えています。社内では、Training Compute Platformと呼ばれるプラットフォームを持っています。これは社内のKubernetesチームの上に構築されています。また、別の計算バックエンドとしてAWS Batchをターゲットにすることもでき、これについては後ほど少し触れます。
Training Compute Platformは、ユーザーにジョブ管理UI、メトリクス、ログ統合、そしてハイパーパラメータチューニングを提供することができます。また、ML対応の開発サーバーへのアクセスも可能です。これは、ユーザーが迅速に反復作業を行えるように事前にパッケージ化された開発環境です。ここで、リソース管理とスケジューリングに関する重要な機能を一つ紹介したいと思います。私たちは、compute platformチームのパートナーと協力して、プロジェクトごとのクォータを実装し、各チームがアクセスできるGPUの量を設定しました。

ここには2つの概念があります。1つはGPUの保証リソースについてです。これは各チームに保証される最小限のGPU量であり、それに加えて、共有GPUプールである最大値まで拡張できます。今後は、プリエンプションとギャングスケジューリングの実現方法も検討しています。ギャングスケジューリングは、分散トレーニングワークロードを実行する際に非常に重要になるからです。統一されたオーケストレーションレイヤーを持つことのもう一つの興味深い結果は、Pinterestで起動されたすべてのジョブ、対応する設定、使用されたDockerイメージのデータセットを持っていることです。
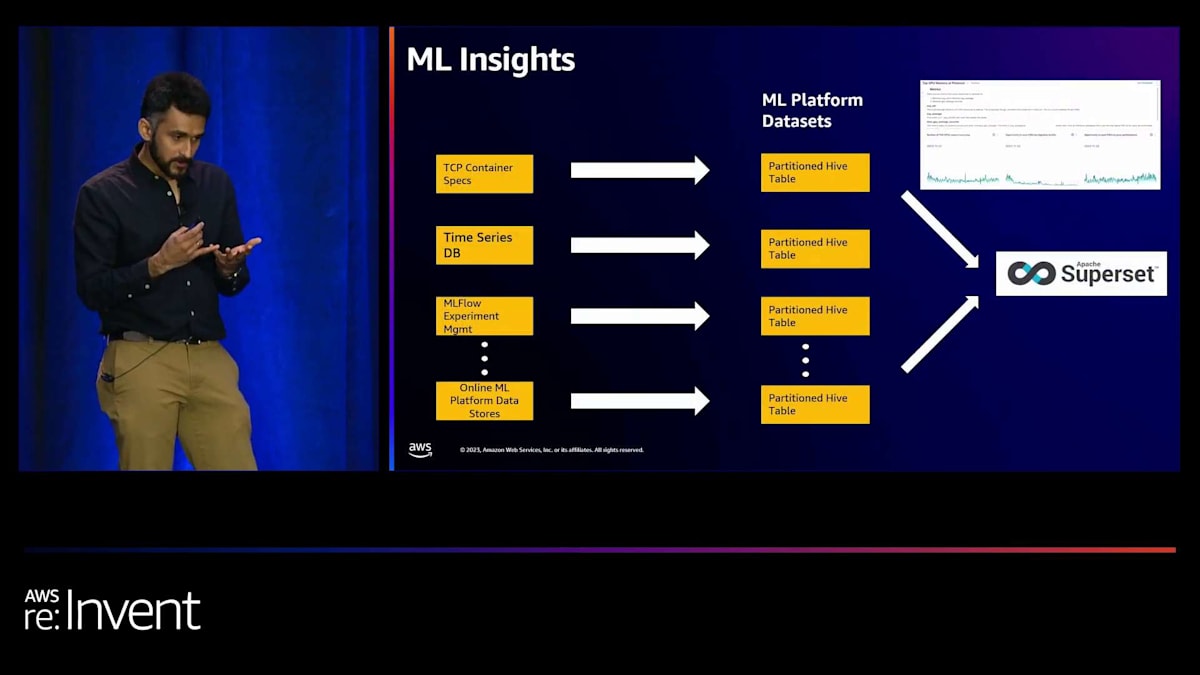
Rayを活用したデータ処理の最適化
これらすべてをダンプし、パーティション化されたHiveテーブルにしています。これには、Kubernetes仕様、すべてのジョブのメトリクスを持つ時系列データベース、MLflow実験が含まれます。これらすべてがHiveテーブルとして利用可能になったことで、オフライン分析を行い、どのユースケースが最も多くのGPUを使用しているか、どれだけ無駄にしているかなどについて、本当にインテリジェントな情報を提供できるようになりました。また、ジョブの失敗率や、どのユースケースを最適化すべきかについても推論できるようになり、支出に応じて最高のROIを得ることができます。
これは、データ駆動の意思決定を行う上で、キャパシティプランニングにも非常に価値のあるものとなっています。

最後に、トレーニングハードウェアについて説明しましょう。私たちはAWSで運用しており、最初からAWSを使用しています。2018年には、線形モデルを使用してCPUインスタンスでトレーニングを開始しました。分散トレーニングは依然として使用していましたが、モデルは十分に小さく、目標は単により多くのデータでトレーニングすることでした。モデルが大きくなるにつれて、GPUの採用を開始しました。2022年頃には完全にp4dsを使用していましたが、それはかなり高価になりました。すべてのユースケースが実際にp4dsを必要としているわけではないことに気づき、MLトレーニング用にg5インスタンスファミリーも含めるようGPUインスタンス戦略を多様化しました。利点はコストが下がったことと、g5インスタンスファミリーがサービングにも使用されることでした。トレーニングとサービングで同じ基盤となるインスタンスファミリーを共有できるようになったことで、両方に共通のインスタンスセットが確実に利用できるようになりました。

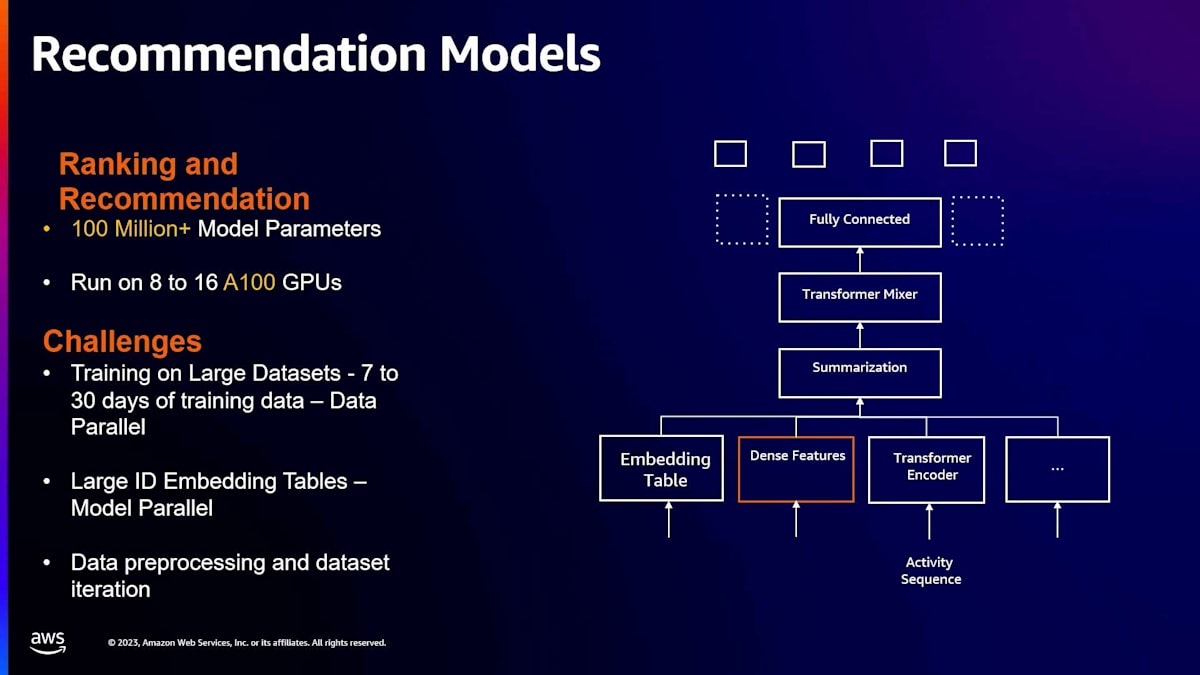
次に、2つのユースケースについて、分散トレーニングをどのようにスケールしたかを示すケーススタディについてお話ししたいと思います。 まず1つ目はレコメンデーションモデルです。私たちのレコメンデーションモデルは、現在の業界で一般的なパターンに従っています。つまり、密な特徴量とスパースな特徴量を組み合わせたTransformerモデルです。これらは、ユースケースに応じて8から16のGPUで学習されます。私たちが直面する課題は3つあります。1つ目は、これらのレコメンデーションモデルが通常、17日から30日分のデータという大規模なデータセットで学習することです。2つ目は、スパースな特徴量を扱う際に重要となるID埋め込みテーブルの問題です。これらの大規模な埋め込みテーブルは通常1つのGPUに収まらないため、シャーディングの方法を考える必要があります。3つ目は、MLエンジニアがパフォーマンス向上のためにデータセット自体を頻繁に改良することです。例えば、サンプリング戦略を変更したり、データセットの各行の重みを調整したりします。これには、トレーナーに投入する前のデータ前処理が必要となり、これも解決すべき課題の1つです。

それでは、私たちにとって効果的だった方法を1つずつ見ていきましょう。まず、大規模データセットの扱いについてです。PyTorchにはDistributedDataParallelというラッパーがあり、これは現在業界でもかなり標準的に使用されています。これは大量のデータを学習する上で非常に有用です。通常、モデルは複数のGPUにレプリケートされ、データはこれらのGPU間でシャーディングされます。逆伝播の際には、勾配のall-reduceステップがあり、これによってすべてのGPUデバイス間で勾配が同期されます。その後、最適化ステップに進み、全てが完了したら、再びデータが供給されます。これはかなりうまく機能し、DistributedDataParallelを使用して多くのモデルを本番環境に導入することができました。埋め込みテーブルが十分に小さければ、これでほぼ十分です。
コンテンツ理解モデルのトレーニングとUltraClusterの活用
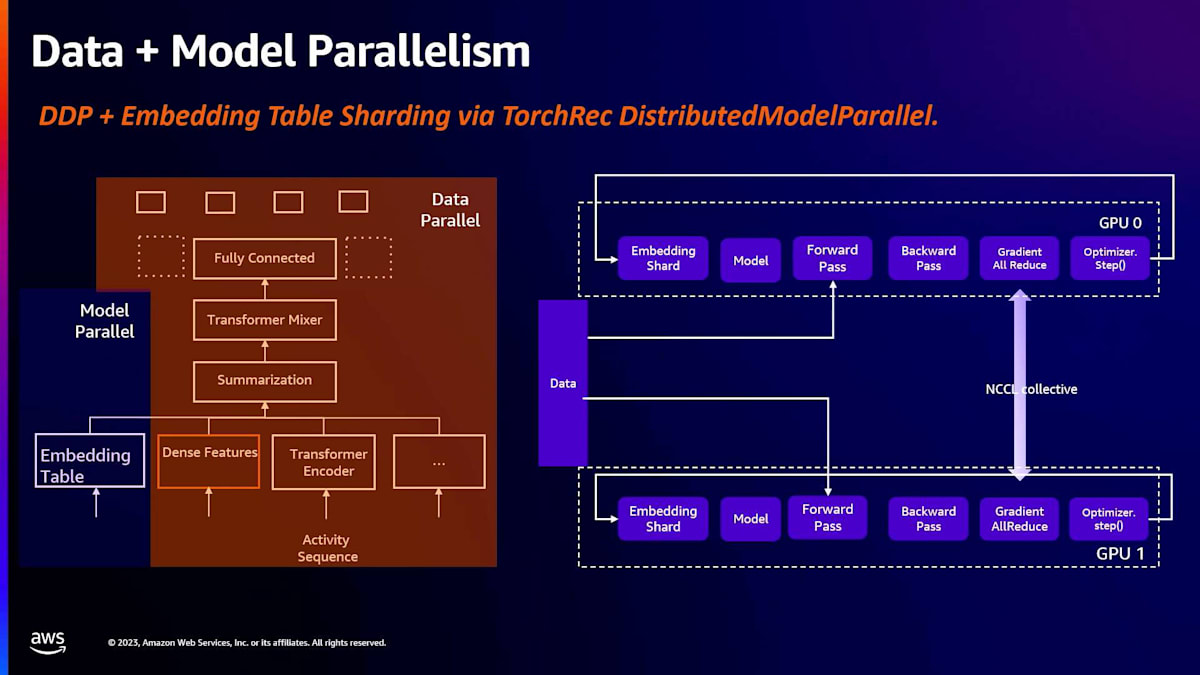
しかし、埋め込みテーブルが大きくなるとどうなるでしょうか?1つのGPUに収まらなくなる可能性があります。例えば、レコメンデーションシステムを構築する際、製品やユーザーなどのエンティティを表現したいと思います。2億のエンティティがあり、各々の埋め込み次元が64だとすると、約50ギガバイトのメモリが必要となり、これはどのGPUにとっても扱うのが難しい大きさです。一般的な方法は、埋め込みテーブルをデバイス間でシャーディングすることです。このために、PyTorchコミュニティにはTorchRecというライブラリがあり、これを使って埋め込みテーブルをシャーディングすることができます。私たちは、TorchRecを使って埋め込みテーブルをシャーディングし、さらにデータパラレルを併用することで、大規模なデータセットでの学習を可能にしています。
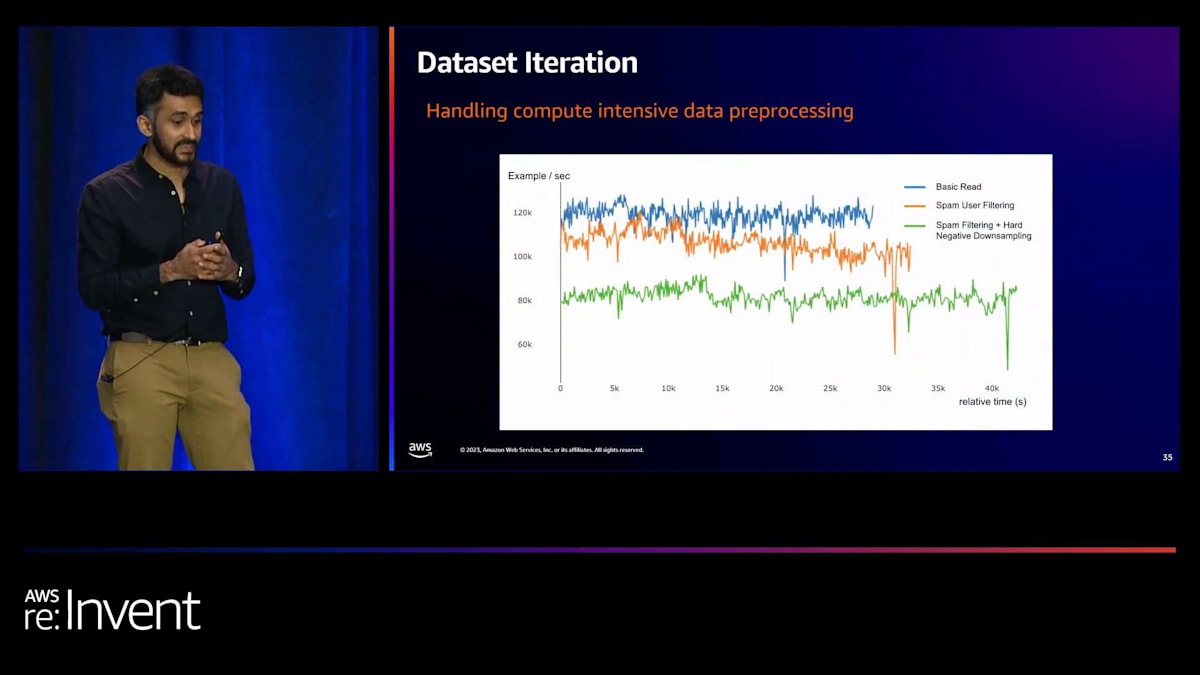
次はデータセットの反復処理についてです。先ほど述べたように、ユーザーはトレーナーにデータを投入する前のデータセットの処理方法を改良したいと考えています。ここに3つの例があります。一番上は基本的な読み込みで、S3にあるデータセットをそのまま読み込んでトレーナーに投入します。興味深いパターンとして、スパムフィルタリングのような処理を行いたい場合があります。スパムでないユーザーのデータだけを学習に使用したい場合、データを読み込む際にフィルター関数を書く必要があります。ご覧の通り、これらはCPU集約型の処理なので、学習のスループットが低下します。この影響は、さらにデータ前処理を追加すると一層顕著になります。
スパムフィルタリングに加えてハードネガティブのダウンサンプリングなど、追加のデータ前処理を行うと、スループットはさらに低下します。スループットが低下した理由を調べたところ、GPUインスタンス上でCPUがボトルネックになっていることがわかりました。GPUインスタンス上のCPUリソースが足りなかったのです。そこで、データ処理層とGPU計算層を分離する方法を検討しました。そこで注目したのがRayです。
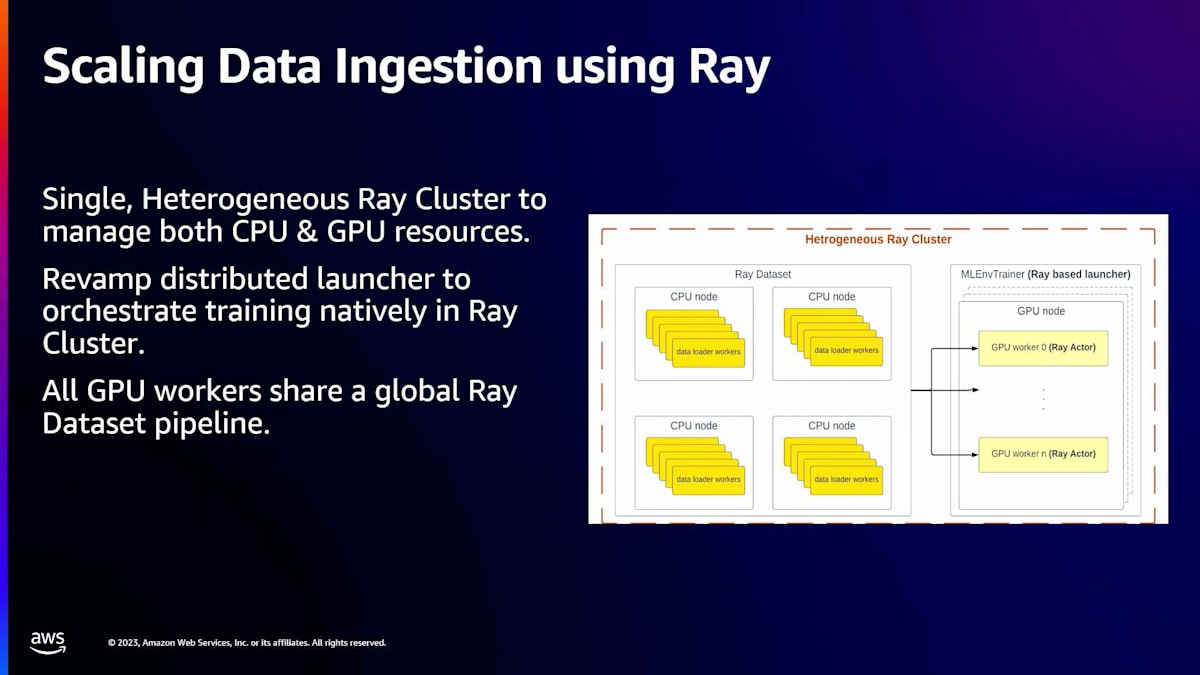
Rayは分散Pythonアプリケーションを構築するためのオープンソースフレームワークですが、機械学習にも非常に適しています。私たちは、CPUによる前処理とGPUのためのアクターを別々のインスタンスに持つ単一のRayクラスターをセットアップしました。これにより、N台のCPUマシンからなるデータ前処理フリートが構築され、すべてのマシンがデータ前処理ステップを実行し、GPUにデータを送り込んでいます。この利点は、GPUの利用率が高くなり、より高いスループットを実現できることです。
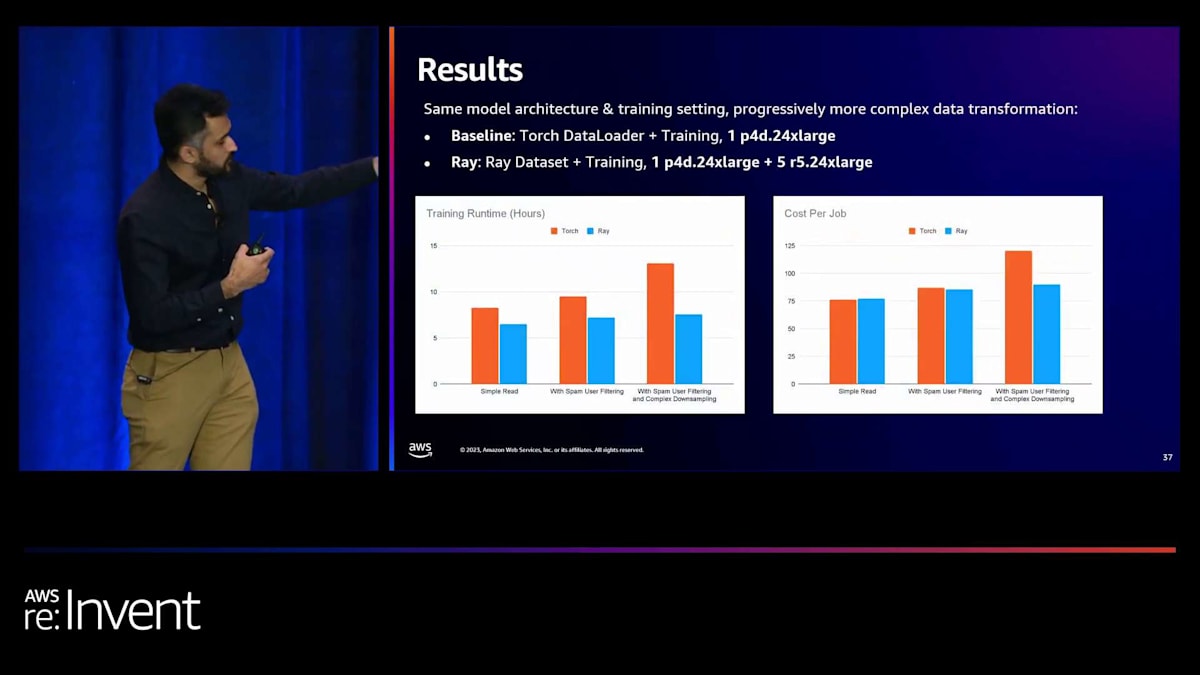
数字で見ると、ある特定のデータ前処理のユースケースでは、オレンジ色の単純な読み取りがTorch、青がRayを使用した場合です。これがベースラインです。しかし、より複雑なデータ前処理を追加すると、Torchだけを使用した場合、トレーニング時間が増加します。一方、Rayを解決策として使用すると、トレーニングの実行時間はそれほど増加しません。同様に、ジョブあたりのコストもRayを使用した場合、それほど増加しないことがわかります。これは、データセットの反復をスケールアップするための非常に効果的な方法となっています。
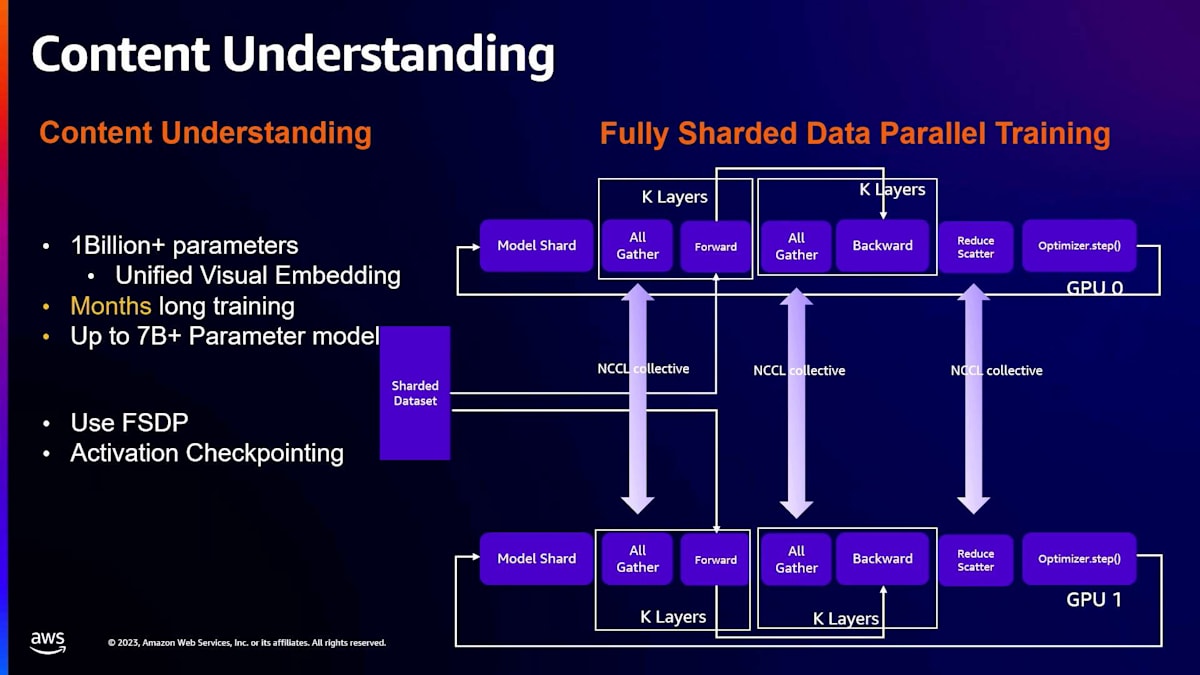
次に話したいモデルのクラスは、コンテンツ理解モデルです。ここでは、モデルのサイズが通常大きくなり始めます。一例として、unified visual embeddingがあります。このユースケースでは、Pinterestの画像に対して、embeddingを使って表現することを目的としています。これらのトレーニングには非常に長い時間がかかります。制限の一つは、これらのモデルが大きいため、単一のGPUに収まらないことです。そのため、distributed data parallel trainingのような手法が、モデルが単一のGPUに収まらないという理由で実行不可能になります。
PyTorchには、Fully Sharded Data Parallel (FSDP) trainingと呼ばれる拡張機能があり、これがこのユースケースに最適です。これは、distributed data parallel trainingと似ていますが、モデル全体を1つのGPUにロードする代わりに、複数のGPU間でモデルをシャーディングできる点が異なります。トレーニングフェーズでは、単一のレプリカが保持していないパラメータを必要とする場合、ネットワークを介してパラメータをフェッチし、フォワードパスやバックワードパスで必要な処理を行います。マルチノードトレーニングを行う場合、これらのパラメータ交換はすべてネットワーク経由で行われ、NVIDIA NCCLコレクティブを使用します。
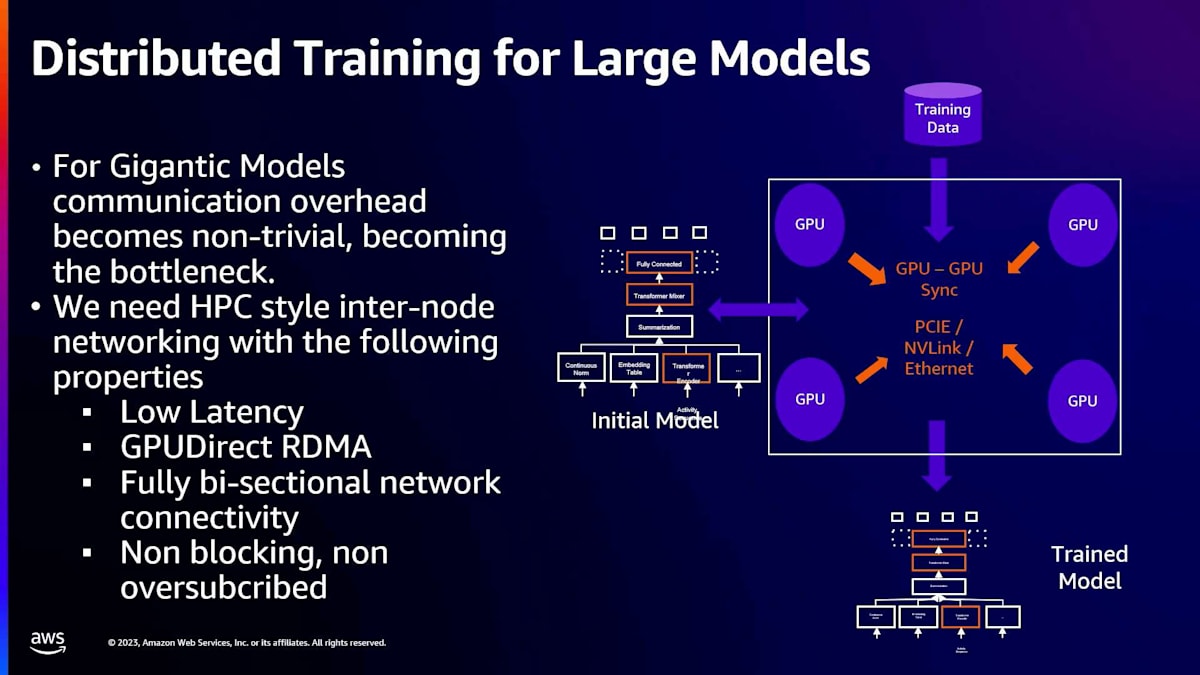
しかし、これらすべてが意味するのは、マルチノードトレーニングでFSDPを行いたい場合、通常、ネットワークがボトルネックになるということです。私たちは、HPCスタイルの内部ノードネットワーキングが以下の特性を持つ必要があることに気づきました:低レイテンシー、GPUDirect RDMA(NCCLコレクティブがOSを経由しないようにするため)、完全な双方向ネットワーク接続性(ノンブロッキングかつ非オーバーサブスクライブ)。これらの要件に対して、UltraClusterが私たちにとって完璧な選択肢となりました。
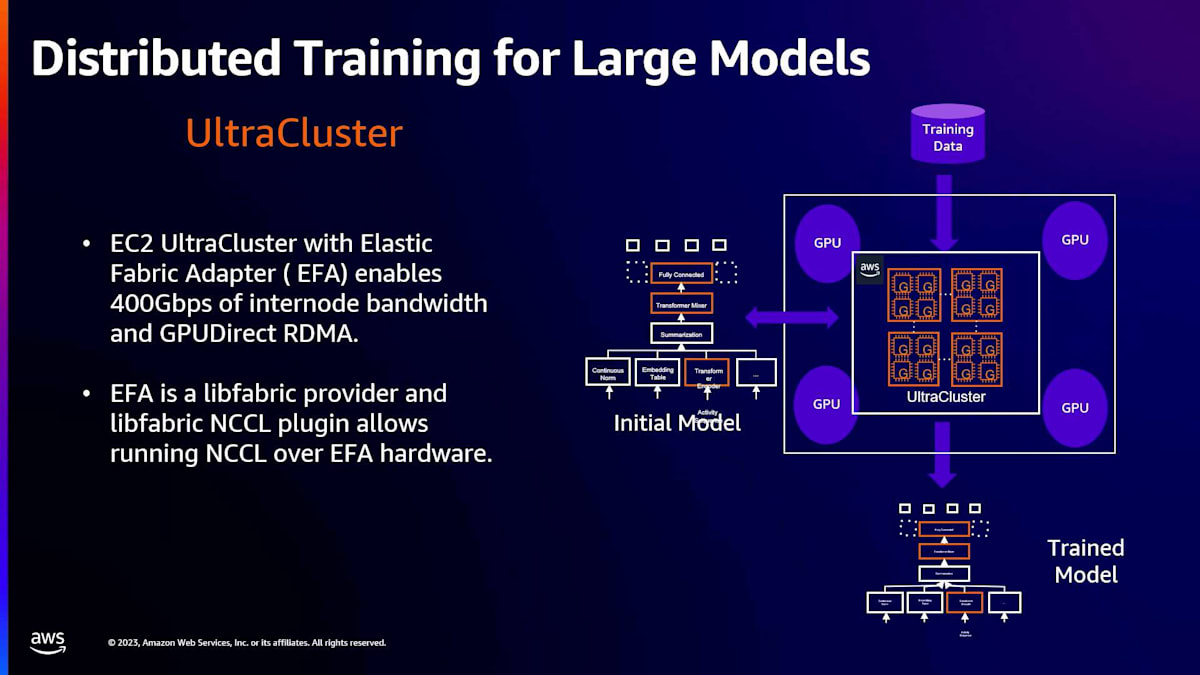

UltraClusterは、同じラック内にGPUマシンを集約したデプロイメントです。また、EFAと呼ばれるネットワークデバイスも備えており、ノード間で400 Gbpsの帯域幅とGPUDirect RDMAを実現します。私たちがデプロイした方法では、PyTorchを含むように特定の方法でNCCLバージョンをビルドするだけで済みます。ユーザーの観点からは、実際には何も変更する必要がありません。トレーニングアプリケーションは同じままで、私たちが基盤となるNCCLバージョンを管理しているため、NCCLをEFAとlibfabricでビルドするだけで、コンピュートオーケストレーターがMLアプリケーションをUltraClusterにターゲティングできるようになります。
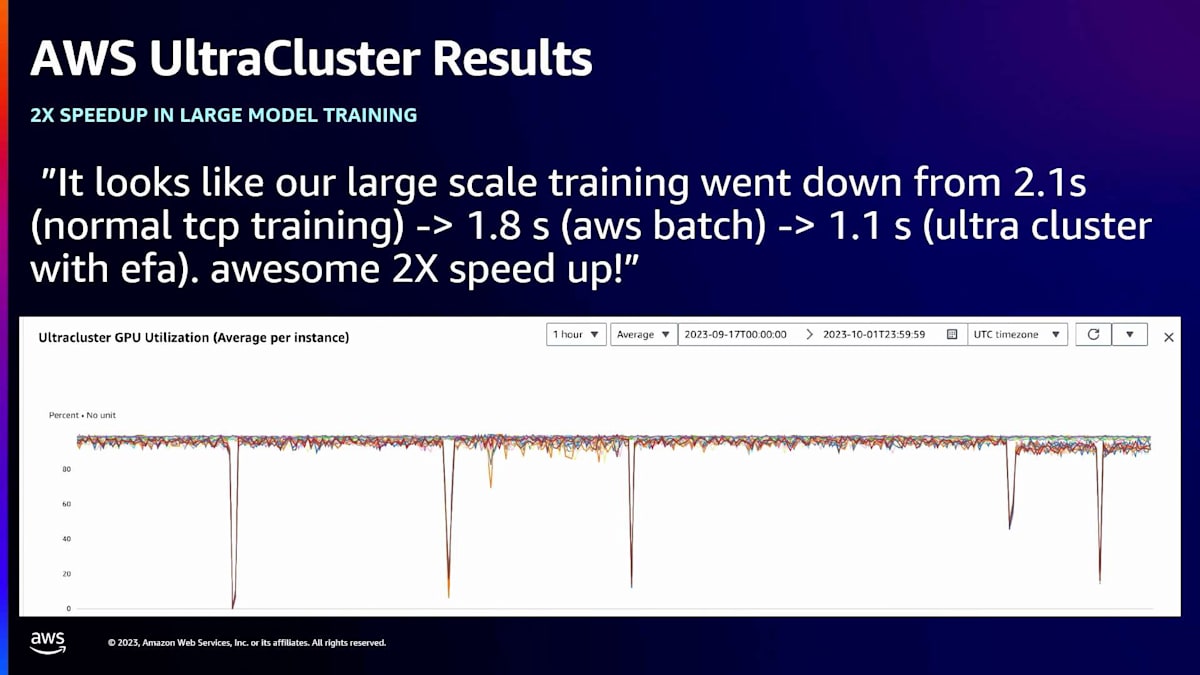
このため、ユーザーの関与やユーザー側のコード変更なしに、この変更を行うことができます。結果はかなり良好です。大規模モデルトレーニングジョブの一部では、2倍のスピードアップを達成しました。ここに示されているのはGPU使用率で、GPUをかなり効率的に飽和させることができています。これは別のモデルですが、UltraClusterを使用することで2.5倍のスピードアップを達成しました。
MLスタックの更新とPyTorchアップグレードの重要性

次に紹介したいケーススタディは、MLスタックの更新です。これは非常に重要です。ご存知の通り、ML分野では毎日新しい開発が行われており、新しいモデルが登場し、モデルはますます大規模化しています。

多くのイノベーションは、モデルを効率的にトレーニングし、提供する方法に関するものです。私たちや業界が重視する最適化の多くは、通常PyTorchに組み込まれます。例えば、高速トランスフォーマーのためのスケールドドット積やflash attentionなどは、すべてPyTorchに実装として組み込まれます。PyTorchのバージョンを確実かつ迅速にアップグレードできることは、モデルを効率的にトレーニングし、提供するために非常に重要です。

ここに、PyTorchをアップグレードすることで得られた成果のリストがあります。現在、私たちはPyTorch 2.0を使用しており、これによってFully Sharded Data Parallel (FSDP)を使用してより大規模なモデルを構築することができています。PyTorch自体をアップグレードするのに必要な作業を見てみると、ボトムアップの依存関係があります。PyTorchは特定のバージョンのCUDAに依存し、特定のバージョンのCUDAは一部のNVIDIAドライバーでサポートされています。そのため、まずドライバーを更新し、次にCUDAライブラリに対してPyTorchをビルドし、最後にトレーニングアプリケーションで利用できるようにする必要があります。
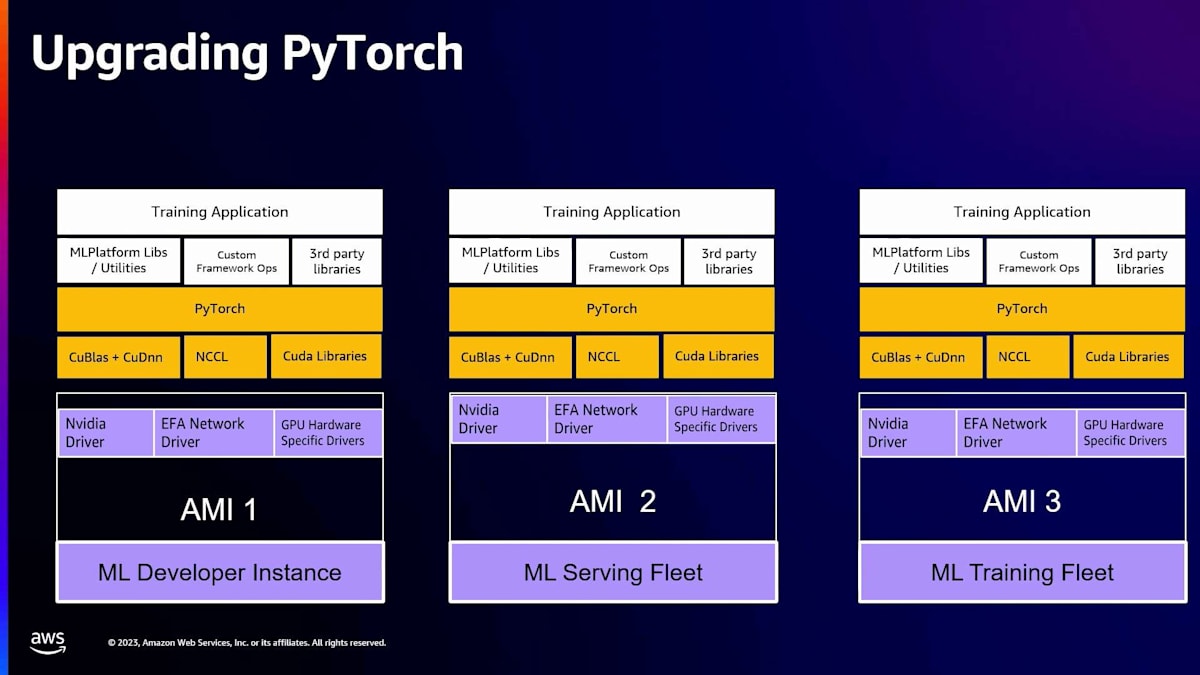
以前の方法では、3つの別々のサービングフリートを使用していました。ML開発者インスタンス、MLサービングフリート、そしてMLトレーニングフリートがあり、それぞれが異なるAMIを使用していました。これは、MLトレーニングインフラを担当する私たちにとって、まずNVIDIAドライバーをアップグレードするために各チームと個別に作業する必要があることを意味していました。これには、このタスクを他のチームのロードマップに組み込み、確実に実行してもらうことが含まれ、AMIの構築方法に細かな違いがある可能性もありました。そのため、このプロセスは煩雑になり、また個別にテストする必要もありました。


私たちは、すべてのGPUインスタンスで動作する単一の統合AMIを持ちたいと考えました。そこで、AWS DLAMIチームと協力して、共有ベースAMIを作成しました。この共有ベースAMIは、すべてのML開発者インスタンス、MLサービングフリート、MLトレーニングフリートに使用されています。これにより、私たちが必要とするNVIDIAドライバーが提供されます。そして、このベースAMIを継承して、トレーニング、サービング、開発者インスタンスなど、私たちが必要とする異なるインスタンス固有のAMIが形成されます。これにより、総所有コストを削減し、PyTorchのバージョンを3倍速くロールアウトできるようになりました。

私たちにとっての教訓は、MLスタックを標準化することで、MLスタックのアップグレードを迅速に行えるということです。これは、共有モデルを構築したい場合、全員が迅速に移行できるようにするために重要です。標準化により、一定数のMLエンジニアがいる場合、彼らがオペレーションに時間を費やす必要がなくなります。そのため、PyTorchの単一バージョンを使用したり、全員がPyTorchを使用したりすることが本当に役立ちます。レコメンデーションモデルの場合、DistributedDataParallel、DistributedModelParallel、そしてRayを介したリモートデータローディングの組み合わせが有効です。10億パラメータ以上のモデルの場合、FSDPの使用が有効です。

私たちにとって、UltraClusterの使用はゲームチェンジャーとなり、2倍から2.5倍のスピードアップが見られました。DLAMIやDLCのような十分にテストされた製品を使用することで、総所有コストが削減され、もちろんMLスタックのアップグレードも容易になります。いくつかの成果として、Large Model TrainingsとUltraClusterの使用で2倍のスピードアップ、ハードウェアアップグレードの3倍速いロールアウト、そしてDLAMIの採用により総所有コストも削減されました。これが私のセクションの主な内容です。次に、Zlatanにソリューションアーキテクチャについて話してもらいます。
AWS BatchとUltraClusterを活用したPinterestのMLインフラストラクチャ

皆さん、こんにちは。私はZlatanです。PinterestでKarthikの非常に才能あるチームと一緒に働いており、彼らが話していたこれらの素晴らしいものを構築するのを手伝っています。私たちは、サービスチームと密接に協力して機能などを構築しています。これは皆さんにとって非常に重要であり、私たちがいかに顧客志向であるかを示しています。なぜなら、皆さんが私たちに伝えること、そしてサービスをどのように構築してほしいかを受け取り、それに応じて構築しているからです。

AWS Batchは主にMLタイプのプラットフォームとして使用されていたわけではありませんでした。単にジョブを作成し、それらを積み上げ、ジョブ間の依存関係を作成するための非常にシンプルな方法として見られていました。
さらに、比較的シンプルな定義を使用してマルチノード処理ジョブをセットアップすることができます。ジョブ内で直接的な順次依存関係を持たせ、ハードワークを行うことができます。これには、コンテナイメージ、IAMロール、マウントポイント、そしてジョブの実行方法を定義するパラメータが含まれます。
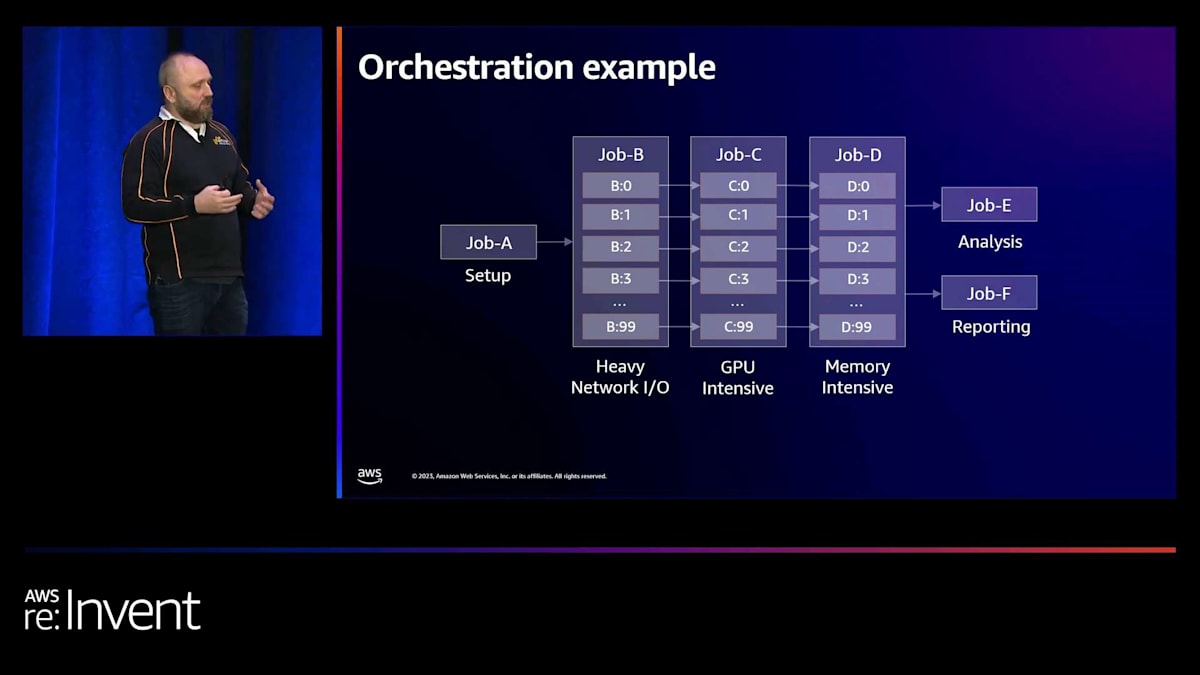
これをオーケストレーションに拡張する際に、特にPinterestにとって重要なのは、これらのジョブがどのように扱われるかです。まず、ジョブの提出をクラスター内で実行される複数の異なるプロセスとして扱わないことです。ジョブの概念を持ち、このジョブが複数の異なるノードにまたがって実行されていることを理解する必要があります。これらのノードは、それ自体が異なるタイプのハードウェアである可能性があります。ネットワークI/Oが高い、GPU集約型、メモリ集約型などがあり得ます。リソースの非対称な使用を防ぎ、これらのリソースを適切に飽和利用するように負荷を本当に分散させます。このようにして、非常にコスト効率が良く、同時に持続可能な方法で実行することができます。

これはまた、すべてのインフラストラクチャの問題を軽減し、特に私たちのコンピュート環境をどのように扱うかに大きく依存します。Min vCPUの更新など、いくつかの異なる更新がありました。実行中のインスタンスがまず第一にUltraClusterで実行されていることを確認します。UltraClusterとは、同じスパイン上で実行される高密度コンピュートクラスター環境を意味します。そのため、これらのインスタンスはこの場合Pinterestが使用するために専用となります。それらのどれも実際に失敗しないようにし、もし失敗した場合でも、そのリスクと問題を軽減できるようにしたいと考えています。
マルチノード並列ジョブが実行される際、GPUリソースを含むすべてのリソースが考慮されるようにし、それらが不足しないようにします。ジョブに関して適切な階層化を行っています。Pinterestからの要求の1つは、異なる階層のジョブを持つことでした。Karthikが言及したpreemptiveとreserveの階層のようなものを聞いたかもしれません。異なるMLチームによって使用されるリソースの階層を予約したいと考えていますが、同時に、このリソースプールに入り込むことができるpreemptiveキューも持ちたいと考えています。ただし、より重要なジョブが来た場合、それらのリソースを取り戻し、適切な優先順位を持つより重要なジョブを再優先化したいと考えています。

これは、AWS Batchにフェアシェアスケジューリング機能が導入された時期です。この機能と、Min vCPU機能についてもぜひチェックしてみてください。現在では、実行可能なすべてのジョブを統合して表示し、使用したいインスタンスタイプを選択し、それらをどのように使用するか、そして複数の異なるコンピュート環境でどのように実行するかを決定できるようになりました。クラスターの実際の動作は、インスタンス上で実行されているエージェントとそれらがコントロールプレーンに対してどのように信号を送るかによって定義されます。そのため、実際には異なるタイプのハードウェアアーキテクチャをサポートすることができるのです。
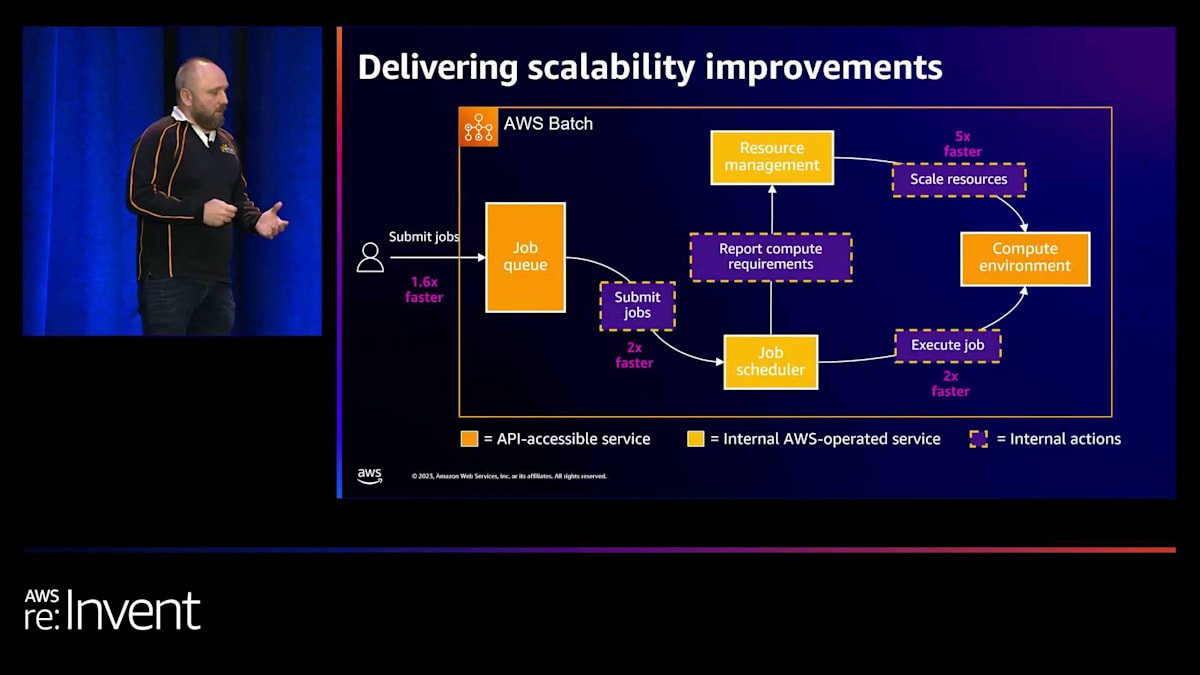
Pinterestとの協力を通じて、ジョブの投入を1.6倍速くすることができました。裏側では、実際のジョブスケジューラーへの投入が2倍速くなりました。リソースのスケールアップは5倍速くなり、信頼性も大幅に向上しました。また、ジョブの実行も2倍速くなりました。この進歩は、ソリューションの構築とAWS Batchサービスチームとの協力によって達成されました。ソリューションが構築される過程で、私たちは実際の実行方法を最適化していきました。

重要な要素の一つがODCR(オンデマンドキャパシティリザベーション)です。これにより、キャパシティを作成して予約し、Savings PlanやReserved Instanceだけでなく管理することができます。ODCRを使用すると、アベイラビリティーゾーン、インスタンスタイプ、テナンシー、OS、その他の要因に基づいて、アドホックにキャパシティを作成し予約することができます。Pinterestのソリューションにとって重要だったのは、カスタムODCRを作成し、同じスパイン内にインスタンスを予約することで、すべてのp4dインスタンス間で最適なレイテンシーを提供することでした。これにより、それらのインスタンスがシャットダウンされることなく、何度も再利用でき、必要に応じて同じスパイン上でキャパシティを維持できます。
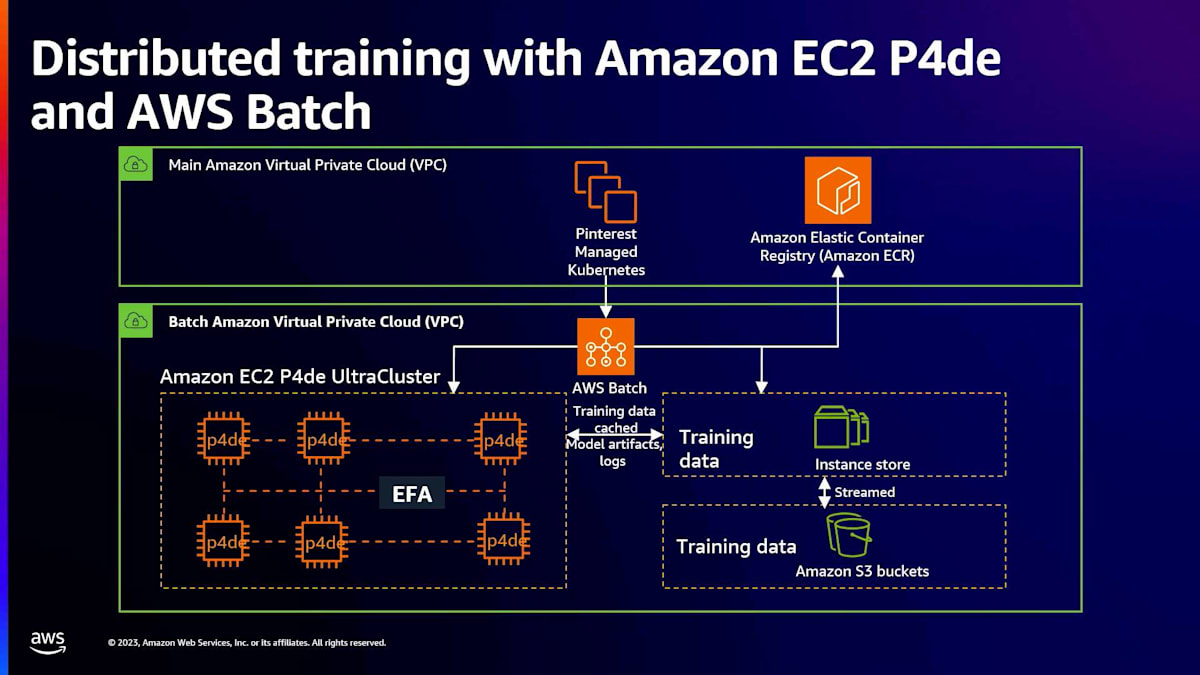
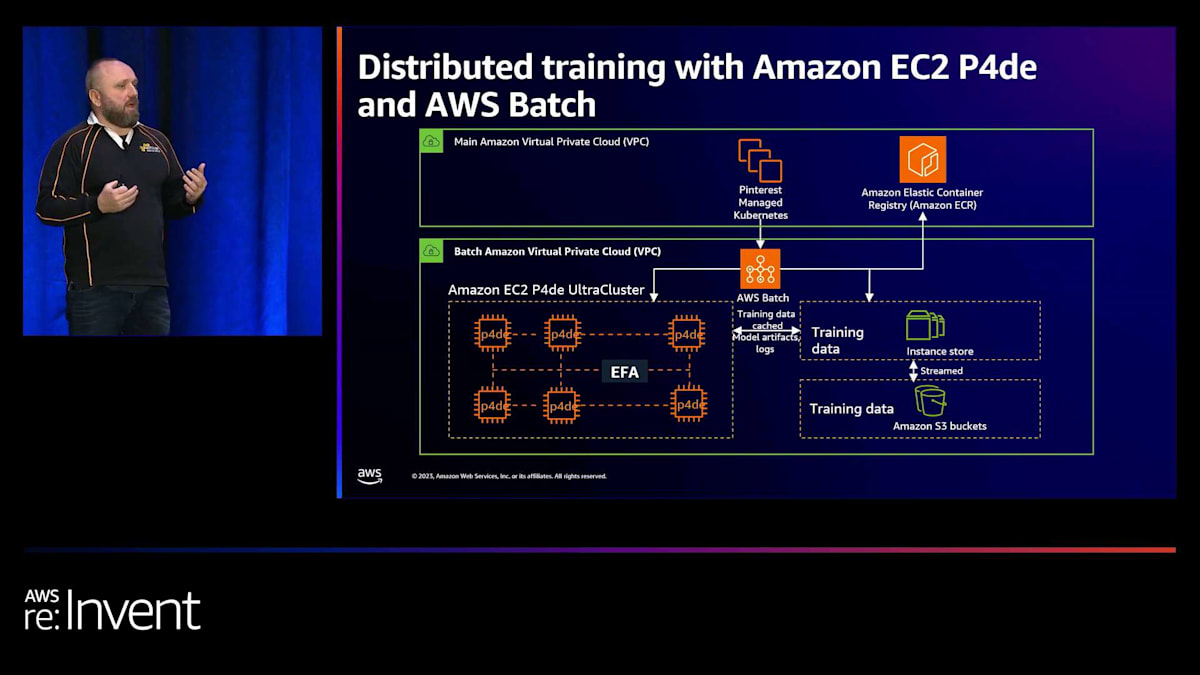
全体的なアーキテクチャを見ると、PinterestのマネージドKubernetesまたはPin computeチームがオーケストレーションを担当していることがわかります。これらは直接AWS Batchにジョブを投入し、データサイエンティストやML実践者から多くの複雑さを抽象化し、簡素化します。これにより、彼らは実行するジョブに集中でき、パラメータや属性を通じてUltraCluster上での実行に必要なアフィニティと特定のキューイングの両方を定義できます。

UltraCluster内では、Elastic Fabric Adapter(EFA)を使用しており、これはNVIDIA Collective Communication Librariesを直接利用してGPUを非常に迅速にスケールアップします。また、GPUDirect RDMAを使用して、異なるp4インスタンス(A100インスタンス)上のGPU間で超低レイテンシーを実現しています。Pinterestのアプローチのユニークな点の一つは、彼らが行うすべてのことにオブジェクトストレージを大胆に使用する戦略です。トレーニングデータはAmazon S3に保存され、インスタンスストア、特にI4iインスタンスを使用してインスタンスにストリーミングされます。キャッシングとストリーミングを行いながら、効果的に使用することができます。
私たちはS3チームと協力しており、これを大幅に改善する新機能についていくつか発表があります。水曜日の午後に予定されているので、その内容を先取りすることは控えますが、このアプローチは非常にユニークです。通常、お客様はAmazon FSxやその他のファイルシステムを使用しますが、私たちはここでそれとは異なる方法を採用しています。
Pinterestの大規模モデルとグラフニューラルネットワークの実装
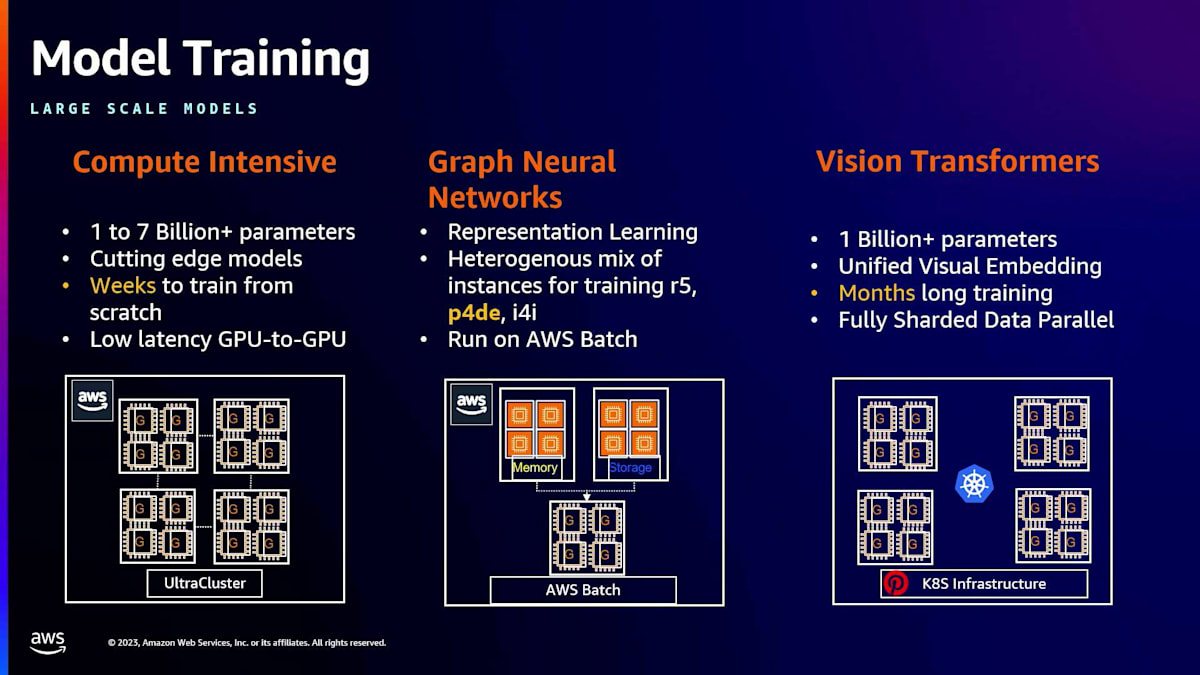
Karthikは、使用されている様々な種類の大規模モデルについて説明しています。これらは計算集約型で、1億から70億のパラメータを持ち、最先端のモデルを使用しています。これらのモデルは、ゼロから学習させるのに数週間かかり、GPU間の低遅延通信を最大限に活用します。パフォーマンスの要求も非常に高いです。Karthikが私に「400 Gbpsを可能にするこのEFAがありますが、1,600 Gbps、つまり1.6 Tbpsが必要なんです」と言ってきたとき、私は「いいでしょう!P5とA100も用意しましょう」と答えました。彼の分野ですからね。実際、現在では3.2 TBpsが利用可能になっています。
おそらく来年、P5の実装について皆さんとお話しするときは、非常にエキサイティングな内容になるでしょう。これが非常に重要な理由であり、スループットと遅延が非常に重要な理由です。この観点から見ると、低遅延は重要ですが、スループットはさらに重要です。
次にグラフニューラルネットワークがあります。正直なところ、私の個人的な意見では、Pinterestがこの分野をリードしており、これらのモデルの使用方法について業界を形作っています。彼らは長年にわたってこれを完成させてきました。彼らのブログへのリンクを含む多くの出版物があり、皆さんにぜひ読んでいただきたいと思います。これらは実際に、他の多くの企業、顧客、そして私たち自身がグラフニューラルネットワークをどのように使用するかを定義しています。これも現在はAWS Batchで実行されています。
そして、同じく10億のパラメータを持つVisual Transformerがあります。グラフニューラルネットワークは異種のインスタンスミックスで実行されます。つまり、P4deインスタンスだけでなく、複数の異なるインスタンスタイプに本当に分散されています。Unified Visual Embeddingsのようなvisual transformerも同様です。Pinterestが書いた多くの論文は、この点でかなり素晴らしいものです。これはKubernetesインフラストラクチャで実行され、Karthikが話していた方法で完全にシャーディングされたデータ並列処理を行っています。彼らのコアモデルは、長期間の学習に数ヶ月かかりますが、これは信頼性が高く一貫した方法を提供するために重要です。

残り10分となりましたので、主なポイントを振り返りましょう。私たちは特定の主要機能を構築し、Pinterestとの協業は複数のチームのロードマップを大きく変えました。その一つがArindamが話していたAsimovチームです。他にもBatch、UltraCluster、EC2チーム、そしてfair-share scheduling、Min vCPU、dynamic compute environment updates、7日間のジョブ保持、アイドル状態や十分に活用されていないインスタンスを減らすためのスケーリング改善などの機能があります。
まだリリースしていないものとしては、モニタリングの観点から問題を一元的に把握するための機能があります。「ジョブが失敗した場合、なぜ失敗したのか、最下層のハードウェアレベルまで全て見たい」というものです。そして、さらに多くのサポートを構築し続けています。もう一つは、BatchがEKSで動作するようにすることです。これはPinterestがプラットフォームとしてEKSを採用していることと密接に関連しているため、非常に重要です。
繰り返しになりますが、レイテンシーとスループットのバランスは極めて重要です。彼らはそのことについて話しました。オーケストレーション、スケジューラー、そして私たちが話したすべてのことが非常に重要です。AWS Deep Learning AMIs (DLAMIs)とDeep Learning Containers (DLCs)は本当に大きな違いを生み出しました。数字を見ていただいたとおりです。そして、再度強調しますが、Amazon S3からのストリーミングデータと、異なるフォーマットでのインスタンスストアキャッシングを通じたハードワークが非常に重要です。彼らは主にParquetを使用しています。
重要なポイントの一つは、これが彼らにとって使用可能になるとすぐに、ATGのような他のチームを非常に迅速にオンボーディングできたことです。特別なトレーニングは必要ありませんでした。彼らはwikiに情報を掲載し、人々はそれを読むだけですぐに使い始めることができました。これは本当に素晴らしいことで、非常に限られたサポートで実現できました。そう、とても迅速で、とても良かったですね。
セッションのまとめと質疑応答
ありがとうございました。先ほど申し上げましたが、私の名前はZlatanです。そして、ArindamとKarthikも同席しています。最後になりますが、これまでお聞きいただいた内容について、何かご質問がありましたらどうぞお聞かせください。

こちらは必ず参照していただきたいリソースです。ぜひ写真に収めておいてください。最初のリンクはPinterestの出版物へのリンクです。写真を撮りながら、何か質問があればどうぞおっしゃってください。マイクが用意されると聞いていましたが、もしなければ、このセッションが終わりましたら直接私たちのところまでお越しいただいても構いません。ありがとうございました。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion