re:Invent 2023: AWSがSageMaker Studioの新機能を紹介 - BMWの活用事例も
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Scale complete ML development with Amazon SageMaker Studio (AIM325)
この動画では、AWSのSumit ThakurとGiuseppe Porcelliが、SageMaker Studioの最新機能を紹介します。驚異的に高速な起動体験、AIベースの開発支援、そしてCode Editorの追加など、機械学習開発をスケールアップする革新的な機能が解説されます。さらに、BMWのMarc Neumannが登場し、SageMaker Studioを活用して自動車産業でAIを拡張する取り組みについて語ります。機械学習の最前線を体感できる貴重なセッションです。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
SageMaker Studioを使用したML開発のスケーリング:イントロダクション

みなさん、こんにちは。木曜の午後にMandalay Bayにお越しいただき、ありがとうございます。私はSumit Thakurと申します。AWSのAmazon SageMakerのプロダクトマネジメントのシニアマネージャーを務めています。本日は、同僚のGiuseppe Porcelliと一緒に来ています。彼はAWSのプリンシパルMLソリューションアーキテクトです。そして、BMW GroupのマシンラーニングとAIプラットフォームのプロダクトオーナーであるMarc Neumannも同席しています。私たちは一緒に、SageMaker Studioを使用してマシンラーニング開発をどのようにスケールアップできるかについてお話しします。
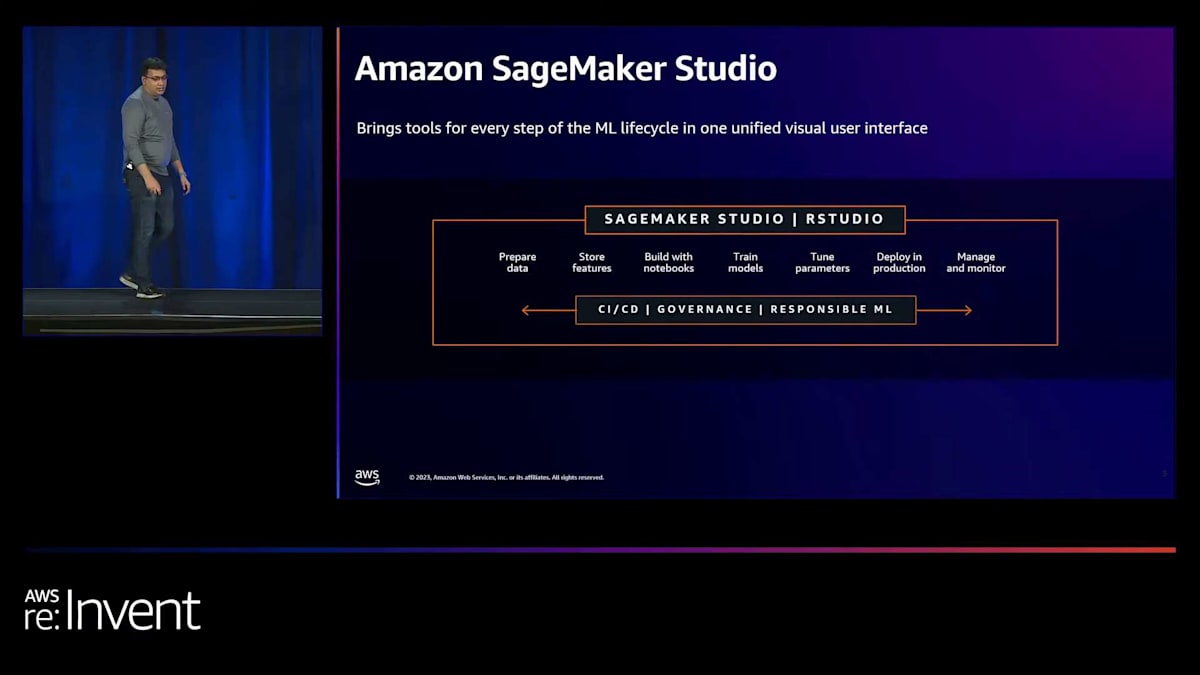
SageMaker Studioを使ってマシンラーニング開発をスケールアップする方法について説明する前に、簡単におさらいをしたいと思います。SageMaker Studioは2019年のAWS re:Inventで、マシンラーニングのための初めての完全統合開発環境として発表されました。これは、MLに必要なすべてのものを1つの統一されたビジュアルインターフェースにまとめたもので、つまり、マシンラーニングワークフローの各ステップに特化したツールが同じビジュアルインターフェース内でアクセス可能になっています。これには、データラベリング、特徴量エンジニアリング、コードエディタを使用したモデル構築、そしてチューニング、デプロイ、エンドツーエンドのマシンラーニングワークフローの管理のためのツールが含まれています。同じビジュアルインターフェース内ですべてのステップのツールを見つけることができ、これらのステップ間を素早く行き来し、変更を加え、結果を観察し、迅速に反復することで、組織内で新しいマシンラーニング機能を迅速に展開できます。
現在、数万の顧客がSageMaker Studioを使用しており、これらの顧客と協力してマシンラーニング開発者の体験に影響を与えるトレンドを理解する非常に貴重な機会を得ています。これらのトレンドのいくつかについてお話ししたいと思います。
AI採用の加速と開発者体験に影響を与えるトレンド

まず最初に取り上げたいトレンドは、AIの採用ペースの加速です。AIが私たちの経済に浸透していることを示す重要な指標の1つは、AI投資の成長です。スタンフォード大学が今年初めに発表したAI Index Reportによると、AIへのグローバル企業投資は過去10年間で驚異的な13倍に成長しました。このトレンドは止まることなく、生成AIによってさらに加速すると予想されます。開発者体験にとって、これは開発者がデータからモデル、そして洞察へと素早く到達するために、高性能で生産性の高いツールを求めていることを意味します。
次に議論したいトレンドは、データとAI特有の職種や専門分野の増加です。マシンラーニングは非常に複雑なため、1人の人間がモデルの開発とデプロイに必要なすべてのスキルセットを持っている可能性は低いです。例えば、データエンジニアは複数の異なるソースからデータを収集し、統合し、分析やマシンラーニングに有用な形に変換することに特化しているかもしれません。データサイエンティストは、このデータの上に特徴量エンジニアリングを行い、モデルを構築し実験するためのアルゴリズムを選択することに特化しているかもしれません。マシンラーニングエンジニアは、このモデルを本番環境にデプロイし、デプロイプロセスを自動化し、一定の頻度でモデルを再トレーニングするスキルセットを持っているかもしれません。AI関連の役割がこのように急速に増加していることから、より多くのマシンラーニング開発者が、特定のタスクに特化したツールを求めるようになっています。
3つ目のトレンドは、機械学習モデルをプロトタイプから本番環境へ移行する際の継続的な障壁についてです。Gartnerの調査によると、モデルの50%強しか本番環境に移行できていないとのことです。モデルの構築とデプロイでは、必要なツール、スキルセット、プロセスが大きく異なります。開発者は、モデル構築者が迅速にプロトタイプを本番環境に移行できるような、よりセルフサービス型のツールを求めています。

皆さんにとって分かりやすいように、これらの主要なトレンドを4つのPという形でまとめてみましょう。最初の2つはperformance(性能)とproductivity(生産性)です。先ほど述べたように、AIの採用ペースに追いつくためには、開発者は高性能で、差別化されていない重労働を排除して生産性を向上させるツールを必要としています。次のPはpreference(好み)です。データ関連の役割が増加していることを考えると、開発者は特定のタスクに特化した目的別のツールを必要としています。
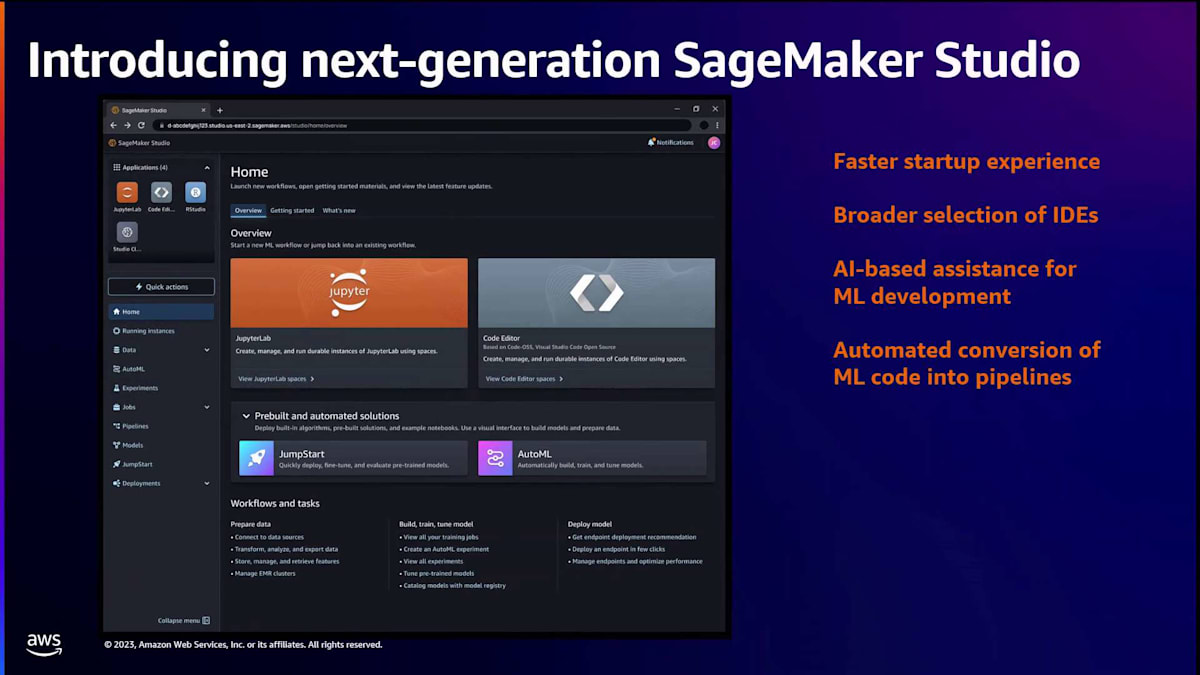
そして最後はproductionization(本番化)です。モデル構築者は、プロトタイプを本番環境に移行するためのよりセルフサービス型のツールを必要としています。これら4つのP、つまり開発者体験の4つの重要な柱に対応するため、 次世代SageMaker Studioの立ち上げを発表できることを嬉しく思います。これには、驚異的に高速な起動体験、さらに幅広いコードエディタの選択肢、すべてのMLタスクに対するAIベースの支援、そして機械学習コードを自動的にパイプラインに変換する新しいツールが含まれています。これらのツールの一部は、過去2日間のリーダーシップキーノートで発表され、最新のものはWerner Vogels氏が今朝のキーノートで発表したCode Editorです。これらの革新的な機能について、一つずつ詳しく見ていきましょう。
次世代SageMaker Studioの高速起動体験


まず、performanceについて、そして新しい驚異的に高速なStudioの起動が、現代の機械学習開発者の性能基準をどのように満たしているかについて話しましょう。起動体験を改善するために、いくつかの工夫をしました。Studioの初期セットアップが大幅に簡素化され、たった1回のクリックで、IAMベースのアイデンティティとアクセス管理、パブリックインターネットへの完全管理された接続、そして機械学習モデル構築のための基盤となるコンピューティングとストレージを備えたSageMaker Studioドメインをセットアップできるようになりました。Studioのセットアップは、文字通り、スマートフォンの電源を入れるスイッチを押すくらい簡単になりました。
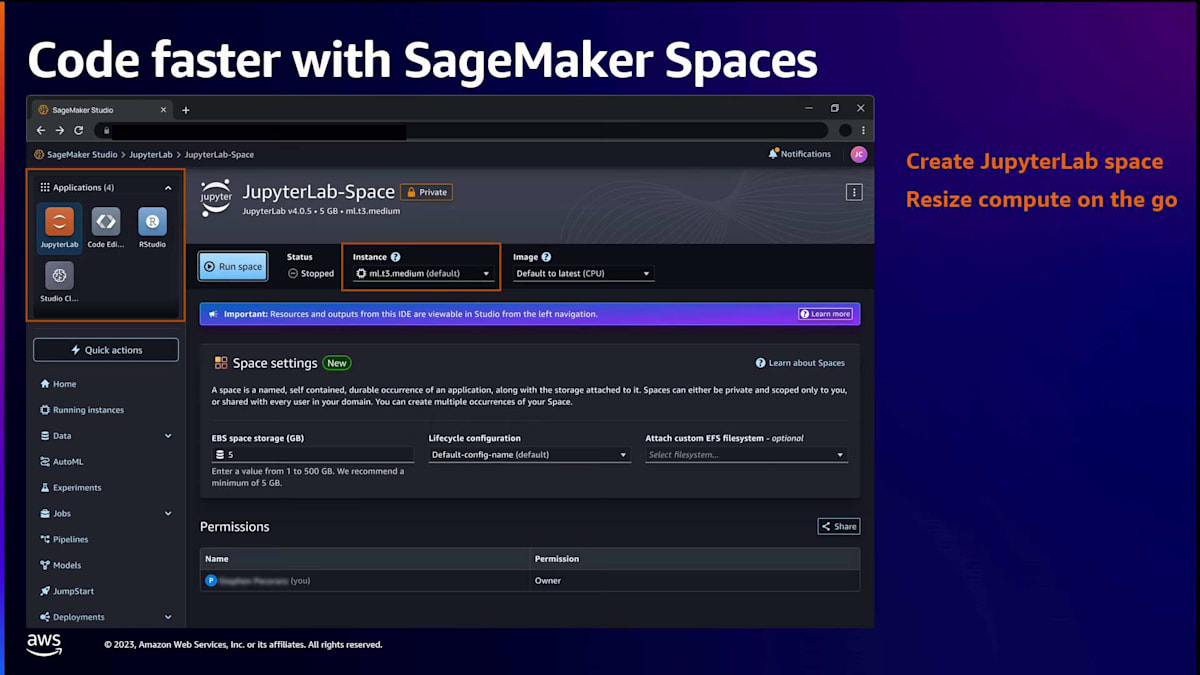
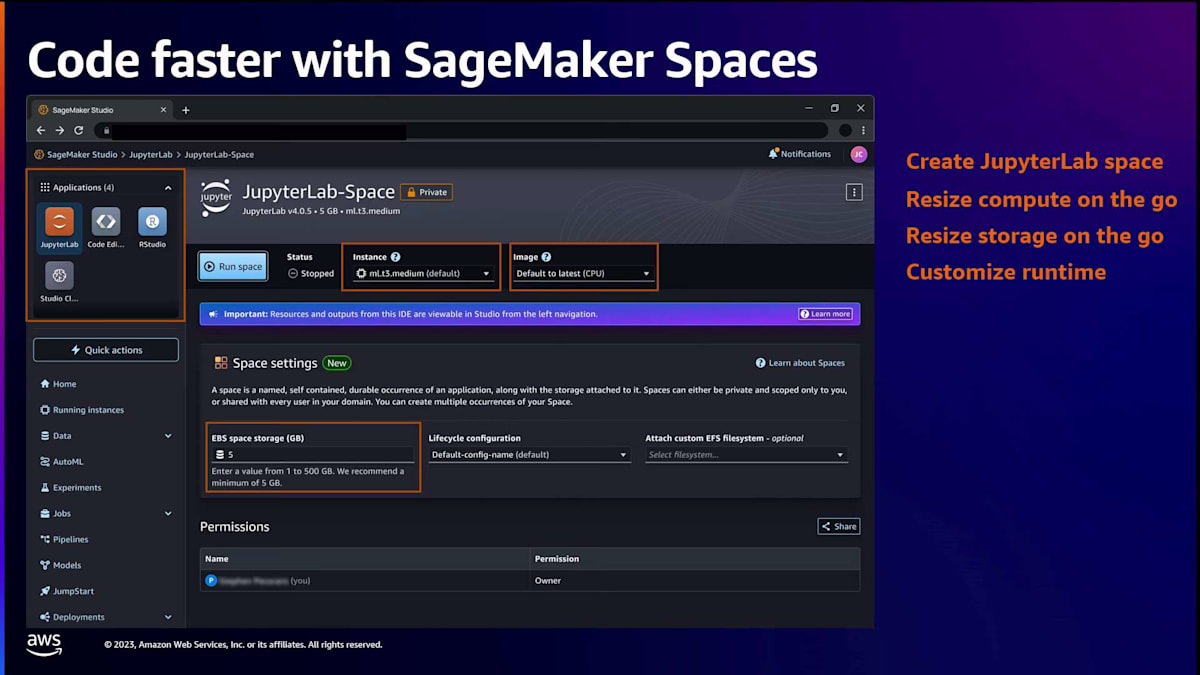
Studioをセットアップしたら、シンプルなクリックで起動でき、5秒以内にブラウザにアプリケーションが読み込まれ、すべてのツールに即座にアクセスできます。最初にやりたいことの一つはコードを書き始めることでしょう。そのためにはコードエディタを立ち上げる必要があります。SageMaker spaceを作成します。これは、開発環境のコンピューティング、ストレージ、ランタイム設定を保存するクラウド上のワークスペースのようなものです。このspaceには多くの機能があります。例えば、spaceを停止し、後で戻ってきて再起動し、中断したところから作業を再開することができます。すべての作業は、基盤となるEBSストレージに自動的に保存されます。
また、スペースのコンピューティングとストレージを簡単なクリックで拡張縮小することもできます。例えば、データ探索を行う際には軽量なCPUインスタンスでスペースを開始し、モデルトレーニングを始める際にはすぐにパワフルなGPUインスタンスに切り替えることができます。スペースには、チームメンバーとアーティファクトを共有・コラボレーションするための機能も備わっています。Amazon EFSのような共有ファイルシステムをスペースに接続して、コード、データセット、アーティファクトをチームと共有することができます。さらに、共有スペースを作成して、あなたと同僚がリアルタイムでファイルをレビューし、共同編集することも可能です。
スペースのセットアップが完了したら、JupyterLabやRStudioなどのIDEをスペースから起動できます。JupyterLabは数秒でブラウザに読み込まれ、SageMaker Distributionが事前設定されています。SageMaker Distributionは、データサイエンスと機械学習のランタイムで、多くの人気のあるデータサイエンスと機械学習パッケージが事前設定されているため、すぐに機械学習コードの作成を始めることができます。この全体験のデモをお見せしますが、まず、ビジュアル体験がどのように見えるかについて、いくつかのスライドをお見せします。
SageMaker Studioの新機能:Code EditorとVS Code統合

これが新しいSageMaker Studioのホームページです。左上に、好みのコードエディタを選べるアプリケーションギャラリーがあります。例えば、JupyterLabを選んだとします。すぐに画面中央にモーダルが開き、JupyterLabスペースの作成をサポートします。スペースのコンピューティング、ストレージ、ランタイムを選択するだけです。それぞれにデフォルトが設定されており、ランタイムのデフォルトはSageMaker Distributionとなっています。

これらの選択肢を決定または確認したら、すぐにスペースを起動してコードの作成を始めることができます。複数のプロジェクトや実験を同時に進めている場合、異なるコンピューティング、ストレージ、ランタイムの組み合わせで複数のスペースを並行して実行できます。このページに戻って、実行中のすべてのスペースを確認し、スペースの終了、停止、再開を行うことができます。これらすべてをこの一つの中心的な場所から行えます。そして、先ほど申し上げたように、この体験のデモをすぐにご案内します。



次のP、つまりpreferenceについて話しましょう。開発者は特定のタスクに対して好みのツールを求めています。先ほど見たように、SageMaker StudioはJupyterLabとRStudioの両方をサポートしていますが、私たちの顧客はさらに多くの選択肢を必要としていると言っています。デバッグ、リファクタリング、デプロイメントツールのサポートがより充実したIDEが必要だと。そして、彼らが求めているIDEの一つがVS Codeです。


SageMaker Studioに、Visual Studio Codeのオープンソースをベースにした新しいCode Editorの登場を発表できることを大変嬉しく思います。これはAWSによって開発され、Visual Studio Codeのオープンソースコードを使用しています。つまり、皆さんがお馴染みのVS Codeのショートカット、ターミナル、デバッグ、リファクタリングツールがCode Editorでも使えるということです。また、Eclipse Foundationが提供するOpen VSXを利用した拡張機能マーケットプレイスが事前にインストールされており、3000以上のVS Code互換の拡張機能にアクセスできます。Code Editorに事前インストールされている人気の拡張機能の1つが、AWS Toolkitです。これにより、Lambda、S3、Redshift、CodeWhispererなど、多くのAWSサービスに簡単にアクセスできるので、AWSでのアプリケーション開発とデプロイをすぐに始められます。
最後に、JupyterLabと同様に、VS CodeはSageMaker space上で動作するため、spaceのすべての利点を得られます。共有ファイルシステムを接続したり、コンピューティングとストレージのサイズを動的に変更したりできます。また、SageMaker Distributionが事前に設定されているので、すぐにコーディングを始められます。SageMaker Studio内で幅広いIDEの選択肢が利用可能になったことで、機械学習の作業者は、手元のタスクに応じて好みのツールを選択できるようになりました。
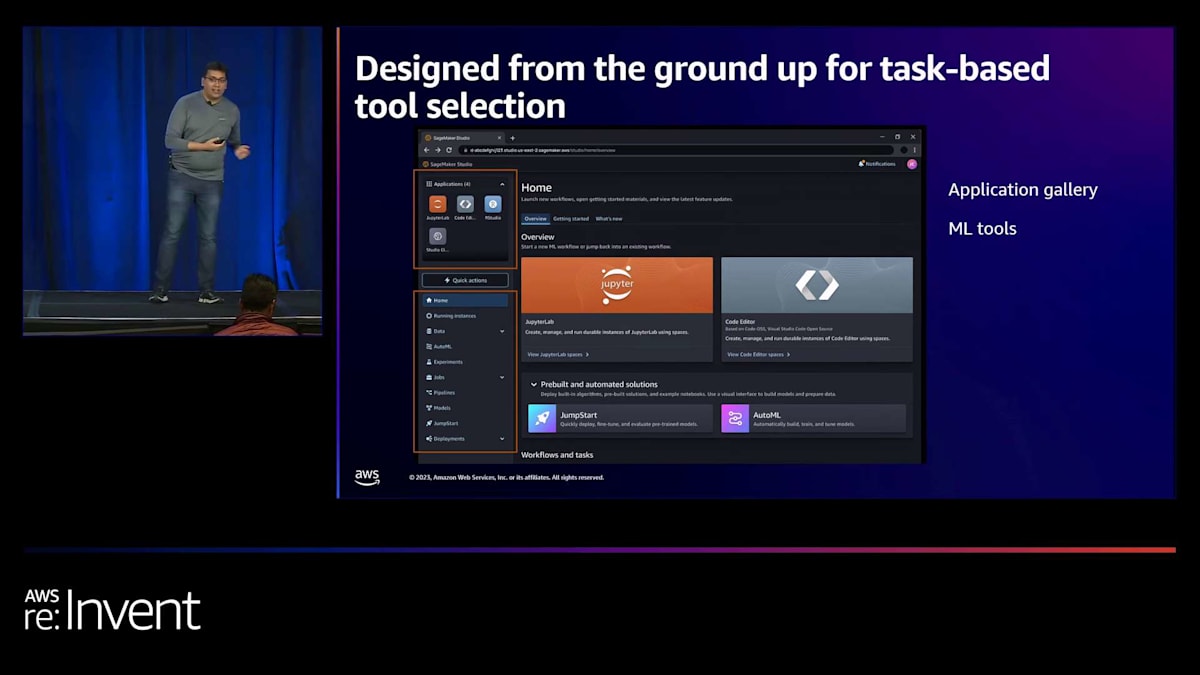

例えば、データサイエンティストはアプリギャラリーからJupyterLab IDEを選び、ツールギャラリーから実験追跡ツールを選んで、モデルの構築と実験を始めることができます。一方、機械学習エンジニアは、アプリギャラリーからVS Code IDEを選び、ツールギャラリーからパイプラインツールを選んで、モデルパイプラインのデプロイと自動化を始めることができます。
AIベースのアシスタンス機能:生産性向上のための新ツール


次に、3つ目のP、生産性について話します。開発者はデータからインサイトを得るためのより効率的な方法を求めています。新しいSageMaker Studioには、すべての機械学習タスクに対応した生成AIベースのアシスタンス機能が組み込まれています。JupyterLabやVS Codeなどのエディタには、Amazon CodeWhispererによる自動コード生成機能が事前にインストールされています。つまり、IDEにプレーンな自然言語でコメントを追加するだけで、Pythonやデータサイエンスのコードを生成できるようになりました。もはやインターネットからコードサンプルを探し、それらをデバッグしたり、APIの構文を覚えたりする必要はありません。IDEですぐにコーディングを始められます。

社内の調査によると、CodeWhispererを使用する開発者は、使用しない開発者と比べて57%生産性が高いことがわかりました。また、IDEにはAIベースのチャットコンパニオンも組み込まれています。これにより、コード生成以外のタスクについても自然言語で会話ができます。例えば、コードサンプルの説明を求めたり、エラーのデバッグを依頼したり、コードのリファクタリングに関する提案を求めたりすることができます。このチャットコンパニオンは非常に強力で、高度にカスタマイズ可能です。
基盤モデルを選んでチャットコンパニオンを動かすことができます。例えば、Amazon Bedrock で利用可能な Anthropic 社開発の Claude V2 モデルを選択したり、SageMaker JumpStart モデルハブで利用可能な Hugging Face 社開発の StarCoder を選択したりできます。JumpStart Model Hub には現在、様々なタスク向けに150以上のオープンソースモデルが用意されており、これらのモデルは JumpStart インターフェースから簡単に SageMaker エンドポイントにデプロイできます。そこから、チャットインターフェースを動かすのに使用できます。IDE 内でこれらのモデルを試すこともできます。とても楽しい体験なので、ぜひ皆さんに IDE 内で様々なモデルを試してみることをお勧めします。
モデルのプロトタイプから本番環境への移行を簡素化


次に、最後の P である productionization についてお話しします。 これは、モデル開発者がプロトタイプを本番環境に移行するためのセルフサービスツールを構築する方法に焦点を当てています。 ここでいくつかの革新を行いました。SageMaker Python SDK を大幅に変更し、新しいデコレータのセットを導入しました。これを使用して Python コードに注釈を付け、そのコードを自動的に SageMaker のジョブとして実行できます。デコレータは、実行時に提供する requirements ファイルや YAML ファイルに基づいて、コードをジョブとして実行するために必要なランタイムを自動的に決定します。つまり、ラップトップで書いてデバッグしていたコードを、満足のいく状態になったら、コードを変更することなく、単にデコレータを追加するだけで、クラウド上のより強力なインスタンスに素早くスケールアウトできるのです。
これは1つの Python 関数だけでなく、複数の Python 関数にも適用できます。コード内に特定のタスク用に設計された複数の関数がある場合、それらを SageMaker 上のパイプラインにつなげることができます。必要なのは、Python SDK のステップデコレータでそれらの関数に注釈を付けることだけです。ノートブック開発者で、ノートブックをジョブとして実行したい場合は、SageMaker Studio でさらに簡単です。SageMaker Studio に行き、ノートブックを選択し、このノートブックをジョブとして実行するスケジュールを作成できます。SageMaker は自動的にジョブをトリガーし、ノートブックの作成に使用された依存関係を特定し、それを使用してコンテナを作成し、このノートブックを SageMaker 上でジョブとして実行します。ジョブのすべての出力を SageMaker Studio に戻し、レビューと監視ができるようにします。
さらに、このような複数のノートブックをパイプラインの形で調整することもできます。実際に、これらの実行中のノートブックの DAG を作成できます。例えば、S3 からデータを取り込み、特徴量エンジニアリングを行うノートブック、これらの特徴量を取り込んでハイパーパラメータチューニングを行う別のノートブック、モデル候補を取り込んでモデル評価を行い評価レポートを生成する別のノートブックなどがあるかもしれません。新しい SageMaker Python SDK を使用して、これらをパイプラインにつなげることができます。
最後に、モデルのデプロイプロセスを大幅に簡素化しました。今では、わずか2つの簡単なステップで SageMaker にモデルをデプロイできます。SageMaker Python SDK の新しい model builder クラスを使用すると、モデルアーティファクトを選択し、model.build 関数を呼び出すだけで、SageMaker が自動的にこのモデルをエンドポイントにデプロイするためのすべての要素を決定します。これには、Triton サーバーや Tensor サーバーなど、モデルアーティファクトの種類に応じて適切な推論サーバーの決定が含まれます。また、このモデルを実行するのに適切なコンピュートも決定します。さらに、入力される推論リクエストをモデルが消費するのに適した形式に変換し、モデルが生成したレスポンスを REST API 出力にパッケージ化するグルーコードスクリプトも自動生成します。SageMaker はこれらすべての要素を取り込み、高スループット、低レイテンシー、耐障害性のあるエンドポイントにデプロイします。
機械の故障検知:SageMaker Studioを使用したMLワークフローのデモ
これらの素晴らしい機能のデモをお見せするために、Giuseppe を再び舞台にお招きして、ライブデモをお手伝いいただきます。

ありがとうございます。Sumit さん、ありがとうございます。デモに入る前に、今日私たちが解決しようとしているユースケースについて少しお話しさせてください。私たちが解決したい問題は、 機械学習を使って機械の故障を検知することです。これは難しい問題ですが、今日扱うデータに基づけば比較的シンプルです。University of California Irvine Machine Learning Repository の AI4I predictive maintenance データセットを使用します。このデータセットには、スライドに示されているいくつかの特徴が含まれています。機械のタイプ、温度、回転速度、プロセス温度、そして予測したい変数である機械の故障(二値変数)などです。ご想像の通り、このユースケースに対処するために二値分類モデルを訓練したいと思います。


機械学習モデルの構築、訓練、デプロイには Amazon SageMaker Studio を使用します。さらに、機械学習ワークフロー全体のオーケストレーションには Amazon SageMaker pipelines を使用します。では、デモに移りましょう。Sumit が言及したように、SageMaker Studio へのオンボーディング体験を非常にシンプルにしました。文字通りワンクリックで Studio にオンボーディングできます。 ここの「Set up for single user」ボタンをクリックすると、SageMaker Studio ドメインが自動的に設定され、 デフォルトの設定で単一のユーザープロファイルが作成されます。これには、Amazon SageMaker full access 実行ロール、デフォルトのネットワーク設定などが含まれます。このドメインですぐに始めることができます。


あるいは、組織向けに Studio をセットアップしたい場合も、ウィザードベースのユーザーインターフェースでそのプロセスを簡素化しました。これにより、組織内で SageMaker Studio をどのように設定すべきかをカスタマイズできます。この例では、すでに事前に作成されたドメインがあります。そのドメインにアクセスし、この特定のユーザー向けに SageMaker Studio を開いてみましょう。これで新しい SageMaker Studio ユーザーインターフェースに入りました。ご覧のように、左上にアプリケーションギャラリー、左側にナビゲーション、 そしてメイン画面にランディングページがあり、ここで JupyterLab または Code Editor で作業するかを選択できます。 また、入門リソースにもアクセスできます。

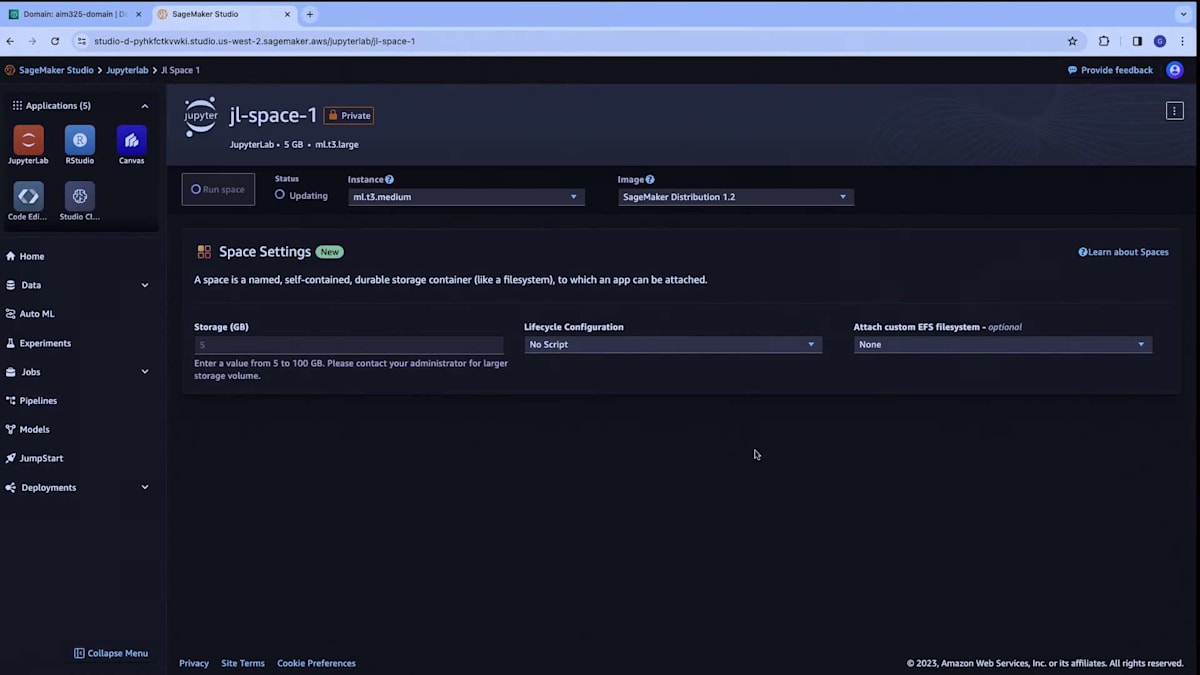
問題を解決するためにこの二値分類モデルを訓練したいので、データサイエンティストとして最初にやりたいのは、JupyterLab を使ってデータを探索し、前処理を行い、そして機械学習モデルを構築することです。 そこで、ここで JupyterLab スペースを作成します。名前を付けましょう。 スペースはすぐに準備され、Sumit が言及したように設定をカスタマイズできます。このスペースに割り当てたいストレージを設定し、基盤となるインスタンスのブートストラップ時に実行されるシェルスクリプトを通じて環境の設定をカスタマイズするライフサイクル設定の追加を選択し、カスタム EFS ファイルシステムを接続し、CPU や GPU インスタンス、さらには1分以内に起動する高速起動インスタンスなど、さまざまなコンピューティングリソースから選択できます。
例として、インスタンスを選択し、デフォルトで設定されているSageMaker Distributionをランタイムイメージとして使用しましょう。このスペースを実行して、SageMaker Distributionについてもう少し詳しく説明させてください。5月に、私たちはJupyter current SageMaker Distributionプロジェクトを立ち上げました。これは、機械学習用の最も一般的なフレームワークとライブラリを1つのディストリビューションにまとめたオープンソースプロジェクトです。正しい依存関係とバージョンを持つcurrent環境として構築されていることを確認しています。また、このディストリビューションをDockerコンテナとして提供しているので、GitHubにアクセスして、このDockerコンテナをローカルで試すこともできます。SageMaker DistributionはSageMaker StudioのJupyterLabアプリケーションとCode Editorスペースの両方を支えており、これは非常に重要です。つまり、同じランタイムを使用して、一方の環境から他方の環境に移動できるのです。
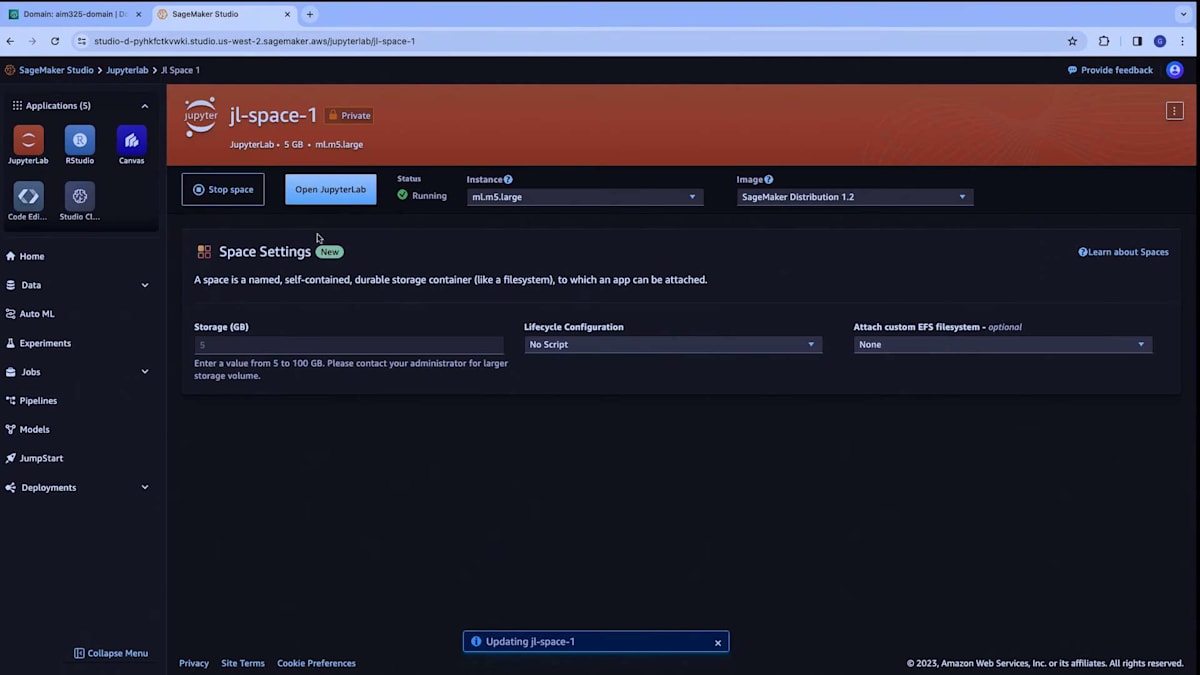

このおかげで、ある場所から別の場所に移動する際にカスタマイズする必要なく、ランタイムを一貫して保つことができます。素晴らしいですね。ご覧のように、1分もかからずにスペースの準備が整いました。ただ、私は既に必要なコードをすべて含むスペースを作成済みです。ここでJupyterLabを開いてみましょう。JupyterLabが読み込まれます。先ほど言ったように、これは今回の例のために私がクローンしたリポジトリです。最初のノートブックを開きましょう。
JupyterLabでのデータ探索とモデルトレーニング
データサイエンティストとして、このデータを探索し、前処理を行い、モデルを適合させて訓練できることを確認したいと思います。先ほど述べたように、SageMaker Distributionには既に最も人気のあるフレームワークとライブラリが含まれています。ここでは、Pandas、XGBoost、scikit-learnを使用したいと思います。私たちがこれから行うのは、scikit-learnとPandasを使ってデータの変換、データ探索、前処理を行うことです。そして、XGBoostを使用して二項分類モデルを作成します。もちろん、必要に応じて追加のライブラリをインストールしてランタイム環境をカスタマイズすることもできます。今回の場合、Seabornという可視化ライブラリをインストールしています。

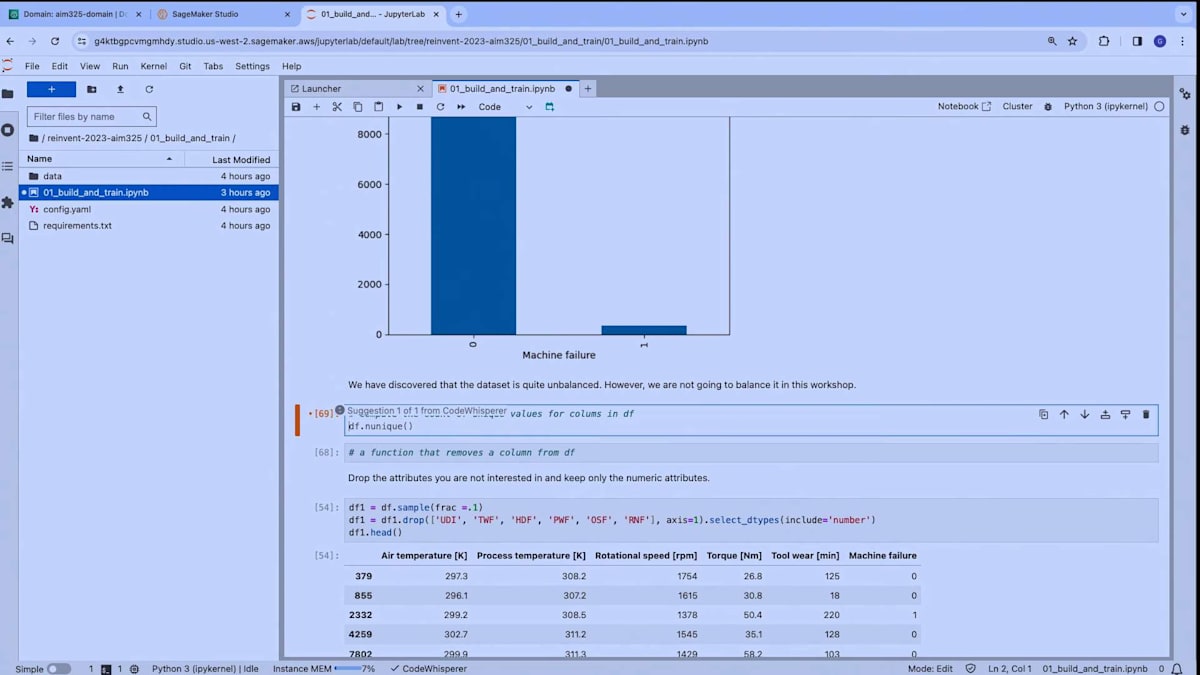
次に、University of California Irvine Machine Learning Repositoryからデータセットをダウンロードし、探索的データ分析を始めます。これらのセルのいくつかを実行してみましょう。ここで見ていただけるように、まずデータセットを確認し、それを記述し、そして機械の故障に関する値のカウントをチェックしています。つまり、このデータセットにおける正例と負例の数を確認しています。そして、この情報をプロットしています。これは標準的なプロット操作です。そして、ある時点で、このデータフレームの列ごとにユニークな値の数を計算したいのですが、必要なAPIを思い出せないかもしれません。



ここで使えるのが、今JupyterLab上で動作しているAmazon CodeWhispererです。この関数に対する提案を提供してくれます。もう1つ、データフレームから列を削除する関数が欲しいとします。はい、ここでCodeWhispererの提案が表示されました。これらの提案を受け入れれば、関数の準備が整います。ノートブック内での開発を支援する非常に強力なツールですね。素晴らしい。先に進みましょう。ここで行っているのは、この特定の問題に不要な列、含めたくない列を削除しています。そして、Seabornを使用して、変数間の潜在的な相関関係を見つけるためにプロットしています。
次に、データ準備コード、つまりデータの前処理コードに入ります。 このコードは、予想通り標準的なPython関数として定義されており、pre-processという名前で、すべてのデータを含むデータフレームを入力として受け取り、いくつかの操作を行います。例えば、トレーニング、検証、テストデータの分割を行います。そして、scikit-learnを使用していくつかの変換を適用します。具体的には、数値属性のスケーリングとカテゴリカル属性のone-hotエンコーディングを行い、後でモデルをフィットさせます。そして、この関数は見ての通り、変換されたデータ、つまり前処理されたデータと、scikit-learnで作成されたfeaturizerモデル自体を返します。このfeaturizerモデルは、データを変換することができます。



この関数を実行すると、ここに新しいモデル、featurizerモデルができあがります。 これがこのモデルの表現です。そして、変換されたデータを見ることができます。ここでは標準的な前処理操作が行われています。次に、モデルのトレーニングに移ります。 ここでも、前処理されたデータ、つまりトレーニングデータと検証データ、そしてXGBoostアルゴリズムのいくつかのハイパーパラメータを入力として受け取るtrain関数があります。そして、XGBoostモデルをフィットさせます。ここで行っているのはそれです。ここでモデル、XGBoostモデルをトレーニングしています。 この関数の戻り値はXGBoostモデルです。
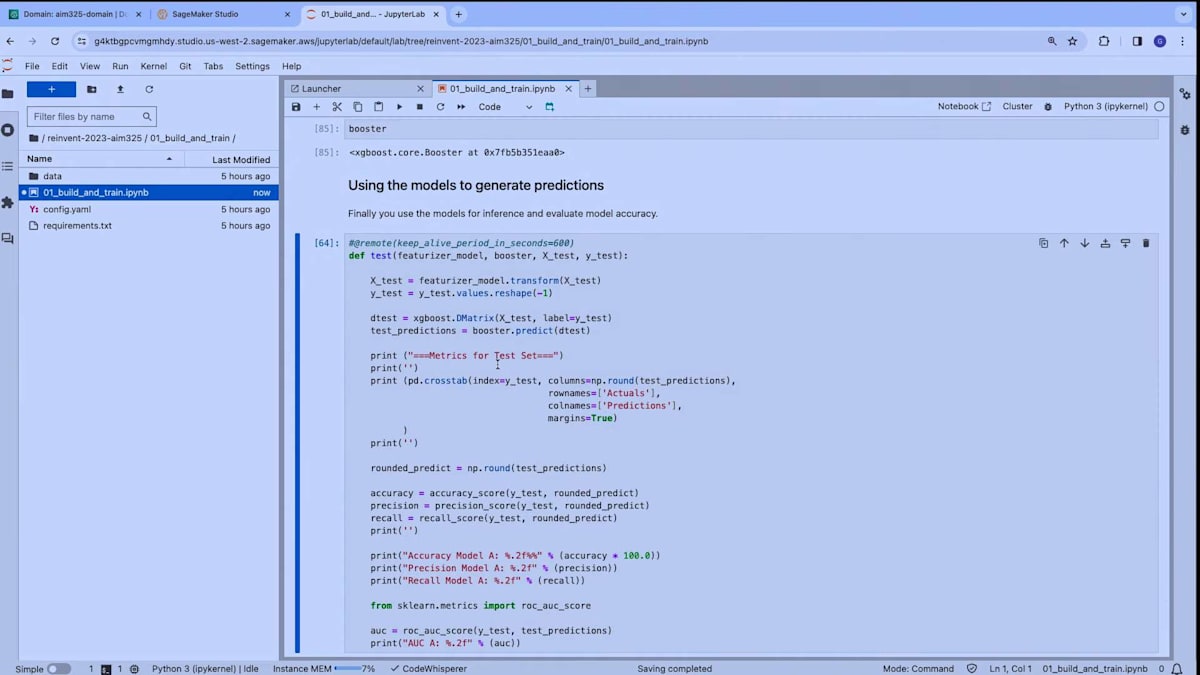
素晴らしい、関数を実行してフィットさせています。また、accuracy、precision、recallなどのメトリクスも計算しています。これらは二値分類問題を扱う際にとても便利です。良いですね。さて、データサイエンティストとして最後にやることは、 おそらくこれら2つのモデルを使ってテストデータセットで推論を実行することです。それがここでこの関数で行っていることです。素晴らしい。ここまでノートブックで行ったことに満足したとして、このコードを異なる計算インフラでスケールさせたいとしましょう。これには複数の理由があるかもしれません。例えば、データセットのサイズが大きくなり、機械学習モデルのトレーニングにより大きなインスタンスやインスタンスのセットを使用したいからかもしれません。
ノートブック環境からより本番環境に近いセットアップに移行するもう一つの理由は、コードの実行を自動化したいからかもしれません。ノートブックで作業している間、コードがパイプラインの一部として実行できることも確認する必要があります。

これをどのように実現できるか見てみましょう。少なくとも2つのオプションがあります。 一つのオプションは、JupyterLab環境で利用可能な統合ノートブックスケジューリング機能を使用することです。この機能を使用すると、ノートブック全体の実行を即時または定期的なスケジュールで設定できます。これはSageMakerジョブの形で実行され、SageMakerインフラストラクチャを利用します。

もう一つのオプションは、先ほど言及したremote decoratorです。これを使えば、たった1行のコードでデコレータをインポートし、Python関数に適用できます。このコードを実行すると、ノートブックで実行しているのと全く同じ関数が、別のインフラストラクチャ上でSageMaker training jobとして実行されます。デコレータは関数を取り、ランタイム環境の設定を理解し、この関数をSageMaker training jobとして実行します。
Code Editorを使用したモデルのデプロイメント

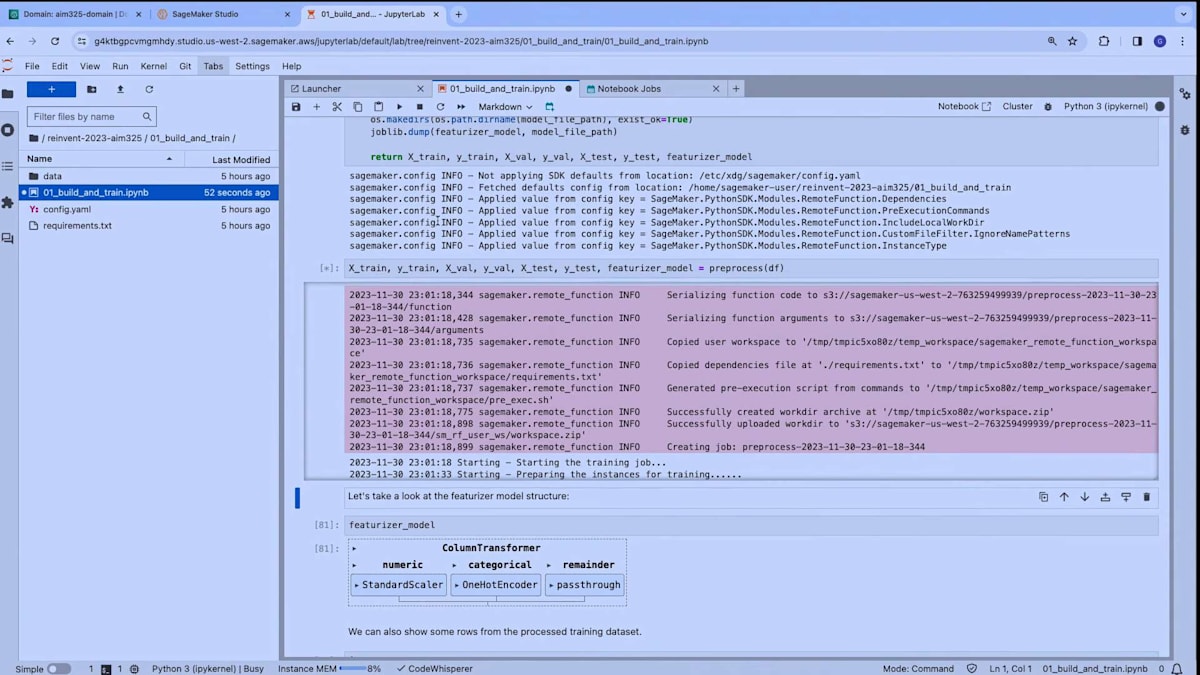
ジョブの実行を監視したい場合は、SageMaker Studioに戻り、Job Screensセクションに移動できます。ここでは、現在実行中のtraining jobを確認できます。この場合、1つのジョブが実行中で、これは前処理コードが現在SageMaker trainingインフラストラクチャ上で別のジョブとして実行されているものです。

これらのジョブに関する詳細情報、例えば入力アーティファクトやその他の設定を確認できます。ここで強調したいのは、ランタイム環境が自動的に選択されていることです。SageMaker Distributionが、training jobを実行するためのDockerコンテナとして使用されています。これにより、JupyterLab環境、Code Editor環境、そしてジョブ間でランタイム環境の一貫性が確保されます。ジョブに移行する際、一貫した環境を維持することで、ランタイムの設定に必要な作業量が減ります。
ジョブが現在実行中ですが、その実行完了を待つ必要はありません。2つのジョブ、つまりデータの前処理用と実際のモデルトレーニング用を実行したとしましょう。これで、2つのモデル(特徴抽出モデルと分類を行うXGBoostモデル)が手に入りました。この時点で、ML engineerと協力してこのモデルをリアルタイムエンドポイントにデプロイしたいと思います。


これを実現するために、SageMaker Studioに戻り、Code Editorを開くことができます。このデモでは新しいスペースは作成しません。手順はJupyterLabで見たものと同じだからです。単純に、既に環境で実行中のCode Editorを開きます。ここでCode Editor環境がロードされるのが見えるでしょう。
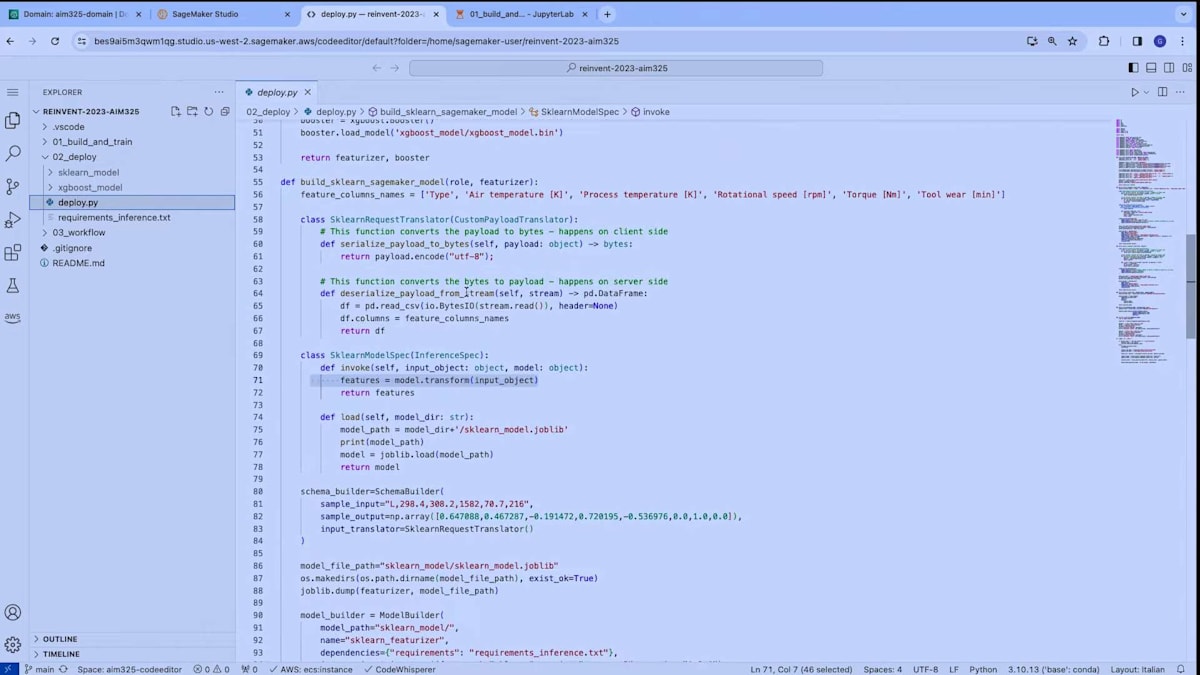

ユーザーのホームディレクトリにクローンしたリポジトリの特定のフォルダを開いて、デプロイメントモジュールに移動しましょう。デプロイメントは標準的なPythonスクリプトとして定義しています。デプロイメントの手順を大まかに説明すると、次のようになります:まず、2つのモデル(featurizerモデルとXGBoostモデル)をメモリにロードします。次に、2つのSageMakerモデルを作成します。SageMakerモデルは、モデルをリアルタイムエンドポイントにデプロイするために必要な追加のメタデータを表します。SageMakerモデルを構築するには、先ほど紹介した新しいmodel builderクラスを使用します。
2つのSageMakerモデルを構築した後、それらをSageMakerのserial inference pipelineと呼ばれるものに組み合わせます。これは、SageMakerでマシンラーニングモデルをリアルタイムエンドポイントにデプロイする方法の1つです。この方法を採用する理由は、最初のモデルに提供される入力が、現場から得られる可能性のある生データであることを確実にするためです。このモデルがデータを変換し、実際の推論のためにXGBoostモデルに渡します。最後に、モデルをデプロイします。
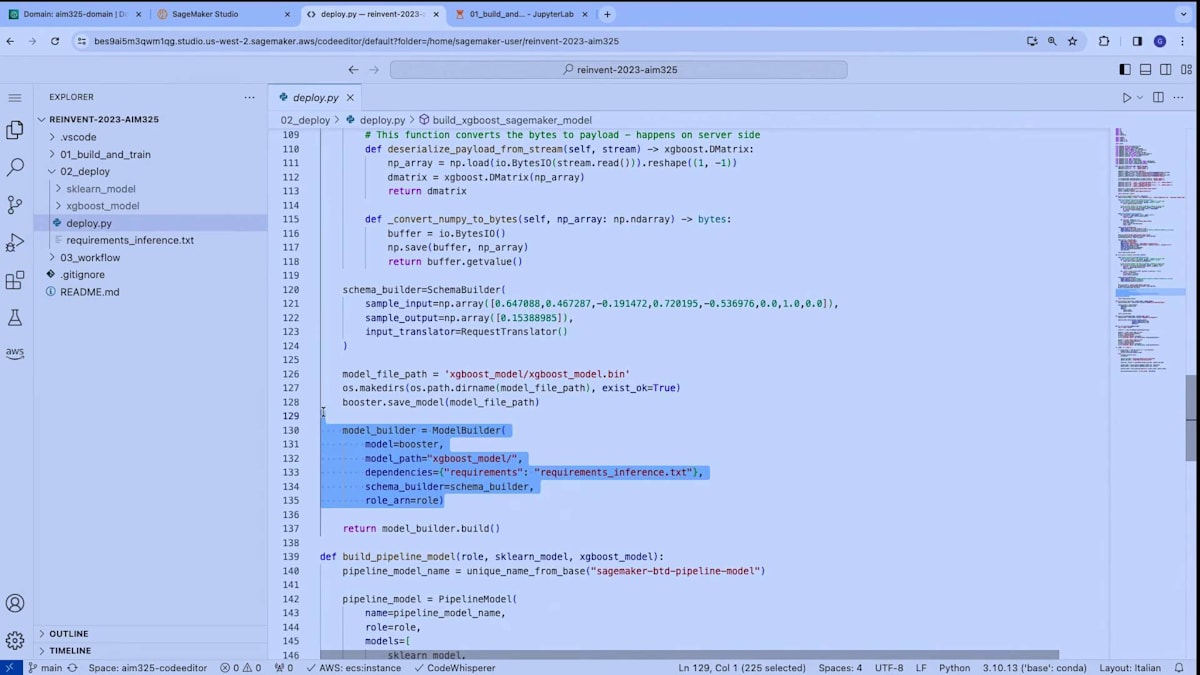
ここでは、モデルの構築方法に特に焦点を当てたいと思います。新しいmodel builderクラスを見てみましょう。model builderクラスは、実際のXGBoostモデルを入力として受け取ります。そして、推論に必要な要件などのいくつかのパラメータを指定し、最も重要なのは、schema builderを渡すことです。schema builderは、モデルの入力データと出力データの構造を定義します。
schema builderを通じて、モデルのマーシャリング関数を自動的に計算し、データのシリアル化とデシリアル化の方法を決定することができます。同時に、追加のクラスを使用してこれをカスタマイズすることもできます。この場合、Request Translatorを使用しています。なぜなら、モデルへの入力の提供方法をさらにカスタマイズしたかったからです。
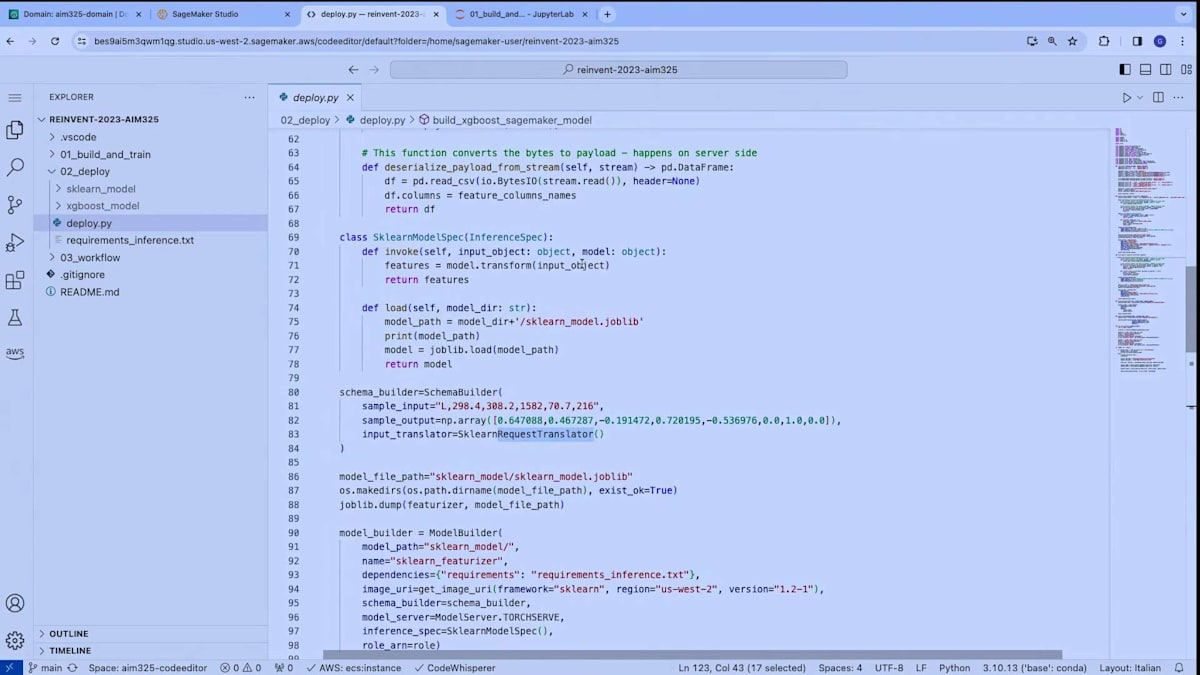
「実際の推論の方法をカスタマイズしたい場合はどうすればいいのか?」と疑問に思うかもしれません。scikit-learnモデルでは、inference specクラスを記述することで、model builderを通じて実際の推論の動作方法もカスタマイズできるようにしました。なぜでしょうか?それは、scikit-learnモデルでpredictメソッドを呼び出すのではなく、データを変換するためにtransformメソッドを呼び出したかったからです。
では、デプロイメントに移りましょう。新しいターミナルを開いて、 Deployフォルダに移動し、python deploy.pyを実行します。ここで起こっているのは、model builderクラスが私たちのモデルをパッケージ化し、推論に必要なコンテナイメージの設定を自動的に理解しているということです。serving stacksに適切な設定を行い、機械学習モデルをデプロイしています。

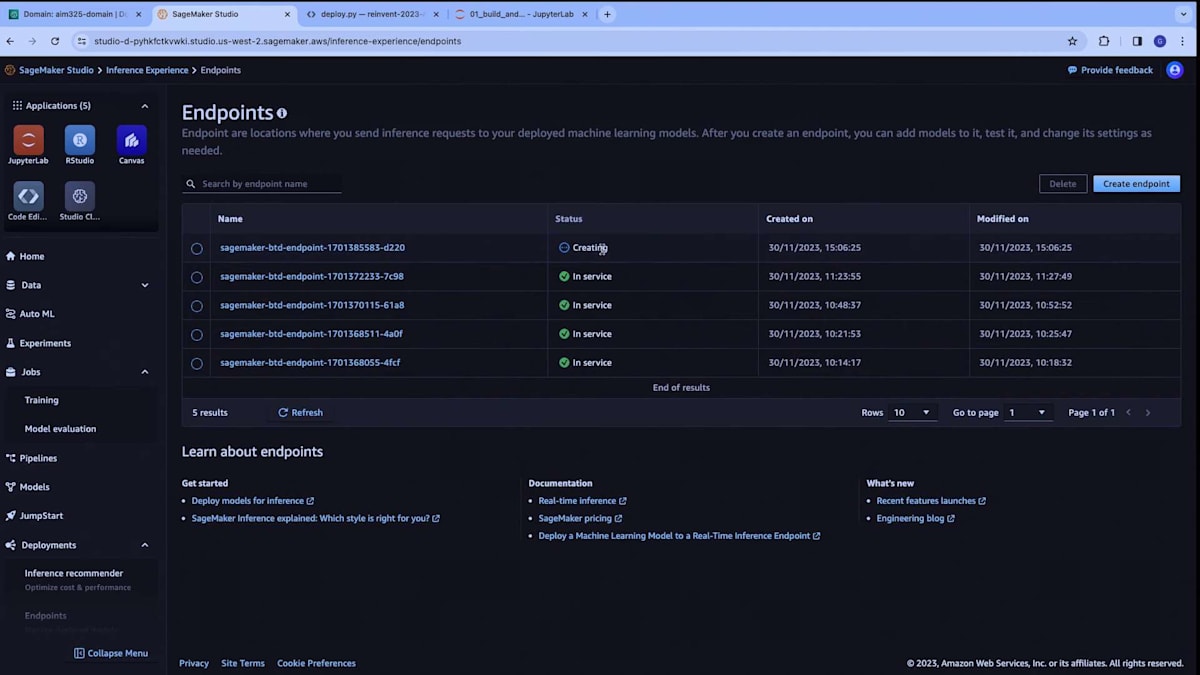
SageMaker BTD endpointという名前に接尾辞を付けたエンドポイントを作成しています。これを確認するために、SageMaker UIに戻り、エンドポイントセクションに移動すると、creating状態のエンドポイントが表示されます。 これが現在構築中のエンドポイントです。
SageMaker pipelinesを使用したエンドツーエンドのMLワークフロー
推論をテストしたい場合は、既に稼働中のエンドポイントを使用します。このスクリプトに追加した--run-inferenceという引数を使用して、いくつかの推論を実行し、予知保全問題における正例と負例の結果を確認できます。属性に基づいて、結果に最も影響を与えているのは回転速度だと思われます。ここでは、正例と負例の結果が得られています。

ここまでで、探索、データの前処理、モデルの構築、そしてデプロイの方法を見てきました。次は、これらすべてをSageMaker pipelineでつなぎ合わせたいと思います。これには、新しく導入されたstep decoratorを使用します。ここでworkflowに移動し、pipelineを開きましょう。pipelineの詳細に入る前に、作成するステップをお見せしたいと思います。


最初のステップは前処理ステップです。 ご覧のように、これはノートブックで実行していたのと全く同じ前処理コードです。 同じ関数をPythonスクリプトに移動させただけです。次にtrain関数がありますが、これも同様にノートブックで実行していた関数を Pythonスクリプトに移動させたものです。ステップ自体を定義するための特別なSDKコードを書く必要はありません。
次に、評価関数があります。これはノートブックにあったテスト関数とよく似ていますが、評価レポートも返します。これは、2つのモデルをトレーニングした後、デプロイする前に、SageMaker model registryに保存し、評価レポートを添付するためです。これにより、後でmodel registryにアクセスし、特定のバージョンを確認して、モデルのパフォーマンスをチェックすることができます。
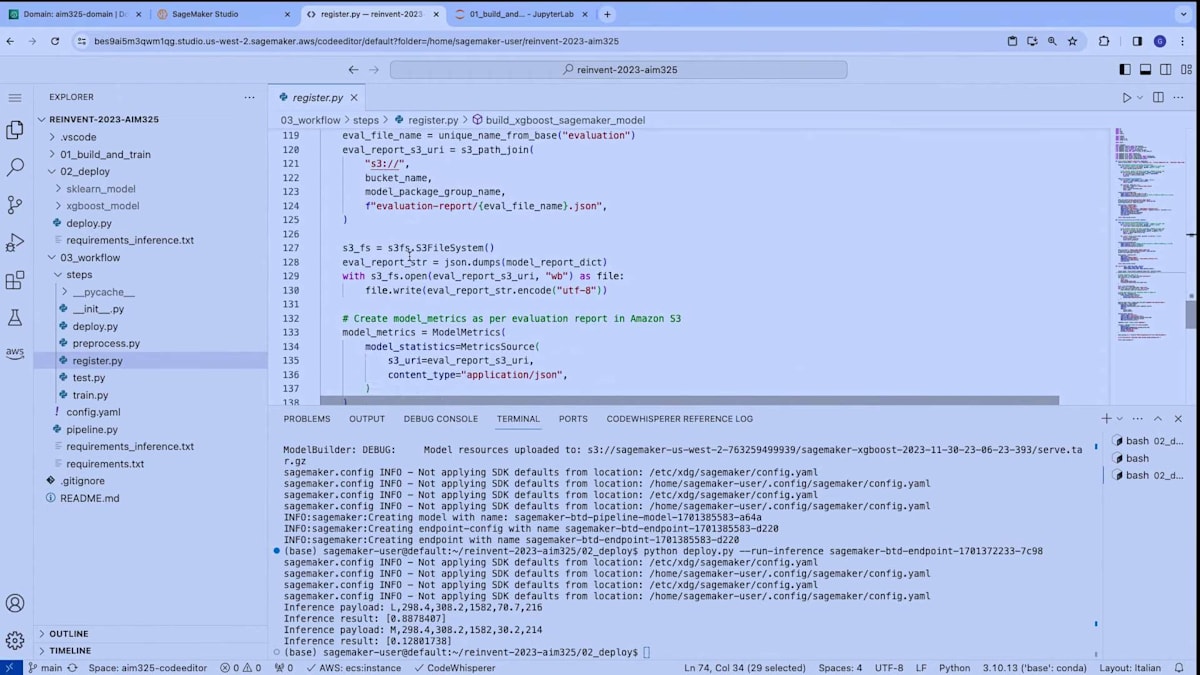
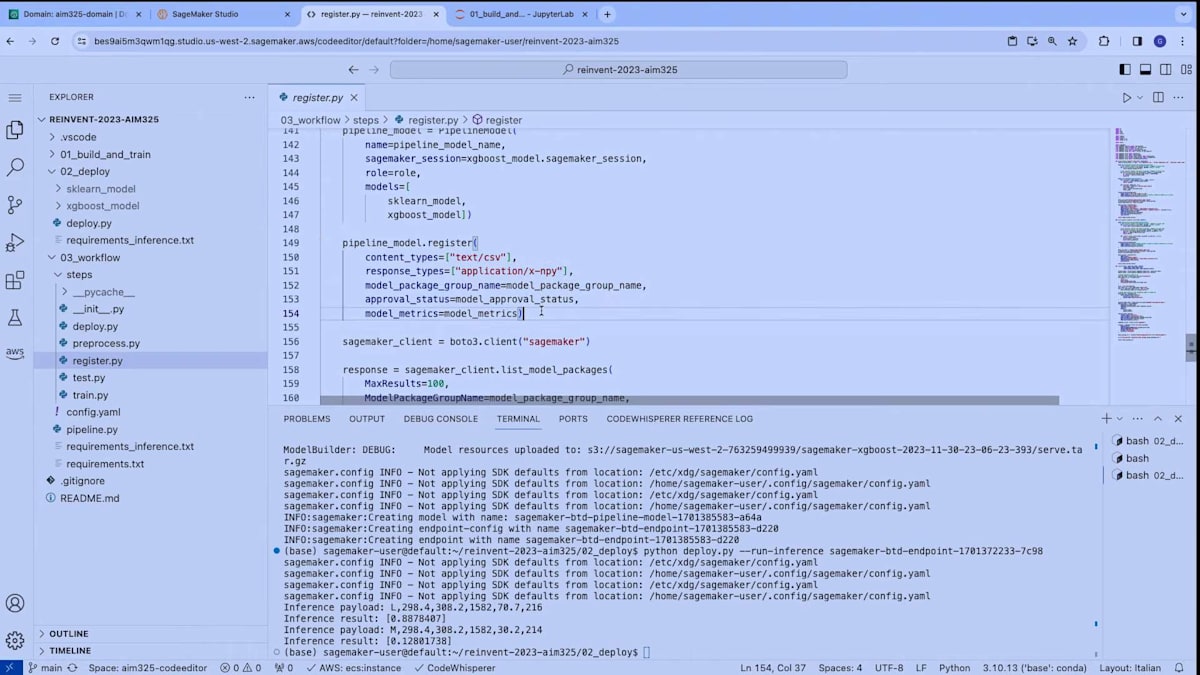
最後に、register modelステップがあります。このステップは、2つのモデル(scikit-learnのSageMakerモデルとXGBoostのSageMakerモデル)を作成します。これらは、デプロイメントに使用したのと同じ関数です。次に、これら2つのモデルをパイプラインモデルとしてまとめ、SageMaker Model Registryに登録し、評価レポートを添付します。パイプラインの最後のステップはデプロイメントです。このステップは、単にmodel registryからモデルを取得し、SageMakerエンドポイントにデプロイします。
さて、これらのステップをどのようにまとめるのでしょうか?どうやってつなぎ合わせるのでしょうか?ステップを作成するこの関数を見てみましょう。ここではステップデコレータを使用しています。これはPythonの関数です。ここでは、アノテーション構文でデコレータを使用するのではなく、関数としてデコレータを使用しています。その理由は、モジュール化されたコードを実装しているからです。モジュール性を考慮してコードを設計しているのです。
これまで見てきた様々な関数(pre-process、train、test、register、deploy)をデコレータに渡しています。さらに、前のステップの出力が、標準的なPythonコードで適切に後続のステップに渡されるようにしています。最後に、SageMakerパイプラインを作成し、ステップをパイプラインに渡し、eta、max_depth、そしてモデルをデプロイするかどうかを決定するブール変数であるdeploy_modelなどのパラメータを定義します。そして、パイプラインをupsertし、パイプライン定義をシステムに挿入して実行を開始します。

これがどのように機能するか見てみましょう。デコレータにより、これまで見てきたPython関数を、追加のSDKコードを書くことを気にせずに自動的にSageMakerパイプラインステップに変換することができます。今、パイプラインをシステムに追加し、その実行を開始しています。SageMaker Studioに戻ると、パイプライン画面を見ることができます。これが私のパイプラインです。今開始したばかりの実行中のものが1つあります。このパイプラインのグラフを見ることができ、確かにpre-process、train、evaluation、model registryへのモデル登録、そして最後にモデルのデプロイメントが表示されています。

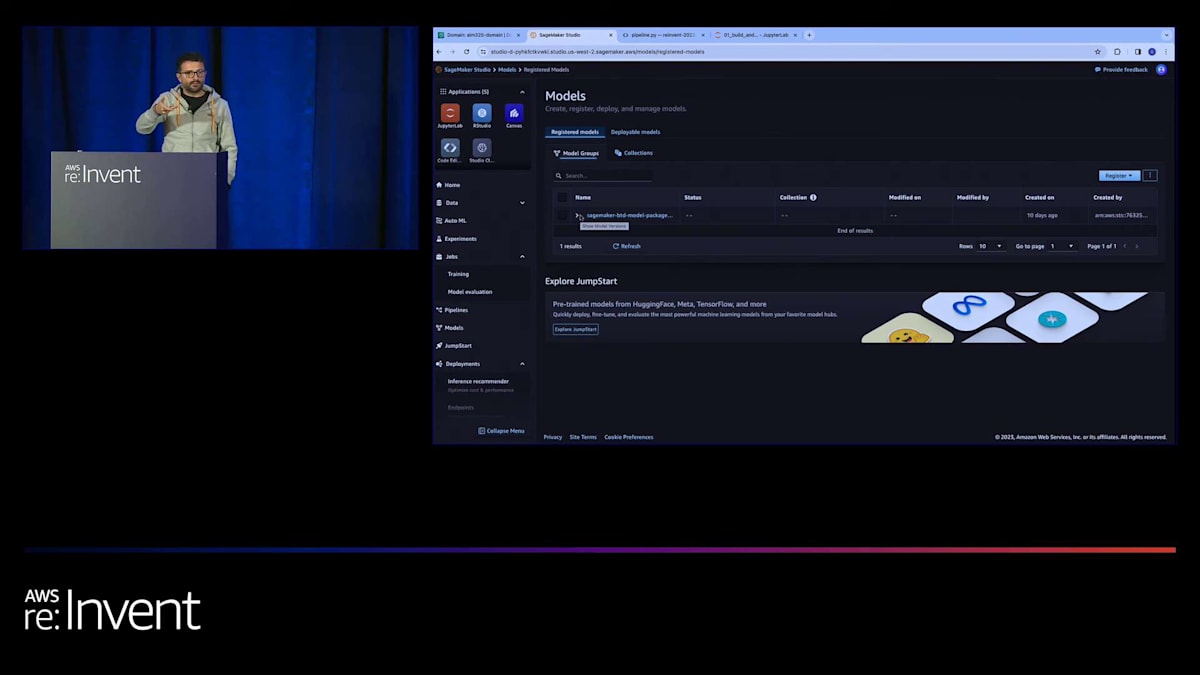
特定の実行を見てみると、現在どの段階にあるかがわかります。今回はプリプロセッシングの段階にあります。また、このパイプラインを実行するために使用されたパラメータや、この特定の実行に関連する追加情報やメタデータも確認できます。最後にお見せしたいのは、SageMaker Model Registryについてです。パイプラインのステップの1つで、 SageMaker Model Registryに新しいモデルバージョンが登録されます。これにより、このバージョンを以前のモデルバージョンと比較して、本番環境にプロモートするかどうかを決定できます。
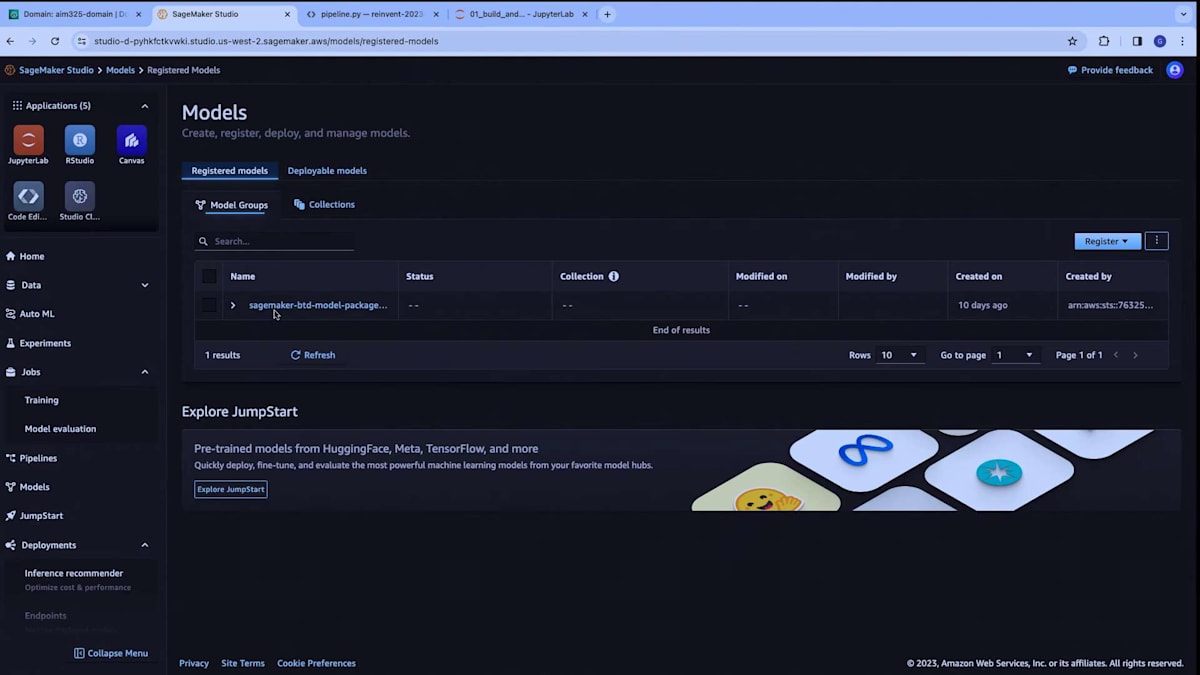

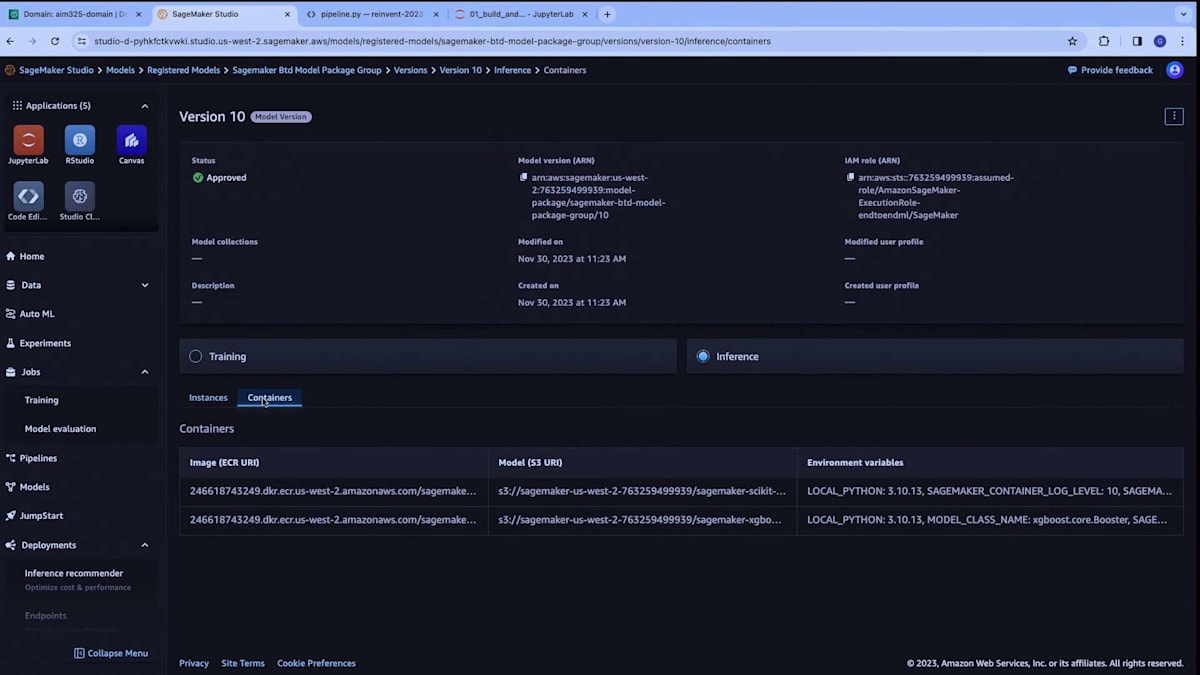
ModelPackageGroupと呼ばれるものを開きました。これは、これまでに生成したモデルのすべてのバージョンをリストアップしています。例えば、ここにあるバージョン10を見てみましょう。ここでは、Model Registryにアタッチしたモデルの評価レポートを確認できます。 XGBoostモデルの精度メトリクスが表示されています。また、このモデルをリアルタイム推論用にどのようにデプロイするかも確認できます。 コンテナ、環境変数、サービングスタックの設定方法などの情報は、モデルビルダークラスを通じて自動的に適用されています。
BMW GroupにおけるAIの活用:多様なビジネスプロセスでの応用

以上でデモを終わります。BMW GroupのMarc Neumannさんをステージにお招きしたいと思います。彼は、BMWがAmazon SageMaker Studioを使用して機械学習開発をスケーリングする方法について話してくれます。ありがとうございます、Giuseppe。BMWグループがマルチブランドの自動車会社であることをご存知でしたか?もちろん、私たちはBMWの車やバイクで知られていますが、他のブランドもあります。 MINIブランドで生活を豊かにするMINI、そしてBMWグループの高級自動車部門であるRolls-Royceもあります。北米では、BMWグループが実際に最大の自動車輸出企業であることをご存知でしたか?サウスカロライナ州に工場があり、来週そこに行く予定ですが、そこではSUVのXシリーズ車種を生産し、世界中に配送しています。もちろん、大部分は米国で販売されていますが、世界中に配送しています。

私のチームは、AIと機械学習のプラットフォームサービスの構築と提供を担当しています。 私たちは、AIソリューションの構築を支援するために、さまざまなビジネスセグメントと密接に協力しています。例えば、スパータンバーグを含む世界中の工場での自動品質検査を担当するチームと協力しています。過去数年間、彼らは工場で必要とされる高品質な検査を実現するグローバルソリューションを開発してきました。

このチームは、ビデオカメラ、音響録音、その他のセンサー測定などのセンサーを生産ラインに設置しています。これらの記録を評価するためにAIモデルを使用しています。画像に示されているように、カメラが生産ラインに向けられ、通過する車両ごとに画像をキャプチャしています。この場合、部品の存在検出が目的です。AIモデルが画像を分析し、緑色でハイライトされた部品をチェックします。他のユースケースには、正しい部品の使用の確認、異常の検出、部品間の距離の測定などがあります。
このシステムの重要性は明らかです。彼らは毎年モデル数を倍増させ、現在では数百のモデルが生産ラインで訓練と開発を必要としています。工場の照明調整や生産セットアップの変更などが発生すると、これらのモデルは再訓練が必要になります。このプロセスには相当な労力と適切な環境が求められます。私たちの役割は、この環境を提供し、彼らがインフラ構築ではなくモデル開発に集中できるようにすることです。


AIの恩恵を受けているのはこのセグメントだけではないことに注意が必要です。 例えば、製品開発では、機械学習とAIを使用して、お客様に喜ばれる機能やモデルを設計しています。機械学習を使用して、車両機能のパフォーマンスに影響を与える制御レベルを特定することができます。これは主に説明可能性のためであり、モデルを実際の製品に使用するためではなく、制御レベルを理解するためです。



サプライチェーンとロジスティクスでは、AIが需要をより正確に予測し、計画の労力を削減するのに役立っています。これは特に、半導体不足のような課題を考えると、近年非常に重要になっています。 車両生産では、品質検査以外にも、予知保全にAIを活用しています。 販売とアフターサービスでは、顧客とのやり取りを改善しています。従業員に対しても、AIは効率性を高めており、特に大規模な企業内で適切な情報を見つけるのに役立っています。
BMW GroupのAIプラットフォームサービス:課題と解決策
これらのビジネスプロセスでAIを拡張するには、強力なプラットフォームが不可欠だと考えています。これにより、個々のユースケースチームが、セットアップ作業に煩わされることなく、特定のニーズに集中できるようになります。そのため、私のチームはこれらのプラットフォームサービスを提供しています。機械学習とAI開発についてより深く掘り下げる前に、プラットフォームサービスの概要と、私たちがどのようにスケーリングにアプローチしているかを大まかに説明したいと思います。

私たちが持っているコンポーネントの1つは、AI business servicesです。これは本質的に、特定のドメインに限定されず、すべてのドメインで使用できるサービスのクラスターです。例えば、テキスト翻訳や文書からの情報抽出のためのAPIがあります。利点は、チームが一から作り直す必要がなく、これらのサービスを自分たちのプロセスに簡単に統合できることです。

次に、車両生産で見たようなカスタム機械学習AIの部分があります。これには、データサイエンティストやビジネスドメインの専門家向けのツールを提供しています。

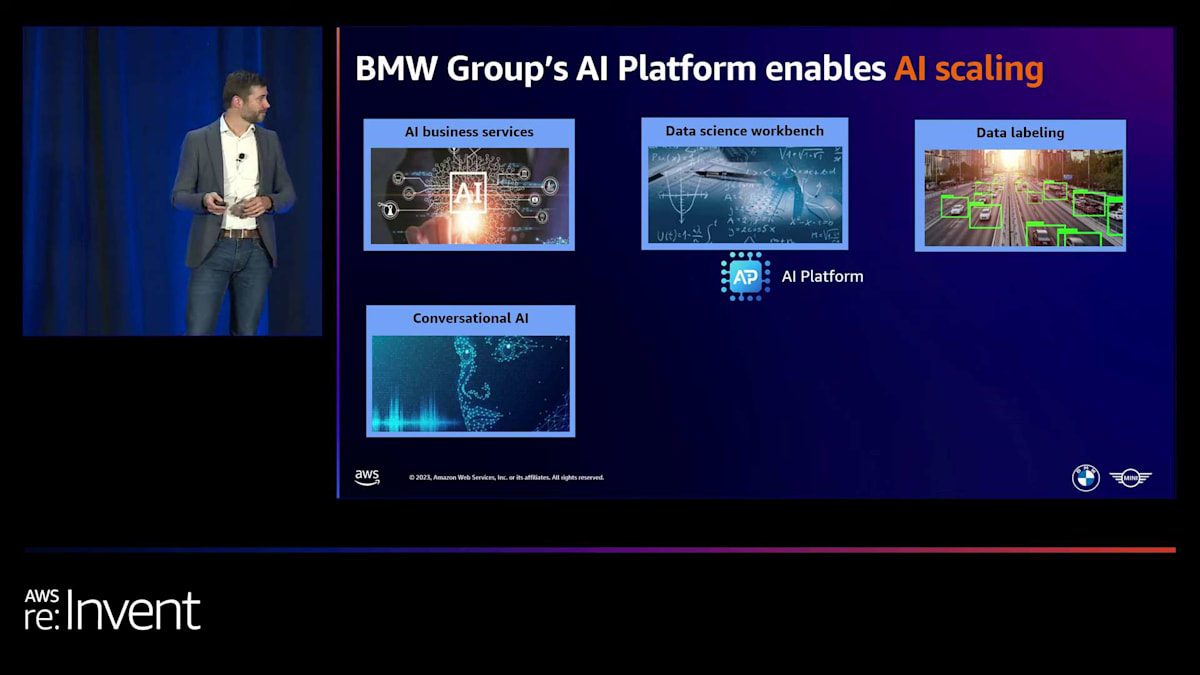

また、画像や音声データなどの非構造化データを管理するシステムもあります。これらのデータを記録、管理し、画像や音声にアノテーションを付けるためのラベリングツールやサービスを提供する必要があります。デジタルデータアシスタントにとっては、安全な方法でこれらのアシスタントを開発・運用できるプラットフォームが役立ちます。 MLOpsでは、開発したAIモデルを産業化するためのベストプラクティスソリューションを提供しています。 デモで見たように、AI開発と本番環境の間でよりスムーズな統合が行われるでしょう。これも私たちが活用していくものです。


最後の部分は、最近ますます重要になってきているAIのガバナンスです。 AIのユースケースの全体像を把握する必要があります。それらがどこにあり、何を使用しているかを知る必要があります。すべてのAIモデルの中央リポジトリがあり、安全で改訂証明可能な保存と、関連するすべてのメタデータを持っています。個々のAIユースケースを評価するリスクアセスメントプロセスさえあります。これがポートフォリオの概要ですが、今日は機械学習開発の部分、つまりデータサイエンティストと機械学習エンジニア向けのコード中心の部分に深く掘り下げたいと思います。


私たちにとって、すべては特定目的の環境から始まりました。約7年前を振り返ると、 非構造化データ - 画像、音声、テキスト - を扱うユースケースが増加していました。それらは主に、既存の大規模モデルを取り、私たちのデータで転移学習を行ってこれらのユースケースを解決していました。十分なGPUパフォーマンスと相当量のメモリが必要でした。そのため、私たちはこのディープラーニングプラットフォームを立ち上げました。ここでは、Jupyterノートブックとターミナルをコンテナ化された環境で使用でき、オンプレミスの自社データセンターで運用し、管理していました。
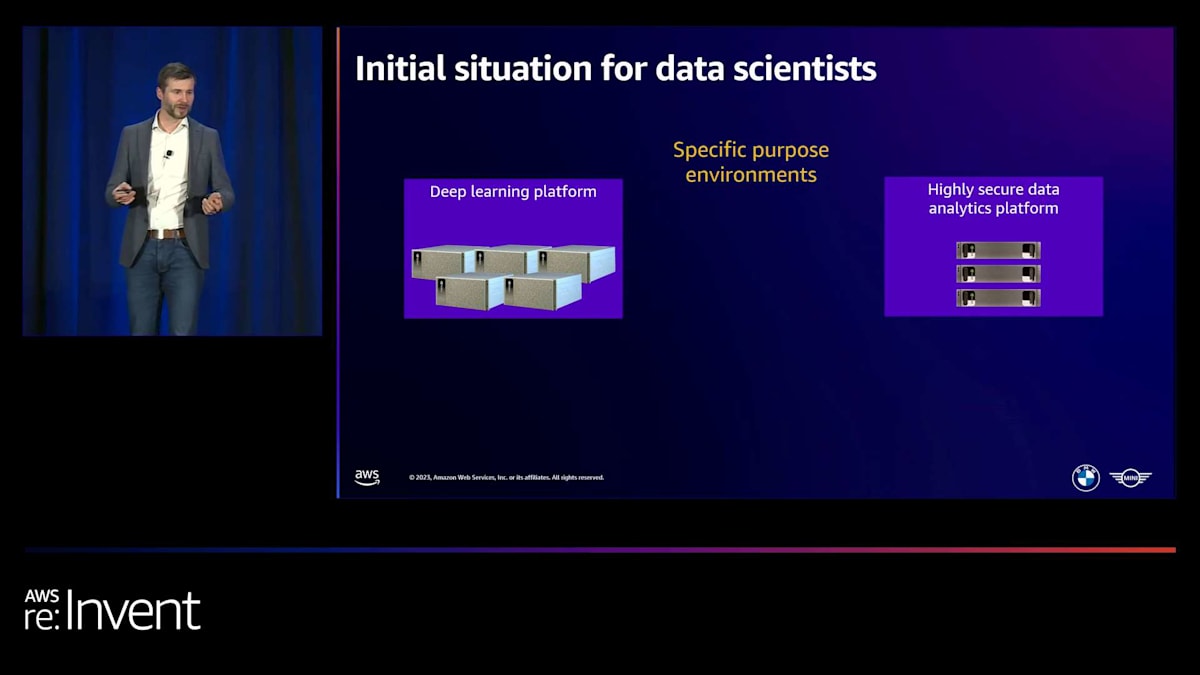
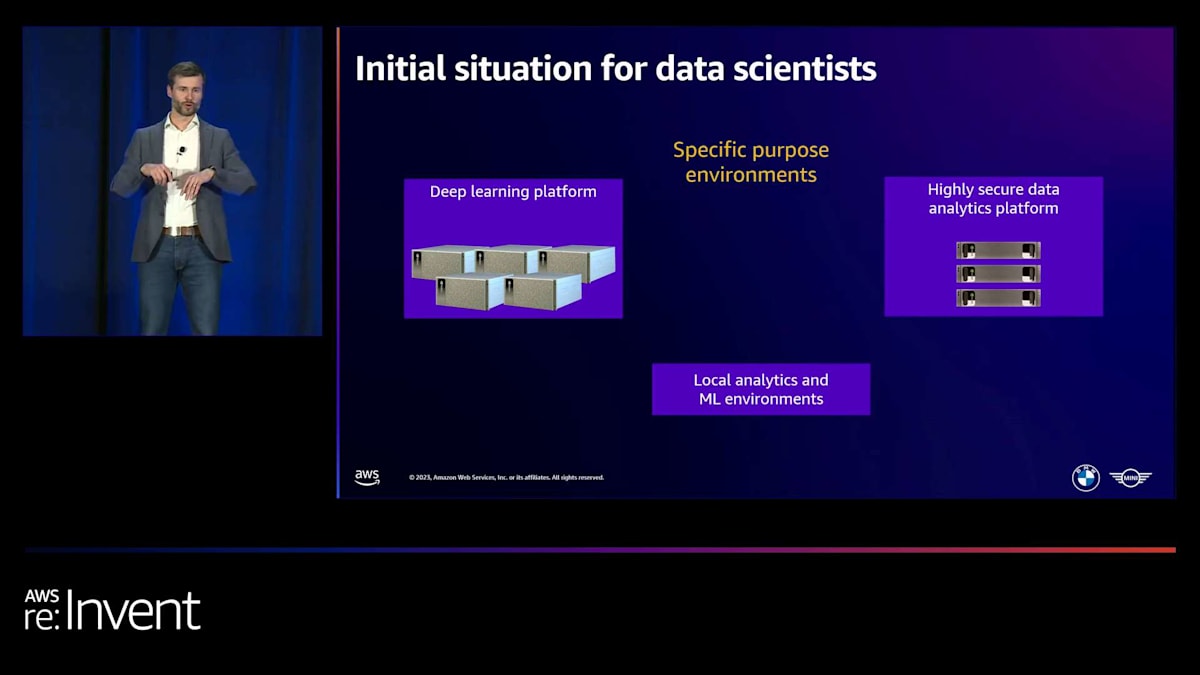
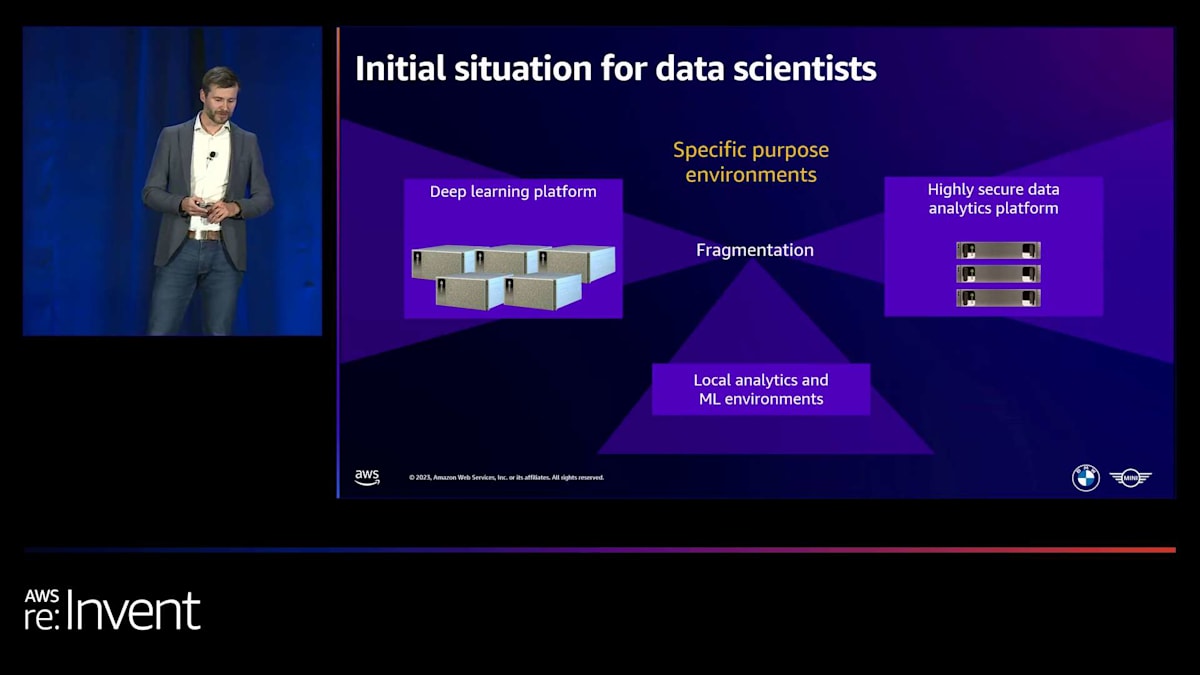
その後、より機密性の高いデータを使用したいユースケースが出てきて、量子プラットフォームアプローチの限界が見えてきました。 そこで、必要なセキュリティレベルを提供する新しいプラットフォームを立ち上げました。もちろん、多くのデータサイエンティストや機械学習エンジニアはローカルで作業し、そこで実験を行っており、他のソフトウェアベンダーとの様々な他のローカルソリューションもありました。この断片的なアプローチで私たちが直面した課題は、 私たちとユーザーの両方にとって、運用とガバナンスのオーバーヘッドが多岐にわたることでした。異なるユースケースや側面に取り組む場合、異なるプラットフォームを使用しなければなりませんでした。
コンピューティング需要の管理には本当に課題がありました。事前に計画を立て、ハードウェアを購入し、スケールアップし、既存のハードウェアを交換する必要がありました。非常に大変でした。ユーザーが不満を感じるピーク時や、週末などハードウェアが適切に使用されない時期もありました。管理が本当に難しかったので、この断片化と課題を克服するために、解決策を考え出すことにしました。 それは、これらのプラットフォームを置き換え、ローカルユーザーでさえ中央のソリューションに切り替えてすべてのワークロードをそこに持ち込むように動機づける、オールインワンのソリューションです。

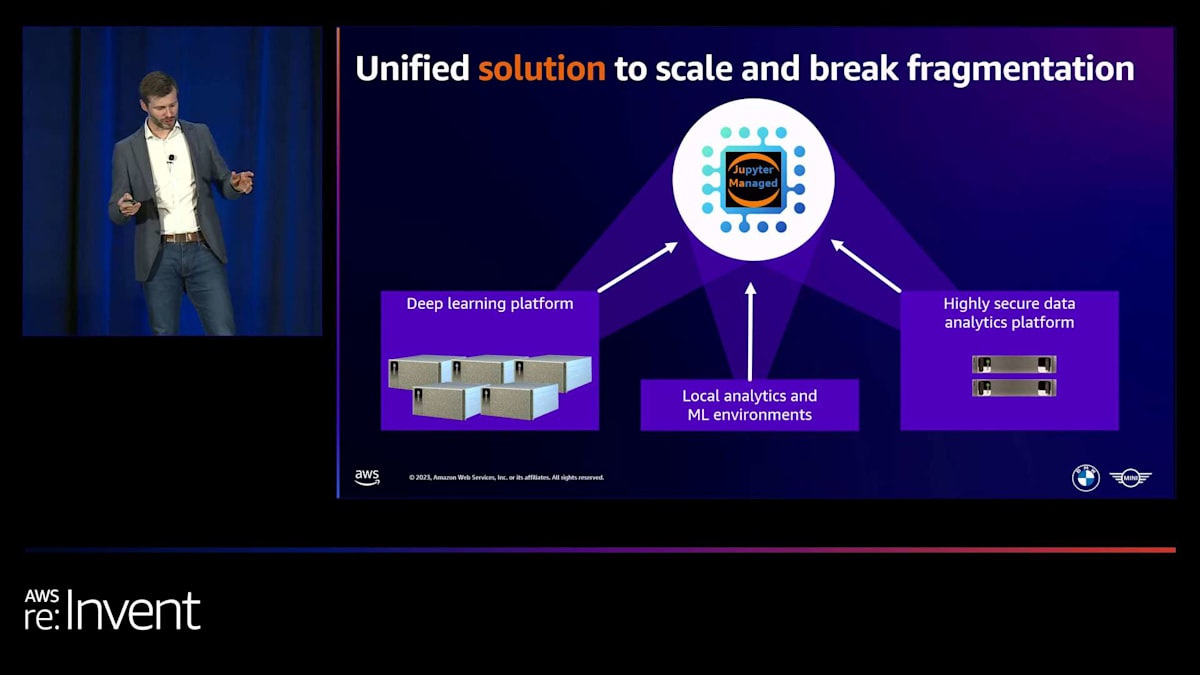
このソリューションを「Jupyter Managed」と名付けました。なぜなら、異なるユースケースからのすべての要件を組み合わせて取り込むべき、オールインワンのアプローチがあることを明確にしたかったからです。まず、ツールから始めて、彼らが必要とするすべてのツールを提供する必要がありました。そして、その需要は増加していくでしょう。誰もが自分のデータにアクセスできる必要があります。それがグループ全体のデータレイクであれ、クラウドデータハブであれ、オンプレミスのデータベースであれ、ローカルデータのアップロードであれです。新しいソリューションは、主要な要件の1つとして、需要に応じて弾力的にスケールする必要があり、運用の労力も低くする必要がありました。
BMW GroupによるSageMaker Studioの採用と統合
セキュリティの観点から、セキュリティインシデントイベントレポートや、アイデンティティとアクセス管理システムとの統合、データをアップロードする人々のためのマルウェアスキャンなど、企業の標準を取り入れる必要がありました。BMW Bankや自動車部門の人々を含む、異なるチームから異なる法人単位まで対応し、コンプライアンスを保ちながら彼らの環境を分離する必要がありました。最後に、しかし重要なこととして、チーム内でのデータ共有やコード共有によるコラボレーションを促進したいと考えました。
私たちは様々な選択肢を検討し、最終的にAmazon SageMaker Studioを選び、そのソリューションを使用することにしました。SageMaker Studioは既に多くの要件を満たしていたため、私たちのチームは実際に統合作業に集中することができました。つまり、プラットフォームをゼロから構築する必要はなく、統合作業に取り組むことができたのです。
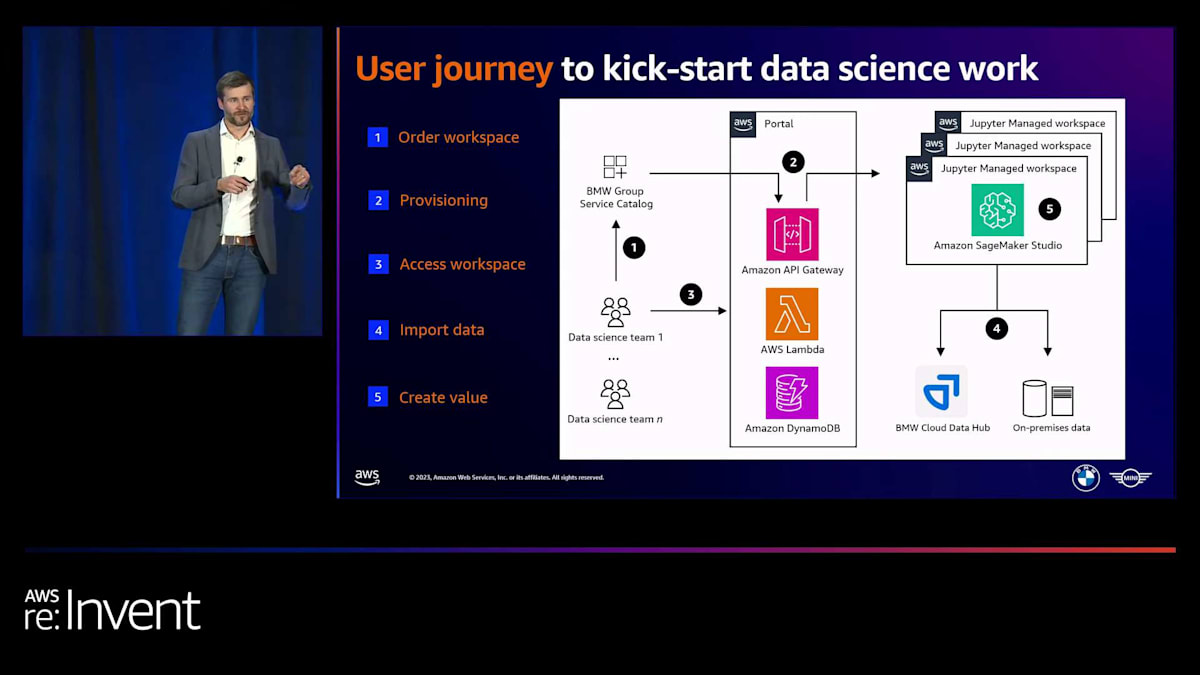
チームのためのこのプロビジョニングとオンボーディングプロセスが、現在BMWでどのように行われているかを少しお見せしたいと思います。私たちが持っているのは、ITサービスのためのBMW固有のサービスカタログです。新しいデータサイエンスチームがそこに行き、新しいワークスペースをリクエストします。例えば、コストセンターを指定する必要があります。なぜなら、内部的に彼らにコストを請求する必要があるからです。その後、自動化されたプロセスが開始され、このプロセスは私たちが管理する新しいAWSアカウントを彼らのために作成します。そして、SageMaker Studioドメインや、必要なカスタムカーネル、必要なライフサイクル設定、追加するセキュリティ機能など、すべてのインフラストラクチャをそこにプロビジョニングします。
これが設定されると、すべてのユーザーは中央ポータルにアクセスし、自分のワークスペースを利用できるようになります。Studioに入ると、データレイクから直接データをインポートできます。オンプレミスのデータベースと統合し、基本的に直接価値を生み出すことができます。設定やセットアップ、セキュリティなどの面倒な作業に煩わされる必要はありません。それらは私たちが対応します。

先ほど申し上げたように、SageMaker Studioのおかげでこの統合に集中できました。私たちが特に評価している機能をいくつか挙げたいと思いますが、他にもたくさんあります。例えば、異なるワークロードに対して異なるインスタンスサイズを選択できることは、私たちにとって非常に有益です。なぜなら、すべての異なるケースに対して1つのプラットフォームを使用できるからです。大規模なワークロードには、分散トレーニングジョブを使用したSageMaker trainingを利用できます。また、データレイクとやり取りするためのBMW固有のライブラリを含むカスタムカーネルを導入することもできます。そして、ノートブックのスケジューリングオプションもあります。デモでも見ましたが、一部のユーザーにとってはこれが非常に重要です。
全体として、SageMaker Studioを使用した現在のソリューションは私たちにとって非常に良いものです。今日見たような新機能、そして常に追加される機能の恩恵を受けられるからです。また、SageMaker StudioがVS CodeやJupyterLabなど、今日見たようなオープンソースコンポーネントを基盤としていることも高く評価しています。これは私たちにとって非常に重要です。
BMW GroupのSageMaker Studio活用の今後と結びの言葉

では、BMW GroupのSageMaker Studioの今後はどうなるでしょうか? 新しいソリューションへのチームのオンボーディングを続けていきます。まだすべてのチームがオンボードされているわけではないので、これはまだ進行中です。そして、現在取り組んでいるのは、数年前から使用しているAWS向けのMLOpsソリューションの統合です。すでにSageMakerベースのMLOpsソリューションを持っているので、よりスムーズな体験のために統合を進めています。もちろん、コード生成などの開発者やデータサイエンティストの生産性向上のための機能も活用していきます。多くのユーザーがノートブックの起動時間の短縮に大きな期待を寄せています。これは本当に評価されています。
そして最後に、もちろん開発環境内で大規模言語モデルやその他のファウンデーションモデルへのアクセスを提供します。例えば、大規模言語モデルを使用してテキスト分析やクラスタリングを行うことができるようになります。このように、私たちは十分な準備ができていると考えており、新しいStudioリリースを本当に高く評価しています。それでは、SumitとGiuseppeをステージにお呼びしたいと思います。
デモとリリースをありがとうございました。本当に感謝しています。
Marc、BMWでのStudioの使用方法について洞察を共有してくださり、ありがとうございます。そして、皆様は素晴らしい聴衆でした。本日のセッションにお越しいただき、誠にありがとうございました。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion