re:Invent 2024: AWSのChaos Engineeringアプローチと実践事例
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Chaos engineering: A proactive approach to system resilience (ARC326)
この動画では、AWS ResilienceチームのPrincipal EngineerであるAdrian HornsbyがChaos Engineeringについて解説しています。システムの前提条件を検証する方法論としてのChaos Engineeringの重要性や、Requestsライブラリ、WebRequestメソッド、MySQLコネクタなどのデフォルトタイムアウト設定の問題点が具体的に示されます。AWS Fault Injection Serviceを使用したデモでは、アドホックな実験、GameDay、継続的な実験の3つのアプローチが紹介され、最後にBMW GroupのHrvoje Lukavskiが、2,300万台以上のコネクテッドカーを運用する中でのChaos Engineering実践事例を共有しています。特に、Availability Zone障害実験を通じたMQTTサービスの改善など、具体的な成果が示されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Chaos Engineeringの概要と重要性

皆様、こんにちは。本日は、ストリップの向こう側にあるMandela Bayまでお越しいただき、ありがとうございます。私はAdrian Hornsbyと申します。ResilienceチームのPrincipal Engineerとして、Fault Injection Serviceを担当しています。本日は、私たちのチームのエンジニアであるUlianaと、BMW GroupのHrvoje Lukavskiが同席しており、彼らのChaos Engineeringの取り組みについてお話しいただく予定です。

この会場で、現在Chaos Engineeringを実践している方は手を挙げていただけますか?単なるChaosではなく、Chaos Engineeringについてお聞きしています。実践されている方々の中で、成熟度はどの程度でしょうか?始めたばかりですか、それとも既に進んだ段階にいらっしゃいますか?これは、私がChaos Engineeringについて講演してきた9年間をよく反映しています。多くの関心がある一方で、実際に取り組んでいる人はまだ少ないのが現状で、これは決して簡単な取り組みではないことを示しています。


まず、Chaos Engineeringとは何かについてお話しし、その後デモへと進めていきたいと思います。Chaos Engineeringの公式な定義は、システムに故障を注入する実験の規律であり、混乱した状況からシステムが回復する能力に対する信頼を得ることです。これが標準的な定義ですが、 私は、これを私たちの前提条件を検証する方法論として捉えることを好んでいます。
システムのバイアスとデフォルト設定の落とし穴
私たちは人間であり、私たちのシステムは技術も含みますが、主に人間のシステムです。そして人間には多くのバイアスがあります。システムを構築し、運用する際、確証バイアス、利用可能性バイアス、近接性バイアスなど、あらゆる場所にバイアスが存在し、それらは私たちの意思決定に完全に影響を与えています。過去2ヶ月以内に障害を経験した場合、次に作成する設計文書は、間違いなく直近で経験したことに焦点を当てることになるでしょう。また、新しい技術に関しては、私たちエンジニアは楽しく新しいものを使いたがるバイアスがあります。

基本的に、私たちのシステムはバイアスで満ちており、Chaos Engineeringはそのバイアスを再確認し、前提条件を検証するのに非常に適しています。なぜなら、データや、システムの反応、メトリクスに嘘をつくことはできないからです。私たちの前提条件がいかに設計とシステムを導いているかを示すために - この会場にPython開発者の方はいらっしゃいますか?Requestsライブラリをご存知ですか?これはエンドポイントに対してHTTPリクエストを行うライブラリですが、デフォルトのタイムアウトが設定されています。このライブラリのデフォルトタイムアウトは何秒だと思いますか?10秒、30秒、1分、それとも無限でしょうか?

実は、タイムアウトが設定されていないのです。デフォルトではタイムアウトがありません。つまり、このライブラリを使用する際にタイムアウトをチェックしていない場合、例えばデータベースへの接続は、データベースやシステム、依存関係が自らタイムアウトするまで永遠に開いたままになってしまいます。もし依存関係に何か問題が発生すれば、その接続は失われてしまい、これは非常に深刻な問題となります。

.NET開発者の方はいらっしゃいますか?WebRequestメソッドについて考えてみましょう。デフォルトのタイムアウトは10秒、30分、それとも無限でしょうか?実は100秒なんです。分散システムの世界では、これはかなり問題になる可能性があります。
分散システムにおいて、2分という時間は無限に等しく、その間に多くのことが起こり得ます。リトライストームが発生する可能性もあります。一般的に、ユーザーの待機限界は7.5秒と言われています。タイムアウトを適切に設定せずにユーザーが再試行を繰り返すと、それだけで問題になります。数百万人のユーザーを抱える分散システムでは、100ミリ秒のタイムアウトだけでシステムがダウンする可能性があります。通常、タイムアウトは数百ミリ秒、システムによっては200-300ミリ秒、時にはそれよりもさらに短く設定する必要があります。


MySQLコネクタを使用していますか?デフォルトのタイムアウトはご存知ですか?さあ、よく使用されているデータベースですよ。MySQLを使用している方はいますか?デフォルトのタイムアウトは何秒でしょうか?実は定義されていないんです。ゼロは無限を意味します。これはデータベースコネクタの話です。お分かりいただけたと思いますが、こうした想定が多くの障害の根本的な原因となっています。だからこそ、これらに注意を払うことが重要なのです。決して想定に頼らず、実際に確認することが大切です。
考えてみれば、私たちのシステムには数十から数百の依存関係やパッケージがあり、それらすべてにデフォルトのタイムアウト値が設定されています。タイムアウトに限らず、何らかのデフォルト値が必ず存在します。そのパッケージやライブラリを作成した誰かが、システムの要件を知らないままデフォルト値を設定しているのです。これらを確認しないと問題が発生します。数百もの依存関係がある場合、一つ一つ確認することは現実的ではありませんし、たとえ確認したとしても、時間がかかり、どこかで見落としが発生するでしょう。最善の方法は、システムをテストし、故障を注入して実際に何が起こるかを確認することです。これがChaos Engineeringの本質なのです - 想定を検証することです。
AmazonにおけるChaos Engineeringの実践と規制の影響

みなさんの中で、システム障害のおかげでシニアエンジニアになった方はどのくらいいらっしゃいますか? 私たちが学ぶ最も大きな教訓は、通常システム障害から得られるものです。私自身の経験を振り返ると、失敗の連続でしたが、だからこそいつも話題にしているんです。システム障害を数多く経験することで、シニアエンジニアになれたと感じている方はどれくらいいますか?間違いなく、システム障害を多く経験すれば経験するほど、より優れたシニアエンジニアになれると私は確信しています。

10-15年前は、システムの回復力や信頼性が今ほど高くなかったため、復旧スキルを練習する機会が多くありました。コマンドラインは完璧に暗記していましたし、チームの60-70%がクラウドでの運用を担当していました。Auto Scalingやマネージドサービスなどは存在せず、それらはすべて私たちが手作業で行わなければならない仕事でした。しかし現在のシステムははるかに回復力が高くなり、何ヶ月もシステム障害が発生しないこともあります。数ヶ月もスキルを使用しないでいると、スキルが衰えてしまいます。つまり、忘れてしまうということです。そして、忘れてしまうと、問題が発生したときに対処方法を思い出すのに多くの時間がかかってしまいます。Chaos Engineeringは、経験を圧縮するアルゴリズムのようなものだと私は考えています。継続的にスキルを練習し、新しいスキルを発見し、技術を失わないようにすることができるのです。

なぜこれらのことを気にかける必要があるのでしょうか?いくつか例を挙げましたが、ビジネスの観点から見て、なぜ重要なのでしょうか? その大きな理由の一つは、システム障害のコストが非常に高額だからです。企業の90%において、システム障害のコストは約30万ドルにも上り、さらに41%の企業では、ダウンタイム1時間あたり100万から500万ドルのコストがかかります。これは私の推測ではなく、2024年の調査結果です。復旧訓練を実施している企業は、実施していない企業と比べて、システム障害1時間あたりのコストが16分の1で済むのです。このことからも、大きなインセンティブがあることがわかります。

企業にとって、より迅速な復旧を実現することには大きなメリットがあり、その最善の方法は復旧の練習を重ねることです。このグラフに示されているシステム障害の解剖図を見ると、検知、評価、対応、復旧、確認という段階があります。右側の4つのステップ、つまり評価から確認までは、非常に人間主導のプロセスであり、練習が必要です。これらの作業に時間がかかれば、それだけシステム障害は長引き、コストも増大することになります。

Amazonでは2000年代初頭から何らかの形でChaos Engineeringを実施してきました。これを始めたのは、写真に写っているJesse Robbinsです。彼は消防士としてのキャリアを持ち、Master of Disasterという素晴らしい肩書きを持っていました。彼は消防士としての経験を活かし、GameDaysというプログラムを立ち上げました。AmazonのGameDaysは、Chaos Engineeringを使用して復旧スキルを練習するプログラムです。彼はこれを使って運用チームに迅速な復旧を訓練し、それは2000年代初頭から続いています。現在でも、すべてのサービスのすべての機能リリースに対してこれを実施しています。Operational Readiness Reviewと呼ばれるレビューがあり、そのレビューでは定期的なGameDaysの実施が義務付けられています。
Chaos Engineeringの実験手法とデモンストレーション


Amazonでの GameDays の詳細、その起源や計画方法についてさらに知りたい方は、2011年の Jesse Robbins のプレゼンテーションへのリンクを添付しておきました。これは絶対に皆さんにご覧いただきたい素晴らしいプレゼンテーションです。Chaos Engineering を行うもう一つの理由は規制です。ここ数年、金融サービス業界で Chaos Engineering の導入が急増しており、規制によってそれが必要とされているため、現在では Chaos Engineering の発展を牽引していると言えるほどです。欧州では来年から DORA が施行され、企業は Chaos Engineering や災害復旧を含むレジリエンス演習の実施が義務付けられます。これは自動車業界にも適用され、BMWが Chaos Engineering に取り組んだ大きな理由の一つとなっています。


規制対象となる分野で事業を展開している場合、特に注目すべき点です。Chaos Engineering について理解しておくべき重要なポイントの一つは、開始と終了が明確な標準的なプロジェクトとは大きく異なるということです。これは時間とともに複合的に発展していくものであり、今日始めて6ヶ月後に終わるというような性質のものではありません。実際には決して終わることのない継続的なプロセスなのです。現在のサイバーセキュリティと同じように、Chaos Engineering も戦略の継続的な一部として捉えるべきです。BMWは、このような長期的な計画と Chaos Engineering の視点について、経営陣のサポートを得るためのヒントを共有する予定です。
これは一般的な企業の Chaos Engineering における成熟度の進展を示しています。最初の導入から始まり、学習を経て、FMEA(Failure Mode and Effects Analysis:故障モード影響解析)と呼ばれるものを実施します。これは非常に重要で、実験の前後に行うことが Chaos Engineering で最も重要な部分だと言えるかもしれません。実験自体は素晴らしいものですが、学習の大半は実験の前後で発生します。故障モード影響解析と実験後の振り返りこそが、学びが得られる場面です。これが企業が Chaos Engineering を採用する典型的な方法です。今日は、アドホックな実験と GameDays、そして最終的には継続的な実験に焦点を当て、これらについてのデモをお見せする予定です。
故障モード解析について話したいと思います。これは、システムに対してどのような実験を行いたいかを決定し、始めるための重要な部分だからです。AWSのチームと作業を行い、運用準備レビューを実施する際、私はこれら3つのカテゴリーの障害について考えることにしています。というのも、システムの潜在的な問題を考える上で、非常に優れたフレームワークを提供してくれるからです。


最初の一つは障害分離境界です。これはアプリケーションの潜在的な影響範囲、つまり障害がどの程度広がるか、あるいは制御されるかを定義します。バタフライ効果という言葉をご存知でしょう。障害分離境界は、1つのコンテナの障害がクラスター全体に影響を及ぼし、さらにサービス全体に影響を与えるような連鎖的な障害を防ぐのに役立ちます。連鎖的な障害と障害分離境界について考えることは、アプリケーションの設計において非常に重要です。したがって、テストを考える際や、どのような実験を行いたいかを考える際にも重要になってきます。

2番目は依存関係についてです。タイムアウトについてはすでにお話ししました。依存関係は常にシステム障害の要因となっており、これは決して止まることはありません。依存関係は増える一方で、APIを通じたサードパーティへの依存だけでなく、パッケージの依存関係も含まれます。NPM installを実行したり、大量のパッケージをダウンロードしたりする際、それらすべてが独自のデフォルト設定や問題を抱えた依存関係となり、いずれ対処が必要になります。そして、バイモーダル動作についてですが、これは私の個人的なお気に入りです。これは異なる条件下でシステムが全く異なる動作をする状況を表しています。最も分かりやすい例がキャッシュシステムです。キャッシュシステムでは、通常リクエストがキャッシュに送られます。ヒットした場合は値が返されます - これが1つ目の動作モードです。しかし、キャッシュがミスした場合やキャッシュが失敗した場合は、データベースにアクセスします - これが2つ目の動作モードです。同じリクエストに対して2つの動作モードが存在し、キャッシュ使用時はレイテンシーが効率的ですが、データベースにアクセスする場合はパフォーマンスが低下します。

これがデモで使用するアプリケーションのアーキテクチャ図です。比較的シンプルな構成になっています。皆さんもAmazon ElastiCacheについてはご存知かと思います。これは、Auto Scalingグループを含むマネージドキャッシュサービスです。基本的に、複数の場所にまたがるアーキテクチャとなっています。インスタンスがあり、データベースにアクセスするためのVPCエンドポイントがあり、その間にキャッシュが配置されています。ElastiCacheは一時的なデータレイヤーとして、Amazon DynamoDBは永続的なデータレイヤーとして機能し、Application Load Balancerがトラフィックを受け取って複数のAvailability Zone間で分散します。
障害モード分析の観点から、フォールトアイソレーション境界、依存関係、バイモーダル動作について考えると、どのようなフォールトアイソレーション境界があるでしょうか?明白なのは、多くのお客様が最も重視するAZアイソレーションのテストです。ElastiCacheは、キャッシュのヒットとミスに応じてバイモーダルな動作を示します。マルチリージョンシステムの場合、Chaos Engineeringを通じて、あるリージョンの影響が他のリージョンに影響を与えるかどうかを検証する必要があります。他のリージョンへの依存関係はありますか?これは、マルチリージョンのワークロードを持つお客様が確認したい点です。他にもいくつかありますが、最も見落とされがちなのはプロセスです。
コンテナはすべてフォールトアイソレーション境界です。プロセスについて考えてみましょう。プロセスが失敗した場合、その影響はプロセス空間内に閉じ込められる必要があります。コンテナを停止させたり、クラスターを停止させたり、障害を伝播させたりしてはいけません。つまり、本当に小さな単位から始める必要があります。また、Auto Scalingグループも明確なフォールトアイソレーション境界であり、Auto Scalingグループに影響を与えた場合や、Spotインスタンスで発生する可能性のあるキャパシティエラーなどの障害を注入した場合の影響をテストする必要があります。
依存関係については、明らかにAmazon DynamoDBとAmazon ElastiCacheがありますが、隠れた依存関係もあります。おそらくIAMポリシーや、DynamoDBのデータを暗号化するKMSなどがあるでしょう。図表にはこのような依存関係が示されていないことが多いので、Chaosの実験を行う際には、これらを表面化させて考慮する必要があります。依存関係を、明白なもの、隠れているもの、すべてのリクエストに関係するもの、アプリケーションの初期化フェーズにのみ関係するものなどに分類する必要があります。Secrets ManagerやConfigなど、設定を配布するための依存関係も多数あり、これらについても検証が必要です。
アドホックな実験からGame Dayへの発展


それでは、Ulianaに実際の動作をお見せしていただきましょう。よろしくお願いします。 それでは、Chaosを実際に見ていきましょう。まずはアドホックな実験から始めていきます。アドホックな実験は、アプリケーションにおける未知の未知を発見するための直接的なアプローチです。数ヶ月前にこのデモの準備を始めた時、Chaos Engineeringの実験を見せるためにどんなアプリケーションを作るべきか考えていました。そこで分かったのは、Chaos Engineeringは既存のアプリケーションのテストだけでなく、新しい技術を学ぶのにも役立つということです。というのも、このデモアプリケーションにECSサービスを選んだからです。

私はこの技術にあまり詳しくなかったのですが、Chaos Engineeringの実験を繰り返し行うことで、多くのことを学ぶことができました。これこそがChaos Engineeringの力なのです。では、アドホックな実験を始めましょう。Adrianが既に説明した、GETとPUT APIエンドポイントを持つサンプル商品カタログアプリケーションのアーキテクチャを使用します。詳しく見ていきましょう。
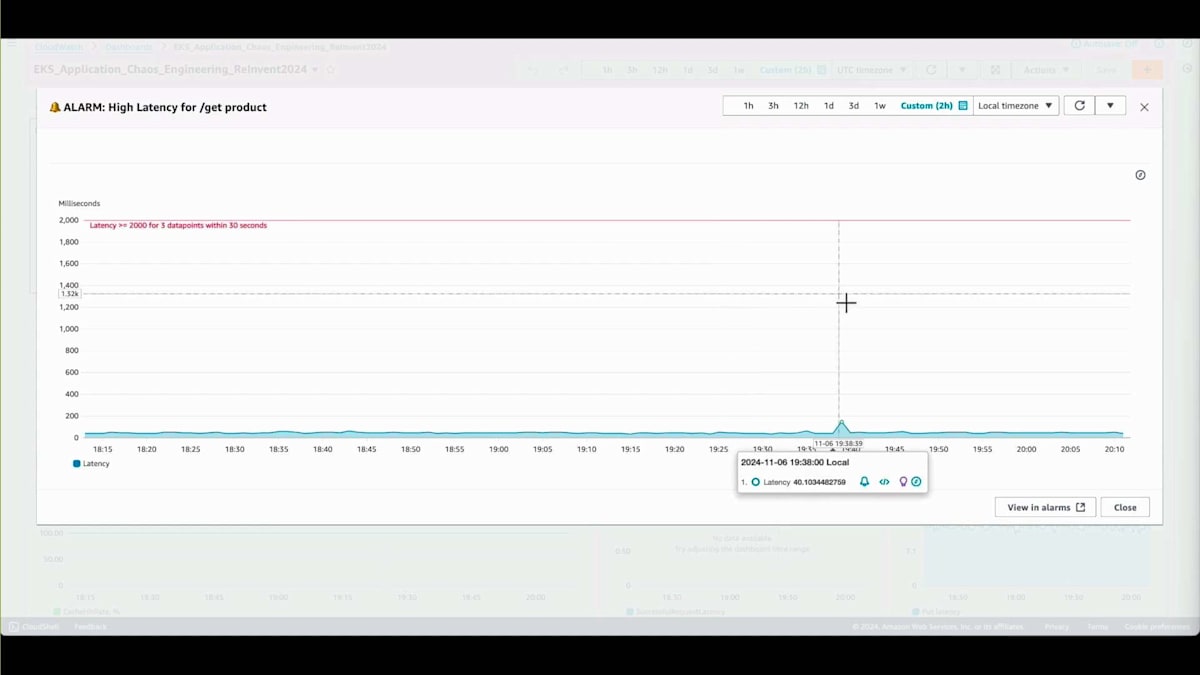

まず、定常状態を定義することから始めます。定常状態を定義する必要があるのは、Chaos Engineeringの実験を実行する前と実行中でアプリケーションの振る舞いがどう変化するかを比較し、何か問題が発生したかどうかを特定するためです。 このアプリケーションの運用ダッシュボードを見てみましょう。ここにカスタマーメトリクスがあります。まず、これらはビジネスメトリクスです。1つ目は、GET製品APIの高レイテンシーに関するアラームです。ここで重要なのは、レイテンシーがしきい値をはるかに下回っているということで、これは素晴らしい定常状態です。


このエンドポイントのカスタマー成功率は100%で、キャッシュヒット率も100%です。つまり、データは完全にキャッシュから取得されているということです。ここで興味深いことが分かります。アプリケーションの永続層であるDynamoDBへのクエリレイテンシーにデータが表示されていないのです。 これは、このGETリクエストAPIのバイモーダルな動作が完璧に機能していることを意味します。通常の操作では、データはキャッシュからのみ取得され、DynamoDBは関与していません。これが定常状態です。
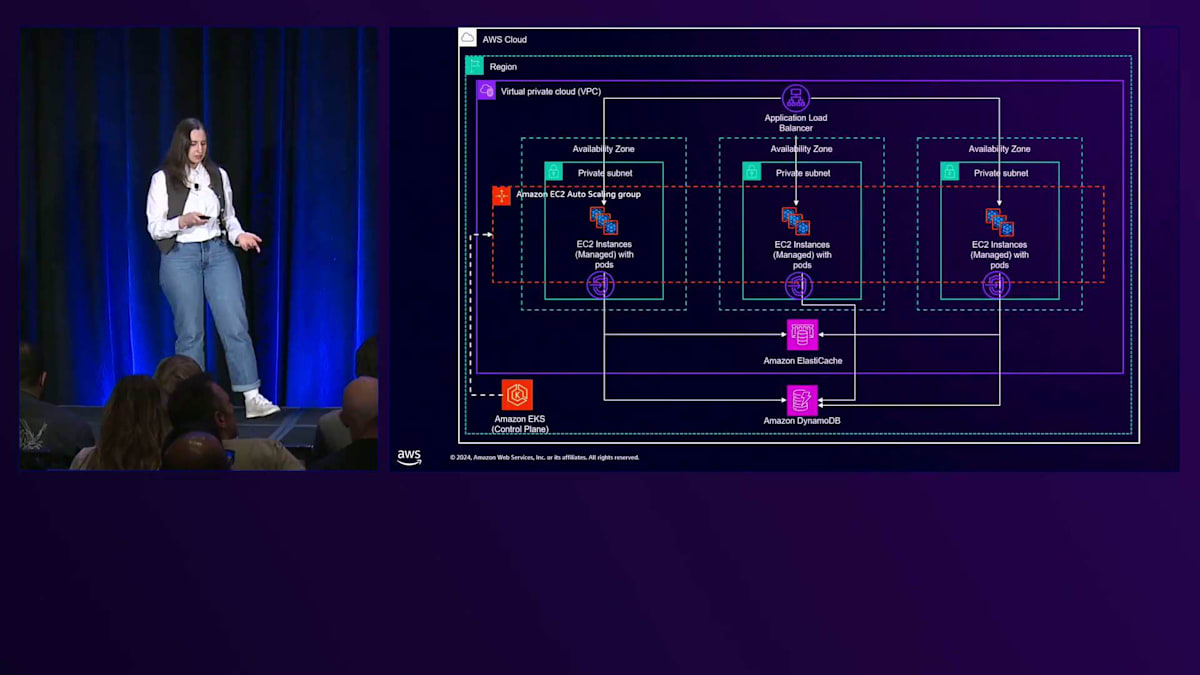
次に、Chaos Engineeringのテスト中に検証したい前提条件を特定していきます。 このアーキテクチャ図に戻ってみましょう。ここには、Application Load Balancer、3つのAvailability Zone、そしてElastiCacheとDynamoDBが見えます。

このアーキテクチャに基づき、GETリクエストAPIはまずElastiCacheからデータの取得を試みます。ElastiCacheにデータが存在しない場合は、Adrianが説明したように、DynamoDBにアクセスします。これが、私たちが検証したい前提条件です。アドホックな実験の中で、マイクロサービスのPodがElastiCacheにリクエストを送る際に、追加の遅延を注入します。許容できる遅延は2秒なのに対して、10秒という非常に長い遅延を注入した場合、期待される動作としては、リクエストがDynamoDBに移行してそこからデータを取得するはずです。これが本当かどうか確認してみましょう。




AWS Fault Injection Serviceを使用してカオスエンジニアリング実験を実施します。まず、カオスエンジニアリング実験の設定である実験テンプレートを作成します。説明を入力し、アクションを設定することでこの実験テンプレートを作成します。アクション自体は、注入する障害であり、今回はPodのネットワーク遅延です。この実験は20分ごとに実行されるように設定し、さらにこの実験を実行するために必要な権限も設定しました。
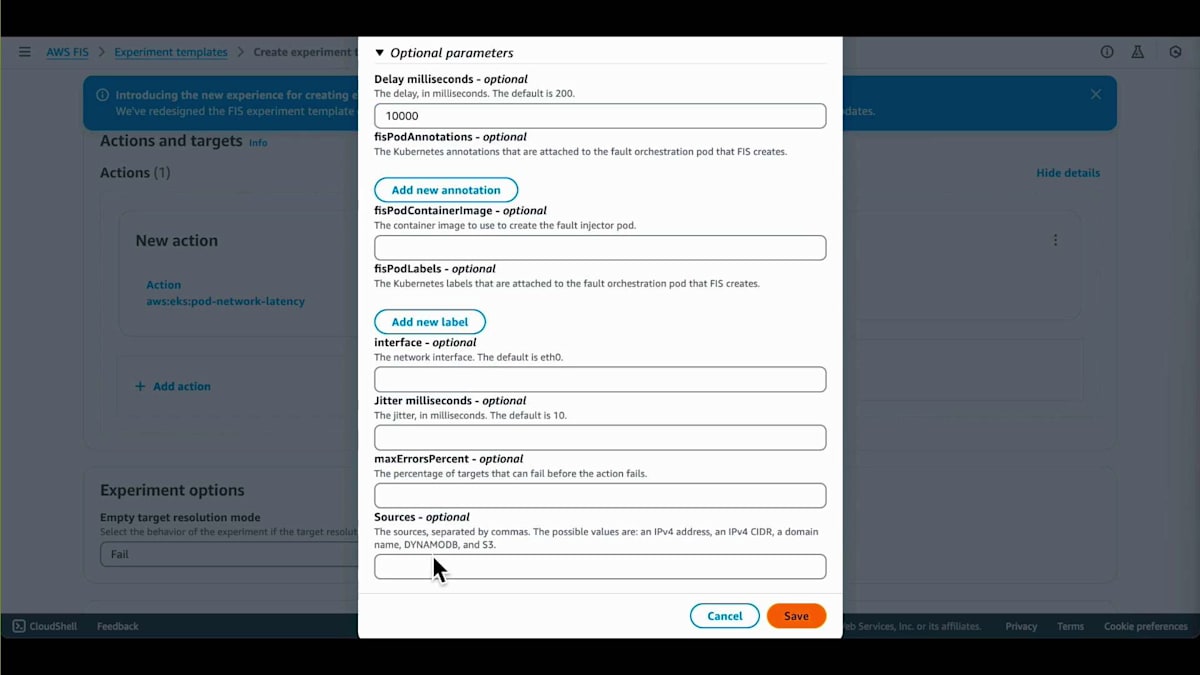
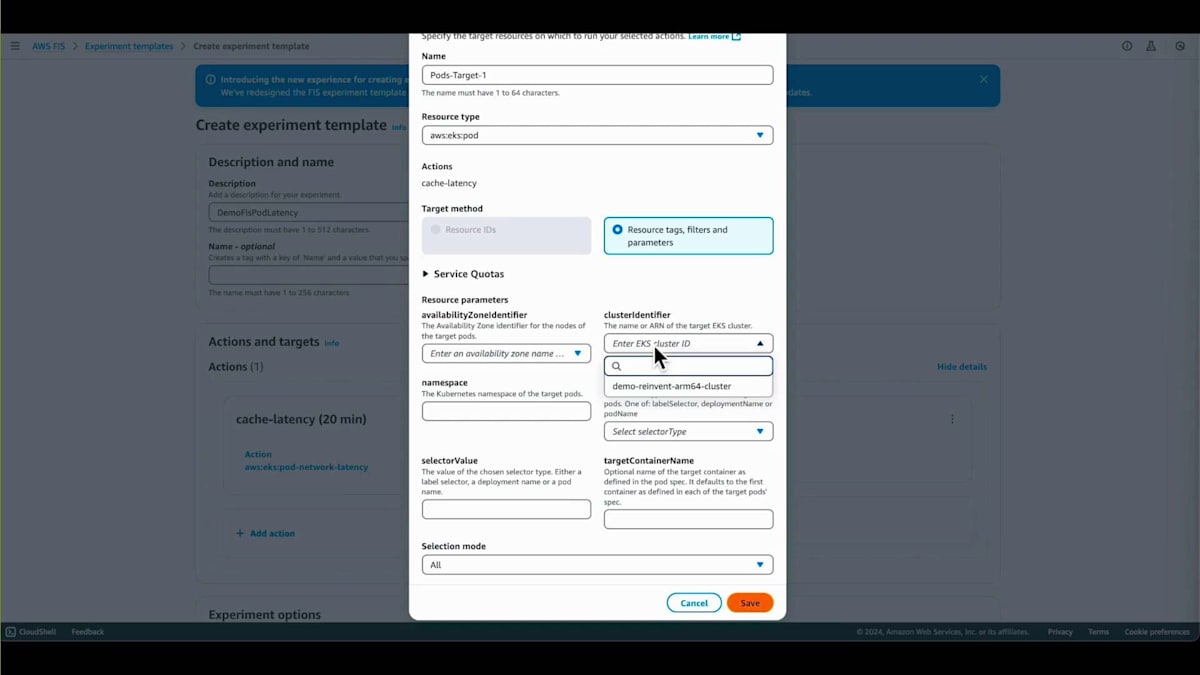



注入する遅延は10秒です。ソースを見ると、これがエンドポイント、つまりキャッシュエンドポイントで、まさにここに遅延が注入されます。ターゲットの設定では、障害注入の対象となるクラスターとPodを指定します。選択したラベルはup for inlineで、これはPodに付けられたラベルであり、実験実行時にPodを特定するために使用されます。次に、実験の権限を設定します。管理者ロールを選択しましたが、これはデモアプリケーション用なので、本番環境では決してこのようなことはしないでください。これらが実験実行のログです。


実験テンプレートを作成したので、実験を開始できます。この時点で、実験が異なるステップを経ていることが確認できます。実行中になると、障害注入がアクティブであることが確認できます。アプリケーションが障害注入に完全に反応できるよう、実験完了まで20分待ちます。その後、分析ステップに移り、障害注入中に何が起こったかを運用ダッシュボードで確認します。

ここが興味深い部分です。実験が完了し、カスタマーメトリクスを確認すると、レイテンシーが非常に高く、閾値をはるかに超える10秒になっており、アラームが発報されています。カスタマーの成功率も良くありません。最も興味深いのは、DynamoDBのリクエストレイテンシーにまだデータが表示されていないことです。これは私たちの前提が間違っていたことを意味します。GETリクエストAPIはDynamoDBに移行せず、キャッシュヒット率が100%であることからわかるように、依然としてキャッシュからの応答を待ち続けていたのです。


ここで興味深い点を見ていきましょう。少し立ち止まって考えてみましょう。なぜこの問題が発生したのか、お分かりでしょうか?リクエストは10秒間待機し、その後でようやくキャッシュからデータを取得していました。なぜDynamoDBにアクセスしなかったのでしょうか?そうです、タイムアウトですね。コードを確認してみましょう。Redisクライアントを確認する必要がありますが、タイムアウトのパラメータが設定されていないことが分かります。


Redisクライアントのドキュメントを確認してみると、両方のタイムアウトプロパティがnoneに設定されていることが分かります。これは、キャッシュからデータを取得するのに必要な時間を無制限に待つという意味です。今回の場合、実験実行中に注入された10秒のレイテンシーを待っていたわけです。そこで、これら2つのプロパティを0.5秒に設定しました。これは、2秒のしきい値を持つデモアプリケーションにとって適切な値です。0.5秒なら問題ないでしょう。そしてアプリケーションを再デプロイしました。




この時点で、最後のステップとして、修正が機能しているかを確認し、さらに新しい発見があるかもしれないので、もう一度プロセスを繰り返します。すでに作成済みの同じ実験テンプレートに移動し、実験を再度実行します。実験が異なるステップを進んでいくのが確認できます。実験が実行状態になったら、アプリケーションがフォールトインジェクションに完全に反応するまで、また20分間待ちます。

完了したら、Operational Healthダッシュボードに移動して結果を確認しましょう。ここでは両方の実験のメトリクスを確認できます。最初の実験ではレイテンシーが非常に高かったのですが、2回目の実行では実際には正常でした。タイムアウトを導入したため、2秒以下に収まっていました。そして、Getリクエストのバイモーダルな動作が正しく機能していることを確認するため、DynamoDBを確認すると、メトリクスが表示されており、データがDynamoDBから取得されたことを示しています。ElastiCacheのキャッシュヒット率を確認すると、実験実行中は0%でした。これは実験が成功し、アプリケーションが修正後に期待通りの動作をしたことを意味します。

これがアドホックな実験の簡単な例です。仮説を立て、アプリケーションにアクセスし、AWS Fault Injection Serviceで実験を実行し、その結果を確認します。この時点で、多くの知識を必要としないアドホックな実験は完了しましたが、次はカオスエンジニアリングのより包括的なアプローチであるGameDayに移ります。Adrianも既にGameDayについて言及しましたが、これは定期的なプロセスで、ランブックのテスト、アラームが適切に設置され設定されているかの確認、そして問題が発生した際にオンコール担当者が実際にランブックに従って問題の所在を理解できるかを検証するものです。
継続的な実験とChaosパイプラインの導入

本日は、組織が始めようとする際の GameDay のエンド・ツー・エンドのプロセスを簡単にご紹介します。 GameDay のプロセスは単なるドキュメントです。これは、このデモアプリケーション用に作成したドキュメントの例で、GameDay で達成したいことを記述しています。計画段階、実行、分析とレポートの3つのフェーズがあります。GameDay の計画段階では、実際に何をしたいのかを記述します。今回の場合、障害分離をチェックしたいので、AWS Fault Injection Service で利用可能な AZ Availability Power Interruption シナリオを使用して可用性の低下をテストします。このシナリオは、Availability Zone に存在するすべてのリソースに対してあらかじめ定義された実験テンプレートです。ここでのアクションは、Availability Zone の完全な中断が予想される症状を注入することです。この計画段階で立てた前提は、マルチAZアプリケーションを構築したという考えから、顧客への影響は見られないはずだということです。1つの Availability Zone に障害が発生しても、まだ2つの正常な Availability Zone があるからです。実行段階では、GameDay の実行方法を記述します。これは AWS FIS CLI コマンドで、実験を開始するためのコマンドです。このコマンドで実験を開始すると、GameDay が始まります。


GameDay 実行後の分析とレポートフェーズでは、GameDay から得られた成果と学びを定義します。これが GameDay のプロセスです。次のステップは、アプリケーションの定常状態を確認することです。 Get Product と Put Product API に関する顧客メトリクスを使って、アプリケーションの定常状態を比較できます。メトリクスは高い内部障害率を示していますが、定常状態では、このデモアプリケーションの仮想顧客は満足していることがわかります。両方の API で顧客成功率は100%で、キャッシュヒット率も100%となっており、アプリケーションが正常に動作していることを示しています。右側には、Availability Zone ごとにグループ化された3つのメトリクスグループがあります。各グループは、それぞれの Zone で正常なターゲットが何個あるかを示しており、各 Zone に1つずつ正常なターゲットがあることがわかります。




この時点で、次のステップである実際のプレイに移ることができます。プレイとは GameDay を実行することで、通常はカオスチャンピオン、もしくは AWS の場合は、プライマリのオンコール担当者がイベントにどのように対応するかを測定するために GameDay を実行する人が行います。では、GameDay を開始しましょう。この例では、 GameDay プロセスにあった CLI コマンドを使用して実験を開始しました。 これにより AWS Fault Injection Service の実験実行が開始されました。レスポンスからその ID を取得して、 FIS ツールでその ID を検索し、現在アプリケーションで利用可能なリソースを確認しています。

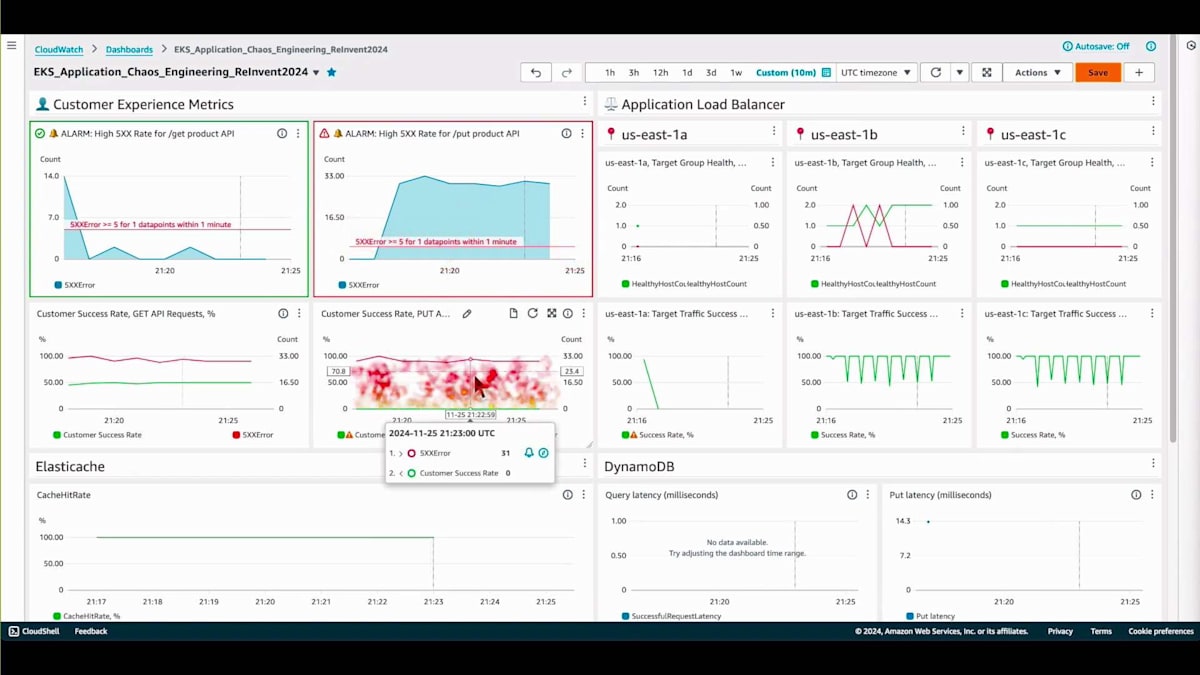

オペレーショナルヘルスボードに戻ると、多数の5XXエラーが発生していることを示すアラームが発報しているのが確認できます。 顧客成功率も0%で警報が出ており、ページングが発生します。オンコール担当エンジニアにインシデントに関するメッセージが送信されます。ページを受け取った後の最初のステップは、アラームを確認することです。 Cloud アラームダッシュボードには、このインシデントが発生した場合の対処方法、問題の調査方法、取るべきステップについてのガイダンスが記載されています。このガイドは、Runbook へのナビゲーション、特定のセクションの確認、必要なアクションの実行を支援します。





GameDay の実行中は、問題を調査する時間です。これは通常、オンコール担当エンジニアが行います。調査を開始し、 アラームページで案内された Runbook を確認します。Runbook の症状を確認して、現在発生している問題と同じかどうかを検証し、システムが実際に一致することを確認できます。次に、 オンコール担当エンジニアがチェックすべき手順が含まれているルートコース分析チェックリストを確認します。対策手順の中にログへのリンクがあり、それを確認すると興味深いエラーが見つかりました:us-east-1a ゾーンの DynamoDB VPC エンドポイントへの接続タイムアウトです。これが問題なのは、us-east-1 a ゾーンが、この実験中に障害が発生しているゾーンだからです。その後、アプリケーションのすべてのインスタンスに配布されている設定ファイルを確認すると、このエンドポイントがすべてのゾーンに対してハードコードされていることがわかります。つまり、アプリケーションが異なるゾーンに存在していても、以前のゾーンへの接続を試みることになります。

それでは、Game Dayを締めくくり、問題を視覚的に確認してみましょう。ここに3つのAvailability Zoneが見えます。最初のゾーンは障害が発生していましたが、他の2つは正常な状態でした。


しかし、2つのゾーンが正常であったにもかかわらず、これらは依然としてus-east-1aの障害が発生していたDynamoDB VPCエンドポイントに接続しようとしていたため、機能しませんでした。DynamoDBに到達することは不可能でした。解決策の1つとして、インスタンスが配置されているゾーンのDynamoDB VPCエンドポイントにintra接続する方法が考えられます。これが1つのアイデアです。このGame Dayは、開発チームへの課題チケットを発行し、開発プロセスとリリースプロセスを経てバックフィックスを行うという形で終わることになるでしょう。



これでGame Dayは終了し、次は継続的な実験に移ります。アドホックな実験に満足し、それらの実験をスケジュールで実行したい場合は、スケジュール実験を行うことができます。この機能はFault Injection Serviceで利用可能です。Chaosパイプラインについて説明した後で、簡単なデモをお見せします。実験をリリースパイプラインに追加することは望ましくないかもしれません。実験の実行に十分な時間を確保したい場合があるためです。また、リリースパイプラインとは異なるワークロードで実験を実行したい場合もあるでしょう。このために、別個のChaosパイプラインを使用できます。



最後に重要なのは、AWSでのオンコール体制です。定期的にGame Dayを実行する二次オンコール担当者がいて、Runbookが最新の状態であること、オペレーションが適切であること、そしてオンコール担当者がRunbookに従って問題を解決できることを確認します。では、実験のスケジュール方法について簡単なデモをお見せします。AWS Fault Injection Serviceでは、これがGame Dayで使用した実験テンプレートです。新しいスケジュールを作成し、説明を追加し、実験を実行する頻度を設定します。例えば、24時間ごとに実行するように設定してみましょう。開始時刻を設定し、権限を付与すれば完了です。これで実験は定期的に実行されるようになります。
BMW GroupにおけるChaos Engineeringの実践事例


デモはここまでです。次に、BMWからLexをお招きして、彼らのChaos Engineeringの取り組みについてお話しいただきます。ありがとうございました。皆様が私たちと同様にre:Inventを楽しんでいただけていることを願っています。また、最初の2つのパートが興味深いものであったことを願っています。私のニックネームはLexですが、本名はHrvoje Lukavskiです。BMW Groupから来ました。私はConnected Vehicle Platformのアーキテクトおよびプロダクトオーナーとして、CI/CDオファリングを担当しています。私たちの知見を共有させていただきます。BMWでは、スピード、パフォーマンス、そして運転する喜びに情熱を注いでいることはご存知かと思います。多くの方が、私たちが頻繁に宣伝している「Freude am Fahren」(運転する喜び)というフレーズをご存知だと思います。

私たちは、ますますソフトウェア主導の企業になりつつある中で、車に対する情熱をデジタルサービスにも反映させたいと考えています。スライドでご覧いただけるように、車内でのビデオストリーミング、位置情報サービス、リモートソフトウェアアップグレードなど、多くの魅力的なサービスを提供しています。実際にはもっと多くのサービスがありますが、今日は特にこれらをハイライトとしてご紹介したいと思います。また、これらのサービスがいかに複雑で、車両とバックエンドサービスを提供するシステムとの接続性において完璧さが求められるかを、いくつかの数字でご説明したいと思います。約20年前、私たちは最初のコネクテッドカーをリリースしました。現在、2,300万台以上のコネクテッドカーを運用しています。毎日、
世界中で900万台以上の車両をアップグレードしています。2,300万台以上という数字は、地球上で最大のコネクテッドカーフリートを意味します。これらのアップグレードは1日あたり197テラバイトのデータ量に相当し、毎日140億件のリクエストを処理する必要があります。ここで、私たちが信頼性とレジリエンスを非常に重視している理由がお分かりいただけると思います。この点については後ほど詳しくご説明します。現在、100個のAWSアカウントに1,300以上のマイクロサービスが分散しており、約99.95%の信頼性を達成していますが、これを維持しさらに向上させることを目指しています。




2020年頃、私たちは最初のオンプレミス環境でのスキル実験を実施しました。このオンプレミスでのスキル実験では、レジリエンスとフェイルオーバー機能をテストするために、実際に誰かがコンセントからプラグを抜くという方法を取りました。本番環境で実際にプラグを抜くという体験は、かなり興味深いものでした。オンプレミスからAWS Cloudへの移行に伴い、2023年頃には、アーキテクチャが大きく変更されたため、重要なコンポーネントを特定する必要が出てきました。


これらのコンポーネントを特定する過程で、クラウド環境でこのテストアプローチをどのように再現できるか検討していました。より洗練された方法が必要でした。そこで私たちは、AWS Fault Injection Serviceが提供するAZ Power Outageというブループリントを発見し、これが私たちのニーズに完璧にマッチすることがわかりました。現在までに、本番環境で11回のカオス実験を成功裏に実施しています。2025年には、これを10倍に増やし、本番環境で数百回のカオス実験を実施することを目指しています。これを実現するために、自動化を進め、サービスオーナーがポータルを通じて必要な実験を選択し、自身の環境で数百の小規模な実験を実行できるようにする予定です。

カスタマーアカウントとアーキテクチャの詳細に入る前に、私たちのプラットフォームについてご説明したいと思います。私たちは、すべての開発チームのための中央ビルディングプラットフォームとして、Orbitというクラウド開発者プラットフォームを持っています。このプラットフォームにより、1,300のマイクロサービスすべてに対して、一元的に安定性を高め、レジリエンスを向上させることが可能になります。このプラットフォームは、CI/CD、分析とロギング、コンピューティングとネットワーキング、その他様々なコンポーネントで構成されています。すべてのバックエンドサービスがこのプラットフォームに依存しているため、そのプラットフォームの成功は私たちにとって極めて重要です。そのため、あらゆる側面を調査するためのカオス実験に多大な投資を行っています。


一般的なAWSアカウントの一例を見てみましょう。ここでご覧いただけるのは、Platform VPCとProduct VPCで構成された一般的な顧客のAWSアカウントです。Platform VPCでは、3つのAvailability ZoneにまたがってコンピューティングにはEKSサービスを使用しており、キャッシュにはEBSボリュームを使用し、サードパーティのバイナリ管理システムをホストしています。Product VPCでは、永続的なデータレイヤーとしてAmazon Auroraを使用しています。

このAmazon Auroraは通常、サービスオーナーチームによって運用されています。マルチAvailability Zoneモードでのフェイルオーバー機能と耐障害性を高めるため、PostgreSQL版のAmazon Auroraを使用しています。ここで私たちが実施したのが、先ほど言及した障害注入実験です。1つのAvailability Zone内でプラットフォームにホストされているすべてのサービスに影響を与えることにしました。
結果として、1つの問題を除いてほぼすべてが正常に動作しました。EBSボリュームがゾーン単位のサービスであるという、よく知られた制限に遭遇しました。具体的には、クラスターが他の2つの正常なAvailability Zoneで新しいノードと新しいPodを立ち上げて回復を始めましたが、ボリュームは影響を受けた別のAvailability Zoneにバインドされたままで、アプリケーションエラーが発生しました。サードパーティのバイナリ管理システムは、回復するまでの15~20分間、大幅な性能低下という最適でない状態で動作しました。この実験で発見した問題を修正する機会を得ることができました。事前にこれを発見し、修正し、改善し、問題を克服し、耐障害性と安定性を向上させることができました。同じような状況が再び発生しても問題は起きないため、その後の引き継ぎもよりスムーズになりました。


では、私たちが用意した2つ目の例をご紹介しましょう。これも非常に興味深い事例です。ここではMQTTについてお話しします。車両と私たちのバックエンドサービス間の通信はMQTTサービスを通じて行われています。このMQTTサービスが問題なく安定して動作することは非常に重要です。MQTTには既製のソフトウェア製品を使用しており、このソフトウェア製品は3つのAvailability ZoneにまたがるEC2インスタンス上でホストされ、相互に接続されたクラスターを形成してすべてのメッセージング要求を処理しています。BMWでは、MQTTはリモートサービスリクエスト、車両テレメトリなどの機能にも使用されています。


もう一度プラグを抜いて、MQTTで何が起きたかをお見せしましょう。MQTTについては、1つのAvailability Zoneのすべてのリソースを終了させ、インスタンス容量不足エラーを注入することで、同じAvailability Zoneでの再起動を防ぐという実験を行いました。ほとんどの部分は予想通りでしたが、特に高トラフィック時に遅延とリトライが観察され、これは車両の数とリクエスト数を考えると非常に危険な状況となります。どのような遅延も許容できません。
私たちはMQTTサービスに使用しているソフトウェアプロバイダーにこの問題を指摘しました。彼らは非常に協力的で、ソフトウェアのデフォルト設定が予期せぬ状況を引き起こしていたため、一緒に解決策の最適化に取り組みました。MQTTのソフトウェアプロバイダーと問題を解決した後、実験を再度実施したところ、Availability Zone間のハンドオーバーが大幅に改善され、想定通りにスムーズに進行することが確認できました。
Chaos Engineering導入の教訓と今後の展望



BMWの事例で最も共有すべき価値があるのは、得られた教訓です。まず第一に、チーム間のコラボレーションが非常に重要です。ナレッジ共有ワークショップの開催や、異なるチームの調整、さまざまな部門を集めることで、私たちが目指していたChaos Engineeringの取り組みが大きく促進されました。 二つ目の発見は、リーダーシップの支持を得ることが極めて重要だということです。本番環境でこのような取り組みを行う際には、リーダーシップのサポートが必要不可欠です。彼らのサポートなしでは、見た目ほど簡単ではありません。 三つ目は、そして最も重要な点は、心理的安全性です。これは私の意見では最も重要な学びでした。失敗を恐れない環境、失敗を学びと改善の機会として捉える環境づくりに投資することを、皆さんにお勧めします。
私のアドバイスは、下位環境での小規模な実験から始めて、自信を築いていくことです。その過程で、徐々に本番環境へと進み、最終的には停電のような非常に複雑な実験(これは私たちが社内で実施した最も複雑な実験です)に取り組むということです。BMW Groupでは、このアプローチを根本的に見直すことで、単純に壁からプラグを抜くような実験から、クラウドでの洗練されたカオス実験へと進化させることができました。これに心理的安全性、チーム間のコラボレーション、そしてリーダーシップの支持が組み合わさることで、私たちが目指していたものが大きく推進されました。

Vice Presidentのdr. Céline Laurent-Winterが素晴らしい言葉で表現してくれました。これは私たち全員にとって真の変革の旅でしたが、ここで止まるつもりはありません。私たちは今、これまでに述べたすべてを活用し、自動化を通じてChaos Engineeringを全く新しいレベルへと引き上げることを約束します。これらの発見を覚えておいてください。私たちは実践しながら学んできましたが、もし事前にこれらのことを知っていれば良かったと思います。

より詳しい情報をお知りになりたい方のために、時間の制約がある本日の発表とは別に、ブログ記事を公開しています。AWSのメンバーとBMW Groupが共同で、本日ご紹介した内容について詳しく執筆しました。QRコードをスキャンするか、後ほどスライドをご確認いただき、ぜひお読みください。より深い洞察が得られると思います。また、発表後も会場に残っておりますので、ご質問がございましたらお気軽にお声がけください。

ご清聴ありがとうございました。私たちの発表から何か学びを得ていただけたなら幸いです。そして、旅こそが目的地であることを覚えておいてください。特にChaos実験においては、最終地点というものはなく、小さな進歩の積み重ねが大切なのです。会場の皆様、そしてオンラインでご視聴の皆様の今後のご活躍を心よりお祈りしております。本日は誠にありがとうございました。それでは、AdrianとDianaにマイクをお返しします。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion