re:Invent 2023: AWSがSageMaker HyperPodを発表 大規模AIモデルの効率的トレーニングを実現
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - [LAUNCH] Introducing Amazon SageMaker HyperPod (AIM362)
この動画では、Amazon SageMaker HyperPodの機能と利点について詳しく解説しています。foundation modelの大規模トレーニングにおける課題や、自動修復機能によるハードウェア障害からの迅速な回復方法を紹介しています。Hugging Faceの事例を交えながら、HyperPodがどのようにモデルトレーニングを効率化し、イノベーションを加速させるかを具体的に説明しています。さらに、Llama 2の事前学習デモを通じて、HyperPodの実際の動作も見ることができます。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
SageMaker HyperPodの紹介:foundation modelトレーニングの革新


みなさん、こんにちは。re:Inventの最終日にお集まりいただき、ありがとうございます。昨晩のre:Playで楽しみすぎなかったことを願っています。ちょっとお聞きしたいのですが、foundation modelの事前学習や、マルチノードの分散学習を経験された方は手を挙げていただけますか?素晴らしいですね。今日のセッションはそういった方々にとって非常に関連性の高い内容になります。本日は、SageMaker HyperPodについてご紹介させていただきます。


私はIan Gibbsと申します。Amazon SageMakerのSenior Product Managerを務めています。本日は、Pierre-Yves AquilantiとMario Lopez-Ramosが同席しています。残念ながら、Hugging Faceからお招きしていたGuillaume Salouさんが来られなくなってしまったので、素晴らしいMarioが代わりを務めてくれることになりました。
foundation modelトレーニングの課題と複雑性
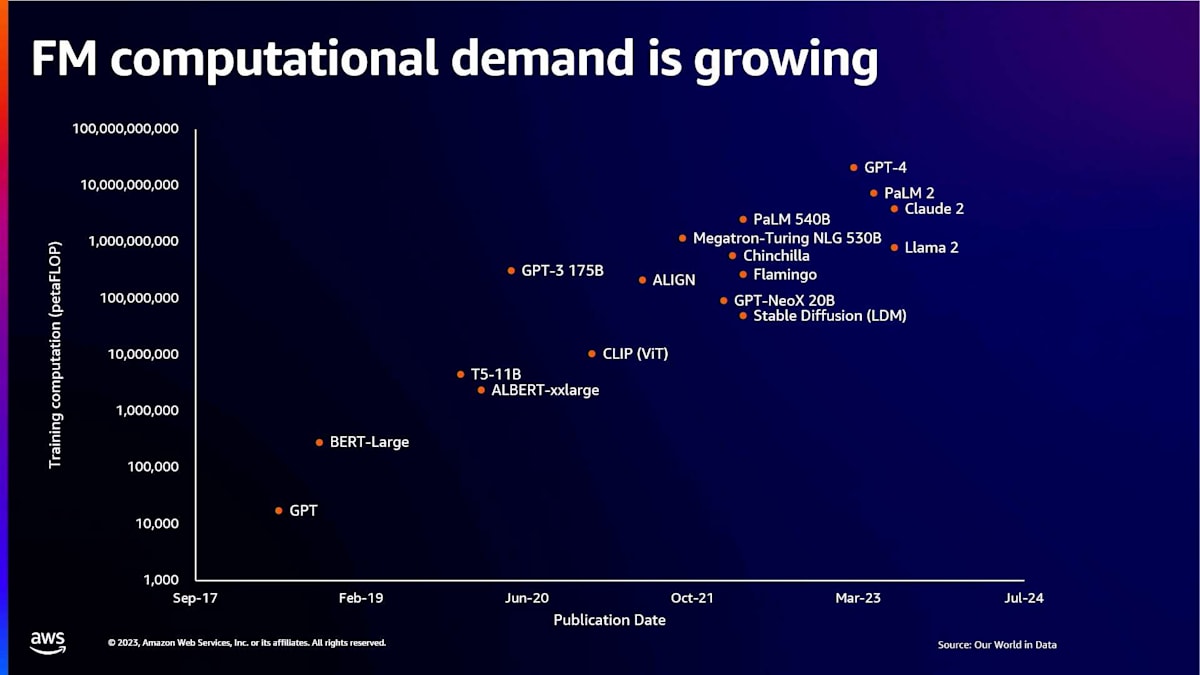
まず始めに、大規模なfoundation modelのトレーニングに関する全体的な計算需要について説明したいと思います。確かに今年は生成AIの年でしたが、トレーニングに携わる私たちにとっては、ここ数年がまさにクレイジーな時期でした。Transformerモデルアーキテクチャの登場により、技術と分野に大きな成長がありました。これらの新しいアーキテクチャにより、モデルのトレーニングに必要な計算能力の需要が高まっています。この成長は非常に異例のものであり、今日お話しする新製品のHyperPodは、これらのモデルのトレーニング方法に関する核心的な懸念事項の多くに対応しています。
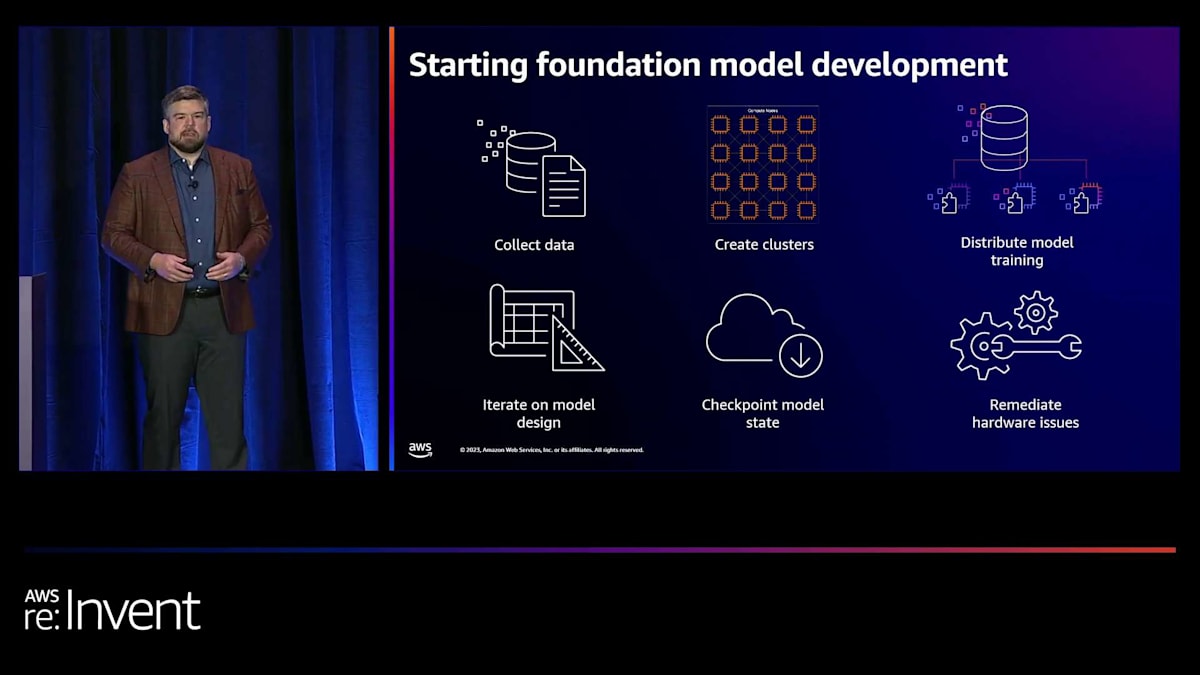
foundation modelの開発を始めるのは非常に複雑なプロセスです。データを収集し、そのデータを全ての分散ワーカーノードで処理するためのクラスターを作成し、全てのワーカーにワークロードを分散させるコードを開発する必要があります。適切な時間内にモデルを処理するには、スケールが必要です。多くの場合、スケール要件はこれらのモデルをトレーニングする上で固定的な制限となります。言い換えれば、数千のGPUを持つ128ノードが必要かもしれませんが、そのうちの1つのノードがダウンしたり利用できなくなったりすると、行き詰まってしまいます。
さらに、これらのモデルをトレーニングする際には、モデル設計を繰り返し改善することが重要です。私たちはよく、新しいモデルアーキテクチャを開発している研究機関と協力しています。おそらく分散トレーニングを最適化する新しい方法を開発し、彼らは本当にテックスタックを深く掘り下げ、モデルのトレーニング方法を検討する必要があります。その過程で、モデルのチェックポイントも保存しています。なぜなら、途中で変更を加える可能性があるからです。オプティマイザーを入れ替えたり、学習率やバッチサイズを変更したりすることがあり、それは非常に反復的なプロセスです。そのため、常に停止、開始、チェックポイントからの再読み込みを行っています。最後に、モデルの事前学習の全体的な進捗を妨げるハードウェアの問題に対処する必要があるかもしれません。

このような大規模なモデルのトレーニングには、いくつかのユニークな課題があります。まず、クラスターのプロビジョニングと管理が非常に複雑になる可能性があります。多数のコンピュートノードを見つけ、それらをネットワークで接続する必要があります。AllReduceやAllGather操作のために、ノード間でネットワーク通信ができなければなりません。モデルを実行し、効率的にトレーニングするには、特殊なデバッグツールやフレームワークが必要になるかもしれません。また、インフラの安定性が大きな問題となります。これは、トレーニングプロセス自体が直列的なプロセスであるためです。つまり、分散トレーニングジョブに割り当てたワーカーノードのうち1つでも停止すると、作業が止まってしまいます。そして、ハードウェア障害が発生するたびに、数時間から数日間作業が停滞する可能性があります。これは、新しいモデルを市場に投入する上で大きな問題となり得ます。
さらに、最適なパフォーマンスを実現する方法も大きなボトルネックとなる可能性があります。特にAWSでは、ノード間通信におけるネットワークの最適なパフォーマンスを確保することが、全体的なトレーニング時間の短縮に非常に重要です。そこで、インフラの安定性と分散トレーニングのパフォーマンスについて、そしてSageMaker HyperPodがどのようにそれらをサポートするかについて少しお話しします。
SageMaker HyperPodの主要機能:レジリエンスとパフォーマンス

SageMaker HyperPodには、foundation modelのトレーニングにおいて顧客に利益をもたらす3つの主要な領域があります。1つ目は、レジリエントなトレーニング環境を提供することです。
HyperPodでプロビジョニングできるクラスターは自己修復機能を備えています。ハードウェア障害が発生した場合、HyperPodは自動的にその障害から回復し、最後のチェックポイントから再ロードして、トレーニングを再開します。これらはすべて顧客の介入なしで行われます。大規模な環境では、これによりトレーニング時間を最大20%短縮できます。さらに、AWSのネットワークインフラに最適化されたSageMakerの分散トレーニングライブラリへのアクセスも提供しており、これによりトレーニング時間をさらに20%短縮できます。

モデル設計の迅速な反復には、ユーザーエクスペリエンスが非常に重要です。低レイテンシーでジョブを開始・停止する機能、任意のクラスターインスタンスへのSSHアクセス、そしてこれらのモデルのトレーニングに必要なフレームワーク、デバッグツール、ソフトウェアライブラリ、カスタム最適化をインストールする能力は、多くの顧客にとって不可欠です。
SageMaker HyperPodをプライベートプレビューで使用しているお客様の例をいくつか見てみましょう。その一つがStability AIで、オープンソースの生成AIをリードする企業です。彼らの大きな課題は、ハードウェア障害によって開発サイクルが中断され、モデル設計の革新という本来の仕事から注意がそれてしまうことでした。研究者たちは、クラスターの修復を何時間も何日も待つのは避けたいと考えていました。HyperPodでは、障害が検出されると自動的にインスタンスが置き換えられます。結果として、Stability AIはトレーニング時間とコストを50%削減することができました。

もう一つの成功事例は、最初の会話型Q&Aエンジンを提供するPerplexity AIについてです。彼らの課題は、LLMトレーニング実験のスループットの低さでした。SageMakerの分散トレーニングライブラリは、クラスターのワーカーノード間でモデル並列性とデータ並列性の観点からワークロードを分割・分散するように最適化されています。これらのライブラリはTensorFlowとPyTorchに最適化されており、最小限のコード変更で使用できます。Perplexity AIはこれらのライブラリを使用することで大きな利点を見出し、実験のスループットを2倍に増やすことができました。

Hugging Faceもこの製品を使用している素晴らしいパートナーの一つです。彼らの研究者は、基盤モデルの分散トレーニングにカスタム最適化を行っているため、テックスタックを深く掘り下げる必要がありました。マネージドインフラストラクチャが邪魔になるのではないかという心配なしに、お客様がイノベーションを起こせるようにすることが重要です。私たちはHugging Faceに、フレームワーク、コンテナ、デバッグツール、トレーニング環境に必要なソフトウェアライブラリのインストールなど、さまざまな側面をカスタマイズする能力を提供しています。これにより、お客様は抽象化のレベルを提供することなく、トレーニング環境と直接やり取りし、ニーズに合わせてカスタマイズすることができます。Hugging Faceにとって、これは研究者たちに迅速にイノベーションを起こす自由を与えました。
HyperPodの構築と管理:簡単さと柔軟性

以上を踏まえて、HyperPodについてもう少し詳しく説明するために、PYに引き継ぎたいと思います。

ありがとう、Ian。私の名前はPierre-Yves Aquilantiです。名前が長いので、皆さんはPYと呼んでいます。これからHyperPodについて詳しく説明し、その内部について少しお話しします。HyperPodは3つのことのために作られています:パフォーマンス、レジリエンス、そして使いやすさ、さらに柔軟性とカスタマイズ性です。パフォーマンスについて言えば、私たちは特定した最高のアーキテクチャ、お客様が使用している最適化されたアーキテクチャ、そして業界標準のアーキテクチャを採用しました。これらはAWSの異なるサービスで構成されており、それらを集約して、分散トレーニングワークロードを簡単に実行できる製品を構築しました。コンピューティングにはAmazon EC2を使用しています。
例えば、トレーニングにはP5やP4dインスタンスを使用できます。また、これらのインスタンスを相互接続してモデルを並列トレーニングできるように、Amazon Elastic Fabric Adapter (EFA)も提供しています。さらに、クラスターに接続できるAmazon FSx for Lustreも含まれており、データセットやチェックポイントを保存できます。必要に応じて、Amazon S3やその他のサービスも使用できます。加えて、SageMaker Model Parallelism (SMP)やSageMaker Data Parallelism (SMDDP)といった分散トレーニング用のSageMaker最適化ライブラリも提供しており、モデルのトレーニング時に追加のパフォーマンスを発揮します。
耐障害性に関しては、業界での最大の懸念の1つが中断の可能性であることを認識しています。私たちはこの問題を真剣に受け止め、解決策を実装しました。クラスターは自己修復が可能で、ジョブは自動的に再開されるため、トレーニングプロセス中の中断時間を最小限に抑えることができます。これについては後ほど詳しく説明し、どのように対処しているかをお話しします。
使いやすさと柔軟性に関しては、お客様がHyperPod上で自分のスタックをカスタマイズできるようにしています。これには、ライブラリ、システム設定、モデル、フレームワークが含まれます。自分のマシンで実行する場合と同じように、独自のカスタマイズを実行し、構築できます。より詳細な情報が必要な場合は、ノードにSSHで接続することもできます。また、トレーニング中に使用する可能性のある追加の監視ツールやその他のツールをインストールすることもできます。
HyperPodの実践的な利用:ワークロード管理とジョブ投入

では、実際にHyperPodをどのように作成するかについてお話しします。プロセスはかなり簡単です。まず、VPC、ネットワーク、サブネットを作成します。これらは、ストレージをセットアップするために必要です。例えば、Amazon FSx for Lustreのような共有並列ファイルシステムが必要な場合や、特定のデータベースをサーバーにセットアップする必要がある場合などです。
次に、ライフサイクルスクリプトと呼ばれるものをプッシュしてクラスターを作成します。これらは実行可能なbashファイルです。また、それらのbashファイルから呼び出されるPythonファイルを含めることもでき、クラスターをカスタマイズできます。これらのスクリプトは、チーム全体のユーザーを作成したり、特定のアプリケーションをインストールしたり、システムにカスタマイズを加えたりするのに使用できます。

その後、設定ファイルを定義します。このファイルでは、ヘッドノードを定義します。ヘッドノードは、ユーザーがSSHを通じて接続し、ジョブを投入したりファイルを操作したりするインスタンスです。また、コンピュートノードも定義し、どのようなコンピュートノードを使用するかを指定します。この例ではP5インスタンスを使用していますが、例えばP4インスタンスを使用することもできます。ライフサイクルスクリプトの保存場所も定義します。通常はS3に保存されます。HyperPodはデプロイ時にこれらのスクリプトを実行します。

HyperPodのカスタマイズと障害対応:柔軟性と自動修復
クラスターの作成は、AWS SageMaker create-clusterという1つのコマンドで行われます。このコマンドがリソースのスピンアップ、Amazon FSx for Lustreの接続、ライフサイクルスクリプトの実行を担当します。例えば、PyTorchなどのソフトウェアをインストールしたい場合、この段階で行われます。

クラスターが作成された後、ユーザーはAWS Systems Managerを介してクラスターに接続できます。必要に応じて個々のノードにも接続できます。これは、デバッグやトラブルシューティング、調査に役立ちます。特定のノードにファイルが配置されている場合があるためです。


実際には、以下のような形になります。 管理者やDevOps管理者がFSx for Lustreファイルシステムを作成し、SageMaker HyperPodエンドポイントを呼び出してクラスターをスピンアップします。ご覧のように、 ヘッドノードがあり、ユーザーはSSHを通じてこのノードに接続します。ジョブを投入することでヘッドノードを介してやり取りします。HyperPodのスケジューラーはSlurm(HPCバッチスケジューラー)で、ジョブの投入や、ワークロード実行時の様々な対話方法を提供します。


その前に、カスタマイズについて話しましょう。ライフサイクルスクリプトを通じてクラスターをカスタマイズできます。これらは一貫性を確保するためにクラスター作成時にデプロイされます。例えば、会社やチーム全体でクラスターをデプロイする必要がある場合、特定の設定やユーザーIDなどを使用できます。これらは作成時に実行されます。クラスターを作成した後、 トレーニングやその他のワークロードをクラスター上で実行する必要がある場合は、コンテナを使用できます。これらはDockerか、NVIDIAが開発したPyxisとEnrootを使用できます。これらのツールはコンテナファイルをsquashファイル(すべてのノードがアクセスできる共有ファイルシステムに保存されるフラットファイル)に変換します。

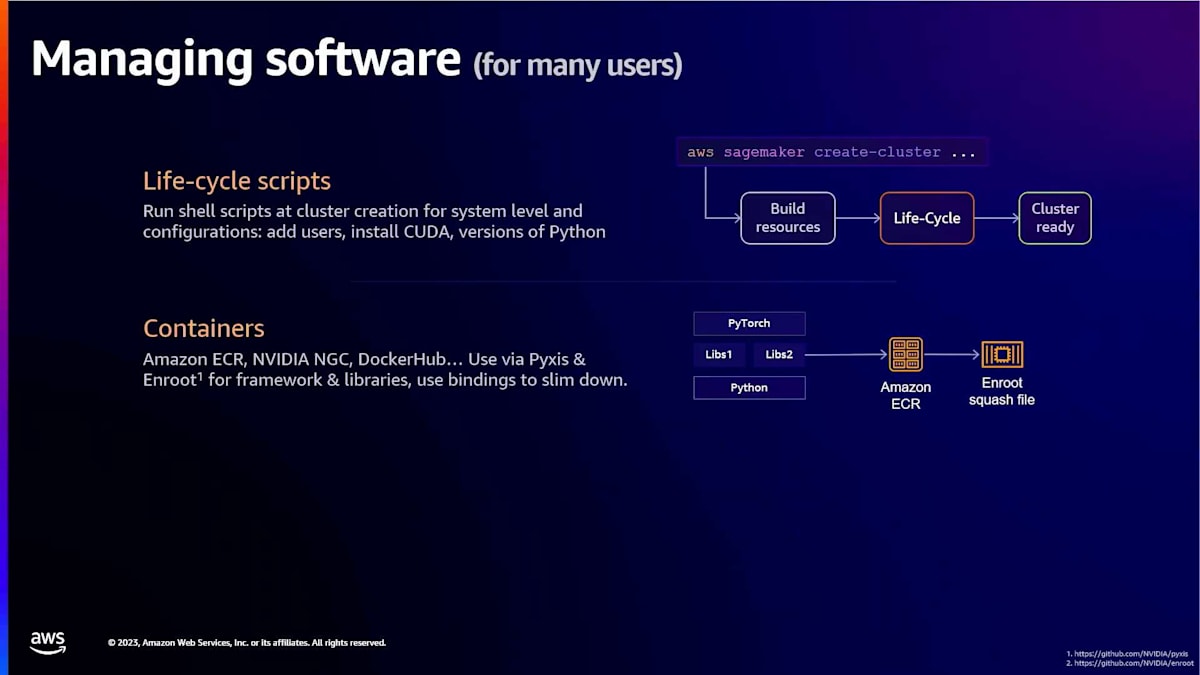
つまり、複数のノードにファイルを送信する必要がありません。すべてのノードが同じファイルシステムにアクセスできるからです。最後のオプションは、LustreやZFSなどの共有ファイルシステムの使用です。例えば、FSx for LustreやFSx for ZFSを使用できます。ここにアプリケーションを保存できます。例えば、hubsディレクトリに保存します。データ専用のファイルシステム、チェックポイント専用のファイルシステム、その他の目的のファイルシステムを持つこともできます。 もちろん、FSx for LustreをS3に接続し、データセットをS3に保存することもできます。トレーニング時にこれらを取得できます。遅延ロード機能を使用するか、パフォーマンス上の理由から通常推奨されるプリキャッシュを使用します。
Slurm経由でのHyperPod活用:バッチ処理とインタラクティブな開発

HyperPodをSlurm経由で利用する方法について説明しましょう。まず最も一般的なのはバッチファイルの使用です。必要なリソースを指定したファイルを作成します。例えば、16インスタンスで各インスタンスに8 GPUを要求し、これらのマシンを排他的に使用するよう指定できます。これにより他のユーザーがそれらのマシンを使用することを防ぎ、「ノイジーネイバー」問題を回避できます。リソースを宣言し、実行したいコマンド(例えば「srun python train」など、フレームワークによって異なります)を指定するだけなので、非常にシンプルです。


もう一つの方法は、クラスターの一部を割り当てる、つまり「切り分ける」ことです。16ノードを一定期間(時間制限付きまたは無制限)専有することができます。この方法では、インタラクティブな開発や、大規模実行時にのみ発生する問題の再現やトラブルシューティング、あるいはリソースの一部では時間がかかりすぎるタスクなどに利用できます。使用が終わればリソースを解放できます。HyperPodを利用するもう一つの方法は、フレームワークを活用することです。すでにいくつかの統合が存在しています。例えば、PyTorch LightningをSlurムと一緒に使用できます。

他の例としては、NVIDIA NeMoを使用する場合のNeMo Launcher、Facebook researchのSubmitit、さらにRayやMosaicML Composerなどがあります。実際、HyperPodの使用を開始するのに役立つ例をいくつか用意しており、後ほどのスライドでご紹介します。実際の動作を説明すると、例えばユーザーAがバッチファイルを使用してジョブを投入し、クラスターの一部を使用します。次にユーザーBが割り当てを要求します。これはトラブルシューティングが必要な場合や、よりインタラクティブな作業が必要で、ジョブがキューで待機するのを避けたい場合、あるいは実際にインタラクティブに作業する必要がある場合などです。

そして別のユーザーが、例えばNVIDIA NeMoを使用してトレーニングジョブを投入するかもしれません。さらに、ユーザーDがジョブを投入したとしましょう。この場合、そのジョブはキューに入ります。ただし、ワークロードを実行するには他にも多くのオプションがあります。例えば、プリエンプションを使用できます。Ianが先ほど言及した顧客の一人は、優先度の低い前処理ワークロードを実行しており、本番ジョブが実行されると中断されるようになっています。前処理は常に再開できるため、これで問題ありません。中断されても、最終的には完了します。これはバッチスケジューラーを通じて自動的に行うことができ、ユーザーや管理者が積極的に管理する必要はありません。
Hugging Faceの事例:機械学習の民主化とHyperPodの活用


ここで重要なのは、ジョブの失敗とそれにどう対処するかという点です。失敗にはさまざまな性質があることがわかっています。時々発生するハードウェア障害もその一つです。例えば、インスタンスの接続が失われることがあります。また、設定ミスなどのソフトウェア障害もあります。クラスター上の問題や、ジョブを投入した際のパラメーターの誤り、あるいはジョブがメモリ不足に陥り再設定が必要になるなどの場合が考えられます。問題は、1つのインスタンスを失うと、これらの訓練ワークロードは密接に結合されているため、ジョブ全体がクラッシュしてしまうことです。つまり、16インスタンス、すなわち16ノードがジョブを失うことになります。このような状況でどうすればよいのでしょうか?

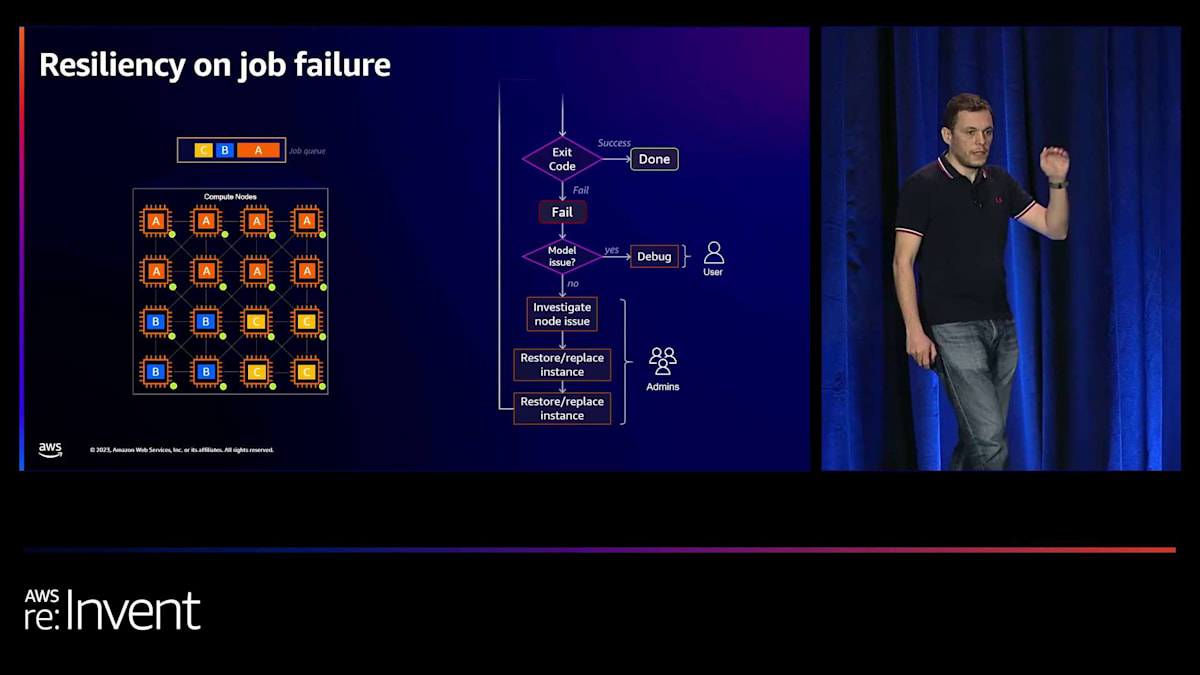
このキャパシティはまだアイドル状態かもしれません。なぜなら、実際にはより小規模なジョブを実行できないからです。キャパシティ、ジョブ、設定を調整して、「このジョブを実行するには16インスタンスとこれだけのGPUが必要だ」と指定しています。コンピュートの予算を再計算する必要がない限り、特定の期間内に成果を出す能力に影響を与える可能性があります。これは実際に一部の顧客から聞いた話です。そして、デバッグに要する時間、つまりソフトウェアの問題なのかハードウェアの問題なのかを特定する時間も考慮する必要があります。 私たちが行っているのは、障害を検出するエージェントを配置してこの問題を切り分けることです。そして、問題を調査し、復旧し、交換するという長いプロセスを経る代わりに - これには場合によっては数時間、本当に問題の所在がわかっていれば数分で済むこともありますが、2日かかったケースもあります -


私たちはこれを自動化されたプロセスに置き換えています。このエージェントは障害の検出だけでなく、 障害が発生した際にインスタンスを交換したり再起動したりして、ジョブを再開し、作業を継続し、トレーニングを続行できるようにします。実際の動作としては、ソフトウェア側でジョブを再開する際に、例えば1000イテレーションごとにチェックポイントを設定するなど、定期的にチェックポイントを作成します。アラームが発生すると、 インスタンスを復元し、ジョブを再開します。具体的には、例えばバッチファイルの中に、前処理コマンドやトレーニングコマンドなど一連のコマンドを記述します。

例えば、bash run_training.sh というコマンドがあり、これが実際には srun を呼び出しています。この場合、Slurm を通じて python training.py を実行しています。まず、チェックポイントがあるかどうかを確認し、あれば最新のものを取得して、ジョブを開始する際の入力として使用します。そうすることで、中断された場合でも最新のチェックポイントから再開でき、時間のロスと中断の影響を最小限に抑えられます。これはステップ単位で行われます。つまり、複数のコマンドを順番に実行するワークフローがある場合、中断されたステップから再開されます。
ユーザーからよく出る質問の一つに、ソフトウェアの管理方法があります。先ほど少し触れましたが、ライフサイクルスクリプトを展開できます。これは通常、クラスターを運用する管理者やDevOps担当者が行います。ユーザーには、Docker を通じてコンテナを実行するか、Conda や仮想環境を使用するオプションがあります。共有ファイルシステムがあり、すべてのノードから見えるからです。アプリケーションを apps や share にデプロイして、任意のノードから呼び出すことができます。すべてのノードが同じパスを見て、同じバイナリとライブラリにアクセスできます。これにより、インストールが容易になります。必ずしもすべてをコンテナを通じて再デプロイする必要はありませんが、そうすることもできます。コンテナ、Conda 環境、Enroot & Pyxis の3つのオプションがすべて可能です。時間が経つにつれて、さらに創造的なソフトウェアの実行方法が出てくるでしょう。

パフォーマンスについても触れたいと思います。これは最初に言及したポイントです。 スタック全体を最適化しました。まず、さまざまな顧客、特に最も先進的な顧客から見られるベストプラクティスを含むインフラストラクチャを定義しました。これには Amazon EC2 UltraCluster、Amazon EFA、Amazon FSx for Lustre、Amazon S3 が含まれ、これらを HyperPod に組み合わせることができます。ソフトウェア面では、ライブラリを常に最適化しており、Amazon SageMaker SMP や Amazon SageMaker SMDDP などの独自の最適化ライブラリも開発しています。


これらのライブラリは1つのコマンドで使用できます。この場合、単にインポートするだけです。 ここで見られるように、ライブラリをインポートしてコードに含めます。 例えば、PyTorch FSDP のバックエンドをデフォルトのバックエンドではなく SMDDP を使用するように設定できます。これにより、モデルとパラメータの設定によっては、最大10〜20%のパフォーマンス向上が得られる可能性があります。
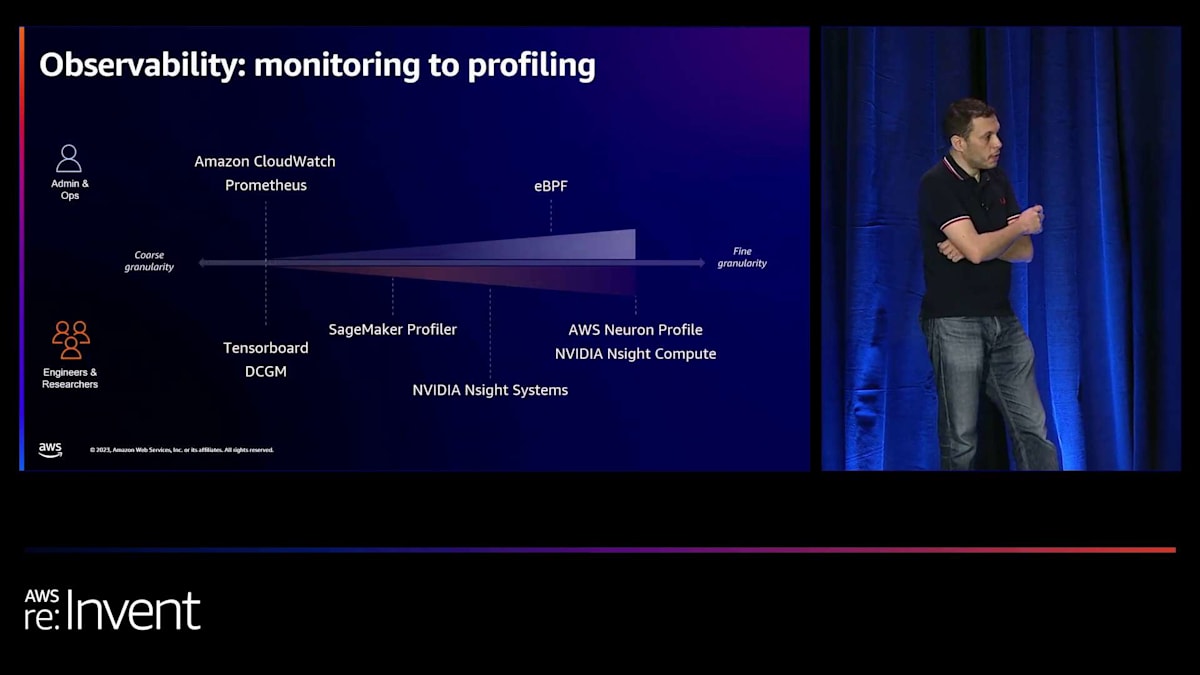
最後に観測可能性についてです。これらは計算集約型のワークロードなので、システムで何が起こっているかを把握し、問題が発生した場合にトラブルシューティングする必要があります。Amazon CloudWatch を使用して、GPU 使用率やメモリ使用率などの GPU メトリクスを取得できます。また、Prometheus をインストールし、NVIDIA の DCGM エクスポーターや Prometheus ノードエクスポーターなどのツールを使用してシステムレベルのメトリクスを取得することもできます。ユーザーとしては、Tensorboard や DCGM を使用して GPU 使用率データを取得できます。また、SageMaker トレーニングで利用可能な SageMaker プロファイラーの使用も検討しています。
管理者の方々は、eBPF を使用してより深い洞察を得たり、さまざまなプロファイラーを通じてトラブルシューティングを行ったりできます。これらのプロファイラーは実行時間を少し遅くする可能性がありますが、アプリケーションのより深いメトリクスを取得する能力を提供します。また、コードの特定の部分の使用率を識別し、プロファイラーに表示できる追加データを提供するポインターをコードに含めることもできます。これらは HyperPod で使用できるさまざまなオプションであり、将来的には新しいユースケースも登場すると確信しています。それでは、次のトピックに深く掘り下げる Mario にマイクを渡します。
Hugging FaceのStarCoderトレーニング:HyperPodの実践的利用

私の名前は Mario で、フランスの AWS でプリンシパルソリューションアーキテクトをしています。ここ数年は Hugging Face をサポートしてきました。残念ながら、Hugging Face の機械学習インフラストラクチャ責任者である Guillaume Salou は今日参加できませんでした。彼は今日帰国の飛行機に乗っており、私に代わりを頼みました。私は彼らの AWS の使用状況に精通しているからです。


まず、Hugging Faceについて少し背景をお話しします。彼らのミッションは機械学習を民主化することです。それは、Transformersアーキテクチャがオープンソースの世界で数多くの異なるモデルを生み出したことから始まりました。これらのモデルは、要約、翻訳、分類などのさまざまな課題を解決していました。数年後、Stable Diffusionで同様の現象が起こりました。これはオープンソースのテキストから画像生成で、さまざまな目的を改善するための異なる技術を持つオープンソースモデルが爆発的に増加しました。

素晴らしい時代に生きていますが、これらのモデルはそれぞれ少しずつ異なる方法で動作し、アーキテクチャにも違いがあるため、フォローしたり実装したりするのは難しい状況でした。そこでHugging Faceが登場し、これらすべてのモデルを同様の方法で実行するための共通プラットフォームを提供しました。これには2つの側面があります。1つは、多くの方がご存知のHugging Face hubの視覚的な部分で、そこではモデルを閲覧できます。タスクによってフィルタリングでき、画像生成、分類、音声からテキスト、テキストから音声などがあります。また、モデルカードを確認することもでき、機械学習モデルがどのように訓練されたか、どの言語で訓練されたかなどが記述されています。


さらに、現在ではオープンな大規模言語モデルのリーダーボードがあり、これらの異なるモデルをパフォーマンス、精度、バイアスなどの要因に基づいてランク付けしています。もう1つの側面は、hubから適切なモデルを指定し、数行のコードで推論を実行できるライブラリです。これは、Transformersライブラリを使用して画像内のオブジェクト検出を行う簡単な例です。テキストから画像生成も同様です。適切なモデルを選び、diffusersパイプラインを作成するだけで画像を生成できます。
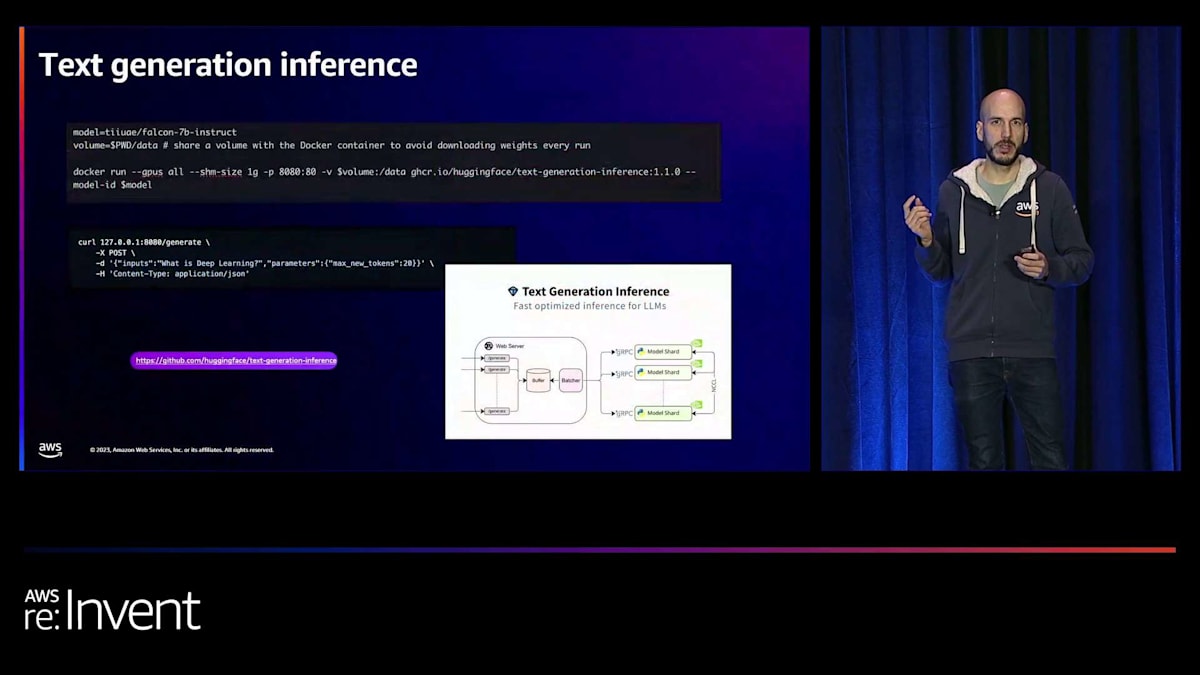
Hugging Faceは、text generation inferenceを使用して推論サービングスタックの改善にも取り組んでいます。1行のコードで、適切なモデルを選択し、Rustを使用して最適化されたWebサーバーを通じてサービスを提供するDockerイメージを起動できます。これが推論部分についての説明です。

機械学習を民主化するというミッションの一環として、Hugging Faceはモデルトレーニングにも取り組んでいます。モデルトレーニングの例としては、StarCoderやIDEFICSがあります。彼らのミッションは次のLlamaや次のMistralを生み出すことではなく、誰もが自分のモデルをトレーニングできるようにツールを提供することだということを理解することが重要です。彼らはこれらのモデルトレーニングの一部でコミュニティと協力して実現しています。
例えば、StarCoderはコード生成モデルで、GitHub CopilotやAmazon CodeWhispererと同様のものです。80以上のプログラミング言語をサポートする150億パラメータのモデルで、特にPythonなどの言語で優れたスコアを示しています。これは、BigCode Projectと呼ばれるコミュニティの取り組みによって作成されたオープンアクセスモデルで、30カ国以上から500人以上の参加者が関わっています。誰でもこの取り組みに参加して、彼らと一緒にこのモデルを構築することができます。
もう一つの例はIDEFICSで、これは画像について質問できるビジュアル言語モデルです。公開されているデータのみを使用して構築された、Flamingoのオープンアクセス版で、90億パラメータと800億パラメータのバージョンがあります。
これがHugging Faceのデータサイエンスチームが行っていることです。クローズドソースモデルを再現し、最新の研究論文の技術を調査し、実装し、コミュニティと共有しています。
そのために、彼らは計算リソースを必要としました。約1年前、Hugging FaceのML infrastructureの責任者であるGuillaume Salouから連絡があり、「1,800以上のGPUを持つクラスターが必要になります。協力してもらえますか?ちなみに、私のチームはSlurm jobsと共有ファイルシステムの使用を好みます」と言われました。そこで私はPierre-Yvesに連絡し、数週間後には皆でパリの彼らのオフィスに行き、HyperPodの構想を示しました。クラスターの作成方法、FSx for Lustreへの接続方法、トレーニングジョブを開始できるようにすべてをセットアップする方法をデモンストレーションしました。彼らはベンチマークを行い、満足して、それ以来使用しています。

では、特定のモデル、つまりStarCoderのトレーニングセットアップの例を見てみましょう。彼らはこのトレーニングのために、クラスターの容量の一部であるパーティションを使用しています。これにより、残りのGPUを同時に他のジョブに使用することができます。これがHyperPodの優れた点の一つです。この具体的な例では、Megatron-LMを使用した3D並列処理で、24日間にわたって1兆トークンを処理しています。
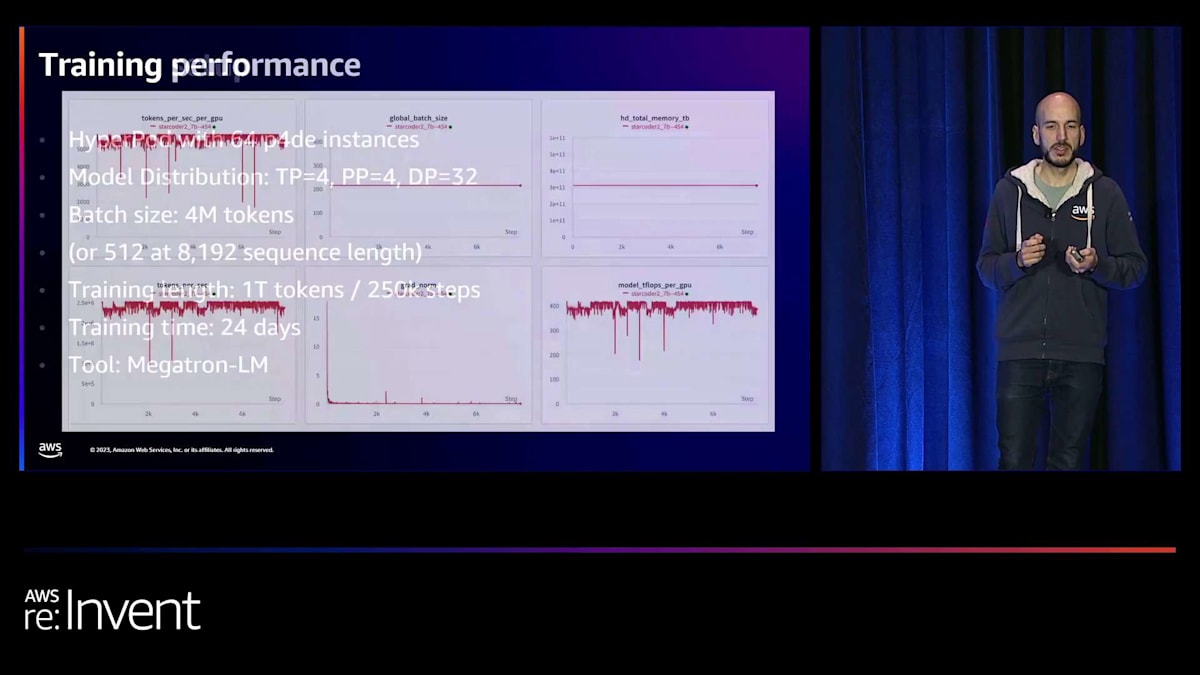
これはトレーニング中の彼らのメトリクスのスクリーンショットです。ここで興味深いのは、彼らが一貫してGPUあたり400モデルTFLOPSに達していることです。また、モデルの重みをチェックポイントとして永続化している間、パフォーマンスが低下する垂直な線がいくつか見られます。彼らはまず超高速のローカルNVMEに永続化し、その後S3に送信するジョブを実行しています。トレーニングデータはFSx for Lustreにあります。

これは、node exporterがPrometheusにメトリクスを送信するように設定した監視ツールの別のスクリーンショットです。ここで見られるのは、GPUの使用率が常に100%であることと、彼らが非常に重視しているCO2排出量も追跡していることです。

まとめると、Hugging FaceがHyperPodを選んだ理由は何でしょうか?彼らには60人以上のデータサイエンティストが同時にクラスターを使用して、多くの異なるジョブを実行しています。彼らのウェブサイトのOpen LLM Leaderboardの評価を行うジョブは、毎日Slurmジョブとして提出されています。また、いくつかのトレーニングジョブも同時に実行されています。HyperPodを使用することで、彼らは全員でこの同じキャパシティを共有し、100%の利用率を達成できます。なぜなら、キューには常に次のジョブが待機しており、計算を実行する準備ができているからです。
前述の耐障害性は彼らにとって重要な要素でした。障害が発生した際にトレーニングジョブを素早く一時停止し再開できるため、多くの時間と高価な計算リソースを節約できるからです。最後に重要なのは、このソリューションを本当にカスタマイズできるという点です。デバッグのために任意のノードにSSHでアクセスし、監視やデバッグ用の独自ツールをインストールできるため、大きな自由度を持って反復作業を行うことができます。
HyperPodの自動修復機能:Llama 2トレーニングのデモンストレーション

以上で私の説明は終わりです。次は、自動修復のデモンストレーションに戻りましょう。 これまで話してきたように、SageMaker HyperPodは、

私たちが提供する管理されたベネフィットは、このような基盤モデルを開発するお客様が、イノベーションや新しいモデルアーキテクチャ、新しい最適化に集中できるようにすることを目的としています。インフラストラクチャの管理やハードウェア障害への対処に時間を費やす必要がないようにするためです。これがどのように機能するかについて多くの話をしてきましたが、実際にそれを動作中に見てみましょう。これからデモをご覧いただきます。FSDPを使用したLlama 2の事前学習のデモンストレーションを行います。
すでにトレーニングスクリプトを準備しています。sbatchを使用してジョブを投入します。ここで見ていただくのは、ハードウェア障害を引き起こし、Amazon SageMaker HyperPodがその障害から自動的に回復する様子です。ここで、sbatchを使用してトレーニングジョブの投入を開始しています。これは私たちのトレーニングコードを呼び出します。まず、トレーニングコードを見てみましょう。これは典型的なsbatchコマンドで、すべてのトレーニングコードが含まれています。このトレーニングジョブの実行には2つのノードを使用します。
ここでは、Llama 2のトレーニングパラメータを見ています。いくつかのパラメータを変更しますが、100ステップごとにチェックポイントを作成します。後ほど、自動修復機能によってこれがどのように再開されるかを見ていきます。この特定のワークロードの自動再開を有効にするために、auto-resume=1を追加します。これにより、エージェントがハードウェア障害を検出した場合、HyperPodにそのワークロードを自動的に再開するよう指示します。これはお客様が必要に応じて有効または無効にできる機能です。データ処理ジョブの場合、耐障害性はそれほど重要ではないかもしれませんが、大規模なトレーニング実行の場合は有効にすることができます。
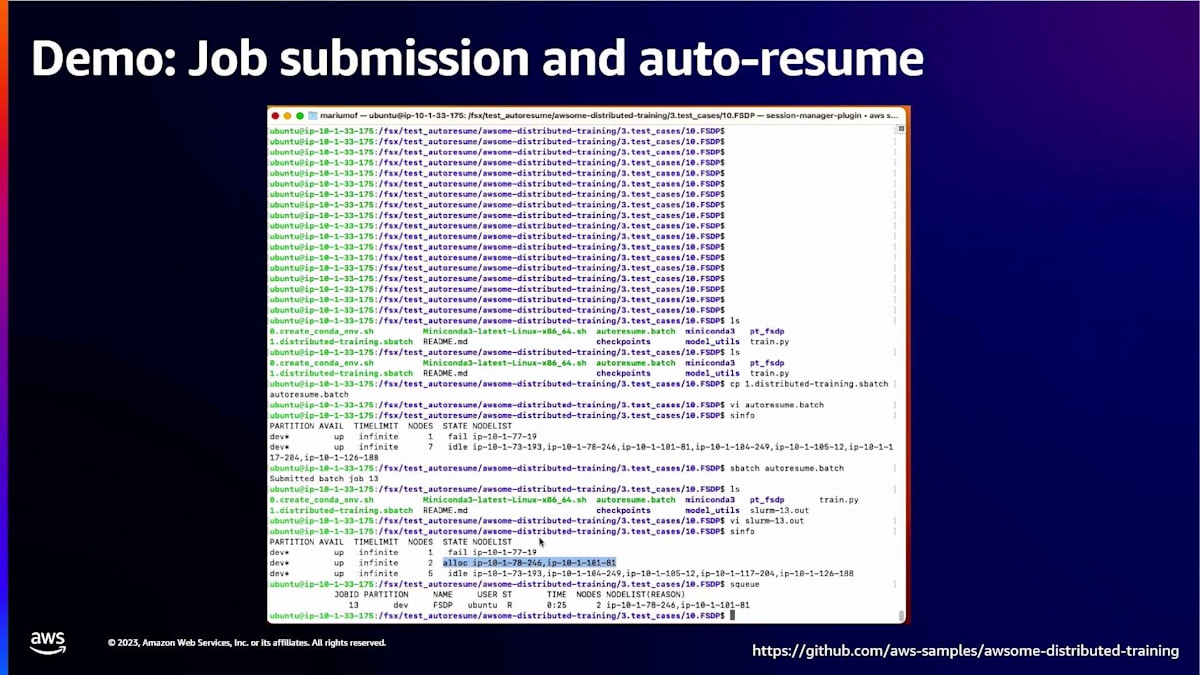
これからジョブを投入しようとしています。ここでは、すでにHyperPod上で実行中のクラスターがあります。8つのノードがあり、7つがアイドル状態で、1つが障害状態です。2つのノードのジョブを投入します。Slurmにsbatchを投入します。ジョブが投入され、sinfoを再度実行すると、2つのノードが割り当てられたことが分かり、出力ファイルに生成された出力が表示されるはずです。
ここで、その出力ファイルを見始めています。sinfoを再度実行すると、今度は2つのノードが割り当てられていることが分かります。ノード識別子がIPアドレスをリストしていることに注目することが重要です。自動修復機能を通じて、新しいノードが入ってくるのを見ることになります。ジョブの開始時に使用したノードに関する情報を記録しています。それらのIPを記録しています。後ほど比較を行い、HyperPodによって自動的に新しいノードが置き換えられたことが分かるでしょう。


さて、トレーニングジョブが実行中です。損失が減少し始めているのが見えますね。 モデルが反復を進めるにつれて、他のすべてのトレーニングメトリクスも確認できます。予想通り、損失が再び減少しています。実際に起こっているのは、ノードが立ち上がっていることです。DCGM fault injectionを使用しているので、GPUに仮想的な障害を発生させることができます。 そうすると、HyperPodがそれらのインスタンスを実際に置き換えます。
エージェントが起動してインスタンスの置き換えを開始し、Slurmが停止した時点から自動的にステップを再開します。再開用のフラグのおかげで、間違いでなければデフォルトで有効になっていると思いますが、環境変数を使用することもできます。このステップから再開されます。チェックポイントがある場合、例えばここでは100ステップですが、1,000ステップなどでも構いません。お客様によって異なる運用をされると思いますが、最後に保存されたチェックポイントから再開されます。
また、例えばAmazon FSx for Lusterや少なくとも共有スペースの使用、あるいはチェックポイントを共有スペースにプッシュすることをお勧めする理由もここにあります。例えば、Amazon S3やFSx for Lusterに保存できます。スループットとパフォーマンスの観点から、NVMEディスクにプッシュしてからS3に移動することもできます。インスタンスを置き換える必要がある場合でも、それを戻してジョブを復元できます。グラフ上でどのように見えるかについて、Ian、損失曲線について説明してもらえますか?
以前見たトレーニングプロセスの可視化があります。


はい、申し訳ありませんが、ビデオの品質が悪いですね。 通常、そのトレーニング実行では損失が蓄積し始めるのが見えるはずです。しかし、ハードウェア障害が発生すると、ジョブがクラッシュします。 ログ出力ファイルでは、HyperPodのエージェントがハードウェア障害を自動的に検出し、ノードの置き換えを実行しているのが確認できます。これらのログはCloudWatchに出力され、HyperPodを使用しているお客様が、トレーニングジョブの状況やHyperPodが障害からどのように回復したかを理解するのに役立ちます。
HyperPodがハードウェア障害から回復するのにかかる時間について、このlossプロットで確認できます。Llama 2を使用したモデルトレーニングのloss曲線を示しています。ステップ時間ではなく実時間で表示して、回復にかかる時間を示しています。ここで1回目のハードウェア障害が発生し、そしてここで2回目の障害が発生しています。2回の障害を示しています。最初にチェックポイントの保存が行われ、これらのチェックポイント保存はハードウェア障害が発生したときに行われます。その直後に、HyperPodが新しいノードを導入した部分が見られます。その後、チェックポイントからリロードしている部分があり、トレーニングが再開されます。ここでお客様の操作は一切必要ありません。
その後、ハードウェア障害に対応できる別のインスタンスが利用可能になっています。平均して、ハードウェア障害が発生した場合、約2〜3分程度で再開しています。これは、例えば今週お話しした、大規模なトレーニングクラスターを運用していたお客様が、不運にもハードウェア障害に遭遇し、3日間ダウンしてしまったケースとは対照的です。特に新製品を市場に投入するためにfoundation modelを開発している場合、foundation modelのトレーニングの進捗に大きな問題となる可能性があります。このように、自動的に回復できることを示しています。
HyperPodの今後の展望:機械学習ライフサイクル全体のサポート

最後に、HyperPodについてもっと詳しく知りたい方、始め方を知りたい方は、ぜひサービスページをご覧ください。今日お話ししたHyperPodの機能や利点について、高レベルの情報が提供されています。また、使用方法に関する豊富なドキュメントも用意しており、表示されているリンクからアクセスできます。さらに、HyperPodを新しい革新的な方法で使用しているお客様についていくつかのブログ記事を既に公開しており、近い将来さらに多くの記事を公開する予定です。
ご想像の通り、ここではfoundation modelのトレーニングについて多く話していますが、データ処理についても言及してきました。推論も、このような環境での新たなユースケースとして浮上しています。私たちは、foundation modelのデータ処理や推論を含む、機械学習モデル開発のライフサイクル全体をサポートしたいと考えています。現在はSlurmをサポートしていますが、将来的には他のオーケストレーターもサポートする予定です。お客様が迅速にイノベーションを起こせる環境を提供しようとしているのと同様に、使用するオーケストレーターについてはあまり固執していません。現在はSlurmをサポートしていますが、将来的にはKubernetesやRayなど、他のオーケストレーターもサポートする予定です。
最後に、アナウンスをご覧ください。Pierre-Yvesが言及したように、先ほど見たFSDPを使用したLlama 2の事前トレーニングの例を含む、素晴らしいリポジトリを作成しました。foundation modelトレーニングのためのHyperPodのアーキテクチャ設計方法、そのような計算環境のセットアップに関する重要な考慮事項やベストプラクティスに加えて、すぐに始められるモデルトレーニングの例など、多くの優れた情報が含まれています。本日はお時間をいただき、ありがとうございました。質問の時間はありますでしょうか?
質疑応答
はい、質問の時間です。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion