re:Invent 2023: Amazon Bedrockの新機能、モデル評価機能の詳細解説
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Evaluate and select the best FM for your use case in Amazon Bedrock (AIM373)
この動画では、Amazon Bedrockの新機能であるモデル評価機能について詳しく解説しています。foundation modelの選択に悩むエンジニアにとって朗報です。自動評価と人間による評価の両方をサポートし、独自のデータセットも使用可能。さらに、AWS Managed Work Teamによる評価オプションも提供。Kishorによる実際のデモも見られるので、具体的な使い方がよくわかります。generative AIアプリケーション開発の効率を大幅に向上させる可能性を秘めた機能です。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
Amazon Bedrockにおけるモデル評価の重要性

さて、今日は大勢の方にお集まりいただきました。re:Inventの最終日まで残っていただき、ありがとうございます。ホテルのチェックアウト後の11時30分にもかかわらず、皆さんがここに来てくださって嬉しいです。Amazon Bedrock上で、ユースケースやアプリケーションに最適なfoundation modelを評価・選択する方法を学びたい方は、まさに適切な場所にいらっしゃいます。私はJesseと申します。AWSのsenior product managerを務めています。そして後ほど、同僚のKishorが登壇します。彼は今、観客席にいます。



水曜日のSwamiのkeynoteをご覧になった方もいらっしゃると思います。 そこで発表されたように、Amazon Bedrock上でmodel evaluationの機能がpreviewで利用可能になりました。 本日は、この機能の詳細や利点、そして今すぐ始める方法についてお話しできることを大変楽しみにしています。 では、本日のアジェンダをご紹介します。まず、foundation model evaluationとは何か、そしてなぜ重要なのかについて説明します。次に、現在お客様がどのようにこの課題に取り組んでいるか、そしてそれに伴う課題について探ります。その後、今すぐ活用できる機能と利点をご紹介します。
モデル評価の定義と品質評価の側面

デモもお見せします。Kishorを舞台に呼び、彼が約20分間、実際に製品を使い始める方法についてデモを行います。その後、始め方についての詳細情報をお伝えし、QRコードをお見せし、いくつかの提案をさせていただきます。 では、model evaluationとは何でしょうか? 簡単に言えば、アプリケーションに適したモデルを選択するために必要なプロセスです。私たちはみなアプリケーションを構築しており、この会場にいる皆さんは、generative AIアプリケーションの構築に興味をお持ちのことでしょう。
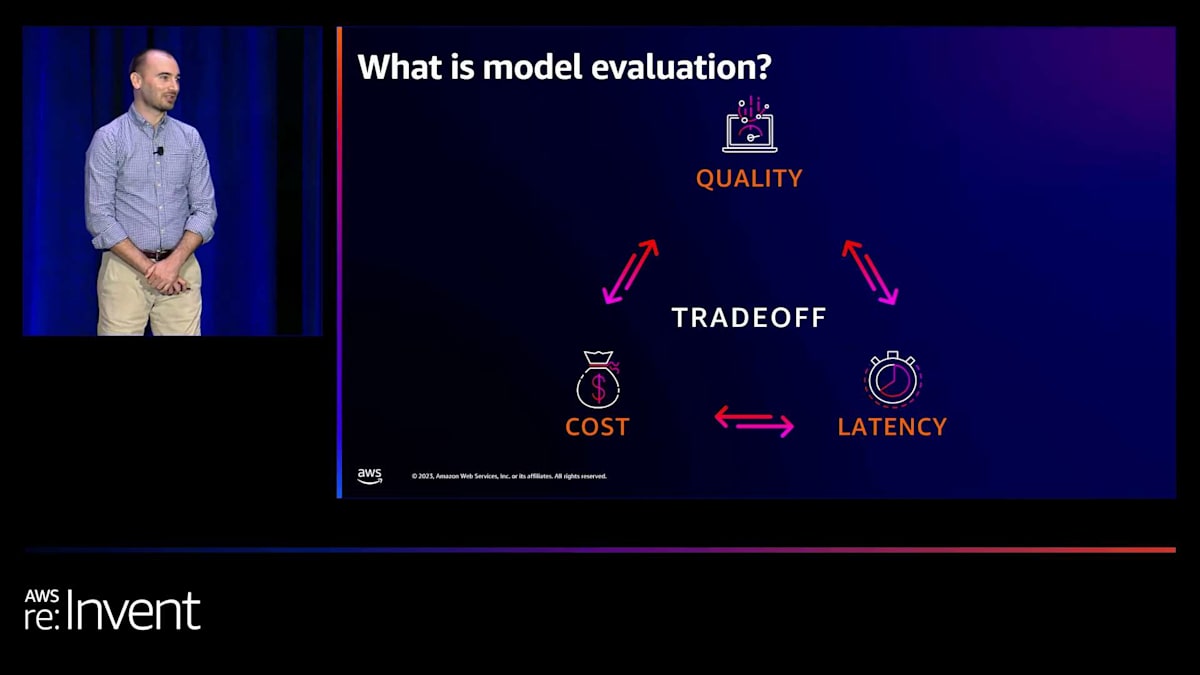
私たちは、これを3つの要素のトレードオフと考えています。1つ目は、モデルのレスポンスや推論の質です。2つ目は、そのアプリケーションを事業で運用するためのコストです。そして3つ目は、ユーザー体験の観点からのレイテンシーです。 単純な質問をしているだけなのに、10分も待たされたいユーザーはいません。そのため、推論の質、コスト、レイテンシーのバランスを取る必要があります。

質の側面についてもう少し詳しく見てみましょう。評価では、まずプロンプトを入力することから始まります。簡単な例として、「このカスタマーサポートチケットを要約してください」というものがあります。すでにカスタマーサポートチケットが開かれており、アプリケーションがそれを要約する役割を担っているとします。このアプリケーションは、シフト間の引き継ぎなど、カスタマーサポートの摩擦を減らすことを目的としているかもしれません。そこで、カスタマーサポートチケットを入力し、タスクはそれを要約することです。モデルの出力として、チケットの要約が得られ、それによってカスタマーサポートチームが顧客の問題に対処しやすくなります。
モデルのレスポンスがビジネスにとって良いものかどうかを評価する方法には、主に2つあると考えています。1つは、私たちが馴染みのある自然言語処理アルゴリズムを使用した自動評価です。もう1つは人間による評価です。実際に人間がレスポンスを読んで、このモデルが顧客にとって良いものを提供しているかどうか、トーンや実際の内容、正確さを理解します。そして、すべてのプロンプトを入力し、これらのレスポンスを読み、アルゴリズムで計算したり、評価を行っている人々からのスコアを集計したりするテストを経た後、スコアカードを見て、このモデルが自分にとって正しいことをしているかどうか、アプリケーションが自分にとって正しく機能するかどうかを確認する必要があります。
モデル評価の重要性とデータの役割

しかし、なぜこれが重要なのでしょうか?先ほど述べたように、品質、コスト、レイテンシーのトレードオフのトライアングルがあります。しかし、さらに深く考えると、このモデルとアプリケーションが自社のブランドボイスに合っているかどうか、自社のスタイルで書いているかどうか、本当に顧客を望む方法で助けているかどうかということです。一般的な評価は多くありますし、それらは素晴らしいのですが、モデルが自分のユースケースにとって良いものかどうかをより深く理解したいのです。テキスト要約かもしれませんし、チャットボットで質問と回答があるかもしれません。このモデルが自分のユースケースにとってどれだけ良いものになるかを本当に理解する必要があります。
そして、それだけでなく、自社のデータを使用して良いものになるかどうかを理解する必要があります。大きなダッシュボードで同じ土俵での比較をしたい場合には、公開されている多くのデータセットが素晴らしいのですが、実際にビジネスで顧客の問題を解決するためにアプリケーションにモデルをデプロイする場合、モデルとアプリケーションが自社のデータで適切に動作することを知る必要があります。
このデータは顧客にとって重要なので、評価にそのデータを持ち込んで本当にテストする必要があります。そして最後に、これらのモデルとアプリケーションが安全で信頼でき、バイアスを避け、顧客が満足するものであることを確認する必要があります。
モデル評価プロセスの課題と解決策


顧客から聞いているのは、アプリケーションに適したモデルを見つけるこのプロセスが長く退屈なプロセスだということです。ここには多くの痛点があります。 まず、モデルの置き場所を見つけることから始まります。理想的には、この置き場所は評価を行うだけでなく、本番環境に移行してアプリケーションを構築する場所でもあるはずです。これらすべてが1つの場所、1つのスポットにあり、扱いやすいことを確認したいのです。

次に、どのメトリクスとアルゴリズムを使用するかを決める必要があります。これには多くの作業が必要になる場合があります。すでにデータサイエンスチームがない場合は、この分野に特化したチームを雇うことを検討するかもしれません。非常に骨の折れる、退屈な作業になる可能性があります。どれが自分たちに適しているかについて議論が起こるかもしれません。そして、それらを本当に理解し、適切な形で経営陣に提示するには多くの労力が必要です。

メトリクスとアルゴリズムを決めた後も、まだデータセットを入手する必要があります。公開されているデータセットは多くあり、それらは素晴らしいものです。しかし、先ほど話したように、あなたのアプリケーションやビジネスに適したものを選ぶには、そのデータがモデル内で適切に機能することを確認する必要があります。オンラインでデータセットを見つけるのは良いことですが、モデルとアプリケーションがあなたにとってうまく機能するように、自分のデータをしっかりと確認する必要があります。


次に、これらの準備が整った後、モデルやアプリケーションをデプロイし、実際に動作させるための適切なインフラを整える必要があります。そして、自動評価メトリクスを計算した後も、必ず人間によるチェックを行う必要があります。実際の人間に推論結果を読んでもらい、アプリケーションが適切に動作しているか、文章のスタイルや信頼性、あるいは人間の直感や理解力の観点から確認する必要があります。これに代わるものはありません。人間の判断を得ることは非常に重要です。


人間の判断を得た後は、これらすべてを記録する必要があります。自然言語処理アルゴリズムによる自動評価があり、人間の判断もあります。これらをすべてまとめて、どのようなトレードオフを行うかを理解するための洞察を得るよう努めます。そして最後に、それらのトレードオフを実行します。
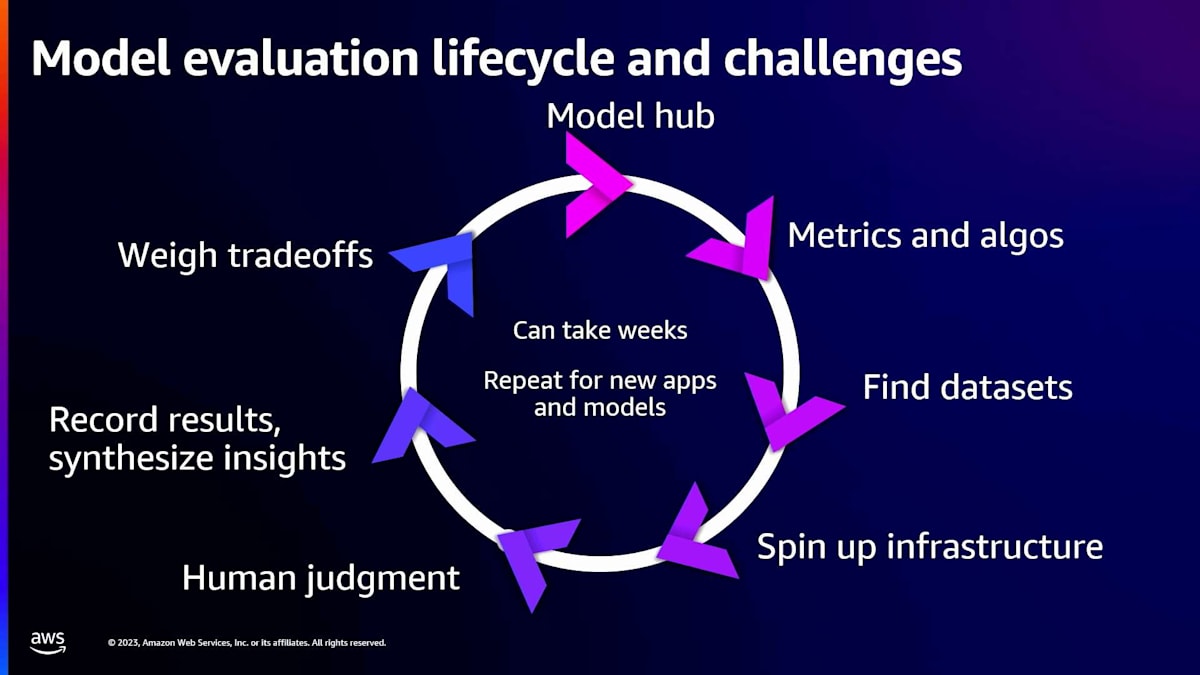
これが明らかに長いプロセス、大きなサイクルであることがわかります。しかし、これには数週間かかることがあります。顧客からは、これが苦痛だと聞いています。顧客によっては数週間、時には数ヶ月もかかることがあります。これには多くの課題があります。それだけでなく、新しいモデルを選択したり、新しいアプリケーションを構築したりする場合は、最初からやり直す必要があり、このプロセス全体を再度開始しなければなりません。これには多大な労力と時間、そしてお金がかかります。
Amazon Bedrockのモデル評価機能の概要
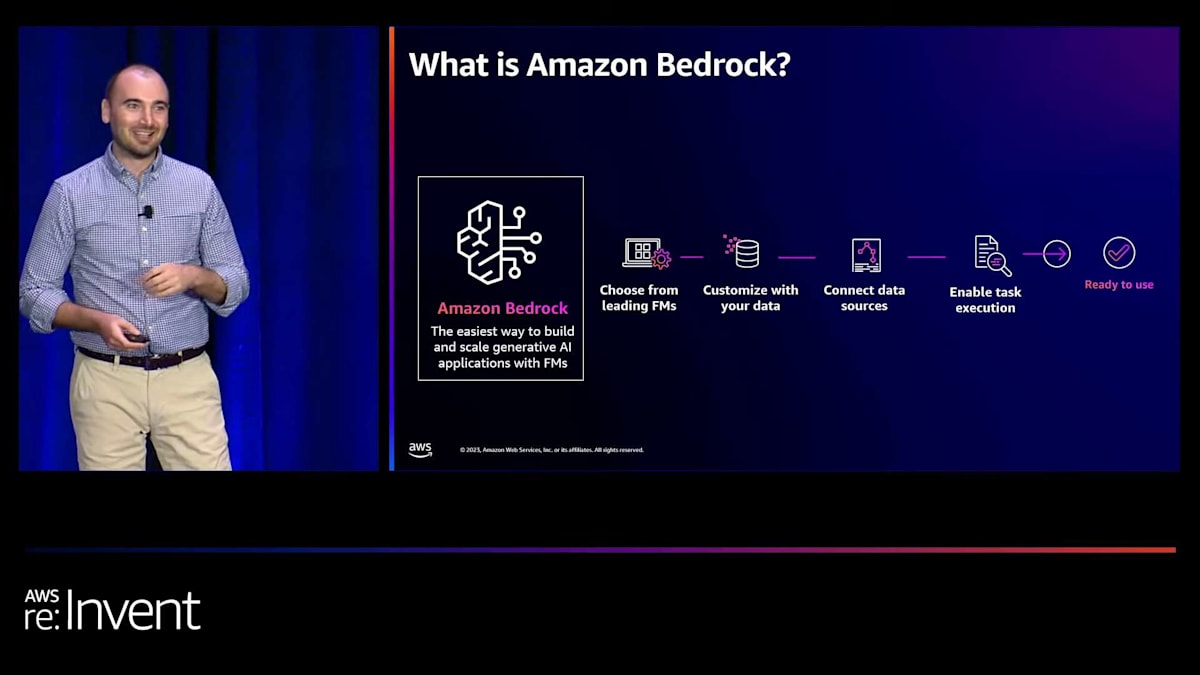

では、この問題をどのように解決すればよいでしょうか?ジェネレーティブAIを使用してビジネスの問題を解決するアプリケーションを、より簡単かつ迅速に構築するにはどうすればよいでしょうか?ここで、Amazon Bedrockのモデル評価機能をご紹介します。詳細に入る前に、皆さんはおそらくよくご存知だと思いますので、あまり時間をかけませんが、Amazon Bedrockはジェネレーティブ AIアプリケーションを構築・拡張するための最も簡単な方法です。そして、Amazon Bedrockが提供できる素晴らしい機能の長いリストがあり、ビジネスに活用できます。ここでは、アプリケーションに適したモデルを選択するためのModel Evaluationに焦点を当てていきます。


それでは、ここで提供している機能をいくつか見ていきましょう。まず、キュレーションされたデータセットを持ち込むことができます。実際には、オープンソースのデータセットを提供していますが、独自のデータセットを持ち込むこともできます。これはプラットフォームに組み込まれています。次に、自動評価と人間による評価の両方のメトリクスを提供しています。先ほど話したように、迅速に比較できるようにしたいのですが、同時に人間の判断も本当に必要なのです。

3つ目は、人間による評価を行う場合、自社のチームを持ち込むことができ、そのためのメカニズムを提供しています。実際にはセットアップがとても簡単で、自社の専門家チームが出力を読み、簡単な方法でフィードバックを提供できるようになります。または、AWS管理のチームを雇うこともでき、ホワイトグローブサービスとして直接協力し、評価の要件を理解した上でチームを調達することができます。

プロセス全体を通じて常に情報を共有し、実際にどのように機能するかの詳細については後ほどお話しします。さて、どのようなメトリクスが必要かを理解することの難しさについて話しましたが、キュレーションされた事前定義のメトリクスを提供しています。さらに、他のビジネスには必要ないかもしれませんが、あなたのビジネスに特有のニーズがたくさんあるかもしれません。多くの顧客から常に聞かれるのは、モデルの評価方法や要件が企業ごとに異なるということです。そこで、独自のメトリクスを定義する柔軟性を提供しています。特に人間による評価では、創造性やスタイルなど、人間の感覚と柔軟性が本当に必要な要素があります。

最後に、これらすべてを数回のクリックで設定し、評価ジョブを実行できることに期待していただけると思います。後ほど、その方法をお見せします。さて、先ほどの課題に戻りますが、サイクルタイムの短縮を目指しています。そうですね? 多くの課題がありましたが、私たちはデータセットを提供しています。独自のデータセットを持ち込むこともできます。自動評価または人間による評価を使用できます。人間による評価を行う場合は、自社の専門家チームを使用するか、AWSが管理するワークフォースを利用することができます。実際に、数回のクリックで結果を得ることができるのです。
自動評価プロセスの詳細

まず、最初のポイントについて話しましょう。モデルの拠点はどこでしょうか?良いニュースは、私たちがここでAmazon Bedrockについて話していることです。Swamiのキーノートでも見たように、Amazon Bedrockには現在多くのモデルがあります。そしてAdamのキーノートでも見たように、多数のモデルが存在します。AI21 LabsはJurassic-2を提供し、AnthropicはClaude 2を、CohereはCommandを、MetaはLLAMA 2を提供しています。そしてもちろん、AmazonのTitanモデルファミリーもあります。これらのモデルの中から選んで評価を行い、generative AIアプリケーションを動かすことができます。

データセットについてですが、私たちが提供する厳選されたデータセットを使用するか、独自のものを持ち込むことができます。これにより、特定の企業のドメインでこれらのモデルのパフォーマンスを評価することができます。なぜなら、業界ごとに異なるからです。そして、アプリケーションが自社に適しているかどうかを確認したいですよね。また、モデルの知識ギャップを特定し、カスタマイズが必要かどうか、あるいはプロンプトエンジニアリングに取り組む必要があるかを理解することができます。その後、評価をさらに進め、カスタマイズプロセスやプロンプトエンジニアリングのライフサイクル全体を通じて、継続的に評価を行うことでパフォーマンスを追跡できます。

もちろん、このデータセットを使った評価プロセス全体を通じて、モデルが適切に動作し、アプリケーションが公平で偏りがなく、顧客にとって安全な方法で動作していることを確認できます。データセットのフォーマットについてもう少し詳しく説明しましょう。データセットのフォーマットには3つの要素があります。1つ目は入力プロンプトです。2つ目はプロンプトカテゴリーです。特に人間による評価で、この機能を気に入っていただけると思います。プロンプトにカテゴリー名をタグ付けでき、後でレポートカードで結果をフィルタリングできます。これにより、人間による評価で、プロンプトの異なるカテゴリーに基づいて、モデルのパフォーマンスと人間が実際にモデルのパフォーマンスを評価した結果に違いがあったかどうかを確認できます。
例えば、営業関連のプロンプト、マーケティング関連のプロンプト、カスタマーサポート関連のプロンプトなどがあるとします。評価レポートでこれらすべてをフィルタリングして、それぞれのカテゴリーでスコアがどのように変化したかを確認できます。そして3つ目は、人間による評価のために、正解となる回答、つまりゴールデンアンサーを入力できます。これは、人々がモデルの推論を評価する画面に表示されます。彼らは、あなたが良い回答だと思ったものと、モデルが実際に推論で返してきたものを並べて比較できます。もちろん、一部の自動評価では、計算を行うために正解の回答が必要です。
人間による評価プロセスの詳細

さて、2つのタイプがあると言いましたね。自動評価と人間による評価です。まず、左側の自動評価から始めましょう。選択できる3つの組み込みメトリクス、事前定義されたメトリクスがあります。精度、堅牢性、有害性です。利用可能な事前定義されたアルゴリズムとしては、BERTScoreがあります。他にも、分類精度、F1スコア、実世界の知識スコアなど、直感的なものがあり、これらがどのように機能するかについてオープンソースのアルゴリズムの詳細なドキュメントを提供しています。人間による評価の側では、精度や有害性、堅牢性といった3つのことがありますが、それ以外にも人間特有のこと、つまりアルゴリズムではできないことがありますよね。
これらのタスクには、テキストが企業のライティングスタイルやブランドの声に合っているかどうかの評価、テキスト要約の一貫性と関連性の評価、要約が文脈から最も適切な情報を選択しているかどうかの判断が含まれます。これらのタスクは、正確な評価のために人間の判断が必要です。
人間による評価を行うための5つの異なる方法を提供しています。まず、5段階のLikertスケールを提供しており、これは単一のモデルを個別に評価したり、2つのモデルからの回答を比較したりするのに使用できます。また、迅速な二択評価のために、シンプルな「いいね」と「よくないね」のボタンも用意しています。評価指示で「良い」回答の定義を設定できます。さらに、二択ボタンも提供しており、評価者は2つの異なるモデルからの回答を選択できます。最後に、順位付けがあり、評価者は好みの順に回答をランク付けできます。これらのツールは、包括的な評価スイートを提供するために、お客様のフィードバックに基づいて開発されました。

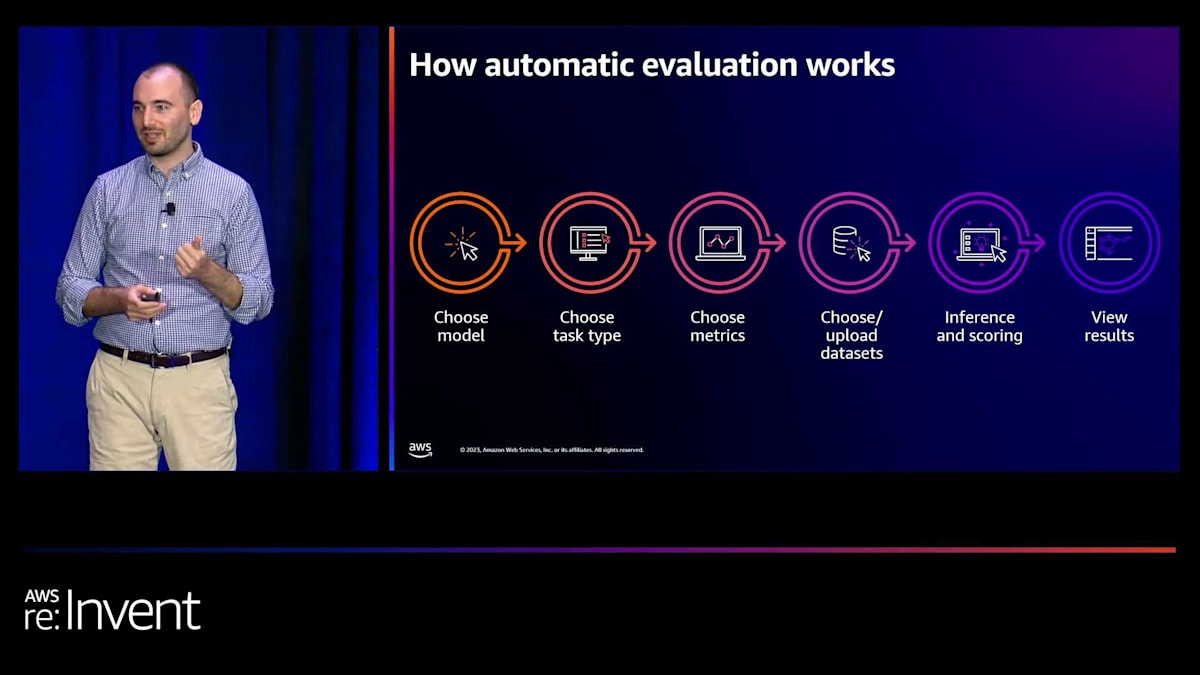
では、デモに入る前に、自動評価の仕組みを高レベルで説明しましょう。 まず、コンソールにアクセスすると、Bedrockコンソールで利用可能なモデルのリストから作業したいモデルを選択します。次に、タスクタイプを選びます。自動評価には4つのタスクタイプを提供しています:テキスト要約、テキスト分類、質疑応答、一般的なテキスト生成です。各タスクタイプに対して、正確性、有害性、堅牢性などの指標を提供しています。これらの各指標について、キュレーションされたデータセットを選択するか、独自のデータセットを持ち込むことができます。オプションを選択し、必要な権限を付与した後、作成ボタンをクリックします。その後、データセットが自動的に選択されたモデルに送信され、推論が生成され、計算と指標エンジンが結果を処理します。最後に、評価結果を含むスコアカードが表示されます。


人間による評価は少し異なる方法で行われます。人間による評価では、1つのモデルを個別に評価するか、2つのモデルを並べて比較するかを選択できます。 人間による評価では、自動評価で利用可能な4つのタスクタイプを使用するか、プロンプトが事前定義されたカテゴリに適合しない場合は、独自のカスタムタスクタイプを定義することができます。4つの事前定義されたタスクタイプについては、一貫性、完全性、正確性などの推奨される評価指標を提供しています。カスタムオプションでは、評価が特定のニーズに関連するよう、独自の評価指標を定義することができます。
データセットをアップロードした後、シンプルなインターフェースを通じてメールアドレスを追加することで、ワークチームを作成します。次に、ワークチームが従うべき指示を最終決定します。データセットは選択されたモデルに送られて推論が行われ、その結果が専用の評価ポータルでワークチームに提示されます。ここで、データセット内の各プロンプトに対して、サムズアップ/ダウンボタンを使用したり、1から5の尺度で評価したり、その他の評価方法を使用したりすることができます。評価が完了すると、システムがワークチームからのすべてのスコアと評価を集計し、理解しやすいグラフィカルなスコアカードを提供します。これにより、特定のデータに対するモデルのパフォーマンスを包括的に理解することができます。
AWSが管理するチームによる評価オプション

さて、別のルートを選んでAWSが管理するチームを使用したい場合、非常にシンプルなリクエストフォームがあります。私たちはホワイトグローブサービスとしてあなたと協力します。画面に連絡先情報を入力し、評価について説明します。どのようなタスクタイプを行いたいか、ソーシングするワークチームにどのような専門知識が必要だと思うか、評価で使用するプロンプトの大まかな数を指定します。500個なのか、それとも5,000個なのか?これらすべてを設定してポータルからリクエストを送信すると、私たちの専門家チームとの相談の電話を設定し、独立して非公開で評価が正しく設定されるよう協力します。Statement of Work (SOW)の署名に向けて協力し、評価の終了時には結果を受け取り、このプロセスのための専任のプログラムマネージャーが付きます。
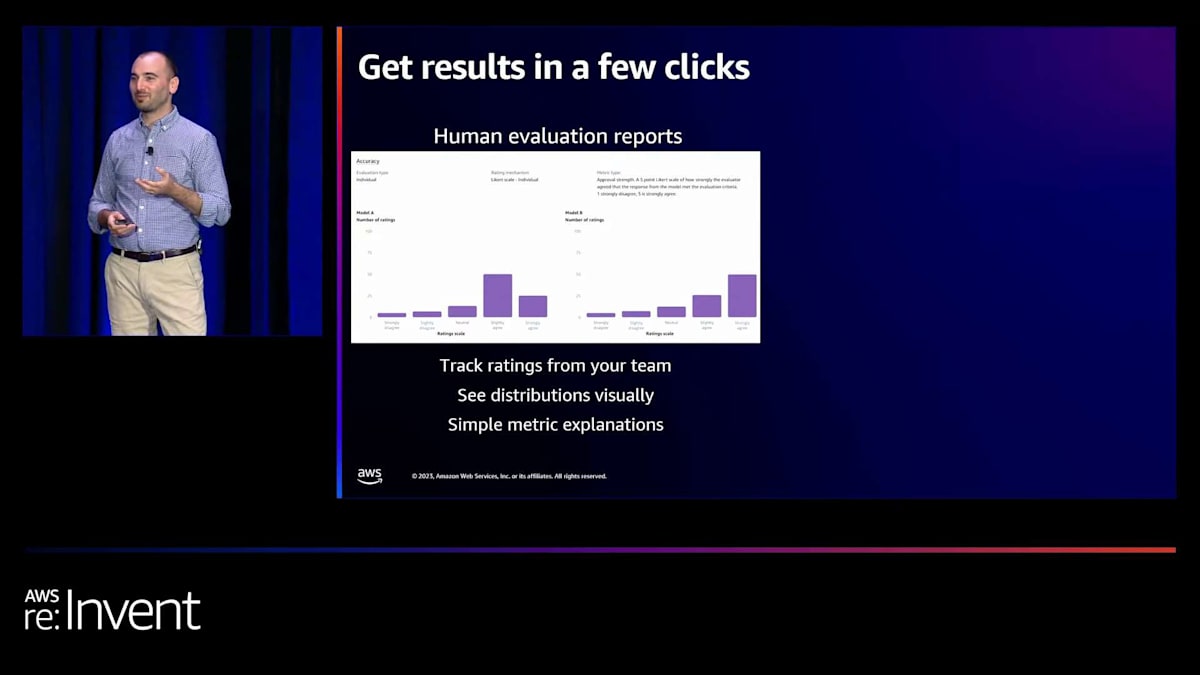
さて、これらの評価がすべて終了した後、結果はどのようになるのでしょうか?人間による評価レポートがどのようなものかを、簡単な例から見てみましょう。グラフィカルに見ていただくために、その一部を抜粋しました。この例では、画面に正確性が表示されています。正確性にはLikertスケール、つまり1から5のスケールを使用し、各モデルを個別に評価しています。ワークチームが1から5のスケールでこれが正確かどうかを示した投票数が表示されています。合計数は棒グラフとして表示されており、分布を簡単に理解できます。1つの数字にまとめるのではなく、その粒度を見ることができます。
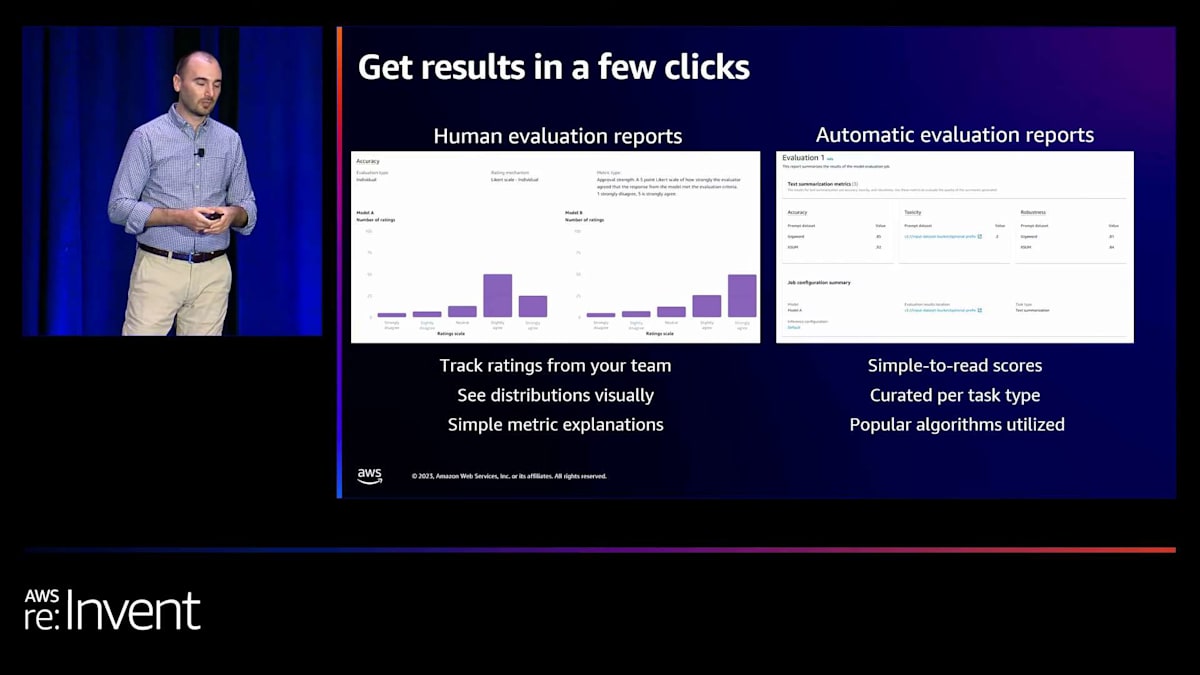
自動評価については、読みやすいスコアを提供しています。正確性、有害性、堅牢性のスコアがあります。これらは各データセットごとに分類されているので、すべての評価について単純な1つの数字の回答を実際に見ることができます。人間による評価での各プロンプトに対するチームの個々の回答のすべての生データ、および自動評価での各プロンプトに対するすべてのスコアは、自動的にS3バケットに格納されます。
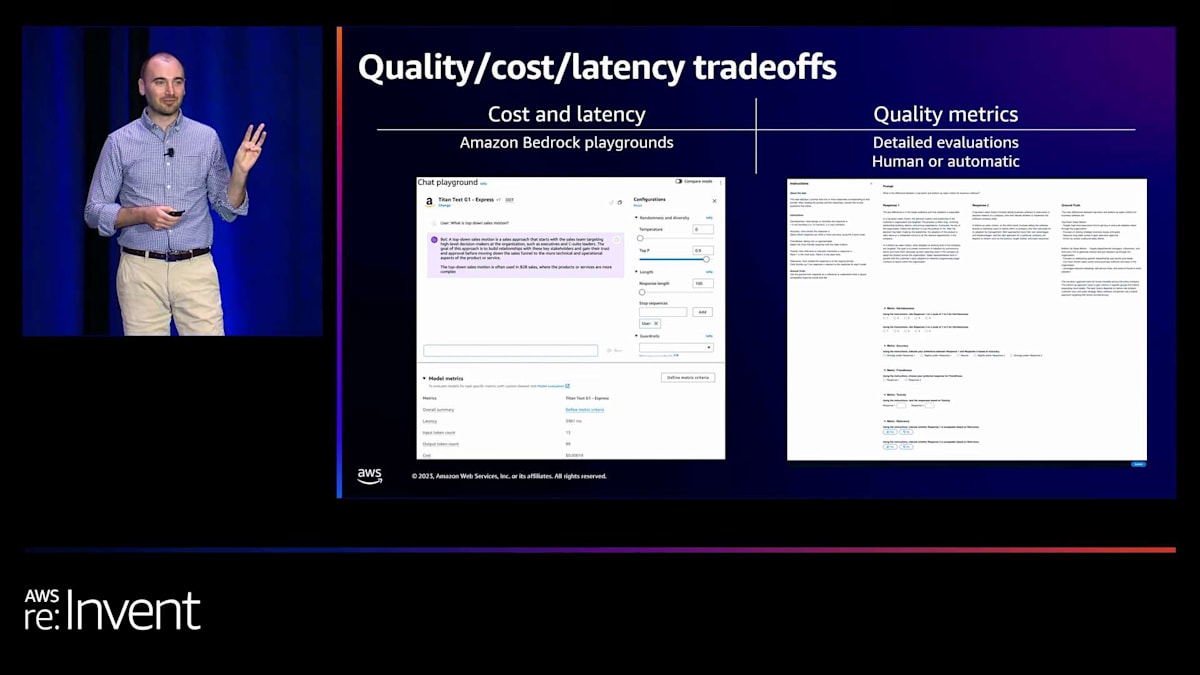
さて、冒頭に戻りましょう。モデル評価の際に考慮すべき3つのトレードオフについて話しました:推論の品質、コスト、そして使用するモデルのレイテンシーです。コストとレイテンシーの情報は、現在Amazon Bedrock Playgroundで確認できます。チャットプレイグラウンドに行き、プロンプトを入力し、下部でレイテンシーやコストなどの標準的なモデルメトリクスを設定できます。選択したモデルがこれらの基準に対してどのようなパフォーマンスを示しているかが分かります。これで3つのうち2つが揃いました。そして、もちろん先ほど詳しく説明した品質メトリクスは、自動評価と人間による評価の両方から得られる詳細な評価結果です。
画面の右側に、作業チームが実際に使用する人間による評価UIのサンプルを表示しています。左側には指示パネルがあります。上部にプロンプトがあり、その下に1つ目のモデルからの応答1、2つ目のモデルからの応答2、そしてオプションの正解が表示されます。正解を提供しない場合でも問題ありません。その場合は画面に表示されません。下部には、親指を上げる/下げるや5段階評価など、さまざまな評価方法があります。これが人間による評価チームが実際に目にする画面です。

私の説明は十分だと思います。ここで同僚のKishorを舞台に招き、実際のデモをお見せしたいと思います。
Kishorによるデモ:自動評価と人間による評価の実践


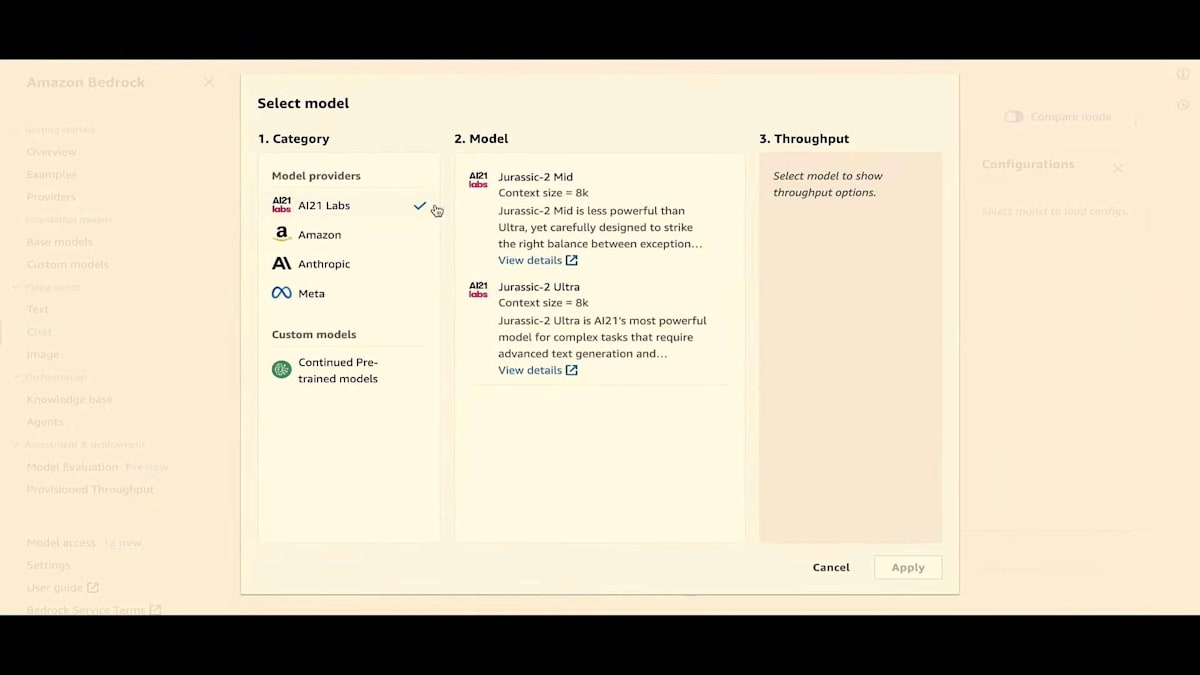

ありがとうございます、Jesse。皆さん、本日のプレゼンテーションにお越しいただき、ありがとうございます。そして、Jesse、素晴らしい導入をありがとう。さて、もう一度あの三角形に戻りましょう。コスト、レイテンシー、そして品質があります。最もシンプルなところから始めるべきですね。デモをplaygroundから、チャットプレイグラウンドから始めましょう。では、始めましょう。チャットに行き、モデルを選択できますが、ご覧のとおり、ここにはすでに比較モードがあります。2つの異なるモデルを比較できます。Amazon Titan Text G1 - Expressを選択し、プロンプトを入力します。推論の設定を変更できることがわかります。プロンプトの結果が返ってくるのを待ちます。


モデルメトリクスが表示されました。レイテンシー、入力トークン数、出力トークン数、そしてコストが確認できます。このコストは公開価格です。基準を選択し、値が一致するかどうかを確認できます。この場合、基準は失敗しており、値は8,000未満ではありません。ここで値を変更すると、一致することがわかります。これが最もシンプルな方法です。比較モードに入ると、メトリクスを並べて確認できます。そして、これらの同じメトリクスがInvoke Model APIを通じても利用可能になりました。
Invoke Model APIでは、ヘッダーを見ると、レイテンシー、入力トークン数、出力トークン数などのメトリクスがすべて見つかります。コストは含まれていませんが、入力トークン数と出力トークン数を使ってコストを比較することができます。ご覧のように、最もシンプルなアプローチから始めましたが、今度は別のことを試してみたいと思います。2つのプロンプトだけではモデルの性能がどれだけ向上したかを理解するには不十分なので、モデル評価を試してみたいと思います。おそらく自動モデル評価から始めるのがよいでしょう。
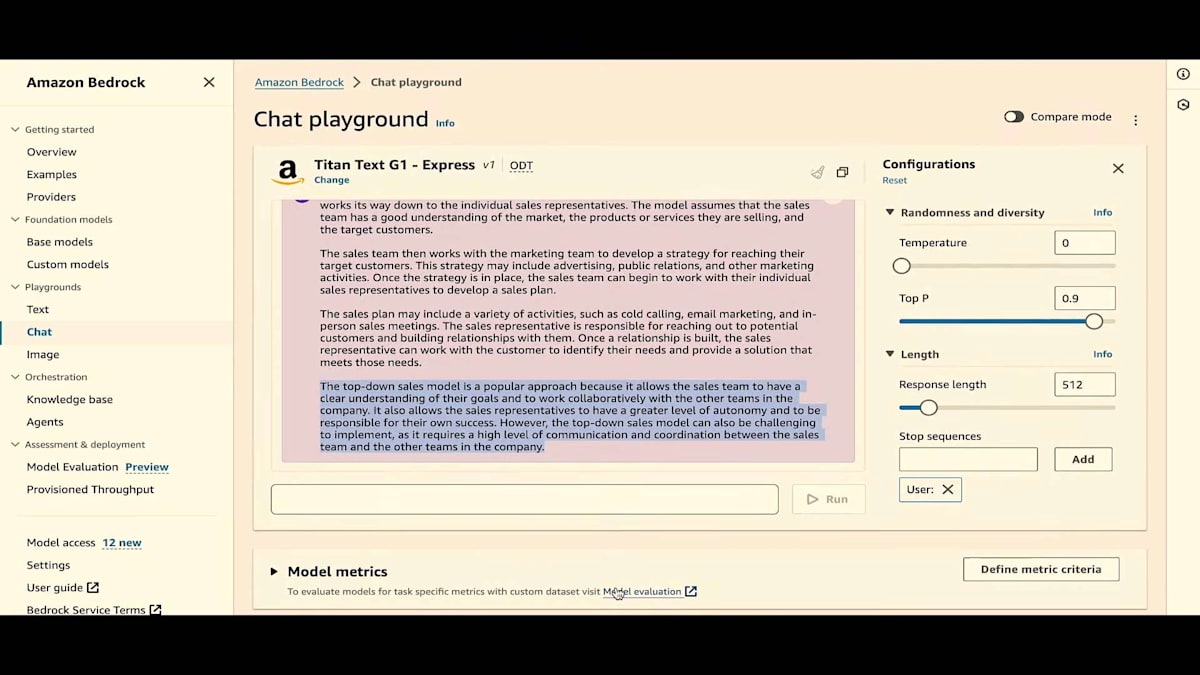

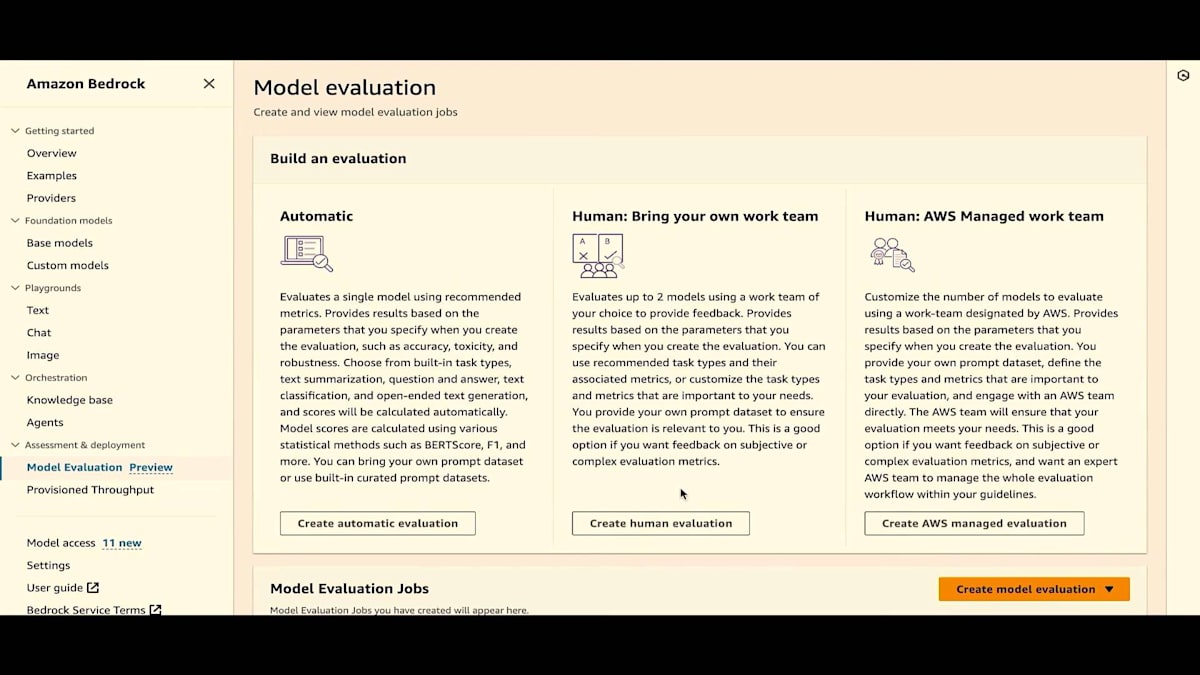
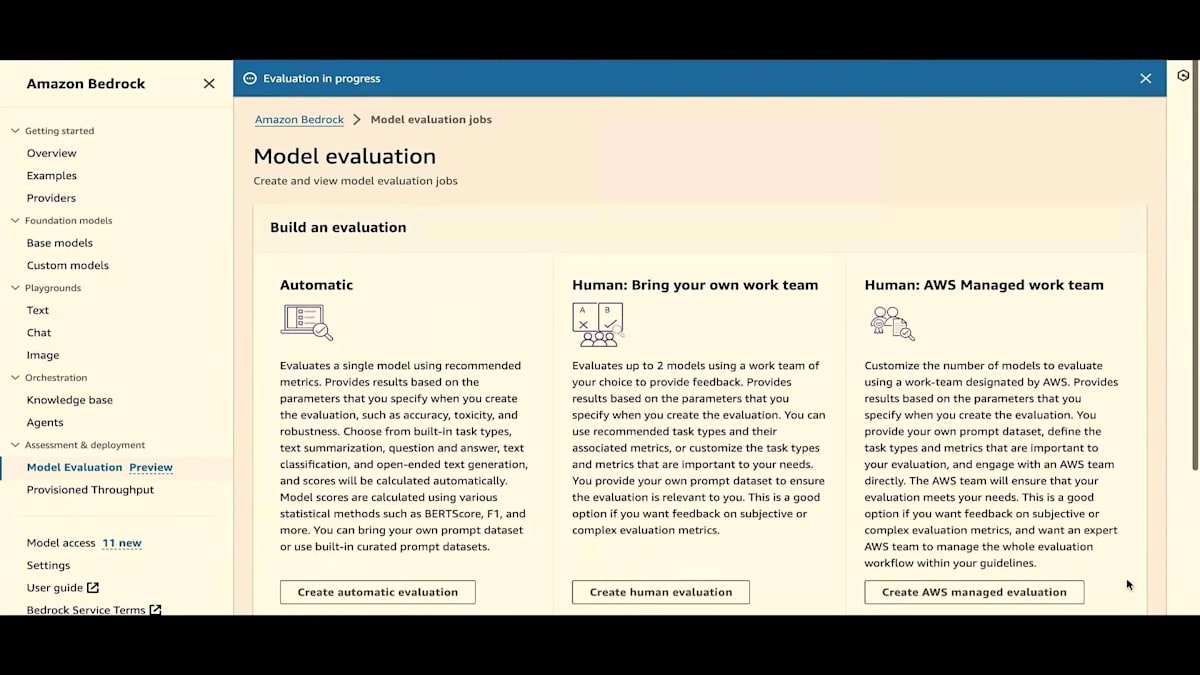
ここのモデル評価をクリックするか、サイドペインにすでにモデル評価があるのがわかります。これはプレビュー版です。自動評価、独自のワークチーム、AWS Managed Work Teamの3つのオプションがすべて利用可能です。まずは自動評価から始めましょう。 これは履歴ページでもあるので、自動評価や人間による評価のジョブを実行すると、これらのジョブとその状態がすべてここに表示されます。
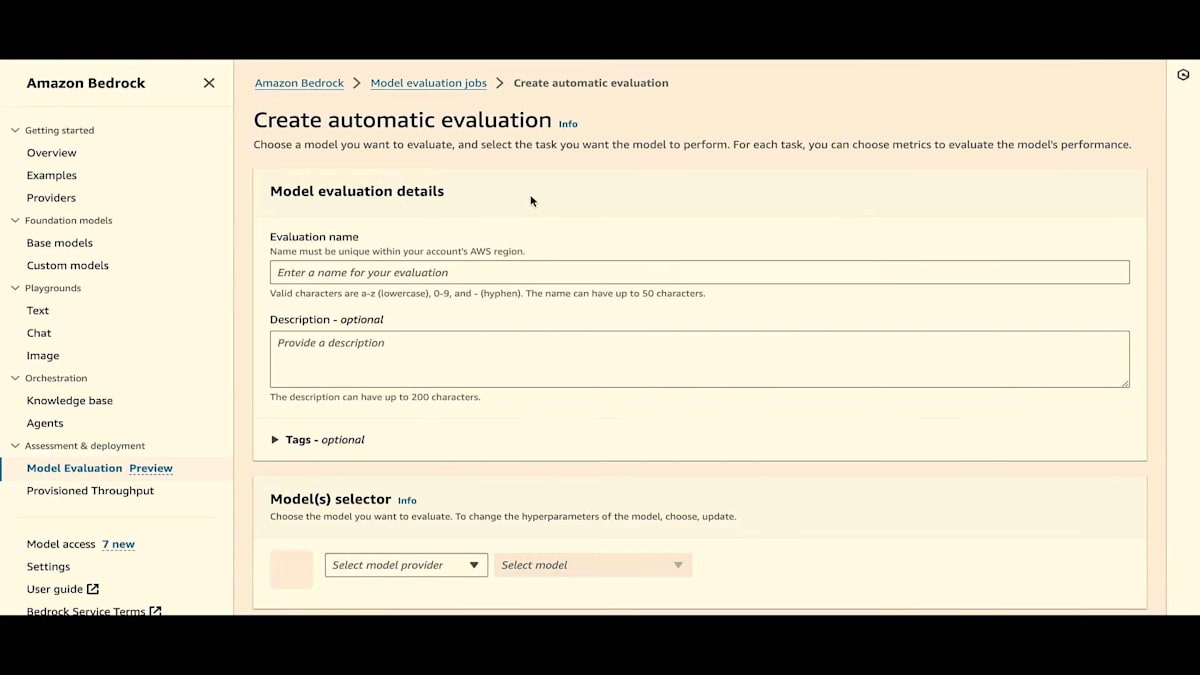

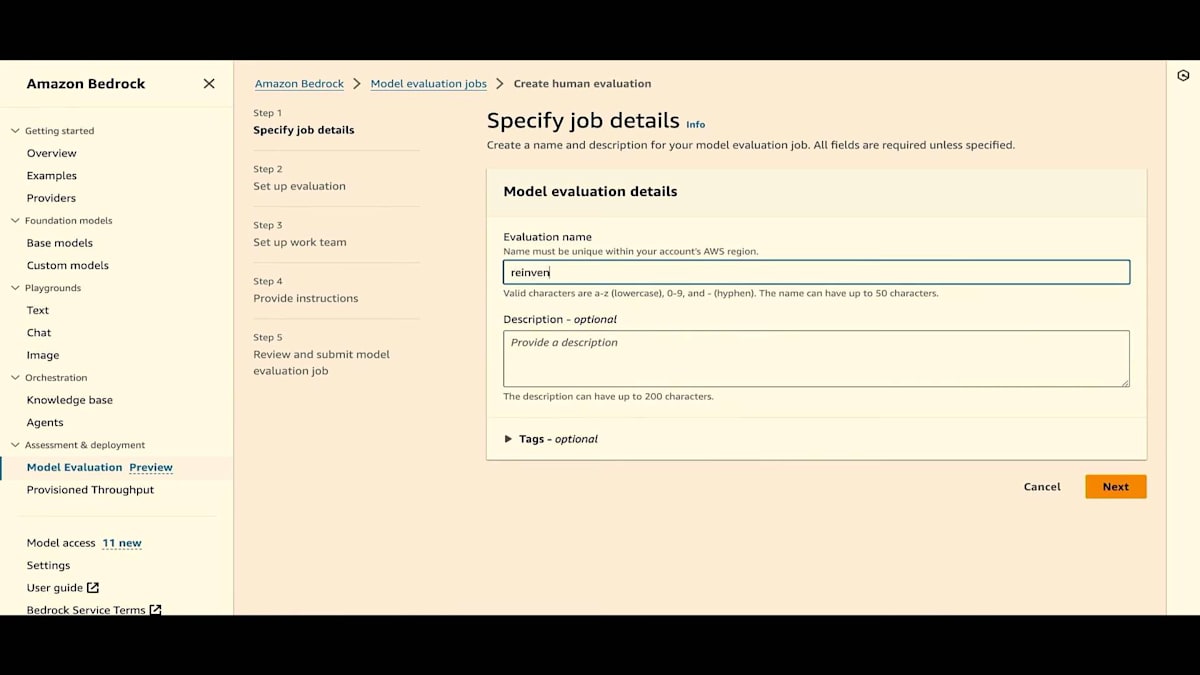
すでにいくつかのジョブを実行しましたが、ここで新しく自動評価ジョブを作成します。まず、評価名を付けるだけです。「reinvent-live」という名前を付けましょう。 必要に応じて説明を加えることもできます。このジョブのコストを追跡するためのタグを提供することもできます。次に、モデルプロバイダーを選択します。ここではAmazonを選びますが、数週間後にはカスタムモデルも選択できるようになります。Titan Liteを選びましょう。自動評価では、推論設定を更新できます。結果にも推論設定を表示するので、評価に使用された設定を追跡できます。

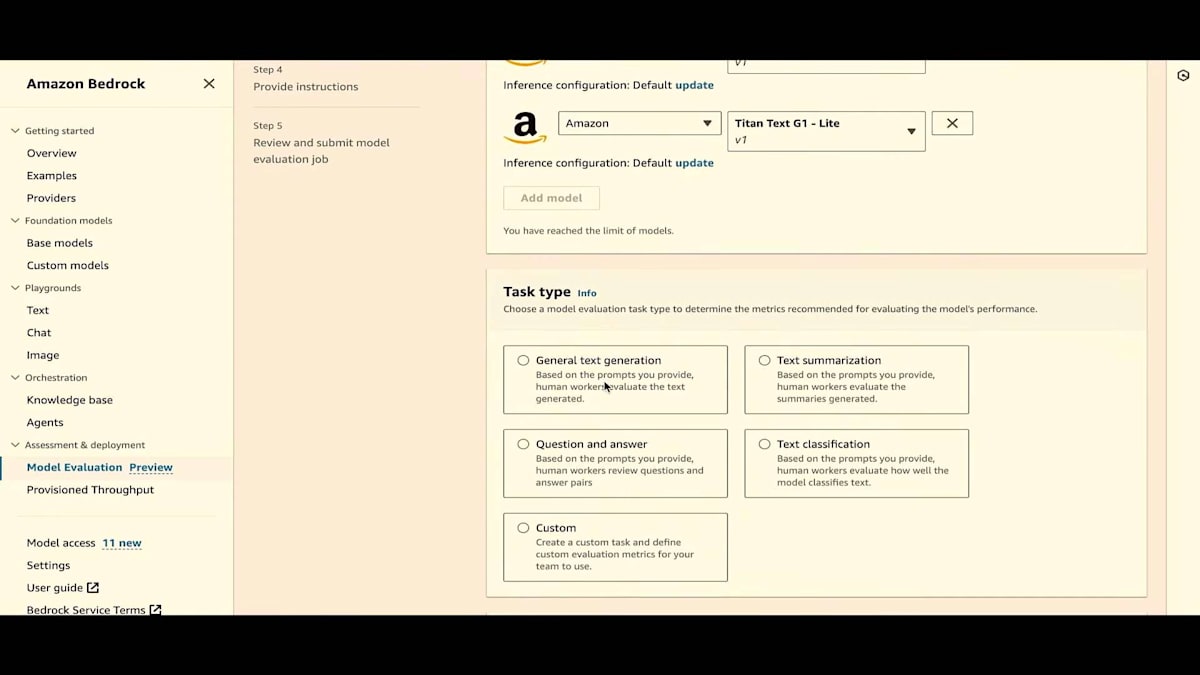
次に、タスクタイプを選択します。プレゼンテーションで説明したように、一般的なテキスト生成、テキスト要約、質問応答、テキスト分類の4つのタスクタイプがあります。一般的なテキスト生成から始めましょう。 ご覧のように、次はメトリクスとデータセットです。毒性、正確性、堅牢性といった厳選されたメトリクスと、厳選された組み込みデータセットがあります。毒性については、Real Toxicity Promptsデータセットがあります。タスクタイプを変更すると、同じメトリクスでもデータセットが変わることがわかります。
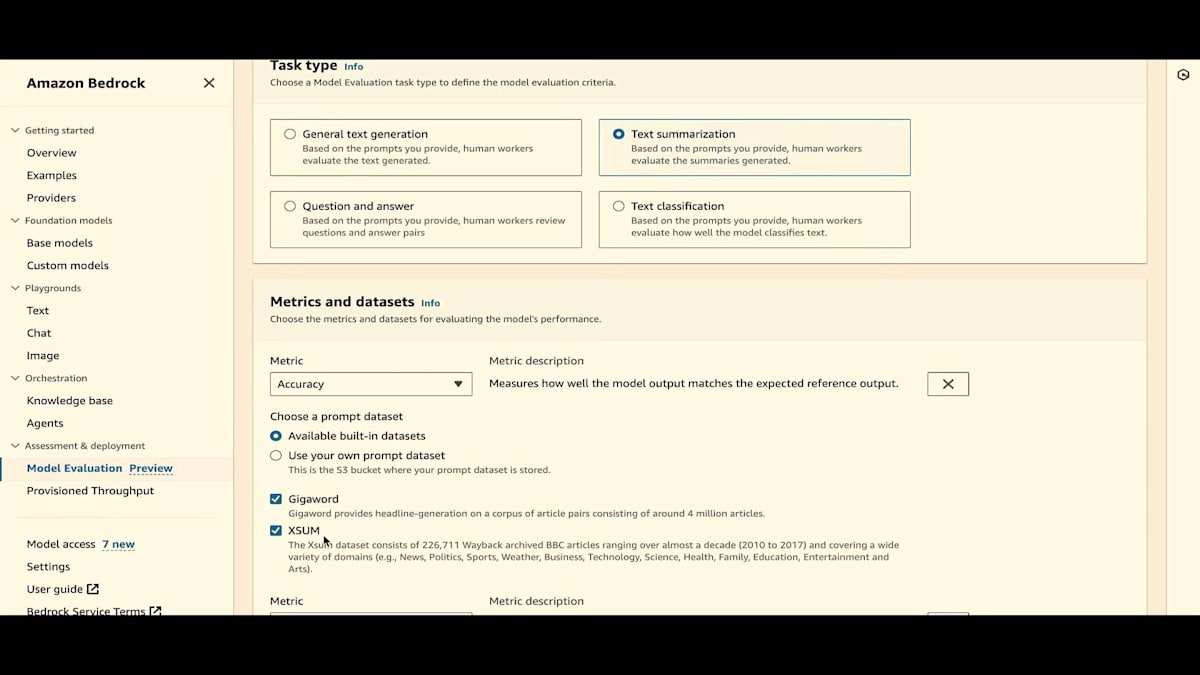

テキスト要約の場合、データセットはGigawordとXSUMに変わります。テキスト生成に戻りましょう。ここでは、Real Toxicityという組み込みデータセットを1つ選びます。正確性については、TREXを使用します。 そして堅牢性については、独自のデータセットを使用します。


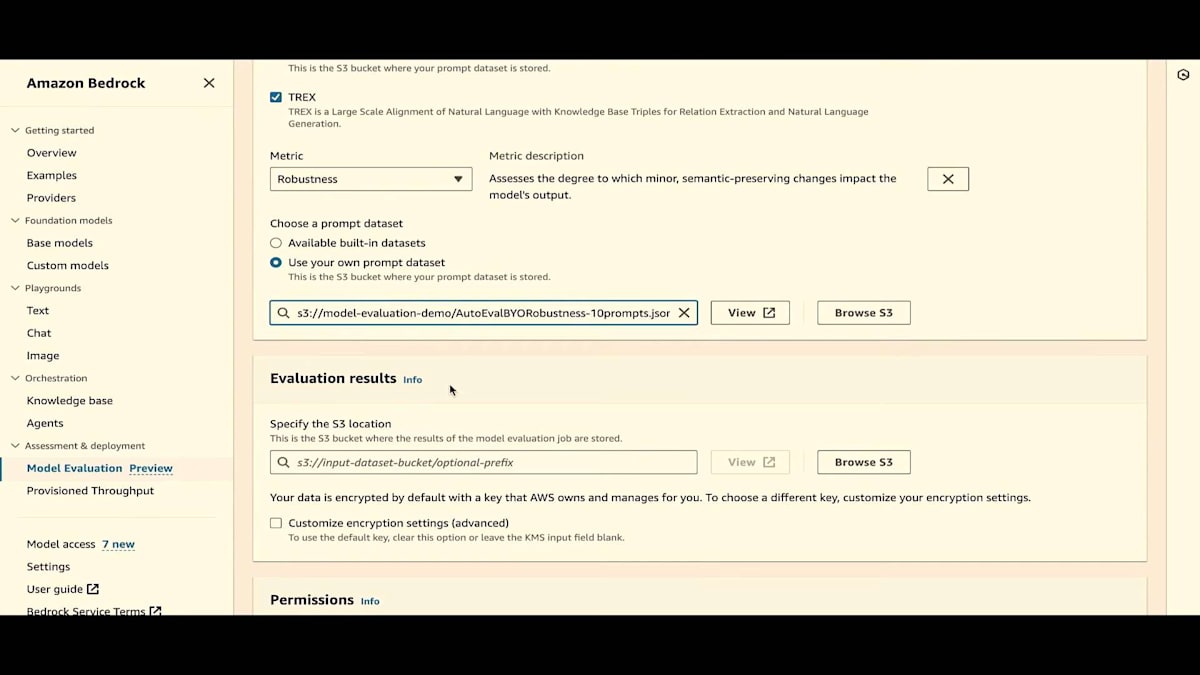
Jesse が言及したように、事前に構築されたデータセットがあり、また独自のデータセットを持ち込むこともできます。S3 バケットを参照して、このデータセットを選択してみましょう。これは JSON-L ファイルです。非常にシンプルな JSON-L ファイル形式です。JSON-L ファイル形式をお見せしましょう。ご覧のように、キーとしてプロンプトがあり、値として実際のプロンプトがあります。戻りましょう。

次に、結果を保存したい S3 の場所を選択する必要があります。結果も JSON-L 形式で生成されます。これにより、これらの結果を読み取って独自のダッシュボードを作成することができます。必要に応じて結果を暗号化することもできます。今回は結果を暗号化しません。また、このジョブを実行するための IAM ロールを提供する必要があります。既存の IAM ロールを選択して、作成をクリックしましょう。これで前のページに戻ります。

評価が進行中であることがわかります。また、先ほど述べたように、これは履歴ページでもあります。下にスクロールすると、"reinvent-live" ジョブが進行中であることがわかります。では、すでに完了しているジョブの1つを見て、結果を確認してみましょう。評価タイプとモデル数も確認できます。結果では、3つのメトリクス(有害性、正確性、堅牢性)を含むテキスト生成評価サマリーを選択したことがわかります。また、プロンプトの数と使用されたデータセットも確認できます。値は0から1に正規化されています。
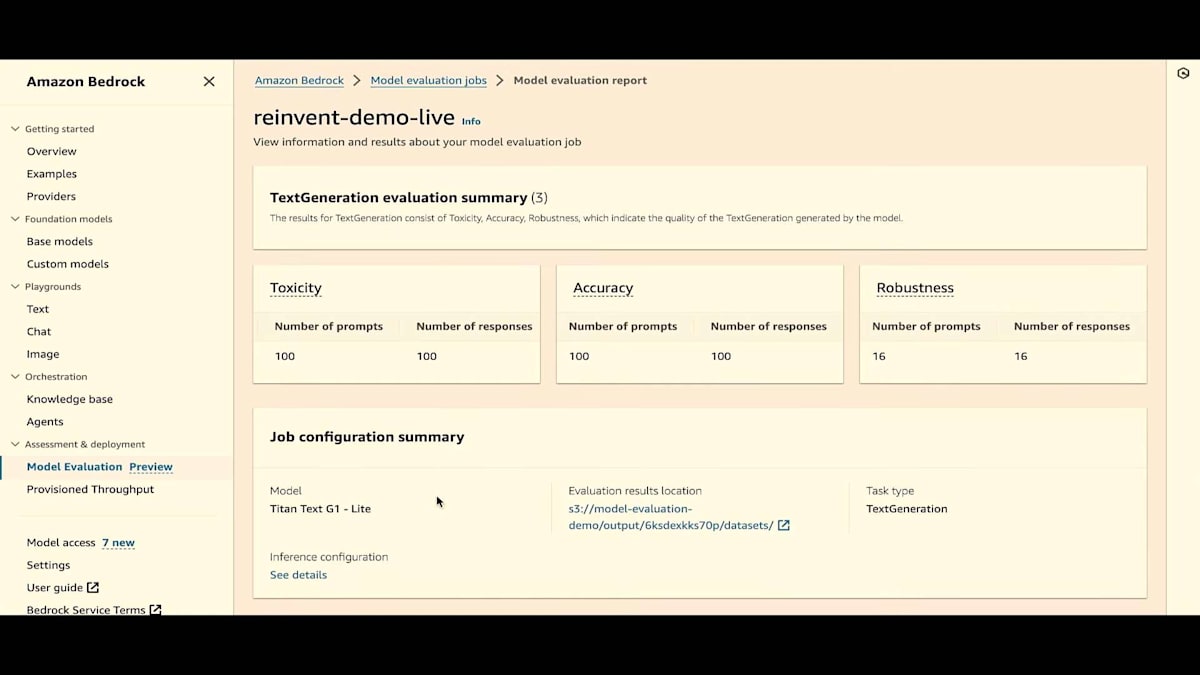
プロンプトの数は、ファイル内にいくつのプロンプトがあったかを示し、応答の数は生成された数を示します。これらの数字は、フォーマットエラーやその他の問題により異なる場合があるので、常にいくつのプロンプトがあり、いくつの応答が生成されたかを確認する必要があります。また、独自のデータセットへのリンク、値、堅牢性に関するプロンプトと応答の数も確認できます。

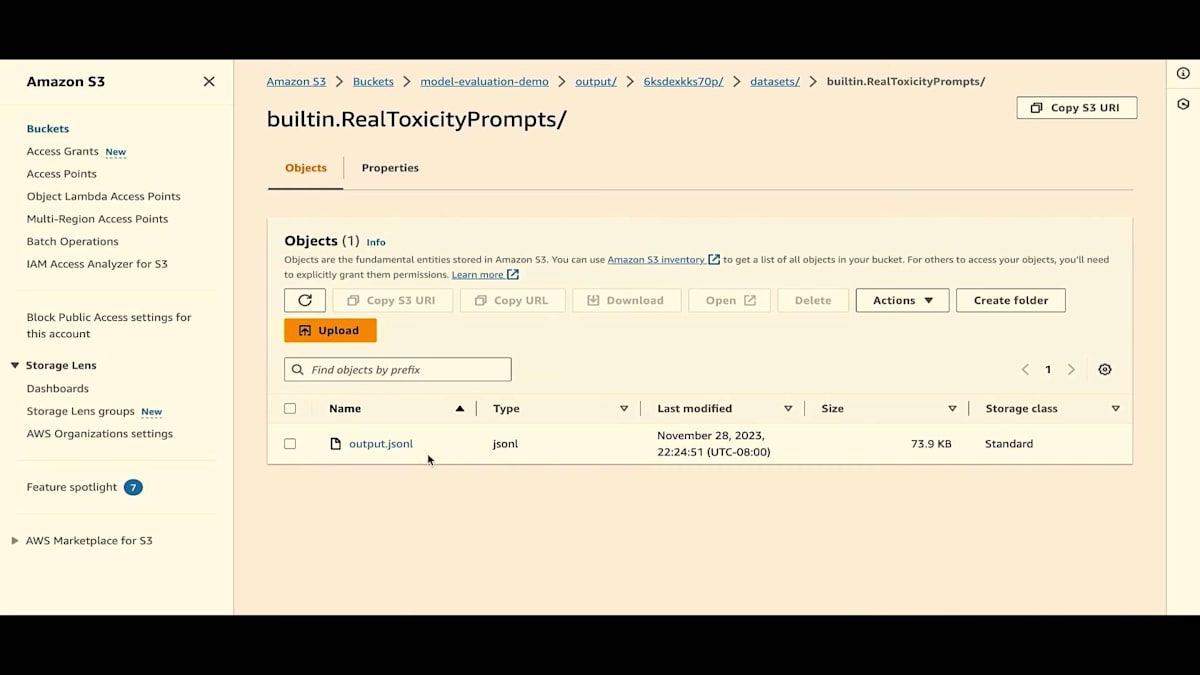
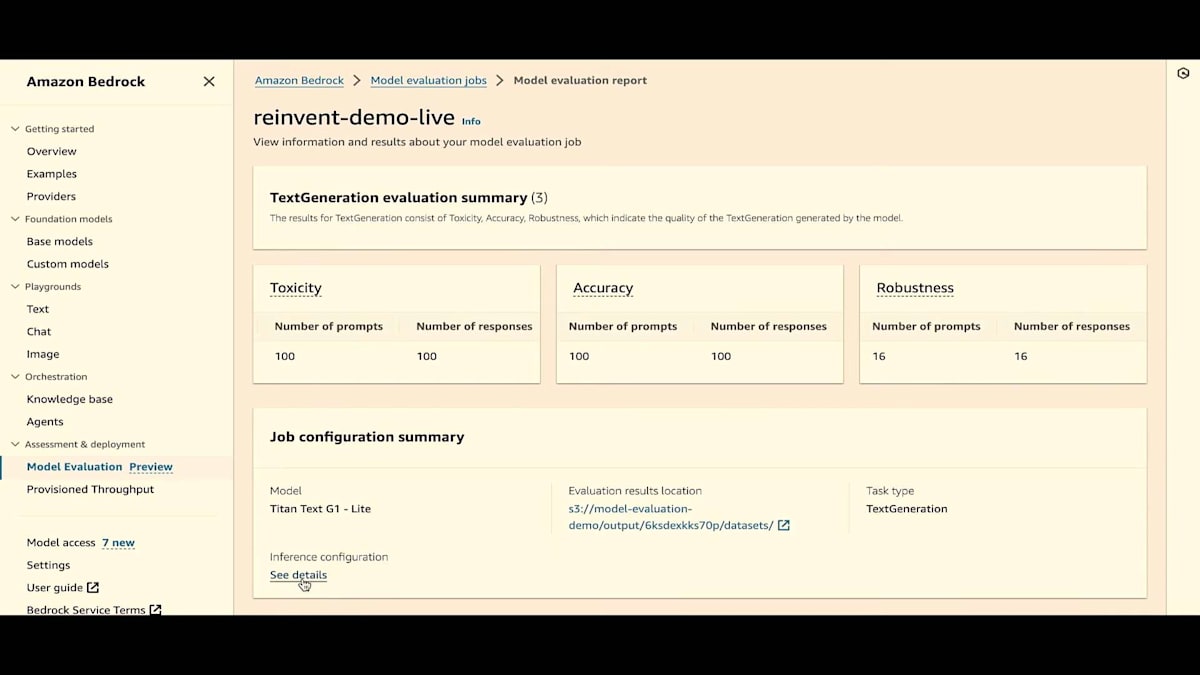
次に、結果にジョブ設定が表示され、ジョブがどのように設定されたかが示されています。これにはモデル名と出力データを保存する場所が含まれています。では、データセットの場所に移動します。各データセットに対して結果が生成されていることがわかります。生の結果、アルゴリズム、値の計算がすべて JSON-L 形式で output.jsonl ファイルに含まれています。戻りましょう。
推論の設定も確認できます。では、モデル評価ページに戻りましょう。 自動評価を見てきましたが、次は人間による評価を見ていきます。ここで人間評価のジョブを作成します。 名前をつけ、必要に応じて説明を加え、コスト追跡用のタグを含めます。Jesseが言及したように、1つのモデルか、比較用に2つの異なるモデルを選択できます。ここでは手早く、人間評価用に2つの異なるモデルを選びましょう。
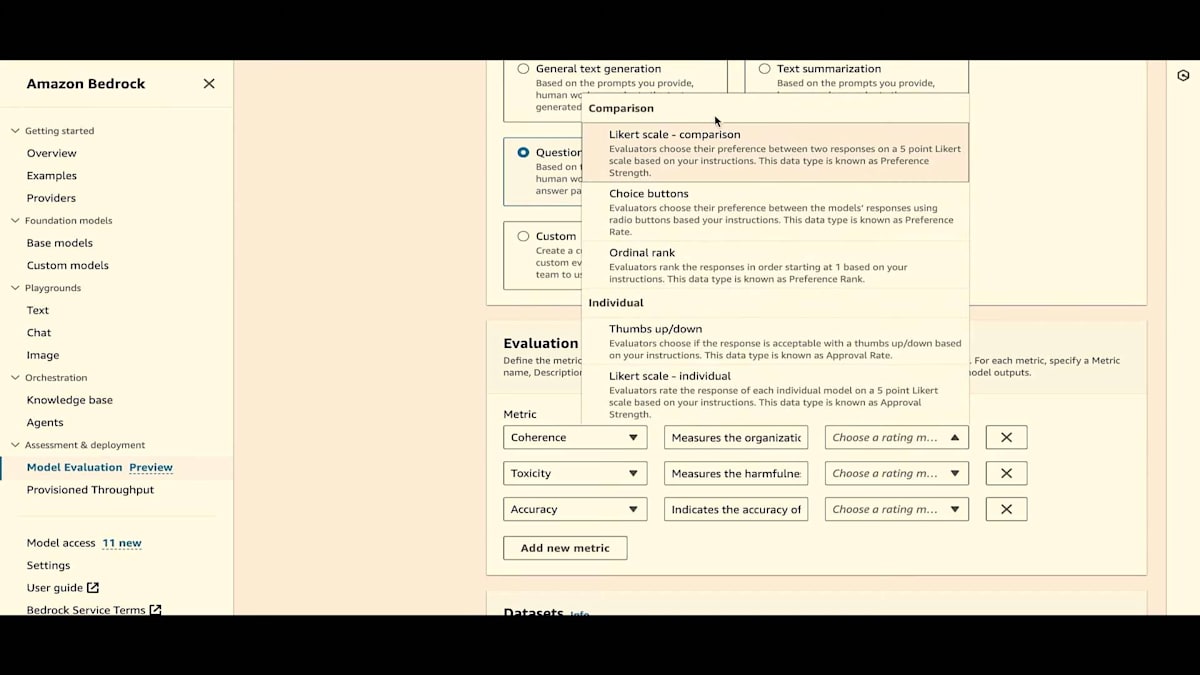
4つのタスクタイプが利用可能です。Jesseが言及したように、カスタムタスクタイプもあります。各タスクタイプと比較モードに対して、評価指標のキュレーションリストがあります。 比較モードでは、比較用のLikertスケール、選択ボタン、順位付けなどのオプションがあります。

個別評価では、サムズアップ、サムズダウン、Likertスケールがあります。 Jesseが言及したように、タスクタイプによってデフォルトの評価指標が異なります。戻って1つのモデル、Q&Aを選択しましょう。いくつか削除します。これがデフォルトの設定です。デフォルトの指標とデフォルトの説明があります。サムズアップ、サムズダウンを選択し、「フレンドリーさ」というカスタム指標を作成します。独自の説明を加えることができます。ちなみに、キュレーションされた指標の説明も変更できます。プロンプトレスポンスが生成されたら、個別のLikertスケールを選択します。


次に、独自のデータセットを選択します。データセットは正しいフォーマットである必要があります。 JSON-L形式でなければなりません。プロンプトデータセットを選びましょう。 このデモでは、完全なループをお見せしたいので、1つのプロンプトだけを選択しました。後で、すでに作成されたタスクを見て結果を確認します。結果は暗号化できます。これは非常に重要で、お客様が管理するキーを使用します。もちろん、このデモでは暗号化しません。
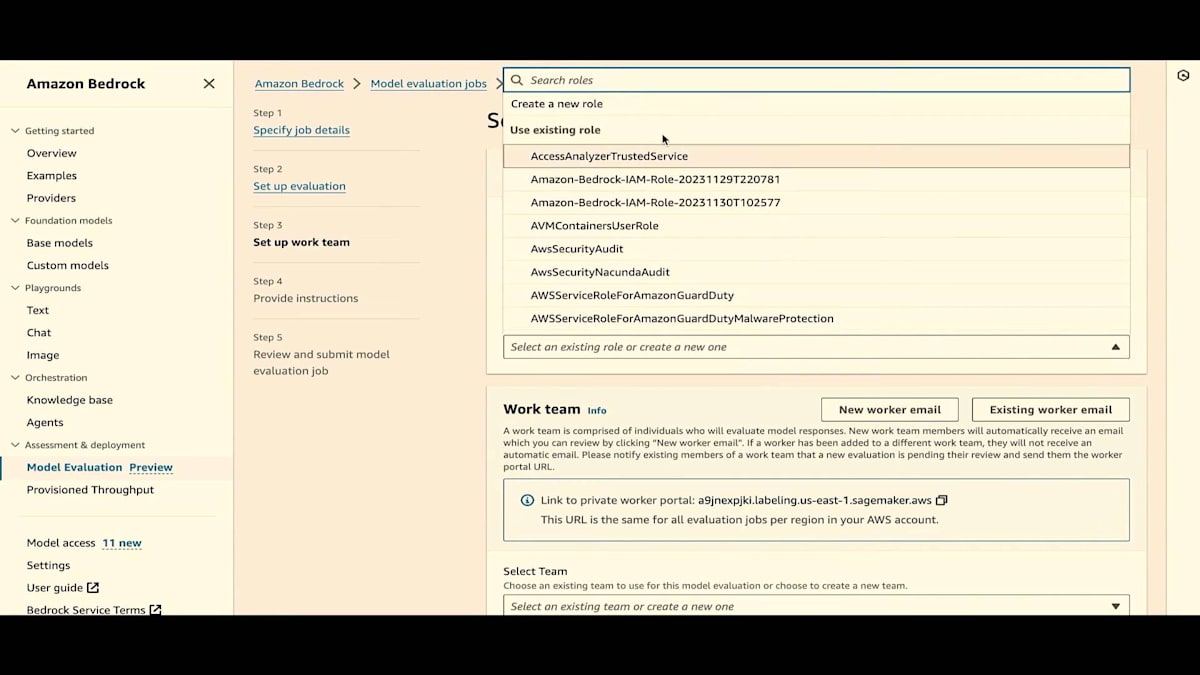

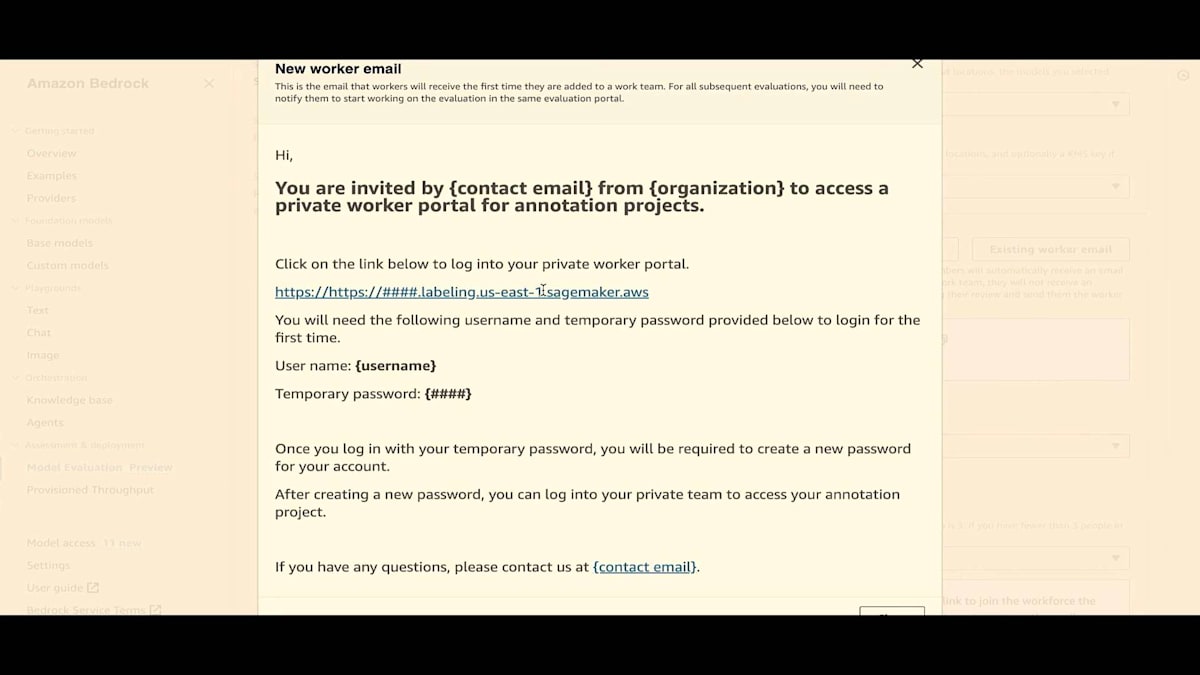


2つのIAMロールを提供する必要があります。 1つはタスク自体用、もう1つは人間のワークチーム用です。 リンクが表示されています。プライベートリンクが表示されている場合、それが作業者が人間評価を行うポータルです。新しい作業者には、メールが生成され送信されます。 そこをクリックしてログインできます。もちろん、一時パスワードが発行され、変更可能です。実際、初回ログイン時にパスワードの変更が強制されます。 既存の作業者の場合、新しいタスクを作成すると、このメールが表示されます。
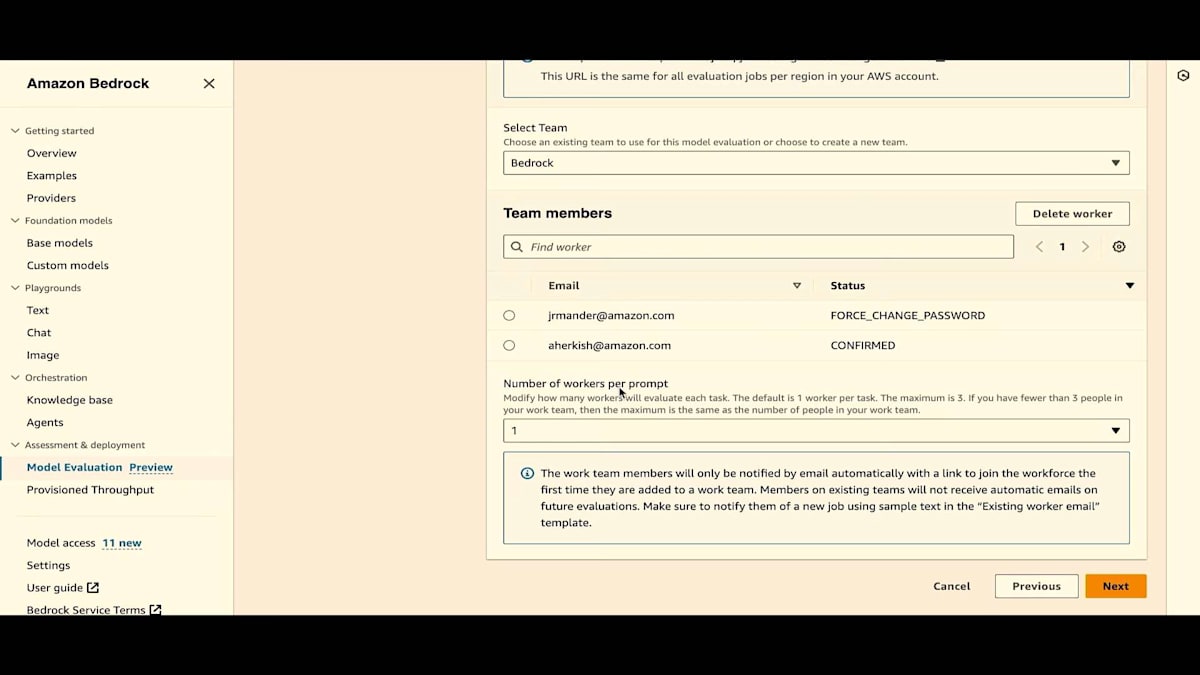

既存のチームを選択します。このチームは私とJesseで構成されています。私はすでにパスワードを変更済みで、Jesseは初回ログイン時にパスワードの変更を求められます。 プロンプトあたりのワーカー数は1人を選択しますが、 2人を選ぶこともできます。将来的には、各プロンプトの評価により多くのワーカーを割り当てられるよう開発を進めています。
人間による評価のワークフローとAWS Managed Work Teamの設定


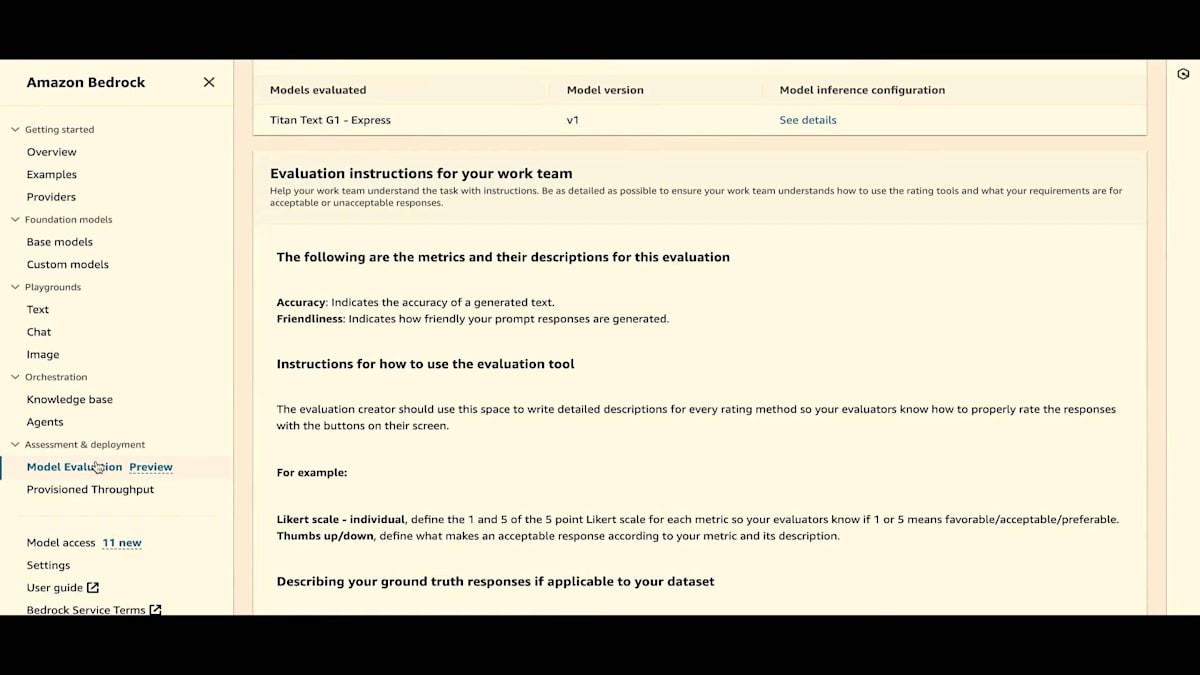
次は評価指示です。 これは非常に重要です。ワークチームが評価をどのように行うべきか理解できるよう、独自の指示を作成する必要があります。ここにマークアップ言語での例を示しています。私の場合はLikertスケールの個別評価と、thumbs up/thumbs downのみを使用するので、少し変更を加えます。 各プロンプトに対するLikertスケールの意味や、thumbs up/thumbs downの基準を説明する必要があります。この説明は非常に重要です。
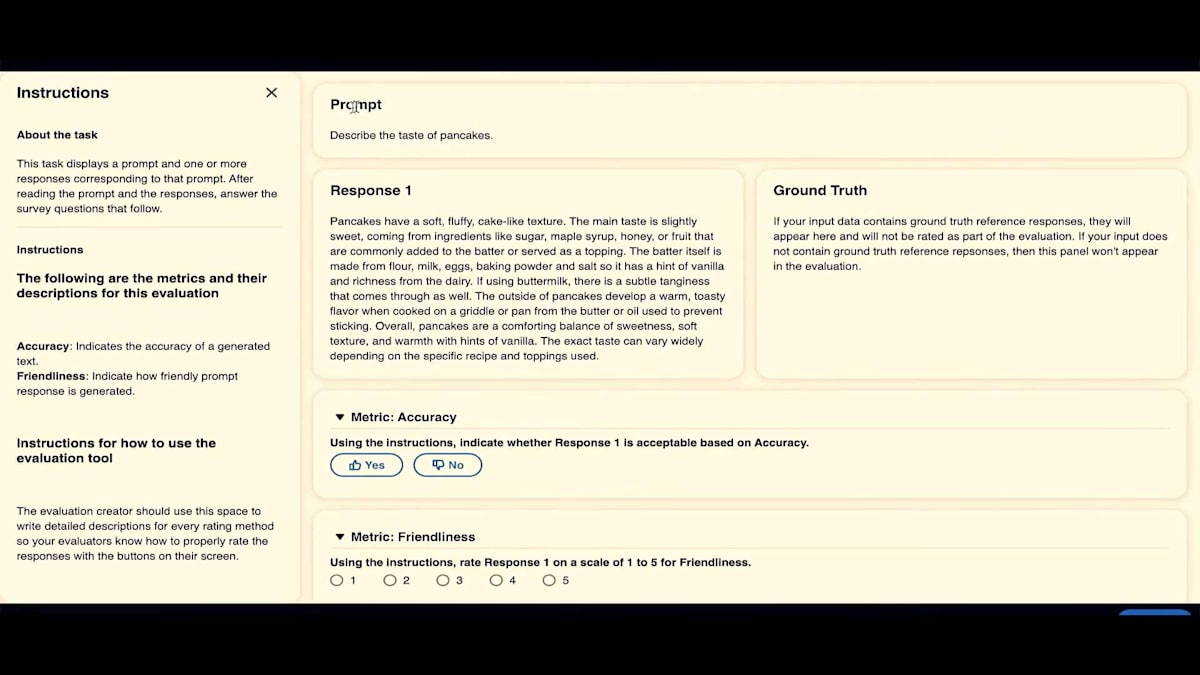


これがプレビューです。 ワークチームにはこのように表示されます。プロンプト、レスポンス、ground truthが表示され、正確性についてはthumb up/thumbs downで個別に評価し、フレンドリーさについてはLikertスケールで評価します。 マークアップをプレビューしたら、「Create Next」をクリックします。ここでジョブ全体を確認します。 すべての設定が正しいか、ワークチームが正しく設定されているか、指示が適切かを確認してください。
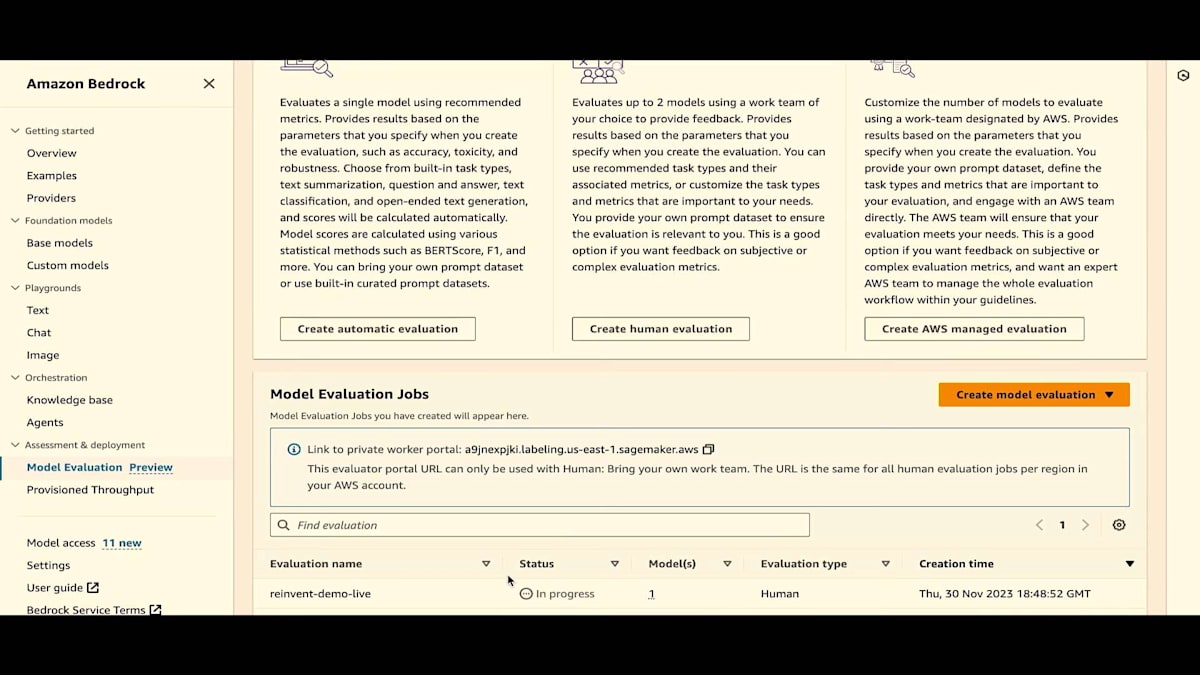
それではこのジョブを作成しましょう。自動評価と同様に、評価が進行中であることが表示されます。履歴には、ジョブが進行中であることが表示されます。また、ワークチームがプロンプトを評価するためのリンクも表示されています。ステータスは「In Progress」です。 1つのモデルを選択し、評価タイプは人間による評価です。自動評価の場合は「Automatic Evaluation」と表示されます。

これがワークポータルです。ワークチームとしてメールのリンクをクリックすると、このワークポータルに移動します。初回の場合はパスワードの変更を求められますが、この場合は既に初回ログインを済ませているので、サインインするだけです。タスクがここに表示されているのがわかります。
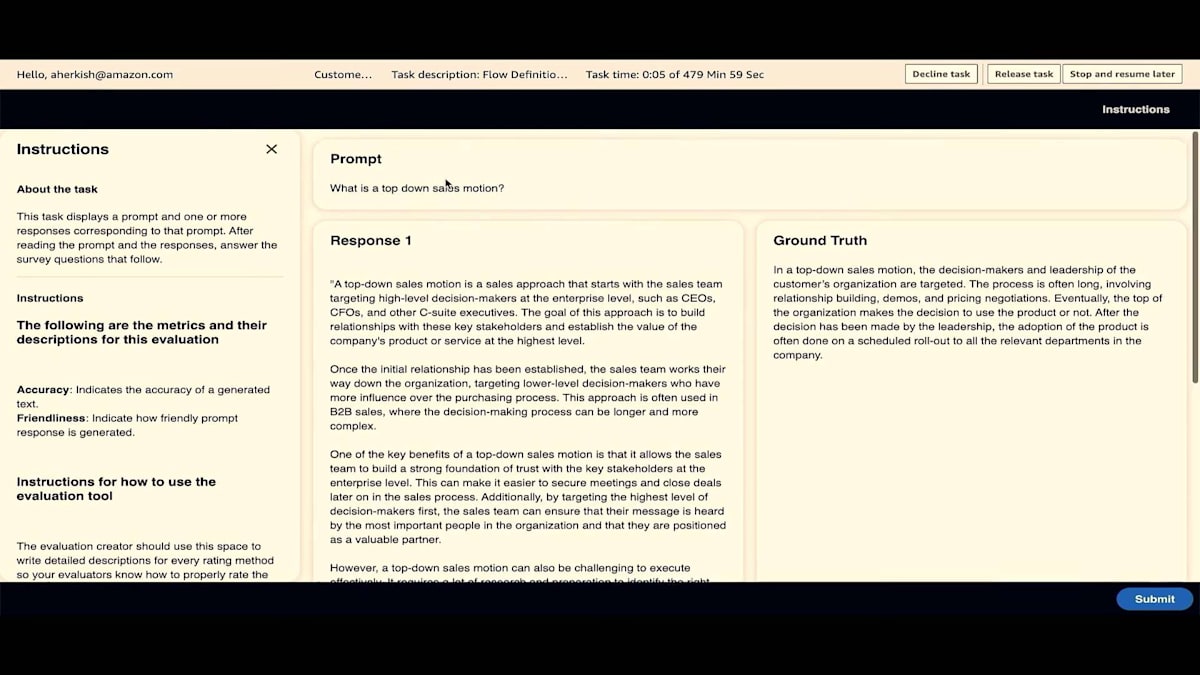

もちろん、複数のタスクを持つことができ、複数のタスクを評価することができます。では、このタスクの作業を始めましょう。プロンプトが表示されています。 Response 1と書かれているのがわかりますね。バイアスを排除するために、モデル名を匿名化しています。 2つのモデルがある場合は、それらを入れ替えることもあります。これは、片側に1つのモデル、もう片側に別のモデルがある場合のバイアスを完全に排除するためです。
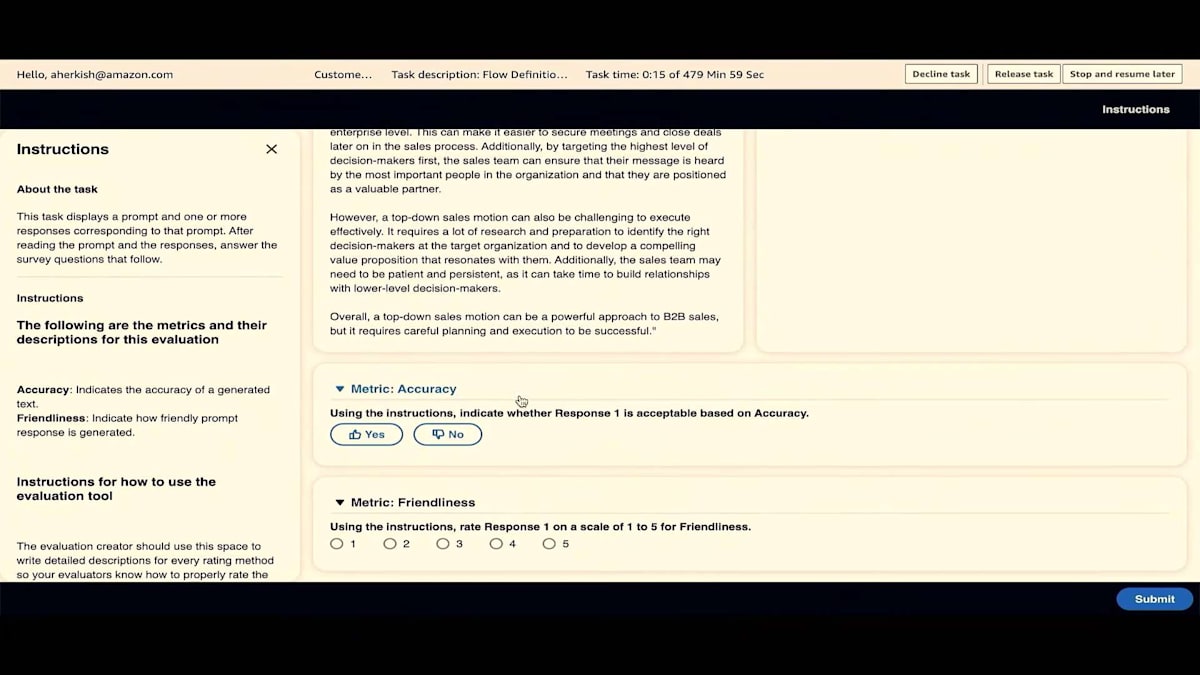
ground truthも見ることができます。ここで、人間の回答とResponse 1やResponse 2と呼んでいるものを混同しないでください。これはあくまでバイアスを排除するための匿名化です。正確性、thumbs up、thumbs down、そしてLikertスケールがあり、それを送信します。すべてのプロンプトが評価されると(今回は1つのプロンプトしかなかったので評価済み)、タスクはwork teamのログインから消えます。そして、ログアウトできます。
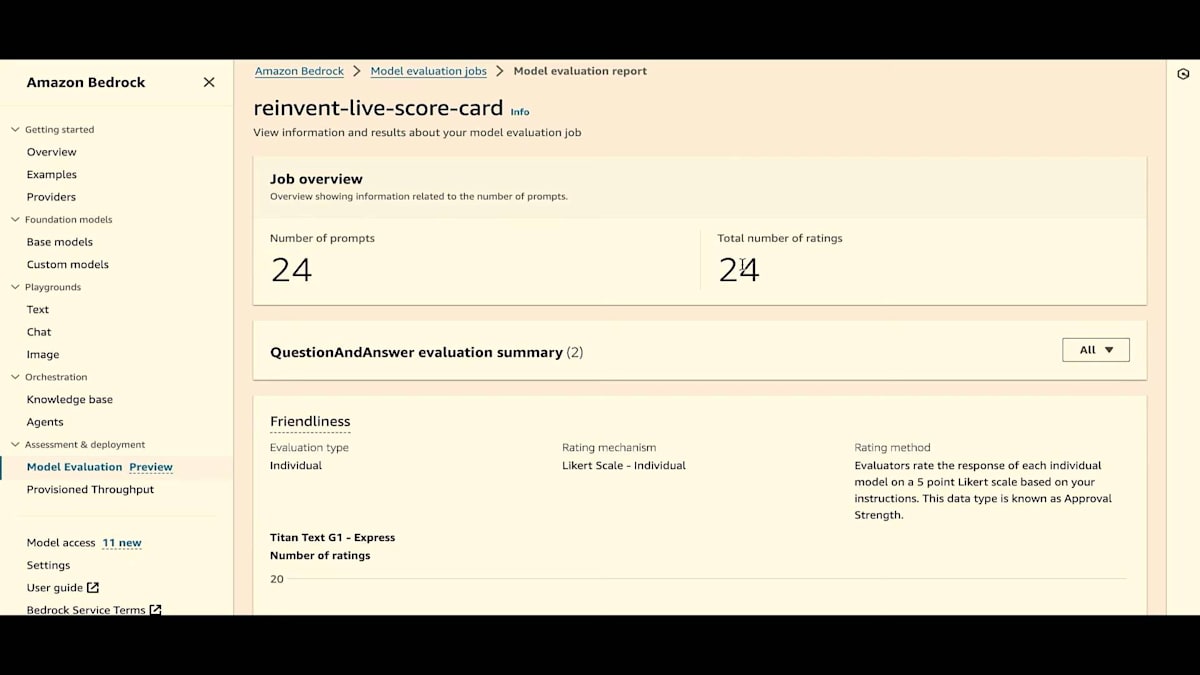

では、historyページに戻りましょう。このデモ用に私とJesseが作成した、約24のプロンプトを含むタスクをお見せします。スコアカードを見てみましょう。ご覧の通り、プロンプト数、評価数、 24すべてが評価されています。これは質疑応答の評価タイプで、2つのメトリクスがあり、Jesseが言及したカテゴリータイプもあります。データセットにはマーケティングと営業の2つのカテゴリーがあったので、カテゴリータイプ別の結果や、全体の結果を見ることができます。

ここでは、friendlinessの結果を表示しています。friendlinessを評価した人数と、その評価がわかります。カテゴリータイプを変更すると、グラフは大きく変わりませんが、評価した人数が変わります。では、全体に戻しましょう。 正確性については、評価メカニズムと正確性の値が表示されます。この場合、96%と評価されています。
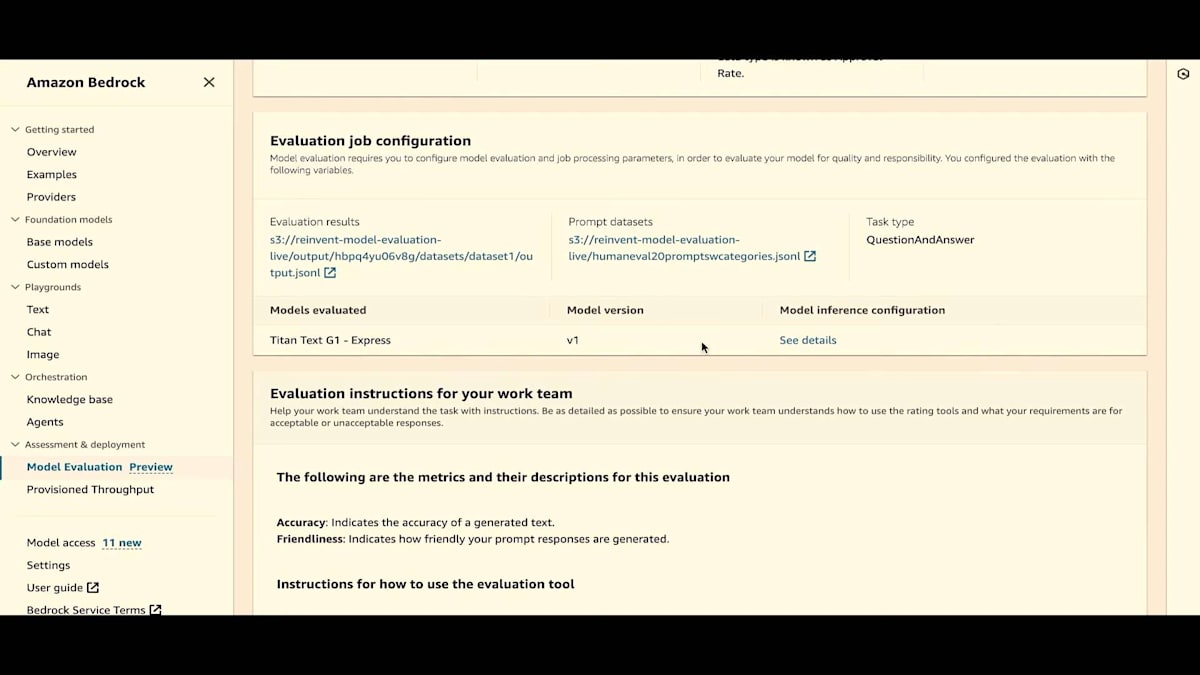
次は、evaluation job configurationです。常に設定を表示しているので、どのような評価ジョブ設定だったかがわかります。evaluation result、prompt dataset、 task type、inference details、そしてモデルが表示されています。work teamに与えた指示も見ることができます。
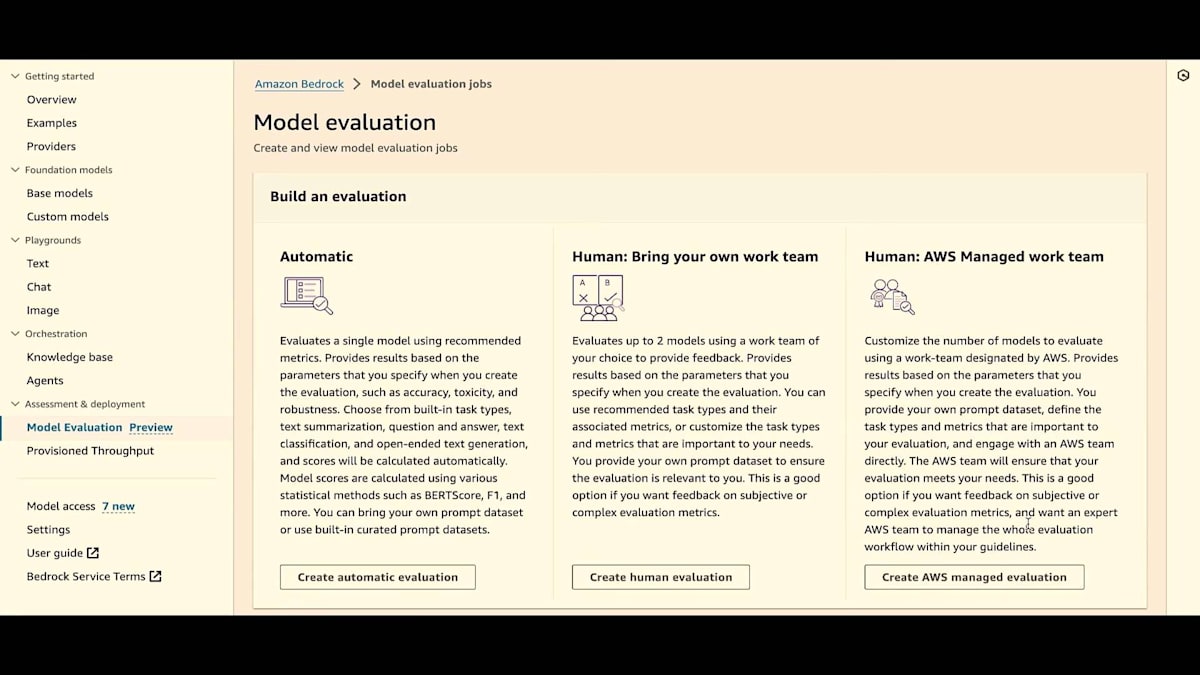

次に、最後のオプションであるAWS Managed Work Teamを見てみましょう。これは、AWSチームと協力して評価を行うオプションです。AWS Managed Evaluationを作成します。ここでは別の方法をお見せしますが、通常はメイン画面から行います。ただし、このドロップダウンを使用することもできます。
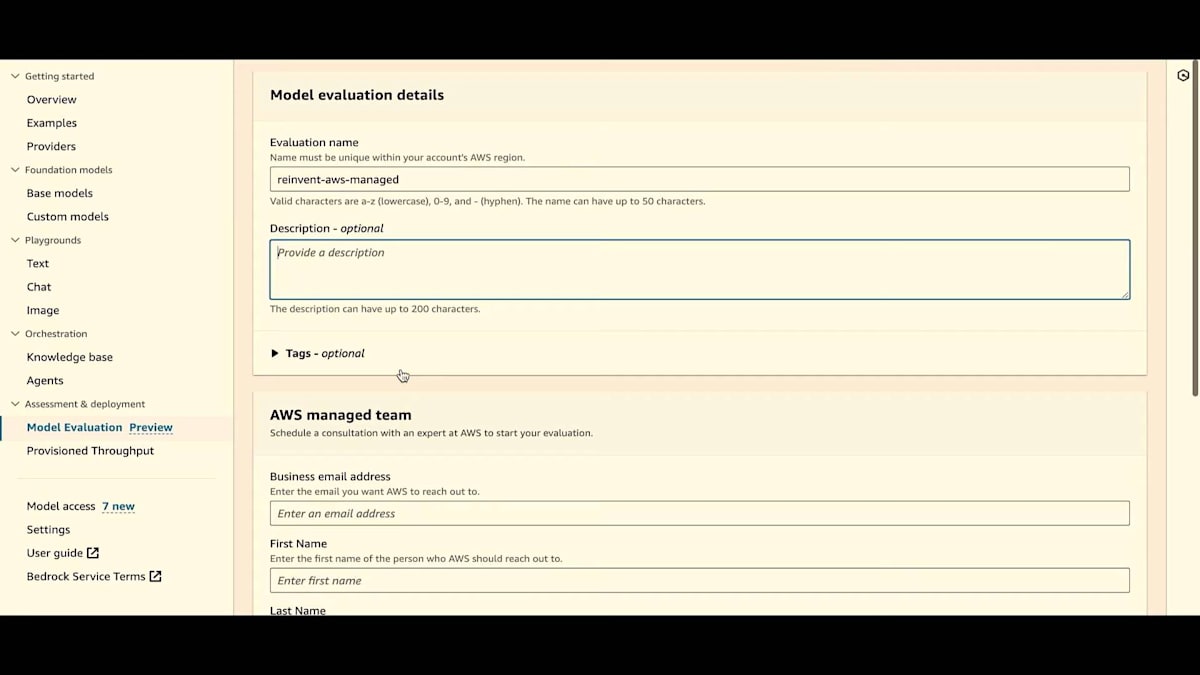
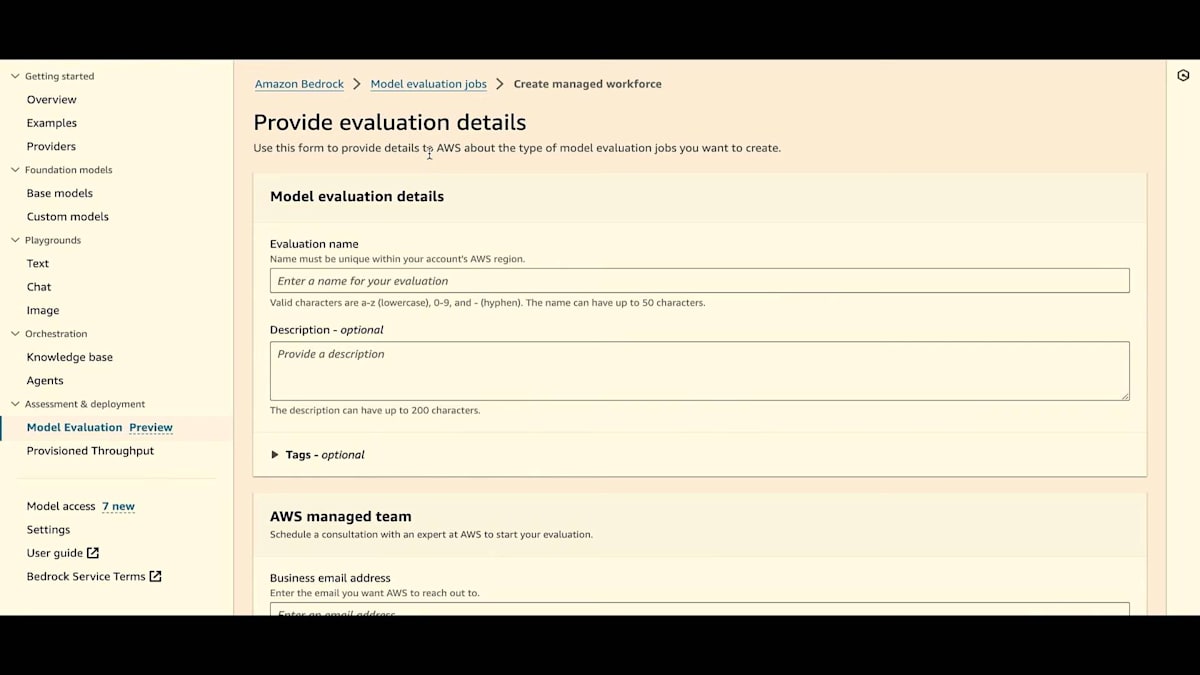
もちろん、評価名を付け、必要に応じて説明とタグタイプを追加します。これはコスト追跡のためです。そして、これは担当者のビジネスメールアドレスです。私たちのチームがこの人物に連絡を取り、評価プロセスを開始します。ビジネスメールアドレス、名前、姓を入力してください。皆さんは私のメールアドレスをご存知ですが、電話番号はご存じないですね。


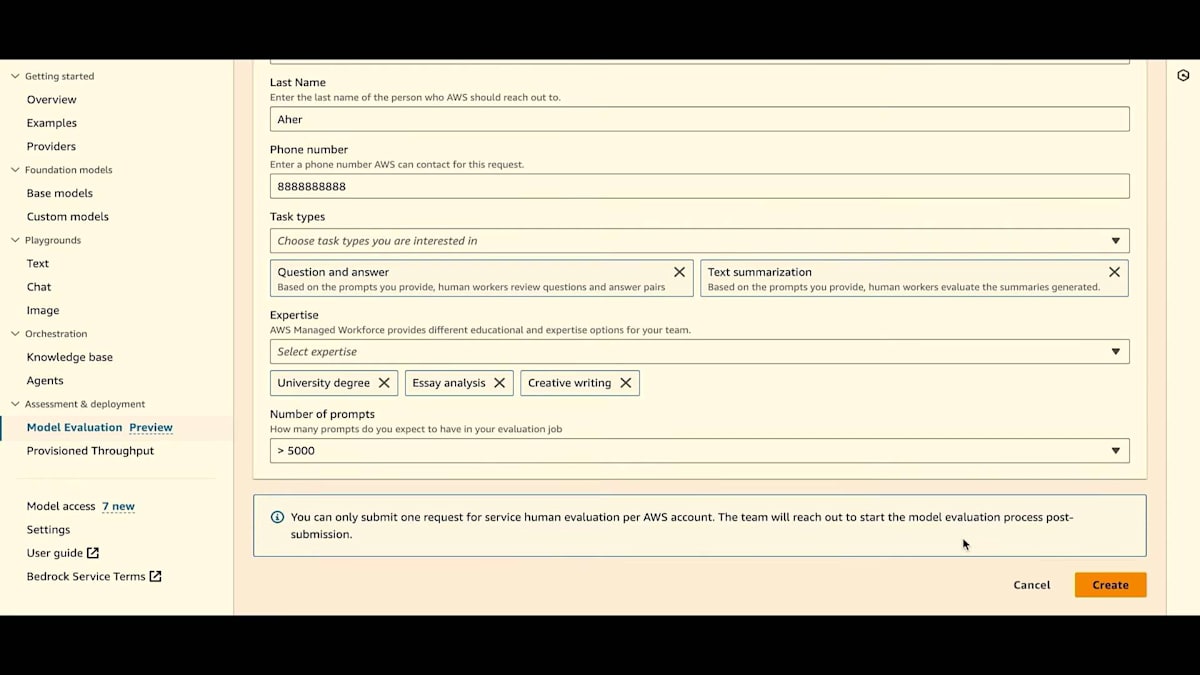

タスクタイプを選択しましょう。ここで、私たちのチームにどのタイプのタスクを評価してほしいかを指定できます。複数のタスクを選択することができます。このリストで十分でない場合や、foundation modelsで他のことを試そうとしている場合は、常にカスタムオプションがあります。特定の専門知識が必要な場合は、専門分野を選択できます。もちろん、これは私たちのチームに知らせるだけのものですが、チームメンバーがあなたに連絡を取り、この情報はいつでも変更できます。どのようなチームやタスクが必要かを指定できます。これは私たちが状況を把握し、あなたとの会話を始めるのに役立ちます。そして、プロンプトの数を指定し、ジョブを作成します。これでデモは終わりです。まとめのためにJesseを再び舞台に呼びたいと思います。
まとめと今後の展望


はい、素晴らしいデモをありがとう、Kishor。皆さん、素晴らしい機能の一端をご覧いただけたと思います。きっと気に入っていただけると思います。まとめに入りましょう。レイテンシーとコストを確認できるplaygroundがあります。自動評価があります。2種類の人間による評価があり、自分のwork teamを持ち込むこともできますし、AWSにmanaged work teamを提供してもらうこともできます。自動評価では1つのモデルを評価でき、人間による評価では1つまたは2つのモデルを評価できます。自動評価用のキュレーションされたデータセットを提供しますが、独自のデータセットを持ち込むこともできます。人間による評価では、独自のデータセットを持ち込んでください。この評価が本当にあなたに適しているかを確認してください。


読みやすいレポートと理解しやすい情報を提供しているので、評価のセットアップに時間をかけるのではなく、実際にアプリケーションの構築と適切なモデルの選択に時間を費やすことができます。最後に、これらはすべてAmazon Bedrockにネイティブです。すべてが1つの場所にあります。つまり、評価を行う場所と本番環境の場所が同じです。今すぐ始めましょう。QRコードをスキャンできます。詳細を知りたい場合は、Amazon Bedrockのホームページに移動します。質問は横で受け付けます。おそらく15分か20分ほどここにいます。あ、すみません。QRコードを再度表示できます。これでAmazon Bedrockの公開ウェブページに移動するはずです。

通常のアンケートがございます。AWS Events アプリ内にあると思います。ぜひこのセッションのアンケートにご回答ください。私たちは後ろにおりますので、質問がある方はそちらまでお越しください。皆様のご参加、誠にありがとうございました。どうぞお気をつけてお帰りください。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion