re:Invent 2024: bpのトレーディング部門がAWSで実現したデジタル変革
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - bp's energy trading digital transformation on AWS (ENU308)
この動画では、bpのトレーディング部門におけるAWSを活用したデジタルトランスフォーメーションの事例が紹介されています。年間40億バレルの原油取引を扱う大規模なトレーディング企業であるbpが、2016年からデータセンターからの撤退を開始し、ETRMシステムのクラウド移行を経て、Position ManagerやMarket Riskアプリケーションのモダナイゼーションを実現した過程を詳しく解説しています。特に、Amazon MSK、EMR Serverless、Amazon Bedrock Flowsなどを活用した新しいアーキテクチャの構築により、コスト削減、パフォーマンス向上、災害復旧時間の短縮などの具体的な成果を上げた点が印象的です。また、小売サイトの燃料価格設定における生成AI活用など、最新のイノベーション事例も紹介されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
bpのAWSを活用したデジタルトランスフォーメーション:概要


Enu 308へようこそ。現在、実際にマイグレーションに取り組んでいる方、あるいは企業のモダナイゼーションの何らかの段階にいる方は何人いらっしゃいますか?エネルギー業界から来られた方で、エネルギーやコモディティトレーディング、あるいはトレーディング全般に携わっている方はいらっしゃいますか?素晴らしいですね。このセッションは、そういった方々をはじめ、皆様のためのものです。今回は、bpのトレーディング部門におけるAWSを活用したデジタルトランスフォーメーションについてお話しします。具体的には、レガシーアプリケーションのAWSへの移行から、AWSでのインフラのモダナイゼーション、そして現在のAWSを活用したイノベーションまでをご紹介します。

私はAmruta Karnikと申します。AWSのSenior Solutions Architectとして、主にbpのようなエネルギー企業のお客様を担当しています。本日は、Digital Supply Trading and ShippingのVPであるTara Wannerと一緒に発表できることを大変嬉しく思います。このセッションでは、企業がクラウド導入を通じてデジタルトランスフォーメーション全体をどのように考えているかについて説明します。その後、Taraが実例を詳しく解説し、bpがAWSを活用してどのように複雑な課題を解決し、プロセスを最適化し、革新的なソリューションを構築して新たな機会を生み出したのかを学んでいきます。それでは、Taraにbpの事例をお話しいただきましょう。
クラウド移行の旅:課題とメリット


皆様、おはようございます。Amrutaの紹介にもありましたように、私はTara Wannerです。bpのSupply Trading and Midstreamアプリケーションポートフォリオを担当しています。約600のアプリケーションからなる複雑なポートフォリオを管理しており、世界中に1000人以上のチームメンバーがいます。bpについてご存じない方のために説明させていただきますと、私たちは世界有数のコモディティトレーディング会社の一つです。世界40のオフィスに約2000人のスタッフがおり、Houston、London、Chicago、Singaporeの4つのトレーディングハブを持ち、約12,000の顧客にサービスを提供しています。規模感をお伝えすると、年間約40億バレルの原油を取引し、235のパイプラインを通じて約14BCFの天然ガスを輸送しています。このように、私たちは非常に大規模で複雑なビジネスを展開しており、それを支える多くのシステムを持っています。背景に映っているのは、私も現在拠点を置いているHoustonのトレードフロアです。

本日は、私たちのクラウドへの移行についてお話しします。具体的には、マイグレーションの方法、最適化へのシフト、アプリケーションのモダナイゼーション、そして現在AWSとパートナーシップを組んで進めているトレーディングアプリケーションのイノベーションについてです。私たちのクラウドジャーニーは、2016年にデータセンターからの撤退を企業として決定したことから始まりました。米州では少し早めに開始し、2023年頃には私たちのデジタル資産全体をクラウドで運用するようになりました。トレーディング部門に関しては、いくつかの例外を除いてほぼすべてがAWS上で稼働しています。最初のステップは単純なリフト&シフトでした。オンプレミスのデータセンターからアプリケーションを移行し、クラウドに移して、クラウドでの運用に必要な社内の能力を構築することが目的でした。
現在では数年の経験を積み、さらなる最適化とモダナイゼーションを目指しています。2023年までには完全にクラウドでの運用体制が整いました。後ほど詳しくお話ししますが、大規模なETRM(Energy Trading Risk Management)システムを2019年に移行し、その後はこれらのアプリケーションのさらなる最適化に取り組んでいます。
また、私たちはAWSのネイティブアーキテクチャを活用して、独自のアプリケーションの構築も本格的に始めています。これについても後ほど詳しくお話しします。
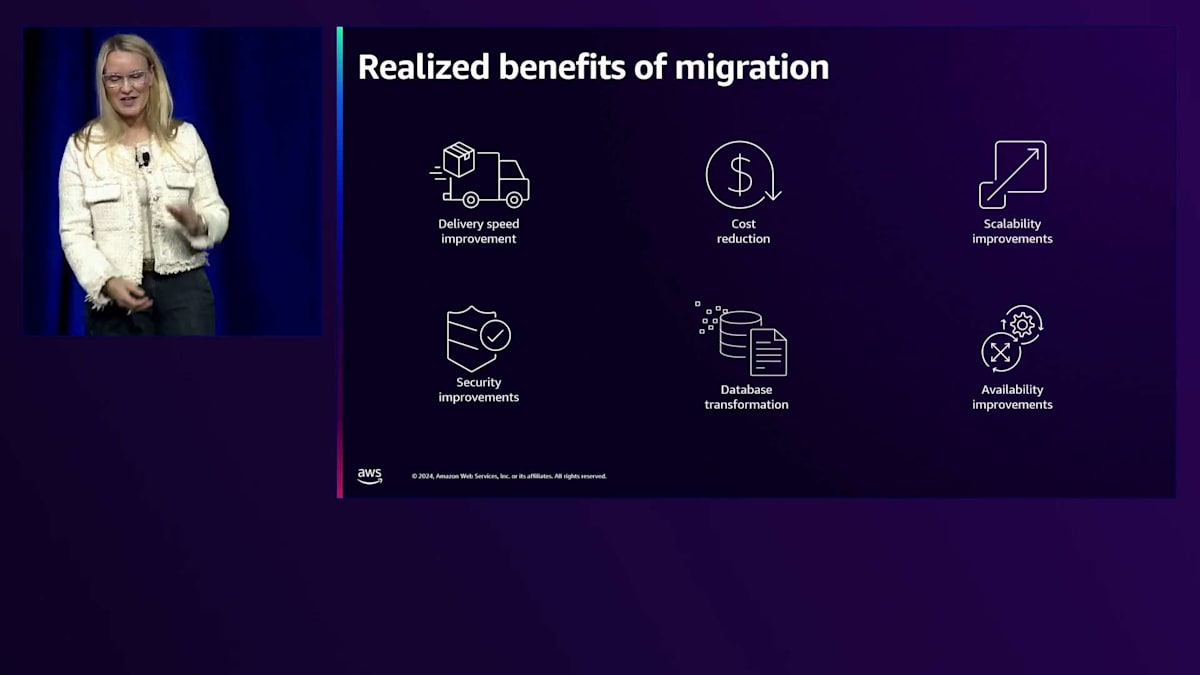
皆さんの中で何人かがコモディティトレーディング業務に携わっているとお手を挙げていただきましたが、トレーディングビジネスはデータとシステムで成り立っているということをご存じでしょう。可用性、信頼性、セキュリティへの依存度が非常に高いのです。では、クラウドはこれらの課題にどのように役立ってきたのでしょうか?ここではbpで実感している主要なメリットのいくつかをご紹介します。これは網羅的なリストではありませんが、クラウドへの移行により多くの点で改善が見られています。
その一つが提供スピードです。オンプレミスのデータセンターでは、インフラを拡張したり新しいサーバーを導入したりする度に、Technical Infrastructure Planと呼ばれる文書を作成する必要がありました。これは様々な承認プロセスを経なければなりませんでした。冷却能力の増強が必要か、ラックスペースは十分か、拡張が必要かなどを検討する必要があり、このプロセスは文字通り数ヶ月、時には数年かかっていました。ハードウェアの調達、ステージング、インストールまでを含めると、新しいソリューションの構築を開始できるまでに1年ほどかかっていたのです。クラウドへの移行により、これがほぼ瞬時に実現できるようになりました。概念実証のための環境構築や、新製品のテスト、新しい金融商品のモデリングなどを、あっという間に行えるようになりました。ビジネスに対する市場投入までの時間と提供能力は、クラウドで大幅に改善されました。
トレーディング業務でもう一つ重要なのが、レジリエンシーです。以前は、North HoustonとバックアップサイトのChicagoにオンプレミスのデータセンターを持っていました。Houstonにお住まいの方ならご存知でしょうが、年間6ヶ月間はハリケーンシーズンと呼ばれています。私は、Rita、Harvey、Ike、そしてWinter Storm Uriなど、実際の災害復旧やビジネス継続性のシナリオに直面した経験が少なくとも4回はあります。オンプレミス時代には、ハリケーン回廊にあるNorth Houstonのデータセンターから何百ものコンポーネントをChicagoにフェイルオーバーするのに何日もかかっていました。人を見つけるのが困難で、連絡を取るのに苦労し、あるデータセンターでシステムを停止して別のデータセンターで再起動するという非常に複雑なオーケストレーションが必要でした。規制対象企業として毎年実施しなければならない災害復旧訓練は、以前は週末丸々かかっていたものが、今では数時間で済むようになりました。なぜなら、Availability Zone間のフェイルオーバーがそれほど迅速にできるからです。また、私たちが利用しているAvailability Zoneがハリケーン回廊にないことも大きな利点です。AWS Ohioには感謝しています。
もう一つの大きなメリットはコスト削減です。コストの最適化が可能になりました - 以前は一時的な用途のために環境を停止したり起動したりする柔軟性がありませんでした。End-of-dayシナリオのような計算集約型プロセスのために拡張できるバースト容量もありませんでした。数年の経験を経て、今ではこれを完全に習得しています。コストの可視性と透明性が大幅に向上し、より機動的に管理できるようになりました。コスト削減の面で良好な成果を上げています。以前は3〜5年ごとにインフラを更新していましたが、実際にインフラを調達して導入するまでの間、最高クラスのマシンやインスタンスタイプを利用することができませんでした。今では、常に最新のポートフォリオを維持できており、これはデータアクセスとトレーディングのスピードが重要な私たちにとって非常に大きな意味を持ちます。最高クラスのマシンを自由に使える環境は、私たちにとって画期的な変化をもたらしました。 では、AWSに移行したアプリケーションや、AWS上で新たに構築したものについて少しお話ししたいと思います。まず、私が関わってきたものからご紹介します。
ETRMシステムのAWS移行とPosition Managerの再構築
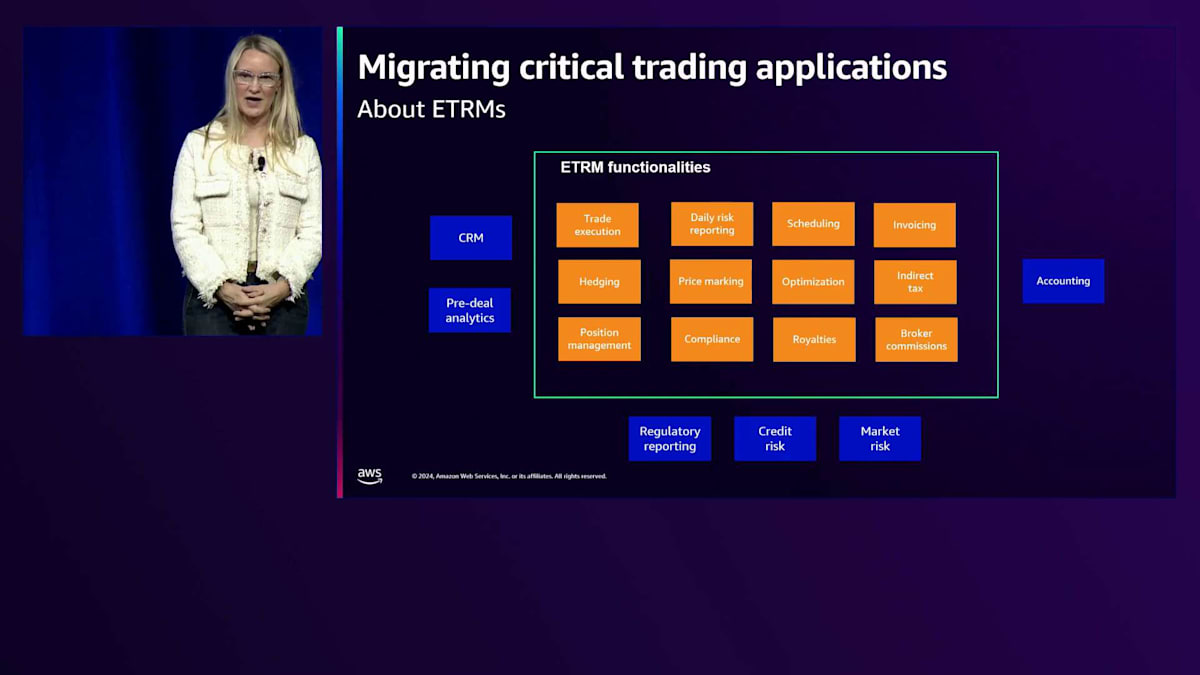
私はこの分野で長年にわたって密接に関わってきました。2003年からbpに入社し、現在まで約22年間在籍していますが、その間ずっとエネルギー取引システムやトレーディングモデルに携わってきました。この進化を間近で見てきた経験があり、特にETRM(Energy Trading Risk Management)システムとの関わりが深いです。ETRMシステムは、取引管理の中核となるシステムで、取引前の分析、取引の記録、評価、ポジション管理から、実際に現金が入金されるまでの取引の決済まで、すべてを網羅しています。

bpは大規模な現物取引ビジネスを展開しているため、商品をAポイントからBポイントに移動させる複雑なロジスティクスが必要で、取引のライフサイクル全体を通じてそれらを最適化する必要があります。私たちはETRMのデータセットを使用して規制報告を行い、ETRMデータに基づいて信用リスクと市場リスクを管理しており、これは私たちにとって重要な取引アプリケーションとなっています。私たちは主要なETRMの1つとしてION社のEndurを使用しており、これをグローバルにガス、電力、LNGの取引に活用しています。本日は、クラウド移行の過程で移行した最大級のアプリケーションの一つとして、このEndurについてお話ししたいと思います。
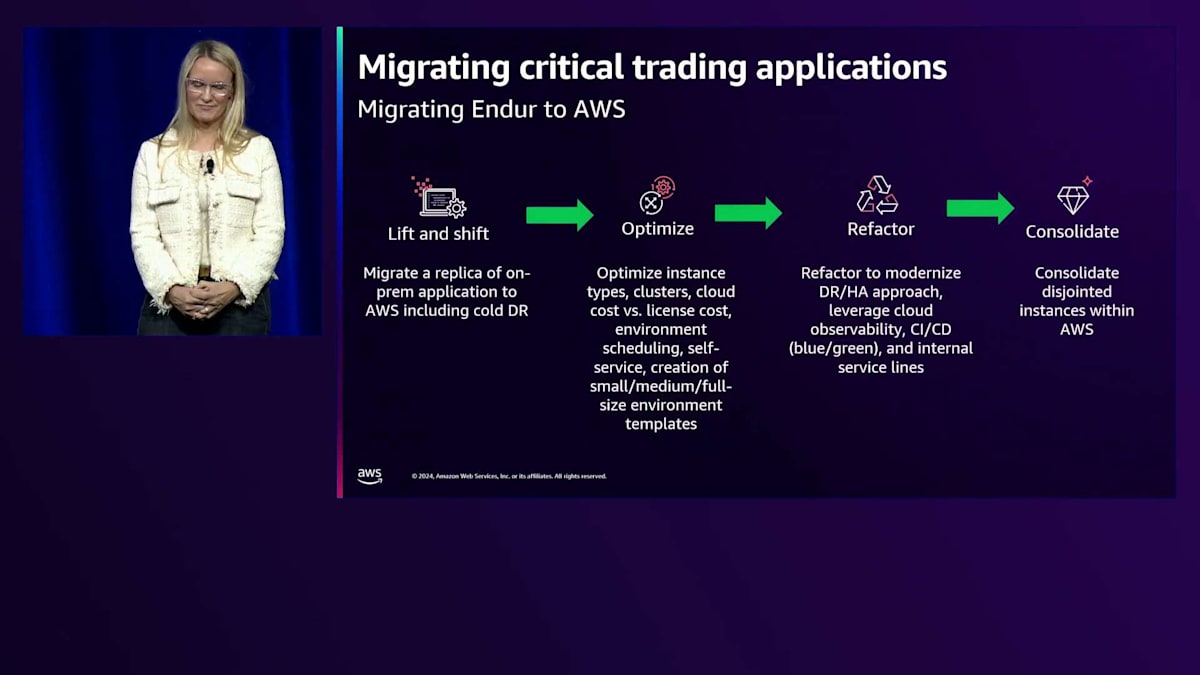
規模感をお伝えすると、現在Endurには約700人のユーザーがおり、431台のサーバー、60のインスタンスを運用しており、システムを通じて計算負荷の高い評価プロセスを多数実行しています。年間数百万件の取引を処理しており、Endurのインスタンスを3つ運用している大規模なインストレーションとなっています。
最初の焦点は、このシステムをオンプレミスのデータセンターからクラウドに移行することでした。私たちは、実際にEndurをAWSに移行した最初の顧客の一つだったと思います。その過程で、スプレッドメッセージング、ユニキャスト、マルチキャストなど、いくつかの課題に直面しましたが、IONとAWSと協力して解決していきました。指導やガイダンス、サポートを受けながら、最終的にクラウドでの運用準備が整いました。それ以降は、弾力性やバースト容量の活用方法の最適化、パフォーマンスの向上、クラウドでの効率的な運用に注力してきました。また、うまく機能していない機能をどのように最新化したり置き換えたりできるかについても検討してきました。


そうした機能の一つがPosition Managementで、これは取引において重要な機能です。トレーダーが取引量、エクスポージャー、リスクレベルに関する意思決定を行う際の支援となります。また、トレーダーがオペレーターとコミュニケーションを取る上で優れたツールとなっており、取引量の現状と必要な移動先、利用可能な保管場所、リスクの程度などを判断することができます。リアルタイムでのポジション把握は非常に重要です。 現在のソリューションにはいくつかの課題があります。コストがかかり、パフォーマンスが良くなく、エラーからの回復に時間がかかるのです。ポジションを得るまでには多くのアップストリームプロセスが実行されており、その日の開始時のポジションが正しく設定されていないと、回復が非常に困難になります。これは市場での取引時間の損失につながってしまいます。
これらの課題に直面し、私たちはAWSと協力して独自のPosition Managerを構築しました。現在のソリューションの欠点は、Endurアプリケーションと密接に結合しており、複数のソースからのデータを調整できないことです。柔軟性に乏しく、拡張性も低く、カスタマイズも難しく、さらに実用的な可視化機能もありません。私たちはAWSと共により良いものを作ることを目指し、喜ばしいことに有望なプロトタイプが完成しました。EndurからAuroraへのKafkaストリーミングにMSKを使用し、可視化にはQuickSightを採用しています。ここで、詳細についてAmrutaに説明を譲りたいと思います。
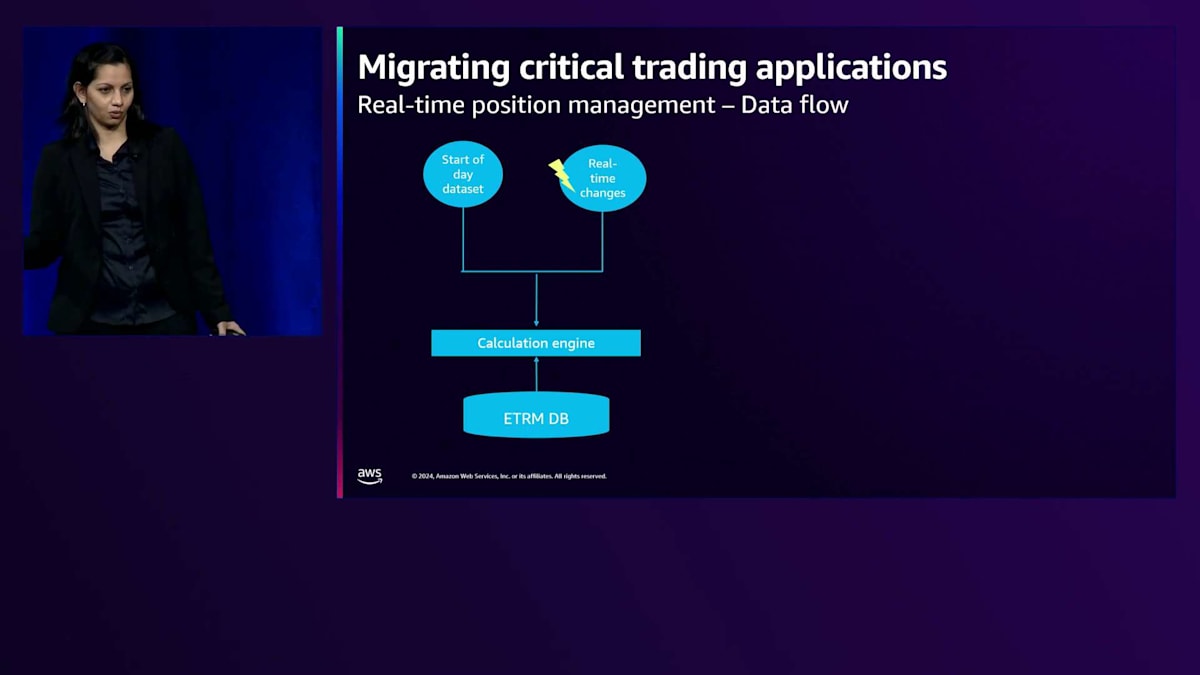
ありがとうございます、Tara。Taraが先ほど説明した課題を考慮して、bpは既存のPosition Management Solutionに関する選択肢を検討することにしました。その一つが、クラウドネイティブアーキテクチャによる既存機能の拡張でした。画面に表示されているのは、Position Managerで使用するためにETRMシステムを通じて流れるデータです。データフローには2つの方法があります:一つは、価格調整を適用して翌営業日のデータを準備する夜間バッチ処理である開始時データセット、もう一つは通常の営業日プロセス中にアプリケーションを通過するリアルタイムの変更です。規模に関して言えば、バッチプロセスの一部として処理する必要がある約7,000万件のレコードを扱い、通常の営業日が始まると1分あたり1,000件のレコードが生成されることになります。
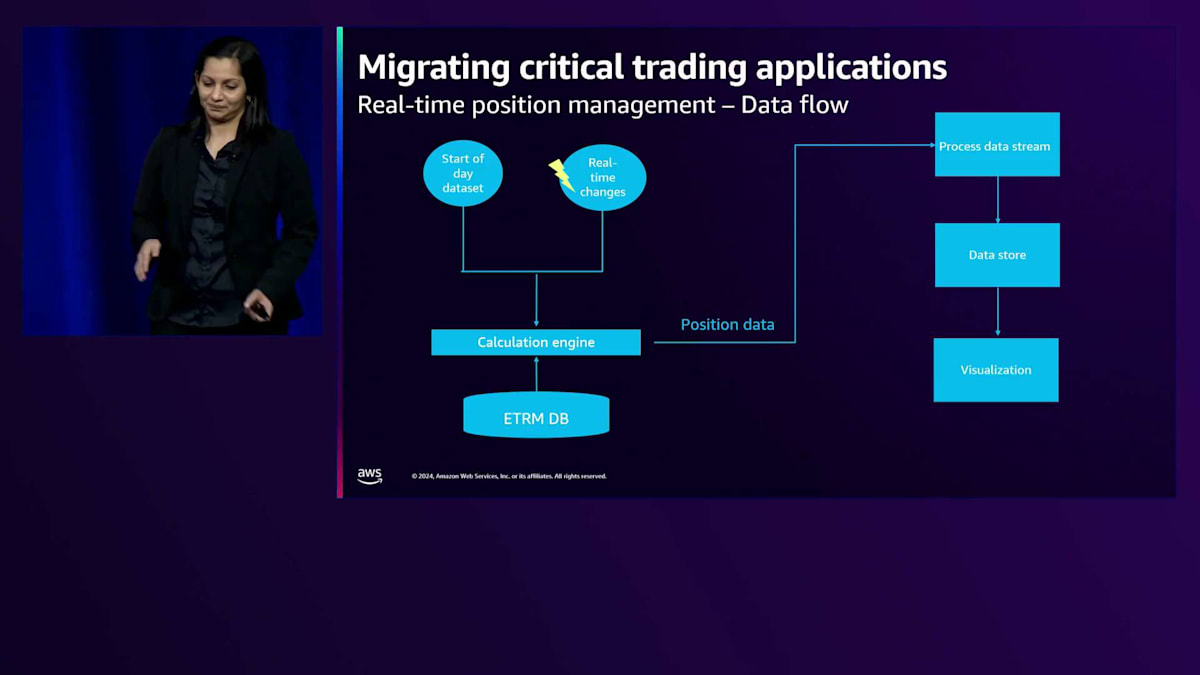
アーキテクチャの構成要素を見ていきましょう。ポジションに関するデータである計算エンジンからのデータを、まずストリームに配置する必要があります。次に、このデータを保存し、変換を適用し、可視化アプリケーションやツールで利用できるようにするためのデータストアまたはデータベースが必要です。SLA、データ量、機能性を考慮して、先ほどTaraが言及したアーキテクチャを検討することにしました。実際のSLAに関しては、データがストリームに到達してから1分以内に可視化アプリケーションで表示される必要があります。機能面では、データに追加のコンテキスト情報を付加するためのリアルタイムでのデータセット結合能力、行列レベルのフィルタリングに基づくアクセス制御メカニズム、特定のユーザーやユーザーグループに対する特定のダッシュボードや可視化の制限などを検討しました。
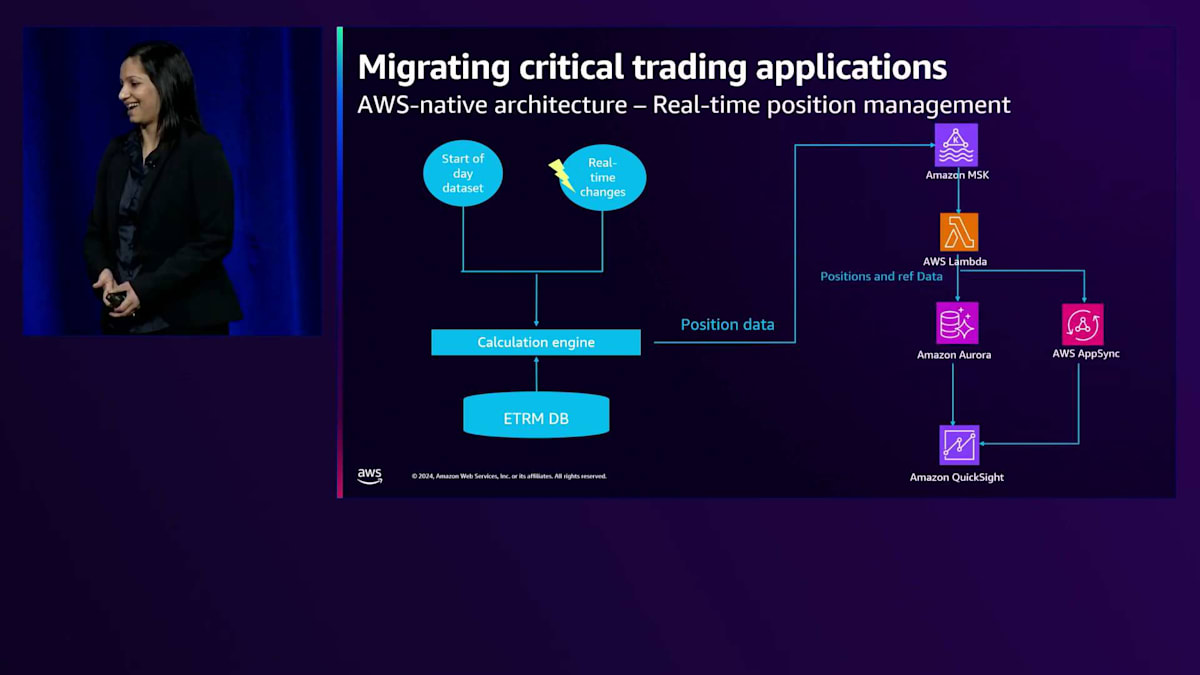
これらの要件を考慮して、私たちが提案したのがこのAWSネイティブアーキテクチャです。ストリーミングサービスには、重要なビジネスアプリケーションであるため、複数のアベイラビリティーゾーンにデプロイされたAmazon MSKを使用しています。AWS Lambdaは、MSKをイベントソースとして持ち、メッセージを処理し、変換して、Amazon Auroraデータベースへのアップサートまたは挿入を行います。可視化アプリケーションには、Amazon QuickSightを選択しています。QuickSightは各データソースへの直接クエリオプションを提供し、管理者やライターが異なるデータセットを結合して新しい可視化を作成できる管理インターフェースを提供します。また、QuickSightはユーザーやユーザーグループに対するアクセス制御メカニズムを、行列レベルのフィルタリング機能とともに提供します。これは数値の表形式データなので、bpはセルをクリックしてそのデータを構成する行を確認できるドリルダウン機能を備えたピボットテーブルとして表示することを望みました。このオプションは、bpが検討していた他のソリューションと比べてコストが約3分の1で済むため、bpはこのプロトタイプをさらに進めることを決定しました。
Market Riskアプリケーションのモダナイゼーション

それでは、Taraにバトンを渡します。これは、ライセンスコストの削減、パフォーマンスの向上、より多くの機能を備え、ビジネスにとってより良く機能するものを構築できた素晴らしい例でした。アプリケーションのモダナイズとアーキテクチャの再設計を行った別の例として、Market Riskアプリケーションがあります。
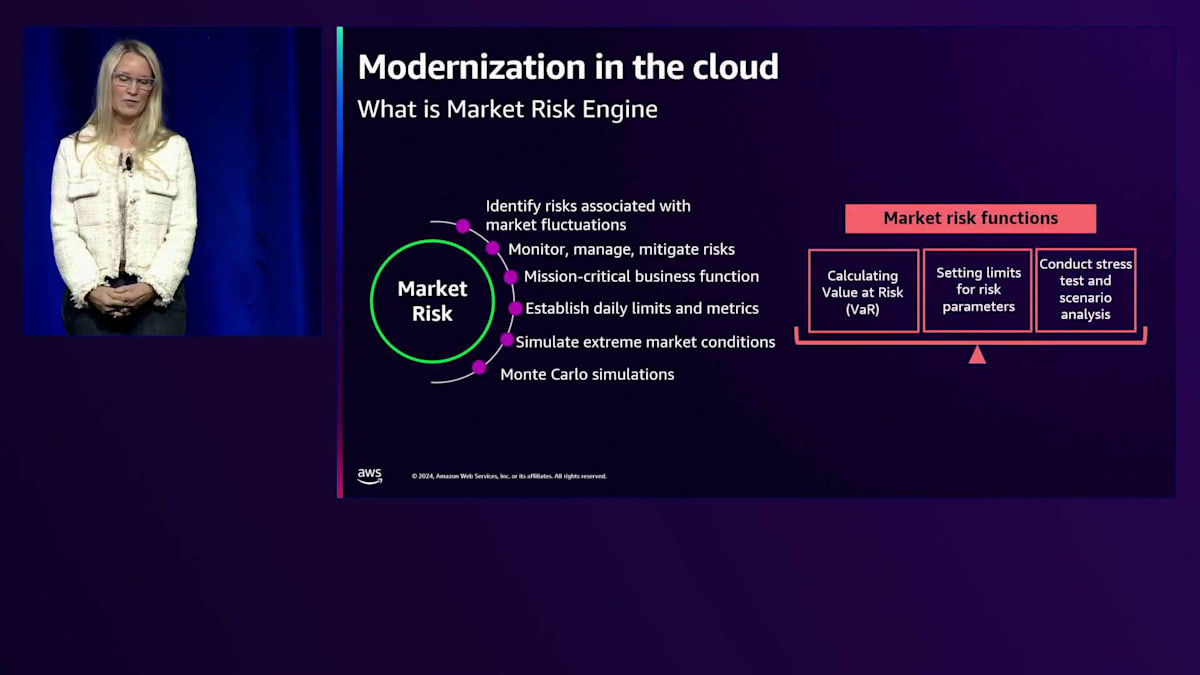
トレーディングに携わっている方々は、Value at Riskについてご存知かと思います。Value at Riskとは、市場価格の変動によってポートフォリオで発生する可能性のある最大損失を算出する、計算負荷の高いプロセスです。簡単に言えば、どれくらいの損失が発生する可能性があるのか、その損失が発生する確率はどのくらいか、そしてどの程度の期間でその損失が発生する可能性があるのかを示すものです。これは、利益を守り、ポートフォリオ全体のリスクを管理する上で非常に重要な指標となります。

一見シンプルに聞こえるかもしれませんが、実際には価格変動、地政学的混乱、気象現象、その他の潜在的なシナリオをモデル化するデータを生成する、複雑なMonte Carloシミュレーションの連続処理です。私たちは、ポートフォリオのリスクを積極的かつ予防的に管理・軽減するために、ストレステストと負荷テストを実施しています。以前の解決策は、やや古い技術で構築されており、日中の分析ができないなど、パフォーマンスが十分ではありませんでした。処理が非常に遅く、What-ifシナリオ分析もほとんどできない状況でした。そこで、より良いソリューションを開発するために、AWSとパートナーシップを組みました。
Value at Risk計算で処理されるデータの規模と量を示すと、2億5000万の価格予測を処理し、25,000×25,000の相関行列を生成して計算を行い、膨大な量のデータを処理します。この問題を解決するにあたり、これらすべての要素を考慮する必要がありました。最近まで、私たちはApache IgniteとMATLABで構築されたリスクエンジンを使用していましたが、より良いソリューションがあるはずだと考えました。ここで、この問題を解決するために開発したアーキテクチャについて、Amrutaに説明を譲りたいと思います。
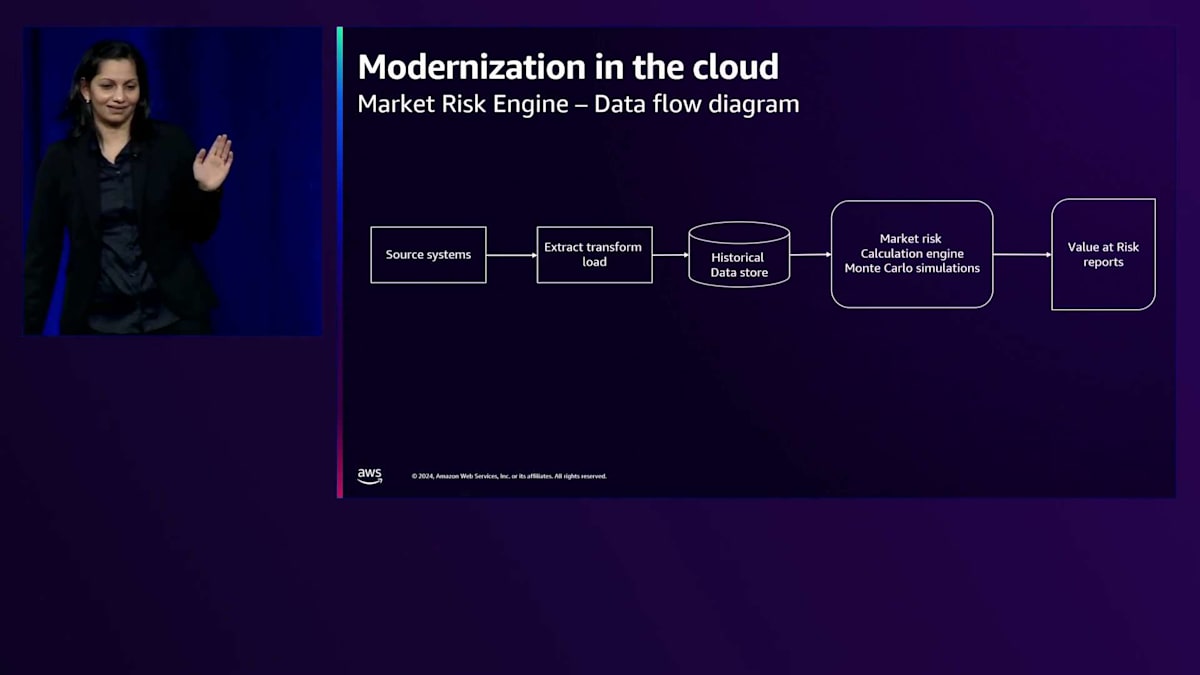
ここに示されているのがデータフローの図です。bpが取引する様々なコモディティの価格に関するデータを含むソースシステムがあります。このデータは抽出、変換、ロードされて履歴データストアに格納されます。Market Risk Engineは、このデータストアに対してMonte Carloシミュレーションを適用し、Value at Riskなどのレポートを生成します。先ほど述べたように、このエンジンは以前MATLABとApache Igniteを使用して作成されていました。アーキテクチャは、スケーリングができない構造になっており、ピーク容量に対して常にプロビジョニングが必要でした。それでも、市場が不安定な時期にはエンジンがクラッシュし、計算が失敗することがありました。bpは複数の市場で取引を行っており、ある市場の終値が別の市場の始値となるため、大規模なコモディティの処理には非常に時間がかかっていました。そのため、bpはこのエンジンの再設計を決定しました。
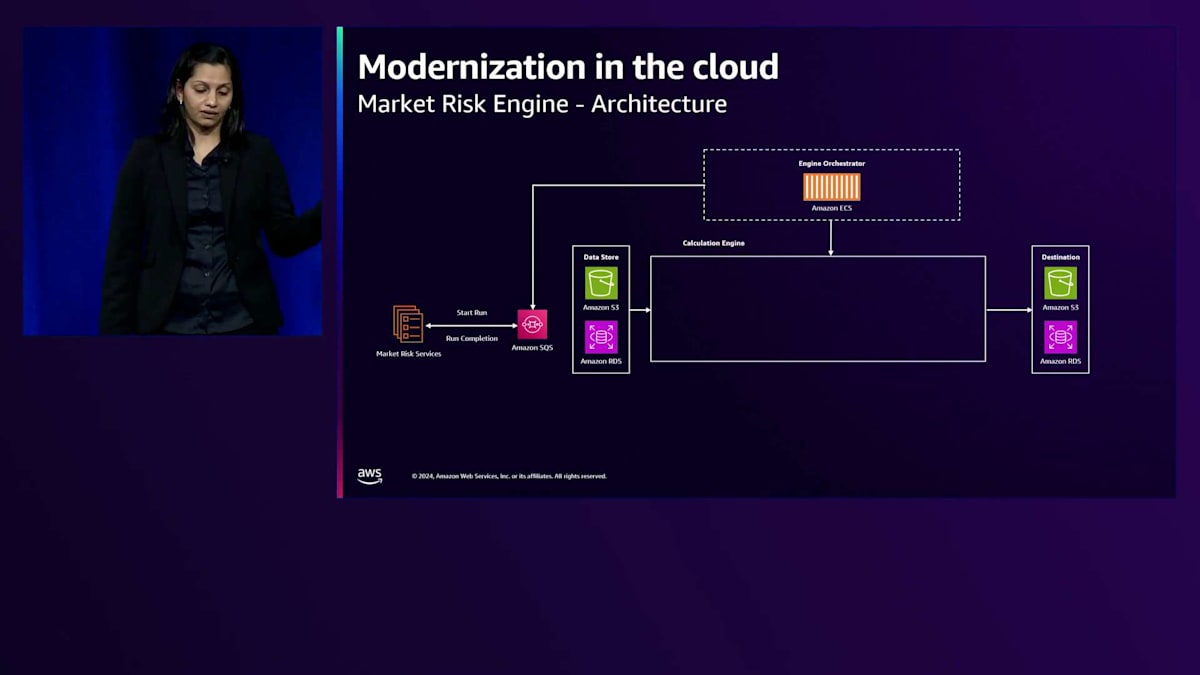
アーキテクチャを詳しく見ていきましょう。まず、ETLプロセスであるMarket Risk Engineサービスがあります。これらは異なるコモディティからデータを収集し、Amazon RDS PostgreSQLデータベースに挿入され、ファイルベースのデータセットについてはS3をデータストアとして使用しています。次に、計算エンジンへの計算リクエストをどのようにオーケストレーションするかを見ていきましょう。複数の市場とコモディティを扱っているため、いくつかのコモディティのデータが準備できた時点で、それらをキューに入れて分散させる必要があります。特定のコモディティのデータが準備できると、Amazon SQSキューにメッセージが配置されます。Amazon ECSにデプロイされたエンジンオーケストレーターが、Amazon SQSキューをプルしてメッセージを処理します。このエンジンオーケストレーターはエンジンへのエントリーポイントとして機能し、エンジンへのアクセスがオーケストレーターを通じてのみ可能となるため、追加のセキュリティレイヤーも提供しています。
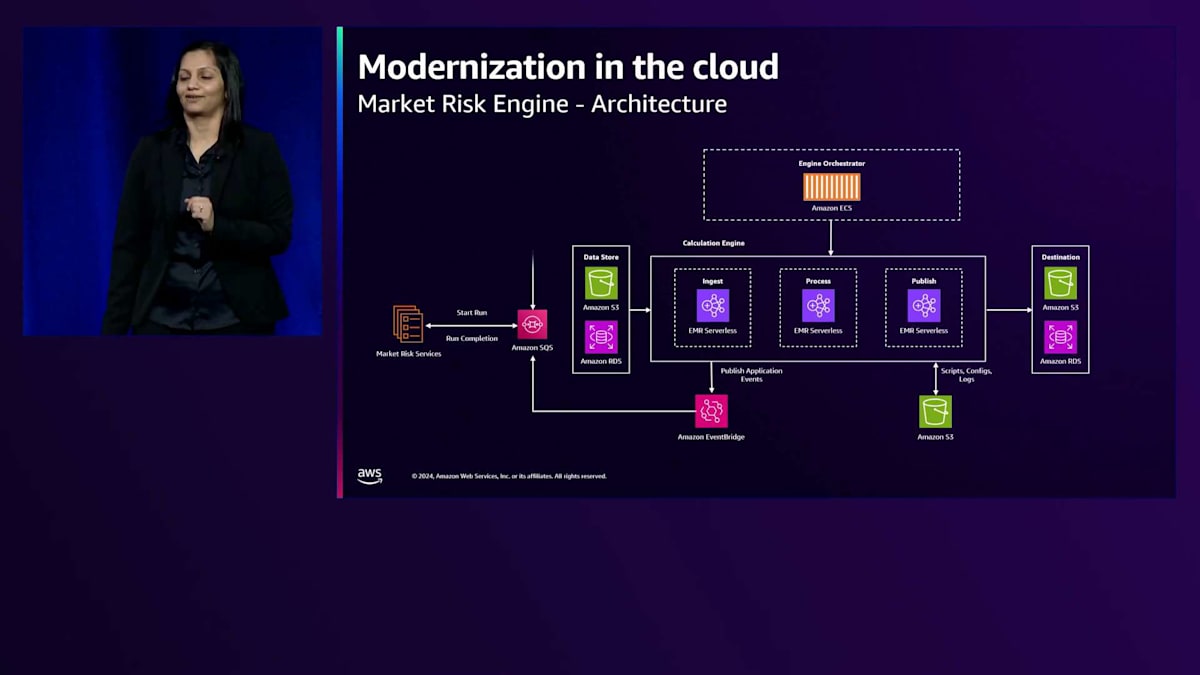
このエンジンで処理されるジョブはすべて大規模なものであり、そのため、Amazon SQSにメッセージを配置する同期的な方式で処理が行われます。ただし、RESTを使用して処理される小規模なジョブもあります。 では、実際の計算エンジンについて見ていきましょう。Monte Carloシミュレーションを実行する計算エンジンは、EMR Serverlessを使用して構築されています。EMR Serverlessは、エンジンが必要とするリソースを自動的に計算し、それらのリソースをプロビジョニングし、ジョブの実行が完了すると解放します。
アドホックな計算のためのインタラクティブなデータ分析など、数秒以内の応答が必要なジョブについては、EMR Serverlessは事前初期化された容量をサポートしています。これらのジョブでは、事前初期化された容量の識別子を含むメッセージがAmazon SQSに配置されます。オーケストレーターには、Executorの数やメモリ実行を設定するルールがあり、このEMR Serverlessアプリケーションが作成されるときにWorkerのウォームプールが作成されます。
取り込みプロセスとパブリッシュの部分を詳しく見てみましょう。このアプリケーションでは、ジョブ設定を定義するためにYAML設定ファイルを使用しています。設定ファイルには、コネクター、データソース、ファイル形式、複数のデータセットがある場合のデータ処理順序に関する情報が含まれています。このデータは処理され、Parquetファイルに変換されて、S3バケットに保存されます。処理部分ではMonte Carloシミュレーションが行われますが、これは負荷に応じてスケールできないために従来失敗していた部分です。
この処理部分では、データに対してMonte Carloシミュレーションを適用します。結果はAmazon RDS PostgreSQLデータベースに保存され、レポートはS3バケットに書き込まれます。これは非常にモジュール化された疎結合のアプリケーションであり、そのため、フレームワークが構築された後、bpは新しいユースケースを簡単に追加し、この新しいアーキテクチャに新しいコモディティを容易にオンボードすることができました。これは既存のアプリケーションの再設計だったため、このアプリケーションの再設計にかかる時間と労力が成功を決定する重要な要因でした。bpのチームは、オーケストレーター用に以前持っていたコードの大部分を使用することができ、EMRサービスやストアドプロシージャでも80%のクエリを再利用することができました。

では、モダナイゼーションの利点について説明するため、Taraにバトンを渡します。 最も簡単に言えば、サードパーティに支払っていたライセンス費用を100%削減できました。新しいアーキテクチャでは計算コストを35%削減でき、新しいユースケースをより迅速にオンボードできるようになりました。以前のツールと比べて40%のパフォーマンス向上を実現し、ポートフォリオで行われている他の処理と並行してシミュレーションを実行できるようになりました。以前のソリューションと比べて、より優れたパフォーマンスを低コストで実現できています。
AIを活用した価格設定プラットフォームの構築


私たちはいくつかのアプリケーションの移行、最適化、そしてアーキテクチャの再設計を行ってきました。今の時代、AIに触れずにテクノロジーの話をするのは適切ではありませんね。 そこで、AWSのネイティブアーキテクチャを活用し、AIを事業に取り入れている具体例についてお話ししましょう。ここで少し視点を変えて、Supply Trading and Shippingのサプライサイド、つまり私たちの燃料供給とミッドストリーム事業について、そして小売サイトの燃料価格設定を行うグローバル統合価格設定プログラムの例をご紹介します。これまで使用してきたシステムはサードパーティ製で、かなり古く、カスタマイズや設定、管理が難しく、世界中に断片的なソリューションが点在していました。そこで、よりシンプルで効率的な統一プロセスを構築し、グローバルで統一されたプラットフォームを実現することで、エンドユーザーのお客様により競争力のある価格を提供できるようにしたいと考えました。
私たちは、小売サイト向けの独自の価格設定プラットフォームとソリューションの構築について、Amazonとタッグを組みました。ちなみに、最近bpがAmazonとパートナーシップを結んだことをご存知かもしれません。Amazon Primeのお客様は、私たちの小売サイトでアプリを使用すると1ガロンあたり10セント割引が受けられます。これに関連して、ポンプでの価格設定は、競合他社のデータや市場データを分析して最適な価格を算出するAugmented Intelligenceに基づいて行われることになります。これは段階的なプログラムで、米国ではまだ展開していませんが、現在約4,300の小売サイトで使用されています。

それでは、私たちが活用しているツールとAIの側面について、Amrutaに説明してもらいましょう。ありがとう、Tara。bpが構築した価格設定プラットフォームが差別化要因となり、重要なビジネス上のメリットをもたらしていることは明らかです。 このプラットフォームは、bpがクラウドネイティブ技術を使用して一から開発した大規模プログラムの例で、AWSで構築されています。後ほど、この価格設定プラットフォームが、bpが開発したデータ分析とAIのための2つの他のプラットフォームをどのように活用しているかについても見ていきます。
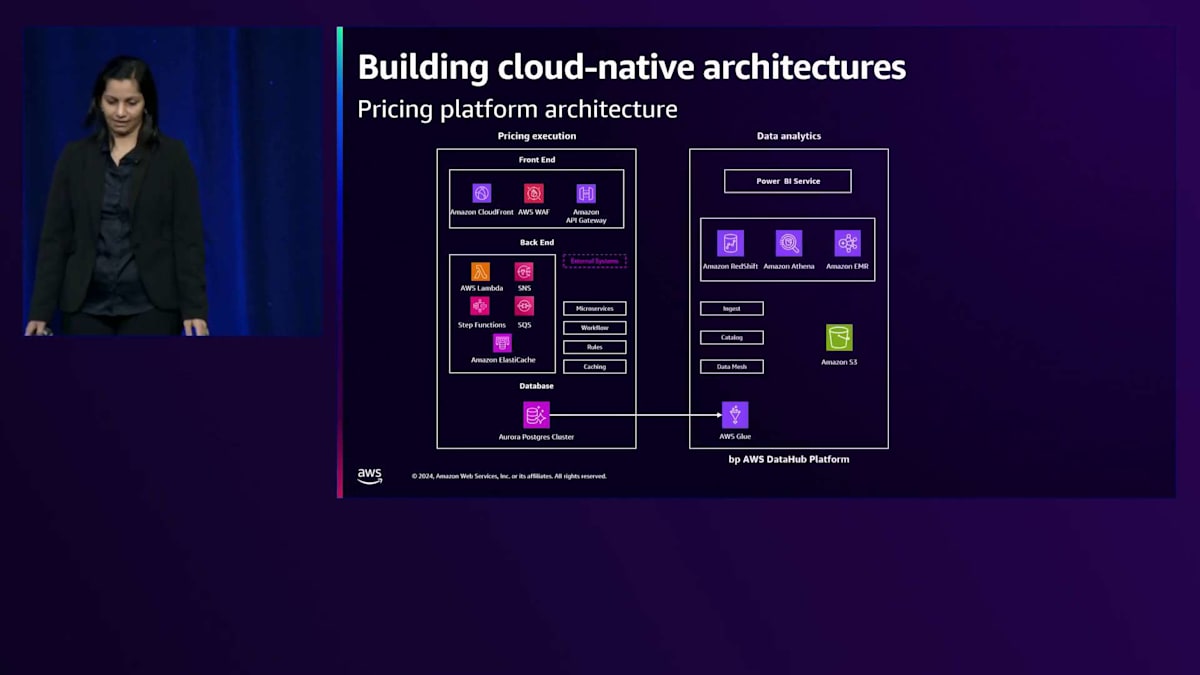
画面に表示されているのは価格設定の実行プロセスです。この価格設定プログラムは、24時間365日稼働するグローバルアプリケーションで、変動する負荷に対応できる必要があり、複数のコンポーネントを持っています。Reactフロントエンド、すべてのビジネスプロセスを管理するバックエンド、そしてデータベース層があります。フロントエンド側では、コンテンツ配信にAmazon CloudFrontを使用し、AWS WAFでインフラを保護しています。このアプリケーションのすべてのAPIは、Amazon API Gatewayで管理・デプロイされています。
このアプリケーションとのユーザーのやり取りはAPIを介して行われ、それらは全てAWS Lambdaで構築されたマイクロサービスを呼び出します。これは非常に疎結合なアプリケーションで、あるマイクロサービスが別のマイクロサービスを直接呼び出すことはありません。すべての通信はAmazon SQSとSNSを介して行われます。価格変更のワークフローはAWS Step Functionsを使用して行われ、Lambda関数を通じて複数のAPIを呼び出し、政府機関、規制当局、価格情報サイト、天候パターン、交通パターンなどの外部システムとやり取りすることができます。また、このアプリケーションはSAPや他の様々なレポーティングツールなどの内部システムとも連携しています。
価格変更が発生するたびに、このアプリケーションは数千件のデータイベントに対応する必要があります。これは、複数のリージョンで数分ごとに価格変更がトリガーされるためです。このアプリケーションは非常にモジュール化され疎結合な設計となっているため、複雑なルールセットの要件に対応し、価格戦略を構築する際にローカライゼーションや現地法への準拠をサポートすることができます。また、このアプリケーションは非常にトラフィックが多く、複数のレポーティングアプリケーションがデータを必要とし、価格変更を即座に報告する必要があるため、データベースの負荷を軽減するためにキャッシュ層としてAmazon ElastiCacheを導入しています。データベース層では、複数のAvailability Zoneにリーダーノードを持つAmazon Aurora Postgresクラスターを使用しています。レポーティングソリューションはリーダーノードに接続し、このアプリケーションはAWSサービスを使用して構築された高負荷なアプリケーションであるため、デフォルトのサービス制限に到達または超過していないことを確認するためにサービス制限のモニタリングも設定しています。制限に近づいた場合はアラートが送信され、必要に応じて制限引き上げのリクエストを行うことができます。
これは重要なアプリケーションであったため、各主要リージョンでの本番稼働前に複数回のパフォーマンステストを実施しました。見落としていた可能性のある問題を発見するのに常に役立つWell-Architected Frameworkレビューも実施しました。DRストラテジーの一環として、ビジネスによって設定されたRTOとRPOの要件を満たすことを確実にするため、AWS Resiliency Hubを実装しました。また、AWSの組織と協力して、AWS Countdownを導入しました。これは、主要なアプリケーションの本番稼働前に多くの顧客が利用する包括的なソリューションで、モニタリングダッシュボードの構築をサポートします。このアプリケーションについてビジネスが強調した主な特徴は、その安定性と動的にスケールを処理する能力でした。これは、AWSのネイティブなアーキテクチャのベストプラクティスとガバナンスを活用することで実現しました。
価格設定プログラムの高度な分析部分は、AWSのデータレイクのコンセプトとService Data Lake Frameworkを使用するbp AWS DataHubプラットフォーム上に構築されています。このData Hubは、異なるビジネスドメインからのデータの中央リポジトリとして機能し、ユーザーはデータウェアハウス、データマート、ユースケース固有のデータセットなどのデータ分析ユースケース向けにデータモデルを作成します。このData Hubには、バッチまたはニアリアルタイム処理を使用して、さまざまなアプリケーションやシステムからデータが挿入されます。この場合、取り込みにはAWS Glue、Amazon DMS、APS、Amazon AppFlowを使用し、データがRaw、Conformed、Transformed、Enrichedなどの異なるゾーンを通過する際に、AWS Glue、Amazon EMR Serverless、AWS Lambda関数を使用して変換を適用します。
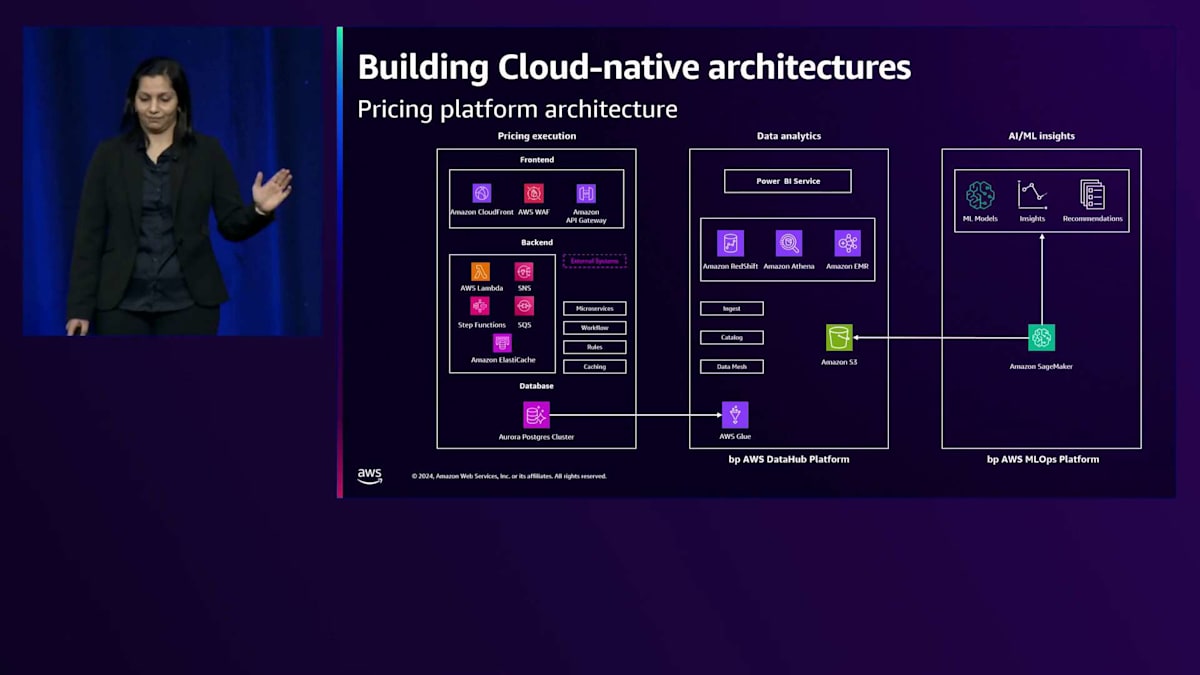
データがこれらのゾーンで利用可能になると、Amazon Redshift Spectrum、Amazon Athena、BIソリューションを使用してクエリを実行できます。Data Scienceプラットフォームは、このData Hubを使用して機械学習のユースケースを構築します。このData Hubは、AWS Glue DataBrewを通じて探索的データ分析もサポートし、ビジネスアナリストに利用可能な最も粒度の細かい生データへのアクセスを提供します。このプラットフォームは、ビジネスユーザーが他のチームが利用できる新しいデータプロダクトを作成できるData Meshアーキテクチャをサポートしています。私たちのケースでは、リーダーノードから1日に数回データが取り込まれ、アナリストはこのデータを他のコンテキスト情報と結合します。価格アナリストは、このData Hubを使用して価格戦略とレポートを構築します。最近、このData HubはApache Icebergテーブル形式のサポートを開始し、運用ユースケースに適したトランザクショナルデータレイクとなりました。
このPricingプラットフォームは、価格戦略のパフォーマンスを評価し、アナリストが検討できる価格に関する機械学習の推奨事項を得るためにAIを使用しています。このAIは、Amazon SageMakerを使用してbp MLOpsプラットフォーム上に構築されています。MLOpsは、モデル本番環境のためのアーキテクチャのベストプラクティスガイダンスを提供するワークロードオーケストレーターです。これにより、データ準備、モデルトレーニング、チューニング、モデルデプロイメントモニタリング、モデルエンドポイントでの推論実行まで、モデルのライフサイクル全体を構築することができます。生成AIの出現に伴い、このプラットフォームは拡張され、Large Language Model Operations(LLMOps)を追加しています。生成AIについて言えば、この価格設定プログラムには生成AI搭載の価格アナリストアシスタントも含まれています。
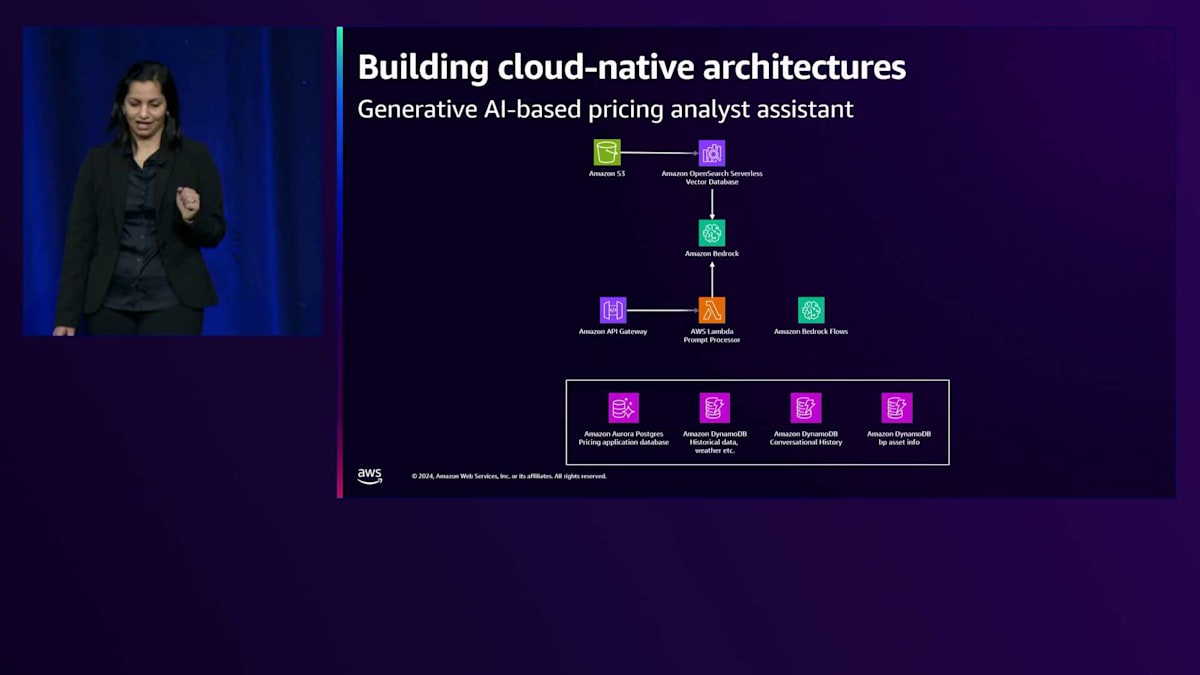
画面に表示されているのは、Generative AI ベースの価格分析アシスタントのアーキテクチャです。価格アナリストはデータ重視の専門家で、異なる市場のデータを分析し、価格戦略を構築し、地域の法規制に精通しながら過去のデータを考慮に入れます。これらを踏まえて、bp は Generative AI ベースの価格分析アシスタントを導入することを決定しました。価格アナリストはこれをトレーニングに使用でき、bp の価格戦略についてチャットで質問したり、特定地域の規制法について情報を得たりすることができます。
新しい価格戦略を構築する際、価格アシスタントは、価格アナリストが監視している外部システムに変更があった場合に、価格変更を実施するよう推奨事項をアラートまたはトリガーすることができます。また、価格アナリストは、検討すべき地域の価格推奨事項をアシスタントに積極的に問い合わせることもできます。これは先ほど見た価格設定実行の一部です。ユーザーとのやり取りは Amazon API Gateway でフロントエンドされた API を通じて行われ、AWS Lambda を使用して構築されています。Lambda がリクエストを受け取ると、適切な処理メカニズムを通じて処理されます。
価格戦略に関する情報を取得するリクエストの場合、Amazon OpenSearch Serverless ベクターデータベースを使用して埋め込みを保存する Amazon Bedrock のナレッジベースに送られます。一方、新しい価格推奨事項を取得するリクエストの場合は、Amazon Bedrock Flows のルートが使用されます。Flows にはオーケストレーション機能があり、複数の AWS サービス、プロンプト、基盤モデルを接続してワークフローを構築できます。また、エンドツーエンドの Generative AI ソリューションを構築できるビジュアルビルダーもサポートしています。画面下部には、Flows がプロンプトの開発とデータソースの分析のために連携する様々なデータストアが表示されています。Flows を使用することで、価格アナリストがデータを分析し価格推奨事項を生成する際のプロセスをモデル化することができます。


それでは、利点について説明するため、Tara にバトンを渡します。 パフォーマンスが向上し、価格アナリストの業務効率が上がっています。これまで分散していたアプリケーションを統合し、プロセスを一本化しました。現在も展開を続けていますが、bp にとって革新的でゲームチェンジングな成果となっています。 お話の中でお分かりいただけたと思いますが、AWS との取り組みは bp にとって革新的なものでした。私たちは今、クラウドネイティブなアプリケーションを構築できるようになっています。レジリエンスの向上、スピードの向上、コストの削減を実現し、率直に申し上げて、AWS のツールセットを使用することでより優れたソリューションを構築できています。Amruta は実際に私たちのフロアで一緒に仕事をしているので、これまでの説明と、これまでのサポートに感謝します。そして本日お話しする機会をいただき、ありがとうございました。
最後に、リソースへアクセスできる QR コードをご用意しています。 一つは、トレーダーブローカーのチャットメッセージから情報を抽出する ML ベースの価格キャプチャに関して、昨年 bp と実施した Chalk Talk です。また、このセッションは今年初めに Energy Symposium でも行いました。そして、Generative AI ベースの価格アシスタントを構築する際に大きな転換点となった Amazon Bedrock Flows についても強調しておきたいと思います。以上で、本日の朝のセッションにご参加いただいた皆様に感謝申し上げます。特に、Tara には時間を割いていただき、bp のストーリーを共有していただき、ありがとうございました。次のセッションにお急ぎのことと存じますが、どうぞセッションサーベイにご協力ください。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion