re:Invent 2024: FordがApache IcebergとAWSで実現したリアルタイム分析


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - How Ford unlocked real-time insights using Apache Iceberg on AWS (AUT311)
この動画では、Ford Motor Companyが2,000万台以上の車両を管理するConnected Vehicle Platformについて、データ分析基盤の構築事例が紹介されています。特に、Apache Icebergを活用したEvent Storeの開発と最適化に焦点が当てられ、毎秒100万メッセージという大量データの処理における課題と解決策が具体的に説明されています。AWS GlueやAmazon Athenaなどのサーバーレスサービスを組み合わせ、クエリ実行時間を1分39秒から12秒へと80%改善した事例は、Connected Vehicleプラットフォームにおけるデータ処理の実践的な知見を提供しています。また、バッチ処理からストリーミング処理への進化など、プラットフォームの継続的な改善についても言及されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Connected Vehiclesの概要とセッションの導入

re:Inventへようこそ。これは月曜日の朝一番目のセッションです。簡単なアンケートから始めましょう。スマートフォンのアプリを使って車を遠隔で始動させている方は何人いらっしゃいますか?何人かの手が挙がっているようですね。ありがとうございます。本日のセッションのテーマはConnected Vehiclesです。Connected Vehiclesは、特に冬場に車を遠隔で始動して暖機運転するなど、スマートフォンアプリから実行できるリモート操作を可能にする重要な技術です。Connected Vehiclesの時代において、顧客体験の向上と業務効率の改善のためにリアルタイムデータの洞察を活用することは、お客様にとって極めて重要となっています。
私はVijai Thoppaeと申します。自動車業界のお客様をサポートするAWSのSenior Solutions Architectです。本日は2名の講演者をお迎えしています。自動車業界を担当するSenior Analytics Solutions ArchitectのYiani Ambashta、そして今回のユースケースを主導していただいたFord Motor CompanyからSenior Software EngineerのUmamaheshwara Gupta Karnatiです。本日は、FordがAWS上のApache Icebergを使用してリアルタイムの洞察を実現した方法についてお話しします。このセッションでは、FordのConnected Vehicle PlatformにおけるEvent Storeという重要なサービスについて詳しく見ていきます。

本日は盛りだくさんの内容をご用意しています。まずはConnected Vehiclesの概要から始め、その後AWS上でApache Icebergを使用してどのように最新化を図ることができるかについてお話しします。さらに、FordのConnected Vehicle Platformについて深く掘り下げ、FordがApache Icebergを活用して課題を克服し、Event Storeサービスを構築・拡張した方法について最適化の観点から説明していきます。
AWS上のConnected Vehiclesプラットフォームとデータの重要性

では、AWS上のConnected Vehiclesについて簡単な概要から始めましょう。AWSのインフラストラクチャを使用すると、革新的なモビリティ機能やアプリケーションを構築し、クラウドとエッジの両方でグローバルな規模で実行できる形で、車両の接続とセキュリティを容易に確保することができます。左上には、安全でスケーラブルな自動車向けクラウドインフラストラクチャが示されています。車両がインターネットやさまざまなデジタルエコシステムに接続されるようになるにつれ、自動車メーカーがドライバーや乗客に合わせた没入感のあるユーザー体験を創出する機会が生まれています。
中央に示されているのは車両で、これは自動車、トラック、バス、ボートなどが該当します。内蔵モデムを搭載したConnected Vehiclesは、クラウドへの接続を可能にし、IoT SDK、各種機能、データベース、セキュリティ、エッジでの機械学習といったIoTエッジコンピューティングの構成要素を活用して豊富な機能を提供します。IoTフレームワークは、初期アクティベーション、証明書管理、ローテーション、プロビジョニングポリシーなど、IoTデバイスのライフサイクル管理を、より制御された方法で実現します。
右下のビジネスレイヤーは、本日のトピックの中心となるConnected Vehicle Data Lakeです。ここでは、すべてのテレメトリーデータが保存され、お客様向けの様々な機能やアプリケーションを実現するために処理されています。主な目的は、自動車メーカーグループ全体の組織が、Connected Vehicleから収集される膨大なデータから意味のある洞察を得られるようにすることです。これにより、カスタマーエクスペリエンスの向上、業務効率の改善、そして意思決定の向上につながります。APIセットを公開することで、消費者向けのリモート機能や、フリート、充電プロバイダー、ビジネスインテリジェンスダッシュボードとのサードパーティ連携を可能にします。さらに、Machine LearningやAnalyticsを活用した新しいユースケースも実現できます。

では、Connected Vehicleのユースケースについて詳しく見ていきましょう。Predictive Maintenanceでは、車両の稼働時間を向上させ、メンテナンスコストを削減し、お客様満足度を高めることを目指しています。次のProactive Maintenanceは、パーソナライズされたデータ駆動型のサービス推奨を提供することで、全体的なカスタマーエクスペリエンス、車両の信頼性を向上させ、ディーラーのメンテナンス業務を最適化します。3つ目のカテゴリーは車両の健康状態で、これは車両のアップデートを確認する上で重要です。ディーラーへの顧客の来店回数を減らし、OEMの全体的なコスト削減にもつながります。
次は車両イベントの観測性です。ここでは、運転パターン、特に急ブレーキ、オイル寿命、速度など、ドライバーがどのように車両を運転しているかを追跡します。これにより、異常検知とドライバーへのタイムリーな通知が可能となり、運転習慣や車両寿命の改善につながります。イベント発生時には、ドライバーに通知を行い、収集されたデータは、イベント中および事後処理の両方で役立ちます。特に、インシデント発生時の状況を理解するのに役立ち、これらのデータは問題解決に貢献します。

Connected Vehicleにとって、データは極めて重要です。 この図に示されているように、車両がクラウドに接続され、データに素早くアクセスするために重要な4つのコンポーネントがあります。私たちは、プラットフォームのコストを管理し、新しいユースケースに対して最適化され、対応できることを確認したいと考えています。データは継続的にループで流れており、これら4つのカテゴリーは常にチェックされ、新しいユースケースを実現し、ドライバーエクスペリエンスを最適化することを確実にしています。

Connected Vehicleのデータは、データ量の面で課題があります。Connected Vehicleが増えるにつれて、データ量は複雑さとともに増加します。リモート機能やリモート機能の有効化など、特にリアルタイムまたはそれに近いデータ消費が必要なユースケースがあります。Data Lakeのスケーラビリティは重要なカテゴリーで、車両のクラウド接続が増加するにつれてスケールする必要があります。高いデータ量と同時実行性に対応しながら、そのデータ量によってエンドユーザーに影響を与えないようにする必要があります。
Apache Icebergによるデータレイクの近代化
それでは、Yianiに引き継ぎたいと思います。Connected Vehicleのユースケースとそれを扱うデータプラットフォームの必要性について、洞察に富んだ概要説明をありがとうございました。皆様、おはようございます。Redman 2024の月曜日朝一番のセッションへようこそ。私はYiani Ambashta、AWSのAnalyticサービスでAnalytics Specialist SAとして働いています。業界での15年以上の経験があり、多くの企業のデータ戦略構築やデータ・アナリティクスプラットフォームの近代化についてコンサルティングを行ってきました。AWSでの私の役割は、大手自動車メーカーやOEMと協力し、これらのお客様がData Lake側で直面する課題に取り組むことです。


本日は、AWSがこれらの課題をどのように解決しているか、特にData Lakeをトランザクショナルなデータレイクへと近代化することについてお話しできることを嬉しく思います。ここで右下に示されているConnected Vehicle向けのData Lakeに焦点を当てていきます。実際の成功事例をご紹介する前に、3つのポイントについて簡単にお話しします。まず、オープンテーブルフォーマットによるモダンData Lakeの進化について。次に、Apache Icebergの進化とトレンドについて。そして最後に、Connected Vehicleプラットフォームにもたらすメリットについてです。 Data LakeとモダンData Lakeについて話す際、私の業界での経験を通じて...

トランザクショナルなリレーショナルデータベースからData Warehouse、そしてData Lake、さらにトランザクショナルData Lakeへと進化していく過程を目の当たりにしてきました。オープンテーブルフォーマットを備えたトランザクショナルData Lakeが、現在私たちが取り組んでいる最新のトレンドです。従来のData Lakeの観点からは、シンプルなメンテナンス、トランザクションによるデータセキュリティ、複雑なクエリのサポートが必要でした。一方で、ビッグデータアナリティクスとオープンデータエコシステムについても耳にしてきました。これらのオープンテーブルフォーマットによって、従来のData Lakeのベストプラクティスとオープンな世界のテーブルエコシステムを組み合わせた両方の利点を得ることが可能になっています。

主に3つのオープンテーブルフォーマットがあり、多くの方々がすでにご存知かもしれません:Apache Hoodie、Apache Iceberg、そしてDelta Lakeです。これらのテーブルフォーマットが注目を集めているのは、従来のフォーマットとは異なり、Data Lakeにコスト効率の高いスケーラブルなソリューションを提供する優位性があるためです。AWSでは、この3つのテーブルフォーマットすべてをサポートしており、お客様のユースケースに合わせて選択していただけます。 AWSではこれら3つのテーブルフォーマットをサポートしていますが、特にApache Icebergは、わずか1年の間にエンドユーザーが約81%増加するなど、広く採用が進んでいます。
NetflixやAirbnb、Adobeといった大手企業はすでにApache Icebergを活用して、大規模なビッグデータアナリティクスの近代化と構築を行っています。Apache Icebergには幅広いオープンエコシステムがあり、多くのクラウドプロバイダーやベンダーが、トランザクショナルデータの観点から積極的にサポート、貢献、機能強化を行っています。AWSでは、Snowflake、Databricks、Clouderaなどのパートナーと共に貢献を続けています。AWSで見られる高い需要と関心から、私たちはApache Icebergを戦略的なオープンテーブルフォーマットとして位置づけています。

私たちのこのポジショニングは、日々お客様やパートナーと協力しながら、データの各部分との相互作用やパフォーマンスを評価し続けることに基づいています。私たちのサービス提供は、お客様のニーズとパートナーの要件に合わせて調整されています。Apache Icebergは単なるオープンコミュニティのソリューションを超えて、その使いやすさ、パフォーマンス、スケーラビリティが認められ、お客様のData Lakeやモダナイゼーションのニーズに応える魅力的な選択肢となっています。 コネクテッドビークルデータにおける主要なメリットの1つが、ACID準拠であることです。トランザクショナルデータベースシステムの経験がある方なら、データ操作においてACID準拠がいかに重要か、つまりデータの原子性、一貫性、耐久性、分離性を確保することの重要性をご存じでしょう。これこそがApache Icebergがデータレークの世界にもたらしているもの、つまりトランザクショナルなData Lakeの世界の実現です。
では、これがコネクテッドビークルにとってなぜ重要なのでしょうか?例を挙げて説明させていただきます。自動車関連のお客様が、数百万台の車両からペタバイト規模のデータを収集するプラットフォームを持っており、テレメトリーデータをシステムに挿入または更新する必要がある場合を考えてみましょう。システム障害やネットワーク障害が発生した場合、プラットフォームの所有者として、部分的な書き込みによる破損データがないよう、Data Lakeが一貫した状態を保つことを確保する必要があります。誤検知や見逃しの入力が車両安全システムに影響を与える場合、それがもたらすリスクの規模を考えてみてください。
ここでApache Icebergが提供する信頼性と一貫性が重要になります。データがシステムに書き込まれる際、完全に完了するか、まったく更新されないかのどちらかになります。2つ目のメリットは、スキーマの強制とスキーマ進化です。時間の経過とともにデータ構造が変化する場合、これらのスキーマ変更に対応できるプラットフォームが必要です。例えば、Connected Vehicle Platformで新しいテレメトリーデータや機能を追加する必要がある場合、データ構造が変更される可能性があります。既存のデータセットを中断することなく、これらのスキーマ変更に対応できるプラットフォームが必要です。これがまさにIcebergが提供する機能です。
スケーラビリティとパフォーマンスに関して、お客様が1日あたり1~2テラバイトのデータを取り込む必要があり、100万台の車両が平均10時間のデータを生成する企業の場合を考えてみましょう。2つの点を確保する必要があります:日々のテラバイト規模のデータ書き込みを効率的に処理すること、そしてペタバイト規模のレコメンデーションを扱う際の適切な読み取り能力です。Icebergは、ペタバイト規模のデータをサポートするスケーラビリティと、下流のユーザーに影響を与えることなく日々のスパイクを処理する書き込みスケールの両方を提供します。
最後のメリットは、Icebergがエンジンに依存しないことです。つまり、お好みの計算エンジンを使用できます。オープンソースの特性により、Spark、Trino、Presto、その他多くのオープンソースツールからIcebergテーブルにクエリを実行できます。ここで、これらの理論的な基本概念から実際の事例に話を移したいと思います。私たちの最大の自動車関連のお客様であるFord Motor Companyから、Umamaheshwara Gupta Karnatiさんをお招きしています。Apache Icebergを採用してData Lakeをどのように刷新したかについてお話しいただきます。それでは、Umaさん、お願いいたします。
FordのEvent Store:Apache Icebergを活用した実践例

オープンテーブルフォーマットとIcebergの利点について、詳しくご説明いただきありがとうございます。皆様、おはようございます。本日は、私たちの可観測性ニーズに対応するデータレークソリューションであるEvent Storeの構築における学びと journey についてお話しできることを大変嬉しく思います。 まず、Connected Vehicle Platformの概要を簡単にご説明させていただきます。このプラットフォームは、車両とクラウドの間の双方向通信を可能にします。双方向とは、車からクラウドへ、そしてクラウドから車へとデータをやり取りできることを意味します。現在、このプラットフォームは世界中で2,000万台以上の車両を管理しています。
このプラットフォームの機能について、実例を挙げてご説明します。タイヤ空気圧、オイル量、燃料レベル、走行距離計の読み取りなどのテレメトリー信号の取り込みといった重要な機能を提供しています。また、最新技術を搭載した車両を維持するためのOTAソフトウェアアップデートの配信においても重要な役割を果たしています。さらに、リモートでの施錠、解錠、エンジン始動、停止といったリモート機能も提供しています。冬季と夏季には、リモート始動の要求が大量に発生します。理由は単純で、冬は車内を暖めておきたいし、夏は乗車前により快適な環境にするために冷房を効かせておきたいからです。

では、Event Storeとは何でしょうか?Event Storeは、先ほど説明したプラットフォームのための分析ソリューションです。テレメトリー、リモート機能フロー(社内ではCommandsと呼んでいます)、接続フローなど、さまざまなワークフローから生成されるイベントを収集・分析します。このプラットフォームは、主にAWS GlueとAmazon Athenaを活用したApache Icebergを使用して構築されています。GlueとAthenaはどちらもサーバーレスという特性により、データ処理用のSparkクラスターやクエリ実行用のインフラストラクチャーの構築が不要になりました。Grafanaベースの可視化ツールを備えており、ユーザーはプラットフォームが収集したデータをクエリして、監視や重要なKPIメトリクスの追跡に利用できます。異なるデータセットを扱うための統合プラットフォームとして機能し、すべてのデータを一元的に表示できます。


それでは、Event Store構築のjourneyについてお話しします。開始当初、スコープは非常に限定的で、主にデータの鮮度要件が中程度のhigh cardinalityデータという特定のケースに焦点を当てていました。誰もがそうであるように、私たちの課題はコスト効率の良いソリューションを作ることでした。AWSのテクノロジーを活用することで、迅速にソリューションを開発し、本番環境へ移行することができました。これは大きな成功を収め、収集される情報の莫大な価値を誰もが認識するようになりました。自然な流れとして、他のワークフロー(リモート機能ワークフロー、テレメトリーワークフロー、接続ワークフロー)のオンボーディング要請を受けるようになりました。短期間のうちに、プラットフォームには多数のデータパイプラインがオンボードされ、各パイプラインは特定の種類のデータを取り込んでいました。すぐに、予想を大きく上回る処理量に直面し、スケーラビリティの課題が浮上しました。

スケーラビリティの課題の詳細に入る前に、開始時にどのように構築したかについて、アーキテクチャの概要を簡単にご説明させていただきます。これが私たちの初期アーキテクチャで、大きく分けてデータ取り込みコンポーネント、データ処理コンポーネント、分析コンポーネントという3つのコンポーネントで構成されています。
データの取り込みについて説明します。データプロデューサーは、私たちのConnectivity Cloudプラットフォームを構成するマイクロサービスです。これらがイベントを生成し、私たちが開発したData Lake Sinkサービスがデータプロデューサーから生成されたデータを読み取り、Amazon S3に同期します。このサービスはJavaで書かれており、Apache Kafka Connectフレームワークを使用して実装されています。このサービスは5分ごとにすべてのプロデューサーからのデータをS3にフラッシュします。これが、Raw Zoneと呼んでいるデータ取り込み層の仕組みです。これまでに、このRaw Zoneには約2ペタバイトのデータが蓄積されています。
2番目のコンポーネントは処理層です。データを取り込んだ後は、それを処理してより検索しやすい形式に変換する必要があります。それが処理層の役割です。ここでは、Pythonで書かれた複数のAWS Glueジョブがデータを読み取り、必要な変換を適用し、機密データを削除し、すべての処理ロジックを実行して、AWS Glue Data Catalogで管理されるHiveテーブル形式でデータを保存します。テーブルは内部的にS3をストレージとして使用しており、これをClean Zoneと呼んでいます。

分析部分では、システムに保存されたデータをクエリできるAWS Glue Data Catalogに接続するAmazon Athenaを使用しています。一般的な可視化ニーズにはGrafanaを使用しています。Athenaをプラグインで統合したので、ユーザーはGrafanaを使って保存されたデータをクエリすることもできます。先ほど述べたように、私たちは最小限のスコープでプロジェクトを開始し、その後多くのパイプラインをオンボードしました。時間とともにプラットフォームは大きく成長し、これらの要因によってデータ量は非常に大きくなりました。例えば、あるフローでは1秒あたり約100万のメッセージを受信していました。

プラットフォームがこのような大量のデータを受信し始めると、スケーラビリティの問題が発生し始めました。これらの影響を4つのグループに分類しました。まず、Clean ZoneのAWS Glueジョブの処理時間が長くなりました。次に、データ処理の遅延が発生しました。3番目に、ユーザーがクエリを実行する際のパフォーマンスが低下し、処理時間が長くなったり、S3のレート制限による例外で失敗したりするようになりました。4番目に、プラットフォーム全体の管理におけるストレージとコンピューティングのコストが増加しました。また、後で説明するデータエージングの問題も発生し始めました。



では、最適化の過程を見ていきましょう。私たちはこれらの問題を解決する道を進みました。最初の3つの問題を見ると、Clean Zoneに関連する問題が多いことがわかります。そこで、2段階のアプローチを考えました。第1段階では、アーキテクチャを変更せずにClean Zoneの問題を解決するため、既存のジョブの最適化とApache Icebergの採用を行いました。第2段階では、ストリーム処理を採用し、すべてのバッチジョブをEMRインフラストラクチャを使用したストリーム処理に変換することで、プラットフォームをさらに強化しました。
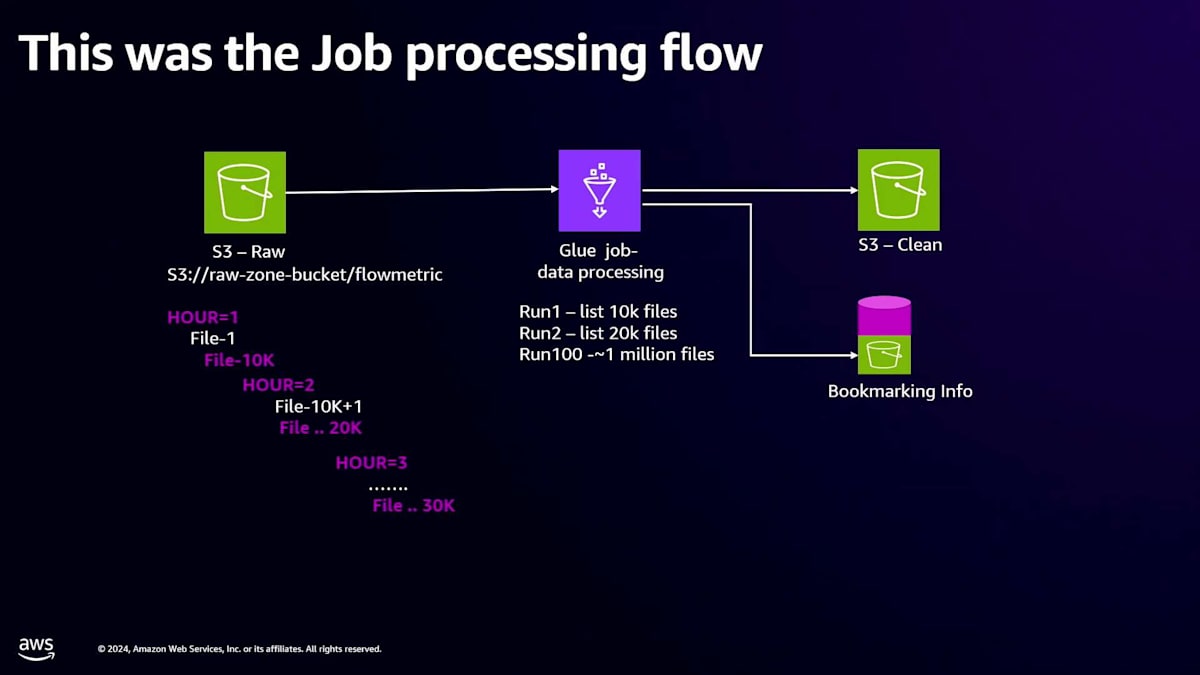
最適化の過程について振り返ってみたいと思います。私たちはPythonで書かれたジョブを使って、データを読み取りClean Zoneに書き込んでいます。主な問題として、ファイルのリスト処理でプラットフォームにオーバーヘッドが発生していました。より詳しく説明するために、ジョブの流れについて詳しく見ていきましょう。例えば、Raw ZoneにFlow Metricsというディレクトリにデータがあるとします。1時間ごとにデータが入ってきて、1時間目にそれを処理するジョブがスケジュールされています。データ処理の仕組みを説明させてください。
1時間ごとにスケジュールされたジョブが実行されます。最初の実行では、1時間目のファイル(例えば10,000個)を処理し、Clean Zoneにデータを書き込みます。次回の実行で同じデータを再処理しないように、Bookmarkingを使って処理済みのデータを追跡します。しばらくして2時間目には、さらに10,000個のファイルが追加されます。2回目の実行時には、ジョブは20,000個のファイルをリストアップし、Bookmarking情報を使って最初の10,000個をスキップし、新しいデータセットのみを処理します。
1週間や1ヶ月後、つまり100回目の実行時には、データが継続的に追加されるため100万個のファイルが蓄積されているとします。ジョブがこれらを処理しようとする際、まず100万個のファイルをリストアップする必要があり、処理すべき新しいデータを特定する前から、当然ながら多くの時間がかかります。これが全体の処理時間における主なボトルネックであることがわかりました。このため、このロジックを処理するDriverでメモリ不足エラーが発生することもありました。

このメモリ不足エラーをどのように解決できるでしょうか?解決策はシンプルです - すべてのファイルを一度にロードしてリストアップするのではなく、Lazy Loadingのようにバッチ単位でリストアップする必要があります。AWS Glueでは、これは非常に簡単です。Glueを使用する場合、useS3ListImplementationをtrueに設定するだけです。これを行うと、Glueが自動的にすべてを一度にロードする代わりにLazy Loadingを使用するようになります。また、処理の過程で、カスタムUDFにパフォーマンスのボトルネックがあることも発見したため、より良いパフォーマンスを得るためにSpark Native関数に置き換えました。さらに、データをソースディレクトリに保持する代わりにバックアップファイルに移動することで、GlueジョブのS3ファイルリスティングのボトルネックを軽減できることもわかりました。これらの最適化により、遅延データ処理時間という最初の問題を解決することができました。

次に、私たちが直面していた2つ目の問題、クエリのパフォーマンス低下について説明しましょう。詳細に入る前に、クエリのパターンがどのように機能するかを理解しましょう。仮想的な例を挙げてみます。Clean Zoneにはデータ処理プログラムによって書き込まれたデータがあり、テーブルは年、月、日、時間、Flow名で分割されています。データはS3フォルダ内で、時間レベルとFlow名レベルまでのディレクトリ構造で整理されています。ユーザーがAmazon Athenaを使用してカウントを検索するクエリを実行すると、AWS Glue Data Catalogに接続し、パーティション情報を特定してファイルの場所を特定し、S3からそれらのファイルを取得して、必要な計算を実行し、結果を返します。
Hour 0とHour 1のクエリを実行すると、それらのS3フォルダーからデータを取得します。これは少量のデータでは問題なく機能します。しかし、私たちの毎秒100万メッセージのフローの例では、1時間あたり約100個のファイルがありました。Athenaがそれらのファイルをリストアップし、特定して読み込もうとすると、すぐにS3のレート制限の問題に直面しました。読み込める量には常に制限があります - Athenaはアドホッククエリ向けのため、2〜3分という短時間で10万個のファイルを読み込むことはできません。小さなファイルの問題は、データエンジニアリングの世界では非常によくある課題です。解決策はシンプルで、より効率的な方法でコンパクトにまとめる必要があります。この方法により、小さなファイルでは非常にコストが高くなる問題を解決し、レート制限の問題も解決できます。これが私たちが直面していたレート制限の問題でした。
そういった2つの課題に取り組んでいた中で、現在のHiveテーブル形式のモデルでは、カラム名の変更が常に問題になることもわかりました。カラム名を変更する場合、すべてのデータを再処理する必要があります。他にも同様のケースがいくつかあり、調査を進めた結果、これらの問題はすべて使用していたフォーマットに関連していることがわかりました。スケールとフォーマットが私たちの求めるレベルでうまく機能していなかったため、それがApache Icebergを見つけるきっかけとなりました。


私たちはIcebergが前進への道だと判断しました。アーキテクチャは何も変更せず、最初はHiveテーブル形式を使用していたものを、Iceberg形式に変更しただけです。移行は簡単でした。 当初、ユーザーは直接テーブルにアクセスしていました。直接のテーブルアクセスの代わりに、既存のテーブルにViewを作成し、ユーザーにはルートテーブルへの参照としてViewを使用するよう依頼しました。Iceberg形式でテーブルを作成し、新しいデータを新しいテーブルに書き込むようにジョブを更新し、Viewを更新してレガシーテーブルとIceberg形式の新しいテーブルの両方を参照するようにしました。これにより、ダウンタイムなしで移行を実現できました。

Icebergはテーブルのコンパクション機能も提供しています。このテーブルコンパクション機能を使用することで、いくつかのIceberg関数を呼び出すだけで、小さなファイルを適切なサイズに自動的にコンパクトにまとめることができました。最初は特別なジョブを実行していましたが、最近AWSがこれをサービス機能として実装しました。AWS Glueで設定を適用するだけで、Icebergテーブルのコンパクションを実行する独自のカスタムジョブを維持することなく、テーブルコンパクションを処理してくれます。これも私たちにとって良い追加機能でした。

これらの変更により、大きな成果を得ることができました。Hive形式でのクエリに関する最初のスライドを見ると、クエリの実行に1分39秒かかっていました。同じテーブルをIcebergに移行した後、約12秒になりました - これはほぼ80%の改善です。Hiveテーブルのビューをより詳しく見てみると、ファイルの特定に苦労していたため、プランニング側に問題がありました。Icebergでは、パーティションカラムに基づいて関連ファイルを素早く見つけるために独自のメタデータレイヤーを使用するため、より簡単です。これが、クエリ実行の経験を改善し、計算コストも削減できた大きな違いでした。

これらすべての改善により、私たちは以下のような成果を達成しました。アーキテクチャは基本的に同じままですが、主な変更点はIcebergへの適応です。このソリューションにより、最初の3つの問題を解決することができました:ジョブ処理時間の改善、クエリの問題の解決、そしてこれら2つの問題に対処することで、以前と比べてコストも削減できました。これら3つのレイヤーでは、各ステージが約5分かかるため、Event Store内のデータを処理するには、処理時間に加えて最低10分かかります。

これが私たちの現在までの journey であり、今後さらに改善できることを検討しています。 次のステージでは、ストリーミング処理フレームワークを採用することで、このプラットフォームをより良くできないか検討しています。私たちのお客様の一つである Production Engineering チームは、特にインシデントのトラブルシューティングや影響分析を行う際に、このデータに大きく依存しています。彼らは特定の障害によって何台の車両が影響を受けたかを知る必要があり、そのためにGrafanaを使用してデータベースにクエリを実行しています。問題は、そのような状況で10分も待てないということです。これらのユーザーに対しては、バッチ処理が最適なソリューションではないかもしれないと判断し、ストリーミングとバッチ処理の両方をサポートできるソリューションの提供に取り組んでいます。ストリーミングはよりリアルタイムなユースケース向けです。これが、EMR サーバー上で Spark ジョブを実行する Clean Zone で現在進めている作業です。
Clean Zoneでは、データプロデューサーからデータを読み取り、Apache Icebergに直接書き込みます。データプロデューサーが生成したトピックから直接データを読み取り、Icebergに書き込むため、遅延はありません。これにより、できるだけ早くデータを利用可能にしています。また、同じストリーミングアプローチを使用して、バックアップ用の他のジョブも実行しており、生データをバックアップ用のS3ストレージに書き込んでいます。これにより、将来の処理や開発のためにこのデータを使用することができます。このようにして、ストリーミングを活用することですべての課題に対処し、機能を改善することができました。
AWSエコシステムとApache Icebergの統合がもたらす可能性

Umarの印象的な成功事例をご紹介いただき、ありがとうございます。 Umarが共有してくれた実際の経験から分かるように、Apache Icebergを採用することの影響は、単にシンプルでオープンなテーブルフォーマットを持つということだけではありません。バッチワークロード、ストリーミングワークロード、そしてスケールでのデータ処理のために、トランザクショナルデータレイクをどのように最新化できるかを示しています。最後に、AWS分析サービスとApache Icebergを組み合わせることの変革的な力を強調したいと思います。左側には、Icebergが提供するトレンドのユースケースと機能の一部が表示されています。小さなファイルの問題とそれをCompactionがどのように解決するかなど、その一部はUmarの事例でも紹介されました。さらに、構造化データだけでなく半構造化データの処理とストレージ管理も扱うことができ、マルチエンジンのサポートも提供しています。
Apache Icebergを真に特別なものにしているのは、右側に示されているAWSエコシステムサービスからの包括的なサポートです。ビッグデータ処理と分析ワークロード向けのAmazon EMR、ETLワークロード構築のためのAWS Glue、そしてFordの事例でも触れられたSQL クエリ用のAmazon Athenaがあります。ML側では、SageMakerなどの機械学習サービスからIcebergに直接アクセスする進化が見られています。分析とウェアハウジングのワークロードには、Amazon Redshiftがあります。これらすべてのサービスは、トランザクショナルデータレイク内のテーブルをクエリするためのSQLの簡便さとともに、Apache Icebergをシームレスにサポートしています。

最近、私たちはこのファミリーに Amazon Data Firehose を追加し、Iceberg を使用したリアルタイムのストリーミングワークロードをトランザクショナルデータレイクにスムーズに取り込めるようにしました。これらすべての統合の中心には AWS Glue Catalog があり、統一されたカタログを持ちながら、これらのサービスすべての相互運用を可能にする統合メタデータリポジトリとして機能しています。圧縮などの Iceberg の最適化については、Glue Catalog を通じてこれらのオプションを有効にしています。そしてこれらすべての基盤として、トランザクショナルデータレイク向けの Iceberg を保存する Amazon S3 があり、コスト効率の高いスケーラブルなソリューションを提供しています。以上でセッションを終了させていただきますが、月曜の朝をこのセッションに参加していただいた皆様に感謝申し上げます。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion