re:Invent 2024: AWSが解説 S3上のData Lake構築と最適化
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Build and optimize a data lake on Amazon S3 (STG323)
この動画では、架空のEコマース企業Forever Ecommerceを例に、Amazon S3上でのData Lake構築と運用について包括的に解説しています。Raw、Processed、Curatedの3層構造でのデータ管理や、Apache IcebergとS3 Tablesを活用したテーブル管理、AWS Lake FormationとAmazon DataZoneによるセキュリティとガバナンスの実装方法を詳しく説明しています。また、パフォーマンス最適化のためのパーティショニング戦略やZ-orderソートの活用、Amazon S3のストレージクラスを使い分けたコスト最適化など、実践的なベストプラクティスも紹介しています。さらに、AWS CloudTrailやCloudWatchを用いた監査やモニタリングの方法まで、Data Lake運用の全体像を具体的に示しています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon S3上のData Lake構築:Forever Ecommerceの事例紹介


本日は、セッションSTG323「Amazon S3上でのData Lakeの構築と最適化」についてお話しさせていただきます。私はAWSのSenior Principal EngineerのBryan Lilesです。本日は同じくAWSのPrincipal EngineerであるCarl Summersと一緒に発表させていただきます。 Data Lakeの構築方法を最も効果的に説明する方法を考えた結果、より魅力的で興味深いストーリーにするため、Forever Ecommerceという架空の企業を作り、このトークではForeverのData Lake構築から運用、保守に至るまでの道のりについてお話しします。まず、Foreverの主な事業目的は、Widgetの販売です。


2024年、Widgetは大きな注目を集めており、彼らはある程度の成功を収めています。皆様と同じように、彼らも次第に多くのデータを収集するようになりました。このデータの一部は、データベースに格納された構造化データですが、それ以外にも非構造化データや画像、様々なテキストデータがあります。 データの一部はデータベースに、一部はファイルシステムに、そして一部はS3に保存されています。蓄積されるデータ量と保存先の多さが状況を複雑にし、課題を生み出しており、これが事業の足かせとなっていました。

より分かりやすく説明するため、このトークを6つのフェーズに分けました。第1フェーズは「気づき」です。問題を解決するには、まず問題があることを認識する必要があります。次に、Data Lake周りのレジリエントなアーキテクチャを構築する必要があります。PIIやセキュリティ関連、機密性の高いデータを扱う可能性があるため、データセキュリティとガバナンスについて考える必要があります。フェーズ4では、そのデータを取り出せるようにする必要がありますが、S3上のData Lakeでは、クエリの最適化において考慮すべき点があります。大量のデータを扱う場合、Eコマースグループ、運用グループ、データサイエンスグループから生成された変換済みデータの管理について考える必要があります。最後に、持続可能な成長に向けた準備について考えていきます。
データ管理の課題とData Lakeアーキテクチャの設計


Forever EcommerceはAWS上で運営されており、オンラインでWidgetを販売しています。よく言われるように、問題を解決するにはまず問題を認識する必要があります。 このプレゼンテーションには何人かの登場人物がいます。まず一人目は、Forever EcommerceのCIOであるMarcus Prestonです。彼は確実なインサイトを提供しながら、急増するデータの管理という課題について語っています。目標はとてもシンプルです:データへの確信です。



Marcusには相方がいます。CDOのEugene Tateです。Eugeneは自分のチームに「すべてのデータをS3に保存すれば、それで終わりだ」と言います。 しかし、事態はそう単純には進みませんでした。このトークを2つの小さなセクションに分けたいと思います。Data Lakeに保存する可能性のある2種類のデータとして、注文の収集とWebクリックのストリーミングについて説明します。まず、Webアプリケーションについてです。 このWebアプリケーションでは、ユーザーが注文を行い、注文データ、取引データ、すべての詳細情報、購入者、購入場所、配送先といったデータが生成されます。

私たちは、すべてのWebサーバーからこの情報を収集し、定期的にバルクアップロードを行っています。トランザクショナルデータベースに書き込む一方で、データベースからダンプするなどしてすべての情報を抽出し、定期的にAmazon S3にアップロードしています。

また、リアルタイムでClickstreamデータも取り込んでいます。これは、ユーザーがWebサイトをクリックし、商品を探し、前後のページを行き来したり、カートに商品を入れたり削除したりする様子を表すデータです。これは異なるタイプのデータで、リアルタイムで届きます。私たちは、Amazon Managed Streaming for Apache Kafka(以降MSKと呼びます)とAmazon Data Firehoseを使用しており、Data Firehoseはデータを直接S3に送信します。シンプルに言えば、データサイエンティストが何が起きているのかを理解したいと考えており、Amazon Athenaを使用してクエリを実行しています。

このプレゼンテーションでは、多くの異なるサービスが関係する可能性のある数多くのトピックについて説明します。これらのトピックを整理し、特定のサービスに焦点を当てていきますが、データレイクの構築方法はこれだけではないことを認識しています。Athena、MSK、その他これから説明するサービスを使用する方々へのガイダンスを提供します。物語の真の主役は常にOperationsの担当者で、彼らは注文データとClickstreamの両方が新しく入ってくることで、いくつかの課題に直面していることを特定しました。



このトークで取り上げる問題について説明しましょう。まず、複数日や数週間分のデータに対するクエリの処理に時間がかかりすぎています。多くの方がこの問題を経験されているはずです。もう1つの懸念は、機密データへのアクセスが広範囲に及んでいることです。例えば、Data Science Teamが顧客情報にアクセスできる一方で、国別のOperations Teamは自国のデータにのみアクセスできるようにすべきです。さらに、データレイクやS3内の特定のデータを見つけることが難しくなっています。例えば、Finance Teamが先月出荷された注文に関する情報を見つけるのに苦労しています。


重要なポイントは、データベースにデータを追加し、様々な方法でクエリを実行し、システムにより多くの人々を招き入れるにつれて、コストが増加しているということです。これをどのように考えるべきでしょうか?私たちは3つの異なる方法でアプローチします。データのレイヤリングを検討し、データレイクへのデータの処理と取り込み方法について議論し、Raw Data、Processed Data、Curated Layerについて探ります。また、迅速なデータ取得のためのデータのパーティショニングによってS3を効率的にする方法についても取り上げ、セキュリティとガバナンス - 誰がデータを使用し、どのような目的で、誰が承認したのかを理解することについても説明します。
S3データレイクの構造化とデータ処理の最適化

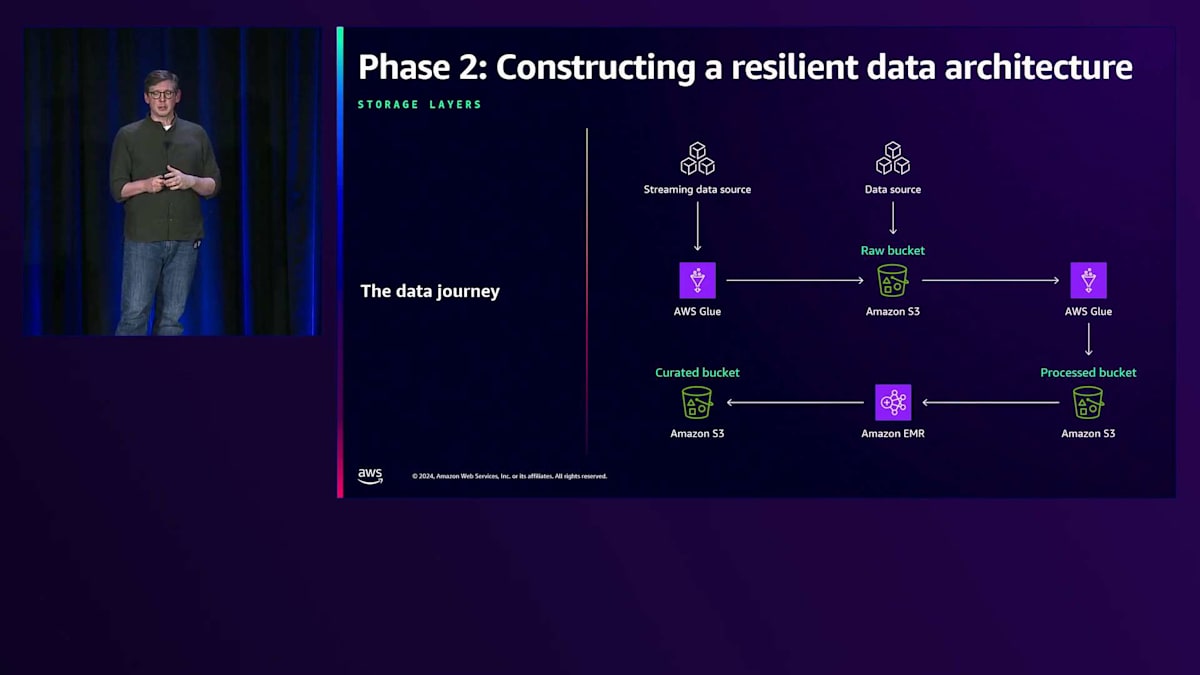
Forever が最初に取り組んだ課題は、データアーキテクチャの見直しでした。ここでは、S3 でのデータの保存方法について考察していきます。 S3 データレイクにおけるデータ構造化の推奨メンタルモデルについて、ハイレベルな視点から説明します。データは Raw、Processed、Curated という3つのレイヤーまたはステージを通過します。各ステージでデータはよりクリーンになり、場合によって拡張され、物理的なレイアウトとスキーマの両面でより構造化されていきます。
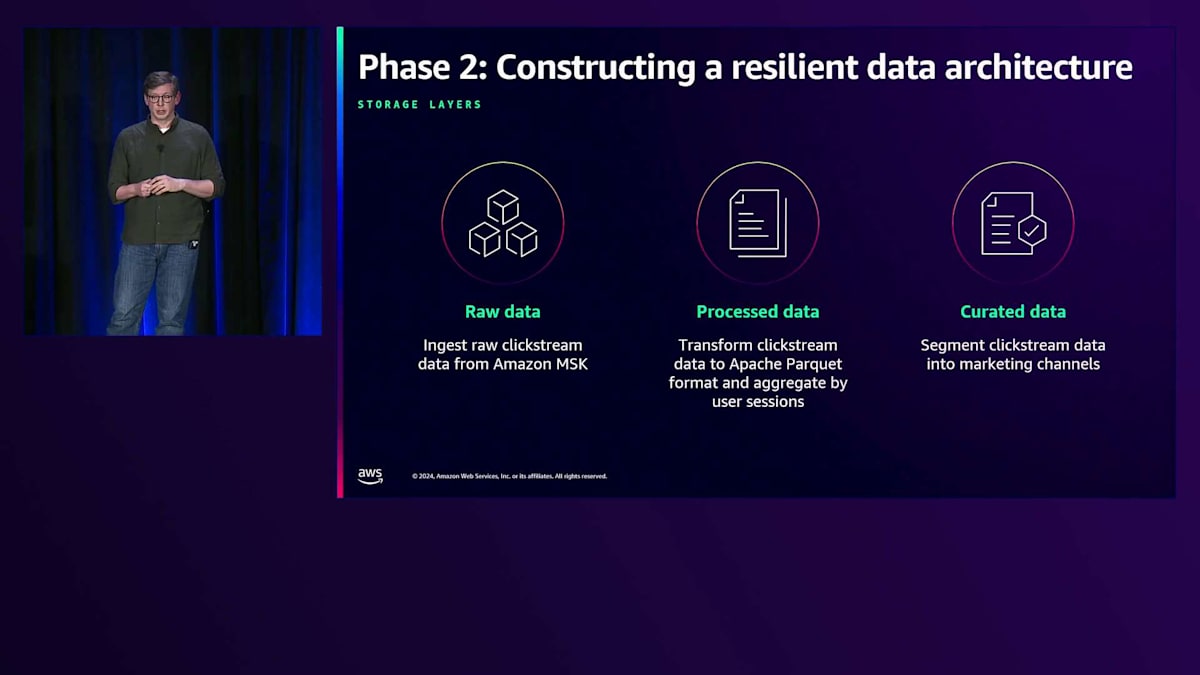
これを具体的に理解するため、このデータレイクにおけるClickstreamデータの流れを追ってみましょう。Clickstreamデータは MSK クラスターから送られ、JSONL ファイルのバッチとして格納されます。これを ETL 処理して Parquet 形式のテーブルに変換します。あるテーブルはセッション別に、別のテーブルは製品ライン別に、さらに別のテーブルは顧客セグメント別に整理されるかもしれません。この段階で、Clickstreamデータと顧客履歴などの他のデータを結合したり、その他の方法で拡張したりすることがあります。最後に、そのデータの一部を、マーケティングチャネルや顧客セグメントごとの過去のパフォーマンス指標を提供する Curated データセットにロードします。


データレイクは、ビジネスオペレーションからの直接的な出力を表す Raw データを Amazon S3 に収集することから始まります。これには、Clickstreamデータ、カスタマーサポートのチャットログ、倉庫からの注文状態変更データ、アプリケーションサーバーからのログなどが含まれます。 Clickstreamデータは、ストリーミングプラットフォームである Amazon MSK から供給され、自然と時系列で整理されます。Amazon S3 に格納する際の合理的なキー構造は、年、月、日を含む日付でセグメント化し、最後にセッションIDを付与するというものです。


一般的な Amazon S3 バケットは、非常に高いリクエストレートに自動的にスケールします。重要なのは、S3 にはディレクトリは存在せず、フラットな名前空間があるということです。その名前空間の各プレフィックスは、最大で3,500 TPS のPutまたは5,500 TPS のGetをサポートでき、バケットには無制限のプレフィックスを持つことができます。このデフォルトのスケール性能により、ほとんどのワークロードでは深く考える必要がありません。 しかし、データレイクへの取り込みはバースト的になる可能性があり、新しいクエリパターンによってデータレイクへの予測不可能なトラフィックが発生する可能性があります。例えば、マーケティングキャンペーンの開始により、ウェブサイトのトラフィックが増加し、それに伴ってアナリストがその期間の顧客行動を理解しようとするアクセスも増加するかもしれません。
提案されたキー構造では、毎時の先頭で新しいトラフィックが発生します。最終的に Amazon S3 は、トラフィックが新しいプレフィックスに移動したことを認識し、下層のスケールを調整します。しかし、その調整が行われるまでの間、アプリケーションやデータ取り込みで503エラーや遅延が発生する可能性があります。これは12時から13時、13時から14時というように、毎時の変わり目に発生します。高ボリュームのアプリケーションや、集計で3,500 TPS のPutまたは5,500 TPS の読み取りを超えるデータ取り込みの場合、複数のプレフィックスにヒートを分散させるようにこのキー構造を調整する必要があります。

この例では、Session IDには本質的にランダム性が含まれていることに気付きます。このSession IDを取り出し、キースペースの中でより上部または左側に移動させ、残りの構造はそのまま維持することができます。これによりAmazon S3はトラフィックを複数のノードに分散させることができ、アプリケーションの利用可能なRPSを向上させることができます。ただし、これにより新しいデータの発見が難しくなります。その日の新しいトラフィックが到着したかどうかを確認するために、可能性のあるすべてのSession IDフォルダを探索する必要があるためです。この問題に対するApache Icebergによる解決方法については、後ほど説明します。

定義上、私たちのRawデータは高度に構造化されているか、部分的に構造化されています。クリックストリームデータは妥当なスキーマを持つJSONファイルとして入ってきますが、カスタマーサポートとのチャットログは自由形式のテキストです。お客様から直接アップロードされた画像やドキュメントが含まれる場合もあります。AWS Glueクローラーは、データからスキーマ情報を自動的に抽出し、Data lakeに新しいデータが入ってきたことを検知して、Processレイヤーへの次のステップに備えることができます。

Processレイヤーでは、データは最も構造化が進みます。データのクリーンアップを行い、重複を除去し、不正確または不完全なエントリを修正し、消費者が理解しやすく、クエリを実行しやすいようにスキーマを適用します。ほとんどの探索的分析はこの段階のデータに対して行われるため、クエリを高速かつ低コストで実行できるよう、データ構造の核となる要素を効率的に整理します。また、どのデータを保持し、どのデータを破棄するかという重要な判断も行います。

このプロセスで最も重要な決定事項の2つが、データフォーマットとレイアウトです。ファイルフォーマットとしては、優れた圧縮率を実現し、多くの種類のクエリ最適化を可能にするApache Parquetがほぼ常にデフォルトの選択として適切です。ただし、消費者がすべてのカラムを必要とすることが分かっている場合など、Apache Avroのような行指向フォーマットが適している場合もあります。ファイルフォーマットに加えて、テーブルフォーマットも選択する必要があります。表示されているキー構造では、パーティションがキー構造内のフォルダとして表現される典型的なレガシーまたはHiveフォーマットのテーブルを示しています。このようにデータを構造化することで、クエリエンジンはクエリを満たすために不要な部分を除外することができます。このタイプのテーブルフォーマットは多くの場合に有効ですが、これはAmazon S3の汎用バケットでは利用できない、アトミックなフォルダ名の変更などの機能や不変性を提供するファイルシステム向けに設計されていました。

テーブルの内容を特定するためにリスト操作を使用する必要があるため、リーダーは部分的な書き込みや進行中の書き込みを見る可能性があります。失敗した書き込みによって、テーブルに不整合を引き起こすデータが残ってしまう可能性があります。さらに、人気のあるパーティションへのクエリは特定のS3プレフィックスにヒートを集中させ、クエリの遅延や失敗を引き起こす可能性があります。
Apache Icebergテーブルフォーマットは、ファイルのレイアウトをテーブルのコンテンツと構成から切り離します。ディレクトリを使用する代わりに、テーブル構造は一連のメタデータファイルに保持され、パーティションとスナップショットのメンバーシップに従ってデータファイルをカタログ化し、指し示します。Icebergテーブルに書き込む際は、キー構造にランダム性を注入するようにオブジェクトストレージの書き込みを有効にする必要があります。これにより、Amazon S3はテーブルのあらゆる読み取りや書き込みの量に対応できるようになります。Icebergのコミットプロトコルは、部分的または失敗した書き込みがユーザーから見えることを防ぎ、タイムトラベルやロールバックなどの高度な機能を可能にします。また、データ書き込みのコストをクエリ時間に先送りできる、効率的な行レベルの更新と削除を実現します。このデータとストレージの場所の分離により、アナリストやビジネスのニーズの変化に応じてテーブル構造をより柔軟に進化させることができます。

もちろん、Apache Icebergの採用にはトレードオフが伴います。失敗した書き込みによってテーブルの状態に不整合が生じることはありませんが、バケット内にクリーンアップが必要なデータファイルが残されることになります。また、テーブルからデータを削除しても、必ずしもデータが削除されるわけではなく、単にそのデータが利用できない新しいスナップショットが作成されるだけということを理解しておくことが重要です。そのデータを確実にクリーンアップするために、適切にスナップショットを期限切れにする必要があります。

このステージでは、データが簡単にアクセス、理解、管理、進化できることが非常に重要です。その重要な部分として、テーブルをデータカタログに登録することが挙げられます。AWS Glue Data Catalogを使用すると、アナリストのノートブック、EMRジョブ、Amazon Athenaクエリなど、複数の場所から簡単にアクセスできるようにテーブル定義を保存できます。このステージのテーブルやエンティティは、生の入力データと直接対応している必要はありません。多くの場合、次のステージで複数の出力につながる場合、このレイヤーで結合やその他の変換を行うことが理にかなっています。次のステージでは、これらのキュレーションされたデータセットを導出することになります。

これらのテーブルとデータセットは通常、ビジネスの特定の質問に答えるために高度にカスタマイズされています。十分なドキュメント化が必要で、使いやすくなければならず、通常は時系列での履歴ビューを提供するために高度に集計されています。ほとんどの場合、これらのテーブルはAmazon Redshiftのようなデータウェアハウスにロードされ、アクセスの容易さとクエリの実行を可能にします。ただし、プロセスレイヤーで見たのと同じような考慮事項の対象となるAmazon S3に保存することもできます。プロセステーブルと同様に、これらのテーブルもユーザーから見えるようにカタログに登録する必要があります。

このレイヤーのユーザーは、データ品質にも大きな関心を持っています。つまり、カラムに正しい値のみが含まれているか、予想される行数があるかということです。また、データの系統にも関心があり、Apache Splineのようなツールは様々な計算プラットフォームと連携してこの系統データを提供できます。このセクションの重要なポイントは、データレイクでデータを構造化するための考え方です:Raw、Processed、Curatedの形式、適切なファイル構造とテーブル構造の選択、そして高いパフォーマンスとスケールを実現するためのAmazon S3の利用計画です。これらすべてを行うことで、セキュリティとガバナンスを通じてデータレイクを成熟させるための強固な基盤を提供することができます。
データセキュリティとガバナンスの実装

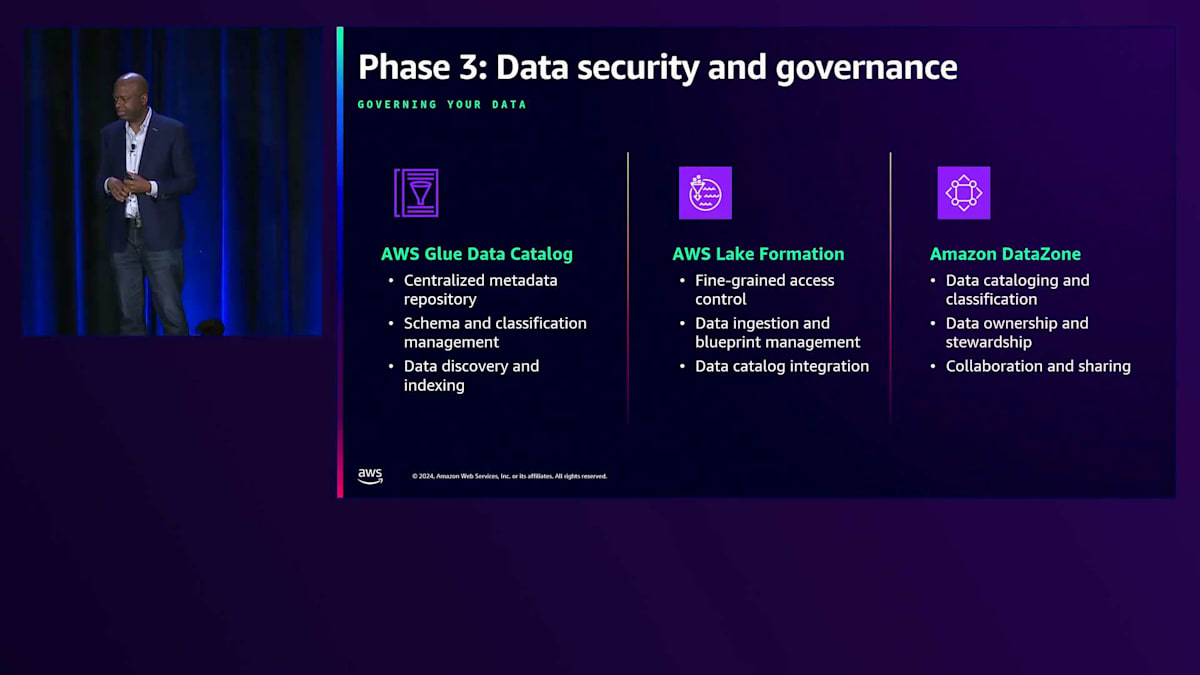
このプレゼンテーションのすべてのパートが私のお気に入りなのですが、 ここが特に私のお気に入りのパートです。Forever Ecommerceの CISO である Sheila Vivien の話です。彼女が考えていたのは、「Foreverは堅牢なデータアーキテクチャを構築したので、次はセキュリティとガバナンスに注力する必要がある」ということでした。このセクションでは、データプラットフォームのセキュリティとガバナンスに不可欠な要素について見ていきましょう。 データプラットフォームのセキュリティとガバナンスを考える際、基本となる3つのコアサービスについてお話しします。1つ目は、テーブル、スキーマ、メタデータを管理するAWS Glue Data Catalogです。2つ目は、ユーザーが閲覧できる内容のオントロジーを構築できるAWS Lake Formationです。3つ目のプロダクトは、Amazon DataZoneです。
AWS Glue Data Catalogが技術的な側面を扱うのに対し、Amazon DataZoneはより人的な側面に焦点を当てており、セキュアなデータ共有を可能にしながら、グループが必要に応じてデータを管理・共有できるようにします。
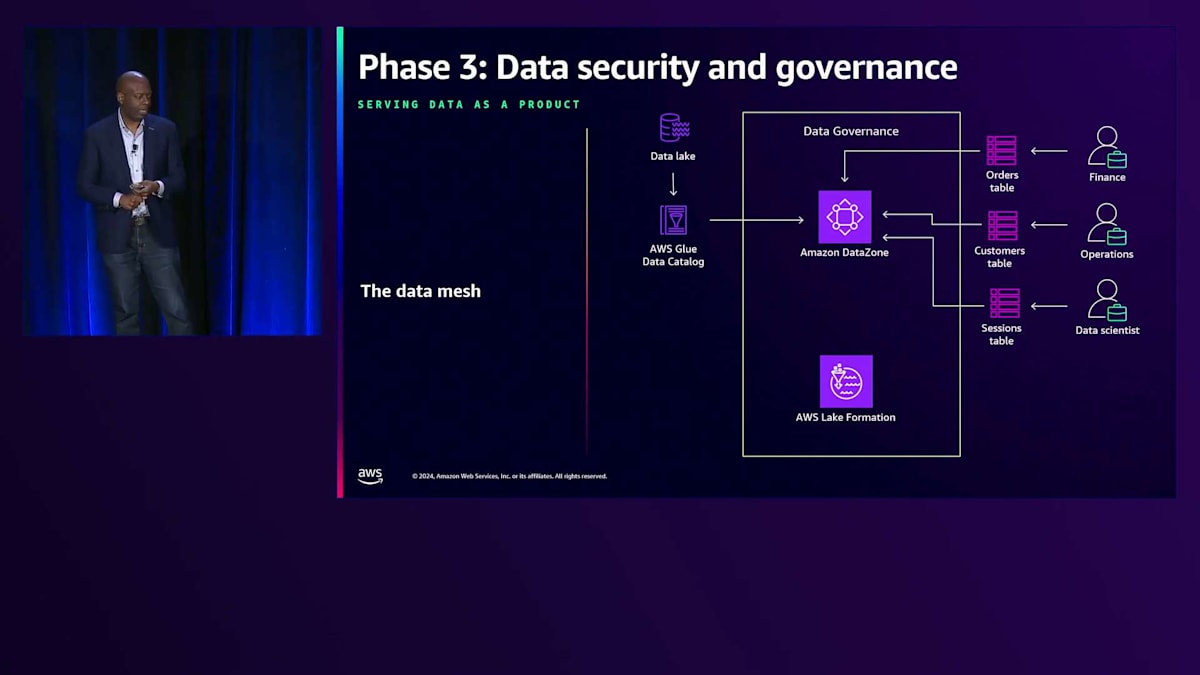
私が特に気に入っている用語の1つが「Data Mesh」です。ここで私の指が全て繋がっているように、メッシュ状のデータをイメージしてください。Data Meshは、データを整理する現代的な方法で、所有権を分散化し、組織が大規模なデータを扱いやすくします。単一のチームがすべてのデータを管理するのではなく、実際のデータオーナーにデータの所有権を与えることができるようになりました。この手法は、小規模から始めて大規模な運用にスケールする際に特に効果的です。

Data Meshにアプローチする際には、いくつかの基本原則を考慮することが重要です。その核心は、財務、運用、マーケティングなど、各ドメインへの所有権の移行です。各ドメイン内のデータを独自のデータプロダクトとして扱うことで、データを最もよく理解しているチームが、最適な共有方法を知ることができます。私たちは、チームがAmazon DataZoneの支援を受けてデータをパッケージ化する「データ・アズ・ア・プロダクト」という概念を導入しています。アクセス権限、使用方法、使用期間を指定し、その使用状況を追跡することができます。このマインドセットにより、組織全体でデータがより利用しやすくなり、規制の厳しい環境で働く人々にとっては、小規模から大規模まで、データガバナンスを容易に管理できる仕組みを提供します。


次に、このスペースにおける他のツールの1つであるAWS Lake Formationについて説明しましょう。Lake Formationでは、一般的に行形式で存在するデータに対して、適切なアクセス権を確実に付与する必要があります。これが実際にどういうことなのか、例を挙げて説明しましょう。 最初の例は、フランスのオペレーションチームに関するものです。GDPRやその他の社内外の要件により、フランスのオペレーションチームにはフランスで発生することのみを閲覧してもらいたいと考えています。すべてのSQLクエリに「country equals France」を追加するよう要求する代わりに、Lake Formationを使用してこれを上流で設定し、フランスのデータのみを閲覧可能とし、それ以外のスコープのデータは見えないようにすることができます。


きめ細かなアクセス制御を提供するもう一つの方法は、列単位のデータ制御です。時として、すべての人がデータのすべての列にアクセスする必要があるわけではありません。例えば、Data Science Teamは個人の名前や識別情報を知る必要はありません。Lake Formationを使用して列フィルターを適用することで、その列をデータから完全に除外することができます - 誰もそれを照会できなくなります。パワフルな機能の一つは、Lake Formationを使用して列と行のフィルタリングを組み合わせ、真にきめ細かなデータアクセスを実現できることです。次のステップは、これらのフィルターを権限に割り当てることです。行レベルや列レベルのフィルターを定義した後、誰がどのデータにアクセスできるかを設定できます。
アクセスが確立されると、ユーザーがデータに対して実行できるアクションを指定できます。この例では、下から2行目に注目すると、これは読み取り専用のロールです。このデータにアクセスできる人々は、データの説明(describe)と選択(select)のみが可能です。データの更新も許可するように設定することもできますが、この場合は注文データを変更させたくないため、説明と選択のみに制限しています。


AWSでできることは、プリンシパルとして、ロールやSAMLを使用できること、そしてTrusted Identity Propagationという概念があることです。これにより、組織のActive Directory内で誰が何の所有権を持っているかを定義できます。ここで素晴らしいのは、誰がアクセスできるかということと、それらの人々を定義する方法を切り離したことです。私たちにはData Lakeがあり、そのData Lakeには大量のデータがあります。しかし、Data Lakeの問題の一つは、人々がデータを投げ込みがちだということです。Data Lake内で何も見つけられないのであれば、それはどれほど有用でしょうか?
では、このデータの実際のガバナンスについて話しましょう。まず、Amazon DataZoneについて説明します。DataZoneでは、会社や会社内のビジネスユニットなど、データのドメインを定義できます。ドメイン内には複数のカタログを持つことができます。これは重要です。なぜなら、昨日Matt GarmanがAmazon SageMaker Studioについて話し、Studioの大きな特徴の一つは、すべてのデータにアクセスできることだからです。このカタログを定義することで、データへのアクセスを作成でき、これらのカタログ内でプロジェクトを持ち、データのクエリを実行できます。

Amazon DataZoneのパワフルな点は、セントラルカタログ内でのデータ管理を効率化し、Amazon S3やAmazon Redshiftのデータを効果的に管理できることです。下流のユーザーは、これらについて考える必要がありません。DataZoneは、データ管理をより簡単で効率的にする複数の強力な機能を提供します。これには、データカタログ作成とアクセス管理が含まれ、複数のアカウント間でのデータ共有とアクセスを制御するポリシーを設定できます。また、DataZoneはデータ品質と系統追跡も提供し、データの正確性を検証し、その出所を追跡することができます。
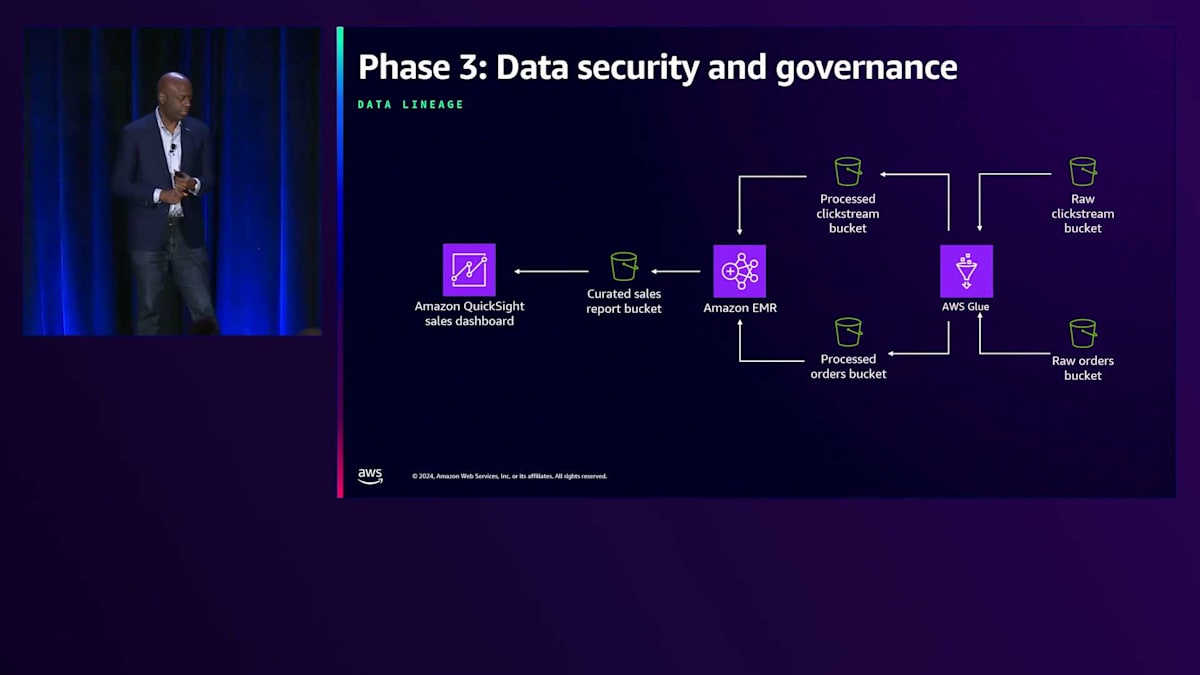
特に Data lineage について強調したいと思います。例えば、Amazon QuickSight の売上ダッシュボードでデータを使用していて、役員会議でその数字を確認しているときに「このデータはどこから来たの?」と質問されたとします。通常であれば、データエンジニア、データサイエンティスト、開発者がクエリやログを検索して、ソースを特定する必要があります。しかし、Amazon DataZone でデータを管理していれば、この機能が組み込まれています。先ほど Carl が説明した Raw データ、Processed データ、Curated データのトラックを通してデータを移動させる際、データの出所だけでなく、なぜそこに配置されたのかも説明できます。Amazon QuickSight のダッシュボードから、Raw な注文データの Bucket や QuickStream Bucket まで追跡できるのです。


では、Amazon DataZone のベストプラクティスについて説明しましょう。まず、データにタグを付けて、ユーザーが見つけやすくし、発見に役立つ情報を提供します。AWS Lake Formation を通じて Fine-grained access control を使用しつつ、誰がデータを使用しているかを把握するためにデータの使用状況をモニタリングします。そして、このデータを将来的に自動化し続けるための方法を検討します。最後に、Data lake は名前に反して、単一のエンティティではないことを覚えておいてください。Data lake を構築する際は、複数のアカウントと複数の Amazon S3 Bucket という観点で考える必要があります。
クエリパフォーマンスの最適化とApache Icebergの活用
このアプローチには2つの重要な理由があります。1つ目は、誤削除からの保護です - 一つのセグメントで Bucket が削除されても、すべてのデータを失うことはありません。2つ目は、複数の境界によるセキュリティの強化です。誰かが1つのアカウントに侵入しても、すべてのアカウントにアクセスすることはできません。そして、このアーキテクチャでは、アカウント間で統合された機能を維持できます。


データは常に暗号化された形式で保存・転送することが基本です。S3 は現在デフォルトですべてを暗号化していますが、特にデータ保管時の暗号化は必須であることを強調しておきたいと思います。S3 が提供する暗号化を利用するか、独自のキーを提供するか、場合によっては二重の保護を実装することができます。このセクションの重要なポイントは、Fine-grained access control の実装、分離のためのクロスアカウント共有の活用、データの検索と利用を支援するためのデータガバナンスと発見機能の確立、すべてのデータの暗号化、そして成長に合わせて拡張できる柔軟なセキュリティモデルの設計です。

Forever社がデータガバナンスの課題に対処できたので、次はクエリのパフォーマンス改善に注力できます。クエリの最適化は一種の深遠な技術で、この話題だけでも何時間も議論できるでしょう。しかし、ストレージの観点からは、影響力が大きく、しばしば容易に達成できる改善点がいくつかあり、多くの場合、ユーザーには透過的に実装できます。

データのプロセスレイヤーについて説明する際、パーティショニングについて触れましたが、これによってクエリエンジンは大量のデータの中から不要な部分を効率的に除外することができます。例えば、特定の日付のデータを検索するクエリを実行する場合、データがその項目でパーティション化されていれば、SparkやAthenaなどのエンジンは2024/10/19のような関連するディレクトリのデータのみを読み込めば良いことになります。ただし、パーティショニングはストレージレイヤーにおけるデータレイアウトに直接影響を与えることを理解しておく必要があります。また、カーディナリティの高いカラムでパーティション化すると、非常に小さなデータファイルが生成され、クエリが高度に選択的でない限り、クエリの効率が低下する可能性があります。
従来のテーブルフォーマットでは、パーティションはテーブルの明示的なカラムとして表現され、同時に基盤となるストレージレイヤーのディレクトリ構造としても表現されています。これにより、2つの重要な問題が生じます。1つ目は、パーティショニング戦略を変更する際に、新しい構造に合わせてテーブルデータ全体を書き直す必要があることです。2つ目は、多くの場合データエンジニアではないクエリ作成者が、特定のパーティショニング戦略を理解し、直感的でない方法でクエリを書かなければならないことです。例えば、Clickstreamエントリにイベントタイムスタンプがあるのは自然ですが、これらのイベントをパーティション化するには、そのタイムスタンプを年、月、日の個別のカラムに分解する必要があります。

Apache Icebergテーブルフォーマットは、これらの課題の両方に対処します。パーティションのメンバーシップは物理的なレイアウトではなくテーブルメタデータによって決定されるため、テーブル全体を書き直すことなく、新しいデータに対してパーティションを変更することができます。例えば、アナリストが特定の顧客セグメントを頻繁にクエリする場合、この属性でパーティション化することでクエリのパフォーマンスを大幅に向上させることができます。さらに、Icebergは隠しパーティショニングをサポートしており、自然なカラムに対する変換によってパーティション値を決定することができます。これにより、クエリ作成者はタイムスタンプを個別のコンポーネントに手動で変換することなく、自然なカラムを使用してクエリを表現できます。

パーティション内のデータは通常、複数のファイルに書き込まれ、Apache Parquetのようなフォーマットを使用する場合、 カラムの最小値や最大値などのメタデータはファイルフッターに格納されます。よく検索されるカラムでデータがソートされている場合、エンジンは探している値がそのファイルに存在しないことが分かれば、セクションやファイル全体を無視することができます。
Icebergはこの点でも役立ちます。多くの情報をテーブルメタデータに昇格させることで、エンジンがデータファイル自体を参照する必要がなくなります。複数の次元での線形ソートは効果が逓減し、ソート階層の下位にあるフィールドのソートの恩恵を受けるには、その階層の要素に対する述語が必要です。複数の次元にわたって自然なクラスタリングがあり、読み取り側が多様なクエリ要件を持つ場合に非常に有用で大きな利点をもたらすZ-orderソートというアルゴリズムについて、覚えておいていただきたいと思います。
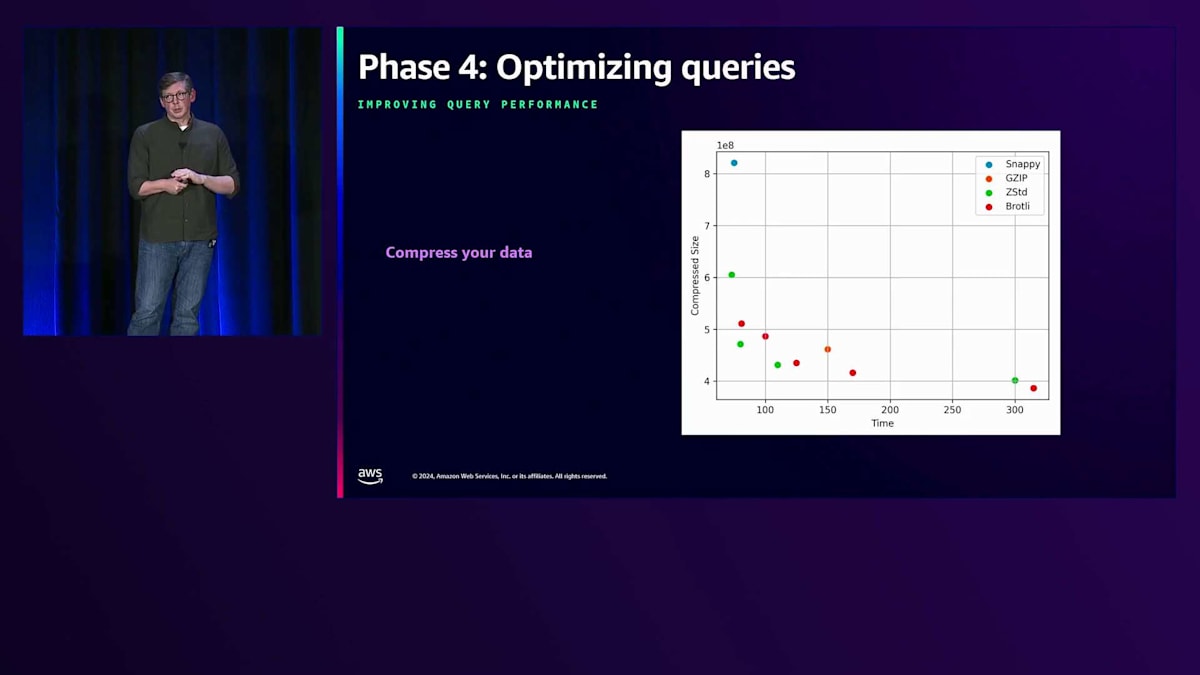
データを圧縮することは、かなり明確な選択肢です。データが小さくなれば、読み込みが速くなり、クエリのパフォーマンスも向上します。Apache Sparkのような多くのライターは、デフォルトで出力を圧縮しており、これは素晴らしいことです。しかし、異なる圧縮アルゴリズムがもたらすサイズと速度の違いは、必ずしも明白ではありません。圧縮の効果は多くの場合、データの性質に大きく依存するため、実験が必要です。私たちの社内Data Lakeでは、同じCPU時間とコストで、Zstdをレベル9で使用した場合でも、平均5〜6%のストレージ削減を実現しています。この変更の最も良い点は、現在ではZstdのサポートがほぼ普遍的であり、多くの場合、開発の労力は設定変更程度で済むということでした。

良好な圧縮を実現するには、圧縮ウィンドウ内に十分なデータがあることを確認する必要があります。私たちの経験では、Data Page Sizeと呼ばれる設定を約1MBにした場合に最高のパフォーマンスが得られます。通常、これには約128MBのRow Group Sizeが必要ですが、それ以上では効果は逓減します。 一般的に、クエリのパフォーマンスを向上させるためにデータをソートしたいところですが、明確なメリットが得られるフィールドがない場合や、単に分からない場合でも、ソートは圧縮の効果を大幅に改善できます。私たちは社内のData Lakeで、テーブル内の2つのフィールドのあらゆる組み合わせでデータをソートする実験を行いました。いくつかの例では、最も効率的なペアが、Data Lakeに到着した時点での自然なソート順と比べて、最大22%も優れた結果を示しました。もちろん、ソートにはコストがかかるため、クエリの恩恵が得られない場合は、データが長期間保存される場合にのみこのコストを支払う価値があります。

このセクションで何度かApache Icebergについて触れてきました。残りの機能について詳しく説明する時間はありませんが、私たちにとってIcebergの主な利点は、アセット保証が得られること、ペタバイト規模のテーブルのクエリ時の効率性を高められること、そしてニーズの変化に応じてパーティショニングとスキーマの両方を進化させる能力にあります。パフォーマンス改善の文脈で、Icebergのコンパクション機能について簡単にお話ししたいと思います。小さなデータファイルは、それらのファイルを開くためのオーバーヘッドが発生するため、クエリの非効率性につながる可能性があります。このオーバーヘッドの影響は、平均ファイルサイズが小さくなるほど大きくなります。このオーバーヘッドを軽減する一つの方法は、複数の小さなファイルを収集して1つの大きなファイルに書き直すことです。Icebergは、まさにそれを行うrewriteDataFilesというストアドプロシージャを提供しています。

これはまた、Z-orderソートを含むソート順を変更する絶好の機会でもあります。ただし、これらのコンパクションワークフローは、テーブルの新しいスナップショットを生成し、他の書き込みワークロードと競合する可能性があります。非常に大きなテーブルや書き込みボリュームの多いテーブルの場合、パーティションごとにコンパクションを実行し、Partial Progress機能を有効にして、競合するコミットの可能性と影響を減らすことをお勧めします。 昨日、Amazon S3は、S3におけるApache Icebergテーブルの完全マネージドソリューションであるS3 Tablesの一般提供を発表しました。S3 Tablesは、ストレージレイヤーでのチューニングによる優れたクエリパフォーマンスなど、いくつかの利点をもたらします。また、テーブルがファーストクラスの存在となったことで、セキュリティの改善と簡素化も実現しています。さらに、多くの管理責任をAmazon S3に委譲し、設定で制御できるようになったことで、私たちの多くの作業が簡素化されました。

Query Engineとその最適化について、特にAmazon Athenaに焦点を当てて説明させていただきます。ご存知の方も多いと思いますが、AthenaはTrinoとSparkエンジンの両方に対応したマネージドサービスです。特に複雑なJoinを含むクエリに関して、パフォーマンスエンジニアリングのための多くの有用なツールを提供しています。Athenaを使用する際は、ユーザー間のリソース利用を分離するためにWork Groupsを活用し、また、コスト配分やCloudWatchメトリクスを使用してコストの監視と制御を行うことが重要です。さらに、AthenaはAWS CloudTrailにその使用状況を記録するため、誰がデータにアクセスし、どこに結果を書き込んでいるかを特定する有用な手段となります。


クエリの最適化は、ミクロとマクロの両方の選択において行われます。Apache Icebergがもたらすメリットについては既にお話ししましたが、クエリに適切なコンピューティングプラットフォームを適用することも考慮すべきです。Athenaについては既に触れましたが、Amazon Redshiftは複数の異なるデータセットにまたがる複雑なクエリの実行に非常に適しています。また、SpectrumテクノロジーやS3テーブルとの統合により、適切なストレージテクノロジーを選択する柔軟性を提供し続けています。 このセクションの重要なポイントは、効率的なデータフォーマット、パーティショニング戦略、ソート順序を選択することです。データに最適なものを見つけるために実験を重ねてください。ユーザーの一般的なクエリを特定するためにモニタリングを行い、それに応じてパーティショニング戦略やソート戦略を進化させていきましょう。Apache Icebergのようなオープンテーブルフォーマットを採用することで、これらのパフォーマンス上の利点や改善を、より簡単に、かつユーザーに意識させることなく実現できます。
データ品質の向上とストレージコストの管理



Forever Ecommerceは、データレイクのパフォーマンスを最適化した後、データ品質の向上とストレージコストの管理に取り組むことにしました。これからデータ品質を測定・管理するための2つの重要な手段と、データレイクの規模が拡大するにつれてコストを簡単に管理できるようにする主要なAmazon S3の機能についてお話しします。私たちの意思決定の質は、データの質によって決定されます。 データがRaw、Processed、Curatedの各レイヤー間を移動する際、問題を監視し、アラートを出し、発見された問題を修正することが重要です。AWS Glue Data Catalogは、カラムが期待値を持っているか、その値が期待される範囲内にあるかといったデータの正確性の検証に使用できるほか、データの完全性の監視にも使用できます。これらのルールの評価結果に基づくメトリクスとイベントは、Amazon CloudWatchメトリクスとEventBridgeに発行され、そこで不正なデータの通知や修正ワークフローのトリガーのための自動化とアラームを設定できます。

Apache Icebergは、GitスタイルのCommitログのような機能もサポートしており、TagsやBranchesなどの機能を利用できます。データ品質の観点で重要なのは、Write-Audit-Publishワークフローと呼ばれる手法が可能になることです。ProcessedやCuratedテーブルへの新しい書き込みは、Stagingブランチで行われます。書き込みが完了した後、必要に応じて手動での確認を含むデータ品質分析や監査を実行できます。新しいテーブルやそのデータの品質に満足したら、メインラインにFast-Forwardし、標準的なユーザーから見えるようにすることができます。このワークフローは、クロステーブル検証を行う複数のテーブルにも拡張できます。すべてのテーブルの状態に満足したら、それらをFast-Forwardし、Tagを付けることで、どのバージョンを組み合わせて使用できるかをユーザーに知らせることができます。

データの旅のすべての段階で、Amazon S3はアクセス時間とコストのトレードオフを考慮した、コスト効率の良いストレージオプションを提供しています。これらの選択は、一般的にデータのアクセスパターンを理解することが必要です。Rawデータは、S3に到着した直後に何度もアクセスされる可能性が高いものの、その後はあまりアクセスされない傾向にあります。しかし、コンプライアンス要件を満たすため、あるいはビジネスニーズの理解が進化するにつれて新しい洞察を得るために、このデータを長期間保持しておくことは有用です。このような場合、データをS3 Standardに配置し、数週間または数ヶ月後にAmazon S3 Glacier Deep Archiveなどのアーカイブ層に移行して、低コストで長期保持することが望ましいでしょう。

私たちの処理済みデータセットは、データサイエンティストが常に分析手法を進化させたり、緊急のビジネスニーズに対応したりしているため、アクセスパターンが不明確であったり変化したりする可能性が高いです。このような場合、S3 Intelligent-Tieringを使用するのが最も理にかなっています。これは、アクセス頻度に基づいて、最もコスト効率の良いストレージ層にデータを自動的に移動させてくれるからです。

非常に大まかに言えば、アクセスパターンを十分に把握している場合は、明示的なライフサイクルポリシーを使用してストレージクラス間でデータを移行します。それ以外のケースでは、データを直接S3 Intelligent-Tieringに配置することをお勧めします。このセクションでは、データ品質の高い基準を確保するための重要な戦略と、S3 Intelligent-Tieringを使用する場合を含め、ストレージクラスを通じてストレージコストを管理する方法について説明しました。
長期的なData Lake運用:メトリクス収集と監視の重要性



さて、フェーズ6に入り、長期的な視点でデータレイクを運用する方法について考える必要があります。このセクションでは、長期的なデータレイクの運用に関するいくつかのポイントを見ていきましょう。まず最初に行うべきことは、すべてのメトリクスを収集することです。メトリクスの収集と言っても、Amazon S3だけを考えるのではありません。AWS Glue、Glue Crawler、Glue Data Qualityについても考え、そこからメトリクスを収集する必要があります。Amazon EMRを使用している場合は、EKS、Serverless、EC2のいずれであっても、そこからメトリクスを収集する必要があります。また、Amazon Athenaでクエリを実行している場合や、この例のようにAmazon MSKを使用している場合も、データレイクを構成するすべてのサービスからメトリクスを収集する必要があります。
次に考えるべきは、ダッシュボードとアラートです。何かが間違っている場合や、すぐに問題が発生しそうな場合に通知する手段がなければ、メトリクスを収集する意味がありません。重要なメトリクスを特定してKPIを設定し、重要度に応じてアラートを設定する必要があります。重要な項目のリストを示したいところですが、これは実際のユースケースによって大きく異なります。アラートや通知はSNSを通じて発信するか、他のサービスを使用することができます。

主要なメトリクスについて考える際は、本当に重要な点に焦点を当てる必要があります。まず、データが正しく、有効なデータであることを確認する必要があります。また、クエリや処理が適切な時間内で完了するよう、データが利用可能で、かつパフォーマンスの面でも問題ないことを確認する必要があります。さらに、ストレージとコストの管理について考え、コストの発生箇所を理解し、データレイクの請求書が予想外のものにならないようにする必要があります。そして、セキュリティについても考える必要があります。誰が何にアクセスできるのか、誰が何にアクセスしたのか、そしてそのアクセス権限を誰が付与したのかといった点です。

このデッキが最初に作られた時、このスライドは実は横向きで、それぞれの項目の下に5つの要素がありました。これはKPIsを考える際の良い出発点となるリストです。ストレージのコストと効率性について考え、データを費用対効果の高い方法で保存・アクセスしているか確認しましょう。もう1つはスケーラビリティです - データの流入速度とAnalyticsツールのスケーリング状況を監視します。EMRやEKSを使用して新しいノードがスピンアップしている場合、その速度を把握します。データ品質について考え、常に不良データを取り込んでいないかを確認します。データが使用可能か、Amazon DataZoneに保持しているすべてのデータのメタデータがあるかを検討します。

最後に、考慮すべきもう1つの点として、監査のためにAWS CloudTrailを使用することがあります。多くの人が見落としがちな興味深いアプローチがあります:すべての監査データをData Lakeに入れるのです。そうすることで、ビジネス機能に使用しているのと同じ方法で、実行した操作に関するデータを同じツールでクエリできるようになります。

成長は必ず訪れるので、人間の介入をなくしたいと考えています。Amazon CloudWatchを使用して継続的なモニタリングを行い、CloudTrailを使用してセキュリティとコンプライアンスを確保するための監査を実施します。予期せぬ支出を避けるためのコスト管理について考え、将来的にData Lakeが大きくなることを見据えて、スケーラビリティがどのようなものになるかを検討する必要があります。これらの問題をすべて1人で解決できる人はいないため、自動化を構築する必要があります。
まとめ:スケーラブルなData Lakeの構築と運用のポイント






6つのフェーズについて説明しましたが、Forever Ecommerceはこれらのアイデアを使用してData Lakeを成長させ、成熟させました。このトークからの重要なポイントは何でしょうか? 1つ目は、Amazon S3を基盤として使用してスケーラブルなアーキテクチャを確立することが良いスタートとなるということです。 2つ目は、AWS Glueやストリーミングソリューションなどのサービスを使用して、効率的なデータ取り込みを実装することです。次に、パーティショニング、 ファイルフォーマット、ソート戦略を通じてクエリのパフォーマンスとコストを最適化することです。 AWS IAMの実装方法に注意を払い、AWS Lake Formationについて考え、AWS Glue Data Catalogに出入りするものを把握することで、アクセスのセキュリティを確保したいと考えています。 そして、特に現在の規制を考慮すると、データがどのようにアクセスされているかを理解するためのガバナンスを確実に実施する必要があります。

最後に、ロギングと監査について考えましょう。システムの状態を把握できる情報があってこそ、その価値が発揮されます。現時点では想定していない将来の用途のためにも、確実にその情報を保持しておいてください。以上で終わりとなりますが、ご質問があればお答えいたしますので、よろしくお願いします。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion