re:Invent 2024 - Keynote with Dr. Swami Sivasubramanian
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Keynote with Dr. Swami Sivasubramanian
この動画では、AWS AI/DataのVice PresidentであるDr. Swami Sivasubramanianが、Generative AIの最新動向と新機能について解説しています。Amazon SageMaker AIの新機能として、Foundation Modelのトレーニングを効率化するHyperPod フレキシブルトレーニングプランや、コンピューティングリソースの最適化を実現するTask Governanceが発表されました。Amazon Bedrockでは、100以上の専門Foundation ModelにアクセスできるMarketplaceや、コストとレイテンシーを大幅に削減できるPrompt Caching機能などが紹介されました。また、Amazon Kendra Generative AI IndexやAmazon Bedrock Knowledge Basesの機能拡張により、構造化データや非構造化データの活用が容易になりました。さらに、Amazon Q DeveloperのSageMaker Canvas統合や、QuickSightでのシナリオ分析機能など、AIを活用した新しいツールも発表されています。教育支援としては、AWS Education Equity Initiativeを立ち上げ、今後5年間で最大1億ドルのクラウドコンピューティングクレジットを提供する計画も発表されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
AIイノベーションの新時代:Wright兄弟の飛行から生成AIまで
AWS AIおよびDataのVice Presidentである Dr. Swami Sivasubramanianをお迎えしましょう。皆様、おはようございます。re:Invent 2024へようこそ。今年も記念すべき1年となりました。あらゆる業界のすべての組織が現状に挑戦を続けている年です。破壊的イノベーションは新たな常識となり、急速なイノベーションは今や当たり前のものとなっています。
歴史を振り返ってみると、私たち創造者、いじり屋、技術者には、常に自然の限界を超えようとする本来的な欲求があります。私たちは、前人の成果の上に積み重ねていき、やがてある日、すべての積み重ねが突然、部分の総和以上の何かへと結実する魔法のような瞬間を経験します。そしてすべてが飛躍的に進展するのです。




航空史における画期的な breakthrough を振り返ってみましょう - 1903年のWright兄弟による初飛行です。この12秒間の飛行は単独で起こったわけではありません。それは何世紀にもわたる技術の進歩を表していました。 da Vinciのスケッチによる人類の飛行の概念的基礎づけから、 揚力と推進力の概念を分離した初期の固定翼機の設計まで。そしてもちろん、動力飛行の可能性を示した最初の蒸気動力航空機や、Wright兄弟に直接インスピレーションを与えた 揚力と抗力に関する重要なデータを提供した一連のグライダー実験も含まれています。

振り返ってみると、これらすべての成果に加えて、材料科学、製造技術、内燃機関における革新が結びつき、最終的に動力飛行を可能にしたのです。Wright兄弟は12秒間の成功のすべての功績を独り占めすることはできませんが、 彼らより前の夢想家たちの仕事の上に築き上げたすべての人々のインテグレーターとなったのです。
生成AIの進化とAWSの貢献



今日、私たちはGenerative AIにおいて同様の収束点に立っています。AIイノベーションの新時代は、 何十年にもわたる研究と科学の進歩を結集させています。最初の人工ニューラルネットワークであるPerceptronモデルから、 多層モデルの効率的なトレーニングを可能にしたBackpropagation、そして すべてのビットにアノテーションを必要としないデータからの学習能力を与えた教師なし事前学習の巨大な可能性の発見まで。そしてもちろん、 自然言語処理に革命をもたらしたTransformerアーキテクチャも含まれています。

しかし、これらの発見だけでは十分ではありませんでした。大規模なデータセット、専用のコンピュート、そしてそれらがクラウドを通じて利用可能になったという要素が重なり合って、AIが発展するための完璧な条件が整いました。そして今、私たちは生成AIによってさらなる転換点を迎えています。新しいツールやユーザーインターフェースによって、かつてない速さで幅広い導入が進み、私たち全員の効率性と創造性を解き放っています。カスタマーサービス担当者は、AIを使って数秒で個別化された顧客対応を行っています。マーケターは魅力的な広告コピーや画像を生成しています。開発者は、生成AIのアシスタンスを活用して、ソフトウェア開発プロセス全体から重労働を取り除いています。

生成AIを可能にしたこの要素の融合を振り返ると、私はAmazonでの18年間の旅路とAWSの誕生を思い返さずにはいられません。私は実験がどこに導くのか常に分かっていたわけではありませんでした。私を動かしていたのは、とどまることを知らない好奇心と、実際のお客様の問題を解決したいという本質的な欲求でした。


Amazon S3によるスケーラブルなインフラストラクチャから、Amazon DynamoDBによるデータベースのブレークスルー、Amazon EMRやAmazon Redshiftによるスケーラブルな分析、そしてもちろんAmazon SageMakerやAmazon Bedrockによる機械学習の民主化まで、私たちの旅路で提供してきた各イノベーションは、前のものの上に積み重ねられてきました。時間とともに進化するお客様のユースケースに対して、段階的な価値を提供してきました。例えば、IntuitはAWS上でデータレイクを構築するためにAmazon S3を活用し、分析を実行するためにAmazon Athena、Amazon EMR、AWS Glueを使用し、ML戦略の中核要素としてAmazon SageMakerを使用しています。また、GE HealthCareは、Amazon S3、Amazon Redshift、Amazon SageMakerを使用して、すべての医療ユースケースに対する分析とMLワークフローを実行しています。
次世代Amazon SageMakerの登場

これらのサービスの幅広さと深さは、お客様がデータとML関連のプロジェクトをスケールアップする際に不可欠でした。しかし、より多くのお客様が同様のデータセットを複数のユースケースで活用したいと考えるようになり、仕事を完了させるために複数のサービスを行き来することを望まなくなりました。私たちは、ビッグデータ分析、機械学習、そして今では生成AIの融合を活用して、ワークフローを加速し、コラボレーションを強化する新しい統合されたエクスペリエンスを作り出す大きな機会を見出しました。

そのため、昨日Mattが共有したように、次世代のAmazon SageMakerは、すべてのデータ分析とAIの中心となりました。ビッグデータ、高速SQLアナリティクス、機械学習、モデル開発、生成AIにわたる私たちの主要な学びを、1つの統合されたプラットフォームにまとめています。これは単なるツールの統合以上のものです。何年もの作業、数え切れないお客様との会話、そしてAWS全体のチームの集合的な専門知識を表しています。私たちはこの新しいエクスペリエンスを提供できることを大変嬉しく思っていますが、これは皆様が今日既に知り愛しているAmazon SageMakerの機能、特にトレーニング機能(現在はAmazon SageMaker AIと呼ばれています)の強化を遅らせることを意味するものではありません。


Amazon SageMaker AIは、データとMLの世界におけるイノベーションの新たな融合を体現しています。Deep Learningをより身近で拡張可能なものにするため、数十年にわたるニューラルネットワーク研究の成果の上に構築されています。これは、計算能力、ML分散システム、そしてユーザーエクスペリエンスデザインにおけるブレークスルーの集大成と言えます。Amazon SageMaker AIは、データ準備からMLモデルの作成、トレーニング、MLのデプロイメント、そして可観測性に至るまで、機械学習とアナリティクスのライフサイクルから重労働を取り除くツールとワークフローを提供します。これらすべての機能を1つの場所に集約して提供しています。
大規模基盤モデルのトレーニングにおける課題

そのため、何十万ものお客様がAmazon SageMaker AIを使用して、データを活用した基盤モデルのトレーニングとデプロイを行っています。昨年から、お客様がより迅速かつ効率的にモデルを構築できるよう、140以上の新機能をリリースしてきました。しかし、Generative AIの出現により、数十億、数百億のパラメータを持つこれらの非常に大規模なモデルのトレーニングと推論をサポートするための、新しいツールと機能が必要になってきました。

これは、大規模な基盤モデルの構築とトレーニングが複雑で、深い機械学習の専門知識を必要とするためです。まず、大量のデータを収集する必要があります。次に、機械学習アクセラレータの大規模クラスターを作成します。そして、これらのクラスター全体にモデルトレーニングを分散させます。数週間に及ぶこのプロセスの間、モデルが収束しているかどうかを頻繁に確認し、収束していない場合は適切な修正を行う必要があります。さらに、この長いプロセスの途中でハードウェアアクセラレータが故障した場合、これらの問題を手動で修正しなければなりません。このトレーニングプロセスに関連する重労働を支援するため、昨年

Amazon SageMaker HyperPodを発表しました。HyperPodは、フルスタック全体での障害から自動的に回復できる高度な回復機能を備えています。高速なチェックポイントと、アクティブなコンピュートリソース管理機能を持っています。 HyperPodは、お客様が基盤モデルをトレーニングするための選ばれたインフラストラクチャとなっています。WriterやPerplexityなどの有力なスタートアップ企業から、Thomson ReutersやSalesforceなどの大手企業まで、HyperPodを活用してモデル開発を加速しています。



しかし、この分野は急速に進化しており、かつてない規模で成長を続けているため、モデルがますます高度化する中で、モデルトレーニングに関して重要な転換点を迎えています。コンピュートリソース、エネルギー消費、データ品質に関して前例のない課題に直面しています。数十億、そして近い将来には数兆のパラメータを持つ巨大なモデルをトレーニングする現在のパラダイムは、より効率的なアーキテクチャとトレーニング方法を探求する必要性を迫っています。従来のスケーリング技術は物理的・経済的な限界に近づきつつあり、私たちの手法の根本的な見直しが求められています。
Amazon SageMaker HyperPod フレキシブルトレーニングプランの導入

月曜日にPeterが言及したように、私たちはTRN2との特殊なGPUインスタンスを備えた、最高クラスの機械学習インフラを提供するために多大な投資を行っています。しかし、特にこれらのコンピューティングリソースのセキュリティと効率的な管理に関して、皆さんがまだモデルのトレーニングと推論に課題を抱えていることも承知しています。典型的な例を見てみましょう。アクセラレータを使用して大規模言語モデルを合計30日間トレーニングする必要があるとします。これらのインスタンスは需要が高いため、長期の時間枠の中でAZやリージョン全体で利用可能なキャパシティを探すのに多くの時間を費やすことになります。

キャパシティを確保しても不連続なブロックしか得られない場合、これらを管理し、チェックポイントの保存と復元を行い、キャパシティを確保できたAZやリージョンにトレーニングデータを移動させる必要があります。そこで私たちは、コンピューティング要件と希望するトレーニング期間を定義すれば、後はSageMakerが対応してくれたら素晴らしいと考えました。そのため、本日Amazon SageMaker HyperPod フレキシブルトレーニングプランを発表できることを大変嬉しく思います。



これは考えてみると素晴らしい機能です。トレーニングプランを素早く作成してキャパシティを自動的に予約し、クラスターをセットアップし、モデルトレーニングジョブを作成することで、データサイエンスチームのモデルトレーニングに要する期間を数週間短縮できます。HyperPodはEC2キャパシティブロックを基盤として、タイムラインと予算に基づいて最適なトレーニングプランを作成します。先ほどの例を見てみると、この場合、HyperPodは個々のタイムスライスとAZを提示し、効率的なチェックポイントと再開によってモデルの準備を加速します。HyperPodは自動的にインスタンスの中断に対処し、ダイナミックに変化する世界規模のキャパシティ状況において、手動介入なしでトレーニングを継続できるようサポートします。これは間違いなくゲームチェンジャーとなるでしょう。
コンピューティングリソース管理の最適化:HyperPod Task Governanceの発表



さて、お客様が直面しているもう一つの課題は、複数のチームやプロジェクト間でコンピューティングリソースを効率的に管理する方法です。私たちは、コンピューティングリソースが有限で高価な世界に生きており、通常スプレッドシートやカレンダーで行われるリソースの利用率の最大化と効率的な割り当ては困難な場合があります。例を見てみましょう。日中にTRN2のような1000個のアクセラレータがあるとします。これらは推論に大いに活用されていますが、夜間には推論の需要が非常に低くなり、これらの高価なリソースの大部分が遊休状態となっています。

リソース割り当てに戦略的なアプローチがなければ、機会を逃すだけでなく、お金も無駄にしていることになります。「これは簡単な問題だ - あるプロジェクトから別のプロジェクトにキャパシティを移動するスクリプトを書けばいい」と思うかもしれませんが、実世界では、複数の推論プロジェクト、複数のトレーニングプロジェクト、ファインチューニングや実験プロジェクトが同時に実行され、すべてが同じコンピューティングリソースを奪い合うため、はるかに複雑になります。


これは、Generative AIで急速にスケールアップする中で、Amazonの社内チームにも当てはまる課題でした。この重労働を解消するため、私たちはコンピュートリソースを動的に割り当てるソリューションを開発しました。また、コンピュートの割り当てと使用率についてのリアルタイム分析とインサイトも構築しました。これにより、Amazon内のプロジェクト全体で高速コンピュートの使用率を90%以上に引き上げることができました。

このサクセスストーリーをCIOやCEOと共有したところ、彼らもスケールアップする際に全く同じ問題に直面しており、SageMakerでもこのソリューションを活用したいと言っていました。そこで本日、私たちはまさにそれを実現します。Amazon SageMaker HyperPod Task Governanceの発表を大変嬉しく思います。このイノベーションは、Generative AIタスクの優先順位付けと管理を自動化することでコンピュートリソースの使用率を最大化し、コストを最大40%削減することができます。


HyperPod Task Governanceを使用すると、Inferenceから Fine-tuning、Trainingなど、様々なモデルタスク間で優先順位を簡単に設定できます。そして、ビジネスリーダーや技術リーダーとして、チームやプロジェクトごとにコンピュートリソースの制限を設定でき、HyperPodが動的にリソースを割り当てて、最優先のタスクにリソースが確実に配分され、期限内に完了するようにします。また、リソースの使用状況を監視し、タスクに関するリアルタイムのインサイトを得ることで、優先順位と割り当てを常に調整してタスクの待ち時間を短縮することができます。
Amazon Bedrockとサードパーティアプリケーションの統合

顧客がSageMaker AIを活用してMLモデルの構築とトレーニングを行う一方で、MLOpsライフサイクルの様々な部分をサポートする専門的なサードパーティアプリケーションも使用したいという要望がありました。例えば、Comet、Deepchecks、Fiddler、LAKERAなどの人気のあるAIパートナーアプリケーションがあります。これらのアプリは、トレーニング実験の追跡と管理、モデルの品質評価、本番環境でのモデルパフォーマンスのモニタリング、AIアプリのセキュリティ脅威からの保護など、様々なユースケースに対応しています。

しかし、皆さんからは、SageMaker上のこれらのパートナーアプリは気に入っているものの、SageMakerと組み合わせるのに時間がかかるという声を聞いていました。例えば、適切なソリューションを見つけ、これらのアプリケーションのインフラを管理し、そしてMLOpsパイプラインをスケールアップする際に時間とリソースを費やす必要がありました。また、データのセキュリティを懸念し、複数のサードパーティツールにまたがってVPC外でデータを共有したくないと考える方もいるかもしれません。


私たちは、これらの専門的なアプリケーションのパワーと、SageMaker AIの管理機能とセキュリティを簡単に組み合わせられるようにしたいと考えていました。そこで本日、これらのパートナーアプリをすべてSageMakerにデプロイできるようになったことを発表できることを嬉しく思います。これらのアプリは、インフラのプロビジョニングや管理が不要なシームレスな完全マネージド体験を提供し、データがSageMaker開発環境のセキュリティとプライバシーから外部に出ることはありません。
Autodeskが語る3D生成AIの革新



皆様にこれらの機能を実際に体験していただけることを楽しみにしており、近々さらに多くのパートナーアプリをSageMaker AIに追加していく予定です。本日ご紹介したSageMakerのこれらの進化により、トレーニングの効率を最大化し、コストを削減することで、Foundation Modelの構築とスケーリングの方法を根本的に再考しています。次に、AutodeskのEVP兼CTOであるRaji Arasuをお招きして、SageMakerを活用して3Dデザインに革新をもたらしている事例についてお話しいただきます。 Autodeskは40年以上にわたり、デザインと製造の分野でパイオニア的存在でした。

象徴的な建造物、画期的な製品、そして印象に残るエンターテインメント - 私たちが日々体験している素晴らしいものの多くは、Autodeskのソフトウェアで作られています。今日、私たちのお客様は、かつてない需要と混乱に直面しています。


建築家や建設業者は、タイムリーで手頃な価格で持続可能なインフラや建物を建設するよう強いプレッシャーにさらされています。製造業者は、深刻なサプライチェーンの遅延と人手不足に直面しながら、新製品を迅速に市場に投入することを求められています。そして、あらゆる規模の制作スタジオが、消費者の絶え間ない新しいコンテンツへの需要に対応するのに苦心しています。


これこそが私を奮い立たせるものです - イノベーターやクリエイターが今日直面している多次元的な課題を解決する機会です:より速く、コストを削減し、より少ないリソースを使用し、あらゆる段階で持続可能性を確保すること。これらの破壊的な力に先んじてお客様を支援するため、AutodeskはAWSを活用して3D Generative AIの分野をリードしています。
AutodeskのFoundation Model開発:AWSとの協力



私たちは、現存するものとは一線を画す生成系AIのFoundation Modelを開発しています。私たちのFoundation Modelが他と異なる点とは何でしょうか?まず第一に、設計や製造のためのAI入力とその出力が非常に複雑だということです。数十億のパラメータを持つProject Berniniは、これらの課題を克服した代表的な例です。他のモデルとは異なり、このモデルはクリエイターの設計プロセスを再現する、テキスト、スケッチ、ボクセル、ポイントクラウドなどのマルチモーダルな入力を受け付けます。

第二に、汎用AIとは異なり、これらのモデルは物理法則に基づいた空間的・構造的な推論を必要とする2Dおよび3D CADジオメトリを生成するように設計されています。私たちのFoundation Modelは、ジオメトリとテクスチャを区別することで、お客様が視覚的に魅力的なだけでなく、精密で正確に製造可能なデザインを作成できるようにしています。



私はこれが大好きです。いつまでもこの話をしていられます。Autodeskは世界中の何百万ものプロジェクトで培った物理世界とデジタル世界をつなぐ深い専門知識と、最先端のAI研究を組み合わせることで、この課題に取り組むユニークな立場にあります。私たちがこの野心的なFoundation Model構築の旅を始めたとき、過去15年にわたってクラウドデータとAIのパートナーであるAWSに相談しました。


最初の課題は、大規模な設計ファイルから膨大な情報を抽出し、それをクラウドベースの粒度の細かいデータに変換することでした。一つのオフィスビルのフロアには約100MBの設計データが含まれていることを想像してください。これが30階建ての高層ビルになると3ギガバイトのデータになります。さらに、オフィスビル、住宅タワー、そしてインフラを含む複雑な開発プロジェクトまで規模を拡大してみましょう。ちなみに、これは1つのプロジェクトに過ぎません - 私たちは何百万ものプロジェクトを扱っており、その結果、様々なサイズ、形状、ワークロードを持つ数十億のオブジェクトとペタバイト規模のデータが生まれています。
AutodeskのAI活用:データ処理からモデルトレーニングまで

Amazon DynamoDBをプライマリデータベースとして使用し、これら数十億のオブジェクトを処理できる標準的なデータモデルを作成しました。何百ものパーティションにまたがる書き込みでDynamoDBの限界に挑戦し、AWSとのパートナーシップにより、スケールアップとチューニングを実現することができました。


この最適化により、高いスループットとほぼゼロのレイテンシーを実現することができました。次は、データの準備です。膨大で複雑な過去のデータに対して、特性分析、特徴量化、トークン化といった重要な処理をパイプラインで処理できるか不安でした。しかし、Amazon EMR、Amazon EKS、AWS Glue、そしてAmazon SageMakerを組み合わせることで、シームレスにスケールアップできただけでなく、高品質かつコンプライアンスに準拠した結果を提供することができました。同じクラウド内で全てを完結させることで、運用の効率化とセキュリティ態勢の強化という大きな副次的効果も得られました。


次の課題は、Foundation Modelのトレーニングをコストを抑えながら迅速に行うことでした。これは皆さんも気にされているポイントだと思います。多様なGPUオプションが利用可能な中で、Amazon SageMakerのおかげでインフラ管理の手間なく様々なインスタンスをテストすることができ、私たちの得意分野であるデータ準備、モデル開発、そしてお客様向けAI機能の開発に集中することができました。Elastic Fabric Adapterの活用でさらにパフォーマンスが向上し、分散Rayジョブの処理が加速され、予想をはるかに超える50%のトレーニング時間短縮を達成しました。




最後の課題は、大規模なFoundation Modelの推論の複雑さへの対応でした。Amazon SageMakerの自動スケーリングとマルチモデルエンドポイントにより、リアルタイムとバッチ推論の両方をシームレスにサポートし、高スループット、最小限のレイテンシー、そして最大限のコスト効率を実現しています。全体を振り返ると、Amazon SageMakerと関連するAIサービスによって実現されたこの機械学習環境は、Autodeskにとって革新的なものとなりました。Foundation Modelのデプロイメント時間を半減させ、運用コストを抑えながらAIの生産性を30%向上させることができました。
AutodeskのAI機能:設計プロセスの革新


これは社内の生産性と効率性の向上にとどまりません。私たちはこれらのFoundation Modelを基盤としたAI機能をお客様に提供し始めており、非常に好評をいただいています。スケッチの制約を自動生成したり、製品設計におけるパーツを特定して分類したりする機能です。Swamiが言及したように、これは現代的な開発以上のものです。直感的な人間とのインタラクションを確保することが重要なのです。これらは直感的なAI機能であり、お客様のデザインパートナーとして機能し、材料強度とコストなどのパラメータのバランスを取りながら、最適なデザインに絞り込むことをサポートします。これにより、単調な作業を最小限に抑え、創造性を最大限に引き出すことができます。



私たちがAWSと共に構築しているものに、大きな期待を寄せています。AIを活用して、工場がほぼゼロのダウンタイムで製品ラインを即座に切り替えられる未来を想像してみてください。また、このフロアにいるメディアやエンターテインメント関係の方々に向けて、制作スタジオがアニメーションキャラクターを入れ替え、バーチャルシーンを数秒で生成できるとしたらどうでしょうか?建築家や請負業者にとっては、AIが既存の構造物を分析し、問題を特定して、解決策を提案することができます。Autodeskが自社のAIチームの開発速度を5倍に加速できるとしたらどうでしょうか?Amazon SageMaker Unified Studioのおかげで、それが可能になるのです。



AWSとともに、私たちは現在のクリエイターたちを支援するだけでなく、次世代のクリエイターたちがよりスマートな、より持続可能な世界を構築できるよう刺激を与えています。LA 28 Olympic and Paralympic Gamesのデザイン、未来の太陽光発電スマートビークルの創造、あるいは海底を変革し再生するサンゴ礁骨格の開発など、私たちはお客様の未来を形作り、あらゆるものを作れるようにサポートしています。そして、これはまだ始まりに過ぎません。
ありがとう、Rajeev。Autodeskが長年のAWSとの協力を通じて成し遂げてきたイノベーションには感銘を受けており、Generative AIを活用して3D CADの限界に挑戦している姿に胸が躍ります。私が学部生時代にエンジニアリングを学んでいた頃は、デザインがこれほどまでに変革されるとは想像もしていませんでした。
Amazon Bedrockの進化:Inferenceプロセスの強化


AWSは、Foundation Modelの構築とスケーリングの方法を再考し続けていますが、同時に、これらのFoundation Modelを活用してGenerative AIアプリケーションをInferenceプロセスを通じて構築・展開できるようサポートしています。Inferenceとは、Foundation Modelが研究室から実世界に飛び出し、産業を変革し、命を救い、あるいは日常体験をより魔法のようなものにする決定を支援する段階です。しかし、多くの方々が大規模なInferenceの実行を目指す中で、モデルをデータでカスタマイズするためには、より高度なツールが必要となってきます。



MLサイエンティストはこうした進化するニーズに対応する専門知識を持っていますが、Generative AIアプリケーションの構築を任されている多くのアプリケーション開発者にはその専門知識がありません。そこで私たちはAmazon Bedrockを開発しました。Bedrockは、Generative AI Inferenceのためのビルディングブロックです。アプリケーション開発者が最新のモデルイノベーションとツールに一か所でアクセスしながら、Generative AIアプリケーションを簡単に構築・スケーリングできる完全マネージド型サービスです。私たちは、最適なモデルの選択、コスト・レイテンシー・精度の最適化、データを使用したモデルのカスタマイズ、安全性とResponsible AIのチェックの適用、AIエージェントの構築とオーケストレーションなど、あらゆるInference関連タスクに対応する適切なツールを備えたシームレスな開発者体験の創造に投資してきました。



Bedrockにおけるシームレスな開発者体験の創造に多大な投資を行ってきましたが、私たちはGenerative AI開発者が直面している更なる障壁にも取り組み続けています。本日は、最適なモデルの選択と最適化から始めて、これらの各領域について詳しくお話ししたいと思います。まず、開発者はアプリケーションに適したモデルを必要としています。そのため、私たちは事実上あらゆるタスクに対応できる多様なオプションを提供しています。これには、Anthropic、Meta、Mistral AI、Amazon、Stability AI、Cohereなど、主要プロバイダーによる強力なモデルが含まれます。


この会場にいらっしゃる多くの方々は、これらのモデルを既に試されているかもしれません。AIのブレークスルーが毎週のように起きているこの時代において、私たちは最新のイノベーションへのアクセスを皆様に提供し続けることに注力しています。3月には、Mistral AIのオープンウェイトを持つ高性能フロンティアモデルのサポートを開始し、7月には、世界最大の公開LLMであるMetaの405B Llama 3.1のサポートを追加しました。9月には、Stability AIの最高峰の画像生成モデル3つをBedrock上で提供開始し、そして先月には、コンピューターインターフェースを認識して対話できるAnthropicの画期的なClaude 3.5 Haikuモデルのサポートを発表しました。
Amazon Bedrockの新機能:多様なモデルとIntelligent Prompt Routing

昨日、Amazon Bedrockで新しいAmazon Novaファミリーのモデルを発表したばかりです。この新しいコレクションには、マルチモーダル理解モデル、動画・画像生成モデル、そしてコストパフォーマンスに優れたテキスト変換モデルが含まれています。Andyが述べたように、私たちの社内チームは既にこれらのモデルの一部をAmazon全体で活用しており、初期の結果は驚くべきものとなっています。しかし、Amazonらしく、最新のホットなスタートアップのモデルを含め、お客様がアクセスできるモデルの数を拡大する取り組みを止めることはありません。

そのため、本日はPoolsideが来年初めにBedrockに登場することをお知らせできることを嬉しく思います。Poolsideはソフトウェア開発ワークフロー向けに設計された素晴らしいスタートアップで、そのアシスタントはMalibuモデルとPointモデルによって動作します。コード生成、テスト、ドキュメント作成、その他の開発タスクで優れた性能を発揮します。AWSは、Poolside Assistantとそのフルマネージドモデルへのアクセスを提供する最初のクラウドプロバイダーとなります。開発者の課題に対応するモデルに加えて、最新の画像生成モデルでもイノベーションを実現できるようにしています。


最新の画像生成モデルによるイノベーションの実現に向けて、本日、Stability AI Stable Diffusion 3.5モデルもAmazon Bedrockに登場することを発表できることを嬉しく思います。Amazon SageMaker HyperPodで訓練されたこの高度なテキスト画像変換モデルは、Stable Diffusionファミリーの中で最も強力なモデルです。テキストの説明からコンセプトアート、ビジュアルエフェクトのプロトタイピング、詳細な製品画像など、高品質な画像を生成することができます。


多くのお客様から最先端のビデオ生成モデルへのアクセスを望む声をいただいており、そのためユースケースに対応するオプションをさらに追加しています。本日、Luma AIがAmazon Bedrock に近々登場することを発表できることを大変嬉しく思います。Lumaのモデルイノベーションは、AI支援による動画作成において大きな進歩を示すもので、テキストや画像から驚くべき効率性と卓越した品質で高品質でリアルな動画を生成することを可能にします。Bedrockのお客様は、Lumaの最新かつ最も高度なビジュアルAIモデルにいち早くアクセスすることができます。
Luma AIのビデオ生成技術:Amazon Bedrockでの展開



Luma AIのCEOであるAmit Jainを壇上にお迎えし、最新のイノベーションについてお話しいただきます。Swamiさん、ご紹介ありがとうございます。本日はこの場に立てることを大変嬉しく思います。Lumaの目的は、次世代のインテリジェンスを構築することです。それは私たち人間と協力し、私たちが素晴らしいことを成し遂げられるよう支援してくれるものです。インテリジェンスの未来は、非常に豊かで視聴覚的なものになるでしょう。これを実現するには、Language Modelをはるかに超えるAIが必要です。私たちの世界を見て理解し、インタラクティブなスピードで動作するAIが必要なのです。まるでAIがクリエイティブなパートナーとして協力してくれるようなものです。



Swamiが本日発表したように、私たちはLuma AIモデルをAmazon Bedrockに提供する準備を進めています。具体的には、私たちの新しいビデオAIモデル、Luma VRAY 2についてです。これが何であり、なぜ皆さんがワクワクすべきなのか、お話しさせていただきます。Luma RAY 2は、最も高性能で高品質なテキストから画像への変換、そしてテキストから動画への生成モデルとなります。これは、私たちが先駆的に開発した新しい生成モデルアーキテクチャによって実現され、皆さまの新しいデザイン、マーケティング、ビデオ制作ワークフローを可能にするために一から構築されています。


ご覧いただいているこれらのビデオは、すべてRAY 2で作成されたものです。テキストによる指示や画像フレーム、さらには撮影済みの動画から、非常にリアルな放送品質の動画を生成します。RAY 2はまた、構図、色彩、カメラワーク、アクションに対する画期的な制御を可能にします。これにより、ブランドアイデンティティ全体をモデルに取り入れ、高度な制御で望み通りの映像を作成することができます。RAY 2は、1分間の完全な動画を作成し、キャラクターやストーリーの一貫性において比類のない性能を発揮することで、動画生成の最先端を押し広げています。さらに、史上初めてリアルタイムの驚異的な速度でこれを実現します。RAY 2を使用すると、想像したことが目の前に現れるような感覚を味わえます。これにより、映画やデザイン、エンターテインメントの分野で全く新しい種類のワークフローが可能になります。

私たちは、RAY 2がクリエイティブAIの世界において大きな飛躍だと考えています。そして今、この素晴らしいモデルファミリーとその機能が、Amazon Bedrockを通じて皆様がご利用いただけるようになります。これらのモデルがどのように訓練されたのか、舞台裏をお見せしましょう。私たちのモデルは、最大規模のLLMと比べても約1000倍多いデータから学習しています。これを可能にするため、私たちは使用する計算クラスターから最大のスループットを得られるよう、トレーニングの実行のあらゆる側面を最適化しています。つまり、私たちのワークロードはAWSで使用する計算リソースに最大限の性能を要求します。私たちは、これを理解し、最先端を押し広げるモデルの構築に必要な要件を満たすクラウドプロバイダーを見つけました。

GPUコンピューティングのスペクトル全体で様々なオプションを試した結果、私たちはAmazon SageMaker HyperPodを選択しました。HyperPodは私たちにとって最も信頼性が高く、スケーラブルなクラスターでした。そのため、AWSへの投資を更に強化し、次世代モデルのトレーニングのために契約を締結してからわずか4ヶ月で、コミットメントを4倍に増やしました。

このスタック内のすべてのコンポーネントが完璧に調和して動作する必要があります。 GPU、インターコネクト、電源、ネットワーク、ストレージ、そしてソフトウェアのすべてが、安定したトレーニング環境を作り出すために極めて高い信頼性で動作しなければなりません。これが実現できなければ、フラストレーションの蓄積、コンピューティングリソースの低使用率、そして市場投入の遅れにつながってしまいます。私たちはAWSのインフラが素晴らしいものだと実感しており、グローバル規模のコンピューティングを運用するAWSの専門知識は、HyperPodのスケーラビリティに如実に表れています。

急成長中のスタートアップとして、私たちは信じられないスピードで実行する傾向にあります。AWSのチームは、オンボーディングから評価、最適化に至るまで私たちのペースに合わせて動いてくれ、HyperPod上でRay 2を記録的な速さでトレーニングすることができました。コンピューティングに加えて、AWSのチームは、Lumaのテクノロジーを世界中の顧客に届けるための流通やGo-to-Marketについても、私たちと深く協力してくれています。



これらの新しいモデルは、クリエイティブで豊かで高度な視聴覚的な次世代のインテリジェンスを構築するという私たちのミッションに、一歩近づくものです。言語モデルだけでは、私たちが目指す場所には到達できないと考えています。Luma AIの顧客のためにこの未来を実現するため、私たちは人類のデジタルフットプリント全体から学習する大規模なトレーニングとデータシステムを構築しています。現在、Lumaのモデルは、ファッションデザイナー、スタジオ、広告代理店、マーケティングチーム、そして世界中のビジュアルシンカーたちによって、アイデア創出から制作まで、彼らのワークフローの中で既に活用されています。



間もなくAWS上でこれらのモデルを試すことができるようになります。研究と製品開発を垂直統合した企業として、私たちは不可能な製品を可能にするためにこれらのモデルをトレーニングしています。私たちの人気製品からのフィードバックは、継続的にモデルを強化しており、APIユーザーの皆様は、これらの貴重な進歩の恩恵を受けることができます。Swamiさん、Lumaがre:Inventに参加する機会を与えていただき、ありがとうございます。皆様もBedrockで私たちの新しいモデルをぜひチェックしていただき、一緒に未来を築いていきましょう。
Amazon Bedrockの機能拡張:データ活用からResponsible AIまで

ありがとう、Ahmed。彼がこれらのモデルの構築を始めた年初めに、初めてChimeで通話したことを今でも覚えています。適切なツールがあれば、スタートアップが前例のないペースで進化できることは本当に素晴らしいですね。Luma AIは、AIの力を通じてビデオコンテンツ制作の境界を真に押し広げています。適切なFoundation Modelは信じられないような可能性を解き放つことができ、業界で最も革新的なモデルプロバイダーへのアクセスを提供するBedrockは、様々なユースケースやモダリティにわたる可能性の世界を切り開いています。


これらのモデルは幅広いタスクをサポートできますが、皆様が新興の専門的なタスクベースのモデルにも関心を持っていることも承知しています。例えば、EvolutionaryScaleの最先端の生物学向け言語モデルは、創薬や炭素回収などの分野で進歩を遂げています。また、IBMの Granatファミリーのモデルは、様々なビジネスアプリケーションを加速させています。お客様からは、これらの専門モデルの能力とBedrockの開発ツール群を組み合わせることで、ビジネスにさらなる価値をもたらしたいというご要望をいただいていました。そこで本日、私たちはまさにそれを実現します。Bedrock Marketplaceの発表を大変嬉しく思います。


Bedrock Marketplaceでは、主要プロバイダーが提供する100以上の新興・専門Foundation Modelにアクセスできます。Bedrockコンソールの統合されたインターフェースを通じて、これらの新興・専門モデルを発見してテストできるため、開発ワークフローを効率化できます。これらのモデルをデプロイすると、Bedrockの統一APIを使用して、Knowledge Bases、Guardrails、Agents、そしてこれらの機能に加えて、Bedrockに当初から組み込まれているセキュリティとプライバシー機能を活用できます。

Bedrockでは、あらゆるユースケースに最適なモデルを提供することをお約束します。しかし、モデルの選択は重要ですが、推論のための構築においては、それは本当に最初のステップに過ぎません。開発者は、特にコストとレイテンシーなどの要因の評価に多くの時間を費やします。これらは繊細なバランスを必要とし、一方を最適化すると通常は他方で妥協が必要になります。これは、より高性能で知的なモデルほど多くのアクセラレーターハードウェアを消費するため、コストと応答レイテンシーがモデルの精度と反比例の関係にあるためです。

今週、私たちはユースケースに応じた適切なバランスを見つけやすくする新機能を導入しました。その中には、Bedrockの新しいモデルDistillation機能が含まれており、大規模で精度の高いモデルから、より小規模で効率的なモデルへ特定の知識を簡単に転送できます。これにより、最大500%の高速化と最大75%のコスト削減が可能になります。また、主要なAIモデル向けに、最新のAIハードウェアやその他のソフトウェア最適化にアクセスできる、レイテンシー最適化推論キューも導入しました。


私たちは、このプロセスをさらに最適化することで、お客様のために解決できる問題がまだあると考えていました。推論はプロンプトから始まります。プロンプトとは、モデルに出力を生成させるために与える入力と指示のことです。モデルにプロンプトを送信し、モデルがクエリに応答すると、トークンが生成されます。トークンは、モデルが理解できる言語の断片と考えることができます。送信するトークン数が多いほど、つまりプロンプトが長いほど、コストは高くなります。このプロセスがユースケースに合わせて最適化されていない場合、特にプロンプトが頻繁に繰り返される場合、トークン生成のコストは急速に上昇する可能性があります。

例えば、法律事務所で毎日何千もの文書が出入りしているような状況を想像してください。弁護士たちが自分の事務所が担当している買収案件の最新状況を把握したいと考え、支払い構造や保証条項などについて質問をします。これらの質問をする際には、これらの文書に含まれるコンテキストが必要となるため、Promptの一部として送信することになり、その結果、クエリのレスポンス時間が遅くなりコストも増加してしまいます。


私たちは、このような問題をキャッシングで解決できることを知っていました。このシナリオでは、トークンの生成とエンコードを一度行った後、文書全体をキャッシュすることで、後続のPromptで再処理する必要がなくなり、入力トークンの処理をスキップすることができます。私たちは、お客様が精度を損なうことなく、繰り返し使用されるPromptを動的にキャッシュして、コストとレイテンシーを削減できる簡単な方法を提供したいと考えていました。そこで本日、Bedrockでのプロンプトキャッシングのサポートについてお知らせできることを嬉しく思います。これは、コスト削減の面で非常に大きな意味を持ちます。なぜなら、プロンプトキャッシングを使用することで、複数のAPIコール間で頻繁に使用されるPromptプレフィックスをキャッシュすることにより、レスポンスのレイテンシーを低下させ、コストも削減することができるからです。


始めるのは簡単で、BedrockのAPIを使用するか、PlaygroundのUIで実験して、ユースケースでどれだけの節約ができるかを確認できます。この機能により、サポートされているモデルでは、レイテンシーを最大85%、コストを最大90%削減することができます。さらに、これらの頻繁に繰り返されるPromptの最適化に加えて、開発者からは、各ユースケースに適したサイズのモデルにリクエストをルーティングすることが難しいという声も聞かれました。一部のPromptでは、高度で高性能なモデルが必要な場合もありますが、実際には非常にシンプルで高速なモデルで十分な場合もあります。現在、開発者は各ユースケースに最適なモデルを見つけるために、様々なモデルで実験を行うのに多くの時間を費やしています。


例えば、旅行計画のWebサイトを管理していて、様々な顧客の質問に対応する最適なモデルを選択したいとします。まず、「12月に家族で訪れるのにおすすめの場所を提案してください」といったシンプルなクエリをテストします。同じファミリーの3つのモデルでテストを行い、それぞれのレスポンスの速度、精度、コストを評価します。その結果、より小規模で安価なModel Aが、精度とパフォーマンスのバランスが適切であることがわかります。


次に、より複雑なシナリオをテストします:「ヨーロッパの複数の暖かい気候の目的地を巡る7日間の旅程を作成してください。最終日はパリで友人と会う予定です。」各モデルでこのクエリを評価すると、最も高度なModel Cがこのリクエストのニュアンスを処理できることがわかりますが、よりシンプルな問題に対しては過剰な性能かもしれません。ここで、数百の異なるユースケースや想定される質問に対して、それぞれのリクエストをルーティングするためにこれを繰り返す必要があることを想像してください。どのPromptをどのモデルにルーティングするかを手動でコーディングし、顧客のリクエストパターンが変化したり、新しいモデルが利用可能になったりするたびに、これを何度も繰り返す必要があります。


私たちは、あらゆるユースケースで最適なプロンプトを適切なモデルにルーティングできるようにしたいと考えていました。そこで本日、Amazon Bedrockの新機能であるIntelligent Prompt Routingの発表をさせていただきます。この機能は、モデルファミリー内の異なるFoundation Modelにプロンプトをルーティングし、応答のコストと品質の最適化を支援します。使用したいモデルを選択し、各リクエストのコストとレイテンシーの希望するしきい値を設定するだけで、Bedrockが最も適切な応答を最低コストで提供できるモデルに動的にリクエストをルーティングします。実際、Intelligent Prompt Routingは精度を損なうことなく、コストを最大30%削減することができます。これらの機能により、様々なユースケースにおける推論の最適化の試行錯誤を省くことができます。
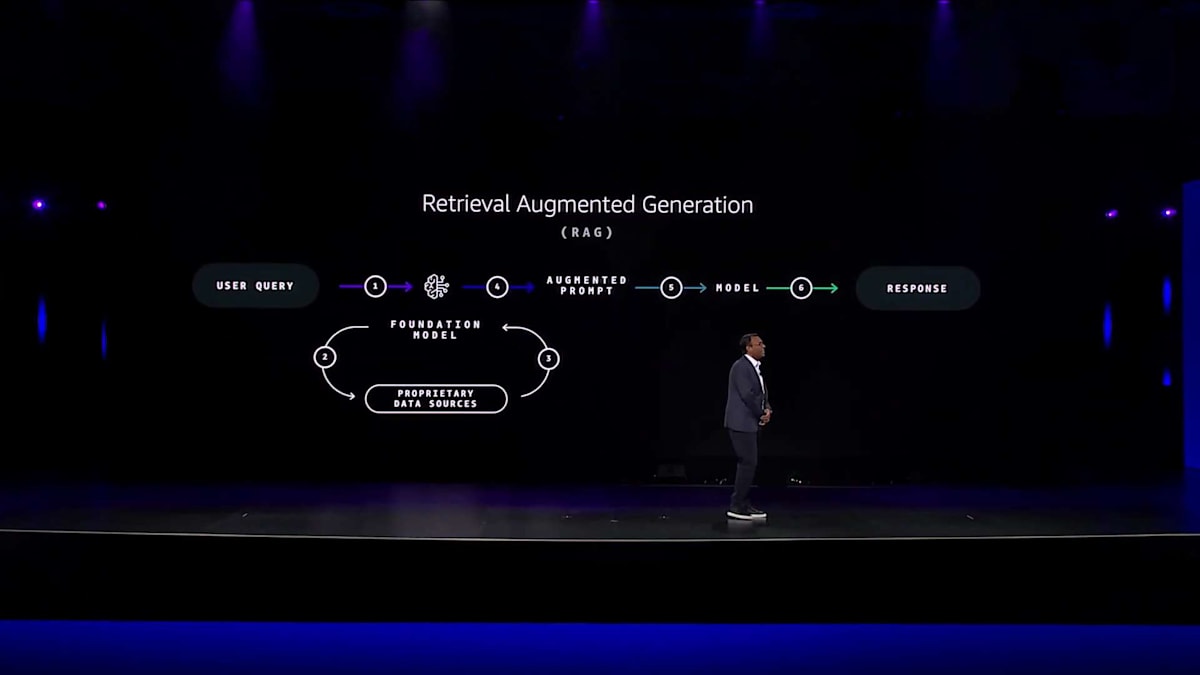

お客様独自のエクスペリエンスを構築する際、真の魔法は、これらのモデルをお客様のデータでカスタマイズする時に起こります。これを実現する最も簡単な方法は、Retrieval Augmented Generation(RAG)です。RAGを使用すると、独自のデータでプロンプトを強化し、お客様からの質問やリクエストに対してより良い応答を生成できます。例えば、オンラインのコンピュータ販売店を運営していて、お客様が複雑な互換性に関する質問をよくする場合を想像してみてください。お客様がGenerative AI搭載のチャットアプリで最近購入したラップトップの注文状況について質問した場合、注文管理システムや配送データベースからのデータを含めることで、モデルにより多くのコンテキストを提供し、より正確で関連性の高い応答を生成することができます。

このRAGのプロセスは一見シンプルに見えますが、実際には相当な手作業が必要です。最高クラスのEmbeddingモデルでデータをインデックス化し、Vector Databaseに埋め込みを保存し、応答生成時にカスタムの検索メカニズムを作成し、適切なモデルでプロンプトを強化する必要があります。このプロセス全体が、RAGを効果的に実装することを困難にしています。私たちは、Amazon Bedrock Knowledge Basesを使用して、RAGワークフロー全体を簡単に管理できるようにしました。Knowledge Basesは、コンテキストに応じた関連データで応答をカスタマイズできる、フルマネージドのRAG機能です。データソースの統合とクエリの管理のためのカスタムコードを書く必要性をなくし、完全なRAGワークフローを自動化します。


Ericsson、F1、Travelersなどのお客様は、Knowledge Basesを使用して、より正確で魅力的な出力を生成しています。Amazon Bedrock Knowledge BasesはRAGワークフローの強固な基盤を提供しますが、膨大な企業データソースに対する効率的で高精度な検索は依然として課題となっています。ここでAmazon Kendraの出番です。Kendraは、機械学習を使用してより関連性の高いデータを表示するのに役立つ、インテリジェントな企業検索サービスです。
Amazon Kendraは、ベクトル埋め込みの作成と管理を支援しながら、そのセマンティック理解を活用してアプリケーションの検索精度を向上させることができます。40以上の企業ソースに対応した組み込みコネクタを備えています。お客様は、最適なEmbeddingモデルの選択、ベクトル次元の最適化、検索精度の微調整を支援する、すぐに使えるVector Indexを求めていました。また、Knowledge BasesやGenerative AIスタック全体とシームレスに統合することも望んでいました。


本日は、Amazon Kendra Generative AI Indexの発表をさせていただきます。この機能により、40以上のエンタープライズデータソースに対応したコネクタを備えた、Amazon Bedrockのための管理型検索機能が提供されます。これをBedrock Knowledge Baseとして利用し、エージェント、プロンプトフロー、Guardrailsなどの機能を備えたAIアシスタントを構築できます。さらに、Amazon Q Businessアプリケーションなど、他のユースケースでもこのコンテンツを活用できます。エンタープライズアプリケーション全体のデータ接続を容易にするだけでなく、Generative AIアプリを構築する際により多くのデータを扱えるようにしました。これには、データウェアハウスやデータレイクに格納された構造化データ、ドキュメントやPDFなどの非構造化データ、さらには画像や動画とテキストを組み合わせたマルチモーダルデータも含まれます。


まず、構造化データについて詳しく見ていきましょう。企業は通常、すべての運用データをデータウェアハウスやデータレイクに保存しています。しかし、RAGで構造化データを活用するには、テーブルの1行を参照するだけでは不十分です。例えば、「先月のWashington州における最も重要な製品カテゴリを売上高で教えて」といった自然言語クエリを考えてみましょう。このリクエストを処理するには、フィルタリング、テーブルの結合、データの集計を行うSQLクエリを作成する必要があります。この自然言語からSQLへの変換プロセスは、ドキュメントに対するVector Storeと同様に重要です。


会場の多くの方が「なぜそれがそんなに難しいのか?単にLLMにプロンプトを与えれば良いのでは?」と考えているかもしれません。しかし、実際にはそれほど単純ではありません。効果的に実現するには、カスタマイズされたスキーマ埋め込み、クエリ分析、データサンプリング、クエリ修正ループなどの技術を実装し、同時にプロンプトインジェクション攻撃などのセキュリティ上の懸念にも対処する必要があります。これらの課題に対処するため、開発者は正確なSQLクエリ生成のために複雑なカスタムSQLソリューションの構築に時間を費やしています。



本日、私たちはこの問題をお客様のために解決します。Bedrock Knowledge Basesが構造化データの検索をサポートすることを発表できることを嬉しく思います。これにより、多くの新しいGenerative AIのユースケースが可能になります。これは、Generative AIアプリケーションのために、保存場所にあるすべての構造化データをネイティブにクエリできる、最初の完全マネージド型のRAGソリューションの1つです。Amazon SageMaker Lakehouse、Amazon Redshift、そして最近発表されたIcebergをサポートするS3 Tablesのデータに対して、自然言語でクエリを実行できます。Knowledge Basesは自動的にSQLクエリを生成・実行してデータを取得し、モデルの応答を強化します。また、スキーマやデータに適応し、クエリパターンから学習し、精度を向上させるためのカスタマイズオプションも提供します。


RAGで構造化データに簡単にアクセスできるようになったことで、より強力でインテリジェントなエンタープライズ向けGenerative AIアプリケーションを開発できるようになります。しかし、多くの方々がRAGアプリケーションの開発を続ける中で、関連性と精度への期待はますます高まっています。RAGで関連性の高い応答を生成することは特に難しい課題です。なぜなら、情報は単一のドキュメントに含まれているわけではなく、通常は複数のソースや複数のドキュメントに分散しているからです。例えば、スマートホームデバイスの不具合についてオンライン小売業者に問い合わせるお客様のシナリオを考えてみましょう。オンラインアシスタントは、お客様の購入履歴、過去のチケット、製品詳細、関連するナレッジベース記事など、複数の情報を素早く結び付ける必要があります。しかし、これらの様々なデータソースを結びつけて、カスタマイズされた関連性の高い応答を提供することは困難です。

このような情報をすべて捕捉するために本当に必要なのは、Knowledge Graphです。Knowledge Graphは、まるでウェブのように、異なる情報の断片をつなぎ合わせることでデータ間の関係性を作り出します。この例では、顧客がノードとなり、購入履歴には購入ステージを通じて、サポートチケットには送信エッジを通じて接続されます。これらの関係性がGenerative AIアプリケーション用のグラフ埋め込みに変換されると、システムは簡単にこのグラフを走査し、これらのつながりを取得して、顧客データの全体像を把握することができます。


Knowledge Graphを使用することで、システムは最近の購入を既知の問題と関連付け、関連するサポート情報を見つけ、解決策を提案することができるようになります。しかし、Knowledge Graphを使用したRAGシステムの構築には高度な専門知識が必要です。開発者はRAGを活用したアプリケーションにグラフを統合するためのカスタムコードを書き、より適切な応答を生成するためにプロンプトを強化する追加作業が必要になります。私たちは、このプロセス全体をもっと簡単にできると考えていました。

そこで本日、Amazon Bedrock Knowledge BasesがGraphRAGをサポートすることを、大変嬉しく発表させていただきます。これは、Amazon Neptuneを使用して自動的にグラフを生成し、様々なデータソース間の関係性をリンクする全く新しい機能で、グラフの専門知識がなくても、より包括的なGenerative AIアプリケーションを作成することができます。また、Knowledge Basesは接続関係とソース情報を明示することで、より良いファクトチェックのための説明可能性も向上させています。GraphRAGのサポートにより、お客様は単一のAPI呼び出しを通じて、アプリケーションのためのより正確な応答を生成できるようになりました。

最後に、開発者がマルチモーダルコンテンツをGenerative AIで扱う際に直面する課題をいくつか見てみましょう。企業のデータの大半は非構造化で、ドキュメント、ビデオ、画像、音声ファイルなどのマルチモーダルコンテンツに含まれています。このようなデータをGenerative AIアプリケーションで簡単に活用できたら素晴らしいと思いませんか?しかし残念ながら、非構造化データは抽出が難しく、使用できる状態にするには処理や変換が必要です。



具体的な例を見てみましょう。あなたがストリーミングサービスで働いていて、TV番組や映画の中に関連性の高い広告をインテリジェントに配置するアプリケーションを開発したいとします。これを実現するためには、まず何十万時間もの動画コンテンツを分析してインデックス化する必要があります。それと並行して、すべての広告もインデックス化し、関連性の高い広告をマッチングして、視聴者により良い体験を提供し、広告主により高いROIを届けるための完璧なタイミングで配置する必要があります。


例えば、大手銀行に勤務していて、各ローン申請パッケージ内の非構造化データを活用した自動ローン承認ワークフローを構築したいとします。パッケージ内の各文書を分類・分離し、データを抽出して正規化し、データベースに読み込む前に変換する必要があります。業界や分野に関係なく、ほとんどの方がこのプロセスをご存知だと思います。データベースの世界では、これはETLと呼ばれています。

私たちは、マルチモーダルコンテンツをGenerative AIで活用しやすくしたいと考えました。そこで本日、Amazon Bedrock Data Automationの発表を嬉しくお伝えします。この機能は、コードを書くことなく、非構造化のマルチモーダルコンテンツを構造化データに自動変換し、Generative AIアプリケーションを強化します。これは非構造化データのためのGenerative AI駆動型ETLだと考えています。この機能を使用すると、単一のAPIですべてのマルチモーダルコンテンツを大規模に抽出、変換、処理することができます。スキーマに合わせたカスタム出力の生成、Generative AIアプリケーション用のマルチモーダルコンテンツの解析、あるいは単純に分析用の変換データとしての読み込みが可能です。

Amazon Bedrock Data Automationは、信頼性スコアを提供し、レスポンスを元のコンテンツに基づいて検証することで、ハルシネーションのリスクも軽減します。自動化された請求処理ソリューションを提供するデジタル企業のSymbeoなど、お客様はすでにこの機能で成果を上げています。Symbeoは、保険金請求や医療費請求書をアプリケーションデータに抽出・変換するプロセスを効率化し、請求処理の効率性を高め、顧客の処理時間を短縮しています。


私たちは、コンテキストをより意識した Generative AI アプリケーションを構築できるよう、すべてのデータを活用する力を皆様に提供しています。しかし、Generative AIが様々なモデルやデータタイプにわたって進化を続ける中、開発者が適切な保護措置を確実に実装することは難しい場合があります。そこで、私たちはAmazon Bedrock Guardrailsを提供し、アプリケーションに設定可能な保護機能を実装できるようにしています。

Guardrailsは、Amazon BedrockのFoundation Modelsがネイティブで提供する保護機能と比べて、有害なコンテンツを最大85%多くブロックすることができます。暴力や侮辱などの有害なテキストコンテンツを検出してブロックできるコンテンツフィルターを備えています。また、ハルシネーションを検出・フィルタリングするコンテキストグラウンディングチェックも提供します。今週、新しい自動推論チェック機能を発表しました。これにより、Amazon Bedrockは、モデルが行う事実に基づく記述が、数学的な検証に基づいて正確かどうかをチェックし、その結論に至った過程を正確に示すことができます。


最新のマルチモーダルモデルをより多くの方々がユースケースに活用されるようになるにつれ、非構造化データに含まれる有害なコンテンツにも対処する必要が出てきています。そこで本日、Amazon Bedrock Guardrailsにマルチモーダル有害性検出機能が追加されたことをお知らせできることを嬉しく思います。この機能によりBedrockの設定可能な保護機能が画像データにも拡張され、安全なマルチモーダルの生成AIアプリケーションを構築できるようになりました。例えば、オンライン広告のクラシファイド企業では、ヘイト、暴力、不適切な行為などの有害な画像コンテンツとユーザーが接触することを防止できるようになります。このアップデートは、ファインチューニングされたモデルを含め、画像コンテンツをサポートするAmazon Bedrockのすべてのモデルで利用可能です。
AIエージェントの進化:複雑なタスクの自動化

ここまで触れてきたモデルの選択からResponsible AIまで、すべてのツールと課題は、より多くの方々がFoundation Modelを活用して問題解決や代理アクションを行うようになるにつれ、ますます重要になってきています。AIエージェントと同様に、エージェントは受動的な言語理解から能動的な推論とマルチステップの問題解決へと私たちを導き、これまでは不可能だった新しいレベルの自動化を実現します。エージェントは特定の目的を達成するように設計されており、熟練のプロフェッショナルのように複雑なタスクを管理可能なステップに分解することができます。


具体例を見てみましょう。私の妻は素晴らしい母親であるだけでなく、訓練を受けたパティシエでもあり、食事に関して非常に高い基準を持っています。そのため、私は最高のレストランを見つけることを真剣に考えています。しかし、元大学院生の私はいつも思うのです。素晴らしい食事より素晴らしい無料の食事の方がいいに決まっている、と。re:Inventのような大規模なカンファレンスでは、スポンサーイベントやパーティーで最高の食事を見つけるのは非常に難しいものです。そこで、マルチエージェントワークフローを使って、お腹が空いて機嫌が悪くなる前に無料の食事を見つける方法を見てみましょう。
最初のエージェントは、イタリアン料理が食べたい、肉や魚介類は食べられないといった、あなたの食事の好みを取得します。次のエージェントはカンファレンスイベントを分析して、どのレストランがパーティーを開催しているかを判断し、3番目のエージェントはレストランとスポンサーに関する詳細情報を収集して、どのパーティーに参加するかの判断を手助けします。4番目のエージェントはパーティーの開始時間と到着までにかかる時間を教えてくれ、最後のエージェントがあなたのカンファレンス情報を使って自動的にイベントに登録してくれます。この楽しい例からわかるように、利用可能なエージェントはあなたに代わって行動を起こすことができます。


お客様が独自のエージェントを簡単にスケールアップできるよう、私たちはAmazon Bedrock Agentsを提供しています。Bedrock Agentsは、複雑なワークフローのオーケストレーションと自動化のために特別に設計された高度なAIコンポーネントを提供します。Foundation Modelの言語理解能力と推論・実行能力を組み合わせ、高レベルの目標を順序立てたステップに分解し、必要な計画を立てることができます。そして今週から、Bedrock Agentsはマルチエージェントコラボレーションをサポートし、複雑なワークフローを実行するための専門化されたエージェントの構築と調整が容易になりました。PGA TOURを含む多くのお客様がBedrock Agentsを使用して、よりイノベーティブで関連性の高い体験を作り出しています。PGA TOURはリアルタイムのデータとインサイトを変換するためにBedrock Agentsを活用しています。


個々のファンの好みや言語に合わせたエンゲージメントの高いコメンタリーを提供できます。このパーソナライズされたAIパワードソリューションは、適切なモデルの選択から、モデルの最適化、データを活用したモデルのカスタマイズまで、Amazon Bedrockの包括的な機能を活用する方法の一例に過ぎません。Generative AIを活用して構築するために必要なすべての機能が、Amazon Bedrockに集約され、開発者体験を簡素化し、組織がAIの力を最大限に引き出せるようになっています。
Rocket CompaniesのAI活用事例:住宅ローン業界の変革


ここで、RAGからAgentまで、住宅ローンや金融サービス業界における変革を推進している企業をご紹介したいと思います。Rocket CompaniesのCTOであるShawn Malhotraさんをお迎えしましょう。私はRocketに入社してまだ7ヶ月足らずです。20年のキャリアの中で会社を変えたのはこれが2回目だけなので、この転身には説得力のある理由がなければなりませんでした。Rocketには素晴らしい点が多くありましたが、最終的に私の決断を後押ししたのは、最先端のテクノロジーを活用して、誰もが住宅を手に入れられるようにするという非常に価値のあるミッションに貢献できる機会を見出したからです。


住宅所有は「アメリカンドリーム」の礎石ですが、その夢を実現するまでの道のりには、今でも摩擦とストレスが満ちています。実際、ミレニアル世代とGen Z世代の住宅購入者の60%が、そのプロセスで frustrationの涙を流しているほどです。これは夢というよりも悪夢のように聞こえます。山のような書類作業、手作業のプロセス、深いパーソナライゼーションの欠如など、詳しく見ていくと、適切なデータと最新のGenerative AIのようなツールを使えば、これらの課題の多くは解決可能だということがわかります。

長年にわたり、Rocketは業界のパイオニアでした。住宅ローンをインターネットに持ち込んだ最初の企業であり、モバイルに持ち込んだ最初の企業でもあります。そして今、AIによって新たなレベルへと進化させています。この業界はDisruptionを待ち望んでおり、私たちの10ペタバイトのデータ、住宅所有の旅全体を通じたクライアントの360度ビュー、そして素晴らしい人材とAWSとの緊密な協力により、そのDisruptionは既に始まっています。しかし、これはまだ始まりに過ぎず、氷山の一角に過ぎません。


AIは世界にとってもRocketにとっても新しいものではありません。私たちは2012年に最初のAIモデルをリリースしました。今日では210以上の独自モデルが本番環境で稼働していますが、私たちは新しいAIの時代に突入しています。これは単なるHypeではありません。私はCTOとして、一般的に新しいものや非現実的な期待に対して少し懐疑的な立場ですが、今回は違います。これは、私の子供たちが私や妻に共感できなくなるようなテクノロジーであり、それは急速に近づいています。

私たち Rocket は、クライアントのニーズに応えてこの時代を乗り切るためには、AWS のような世界最高のパートナーと手を組む必要があることを理解しています。AWS Executive Briefing Center や Gen AI Innovation Center の AWS チームは、私たちの変革を支援する重要な同志として活躍してきました。彼らは、私たちの業界とクライアントに合わせた、スケーラブルでインテリジェントなソリューションの設計と構築を支援してくれました。AI エージェントのオーケストレーションや作成といった新しいコンセプトを活用するためのフレームワークを定義する際にも、共に取り組んでくれました。

皆さんと同様、私たちも AWS の「バックワード・ワーキング」や経験に基づく加速というアプローチを高く評価しています。これらの手法により、より迅速かつ効果的にイノベーションを起こし、フィンテック業界の最も厄介な問題を解決することができています。先ほど、Generative AI はただのブームではないと申し上げましたが、今日の私たちのビジネスとクライアントにもたらしている具体的な成果についてお話ししたいと思います。その中心となっているのが、私たちが特許を取得した AI 駆動型プラットフォームです。これは、数多くの AI エクスペリエンスを構築するための基盤となっており、Amazon Bedrock と AWS によって支えられています。この緊密な協力関係が、私たちの成功には不可欠でした。


このプラットフォームを基に構築したものの一例が、クライアントの住宅所有への道のりをガイドする AI パワードエージェント機能です。このパーソナライズされたエージェントと今すぐチャットすることもできますが、基調講演の後まで待ってください。実際に体験していただければ、その利点を直接感じていただけると思います。



私たちのクライアントの80%と同様に、電話よりも AI チャットを好み、ローン契約の成立確率が3倍になることを実感していただけるでしょう。これらの数字は、Agentic AI のようなバズワードを実際の価値に変換できることを示しています。この例では、初めて住宅を購入する方の夢への道のりをサポートし、対話の70%を自律的に処理している様子がわかります。この時間の節約により、私たちのチームはクライアントにより集中し、より個人的な質問に答え、ニーズをより深く理解し、AI と Amazon Bedrock の大きなサポートを受けながら、真に人間中心のエクスペリエンスを提供することができています。
Amazon Bedrock を活用した AI プラットフォームにより、文書処理、メモ作成、住宅ローンに関する複雑な文書の検索と質問への回答など、多くのタスクを自動化しています。これは私たちのビジネスとクライアントにとって何を意味するのでしょうか?初回での問題解決率が10%向上し、ビジネスの一部では、クライアントが回答を得るまでの時間が68%短縮されています。これは実際の価値であり、実際の人々が助けられているということです。そして願わくば、私たちがサービスを提供している住宅所有者の方々の涙を減らすことができればと思います。

Generative AI はもう一つの大きな影響をもたらしました - それはイノベーションの民主化です。私たちは社内でNavigatorというノーコードツールを開発しました。これにより、技術者だけでなく、会社の全員が世界最高のLLMにアクセスできるようになりました。RAG(Retrieval Augmented Generation)という用語を知らなくても、そのようなAIパターンを活用できます。また、ビジネスパートナーが技術チームを介さずに、データから深い洞察を得られるよう、データベースクエリを自動生成することもできます。これにより、会社全体の想像力が解き放たれ、7月の立ち上げ以降、イノベーションのペースが加速しています。



わずか数ヶ月の開発期間で、2,400人のチームメンバーがこのツールを使用し、LLMとの68,000回のやり取りを行い、ユーザーは133の カスタムアプリを開発しました。これらはすべてAmazon Bedrockによって実現されました。私たちがわずか数ヶ月で構築できたものは、これがなければはるかに長い時間がかかっていたでしょう。全体として、Bedrockを活用したAIで大きなビジネス価値を生み出しています。効率性を向上させ、クライアント体験を強化し、数ヶ月や数年ではなく、数週間から数ヶ月で複数の製品や体験にAIを迅速に展開できました。これらを合計すると、年間80万時間の チームメンバーの時間を節約できています。これにより、彼らは本来の仕事 - クライアントの夢を深く理解し 、その実現を支援することに集中できるのです。
AWSチームには感謝しています。彼らは私たちの歩みの一つ一つに寄り添ってくれました。両組織ともイノベーションと起業家精神がDNAに組み込まれており、それが協働をとても容易にしています。Rocketでは、ISMsと呼ぶ基本的な価値観と原則があります。その中のいくつかは、私たちがAWSとともに歩んできた道のりを本当によく表しています:「より良い方法を見つけることへの執着」と「イノベーションは称賛される。実行は崇拝される」です。私たちは、AIで住宅所有のプロセスを変革する方法を見出し、そのビジョンを裏付ける実際の成果を出すことに、絶え間なく取り組んできました。

大きな進歩を遂げましたが、これはまだ始まりに過ぎません。先ほどご覧いただいたクライアント向けAIアシスタント にリアルタイムでコンテキストを意識したパーソナライゼーションを導入するなど、AWSと一緒に大きなプロジェクトに取り組んでいます。この技術の可能性を追求し続けることで、素晴らしい成果が生まれるでしょう。オンラインで本を買うように簡単に家が買えるようになるまで、私たちは止まりません。そうなって初めて、すべての人の住まいを支援するという私たちのミッションを本当に実現できたと言えるでしょう。
Amazon Qの進化と教育分野におけるAIの活用


ありがとうございます、Chan。Rocket Companiesがこれらのテクノロジーを ビジネスに活用している様子を見るのは素晴らしいですね。特に、エージェント型システムの未来に向けて期待が高まります。これらのエージェント型システムは、仕事をより速く完了するために不可欠となるでしょう。そのため、私たちはAmazon Qのようなツールを提供しています。Qを使用すれば、開発者からデータアナリスト、ビジネスユーザーまで、従業員全体の生産性を向上させる Generative AIをすぐに始められます。Amazon Bedrockを基盤とし、強力なFoundation Modelとエージェント機能を備えており、明確な目的と方向性を持って複雑な問題に取り組むことができます。Amazon Q Developerを例に取ると、

AWSのエキスパートであり、ソフトウェア開発のための最も有能な生成AIパワードアシスタントです。昨日、Mattは、コード生成や機能開発からテストの作成やドキュメント作成、レガシーアプリケーションの変換の加速、開発タスクの効率化や運用インシデントのデバッグに至るまで、エンドツーエンドの開発ライフサイクル全体を通じてQがどのようにサポートできるかについて説明しました。



Q Developerは、これまでに素晴らしい進歩を遂げています。実際、ソフトウェア開発向けのQのエージェントは、現在SWE Benchの検証済みリーダーボードで最高のパフォーマンスを示しています。今日、Qはこの人気の高いベンチマークで54.8%のソフトウェア開発の問題を解決できます。これは、アドオンコーディングの問題を解決する際の標準的な指標となっています。この数字は、わずか7ヶ月前にリーダーボードのトップに立った時と比べて2倍以上の問題を解決できるようになったことを示しています。Qチームによるこの改善のペースには驚かされますし、私たちのお客様も同様です。DFL Bundesliga、United Airlines、BT Groupなどのお客様は、コード生成、プラットフォーム統合、JavaのアップグレードにおいてQを活用しています。


Qを最初にローンチした時、私たちの主な焦点は従来のソフトウェア開発ライフサイクル全体での生産性向上でした。しかし、その機能をさらに探求していく中で、日常的な開発タスクをはるかに超えた可能性があることにすぐに気づきました。また、MLモデルをより速く構築するためにQが大きな可能性を持っていることも分かりました。モデルの構築には高度なML専門知識が必要で、特徴量の選択や特徴量エンジニアリング、最適なアルゴリズムの選択、そしてトレーニング、ハイパーパラメータのチューニング、モデルの評価など、時間のかかるタスクが含まれます。

Amazon SageMaker Canvasなどのツールを使ってML全体のワークフローを扱い、MLモデルを構築することを容易にしてきましたが、特にMLモデル開発の経験が少ないお客様のために、生成AIの力を活用してさらに多くのことができると確信していました。そこで本日、SageMaker CanvasでQが利用可能になったことを発表できることを嬉しく思います。この機能により、1行のPythonも書いたことがない方でも、自然言語でビジネス上の課題を述べるだけで、Qがモデル構築のプロセスを案内してくれます。


例えば、製造業で働いていて、製品が品質検査に合格するか不合格になるかを予測するモデルを構築したいとします。SageMakerカタログにあるテストデータセットを使用すると、Qが問題を一連のタスクに分解するステップバイステップのガイドを提供します。その後、データの準備、ML問題の定義、モデルの構築、評価、デプロイまでサポートしてくれます。

この機能が皆様のML Model開発にどのように役立つのか楽しみですが、私たちはAmazon Qを開発者タスクやMLワークフローのためのアシスタント以上のものとして設計しました。また、2つのGenerative AI搭載アシスタントによって、ビジネスユーザーの業務効率化も実現します。1つ目はAmazon Q Businessです。これは、従業員が企業システムに保存されているデータや情報に簡単にアクセスできるようにするものです。Q Businessは、質問への回答、要約の提供、さらにはコンテンツ生成により、従業員の効率を向上させ、組織に素早く価値をもたらします。




例えば、NFLはQを活用してプロデューサー、編集者、クリエイターのためのGenerative AIアシスタントを作成し、コンテンツ制作を加速させました。このソリューションにより、新入社員のトレーニング時間が67%削減され、従業員は最大24時間かかっていた質問への回答が数秒で得られるようになりました。この生産性の向上について考えてみてください。Q Businessに加えて、私たちはQuickSightとQを組み合わせることで、ビジネスユーザーのデータ駆動型の意思決定を加速させています。QuickSightとQは、Generative AIの力を活用して、より多くのユーザーにインサイトを提供します。Qはダッシュボードの自然言語による要約を提供し、データに関する質問に対して複数の視覚的なチャートやグラフを用いて回答することで、意思決定のスピードアップを支援します。お客様は様々な業界やユースケースでQuickSightとQを活用してビジネスインサイトを引き出しています。


その一例がFormula Oneレーシングです。Formula Oneエンジンの組み立て工程において、Scuderia Ferrariは、エンジニアがより良いインサイトを得られるよう、膨大なデータへのアクセスを民主化する機会を見出しました。Qのダッシュボード作成機能により、エンジニアは自然言語を使用してダッシュボードを作成し、製造プロセスにおける異常を発見することができます。Business IntelligenceとGenerative AIの融合は、Amazon Qを通じて、お客様に新たな可能性を提供し続けます。

これらのモデルがより強力になるにつれ、私たちはデータ駆動型の意思決定をさらに加速させる方法があると考えました。今日、多くのビジネスユーザーは、データに対する単純なQ&Aでは直接答えられない質問に直面しています。私はAmazon DynamoDBを数年前にローンチした際にこれを経験しました。最適な無料利用枠の期間を決定しようとしていた時のことです。私たちの大きな疑問は、すぐに多くの小さな疑問に分かれ、それぞれがデータ分析を必要とし、場合によっては問題を解決するために仮説的なシナリオを作成する必要がありました。例えば、ユーザーあたりのコストを決定するために、インフラコストと各オプションについての詳細な分析を必要とする使用シナリオを組み合わせなければなりませんでした。



DynamoDBのローンチは今では過去の出来事となりましたが、様々なスプレッドシートで何時間も、時には何日もかかる面倒な分析に費やすビジネスユーザーにとって、この問題は今でも存在します。私たちは、Amazon Qがこのようなシナリオ分析をお客様にとってより簡単にできると確信していました。そこで本日、QuickSightとQにおけるScenariosのプレビューを発表できることを嬉しく思います。これは、ビジネスユーザーが自然言語を使用して複雑なビジネス上の問題を解決するのをQが支援する、エキサイティングな機能です。Qは関連するデータを見つけ、分析を提案し、各ステップを計画して実行し、詳細なインサイトと提案を提供します。この機能により、ビジネスユーザーは従来のスプレッドシートスタイルの分析ツールと比べて最大10倍速く分析を実行できるようになります。





実際の動作を見てみましょう。「最適な無料トライアル期間はどのくらいか?」というようなシナリオを説明できます。すると、Qは私のダッシュボードから関連データを検索し、分析の準備を行います。自動的に問題を、答えるべきより小さな質問に分解してくれます。分析する質問を選択し、この分析が始まっている間に、さらに質問を追加することができます。例えば、すべてのトライアルが30日間だったらどうなるかを尋ね、無料トライアルが収益に与える影響を探るための仮説的なシナリオを追加できます。分析の修正も簡単で、例えば、0日トライアルとして表示される直接購入を、Qにこれらのレコードを無視するよう指示することで除外し、更新された回答を得ることができます。




それぞれの回答により、情報に基づいた意思決定に必要なデータとインサイトを簡単に得ることができます。例えば、トライアル期間全体にわたるコンバージョン率の変動や、長期トライアルには収穫逓減点があるというインサイトなどです。作業を進めるにつれて、Qは各ステップを考慮し、私たちが回答にたどり着いた過程を確認し、必要に応じて変更を加えることができます。Q と QuickSight のシナリオ機能はビジネス分析を劇的に加速させますが、ツール、データ、AIの融合は、Amazon Qを使用する顧客のインサイト獲得を可能にするだけでなく、データレイク上での高速SQLアナリティクスとビッグデータ処理を実現し、Amazon SageMaker AI上でのモデルトレーニングを加速し、Amazon Bedrock上で新しいGenerative AI駆動のエクスペリエンスを生み出しています。これらすべてが次世代Amazon SageMakerによって、分析とマシンラーニングのワークフロー全体を効率化するために統合されています。

Amazon SageMakerを通じてこれらすべてのイノベーションを活用する方法をご紹介するため、Shannon Kaliskyをステージにお迎えしたいと思います。

1,330,432GB - これは、携帯電話だけを数えても、この部屋に今存在するデータ量のおよその値です。私たちはデータに囲まれており、ほぼすべてのタスクにおいて、データ、AI、分析の融合が進んでいるのを目にします。しかし同時に、それに伴う複雑さも目の当たりにしています:適切なデータセットを探し回ることや、仕事を完了させるためだけにコンソール間を行き来する煩わしさ、そして協力することの難しさです。でも、もしこの混沌に秩序をもたらし、適切なデータを簡単に見つけ、必要なツールをすべてひとつのインターフェースで利用でき、他の人々とシームレスに協力できるとしたらどうでしょう?次世代のAmazon SageMakerなら、それが可能です。


もう少し詳しく見てみましょう。ロボティクスのスタートアップ企業のデータワーカーだと想像してください。私たちの課題は売上を増やすことです - まさにデータの混沌が大好きな、あいまいな大きな問題です。でも、やってみましょう。売上を増やしたいということは、リードを増やす必要があるということです。では、最初から最後まで見ていきましょう。ステップ1:より多くのリードを獲得する - これは明白ですね。ステップ2:分析 - はい、とても論理的です。そしてステップ3:リードの優先順位付けです。どのリードを追求すべきか知る必要があります。新しいSageMaker Unified Studioがどのように役立つか見てみましょう。



それでは、ステップ1から始めましょう。この会場やライブストリームの様子からは想像できないかもしれませんが、私たちは実際にはとても小さなチームなんです。そこで、ウェブサイト上でお客様と対話し、自動的にセールスリードを生成するチャットエージェントを作成します。まずは、Generative AI Playgroundを起動します。ここでは、モデルを横並びで比較し、お客様が興味を持ちそうなプロンプトを試すことができます。「パッケージング用ロボットについてもっと知りたい」というように入力すると、どのモデルが私たちのニーズに最も適しているかを確認できます。


好みのモデルが見つかったら、Amazon Bedrock IDEでAIアシスタントの構築を開始できます。ここでは、Guardrailsの設定、Knowledge Basesの追加、そしてリード生成機能の作成が可能です。必要なのは、機能に名前を付け、説明を加え、CRMと連携するためのスキーマを統合することだけです。CRMとの連携が完了したことを確認し、最後にエクスポートすれば、サイトに組み込んでお客様のサポートとセールスフォローアップ用のリード生成を開始できます。



さて、ここで未来に飛んでみましょう。他にどうやって未来に行けると思いますか?私たちのAIアシスタントは現在、1日に何百ものリードを生成しており、そのデータを分析したいと考えています。新しいZero-ETL for Applicationsの統合機能を使用して、CRMからデータをSageMakerに取り込み、データアナリストが作業できるようにします。これでステップ2の分析に進みます。優先順位付けを容易にするため、リードをグループ化する方法が必要です。そのために、データアナリストはリードと他のデータセットを組み合わせて、カスタマーセグメントを作成します。



しかし、その前に適切なデータを見つける必要があります。SageMakerには2つのオプションがあります。データカタログを使用して「leads」などのキーワードで検索すると、キーワードと意味的な一致が見つかります。もう1つの方法は、Amazon Qを使用して「AIアシスタントが生成したリードを含むデータセットはどこにありますか?」といった質問をすることです。Qは必要なデータを見つけ、結果を生成し、情報のプレビューを表示します。そのデータを使用したい場合は、サブスクライブするだけです。分析を開始するには、Query Editorを起動し、サブスクライブしたデータにアクセスします。


Amazon RedshiftまたはAmazon Athenaのどちらでデータをクエリするかを選択し、セグメントの構築を開始できます。市場データ、テクノグラフィックデータ、コンバージョン率などのパターンを探り、それらすべてを組み合わせたデータセットを作成して、セグメント定義を保存します。最後に、これらすべてをLakehouseに書き戻して、共同作業者が利用できるようにします。




ステップ3では、どのリードを追求すべきかを判断する必要があります。そのために、Data Scientistが機械学習モデルを作成し、入ってくるリードのスコアリングと優先順位付けを行います。 これまでは、複数のノートブックが必要になることは確実でした。おそらく、Amazon EMRでデータの準備と前処理を始め、その後Amazon SageMakerに移って モデルの構築とトレーニングを行うという流れでした。しかし今では、必要なコードに適切なコンピュートを適用することで、1つのノートブックですべてを実行できるようになりました。


このモデルを構築する際、どの手法が最も効果的かを確認するために、さまざまな方法を試してみたいと思います。Amazon Qを使用して必要なコードを生成できます。例えば、Random Forestを使用してリードをスコアリングするモデルなどです。コードが生成されたら、簡単にノートブックに追加でき、Amazon SageMaker内でモデルのトレーニングとデプロイを行い、新しいリードが入ってきた際の推論に使用できる状態にできます。ただし、これを本当に有用なものにするためには、営業部門が結果に基づいて行動できる方法が必要です。そこで、結果をLakehouseに書き戻します。これにより、他のAWSサービスがデータにアクセスし、ビジネスダッシュボードで可視化できるようになります。


これで、営業部門は毎日ログインすると、追求すべき優先度の高いリードを確認でき、より多くの取引を成立させ、売上を増加させることができます。次世代のAmazon SageMakerで、このようなデータの混沌を解決しましょう。複雑なエンド・ツー・エンドの問題を、バラバラなデータシステムの複雑さなしに、協力して解決できるよう、必要なものがすべて1つの場所に揃っています。この次世代のAmazon SageMakerは、本日からプレビューでご利用いただけます。皆様がこれを使って何を実現されるのか、とても楽しみです。
Shannon、素晴らしく活気のあるデモをありがとうございました。私たちはバックステージでこのジャンプの練習をしていました。後でやるかもしれませんね。皆様がこの新しい統合プラットフォームを活用されることを楽しみにしています。ご覧の通り、テクノロジーは強力ですが、テクノロジーだけでは十分ではないと私は考えています。適切なタイミングと適切な環境で適用することこそが、真の違いを生み出すのです。

これは、Malcolm Gladwellの著書「The Tipping Point」の興味深い概念を思い起こさせます。Gladwellは、コンテキストのような周囲の条件が、アイデアやイノベーションが成功するかどうかを決定する上で重要であることを探求しています。可能性を持っているだけでなく、その可能性を育み、増幅させる準備ができた環境に存在することが重要なのです。ご自身のキャリアにおけるこのコンテキストについて考えてみてください。あなたの成長と成功にとって、コンテキストが完璧だった瞬間とは何でしたか?おそらく、あなたを信頼し、チャレンジングなプロジェクトを任せてくれた上司との出会い、あるいは私がAmazonで経験したように、リスクテイクとイノベーションを奨励する文化を持つ企業に参画した時かもしれません。



この考え方は、特に教育について考えるとき、私の心に深く響くものです。私たち全員がキャリアで成功するために適切な環境を必要としたように、学生たちも、この生成AIの時代に成長するための適切な環境が必要です。しかし、グローバルな視点で見ると、質の高いデジタル学習機会へのアクセスは依然として課題となっています。UNESCOによると、世界中で5億人の学生がデジタル学習にアクセスできず、その大半が最貧困層や農村部の学生たちです。AWSは長年にわたり、教育を推進し、多様な背景を持つ学習者たちをエンパワーすることに取り組んできました。



そのため、2023年に発表したAI Ready Initiativeは、すでに世界中で200万人以上の学習者に無料のAIスキルトレーニングを提供するという目標を達成しました。私たちのAI and ML Scholarship Programは、恵まれない学生たちが最先端のAIテクノロジーを学べるよう、2,800万ドルの奨学金を提供し、Amazon Future Engineer Programは、十分な支援を受けていないコミュニティの未来のビルダーたちに4,600万ドルの奨学金を提供してきました。そして、2025年の目標を1年前倒しで、世界中で2,900万人に無料のクラウドコンピューティングスキルトレーニングを提供するという目標を達成できたことを、大変嬉しく思います。これは本当に大きな成果です。



これらの統計の背後には、変革とインパクトのストーリーがあります。AWS AI and ML Scholarshipを受けたPrerana Sapkotaは、AIを活用してネパールの水不足問題に取り組んでおり、Gideon Baendeは電気自動車のバッテリーのセカンドライフ活用を支援するAIソリューションを開発し、世界中でより持続可能なテクノロジー利用への道を切り開いています。実は、Gideonは今日この会場に来ていますので、彼の素晴らしい取り組みを認識したいと思います。Gideonのような個人とAI教育で私たちが達成できたすべてのことを非常に誇りに思っていますが、まだやるべきことがあることも認識しています。


今日のAI教育格差の規模は革新的なソリューションを必要としており、AIソリューションの活用はアクセス拡大に不可欠です。教育テクノロジー分野の組織など、多くの組織が実装・展開の準備が整った学習ビジョンを持っていますが、資金不足がそれらの計画の実行を妨げています。私たちは、これらの献身的な組織が世界中でより多くの学習者にリーチできるよう支援できることを知っています。そこで本日、AWS Education Equity Initiativeの立ち上げを発表できることを嬉しく思います。

このイニシアチブは、世界中の恵まれない学習者向けにデジタル学習ソリューションを構築・拡張する組織をエンパワーします。このビジョンを実現するため、今後5年間で最大1億ドルのクラウドコンピューティングクレジットを提供し、AWSの専門家による技術的なガイダンスを提供することを約束します。このイニシアチブは、組織が教育ソリューションを構築・拡張するために必要な財務的障壁を軽減し、適切な技術的ガイダンスを提供します。これには、アーキテクチャのガイダンス、AIと責任あるAIの実装のベストプラクティス、継続的な最適化サポートが含まれます。

この取り組みを通じて、私たちはCode.orgとの長年のパートナーシップをさらに発展させることができることを嬉しく思います。この10年間、AWSはCode.orgを支援し、100カ国以上の何百万人もの学生に無料のコンピューターサイエンスカリキュラムを提供してきました。そして今回のイニシアチブにより、Code.orgはAmazon Bedrockを活用して学生のプロジェクト評価を自動化し、何百時間もの教育者の時間を個別指導や個々に合わせた学習体験に充てることができるようになります。




このイニシアチブは、インドで幼児教育に取り組む組織であるRocket Learningにも力を与え、Amazon QとQuickSightを使用して300万人以上の子どもたちの学習成果を向上させることができます。ここでは、Amazon Qが、異なる言語や微妙なニュアンスを持つ多様な地域の子どもたちに提供すべきコンテンツの最適化を支援します。Generative AIにより、すでにグローバルな規模で素晴らしい活動を行っている組織の影響力をさらに高めることができます。しかし、アメリカ国内でも、学生たちが時として支援の網から漏れてしまうことがあります。それでは、Qを使って教育者の支援を行っている別の企業についても見てみましょう。
元小学1年生の教師として言えることですが、教師はカウンセラーであり、サポートシステムであり、生徒にとって本当にすべての存在です。しかし、授業と授業の間の時間のやりくりが大変です。わずか10分の休み時間で、出席状況から、生徒指導の記録、保健室の利用状況、評価の成績まで、非常に膨大なデータに基づいて指導方法を調整し、軌道修正しなければなりません。AWSのクラウドは、これらすべてをデジタル化し、一つの中央リポジトリにまとめる上で非常に重要な役割を果たしました。

SchoolToolは、ニューヨーク州の400以上の学区で使用されている学生管理システムです。AWSとともに、私たちはGenerative AIを活用してインサイトを得るという旅を続けています。これは本当に大きな変革です。
Amazon QとAmazon QuickSight導入以前は、教育者がシステムからデータを抽出するために、データエンジニアと何週間もかけて作業する必要がありました。しかし今では、Amazon QとQuickSightのパワーにより、簡単な質問を普通の英語で入力するだけで、即座に回答を得ることができます。例えば、昨年と今年の生徒の成績を比較する質問をすれば、すぐにデータの可視化結果が得られます。自分でダッシュボードを構築し、いわばコマンドセンターのようなものを作ることができるのです。
これにより、学区全体のすべての個人が、必要なときに必要な答えを得ることができるようになります。Amazon Qと生成系AIの力により、教師がデータをより快適に扱えるようになります。データ分析を完全にエンドユーザーまで民主化するのです。教育者という仕事は最も困難でありながら、やりがいのある仕事の一つですが、指先一つでデータにアクセスできることで、指導する生徒たちの成功につながっていくでしょう。

本日お話ししたすべてのテクノロジーが、私たちの生徒や顧客、そして世界までも積極的に変革している様子を見るのは、とても心が躍ります。 Foundation Modelを大規模にトレーニングするための強力なツールから、生産性を革新的に向上させる生成系AIアシスタントまで、私たちは皆、はるか昔からの夢想家たちの基盤の上に立ち、この歴史的な技術の融合の瞬間に積極的に参加しているのです。次世代のテクノロジーパイオニアたちへの道を切り開くことで、私たちは現在を形作るだけでなく、新たなイノベーションが飛躍するための基盤も築いているのです。

この素晴らしい変革を推進するために尽力してくださった私たちのパートナーの皆様、そしてこれらすべての機能を構築した素晴らしいチームの皆様に、個人的に感謝の意を表したいと思います。皆様の次なる挑戦が待ち遠しいです。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion