re:Invent 2023: AmgenがAWS HealthOmicsで実現するオミクス解析の高速化と効率化
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Omics innovation with AWS HealthOmics: Amgen’s path to faster results (AIM215)
この動画では、AWSのプリンシパルソリューションアーキテクトAriellaとAmgenのシニアサイエンティストIttaiが、AWS HealthOmicsを活用したバイオインフォマティクス解析のスケールアップと加速について語ります。AmgenでのHealthOmics活用事例や、nf-coreパイプラインの実装、CI/CDワークフローの統合など、具体的な技術的洞察が満載です。オミクスデータの自動処理や、コスト削減、処理時間短縮の実績など、最先端のライフサイエンス研究を支えるクラウド技術の可能性を探ります。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
AWS HealthOmicsの紹介と2023年の振り返り

皆さん、おはようございます。re:Inventへようこそ。私はAriella Sassonと申します。AWSのプリンシパルソリューションアーキテクトとして、ヘルスケアとライフサイエンス分野のお客様をサポートしています。本日はIttai Eresさんと一緒に、バイオインフォマティクス解析をスケールアップして加速する方法をご紹介します。

AWS HealthOmicsにとって、素晴らしい1年でした。 お客様がHealthOmicsを使ってワークフローをサポートする様子を見て、大変興奮しています。これは、私たちがお客様のニーズを念頭に置いてこのサービスを構築した理由を思い出させてくれます。今日は、IttaiさんのAmgenでの成功についてお話しする時間を多く取りますが、まずは今年の振り返りと、これまでに起こった素晴らしいことについて少しお話しします。その後、Ittaiさんが後ほど話す内容の準備として、サービスの技術的な側面について基礎を説明します。
AWS HealthOmicsの目的と主要投資分野

AWSでは、常にお客様のニーズを念頭に置いて始めます。お客様は、このサービスで素晴らしいことを実現しています。私たちが正しい道を歩んでいることを確信させてくれるのは、ヘルスケアとライフサイエンスの多様な分野のお客様が、それぞれの方法で価値を見出していることです。シーケンシング、臨床診断、学術研究センター、製薬R&Dなど、様々な分野で多くの問題解決をサポートしています。これには、低コストでデータを安全に保管し、簡単に発見・共有できるようにすること、他の研究グループとの協力、臨床診断テストに必要なスループットを達成しながら所要時間を満たすこと、そして科学者が必要とするタンパク質構造予測や分子動力学をスケールアップして加速することなどが含まれます。
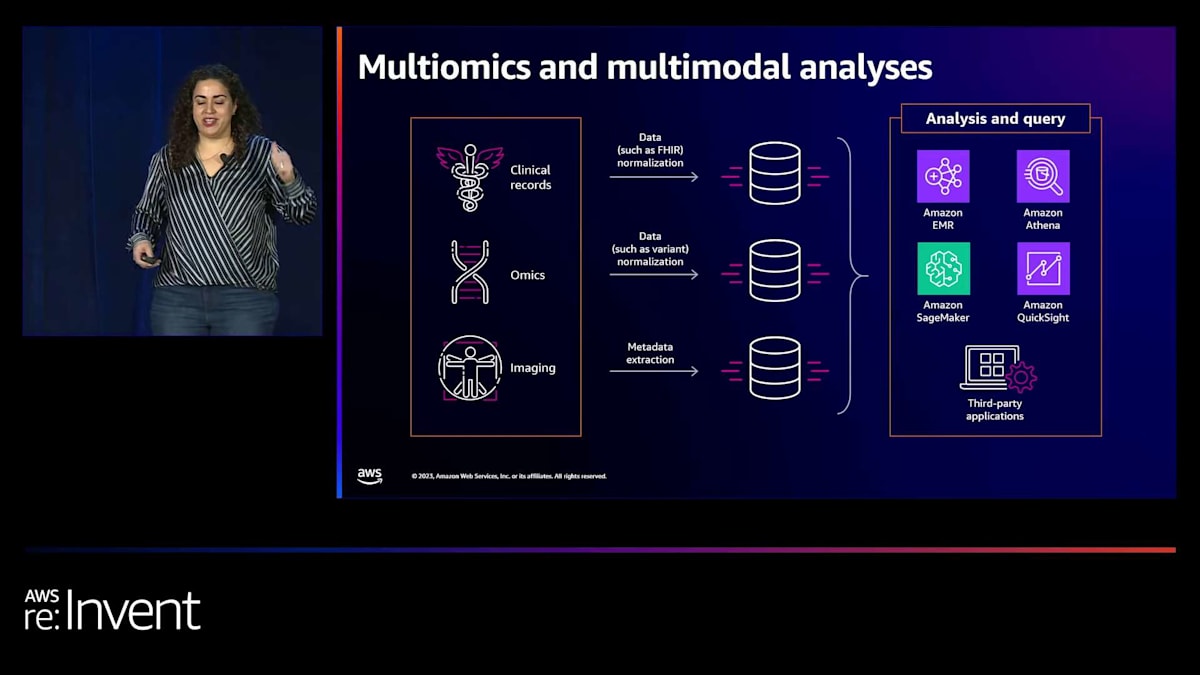
結局のところ、私たちAWSが目指しているのは、差別化されていない重労働を取り除き、お客様が科学に集中できるようにすることです。AWSには200以上のサービスがあり、今朝のAdamのキーノートでも多くの新しいサービスについて聞きました。 おそらく今週中に、新しいサービスやエキサイティングな機能についてもっと聞くことになるでしょう。ここで強調したいのは、AWSがヘルスケアとライフサイエンスの複数の分野に投資していることです。臨床記録には、AWS HealthLake、Amazon Comprehend Medical、そして新しく発表されたAWS HealthScribeがあります。オミクスについては、今日より深く掘り下げるHealthOmicsがあります。そして画像処理には、最近一般提供が開始されたAWS Imagingがあります。
お客様との対話から分かったことは、このデータが彼らの持つすべてのデータではないものの、大部分を占めているということです。そして、非常に似たパターンがあります。お客様はメタデータを抽出し、正規化を行い、高度にネストされたFHIRデータ用のETLを作成し、それをクエリする必要があります。また、半構造化された変異データをクエリ可能なデータに変換し、最後にDICOM画像から重要なメタデータを抽出する必要があります。このデータから洞察を生成するための計算方法についても考慮すべき点があります。これらすべてを知った上で、私たちの目標は、お客様の作業を容易にすることです。お客様が選択したツールやデータを持ち込み、他のデータモダリティと組み合わせて分析することを容易にしたいと考えています。私たちは、これらをすべて簡素化し、まとめて新しい洞察を生み出すために懸命に取り組んでいます。
AWS HealthOmicsの主要機能と投資分野

AWS HealthOmicsは約1年前、Adamの2022年re:Inventキーノートで誕生しました。当時はAmazon Omicsとして知られていました。今年は多くの出来事があり、名前の変更を含む小さなアイデンティティ危機もありましたが、とてもエキサイティングな1年でした。AWS HealthOmicsは、お客様のために3つの主要な分野に投資してきました。まず、大量のデータを安価かつ効率的に保存しながら、簡単に発見できるようにするという課題の解決に取り組んでいます。これは、シーケンスストアへの投資の基盤となっています。FASTQ、BAM、uBAM、CRAMファイルの非常に一般的なアクセスパターンに対して、魅力的なコスト最適化を提供できます。
一方で、多くのお客様から、バリアントデータを大規模に構造化、整理、分析し、他のモダリティと組み合わせる必要があるという声を聞いています。そこで、バリアントストアとアノテーションストアのゼロETL変換に投資しています。単一のAPI呼び出しで、半構造化データを構造化し、クエリ可能にすることができます。
インサイトを生成するために必要な最後のピースは、バイオインフォマティクスの計算能力です。私たちは、データ処理を容易にするさまざまな機能を提供するマネージドワークフローを提供しています。今日ここでお伝えしたいのは、AWS HealthOmicsが、お客様がデータの保存と処理を可能な限り簡単かつコスト効率よく行えるようにし、最も価値のある科学的インサイトの創出に時間を費やせるようにしたいということです。
AWS HealthOmicsの新機能と顧客の成果

このことを念頭に置いて、これらが私たちの主要な投資分野であり、以下がその実現方法です。私たちは多くの新機能をリリースしてきました。最初の質問の一つは、AWS HealthOmicsを中心にアプリケーションスイートをどのように構築するかということでした。これに応えて、AWS CloudFormationとEventBridgeの連携機能をリリースしました。分析をより簡単にするために、より良いログ、より詳細なエラー情報の提供、Ready2Runワークフローによるよりプッシュボタン的な体験の提供など、多くの投資を行ってきました。私たちは、お客様の声に基づいて投資を続けています。タンパク質フォールディング、分子動力学、NVIDIAツールの実行など、ワークフロー用のGPUの必要性を聞き、5月にそれをリリースしました。また、「WDLとNextflowは素晴らしいけれど、Common Workflow Languageのワークフローがある」というお客様の声を聞き、6月にワークフローにCWLサポートを追加しました。

このトークのこの部分で一つだけ覚えておいていただきたいのは、もし私たちのサービスに何か機能が見当たらない場合は、ぜひお尋ねくださいということです。私たちはお客様に代わって機能を構築し、より使いやすくしたいと考えています。その分野でイノベーションを続け、成果を出し続けたいと思っています。 そしてそれはサービスやサービス機能だけではありません。お客様がAWS全体をどのように利用されているかを考え、それをより簡単にすることも非常に重要だと考えています。

実際のサービス機能に加えて、私たちのチーム、つまりサービスチームとSolutions Architectsのチームは、その分野での多くの規範的なガイダンスを開発してきました。その良い例の一つが、バイオインフォマティクス解析をより簡単に実行できるようにする方法です。一般的なパターンは、リポジトリを見つけ、クローンを作成し、ワークフローをHealthOmicsに登録することです。そこで私たちは、GATK best practices、nf-coreパイプライン、variant effect predictor、AlphaFold2やESMFoldなど、簡単に設定できるワークロードをHealthOmicsに非常にシンプルに取り込めるようにする作業を進めてきました。ここには多くのものがあり、AWSだけではありません。SentieonやNVIDIA、Element Biosciencesなどのパートナー企業も同様のことを行っています。

その結果はどうだったでしょうか?私たちのお客様は素晴らしいことを成し遂げています。私たちが見てきたすべてについて詳細をお話しすることはできませんし、Amgenでのイッタイの素晴らしい仕事についてはこの後少しお聞きすることになりますが、お客様がAWS HealthOmicsを使用して目標を達成している様子を理解していただくために、統計のハイライトをご紹介できます。まず第一は規模です。何百もの同時実行をサポートしたり、何千もの同時タスクを処理したり、一連の分析で何百ものGPUや何万ものvCPUをスピンアップしたり、variant storeに何ペタバイトものデータを保存したりすることができます。お客様が科学を進歩させるためにこのサービスを多様な方法で使用していることを、私たちは非常に喜ばしく思っています。
AWS HealthOmicsの技術的側面とセキュリティ


さて、ここからはHealthOmicsの技術的な側面についてもう少し深く掘り下げていきます。あまり深入りはしませんが、矢印をいくつか追加し、アーキテクチャ図を示して、すべてがどのように連携しているかをよりよく理解していただきます。 私たちにとって、AWS HealthOmicsを考える際には、お客様のエンドツーエンドの旅が全てです。シーケンスデータを保存し、処理し、そして全ゲノムシーケンスの出力であるバリアントを取り出し、保存して、AthenaやEMRで簡単に分析できるようにします。ここで見える薄い青い線は意図的なものです。このサービスを考える際、私たちはそれがシームレスに連携することを望んでいますが、非常にモジュラーな方式で構築しました。お客様のニーズに合わせて、1つまたは3つすべてのサービスを使用することができ、お客様の特定のワークロードをサポートしたいと考えています。このモジュール性は、HealthOmicsの探索を始める際に覚えておくべき重要なポイントの1つです。

すべてのAWSサービスと同様に、セキュリティは私たちの最優先事項です。AWS HealthOmicsは、HIPAA、HITRUST、FedRAMP Moderate、ISOなどの基準への準拠を確保しています。
AWS HealthOmicsはセキュリティを最優先に設計されており、リソースの分離などのセキュリティベストプラクティスをサポートし、実現します。HealthOmicsの各実行は、専用のリソースを持ちます。お客様が管理する権限により、HealthOmicsは明示的に許可されたリソースと権限のみを使用します。エンドツーエンドの暗号化、データプロベナンス、ログ記録により、誰が何をどこでいつ実行したかを把握できます。さらに、AWS HealthOmicsはHIPAA適格、HITRUST認証、GDPR対応であり、FedRAMP ModerateとISO認証を取得しているため、コンプライアンスニーズに対応できます。

ストレージについては、相互に連携する2つのストアがあります。リファレンスストアでは、すべてのリファレンスを1か所に保存し、簡単に識別できるようタグ付けできます。シーケンスストアは、FASTQ、BAM、そして最近ではu-BAMとCRAMおよびそれらに関連するメタデータをサポートしています。一度ロードされたファイルは不変です。このデータは、簡単なAPI呼び出しで、いつでも容易にエクスポートしたり、ローカルファイルシステムにコピーしたりできます。
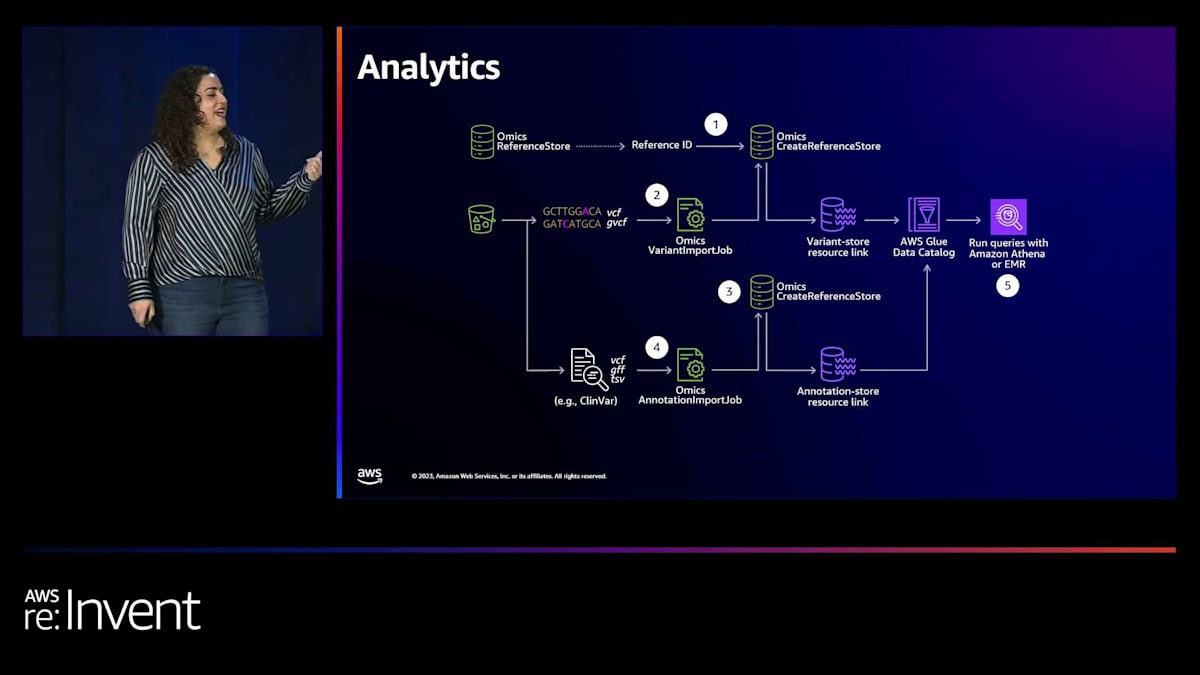
分析については、最も簡単な考え方は管理されたETLであり、お客様の計算コストはかかりません。VCF、GVCF、アノテーションソースを持ち込み、そこから簡単なAPI呼び出しでデータのインポートと変換を開始し、クエリの準備ができます。このサービスに組み込まれた重要な利点の1つは、バリアントとアノテーションソースの分離です。これらは独立しており、独立した更新サイクルを持つため、VCFを再アノテーションすることなくアノテーションソースを更新できます。新しいバージョンをアップロードし、Athenaクエリを新しいバージョンのアノテーションストアに向けるだけです。
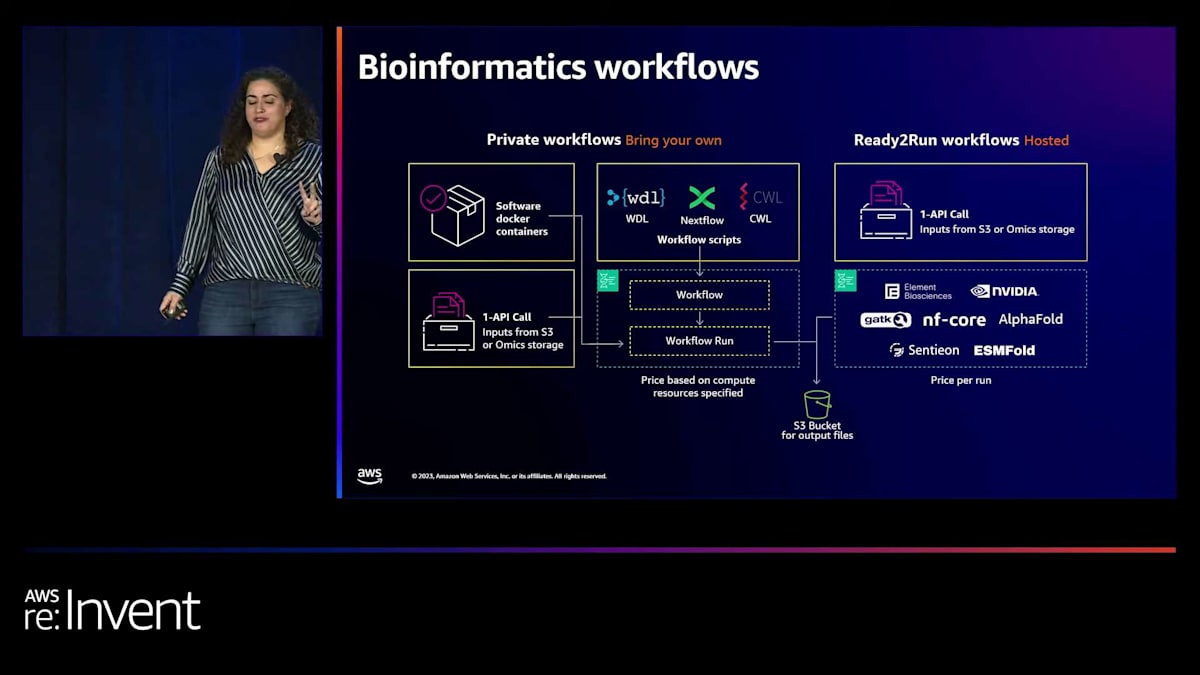
計算については、バイオインフォマティクスワークフローには2つのモードがあります。プライベートワークフローでは完全な柔軟性があり、パイプラインからDockerコンテナ、ワークフロースクリプトまで、すべての側面をお客様が所有します。Ready2Runモードでは、AWS HealthOmicsがすべてを管理し、固定価格で提供します。いずれの場合も、これらのワークフローは1つの簡単なAPI呼び出しで実行できます。

私たちのお客様は、多様なバイオインフォマティクスパイプラインを実行しています。精密医療を可能にするさまざまなシーケンシングパイプラインから、創薬を支援するタンパク質折りたたみ、注目分子をより深く理解するための分子動力学まで、幅広く使用されています。これは、お客様がワークフローを使用している範囲のほんの一部です。まもなくIttaiから、彼がどのようにプライベートワークフローを使用して科学者たちのイノベーションを加速させたかについて聞くことができるでしょう。

ワークフローには主に3つのステップがあります。まず、ツールをコンテナ化してECRに格納することでツールを構築します。次に、WDL、Nextflow、またはCWLでワークフローを構築し、HealthOmicsに登録します。最後に、HealthOmicsストレージやS3にあるデータを持ち込み、ワークフローを実行します。スピンアップ時間ではなく、実行中に使用したタスクとファイルシステムに対してのみ料金が発生します。

すぐにワークフローを始めたい場合や、AWS HealthOmicsのワークフローをテストしたい場合は、Ready2Runを検討してみてください。これが最も早く始められる方法です。これを理想的な道筋だと考えてください。データを持ち込み、実行を開始するだけで、設定された価格で利用できます。AWS HealthOmicsは現在35のReady2Runワークフローをサポートしています。Ready2Runがうまく機能しているものの、より大きなファイルやより長いタンパク質配列を実行する必要がある場合も、私たちがお手伝いできます。Ready2Runワークフローをプライベートワークフローに変換するためのブログやツールを用意しているので、必要なデータを自由に実行できます。
さて、私たちが待ち望んでいた部分に来ました。Ittaiを紹介できることを嬉しく思います。彼がAmgenでイノベーションを加速するために行った素晴らしい仕事について話してくれます。
Amgenの紹介とAWS HealthOmicsの活用

ありがとう、Ariella。私の名前はIttai Eresです。人類遺伝学の博士号を持ち、Amgenで計算生物学とバイオインフォマティクス技術のシニアサイエンティストを務めています。今日は、AWS HealthOmicsを使って私たちが行ってきた仕事について皆さんと共有できることをとてもうれしく思います。

私たちAmgenとは何か? Amgenの使命は、特に重篤な病気に苦しむ患者さんに貢献することです。この使命がAmgenの世界における影響を定義し、私たちのほぼすべての意思決定の指針となっています。現在、私たちのポートフォリオにはFDA承認済みの医薬品が27品目あり、そのうち約3分の2が重篤な疾患に対する画期的な革新的医薬品です。私たちのパイプラインは、大きな臨床的効果を示す高品質の候補薬に焦点を当てており、パイプラインの分子の約4分の3が、新しい治療法が切実に必要とされる重篤な疾患に対する潜在的な画期的医薬品です。

ここで、私たちの会社に関するいくつかの重要な事実と少しの歴史をご紹介します。私たちは1980年、バイオテク産業の黎明期に、カリフォルニア州Thousand Oaksでわずか数人のスタッフで設立されました。その場所は今日も本社として残っています。それ以来、私たちは長い道のりを歩んできました。現在、世界約100カ国で25,000人以上のスタッフが働いています。この世界的な展開により、年間約1,000万人の患者さんに私たちの医薬品を提供することができています。2022年の総収益は263億ドルを少し上回り、そのうち44億ドルを研究開発に再投資しました。また、Amgen Safety Net Foundationを通じて、世界中の適格な保険未加入または保険不足の患者さんに22億ドル相当の医薬品を無償で提供したことを、非常に誇りに思っています。


Amgenでは、3つの治療領域に注力しています。具体的には、オンコロジー、炎症、そして一般医療です。特に、大きなアンメットニーズがあり、必要とされる治療法が世界中の何百万人もの人々に影響を与える可能性のある疾患に焦点を当てています。がん、心血管疾患、骨粗鬆症、重症喘息、関節リウマチ、その他さまざまな炎症性疾患などが対象です。これらを実際に行う際、そして科学的アプローチをどのように行い、効果を確実にするかについて、私たちはいくつかの重要な戦略的R&D優先事項に従うようにしています。
まず、患者さんにとって重要な分子の発見と医薬品の開発における成功率を向上させたいと考えています。そのためには、疾患の観点からだけでなく、個々の標的と全体的な健康の観点からも生物学を理解する必要があります。人工知能と機械学習、精密医療、革新的な臨床試験を含む、最も有望な技術と活動に私たちの強みを集中させています。次に、新薬を必要とする患者さんにこれまで以上に早く届けられるよう、サイクルタイムを短縮したいと考えています。患者さんへの迅速な提供は私たちにとって最重要課題であり、そのため、臨床試験の多様性の向上、精密医療アプローチを可能にするためのヒトデータの適用など、臨床試験における革新を追求し、より迅速で成功率の高い承認ルートを提供しています。

最後に、私にとって非常に重要なのは、「すべての患者さんに解決策を」というアプローチです。FDAやその他の規制当局の承認だけでなく、世界中のすべての患者さんに対して、私たちの医薬品へのアクセスと使用をいかに改善するかを実際に考えることです。その追求において、私たちは引き続きヒトデータと実世界データを活用し、パートナー、規制当局、支払者との関係を構築して、私たちの治療法へのより広範かつ迅速なアクセスを可能にしています。つまり、Amgenの科学で私たちが目指していることをまとめると、世界で最も困難な疾患との闘いを強化するために科学研究を加速させることです。
Amgenにおける計算生物学とAWS HealthOmicsの役割

確かに、Amgenの研究開発戦略ビジョンには、科学があらゆる病気を克服する世界が含まれています。このビジョンを支えるため、私たちは世界中の患者さんに人生を変える医薬品を発見し、開発し、届けることを目指しています。その一環として、私はAmgenのComputational Biology and Bioinformatics Technologies部門で計算生物学者として働き、様々な部門のAmgen科学者たちのオミクスデータ解析を幅広くサポートしています。テクノロジーとバイオテクノロジーの融合により、私たちは今まさに創薬開発の転換点にいます。Amgenの科学的成功は、人工知能、生成生物学、精密医療、ヒトデータなどの最先端ツールや、新しいタイプの医薬品の発見・開発における速度と精度を高める新しい臨床試験のイノベーションといった、独自の能力に根ざしています。

これらはすべて、多様な人材と、イノベーションと進歩を推進するパートナーシップなしには実現できませんでした。本日は、AWSとのパートナーシップについてお話しできることを大変嬉しく思います。しかし、その話に入る前に、 Amgenのようなバイオテクノロジーやバイオファーマ企業における計算生物学の目的について、簡単に概要をお話ししたいと思います。面白いことに、私が計算生物学者だと言うと、時々混乱する人がいます。特に、この分野をあまり聞いたことがない人にはそうです。「コンピューターと生物学は正反対だと思っていました。全く相容れないものだと思っていました」と言われることもあります。
また、少し知識のある人でも、計算生物学者と言うと、何か合成生物学の仕事をしているのだろうと思う人もいます。しかし、そうではありません。皆さんもご存じの通り、特に今日では、生物学に関するほぼすべてのことにコンピューテーションが必要です。特に、私たちがデータを収集している規模を考えると、なおさらです。
最高の治療法を開発するためには、標的(つまり個々の遺伝子や特定の分子)と疾患の生物学の両方について深い理解が必要です。これらの理解は、様々な種類の膨大な分子データやオミクスデータの生成、管理、分析に基づいています。これらのデータの保存と計算は簡単ではありませんが、創薬に役立つ推論を行うために不可欠です。私が面白いと思うのは、これが私たちのパイプラインの一箇所だけに限られているわけではないことです。タンパク質製造からターゲット発見まで、そしてその間のあらゆる段階で計算が重要な役割を果たしています。つまり、私たちにとって計算は非常に重要なのです。

それでは、AWS HealthOmicsで実際に行っている具体的なユースケースについて、詳細に入る前にお話ししたいと思います。その後、AWS HealthOmicsの使い方についてのガイダンスをご紹介します。左側の例では、nf-coreのCut & Runパイプラインを使用してデータを分析した事例を示しています。これは興味深い例で、ウェットラボの科学者たちがエピジェネティクスの特定のターゲットに最適な抗体を見つけたいと考えていました。エピジェネティクスに詳しい方はご存知かもしれませんが、これらの抗体は非常に扱いにくく、特異性に乏しいことで知られています。そのため、最も正確な抗体を選ぶために意味のある推論を行うことが非常に重要なのです。
AWS HealthOmicsを使用することで、同じターゲットに対する複数の抗体からのデータを迅速に分析することができました。このパイプラインとプラットフォームを使用することで、通常なら1週間ほどかかる作業が1日程度に短縮されました。その結果、ウェットラボの科学者たちに素早くフィードバックを提供し、「興味のある各ターゲットについて、遺伝子やゲノム上の位置での濃縮度に基づいて、これらが最適な抗体です」と伝えることができました。右側には、AWS HealthOmicsの私たちのプライベートワークフローですでに実装されているパイプラインを列挙しています。これらはデータタイプですが、ここに挙げられているパイプラインはすべてnf-coreからのものです。nf-coreについては後ほど詳しく説明しますが、Nextflowのバイオインフォマティクスパイプラインを探す際の優れたリソースであり、どれが最適かを検討する際に役立ちます。

現在実装されているこれらのパイプラインに加えて、さらに30ほどのパイプラインを移行する計画があります。これらにはnf-coreのものと、社内で開発したカスタムパイプラインの両方が含まれます。これは、このプラットフォームの有用性が実証されたためです。この問題の歴史について少しお話ししますと、AWS HealthOmicsが登場する以前からオミクスに取り組んでいなかったわけではありません。オミクスデータの分析は、このサービスが発表されるずっと前から必要とされており、長年にわたって行われてきました。以前のオミクス解析ソリューションもAWSを利用していました。それは一部の面では強力で効果的でしたが、確かに欠点もありました。セルフサービスが容易ではなく、セットアップにはIS部門の助けが必要でした。何かがスムーズに進まない場合のトラブルシューティングも非常に困難でした。バイオインフォマティクスの経験がある方なら、最初の試行でスムーズに進むことはめったにないことをご存じでしょう。
また、多くの場合、独自の環境を作成するために重複した努力が必要となり、分析の透明性も低下していました。なぜなら、すべてを簡単に一元的に見ることができなかったからです。私たちにとって、AWS HealthOmicsはこれらの問題それぞれに対処するのに役立っており、研究を加速し、患者さんにより早く成果を届けるという私たちの使命を果たすために、クラウドコンピューティングの最先端を行く別の方法を提供してくれています。
AWS HealthOmicsを選択した理由とメリット
なぜ他の潜在的なソリューションではなく、AWS HealthOmics を使用しているのでしょうか?簡単に言えば、私たちが IT ではなく発見に焦点を当てているからです。これにより、生物学、標的、疾患に関する理解を深め、最終的にさまざまなビジネス上の意思決定に情報を提供することができます。Amgen のような規模の企業にとって、すべてを一箇所に集約することは、透明性、権限付与、セキュリティの面で非常に重要であり、これらはすでに最初から提供されています。さらに、Nextflow をサポートし、nf-core に関する多数のチュートリアルがあります。また、将来的に WDL や CWL などの他のワークフロー言語に拡張したい場合にも対応できます。
将来を見据えると、ワークフローとシームレスに統合される HealthOmics storage や HealthOmics analytics の使用にも興味があります。最後に、もう一つの大きな利点は、HealthOmics が以前のソリューションにはなかったスケールと安定性を提供してくれることです。以前は、これが IT スタッフが本当に苦労していた点の一つでした。異なるキューサイズやインスタンスパラメータを調整して動作させようとし、場合によっては本当に苦労していました。しかし今では、それらすべてが AWS 側で処理されています。
結局のところ、なぜこのサービスを使用しているのでしょうか?車輪の再発明をする必要がないからです。彼らはすでに素晴らしいサービスを提供しており、多くの企業のニーズに応えられると思います。繰り返しになりますが、車輪を再発明する必要はありません。彼らは素晴らしいものを持っており、直接利用することができます。

このサービスを使用する他のメリットは何でしょうか?先ほど述べたように、科学者はセルフサービスを実行する権限を与えられており、 IT スタッフがすべてをセットアップするのを待つ必要がありません。共有パイプラインが一箇所にあることで、堅牢性、再現性、サイクルタイムの短縮につながります。バイオインフォマティクスのワークフローを実行するために独自の計算環境をセットアップしたい人はいないでしょう。「クラウドですでにセットアップされているから、数回クリックするだけで使えるよ」と言えば十分です。
さらに、入力と使用する特定のパイプラインに応じて、以前のソリューションと比較して40〜60%のコスト削減が見られています。これらのワークフローの計算時間も、以前のソリューションと同じか、より高速です。私のようにこれらのワークフローを常に使用している人にとって非常に重要なのは、デバッグがより透明で、トラブルシューティングがはるかに簡単になったことです。実行メタデータは CloudWatch ログに保持され、リアルタイムの進捗モニタリングと迅速なトラブルシューティングが可能になります。また、Laboratory Information Management Systems(LIMS)などの他のシステムとの接続も可能で、これは本当に重要です。

そして最後に、あまりエキサイティングではないかもしれませんが、非常に重要なこととして、請求に関する実行レベルの可視性を提供します。私個人的には請求を扱うことはありませんが、ありがたいことに、これは明らかにAmgenのような規模と請求の複雑さを持つ企業にとって非常に大きな意味を持ちます。ここまでの背景をまとめると、このサービスについて私はどう考えているでしょうか?オミクスパイプラインのアクセシビリティ、使用、可視性を広げることに興味がある場合、AWS HealthOmicsは独特の魅力と目的に適した解決策を提供し、私自身も多くの有用性を得ています。
ワークフロー移行のヒントとトラブルシューティング

さて、ここからはワークフローの移行に実際に何が必要かについて、もう少し詳しく掘り下げてみたいと思います。これに興味がある方にとって、どのようなものになるかを少しお見せしましょう。まず、一般的な広範なヒントから始めます。最初に注意したいのは、すべてのシステムが少し異なるということです。ここにいる皆さんにとっては新しい情報ではないでしょうが、過去に一つのシステムで機能したからといって、新しい環境で同じように機能するとは限らないということを心に留めておくことが重要です。試してみる価値は常にありますが、このことを念頭に置くことが大切です。そのため、コンテナなどでコンピュート環境を定義することが非常に重要なのです。
そして、次のヒントとして、Ariellaが指摘したように、コンテナとS3の権限を必ず検証することです。コンテナはワークフロー内の個々のプロセスを実行し、その中のコンピュート環境を定義します。そのため、コンテナからデータを取得するための適切な権限があることを確認する必要があります。第三に、オープンソースのヘルパーについてです。私は約1年間、このサービスについてAWSと頻繁にやり取りを行ってきましたが、そのやり取りと開発に非常に満足しています。関連して、nf-coreパイプラインがあなたのニーズに適していて、求めているものに合うと判断した場合は、AWSのnf-coreパイプライン移行ワークショップを参照することをお勧めします。
私はnf-coreの大ファンです。nf-coreをご存じない方のために説明すると、これはNextflow coreのことで、異なるデータタイプに対するバイオインフォマティクス分析の金字塔的な標準セットを確立するためのコミュニティの取り組みです。分析者や科学者として、私は常にこれらのデータをどのように正しく分析するかを考えています。ありがたいことに、これは、バイオインフォマティクスの異なるデータタイプに対するベストプラクティスを確立するための幅広いコミュニティ、学術界、そして産業界の取り組みを可能にすることで、その一部を抽象化してくれます。
もう一つ興味深いのは、最初は本当に理解できなかったのですが、Nextflowで非常に効果的に使用するようになったのが、タスクごとのNextflowリトライ戦略を使用して進捗の損失を避けることです。ここではメモリ不足の問題によるものと記しましたが、メモリ不足だけでなく、タスクの失敗につながる様々な要因があります。Nextflowでは、実際にパイプラインで設定することができ、特定のタイプのエラー失敗が発生した場合に、異なるパラメータでタスクを再試行させることができます。非常に一般的な例としては、メモリ不足があります。メモリ不足エラーが発生して失敗した場合、タスクを再試行し、より多くのRAMを与えるように設定できます。
もちろん、メモリ不足エラーでない場合はそのような対応をする必要はありません。逆に、私が取り組んだ例では、タスクがメモリ不足ではなく別のエラーコードで失敗することがありました。その場合は、「タスクを再試行してください。ただし、今回は少し異なるパラメータを使用してみてください」と指示します。最後に、サービスチームに必要なものを本当に伝えることが大切です。この会議で見てきたように、そして皆さんの多くがすでにご存知かもしれませんが、AWSは非常に顧客重視です。私たちは彼らと協力する中で素晴らしい経験をしました。それは基本的に、私たちが「この機能に本当に興味があり、これを構築したいのです」と伝えると、彼らが「わかりました。どのように構築すればよいでしょうか?」と応答するような流れでした。

ここで、ワークフロー移行を始めるための具体的なヒントをもう少し掘り下げてみたいと思います。先ほど少し触れましたが、まず最も重要なのは、自分のニーズを確認することです。どのようなデータモダリティを、どのように評価したいのでしょうか?というのも、任意のデータを評価する方法は数多くあるからです。そして繰り返しになりますが、nf-coreをお勧めします。もし馴染みがなければ、ぜひチェックしてみてください。かなり充実したウェブサイトがあります。素晴らしいコミュニティリソースで、労力を減らし、データを見る方法の妥当性に対する自信を高めてくれます。
先ほど述べたように、コンテナレジストリの権限が適切に設定されていることを確認してください。これはコマンドラインからは比較的簡単ですが、コンソールからは少し扱いにくいかもしれません。
コンソールを使用する場合、ECRのチェックボックスをクリックし、右上の小さなドロップダウンアクションバーを探して権限を編集する必要があります。しかし、これらはすべて実行可能で、AWSが提供するガイドに詳しく説明されています。3つ目は、すべてをパラメータ化することです。これも私が理解するのに少し時間がかかりましたが、強くお勧めします。パイプラインでハードコードされているものをほぼすべて取り除きましょう。アプローチをできるだけ柔軟にしたいのです。たとえ現時点で自社が特定の参照ゲノムを使用して特定の分析を行うだけだと考えていても、そのように設定しておくことが有益です。後になって誰かが「カスタムゲノムがあります」や「別のゲノムを見たいのですが」と言ってきたときに、新しいパイプラインを作る必要がなく、簡単にパラメータを入力できるようにしておくのです。「デフォルトではヒトゲノムに設定していますが、別のものを使いたい場合は、ここに新しいパラメータファイルがあります」と伝えるだけで済むのです。ですので、すべてをパラメータ化し、将来の自分のために簡単にしておきましょう。

最後に、もちろんpublishディレクトリを確認してください。HealthOmicsが適切にS3に書き戻すようにスクリプトを修正する必要があります。計算にかかる時間、労力、エネルギー、お金をすべて費やして、うまくいったように見えても、結果をS3にプッシュするのに失敗してしまうのは非常に残念です。そんなことは避けたいですよね、とてもフラストレーションがたまります。これが、大まかに考えて始める方法です。しかし、実際に必要なようにワークフローを修正し、AWS Omicsの移行ワークフローを確認してそれらのステップを経て準備ができたら、ワークフローアーティファクトをzip形式で作成し、S3の場所にアップロードします。次に、パラメータのJSONファイルを準備します。ここでは2つのファイルが必要です。1つはパラメータのテンプレートで、パラメータの内容とオプションかどうかを記述します。もう1つは、実際に入力テストデータを含むもので、理想的には小さなテストケースでパイプラインを実行してみることができます。

再度強調しますが、重要なのは小規模なテストケースを使用することです。これにより、パイプラインを迅速に進め、期待通りに機能することを確認できます。この点でも、nf-coreは非常に役立ちます。なぜなら、彼らがリリースする全てのパイプラインには、テストデータも一緒に提供されるからです。そのため、直接nf-coreからテストデータを取得し、パイプラインが期待通りに機能することを確認できます。そして、これも何度か言及していますが、権限を確認することが重要です。適切なIAMポリシーを持っていることを確認してください。セットアップに時間とエネルギーを費やしたり、計算を実行したりしても、権限拒否エラーで進捗が妨げられるのは非常にフラストレーションがたまります。
ここで、トラブルシューティングについていくつかのアイデアを簡単に提供したいと思います。このプラットフォームでのトラブルシューティングは、前述したように、Amgenで以前使用していたソリューションよりもはるかに簡単です。run levelとtask levelの両方でログを使用することをお勧めします。個々のrunは多くの異なるtaskを起動し、task logで個々のプロセスで何が失敗したかを詳しく知ることができます。さらに、一段階上のrun logを見ることで、Nextflowやその他のワークフローエンジンの直接の出力を確認できます。これにより、taskが失敗した理由、その後どのようなエラーメッセージが出たか、taskの実際の呼び出し方、どのようなエラーが発生しているかについての追加情報を得ることができ、適切な再試行戦略を実装したい場合に役立ちます。

再試行戦略については、先ほど述べたように、エラーの種類によって本当に異なります。メモリ不足エラーが発生していないのにRAMを増やしても、おそらく同じエラーが再び発生するだけで、そうする必要はありません。そうすれば、計算リソースを無駄にするだけです。しかし、RAMを増やしたり、使用している実際の関数に対して異なるパラメータを呼び出したりすることができます。Nextflowには、さまざまな再試行戦略を行う方法が多数ネイティブに組み込まれています。最後に、コミュニティを本当に活用してください。nf-core Slackは、GitHubリポジトリよりも、私の経験では全てのパイプラインに関する情報とトラブルシューティングが非常に最新の状態に保たれています。Slackで多くの開発が行われているためです。特定のパイプラインがHealthOmicsで動作しないと思ったことが何度かありましたが、それは私の実装が間違っていたからで、Slackを調べてみると、「いや、このバージョンは今のところ誰にも動いていないんだ」ということがわかり、1つ前のバージョンにロールバックする必要があっただけでした。そう、nf-core Slackは非常に役立ちます。そして、アカウントチーム、サービスチーム、AWS全般が、このサービスを最大限に活用できるようサポートしています。ですので、疑問がある場合は、拡張したい新機能についてだけでなく、期待通りに動作させようとして行き詰まっている場合にも、彼らに問い合わせてください。彼らは本当に支援するためにいるのです。
AmgenのAWS HealthOmics活用の将来ビジョン
最後に、ワークフローへの継続的インテグレーションと継続的デリバリー(CI/CD)の統合について簡単に説明したいと思います。多くの開発者、私も含めて、これは非常に気にかけていることだと思います。変更を加えた後、実際に機能するかどうかを確認できるからです。HealthOmicsプラットフォームは既存のCI/CDと連携するように調整されていることを嬉しく思います。お好みのプラットフォームを使用でき、実際にAmgenでは自社環境内でこれを設定するためにGitlabを使用しています。そして、ここでも強調したいのは、特にCI/CDワークフローの場合、時間と計算リソースを無駄にしないように、適切で比較的小規模なテストデータを選択することが非常に重要だということです。これが現在のAmgenでの状況であり、AWS HealthOmicsで行ってきたこと、そして効果的に使用するためのいくつかのヒントです。このプラットフォームの将来について、私たちが構想していることについて簡単に触れたいと思います。

先ほど述べたように、私たちは30数個のパイプラインを移行しています。内部パイプラインの大部分を、コストと共有可能性の目的でこのサービスに移行しています。プラットフォーム上ですでに実装したnf-coreパイプラインの一部を更新し、Nextflowワークフローでカスタムパイプラインを追加したいと考えています。私はNextflow開発者ではありません。Nextflowについて知っていることは全て、AWS HealthOmicsに取り組む過程で学んだものです。Nextflow開発者ではないけれど興味がある方々のために、このことを言及しておきます。学ぶのはそれほど難しくありません。私もJavaのバックグラウンドはありませんでしたが、可能です。
私たちは、これを様々な社内システムと連携させたいと考えています。現在、Laboratory Information Management Systems (LIMS) の一部で移行作業を行っていますが、クロスシステムのメタデータ管理の連携と有効化、そして興味深いことに、自動化された実行パラメータの生成と自動実行開始に取り組んでいます。会場の多くの方々は、製薬業界におけるエンド・ツー・エンドソリューションという概念をご存じだと思います。Amgen の他のステークホルダーと話をすると、彼らは文字通りエンド・ツー・エンドについて話しています。彼らは、データがシーケンスされたらすぐに自動的にデザインファイルを生成し、自動的に実行を開始し、分析を行うべきだと言います。そうすれば、科学者が朝出勤してきたときには、データの分析が既に完了しているというわけです。私たちは、多くの人が本質的にオミクスデータの前処理と考えるようなことを行うために、単に人間の介入を必要としないのです。
つまり、ビジョンとしては、人間の介入を減らし、データを迅速に分析できるようにすることです。そして先ほど述べたように、私自身とAmgenの他の科学者たちにNextflowの知識を身につけてもらいたいと考えています。なぜなら、nf-coreはこのプラットフォーム上でパイプラインを実装する素晴らしい方法の一つですが、唯一の方法ではないからです。どのようなNextflowパイプライン、Common Workflow Language (CWL)、Workflow Description Language (WDL) でも、ここで実装することができます。つまり、これらの言語を使って独自のカスタムパイプライン開発を行うことが本当に可能になるのです。そして、前のスライドで述べたように、堅牢で標準化されたバージョン管理とパイプラインの定期的な更新を確実に行うために、CI/CDワークフローの開発に取り組んでいます。

将来のビジョンについてもう少し詳しく説明しますと、大まかな目標は、あらゆる種類のオミクス解析をポイント&クリック操作のように簡単にすること、あるいはさらに良いことに、先ほど述べたように、ほとんど自動化され、データがオンラインになってすぐに結果にアクセスできるようにすることです。そして、これまでの使用状況はワークフローに焦点を当てていたので、あまり触れませんでしたが、非常に興味深いことに、将来的にはOmics storageの使用に興味があります。現在S3に保存されているFASTQやBAMなどの様々なオミクスファイルをOmics storageに移行することに本当に興味があります。これは、プラットフォームとの統合のためだけでなく、コスト削減のためでもあります。ギガベースとギガバイトの比較、私にとってはこれは信じられないことです。どのようにしてそれを実現しているのかわかりませんが、非常に興味深い見通しです。
このプレゼンテーションで、Amgenがこのサービスをどのように利用しているかについて、興味深い概要を提供できたことを願っています。私たちにとって、これはオミクス解析を民主化するためのもう一つの取り組みであり、私たちが奉仕する患者のためにすべてを尽くすという最先端の取り組みの一つです。ご清聴ありがとうございました。では、Ariellaにバトンを渡します。
AWS HealthOmicsの今後の展望とre:Inventの案内


Ittaiさん、素晴らしいプレゼンテーションをありがとうございました。科学があらゆる病気を克服する世界、それは私の心に強く響きます。さて、次は何かと思われるかもしれません。 HealthOmicsについてもっと詳しく知りたい方は、Developer's GuideやOmicsのランディングページをご覧ください。3つのサービスすべてについて、より実践的なガイド付き体験をお望みの方は、HealthOmics End-to-Endワークショップをチェックしてみてください。コンソール、AWS CLI、SDKを使用して、3つのサービスすべてについてガイド付きの体験を得ることができます。

そして、私たちの顧客が素晴らしいことを成し遂げているもう一つの例をご紹介します。Ittaiが言ったように、患者さんへの迅速な対応が重要です。Children's Brain Tumor Networkは、AWSを基盤として多様なデータ共有と分析プラットフォームを構築し、30の機関にまたがるデータを統合してオープンサイエンスを実現しています。今年、私たちは再発性退形成上衣腫の5歳の患者、Cameronくんがデザインした限定ピンを配布する予定です。このピンは、クラウドベースのイノベーションが患者さんに与え続ける影響と、機関を超えたデータ集約の重要性を象徴的に思い起こさせるものです。


最後に、re:Inventを通して、もし本当にクールなヘルスケアとライフサイエンスに焦点を当てたデモを見たい、またはAWSのHCLsについて質問がある、あるいは単に交流したいという方は、Healthcare and Life Sciences demo Pavilionで私の非常に優秀な同僚たち、そしておそらく私自身も、皆さんのどんな質問にも答える準備ができています。そして最後に、これでも物足りない方で、re:InventでAWS HealthOmicsについてもっと聞きたい方のために、他にもいくつかのセッションを用意しています。本日後半には、StanfordがAWS HealthOmicsを使用して精密医療プラットフォームを構築している方法に焦点を当てたセッションがMGMで行われます。また、いくつかのワークショップも用意しています。これらは同じ内容の繰り返しですので、健康データの完全なマルチモーダル分析の構築方法について、都合の良い時間をご覧ください。

最後に、IttaiとPrivateに参加していただき、ありがとうございます。IttaiとPrivateはここで、あるいは追い出された後は廊下で質問にお答えします。しかし、お帰りの前に、AWSはデータ駆動型の企業であることをお忘れなく。お時間を取ってアンケートにご記入ください。ご清聴ありがとうございました。お時間をいただき、ありがとうございます。残りのre:Inventも素晴らしいものになりますように。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion