re:Invent 2024: 金融サービスにおけるGenerative AIの活用事例3選
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Beyond productivity: Using generative AI to grow in financial services (FSI202)
この動画では、金融サービスにおけるGenerative AIの活用事例について、3社の取り組みが紹介されています。Bridgewater Associatesは、市場と経済の理解を深めるためにマルチエージェントアーキテクチャを構築し、Investment Associateの業務効率化を実現しました。MUFG Bankは、法人営業活動の変革のためにGenerative AIを導入し、リード創出を10倍に増加させることに成功しました。Crypto.comは、暗号資産市場のニュース分析において、Amazon BedrockとSageMakerを活用したマルチエージェントによるSentiment Analysis systemを構築し、90%以上の精度を達成しています。3社の事例は、いずれもAWSのサービスを活用し、具体的な成果を上げている点が特徴的です。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
金融サービスにおけるGenerative AIの活用事例

こんにちは。本日は金融サービスにおけるGenerative AIを活用した成長戦略についてのセッションにご参加いただき、ありがとうございます。私はJohn Kainと申しまして、AWSの金融サービス部門でマーケット開発を統括しております。私たちのチームは、お客様のAWS活用とビジネス目標の達成を支援し、業界特有のニーズに応じたソリューションを提供することに尽力しています。


今日のお話は、一部の方にとってはデジャヴのように感じられるかもしれません。Amazon Bedrockの一般提供開始から6ヶ月後の昨年、 実際の本番環境でGenerative AIを活用している3社のお客様に、業界視点からの導入事例についてご紹介いただく機会がありました。これらの企業は全て、 強固なデータ基盤の上に構築されていました。Sunlifeは、Experience Based AcceleratorやプロトタイピングチームといったAWSのプログラムを活用して、社内業務アプリケーションのROIを判断し、プロトタイプの検証を通じて、より迅速な市場投入を実現した事例を共有してくださいました。
また、Verafinからは、Generative AIを文書要約に活用することで、不正調査にかかる研究者の時間を70%以上削減できた事例が紹介されました。さらに重要なのは、ROIを向上させるためのモデル選択の重要性を示してくれたことです。特に、Amazon Bedrockの柔軟性を活かして、異なるモデルをテストすることで、経済性や成果を最適化できることを実証しました。
Natwestは、Generative AIを活用してリテールバンキング口座の個別マーケティングを行い、クリック率や成約率の向上を実現した事例を共有しました。彼らは、Generative AIをチェックするためにGenerative AIを使用するという、画期的な事例を示してくれました。これにより、企業のメッセージングの一貫性を保ちながら、誤検知や幻覚を減らすためのパイプラインを構築しました。
Generative AIの進化と金融サービスへの影響
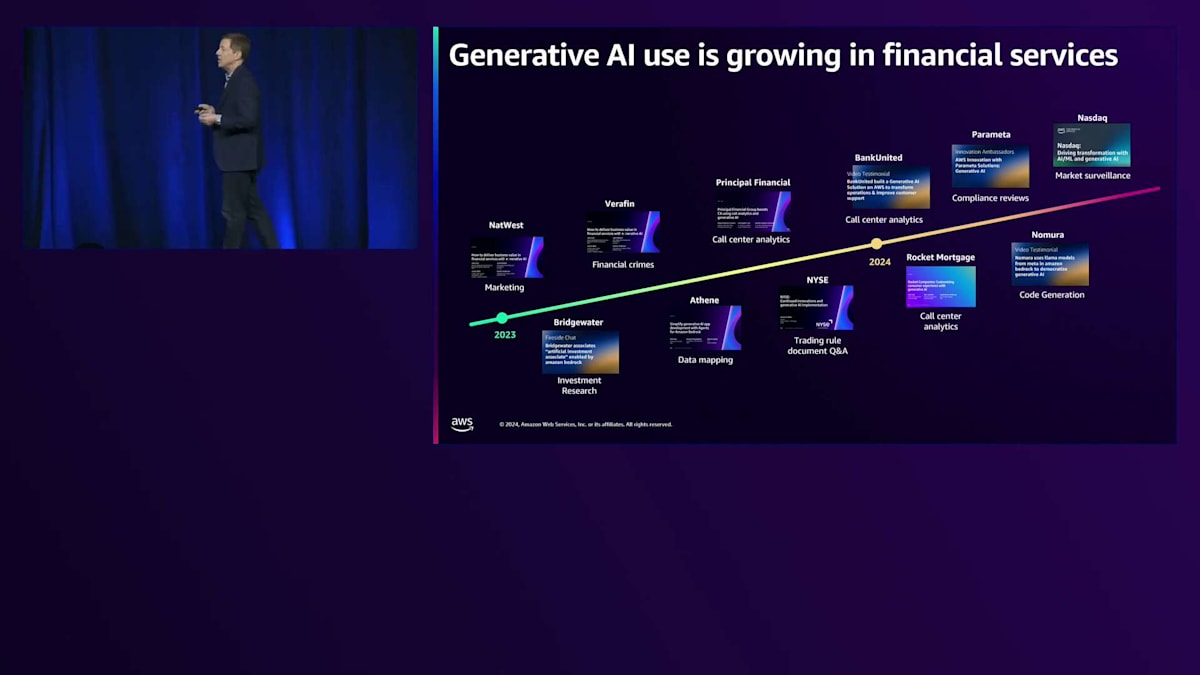
これらの事例を基準として共有させていただいたのは、業界に大きな進展があったからです。金融サービスにおける価値提案の観点から、 re:Inventで紹介された実際のビジネス価値をもたらす重要な領域がいくつかあります。New York Stock ExchangeやLine Dataのような知識管理のためのRAGパターンを活用することで、複雑な文書から一般のアナリストが実用的な洞察を得ることができるようになりました。保険会社における複雑な保険金請求では、保険の補償範囲を理解する能力が業務効率を向上させています。
私たちは、ますます高度なユースケースが登場するのを目にしてきました。コンプライアンスの分野では、自動化によってこれらのプロセスにおける人的コストが劇的に削減され、GenPactやNasdaqでは33%から60%の時間削減を実現しています。コールセンターでは、顧客とのやり取りから洞察を得られることが、業界全体で最も影響力のあるユースケースの1つとなっています。私のお気に入りは、ETLの観点からデータ変換を行う能力です。Generative AIを使って初期の変換ルールを作成し、その変換を説明し、複雑な顧客オンボーディングを数ヶ月ではなく数週間で実現できるようになりました。


1年前のこれらのユースケースは、Generative AIの観点からは比較的単純なものでした。RAGパターンを使って企業データへのアクセスを改善する方法、要約機能を使って研究者がビジネスプロセスの効率を高める方法、比較的シンプルなアカウントを持つ個人向けにコミュニケーションをカスタマイズする方法などを検討していました。それから1年後の今日、私のスピーカーの方々が皆さんにお話しするのは、 Generative AIで可能なことの範囲がいかに拡大したかということです。複雑なアイデアを受け取り、それをよりエージェント的なワークフローに分解して、市場に対する実質的な洞察を導き出すことができる投資リサーチアシスタントの構築方法について説明します。昨年Natwestが個人向け商品について話した一方で、今回は法人の視点からこのアプローチを検討し、ビジネスのニーズを理解し、様々な商品を通じてより効果的にエンゲージメントを図る方法を紹介します。また、過去のデータからの洞察を得るだけでなく、リアルタイムでそれを行い、必要な瞬間にGenerative AIから洞察を得る方法についても探ります。

Generative AIの未来がどのようなものになるかを考えるとき、その未来の一部を今日この舞台で見聞きすることになるでしょう。 より効果的な結果を導くために、エージェントやツールによって推進できる、より大きなプロセスを小さなプロセスに分解することの利点を理解することができます。テキストだけでなく、他のメディアを扱うマルチモーダル型のモデルの機会がますます増えていくでしょう。また、Generative AIを使用する大規模言語モデルか、現在最も成功している従来型のモデルパイプラインかを問わず、適切なタスクに適切なモデルを選択し、それらを組み合わせて効率を高めることの重要性も理解できるでしょう。

今日はあまり詳しく触れませんが、これらすべての基盤となるのは、 金融サービスを成功に導くすべてのポリシー、ガバナンス、透明性です。本日は、Bridgewater AssociatesのAIA LabsのCTOであるAaron Linsky氏、MUFG BankのQuant Innovation部門長のTetsuo Horigane氏、そしてCrypto.comのSVPでAI Innovation Technology部門長のSunny Fok氏にご登壇いただきます。それでは、同社の取り組みについてお話しいただくため、Aaronさんをステージにお迎えしたいと思います。
Bridgewater AssociatesのAIA Labsによる投資プロセスの革新


ありがとうございます。Bridgewater AssociatesのAIA LabsのCTOのAaron Linskyです。過去18ヶ月間にGenerative AIを使って構築してきたものについて、皆様にお話しできることを嬉しく思います。その前に、Bridgewaterがどのような会社かについてお話ししたいと思います。 Bridgewaterは設立からほぼ50年になりますが、その間ずっと1つのシンプルな使命を持ち続けてきました。それは、市場と経済について世界最高の理解を構築し、維持することです。そして、その理解を基に市場でのポジションを生成します。例えば、米国株式のロングや日本国債のショートなどです。最後に、主に基金、年金基金、政府系ファンドなどのクライアントと協力して、単なるポジション以上に、彼らのポートフォリオ全体をサポートしています。
大まかに言えば、私たちはResearch Circleのプロセスを使ってこれを行っています。このプロセスはどの段階からでも始められますが、まずは「知覚」から始めましょう。知覚のきっかけは様々で、新聞記事を読むことかもしれませんし、大きな市場の動きかもしれませんし、あるいは予期せぬ利益や損失を見つけることかもしれません。次に、その原因と結果の関係性について仮説を立てます。なぜそのような知覚や驚きが生まれたのか、私たちが見落としていた因果関係は何かを考えます。そして、その仮説をデータで検証し、その関係性が時間や国を超えて存在するかどうかをコードを書いて確認します。最後に、それらを統合して、シグナルを変更すべきか、研究レポートを書くべきか、あるいは仮説が正しくなかったため後で再検討するために保留にするかを判断します。

これがBridgewaterのミッションとプロセスであり、私たちは過去50年間にわたってこのプロセスを使用して、非常に複雑で影響力のあるエキスパートシステムを作り上げてきました。最初はメモ帳上のルールから始まり、Excelへと進化し、現在ではAmazon EKSや他のさまざまなAWSサービス上で稼働しています。AIAはArtificial Investment Associateの略で、これについては後ほど説明します。まず、私たちがどのように始めたかをお話ししましょう。約2年前、投資家やデータサイエンティスト、テクノロジストのグループを集めて、AIとMLを使用してBridgewaterが市場と経済をどのように理解するかを再考しました。私たちは依然として、この経済システムがどのように機能するかについて最高の理解を得ることを目指していますが、より多くの異なるツールを使用し、このResearch Circleの進め方も変更しています。

私たちのアプローチは3つの要素に基づいています。第一に、すべてが因果関係に基づいている必要があります。市場を動かすのは因果関係であり、データの中に偶然存在する関係性だけで取引することはできないと考えています。第二に、人間による適切な監督やフィードバックを可能にするため、あらゆる段階で診断可能である必要があります。そして最後に、人間のInvestment Associateと同様に、自己改善能力が必要です。これは非常に競争の激しい業界であり、私たちは進化し続ける必要があり、AIA自体も進化する必要があります。
2023年の春にこの取り組みを始めた時、私たちも皆さんと同じような疑問を持っていたでしょう:これらのモデルはどれほど優れているのか?これらのモデルは私たちのInvestment Associateに取って代わるのか?1年目のアナリストの仕事を代替できるのか?3年目の仕事はどうか?Chief Investment Officerは危機に瀕しているのか?すぐに、LLMsが私たちのアナリストに取って代わるにはまだ程遠いことがわかりました。単純な質問をしても、人間の包括性と精度には及びません。
また、LLMsに構造化された一連の質問を与えることで、実際にかなり有用な結果が得られることもすぐにわかりました。2023年のモデル、そして現在でも、推論や計画は得意ではありませんが、私たちが「Blueprint」と呼ぶこの計画を提供することで、その主要な弱点に対処できます。この過程で、最高のプロンプトエンジニアはチームの開発者ではなく、Subject Matter Expert、つまりアナリストやInvestment Associate自身であることがわかりました。そのため、彼らがモデルと直接対話し、素早く反復できるインターフェースの作成に多くの労力を費やしました。

これは私たちのInvestment Associatesが作成したBlueprintの1つで、ポートフォリオに関するあらゆる質問に答えることができます。日本円のポジションをどのように構築したのかを尋ねることもできますし、現在の日本円のポジションとその理由について質問することもできます。また、南アフリカの株式ポジションについて尋ねることもできますが、これは私たちが取引していないものなので、取引していないという回答が返ってきます。 ここにある14の異なる質問に対して、システムはデータベースにアクセスし、時には実際のポジション情報を参照しながら、情報を統合して、新人アナリストから得られるような満足のいく回答を作成します。システムについて何も知らなくても、有用な情報を得るための質問ができるのです。画面の下部には対話型のチャートがありますが、これはまだ単なる出力です。LLMsが直接これらのチャートを作成しているわけではなく、既存のチャートの中から質問に関連するものを見つけ出しているのです。

これは素晴らしいスタートでしたが、私たちが目指す最終的な姿ではありません。Blueprintは情報の統合から学習までを可能にしましたが、 私たちが目指しているのは、AIが完全なサイクルを回せるようになることです。基本的にどんなトピックや職業、認識に対しても、AIが関係性を提案し、データを見つけ、そのデータを(通常はコーディングによって)分析し、その関係性の結果を統合して、最初に提案した関係性を更新できるようにしたいのです。この仕組みについては後ほど詳しく説明します。

その前に、実際のアーキテクチャについてお話ししたいと思います。これは私たちのマルチエージェントアーキテクチャです。 図には多くの異なるAgentが表示されていますが、順を追って説明していきます。実際には見た目ほど複雑ではありません。現時点では、各Agentの責任範囲を限定することが、システム全体の品質向上に非常に重要で有効だということがわかっています。将来的には、多くのツールにアクセスできる単一のLLM Agentと複雑なプロンプトで同様の結果を得られる可能性もありますが、現時点では、それらすべてを1つのLLMコールに組み込むことは、モデルの能力を超えています。
MUFG BankのGenerative AIを活用した法人営業活動の変革
図には多くの要素がありますが、すべて説明していきます。これらのAgentにはそれぞれ、利用できるツールセットがあります。会話履歴の取得のように共有されているツールもあれば、個々のAgentに固有のツールもあります。また、すべてのAgentには独自のプロンプトがあり、望む結果を得るために各Agentのプロンプトの調整に相当な時間を費やしてきました。では、フローを見ていきましょう。ユーザーからの質問は最初にPlannerに渡されます。Plannerは既存の計画(承認された質問と計画)のセットを持っており、入力された質問に類似した質問を探して、それらの計画を返します。これをInstruction Retrievalと呼んでいます。これは、現在のAgentの能力の範囲内で実行可能な妥当な計画をPlannerに出力させるのに非常に役立ちます。単に計画を立てるように依頼すると、妥当な計画を立てることもありますが、完全に実行不可能な計画を立てることもあります。
次に、その計画はSupervisorに渡されます。Supervisorが制御を引き継ぎ、各AgentとサブAgentを順番に実行しながら計画を遂行します。時には、サブAgentの1つが計画を変更したり無効にしたりすることがあります。そのような場合、Supervisorは計画を立て直すか、ある程度即興で対応します。一般的に、これは非常にうまく機能しており、Supervisorが即興で対応を選択する場合でも、モデルの性能が向上しているため、合理的な判断を下すことができています。

デモに入る前に、もう1枚のスライドをお見せしたいと思います。こちらが私たちのアーキテクチャです。 これは、Generative AIアプリケーションの開発とデプロイメントのために非常に優れたプラットフォームであることが分かりました。私たちは10年以上にわたってAmazonを活用してきており、Amazon EKSのローンチ以来、基本的にそのプラットフォーム上でシステムを運用してきました。これらのコアサービスを基盤として活用しながら、Amazon Textractのような高レベルのサービスも非常に有用であることを実感しています。そして最後に、皆様もご存知の通り、Amazon Bedrockは私たちのGenerative AI機能の重要な推進力となっており、AWSのセキュリティと運用保証を備えた世界クラスのモデルを提供しています。

それでは、デモに移りましょう。 今回の質問は「短期金利の変動は成長とインフレにどのような影響を与えるのか?また、株式市場と債券市場のリターンにどのような影響が及ぶのか?」というものです。これは投資アソシエイトに尋ねるような質問です。単純明快な問題ではありません - 短期金利が成長に影響を与えることもあれば、成長の鈍化やインフレ率の上昇に対応して連邦準備制度が短期金利を変更することもあります。

こちらが私たちのマルチエージェントインターフェースです。会場の皆様からは見づらいかもしれませんが、詳しく説明していきます。現在、2つのペインが表示されていますが、実際には合計4つのペインがあります。右側には、この質問に答えるために指示検索を使用して生成された計画が表示されています。AIAにこの質問を過去にしたことはありませんが、様々な概念や関係性について同様の質問をしてきたため、6段階の計画を立てることができました。
ここには表示されていない2つのペインがありますが、これらはユーザー体験において重要です。1つは批評ペインで、エージェントが作業している間にいつでもフィードバックを与えることができます。間違ったステップを修正したり、計画全体がダメだと指摘したり、あるいは正しい方向に軌道修正したりすることができます。これは、ほぼ正解だけれども完璧ではないような場合に非常に役立ちます。また、コード実行ペインもあり、エージェントが作成したコードはすべてここに表示され、ユーザーが直接編集することができます。ちょっとした変更や小さなエラーの修正が必要な場合も多く、手動で介入できる機能は、エンドユーザーにとって非常に便利な機能となっています。

最初の質問は、私たちが話している概念についてのCausal Mapをグラフ形式で作成することです。このCausal Mapはエージェントが直接生成します - データベースは参照せず、トレーニングから得た知識のみを使用します。このエージェントはClaude 3.5をベースにしており、非常に優れたCausal Mapを作成することができます。 このマップは、私が10分かけて書くよりもずっと良いものを、わずか10秒で作成しました。ここから、これらのノードを見ていき、次のDataFinderエージェントが、これらのノードを分析して、私たちのデータベースから代表的な時系列データを探していきます。

ここでは5つの異なる時系列データが見つかっていることがわかります。 こちらに詳細を示した拡大表示があり、時には完全に一致しないものの、近い系列が見つかることもあります。例えば、インフレーションについて尋ねた場合、インフレーションはCPIの変化に過ぎません。システムはCPIを見つけ、簡単な変換が必要だとコーダーに伝えています。

これは1年目のアナリストに教えるようなことですが、システムがそれを理解しているということです。次のステップでは、そのデータをコーダーに渡します。 コーダーは相関分析のコードを書いています。これは厳密にはBridgewater Associatesで行っているものとは異なりますが、私たちのワークフローに近く、代表的な例として公に共有できるものです。



出力にはデータの中で見つかった関係性が含まれており、それを裏付ける作業も示されています。次に、最も強い関係性を取り上げ、最も相関の高い2つの系列を示すチャートを作成します。また、 私たちが問い合わせた2つの市場のリターンを示す別のチャートも作成します。そして最後に、 Market Analystに戻って理解を更新します。これは以前より小さなCausal Mapですが、このCausal Mapはデータに裏付けられています。これは単純なモデルとのやり取りで生成できるものよりも、実際のInvestment Associateに期待するものにずっと近いものです。

さて、これが現在の状況です。昨年のBlueprintsから良い進展があり、完全なAgentic Workflowsへの道を進んでいます。現時点では Investment Associateを置き換えているわけではありませんが、彼らの業務の進行を加速させるのに役立っています。Bridgewater Associatesはフィードバックと振り返りで知られていますので、この分野で過去18ヶ月間開発に携わってきた私の考えをお伝えして締めくくりたいと思います。
最初の考えは、私たちが知っている通り、LLMは完璧からはほど遠いということです。しかし、その長所を活かし、弱点に対してはサポートを構築または導入することで、大きな価値を引き出すことができます。BlueprintsやInstruction Promptingあるいはinstruction retrievalはそのような例です。次に、ユーザーをモデルに近づけることが非常に重要です。彼らはより優れたPrompt Engineerになるだけでなく、モデルの出力に精通することで、より効果的に活用できるようになります。単に出力を見るだけで、なぜそうなったのかわからない場合、そのロジックを公開している場合に比べて支援できることは限られます。
これが私たちの戦略です。必ずしもすべての人に当てはまるわけではありませんが、皆さんの多くも苦労されているように、この分野では絶え間ないイノベーションが起きており、すべてに追いつくのは大変です。実際、多くの課題があり、皆さんや皆さんの企業が提供するものを活用したいと考えています。私たちは、自社のデータと業務フローに必要なツールにのみ焦点を当て、そこに時間と労力の大半を費やすようにしています。最後に、目標を明確にすることは、どんな技術においても重要です。何を望むのかわからなければ、適切なものを構築するのは非常に困難です。そして、早い段階でEvalを構築することが非常に有効だとわかりました。これは開発中の進捗測定に役立つだけでなく、システムが本番環境に入った後も、期待通りに機能していることを確認するのに役立ちます。
これらのシステムは、わずか5年前のシステムとも異なります。私たちのGenerative AIにおける開発の簡単な概要から、何か得るものがあったことを願っています。この18ヶ月間で構築・組み立てるべきものが多くあり、AIの機能を構築するパートナーを常に探しています。対話の機会があると思われる方は、ぜひご連絡ください。ありがとうございます、Aaron。本当にありがとうございます。Aaronと初めてプレゼンを聞いた後に話し合ったように、これらの成功を導くには人間の知性という人的要素が極めて重要だということを認識することが大切です。Large Language Modelによって生成された因果関係マップは非常に印象的ですが、元のプロンプトを分解する際の実際の計画とプランモデルは、人間のアナリストの洞察によって導かれています。これらの取り組みで成功するためには、業界の専門家と技術の専門家の緊密な連携が不可欠です。この点については、Horiganeのプレゼンテーションでも触れられます。
Crypto.comのGenerative AIを用いた市場感情分析の改善

皆様、本セッションをお選びいただき、ありがとうございます。私は堀金哲夫 と申しまして、MUFG Bankで AI/MLチームを率いています。本日は、Generative AI技術を通じて法人営業活動をどのように変革したかについて、お話しさせていただくことを大変嬉しく思います。商業銀行として、サービス提供の成功には広範なデータ分析と長年の経験が必要であり、これが法人顧客へのアクセシビリティを制限していました。ここで私たちは、Generative AI技術を適用して、そのようなプロセスを効率的で拡張可能、そして積極的に進化させることができるようにしました。実際、リード創出を10倍に増やすことができました。これは非常に大きな数字で、今年達成したばかりです。どのようにしてこれを実現したのか、そしてGenerative AIプラットフォームに基づいて、担当者の日常業務がどのように変革されたかをお示ししたいと思います。私の話が皆様のGenerative AIの取り組みの参考になれば幸いです。

MUFGについて説明させていただきます。MUFGは三菱UFJフィナンシャル・グループの略で、日本最大の金融グループ です。世界50カ国以上で事業を展開し、100年以上の歴史を持っています。個人のお客様も法人のお客様も多数いらっしゃいます。本日は、100万社の法人顧客に2,000人の従業員がサービスを提供しているグローバルキャピタルマーケット事業に焦点を当ててお話しします。

Generative AIの詳細に入る前に 、私たちの技術の歩みをお話しさせていただきます。2016年にCloud-First戦略を宣言して以来、多くのワークロードとデータを、特にAWSのクラウドに移行しています。2021年には、ビジネスのためのAI/MLモデルの本番展開を加速するために、社内にAI/MLチームを立ち上げました。私たちはAWS上のSageMakerをベースに数十のプロダクトをリリースし、SageMaker上にMLプラットフォームを構築できたことを喜ばしく思っています。正直なところ、本日のキーノートで、AWSもSageMakerへの投資を続け、このようなツールを再創造していることを聞いて、大変驚き、また嬉しく思いました。

次に、Generative AIについてお話しします。2023年にGenerative AI技術が登場して以来、私たちは社内での活用を進めています。本日は、法人営業活動をどのように変革しているかについてご紹介します。まずはユースケースと直面している課題を明確にしたいと思います。私たちのクライアントは、SaaS型ビジネスを展開している企業であれ、従来型のビジネスを展開している企業であれ、金融市場リスクに直面しています。具体的に説明しましょう。例えば、金利が上昇すると返済額が増加します。また、為替レートが変動すると、輸出入における製品価格に影響を与え、最終的なP&Lにも影響を及ぼします。このようなリスクを管理するため、クライアントは私たちから金融商品を購入したいと考えています。
難しい点は、私の例で示したように、金融市場リスクは将来に依存しており、将来何が起こるかは誰にもわからないということです。クライアントは、ポップアップが表示される派手な一般公開サイトを購入判断の参考にはしません。その代わりに、法人クライアントは、個々のクライアントがどのような金融リスクに直面しているか、どのようなリスクを管理すべきか、どのような商品を適用すべきかを理解し、明確にするための個別の文書や提案書を必要としています。このプロセスは、クライアント理解とソリューション創出という2つの要素で構成されています。クライアントの状況を正しく理解するためには、数百から数千ページにも及ぶ複数の文書を読む必要があり、これには最大2時間から数十日かかります。データが準備できたら、適切なソリューションを開発するために数年の経験が必要で、スキルへの依存度が非常に高くなります。これは時間がかかりスキルに依存するプロセスであるため、従来型のAIを基盤として効率化とスケール化を図りたいと考えましたが、うまくいきませんでした。なぜなら、従来型のAIはテキストや動画、音声などの非構造化データの処理が得意ではないからです。また、法人クライアントのユースケースは通常サンプル数が限られているため、従来型のAIのトレーニングが困難になります。

ここで、これらの課題に対処するためにGenerative AIが登場します。私たちがGenerative AIの活用を決めた理由は、非構造化データの処理に優れており、高い柔軟性と推論能力を備えているからです。これにより、法人クライアントサービス活動が変革される可能性があると考えています。今年、Proof of Conceptを開始し、後ほどデモをお見せするGenerative AIベースのプラットフォームを構築しました。これにより、プロセスがより効率的でスケーラブルになり、プロアクティブな対応が可能になった結果、リード創出が10倍に増加しました。

先ほど説明したように、法人サービスチームは数百から数千ページの文書を手作業で読む必要があり、時には数時間から数日かかることもありました。現在は、Generative AI技術を使用して各文書から重要な情報を抽出し、S3やその他のストレージソリューションに保存しています。例として証券レポートのケースを図示しました。左側と右側のHTML形式の両方のフォーマットを扱っています。正直なところ、そのコンテンツをそのままLanguage Modelに入力すると、左側には関連情報が限られている多くのターゲットが含まれているため、トークンコストが高くなってしまいます。データパイプラインの構築にあたっては、関連性のないターゲットを除外し、信頼性の高いデータ抽出において80-90%の精度を達成しています。

スケーラビリティに関して、データが準備できたら、営業担当者は個々のデータポイントを統合して法人クライアントに提示し、ソリューションを開発する必要があります。従来、このプロセスは個々の営業担当者が自分の頭の中にロジックを保持していたため、共有することができませんでした。この課題に対処するため、私たちはGenerative AIの柔軟性と推論能力を活用しました。営業チームと協力してプロジェクトチームを結成し、100ページにわたるステップバイプロセスを開発しました。このプロセスを通じて、裏側でBedrockとClaude 3を利用したチャットボットを備えたPlaygroundを用意し、必要な時にいつでもGenerative AIを利用できるようにしました。

アダプタビリティに関して、ビジネス環境は急速に変化するため、一度限りのデータパイプラインやソリューションでは持続可能性を確保できません。現在、このサイクルを実行する中で2種類のデータを収集しています。1つは営業担当者とGenerative AIとのチャット履歴、もう1つはクライアントに実際に提示したプレゼン資料とそのフィードバックです。これらの要素を組み合わせることで、AIの出力と実際のプレゼン資料との乖離を監視し、プロンプトをいつどのように改善すべきかを判断しています。このサイクルを何度も繰り返すことで、AIプラットフォームの品質向上を実現してきました。

これらの機能をどのように実装したのか、ご説明させていただきます。アーキテクチャはシンプルで、データ抽出は主にSageMakerとBedrock、そしてClaude 3で処理しています。大量のドキュメントを扱う必要があるため、オンデマンドリクエストよりもコスト効率が良く安定しているBatch処理を採用しています。チャット履歴はDynamoDBに保存しています。
プロンプトとドキュメントはAmazon S3で共有しています。意思決定者を通じて乖離を確認することができます。現在のプロセスは半自動的なものであり、人間の介入が必要です。しかし、営業チームがより多くの時間を企業クライアントとの直接的なコミュニケーションに費やせるよう、可能な限り自動化を進めることを目指しています。




デモンストレーションをお見せしましょう。 これは、私たちがカスタマーサービスチーム向けに構築して提供しているパブリケーションプラットフォームです。このプラットフォームにはAI機能と分析機能を統合しています。誰かがクライアントへのセールスのアイデアを展開したい場合、企業名、分析タイプ、視点を選択します。 左側にAIの出力が表示され、AIがどのように情報を処理し結論に至ったのかを全員が理解できるよう、プロンプトも公開しています。 右側では、数値、グローバルフォルド、予算明細書など、様々な形式でアクセス可能な図表やドキュメントをすべて整理しています。


これが、私たちのプラットフォームで営業担当者向けにAIと分析を統合している方法です。さらに詳しく説明すると、「P&Lのトレンドを教えてください」というような質問を入力することができます。クエリに多少のミスがあっても、システムは理解してくれます。システムプロンプトとバックエンドのデータストレージにすべてのデータを格納しているため、AIは10〜20秒以内にクライアントに関する具体的な質問に答えることができます。 ユーザーが結果に満足したら、右側のボタンをクリックするか、コピー&ペーストで、自動作成されたすべての下書きやプレゼンテーションをダウンロードできます。このプロセスにより、以前は数時間から数日かかっていたプレゼンテーションの準備が、カスタマーサービス担当者にとってわずか1〜2分で済むようになりました。

私たちの取り組みによるビジネス成果をまとめてみましょう。データ準備における時間のかかる作業を削減し、アイデア創出やプレゼン資料作成におけるスキル依存度を下げることで、実際のクライアントと検証した結果、約30%の成約率を維持しながらリード獲得を10倍に増やすことができました。私たちは今年この取り組みを開始し、数ヶ月でこのアプリケーションプラットフォームを構築しました。この成功は、営業担当者と開発者の緊密な連携や、CloudやAIに関する社内の専門家といった内部資産だけでなく、特にMLワークショップやプロトタイピングチームを通じたAWSアカウントチームの献身的なサポートにも起因しています。

最後に、私たちの取り組みから得られた教訓を共有させていただきます。Generative AIは企業活動をより効率的で、スケーラブルで、積極的に適応可能なものへと変革しています。ビジネスパーソンと開発者の深い連携が不可欠です。Generative AIは技術者だけのものではなく、すべての人のためのものであり、実世界からのフィードバックがGenAIOpsを推進します。AWSのマネージドサービスを活用することで、Generative AIの取り組みにおける試行錯誤が容易で、安全で、俊敏になります。AI技術の進歩は目覚ましく、今すぐ始めることで、ビジネスを変革することができます。このイベントは学びを始めるのに最適な場所であり、次回は皆様のストーリーをお聞きできることを楽しみにしています。
Crypto.comのSentiment Analysis実装とその応用
Aaronのプレゼンテーションでは、データからインサイトを探ることで、投資の観点や営業の観点から、人間がデータセットを探索し、ユニークな仮説を導き出すことができました。しかし、今私たちが話しているのは少し異なります。時には、後で調査を待つのではなく、市場の変化にリアルタイムで対応する必要があります。Sunnyが、Crypto.comがどのようにGenerative AIを活用してよりリアルタイムに市場のインサイトを得ているかについて説明してくれます。


数ヶ月前、私たちはまだどのトピックを取り上げるか検討している段階でした。当時は市場はそれほど活況ではありませんでしたが、今日では素晴らしいトピックとなっています。暗号資産市場で取引を行う全ての人が最高のトレンドを見つけ、最良の判断のためにその波を捉えたいと考えているため、本日は市場インサイトのための感情分析の改善についてお話しさせていただきます。課題、私たちのソリューション、AWSでの効果的な実施方法、そして学んだことについてご説明していきます。


Crypto.comについて簡単にご紹介させていただきます。私たちは400以上の暗号資産をサポートする、ライセンスを取得した暗号資産取引プラットフォームです。私たちのミッションは、世界の暗号資産への移行を加速することです。世界90カ国で1億人以上のユーザーを抱え、25の言語をサポートしています。私たちのGenerative AI革新の取り組みは2023年から始まりました。Prompt Engineeringから始め、それをシステム研究に適用し、アプリ内でユーザーをサポートするAIアシスタントを作成しました。
2024年、私たちはより本格的な取り組みを進めています。Model Fine-tuningに取り組み、1億人のユーザーをカバーする初のカスタマーサービスChatbotを構築し、マーケティングや広告のためのVisual Content Generationを活用しています。Fine-tuningを用いたニュースのSentiment Analysis初号機を開発し、これについては後ほど詳しくご説明します。最近では、ユーザーがより良い判断を下せるよう、ニュースとテクニカル指標を組み合わせた初のAI Market Insightsをプラットフォームにデプロイしました。オンチェーンの用途としては、ユーザーがブロックチェーンの知識がなくてもウォレットを管理できるAI Agent SDKを提供しています。また、Visionモデルや複数の新しいモデル、最新技術であるGraph RAGを活用して、カスタマーサービスChatbotを強化しました。数週間前には、CEOが非常にエキサイティングで革新的なプロジェクト「Cortex AI」を承認しました。これについては、私たちが使用している魅力的なAI技術をすべて1つの製品に統合したものだということ以外は、まだ公表を控えるように言われています。

このSentiment Analysisを行う上での課題は何でしょうか?ご存知の通り、ニュースは従来のプラットフォームやソーシャルメディアなど、あらゆる場所から発信されています。これらを効果的に統合し、重複を排除し、どのニュースがより重要かを見極める必要があります。また、情報源の信頼性が異なるため、それに応じてランク付けや評価を行う必要があります。最終的に、そのニュースが市場に影響を与え、価格を動かすかどうかを判断するには、結果の正確性がより重要になります。私たちはこの結果を達成するために複数のLLMを使用しています。

これは非常にシンプルなSentiment Analysisの例で、誰もがLLMに指示を出す際に行うようなものです。LLMに経験豊富な暗号資産アナリストとしての役割を与え、分析すべきニュースを提供します。そして、そのニュースが何のトークンに関するものか、またそれが強気(Bullish)なのかどうかについての見解を求めます。

ニュース分析は、特定の暗号資産や市場全体のセンチメントを判断します。例えば、Galaxy Digitalがビットコインを購入した場合や、BlackRockのCEOが選挙は暗号資産に影響を与えないと発言した場合、これらは明らかに市場にとってBullishな例と言えます。
このソリューションを開発する中で、私たちは大半のLarge Language Modelが主に英語のコンテンツとデータセットで学習されているという事実に気付きました。例えば、Llamaのデータセットの95%が英語であり、そのため異なるニュースソースを単一の言語に変換する方が信頼性が高くなります。時価総額の低いコインや中程度のコインは通常、ローカライズされたソースから情報が発信されるため、まずAmazon Bedrockを使用して英語に翻訳し、翻訳の効果を評価します。このタスクに最適なモデルを見つけるため、異なるモデル間で切り替えを行うことができます。

ここでは、マルチエージェントによるコンセンサス形成のフローを実装するコア部分についてご説明します。 英語のニュースフィードを取得したら、それを複数のモデルに並列で入力して評価を実行します。最上位レベルでは、新しいモデルへの適応性が高いAmazon Bedrockを使用しています。現在はClaude 3 Haikuを使用していますが、バージョン3.5に移行しました。中間層では、Amazon SageMaker上でホストされている自社で訓練した Fine-tuned モデルを使用しており、これによって継続的な Fine-tuning と新バージョンの容易なデプロイが可能になっています。このモデルは最終的にリーダーとなる予定です。第三のコンポーネントとして、GPTをリファレンスとして使用しています。これらのモデルがすべて合意に達した場合、高い信頼性を得られたとしてそのデータを私たちのデータセットに追加します。意見が分かれた場合は、ニュースソースの信頼性によるフィルタリングや多数決といった、特定の基準に従って解決します。

時間の経過とともに、リーダーモデルの重みが増していきます。データセットが準備できたら、それをFine-tuneモデルにフィードバックします。バッチでFine-tuningを実行し、新バージョンを本番環境にリリースします。時間とともに、中間層のFine-tunedモデルの信頼性と確信度が高まり、よりリーダー的な役割を担うようになります。 完全な合意と多数決により、90%以上の精度を達成しました。さらに重要なのは、Proof of Conceptから本番環境での完全なスケールまでを6週間で実現したことです。これは、厳格なセキュリティ要件を持つ暗号資産取引所の環境では特に困難な課題でした。この迅速なデプロイメントとスケーリングは、急速に変化する暗号資産市場に対応するため、機能を数ヶ月ではなく数週間でリリースするという当社のベストプラクティスに沿ったものでした。

このソリューションはここで終わりではなく、他の潜在的なユースケースもご紹介します。 1つ目はデータ駆動型のアップグレードです。オープンソースの世界では四半期ごと、あるいは月単位で新しいモデルがリリースされているため、それらの可能性と全体的な結果への影響を評価したいと考えています。すべてのLarge Language Modelが同じトレーニングデータと方法論を使用しているわけではないので、新しいモデルを統合しても必ずしも良い結果が得られるとは限りません。収集したデータセットを評価プロセスにフィードバックすることで、Bedrockでプラグアンドプレイ的にモデルを切り替え、パフォーマンスを評価することができます。言語モデルを扱う際、3.5から4百万パラメータへの移行などバージョンを変更すると、プロンプトや結果も調整する必要が出てくることが多いのです。
この方法により、新しいモデルを簡単に評価し、置き換え、最新のモデルに追従することができます。もう1つのユースケースは、私たちのリーダーモデルに関するものです。低コストで簡単にFine-tuningできるよう、小規模なモデルを選択しました。当時はLlama 3.8Bモデルを選択しましたが、毎日、毎月新しいモデルが登場しているため、同じ方法を使って次にFine-tuningするモデルを評価しています。

これがデータ駆動型のユースケースです。もう1つは、より興味深く刺激的なものです。投資の世界では通常、テクニカルデータを重視しますが、 暗号資産の世界ではマーケットセンチメントがより大きな影響力を持っています。両者を組み合わせたらどうでしょうか?前のスライドで、すでにかなり確実なセンチメントデータを確立しています。また、マーケットウィンドウから市場データも取得しており、これらを組み合わせることで全体像を把握し、質問と回答を生成することができます。つまり、市場で何が起きているのかを、その時点で出たニュースと照らし合わせて説明することができるのです。大きな影響を与えると予想されたニュースが実際には価格変動に影響を与えず、逆に他のニュースがより大きな影響を与えるというケースもあります。これは、この取り組みから得られる非常に価値のある情報です。

次に重要なのは、過去のパフォーマンスの分析だけでなく、次のサイクルで何が起こるかということです。ご存知の通り、暗号通貨はサイクルで動いています。例えば、このブルーのサイクルでは、どのニュースがより影響力があり、どのニュースが特定のコストを特定の方向に動かすのかを知りたいと考えています。これは、そのための非常に優れたプラットフォームです。そして、これが実際の作業図 で、Amazon SageMakerとAmazon Bedrockを使用して、私たちが行ったことを実現する方法を示しています。昨日、SageMakerとBedrockのセクションについて多くを学ばれたと思いますので、詳細には触れませんが、これが私たちのSageMakerの使用方法です。環境全体では、Jupyter Notebookをセットアップし、IAMセキュリティを使用して、同じグループでこのJupyter Notebookを共有し、Fine-tuneの指示を生成してAmazon S3に保存できます。実行するトレーニングジョブを共有でき、結果もS3に保存されます。生成が完了したら、本番環境にデプロイするバージョンを決定できます。

Amazon SageMakerの助けを借りて、短時間で簡単にデプロイでき、本番環境で稼働させることができます。最新のトレーニング済みモデルを使用して推論を行い、CloudWatchから結果をモニタリングすることもできます。このプロセス全体から何を学んだのでしょうか? まず、タスクを解決する前に、すべてのニュースを英語に正規化し、マルチモーダルなマルチエージェントのコンセンサスワークフローを使用してリスクを分散し、主観的な結果を減らしました。外れ値データセットを継続的に収集し、後でFine-tuningを行い、新しいモデルを評価し、タスクのパフォーマンスを向上させるためにLLMsを継続的にFine-tuningしています。このワークフロー全体は、この用途だけでなく、ニュースよりもさらに複雑なソーシャルメディアの分析など、さまざまなユースケースにも適用しています。この全体的なGenerative AIの取り組みは、私たちの生産性と市場投入までの時間を改善するのに役立ちました。Generative AIがなければ、このタイムラインの中でこれを実現することはできなかったと思います。
セッションの総括と今後の展望
以上が私が皆様と共有したかったことです。皆様も同じように素晴らしいAIの旅を経験し、将来素晴らしい製品を生み出せることを願っています。ありがとうございました。もう一度、スピーカーの皆様、Sunny、John、Son、Aaronに感謝の意を表したいと思います。ありがとうございました。セッション時間が迫ってきましたので、スピーカーの方々はセッション終了後、部屋の外でさらなる会話を続けることができます。本日は皆様の貴重なお時間をいただき、ありがとうございました。Vegasに来て、利用可能な全てのセッションを調整することは、皆様にとって大きな投資だと理解しています。本日、私たちと時間を共有していただき、ありがとうございます。同様に重要なことですが、モバイルアプリを使用して、アンケートにご記入ください。これらのセッションに関する皆様の洞察とフィードバックは、来年のセッションを選択し、調整する際の参考とさせていただき、業界全体のニーズにより良く応えることができるようにしたいと考えています。数分お時間を取っていただき、何が良かったか、何が良くなかったかをお聞かせください。来年また皆様にお会いできることを楽しみにしています。改めて、お時間をいただき、ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion