re:Invent 2024: Amazon BedrockによるGenerative AI導入の課題解決
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Cost-optimized and scalable enterprise workloads with Amazon Bedrock (AIM356)
この動画では、Generative AIの企業導入における課題とAmazon Bedrockによる解決策が解説されています。世界の企業の80%以上がGenerative AIに投資する一方で、本番環境での運用は24%に留まるという現状を踏まえ、エンタープライズレディな実装に向けた3つの重要な柱を紹介しています。コンプライアンスとガバナンス、コストとパフォーマンス管理、Operational Excellenceの各観点から、Amazon Bedrockの具体的な機能と活用方法が説明されています。特に、Inference Profile、Cross-Region Inference、Guardrails、Prompt管理などの機能を用いた実践的なアプローチと、集中型・分散型・ハイブリッド型のアーキテクチャパターンについて、詳細な解説がなされています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon Bedrockが解決するGenerative AIの導入ギャップ

それでは始めましょう。Rain Band 2024へようこそ。みなさん、わくわくしていますか?もっと声を聞かせてください。今このセッションだけですので、大きな声を出しても大丈夫です。ここで皆さんにお伝えしたいことがあります。GardnerやMcKinsey、そしてAWS独自のデータによると、世界中の企業の80%以上が現在、Generative AIへの投資を行っています。しかし、そのうち実際に本番環境でワークロードを運用しているのは24%に過ぎず、ガバナンスやコスト管理のための適切な基盤やフレームワークを持っているのはわずか21%です。これは大きなギャップです。私はAntonio Rodriguezと申します。Amazon Bedrockプロダクトチームのジャッキー・ジェラルとともに、Amazon Bedrockがこのギャップを埋め、エンタープライズレディネスを実現するためのアイデアをご紹介したいと思います。データが示すように、エンタープライズレディネスがなければ、Generative AIワークロードを効果的に本番環境にデプロイすることはできないと考えています。

アジェンダでは、まず私たちが言うところのエンタープライズレディネスとは何かについて説明します。そして、エンタープライズレディネスにとって重要な3つの領域、すなわちコンプライアンスとガバナンス、コストとパフォーマンス管理、そして運用の優位性について説明します。最後に、私たちが「Generative AIプラットフォーム」と呼ぶものと、Generative AIを大規模に実装する際のアーキテクチャがどのようなものになるかについてまとめます。


まず、このエンタープライズレディネスという概念から始めましょう。企業におけるGenerative AIについて語るとき、多くの方が次のような要素の組み合わせを求めていることに同意されると思います。まず、ニーズに応じて段階的にスケールできるソリューションが必要です。小規模から始めて、最終的には数百、数千のユースケースを本番環境でサポートできるところまでスケールできる必要があります。また、市場で入手可能な最新のFoundation Modelを使用でき、それらのモデルをプラグアンドプレイで使用できることも重要です。つまり、アプリケーションに大きな変更を加えることなく、新しいモデルを簡単に実装できる必要があります。さらに、RAGパターンやAgentic パターン、Fine-tuningなど、あらゆるタイプのカスタマイズに対応できるツールも必要です。そして最後に、しかし重要なこととして、データのセキュリティが確保され、Generative AIを使用するすべての場面でプライバシーが保護されていることを確認する必要があります。
エンタープライズレディネスの3つの柱:コンプライアンス、コスト管理、運用優位性
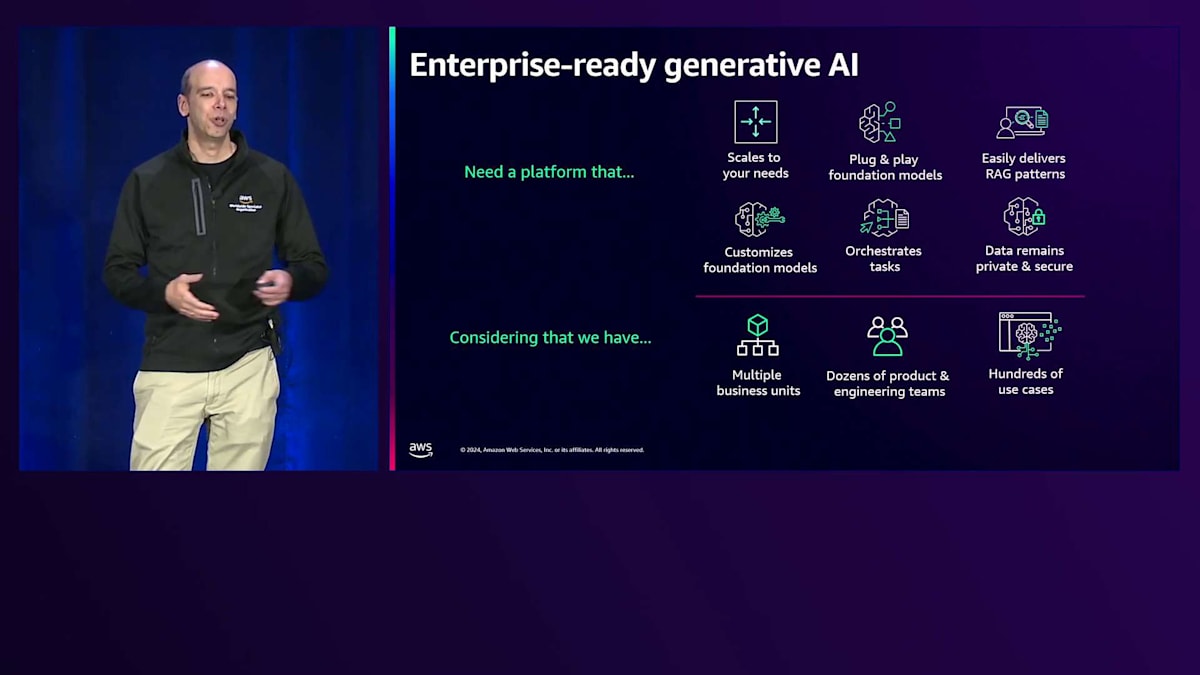
これは、複数のビジネスユニットやチームがGenerative AIを使用する必要がある場合、さらに複雑になります。場合によっては、数十の製品開発チームやエンジニアリングチームが協力して作業を行い、数百、時には数千のユースケースが並行して進行し、それぞれがGenerative AIに対する固有のニーズを持っています。これから数分間、本番環境でGenerative AIアプリケーションをデプロイする際の3つの主要なステージについてお話しします。

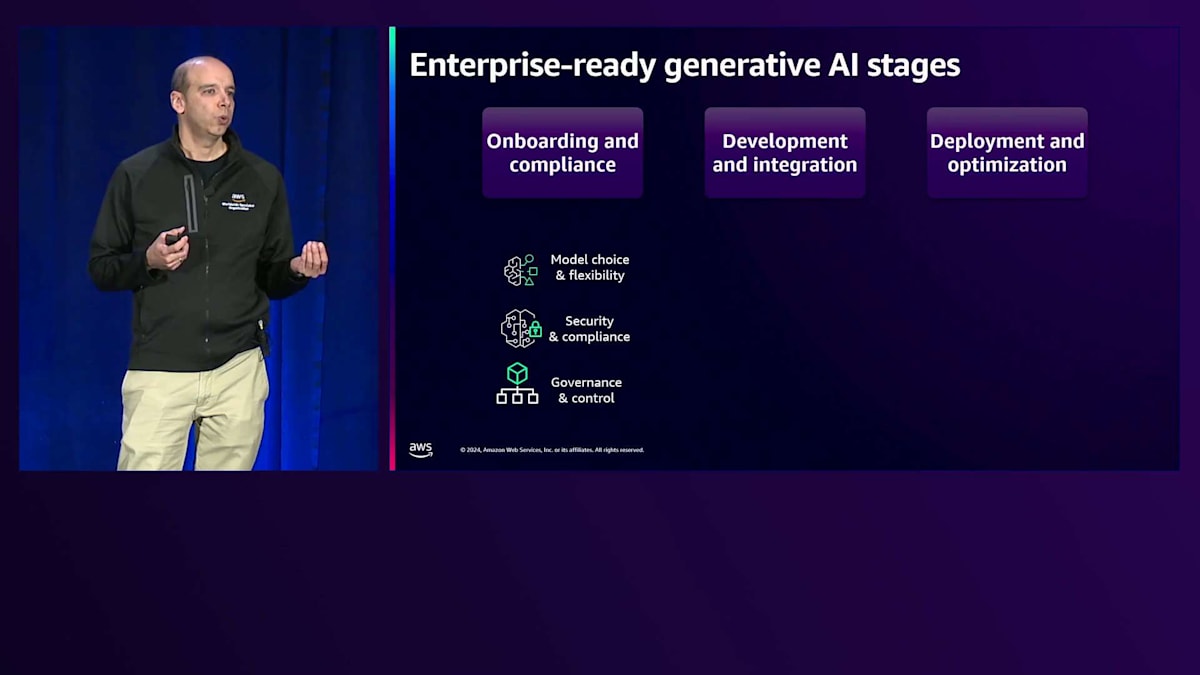
第一のステージは、オンボーディングとコンプライアンスと呼ばれるものです。このステージは、自社で使用する予定のモデルやツールが、規制や社内ポリシーに準拠していることを確認するプロセスとして考えることができます。これにより、それらのモデルを本番環境で使用でき、すべてが望む方法で安全に保護されていることを確認できます。そのために、Amazon Bedrockでは、適切な仕事に適切なモデルを選択できるという重要な要素である「モデルの選択と柔軟性」を提供しています。もちろん、ここで最初に挙げるべきは「セキュリティとコンプライアンス」です。すべてが規制や社内ポリシーに準拠していることを確認する必要があります。そして最後に、「ガバナンスとコントロール」が必要です。これは、各ケースに応じて、ユーザーやグループレベル、プロジェクトレベルで非常に細かいアクセス制御ができること、そしてすべてのアプリケーションでコスト管理ができることを意味します。
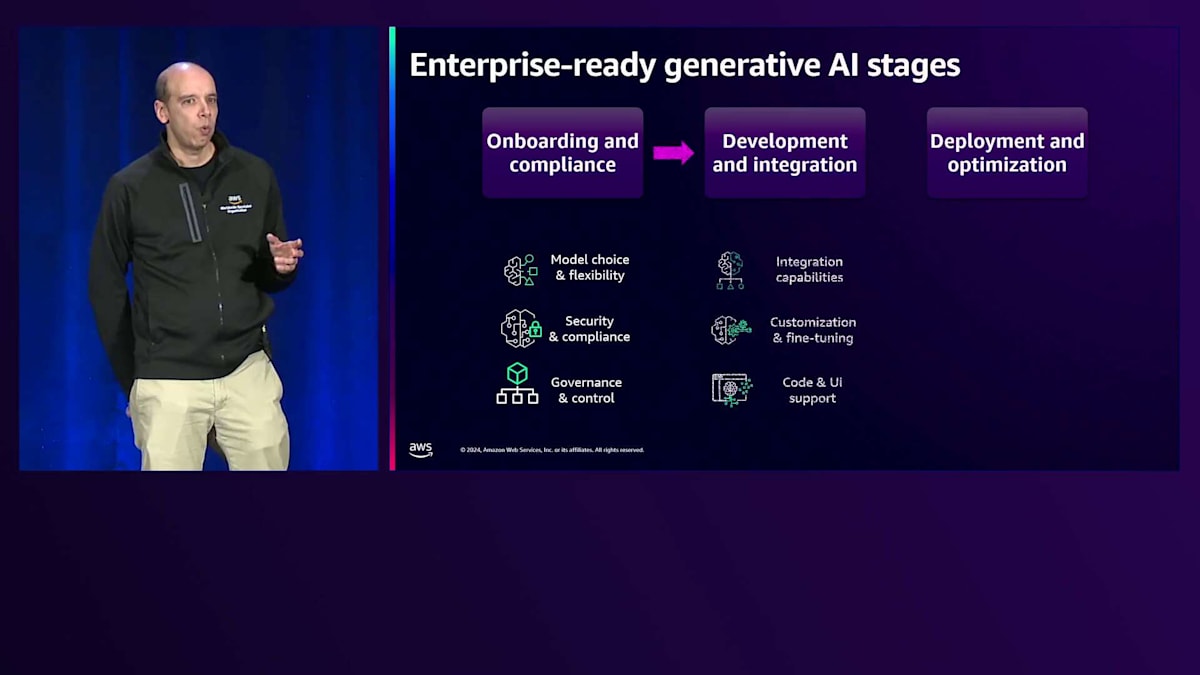
第2段階は、通常アプリケーション開発者が担当する部分です。そのためには、自社のツール、オープンソースフレームワーク、その他のAWSサービスとの統合機能が必要となります。また、組織内の独自のデータやデータソースを使用して、Fine-tuningのカスタマイズを行うための機能も必要です。さらに、コードベース、ローコード、ノーコードのアプリケーションを使用して、企業内での開発プロセスを迅速に進められるようにする必要があります。今週は、私たちが実際にローンチする多くの新機能について学んでいただけます。
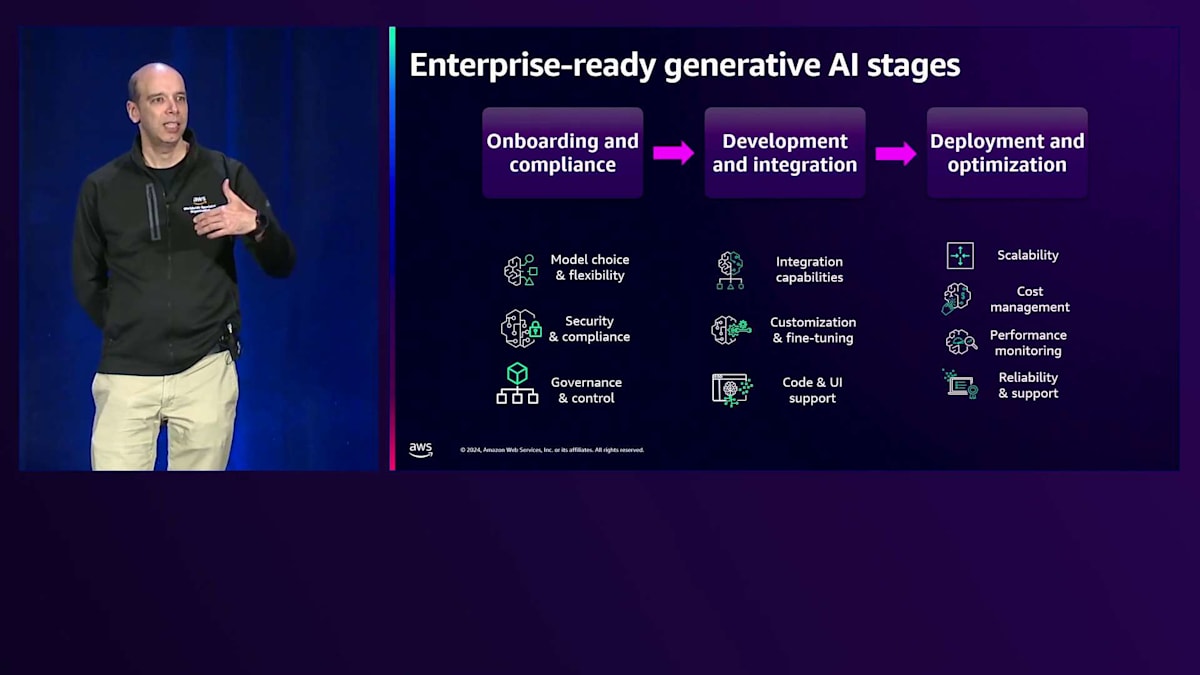
明日と明後日は特に、エキサイティングな発表が多数控えていますので、ご期待ください。 最後のパートは、本番環境へのワークロードの移行です。つまり、実際にワークロードを本番環境にデプロイすることを意味します。そのためには、デプロイ時に自動的にスケールできる柔軟性があること、コスト管理と制御が考慮されていること、そして非常に重要なパフォーマンスモニタリングと可観測性が備わっていることを確認する必要があります。最後に、信頼性が高く、サポートの観点から必要なものがすべて揃っていなければなりません。

もちろん、Amazon Bedrockがこれらすべての課題を簡素化することをお伝えしたいと思います。現在、Amazon Bedrockは市場の主要なFoundation Modelプロバイダーからモデルを選択できる機能を提供しています。また、独自のデータを使用したカスタマイズのためのツールや、先ほど申し上げたようにオープンソースとの統合、さらには自社のシステムや必要に応じて他のサービス、サードパーティとの統合も提供しています。また、ユーザーのネイティブAIの使用状況を簡単に管理できるよう、コストとパフォーマンスの管理機能も提供しています。最後に、そして何よりも重要なのは、ユーザーやチームの活動を制御するという重労働を心配する必要がないよう、セキュリティとガバナンスが整っているということです。
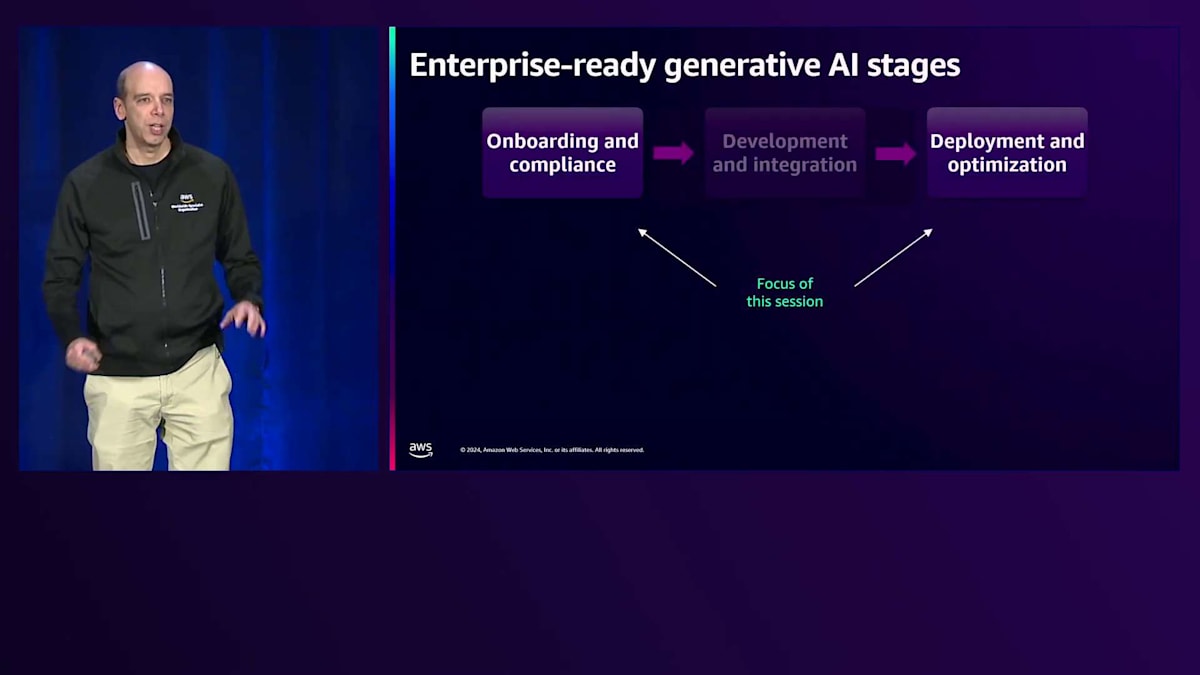
このセッションでは、先ほど示した3つのステージのうち、特に最初と最後のステージに焦点を当てていきます。中間のセクションについては、今年のre:Inventの他のセッションで多くのコンテンツをご用意しています。では、Bedrockがこれらのタスクにどのように役立つかについて、具体的にJaricからエンタープライズ評価についてお話しいただきます。
Amazon Bedrockの機能:コンプライアンス、ガバナンス、コスト管理

ありがとう、Antonio。皆さん、こんにちは。 エンタープライズレベルの生成AIアプリケーションの構築が非常に困難であることは、私たちすべてが認識しています。革新的である一方で、多くの考慮事項が伴いますが、まさにそこでAmazon Bedrockが登場し、この journey を容易にするのです。Amazon Bedrockは、主要なAIラボからFoundation Modelを選択できる完全マネージド型サービスです。RAGやFine-tuningなどのテクニックを使用してFoundation Modelをカスタマイズすることができます。さらに、特定のタスクを実行するAgentを構築し、Foundation Modelを評価することもできます。これらすべてを、基盤となるインフラストラクチャについて学ぶ必要なく、セキュアでプライベートな方法で実現できます。
エンタープライズ向けの生成系アプリケーションを構築する上で非常に重要な柱の1つが、コンプライアンスとガバナンスです。Amazon Bedrockは、コンプライアンスとガバナンスに関して3つの異なる側面でサポートを提供します。1つ目は、お客様がプロバイダーと締結する法的合意書であるEULAを提示し、特定のLLMを使用する際の契約内容や利用規約を明確に理解できるようにすることです。これはオンボーディングの時点で確認できます。2つ目は、すでに各種コンプライアンス認証の対象となっていることです。これについては後のスライドで詳しく説明します。3つ目は、Amazon Bedrockがガードレールを使用した高度な保護機能を実装する機能を提供していることです。
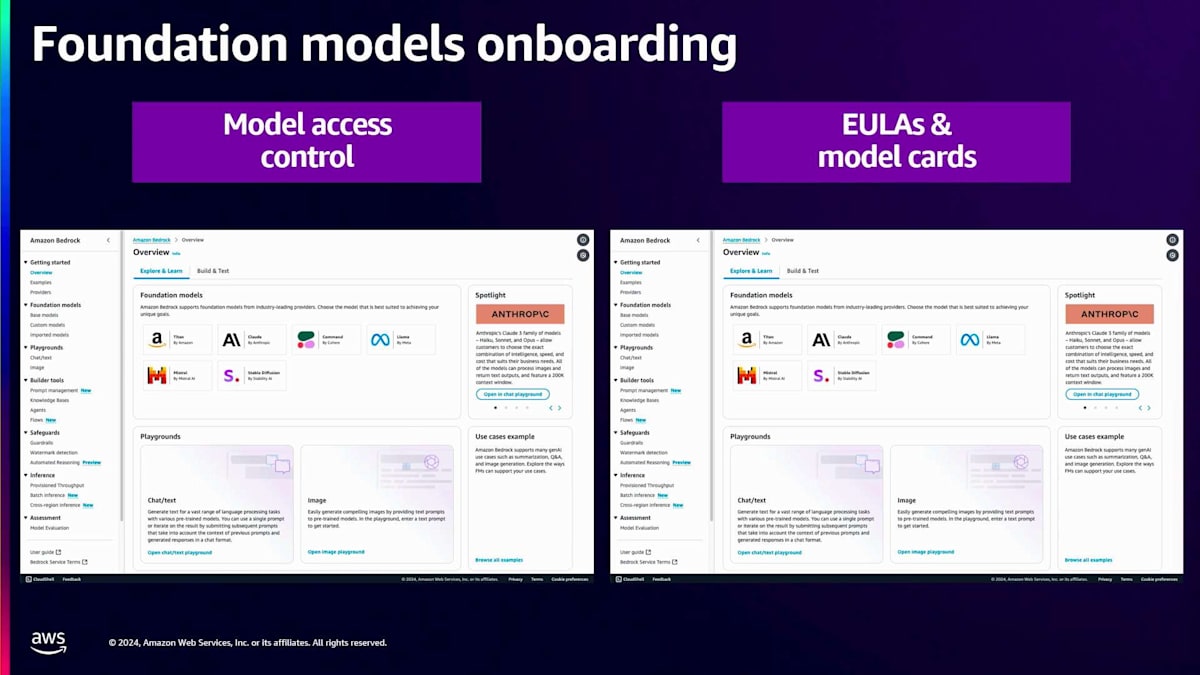
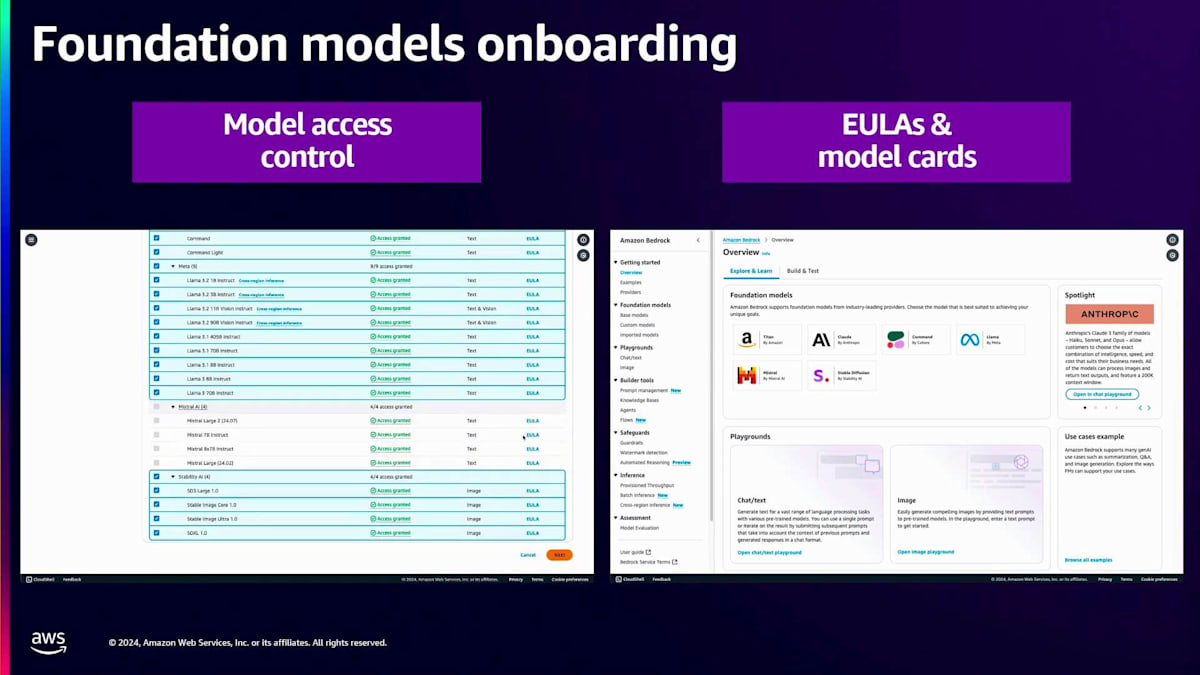
それでは、Bedrockコンソールでのオンボーディングの流れを簡単なデモでご覧いただきましょう。左側のパネルにModel Accessがありますので、そこから一覧表示されているすべてのモデルへのアクセスを取得できます。Bedrockコンソールに初めてアクセスする場合は、まずアクセスが必要なモデルをすべて選択する必要があり、数分以内にアクセス権が付与されます。モデルの一覧と共に、アクセス状況と各モデルに関連するEULAが表示され、クリックして内容を確認することができます。
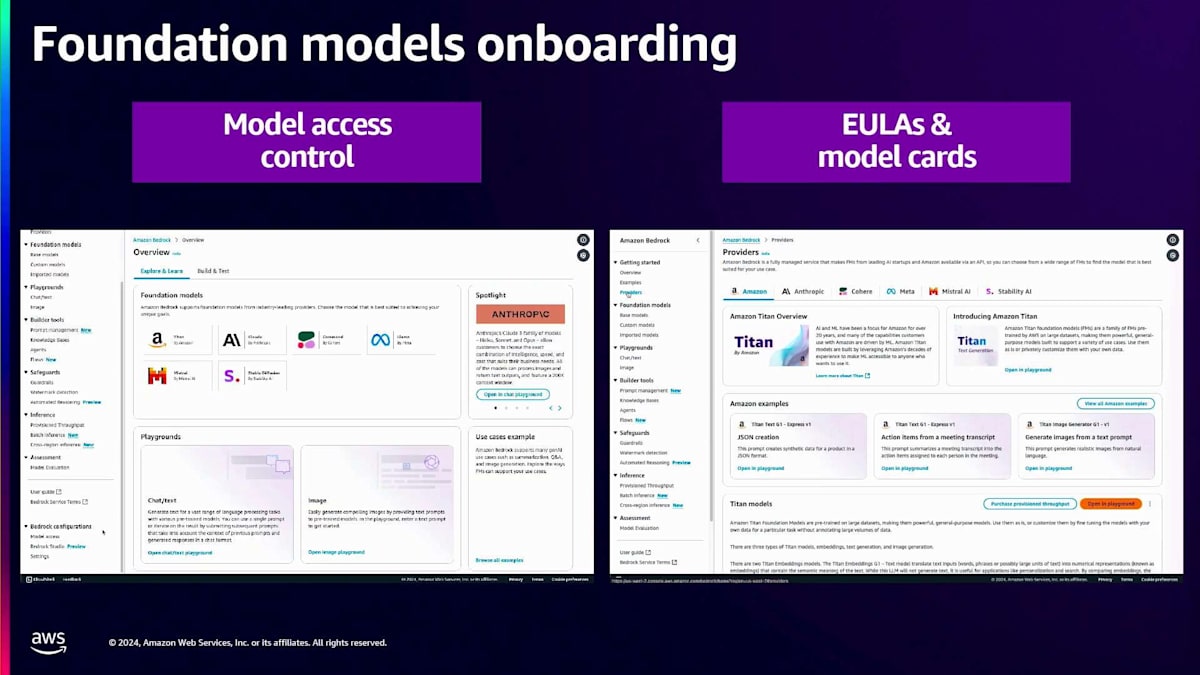

次のデモに移りましょう。左側のパネルにProvidersがあります。Providersをクリックすると、コンソールに全プロバイダーが一覧表示されます。 各プロバイダーにはModel Cardも用意されています。Model Cardには、そのモデルがどのような用途で使用されているかが記載されています。
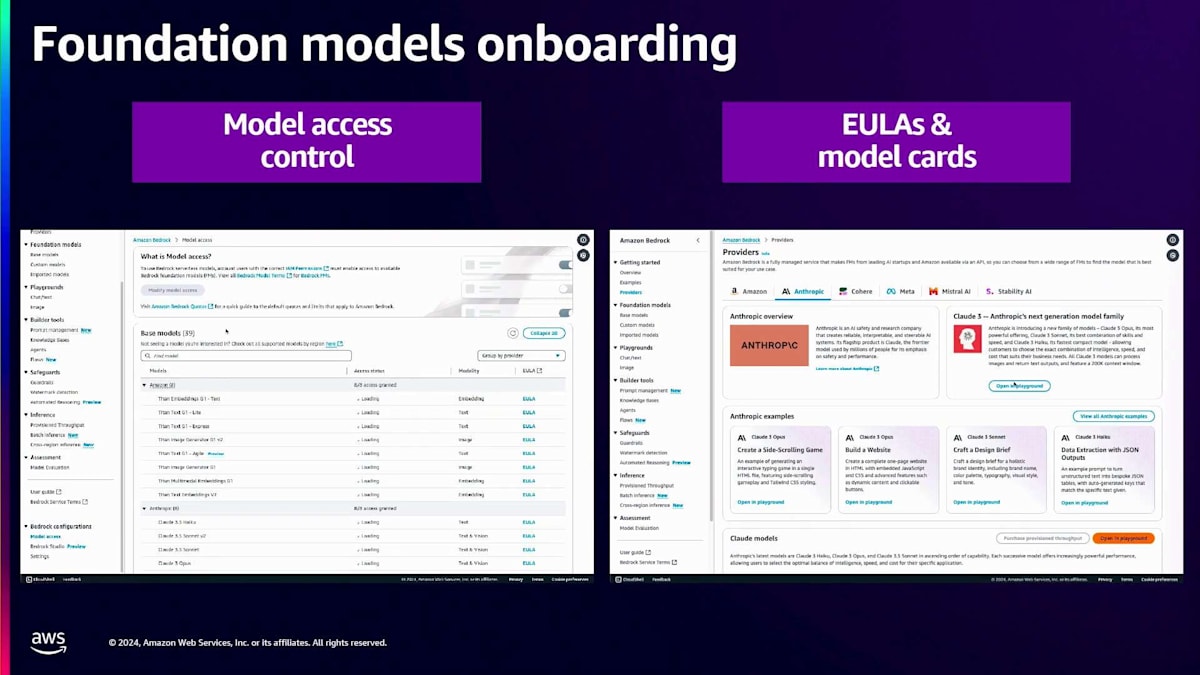

用途に応じて適切なモデルを選択できますが、Model CardにはEULAへのリンクも含まれており、モデルへのアクセスを申請する前に、必ずEULAの内容を確認してください。
Amazon Bedrockは、複数のコンプライアンス基準の対象となっています。例えば、ISO、CSA STAR、GDPR、HIPAAに準拠しており、GOV Cloudリージョンでは FedRAMP Highの認定サービスとなっています。次に、Amazon Bedrockのデータセキュリティについてお話ししましょう。Amazon Bedrockでは、Foundation Modelをカスタマイズするために使用するデータを管理することができます。このデータは、転送中も保存時も、AWS KMSサーバーを使用してエンドツーエンドで暗号化されます。さらに、Amazon Bedrockでは、このデータを使用してFoundation Modelをさらに改良することはありませんし、プロバイダーにデータを送信することもありません。また、Private Linkを使用してAmazon VPCとAmazon Bedrock間の接続を確立することで、インターネットへの露出を防ぐことができます。
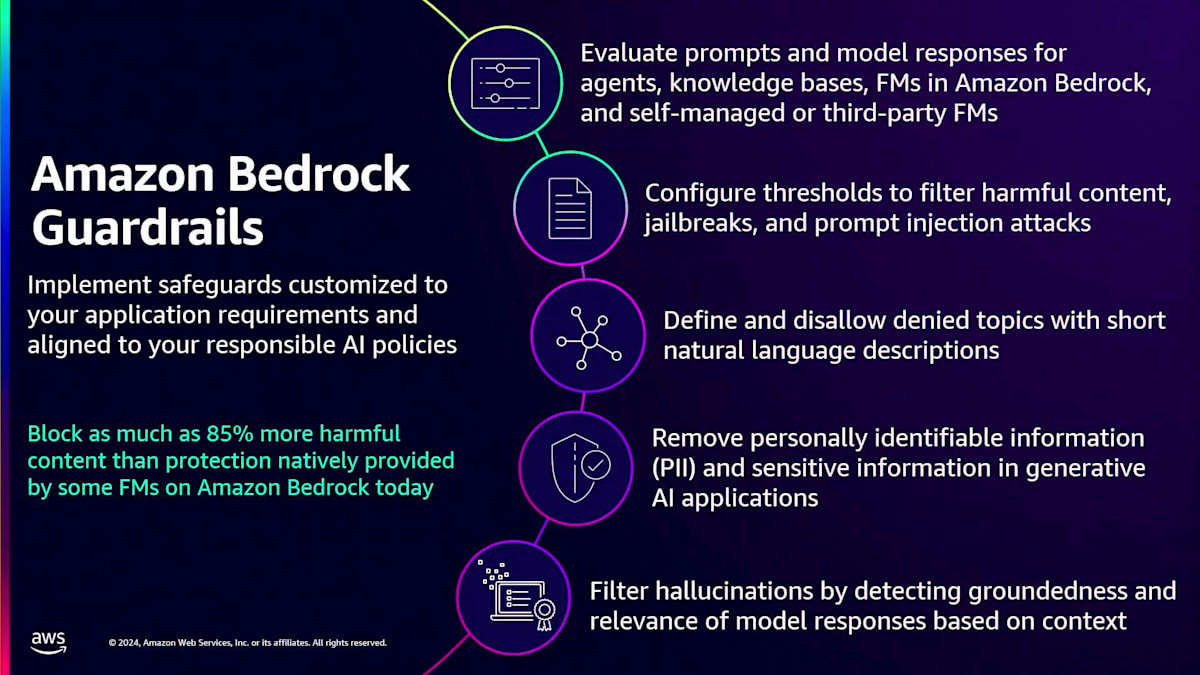
次にAmazon Bedrockのガードレールについてお話しします。お客様からは、AIを使用する際に有害なコンテンツ、有毒なコンテンツ、無関係なコンテンツを排除したいというご要望をいただいています。また、機密データを保護し、レスポンスから除外したいという声や、ハルシネーション(幻覚)をフィルタリングしたいというニーズもあります。Amazon Bedrockのガードレールは、これらすべての課題に対応します。ガードレールの主要な特長の1つは、お客様固有のビジネスユースケースに合わせて保護機能をカスタマイズし、実装できることです。現在、Amazon Bedrock上の一部のFoundation Modelがネイティブで提供する保護機能と比較して、最大85%多くの有害コンテンツをブロックすることができます。現在、ガードレールはKnowledge Base Agent、Foundation Model、そしてBedrockのFoundation Modelだけでなく、サードパーティのモデルや自社ホスティングのモデルもサポートしています。

次の柱であるコストとパフォーマンスの管理に移りましょう。Generative AIアプリケーションの構築において、使用制限や課金アラートの設定、そしてより耐障害性が高く可用性の高いアプリケーションの開発を可能にするため、コストとパフォーマンスの管理は非常に重要です。Bedrockプラットフォームでは、これを実現するための3つの方法があります:コストタグ付け、クロスリージョンルーティング、そしてInferenceモードです。それぞれのオプションについて詳しく見ていきましょう。

お客様からは、ビジネスにGenerative AI技術を導入し、すべてのプロジェクトやビジネスユニットでこの技術を活用するようになると、コストの管理と追跡が非常に困難になり、さらに特定のビジネスユニットへのコスト配分も難しくなるという声を聞いています。Amazon Bedrockのコストタグ付けと管理オプションは、これらの課題に対応します。まず、プラットフォーム上で生成されるすべてのリソースにタグを付けます。1つのリソースに複数のタグを関連付けることができ、リソースにタグを付けた後、アラームや通知を設定することもできます。しきい値を設定し、値がそのしきい値を超えた場合にアクションを実行することも可能です。では、Amazon Bedrockでのリソースのタグ付けについて見ていきましょう。
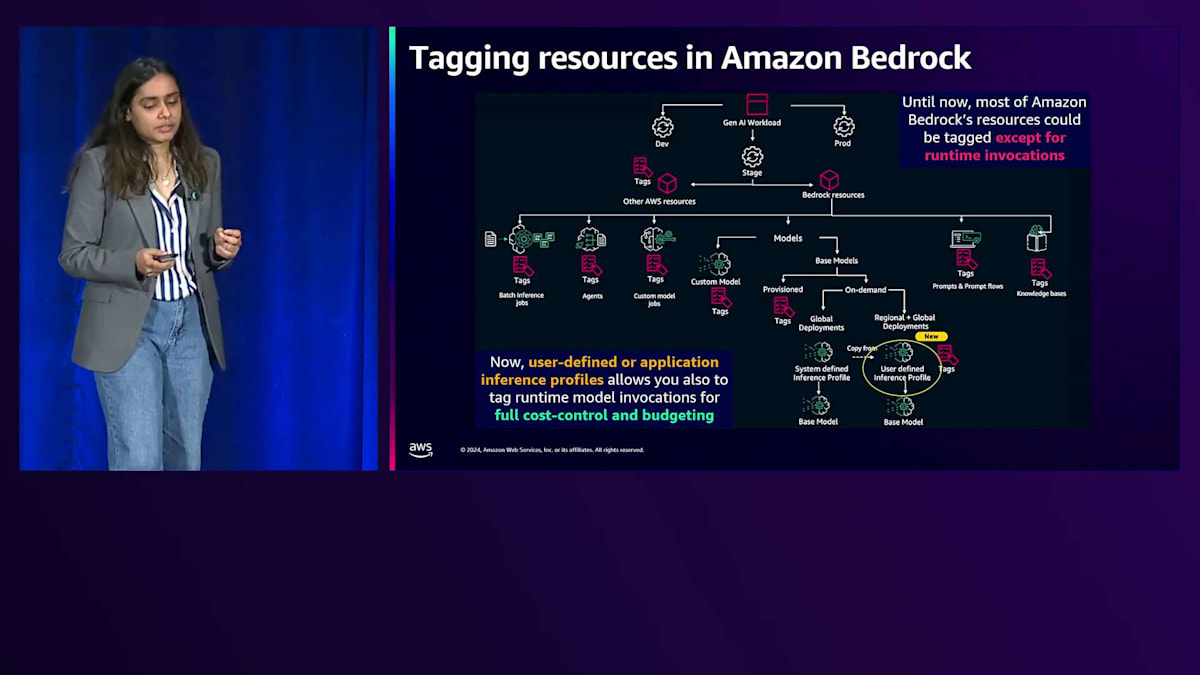
これまで、Amazon Bedrockのほとんどのリソース(Batchジョブ、Agent、カスタムモデル、Provisioned Throughput、Knowledge Base、PromptとPrompt Flow)に対してタグ付け機能がありました。以前はオンデマンドInvocationにタグを付ける機能がありませんでしたが、現在はInference Profileを使用してこれが可能になりました。Inference Profileとは何か、そしてコストタグ付けがどのように機能するのかをデモで確認していきましょう。
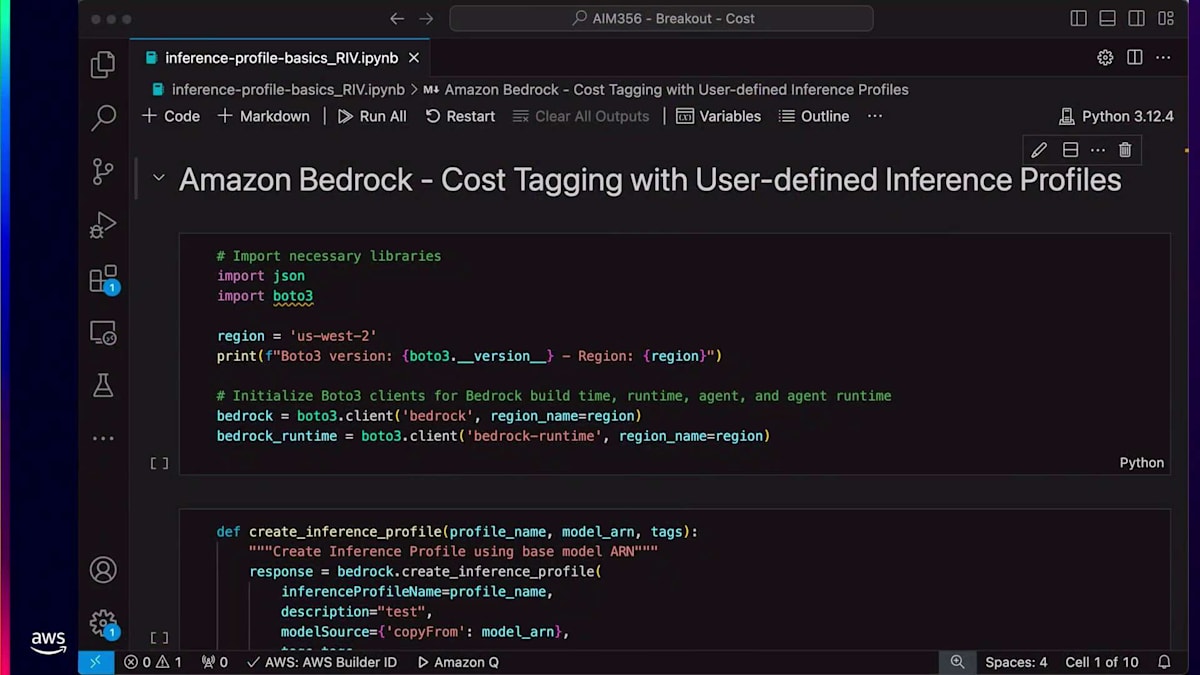
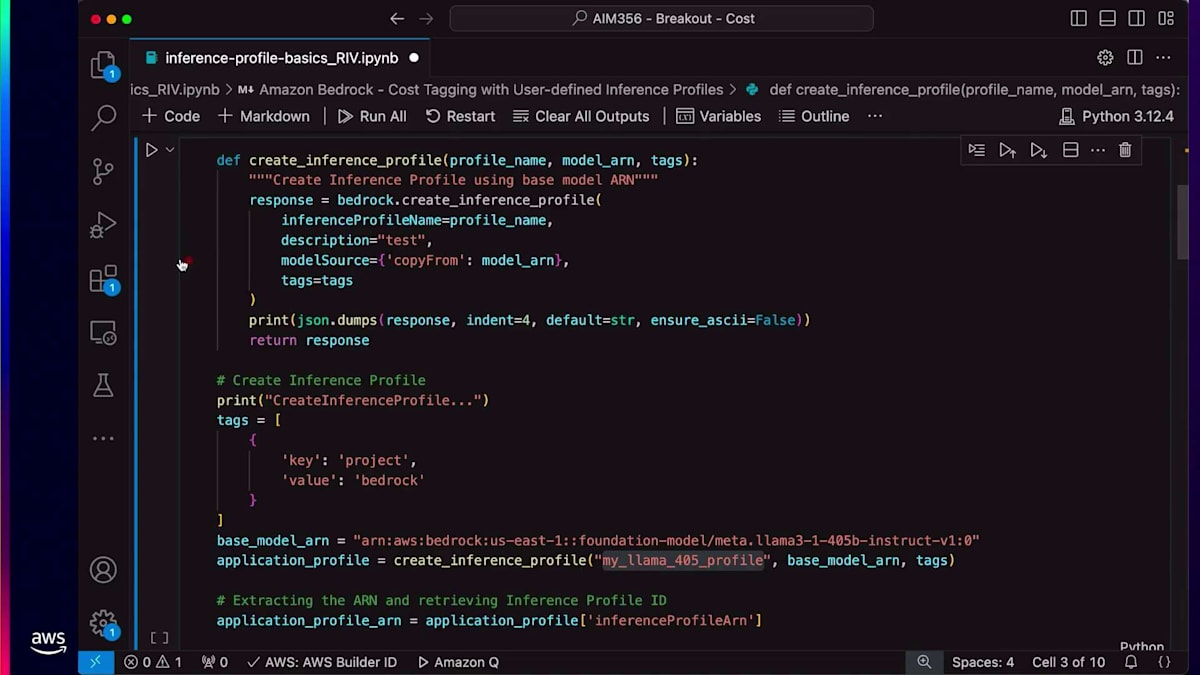
このInference Profileを使用したデモでは、Inference Profileリソースでコストタグ付けを作成する方法をご紹介します。コストタグ付けを設定すると、Converse APIを実行できるようになります。その後、コンソールで特定のリソースとタグに関連するすべてのコストを確認することができます。 ご覧のように、Create Inference Profile APIはパラメータとしてModel ARN、タグ、Profile名を受け取ります。モデルパラメータとキーバリューペア形式のタグを設定すれば、Inference Profileを作成することができます。
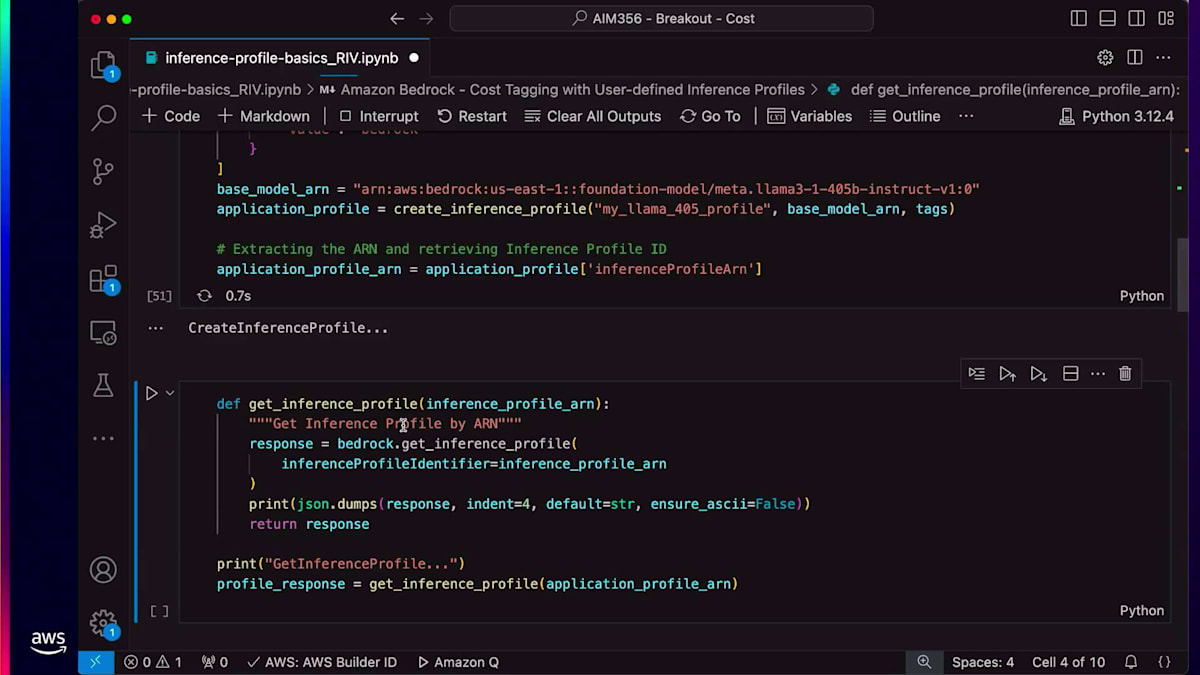
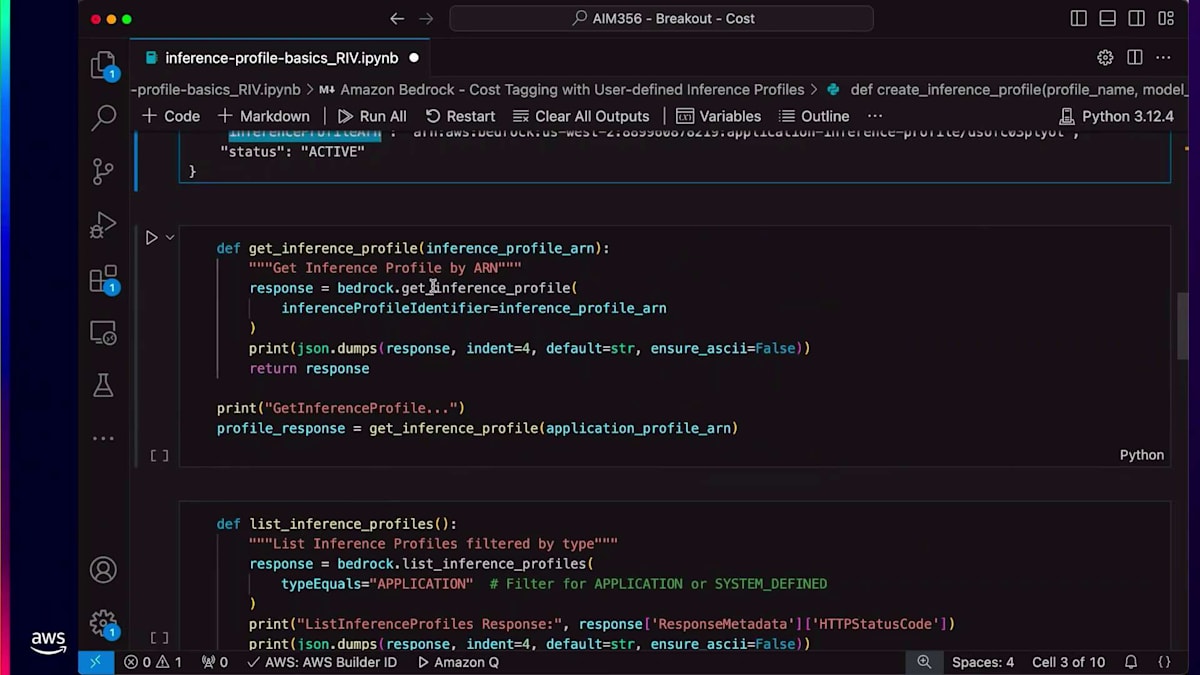
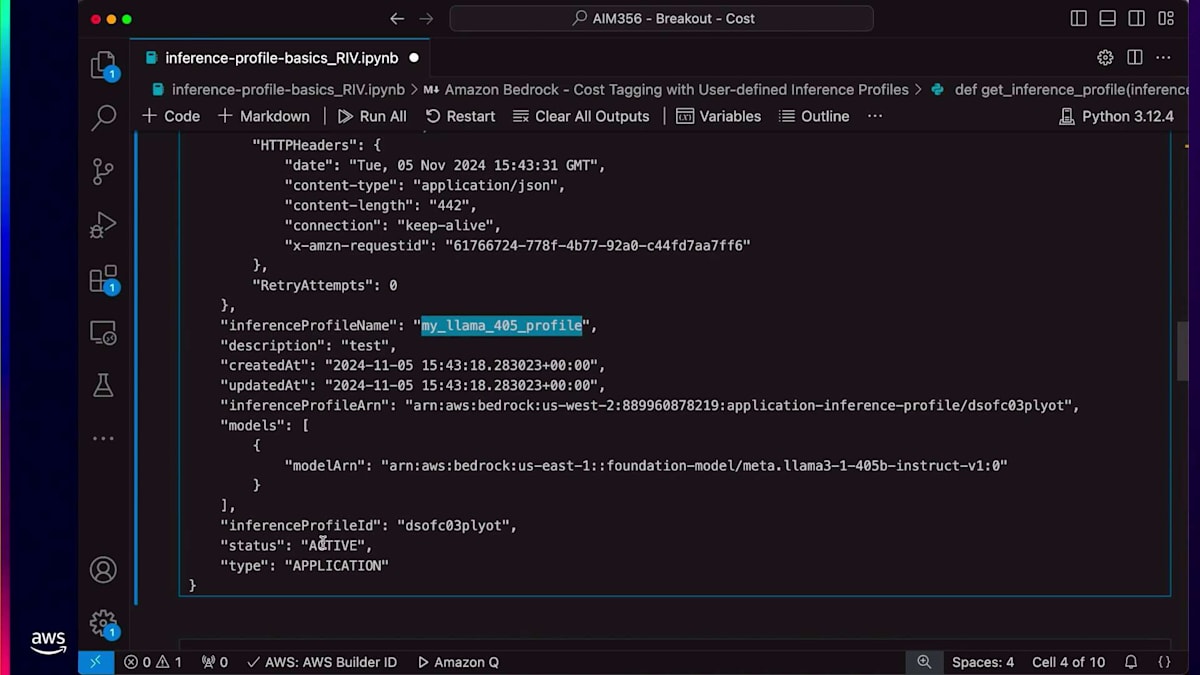
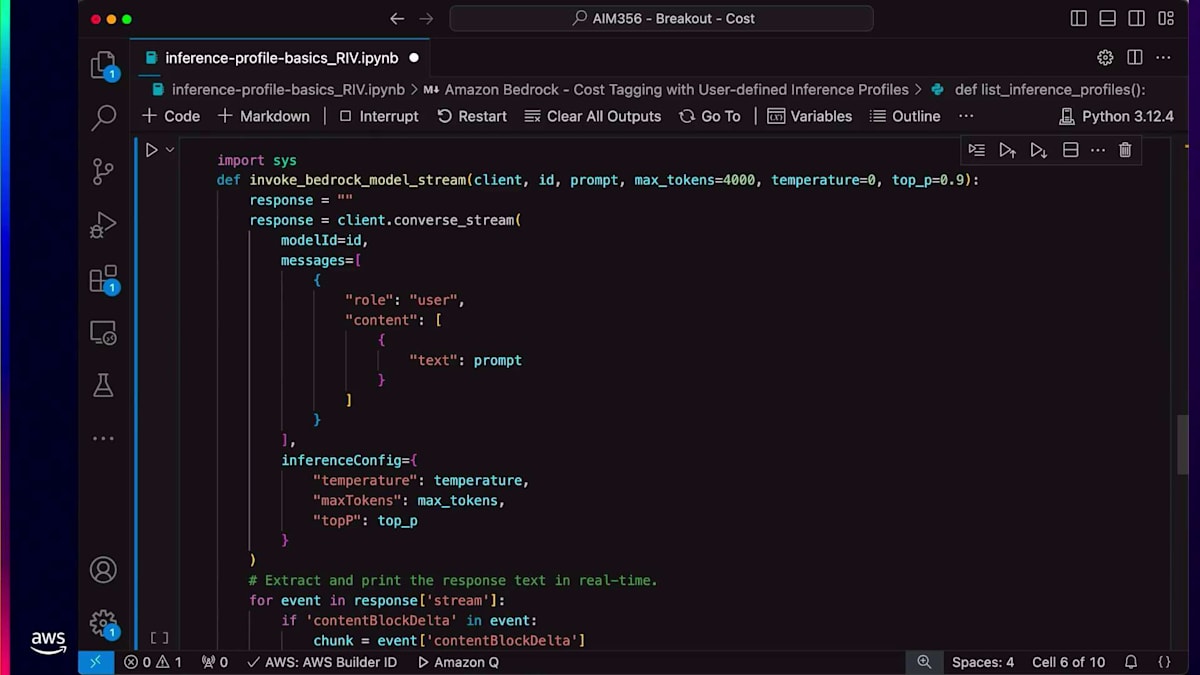

このInference Profileのステータスがアクティブであることが確認できます。Inference Profileを作成すると、そのリソースの一意の識別子となるARNが返されます。作成したInference Profileのすべての情報を取得するにはget APIを使用できます。また、list inference profile APIを使用して、アカウントで作成されたすべてのInference Profileをリストアップすることもできます。次に、Converse APIの使用方法についてご説明します。皆さんの中で、Converse APIを使用したことがある方は挙手をお願いします。
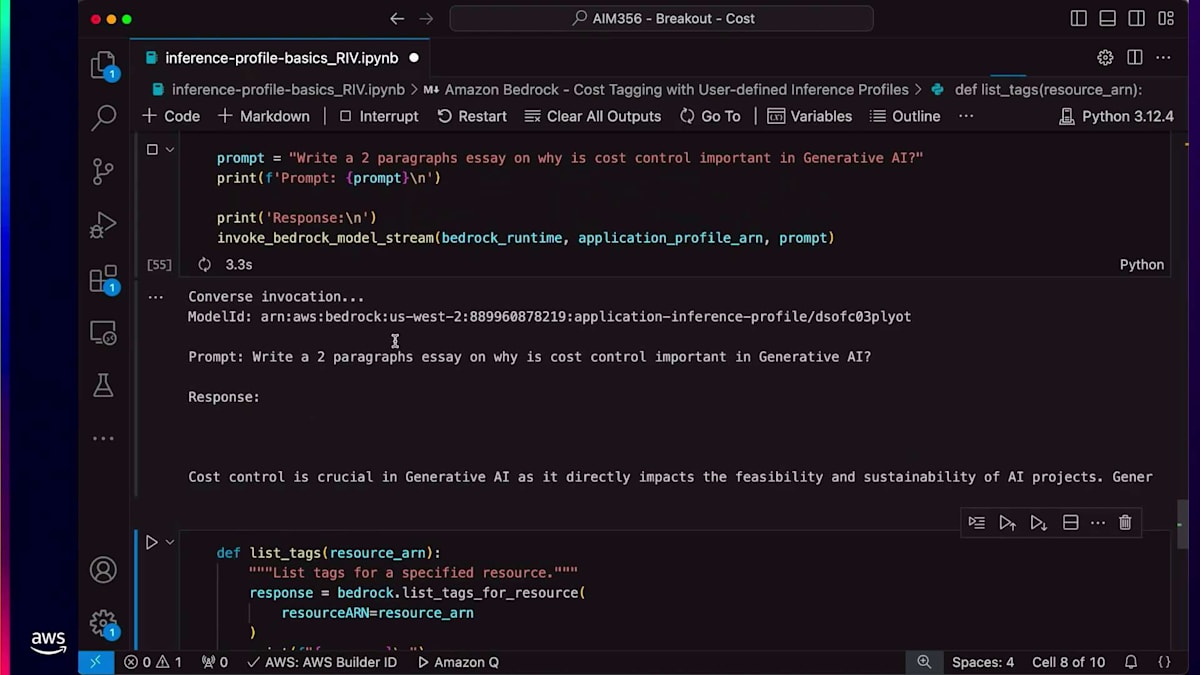

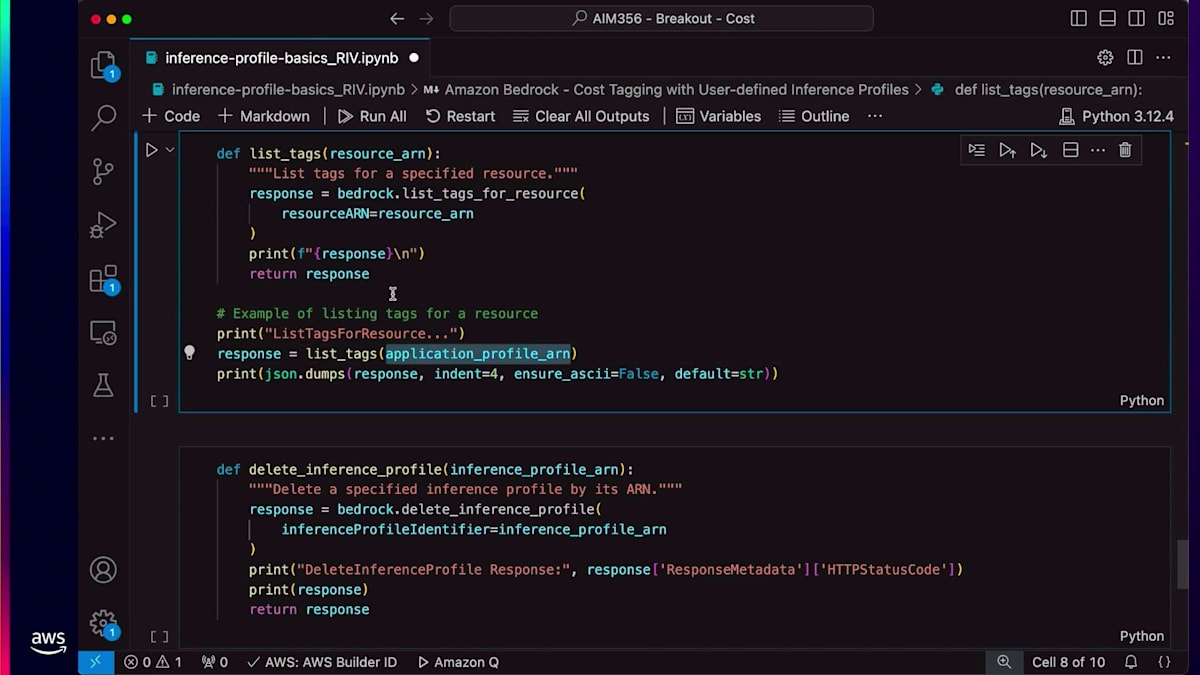
ありがとうございます。これからLLMでプロンプトを実行するためにConverse APIを使用していきます。このAPIはパラメータの1つとしてInference Profile ARNを受け取ります。ご覧のように、APIを実行すると応答が生成されています。 タグに関しては、list tagsを使用して特定のInference Profileに関連付けられたすべてのタグを一覧表示できます。最後に、delete inference profileを使用してARNを削除することができます。
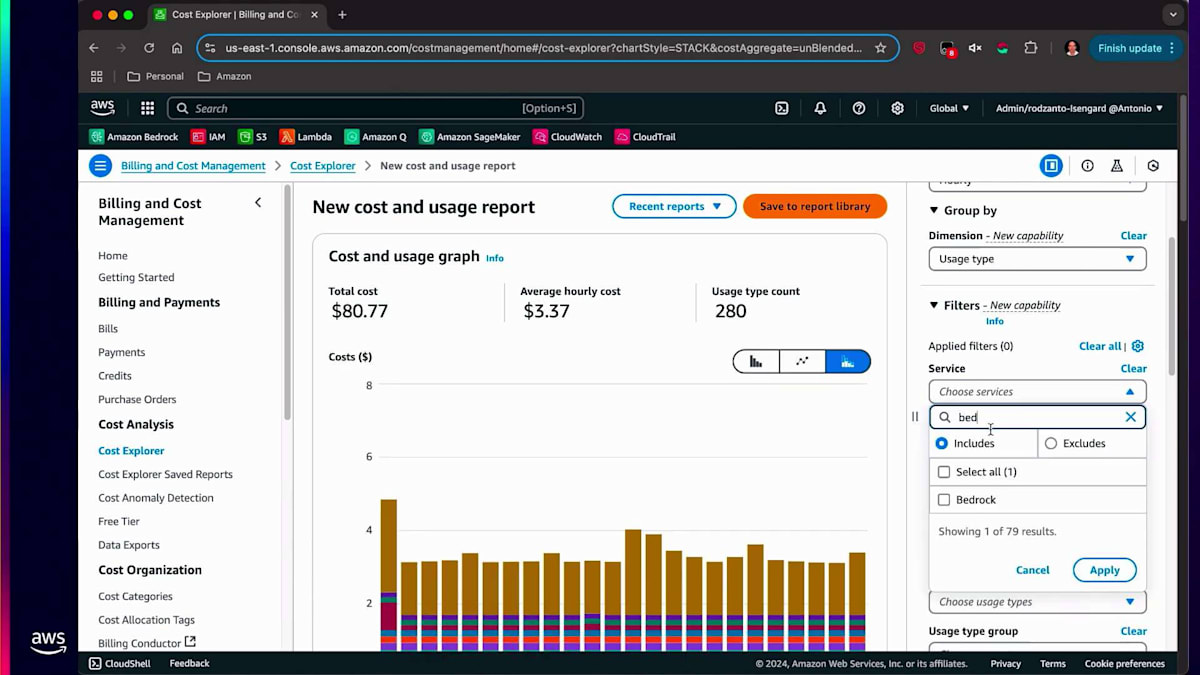
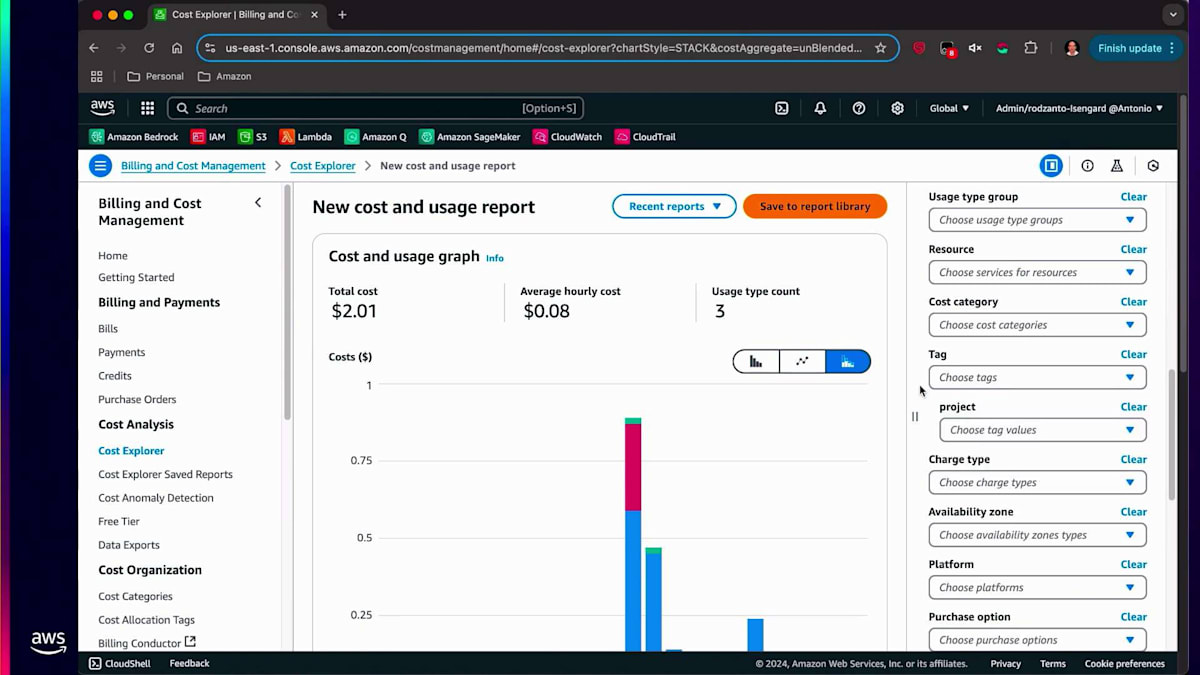
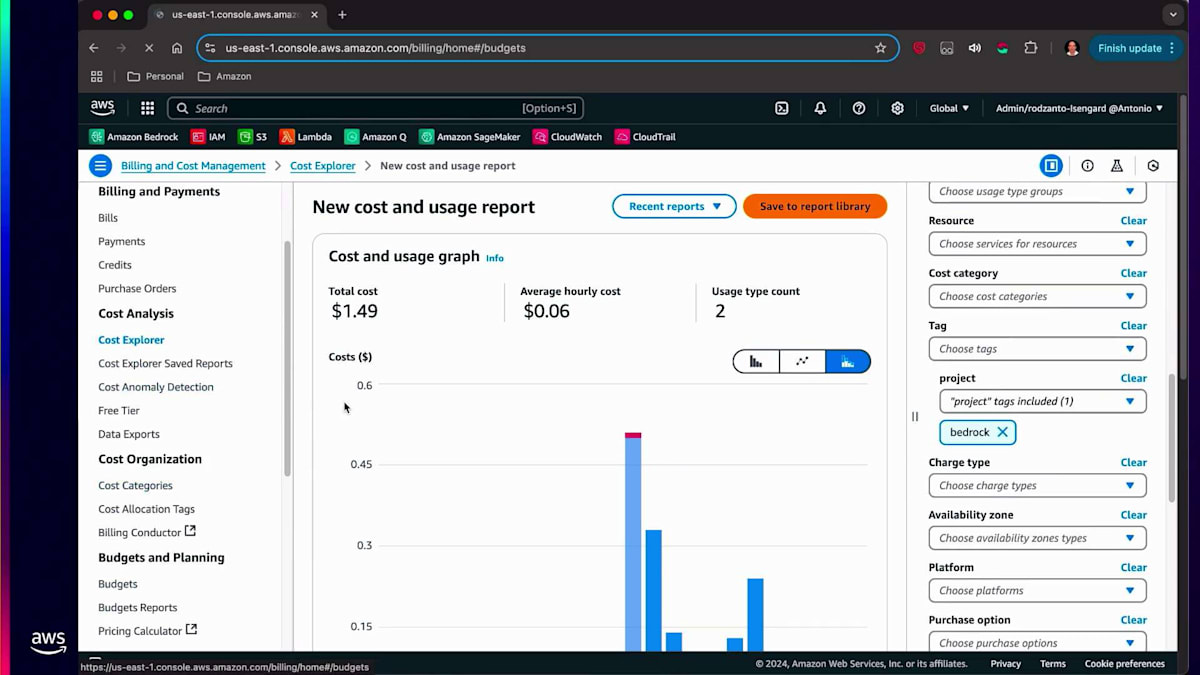
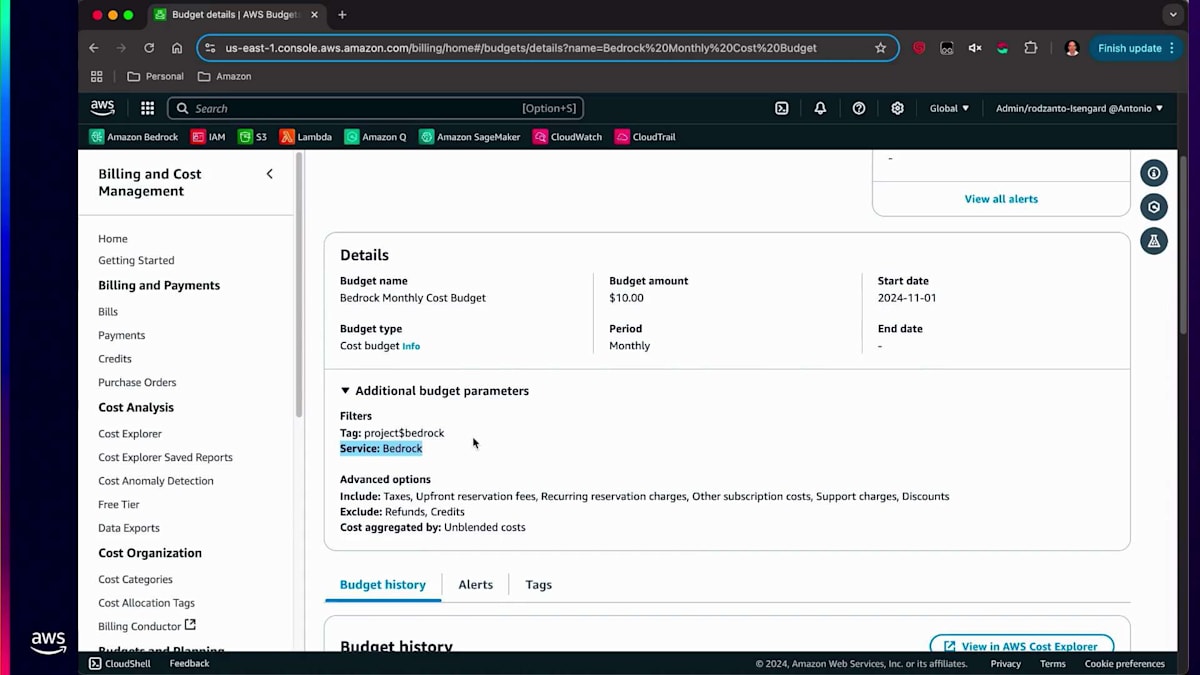
次に、コンソールでの操作体験についてお話しします。特定のビジネスユニット用に作成したタグについては、そのビジネスユニットで発生したコスト、設定された当初の予算、そして予算に対する進捗状況を確認することができます。使用タイプ、サービスタイプを設定し、タグを検索します。ProjectがタグでBedrockを選択すると、そのタグに関連する情報が画面に表示されます。Budgetsに移動すると、このビジネスユニットに設定された当初の予算が10ドルで、現時点で10ドルを使い切っていないため、しきい値はOK状態であることが確認できます。これらの制限を設定することができます。例えば、使用量の80%をしきい値として指定することができます。
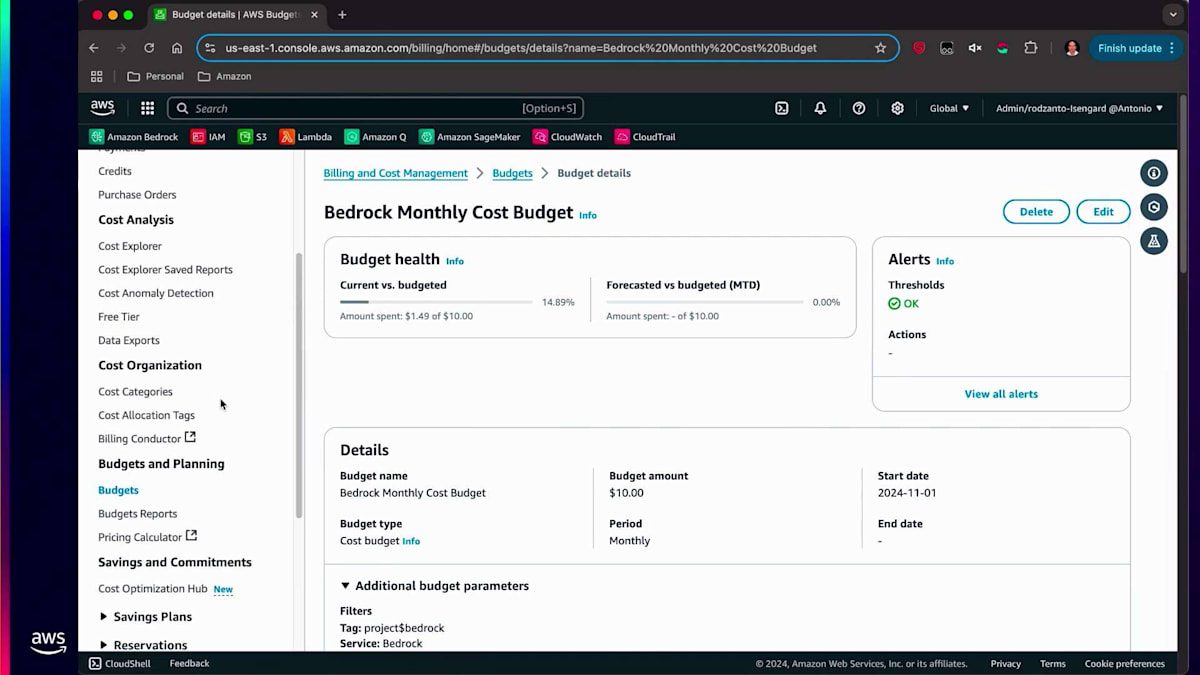
そして、制限を設定すると、それに基づいてアクションを取ることができます。特定のしきい値に達した時点で、モデルへのすべてのアクセスを取り消すことができます。これらが、組織全体のコストを管理するためにAmazon Bedrockで実行できることです。コストの追跡と配分は、モデルに依存しない方法で行うことができるため、組織全体のAI支出を把握することができます。

次に、Amazon Bedrock推論の消費オプションについてお話しします。Amazon Bedrock推論モードは、アプリケーションのコストとパフォーマンスを管理する上で非常に重要です。皆さんの固有の生成AIユースケースに基づいて、どれを使用するか、またはこれらを組み合わせて使用するかを決定できます。まず、Batch Inferenceについてお話ししましょう。Batch Inferenceは、モデル評価、実験、オフライン処理のためのレスポンスを得るために、プロンプトをバッチで処理します。このBatch InferenceはSLAが24時間であるため、オンデマンド推論モードと比べて50%低いコストで利用できます。時間に余裕のあるワークロードであれば、ぜひBatch Inferenceをご利用ください。
オンデマンドの従量課金オプションには、契約期間の縛りはありません。このオプションでは、99.9%のアップタイムで最高のレイテンシーを実現できます。ただし、このオンデマンドモードには一定のクォータが設定されていることにご注意ください。これらのクォータは分単位で設定されており、1分あたりのリクエスト数とトークン数に制限があります。一定のスループットを保証する必要がある場合は、Provisioned Throughputをお選びください。Provisioned Throughputでは、1分あたりの入力トークン数や出力トークン数を24時間365日確保することで、アプリケーションのパフォーマンス要件を満たすことができます。
契約期間は1ヶ月または6ヶ月から柔軟に選択できます。また、時間単位の料金で利用できる契約期間なしのオプションもご用意しています。契約期間なしを選択した場合は時間単位の料金が適用されますが、長期の契約期間を選択いただくと割引が適用されます。本番環境のワークロードやカスタムモデルの推論に最適です。特にカスタムモデルはProvisioned Throughputとの相性が非常に良いです。
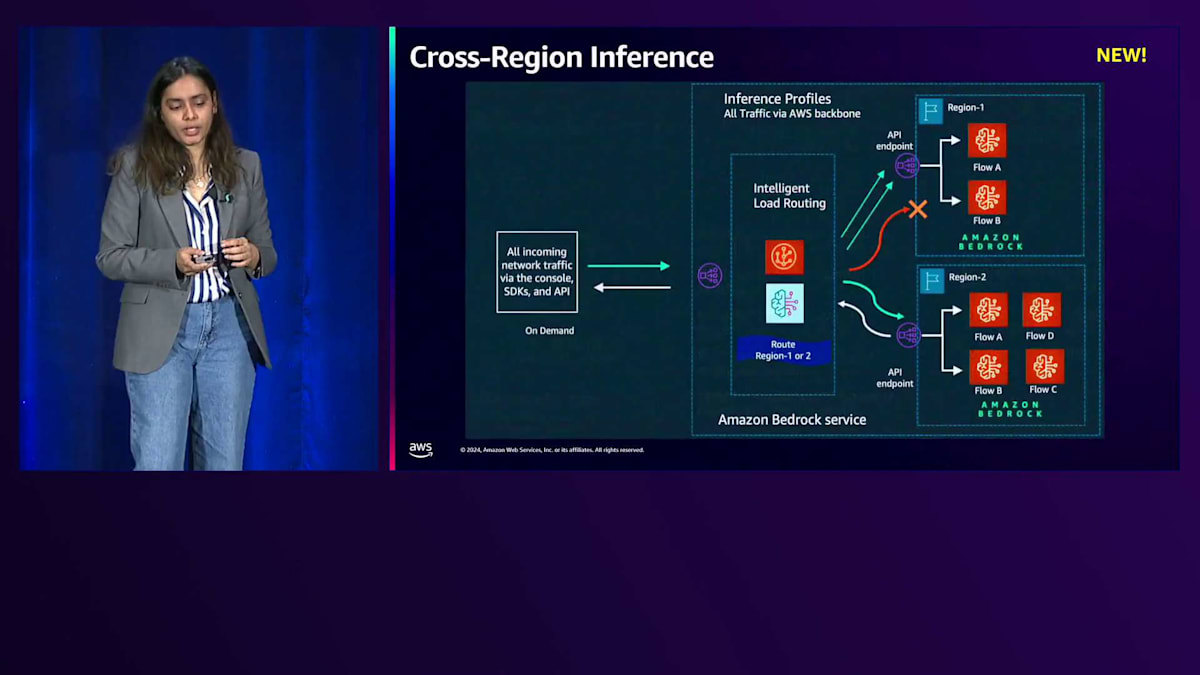
次に、Cross-Region Inferenceの機能についてご説明します。先ほど申し上げたように、オンデマンドには分単位でクォータが設定され、適用されます。アプリケーションの継続的なパフォーマンスを確保するためには、トラフィックの急増に対応できる必要がありますが、これはCross-Region Inferenceを活用することで実現できます。Cross-Region InferenceはInference Profileと連携して動作します。先ほどの例でお話ししたように、Inference Profileに関連付けられた全てのリージョンに対して、ソースリージョンからのリクエストがルーティングされ、いずれかのリージョンでリクエストが処理されることが保証されます。これにより、アプリケーションの回復性と高可用性を確保することができます。

Cross-Region Inferenceを使用する際の注意点をいくつかご説明します。通常のリージョン内オンデマンド実行では、アカウントに設定されたクォータしか使用できませんが、Cross-Region Inferenceでは最大で2倍のクォータを使用することができます。料金に関しては、Inference Profileを使用してリクエストを実行する場合、ルーティング先のリージョンではなく、ソースリージョンの料金が適用されます。
Operational Excellenceを実現するAmazon Bedrockの自動化と可観測性
Operational Excellenceは、エンタープライズ向けGenerative AIアプリケーションを構築する上で3番目に重要な柱です。Operational Excellenceには、自動化と可観測性という2つの要素があります。Operational Excellenceが重要である理由は、生産性を向上させ、時間とともにコストを削減できるアプリケーションを構築できるからです。それでは、これらの側面について詳しく見ていきましょう。
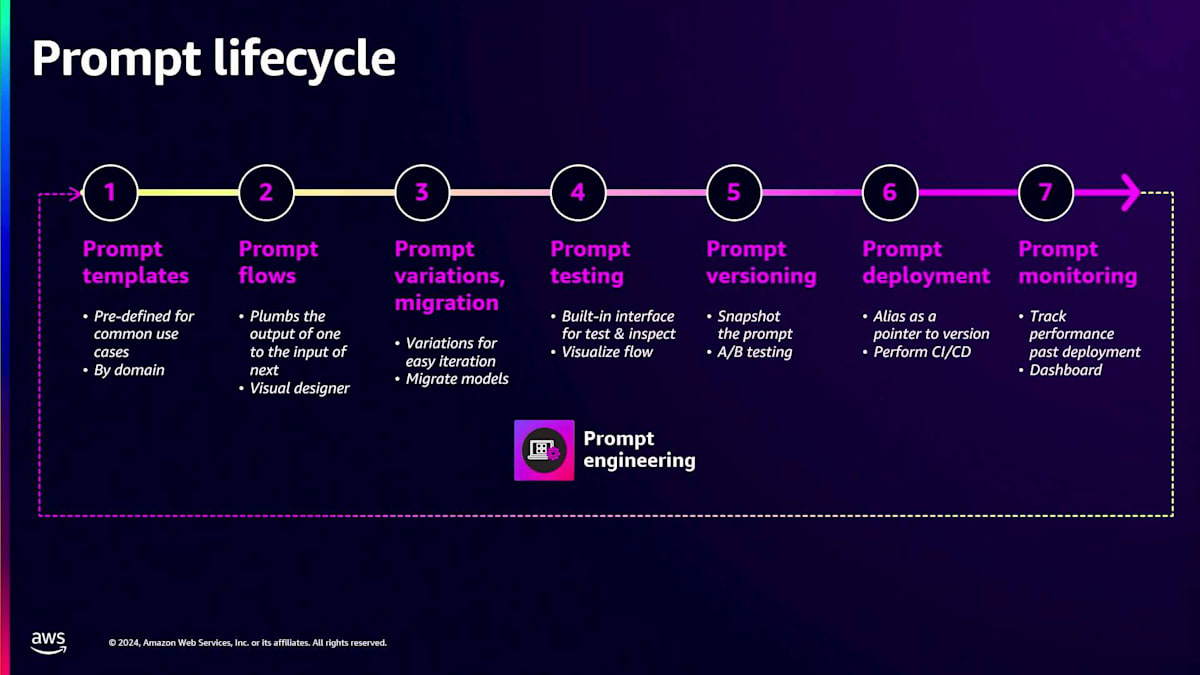
Prompt engineering は、言語モデルを活用する上で最もコスト効率の高い方法の1つです。言語モデルでプロンプトを実行する際は、望ましい応答を生成できるよう、プロンプトが十分に最適化されていることを確認する必要があります。Amazon Bedrockは、要約や質問応答などの一般的なユースケース向けの事前定義テンプレートであるPrompt templatesをはじめ、Prompt engineeringを容易にする様々な機能を提供しています。さらに、プロンプトの作成、保存、他のワークフローでの再利用を可能にする包括的なPrompt管理システムも備えており、時間の節約に役立ちます。ユーザーはこれらのプロンプトのバージョンを作成してテストし、そのテスト結果に基づいてアプリケーションで使用するバージョンを決定できます。また、デプロイ後のモニタリングにも役立ちます。
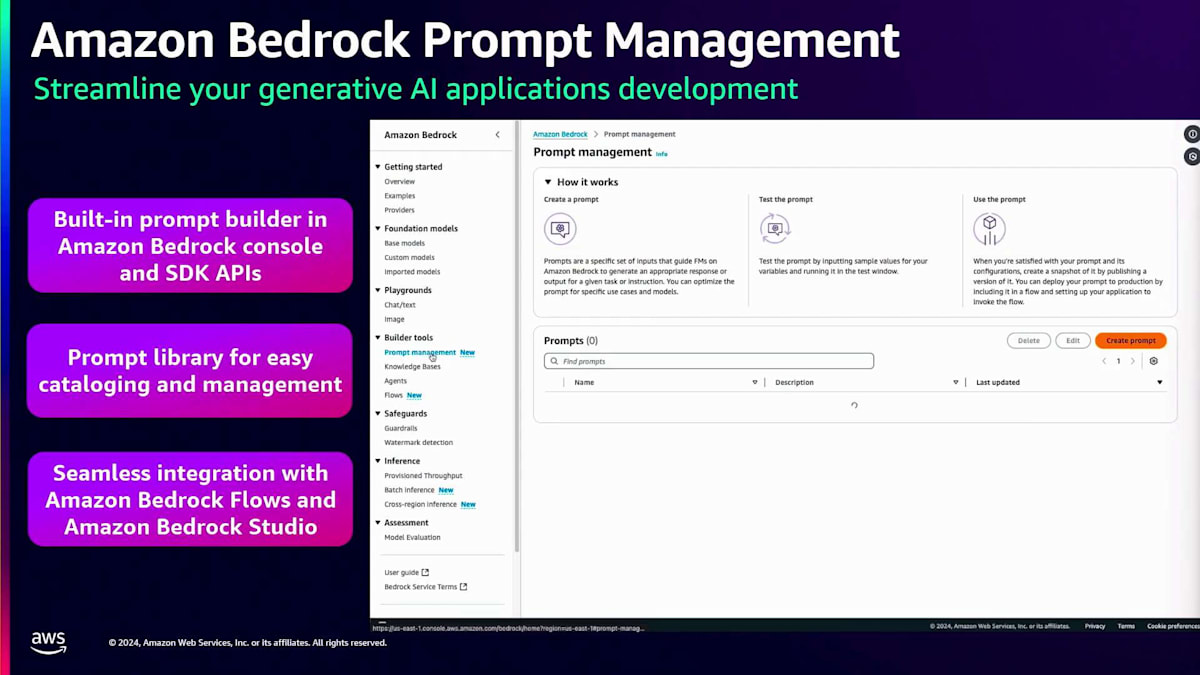
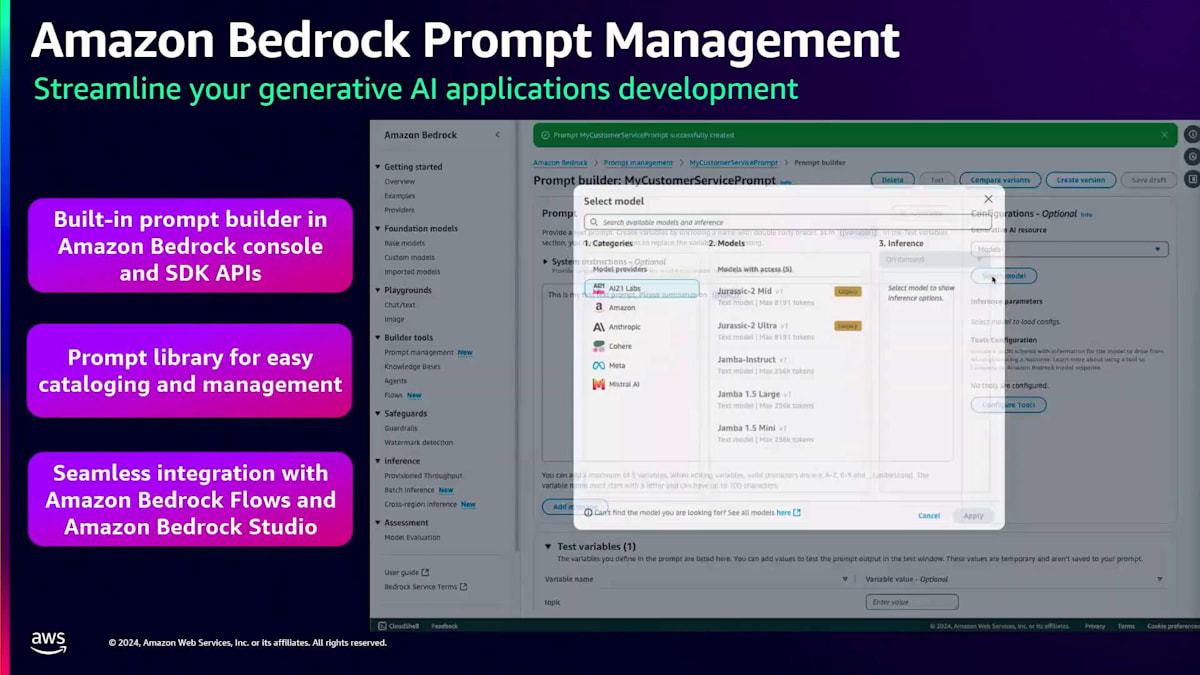
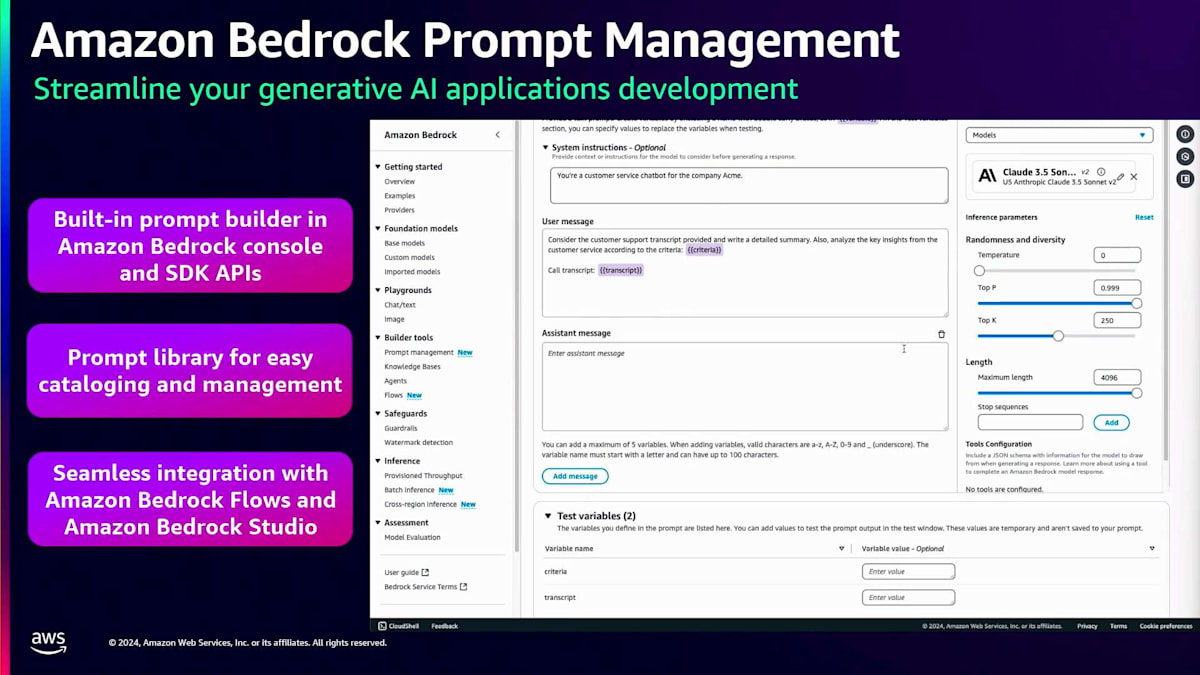
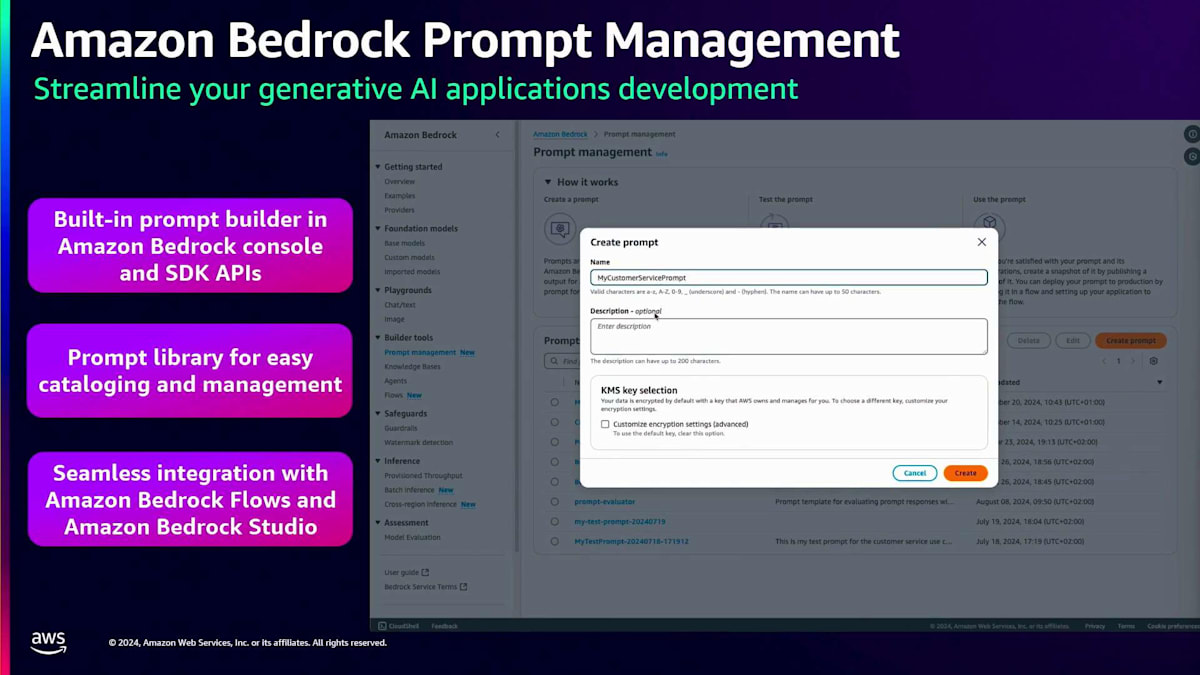
このPrompt管理の仕組みを例を使って理解しましょう。 コンソールの左パネルにPrompt管理のオプションがあります。プロンプトを作成する際は、名前と説明を入力すると、 このようなコンソールがポップアップ表示されます。ここでプロンプトの全文を入力でき、変数も一緒に使用できるようになっています。これにより、異なるユースケースに応じて必要な箇所で変数を変更することができます。さらに、プロンプトにコンテキストを追加することで、言語モデルが より適切な回答を提供できるようになります。変数の値をすべて追加したら、右パネルでプロンプトを実行して出力を確認できます。作成したプロンプトを保存し、バージョン管理することもできます。このように、Amazon Bedrock でのPrompt engineeringは非常に簡単に始められます。
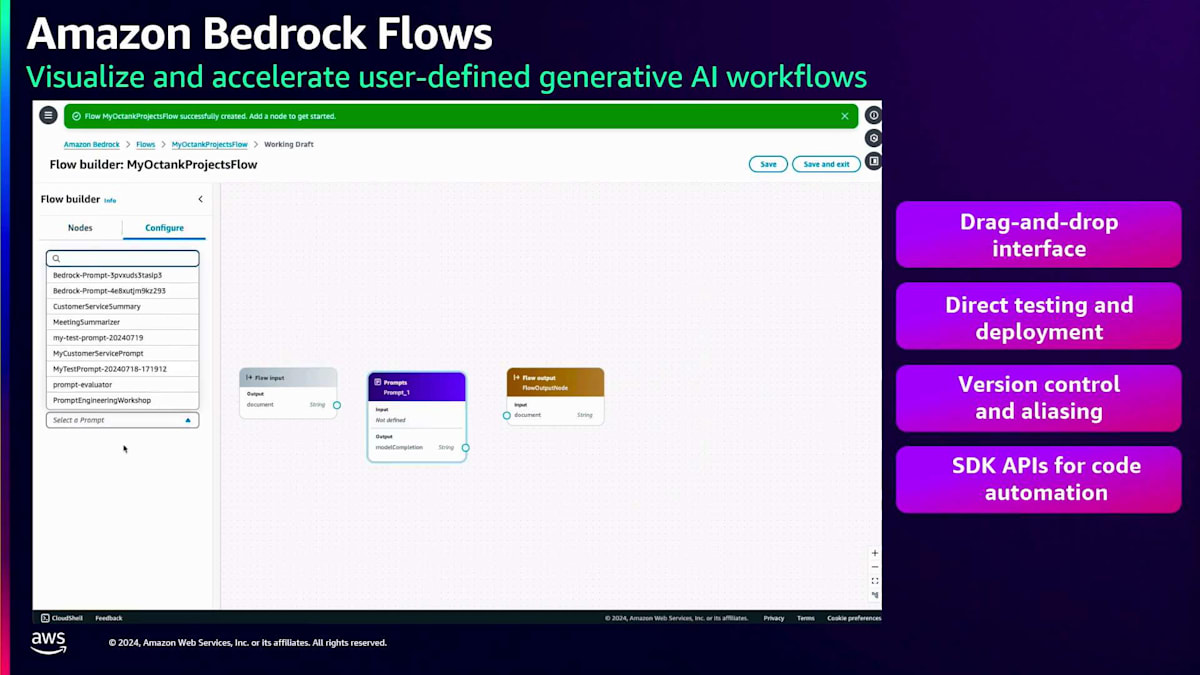
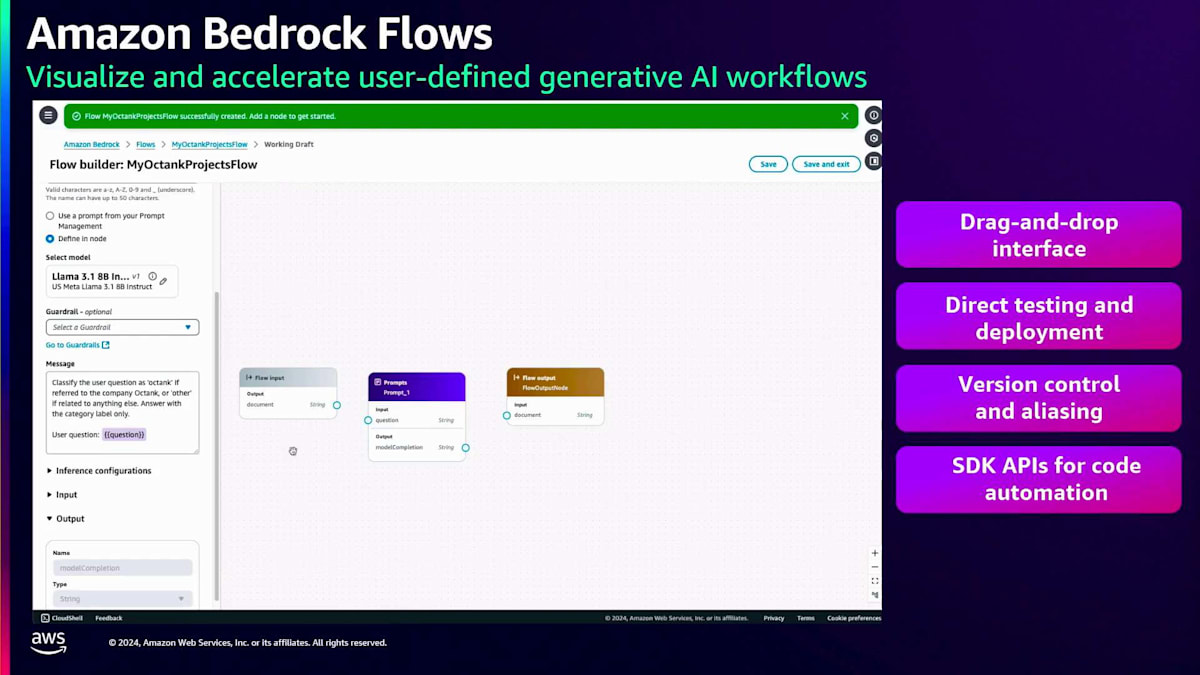
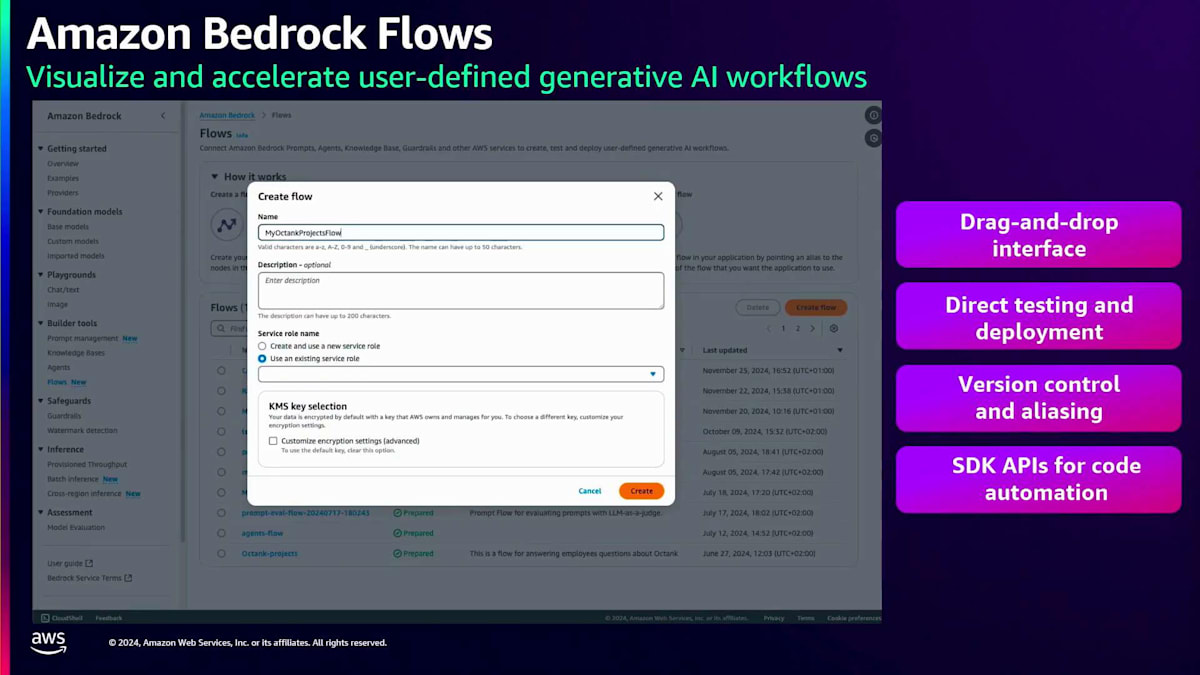
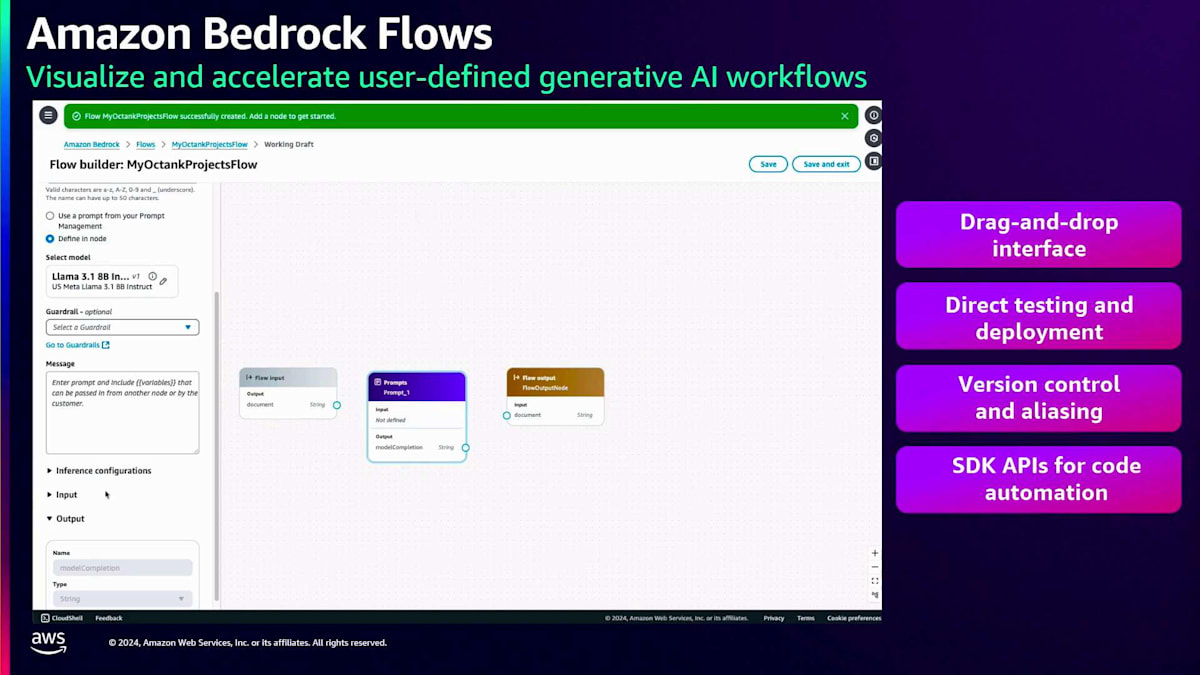
プロンプトを作成したら、 次のステップはそれをアプリケーションに組み込むことです。多くの場合、アプリケーションはより複雑で、複数のプロンプト、Knowledge bases、Agents、Guardrailsで構成されています。ここでAmazon Bedrock Flowsが重要になってきます。これらのコンポーネントをすべて連携させ、ワークフローを構築する必要があるからです。フローを作成して名前と説明を入力すると、 お客様向けの非常にわかりやすいドラッグ&ドロップインターフェースを備えた空のキャンバスが表示されます。左パネルから 別のプロンプトやKnowledge baseノード、Guardrailノードなど、様々なノードをドラッグ&ドロップできます。
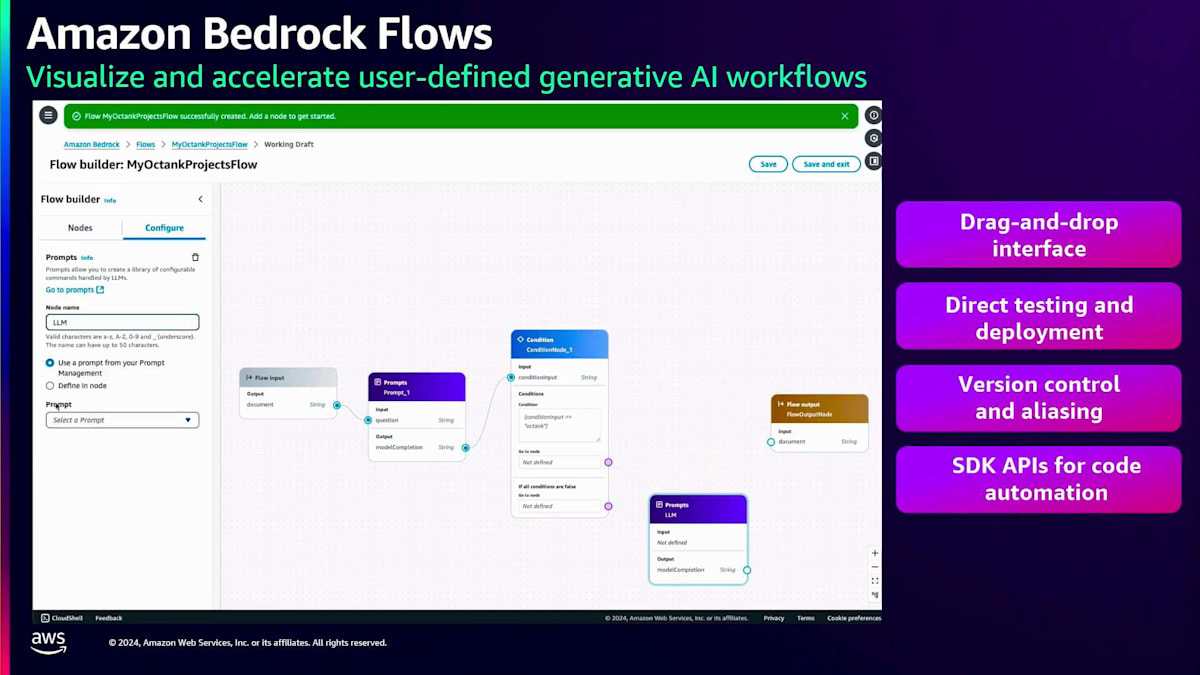
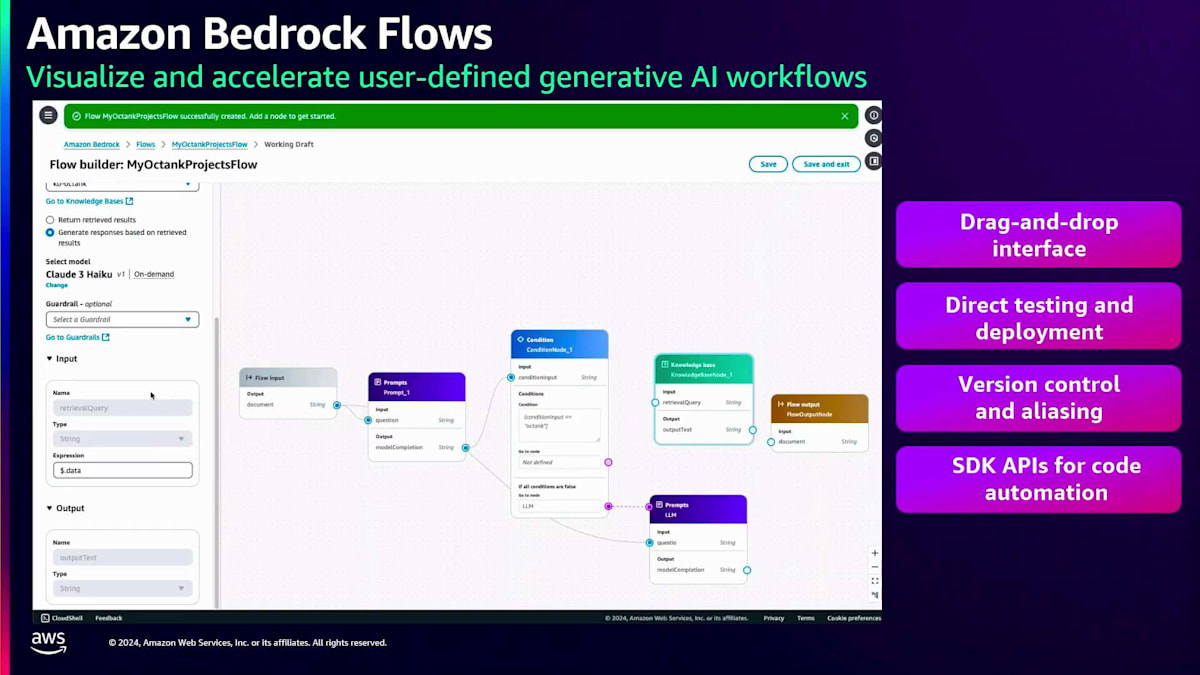
この例では、 プロンプトと条件を設定し、プロンプトの結果に特定の 単語が含まれている場合はKnowledge baseコンポーネントにルーティングし、そうでない場合は別のプロンプトにルーティングするようにしています。つまり、自社のデータに関する質問やプロンプトがある場合、自社のKnowledge baseデータを参照することになります。
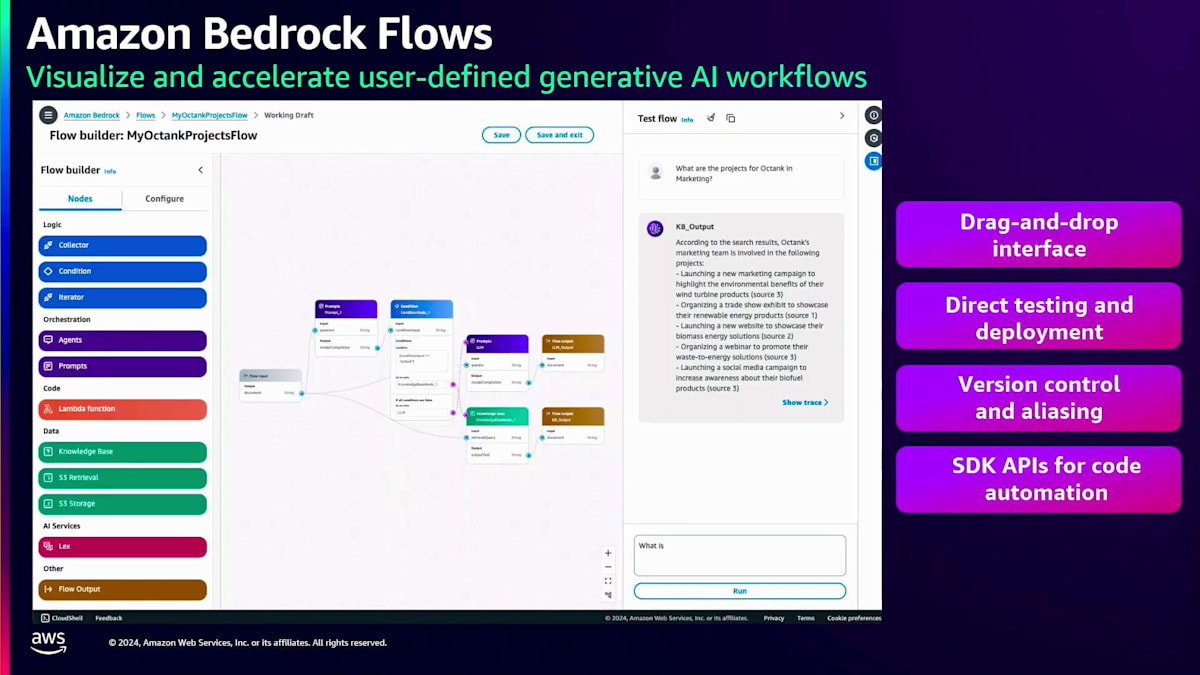
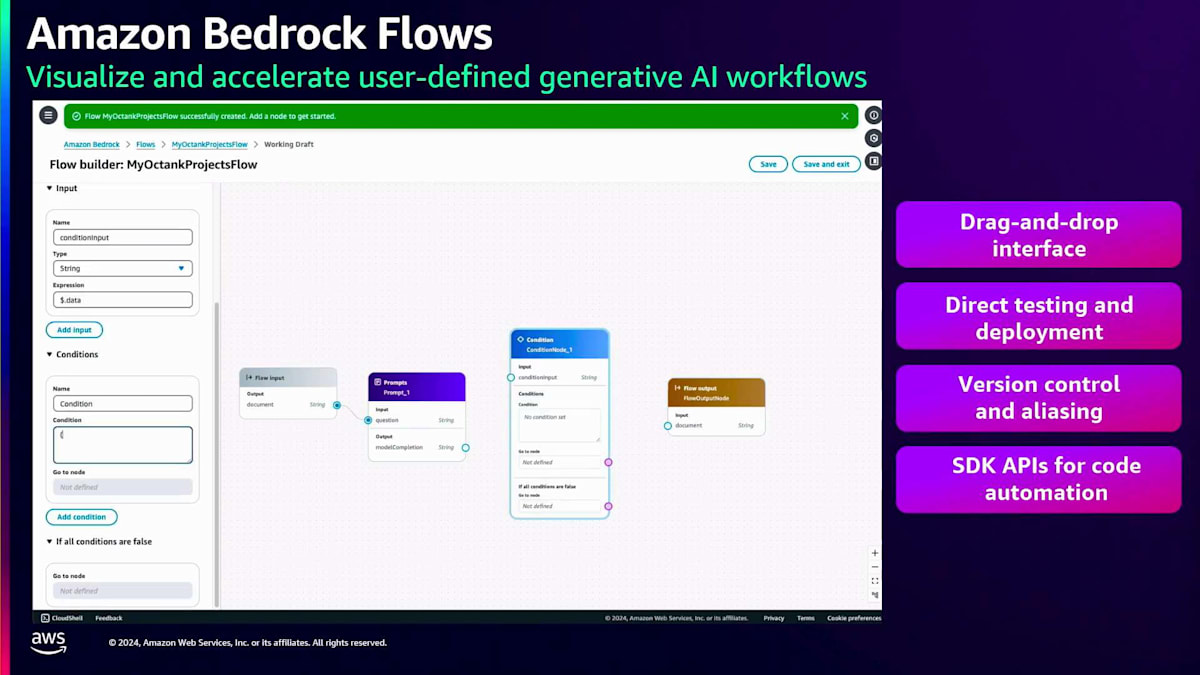
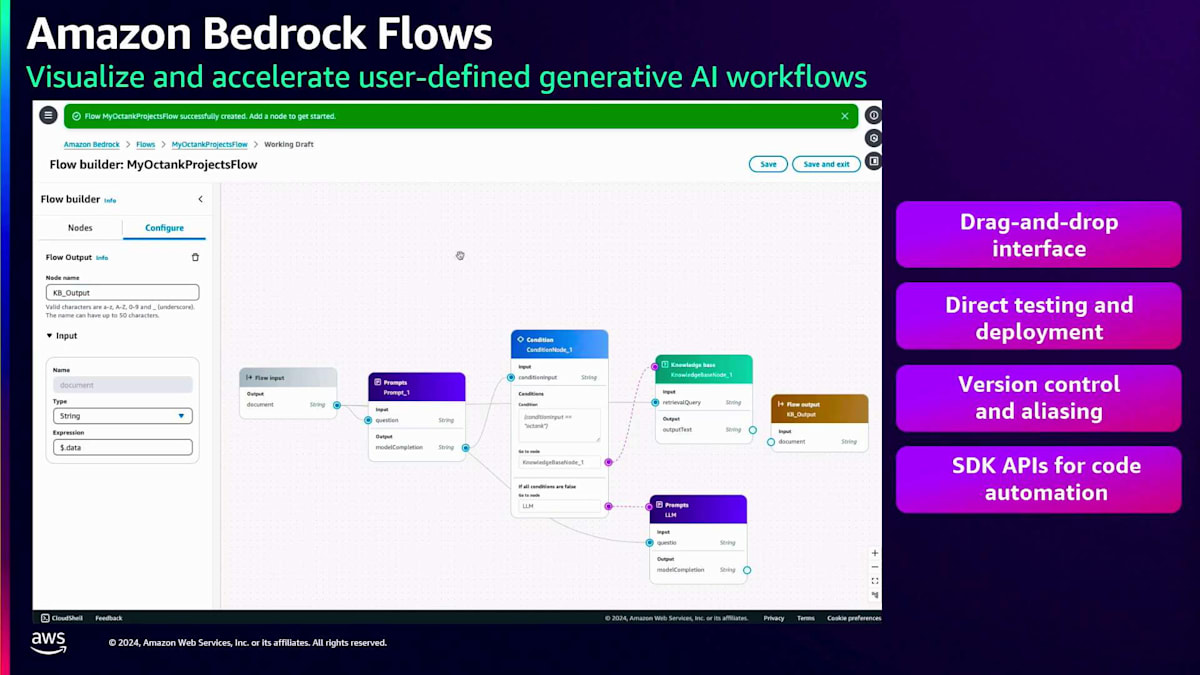
自社のデータに関する質問やプロンプトの場合は、自社のKnowledge baseデータを参照して そこからデータを取得します。一方、他社に関するプロンプトの場合は、一般的な言語モデルのプロンプト応答を使用します。 Amazon Bedrock Flowsは、 サービス指向の優れたエクスペリエンスを提供します。複雑なコードを書いたり、コンピューティングインスタンスにコードをホストしたり、コンピューティングリソースを購入したりする必要はありません。すべては抽象化されています。必要なのはこのドラッグ&ドロップモデルを使用することだけで、 バージョン管理、テスト、デプロイも可能です。これらはすべてSDK APIを使用して実行することもできます。

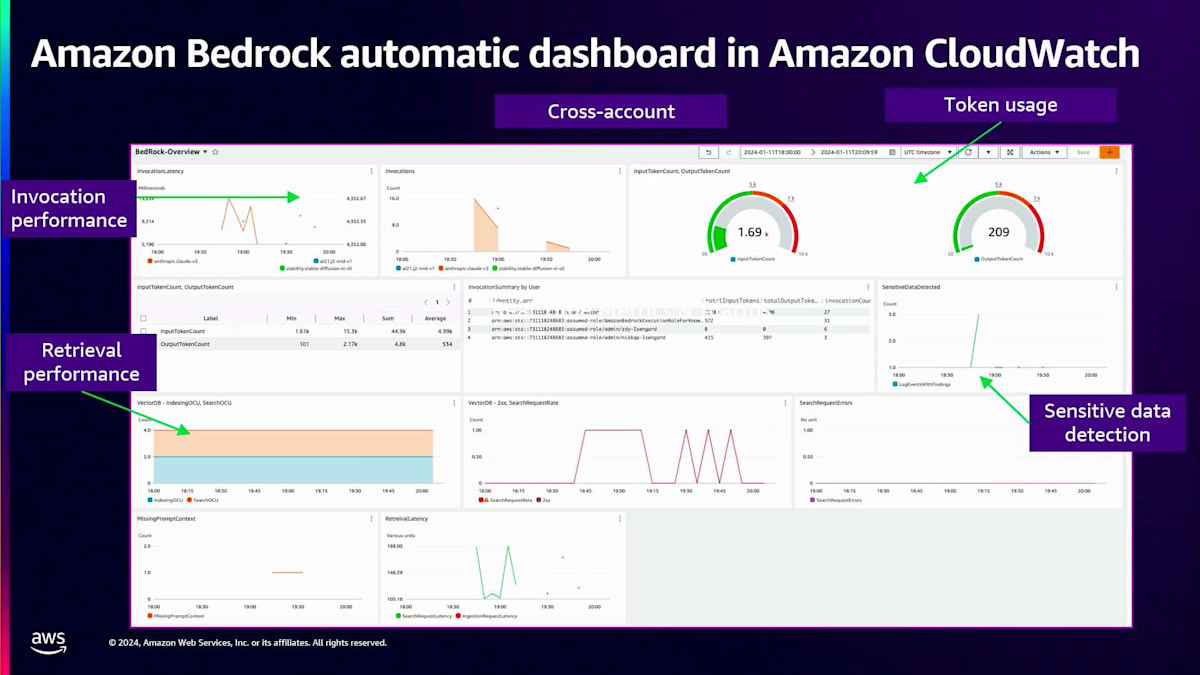
次にObservabilityについてお話しします。多くのお客様が、Generative AIアプリケーションにおけるObservabilityの課題について言及されています。主な課題として挙げられているのは、複数のアカウントやアプリケーションにおけるメトリクスの収集です。呼び出しログの収集と解析が難しく、そのような生データを洞察やメトリクスに変換することに苦労されています。適切な洞察が得られないと、アプリケーションに関する有用な判断を下すことができません。Amazon Bedrockは、他のAWSサービスとも統合されているおなじみのAmazon CloudWatchと連携することで、これらの課題をすべて解決します。CloudWatchはデータを処理してリアルタイムのメトリクスに変換し、それらのメトリクスをグラフ化することもできます。さらに、特定のしきい値に基づいてアラームや通知を設定でき、しきい値を超えた場合にアラートを受け取ることができます。これがCloudWatchの包括的なダッシュボードのスナップショットです。
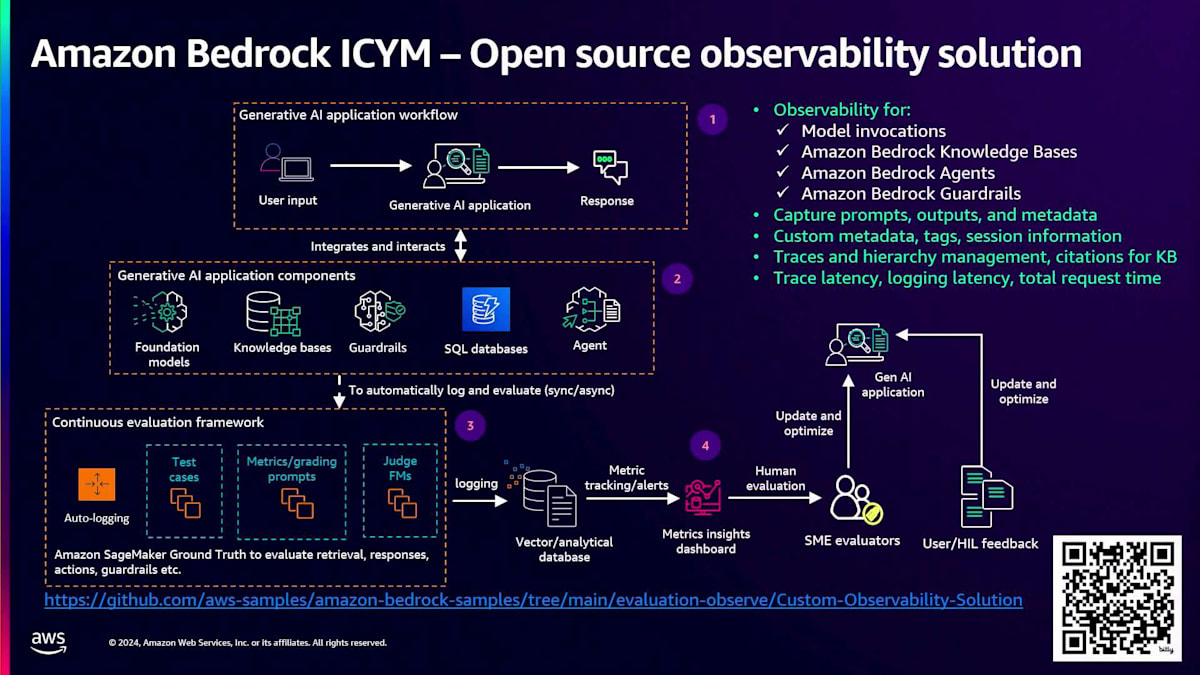
さらに、CloudWatchが提供するObservability機能に加えて、私たちはカスタムソリューションも構築しました。これはまだAmazon Bedrockの一部ではありませんが、高レベルで説明すると、このカスタムソリューションは、ユーザーがGenerative AIアプリケーションにプロンプトを入力し、それに対する応答が生成される際に機能します。Generative AIアプリケーションは複数のコンポーネントで構成されており、各コンポーネントについてデータを取得し、分析して、これらのコンポーネントの改善に向けた有用な洞察やメトリクスを生成できるようにしたいと考えています。この新しいカスタムソリューションは、このプロセス全体をサポートします。このソリューションは、Amazon Bedrock Knowledge Bases、Agents、Guardrailsのモデル呼び出しをサポートしており、PythonとNode.jsで利用可能です。また、プロンプト、出力、メタデータ、カスタムメタデータタグの取得に加えて、トレースレイテンシー、ログ記録レイテンシー、リクエスト総時間などのメトリクスの追跡もサポートしています。
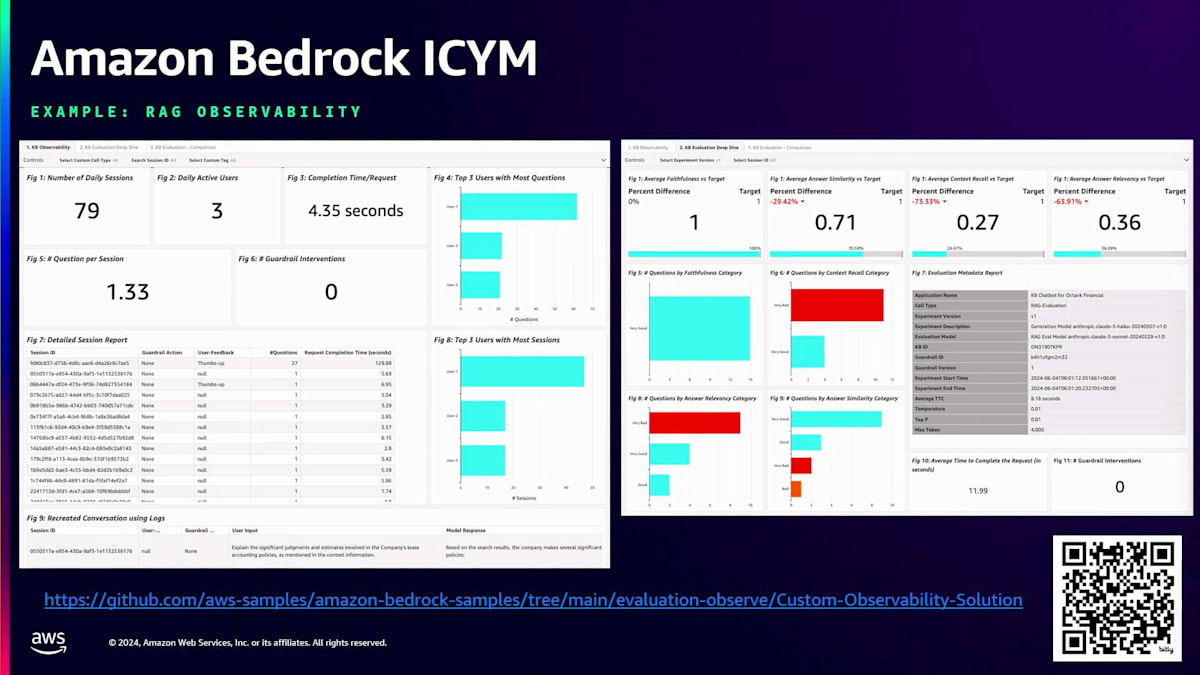
このソリューションのダッシュボードを見てみましょう。ここではRAG Observabilityの例を取り上げています。ご覧の通り、この特定のユースケースに対する非常に包括的なダッシュボードとなっています。ハイレベルなダッシュボードと、そのダッシュボードの詳細版の両方が用意されています。これらが、エンタープライズレベルのGenerative AIアプリケーションの構築をより容易にするためにAmazon Bedrockが提供するソリューションです。ここで、Amazon Bedrockを使用したAIプラットフォームへの移行と最新のアップデートについて、Antonioにバトンタッチしたいと思います。
スケーラブルなGenerative AIプラットフォームの構築アプローチ
昨日、Amazon Bedrockの評価機能に新しい機能を追加しました。評価ペインにROC評価が組み込み機能として追加され、LLM as a judgeも利用できるようになりました。ぜひご確認ください。また、先ほど触れなかった機能として、自動プロンプト最適化があります。先ほど見たプロンプト管理コンソールには最適化ボタンがあり、ページから開始して最適化をクリックすると、モデルプロバイダーのベストプラクティスを考慮した最適化されたバージョンのプロンプトが即座に提供されます。例えば、Claude 3.5、Sonnet、またはHaikuに対して最適化する場合、より良い品質の出力を確保するためにそれらが考慮されます。プロンプト最適化は現在パブリックプレビュー中です。

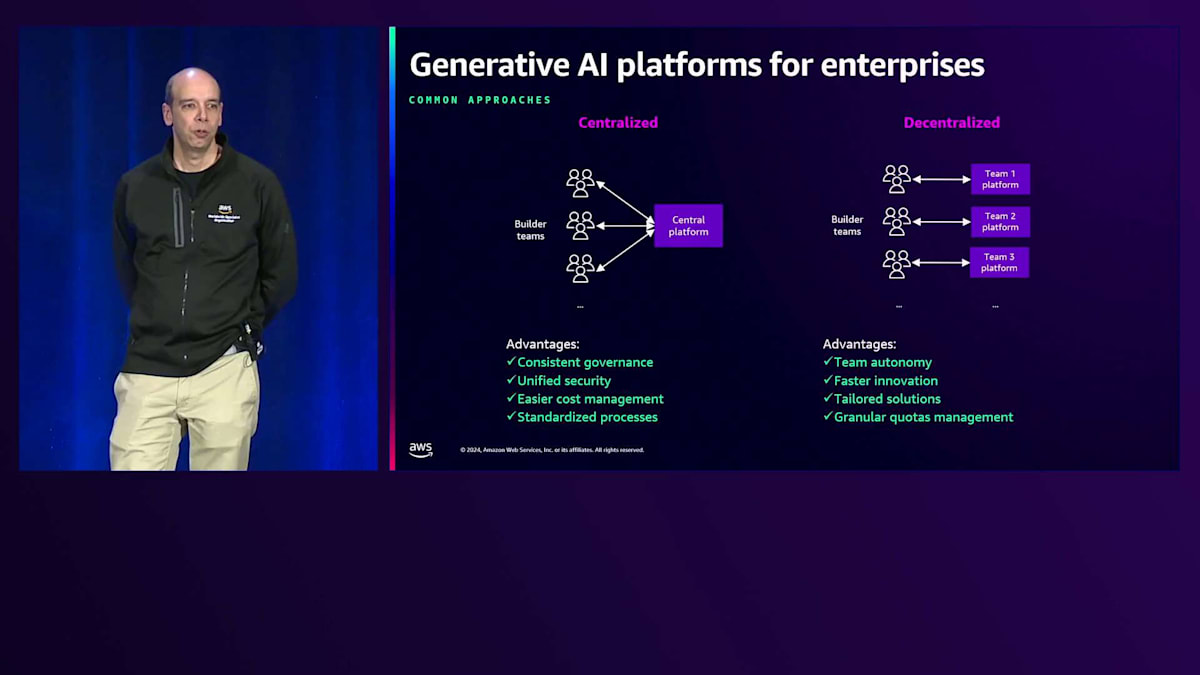
これらすべての機能を考慮すると、どのようにしてすべてを組み合わせるのか、スケールでこのプラットフォームをどのように構築するのかを考える必要があります。お客様がスケールでGenerative AIを実装する際に見られる異なるアプローチについて考えてみましょう。一般的なアプローチの1つ、特に少数のユースケースやプロトタイプから始める場合は、集中型アプローチです。通常、単一のAWSアカウントまたは環境で作業を行います。1〜2チームから始めて、最終的には同じアカウントで10〜15チームが協力して作業するようになることもあります。これはガバナンスの観点から複数の利点があります:一貫したガバナンスポリシー、アクセス制御、統一されたセキュリティ、そして同じAPIで運用されるため、コスト管理が容易になります。また、全員に対して標準化されたプロセスを提供できます。
しかし、このアプローチには各チームに自律性を提供する上での課題もあります。例えば、マーケティングチームが特定のモデルにアクセスする必要がある一方で、異なるユースケースに取り組むエンジニアリング、ビジネス、セールスチームにはそのアクセスを与えたくない場合はどうでしょうか?イノベーションを促進したい場合や、一部のチームが新機能を試してみたいものの、それを全員に公開したくない場合はどうでしょうか?あるチームがAmazon Bedrockでファインチューニングやカスタムモデルを使用したいが、それを全体に許可したくない場合は?全員で単一のクォータを共有するのではなく、きめ細かな管理が必要な場合はどうでしょうか?

私たちがよく目にするのは、最初は自由な環境で全員にアクセスを許可したものの、その後にコントロールを実装してトレードオフを行う必要性が出てくるということです。そこで、イノベーションとガバナンスを両立させる分散型アプローチが重要になってきます。興味深いことに、本番環境でGenerative AIを実装している企業の21%が、私たちがハイブリッドアプローチと呼ぶ方法を採用しています。このアプローチは、集中型アプローチによるセキュリティの強化、最適化、包括的なモニタリングと、チームごとの柔軟性、スケーラビリティ、カスタマイズ性、きめ細かなクォータ管理を組み合わせたものです。
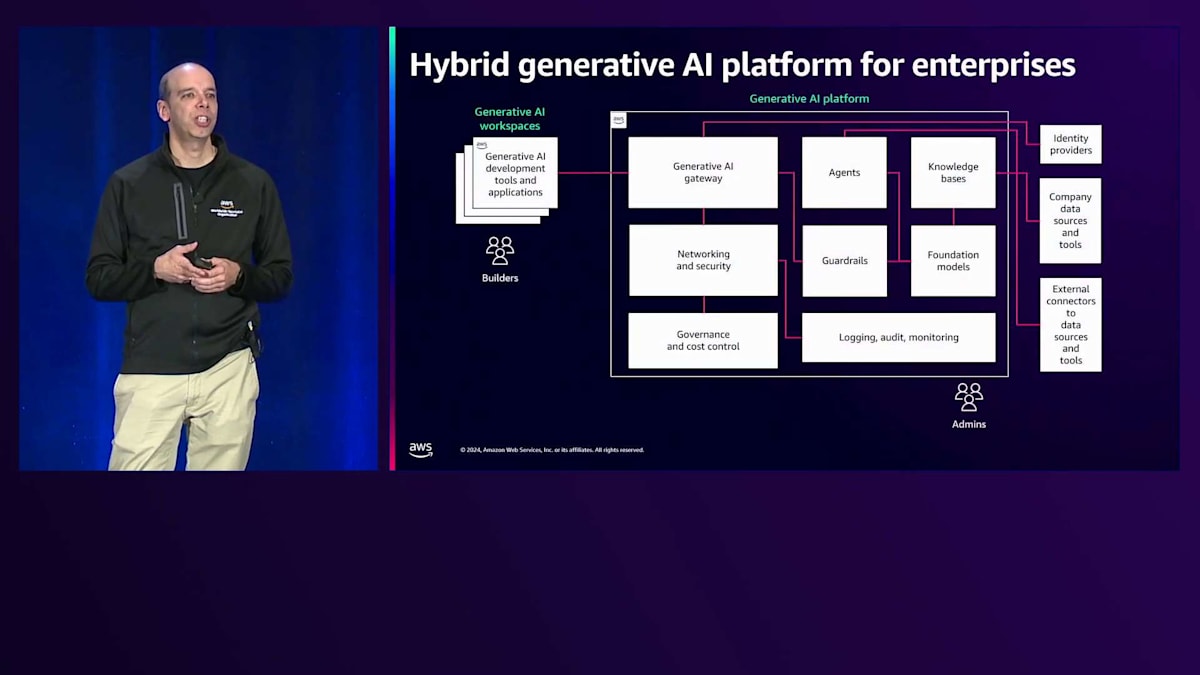
これを踏まえて、このようなアーキテクチャを考えることができます。これは共通の基盤であり、各企業の具体的な要件に応じて異なる形になります。一般的に、右側に管理者視点で管理される中央のGenerative AIプラットフォームがあります。ITの管理者やCenter of Excellenceの管理者など、その責任者が誰であれ、公開するAPIを通じて誰が何にアクセスできるかをコントロールできる、全員のためのGenerative AIゲートウェイが存在します。
システムには、新しいFoundation Modelをオンボードする際のセキュリティ対策が組み込まれています。新しいモデルのリリースがある度に、コンプライアンスへの準拠、規制の遵守、EULAの確認が必要です。セキュリティチームにすべてのモデルの承認を得ます。そのプラットフォームには、集中型のロギング、監査、モニタリング機能に加えて、コスト管理とアクセス管理機能があります。
ツーリングに関しては、組織で共有するAgentや設定がある場合や、Vector Databaseを作成して管理したいナレッジベースがある場合、自社のシステムとの統合を管理できます。これには、Identity Provider、自社のツール、サードパーティツール、自社のデータソースとの連携が含まれます。例えば、ドキュメント、Data Lake、その他のリソースと接続することができます。
左側には、異なる開発者向けのスペースがあり、これを私たちはGenerative AI Workspaceと呼んでいます。これらのスペースでは、異なる環境を想定することができます - 一部の顧客では、これらは異なるAWSアカウントとなっており、アプリケーションを自由に開発できる環境となっています。これは通常、ゲートウェイを通じて中央プラットフォームと統合されるスペースであり、先ほど議論したハイブリッドアプローチを実現しています。
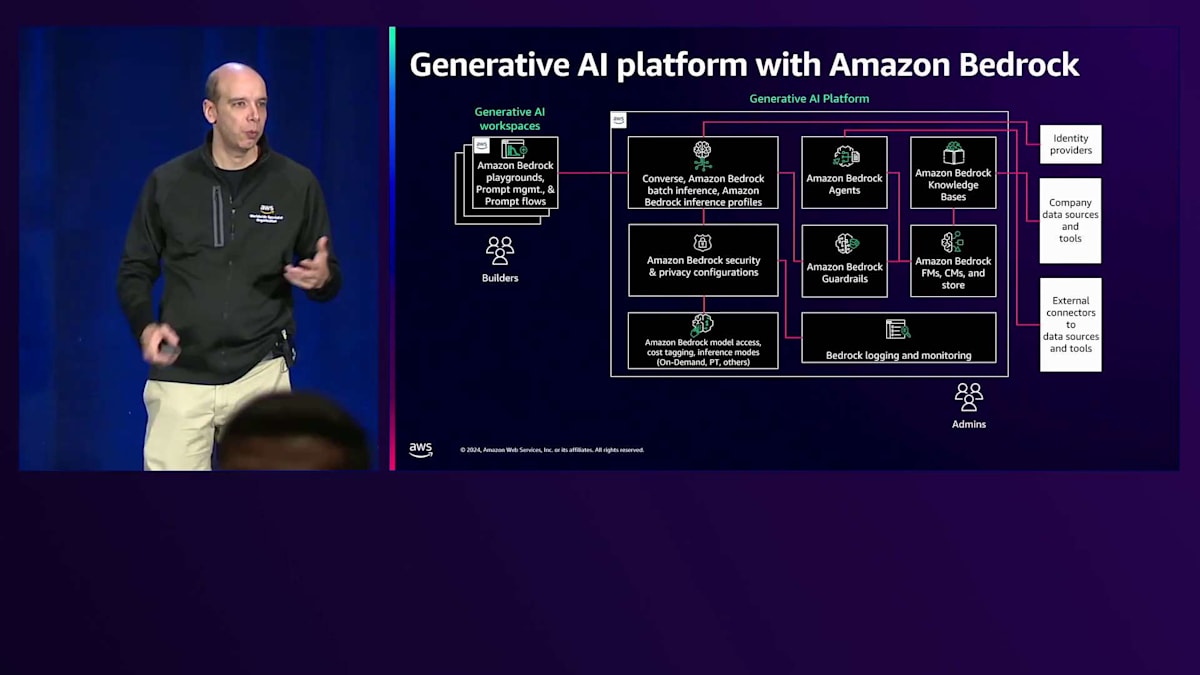
これらの機能をAmazon Bedrockにマッピングすると、次のようになります:左側にはAmazon Bedrock Playgroundがあり、マーケティングチーム、セールスチーム、エンジニアリングチームなどのユーザーが素早く実験を行い、どのモデルが最適な回答を提供するかを判断できます。Prompt管理を使用してPromptのライフサイクルを構築し、ユースケースに合わせてPromptを開発・最適化します。また、自動的に、あるいはドラッグアンドドロップで、マルチエージェントワークロードのロジックを定義するFlowsを実装できます。
右側の中央プラットフォームには、中央のGenerative AIプラットフォームのコンポーネントがあります。Converse API、Model API、Inference Profile、バッチユースケース向けのBatch Inference、そしてAmazon Bedrock Agents、Knowledge Base、Guardrails、Foundation Modelなどのツーリング機能といったAmazon Bedrock APIがあります。また、Amazon Bedrockが標準で提供するすべてのロギングとセキュリティ機能があり、ガバナンスやFoundationレイヤーのセットアップという重労働を行う必要がありません。

コスト管理に関しては、ここで中央のCost Taggingを実装し、異なるチームのプロジェクトをマッピングして、各チームのGenerative AI Workspaceでの使用状況を追跡できます。これは請求コンソールのCost Explorerで確認したり、予算を設定して通知を送信したり、スロットリングアクションを実装したり、モデルアクセスを削除したり、チームが予算を超過した場合に通知を送ったりすることができます。
エンタープライズレディなGenerative AI導入のまとめと今後の展望
これまでの内容をまとめましょう。私たちは業界における重要なギャップを特定することから始めました - 世界中の企業の80%以上がGenerative AIに投資していますが、本番環境への移行に成功しているのはわずか24%です。このギャップを埋めるため、エンタープライズレディな方法で本番環境に移行するためのプレイブックの構築についてのアイデアを提供してきました。まず、この journey には3つのフェーズがあることを覚えておいてください:オンボーディング、アプリケーションの開発、そしてデプロイメントです。適切なコンプライアンスとガバナンスを実装する必要があります。そして、これは現実の事実ですが、現在のGenerative AI業界におけるモデルのライフサイクルは6ヶ月未満となっています。
これは、モデルの寿命が6ヶ月未満で Legacy となることを意味します。以前の機械学習の世界では、Flanのようなモデルが何年も本番環境で使用されていたことを考えると、これは非常に驚くべきことです。今や私たちは、スピードが全く異なる新しい時代に入っています。モデルの承認とオンボーディングのパイプラインを非常に効率的に自動化する必要があります。モデルの手動検証やオンボーディングに関連する官僚的な手続きは避け、自動化する方法を見つける必要があります。そのために、Amazon Bedrockが提供するモデルアクセスと、モデル承認パイプラインの設定に関してAWSチームから得られるすべてのサポートを活用してください。
二つ目は、効率的なコストとパフォーマンスの管理を確実に行うことです。そのためには、ユーザーに柔軟性を与えながらも、すべてのユーザーが規制されたアクセスを持ち、実際に必要なリソースにアクセスできるようにする必要があります。Application Inference Profileを通じたコストタギングなどの機能を活用することで、各チームの消費を非常に細かく把握することができます。先ほど定義した消費オプション(On-demand、Provisioned Throughput、そして近日公開予定のその他のオプション)を適切に組み合わせ、常にワークロードのコストを最適化することを確実にする必要があります。
運用の優秀性に関して、Prompt Engineeringで自動化を実装する例を見てきました。プラットフォームで行うすべての作業において、自動化は必須です。これには、利用可能なすべてのツールが含まれます。ご覧の通り、私たちはその journey をサポートするための機能をますます多くリリースしており、今後数日でさらに多くの情報をお届けする予定です。もう一つの重要な側面は、強力な可観測性を持つことです。複数のユーザーがChatbotを使用するユースケース、例えばRacket upやAgentの例を考えてみてください。同じユーザーがアプリケーションの異なる要素を通過し、一日の異なる時間帯に同じアプリケーションと対話していることを追跡できることが非常に重要です。これは、トラブルシューティング、コスト管理、サービス品質、そして全体的なコスト管理に必要です。
これを実装する方法は、健全な可観測性ツールを導入することです。モニタリング、ロギング、トレーシングのための機能を備えたAmazon Bedrockを活用し、Guardrailsも活用してください。Amazon Bedrock Guardrailsは、アプリケーションとデータを保護し、機密データやプライベートデータを露出させないようにするための多くの機能を提供します。最後に、スケールできる適切なアーキテクチャを選択してください。先ほど述べたように、私たちは皆シンプルに始めます - これは明らかに、Generative AIを実験し始めるための最も推奨される方法です。しかし、最終的には、潜在的に数十、数百、あるいは数千のユースケースを本番環境で持つ可能性のある大規模な組織の一員である場合、アーキテクチャに障壁を作らないようにする必要があります。最も成熟した顧客は、先ほど示したHybridアプローチやHybridパラダイムに向かっていることを念頭に置いてください。


さて、これで詳しく学ぶためのリソースをいくつか紹介したいと思います。ここにブログ投稿や記事のリストがあり、さらにGitHubには、Amazon Bedrockでアクセスゲートウェイを実装するためのカスタムソリューションもあります。これにより、サードパーティのモデルプロバイダーや、Amazon SageMakerなどの他のサービスへのアクセスも可能になります。これらのリソースをチェックすることをお勧めします - リンクを短く簡潔にまとめてありますので、ご確認ください。最後に、AWSのMachine Learningブログには、ここで話したすべての機能についての詳細情報があります。もちろん、これらのトピックについてさらに詳しく知りたい場合は、担当のアカウントチームにお問い合わせください。以上で終わりです。ありがとうございました。連絡先の詳細がここにありますので、re:Inventで素晴らしい一週間をお過ごしください。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion