re:Invent 2023: AWSが語るアプリケーションネットワーキングの最新動向と活用事例


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - What can networking do for your application? (NET203)
この動画では、AWSのApplication Networkingの最新動向が紹介されます。Elastic Load Balancing、PrivateLink、API Gateway、そして新サービスのVPC Latticeについて、セキュリティと可用性の向上に焦点を当てた具体的な機能アップデートが解説されます。特に、VPC Latticeが提供する「エコシステムのエコシステム」という概念や、BlockのCISOであるMike Wittigによる実際の活用事例は、アプリケーションネットワーキングの未来を垣間見ることができる貴重な内容です。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
Dave Wardによる自己紹介とApplication Networkingの概要

みなさん、今日はいかがお過ごしですか?元気ですか?素晴らしいですね。Caesar's Forumまでお越しいただき、ありがとうございます。ここまでの道のりは少し大変だったかもしれませんね。私はDave Wardと申します。Amazon Web ServicesのApplication Networkingの General Managerを務めています。そして、本日はBlockのChief Information Security Officerであり、VP of Foundational EngineeringでもあるMike Wittigさんにもご参加いただいています。今日は、ネットワークがアプリケーションに対してどのような役割を果たすかについてお話しします。エキサイティングで内容の濃いセッションになりますよ。まずは、Application Networkingとは何かを定義することから始めましょう。これはIaaSやPaaSという言葉が昔そうだったように、まだあまり理解されていない用語なんです。

私のチームが今年取り組んできたことや、より回復力が高く、可用性の高いアプリケーションの構築にどのように役立つかについて少しお話しします。最後に、Mikeが締めくくりとして、彼のチームがApplication Networkingをどのように活用しているか、特に私たちの最新のApplication Networkingサービスであるamazon VPC Latticeについてお話しします。それでは、始めましょう。
Application Networkingの定義とAWSのアプローチ

Application Networkingとは何でしょうか?Amazonでは、常にお客様から逆算して考えます。私たちが考える主要な2つのペルソナがあります。1つ目はネットワーキングとセキュリティのエンジニアです。彼らは主にコンプライアンス基準に注目し、可能な限り最高のセキュリティを確保すること、そしてポイントAからポイントBへの接続を確実にすることに焦点を当てています。もう1つは、アプリケーション開発者です。彼らはエンドユーザーのためのビジネスアプリケーションやビジネスロジックの構築に注力しています。
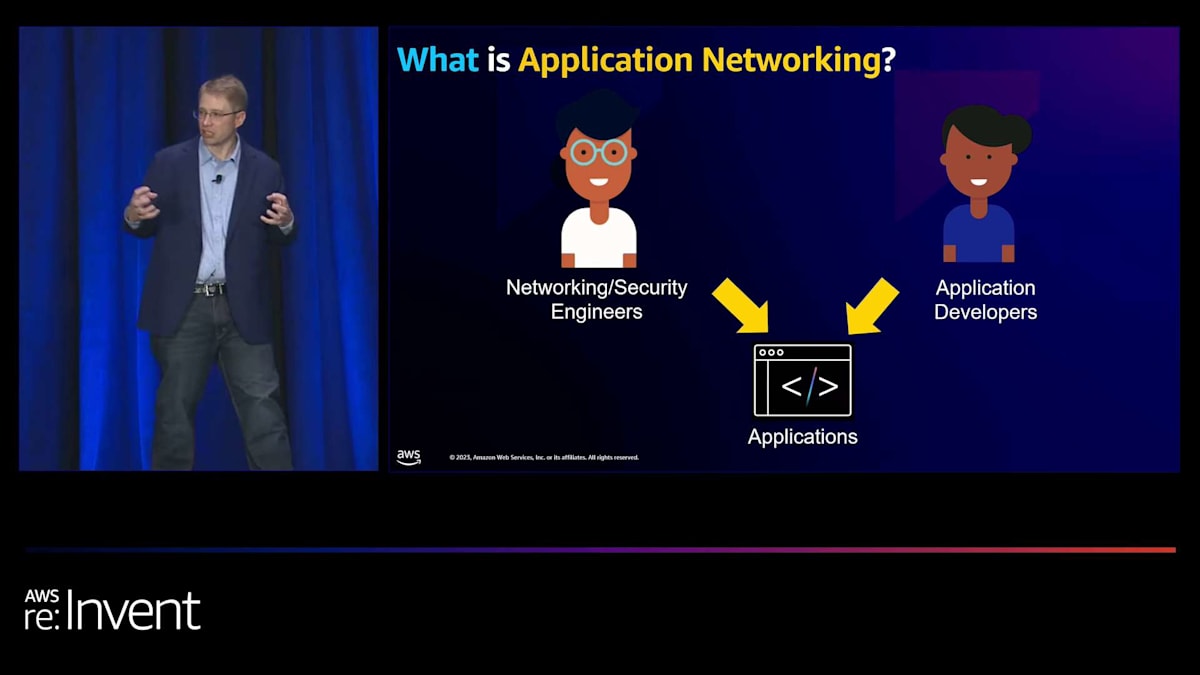


Application Networkingは、これら2つのグループの間を取り持つマネージドサービスを構築することです。詳しく見ていくと、両グループが共通して使用する基本的な機能セットがあります。 それは、接続、セキュリティ確保、アプリケーション内で何が起こっているかを理解すること、そして問題が発生した際のトラブルシューティングができることです。これが、 私たちがApplication Networkingサービスを構築した理由です。これにはElastic Load Balancing、AWS PrivateLink、Amazon API Gateway、そしてAmazon VPC Latticeが含まれます。


これらに共通しているのは、マネージドサービスであるということです。私たちの目標は、この2つのグループが必要とする差別化されていない重労働を取り除くことです。しかし、AWSではこれを少し違った角度から考えています。毎週、私は1500人の顧客、つまり社内の顧客と話す機会があります。これらのチームは、 中央集権的なレイヤーに置くことで、可用性とセキュリティを向上させる方法をしばしば教えてくれます。そして、それがApplication Networkingで私たちが計画していることなのです。これは、ELBだけでなく、すべてのアプリケーションの可用性とセキュリティを向上させることが本当の目的なのです。
Elastic Load Balancing (ELB)の製品ラインナップとセキュリティ強化

そのため、今年の私たちの優先事項は、セキュリティの強化、可用性の向上、そして特に、パートナーとの連携を拡大し、追加機能を提供することに焦点を当ててきました。まずは最初のサービス、Elastic Load Balancingについて詳しく見ていきましょう。Elastic Load Balancingには、ご存知ない方のために説明すると、4つの主要な製品があります。

1つ目はApplication Load Balancer(ALB)です。これはレイヤー7で動作するリクエストベースのロードバランサーです。次にNetwork Load Balancer(NLB)があります。これはレイヤー4で動作するコネクションベースのロードバランサーです。Gateway Load Balancer(GWLB)は、トラフィックを透過的に検査し、ネットワーキングアプライアンス間でルーティングとロードバランシングを行う方法で、レイヤー3とレイヤー4で動作します。最後に、Classic Load Balancer(CLB)があります。これは、レイヤー4とレイヤー7の両方に対応した当社の最初のロードバランシング製品で、お客様のオプションとして残しています。

ELBのこれらすべての製品において、私たちの最優先事項は間違いなくセキュリティです。なぜなら、多くのお客様がインターネットトラフィックの大部分をアプリケーションネットワーキング、特にELBを通して運用しているからです。今年、多くのお客様から、コンプライアンス部門が高まる基準を満たすために必要な要件について伺いました。さらに、ロードバランシング層でより多くのことができないかというご要望も多数いただきました。そのため、今年リリースした多くの機能について、ここでご紹介できることを嬉しく思います。
ELBのセキュリティ機能強化:TLS 1.3からmTLSまで

まず、多くのお客様からTLS 1.3がコンプライアンス部門の要件になっているとお聞きしました。TLS 1.3を使用すると、1ラウンドトリップのTLSハンドシェイクを使用して低レイテンシーのアプリケーションを構築できます。NLBとALBの両方で利用可能なELB用のTLS 1.3を使用すると、7つの事前定義されたTLSポリシーから1つを選択して、さまざまなコンプライアンス基準を満たすことができます。さらに、特定の暗号スイートの使用を避けることで、Perfect Forward Secrecyを実現することもできます。
次に、米国政府のTLS基準を満たしたいというお客様の声がありました。これは、クライアントからロードバランサー、そしてロードバランサーからターゲットまでのエンドツーエンドの暗号化を意味します。しかし、FIPS準拠を満たすため、ALBとNLB用のFIPSをリリースしました。ALBとNLB用のFIPSはAWS Lib Cryptoを使用して実装されました。これは実質的に、AWSの暗号チームが管理するNIST認証モジュールです。
私たちは、TLS 1.3とS2Nの上に機能を追加しました。S2Nは、長年かけて構築してきた高速で安全性重視の、正式に検証されたTLS実装です。これらに加えて、組織内の異なるアカウント間でコンプライアンス基準を確保したいというニーズがありました。そこで、新たにIAM条件キーを導入し、組織内のすべてのアカウントでTLSポリシーやIPベースのアクセス制御を指定できるようにしました。

間違いなく最も要望の多かった機能、おそらくAWS全体でも最も要望の多かった機能の一つが、TLSまたは相互TLSを使用してクライアントを認証する機能です。これにより、適切な秘密鍵で検証することで、接続の両端の当事者を確認できます。これは、計算コストが低く、軽量なセキュリティメカニズムを必要とするIoTアプリケーションやモバイルアプリケーションでよく使用されます。そのため、ALBの相互TLSの発表を非常に嬉しく思います。

ALBの相互TLSには、2つのオプションがあります。1つ目はパススルーモードです。パススルーモードでは、証明書チェーン全体をHTTPヘッダーに追加し、それが実際にエンドターゲットに渡されて検証を行うことができます。もう1つのオプションは、フル検証モードと呼ばれるものです。このモードでは、ロードバランサー自体で検証を行います。2つの選択肢があり、1つはサードパーティの認証局を使用する方法、もう1つはACM private certificate authoritiesを信頼ストアとして使用する方法です。さらに、証明書を削除する必要がある場合に備えて、証明書失効リストのメカニズムも用意しています。
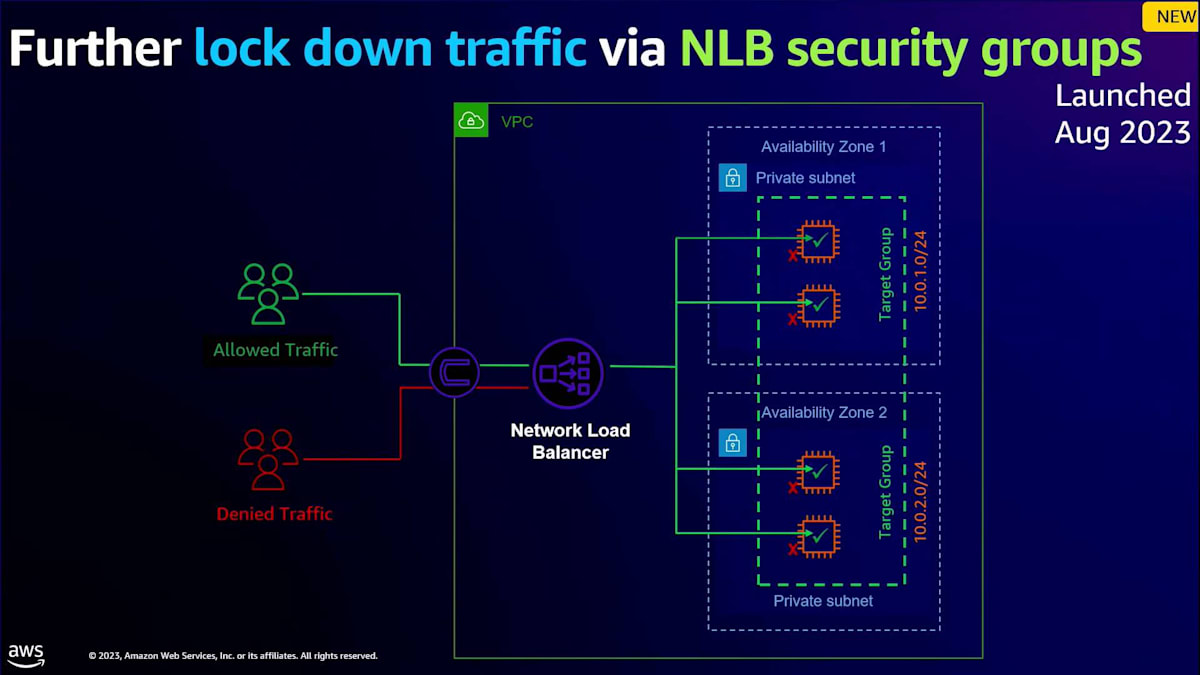
多くの要望があったもう一つの分野は、NLBのセキュリティグループに関するものでした。以前は、多くの方がターゲット自体にセキュリティグループを使用してトラフィックを拒否していました。これの課題は、トラフィックがインターネットから来て、拒否される前にターゲットに到達していたことです。代わりに、皆さんが望んでいたのは、NLB自体にセキュリティグループを設定し、実際のフローのより早い段階でトラフィックを拒否することでした。そのため、今年の初めにこれをリリースしました。NLBのセキュリティグループを使用すると、IPv4とIPv6の両方の入力ルールと出力ルールを設定できるほか、セキュリティグループの参照も使用できます。これは現在、NLB全体でベストプラクティスになりつつあり、まだ試していない方は是非チェックしてみることをお勧めします。
ELBの可用性向上:グレー障害対策と理想的なアーキテクチャ

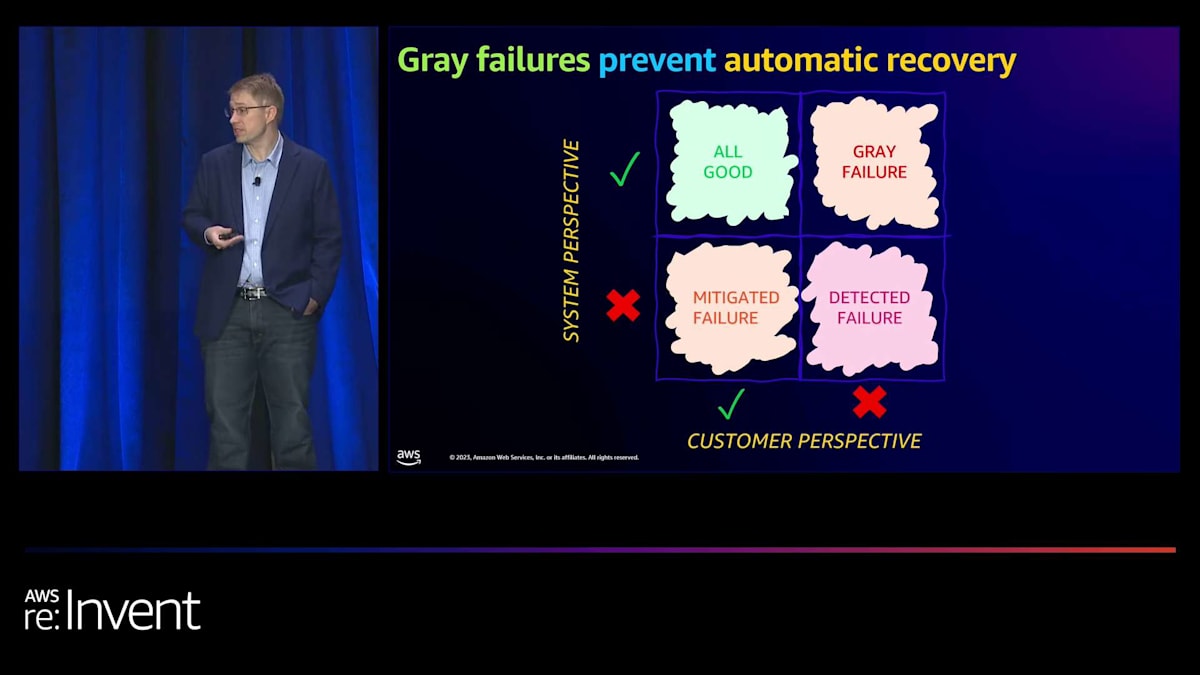
セキュリティは間違いなく最優先事項ですが、皆さんからよく聞く別の分野として、可用性も最優先事項でなければならないということがあります。そのため、私たちは絶対的にそれに焦点を当てています。NLBは、クリーンな障害を検出し、非常に高い可用性を維持することに関しては素晴らしい性能を発揮してきました。しかし、グレー障害時の動作を改善する機会があると考えました。グレー障害とは、ご存知ない方のために説明すると、ターゲットやロードバランシングインフラストラクチャが正常かどうかを知る主要なメカニズムであるヘルスチェックが、実際には問題があるにもかかわらず失敗しない状況のことです。

例として、ターゲット上にアプリケーションの問題があるかもしれませんが、ヘルスチェックが十分に深くないため検出されていない可能性があります。グレーな障害が発生する主な2つのシナリオがあります。1つ目は、Availability Zone (AZ) の障害です。これは、物理的なネットワーク障害 や電源障害により、依存関係ツリーの一部が完全に障害を起こしていないにもかかわらず、ヘルスチェックが通過し続けている状況です。2つ目は、ターゲットの障害です。これは、アプリケーションが失敗した場合(例えば、不適切なデプロイメント)でも、ターゲットがヘルスチェックを通過し続け、結果として5XXエラーやその他のエラーを引き起こすようなシナリオです。

そこで、これらのグレーな障害を根絶するために、段階的なアプローチを取りました。 まず、障害からの回復に最適な理想的なアーキテクチャを実現するための支援に焦点を当てました。次に、問題からより迅速に回復するための手動ツールを提供しました。これらは、アプリケーションに問題がある場合にAWS内部で使用しているのと同じ種類のツールです。最後に、私の子供たちが「オートマジカルモード」と呼ぶものですが、問題が発生したときに自動的に検出して軽減する機能です。
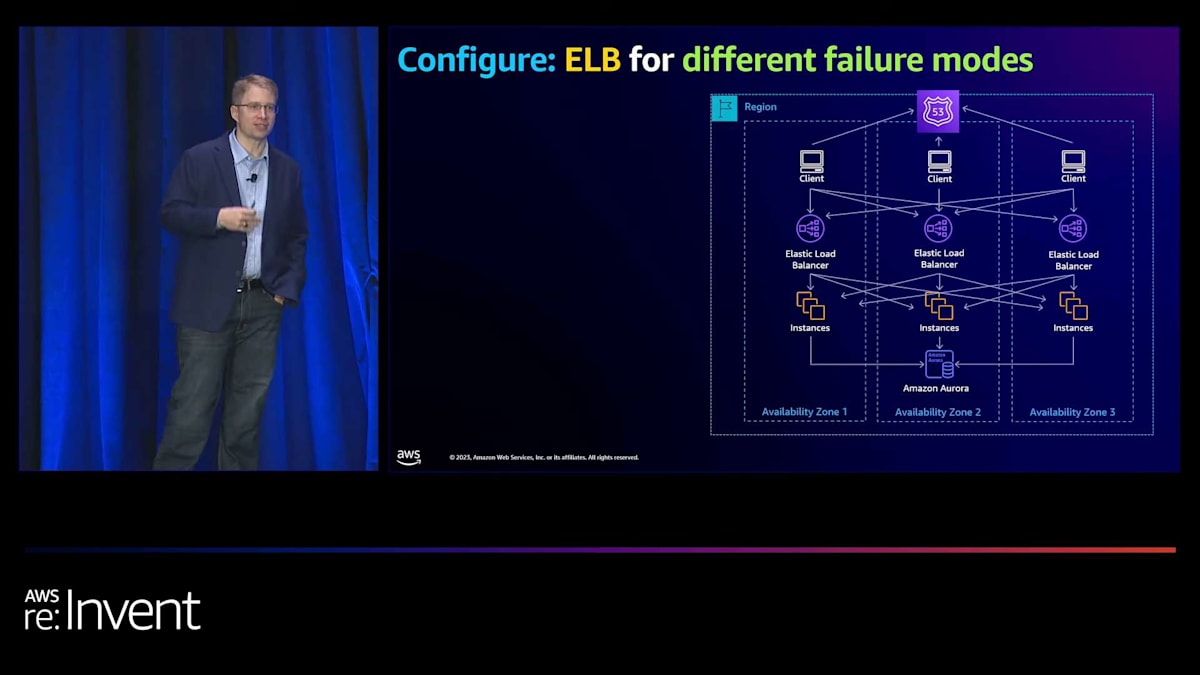
詳しく見ていきましょう。 AWSでは、常にバックワードワーキングを心がけています。そのため、私たちが目指すアーキテクチャを理解することが重要です。世の中には多くの異なるアーキテクチャがありますが、私たちはその中の1つに焦点を当てました。これはAWS内部で構築している方法です。多くの皆さんも今日このようなアーキテクチャを採用しているかもしれません。つまり、AZ間の通信があるということです。
このAZ間通信は、クライアントからロードバランサー、そしてロードバランサーからターゲットの両方で発生します。これは場合によっては有用ですが、グレーな障害が発生した際には非常に困難な状況を引き起こします。さらに、障害からより迅速に回復したい場合、AZ全体を一度に除外できれば、根本原因がわからなくても問題を軽減し、本質的にお客様の問題を解決できます。そのため、この理想的なアーキテクチャを設計する際には、AZ間の依存関係を最小限に抑えることが本当に重要なのです。
アーキテクチャの最上部から順に見ていきましょう。まず、ヘルスチェックがあります。ヘルスチェックには2種類あります:AZ用とターゲット用です。AZについては、デフォルトでは、AZから切り離すためにはターゲットの100%が失敗する必要があることがわかりました。これは明らかに、部分的な障害シナリオでは理想的ではありません。また、ターゲットの観点からは、障害が発生した場合に非常に迅速にターゲットを除外できるようにしたいのですが、フラッピングを防ぐために再び追加するのは非常にゆっくりと行いたいのです。
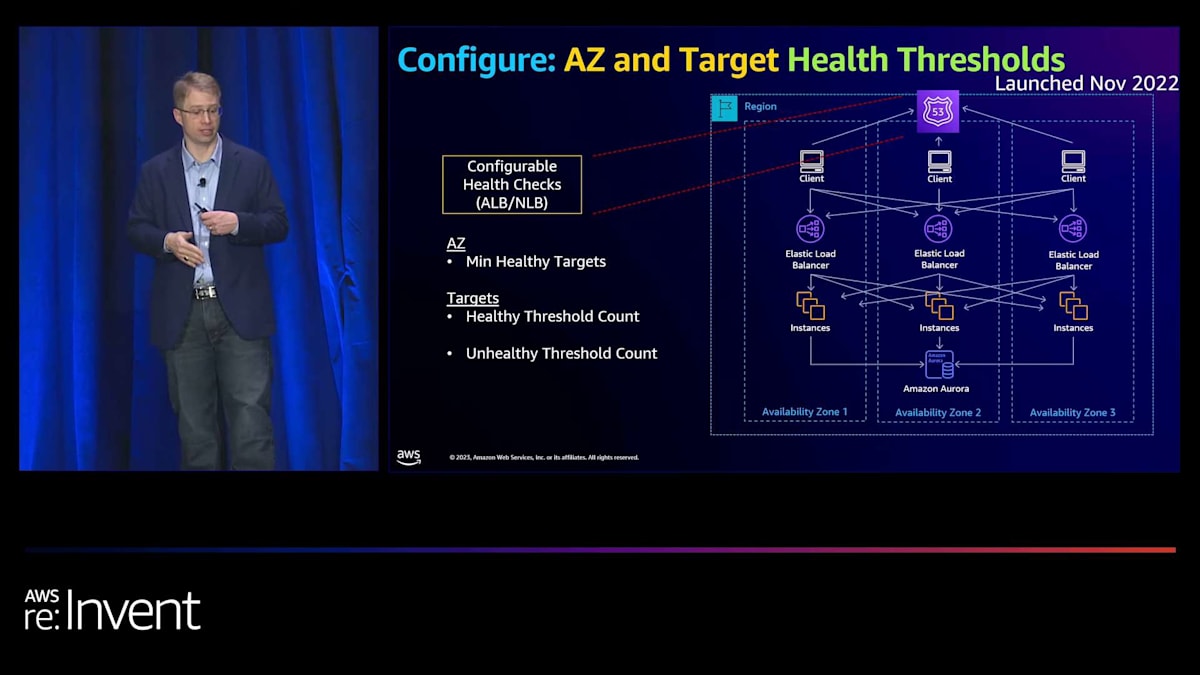
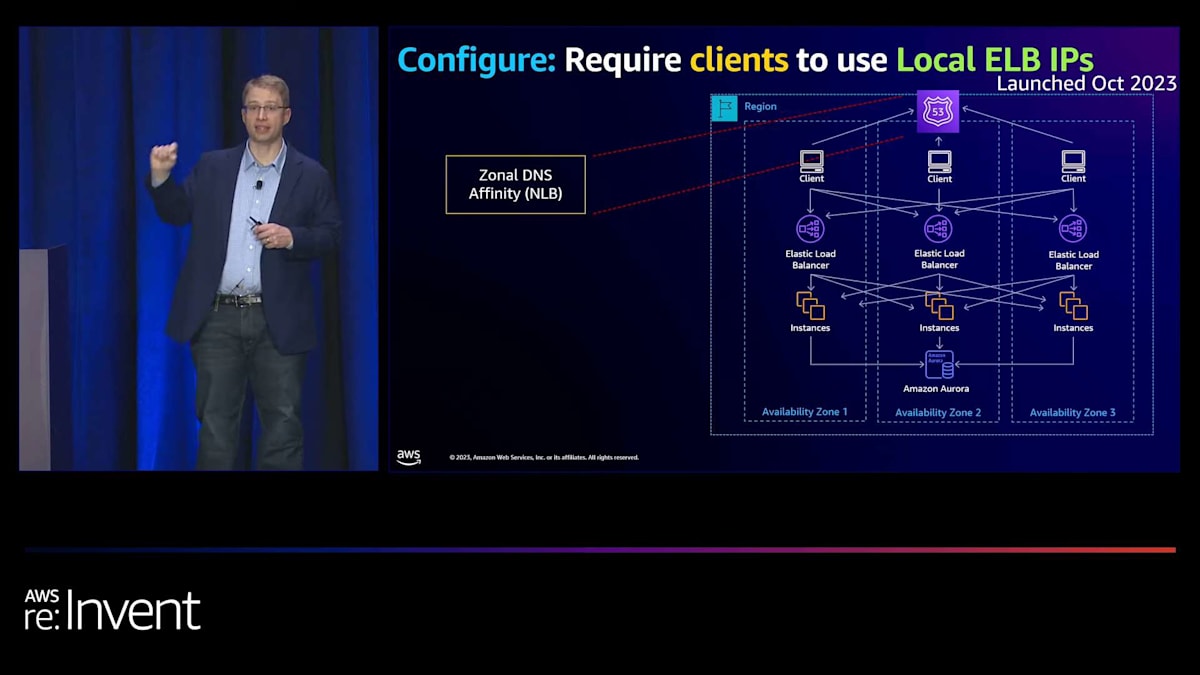
さて、私たちは2つの異なる設定を導入しました。 1つ目は、Availability Zoneからフェイルアウェイする前の最小限の健全なターゲット数に関するものです。2つ目は、キャパシティを追加または削除する前に、成功または失敗する必要のあるヘルスチェックの回数に関するものです。次に、トラフィックをローカルに保つ方法に焦点を当てました。 最初のものは、クライアントとロードバランサー間のトラフィックをローカルに保つことに関するものです。NLBでは、Zonal DNS Affinityと呼ばれるものを導入しました。これは基本的にクロスAZトラフィックを排除し、1つの例外を除いてローカルに保ちます。そのAZのロードバランサーインフラストラクチャが不健全な場合、他のAvailability Zoneへの接続を試みます。これは非常に有用な機能です。また、クロスAZデータ転送料金の削減にも役立ちます。
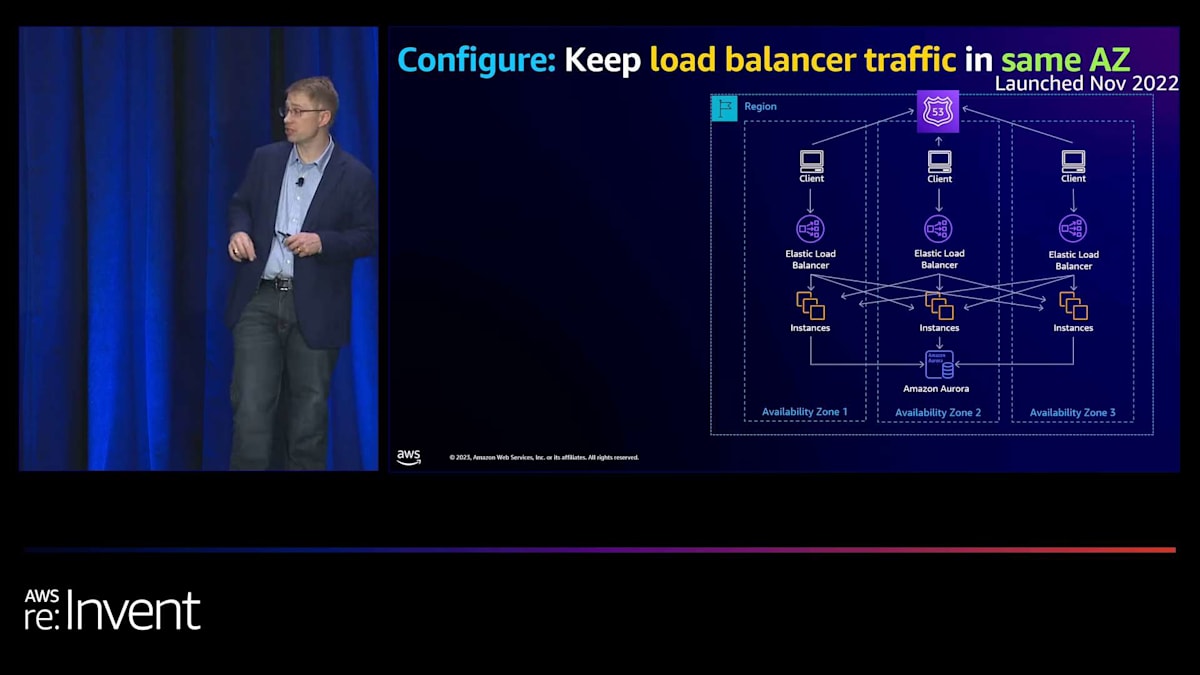
次に、ロードバランサーからターゲット自体へのトラフィックを制限したいと考えました。そこで、disabled cross-zone load balancingと呼ばれる新しい設定を導入しました。これはNLBとALBの両方で利用可能で、効果的にそのロードバランサーからそのAvailability Zone内のターゲットにのみトラフィックを分散します。ただし、注意点があります。これを使用するには、そのAvailability Zoneに十分なキャパシティがあることを確認する必要があります。十分なキャパシティがなく、Availability Zoneの1つが失敗した場合、アプリケーションに対応するのに十分なキャパシティがない可能性があります。その場合、回復を目指しているのに、エラーを引き起こすことになります。したがって、AZの障害に耐えられるよう、各AZに十分なキャパシティがあることを確認してください。
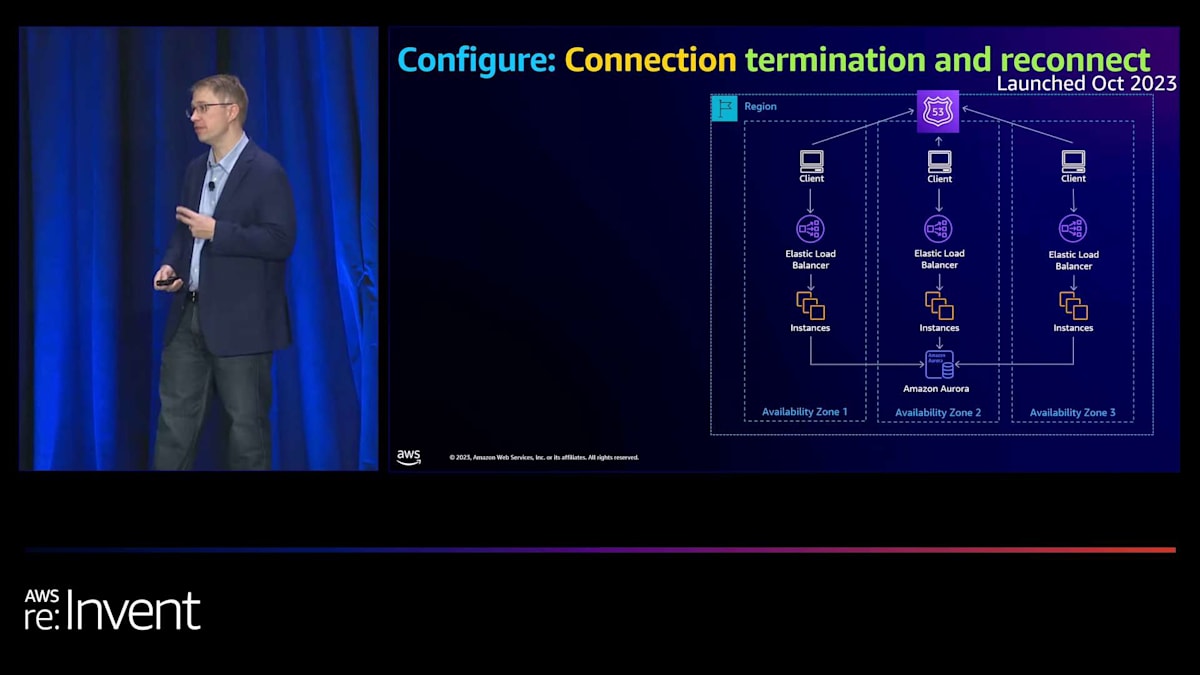
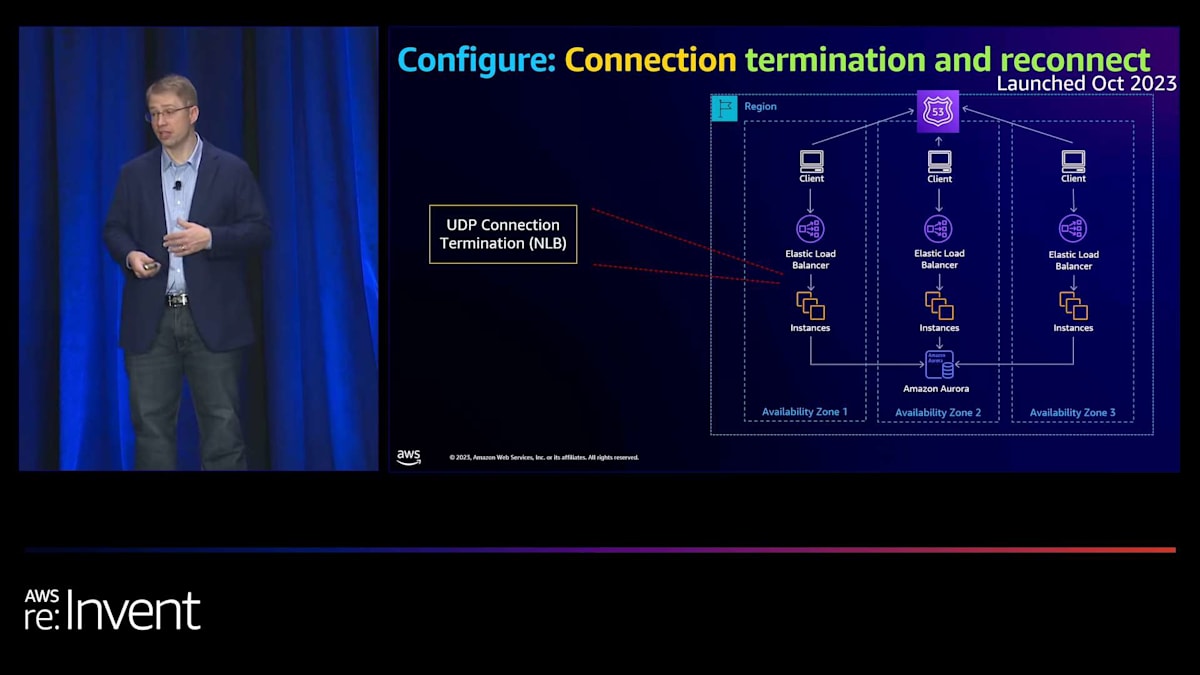
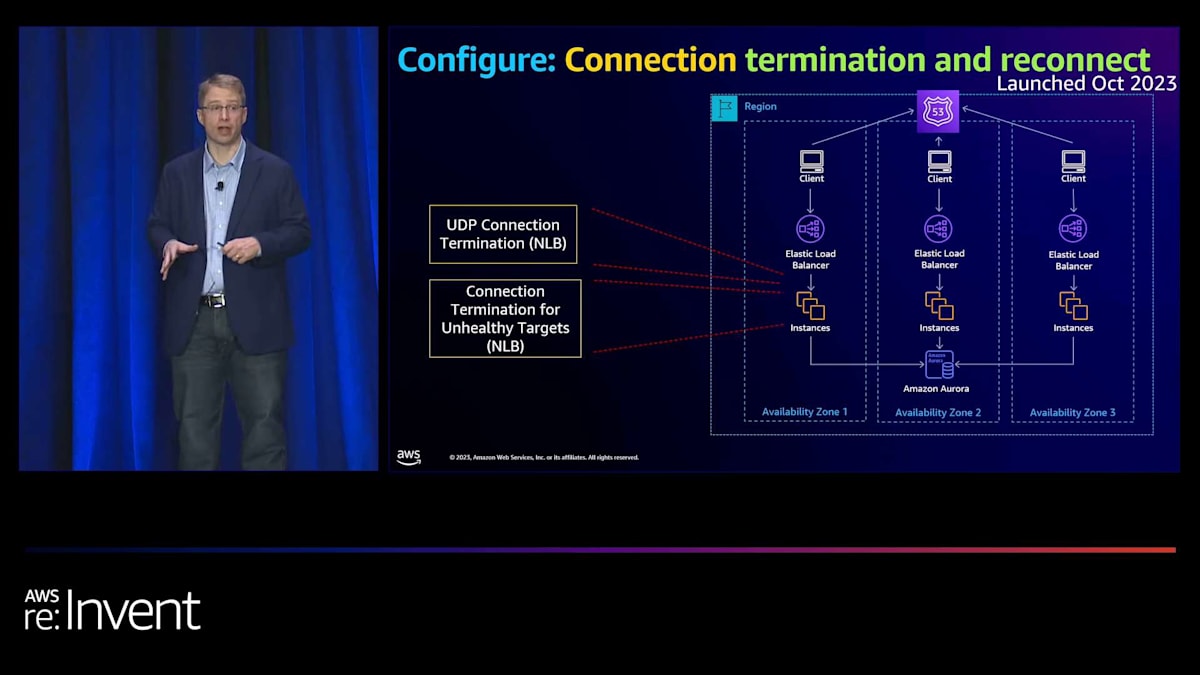
さて、最後に接続層を見てみました。接続を改善するために何ができるかを考えました。 2つの異なる領域が見えました。1つ目はUDPに関するものです。プロトコルの仕組み上、ターゲットが消えたり不健全になったりした場合にトラフィックがブラックホール化する可能性があります。 そこで、UDPの接続に関連する最大タイムアウトを導入しました。2つ目は、サンダリングハードシナリオを防ぐことです。 これは、ターゲットやAvailability Zoneが不健全になった時に、すべての接続がリセットされ、別のAZやターゲットに移動することで起こります。これは、通常の定常状態では問題ないアプリケーションを圧倒する可能性があります。そこで、不健全なターゲットに対する接続終了を導入しました。これにより、クライアントが通常切断するタイミングでのみ自然に切断し、フェイルオーバー時の接続を段階的に行うことができます。
ELBの進化と他のサービスとの統合
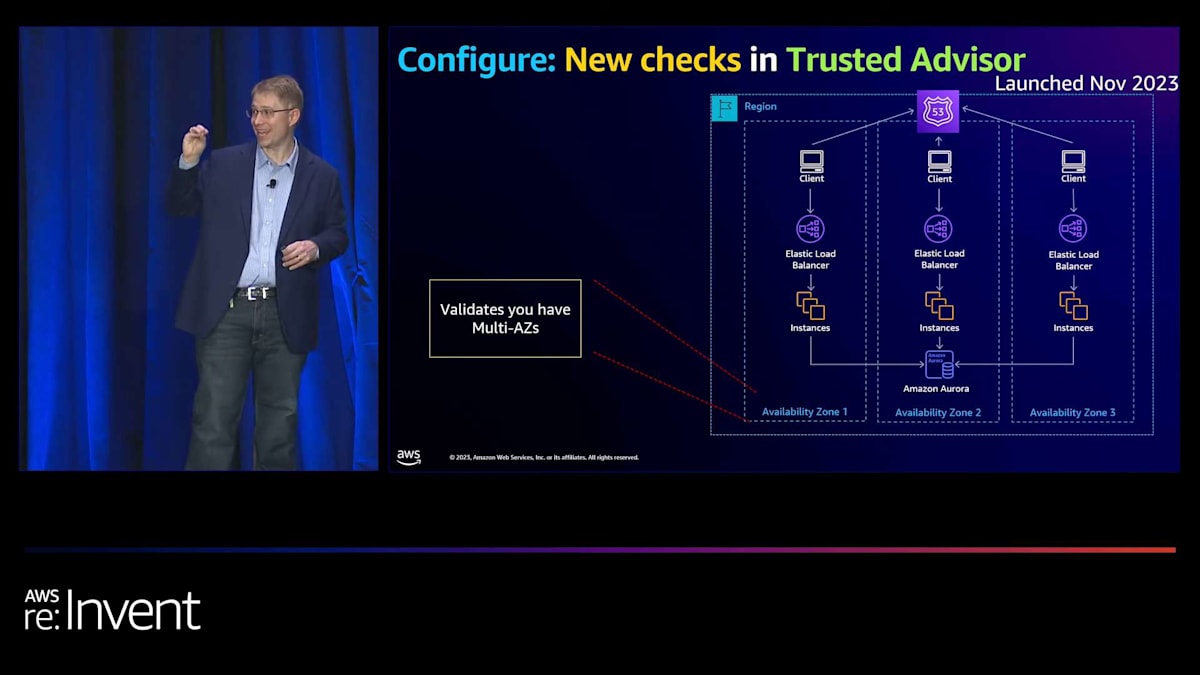

素晴らしいですね。これで理想的なアーキテクチャができました。次の領域は、Trusted Advisorを更新して、これらの情報の多くをそこに含めるという旅の始まりです。まずは、複数のAZにあるかどうかを検出する機能を追加しています。 ご覧の通り、NLBがそのDNSレコードを維持することで、私たちはあなたに代わって多くのことを行うことができます。NLBを孤立させないようにすることをお勧めします。そして、これが最初のチェックです。
素晴らしい、理想的なアーキテクチャができました。可用性を向上させる機会があることをお伝えする旅を始めました。次は、フェイルアウェイできるツールを提供することです。Amazonの内部では、問題が発生した時、最初に尋ねる質問は「それは単にAvailability Zoneに限定されているか?」です。もしそうなら、そのAvailability Zoneを単に削除して回復に戻ることができます。そのため、常に最初に緩和に焦点を当てています。Zonal shiftは、まさにそのことを可能にします。ゾーンごとにデプロイメントを行っている場合、単にロールバックする代わりに、待機することができます。そして、クライアントが適切なTTLを持っていれば、潜在的にはるかに長い期間ではなく、数分以内に回復することができます。これは、あなたの手中にもあります。


でも、また子供たちの話に戻りますと、彼らは本当に「オートマジカルランド」にいたがっています。そう、IPアドレスを削除して待機させることはできますが、彼らが望むのはオートマジカルランドなのです。私たちが自動的にアクションを取れる場所が2つあります。1つはロードバランシング層、もう1つはターゲットです。
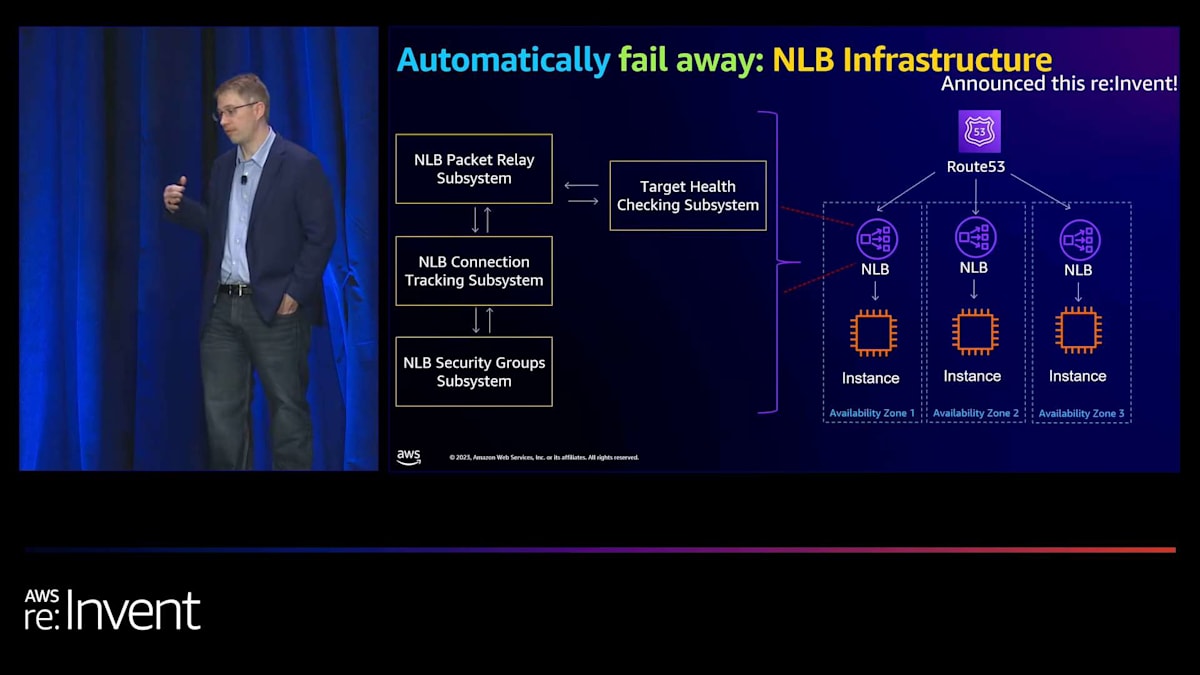
ロードバランシング層自体では、Application Load Balancer (ALB)が長年、ロードバランシングインフラに関連する異常を検出する機能を持っています。Network Load Balancer (NLB)の場合は少し厄介で、各ターゲットに対して具体的にヘルスチェックを行い、100%のターゲットが失敗した場合にのみ待機させます。これは、すべてのターゲットで一貫した障害モードが発生し、実際のロードバランサーインフラに問題がある場合を検出するという前提です。これは灰色の障害(部分的な障害)に対しては理想的な例とは言えず、私たちが望むほどうまく機能しません。そのため、最近(先週のことですが)、インフラを更新して、インフラ全体に対してより深いヘルスチェックを行うようにしました。
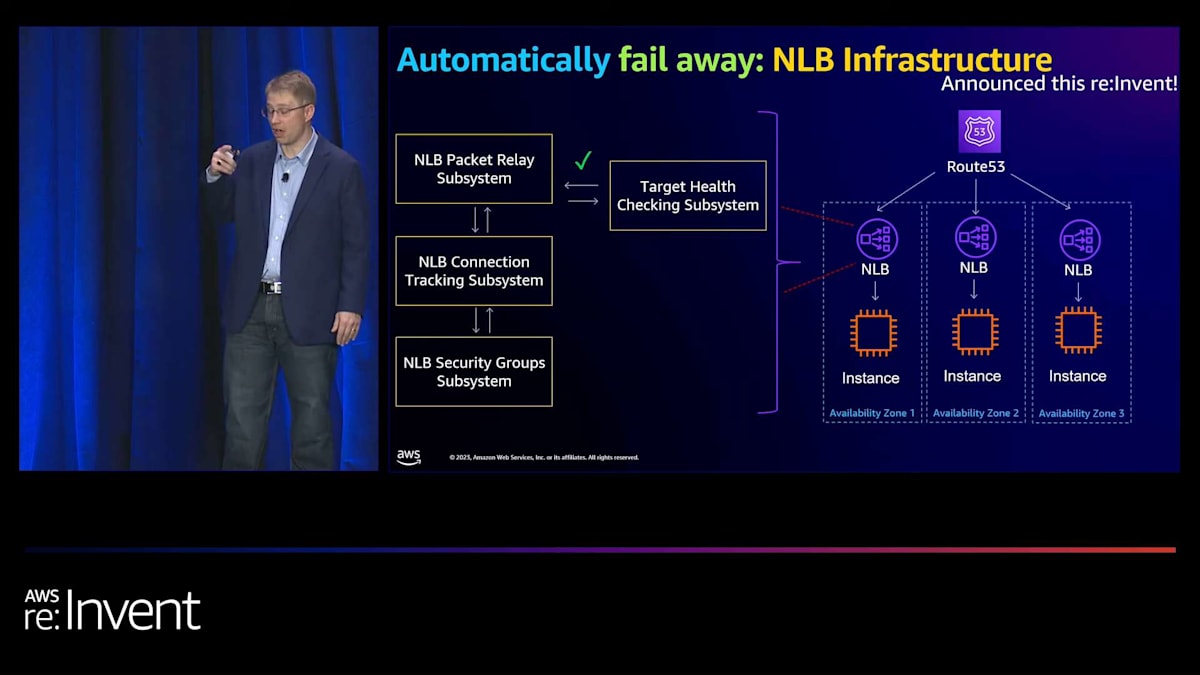
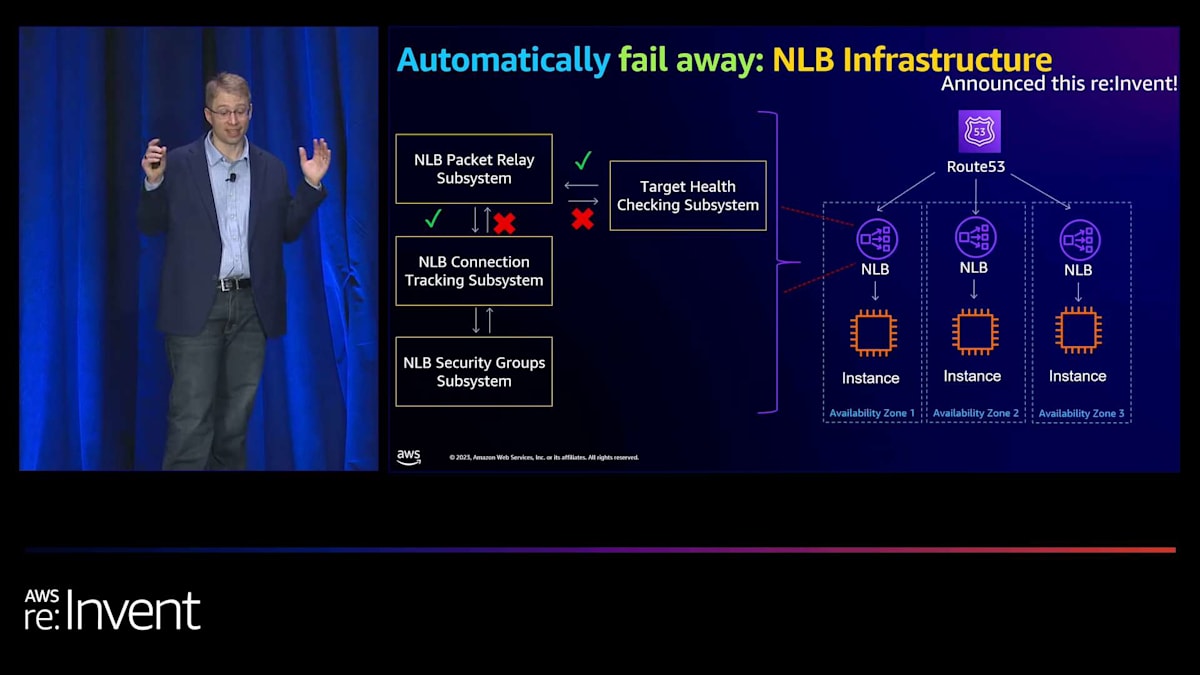

その仕組みは、ターゲットヘルスチェックサブシステムが実際のロードバランシングインフラの詳細な検査を行い、そのインフラの一部に障害が発生した場合、ターゲットヘルスチェックサブシステムに「このアベイラビリティーゾーンに障害があります。ここのインフラに障害があります」と報告し、自動的に待機させるというものです。つまり、灰色の障害が発生した場合、私たちが自動的に回復するシナリオになります。例えば、AZの障害やその他の問題が発生した場合、はるかに速く回復できるようになります。

さて、ロードバランシング側はカバーしたので、今度はターゲットに焦点を当てましょう。ターゲットのヘルスチェックを適切に行うのは難しいものです。これは社内の開発者からもよく聞く話で、Amazonの開発者でさえ、軽すぎるヘルスチェック(単にターゲット自体にpingを送って「はい、接続できます」と言うだけ)を作成したり、逆に非常に深いヘルスチェックを作成しても、デプロイ失敗時にインフラ全体を削除してしまったりするケースが驚くほど多いのです。

そこで、ロードバランシング層で何ができるかを考えました。実は、特にレイヤー7レベルでは、アプリケーションに関する多くの情報を持っています。そこで、各ターゲットの理想的な重み付けを算出できるはずだと考えました。この最初のイテレーションは、主にヘルスに焦点を当てています。そこで、Automatic Target Weightsというものを導入しました。これは今週リリースされたばかりです。基本的に、インスタンスに障害が発生した場合、そのターゲットへのトラフィックを段階的に減らし、ターゲットが過負荷でなくなって応答し始めるか、あるいはごくわずかなトラフィックを送り続けて健全性を監視しながら使用から除外するかのいずれかの状態に持っていきます。
これにより、非常に迅速に回復できる状態になります。先ほどの例に戻りますが、一度に1つのアベイラビリティーゾーンに開発とデプロイを行う場合、デプロイ中に自動的に回復することができます。これには2つのモードがあります。1つ目はCloudWatchメトリクスを発行するモードです。2つ目はこれを削減するモードです。CloudWatchメトリクスを利用できるため、自動ロールバックも可能になります。これは、可用性を向上させるための非常に強力なツールとなります。

今すぐ試してみることをお勧めします。これは、数週間から約1ヶ月にわたって、多くのアプリケーションでシャドーモードで実行してきたものの1つです。そして、これらのアプリケーションで改善できた可用性の量は相当なものでした。ぜひチェックしてみてください。 Elastic Load Balancing (ELB)の簡単な振り返りとして、非常に充実した1年でした。Mutual TLS (mTLS)のようなセキュリティ面や、Automatic Target Weightsのような可用性の面で多くの進展がありました。
お話しする機会がなかったことの1つに、EKSコントローラーを使ったAmazon EKSとの統合があります。過去1年間で、この分野で大きなイノベーションがありました。例えば、最近の機能の1つでは、クラスター全体で同じロードバランサーを使用できるようになり、大幅なコスト削減の機会が得られます。これについても確認してみることをお勧めします。
API Gatewayの概要と成長

Network Load Balancerの側面でも、NLBのセキュリティグループから、Zonal DNS Affinityのような可用性の改善まで、非常に充実した1年でした。お話しする機会がなかったことの1つに、ターゲットの登録と登録解除の遅延に関する改善があります。皆様からいただいたフィードバックの1つに、登録や登録解除に時間がかかりすぎるというものがありました。そこで、この点に多くの取り組みを行い、関連する遅延を大幅に削減しました。ぜひこちらもチェックしてみてください。では、次のサービスであるAmazon API Gatewayに移りましょう。

Amazonでは、世界をビルディングブロックの観点から考えています。最も基本的な層から始め、適切なノブとコントロールを提供し、そこからスタックを上に積み上げていきます。特に、皆様からLambdaと連携するコントロールプレーンが欲しいという声を聞きました。そこで2015年に、API Gatewayを導入しました。これにより、任意のスケールでAPIの作成、公開、維持、監視、セキュリティ確保が可能になりました。
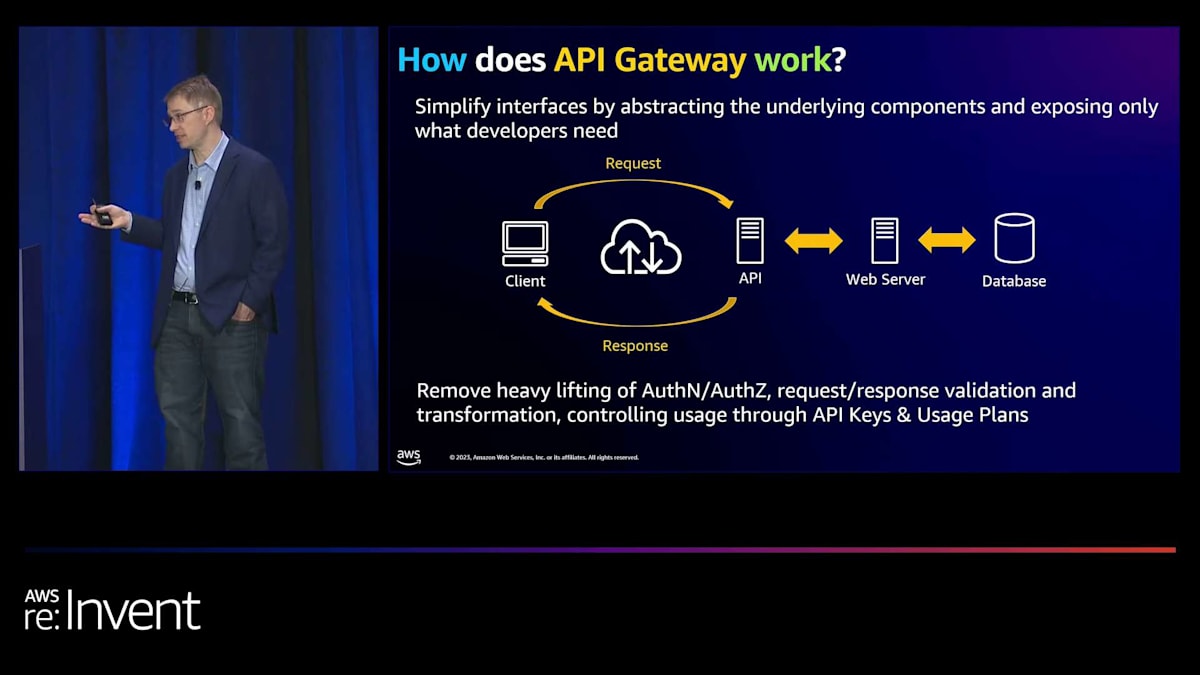
API Gatewayの仕組みは、事前に定義したAPIを含むエンドポイントをインターネット上に公開するというものです。そのAPIが呼び出されると、同期または非同期のワークフローが開始されます。また、認証や認可、リクエストとレスポンスの変換、バリデーション、APIレート制限などの機能も備えています。

API Gatewayは、私たちが基盤的なサービスと考えているものの1つです。社内では80以上のAWSサービスで使用されており、お客様から聞く使用事例は、エレベーターの操作から心臓移植の物流まで多岐にわたります。このサービスは絶対に重要で、完璧に仕上げる必要があります。
API Gatewayの改善と将来の展望
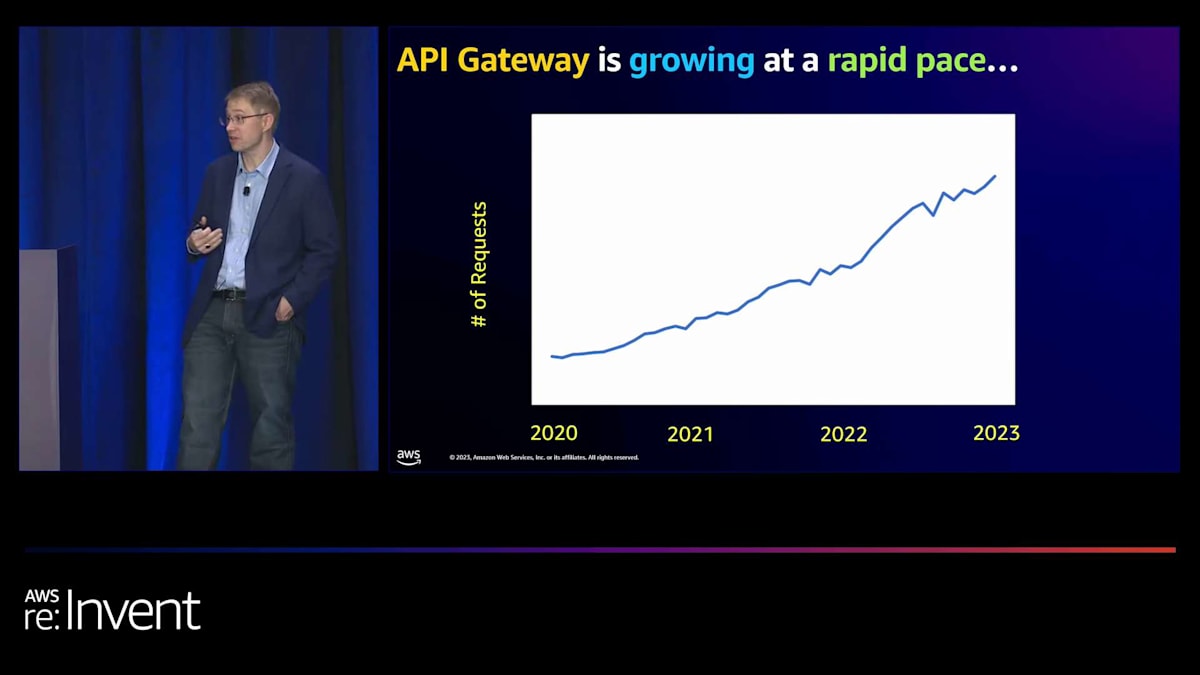
API Gatewayの成長は驚異的で、社内で設定した非常に野心的なマイルストーンを超えています。とてもエキサイティングなサービスで、コントロールプレーンを構築する際に顧客体験を大幅に簡素化するため、それほど驚くことではありません。

このようなサービスを構築する際、私たちは内部的にシンプルさを保つことに多くの時間を費やします。これは、S3のような他のサービスと非常によく似ています。S3では、非常にシンプルな体験を提供するために、舞台裏で複雑なエンジニアリングに多くの時間を費やしています。API Gatewayでは、可用性を向上させるためのプロジェクトの例として、Elastic Load Balancingで見られるものと似ていますが、実際には抽象化されています。
私たちは、セルラーアーキテクチャに焦点を当て、そのアーキテクチャの全体の一部を自動的に切り離せるようにしています。また、特にグレーな障害に対する平均復旧時間や、非常に迅速に追加容量を増やす能力、停電時にゼロから始めて全インフラストラクチャを立ち上げる能力にも注力しています。お客様に代わって処理する複雑さが多くありますが、これは素晴らしいことです。ただし、可用性のロードマップに関しては、ELBと非常によく似ています。

私たちが多くの時間を費やしているもう一つの分野は、開発者エクスペリエンスです。特に API Gateway に関しては、多くの方がインフラストラクチャーアズコードや私たちの API を使用していますが、新しい API ゲートウェイを作成したり実験したりする際には、AWS Management Console を活用していると聞いています。皆さんからのフィードバックによると、以前のコンソールはそれほど直感的ではなく、アクセシビリティの改善の余地があったようです。
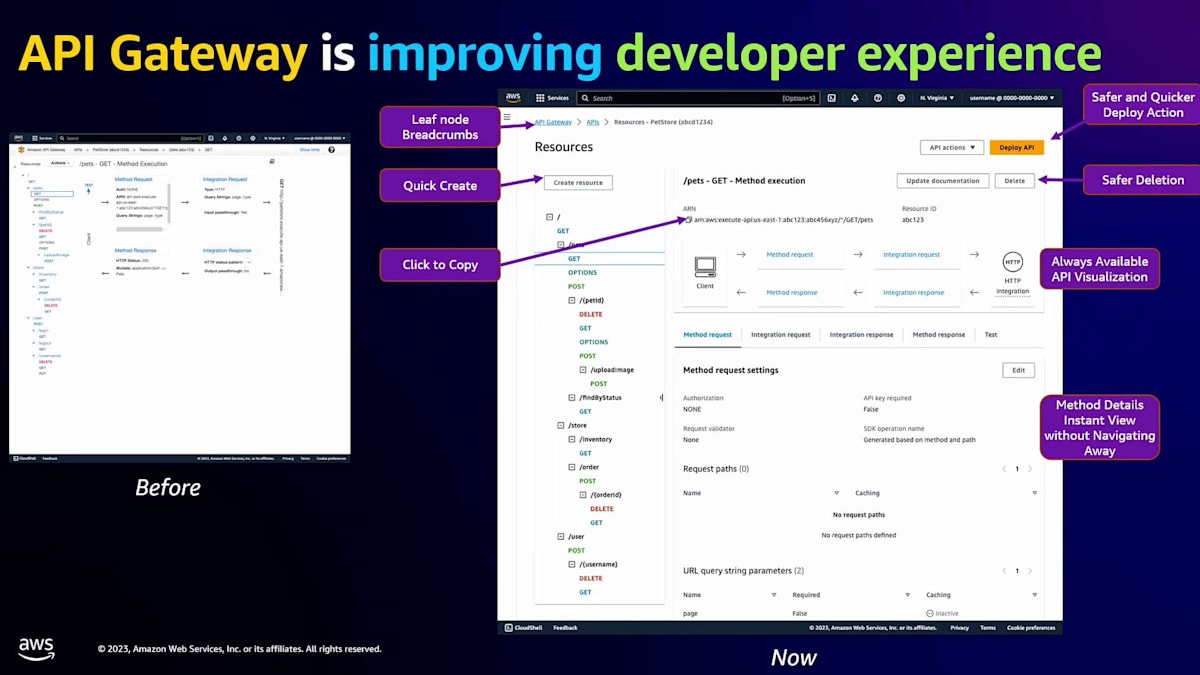
この1年間、私たちはその改善に本腰を入れて取り組んできました。115以上のビューを変更し、ダークモードを含む549もの異なるアクセシビリティの改善を行いました。これは大幅な改善です。皆さんからのフィードバック(ありがとうございます)によると、実際のユーザーエクスペリエンスが確実に向上したとのことです。まだご覧になっていない方は、ぜひチェックしてみてください。
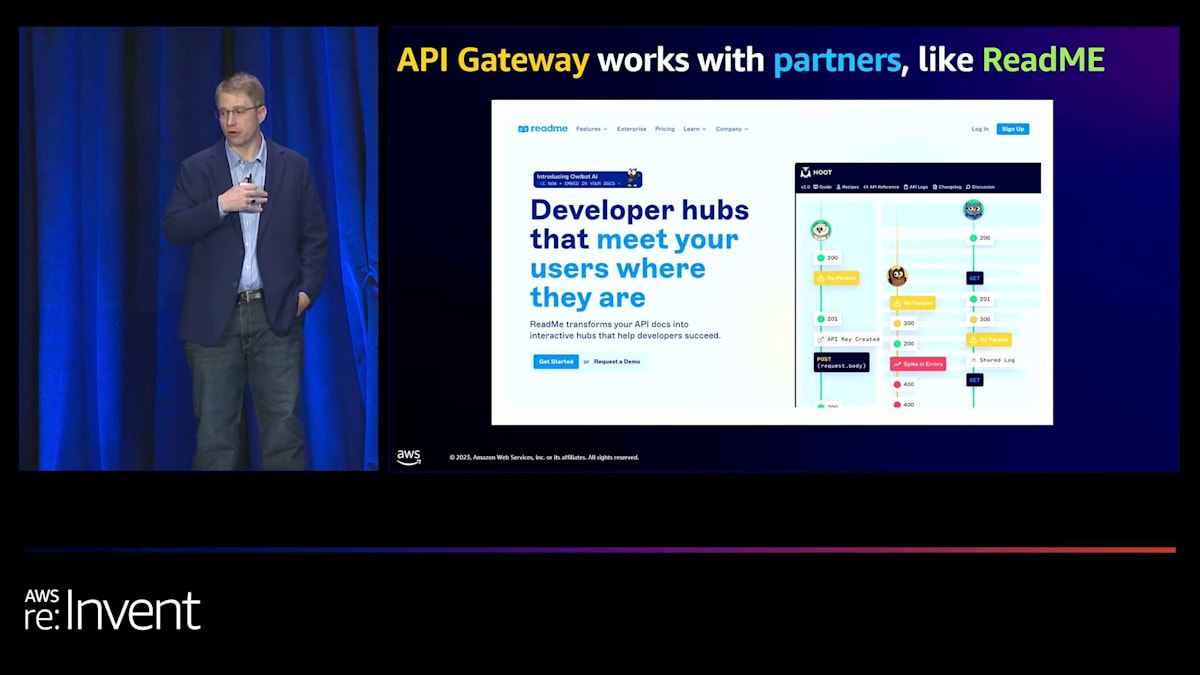
最後にお話しするのは、パートナーに関する取り組みです。この分野では、皆さんに多くの選択肢と機能を提供したいと考えています。その良い例が、開発者ポータルを提供する ReadME です。コードサンプルやドキュメント、API リファレンスの作成、リアルタイムのロギングを使用したコードの試行など、アプリケーションで何が起こっているかをリアルタイムで理解することができます。開発者ポータルのようなユースケースをお持ちの方は、ReadME や他のパートナーオプションをチェックしてみることをお勧めします。

API Gateway は、アプリケーションネットワーキングの責任者である私が特に注目している分野です。私たちは多くの投資を行っており、来年リリースする予定のすべてのものに胸を躍らせています。2024年にご期待ください。舞台裏での取り組みだけでなく、外部からも目に見える形で追加の機能をお届けする予定です。
PrivateLinkとGateway Load Balancerの活用
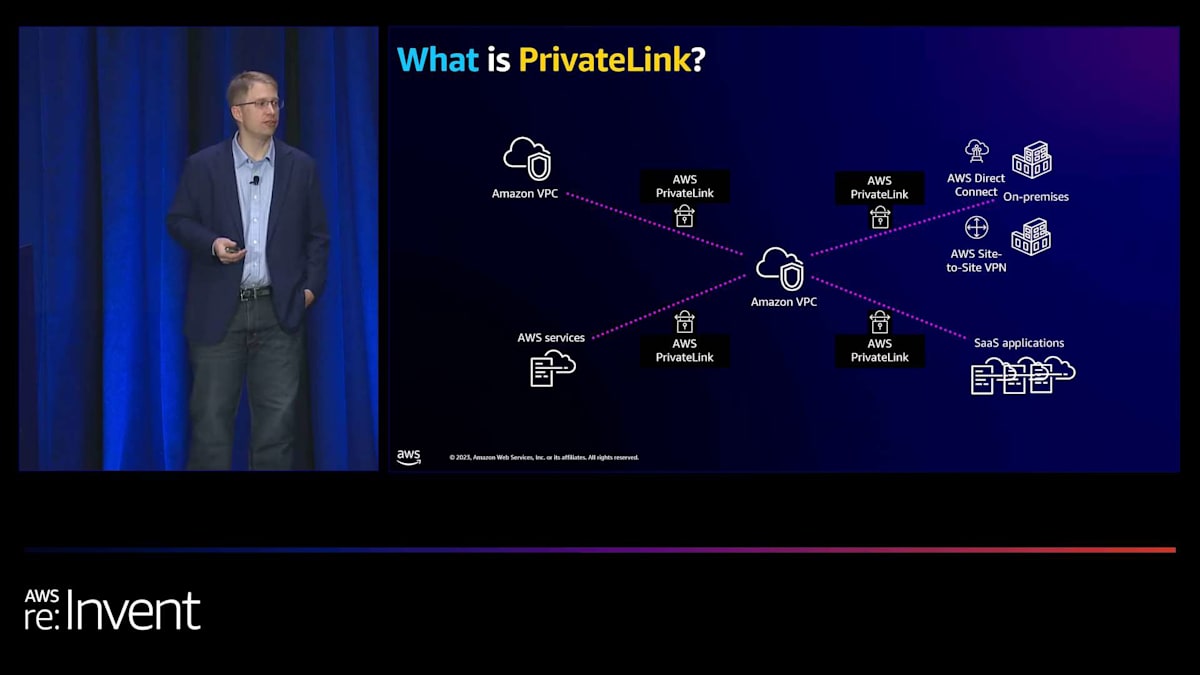
次のサービスは PrivateLink です。PrivateLink を使用している方はどれくらいいらっしゃいますか?かなりの数の方がいらっしゃいますね。PrivateLink は、他の AWS アカウントや VPC にある SaaS アプリケーションや AWS サービスに簡単に接続できるようにするものです。これは、パブリックインターネットを使用せずに、安全かつプライベートにサービスに接続するためのデフォルトの方法になりつつあります。

お客様がPrivateLink を好む理由はいくつかあります。まず第一に、接続はクライアント側から開始されます。 つまり、サードパーティのプロバイダーにアクセスする場合、そのアプリケーションにアクセスできますが、プロバイダー側からあなたのVPCに逆接続することはできません。第二に、セキュリティに関して豊富な機能を持ち、AWSサービスを使用する際にIAMユーザーがアクセスできるVPCやAPIを指定できます。さらに、PrivateLink はオンプレミス環境から異なるAWSアカウントやVPCへのサービスアクセス、およびその逆も可能にします。最後に、Contributor Insights によるトップトーカー情報など、充実したモニタリング機能を提供します。


現在、PrivateLink の主な使用例は2つのカテゴリーに分類されます。 1つ目はサービス、2つ目はネットワーキングアプライアンスです。サービスに関しては、主に3つのタイプがあります。まず、すでに155以上のAWSサービスがPrivateLink と統合されています。次に、中央のVPCでホストしたい社内開発アプリケーションがあります。そして、インターネットを経由せずにアクセスできるサードパーティプロバイダーのアプリケーションです。 PrivateLink を通じて200以上のパートナー提供サービスが利用可能です。特定のサービスが利用できない場合は、AWSアカウント担当者やサードパーティプロバイダーに連絡して、PrivateLink 統合をリクエストすることをお勧めします。これは安全な接続の新しい標準になりつつあります。

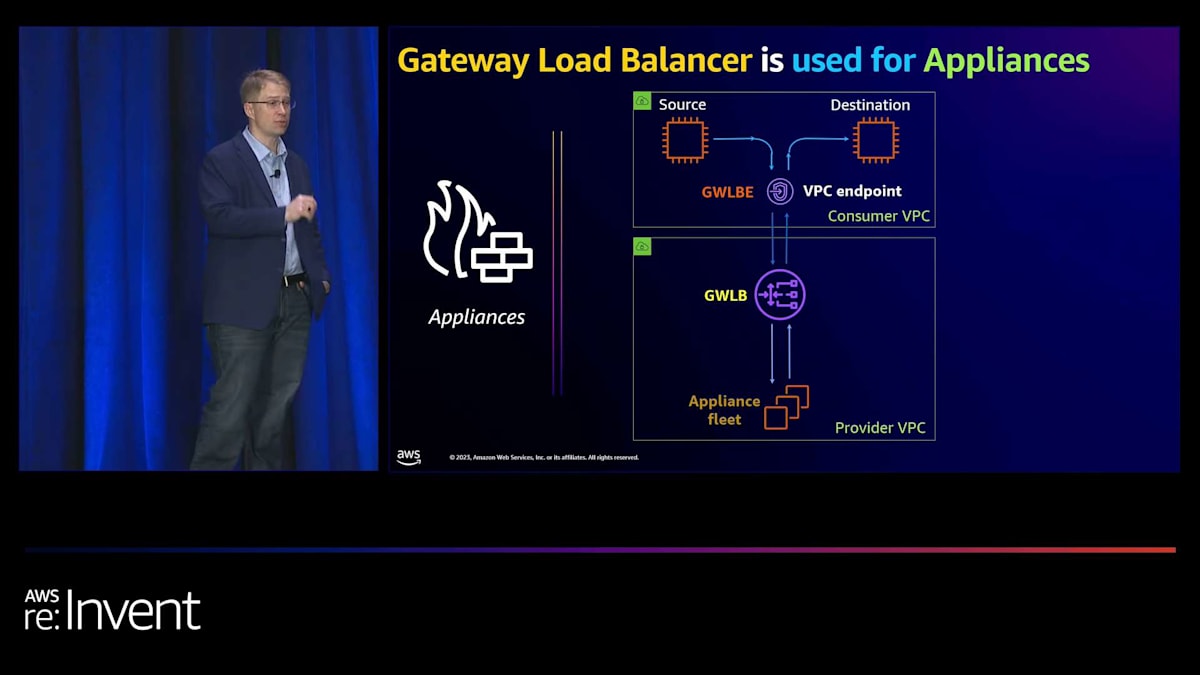
PrivateLink の2つ目の主な使用例は、Gateway Load Balancer を通じて実装されることが多いネットワーキングアプライアンスです。Gateway Load Balancer は、送信元と宛先の間のトラフィックを透過的に検査する機能を提供します。これは、VPC内のIPアドレスである Gateway Load Balancer エンドポイントを作成することで機能します。このエンドポイントをルートテーブルに追加することで、別のVPCやアカウントの Gateway Load Balancer への透過的なルーティングが可能になります。Gateway Load Balancer はその後、ネットワーキングアプライアンス間でトラフィックを分散し、Firewall as a Service などのサービスを可能にします。
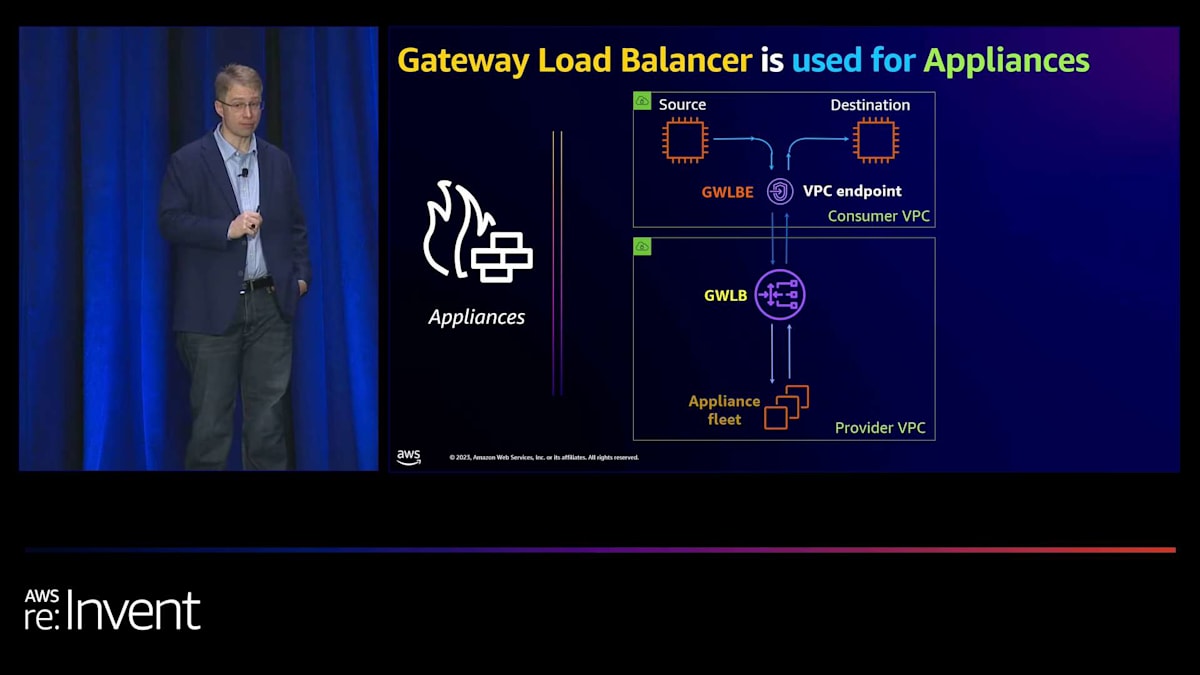
これらのネットワーキングアプライアンスは、トラフィックをドロップするか宛先に送信するかを選択できます。このアーキテクチャは、直接ルーティングを使用するEC2インスタンスの以前の方法と比べていくつかの利点があります。障害時に異なるネットワーキングアプライアンスにトラフィックをルーティングできるため、信頼性が向上します。ロードバランサーアプライアンスがスケールアウトできるため、スケーラビリティが向上します。IPアドレスを保持するため、トラフィックが送信元から直接来ているように見えます。最後に、ネットワーキングアプライアンスを異なるVPCやアカウントに配置できるため、より大きな柔軟性を提供します。
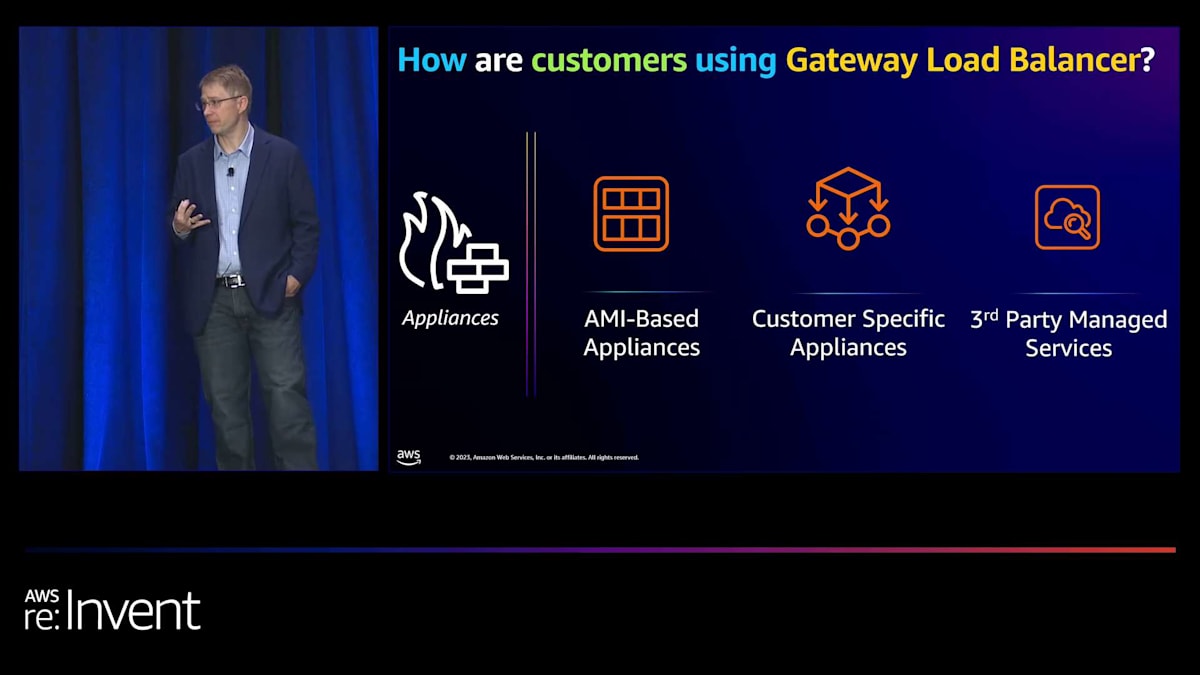
Gateway Load Balancer を使用するための主なアプローチは3つあります。1つ目は「DIY」方式で、Palo Alto や Fortinet などのベンダーが提供する AWS Marketplace のプリビルトAMIを使用して、Gateway Load Balancer の背後でソフトウェアがプリインストールされたインスタンスを実行できます。2つ目のオプションは、独自のアプライアンスを構築することです。これは、透過的なトラフィック検査、ロギング、カスタムファイアウォールサービスの実装などのタスクに役立ちます。3つ目のアプローチは、サードパーティのマネージドパートナーを利用することです。

Gateway Load Balancerに関して、様々なユースケースを提供する幅広いパートナーがいます。例えば、Palo AltoやFortinet はファイアウォールをサービスとして提供しています。NetScoutのような分析パートナー、Terraformのようなネットワーク管理パートナー、そしてGateway Load Balancerを広範囲に活用するAccentureのようなシステムインテグレーターもあります。

Gateway Load Balancerを最初に開発した時、私たちは多様なユースケースとパートナー統合に対応することを目指しました。主にインターネットトラフィックとサービス間のトラフィックに焦点を当てていました。しかし、オンプレミスのソースからのトラフィックを検査する機能を求める顧客からのフィードバックを受け、Virtual Gateway(VGW)との統合を行いました。統合には主に2つの方法があります。1つ目はIPSecを使用してインターネット経由でトラフィックを送信する方法、2つ目はより安全なオプションであるDirect Connectを活用する方法です。PrivateLinkとGateway Load Balancerはこの分野での興味深い進展であり、サードパーティのサービスを効果的に活用することができます。これらのオプションをさらに探ってみることをお勧めします。
VPC Latticeの導入:ネットワーキングの複雑さを簡素化

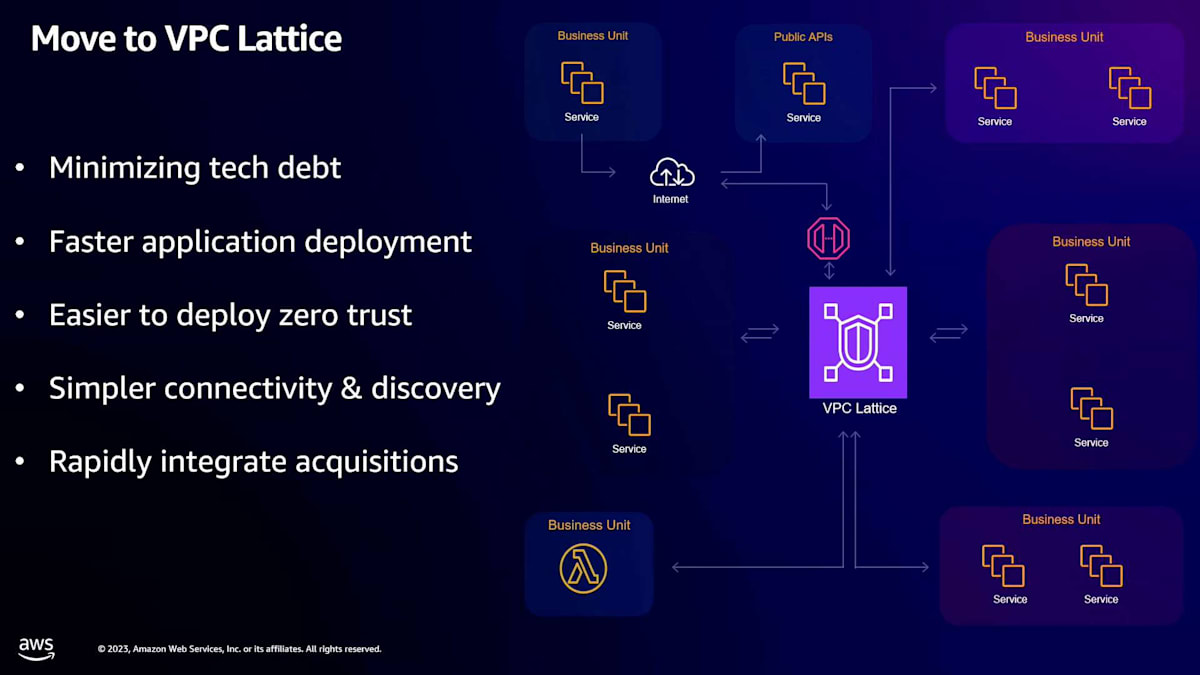
昨年、私たちは今まで議論してきたすべての分野でネットワーキングの複雑さを簡素化するミッションに着手しました。アプリケーション開発者、システムエンジニア、セキュリティエンジニア、ネットワークエンジニアにとって課題となる、大量のネットワーキングの複雑さが存在することを認識しました。私たちの目標は、アプリケーション開発者がアプリケーションを構築しやすくする一方で、システム、セキュリティ、ネットワークエンジニアが複数の層で防御を効果的に実施できるようにすることでした。ネットワーク設計と図を簡素化したいと考えました。これがVPC Latticeの導入につながりました。

VPC Latticeは、基盤となるネットワーキングの概念を深く理解する必要なく、アプリケーションの接続、セキュリティ確保、監視を可能にする管理型アプリケーションネットワーキングサービスです。Application Load Balancer、Transit Gateway、PrivateLinkを効果的に組み合わせたものです。VPC Latticeは、ネットワークガバナンスのためのガードレールとポリシーを定義する機能、アプリケーション層のロードバランシングや重み付けされたターゲットグループなどのトラフィック管理ツール、ブルー/グリーンデプロイメントのサポートを提供します。さらに、アプリケーションの保守とトラブルシューティングに必要な多くのツールも提供します。

VPC Latticeの特徴は、好みのコンピューティングプラットフォームを柔軟に活用できることです。 例えば、Amazon EKS、Amazon ECS、Auto Scalingを使用し、それらのネイティブな構成要素で相互作用することができます。これは、ネットワーキングの複雑さに深入りしたくないアプリケーション開発者にとって特に有益です。もう1つの注目すべき機能は、PrivateLinkの機能と同様に、VPC Latticeを使用して異なるアカウントやVPCにアクセスできることです。これにより、複数のコンポーネントをリンクしてアプリケーション全体を作成するプロセスが大幅に簡素化されます。

VPC Latticeは、セキュリティグループなどの既存のルールや設定も尊重します。おそらく最も印象的な機能は、提供する強化されたセキュリティです。多くの組織がVPC Latticeに移行しているのは、ゼロトラストセキュリティを提供するからです。VPC内のすべてを信頼するという従来のアプローチとは異なり、VPC Latticeは個々のサービスの保護に焦点を当てています。 リンクローカルIPアドレスを使用して、ソースから宛先サービスまでのトラフィックをプライベートにルーティングできます。そして、IAMポリシーなどの追加のセキュリティレイヤーを追加し、サービスをIAMポリシー内のリソースとして扱うことができます。これにより、VPC Latticeに対してリッチなポリシーを構築でき、今日構築可能なものよりもはるかに安全なサービス間接続を提供します。
最後に、多くの顧客と話し合う中で最も重要な側面の1つは、自分のペースで移行できることです。VPC Latticeを最初に検討する際、すべてを一度に移行する必要があると考える人もいるかもしれませんが、そうではありません。個々のサービスから始めて、Amazon ECSや他のプラットフォーム上のNetwork Load BalancerやApplication Load Balancerを使用して既存のサービスを統合できます。これにより、より多くのサービスを追加するにつれて指数関数的に価値が高まりながら、徐々に移行することができます。

昨年のre:InventでVPC Latticeをプレビューでローンチし、今年の3月に一般提供を開始しました。GA(General Availability)リリースでは、IPv6のサポートを導入しました。これはビジネス全体で使用されるIPアドレスの数を最小限に抑えることでコスト削減に役立ちます。また、特にコンテナの世界で有益なIPv6通信を可能にします。さらに、カスタムドメイン名のサポートも開始しました。VPC LatticeはリンクローカルのIPアドレスを指すDNSアドレスを使用するため、既存のインフラストラクチャへの統合と作業が非常に簡単になります。
Mike WittigによるBlockの事業紹介とVPC Lattice活用計画
このアプローチにより、DNSはよく知られた概念であるため、作業しているクライアントやサービスが必要な場所に接続するのが非常に簡単になります。カスタムドメイン名を使用すると、ルーティングしたいFQDNの人間が読みやすいバージョンを作成できます。最後に、より多くのリージョンに拡大しました。VPC Latticeについて私が素晴らしいと思うすべてのことを単に私から聞くのではなく、Mike Wittigに話を譲りたいと思います。MikeはNikeそして現在はBlockで優れたエグゼクティブスポンサーであり、彼のチームは私のチームと緊密に協力してVPC Latticeを進化させてきました。ありがとう、Mike。


ありがとう、Dave。みなさん、こんにちは。お集まりいただきありがとうございます。Latticeに関する計画についてお話しする前に、私たちの会社について少しお話ししたいと思います。 私たちには複数のビジネスユニットがあり、そのうちいくつかについて簡単に触れたいと思います。最初のユニットはSquareで、以前は会社全体がSquareと呼ばれていました。昨年初めにBlockに社名変更しましたが、その理由の1つは、他のビジネスユニットのためにブランド内にスペースを作ることでした。これらのビジネスユニットはそれぞれが独立した垂直型ビジネスです。
Squareは当初、iPhoneやiPadに取り付けられるカードリーダーとして始まり、それまでクレジットカード決済ができなかった多くの企業に決済の機会を提供しました。その後、コーヒーショップの運営に使えるPOSシステムにまで拡張しました。また、スタッフィングソリューションも含まれており、例えばペイストリーショップで働く人々が異なるシフトを確認し、交換することができます。さらに、給与機能もあり、Square payroll invoicesを通じてスタッフに給与を支払うこともできます。これらのサービスを企業が多く利用するほど、私たちとの関係が強くなり、さらに重要なのは、彼らが自身のビジネスに集中できる時間を多く提供できることです。
Cash Appは、Square内のハックウィークプロジェクトとして、個人間送金のために始まりました。多くの人がこの製品を最初に知るのはこの機能からです。しかし、これはあなたにとって銀行商品にもなり得ます。私たちは貯蓄計画を設定できる貯蓄商品や、直接預金など、個人が金銭関係で必要とするであろうさまざまな機能を提供しています。

TIDALは音楽ストリーミングサービスで、特にデビューしたばかりのアーティストとのインタラクションも可能です。Afterpayは、昨年買収したオーストラリアを拠点とするBuy Now, Pay Later企業です。企業側にBuy Now, Pay Laterを提供する機能と、その選択肢を利用したい消費者側の機能の両方があります。Spiralはオープンソースプロジェクトで、コミュニティに還元しています。そしてTBDは、私たちが構築中の分散型アイデンティティサービスで、他の機能の中でも、国境を越えた送金を安全かつ透明性を持って行うことができます。
昨年の投資家向け説明会で共有したこのスライドは、私たちのビジネスを「エコシステムのエコシステム」として描いています。これはどういう意味でしょうか? まず、Squareが提供する様々なサービス - 決済、給与計算、人材配置、請求書など - それ自体がひとつのエコシステムです。また、Cash Appもピアツーピア決済サービス、銀行業務、貯蓄、直接入金などを含むエコシステムです。これらのサービスからさらに大きな力を引き出せるのは、それらを連携させることができるからです。
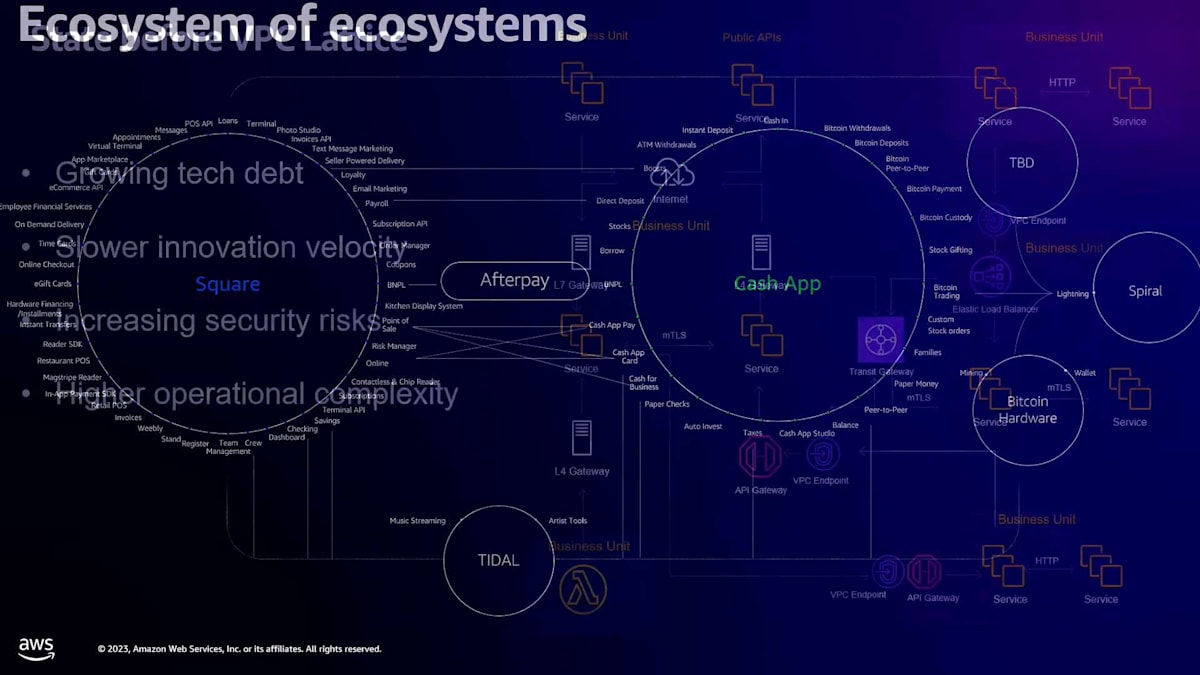
その一例として、Square SellerがAfterpayを購入オプションとして提供し、消費者であるあなたがCash Appを使ってAfterpayの支払いオプションでその取引を完了するというケースが挙げられます。もう一つの例として、すでに大きな成長を見せているのが、Square sellerがSquare payrollを使って従業員に給与を支払い、従業員がCash Appの直接入金機能でその給与を受け取るというケースです。この場合、資金は私たちのエコシステム内に留まり、Square sellerにとっては直接入金と給与計算の設定が容易になり、従業員にとっても便利になります。このようにエコシステムを連携させる能力が、私たちの会社の次の成長フェーズとなるのです。
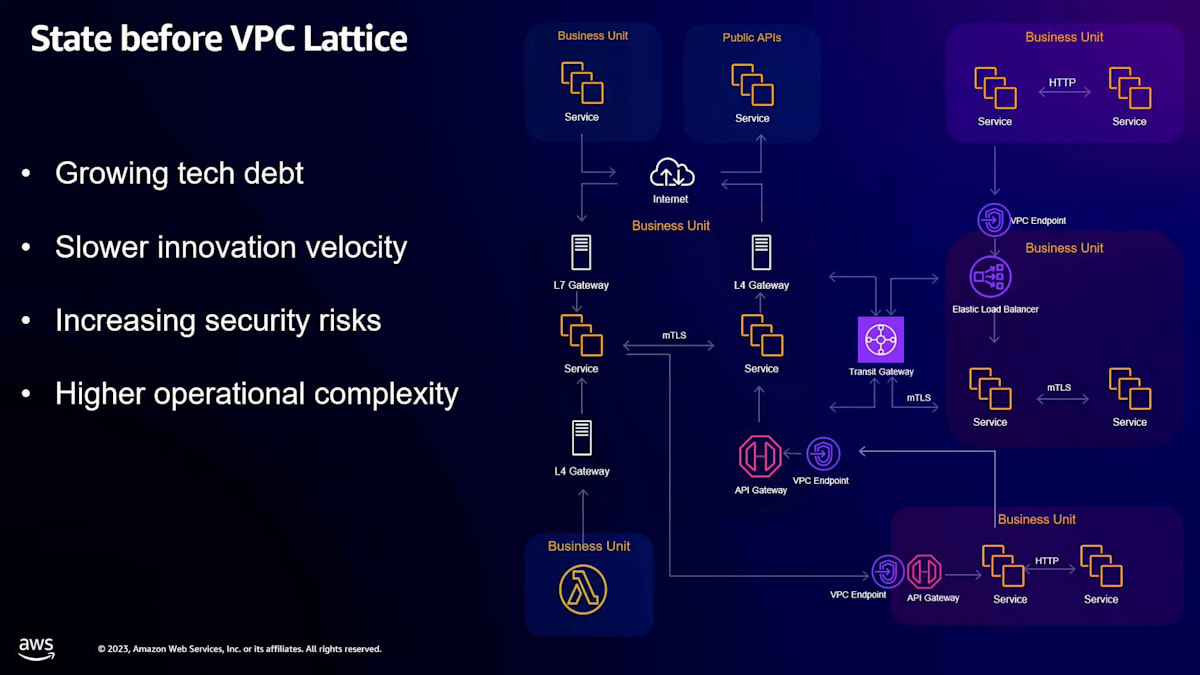
しかし、現在の連携の仕方を見てみると、少し一貫性に欠けています。セキュアではありますし、CISOとして自信を持ってセキュアだと言えますが、おそらく必要以上に認知的負荷がかかっているのも事実です。
その理由は2つあります。1つは、これらが独自に成長してきた異なる垂直ビジネスであるため、使用している技術のスタックが少し異なっているということです。私たちはAPI Gatewayを使用していますが、いくつかの異なるサイドカープロキシ技術も使用しています。また、買収を通じて、場合によっては、先ほど話したエコシステム接続を行おうとすると、同じ会社内で接続しているようには感じられず、外部の第三者企業に接続しているように感じられます。セキュアではありますが、セキュリティを確保するだけでなく、開発者にとっても認知的に追跡する必要のある要素が多く、少し難しくなっています。
現在のセットアップでは、開発者がそのエコシステム接続を実現する方法を考えるのが難しすぎます。これらの異なるビジネスユニット間の接続性とセキュリティに関して、ナビゲートする必要のある複数の異なる要素があるからです。そこでVPC Latticeの登場です。私たちがこれにとてもワクワクしている理由の1つは、私たちがmTLSを使用しているからです。Daveとチームのみなさん、mTLSをサポートしてくれてありがとうございます。 もう1つの側面は、Daveも話していましたが、段階的に統合できる能力です。前のスライドで見たすべてをVPC Latticeに一気にシフトする必要はありません。時間をかけて行うことができますが、そうすることで得られる利点は、これらの異なるビジネスユニット間の境界について考えることが少なくなるということです。
そのため、セキュリティの確保が容易になり、さらに重要なのは、これらのエコシステム間の接続を構築しているすべてのエンジニアリングチームにとって、はるかに予測可能な開発プラットフォームになるということです。私たちは何年もこの製品を追跡してきました。Daveが言ったように、以前別の場所にいたときに、当時Project Mercuryと呼ばれていたものについて初めて聞いたとき、その可能性に非常に興奮しました。なぜなら、Nikeでは独自のサービス間認証メカニズムを構築しなければならなかったからです。それは重要なことですが、大変で楽しくありませんでした。そのような差別化されていない重労働を、VPC Latticeに任せられるのは素晴らしいことです。
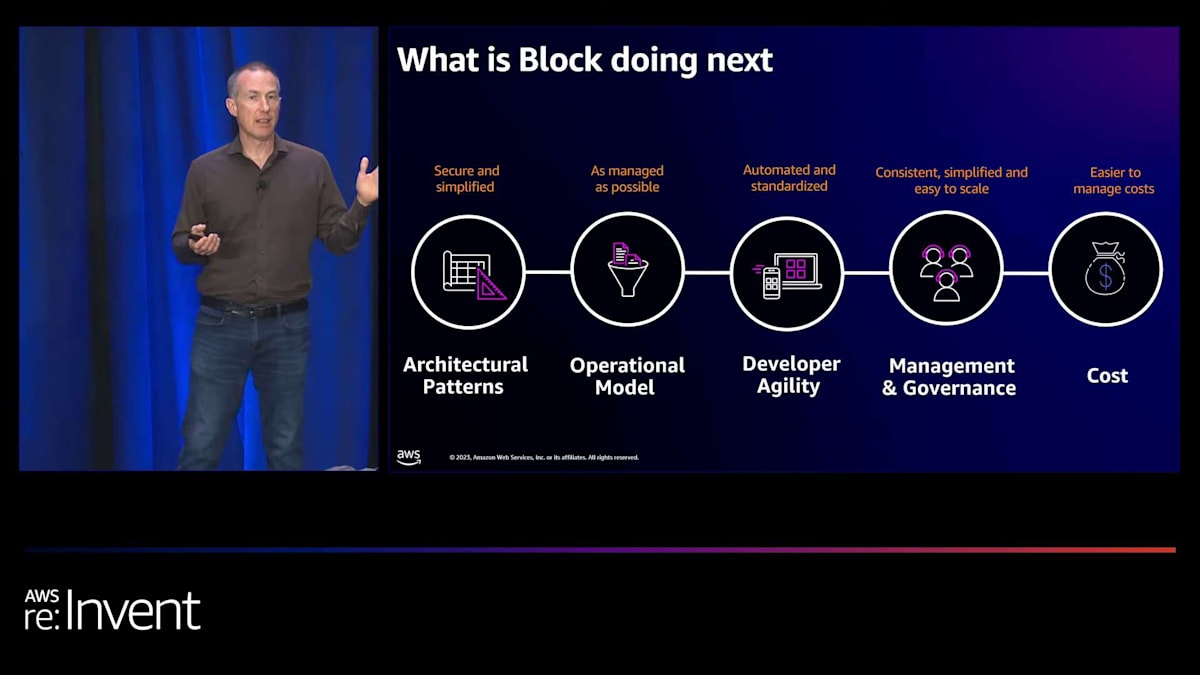
つまり、開発者に予測可能性を提供し、これらのエコシステムを接続する方法のセキュリティを向上させます。次に私たちがどこに向かっているかを見てみましょう。 私たちはクラウド移行を完了しつつあります。データセンターからAWSにすべてのバックエンドサービスを移行するまであと7ヶ月ほどです。来年の夏までにすべてのバックエンドサービスをAWSに移行したら、VPC Latticeの採用を開始し、これらのサービスを接続する一貫した方法を持つことができます。また、開発者がVPC Latticeを使用してこれらのサービスを構築しやすくする方法を検討しており、サービス呼び出しがどのように行われ、認証されるかについて多くの教育を行っています。
そしてもう1つはコストです。最初のスライドで示した現在の状況を考えると、コスト最適化の観点から管理する必要のある多くの異なる接続ポイントと技術があります。VPC Latticeを使用することで、1つの方法で行うことができ、一貫性があり、セキュリティを確保し、コストの観点から管理できることがわかります。これが私たちの計画です。では、Daveに戻したいと思います。ありがとうございました。
VPC Latticeの進化と新機能


マイク、ありがとうございます。素晴らしいですね。さて、少なくとも1人の他の顧客の声を聞いていただきましたが、他にもたくさんの顧客がこの流れに乗っています。これは、かなり長い間でアプリケーションネットワーキングにおける最もエキサイティングなアップデートの1つだと言えるでしょう。私自身が言うのもなんですが。そのプロジェクトに携わることができて、本当にワクワクしました。VPC Latticeは、私たちが革新を続けている分野の1つです。 3月の立ち上げ以来、ほぼ毎月リリースを行ってきました。 多くのお客様が移行するために必要とするさまざまな機能があるため、私たちはこの分野で非常に迅速に動いています。
この1年間、まず最初に、ALBを前面に置いたアプリケーションを持っている方々や、オンプレミス、ECSを使用している方々と話をしました。そこで、ALBをターゲットとして追加しました。また、多くの方々から、Resource Access Managerを使用して、どのIAMユーザーが特定のサービスネットワークにサービスを追加できるかなどのポリシーを作成する機能が欲しいという要望がありました。そこで、カスタマー管理権限を追加しました。次に、異なるネットワーク間でルーティングを行いたいという潜在的なニーズについて話し合い、Shared VPC Supportを追加しました。その後、より高いレベルのセキュリティとコンプライアンス基準を必要とする重要なアプリケーションの流入がありました。そこで、SOC2、PCI、HIPAAなど、多くのコンプライアンス基準を追加しました。これらの多くは実際にVPC自体から直接来ているものですが、VPC製品であるため、一部は少し異なります。
次に、多くのお客様がターゲット自体に追加の認証を加える機能を求めていた領域に移りました。まず、Lambdaに焦点を当て、どのサービスネットワークから来たのか、どのVPCから来たのかなど、本当に重要なデータを追加することを確認しました。そしてLambdaでそれを行った後、Amazon EKSに移り、渡されるアイデンティティヘッダーにそれを追加しました。
興味深いことに、この機能は部分的にBlockからのフィードバックによって構築されたのですが、お客様は物事を連鎖させる能力を求めていました。そのため、このアイデンティティを実際に渡すことで、そのデータを取り、そのアイデンティティを別のサービスであるかのように渡すことで、マルチリージョンに移行することができます。このように、これらの機能を使って非常に賢明なことができるのです。

おそらく最も興味深い分野は、EKSのイノベーションとそれに関連する作業です。特に、多くのお客様がPreviewでVPC LatticeをEKSと一緒に使用しており、GAではEKSコントローラーのAlphaバージョンをリリースしました。これは、VPC LatticeをEKSにネイティブに統合する方法です。過去9ヶ月ほどの間に多くのフィードバックをいただきました。そのフィードバックを取り入れ、改良を重ね、機能の同等性を確保し、主要なマイルストーンに対応できる段階まで到達しました。
EKS controller for VPC Latticeが一般提供開始となったことを嬉しくお知らせします。これはオープンソースプロジェクトですので、もしよろしければ皆さんも貢献することができます。ロードマップにも貢献できます。画面に表示されているリンクは、そのGitリポジトリに直接つながっています。すでに貢献してくださった方々には感謝申し上げます。VPC Latticeに関しては、コンテナやKubernetesなど、豊かなエコシステムを持つコミュニティと積極的に関わっていきたいと考えています。
ですので、私たちの目標は皆さんと協力することです。VPC Latticeをまだチェックしていない方は、ぜひ見てみてください。これは、時間とともに私たちが目指す北極星のようなものです。私たちの目標は、それを簡素化し、差別化されていない重労働を取り除くことです。アーキテクチャの違いと簡素化は実際に素晴らしいものでした。この会議で今まで交わした会話の中で、ネットワーク設計とインフラストラクチャをどのように次のレベルに引き上げ、本当に簡素化できるかが示されています。
セッションのまとめと今後の展望

予定より早く終わりそうです。予想よりも少し早く話してしまったようです。しかし、私たちが話した各領域は、実際にはかなりの時間をかけて議論できるものです。実際、VPC LatticeとELBのセキュリティと可用性の改善について、詳細な説明セッションを用意しています。これらのセッションをカバーしていますので、機会があればぜひチェックしてみてください。一部は今日遅くに、残りは今週後半に行われます。

皆さんには、どこに行くか、どのプレゼンテーションを見るかの選択肢があることは承知しています。今日ここに来てくださったことに感謝します。Mikeさん、一緒に話してくれてありがとう。AWSでは、皆さんからのフィードバックを受けて進化させていくという方法で運営しています。アプリケーションネットワーキングの責任者として、前回のre:Inventからの様々なフィードバックを見ることができ、それを基に今回のコンテンツを調整しています。
ぜひアンケートにご協力ください。モバイルアプリから回答できます。最後に時間を取っていますので、そこで回答してください。その後、MikeとI私は後ろで質問を受け付けます。チームのメンバーは見当たりませんが...あ、今ちょうど来たところです。私が答えられない質問があれば、追加のスタッフが対応できます。お時間をいただき、今日参加してくださってありがとうございました。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion