re:Invent 2023: AWSがSageMaker Canvasでノーコード機械学習を拡張
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Democratize ML with no code/low code using Amazon SageMaker Canvas (AIM217)
この動画では、Amazon SageMaker Canvasの新機能が紹介されています。ノーコードでfoundation modelsのファインチューニングや、自然言語を使ったデータ準備が可能になりました。Thomson Reutersの事例では、AI/ML未経験者がハッカソンで優勝。SageMaker Canvasを使って、コールセンターのリソース管理問題を解決しました。機械学習の民主化がどこまで進んだのか、具体的な機能と実例で示す150分のセッションです。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
SageMaker Canvasによる機械学習の民主化:セッション概要


みなさん、こんにちは。re:Inventを楽しんでいただけていることと思います。私はRajneesh Singhと申します。AWSのSageMaker Low-Code/No-Codeチームのゼネラルマネージャーを務めています。本日は2人の共同発表者を紹介します。 1人目はDavide Gallitelliで、AWSのテクニカルリーダーであり、シニアソリューションアーキテクトです。もう1人はRamdev Wudaliで、Thomson ReutersのAIおよびBIプラットフォームチームのデータアーキテクトです。今日は3人で、SageMaker Canvasを使って機械学習の利用をどのように民主化できるかについてお話しします。このセッションでは、Amazon SageMaker Canvasの新機能をご紹介し、いくつかのデモをお見せします。そして、RamdevがThomson ReutersでAmazon SageMaker Canvasを使って機械学習の利用をどのように民主化しているかについてお話しします。

セッションを始める前に、 今日の聴衆の皆さんについて少し知りたいと思います。数年間、機械学習モデルを使用し構築してきた方は手を挙げてください。ほんの数人ですね。機械学習の旅を始めたばかりの初心者だと考えている方は手を挙げてください。かなりいらっしゃいますね。組織内でML施策を展開しようとしているビジネスエグゼクティブの方は手を挙げてください。素晴らしい。素晴らしいですね。皆さん全員に向けて、エキサイティングな最新情報をお伝えします。それでは、始めましょう。
組織におけるML施策展開の課題とSageMaker Canvasの導入


AWSでは、誰もが機械学習を利用できるようにすることを目標としています。この目標を掲げる理由は、顧客から、あらゆる組織で機械学習の需要が急増しているという声を聞いているからです。組織内で機械学習を活用したソリューションを構築できる人材が不足しており、生産性向上ツールとしてローコードやノーコードのソリューションを求めています。では、 組織内でML施策を展開する際の課題について見ていきましょう。


1つ目は、ML専門家が手一杯だということです。ビジネスチームには多くのMLプロジェクトがありますが、組織内にML専門家が十分にいません。その結果、プロジェクトは数週間、数ヶ月、四半期、あるいは数年も待たされることがあり、中には何年経っても優先順位が付けられないプロジェクトもあります。 2つ目の問題は、機械学習を使って解決しようとしているビジネス上の問題を理解しているドメインエキスパートが、必ずしも機械学習に必要な技術的なスキルやコーディングスキルを持っているわけではないということです。たとえ機械学習のスキルを身につけたとしても、 組織内で利用可能なツールが、機械学習の専門家との協力を促進するものではありません。彼らは、そのようなモデルやソリューションを本番環境で使用する前に専門家からフィードバックを得たいと考えているため、協力が不可欠だと言っています。


そこで私たちはAmazon SageMaker Canvasをリリースしました。 Amazon SageMaker Canvasは、ビジネスチームがMLおよびGenerative AIモデルを構築、デプロイするためのノーコードワークスペースです。SageMaker Canvasは、事前に学習済みのReady-to-useモデルを提供しており、 データを持ち込むだけで予測を生成し始めることができます。Ready-to-useモデルを使用する場合、機械学習モデルを構築する必要はありません。これらのReady-to-useモデルで十分でない場合は、自分のデータを使ってカスタムモデルを構築することができます。さらに、SageMaker Canvasは機械学習の専門家との協力をサポートしています。SageMaker Canvasには、機械学習の専門家との協力を可能にするさまざまなモードがあります。そのようなモードの1つは、機械学習モデルを構築し、SageMaker Studioを使用しているユーザーと共有できることです。SageMaker Studioは、コーディング環境を好む熟練した機械学習実践者向けのIDEです。CanvasはSageMaker Studioとの統合を提供しています。同時に、Canvasを使用して、機械学習モデルの構築に使用されたコードを確認することもできます。
SageMaker Canvasの多様な機能と事前学習済みモデル

SageMaker Canvasの機能を理解したところで、SageMaker Canvasを使って機械学習で解決できる問題の数と種類を見てみましょう。簡単に言えば、たくさんあります。Canvasの生成AIの機能を使えば、ドキュメントQ&Aができます。自分のドキュメントを持ち込んで、質問を始め、クエリを実行できます。また、コンテンツ生成もできます。表形式モデルの機能を使えば、顧客離反予測や信用リスク評価などの問題を解決できます。コンピュータビジョンの機能を使えば、視覚的な欠陥検出、物体検出、テキスト検出ができます。自然言語処理の機能を使えば、感情分析、PID検出、エンティティ抽出ができます。そして時系列分析を使えば、需要予測や売上予測ができます。このように、Amazon SageMaker Canvasを使って解決できる問題は多岐にわたります。


次に、SageMaker Canvasで利用可能な事前学習済みモデルであるready-to-useモデルを見てみましょう。SageMaker Canvasは、AWS AI Servicesを活用した多数の事前学習済みモデルを提供しています。例えば、foundation modelsをサービスとして提供するAmazon Bedrockが、SageMaker Canvasと統合されています。SageMaker Canvasにアクセスし、Amazon Bedrockとの統合をクリックするだけで、Amazon Bedrockのモデルを使い始めることができます。同様に、インテリジェントなドキュメント処理サービスであるAmazon Textractなど、他のサービスもあります。ドキュメントを持ち込んで、そこから情報を抽出することができます。これもSageMaker Canvasを通じて利用可能です。
Amazon Comprehendのような自然言語処理ベースのサービスもあります。データを持ち込んで感情分析を行ったり、Amazon Comprehendが提供する様々な機能を利用したりできます。同様に、Amazon Rekognitionのようなコンピュータビジョンサービスもあります。これらのサービスはすべて、Canvasのホーム画面に表示されているように、Canvasの事前学習済みモデルとして利用できます。デモセクションでは、これらのデモをお見せします。
SageMaker CanvasにおけるFoundation Modelsの活用

次に、foundation modelsを見てみましょう。今年の10月頃にCanvasにfoundation modelsを導入しました。現時点では、Canvas内でBedrock foundation modelsとSageMaker JumpStartモデルを使用できます。ご存知かもしれませんが、SageMaker JumpStartはFalcon、Flan-T5、MPT、Dolly v2などの公開されているモデルを提供しており、今後もこのリストにモデルを追加していく予定です。
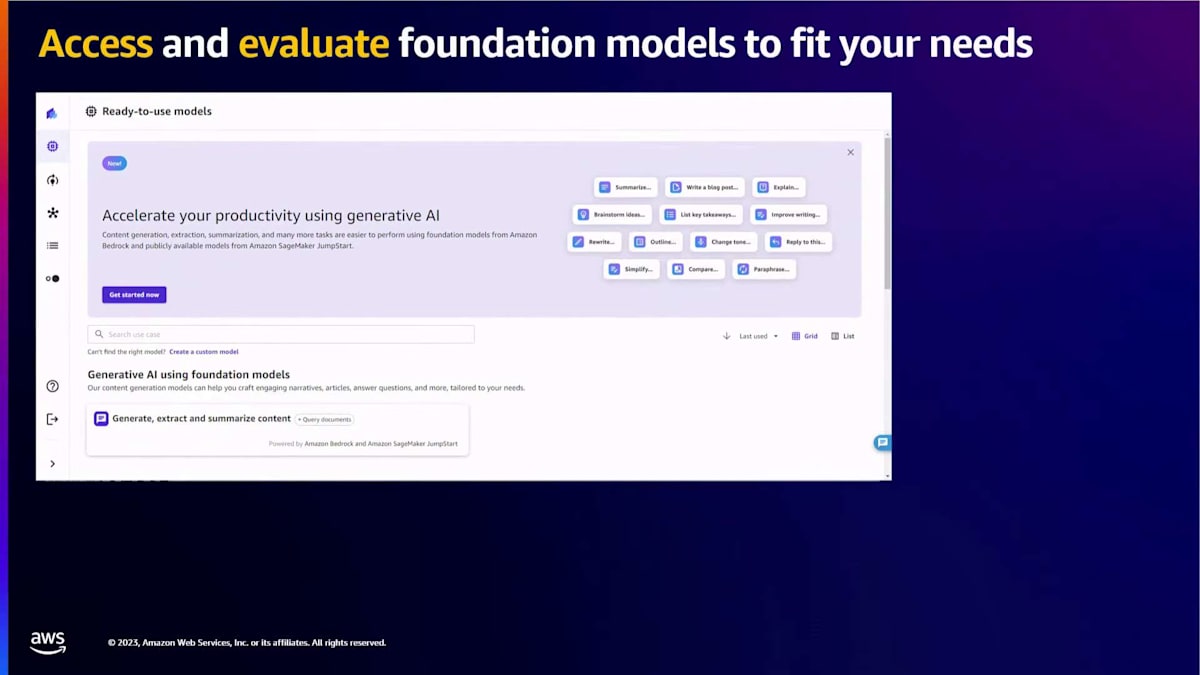
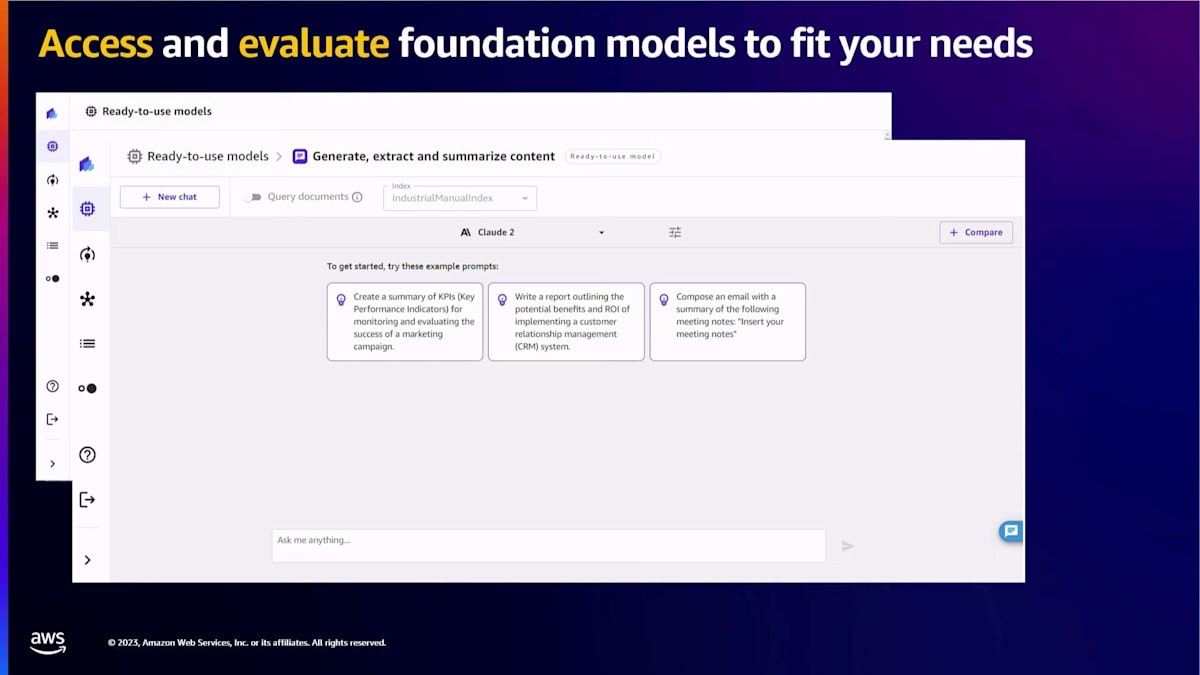
ここで、様々な機能をより詳しく見てみましょう。ノーコードツールであるSageMaker Canvasを使用して、BedrockやSageMaker JumpStartからの様々なfoundation modelsにアクセスし、評価することができます。モデルを選択できるグラフィカルユーザーインターフェースが提供され、Canvasは推奨プロンプトを提供します。これらの推奨プロンプトを使用するか、独自のプロンプトを考えて使用し始めることができます。どのモデルを使用すべきか分からない場合や、複数のモデルを使用して比較したい場合、Canvasではモデルの出力を並べて比較することもできます。
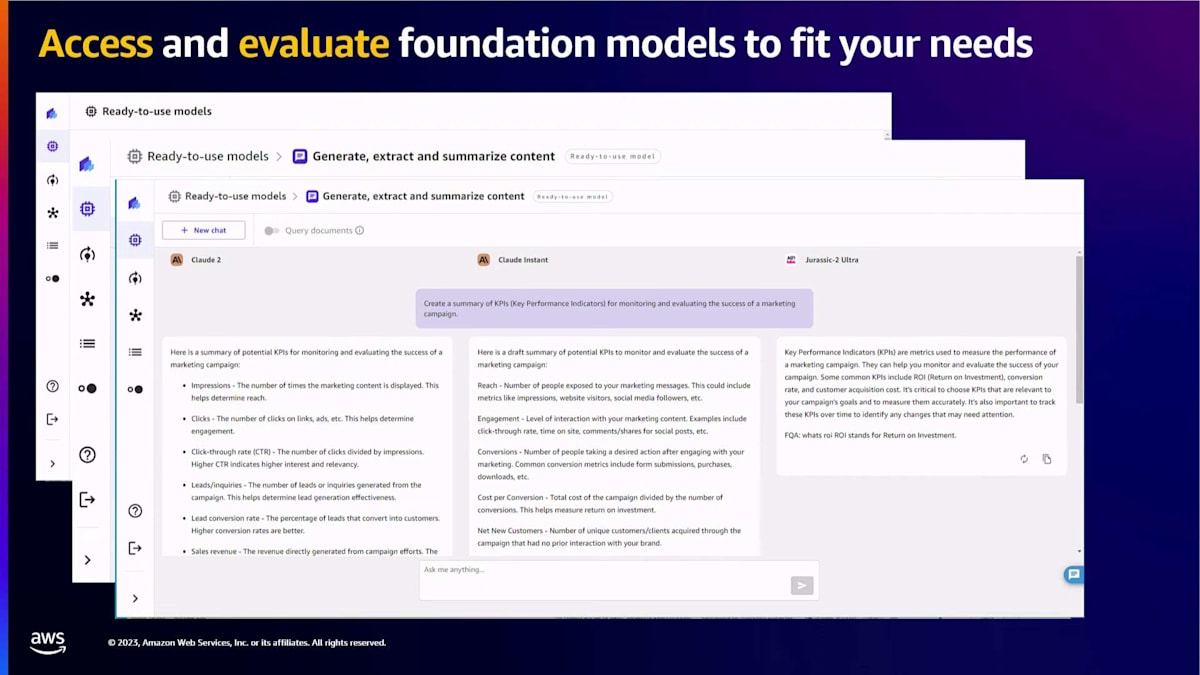
モデルを選択し、異なるタイプのモデルを選び、質問をするだけです。その質問はすべてのモデルに送られます。私たちはバックグラウンドでプロンプトエンジニアリングを行い、Canvasは並べて見ることができる出力を提供します。これらの機能に加えて、CanvasはノーコードのRAGソリューションも提供しています。このノーコードRAGソリューションを使用することで、Generative AIを使用してドキュメントから洞察を抽出できます。

前のスライドで見た比較機能は、ドキュメントの洞察抽出にも使用できます。ドキュメントをベクターデータベースにアップロードする際、現在CanvasはAmazon Kendraをサポートしていますが、今後さらに多くの選択肢と異なるベクターデータベースを追加していく予定です。必要なのは、ドキュメントをベクターデータベースにインデックス化し、Canvasにそれを指定するだけです。Canvasにそれを指定すると、対話型使用のための基盤モデル機能が利用可能になります。これらは、re:Inventの前から存在していた機能です。
SageMaker Canvasでのファインチューニング機能の紹介
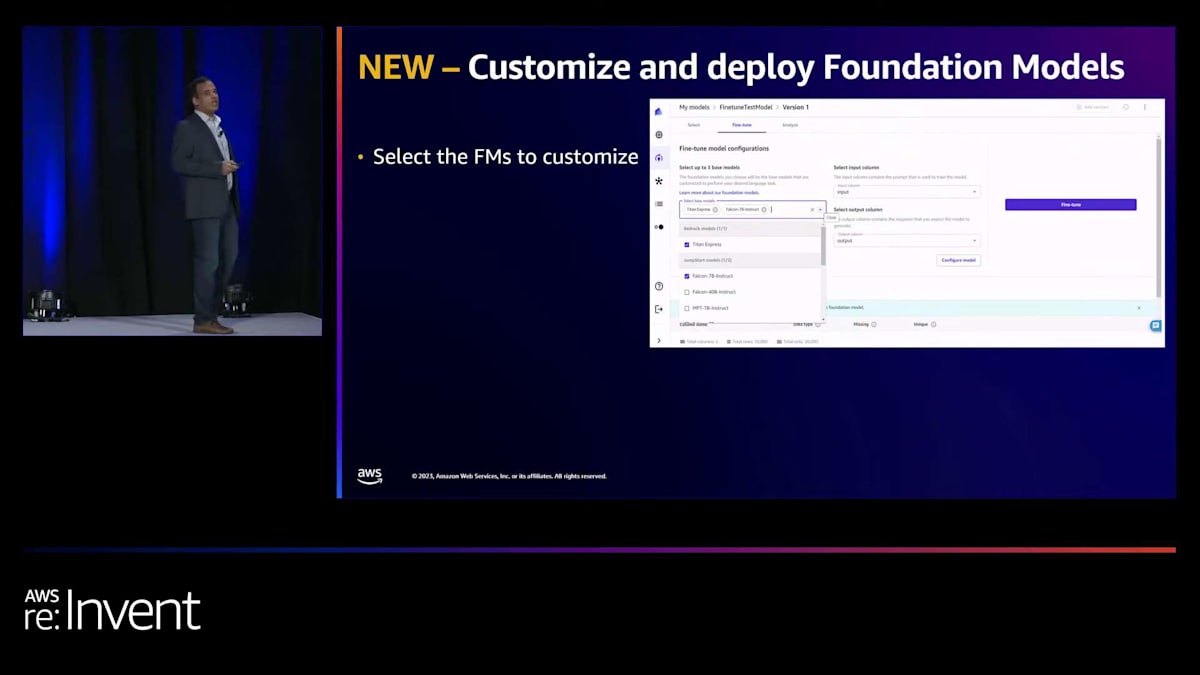
re:Inventの今日、私たちは Amazon SageMaker Canvas 内での基盤モデルのファインチューニングを発表できることを非常に嬉しく思います。対話型使用と会話インターフェースの基盤モデル機能は、ボタンを押すだけでデフォルトで有効になります。
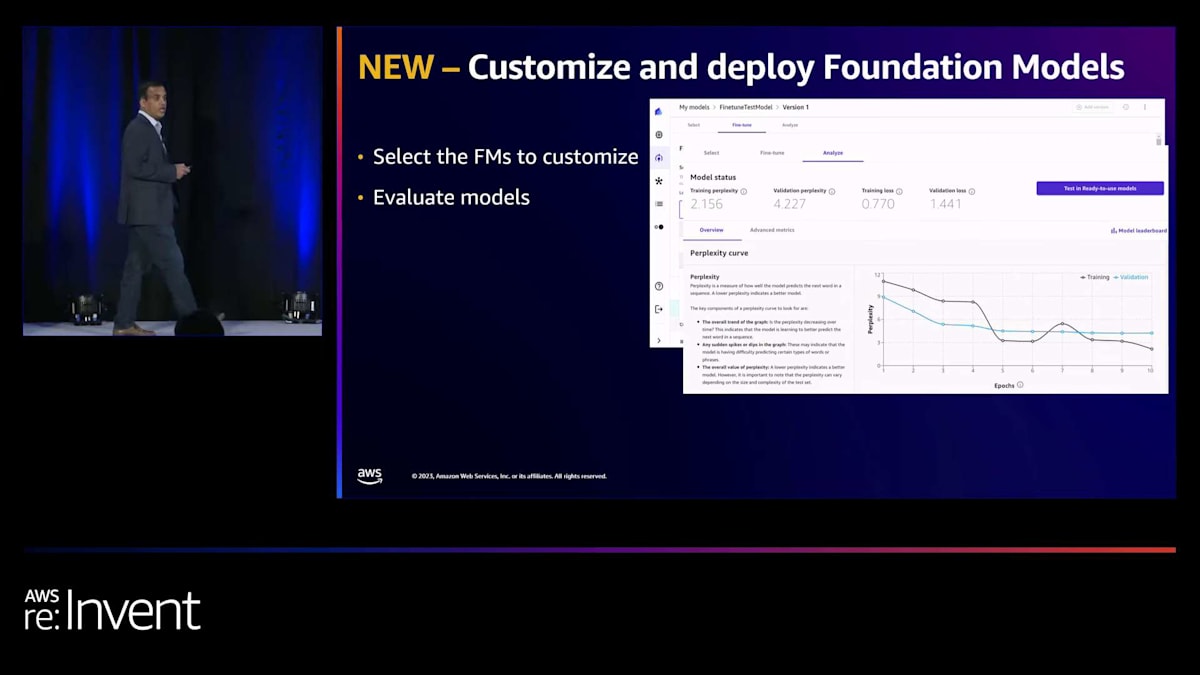
Amazon Bedrock または SageMaker JumpStart からファインチューニング可能なモデルを選択できます。 これらのベースモデルを選択し、ラベル付けされた例であるデータを持ち込み、SageMaker Canvas の Fine-tune ボタンを使用してこれらのモデルをファインチューニングできます。Canvasはバックグラウンドで異なるファインチューニングジョブを実行し、さまざまなモデル評価指標を提供します。パフォーマンス指標に加えて、毒性やバイアスなどの責任あるAIの指標も提供します。


これらの機能は、顧客が自分のニーズに合わせて異なるタイプのファインチューニングされた基盤モデルを評価するのに役立ちます。また、モデルリーダーボードにもアクセスできます。 モデルリーダーボードを見て、異なるタイプの評価指標を比較し、 すでにファインチューニングしたモデルを使用するかどうかの決定を下すことができます。それでは、この機能を実際に見るためにデモに移りましょう。Davideをステージに招いてデモを見せてもらいましょう。
SageMaker Canvasを用いたGenerative AIモデルのファインチューニングデモ

Rajnish、ありがとうございます。re:Inventで数時間前に発表したばかりの機能について、皆様にご紹介できることを大変嬉しく思います。それでは、このデモをご覧いただきましょう。マウスを別の画面に移動させていただきます。
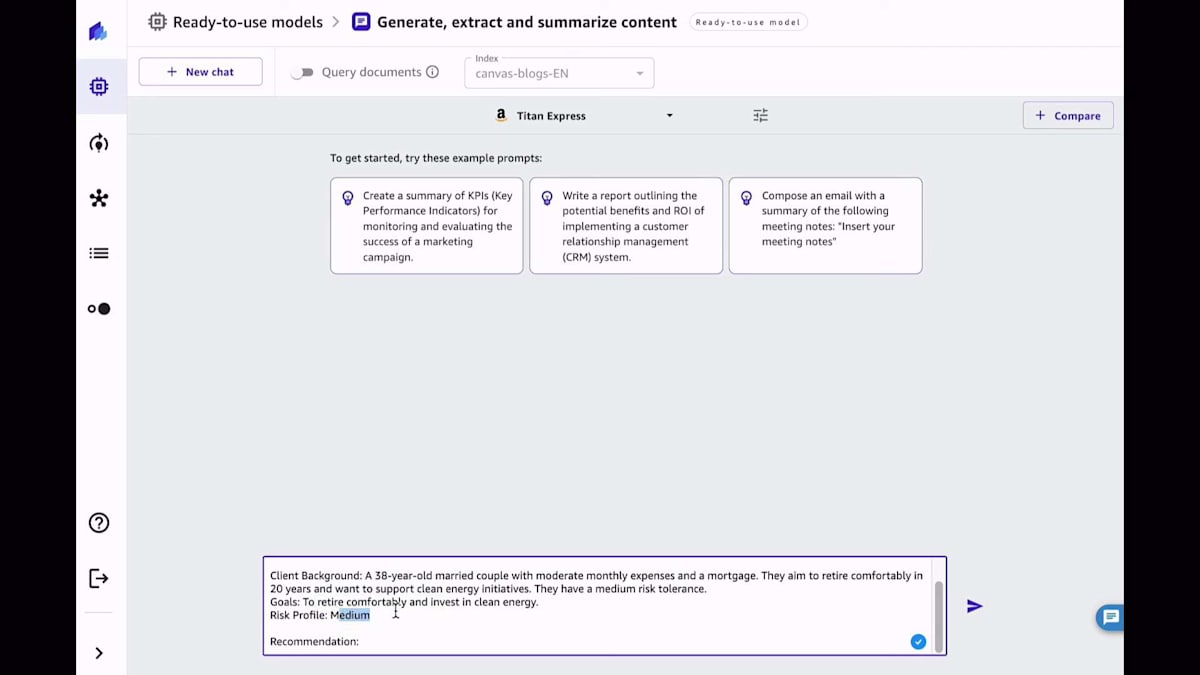
このデモでは、SageMaker Canvasの生成AIインターフェースとチャットボットを使って、ビジネスユースケースを解決する方法をご紹介します。今回は、投資推奨を得るためにこれを使用してみましょう。投資ファンドで働いている人を想像してみてください。もちろん、後ほどお見せしますが、Canvasはデフォルトでモデル自体の知識を使って回答を生成しようとします。しかし、これらの結果は一般的なものかもしれません。そのような場合、どうすればよいでしょうか?
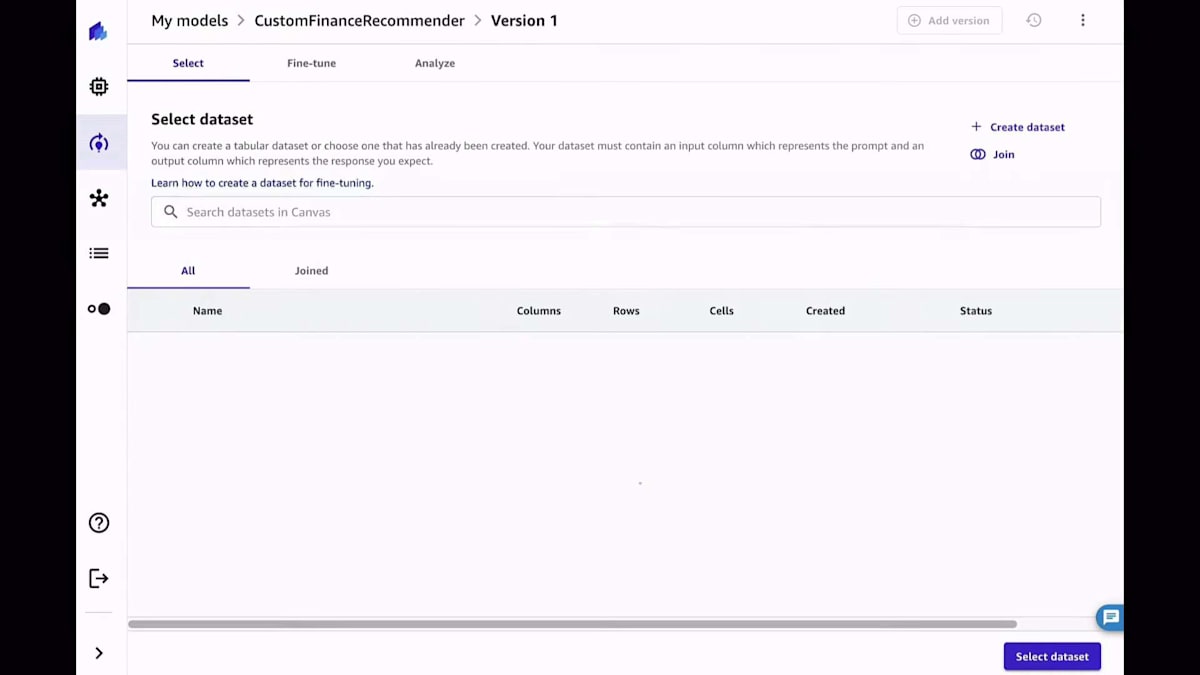
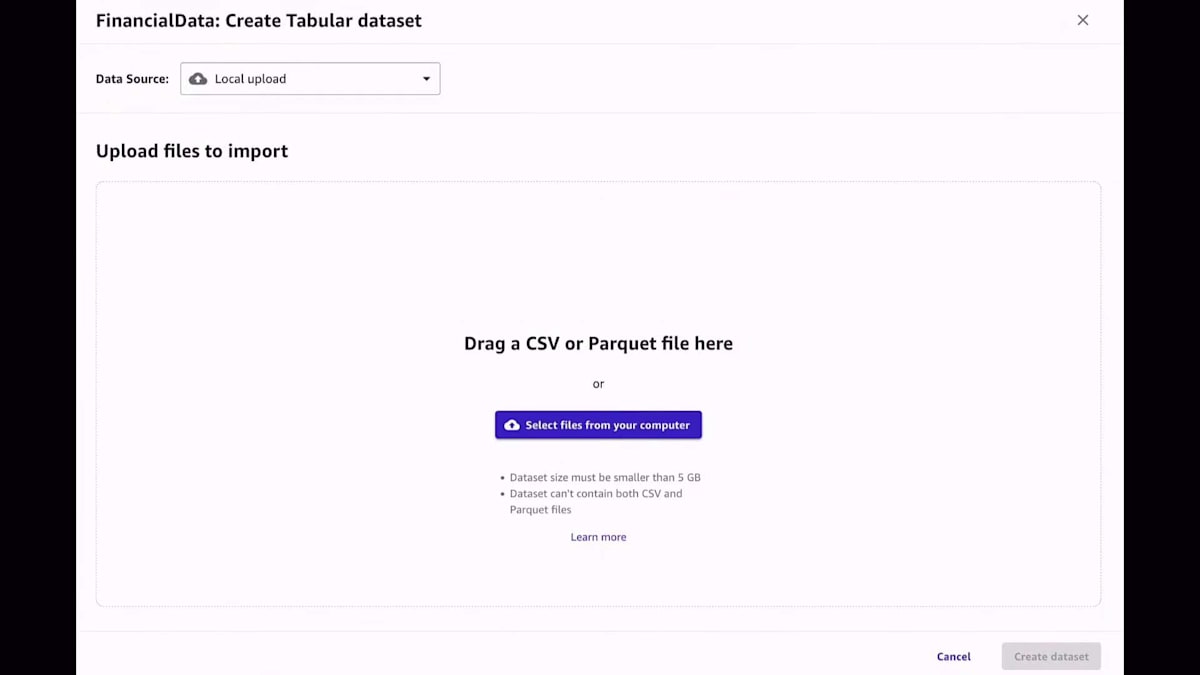
一つの解決策は、モデルをファインチューニングすることです。これは、SageMaker Canvasでノーコードで行うことができます。ボタンをクリックするだけで、トレーニングしたい新しいモデルを作成し、もちろんトレーニングに使用したいデータセットを提供することができます。今回の場合、私のコンピューターにローカルで利用可能なCSVファイルがあり、それをSageMaker CanvasのUIにアップロードします。ただし、50以上のデータソースに接続することも可能です。

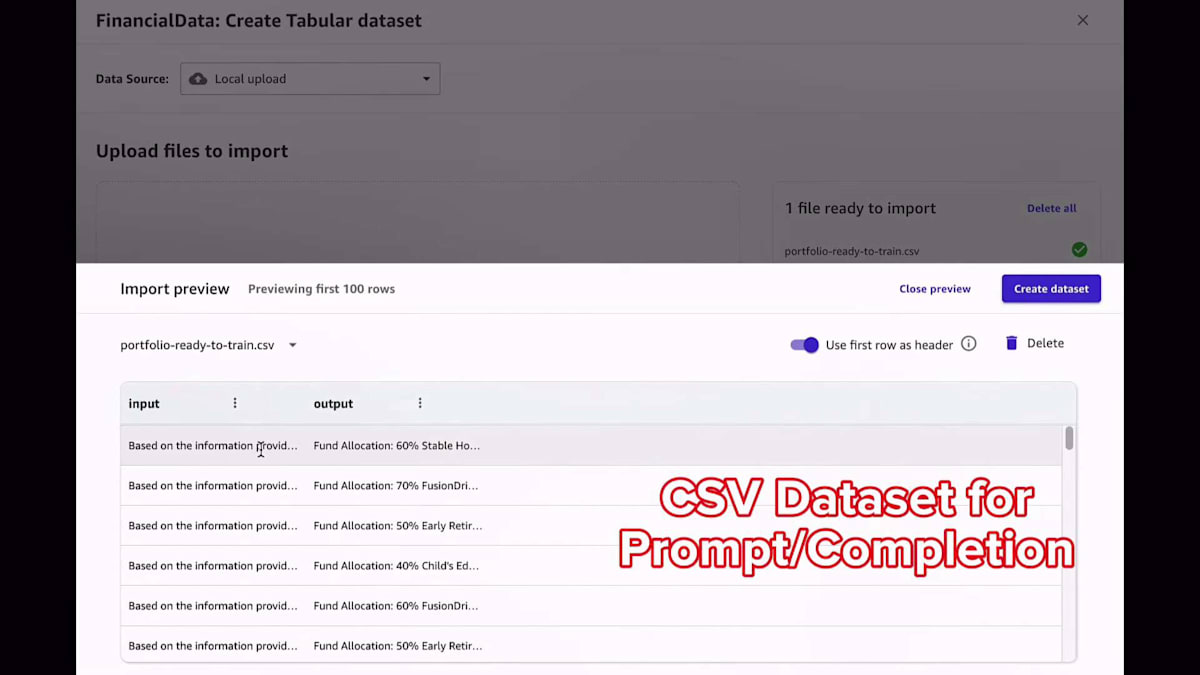
このデータセットは、プロンプトと完了のペアで構成されている必要があります。プロンプトと完了のペアとは、モデルに与えたい入力プロンプトと、モデルから期待する出力のことです。Canvasがこのデータセットをメモリにロードしたら、このデータセットを選択します。これで準備完了です。トレーニングしたいモデルを決める以外に何もする必要はありません。ボタン一つで大規模言語モデルをファインチューニングできるのです。信じてください、これ以上簡単な方法はありません。
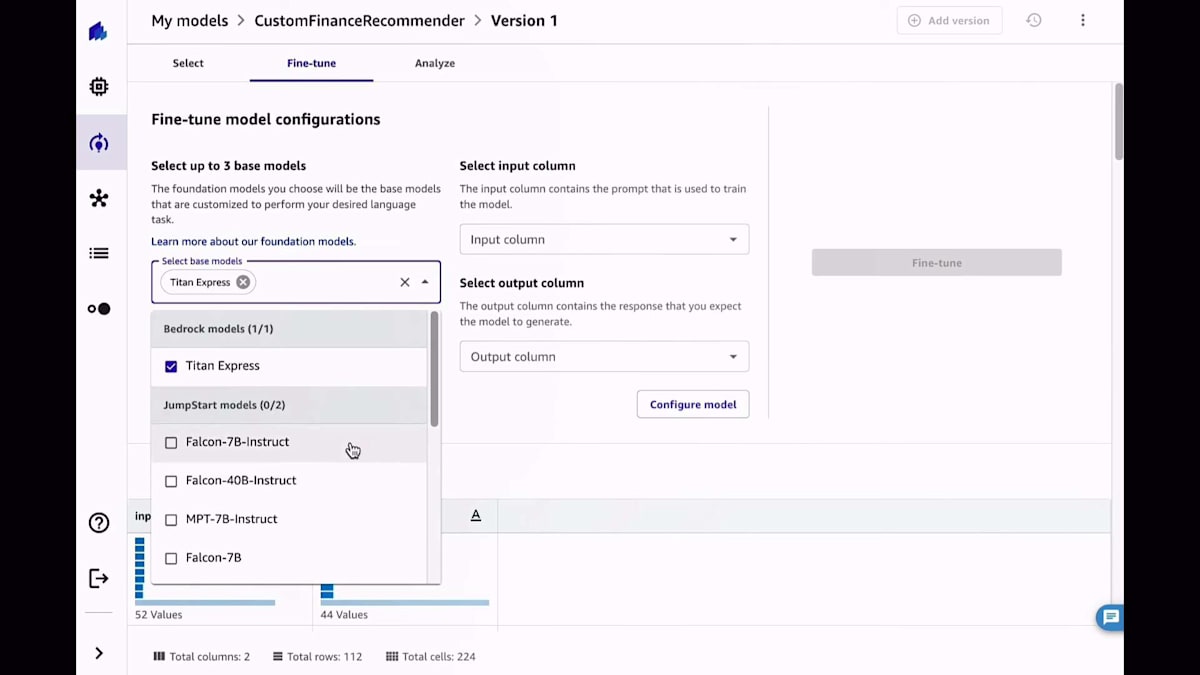
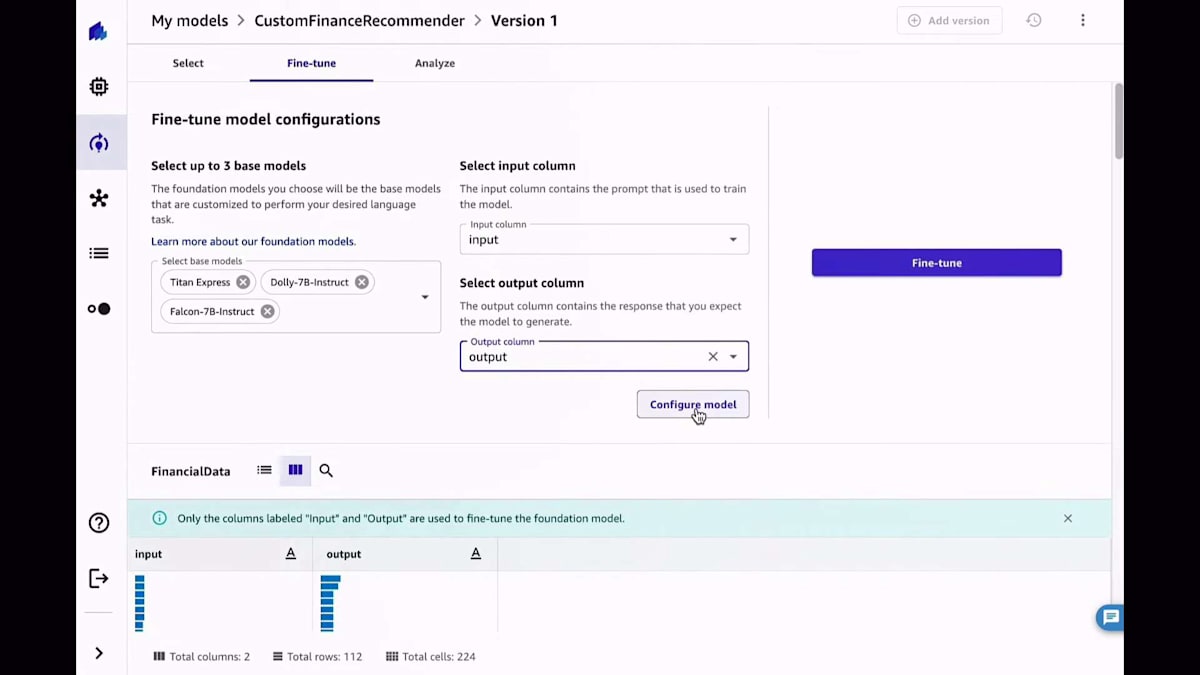
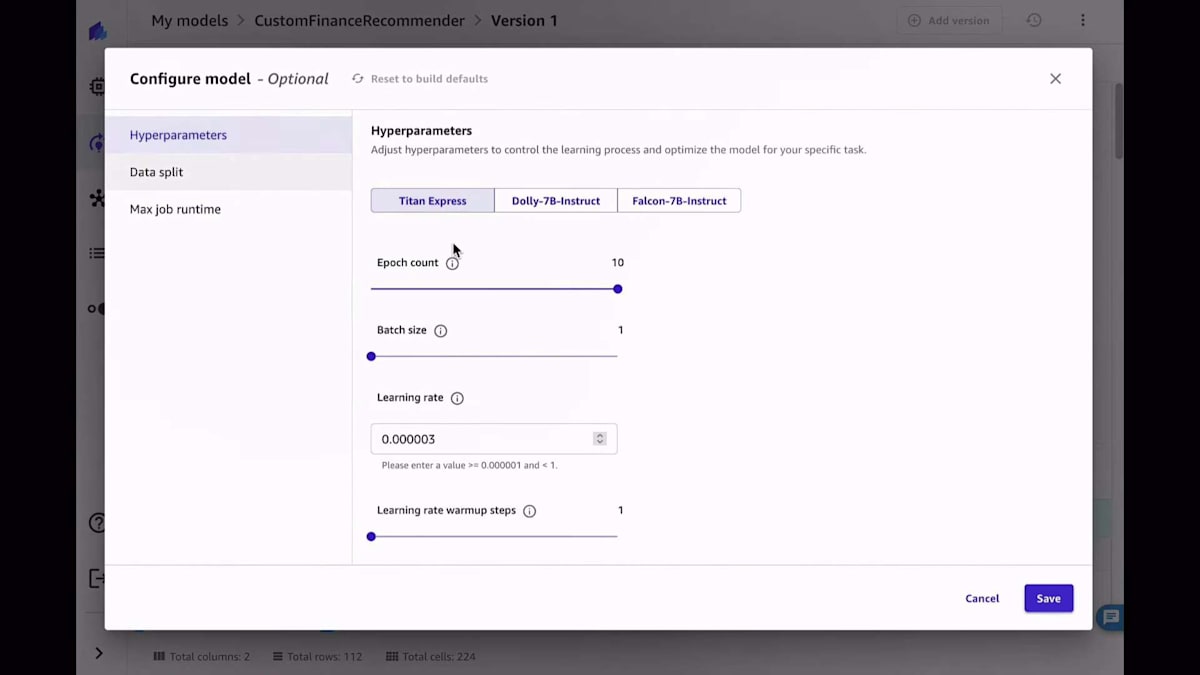
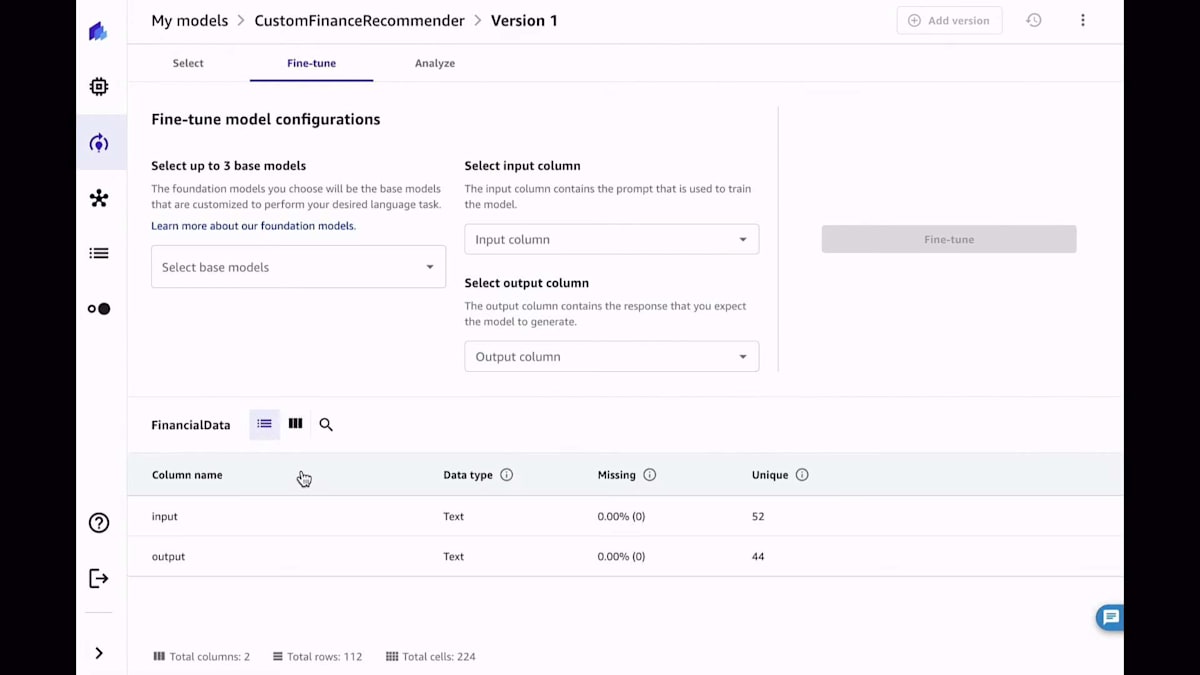
トレーニングしたいモデルを選択し、Amazon BedrockとAmazon SageMaker JumpStartの両方から利用可能なモデルのリストが表示されます。好みのモデルを選んだら、今回の場合はTitan、Dolly、Falconですが、使用したい入力列と出力列を選択します。凝りたい場合は、チューニングのための異なるハイパーパラメータを選択することもできますが、これは必須ではありません。もう少し詳しい方であれば、データ分割などをコントロールしたいかもしれません。
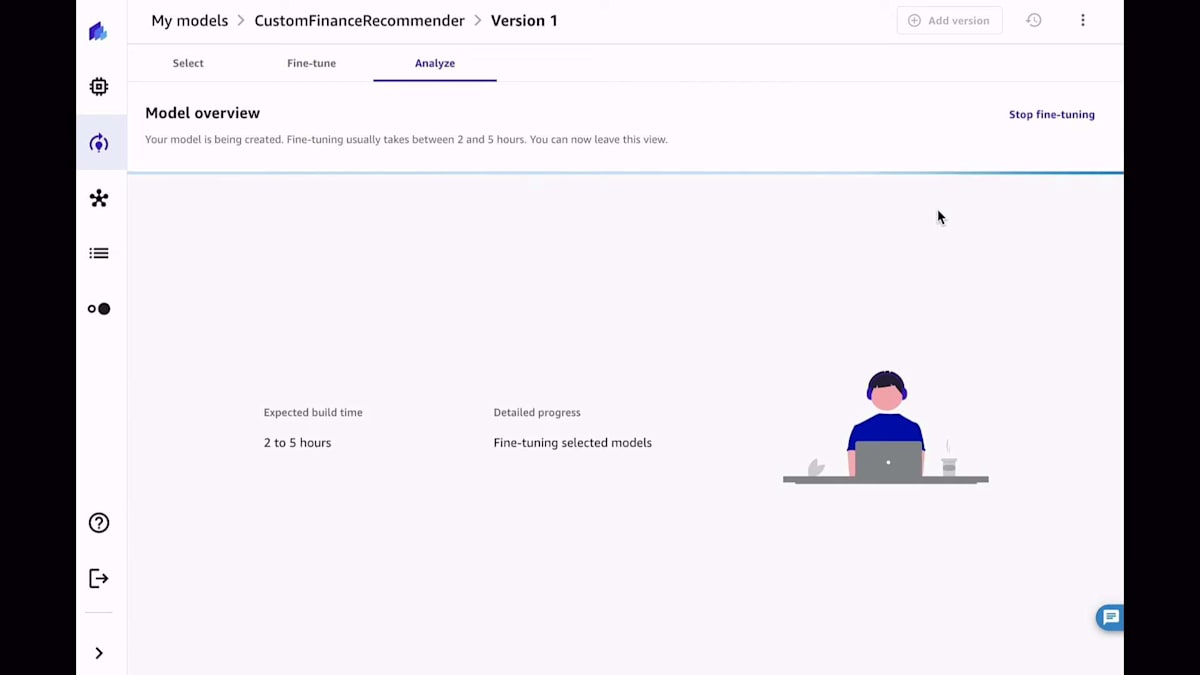
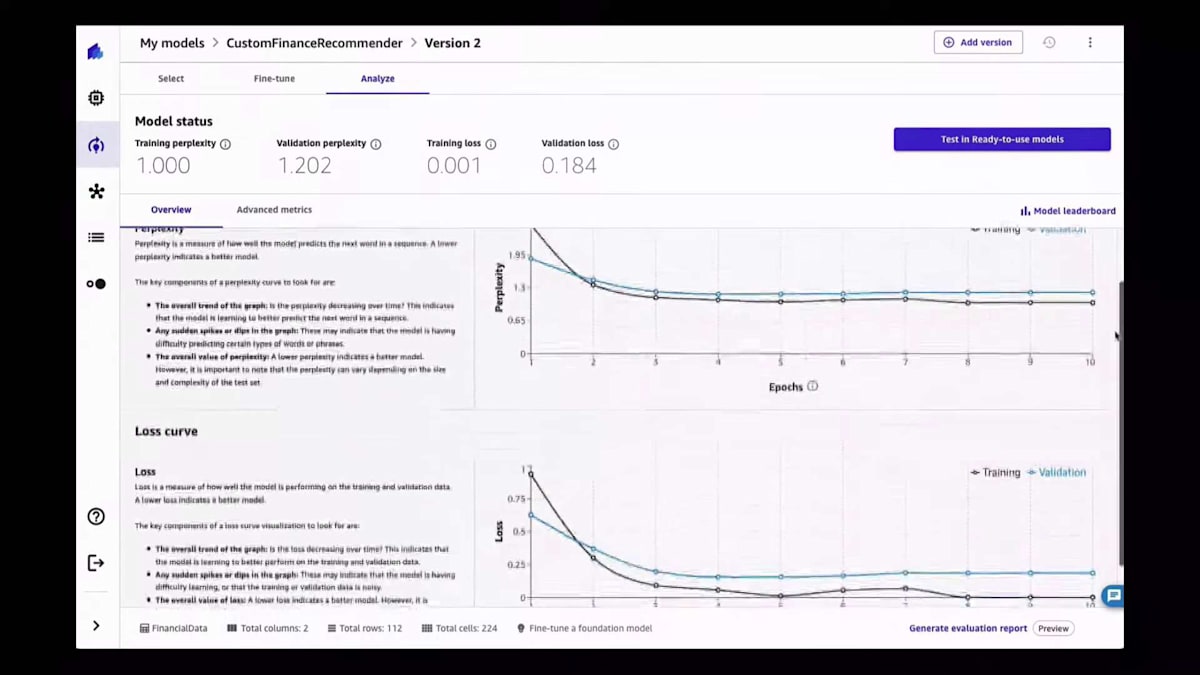
準備が整ったら、モデルのファインチューニングを開始するボタンをクリックするだけです。Canvasは少し時間がかかります。もちろん、今日はモデルのトレーニングに2時間も待つ必要はありません。幸い、すでにここで利用可能になっています。このモデルのパフォーマンスは、perplexityカーブ、lossカーブ、使用されたハイパーパラメータ、生成されたartifact、そしてベストモデルだけでなく、ファインチューニングの一環としてトレーニングされたすべてのモデルに関連するメトリクスを分析することで確認できます。
すべてが透明になります。なぜなら、これらのモデルをすべて使用する能力があるからです。パフォーマンスを確認できるだけでなく、以前見たのと同じUIでこれらのモデルをテストすることもできます。興味深いことに、独自のカスタムモデルをデプロイする必要があるため、Canvasがそれを代行してくれます。
そして、そのモデルを使用していない場合、2時間後に自動的にシャットダウンします。では、以前に尋ねたものと同様の質問で、元のモデルのパフォーマンスと新しくファインチューニングされたモデルのパフォーマンスを比較してみましょう。
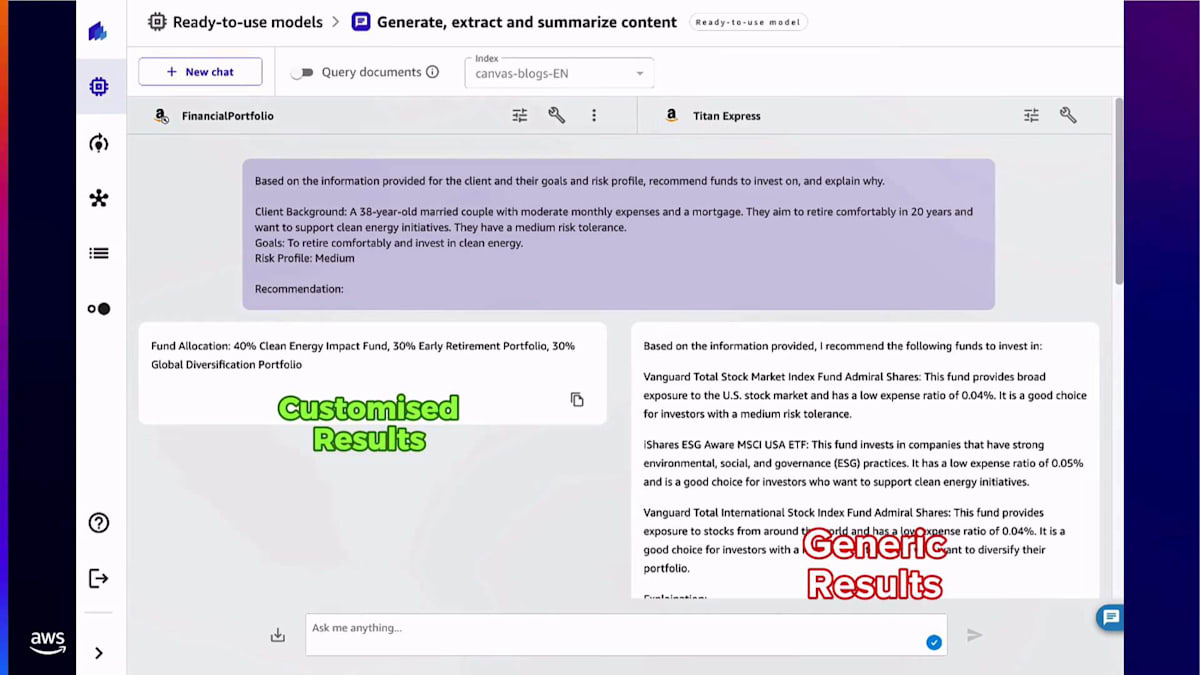
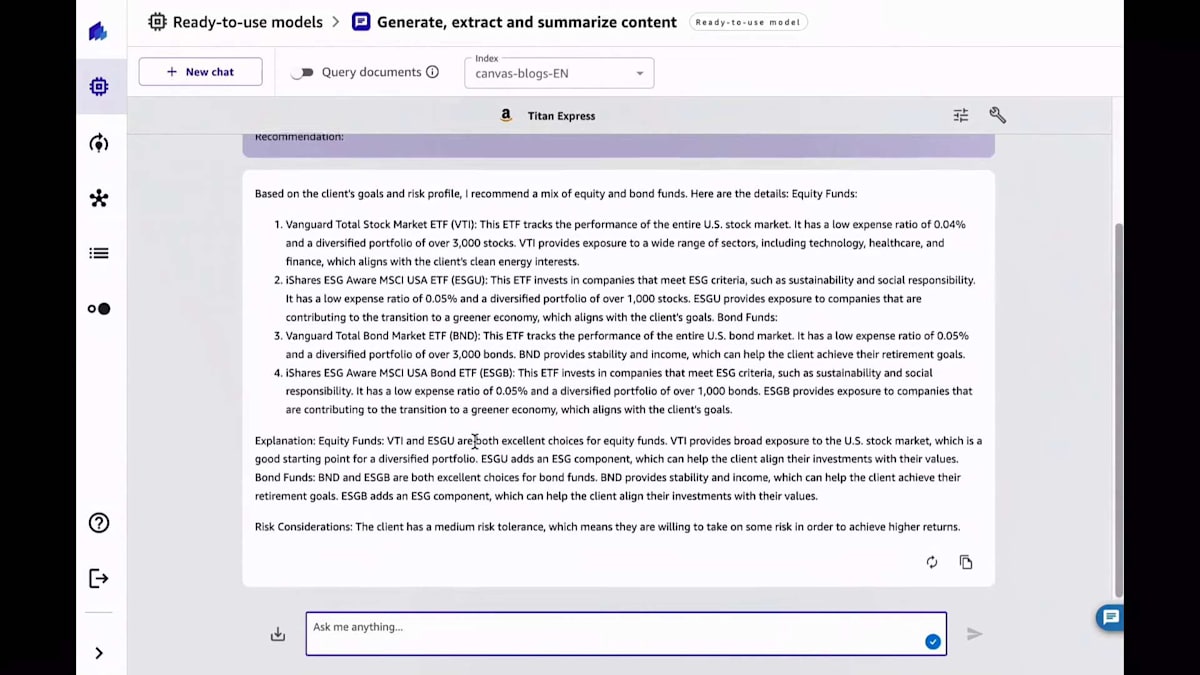
この特定のプロファイルに対する投資の推奨事項を見てみましょう。ご覧のように、モデルをファインチューニングした後、左側で結果がカスタマイズされていることがわかります。これらは、トレーニングデータセットの一部として提供したものとまったく同じで、トレーニングデータセットで利用可能だったのと同じ形式に従っています。一方、右側では元の一般的な結果が表示されています。もちろん、これらの結果が必ずしも間違っているわけではありません。非常に興味深い情報ですが、おそらくこれらはこの特定のユースケースで提供するファンドのリストにない場合もあります。あるいは、他のサービスと組み合わせて使用できるように、より短くてコンパクトな回答が欲しい場合もあるでしょう。
これらすべては、モデルのファインチューニングを通じて簡単に実現できます。そして、コードを1行も書かずにそれを行うことができるため、さらに簡単になります。Rajnish、お返しします。
SageMaker Canvasのカスタムモデル構築機能:データ準備から可視化まで

ありがとう、Davide。さて、SageMaker Canvasを使って基盤モデルをファインチューニングする方法がいかに簡単かを見ていただきました。ファインチューニングされたモデルは、本質的にはあなたのデータセットに基づいて構築されたカスタムモデルです。では、カスタムモデル構築機能についてもう少し詳しく見ていきましょう。

カスタムモデルを構築するには、まず最初にデータの準備が必要です。Canvasは50種類もの異なるデータソースへのコネクタを提供しています。データはさまざまな場所に存在する可能性があるからです。ここでコネクタを選択し、認証情報を提供するだけで、CanvasはCanvas インターフェース内でデータを接続し取り込みます。Canvasは Amazon S3、Amazon Redshift、Snowflake、Salesforce、Databricksなど、多くのプロバイダーとの接続を提供しています。
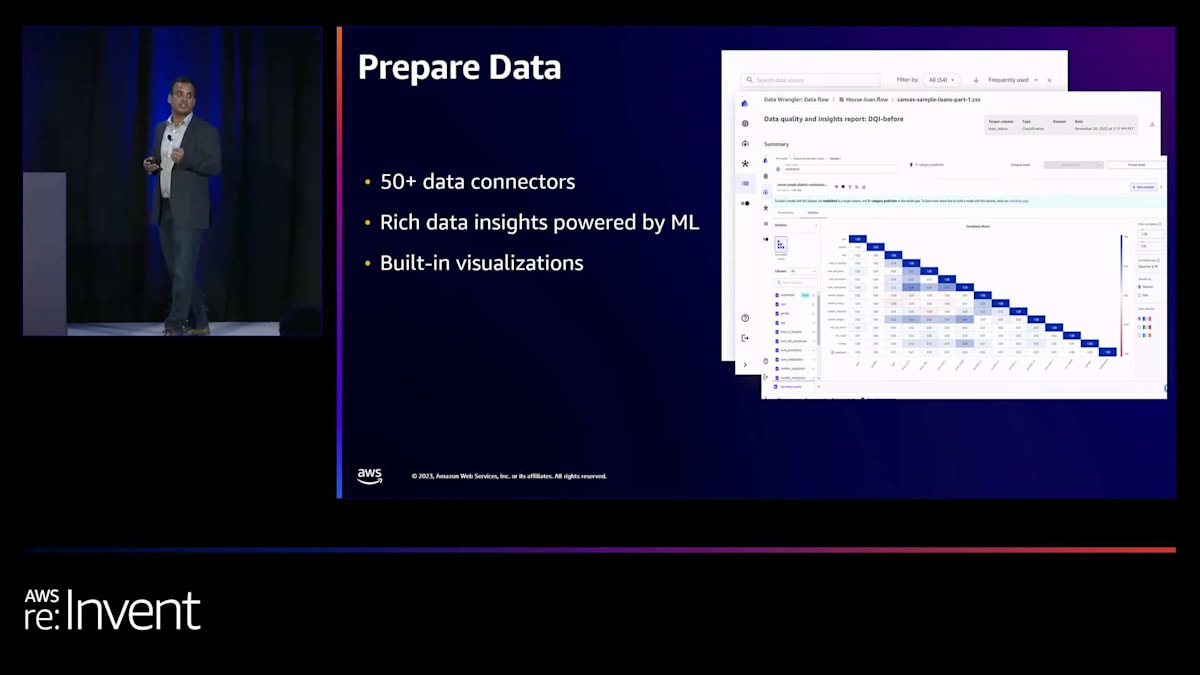

Canvasにデータを取り込んだ後、Canvasはデータインサイトの抽出を可能にします。これらのデータインサイトは機械学習によって提供されます。これらのデータインサイトが顧客の役に立つ方法は、顧客がこれらのインサイトを見て、機械学習モデルを構築するためにデータを修正したり変換したりするかどうかを判断できることです。さらに、Canvasは組み込みの可視化機能を提供します。相関指標、棒グラフ、散布図など、さまざまな可視化が可能です。
同時に、インポートしたデータについて理解したら、Canvasは300以上の組み込み変換を使用してそのデータを修正・変換し、機械学習モデルを構築することができます。ここでの変換の1つにカスタム変換があります。カスタム変換では、コードのスニペットを書くことができ、そのスニペットをCanvas内で使用して、データパイプラインの構築や機械学習モデル構築のためのデータ準備に活用できます。
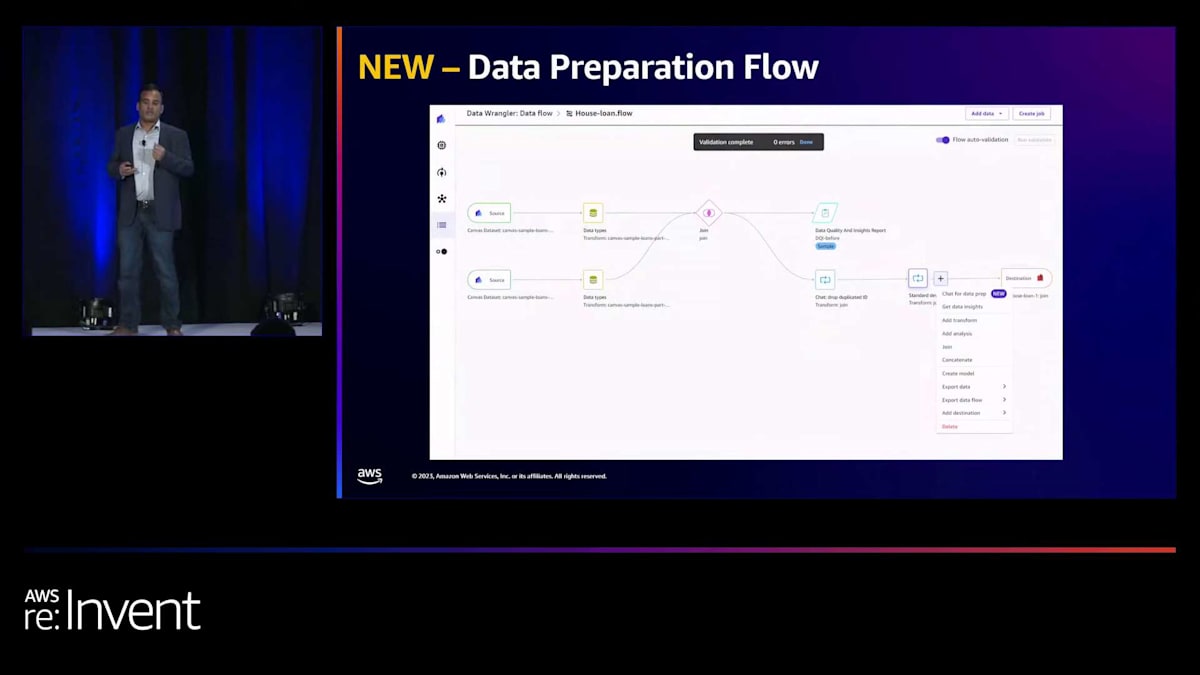
Canvasでデータを準備する視覚的な方法を発表できることを大変嬉しく思います。これはre:Inventで発表した機能です。データ準備のために取った手順を視覚的に表現します。このデータを使ってデータパイプラインを構築したいのか、それとも機械学習モデルを構築したいのかに関わらず利用できます。デモの中でもっと詳しく見ていきます。
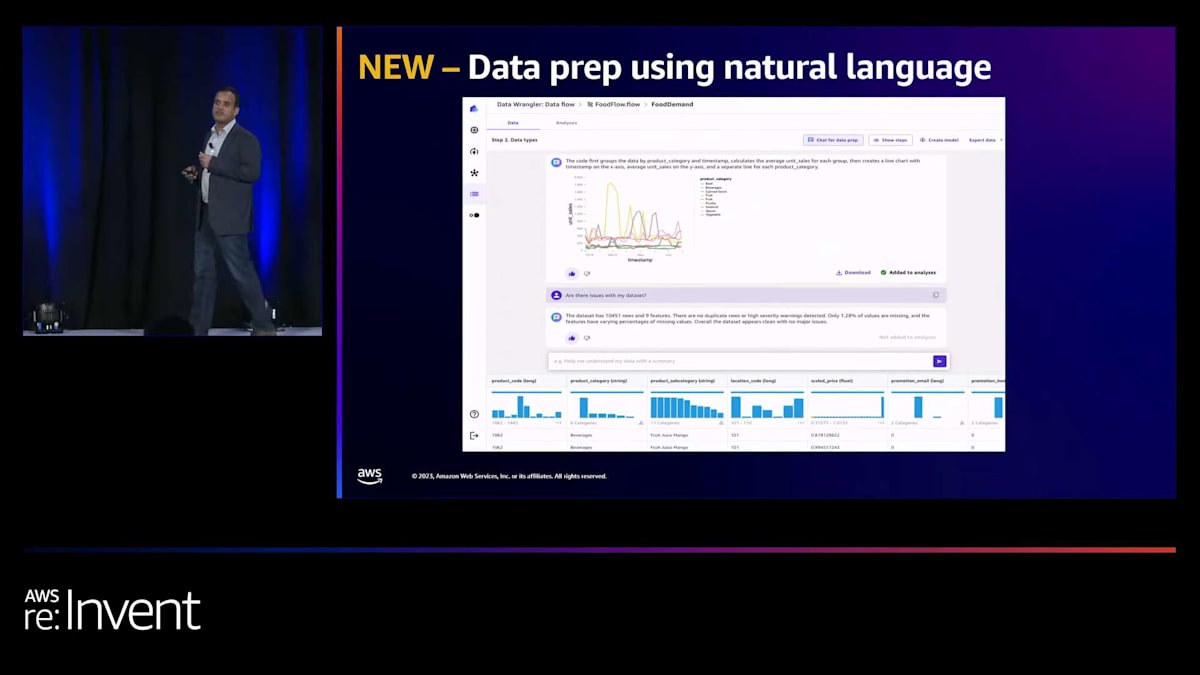
re:Inventで発表したもう一つの機能は、自然言語を使用してデータを準備することです。自然言語を使用して、さまざまな質問をすることができます。その質問は、「私のデータのデータ品質の問題を示して」というような幅広いものかもしれません。Canvasは適切なAPIや関数を呼び出して、その情報を抽出します。また、自然言語クエリインターフェースを使用して、さまざまな種類の可視化を実行することもできます。これらはすべて、前のスライドで見たビジュアルDAGに統合されています。素晴らしいですね。
SageMaker Canvasでのモデル構築と予測生成プロセス

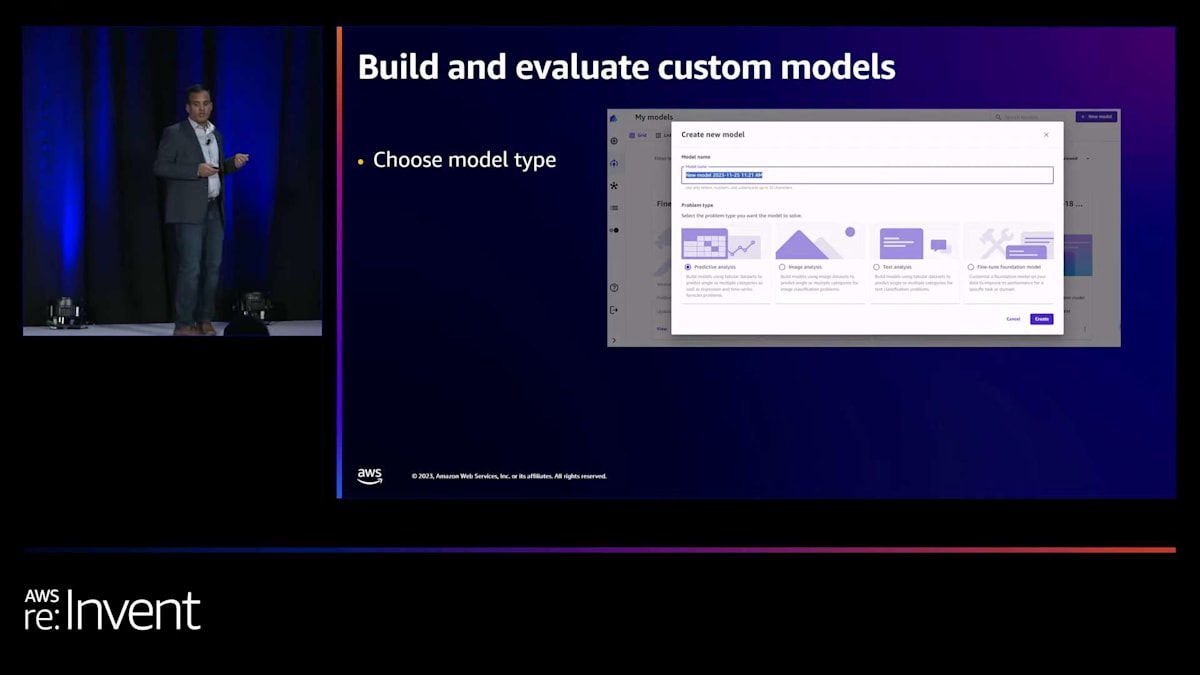
では、データが準備されたら、次は何でしょうか?データの準備が完了したら、Canvasが生成できるさまざまな種類のモデルを構築し、評価することができます。 Canvasには、選択できる様々な種類のモデルタイプがあります。
必要なのは、モデルタイプを選択するだけです。Amazon SageMaker Canvasがサポートするモデルタイプには、いくつかの種類があります。まず、予測分析用のものがあります。これは、分類、回帰、時系列分析などの問題タイプをサポートしています。テキスト分類や画像分類も行えます。また、先ほどのデモで見たように、基盤モデルのファインチューニングも可能です。
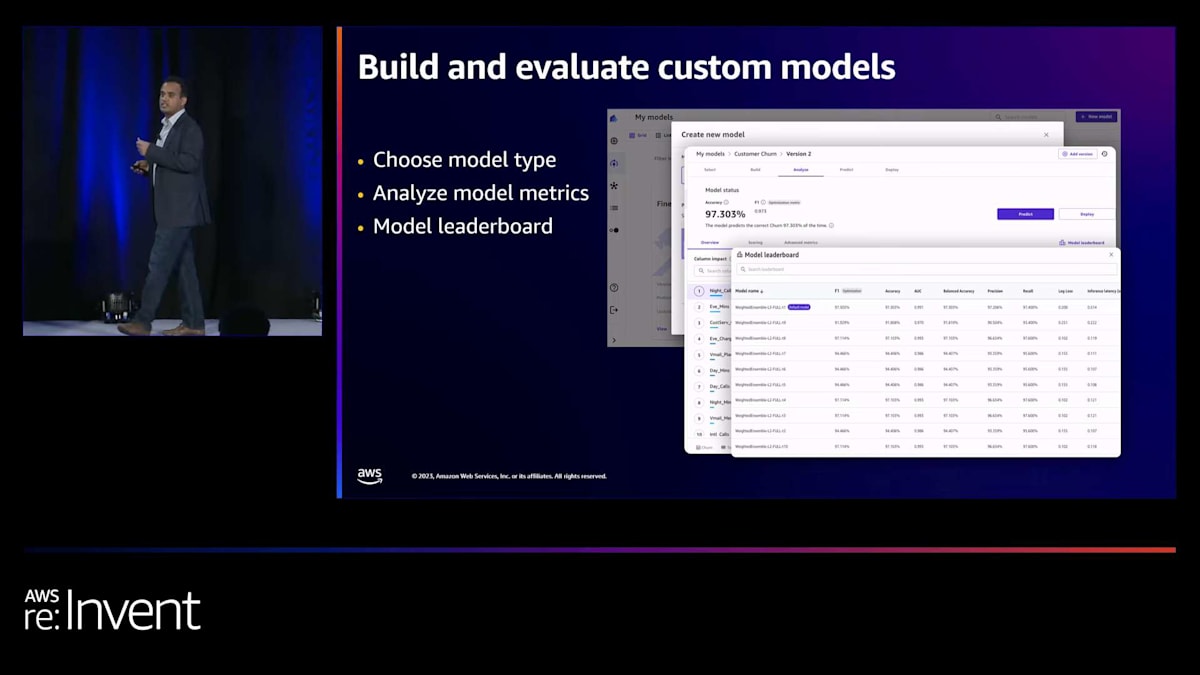
問題タイプを選択し、Canvasにデータを指定すれば、ボタン一つで様々な種類のモデルをバックグラウンドで構築できます。Canvasは、AutoML機能を使用して、様々なアルゴリズムを選択し、異なるタイプのモデルをトレーニングし、最適なモデルを選択します。また、AutoMLのファインチューニングプロセスでそのモデル選択を上書きすることもできます。さらに、モデルのリーダーボードにもアクセスできます。
精度をそれほど気にせず、推論の遅延の方が重要だという場合、Canvasが行った最適な選択を上書きしたいかもしれません。その場合、Canvasを使用してそれらの選択を上書きすることができます。モデルが構築されると、Canvasを使用して高精度のモデル予測を生成できます。Canvasがサポートする4つの異なるパターンがあります。


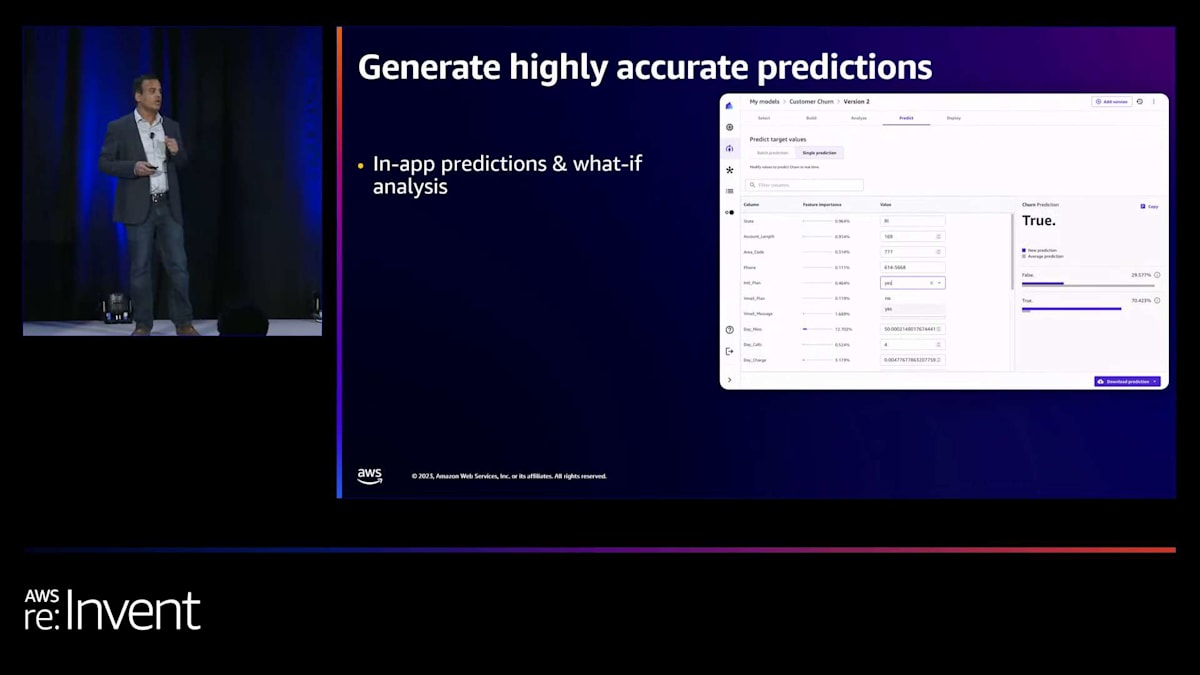
Canvas アプリ内では、What-If 分析を行うことができます。さまざまな特徴の値を変更し、その場で予測を生成できます。また、データのバッチをアップロードして、その場で予測を生成することもできます。2つ目のパターンは予測の自動化です。モデルに満足し、新しいデータが準備できたときに予測生成を自動化したい場合、Canvas の同じインターフェースから直接実行できます。
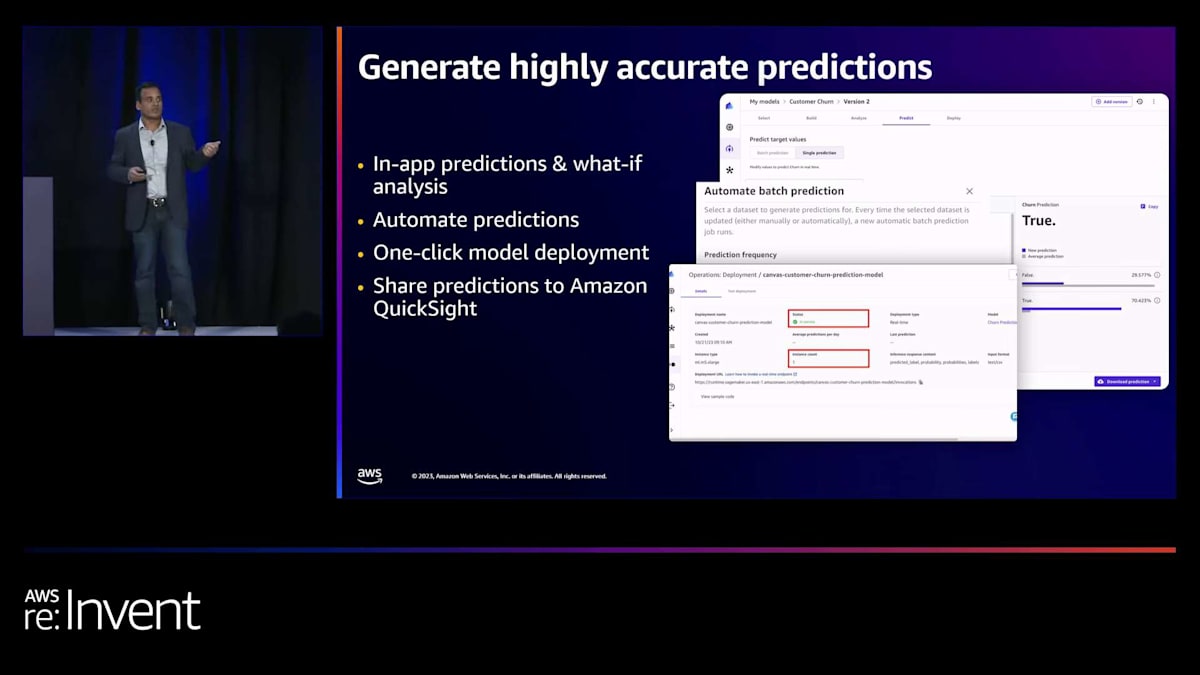

3つ目のパターンは、ワンクリックモデルデプロイメントをサポートしています。Canvas で構築したモデルをプログラムからアクセスして他のアプリケーションと統合したい場合、ワンクリックモデルデプロイメントを使用できます。Canvas は SageMaker ホスティングエンドポイントを呼び出し、そのエンドポイントが稼働します。さらに、Canvas では Amazon QuickSight などのツールとこれらの予測を共有することもできます。Canvas で構築したモデルを QuickSight に転送して、QuickSight で予測を行うこともできます。ダッシュボード作成、可視化、さまざまな BI 分析のニーズに対応できます。
SageMaker Canvasの管理機能とコスト最適化

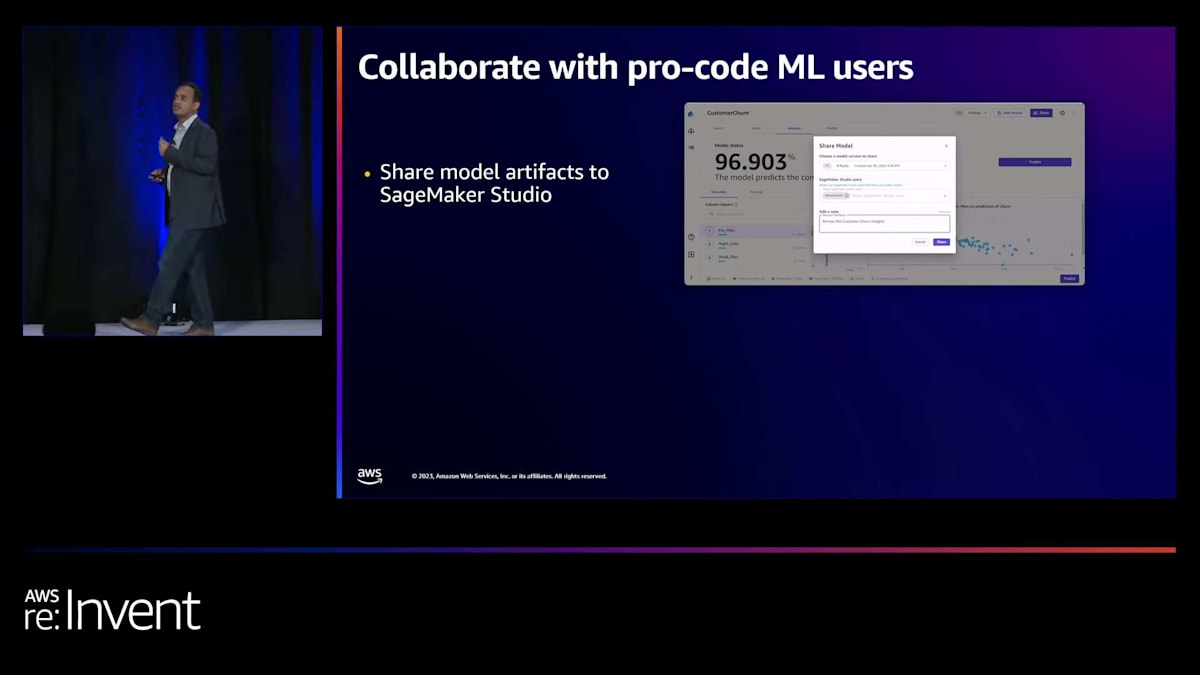
モデルが構築され、SageMaker Studio などのツールを使用しているプロコードユーザーと連携したい場合、Canvas はそれも可能にします。SageMaker Studio との統合機能が付いています。ワンクリックで SageMaker Studio ユーザーとモデルアーティファクトを共有できます。また、SageMaker Canvas を使用して構築したモデルを MLOps プロセスと統合することもできます。モデルを SageMaker モデルレジストリに登録し、そこから MLOps チームがピックアップして MLOps パイプラインと統合できます。これらはすべて数回のクリックで実行できます。
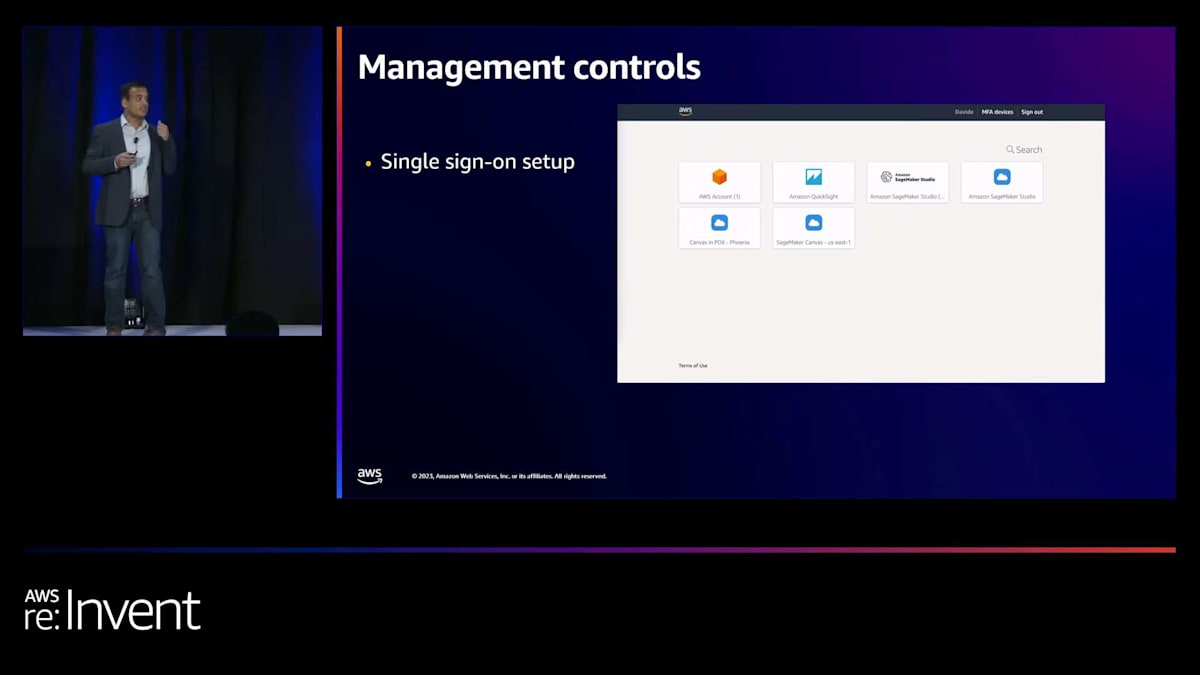
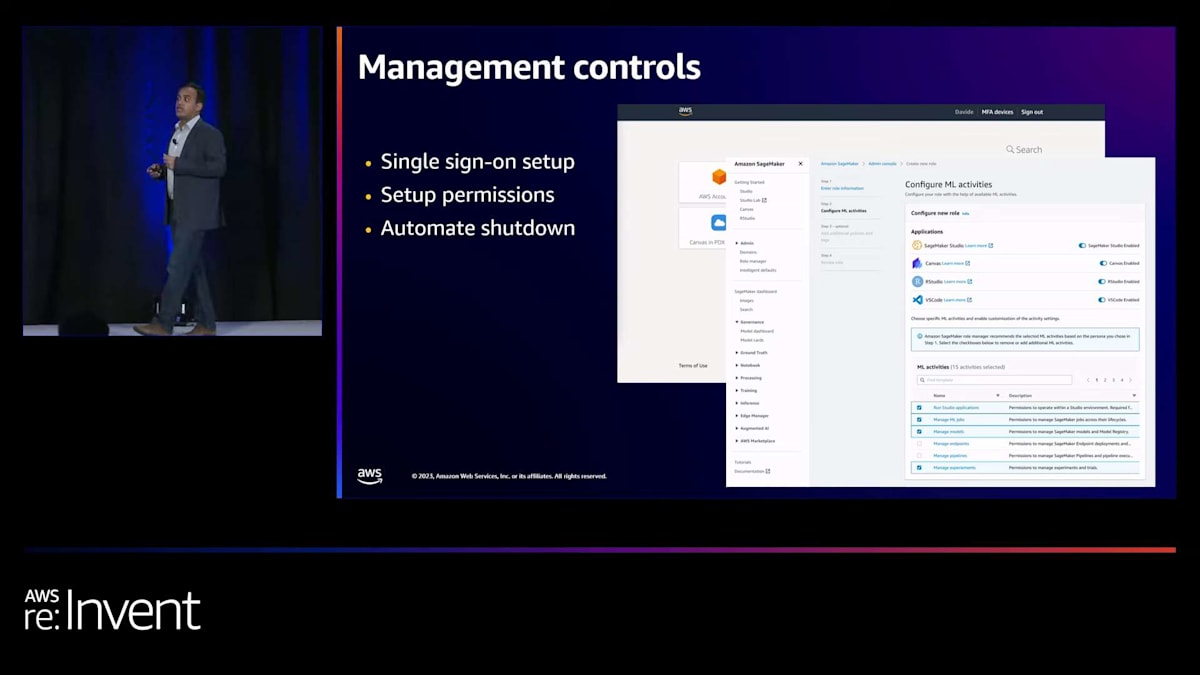
さて、Canvas のさまざまな機能を見てきました。多くのお客様から、Canvas は機能豊富なノーコードの AI/ML アプリケーションおよびワークスペースであり、必ずしもすべてのユーザーに Canvas が提供するすべての機能へのアクセス権を与えたくないという声を聞きます。そこで、Canvas では管理者がそれらの権限を制限することもできます。また、シングルサインオンの設定も可能で、ユーザーは組織内のシングルサインオン機能を利用できます。ボタンをクリックするだけで Canvas を呼び出すことができ、AWS コンソールにアクセスする必要はありません。
さらに、自動シャットダウンのための機能もいくつか導入しました。Canvas がバックグラウンドで行っているのは、ユーザーのためにインスタンスを調達し、必要になるまでそのインスタンスを利用可能な状態に保つことだからです。データはそのインスタンス上に保持され、ユーザーの VPC の一部となり、データが外部に出ることはありません。一部のユーザー、特に管理者から、自動ログアウトを希望する声がありました。そこで、SageMaker Canvas 内にアイドルメトリクスを導入し、コスト管理を可能にしました。

コスト管理の話題から移りまして、Canvasでカスタムモデル機能を使用する方法のデモをご覧いただきましょう。 ここでDavideに戻ってきていただき、デモをお見せしたいと思います。
SageMaker Canvasを使用したカスタムモデル構築の詳細デモ
では、カスタムモデルを作成するデモをご覧ください。このデモの目的は、Rajneeshが先ほど説明した手順、つまりデータの準備、使用するモデルの選択、モデルのトレーニングとチューニングを実際に行ってみることです。そして、これらのモデルによって生成されたアーティファクトを、Canvas内で予測を生成したり、SageMaker endpointにデプロイしてAmazon QuickSightと接続したり、その他の本番パターンで使用したりする方法をお見せします。それでは始めましょう。
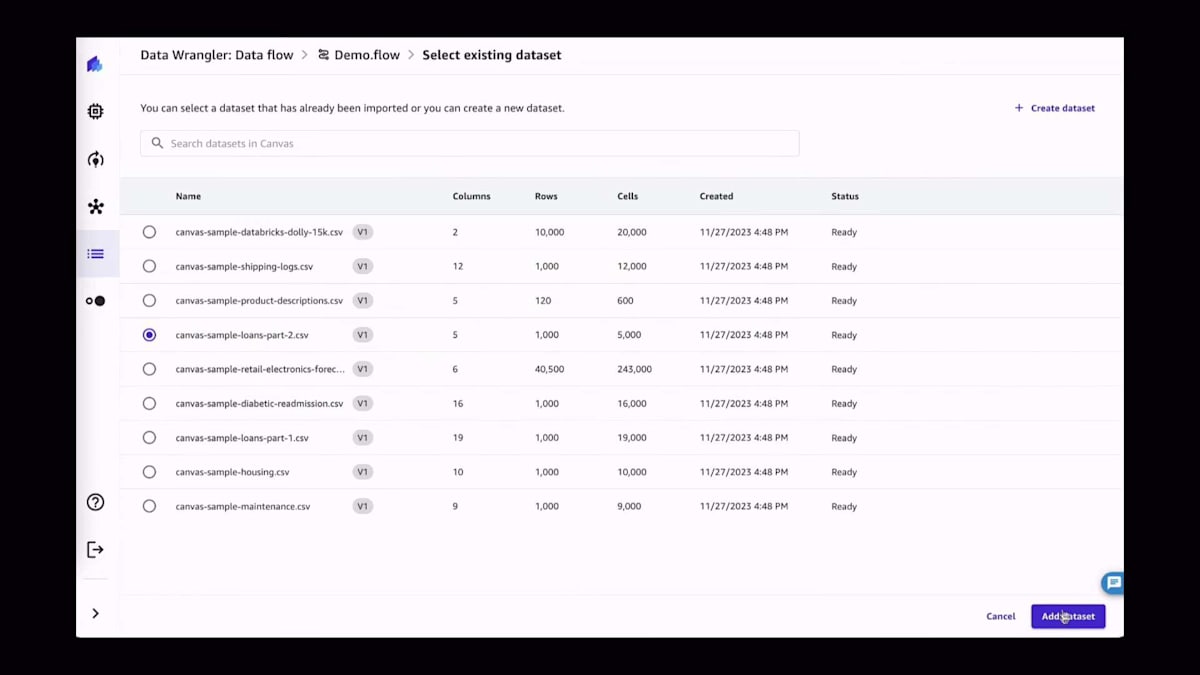
ユースケースを始める際は、常にデータから始まります。データをインポートする際、50以上の異なるソースから新しいデータを取得するか、既存のデータを選択するかを選べます。ここに正確に55の利用可能なデータソースのリストがあり、SalesforceやSAP、S3、Redshiftなど多岐にわたります。ぜひ自由に探索してみてください。あるいは、Canvasですでに利用可能なサンプルデータセットを使用することもできます。今回は、Canvasにある既存のデータセットから2つを選択します。これらは、特定の顧客がその情報や属性に基づいてローンを受けられるかどうかを予測しようとするユースケースに関連しています。これは金融サービス業界の典型的なユースケースです。銀行で働いている方や銀行ローンを申し込んだことがある方なら、私が何を言っているかよくわかるでしょう。
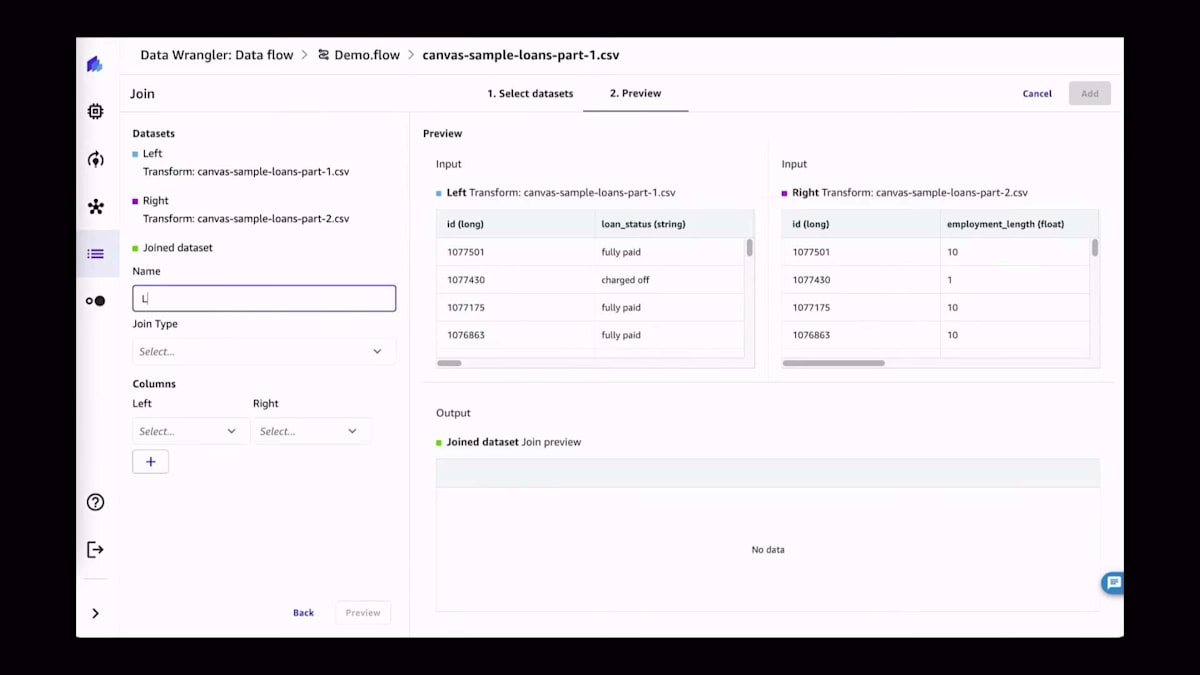
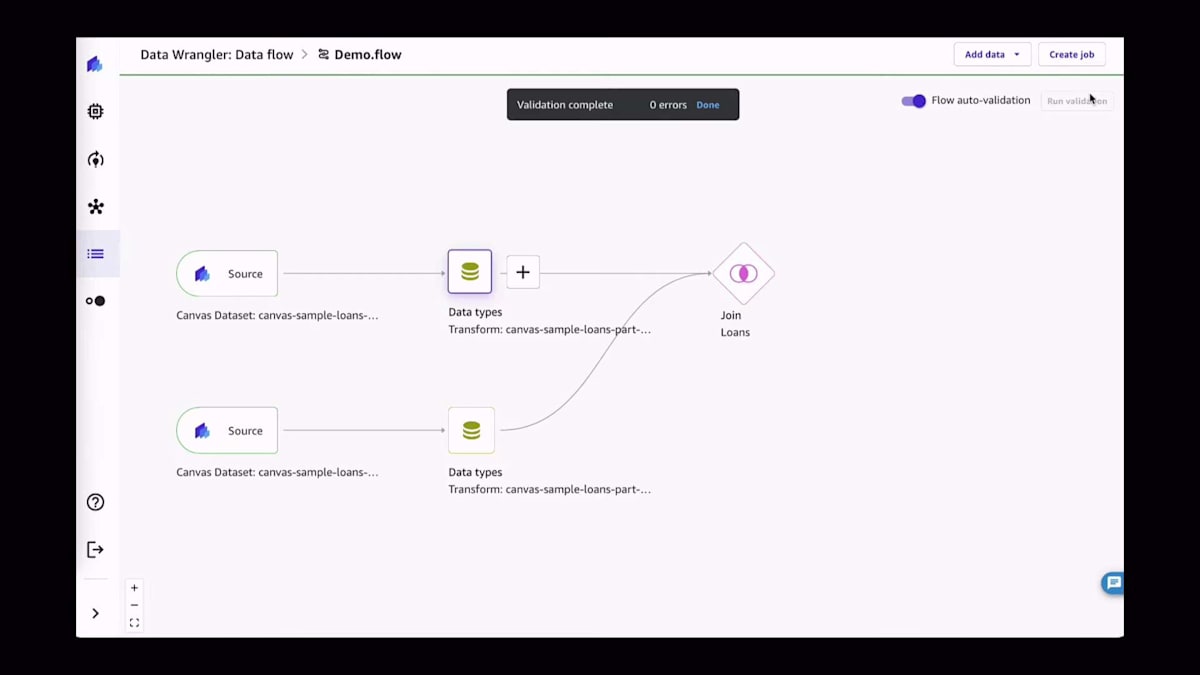
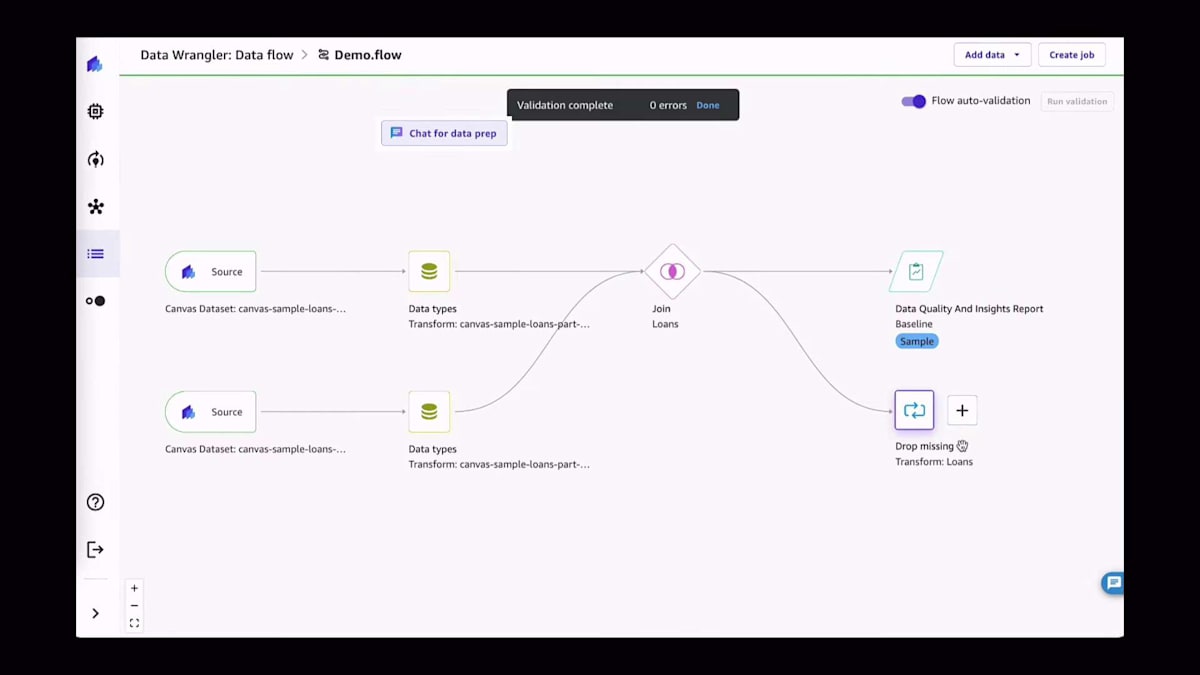
データをインポートしたら、次はデータの準備に移ります。変換には、値の削除や欠損値の置換、外れ値の検出などの標準的な操作が含まれる場合があります。今回の場合は、2つの異なるデータセットを結合します。ご覧のように、Canvasでのすべての操作は非常に簡単です。すべてUIで行われ、コードを1行も書く必要がありません。ここでは、2つの異なるソースを取り込み、特定のIDで結合し、そして2つのデータセットから3つ目のデータセットを作成しているのがわかります。
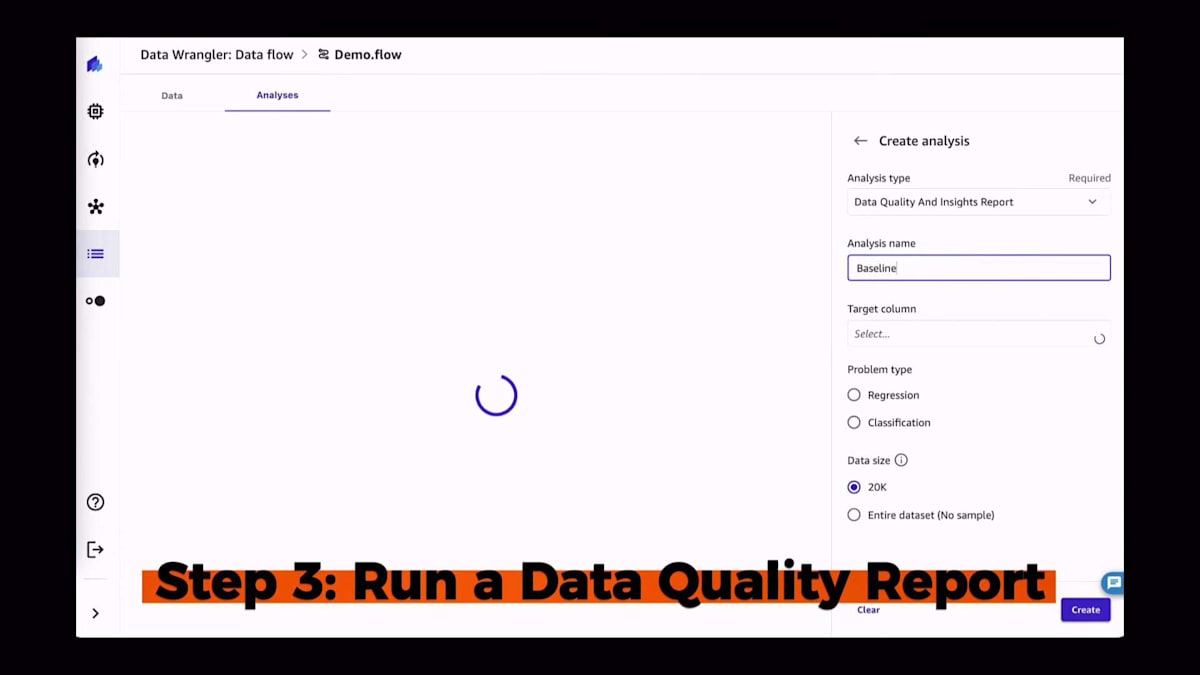
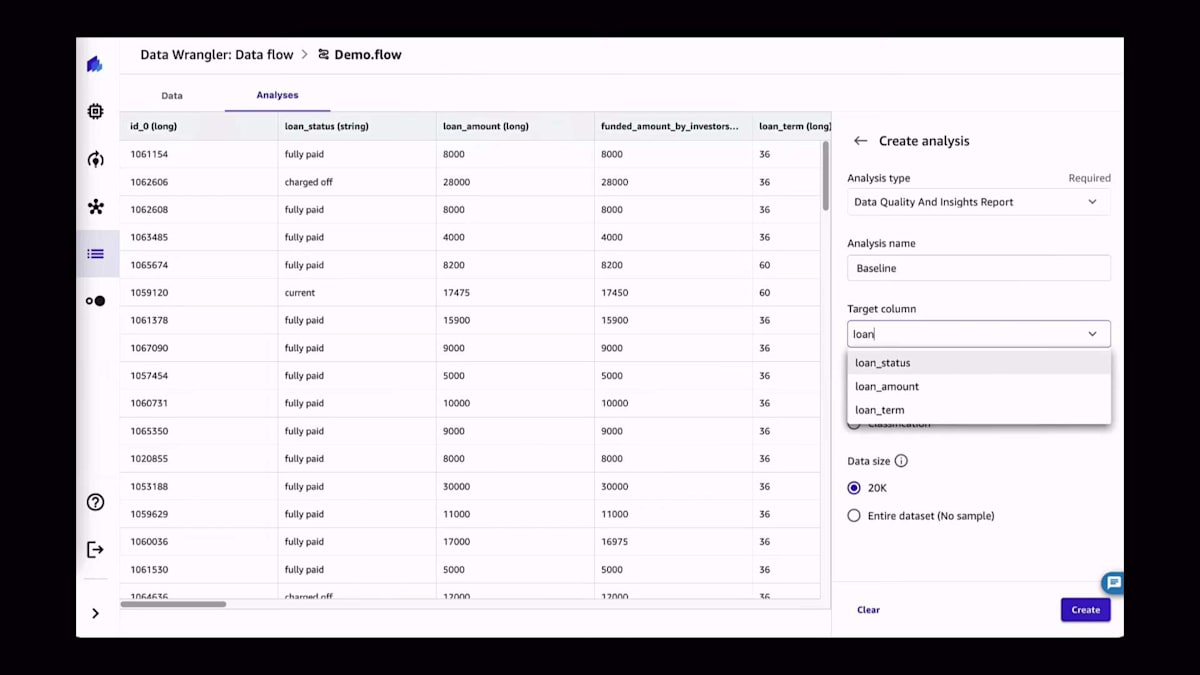
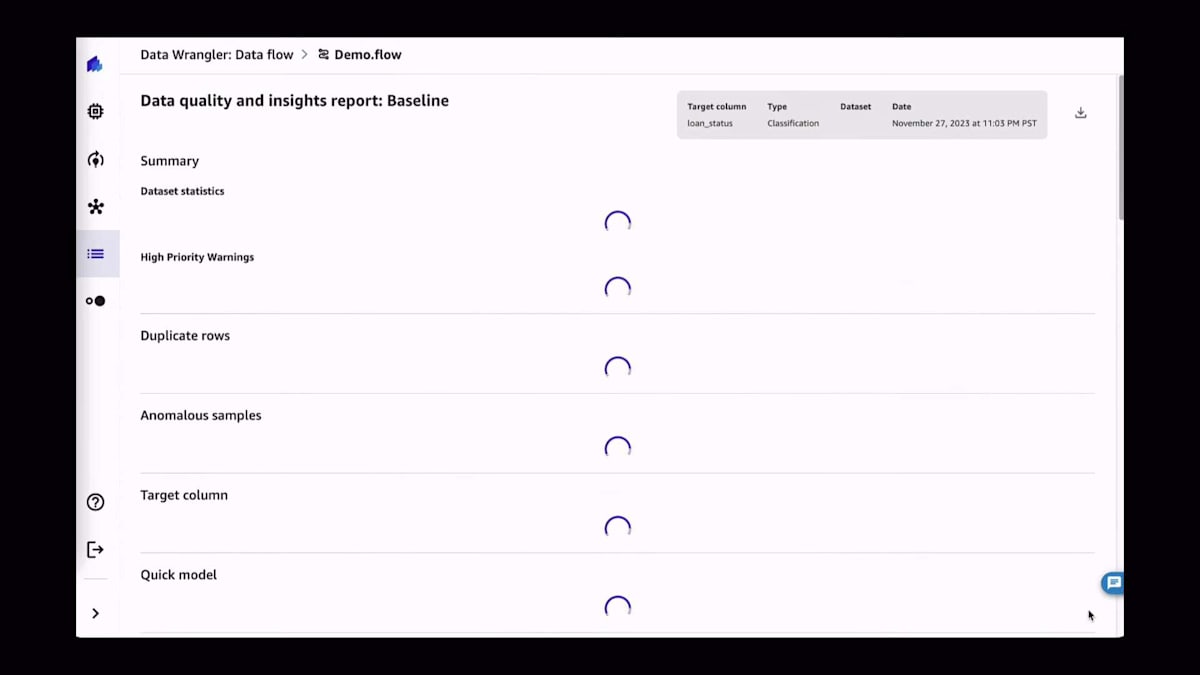
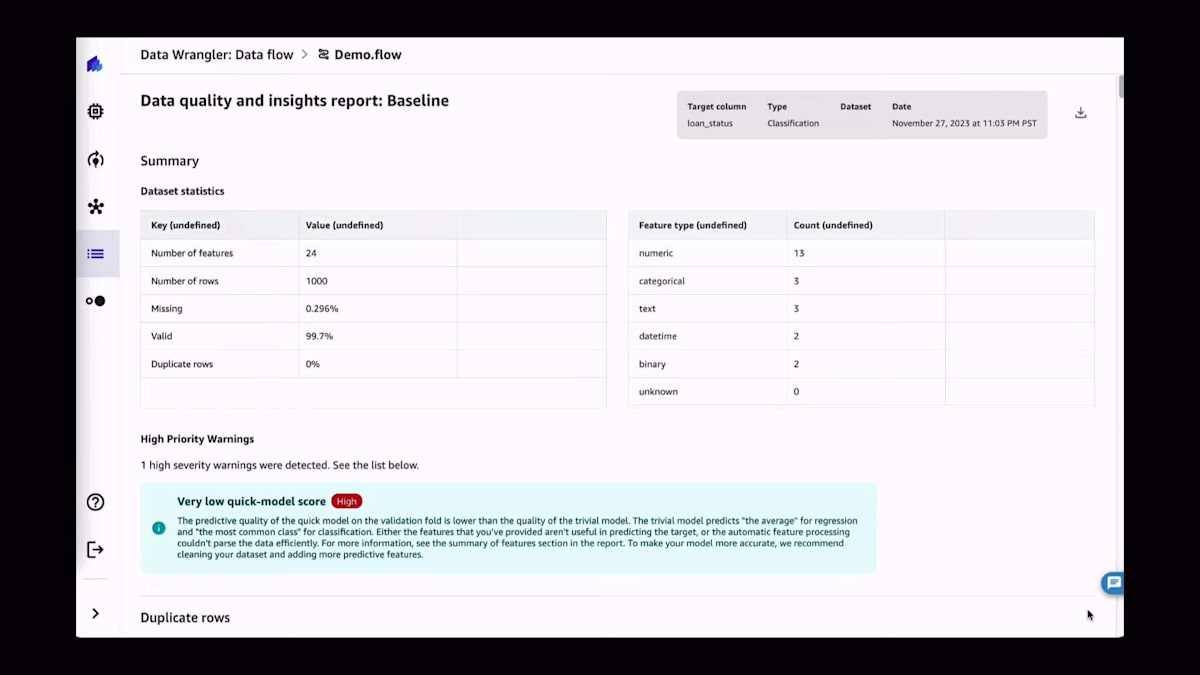
新しいデータセットを使い始める際の良い習慣は、Data Quality Reportと呼ばれるものを実行することです。これは、データセットがどのようなものかを把握するためのものだと考えてください。解決しようとしている問題の種類に応じて、欠損値が多すぎないか、あるいは予測しようとしていることを実際に予測するのに十分な情報があるかなどの情報を抽出したいでしょう。ご覧のように、ほんの数回クリックするだけで、すぐにデータセットの統計情報や最も重要な優先警告などの情報が得られます。この場合、後ほど詳しく説明しますが、クイックモデルスコアが非常に低くなっています。一般的に、データセットがどのように振る舞うか、そのデータセットに基づいてモデルをトレーニングした場合にどうなるかについて、多くの情報が得られます。
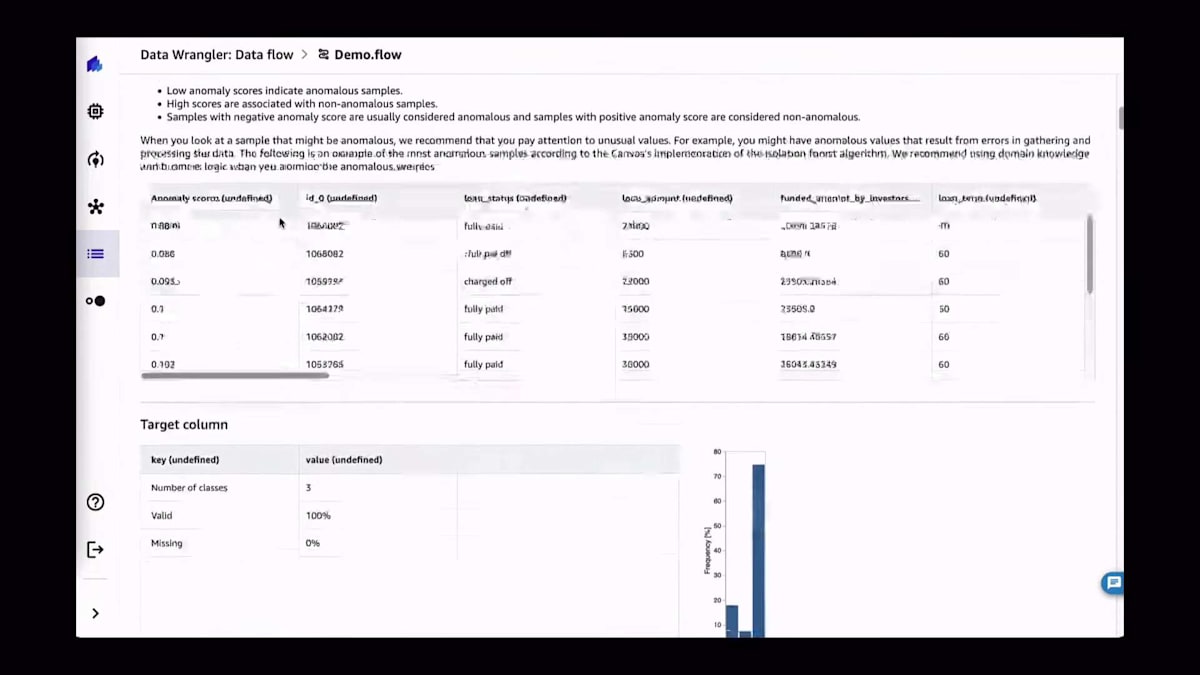
このレポートで利用可能なその他の情報には、ご覧の通り欠損値の数が含まれています。また、最優先の警告、重複ルールの数、そして異常な例も表示されています。もちろん、ユースケースを最もよく知っているのはあなたですので、データセットで統計的に見つかった異常値をいくつか提案していますが、これらが特定のケースに必ずしも当てはまるとは限りません。また、バックグラウンドで非常に小さなモデル(クイックモデル)を学習させ、そのモデルの精度に関する基本的な情報を提供しています。データ品質レポートは常に存在し、常にデータフローの一部であることに注意してください。


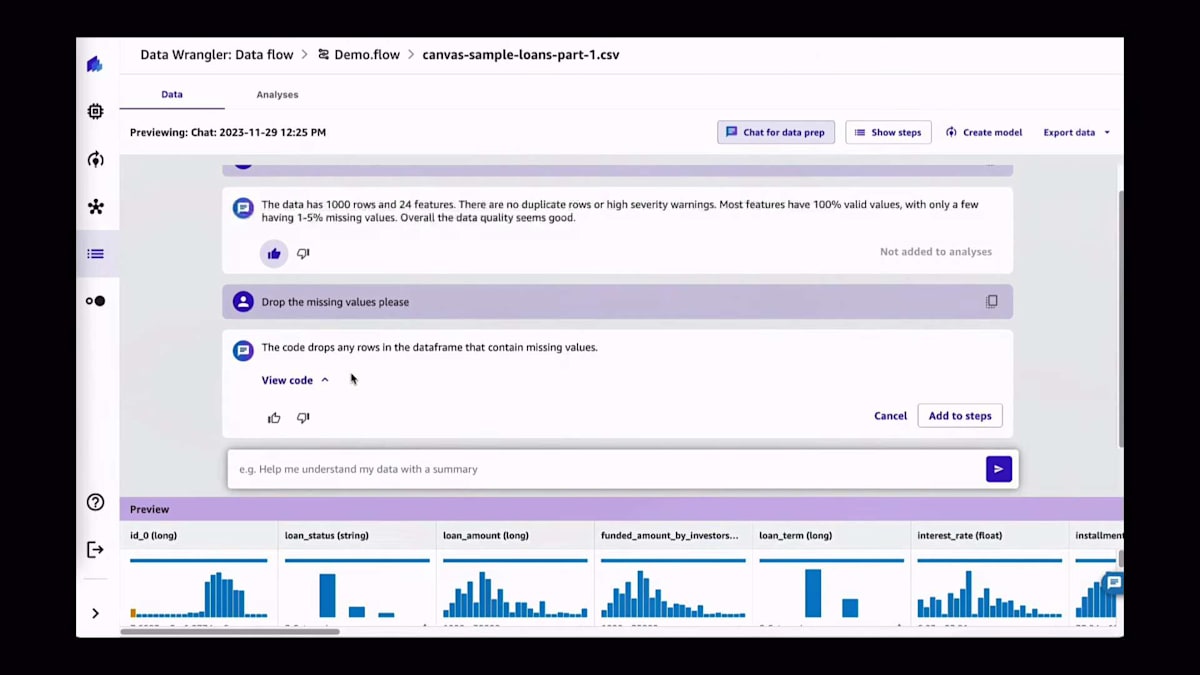
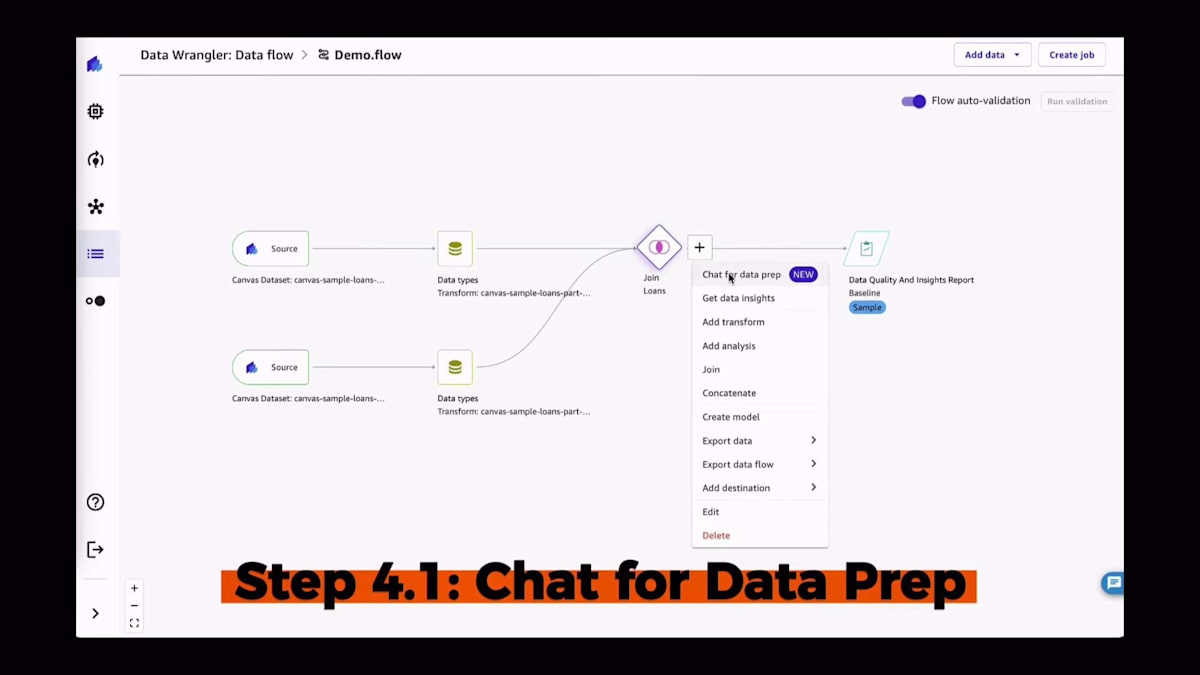
本日のre:Inventで、データ準備用のチャットを発表しました。これは、最近のあらゆるものがチャットボットインターフェースや自然言語を通じて行われていることを考慮し、データ準備を次のレベルに引き上げるものだと考えてください。ここでのアイデアは、データ準備もその流れに沿うようにすることです。質問を始められるチャットインターフェースがあるというわけです。例えば、「私のデータの品質についてどう思いますか?」や「どんな変換をすべきですか?」、あるいは「この変換を実行してください」などと尋ねることができます。AIの支配者には常に「お願いします」と言うことを忘れないでくださいね。気に入ったステップがあれば、そのまま追加できます。右側を見ると、そのステップがデータフローに追加されているのがわかります。先ほどのDAGの可視化に戻ると、進行に伴って追加のステップが構築されていくのがわかります。
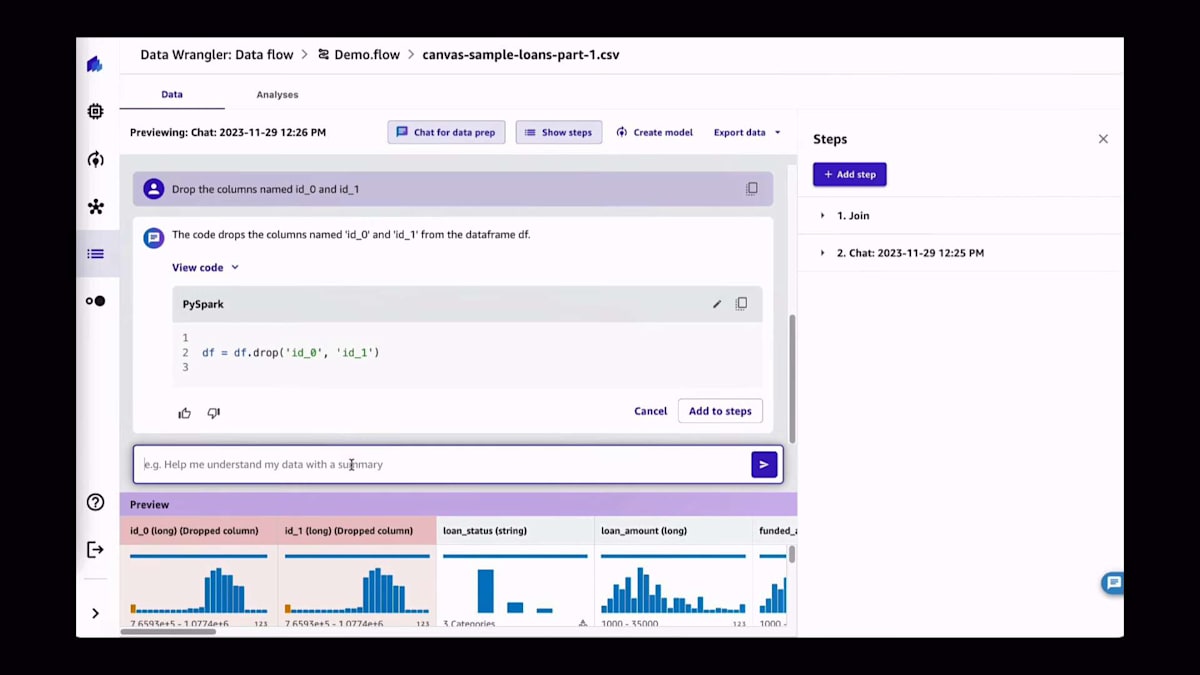
プロセスが進むにつれて、追加のステップがすべて構築されていくのが見えます。そしてそれらはすべてコードを提供するので、アルゴリズムが提案したコードを変更したい場合は、そうすることができます。さて、もう一つの例を見てみましょう。'id_0'と'id_1'という名前の列を削除します。ご覧の通り、非常に簡単なコードで、特に凝ったものではありません。しかし、PythonでPandasのコードを一行も書いたことがない人にとっては、これは新しいものかもしれません。

散布図をプロットするような、もう少し高度なことはどうでしょうか?SeabornやAltairなどのドキュメントで時間を無駄にしたことは確かです。もうそんなことをする必要はありません。Canvasに「散布図をプロットしてくれますか?」と尋ねるだけでいいのです。あなたのケースで何を散布図にしたいかを伝え、クエリを送信すれば、数秒でプロットが完成します。ここでは、ローンステータスで色分けするようにさらに指示しました。数秒で完了し、コードが散布図を作成します。もちろん、このデータセットは架空のものなので、実際の値にはあまり注目しないでください。しかし、プロットが生成されたのがわかります。Canvasで直接ズームインでき、さらに重要なのは、このプロットをダウンロードできることです。PowerPointプレゼンテーションの一部にしたり、下流のユースケースで使用したりしたい場合は、もちろんそうすることができます。
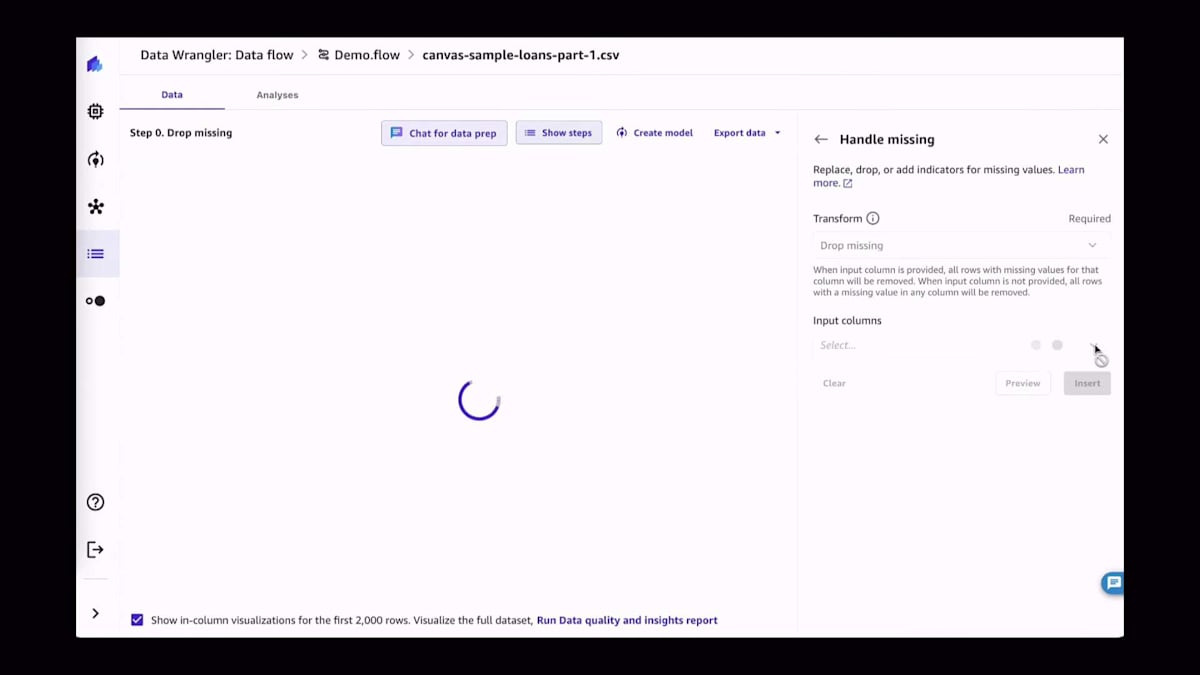
さて、一歩戻って、他のデータ準備について再度見ていきましょう。もちろん、自然言語インターフェースを通じて自動的にデータ準備を行うこともできますし、利用可能な300以上のデータ準備ステップのリストから選択して手動で行うこともできます。この場合、非常に単純に欠損値をいくつか削除しているだけで、特に凝ったことはしていません。ただモデルのパフォーマンスを向上させるためです。しかし、もちろん特定の値の置換や特定の列のベクトル化、あるいは特定の列のワンホットエンコーディング(ワンホットエンコーディングに馴染みのある方向けに)など、より複雑な変換を行うこともできます。時系列データを扱っている場合は、リサンプリングや欠損値の補完など、時系列データセット特有のデータ準備ステップも多数用意されています。
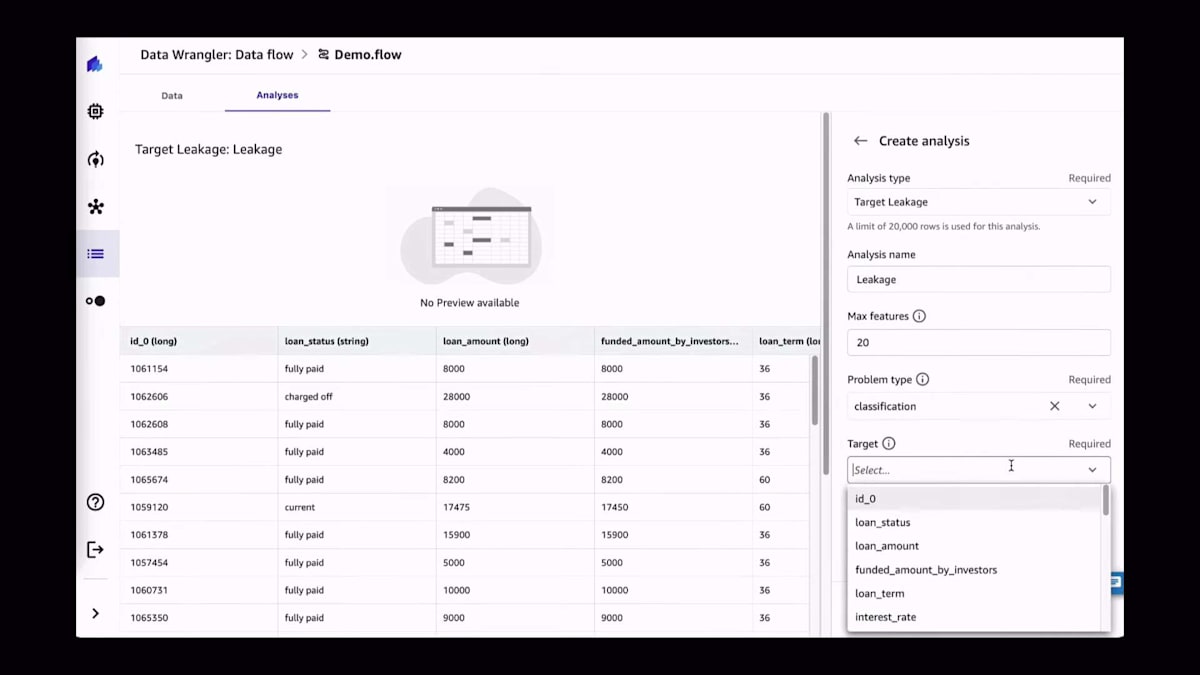
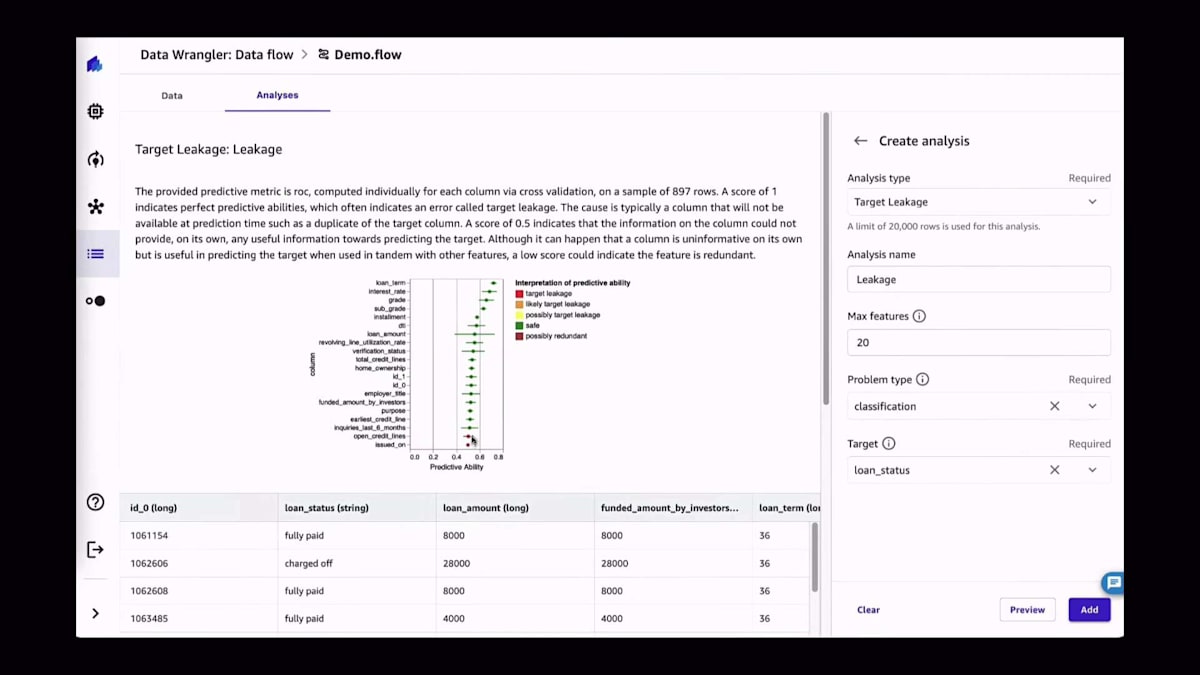
データ品質レポートは利用可能な分析の1つです。現在、特徴量の相関性やマルチコリニアリティなど、さまざまな分析が利用可能です。私が特に気に入っているのはターゲットリーケージです。機械学習の経験が比較的少ない人が機械学習を始める際、実際のターゲットを予測特徴量として使用することがあります。データサイエンティストであれば、これが大きな間違いであることはご存知でしょう。ここでターゲットリーケージが役立ち、その問題を説明できます。例えば、ある特徴量で情報を漏らしてしまっている可能性があります。
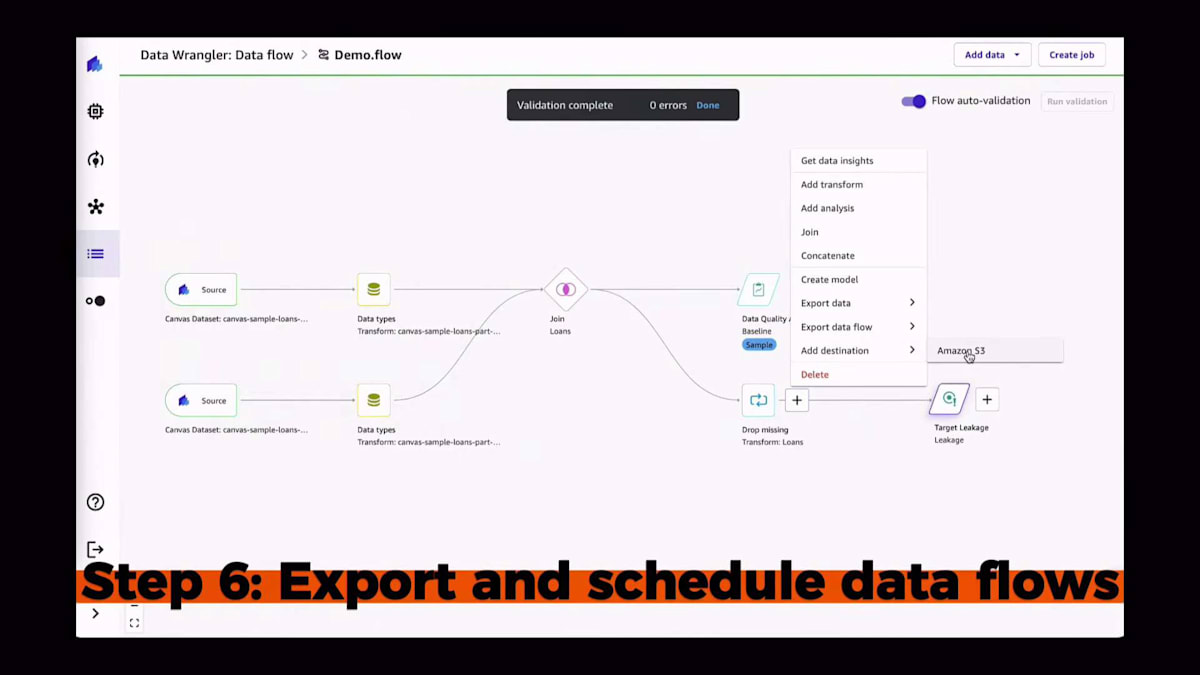

もちろん、データフローの構築が終わりではありません。これはデータ準備の一部です。データフローの構築が完了したら、データのエクスポート先を選択できます。例えば、ここで使用しているケースでは、CSVファイルをAmazon S3バケットにエクスポートするためのダミーバケットを使用しています。もちろん、下流の情報を構築したい場合や、目的地が他にある場合にも非常に便利です。目的地を設定したら、この変換されたデータセットを生成するジョブを作成できます。
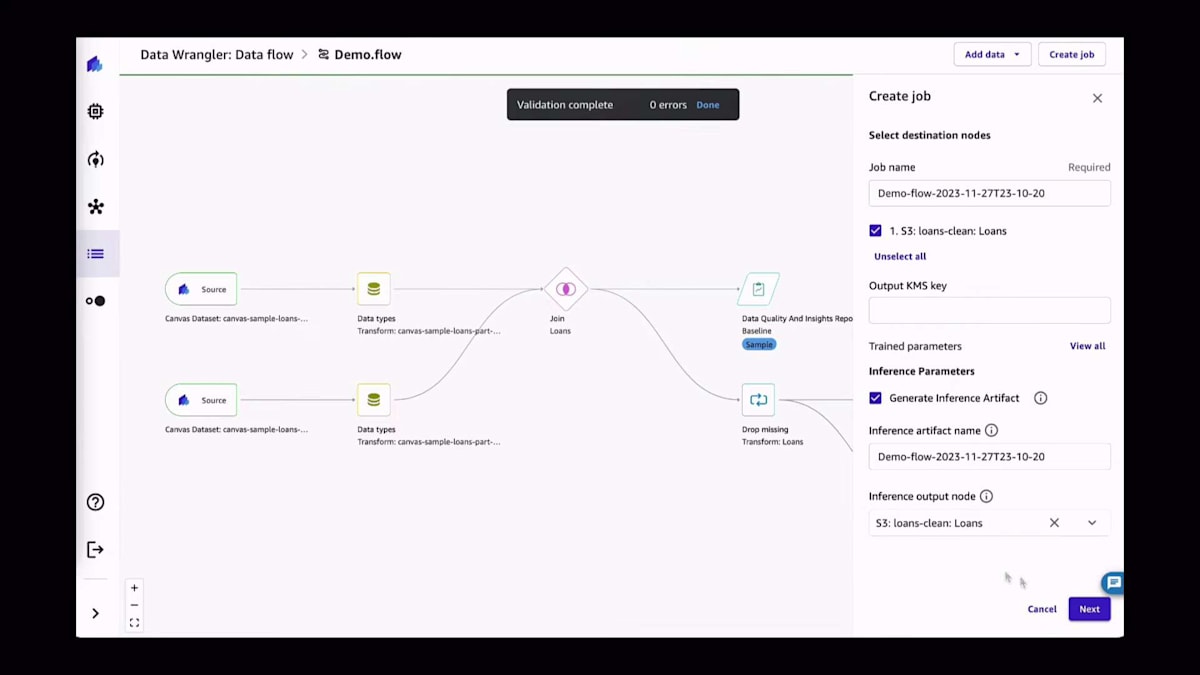

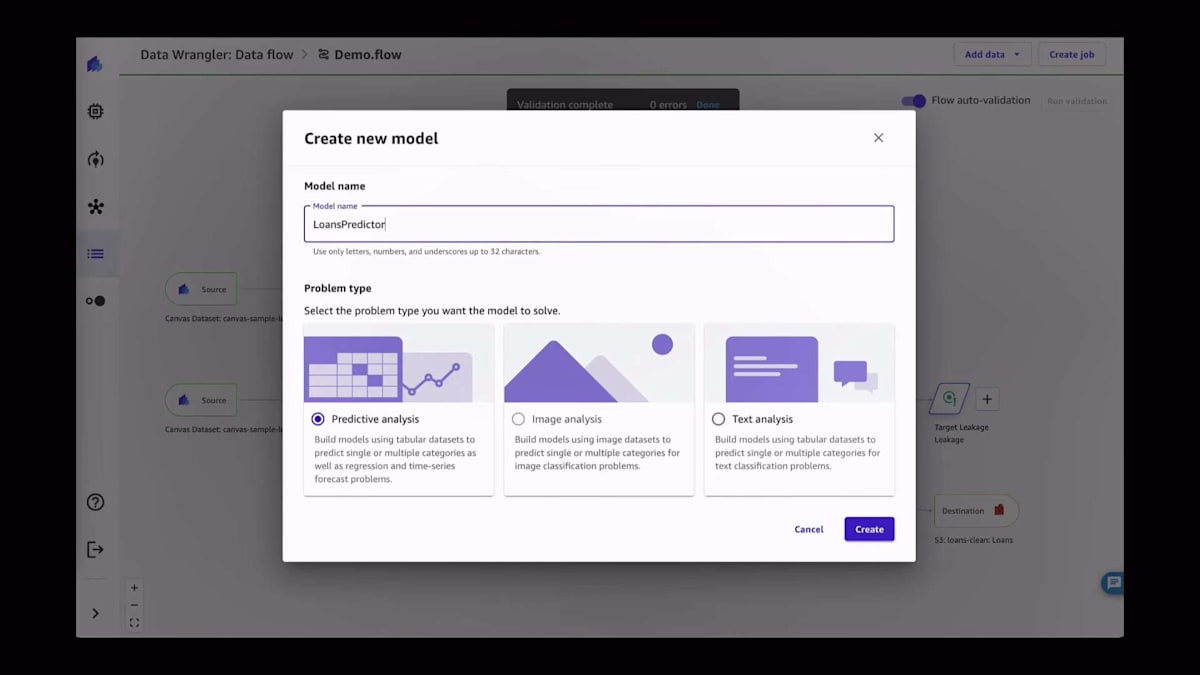
このアプリでは、それほど大きくないデータセットを使用することを想像してください。しかし、複数のインスタンスやより大きなインスタンスに水平方向にスケールアウトしたい場合、一度にテラバイト単位のデータを使用し、このデータ準備をスケジュールすることもできます。データ準備に満足したら、次のステップはモデルを作成することです。ボタン1つでできます。Create modelをクリックし、作成されるモデルに名前を付けるだけです。この場合、予測分析モデルをトレーニングしています。これは表形式データセットモデルですが、時系列予測もサポートしています。画像を使用して、コンピュータビジョンモデルをトレーニングしたり、NLPモデルをトレーニングしたりすることもできます。
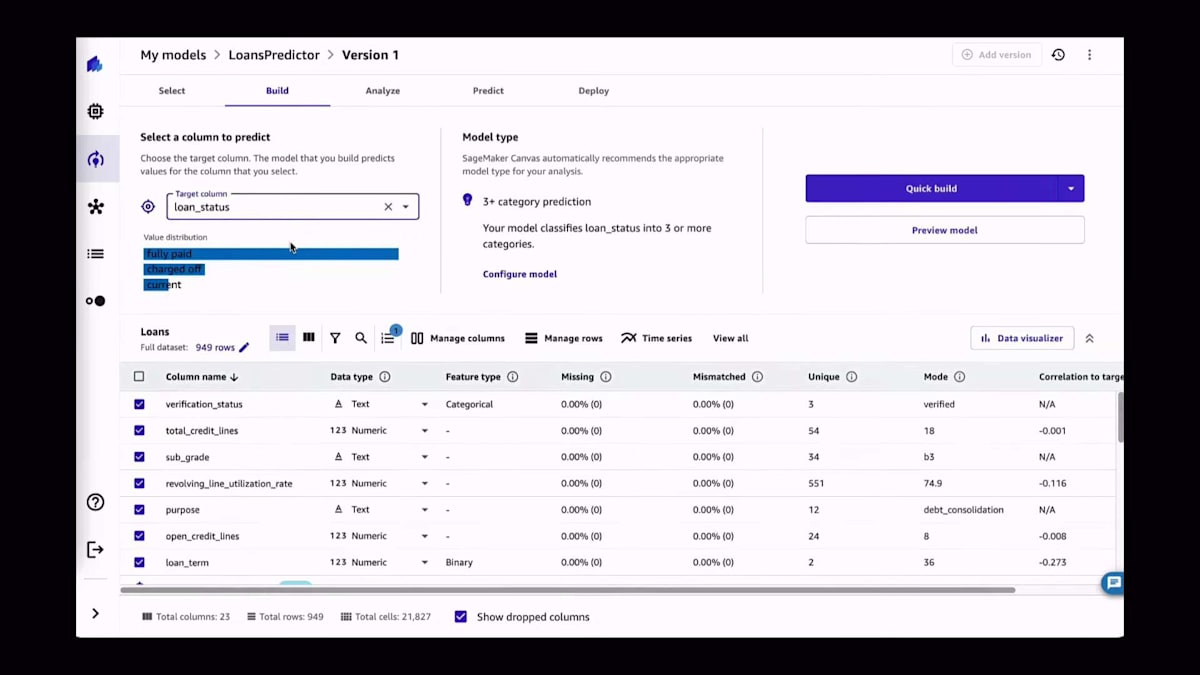
すべてのモデルで、プロセスは同じです。ターゲットを選択し、モデルを設定し、最後にトレーニングを開始します。データサイエンスについてより詳しい場合は、トレーニングする特定のアルゴリズムを設定することもできます。CatBoost、XGBoost、Neural Network Searchなどです。データ分割を設定したり、トレーニングの実行時間を設定したりすることもできますし、すべてをデフォルトのままにしておくこともできます。これがAutoMLの素晴らしいところです。何も設定する必要がありません。完了したら、クイックモデルまたは非常に高性能なモデル(標準ビルドと呼んでいます)のトレーニングを開始します。

Canvasはバックグラウンドでデータセットに対するモデルのパフォーマンスを検証します。欠損値が多すぎないか、うまく機能しない部分がないか、時系列にポイントが欠けていないかなどを確認します。その後、AutoMLプロセスを開始します。このAutoMLプロセスは最大45分かかる場合があります。データセットが小さければ短くなり、大きければ長くなります。一般的に45分、あるいは30分程度と言えるでしょう。
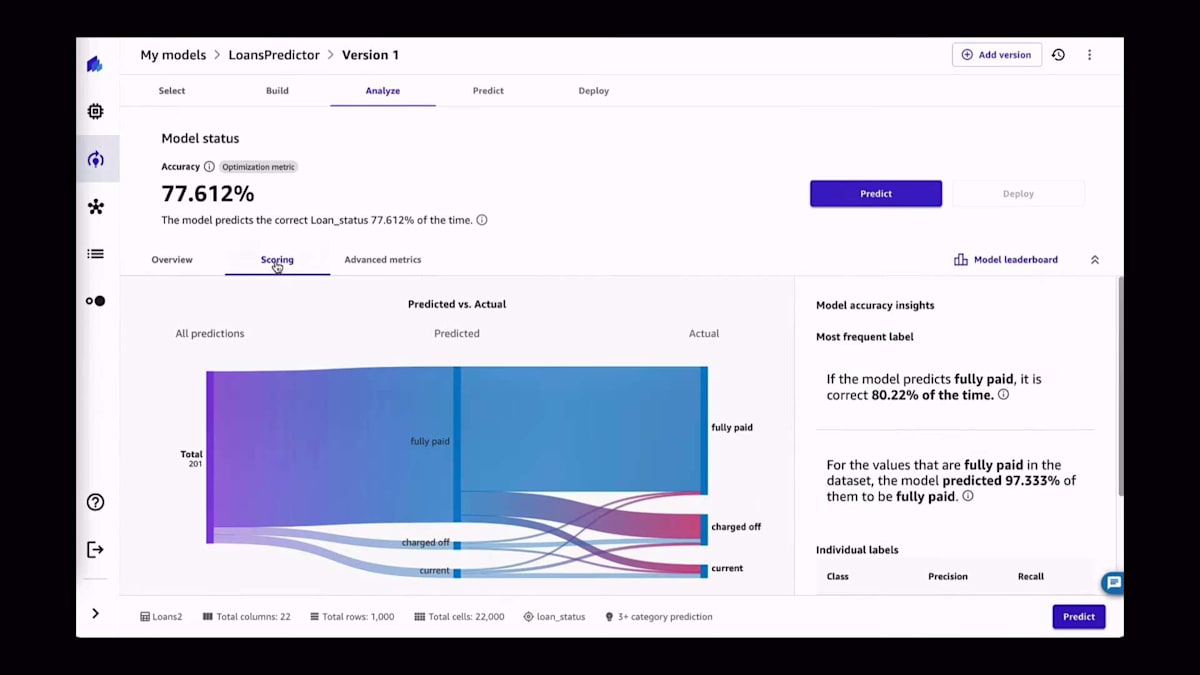


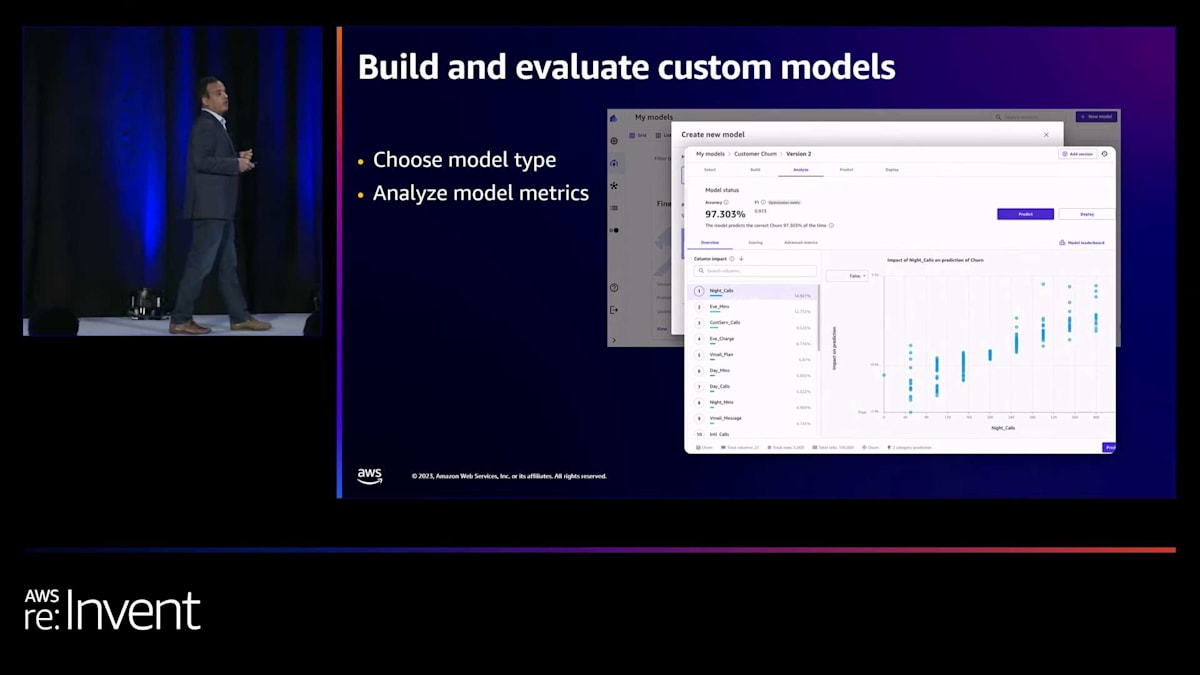
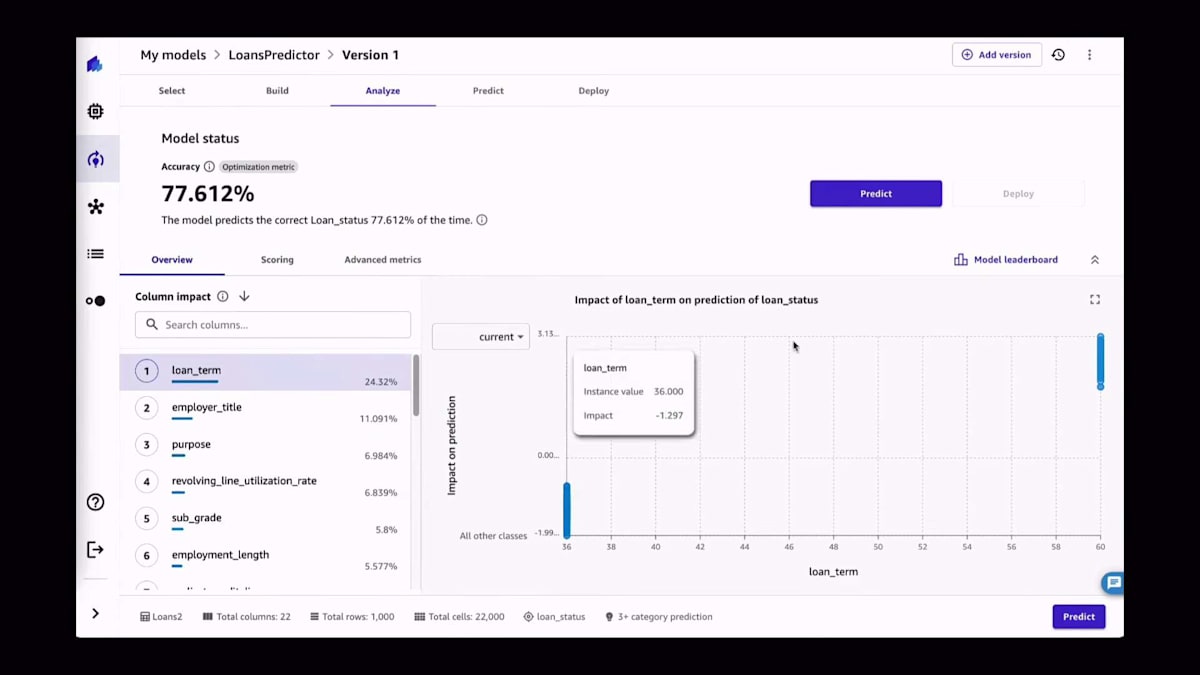
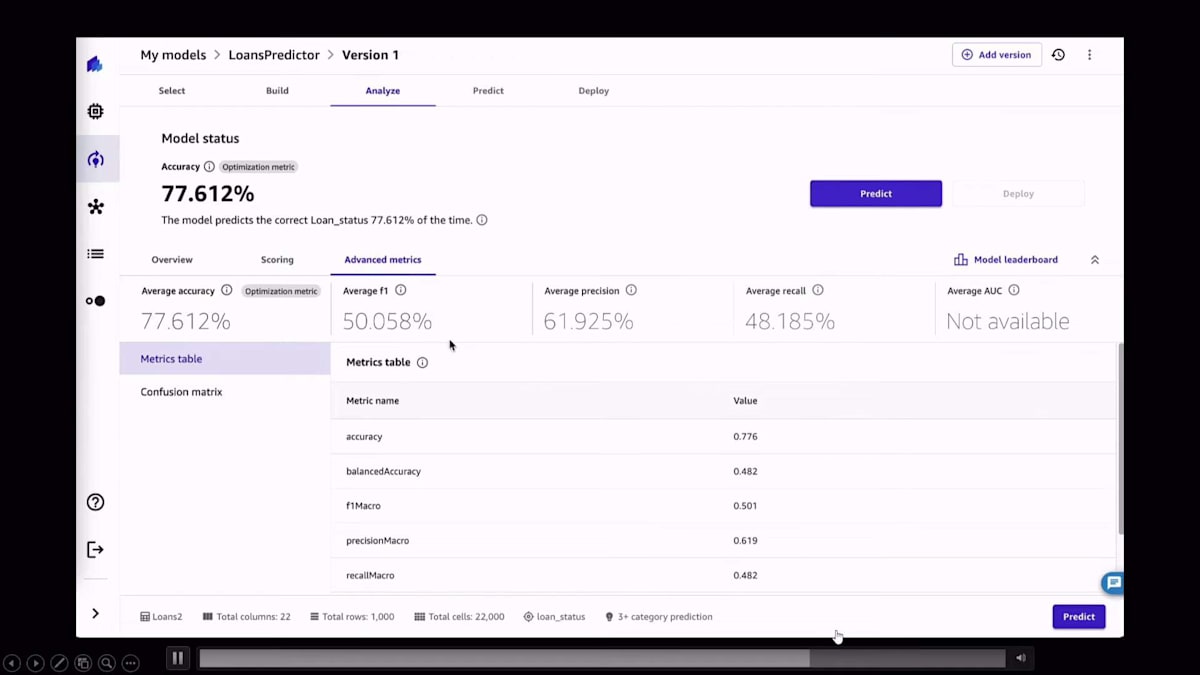
モデルのトレーニングが完了すると、精度の指標が得られ、各列の影響度に関する情報や、予測値と実際の値を比較したSankey plotのような高度な情報も入手できます。プロセス中に生成された指標を正確に確認でき、詳細を知りたい場合は混同行列も見ることができます。これは最良のモデルだけでなく、Amazon SageMaker CanvasのAutoMLプロセスの一環としてトレーニングされた全てのモデルについて当てはまります。さらに、個々のモデルだけでなく、プロセスの一部としてトレーニングされた全てのモデルアンサンブルについても同様です。
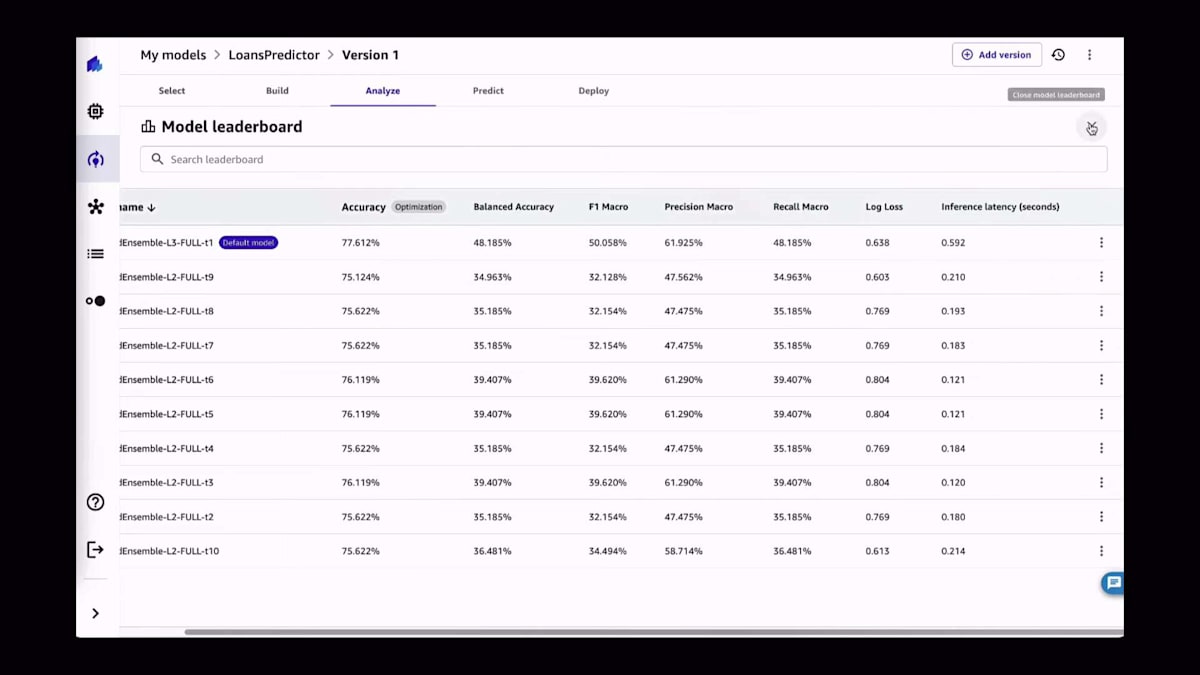
何らかの理由で特定のモデルが気に入った場合、例えば推論の遅延が低いとか、お好みの指標が高いといった場合、そのモデルをデフォルトモデルとして選択することもできます。最後のステップは、このモデルを使って予測を生成することです。素晴らしい点の一つは、コードを書くことなくCanvasアプリ内で直接、バッチデータに対する予測を生成できることです。常に新しいCSVファイルが入ってくるような状況を想像してみてください。手動で予測を行うことも、CSVファイルが生成されるたびにジョブをスケジュールすることもできます。
予測を生成すると、それらの予測はCanvasで簡単に確認でき、Amazon QuickSightに直接送ることもできます。既存のBIダッシュボードを強化したい場合は、お気に入りのQuickSightユーザーを指定して、データをそのQuickSightユーザーに送り返すことができます。さて、利用可能な様々な予測や指標についてもっと詳しく見ていきましょう。ここでご覧のように、再度利用可能な全てのコンテンツを確認しています。ちょっとここを飛ばしますね。はい、こんな感じです。

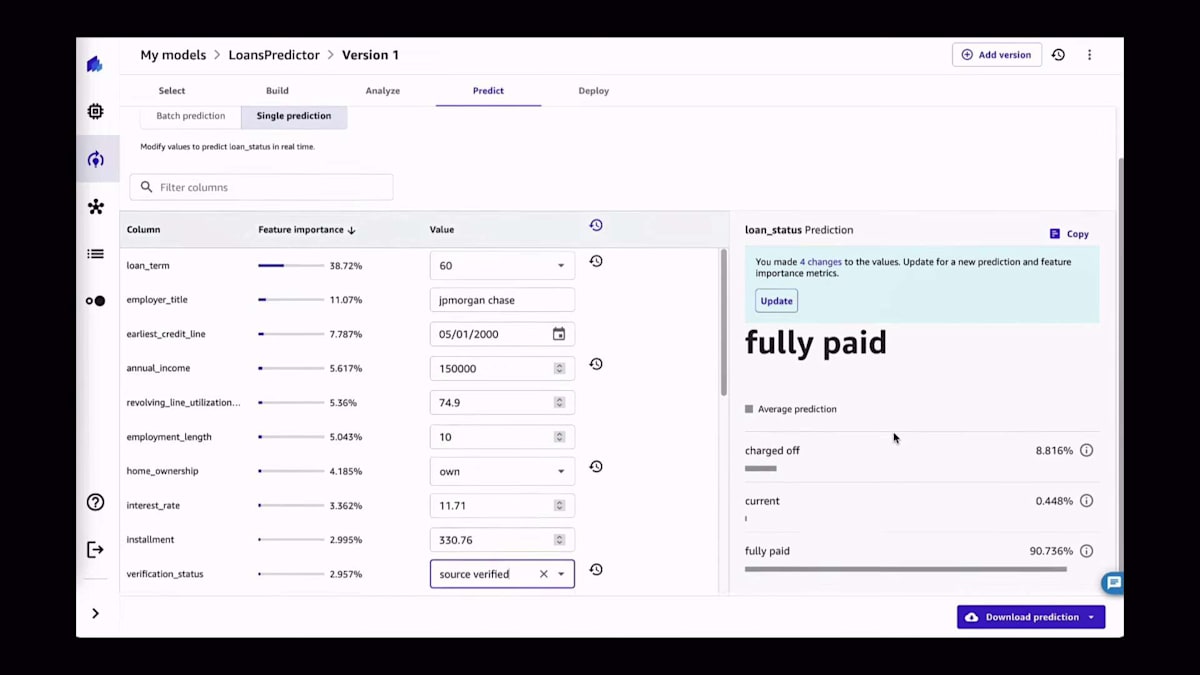
ここでテーブルに表示されている別のオプションは、Canvasアプリで直接モデルを使用して、1件ずつ予測を生成することです。実際、これらの値を1つずつ変更して、各値の変更が単一の予測の生成にどのように影響するかを確認できます。ここでご覧のように、これらの値を1つずつ変更して、「この値を変えたらどうなるか?」「あの値を変えたらどうなるか?」といった具合に、予測の生成にどう影響するかを確認しています。この例からわかるように、特定の値に対する精度の割合が変化します。この場合、予測自体は同じですが、その予測の信頼度スコアが変化しています。
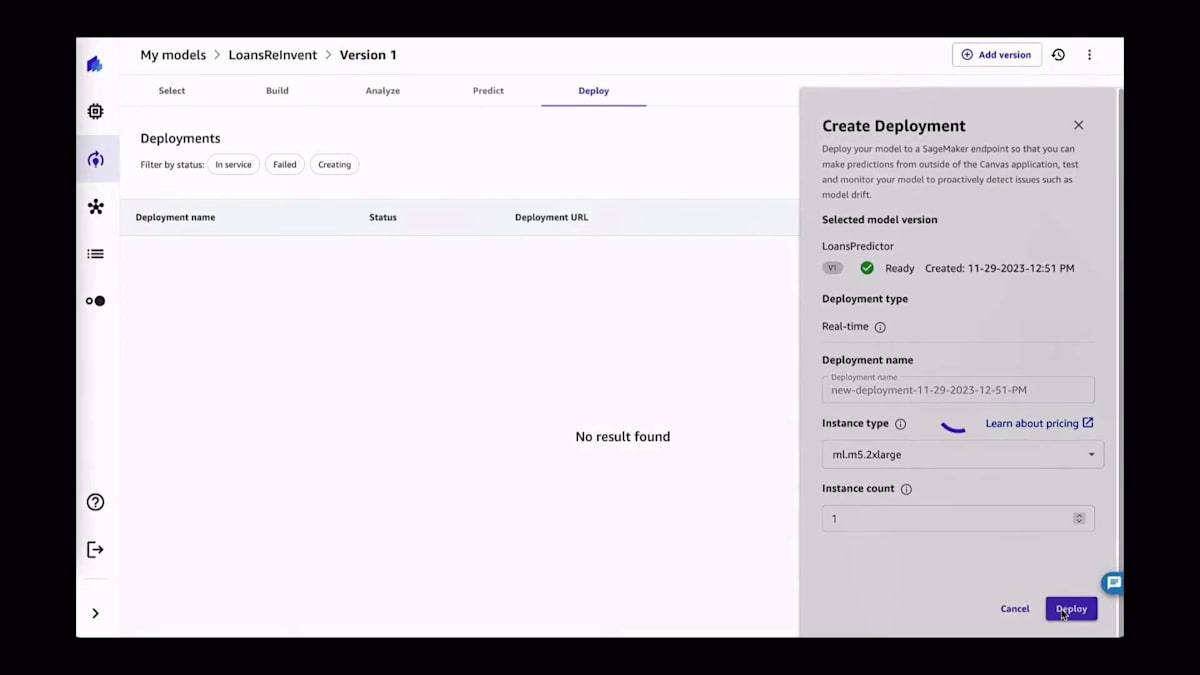
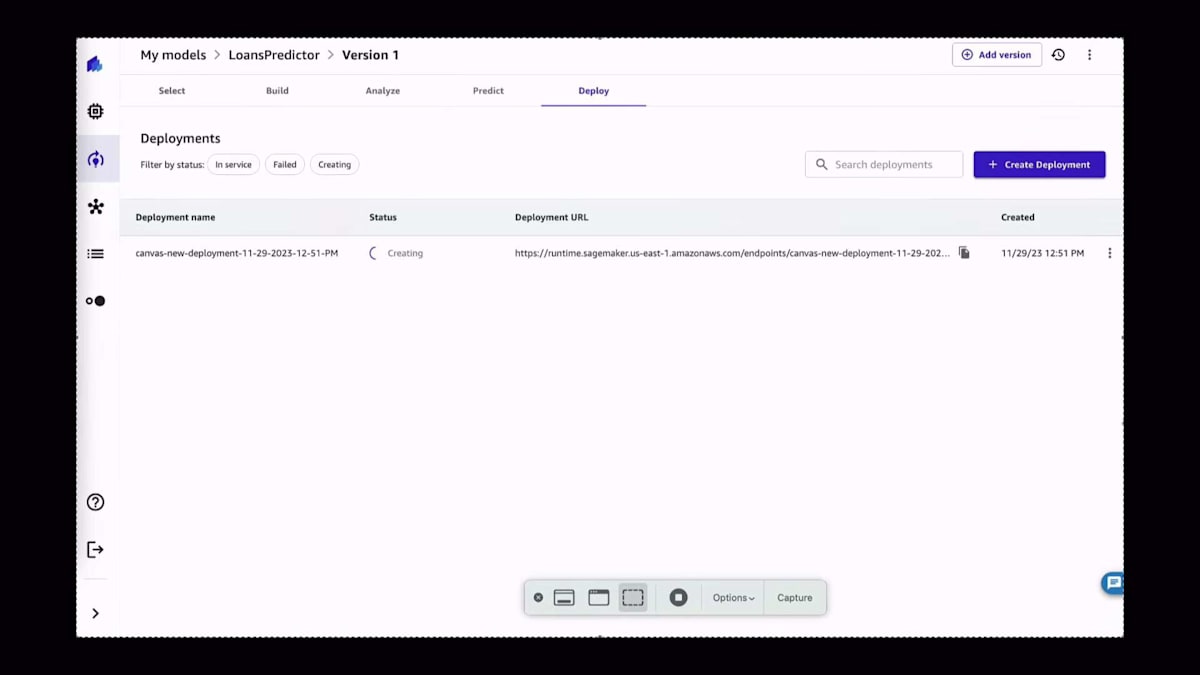
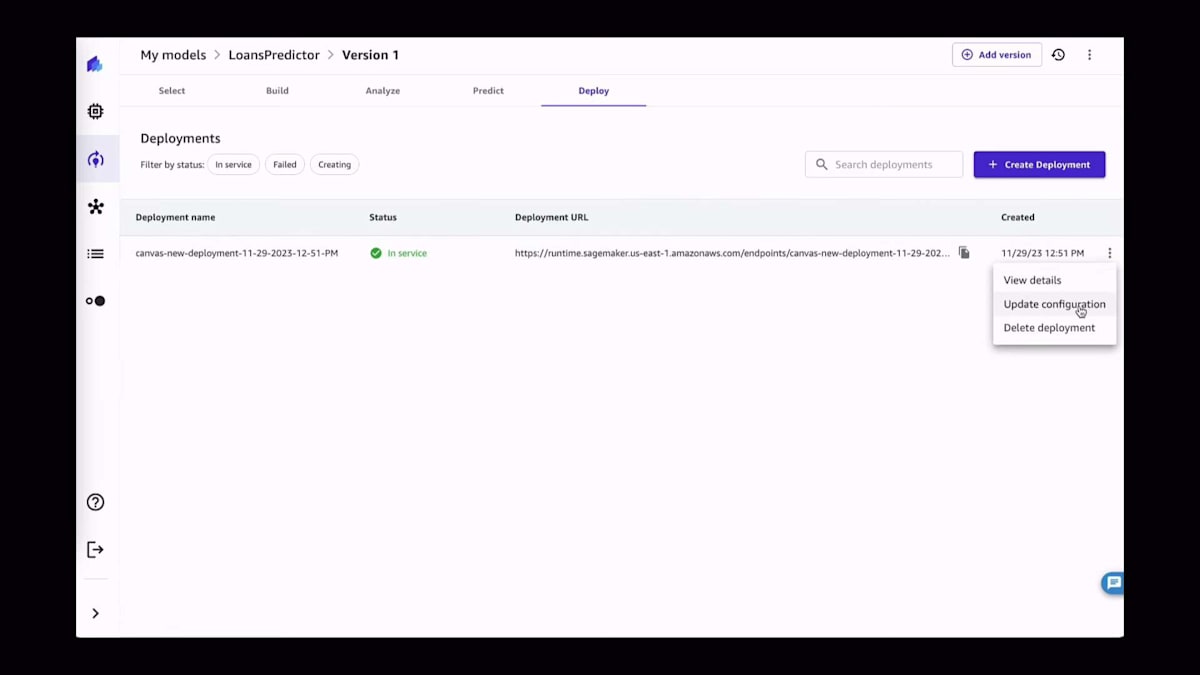
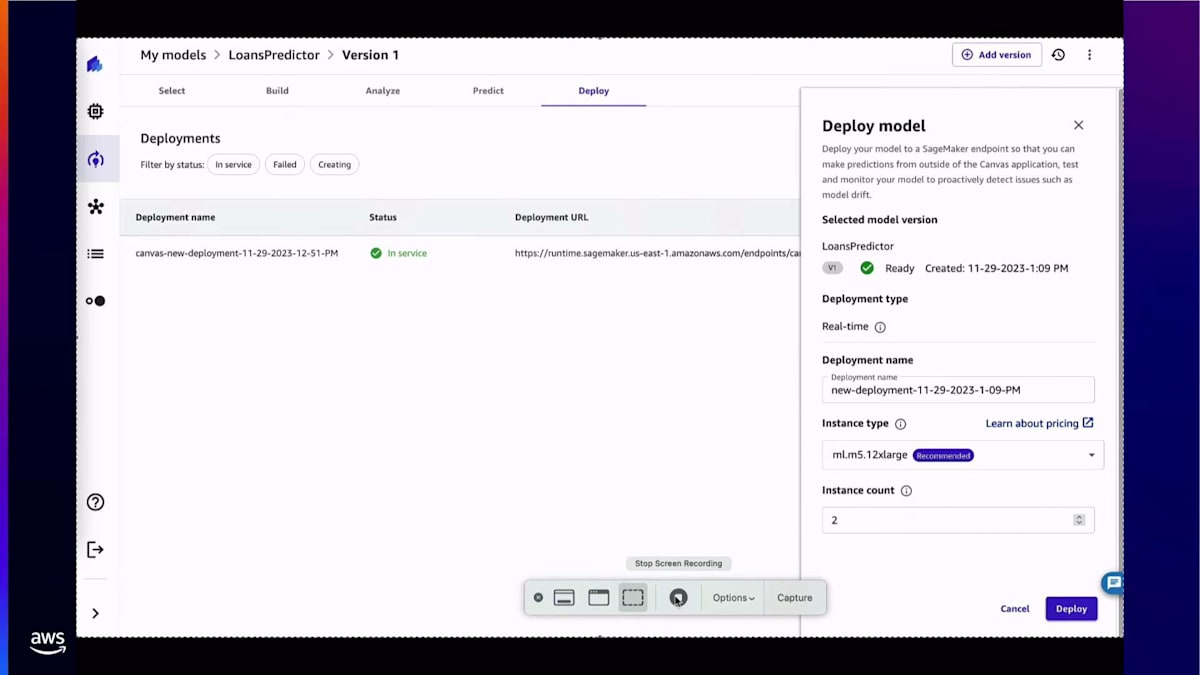
これらの予測に満足したら、モデルを本番環境に移行できます。モデルの本番環境への移行とは、4つの異なるパターンのうちの1つを指します。1つ目は今ご覧いただいているものです。SageMakerエンドポイントにモデルをデプロイすることです。SageMakerエンドポイントをデプロイする際、使用するモデル、使用するインスタンス、使用するインスタンスの数を選択します。そして、しばらくすると、ここにサービスとして利用可能なモデルが表示され、開発者が予測を生成するために使用できるデプロイメントURLが表示されます。
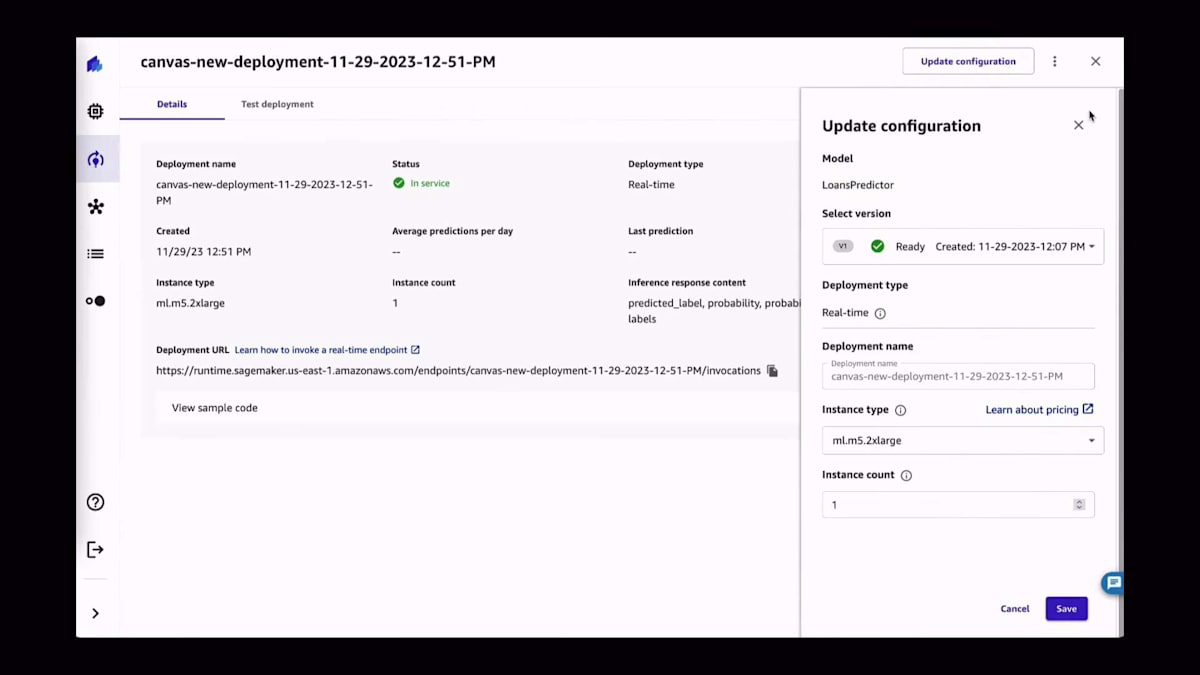

このエンドポイントを呼び出すためにどのようなコードを使用できるかを見てみたい場合、SageMaker Canvas内にサンプルコードとして用意されています。また、必要に応じてそのエンドポイントに関連する設定を更新することもできます。本番環境のパターンに関する他の可能性としては、モデルレジストリへの追加があります。これは非常に興味深いものです。なぜなら、モデルを特定のモデルレジストリに追加し、そのモデルに関連するすべての情報をモデルレジストリに提供することができるからです。これにより、MLOpsエンジニアは、アーティファクト、モデルのトレーニングに関連するコンテナ、そしてモデルのトレーニングプロセスに関連するあらゆる情報を簡単に取得し、MLOpsパイプラインの一部として使用することができます。
これは素晴らしいことです。なぜなら、すでに自分のアカウントにMLOpsパイプラインを設定している場合、これはそのパイプラインにぴったりと収まるからです。モデルレジストリは、Canvasで行われるトレーニングプロセスとMLOpsパイプラインで行われるデプロイメントプロセスの間のバッファとして機能します。QuickSightへの送信についてはすでに説明しました。予測をQuickSightに送信できますが、モデルを直接QuickSightに送信することもできます。他のオプションとしては、AutoMLプロセスに関連するノートブックを表示することができます。デモでご覧いただけるように、このノートブックは候補生成プロセスに関する詳細な洞察を提供します。
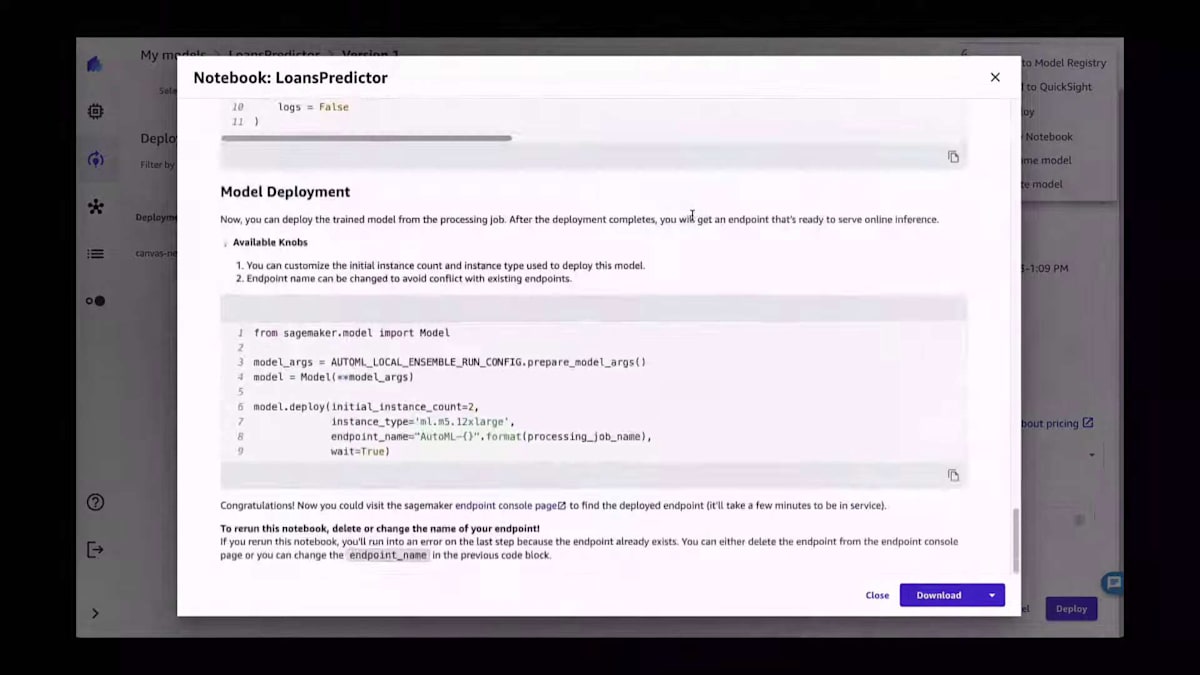
ここでは、AutoML候補の定義に到達するためにバックグラウンドで実行しているすべてのコードが表示されます。これにより、使用するハイパーパラメータとトレーニングしようとしているモデルを正確に制御することができます。本質的には以上です。AutoMLで行われるすべてのホワイトボックス、すべての魔法にアクセスできます。もしそこまで踏み込みたい場合は、コードも利用可能です。
さて、これで Amazon SageMaker Canvasのカスタムモデルトレーニングに関して知っておくべきことをすべてカバーしました。このデモが有益で、楽しく、そして新しいことを学べたことを願っています。Canvasについて私が最も気に入っている点の1つは、文字通り誰もが、機械学習の知識がない人でさえ、機械学習を始めることを可能にしていることです。先ほど機械学習の知識がない人が何人いるかを尋ねたとき、多くの手が挙がったのを見て嬉しく思いました。
実際、その素晴らしい例が間もなく紹介されます。ここで、Ramdevをステージにお招きして、Thomson Reutersが実際にSageMaker Canvasをハッカソン、イベント、さらには日々の本番システムでどのように使用しているかについて少しお話しいただきたいと思います。Ramdev、よろしくお願いします。
Thomson ReutersにおけるAI/MLプラットフォームの進化

ありがとうございます、Davide。私はRamdevと申します。Thomson ReutersのAI/MLプラットフォームのデータアーキテクトを務めております。簡単に背景をご説明させていただきます。 Thomson Reutersは、メディア、法律、税務、コンプライアンスの専門家向けに製品を開発するコンテンツ駆動型の技術企業です。AIとの関わりは1990年代初頭にさかのぼり、当時、Westlaw Is Naturalという商用アプリケーションを開発した最初の企業の一つでした。これは、検索に自然言語処理を取り入れた法律調査アプリケーションです。

それ以来、Thomson Reutersは、named-entity認識と解決、分類、製品内での推奨などの技術を通じて、製品提供を改善するためにAI機能を積極的に取り入れ、活用してきました。このようなAI技術の有機的な成長に伴い、ビジネス機能全体でベストプラクティスの使用を可能にし、企業全体の様々な役割の人々がそれを行えるようにする、標準化されたプロセスを構築することが不可欠になりました。ご覧のように、この期間中、私たちは様々なことを行ってきました。最近では企業を買収しており、それらのプロセスを取り入れて、標準的な方法を確立する必要がありました。
この1年間に起きた全ての進歩により、シチズン開発者の間でAIソリューション開発への関心が高まっています。私たちは、AIプラットフォームを通じて、SageMaker Canvas、Amazon Bedrock、SageMaker JumpStartなど、様々なローコード・ノーコードのAWSサービスへのアクセスを可能にしました。これにより、ユーザーは数回のクリックだけで、Thomson Reutersのデータを安全に使用しながら、これらのツールで実験やソリューションの構築ができるようになりました。プラットフォームは、セキュリティやインフラストラクチャのプロビジョニングの複雑さをユーザーから抽象化し、ユーザーがデータサイエンスの問題に集中できるようにしています。
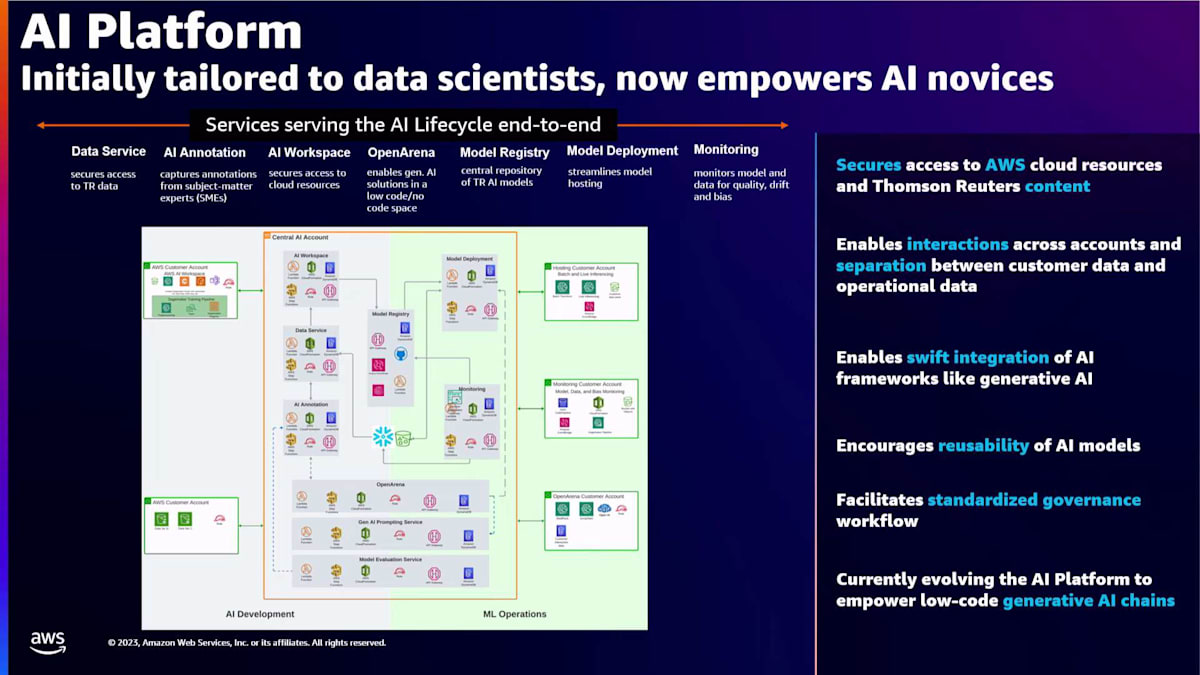
このダイアグラムでご覧いただけるように、当初はデータサイエンティスト向けに調整されていたAIプラットフォームは、現在ではAI初心者にも力を与えています。そのサービスは、データへの安全なアクセス、データの注釈付けとラベリング、AWSサービスと実験ツールへの安全なアクセス、中央モデルレジストリへのモデルの登録(これによりモデルのガバナンスが可能になります)、そして本番環境へのデプロイと可観測性のためのモニタリングまで、モデルのライフサイクル全体をカバーしています。
その設計の鍵は、様々なマイクロサービスを通じて提供される柔軟性にあり、最新の生成AIフレームワークを迅速に統合し、顧客データと運用データを分離する能力を持っています。AIプラットフォームは、アカウント間の相互作用を可能にし、各チームに必要な分離を提供しながら、中央レジストリを通じてモデルのコラボレーションと再利用性を促進します。チームは、ローコード/ノーコードの生成AIチェーンを通じて生成AIを生成する能力を強化するため、AIプラットフォームを継続的に進化させています。AIプラットフォームは大きく開発フェーズと運用フェーズに分類されます。開発フェーズはデータサービス、アノテーションサービス、ワークスペースサービスで構成されています。運用フェーズはデプロイメントサービスとモニタリングサービスで構成されています。モデルレジストリはこれらのフェーズを橋渡しし、モデルがガバナンスとリスク評価を経ることを可能にします。
Thomson ReutersのAIプラットフォームとハッカソンの実施
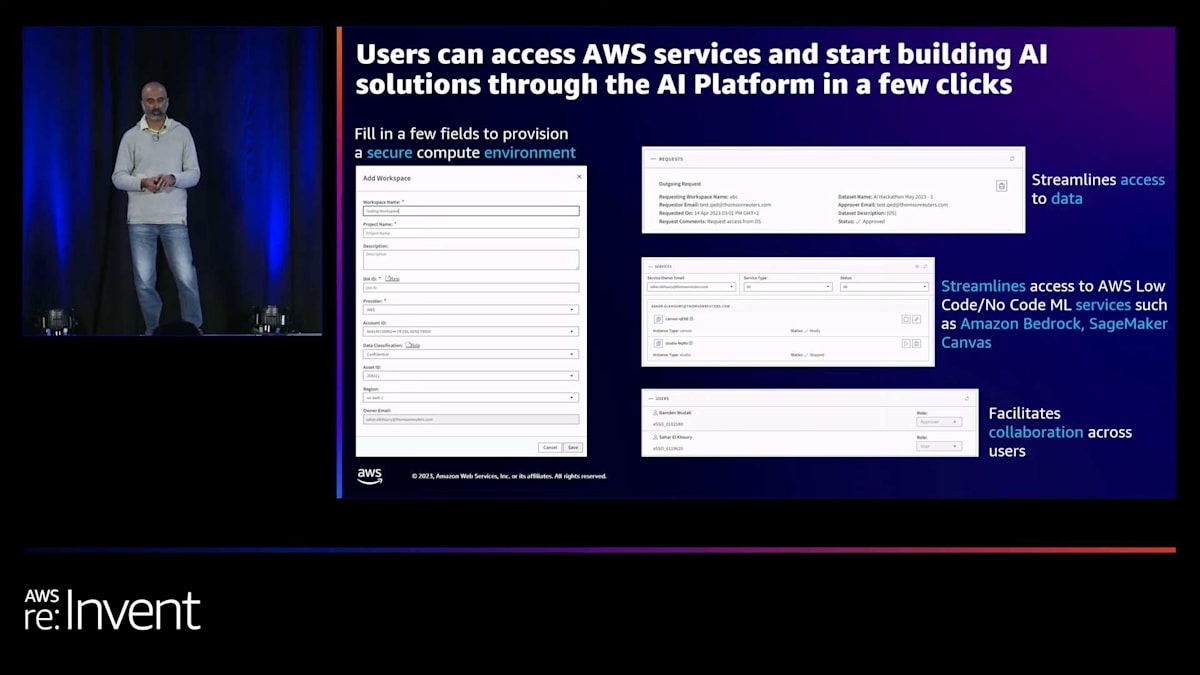
これは、ユーザーがAWSアカウント内にAIソリューションの構築を開始するためのセキュアな空間を作成する方法の例です。ユーザーは主要な要素をいくつか入力するだけで、プラットフォームがセキュアな環境のプロビジョニングを行います。その後、ユーザーは数回のボタンクリックで、データにアクセスしたり、EMRクラスター、EC2インスタンス、SageMaker StudioやSageMaker Canvasインスタンスをスピンアップしたりできます。また、同じ空間内で他の科学者やユーザーとコラボレーションすることも可能です。このアーキテクチャにより、AIプラットフォームはサービスやデータへのアクセスを確保するアプローチを標準化できます。

この1年間、私たちは組織内で実際に取り組まれている問題を扱う複数のハッカソンを企業全体で実施してきました。これらのハッカソンの目的は、イノベーションを促進し、ユーザーが問題に対するAI/MLソリューションを探求できるようにすると同時に、企業全体のユーザーにAIプラットフォームを紹介することでした。今年5月には、SageMaker Canvasの使用に特化したハッカソンを実施しました。そこでは3つの異なる問題を提示しました:ピークシーズン中のリソース管理のためのコールセンター予測問題、トライアル後にサブスクリプションを購入する可能性を予測する転換予測、そして顧客の活動、洞察、パターンを明らかにする顧客プロファイリング問題です。

これらのハッカソンには、様々なペルソナが参加しました。その範囲は、サブジェクトマターエキスパートからデータサイエンティスト、研究者、データアナリスト、MLOps エンジニア、そして AI/ML の経験がないソフトウェアエンジニアにまで及びました。私たちが受け取ったフィードバックは非常に肯定的で、AI プラットフォームを通じて提供しているこれらのサービスが実際に歓迎され、必要とされていることを示していました。これまでプラットフォームを使用したことがなかったユーザーの中には、SageMaker を使い始め、それ以降、彼らの定番ツールになったケースもありました。

ハッカソンでのSageMaker Canvas活用事例:コールセンターリソース管理
ハッカソンで優勝したユースケースの1つを詳しく見てみましょう。そのチームは、ピークシーズン中の顧客コールセンターリソースを管理するために Canvas で開発されたソリューションを提案しました。課題は、人間が行うよりも費用対効果が高く、最適なソリューションを提供することでした。チームは、ストレージエンジニア、ビジネスアナリスト、そして2人のソフトウェアエンジニアで構成されており、全員が AI/ML 技術の経験がないユーザーでした。

問題の本質は、Snowflake の特定のソースにあるデータにアクセスしようとすることでした。ユーザーは、Snowflake が Canvas が接続できるデータソースの1つだったため、カスタム接続を作成しました。彼らは Canvas を Snowflake に接続し、ハッカソンで使用するはずのデータにアクセスし、データの分析を開始しました。その後、特徴量エンジニアリングを行い、データから関連する特徴を抽出し、コール量に影響を与えるパターンやトレンドを特定しました。彼らはそれが特徴量エンジニアリングと呼ばれることを知らなかったかもしれませんが、効果的にコール量に影響を与える関連する特徴やパターンを特定しました。Canvas は、特定された特徴を使用してカスタムモデルをトレーニングするために使用されました。
Davideがデモンストレーションしたカスタムモデルトレーニングを使用して、彼らはカスタム予測モデルを作成しました。AIプラットフォームの統合とガバナンスソリューションも活用され、モデルの登録が行われました。Davideのデモでは、ユーザーがモデルレジストリ内で登録し、モデルを承認してダウンストリームのワークフローをトリガーすることができました。このハッカソンでは完全に活用されませんでしたが、モデルは確かに中央のモデルレジストリに登録され、Canvasを使用する際のユーザーの可能な経路であることが証明されました。

モデルのトレーニングと登録が完了すると、彼らはそれをデプロイして予測を行いました。これらの予測が最終的にハッカソンでの勝利につながりました。 このプロセスにより、チームはAWSが提供するAIの問題に対処し解決するためのソリューションについて学ぶことができました。これらは彼らが以前は知らなかったものでした。彼らはMLモデルの実装方法を学び、データの処理と扱い方を理解しました。Machine Learningモデルのトレーニングは比較的簡単で、このプロセスが初心者にも優しいものであることに気づきました。
今年、複数のハッカソンやその他のイベントを通じて、AWSチームと協力してサポートを得られたことは素晴らしい経験でした。エンタープライズの観点から必要な機能について、例えば特定のプロセスをどのように安全にし、バランスを取るかなど、エンタープライズレベルでそれらすべてを標準化する方法についてフィードバックを提供することができました。今後も同じレベルのコラボレーションを楽しみにしています。以上です。Rajnishに引き継ぎます。ありがとうございました。
SageMaker Canvas活用のためのリソースと今後のセッション案内


ありがとう、Ramdev。機械学習の専門家でさえない人々が機械学習ハッカソンで勝利したという、とても興味深い話ですね。これがSageMaker Canvasのようなツールの力です。自組織内で同様の例を持ちたい場合や、SageMaker Canvasを使用したい場合は、様々なリソースにアクセスできます。最初のリソースは、Courseraのコースです。これは、顧客がビジネス上の問題を機械学習の問題に変換する方法を理解するのに役立ちます。 これは顧客から聞く意見です:ドメイン専門家は解決したいビジネス上の問題に精通していますが、そのビジネス上の問題を機械学習の問題に変換するのに助けが必要です。そのため、Courseraでコースを作成することになりました。皆さんが利用できるようになっています。

2つ目のリファレンスは、ハンズオンラボです。これは様々な例が用意された自己ペースのラボです。これらの例を通して学ぶことができます。Davideが話したように、Canvasにはサンプルデータセットが付属しています。これらのサンプルデータセットを使用して、様々な種類の機械学習モデルを構築し、このアプリケーションの感触をつかむことができます。以上で今日のセッションを終了しますが、明日予定しているいくつかのセッションをご紹介して締めくくりたいと思います。
Generative AIのさまざまな機能についてさらに深く掘り下げたい場合、foundation modelsのファインチューニングやデータ準備の自然言語的な方法を含めて、AIM339というセッションに参加することをお勧めします。このセッションは明日、11月30日の午後2時30分から3時30分まで、Caesars Forumで開催されます。また、さまざまなデモや例を見たい場合は、SageMaker Canvasのチョークトークがあります。これも明日、午後4時から5時まで、Mandalay Bayで開催されます。
同様の機能を探している同僚がいて、今日のセッションが役立ったと感じた場合は、皆さんのために計画しているセッションから彼らも恩恵を受けられるよう、ぜひお知らせください。 以上で、本日は皆様のお時間をいただき、ありがとうございました。ご清聴ありがとうございます。皆様がSageMaker Canvasをご利用いただけることを楽しみにしています。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion