re:Invent 2024: AWSが解説 PostgreSQLでのVector検索実装とpgvector新機能
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Best practices for querying vector data for gen AI apps in PostgreSQL (DAT423)
この動画では、AWSのPrincipal Product Manager - TechnicalのJonathan KatzがPostgreSQLでのVector検索の実装について詳しく解説しています。pgvectorの内部構造に踏み込み、HNSWやIVF Flatなどの検索手法の特徴や、Recallとパフォーマンスのトレードオフについて具体的なデータを示しながら説明しています。特にpgvector 0.8で導入された新機能であるフィルタリング機能に焦点を当て、選択性の異なる条件での検索パフォーマンスの比較データを示しています。また、Amazon Aurora Optimized ReadsやLimitless Databaseなど、Vector検索を効率的に行うためのAurora固有の機能についても言及しており、実践的なVector検索の実装方法を学ぶことができます。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Vector検索の重要性とRAGの概要

みなさん、こんにちは。「Best Practices: Recording Vector Data for Gen AI Apps and PostgreSQL」へようこそ。私はAWSのPrincipal Product Manager - TechnicalのJonathan Katzです。本日の発表を担当させていただきます。これが私の初めてのライブセッションですので、もし何か問題が発生しても、ご容赦いただければと思います。本題に入る前に、これはL400レベルのトークであることをお伝えしておきたいと思います。pgvectorの内部構造に踏み込み、pgvectorとPostgreSQLの仕組みを深く理解することで、アプリケーションに最適な判断を下せるようになることを目指します。多くのデータとチャートを見ていきますが、段階的に説明を進めていきますので、ご安心ください。


幸いなことに、この講演は録画されますので、後で振り返りたい部分があれば、そちらをご覧いただけます。60分間しっかりと内容を説明させていただきたいので、質問は講演後にお受けしたいと思います。 まず、なぜこれが重要なのか、なぜデータベース内のベクトル検索に注目する必要があるのかを考えてみましょう。例えば、注文情報を取得するような、パーソナライゼーションが必要な質問があったとします。Foundation ModelやGenerative AIモデルの素晴らしい点は、きめ細かなパーソナライズされた応答が可能なことです。しかし、データベースに存在するデータをFoundation Modelの応答に結びつける方法が必要です。というのも、プライベートなデータソースに存在するデータについては、おそらくモデルは学習していないからです。



この課題に対処するために開発された効果的な手法が、Retrieval Augmented Generation(RAG)です。RAGのアイデアは、パーソナライズされた応答に必要なコンテキストを取り込む機能を提供することです。通常、Foundation Modelは公開情報のみで学習されています。 そのため、「この青い靴はいくらですか?」といった具体的な質問をしても、答えることができません。 しかし、商品カタログや価格カタログ、関連情報を取り込むことで、Foundation Modelはその青い靴の正確な価格情報を提供できるようになります。

データベースからデータを取り出し、Foundation Modelに取り込む方法が必要です。さまざまな種類の情報がありますが、ラベル付けされていない生のテキストや画像、動画などの非構造化データは、検索可能な形式で表現する必要があります。テキストデータの検索自体は新しいものではなく、全文検索は何年も前から行われてきましたが、ベクトルという数学的構造でテキストデータを包み込むことで、距離計算による比較が可能になります。これにより、テキストと画像、テキストと動画、画像と動画の比較など、他の種類の検索も可能になります。なぜなら、ベクトルという数学的表現を共通言語として持つことができるからです。

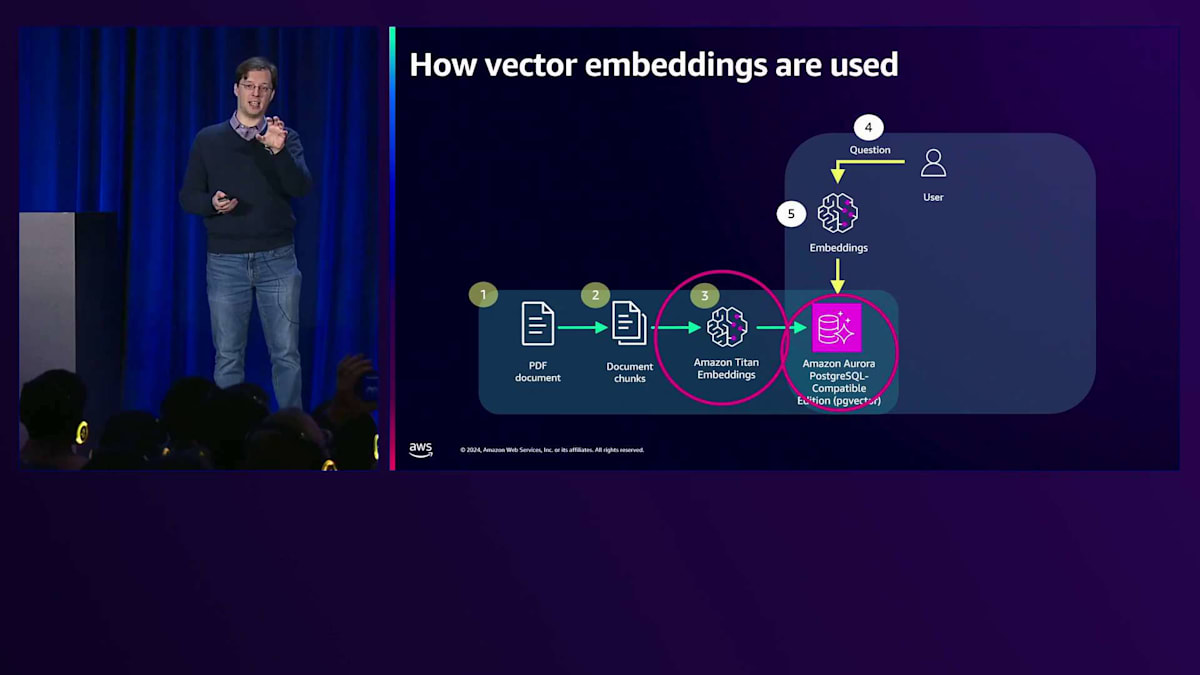

取り込みワークフローでは、PDFドキュメントなどの非構造化データがあり、それをEmbeddingモデルで使用できるように準備する必要があります。Embeddingモデルは非構造化データをベクトルに変換し、それらはAmazon Auroraデータベースに保存されます。 そして興味深い部分が、アプリケーションにエージェントワークフローとして公開することです。ユーザーが青い靴の価格を尋ねた場合、そのコンテキストを取得するために質問をベクトルに変換する必要があります。 その後、データベースに最も類似した結果を問い合わせ、その質問とコンテキストをFoundation Modelに入力して応答を生成することができます。
Vectorデータの課題とRecallの重要性



Vectorは扱いが難しく、それが私がこのトピックに惹かれた理由です。 まず、Vector embeddingの生成には時間がかかります。100ミリ秒かかるとして100万のVectorがある場合、そのため、どこかに保存する必要があります。最近のEmbeddingはかなり大きく、1536次元のVectorは6キロバイトのペイロードになります。一見それほど大きくないように見えるかもしれませんが、リレーショナルデータベースに保存されているデータと比較すると、通常の1行あたりのサイズは恐らく1キロバイト未満なので、データの膨張が起きる可能性があります。圧縮を提案されるかもしれませんが、これは長年行われてきたことですが、ランダムな浮動小数点数には実質的なパターンがないため、圧縮することは困難です。サイズを縮小する技術はありますが、それらの技術を使用すると情報の損失が発生します。最後に、距離演算を行うため、すべてのVectorを比較しなければならないという検索時間の考慮も必要です。

最初の256次元だけを比較すれば良いというEmbeddingモデルもありますが、それでも256回の比較が必要です。100万のVectorを含むデータセットでそれを行うとなると、かなりの時間がかかってしまいます。そのため、高速化の方法が必要になります。



このトークの要点は、近道は実際にはないということです。Approximate nearest neighbor searchと呼ばれる技術があり、これを使用すると、クエリVectorをデータセット内のすべてのVectorと比較する代わりに、近似的に比較することができます。そして素晴らしいのは、100万のVectorと比較する代わりに5000のVectorだけを比較する場合、その5000回の演算の方がはるかに高速になるということです。ただし、Recallと呼ばれる新しい変数が追加されます。Recallは期待される結果のパーセンテージです。

これはどういう意味でしょうか?exact nearest neighbor searchを行う場合、つまりクエリVectorをデータセット内のすべてのVectorと比較する場合、これら10個のVectorが返されることが期待されます。しかし、approximate nearest neighbor searchでは、そうならない可能性があります。期待される10個のうち8個しか返さない可能性があり、その場合Recallは80%となります。これは、このトーク全体を通して覚えておくべき重要な指標です。なぜなら、Recallを理解せずにVector検索の比較を行うことはできないからです。これは、皆さんが構築しているアプリケーションにも直接関係します。なぜなら、これが検索品質の測定基準となるからです。つまり、私の検索はどれだけ良いのか、そしてその検索は私のアプリケーションのビジネス要件を満たすのに十分な品質なのか、というのがこのゲームの本質です。


Vectorの保存方法と検索方法の選択に影響を与える一般的な要点について、詳しく説明する前にいくつか触れておきましょう。最初は、コストです。コストは決定的な要因ではないかもしれませんが、データベースは全体の一部分に過ぎないため、Generative AIアプリケーションの構築方法を考える上で全体的な要因となります。実際、データベースにより多くの費用をかけることで、最終的に最大のコストとなるFoundation modelの全体的なコストを削減できる可能性があります。


Generative AIアプリケーションを開発する際に念頭に置いておくべき重要なポイントは、どのEmbeddingモデルを使用するか、そしてどのFoundation Modelを使用するかという選択です。これはGenerative AIアプリケーションのGenerative AI部分であり、これらの決定は最終的にデータの検索方法に影響を与えます。後ほど見ていきますが、検索の品質にも大きく関わってきます。 また、開発のしやすさも重要な要素です。多くの場合、これらのアプリケーションは急速にプロトタイピングを行う必要があり、慣れ親しんだものを使って作業したいと考えるからです。Vector検索は一つの機能に過ぎないので、使い慣れたシステムで開発できる機会は数多くあります。

最後に、クエリのパフォーマンスとデータの取り込みについてですが、これらは密接に関連しています。クエリのパフォーマンスについては、目標とする応答時間はどの程度でしょうか?アプリケーションによっては、最高のRecallレベルで最速の応答時間が必要かもしれませんし、コストを重視して応答時間を妥協できる場合もあるでしょう。同様に、データを一度だけ調整してVectorインデックスを構築するのか、それとも継続的にデータを追加していくのかによって、どのインデックス方式を選択するかが変わってきます。
PostgreSQLとpgvectorの特徴


私はこれをトライアングルの形で考えるのが好きで、そのトライアングルの軸となるのがRecallです。 Recallは最終的にすべての決定を左右することになります。例えば、インデックスを作成する場合を考えてみましょう。 通常、インデックスを構築する際には、そのサイズと構築にかかる時間を考慮します。これはVector検索において特に重要になってきます。インデックスの構築に時間をかければかけるほど、より良いRecallが得られることがわかっています。ただし、トレードオフとして、データのインデックス作成により多くの時間がかかることになります。

同様に、クエリのパフォーマンスも重要です。通常、クエリパフォーマンスについて考える際には、スループット(1秒あたりに送信できるクエリの数)とレイテンシー(情報を返すのにかかる時間)を考慮します。スループットはシステムをスケールアウトすることで対応できますが、レイテンシーについてはそう簡単には解決できません。私の経験では、最高のスループットと最高のレイテンシーの数値を達成しても、Recallがゼロになることがありました。だからこそ、すべてはRecallにかかっていると繰り返し申し上げているのです。



今日のトークで一つだけ覚えて帰っていただきたいのは、何をするにしても、最終的にはRecallで測定する必要があるということです。このプレゼンテーションを通じて、Recallについて触れない部分もありますが、その理由と重要性については説明させていただきます。 さて、パフォーマンスメトリクスに影響を与える要因は何でしょうか? ポイントは、これらすべての要素について、このトーク全体を通じて詳しく見ていくということです。これらはすべて相互に影響し合っています。例えば、Quantizationを行えばインデックスの全体的なサイズは小さくなりますが、Recallに影響を与え、目標とするRecallに到達するためにより多くの検索が必要になる場合は、検索時間にも影響を与える可能性があります。これらすべての要素が重要で、設計の決定を行う際には、アプリケーションから最終的に何を得たいのかを考慮しながら、それぞれのステップを慎重に検討する必要があります。さて、PostgreSQLの具体的な話に入る前に、 AWSには多くの異なるサービスでVector検索が提供されているということを押さえておく価値があります。
これらのシステムに精通していて、すでにデータを保有している場合は、それを選択してアプリケーションの構築を開始できます。しかし、今日Amazon AuroraやAmazon RDSでPostgreSQLを使用することを選択する場合、これからPostgreSQLをベクトルストアとして詳しく見ていきましょう。

私たちは従来、PostgreSQLをリレーショナルデータベースとして考えてきました。非常に長い歴史を持っており、実は私自身がBerkeleyプロジェクトの原型とほぼ同い年なのです。PostgreSQLには約30年に及ぶオープンソースの歴史があります。PostgreSQLのオープンソースという性質により、多くの興味深い発展がありました。特に私が強調したいのは、その拡張性です。PostgreSQLはオブジェクトリレーショナルデータベース管理システムと定義されていますが、私はこれを拡張可能なデータベースシステムだと考えています。なぜなら、アップストリームのデータベースに組み込んだり、新製品を作るためにデータベースをフォークしたりすることなく、機能を追加できるからです。この良い例が地理空間検索です。PostGISは地図アプリケーションで広く使用されていますが、これはPostgreSQLと並存する単なる拡張機能なのです。

この拡張性がベクトル検索にも適用されるのは、地理空間検索を考えると理解しやすいでしょう。地理空間検索では3次元や4次元のベクトル、あるいは2次元のベクトルを扱います。これらは小さなベクトルで、それらに対する厳密な検索を行うための非常に効率的な手法がいくつかあります。PostgreSQLでベクトル検索を実現するために、拡張機能と並行していくつかの新しい要素を開発する必要がありました。便利なのは、PostgreSQLのための既存のツール群の多くがそのまま機能することです。実質的にベクトルデータ型を追加し、ツールをそれに対応させるだけなのです。おそらく、アプリケーションと連携させたいPostgreSQLデータベース上のデータをすでにお持ちでしょう。

より詳しく説明したい点が一つあります。それは最後に挙げたACIDについてです。ACIDはデータの保存方法に関する取引保証を提供します。これはエンドユーザーの観点から見て、必要な場合には非常に重要です。ACIの部分を見ると、データの可視性に関する保証があります。つまり、コミットされたデータはそこに存在し、次のセッションで即座にそのデータにアクセスできます。特にリアルタイムでデータを更新する場合、これは非常に重要な概念です。私はDurability(永続性)を特に強調したいと思います。ACIDの各文字は重要ですが、Durabilityはデータが永続的に保存されることを保証します。これがここでのACIDの最も重要な特性です。なぜなら、ベクトルはあなたのデータであり、結果を得るために運用システム内で使用されるからです。

では、pgvectorに話を移しましょう。 pgvectorは、PostgreSQLにベクトルデータ型をもたらす拡張機能です。ベクトルデータ型に加えて、これらの検索を実行するために必要なすべての操作、比較演算、インデックス作成方法などを提供します。これはオープンソースで、活発に開発が進められています。AWSはpgvectorへの2番目に大きな貢献者であり、先ほど説明したすべての理由から、PostgreSQL内でのベクトル検索を実現するために重要だと考えているのです。
pgvectorの進化とHNSWインデックスの仕組み


データベースにおけるVector検索自体が急速に進化しています。昨年は、多くの人々がpgvectorを使用していました。それは、PostgreSQLと互換性のある拡張機能として存在し、既存のアプリケーションでも動作するからです。しかし、Generative AIの普及が進み、より複雑なアプリケーションを構築できるようになるにつれて、これらのワークロードは様々な面でスケールアップとスケールアウトを遂げてきました。そのため、ロードマップの多くは、pgvectorのスケーラビリティの向上、新しいインデックス手法の追加、本日ご紹介するフィルタリングなどのより複雑なワークフローのサポートに焦点を当ててきました。これらの多くは、オープンソースコミュニティからの直接のフィードバックや、お客様との対話を通じて、これらのワークロードをサポートするために何ができるかを理解することから生まれています。



この2年間で起きたことについて、一つ一つは詳しく説明しませんが、最初の部分は、世界中で見られる様々なVector検索ソリューションと同等のレベルにpgvectorを引き上げることでした。その後、より細かい点に焦点を当て、より少量の情報を保存し、WHERE句やJoinなどのより複雑な検索パターンに対応しながら、正確で関連性の高い効率的な結果を提供できるようにしました。これは現在も進行中の開発です。すでに多くの方々が本番環境でpgvectorを運用していますが、これらは私たちが注目している要素であり、PostgreSQLでこれらのワークロードをできるだけ簡単に、かつ高性能に実行できるようにすることを目指しています。
このトークの本質は、Approximate Nearest Neighbor検索についてです。なぜなら、すべてのデータを検索することで、Exact Nearest Neighbor検索の仕組みを理解することはできますが、最終的には、データセットのサイズ、利用可能なコア数、計算に費やしたい時間によって制限されることになるからです。


pgvectorは2つのApproximate Nearest Neighbor検索手法を提供しています。クラスターベースのIVF Flatと、グラフベースのHNSWです。それぞれにトレードオフがあります。IVF Flatは比較的サイズが小さく、構築が速い傾向にありますが、目標とするRecallに到達するのが難しい場合があります。Recallの目標を達成しようとすると、クエリが非常に遅くなる可能性がある一方、HNSWは全体的に管理が容易な傾向にあります。このトークの残りの部分は主にHNSWに焦点を当てます。なぜなら、これがVector検索において最も人気のある手法の一つ、もしくは最も人気のある手法となっているからです。



簡単なチートシートをご紹介します。Exact Nearest Neighborが必要な場合は、Vectorインデックスを使用しません。これは少し誤解を招く可能性がありますが、データをフィルタリングできることが分かっている場合は、B-treeインデックスやGINインデックスなど、他の種類のインデックスを使用することもあります。しかし、データセット全体を検索する必要がある場合は、Approximate Nearest Neighborインデックスは使用できません。高速なインデックス作成が必要な場合、特に非常に静的で、クラスタリングが上手くいくデータセットであれば、IVF Flatが適しています。その場合、1つか2つのセンターだけを訪問すれば良いのであれば、IVF Flatは検索も非常に高速になります。

ほとんどの場合、フィルタリングを除いて、何らかの形でHNSWを使用することになります。フィルタリングについては、選択性に関わる重要なトピックなので、今日は多くの時間を費やして説明します。データの選択性が高い、つまりフィルターによって大部分の行が除外される場合は、HNSWインデックスを使用しない方がよいかもしれません。その代わりに、この操作を効果的に処理できる従来型のインデックスを使用することをお勧めします。しかし、選択性が低い場合は、全体的な速度が速くなるため、HNSWインデックスを使用することをお勧めします。


今日のこのトークを通じての目標は、それを実証することです。つまり、選択性に基づいて、目標とするリコール率とパフォーマンスを達成するための適切なインデックスを選択できることを示したいと思います。これから、pgvectorの最適な戦略について、グラフやチャートを見ながら詳しく説明していきます。今日はおおよそこの順序で進めていきますが、途中で少し順序が前後することもありますが、すべてはストレージから始まります。
ストレージとTOASTの影響

なぜストレージから始めるのかというと、実は私自身、アプリケーション開発者として育ってきて、pgvectorについて学ぶまではページやページサイズについてあまり考えたことがありませんでした。しかし、これはPostgreSQLが使用する基本的なストレージユニットである8キロバイトという単位が重要になってきます。これが重要な理由は、pgvectorでデータをインデックス化する際に、この8キロバイトという制限に縛られることになり、結果として、インデックスに無駄なストレージが発生する可能性があるからです。

1つのインデックスページに収まるベクトルの数の例を見てみましょう。ベクトルが小さい場合は、1つのインデックスページにより多くのベクトルを格納できます。しかし、ベクトルが大きくなると、1つのインデックスページに1つしか格納できなくなり、そこにはオーバーヘッドが発生します。興味深いのは、1024次元のマークでは、1つのインデックスページに1つのベクトルしか格納できず、そのため約4キロバイトのスペースが無駄になってしまうということです。これはストレージ容量に影響を与える可能性がありますが、ストレージを効率的に使用していなくても、必ずしもアプリケーション全体に影響を与えるわけではないことを覚えておいてください。


ページサイズは変更できると聞いたことがあるかもしれませんが、PostgreSQLの全体的なページサイズはコンパイル時のフラグで、ほとんどの人が8キロバイトのままにしています。しかし、インデックスページはサイズを変更することができず、これは特に浮動小数点数を扱う場合に問題となります。より大きなベクトルになると、現時点では完全にインデックス化することができません。元のベクトルをインデックスページに格納するための技術はあるかもしれませんが、現在のところ、これらは量子化する必要があります。これについては後ほど見ていきます。
でも皆さんはこう思ったかもしれません。「大きなテキストBlobなどの大容量データを以前からテーブルに保存してきたじゃないか」と。そうですね。それを実現するのがTOASTと呼ばれるシステムです。TOASTは「The Oversized-Attribute Storage Technique」の略です。

基本的な考え方としては、特定のしきい値を超えるとPostgreSQLは別のテーブルにそのデータを保存できるというものです。これには複数の方法があり、これらの異なるストレージタイプは、テーブルにデータを保存する方法に影響を与え、パフォーマンスにも大きく関わってきます。


PLAINストレージは、ベクトルをテーブル内の他のデータと一緒にインラインで保存します。つまり、すべてのデータが1か所にまとまっているわけです。一方、EXTERNALとEXTENDEDは、ベクトルをTOASTテーブルに保存します。これは、しきい値を調整しない限り、2キロバイトを超えるサイズの場合にデフォルトで行われます。 pgvector 0.6.0以降、pgvectorはデフォルトでEXTERNALを使用するようになりました。これは圧縮なしで別テーブルに保存するという意味です。圧縮できないものを圧縮しようとして無駄なCPUサイクルを使うことを避けるためです。


なぜこれが重要なのか、視覚的に見てみましょう。 PLAINストレージの場合、テーブル内のすべてのデータが一緒に保存されますが、EXTENDEDとEXTERNALでは、ベクトルは実質的に別のテーブルにある異なるページに保存されます。TOASTは、頻繁にアクセスされないデータを扱うために発明されました。しかし、ベクトルの場合は、検索対象として常にベクトルを使用する必要があることがわかっています。 テキストや他の大容量データの場合、必ずしも比較操作を行う必要がないため、別の場所に保存することは理にかなっています。ただし、これはパフォーマンスに影響を与えます。データセットによってはTOASTを使用する必要があるかもしれませんが、そのパフォーマンスのトレードオフを理解しておく必要があります。

QPSの観点から具体例を見てみましょう。この例では、5,000個のベクトルを使用して、さまざまな次元数でCosine距離を計算しました。512次元を超えると、EXTERNALフォーマットで保存されているデータのパフォーマンスが大幅に低下することがわかります。これは、PostgreSQLが別テーブルからデータを取得し、メモリに読み込んでから比較を行う必要があるため、大きなペナルティが発生するためです。インデックスを検索する場合、このペナルティはそれほど顕著ではありません。なぜなら、インデックスページはすべてのベクトルがインラインで保存されるPLAINフォーマットで保存されているからです。
インデックスの計算や完全一致の最近傍検索を行う場合、TOASTに頻繁にアクセスすることでパフォーマンスが低下する可能性があります。これが、インデックス作成に時間がかかる原因かもしれません。データがホットパスにあることが分かっている場合は、ベクトルをPLAIN形式で保存することを検討してください。ただし、その場合はすべての行が1ページに収まるようにする必要があり、これはデータ次第で可能な場合もあります。




これはクエリプランニングにも影響を与えます。 128次元のベクトルで完全一致の最近傍検索を見てみると、6つの並列ワーカーが確認できます。 しかし、同じクエリプランで1,536次元の場合は、4つの並列ワーカーになります。より大きなベクトルの方が計算時間が長く、より多くのデータを扱うため、これは直感に反するように思えます。この問題の原因は、 PLAIN形式の場合、単一ページ内のすべてのデータが見え、1つの完全なページとして認識されますが、 TOASTの場合、個々のページにより多くのデータが蓄積され、見かけ上小さく見えてしまうことにあります。
HNSWインデックスのパラメータ設定とパフォーマンス


幸いなことに、min_parallel_table_scan_sizeパラメータを設定することで、このクエリを完了するために実際には11の並列ワーカーが必要だとPostgreSQLがより適切に見積もることができます。アプリケーション開発者としては、これらの考慮事項を意識していなかったかもしれませんが、このようなパラメータが利用できることは重要です。 データの保存に関する一般的なガイドラインとしては、ベクトルがホットパスにある可能性がある場合はSTORAGE PLAINを使用し、ホットパスにない場合は他のオプションを使用できます。そして最終的に、TOASTはインデックス作成には利用できません。

次に、HNSWのビルドとストレージパラメータのベストプラクティスについて説明しましょう。 HNSWでは、これらのビルドパラメータから始まるストレージ戦略も重要です。最も重要なパラメータはMで、おそらく変更する必要はありませんが、特定のケースで変更した場合どうなるかを見ていきます。次にef_constructionがありますが、これはインデックスを構築する際の実質的な検索半径です。

ef_constructionの推奨値は64から256です。なぜ64がデフォルトで、そしてなぜデフォルトが実際にはかなり良いのかを見ていきましょう。256でわずかに高いRecallを達成できますが、考慮すべきクエリパフォーマンスのトレードオフがあることを確認します。昨年このプレゼンテーションを行った際には256を推奨しましたが、より多くのデータが得られた現在では、その推奨を若干修正しています。

もうひとつの重要なパラメータは、ボトムレイヤーを検索する際に使用される検索パラメータであるef_searchです。これについて詳しく見ていきましょう。以前は、フィルタリングのケースや十分な結果が得られない場合、ef_searchを増やすことが一般的でした。しかし、pgvectorの最近の変更により、その計算方法が変わり、フィルタリング用に調整できる追加のパラメータが導入されました。

HNSWインデックスを作成すると、トップレイヤーから始まります - HNSWのHはHierarchical(階層的)を表します。トップレイヤーで最も近いベクトルを見つけ、次のレイヤーで最も近いベクトルを見つけるために下層に移動します。 複数のレイヤーが存在する可能性があり、最下層では、最も近いベクトルのセットに収束するまでグラフをたどって、最近傍のベクトルセットを見つけます。これは非常に効率的で、ツリーをたどるような感覚です。グラフはツリーのスーパーセットなので、グラフの構築方法や検索方法に関する決定が、最終的に検索時間に影響を与えることになります。


検索プロセスでは、pgvectorは既に訪れたベクトルのリストを保持して、コストのかかる計算の重複を避けます。そして、クエリベクトルに最も近いベクトルである候補ベクトルの順序付きリストを維持します。 興味深いのは、グラフの異なるレイヤーを最下層まで移動する際、ef_searchは1となっていることです。最良の結果を見つけるために、非常に小さな半径で検索を試みているのです。最下層では、ef_searchの値に基づいて完全な検索により多くの時間を費やすことになります。

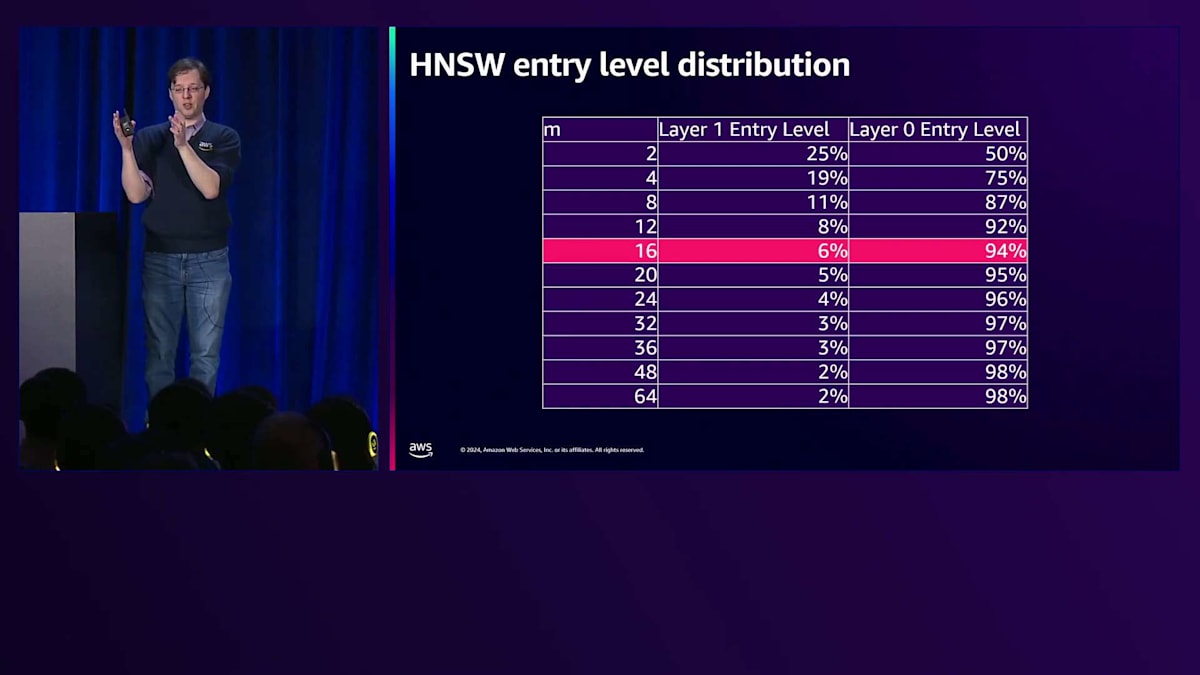
これが重要なのは、グラフの上層部分をどの程度メモリにインデックス化できるかを考慮する必要があるからです。インデックス化の重要な側面は時間的局所性で、 インデックスのホットな部分はメモリに留まり、リーフ部分やアクセス頻度の低い部分はディスクに移動します。HNSWでは、レイヤー0であるリーフ部分の検索に多くの時間を費やします。Mが16(デフォルト値)の場合、インデックスの約6%が上層に存在することになり、インデックス全体をメモリに収めない限り、インデックスの約6%に対してのみ非常に強い局所性を得ることができます。
これが重要なのは、メモリに保持するインデックスが多いほど検索が速くなるからです。特に検索が非常に徹底的な場合はそうです。できるだけ多くのインデックスをメモリに保持するために、Mを2にすべきだと考えるかもしれません。しかし、トップレイヤーではef_searchが1なので、グラフの下部に到達する際に最適な候補ベクトルを訪れていない可能性が高いのです。これは最適ではない配置と低いRecallにつながるため、通常はpgvectorでMを16から始めて、そこから調整していきます。

Mが検索にどのように影響するかを見てみましょう。これは私がこのプレゼンテーション全体で最も気に入っているスライドかもしれません。サイズの異なる5つの異なるEmbeddingモデルを使用した5つの異なるデータセットがあります。pgvectorのデフォルト設定をすべて使用すると、ef_constructionが40の場合、ほぼ同じ数のベクトルを検索していることがわかります。これはHNSWアルゴリズムの強力な特徴です - データセットのサイズではなく、主にビルドパラメータMに基づいてスケールするのです。より大きなデータセットではより多くのベクトルを検索する必要がありますが、検索する必要のあるベクトル数を決定する主な要因はMなのです。

このスライドはその関係性を示しています。Mが16の場合と64の場合を比較した2つの異なるデータセットがあります。Mを変更すると、より多くのベクトルをスキャンすることになります。より多くのベクトルをスキャンすることで、おそらくより質の高い結果が得られますが、そのトレードオフはクエリのパフォーマンスです。5000個のベクトルをスキャンする場合、1〜4ミリ秒かかることがわかっています。

スキャンするベクトルが多ければ多いほど、それらのクエリを完了するのに時間がかかります。50-100次元のデータセットでは、2300個のベクトルをスキャンするのに一定の時間がかかり、768次元のデータセットでは3000個のベクトルになります。これはEmbeddingモデルの選択に関係してきます。Embeddingモデルは、すべての情報をどれだけ早く収束させることができるかに影響を与えます。これは重要なポイントです。なぜなら、これらのビルドパラメータを選択する際にEmbeddingモデルとその特性を理解する必要があり、そうでないと、必ずしも望ましい結果を得られないまま、より多くの時間を要するインデックスビルドパラメータを選択してしまう可能性があるからです。

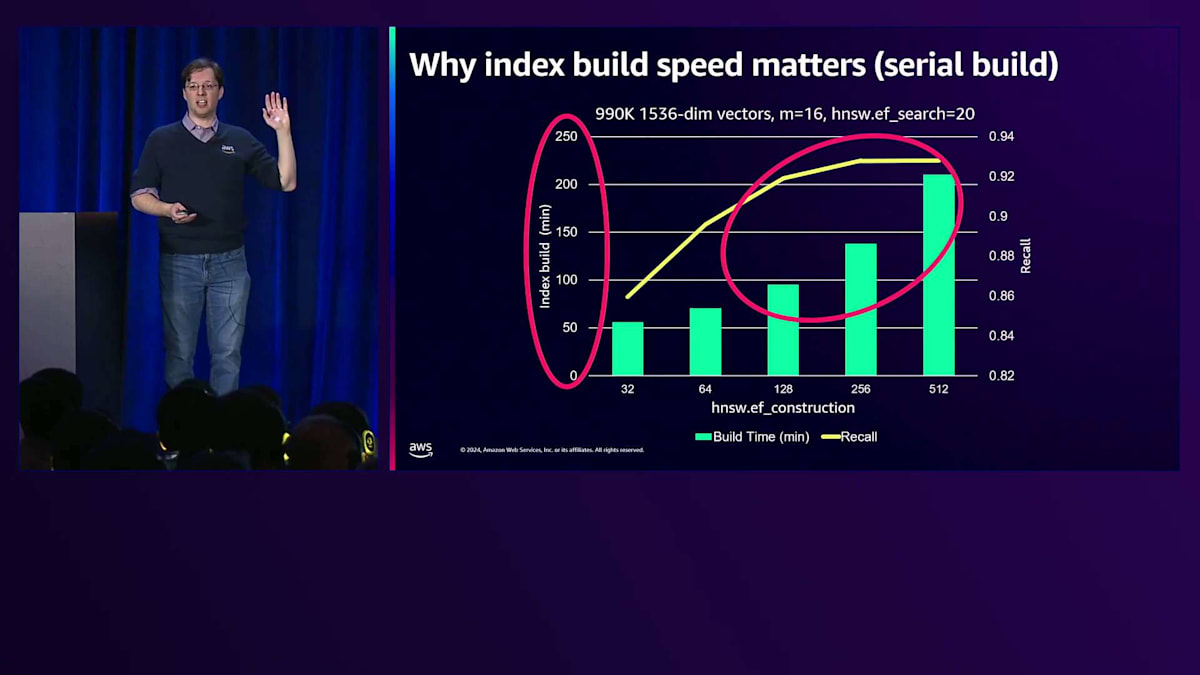

このような情報のインデックス作成において、インデックスビルド速度が重要です。なぜなら、インデックス作成に時間をかければかけるほど、より質の高いインデックスを構築できるからです。ただし、最終的には収穫逓減に達することがわかります。これはpgvector特有のことですが、ef_constructionは256で頭打ちになります。インデックスビルド時間を見てみると、シリアルワーカーを使用してインデックスを構築する場合、数時間単位の話になります。 ef_constructionを増やすと、数時間も待てない場合があります。しかし、並列ビルドを使用すると、 同じようなRecallを得られますが、所要時間は数分で済みます。ここで、ベクトルを一括でロードするのか、それとも反復的に追加するのかを決める必要があります。それに基づいて、取り込み方法を変更するか、マシンで利用可能なリソースを理解する必要があります。数時間ではなく数分でデータを準備できる並列ビルドを行う方が理にかなっているからです。

ef_constructionがクエリパフォーマンスにどのように影響するかについて、昨年私が行った推奨事項を修正したいと思います。ef_construction 256は最高のRecallとインデックスビルド時間を提供しますが、実際にはQPSが若干低下します。961次元のこのデータセットを含む複数のデータセットでこのテストを実行しましたが、低下は深刻ではありません - およそ10%程度です。しかし、より良いRecallを得るためにその10%の低下を許容できるかどうかを考える必要があります。ef_constructionは、データセット全体のRecallを向上させる最も簡単な方法ですが、最終的にクエリパフォーマンスに若干影響を与えます。これがあなたのケースで許容できるかどうかを判断する必要があります。

データの取り込みについて説明する前に、Mがインデックスの構築時間と検索品質にどのように影響するかを考えてみましょう。Mを調整すると、高い確率でRecallは向上しますが、インデックスの構築にかかる時間も変化します。ここでは並列インデックス構築を使用しているため、数分で完了しますが、64コアのマシンでインデックスを構築していない場合は、その時間は増加します。M=16は素晴らしい出発点です。良質なインデックスと高速なクエリ時間を提供してくれるからです。ただし、Mを増やすとスキャンするベクトルが増えるため、クエリ時間は遅くなることを覚えておいてください。これらはアプリケーションに応じて検討すべきトレードオフです。
データ取り込み方法とQuantizationの影響

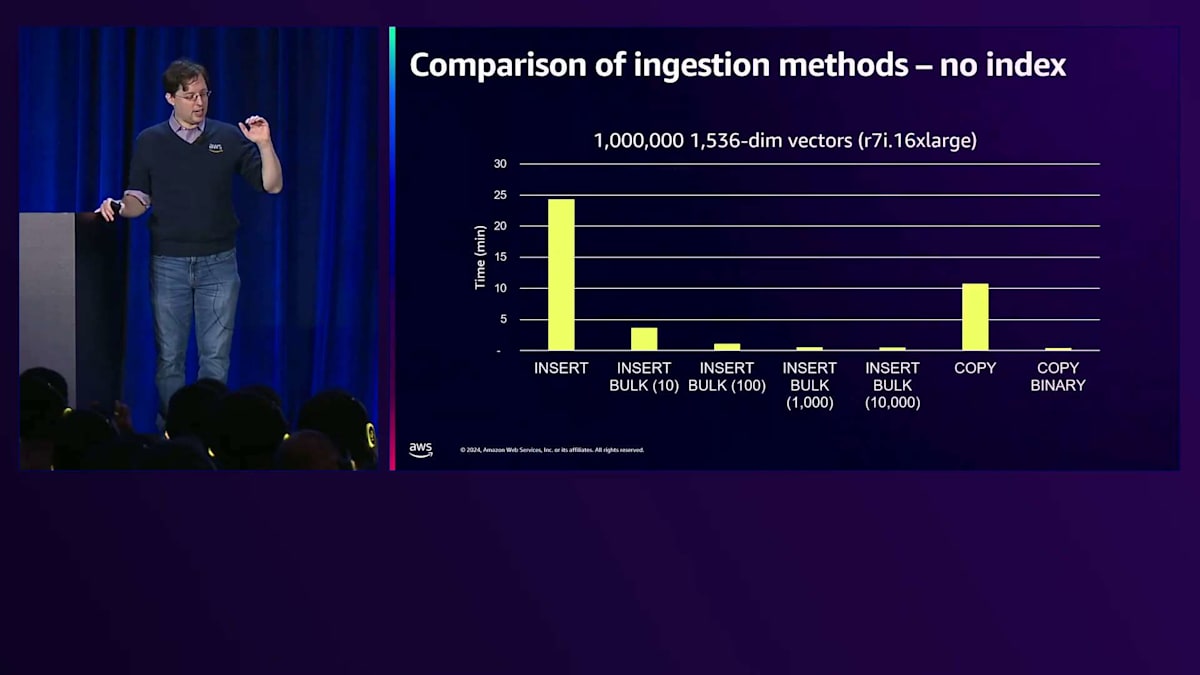

次にデータの取り込みについて説明しましょう。先ほど見たインデックス構築では、基本的にすべてのデータがテーブルにある状態でインデックスを構築しました。 しかし、実際にはデータをストリーミングで取り込んだり、顧客がデータを追加したりすることが多いものです。データの取り込み方法を理解する必要があります。一括でデータを読み込んでインデックスを構築できる場合、それが最高のパフォーマンスを発揮します。しかし、インデックスが事前に計算された状態でデータを反復的に取り込む場合は、適切な方法を見つける必要があります。 ここでは、これらすべての方法がシリアル取り込み(1つのワーカー、1つのクライアントでベクトルを取り込む)を使用しているケースを見てみましょう。方法によって大きな違いがあることがわかります。Bulk Insertが最適な方法のようで、最終的にはこのデータセットで収穫逓減が見られます。私の場合、一度に1000個のベクトルをBulk Insertすることが最適な数でした。また、Serial Insertは非常に時間がかかることもわかります。もう1つの興味深い比較は、COPYとCOPY BINARYの違いです。COPYはPostgreSQLのコマンドで、データを高速に取り込むのに役立ちます。 しかし、バイナリ形式を使用しないCOPYには課題があります。

COPYを使用する場合、バイナリ形式のベクトルをテキスト表現に変換し、ネットワーク経由で送信し、PostgreSQLがそれを再度バイナリ形式に変換します。これはコストがかかります。特にベクトルが1500次元の場合、1500個のfloatを1500個のテキスト値に変換し、さらに1500個のfloatに戻すことになるからです。COPYを使用すると、マシンが苦戦している様子を実際に目にしたことがあります。一方、COPY Binaryでは ほとんど処理が必要ありません。この方法を使用するだけで、取り込み速度が34倍も速くなるケースを見たことがあります。

既存のベクトルインデックスに対してデータを一括で読み込み、シリアル挿入を行う場合、Bulk Insertとバイナリ形式のCOPYという2つのオプションがあります。並行性を加えると、さらに興味深い結果になります。 複数の取り込みジョブがある場合、収穫逓減が始まります。Bulk Insertを使用しなくても、INSERTはかなり高速に見えてきます。時間がかかるため、おそらくまだ避けたほうが良いでしょうが、並行性によってシリアル読み込みの問題の一部が隠されます。他の方法は引き続き有効で、バイナリ形式を使用しないCOPYもこの時点ではかなり高速に見えます。ワーカーが1〜2個を超えると、COPY Binaryを使用してもそれほど速くなりません。

これらは取り込み時に覚えておくべき重要なポイントです。最後に、一度にインデックスを構築できる場合は、そうすべきだということを証明しておきましょう。並列ビルドを使用したCREATE INDEXには敵いません。特にpgvectorのメモリ改善が バージョン0.6から始まり、0.8でさらに改善されて非常に高速になっています。一括でインデックスを構築できる場合はそうすべきですし、できない場合は他のいくつかの方法を使用できます。



HNSWのベストプラクティスをまとめると、まずはデフォルト設定から始めることです。pgvector のリポジトリで、デフォルト設定を使用していないケースで問題が発生しているのを見かけています。現在調査を進めていますが、クエリのパフォーマンスをトラブルシューティングするための十分な情報がない場合、対処方法がわからなくなる可能性があります。デフォルト設定は十分に最適化されていますが、Recallを向上させる必要がある場合は、ef_constructionを256に上げることができます。 一般的に、テーブルデータでPLAINストレージを使用できる場合、それがパフォーマンスを最大限に引き出すことができます。データの取り込みに関しては、Bulk insertか バイナリフォーマットを使用したCOPYを使用するようにしてください。これにより、非常に高速な処理が可能になります。


最後に、Quantizationは全体的なストレージを削減するのに役立つテクニックで、 これについてはFilteringの説明に入る前に簡単に触れておきましょう。Quantizationは、ベクトルのもう一つの変換方法です。4バイトの 浮動小数点ベクトルを2バイトの浮動小数点ベクトルに量子化する場合、これはScalar Quantizationの一種です。さらに進めて、Binary Quantizationまで行くと、32ビットの値を1ビットに変換することになります。これは非常に極端な形式で、多くの情報が失われることになります。

これらは非常に効果的なストレージ技術ですが、トレードオフがあります。PostgreSQLには、不変関数を持つ場合に、 その関数を使用してデータをインデックスにマッピングできるExpression Indexという概念があります。これは非常に優れた機能です。なぜなら、Scalar Quantizationでは、4バイトの浮動小数点ベクトルを2バイトの浮動小数点ベクトルにマッピングしているからです。これをpgvectorに実装するのにそれほど多くの作業は必要ありませんでした。Binary Quantizationについても同様で、pgvectorにその機能を実装する関数があります。

Binary Quantizationでは、多くの情報が失われます。最終的には、 インデックス検索を効率的に使用してデータを検索し、その後再ランク付けを行うためのクエリを実行する必要があります。アプリケーション開発者にとっては、これは少し不安に感じるかもしれません。これはCommon Table Expressionを使用して実現することもできます。私はこのようなサブクエリを書くことに慣れていますが、重要なポイントは、Binary Quantizationを使用する場合、再ランク付けが必要になるということです。ただし、Embeddingモデルがバイナリのモデルである場合は、この作業は不要で、非常に高速な検索が可能になります。



こちらは5,000個の1,500次元ベクトルを使用した特定のデータセットでのテスト結果です。左の列が元のベクトル、次が2バイト浮動小数点ベクトル、そして最後がBinary Quantizedベクトルです。サイズの違いとインデックスのビルド時間の違いは明確です。Binary Quantizedベクトルの方がビルド時間が大幅に短くなっています。しかし、Recallへの影響も見てみましょう。Binary Quantizedベクトルは高速ですが、同じef_searchレベルでは、Recallが大幅に低下します。もちろん、Recallは改善できます。ef_searchは調整可能なレバーの一つですからね。 Binary Quantizedベクトルを使用した検索は高速になりますが、ここでも重要なのは、Recallのトレードオフをどう考えるか、これで十分なのかということです。
より高速な検索、より小さなインデックス、そしてより多くのデータをメモリに保持できるようになります。しかし結局のところ、すべては検索品質にかかっています。このトレードオフが自分のケースに適しているかどうかを判断する必要があります。
フィルタリング戦略とその影響

Quantizationの重要なポイントは、情報の損失を伴うということです。チームがそれを受け入れられるか確認し、最も関連性の高い結果が得られているかテストする必要があります。Quantizedデータをインデックスに追加していくと、特にBinary Quantizationの場合、似たようなビット列が生成され、値が非常に似通ってくるため、より良い結果を得るにはインデックスのより多くの部分を検索する必要が出てきます。私が最初にpgvectorでBinary Quantizationをテストした時、G-960データセットを使用したのですが、pgvectorで見たことのない最速の結果が出ました。しかしRecallを確認してみると、それは0でした。これは、こうした手法が検索品質にどのような影響を与えるかを理解することがいかに重要かを示しています。


次は、フィルタリングという興味深いトピックについてお話しします。これは私が最も興味を持っている部分です。データベースで何百万回も実行してきた単純なクエリですが、Approximate Nearest Neighbor検索では非常に興味深い影響があります。 WHERE句をクエリに含める場合、プロセスは選択を行います。クエリプランナーは、インデックスを使用するか、他の方法を使用するか、あるいはインデックスを使用しても十分な結果が得られない場合(これがOver-filteringの問題です)を判断します。Post-filterを使用することも可能で、場合によっては許容できますが、選択性によっては非常に遅くなる可能性があります。なぜなら基本的にテーブル全体を検索し、それらの値に基づいてすべての結果をフィルタリングすることになるからです。


フィルタリング戦略をどのように決定すればよいのでしょうか?これは特にpgvector 0.8の最新リリースで重要になってきます。なぜなら、選択できるオプションが大幅に増えたからです。まず、クエリパターンを考慮します - フィルタリングされたクエリと、ベクトルインデックス全体を検索するフィルタリングされていないクエリの割合はどうでしょうか? フィルタを全く使用しないことが分かっている場合は、Approximate Nearest Neighborインデックスを使用します。フィルタの選択性が高いことが分かっている場合は、Approximate Nearest Neighborインデックスを使用しないでください。


選択性は非常に重要です。アプリ開発者として働いていた時は、DBA側に来るまで選択性について考えたことがありませんでした。以前はインデックスは単に処理を高速化するものだと考えていましたが、実際にはインデックスが処理を高速化するのは、扱っているデータの選択性が非常に高く、ほとんどの行がフィルタリングされるからでした。 これは先ほどのベクトル演算のスライドに関連します。r7iでこのサイズのベクトルに対して5,000回の距離計算を行うとこれくらいの時間がかかることが分かっています。これは良いベンチマークとなります。なぜなら、HNSWスキャンを含む多くのクエリは、おそらく5,000回の計算の範囲内に収まるからです。

ここでのQPSは、これらすべてのベクトルに対する上限となります。テーブルスキャンを使用する場合、5,000個のベクトルを比較すると、上限は1秒あたり約500クエリとなります。これは、異なるフィルターを検討する際に重要になってきます。なぜなら、これが最速であることがわかれば、Approximate Nearest Neighborインデックス、反復スキャン、またはB-treeのどれを使用するかを判断できるからです。


pgvector 0.8以前は、効率的なフィルタリングの方法は実質的に2つありました。WHERE句を使用したPartial Indexの作成か、パーティショニングです。これらの手法は確かに機能します - 私は実際に、本番環境で10億規模のデータを扱うお客様と一緒にこれらを実装してきました。 ただし、これらの方法は管理やメンテナンスの手間が増え、データセットとその動作について深く理解している必要があります。

最近リリースされたpgvector 0.8では、フィルタリングに影響を与える2つの重要な変更がありました。1つ目は、PostgreSQLのクエリプランナーがHNSWスキャンの所要時間をどのように見積もるかという点です。このリリース以前は、HNSWインデックスのスキャンにかかる時間を過小評価していました。先ほど見たチャートのデータは、実はより正確な見積もりを実現するための根拠となったものです。HNSWインデックススキャンに時間がかかりすぎると判断された場合は、別の種類のスキャンを行うようにしましょう。選択性が低い場合や、フィルターで行数を十分に絞り込めない場合には、HNSWインデックスを使用してポストフィルタリングを行うことが理にかなっています。ここでHNSW反復スキャンパラメータが重要になってきます - HNSWインデックスをスキャンしていて、ef_searchを超えても制限を満たせない場合、スキャンを継続します。これは要件を満たす十分な結果を返すために非常に重要です。

もう少し具体的に説明しましょう。 ここに約500万行のデータセットがあり、4つのフィルターが関係していて、それぞれ異なる選択性を持っています。これは、異なる選択性レベルでNearest Neighbor検索を実行するクエリです。10%の選択性は50万行が一致することを意味し、1%は5万行、0.1%は5,000行というように続きます。これはフィルターを実行しようとすると目にする光景かもしれません - 高選択性の場合、このクエリを実行しても十分な行数が返ってこないか、まったく行が返ってこないことがあります。これは非常に良くない体験です。
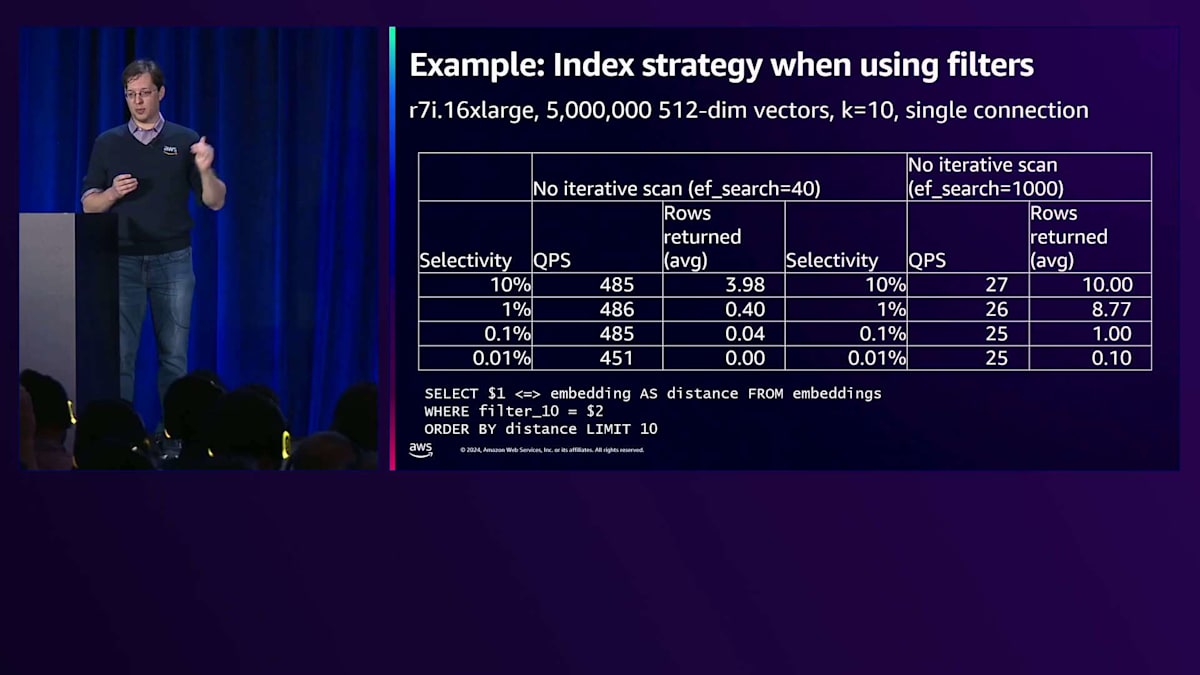

このリリースまでは、 唯一の対処法は、ef_searchを最大値である1000まで増やすことでした。しかし問題は、低選択性のケースをある程度解決できるものの、まだ十分ではないということです。過度なフィルタリングが発生する可能性があり、高選択性の場合は十分な行数が返ってこない可能性があります。さらに、パフォーマンスも非常に遅くなってしまいます。しかし、新しいツールが登場しました。 問題を解決するために継続的にスキャンを行う反復スキャン機能です。素晴らしいのは、十分な行数が返ってくるだけでなく、ef_searchを40に設定しているにもかかわらず、ef_searchを1000に設定した場合よりも優れたパフォーマンスが得られることです。

しかし、高選択性の場合、つまり十分な行数が返ってこない場合、逐次スキャンは性能が低下するだけでなく、おそらく最大タプルスキャン数である20,000タプルに達してしまうため、十分な行数を取得できません。ただし、そのフィルターに一致するベクトルは約500個程度であることを覚えておいてください。ここでB-treeの出番となります。逐次スキャン方式とB-tree方式を比較してみましょう。選択性が低い場合は逐次スキャンの方がはるかに高速になりますが、選択性が高い場合はB-treeの方が高速になります - 先ほどの例よりもずっと速い結果が得られます。
これは非常に興味深い点です。選択性が高いことがわかっている場合、B-treeを使用することで必要な結果を素早く取得できます。ただし、選択性が0.1%の場合、常に10行が返ってくるわけではありませんでした。これはおそらく、クエリプランナーがHNSWインデックスの方が適していると判断した際の特異な現象でしょう。コストに基づいてそちらを選択したということです。このように、Vector検索は進化し続けているトピックであり、今後もコスト推定の精度は向上していくことでしょう。

さて、マルチフィルターも面白いテーマです。「AがXかつBがY」というような条件は頻繁に出てきます。ここでは、2つの選択性レベルを持つマルチフィルターのテストを行いました。3つの異なる方法を試しました:まず逐次スキャン方式、次にB-treeマルチカラムインデックス、そして最後にすべてのデータをJSON列に格納する方法です。結果は興味深いものでした。まず、すべての行を取得することができました。これがリコールの上限となります - 10行が返ってくれば、リコールは最大で100%になる可能性があります。また、パフォーマンスの数値も興味深く、マルチカラムインデックスで良好なクエリパフォーマンスを得ることができました。

JSONの数値はそれほど良くありませんでしたが、JSONにフィルターを入れることについて指摘したい点があります。明確に定義されたフィルターがない場合、つまり常にAとBで検索するとは限らず、100や50など任意の数のフィルターがある可能性がある場合、PostgreSQLのJSONタイプを使用することは良い万能策となります。まだ decent なクエリパフォーマンスを得ることができますが、B-treeほど良くはないでしょう。最後に、これは二者択一の話ではありません。素晴らしいことに、これらすべてを同時に持つことができます。インデックスのメンテナンスコストがかかるため、すべてを同時に持ちたくない場合もありますが、すべてを一緒に保持することは可能です。一般的に、これらの他のインデックス方式は、HNSWと比べてはるかに小さいため、メンテナンスコストが大幅に低くなります。

最後に、フィルタリングのベストプラクティスについてお話しします。過去2年間、Vector検索を深く研究してきた経験から申し上げますが、Vectorインデックスを使う必要がない場合は、使わないでください。他のインデックスを使用してください。選択性が混在している場合は、HNSWインデックスとB-treeインデックスを組み合わせることができ、PostgreSQLがクエリを満たすのに最も適したものを賢く選択します。最後に、パーティショニングやパーシャルインデックスという従来のツールもまだ有効です。データを分割できることがわかっていて、データの選択性が高い場合は、特定のパーティションにデータを配置し、そこからさらに絞り込むのが良いかもしれません。セッションも終わりに近づいてきましたので、Vector検索に役立つAmazon Auroraの機能についてお話ししましょう。
Amazon Auroraの機能とVector検索への適用

まず、Amazon Auroraをご存じない方のために説明させていただきますと、これは MySQLとPostgreSQLとの互換性を提供する当社の商用データベースで、データベースワークロードの管理に必要なすべての機能を備えています。アプリ開発者としての経験から申し上げますと、データベースの管理について考えたくないんですよね。ただ物事を構築でき、自動的にスケールし、さまざまなセキュリティやコンプライアンスの要件を満たしてくれればいいのです。

ベクトルワークロードに特に役立つ機能がいくつかあります。1つ目は Amazon Aurora Optimized Reads で、これはローカルNVMeを階層型キャッシュとして利用できる機能です。メモリ内のデータが変更され、何らかの理由で退避された場合、そのページをストレージから再取得する代わりに、Aurora インスタンス上の階層型キャッシュに格納されます。このメリットは、そのページを再度呼び出す際、ストレージまで取りに行く必要がなく、ローカルNVMeにアクセスするだけで済むため、特に同時実行性の高いワークロードでパフォーマンス上の利点があります。



また、Auroraには、R7やRS7インスタンスを使用できる、より大きなメモリを持つインスタンス があり、より多くのベクトルデータをメモリに保持できます。これまで見てきたように、ベクトルデータ、特にインデックスベクトルデータはかなり大きくなる可能性があります。ワークロードが単一インスタンスのサイズを超える場合は、Amazon Aurora PostgreSQL Limitless Databaseを使用すると、データを複数のインスタンスに自動的にシャーディングします。また、Amazon Aurora データベース内のデータを Amazon Bedrock の埋め込みモデルに接続したり、その逆に、外部データソースからベクトルに変換して Aurora データベースに格納したりすることを簡単に行えるビルダー機能もあります。これらの機能は既に利用可能で、最後に、Amazon Aurora は PostgreSQL互換なので、多くのビルダーツールがすでに対応しています。

Optimized Reads機能をより具体的に説明しましょう。これは10億のベクトルを使用したワークロードで、意図的にメモリに収まりきらない小さなインスタンスで実行しました。Amazon Aurora標準I/Oインスタンスと、Optimized Readsを有効にしたAurora Optimized I/Oインスタンスで、同時実行性を徐々に上げていき、どちらが優れているかを検証しました。Optimized Readsインスタンスは9倍速く、特にメモリを激しく使用し、データを頻繁にメモリの出し入れする状況で効果を発揮しました。繰り返しになりますが、NVMeレイヤーがあることで、メモリから退避されたページを取得する際にネットワークを介する必要がなく、ローカルのNVMeにアクセスするだけで済むのです。


Amazon Aurora Limitless Databaseについて簡単に補足させていただきますと、書き込みが多すぎたり、1つのインスタンスに収まりきらなかったりと、システムのリソースを超えるワークロードの場合、Limitlessを使用してベクトルを複数のインスタンスに分散して保存できます。Amazon Bedrock Knowledge Bases は、このパイプラインを自動化する方法です。S3バケット内にあるドキュメントやその他のデータをRAGのために検索したい場合、Knowledge Basesに接続することで、データのパイプラインを自動的に管理し、Auroraデータベースに挿入します。そして、Amazon Bedrock Agents と連携させることで、ワークフローとアプリケーションとの連携方法を定義すれば、自動的にデータベースにクエリを実行します。このように、すべてが完全マネージド型で提供されています。
pgvectorの今後の展開と講演のまとめ


では、pgvectorの今後の展開について見ていきましょう。先ほど申し上げたように、フィルタリングが注目のトピックです。私がこのトピックについて、そして本日初めて共有されたデータについて、とても興奮していることがお分かりいただけたと思います。しかし、フィルタリングについてはまだやるべきことがあります。大きな領域の1つが事前フィルタリングです。これは、フィルタリングが必要なデータをVector indexと一緒に保存し、効率的に処理できるようにするという考え方です。この分野はまだ活発に研究が進められている段階です。有望な手法がいくつかありますが、まだ決定的なものは出ていないと考えています。pgvectorが掲げる約束の1つは、PostgreSQLと同様に、基盤となるデータ形式を変更して、コストのかかるreindex操作を強いることは避けたいということです。
さらに多くのDimensionデータタイプが登場する可能性があります。1バイトの浮動小数点Vectorと1バイトの整数Vectorの両方についてパッチがオープンになっています。これらが有用だと思われる方は、オープンイシューに意見を寄せてください。PostgreSQL 17の機能であるStreaming I/Oを使用すると、ディスクからのI/Oを文字通りストリーミングでバルク処理できます。これがpgvectorに恩恵をもたらすかどうか、特にIVFFlatメソッドでの読み取りについて初期テストを行っています。HNSWでも同様に機能する可能性がありますが、IVF flatでより大きな恩恵が得られる可能性があります。
pgvectorは、ディスクからの読み取り時にIVF flatメソッドで特に効果を発揮します。これは、多くのストリーミングブロックを読み込む必要があるためです。統計的量子化を含む追加の量子化技術が有望視されており、必要に応じてParallel queryもサポートしていく予定です。

かなり長く、内容の濃い講演でしたが、最後までお付き合いいただきありがとうございました。多くのグラフやチャートをお見せしましたが、アプリケーションに関する適切な判断を下すために必要な情報を提供できたと思います。これらの要素を全て結びつける300レベルの講演もありますが、この講演では、Postgresの観点から仕組みを深く理解することに焦点を当てました。これで皆様は、データの保存方法、インデックス作成方法、そして設計上のトレードオフに関する判断を行うための戦略を手に入れられたはずです。
結局のところ、最終的にはRecallとクエリパフォーマンスに帰結します。なぜなら、これらがユーザーに直接提供される価値だからです。ユーザーは検索の品質と応答速度を実感します。これらの目標が明確になれば、どこに投資すべきかが分かります。スキーマ設計やアプリケーション設計への投資と同様に、インフラへの投資も必要です。Amazon Auroraは、ワークロードのスケーリングと構築を簡単にするための機能を提供しています。
冒頭でお話ししたように、私は昨年も同様のプレゼンテーションを行いましたが、今回はほぼ全面的に書き直しました。スライドの一部は似ていますが、これは今日のことだけでなく、明日のことも計画する必要があるということを示しています。Vector検索はデータベース分野全体で安定性を増していますが、新しいアルゴリズムが開発されるにつれて、さらなるイノベーションが生まれるでしょう。Pre-filteringは来年にかけてとても注目される分野になると考えています。この技術は現在、本番環境のアプリケーションを構築できるほど成熟しており、本日のトークの目的は、皆様にそうした判断に必要なツールを提供することでした。本日はご参加いただき、誠にありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion