re:Invent 2024: AWS ConfigでItaú Unibancoのビジネスインサイト創出


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Unlocking business insights with AWS Config, featuring Itaú Unibanco (COP326)
この動画では、AWS ConfigとItaú Unibancoのリソース構成管理に関する事例が紹介されています。AWS Configの基本的な機能や、Configuration Item、Configuration Recorder、Delivery Channelなどの仕組みについて解説した後、9,000以上のアカウントと4,000万のConfiguration Itemを持つItaú Unibancoでの活用事例が共有されています。特に注目すべきは、AWS Config、AWS Glue、Amazon QuickSightを組み合わせて構築したCloud Metadataプラットフォームで、これによりEC2インスタンスの世代やLambdaのランタイムバージョンなど、組織全体のリソース状況を可視化し、コスト最適化やレジリエンシー向上のための意思決定を支援している点です。AWS Configが単なるコンプライアンスツールを超えて、ビジネスインサイトを生み出すプラットフォームとして活用できることを示す具体例となっています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
AWS ConfigとItaú Unibancoのビジネスインサイト:セッション概要

AWS ConfigとItaú Unibancoに関するビジネスインサイトのセッションへようこそ。皆様は世界有数の金融機関の一つであるItaú Unibancoについてより深く知りたいとお考えのことと存じます。セッションを始める前に、自己紹介をさせていただきます。私はGuilherme Grecoと申します。ブラジルを拠点とするAWSのPrincipal Solutions Architectです。また、本日は共同発表者もご紹介させていただきます。皆様、こんにちは。Matheus Arraisと申します。テキサス州ダラスを拠点とするSenior Worldwide Solutions Architectです。そして、Thiagoもご紹介します。皆様、こんにちは。Thiago Moraisです。Itaúのクラウドプラットフォームを統括しています。

それでは、セッションを始めましょう。リソース構成の可能性と価値について、皆様にご紹介していきます。まず、AWSの観点からリソース構成が何を意味するのかについて説明し、その後、これを実装するのに役立つAWS Configの機能についてお話しします。このプレゼンテーションを通じて、大規模なリソース構成の実装方法と、この情報に基づいてビジネス上の意思決定を行う方法について、より深く理解していただけるはずです。 本題に入る前に、一つ質問させていただきます:皆様の会社で、リソースインベントリやリソース構成を使ってビジネス上の意思決定を行った経験がある方は、手を挙げていただけますでしょうか。

会場を見渡すと、このような経験をお持ちの方はあまり多くないようですね。つまり、皆様は今日のセッションに最適な場所にいらっしゃるということです。なぜなら、まさにこれが本日お話しする内容だからです。リソース構成の実装におけるお客様の課題について議論し、AWS Configを通じてAWSがどのようにアーキテクチャパターンでサポートできるかをご紹介します。AWS Configのデモをご覧いただき、その後Itaúの事例に移ります。そこでは、異なるAWS Organizationsにまたがる数千のアカウントで数百万のリソースを活用し、リソース構成を抽出してビジネス上の意思決定を行う方法をご紹介します。Thiagoも彼らの経験を共有し、最後に重要なポイントとリソースについてまとめます。
AWS Configの基本機能と大規模リソース構成管理の課題

AWSは多くのサービスを提供しており、それぞれが独自のAPI設定と構成を持っています。これらのサービスで発生するすべての変更を追跡することは、お客様にとって大きな課題となっています。モダナイゼーションの取り組み、パイプライン、分散化された運用により、お客様の環境は常に変化しています。市場投入までの時間を考慮して、私たちは常にインフラストラクチャとアプリケーションを進化させています。このような変化の中で、継続的なガバナンスと継続的なコンプライアンスを維持しなければなりません。



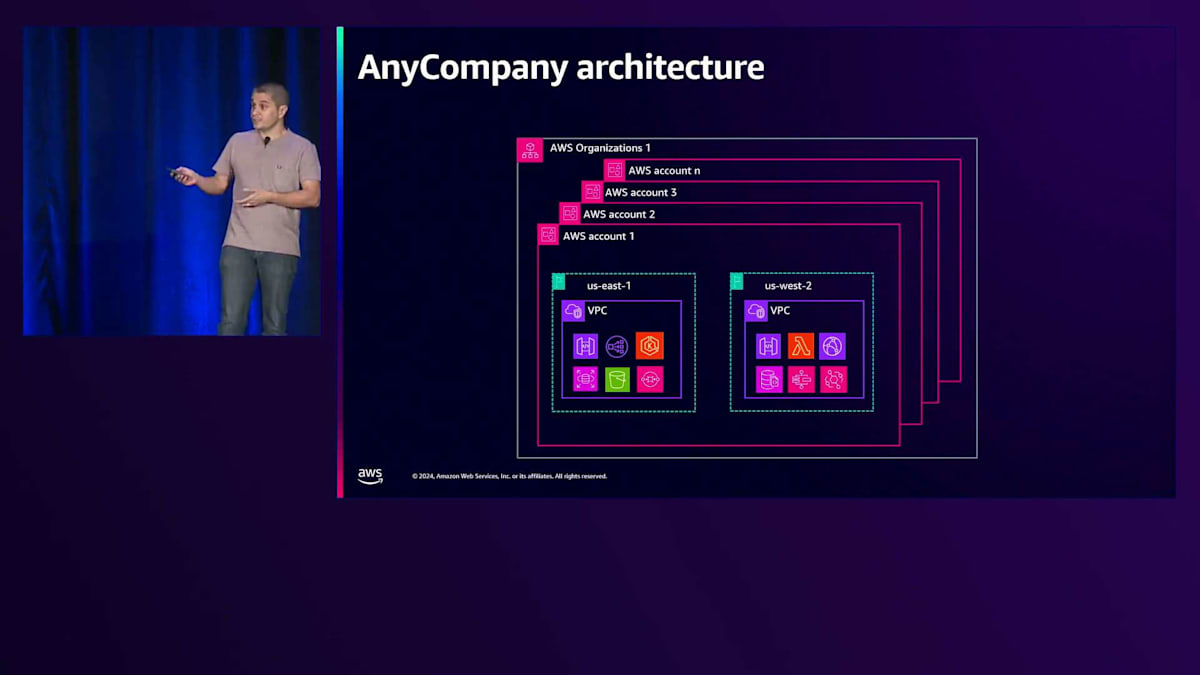
より具体的な例として、あなたが企業のCTOだとしましょう。 最初は1つのアプリケーションから始まり、特定のリージョンにアプリケーションを配置するためにAWS Control Towerと1つのAWS Organizationsを使用していたとします。 その後、別のリージョンに運用を拡大する必要が出てきました。VPCを展開してアプリケーションを再度デプロイするだけなので、簡単そうに見えます。 しかし、その後、異なるアプリケーションを持つ部門が増え、追加のアカウントが必要になります。 さらに、リージョンに関する要件が異なる複数の製品とアプリケーションが加わり、それに伴ってアカウントも増えていきます。
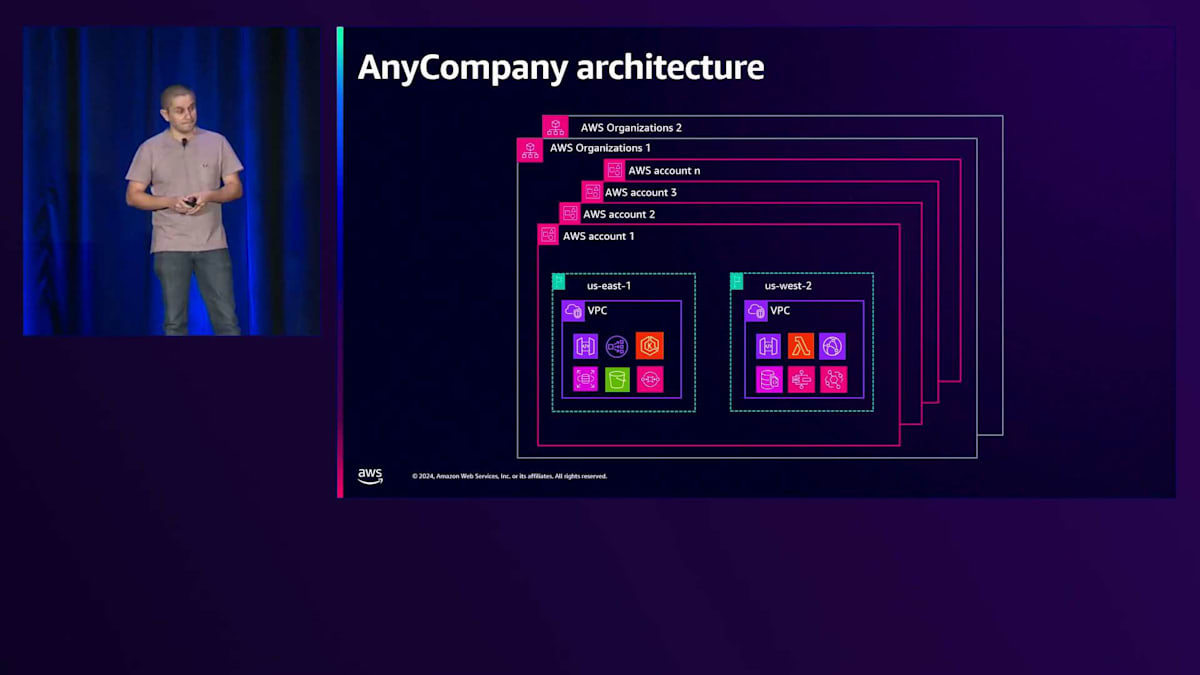

最終的には、1つのAWS Organizationsの下に数百から数千のアカウントを持つことになるかもしれませんが、それだけではありません。 規制上の制約により、さらに追加のAWS Organizationsを作成する必要があり、そこにもまた多くのアカウントとアプリケーションが存在することになります。 そして、急速な成長期にあり、合併買収のプロセスの最中であることを考えると、さらに多くのOrganizations、アカウント、アプリケーションが必要になることを覚えておいてください。分散したアカウントを持つ分散環境になっていることに気付きますが、マルチアカウント戦略でAWSのベストプラクティスに従い、障害を分離し、コスト、リソース、アクセスを制限できる論理的な区画としてアカウントを扱うことで、正しい方向に進んでいるのです。
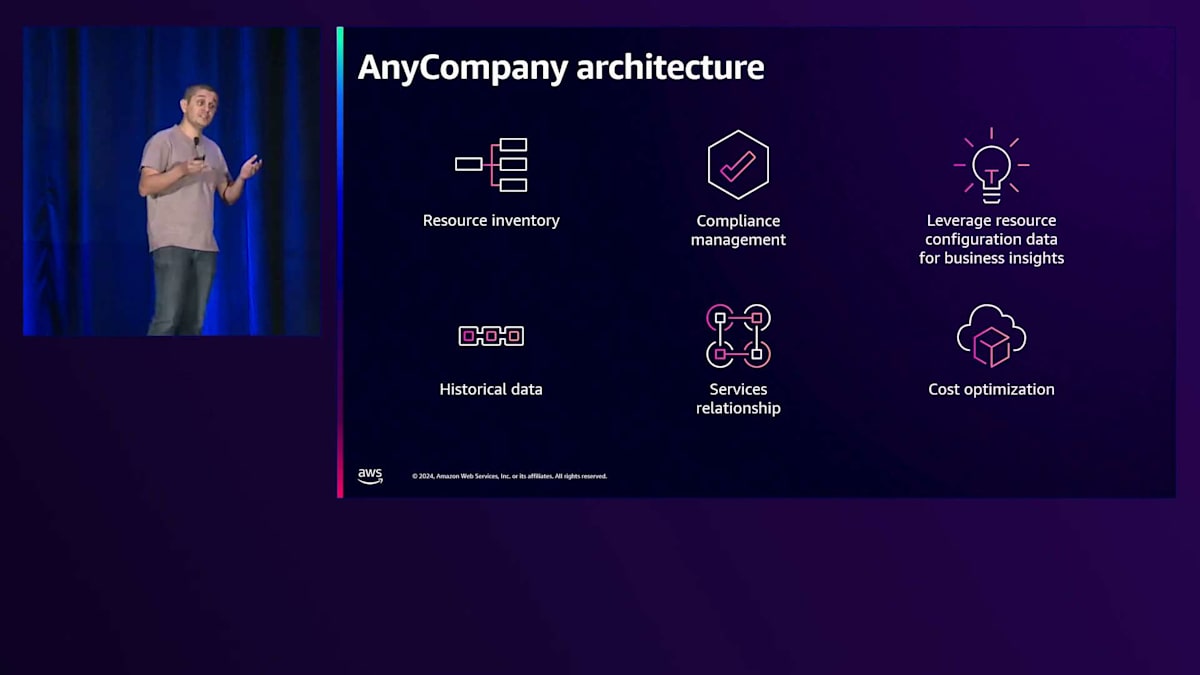
すべてが順調に見えた矢先、経営陣から次々と質問が投げかけられます:リソースは全部でいくつあるのか?特定のビジネスユニットや製品に属するものはいくつか?それらはどこに配置されているのか?コンプライアンスに準拠しているものはいくつか?リソース構成のトレンドはどうなっているのか?これらをビジネスの側面と結びつけると、大規模なリソースインベントリが必要だということに気付きます。 履歴データを理解する必要があります。なぜなら、そのリソースで何が変更され、いつ変更され、誰が変更したのかを知ることが重要だからです。異なるリソース間の依存関係を理解し、構成とコストを関連付ける必要があります。というのも、インフラストラクチャからインサイトを得て、コスト効率を高めるために、誰もがこの情報を必要としているからです。

お客様は、リソース構成を使用してこの課題に対処しています。 リソース構成とは、リソースからデータとメタデータ情報を抽出し、それをデータストアに保存するために構造化または正規化する方法と考えることができます。ここにあるJSONファイルには、リレーションシップ、サイズ、ネットワーク、セキュリティなど、私が持っているリソースを説明するフィールドがあることがわかります。このファイルの重要性に疑問を持つかもしれませんが、このファイルが大規模なリソース構成の基盤になることをお伝えできます。そして、このファイルをどのように作成できるのかと再び質問されるかもしれません。分散化されたアカウントがある場合、異なるサービスから異なるAPIがあるため、すべてのサービスをスクレイピングするのは現実的ではありません。異なるAPIをスクレイピングし、異なるレスポンスを処理し、これをデータストアに保存するのは合理的ではありません。



しかし、これがリソース構成の基盤であるならば、どのように実現できるのでしょうか?AWSには、これを大規模に実装するのに役立つサービスはありますか? はい、あります - AWS Configです。Landing ZoneでAWS Configを有効にしている方は手を挙げてください。多くの方がいらっしゃいますね。簡単に説明させていただきます。 AWS Configは、リソースで発生する変更を記録する責任を持つAWSマネジメントサービスです。つまり、リソースに変更が発生するたびに、AWS ConfigはAWS Config Recorderを通じてそれを記録します。変更に対してルールを実行し、アーキテクチャパターンと比較して、コンプライアンスに準拠しているかどうかを確認することができます。独自のルールを使用することも、AWS Configのマネージドルールを活用することもできます。

アカウント、リージョン、またはAWS Organizations全体の異なるリソースからの集約されたビューを得ることができます。Systems Managerとの統合を活用し、コンプライアンスに準拠していないリソースに対して自動化を実行するためにAWS Automation Documentsを利用することができます。AWS ConfigはSNS、CloudWatch、S3、CloudTrail Lake、EventBridgeなど他のサービスとも統合されています。いくつかについて説明しますが、ここではリソース構成について話しています。 Config内では、Config Recorderがリソース構成の記録を担当しており、それが発生すると、Configuration Itemが生成されます。先ほど議論していたのと同じファイルに戻ってきましたが、今回の違いは、このファイルがAWS Configによって管理されているということです。
AWS Configの高度な機能:コンプライアンスとカスタマイズ

AWS Configには、メタデータ、属性、リレーションシップ、現在の設定といった標準的な属性があります。それぞれについて詳しく説明しましょう。メタデータは、リソースがいつ変更されたか、その変更がいつ捕捉されたか、そしてアカウントIDが何かを示します。次に属性では、リソースタイプ、リージョン、該当する場合はアベイラビリティーゾーンが表示されます。そしてリレーションシップですが、これは私のお気に入りで、このフィールドを使用することでリソース間の依存関係を確認できます。この例ではセキュリティグループを見ていますが、現在の設定に関連付けられているインスタンスを確認することができます。リソースに関する詳細な情報が提供されます。セキュリティグループについて話していますので、IPアドレス、CIDR、ポートなどを確認できます。



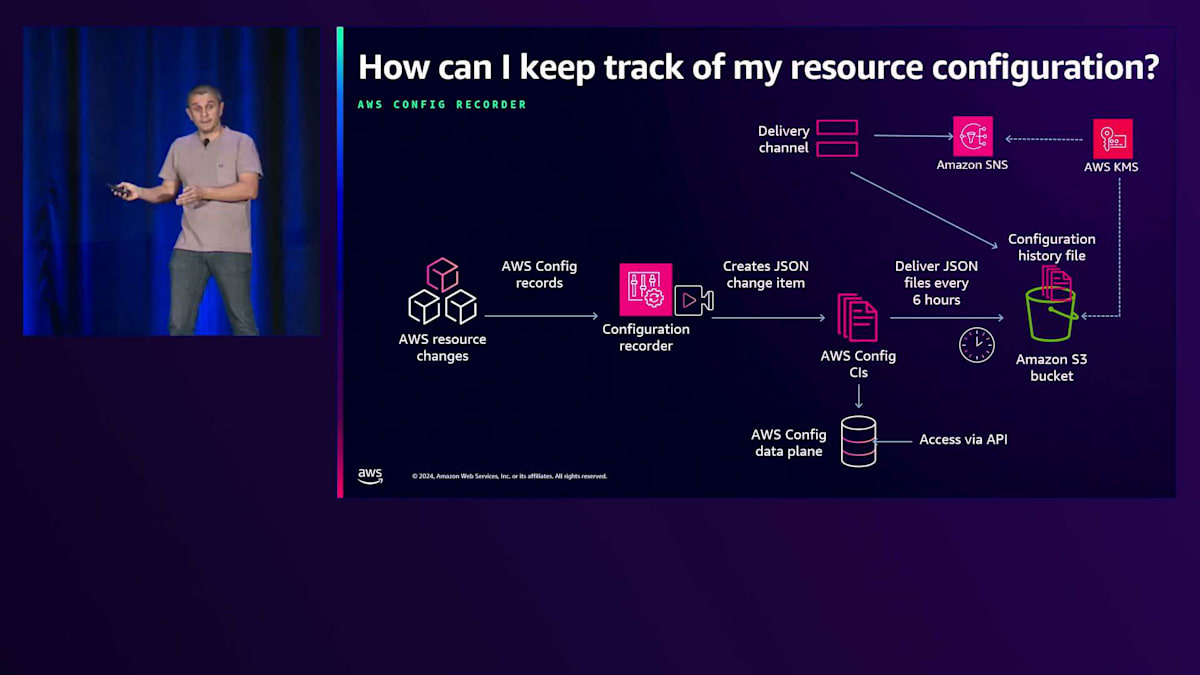
AWS Configでは、同じ設定に2つの状態があります。1つ目は一定期間にわたる設定項目のコレクションである設定履歴で、2つ目は特定時点のキャプチャである設定スナップショットです。これを実現するために、Configuration Recorderを使用して記録し、Delivery Channelを使用して配信します。その仕組みを説明するために、まず設定履歴から始めましょう。リソースに変更が発生すると、Configuration Recorderがそれを記録します。そして設定項目のコレクションが生成されます。その後、Delivery Channelが、お客様のアカウントまたは別のアカウントに配置されているバケットに設定項目のコレクションを転送します。
Delivery ChannelはSNSと統合されており、自動化を実行するためにLambda関数やSQSキュー、HTTPエンドポイントをサブスクライブすることができます。Delivery Channelは6時間後に設定項目のコレクションを転送し、インフラストラクチャチームがバケット内のJSONファイルにアクセスして分析を実行できるようになります。データにオンラインでアクセスする必要がある場合は、AWS Configのデータプレーンに直接アクセスしてクエリを実行することができます。


インフラストラクチャチームが設定項目にアクセスするために6時間待ちたくないというバケットのシナリオを考えてみましょう。AWS Config APIを呼び出して設定スナップショットを生成することで、特定時点のキャプチャを実行できます。その後、Delivery Channelが設定項目のコレクションをS3バケットに転送し、インフラストラクチャチームがそれらのファイルにアクセスして分析を実行できるようになります。これは、アカウント内にデプロイされているすべてのものの完全な全体像を把握したいインフラストラクチャチームにとって特に有用です。



AWS Configは設定スナップショットと設定履歴をサポートしていますが、特定のリソースタイプを記録対象から除外することができます。リソース変更の設定が報告されます。ここで、IaCアプリケーション、つまりアプリケーションのデプロイと削除を行うパッケージやTerraformモジュールがあるという別のシナリオを考えてみましょう。このような場合、それらのリソースに対するすべての変更を記録することは意味がないかもしれません。AWS Configでは、Configuration Recorderによる記録から特定のリソースタイプを除外することができ、これによってコスト効率を高めることができます。同様に、非本番環境のアカウントでは、すべての変更を記録する必要がない場合があるため、AWS Configを使用して日次ベースのクエリを実行することで、コスト効率を維持することができます。


AWS Configはアプリケーションや環境のニーズに応じて適応することができます。設定履歴や設定スナップショットに加えて、カスタムデータを追加することも可能です。 企業情報をリソース設定に取り込んでデータを充実させたり、オンプレミスや他のクラウドにデプロイされたサードパーティソフトウェアのリソース設定を作成したりすることができます。EKSクラスターの管理を担当するプラットフォームチームの一員だとしましょう。 EKSはAWS Configでサポートされていますが、プラットフォームチームはマネージドノードグループやアップグレード要件についてより詳細な情報が必要かもしれません。


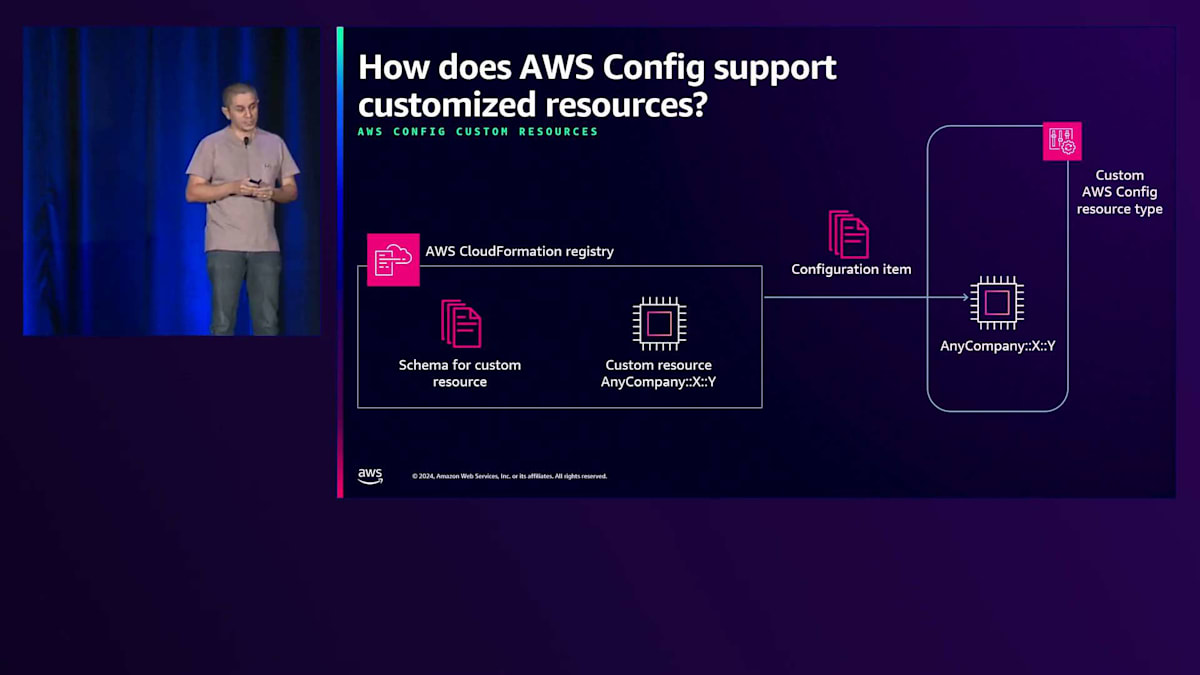
AWS Configでカスタムリソースタイプを作成することで、私たちにとって最も重要な情報でデータを充実させることができます。 この機能は、オンプレミスや他のクラウドサービスプロバイダーにデプロイされたサードパーティソフトウェアにも拡張できます。これはCloudFormation Registryを通じて実現できます。これにより、AWS内でカスタムリソースを生成するカスタマイズされたスキーマを作成できます。CloudFormation Registryを使用してタグとCloudFormationをカスタマイズし、AWS Config APIを呼び出して、特定のカスタムリソースのリソース設定を登録し、設定項目を作成することができます。ご覧の通り、AWS Configの設定機能を拡張し、 カスタムリソースタイプを作成する素晴らしい機会となります。

以上で私のパートを終わり、Matheusに引き継ぎたいと思います。ありがとうございました。
AWS Configを活用したコンプライアンス管理とデータ集約


それでは、大規模なコンプライアンスとリソースインベントリにとって非常に重要な、設定変更の記録について話しましょう。ここで、コンプライアンス自体とAWS Configがどのように役立つのかについて説明する必要があります。まずこの例を見てみましょう。 2024年10月17日午後3時11分のこの特定の変更に基づくと、ポート22のセキュリティグループには、このセキュリティグループが接続されているEC2インスタンスに接続できる特定のIPアドレスがありました。しかし、その間に何かが起こりました。AWS Configはこれらの変更をすべて追跡します。午後3時23分に、アクセス権を持つ誰かがそのIPを変更し、ポート22のセキュリティグループを介して誰もがアクセスできるようにしたことがわかります。これは良いことでしょうか、悪いことでしょうか?実際にはわかりませんが、これを評価して検出できる何かを用意しておく必要があります。AWS Configには、大規模なコンプライアンスを支援するルールがあります。


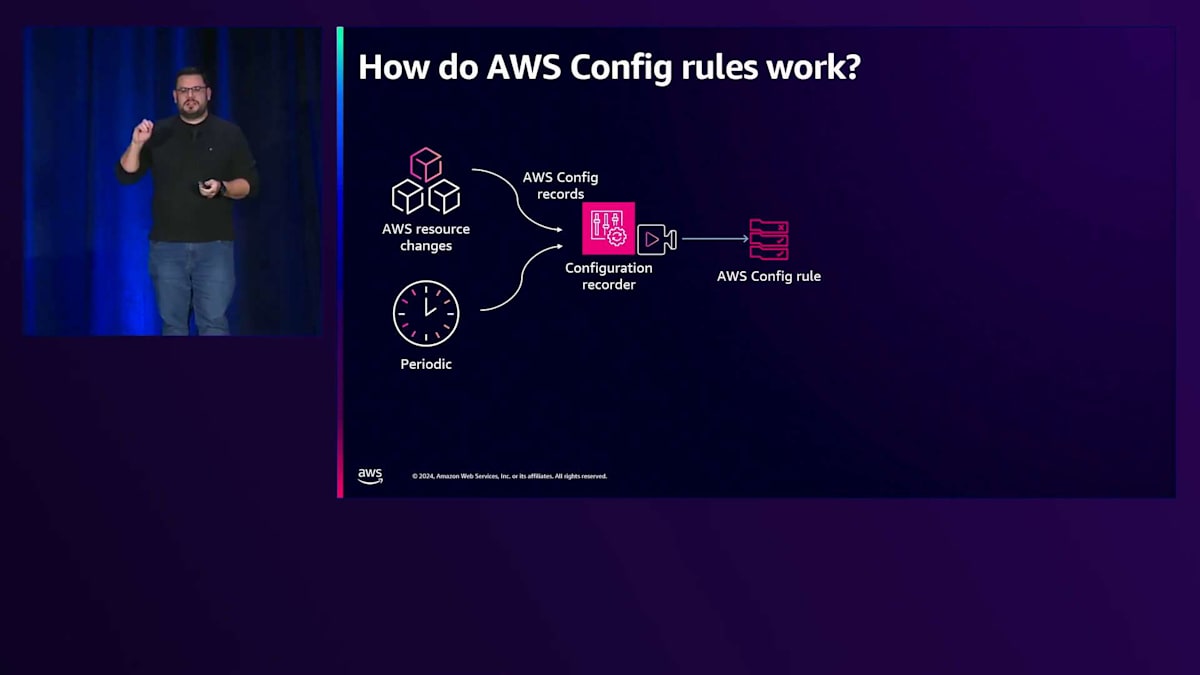


AWS Configルールがどのように機能するか説明しましょう。トリガーメカニズムには2つのタイプがあります。1つ目は定期的なもので、毎時、3時間ごと、または毎日など、指定した時間にルールを実行できます。最も一般的なのはリソースの変更に基づくものです。このセキュリティグループの例では、セキュリティグループが変更されるたびに、それを確実にキャプチャしたいと考えています。 AWS Configルールはレコーダー自体と接続されており、レコーダーにはConfigルールがあります。そのルールは望ましい状態を表しており、これは変更されたリソースが望ましい状態と一致するかどうかを確認したいということです。評価が行われた時、リソースの変更と望ましい状態が一致する場合、つまりコンプライアントである場合、コンプライアントとしてマークされます。しかし、このセキュリティグループの例では一致しないため、非コンプライアントとしてマークされることになります。



AWS Configは、AWS Systems Manager automationと統合されており、セキュリティグループを元の状態(つまり望ましい状態)に自動的に戻すドキュメントを自動的にトリガーして実行します。これらの機能により、人の手を介することなく、自動的かつ継続的なコンプライアンスを維持することができます。Config rulesには、マネージドとカスタムの2種類があります。マネージドルールについては、最小限の設定で、あるいは設定不要で使える500以上のルールが用意されています。これらのルールはAWSによって管理されています。例えば、先ほど話題に出たSSH制限のrestricted-ssh、よく使用されるrequired-tags、そしてRDSストレージの暗号化検証などのルールがあります。もしこれら500以上のルールの中に、お客様のガバナンスやコンプライアンスのニーズに合うものがない場合は、独自のルールを作成することができます。どの企業でも、AWS Lambda、AWS CloudFormation Guard、RDKを活用してrule1、rule2、rule3などを作成することができます。


この具体例では、許可されたインスタンスタイプのリストに含まれているかどうかを評価するルールをPythonで作成しました。ご覧のように、フォントは小さいですが、実際には121行のコードがあります。しかし、もっと簡単な方法があります。私たちが推奨する方法は、AWS CloudFormation Guardを使用することです。先ほどのルールと同じものが、CloudFormation Guardを使用するとわずか5行で記述できます。CloudFormation Guardは、GitHubで公開されている私たちのドメイン固有言語で、ポリシーをコードとして実装するためのツールです。

GitHubでは、CloudFormation、Config、そしてHooksとの統合方法を確認できます。Lambdaを使用しないため、Configがそのレイヤーを抽象化してくれるので、エラー処理が少なくて済みます。すべてをコンソールまたはAPIを通じて実行できます。そこにQRコードがありますが、これはGuardを使用したサンプルルールがあるGitHubへのリンクです。確認してみてください。Lambdaを使用しないため、より簡単な作成とデプロイが可能になります。


ここで理解しておく必要があるのは、Configは基盤となるサービスだということです。実際に他のAWSサービスがバックグラウンドでConfigを使用しているほど基盤的なサービスなのです。ご覧のように、すべては記録と先ほど説明したルールから始まります。上のリストには、Config rulesを使用している多くの他のAWSサービスがあります。例えば、AWS Security Hubは、使用されているフレームワークに基づいて、検知コントロールとしてより包括的なセキュリティとコンプライアンスの状態を提供するために、これらのAWS Config rulesを活用します。Audit Managerも同様に、評価したい特定のフレームワークに対する評価と証拠収集にこれらを組み込んでいます。この例は、Configが活用できるAWSの中核的なコンプライアンスサービスであることを示しています。




記録を取得し、コンプライアンスの追跡方法を理解したところで、これらのデータをすべてまとめる必要があります。そのために、データ集約について説明する必要があります。アグリゲーターは、設定項目、複数のリージョンとアカウントにまたがるコンプライアンス情報など、Configで収集したデータの読み取り専用ビューです。仕組みとしては、アカウントとリージョンにConfigがあり、そのデータがConfigによって収集され、そのデータがアグリゲーターに送信され、そこですべてのデータをまとめて表示できます。とてもシンプルで簡単です。AWS Config aggregatorは無料で提供されています。必要な数のアグリゲーターを作成でき、個別アカウントタイプや組織アグリゲータータイプなど、さまざまなタイプのアグリゲーターを使用することができます。


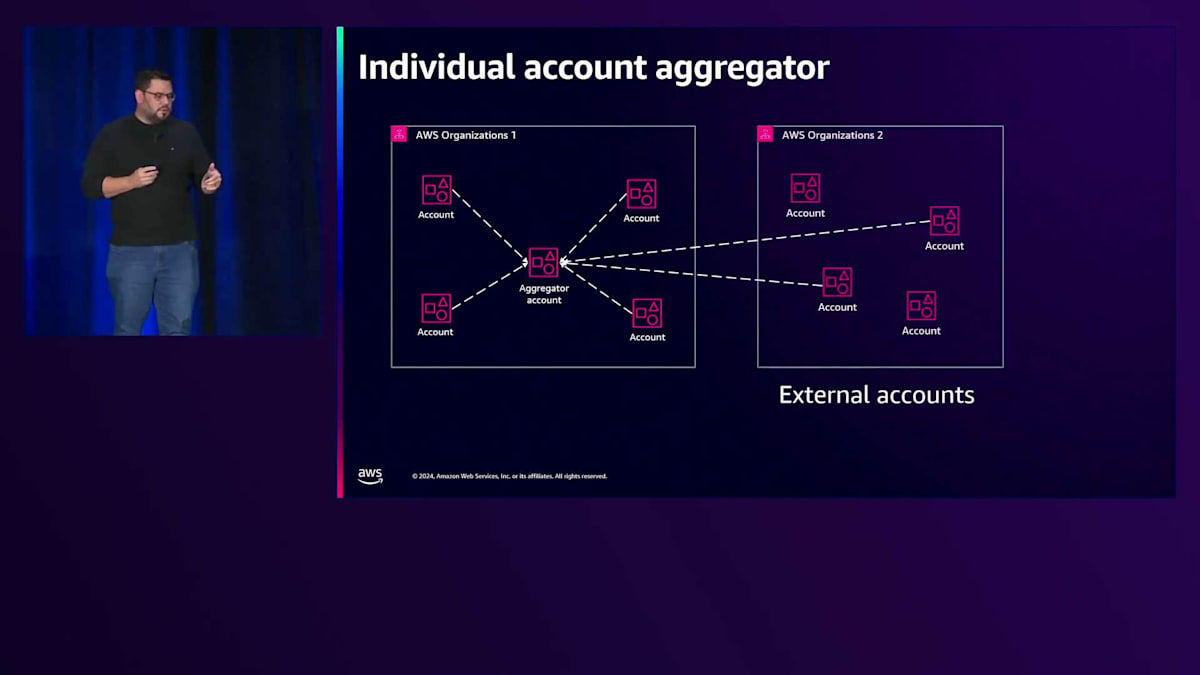
Aggregatorの活用方法の一例を見てみましょう。1つのアカウントで複数のリージョンを使用している場合、1つのリージョンをAggregatorとして選択し、すべての情報をその中央リージョンに送信することができます。ソース認証メカニズムを使用して、各アカウントを個別に承認することができます。同様に、1つのOrganizationで複数のアカウントがある場合、すべての情報を1つの特定のアカウントで確認できるAggregatorアカウントを設けることをお勧めします。さらに、この個別アカウントAggregatorのセットアップでは、外部アカウントから特定のAggregatorアカウントに情報を送信することも可能です。

AWS Organizationsを通じた集約に関して、AWS Organizationsレベルで信頼関係が確立されているため、各アカウントへの個別の承認が不要となり、すべての情報をAWS Organizationアカウントで収集することが効果的です。すべてのデータはManagementアカウントに送信されます。ただし、Managementアカウントへのアクセスを制限し、そこでワークロードを実行しないことを推奨しているため、ベストプラクティスとしては委任管理者(Delegated Admin)の活用を推奨しています。Configには委任管理者機能があり、Configを有効にしているOrganizationアカウントからのデータを、Managementアカウントではなく、指定したメンバーアカウントに送信することができます。

さらに、すべての情報を収集することも重要ですが、その情報から実際にインサイトを得られることを確認する必要があります。

AWS Configの高度なクエリ機能を使用することで、Aggregator上でSQLステートメントを使用したアドホッククエリを実行できます。そのため、Aggregatorの選択と設計が非常に重要になります。構造化クエリ言語(SQL)コマンドを使用するため、非常にシンプルです。コスト最適化のために、EC2にアタッチされていないEBSボリュームの数を確認したり、SecurityGroupで開放されているポートを確認したりすることができます。これにより、セキュリティと運用インテリジェンスの両方が向上します。

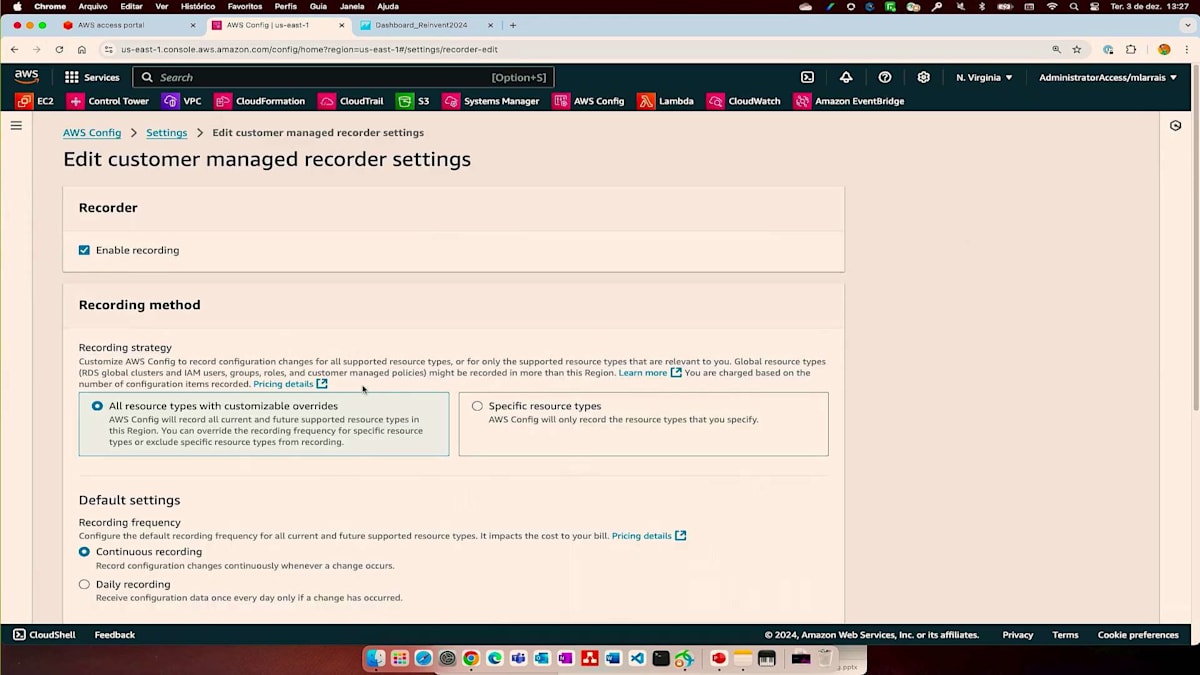


それでは、実際の動作を確認するためにデモに進みましょう。ご覧の通り、私はすでにConfigのDelegated Adminアカウントにいます。Grecoが言及した記録に関する部分を簡単にお見せしたいと思います。記録設定を編集することができます。デフォルトでは継続的な記録になっていますが、日次記録を選択し、デフォルトからの設定を上書きしてConfigレコーダーからグローバルリソースを除外することができます。これは実際、グローバルリソースのコスト最適化に有効です。IAMはグローバルなサービスなので、すべてのリージョンで記録する必要はなく、1つのリージョンでの記録をお勧めします。Grecoが言及したように、Configのコストを最適化するために、グローバル設定を上書きして一部のリソースを除外することができます。
Itaú UnibancoにおけるAWS Configの実践的活用事例



Aggregatorのセクションに移りましょう。先ほど説明した種類のAggregatorがあります。Demo Orgs Aggregatorという組織のAggregatorがありますが、私はメンバーアカウントにいるため、この特定のアカウントに委任されています。前回のイベントでリリースしたこのダッシュボードを選択すると、Aggregatorに基づいたウィジェットを使用してコンプライアンスを簡単に確認できます。非準拠リソースのサマリーと非準拠アカウントの数が一目で分かります。同じAggregatorを使用したインベントリ管理では、リソース数で見たトップリソースタイプやカスタマイズの方法に関する情報を確認できます。これは無料で利用できます。先ほど説明したように、Aggregatorを持ち、設計セットを使用できる状態にしておくだけです。




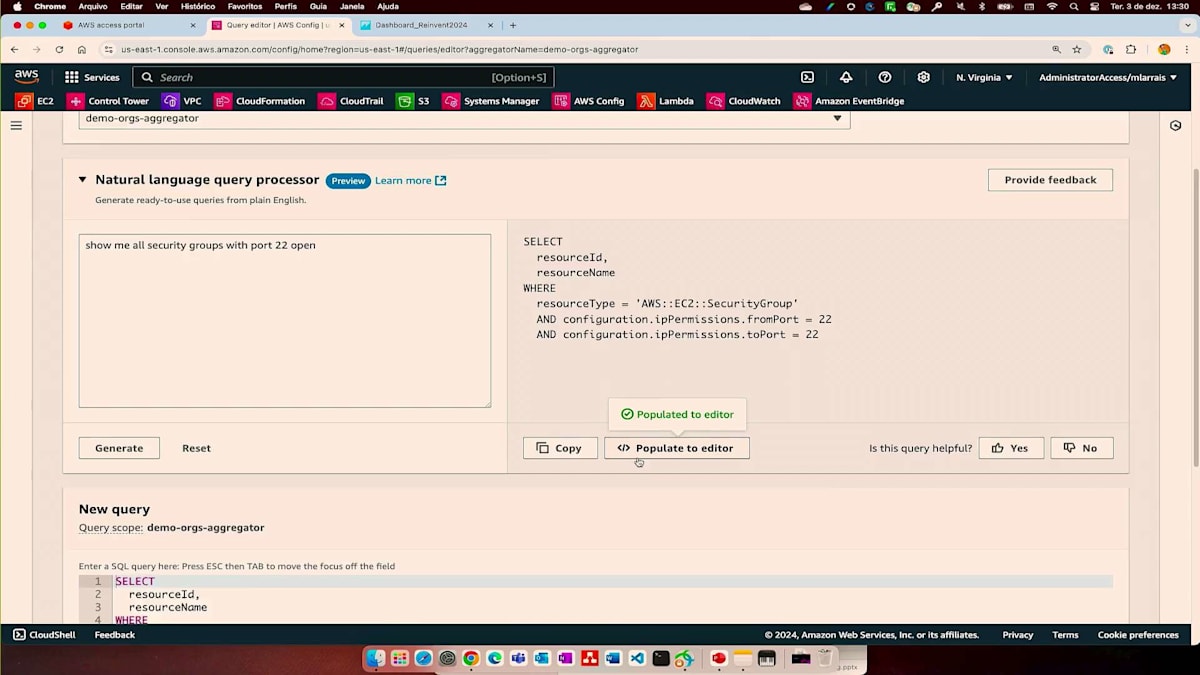
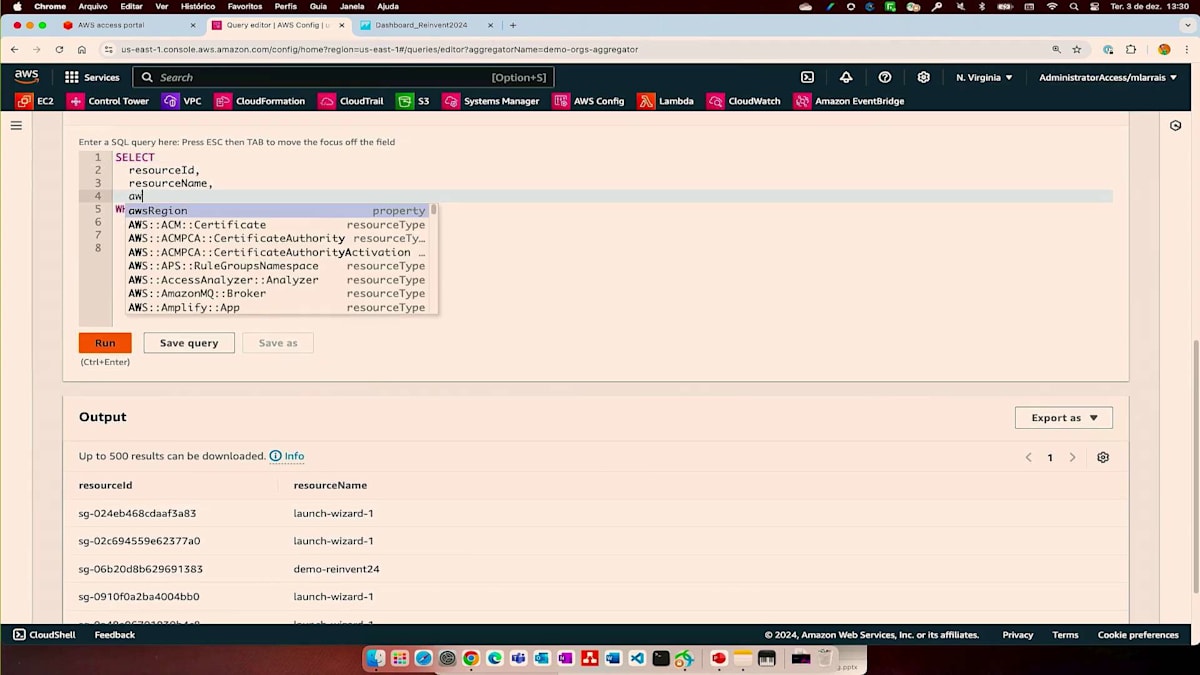
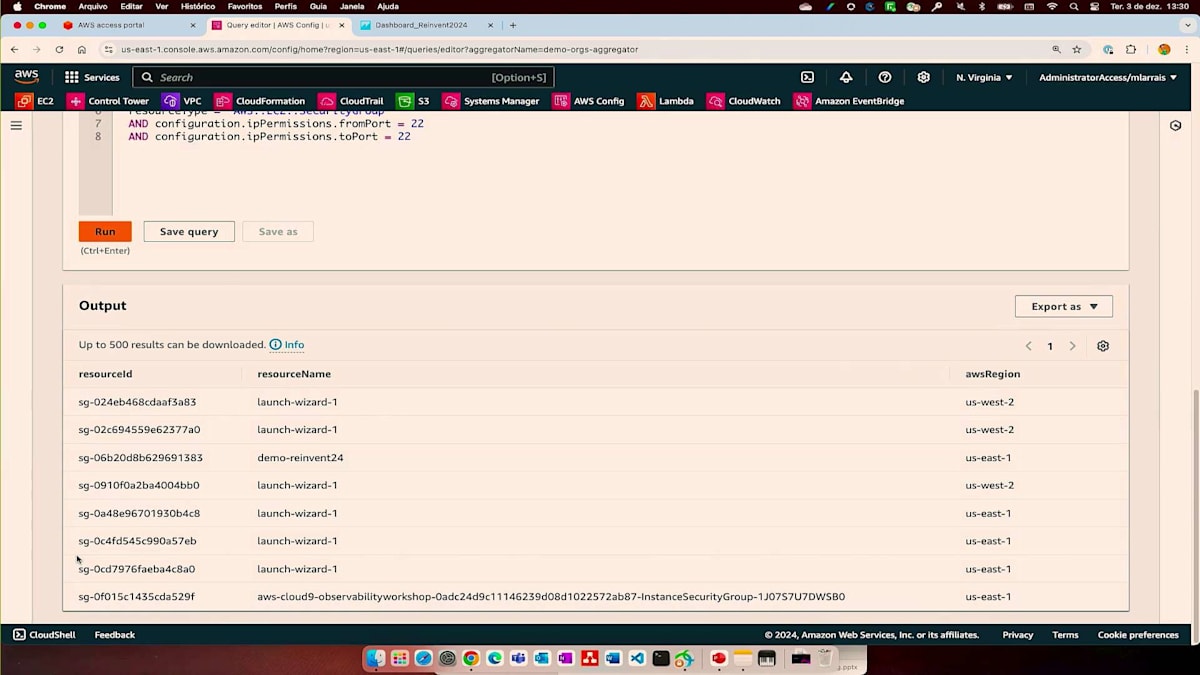
さらに重要なのは、私たちが議論しているAggregatorの部分について、SQLステートメントを使用できる高度なクエリ機能です。すぐに使える58個のクエリが用意されていますが、新しいクエリを作成したい場合は、Aggregatorを選択してここでSQLステートメントを作成できます。SQLステートメントに慣れていない場合でも、利用可能な自然言語クエリプロセッサを使用できます。例えば、ポート22が開いているすべてのセキュリティグループを表示したい場合、SQLステートメントに詳しくない監査担当者でも、委任されたアカウントアクセスを持っているため、これは非常に便利です。ご覧の通り、SQLステートメントが生成され、実行することができます。特定のリージョンを追加したい場合は、オートコンプリート機能がすでに組み込まれており、ここでその情報にアクセスできます。高度なクエリを使用することで、非常に分かりやすくなっています。


では、プレゼンテーションに戻りましょう。このリソース構成に関する情報は非常に価値がありますが、それだけではありません。リソース構成から抽出できるビジネス価値も重要です。そこで、Itaúのユースケースについて説明するために、Thiagoさんをお招きしたいと思います。ありがとうございます、Matiasさん。皆さん、こんにちは。私はThiagoと申します。Itaúのクラウドプラットフォームチームのリーダーを務めています。本日はお招きいただき、ありがとうございます。Itaúは100年の歴史を持つユニバーサルバンクです。ブラジル国内外に96,000人以上の従業員を抱える、ラテンアメリカ最大の金融機関です。

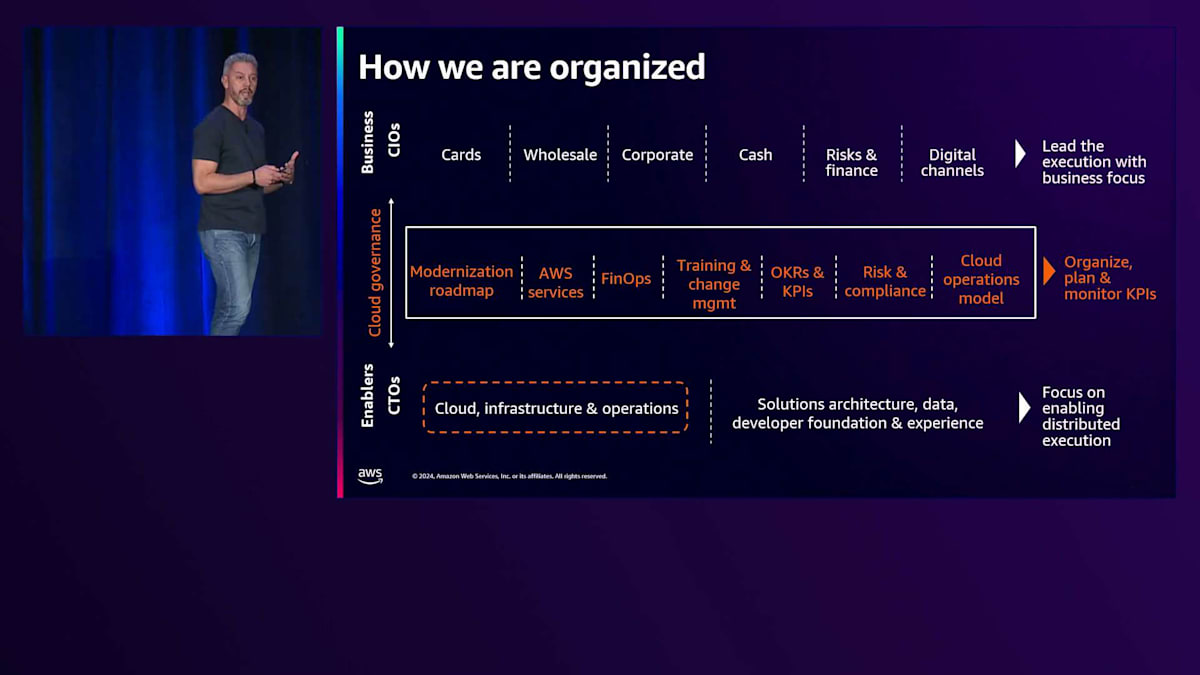
技術的な詳細に入る前に、私たちのテクノロジーチームがどのように組織されているかを説明させていただきます。スライドの下部にCTOがいます。私たちは enabler(イネーブラー)として、他のチームが活用できるプラットフォームを構築しています。私のチームはクラウドインフラストラクチャ運用を担当しています。スライドの上部にはCIOがいます。これらのチームは、お客様向けのソリューション、つまり私たちのプラットフォーム上で構築される、お客様が実際に使用する製品の開発に注力しています。
スライドの中央には、私たちのモダナイゼーション戦略とテクノロジー戦略にとって非常に重要なCloud Governanceがあります。Cloud GovernanceはCTOとCIOを結びつける接着剤のような役割を果たしています。ここでは、モダナイゼーションロードマップ、AWSのベストサービス、ベストプラクティス、FinOpsの情報、トレーニング認定など、すべての情報を一元化したビューを提供し、CIOが私たちの戦略を分散実行できるようにしています。

AWSでの私たちのフットプリントを見てみると、数千のアカウント(9,000以上)、5つのAWS Organizations、そして組織全体に分散する4,000万のConfiguration Itemがあります。さらに、この基盤を日々運用している複数のチームが存在します。これにより管理すべき複雑さが増し、これだけの規模で運用する際に直面するコンプライアンスやコストなどの課題について、すべてのリソースの情報を一元的に把握し、解決策を見出すにはどうすればよいのかという課題が生じています。

このことから、AWS Configを使用する上で3つの重要な柱が見えてきました。1つ目は可視性です。組織やプラットフォームにデプロイされているすべてのリソースの可視性をどのように確保し、この情報を一元的に集約できるかということです。2つ目はモニタリングです。インフラストラクチャに適用しているルールに基づいて、リソースのコンプライアンス状況を理解することが非常に重要です。3つ目は計画です。チームが日々の運用で問題を修正したり、作業の優先順位を決めたりする際に、事前にどのような情報を提供できるかということです。


そこで私たちは、Cloud Metadataと呼ぶものの構築を開始しました。最初は、1人のエンジニアが組織内の監査アカウントにログインし、クエリを実行して、データを抽出し、CSVファイルやExcelファイルを使って組織内のリソース数を把握するという方法を取っていました。しかし、この監査アカウントは集約されたログをすべて含む非常にセンシティブなリソースであるため、これは適切な作業方法ではありませんでした。
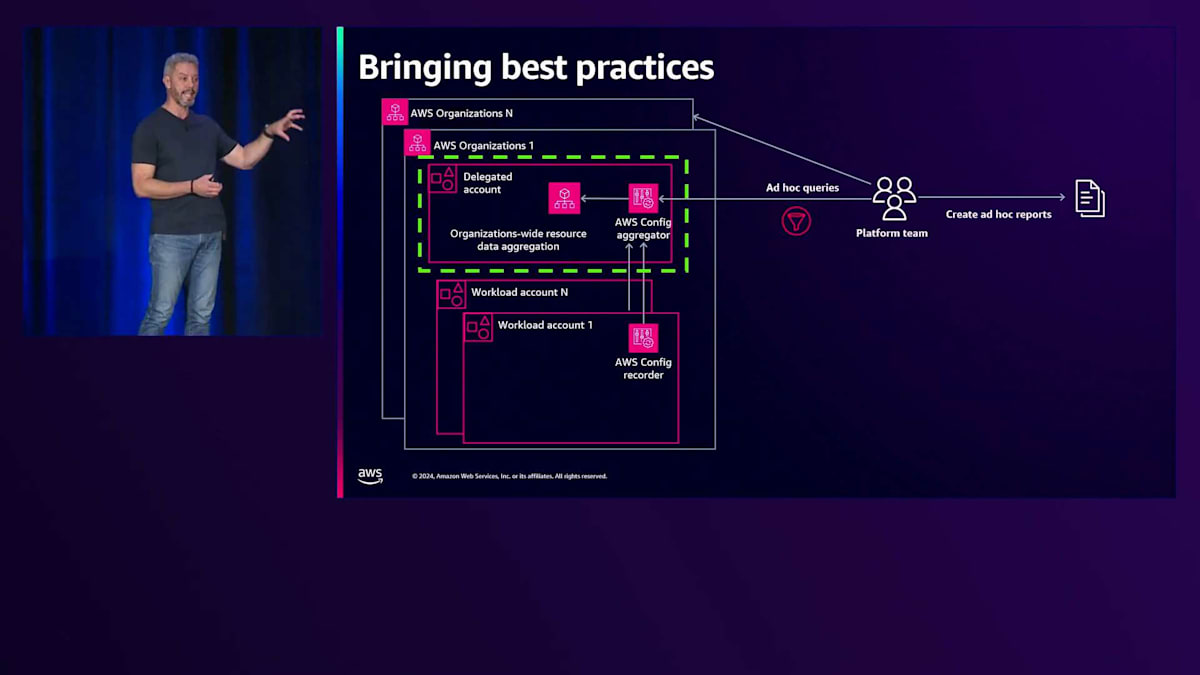
その後、ベストプラクティスに従って進化させました。AWS Configを使用してリソース全体の情報を集約する委任アカウントを設置し、すべてのインベントリとConfiguration Itemを1つのアカウントで受け取れるようになりました。しかし、それでもプラットフォームチームは手動でクエリを実行し、データをエクスポートして一元的な視点を得る必要がありました。


そこで、この情報に対してデータパイプライン戦略を導入し始めました。手動でデータを抽出する代わりに、AWS Glueジョブを追加してデータを抽出し、このデータパイプラインを通してデータをクリーニングし、すべてのリソースの一元的なビューを作成しました。これにより、エンジニアは手動でクエリを入力する代わりに、Amazon QuickSightを使用してすべての情報を一元的に確認できるようになりました。

私たちはビジネスに関連するコンテキストをさらに追加したいと考え、ビジネスチームがこれらのリソースやデータの所有権を理解できるようにする方法を検討しました。そこで、すべてのデータを全員が利用できるようにすることにしました。 CMDBからデータを取得し、それらのアカウントの所有者情報を組織のトポロジーや組織構造と関連付けて統合しました。これにより、ビジネスユニットのチームは、トポロジーやチーム構造の各レイヤーに接続された自分たちのリソースを確認できるようになりました。チーム構造に関して、
ビジネスユニットチームは、Platformチームにデータを提供してもらう必要がありません。私たちは一元管理を提供していますが、戦略の実行は組織の端々で分散的に行われています。ビジネスユニットチームは、FOPについて知りたい場合、バックレベルで自分たちの戦略を理解できるようになりました。インフラストラクチャにデプロイされたリソースに関連する戦略がコストとどのように相関しているか、そしてFOP戦略がデプロイされたリソースとどのように整合しているかを確認できます。
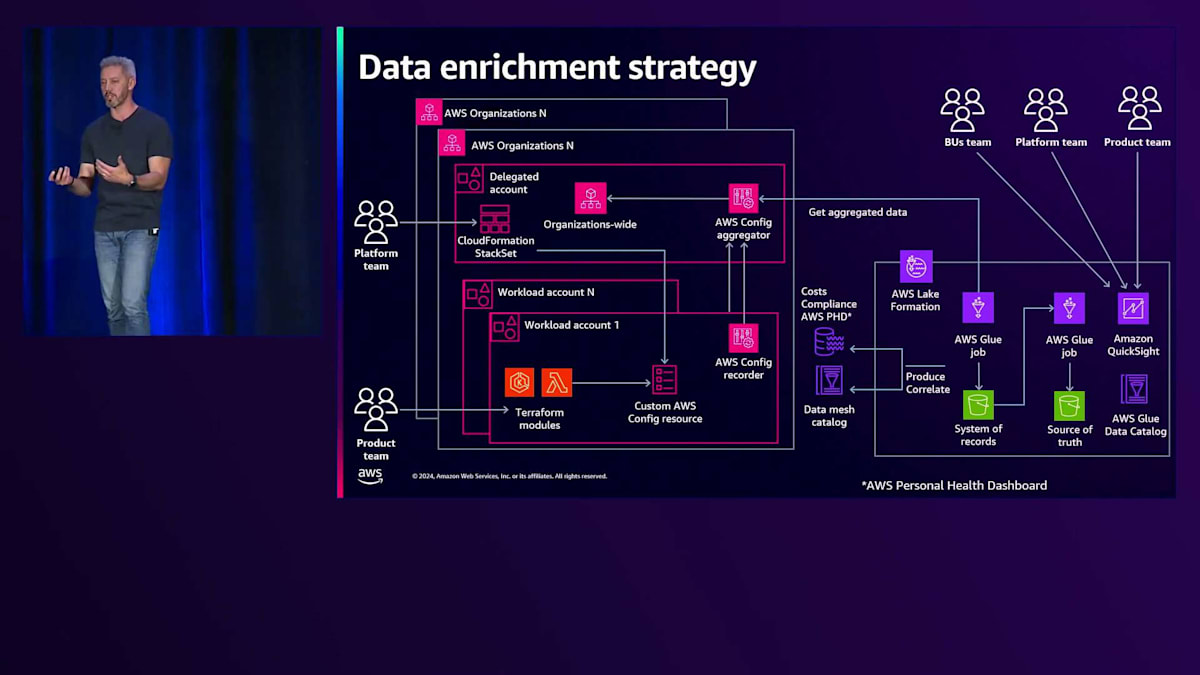
その戦略を展開する中で、プロダクトチームがデータを充実させたいと考えていることがわかりました。例えば、EKSチームやコンテナチームは、組織内にデプロイされた各クラスターにインストールされているアドオンについてより詳しい可視性を求めており、AWS Lambdaチームはデプロイされたランタイムのバージョンを把握したいと考えています。そこで、チームが特定のプロダクトのデータを充実させるために、パイプラインにデータや特定のコードをプッシュできる戦略を採用しました。パイプラインを通じて、データを充実させ、各チームに異なるビューを提供できます。

Platformチームは、リソースが組織全体でどのように分散しているかを理解できます。プロダクトチームはデータを充実させ、デプロイされた製品についてより多くの洞察を得ることができます。ビジネスユニットチームは、そのプラットフォームで見える情報に基づいて、コストとレジリエンシーのどちらを優先すべきかを判断するために、自分たちのインフラストラクチャとアーキテクチャを理解できます。では、デモをお見せしましょう。これがアナリストやエンジニアがAmazon QuickSightにログインした際に最初に目にする画面です。
ここでは特にAWS Lambdaプロダクトを見ています。組織の特定のデータを見たい場合は、フィルタリングすることができます。CTOやビジネスユニットのオーナーとして、ここでフィルタリングし、CMDBから充実させたデータを使用してLambdaの特定のランタイムのバックレベルを理解できます。サービスのTier、その特定のサービスのクリティカリティ、そしてバックレベルが特定のジャーニーにどのように影響するかを確認できます。特定のプロダクトのオーナーであれば、バックレベルのLambda関数を新しいバージョンのランタイムに移行する作業に優先順位をつけることができます。

中央のセクションでは、Lambdaファンクションのランタイムごとの分布が確認できます。各ティアやランタイムにおけるワークロードやLambdaファンクションの分布状況を把握することができます。また、本番環境、QA環境、開発環境ごとの内訳を見ることで、Lambdaの分布における影響を理解することができます。興味深いのは、これらの古いバージョンのランタイムが時間とともにインフラストラクチャにどのような影響を与えるのかが可視化できることです。ビジネスユニットのチームは、このバックレベルの対応に向けてエンジニアリングの取り組みをいつ集中させるべきかを計画することができます。
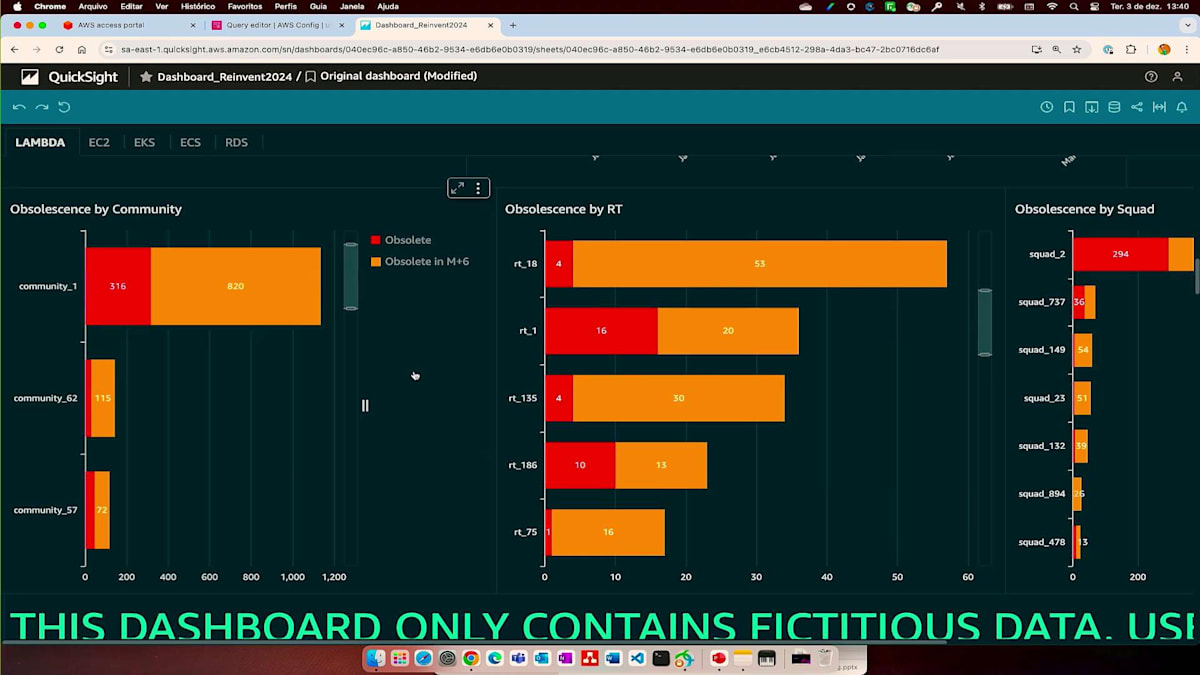


こちらがチームとトライブごとのより詳細な表示です。各エンジニアリングチームが、そのバックレベルによってどのような影響を受けるのかを理解することができます。EC2に関して言えば、現在の環境にどれだけのEC2インスタンスがデプロイされているかを把握したいと思います。ビジネスの観点から興味深いのは、古い世代のEC2を多く使用している場合、より効率的な運用を実現できるため、そのインスタンスの世代を上げていきたいということです。
ここでは、EC2の各バージョンを一目で確認することができます。ここにT2がありますが、ズームインしてみましょう。各サービスのティアがEC2インスタンスのタイプをどのように使用しているかを確認できます。最悪のシナリオであるC1ミディアムが稼働していることがわかります。非常に古いEC2インスタンスを実行しているため、C5、C6、C7などの新しいバージョンにアップグレードしたいところです。ここでアカウント所有者はコストに関する洞察を得ることができます。古いバージョンのEC2で多額のコストがかかっており、この具体的な洞察によってコスト削減の機会があることがわかります。
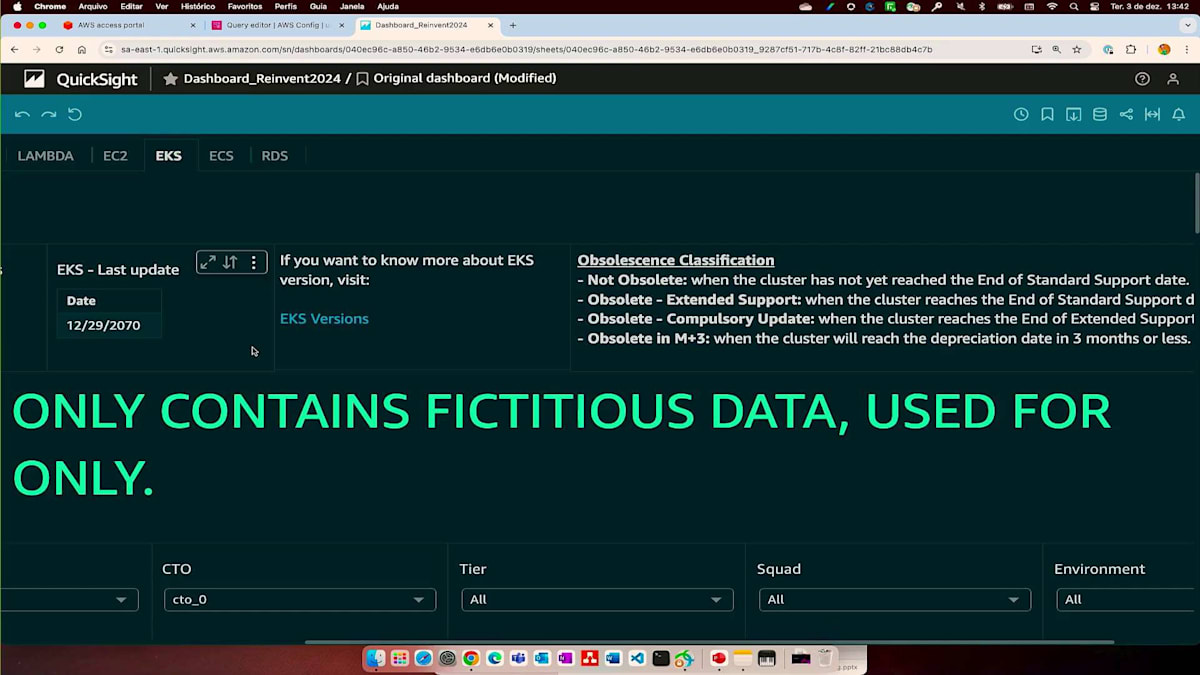


そして今では、プラットフォームチームが常にビジネスユニットに情報をプッシュする代わりに、ビジネスユニット側が主体的にこれらの情報を取得し、特定のシナリオに対してシステムのどの部分に取り組むべきかを優先順位付けすることができます。これらの古いバージョンについては、Extended Supportの影響を受けているかどうかを知ることが重要です。EKSのインフラストラクチャのコストと、同時にExtended Supportにいくら支払っているかを確認できます。これにより、AWSが予期せずバージョンアップを行う可能性があり、そのためのExtended Supportを支払っているという、レジリエンシーの問題があることがわかります。このように、私たちが注意を払うべき点として、レジリエンシーとコスト効率という2つの側面があります。同時に、時間の経過とともにバックレベルまたは古くなるクラスターの数の傾向を確認し、それに基づいて作業の優先順位を付けることができます。

プレゼンテーションに戻りますが、私たちは3つの主要な柱を計画していると述べました。第一は可視性です。環境を見て理解し、デプロイされているリソースを確認するにはどうすればよいでしょうか。第二はモニタリングです。非準拠リソースが組織全体に与える影響をどのように理解し、それらのリソースに対してどのように行動できるでしょうか。第三は計画です。チームは今、インフラストラクチャへの影響を理解し、バックレベルや非準拠リソースの優先順位をどのように付けるべきかを理解できます。最後に、将来について考えていることは、Generative AIを活用して、このデータに関する洞察を取得し、各エンジニアに対して、インフラストラクチャ全体のアップグレードや作業の優先順位付けをどのように行うべきかについて、より具体的で詳細な情報を提供する方法です。
セッションの振り返りと今後の展望

ありがとうございます。皆さんがどう感じられたかはわかりませんが、私にとってはまさに金字塔でした - Configの上にインテリジェンスをどのように活用できるかを理解できたことは。そして、Thiagoが先ほど説明したすべてが、AWS Configによって実現されているのです。これは、AWSにとっても、そしてお客様にとっても、このサービスがいかに重要であるかを示しています。この活用事例と、AWS Configのデータを新たなレベルで活用する方法について、私は非常に興奮しています。

ここで、このセッションの振り返りをさせていただきます。AWS Configは、多くのお客様にとって主にコンプライアンスツールとして認識されています。確かにその通りですが、Thiagoのプレゼンテーションで見たように、そしてItaúがどのように活用しているかを見たように、リソースインベントリ管理にも使用できます。これは非常に大きな価値をもたらします。皆さんはすでにバケット内でそのデータを使用していますので、ぜひ活用してください。その情報は非常に重要で、トラブルシューティングや修復にも役立ちます。何かが起きた正確なタイミングが不確かな場合は、履歴を遡って確認することができます。もちろん、CloudTrailを使用して確認することもできますが、AWS ConfigとCloudTrailを組み合わせることで、より高度なトラブルシューティングが可能になります。

このセッションから、皆さんに持ち帰っていただきたいポイントがいくつかあります。スケールでのAWS Configは、リソースインベントリの構成管理のためのものです。そのデータと情報を今すぐ使用できることがお分かりいただけたと思います。皆さんはそのデータに対して料金を支払っているのですから、その情報も活用できるはずです。構成情報から価値を見出すことができます。Thiagoのプレゼンテーションで見たように、ビジネスインサイトを得るために相関付けできる価値が多くあります。そうすることで、製品や移行の優先順位付け、あるいは来年や来月何をすべきかについて、データに基づいた意思決定を行うことができるようになります。


ここで、いくつかの参考リソースを共有させていただきます。最初はAWS Configの使い始め方について、真ん中はAWS Configを使用した構成のトラッキングに関するYouTubeガイドライン、そして3番目は、この構成全体にとって非常に重要なAggregatorについてです。これは、組織全体のセットアップ方法と、AWS OrganizationsでAggregatorを使用する方法についてのブログ記事です。 キオスクについていくつかお知らせがあります。AWS Village Experienceブースでは、ギブアウェイを用意しています。ガバナンスとコンプライアンスに特化したブースがあり、そこにはConfigやControl Tower、Organizationsに関するスペシャリストがいます。私もGrecoも参加する予定です。ぜひお立ち寄りいただき、ご質問ください。このセッションにご参加いただき、ありがとうございました。アンケートの記入をお忘れなく、そして私たちのチームがリソース構成管理に関するさらなるコンテンツをリリースしていきますので、このような活用事例にご注目ください。私やThiago、Grecoに質問がある方は、後ろでお待ちしています。ありがとうございました。re:Inventの残りの日程もお楽しみください。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion