re:Invent 2024: AWSがSageMaker Canvasでコードレス機械学習を実現
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Accelerate innovation with generative AI and no-code machine learning (AIM227)
この動画では、コードを書かずに機械学習を実現できるAmazon SageMaker Canvasの機能と活用事例について解説しています。時系列予測に焦点を当てた実践的なデモを通じて、データの準備からモデルのトレーニング、デプロイまでの一連の流れを紹介しています。特に注目すべき事例として、Gosoft ThailandがSageMaker Canvasを活用して実現した在庫管理の改善が紹介されており、店舗スタッフの補充作業時間を120分から1.5分に短縮し、品切れを40%削減した具体的な成果が示されています。Foundation Modelのファインチューニングや、AutoMLを活用した予測モデルの構築など、コードレスで実現できる高度な機械学習の実装方法についても詳しく解説されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon SageMaker Canvasによる機械学習の加速:セッション概要

皆様、こんばんは。re:Inventを楽しんでいただいていることと思います。また、私の声がよく聞こえているでしょうか。本日のセッションにご参加いただき、ありがとうございます。私はAWSのプロダクトマネジメントのシニアマネージャーのUrvashi Chowdharyと申します。本日は、Gosoft ThailandのDr. Sirawit Sopchokeと、AWSのPrincipal AI Specialist Solutions ArchitectのDr. Charles Laughlinをお迎えしています。セッションを始める前に、本日の参加者の皆様についてお伺いしたいと思います。機械学習モデルの開発を1年以上経験されている方は手を挙げていただけますでしょうか。また、機械学習を始めたばかりで、アイデアを実践してみたいと考えている方は手を挙げていただけますでしょうか。そして、会社全体で機械学習の取り組みを展開したいとお考えのデータ、テクノロジー、ビジネスのリーダーの方は手を挙げていただけますでしょうか。本日はご参加いただき、誠にありがとうございます。このセッションは皆様にとって非常に興味深いものになると確信しています。

それでは、早速内容に入っていきましょう。本日は3つのトピックについてお話しします。まず、Amazon SageMaker Canvasを使用して、コードを1行も書かずに機械学習を加速する方法についてお話しします。次に、Charlesが予測という特定の機械学習問題タイプに焦点を当てて、SageMaker Canvasの動作デモを行います。最後に、Dr. Sopchokeから、Gosoftが当社のサービスを使用して商品予測の精度を向上させ、具体的なビジネス上のメリットを実現した事例についてお話しいただきます。
Amazon SageMakerの概要と機械学習の課題

AWSでは、機械学習とイノベーションは私たちのDNAの一部です。そして、私たちのミッションは、誰もが機械学習を活用できるようにすることです。このミッションを実現するために、私たちは機械学習モデルの構築、トレーニング、デプロイ、管理を大規模に行うための最も幅広いツールセットを提供するAmazon SageMakerを構築しました。Amazon SageMakerを使用することで、データサイエンティストやML専門家は、幅広い機械学習ツールにアクセスできます。SageMaker Studioを使用すれば、AWSの最新ハードウェアと分散トレーニングライブラリを活用して、分散コンピューティング環境で簡単にモデルをトレーニングし、機械学習モデルやFoundation Modelを構築できます。また、エンドツーエンドのMLプロセスを効率化し、MLガバナンスとResponsible AIを適用するとともに、人間のフィードバックの力を活用して、機械学習をすべての人に提供することができます。

お客様がSageMakerでデータサイエンティストと機械学習の専門家を標準化するにつれて、共通の課題が浮かび上がってきました。まず、機械学習によるイノベーションのアイデアと機会は豊富にありましたが、専門家の不足により制限されており、専門家へのアクセスにボトルネックがありました。その結果、多くのプロジェクトが、優先順位付けを待つか、データサイエンスと専門家の空き待ちの状態で、何週間も、何ヶ月も、時には何年も待機リストに残されていました。お客様は、組織全体のより広い層が機械学習によるイノベーションを加速できるようにしたいと考えていました。ドメインやデータの専門家が機械学習を適用し、アイデアを本番環境に移行できるようにしたいと考えていました。しかし、より広い層の人々は、必要な技術的なコーディングとML知識に苦労していました。Python、機械学習アルゴリズム、フレームワークを知る必要があることは、克服が難しい技術的な障壁となっていました。そして最後に、組織は、これらのモデルが誰によってどのように構築されたかに関係なく、同じMLプロセス、ワークフロー、ガバナンスに従うことを確実にしたいと考えていましたが、既存のツールではこのような協力体制を実現することができませんでした。

これらの課題を解決するために、私たちはAmazon SageMaker Canvasを一から構築しました。これは、コードを1行も書かずにエンドツーエンドの機械学習を実行できるビジュアルなノーコードインターフェースです。SageMaker Canvasでは、Foundation Modelを含む、すぐに使える機械学習モデルにアクセスできるため、高品質なMLモデルを構築するためのML知識は必要ありません。
SageMaker Canvasは、コードを一切書くことなく、データ準備からモデルのトレーニング、モデルのデプロイメントまでの機械学習モデル構築を実現します。最も素晴らしい点は、SageMaker Canvasで行ったすべての作業をPythonコードやJupyterノートブックとしてエクスポートできることです。これにより、データサイエンティストやMLエンジニアなどの専門家と共有することができ、彼らは簡単に作業内容をレビューし、あなたと共に改善を重ね、さらに再作業の必要なく、他のMLパイプラインのモデルと同じように実装することができます。

私たちのお客様は、さまざまな分野やユースケースでAmazon SageMaker Canvasで構築したモデルを活用しています。 技術文書の作成、Q&A、診断ガイドの作成には、Generative AIでファインチューニングしたモデルを使用しています。表形式データや時系列データを使用して、解約予測モデル、予知保全、売上予測などを構築しています。非構造化データを使用して、Computer VisionやNLPモデルを構築し、欠陥検出、感情分析、エンティティ抽出を行っています。私たちの社内チームでも、SageMaker Canvasを使用して、今後の四半期の顧客収益を予測したり、解約率や顧客セグメンテーションなど、顧客に関するより深い洞察を得たりしています。
SageMaker Canvasの機能と予測モデル構築プロセス



SageMaker Canvasがどのようにして機械学習ライフサイクル全体での迅速な反復を可能にするのか見てみましょう。すべての機械学習は通常、 データから始まりますが、SageMaker Canvasを使用すると、Amazon S3、Redshift、Athenaなどの AWSデータソースや、Snowflake、Salesforce、Databricksなどのサードパーティのデータソースなど、50以上のデータソースに接続できます。 ビジュアルインターフェースを使用して機械学習パイプライン全体を可視化し、自動化することで、ペタバイト規模のデータまでスケールすることができます。バックグラウンドでは分散EMRクラスターを活用しているため、追加のコードを書くことなく、小規模なデータセットからペタバイト規模まで、データ準備をスケールすることができます。

機械学習を行う前に、データを理解し、 分析し、トレーニング用のデータセットを準備する必要があります。つまり、データを探索してインサイトを生成する必要がありますが、SageMaker Canvasはボタン一つで詳細なデータインサイトと品質レポートを提供します。このレポートは、データの実際の様子、異常値や外れ値、さらにターゲットリーケージやクラスの不均衡など、モデルの品質に影響を与える可能性のある詳細な属性を理解するのに役立ちます。また、コードを書くことなく、これらの問題を解決するためのデータ変換の推奨事項も提供します。通常、このプロセスにはデータサイエンティストが何時間も、時には何日もかかることがありますが、熟練したデータサイエンティストでさえ、生成されるデータ品質のインサイトを高く評価しています。




SageMaker Canvasには、 相関行列やFeature Importanceなど、データインサイトの深い関係性を理解するための組み込みの可視化機能や、 データを簡単に準備できる300以上の組み込み変換機能も用意されています。これらのデータ変換は、列の削除や欠損値の補完といった行と列の操作から、One-hot encodingやデータセットのバランシングといったML重視の変換まで、さまざまです。さらに、 自然言語による指示をサポートすることで、データ準備をより簡単にしました。例えば列の削除など、 実行したいデータ準備作業を入力するだけで、Canvasはバックグラウンドでコードを生成し、それを編集したり、データ準備パイプラインのステップとして追加したりすることができます。同様に、この例では散布図のように、得たい可視化やインサイトの種類を説明すると、Canvasがコードを生成し、これらの可視化をダウンロードすることもできます。このようなコードは単純に見えるかもしれませんが、技術的な専門知識を持たない多くの視聴者やお客様にとっては、単純なPythonを書くことでさえ難しい場合があるため、これは彼らにとって素晴らしい方法となっています。
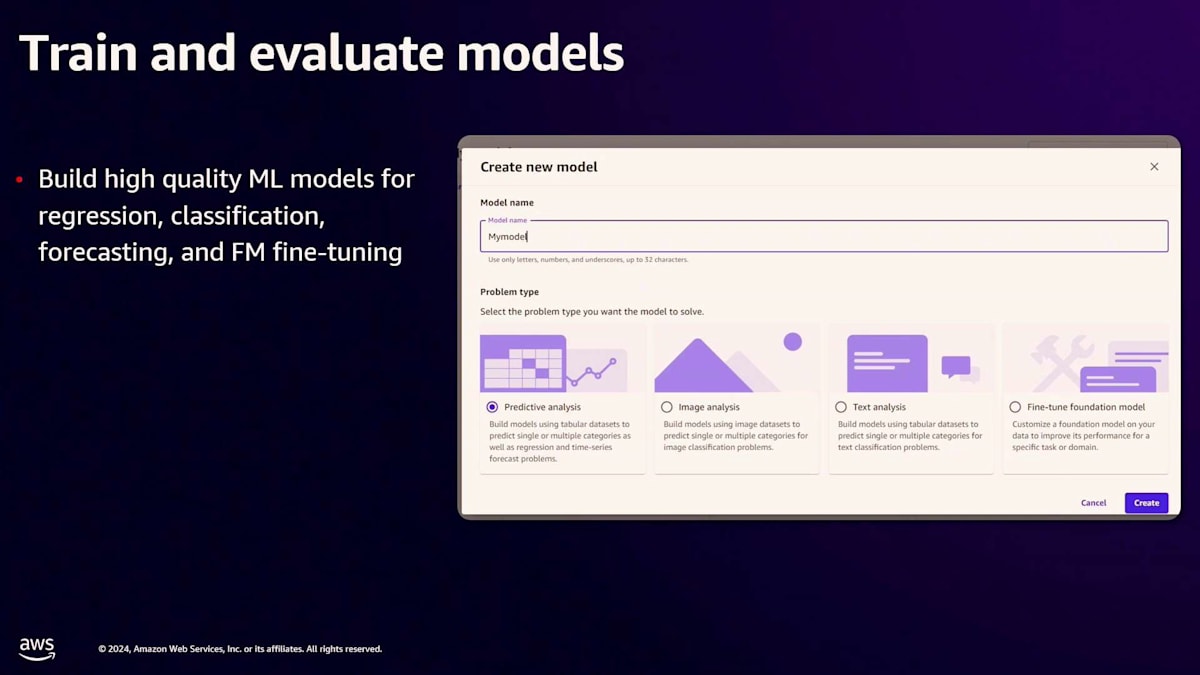
トレーニング用のデータセットが準備できたら、次のステップはMLモデルの構築です。SageMaker Canvasを使えば、予測分析、回帰分析、二値分類・多クラス分類、画像分析、テキスト分析、さらにはFoundation Modelのファインチューニングなど、高品質なMLモデルを構築することができます。

先ほどML専門知識は不要だとお話ししましたが、その理由は最先端のAutoML技術が重要な作業を代行してくれるからです。SageMaker Canvasでモデルをトレーニングする際、バックグラウンドでは最高のパフォーマンスを実現するために、異なる設定で複数の実験を並行して実行します。様々なML手法を用いてパラメータ空間を探索するHyperparameter Optimizationや、多数のジョブを並行して実行して結果を組み合わせるアンサンブル手法などを選択できます。また、トレーニングに使用する特定のアルゴリズムを選択することもできます。同様に、ジョブ実行のデフォルト設定を提案しますが、データ分割、ジョブ実行時間、その他のパラメータを変更してジョブ実行をカスタマイズすることも可能です。


トレーニングが完了すると、SageMaker Canvasは F1スコア、精度、特徴量の重要度など、モデルの実際のパフォーマンスを深く理解するための詳細なモデルインサイトを提供します。また、詳細なモデルリーダーボードにより、異なるモデル実行とトレーニング済みモデルのパフォーマンスを確認することができます。ここでは、各モデルが異なる評価指標でどのようなパフォーマンスを示しているかを簡単に比較でき、ベストモデルを推奨する一方で、別のモデルを選択することも可能です。例えば、精度よりも推論のレイテンシーが低いモデルが必要な場合もあるため、リーダーボードを使用してユースケースに最適なモデルを選択できます。



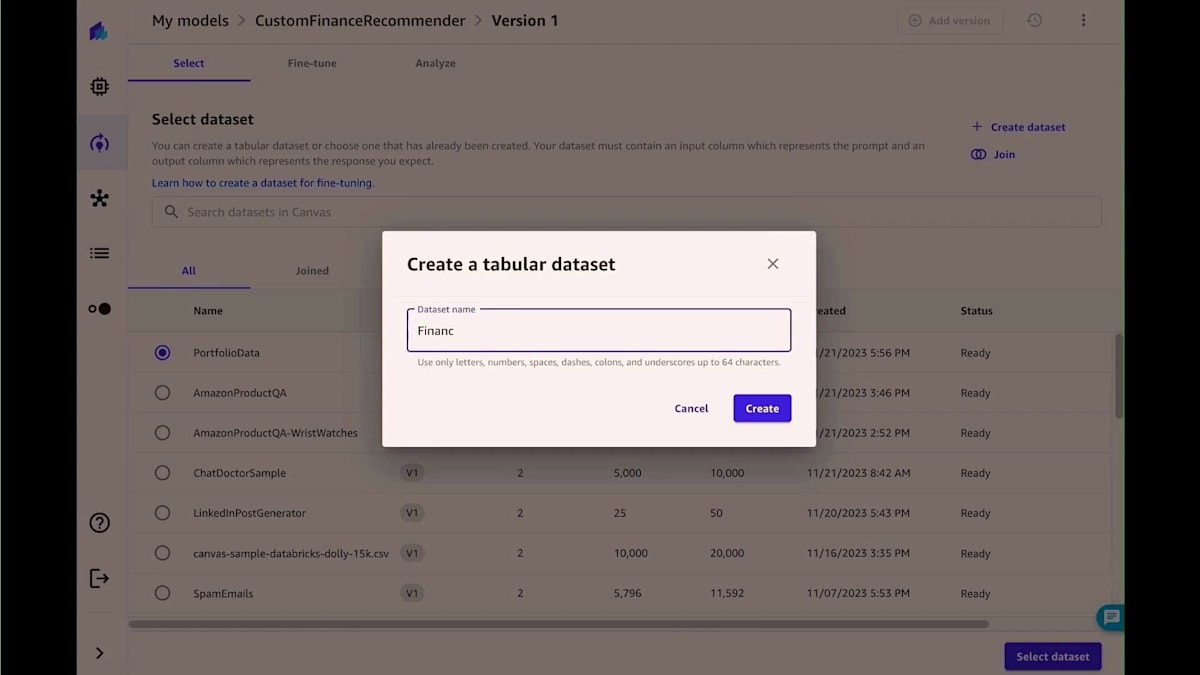
Foundation Modelのファインチューニングにも、同様のシンプルさを実現しています。Amazon BedrockやSageMaker JumpStartからモデルを選択し、コードを書くことなくファインチューニングを行い、詳細なモデルの評価指標を取得し、リーダーボード上でモデル実行を比較することができます。実際の例を見てみましょう。ある投資ファンドで、顧客プロフィールに基づいて最適なファンドを推奨するチャットボットを構築しているとします。パブリックデータでトレーニングされたパブリックモデルを選択した場合、結果は一般的なものとなり、私たちが提供するファンドに特化したものにはなりません。この問題を解決するために、私たちのデータセットを使用してFoundation Modelをファインチューニングしてみましょう。ここでは、過去の顧客からの問い合わせと、推奨されたファンドで構成されるプロンプト・コンプリーションのデータセットを使用します。これにより、Foundation Modelは顧客プロフィールと提供するファンドの関係性を学習することができます。

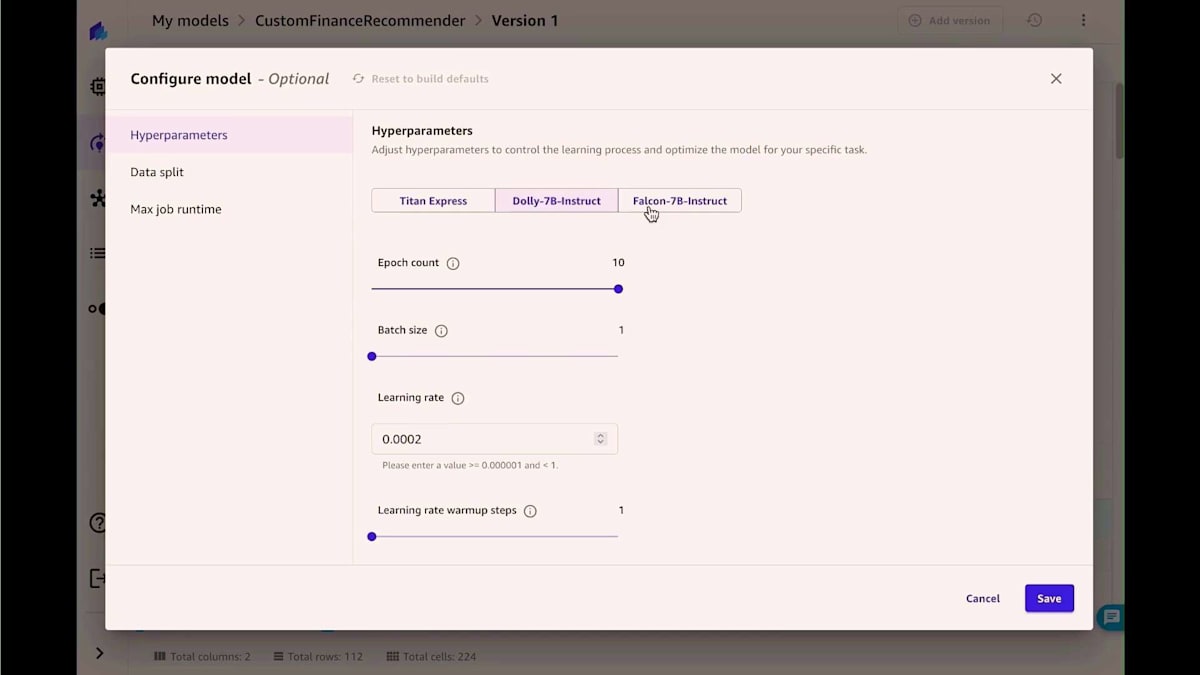


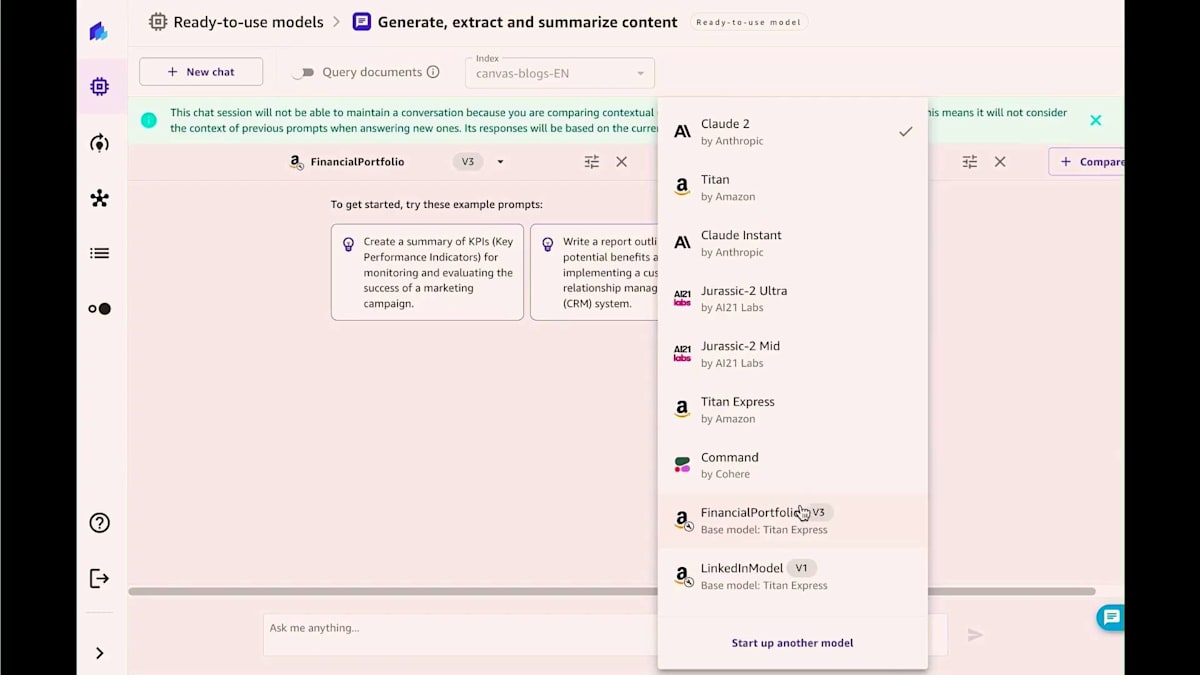

データセットをアップロードし、ファインチューニングしたいモデルを選択するだけです。ここでは3つのモデルを選択しました。 入力列と出力列を指定し、必要に応じてトレーニングパラメータを設定するだけで、 ファインチューニングジョブを開始できます。バックグラウンドでは、最高のパフォーマンスを発揮するモデルを提供するために、複数のファインチューニングジョブを実行しています。ここでは、詳細なモデルの評価指標を確認したり、モデル詳細のリーダーボードを確認したりすることができます。ファインチューニングされたモデルが一般的なモデルと比べてどのようなパフォーマンスを示すか比較してみましょう。比較すると、左側のファインチューニングされたモデルの方がより具体的で詳細な結果を提供していることがわかります。これは一般的なモデルと比較した場合の違いです。このように、コードを書くことなくモデルをファインチューニングし、すべてのモデル評価指標と詳細なモデル評価レポート、成果物をダウンロードすることができます。高品質な機械学習モデルが完成したら、次のステップは通常、モデルを評価して予測を生成することです。



Amazon SageMaker Canvasは、アプリ内予測や What-if分析機能を提供することで、簡単に予測を行うことができます。入力パラメータを変更するだけで、モデルの応答がどのように変化するかを確認できます。これにより、素早い反復と評価が可能になります。また、データのバッチ予測を実行し、特定の頻度やデータが変更されたときに予測を自動化することもできます。ボタンをクリックするだけで、これらのモデルをSageMakerエンドポイントにデプロイしてリアルタイム推論を行い、Amazon QuickSightと予測を共有し、さらにAmazon QuickSightとモデルを共有して予測分析ダッシュボードを構築することができます。
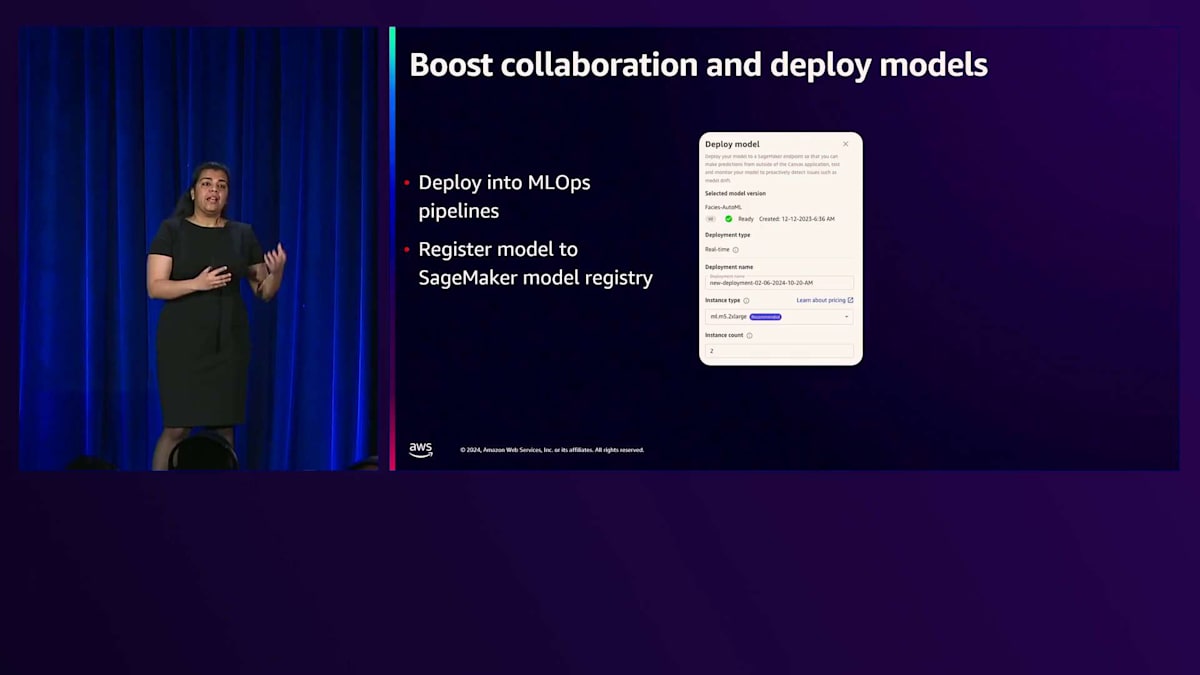

先ほど、専門家と非専門家の協力が重要だとお話ししました。Canvasで行われるデータ準備やモデル構築などのすべての作業は、簡単にエクスポートしてSageMaker上の本番環境にデプロイでき、専門家が使用しているのと同じMLOpsとMLガバナンスを提供します。すべてのモデルはSageMaker Model Registryにデプロイできます。これはMLOpsプロセスのバックボーンとして機能します。Model Registryは、モデルを一元的にカタログ化し、承認し、本番環境への昇格に使用する場所だと考えることができます。また、コードをJupyterノートブックとしてエクスポートし、データサイエンティストと共有することもできます。データサイエンティストはSageMaker Studioでこれらをレビューし、一緒に反復作業を行い、パフォーマンスの改善を支援したり、コードを書き直すことなくこれらのモデルを本番環境に移行したりすることができます。SageMaker Canvasによって、データサイエンティストと非専門家の相互運用性とコラボレーションが大きく向上します。
時系列予測モデルの構築:Charles Laughlinによるデモ
ここでCharlesに予測についてのデモと説明をお願いしたいと思います。本日は時間を共有していただき、ありがとうございます。私はCharles Laughlinで、AWSのAIスペシャリストとして働いており、今回で6回目のre:Inventの参加となります。私がここにいる理由の1つは、この夏、GosoftとAWSのチームと一緒に実験を行い、アーキテクチャを設計し、最終的に価値を生み出す本番パイプラインを提供したことです。Dr. Sopchokeのセクションでは、Gosoftにもたらされた価値を実際に数値化してお話しいただきます。私のセッションでは、時系列予測モデルを構築するエンドツーエンドのプロセスについて説明し、Gosoftと共に作成したアーキテクチャについてご紹介します。

時系列予測の概念に馴染みのない方のために、このスライドで概念を説明させていただきます。まず、過去の既知の期間における既知の真実から始まります。モデルはデータのパターンを学習し、それを抽出して保存することができます。保存されたモデルから、顧客は未知の将来をナビゲートし、計画の意思決定を支援するための予測を生成することができます。小売業の予測では、消費者の需要に応えるために適切な場所に十分な商品を配置することが重要です。そのため、商品が多すぎる、あるいは少なすぎるというジレンマのバランスを取る必要があります。



ここでCanvas UIのデモをご紹介します。エンドツーエンドで説明していきます。このCanvas UIでデモを行いますが、Gosoftを含む多くの顧客は、UIを使用せずに完全に自動化することを選択しています。どちらの方法も有効で、基本的な精度も同じです。まずは、デモで使用するサンプルデータセットについて説明します。これは表形式のデータを見る例です。オプションの特徴量と必須の特徴量があり、これらについて説明していきます。データ準備は最も重要な側面の1つです。ここではケース数量というターゲット特徴量が必要です。これは単位数、金額、リソース、パレット、各ケースなどが該当します。また、日付期間も必要で、ここでは週次データですが、分単位から年単位まで、またはその間の任意のポイントのデータも可能です。次に、顧客は商品レベルまたは類似のレベルで予測を行いたいと考えています。これは多くの場合、商品やSKU、製品と場所の組み合わせとなります。私たちのシステムは、最大10個のこれらのディメンションをサポートしており、高い粒度または細かい粒度で予測を生成することができます。

ここでは、倉庫(Warehouse)とカテゴリー、または商品カテゴリーを例として使用しています。


次に、予測の精度を高めるために外部データを取り込むことができます。例として、気温、燃料価格、インフレーションデータなどが挙げられます。ビジネスの推進に重要だと考えられるデータは、どんなものでも取り込むことをお勧めします。Amazon SageMakerは、そのFeatureがビジネスにとって重要かどうかをフィードバックしてくれます。また、特別なイベントや休日を予測するために、カレンダーやイベントデータを取り込むこともできます。例えば、タイでは4月に新年を祝います。水をかけ合って祝うお祭りなので、その週には水やペットボトルの水、水関連商品の売上が増えるのは当然のことです。

小売業の需要予測において、小売業者は消費者の購買を促進するために、さまざまな施策を同時に実施することがあります。広告費、商品の在庫状況、季節要因、値引きなどの商品プロモーションなど、これらはすべてビジネスに影響を与える要素です。ここでも、重要だと思われる要素はすべて取り込むことをお勧めします。重要でない場合にどうなるかを示すために、「Random」というFeatureを作成しましたので、後ほど説明可能性レポートでその結果をお見せします。


データについて説明したところで、モデルの作成方法を見ていきましょう。ここにカーソルを合わせて「Create a model」をクリックするだけです。分かりやすい名前を付けたら、次にユーザーとして行うのは、ターゲットとなるFeatureの選択です。つまり、何を予測したいのかを決めます。この場合は、ケース数量になります。
需要予測の詳細:データ準備からモデル評価まで
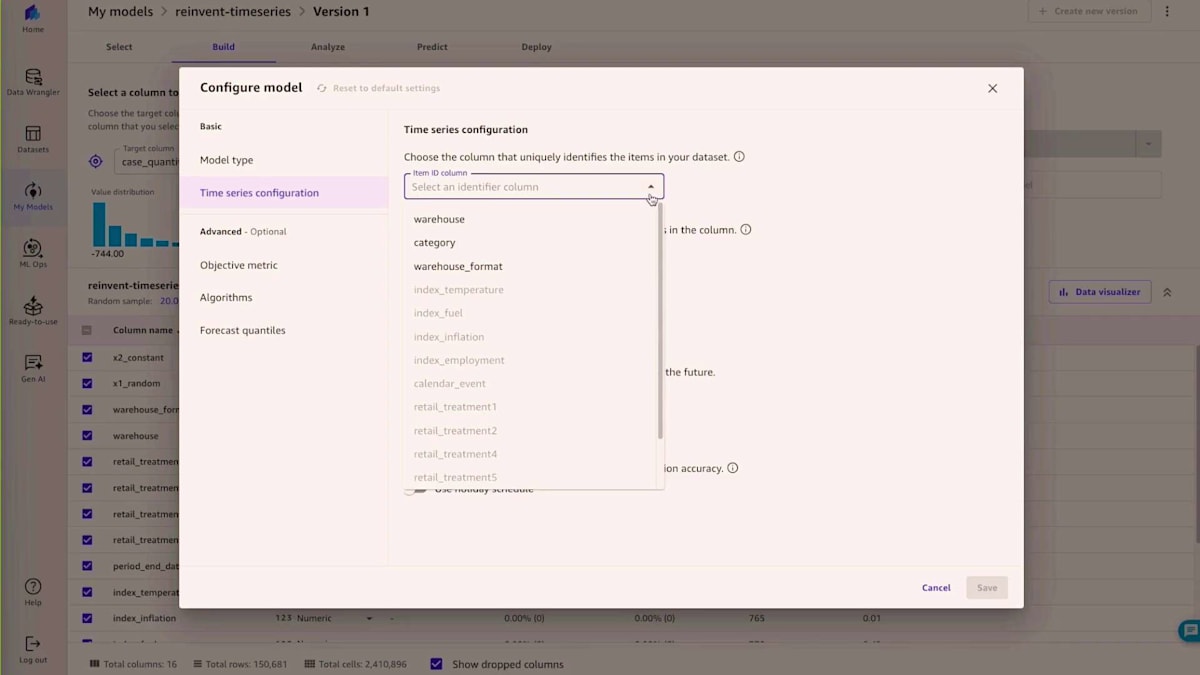
次に、UIがモデルの設定を促していることに気付くでしょう。予測の次元として使用するFeatureを選択する必要があります。この例では、Warehouseを選択しています。Warehouseと商品カテゴリーのレベルで予測を得ることができます。Amazon SageMaker Canvasは、データが週単位でサンプリングされていることを自動的に認識するので、12週先までの12個の予測を生成するようリクエストすることができます。


Canvasの主要な特徴の1つは、ニューラルネットワークモデルと、数十年にわたってサプライチェーンで使用されてきた統計モデルの両方を組み合わせて使用できることです。それぞれのモデルが価値を生み出しますが、それらを組み合わせることで、単一のモデルよりも高い精度を実現できます。コードを1行も書くことなく、ここでボタンをクリックするだけでモデルの構築を開始できます。これはUIを通じて、あるいはAPIを通じて実行することができます。
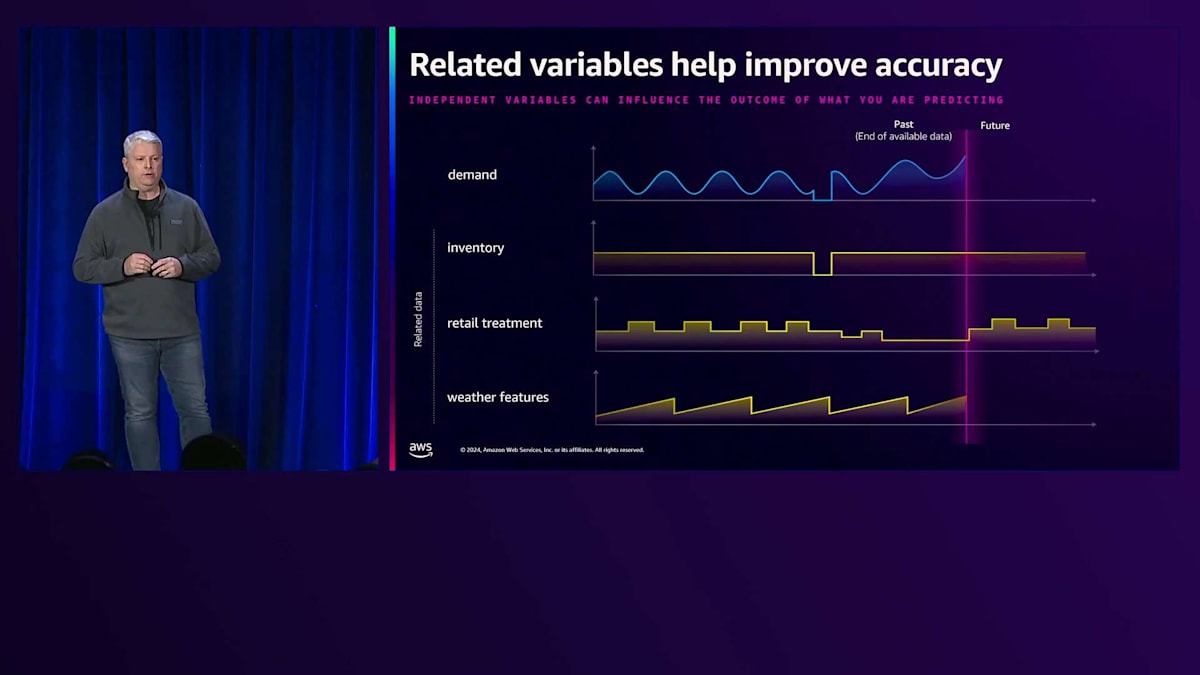

トレーニング中の主なアイデアは、MLモデルがデータのパターンを学習しているということです。需要と需要自体の関係性、そして在庫や小売施策といった提供された特徴量との関係性を学習しています。モデルはこれらの変数間の関係を学習します。例えば、棚が空になっている場合、商品が在庫切れの場合、それは制約として機能し、販売可能な数量を制限することになります。ほとんどの小売業者は品切れを避け、需要を満たすのに十分な供給を確保することを好みます。




これまでは概念的な説明でしたが、次はトレーニング中に実際に起こっている計算処理の観点から見ていきましょう。UIまたはAPIからこの時点でモデルのトレーニングを要求すると、Amazon SageMakerはデータのサイズを認識し、適切なサイズのクラスターを選択します。データを取り込み、そのクラスターに対してトレーニングを開始します。時系列アプリケーション全般に最適な単一のモデルは存在しないことはよく知られているため、SageMakerは最大20以上のコンテナを同時に起動します。異なるアルゴリズムが試され、異なる期間がサンプリングされ、ハイパーパラメータの最適化が行われます。同時に実行されるこれらの独立したコンテナそれぞれの目標は、利用可能な最高レベルの精度を達成することです。Amazon SageMakerはこれらを監視し、すべてが完了すると最適化プロセスを実行します。

この最適化プロセスはアンサンブルと呼ばれます。ここでのアイデアは、データセット内の各アイテムに対して、1つのアイテムであれ数万のアイテムであれ、独自のレシピを作成することです。各アイテムに対して独自の重み付け比率を生成します - 商品1では100% ARIMAモデルかもしれませんし、商品2では統計モデルとニューラルモデルを50-50で組み合わせるかもしれません。アンサンブルは各アイテムに対して最高の精度を生み出します。そのアンサンブルモデルは保存され、他のすべての基本候補モデルも保存されます。お客様は、アンサンブルモデルまたは他のモデルのいずれかから予測を行う自由があり、後ほどCanvas UIに表示されるリーダーボードをお見せします。



約1時間が経過すると、製品ではこのように表示されます。ページの上部にはグローバルな精度指標が表示されます。データセットのトレーニング結果がどれほど良好だったかを、パーセンテージと単位の両方で示す一般的な精度指標が表示されます。他のアーティファクトも生成され、それらすべてのアーティファクトはAmazon S3に保存されます。その中の1つ、Explainabilityレポートについてご説明します。Explainabilityレポートのアイデアは、提供したオプションのデータ特徴量が有用だったかどうか、そしてどの程度有用だったかについてフィードバックを提供することです。


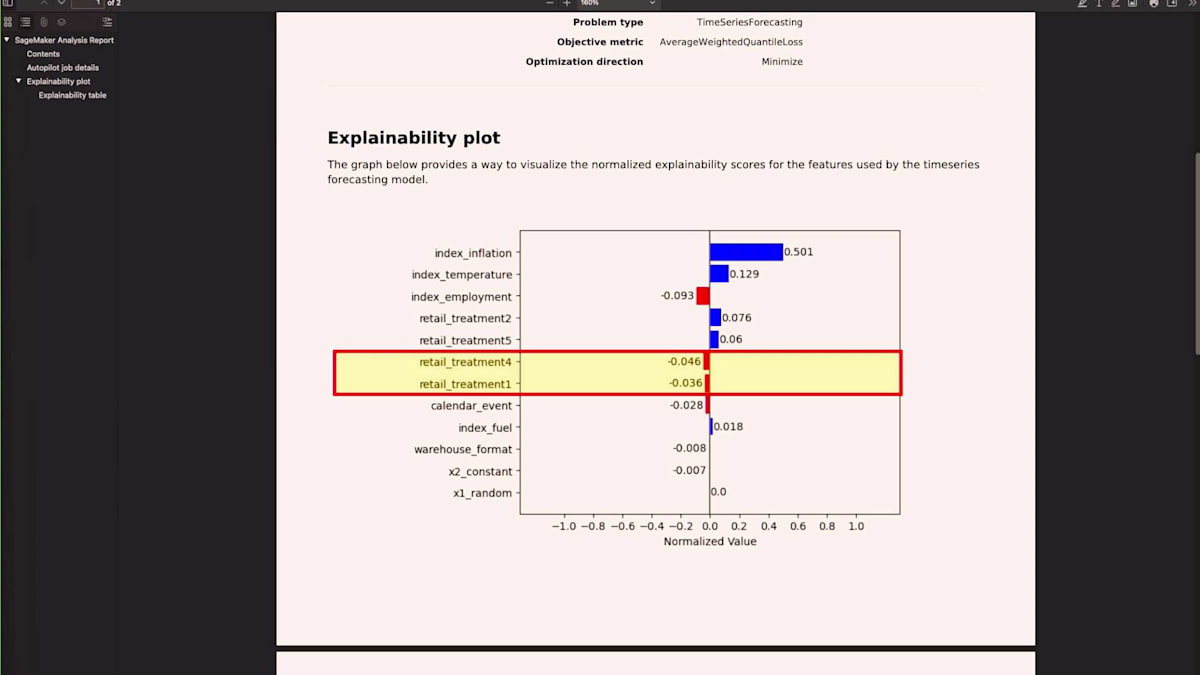
この例では、インフレーションという項目に注目してみましょう。収益を予測する場合、これは正の数値を示しており、インフレーションが上昇すると予測される収益も増加することを表しています。これは人々がより多くの商品を購入するということではなく、1単位あたりの収益が増加しているということです。小売りのTreatment 2と5に関して、これらは収益増加につながる広告支出の例かもしれません。これらは維持したい正の数値です。同時に、小売りでは多くのことが並行して起こっているため、Treatment 1と4のように単位需要は増加するものの、収益は減少するような割引や買い一つで一つ無料といった施策もあるでしょう。


最後に、先ほど説明したランダムフィーチャーについて思い出してください。重みがゼロまたはゼロに近い場合、データセットをできるだけシンプルかつスリムに保つため、これらをデータから削除することをお勧めします。トレーニングが完了し、Explainabilityレポートを確認したところで、モデルのリーダーボードについてご説明しましょう。各モデルの結果を見ると、一番上の行が任意の列に対して精度指標を提供する私たちのモデルアンサンブルです。これがリーダーで、他の候補よりも優れた精度を提供しています。例えば、0.121という平均重み付け分位損失は他のどの項目よりも低く、アンサンブルの強さ、つまりそれを構成する個々の部分よりも強力であることを示しています。



お客様は、このアンサンブルでも他のモデルでも、これらのモデルのいずれからでも予測を選択することができます。UIで予測を行う方法を見てみましょう。SageMaker Canvas UIでは、バッチ予測または単一アイテム予測のいずれかを実行することができます。これらはAPI形式でも実行可能です。単一アイテム予測をクリックして、Atlantaの倉庫における調理器具全般の売上を予測するためのディメンションを選んでみましょう。12週間の予測を行ったので、過去の実際のデータである12週間の履歴と、これから先の12週間が表示されます。
2024年の感謝祭週の調理器具の売上をより詳しく見ると、前後の週よりもやや高い売上が見込まれることがわかります。ここで重要なのは、一つの真実だけではなく、確率的な予測があるということです。81個あれば50%の確率でその市場の需要を満たせますが、50%というのはコイントスのようなもので、十分ではない可能性があります。70%の確率で十分な在庫を確保したい場合はどうでしょうか?その場合は110個必要になります。これは特に自社製品について、すべての需要を満たすために十分な在庫を維持したい小売業者にとって非常に重要です。

ここまでご説明したのは、データを確認し、モデルをトレーニングし、そのモデルを分析し、そしてそのモデルから予測を生成するというプロセスです。このシステムを使用する場合、予測されたポイントはAmazon S3上にParquet形式またはCSVファイルとして保存されるため、予測結果を必要な場所で簡単に利用することができます。
このスライドの目的は、この夏Gosoftに提供された実際のソリューションを説明することです。これが彼らのトレーニングアーキテクチャです。このプロセスは月に1回実行され、左側からGosoftが過去の売上データを抽出することから始まります。先ほど見たような特徴量がS3に格納され、大量のデータが蓄積されます。需要の特性に基づいて全商品を異なるクラスターに分類するクラスタリング手法を設計しました。変動性が1つの特徴量、売上数が別の特徴量となり、そのデータもS3に格納されます。データが格納されると、GosoftはStep Function内で呼び出されるAWS Glueを使用します。AWS Step Functionは、ワークフローを管理する方法としてこのすべてを統括するプロセスです。Step FunctionはS3上の元のデータを開き、適切なシャードに分割し始めます。

そのAWS Glueジョブの出力は、複数の並列実行されるSageMaker学習ジョブに送られます。これらの処理はすべて並列で行われ、Gosoftは分散処理によって学習に必要な実時間を短縮することができます。それぞれの学習ジョブは、モデルの統計、バックテストの結果、そして先ほど見た説明可能性レポートを含むアーティファクトをS3に生成します。
彼らの推論アーキテクチャは、先ほど見た学習アーキテクチャとそれほど変わりません。このプロセスはGosoftで毎週実行されます。左側から始まり、最新の実測データから最新の週次売上データまでがS3にアップロードされます。そのデータはStep Functionによって統括され、Glueジョブが一枚岩のデータをシャードに分割し、その後SageMaker推論ジョブを使用します。並列ジョブの数はStep Functionによって制御され、Gosoftは要求されたSLA内で毎週約2億5000万のアイテムと店舗の組み合わせに対する予測を行うことができます。サーバーレスのSageMaker推論ジョブのパワーを活用して分散処理を行い、予測結果はS3に格納され、次の補充サイクルへの入力となります。


これが最後のトピックで、少し高度な内容ですが、ついてきてください。ここでは、供給のジレンマのバランスについてお話しします。まず、完璧な予測は存在しないということを強調したいと思います。商品が多すぎるか少なすぎるかというジレンマに直面した場合、小売業者は必要以上に持つ方向に傾きますが、最小限に抑えます。特定の店舗における商品について、5日間の期間を振り返ってみましょう。

これはバックテストデータについて説明すべきですね。バックテストデータとは、学習サイクルでは見ていない過去のデータを保持しておき、実際の過去の値と将来の予測を並べて比較できるものです。これは盲目的に学習され、これがカナリアとなります。これがうまく機能すれば、世の中の状況が同じであれば、これが将来の予測がどのようになるかの例となります。SageMakerプロダクトによって自動的に処理される仕組みは、予測期間が5日間であれば5日間を保持し、5週間や5ヶ月であっても、予測期間と同じ期間がこのカナリア期間として使用されます。 過去5期間を振り返る余裕があり、顧客が購入するであろう真の必要数は218個でした。ここでのP50値は、確率的な50%の確率で、合計は189となっています。
つまり、189個の在庫があれば足りる確率が50%あるということです。逆に言えば、不足する可能性も50%あるということになります。実際の数値と比較すると、約30個不足していることがわかります。小売業者の立場であれば、最初の189人の購入者に対応でき、189回分の利益を得ることができます。
P50を超えて、より高い分位数を見てみましょう。これにより、在庫切れを最小限に抑えながら、余剰在庫も最小限に抑えるための判断材料が得られます。P60では、208個の在庫が足りる確率が60%、不足する確率が40%となります。これが実際の状況で、10個不足しています。最初の208人の購入者に対応でき、208回分の利益を得られますが、余剰はありません。
この傾向はP70でも続きます。ここで初めて、実際の供給量である228個が需要を上回ることがわかります。つまり、すべての購入者に対応できるということです。誰も空の棚に遭遇することなく、代替品を探す必要もありません。228回分の利益を得られ、多くの企業にとってこれは非常に重要です。利益を得ながら、購入者を満足させるという目に見えない利点もあります。P80やP90まで上げていくと、少なくともこの商品に関しては、過剰供給になってしまいます。
要するに、このLocation AのSKU 1に関しては、P70が適切な数値です。過去のこのバイアスを使用することで、これがアルゴリズムによる判断となります。在庫過多と在庫不足のジレンマのバランスを取るのに役立ちます。ここでのポイントは、アルゴリズム駆動型、データ駆動型であることです。これにより、手作業での編集や判断による予測を避けることができます。顧客は何千、何百万もの商品でこれを行う必要があることを認識しています。Dr. Sirawit Sopchoke氏がGosoftでの成果についてお話しします。この手法はGosoftで使用され、彼が皆様と共有する成果の一部に貢献していると言えます。
Gosoft ThailandのAI需要予測導入事例

以上で私の発表を終わります。それでは、Dr. Sopchoke氏をお迎えしたいと思います。ありがとうございました。こんにちは。タイを訪れたことのある方はいらっしゃいますか?もしタイを訪れたことがあれば、皆様は私たちの顧客の一人かもしれません。私はSisと申します。Gosoft Thailandから参りました。本日は、Amazon SageMaker Canvasを使用したAI需要予測の経験について、皆様と共有できることを光栄に、また嬉しく思います。

まず初めに、私たちの会社と事業内容について簡単にご紹介させていただきます。私たちはCPALLの者です。 CPALLはCP Groupの傘下に位置する企業です。左上に7-Elevenのロゴがありますが、そうです、私たちCPALLはタイにおける7-Elevenのライセンスを保有しています。GosoftはCPALLが設立したIT企業で、グループのITコンポーネントの開発・運用を担当しています。CPALLはコンビニエンスストアだけでなく、カフェ、薬局、卸売り、ハイパーマートまで、幅広い事業を展開しています。

ここでタイにおける私たちの展開状況についてお話しさせていただきます。タイ全土で15,000店舗の7-Elevenを運営しており、現在はカンボジアやラオスなどの近隣諸国でも7-Elevenを展開しています。タイのお客様向けに20万以上のSKUを取り扱っており、全国で3,000万世帯のお客様にご利用いただいています。統計を見ますと、1日あたり3,000万人のお客様が4,000万件の取引をされています。つまり、タイの全ての家庭が毎日私たちから何かを購入されているということになります。そして、これだけの業務量は全てAWSのプラットフォーム上で処理されています。


AWSプラットフォームでは、Amazon EC2、Amazon S3、Amazon RDSといった基本的なサービスから、Amazon PersonalizeやAmazon SageMakerといった高度なサービスまで活用しています。コロナ禍では、事業を継続するために数日間店舗を閉めることを余儀なくされましたが、その中で7-Eleven deliveryというアプリケーションを立ち上げ、最寄りの7-Elevenから30分以内でお客様のご自宅まで商品をお届けするサービスを開始しました。それ以来、7-Eleven deliveryは私たちのスーパーアプリケーションとなりました。このアプリケーションでは、パーソナライゼーション、デジタルクーポン、プロモーションなどを提供し、ロイヤリティプログラムから店舗運営に至るまで、お客様に関する様々な分析を行っています。

店舗運営の中でも需要予測と在庫補充は重要な業務です。簡単に説明しますと、過去のデータに基づいて需要予測が自動的に生成され、それを店舗スタッフが確認して必要に応じて発注を手動で調整するという流れです。この作業には毎日約2時間を要しており、18時間の営業時間の約8%を占めています。国全体で見ると、毎日約3万時間の作業時間がかかっています。もしこれを自動化できれば、店舗スタッフはお客様のケアに時間を割き、顧客満足度の向上に注力できるのではないでしょうか。


このプロジェクトの主要なKPIは、在庫日数(Stock day)と欠品(Stock out)の2つです。在庫日数は、現在の在庫における特定商品の保有期間を示します。在庫日数が長いということは、在庫スペースを無駄に使用していることを意味し、商品が売り切れる前に賞味期限切れとなる可能性が高くなります。2つ目のKPIである欠品は、在庫における特定商品の不足を示します。欠品が多いと、販売機会の損失につながり、お客様の満足度にも影響を及ぼす可能性があります。つまり、需要予測の目的は、これら2つのKPIを削減することで、店舗の在庫管理の効率を最大化することにあります。


タイでは長年事業を展開してきましたが、年々複雑さを増しており、特にここ4年は顕著です。先ほど申し上げたように、在庫補充は手作業で行われており、約2時間かかっています。また、これら2つのKPIでも苦戦しています。この課題に対応するため、在庫補充作業をシンプル化し、必要なときにいつでも正確に実行できるようにしたいと考えています。 そこで、自動需要予測ソリューションに焦点を当てたイニシアチブを立ち上げ、大量のデータを効果的に処理できるようにすることを目指しました。

このイニシアチブをAITKと呼んでいます。AITKは、Artificial Intelligence Tanpin Kanriの略です。Tanpinは日本語で、7-Eleven Japanが先駆けとなった商品管理アプローチです。これは商品カテゴリーではなく、店舗ごと、商品ごとの需要を考慮します。AITKの目的は、AIとMachine Learningを活用して、 予測精度を最大化し、先ほど述べた在庫日数と欠品という2つのKPIを満たすことで、店舗の在庫補充を支援することです。日々のオペレーションを対象としているため、データを体系的に処理する必要があります。

最初のステップであるデータ収集では、 過去の実績データと在庫関連のデータを取得しました。これには、販売実績、商品プロファイル、毎週共有されるプロモーションデータ、店舗プロファイルが含まれます。



各店舗の在庫数など、在庫に関連するデータを保有しています。さらに、2,100のSKUに関する情報や、学校やガソリンスタンド近くの店舗といった店舗プロファイル情報も持っています。 このステップの後、Amazon SageMaker AutoMLを活用して出力を得ます。 ビジネスロジックに従ってモデルを構築し、自動化します。

このAI実装の背後では、4つの主要なAWSサービスを活用しています。ワークフローのオーケストレーションにはAWS Step Functionsを使用し、データ変換にはAWS Glueジョブを使用して、セグメンテーション、シャーディング、統合を行っています。すべてのデータはAmazon S3に保存しています。最も重要なコンポーネントであり、成功の鍵となっているのは、データの前処理、特徴量エンジニアリング、機械学習を自動化し、開発工数を大幅に削減してくれるAmazon SageMaker AutoMLです。
Amazon SageMaker Canvasの AutoMLを導入することで、私たちは素晴らしい成果を上げることができました。補充作業にかかる時間が120分から1.5分に短縮され、95%の改善を実現しました。在庫管理においては、在庫日数が5%減少し、品切れが40%削減されるという大幅な改善が見られました。この日々のプロセスを自動化することで、スタッフはよりお客様のケアに注力できるようになりました。以上が、需要予測ソリューションにおいて私たちがAmazon SageMakerをどのように活用したかについての説明です。
セッションのまとめと今後の展望
はい、タイからご参加いただいたDr. S、この素晴らしい成功事例をご共有いただき、ありがとうございます。Gosoftが達成した補充作業時間の95%削減について、もう一度強調させていただきたいと思います。店舗スタッフが予測業務に費やしていた1日120分の作業時間が、現在では1.5分にまで短縮されました。これは、節約された時間のすべてを顧客体験の向上と店舗での接客サービスに振り向けられるということを意味します。これは素晴らしい成果であり、Gosoftと密接に連携してこのような結果を実現できたことを大変嬉しく思います。

最後に、本日の討議から3つの重要なポイントをお伝えして締めくさせていただきます。 まず、Amazon SageMaker Canvasを使用することで、1行のコードも書くことなく機械学習を加速し、アイデアを本番環境に展開できることについてお話ししました。SageMaker Canvasを使用すれば、コードを書かなくても、深い機械学習の経験がなくても、高品質なMLモデルを構築できることを確認しました。高品質なモデルを構築できるだけでなく、それらを自信を持って本番環境に展開し、トレーニングと推論のパイプラインを自動化することもできます。最後に、Gosoftの事例を通じて、具体的なビジネス成果を実現できることを確認しました。皆様がSageMaker Canvasでどのようなイノベーションを実現されるのか、大変楽しみにしています。また、皆様からのフィードバックもお待ちしております。本日はご参加いただき、ありがとうございました。この後、個別の質疑応答の時間を設けておりますので、どうぞお気軽にお声がけください。ありがとうございました。それでは、よい1日をお過ごしください。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion