re:Invent 2024: AWSのServerless開発者向けベストプラクティス (SVS401)


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Best practices for serverless developers (SVS401)
この動画では、Serverlessコンピューティングのベストプラクティスについて、AWS LambdaやAWS Fargateなどの主要サービスを中心に解説しています。Amazon EventBridgeのレイテンシー改善による新しいアーキテクチャの可能性や、AWS Step FunctionsとEventBridgeを組み合わせたワークフローの実装方法、Lambda関数のCold startへの対処法など、実践的な知見が共有されています。また、レジリエンス、可観測性、セキュリティ、ガバナンスの観点から本番環境に対応したServerlessサービスの構築方法を詳しく説明し、AWS Lambda Powertoolsを活用した実装例も紹介しています。さらに、組織全体でServerlessのベストプラクティスを展開するためのService Blueprintsやアーキテクチャパターンの活用方法まで、包括的な内容となっています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Serverlessコンピューティングの進化と本セッションの概要

みなさん、こんにちは。目を閉じて、アプリケーションが完璧に動作し、需要の変動に合わせて自動的に適応する未来を想像してみてください。サーバーのメンテナンスも、スケーラビリティの心配で夜も眠れないこともありません。この未来は夢ではなく、Serverlessコンピューティングという現実なのです。Serverless開発者のためのベストプラクティスへようこそ。素晴らしい聴衆の皆様にお会いできて光栄です。別のホテルでも同様のセッションが行われているようですので、ヘッドフォンを着けている皆さんにも手を振っておきましょう。このセッションは後でYouTubeで公開されますので、YouTubeをご覧の皆様も、未来からこんにちは。

Ranが後ほど登場しますが、私たち二人で、皆様にServerlessのベストプラクティスについて有益な情報をお伝えできればと思います。 私はJulian Woodです。AWSのServerlessチームのDeveloper Advocateとして働いており、開発者の皆様がServerlessテクノロジーを使ってクラウドでアプリケーションを構築する際のサポートをすることに情熱を注いでいます。また、皆様の声を社内に届け、製品チームやエンジニアと協力して、皆様がServerlessのベストプラクティスを次のレベルに引き上げられるよう、最高の製品と機能の開発に取り組んでいます。

ベストプラクティスは非常に広範なトピックで、いくつかのセクションに分けて説明していきます。このトークでは多くの内容を扱いますので、その点についてご了承ください。YouTubeでご覧の方は、再生速度を遅くすることができるという利点があります。さらに多くの情報を提供したいと思いますので、QRコードでリソースのスライドを用意しました。スライドや他の多くのリソースと共に、最後に共有させていただきます。このトークは以前のre:Inventでも行われましたが、毎年内容を更新しています。以前のトークをご覧になっていない方は、リソースのスライドにリンクがありますのでご確認ください。
クラウドとServerlessの歴史:AWSサービスの発展



私の考えでは、Serverlessの進化はまさにクラウドの物語そのものです。2006年にAmazon S3やAmazon SQSなどのサービスが登場した時、クラウドはServerlessとして生まれたと言えるでしょう。これは、Amazon EC2のような仮想マシンをレンタルできるようになるよりもずっと前のことでした。私たちは従量課金制で、インフラストラクチャの管理が不要なサービスを次々と追加していきました。 しかし、Serverlessが本当に活気づいたのは2014年でした。AWS Lambdaの登場は革新的でした。コードをクラウドにアップロードするだけで、私たちが安全に実行します。高可用性とスケーラビリティを備え、同じ年にコンテナ管理のためのAmazon ECSもリリースされました。 AWS Fargateの登場により、Serverlessコンテナの実行と管理も可能になりました。



AWS LambdaとAmazon ECSのお誕生日おめでとう!今日は皆で「ハッピーバースデー」を歌おうかと考えていたのですが、Ranが「Julian、ベストプラクティスの内容が多すぎるから無理だよ」と言うので断念しました。 現在では、コンピューティング、ストレージ、ワークフロー、その他多くの統合機能、データベース、分析など、膨大な数のServerlessサービスがあります。これはAWSだけでなく、多くのパートナーも最適なツールを使用できるようServerlessソリューションを提供しています。 これらの名前を見てください。Serverlessはスタートアップから大企業、政府機関まで、あらゆる業界のあらゆる場所に存在しています。 彼らは、Serverlessを採用することで、より迅速にアイデアを試し、顧客の前に製品を届けられることを知っています。


クラウドでServerlessを採用する利点の1つは、自分で何もしなくても常に改善され続けることです。Amazon EventBridgeの場合、時間の経過とともにイベントの配信レイテンシーが劇的に改善され、最大94%も削減されました。実際、イベントの配信が速すぎるため、アプリケーションに問題があるのではないかという問い合わせを受けたほどです。これは単にサービスが改善されただけだと知って、お客様は安心して喜んでいました。 このEventBridgeの変更は、もう1つのパターンを浮き彫りにしています - 変更前はイベントの配信にスパイクが見られましたが、変更後はレイテンシーが低下し、イベントの配信をランダムに待つことなく、より予測可能になりました。
EventBridgeとAppSyncの新機能:非同期通信の実現


クラウドバックエンドからタイムリーな更新を受け取りたいフードデリバリーのモバイルアプリケーションを考えてみましょう。このアプリは注文情報を取得するために複数のサービスに同期的な呼び出しを行い、Frontend-to-Backendパターンを使用して複数のバックエンドと通信する可能性があります。 さらに、フロントエンドに更新を通知する必要のある追加サービスも多数存在します。
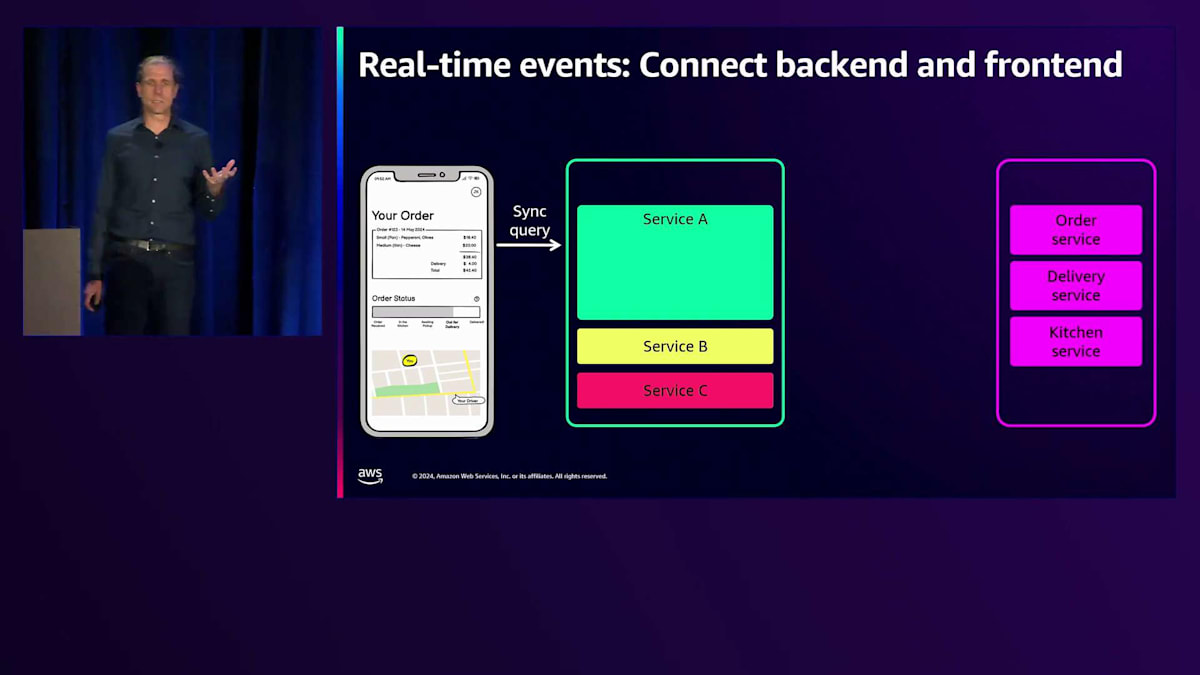


これらのサービスと同期的に通信すると、 繰り返しポーリングを行う必要がある場合、コストのかかるブロッキング呼び出しとなります。これは待ち時間によって悪いユーザーエクスペリエンスを引き起こします。 フロントエンドがポーリングやブロッキング呼び出しを行うことなく、バックエンドサービスからステータス更新を非同期で受け取ることができれば理想的です。
Amazon EventBridgeとAWS AppSyncの間に2つの新しい連携機能があり、フロントエンドがイベントの更新を購読できるようになりました。1つ目のオプションは、GraphQLを使用してイベントをAppSyncに非同期でルーティングすることです。GraphQLは、クライアントが異なるサービスに何度もラウンドトリップすることなく、必要なデータだけを取得できるため、データの集約に非常に強力です。2つ目の連携は、新しいAppSync Events APIに直接接続するもので、シンプルなWebSocket Pub/Subトピックにイベントを簡単に配信できます。GraphQLについて知る必要はなく、単にイベントを送信すれば、フロントエンドのSubscriberがすぐに結果を受け取ることができます。


EventBridgeコンソールでAppSyncターゲットを設定するのは簡単です。コンソールを使用する場合、GraphQLスキーマが表示され、ドロップダウンリストで利用可能なMutationオプションを確認できます。AppSync Eventsを使用する場合、数行のコードでSubscriberを接続してAPIをSubscribeし、APIデスティネーションがそれらのイベントをプッシュできます。一見何気ないEventBridgeのレイテンシー削減が、これらの接続性を向上させ、スピンを減らし、全く新しい一連のユースケースを可能にしています。これにより、高速な非同期のイベント駆動アーキテクチャを実現できるようになりました。
Service-fullなServerless:マネージドサービスの活用



次のトピックは、コードではなく設定を使用し、可能な限りマネージドサービスを活用するService-fullなServerlessについてです。DevOpsの第一人者として知られるPatrick Debois氏や、AWS Serverless HeroのBen Kehoe氏らが、このコンセプトについて語っています。Service-fullとは、アプリケーションがよりServerlessになるにつれて、システムの構成要素として外部サービスへの依存度が高まることを意味します。大規模なコンピュートコードベースにすべてのアプリケーションを集約する代わりに、それらのコンポーネントを個別のマネージドサービスに移行できます。例えば、APIをAmazon API Gatewayに分割することで、キャッシング、ルーティング、認証の処理を任せることができます。

最適なサービスを活用してメッセージの転送と保存を行うことができます。サービスを小規模に分けることで、ネイティブなサービス機能を活用し、重要な部分はAWSに任せることができます。これによりアプリケーションのスケーリングが容易になり、AWSが困難な部分を処理し、アプリケーションに必要な回復性とセキュリティを提供します。多くの場合、コストの削減にもつながります。アプリケーションの分散化が進むにつれて、オーケストレーションとコレオグラフィーをアプリケーションの異なる部分間のコミュニケーションモデルとしてどのように活用できるかを考える必要があります。


独自のコードを書く代わりに、設定として管理します。オーケストレーションでは、中央のコーディネーターがサービスの相互作用と使用順序を管理します。コレオグラフィーでは、中央での制御が少なく、サービス間でイベントが反応的に流れます。多くのアプリケーションでは、異なるユースケースに応じてコレオグラフィーとオーケストレーションの両方を使用しています。オーケストレーションをワークフロー、コレオグラフィーをイベントと考えることができます。AWS Step Functionsは、中央での調整とすべてをワークフローとして管理する優れたワークフローオーケストレーターの例です。一方、Amazon EventBridgeは、厳密な順序付けやワークフローが不要で、中央制御なしでイベントをシームレスに流すことができる優れたコレオグラファーです。

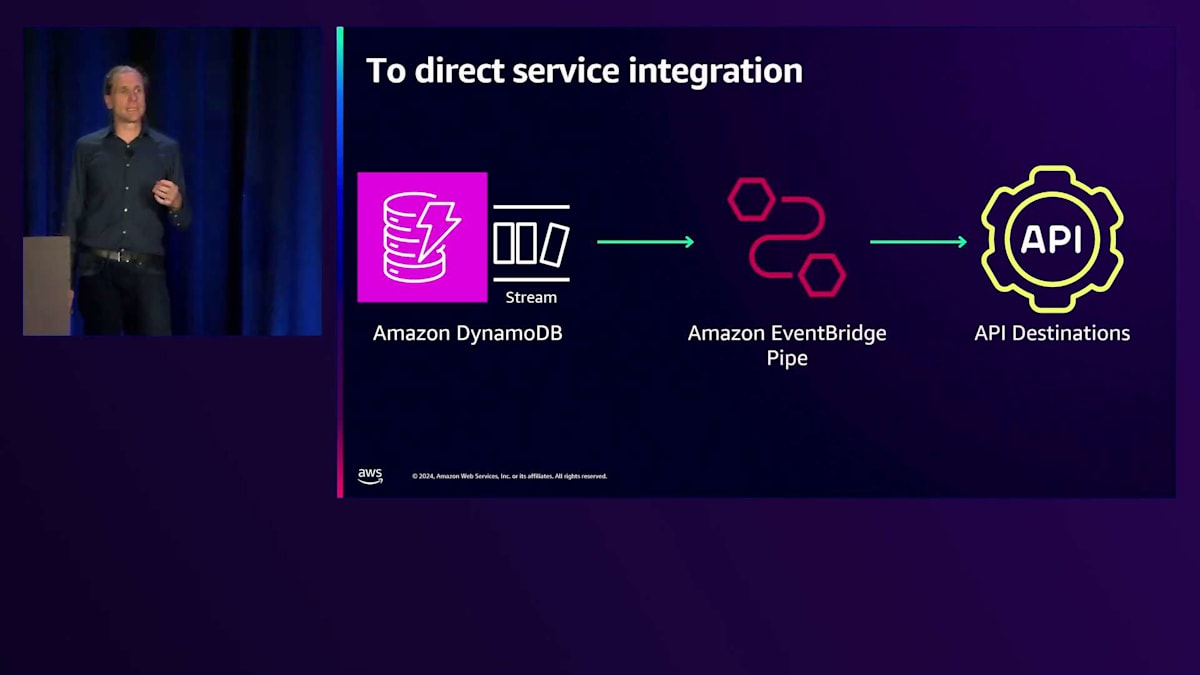
これらのサービスを使用することで、コードを大幅に削減できる機会があります。AWS Lambdaでよく使用されていた一般的なパターンの1つは、Amazon DynamoDBの変更イベントをキャプチャすることでした。左側では、DynamoDBがイベントを渡し、それらを別のサービス、イベントバス、あるいは下流の処理のための別のAPIに送信します。しかし、ネイティブサービスを使用することで、EventBridge Pipesを使用してLambdaを排除できます。コードを管理する必要はなく、PipeにDynamoDBからの読み取りを設定し、API送信先のパラメータを設定するだけです。Pipesが自動的にイベントをAPIに送信し、リトライと認証を処理してくれます。


AWS Step Functionsでは、さらにコードを削減できる機会があります。JSON pathを使用する最近のアップデートにより、これはさらに強力になりました。左側のステートマシンはLambda関数でかなりの論理を実行していますが、その中身を見ると、実際にはほとんどが他のAWSサービスを呼び出しているだけです。このように直接のSDK統合を使用してステップを最適化し、Lambda関数の実行と課金なしで同じビジネスロジックを実装できます。これらの異なるアプローチを組み合わせることができ、ワークフローの内容を完全にコントロールできます。
Step FunctionsとExpress workflows:ワークフローの最適化

ワークフローの内容を完全にコントロールできることは、多くのアプリケーションアーキテクチャにおいて、様々な方法でワークフローを導入できることを意味します。世界中がGen AIアプリケーションの構築に注目している中、多くのGen AIアプリケーションは、他のアプリケーションやアーキテクチャと同じようにワークフローを活用できます。Tool useはGen AIの一部であり、Function callingとも呼ばれ、既存のツールをGen AIエージェントに登録することができます。この例では、在庫データベースに問い合わせて最新情報を取得する内部チェックを呼び出します。このサンプルでは、特定の車種のタイヤ交換の予約を特定の時間に行うというユーザーのプロンプトから自然言語を解析するためにGen AIモデルを使用します。Gen AIモデルは、登録されたツールの中から必要な情報を提供できるものを判断し、フォーマットされたJSONを生成します。

データベースに問い合わせを行い、AWS Step Functionsがワークフローのオーケストレーション、利用可能なツールの登録、そして自然言語プロンプトをLLMに送信して適切なツールとJSONペイロードのレスポンスを受け取る処理を担当します。その後、コードが在庫確認APIを呼び出し、予約をスケジュールし、結果を保存し、完了時にイベントを発行することができます。これは強力なパターンとなり、マイクロサービスのバウンデッドコンテキスト内でStep Functionsを使用し、完了時にイベントを発行することで、ワークフローとイベントの両方を組み合わせた効果的なマイクロサービス間のコミュニケーションが可能になります。


Step Functionsには2つの異なるタイプがあります。Standard workflowsは最大1年間継続可能で非同期的である一方、Express workflowsは高スループット向けに設計された高速なワークフローで、最大5分間実行可能で同期的に実行できます。価格体系も異なり、Standard workflowsは状態遷移ごとの課金、Express workflowsは実行回数と設定されたメモリに基づいて課金されます。Express workflowsは大幅にコストを抑えることができます。例えば、100万回のStandard workflow実行では420ドルかかるのに対し、Express workflowsでは12.77ドルで、実行あたり0.5秒速くなります。既存のステートマシンを見直してコスト削減の可能性を検討し、まずはExpress workflowsの使用を検討することをお勧めします。


さらに良いのは、Standard workflowの中にExpress workflowをネストして、両方を組み合わせて使用できることです。コールバックをサポートする長時間実行のStandard workflowの中に、高速で高スケールなExpress workflowをネストし、それが完了したら親ワークフローに戻ることができます。これは両方の利点を活かす素晴らしい方法で、多くの場合、予算の面でも非常に有効です。
AWS Lambdaの仕組みと最適化:実行ライフサイクルとCold start


カスタムコードを実行する必要がある場合がよくありますが、可能な限りAWS Lambdaを使用しないことを提案しつつも、Serverlessファンクションやコンテナをサービスとして実行することには興味深い機能があります。AWS Lambdaのイベント駆動実行モデルを理解しておく価値があります。何かがInvokeを引き起こすと、アクションを実行するコードを含むLambda関数が実行されます。現在、140以上のサービスがAWS Lambdaと3つの方法でネイティブに統合されています:APIの背後でよく使用されるリクエスト・レスポンス型の同期的な方法、レスポンスを待たない非同期的な方法、そしてAmazon Kinesis、Apache Kafka、Amazon SQSなどのサービスからアイテムを読み取るAWS Lambdaのマネージドポーラーを使用するストリームまたはポールベースの方法(Event source mapping)です。


AWS Lambdaのパフォーマンスは基本的にプラグアンドプレイですが、パフォーマンスの微調整には主にメモリ設定が関係してきます。メモリを設定すると、それに比例したCPUとネットワークスループットが得られます。つまり、メモリが多いほどCPUも多くなります。AWS Lambdaでは、128 MBから10 GBまでの範囲でメモリを設定できます。このグラフは完全に正確というわけではありません。実際には直線ではなく階段状の関数になりますが、メモリを増やすとCPUが増え、10 GBのメモリでは最大6つの仮想CPUが得られることを示しています。この能力を活用するには、コードが複数のコアで実行できるように対応している必要があります。シングルコールのパフォーマンスは約1.8 GBのメモリで頭打ちになるためです。マルチスレッド化されていないコードでCPUスループットだけを目的にメモリをスケールアップしても、1.8 GB以上ではあまり効果が得られず、その分余計なコストがかかってしまいます。


次のトピックはAWS Lambdaの実行ライフサイクルとCold startについてです。実は、AWSに関する話題の中でもCold startについては特に多くの記事が書かれています。Cold startは、AWS Lambdaが新しい実行環境でコードを実行する必要がある場合に発生し、環境の立ち上げ、ランタイムの起動、利用可能な状態にする、関数の初期化といった時間が必要になります。これは、私たちが実行しなければならないアクションと、コードの一部として発生する処理の2つの場面で起こります。重要なのは、本番環境での呼び出しのうちCold startの影響を受けるのは1%未満だということです。ある程度一定のトラフィックがある本番のワークロードでは、Cold startは実際にはトラフィックの末端でごくわずかしか発生しません。
ただし、APIを介して消費者が待ち受けている同期的なワークロードを実行している場合、そのCold startは重要な意味を持つかもしれません。そこで、いくつかの対策について説明していきましょう。Lambdaはマネージドサービスで、私たちは裏側で多くのことを処理しています。これがLambdaの魔法のような部分です。時々、ホストに障害が発生した場合やフリートの再バランスが必要な場合には、実行環境を置き換える必要があります。

Lambdaのライフサイクルをより詳しく見ていくと、Cold startがどこで発生するのかがわかります。まず実行環境を作成し、ホスト上でコードを実行するためのリソースプールを見つける必要があります。次に、コードまたはコンテナイメージをダウンロードし、ランタイムを起動し、その後、初期化のための関数のプレハンドラーコードが実行されます。ここでは、シークレットの取得やデータベースへの接続などを行い、その後、関数はWarm状態になって呼び出しの準備が整います。


マネージドランタイムの世界では、私たちがコントロールできる部分とAWSがコントロールする部分との境界線があります。初期化時間までのすべてが私たちの担当で、Lambdaチームは文字通りミリ秒やナノ秒単位で時間を削減し、可能な限り効率的にするために多大な時間を費やしています。境界線の向こう側は、お客様が対応・制御できる部分です。Lambdaのライフサイクルを理解することで、Lambdaの料金体系も説明がつきます。コスト面では、マネージドランタイムの場合、呼び出しに対してのみ課金され、それはミリ秒単位の時間、関数のメモリ量、実行時間に基づいています。コンテナイメージやOSのみのカスタムランタイムを使用する場合、または初期化が10秒を超える場合は、実際に初期化時間に対しても課金されます。
Lambda関数の最適化:初期化とSnapStartの活用


初期化前のコードに関するベストプラクティスとして、不要なものはロードしないようにしましょう。多くの場合、開発者は初期化コードに不必要なものを含めてしまいがちです。ライブラリの遅延初期化を心がけ、接続をどのように確立するかについても考慮する必要があります。関数の後続の実行で接続を再利用できるように、初期化フェーズで接続を確立したい場合もあるでしょう。また、Lambda関数での状態の使用方法についても検討が必要です。最初に状態を生成して将来の呼び出しのために保持することは有用かもしれませんが、セキュリティやプライバシーの観点から、後続の呼び出しで不適切なデータが利用可能な状態にならないよう注意が必要です。


SnapStartを含むLambdaのライフサイクルにはいくつかのバリエーションがあります。SnapStartは2年前にJava向けにリリースされ、現在はPythonと.NETもサポートしています。この機能を使用すると、初期化コードを事前に実行することができます。事前初期化されたコードのスナップショットを取得すると、関数をすぐに開始できます。これは特に、コンパイルや最適化が必要な.NETや、LangChainやDotDBなどのフレームワークを使用するPythonで有用です。 SnapStartを使用する関数へのすべての呼び出しは、その事前初期化された環境から開始されます。考慮すべき点はわずかです。データベースに接続する場合、そのデータベース接続やネットワーク接続の再確立を処理する必要があります。これは、その接続がイメージ内で凍結されているためです。それ以外は、追加のツールは必要ありません。ただし、これを機能させるためには、$LATESTではなく、特定の関数バージョンをターゲットにする必要があることを覚えておいてください。



Lambdaのスケールアップについて説明すると、呼び出しモデルに関係なく、一度に1つのリクエストを処理します。リクエストが増えてくると、Lambdaは追加の実行環境をスピンアップする必要があり、 これによりコールドスタートが発生し、イベントの処理が開始されます。しかし、 最初の環境が空き、別の呼び出しが来た場合、Lambdaサービスは温かい実行環境が利用可能であることを認識し、そのイベントをそこに渡します。コールドスタートを避けるため、これらの実行環境は意図的に一定期間保持されます。利用可能な環境がない場合、Lambdaは必要に応じて別の関数をスケールアップしますが、このプロセスを管理やコントロールする必要はありません。

これにより、実際に実行中の実行環境の数に相当する同時実行数をカウントすることができ、同時実行数の監視に利用できます。


CloudWatchメトリクスを使用して、すべての関数または個別の関数の同時実行数を確認できます。 同時実行数は、リレーショナルデータベースや特定の容量しか処理できないAPIなど、下流のリソースを扱う際の1秒あたりのトランザクション数に関連します。これは、影響を受ける接続数によって制限される可能性があります。実行に1秒かかる呼び出しが10個あれば、実質的に1秒あたり10トランザクションということになります。 しかし、関数の実行時間が半分になれば、10の同時実行数を維持しながら、その時間内に20の呼び出しを収めることができます。パフォーマンスは、同時実行数と関数の実行時間の両方に依存し、これらが組み合わさって1秒あたりのトランザクション数が決まります。下流のサービスが1秒あたり15トランザクションでスロットリングする場合、同時実行数の計画と関数の実行時間にこれを考慮する必要があります。
Serverlessアプリケーションの本番環境対応:レジリエンスと可観測性


この動作を管理するための強力なコントロール機能があります。 Reserved concurrencyを使用すると、関数が実行できる同時実行数の上限を設定できます。データベースへの接続を20に制限したい場合や、APIへの接続を50に制限したい場合、それに応じてLambda関数の制限を設定できます。また、下流のシステムに問題が発生した際のオフスイッチとしても使用でき、Lambdaを一時停止して下流の問題を修正し、その後同時実行数を元に戻すことができます。 Provisioned concurrencyは、コールドスタートを解消する別の同時実行制御機能で、すべての言語で利用可能です。特定の値を設定すると、実際の呼び出しを行わずにLambdaの初期化を事前に実行します。その後の呼び出しが来た時には、初期化が既に完了しているためコールドスタートが発生しません。11番目のリクエストが来た場合は、コールドスタートを伴うオンデマンド呼び出しが行われますが、これらすべてをバックグラウンドで管理しています。



Provisioned concurrencyには2つの重要な考慮点があります。 1つ目は、使用しないProvisioned concurrencyに対して料金を支払うべきではないということです。コスト削減につながる閾値はありますが、無駄は避けたいものです。これはCloudWatchメトリクスを使用して監視できます。 2つ目は、$LATESTではなく、関数のバージョンとエイリアスを使用する必要があるということです。期待通りのProvisioned concurrencyが見られない場合は、これを確認してみてください。 同時実行について議論する際は、アカウントとスケーリングのクォータについても考慮する必要があります。アカウントの同時実行クォータは、特定のリージョン内のすべての関数で共有される最大値です。デフォルトでは1,000ですが、数万まで引き上げることができます。


昨年、個々の関数のスケーリングモデルを強化しました。 現在、すべての関数は10秒ごとに1,000までの同時実行数の増加が可能です。これは素晴らしい機能で、AWSにおいてアプリケーションに大規模なコンピューティングパワーを提供する最速の方法であり、Lambdaが管理する裏側では大きなイノベーションが起きています。 同期的なスケーリングについては、いくつかのベストプラクティスがあります。事前に負荷テストを実施してクォータが負荷に対応できることを確認すること、タイムアウトを適切に設定すること(API Gatewayは29秒)、システムの過負荷を避けるためにバックオフやジッターを使用したリトライを実装すること、そして重複リクエストを適切に処理するためにべき等性を確保することなどです。

ストリーム処理については、 具体的な推奨事項があります。KafkaやKinesisを使用する場合、フィルタリングを使用して不要なメッセージの処理を避けることができます - これはより迅速で安価です。Lambdaはパーティションごとに順序通りにレコードを消費するため、パーティションキーが適切に分散されていることを確認してください。関数のリソースを管理し、より効率的な処理のためにコードを最適化することができ、より大きなバッチも役立ちます。Kinesisは並列化係数やEnhanced Fan-outなどの追加機能を提供しており、モニタリングによってストリーム処理が適切なペースを保っていることを確認できます。

もう1つのサーバーレスコンピューティングのオプションはコンテナを使用することで、これはアプリケーションを構築する人気のある方法です。 コンテナイメージを作成し、必要なものを内部に組み込み、ローカルで動作確認をしてから、クラウドにプッシュして実行することができます。主要なコンポーネントは2つあります。1つはAmazon ECSで、これは完全に管理されたサーバーレスのコントロールプレーンで、個々のコンテナをタスクとして実行したり、ヘルス管理やAZアウェアネスを備えたサービスとしてまとめたりすることができ、ウェブサイトの運用などに適しています。もう1つはAWS Fargateで、これはデータプレーンとして機能するサーバーレスコンポーネントです。
AWS Fargateは、AWSがインスタンスを管理してくれるサーバーレスオプションです。Lambdaとは異なり、イベント駆動型ではなく、ポートやソケットを使用する従来型のアプリケーション実行方式を採用しており、好きな方法でアプリケーションを実行できます。トラフィックのルーティングが必要な場合は、その前にロードバランサーを配置することができます。

責任分担が明確に分かれており、AWSはインスタンス管理、スケーリング、パッチ適用、基盤となるホストの維持管理を担当します。 Lambdaと比較すると、より多くの管理責任が発生します。具体的には、コンテナ内のコード、オペレーティングシステム、ライブラリのパッチ適用に加え、ロードバランシング、イングレス、一部のネットワーク面の管理が必要になります。コンテナは、Amazon CloudWatchやサードパーティのメトリクスを使用したAuto Scalingにより、様々なトリガーに基づいてスケールアップ・ダウンが可能です。Amazon ECSとAWS Fargateについては、リソースで紹介している数多くのベストプラクティスがあります。

Lambdaがミリ秒単位の使用量に応じた課金であるのに対し、Fargateの料金モデルは、プロビジョニングした分に対して課金されます。 コンテナが起動すると、CPUとメモリの設定に基づいて秒単位で課金されます。つまり、高い同時実行性が必要な場合により効率的に運用できる可能性があります。Lambdaは単一の同時実行であるのに対し、Fargateでは複数の同時実行が可能で、リクエストあたりのコストを低く抑えられる可能性があります。

両者を選択する際には、多くの考慮点があります。Lambdaのプログラミングモデルで問題なければ、Lambdaの方がより多くの部分を管理してくれ、一度始めると素早く反復開発できます。Fargateではコンテナ内で好きなことができ、非常に柔軟で、より多くの制御が可能で、既存のコンテナツールをそのまま使用できます。複数の同時実行、より大きなコンテナ、より多くのリソース、複数のネットワークモードをサポートし、複数の同時実行で無期限に実行できます。一方、Lambdaは15分の制限がありますが、強力なイベントベースの統合機能を備えています。

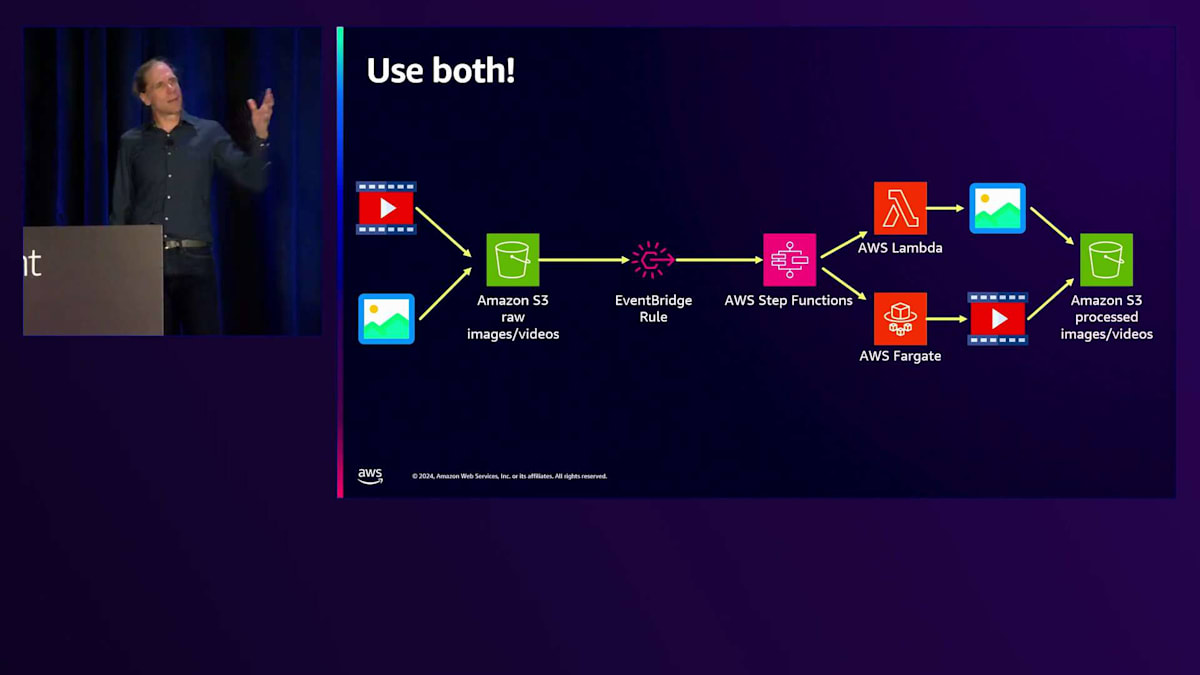
簡単に言えば、Fargateは長時間実行される安定した大容量・高リソースのイベントソース向けの柔軟なオプションで、 Lambdaはその他のほとんどのイベントソース向けのシンプルなオプションと考えてください。 これは二者択一の状況ではありません。実際、Amazon EventBridgeやAWS Step Functionsを使用して、同じアプリケーション内で両方を使用できます。Step FunctionsはFargateタスクも開始できます。例えば、画像と動画を処理するアプリケーションでは、Amazon S3にファイルがドロップされると、EventBridgeルールがトリガーされ、Step Functionsワークフローが開始されます。選択ステートを使用して、画像処理か動画処理かを選択します。15分以上かかる可能性のある動画処理にはFargateが適しており、Step FunctionsがECSを呼び出して動画変換用のFargateタスクをスケジュールします。ECSタスクが完了すると、成功トークンをStep Functionsに送り返します。画像の場合は、Lambdaで素早く簡単に処理できます。
Ran Isenbergによる本番環境対応Serverlessサービスの構築ガイド


Julian、ありがとうございます。私はRan Isenbergと申します。CyberArkのプラットフォームエンジニアリング部門でPrincipal Software Architectを務めています。AWS Heroであり、theburningmonk.cloudというウェブサイトを運営しており、そこでAWSやサービス全般について情報を発信しています。 本日は、本番環境に対応したサービスの構築についてお話しさせていただきます。CyberArkでの過去5年間で得た、そのようなサービスを構築するためのヒントと知見を共有したいと思います。


ここに、シンプルなServerlessサービスがあります。Amazon SQSキューがあり、Lambda serviceがキューをポーリングして、一括処理のアイテムでLambda functionを呼び出し、そのfunctionがアイテムを反復処理してAmazon S3バケットに挿入します。シンプルですよね?でも、これは本番環境に対応したサービスと言えるでしょうか? 答えは「いいえ」です。まだまだ十分とは言えません。本番環境に対応するためには、5つの側面について考える必要があります:レジリエンス、可観測性、セキュリティ、ガバナンス、そしてLambdaのベストプラクティスです。


まずはレジリエンスから始めましょう。 Dr. Werner Vogelsの「すべてのものは常に失敗する」という印象的な言葉がありますが、これは真実です。 実際に、すべてのものは常に失敗しており、サービスを設計する際にはこのことを考慮に入れなければなりません。例えば、このケースでは、アイテムがS3バケットに書き込めない可能性があります。これは様々な理由で起こり得ます - 例えば、S3が一時的にダウンしている場合や、より一般的なケースとして、Lambda functionのコードにバグがある場合です。この場合、アイテムのバッチ全体が失敗し、Lambda serviceはfunctionを再試行し、また失敗し、さらに再試行を繰り返します。最終的には、アイテムの保持期間が切れて、アイテムは永久に削除されてしまいます。

つまり、これは本当の意味でレジリエントとは言えません。問題がありますが、修正することはできます。 Dead Letter Queue(DLQ)を追加することができます。この場合、設定された回数の失敗の後、アイテムはDLQに移動し、少なくとも当面は再試行されなくなります。

このパターンに関するベストプラクティスをいくつか共有させていただきます。 まず、バッチサイズは10アイテムを使用すべきです。これは最大サイズであり、Lambda functionに最適なスループットを提供します。Visibility timeoutはfunction timeoutの少なくとも6倍に設定すべきです。これにより、Lambda failuresやfunctional failures、Lambda throttlesを考慮しながら、バッチの処理を確実に完了させることができます。また、Maximum receive countは少なくとも5に設定すべきです。これは、アイテムがDead Letter Queueに移動するまでの事前設定された回数であり、throttlesとretriesを考慮した上で良いバランスとなっています。最後に、DLQのMessage retention periodは長めに設定し、アイテムが期限切れで削除されないようにすべきです。この数値については、後ほどさらに詳しく説明します。

さて、DLQができましたが、そこにアイテムが溜まっているだけでは意味がありません。そこで、Redriveメカニズムを追加していきましょう。これは基本的に、1日1回や2回など、設定した頻度でLambda関数を呼び出すEvent Schedulerです。このLambda関数はAPIを呼び出して、Dead Letter QueueからオリジナルのSQSキューにアイテムを移動し、再処理を行います。今度はS3が復旧しているか、関数のバグが修正されているはずなので、正常に処理されることを期待できます。

ここで、いくつかのベストプラクティスをご紹介しましょう。DLQに移動するアイテムは、スロットリングやバグなど、再試行可能な失敗に限定すべきです。無限にRedriveすることは避けるべきです。例えば、入力検証スキーマの問題でアイテムが失敗する場合、何度やっても失敗するのでDLQに移動せず、エラーログを残して次のアイテムに進むべきです。また、DLQの保持期間はRedriveのCron実行頻度よりも長く設定する必要があります。これは当然ですが、Cronが実行されたときにDead Queueからキューに移動できるアイテムが存在している必要があるからです。最後に、べき等性について考える必要があります。同じアイテムを複数回再試行する場合、Lambda関数で副作用が発生する場合は、それらが一度だけ発生するようにする必要があり、べき等性はそれを保証するメカニズムです。
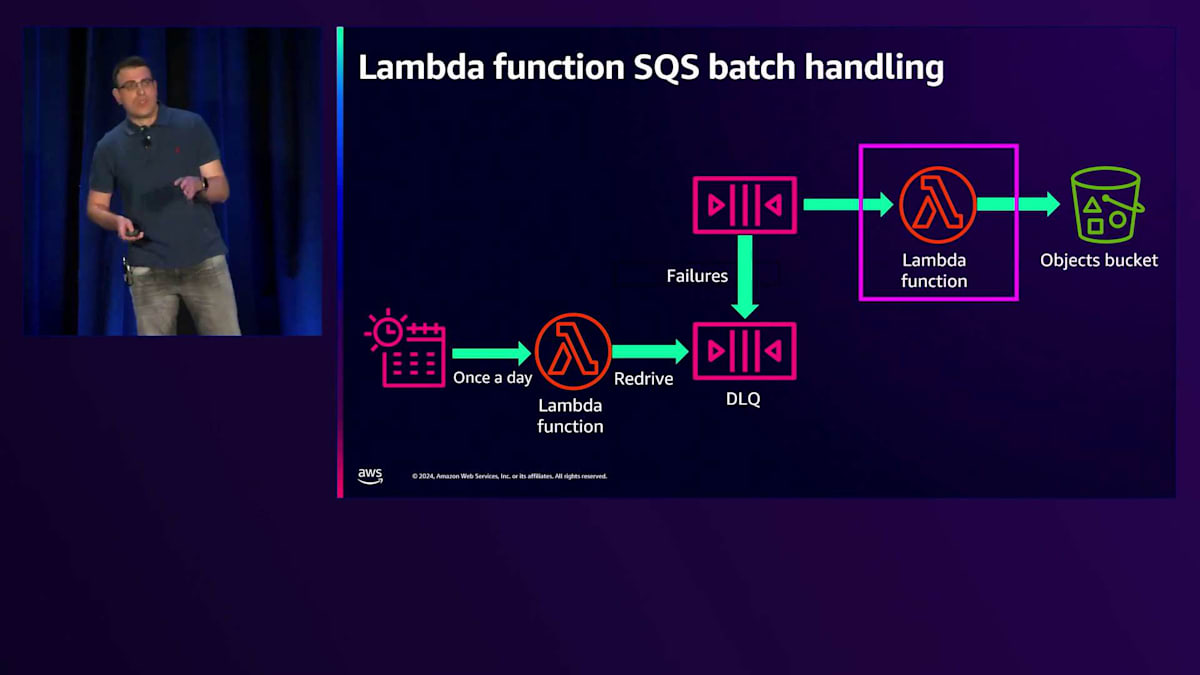

Redriveの仕組みとDead Letter Queueができました。素晴らしいですね。では、Lambda関数の詳細を見て、バッチ処理をどのように実装できるか見ていきましょう。Lambda関数はアイテムを反復処理し、AWS SDKを使ってアイテムをバケットに格納します。AWS SDKには組み込みのリトライとバックオフの設定があり、これらは変更可能です。デフォルトの設定は長すぎて実用的でない場合があるので、適切な設定方法を見ていきます。もう一つの重要な概念は部分的な失敗の処理です。10個のアイテムのバッチで1つが失敗した場合、10個全てをDLQに移動するのではなく、失敗した1つだけを移動したいですよね。ここではPowertools for AWS Lambdaを使用します。これは素晴らしいオープンソースライブラリで、本番環境で使える便利なユーティリティ群が揃っています。


それでは、Lambda ハンドラーをPythonで書いていきましょう。Powertoolsのバッチハンドラープロセッサーを使用します。6行目でバッチプロセッサーを定義し、タイプをSQSに設定します。SQS以外のオプションもあります。次に、OrderSqsRecordのモデルを設定します。これは各アイテムの入力検証スキーマとなるPydanticモデルです。パース処理が組み込まれています。9行目から14行目で、バッチ処理自体を呼び出し、event、processor、context、そしてrecord handlerを渡します。record handlerは、バケットにアイテムを挿入する実際のビジネスロジックを含む関数です。Powertoolsは全バッチを反復処理し、入力検証を行い、個々のアイテムでrecord handlerを呼び出します。ここでrecord handler自体を見てみましょう。Julianが言及したように、1行目では最小限のインポートを行います。clientだけをインポートします。
5行目でグローバル初期化を行います。これはLambdaがウォームな状態のとき、S3への接続を維持したままにできるので、レイテンシーを1回分削減できるためです。最後に8行目で、put objectを呼び出します。この定義では、AWS SDKのデフォルトのリトライとタイムアウトの設定が使用されます。

先ほど申し上げたように、botocoreライブラリのConfigクラスを使用して設定を変更することができます。ここでご覧のように、リトライ回数、最大試行回数、モード(AdaptiveかStandard)を変更できます。どちらが適しているかを判断するために、ドキュメントを確認することを強くお勧めします。読み取りタイムアウトや初期接続タイムアウトも変更可能です。14行目では、カスタム設定をクライアント自体に渡しています。

ここでコード全体をご覧いただけますが、部分的な失敗の概念に焦点を当てたいと思います。11行目では、put_objectをキーとして呼び出しています。ここで例外が発生した場合、Powertoolsは自動的に例外をキャッチし、そのアイテムを失敗(部分的な失敗)としてマークし、次のアイテムに進みます。つまり、部分的な失敗の機能が非常に透過的な方法で最初から利用できるということです。また、べき等性も重要です。11行目の後に他の副作用を使用する場合を考えてみましょう。このコードは複数回リトライされる可能性があるため、べき等性が必要になります。Powertoolsには組み込みのべき等性機能があり、それを利用できます。PowertoolsとCDKでべき等性を使用する方法についてもっと知りたい場合は、以下のQRコードにある私のブログ記事をご確認ください。
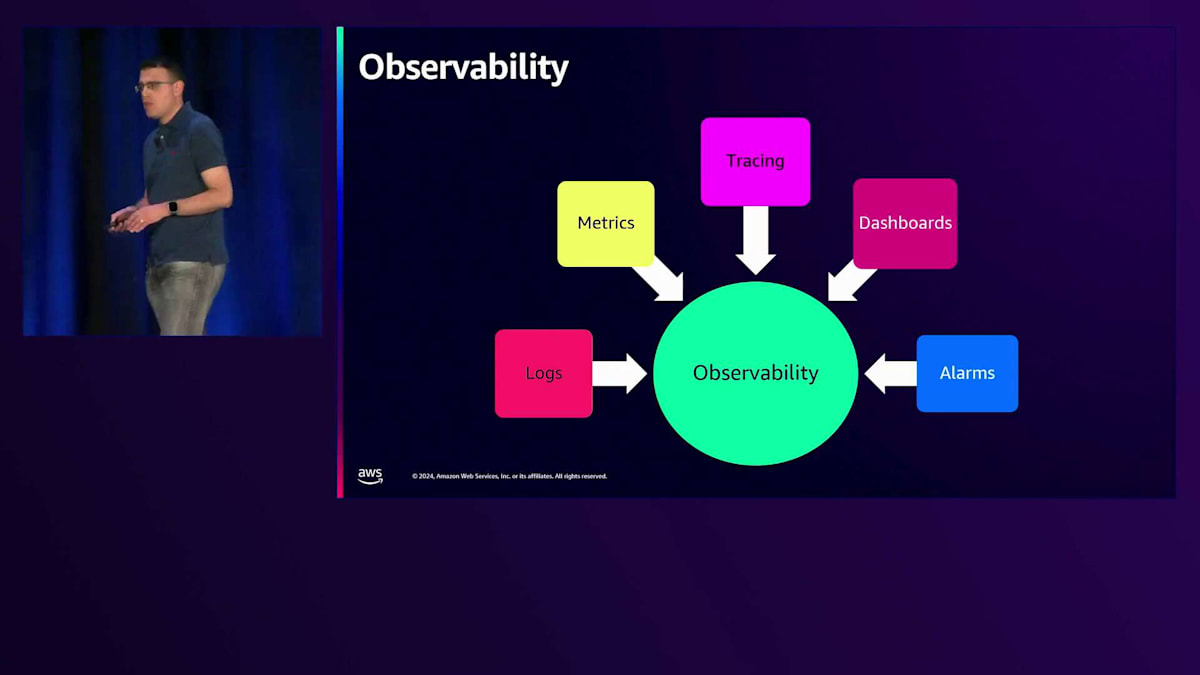

次に、本番環境で稼働するサービスのもう一つの重要な側面である、Observabilityについて説明しましょう。Observabilityは、組織全体で統一された言語のようなものです。複数のチームやサービスにまたがる顧客リクエストのデバッグを可能にします。これはCloudWatch Logs、CloudWatch Metrics、X-Ray Traces、CloudWatch DashboardsやAlarmsで構成されています。
まずはLoggingについてお話ししましょう。一般的なヒントをいくつか紹介します:CloudWatchコンソールで任意のフィールドでフィルタリングできるように、構造化されたJSONロギングを使用すべきです。エラーログだけでなく、すべてのログに相関IDと顧客IDを追加すべきです。これは、エラーが発生した際に、相関IDと顧客IDを使用して、最初からエラーが発生するまでの複数のサービスにわたる顧客リクエストの全フローを確認できるようにするためです。ログは保存する必要があり、コストが積み重なる可能性があります。そこで、いくつかのヒントを紹介します:デフォルトのログレベルをINFOに設定し、すべてのログをDEBUGレベルで使用し、INFOレベルで何を使用するかを慎重に検討してください。INFOとして選択する各ログは、本当に重要で、ユースケースに関連する重要な情報を提供するものでなければなりません。最後に、ロググループの保持ポリシーを14日間に設定すべきです。14日間あれば十分だと思いますが、必要に応じて変更することもできます。

CloudWatch MetricsとAlarmsは、サービスのパフォーマンスを示し、顧客から問題を指摘される前に、差し迫った問題を知らせてくれます(顧客から指摘されるのは望ましくありません)。私たちのサービスに関連するメトリクスとしては、SQSのNumberOfMessagesDeletedがあります。この数が0の場合、メッセージが削除されておらず、実際に失敗が発生していることがわかります。Dead Letter Queueについては、ApproximateNumberOfMessagesVisibleが重要です。短時間に大量のメッセージが存在する場合はアラームを設定すべきです。これは失敗が発生し、メッセージがDLQに移動したことを意味し、何かが間違っているということです。最後に、Lambdaのスロットルやエラー(コードで適切にキャッチできなかった例外)、およびコード内の特定の重大な失敗を示すエラーログについても、メトリクスアラームを設定すべきです。また、プロダクトチームがサービスのKPIや機能採用状況を定義するのに最適なカスタムCloudWatchメトリクスも使用すべきです。

X-Rayは、サービス全体のパフォーマンスとボトルネックを理解するための素晴らしいサービスです。これは実際のサービスのトレース例ですが、関数の全体的な実行時間、初期化時間、S3へのAPI呼び出しの時間が確認できます。このように、サービスのパフォーマンス特性を詳細に把握することができます。

これにより、Record Handler関数を詳しく分析し、どの関数により多くの時間がかかっているかを理解して、改善や最適化を行うことができます。 Amazon CloudWatchダッシュボードでは、これまで説明してきた観測可能な要素をすべて1か所で可視化できます。Infrastructure as Codeでダッシュボードを作成し、2種類のダッシュボードを定義することを強くお勧めします。1つは、インシデント対応チームやプロダクトチームがサービスの問題を素早く把握できるハイレベルなダッシュボード。もう1つは、メトリクスを詳しく分析し、サービスのすべてのログを確認して、より深刻な問題を発見できるローレベルなダッシュボードです。CDKのコード例を使用してCloudWatchダッシュボードを構築する方法の詳細については、以下のQRコードをご確認ください。


AWS Lambda Powertoolsを使用して、Lambda Handlerに可観測性を追加してみましょう。Powertoolsには、JSONロガー、AWS X-Rayとの連携、カスタムCloudWatchメトリクスなど、包括的な機能が組み込まれています。7行目から9行目で、ロガー、トレーサー、カスタムメトリクスハンドラーを初期化します。 デコレータを設定し、10行目のRecord Handler関数にデコレータを付けることで、この特定の関数の実行時間を計測できます。12行目ではデバッグレベルでログを記録し、14行目ではBucket ItemsというカスタムのCloudWatchメトリクスを追加して、S3バケットに正常に書き込まれたアイテム数を+1ずつカウントしています。このように、Powertoolsを使えば、Lambda関数に可観測性を簡単に追加できるのです。



最初は3つのアイコンでしたが、今では8つのアイコンになりました。しかし、まだ終わりではありません。セキュリティについて話しましょう。 共有責任モデルについてはご存じだと思います。AWSがクラウドのセキュリティを担当し、私たち顧客はクラウド内のセキュリティ、つまりビジネスドメインロジックのコードやインフラストラクチャのコード設定を担当します。 重要なセキュリティのヒントをいくつか紹介します:顧客のPII(個人識別情報)をログに記録しない、Infrastructure as Codeでセキュアな設定を行う、転送中および保管時の暗号化を有効にする、プライベートリソースへのパブリックアクセスをブロックする、そして顧客データへのアクセスを監査することです。



私たちのサービスを振り返ってみると、S3バケットがありますが、これは本当にセキュアで本番環境に対応できているでしょうか?いいえ、まだですが、 パブリックアクセスのブロック、アクセスログバケットの接続、S3管理キーまたは顧客管理キーによる暗号化の有効化、SSL通信の強制により、セキュアにすることができます。ここに、このセキュアなバケットを構築するCDKのコード例があります。 CreateBucket関数は、アクセスログバケットと本番環境かどうかを示すブール値を入力として受け取ります。10行目でS3管理の暗号化を有効にし、11行目でパブリックアクセスをブロックし、13行目でSSLを強制し、16行目で監査ログを接続します。12行目では、開発環境の場合は顧客データを含まないためRemoval Policyをdestroyに設定していますが、本番環境では顧客情報が含まれているため、削除された場合でもバケットを保持するようにしています。

ガバナンスも重要な要素です。通常、ガバナンスはITチームやDevOpsチームによって、AWS Config、AWS Control Tower、AWS Organizations SCP、そして最近リリースされたRCPを通じて管理されています。開発者はガバナンスについて、特にスタックタグに関して意識する必要があります。サービス、マイクロサービス、チームを識別するためのスタックタグを追加すべきです。これは、複数のチームが同じAWSアカウントにデプロイする場合に非常に役立ち、どのリソースがどのチームに属しているかを理解できるようになります。AWS Cost Explorerを使用する際、これらのタグでフィルタリングすることで、各サービスのコストを把握できます。また、CDK-nagやcfn-lintなどのオープンソースツールを使用して、デプロイ前にセキュリティスキャンを実施すべきです。私はCDK-nagを使用していますが、これはデプロイ中にCloudFormationテンプレートの出力をスキャンします。

CDK-nagは設定ミスやセキュリティの問題をスキャンし、問題が見つかった場合はデプロイを失敗させます。 私たちは3つのアイコンから始めて、最終的に9つのアイコンになりました。これはかなりの数です。CDKコード、CI/CDパイプライン、テストを含むGitHubリポジトリ全体を確認することができます - すべてがGitHubリポジトリで利用可能です。



本番環境に対応したServerlessサービスの構築は複雑で、多大な労力が必要です。CyberArkでは、1つのサービスを完成させた時、ASAを構築する過程で、さらに多くのサービスを構築する必要があることを理解しました。 構築すべきサービスは何百もありました。そこで、これらの原則 - レジリエンス、可観測性、セキュリティ、ガバナンス、Lambdaのベストプラクティスをどのように複製できるか考えました。 これらの原則をどうすれば組織全体に素早く展開できるのでしょうか? つまり、Serverlessのベストプラクティスをスケールさせるためのベストプラクティスとは何でしょうか?答えはとてもシンプルです:サービスブループリントとアーキテクチャパターンです。

まずはサービスブループリントから見ていきましょう。Serverlessサービスブループリントは、実際には 最小限のServerlessサービス実装を含むGitHubテンプレートリポジトリです。開発者にとって素晴らしい出発点となります。認知的負荷を減らし、ビジネスドメインロジックの作成に集中できるからです。レジリエンス、セキュリティ、可観測性、ガバナンスに関するすべてのベストプラクティスが含まれています。例えば、CyberArkでは、API Gateway、Lambda、DynamoDBを使用したCRUD APIブループリントを構築し、これらすべてのツールとベストプラクティスをCI/CDパイプラインのインフラストラクチャアズコードに組み込み、初日から完全にデプロイとテストが可能な状態にしました。

私は「Awesome AWS Serverless Blueprints」という新しいオープンソースプロジェクトを作成しました。 これはコミュニティのサービスブループリントのコレクションです。さまざまなバックエンドサービス、CI/CDパイプライン、インフラストラクチャアズコードの言語、プログラミング言語が用意されています。皆さんへのアクションアイテムは、これを確認して自分に合うものを見つけることです。もし適切なものが見つからない場合は、これらを参考に独自のものを作成し、オープンソース化してPRを出してください。
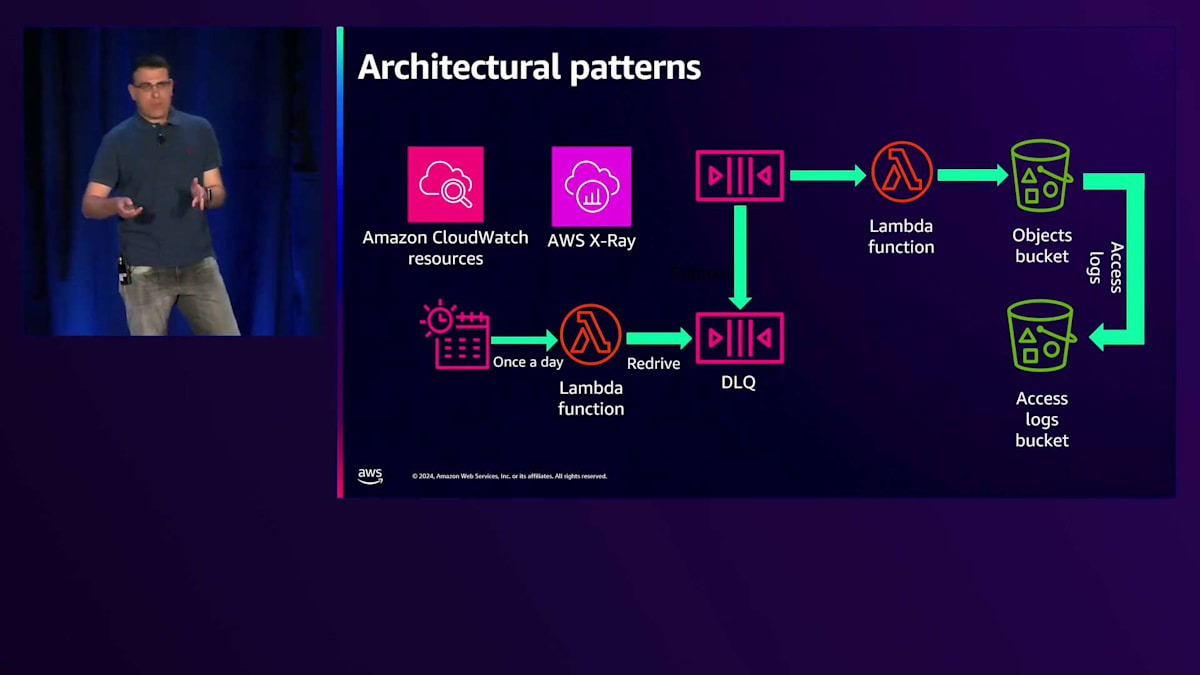

2番目のベストプラクティスはアーキテクチャパターンです。 私たちのサービスを振り返ってみると、2つのアーキテクチャパターンを見つけることができます。これらのパターンにはビジネスドメインロジックが全く含まれておらず、他のサービスでも再利用できるように切り出すことができます。 これらは、ベストプラクティスのための再利用可能なブラックボックスであり、ガバナンスとセキュリティを強化し、開発者は考えることなくCDK ConstructsやTerraformテンプレートの形で使用することができます。無料のアーキテクチャパターンを提供しているウェブサイトをいくつか集めてみましたので、ぜひチェックしてみてください。



本番環境対応のサービスについて説明してきましたが、 ここで本番環境対応のLambda関数に話を戻して、いくつかのヒントをお伝えしたいと思います。 新しいサービスの構築を始める際には、フォルダ構造について考える必要があります。私の場合、すべてのLambdaコードが置かれるビジネスドメイン用のserviceフォルダ、ユニットテスト、インテグレーション、エンドツーエンドテスト用のtestフォルダ、 そしてCDK用のinfrastructureフォルダを用意しています。これは、サービスが開発者のDevOps文化の活用を支援する素晴らしい例です。新しいLambda関数を追加したい場合、CDKフォルダにCDKコードを追加し、serviceフォルダにビジネスドメインロジックを追加するだけでよいのです。
Serverlessの未来と開発者体験の向上:最新のツールと機能

2番目の興味深いベストプラクティスは、Hexagonal Architectureまたはアーキテクチャレイヤーの使用です。Handlerレイヤー、Logicレイヤー、Data Accessレイヤーがあります。Handlerレイヤーは入力の検証、グローバル設定の初期化を行い、入力をLogicレイヤーに渡します。Logicレイヤーはビジネスドメインロジックを処理し、DALインターフェースを使用して具体的なデータベース実装とやり取りします。


AWS Lambda Powertoolsは非常に便利です。Pythonバージョンを見てきましたが、他の言語もあります。4つの異なる言語があり、 データ抽出、ストリーミング、キャッシング、フィーチャーフラグなど、他にも多くのユーティリティがあります。ぜひチェックしてみることをお勧めします。

Julianが言及したように、AWS Lambda関数のメモリを増やすとCPUとネットワーク帯域幅が増加しますが、CPUアーキテクチャをARMベースのアーキテクチャであるGravitonに変更することもできます。多くの場合、同様のパフォーマンスを得られながら、コストを40%削減できます。最適な価格対パフォーマンス比を見つけるには、Lambda Power Tuningを使用すべきです。これはオープンソースツールで、 Step Functionをスピンアップし、複数の設定でLambda関数を呼び出して、グラフを生成します。このグラフで最速の実行時間と最低コストを確認でき、あなたにとって最も意味のある比率を選択することができます。
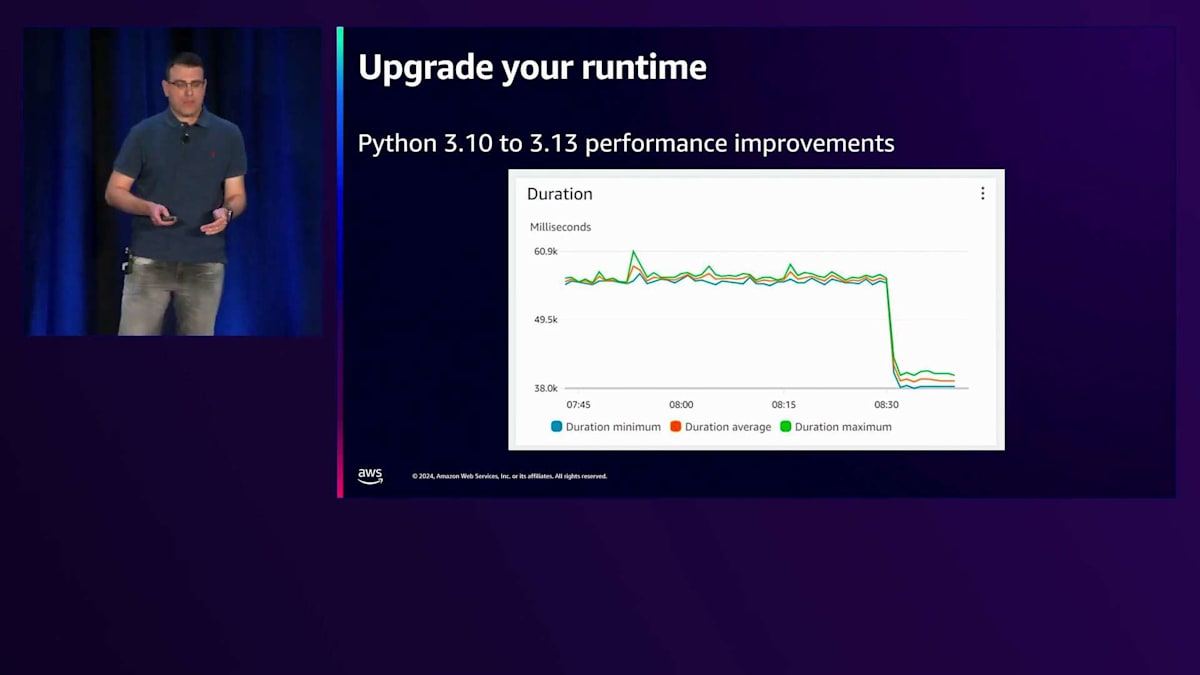
ランタイムもアップグレードする必要があります。 先ほど申し上げたように、ランタイムをアップグレードする際には共有の責任があります。セキュリティ機能が強化されることもありますが、パフォーマンスが向上することもあります。Julian、お願いします。ありがとう、Ann。実は、ランタイムのアップグレードは、コンピュータサイエンスの中で最も簡単なハックの1つです。つまり、システムを常に最新の状態に保つということです。もちろんセキュリティ面での効果もありますが、パフォーマンスへの影響についてはあまり考えられていません。AWS Lambdaではミリ秒単位で課金されるため、単純にシステムをアップグレードするだけで、より高速で効率的になります。


Lambdaがオペレーティングシステムやライブラリなどを最新の状態に保ってくれるため、適切なテスト環境があり、AWSのベストプラクティスに従ってスケーリングを行っていれば、すべてがうまく連携し、関数コードの管理だけに集中できます。ランタイムのアップグレードがより簡単になることが期待できます。とはいえ、私が軽々しく言っているように、ランタイムのアップグレードが常に簡単というわけではないことも理解しています。 そこで、Gen AIの力を借りることができます。Amazon Qにはコード変換機能があり、 実際に私も試してみましたが、手動での変換よりもずっと速くアプリケーションを変換できました。
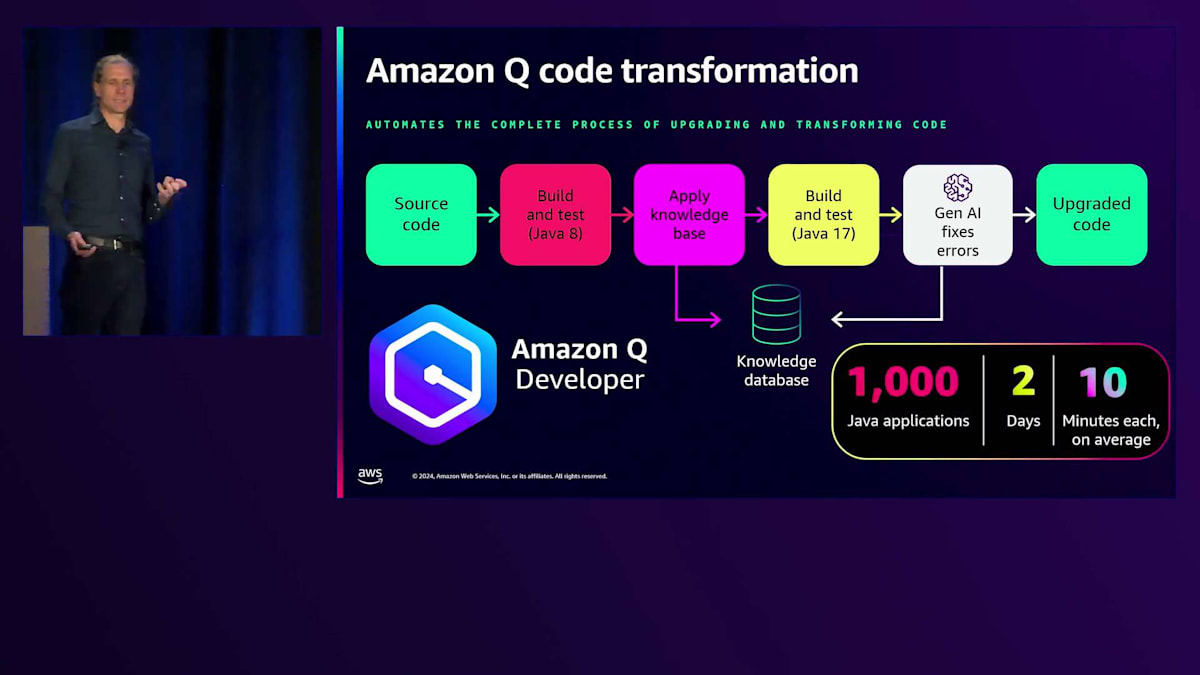
現在はJava 8からJava 17への変換に対応しており、.NETへの対応も進めています。優れたGen AIツールとして、パッケージの依存関係、フレームワーク、非推奨コードを確認し、セキュリティのベストプラクティスを追加します。さらにAmazon Qは、アプリケーションの検証とアップグレードのためのテストも実行できます。 社内で1,000以上のアプリケーションをJava 8からJava 17にアップグレードすることに成功しました。わずか2日間で完了し、アプリケーション1つあたりの平均所要時間は10分でした。最も時間がかかったものでも1時間弱でした。コードの説明、作成、ユニットテスト、CloudFormationの作成を支援してくれるツールは非常に便利です。そのような用途にはAmazon Qをお勧めしますが、他のコーディングアシスタントもServerlessアプリケーションの構築に大変役立ちます。

多くの人が「Serverlessの次は何か?もう完成したのか?」と質問してきます。いいえ、まだまだです。今日のre:Inventでこの会場が満席になっていること、Serverlessのセッションがすべて満席になっていることからも、明るい未来が待っていることがわかります。私たちは、Well-Architecturedのベストプラクティスをサービスにネイティブに組み込み続け、開発者体験の向上に努めています。最近、Visual Studio Codeのような新しいLambdaコンソールをリリースしました。クラウド上で環境変数の確認や、Lambdaコンソール内で直接ログのリアルタイム表示ができるようになりました。
ローカルIDEの体験も改善しています。Visual Studio Codeを使用している場合、AWS Toolkit for Visual Studio CodeのServerlessセクションが強化されました。Application Builderという新しいセクションが追加され、1か所でアプリケーションの構築、運用、同期、デプロイ、モニタリングができるようになりました。Lambdaとの対話やアプリケーションの構築のためにIDEを離れる必要はありません。AWS Toolkit for Visual Studio Codeの最新版に自動的に更新される部分にある新しいApplication Builderをぜひご確認ください。これは始まりに過ぎません。さらに多くの開発者体験機能を追加していく予定です。サービスに対するより多くのコントロールも提供していきます。この1、2年で多くのガバナンス機能をリリースしており、組織内でLambdaや他のServerlessサービスを確実に実行できるよう重点的に取り組んでいます。昨晩、Step FunctionsとEventBridgeにプライベートAPI統合機能が追加され、VPC LatticeやVPCエンドポイントを使用した接続がより簡単になりました。また先週、CAFAを使用したデータ処理向けに、リソースを事前にプロビジョニングできる新しいプロビジョニングモードが追加されました。さらに、ストリーミングデータを迅速に処理するためのリソースをプロビジョニングし、ネットワーク機能を抽象化する新しいプロビジョニングモードもAWS Lambdaに追加されました。

これは素晴らしい開発者体験を提供します。今後、さらにシンプルで幅広い統合機能を追加して、Serverlessサービスでより多くのことができるようにしていく予定です。本日の時間で、たくさんの内容をカバーすることをお約束しました。 皆さん大丈夫ですか?一息つく必要がありますか?水が必要ですか?前列で頷いている方がいらっしゃいますね、ありがとうございます。
明らかに、これらの内容を消化する時間が必要ですね。そこで私たちは、まずサービスの進化の裏側を見てきました。Amazon EventBridgeのレイテンシーに関する一見些細な変更が、まったく新しいアプリケーションアーキテクチャの可能性を開くことになりました。Service統合を使用することで、設定だけで、実際に必要なコードよりもはるかに少ないコードで非同期機能を実現できます。AWS LambdaとAWS Fargateの強力な機能 - Lambdaの柔軟性とスケーリングメカニズム、そしてECSとFargateが長時間にわたって大規模なワークロードを処理できるコンテナを実行できる能力について見てきました。

さらに一歩進んで、本番環境に対応したServerlessアプリケーションの構築に関するセクションが私のお気に入りです。Blueprintsを使用してスケールアウトし、組織全体で適用できるアーキテクチャを作成することで、効率的にServerlessアプリケーションを構築できるCookie-cutterアプローチを実現できます。しかし、まだ多くのベストプラクティスがあります。QRコードをご覧ください。各セクションへのリンクと、Serverlessアプリケーションを最適に構築する方法に関する情報が用意されています。 AWS Skill Builderを通じてAWS Serverlessの学習を続けることができ、ランプアップガイドやデジタルバッジも用意されており、Serverlessの知識を証明することができます。

私たちのお気に入りのサイトの1つがServerlessland.comです。 AWSのServerlessに関するベストリソースです。Blueprints、CDKコード、Terraformコードなど、パターン、ワークショップ、サンプルコードが豊富に用意されており、Serverlessアプリケーションを構築するための膨大なリソースがServerlessland.comで利用可能です。Ranには大変感謝していますし、本日皆様にご参加いただいたことにも大変感謝しています。忙しいre:Inventの中、時間を割いていただき、ありがとうございます。皆様に考えていただける面白い内容をお届けできたと思います。

深い技術的な内容がお好みでしたら、セッションカタログでフィードバックをいただけると幸いです。これは400レベルのセッションで、十分な技術的深さを提供できたと思います。5つ星の評価をいただければ、来年もさらに深い技術的内容を持って戻ってくる励みになります。私たちの連絡先はスライドに記載されています。 また、この場所や廊下でも質問を受け付けていますので、さらに質問がありましたらお声がけください。ご参加いただき、ありがとうございました。残りのre:Inventもお楽しみください。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion