re:Invent 2024: AWSが語るデータ保護 - 文化と技術の融合
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Better together: Protecting data through culture and technology (SEC302)
この動画では、データ保護の意味とAWSにおける実現メカニズムについて、AWS Principal Solutions ArchitectのPeter O'DonnellとRam Ramaniが解説しています。セキュリティは文化と人材が基盤であり、全員の責任として取り組む必要性を強調しています。AWS KMS、CloudWatch、CloudTrail、Amazon SNSなどの具体的なサービスを活用したデータ保護の実践方法や、Post-quantum暗号化への対応、そしてGenerative AIアプリケーションにおけるデータ保護の課題とAmazon Bedrock Guardrailsなどの解決策について、実践的な知見を交えながら包括的に説明しています。特に、Generative AIにおけるFine-tuningデータの取り扱いやRAGプロセスでの認可の重要性など、最新のトピックにも深く言及しています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
データ保護の重要性とAWSのセキュリティカルチャー


おはようございます。本日は、データ保護の意味と、それを実現するためのAWSにおける様々なメカニズムについて、皆さんがまだ知らないかもしれないものも含めてお話しします。 そして、皆さんや同僚、リーダーの方々がまだ詳しくないからこそ、さらなる可能性があるのです。この講演の本質は、AWSで実現できることの範囲をお伝えすると同時に、私たちの実践や顧客から得た知見を共有することにあります。


セキュリティプログラムで最も重要なのは人材です。しかも単なる人材だけでなく、互いに対して、そして自分自身に対して持つべき規範と期待される行動の集合体なのです。私はPeter M. O'Donnellと申します。 Principal Solutions Architectとして9年半勤務しており、今朝のステージに登壇したような exciting な企業を含む、最大級で最も挑戦的なお客様との仕事に携わる機会に恵まれてきました。このカルチャーという概念は理解が難しい場合があります。私が提唱したいのは、カルチャーの目的は再交渉を不要にすることだということです。最初に聞くと少し変に聞こえるかもしれませんが、これは、もはや議論の余地のない基準や期待される規範、行動があるということを意味します。それらを広めるための対話は必要ですが、もはやその内容自体は議論の対象ではないのです。
AWSにおけるセキュリティの全員責任と厳密さの重要性

西洋の地下鉄では階段の右側を下りますが、東京の素晴らしい地下鉄システムでは左側を下ります。それは単にそうするものだからです。もはや議論や調整の対象ではなく、守るべき行動規範なのです。AWSでは、 そして皆さんの組織でも育んでいただきたいのですが、セキュリティは文字通り全員の責任です。確かに私たちにはAWS Securityという高度な組織がありますが、セキュリティはエンジニアリング、製品定義、サポート運用から始まります。私は若い頃にテクニカルサポートをしていた経験がありますが、サポートは特別なレベルのアクセス権を持つことがあります。しかし、セキュリティは全員の責任であり、スタックのすべての層に組み込む必要があるのです。

何が問題になり得るか、そしてそれに対してどう対処するかを考える必要があります。 私たちはこれを「リゴー(厳密さ)」と呼んでいます。今日お話しする技術的な機能を探求し、厳密に適用し、理解し、管理目標に合わせ、適切に設定し、そして時間をかけて観察して、すべてが正常に機能していることを確認する必要があります。予防的コントロールと発見的コントロールについて議論したことがある方もいるでしょうが、残念ながら予防的コントロールが機能していることを確認するためには、発見的コントロールも構築する必要があります。


今日ここでお話しする内容を進めていく中で、理解していただきたいのは、善意は機能しませんが、メカニズムは機能するということです。 コントロールを実装し、設定を正しく安全に保ち、時間とともにそれを維持するためのメカニズムをより多く構築することで、本当に質の高い成果を得ることができます。しかし、すべては人から始まると申し上げました。Amazonには Security Guardiansというプログラムがあります。これは本質的に、AppSec(私たちが予防的セキュリティと呼ぶもの)をどのようにスケールアウトするか、つまり全員をセキュリティ担当者にするにはどうすればよいかということです。「トレーナーを育成する」という考え方や、パワーユーザーを最初に育成して広めていくという方法をご存知かと思いますが、セキュリティも同じように機能し、これが私たちのやり方です。私たちのやり方がすべてのお客様に適しているわけではありませんし、もちろん皆さん独自の判断ができますが、このモデルを採用し試みたお客様からは

構築する理由は、非常にうまく機能するということです - 担当者を任命し、組織全体、特にエンジニアリングとプロダクト組織全体でセキュリティを確保することができます。私は多くのCSOと話をしてきましたが、彼らが抱えている問題は、実際にはエンジニアリングチームやプロダクトチームに属する問題だと説明しています。それらのチームとCEOは、セキュリティが最優先事項であると信じなければなりません。一度この流れが生まれると、期待される利点は計り知れません。より安全になるという文脈での利点だけでなく、社内外のステークホルダーにとっても有益です。Sarbanes-Oxley法の要件、取締役会や上場企業としての義務、規制上の課題などがある場合、どのような外部の監督者であっても、セキュリティ担当者やコンプライアンス担当者と同じことを求めています。

私たちは、製品やテクノロジーだけでなく、開発チームにもセキュリティを組み込むことを推奨しています。継続的なコンプライアンスを実現する方向に進むことができます。SREが必要とするもの - 優れた可観測性、適切なログ、再現性、Infrastructure as Code - を考えてみると、コンプライアンス担当者も全く同じものを求めています。監査担当者も同じです。セキュリティ担当者をビルダーチームに組み込むのと同じように、監査担当者をセキュリティチームやエンジニアリングチームに組み込むべきです。敵対的な関係であってはならず、私は両方の立場を経験してきましたが、よくそうなってしまうことは理解しています。

セキュリティ担当者と同様に、早期に彼らを参加させることができれば、同僚とより生産的で、文字通り健全で、心理的に安全で、より良い会話ができるようになります。なぜなら、皆が本当に同じことを望んでいるからです。コンプライアンスとエンジニアリングチームについて考える際は、早期に参加させてください。私たちは、重要なコンプライアンス目標を達成するための多くの技術的な機能と可能性を提供しています。エンジニアリングマネージャー、セキュリティエンジニア、ソフトウェアエンジニア、またはコンプライアンス担当者であっても - おそらく皆さんの約80%がこれに該当すると思いますが - これらは重要な目標です。しかし繰り返しになりますが、他のすべてのエンジニアリングやセキュリティ作業と同じ方法でこれらを達成することができます。
AWSのデータ保護メカニズムと暗号化の進化


データを保護するさまざまな側面について話しましょう。文化が基盤だとすれば、他に何が残っているでしょうか?これらについて手短に見ていきましょう。ここには多くの要素があり、これらのトピックのほぼすべてについて、個別の詳細な講演が用意されています。これらは古典的な側面であり、私たちはこれらの目標を達成するための多くの優れた製品とサービスを提供しています。また、データを保護するには長い道のりが必要であることも知っています - はい、最終的な保存場所でデータを保護する必要があります。しかし繰り返しになりますが、セキュリティが全員の責任であるということは、インフラストラクチャのさまざまな役割にわたって、文字通り全員の責任であることを意味します。

ネットワークチームには果たすべき役割があり、メッセージングバスやキューシステムを管理する人々にも果たすべき役割があります。なぜなら、ここには長いライフサイクルがあり、あらゆる段階でデータを保護する必要があるからです。信じられないほどの価値を得られる古典的な見落とされがちな方法の1つは、データにアクセスできるのは、自社のインフラストラクチャ内から、自社の認証情報を使用する自社の従業員のみであることを確実にすることです - つまり、自社のインフラストラクチャ外からの認証情報でのアクセスや、他者の認証情報による自社のインフラストラクチャ外からのアクセス、他者の認証情報による自社のインフラストラクチャ内からのアクセスを防ぐということです。悪意のある人物は、自分の認証情報を持って皆さんの家にやってくるのです。

私たちは、Data Perimeterと呼ばれるこの考え方について、いくつかの重要なコントロールを用いて検討することをお勧めしています。これは文化的な厳格さの話であり、一つのことだけでは不十分で、複数の対策を講じる必要があります。そうすることで、悪意のある意図や事故によって一つが失敗しても、単一のコントロールに依存することがなくなります。以前は文字通り境界防御でしたが、これを長年Defense in Depthと呼んできました。しかし、これは異なる領域でコントロールを適用し、質の高い成果を得るためのDefense in Depthでもあります。

アイデンティティについて考え、接続先のリソースについて考え、そしてネットワークについて考えることで、私たちは包括的なポートフォリオ全体にわたって強力な機能を提供します。これらすべてについての詳細な解説が用意されています。最近、Resource Control Policiesと呼ばれる新しいタイプのポリシーコントロールを発表しましたが、これはデータ保護の成果にさらなる安全性を追加する方法の一つです。

このData Perimeterの考え方により、リソースに対してポリシーを適用し、適切な方法でのみアクセスされることを確実にする、質の高い成果を達成できます。ここで見ていただいているのは、アクセスが自分のAWS Principal Organization IDに属する認証情報、つまり自分のAWSユニバースから発行された認証情報からのみ可能であるということです。これにより、攻撃者や熱心すぎる開発者が自分の個人的な認証情報を持ち込んで、インフラストラクチャ内で使用しようとすることを防ぐことができます。



同じ考え方がネットワークにも適用され、エンドポイントの使用は、それが自分のものである場合にのみ、これらの認証情報が自分のものである場合にのみ許可されます。リソースに関する別の例を挙げると:このキューにメッセージを入れることができますが、それが実際に自分のキューである場合に限ります - あらゆる面で二重三重の安全対策を施しています。そしてカフェにいる誰かが直接あなたのバケットにアクセスすることを防ぎたいと考えています。S3バケットはデフォルトでロックダウンされていますが、チームがそれらのポリシーを受け入れがたい方法で変更できる可能性があります。Data Perimeterについての詳細な解説が用意されています - オンラインでこのフレーズを検索すると、素晴らしいコンテンツが見つかります。


暗号化は保存データを保護する従来からの方法の一つです。私たちから暗号化を利用する場合、高品質な暗号化と世界クラスのチームがそれらのツールを構築しています。データを保存および処理するすべてのAWSサービスに対して、保存時と転送時の両方の暗号化を提供しています。最近、データ転送に関していくつかの重要なマイルストーンを達成しました - 現在、すべての場所でTLS 1.3をサポートしています。TLS 1.3は、より優れた安全性を備えているだけでなく、特にサーバーとクライアントが既に接続したことがある場合、最初の暗号化バイトがより高速です。これにより、リモートユースケースでのテールレイテンシーが大幅に削減されるため、TLS 1.3の採用をお勧めします。

AWSにおける暗号化について、クライアントサイドの暗号化を実装することができます。私たちはオープンソースのSDKを提供しており、その中には DynamoDBのクライアントサイド暗号化のための非常に優れたオープンソースSDKも含まれています。これは、以前は不可能とされていた検索可能な暗号化を実現しています。また、目に見えない下層のインフラストラクチャーレベルでも暗号化を提供しています。AWS管理施設を接続するすべてのネットワークは下層レベルで暗号化されており、リージョン間のVPCピアリングも独自の暗号化を実装しています。リージョン間VPCピアリング上にTLS接続を構築すると、そのスタックには文字通り4つの異なる暗号化レイヤーが存在することになります。

私たちは優れたツールを提供しています - AWS KMSがその最適な選択肢です。AWS KMSを使用すると、ポリシー制御で多くのことができ、非常に賢く運用できます。これは高度なユースケースですが、確実に使用すべきものです。認証情報とログインはAWS IAMから提供されますが、現在ではX.509証明書を使用してIAMにアクセスすることも可能です。既にPKIを通じて暗号化されたアイデンティティをお持ちの場合、そのPKIインフラストラクチャーを使用してロールを引き受けることができます。私たちは証明書製品を提供しており、証明書製品における厳密さを確立し、適切なパターンを見出すことが重要です。ACMをELBと統合して使用すれば、システムが自動的に処理するため、TLS証明書の期限切れに悩まされることはありません。
量子コンピューティング時代に向けた暗号化の準備

しかし、現代の暗号技術には影が忍び寄っていることも認識しています。 その影とは、十分に強力な量子コンピュータが出現する可能性です。暗号技術は一連の前提に基づいており、非対称暗号の場合、その前提の1つは素数の因数分解が極めて困難だということです。強力な量子コンピュータが出現すると、素数の因数分解はもはや極めて困難ではなくなります。

これは基本的な前提を崩すことになります。 特定の顧客にとって興味深い長期的な脅威があります。それは、攻撃者が今日の暗号化されたトラフィックを収集し、10年、20年、30年、あるいは100年間(誰も確実な期間は分かりません)保存しておくというものです。新しい能力を手に入れた時点で、保存された暗号を解読できる可能性があるのです。

これは、今日私たちがこの問題に対処しなければならないことを意味します。 なぜなら、新しい標準を構築するには時間がかかり、その標準を批准して完全に検証するにはさらに長い時間がかかるからです。ポスト量子時代に生き残れる新しい標準を作成する際は、従来型の攻撃にも脆弱であってはなりません。良いニュースは、業界とAmazon自身がこの問題に長年取り組んでおり、ポスト量子時代をサポートするための暗号化モジュールが既に選定されているということです。Amazonは今後5年間でこれらへの移行を進めていく予定です。
暗号化機能を当社から利用している場合(Elastic Load Balancing、CloudFront TLS、その他同様のサービスなど)、必要になる前に対応を完了させています。もし、あなたのコアプロダクトが暗号化に関連している場合(ウェブサイトのTLSだけでなく、ファームウェアの署名など、特に長期的な資産に関わる暗号化機能がある場合)、これは気にかける必要がある事項です。ただし一般的に、当社から暗号化機能を利用している場合は、私たちが対応を行い、必要になる前に準備を整えます。今週、素晴らしいブログ記事を公開する予定ですので、Post-quantum暗号化に関する現状と今後の展望について、オンラインで検索してご確認ください。


AWS Transfer Family(基本的にマネージド型SFTPとマネージド型SCP)を使用してファイルを転送している場合、現時点でPost-quantum暗号アルゴリズムを利用できます。 ここには責任共有モデルがあります。私たちは必要になる前に準備を整えますが、お客様側でもソフトウェアの置き換えやアップデートを行う能力を構築する必要があります。これは今後5年、10年、15年の間にPost-quantum暗号化に備えるために必要な能力であり、そもそもソフトウェアのインベントリと迅速な変更・アップデートのリリース能力は必要なものです。
朗報として、TLS 1.3のPost-quantum暗号アルゴリズムとそのサポートに関して、今すぐ取り組む理由があります。Post-quantum暗号アルゴリズムはTLS 1.2には実装されないため、1.3への移行準備を進める良い理由となります。システムのインベントリ方法を把握し、合理的かつ大規模に、そして高い保証レベルでソフトウェアを置き換える能力を構築する必要があります。なぜなら、AWS SDKsやCLIの置き換えが必要になるからです。また、Post-quantum暗号化の使用を開始したい場合、ブラウザやTLSを使用する他のすべてのものもアップデートする必要があります。


クライアント側のアップデートが必要になります。私たちは自社側の対応を行っていますが、Load Balancerが Post-quantum暗号アルゴリズムをサポートしているからといって、それを活用する準備が整っているとは限りません。準備が整い、クライアントがサーバーにその機能を通知し始めたとき(TLSの仕組みでは、クライアントが実行可能な内容を伝え、サーバーがそれに応じて応答します)、クライアントがPost-quantumを優先すると指定した場合、即座にサポートします。これが今後数年間の私たちの計画です。 次は、Observabilityについて話しましょう。Observableは私たちが議論している多くのダイナミクスに適合します。
AWSのObservabilityとデータ保護機能
先ほど、予防的コントロールを構築しても検知的コントロールが必要であり、特にセキュリティやコンプライアンスの成果に直接関連する期待通りの動作が継続していることを確認する必要があるという話をしました。これはAWSサービスで実現できます。CloudWatchによるログの取り込みや、メトリクスの取り込み、新しいメトリクスの合成的な作成など - このプロダクトの最も優れた機能の1つは、特定のイベントの発生回数を観察し、それらのイベント間の比率を作成できることです。イベント123は、イベント345の20%を超えた場合にのみ本当に懸念すべき事項となります。CloudWatchでこれが可能で、これは大きなセキュリティ成果につながります。SSHの失敗試行を見ることは悪いことですが、それが接続の大部分を占める場合はさらに悪いことです。AWSサービスを使用して、非常に質の高いObservabilityを構築できます。
このような目的のためのもう1つの重要なAWSサービスがCloudTrailです。CloudTrailは必要不可欠な記録システムです。何か問題が発生した後の分析に重要なだけでなく、CloudTrailをデータソースとして活用することで、運用の改善、開発やデプロイメントパターンの理解、そしてそれらの経時的な観察が可能になります。このような豊富なデータを活用することで運用の優秀性を高めることができ、それが直接的に高品質なセキュリティ成果につながります。

この講演のきっかけの1つは、あるお客様から聞いた話でした。そのお客様は、コールセンターアプリケーションから納税者IDと社会保障番号を削除したことを誇りに思っていました。1年後、エージェントが入力するかもしれないコメントに対して自然言語処理を行いたいと考えました。S3リソース内のクレジットカードや社会保障番号を検出できるデータ検出製品のMacieを使い始めたところ、コールセンターからの非構造化データプールに社会保障番号が存在することを発見して驚愕しました。何が起きたかというと、フォームからフィールドを削除したことで、コールセンターのエージェントは社会保障番号をコメント欄に入力するようになり、知らず知らずのうちにダウンストリームのデータリポジトリにSSNが混入してしまっていたのです。

これは、あらゆるステップとレイヤーでセキュリティに対する厳密さを適用することの重要性を示しています。現代の分散システムには、あるコンポーネントが別のコンポーネントを呼び出す多くのメッセージングバスが存在します。AWSを使用している場合、それを実現する最適な方法の1つがAmazon SNS(Simple Notification Service)です。SNSは、ソフトウェアがメッセージを送受信できるユビキタスなメッセージングバスです。SNS自体にはPIIを検出する機能があります。PIIを検出する他の場所があるかもしれませんが、これは文化的な執着的厳密さのもう1つの例であり、メッセージングバスがそれらのストリーム内の望ましくないデータを監視し検出する機会を提供しています。

この機能はSNSだけでなく、Amazon CloudWatchでもサポートされています。これは特に「ログスピル」と呼ばれる恐ろしい事象があるため重要です。誰もが顧客データベースを保護する必要性を知っていますが、運用環境には本来あってはならないデータで汚染される可能性のある他の場所があります。開発者がWebアプリケーションの誤ったデバッグフラグをオンにすると、ログ内のクエリ文字列に突然、顧客の機密情報や企業の機密情報が含まれる可能性があります。CloudWatch Logsにデータを取り込む際、存在してはならないものを検出する機能があり、これは非常に強力なパターンであり、厳密さが求められるもう1つの例です。

この概念は、データ保護ポリシーとして、SNSとCloudWatch Logs - データ保護に関して普段意識されないかもしれない2つのサービスの両方で具現化されています。これは、厳密さと深い当事者意識を全員に適用することで、高品質で、コンプライアンスに準拠し、保証され、監査に耐えうる環境管理を実現するための重要な部分です。ログ取り込みシステムに携わる人々は、「単なるログシステムだから」と顧客データの保護は自分たちの仕事ではないと考えるかもしれません。しかし、セキュリティは全員の責任でなければなりません。

このプリンシプルをサポートするために、私たちはデータ識別子を管理しています。そのため、皆さんは引退するまでパターンを考え出す必要はありません。Amazon SNSやAmazon CloudWatch Logsのこれらの検出機能には組み込み機能があり、自動的にこれらを検出して、コア製品の一部として追加料金なしで機能として提供します。

ここには本当に優れたメリットがあります。メッセージングサービス自体の一部であるため、優れたスケーラビリティと可視性が得られます。これは2つの質問に答えます:物事が正しく機能していることを確認するだけでなく、上司や、その上司、監査担当者に対して、すべてが安全であることを証明できるということです。私たちには3つの方法があります:まず、フロントエンドで問題のあるものが入らないようにしました。次に、それらの間のフローで、決して存在しないことを確認しました。そして最後に、バックエンドでもそのデータをスキャンしていました。ベルトとサスペンダーのような複数の制御により、悪意のある意図や設定ミスによって1つの制御や技術が失敗しても、高品質な結果を得ることができます。
Generative AIアプリケーションにおけるデータ保護の課題と対策

ここで、私の親愛なる同僚を舞台に招いて、最近誰もが注目しているGenerative AIについて話してもらいたいと思います。RobとはずっとAWSで一緒に働いてきました。Peter、ありがとうございました。皆さん、こんにちは。私はRam Ramaniで、Principal Security Solutions Architectです。AWSで約8年働いています。通常の会話を続けて、Generative AIアプリケーション内のデータ保護について話していきたいと思います。

Generative AIを活用したアプリケーションを構築しようとする際、複数のペルソナが参加します。Applied Scientist、Data Scientist、そしてDeveloperがいます。Applied Scientistはモデルを構築し、Data Scientistはデータセットを準備し、そしてDeveloperもいます。Peterが分散型セキュリティ所有モデルについて話しましたが、これらすべてのペルソナがセキュリティの観点を持ちながら協力し、セキュリティの専門家とも協力して、Generative AIを活用した安全なアプリケーションを構築するために必要な厳密さを確保することが重要です。手を挙げていただけますか。組織内でGenerative AIアプリケーションを実際に構築している方は何人いらっしゃいますか?何人かいますね。素晴らしいです。

プレゼンテーション中で使用する用語をいくつか定義させていただきます。これらの用語は様々な定義があるためです。Tokenについて話す際、これは通常、単語または単語の一部を指します。MaskまたはSanitizeと言う場合、元のデータとは関係のない識別子でデータを置き換えることを指します。Guardrailsについて話す際は、望ましくない動作を防ぐための保護手段を提供する方法を指します。RAGと言う場合は、モデル推論の品質を向上させるために組織のデータを使用することを指します。


これから3つの主張について見ていきたいと思います。このセクションの最後で、これらの主張が真実か、誤りか、あるいは議論の余地があるのかを判断していきます。 1つ目は、Generative AIを活用したアプリケーションを構築する際にGuardrailsを使用すべきだということ。2つ目は、Generative AIプロセスで使用されるデータの認可を考慮する必要があるということ。そして3つ目は、データをGenerative AIプロセスに入力する前に、サニタイズする必要があるということです。

ここで重要な定義をいくつか共有させていただきます。Generative AIアプリケーションを構築する際、リスクとは、責任のあらゆる側面に影響を及ぼす可能性のある有害な事象のことを指します。セキュリティの観点では、ML/AIシステムの機密性、整合性、可用性を損なう可能性のある脅威にさらされることを意味します。プライバシーの観点からは、ML/AIシステムとの相互作用における機密データや個人データの露出や不適切な取り扱いに注目します。

皆さんの組織では、おそらくデータに対するアクセス制御が既に実施されており、画面に表示されているような詳細な分類がすでに存在するかもしれません。

画面に表示されている分類について説明させていただきます。Generative AIを活用したアプリケーションを構築する際に、これらのデータタイプの中には、Generative AIプロセスに入力させないと判断するものもあるでしょう。従来、多くの組織では高レベルの分類のみを行っていましたが、Generative AIがコードや他の多くのデータタイプに関わるようになった今、これらの分類すべてが非常に重要になってきています。

データタイプについてさらに詳しく見ていくと、組織内のデータの大部分が非構造化データであることがわかります。お客様がGenerative AIを活用したアプリケーションを構築する際、パブリックおよびプライベートの構造化データと非構造化データの両方を使用しています。 Generative AIアプリケーションの構築には新たな課題が伴います。これらは、望ましくない無関係なトピックの表示、ブランドや組織にリスクをもたらす可能性のある有害な言葉の使用、機密データの露出、偏見やステレオタイプの助長といった、Responsible AIに関連する広範な課題です。このセクションでは、データ保護、つまり機密データの露出に焦点を当てていきます。



それでは、Generative AIにおけるデータリスクについて詳しく見ていきましょう。 Generative AIを活用したアプリケーションを構築する際、プロンプト、モデルの継続的な事前学習用の未ラベルデータ、モデルのFine-tuning用のラベル付きデータ、 そしてRAGやエージェントで使用する構造化・非構造化データがあります。さらに、独自のトレーニングデータセットで独自のモデルを構築する場合もあるでしょう。

これらすべてのデータがモデルに入力されます。それは、Amazon Bedrockが提供するAmazonのモデルかもしれませんし、SageMakerで構築したモデルや、サードパーティのモデルかもしれません。そして、ユーザーに応答が返されます。ここで挙げたデータについて、関連するデータリスクを考慮する必要があります。 プロンプトにも応答にも機密データが含まれる可能性があります。そして、従業員が利用する社内アプリケーションと、インターネット上で提供する外部顧客向けアプリケーションの両方について、機密データの漏洩リスクを考える必要があります。

Fine-tuningについて説明しましょう。ラベル付きデータがFine-tuningプロセスに入力され、最終的にいずれかのモデルタイプで処理されると、特定のタスクの精度が向上したFine-tuned modelが生成されます。少量のラベル付きデータでモデルをFine-tuningする場合、このデータが改ざんされないよう適切なアクセス制御が必要です。また、最小権限の原則に従い、Fine-tuningプロセスのみがラベル付きデータにアクセスできるようにする必要があります。



RAG(Retrieval Augmented Generation)について説明すると、 ユーザーがチャットボットアプリケーションと対話を行い、RAGプロセスは組織内のデータを使用してコンテキストを生成し、 それをシステムプロンプトに追加します。質問がモデルに送信され、ユーザーに応答が返されます。RAGを考える際には、 この検索プロセスがアクセスする組織内のデータについて、サニタイズが必要か、あるいはアクセス制御を検討する必要があるかを考慮しなければなりません。これらについては後ほど詳しく見ていきます。



このディスカッションを、リスクと対策について検討する具体的なユースケースに分解してみましょう。 ここでのリスクは、Generative AIを活用したアプリケーションで使用しているモデルが、企業の機密データを漏洩する可能性があることです。このリスクに対してどのような保護対策を構築しているでしょうか。このリスクを自動車の運転に例えて考えてみましょう - 最高のユーザーエクスペリエンスや運転体験を得るために速く走りたいと思う一方で、何か問題が発生した場合に備えてガードレールが必要です。
そのため私たちは、Amazon Bedrock Guardrailsを構築しました。これは、アプリケーションの要件やResponsible AIのニーズに合わせて、独自のセーフガードを実装できる手法です。ハルシネーション(幻覚)の防止、機密データの露出防止、あるいはお客様のユーザーベースにとって有害または不適切な特定のトピックを拒否するといった用途に活用できます。このスライドに示されているこれらのディメンションは、通常すべて並行して評価されます。ここでは機密データの露出というディメンションに焦点を当てています。並行して評価する理由は、Generative AIを活用したアプリケーションのユーザーに対して、可能な限り低いレイテンシーを提供することが極めて重要だからです。


Amazon Bedrock Guardrailsについて、これはAmazon Bedrockがサポートするモデル、SageMakerで構築したモデル、またはサードパーティのモデルと連携できます。これらは独立したGuardrailsであり、その呼び出しにモデルの呼び出しは必要ありません。モデルを呼び出すことなくGuardrailsを適用できるのです。Guardrailの呼び出し自体は、Lambda関数、コンテナアプリケーション、あるいはその他の構築したスタックの中で行うことができます。結局のところ、先ほどお見せしたフィルターのGuardrailsを適用するために呼び出すのは、RESTful APIなのです。

別のユースケースを見てみましょう。ここで話題にしているリスクは、RAG(Retrieval Augmented Generation)プロセスで組織の機密データが使用されることです。考慮すべき質問は次の通りです:RAGプロセスに入るデータをサニタイズする必要があるか、そして要求する個人に対して認可されたドキュメントのみが取得されるよう、組織内の検索プロセスにどのようなメカニズムを構築しているか?これは最小権限の原則に関連します。




これがどのように機能するか見てみましょう。ユーザーのAliceがチャットボットアプリケーションに質問をすると、この場合の検索プロセスはアイデンティティを認識します。AliceがRAGプロセスで使用する組織のデータにアクセスする権限があるかどうかをチェックできるのです。もし認可されている場合、コンテキストが生成され、それがシステムプロンプトと質問に追加されて、いずれかのモデルに送信されます。認可されていない場合は、コンテキストは生成されず、システムプロンプトと質問のみがモデルに送信され、応答がAliceに返されます。ただし、Aliceに返される前に、設定したGuardrail構成によってフィルタリングされます。

同様に、検索プロセスがアイデンティティを認識しない場合、AIエージェントを使用してアイデンティティの認識を組み込むことができます。この場合、Aliceはチャットボットアプリケーションとやりとりし、AIエージェントがAliceに権限があるかどうかをチェックします。承認された場合のみ、アイデンティティ認識機能を持たない検索プロセスに対して、類似性検索と質問に基づいてコンテキストを生成するよう指示を出します。最終的に、応答はGuardrailによってフィルタリングされてからAliceに返されます。

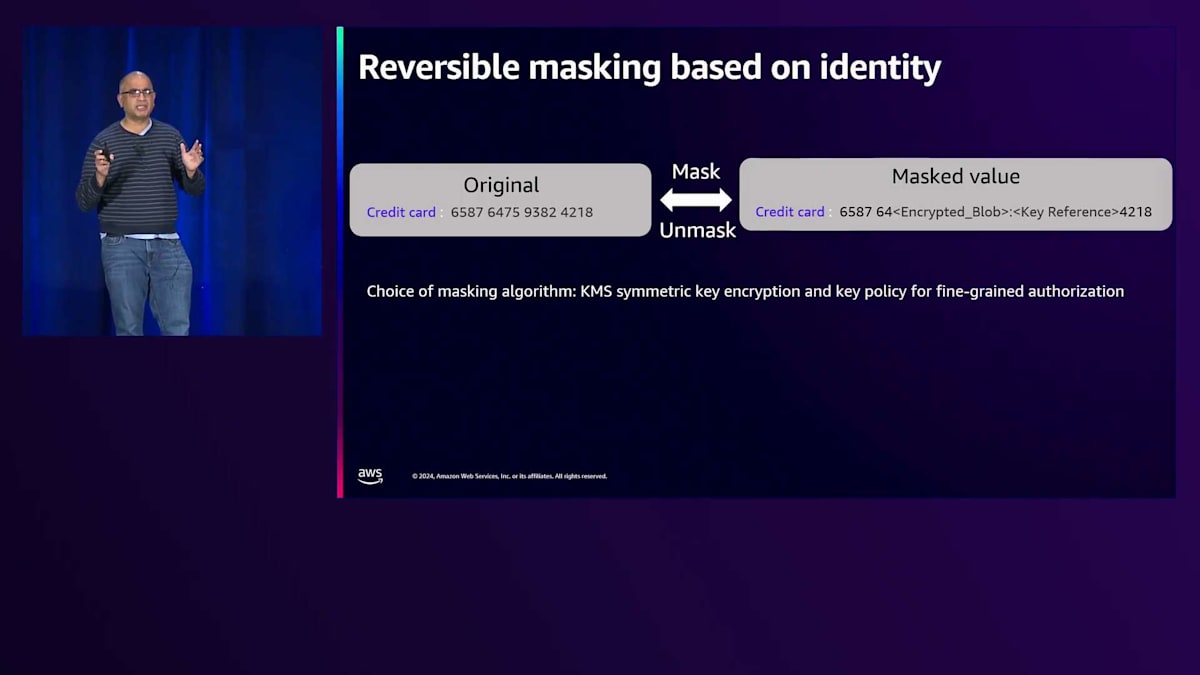
もう少し詳しく、Fine-grainedな認可について見ていきましょう。 これまで話してきたのは、Identity視点での粗い粒度の認可でした。ここで見ていただけるように、名前はプレースホルダーに置き換えられ、同様にメールアドレスも置き換えられています。しかしクレジットカードの場合、私が行っているのは、いくつかの桁をアスタリスクで置き換えることです。 中には、特定の個人やグループに対して、Fine-grainedな認可と可逆性、つまり再識別が可能な形での対応を望まれる方もいらっしゃるでしょう。この例では、クレジットカードの一部の桁を、AWS KMSキーで暗号化されたBlobと、可逆性のためのキー参照に置き換えています。


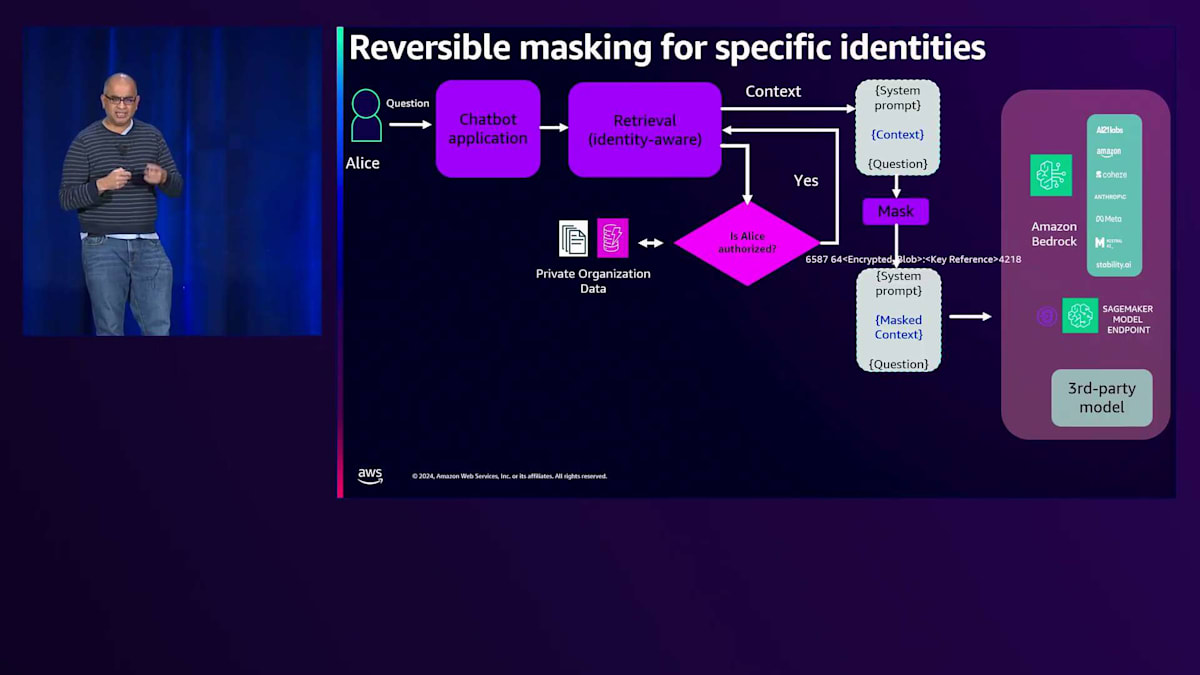
Generative AIのコンテキストでこれがどのように機能するか見ていきましょう。 可逆的なマスキングについて話しましたが、この場合、Aliceは再びChatbotアプリケーションと対話しており、そのRetrievalプロセスはIdentityを認識し、 Aliceが認可されているかどうかをチェックします。認可されている場合、System Promptと質問に追加されるコンテキストが生成されます。 その後、別のプロセスでマスキングが行われ、先ほどのスライドでお見せしたように、KMSを使用して一部のクレジットカードデータをマスクしたコンテキストが生成されます。
Generative AIのFine-tuningとセキュリティの考慮事項
モデルからのレスポンスには、設定したレスポンスポリシーに基づくGuardrailが適用されます。Aliceの場合、クレジットカード番号の全体をプレーンテキストで見る権限があるため、Aliceに返される前に、マスクされていたクレジットカード番号の部分が元に戻されます。これはKMSのKeyポリシーを通じて機能します。AliceがKeyポリシー内のPrincipalであり、復号化の権限を持っている場合、データまたはクレジットカード番号の一部を彼女に送り返す前にマスク解除することができます。これにより、Generative AIを活用したアプリケーション内でFine-grainedな認可を構築する方法が提供されます。これはGenerative AIに限った新しい話ではありませんが、トークンの入出力というコンテキストにおいて、これらのメカニズムは望ましいものとなっています。

多くのHealthcareや金融機関から、Generative AIを活用したアプリケーション内で構築できるFine-grainedな認可について問い合わせを受けています。 3つ目のユースケースとして、組織の機密データをモデルのFine-tuningに使用する場合についてお話ししたいと思います。皆さんが抱える疑問は次のようなものです:Fine-tuningされたモデルのダウンストリームでの使用においてGuardrailなどの保護が適用される場合、Fine-tuningデータを事前にSanitizeする必要があるのか、そしてSanitization後のFine-tuningされたモデルの精度を評価する必要があるのか、ということです。
これは議論の余地があり、その議論は主に集中型と分散型のガバナンスモデルを巡るものです。先ほどPeterが言及した、厳密性とコラボレーション、そして分散されたセキュリティの所有権について思い出してください。Fine-tuningされたモデルのダウンストリームユーザーがGuardrailなどの保護を使用しているかどうかわからない場合は、データをSanitizeする方が安全です。しかし、Sanitizeしない場合は、Guardrailなどのダウンストリームでの保護についてより強力なガバナンスが必要になります。ただし、どのようなデザインを追求する場合でも、Guardrailを使用することを推奨しています。Fine-tuningプロセスに入る前にデータをSanitizeすることで、非常に厳密なデータ最小化戦略に従いたいユースケースもあります。

データのサニタイズを行うことを決めた場合、Fine-tuningしたモデルの有効性をユーザー体験の観点から評価し、サニタイズによって精度が向上し、より良いユーザー体験が得られるかどうかを確認する必要があります。アプリケーションにとって、モデル評価は極めて重要であり、効果的なモデル評価のパイプラインを持つことが不可欠です。Guardrailsやその他の保護機能を適用する場合でも、Applied Scientistが取り組むFine-tuningなどのプロセスでは、セキュリティに関連するIdentity-based Authorizationやサニタイズについて考慮する必要があります。組織やチームがGenerative AIを活用したアプリケーションを構築する際には、分散型の所有権モデルと、厳密性とセキュリティの確保が極めて重要となります。

ここで取り上げたいリスクは、これまで説明したすべての保護機能を適用しても、機密データが漏洩する可能性があるということです。Guardrails、Identity-based Authorization、さらにはサニタイズ、マスキングの可逆性といった保護機能を使用しても、アプリケーションが組織の機密データを漏洩させる可能性はあるのでしょうか?ここで再び厳密性に注目したいと思います。なぜなら、モデルパイプライン内でPromptの変異を用いたFuzzingを行う厳密なRed Teamingプロセスを持つことで、機密データの露出につながる可能性のある脆弱性やJailbreaksを発見できるからです。セキュリティの文化と分散型の所有権は、Generative AIを活用した安全なアプリケーションの構築と、お客様のユーザー体験の向上に大きく貢献します。

このセクションの冒頭で示した主張に戻りましょう。 1つ目は、Generative AIを活用したアプリケーションを構築する際にGuardrailsを使用すべきというもので、これは正しいです。2つ目は、Generative AIプロセスで使用されるデータの認可を考慮する必要があるというもので、これも正しいです。そして3つ目は、AIプロセスに入る前にデータをサニタイズする必要があるというもので、これは選択するガバナンスモデルによって議論の余地があります。

ここで、主要なポイントをまとめてみましょう。Peterは、より良いデータ保護のための文化と分散型所有権の重要性について話しました。ポリシーを含む利用可能なすべてのツールやメカニズムを使用してデータペリメーターを保護することについて議論しました - これらの実装を検討してください。Post-quantum時代に向けた準備を始める必要があります。s2nやAWS-LCなどのライブラリ、さらにはPost-quantum鍵合意でTLSハンドシェイクを開始できる一部のサービスを使って実験できるように、私たちは簡単に試せる環境を用意しています。試してみて、組織内で追求したいものかどうかを確認してください。また、インベントリの可観測性とログ保護について考え始めることも必要です。AWSで利用可能なすべてのツールを活用し、最後に、Generative AIを活用したアプリケーションを構築する際のリスクとトレードオフについて考えてください。

ご清聴ありがとうございました。私Ram RamaniとPeter O'Donnellの LinkedInプロフィールをここに掲載しています。この後、会場の外で待機していますので、さらに質問がある方はお気軽に話しかけてください。ご質問にお答えし、お手伝いさせていただきます。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion