re:Invent 2024: Amazon DocumentDBでのVector Search実装とRAG
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Supercharge app intelligence using gen AI with Amazon DocumentDB (DAT320)
この動画では、Amazon DocumentDBでのGenerative AIアプリケーション開発について、Vector Searchの基礎から実装方法まで詳しく解説しています。HNSWとIVF Flatという2つのインデックスタイプの特徴や、それぞれのパフォーマンスの違い、選択基準について具体的に説明しています。また、DocumentDBでVector Searchを実装する際の重要なパラメータ設定や、ef_search、ef_construction、probesなどの調整方法についても言及しています。さらに、Retrieval Augmented Generation(RAG)アーキテクチャを用いたチャットボットの実装デモを通じて、DocumentDBを活用したGenerative AIアプリケーションの実践的な構築方法を紹介しています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon DocumentDBを活用したGenerative AIアプリケーションの強化:セッション概要

はい、みなさん、Re:Invent 2024へようこそ。ここでヘッドフォンを装着していただく時間かと思います。このマイク以外にマイクはありませんが、このマイクの音声は直接皆さんのヘッドフォンに入るはずです。みなさん、聞こえていますか?はい、後ろの方まで大丈夫ですね。完璧です。では、まず正しい場所にいらっしゃることを確認させていただきます。こちらはDAT320です。本日は、Amazon DocumentDBを使用したGenerative AIによるアプリケーションインテリジェンスの強化についてお話しさせていただきます。

今日お話しする内容は、皆さんが参加されたかもしれない他のGenerative AIセッションとは少し異なります。DocumentDBにおけるGenerative AIについて説明していきます。まず、Vector Searchの基礎から始めて、主要なコンポーネントについて説明します。その後、特にDocumentDBのお客様が実際に使用しているアクセスパターンについて説明します。さらに、Amazon DocumentDBにおけるVector Searchの仕組みや設定方法について詳しく説明します。これは、最新の検索操作を作成する際に非常に重要になってくるからです。そして、そのベストプラクティスについても説明します。繰り返しになりますが、Generative AIのデータベース側に重点を置いた内容となります。LLMやその選択肢についても触れますが、かなり限定的な説明になります。

これは300レベルのコースです。そのため、DocumentDBについての基礎知識をお持ちで、改めて紹介する必要がないことを前提としています。ドキュメントデータベースとは何か、JSONモデルとは何かをご存知の方向けの内容です。後ろの方から私たちの姿が見えない場合は、このような感じです。 私はCody Allenで、Principal DocumentDB Solutions Architectです。チームに所属して約4年になります。テキサス州ダラスを拠点としています。そして、こちらがDoug Bonserです。実は私たちはほとんど同じような経歴で、ダラスを拠点に約4年間チームに所属しています。これって高可用性のフェイルオーバーみたいですね。誰がPrimaryで誰がSecondaryなのか?それは後でお答えしましょう。
Vector Searchの基礎とEmbeddingの重要性

まずはVector Searchについて説明していきましょう。Vector Searchの概念は、データベース上でVector Embeddingを構築し、検索し、管理し、使用することです。これらのEmbeddingに対してVector Searchを実行することで、文脈的に関連性の高い回答を得ることができます。フレーズを探す単純なテキスト検索とは異なり、文脈や関連性、適合性を重視した検索が可能です。使用できるデータベースには多くの選択肢があります。OpenSearchやDynamoDBでのVector対応を発表しましたし、Pineconeなどのサードパーティツールも利用可能です。そして今回、DocumentDBでもVector Embeddingに対応しました。ユースケースに合った適切なVectorデータベースを選択することが重要です。セキュアで、最も文脈的に関連性の高い結果が得られ、データに近い場所にあることが求められます。

まずはVector Embeddingについて説明しましょう。これが今回のトークの中心となる重要な要素です。まず、ドメイン固有のデータから始めて、それを異なる要素に分解します。これらの要素は単独で意味を持ち、これをTokenizationと呼びます。これらの要素は、単語、段落、文、あるいは文書全体になる可能性があります。実際には、ユースケースに応じて適切なものを選択します。これらの異なる要素、つまりすべての部分を手に入れたら、Tokenizationというプロセスで大規模言語モデルに通します。これにより、それらの要素は本質的に非常に大きな数値の配列に変換されます。使用するLLMに応じて、200個程度の数値から4000個以上の数値まで、さまざまなオプションがあります。

これらの数値は多次元空間に存在し、類似したアイテムは互いに近い位置に配置されます。つまり、意味的に類似した結果を見つけるには、2つの要素間の距離を求める数学的な関数を使うだけでよいのです。このプロセス全体は、ユースケースに合った適切なオプションを選択し、それらのEmbeddingを作成することに集約されます。要するにそういうことなのです。
Embeddingについてさらに詳しく説明すると、重要なのはそれらがデータから生成されるということです - すべてはデータから始まります。これこそが重要な点であり、ChatGPTのような一般的なGenerative AIアプリと、あなたのビジネスやカスタマーを理解するアプリとの違いを生み出すものです。ここにいる皆さんは、同じLLMや同じFoundation Modelにアクセスできます。
先ほど、いくつか新しいものを発表したばかりです。はい、私はre:Inventが大好きです。とても楽しいイベントで、いつも新しいことを学べます。でも、多くの場合、ここにいる皆さんが私たちよりも先にAWSのサービスについて知ることがあります。お客様から「あの新しいサービスについて教えてください。AWS Beluga Whaleって?」なんて聞かれることもよくあります。もちろんそれは実在しませんが。Novaですか?ありがとうございます。まさにそういうことです - Nova、素晴らしいですね。
RAGアーキテクチャの実践:スニーカー返品の例

これらのModelにデータを通すことこそが、真の違いを生み出します。素晴らしいことに、自分でModelをトレーニングする必要はありません。そのために私たちはこれらすべてを提供しているのです。しかし、Retrieval Augmented Generation(RAG)というプロセスを通じて、運用データを使ってこれらの操作やModelを微調整することができます。例えば、靴店を経営しているとします。お客様を支援するためにChatbotを作成します。誰かがChatbotにアクセスして「靴を返品して全額返金してほしい」と言ってきました。
ここで運用データストアの出番です。まず、エージェントは事実確認を行います - 注文テーブルからその人の注文情報を探し、在庫テーブルを確認してその靴の在庫状況や他の靴の情報を調べます。次に、エージェントはポリシードキュメントを保持するテーブルに対してVector類似性検索を実行します。例えば、30日以上前の注文には10%の在庫補充料がかかるというポリシーや、2週間以内の返品なら全額返金または交換が可能というポリシーがあるかもしれません。
もし交換用の靴が在庫切れの場合、同じようなヒールドロップや似たような幅、サイズの靴を探すことになります。つまり、お客様の靴の返品に関する判断を行うために、データや知識ベースに対して類似性検索を行うわけです。これがRAGの基本的な考え方です。では、Dougがこれらの要素がどのように組み合わさっているのかをより理解するために、アーキテクチャの例を説明してくれます。
DocumentDBのVector Search機能:HNSWとIVF Flatインデックスの比較

ありがとう、Cody。それでは、このRetrieval Augmented Generation(RAG)アーキテクチャがどのようなものか、詳しく見ていきましょう。 Codyの例で言えば - 彼がスニーカー好きなのはご存知の通りですが - スニーカーヘッドの方はいらっしゃいますか?おお、同志がいますね。素晴らしい。Caesarsに行ってみてください。そこには素晴らしい靴屋がありますよ。Nikeの店ではDunksが30%オフで売っていますが、話がそれましたね。

Codyがスニーカーを購入して、何らかの理由で返品したいと考えているとします。このアーキテクチャの文脈で、そのフローがどのようになるか見ていきましょう。 ここでCodyはAIアプリケーションと対話し、通常は質問を投げかけます。例えば「このスニーカーを返品できますか?サイズが合わないんです」とか「色が違う」、「期待していたものと違った」といった具合です。

このタイプのアーキテクチャでは、まずアプリケーションがデータストアにアクセスして、もしCodyが以前にエージェントとやり取りしていた場合や、会話の途中である場合の会話履歴を確認します。これが一定期間続く複数のステップを含む会話である場合、その履歴を追跡し続けることになります。 次のステップでは、エージェントが他のリポジトリにアクセスします。これがCodyが先ほど言及したファクトルックアップです。Codyが言及した靴や注文内容、返品ポリシー、その商品や類似商品の在庫状況など、様々な事実を検索します。

つまり、このアプリケーションは、Codyがエージェントと行っている会話に関連する情報を取得するために、企業の他のリポジトリにアクセスするということです。 この時点で、エージェントはCodyが入力したプロンプトを取り込みます。プロンプトと言えば、通常はCodyが入力したものをそのまま使用することは避けたほうがよいでしょう。
このようなチャットアプリケーションの多くには、あらかじめ定義されたテンプレートが用意されています。Codyがチャットに入力した情報をテンプレートの適切な位置に配置することで、ユーザーが入力した内容をそのまま送信するのではなく、より一貫性のある、より適切な応答を得ることができるようになっています。

この時点で、テンプレート、Codyがアプリケーションに入力したテキスト、会話履歴、そして他のエンタープライズリポジトリからの事実確認情報を取得します。これらの情報すべてをフォーマットし、Large Language Modelに送信して、Codyが何をしたいのか、どんな靴を注文したのか、在庫状況、返品ポリシー、これまでの経緯など、すべての情報をトークン化します。アプリケーションはこれらの情報をLarge Language Modelに送信してベクトル化し、 その後、ベクトルデータベースに保存されているベクトルの中から、最も類似度の高い結果を取得します。つまり、特定の靴やサイズに関連する情報、基本的にはLarge Language Modelでトークン化したベクトルに含まれる情報を検索しているわけです。



アプリケーションは その後、その応答を再度Large Language Modelに送って、返答を生成します。Codyの質問から、チャット履歴、事実確認情報、ベクトルデータベースからの類似情報まで、すべてを含めてLLMに送り、最終的にCodyに返信する応答を生成するためにもう一度トークン化します。その返信を送る前に、 会話履歴を更新します。これにより、Codyが今日や明日また戻ってきたときに、これまでの会話内容を把握できます。 そして最後に、アプリケーションがすべての情報をCodyに送り返します。

ここでは、会話履歴、エンタープライズリポジトリ、Large Language Model、そしてベクトルデータベースなど、多くのシステムが関係してきます。特に私たちが注目しているのは、Amazon DocumentDBのVector Searchと、DocumentDBのVector Indexです。このようなアーキテクチャにDocumentDBを使用することで、システムをシンプルにすることができます。Vector StoreとしてのDocumentDBはベクトルを保存でき、さらに以前は他のシステムにあった情報も取得することができます。注文や在庫情報の保存システムとしてDocumentDBを使用することで、すべての情報を一箇所に集約できます。 DocumentDBでベクトル検索を行い、必要な関連情報もすべてDocumentDBから取得できるため、このようなアーキテクチャをよりシンプルで使いやすいものにすることができます。
Vector Searchのパフォーマンスチューニング:トレードオフとベストプラクティス


RAGシステムを使った経験のある方はいらっしゃいますか?ちょっと気になりまして。私はカウントに入れない方がいいですかね?かなりいらっしゃいますね。素晴らしいことです。それでは、ここからDocumentDBについて少し詳しく見ていきましょう。Vector Searchの入門と一般的なRAGアーキテクチャについて説明してきましたが、 ここからはDocumentDBとその機能に焦点を当て、まだDocumentDBを Vector Storeとして使用していない方に、なぜDocumentDBが良い選択肢となるのかをお話ししたいと思います。スライドにも示されているように、その理由の一つは、データの同期や移動の必要性を減らせることです。先ほどのスライドでご覧いただいたように、他の運用データストアやVector Store、さまざまなシステムを呼び出し、それらの間でデータを同期する必要がありました。DocumentDBのようなデータベースを使用すると、運用データとベクトル(または埋め込み)を関連するドキュメント内に保存できます。複数のシステム間でのデータ同期が不要になり、シンプルで高速なシステムを実現できます。DocumentDBで更新すれば、他のシステムとの同期を待つことなく、すぐにデータを利用できます。もう一つの検討理由は、要件を満たす使い慣れたツールを使用できることです。これには2つの側面があります。その1つはデータベース自体です。
例えば、すでにAmazon DocumentDBを使用しているものの、Vector StoreやVector Search用途では使用していない場合を考えてみましょう。皆さんはすでにDocumentDBの使い方を知っており、運用チームも管理方法を把握していて、うまく機能しています。そのため、Vectorを保存するために新しいシステムを導入して、チームがそれを習得する必要があるという状況を作り出す代わりに、DocumentDBにVectorを保存することができます。
もう一つの側面は、コーディングの観点からです。すでに使い慣れているAPIを引き続き使用できます。先ほどの例に戻りますが、すでにDocumentDBを使用している場合、そのAPIやデータへのアクセス方法、データの挿入、更新、クエリの方法に慣れています。別のVector Databaseとやり取りするために新しいAPIを学ぶ必要はありません。三つ目の側面は、エンドユーザーにより迅速な体験を提供することです。これは主に、チャットのプロセス全体で連携するシステムの数を減らすことで実現します。Codyがスニーカーを返品して交換できるかどうかを確認している間、できるだけ早く回答を提供したいと考えています。そのため、連携するシステムが少ないほど、より速い応答が可能になります。
最後に、追加のライセンスや管理を避けることができます。先ほど触れたように、すでにDocumentDBに慣れている場合、その運用方法も理解しています。新しいデータベースを導入することは、その運用方法を学ぶだけでなく、異なるライセンス要件にも対応する必要があることを意味します。つまり、2つの異なるデータベースに対して2つの異なる管理体制が必要になりますが、1つに統一することで、それを避けることができます。

さて、手短にですが、DocumentDBについてあまり詳しく説明しないと言いましたが、ここで少し文脈を説明させてください。Vector SearchとDocumentDBを使用したVectorの保存に焦点を当てていますが、DocumentDBをご存じない方のために重要なポイントをいくつか挙げます。まず、高速でスケーラブルです。クラウドネイティブなアーキテクチャにより、ComputeとStorageが分離されており、それぞれ独立してスケールすることができます。Storageは自動的に128テラバイトまでスケールアップでき、ユーザーの操作は必要ありません。データやVectorを追加すると、それに応じてStorageが拡張されます。Compute層は現在、インスタンスベースなので、インスタンスとそのサイズを管理する必要がありますが、データ量に関係なく、1つから16個までのインスタンスを持つことができます。
見方を変えると、たった1つの小さなインスタンスで128テラバイトの完全なデータセットを持つことができます。本番環境では応答時間が期待通りにならない可能性があるため、おそらくそうはしないでしょうが、StorageとComputeの分離により、このような構成も可能です。これは完全マネージド型サービスなので、他のデータベースで必要となる可能性のある差別化されていない重労働は、すべてAWSが代わりに処理してくれます。
エンタープライズ向けに99.99%の可用性と高い耐久性を備えたデータを提供しています。クラスター内では、データは自動的にクラスターがデプロイされているリージョン内の3つのアベイラビリティーゾーンにレプリケーションされます。データベースが複数のレプリカを自動的に管理してくれるため、ユーザー側で気にする必要はありません。さらに単一リージョンを超えて、マルチリージョンのワークロード向けにGlobal Clustersを提供しています。Global Cluster構成では、1つから5つのセカンダリリージョンを持つことができます。これは、ローカルでの読み取りレイテンシーを削減したい場合や、高可用性が必要で何か問題が発生した際に別のリージョンにフェイルオーバーしたいようなDRユースケースに役立ちます。
最後に、DocumentDBはMongoDBと互換性があります。MongoDB互換とは、MongoDBがサポートするAPIやオペレーターの100%をサポートしているわけではありませんが、サポートしている機能については明確に文書化されているということです。サポートしている機能に関しては、DocumentDBから同じ結果が得られ、その互換性によって同じドライバーやツールを使用することができます。

DocumentDBをすでに使用している方はどのくらいいらっしゃいますか?素晴らしいですね。多くの方が初めて使用されるようですので、ここにいらっしゃることを嬉しく思います。 Amazon DocumentDBとそのエンタープライズアプリケーションに適した機能についてより理解が深まったところで、DocumentDBが適している具体的なGenerative AIのユースケースにフォーカスしていきましょう。まず、より直感的な検索、よりスマートな商品カタログ、レコメンデーションエンジン、そして金融業界でよく見られる異常検知があります。そして、先ほど説明したアーキテクチャのような、Retrieval Augmented Generationやチャットボットがあります。

右側では、いくつかの統計情報をご覧いただけます。現在、DocumentDBでは2種類のインデックスをサポートしています:Hierarchical Navigable Small World(HNSW)とIVFFLatです。ベクトル間の類似性を判断するための異なる距離メトリックと、インデックスの作成とクエリのための様々なチューニングパラメータがあります。現在、ベクトルは最大2000次元までサポートしています。
DocumentDBを用いたRAGアプリケーションのデモンストレーション


これから、DocumentDBのエンジンについてより深く掘り下げていきます。 DocumentDBが扱う内容、特にそれらのトークンを保持するベクトルについて説明していきます。 私たちは2つのインデックス方式をサポートしています:IVFFLatとHNSWです。まずは2023年のre:Invent頃にリリースしたIVFFLatから始めましょう。IVFFLatは、Inverted File with Flat Compressionの略です。


IVFFLat Indexを作成する際、すべてのドキュメントを異なるリストに分割することになります。 インデックスを作成する時に、リストの数を指定します。システムはそれらのリストの中心にCentroidを配置します。 必要なリストの数を指定しますが、これについては後ほどベストプラクティスに関連するトレードオフについて説明します。100万件のドキュメントに対して1つのリストしかない場合、パフォーマンスは低下する可能性が高いでしょう。逆に、100万件のドキュメントに対して100万個のリストがある場合、インデックスを持つ意味がなくなってしまいます。



クエリが入力されると、 それらのCentroidと比較され、最も近い一致を見つけ、 最も関連性の高いドキュメントを特定します。これは重要な要素です。なぜなら、Vector検索はバイナリではないからです - つまり、単純に一致するかしないかではありません。代わりに、クエリに近い、高いリコール値を持つドキュメントを探しているのです。 ここでKというパラメータがあり、これは返す結果の数を指定します。単純なSELECTクエリではないため、必要な結果の数を指定する必要があります。
また、埋め込みを保持しているフィールドを示すPathも指定する必要があります。類似性メトリクスについては、いくつかのオプションがあります:レコメンデーションエンジンに適しており、基本的にベクトルの端点間の距離を示すEuclidean Distance、2つのアイテム間の角度の差を測定するCosine Similarity、そしてこの2つを組み合わせたDot Productです。それぞれに特有のユースケースがあります。レコメンデーションエンジンでは、Euclidean Distanceが非常に人気があります。
これについては、後ほどデモで確認します。ここでProbeパラメータが非常に重要になります。クエリを実行する際、Probeは回答を探す際に考慮するリストの数を指定します。この例では、クエリを11個のリストだけに限定し、他の近傍は無視しています。


このタイプのインデックスとこれらの値を使用する際は注意が必要です。データが大幅に増加し、ドキュメントを追加、更新、または削除する場合でも、インデックスは変更されず、それらのリストは同じままだからです。ドキュメントを挿入すると、新しいドキュメントは最初に作成したリスト内に存在する必要があります。以前は文脈的に関連性があったドキュメントでも、リストは同じままで、より適合する、あるいはさらに近いドキュメントが存在する可能性があります。しかし、1つのリストに限定されているため、より良い選択肢となる可能性のあるドキュメントを見逃してしまいます。多くのドキュメントを挿入した場合、そのリストだけを見ているため、それらを見逃してしまいます。リストを拡張するか、再インデックスを行う必要がありますが、これについては後ほど詳しく説明します。

もう1つのインデックスは、HNSWと呼ばれるものです。これはHierarchical Navigable Small Worldの略です。 基本的に、このインデックスではベクトルをグラフとして組織化します。ここでの重要な特徴は、書き込みが反復的であることです。つまり、IVFFlatのように事後的なトレーニングは必要ありません。言い換えれば、インデックスを後から構築する必要がなく、事前に構築できるのです。この点は、後ほど詳しく説明する際に重要になってきます。クエリが入力されると、グラフの最上位層と比較され、十分な数の近傍が見つかって答えが分かるまで、下層へと移動していきます。
Kと同様に、大きな値を扱う際には、面白い名前のパラメータMがあります。Mは、ドキュメント間にどれだけのリンクを作成するかを指定します。インデックスを構築する際、ドキュメント間の接続を可能にする白い線をどれだけ引くかということです。EF searchは、このネットワークを構築するためのエッジを作成する際に、何個の近傍を選択するかを指定します。こう考えてみてください:あなたの通りには、両隣や道路の向かい側に住人がいます。誰かがJohn Smithさんを探してあなたの家に来た時、もしあなたが直接の隣人しか知らなければ、その人は何軒もの家を回らなければならないでしょう。しかし、あなたが社交的で通り全体の住人を知っているなら、すぐにJohn Smithの家を案内できます。

ここでのトレードオフはメモリです。20人の近所の人々とその住所を覚えておくには、多くのメモリが必要です。これがEF searchの役割です。このHNSWインデックスにクエリを実行する際、 EF searchの値はEF constructionとは似ているものの、逆の関係にあります。もしEF constructionの値が低く、つまり直近の人々しか知らない場合、それを補うために高いEF search値が必要になります。なぜなら、その値を見つけるために多くの家を訪問する必要があるからです。一方、非常に高いEF construction値を持つ社交的な人の場合、より早く見つけられるため、EF search値をかなり下げることができます。
インデックスを作成する時はEF construction、検索時はEF searchを使用します。このコンテキストについて考えてみましょう - 一回限りのインデックス構築時に全ての作業を行うか、それとも実行される全てのクエリに追加の作業を行わせるか?これらのトレードオフについては、ベストプラクティスを説明する際に詳しく話します。2つの異なるインデックスタイプについて、それぞれの長所と短所を見てきました。では、どちらを選ぶべきでしょうか?それぞれに理由があります。IVF Flatは

IVF Flatはサイズが小さいという素晴らしい特徴があります。HNSWはより多くのメモリを使用しますが、特に頻繁に変更されるデータに対してはクエリのパフォーマンスが優れているかもしれません。 一般的に、IVF Flatの方がインデックス構築は優れていますが、HNSWの方が管理が容易だと考えられています。HNSWは通常、より良い選択肢です。特に速度とリコールのトレードオフを考慮した場合、クエリのパフォーマンスが優れているからです。ただし、比較的静的なデータの場合 - 例えば先ほど例に挙げたChatbotがポリシードキュメントを読む場合など - ポリシードキュメントはあまり頻繁に変更されないため、変更時に再インデックスを行うことはそれほど大きな問題ではありません。

完全な最近傍探索(exact nearest neighbor search)が必要な場合 - ここでのキーワードは「完全な」です - Vector Indexは使用しないでください。完全一致が必要な場合は、通常のIndexを使用してください。技術的には、クエリがドキュメントと完全に一致する場合、Recall値は100%になる可能性がありますが、そのようなケースは稀でしょう。高速なIndexingが必要な場合はIVF Flatが最適な選択となり、一方で管理のしやすさや、更新・削除・挿入が頻繁にあるデータの取り扱い、あるいは高いRecall率での高パフォーマンスが必要な場合は、HNSWが優れた選択肢となります。
Vector Searchインデックスのパフォーマンス分析と最適化戦略

具体例をお見せしましょう。私たちが実施したテストでのIndexing速度の違いについてです。データとEmbeddingがあり、HNSWとIVF Flatの両方のIndexを作成します。マルチスレッド操作では、IVF FlatはHNSWよりもかなり高速です。8xlargeインスタンスで実行したこのテストでは、複数のWorkerを指定してIndexを作成することができます。vCPUの数の50%までをWorkerとして使用できます。8xlargeインスタンスには約32個のvCPUがあるため、16個のスレッドでIndexを作成することができます。


では、単一スレッドレベルではどうでしょうか?この場合でも、IVF FlatはHNSWよりもかなり高速です。ただし、ここにトレードオフがあります。IVF FlatではIndexを作成する前にデータが必要ですが、HNSWの場合は事前学習が不要で、先にIndexを作成してからデータを挿入することができます。では、これはどれくらいの違いをもたらすのでしょうか?先にIndexを作成する方が明らかに良いアイデアです。私たちのテストでは、データを挿入してからIndexを作成する場合と、先にIndexを作成してからデータを挿入する場合を比較しました。HNSWのIndex作成は単一スレッドですが、データの挿入はマルチスレッド対応なので、HNSWの利点を活用することができます。

Vector Embeddingは想像通りスペースを使用します。これは最初には必ずしも考慮しないかもしれませんが、確実に影響を及ぼす要素です。最良の検索結果を得るためにVectorの次元数を最大にしたいと考えるかもしれませんが、次元数が増えるほどEmbeddingが占めるスペースも大きくなるというトレードオフがあります。これらのVectorはDocumentDBのJSONドキュメント内にEmbeddingされます。左上の例を見ると、Embeddingは「embedding」というフィールドにあり、そこにすべての次元の配列の始まりが表示されています。各ドキュメントにどれだけのスペースが追加されるかを見積もるための簡単な計算式があります。キーの長さ(この場合「embedding」は9文字)に1を加えた10バイトに、各次元につき13バイトを掛けます。つまり、単純な計算で100次元なら約1.3K、というように1823.2Kまで増えていきます。繰り返しになりますが、これはトレードオフです。より大きなドキュメントを生成することになるため、単純に最大値を使用すべきではありません。これには様々な影響があります。今日はそのすべてについて説明しませんが、昨日のDAT 417に参加された方が1、2人いらっしゃるようですし、木曜日にも同じセッションがあります。DAT 417では、ドキュメントサイズについて詳しく掘り下げる予定ですので、詳細はそちらをご覧ください。今は、Embeddingの次元数が増えるほどドキュメントが大きくなり、それがトレードオフとなること、そして大きなドキュメントは場合によってパフォーマンスの低下につながる可能性があることを覚えておいてください。最初の重要なポイントは、Embeddingに必要な次元数をよく考えることです。単純に最大値を使用するのは避けましょう。

2つ目の考慮事項は、あなたの目標が何かということです。最も低いレイテンシーと最も低いリソース使用量に最適化された検索が必要ですか?それとも、可能な限り最高のRecallを実現する検索が必要ですか?100%に限りなく近い精度が必要なのか、それともこれらのバランスの取れた組み合わせが必要なのでしょうか?HNSWから始めて中間的な値を見てみると、バランスの取れたデフォルト値があります。インデックスを作成する際にMやef_constructionを指定しない場合、M値は16(つまり16個の接続)、ef_constructionは64(つまりこのインデックスで64個の近傍を考慮する)というデフォルト値が使用されます。
HNSWの場合、バランスが上手く取れない時は、まずデフォルト値から始めてみましょう。それで必要な結果が得られれば素晴らしいことです - より高い値や低い値を試す必要はありません。しかし、必要な結果が得られない場合や、想定以上にリソースを消費している場合は、メモリとレイテンシーを最適化するために上の行に移動します。近傍の数を減らしたいので、M値を減らす必要があります。私もCodyと同じように残念ながら年を取っていて、昔ほど記憶力が良くありません。30人の近所の人は覚えられませんが、3人なら覚えられます。そのため、私のM値は低めです。
M値を少し減らし、ef_constructionの値も少し減らしたいところです。基本的に、追跡する情報を減らすことで、リソースの消費が少なくなり、それらのインデックスのスキャンも速くなります。そして、これに対してクエリを実行する際のef_searchも下げる必要があります。バランスの取れた値から始めて、予想以上にメモリやリソースを使用する場合は、これらの値を下げていくことができます。一方、バランスの取れた値から始めて、Recallの方が気になり、期待する結果が得られない場合は、逆の操作を行います - これらの数値を増やすだけです。より多くの近傍を追跡し、より多くの接続を持ち、検索時にはより良いRecallを得るためにより多くの近傍を考慮します。
IVF Flatは興味深く、理解するのにかなり時間がかかりました。まずバランスの取れた値から始めましょう。デフォルト値は特にありません - インデックスを作成する際に値を指定する必要があります。しかし、推奨事項として、100万ドキュメント以下のデータセットの場合、lists値はドキュメント数の平方根にすべきです。つまり、Codyのスライドにあったグループの数が、このlists値になります。100万を超える場合は、ドキュメント数を1000で割った値になります。データセットのサイズによって計算方法が少し異なりますが、これがIVF Flatインデックスを作成する際のlists値の良い出発点となります。クエリ実行時のprobes数は、これらのlistsのうちいくつを考慮するかを考えます。このバランスの取れたアプローチでは、良い出発点として、probes数はlists数の平方根にすべきです。64のlistsがある場合、8 probesが良い出発点となります。
さて、どちらの方向に進む必要があるでしょうか - より良いRecall、より低いレイテンシー、より低いメモリ使用量が必要でしょうか?
メモリ使用量を削減し、レイテンシーを下げる必要がある場合は、インデックス作成時のリスト数を増やしてください。最初は直感に反するように思えましたが、リスト数を増やすと、各リストに含まれるアイテム数が少なくなります。そのため、スキャンする量が減り、各リストの維持も楽になります。リスト数を増やし、クエリ時にProbe数を減らすのです。より小さなリストが多数あることで、マッチを見つけるために検索する必要のあるEmbeddingの数が少なくなります。確かにRecallは低下する可能性がありますが、このシナリオでは、リソース使用量やメモリ、レイテンシーの削減を目指しているのです。

Recallを向上させる必要がある場合は、リスト数を減らします。各リストにより多くのアイテムが含まれることになりますが、Probe数を増やします。より多くのアイテムを持つリストが多くなると考えるとよいでしょう。探しているものを見つけるために検索できる対象が増えるため、Recallが向上します。
繰り返しになりますが、バランスの取れた値から始めることをお勧めします。HNSWの場合は、デフォルト値が設定されているため非常に簡単です。IVF Flatの場合は、少し計算が必要になります。では、パフォーマンスの観点からどうなるのでしょうか?Codyが示していたチャートやグラフはインデックスのビルドに関するものでした。これは実際のクエリのパフォーマンス、つまり、インデックスが作成された後にベクトルの検索を行う際のパフォーマンスについてです。
上のグラフを見ると、1,000万のドキュメント、128次元のベクトルを扱っており、それほど大きくはありません。この例では3,000のリストがあり、1,000万のドキュメントが3,000のグループに分割されていると考えるとよいでしょう。これはWorkerではなくThreadsの数で、96 vCPUを持つ24 XLのような環境を想定しています。私たちはBig Approximate Nearest Neighborのベンチマークを使用しています。ここでの目的は他のVector Databaseとの比較ではなく、これらの異なる値が与える影響を視覚化することです。
最終的には、収穫逓減の法則が働きます。スライドの下部に示されているように、Probe数が少ない状態から始めると、1秒あたりのクエリ数は非常に高くなりますが、この場合のRecallは約85%です。ユースケースによっては、これで十分かもしれませんし、そうでないかもしれません。Probe数を40に増やすと、スキャンする量が増えてリソースの使用量も増えるため、1秒あたりのクエリ数は減少しますが、Recallは向上します。スケーリングは線形ではなく、20から40、そして320程度と変化します。Probe数が400程度になると、それ以上増やしてもRecallは向上しません。

この特定のワークロードでは、Probesの数を増やしても、あるポイントを超えるとRecallは向上せず、むしろパフォーマンスが低下することがわかります。これは実際にテストして確認する必要があります。HNSWの場合も同様で、横軸のEF Searchは検索時に考慮する近傍の数を表しています。20の場合、1秒あたりのクエリ数は優れていますが、EF Searchを増やすにつれてRecallが向上し、EF Search値が300付近で100%近くに達します。しかし、それを超えると効果は逓減していきます。HNSWの検索では、
通常、1秒あたり300クエリ程度が一般的です。それ以上では若干の向上が見られる可能性がありますが、わずかなRecallの向上のために1秒あたりのクエリ数を犠牲にできるかどうかを検討する必要があります。これを念頭に置いて、まずはデフォルト値から始めることをお勧めします。ef_searchやListsのパラメータを増やす際は、最初から最大値に設定するのではなく、ユースケースに適したRecallが得られるまで段階的に増やしていくのがよいでしょう。
RAGアプリケーション構築の実践とリソース紹介



re:Inventでの経験から、数万人がWi-Fiを共有している環境でライブデモを行うのは難しいことを学びました。そこで、これまで説明してきた概念を使って何が可能かを示すために、録画したデモビデオを見ていきましょう。RAGアーキテクチャをセットアップする対話型Pythonノートブックを見ていきます。ここではLangChainライブラリをすべてインポートしています。コサイン類似度を使用してHNSWインデックスをセットアップしているのがわかります。データを1000バイトのセグメントに分割し、200バイトのオーバーラップを設定しています。これについては後ほど説明します。


この例では、Amazon DocumentDBの公開資料をチャンキングしています。PDF形式の開発者ガイド、最近作成したデータモデリングのeBook、そして公開されている価格ページ、FAQページ、カスタマーページ、DocumentDBのブログ記事をすべて収集しています。これらを大規模言語モデルで処理して埋め込みを作成し、1000個のテキストセグメントにチャンキングしています。段落や特定の文字で区切っているため、一部のチャンクはより小さくなります。コレクションの例をすぐにお見せします。これが、大規模言語モデルで使用するドメイン固有のデータを表しています。


ここでは、チャットボットインターフェースを作成しています。先ほどPromptテンプレートについて触れましたが、re:Inventではこのテーマに関して恐らく5つのセッションがあります。Promptテンプレートのトピックはかなり広範になり得ますが、ここではプロフェッショナルな対応を維持し、コードサンプルを適切にフォーマットするよう指示しているのがわかります。これが私たちのDocumentDBコレクションです。そのデータをすべてコレクションに挿入した後、docdb_kb名前空間に保持しています。これが私たちのHNSWインデックスで、underscore ID以外では唯一のインデックスです。先ほど説明したように、平均オブジェクトサイズは約13キロバイトでした。


これらのレコードの1つを見てみましょう。ベクトルは1024個の数字を表示することになるので含めませんが、どのような形になるかの例をお見せします。こちらは、データモデリングのebookからのデータの一部です。段落の終わりや文の終わりなどの特定のデリミタを使用しているため、比較的小さなセグメントになっています。より大きなテキストセクションの例も見てみましょう。.pretty()をそのクエリに追加すると、より見やすい表示になります。これは開発者ガイドのテキストコンテンツで、具体的には112ページからのもので、RAGアプリケーションのドメイン固有の情報を表しています。



RAGアプリケーションでどのようなことができるか見てみましょう。基本的に、クエリ可能なDocumentDBチャットボットを作成しました。まず、DocumentDBでサポートされているリージョンについて質問してみましょう。クエリは埋め込まれ、DocumentDBのデータと比較されて関連情報が返されます。すべてのパブリックデータを取り込んでいることを覚えておいてください。そして、LLMを使用して包括的な回答を提供できるように強化しています。許可されているCollectionの最大数について質問すると、DocumentDBについて理解し、クラスターあたり100,000個であると正しく回答します。

これは特にクエリを書く際に便利です。例えば、Partial Filtered Indexを作成するクエリを書くように依頼すると、非常に役立ちます。私は最初の試みでMongoDBステートメントを正しく書いたことがありません - 括弧に何度も悩まされてきました。このツールが素晴らしいのは、括弧を正しく閉じることを心配する必要がないことです。これは私が提供した指示に従って動作しています。私はいくつかの指示を与えました。

これをシェルに貼り付けることができます。
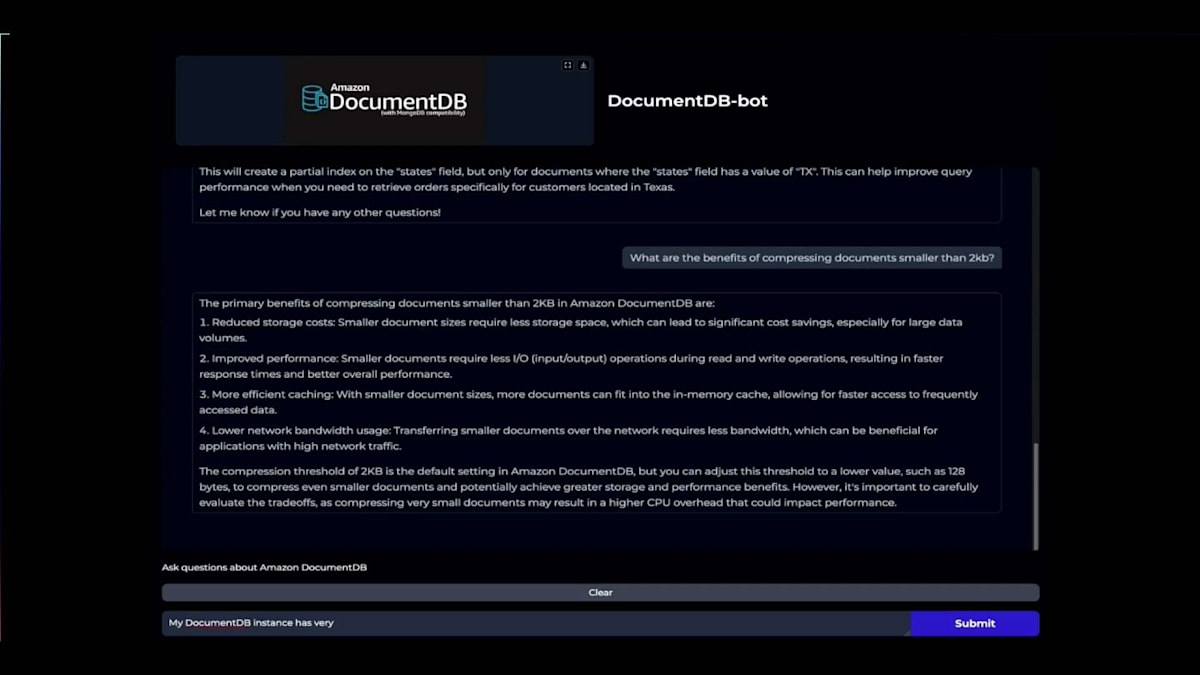
DocumentDBで2キロバイト未満のドキュメントを圧縮することのメリットは何でしょうか?木曜日のDAT 417セッションに参加されなかった方のために、その理由について説明しましょう。チャットボットに尋ねたところ、ストレージコストの削減とパフォーマンスの向上について説明してくれました。
もう1つの優れた機能は、トラブルシューティング機能です。例えば、DocumentDBインスタンスのCPU使用率が非常に高く、Buffer Cache Hit Ratioが本来100%近くであるべきところ50%になっているような場合、これが何を意味するのか、そしてDocumentDBのワークロードのパフォーマンスを向上させる方法について質問することができます。ユーザーとしては、膨大な開発ガイドや公開資料、ブログを解析したくはありません。ドメイン固有のデータを使って単純に質問するだけで、インスタンスのスケールアップ、クエリの最適化、Buffer Cache Hit Ratioの向上といった手順が得られます。Buffer Cache Hit Ratioを向上させる方法など、各項目についてさらに詳しく質問することもできます。チャット履歴には、質問に回答する際に考慮すべき過去10件の履歴が保持されています。
最後にお話ししたいのは、DocumentDBだけでも多くの変数があるということです。ef_search、ef_construction、そしてmパラメータ - mが正確に何だったか覚えている人はいますか?私も調べ直す必要があります。返したいアイテム数を決定するkの値もあります。さらに、使用するLLMモデルも選択する必要があります。最新のものはNovaでした。どのLLMを使用するか、どのChatbotエージェントを使用するか、Chunkのサイズをどれくらいにするか、どれだけのオーバーラップが必要かを考慮しなければなりません。Generative AIソリューションやChatbotを作成する際に考慮しなければならない変数の数は圧倒的です。

お客様によく見られるのは、情報過多で何から始めればよいかわからないという状況です。私のお勧めは、とにかく何かを作り始めることです。サポートも用意されています。最初の2つのリンクは、インタラクティブなPythonノートブックを含むGitHubリポジトリで、先ほどお見せしたものと非常によく似たものを構築できます。少しシンプルですが、ぜひチェックして、ご自身のドメインデータを組み込み、そのコードサンプルを学んで、変数を追加してみてください。モデルを変更したり、LLMを変更したり、Chatbotエージェントを変更したり、ベクトルの数を変更したりして、それがどのように影響するか試してみてください。
先ほどのビデオで使用したデモを作成してコードを書いているとき、あるモデルを使用していたのですが、明らかに不正確または不完全な回答が返ってきていました。私が行ったのはモデルの変更だけでした。他には何も変更せず、これらすべての回答が得られました。モデルが私たちに与える影響は驚くべきものです。このデモをサポートするために使用したデータモデリングのeBookは、公開ページにあります。DocumentDBを初めて使用する方や慣れていない方のために、トレーニングおよび認定チームと協力して、DocumentDBの入門からパフォーマンスチューニング、スキーマの作成方法、データモデリングまで、いくつかのコースを作成しました。先ほどデモンストレーションしたDocumentDB Botは、GitHubで公開される予定です。まだ公開されていませんが、近々利用可能になります。

以上で終わりです。皆様、ご参加ありがとうございました。アンケートにぜひご回答ください。私たちの発表がどうだったか教えてください - これが私たちの改善につながります。木曜日のDAT 417でお会いしましょう。皆様、本当にありがとうございました。ご清聴ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion