re:Invent 2024: MonzoのEKS移行 - KarpenterとEC2 Spotで15%コスト削減


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Run workloads efficiently on EKS with Karpenter and EC2 Spot Instances (CMP213)
この動画では、AWSのコンピュートワークロードの最適化について、EC2 Spot、Graviton、Karpenterなどの活用方法が解説されています。特に、英国のデジタルバンクMonzoが、自前のKubernetesクラスターからAmazon EKSへの移行を行い、Karpenterの導入とEC2 Spotの活用によってコンピューティングコストを15%削減した事例が詳しく紹介されています。Monzoは1,000以上のマイクロサービスを運用しており、サービスの重要度に応じてTier0からTier3までの階層分けを行い、段階的にSpotインスタンスを導入することで、コスト最適化とサービスの安定性を両立させました。また、KarpenterがSpotインスタンスの管理を自動化し、運用の手間を大幅に削減できることも示されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
AWSのSpecialist組織とre:Invent 2024セッションの概要

みなさん、こんにちは。re:Invent 2024へようこそ。1日目を楽しくお過ごしいただけたことと思います。このように月曜の午後の時間帯にお集まりいただき、ありがとうございます。私はMike Dukesと申します。EMEAのStartup SpecialistsのSenior Managerを務めており、AWSのSpecialist組織に所属しています。AWSのお客様は、データベース、ネットワーキング、コンテナなど、さまざまな領域や製品のSpecialistのサポートを受けることができます。Specialistのサポートをご希望の場合は、担当のアカウントチームにご相談ください。
本日は、ロンドンから一緒に来ていただいた素晴らしい同僚のMiles Bryant氏をお迎えできることを光栄に思います。MonzoのKubernetesへの取り組みと最適化について、EC2 Spot、Karpenter、Amazon EKSをどのように活用したか、そして何より重要なのは、これらによってクラウドコストを最適化しながらサービスをシームレスにスケールできるようになった経緯についてお話しいただきます。

本日のセッションは2部構成になっています。第1部では、AWSで効率的なコンピュートワークロードを実行する方法について、コンテナの観点からお話しします。Amazon EC2、EC2 Spot、Gravitonについて触れますが、これらはEKSを使用する際の優れたコスト最適化のレバーとなります。Karpenterは、そのような取り組みをさらに促進するものです。第1部の最後では、EKSによる一般的な最適化の取り組みと、活用できる有用なレバーについてお話しします。
EC2、Spot、Gravitonを活用したコスト最適化戦略


その後、Milesに引き継ぎ、Monzoの取り組みについてお話しいただきます。まず、Monzoをご存じない方のために簡単な紹介をし、その後、自社管理のプラットフォームからKarpenterを使用したEKS、そしてSpotへと移行していった道のりについてお話しします。 最後に、彼らが得た教訓についてまとめます。では、第1部のEC2、EC2 Spot、Gravitonについて始めましょう。AWSは実際、800種類以上のインスタンスタイプを提供しており、事実上あらゆるワークロードを実行できる最も幅広いインスタンスタイプを取り揃えています。


このように多くのインスタンスタイプを用意している理由は2つあります。1つ目は、汎用、バーストタイプ、メモリ集約型、コンピュート集約型など、ワークロードの種類に応じて異なるカテゴリーを用意していることです。2つ目は機能に関するもので、各インスタンスタイプで特定の機能を選択できます。サイズ、ネットワーク要件、メモリサイズ、CPUプロセッサ(Intel、AMD、AWS Gravitonチップ)などが含まれます。

EC2の中核となっているのは、とても素晴らしいカスタムシリコンのイノベーションです。1つ目はNitroで、もしNitroをご存じない方がいらっしゃれば、これはEC2の秘密の sauce(ソース)のようなものです。セキュリティやストレージ、ネットワーキングなどのコンポーネントを外部化した、超軽量なハイパーバイザーです。実際、これのおかげでAWSのハードウェアからより多くを引き出し、膨大な数のインスタンスタイプを提供することができています。Nitroは本当に素晴らしいのですが、今日はこれ以上詳しくお話しすることはありません。今週のre:Inventでは、これに関する多くのセッションが用意されています。

2つ目のカスタムシリコンは、AWS Gravitonチップです。このチップセットは、クラウドワークロードに対して最高の価格性能比を提供します。 最後に、いくつかの購入オプションがあります。On-demandインスタンスについては皆さんご存じかと思いますが、より重要なのは、どのような種類のワークロードでOn-demandインスタンスを使用するかということです。これは、スパイク的なステートフルワークロードがあり、状態を保持する必要があり、使用レベルが予測できない場合に本当に便利です。次にSavings Plansがあります。これは、一定期間の使用量にコミットし、その使用量を正確に把握できる場合に、大幅な割引を受けられるものです。

最後に、AWSの余剰キャパシティを活用するEC2 Spotインスタンスがあります。実質的に、さまざまな場所の余剰キャパシティを活用し、大幅な割引を受けることができます。Spotインスタンスは、スパイク的なステートレスワークロードに使用する必要があり、これについては後ほど詳しく説明します。EC2 SpotとGravitonは、コンテナに関して言えば、最強の組み合わせです。先ほど申し上げたように、Spotは最大90%の割引を提供できます。コンテナを使用しているお客様の場合、通常65%から68%の節約が見られます。



Spotインスタンスの重要な特徴は、中断可能なインスタンスであることです。そのため、EC2 Spotを使用する際は、中断に備える必要があります。 EC2 Spotを使用するワークロードは、ステートレスで、耐障害性があり、柔軟である必要があります。コンテナに関して言えば、コンテナは本質的に不変です。作成、破棄、複製が可能です。これは、ワークロードがステートレスである限り、Spotに最適です。AmazonはSpotとの広範な統合を構築しています。今日はKarpenterを使用したAmazon EKSについてお話ししますが、 Amazon ECSやAWS Fargateとの統合も提供しています。

Spotについて覚えておくべき重要なポイントは、異なるインスタンスプール間で多様化する必要があるということです。AWS Spotインスタンスは余剰キャパシティなので、より多くの場所から余剰キャパシティを確保できれば、より良い体験が得られます。多様化とは、異なるインスタンスタイプ、インスタンスサイズ、ファミリー、さらにはアベイラビリティーゾーンを活用して、最適な余剰キャパシティを利用することを意味します。




次はGravitonについてです。GravitonインスタンスとチップセットはEC2上で実行されるクラウドワークロードに対して、最高のコストパフォーマンスを提供します。実際に最大40%のコストパフォーマンス向上が見られます。コストパフォーマンスには2つの側面があります。1つ目はインスタンス価格が競争力があり大きく異なる点、2つ目はGravitonからより多くのパフォーマンスを引き出せる点です。GravitonはARM64命令セットで動作し、現在では大規模なエコシステムのサポートがあります。様々なコンテナレジストリからARM64をすぐに利用できるコンテナを入手できます。また、ISVソフトウェアにも優れており、多くのISVサポートがあります。現在は第4世代のGravitonとなり、さらなるパフォーマンスの向上をもたらしています。実際、今週もいくつかの新しいインスタンスをリリースしました。

Gravitonの私のお気に入りのポイントは、同等のEC2インスタンスと比較して最大60%のエネルギー消費を削減できることです。Gravitonはコストパフォーマンスとサステナブルなワークロードの両面で優れており、本当に素晴らしい組み合わせです。まだ試していない方は、ぜひ検討してみることをお勧めします。さて、なぜKarpenterとEKSのセッションでこの話をしているのでしょうか?KarpenterはEC2 SpotとGravitonの両方を簡単に利用できるようにしてくれます。EC2 Spotについては、Spotの中断処理やインスタンスタイプの分散など、多くのベストプラクティスが組み込まれています。Gravitonについては、ARM64ベースイメージの導入とGravitonインフラストラクチャのプロビジョニングを簡単に行えます。さらに、SpotとGravitonは相性が良く、一緒に使用することができます。
Amazon EKSとKarpenterによるクラスター管理の革新




これがEC2の概要です。私は最適化の話をする際には、EKSについての基本的な理解を確認するのが好きです。それでは、EKSとKarpenterについて見ていきましょう。Kubernetesにおけるスケーリングについて、全員の理解を揃えておきましょう。2つの異なる側面があります。1つ目はアプリケーションスケーリング - Kubernetes上でアプリケーションをどのようにスケールさせるか?2つ目はデータプレーンスケーリング - 特定のアプリケーションの要件に対応するためにインフラストラクチャをどのようにスケールさせるか?です。アプリケーションスケーリングについては、Horizontal Pod Autoscaler(HPA)というものがあります。


また、垂直方向のポッドスケーリングを扱うVertical Pod Autoscaler(VPA)もあります。さらに、より高度なメトリクスに基づいてスケーリングを行うKubernetes Event-driven Autoscaler(KEDA)もあります。データプレーンスケーリングの観点からは、2つの選択肢があります。Cluster AutoscalerとKarpenterについて話す際、これらは基本的に同じ仕事をしています。つまり、アプリケーションの要件に基づいてインフラストラクチャをスケールアウトするのです。

この2つを比較してみましょう。これは典型的なCluster Autoscalerのセットアップです。ご覧のように、異なるAuto Scaling groupsによってバックアップされた3つのノードグループがあります。Cluster Autoscalerの課題として私たちが発見したのは、異なるタイプのワークロードごとにノードグループを用意する必要があるということです。例えば、C6iで上手く動作するワークロードがあれば、そのノードグループに配置し、M6gで動作する別のワークロードがあれば、そちらのノードグループに配置し、P4の場合もそのノードグループに配置する、といった具合です。これにより、ワークロードを特定のノードグループに押し込むか、より多くのノードグループを作成する必要が出てきました。お客様が大量のノードグループとAuto Scaling groupsを作成している状況を目にし、運用面での負担が非常に大きくなっていることがわかりました。


ここで Karpenter の出番となります。Karpenter は、あらゆるタイプのワークロードに対してデータプレーンを最適なサイズに調整します。実際には、グループという要素とグループ構造を取り除き、アプリケーションの要件に基づいて適切なサイズのインフラストラクチャをプロビジョニングします。Karpenter の本質について説明すると、まさにアプリケーション・ファーストなインフラストラクチャです。Pod の要件に基づいてノードをプロビジョニングするのです。また、SpotインスタンスとOn-Demandインスタンスの分散化も非常に得意としています。Spotの中断に対して標準で対応でき、異なるインスタンスタイプ間で分散化し、必要に応じてOn-Demandを活用できます。
さらに、グループレスのオートスケーリングも備えています。先ほど申し上げたように、データプレーンをシンプルにし、ノードグループの概念を取り除くことで、より単純化を図ります。これにより、ワークロードの要件に基づいてインフラストラクチャがプロビジョニングされる仕組みが実現します。例えば、arm64のコンテナイメージを新たにインフラストラクチャにプロビジョニングする場合、それまでGravitonが存在しなかったとしても、Graviton対応のコンテナイメージを導入することで、Gravitonインフラストラクチャをプロビジョニングできるようになります。最後に、Karpenterには Consolidation と呼ばれる最適化のための優れた機能があり、インフラストラクチャとクラスターを継続的に最適化してサイズ調整とビンパッキングを行います。



パート1の締めくくりとして、具体的なAmazon EKSの最適化の例をご紹介します。つい最近、あるお客様から、EKSを最も安価かつ迅速に最適化する方法について質問を受けました。まず最初に行ったのは、最も重要な要素であるワークロードの確認と、その特性の把握でした。このケースでは、お客様はEKSを使用しており、Cluster Autoscalerを利用していました。ワークロード自体については、GoとPythonベースのアプリケーションを実行しており、すでにフォールトトレラントでステートレスな状態でした。これらは重要なキーワードです。



最適化の最初のステップは、コストを最適化し、まずそのコストのベースラインを設定して、その後の過程を追跡し、削減額を測定することです。そして、Karpenterです。Karpenterは、これらの新しいEC2やEC2 Spot、Gravitonのテクニックを可能にするだけでなく、クラスターの最適化も非常にうまく処理します。Karpenterを導入するだけで、お客様はコスト削減を実現できました。この特定のケースでの次のステップは、Spotの導入でした。ワークロードがフォールトトレラントでステートレスであることが分かっていたため、Spotの実装は非常に簡単でした。


Spotを導入する際の重要なポイントは、適切なワークロードに対して実装することです。先ほど述べたように、ステートレスで柔軟性があり、フォールトトレラントである必要があります。最後に、Gravitonについて検討しました。Gravitonはさらなる価格性能比の向上をもたらしました。Gravitonを検討する際の唯一の考慮点は、ワークロードがARM64命令セットをサポートしている必要があることですが、これは現在では非常に一般的になっています。この最適化の過程で最後に考慮すべき点、そしてプロセス全体を通じて考慮すべき点は、Podの要件を適切なサイズに調整することです。これらのPodの要件はKarpenterがインフラストラクチャをプロビジョニングする際に使用されるため、これらを最適化し、適切に設定することで、最適化の過程全体を通じて効果を発揮します。
MonzoのEKS最適化への道のり:Karpenterとスポットインスタンスの活用

それでは、Monzoの EKS 最適化への道のりについてお話ししていきたいと思います。では Miles、お願いします。ありがとうございます、Mike。素晴らしい導入をしていただき、Monzoの EKS 最適化への道のりについてお話しできることを嬉しく思います。まず自己紹介させていただきますと、私は Monzo の Senior Platform Engineer の Miles Bryant です。Monzo で約6年半、Kubernetes とサービスメッシュのインフラに携わっており、現在はコンピューティングとネットワークに関するすべてを担当するインフラストラクチャプラットフォームチームをリードしています。まず簡単なアンケートですが、この中で Monzo をご存知の方はどれくらいいらっしゃいますか?何人かいらっしゃいますね、素晴らしい。私たちの使命は、銀行取引を簡単で苦痛のないものにすることです。単一のインターフェースを通じて、お金を使い、貯め、管理することができます。ご存じない方のために説明しますと、私たちは非常に鮮やかなコーラルカラーのカードを提供しています - 目にすると本当に印象的です - そして英国では約1,000万人の顧客を持ち、米国でも小規模ながらサービスを展開しています。基本的に、お客様の金融生活を管理するための統合された場所を提供しているのです。



デジタルバンクをゼロから構築するには、多くの異なる機能とシステムが必要です。当然ながら、普通預金、銀行間送金、ローン、予算管理など、銀行に期待される一般的な顧客向け機能をすべて備えています。しかし、これは氷山の一角に過ぎません。金融犯罪のチェックからビジネス分析、セキュリティまで、バックグラウンドでは多くのことが行われています。これは私たちが最初から目指していたものでした。マイクロサービスアーキテクチャから始め、それを本格的に構築していきました。マイクロサービスを選んだ理由は、複数のチームやエンジニアがシステムの異なる部分を独立して変更・管理できるようにするためです。このマイクロサービスのおかげで、9年経った今でも、安全に、そして高速に変更をデプロイすることができています。

もちろん、マイクロサービスには運用上のオーバーヘッドが伴いますが、その運用上のオーバーヘッドの一部を解消する非常に自然な選択肢が Kubernetes です。これは、Kubernetes によって、インフラストラクチャと基盤となるコンピューティングの実行に関する懸念と、コードを書いてプロダクションにデプロイすることに関する懸念を分離できるためです。Monzo では約8年間 Kubernetes を使用してきました。最初に使い始めた頃は、クラウドプロバイダーがマネージドプラットフォームを提供しておらず、自前で運用する以外に選択肢がありませんでした。長年にわたって Kubernetes を運用してきて多くの楽しい経験をしましたし、非常に興味深く知的な刺激にもなりますが、多大な時間と労力が必要です。そこで、マネージド Kubernetes サービスとして Amazon EKS を利用することで、この部分を AWS にオフロードすることにしました。最近、自前でホストしていたクラスターから EKS への完全な移行を完了しました。

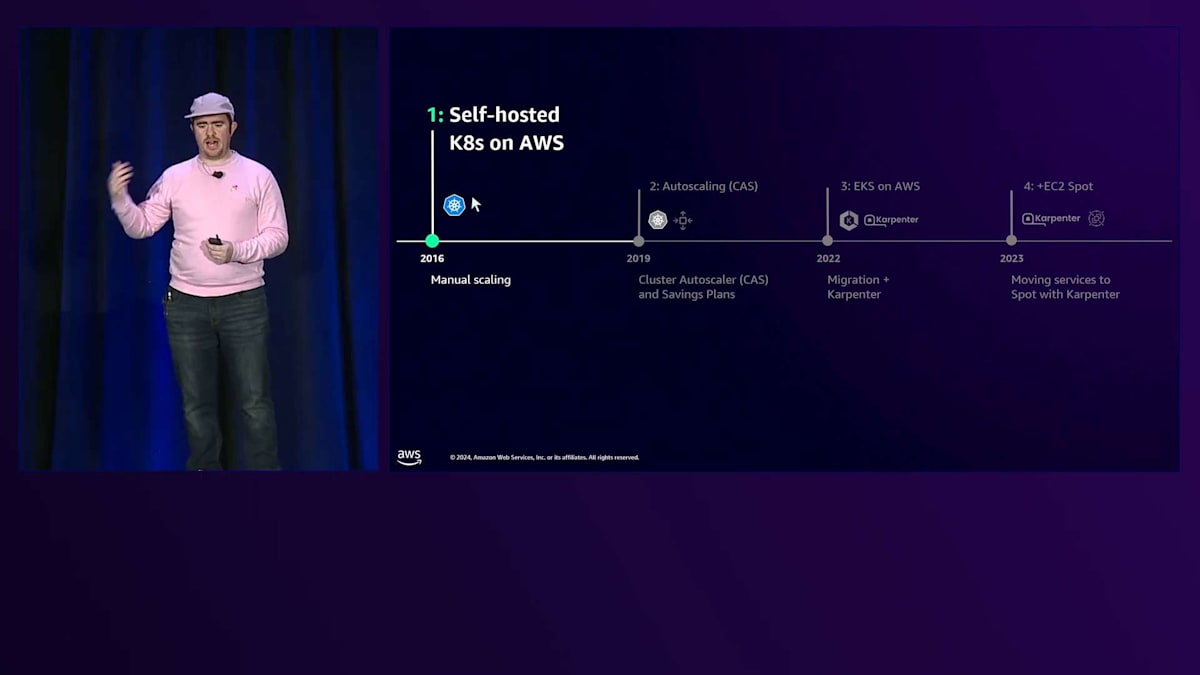
では、EKS への移行とクラウドコストの最適化についてお話ししましょう。2016年まで遡りますが、この時点で Monzo はまだエンジニアが数人しかいない小さなスタートアップでした。当時は Monzo という名前すら使っていませんでした。先ほど申し上げたように、AWS 上で独自の Kubernetes クラスターを立ち上げ、そのアーキテクチャについてお話しさせていただきます。


初期の段階では、約150のステートレスな Go マイクロサービスがありました。その後数年間で、製品や機能を追加していくにつれて、1,000以上まで増加しました。全体的なアーキテクチャはシンプルでした。単一のリージョンに1つのプロダクションクラスターを持ち、サービスワーカーコンピュートのための1つの Auto Scaling グループがあり、単一のインスタンスタイプのみを使用し、約300のノードがありました。

この時点で、私たちのシステムは非常に静的なものでした。アプリケーションやサービスは、必要に応じてCPUメモリを更新することで手動でスケーリングされていただけでした。これは、クラスターも同様に静的で、スケーリングプロセスが単純だったことを意味します - より多くのコンピュートリソースが必要になった時は、誰かがAWS Consoleにログインし、ボタンをクリックしてAuto Scaling Groupのサイズを更新するだけでした。比較的小規模な段階では、これで全く問題ありませんでした。余分なCPUサイクルに無駄なコストをかけることもなく、Auto Scalerのセットアップやデバッグに時間を費やす必要もなかったため、他の優先事項に集中できました。


次の段階についてお話ししましょう。2018年から2019年頃には、私たちは次のステップに進む必要がありました。当時のMonzoは非常にエキサイティングな場所でした - まず、私がジョインしたタイミングです。しかしより重要なのは、プリペイドカード製品から当座預金口座への非常に困難な移行を完了し、UK銀行ライセンスを取得したことでした。素晴らしい成長の年で、新規顧客数は月間6万人から20万人以上に増加しました。また、クラウドファンディングでは、わずか2日間で顧客から2,000万ポンドを調達しました。この期間中、私たちは常に新機能をリリースしていました - 当座貸越、ローン、ビジネスバンキング、さらには最初のUS向け製品もローンチしました。

これをお話しする理由は、より多くの顧客とより多くの製品は、これらのニーズに対応するためのより多くのMicroservicesの開発を意味したからです。より多くのMicroservicesとプラットフォームへの負荷増加は、さらなるスケーリングを必要としました。そのスケーリングは、誰かがAWS ConsoleでボタンをクリックしてAuto Scaling Groupを更新する時間をより多く必要とし、何もしていないCPUにより多くの無駄なコストを費やすことを意味しました。次のステップに進むべき時が来たのです。

そこで私たちはAuto Scalingを導入しました。まずはアプリケーション層から始め、CPUメモリを適切なサイズに調整する垂直スケーリングに焦点を当てました。それに満足した後、負荷に応じてサービスをスケールアウトできる水平スケーリングを追加しました。サービスが動的にスケールアップ・ダウンするようになったため、Kubernetes Cluster Autoscalerを追加してノードのスケーリングを処理するようにしました。この時点で、ベースライン使用量も十分に理解できていたため、コンピュートの支出をコミットし、コスト最適化のためにSavings Plansを購入しました。


アーキテクチャを振り返ってみましょう。この時点で、私たちは800以上のMicroservicesに成長しており、この成長に減速の兆しはありませんでした。しかし、基盤となるAWSのコンピュートアーキテクチャはそれほど変わっていませんでした - まだかなりシンプルでした。より多くのメモリを必要とするPrometheusモニタリングなど、異なるワークロード要件に対応するために、いくつかの新しいAuto Scaling Groupを追加しただけでした。



2022年までに、Auto Scalingにより、クラウドコストを最適化するための強固な基盤を構築していました。そこからさらに一歩進める時期が来ていました。この時点で、私たちは自前でホストしているクラスターに限界を感じていました。アップグレード作業は本当に大変でした。当然ながら、自前のクラスターで発生する問題はすべて自分たちで解決しなければなりませんでした。
私たちは、Kubernetesを自前で管理することよりも、もっと価値のある仕事に時間を使えるのではないかと気づきました。すでにAWSを利用していた私たちにとって、Amazon EKSは自然な選択でした。約18ヶ月前から移行を開始し、並行して新しいEKSクラスターをセットアップしました。その18ヶ月の間、Service Meshのトラフィックシフティングを使って、サービスをダウンタイムなしで1つずつ段階的に移行していきました。現在では移行を完全に完了し、古いクラスターは廃止しています。

EKSへの移行と共に、Cluster Autoscalerの代替としてKarpenterの導入も決定しました。Karpenterは私たちにとって重要な機能をいくつか実現してくれました。アプリケーションのニーズに応じてコンピュートリソースをスケールさせ、運用の手間をかけずに少数のインスタンスサイズに制限されない世界に移行したいと考えていました。また、後ほど詳しく説明しますが、Spotを導入してさらなるコスト最適化も実現したいと考えていました。Cluster Autoscalerでも複数のノードプールを設定することでこれらは実現可能ですが、より難しく、運用の手間も増えてしまいます。Karpenterの導入は、まずCluster AutoscalerのオートスケーリンググループをシンプルにKarpenterのノードプールに移行することから始めました。そこから、私たちのニーズに合わせて段階的に複雑な設定を追加していきました。


古いクラスターでCluster Autoscalerを稼働させながら、新しいEKSクラスターにKarpenterをデプロイしたことで、2つのクラスター間でサービスを移行しながら、Karpenterの動作を段階的にテストすることができました。現在のKarpenterを使用したEKSアーキテクチャでは、様々なインスタンスタイプとサイズを利用しており、異なるインスタンスタイプを管理するためのAuto Scaling Groupは必要ありません。Karpenterがインスタンスのプロビジョニングを直接管理できるためです。Karpenterの導入により、EC2 Spotに移行してさらなるコスト最適化を実現できるようになりました。

Monzoのコンピュートリソースの需要は非常にダイナミックで、ユーザーの行動、つまりアプリの使用やMonzoカードでの店舗での支払いによって変動します。現在の顧客は主にイギリスに集中しているため、ワークロードは予測可能な日次パターンに従っています。このような負荷パターンに対して、Savings Planは実はあまり適していません。なぜなら、Savings Planを控えめに設定して動的なピークをオンデマンドでカバーしてより多くの支出が必要になるか、あるいはSavings Planを多めに設定して夜間の基準負荷時に使用していないコンピュートリソースの支払いが発生するかのどちらかになってしまうためです。ここでSpotが私たちの救世主となりました。日々のピーク時の需要もコスト最適化しながら柔軟に対応できるためです。私たちはステートレスなマイクロサービスを使用しており、いつでも停止できる設計になっていたため、もともとSpotに適した構成だったのです。

Spotが私たちに適していると確信していましたが、それでも段階的に導入し、使用に慣れていく必要がありました。Monzoの各サービスは、その重要度に応じて分類されています。Tier0は決済や顧客サポートなど、銀行の基本機能を支える最重要サービスで、Tier3は最も重要度の低い、小規模なバックオフィスサービスで、仮に障害が発生しても、しばらくは誰も気付かないようなものです。私たちはこの階層分けを活用し、小規模なKubernetes Admission Controllerを作成して、サービスの階層と設定に基づいてPod Topology Spreadを注入するようにしました。このPod Topology Spreadは、Karpenterに対してポッドをどこにプロビジョニングしてスケジューリングすべきかのヒントを与え、パーセンテージを設定できるようにしました。これにより、サービス階層ごとにSpotとOn-Demandで実行したいポッドの割合を設定できるようになり、重要度の低いサービス階層から最重要サービスまで、段階的に展開することが可能になりました。

Spotを導入した後のアーキテクチャをもう一度見てみましょう。実際にはそれほど大きな違いはありません。ここで強調したいのは、KarpenterがSpotのプロビジョニングのあらゆる側面を管理してくれるということです。Spot中断メッセージを自動的に処理してノードを置き換え、最も安価なSpotオプションを見つけ、ワークロードを自動的に統合して移行します。何らかの理由でSpotをプロビジョニングできない場合は、On-Demandを使用するので、常にカバーされています。


時系列で私たちの取り組みがどのように進展してきたかをお見せしたいと思います。このグラフは、2023年7月から左側に向かって、カテゴリー別のコンピューティング支出の内訳を示しています。当初はSavings Plansを全面的に活用し、約25%がOn-Demand使用でした。時間とともに、段階的にSpotの利用を増やしていき、2024年1月にSavings Plansの一つが終了したときには、そのほとんどをSpot利用で補うことができました。さらに最近では、EKSへの移行を完了し、現在では99%をSavings PlansとSpotでカバーしています。

この取り組みから何を学んだのでしょうか? Karpenterは全体的に素晴らしかったのですが、考慮すべき細かな点もありました。スケールダウンが非常に遅くなることがあり、これを解決するために、ポリシーの分散を調査・最適化し、ノードからのポッドの退避をブロックしているPod Disruption Budgetを見つける必要がありました。Karpenterは非常に活発に開発が進められており、新機能が素早く追加されるのは素晴らしいことです。主要なKarpenterのアップグレードで問題は発生しませんでしたし、ドキュメントも充実していて比較的スムーズでしたが、それでもアップグレードの仕組みを理解し、安全に実行するための作業は必要でした。

また、Karpenterが特定のポッドについてなぜそのような判断を下したのかを理解することが難しい場合もあり、Karpenterのデバッグ方法を学ぶ必要がありました。例えば、特定のポッドが特定のノードにスケジュールできない理由や、プロビジョニングエラーによってノードがプロビジョニングできない理由などです。Spotについても考慮すべき点がありました。リスクを分散し、軽減するために、十分な数のインスタンスタイプを設定する必要がありました。これを支援するために、Spot Placement ScoreとSpot中断率のモニタリングに投資し、システムの混乱を引き起こす可能性のある大規模なSpot中断のリスクを最小限に抑える必要がありました。

私にとって最も興味深い課題は、実はプラットフォームのユーザーやエンジニアの認識でした。Spotによってサービスが終了した場合どうなるのかという懸念についてです。これは技術的な問題というよりも、実際には教育的な問題でした。私たちはSpotのコスト削減効果とクラウドコスト最適化への貢献を示すことで、この問題を解決しました。また、サービスPodが終了することで、サービスの回復力を継続的にテストできることも強調しました。私たちが示した重要な論点は、実際にはサービスPodは常に終了していているということでした。私たちのシステムは動的で、常にスケールアップとダウンを繰り返しているのです。

Karpenterは、ノードの統合に関して多くの作業を行っており、空のノードや半分空のノードを見つけて、そこからワークロードを移行することができます。データから分かったことですが、サービスが終了する可能性は、Spotの中断よりも統合による場合の方が20倍も高いのです。では、私たちの次のステップは何でしょうか?アプリケーションのRight-sizingをさらに調査し最適化を進めたいと考えています。また、サービスの垂直スケーリングについても検討しています。現在、水平スケーリングで非常に小さなレプリカを多数持つサービスがありますが、これをより少ない数の大きなレプリカに変更したいと考えています。

また、Gravitonの採用も検討しています。Gravitonは優れた価格性能比をもたらし、Spotインスタンスタイプとワークロードをさらに多様化する機会を提供します。また、Mikeが先ほど述べたように、より持続可能であり、これは皆にとって良いことです。そして、私たちのサービスはGoで書かれているため、サポートは比較的簡単なはずです。まず最も重要なのは、現在のコストを観察してベースラインを確立することだと思います。そこから、コスト最適化の取り組みで実際に達成したいことを決定し、目標に対して継続的に測定することができます。
コスト最適化の作業は常にトレードオフがあることを強調しておく必要があります。どれだけお金を節約すべきかと問われれば、できるだけ多くという答えになりがちです。しかし、これらの最適化には多くの場合、隠れたコストが存在します。例えば、これらのソリューションを実装するために多くのエンジニアリング時間を費やす必要があり、そのエンジニアたちが他のプロジェクトに取り組めないという機会コストが発生します。コストを最適化し自動化するために、これらの新しいコンポーネントをすべて追加することでシステムの複雑さが増す可能性もあります。そのため、何を達成したいのか、そしてそれを実現するためにどのようなトレードオフを受け入れるかを慎重に考えることが重要です。

変更を加えることを決めた場合は、段階的な移行を行い、リスクを軽減しながら徐々に信頼性を構築することをお勧めします。最後に、SpotとKarpenterを採用することで、コンピューティングコストをさらに15%削減することができました。私たちは引き続きシームレスかつ最適にスケールを続けており、将来的にさらなるコスト削減を期待しています。以上で私の発表を終わります。ここでMikeに戻したいと思います。
コスト最適化の総括とre:Inventでの今後の展開

素晴らしいですね。Milesさん、その取り組みについて共有していただき、ありがとうございます。本当に素晴らしい内容でした。私は、KarpenterやSpot、そして将来的にはGravitonが最適化にどのように貢献できるかについて、実際のお客様事例を紹介したいと思っていました。最初のスライドに戻りますが、最適化のレバーをいつ引くべきかについて、皆さんに考えていただきたいと思います。実はMonzoさんと非常によく似た道のりをたどっているのですが、これは全く別のお客様の事例なんです。まず第一に考えるべきは、ワークロードです。コストのベースラインを設定して、どれだけの削減効果が得られるかを測定できるようにすることが重要です。

Karpenterを検討してください。それ自体が最適化を行うだけでなく、Gravitonの導入も可能にします。ワークロードに適している場合はSpotを使用してください。これは本当に強調しておきたいのですが、ワークロードは柔軟で、フォールトトレラントで、ステートレスである必要があります。そしてGravitonを活用して、価格性能比とサステナビリティの両方のメリットを得ることができます。このプロセス全体を通じて、常にPodのリソース要件を適切なサイズに調整する必要があります。皆さんが次にどのような取り組みをされるのか、とても楽しみです。最後に、木曜日にWynnでKarpenterのハンズオンワークショップを開催します。まだ登録されていない方は、Karpenterの実装、Spotの実装、そしてGravitonを使用したマルチアーキテクチャについて、実践的に学ぶことができる良い機会です。また、このフロアのエスカレーター横に、特別なライブデモのアーケード機を設置しています。レトロビデオゲームのSpace Invadersを「Spot Invaders」としてアレンジしたもので、エイリアンを撃つとクラスター内のPodが破壊される実際のデモを見ることができ、SpotとKarpenterでフォールトトレラントを実現できることを示しています。素晴らしいデモですので、ぜひチェックしてみてください。以上で発表を終わります。re:Inventの残りの日程と夜をお楽しみください。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion