re:Invent 2024: AWS DataSyncによる大規模データ転送の自動化と高速化
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Accelerate & automate secure data transfers at scale with AWS DataSync (STG204)
この動画では、AWSのデータ転送サービスであるDataSyncの機能と活用事例について解説しています。DataSyncは大規模データの移動における課題を解決するために開発され、TLS 1.3による暗号化やスケジューリング機能を備えています。特に注目すべき事例として、バイオ製造企業Resilienceが、研究機器から生成される大量のデータを効率的に管理するためにDataSyncを活用し、約1ペタバイト規模のデータ管理を実現した例が紹介されています。また、2023年10月にリリースされたEnhanced modeでは、従来のBasic modeと比較して8-10倍の性能向上を実現し、より大規模なデータ転送を可能にしています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
AWS DataSyncの概要とセッションアジェンダ

おはようございます。本日はご参加いただき、ありがとうございます。Re:Inventをお楽しみいただけていることを願っています。水曜日となりましたが、まだ数日間、元気に過ごせそうでしょうか。本日は皆様をお迎えできて大変嬉しく思います。私はAWS DataSyncチームのPrincipal Product ManagerのJeff Bartleyです。本日はResilienceからAdam Mendezさんをお迎えし、DataSyncを活用してバイオ製造業の能力をスケールアップした経験についてお話しいただく予定です。

本日のアジェンダですが、まずDataSyncサービスの概要から始めて、その後、機能とユースケースについて詳しく掘り下げていきます。その後、Adamに時間をお渡しし、ResilienceについてとCDMO機能におけるDataSync活用事例についてお話しいただきます。続いて、この1年間にリリースした新機能についてご紹介し、今年10月にリリースした最大の機能の1つであるEnhanced modeのデモンストレーションを行い、最後にまとめで締めくくります。
大規模データ移動の課題とAWS DataSyncの解決策

大規模なデータ移動を試みたことがある方なら、テラバイトやペタバイトレベルのデータ、数百万あるいは数十億のファイルを扱う場合、かなりの課題に直面したことでしょう。この作業を自力で行おうとした顧客の方々とお話しする中で、よく耳にする課題をいくつかご紹介します。多くの場合、独自のスクリプトを作成することから始め、場合によっては他のソリューション、商用製品やオープンソースのソリューションと組み合わせて使用するため、大きなオーバーヘッドが発生します。これだけの大量のデータを移動する際にはセキュリティが非常に重要になりますので、転送中や保存時のデータの適切な保護に苦心することになります。
データの検証も重要な課題です。10個や12個のファイルをコピーする場合は目視で確認できますが、数百万、数十億のファイルとなると話が全く違ってきます。効率的な自動化が必要不可欠です。大規模なデータ転送では、ネットワーク、ストレージ、ソフトウェアのいずれかで必ずエラーが発生するため、適切に復旧して転送を継続できる仕組みが必要です。また、こうした大規模なデータ転送は多くの場合スケジュールに従って行われるため、効率的にタイムラインを守る必要があります。ネットワークの可用性の問題も課題の1つです。接続は断続的に切れることがありますが、接続が切れた際にシステムが完全に失敗しないようにする必要があります。そして、パフォーマンス目標の保証と達成も課題となります。

AWS DataSyncは、こうした課題に対応するために開発されました。お客様のデータを迅速、安全、確実に移動できるよう設計されています。並列スループット処理で利用可能な帯域幅を最大限に活用する独自のネットワークプロトコルを採用し、ネットワークの問題が発生しても自動的に復旧して、パケットロスのあるネットワークや一時的な接続問題があっても転送を継続できます。DataSyncはTLS 1.3を使用してすべてのデータを転送中に暗号化し、可能な場合はストレージ上での保存時の暗号化もサポートしています。フルマネージドサービスとして、データの検証、ログ記録、詳細なレポート作成、ストレージサービスへの自動接続など、大規模なデータ転送に通常伴う重労働を私たちが担当します。DataSyncは、スケジューリング、フィルタリング、拡張されたレポートツールなどの機能を備え、使いやすく設計されています。
AWS DataSyncの主要ユースケースと機能


お客様との対話を重ねる中で、DataSyncが主に4つのユースケースで活用されていることがわかってきました。1つ目は、ビジネスワークフローに応じてデータを迅速に移動する必要性です。よくある例として、後ほどAdamが詳しく説明しますが、ライフサイエンス業界では、ゲノムシーケンサーなどのオンプレミス機器から大量のデータが出力されます。これらの結果を素早く分析・処理することがビジネスにとって重要なため、分析と処理のためにそのデータをクラウドに移動する必要があります。データ移行も、DataSyncの重要なユースケースの1つです。データセンターの撤去や、ストレージシステムの停止、あるいは単にデータをAWSに移行する必要がある場合などが該当します。
DataSyncには、移行を支援する多くの機能が備わっています。また、クラウドにデータの二次コピーを作成してデータを保護するために、DataSyncを利用しているお客様もいます。ビジネス継続性や災害復旧を目的として、定期的にデータの二次コピーを作成するようDataSyncをスケジュール設定します。

ファイルやオブジェクトに関して言えば、オンプレミスにあるデータの多くはコールドデータです。例えば、5年前に作成して一度も開いていないPowerPointやExcelファイルが、ただそこに存在しているような状態です。いつかそのExcelスプレッドシートが必要になるかもしれないので削除はしたくありません。このようなコールドデータの多くは、tier oneストレージに置いておく必要はなく、Amazon S3 GlacierやGlacier Deep Archiveに移行して、Amazon S3が提供するコストメリットと耐久性を活用したいというニーズがあります。DataSyncは、このようなアーカイブのニーズにも対応しています。

また、DataSyncはAI/MLワークロードを持つお客様のニーズにも応えています。DataSyncはAmazon S3とFSx for Lustreの両方にデータをコピーできますが、これらは高いスケーラビリティと高スループットを実現する重要なデータストレージ機能です。より多くのお客様が、データを効率的にストレージに移動し、そのデータをクラウドでAI/MLワークロードの一部として活用するためにDataSyncを使用するようになっています。

それでは、お客様がDataSyncをどのように使用しているのか、そして何ができるのかについて詳しく見ていきましょう。DataSyncがコピー元として対応している領域は3つあります。お客様に提供している利点の1つは、様々な場所からデータをコピーできることです。1つ目はオンプレミスのデータで、NFS、SMB、S3などのプロトコルを使用するファイルサーバーやオブジェクトストレージシステムをサポートしています。また、Hadoopクラスターとの間でのデータコピーもサポートしています。これらのデータはすべて、Amazon S3、Amazon EFS、または任意のFSxファイルシステムタイプにコピーできます。AWS内のこれらのストレージシステム間でファイルやオブジェクトを移動できます。重要な利点の1つは、データとメタデータの両方をコピーできることです。特に移行の際には、WindowsのACL、タイムスタンプ、パーミッションなどのメタデータを保持することが非常に重要です。

最近、他のクラウドとの間でデータを移動するサポートを追加しました。Google Cloud Storage、Azure、そして多くのクラウドをサポートしています。他のクラウドにデータを保存していて、そのクラウドがS3互換のオブジェクトストレージを提供している場合、DataSyncで連携できる可能性が高いでしょう。重要なポイントは、他のクラウドからAWSへのデータ移動だけでなく、AWSから他のクラウドへのデータ移動も同様に簡単にできるということです。双方向のデータ移動をサポートしているのです。いずれの場合も、他のクラウドとの通信には常に安全なプロトコルを使用しており、転送中のデータは暗号化されます。

多くのお客様が、AWS内のストレージサービス間でデータを移動するためにDataSyncを利用しています。ワークフローの一環としてサービス間でデータを移動する必要がある場合や、あるリージョンから別のリージョンに移行する場合などです。これらのケースでは、データはAWSバックボーン経由で転送され、AWSの外部に出ることはありません。インフラストラクチャを用意する必要はありませんが、転送時のデータは常に暗号化されます。さらに素晴らしいのは、オブジェクトストアとファイルシステムの間を移動する際のメタデータの変換も自動的に処理してくれるため、これらのストレージ間でスムーズにデータを移動できることです。
ResilienceのAdam MendezによるDataSync活用事例

オンプレミスからの転送を行う場合、デプロイが必要な重要なコンポーネントの1つがDataSync Agentです。通常、Agentはお客様の環境にデプロイされますが、EC2インスタンスとしてデプロイすることも可能です。一般的にはオンプレミスのストレージの近くにデプロイされます。その理由については後ほど説明します。 Agentは、AWS外部のストレージとの通信に使用されます。仮想マシンとしてデプロイできます - VMware、Hyper-V、KVMをサポートしています - また、先ほど述べたようにEC2インスタンスとしてもデプロイ可能です。素晴らしいのは、これが完全マネージド型サービスであり、ソフトウェアのアップデート、パッチ適用、メンテナンスのすべてをAWS DataSyncが処理してくれることです。
すべてがDataSyncサービスによって自動的に処理されるため、お客様側で行うことは何もありません。Agentを使用する場合は、AWSのストレージが配置されているアカウントとリージョンに対してデプロイしてアクティベートします。


AgentをAWS上で実行されているDataSyncサービスに接続する方法として、3つの選択肢を提供しています。 1つ目は、インターネット経由で利用可能なパブリックエンドポイントとFIPSエンドポイントです。FIPSは主に米国のパブリックセクターのお客様や、同様の高度なコンプライアンスが必要な場合に使用されます。また、プライベート接続が必要なお客様向けにVPCエンドポイントもサポートしています。 インターネット経由でDataSyncを使用したくない場合は、AWS内のVPCにVPCエンドポイントを作成し、Direct ConnectやVPN接続を使用してAgentをAWS VPCに接続できます。すべてのトラフィックはインターネットに出ることなく、プライベートネットワーク内に留まります。使用するエンドポイントに関係なく、すべてのトラフィックはTLS 1.3を使用して転送中に暗号化されます。


他のクラウドと通信する際にもAgentを使用しますが、その構成方法は2つあります。 1つ目は、AWSのEC2インスタンスとしてAgentをデプロイする方法です。 もう1つは、他のクラウドにAgentをデプロイする方法です。GoogleやAzureで直接動作するAgentのネイティブフォーマットは提供していないため、こちらの方法は少し手間がかかりますが、ブログやドキュメントで手順を詳しく説明しています。他のクラウドにAgentをデプロイする利点の1つは、AgentとDataSyncサービス間の通信でデータを圧縮できることです。圧縮率の高いデータセットを他のクラウドからAWSに移行する場合、そのクラウドから出る前にデータを圧縮することで、実際に転送されるデータ量が減り、エグレス料金を削減できる場合があります。



DataSyncはオンラインのネットワークベースのデータ転送サービスなので、ネットワークについての理解が重要です。データ転送のネットワークパスには3つの区間があります。1つ目はオンプレミスストレージとAgent間、 2つ目はAgentとDataSyncサービス間、そして最後にDataSyncサービスとAWSサービス間です。ここで重要なのは、 AgentがAWSサービスと直接通信していないということです。AgentはAmazon S3やAmazon EFS、Amazon FSxと直接通信することはありません。 これは、AgentとAWSリージョン間のパスが、典型的にはWANを介した非常に長い経路になる可能性があるためです。他のサービスと通信するためのプロトコルは、必ずしもこのような長距離通信に適していません。DataSyncのカスタムプロトコルは、Agentとマネージドサービス間の長距離通信に特化して設計されており、損失の多い難しいネットワーク環境でも高速な通信を実現できます。

オンプレミスストレージでAgentを使用する際には、いくつかの注意点があります。ストレージとの通信には一般的なプロトコルを使用し、Agentはマルチスレッドアーキテクチャを採用してストレージ転送をスケールさせます。これにより、ストレージシステムに負荷がかかることがあります。メンテナンスが行き届いていない古いストレージシステムにAgentをデプロイすると、DataSyncをうまく処理できないことがあります。このような場合はスロットリングで対応できますが、ストレージが遅いまたはディスクに問題がある場合、ストレージのパフォーマンスに影響が出る可能性があることを認識しておく必要があります。Agentをストレージの近くに配置する理由の1つは、NFSやSMBなどのプロトコルがレイテンシーの影響を受けやすいため、これを最小限に抑えることです。DataSyncは可能な限り、基盤となるストレージとの通信、そしてAgentとマネージドサービス間のパスの暗号化オプションを提供します。前述の通り、このパスはデータ転送において極めて重要です。

接続方式としては、インターネット、AWS Direct Connect、またはVPNをサポートしています。固定帯域幅のDirect Connectのような接続で、他のアプリケーションと帯域を共有する際にDataSyncが全帯域を消費しないようにするため、DataSyncが使用するネットワーク帯域を制御できるスロットリング機能を提供しています。データは転送中に圧縮され、すべてのトラフィックは暗号化されます。

DataSyncサービスとAWSストレージ間の最後の接続については、自動的に処理されます。DataSyncのセットアップ時には、ストレージへのアクセスを設定するだけで、他のすべては自動的に管理されます。ただし、Amazon FSx for WindowsのようなサービスではHDDやSSDなど異なるストレージオプションを選択できるため、ストレージのパフォーマンスに関する考慮事項は依然として重要です。これらの設定がデータ転送に影響を与える可能性があることを認識しておくことが大切です。前述の通り、そのリージョン内のすべてのトラフィックはAWSネットワーク内に留まります。


DataSyncのセットアップと使用は、シンプルな3つのステップで行います。まず、これまでお話ししたエージェントを、オンプレミスのハイパーバイザー環境やEC2、あるいは他のクラウド環境にデプロイします。 次に、DataSyncサービス内のリソースタイプであるロケーションを作成します。これらのロケーションは、オンプレミス、他のクラウド、またはAWS内のストレージへの接続方法を定義し、IPアドレス、プロトコルバージョン、認証情報などの詳細を含みます。 最後に、ソースロケーションからデスティネーションロケーションへデータを移動するためのタスクを作成し、実行します。




タスクは、ソースロケーション、デスティネーションロケーション、そしてタスクの動作方法を決定するオプションという3つの主要コンポーネントで構成されています。 これらのオプションには、データ検証方法、データ移動の設定、スケジューリング、レポート設定が含まれます。エージェントは一度に1つのタスクを実行できますが、複数のタスクをキューに入れることは可能です。 タスクは常に1つのソースから1つのデスティネーションにデータをコピーし、1時間ごと、毎日、毎週、あるいはカスタムのcron式を使用して、様々なスケジュールで実行するように設定できます。

中には、単一のDataSyncタスクが利用できる以上の大きなネットワーク帯域幅を持つお客様もいます。オンプレミスストレージからAWSまでの40ギガビットや100ギガビットのDirect Connect回線を持ち、大規模な移行のためにその帯域幅を最大限活用したいと考えるお客様と一緒に仕事をしてきました。このようなシナリオでは、複数のエージェントをデプロイし、エージェントごとにタスクを作成し、フォルダーやフィルタリングを使用してソースデータセットを分割するというパターンを実装することがよくあります。このアプローチを使用して、1日あたり最大1ペタバイトのデータを移動することに成功したお客様もいます。

多数の小さなファイルを含むデータセットを持つお客様向けに、もう1つのスケーリングオプションを提供しています。複数のエージェントを使用するタスクを定義することで、DataSyncが使用できるスレッド数を効果的に増やすことができます。エージェントはマルチスレッドアーキテクチャを使用しているため、このアプローチにより同時にコピーできるファイル数が増加し、特に小さなファイルが多いワークロードに効果的です。
Resilienceのデータ管理プラットフォーム構築:課題と解決策


それでは、Adamに引き継ぎたいと思います。彼はResilienceとその取り組み、そしてDataSyncをどのように活用してきたかについてお話しします。 皆さん、こんにちは。ResilienceのCloud and Data Engineering責任者のAdam Mendezです。私たちは、DataSyncをオンプレミスデータをクラウドに転送する主要なメカニズムとして使用し、AWSネイティブサービスを活用してこのデータ管理プラットフォームを構築してきた経験を共有できることを嬉しく思います。

まず、私たちがどのような企業であるか、そしてなぜこのデータ管理プラットフォームを構築することになったのか、その背景についてお話しさせていただきます。Resilienceは、San Diegoを拠点とするバイオ製造企業で、Foundryモデルを活用したプロセス設計と製造能力の迅速な立ち上げを提供することに注力しています。これにより、他のBioPharmaのお客様が治療薬を市場に送り出すという目標を達成するお手伝いをしています。
Foundryモデルは、私の個人的な見解では、半導体産業でしか成功例がない手法です。この原則は、高度に効率化された技術移転プロセスを持つ統合ネットワークを構築し、お客様が作成した設計図をもとに、ビジネスの各部門が極めて技術的に複雑な目標に向かって取り組めるようにするというものです。分かりやすい例として、別の業界になりますが、TSMCは最も成功した半導体企業の一つです。彼らの顧客は、巨大企業になる前からのApple、Qualcomm、NVIDIAなど、製品にマイクロプロセッサを使用しているものの、自社では実際にチップを製造していない技術企業です。
このモデルでは、顧客が望むハードウェアの設計仕様を考案し、TSMCと提携して設計を引き渡します。TSMCはそれをパイロットプラントでの製造方法を確立し、量産化へとスケールアップし、顧客が市場に投入する製品のために生産を行います。ここで明らかな疑問が生じます。なぜこれほど成功している企業がこれらすべてのステップに第三者を介するのでしょうか?Appleにお金が足りないわけではありませんよね。その理由は主に2つあります。1つ目は、技術移転プロセスを自社で処理する必要がないため、R&Dが迅速化され、設計に集中するための時間とリソースが大幅に確保できること。2つ目は、アセットライトモデルと呼ばれる方式を採用できることで、良いアイデアを実現するために製造工場を所有する必要がないということです。
Resilienceに話を戻しますと、同じコンセプトで、Resilienceは実際に初のバイオ製造Foundryモデル企業として、バイオロジクス、ワクチン、核酸治療、細胞治療という5つの分野に焦点を当てた医薬品製造能力を提供しています。私たちのお客様は、医薬品の開発パイプラインに集中できる一方、Resilienceがパイロットスケール、QC分析開発、実際のGMP製造サービスを担当し、お客様の医薬品設計を活用して、製造能力への多額の初期投資なしに治療薬を市場に投入することができます。

これらすべてを実現するには、優れた研究チームだけでなく、社内での業務を円滑に進めるための最新のデータ機能も必要です。Resilienceは約4年前に設立され、この間に11のサイト、約2,000人の従業員、100万平方フィートの施設スペース、そして300以上の機器を備えた研究室へと成長しました。これらの数字は誇らしいものですが、実際にはデジタルランドスケープにおける高度な複雑さをもたらしています。特に最後の数字、300台の研究機器に注目していただきたいと思います。これは、研究室に実際に設置されている300台の物理的な機器、つまりバイオリアクター、光度計、デジタルPCRなどを指し、これらすべてがお客様のプロジェクトの分析に必要な重要な研究データを生成しているのです。

実のところ、データ管理は、これまでほぼすべてのバイオテック企業が苦心してきた分野です。 現実には、多くのバイオテック企業では今でも手作業でのデータ移動が日常的に行われており、そうした手作業によるデータ移動で起きた恐ろしい事例をいくつもお話しできます。大量のハードドライブやBoxの使用、最悪の場合には、研究者がスマートフォンで画面を撮影し、デスクに戻ってから結果を転記する - 時には今でも紙のノートに記録するというケースも実際に目にしています。このように破綻したデータ移動の管理体制では、潜在的に機密性の高い発見に関するバージョン管理が完全に欠如してしまうため、スケーラブルな方法としては機能しません。さらに、このような作業モデルでは、チーム間でデータを共有する方法がなく、この問題は研究室チームだけでなく、

ソフトウェアグループにまで及んでいることがよく見られます。というのも、これらの信頼性の低い断片的なデータ共有ツールでは、適切なインフォマティクスパイプラインを開発できないからです。これは、チームの運営方法を批判するために指摘しているわけではありません。むしろ、このような時代遅れの作業方法が、ほとんどのバイオテック企業での日常になっているという現実を強調したいのです。これは単に、チームが最高の仕事をできるようにするためのツールが提供されていなかったことが原因です。そこで私たちは、このデータ管理プラットフォームを構築する第一歩として、この慣習を打破するためにデータ移動の運用上の課題を解決することから始めました。

研究者とエンジニアリングチームの両方のニーズに合わせたソリューションを提供する必要があることを認識していたため、私たちは多くの要件を設定しました。研究側では、構築するものがデータアクセスの中央制御プレーンとして機能し、主要な研究室データがすべて自動的にアップロードされることで、手作業による転記とヒューマンエラーを排除する必要がありました。このソリューションは、生データと処理結果の両方についてバージョン管理と監査可能性を提供しながら、チームが常にワンクリックでデータにアクセスできるようにする必要がありました。また、将来的に様々な機器から生成される、予測不可能なものも含む膨大な種類のデータを扱えるように拡張可能である必要がありました。そして最後に、他のツールやアプリケーションと容易に統合できる機能を確保したいと考えていました。

エンジニアリング側では、構築するものはDevOpsの観点からも拡張可能である必要がありました。つまり、研究室に直接アクセスすることなく、新しい接続をその場で素早く作成できる必要がありました。また、何百もの機器を何十ものサイトにわたって扱えるように拡張可能である必要がありました。さらに、新しいデバイスとの接続を手動設定ではなく、再利用可能なコードスニペットを使用してインフラストラクチャ・アズ・コードとして展開できるようにしたいと考えていました。最後に、ユーザーをサイトごと、チームごとにグローバルに定義できる、非常に広範なものから非常に細かいものまで、きめ細かなアクセス制御を維持したいと考えていました。

アプローチには慎重を期す必要があり、優れたソリューションであれば当然のことながら、最終的なデザインに到達するまでに何度かの改良を重ねました。AWSでのデータ移動のために選択した技術は、AWS DataSyncでした。バージョン1の実装アプローチとして、オンプレミスでホストされるDataSyncエージェントを活用しています。これらは各サイトのローカルESXiクラスタにデプロイされたVMです。これらのエージェント上で、転送したい機器フォルダと1対1でマッピングされるタスクを定義することができます。各フォルダにはネットワーク上にSMB共有があります。ソースロケーションは機器ごとに1つのSMB共有、ターゲットロケーションはAmazon S3です。これらの分散エージェント上で実行されるタスクにより、データをAWSに移動し、保存、構造化、アーカイブできるだけでなく、より適切に整理して理解を深めてから、エンドユーザーに提供することができます。
注意すべき落とし穴がいくつかあります。Jeffが言及したように、まず1つ目は、AWS DataSyncがデフォルトでタスクごとに1時間に1回という実行間隔の制限があることです。つまり、実験を行った直後にタスクが実行されてデータがすぐに移動する場合もあれば、運が悪いと実験直後にタスクが終わってしまい、次の1時間のマーカーまで待たなければならないこともあります。2つ目の要因として、すべての機器が同じペースでデータを生成するわけではないということがあります。タスクが起動し、オンプレミスのリスティング、S3のリスティングを実行して、移動するものが何もない場合、タスクは終了します。これ自体はタスクあたり4~5分程度の無駄に過ぎませんが、1つのAgentに数十のタスクがある場合を考えると、意味のあるタスクの前に待機中の多数のタスクが並んでいるために、データが移動しない深刻なバックログが発生してしまいます。このワークフローをよりイベントドリブンにするために、さらなるエンジニアリングの取り組みが必要だと認識していました。そこで次のイテレーションでは、

機器で生成されるデータの変更をリアルタイムで監視し、新しいデータが出現したタイミングを確実に把握してタスクをトリガーできるよう、スマートデバイスという概念に焦点を当てました。 図の右側と下部は以前と同じで、S3にデータを移動するための機器ごとのDataSyncタスクです。変更されたのは、タスクをトリガーするロジックの部分です。
スマートデバイスのアナロジーをもう少し詳しく説明すると、この新しいセットアップはAWS IoTを活用して、DataSyncが転送するのと同じ共有フォルダをスキャンできるGreengrass Agentを実行します。これらのGreengrass Agentはエッジコンピューティングのエッジ Lambdaを実行し、基本的にラボ機器の最終更新タイムスタンプを確認できます。これをDynamoDBのグローバルルックアップテーブルに保存されている最後に成功したDataSyncタスクの実行タイムスタンプと比較して、変更があったかどうかを確認します。DynamoDBのタイムスタンプの方が新しければ、データが最新であり、新しいデータは出現していないことがわかるため、何も実行されません。しかし、機器のタイムスタンプの方が新しい場合、新しいデータがあることがわかります。これを利用してMQTTトピックを発行し、DataSyncの呼び出しとして機能させ、その時点でタスクは通常のプロセスを実行します。

これにより多くの問題が解決されました。データを移動する前に任意の1時間マーカーを待つ必要がなくなっただけでなく、移動するデータのないタスクの不要な実行も排除され、処理時間が大幅に短縮されました。 具体的な数字を挙げると、わずか数ヶ月の間に、この真にグローバルなデータ取り込みプロセスを構築し、10のサイトにまたがる250以上の機器からのデータを、オンプレミスで生成されてからわずか5分でAWSに集約できるようになりました。インフラの規模についてもう一度触れると、新しい機器との接続を作成する再利用可能なコードスニペットのおかげで、新しい機器のオンボーディングが私たちのチームにとって非常に迅速になり、現在の記録は1日で77台の機器を接続したPhiladelphiaサイトでの実績です。このサイト全体の移行はわずか2日間で完了しました。
これにより多くの問題が解決されました。イントロスライドで言及した最初の一連のハードルを克服し、手動でのデータ転送や転記を排除する方法を確立できました。集中的なデータバックアップの手段を提供し、科学者がより早くデータにアクセスできるようになり、学習サイクルを加速させ、より高度な自動化の実現に向けて本格的に前進することができます。しかし、考えてみれば、これらはすべて次の課題への準備段階に過ぎませんでした。その課題とは、このシステムをユーザーにとって直感的で使いやすい方法でフロントエンド化することです。Amazonは私のパスを取り消すかもしれませんが、実際のところ、ほとんどの科学者はS3のデータを取得するためにマネジメントコンソールにログインしたりはしないでしょう。

そこで私たちは、ユーザーがより使いやすいフロントエンドを提供する必要があると考え、Quiltを採用することにしました。 Quiltをご存知ない方のために説明しますと、これは会社名であり製品名でもあります。彼らは私にお金を払っていませんが、払うべきかもしれませんね。QuiltはS3向けの検索インターフェースを提供する製品です。完全にAWS環境内でホストされており、基本的にはOpenSearchクラスターを使ってバケットの内容をインデックス化し、科学者が簡単にデータを閲覧できるECSホスティングのWebアプリを提供します。これは私たちにとって非常に強力なソリューションでした。なぜなら、DataSyncとIoTで構築したデータ取り込みプロセスを活用できるため、新しいファイルがS3に保存されると、すぐにQuilt上で科学者が確認できるようになるからです。これは意図的に疎結合なアーキテクチャで、データ取り込みの仕組みとユーザーアクセスのインターフェースが分離されており、S3にデータを取り込む以外の追加のDevOps作業は実質的に必要ありません。

このように、私たちにとってQuiltはS3を覗く窓のような存在で、科学者にとって理解しやすいものとなっています。なぜなら、DataSyncで構築した各機器用の整理された構造を活用しており、ユーザーは機器が生成したデータへの正確なナビゲーション方法を把握できるからです。ここで最初のスクリーンショットをお見せしていますが、組織別、サイト別、機器別にデータが配置されており、B actors、フローサイトメーター、デジタルPCRシーケンサーなど、幅広い機器のデータにユーザーが簡単にアクセスできます。Quiltには検索バーも用意されています。これはOpenSearchのElastic検索文字列機能が活用されているところです。Googleの検索のように、ユーザーは文字通りS3内の何百万ものファイルを検索でき、ヒット数に応じてランク付けされて表示されます。ファイル名やプロジェクト、サイトなど、検索オプションは非常に幅広く用意されています。
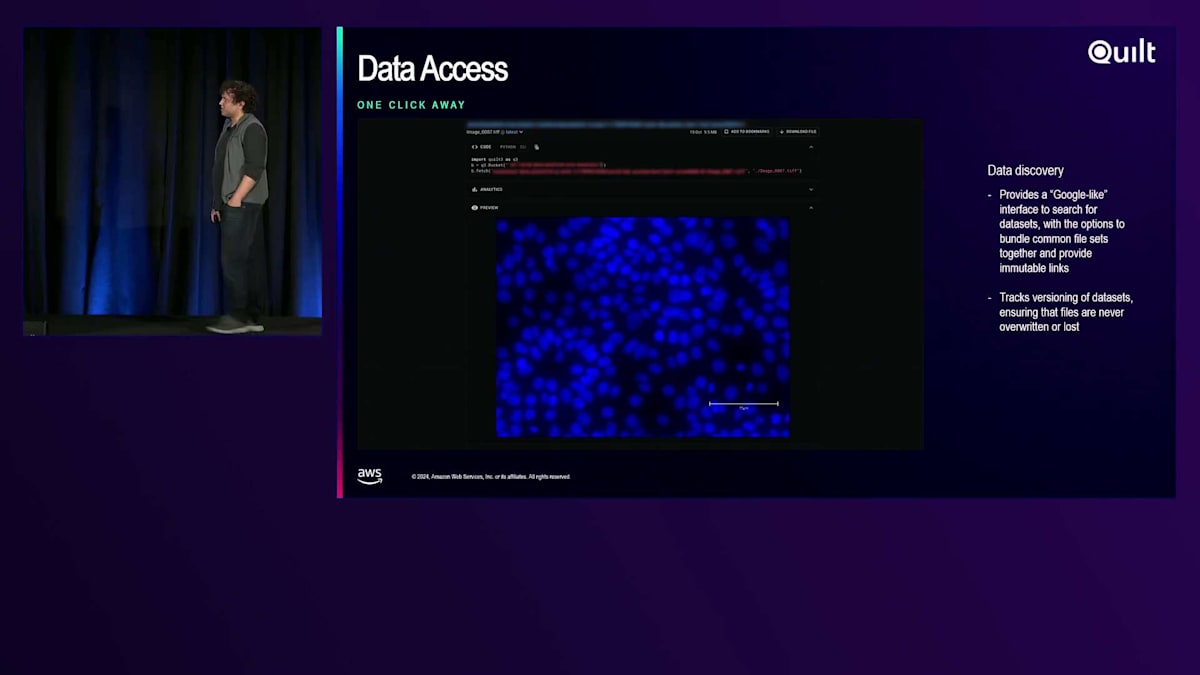
そして、目的のものが見つかったら、 ブラウザ上で直接視覚化することができます。ここで見ているのは、組織切片の核染色による顕微鏡画像です。
そこから、上部のボタンを使ってダウンロードできるほか、プログラムを使って取得することもできます。ここで表示される各ファイルについて、QuiltはAWS CLIやO3を使って取得する方法を示すコードスニペットを自動生成するので、それを使って情報処理パイプラインを開発できます。
このセットアップで活用できるAmazon S3の2番目に重要な機能は、S3データオブジェクトのバージョニングです。バケットでオブジェクトバージョニングを有効にしていれば(これは覚えておいてください - バケットのバージョニングは必ず有効にしましょう)、Quiltはそのファイルの過去のバージョンをすべて表示してくれます。左上にあるハッシュIDのドロップダウンメニューがそれで、S3オブジェクトの各バージョンが不変のリンクとなり、特定の時点に戻すことができます。これはデータの整合性の観点から非常に重要です。というのも、ミスは起こりうるものだからです。例えば、ラボのオペレーターが誤って生データを削除したり上書きしたりしても、DataSyncがそれを検知して新しいオブジェクトバージョンをコピーしますが、私は常にその時点に戻ることができます。生データを誤って削除することは文字通り不可能なのです。なぜなら、それは新しいオブジェクトバージョンとして保存されるからです。その意味で、私たちが構築したこのプロセスは、製造会社として必要なデータ変更の捕捉やデータのアーカイブといったSDMSの機能の多くも果たしているのです。

最後にご紹介するのはQuiltパッケージです。 簡単に言えば、パッケージはGITコントロールのような役割を果たし、ファイルオブジェクトへのポインタを持ち、ユーザーはプロセスと生データの両方を単一のURLの下にまとめることができます。このURLはバージョン管理され、アクセス可能です。ユーザーは独自のメタデータタグやコミットメッセージを追加でき、それらは検索可能になります。これにより、ユーザーはデータセットを公開する際に結果に注釈を付け、変更内容を説明することが推奨され、他のチームが報告書を簡単に見つけられるようになります。

現在の具体的な使用例を2つご紹介します。1つ目は、私たちが運用している多くのInformaticsパイプラインの出力である分析結果をグループ化して提供できるようになったことです。データは先ほど説明したデータ同期IoTプロセスを通じてS3に保存され、その後、シンプルなEventBridgeトリガーが分析パイプラインを起動し、ジョブの設定パラメータを説明するメタデータと共に、処理結果をパッケージとしてS3に公開することができます。これは研究チームにレポートを提供する非常に効率的なプロセスです。2つ目のユースケースは、データセットをELNにリンクすることです。ELNとは電子実験ノートのことで、基本的に科学者が結果の注釈や解釈を提供する場所です。しかし、多くの場合、生データとの簡単な関連付けが欠けています。今では全ての生データがS3とQuiltにあるため、ハードコピーをアップロードしたりファイルを手動で転記したりする代わりに、ELNエントリーにそのパッケージへのリンクを挿入するだけで済みます。このリンクは、裏側でS3内の数十のファイルや、さらにはテラバイト規模のデータを指し示すことができますが、IND申請や規制報告の目的で必要な監査可能性を全て提供する、非常にコンパクトなリンクとなっています。

これらの理由から、AWSとのパートナーシップは非常に意図的な選択でした。彼らのツールを使用することで、科学者と開発者の両方に焦点を当てたツールセットを構築することができ、すでに数百台の機器、約1ペタバイトのデータに対応し、使いやすいWebインターフェースを通じて、ユーザーは文字通り会社全体のあらゆるデータをGoogle検索のように検索することができ、これによりR&Dと製造能力が大幅に加速されました。時間が限られているので、ここで終わってJeffに戻したいと思います。ただし、最後にこのスライドをお見せしないわけにはいきません。 IoTプロセスを構築したエンジニアのJon Rivernider、CJ Stone、Jay Peters、Jiro Koga、そして私の上司のBrian McNattなど、主要なチームメンバーの一部を紹介させていただきます。本日は何人かがここに来ています。
AWS DataSyncの最新機能と改善点

ありがとう、Adam。素晴らしい事例でしたね。特に私が気に入ったのはスケーラビリティです。 これはDataSyncだけの特徴ではなく、AWS全般の特徴であり、特にスケールアップが必要で迅速に動く必要のある企業にとって、自動化やDevOpsなどを通じてプロセスをスケールアップする能力は非常に重要です。素晴らしい事例を共有してくれてありがとう、Adam。では手短に、この1年間にDataSyncで発表した機能をいくつか紹介したいと思います。最初は詳細なデータ転送タスクレポートです。多くのお客様から、「移行作業をしているのですが、上司は全てのデータが正常に移動されたことを確認したがっています。サンプリングをして『このファイルは移動した、あのファイルは移動した、全て問題ない』と言うだけでは納得してくれないんです。詳細なレポートが必要なんです」という声を聞いてきました。
この機能は、そうした課題を解決するために作られました。もう1つは、DataSyncを使用してデータが確実にソースから宛先に移動されたことを示す、監査可能な管理の連鎖レポートが必要なお客様のためです。これらの詳細なタスクレポートは、データとパスだけでなく、チェックサムやS3オブジェクトIDを含むメタデータ情報も記録し、データがAからBにどのように移動されたかを示す監査可能な管理の連鎖を提供します。これらのファイルはJSON形式で、指定したバケットに配置され、GlueやAthenaなどのツールを使用して詳細な分析を実行したり、独自のレポートを生成したりすることができます。多くのお客様がこの機能を有効にしており、大きな成功を収めています。

また、Manifestsと呼ばれる機能もリリースしました。現在のDataSyncの仕組みでは、タスクを開始すると、ソースの場所とデスティネーションの場所をスキャンし、それらを比較して、転送が必要なデータを特定します。しかし、データセットが非常に大きく、その大部分が変更されないにもかかわらず、変更された部分を正確に把握しているお客様もいます。例えば、イギリスのあるお客様は、自動化プロセスを通じて1日に100~200個のファイルを生成し、10億以上のオブジェクトを含むバケットに保存していました。その日に変更された100~200個のファイルを特定するためだけに、10億個のオブジェクトが入ったバケット全体をスキャンする必要はありません。このお客様は、日中に生成されたファイルをManifestファイルにまとめ、別の場所にデータを同期する準備が整った時点で、そのManifestをDataSyncに渡すように自動化しました。これにより、バケット全体をスキャンする必要がなくなりました。

先ほど触れたように、10月にDataSyncの新機能としてEnhanced Modeタスクをリリースしました。DataSyncをご存知の方なら、タスクごとのファイル数の上限や、特定のユースケースにおけるパフォーマンスの制限についてご存知かもしれません。Enhanced Modeは、これらの制限を克服するために設計されており、事実上無制限のファイル数を持つデータセットを、以前のDataSyncバージョンよりもはるかに高速に移動できるようになりました。また、特にマイグレーションシナリオのお客様に役立つ、強化されたメトリクスとレポート機能も提供しています。

Enhanced Modeをリリースした際、従来のバージョンをBasic Modeと呼ぶようになりました。Basic Modeの仕組みは、まずデータ移動を処理するためのリソースを立ち上げるLaunchingフェーズから始まります。次に、Preparingフェーズに移り、ソースとデスティネーションをスキャンして、転送が必要なものを比較します。それが完了してはじめてTransferringフェーズに移行してデータの移動を開始し、完了後に検証を行います。非常に順序立てた処理となっています。


Enhanced Modeでは、特定のタスクにおけるファイル数の制限を克服するために、処理方法を変更する必要がありました。Launchingモードは引き続き存在しますが、順次処理ではなく、Preparing、Transferring、Verifyingのモードが並行して実行されます。ソースとデスティネーションのスキャン中に、発見したファイルを転送キューに送り込み、転送が完了したファイルはすぐに検証キューに送られます。より多くのファイルが見つかる間も、より多くのファイルが比較され転送されるため、データ転送がより効率的に行われます。

また、大容量ファイルのパフォーマンスも向上しました。メディア・エンターテインメントやライフサイエンスなど、数百ギガバイトあるいはテラバイト規模のファイルを扱う可能性のある業界のお客様向けに、DataSyncはEnhanced Modeでより高いレベルのパフォーマンスを提供するようになりました。現在は、これらの大容量ファイルを分割し、それらのチャンクを並行してネットワーク経由で送信します。Basic Modeと比較して8~10倍の性能向上を実現しており、大容量ファイルを扱う業界にとって素晴らしい進歩となっています。

最後に、CloudWatchログの詳細度を大幅に向上させました。これは、問題のデバッグが必要なお客様や、転送されるデータのメタデータを簡単に確認したいお客様にとって、非常に役立つ機能となっています。これにより、ソースとデスティネーションの両方で何が起きているのかを、より詳細なログで確認することができます。
Enhanced modeのデモンストレーションとセッションのまとめ


Enhanced modeを実行している時のConsoleの表示がどのようになるのか、そして並列処理の動作について説明したいと思います。私は2つのS3バケット間の転送でEnhanced modeを開始しました。ソースバケットには200,000個のオブジェクトがあり、デスティネーションには20,000個のオブジェクトがあります。これらの20,000個のオブジェクトは元の200,000個のデータセットの一部で、ここで何かをお見せするために最初に20,000個だけを転送した結果です。


左側で見えているのは、DataSyncがソースバケットのすべてのオブジェクトを処理している様子です。ファイルを見つけて転送の準備をしながらカウントが増えていきますが、同時にスキップされているものもあることが分かります。ソースでファイルを見つけながら、同じファイルがデスティネーションにすでに存在することを確認し、その場合はすでに存在するためスキップしているのです。処理が続くにつれて、ファイルが転送され検証されていく様子が分かりますが、これらすべてが並列で行われています。
この時点で、ソースにある200,000個のファイルすべてを見つけ、その後も準備フェーズのカウントは増え続けています。準備フェーズは同じことを続けています - ソースでファイルを見つけ、デスティネーションと比較します。比較処理では通常、タイムスタンプやファイルサイズを確認し、必要に応じてチェックサムも確認します。ここで見られるように、準備フェーズは180,000ファイルで停止します。ソースでリストアップされた200,000個のうち、20,000個はすでにデスティネーションに存在しており、残りの180,000個が実際に転送段階の準備が行われたということです。
データの転送は継続して実行され、データのスループットが上昇し続けているのがご覧いただけます。最終的に約650メガバイト/秒でピークに達しますが、これは約5ギガビット/秒に相当し、現在のEnhanced modeタスクの単一インスタンスでの上限となっています。転送が完了すると、18万個のファイルすべてが転送され、検証が行われ、成功のステータスが表示されます。この実演で重要なポイントは、以前のBasic modeタスクの逐次的な実行方式と比べて、現在は並列で処理が行われているということです。

まとめとして、いくつかの重要なポイントをご紹介します。DataSyncの主要なユースケースは、移行、アーカイブのレプリケーション、そしてResilienceのAdamが言及したようなデータ移動ワークフローです。DataSyncを使用することで、オンプレミスストレージ、他のクラウド、そしてAWSストレージの間でデータを移動できます。複数のタスクを使用して、利用可能なネットワーク帯域幅を最大限に活用できます。また、先ほど発表したEnhanced modeタスクにより、Basic modeタスクと比較してスケーラビリティとパフォーマンスが向上します。




DataSyncについてさらに詳しく知りたい方は、aws.amazon.com/datasyncにアクセスしてください。このQRコードからもアクセス可能です。 このウェブサイトには、ブログ、デモ、そしてDataSyncについて学べる様々なリソースへのリンクが用意されています。 本日は他にもセッションがあり、午後3時にCaesars Forumでのチョークトーク、そして午後4時にMGM Grandでストレージ全般に関するチョークトークを予定しています。そちらでもDataSyncについて触れる予定です。 また、AWS Storageについてさらに詳しく知りたい方は、こちらに表示されているリンクもご確認ください。ご参加いただいた皆様、そしてResilienceからご参加いただいたAdamに感謝申し上げます。ご質問がある方は、ステージ横でお受けいたしますので、お気軽にお声がけください。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion