re:Invent 2023: AWSオープンソースJupyterチームが紹介するJupyter AI拡張機能
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Jupyter AI: Open source brings LLMs to your notebooks (OPN203)
この動画では、AWSのOpen Source JupyterチームによるJupyter AIの紹介が行われています。Jupyter AIは、大規模言語モデルの力をJupyterノートブックに統合する革新的な拡張機能です。マジックコマンドやチャットインターフェースを通じて、コード生成、エラーデバッグ、ローカルドキュメントの学習、そして1つのプロンプトから完全なノートブックの生成まで可能になります。透明性、協調性、ユーザー主導の設計原則に基づいたJupyter AIが、日々のワークフローをどのように変革するのか、具体的なデモを交えて紹介されています。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
Jupyter AIの紹介と発表者の自己紹介

みなさん、こんにちは。Jupyter AIに関するプレゼンテーションへようこそ。この会場の皆さん、オーバーフロールームの皆さん、そしてYouTubeでご覧の皆さん、こんにちは。私はJason Weillです。AWSのOpen Source Jupyterチームのシニアフロントエンドエンジニアです。同僚のPiyushと一緒に、私たちのチームが開発したオープンソースの拡張機能であるJupyter AIについてお話しします。この拡張機能は、大規模言語モデルのパワーをJupyterノートブックにもたらすものです。
まず、自己紹介をさせていただきます。先ほど申し上げたように、私はJasonで、Open Source Jupyterチームのシニアフロントエンドエンジニアです。また、Jupyter Lab Councilのメンバーであり、Jupyter Diversity Equity and Inclusion Standing Committeeにも所属しています。さらに、JupyterのSecurity Working Groupのメンバーでもあります。ここで、同僚のPiyushを紹介させていただきます。
ありがとう、Jason。皆さん、こんにちは。私はPiyush Jainです。Jupyter Open Sourceチームのシニアソフトウェアエンジニアです。また、Jupyter Server Consoleのメンバーでもあり、Jupyter LabとLangChainプロジェクトにも貢献しています。LangChainは、生成AIアプリケーションを構築するためのフレームワークとして機能するオープンソースプロジェクトで、Jupyter AIで使用している重要なフレームワークです。
Jupyterプロジェクトの概要とJupyter AIの特徴

ありがとう、Piyush。さて、ここにいる方で、Jupyter製品を使ったことがある人はどれくらいいますか?Jupyter Lab?Jupyter Notebook?AWS SageMaker Studio?たくさんの手が挙がっていますね。それは良いことです。Jupyterについてご存じない方のために説明しますと、Jupyterは約20年前に始まったオープンソースプロジェクトで、私たちの上司であるBrian Grangerは、現在のProject Jupyterの共同創設者の一人です。これは対話型コンピューティングのためのオープンソースプロジェクトです。元々はJulia、Python、Rのために設計されました。そこから名前が付けられたのです。しかし、人気が高まったため、現在では考えられるほぼすべてのプログラミング言語用のカーネルと呼ばれるものがあります。そして、AWSを含む多くの企業が、Jupyterをベースに商用製品を開発しています。

これがJupyterノートブックの外観です。上部にはマークダウンを使ってスタイリングされたリッチテキストがあります。中央にはPythonコードがあります。そして、例えばターミナルでPythonスクリプトを実行する場合とは異なり、これは通常ウェブブラウザで実行します。そのため、ウェブブラウザが表示できるもの、例えばここに表示されているようなデータの可視化は、Jupyterノートブック内でレンダリングすることができます。

そこで私たちはJupyter AIを開発しました。Jupyter AIとは何でしょうか?Jupyter AIはProject Jupyterの公式拡張機能です。Project Jupyterによって正式に管理されているため、この部屋にいる皆さん全員がダウンロードできます。BSD-3-Clauseライセンスという寛容なオープンソースライセンスの下で提供されています。バグ報告や機能改善の提案、さらにはプルリクエストを通じてコードを提供することもできます。Jupyter AI自体は大規模言語モデルではありません。私たちは独自のモデルを構築したわけではなく、代わりに皆さんが選択した大規模言語モデルと接続するためのオープンソースのインターフェースを構築しました。そして、2つの方法で利用できます。1つはJupyter Labの左パネルにあるチャットインターフェース、もう1つは任意のJupyterアプリケーションで使用できるマジックコマンドで、これらはノートブック内で実行されます。

これから、Jupyter AIでできることをいくつか紹介していきます。まずは基本的なことから始めましょう。生成モデルを使ってテキストやコードを生成する方法をお見せします。また、コードの説明、コードのエラーのデバッグ、さらには言語モデルを使ったコードの書き直しも紹介します。Jupyter AIのチャットインターフェースは、ローカルデータからも学習できます。そして、埋め込みと生成モデルを使って、そのデータについて質問することができます。そして最後に、私のお気に入りの機能として、たった1つのテキストプロンプトから完全なJupyter Notebookを構築できることをお見せします。
Jupyter AIの設計原則と基本機能

デモに入る前に、Jupyter AIを開発する際に用いた設計原則について少しお話ししたいと思います。これらの原則については、開発初期の段階で多く議論しました。新機能の追加や既存機能の改善を検討する際も、今でもこれらの原則について話し合っています。最初の原則は、Jupyter AIがベンダー中立であるということです。

大規模言語モデルを提供するベンダーは多数存在します。AWSもその1つですが、唯一のものではありません。私たちは、LangChainというオープンソースライブラリを使用しています。これは多くの異なるモデルプロバイダーや多様なモデルと連携します。LangChainに新しい機能が追加されると(これは頻繁に起こります)、それらの機能をJupyter AIにより簡単に追加できます。そして、できる限り多くのベンダーで、すべての機能が最適に動作するようにしています。使用するモデルの選択は、ユーザーの皆さんにコントロールを委ねています。

Jupyter AIは透明性と追跡可能性を重視しています。生成AIを誤用して人々を誤解させることへの懸念が多くあります。そこで私たちは、マジックコマンドを使ってコードセルを生成する際、そのセルがJupyter AIを使って生成されたことをメタデータでタグ付けすることで、そういった懸念を回避しようとしています。チャットインターフェースのgenerateコマンドを使ってノートブック全体を生成する場合、そのノートブックはJupyter AIを使って生成されたことを示します。これによって、この技術への信頼が高まると考えています。

Jupyter AIは協調的です。Jupyterサーバーを実行している場合、同じサーバーを複数の人が同時に使用できます。ノートブックをリアルタイムで共同作業することさえ可能です。チャットインターフェースは、単にあなた一人が知的エージェントと対話するだけでなく、複数のユーザーが共有チャットセッションでAIアシスタントを交えてコミュニケーションを取れるように設計されています。今日はお一人でのデモしかお見せできませんが、これが私たちのJupyter AIの将来のビジョンです。

Jupyter AIは完全にユーザー主導です。Jupyter AIを使用する際、あなたが主導権を握ります。私たちはあなたのコードを勝手にスキャンしたりしません。あなたが明示的に要求しない限り、ファイルシステムをスキャンして言語モデルに送信することもありません。私たちは、ソフトウェアを使用する際に、可能な限りあなたのデータがあなたの管理下に置かれるようにしたいのです。そして、Jupyter AIは人間中心です。私たちの上司であるBrian Grangerは、Project Jupyterの共同創設者の一人で、Jupyter AIを以前使用したことのあるソフトウェアのように感じてほしいと強く望んでいました。そのため、チャットインターフェースは、あなたが使用したことのある任意のチャットプログラムのように見え、感じ、機能します。


マジックコマンドについて、以前Jupyter Notebookでマジックコマンドを実行したことがある方なら、私たちが作成したものは、以前使用したものとまったく同じように見え、機能します。 つまり、簡単に言えば、Jupyter AIはミドルウェアです。Jupyter AIは、オープンソースのLangChainライブラリを使用して、選択した言語モデルと通信します。各マジックコマンドに対して異なる言語モデルを選択できます。チャットインターフェースで言語モデルを変更することもできます。ユーザーの観点からすると、必要なのは言語モデルを選択し、必要なAPIキーを提供するだけです。そうすれば、Jupyter AIがすべてのプロンプトエンジニアリングを処理し、リクエストの送信と結果の解釈を行います。
Jupyter AIのマジックコマンドとチャットインターフェースのデモ


Jupyter AIのマジックコマンドの例を見てみましょう。これはセルマジックと呼ばれるものの例で、ダブルパーセント記号で始まります。 パーセントAIまたはダブルパーセントAIで始まるものはすべてJupyter AIによって処理されます。この場合、AnthropicのClaude Version 1.2モデルを選択しています。これはセルマジックなので、プロンプトは2行目から始まり、好きなだけ長く続けることができます。この例では、「Jupyterについての俳句を書いて」と指示しています。これを実行すると、Jupyter AIがこれを解析し、適切なコマンドをAnthropicのClaude 1.2モデルに送信し、応答を受け取ります。「コードブロックが、マークダウンと生の出力と交互に並ぶ、Jupyter Notebook」。 拍手は聞こえませんでしたが、大丈夫です。Claudeは気にしません。


チャットインターフェースはJupyter Labの左側にあり、ノートブックを変更することなく、好きなだけプロンプトを作成できます。自由形式の質問をしたり、好きなモデルを選んだりできます。そして、あなたの知的アシスタントであるJupyternautが質問に答えてくれます。チャットインターフェースはノートブックから読み取ったり、ノートブックに書き込んだりすることもできます。さらに、ローカルファイルストレージから読み取ったり、ノートブックをファイルストレージに書き込んだりすることもできます。ここには、後ほどのプレゼンテーションでお見せする高度な機能の一部があります。しかし、まずはデモに移って、Jupyter AIを使ってノートブックを構築する方法をお見せしましょう。


はい、ここでは、ローカルのラップトップで動作しているJupyter labのセッションがあります。まず最初に行うのは、Jupyter AIマジックス拡張機能をロードすることです。これは、Jupyter Notebooksと互換性のあるものなら何でも使える拡張機能です。コマンドラインで実行することもできますし、サードパーティのエディタを通して実行することもできます。ご覧のように、すべてのコマンドは「%AI」で始まっています。これらはラインマジックスと呼ばれるもので、1行のコマンドです。あるいは「%%AI」で始まります。これはセルマジックと呼ばれるもので、2行目から始まるセル内のすべてが実行されます。



まず最初に行いたいのは、持っているすべてのモデルをリストアップすることです。ここで左側のパネルを折りたたみます。なぜなら、AI Listは多くの情報を生成するからです。これにより、マジックコマンドで使用できるAIモデルの多く(すべてではありません)が表示されます。これを実行すると、非常に大きな表が表示され、プロバイダーごとに整理された、使用可能なさまざまなモデルが表示されます。また、これらの多くには環境変数があり、例えばAPIキーがあるかどうかも表示されます。ご覧のように、AnthropicやBedrockには長いリストがあります。また、レジストリプロバイダーと呼ばれるものもあります。Hugging Faceを使ったことがある人はいますか?Hugging Faceには30万以上のモデルがあり、そのうちの1%さえもここで表現することはできません。そのため、代わりにこのウェブサイトに行き、

モデルのリストを見つけ、そしてここにそれらのモデルの1つを表現する方法が示されています。これらを試してみることができます。APIキーを持っていて、利用規約に同意できるなら、好きなモデルを使用できます。

ここで下にスクロールすると、このコマンドをAnthropicのClaude 2モデルに送ることができます。「空港の遅延時間を示すpandasのデータフレームを生成してください」と言えます。ご覧のように、ここに追加のパラメータを渡しています。これはフォーマットパラメータと呼ばれるもので、ソースコードを取得したいと指定しています。これを実行すると、Jupyter Labで実行できる実際のコードセルが得られます。これを実行すると、AnthropicのClaude version 2モデルに送信され、pandasデータを生成し、空港の遅延時間を示すpandasデータフレームを生成するコードを書きます。そして、ここに少し追加のマークダウンとともにリストが生成されているのがわかります。
import pandas as pdがあり、データフレームを作成します。4つの空港を選び、それぞれの平均遅延時間を設定しています。先週、私はケネディ空港を利用しましたが、運良く24分の遅延はありませんでした。将来の旅行計画にこれを頼りにすることはお勧めしません。これらの数字がどこから来たのかはわかりません。このコードは他の誰かによって書かれたものです。チームの誰かがコードを書いてあなたに渡した場合、おそらくコミットして本番環境に投入する前にコードレビューをしたいと思うでしょう。AI生成コードも同じです。これはあなたのコーディングアシスタントですが、送られてくるすべてを盲目的に信頼することはできません。
Jupyter AIを使ったコード生成とエラー修正

さて、ここにいる開発者の皆さんにこのコードをレビューしていただきたいと思います。このコードが良さそうだと思ったら、出荷してもいいかどうか教えてください。「Ship it!」と言ってくれる人はいますか?一人でいいんです。Ship it! ありがとうございます。何人かの方から「Ship it!」をいただきました。これは高品質だということですね。実行してみると、正常に動作します。何も表示されませんが、それは問題ありません。表示を求めていませんからね。このコードについては後ほどまた触れたいと思います。次に、Jupyter AIを使ってコードのエラーを修正する方法をお見せしたいと思います。

Python初心者の方は、これが有効なPythonコードではないことに気づかないかもしれません。AとBという2つの変数があり、A + Bを表示しようとすると、具体的にはTypeErrorというエラーが発生します。「Can only concatenate str not int to str」というメッセージが表示されます。これが直感的に理解できない方もいらっしゃるかもしれません。そこで、AI errorというコマンドを用意しました。このコマンドは、セルの実行で最後に発生したエラーの全文を、「このエラーを平易な英語で説明してください」というようなプロンプトとともに送信します。他のAIコマンドと同様に、モデルを選択します。今回はAI 21のJ2-Jumboモデルを選びましょう。


これを実行すると、プロンプトとエラーをJ2-Jumboモデルに送信し、平易な英語での回答が返ってくることを期待します。 このエラーメッセージは、Aの型が5で、これは文字列とみなされることを示しています。一方、Bの型は整数です。print関数でAとBを使用しようとすると、組み合わせようとしていることになりますが、これは不可能です。これは面白いですね。リハーサルではあまり見かけなかったのですが、J2-Jumboモデルが2つの解決策を提示してくれました。これはとてもクールですね。もちろん、レビューした後にこのコードをコピー&ペーストする必要があります。

コードを書き直す別の方法として、補間というテクニックがあります。これはセルマジックです。出力としてコードを取得し、Claude version 1.2モデルを使用します。「次のコードをエラーが発生しないように書き直してください」というプロンプトを使います。ここの中括弧内にはPythonの式があり、「in five」と書かれています。「in」はIPythonの特別なリスト変数で、すべてのセルの入力を含んでいます。左側のセルに小さな番号があることにお気づきでしょうか。これが「in five」で、セル番号5の入力であるソースコードを指しています。

これを実行すると、そのプロンプトに補間され、Claude version 1.2が返すコードは、すでにある程度の一致を見せています。 J2-Jumboの最初の提案と全く同じ解決策のようですね。開発者の方、「Ship it!」をお願いします。このコードは大丈夫でしょうか?これで修正できていますか?Ship it! 実行してみると、正常に動作します。
Jupyter AIの学習機能とその仕組み
では、Jupyternautを見てみましょう。これは私たちのチャットインターフェースで、設定パネルで選択したモデルを使用するプログラミングアシスタントです。プレーンテキストで質問を投げかけることができます。例えば、「re:Inventの期間中の天気は通常どうですか?」と聞くことができます。それを送信すると、選択した言語モデルに送られ、「AIアシスタントとしてリアルタイムデータは持っていません」と返答します。しかし、re:Inventが AWSのカンファレンスであることは知っています。
re:Inventがネバダ州ラスベガスで開催されるAWSのカンファレンスであることを知っています。平均最高気温は華氏60度台半ばから70度台前半(摂氏18度から23度)の範囲です。平均最低気温...今朝早く外出しましたが、これは今日の気温と比べると少し楽観的すぎるようです。今日は平年よりも寒いと思います。しかし、「天候パターンは変動する可能性があることに注意することが重要です」と言っています。信頼できる天気予報を確認すべきだとのことです。これは有用な情報です。少し控えめな表現ですが、このような demo はこれまでにも見たことがあるでしょう。

これは Jupyter AI です。Jupyter Notebookから読み取り、書き込むことができます。このセルをハイライトすると、大規模言語モデルを使用して生成したコードであることを思い出してください。右側のこのコードをハイライトすると、左側に「選択範囲を含める」というチェックボックスが表示されます。プロンプトを送信して、「このコードは何をしていますか?」と聞くことができます。Enterキーを押すと、現在のセルからハイライトされたコードがそのプロンプトに挿入され、選択した言語モデルに送信されます。
そして、このコードスニペットはPythonで書かれており、pandasライブラリを使用し、それをインポートし、DataFrameを呼び出し、いくつかの列があり、平均遅延があると説明しています。これは平易な英語で説明する方法です。実際、他の言語で説明するために複数の言語モデルを使用しました。例えば、フランス語を話す場合、平易なフランス語で説明することができます。
しかし、2番目のボタン「選択範囲を置換」をクリックすると、Jupyter AIにノートブックへの書き込みを許可することになります。例えば、これは4つの空港を示しています。Chicago O'Hare、New York Kennedy、LAX、そして私のチームメイトのBucheが飛んできたSFOのようです。この「選択範囲を置換」ボックスにチェックを入れると、「このコードを書き直して遅延を含めてください」と言うことができます。私のホーム空港はSEA空港ですが、そこは含まれておらず、実際に遅延がありましたので、知りたかったです。他に省略されている空港はありますか?IADですね。YYZ、Zedではありません。

さて、これを送信しましょう。言語モデルから返ってくるすべての内容は、説明文の一部も含めて、選択部分を置き換えてこのセルに戻ってきます。少しプロンプトエンジニアリングを使って、「余分な情報は提供しないでください」と言うこともできます。すると、コードは以前とよく似ていますが、3つの新しい空港が追加されています。私の遅延は10分以上でした。これは平均値で、おそらく作り話でしょう。そのため、平均遅延時間が表示されています。この新しいコードを「出荷」してもいいでしょうか?これで問題ないでしょうか?
ありがとうございます。実行すると、正常に動作します。このように、Jupyter AIを使って、少しのコードを書き、コードを説明し、コードのエラーをデバッグし、さらに追加情報を含めてコードを書き直しました。しかし、これはJupyter AIでできることのほんの始まりに過ぎません。この先については、共同発表者のPiyushに引き継ぎたいと思います。
ベクトル埋め込みとRetrieval Augmented Generationの説明

Jason、ありがとう。大規模言語モデルは一般的な質問に答えるのは得意ですが、事実確認が必要な質問に対しては幻覚を起こす傾向があります。これは通常、これらのモデルがニュース記事、ブログ、Wikipediaなどの公開データソースで学習されているため、これらのソースが時々正確な情報を持っていないことが原因です。Jupyter AIには、この問題に対処できる学習機能があります。その仕組みを見てみましょう。


これは、学習機能を使用せずにJupyter AIで使用したコマンドの例です。「Jupyter AIのインストール方法は?」と尋ねました。これは正しい回答のように見えますが、実際にはモデルが創造的に作り出した回答です。Jupyternautという拡張機能は存在しません。これは間違った回答です。こちらが学習コマンドを使用した後の回答です。Jupyter AIのインストールに関する正しい指示が与えられているのがわかります。これが正しい回答です。

Jupyter AI内でこれがどのように機能するか見てみましょう。このプロセスは、/learnというスラッシュコマンドを使用し、その後にドキュメントが保存されているディレクトリ名を指定します。ここでは/learn docsを使用しています。これを実行すると、Jupyter AIはそれらのドキュメントを読み取り、学習することができます。



学習が完了すると、このような応答が表示されます。これらのドキュメントを学習した後、別のコマンドである /ask コマンドを使用できます。 このコマンドの後に、ドキュメントについて尋ねたいクエリや質問を入力します。この場合、学習したドキュメントを使用し、それを大規模言語モデルに送信して、 より正確な回答を得ることができます。


では、このプロセスが実際にどのように機能するか見てみましょう。プロセスは、/learn コマンドの後にディレクトリ名を入力することから始まります。Jupyter AI がこのコマンドを受け取ると、 ドキュメント内のファイルやテキストを読み取り、それを embedding モデルに送信します。 この embedding モデルは、Jupyter AI の設定パネルで選択したもので、任意の embedding モデルを選択できます。embedding モデルは、ベクトル埋め込みと呼ばれるものを返します。これは、テキスト部分をベクトル埋め込みに変換します。ベクトル埋め込みとは何か、そしてそれがどのように役立つのかについて説明します。


Jupyter AI は、これらのベクトル埋め込みとデータからのテキストチャンクを取得し、 ベクターデータベースと呼ばれるものに格納します。ベクトル埋め込みがどのように役立つのか、 そして実際に何なのかを見てみましょう。ベクトル埋め込みは、テキスト、画像、動画、音声など、あらゆるデータを空間内の点として表現する方法で、これらの点は意味的に意味を持ちます。この概念をよりよく理解するために、いくつかの例を見てみましょう。
これは、いくつかの単語からベクトルへの埋め込みを簡略化して表現したものです。ベクトル埋め込みでは、意味的に類似した単語は互いに近くに集まる傾向があります。例えば、「king」と「queen」という単語は、ベクトル埋め込みの中でより近い位置にあります。同様に、「walking」と「walked」という単語も近くにあります。これがどのように役立つかがわかりますね。「king」のような単語を入力すると、これらの同義語や意味的に類似した単語を返す関数を書くことができます。この概念は単一の単語だけでなく、より長いテキスト部分にも適用されます。


これは、意味的に類似したデータを検索する際に役立ちます。クエリを入力すると、そのクエリに関連するすべての部分を取得できます。これが、ドキュメントの関連データを見つけるのに役立つ仕組みです。Jupyter AI がデータを学習した後、プロセスがどのように機能するか見てみましょう。Retrieval Augmented Generation と呼ばれる技術を使用します。プロセスは、/ask コマンドの後にクエリを入力することから始まります。 Jupyter AI がそのコマンドを受け取ると、このケースでは「What is Jupyter AI?」というクエリを embedding モデルに送信します。


クエリのベクター埋め込みを取得し、元のクエリと共にベクターデータベースに送信します。ベクターデータベースに対して、学習済みデータと学習済み文書のベクター埋め込みに基づいて関連データがあるかどうかを問い合わせます。クエリのベクター埋め込みと学習済み文書を使用して、そのクエリに関連する文章を提供することができます。Jupyter AIは、元のクエリと学習済み文書からの関連データを組み合わせて、言語モデルに送信します。
文書のコンテキストと含まれる文章、そしてクエリという2つのデータを使用して、言語モデルは知識のないものを作り出そうとするよりも正確にクエリに答えることができます。応答を得ると、それをユーザーに返すことができます。この/learnと/askの技術を使用することで、チュートリアル、ドキュメント、API、研究論文などの文書を、モデルが知識を持たないより大きなモデルに接続し、ローカル文書について質問するのに使用できます。
Jupyter AIのgenerateコマンドによるノートブック生成のデモ

Jupyter AIの私のお気に入りの機能は、/generateコマンドと呼ばれるものを使用して、単一のプロンプトだけで完全なノートブックを作成できることです。実際にどのように機能するか見てみましょう。

チャットインターフェースで利用可能なgenerateというコマンドがあります。スラッシュコマンドgenerateに続いて、ノートブックを生成したいトピックを入力できます。例えば、ここではmatplotlibのノートブックを作成しようとしています。送信すると、Jupyter AIは応答を返し、バックグラウンドでノートブックの作成を開始します。ノートブックの作成が完了すると、このような応答が表示され、生成されたファイルの長い名前が見えます。これも大規模言語モデルによって生成されたもので、入力する必要はありません。

generateコマンドがバックグラウンドでどのように機能するか、さらに詳しく見てみましょう。Jupyter AIがgenerateコマンドとクエリを受け取ると、ノートブックのアウトラインを作成するタスクを大規模モデルに送信します。アウトラインを受け取った後、一連のタスクを言語モデルに送信します。例えば、タイトルの生成、ノートブックのサマリーの生成などのタスクがあります。その後、ノートブックの異なるセクションやセルの内容を作成するための別のタスクセットを送信します。これらはすべて非同期で行われ、ブロッキングではありません。Jupyter AIがこれを行っている間も、チャットUIで他の質問を続けることができます。ノートブックでマジックコマンドを使用し続けることもでき、それらは引き続き機能します。


こちらは、先ほど見た generate コマンドで生成された実際のノートブックの例です。ファイル名と一致する長いタイトルが見えますね。ここにはノートブックの内容を説明するサマリーセクションがあります。そして、Jupyter AI によって生成されたさまざまなセクションとセルの内容があります。これらはすべてモデルによって作成されています。それでは、デモに移ってこれらの機能をお見せしましょう。


このノートブックを閉じて、画面をクリアします。 最初に見るコマンドは learn コマンドです。私の Jupyter Lab インスタンスには Docs というフォルダがあります。 これには Jupyter AI のすべてのドキュメントが含まれています。/learn docs と入力して、この Docs フォルダを使用するよう Jupyter AI に learn 指示を出します。

Jupyter AI は今、ディレクトリに入り、すべてのテキストファイルを読み込み、そのデータをチャンク化し、embedding モデルに送信しています。ベクトル埋め込みを取得し、テキストチャンクと一緒にベクターデータベースに保存しています。これで完了し、ask コマンドを使用する準備ができたと表示されています。Jupyter AI がこのようにドキュメントを学習すると、ask コマンドを使用できるようになります。

ここで ask コマンドを使ってみましょう。magic コマンドで利用可能な別の機能である aliases について尋ねてみます。その情報を見つけられるかどうか見てみましょう。「How do aliases work in Jupyter AI magic commands?」と入力します。 今、Jupyter AI は関連する情報をベクターストレージから取得する必要があることを認識しています。このクエリを受け取り、クエリのベクトル埋め込みを取得し、それらのベクトル埋め込みをベクターデータベースに送信し、関連する情報を取得し、それをクエリと組み合わせて言語モデルに送信します。言語モデルは、そのコンテキストを見て、それに基づいて正確な回答を提供できます。
Jupyter AI の回答によると、aliases は register コマンドと一緒に使用でき、line magic の register コマンドでプロバイダーとモデル名を登録できるとのことです。これにより、長いモデル名やプロバイダー名を繰り返し入力する必要がなくなります。
例えば、Anthropic Claude V1.2のためのClaudeというエイリアスの例を挙げています。このエイリアスをノートブックのマジックコマンドで使用できます。これは、ハルシネーションを起こすのではなく、learnドキュメントのコンテキストを使用して、そのコンテキストに基づいて応答する方法です。
別の例を見てみましょう。learnコマンドには利用可能な高度なオプションがあるので、そのコンテキストを見つけられるかどうか確認したいと思います。Jupyter AIのlearnコマンドではどのようなオプションが利用可能ですか?それを見てみましょう。learnコマンドを使用する際に利用できる他のオプションを知りたいと思います。

さて、何か返ってきました。すべての学習データを削除するdeleteオプションがあります。再起動したい場合や、別のフォルダを使用したい場合、またはフォルダを更新した場合は、deleteを使用してすべての学習データを削除し、その後learnコマンドを再度実行できます。これらは高度なオプションです。chunk sizeとchunk overlapがあります。これらは高度なオプションで、チャンクサイズとオーバーラップの大きさを指定でき、これが検索の動作に影響します。これらのパラメータに基づいて検索を調整できます。これは、ドキュメントのコンテキストを使用し、それを言語モデルに渡して、そのコンテキストに基づいてより正確な応答を提供できた別の例です。
それでは、これをクリアしましょう。次に見るのはgenerateコマンドです。generateと入力します。トピックを入力する前に、今日ここで試してみたいトピックはありますか?どんなトピックでも試せます。

ゲストの一人が系図学を提案し、別のゲストが正規表現を提案しました。わかりました。では、「正規表現の使い方を学ぶノートブックを生成する」と入力してみましょう。さて、今からバックグラウンドでこの作業が行われます。先ほど説明したように、まずノートブックのアウトラインを作成するための一連のタスクを送信し、次にノートブックのアウトラインの各部分を埋めるための次の一連のタスクを送信します。
もう完了しています。ノートブックの処理が終わるのを待つ必要はありません。他に質問があれば、続けて聞いてください。これはすべて非同期で行われているからです。ここではもう完了しています。Regular Expressions Learning Notebookという新しいファイルが作成されたと表示されています。それがどのようなものか見てみましょう。

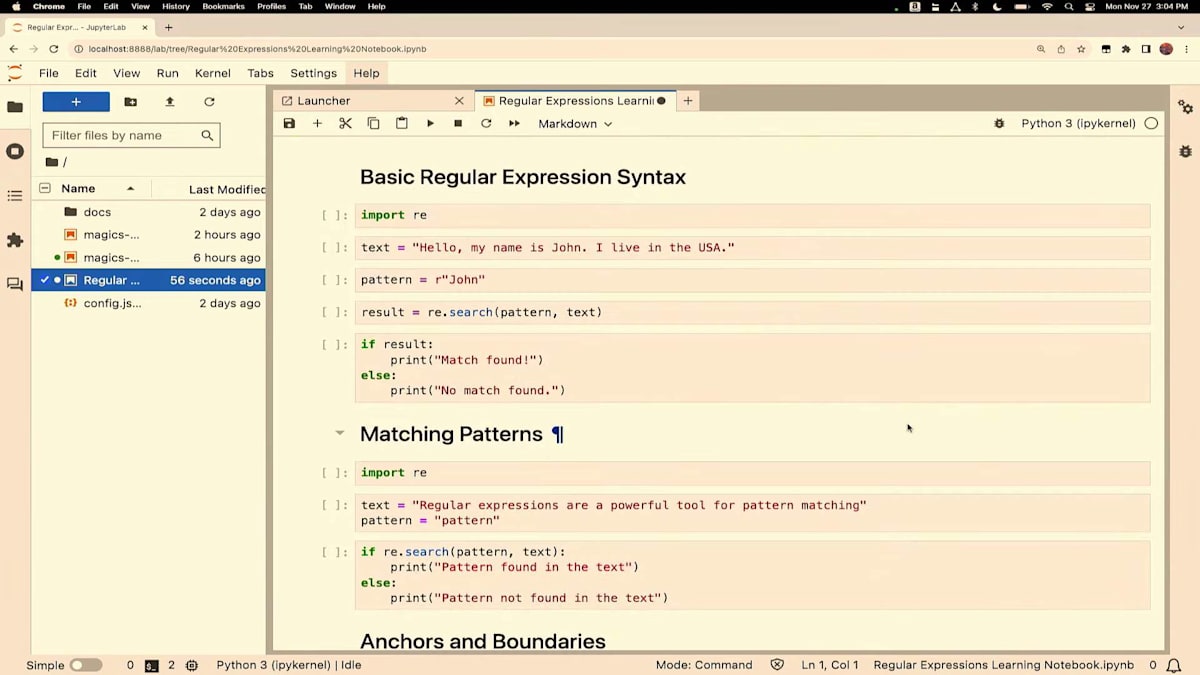
はい、これをここに移動させます。上部にタイトルがあり、導入部分があります。また、このノートブックがJupyter AIによって作成されたことが示されており、さらに使用した generateコマンドも含まれています。下部には、このノートブックの内容を要約した部分があります。そして、これらが様々なセクション で、その後にそのセクションのセル内容が続いています。


私は正規表現に詳しくないので、これが役立つことを願っています。 ただ、私の正規表現に関する知識の範囲では、これはかなり詳細に正規表現について学べるようになっているようです。 デモの後でじっくり確認してみたいと思います。これまでに作成されたものには本当に感心しています。
generateコマンドを使って、学びたいトピックや理解しようとしているトピックについてのノートブックを作成できます。また、generateを使って、同僚と共有したいトピックを作成したり、始めたりすることもできます。生成された後、このノートブックを編集して、新しいことを学び、学んだことを同僚と共有することができるからです。私は新しいことを学ぼうとするときに、これがとても役立つと感じています。
Jupyter AIの機能まとめと設計原則の再確認
さて、スライドに戻りましょう。今日見てきたことを振り返ってみましょう。Jupyter AIは、ノートブック内でテキストの生成、コードの生成、コードのエラーのデバッグ、そしてコードの書き直しとエラーの修正に使えるマジックコマンドを提供していることを確認しました。また、言語モデルに質問するためのアシスタントとして使えるチャットUIも提供しています。learnコマンドとaskコマンドを使って、ローカルの文書を学習させ、それに関連する質問をすることができます。最後に、generateコマンドを見ました。これを使えば、単一のプロンプトで完全なノートブックを作成できます。
これらの機能により、Jupyter AIは皆さんの仕事に取って代わるのではなく、日々のワークフローをサポートし、より優れたビルダーになるお手伝いをすることを目指しています。Jupyter AIの設計原則を振り返ってみましょう。これらの原則は、このプロジェクトを始めた際の動機付けとなりました。Jupyter AIはベンダー中立です。AWSや他のサードパーティプロバイダーとそのモデルを含む、幅広いモデルプロバイダーをサポートしています。透明性があり、追跡可能です。生成されたノートブックやセルは、すべてAIによって生成されたことが明確に示されます。また、協調的です。チャットUIに関する我々のビジョンは、ユーザーとアシスタントの間だけでなく、共有Jupyterインスタンス上のすべてのユーザー間でのチャットインターフェースを提供することです。
Jupyter AIは完全にユーザー主導です。つまり、ソースコードやファイルツリーを受動的にスキャンすることはなく、明示的に要求された場合にのみデータを読み取ります。また、人間中心です。私たちが示したすべてのユーザーインターフェースは、チャットアプリケーションを使用したことがある方や、過去にIPythonやマジックコマンドを使用したことがある方にとって馴染みのあるものになっているはずです。
謝辞とJupyter AIプロジェクトへの参加方法

AWSのシニアプリンシパルテクノロジストであり、Project Jupyterの共同創設者でもある私たちのマネージャー、Brian Grangerに感謝したいと思います。Jupyter AIだけでなく、私のチームが取り組んでいる他のオープンソースプロジェクトについても、彼の指導を受けられたことは幸運でした。また、チームメイトのAndrii IeroshenkoとDavid Qiuに大きな感謝の意を表したいと思います。彼らの貢献と努力なしには、このプロジェクトは実現しませんでした。さらに、プロジェクトに貢献してくださったり、Jupyter AIをより良いプロジェクトにするためのフィードバックを提供してくださったすべてのオープンソースコミュニティのメンバーにも感謝の意を表します。
Jupyter AIはオープンソースプロジェクトで、github.com/jupyterlab/jupyter-aiで利用可能です。すべてのコード、ドキュメント、インストール手順がそこにあります。また、バグや機能改善のリクエストを報告したり、プロジェクトへの貢献方法についての詳細情報を見つけることもできます。Jupyter AIをより良くするためのアイデアや提案がある場合は、GitHubでissueを開くか、プレゼンテーション後に私たちに連絡していただければ、このプロジェクトに関する質問にお答えします。


AWSのオープンソースについてもっと知りたい方は、Developer Solutions Zoneエリアにお越しください。そこではAWSの専門家と話をしたり、ネットワーキングを行うことができます。Jasonと私もそこでJupyter AIに関する質問にお答えする予定です。ご参加いただき、ありがとうございました。re:Invent 2023の残りの時間をお楽しみください。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion