re:Invent 2024: AWSストレージサービスの全体像とData Lake、AI/ML活用事例
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Introduction to AWS storage: Building a data foundation in the cloud (STG101)
この動画では、AWSのストレージサービスポートフォリオの全体像と、お客様のクラウドジャーニーにおけるストレージの活用方法について解説しています。エンタープライズアプリケーションのクラウド移行、Amazon S3を活用したData Lake構築、AIとMLのためのストレージ最適化、そしてAWS Backupによるデータ保護まで、幅広いトピックをカバーしています。特に、S3 Intelligent-Tieringによる40億ドル以上のコスト削減事例や、AdobeがFireflyファミリーの開発でAmazon S3とAmazon FSx for Lustreを組み合わせて実現した「AIスーパーハイウェイ」など、具体的な実装例を交えながら、AWSストレージサービスの活用方法を詳しく説明しています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
AWS Storageポートフォリオの概要とアジェンダ紹介

みなさん、こんにちは。本日はご参加いただき、ありがとうございます。STG 101: Introduction to AWS Storage - Building a Data Foundation in the Cloudへようこそ。私はAWS StorageのPrincipal Storage GTM SpecialistのRajesh Vijayaraghavanです。私はAWS StorageのSenior Product ManagerのRohan Thomasです。そして私はAWS StorageのSenior Product ManagerのBoris Alexandrovです。

本日のアジェンダについてご説明させていただきます。まず、AWS Storageポートフォリオの概要と、データが重要である理由についてお話しします。これは私たちのサービスの詳細な説明ではなく、あくまでも概要のご紹介となります。今週は、これらのサービスの様々な側面について深く掘り下げるセッションが多数用意されていますので、ぜひスケジュールの許す限り、多くのセッションにご参加いただければと思います。
本日は、お客様がクラウドソリューションをどのように実装しているかについて、主にお話しさせていただきます。これを説明するために、お客様からよく見られる一般的な初期ワークロードをいくつか例に挙げていきます。まず、エンタープライズアプリケーションから始めて、お客様がこれらのアプリケーションをクラウドに移行する方法についてお話しします。次に、Data Lakeによるデータの一元化と、お客様がAmazon S3でData Lakeを構築する方法についてご説明します。その後、AIとMLのためのクラウドストレージについて触れ、お客様がデータからインサイトを得る方法についてお話しします。そして最後に、データ保護について取り上げ、お客様がAWSでどのようにデータを保護しているかについてご説明します。
データの重要性とAWS Storageサービスの基本設計


では、AWS Storageの概要について簡単にご説明していきましょう。 ご存知の通り、データは皆様のビジネスの中核を担っています。皆様のビジネスは様々な組織にまたがって大量のデータを生成し、さらに様々なサードパーティのソースからもデータを取得しています。このデータの規模と成長に伴い、セキュリティ、コスト、規制など、データ管理に関する様々な課題が生じています。データの価値を最大限に引き出すためには、これらの課題に対処し、常に最新の状態を保つ必要があります。

それだけではありません。皆様はこのデータを使ってビジネスを運営し、成長させています。多くの方々が、データからインサイトを生成するアプリケーションを構築・運用し、そのインサイトを活用してビジネスの重要な意思決定を行っています。 様々なお客様との協業経験から、私たちはAWSへの移行・変革が一つの旅路であることを実感しています。それは適切なインフラストラクチャから始まり、セキュリティ、可用性、コストなどの基本的な要素を継続的に改善していくことが重要です。適切なアーキテクチャパターンを用いて、アジリティとイノベーションを向上させるための適切なデータとアプリケーションのアーキテクチャを構築することが不可欠です。これらの構成要素はすべて、皆様のビジネスの成長を支援し、成果を最大化するためのものなのです。


ストレージサービスに必要な要素について考える際、私たちは基本的な設計パターンについて検討し、お客様が心配したり苦労したりする必要がないように提供しています。 まず、私たちのサービスは安全性が確保されています。セキュリティは基盤となるものであり、私たちはサービスとインフラストラクチャのセキュリティに徹底的にこだわっています。ストレージサービスは完全マネージド型なので、お客様は価値の高いリソースを革新的な取り組みに集中できます。私たちはお客様のことを第一に考え、高可用性と優れた運用サポートを提供しています。


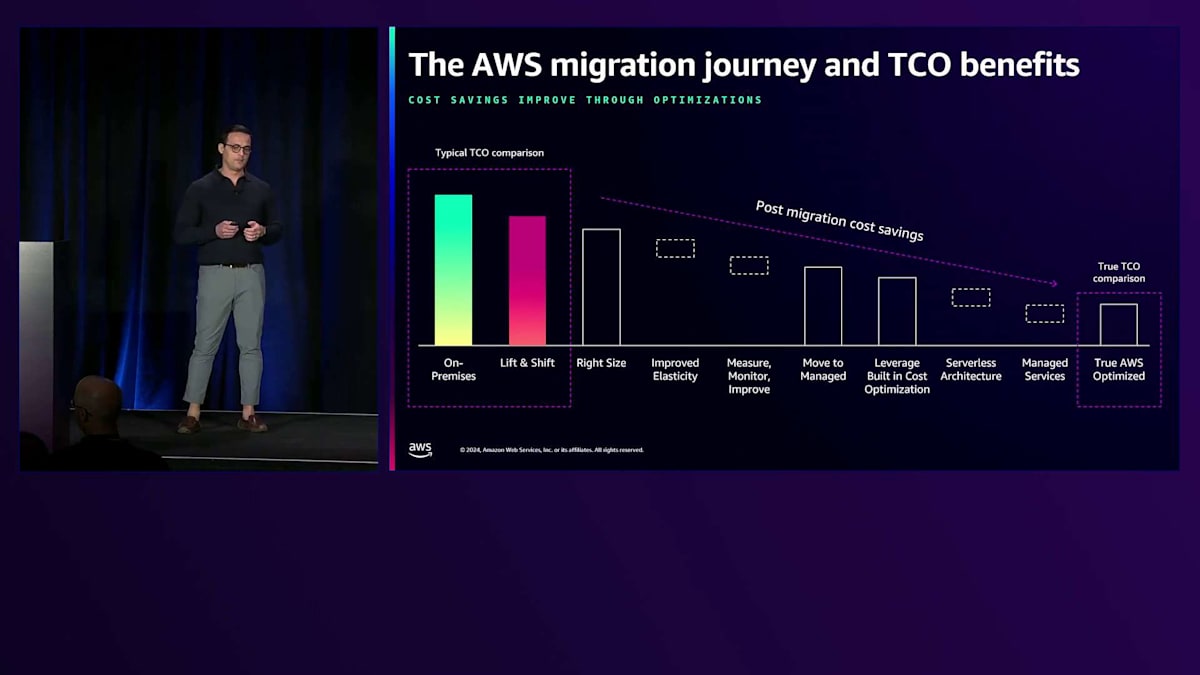
私たちはサービスをグローバルで、スケーラブルで、高性能になるように構築していますが、それだけではありません。 お客様のニーズに焦点を当て、革新を続けています。 ここで、本日会場にいらっしゃる多くの方々にとっても重要な関心事であるコスト効率性についてお話ししましょう。AWSのお客様は継続的にコストの最適化を行っています。お客様が最初にアプリケーションをAWSにリフトアンドシフトする際、クラウドの柔軟性を活かし、ストレージやリソースを過剰に確保する必要がないため、コスト削減を実現できます。その後も、デプロイメントの適切なサイジング、マネージドサービスの利用、各サービス内でのコスト最適化などの取り組みを通じて、さらなるコスト最適化を進めています。完全に最適化された状態では、お客様は平均31%のコスト削減を達成し、ダウンタイムの削減と生産性の向上により、より多くのビジネス施策を実現できるようになっています。
AWS Storageサービスの詳細とエンタープライズアプリケーションの移行

では、ストレージサービスのポートフォリオについて簡単にご紹介しましょう。先ほども申し上げたように、これは各サービスの詳細な説明ではなく、概要をお話しするものです。まず、データを保存するための様々なサービスを提供しています。高性能なブロックストレージサービスのAmazon Elastic Block Store、どこからでも任意の量のデータを保存してアクセスできるオブジェクトストレージサービスのAmazon S3、そして完全マネージド型のファイルストレージサービスであるAmazon EFSとAmazon FSxファミリーがあります。


次に、データの移動を支援するサービスがあります。AWS Transfer Familyは、SFTP、FTPなどのマネージドファイルプロトコルを使用して、他のビジネスや関係者とデータを簡単かつ安全に共有できるようにします。AWS SnowballはAWSとの間のデータ移動を加速するのに役立ちます。AWS Storage Gatewayはオンプレミスのアプリケーションに無制限のクラウドストレージを提供します。そして、AWS DataSyncはオンプレミスからAWSストレージサービス間のデータ転送を簡素化し加速するのに役立ちます。
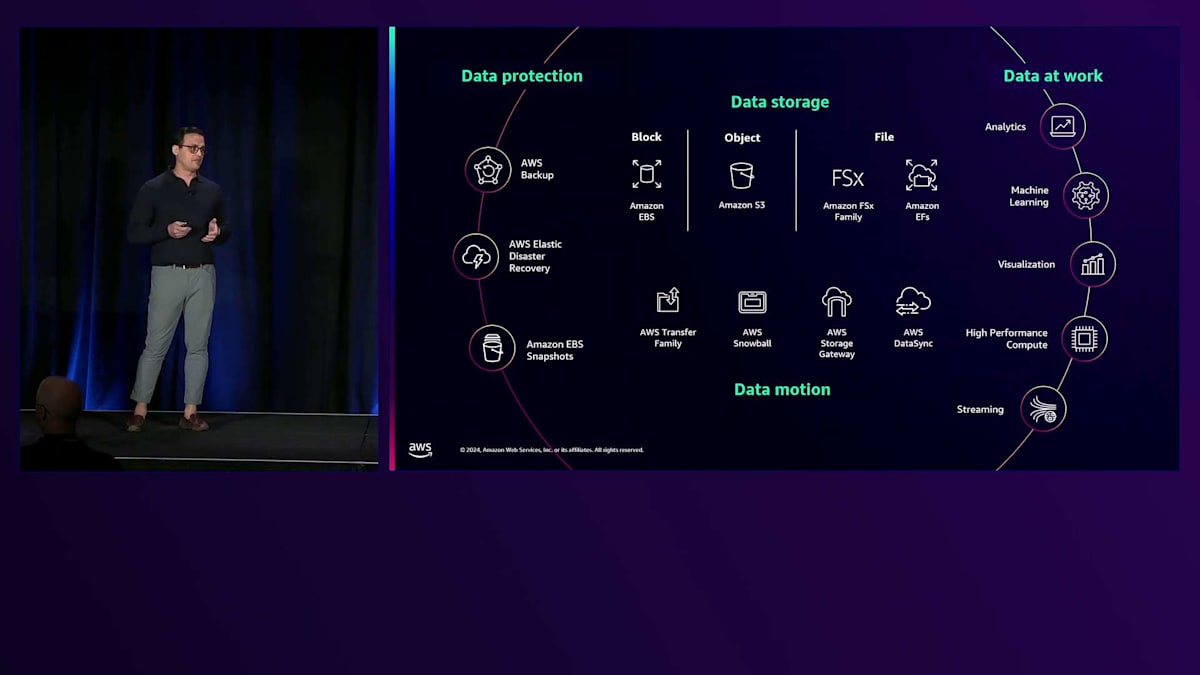
次に、AWS全体でデータを保護するための一連のデータ保護サービスを提供しています。AWS Backupは、データ保護の一元管理と自動化を支援します。AWS Elastic Disaster Recoveryは、アプリケーションの復旧を実現するスケーラブルで費用対効果の高い方法を提供します。また、Amazon EBSスナップショットなど、特定時点のリストアのための様々なスナップショット機能も用意しています。そしてもちろん、データを活用してビジネス判断を行うために、私たちのストレージサービスは、他のAWSサービスと統合されており、データへのシームレスなアクセスを通じて、分析、Machine Learning、High Performance Computing、可視化、ストリーミングワークロードなどを実行することができます。

アジェンダで説明したユースケースの詳細に入る前に、AWSのお客様の journey についてお話ししましょう。お客様は通常、最初にLift and Shift方式でアプリケーションをAWSに移行することから始めます。この移行後、追加のサービスやイノベーションを活用してアプリケーションを最新化し、改善を続けていきます。そしてそれだけではありません。詳細なユースケースを見ていくと分かるように、お客様はAWSが提供する最新のコスト最適化を活用しながら、アプリケーションの最適化を継続的に行っています。
データレイクの構築とAmazon S3の活用

これらの点を念頭に置いていただき、ここからRajeshに引き継ぎ、お客様がデータを使って何を構築しているのかについてお話しいただきます。ありがとうございます、Boris。では、お客様は自社のデータで何を構築しているのでしょうか?Principal Go-to-Market Specialistとしての私の役割では、様々なお客様と関わっています。中小企業もあれば、スタートアップ企業もあり、デジタルネイティブなお客様もいます。金融系のお客様もいれば、あらゆる業種のお客様がいて、それぞれがAWSクラウドジャーニーの異なる段階にいます。しかし、私たちが目にする典型的なパターンがいくつかあります。
ほとんどのお客様は、オンプレミスや他のクラウドからデータのコピーを移行することから、クラウドジャーニーを開始します。バックアップとリストアは比較的影響が少ないため、通常お客様が始めやすい場所です。VeritasやCOMMVAULTなど、お客様が使用している多くのバックアップベンダーには、Amazon S3にデータを保存できるAPIがあります。また、すべてのデータサイロを統合し、Amazon S3上にデータレイクを構築されているお客様も見てきました。AWS上のAmazon S3にデータレイクを構築したお客様は10,000社を超えています。
お客様がデータレイク用にAWSストレージを選択する理由は、データの移動がデータレイク構築の最も困難な部分の一つだからです。すべてのデータをAmazon S3に保存することで、AWSの分析機能を活用することができます。Amazon S3にすべてのデータを統合した後は、AWSクラウドの異なる部分への不要なデータ移動を排除できます。このデータレイクは、AIとMLの優れた基盤となるため、お客様は現在AIとMLを使用してこのデータから洞察を得ることができています。これらすべての業種のお客様がAWSで利用している一般的なワークロードの一つは、ビジネスクリティカルなアプリケーションです。つまり、ほとんどの企業が持っているERPソリューション、データベース、コンテンツ管理システムなどを想定していただければと思います。
ほとんどのお客様は、まずLift and Shiftから始めます。これは、数十年あるいは数年にわたってオンプレミスで運用してきたアプリケーションを、クラウドに移行してから、リファクタリングを検討するというアプローチです。私たちはこれらのワークロードをクラウドにLift and Shiftするための多様なサービスを提供しており、その過程でお客様はコスト削減を実現してきました。

それでは、エンタープライズアプリケーションから始めて、これらのユースケースを見ていきましょう。先ほど申し上げたように、様々な業種の組織が日々、アプリケーションをAWSに移行しています。Windows、SAP、データベース、VMwareなどのビジネスクリティカルなアプリケーションを思い浮かべていただければと思います。お客様の優先順位は、最初にあるワークロードを移行し、その後別のワークロードを移行するというように異なる場合がありますが、目標は通常同じです。主にコスト削減、顧客基盤全体でのイノベーションの推進、顧客体験の向上、そしてAWSでのより良いスケーリングを実現するためです。クラウドへの移行により、お客様はセキュリティ態勢も改善することができました。

では、クラウドで構造化アプリケーションを実行する例をいくつか詳しく見ていきましょう。この分野には何百ものアプリケーションとユースケースがありますが、時間の都合上、お客様がAWSに移行している2つの例に焦点を当てます:データベースワークロードと仮想化ワークロードです。これらのトピックについて話す際、私たちのブロックストレージ製品についても触れることになります。通常、非常に低いレイテンシー、高い耐久性、高いスループットを持つAmazon EBS IO2 Block Expressについて説明します。また、AWSでの一般的なブロックワークロードに対応するためにGP3インスタンスを使用しているお客様もいます。Amazon EBSには、お客様がより多くのIOPSやスループットを必要とする場合に、その場でボリュームタイプを動的に変更できるElastic Volumesも用意されています。しかし最近では、AWSには様々なワークロードに対応する多くのストレージオプションがあるため、いくつかの例を見ながら、お客様がどのように適切なストレージタイプを選択するか見ていきましょう。

まずはSQL Serverから始めましょう。このスライドの目的は、それぞれの実装について深く掘り下げることではありません。私たちが強調したいのは、お客様がワークロードを展開する際に複数のオプションがあるということです。MS SQL Serverの場合、アプリケーションの要件に応じて、これらの展開タイプのいずれかを使用できます。左端には、お客様がデータベースを管理する必要すらないAmazon RDSによる完全マネージド構成があります。また、SQL Server構成を自身で管理したいと考える多くのエンタープライズのお客様もいます。そのようなオプションとして、EC2とAmazon EBSによるスタンドアロンサーバーがあります。この場合、直接的なLift and Shiftとなり、お客様は必要に応じてスケールアップすることができます。フェイルオーバークラスターを実装したいお客様は、EC2とAmazon EBSを使用でき、Amazon FSxも利用できます。この場合、完全マネージド型の共有ファイルシステムにより、お客様の複雑さが軽減されます。ほとんどの場合、お客様はSQL Standardライセンスだけで対応できます。


また、可用性を高めるために可用性ゾーン間でクラスターを展開できるAlways On Availability Groupsを求めるお客様もいます。この場合、SQL Enterpriseライセンスを使用する必要があり、お客様側での管理も若干増えます。ここでのポイントは、アプリケーションの重要性と可用性を異なる運用モードと組み合わせ、お客様が望むTCOに応じてこれらを選択できるということです。では、構造化アプリケーションを実行する別の例を見ていきましょう。VMware仮想化ワークロードについて説明します。ご存知の通り、ほとんどのお客様はVMwareアプリケーションのオンプレミス環境から移行してきています。彼らは既存の運用モデルを維持し、コスト構造を維持しながら、クラウドへの移行を加速させたいと考えています。AWSでのVMwareワークロードに関して、
AIとMLのためのクラウドストレージソリューション
左側には、お客様がよくご存知のVMwareのコンポーネント、右側にはそれらがAWSサービスにどのように対応するかをご覧いただけます。オンプレミスのストレージ管理者にとって馴染み深いvCenterは、AWS Consoleに対応します。VMwareの仮想マシンはAmazon EC2インスタンスに、NSX仮想分散スイッチはAWSリソースを仮想ネットワークに展開できるAmazon VPC(Virtual Private Cloud)に対応します。VMwareのvSphere with vSANは、ブートディスクにはAmazon EBS、データディスクにはFSxを使用するように設定でき、これによりお客様の仮想アプリケーションに最適なTCOを実現できます。最も素晴らしい点は、基盤となるインフラストラクチャがAWSによって完全に管理されているということです。

では、実際のお客様の事例についてお話ししましょう。Salesforce.comです。ほとんどの企業がCRM(顧客関係管理)に利用している企業なので、ご紹介の必要はないでしょう。Salesforceは多くのアプリケーションのユースケース、特にデータベース環境でEBSを活用してきました。そんな中、MongoDBの展開において、非常に低レイテンシーで高性能な環境が必要となるユースケースがありました。これは機械学習による予測のユースケースに使用されていました。彼らは汎用のGP2ブロックストレージから、EBSとEC2でのio2 Block Expressというクラウド上のSAN実装に移行しました。この移行により、アプリケーションのパフォーマンスに影響を与えることなく、より迅速に予測を提供するという目標を達成することができました。最終的に、Salesforce MLワークフローを使用して、お客様により豊かでパーソナライズされた体験を提供することができました。

次に、ITやビジネス部門向けアプリケーションの移行についてお話ししましょう。これらは主にファイルベースのアプリケーションで、お客様はAmazon FSxサービスを利用してきました。これらのアプリケーションは通常、オンプレミスから始まり、その後クラウドに移行されます。部門共有、ホームディレクトリ、アプリケーション共有などが考えられ、多くのユーザーがこれらのファイルを使用し、場合によっては小さな変更後に複数のコピーを作成することもあります。ISVに関して言えば、PerforceやMUXのような金融サービスなど、ファイル形式でコンテンツを作成する機械があります。これらのファイルストレージに関しては、データ保護が非常に重要で、事業継続性、災害復旧、そしてランサムウェアからの復旧も重要です。

これらのファイルベースのアプリケーションについて、オンプレミスからAWSへの移行には、Amazon FSxファイルサービスを使用するのが最も簡単な方法だとわかっています。現在、世界で最も人気のある4つのファイルシステムをサポートしています:Amazon FSx for NetApp ONTAP、Amazon FSx for OpenZFS、Amazon FSx for Windows File Server、そしてFSx for Lustreです。これらは機能が豊富で高性能なファイルシステムでありながら、コスト効率が良く、最も素晴らしい点はAWSによって完全に管理されているということです。お客様は簡単に立ち上げることができ、ニーズに応じてアプリケーションを実行・拡張することができます。

これらのファイルシステムは、オンプレミス環境と同等の機能を持っているため、お客様はオンプレミスで慣れ親しんだのと同じAPIや機能を使用することができます。Windowsに精通した管理者は、FSx for Windowsを使用してWindows File Serverを管理することができます。エンタープライズやEDAワークロードを扱う多くのお客様は、NetAppに精通しています。彼らは数十年にわたってNetAppのファイルストレージアレイを購入してきましたが、FSx for NetApp ONTAPに移行し、これまで慣れ親しんだのと同じデータ管理機能を使用することができています。ストレージ管理者がDay 2オペレーションに精通している場合、AWSに移行しても何も変更する必要はありません。これらのFSxワークロードに移行する際に、アーキテクチャの再設計や再認証、スタッフの再トレーニングが必要なお客様はいませんでした。Amazon FSxは、お客様がクラウドでネットワークアタッチストレージを実行するための最も簡単な方法として活用されています。

フルマネージド型のファイルストレージやブロックストレージを使用することのメリットについて、簡単にご説明させていただきます。最大のメリットは、お客様にとって、複雑さを抑えながら最小限のコストで、より早くサービスを市場に投入できることです。オンプレミス環境では毎年必要だった容量計画について心配する必要がなくなります。ネットワークやバックアップ用のハードウェアについて考える必要もなく、複数のベンダーからの調達や、インストール・設定の課題、アップグレードの管理に悩まされることもありません。AWSを使用すれば、ハードドライブやSSDの故障に対処する必要もありません。

ソフトウェアに関しても、ファームウェアのバージョン、OSのインストール、新しいアプリケーションとの互換性確認、ライセンス管理について心配する必要はありません。さらに、バックアップやセキュリティについても、すべてAWSが対応しますので考える必要がありません。では、別のお客様の事例についてお話ししましょう。教育分野のAWSユーザーであるPearsonは、学習コンテンツやスキルの作成・配信を行っています。彼らの製品は、複数の国の政府機関、教育機関、個人によって利用されています。Amazon FSx for NetApp ONTAPを活用することで、ERPアプリケーションのアジリティとパフォーマンスを向上させることができました。彼らの課題は、ERPシステムの更新とアプリケーションの復旧が容易ではなく、時間がかかっていたことでした。
Amazon FSx for NetApp ONTAPを採用後は、スナップショット機能を使用してデータベースと整合性のとれたバックアップを瞬時に作成し、FlexCloneを使用してアプリケーション環境の仮想コピーを作成できるようになりました。FSx for NetApp ONTAPの導入以降、Pearsonはサプライチェーンのバッチプログラムの実行速度を3倍に向上させることができました。データ管理における圧縮と重複排除の効果により、50%の容量削減を達成しています。ストレージ管理者は、NetApp ONTAPの経験がなかったにもかかわらず、2か月以内にテストから本番環境への移行を完了することができました。

別のデザインパターンについても見てみましょう。AWSには、デジタルネイティブなお客様や、モダンアプリケーションを構築している企業のお客様が数多くいらっしゃいます。モダンアプリケーションと言えば、コンテナやサーバーレスアーキテクチャを使用したマルチテナントのSoftware as a Serviceアプリケーションを指し、ファイルシステムのパフォーマンスがユーザー体験に重要な役割を果たします。Amazon Elastic File Systemは、完全な弾力性を備え、プロビジョニングが不要で、コスト効率が高く、どこからでもアクセス可能であることから、これらのユースケースで広く使用されています。

このデザインパターンを導入したAWSのお客様の一つがAncestryです。ご存知の通り、Ancestryは、お客様が家族の歴史を発見し、生存している親族を見つけ、DNAに基づくルーツについてより深く理解できるよう支援するグローバル企業です。同社のDNAサイエンスチームは、ストレージとコンピューティングリソースのモニタリングやプロビジョニングなしでこれらのリソースをスケールさせることが難しく、将来のワークロードに向けた計画を立てることができないという課題を抱えていました。そこで、オンデマンドコンピューティング用にAmazon EC2を、フルマネージド型ファイルストレージとしてAmazon EFSを使用し、オンプレミスのワークロードをAWSに移行することを決定しました。これにより、Ancestryは異なるチームや地域に所属する複数の科学者が同時にゲノム研究を行えるようになりました。コンピューティングとストレージのリソースを個別にスケールアップ・ダウンでき、新しい科学者たちもゲノム領域の研究にスムーズに参加できるようになりました。ここまでAWS上に展開される典型的なエンタープライズアプリケーションについて見てきましたが、ここで別の重要な分野に目を向けてみましょう。先ほど申し上げた通り、Data Lakeを活用した強固なデータ基盤の構築は、お客様が注目している重要な分野の一つです。
AWS Backupを活用したデータ保護戦略

ありがとう、Josh。ここからは私が説明を引き継ぎます。 AWSでのData Lakeの構築についてお話ししましょう。

多くのお客様から、組織内にデータサイロが存在し、そのデータの管理、共有、ガバナンスに苦心しているという声を聞きます。ちょっと手を挙げていただきたいのですが、皆さんの組織でデータサイロの問題に直面された方はどのくらいいらっしゃいますか?まぶしい照明の中でも、かなりの方が手を挙げているのが見えますね。私たちが話をするお客様は、このようなデータサイロを解消し、データを一元化したいと考えています。 Data Lakeは、組織内の様々なグループが簡単に分類、分析、活用できるように、大量のデータを中央リポジトリに保存できるアーキテクチャパターンです。Data Lakeでは、ほぼあらゆる種類のデータを保存し、データサイエンスや機械学習を含む分析を実行することができます。

Data Lakeを構築する際に最初に考慮すべきは、データの保存場所です。 通常、スケーラビリティ、セキュリティ、エコシステムとの統合など、複数の観点から検討する必要があります。Amazon S3は、これらの多くの面で優れたソリューションです。スケーラビリティについては、S3は4,000億個以上のオブジェクトを保持し、エクサバイト規模のデータを保存し、1秒あたり1億5,000万以上のリクエストを処理する、まさに大規模なスケールを実現しています。セキュリティについては、S3はサーバーサイドおよびクライアントサイドの暗号化オプションを提供します。アクセス制御については、AWS Identity and Access Managementを使用して、リソースベースまたはアイデンティティベースのポリシーを設定できます。
エコシステムとの統合については、S3はAmazon Athena、AWS Glue、Amazon Redshift、Amazon Bedrock、Amazon EMRなどのAWSの分析やAI/MLサービス、さらにSnowflakeやDatabricksなどのサードパーティソフトウェアとも統合されています。これらが、S3が構造化データと非構造化データの両方に対応する最大かつ最高性能のオブジェクトストレージサービスであり、Data Lake構築のためのストレージサービスである理由の一部です。現在、AWSには100万以上のData Lakeが存在します。BMW、Vanguard、GE Healthcareなどの企業は、ビジネス上の意思決定を推進し、顧客に新しい体験を提供するために、AWSのData Lakeをシングルソースオブトゥルースとして活用しています。

それでは、S3上にData Lakeを構築している具体的な企業の例を見てみましょう。 Sweetgreenは、サラダを提供するファストカジュアルレストランチェーンです。私は以前サラダが好きではなかったのですが、Sweetgreenを試してから本当にサラダが好きになりました。最後に確認した時点ではLas Vegasにはまだなかったのですが、皆さんのお住まいの地域にはあるといいですね。Sweetgreenが直面していた課題は、農場、POSシステム、Webやモバイルアプリのユーザー行動データなど、31の異なるデータソースが存在していたことでした。彼らは、California Consumer Privacy Act(CCPA)規制に準拠しながら、これらのデータを一元化したいと考えていました。SweetgreenはS3上にData Lakeを構築し、100テラバイト以上のデータを保存しています。さらに、Amazon EMR Sparkを活用してこれらのデータを匿名化およびマスキングし、CCPA規制への準拠を実現しています。

Amazon S3の素晴らしい特徴の1つは、あらゆるワークロードに対応したストレージクラスが用意されていることです。これにより、データの取り出し性能、アクセス頻度、保存期間などの要件を満たしながら、必要のないものにコストをかけることなく、費用を最適化できます。このコスト最適化の鍵は、適切なストレージクラスを選択することです。データのアクセス頻度に基づいて、温かいストレージクラスから冷たいストレージクラスへと自動的にデータを移動するS3 Intelligent-Tieringがあります。また、頻繁にアクセスされるデータ向けのS3 Standardや、ミリ秒レベルの性能が必要なものの、めったにアクセスされないデータ向けのS3 Glacier Instant Retrievalもあります。

アーカイブデータについては、S3 Glacier Flexible RetrievalとS3 Glacier Deep Archiveストレージクラスを用意しています。これらのストレージクラスは最も低コストですが、データへの即時アクセスはできません。また、昨年のre:Inventで発表したS3 Express One Zoneについても触れておきたいと思います。これは最も低レイテンシーのストレージクラスで、一貫して一桁ミリ秒の性能を提供するように設計されています。

もう一度コスト削減について説明しましょう。S3 Intelligent-Tieringは、性能への影響や運用の手間なしに、アクセス頻度に基づいて最もコスト効率の良いアクセス層にデータを自動的に移動することでコストを削減します。S3 Intelligent-Tieringは、データを自動的に3つの層に保存します:頻繁なアクセス層、最大40%安価な低頻度アクセス層、そして最大68%安価なアーカイブインスタントアクセス層です。さらに、最低コストを実現するためのオプションとして、アーカイブ層とディープアーカイブ層を有効にすることもできます。今朝のMatt Garmanの講演でも触れられたように、S3 Intelligent-Tieringを使用することで、お客様は40億ドル以上のコスト削減を実現しています。

Bynderはそのような顧客の一例です。彼らはS3 Intelligent-Tieringを使用してコストを削減しました。BynderはAIを活用したエンタープライズデジタルアセット管理企業で、顧客のコンテンツライフサイクル管理と価値創出を支援しています。S3でのデータストレージが急速に増加していることに気付き、コストを抑制する方法を模索していました。Intelligent-Tieringを使用することで、性能に影響を与えることなく、コストを65%削減することができました。それでは、AIとMLのワークロードにストレージをどのように活用しているかについて、Rohanに説明してもらいましょう。
まとめと今後の学習リソース

ご存知の通り、これは現在非常に注目されているトピックです。独自のLLMの構築から、既存のLLMの利用とチューニング、そして予測推論のための標準的なAI/MLまで幅広く及びます。先に進む前に、基本的な事項を確認しておくことが重要です。人工知能は1950年代から存在しています。私たちはデータを持ち、そのデータに基づいて予測を行い、システムやコンピュータが人間のように動作できる環境を整えているのです。
これを実現するのが Machine Learning です。大量のデータからパターンを探し出し、それらのモデルを分析するためのロジックを構築します。そして、データの微調整や予測、推論を行います。画面には様々な種類の Machine Learning カテゴリーが表示されていますが、今回は主に Machine Learning 向けのクラウドストレージに焦点を当てていきます。

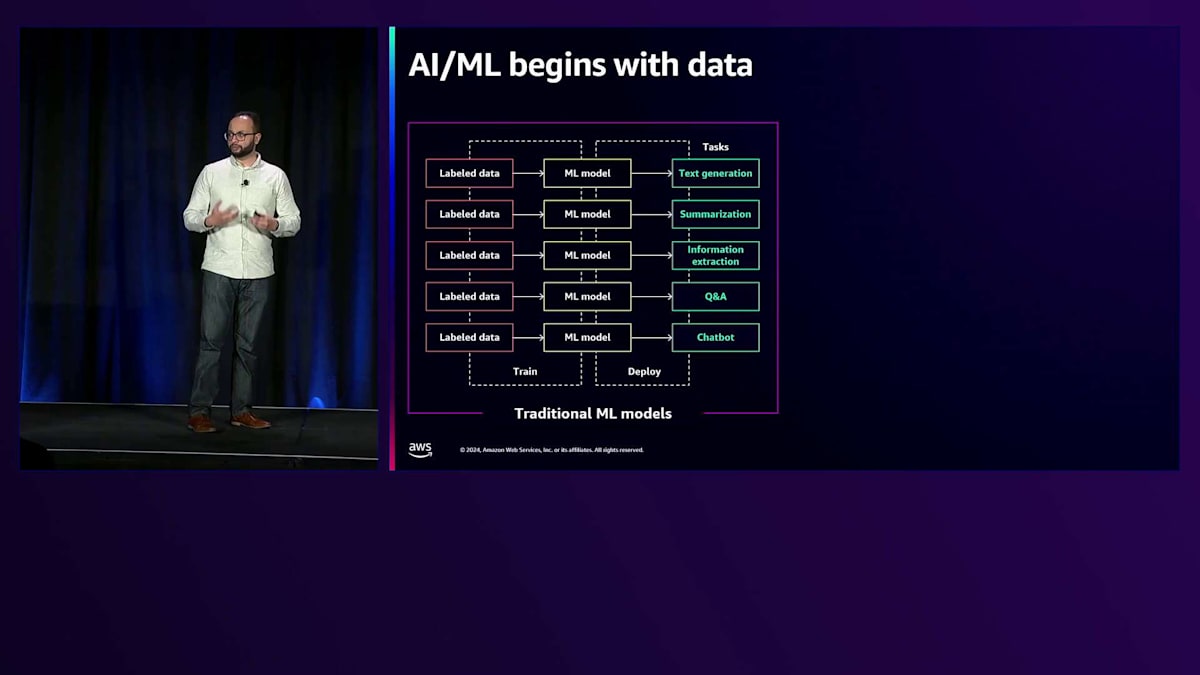
全体として、AI と ML は従来のモデルから Foundation Model へと移行したことで、はるかに容易で労力の少ないものとなりました。以前の従来型 ML モデルでは、解決したい問題ごとに一からモデルを作成する必要がありました。データにラベルを付け、モデルに投入し、それを何かをしたいたびに繰り返していました。テキスト生成や要約、チャットボットの構築など、実現したいタスクに応じて、それぞれ異なるモデルを用意し、個別にトレーニングする必要がありました。ご覧の通り、これは管理が大変で非常に時間のかかる作業でした。
現在では、問題ごとにソリューションを一からモデリングする代わりに、Foundation Model を活用できるようになりました。これらは既に数十億から数兆のパラメータで学習済みで、多様なデータセットでトレーニングされています。また、特定のタスクに合わせて Fine-tuning することも可能です。先ほど挙げたタスクについても、それぞれの目的に合わせて Fine-tuning できます。総じて、Foundation Model は AI と ML を大幅にシンプル化しました。ここからは、そのパイプラインについてお話ししていきます。

このパイプラインは、これまでご覧になってきたアプリケーションとは大きく異なります。準備から構築、トレーニング、そして展開と管理まで、すべてを網羅しているからです。このパイプライン全体を通じて、人間と機械の両方が関わり、それぞれが異なるニーズとデータとの関わり方を持っています。


では、これを詳しく見ていきましょう。かなり複雑に見えるかもしれませんが、それは実際に多くの複雑さが含まれているからです。 まずデータを一元化し、使用する特定の要素をキュレーションすることから始まります。 モデル構築フェーズでは、データサイエンティストがデータと対話し、適切なモデルを選択し、パラメータを決定します。この段階では人間の関与が必要で、人々が直接データに関わります。ここでは SageMaker や自己管理型 AI、AWS AI サービスなどのツールを使用します。
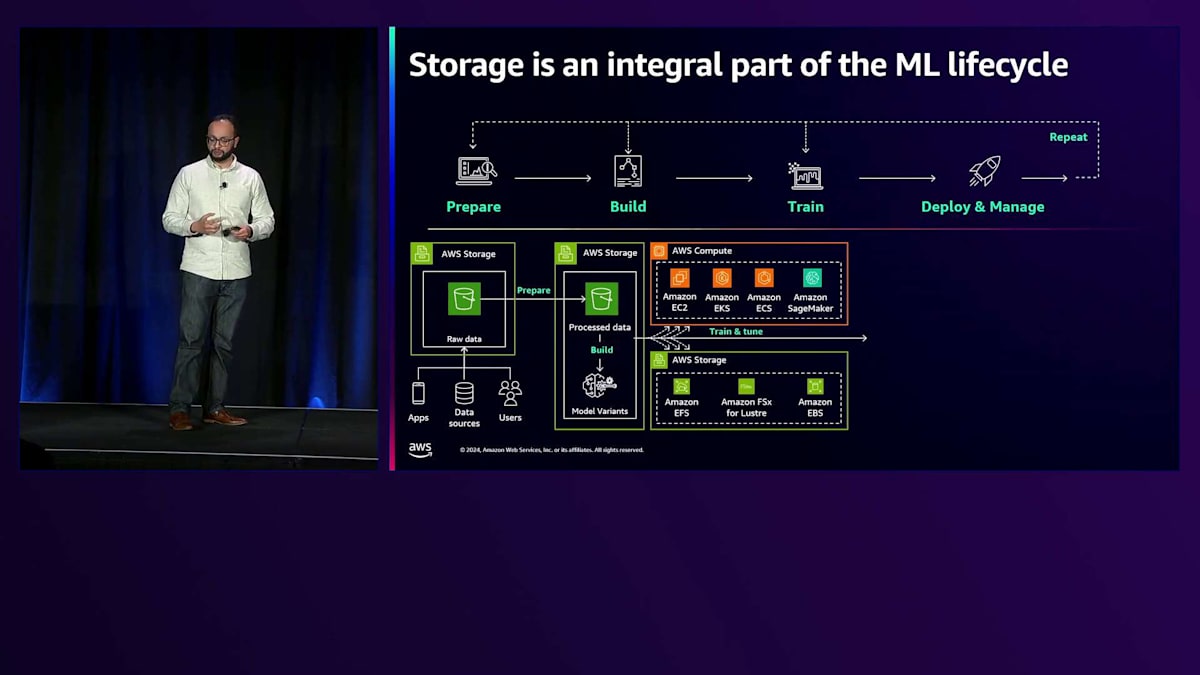

次に、特に計算負荷の高いトレーニングフェーズに移ります。この計算負荷は、標準的なAmazon EC2ベースの計算とは大きく異なります。ここでは、トレーニングと推論サービスを提供するP4およびP5インスタンスについて説明します。これらのサーバーには特定のI/O要件があり、驚くべき速度でデータを処理できます。ここで重要になるのは、これらのサーバーへのデータフローをいかに最適化するかという点です。これについては後ほど説明します。その後、SageMakerやBedrockなどのサービスを使用したMLOpsによるデプロイメントが続きます。ここでモデルが実際に稼働し、ユーザーがデータとやり取りして洞察を得ることができます。このプロセスの素晴らしい点は、データが増え、モデルを調整していくにつれて、このサイクルを継続的に繰り返せることです。

重要な要素として注目すべきなのがAmazon S3です。データレイクを拡張する際、S3は優れた出発点となります。データを中央リポジトリに集約するための戦略を立て、さまざまなユーザーがこのデータとどのように関わるかを考える必要があります。MLトレーニングの面では、お客様のニーズに基づいて、特にGPU使用率に関してユニークなソリューションを実装してきました。P4およびP5インスタンスでは、1つから5つのインスタンスにスケールアップすると、帯域幅が劇的に変化します。AIとML環境のコストの大部分はトレーニングから発生するため、GPUを効率的に稼働させることが重要です。GPUのアイドル状態はリソースの無駄になるだけでなく、トレーニング時間を延長させ、迅速な反復を妨げることになります。

AWS Storageでは、S3(中央の信頼できる情報源)とAmazon FSx for Lustreを組み合わせた革新的なソリューションを作り出しました。これにより、Lustreをバケットにアタッチでき、最初のアクセス時にデータを取り込みながら、スケールに応じてGPUのニーズを満たすサブミリ秒およびサブマイクロ秒のパフォーマンスを提供できます。例えば、長時間のトレーニングセッション中にチェックポイント操作を実行する場合、データはFSx for Lustreに書き込まれ、完了時にS3の中央の信頼できる情報源に転送されます。このアーキテクチャは、本質的にデータの上にパフォーマンスを向上させるアクセラレーターを提供しています。

これはまさにAdobeが実装したものです。Adobeは環境内でさまざまなユースケースにAIとMLを活用していますが、特に彼らのクリエイティブなユースケースに特化した独自のFoundation Modelをトレーニングすることを望んでいました。
彼らはオープンソースで利用可能なものを使用する代わりに、このアプローチを選択しました。他のお客様に比べて彼らが持っていた利点は、Adobe Stockのような自社のマーケットプレイスなど、独自の専有データでトレーニングできることで、これにより知的財産権の問題を回避できました。独自のモデルのトレーニングは素晴らしいものですが、時間と反復が必要です。Amazon S3とAmazon FSx for Lustreを含むAWSサービスを使用して、自社のコンテンツでトレーニングし、時間をかけてモデルを調整することで、Adobeは「AIスーパーハイウェイ」と呼ぶものを作り出すことができました。Adobeは生成AIモデルのFireflyファミリーの立ち上げに成功し、これをPhotoshopやIllustratorなどの主力ソフトウェア製品に統合しました。


それでは最後のトピックであるデータ保護のユースケースに移りたいと思います。これは、クラウド戦略において非常に重要な部分です。企業の規模が小規模、中規模、大規模にかかわらず、すべてのお客様にとってデータ保護は必要不可欠です。 データは増え続けており、AI、ML、Generative AIなどの原動力として、非常に大きな価値を持っています。データには、災害復旧、事業継続性、規制遵守のために、保護とガバナンスが必要です。データ保護ソリューションの設計と導入は、課題と機会の両方を含む旅路といえます。
まず、本日のお話の文脈におけるデータ保護について定義させていただきます。データ保護とは、重要なデータを破損、改ざん、損失から守り、機能的な状態に復元できる能力を提供するプロセスです。事業継続性を維持するために、お客様はクラウドアプリケーションデータを大規模にバックアップまたは保護するためのシンプルで費用対効果の高い一元的な方法を必要としています。また、ランサムウェアからの復旧機能や、データ保護ポリシーと運用に関するコンプライアンスの洞察と分析も必要とされています。

お客様は長年にわたり、COMMVAULTやVERITASのようなソリューションを使用してデータ保護を行ってきました。そして、この10年ほどではRUBRIKやCOHESITYのようなソリューションも使用されています。データ保護を実現する方法は数多くあります。Storage Gatewayを使用してハイブリッドソリューションを構築し、データをAmazon S3に保存してバックアップを管理するお客様もいらっしゃいます。私たちが確認してきたところ、すべてのバックアップベンダーがAmazon S3と統合されています。これらのデータ保護ベンダーのソリューションをオンプレミスで使用している場合、そのAPIをAmazon S3に向けることができます。これらのベンダーのオンプレミスアプライアンスを使用する場合、そのデータコピーをAWSやAmazon S3に移行することができます。

また、これらのパートナーソリューションはAWS Backup APIとも統合できます。クラウドで生成されたデータについては、これらのBackup APIを使用してAWS Backupを利用できます。パートナーソリューションを選択していただければ、AWS Backupを使ってデータのバックアップを代行いたします。 お客様は、複数のサービスにわたってサポートされているバックアップ活動の設定管理とガバナンスを処理し、データ保護ポリシーを一元的に展開することができます。これらは、AWS Backupがすでに統合されている様々なサービスで、AWS Backupを使用して完全に管理されたバックアップを実行することができます。タグ付けを行い、独自のバックアップポリシーを作成し、これらのバックアッププランを使用して、あらゆるバックアップ要件を満たすことができます。例えば、多くの企業には満たすべき様々なコンプライアンス要件があります。また、バックアップの頻度や保持期間もスケジュール設定できます。特定のバージョンや期間のバックアップのみを保持したいというお客様もいらっしゃいます。

先ほど触れましたが、これらはAmazon Partner Networkでサポートしているバックアップおよびリカバリーパートナーの一部です。オンプレミスでこれらのいずれかと連携することが可能です。

私たちはこれらのソリューションを評価し、AWS Backupソリューションとの互換性を確認しました。これらのベンダーと連携することができ、AWS Backupまたはs3のいずれかと接続することが可能です。
実際にAWS Backupを利用したお客様の事例についてお話ししましょう。オーストラリアで2番目に大きい独立系の石油・ガス生産会社であるSantos Limitedの事例です。彼らはEBSボリュームをバックアップするためにLambdaスクリプトを作成してスケジューリングしていました。バックアップの可視性が低く、問題を特定するためにレポートの確認に何時間も費やしていました。アプリケーションの採用が進むにつれ、新しいアプリケーションのデータが適切にバックアップされないという課題も抱えていました。さらに、将来のバックアップのたびにスクリプトの再構築や変更が必要となり、手動スクリプトの運用負担が増大していました。
AWS Backupの利用を開始してからは、バックアップの失敗は一度も発生していません。スクリプトの作成が不要になり、バックアップ管理に必要な人員を削減することができました。バックアップの可視性が向上し、以前は不完全なレポートを確認しなければならなかった21,000個のEBSスナップショットをすべて確認できるようになりました。全体として、生産性が向上し、バックアップ作業時間が約80%削減されました。不要なデータバージョンを削除することで、バックアップに関連する運用コストを50%削減しました。スナップショットの精度は約80%から100%に向上しました。最も重要なのは、すべてのデータをバックアップするように設定した、フルマネージド型のソリューションであるAWS Backupを使用することで、完全な信頼性を得られたことです。

本日は多くの内容をカバーしましたが、これは私たちが提供しているサービスとサポートしているユースケースの紹介に過ぎません。モバイルアプリでセッションのアンケートにご協力ください。本日の良かった点や、今後のセッション改善点についてのフィードバックを大変ありがたく思います。re:Inventでは、これらのユースケースやアプリケーションについてより深く掘り下げるAWS Storageに関連する多くのセッションが用意されています。皆様の学習が今日で終わらないことを願っています。AWS Skill Builderウェブサイトで、自分のペースで学習できるラーニングプランをご用意しています。また、オブジェクトストレージやファイルストレージなど、特定のトピックに焦点を当てたRamp-Up Guidesもご利用いただけます。

re:Invent2日目にご参加いただき、ありがとうございます。ランチタイムが始まっていますが、もう少し長くお付き合いいただき、ご清聴ありがとうございました。私たち一同、心より感謝申し上げます。この後10分ほどこの場にいますので、ご質問がある方や、単にご挨拶したい方は、お気軽にお声がけください。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion