re:Invent 2024: AWSがSageMaker HyperPodの新機能を発表 コスト40%削減へ
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Amazon SageMaker HyperPod: Reduce costs with new governance capability (AIM388-NEW)
この動画では、Amazon Web ServicesのAmazon SageMaker HyperPod task governanceという新機能について解説しています。生成系AIモデルの規模が年間4〜5倍のペースで成長する中、コンピューティングリソースの効率的な管理が課題となっていました。この機能により、チーム間でのコンピューティングリソースの動的な割り当てや、優先度に基づくタスクの実行制御が可能になり、コストを最大40%削減できます。また、Articul8社の事例では、HyperPodとTask Governanceを活用することで、わずか2ヶ月でArticul8 Essential製品の開発を実現した具体例も紹介されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon SageMaker HyperPodの課題と解決策

本日のセッションにお時間を割いていただき、ありがとうございます。私はAmazon Web ServicesのプロダクトマネージャーのKareemです。HyperPodクラスターのガバナンス面を担当しています。本日は、昨日のSwamiのキーノートで発表された新機能、Amazon SageMaker HyperPod task governanceについてお話しさせていただきます。

昨年は生成系AIの大きな進展があり、多くの企業がFoundation Modelの利用とトレーニングを開始しました。モデルの規模は年間4〜5倍のペースで成長し、6ヶ月ごとに倍増する一方、データセットのサイズは8ヶ月ごとに倍増していることが分かりました。 これにより、市場投入までの時間とコストに大きな影響が出て、常に増加傾向にありました。このような状況の中で、お客様はいくつかの主要な課題に直面していました。
最初の課題はデータ収集に関するものでした。モデルのトレーニングや大規模な生成系AIモデルを構築するには、まずデータを入手する必要があります。これは言うは易く行うは難しで、多様なデータを収集し、クリーニングを行い、より良い前処理を施し、準備を整える必要があります。それが完了したら、クラスターをプロビジョニングして作成し、データサイエンティストがトレーニングモデルを実行できるように可用性を管理する必要があります。また、インフラストラクチャの安定性も確保しなければなりません。データサイエンティストがこれらの作業をしている最中にクラスターがダウンしてしまうような事態は避けたいものです。さらに、トレーニングを加速するために、分散トレーニングを可能にするための様々な複雑な戦略を開発する必要がありました。
Amazon SageMakerは昨年、SageMaker HyperPodを導入することでこれらの課題に対応しました。HyperPodは、レジリエントな環境を実現するクラスターのセットです。特定のノードやクラスターがダウンした際に自己修復を行い、分散トレーニングをより簡単にすることで、お客様は煩雑な作業から解放されます。タスクやワークロードの投入方法を制御できるため、リソースの利用効率が向上します。これにより、お客様はトレーニング時間を最大40%削減することができました。
HyperPod Task Governanceの機能と利点

これは素晴らしい成果でした - 私たちは問題を認識し、Amazon SageMaker HyperPodをローンチし、トレーニング時間を最大40%削減し、有名企業からスタートアップまで、幅広いお客様に採用していただきました。 また今年9月には、SageMaker HyperPod向けのAmazon Elastic Kubernetes Serviceサポートもローンチしました。これにより、EKS上でHyperPodクラスターを作成できるようになり、レジリエンシーが向上し、クラスターとジョブがより耐障害性を持ち、停止した地点から再開できるようになり、クラスターはその場で修復されるようになりました。
しかし、お客様から新たな課題が寄せられました。最初の課題は、EKS上でHyperPodクラスターを稼働させる際、チームごとに静的なリソース割り当てを行わなければならないということでした。皆さんもご経験があるかもしれませんが、データサイエンティストのチームや組織には予算があり、その予算に基づいて、高価で希少なコンピュートリソースをチームに割り当てる必要があります。これは静的な割り当てです - チャットボットを運用するデータサイエンティストのチームには一定数のP5を、他のモデルを実行するチームには一定数のP4を割り当てるといった具合です。


ただし、静的な割り当てであるため、過剰割り当てや過少割り当ての問題が発生します。 その結果、コンピュートリソースが遊休状態になることが多く、待機中のタスクに影響を及ぼします。あるチームが多くのタスクを抱えている場合、 他のチームに割り当てられた遊休状態のコンピュートリソースにアクセスできないため、待機タスクが増加し、自動的な優先順位付けができません。データサイエンティストは、優先度の高いタスクを開始するために実行中のタスクを停止しなければならず、管理者はクラスターの使用状況を把握できません。リアルタイムの情報を得る方法がないのです。

これにより、コンピュートリソースの使用率が低下します。しかも、これは一般的なコンピュートリソースではなく、 希少で高価な高性能コンピュートリソースなのです。組織はすでに多額の投資を行い、チームへのコンピュートリソースの予算配分を済ませているにもかかわらず、チームはそれを最大限に活用できていません。待機中のタスクを抱えるデータサイエンティストは、利用可能な遊休コンピュートリソースを実際に使用することができず、生産性が低下します。組織の官僚的な手続きを経て、あるいは他のチームが必要とする時に返却することを前提にノードを移動させなければなりません。結果として、チームの業務に支障が出ないよう、組織はより多くのコンピュートリソースに投資せざるを得なくなり、コストが増加します。
Amazon AIチームの課題とイノベーション
興味深いことに、Amazon RetailチームとAmazon AIチームも同じ課題を抱えていました。ここで、Amazon AIチームから私の友人であるJoyをお招きして、彼らが直面した具体的な課題と、そこから生まれたイノベーションについてお話しいただきたいと思います。ありがとう、Kareem。皆さん、こんにちは。私はJoyです。Amazonの中央効率化チームのリーダーを務めています。Gen AIの課題とイノベーションについてお話しさせていただきます。


多くのお客様やパートナー企業と同様に、AmazonもGen AIへの投資を増やしており、この傾向は2025年以降も続くと予想しています。 投資の増加に伴い、最初の課題として、AI開発に不可欠なコンピュートリソースに対する多くのチームやプロジェクトからの高い需要に対して、割り当てられる供給が少ないという状況に直面しています。 さらに、Kareemが先ほど説明した静的な割り当ては、一部のチームは割り当てられたリソースを持っているものの遊休状態である一方で、割り当てを待っているチームは使用できるリソースがないという状況のため、うまく機能していません。使用率の観点から見ると、非効率な部分が多々あります。チームは使用率の指標を適切に追跡していないため、データサイエンティストやチームは自分たちの使用率が良いのか悪いのかさえ把握できておらず、リーダーやデータサイエンティストが使用率を監視するための標準化された方法もありません。

これらのリソース割り当てと利用率最大化の課題に対応するため、私たちは社内向けのサービスを構築し、社内チーム向けのAIオーケストレーションと割り当てを行っています。すべてのコンピューティングリソースをプールし、独自に開発したダイナミックスケジューリングアルゴリズムを使用することで、全プロジェクトとチームにわたって利用率を最大化できます。また、ジョブのステータスが変更された際に通知を提供することで、研究者やお客様により良い体験を提供するよう努めています。例えば、ジョブが開始または停止した場合に通知を受け取ることができます。
お客様とリーダーに対して、インスタンスの使用時間の観点からだけでなく、コア、メモリ、電力使用量を含むクラスター利用率の観点からも、一元化された利用率メトリクスを提供しています。また、チームがジョブを投入する際に障害が発生しないよう、ノードの定期的なヘルスチェックを実施したり、障害発生時には最後のチェックポイントから自動的にジョブを再開したりするなど、レジリエンシーを高めるための機能も追加しています。この包括的なシステムにより、アイドル状態のキャパシティを活用することで、Amazonチーム全体で90%以上の利用率を達成しています。これにより、需要が高く供給が少なく利用率が低いという先ほどの課題に対処できました。チームは今や、コンピューティングリソースの需要を加速できるだけでなく、開発時間も短縮できるようになりました。全体として、Amazon全体の需要を平準化し、より効率的になりました。
HyperPod Task Governanceの詳細と実装


では、Kareemに戻したいと思います。ありがとう、Joy。ご覧の通り、Amazonも同様の進化と段階を経て、低い利用率がAmazonにどのような影響を与えていたか、そしてJoyと彼女のチームがこの素晴らしいイノベーションを生み出しました。そして、このイノベーションをお客様にもお届けしたいと考えました。そこで、Amazon SageMaker HyperPod task governanceの発表をさせていただきます。Amazon SageMaker HyperPod task governanceを使用することで、モデルトレーニング、ファインチューニング、推論など、あらゆるタイプのワークロードやタスクにおいて、アクセラレーターの利用率を最大化しながらコストを削減することができます。
主なポイントをご紹介させていただき、後のスライドで詳しくご説明します。非常に大まかに言うと、まず、予算を維持しながらチーム間でコンピューティングリソースを動的に割り当てることができます。次に、コンピューティングリソースを待機しているタスクがあり、競合が発生した場合、優先度の高いタスクが低優先度のタスクよりも優先されることを保証し、それによってコンピューティングの価値を高めることができます。管理者として、クラスターの健全性だけでなく、クラスターのガバナンスもリアルタイムでモニタリングおよび監査することができます。ガバナンスとは、チームに対する割り当ての状況を理解することです - チームが過剰使用または過少使用していないか、アイドル状態のコンピュートへのバーストが発生していないか、タスクが待機していないかなどです。このリアルタイムの情報により、管理者はコンピュートの高い利用率を維持しながら、チームに価値を提供し、同時にコストを最大40%削減しながら、設定を調整する機能を持つことができます。



それでは、この機能について説明させていただきます。これから何ができるのか、どのように機能するのか、そしてデモをご紹介します。これはスマートなスケジューラーおよびオーケストレーターで、コンピューティングリソースの動的な割り当てを可能にします。以前のアプローチでは、静的な割り当てが行われていました - MLエンジニアのチームがモデルに取り組んでいる場合、10台のP5や20台のP5といった固定の割り当てが与えられ、再度手動の割り当てプロセスを経なければ変更できませんでした。動的な割り当てでは、クォータが与えられ、そのクォータに応じたコンピューティングが保証されます。クォータを超えて使用する必要がある場合は、再度手動プロセスを経ることなく即座に実行できます。第二に、タスクガバナンスにより、アイドル状態のコンピュートを活用できます。割り当てられていないコンピュートや、チームに割り当てられているものの使用されていないアイドル状態のコンピュートがある場合、他のチームがそのアイドルコンピュートにバーストして利用することができます。これにより、チームの待ち時間が短縮されます。


タスクを実行するためのコンピュートリソースを探し回る必要がなくなります。タスクがキューに入ると、Task Governanceが制御を引き継ぎ、保証されたコンピュートリソースまたはアイドル状態のコンピュートリソースのいずれかに振り分け、ジョブの実行を加速させます。また、リアルタイムのタスク優先順位付けも行われます。キュー内のタスクでリソースの競合が発生した場合、タスク実行時に割り当てられた優先順位に基づいて、Task Governanceが高優先度のタスクが低優先度のタスクよりも先にコンピュートリソースを確保できるようにします。低優先度のタスクが実行中の場合は、高優先度のタスクにコンピュートリソースを確保するためにプリエンプションが行われます。また、リアルタイムの可視性も得られます。デモでそのダッシュボードをご覧いただきます。


Task Governanceを使用することで、コンピュートリソースの利用率が向上し、コストを削減できます。なぜなら、待機中のチームがコンピュートリソースを探し回る必要がなくなり、すでに利用可能なアイドル状態のコンピュートリソースを使用できるようになり、市場投入までの時間を短縮できるからです。私たちがお客様のために実現した最初の一般的なユースケースは、リソース管理です。これは実際に非常に重要で、予算が設定されチームに特定のクォータが与えられる組織におけるリソースの割り当てや管理の最初のステップとなります。チームの予算に応じてこのリソース管理を一度行えば、追加のクォータを探し回る必要なく、すべてのチームが準備完了となります。


Dynamic Allocationとは、チームが割り当てられた以上のリソースを必要とする場合に、アイドル状態のコンピュートリソースにバーストできることを意味します。割り当てられていないが利用可能なコンピュートリソースを動的に使用できるようになります。タスクオーケストレーションについては、すべてのチームがタスクを実行できます。クォータに応じたコンピュートリソースが保証されますが、クォータを使い切った場合は、Task Governanceが自動的にプリエンプションと優先順位付けを処理するため、データサイエンティストがリアルタイムでモニタリングする必要はありません。


クラスターの健全性だけでなく、チームの健全性もモニタリングできます。これは、チームにどれだけの割り当てが与えられているか、どれだけ使用しているか、待機中のタスクがあるか、長時間実行中のタスクがあるか、あるいは大きな割り当てを受けているのにコンピュートリソースを全く使用していないチームがあるかどうかを監視できることを意味します。これにより、常にリソースが不足していてアイドル状態のコンピュートリソースにバーストする必要のあるチームがある場合に調整が可能になります。これらすべての情報により、管理者はクラスターのコストを最適化でき、追加のコンピュートリソースを探し続ける必要がなくなります。



実際の仕組みをアニメーションでご説明し、その後実際のデモをお見せします。すべてのチームで共有されるHyperPodクラスターを持つ組織があるとします。管理者がDynamic Allocationを行い、チーム1には最大100個のP5インスタンス、チーム2には最大50個のP4インスタンスを使用できるクォータが付与されます。これがDynamic Allocationです - 特定のコンピュートリソースではなく、共有クラスターからリソースを使用する権限が割り当てられているのです。


管理者として、クラスターにガバナンスポリシーを定義することができます。 これには、最優先とされるタスクを決定するタスクの優先順位付けポリシーが含まれます。 例えば、推論を最優先、トレーニングを次点、Fine-tuningを3番目、データ処理を4番目というように指定できます。同時に、チームがアイドル状態のコンピュートリソースにどのようにアクセスできるかも設定できます。すべてのチームがアイドルコンピュートを公平に共有できるようにすることが重要です。なぜなら、1つのチームが全てのアイドルコンピュートを独占し、他のチームが待機を強いられるような状況は避けたいからです。その代わりに、5つのチームがある場合、各チームが公平な配分を受けられるように指定できます。これにより、リソースの公平な分配が保証されます。ただし、これは各チームが同じ割合のアイドルコンピュートを得るという意味ではありません。実際には、チームの優先度、割り当てられた割当量を超えて既に使用したアイドルコンピュートの量、そして必要とするアイドルコンピュートの量に応じて決定されます。
ここで公平配分の仕組みが活きてきます。1つのチームがすべてを獲得するわけでもなく、単純な均等分割でもありません。実際には、バックグラウンドで動作する公平配分アルゴリズムに基づいて決定されます。5つのチームがあるとして、公平配分アルゴリズムは、単純な均等分割ではなく、チームの優先度や使用状況などの要因に基づいてアイドルコンピュートを分配します。このアプローチにより、チーム間でより動的で公平なリソース分配が可能になります。

では、これが実際にどのように機能するのか見てみましょう。管理者がこれらのチームを作成する際、バックエンドではオープンソースのキューを使用しています。各チームはキュー内で独自のNamespaceを取得し、さらにローカルキューとなるCluster Queueも取得します。タスクを送信すると、まずローカルキューに入り、その後、コンピュートの割り当て量や必要なコンピュート量に基づいて実際に割り当てられます。このようにセットアップを完了し、動的な割り当てとクラスターポリシーを設定しました。


チーム1がタスク1を送信し、このタスクにはGPUが1つだけ必要なため、割当量内であることから保証された割り当てコンピュートを取得します。チーム2はタスク3とタスク4を実行し、この時点では、全員が保証された独自のコンピュートを使用しています。 待ち時間もなく、スムーズに使用できています。しかし興味深いことに、セットアップ後、チーム1にアイドルコンピュートが残っている状態で、チーム2が新しいタスクを送信しようとしていますが、彼らは割り当てられたコンピュートを使い切っています。 ここでTask Governanceが機能し、このタスクの送信にアイドルコンピュートが使用されるようになります。



さらに状況を複雑にしてみましょう。同じチームが、コンピュートが利用できない状況で、より優先度の高いタスクP6を送信します。Task Governanceは、タスクタイプの優先順位付けに関して定義されたクラスターポリシーに基づいて、T5を有効化された最後のチェックポイントまでCluster Queueに戻し、 その代わりにT6を送信します。 その後、チーム1がT7を送信しようとします。自分たちのアイドルコンピュートを他のチームに貸し出していましたが、チーム1が割り当てられていたコンピュートを必要としている状況です。ここで保証された割り当てコンピュートに戻ることになります。

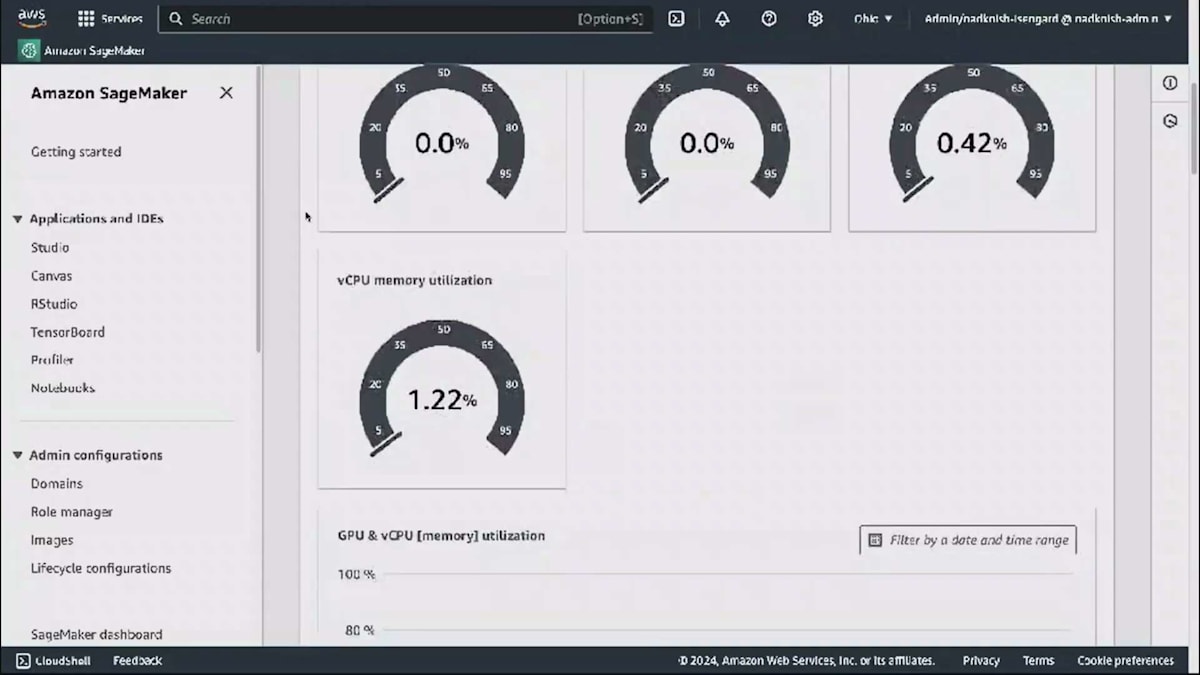
借用したコンピュートで実行されていたタスクはプリエンプトされます。アイドル状態のコンピュートが利用可能になるのを待ち、チームは自身のコンピュートを取り戻してタスクを実行します。これらすべての状況は、管理者がダッシュボードでリアルタイムにモニタリングできます。簡単なデモをお見せしましょう。Amazon SageMaker HyperPodのタスクガバナンス機能は、SageMakerコンソールとSageMaker EIコンソールで利用できます。ご覧の通り、これはAmazon EKSによって管理されているSageMaker HyperPodクラスター上で動作しています。HyperPod上のEKSクラスターにアクセスし、特定のクラスターを選択すると、ダッシュボード、タスク、ポリシーの3つのタブが表示されます。ダッシュボードではリアルタイムメトリクスを確認でき、タスクタブではチームが投入したタスクの実行状況(実行中、待機中、プリエンプト済み)を確認できます。そしてポリシータブでは、先ほど説明した2つのポリシー、つまりアロケーションの設定、チームによるアイドルコンピュートの使用方法、タスクの優先順位付けを定義します。
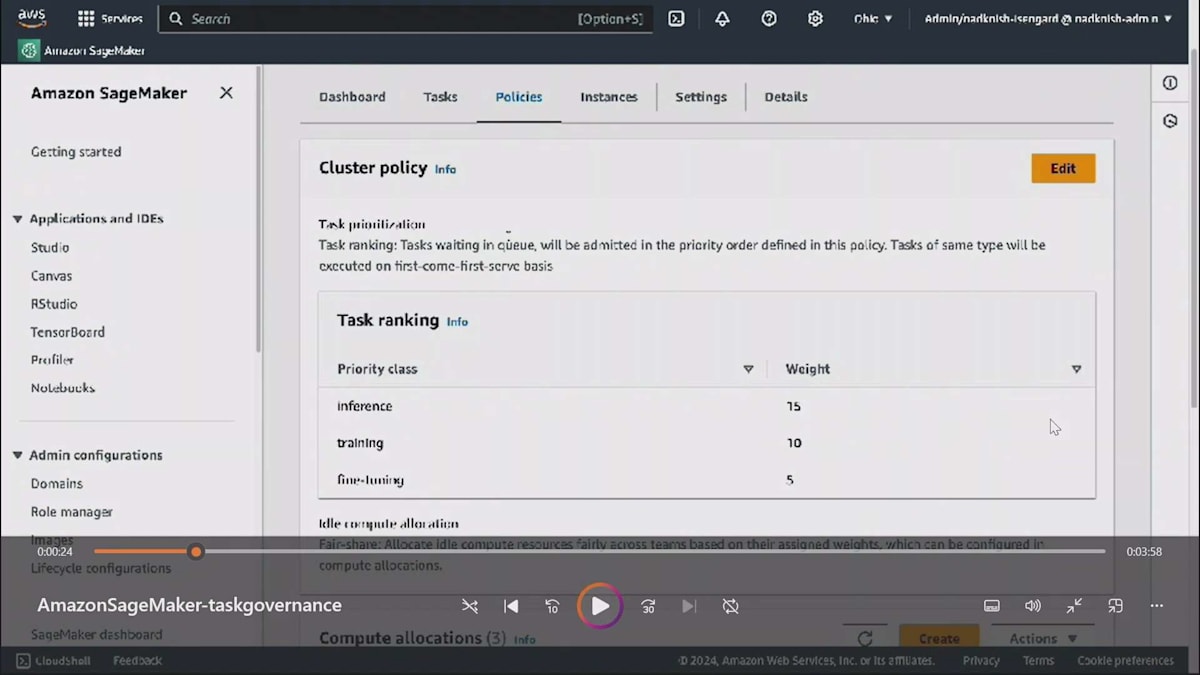
現在、このクラスターでは何も実行されていないため、使用率は低くなっています。クラスター使用率メトリクスは、上部セクションでクラスターの健全性メトリクスを示しています。では、ポリシーを見てみましょう。ここで2種類のポリシーを定義します。1つ目はタスク優先順位ポリシーで、クラスを定義できます。推論の重みを15、トレーニングを10、Fine-tuningを5というように指定できます。これは、クラスター上でリソースを争うタスクがある場合、推論タスクに最も高い優先順位が与えられることを意味します。その下のアイドルコンピュートの割り当てでは、先着順またはFair shareのいずれかを指定できます。Fair shareを選択した場合、チームとその重み(つまりチームの優先順位)、待機中のタスク数、これまでのアイドルコンピュートの使用状況に基づいて、アイドルコンピュートを使用することができます。

このデモでは、Chatbotチーム、研究者チーム、エンジニアチームという3つのチームをシミュレーションしています。それぞれに割り当てた配分が表示されています。Chatbotチームの重みは100、研究チームは75、エンジニアチームは50です。これはチームがコンピュートを争う際に考慮されます。また、各チームがどのインスタンスタイプのクォータを持っているかも確認でき、右端には計算リソース共有戦略が表示されています。最初のChatbotチームは独自の理由でアイドルコンピュートを他のチームに貸し出したくないようですが、他のチームはアイドルコンピュートの貸し借りに同意しています。
Articul8 AIの紹介とGen AIプラットフォーム


特定のチームの割り当て詳細を見ると、そのチームにはml.g5.8xlargeノードが6つ割り当てられていることがわかります。この組織で利用可能な全クラスターのうち、このチームには最大6つのインスタンスのクォータが割り当てられているということです。6つのインスタンスが与えられているわけではなく、最大6つまでのクォータが割り当てられているのです。また、このチームはコンピュートの貸し借りが許可されており、クォータの中でアイドル状態のコンピュートがある場合は貸し出すことができ、割り当てられたコンピュートをすべて使用している場合は借りることもできます。このチームの場合、割り当てられたコンピュートの50%まで借りることができるように指定しています。





すべての設定が完了したので、タスクの状況をお見せしましょう。現在、実行中のタスクはありません。これは先ほどメトリクスダッシュボードで使用率がすべてゼロだったことからもわかります。セットアップを作成し、チームを定義し、割り当ても行いましたが、タスクは実行されていません。MLエンジニアチームがこの環境でLLAMAジョブを投入しようとしています。興味深いことをお見せしましょう。このチームの要件の1つは、このジョブの実行に8つのインスタンスが必要だということです。先ほど見たように、彼らには6つのインスタンスが割り当てられていました。しかし、このジョブを実行するには8つのインスタンスが必要です。彼らはジョブを投入し、更新すると、6つのGPUしか割り当てられていなかったにもかかわらず、このジョブが実行されGPUを使用していることがわかります。ダッシュボードでは、これから...


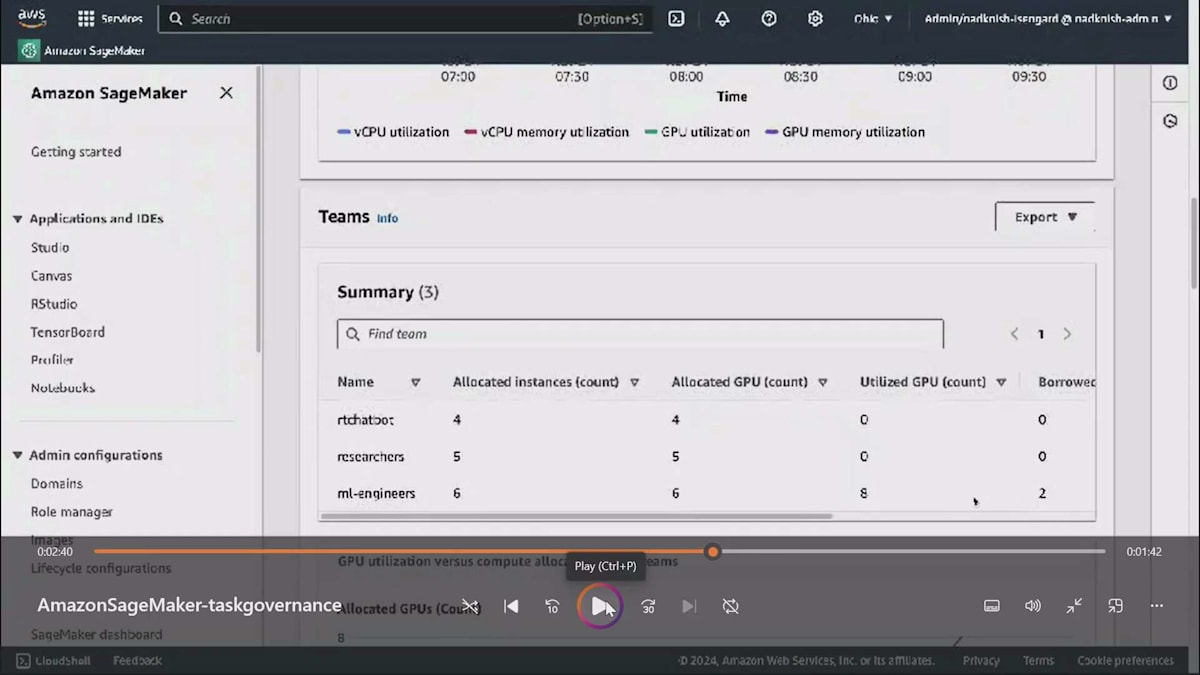
ジョブが実行されているため、Utilizationが点灯しています。これはクラスターのUtilization matrixです。時系列でその特定のUtilizationが上昇しているのがわかります。ここで興味深いのは、これがガバナンスメトリクスだということです。3つのチームがあり、それぞれの割り当てが表示されています:rtchat20が4、Researchersが5、ML-engineersが6ですが、ML-engineersチームは8を使用しています。彼らはResearchチームから2つのリソースを借りており、Researchチームはそのコンピュートリソースを貸し出すことを了承していたのです。

この特定のビューでは、チームの割り当て状況が明確に把握できます。青いバーは割り当てを示し、Y軸はGPUの数を表しており、折れ線がUtilizationを示しています。左側の2つのチームは何も使用していないため、ゼロとなっています。しかし3番目のML-engineersチームは、実際に割り当てられた以上のコンピュートを使用しており、これによってチームが割り当てをどのように使用しているかをリアルタイムで素早く把握することができます。



少し早送りしましょう。Researchチームが戻ってきてタスクを投入しようとしているところをお見せしたいと思います。先ほど説明したように、Researchチームは他のチームに2つのGPUを貸し出していました。しかし今、Researchチームが自身のタスクを投入しようとしています。彼らがそれを実行したとき、ML-engineersチームが投入したタスクは一時停止され、プリエンプトされました。これは他者のコンピュートを借りていたためで、そのコンピュートが必要になったためです。Researchのジョブが現在実行され、そのコンピュートを使用しているのがわかります。


チームメトリクスのリアルタイム表示では、Researchチームが1つの実行中タスクを持っており、ML-engineersチームは1つのタスクがプリエンプトされて保留中となっているのがわかります。ここで私たちが確認できるのは、異なるチームに割り当てを与え、アイドル状態のコンピュートを利用し、他チームのタスクをプリエンプトし、優先順位付けがどのように行われるかということです。ここで、実際の現場でこれをどのように使用しているのか、Articul8の友人に話してもらいたいと思います。


ありがとう、Kareem。本当に感謝します。皆さん、聞こえていますか?素晴らしい。本日はお集まりいただき、ありがとうございます。そして改めて、Kareemさん、ご招待ありがとうございます。私はSham Kumarと申しまして、Articul8 AIという会社に所属しています。Arun Subramaniyanが当社のCEOです。彼の講演を聞きに来られた方がいらっしゃるかもしれませんが、申し訳ありません。本日は私が担当させていただきます。私は当社のCommercial Operationsを率いており、Founding teamのメンバーです。
Articul8 AIのHyperPod活用事例と今後の展望

私たちは、Bedrockと同様のフルスタックのGen AIプラットフォームを開発しましたが、詳細については後ほどお話しします。今年1月に正式にローンチしましたが、その前の約2年間はステルスモードで開発を進めていました。創業チーム全員がAWS出身なので、AWSの仲間たちのことをよく知っています。Gen AIや大規模言語モデルに関する私たちの考えでは、1つのモデルですべての業界のすべてのタスクをうまく解決できるとは考えていません。私たちの設計思想は、当初から、LLMと非LLMの両方を含む複数のモデルが連携して大規模に動作することで、エンタープライズアプリケーションに最適な成果をもたらすというものでした。これを実現するために、ModelMeshと呼ばれる技術を開発しました。ModelMeshには、すぐに使える20~30の異なるモデルが用意されています。
これらにはLLMが含まれていますが、私たちは幅広いタスクや、業界固有、ドメイン固有のタスクに対して、モデルの微調整や継続的な事前学習も行っています。航空宇宙、半導体、金融サービスなど、さまざまな分野でデータパートナーシップを結んでいます。これらのモデルは、特定の業界に対して最高のコストパフォーマンスを提供できると考えています。これもModelMeshにおけるドメイン固有モデルアプローチの一つです。
ビジネスを始めてまだ11ヶ月ほどですが、私たちは成熟したチームです。Gen AIアプリケーションの本番環境での導入において、さまざまな段階にある多くの顧客がすでにいます。また、プラットフォームのすべての機能は自己完結型でパッケージ化されています。ご存知の通り、エンタープライズグレードの本番環境向けGen AIアプリケーションを作るには、通常20~30の異なる技術コンポーネントが連携する必要があり、それを大規模に実現することは課題です。プルーフオブコンセプトや実験は簡単ですが、本格的な本番環境への移行は困難です。そこで、私たちはそれらのすべてのピースを組み合わせました。
これにより、成果を得るまでの時間を短縮できます。Articul8を使えば、本番環境グレードのシステムを数週間で導入できます。自社で構築する場合の数ヶ月と比べて大きな違いです。また、プラットフォーム全体がお客様のAWS VPC内の安全な環境に配置されます。私たちは、Gen AI技術をデータのある場所に持ち込むと言っています。データが顧客環境から外部に出ることは一切ありません。私たちの場合、すべてが自己完結型です。OpenAIなどのラッパー企業ではなく、提供するすべてのモデルがプラットフォームに含まれ、お客様の環境内に配置されます。セキュリティ、スケーラビリティ、本番環境グレードのシステムを私たちが管理し、ビジネスモデルも差別化されています。

約2年前の11月にChatGPTが発表されて以来、 私たち全員が知っているように、システムには多くのノイズがあり、Gen AIに関して多くのハイプがありました。これまでの世界観では、非常に広範な一般知識を持つ1つの大規模モデルがあれば、望むことすべてを実行できるというもので、それが本番環境で導入するモデルだとされていました。しかし、その世界観はすでに変化しています。顧客からは、航空宇宙、半導体、自動車、石油・ガスなどの分野で、特定のユースケースや問題を解決できるドメイン固有モデルへと移行しているという声を聞いています。
Articul8では、設立当初からドメイン固有モデルを構築するためのデータパートナーシップの構築に注力してきました。私のバックグラウンドである航空宇宙分野を例に取ると、5-6階層深く掘り下げて、複合材料設計や空気力学、計算流体力学などに関連することを行おうとすると、確かにChatGPTもある程度の質問には答えられますが、そこまで深い領域になると限界が来ます。そのため、航空宇宙特有の画像理解や、計算流体力学、構造力学に特化した方程式など、各ドメインを深く理解したモデルが必要になってきます。
しかし、それだけでは十分ではありません。誰もが同じ汎用知識モデルと同じドメイン固有モデルを使用していれば、生産性や精度、パフォーマンスの向上も同じになってしまいます。では、競合他社との差別化をどのように図るのでしょうか?次のステップとして私たちが考えているのは、顧客がドメイン固有モデルを自社の環境に導入し、自社のデータを使ってさらにFine-tuningを行うことです。これこそが、競合他社との真の差別化につながると考えています。
私たちのプラットフォームは、まさにこの journey をサポートするものです。高度に抽象化されたプラットフォームで、モデルAPIではなく、プラットフォームAPIを提供しています。これらのプラットフォームAPIを使用することで、Q&A、要約、チャットなどの幅広い汎用タスクを実行できます。また、独自のモデルをFine-tuningするためのAPIも提供しています。プラットフォーム全体がお客様の環境内に存在するため、自社のデータを使ってFine-tuningしたモデルは、すべてお客様のIPとなり、環境外に出ることはありません。

なぜこれが重要なのでしょうか? 私たちの世界観では、12の大規模モデルの世界から、数百、数千のモデルが存在する世界へと移行しています。必ずしも小規模なモデルというわけではありませんが、ビジネスの性質上、小規模になる可能性もあります。数百、数千のモデルの世界では、異なるタスクに対して繰り返しFine-tuningを行うシステムが必要になります。これらは幅広いタスクかもしれませんが、私たちはドメイン固有のタスクになると考えています。

航空宇宙の例に戻ると、初期段階の概念設計で使用するモデルやツール、データは、複合材料の製造などで使用するものとは大きく異なります。そのため、各ドメインで数百、数千のFine-tuningされたモデルが存在することになると考えており、ここでHyperPodが重要な役割を果たすことになります。 私たちのApplied Scienceチーム、Data Scienceチーム、Researchチーム - 私自身はData Scientistではありませんが - は現在、数十人規模に成長しています。私たちが直面していた課題は、多くのData Scientistが、高性能コンピューティングのためのクラスターを自分でセットアップするなど、ITスタッフのような仕事をしていたことです。これは彼らの時間の最適な使い方とは言えません。私たちは24時間365日、新しいモデルのFine-tuning、作成、評価を行っており、これがチームの足かせになり始めていました。
私たちには、これらのプロセスの一部を自動化できるより良いソリューションが必要でした。KareemとJoyが話したように、AIを扱う企業にとって最も貴重なリソースの一つであるGPUリソースをどのように効果的に活用するか、という課題がありました。それには、あらゆる種類の中断を自動的に処理することが重要です。例えば、ノードがダウンした場合、データサイエンティストにそのノードの交換や修復方法を考えさせるのではなく、自動的に対処できるようにする必要があります。私たちは複数のツールを評価しました。私自身、ハイパフォーマンスコンピューティングの分野で、SGE、LSF、PBSなどのジョブスケジューリングツールに数十年携わってきましたが、この世界は大きく変化しています。

課題は、これらの中断をどのように処理し、異なる種類の計算リソース間、異なるプロジェクトやチーム間でリソースをどのように割り当て、そしてそれをスケールを持って自動的に行うかということでした。HyperPodはこれらの課題に非常にうまく対応しています。航空宇宙向けのドメインモデル、半導体向けのモデル、お客様独自のモデルのFine-tuningの支援など、これらの優先順位をどのように設定するか。場合によっては、お客様が自身で行うのではなく、私たちに依頼してくることもあります。そしてここでもHyperPodが役立っています。もちろん、コスト管理と最適化も重要です。スタートアップとしてGPUを扱う場合、支出の60-70%がGPU消費だけです。これらのコストをどのように管理し最適化するか?スケールを持って効率的に実行できる自動化ツールが必要なのです。


詳細には立ち入りませんが、このセッション後に質問を受け付けます。Kareemも私も、前列に座っているAlexも、技術的な質問にお答えする用意があります。最適化のためには測定が必要ですが、Amazon SageMaker HyperPodは単一のインターフェースを通じてこれを非常にうまく実現しています。GPUリソース間の割り当て、GPU使用率の追跡、メモリ使用率の追跡、CPUとGPUの使用状況の管理を行います。多くのデータ取り込みタスクは必ずしもGPUを必要とせず、CPUで処理されるためです。 HyperPod Task Governanceには、これらすべてを効率的に管理し、タスクの優先順位付けを処理するための非常に細かい制御機能があります。


リソースを割り当てる際は、チームと自身に責任を持たせる必要があります。これらのリソースがどのように使用されているかについて期待値を設定し、何が機能し、何が機能していないかを追跡して確認し、それに応じて戦略を調整するための手段が必要です。そのためにHyperPodが活用されています。

時間の関係で、重要なことを共有させていただきます。先ほど申し上げたように、私たちのプラットフォームは、EnterpriseとExpert製品については、お客様自身の環境内に設置されています。ビジネスパーソンとして、数ヶ月前にチームに新製品の開発を依頼しました。この製品はArticul8 Essentialと呼ばれ、2〜3ヶ月という非常に短い期間で開発し、1月に発売することを目指しています。これには先ほど言及したモデルのコレクションが含まれ、Essentialの一部として新しいモデルも開発しています。
このような短期間での開発は、特にTask Governanceを含むHyperPodを活用しなければ実現できませんでした。このシステム全体の一部となる新しいモデルの微調整において、大きな助けとなりました。これを開発したのは、Enterprise製品のインストールに数週間かかるという声に応えるためでした。お客様は数日以内に価値を実感したいと望んでいました。そこで、Sandbox環境を提供する代わりに、現在は無料で提供している製品を作成しました。1月からは、サインアップしてすぐに文書のインジェストなどを始めることができます。ご興味がありましたら、お気軽にご連絡ください。実際の動作をご紹介させていただきます。
これが主要な収益源になるとは考えていませんが、プラットフォームの機能を試すための優れた出発点となります。最終的には、お客様自身の環境にデプロイされることになると考えています。HyperPodなしではこれを実現することは絶対にできませんでした。ここで、Kareemに戻したいと思います。質問にもお答えできます。Articul8の事例をご覧いただきました。彼らはHyperPodとTask Governanceを活用して、1月にローンチする製品を2ヶ月で開発することができました。彼らの成功を祝福し、今後の活躍を期待しています。

では、まとめに入らせていただきます。 Amazon SageMaker HyperPod Task Governanceをローンチしました。これにより、コストを削減しながらアクセラレーターの利用率を最大化することができ、モデルトレーニング、推論、Fine-tuningなど、あらゆるタイプのタスクに適用できます。主なポイントは、チームへのコンピューティングリソースの動的な割り当て、リソースの競合時における優先度の高いタスクの優先実行、そしてタスクの割り当て状況、待機時間、バーストパターン、低利用率などを含むコンピュート利用率のリアルタイムモニタリングが可能になることです。結果として、コストを最大40%削減しながら、リソースの利用効率を向上させることができます。

こちらが撮影できるQRコードです。 これらのユースケースの詳細を説明したブログがあります。Webページには最新の資料が掲載されており、こちらがドキュメントへのリンクですので、よろしければ写真を撮っておいてください。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion