re:Invent 2024: AWSによる効果的なトラブルシューティング手法


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Don't get stuck: How connected telemetry keeps you moving forward (COP322)
この動画では、AWSで18年以上サービスを構築・運用してきた経験を持つ講演者が、トラブルシューティングの効果的なアプローチについて解説しています。システムの問題を特定する際の5つの主要な原因(システムへの変更、入力の変化、制限への到達、コンポーネントの障害、依存関係の障害)を軸に、CloudWatchやAWS X-Ray、OpenTelemetryなどのツールを活用した具体的な調査手法を紹介しています。特に、Application SignalsやContributor Insightsなどの新機能や、Amazon Q Developerによる調査支援機能を用いた並列的な問題解決アプローチが詳しく説明されており、実際のBot-as-a-Serviceシステムでの障害対応事例を通じて、効率的なトラブルシューティングの実践方法が示されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
トラブルシューティングの現場:混沌から秩序へ


ページャーの音で目が覚めます - 自動アラートが発報され、本番サイトに問題があることを知らせてきました。ベッドから這い出してダッシュボードを開き、何が起きているのか把握しようとします。あなたが書いたシステムなので心配はしていません。これまでに何百もの問題に対処してきました。この件も簡単なはずですが、今回は様子が違います。


ダッシュボードは乱雑でノイズが多く、何が問題なのかはっきりしません。ログも同様にノイズが多いのですが、問題が何なのか、どこにあるのかを示す明確なパターンが見当たりません。チームメイトも自分のシステムにアラートが来たため、オンラインになり始めます。彼らはチャットで状況を尋ね始めます。Webサイトがダウンしているのか?Webサーバーに問題があるのか?いいえ、Webサーバーは大丈夫です。バックエンドに問題があるはずですが、あなたがバックエンドを書いたのに、バックエンドは問題なさそうです。少なくとも、それが問題ではなさそうです。
そこで、カンファレンスコールを始めます。全員が口々に話し、会話の方向性が変わり、質問を投げかけ、誰かが考えを述べ終わる前に次の話題に移っていく - 混乱状態です。そして今や、あなた一人だけでなく、チーム全体が行き詰まっています。これは私にとって見慣れた光景です。私はAmazonで18年以上にわたってサービスを構築し、運用してきました。DynamoDBやAWS Lambdaなど、自分が構築したサービスを運用してきました。また、Call Leaderと呼ばれる役割も担当してきました。これは、スピードが特に重要で、問題の複雑さが多くの調整を必要とする場合に、調査を進め、注意散漫を避けながら、状況を整理する役割です。

これから1時間、トラブルシューティングで行き詰まった時にどうやって抜け出すか、そもそも行き詰まらないようにする方法について、私が学んできたことをお話ししたいと思います。トラブルシューティングの目的は、何かを見つけること - いわば隠れた宝石のようなものを見つけることです。具体的に、私たちが対処できる何かを見つけることです。例えば、ロールバックが必要なデプロイメントを見つけたり、キャパシティの追加が必要なスケール不足のマイクロサービスを見つけたりすることです。これらは必ずしもRoot Causeではありません - デプロイメントにバグがあった理由や、そもそもバグが何だったのかは分かりません。サービスがなぜスケール不足になり、なぜキャパシティの追加が必要になったのかという状況も分かりません。
その後、私たちはそれらの状況やバグ、本番環境で問題を引き起こした全てのRoot Causeの性質を解明していきます。まずは影響を止めることに集中し、残りは後で行います。後で、Root Cause Analysisを行い、それを広く共有し、共通のパターンを見つけ、全員が恩恵を受けられるように基盤となるシステムを改善する方法を見つけていきます。しかし、その時点では、とにかく影響を止める必要があるのです。
トラブルシューティングの本質:隠れた宝石を探す


さて、ここでの課題は、もし私たちが障害の真っ只中に放り込まれた場合、問題を探すべき場所が自動的にはわからないということです。そもそも、どんな問題を探せばいいのかさえわかりません。砂漠のどこかに放り出されて、埋もれた宝物、隠された価値あるものを見つけるように言われたことを想像してみてください。それがどこにあるのか、そもそも何なのかもわかりません。隠された価値あるものを探しているのですが - どのくらいの深さにあるのか?どの方向から探し始めればいいのか?まったくわかりません。トラブルシューティングは時としてこのような状況に似ていることがあります。

このトークを通して、私は数多くのObservabilityツールと、一連のトラブルシューティング手法の適用方法をお話ししていきます。ツールについては私が最も詳しいCloudWatchを例に説明しますが、皆さんがどこでどんなObservabilityツールキットを使っているにしても、同じような考え方を応用できるはずです。これらのテクニックは、プレッシャーの中でも冷静でいられるようにしてくれるものです。物事の間をナビゲートし、つながりやヒントを探す方法といった機械的な戦術もありますが、トラブルシューティングのプロセスをどう考えるか、目標は何か、チェックリストをどう考えて確認し、事象を絞り込んだり除外したりするかといった戦略的な部分もあります。

ツールやテクニックについて話すのは素晴らしいことですが、トラブルシューティングはツールがやってくれるものではありません。トラブルシューティングは、ツールが私たちを助けてくれる作業なのです。そうである以上、最も重要なのは私たち自身の思考プロセスや考え方を調整し、磨いていくことです。だからこそ、このトークでは私たちの思考について考えることに十分な時間を割くことが重要だと考えています。では、障害が発生したときにより迅速に対応できるようにするため、トラブルシューティングに関わる人間の思考プロセスを分析してみましょう。

このトークは4つのパートで構成されています。まず、トラブルシューティングの統一理論を形成する5つの原因を含む私の戦略について説明します。次に、ポイントAからB、C、Dへと根本原因に至るまでのナビゲーション方法を探ります。そして、アプリケーションで何が起きているのか、どこで起きているのかを理解するために必要なTelemetryについて検討します。最後に、将来さらに迅速に調査を行うための方法について議論します。

皆さんは全員トラブルシューティングの経験をお持ちだと思いますが、私たちが直感的に行っているこれらのプロセスについて、より形式的に考えてみることは有益です。これらの概念の多くは理解できて共感できるものだと確信していますが、その思考に構造を持たせてみましょう。
トラブルシューティングの統一理論:5つの原因

トラブルシューティングの際に考えるべき質問は「何が変更されたのか」あるいは「何が失敗したのか」を突き止めることだけだと思われるかもしれません。よく考えてみると、障害とは本質的に予期せぬ突発的な変更なので、結局はすべて「変更」に帰着すると言えるでしょう。しかし、この「変更や失敗を探す」という目標は、確かに間違いではないものの、インシデント発生時の効果的な目標としては漠然としすぎていて、範囲が広すぎます。「何が変更されたか」と問いかけると、すべてが変更されているように見えてしまいます。メトリクスは乱れ、ログには関係のないエラーが溢れかえります。これは原因というよりも結果なのです。変更点だけに注目していると、膨大な情報量に圧倒されて身動きが取れなくなってしまう可能性があります。

あえて断言させていただきますが、インシデント管理の目的は、これから説明する5つの原因のうち、どれがインシデントの引き金となったのかを特定することです。障害を調査し、チームで協力して対応する際、有意義な作業をしているとすれば、それはこの5つの要素を探すか、それらに関する情報を共有・伝達しているかのどちらかです。すべての障害は、この5つのトリガーのいずれかに帰着します:システムへの変更(コードのデプロイメントなど)、システムへの入力の変化(トラフィックスパイクなど)、何らかの制限への到達(キャパシティの制約など)、システムコンポーネントの障害(EC2インスタンスのクラッシュなど)、依存しているものの障害(他のMicroserviceの障害など)です。

これらはRoot Causeではありません。問題を止めるために探すべきものなのです。 まず最初に探すのは、私たちや自動デプロイメントシステムが行った変更です:コードのデプロイメント、インフラストラクチャの変更、設定の変更、データベーススキーマの変更、Feature Flag、さらには検出が難しい変更(予期せぬユーザー行動を引き起こすプロダクトカタログの価格エラーなど)です。これらを探す理由は、変更を元に戻すか、その影響に別のプロセスで対処することで、素早く問題を緩和できるからです。


2番目は入力の変化を探すことです。 これは、WebサービスやWebサイトへのリクエストレートが増加したケースや、リクエストレート自体は増加していないものの、各リクエストの処理コストが増加したケース(より負荷の高いクエリを実行するようになったなど)が該当します。このようなワークロードの変化に対しては、負荷の発生源を特定してブロックできることがあります。なぜなら、このタイプのワークロード変化では、システムのレイテンシーが著しく低下し、クライアントから見た可用性が大幅に低下することがあるからです。

呼び出し元に何らかの変更があった場合、私たちは緩和策を探します。同時に、他の5つの原因が当てはまらないかも確認すべきです。例えば、トラフィック増加の原因を特定しようとしている間(これは当時点では仮説に過ぎません)、スケーリングの状況も確認すべきです。Auto Scaling Groupsのスケールアップが必要かもしれません。これらは並行して実施すべき緩和策です。何らかの制限に達している場合、キャパシティの問題が発生していると考えられるため、スケールアップを検討すべきでしょう。


CPUが不足しているなどと考えられる場合は、キャパシティを追加する必要があります。ただし、これが突然発生することは稀なので、並行して対処できる不正な入力がないかも確認すべきです。その間、対策とスケールアップを進めながら、不正な入力をブロックします。ただし、不正な入力の確認に過度に注力するのは避けるべきです。なぜなら、単に前日よりもわずかに高いピークが発生し、限界点を超えただけかもしれないからです。前日からわずかに高いだけなのか判断するのは非常に難しいため、不正な入力の確認に深入りしすぎないようにしましょう。

スケーリングやコンピューティングリソースの枯渇だけが問題ではありません。証明書の有効期限切れに遭遇することもあります。これも証明書の残り時間という意味でのリソース枯渇であり、更新や再発行が必要な即時の障害となります。変更に関連して調査すべきこととして、各リクエストの処理コストがわずかに増加するようなコードのデプロイメントが最近行われた可能性もあります。これも再びある種の制限に達したということですが、そこに至った変更についても調査する必要があります。


直感的ではないかもしれない興味深いシナリオとして、依存している外部サービスの呼び出しが以前より遅くなった場合があります。これにより、クライアント側で同時実行数の制限に達する可能性があります。例えば、すべてのスレッドがその依存サービスの応答待ちで占有されてしまい、スレッドが枯渇する状況です。これらのスレッドは、その依存サービスを必要としない他の作業に使用できなくなるため、これらは全て関連しています。4番目として、コンポーネントの障害を確認します。これは物理的または論理的に分離されており、独立して障害が発生する可能性のあるものです。アプリケーションのメトリクスに基づいて、特定のEC2インスタンスや可用性ゾーン、Podなど、個別の要素で他より成功率が高いかどうかを確認し、独立して障害が発生する可能性のあるものを探して、アプリケーションが特定の要素で遅くなったり障害が多発したりしていないか確認します。



対処方法としては、パフォーマンスの悪いコンポーネントをサービスから外す、ロードバランサーから除外する、またはDNSから削除するなどして使用を停止します。ただし、これで終わりではありません。コンポーネントが過負荷で障害が発生した可能性についても確認する必要があります。特定のワークロードやリクエストが致命的な影響を与えた可能性があります。また、新しいカーネルバージョンを最初に受け取ったホストだったなど、他の変更がないかも確認する必要があります。データベースやキャッシュ、サードパーティのサービスなど、外部サービスへの呼び出しで依存関係の障害が見つかった場合は、自身ではなく依存関係の調査に移行すべきです。

ここでも過度に注力しすぎないように注意が必要です。私たちの視点からは依存関係に障害があるように見えても、実際には依存関係の呼び出し方に問題がある場合があるからです。例えば、過負荷状態のサービスが依存関係を呼び出す場合、依存先が遅いように見えても、実際にはCPU不足で自身が遅くなっているだけかもしれません。依存先からエラーが返ってきているように見えても、実際には不適切な引数で呼び出していることが原因かもしれません。これにはいくつかのパターンがあり、デプロイメントのロールバックが必要な場合もあれば、サービスの呼び出し方が間違っていて、スロットリングやクォータオーバーになっているような不正な入力の場合もあります。
チェックリストとアルゴリズム:効率的な問題解決への道



これら5つの原因をチェックリストとしてアルゴリズムの形で表現する方法もあります。何かを変更したか、インプットが変化したか、制限を超えたかなどを確認できるプログラムです。このアルゴリズム形式の良い点は、各原因に対して対策が対応付けられることです - 何かを変更した場合は、その変更を元に戻します。しかしこれだけでは不完全です - まだアルゴリズムを構築している途中なのです。復旧が実現するまで、このプロセスをループする必要があります。これらのステップを継続的に実行し、ノンブロッキングなので、一つの作業が完了するのを待ってから次の調査に移るということはしません。


このアルゴリズムは再帰的です - 一度に一つのMicroserviceに焦点を当て、注目点を移動させることができます。依存関係の障害があった場合は、今度はそのサービスの依存先に焦点を当てて、同じ調査アルゴリズムを実行します。すべてが分岐し、並列化され、ノンブロッキングなので、これらすべての調査の道筋を同時に進めることができます。このアルゴリズムの素晴らしい点は、並列化が可能だということです - これはあなたとチームが実際にトラブルシューティングを行う方法と一致しています。タスクを分割し、「あなたはこれを見て、私はこれを見る」というように作業を分担し、お互いに発見したことを共有しているのです。

さらに、これら5つの原因をチェックリストとして重視することで、最も可能性の高い原因 - 互いに関連し合うカテゴリーに注目することができます。一つの事象について情報を見つけると、他の原因を確認したり除外したりする手がかりになります。また、これらの各項目がデプロイメントを停止したりロールバックしたりするためのアクションに対応しているため、対策に焦点を当てることができます。

チェックリストがあることで、トラブルシューティング時のトンネルビジョンを防ぐことができます。自然とこれらの原因をパンくずのように追っていくものの、一つのことに過度に集中しがちです。チェックリストがあることで、一歩下がってリソースの枯渇などの他の潜在的な問題をチェックすることを思い出させてくれます。これら5つの項目を体系的に調査することで、行き詰まりを避けることができます。
実践デモ:Robots-as-a-Serviceシステムのトラブルシューティング

では、より具体的なアクションに移りましょう。デモを行い、その後で私の思考プロセスとどのようなツールを使用したかについて、詳しく説明しながら部分的に振り返ります。私が作成した実際のWebサービス群 - Robots-as-a-Serviceシステムを使ってトラブルシューティングを行います。このサービスは、ロボットをプロビジョニングし、指示やスケジュールを送信し、作業を命令するためのAPIを提供します。

トラブルシューティングを進めながら、5つの原因のチェックリストを埋めていきます:私たちが加えた変更、入力の変更、リソースの枯渇、コンポーネントの障害、そして依存関係の障害です。各項目について、YとNはYesとNoを表し、数字は確信度を示します。例えば、8.8は変更を加えたことをかなり確信している状態を、0.5はコンポーネント障害ではないことを50%程度の確信度でしか判断できない状態を表します。

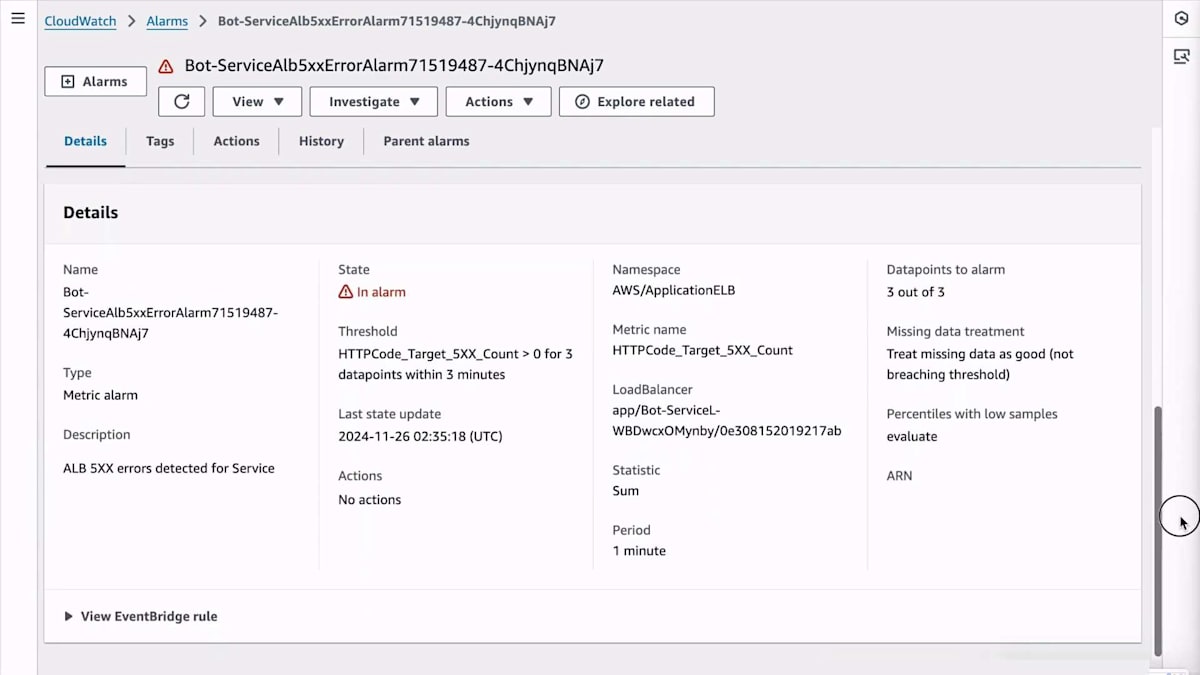
Application Load Balancerからアラームが発生したという通知を受け取りました。その原因を調査してみましょう。アラームページの下部までスクロールして、Runbookを探してみます。残念ながら、私は自分でRunbookやダッシュボードへのリンクを設定していなかったので、代わりに標準機能を活用することにします。


ページを上にスクロールして、新しいExplore関連機能を使ってみましょう。先週リリースされたばかりのこの機能は、調査中にAWS CloudWatchコンソール内を移動しても追従するサイドパネルを開き、調査対象のAWSリソースに関連するリソースやテレメトリーを表示します。データを見ると、リクエスト数がわずかに増加していますが、その変化は非常に小さく、原因というよりは結果のように見えます。トリガーではなさそうだと判断しますが、完全には確信が持てないので、確信度は50%程度としておきます。
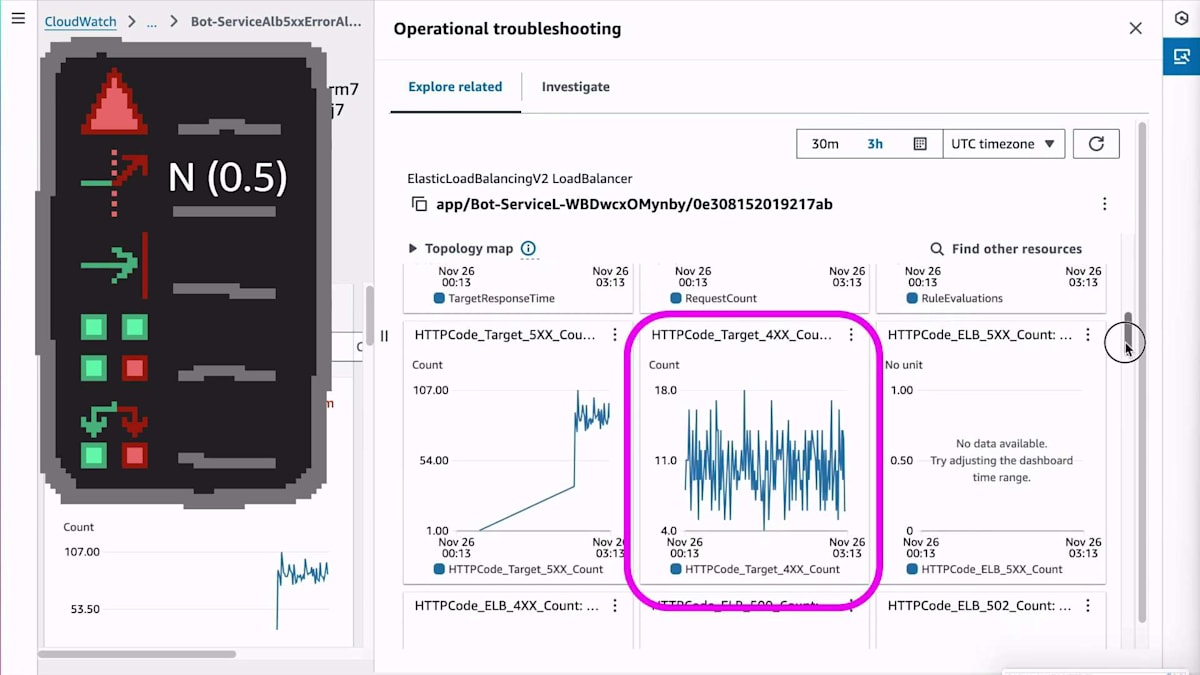

さらにスクロールすると、400エラーの増加は見られないことがわかります。特定のワークロードの抑制やクライアントのレート制限を行っていれば、それらは400エラーとして表示されるはずです。これにより、入力の変更が原因ではないという確信が高まります。他のメトリクスも確認しましたが、特に気になる点は見つからなかったので、さらに調査を進めていきましょう。
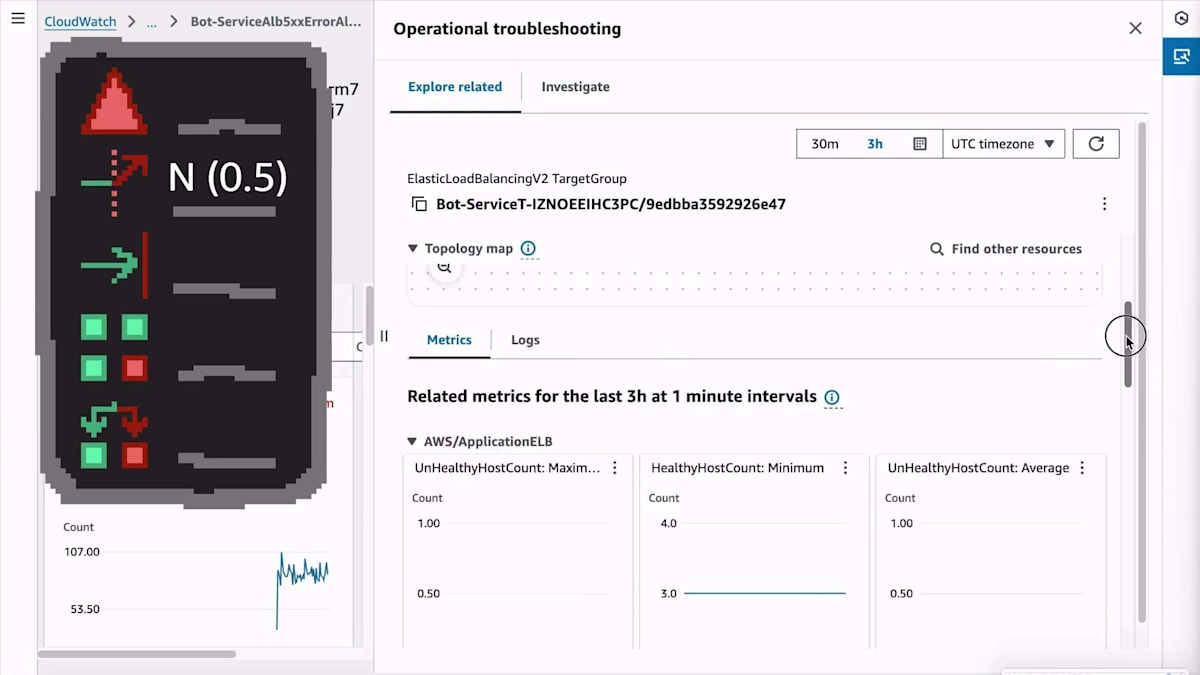
Load Balancerにはターゲットグループがあり、Target Groupには独自のメトリクスがあります。Unhealthy Host Countが増加していないことから、アプリケーションがクラッシュループに陥っていたり、ヘルスチェックに失敗していたりする状況ではないことがわかります。また、Healthy Host Countも増加していないことから、リアクティブにスケールアップしている状況でもないことがわかります。これにより、リソース枯渇の可能性は低いと考えられますが、もし制限に達しているのであれば、Auto Scalingルールが正常に機能していない可能性があります。



他にどんなことが調べられるか、さらに見ていきましょう。Target Groupsは、その背後にあるHostに接続されています。 EC2インスタンスを見てみると、CPUの使用率に大きな変化はありません。これは、リソースが枯渇していないことを示すさらなる証拠となります。また、下に表示されているEC2のステータスヘルスチェックも失敗していないので、 私たちの仮想マシンに物理的な問題があるわけではありません。これにより、ある程度、コンポーネントの障害を除外することができます。
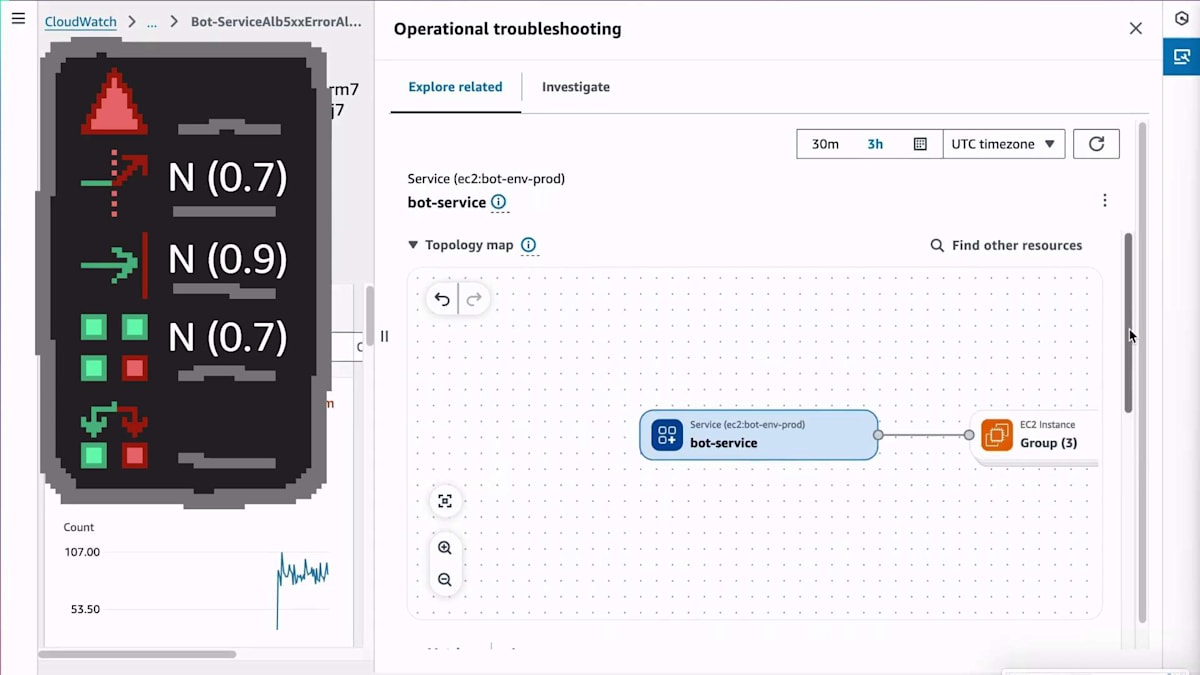


インフラ関連のメトリクスはすでに確認しましたが、ここでアプリケーションの動作についてもっと詳しく見る必要があります。この問題が実際にアプリケーションにどのような影響を与えているのか、より詳細に把握する必要があります。そこで、EC2インスタンスからそのインスタンス上で動作しているアプリケーションへとクリックして進みました。 CloudWatchは、そのインフラ上で動作している何かが、独自のアプリケーションレベルのメトリクス、つまりカスタムメトリクスを発行していることを認識しています。コードが実際に送信しているメトリクスを確認できます。その証拠に、下にスクロールすると、PUT bot scheduleのような特定のAPIに関連するURIが表示されています。これは私のアプリケーションだけが知っている情報なので、このナビゲーションを通じて、私のコードが行っていることを見つけ出したわけです。
Observabilityの重要性:効果的なInstrumentationの実装

インフラストラクチャと、それらのEC2インスタンス上で動作している私のコードは、ログを出力しています。 ここでは、ログの内容のサマリービューを表示しています。通常のログを開くと、膨大な数のユニークな行が表示されるはずです。各ログ行には、固有のリクエストID、タイムスタンプなどがあります。これは機械学習を使用してパターンクエリを実行し、CloudWatch Logs Insightsで要約して圧縮しています。すべてユニークだった88,000行を1行に圧縮して、何が起きているのかが分かるようにしています。しかし、ここでは特に興味深い情報は見つかりませんでした。つまり、間違った場所で針を探しているようなものです。そのため、依存関係の障害かもしれないと考え、別の場所を確認する必要があると判断しました。


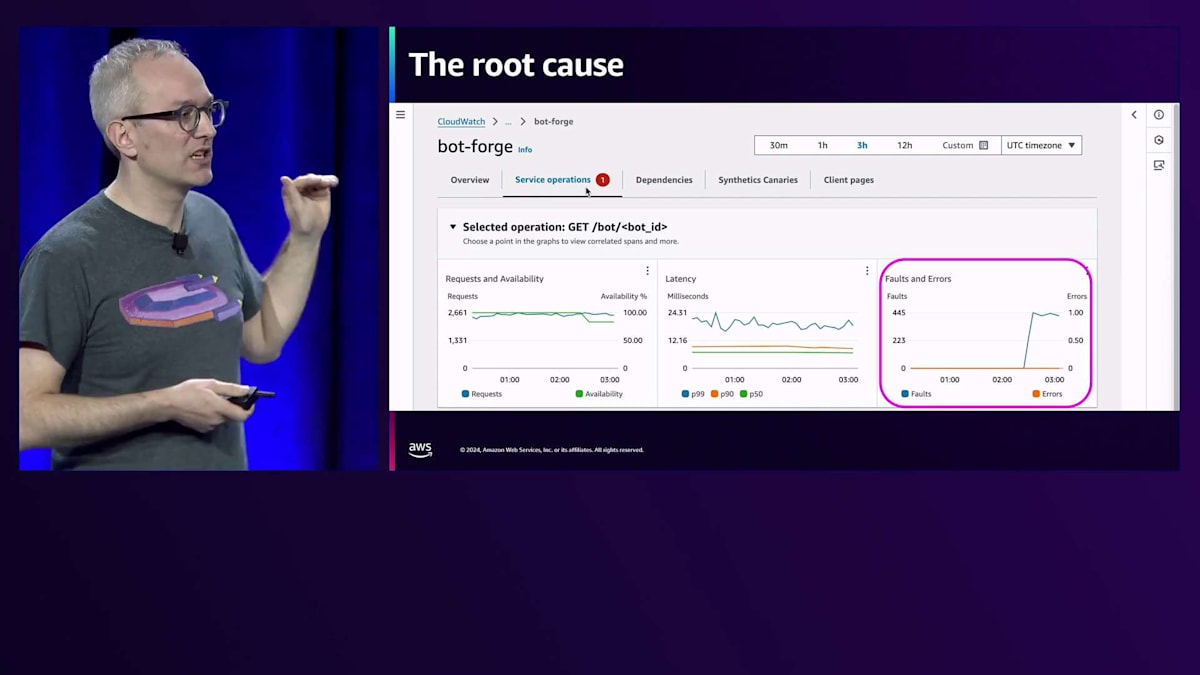
では、別の場所を見てみましょう。 そのために、トップまでスクロールし直してApplication Signalsを確認します。これはCloudWatchの別の部分で、アプリケーション自体の計測データやメトリクスについてより詳しく見ることができます。そこに入ると、インフラ情報とインデックスを結合することで、EC2インスタンス上で実際のサービスマイクロサービスが動作していることを検出していることがわかります。これを見ると、障害のスパイクが発生していることがわかるので、それらの障害がどこから来ているのか理解する必要があります。そのスパイクをクリックすると、調査用のサイドパネルが表示され、クリックできるSpanやTraceが表示されます。
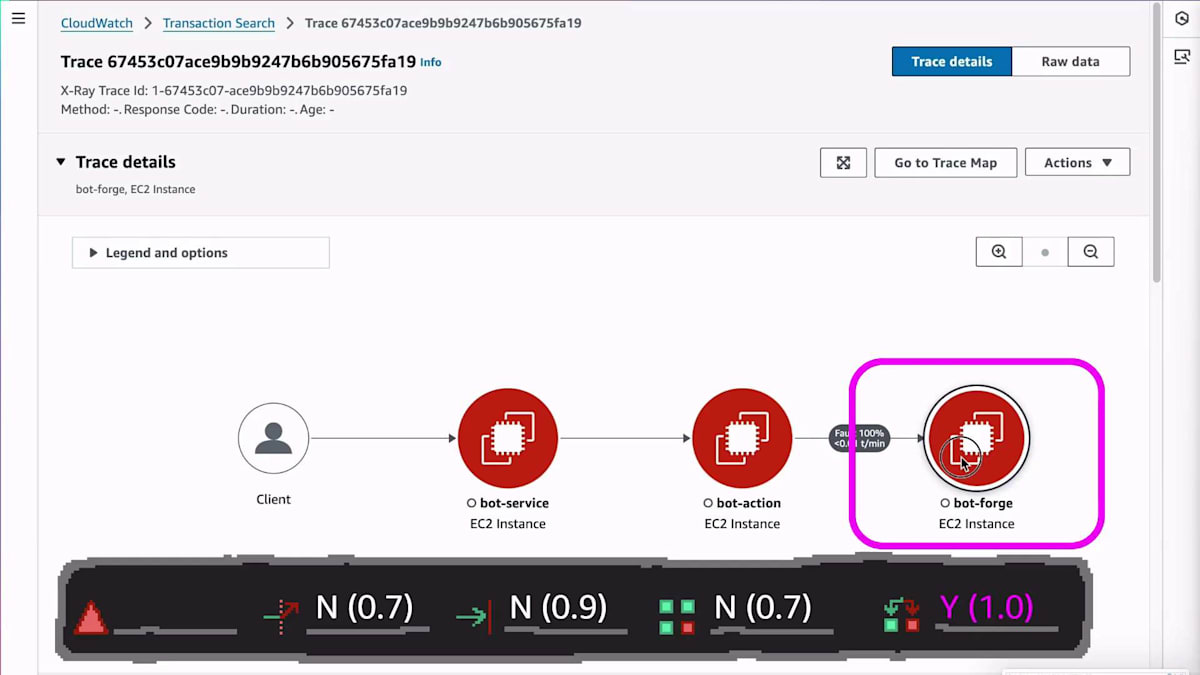

これで、分散システム全体の様子が見えてきました。今はTraceの世界に入り、フローとしてのTraceを見ています。左側のBotサービスを見ていましたが、実際の問題は右側のBot Forgeにある可能性が高いことがわかります。そのため、Bot Forgeサービスを確認する必要があります。これはロボットを設定してビルドするものです。そこをクリックして、そのマイクロサービスのApplication Signalsに戻ってみましょう。依存関係の障害は見られないので、別のマイクロサービスに切り替えたことで、そのチェックリストはクリアになりました。以前のチェックリストは保存されているので、必要があれば戻ることができますが、ここには依存関係の問題はなさそうです。


APIを見てみると、これはApplication Signalsが自動的に生成するダッシュボードのようなものですが、すでにForgeサービスのAPIごとにいくつかの情報が確認できます。このAPIへのリクエストレートの増加は見られませんが、右側を見ると、障害が発生していることがわかります。これで問題があることは分かりましたが、このサービスAPIには明らかに問題があるものの、具体的にどんな問題なのかまではわかりません。そこで、これらの障害を他の要素で分解する必要があります。この場合、トップコントリビューターを見ることで、インスタンスIDなどの次元ごとに障害を分解できます。アプリケーションが特定のEC2インスタンスでのみ失敗しているので、アプリケーションが1つのものでのみ失敗している場合はどうすべきでしょうか?1つのコンピュートやコンポーネント、またはAvailability Zoneをサービスから切り離して、そのものを取り除けばいいのです。そうしたら、これで完了です。


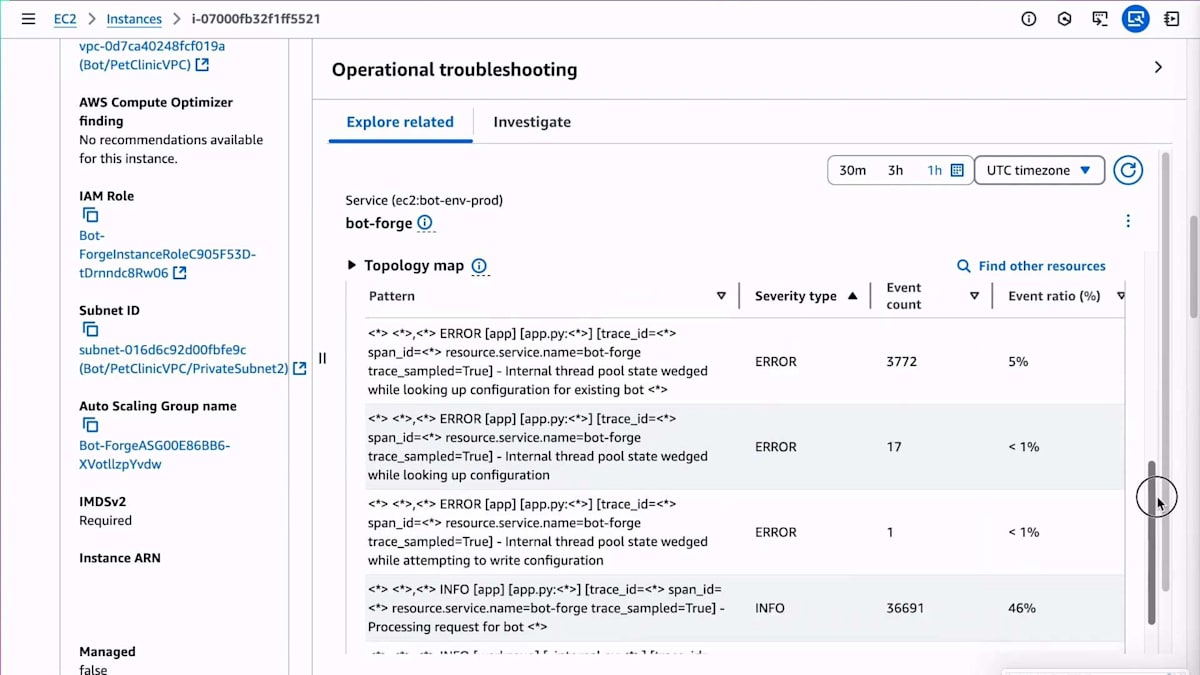
さて、ボーナスラウンドに入りましょう。もう少し詳しく調べるために、そのメトリクスを追跡してEC2インスタンスまで遡ってみました。すでにサービスから切り離したので影響は止まっていますが、CloudWatchの新しいExploreサイドパネルをもう少し見てみましょう。AWSコンソールのどこからでもアクセスできます。ここではEC2コンソールにいて、任意のメトリクスから「関連項目を探索」と選択すると、再びトラブルシューティングを支援するサイドパネルがポップアップします。クリックするだけでそのEC2インスタンスから出力されているログを見つけることができ、パターンを実行することができます。先ほどとは異なるマイクロサービスを見ていますが、ここでエラーが見つかりました。レースコンディションがあり、スレッドプールの状態が固まっているようです。これでこのマイクロサービスで何が起きているのかが分かったので、後でバグを特定できます。ただし、影響は既に止まっています。


影響を軽減し、おまけにバグまで見つけることができました。これで終わりでしょうか?もう寝に戻っていいでしょうか?私はそうは思いませんし、皆さんもそうは思わないでしょう。でも、なぜでしょうか?なぜそのホストで障害が発生したのでしょうか?再発しないことを確認するために、もう少し詳しく知る必要があります。このEC2インスタンスが新しいカーネルバージョンで起動した最初のもので、これからフリート全体を更新しようとしている場合はどうでしょう?コードのデプロイメントを行って段階的にロールアウトしている最中で、このホストに影響が出て、これから残りのEC2インスタンスにも影響が及ぼうとしている場合はどうでしょう?それは良くないですね。


私のアルゴリズムは間違っていました。影響が続いている間は、調査を続ける必要があります。実際には少し違います。影響が続いている間、または再発しないと確信できるまで、という方が正確です。これは主観的なもので、この不確実な環境の中で、安心して寝に戻れるかどうかを判断するために必要な確信の度合いによります。さて、これで終わったので、ツールの背後でこれらの重要な機能がどのように動作しているのかを少し掘り下げてみましょう。皆さんはCloudWatchをそれほど使っていないかもしれないので、ツールが何をしていたのかを解説し、皆さんが自分のツールでも同じことを見つけられるようにしましょう。



私が行っていたトラブルシューティングの戦術の重要な部分は、多くのナビゲーションを行っていたことです。非常に素早くナビゲートし、ループしていました。調査して、見えるものを確認し、次に別の場所に移動して、そこで見えるものを確認していました。どの時点でも、メトリクス、ターミナル、ログ、トレース情報を表示するものがあります。できる限りの情報を収集し、チェックリストをチェックしながら、次に見るべき場所を探してナビゲートしています。UIリサーチには、80年代後半から90年代初頭にXeroxの研究者たちが提唱した「情報の香り(Information Scent)」という概念があります。これは、ウェブページやユーザーインターフェースが、ユーザーが探し求める答えについて何らかの手がかりを発しているという考え方です。

ユーザーは、UIのこの部分や別のページが自分の質問の答えを提供してくれるかどうかを、いわば情報の「匂い」を頼りに探っています。私も同じように、まずはExploreパネルを使って何があるのかを把握し、そしてナビゲーション部分を使って、次に行くべき最も可能性の高い場所を嗅ぎ出していました。上部のUIは、接続状況とヘルス情報を同時に表示してくれていたので、多くの手がかりを提供してくれました。
ナビゲーションとテレメトリー:問題の根源を追跡する

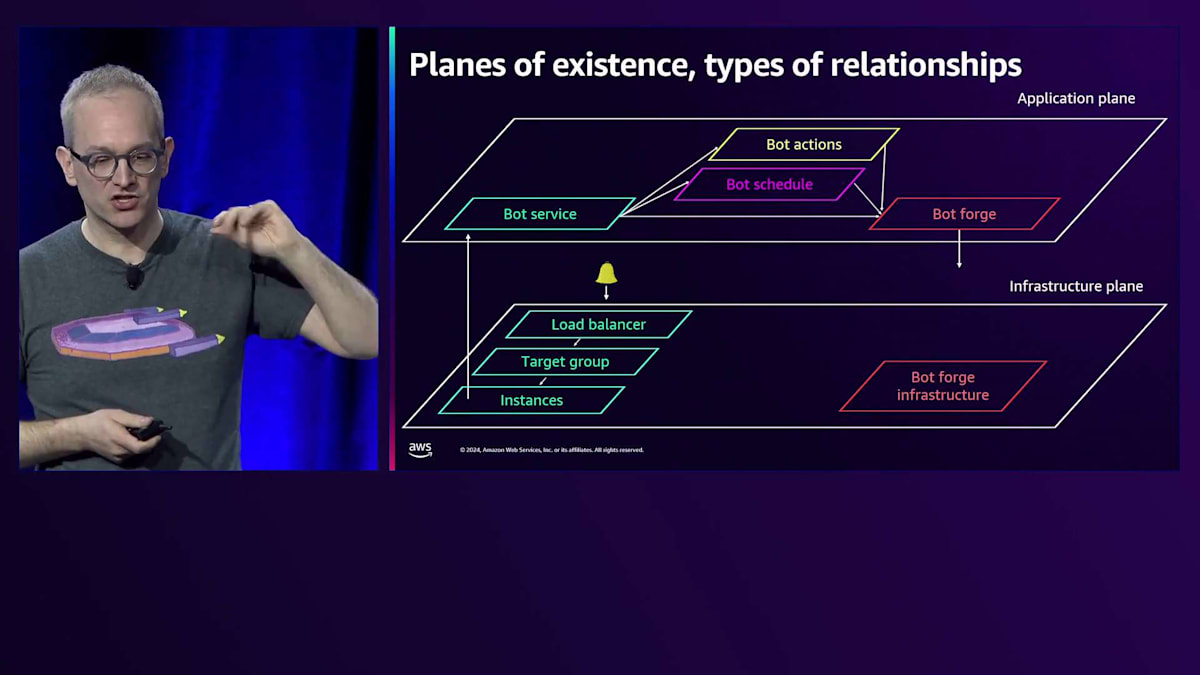
このようなExploreウィジェットの便利な点の1つは、私の探索の道筋をマッピングできることです。Load Balancerから得られたメトリクスに由来するアラームから始まり、そこから調査を進め、すぐにいくつかの可能性を除外し、インスタンスに移動し、CPUの使用率超過などの問題を除外し、そしてアプリケーションへと移動しました。その都度、貪欲アルゴリズムのように、最も可能性が高そうな場所に opportunistic に進んでいきました。必ずしも最適解ではありませんでしたが、行き詰まることはありませんでした。この間、タブの切り替えは一切必要ありませんでした。アプリケーションログのロググループ名を覚えて入力する必要もありませんでした。これまでのナビゲーションや情報の手がかりを得る際の問題点は、次の場所への行き方、Load BalancerからLogへの行き方を記憶しておく必要があったことです。今回は全てクリックだけで、キーボード入力やARNのコピー&ペーストは不要でした。


これが重要なポイントです - 移動とナビゲーションをシームレスにしたいのです。次に、このクリック操作を可能にする接続性について話しましょう。適切な接続があれば、頭を使わなくても次に行くべき場所が分かります。単純に、最も有望な outbound パスを見つければいいのです。新しい場所を想像して考え出す必要はありません。ここで使用した関係性にはいくつかのタイプがあります。Load Balancerからホスト、Target Group、その他へと進んだインフラストラクチャープレーンでは、関係性は比較的シンプルでした。これらはAWSのDescribe APIを呼び出すだけです - Load BalancerにはTarget Groupがあり、そこにインスタンスがあります。そのように接続を確立していますし、このIAM Roleについても同様です - これはDynamoDBテーブルとの通信権限を持つインスタンスのインスタンスプロファイルです。

これは設定時の関係性であり、それらを取り込んでいます。しかし、その後私は異なる領域へとジャンプしました。アプリケーションプレーンに入り、そこで突然、私のコードとBotサービスについて知ることができました。アプリケーションプレーン、特に私のコードとBotサービスについて、その状態や何がログに記録されているかを知ることができました。
テレメトリーを結合キーとして使用し、各インスタンスが特定のインスタンスIDを持っていることを把握しています。CloudWatchはアプリケーションログからメトリクスとテレメトリーを受け取り、そのテレメトリーがどのEC2インスタンスから来たのかを確認できます。コンピュートからのテレメトリーを使用して、インデックスを通じてインスタンスから他のテレメトリーへのリンクを構築します。OpenTelemetryには、このインフラストラクチャーが何の上で実行されているかを指定する相関フィールドや属性があり、これによってプレーン間やテレメトリーの種類間のナビゲーションが可能になります。

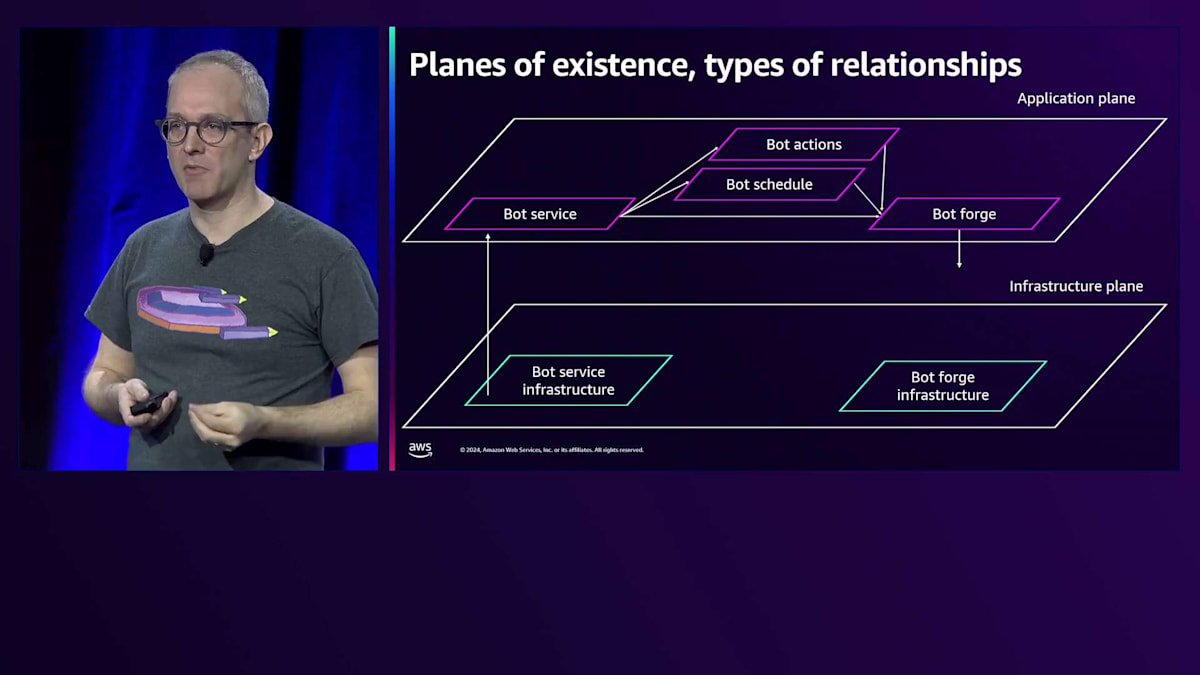

CloudWatchでは、APIコールがどのコンピュートから発生しているかを把握できるため、これを自動的に行うことができます。 インフラストラクチャ層からアプリケーション層に移行したため、マイクロサービスからマイクロサービスへと素早く移動する中で、どのようにナビゲーションするかを決める必要がありました。 アプリケーション間やマイクロサービス間の関係性を確立するには、2つの方法がありました。 1つはトレーシングで、これはアプリケーションの計測において非常に重要です。分散システムにおいて、マイクロサービスが何らかの作業単位に参加する際、それはリレー競争でバトンを渡すようなものです。私がBot Serviceスタックである場合、Bot Action Serviceスタックにバトンを渡します - このバトンとは、伝播させる固有のTrace IDのことです。


関係性を確立するためには、 Spanと呼ばれるトレースのすべての部分をAWS X-Rayのような中央の場所に送信する必要があります。そうすることで、それらを組み合わせてトレースを表示し、サービスマップ全体を構築できます。 AWS Application Signalsは、OpenTelemetryの重要な部分でもあるセマンティック規約を通じて、トレーシングなしでこれらの関係性を構築します。サービスがコールを受け取ると、そのリクエストのパフォーマンスに関するGolden Signalsを発信する必要があります。このテーブルはBot Serviceのレイテンシーなどのメトリクスへのインデックスを表していますが、依存関係がその視点からどのようにパフォーマンスを発揮しているかも記録する必要があります。



これを規約とメタデータから組み立てることができます。サービスメトリクスのテーブルを見ると、 Bot Serviceがあります。これはクライアントメトリクスのテーブルに2回出現するので、2つのアウトバウンドエッジを作成して 2つの異なるリモートサービスを指すようにします。このルックアップを続けていくと - Bot Actionsは別のサービスを呼び出すサービスで、Bot ActionsとSchedulesはBot Forgeサービスを呼び出しています。 これでトレーシングなしで、同じ場所に命名規則に従ってデータを送信するだけでトポロジーが完成しました。

インフラストラクチャとアプリケーションのトポロジーを使用することで、アラームからメトリクスを通じてインフラストラクチャ層へ、そしてアプリケーション層へ、さらにアプリケーション層を通じて問題のある依存関係へ、そしてインフラストラクチャごとのアプリケーションの成功率を測定している2つの層の間をナビゲートしてきました。私たちは、ログを見つけ出すための事実確認作業の方法ではなく、チェックすべき項目や何を探すべきかという重要なタスクに頭を使っていたのです。
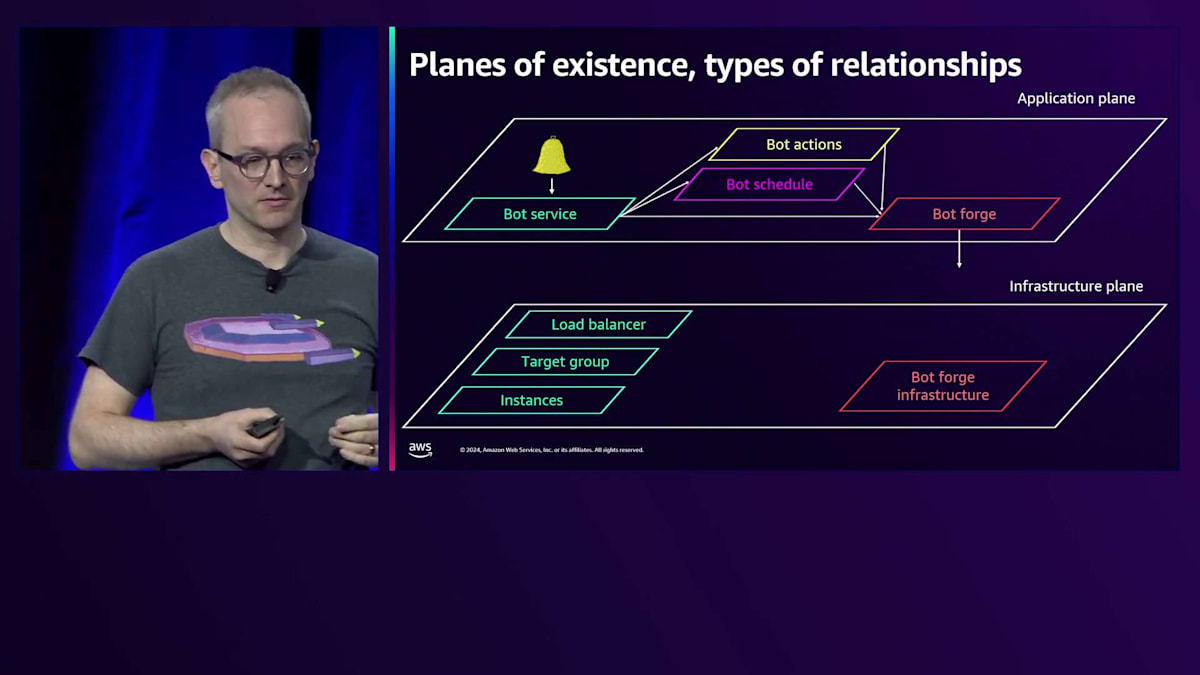

ナビゲーションに役立つもう1つの関係性があります。それはまだ説明していませんが、手動による計測や手動による接続です。 このアラームページで、もっと自分に親切にしておいたらどうだったでしょうか?Runbookへのリンクを入れていなかったために、どこから始めればよいかわからなかったことを覚えていますか?もし入れていたらどうでしょう?これらのアラームのいずれかを受け取ったときは、アプリケーション層を見てみましょう、そこから始めましょう、と。そこでApplication Signalのサービスマップに行けば、何と何が接続されているかを確認できます。


ズームアウトすると、左側にクライアント、右側に最も深い依存関係が表示されます。右端を見ると、Bot-forgeサービスが障害を起こしている主要な依存関係であることがわかります。ヘルスインジケーターは色分けで表示されており、赤色になっています。これをクリックすると、Application Signalsに移動します。
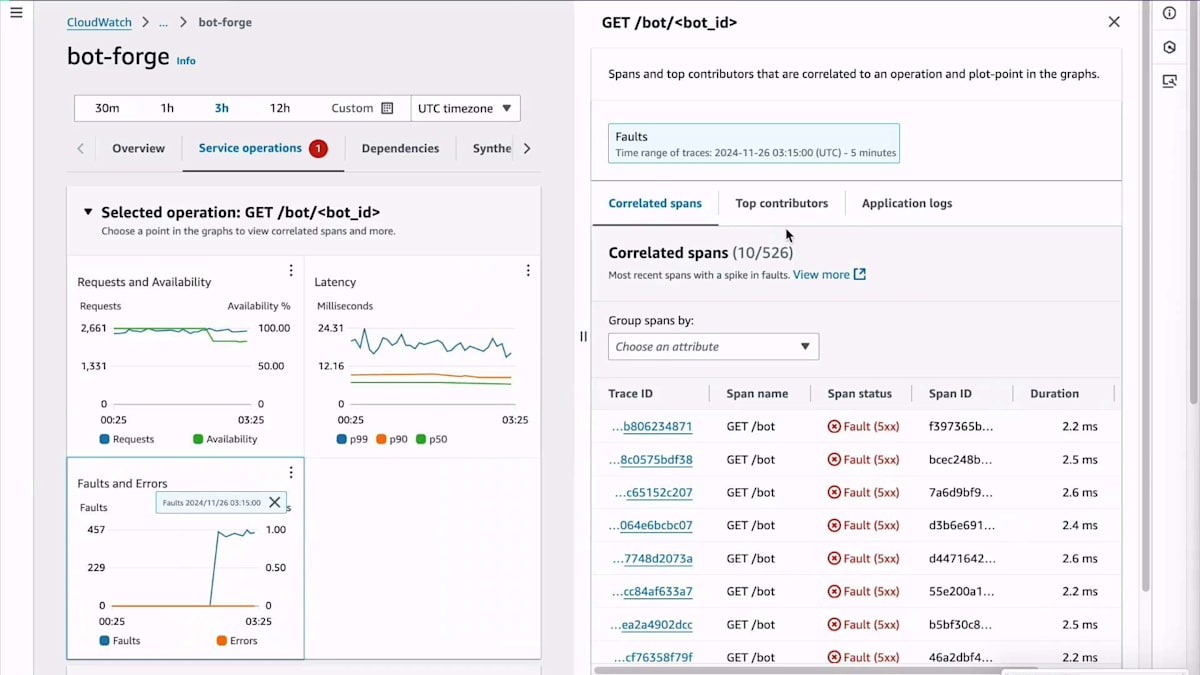
周りを見渡すと、サービスオペレーションが失敗していて、いくつかの障害があることがわかります。トポロジーを通じてここまでたどり着いているので、Spanを見る必要はありません。そこで、EC2インスタンスの障害メトリクスの内訳を確認するため、Top Contributorsに直接移動します。アプリケーション層にたどり着いてからは、サイドルートを通る必要がなく、非常に素早く移動できました。これはアプリケーション層のInstrumentationがなぜそれほど重要なのかを示しています。これはコンポーネント間をサイドルートではなく、ハイウェイで移動するようなものです。とはいえ、ハイウェイにアクセスできなかったり、インフラの問題を掘り下げて特定したりする必要がある場合があるため、サイドルートも必要です。
OpenTelemetryとCloudWatch:最新のObservabilityツール




インシデント発生時に効果的なトラブルシューティングを行うためには、事前に適切なInstrumentationを配置しておく必要があります。このコードを見てみましょう。これはProduct Infoサービスで、eコマースサイトから商品情報を返すものかもしれません。このコードで何か問題が発生した場合、何が起きているのかをどうやって理解すればよいでしょうか?リクエストが失敗した時、どの商品に関するものか、どのお客様からのリクエストだったのかをどうやって知ればよいでしょうか?リクエストが失敗した時、Cacheのヒットまたはミスだったのか、レイテンシーはどうだったのかをどうやって知ればよいでしょうか?データベースとの通信で発生した障害の種類や、データベースクエリの実行時間、返された行数をどうやって知ればよいでしょうか?


私たちにはInstrumentationが必要です。これは実は、OpenTelemetryの自動Instrumentationのおかげで、近年とても簡単になっています。これは完全にInstrumentされたコードですが、私が追加したのはたった2行だけです。私のアプリケーションについて、私だけが知っている情報を追加しました。PythonのFlaskやJavaのSpringなどのフレームワークを通じて入ってくるリクエストなど、その他のすべての相互作用については、OpenTelemetryのプラグインがSpanの開始と終了を自動的に処理し、どのAPIなのか、処理時間はどれくらいかといった詳細情報を埋めてくれます。クライアントフレームワークも同様で、データベースドライバーはクライアントSpanを記録してデータベースクエリの実行時間を表示し、場合によってはクエリの内容まで表示してくれます。
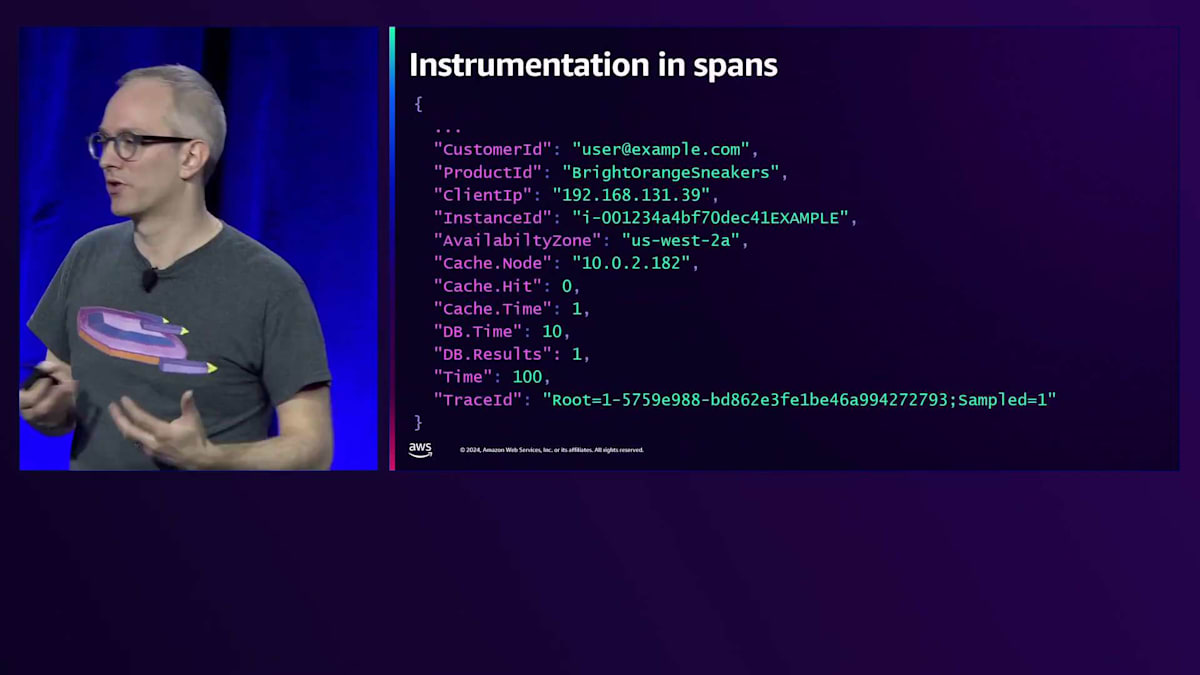



Instrumentationは何を生成するのでしょうか?Webリクエストに関するInstrumentationは、作業の単位であるSpanを生成します。Spanには、誰がリクエストを行ったのか、誰のために実行しているのか、クライアントのIPアドレスは何か、このTraceIDは何の一部なのかといった情報が含まれています。また、これが実行されている場所に関するインフラ情報も含まれています。各コンピュートにおいて、アプリケーションが成功したのか失敗したのかをAvailability Zoneごとに知る必要があるため、どのAvailability Zoneで実行されていたのかを記録する必要があります。さらに、Cacheのヒットの有無やデータベースクエリの実行時間など、タイミング情報も含まれています。

これらは、処理にかかった時間などの測定値と、それらの測定値を分類できる属性に分類することができます。 測定値を分類することは重要な考え方です。調査の初期段階では、ServiceとAPIは分かっていたものの、障害の発生源が分からないグラフを見ていました。そこで、より詳しく調べるために障害を別の観点で分類する必要があり、それが私たちの発見につながりました。


失敗していたリクエストがすべて同じInstance IDから来ていたことを思い出してください。 ここで活用していた Observable の重要な概念の1つが Dimensionality(次元性)でした。Dimensionalityとは、 何かを測定する際に、その測定値やメトリクスを他の次元で分類できるようにするという考え方です。ServiceやAPI、EC2 Instance IDで分類したり、リクエストを顧客ごと、Bot IDごと、クライアントIPアドレスごとに分類したりできるようにします。



この計装は非常に重要ですが、 これらをどのようにプロットし、表示すればよいのでしょうか?なぜなら、測定値を何かで分類するというDimensionalityの考え方には、 Cardinalityという厄介な側面があるからです。Serviceの数は少ないので、マイクロサービスごとのエラーをプロットするのは、マイクロサービスごとに1本の線を引くだけで、それほどコストはかかりません。しかし、 測定値を数が多いもの(たくさんのロボットや呼び出し元IPアドレスなど)で分類しようとすると、その計装データをどのように保存するかを考える必要が出てきます。


では、特定の方法で分類できるかどうかのトレードオフを考えなければならない場合、何を測定すべきでしょうか? 個別に障害が発生する可能性のあるものは、個別に測定すべきです。何かが壊れる可能性がある場合や、その観点で調査する必要がある場合は、独立して測定してラベル付けしなければ、運用することができません。 EC2 Instanceやアベイラビリティーゾーンごとの障害を測定していなければ、どれが壊れているか分かりません。デプロイメントIDごとの成功・失敗や遅延を測定していなければ、デプロイメントが原因で問題が発生したかどうかを知ることができません。トラフィックスパイクが発生した場合、呼び出し元やワークロードごとにトラフィックを測定していなければ、その発生源を特定することはできません。他のテレメトリーから推測することはできますが、最も早い方法は単純に記録しておくことです。

では、どこに記録すればよいのでしょうか?先ほどSpanについて説明しましたが、OpenTelemetryには3つの柱があります:Metrics、Logs、Tracesです。私の経験則では、アプリケーションを計装する際、定期的に測定する項目(CPUの測定やネットワーク関連の項目など)はMetricsとして出力します。デバッグエラー情報やリクエスト処理に関する情報などは、Logsに記録します。リクエストを処理する際に気になる可能性のあるその他のすべての情報は、TraceのSpanに記録します。
これの良いところは、使用している Observable ツールによって、Span に記録したものがすべての状態に重ね合わされるということです。Span に記録したものは CloudWatch では logs として保存されます。先週からは、これらの Span が実際に CloudWatch logs に表示されるようになりました。そのため、ログ分析ツールを使用して詳細を確認できます。CloudWatch logs に記録されているため、そこから CloudWatch メトリクスを生成することもできます。つまり、Span に記録しておけば、ダッシュボードのメトリクスやログなど、必要な場所に表示させたい時は、コードを変更する必要なく設定で対応できるということです。


IPアドレスごとの分析がすぐにコスト高になってしまうという話について - これは Span に記録するだけなら当てはまりません。コストが大きく増えることはありません。なぜなら、Span にデータを記録してログに残し、そこから Contributor Insights のルールを設定できるからです。Contributor Insights はログからデータを取得して測定し、分類しますが、1分あたり上位100件のみを追跡します。これにより、クライアントの IP アドレスごとにメトリクスを作成することなく、クライアント IP アドレスごとのリクエスト数をプロットできます。もし Contributor Insights ルールを書きたくない場合でも、Span のログがあれば、その場でクエリを使って分析できます。IP アドレスごとのトラフィックの内訳を、ログ分析クエリとして実行できるわけです。ダッシュボードとして用意するよりも数秒長くかかるかもしれませんが、調査目的なら許容できます。ダッシュボードに表示する場合は、メトリクスとして用意しておくべきでしょう。
詳細な分析と変更管理:具体的な問題解決例

AWS X-Ray をしばらく見ていない方のために、ここ数週間で大きなアップグレードがあったことをお伝えしたいと思います。 現在では、X-Ray が CloudWatch logs にデータを送るようになったため、サンプリングなしですべての Span を送信できるようになりました。
これには以前とは異なる価格体系が適用されます。X-Ray が OpenTelemetry プロトコル(OTLP)を直接受け付けるようになったため、非常に魅力的なアプローチとなっています。クライアント側で X-Ray 専用の複数の SDK を使用したり、データ変換を行ったりする必要がなくなりました。また、CloudWatch logs でインデックスがサポートされるようになり、クエリをより効率的にするためのインデックスを定義できます。例えば、ロボット ID で Span を検索する必要がある場合、CloudWatch のロググループでそれを設定できます。Span ID によるクエリはデフォルトでインデックス化されており、CloudWatch logs のこれらのインデックスは追加料金なしで、現時点で最大5つまで定義できます。


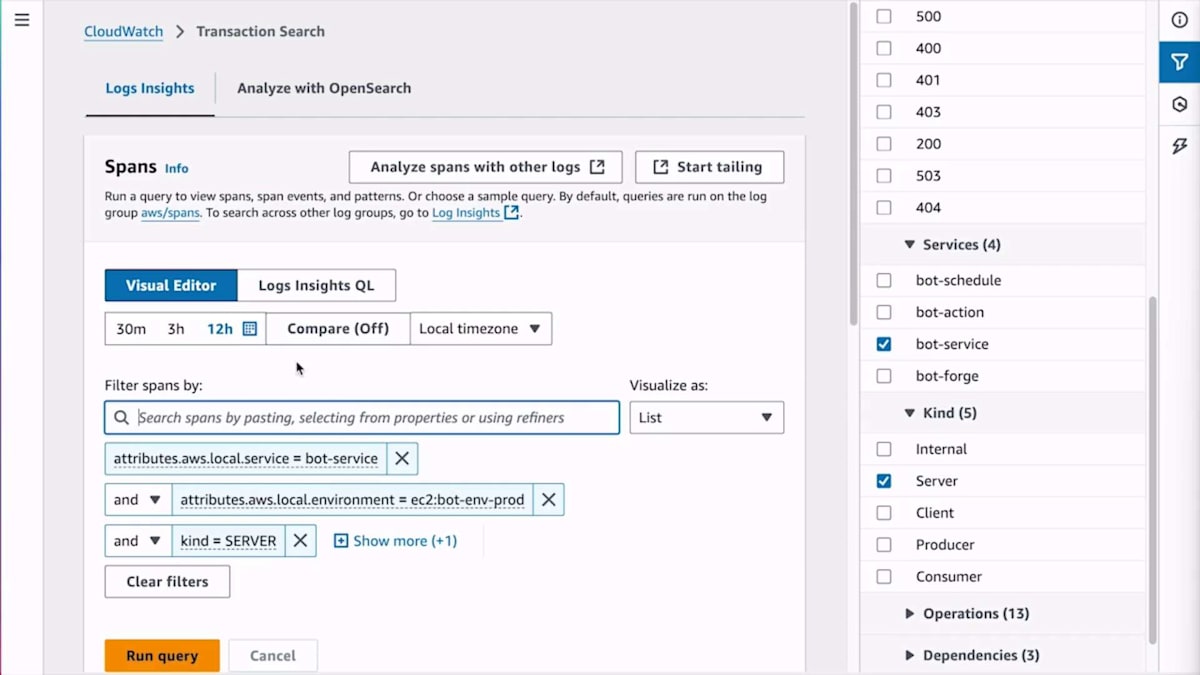
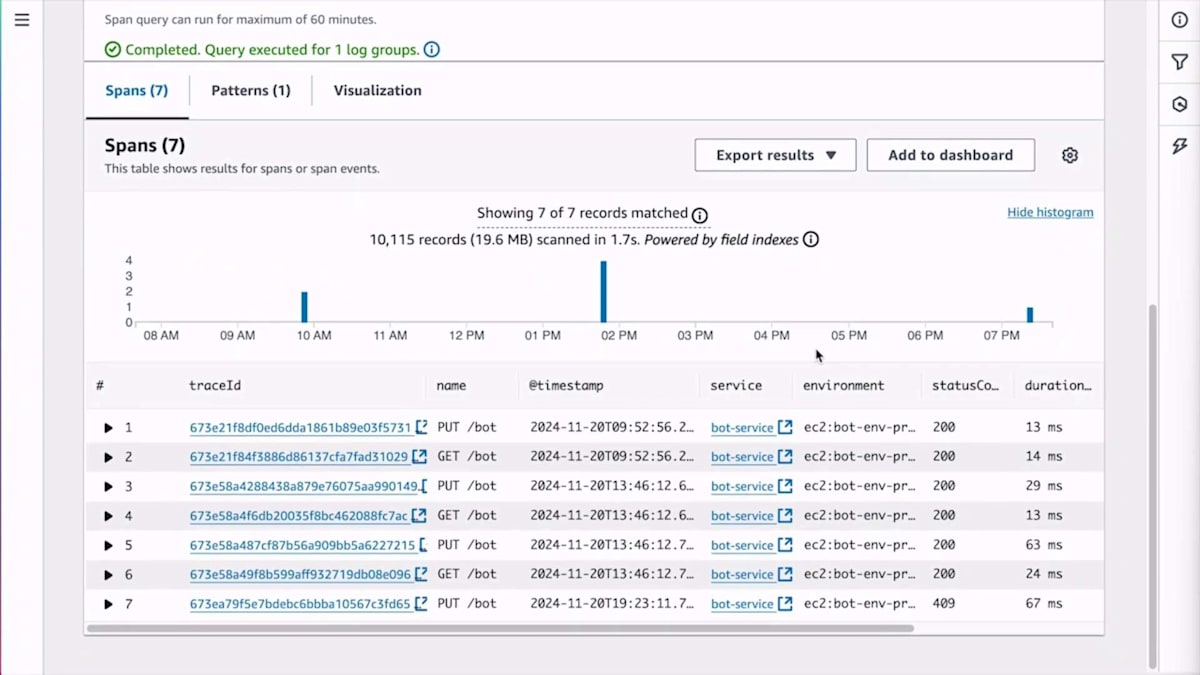
この詳細な分析機能について具体例をお見せしましょう。あるお客様から、ロボットがスケジュール通りに動作していないという苦情がありました。お客様によると、ロボットのスケジュールを設定したのに動かず、さらにそのスケジュールがシステムから消えてしまったとのことです。これを調査するために、実際の顧客とのやり取りを確認して、どこで問題が発生したのかを見る必要があります。各顧客とのやり取りがどのように行われたかを確認するために、トランザクション Span を使用します。 Bot サービス内のすべてのサーバー Span から Bot ID を入力して検索するクエリを視覚的に構築できます。Span の一部としてロボット ID にインデックスを設定しているため、これは高速に実行されます。 クエリを実行すると、レイテンシーは CloudWatch logs で得られる最小限のものとなります。
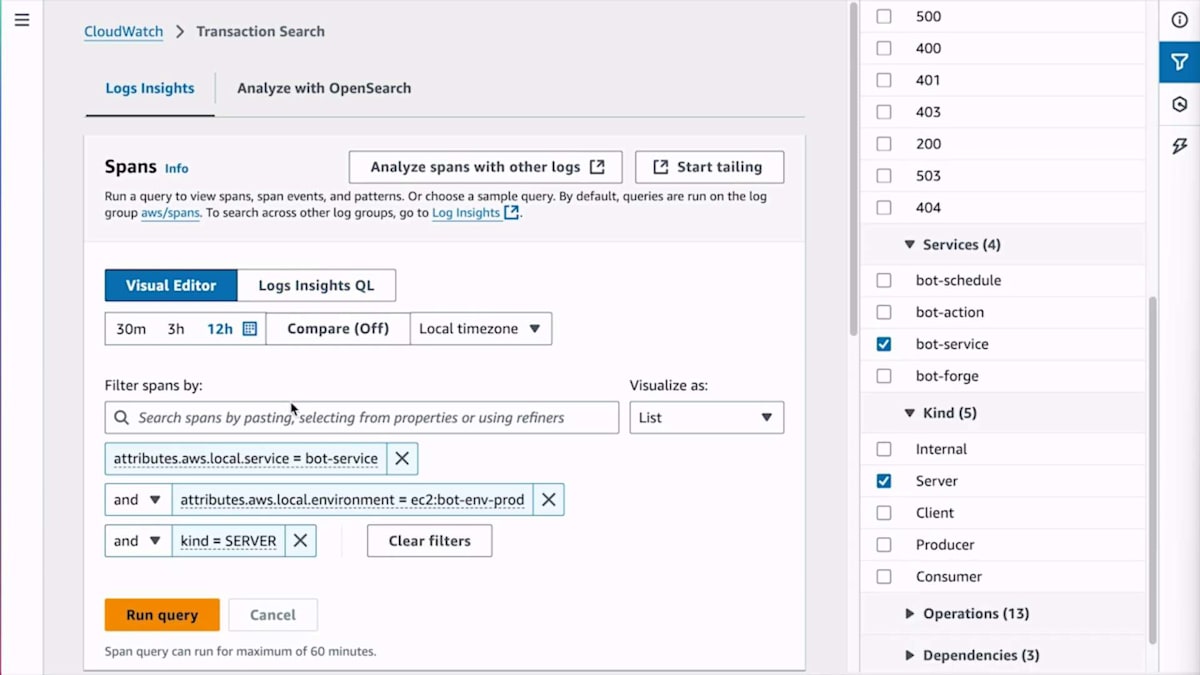

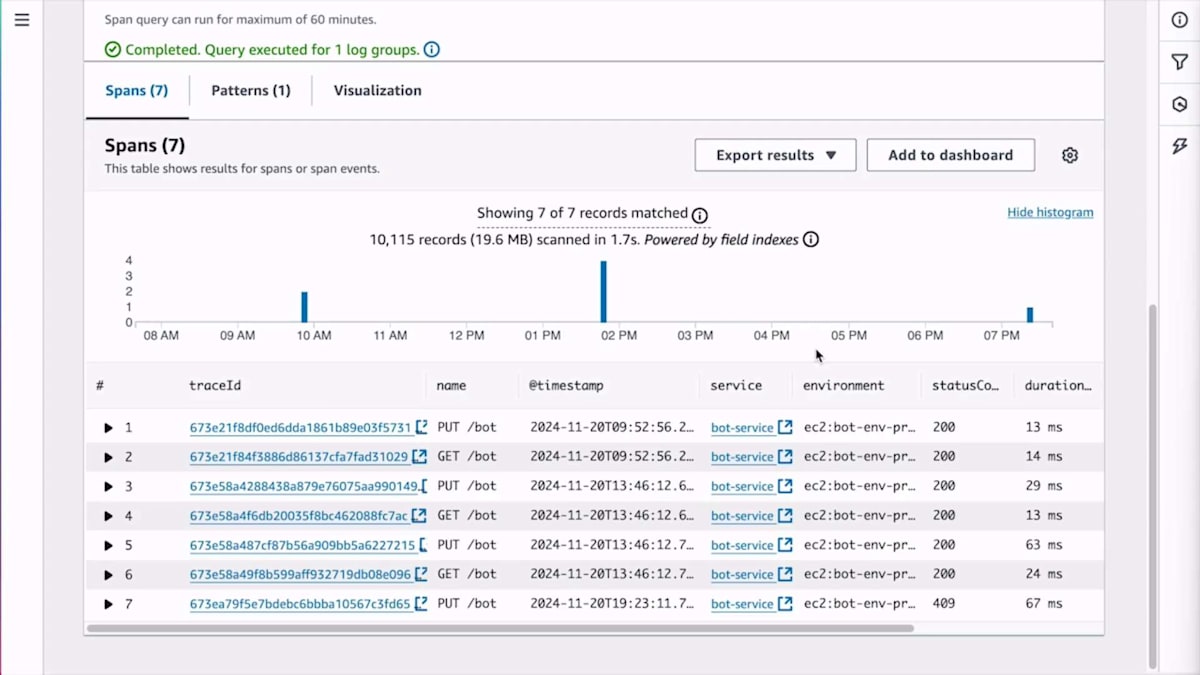


少し早く進みすぎたかもしれません。 このSpanをもう一度検索して、RobotのIDを入力しています。 Spanが表示され、いくつかの異常なパターンが見えます。Spanの1つにはサマリーにHTTPのコンフリクトを示す409ステータスコードが表示されています。 お客様がスケジュールが消えたと言っているので、誤って削除してしまったかどうかを確認するため検索してみます。Delete APIを呼び出したかどうかを確認していますが、呼び出していませんでした。そこで、最初にスケジュールを作成した時点に戻って、その時に何か問題があったかどうかを確認します。 作成時を検索すると、HTTPコンフリクトエラーを返していたことがわかります。これらはすべてTraceなので、TraceをクリックしてそのSpanがシステム全体でどのように流れたかを確認できます。



ここまでの話で、私たちのシステムに存在する最も一般的なChaos Agentの1つを省いていました - それは私が間違いを起こしたために発生する変更です。これらの変更には、インフラの変更、コードのデプロイ、Feature Flagなどが含まれます。別の例を見て、チェックリストを確認してみましょう。素早く進めていきます。Bot Forgeサービスで調査を開始しているので、問題のあるコンポーネントへの移動部分は省略しました。ボードに戻ると、チェックリストがあります。何が起きたのかを探っています。トラフィックスパイクはないことがすぐにわかります。ここから何が起きているのかを見るために、Dependenciesをクリックして調査を進めます。

案の定、Bot ForgeサービスのDependencyの1つがエラーを返しています。何かが枯渇したかもしれないと言及した理由は、DynamoDBから返ってきているのがFaultではなくErrorだからです。これは、DynamoDBの呼び出し方が間違っているということを意味します。DynamoDBから400が返ってくる場合、それは呼び出し方が間違っているか、スロットリングされてQuotaを超過した可能性があります。そのため、エラーはスロットリングによるもので、何らかの制限に達したのではないかと考えました。

さらに調査を続けましょう。これらのエラーの実態を詳しく見るためにクリックしてズームインします。様々な可能性があるからです。今回はSpanの1つを選んで、その内容を詳しく見てみましょう。Bot Config Tableから何が返ってきているか見てみます。例外メッセージには、これはスロットリングではなく、Access Deniedだと書かれています。Access Deniedは突然発生するものではないので、かなりの確度で何らかの変更が加えられたと考えられます。


どこかで何かが変更されたのです。その変更が行われた場所は複数考えられます。なぜそうなったのか、どこで変更されたのかを突き止めましょう。CloudTrailに移動します。CloudTrailは、特にリソースを変更するようなControl Planeイベントを含め、AWSサービスとのすべてのやり取りを記録します。CloudTrail Lakeの構文を覚えていないので、クエリを自動生成してもらいます。Data Planeイベントではなく、変更を加えるManagementイベントをすべて表示するように指定します。必要のない余計なイベントをフィルタリングしたクエリが実行されます。
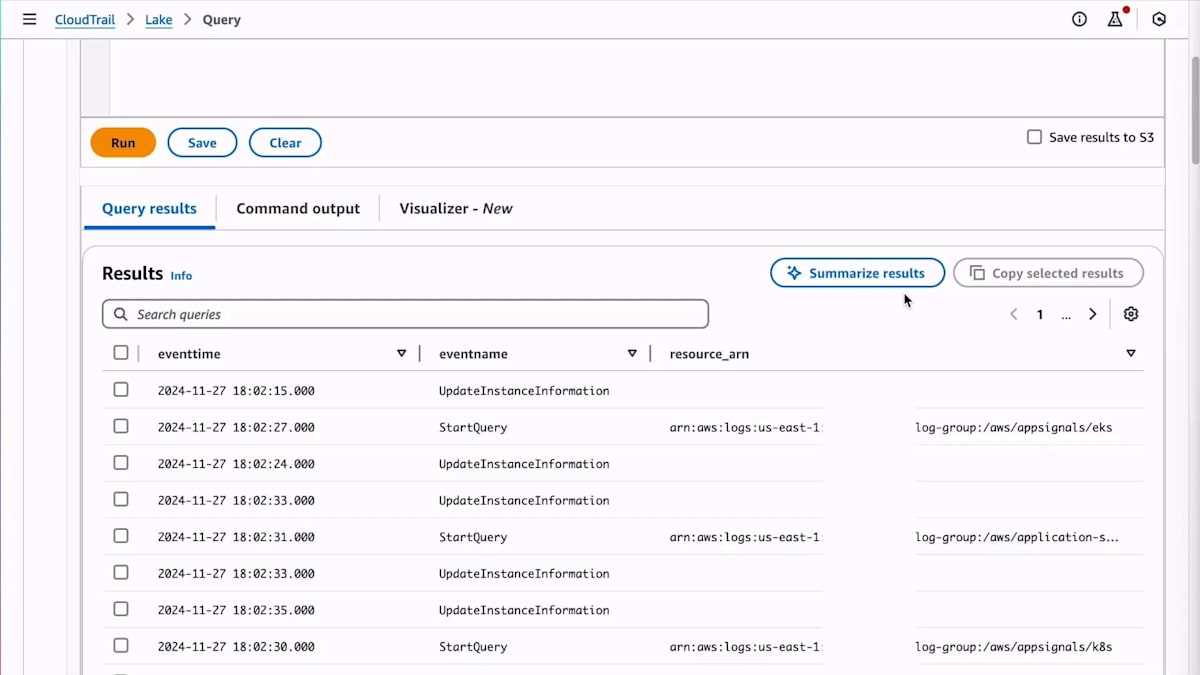

クエリ結果をクリックしてみましょう。 まだかなりノイズが多いですね。明らかに重要ではないこれらのUpdate Instance Information開始クエリイベントがたくさん表示されています。クエリを修正してこれらをフィルタリングすることもできますが、実は私が見落としていたのが、この新しいSummarize Resultsボタンです。CloudTrailに対して、ノイズの多い結果をまとめて、一目で内容を把握できるように要約するよう依頼できます。その要約の中には多くのノイズと共に、Bot Configという名前のDynamoDBテーブルに対するPut Resource Policyが1件見つかりました。これは、まさに先ほど問題が発生していたテーブルですね。Put Resource PolicyはAccess Deniedに関連していそうです。つまり、問題の原因を特定できたということです。

変更を素早く検索して見つけ出せることは重要で、何度も検索をかけ直して情報をふるい分ける必要がないということです。AWSリソースへの変更は簡単に確認できますが、コードデプロイメントに他のツールを使用する場合は、調査に関連する変更を簡単に確認できるようにしておくことが大切です。ここからスピードアップしていきましょう。 ここまで、対処可能な5つの原因を探して検索を続けてきましたが、このプロセス全体を加速し、より迅速に進められるCloudWatchの新機能をご紹介します。
AIによる調査支援:Amazon Q Developerの活用


先ほど、この種の原因特定アルゴリズムの優れた特徴として、より深刻な問題の場合は、複数の同僚からの支援を得て並列化し、それぞれの手がかりを個別に追跡できると言いました。現在、CloudWatchにはさらなる並列化を支援するツールがあります。これは、調査を実行し、すべてのテレメトリーやトポロジーを分析して、発生した可能性のある事象についての提案を行うAIエージェントです。


その調査を見てみましょう。先ほどと同じ調査ですが、今回はエントリーポイントから始めています。最上位のマイクロサービスであるBot Serviceから始めています。これを解明していきましょう。Application Signalsで、いわばゲートウェイとも言えるBot Serviceを確認していると、明らかに何かが起きていることがわかります。アラートが来て、問題が発生し、有用な開始地点がありました。 APIを見ると、Put Bot IDというConfiguration APIで問題が発生していることがわかります。


Investigateをクリックして、調査に名前を付けます:Bot Service Investigationとして、実行します。開始時のSLOメトリクスを見つけ出し、調査を開始します。これは、Amazon Q Developerの新しい調査支援機能です。多くの調査提案が表示されます。バックグラウンドで5つの手がかり、つまり私たちが探している5つの項目について素早く検索を行います。すべての手がかりを追跡し、すべてを確認します。そしてすでに、Bot Serviceの依存関係であるBot Schedule Serviceで何かを見つけ出しました。つまり、すでにトポロジーを追跡し始めているのです。
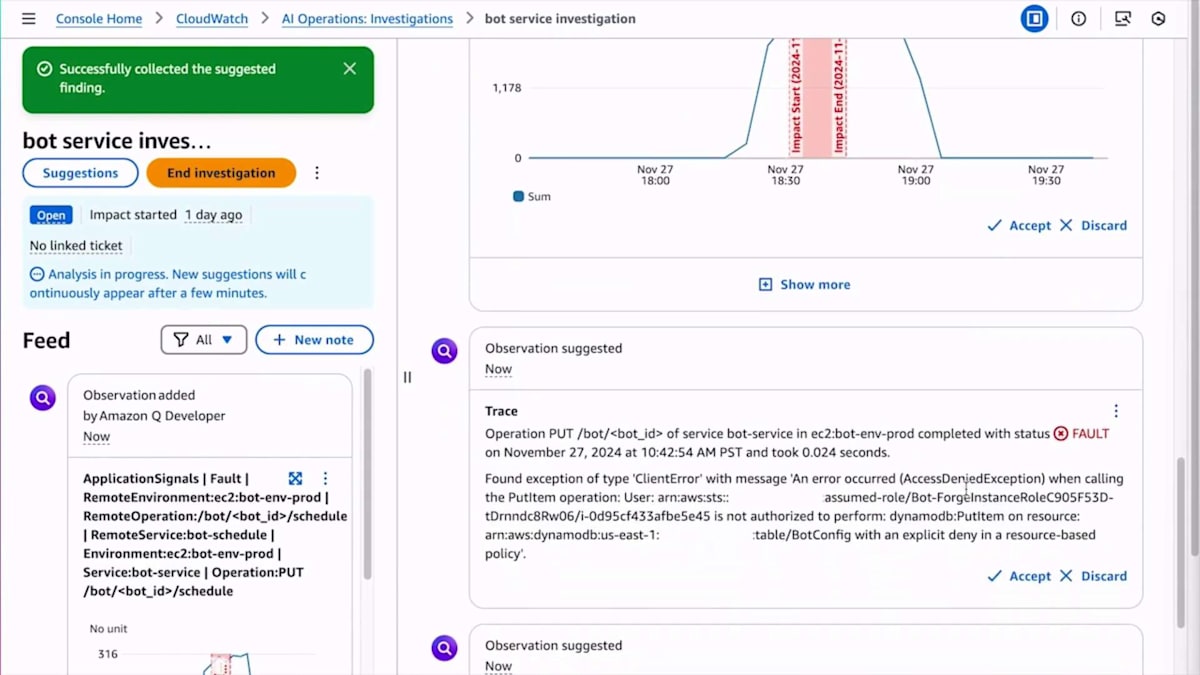

関連性があると判断したアイテムを受け入れたり、破棄したりすることができます。システムはすぐにログの中からアクセス拒否メッセージを見つけました。 Bot-forgeサービスのマイクロサービスとDynamoDBとのやり取りを含む複数のアイテムを発見し、これらのエラーに気付きました。テレメトリーを調査していく中で、さらに多くの情報が見つかりました。このDynamoDBとのやり取りに関連する情報をさらに表示するよう要求すると、追加のエラーが見つかりました。
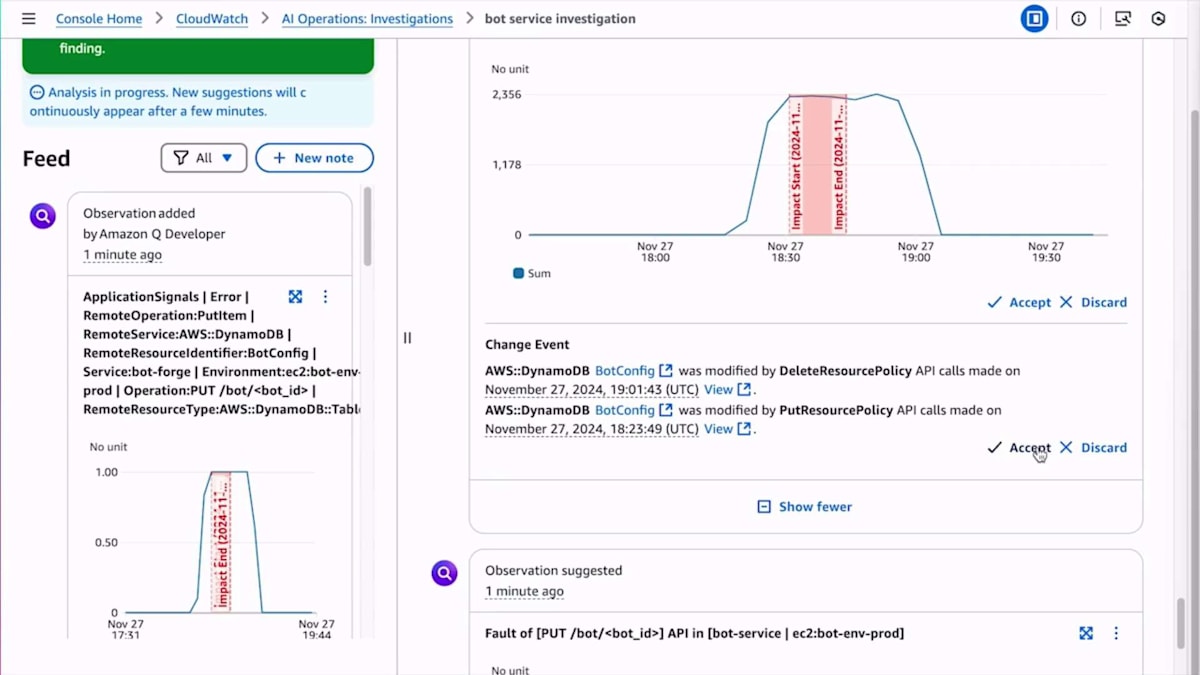

DynamoDBアクセスに関連するエラーがさらに見つかり、そして CloudTrailで変更イベントを発見しました - 具体的には、リソースポリシーを設定した際の変更が見つかりました。これらの情報はすべて非常に有用で、事実確認プロセスを並行して進めることができました。関連するLog Insightsのクエリでいくつかのエラーを見つけたので、 アクセス拒否エラーを示すそのクエリを採用することにしました。


この体験の重要な特徴の1つは、調査に関連性があり興味深いとマークした発見に基づいて仮説を生成することです。これらの採用された発見を分析し、実際に何が起きているのかについての見解を提示します。 最終的に提示された仮説を見ると、非常に興味深いものでした。 この例では、Bot-forgeサービスがBotConfig DynamoDBテーブルでPutItem操作を実行しようとした際に、アクセス拒否エラーによって重大な障害率を経験していたことを特定しました。これらのエラーの引き金として、BotConfigテーブルのリソースベースのポリシーの更新によってアクセスが明示的に拒否されたことを説明しました。これはまさに私が修正する必要があった問題でした。

システムは影響の概要を提供し、この問題がBotサービスなどの依存サービスにどのように波及し、設定テーブルの読み書き操作に影響を与えたかを説明しました。そして次に何をすべきかについての推奨事項を提供しました。 場合によっては、クリックで実行できる実際のAWS Systems Managerランブックを推奨し、その他の場合にはより一般的なアドバイスを提供します。ここでは、最近の変更を確認して元に戻すこと、およびIAMロールを監査することを提案しました。このデモで私を笑わせたのは、ランダムなクリック操作による変更をするのではなく、適切な変更管理ポリシーを実装すべきだと、本質的に私を叱責したことでした。





結論として、根本原因を説明するためのトラブルシューティング時に注目すべき5つの重要な点について説明しました。インフラストラクチャーのトレースとアプリケーション間の接続性とナビゲーションの重要性について説明し、情報を取得し、貪欲アルゴリズムを使用して調査、ナビゲーション、進行する方法について説明しました。また、スパンとインフラストラクチャーのあらゆる計測データを使用してデータを深く掘り下げて分析する方法についても説明しました。そして、チームでトラブルシューティングを行う際にこのアプローチをどのように適用するかを検討しました。これらのツールと認知的な戦略とタクティクスが、次回の障害時間の短縮に役立つことを願っています。これらのアンケートは年々このトークを改善するのに役立つので、ぜひご回答ください。素晴らしいre:Inventの残りをお楽しみください。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion