re:Invent 2023: The New York TimesのAmazon EKS上の開発者プラットフォーム構築事例


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Platform engineering with Amazon EKS (CON311)
この動画では、The New York TimesのAhmed BebarsがAmazon EKS上に構築した内部開発者プラットフォームについて詳しく解説しています。マルチアカウントアーキテクチャやマルチテナントクラスターの選択理由、Backstageを活用したオンボーディングプロセス、そしてCilium、EPTF、Karpenterなどのオープンソースツールの活用方法が紹介されています。プラットフォーム構築の実践的な知見や、今後の展望についても語られており、大規模組織におけるプラットフォームエンジニアリングの実態を学べる貴重な内容となっています。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
re:Inventセッションの開始:プラットフォームエンジニアリングの概要
さて、皆さん。re:Inventの素晴らしく長い初日が終わり、この講演が皆さんとre:Inventの最初の懇親会の間にある最後のセッションだということは承知しています。最後まで付き合ってくださって感謝しています。皆さんがここにいてくださって本当に嬉しいです。できる限り楽しく、そしてより重要なことに、手短に進めていきますので、皆さんはここを出て、お飲み物を楽しみ、素敵なディナーを取ることができるでしょう。


では、簡単に自己紹介をさせていただきます。私の名前はKevin Colemanです。AWSのKubernetesのWorldwide Go-to-marketチームを率いています。 今日は同僚のRoland Barciaも同席しています。彼はAWSのContainersとServerless ServicesのWorldwide Solution Architectureのディレクターです。そして、今日は幸運にも、The New York TimesのAhmed Bebarsをお客様スピーカーとしてお迎えしています。彼は自身とチームがAmazon EKS上に構築している素晴らしいプラットフォームについて話してくれる予定です。
さて、今日の簡単なアジェンダです。まず、EKSの世界におけるプラットフォームエンジニアリングに対する私たちの見方と、お客様がプラットフォームエンジニアリングへの投資で実現している利点のいくつかをお話しします。次に、具体的なお客様の例をいくつか取り上げ、内部プラットフォームの成熟度スペクトルの両極端にいる2つの異なるお客様の例を紹介します。その後、マイクをRolandに渡します。彼はEKSのお客様の間で見られるプラットフォーム実装パターンについて話します。そして、ベストプラクティスに入ります。この会場で現在プラットフォームエンジニアリングチームで内部プラットフォームを構築している方々は、ここで特に注目したいところでしょう。私たちの役割上、EKS上でプラットフォームを構築している世界中の幅広いお客様と協力する機会があり、そこから重要な学びが得られています。Rolandはそれらの顕著な学びを共有し、皆さんのプラットフォームエンジニアリングの取り組みに役立てていただければと思います。最後に、Ahmedが登壇し、彼とThe New York Timesのチームが Amazon EKS上に構築している素晴らしいプラットフォームについて話してくれます。
プラットフォームエンジニアリングとは何か:定義と重要性
さて、これは盛りだくさんのアジェンダですね。では、始めましょう。プラットフォームエンジニアリングとは何でしょうか?この話に入る前に、挙手をお願いします。この会場で現在プラットフォームエンジニアの方はどれくらいいらっしゃいますか? はい、素晴らしい。予想通り多くの手が挙がりましたね。DevOpsやSREタイプの方はどれくらいですか? はい、素晴らしい、良いミックスですね。そして、プラットフォームエンジニアリング組織を率いている方や、会社でのクラウド導入を担当している方はどれくらいですか? はい、素晴らしいですね。


もし皆さんが組織でプラットフォームやクラウド導入を主導しているのであれば、組織がクラウドでアプリケーションを実行できるようにする責任があります。これには移行、近代化、新規構築が含まれる可能性がありますが、ソフトウェア開発チームという幅広い内部顧客を持つことになるでしょう。これらの内部顧客は、おそらく1つか多数か、あるいはアプリケーションのポートフォリオの構築や維持に責任を持つことになるでしょう。そして、それらのアプリケーションは、クラウドの幅広いクラウドインフラストラクチャサービス上で実行する必要があります。もちろん、これにはAmazon EKSやAmazon EC2のようなコンピューティングサービスが含まれますが、ストレージ、データベース、ネットワーキング、モニタリングサービスなども含まれる可能性があります。
さらに、すべてのアプリケーションが同じというわけではありません。それぞれ異なる要件があり、多様性があります。あるアプリケーションはより多くのコンピューティングリソースを必要とし、別のものはより多くのメモリを必要とし、GPUを必要とするものもあるでしょう。しかし、いずれにせよ、これらのアプリケーションはすべてクラウド上で実行される必要があり、あなたがplatform組織やcloud採用組織のリーダーとして、できるだけコスト効率の良い方法でこれを実現する責任があります。皆さんには選択肢があります。これらのアプリケーションを実行するインフラストラクチャを管理する責任は誰にあるのでしょうか。
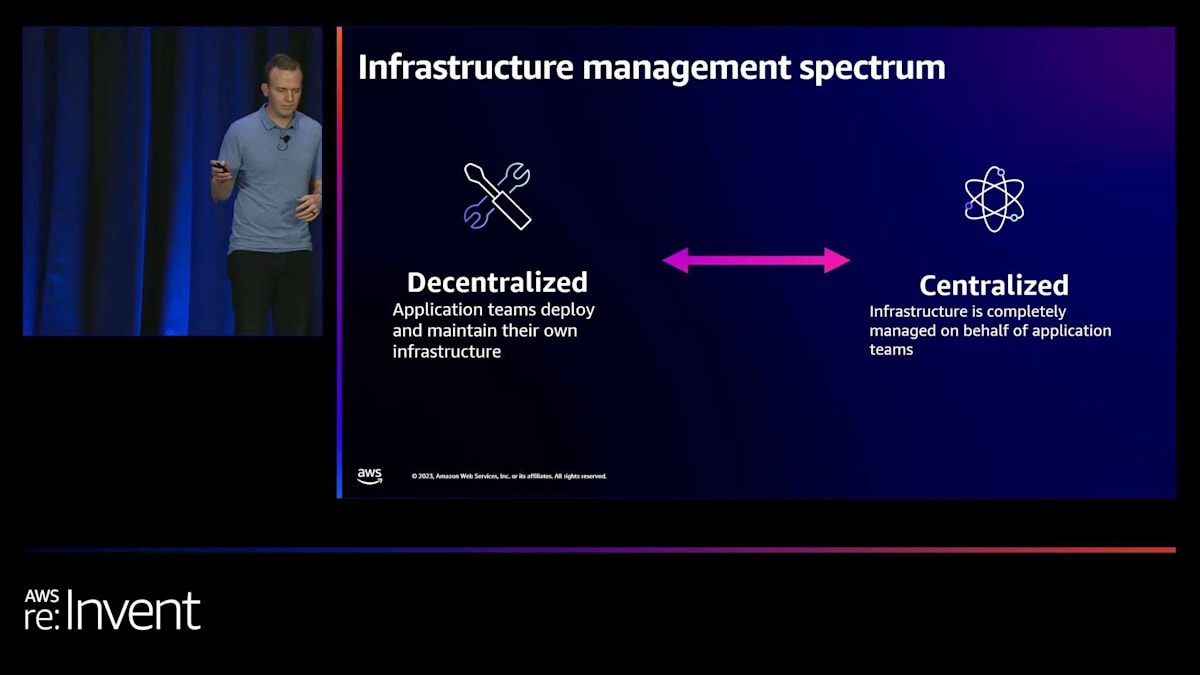
私はこの選択を、インフラストラクチャ管理スペクトラムと呼んでいるものに沿って考えるのが好きです。このスペクトラムの一方の端では、インフラストラクチャ管理の責任を分散させることを選択できます。このモデルでは、アプリケーションを構築するアプリケーションチームが、そのアプリケーションに必要なインフラストラクチャの展開と維持にも責任を持ちます。ここでの意味は、各アプリケーションチームが、自分たちのアプリケーションを実行するために必要な本番環境グレードのインフラストラクチャの展開、維持、そしておそらく最も重要なトラブルシューティングに責任を持つということです。スペクトラムの反対側では、インフラストラクチャ管理を集中化することを選択できます。このモデルでは、中央のチームがインフラストラクチャサービスをplatformの抽象化に組み合わせ、それをサービスとしてアプリケーションチームに提供し、インフラストラクチャ管理の責任を軽減できるようにします。
Platform engineeringは概念的にこの図の左側に傾いています。これは、アプリケーションチームがインフラストラクチャ管理の責任を軽減し、アプリケーションの構築と顧客満足に集中できるようにする抽象化を構築することに関するものです。しかし、EKSの世界では、私たちが協力している顧客が構築している抽象化は実際にかなり異なり、このスペクトラムの異なる点に位置しています。これは、アプリケーションチームと組織が異なる要件を持っているためです。一部のアプリケーションチームは実際にある程度のインフラストラクチャ制御を望んでいます。一方で、他の組織では様々なコンプライアンス要件があるため、そのような制御を許可しない場合もあります。
より詳しく見ると、私たちはplatform engineeringを、内部顧客と組織の固有の要件を満たすコンピューティング抽象化を特定し構築する実践として捉えています。これにより、クラウドの効率的でコスト効果の高い大規模な採用を可能にし、最終的にはソフトウェアの提供を加速させることができます。
抽象化の価値:車のエンジンの比喩

クラウドの文脈において、抽象化がなぜそんなに価値があるのか、少し話してみましょう。これを説明するのに、この図はとてもいい例だと思います。右側にはエンジンのパーツがたくさんあり、これはクラウドインフラストラクチャーやインフラの基本要素を表しています。左側には完成したエンジンが車に搭載されており、これはプラットフォームの抽象化と考えることができます。
もちろん、世の中にはエンジンのパーツを組み立てて完全なエンジンを作り、それを車に取り付けることができる人もいます。しかし、それは労力がかかり、時間もかかり、複雑です。一方で、単にエンジンが車に搭載されていて、車に乗り込んでキーを回すだけで走り出せればいいという人の方がずっと多いのです。
プラットフォームエンジニアリングの文脈で言えば、インフラストラクチャーを組み合わせて、アプリケーションを実行するのに必要な完全な抽象化を作り出せる人はたくさんいます。この会場にいる皆さんの多くがそのスキルを持っているでしょう。しかし、世界中にはもっと多くのアプリケーション開発者やソフトウェア開発者がいて、彼らは必ずしもクラウドでアプリケーションを実行するのに必要な完全なものにインフラストラクチャーを組み立てることを望んでいませんし、そうする必要もありません。彼らはただ自分のアプリケーションの開発に戻り、エンドカスタマーに集中したいだけなのです。
プラットフォームエンジニアリングとは、内部のカスタマーのニーズに合わせた抽象化を構築し、彼らがインフラ管理の責任を軽減して、エンドカスタマーに集中できるようにする実践なのです。
内部プラットフォームの定義と製品としての視点

抽象化の構築とプラットフォームエンジニアリングについて話しましたが、次は内部プラットフォーム全体について話しましょう。なぜなら、それはインフラの抽象化だけではないからです。この講演の準備をしている時に、内部プラットフォームのこの定義に出会い、とても気に入ったので、今日皆さんと共有したいと思います。内部プラットフォームとは、「魅力的な内部製品として構成された、セルフサービスAPI、ツール、サービス、知識、サポートの基盤」です。
この定義には私が本当に気に入っている2つの部分があります。まず、この定義は単にプラットフォームエンジニアリングチームが構築するもの、つまりAPI、サービス、ツール、抽象化だけでなく、知識とサポートを通じて彼らが構築したものの採用をどのように推進するかにも触れています。Amazon EKSの世界で私たちが協力している最も成功しているプラットフォームチームは、ドキュメンテーションや内部顧客へのサポートと教育の提供に非常に力を入れており、これが彼らが構築するプラットフォームの抽象化の採用を促進しています。
私が本当に気に入っている2つ目の部分は、最後の3つの言葉、「魅力的な内部製品」です。内部顧客向けの内部プラットフォームを構築する際、私たちは本当に製品を作っているのです。外部顧客向けの製品を作るのと同じことです。そのため、Amazon EKSの世界で内部プラットフォームの取り組みに最も成功しているチームは、内部プラットフォームの構築に製品中心の考え方を本当に取り入れ、顧客から逆算して彼らの特定のニーズを満たす抽象化を構築しています。
プラットフォームエンジニアリングがもたらすメリット
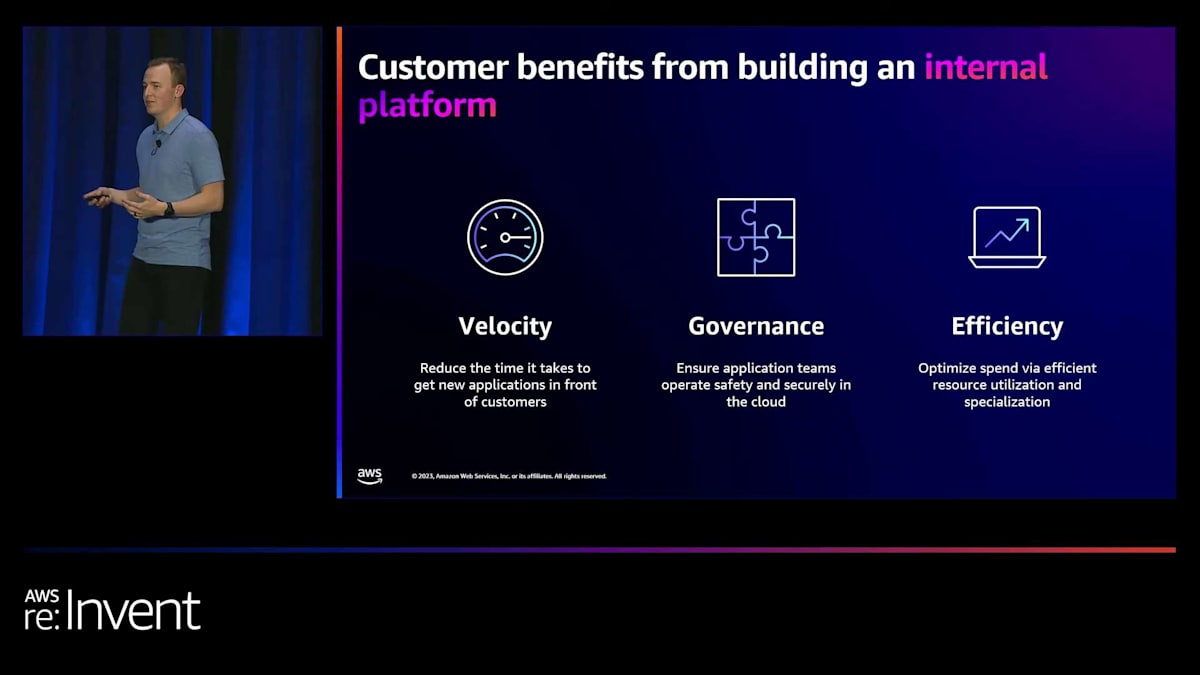
プラットフォームの構築は投資です。時間とともに配当を生むことを期待して、初期コストがかかります。では、Amazon EKSの世界で内部プラットフォームの構築に成功している顧客が達成しているメリットについて話しましょう。

私たちが見ている最初のものは、速度です。これは本当にスピードに関することです。顧客は、内部プラットフォームを通じて、革新的な新しいアイデアやコード、文字通り開発者のラップトップからのコードを、本番環境に出して顧客の前に届けるまでの時間を短縮することができます。各個別チームがインフラストラクチャを自前で用意する必要をなくし、セルフサービスのデプロイメント機能を提供することで、企業は新しいアイデアの市場投入時間を加速させることができ、実際に加速させています。
2つ目はガバナンスです。この文脈でのガバナンスは、セキュリティ、信頼性、スケーラビリティなどを包括する言葉です。抽象化を構築することで、企業はプラットフォーム上で動作するすべてのアプリケーションに対して、これらの懸念事項に関する要件を自動化された方法で強制することができます。そのため、すべてのワークロードがプラットフォームに組み込まれた適切なデフォルト設定の恩恵を受け、アプリケーションチームが個別に設定方法を考える必要がなくなります。
最後に効率性ですが、これは本質的にコスト削減に関わります。プラットフォームがお客様のコストを削減する方法はいくつかありますが、私たちがよく目にする具体例をいくつか挙げてみましょう。
マルチテナント、特にコンテナ化された環境では、プラットフォームを構築することで、異なるチームの複数のワークロードを同じ基盤となるホストインスタンス上で実行できるため、ワークロードのコスト効率を高めることができます。 2つ目のメリットは、人的資本コストの観点からです。個々のアプリケーションチームがインフラの専門知識を持つ必要性をなくし、その専門知識を一元化することで、人的資本コストも削減できます。

お客様からよく耳にするのは、プラットフォームによってクラウドでの規模の経済を実現できるということです。先ほど述べたように、プラットフォームの構築には初期投資が必要ですが、一度構築してしまえば、その後のアプリケーションのデプロイやオンボーディングの限界コストはかなり小さくなり、結果として企業は規模の経済を実現できるのです。
Amazon EKS上の内部プラットフォーム:SalesforceとNASAの事例

社内プラットフォーム構想で成功を収めた Amazon EKS のお客様の具体例を2つご紹介したいと思います。成熟度の両極端にある顧客をご紹介します。1つは非常に成熟しており、現在大規模に運用されているプラットフォームを持つ顧客、もう1つはプラットフォームの旅の初期段階にありますが、初期の成功を収めており、率直に言って EKS 上に構築された非常にクールなユースケースを持つ顧客です。

最初にご紹介したいのは Salesforce です。Salesforce の社内プラットフォームである Hyperforce は EKS 上に構築されています。Hyperforce はパブリッククラウド向けに構築された Salesforce のプラットフォームアーキテクチャの再構築です。2023年において重要なのは、これが Salesforce が顧客に信頼できる AI を提供する方法だということです。Hyperforce のコンピューティング基盤は Hyperforce Kubernetes Platform と呼ばれ、EKS 上に構築されています。HKP により、Salesforce のエンジニアリングチームは自ら EKS クラスターをプロビジョニングする必要がなく、代わりに Kubernetes をサービスとして利用することができます。HKP は開発者体験を効率化し、クラスターをサービスとして提供したり、マルチテナント環境に適したワークロード向けにネームスペースをサービスとして提供するなど、さまざまなレベルの抽象化を提供しています。
今日、Salesforce は Hyperforce フリート全体で HKP を実行しています。これは数百万のポッドと千を超える EKS クラスターで構成されています。つまり、非常に大規模な内部プラットフォームを運用している顧客が、大きな成功を収め、素晴らしい結果を得ているということです。

次に紹介したい顧客は NASA です。NASA はプラットフォーム導入の初期段階にある顧客です。NASA は新しいデータプラットフォームの基盤として AWS を選択しました。このプラットフォームは JupyterHub、Dask、Crossplane、Flux CD などのツールで構築されており、科学者が数分で完全な機能を備えた JupyterHub 環境をプロビジョニングできるようになっています。この新しいプラットフォームは、世界中の科学者がデータやプロセスを共有し、再現可能な結果を生成することで、協力して研究を進められるようにすることを目指しています。このプラットフォームの最終目標は、科学モデルをサービスとして提供することです。つまり、世界中の研究者が馴染みのあるインターフェースから一般的な科学モデルを実行できるようにすることです。
このプラットフォームが非常に素晴らしいと思うのは、White House Office of Science and Technology の Year of Open Source イニシアチブをサポートしているからです。これは、科学研究をより公平で、透明性が高く、アクセスしやすく、協力的なものにすることを目指す動きです。NASA の方々がこのプラットフォームを EKS 上に構築することを選んでくれたことを、私たちは非常に嬉しく思っています。
プラットフォーム実装パターン:開発者の自由とガバナンスのバランス

では、ここからは Roland に引き継ぎます。Roland がプラットフォーム実装パターンについて話をします。
Kevin、ありがとう。皆さん、いかがお過ごしですか? さて、もうすぐビールの時間ですね。この後、展示会場でビールを飲む人は? いいですね。Kevin はプラットフォームエンジニアと DevOps チームの数を尋ねましたが、プラットフォーム上でアプリを開発している開発者やアプリ開発者は何人いますか? ほら、これが問題なんです。顧客はどこにいるんでしょうか?
私たちのチームの存在意義の一つは、開発者やデータサイエンティストが求めるものについての考え方です。彼らは自由を求め、自律性を求め、JupyterHubを使いたがり、Rayを使いたがり、Kubeflowを使いたがり、好きなフレームワークを使いたがります。彼らはコードを書き、マイクロサービスをデプロイし、それを自由に行いたいと考えています。一方で、プラットフォーム構築者がいます。プラットフォーム構築者は、Kevinが話したような標準化やガバナンスを行おうとしています。標準化の方向に行き過ぎると、誰も使わないプラットフォームを作ってしまいます。開発者は川のようなもので、曲がりくねっていて、最小の抵抗で仕事を完了させようとします。なぜなら、彼らは成果物や締め切りを満たそうとしているからです。時には開発を外部チームにアウトソーシングすることもあり、彼らもその成果物を満たさなければなりません。
一方で、開発者に自由を与えすぎると、突然インターネットにURLを公開したり、新しい大規模言語モデル用に割り当てたGPUをすべて使い切ってしまったりします。あるいは、コストを急増させるようなさまざまなことを行い、AWSの請求書を見て「ああ、システムにこの10億のイベントが入ってきてこのようにスケールアップするとは予想していなかった」と思うことになります。

では、これをどう解決するのでしょうか。時間とともに、モダナイズを始める際、通常は自律的に始めます。Amazonが話す「2枚のピザチーム」のように、アプリケーションを構築し、独立したスクワッドを持ちます。現在では、マイクロフロントエンドがマイクロサービスと通信し、所有されたデータプロダクトであるデータメッシュと通信するようになっており、人々はこの自律性を持っています。このようなアプリケーションをどんどん構築していきます。今年の初めは、コスト最適化に本当に焦点を当てていました。経済が打撃を受けたとき、これらのプラットフォームチームが「コスト最適化を手伝ってほしい」「KubernetesのコンテキストでKarpenterのようなものを使ってSpotを使用したい」と言ってくる大きな増加を見ました。そしてGenAIが登場し、そのハイプと波が来て、人々はデータプラットフォームを作り始め、同じプラットフォームが急速にキャパシティストレージ、GPUをスピンアップする必要がありました。そして両面を持つことになりました。
プラットフォームエンジニアリングの課題と設計の選択肢
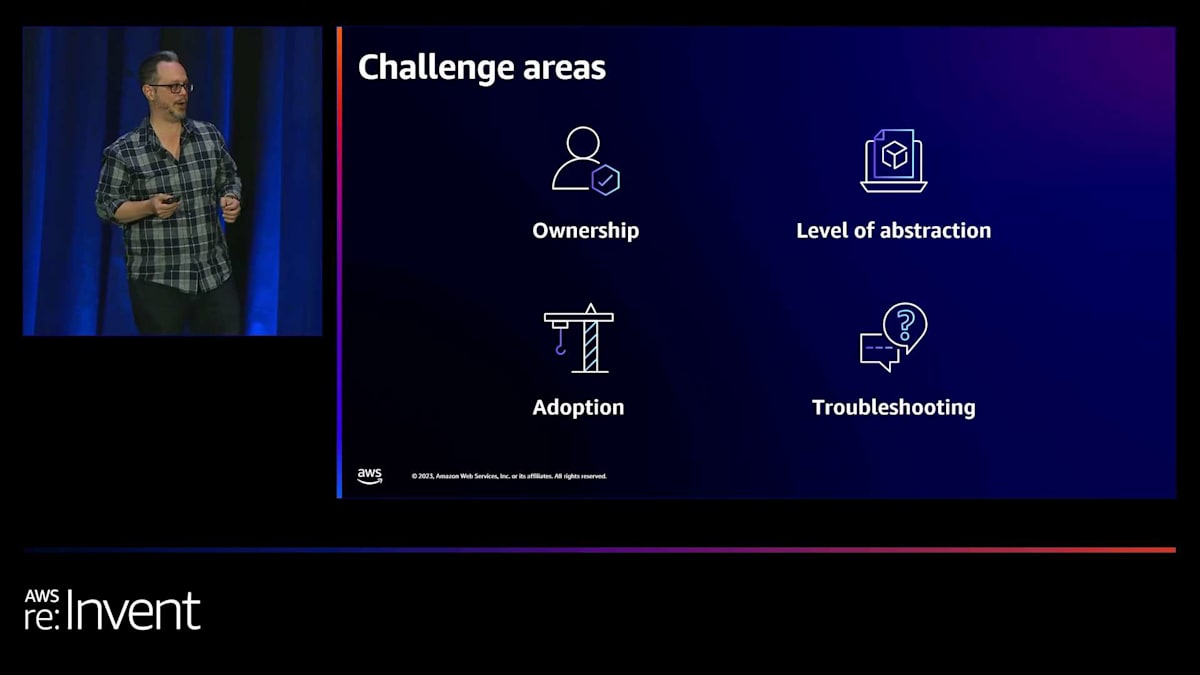
私たちの顧客が直面している課題のいくつかの領域について話しましょう。まず、所有権です。ヨーロッパでの顧客ミーティングに参加しました。そのミーティングには、プラットフォームチームがいて、約25人の開発者がプラットフォームチームに専念し、約200〜300人のアプリケーション開発者、さまざまなプロジェクトをサポートしていました。彼らはかなり良いプラットフォームチームを持っていました。彼らはすべての異なる機能にわたって自動化を構築しましたが、それでも異なるチーム間でいくつかの問題がありました。私たちと一緒にいた1つのチームがありました。開発者たちは「私のコードを取って、デプロイして実行してください」と言っていました。そして、別のチームは「自分専用のクラスターが欲しい。自分で分離して管理したい」と言っていました。彼らは全員を満足させることができませんでした。
そこで、誰がプラットフォームを所有するのかという概念があります。そして時々、プラットフォーム自体が製品であることに人々は気づいていません。プラットフォームエンジニアリングを行うなら、それを製品として扱わなければなりません。そして顧客がいます。その顧客は開発者とデータサイエンティストです。製品を作るとき、私たちは彼らのために作ります。彼らはそこに含まれていますか?次に見られる領域は抽象化のレベルです。「AWSアカウントが欲しい、クラスターが欲しい」から「コードをプッシュできるDevOpsパイプラインだけを与えてください、それだけです」まで、すべてがあります。ここには多くの変動性があり、顧客は自分たちの組織にとってどこに線を引くべきか苦心しています。「このサービスレベルが正しいレベルで、あなたのプラットフォームの問題はすべて解決されるでしょう」という銀の弾丸があると言えたらいいのですが。
もう1つは、「フィールド・オブ・ドリームス」の採用問題、つまり「作れば来る」というものです。顧客から「プラットフォームを構築し、投資しました。とても良いものです。私たちが書いたコードを見てください。GitOpsを使った素晴らしい自動化です。私のGitリポジトリに触れても、pull requestが承認されない限り何も通りません。でも開発者は使っていません」と言われることがあります。そして、スペクトルの反対側では、「プラットフォームを構築しました。このプラットフォームでは、Kubernetesについて何も知る必要はありません。開発者の方は、コードをチェックインするだけです。私がpodをデプロイし、実行します」と言います。しかし、アプリが壊れると「あなたの責任です。Kubectl pod logsを実行してください」と言われます。「Kubernetesを知る必要がないと言ったじゃないですか」と言うと、「何を言っているんですか」と返されます。観測可能性は後付けになりがちで、プラットフォーム設計の一部として考えられていません。なぜなら、私たちは作ること、プロビジョニング、自動化に集中しがちだからです。しかし、このアプローチには限界があります。
おそらく、何かを一度作るだけですが、常に反復し、デバッグしています。では、開発者やユーザーの重心はどこにあるのでしょうか?アプリを構築することでしょうか、それともコードの保守、バージョン管理、トラブルシューティング、デバッグでしょうか?重心は後者にあります。最初はプラットフォームに乗ってもらえるかもしれませんが、トラブルシューティングができない、ログにアクセスできない、何が起こっているかわからないといった理由で、別の場所を探し始めるでしょう。ラップトップでは動いたのに、クラウドやクラスター、podでは動かないということがあります。


あるお客様との会議で、VMのEC2インスタンスからpodにアプリケーションを移行した事例がありました。同じようにサイジングしたのに、突然アプリが動かなくなりました。これは、他のアプリケーションの他のpodが同じノードにスケジュールされていたためでした。そこで彼らは「これは壊れている。自分たちのクラスターが必要だ」と考えました。開発者が自分たちのクラスターを欲しがった理由は、分離が必要だったからです。しかし、分離とは何を意味するのでしょうか?20種類の定義があります。自分のAWSアカウントと権限を持つこと、レジリエンシーのためにリージョンを使うこと、可用性ゾーンを使うことかもしれません。public sectorのような規制産業では、ネットワークの分離が必要かもしれません。自分のクラスターや自分のコンピュートを望む人もいます。この場合、トラブルシューティングの問題が、チームに独自のクラスターが必要だという結論に導いたのです。実際に必要だったのは、独自のノードと独自のスケジューリング方法でした。
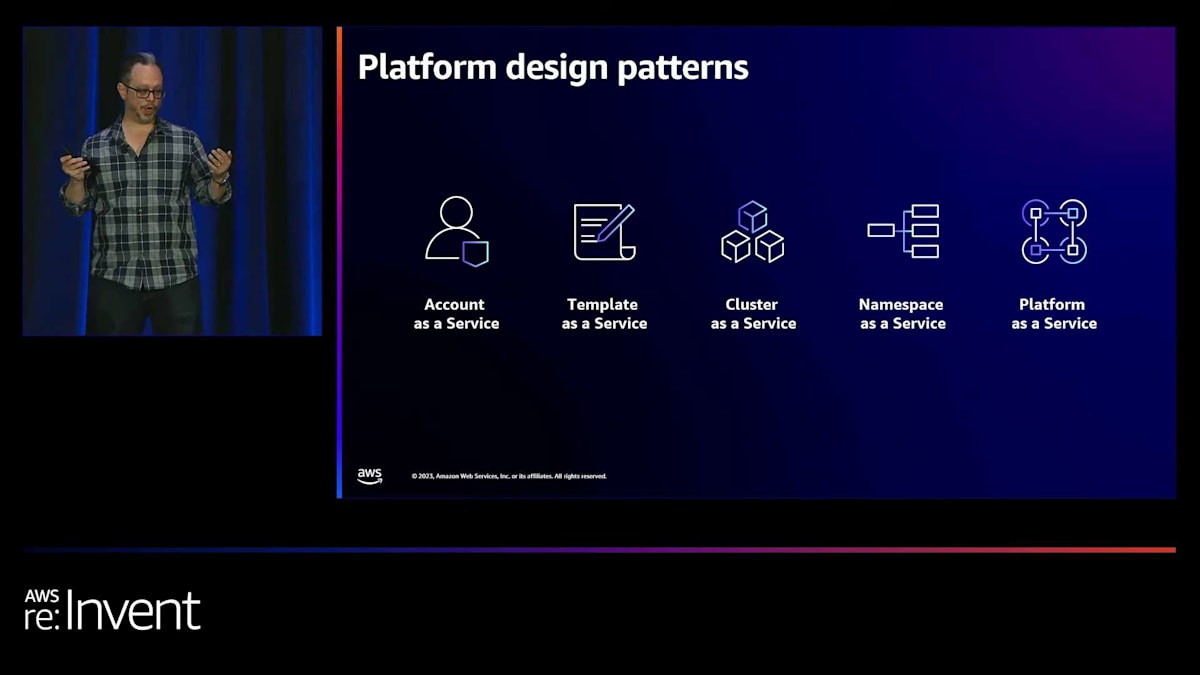
プラットフォーム構築のアプローチ:ツールの選択とベストプラクティス
お客様と一緒に検討する設計の選択肢はたくさんあります。Account as a Service、Template as a Service、Cluster as a Service、Namespace as a Service、Platform as a Serviceなどがあります。ここにいる方々の中で、これらのどれかを実践している人はどれくらいいますか?ご覧の通り、皆さんの意見は一致していませんね。魔法のようなプラットフォームは存在しないのです。これらの選択肢にはそれぞれトレードオフやデメリットがあり、異なる目的に最適化されています。実際には、サポートするワークロードによって大きく変わってきます。例えば、今朝もEBCでお客様とミーティングをしたのですが、そのお客様はアカウントの乱立に悩んでいました。これらのアプローチはどれも乱立の問題を抱える可能性があります。アカウントの乱立、gitリポジトリに放置された大量の古いテンプレート、クラスターの乱立、使われていない大量のnamespace、そして大量のパイプラインなどです。

結論として、万能なアプローチは存在しません。非常に難しい問題なのです。では、どうすればいいのでしょうか?重要なのは、プロダクトマインドセットを持つことです。プラットフォームエンジニアリングを行うなら、それは組織の中で最も重要なプロダクトの一つです。組織のすべてのワークロード、MLパイプライン、データをサポートする必要があるなら、ビジネスドメインから逆算して考える必要があります。結局のところ、人々はビジネス機能を提供するアプリケーションを書いているのです。

そこから逆算して考える必要があります。では、アーキテクチャ的にはどう考えればいいでしょうか?私は大きな枠組みで考えるのが好きです。モジュール式のアーキテクチャで、双方向のドアを持ち、モジュールを構築して再利用できるようにしたいですね。開発者インターフェースも考慮しましょう。開発者にはGUIだけを使ってほしいと思うこともありますが、結局のところ、彼らはたくさんの自動化をサポートしたいと考えています。開発者のライフサイクルはどのようなものでしょうか?データと依存関係は、多くの場合、変動が大きい部分です。共有データベース、独自のデータベース、データベースの所有者など、様々な要素があります。そして、ライブラリ、再利用可能なコード、コードライブラリ、再利用可能なイメージ、ソフトウェアデリバリーと自動化があります。
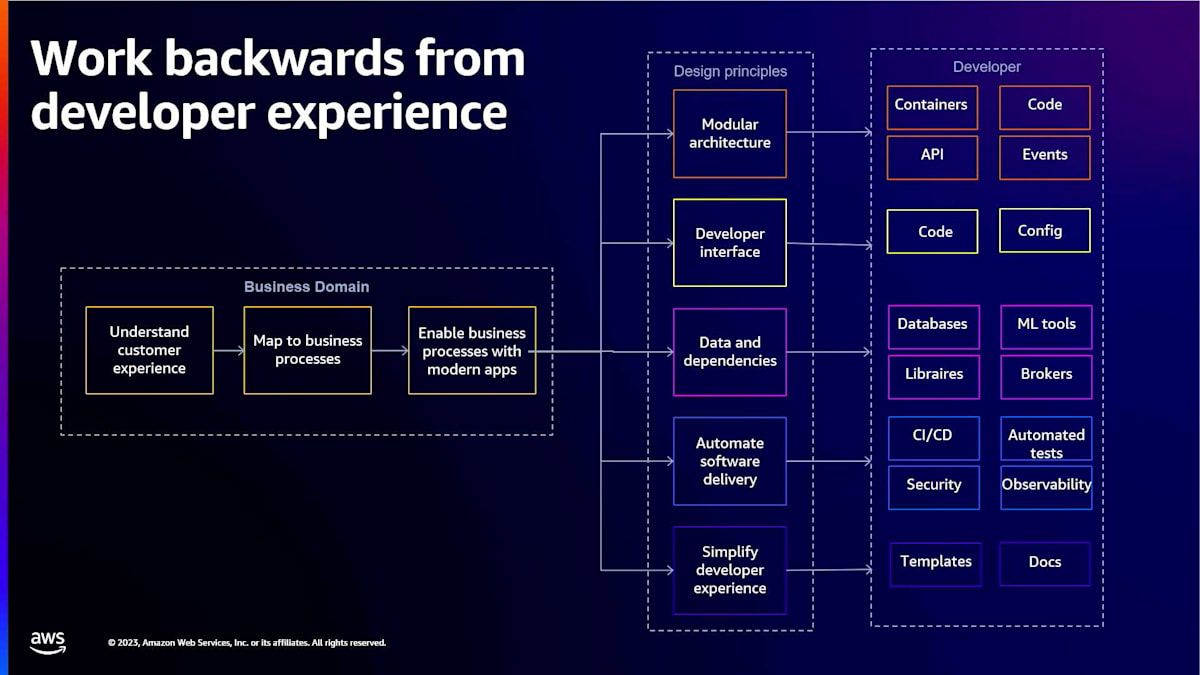
開発者体験の簡素化について説明します。右に進むにつれて、開発者とデータサイエンティストのためにこれらを分解していきます。 開発者はコンテナ、コード、API、イベントについて話します。イベント駆動アーキテクチャは、コンテナ内で構築され、Lambda関数と統合される可能性があるものです。そして、コードと設定があります。設定地獄は実在する場所です。多くの人がそこを経験していますが、適切な設定管理で抜け出すことができます。
プラットフォームを構築する際は、依存関係について考える必要があります。データベース、機械学習ツール、ライブラリ、ブローカーをどのように扱うか?RabbitMQやKafkaを使って何かをしているかもしれません。Kafkaを使っている人はどれくらいいますか?EKS上でKafkaを実行している人は?はい、何人かいますね。自動化されたソフトウェアデリバリーは、私たちが「イリティーズ」と呼ぶものです。開発者のためのDevOpsパイプライン、CI/CDパイプライン、そしてインフラストラクチャ・アズ・コードについて考えます。DevOpsパイプライン用に別の組織を持つ企業もあり、これは追加の顧客またはプラットフォームの一部となる可能性があります。
テストはしばしばプラットフォームの一部として見過ごされがちです。セキュリティは私たちにとって初日からの懸念事項なので、観測可能性と共にプラットフォームの一部である必要があります。最後に、開発者体験の簡素化が重要です。どうすればセルフサービスを実現できるでしょうか?開発者にどのように自律性を与えられるでしょうか?テンプレート、あるいは開発者が機能するテンプレートを提供できるメカニズムが不可欠です。そして、誰もが大好きな開発活動はドキュメンテーションです。コードやスクリプトのドキュメント作成が大好きな人はどれくらいいますか?自己ドキュメント化や自動化は良い習慣です。
Amazon EKSバッジの紹介とThe New York Timesの事例へ
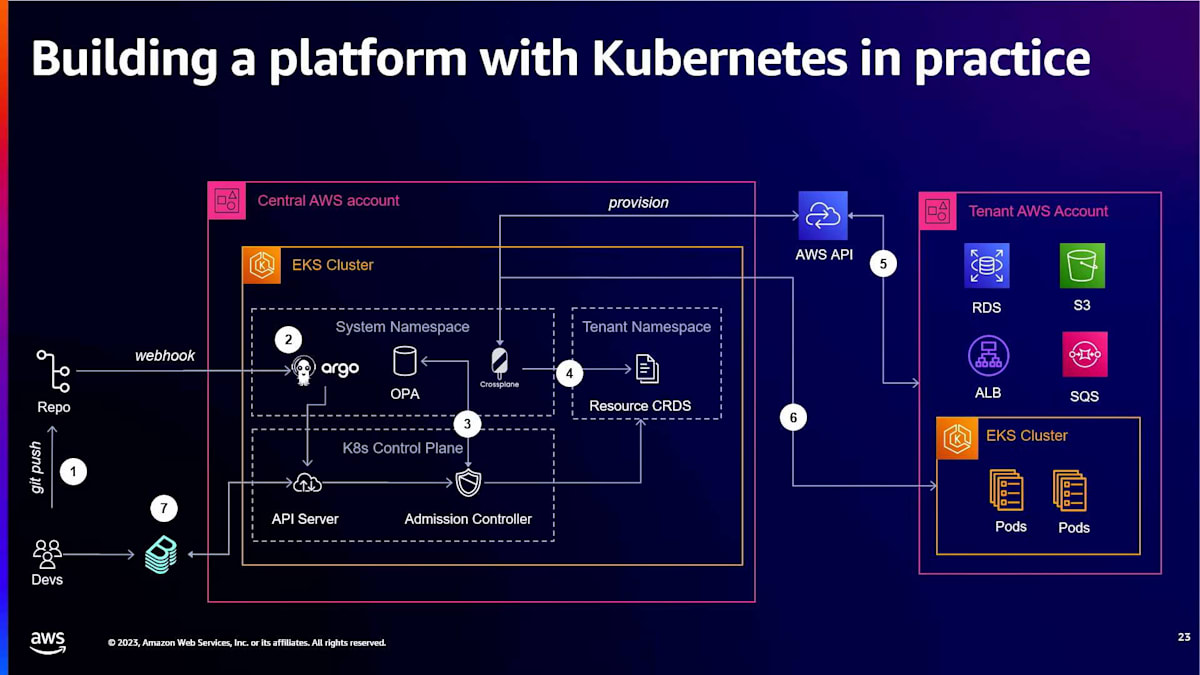
プラットフォームを構築する際には、多くのツールと選択肢があります。クラスター、共有サービス、すべての「イリティーズ」、そしてそれらの背後にあるすべてのツールがあります。様々なツールでプラットフォームを構築できます。これはEKSの話なので、Kubernetesを使用している多くの顧客は、単なる計算リソースとしてではなく、プロビジョニング、スケーリング、セキュリティ確保に使用するAPIとして考えています。これは、多くの顧客と一緒に行った例で、Argo CD、ポリシー用のOPA、AWS Controllersやクロスプレーンなどのツールで構築された管理クラスターがあり、マネージドRDSデータベース、SQSキュー、S3バケットなどのサービスをプロビジョニングおよび管理できるようにしています。

様々なコントロールプレーンの側面があり、クロスプレーンのようなものを使用してクラスターを作成、プロビジョニング、アップグレードする機能さえあります。これはKubernetesを全面的に活用する方法です。今週後半にCON408という「Infrastructure as Code vs GitOps vs CI/CD」というチョークトークセッションがあります。 異なる選択肢があります。Terraform、Pulumi、その他のパートナーツールを使用してクラスター部分を行い、右側でGitOpsを使用することもできます。インフラストラクチャチームから「Gitの使い方さえ分からない、それは開発者が使うものだ」と言われたことがあります。Gitの使い方とGitのセキュリティを知らなければ、GitOpsで成功することはできません。なぜなら、GitOpsはこれらすべてを活用するからです。


このようにツールの選択肢はたくさんありますが、繰り返しになりますが、これらの大きな要素を念頭に置いて、何がそれらをサポートするかを考えることが重要です。 まとめると、プラットフォーム構築で最もよくある間違いの1つは、スポンサーやワークロードなしに何かを構築してしまうことです。最も成功しているプラットフォームチームは、必ずスポンサードプロジェクトを持ち、社内で上手くやっている顧客、2〜3のワークロードがあり、それらの顧客と一緒にプラットフォームを構築しています。開発者やエンジニアをその過程に参加させ、彼らと一緒に構築することが、おそらく最大の成功要因です。

一度にすべてを解決しようとせず、それらのユースケースと共に構築していきましょう。魅力的なユースケースを選び、開発者と協力してください。ステートフルやステートレスのワークロード、容量が必要なもの、リクエストが必要なものなどを選んで、それを基に構築していきます。エスケープハッチを提供することも大切です。

ここで、組織の約80%が簡単なボタン操作のCode as a Serviceを使用することになります。しかし、もう少し制御が必要な場合のことも考えて、異なる承認プロセスを用意します。ドキュメントを読んでもらい、Documentation as a Serviceを提供し、Cluster as a Serviceというエスケープハッチも用意します。1つだけでなく、2つか3つを選び、ユースケースに基づいて優先順位をつけ、その境界線をどこに引くかを変更する方法を学びましょう。なぜなら、今日のデフォルトが明日もデフォルトとは限らないからです。

繰り返しになりますが、すべてのワークロードに一つのサイズが合うわけではありません。最後に、ドキュメントと教育は実際にプラットフォームの旅の重要な部分です。AWSの中では、Technical Field Communities(TFCs)と呼ばれるものを運営しています。今朝、ある顧客とミーティングを行い、彼らがそれを模倣してプラットフォームの一部としていることを知って励みになりました。彼らは実際に、プラットフォームの旅の一部として、イネーブルメントと教育を構築しています。プラットフォームを使ってもらいたいなら、「来てください、私たちがあなたをKubernetes開発者に育て、認定資格の取得を手伝います」というアプローチを取ります。彼らを引き付けるための魅力的な要素を考え、彼らが何をしたいのかを考えてください。

以上が現状です。そして最後に、恥ずかしながら宣伝をさせてください。教育サービスについて話す新しいAmazon EKSバッジを用意しました。フィールドで顧客と働くチームやサービスチームのメンバーから学んでください。このバッジを取得したい方は、今週ここで立ち上げたばかりです。こちらがQRコードです。写真を撮る時間を少し設けます。 私たちは教育を大切にしているので、言葉だけでなく行動で示しています。Amazon EKSで学び、バッジを獲得してください。以上で、Ahmed、あなたの番です。ありがとうございました。
The New York Timesの内部開発者プラットフォーム:動機と主要な柱

ありがとう、Roland。皆さん、こんにちは。私が皆さんとレセプションの間の障害になっていることは承知していますので、手短に済ませるようにします。RolandとKevinが、Amazon EKSの上にプラットフォームを構築する方法について素晴らしい洞察を共有してくれました。そこで、私たちがThe New York Timesでどのように内部開発者プラットフォームを構築したかについてお話しします。

ご存知の通り、The New York Timesの最も認知度の高い製品はニュースとジャーナリズムですが、ゲーム、Wirecutter、オーディオ、The Athletic、料理など他の製品もあります。では、これらの製品すべてをどのように革新し、提供するのでしょうか。これについて考える時、内部開発者プラットフォームを構築する動機について議論しましょう。
まず、エンジニアに一貫した体験を提供する方法を考えます。新しく入社したエンジニアは一貫した体験を得る必要があり、一方で他のチームのエンジニアも新しいサービスやアプリケーションを構築しようとする度に同じ体験を得られるようにします。ソフトウェア開発ライフサイクルのボトルネックになりたくありません。エンジニアが新しいサービスをデプロイしたり構築したりする度に手動で介入したくありません。そのため、チームが自律的に必要な機能を使って構築できるようなセルフサービスアプローチを提供したいと考えています。
また、拡張可能なツールを提供したいと考えています。これが意味するのは、特定のツールに焦点を当てるのではなく、チームが自律的に構築できる抽象化レイヤーを構築したいということです。特定のユースケース向けのツールを提供しなかった場合でも、そのレイヤーを利用して上に構築することができます。最終的に、デリバリーが重要です。そのため、アイデアから本番環境までの時間を短縮し、チームが組織全体で管理のオーバーヘッドとインフラストラクチャを削減し、アプリケーションを迅速に立ち上げられるようにしたいと考えています。

プラットフォームのSenior Product ManagerであるDaniel Cassidyの言葉を紹介したいと思います。「エンジニアは問題を解決し価値を提供するためのシームレスな体験を受けるに値します。開発ライフサイクルのあらゆる段階でエンジニアを支援し、インフラストラクチャの負担と拡散を軽減する集中型の開発者プラットフォームを想像してみてください。」彼が言わんとしていることは基本的にシンプルです。アプリをデプロイしようとする時、アプリを提供するために必要なすべてのインフラストラクチャに焦点を当てる必要はありません。一貫した体験を通じて、デプロイ方法や必要なすべてのステップについて誰かに尋ねる必要はなく、適切に文書化されているべきです。では、内部開発者プラットフォームが組織にとって不可欠なものとなるのは何故でしょうか?


この課題に取り組むため、私たちはプラットフォームのいくつかの重要な柱を特定しました。 まず、標準化です。組織全体で標準を提供し、チームがその上に構築できるようにする必要があります。次に効率性です。これは、時間を短縮し、必要に応じてチームがより迅速に提供できるようにするシームレスな体験を提供することを意味します。


統合も重要な柱の一つです。プラットフォームは多くのツールとの一貫した体験と統合を提供する必要があります。開発体験全体に価値を提供するために、これらのツールすべてを統合する必要があります。スケーラビリティも重要です。ここでいうスケーラビリティは、単に実行時の体験だけでなく、製品自体の相互作用におけるスケーラビリティも意味します。 私たちは、Day 0、Day 1、Day 2 に向けて構築し、さらに機能を追加し続けます。
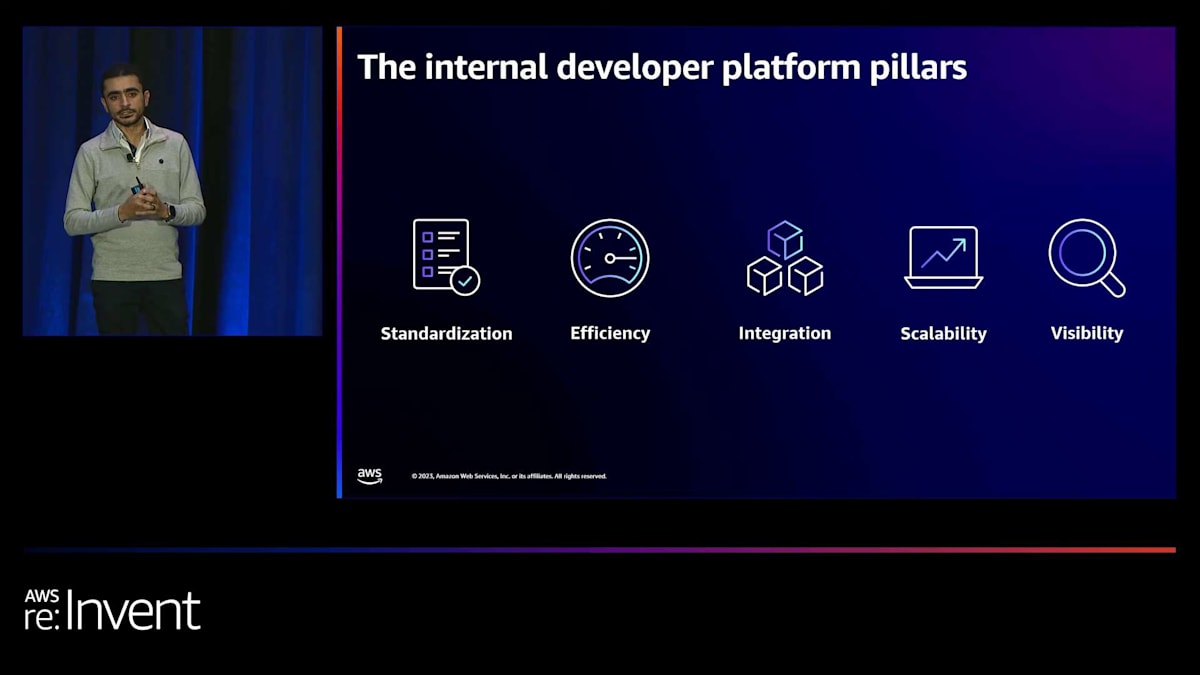
最後に、可視性があります。集中型の内部開発者プラットフォームを共有することで、インフラ全体とプラットフォーム上で提供するサービスのポートフォリオを完全に一貫して把握することができます。
The New York Timesのプラットフォームアーキテクチャ:マルチアカウントとマルチテナント

さて、内部開発者プラットフォームについて話してきましたが、ここでお客様自身について考えてみましょう。私たちは誰のためにこれを構築しているのでしょうか? 私たちは開発者やエンジニアのために構築しています。開発者には、顧客の旅と同様の旅があります。要件を受け取ると、問題の解決方法を考え、設計し、計画を立て、そしてコーディングから納品までのプロセスを経ていきます。
私は、プラットフォームで抽象化し、エンジニアにとってより簡単でシームレスにできるいくつかの要素に焦点を当てました。必ずしもこれを完全に抽象化したいわけではありませんが、一貫した体験と移行を提供し、アプリケーションの開発をより容易にしたいのです。実際に構築したワークフローに移る前に、私たちの目標を再確認したいと思います。私たちの最終的な目標は、エンジニアリングがアプリケーションを開発し提供する際に、シームレスにサポートし、スムーズな移行を確保することです。



まず、作成プロセスについてですが、エンジニアとして、お客様に提供したいアプリがあるとします。アプリを作成し、オンボーディングを行い、GitHub リポジトリやソース管理から必要なテンプレート類をすべて入手することから始めます。 また、CI/CD のビルド、テスト、デプロイ機能や、必要なランタイムとクラウドリソースも手に入れます。 これらすべてを、単にリクエストするだけで手に入れることができるのです。具体的に必要なものを指定し、「はい」をクリックするだけで、これらすべてがすぐに使える状態で提供されます。
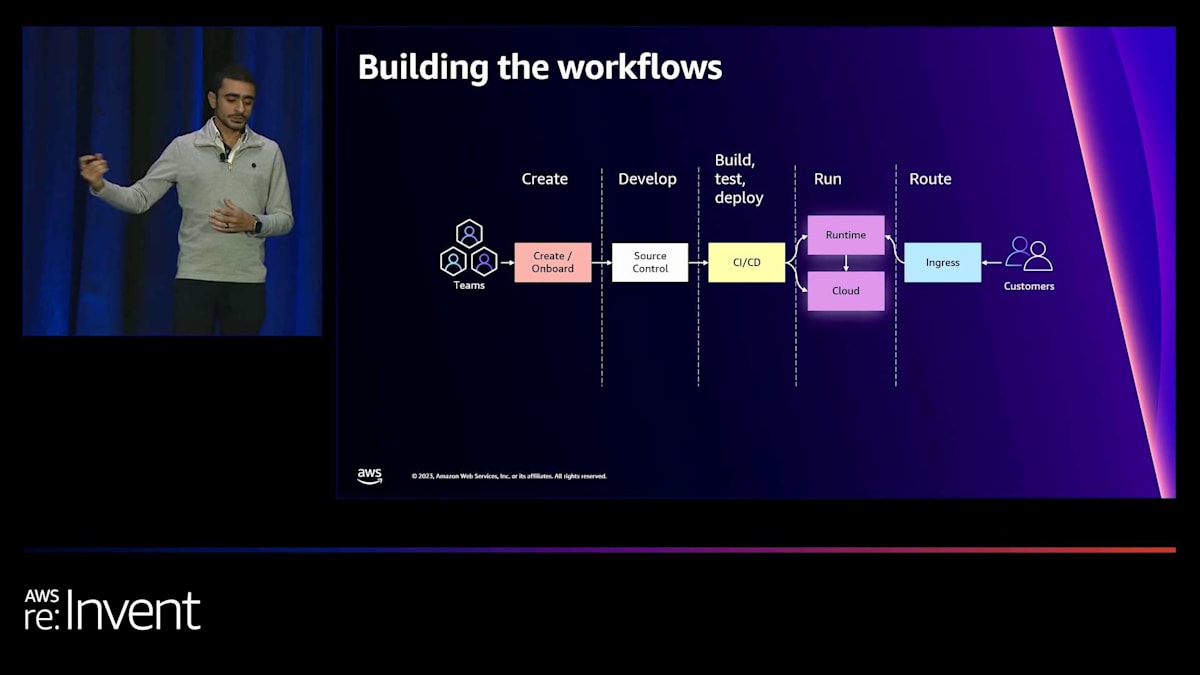

最後に、ルーティング層があります。これは、会社で構築した共有 Ingress モデルで、すべてのトラフィックをお客様に提供することができます。しかし、ここに1つ欠けているピースがあります。それは observability です。これは非常に重要なコンポーネントです。 ご覧のように、observability 層はすべてのステップにまたがっています。すべてのワークフローが観測されていることを確認する必要があり、トレース、ログ、メトリクスなど、ワークフロー全体とライフサイクルを理解するために必要なあらゆるテレメトリデータが大量に存在します。

プラットフォームの構築にあたり、いくつかのアプローチを試した結果、マルチアカウントアーキテクチャの構築に落ち着きました。必要なリソースをすべて単一の AWS アカウントに積み重ねるのではなく、マルチアカウントアーキテクチャを通じてこの体験をどのように提供するかを考え始めました。このアプローチにより、特定のアカウントでワークロードをグループ化し、開発環境と本番環境が同じアカウントに存在しないようにセキュリティ対策を実施し、どのタイプのワークロードがどのアカウントにあるかを理解してコストを管理することができます。

プラットフォームアカウントには、Kubernetes クラスターから Ingress モデル、そして複数のサービスで共有されるものまで、先ほど話した中央集権的なワークロードがすべて含まれています。そして、チームアカウントがあり、各チームは特定のニーズに応じたアカウントのセットを取得します。

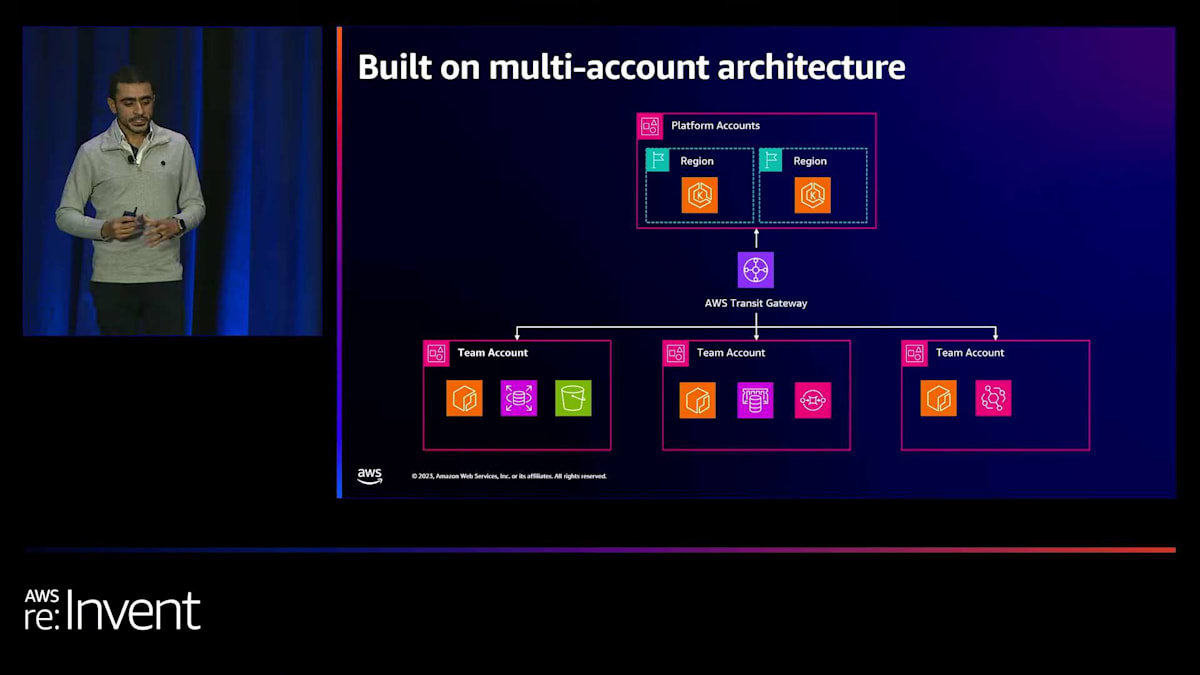
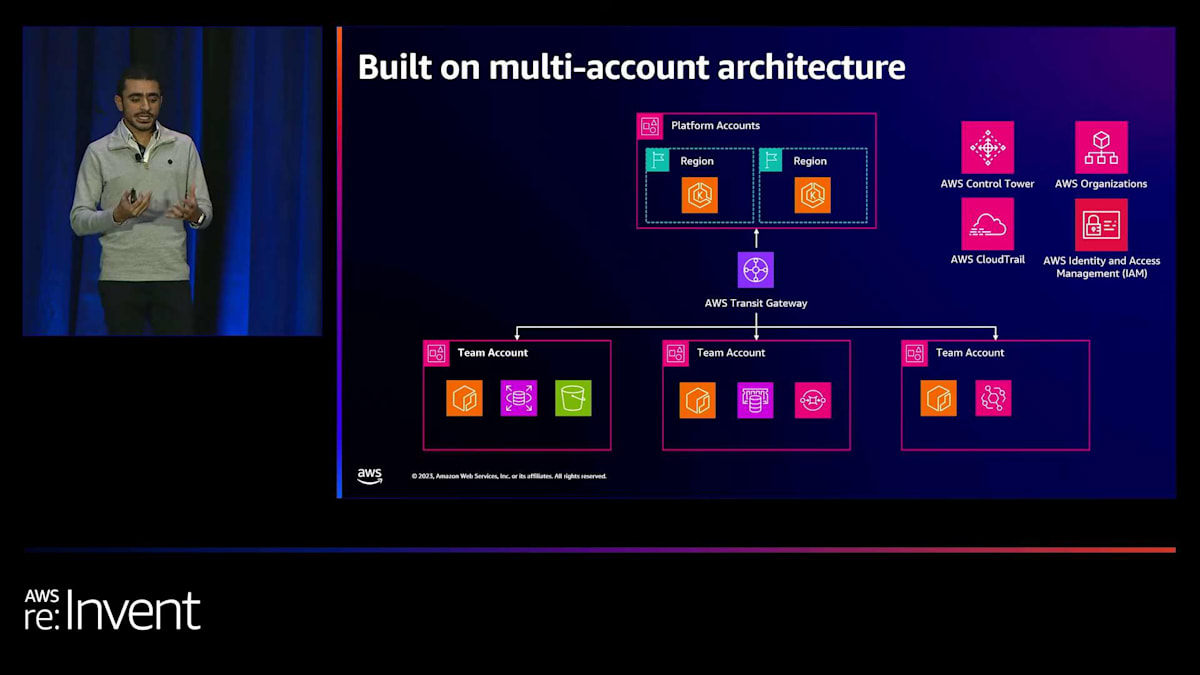
これらのチームアカウントでは、ランタイムで利用可能なリソースを作成できます。これらのリソースには、RDS インスタンス、S3 バケット、SQS、ElastiCache インスタンス、そしてアプリケーションの実行に必要なその他のものが含まれます。これらすべてを接続するために、すべての間に Transit Gateway レイヤーを追加します。 この複雑なセットアップを管理するために、AWS は私たちが利用できる一連のサービスを提供しています。 私たちは、AWS Organizations と共に AWS Control Tower を使用して、プロビジョニング体験全体を管理しています。また、これらのアカウントでどのような API コールが行われているかを確実に理解するために、すべてのアカウントで CloudTrail を有効にしています。ここでのすべては、AWS のシングルサインオンを通じて行われます。これが私たちのマルチアカウントアーキテクチャです。
The New York Timesのプラットフォーム実装:オンボーディングからデプロイメントまで


では、私たちや皆さんの多くが直面するかもしれない別のジレンマに移りましょう。 EKSクラスターを運用している方々の中で、マルチテナントクラスターを使用している人と、シングルテナントクラスターを使用している人はどれくらいいますか?マルチテナントクラスターを使用している人?わお、かなりの数ですね。シングルテナントクラスターを使用している人は?では、説明しましょう。 自社のプラットフォームを構築する際には、シングルテナントクラスターかマルチテナントクラスターかというジレンマがあります。万能な解決策はなく、様々な方法で解決できる問題です。それぞれのアプローチには長所と短所があります。
シングルテナントクラスターでは、ハードテナンシーがあります。各テナントが独自のクラスターを持つため、テナント間のRBACについて考える必要がありません。しかし、管理やアップグレードの作業が増え、オーバーヘッドも増加し、コスト最適化も難しくなります。チームがわずか数個のサービスをデプロイする必要がある場合でも、そのためのクラスターを構築しなければなりません。一方、マルチテナントクラスターでは、テナント間で単一のクラスターまたは少数のクラスターを共有します。これにより、クラスターのコストが大幅に最適化されますが、セキュリティとネットワークの分離をどのように確保するかを慎重に考える必要があり、事前に計画を立てなければなりません。
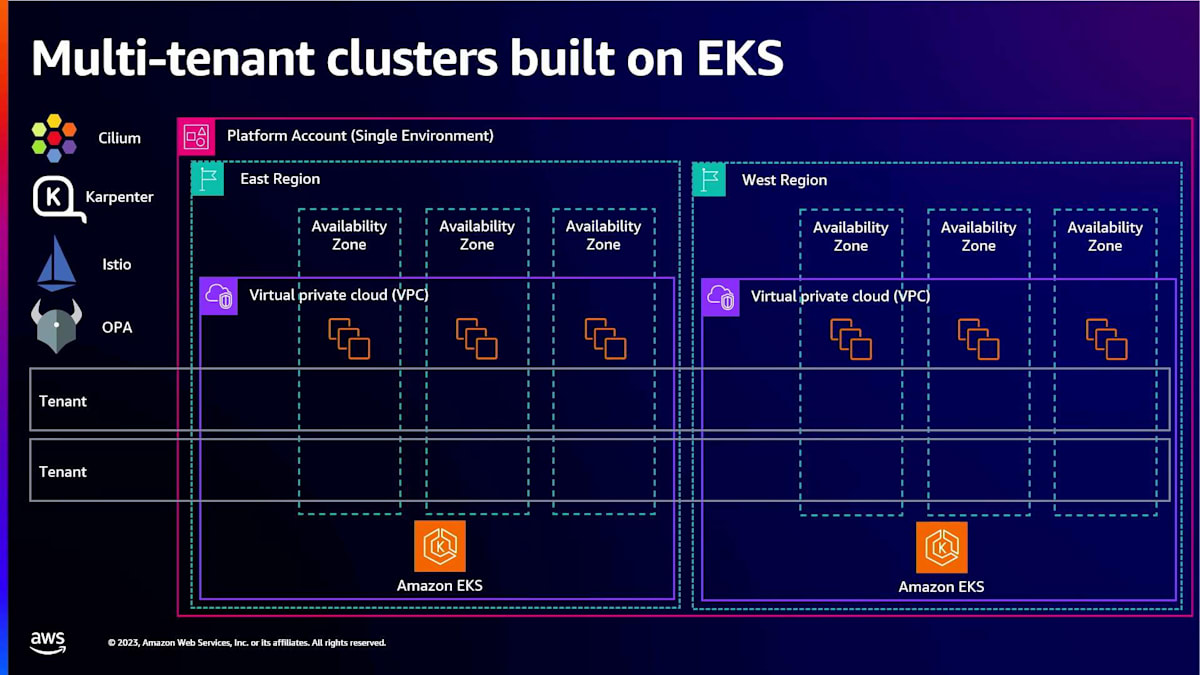
私たちのユースケースでは、プラットフォームのために設計要件を定め、結果としてマルチテナントクラスターを選択しました。特定のユースケースでマルチテナントクラスターからシングルテナントクラスターに移行することを決めた場合、プラットフォームの開発過程でそれを実現できます。では、EKS上にマルチテナントクラスターをどのように構築したのでしょうか? この図は単一の環境を示しており、開発、ステージング、本番、あるいは他の任意の環境が考えられます。私たちは少なくとも2つのリージョンで、複数のアベイラビリティーゾーンにまたがってクラスターを運用しています。これにより、すべてのワークロードに最大限の可用性を確保しています。
テナントは、すべての環境にわたって、すべてのクラスターの特定のnamespaceにアクセスでき、そこで自分たちのワークロードを使用できます。私たちは様々なオープンソース技術とツールを使用しています。ネットワークポリシーにはCiliumを使用し、ルーティングにはEPTFを活用しています。スケーリングにはKarpenterを使用しており、これによりスポットインスタンスとオンデマンドインスタンスの提供方法についてより柔軟に対応できるようになりました。カスタマールートを選択してnode poolsを提供することを決めた場合、Karpenterでそれを実現できます。サービスメッシュにはIstioを使用し、Ciliumのクラスターメッシュと組み合わせています。両者を組み合わせることで、クラスター間のネイティブなルーティングと可用性を実現しています。最後に、Open Policy Agentを使用して、ポリシー、変更、検証が全体的に適用されるようにしています。
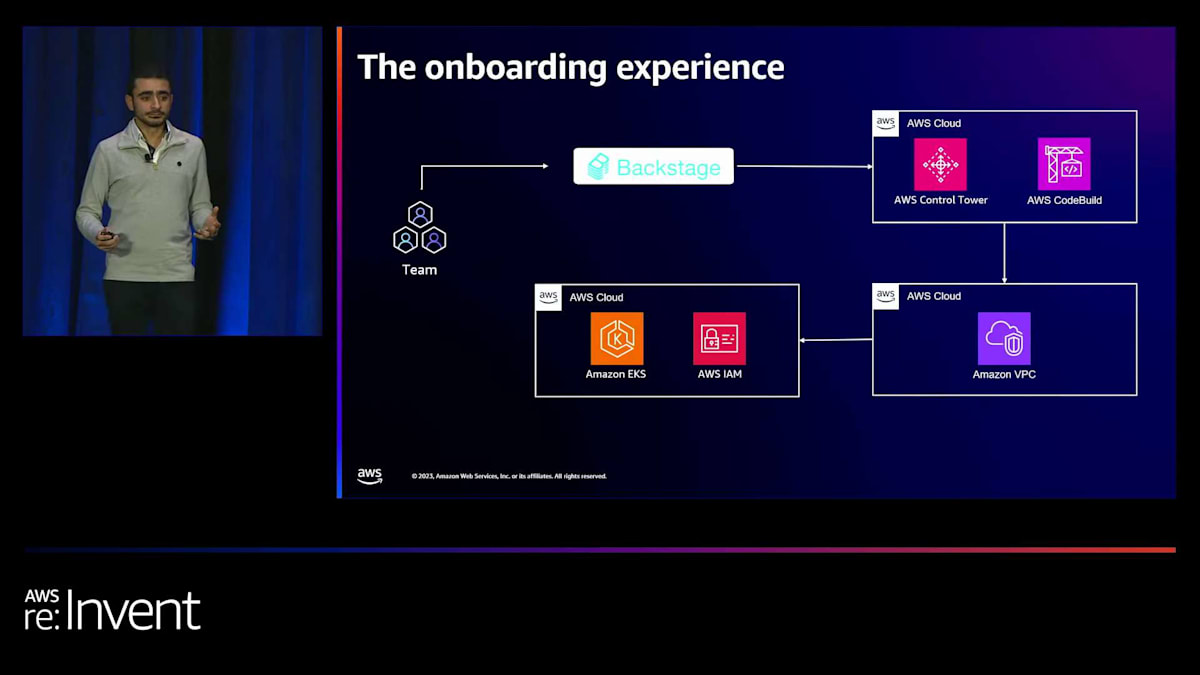
では、アカウントの観点からオンボーディングの体験がどのようなものかを説明しましょう。 プラットフォーム上にまだ何も持っていないチームがいるとします。彼らは新しいベータユーザーです。これはどのように機能するのでしょうか?私たちは内部開発者プラットフォームポータルとしてBackstageを使用しています。彼らはBackstageにアクセスし、フォームに情報を入力してアカウントをリクエストします。このプロセスを通じてアカウントがプロビジョニングされます。


それから彼らはプロセスを進めていきます。これにはAWS Control Towerが関わります。基本的に、AWS Control Towerを通じてアカウントがプロビジョニングされ、その後共有Kubernetesクラスターにオンボーディングされます。それでは各ステップを詳しく見ていきましょう。まず、リクエストが提出されると、それがAWS Control Tower に到達し、アカウントが作成されプロビジョニングされます。プロビジョニングが完了すると、私たちは全体的にInfrastructure as Codeを使用します。 そして、必要なVPC、AWS Backupの設定、AWS Configルール、その他必要なものすべての作成を開始します。

そして、先ほどお話したAWS Transit Gatewayを覚えていますか? Infrastructure as Codeを使用する別のプロセスがあり、これによって特定のアカウントを共有サービスに接続します。必要な場合を除き、すべてのアカウント間でネットワークの漏洩がないようにする必要があります。そのため、共有サービスに接続し、この時点でCiliumによって実現される十分なネットワーク分離があることを確認する必要があります。最後のステップでは、AWS Single Sign-Onですべてを接続します。これにより、チームはアカウント、コンソール、API、またはCLIへのアクセスを得ることができます。


これは見覚えがありますね?前のスライドに似ていますね。 ただし、ここでの追加点は、チームにアカウント用のInfrastructure as Codeを提供し、AWS Management Consoleへのアクセスも与えるということです。これが最初のステップです。ここでAmazon EKSが関わってくるアカウントが作成されています。では、アカウントがプロビジョニングされた後、 イベント駆動型アーキテクチャを使用してこれらのアカウントをEKSクラスターにオンボーディングする方法を見てみましょう。
基本的に、アカウントが作成されたというメッセージを受け取ります。これはプロビジョニングされたという状態とは異なります。プロビジョニングされたとは、アカウントが利用可能になっただけで、リソースはまだ何もない状態を指します。一方、作成されたとは、ネットワーキングやその他必要なリソースがすべて追加された状態を意味します。そしてこれはステップ関数を通過し、AWS Lambdaをトリガーします。基本的に、特定のアカウントに必要なすべてのリソースがあることを確認するためのロジックを実行し、リトライメカニズムを維持します。
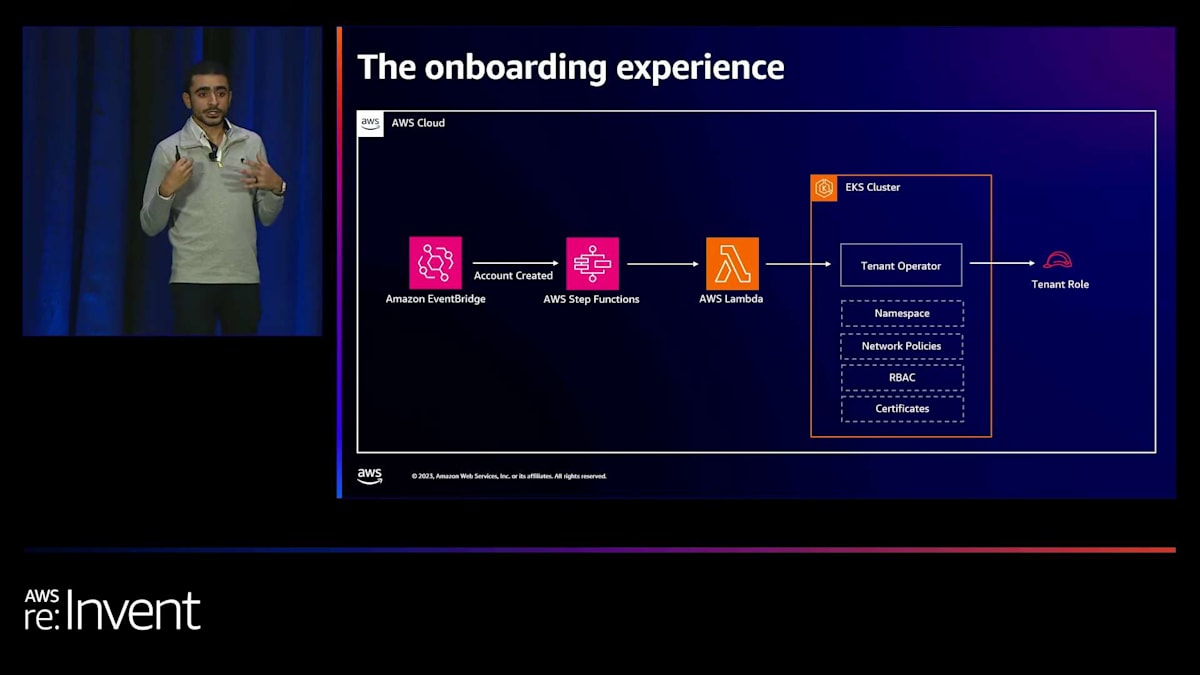
そして、これは内部で作成した「テナントオペレーター」と呼ぶコントローラー用のCRDを持つrebootにプッシュされます。 これが行うことは、このアカウントをクラスターにオンボーディングする必要があると言われたとき、テナント名前空間、ネットワークポリシー、RBACおよび証明書を作成することです。つまり、テナントがプラットフォームにサービスやアプリケーションのデプロイを開始できるようにするために必要なすべてのステップを確実に実行します。しかし、ここで最も重要なのは、IAMからの別のオペレーターを使用して、テナントロールを作成することです。これが基本的に、テナントにクラスターへのアクセス権を付与する方法です。
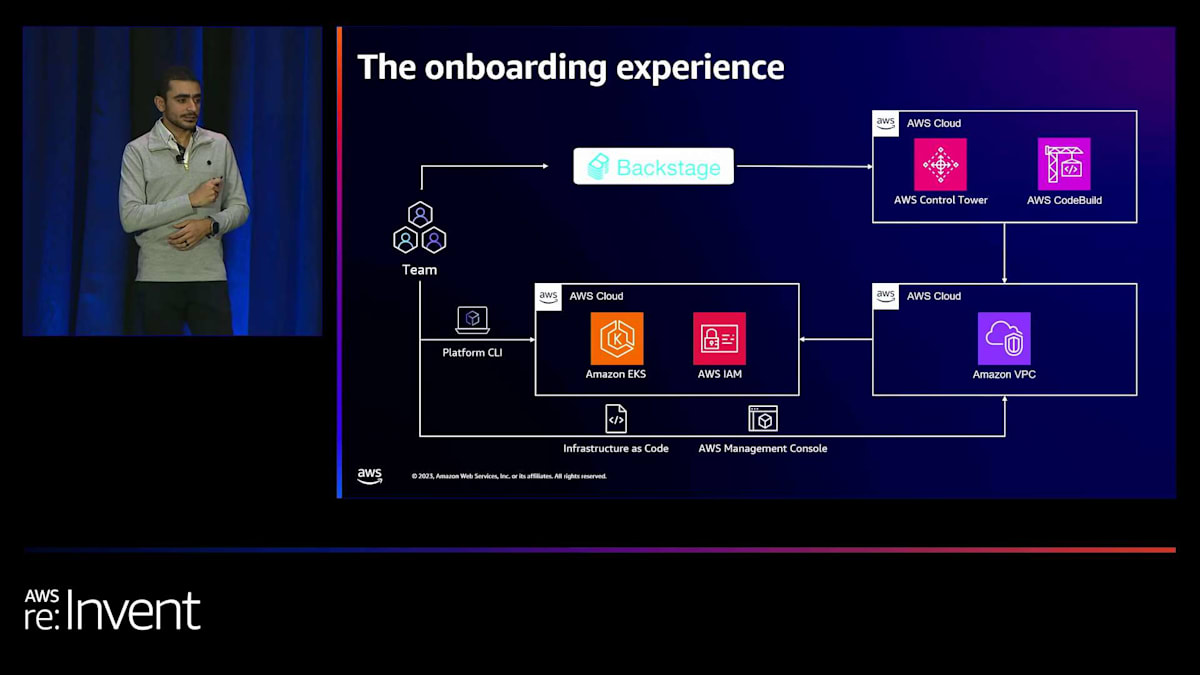
私たちは既に彼らのアカウント情報を知っているので、アカウントにIAMロールを作成し、これを彼らの設定にマッピングして、クラスターへのアクセスを確保します。 そして、これらすべてに加えて、platform CLIというものを追加しました。これも内部で構築したCLIで、チームがクラスターへのアクセスを得るために必要なすべてのステップを踏むのを助けます。基本的には、AWSアカウントクラスターへのアクセス、コンテキストの設定、必要なことをすべて行う1つのコマンドです。
ここから分かるように、これは基本的に新しいアカウントを構築する際に一度だけ行う作業です。しかし、他のアプリを構築する際にも同様の経験があります。そして、platform CLIを他の目的、デバッグ、アクセス、プラットフォーム上で構築する際に経験する他のことにも使用できます。
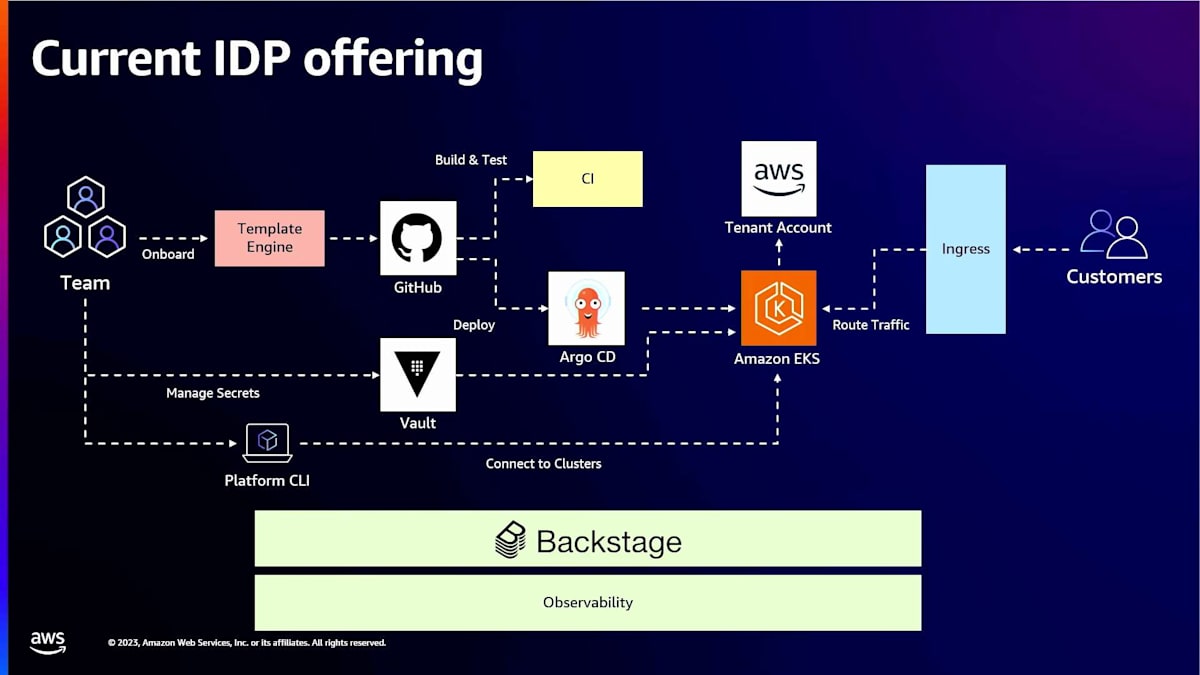
では、現在私たちが持っているものは何でしょうか?これが私たちの内部開発者プラットフォームの提供です。 基本的に、先ほど述べたのと同じワークフローです。オンボーディングを通じて進みます。サービスに必要なすべてのリソースをテンプレート化するテンプレートエンジンがあります。Gitを通じて、GitHubリポジトリを取得し、CIを行い、そしてCDはArgo CDを通じて行われ、Amazon EKSにデプロイされ、テナントアカウントに設定され、Ingressに接続されます。そして、BackstageとObservabilityレイヤーがプラットフォーム全体を一貫して見ています。

さて、私たちの次の目標は何でしょうか?いくつかのことを検討しています。 より多くのマネージドアドオン、またはAWSによるマネージドサービスです。いつかはマネージドIstioが見られることを期待しています。Istioを自分たちで管理する代わりにです。マネージドKarpenterも欲しいですね。Karpenterのデプロイメントと設定の管理方法が課題でした。いつかKarpenterがコントロールプレーンとしてデプロイされる方法についてのissueがコンテナロードマップにあることを見たいですね。現在、私たちはX86ワークロードのみをサポートしていますが、
将来的にはARMサポートを追加したいと考えています。同じクラスター上でこれを行うための概念実証段階にあります。また、より良いIAMプロビジョニングプロセスにも取り組んでいます。新しいテナントをクラスターにオンボードするために必要なconfigmapやすべてのプロセスを扱う代わりに、これに対するAPIがあればいいと思っています。長期的には、プラットフォームにより多くのワークロードを持ち込むことを目指しています。現在、ステートレス、ステートフル、API、アプリケーション、ジョブを検討していますが、将来的にはよりデータ集約型のアプリケーションや機械学習機能を追加することを検討しています。
プラットフォームエンジニアリングの教訓と今後の展望


同僚からの引用をいくつか紹介したいと思います。GamesチームのシニアソフトウェアエンジニアであるBella Virgilioは、プラットフォーム上で最新のゲーム接続をローンチしたことについて語っています。彼女は、プロトタイプから本番環境への移行がいかに迅速に行われたかを強調しています。PublishingチームのStaffソフトウェアエンジニアであるJorge Rasilloも、プルリクエストのデプロイメントやインフラストラクチャの管理を気にすることなくアプリケーションの構築に集中できるその他の機能など、多くの機能をすぐに利用できる状態で開発・提供していることについて述べています。ただし、必要に応じてインフラストラクチャを管理することもできます。


これまでの私たちの旅路についてお話ししてきましたが、ここで過去数年間のプロセスを通じて学んだことをお伝えしたいと思います。ユーザードキュメントは非常に重要です。適切なユーザードキュメントなしでプラットフォームを提供すると、単純なタスクについて多くのサポート質問を受けることになるでしょう。そのため、ユーザーに良質なドキュメントと体験を提供することが不可欠です。採用とパートナーシップも同様に重要です。採用のないプラットフォームは時間の無駄です。先ほどRolandが言及したように、プラットフォームを構築しても誰も使わなければ無駄になってしまいます。私たちは、チームと協力し、早期採用者にプラットフォームを使ってもらい、彼らが必要とするものを正確に伝えてもらう必要があります。


プロダクトとしてのプラットフォームも重要な要素です。他のエンジニアと話をして、プラットフォームエンジニアリングはプロジェクトや一回限りのものではないと聞きました。それは複数のレベルで行われる反復的なプロセスです。一つの反復を経て、うまくいかないこともあるかもしれませんが、反復と改善を続ける必要があります。最後に、顧客からのフィードバックが非常に重要です。常にオープンな姿勢を保ち、柔軟に変化を求める必要があります。最先端の技術を提供するためにプラットフォームを構築しているのではなく、エンジニアリングチームという顧客がサービスを提供するのを支援するためにプラットフォームを構築しているのです。
以上で、Kevinにバトンタッチしたいと思います。はい、素晴らしい。今日はこれで終わりです。AhmedとRolandに感謝します。皆さん、ご参加ありがとうございました。re:Invent happy hourに行けるよう、少し早めに終わらせます。質問がある方のために、私たちはここのステージに残ります。時間があれば、皆さんが構築しているプラットフォームについてもお聞かせいただきたいですし、もちろん質問にもお答えします。それでは皆さん、ありがとうございました。素晴らしいre:Inventをお過ごしください。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion