re:Invent 2024: AWSがCloudWatch Application Signalsを解説
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Implementing application performance monitoring (COP409)
この動画では、AWSのApplication Observabilityを担当するGeneral ManagerのIgor Sedukhinらが、CloudWatchの新機能Application Signalsについて解説しています。Service Level Objectives、サービスマップ、Transaction Analyticsなどの機能を通じて、アプリケーションの全体像を把握し、異常の根本原因を特定できる仕組みを詳しく説明しています。また、PBSのTechnical Operations DirectorのBrian Linkが、Station Video Portalでの実際の活用事例を紹介し、深夜3時に発生したトラフィック急増の原因特定や、Transaction Searchを使ったPassportアクティベーションの追跡など、具体的な問題解決の経験を共有しています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
全体像の重要性:1986年のゴールデンライオン広告賞受賞CM

時間をさかのぼって1986年、あるCMがゴールデンライオン広告賞を受賞しました。このCMは1980年代のイギリスで放映されたものです。カメラが寄っていき、警察に驚いて逃げ出す若いスキンヘッドの男性を映し出すところから始まります。次のカメラは、同じ若い男性が年配の男性に駆け寄り、そのブリーフケースを奪って老人を地面に押し倒す様子を映し出します。最後のカメラで、実はその若い男性が落下してきた建設用プラットフォームから老人の命を救っていたことが明らかになります。そしてこのCMは、全体像を把握していなければ、本当に何が起きているのか理解できないという、非常に力強いメッセージで締めくくられます。部分的な視点だけでは、同じ出来事について全く誤った結論に至ってしまうのです。これが、このCMが賞を獲得した理由でした。
AWSのApplication Observabilityと運用の卓越性

私はIgor Sedukhinと申します。AWSのApplication Observabilityを担当するGeneral Managerです。本日は、AWSのSenior Specialist Solutions ArchitectであるSiva Guruvareddiarと、PBSのDirector of Technical OperationsであるBrian Linkにも登壇していただきます。一緒にApplication Observabilityの全体像という興味深いトピックについて探っていきたいと思います。

AmazonとAWSでは、私たちのビルダーたちは運用の卓越性を誇りにしています。サービスを大規模に運用し、優れた運用を行うという卓越性は、私たちのビジネス成果の重要な部分です。私たちはこの全体像を構築してきました。エンジニアたちは、サービスで何が起きているのかについて、自分たちで正しい判断を下せるよう、全体像を構築してきました。それには複数の視点が必要です。全体像を把握することで、迅速に適切な判断を下すことができます。そして私たちは、それがニーズに応えられるよう、スケーラブルに構築してきました。クラウドファーストで構築したのです。

これは何を意味するのでしょうか?第一に、私たちが構築する可観測性は、他のものが停止している時でも利用可能でなければなりません。これが第一の条件です。そうでなければ、他のアプリケーションやサービスを観測することができません。第二に、スケールしても効率的でなければなりません。そうでなければ、収益は良くありません。そして、ニーズに応じて低スケールから高スケールまで、あらゆる規模に対応する必要があります。昨年のre:Inventで、私たちはCloudWatchに全体像を把握するためのツール、Application Signalsをリリースしました。このツールには、私たちとエンジニアたちを効率的にする多くの運用プラクティスが組み込まれており、皆さんとそのエンジニアの方々の生産性と効率性も向上させることができると期待しています。このツールを使えば、大きな全体像を把握し、何が起きているのか、なぜそれが重要なのかについて、適切な判断を下すことができます。
CloudWatch Application Signalsの機能と新機能
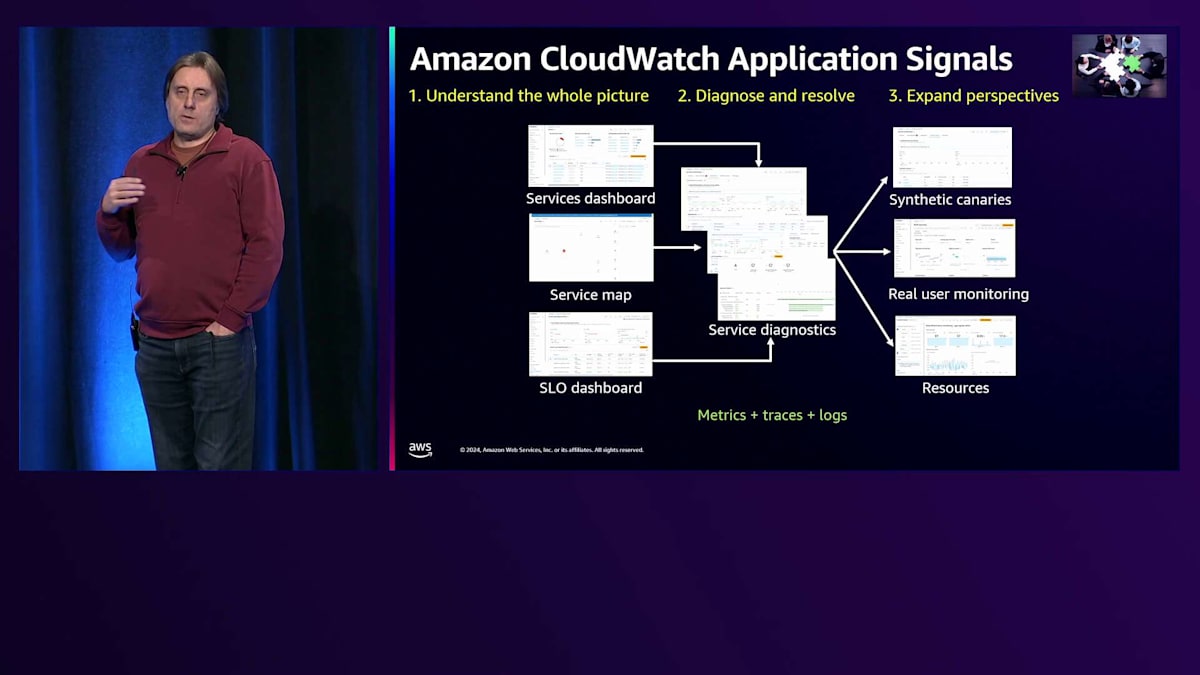
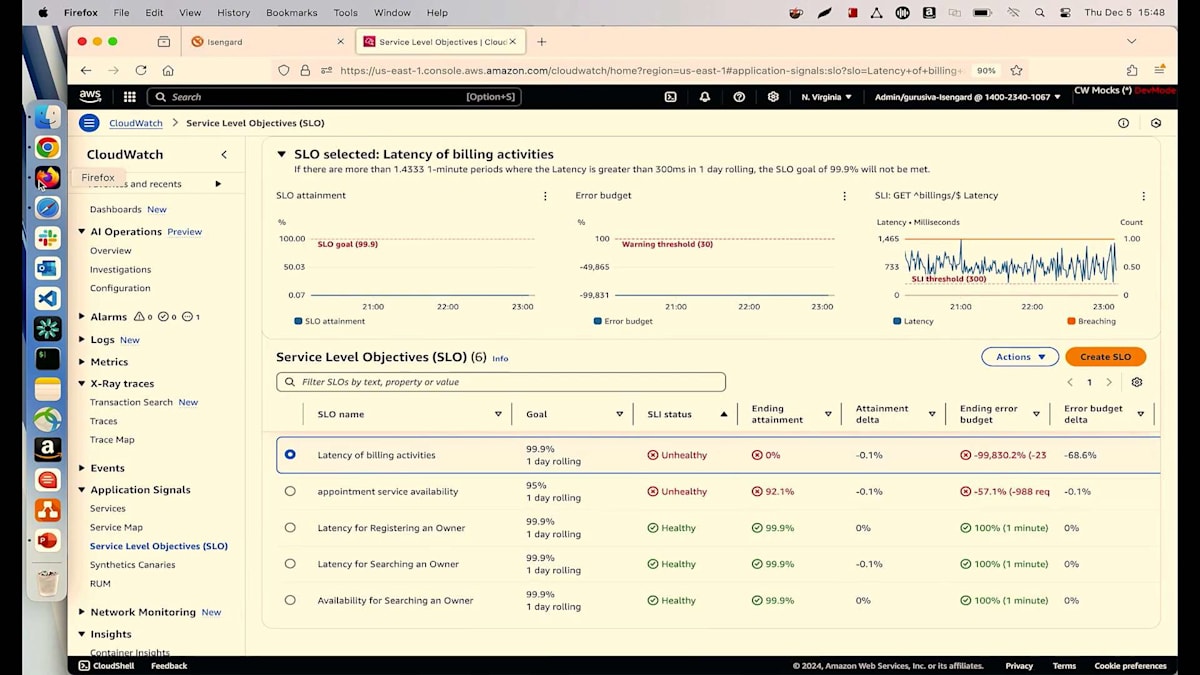
このツールと、それが包含するプラクティスについて簡単に説明させていただきます。このツールでは3つのことができます。第一に、先ほどのCMのように、部分的な視点だけでは誤った判断や結論に至ってしまうため、全体像を理解することができます。第二に、全体像の中で異常を発見したら、それが重要だと分かった後で、その異常の根本原因を診断して特定することができます。第三に、このツールでは追加の視点を取り入れることができます。これは、全体像が本当に完全で、顧客体験やエンドユーザーを真に代表しているかどうかを判断する上で非常に重要です。全体像を理解するために、3つのエントリーポイントを使用できます。第一はService Level Objectivesです。これを使用すると、APIのレイテンシーや可用性など、重要な要素を選択することができます。
お客様が価値を見出すオブジェクトや機能を作成する場合、ユーザーにとってそれが適切に機能しているかを評価するためにService Level Objective (SLO)を設定することができます。すべてのサービスの完全な概要を提供するサービスダッシュボードを使用できます。また、依存関係に関する情報も含まれており、依存するサービスで高いレイテンシーが発生している場合、まずそれを把握し、全体像や意思決定に反映させることができます。
サービスマップでは、アプリケーションの完全なトポロジーを確認でき、接続状況や発生する可能性のある健全性の問題など、アプリケーションの全体像を把握することができます。そこで異常を発見した場合、通常はサービス診断を行います。これには、メトリクスのP99における異常の特定、P99の原因となっているトランザクションの特定、そしてそれらのトランザクションがP99レイテンシーを引き起こす根本原因の特定が含まれます。
カスタマーワークフローをモデル化し、サービスに対して正常に機能しているかを理解するための、外部からの合成的な視点を取り入れることができます。もう一つの視点は、Real User Monitoringで、サーバーではなくブラウザで動作するWebサイトやその他のアプリケーションが、サービスのパフォーマンス低下によって実際に問題を経験しているかどうかを理解することです。典型的な例として、HTTP 500エラーではなく400エラーの場合、ユーザーが値を入力する際に問題となりますが、サービス診断では障害として表示されないことがあります。
アプリケーションが実行されているコンテナや環境などのリソースに関する情報を取り入れることができます。これにより、メモリの問題によってアプリケーションにストレスがかかっているかどうかを理解できます。このツールは、メトリクス、ログ、トレースをアプリケーションの完全な全体像に統合し、さらにAPIや依存関係について、すべてのアプリケーションが持つべき標準的な既製のメトリクスも提供します。

このツールを年初めにリリースし、ご要望いただいた多くの機能を追加してきました。現在、re:Inventで複数の新機能をリリースしています。その一つがTransaction Analyticsで、これにより適切なコストでアプリケーションのトランザクションを100%キャプチャして分析することができます。平均値は正常でも、特定のエンドユーザーがP99レイテンシーを経験している場合に把握する必要があるため、そのような固有の異常を見逃さないように設計されています。
re:Inventで先日発表された Amazon Q Developer operational investigations を追加しました。このツールと統合されたことで、Service Level Objective の違反が発生した際に、AIが何が起きたのか、なぜそれが重要なのかを素早く解析できるようになりました。私たちのソリューションは完全に OpenTelemetry ベースで、独自のエージェントと SDKを提供しています。今年は OpenTelemetry エンドポイントを追加し、より簡単にデータを直接送信できるようになりました。また、リクエスト量や顧客のアクティビティが多い場合に対応するため、ボリュームベースの評価をサポートするように Service Level Objectives を拡張しました。さらに、ランタイムメトリクスを組み込み、特定のノードでGarbage Collectorが過熱した場合など、トランザクションのストレスやレイテンシーとイベントを関連付けることができるようになり、ランタイムメトリクスとアプリケーションメトリクスを連携させています。
OpenTelemetryによるNode.jsと.NETの言語サポートを拡張し、他の言語も使用可能ですが、これらは自動的にすぐに使える解決策を提供している言語です。Lambdaとの統合により、コールドスタートのコストを払うことなく、エージェントやその他のソリューションをインストールする必要もなく、Lambda向けの完全なアプリケーション可観測性を実現しました。データベースのサポートも拡張し、アプリケーションのService Level ObjectiveやAPIパフォーマンスの異常を発見し、その原因がデータベースクエリのパフォーマンスやインデックスの不足にある可能性まで深く掘り下げることができるようになりました。
アプリケーション内での生成AIアナリティクスのサポートを拡張しました。Bedrock APIとモデルの利用において、どのモデルがより良いパフォーマンスを発揮しているかを把握できます。また、Real User Monitoringをすべての商用リージョンに拡張し、他のアプリケーション可観測性ソリューションと同じ場所で利用できるようになりました。これが今年これまでに行ってきたことです。では、Sivaをステージにお招きして、これらすべてを実際にご覧いただきましょう。
ペットクリニックアプリケーションでのApplication Signalsデモ
Igorの素晴らしい概要説明をありがとうございます。私はSiva Guruvareddiarと申します。可観測性に焦点を当てたSenior Specialist Solutions Architectを務めています。このセッションへようこそ。re:Inventをお楽しみいただけていることと思います。 このデモは昨年のre:Inventからの続きです。私がサービスオペレーターとして運営しているペットクリニックアプリケーションについてです。顧客満足度を重視しているため、アプリケーションシグナルを重要視しています。日々の運用のためにアプリケーションシグナルに多大な投資を行ってきました。このアプリケーションを運営するサービスオペレーターとして使用しているシナリオをいくつかご紹介し、顧客満足度を確保する方法をお見せします。
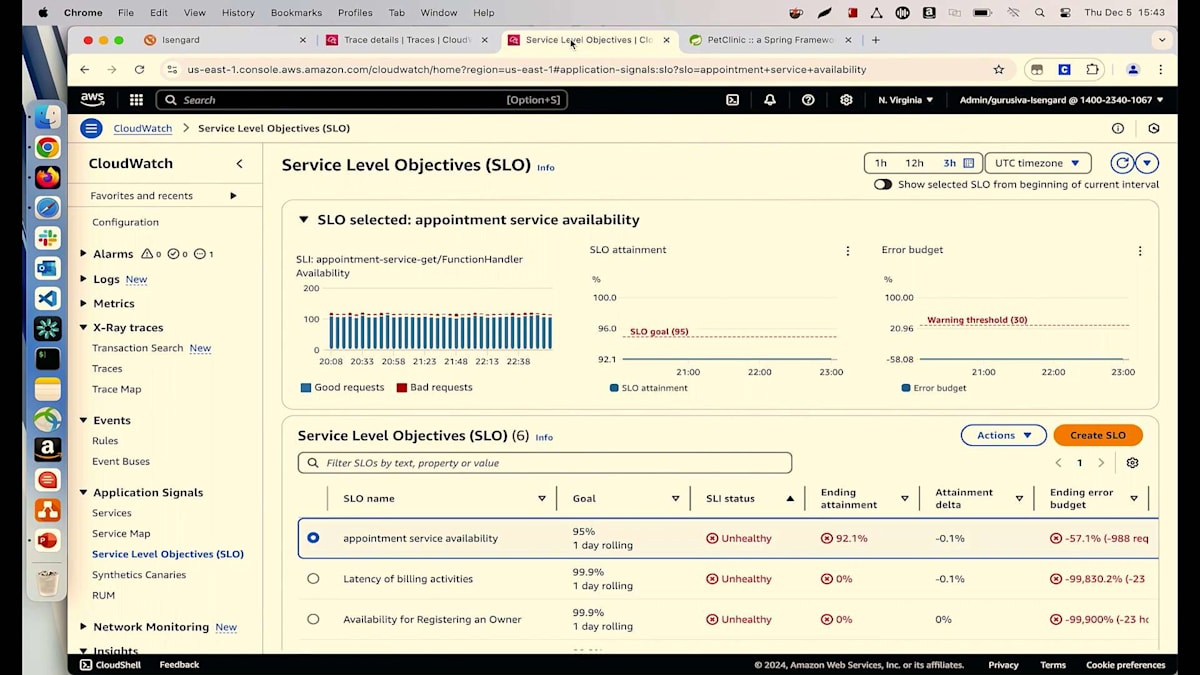
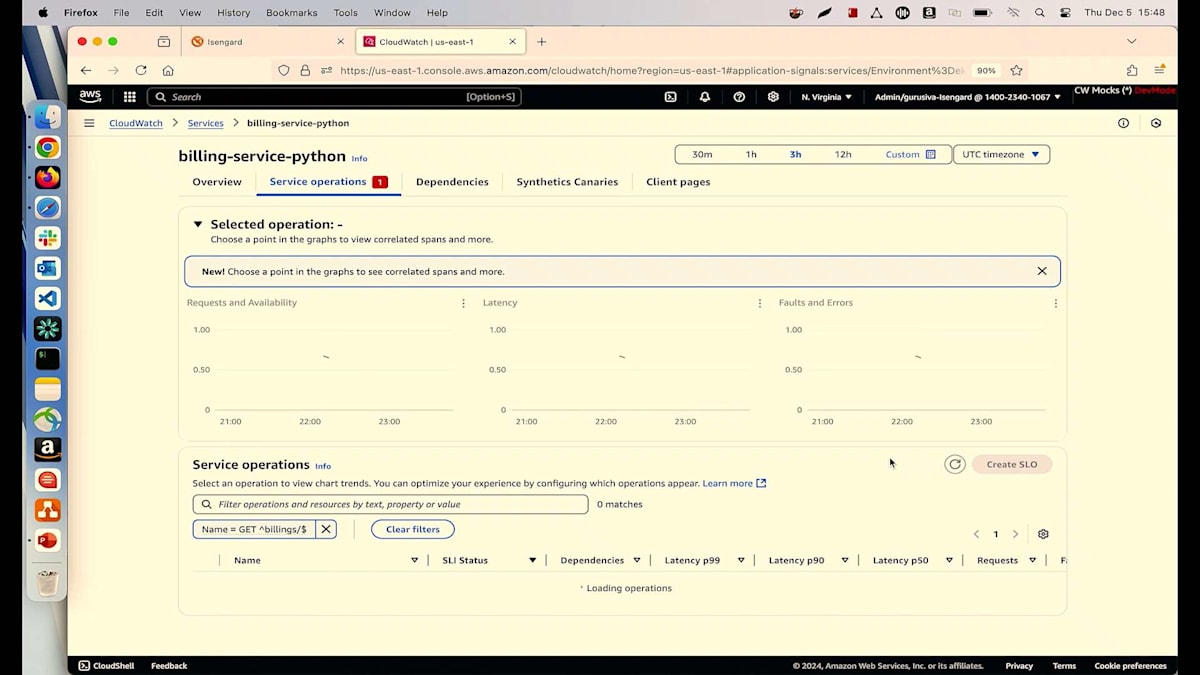
これは、人々が予約を取り、ペットの治療を受け、保険情報や請求の詳細を更新できる、典型的なペットクリニックアプリケーションです。 Lambdaを使用していて、顧客満足度を確保したいと考えている方は手を挙げてください。現在、Lambdaで予約サービスを実行しており、100%の可用性を確保したいと考えています。appointment service availabilityというSLOを作成し、現在SLIで実行されていますが、この根本原因を特定したいと考えています。
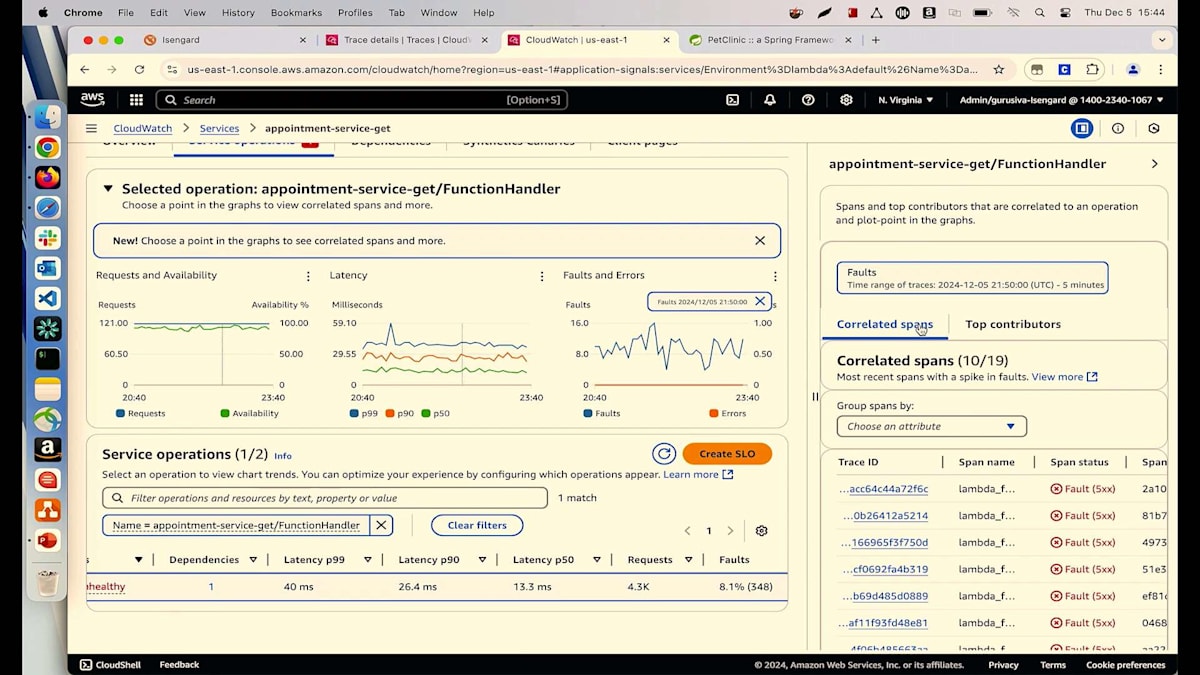
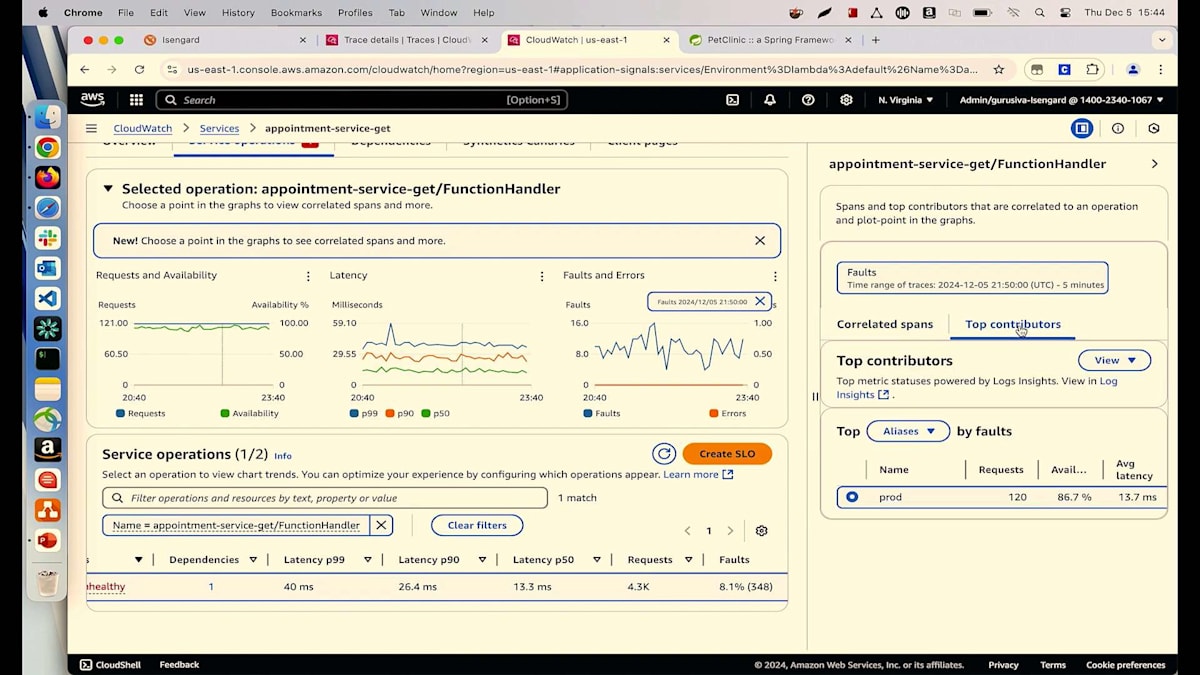
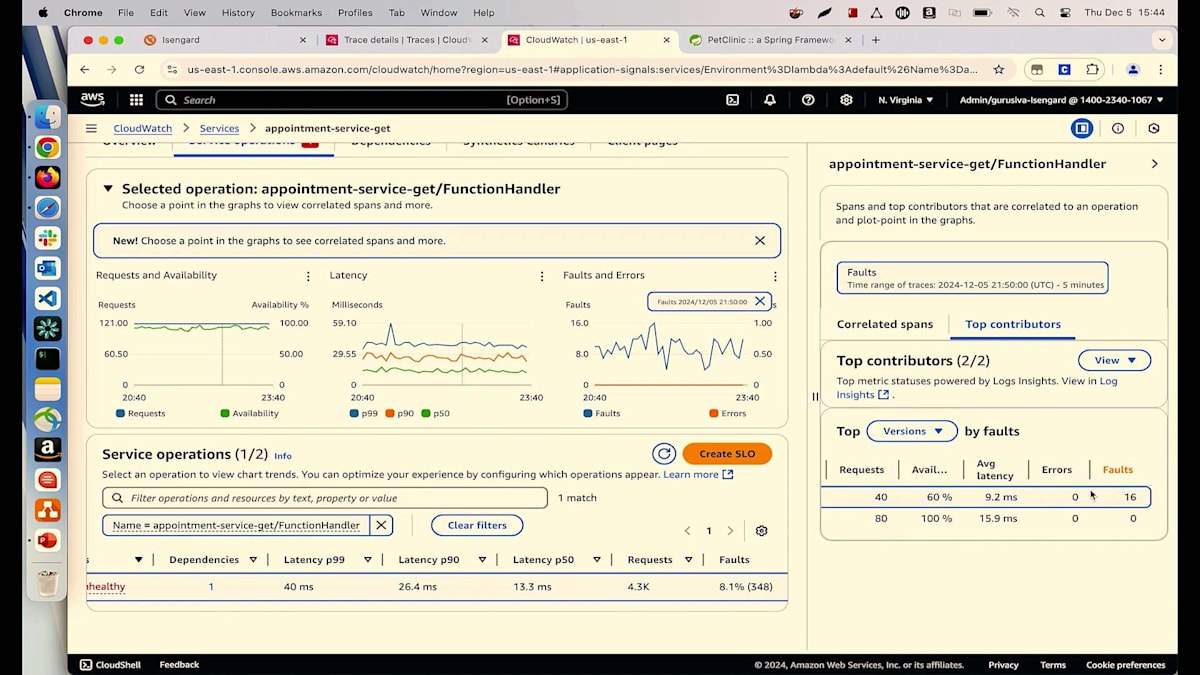
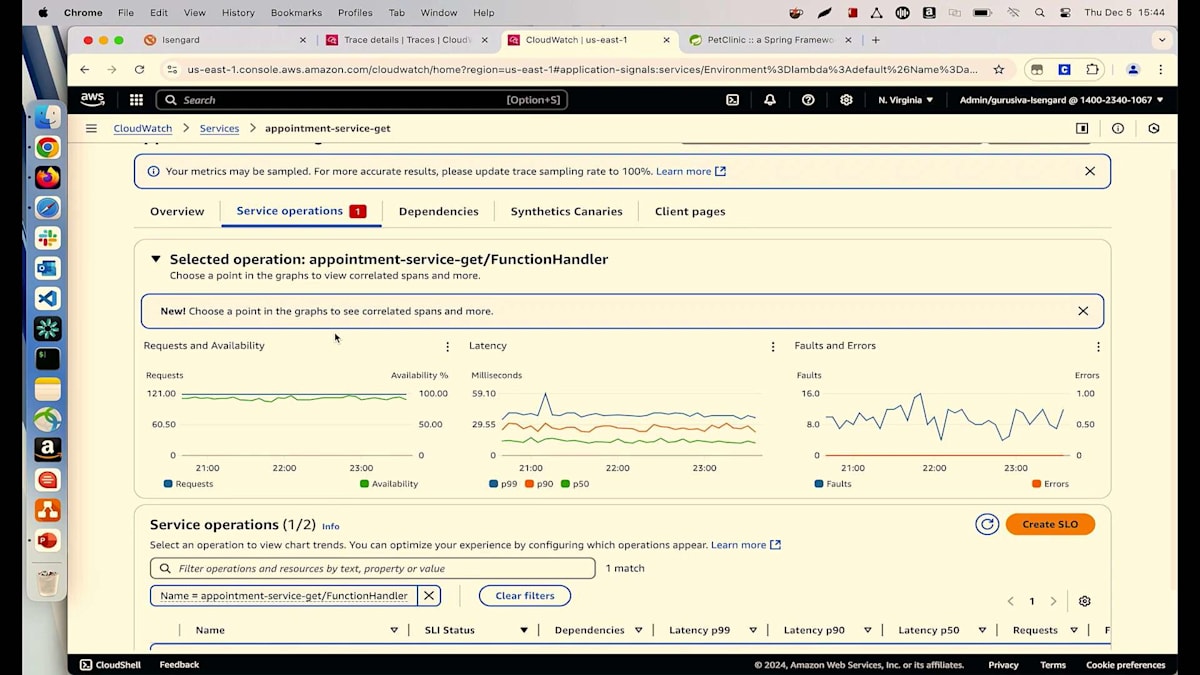
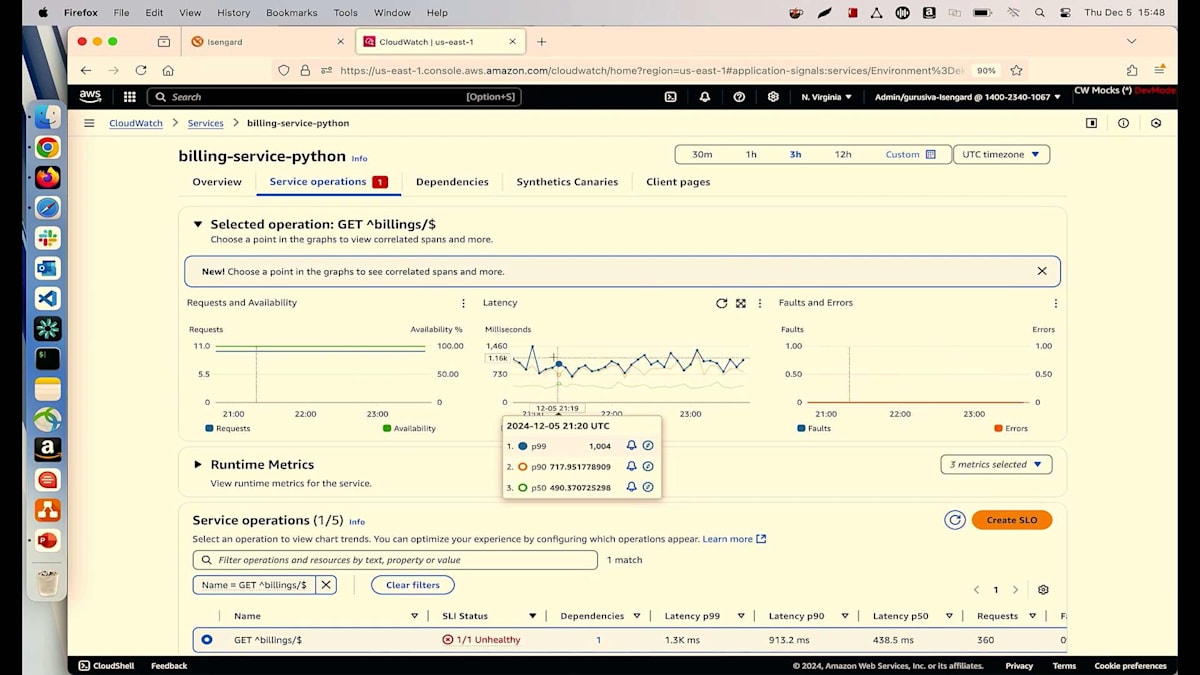
詳細についてご説明させていただきます。リクエストと可用性のチャートをご覧いただいていますが、マウスを合わせると可用性が91%と表示されています。しかし、私たちは100%を目指しています。メトリクスを見ると、8%の障害が発生しているようです。障害とエラーのチャートを見てみましょう。そこにはいくつかの異常が見られます。これらのピークや谷のどれかをクリックすると、すべてのトランザクションが表示されます。見たところ、多くの500エラーが発生しているようです。詳細に入る前に、主要な要因を見てみましょう。バージョン別に確認を始めると、Lambdaの異なる2つのバージョン(バージョン6と5)を実行していることがわかります。そして、すべての障害が最新バージョンのLambdaから発生しているようです。
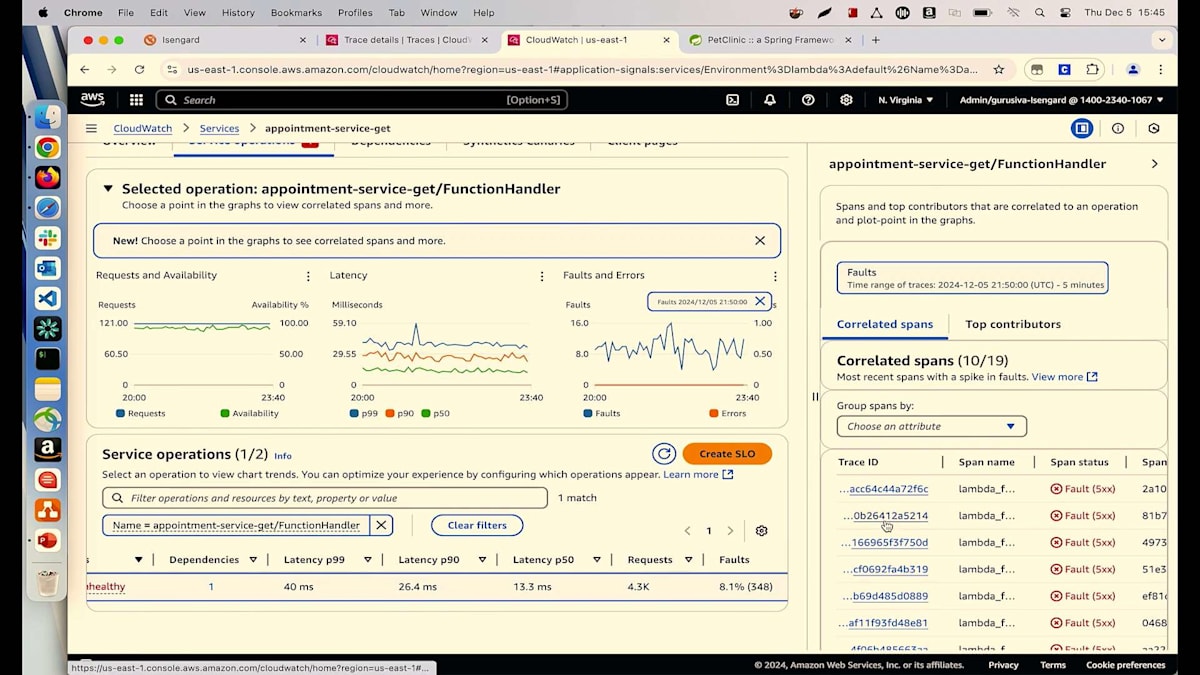
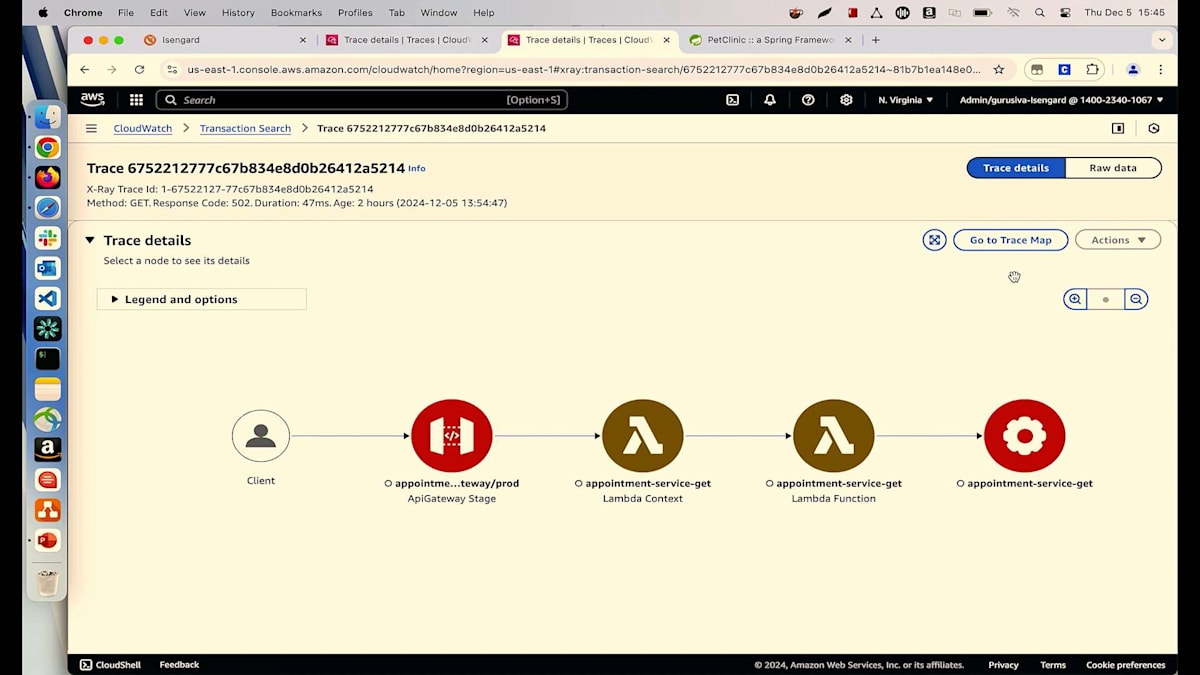
何かを実行していて、すべてが順調に進んでいるのに、突然何かが変更されて問題が発生し始めるという経験をお持ちの方は手を挙げてください。私たちの技術者としての日常でよく目にする光景ですよね。最新のLambdaが根本原因だとわかりましたが、なぜそれが起きているのかはまだ特定できていません。関連するSpanを確認してみましょう。トランザクションのリストが表示されています。ランダムにトランザクションを選んでみましょう。これによってトレースの詳細ページが表示され、ここから多くの情報を確認できます。例えば、各ホップのマップとその進行状況、さらに各ホップでのSPSタイムラインで処理時間を確認することができます。
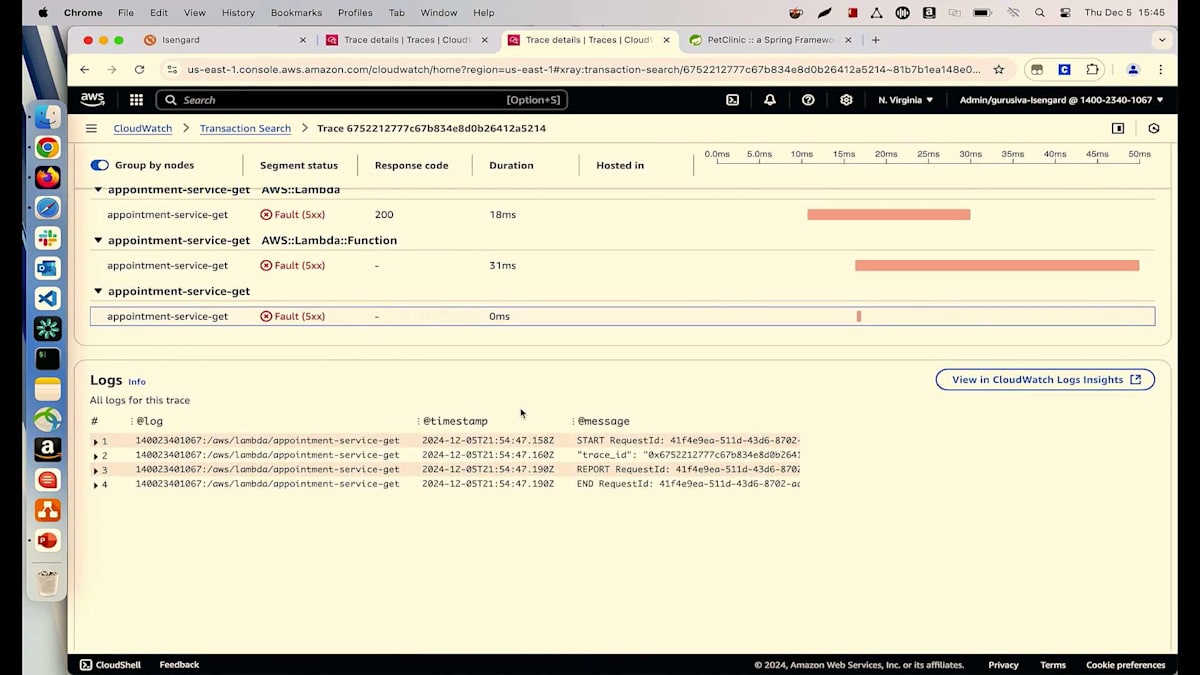
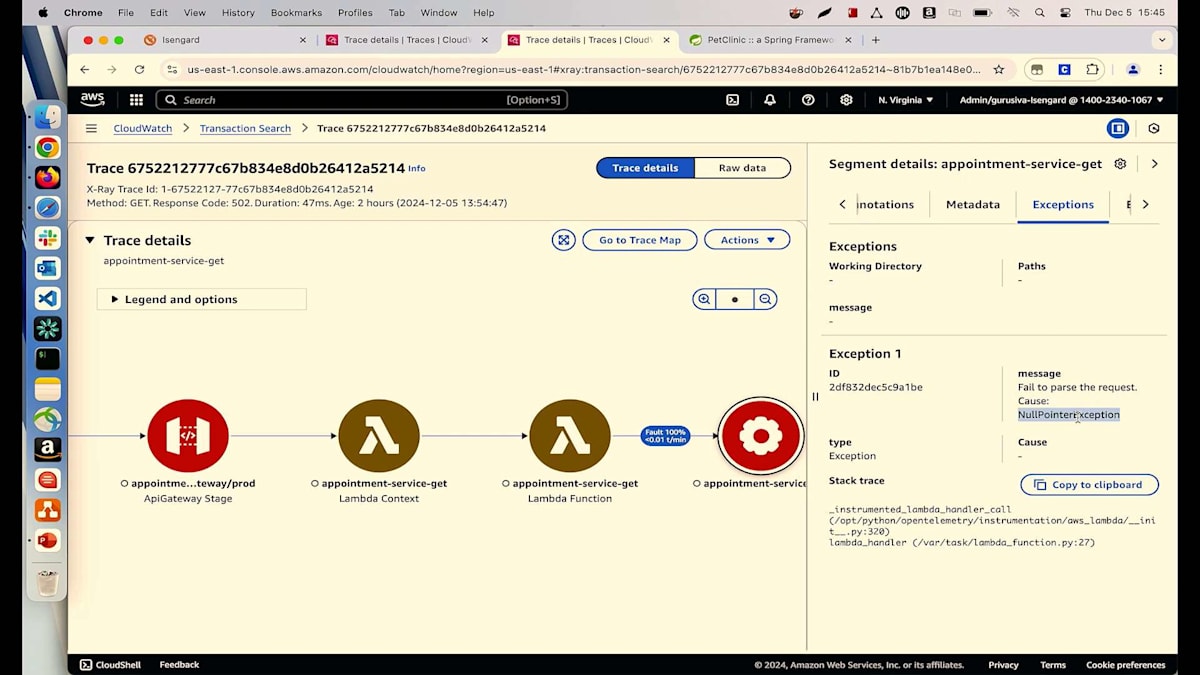
すべてのログを1か所から確認することができます。現在、私たちが注目しているのは取得したアポイントメントについてです。exceptionsタブを見ると、27行目でNull Pointer Exceptionが発生していることがわかります。ご覧の通り、数回のクリックだけで根本原因を特定することができました。最新の変更による問題を特定できただけでなく、コードやIDEを開くことなく、どの行で何が起きているのかまで確認できています。
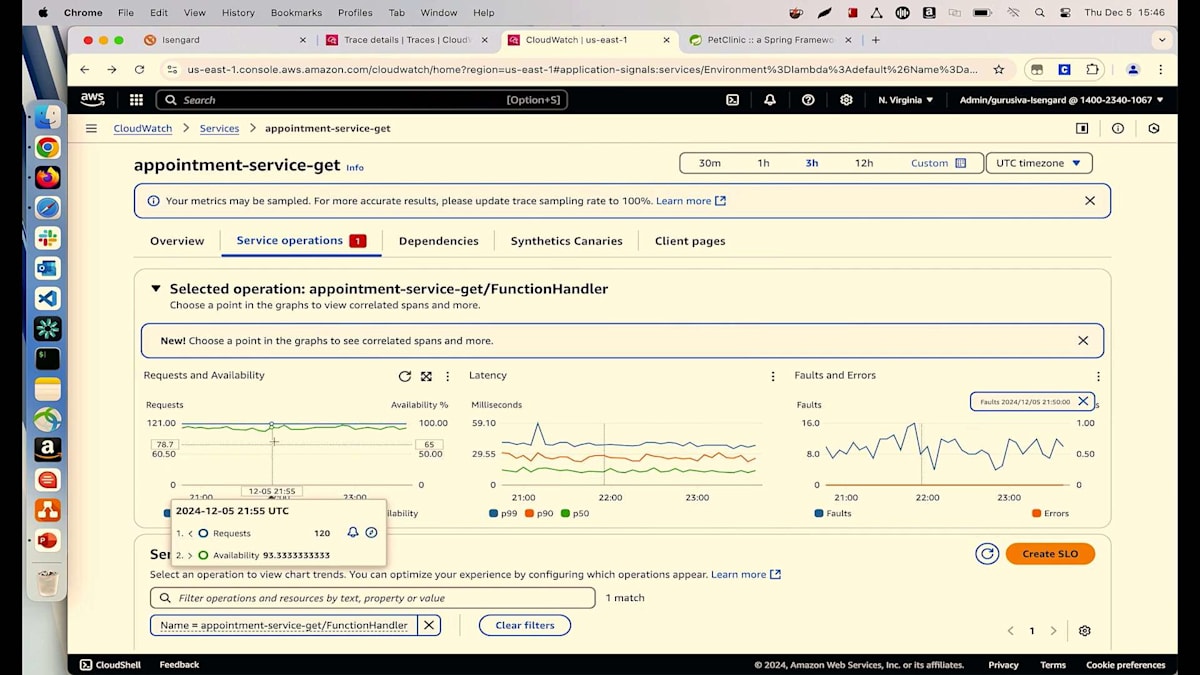
これで開発チームに最新の変更を元に戻し、この問題を修正してプッシュしてもらえば、お客様は再びアポイントメントを予約できるようになります。しかし、話はここで終わりではありません。Null Pointer Exceptionが発生しているのであれば、なぜすべてのリクエストで発生しているのか、そして特に何を探しているのかを理解する必要があります。そこで、何が起きているのか詳しく見てみましょう。Service Operationsページに戻ると、多くのリクエストが入ってきているのが分かり、可用性チャートには青い線が表示されています。これは全リクエストを示しており、ユーザー別にグループ化することができます。Owner IDが私のユーザーですが、ご覧の通り、16から19の範囲で2桁の数のユーザーがシステムとやり取りしています。
これらのユーザーのうち、何人がNull Pointer Exceptionを経験しているのかを確認したいと思います。Faults and Errorsセクションで同じ作業を繰り返すことができます。これで各ユーザーが何回Null Pointer Exceptionを経験しているかを確認できます。この情報をすべてまとめて開発チームに提供すれば、彼らはシステムを修正して円滑に動作させることができます。次のシナリオに移りましょう。アプリケーションでデータベースを使用している方は手を挙げてください。これは当たり前の質問ですね。誰もがデータベースを使用していますから。しかし、本当の問題は監視についてです。どのように監視していますか?私たちはよく、アプリケーションの監視とデータベースの監視を別々に行う断片的な監視を行っています。アプリケーションからデータベース、あるいはその逆の相関関係を確認できたら、どれほど簡単になるでしょうか?
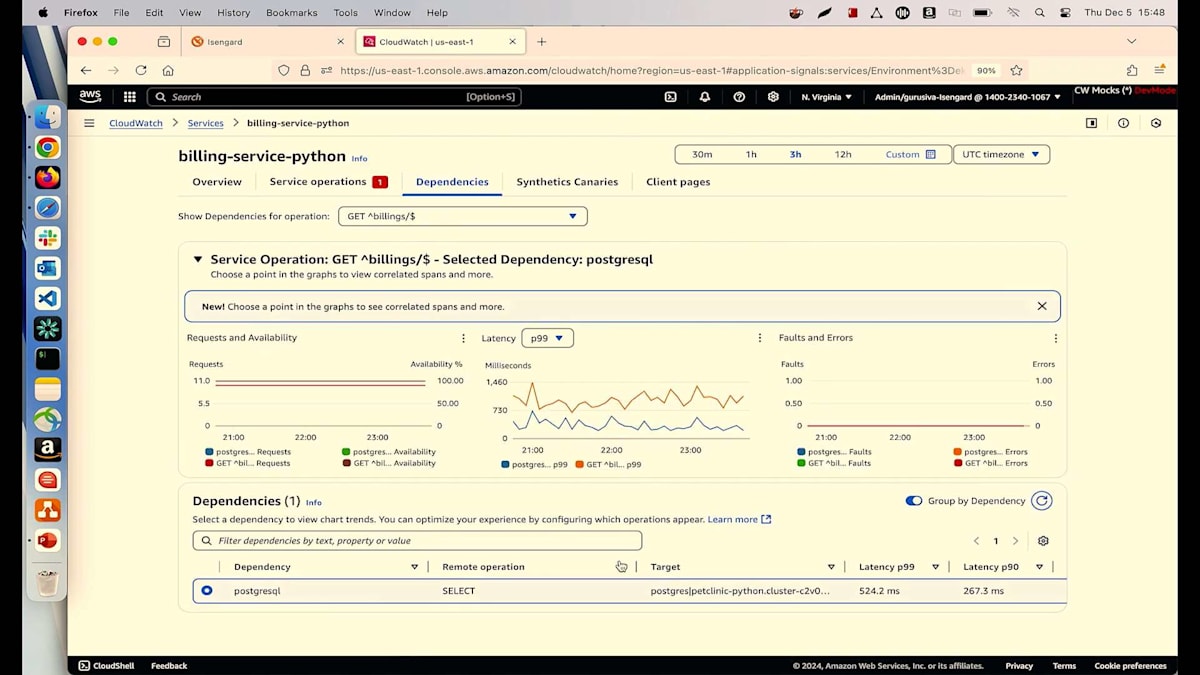
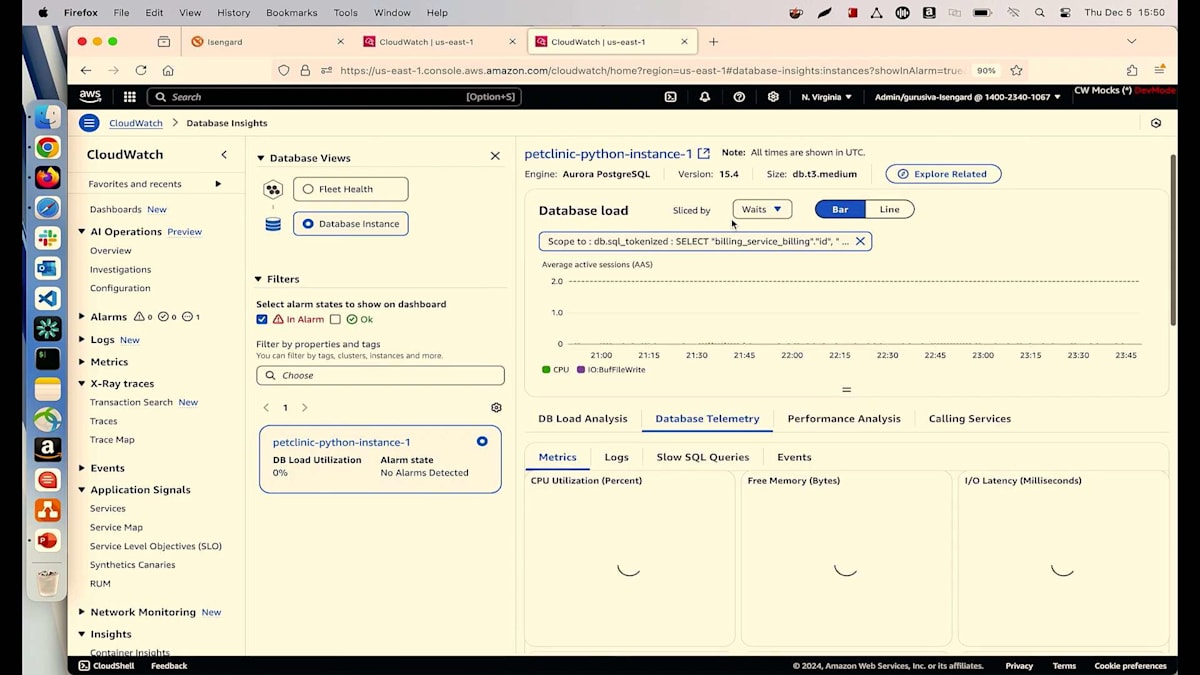
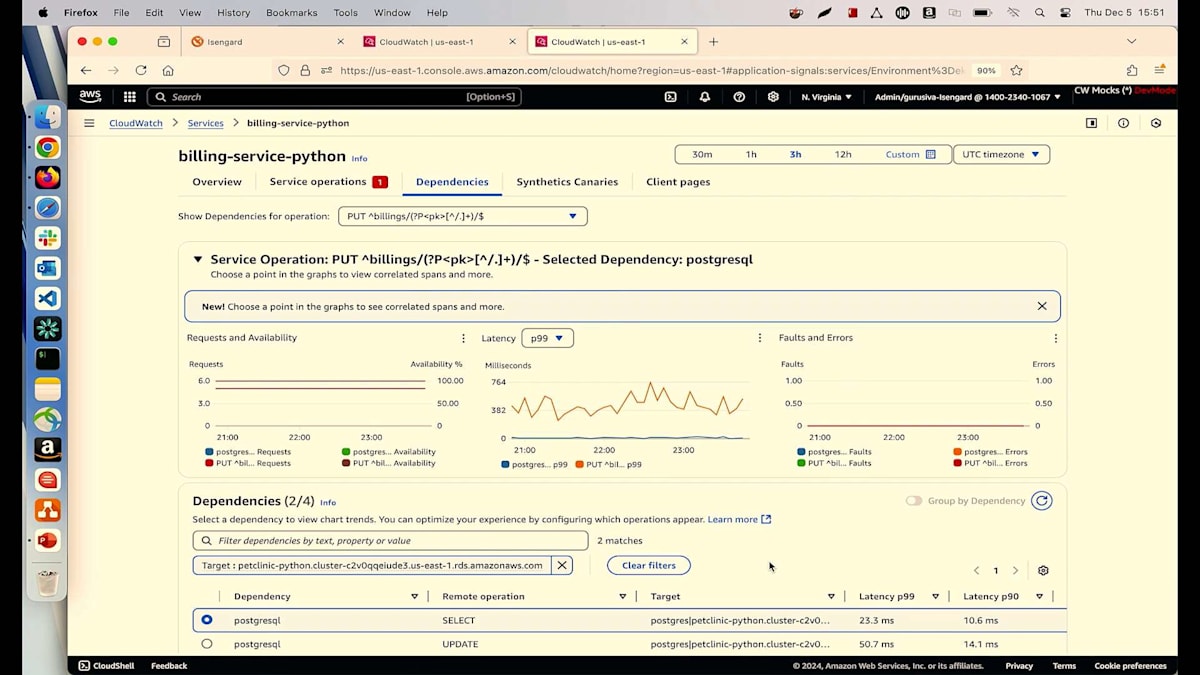
現在、私は別のシナリオを作成しており、そこではBillingサービスが稼働していますが、トランザクション数に関係なく、これらの課金アクティビティのレイテンシーを300ミリ秒以下に保ちたいと考えています。現在は不健全な状態で動作しており、その理由を理解する必要があります。チャートの詳細を見ると、障害のないリクエストが入ってきているのが分かりますが、レイテンシーが問題で、1.5秒にも達しており、これは許容できません。Dependencyセクションに移動して、そのDependencyをクリックして、何が実行されているか確認してみましょう。PostgreSQLデータベースが実行されており、Select操作自体が0.5秒以上かかっているのが気になります。
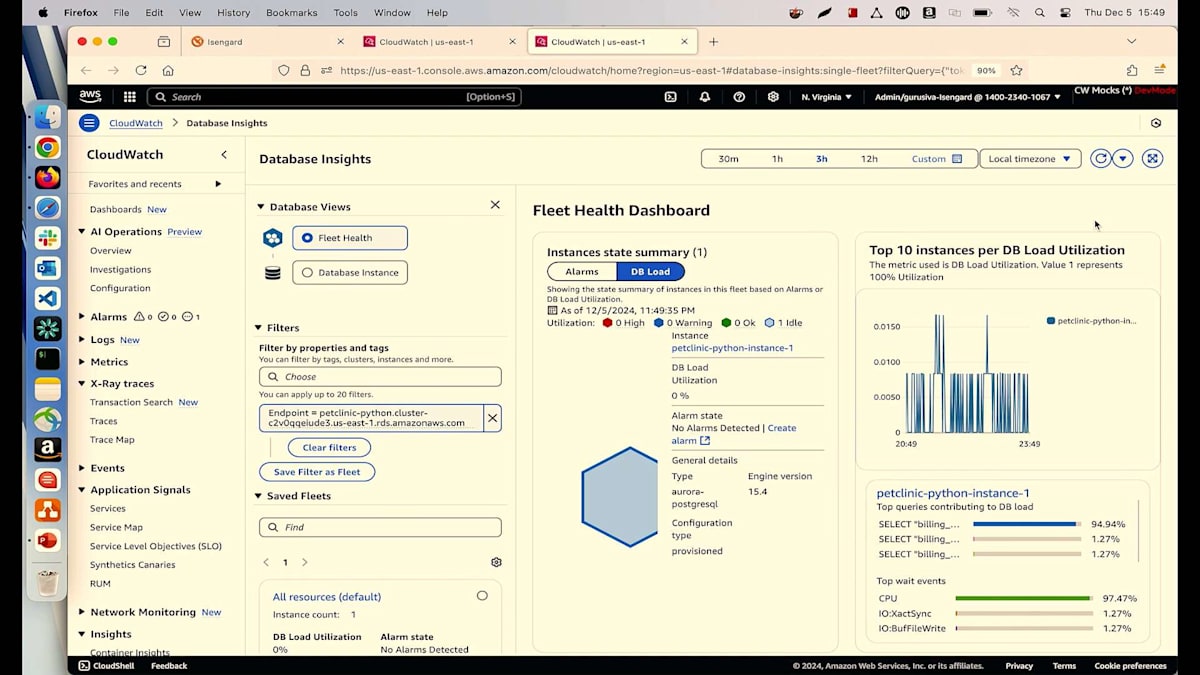
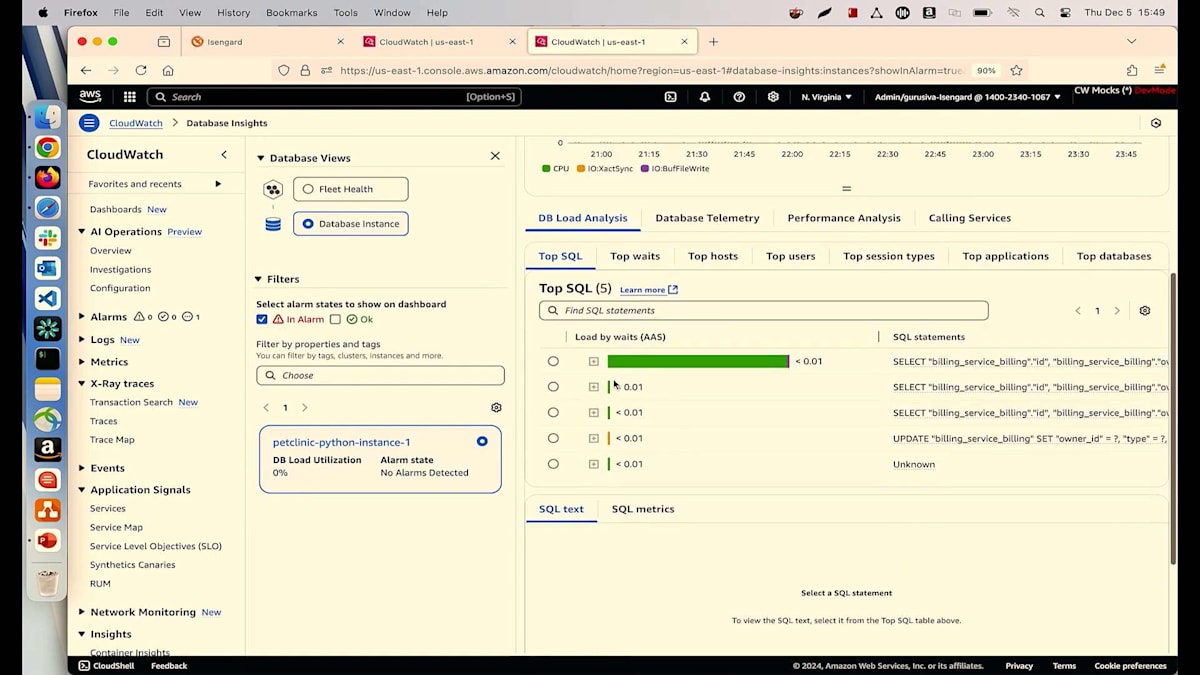
レイテンシーのデータから、サービスが失敗するたびに、PostgreSQLデータベースでも何かが起きていることが簡単に関連付けられます。さらに詳しく調べてみましょう。PostgreSQL操作の青いリンクをクリックすると、右側にDatabase Insightsが表示されます。Database Insightsは、今回のre:Inventで発表したばかりの新機能です。これを使用することで、データベースで何が起きているのかを理解できます。私は単一インスタンスのクラスターを実行しており、Database Insightsタブに移動してトップSQLクエリを見ると、IDEを開かなくても私のSelectクエリを確認できます。
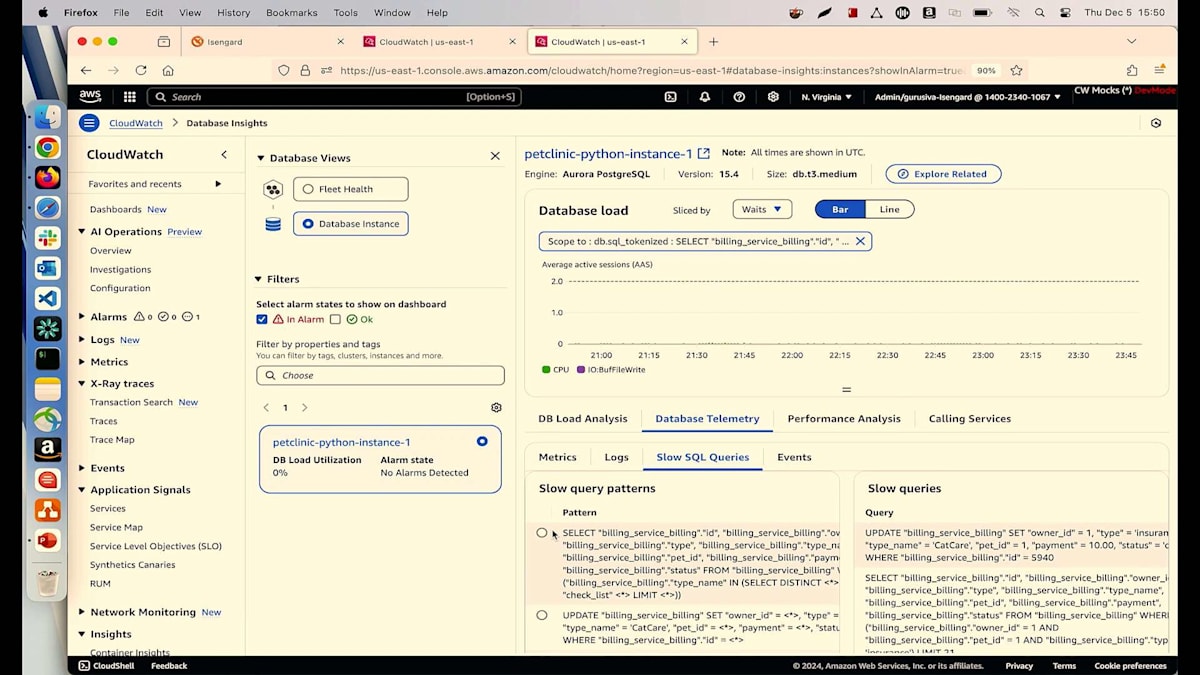
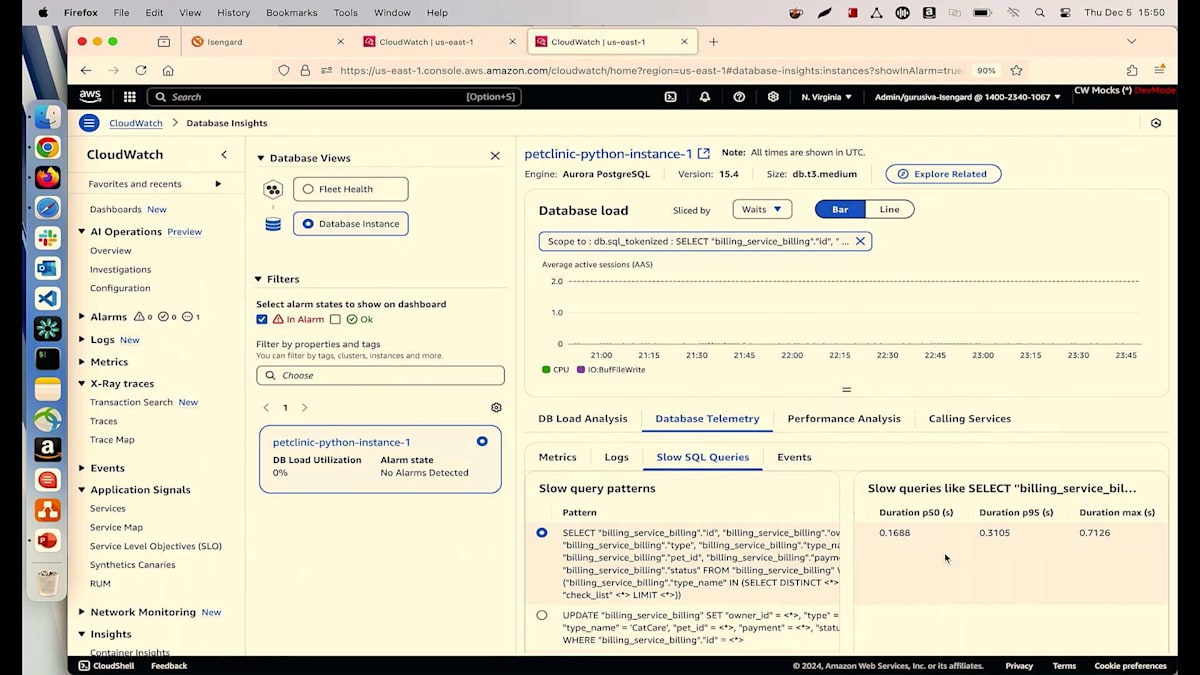
この画面から、どのようなSQLクエリを実行しているのかを正確に確認できます。Billingサービステーブルからすべての課金情報を読み取り、チェックリストテーブルとJoinを実行していることが分かります。開発チームとコミュニケーションを取っているプロダクトオーナーとして、彼らがこの変更を行ったことは知っていますが、DBAがインデックスの作成を忘れていたようです。DBAにインデックスの作成を依頼し、スロークエリのデータベーステレメトリータブで確認することができます。ここでは、すべてのスロークエリを確認でき、Selectクエリが最上位に表示され、その発生頻度も分かります。このSelectクエリには平均レイテンシーも表示されています。
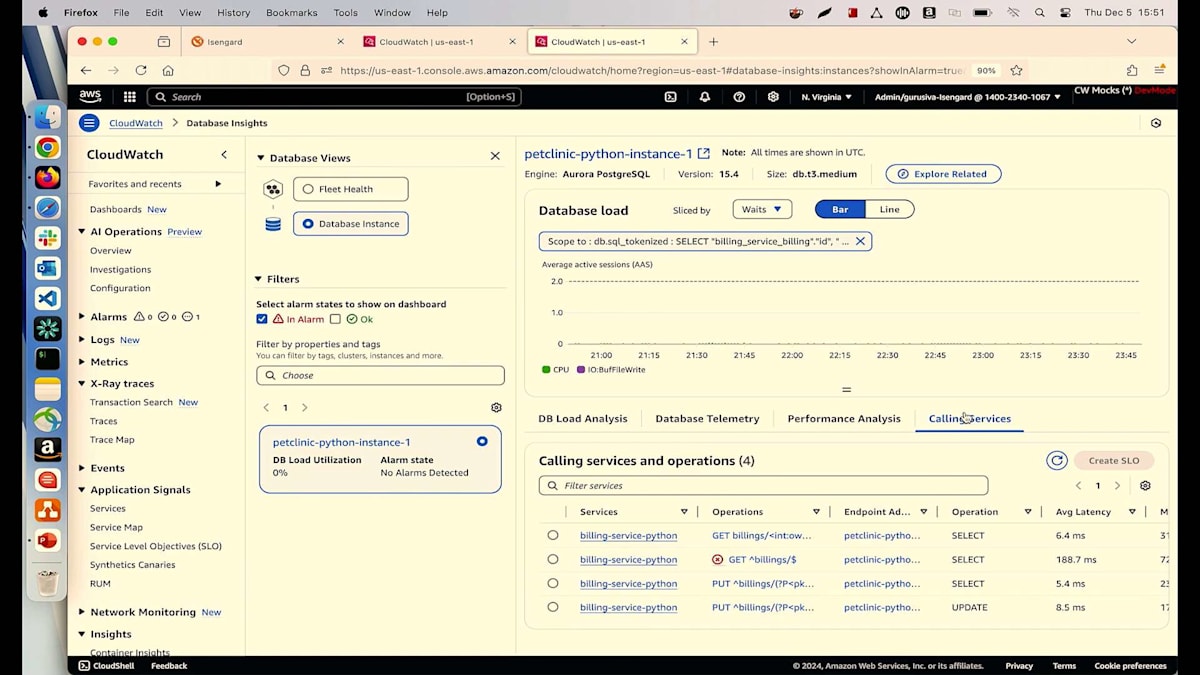
これらの情報をすべてデータベースチームに提供して、修正を依頼することができます。アプリケーション層とデータベース層のギャップをどのように埋めるのかと疑問に思われるかもしれませんが、それを解決するのがCallingサービスです。DBAとして、Database Insightsを見ると、どのようなCallingサービスがあるかが分かります。現在はBillingサービスのみが呼び出しを行っており、平均レイテンシーでソートすることができます。PUTオペレーションで何が起きているのかを確認したり、SLOを作成したりしたい場合は、クリックするだけでアプリケーション層に戻ることができます。このように、Application Signalsを使用すれば、アプリケーション層からデータベース層へ、またはその逆に非常に簡単に移動できます。
Amazon Q Developer Operational Insightsによる問題解決の効率化
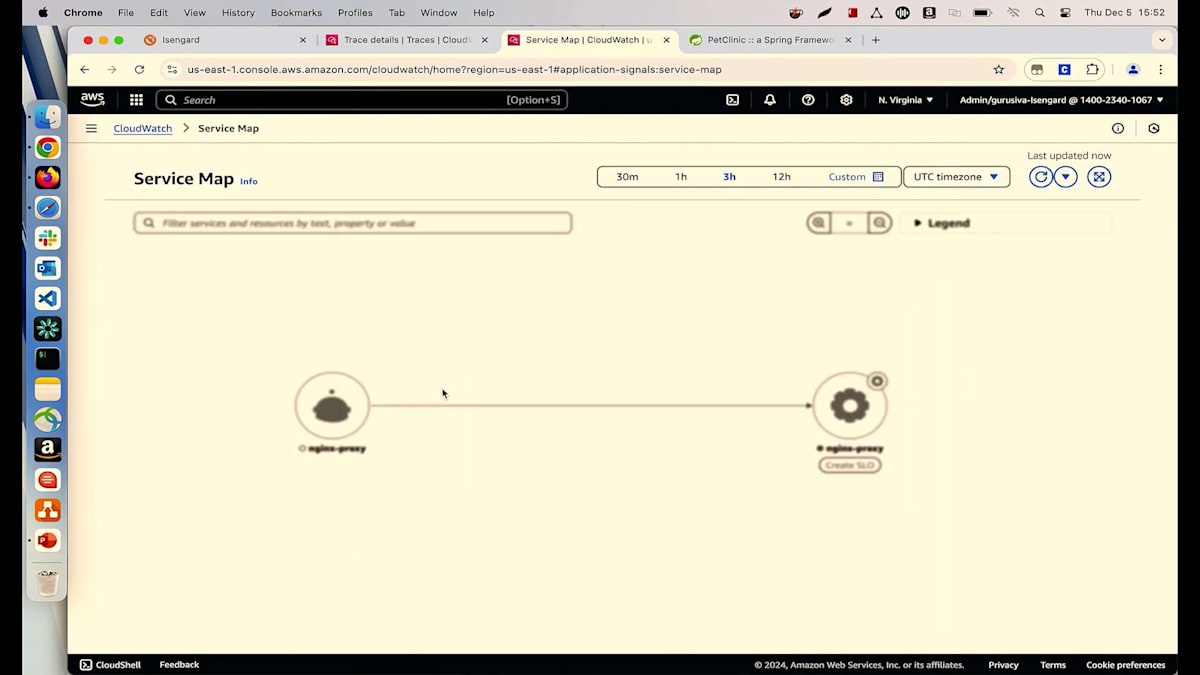
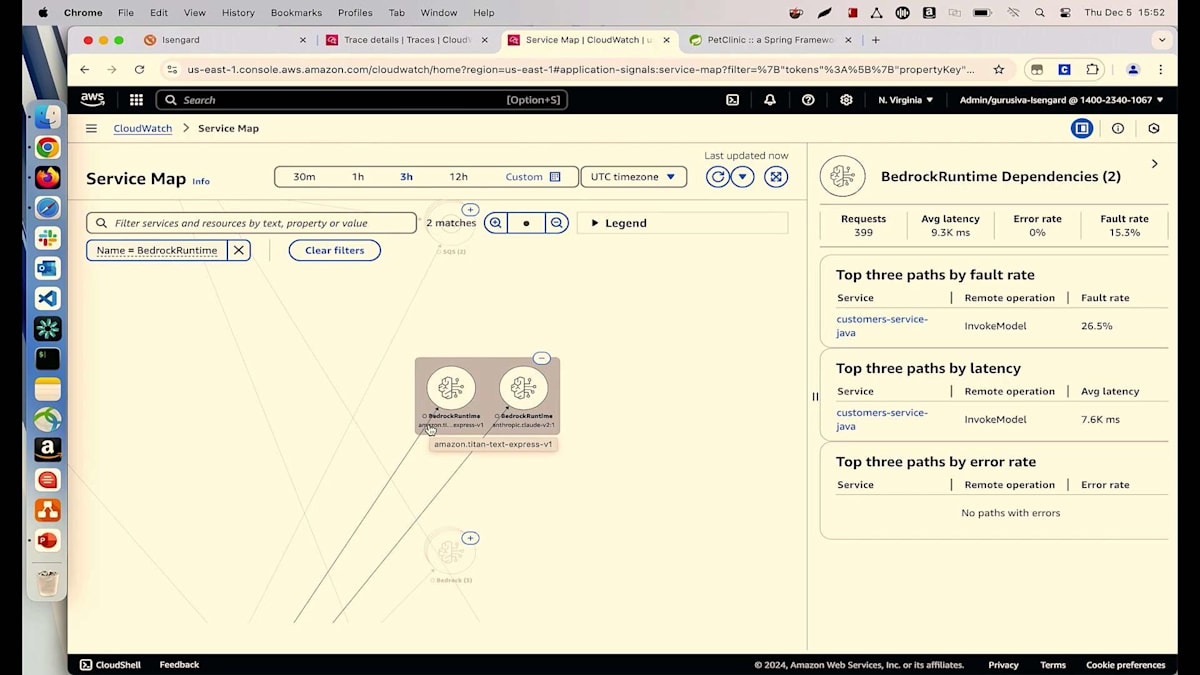
次のシナリオに移りましょう - Gen AIを探索したり、既存のアプリケーションに統合したりするよう経営陣から求められている方は手を挙げてください。Gen AIは新しい標準となっているからです。私たち全員がそれを実現したいと考えていますが、統合した後、どのようにモニタリングするのでしょうか?これは解決すべき大きな課題です。私たちのPetclinicアプリケーションでは、チームがすでにGen AIをアプリケーションに統合しています。例えば、Servicesのサービスマップに移動して、すぐにお見せできます。私はAmazon Bedrockを使用してレコメンデーションを提供するためにCustomerサービスを使用しています。それを使用する際、CustomerサービスがBedrockを呼び出しており、少し縮小表示してみましょう。
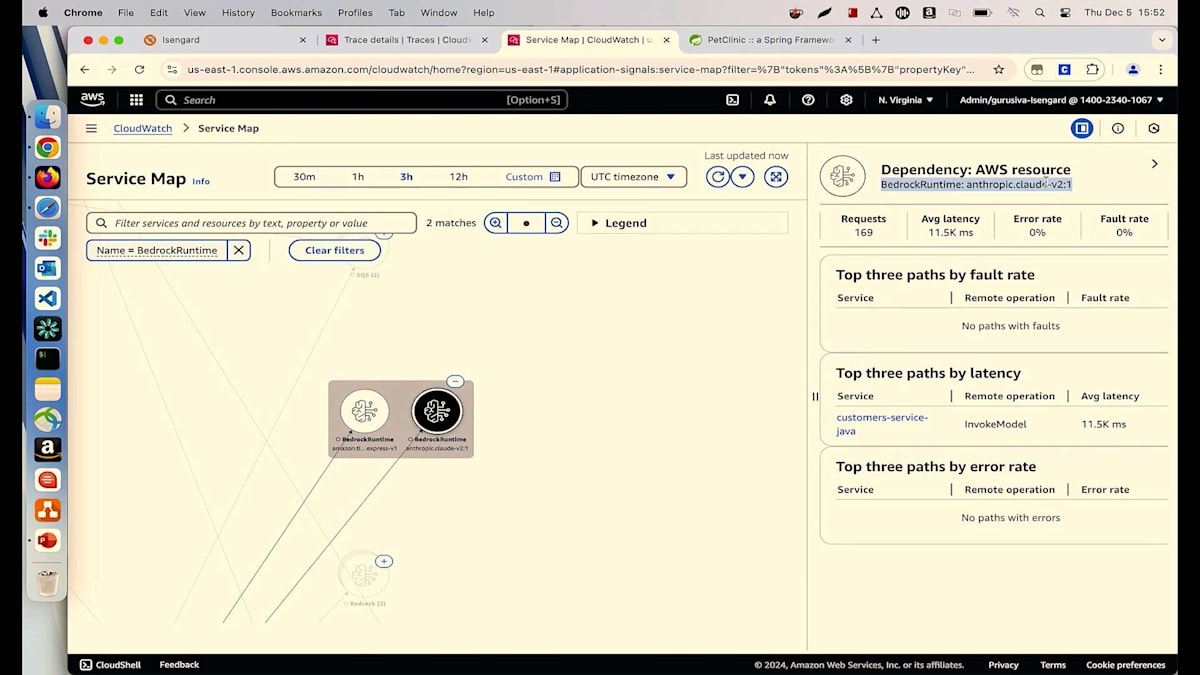
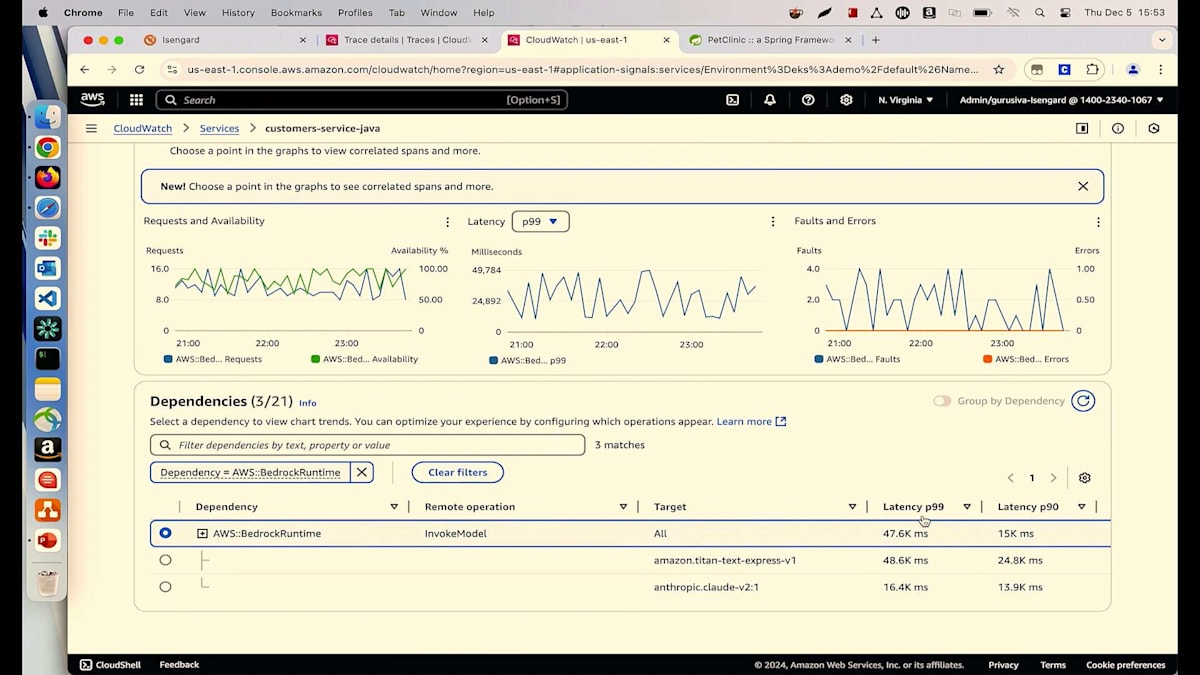
今日は2つの異なるモデルを使用しています。1つは、ペットの病気を推奨するために使用しているAmazonのTitan Text Expressモデルです。もう1つは、AnthropicのクラウドモデルであるClaudeモデルで、顧客がそれらの病気を予防するために取るべき予防措置を提案するために使用しています。一見良好に見えますが、よく見ると、Titan Expressの平均レイテンシーが約8秒、Claudeモデルは10秒以上かかっています。これについて調査してみましょう。さらに詳しく見ると、さらに深刻で、P99が48秒、Claudeモデルのp99は17秒近くになっています。推奨結果を得るのに顧客に48秒も待ってもらいたくありません。
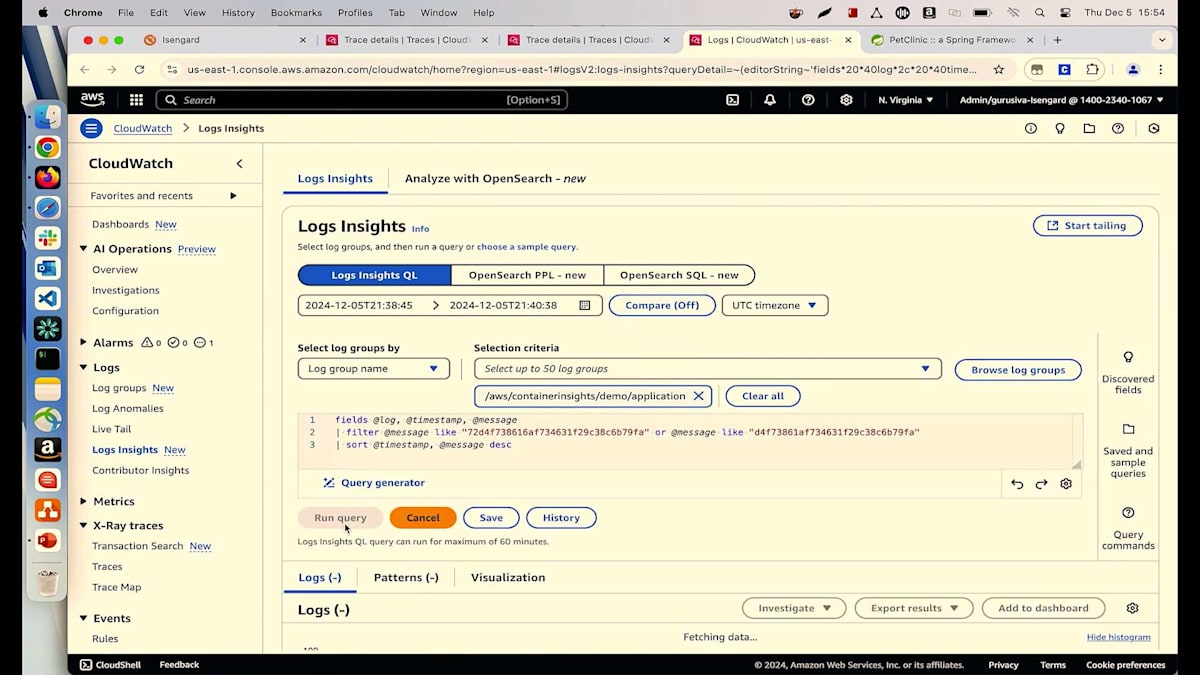
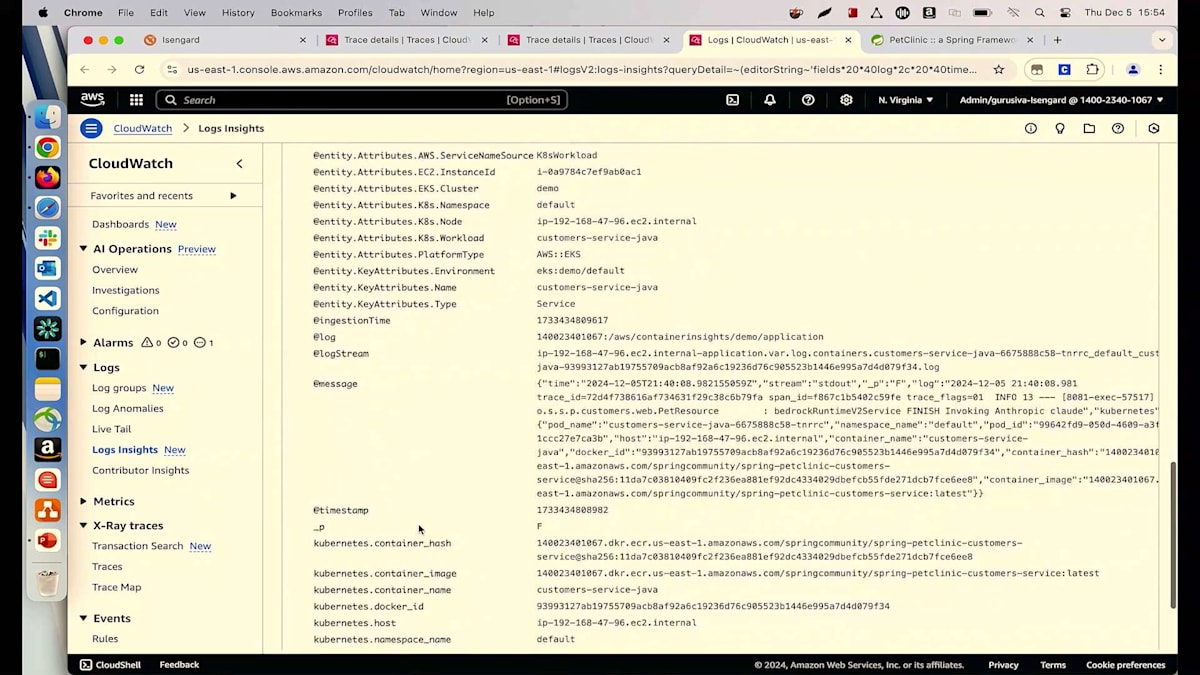
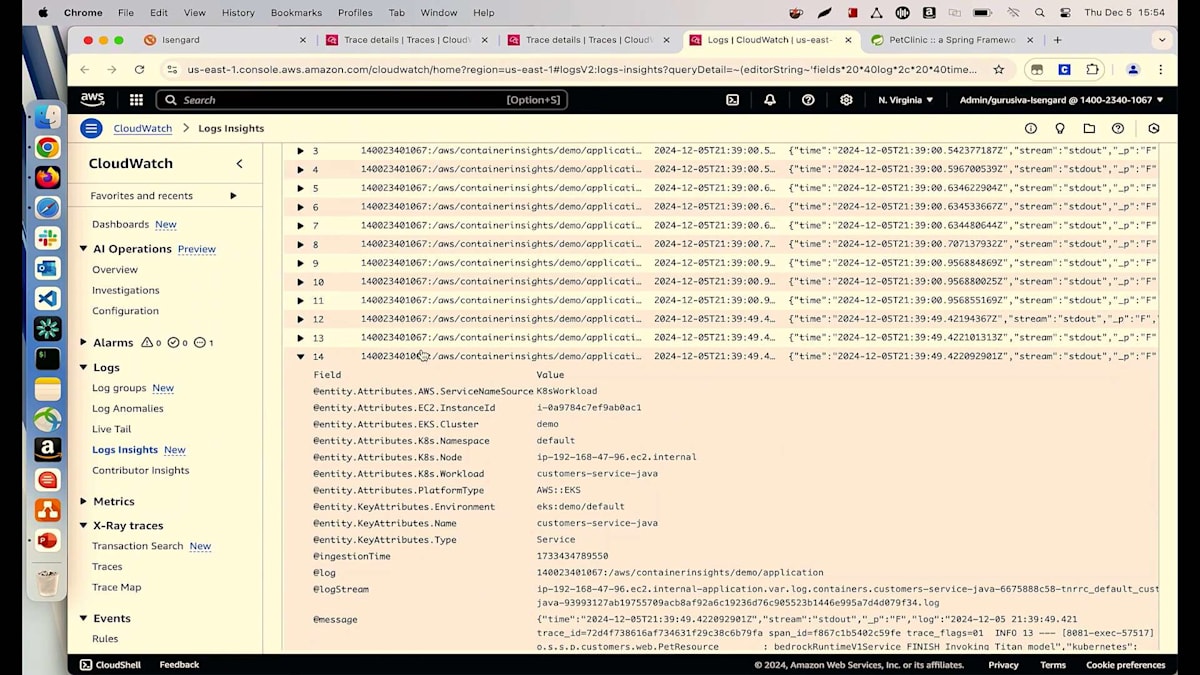
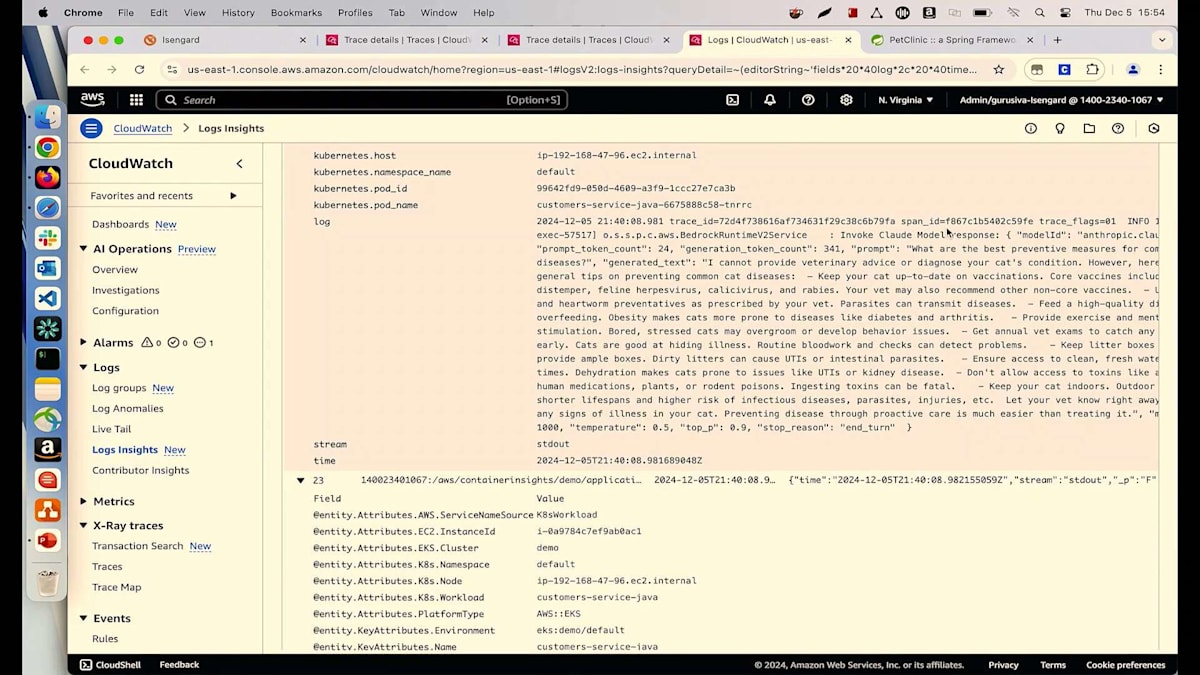
モデルに何を渡して、何を返しているのか確認することで、この問題を解決しましょう。これらのセクションのいずれかをクリックしてTransactionに移動し、詳細を見ていきましょう。ログを確認したいので、下のセクションに移動してCloudWatch Log Insightsに進みます。すべてが事前に入力されているので、実行ボタンをクリックするだけです。これにより、その特定のTransactionで発生しているすべての異なるログが表示されます。ログがどこで発生しているかが分かります。これがClaudeのログです。Titan Expressのログも確認してみましょう。まずはClaudeモデルのレスポンスを見てみましょう。モデルIDがAnthropicでClaudeレスポンスを呼び出しており、プロンプトは「猫の一般的な病気に対する最適な予防措置は何ですか?」と尋ねています。顧客は猫を飼っており、私たちは一般的な病気と予防措置を推奨しています。多くの情報を提供していますが、これは必要以上かもしれません。この量は必要ないと思います - 質の高い推奨に焦点を当てたいのです。ここでMLエンジニアに連絡して、レイテンシーを削減し、顧客にとってより有用なものにするためにこのプロンプトクエリを修正するよう依頼できます。レイテンシーが大幅に削減され、顧客が40秒以上待つことなく推奨を得られるようになり、より効率的になりました。
Generative AIを使用したApplication Signalsとこれらのユースケースのモニタリングにより、これらのプラグインがすべて事前にインポートされているため、プロセスが効率化されます。
次のシナリオに移りましょう。顧客からの問い合わせに対応するサポートエンジニアの場合、それは常に干し草の山から針を探すようなものです。顧客は何についても問い合わせてくる可能性があります - 注文が通らない、Webサイトが遅い、クレジットカードが引き落とされたのに注文確認がない、注文が間違った場所に配達されたなど。サポートエンジニアとして、迅速かつ効率的に適切な回答を提供する必要があります。
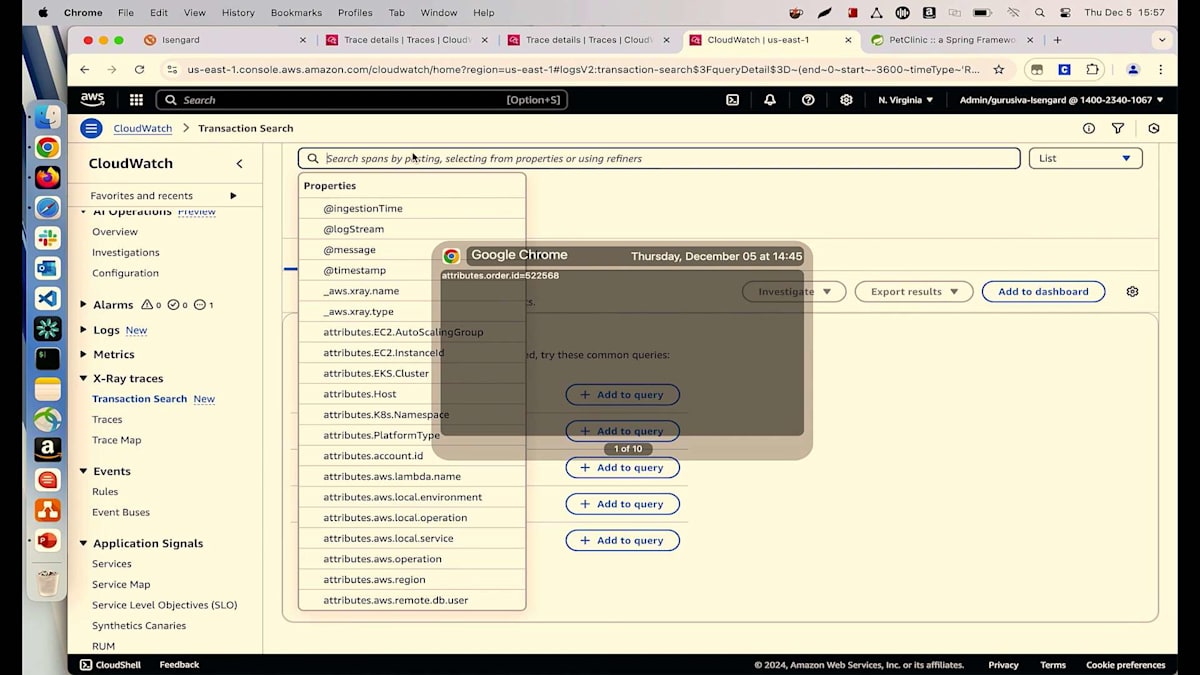
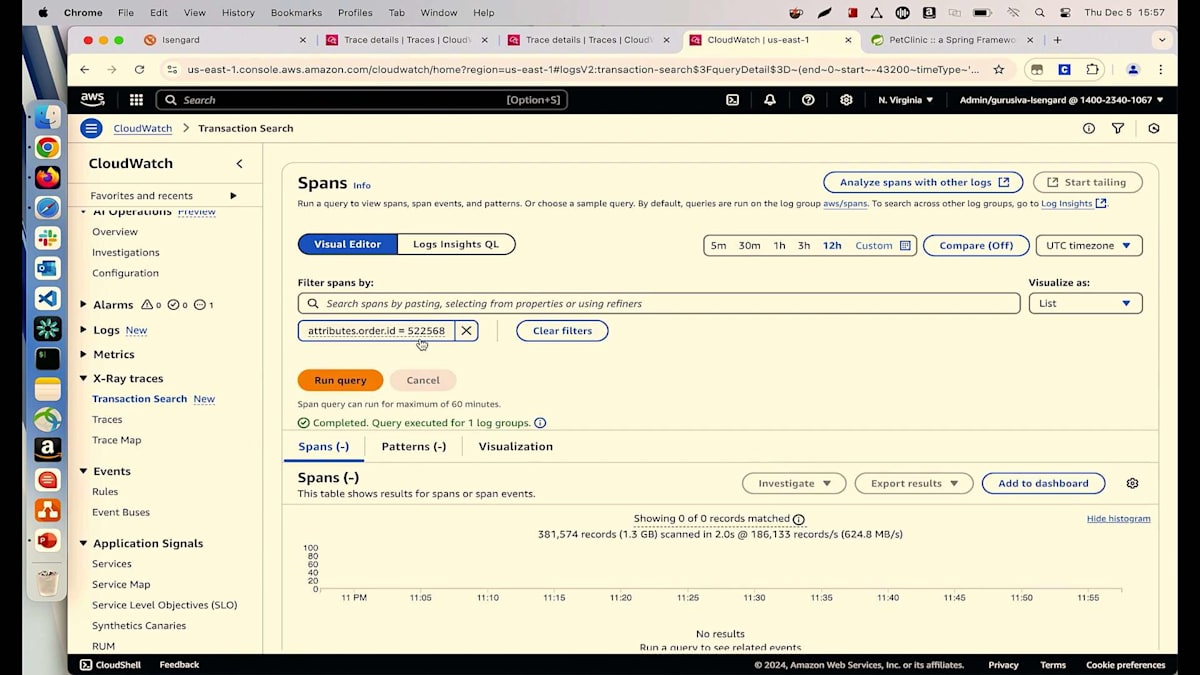
では、APMソリューションとしてApplication Signalsを使用して、これにどのようにアプローチするのでしょうか?現在、私はPet Clinicアプリケーションのサポートエンジニアで、Suzieという名前の顧客から電話を受けています。彼女のIDは6で、注文が通らないと報告しています。私が持っているのは注文IDだけで、彼女が電話中に何が起きているのか知る必要があります。これを調査するために、X-Ray Tracesの下で、数週間前にリリースした新機能であるTransaction Searchに移動できます。これを使用してTransactionを検索できます。注文IDしか分からないので、Suzieのこの注文番号を入力してクエリを実行できます。
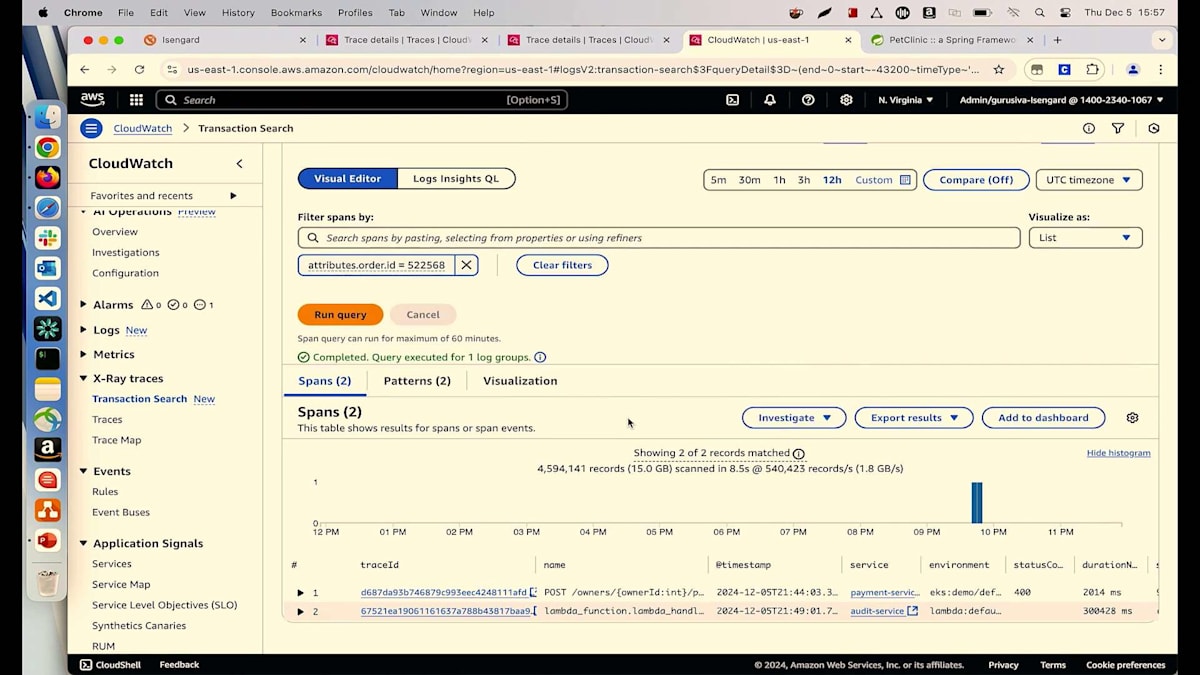
注文がいつ行われたのかわからないので、過去12時間を選んでみましょう。クリックすると、2つの異なるトランザクションが確認できます。1つ目はServiceタブに表示されているPayment Serviceで、2つ目はAudit Serviceです。Payment Serviceで何が起きているのか詳しく見てみましょう。マップの詳細、Spanの詳細、ログの詳細など、包括的な情報が表示されています。フロントエンドがPayment Serviceを呼び出していますが、これは注文フローを管理する役割を担っています。Payment Serviceはマイクロサービスとして、他のサービス - 顧客情報のためのCustomer Service、保険情報のためのInsurance Service、そして顧客が注文した栄養情報のためのNutrition Service - を呼び出しています。
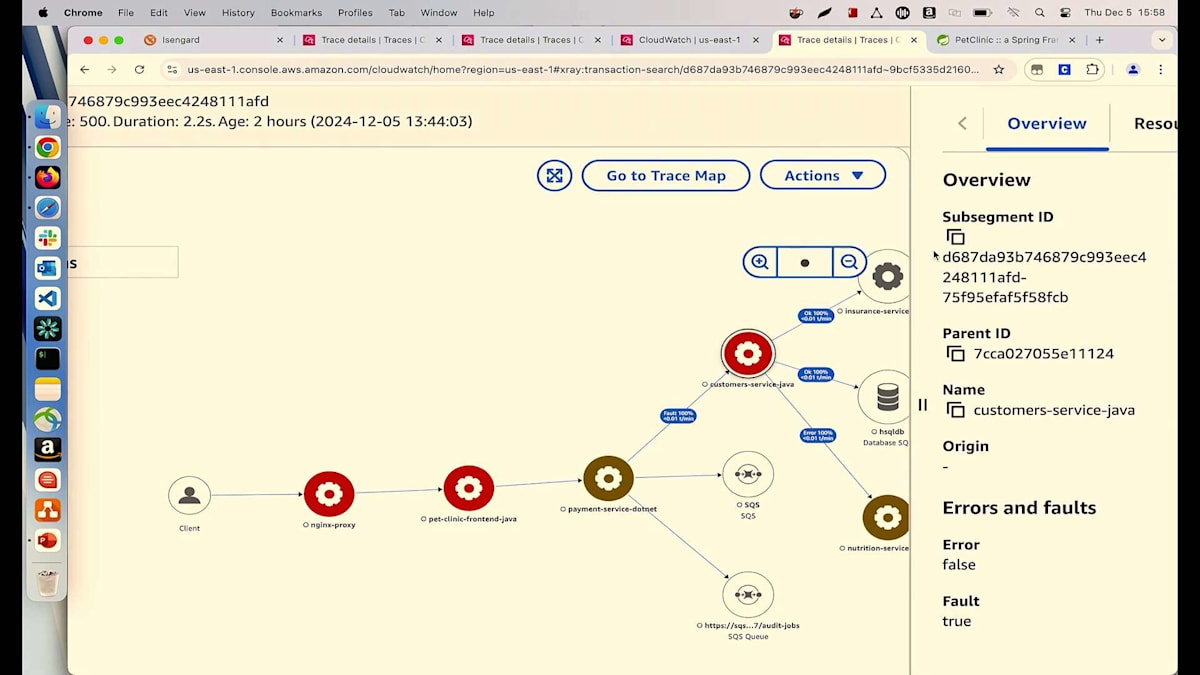
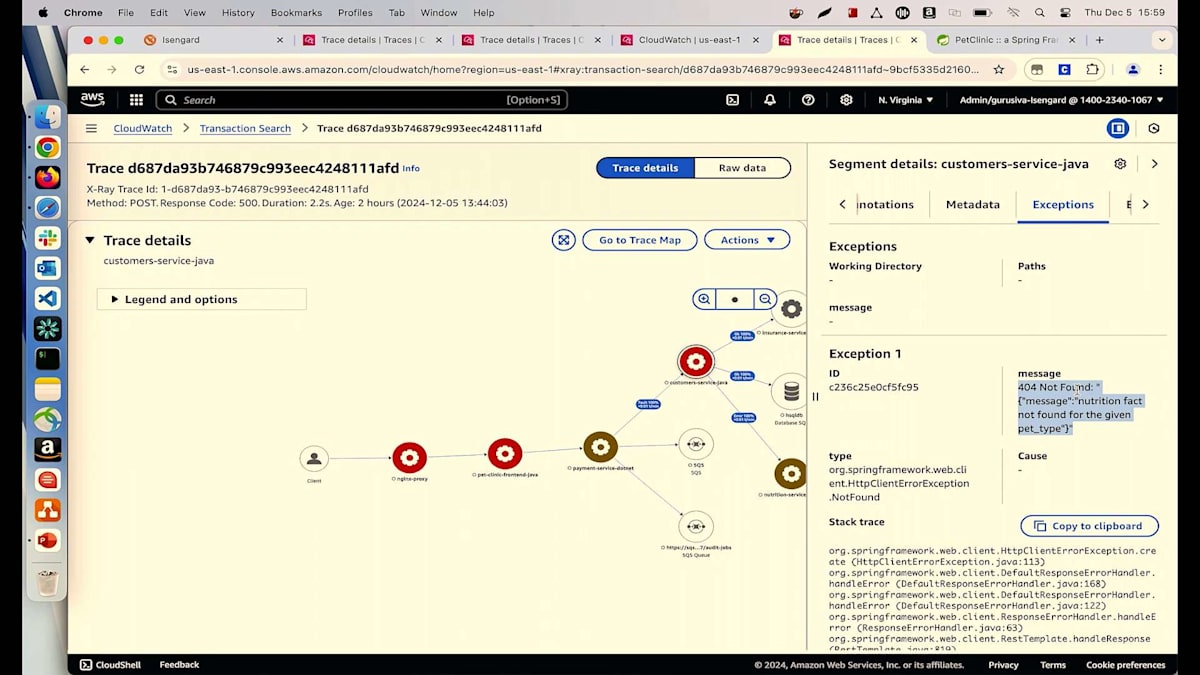
Customer Service Javaが赤いノードとして表示されているのが気になりますので、調べてみましょう。これをクリックしてExceptionを確認すると、404エラーが表示されています。これはクライアントエラーで、探しているものが見つからないことを示しています。メッセージには具体的に、Suzieが探している栄養情報が利用できないと書かれています。これで、Suzieに対して探している栄養情報が利用できないことを明確に伝え、代替案を提案することができます。
ただし、本来Suzieがこの件でサポートエンジニアに連絡する必要はないはずです。これはUIレイヤーでのバリデーションの問題として解決されるべきでした。Suzieが注文を行う際に、商品が利用できないことを確認して通知したり、推奨商品を提案したりできたはずです。同様の問題で顧客から連絡が来ないよう、この情報を開発チームに転送して修正を依頼することができます。しかし、話はここで終わりません。これは日々の運用に重要なPayment Serviceで発生している問題なので、この問題が個別のケースなのか、多くのユーザーに影響を与えているのかを確認する必要があります。多くのユーザーに影響が出ているのであれば、チームによる即時対応が必要です。
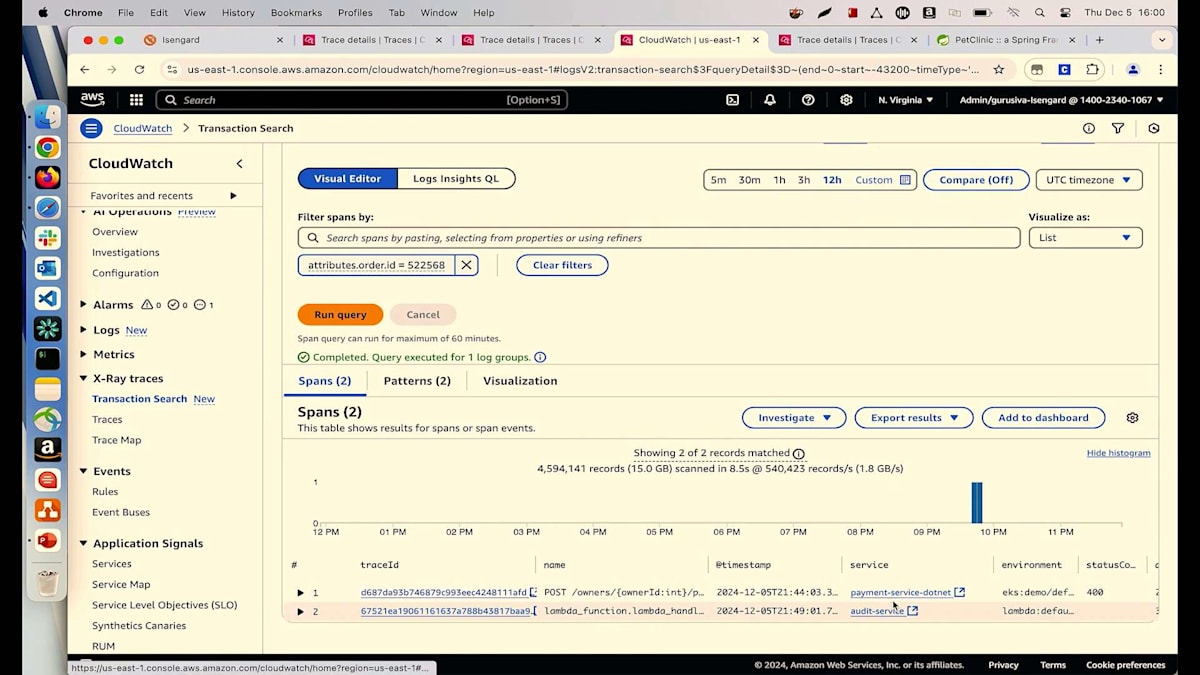
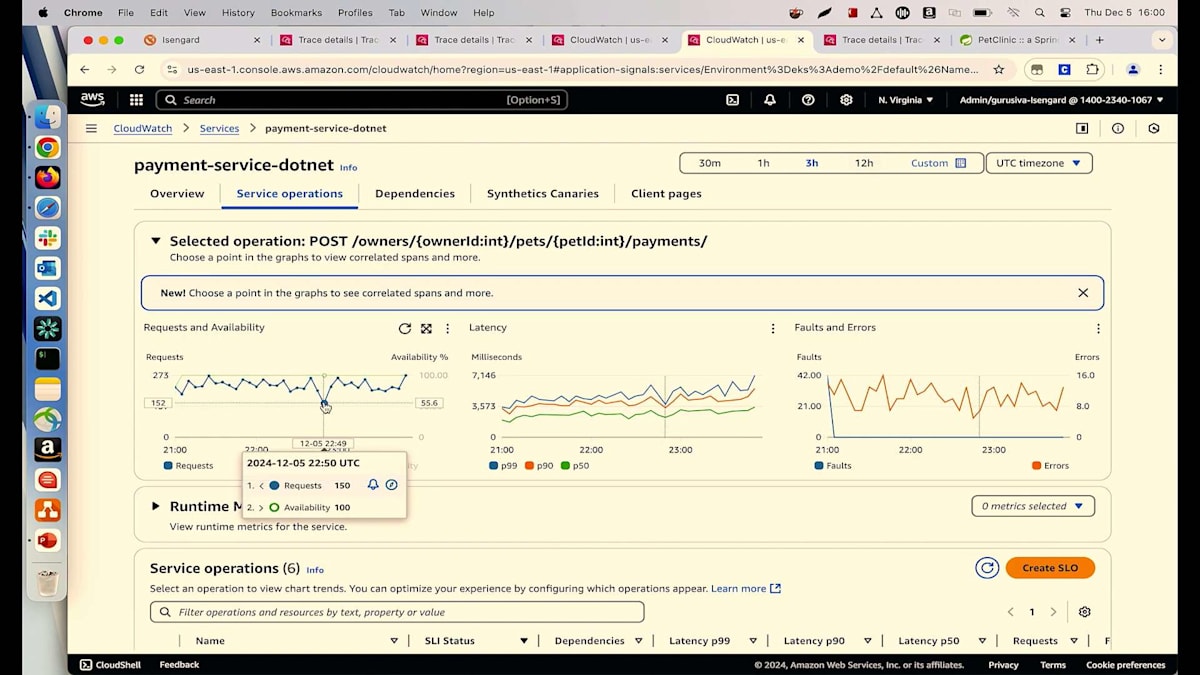
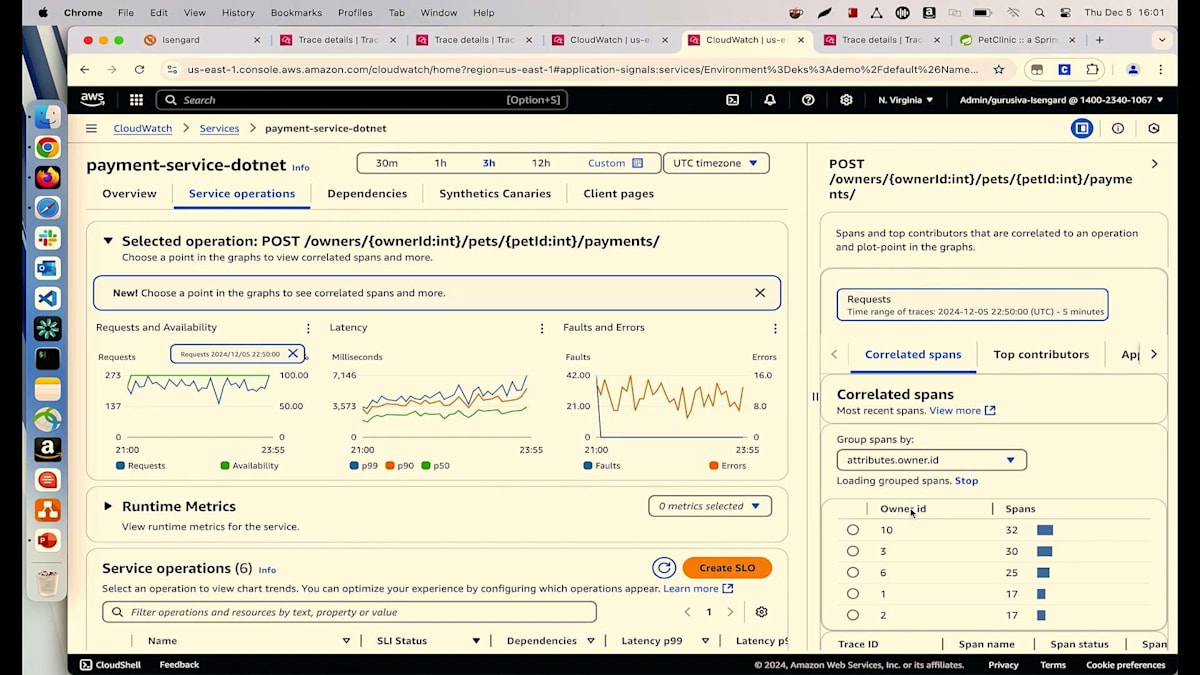
この問題が多くのユーザーに影響を与えているかどうかを調査するために、元の画面に戻りましょう。Traceの詳細ではなく、Serviceに移動します。Payment Serviceに移動し、過去3時間または12時間のService Operationsで、どのようなリクエストが来ているか確認できます。ユーザーでフィルタリングすることができます。ここで見られるように、システムでは5人の異なるユーザーが取引を行っています。
では、何人のユーザーが影響を受けているのでしょうか?それを確認するには、FaultsとErrorsタブを確認する必要がありますが、ちょっと待ってください。これはFaultなのでしょうか、それともErrorなのでしょうか?サービスが利用不可を示しているわけでもなく、エラーをスローしているわけでもないので、明らかにFaultではありません。先ほど確認したように、これは404エラー、つまりクライアントエラーです。そのため、Errorを示すオレンジのチャートを確認し、異常をクリックする必要があります。ここでOwner IDを確認すると、影響を受けているのは1人だけで、それは先ほど連絡のあったSuzieと同一人物であることがわかります。これで、この問題が全ての顧客に影響を与えているわけではないことが特定できました。
この機能は、技術的な問題の解決だけでなく、影響を受けるユーザー数や具体的なユーザーの特定など、ビジネス面での課題解決にも役立ちます。例えば、Susieがプレミアムユーザーだった場合、コールバックしてクレジットを付与し、ロイヤリティを取り戻すことができます。このようなことはApplication Signalsを使えば簡単に実現できます。
今日最後のデモに移りましょう。これまでの作業、つまりSLOの作成、違反時の通知受信、ここに来てあれこれクリックして根本原因を突き止めるといった作業を、まだ手作業で行っている方は手を挙げてください。でも、もしロボットが代わりにこの作業をしてくれたら、どれだけ楽になるでしょうか。ロボットが全ての作業を手伝ってくれれば、私たちは他の生産的なことに時間を使えるようになります。
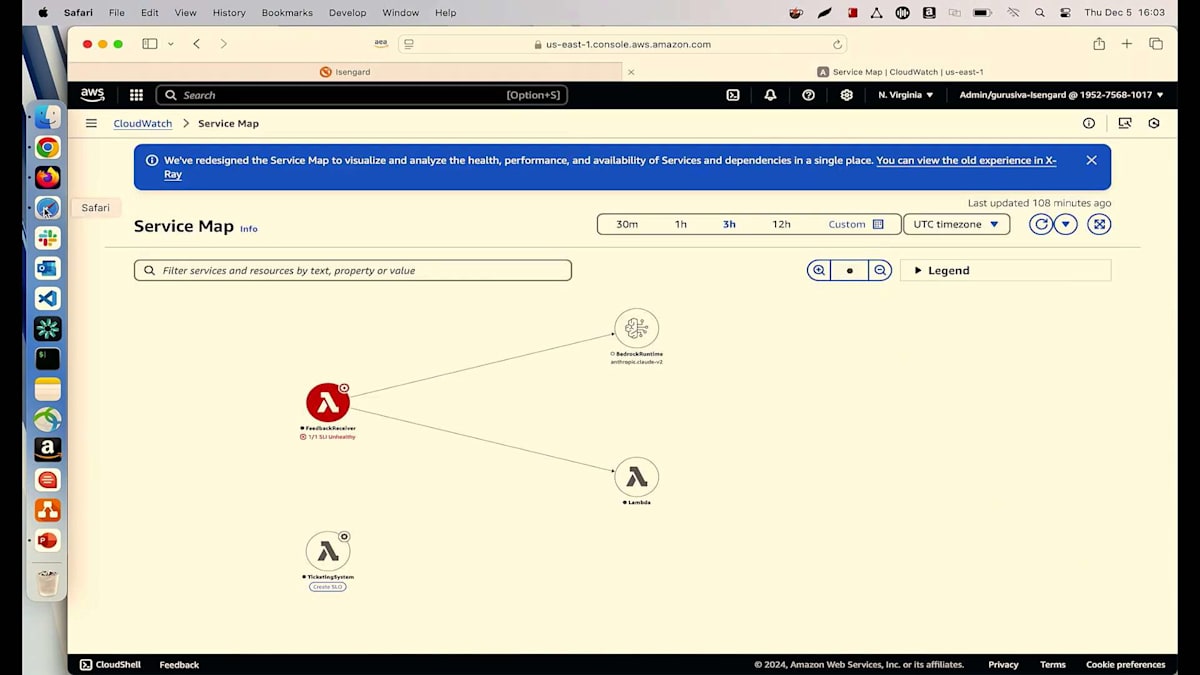
そこで活躍するのが、Amazon Q developer operational insightsです。 私には feedback receiverというもう一つのサービスがあります。これはLambdaで、顧客からのフィードバックを収集し、Bedrockランタイムモデルに送信して、ポジティブ、ネガティブ、ニュートラルに分類します。ポジティブまたはニュートラルであれば、顧客が満足しているので私も安心です。しかし、ネガティブな場合は、そのまま放置したくありません。顧客のフォローアップを行い、確実に満足してもらいたいと考えています。そのために、ticketing system Lambdaを呼び出し、このフロー全体が正常に動作するようにします。ネガティブなフィードバックの場合は、このチケットシステムを呼び出してチケットを作成し、顧客のフォローアップを行って、全員が満足できるようにします。
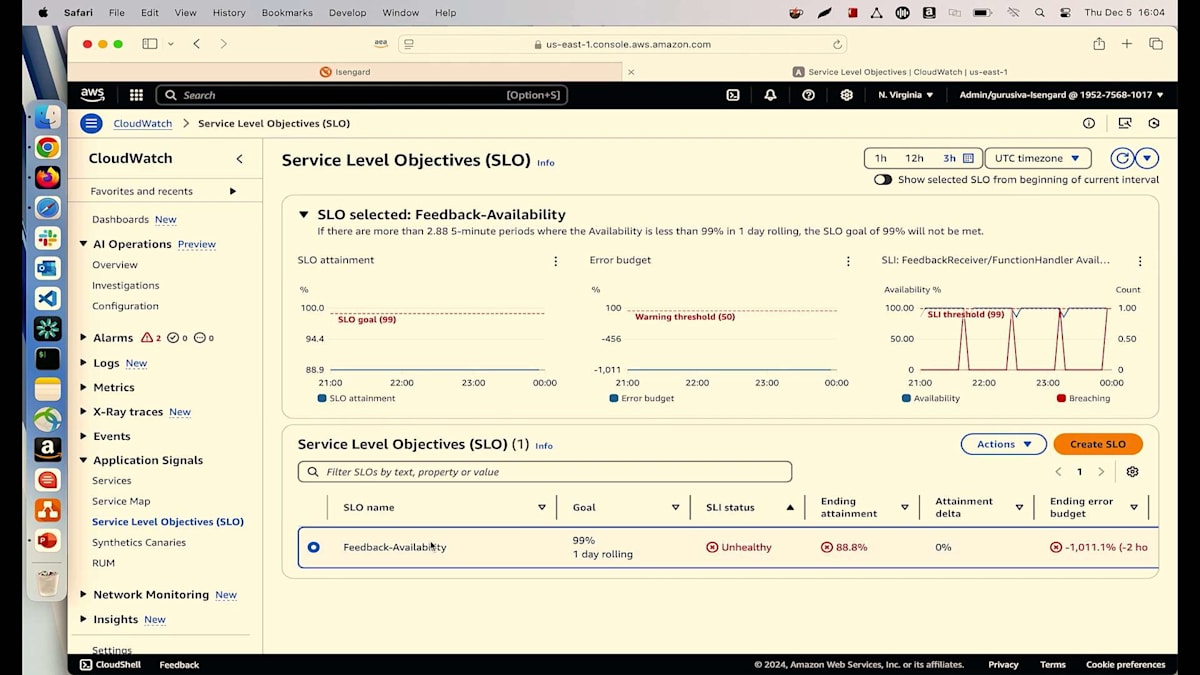
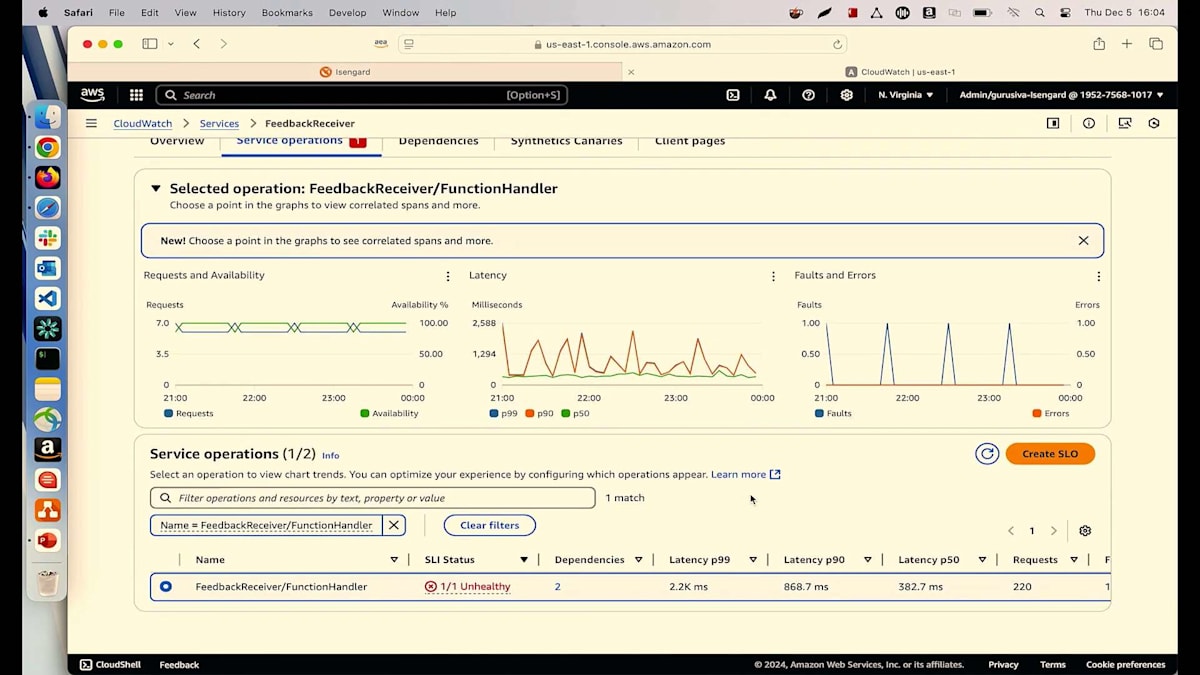
このfeedback receiver Lambdaが正しく動作していることを確認するため、SLOを作成しました。 フィードバックサービスの可用性は100%であるべきです。しかし、ご覧の通り、現在は正常な状態ではないため、その理由を理解する必要があります。 従来の方法ではなく、今回はAmazon Qに作業を任せることにします。Faults and Errorsタブを見ると、スパイクが発生しているので、サービスからのエラーに問題があるかもしれません。
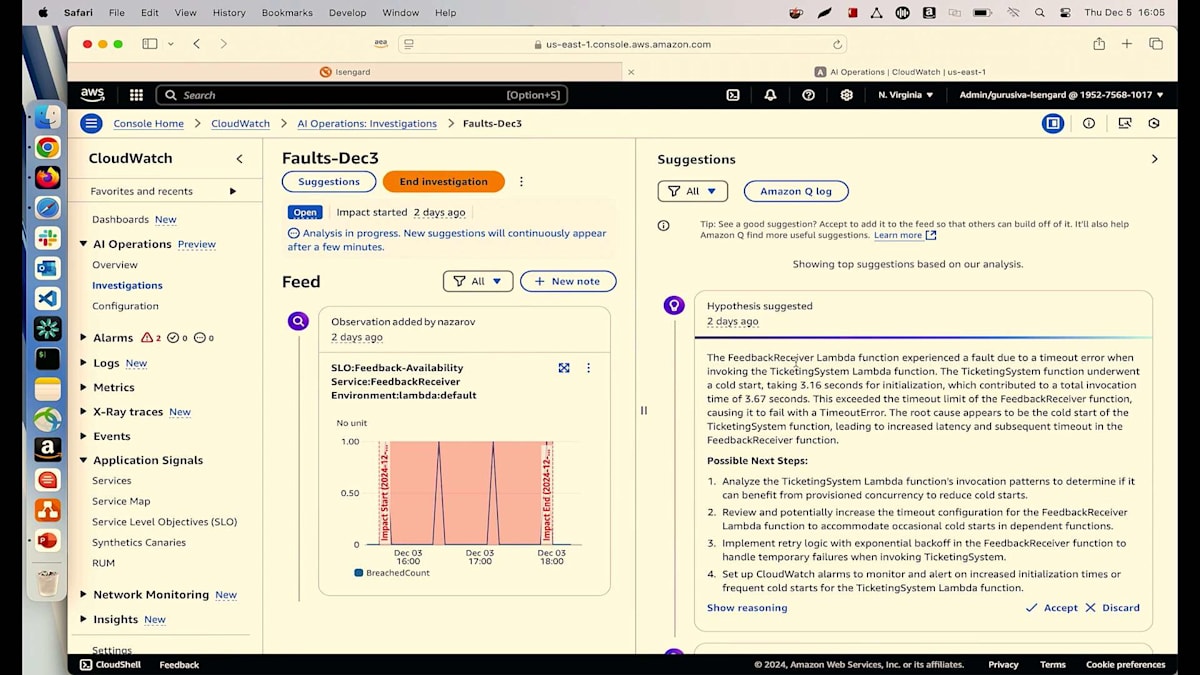
これをクリックしてinvestigatorをクリックすると、新しい調査を開始するか、既存の調査に追加するかを選択できます。時間の都合上、私は既にこの作業を実行済みです。Operationsの下のInvestigationsを見ると、結果を確認できます。 Amazon Q developerによると、feedback receiver Lambdaがタイムアウトエラーによって障害が発生したとのことです。これは、ticketing system Lambdaが3秒以上かかっていることを示しています。最後に、コールドスタートの問題があると指摘しています。まとめると、顧客からネガティブなレビューがあり、feedback receiverがticketing system Lambdaを呼び出そうとしました。ticketing system Lambdaは呼び出されましたが、3秒以上かかり、ticketing system Lambdaが応答する前にfeedback receiver Lambdaがタイムアウトしてしまったということです。
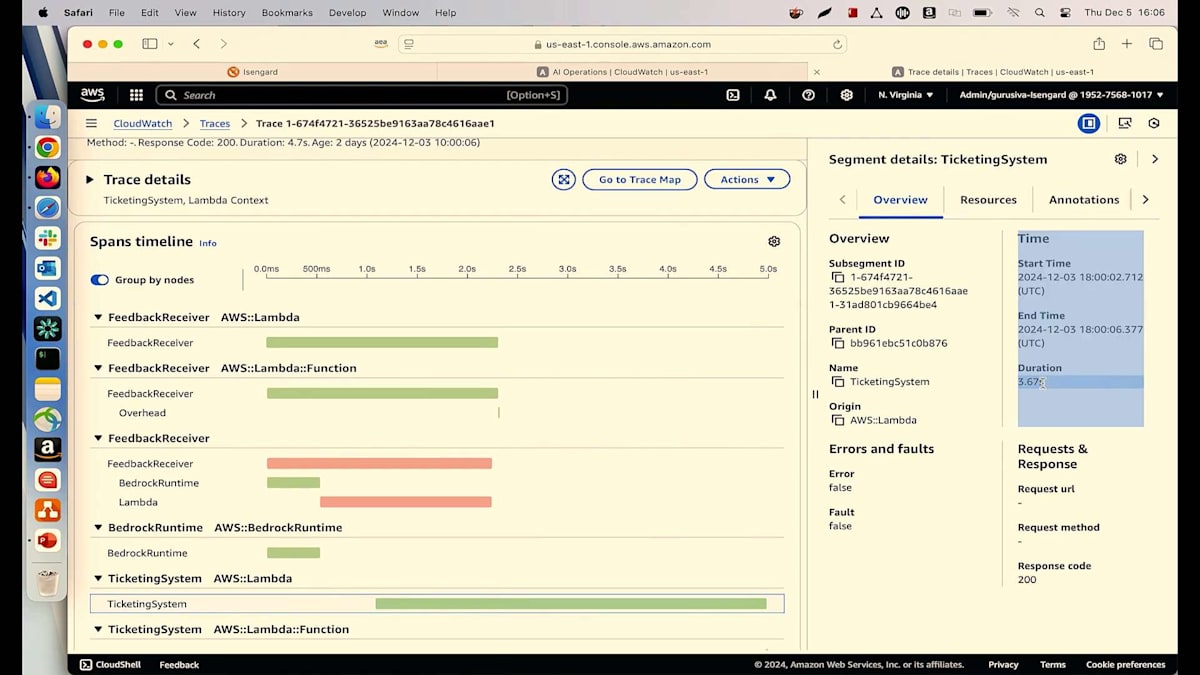
この評価をどのように検証できるか疑問に思うかもしれません。Show reasoningをクリックしてTraceタブに移動すると、Spanタイムラインのデータは嘘をつきません。Spanタイムラインから、この特定のTicketing System Lambdaが確かに3.67秒かかっていることがわかります。
Amazon Q Developerは何が起きているかを説明するだけでなく、次のステップも推奨してくれます。例えば、Ticketing System Lambdaのタイムアウトを増やすか、Feedback Receiver Lambdaにプロビジョンドコンカレンシーを作成することを提案します。あるいは、コールドスタートを防ぐためにTicketing System Lambdaにプロビジョンドコンカレンシーを作成するか、タイムアウトを防ぐためにFeedback Receiver Lambdaのタイムアウトを増やすことができます。開発チームがコールドスタートの問題について知らない場合、正確な問題の特定と解決に何時間も、あるいは何日もかかっていたかもしれません。Amazon Q Developer Operational Insightsを使えば、何日も何時間もかかっていたことが数分で解決できます。
開発チームがコールドスタートについて知らない場合は、Amazon Qを開いてコールドスタートに関する質問を入力すれば、チームに問題について教育してくれます。まとめると、Application Signalsを使用することで、プロアクティブな方法でSLOを作成できます。本番環境で問題が発生した場合、わずか数回のクリックで行番号レベルまで根本原因を特定できます。Amazon Q DeveloperのInsightsとOperational Insightsを使用することで、問題検出時間と解決時間を大幅に短縮できます。
PBSのApplication Observabilityへの取り組み:Station Video Portalの最適化
私の言葉を鵜呑みにする必要はありません。PBSのBrian Linkが、Application SignalsとCloudWatchが彼らの日々の運用をどのように支援し、Observabilityの取り組みをどのように変革しているかについて話してくれます。それでは、Brianに経験を共有してもらいましょう。ありがとうございました。

皆さん、こんにちは。PBSのTechnical Operations DirectorのBrian Linkです。PBSをご存じない方のために説明すると、私たちはアメリカ合衆国にある非営利のパブリックメディアテレビチャンネルです。イギリスのBBC、アイルランドのRTE、カナダのCBCをご存知の方なら、同じカテゴリーだとお分かりいただけるでしょう。私たちは全米約180の放送局を通じて、全国の人々に心を動かす教育コンテンツを提供しています。

Application Signalsがどのように私たちの役に立ったのか、その背景から説明させていただきます。 私たちのStation Video Portalは、基本的にpbs.orgウェブサイトの各放送局向けブランド版といえるものです。各ローカル局は、その地域に関連した独自のコンテンツを制作しています。例えば、Idaho PBSは「Outdoor Idaho」という番組を特集していますし、先月の選挙の際には、Arizona PBSが地元の選挙戦や課題を取り上げた番組を制作しました。これは全国規模の視聴者には必ずしも関心がないかもしれませんが、アリゾナ州の住民にとっては重要な情報です。

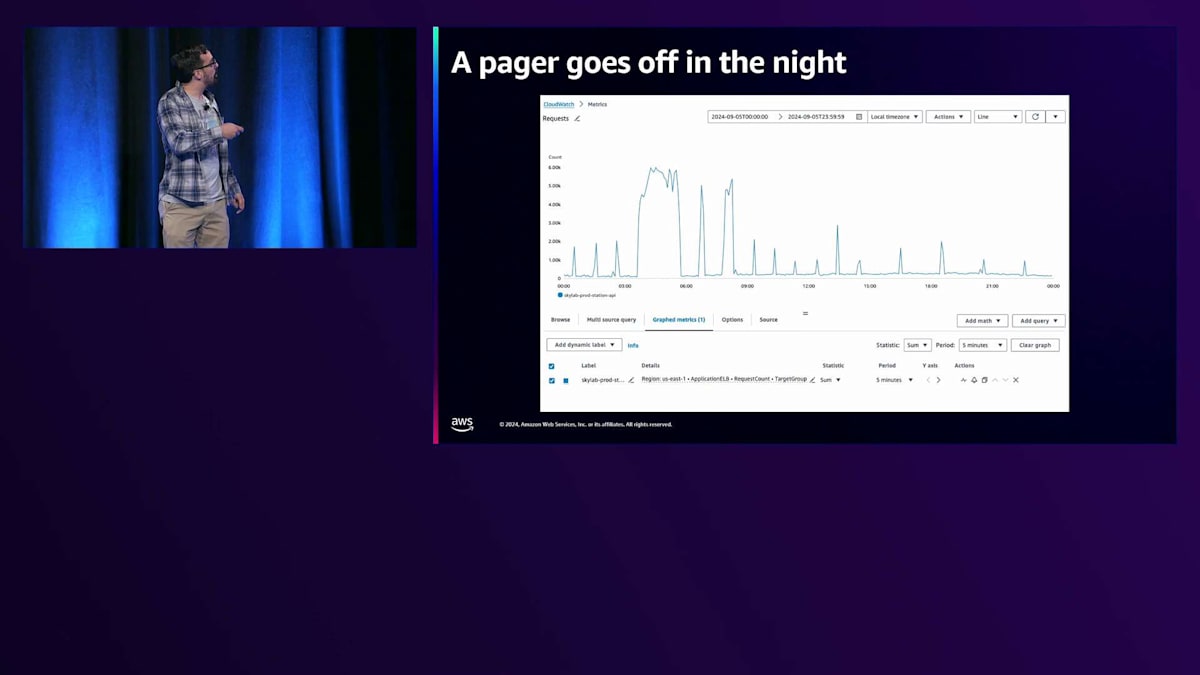
Station Video Portalは、Stations APIを含む私たちの複数のAPIに大きく依存しています。 Stations APIは、約180の放送局に関するメタデータを提供する基本的なマイクロサービスで、寄付リンク、放送局のロゴ、ソーシャルメディアの情報などを提供しています。この話は、ある謎から始まります。PagerDutyのアラートが朝3時に鳴って気分が最悪になった経験のある方は手を挙げてください。はい、かなりの方が手を挙げていますね。私もそうでした。楽しい経験ではありませんよね。そして、その夜ページャーが鳴りました。ここで見ていただけるように、朝3時30分頃、Stations APIのトラフィックが急激に増加し、レスポンスタイムが非常に遅くなり、エラー率も高くなっていました。
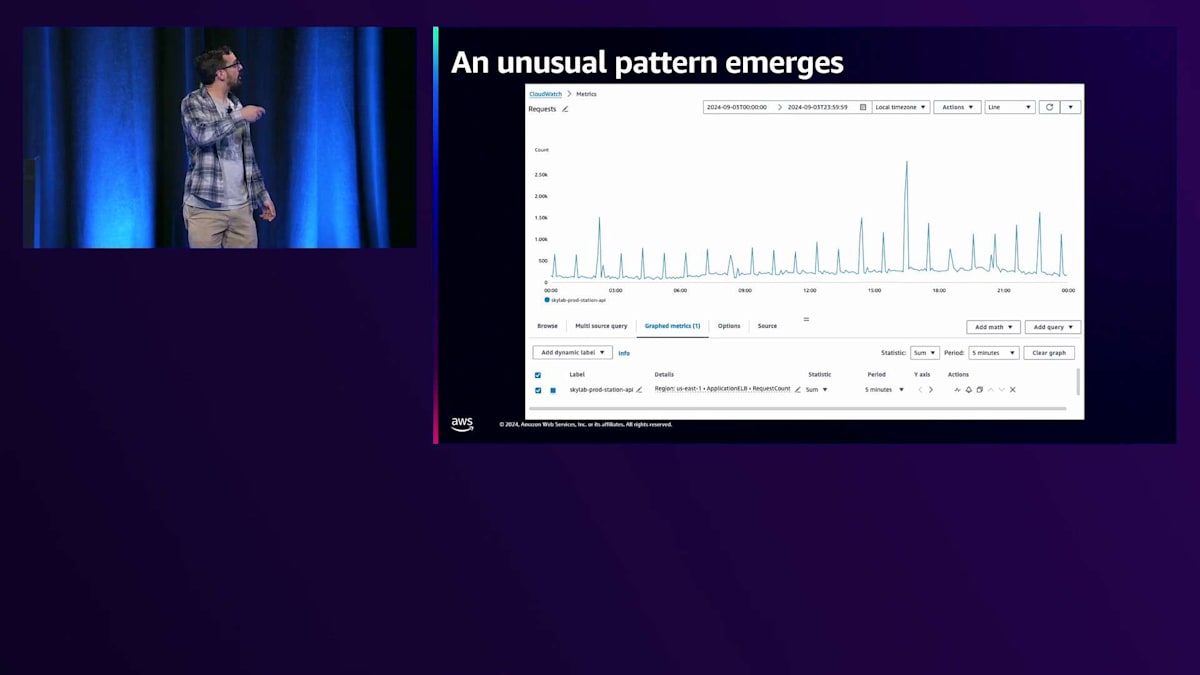
ご想像の通り、朝3時は私たちのプライムタイムとは程遠い時間帯です。Stations APIのスケールアップを行ってトラフィックに対応し、状況が落ち着いた後、過去のメトリクスを調べてみると、あるパターンが見つかりました。時計のように正確に、1時間ごとにStations APIへのトラフィックが大きく急増し、その後すぐに1分ほどで元に戻るのです。
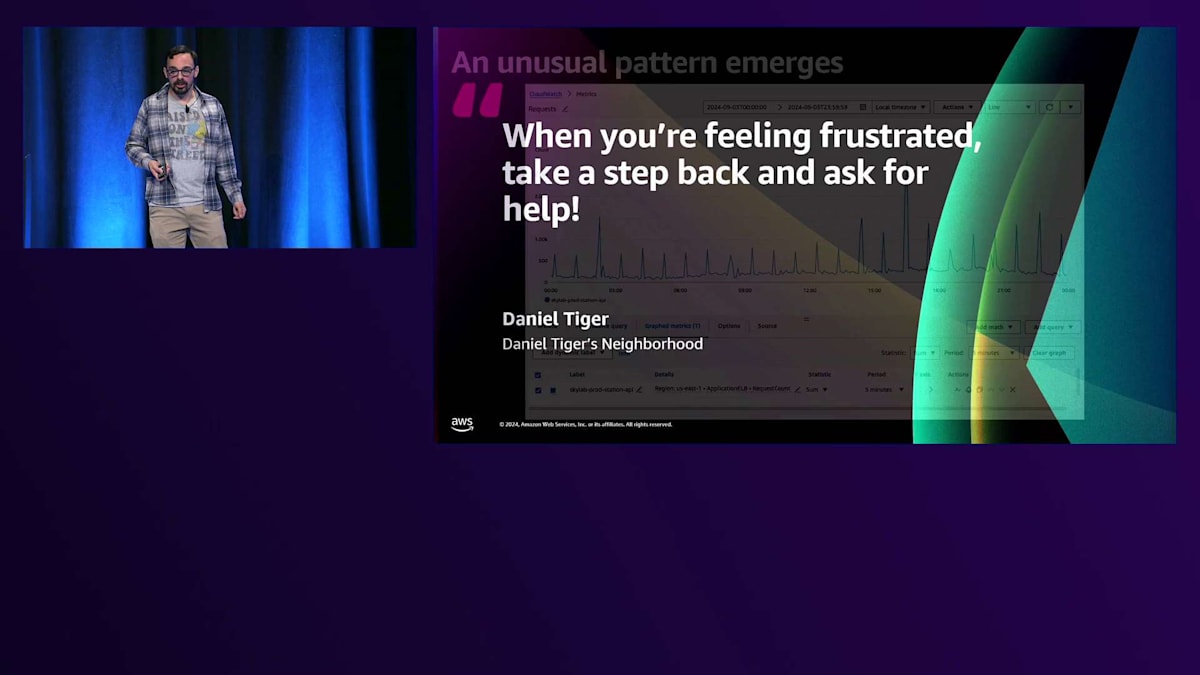

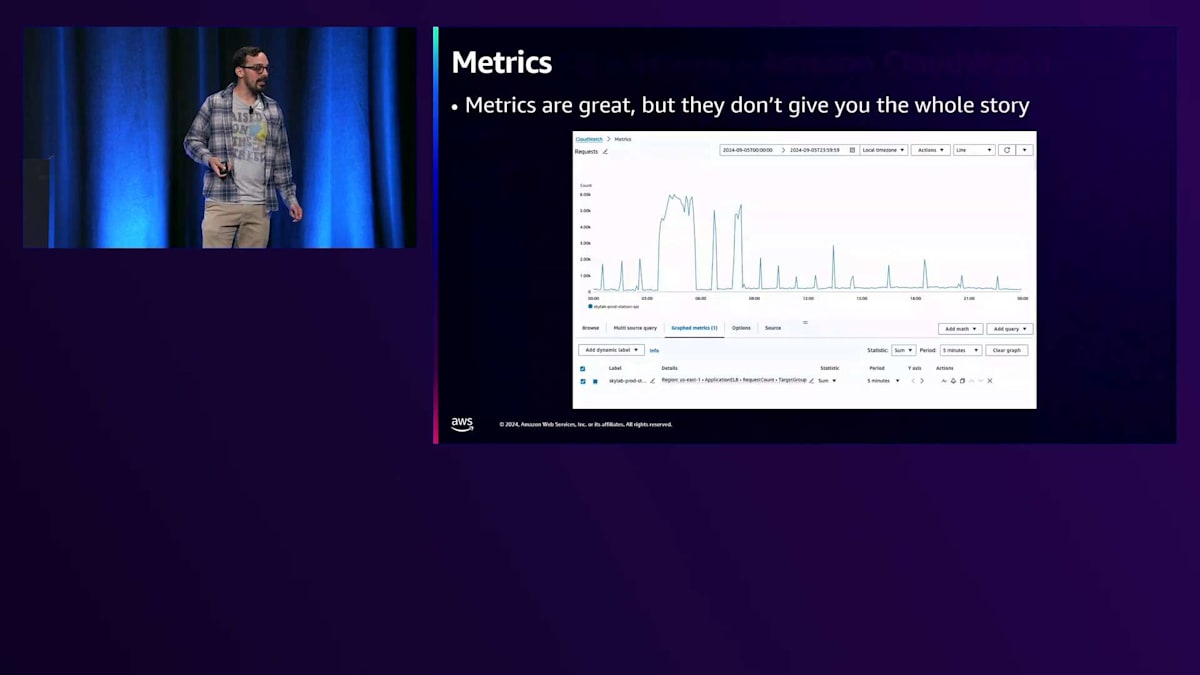
これは本当にイライラする状況でした。一体何が起きているのでしょうか?私の友人であり隣人でもあるDaniel Tigerが言うように、イライラしたときは一歩下がって、助けを求めることが大切です。お子さんがいらっしゃる方なら、私が何を言っているのかよくわかるはずです。そこで最初にすべきことは、すでに用意されているヘルパーを探すことです。CloudWatch、メトリクス、Log Insightsなどの既存のツールを活用します。メトリクスは素晴らしいツールですが、全体像を把握するには不十分です。このグラフからは明らかに問題が発生していることはわかりますが、なぜこの問題が起きているのか、根本的な原因は何なのかまではわかりません。

そこでログの調査を始めることになります。ログは確かに有用ですが、ある程度までです。ログを見てURLパターンを特定するためのクエリを実行することはできます。しかし、この場合、小規模なマイクロサービスであるため、このサービスには1つか2つのエンドポイントしかありません。そのため、何が起きているのかを区別することは難しいのです。IPアドレスの分析を試みることもできますが、残念ながらこれはプライベートIPからプライベートIPへの通信です。リクエスト元は同じVPC内の別の場所からで、Station Video Portalも同様にスケールアップダウンしているため、それらのIPは一時的なものであり、簡単には追跡できません。ログで確認できるもう一つの要素としてユーザーエージェントがありますが、この場合は全く役に立ちません。私たちは主にPythonを使用しており、多くのPythonリクエストを行っているため、すべてのユーザーエージェントがPython requestsとなっているのです。
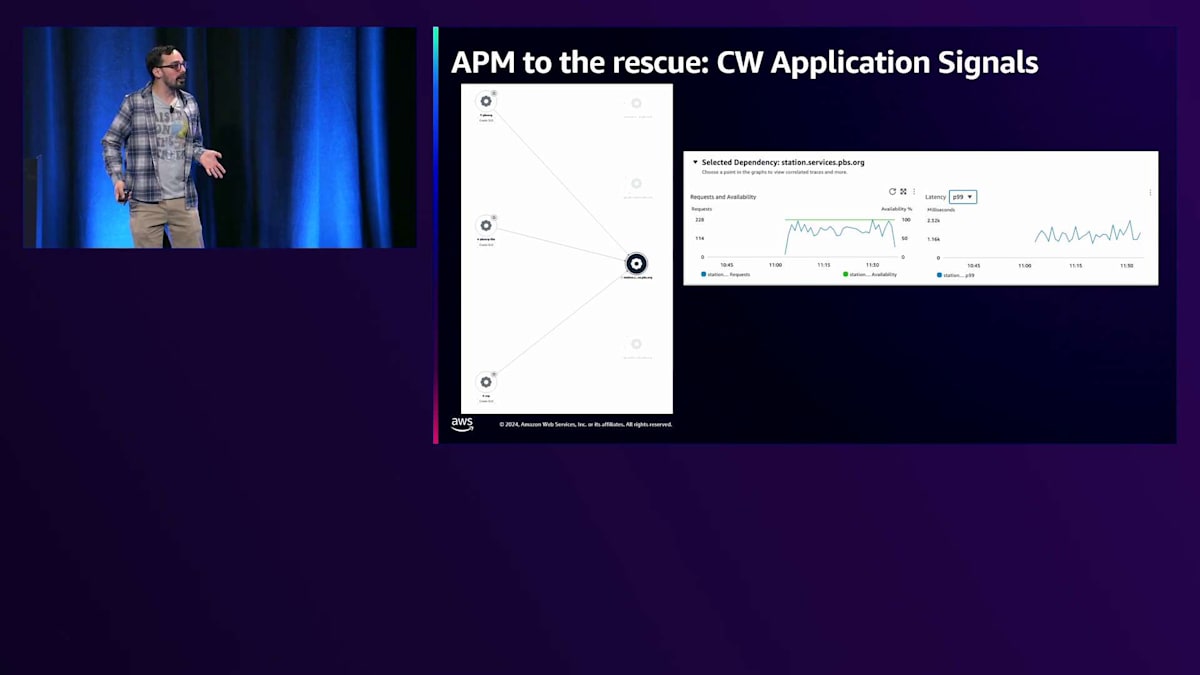
では、私たちはどうしたのでしょうか?私たちは最近、Application Signalsを使った取り組みを始めたところでした。左側のチャートは私たちのサービスマップですが、Station APIにズームインして、誰が消費者なのかを素早く特定し、容疑者を絞り込むことができました。Apple TVアプリ、Rokuアプリ、Androidアプリについては心配する必要がありません - これらはStation serviceを使用していないからです。この場合、PBS.org、PBS.org lite、そしてStation Video Portalだけが関係していることがわかりました。Station Video Portalをさらに詳しく調べると、このトラフィックの大きな急増がどこから来ているのかがすぐにわかりました。
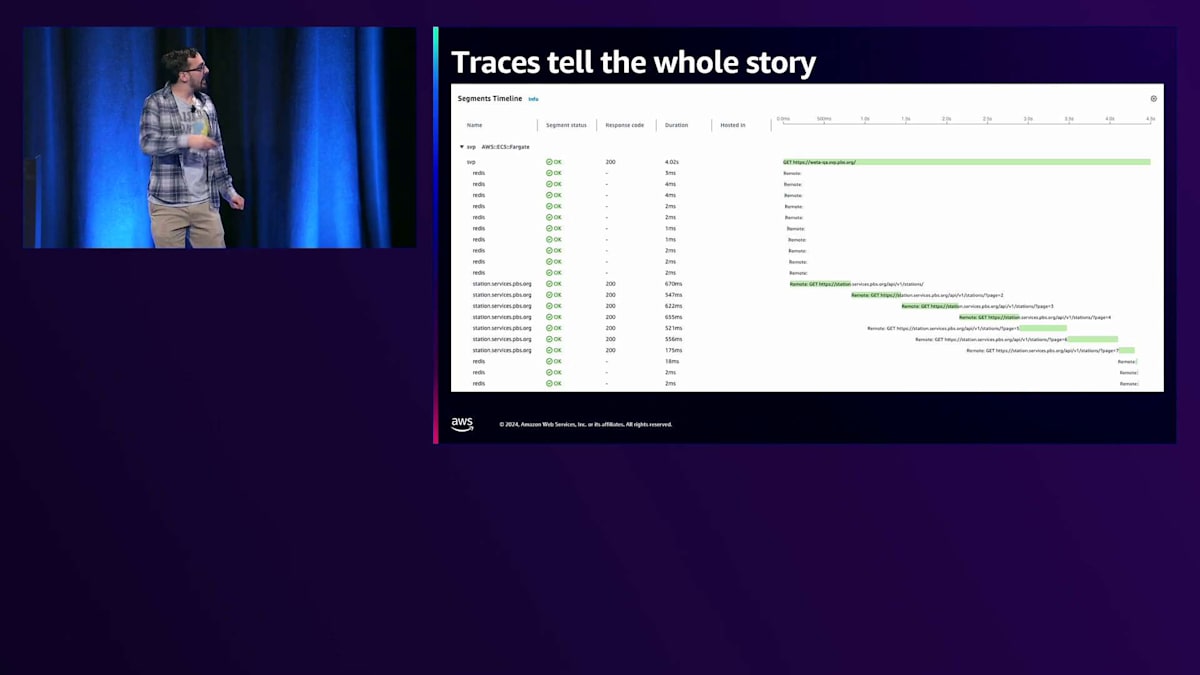
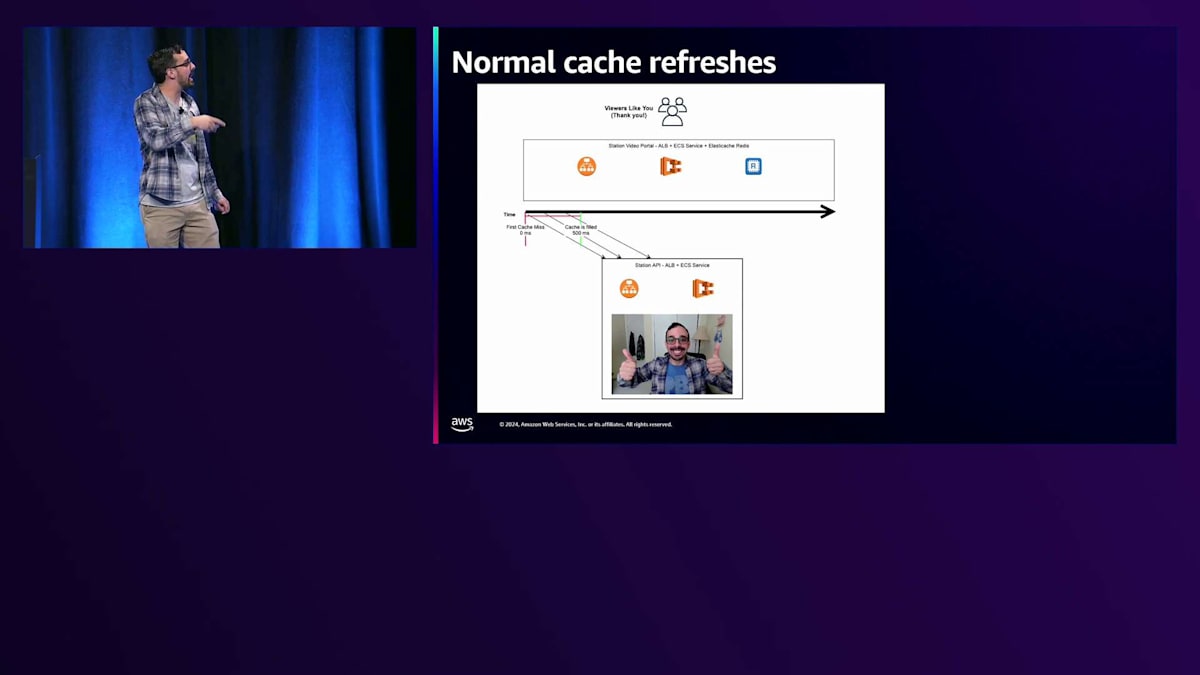
グラフ上のレイテンシートレースのいくつかをクリックすると、Station Video Portalでロードされているページがすぐに確認できます。下の方を見ると、Station servicesを呼び出しているのがわかります。これは大規模なページクエリで、これらの呼び出しの一つ一つが500-600ミリ秒以上かかっており、それが応答を非常に遅くし、このトラフィックの増加を引き起こしているのです。 実は、上部にあるStation Video Portalはとてもシンプルなアプリで、ALBとECSサービス、そしてこれらのStation API呼び出しやその他のAPI呼び出しをキャッシュするためのRedisキャッシュだけで構成されています。下部には、基本的にALBとECSサービスだけで構成されているStation APIがあります。
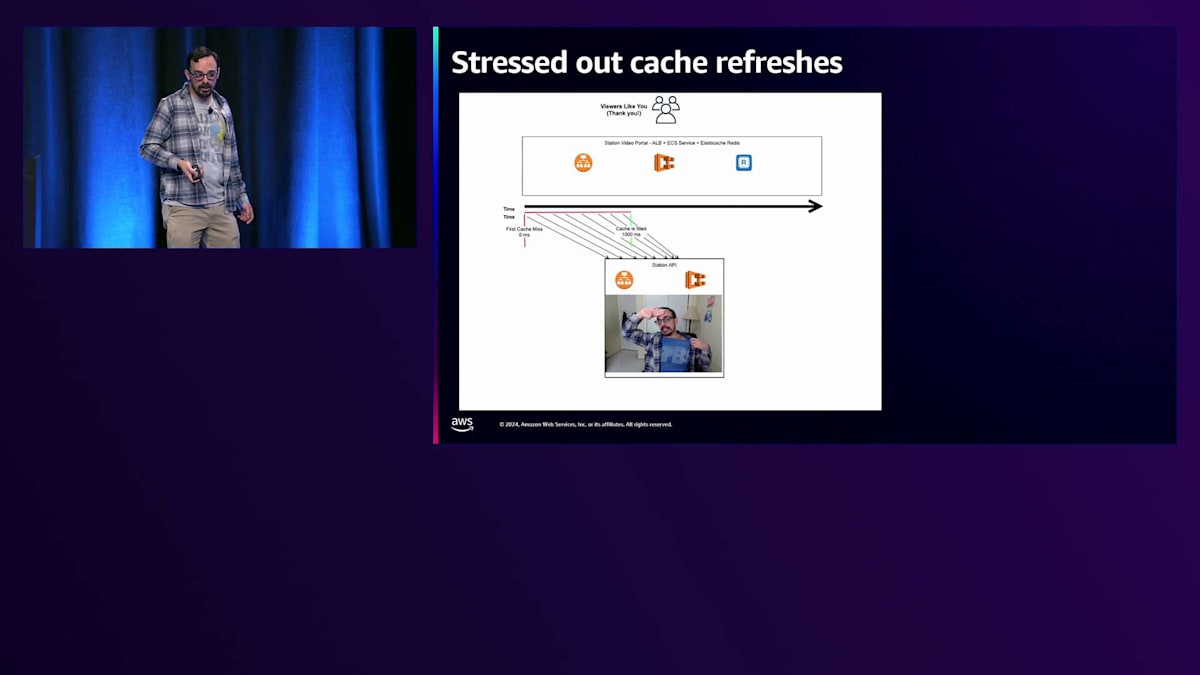
すべてが正常に動作している場合、キャッシュが期限切れになってから新しいキャッシュが作成されるまでの短い時間枠があり、その間、Station Video PortalへのすべてのリクエストがStation APIのキャッシュを更新しようとします。この特定のシナリオでは、それほど大きな問題ではありません - 500ミリ秒程度で、視聴者の皆さんは概ね満足しています。しかし、 もしStation APIが少しストレスを感じていたら、私のように少し調子が悪かったらどうなるでしょうか?
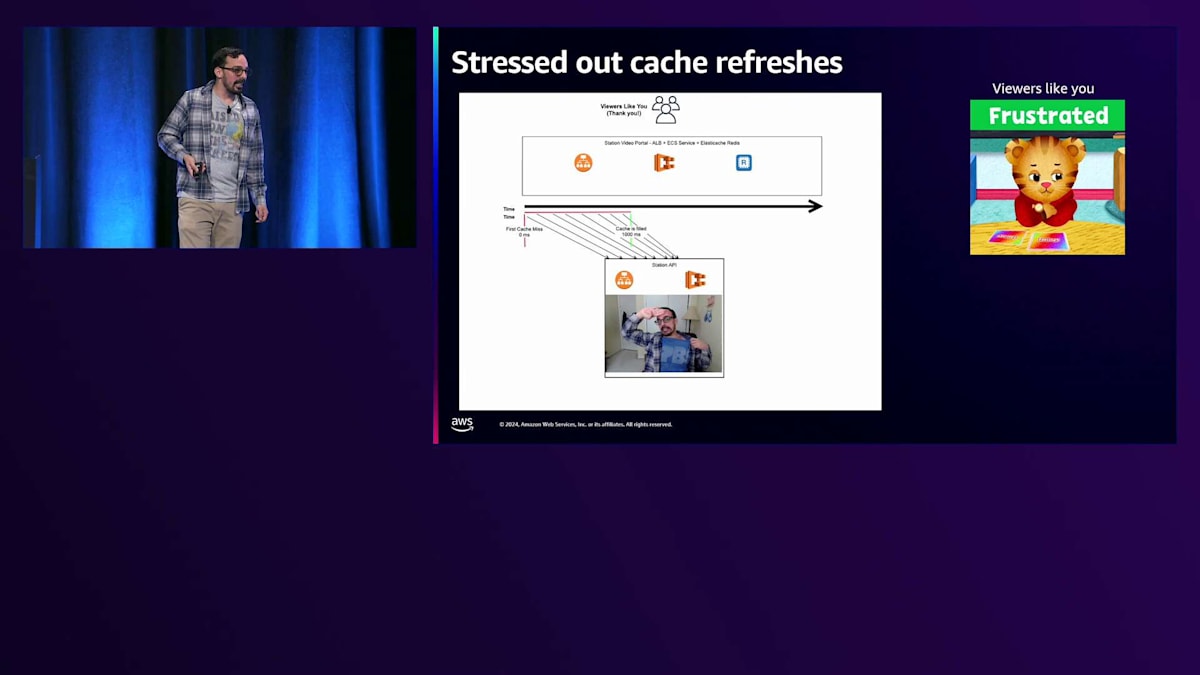
時間枠がどんどん大きくなり、500ミリ秒ではなく、今では1000ミリ秒になっています。そのため、リクエストがStation APIに到達する時間枠が長くなり、より多くのリクエストがStation APIに到達することで、Station APIにさらなるストレスがかかります。 ユーザーは少しイライラし始めます。少し待ち時間は長くなりますが、最終的には正常な状態に戻ります。
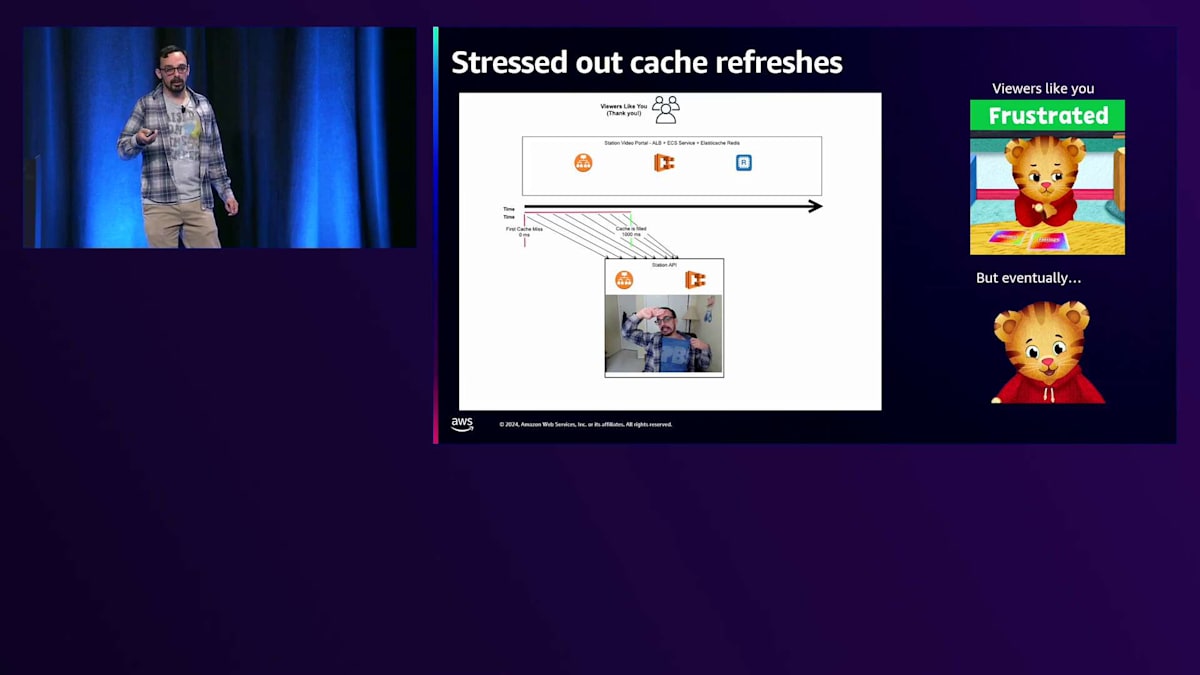
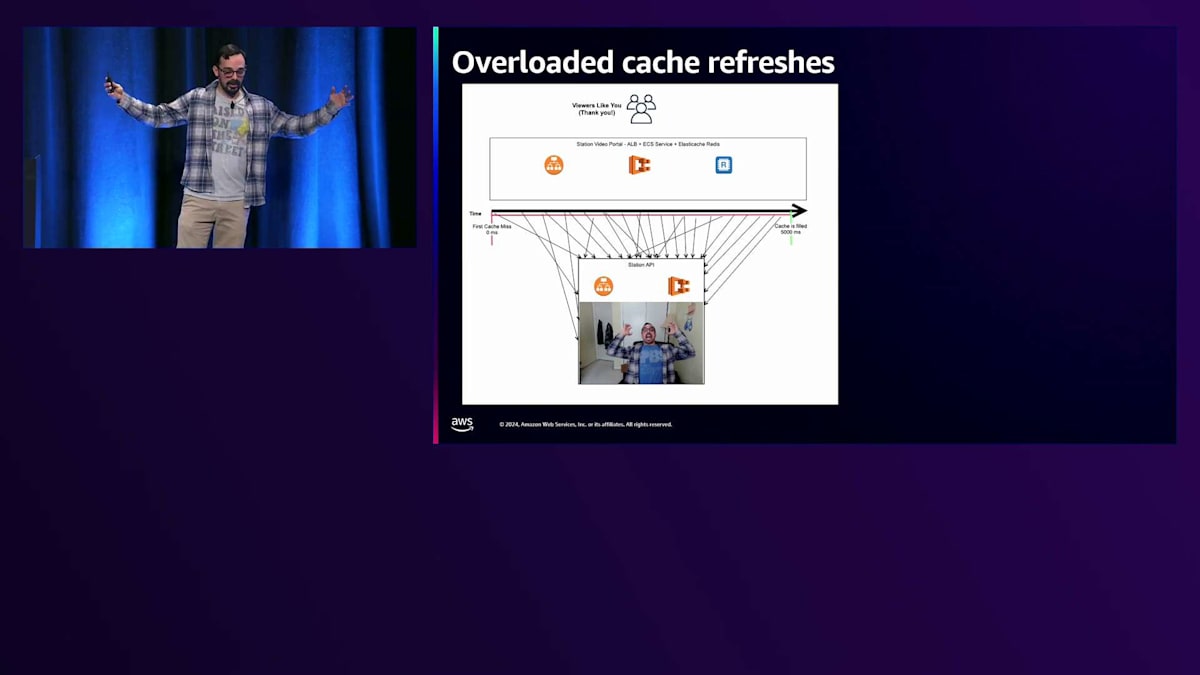
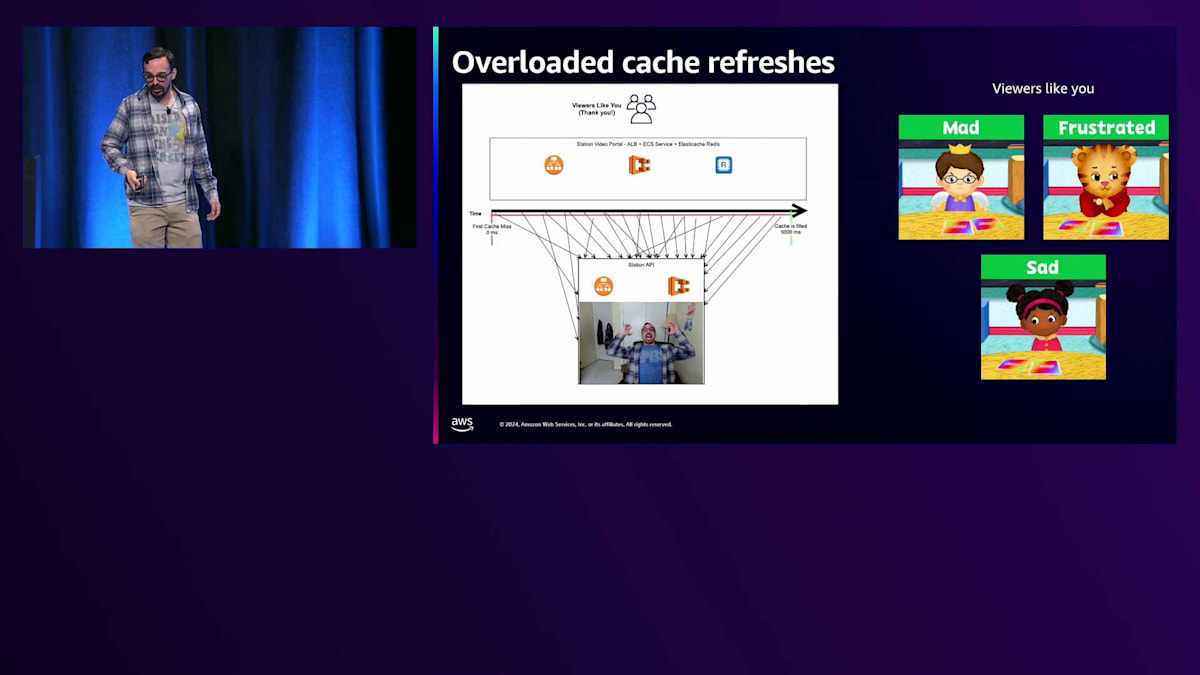
では、私たちが経験した午前3時のPagerDuty通知のような状況で、Station APIが完全にオーバーロードした場合はどうなるでしょうか? この場合、最初のキャッシュミスからキャッシュが埋まるまでの時間枠が膨大になります。5秒、10秒、15秒、時には30秒もかかり、すべてのトラフィックがStation APIに殺到します。これこそが、私たちが経験している「サンダリングハード」パターンの本当の原因なのです。 そして視聴者は怒り、イライラし、悲しい思いをすることになります。
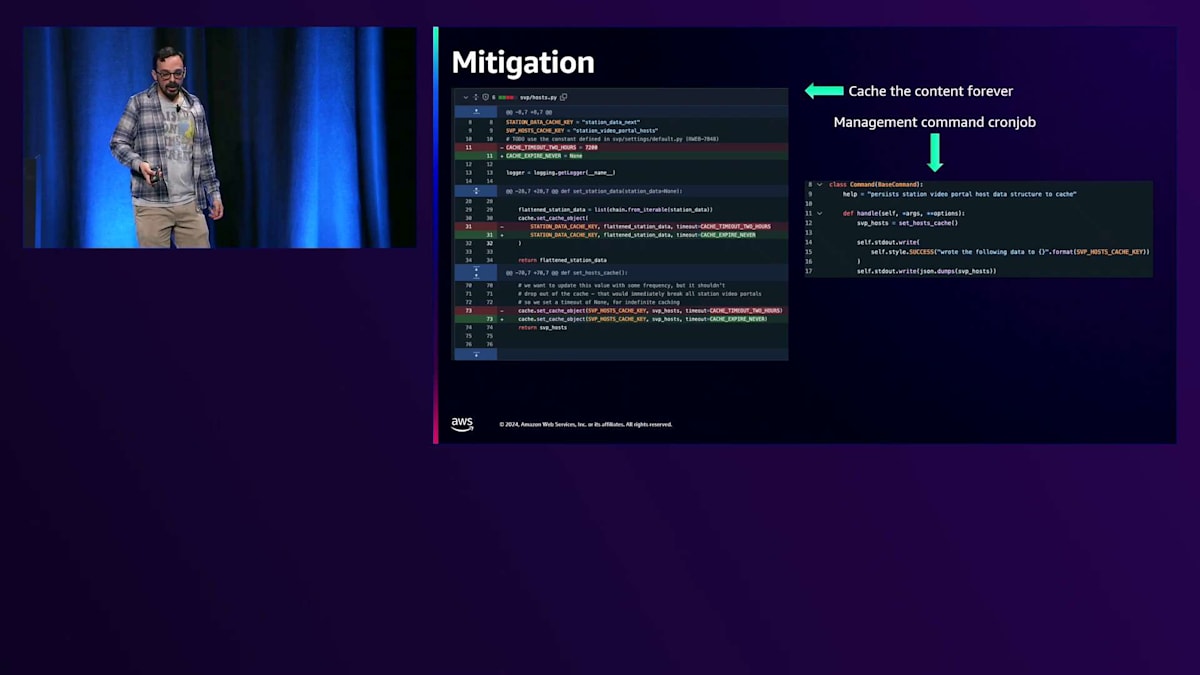
では、このような問題を緩和するために、私たちは何をしたのでしょうか?Station Video Portalのコードを更新することにしました。1時間や2時間のキャッシュではなく、無期限にキャッシュすることにしたのです。そして、このキャッシュ更新を行う別のDjango管理コマンドを作成し、ECSのスケジュールタスクとして設定しました。cronジョブとして設定することで、この更新は非同期で、確実に1回だけ実行されるようになり、とても安全です。何か問題が発生しても、1時間後に再度実行されます。確かに、寄付リンクなどのデータは各放送局によって時々更新されますが、そう頻繁に変更されるわけではありません。1時間程度の同期のずれは許容範囲内です。
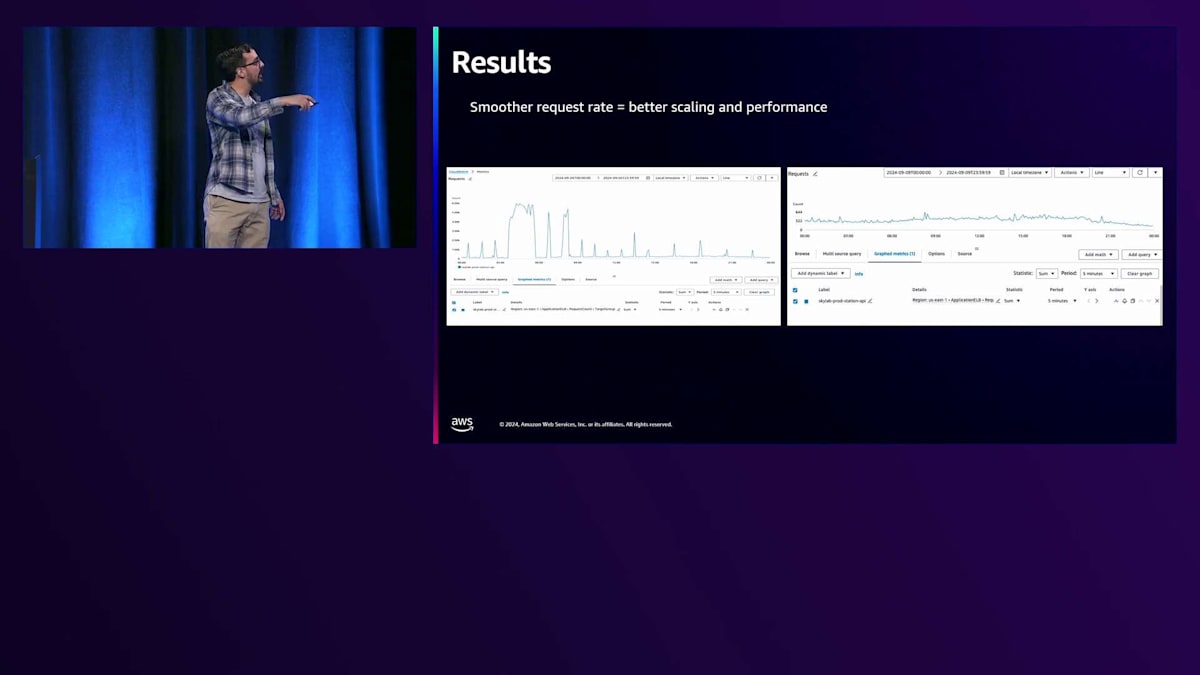
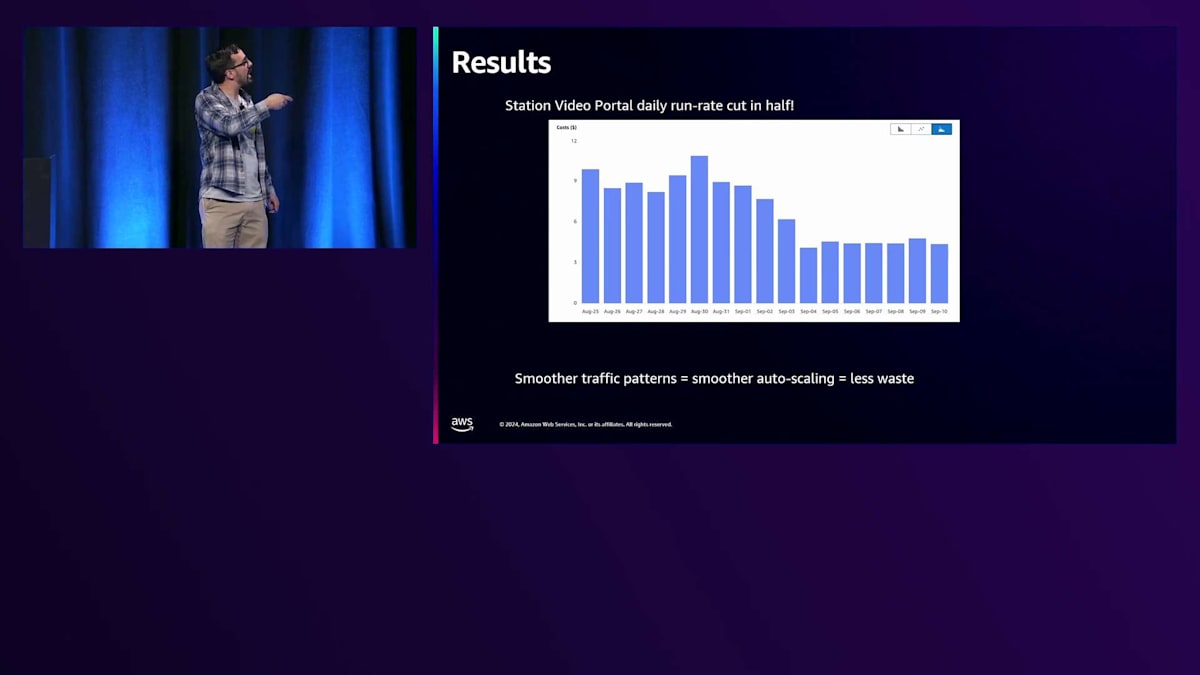
その結果はどうだったでしょうか? 1時間おきや2時間おきに大きなトラフィックスパイクが発生する代わりに、1日を通して非常にスムーズで安定したトラフィックパターンになりました。このような方式により、はるかに優れたスケーリングとパフォーマンスが実現できました。常に上下にスケーリングを繰り返すフラッピングもなくなりました。技術的な観点からも、財務的な観点からも、私たちは非常に満足しています。 Station Video Portalの1日あたりの運用コストは半分になりました。1日9~10ドルだったものが3~4ドルになったのです。会計チームも大喜びで、視聴者の皆様からいただいたお金をより重要な子供向けの番組やゲームなどに投資できるようになりました。


少し話題を変えて、PBSがCloudWatchで行っているもう一つの取り組みについてお話しします。それはビジネスメトリクスです。アプリケーションが正常に動作しているかだけでなく、視聴者に良い体験を提供できているかを追跡しています。 背景を説明しますと、PBS Passportは放送局への寄付者向けの会員特典です。私のように90年代にPBSで育った方なら、「50ドル以上のご寄付をいただいた方には、感謝の気持ちとしてこのトートバッグをプレゼントいたします」というフレーズを覚えているでしょう。これが2024年版なのです。地域の放送局に寄付することで、PBSの番組のバックカタログのストリーミング視聴や、新シーズンの全話を初週からまとめて視聴できる先行アクセスなどが可能になります。視聴者が寄付をしたのに、すぐに番組を視聴できないとなると、当然不満が出ます。月5ドルや年間60ドル、あるいはそれ以上を寄付したのに、見たい番組がすぐに見られないのは困りますよね。
CloudWatchを活用したPBSのビジネスメトリクス追跡
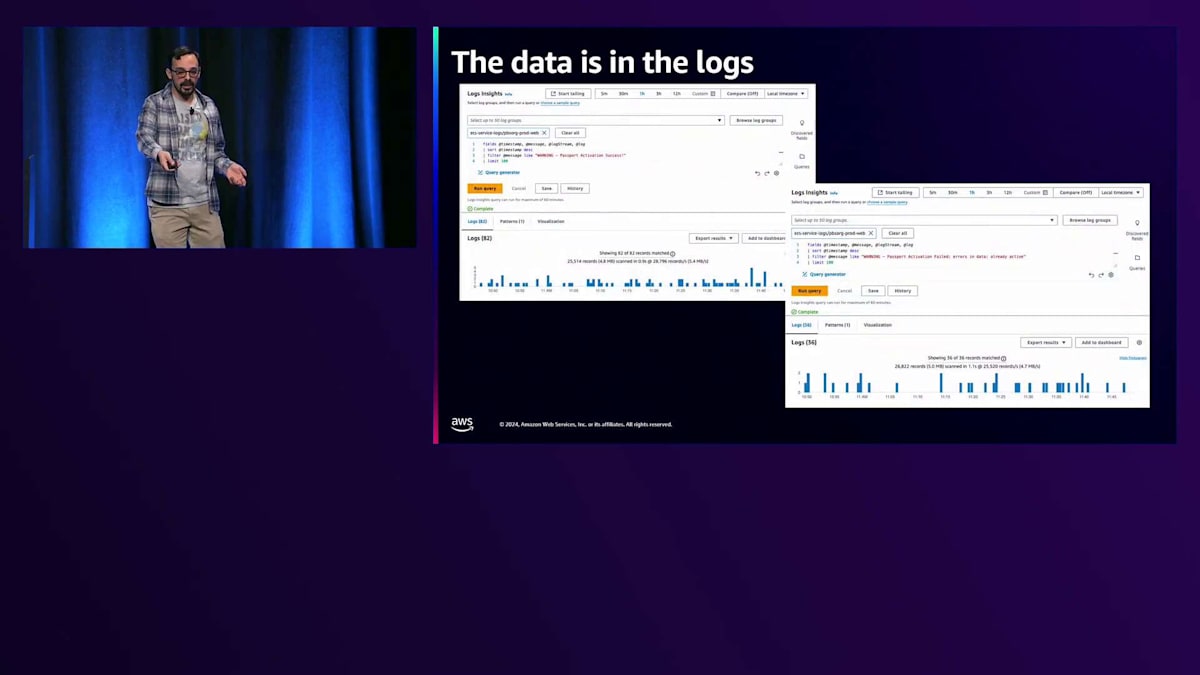
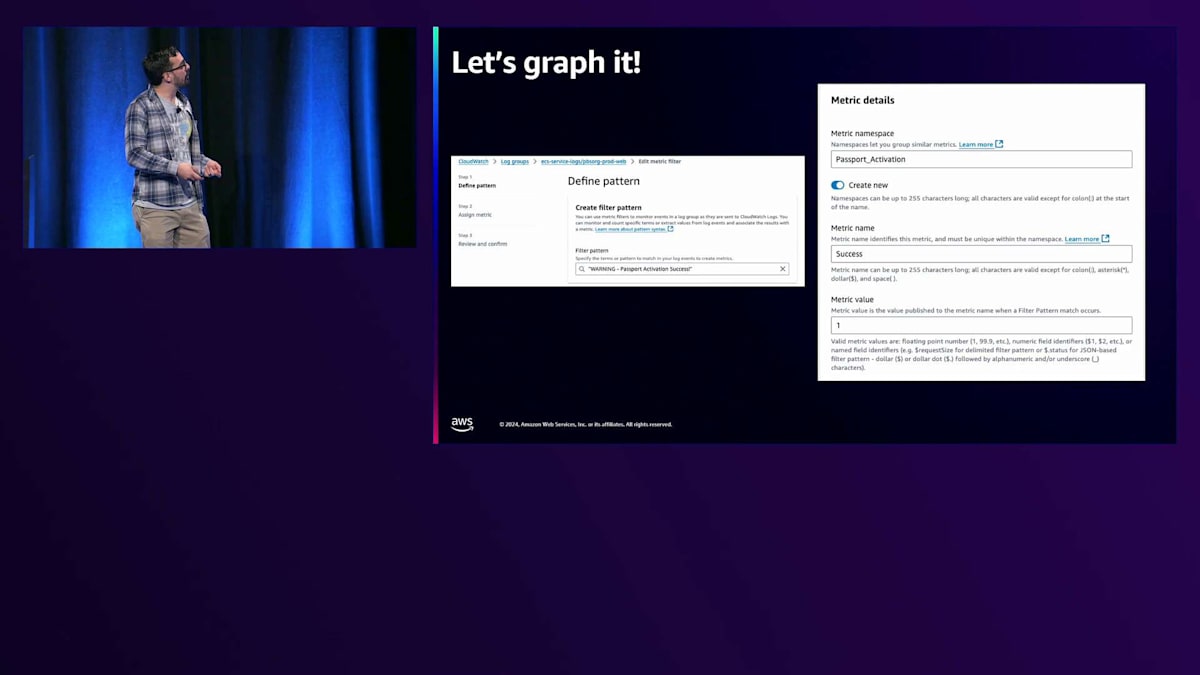
では、これをどのように追跡しているのでしょうか?最初から、このデータはログに記録されていました。アプリケーションはPassportのアクティベーションの成功と失敗をログに記録していたのです。これらのパターンは把握していたので、クエリを実行するのは比較的簡単でした。 そこで、すぐにメトリクスフィルターを設定し、CloudWatchメトリクスに変換することができました。 これにより、時系列で成功と失敗の数を確認できるようになりました。「すでにアクティブ」による失敗は必ずしも大きな問題ではありませんが、他のタイプの失敗も発生する可能性があります。さらに、ログイン試行、成功、失敗の追跡など、同様の取り組みも行いました。パスワードの入力ミスは必ずしも問題を示すものではありません。
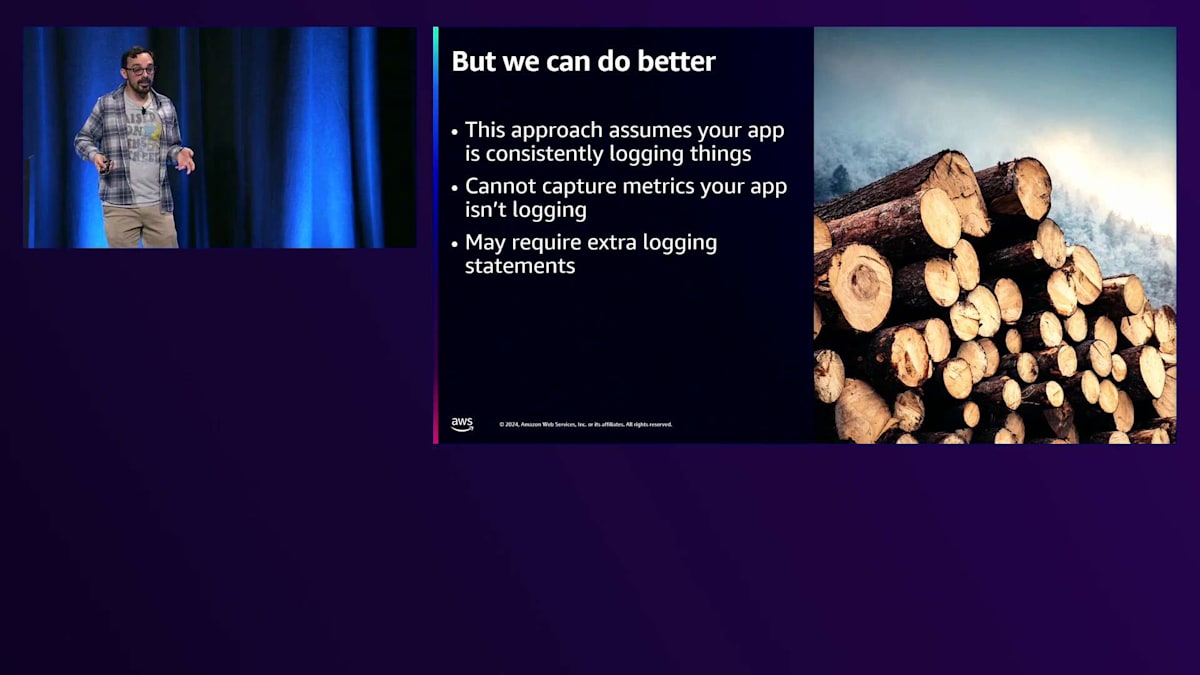
もちろん、誰もログインできないという状況は問題です。しかし、このアプローチにはいくつかの課題があります。 このようなアプローチは、アプリケーションで一貫したログ記録が行われていることを前提としています。開発チームが、これらの事象が発生する場所を把握し、ログステートメントを追加し、ログ形式に従って一貫性を保つなど、すべてを適切に管理する必要があるのです。

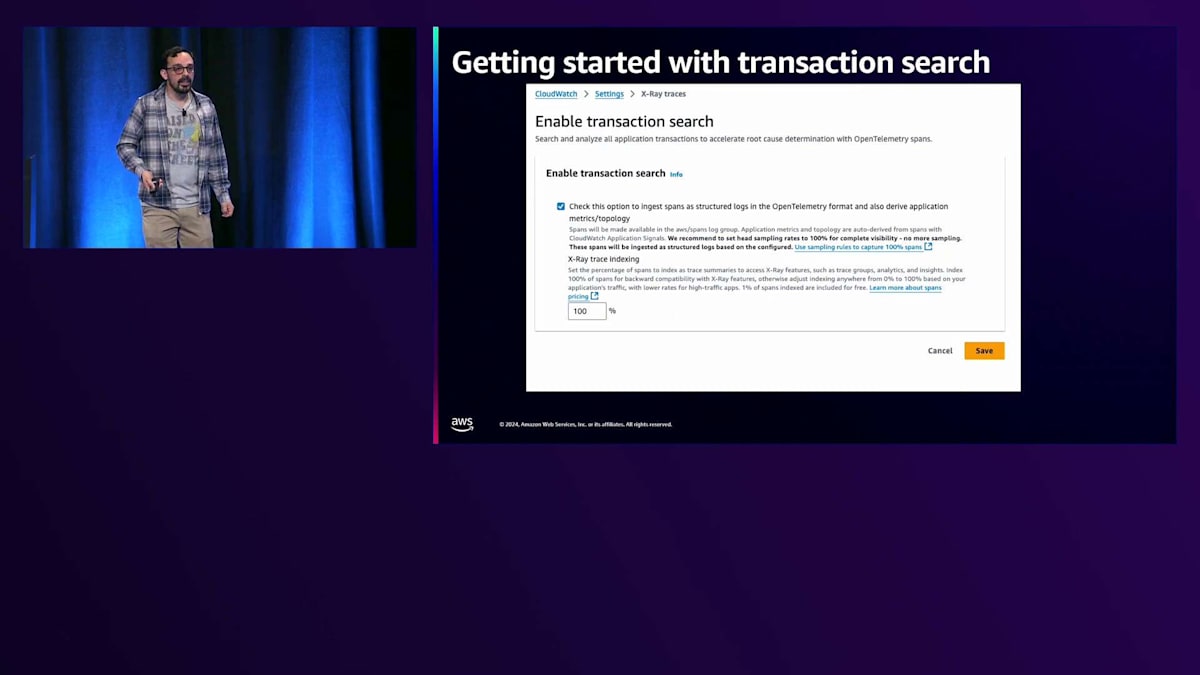
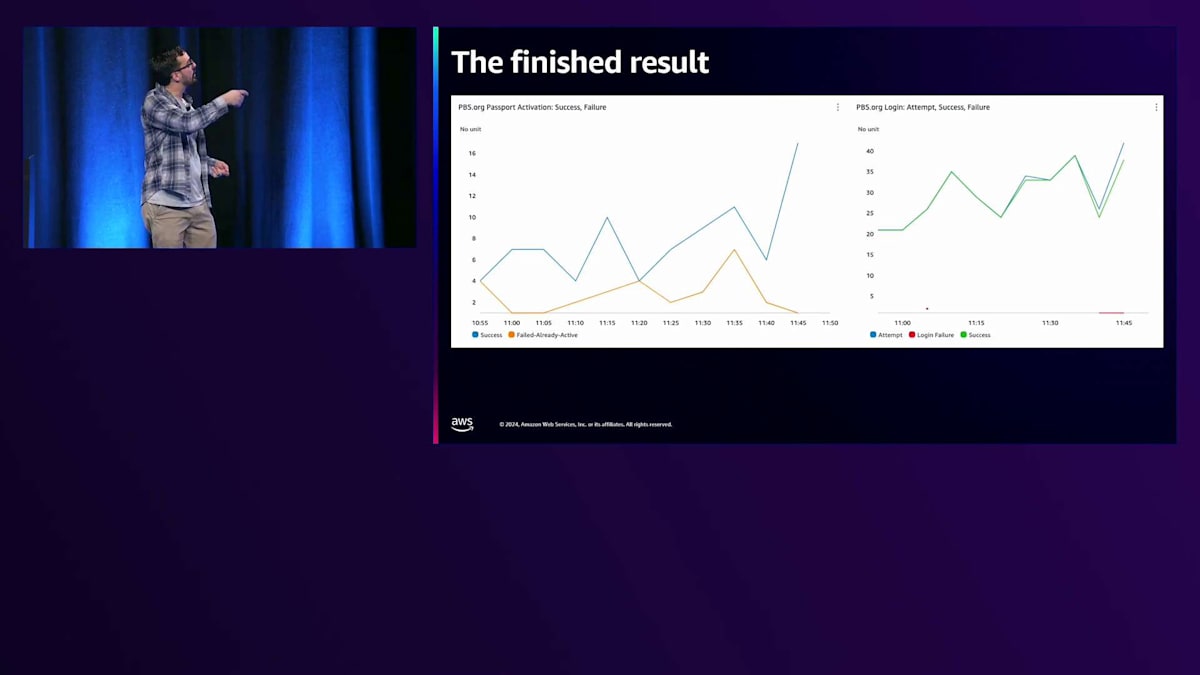
Transaction Searchの登場です。これはAWSとCloudWatchチームが数週間前にリリースした新機能で、私も実際に使ってみて深く掘り下げることができ、とてもワクワクしています。では、このTransaction Searchを使って、Passportのアクティベーションを新しい方法でどのように追跡できるのかご紹介します。 始め方はとても簡単です。CloudWatchコンソールに移動し、設定画面で該当するチェックボックスにチェックを入れ、キャプチャしたいトラフィックの割合をトレーシングインデックスとして設定するだけです。今回の場合は、すべてのトラフィックをキャプチャするように設定しています。
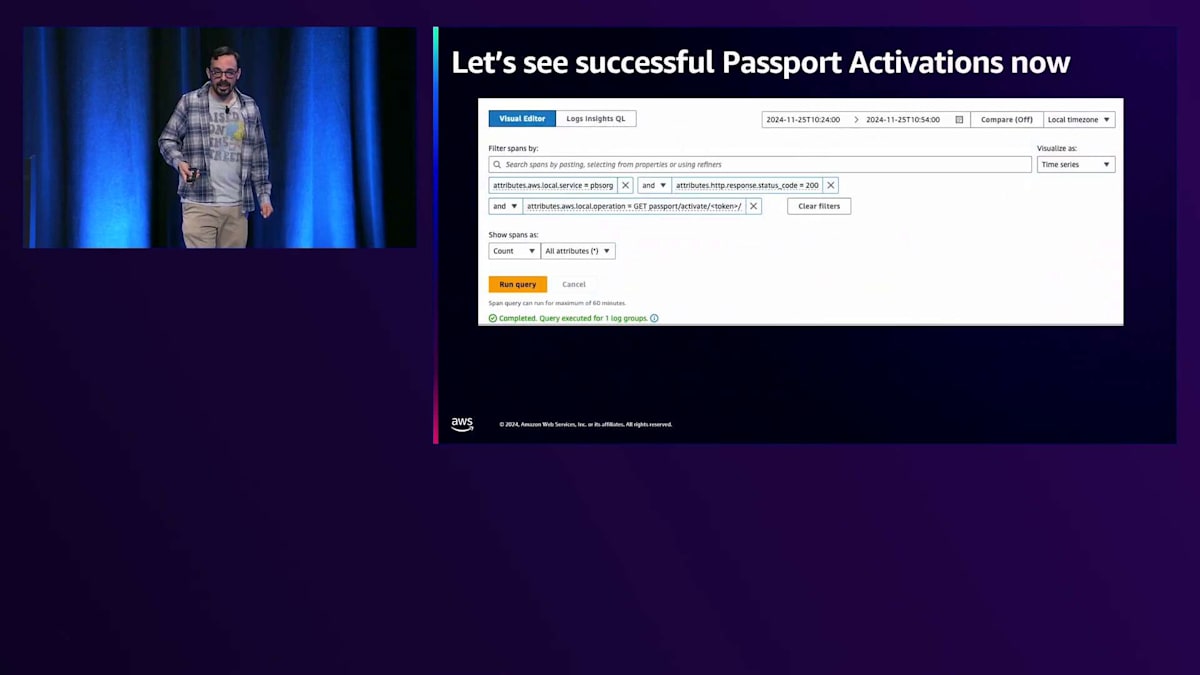
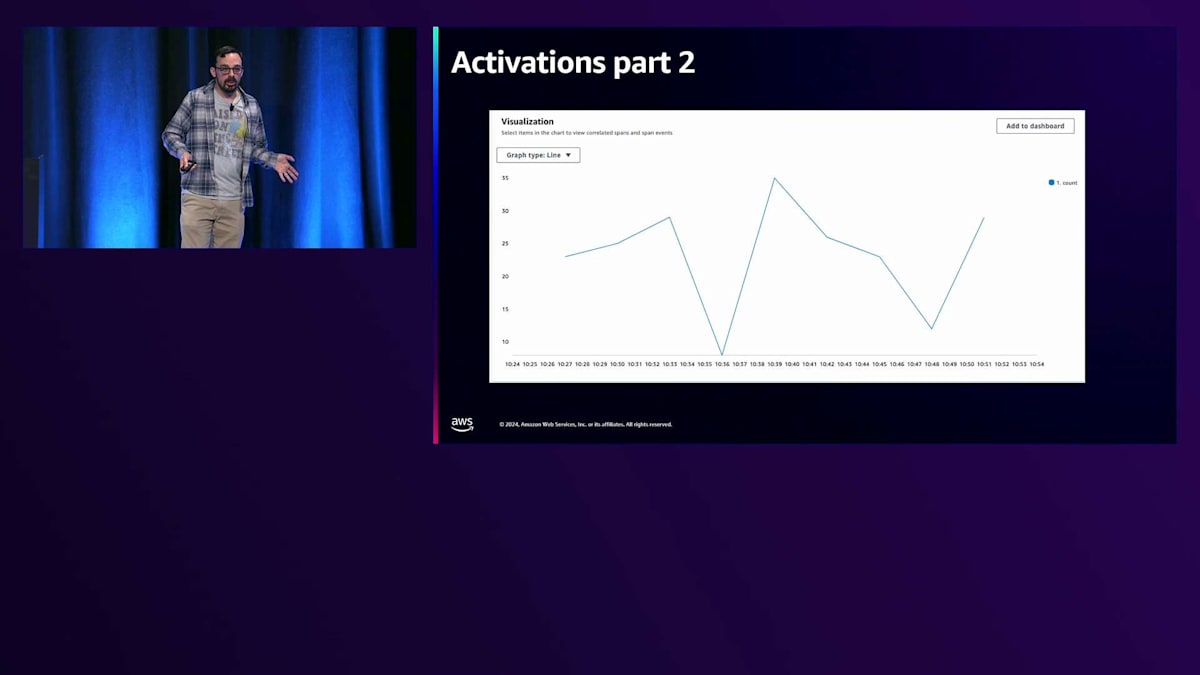
その後、Transaction Search画面に移動して、クエリを作成します。サービスがPBS.orgで、ステータスコードが200、オペレーションがPassportアクティベート、そしてメンバーシップをアクティベートするために使用するトークンという条件を指定します。 これで、アプリケーションに大きな変更を加えることなく、同じデータをグラフ化して確認できます。すでにApplication InsightsやX-Ray、OpenTelemetryでアプリケーションを計測していれば、チェックボックスにチェックを入れてTransaction Searchを使い始めるだけで、すぐに利用可能です。

さらに、Transaction Searchには今後活用できる多くの可能性があります。例えば、PBSにとってローカライゼーションは非常に重要です。全米に180のメンバー局があり、PBS.orgやスマートフォンアプリ、スマートTVアプリにログインする際、アクセス元のIPアドレスを使用して、視聴者が最も利用する可能性の高いローカルPBS局を特定しています。そのため、ラスベガスからPBS.orgにアクセスすると、Vegas PBSのコンテンツがキュレーションされて表示されます。私がメリーランドの自宅からログインすると、Maryland Public Televisionのコンテンツが表示されます。
数年前、ある携帯電話サービスプロバイダー(名前は伏せておきますが)で問題が発生しました。5Gネットワークの構築時に、増加するトラフィックに対応するため、大規模なIPv6アドレスブロックを購入したのですが、IPベースの位置情報を提供するデータベースで、このプロバイダーのIPアドレスがすべてシアトルの本社所在地として登録されていたのです。ある朝、突然「アプリが私の場所をシアトルのCascade PBSだと表示していますが、私はミズーリ州に住んでいます。どうなっているのでしょうか?」という視聴者からの報告が殺到しました。このように、ローカライゼーションのスパイクを追跡できることは重要です。必ずしも問題とは限りませんが、問題のチケットが届く前に、事前に確認して対処できることが重要です。
もう一つの活用例として、レコメンデーションエンジンがあります。アプリやウェブサイトでは、視聴履歴に基づいて「おすすめのタイトル」を表示しています。例えば、自然のドキュメンタリーを視聴した後に「こんな番組もおすすめです」というレコメンドからどれくらいの視聴者がクリックしているのか把握できると良いですね。レコメンデーションエンジンの利用状況を確認できることは非常に有用です。最後に、寄付タイトルの追跡についてです。PBSは視聴者の皆様からの支援で運営されている非営利組織であり、各種アプリでの寄付やワンクリック寄付は、ローカル局にとって非常に重要です。局の運営は皆様からの寄付で支えられています。そのため、どのタイトルが寄付を促進しているのかをより詳しく把握できることは素晴らしいことです。これにより、今後どのようなタイトルを取得するか、どの番組を再放送するべきか、あるいは新シーズンのどの番組を選ぶべきかといったビジネス上の意思決定に役立てることができます。
まとめと今後の展望

まとめとしまして、CloudWatchは私たちのアプリケーションやそのパフォーマンス、その動作状況だけでなく、ビジネス価値、つまりPBSの将来の方向性を決定する上で非常に重要なビジネスメトリクスについても、より高い可視性を提供してくれました。

では、IgorとSivaに壇上に戻っていただきましょう。お時間をいただき、ありがとうございました。このあと、ホールの後ろで質問などお受けできますので、お気軽にお声がけください。Brianさん、私たち全員に共感できる、そしてワクワクするようなストーリーをご紹介いただき、ありがとうございました。実際の運用現場での興味深いお話をお聞かせいただき、感謝いたします。皆様、本日はお時間を割いてご参加いただき、ありがとうございました。re:Inventそして本セッションをお楽しみいただけましたでしょうか。アンケートにご記入いただき、素晴らしい1日をお過ごしください。 私の話が良かったと思っていただけましたら、お近くのPBS放送局へのご寄付をご検討いただければ幸いです。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion