re:Invent 2024: AWSによるResponsible Generative AI評価手法
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Responsible generative AI: Evaluation best practices and tools (AIM342)
この動画では、Amazon Web ServicesのPrincipal Solutions ArchitectのAlessandro CerèとMatthew Monfortが、Responsible Generative AIにおけるモデル評価の重要性について解説しています。従来の機械学習とは異なり、Generative AIは非構造化データを扱い、Foundation Modelに依存する特徴があることから、評価の複雑さが増していることを説明しています。Quality、Latency、Cost、Confidenceの4つの評価領域に加え、Responsible AI Frameworkの8つの柱を基に、リスクの深刻度と発生確率を考慮した包括的な評価方法を提示しています。特に、Amazon Bedrock Model EvaluationやAmazon SageMaker Foundation Model Evaluationなどのツールを活用した具体的な評価手法と、統計的な信頼区間の重要性について詳しく解説しています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Responsible Generative AIにおけるモデル評価の重要性


みなさん、こんにちは。ようこそお越しくださいました。私はAmazon Web ServicesのPrincipal Solutions ArchitectのAlessandro Cerèです。本日はこのような機会をいただき、うれしく思います。今日は、Responsible Generative AIにおけるモデル評価の役割についてお話しさせていただきます。私の同僚のMatthew Monfortも後ほど加わる予定です。 まず私から評価の一般的なアプローチについてお話しし、その後、Large Language Modelを評価する際のツールや具体的な内容について詳しく見ていきます。そして、リスクとは何か、それをどのように軽減できるのか、そしてGenerative AIアプリケーションを本番環境に移行する際に必要な確信をどのように得るかについて検討していきます。質疑応答の時間も設けていますので、ぜひ質問を考えておいてください。

それでは、私たちがここにいる理由という、最も基本的なところから始めましょう。なぜGenerative AIについて話し合うのでしょうか?Generative AIには大きな可能性があることは皆さんご存知の通りです。テキストだけでなく、画像や動画の生成、そして理解力という点で、多くの人々を魅了しています。これにより、新たな可能性の世界が広がっています。 しかし当然ながら、これらの能力とともに、新しいリスクの分類や考慮すべき事項も生まれており、この技術を責任を持って採用することが重要になってきています。
Generative AIの複雑性と評価の必要性

リスクの分類について考えるとき、すでにお馴染みかもしれない従来の機械学習と、この新しい世代のAIを比較すると非常に分かりやすいと思います。従来の機械学習では、多くの場合、特定の入力から特定の出力を生成する点予測に注目しており、モデルの生成に使用されるデータを完全にコントロールできることが一般的です。また、アーキテクチャー全体とパイプライン全体も完全にコントロールできるため、非常に狭い範囲で完全なコントロールが可能です。一方、Generative AIについて話すとき、私たちは潜在的に非構造化された何かを扱っています。生成的な側面は、構造の複雑さが予想以上に豊かである可能性があることを考慮に入れる必要があります。

それだけではありません。Generative AIはしばしばFoundation Modelによって支えられています。これらのFoundation Modelは非常に大規模なモデルで、膨大なデータセットで訓練されており、そのため、それを行う組織は限られています。ほとんどのアプリケーションは、これらの既に訓練されたFoundation Modelを使用することを基本としており、そのため、入力される内容を完全にコントロールできるとは限りません。これはまた、何が出力されるかという疑問も提起します。 モデルは非常に強力になり、単に入力を提供し、その入力を私たちのやりたいことに合わせてエンジニアリングし、出力を得るだけでアプリケーションが成り立つようになっています。

これ自体がすでにアプリケーションとなり得ますが、魅力的に聞こえる一方で、多くの問題も提起します。なぜなら、モデル自体にすでに組み込まれている情報にのみ依存することになるからです。皆さんは、モデルが必ずしも現実を表していない、あるいは私たちのアプリケーションがやりたいことと一致しない何かを生成してしまう、いわゆるHallucinationや作話について聞いたことがあるでしょう。 そのため、パターンアーキテクチャーの出現を目にすることになりました。これは、生成される出力の種類をコントロールするために追加情報を注入したり、複数のモデルを連携させたりする方法です。

私たちは、これらのアプリケーションをコントロール、緩和、調整する手段として、複雑さが増大していることを明確に認識しています。シンプルな入力-モデル-出力から、データソースへの接続、Guardrail、特定のオーケストレーションを含むアプリケーションへと進化しています。 さらに、これらのアプリケーションを既存のスタック全体と統合したいと考えています。インタラクションやユーザーエクスペリエンスと呼ばれるものはすべてアプリケーションの一部となり、これらのコンポーネントの多くは、それ自体が生成AIによって動作しています。例えば、Guardrailは入力を受け入れるべきか拒否すべきかを判断するのに役立つ生成モデルかもしれません。

これらのアプリケーションは、それ自体の複雑さとモデルの数が増加し始めています。問題は、どれだけのモデルがあり、それらをどのように選択できるかということです。このスライドは約1ヶ月前に作成したものですが、現時点ではモデルの数が爆発的に増加しています。ここではHugging Faceのモデルハブだけを見ていますが、他にもさらに多くのモデルが存在し、その数は増え続けています。

まとめると、生成AIアプリケーションの複雑さは増大しています。複数のパターンと要素が関与しており、それらの要素の多くは生成モデルによって動作しています。必ずしも単一のモデルではなく、複数のモデルが貢献している可能性があります。開発チームとプロダクトチームは次のようなジレンマに直面しています:一方では、すべてが正常に動作し、すべての項目、コンポーネント、ユニットが安全であることを確認したいと考えています。他方では、本番環境への移行を進め、アプリケーションを世界に公開したいと考えています。

この2つの要素があり、バランスを見つける必要があります。前に進むための方法は何でしょうか?本番環境での事故や永遠の分析麻痺に陥るのを避けるにはどうすればよいでしょうか?答えは非常に明確です:一貫性のある包括的な方法でテストと評価を行うことです。この講演の残りの部分では、この評価をどのように構造化するかについて見ていきます。評価について話す際、モデルやアプリケーションを一時点で評価するということではありません。開発から本番環境、モニタリングに至るまで、アプリケーションのライフサイクル全体を通じて継続的に行う必要があります。
Generative AI評価の包括的アプローチ


これで全体像が見えてきたので、生成AIの評価が何を意味し、それについての考え方をどのように構造化するかを見ていくことができます。まず必要なのは計画です。これは、アプリケーション全体を評価し理解を構造化する方法です。私のお勧めは、アプリケーションの目的から逆算して作業することです。この計画は3つの具体的な項目として考えています:アプリケーションが何をするのか、特定のトピックに内在するリスクは何か、それが対象とする業界は何か、そしてどのようなデータを扱うのかを理解することです。そこから、リスク評価を作成することが可能になります。このプラクティスについては、後ほどMatthewが詳しく説明します。

アプリケーションに関連するリスクを理解したら、包括的な評価戦略を設計することが可能になります。これが計画です。評価したい内容と、その異なる側面についてより詳しく見ていきましょう。私はこれを4つの異なる領域に分類することを好んでいます。1つ目はクオリティ - 正確性やパフォーマンスと呼んでもいいですが - アプリケーションは期待される仕事をきちんとこなしているでしょうか?これがアプリケーションを開発する理由であり、時間とともに測定・モニタリングしたい要素です。次にLatency - プロセスやアプリケーションが結果を返すまでにかかる時間です。アプリケーションによっては、これが重要な要素となる場合もあれば、そうでない場合もあります。その重要性は、アプリケーションの目的とコンテキストから逆算して判断することになります。
Costは、アプリケーションが成功しているか、期待される収益をもたらしているかを知るために測定したい要素ですが、同時に運用コストについても把握する必要があります。これらの測定と評価は、最適化を行うために重要です。そして、Confidenceという側面に移ります。私は肯定的な表現を好むので、Confidenceという言葉を使っています。Generative AIを責任を持って適用する際、私たちが行っているのは、アプリケーションがリスクを増大させない、害を及ぼさない、恥ずかしい状況を作り出さないという確信を持つことです。これは、アプリケーションが組織内や広い世界でどのように適合するかという理解全体を包含する側面です。特にConfidenceに関しては、具体的なフレームワークを持つことが重要です。

私たちが「Responsible AI Framework」と呼ぶものをお見せしたいと思います。これは、設計方法と測定方法を理解するための8つの柱として整理されています。これについてはもっと多くのことがあり、Responsible AIに関するセッションもいくつかありますが、今回は評価の部分だけを取り上げます。これらの柱のそれぞれが、技術と実践の両方を含む複雑な世界であることは想像できると思います。

評価の側面と含めたい具体的な側面について理解できたところで、評価のアーキテクチャについて見ていきましょう。考慮に入れる必要のある具体的な技術的能力とスキルは何でしょうか?まず、評価したいモデルとアプリケーションへのアクセスが必要です。これは当たり前のように聞こえますが、特に大規模に組織化したい場合に重要になります。例えば、組織全体のためにモデルを集中的に提供するプロバイダーがあり、アクセスのための明確なパターンを確保したい場合などです。これは、どのモデルにアクセス可能で、それらをどのように比較するかという重要なトピックになってきています。
次にデータに移ります。データは、それ自体が巨大な章となります。なぜなら、評価は目的に大きく依存し、その目的は非常に多くの場合、データ自体によって定義されるからです。これは、データの追跡と管理の方法という点でも、関連性のあるデータを持つという点でも課題をもたらします。そのため現在では、本番環境の類似アプリケーションから得られるデータと併せて、合成データの作成がよく見られるようになっています。
私たちはモデルにアクセスでき、データも持っています。そしてもう1つ、時として見過ごされがちな要素があります。それは Input Engineering です。私は単なる Prompt Engineering ではなく、Input Engineering という言葉を使います。なぜなら、入力とは、プロンプトと、入力をどのように設計・処理するかを組み合わせたものだからです。時にはOutput処理も含まれますが、通常は入力が主要な要素となります。評価について話す際、私たちは単にモデルやアプリケーションだけを評価しているわけではありません。実際には、モデルやアプリケーション、データ、そして入力に関わるすべてのエンジニアリングという、これら3つの要素の組み合わせを評価しているのです。
これが重要なのは、これらのコンポーネントの様々なバージョンや組み合わせを評価する可能性があるからです。そのため、下部に追跡ツールがあるのですが、これはすべてのバージョンを追跡し、何が上手くいって何が上手くいかなかったかを再現して確認できるようにするために重要です。すべてをまとめる接着剤となるのが評価ツールで、これは多くの場合、計算を実行するためのインフラストラクチャとソフトウェアパッケージの組み合わせを意味します。
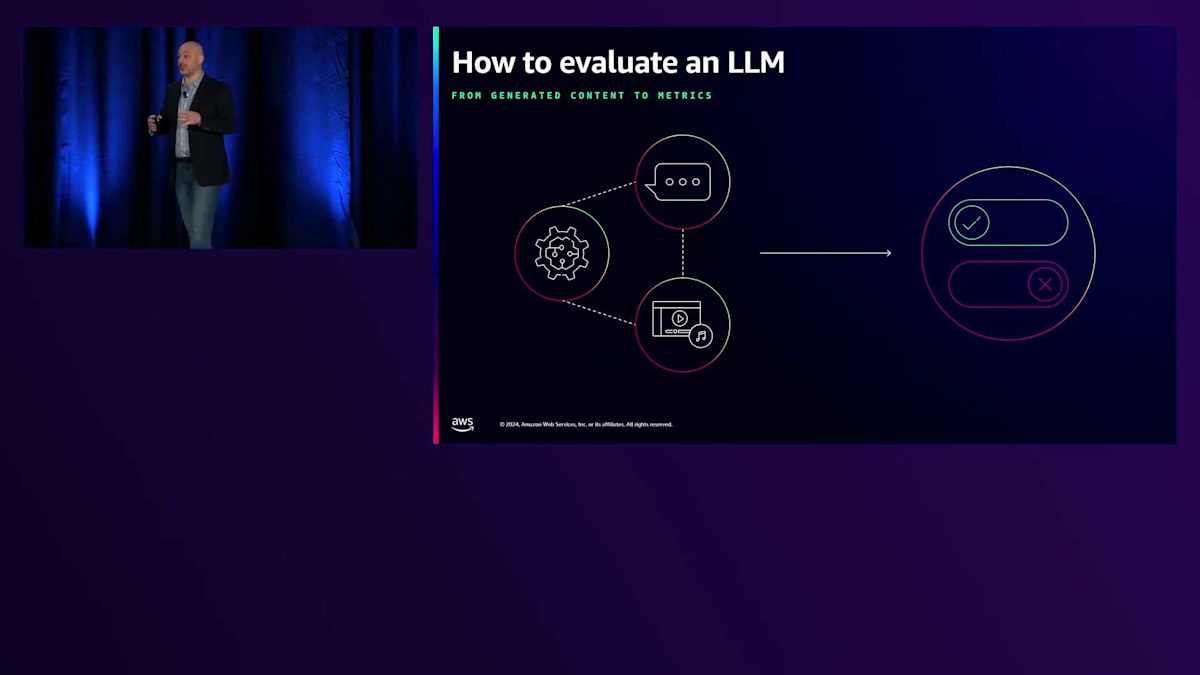
もう少し掘り下げてみましょう。アーキテクチャの概要が分かったところで、他の標準的なシステムと比較した場合のGenerative AIの評価における根本的な課題が何かを見てみましょう。 私たちは、非構造化されているかもしれない、あるいは不確定な形を持つかもしれないものを、測定可能なもの、つまりスプレッドシートやグラフに入れられるものに変換したいのです。これが本当の主要な課題です。なぜなら、私たちは物事を比較したいのですが、2つのテキストを比較することは時としてスケーラブルではないからです。そのため、それを集約できるようにしたいのです。

どのようにしてそれを実現できるでしょうか?どのようなアプローチがあるのでしょうか?ここで私の考え方をお示ししますが、後ほど皆さんが賛成か反対かをお聞きできれば嬉しいです。まず最初は人による評価です。なぜこれから始めるのでしょうか?アプリケーションのプロトタイプを作る際、おそらく既に何が上手くいって何が上手くいかないかについて、自分自身の判断を使っているはずです。スケールアップしたい場合、出力が望むものと一致しているかを評価するのを手伝ってくれるチームを実際に持つことができます。人々は異なる入力を理解し、指示に従い、評価や判断を下すことができる柔軟性を持っていることがわかっています。これは非常にコストがかかりますが、アプリケーションにとって最高品質のデータソースの1つでもあります。そのため、Generative AIの評価において間違いなく中心的な存在となっています。その後、自動評価を検討します。
評価アーキテクチャと自動評価の手法
自動評価には2つの大きな評価指標のファミリーがあります。1つ目は、非構造化システムから指標を生成するために標準的な言語処理ツールを使用するヒューリスティック指標です。これは言語だけでなく、標準的な分析ツールを使用して画像にも適用されます。しかし、Generative モデルの出力の豊かさを考えると、このアプローチだけでは多くの場合不十分です。そのため、Generative AIアプリケーションの出力を判断するためにGenerative AIツールを使用することも検討します。これは時にLLM-as-judgeと呼ばれます。これら2つのアプローチは自動化してスケールすることができますが、生成ツールを使用すると自動ツールよりもコストが高くなります。両方のアプローチが必要であることがわかります。そして、機能の全スペクトルを捉え、意思決定を導くことができるパフォーマンスの側面もあります。

Heuristic指標とLLMをジャッジとして使用する場合の違いについて、さらに詳しく見ていきましょう。 Heuristic指標について話す際、私たちは制限を分析的に理解できる標準的なツールを見ています。例えば、ROUGEを使用して出力と期待される出力の間の単語を照合することは、一部のシステムを評価する優れた方法かもしれません。ただし、同義語を使用したり、長さの異なる出力を生成したりする複雑なシステムの場合、このアプローチは理想的ではないかもしれません。それでもなお、これらは何が良いか悪いかの基準を提供してくれる確立されたツールです。時には、これらのツールでは簡単に説明できないものを捉えたい場合があり、そこでLLMをジャッジとして活用することになります。このアプローチでは、システムのより複雑で興味深い特性を捉えることができ、人間による評価に近い形になります。ただし、バイアスを避けながら、これらの評価ツール自体を説明し理解する必要があるという課題があります。例えば、LLMは自身の出力を好む傾向があるため、ClaudeやNovaを使用してテキストを生成する場合、同じモデルで生成されているため評価にバイアスが生じる可能性があります。

ツールについて理解したところで、メトリクスを見ていきましょう。 私は定量的から定性的までのスペクトラムでこれらを捉えるのが好きです。これは学術的な定義ではありませんが、お客様と何を測定する必要があるかについて話し合う際に便利だと感じています。これらのメトリクスは排他的なものではありません - 私たちは多くの場合、定量的メトリクスと定性的メトリクスの両方を使用して、システムの動作を理解したいと考えています。これらは最も一般的なメトリクスの一部ですが、唯一のものではありません。特に複雑なアーキテクチャを見る際には、組み合わせて使用されることが多いです。


例えば、Retrieval Augmented Generationの場合、 分析的手法と定性的な指標を組み合わせた特定のメトリクスが見られます。また、 Responsible AIに特化したメトリクスもあり、これらはアラインメントや特定の規制への準拠に役立つことがあります。これらのメトリクスは広く適用可能で、場合によっては特定のアラインメントが必要になるかもしれません。
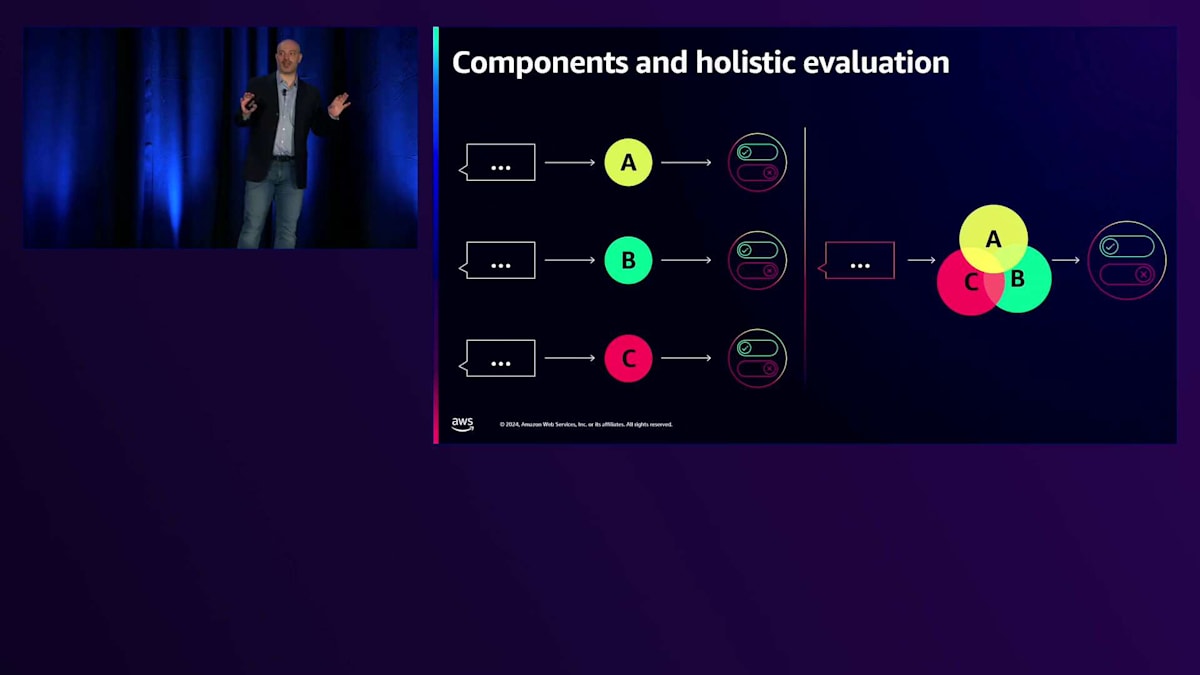
測定したいものとツールについて理解できたところで、実際のアプリケーションに移りましょう。アプリケーションについて考える際、 私は2つの具体的な戦略があると考えています。1つ目はコンポーネント分析です - RAGやAgentを持っている場合、Generative AI要素がある度に、評価したいモデルやアーキテクチャがあります。これはUnit Testのように考えてください。特に最適化できるものです。しかし、システムが非常に複雑な場合、ガバナンス、責任、パフォーマンスの観点から本当に重要なのは、エンドツーエンドの評価です - これはIntegration Testのように考えてください。包括的な評価のためには、両方のアプローチを検討する必要があるかもしれません。

これらのアプローチは、アプリケーションのライフサイクル全体で特に重要です。 ここでは、アプリケーションのライフサイクルを単純に直線で表現しています。フィードバックループによって特徴付けられることは承知していますが、開発の異なる段階では異なるアプローチが特徴となります。Sandboxでプロトタイプを構築している段階や初期プロトタイプの段階では、AIエンジニアやPromptエンジニアとして、品質を判断するために人間のフィードバックを多用するかもしれません。しかし、開発からValidationに移行するにつれて、より構造化されたエンジニアリングと自動化されたツールに依存するようになります。コンポーネントテストとホリスティックテストの両方が、ライフサイクル全体を通じて重要な役割を果たします。

それでは、LLMの評価について見ていきましょう。 まず目につくのがベンチマークでしょう。モデルを選ぶとき、オンラインで検索すると、多くの組織が実施しているベンチマークを見つけることができます。これは初期の判断や理解を得るのに非常に便利です。ただし、これらは必ずしもあなたのアプリケーションやユースケースを反映しているわけではありません。例えば、ベンチマークで示されているレイテンシーは、実際にファイアウォールを通過する際の遅延や、接続性、接続先のリージョンなどは考慮されていません。ベンチマークのすべての項目は、特に自社のデータに関連して、実際に測定してみる必要があるかもしれません。

レイテンシーとコストについて、 AWSコミュニティで開発されたクライアントサイドのレイテンシー、スループット、パフォーマンスを測定するためのツールをいくつかご紹介します。これは評価の中でも比較的確立された分野なので、すでにいくつかのツールをご紹介できることは驚くことではありません。パフォーマンス評価に関しては、今後の展開も考えていく必要があります。


まず、会場の皆さんがすでにご存知だと思いますが、Amazon Bedrock Model Evaluationについてお話しします。もしご存じない方は、ぜひ試してみてください。これは完全マネージド型のサービスで、Bedrockを通じて提供されるすべてのモデルを評価することができます。パフォーマンスを測定し、独自のデータを持ち込むことができます。最近リリースしたのが、LLMを評価の判定者として使用する機能で、これにより測定できる指標が増えました。 自動評価のための従来の評価指標とLLMによる判定を組み合わせることができ、特に重要だと感じているのは、人による評価ジョブを設定して指標を収集し、比較できる点です。


もちろん、すべてのモデルやアプリケーションがBedrockでホストされているわけではありません。そのため、fmevalやSageMaker evaluationも利用できます。これはオープンソースのパッケージで、CI/CDやノートブックとうまく連携し、測定と評価の実践を標準化するのに役立つツールです。SageMakerとBedrockの両方で、自動評価ツールには標準データセットが用意されています。 ここで少し補足させていただきますが、標準データセットは公開されているため、使用しているモデルのほとんどがすでにこれらのデータセットを学習済みである可能性が高いです。テストや指標の理解には便利ですが、ぜひ独自のデータセットを持ち込んでください。それこそが、評価に本当の価値と意味を与えるものです。
LLMとRAGアプリケーションの評価



これが従来の評価指標についてでしたが、先ほどBedrock evaluationで触れたように、 LLMを判定者として使用することもできます。ここでは、新しく考慮できるようになった指標のスクリーンショットをお見せしたいと思います。 LLMを判定者として使用する場合、従来の評価指標を使うにせよLLMを判定者として使うにせよ、自動評価を行うたびに、それが人による評価と一致することを確認する必要があります。そのためには、人による評価を実施し、両者の互換性を確保することが重要です。

これまではLLMの直接的な評価について話してきましたが、次はアプリケーションについても見ていきましょう。 最初に考察するパターンは、Retrieval Augmented Generationです。



従来から検索エンジンの評価にはRecallなどの標準的なメトリクスを使用してきましたが、今回はこれらのメトリクスが、Generative AIのコンポーネントとどのように組み合わさるのかを見ていきます。これは、埋め込みベクトルの生成という意味的な部分と、検索部分の両方に関係します。2日前からは、Amazon Bedrockを使ってRAGの評価を行うことができるようになりました。これはナレッジベースに適用できます。 つまり、ナレッジベースをお持ちの場合、Language Modelを評価者として設計でき、検索部分に関する標準的なメトリクスも取得できます。 さらに、アプリケーションの一部として、検索とResponsible AIのメトリクスを追加することもできます。測定できるメトリクスは、 ユースケースと重要視する項目によって変わってきます。そのために特定のデータセットを作成する必要があります。テストデータセットの構造に応じて、関連性の高いメトリクスも変わってきます。

すべてのRAGがナレッジベースというわけではありません。そのため、私たちはオープンソースの パートナーやライブラリもサポートしています。例えば、多くのお客様が採用している一般的なアプローチとして、Ragasを評価ツールとして使用する方法があります。Ragasの場合、評価者として使用するLLMを自由に選択できます。ただし、評価者としてのLLMに対する事前に用意されたプロンプトの品質や考慮事項は、Amazon Bedrockほど充実していないため、適切な調整を確保するためにより多くの作業が必要になります。これは、どのようなモデルやシステムでも使用できる柔軟性を持つことと、すでに調整済みのものに頼れることとのバランスの問題です。


最後に、Agentの評価について手短にお話ししましょう。これは非常に難しく、まだ新しい分野なので、標準的な手法がまだ確立されていません。お話しするお客様それぞれが独自のアプローチを持っています。標準的なものがあればいいのですが、いくつかの標準が出てきつつあります。 ぜひAgent Evaluation Frameworkをご覧いただきたいと思います。これは私たちのソリューションアプリケーションの1つで、ターンごとの評価とエンドツーエンドの評価の両方で、マルチターンの同時評価が可能で、便利なレポートを提供できる点が気に入っています。CI/CDツールに組み込めるように特別に設計されているので、開発サイクルに統合することができます。

これらの技術をすべてテストする方法として、私たちのワークショップをぜひチェックしていただくことを強くお勧めします。これは常に最新の状態に保たれており、モデルの評価、RAGの評価、Agentの評価についてより詳しく学ぶことができます。この分野が成熟するにつれて、私たちは改善を重ね、新しい技術を追加しています。では、アプリケーションを本番環境に移行する際の信頼性を確保する方法について、より詳しくMatthewにお話しいただきましょう。
リスク評価とユースケース定義の重要性


ありがとうございます、Alessandra。 今のプレゼンテーションでは、Generative AIアプリケーションやLLMを評価する際のモデルパフォーマンスを理解するための一般的な評価方法や様々なアプローチについて、とても分かりやすく説明していただきました。ここからは少し異なる観点に焦点を当てたいと思います。 品質やレイテンシー、コスト、信頼性などについて触れられましたが、私のパートでは特に信頼性、そしてローンチに向けた確信をどのように確立するかという点に重点を置いてお話ししたいと思います。

先ほど表示されたこのスライドをもう一度見てみましょう。 これは多くの開発者が採用している典型的なアプローチです。優れたパブリックリーダーボードや既存のデータセットがあり、私たちのシステムを既存のモデルと比較して理解したいと考えています。現在では、これらのパブリックシステムで素早く実行し、BIG-Benchのようなベンチマークで他のシステムと比較してどのようなパフォーマンスを発揮できるかを理解することができます。しかし、先ほど述べたように、これは私たちのお客様のユースケースや、開発中のアプリケーションと対象ドメインに特有のリスクを本当の意味で反映しているわけではありません。一般的なパフォーマンスの感覚は掴めますが、実際のリリースに向けたローンチの確信を得るには十分ではありません。


ここでは、そのローンチに向けた確信を確立し、製品のローンチとリリースを確実に成功させるために必要な具体的なステップに焦点を当てたいと思います。プロトタイプ評価や他の種類の評価と比べて何が異なるのかを強調しました。ここで重要なのは、実際の本番環境でお客様と向き合うモデルを運用する際に直面する様々なリスクを理解し、考慮に入れる必要があるということです。これらは単なるユースケースの精度、機能セット、 レイテンシー、コストなどの一般的な要素を超えて、先ほど言及された様々なResponsible AIの側面を考慮に入れる必要があります。

ここが私が焦点を当てたい部分です。なぜなら、これらの異なる側面それぞれが、システムをリリースする際に考慮すべき追加のリスクをもたらすからです。下流での潜在的な害、レピュテーションへのダメージ、恥ずかしい結果などに関する異なるリスクが存在します。一般的なパフォーマンスと品質だけでなく、これらすべてを評価プロセスで確実に捉える必要があります。


例として、2つの異なるアプリケーションを考えてみましょう。 1つは音楽をレコメンドするAI、もう1つはX線画像から腫瘍を識別するAIです。 明らかに、これらのシステムは全く異なる潜在的リスクを持っています。ユーザーへの音楽レコメンドで間違いを犯すことと、患者の腫瘍診断を見逃すことでは、その深刻さは全く異なります。このような影響の違いがあり、これらはまさに私たちが測定したい要素です。なぜなら、このようなリスクの重大性の違いによって、リリースに際して私たちが安心できる可能性の閾値も変わってくるからです。


音楽のレコメンデーションで小さなミスを犯すことは許容できても、腫瘍の識別でミスを犯すことは許容できないかもしれません。 このように、成功したリリースに対する私たちの確信度に、これがどのように影響するかを考える必要があります。 そのために、私たちは「責任あるEvaluation戦略」と呼ぶものを策定します。これは社内のチームに推奨しているベストプラクティスですが、今回は外部に向けても、ローンチに対する確信を得るための方法として推奨させていただきます。

これを実行するための最初のステップは、ユースケースを定義することです。 なぜなら、すべての選択はユースケースから派生するからです。このプロセスの次のステップで行うことすべてが、このユースケース定義という重要な要素から生まれてきます。ユースケースを定義するとは、ステークホルダーの特定、対象ドメインの特定、そしてシステムの入出力として想定されるデータの分布を把握することを意味します。これらの情報をすべて把握することで、潜在的なリスクを評価し、Evaluation戦略をどのように進めるかを検討することができます。

ユースケース定義が明確で絞り込まれていることが非常に重要です。一般的なユースケースの例を挙げると、商品説明文を作成するというものです。これが私たちが構築しようとしている対象製品です。想定される一般的なオーディエンスは非常に幅広い層で、誰でも対象となり得るし、どんな種類の商品にも適用できます。Evaluation戦略に取り組む際、データセットの構築、メトリクスの選択、リリース基準の設定など、さまざまなことを行いますが、あらゆるリスクが対象となり得るため、具体的な潜在リスクに焦点を当てることが非常に困難になります。


これは一般的すぎるため、開発者が特定の製品や特定のユースケースを構築しようとする場合、いくつかの対象ドメインが存在します。単一の製品を複数のユースケースから構築することは可能ですが、Evaluationを行う際は、一般的な定義では未知の要素が多すぎるため、一度に1つのユースケースに焦点を当てる必要があります。 より具体的な例を挙げてみましょう。オーディエンスXに商品Yを購入させることに評価の焦点を当てるとします。これにより、ターゲットとするオーディエンスを特定の層に、また商品も特定のものに絞り込むことができます。起こり得るリスクが把握でき、何が起こるのか、考慮すべき点は何か、そして異なるユーザーが実際にどのようにシステムと関わるのかが分かります。


ユースケースを非常に具体的に定義できたら、次のステップとして、 潜在的なリスクに焦点を当て、それらを評価することができます。ここで、Responsible AIの各側面を参照することができます。 ユースケース、アプリケーション、システムに関して、これらの各側面におけるリスクを把握する必要があります。これは単なる一般的なパフォーマンスを超えた考慮が必要で、これから各側面についてより詳しく掘り下げていきたいと思います。
メトリクスの選択とリリース基準の設定


リスクとリスク評価について話す際、私たちは実際にある事象が発生する確率と、その負の影響や深刻度の組み合わせについて議論しています。 これが私たちのConfidence Riskにつながります - 深刻度が高いほどConfidence Riskは高くなり、また事象の発生可能性が高いほどConfidence Riskも高くなります。これが Risk Rating Matrixを形成する方法です。ここで見ていただけるように、深刻度や発生可能性が高い場合、Confidenceのリスクはかなり高くなります。
また、ここで強調しておきたいのは、極めて深刻度の高いリスクが存在する場合についてです。極めて深刻度の高いリスクがある場合、非常に大きな負の影響が発生する可能性が常に存在するため、リリースに対して完全な確信を持つことは難しいかもしれません。評価やリリースを実践する際には常に不確実性が存在するため、これを考慮に入れる必要があります。同様に、深刻度が極めて低い場合、そのリスクの発生可能性が高くても、潜在的なユーザーやシステムへの悪影響が小さいため、より安心して対応できるかもしれません。


この部分については、他のパートにより多くの時間を割く必要があるため、簡単に触れるだけにとどめます。ここで推奨するリスク評価プロセスについて、より詳しく解説したブログ記事へのQRコードを参照してください。 これで私たちが直面するさまざまなタイプのリスクについて理解できたので、次のステップはメトリクスの選択です。それらの事象が発生する可能性を実際に測定するためのメトリクスを選択するプロセスが必要です。


以前に紹介したさまざまなメトリクスのスライドを参照できます。また、Automatic EvaluationやLLM as a Judgeなど、それらを組み合わせるさまざまなアプローチについても見ることができます。 ここで私が詳しく掘り下げたいのは、それらのResponse Dimensionsに関するメトリクスの具体的な内容です。VeracityとRobustnessを考える場合、Similarity、Relevance、Coherence、Faithfulnessなどを捉える必要があります。システムがプロンプトに含まれていない情報や誤った情報を作り出していないこと(Hallucination)を確認し、特定のプロンプトやタスクに関連性があることを確認したいのです。


PrivacyとSecurityについては、PII(個人識別情報)の漏洩などを捉える必要があります。システムが個人の私的な情報を出力しないようにしたいのです。 Safetyについては、システムが有害な出力を生成しないようにする必要があります。これらの領域の中には、特にSafetyとSecurityのように重複する部分があります。Jailbreakingのような事例を考えてみましょう。これはPrompt Injection攻撃の一種で、システムに対して以前の指示をすべて無視するよう要求するようなものです。これらは下流での潜在的なリスクにつながる可能性がありますが、一般的な品質評価では必ずしも捉えられない場合があります。

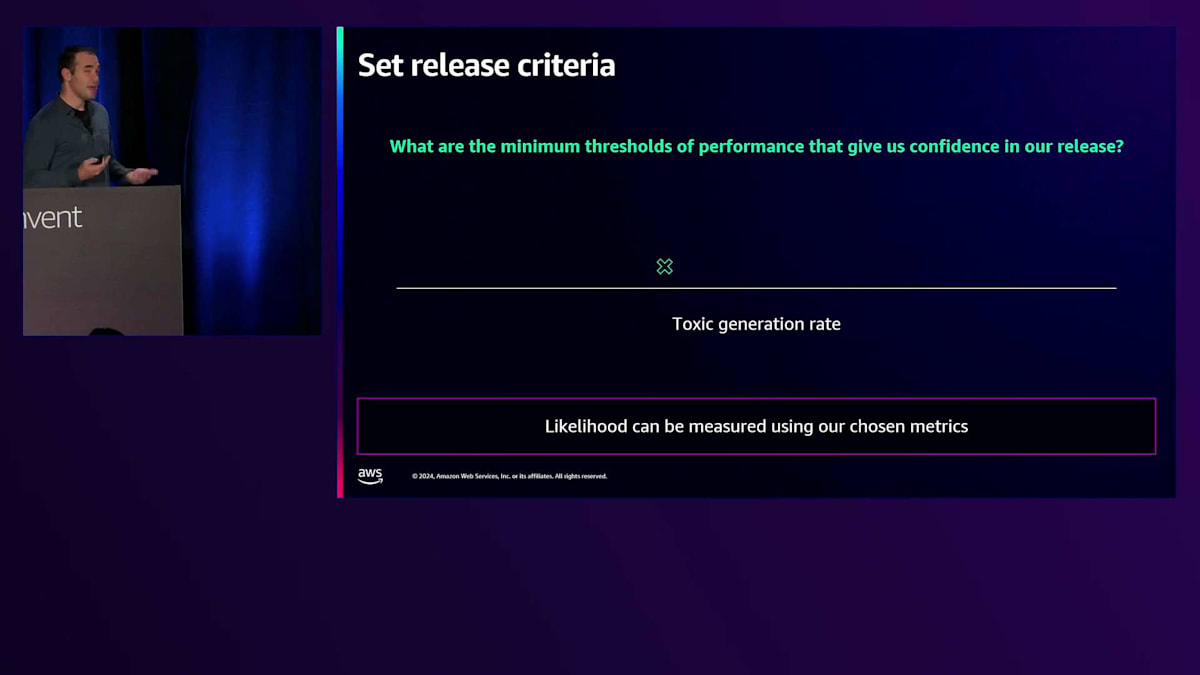
安全性に関して特に注目されているのが、有害性の問題です。私たちは確実に、有害な出力を生成しない製品を作る必要があります。また、定義に応じて、侮辱的、暴力的、あるいは過度に下品なコンテンツを作り出さないようにする必要があります。ここでは例として、toxic generation rate(有害な情報や出力を生成する割合)について説明していきます。


公平性は、常に考慮しなければならないもう一つの重要な要素です。なぜなら、異なる側面でのパフォーマンスが、様々なステークホルダーや人口統計グループにどのような影響を与えるかを理解する必要があるからです。 ここでは、公平性の定義として人口統計的バイアスに焦点を当てており、toxic generation rateの異なる値を確認することができます。それぞれの色は異なる人口統計グループを表しています。これは、ターゲットとする異なる層や、異なるユーザーに特化したプロンプト、あるいは異なるタイプの製品を示している可能性があります。


公平性に関する信頼性を測定する一つの方法は、toxic generationについて、私たちが許容できる最大の割合を設定することです。システムを評価し、各人口統計グループのパフォーマンスがこの許容最大値を下回っているかどうかを確認します。これは minimax fairness(グループ間の最大誤差を最小化すること)と呼ばれるものです。 公平性を測定するもう一つの方法は、グループ間のパフォーマンスの最大格差を見ることです。


リスクを評価し、評価したい指標を選択したら、次はリリース基準を設定する必要があります。 これは、先ほど言及した許容最大値の設定に関連します。リスクマトリックスに立ち返る必要があります。なぜなら、選択したリスクの深刻度と、リリース時に私たちが許容できるそれらのイベントの発生確率について考える必要があるからです。これらのイベントは発生する傾向にあることを理解しなければなりません。システムが完璧で何も問題が起きないと想定するのは非常に難しいのです。これらの事象が発生した際に、私たちが何を許容できるかを確立する必要があります。ただし、リリース基準を厳しくすればするほど、実際にそれを達成するのが難しくなることを理解しておく必要があります。
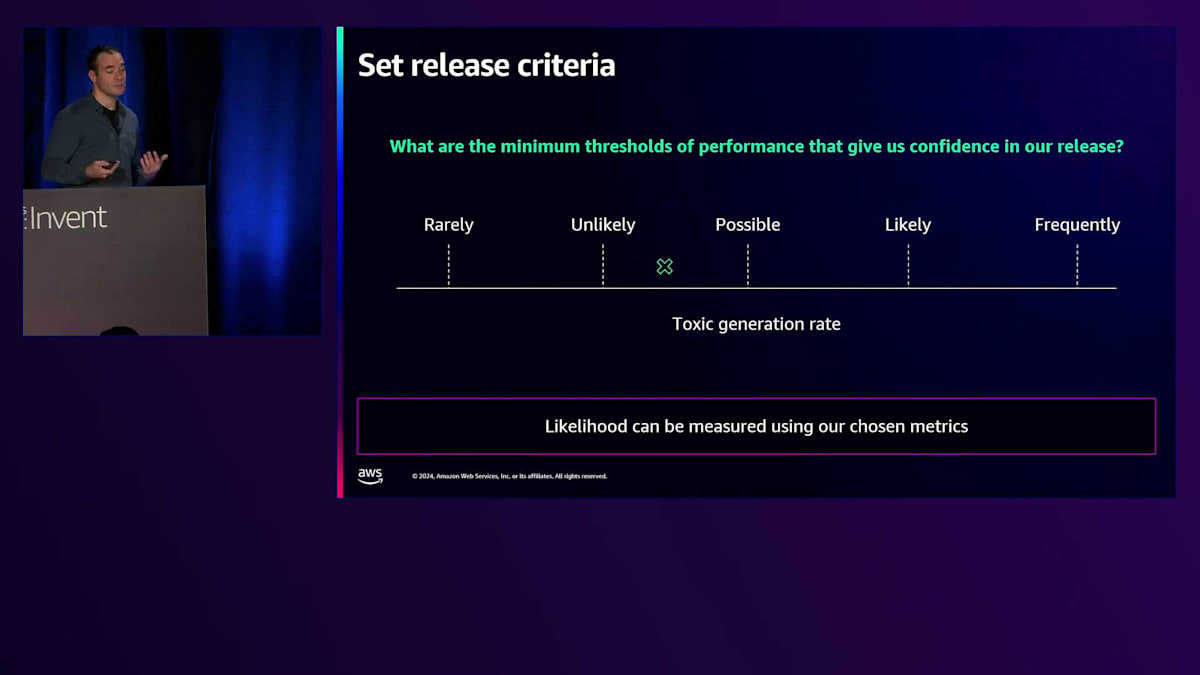
システムの開発能力とリリースに対する安心感のバランスを取る必要があるため、常に深刻度から逆算して考えます。特に深刻度の高いリスクに対しては、より厳格なリリース基準を設ける必要があります。ここでもう一度、toxic generationの例に戻りましょう。 これは少し難しい問題です。なぜなら、この測定値があったとしても、開発者は自分のユースケース、作業しているデータセット、そしてターゲットドメインを本当によく理解する必要があるからです。彼らは、異なるパフォーマンスが「まれに」「可能性が低い」「可能性がある」「可能性が高い」「頻繁に」といった状態にどの時点で対応するのかを解釈する必要があります。これは本当にユースケースに依存するからです。

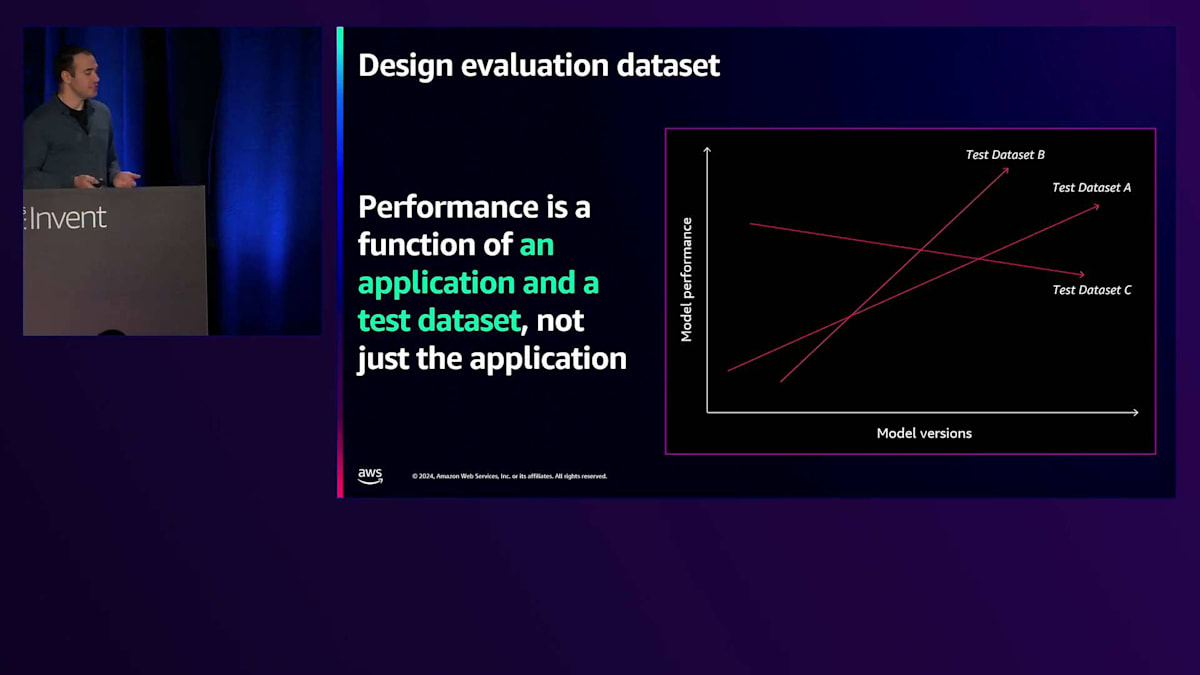

子供向けのChatbotを開発する場合と大人向けのChatbotを開発する場合を考えてみましょう。「起こりにくい」や「まれに発生する」という解釈が、大人向けの場合と比べて異なってくる可能性があります。リリース基準を設定する際には、このような点について考慮する必要があります。 次のステップは評価用データセットの設計です。ここで特に強調したいのは、パフォーマンスはアプリケーションとテストデータセットの関数であるという点です。つまり、アプリケーション単体だけでなく、実はそれ以上の要素が関係しています。パフォーマンスは実際にはリスクの側面、テストデータセット、評価指標など、すべての要素の関数なのです。
これを理解することが重要です。なぜなら、同じシステムでも異なるデータセットで実行すると、評価結果が異なる可能性があるからです。ここでの重要なポイントは、対象とするユースケースを適切に代表するデータでシステムを評価することです。そのため、ユースケースを非常に明確に定義することが重要なのです。なぜなら、それによってデータセットの構築方法が明確になるからです。そのデータセットで確立した性能測定が、実際にデプロイしたときのシステムの期待される性能を反映していることを確認したいのです。
多くのチームが、先ほど説明したような一般的なデータセットをそのまま使用することが一般的ですが、それでは私たちの状況を正確に捉えることができず、デプロイ時にシステムが異なる性能を示すという不確実性につながります。このような事態は避けたいものです。さらに、モデルの更新や異なるシステムを考える際には、常に再評価を行い、開発プロセス全体を通じて、そしてシステムがリリースされた後も継続的にテストを行って、この信頼性レベルを高く保つ必要があります。対象ドメインや顧客のデータセットが時間とともに変化している可能性もあり、そうした挙動もモニタリングする必要があります。




次のステップは評価指標の生成です。評価指標を選択し、評価用データセットを設定し、リスクを特定しました。では、実際にこれらの評価指標をどのように生成するのでしょうか?先ほどのスライドに戻りますが、使用可能な様々な評価指標があります。AWSは、これを実現するための優れたツールを提供しています。 以前説明したAmazon SageMaker Foundation Model Evaluationや、先ほど説明したリスクの側面も捉えることができるAmazon Bedrock Model Evaluationなどがあります。これらのツールを使用することで、Faithfulness、Veracityの測定、さらにはToxicityやステレオタイプなども測定できます。これらのリスクの側面に沿ってパフォーマンスを把握できる優れたツールが利用可能です。
評価結果の解釈と統計的アプローチ



次のステップは結果の解釈です。ここには少し余分に時間を取りました。というのも、多くの人がつまずきやすい部分だからです。一見とてもシンプルに見えます - システムを実行し、データセットで結果を得ました。このように性能が出ています。リリース基準を設定し、システムの性能が良好で、有害な生成の最大許容率をすべて下回り、さらには格差も私たちが許容できるレベルまで減少させることができました。しかし、それは必ずしも正しいとは限りません。

異なるシステムを構築する複数のチームと協働する際、私たちは常にリリースに対する確信を得たいと考えています。しかし、確信を得るためには不確実性を把握する必要があります。これは一般的に見過ごされがちで、十分に注目されていない点です。なぜなら、先ほど説明した異なるデモグラフィックグループに対するこれらの測定値は、実際にはデータセットのサンプルに基づく測定値だと考えることができるからです。この評価用データセットは、ある分布のサンプルとして捉えることができます。

そのデータセットから異なるサンプルを取得して評価を行うと、実際には異なる値が得られる可能性があり、平均値も異なってくる可能性があります。ここで私たちが捉えているのは、このパフォーマンスの分布です。これらの値のうち、どれが正しいのでしょうか?現在、私たちは平均値を取る際に単一の平均値のみを使用していますが、それでは不確実性を捉えきれていません。異なるサンプルを取った場合、リリース基準を満たさない可能性があるのです。これは私たちが確実に考慮したい点であり、この種の不確実性を捉える方法として、信頼区間を含めることが挙げられます。ここでは、各グループに対して95%信頼区間を示しています。これは、各グループに特有の線の範囲内で、私たちのパフォーマンスがこの範囲内にあることを95%の確信を持って言えるということを意味しています。
ここには不確実性があり、私たちはその範囲をある程度まで絞り込んでいますが、正確な位置は分かっていません。これにより、パフォーマンスについての理解と、より良い見方が得られるとともに、先ほど言及した不確実性も捉えることができます。リリース基準についても再度確認できますが、ここでは基準を満たしていません。あるグループの上限を見ると、最大許容率を超えています。

これは私たちのシステムが基準以下のパフォーマンスを示しているということを意味するのでしょうか?実はそうではありません。これは信頼性を組み込む際によく行われることですが、私たちはそれらの境界を見て、それに基づいてリリース基準を設定します。これは、その範囲内に95%の確信を持っているということを示していますが、必ずしも最大許容率を下回っていることを95%の確信を持って言えるわけではありません。それは実際には異なるテストになります。ここで片側信頼区間を形成すると、各グループがこの値以下であるという範囲内にあることを95%の確信を持って言えます。これらの値は異なっており、今では95%の確信を持ってリリース基準を満たしていることが分かります。

これをさらに発展させると、片側仮説検定と呼ばれるものを行うことができます。これにより、各グループが最大許容率を下回っているという確信度を実際に測定することができます。各グループに対して異なる信頼値があることが分かります。リリース基準に達していることについて少なくとも95%の確信を持ちたいと言う場合、グループごとにその基準を満たしていると言えます。しかし、ここで捉えたい重要な点が1つあります - これらの測定値にはそれぞれ不確実性があります。すべてのグループがその値を下回っているという確信を持つためには、これらの測定値それぞれの不確実性を考慮した結合信頼度が必要になります。これが各測定値の不確実性を組み込む方法なのです。

これらの信頼区間を生成し、仮説検定を行うには、複数の異なる方法があります。Z検定やT検定など、さまざまなアプローチが可能です。Python上でstatsmodelsやSciPyなどのライブラリを使用する方法など、オープンソースのツールも数多く利用できます。これらは非常に使いやすいものですが、私が特に強調したいのは、チームがこのような方法でパフォーマンスを測定し、測定の不確実性について十分に理解することの重要性です。


ここでもう一度、信頼区間について掘り下げてみたいと思います。 具体的には、格差をどのように測定するかについてお話しします。最大パフォーマンスの閾値による基準について説明しましたが、では格差をどのように測定すればよいのでしょうか?一般的に、チームは区間の差を見ることが多いのですが、 私はより悲観的なアプローチを推奨しています。つまり、最も低い下限と最も高い上限の間の最大差を見るべきだということです。これはより悲観的な見方を反映していますが、それでも先ほど説明した不確実性の測定方法を完全には捉えきれていません。


より良い方法として、 データと観測結果に基づく格差の確率を組み込んだ、別形式の仮説検定があります。Analysis of Varianceを使用することで、格差が存在するかどうかについてある程度の信頼度を得ることができ、 さらにTukey's Honest Significant Differencesを使用すると、格差の大きさについての信頼区間を得ることができます。素晴らしい点は、異なるサンプルの観測と測定に基づいて、格差の大きさの分布を形成する信頼区間が得られることです。


先ほどと同様に、片側仮説検定を行い、観測された最大格差がある値を下回る確信度を測定することができます。これを各グループに対して行い、ペアワイズ比較ごとに、格差が基準値を下回る確信度を測定できます。そして、リリース基準を下回る格差が観測されないという共同信頼度を形成できます。これが、私たちが推奨する評価と結果の解釈方法です。多くの人が忘れがちな統計の基礎を振り返ることになるため、この部分により多くの時間を割きたいと考えました。 システムをリリースする際に、望ましくない事態が起こりにくいことを確認する必要があるため、これは非常に重要な考え方なのです。
リリースへの自信を高めるための対策と総括

これらの分析を行い、結果を解釈した後で強調したいのは、私たちは利用可能なすべての証拠を使用すべきだということです。点推定、信頼区間、仮説検定、そして私が説明した片側検定やリリース基準のテストなど、さまざまなアプローチを使用すべきです。これらの情報をすべて捉える必要があります。それを透明性レポートにまとめることは素晴らしい方法です。これは、私たちが行っているこれらの厳密なステップとすべての取り組みを伝えることで、顧客の信頼を構築する優れた方法となります。 そして、AWSではこれらの情報をAWS AI Service Cardsを通じて外部に発信しています。
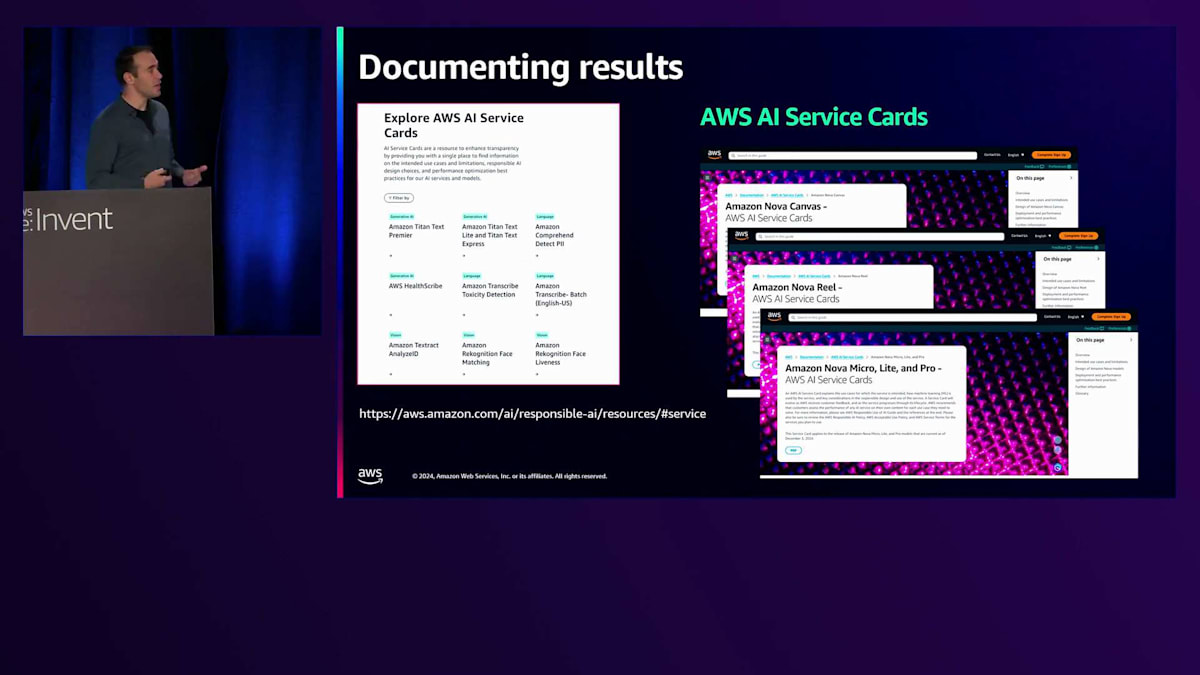
これらは、システムのリスクの可能性、制限事項、評価結果、そしてリリースのための評価時に考慮したさまざまな要素など、重要な詳細を捉えています。私たちはこれらの情報をお客様と共有することで、システムの現状とその期待されるパフォーマンスについて理解していただけるようにしています。


では、リリースに自信が持てない場合はどうすればよいのでしょうか?これまで評価方法についてお話ししてきましたが、自信が持てない状況にどう対処するかについてはまだ詳しくお話ししていませんでした。このような場合、私たちがまず行うのは、自信が持てない原因を特定することです。つまり、どこにエラーがあり、なぜそのエラーが発生しているのかを突き止めます。因果分析を行い、システムを改善する方法を実装することができます。これだけでも1つのセッションになりうるテーマですが、ここで強調したいのは、 これが追加のステップとなるということです。要件やリリース基準を満たしていない場合は、この包括的な対策ステップに取り組む必要があります。


LLMアプリケーションの場合、 システムにフィルターを導入することが一つの方法です。入力レベルでプロンプトをフィルタリングし、出力レベルで生成結果をフィルタリングします。有害な生成を要求する可能性のある有害な入力プロンプトを特定する有害性フィルターを使用して、それらをフィルタリングし、有害な出力もブロックして確実に捕捉します。 Amazon Bedrock Guardrailsは、このようなフィルタリングを行うための製品の一つで、さまざまなフィルタリング方法を設定することができます。現在では、LLMだけでなく、画像フィルタリングなどの機能も追加されています。これは、AWSの優れたツールで、様々なモデルに適用して有害な生成を減らすことができます。


このフィルターシステムと対策を追加した後、リリースに自信を持てるでしょうか?まだそうとは言えません。なぜなら、 メトリクスを再生成し、評価を再実行し、結果を再解釈して、実際に効果があったかどうかを確認する必要があるからです。さらに、 最初に戻って、全体的な品質評価、レイテンシーの測定、コストの測定を行う必要があります。なぜなら、システムに新しいコンポーネントを追加しているので、入力をフィルタリングする際に、レイテンシーやコストが増加したり、品質に悪影響が出ていないことを確認する必要があるからです。

ここで、これまで話してきた内容を簡単に振り返ってみましょう。LLMの評価の意味、AWSで利用可能な様々なツール、深刻度と発生可能性を考慮した評価方法、そしてリリースの信頼性を確立するための対応戦略のステップについて説明してきました。これらはすべて重要な考慮事項ですが、それぞれの要素は独立したセッションや、場合によっては1週間のセッションで扱えるほどの内容です。私が特に強調したかったのは、多くのチームやビルダーが躓きやすい特定の領域であり、それらに注意を向けていただきたいということです。


より詳しい情報をお求めの方は、Responsible AIのウェブページをご覧ください。そこでは、Service Card、ブログ記事、先ほどご説明したリスクアセスメント、そしてAWSチームとしてResponsible AIと評価にどのようにアプローチしているかについての詳細な情報をご覧いただけます。セッションの締めくくりとして、これから質疑応答の時間を設けますが、モバイル端末でのアンケートへのご協力をお願いしたいと思います。このアンケートは、私たちの発表の出来栄え、情報の関連性、満足度、内容の深さについて把握する上で非常に重要です。ぜひアンケートにご回答いただければ幸いです。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion